---
license: mit
language:
- zh
- en
metrics:
- cer
- bleu
tags:
- asr
- automatic-speech-recognition
- automatic-speech-translation
- speech-translation
- speech-recognition
---
# MooER (摩耳): an LLM-based Speech Recognition and Translation Model from Moore Threads
**Online Demo**: https://mooer-speech.mthreads.com:10077/
## 🔥 Update
We release a new model *MooER-80K-v2* using 80K hours of data. Currently, *MooER-80K-v2* supports the ASR task. The AST and multi-task models will be released soon.
## 📖 Introduction
We introduce **MooER (摩耳)**: an LLM-based speech recognition and translation model developed by Moore Threads. With the *MooER* framework, you can transcribe the speech into text (speech recognition or, ASR), and translate it into other languages (speech translation or, AST) in a end-to-end manner. The performance of *MooER* is demonstrated in the subsequent section, along with our insights into model configurations, training strategies, and more, provided in our [technical report](https://arxiv.org/abs/2408.05101).
For the usage of the model files, please refer to our [GitHub](https://github.com/MooreThreads/MooER)
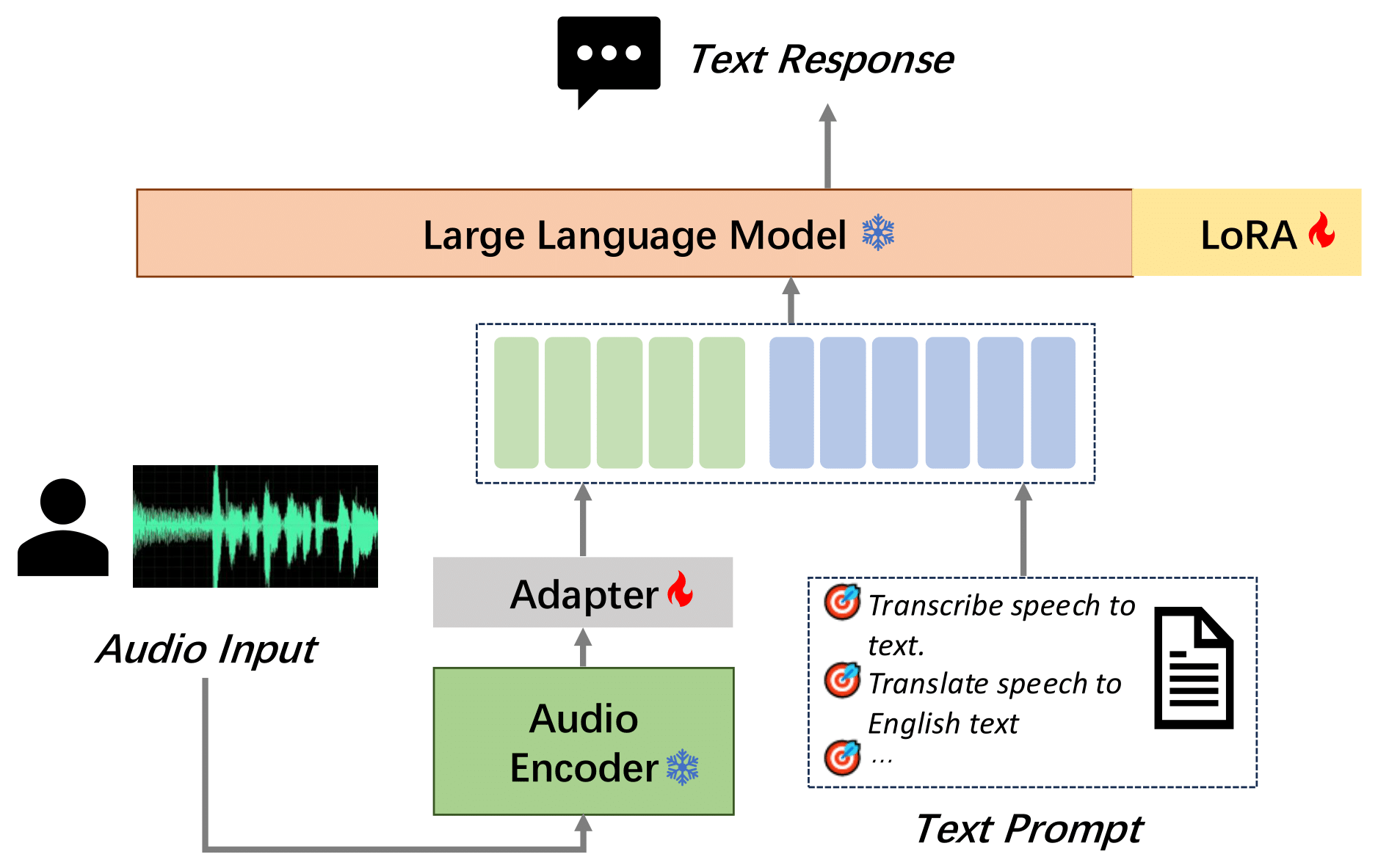
## 🥊 Evaluation Results
We demonstrate the training data and the evaluation results below. For more comprehensive information, please refer to our [report](https://arxiv.org/pdf/2408.05101).
