
Commit
•
e81569f
1
Parent(s):
bd3339f
update readme
Browse files- README.md +35 -1
- images/avg.png +0 -0
- images/enko.png +0 -0
README.md
CHANGED
|
@@ -9,4 +9,38 @@ pipeline_tag: text2text-generation
|
|
| 9 |
tags:
|
| 10 |
- nmt
|
| 11 |
- aihub
|
| 12 |
-
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 9 |
tags:
|
| 10 |
- nmt
|
| 11 |
- aihub
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
# ENKO-T5-SMALL-V0
|
| 15 |
+
|
| 16 |
+
This model is for English to Korean Machine Translator, which is based on T5-small architecture, but trained from scratch.
|
| 17 |
+
|
| 18 |
+
#### Code
|
| 19 |
+
|
| 20 |
+
The training code is from my lecture([LLM을 위한 김기현의 NLP EXPRESS](https://fastcampus.co.kr/data_online_nlpexpress)), which is published on [FastCampus](https://fastcampus.co.kr/). You can check the training code in this github [repo](https://github.com/kh-kim/nlp-express-practice).
|
| 21 |
+
|
| 22 |
+
#### Dataset
|
| 23 |
+
|
| 24 |
+
The training dataset for this model is mainly from [AI-Hub](https://www.aihub.or.kr/). The dataset consists of 11M parallel samples.
|
| 25 |
+
|
| 26 |
+
#### Tokenizer
|
| 27 |
+
|
| 28 |
+
I use Byte-level BPE tokenizer for both source and target language. Since it covers both languages, tokenizer vocab size is 60k.
|
| 29 |
+
|
| 30 |
+
#### Architecture
|
| 31 |
+
|
| 32 |
+
The model architecture is based on T5-small, which is popular encoder-decoder model architecture. Please, note that this model is trained from-scratch, not fine-tuned.
|
| 33 |
+
|
| 34 |
+
#### Evaluation
|
| 35 |
+
|
| 36 |
+
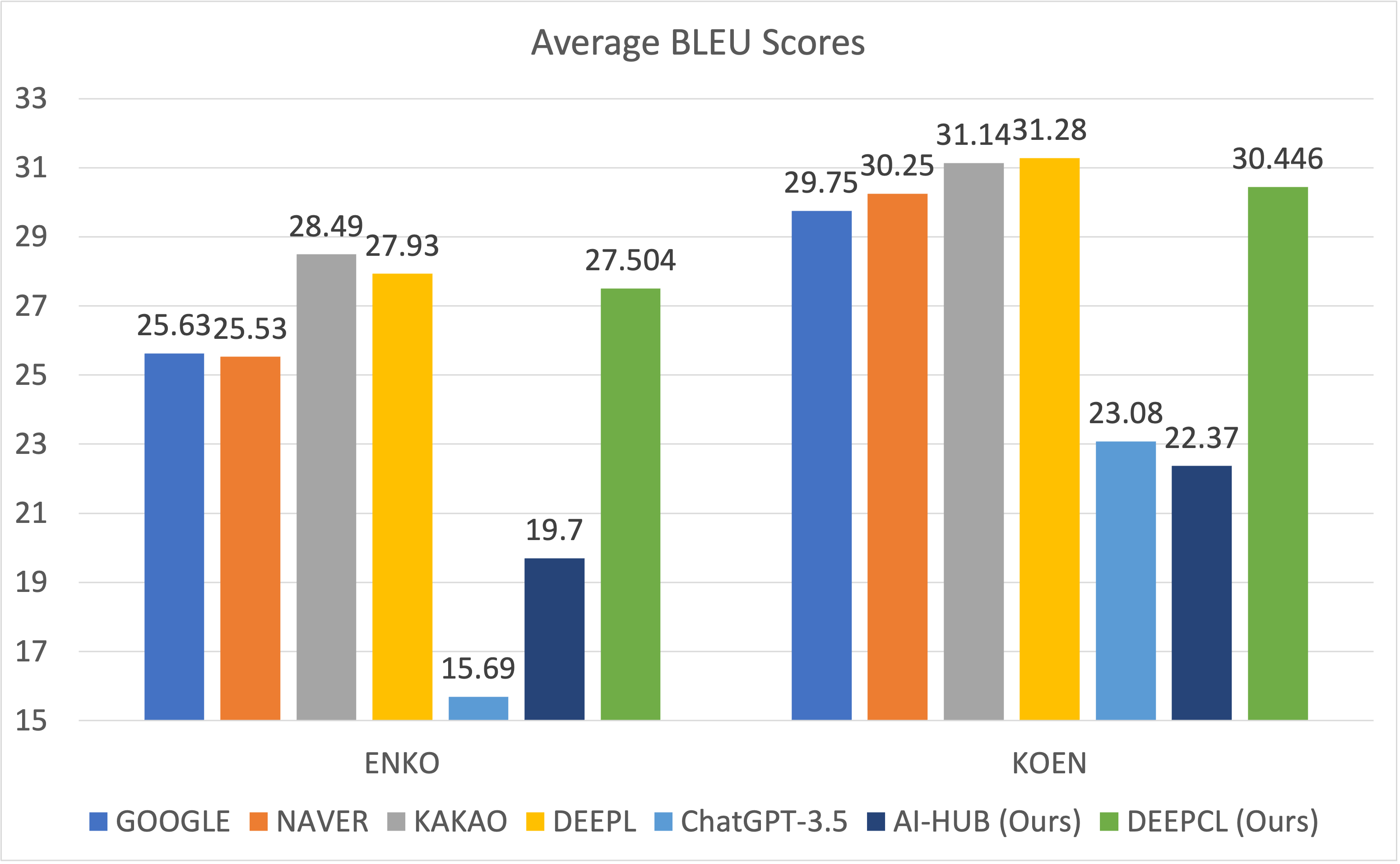
I conducted the evaluation with 5 different test sets. Following figure shows BLEU scores on each test set.
|
| 37 |
+
|
| 38 |
+

|
| 39 |
+
|
| 40 |
+

|
| 41 |
+
|
| 42 |
+
DEEPCL model is private version of this model, which is trained on much more data.
|
| 43 |
+
|
| 44 |
+
#### Contact
|
| 45 |
+
|
| 46 |
+
Kim Ki Hyun ([email protected])
|
images/avg.png
ADDED
|
images/enko.png
ADDED

|