

add readme
Browse files- README.md +91 -0
- datasets.png +0 -0
README.md
CHANGED
|
@@ -1,3 +1,94 @@
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
| 3 |
---
|
| 4 |
+
|
| 5 |
+
# nixie-querygen-v2
|
| 6 |
+
|
| 7 |
+
A [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) fine-tuned on query generation task. Main use cases:
|
| 8 |
+
|
| 9 |
+
* synthetic query generation for downstream embedding fine-tuning tasks - when you have only documents and no queries/labels. Such task can be done with the [nixietune](https://github.com/nixiesearch/nixietune) toolkit, see the `nixietune.qgen.generate` recipe.
|
| 10 |
+
* synthetic dataset expansion for further embedding training - when you DO have query-document pairs, but only a few. You can fine-tune the `nixie-querygen-v2` on existing pairs, and then expand your document corpus with synthetic queries (which are still based on your few real ones). See `nixietune.qgen.train` recipe.
|
| 11 |
+
|
| 12 |
+
## Training data
|
| 13 |
+
|
| 14 |
+
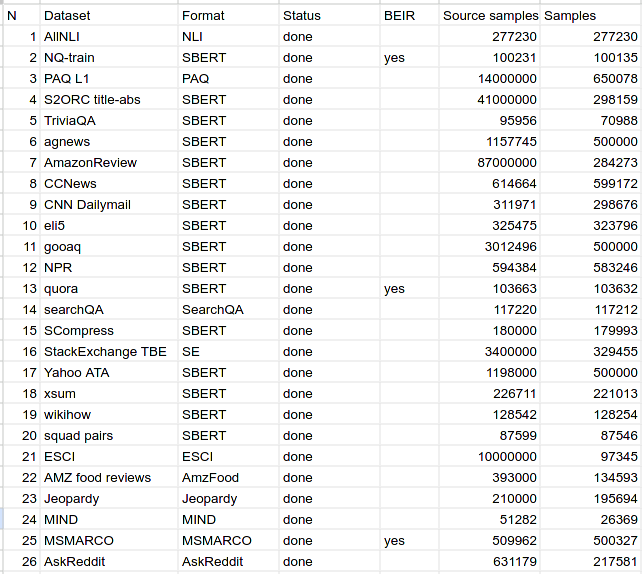
We used [200k query-document pairs](https://huggingface.co/datasets/nixiesearch/query-positive-pairs-small) sampled randomly from a diverse set of IR datasets:
|
| 15 |
+
|
| 16 |
+

|
| 17 |
+
|
| 18 |
+
## Flavours
|
| 19 |
+
|
| 20 |
+
This repo has multiple versions of the model:
|
| 21 |
+
|
| 22 |
+
* model-*.safetensors: FP16 checkpoint, suitable for down-stream fine-tuning
|
| 23 |
+
* ggml-model-f16.gguf: F16 non-quantized llama-cpp checkpoint, for CPU inference
|
| 24 |
+
* ggml-model-q4.gguf: Q4_0 quantized llama-cpp checkpoint, for fast (and less precise) CPU inference.
|
| 25 |
+
|
| 26 |
+
## Prompt formats
|
| 27 |
+
|
| 28 |
+
The model accepts the followinng prompt format:
|
| 29 |
+
|
| 30 |
+
```
|
| 31 |
+
<document next> [short|medium|long]? [question|regular]? query:
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
Some notes on format:
|
| 35 |
+
|
| 36 |
+
* `[short|medium|long]` and `[question|regular]` fragments are optional and can be skipped.
|
| 37 |
+
* the prompt suffix `query:` has no trailing space, be careful.
|
| 38 |
+
|
| 39 |
+
## Inference example
|
| 40 |
+
|
| 41 |
+
With llama-cpp and Q4 model the inference can be done on a CPU:
|
| 42 |
+
|
| 43 |
+
```bash
|
| 44 |
+
$ ./main -m ~/models/nixie-querygen-v2/ggml-model-q4.gguf -p "git lfs track will begin tracking a new file or an existing file that is already checked in to your repository. When you run git lfs track and then commit that change, it will update the file, replacing it with the LFS pointer contents. short query:" -s 1
|
| 45 |
+
|
| 46 |
+
system_info: n_threads = 8 / 16 | AVX = 1 | AVX_VNNI = 0 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 |
|
| 47 |
+
sampling:
|
| 48 |
+
repeat_last_n = 64, repeat_penalty = 1.100, frequency_penalty = 0.000, presence_penalty = 0.000
|
| 49 |
+
top_k = 40, tfs_z = 1.000, top_p = 0.950, min_p = 0.050, typical_p = 1.000, temp = 0.800
|
| 50 |
+
mirostat = 0, mirostat_lr = 0.100, mirostat_ent = 5.000
|
| 51 |
+
sampling order:
|
| 52 |
+
CFG -> Penalties -> top_k -> tfs_z -> typical_p -> top_p -> min_p -> temp
|
| 53 |
+
generate: n_ctx = 512, n_batch = 512, n_predict = -1, n_keep = 0
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
git lfs track will begin tracking a new file or an existing file that is already checked in to your repository. When you run git lfs track and then commit that change, it will update the file, replacing it with the LFS pointer contents. short regular query: git-lfs track [end of text]
|
| 57 |
+
```
|
| 58 |
+
|
| 59 |
+
## Training config
|
| 60 |
+
|
| 61 |
+
The model is trained with the follwing [nixietune](https://github.com/nixiesearch/nixietune) config:
|
| 62 |
+
```json
|
| 63 |
+
{
|
| 64 |
+
"train_dataset": "/home/shutty/data/nixiesearch-datasets/query-doc/data/train",
|
| 65 |
+
"eval_dataset": "/home/shutty/data/nixiesearch-datasets/query-doc/data/test",
|
| 66 |
+
"seq_len": 512,
|
| 67 |
+
"model_name_or_path": "mistralai/Mistral-7B-v0.1",
|
| 68 |
+
"output_dir": "mistral-qgen",
|
| 69 |
+
"num_train_epochs": 1,
|
| 70 |
+
"seed": 33,
|
| 71 |
+
"per_device_train_batch_size": 6,
|
| 72 |
+
"per_device_eval_batch_size": 2,
|
| 73 |
+
"bf16": true,
|
| 74 |
+
"logging_dir": "logs",
|
| 75 |
+
"gradient_checkpointing": true,
|
| 76 |
+
"gradient_accumulation_steps": 1,
|
| 77 |
+
"dataloader_num_workers": 14,
|
| 78 |
+
"eval_steps": 0.03,
|
| 79 |
+
"logging_steps": 0.03,
|
| 80 |
+
"evaluation_strategy": "steps",
|
| 81 |
+
"torch_compile": false,
|
| 82 |
+
"report_to": [],
|
| 83 |
+
"save_strategy": "epoch",
|
| 84 |
+
"streaming": false,
|
| 85 |
+
"do_eval": true,
|
| 86 |
+
"label_names": [
|
| 87 |
+
"labels"
|
| 88 |
+
]
|
| 89 |
+
}
|
| 90 |
+
```
|
| 91 |
+
|
| 92 |
+
## License
|
| 93 |
+
|
| 94 |
+
Apache 2.0
|
datasets.png
ADDED
|