### Training data
We utilize 5k hours of data (MT5K) to train our basic *MooER-5K* model. The data sources include:
| Dataset | Duration |
|---------------|---------------|
| aishell2 | 137h |
| librispeech | 131h |
| multi_cn | 100h |
| wenetspeech | 1361h |
| in-house data | 3274h |
Note that, data from the open-source datasets were randomly selected from the full training set. The in-house data, collected internally without text, were transcribed using a third-party ASR service.
Since all the above datasets were originally designed only for the speech recognition task, no translation results are available. To train our speech translation model, we used a third-party translation service to generate pseudo-labels. No data filtering techniques were applied.
At this moment, we are also developing a new model trained with 80K hours of data.
### Speech Recognition
The performance of speech recognition is evaluated using WER/CER.
| Language |
Testset |
Paraformer-large |
SenseVoice-small |
Qwen-audio |
Whisper-large-v3 |
SeamlessM4T-v2 |
MooER-5K |
MooER-80K |
MooER-80K-v2 |
| Chinese |
aishell1 |
1.93 |
3.03 |
1.43 |
7.86 |
4.09 |
1.93 |
1.25 |
1.00 |
| aishell2_ios |
2.85 |
3.79 |
3.57 |
5.38 |
4.81 |
3.17 |
2.67 |
2.62 |
| test_magicdata |
3.66 |
3.81 |
5.31 |
8.36 |
9.69 |
3.48 |
2.52 |
2.17 |
| test_thchs |
3.99 |
5.17 |
4.86 |
9.06 |
7.14 |
4.11 |
3.14 |
3.00 |
| fleurs cmn_dev |
5.56 |
6.39 |
10.54 |
4.54 |
7.12 |
5.81 |
5.23 |
5.15 |
| fleurs cmn_test |
6.92 |
7.36 |
11.07 |
5.24 |
7.66 |
6.77 |
6.18 |
6.14 |
| average |
4.15 |
4.93 |
6.13 |
6.74 |
6.75 |
4.21 |
3.50 |
3.35 |
| English |
librispeech test_clean |
14.15 |
4.07 |
2.15 |
3.42 |
2.77 |
7.78 |
4.11 |
3.57 |
| librispeech test_other |
22.99 |
8.26 |
4.68 |
5.62 |
5.25 |
15.25 |
9.99 |
9.09 |
| fleurs eng_dev |
24.93 |
12.92 |
22.53 |
11.63 |
11.36 |
18.89 |
13.32 |
13.12 |
| fleurs eng_test |
26.81 |
13.41 |
22.51 |
12.57 |
11.82 |
20.41 |
14.97 |
14.74 |
| gigaspeech dev |
24.23 |
19.44 |
12.96 |
19.18 |
28.01 |
23.46 |
16.92 |
17.34 |
| gigaspeech test |
23.07 |
16.65 |
13.26 |
22.34 |
28.65 |
22.09 |
16.64 |
16.97 |
| average |
22.70 |
12.46 |
13.02 |
12.46 |
14.64 |
17.98 |
12.66 |
12.47 |
### Speech Translation (zh -> en)
For speech translation, the performanced is evaluated using BLEU score.
| Testset | Speech-LLaMA | Whisper-large-v3 | Qwen-audio | Qwen2-audio | SeamlessM4T-v2 | MooER-5K | MooER-5K-MTL |
|--------|-------------|-------------------|------------|-------------|-----------------|--------|--------------|
|CoVoST1 zh2en | - | 13.5 | 13.5 | - | 25.3 | - | **30.2** |
|CoVoST2 zh2en | 12.3 | 12.2 | 15.7 | 24.4 | 22.2 | 23.4 | **25.2** |
|CCMT2019 dev | - | 15.9 | 12.0 | - | 14.8 | - | **19.6** |
## 🏁 Getting Started
Please visit our [GitHub](https://github.com/MooreThreads/MooER) for the setup and usage.
## 🧾 License
Please see the [LICENSE](LICENSE).
## 💖 Citation
If you find MooER useful for your research, please 🌟 this repo and cite our work using the following BibTeX:
```bibtex
@article{liang2024mooer,
title = {MooER: an LLM-based Speech Recognition and Translation Model from Moore Threads},
author = {Zhenlin Liang, Junhao Xu, Yi Liu, Yichao Hu, Jian Li, Yajun Zheng, Meng Cai, Hua Wang},
journal = {arXiv preprint arXiv:2408.05101},
url = {https://arxiv.org/abs/2408.05101},
year = {2024}
}
```
## 📧 Contact
If you encouter any problems, feel free to create a discussion.
Moore Threads Website: **https://www.mthreads.com/**
