---
pipeline_tag: visual-question-answering
---
## MiniCPM-V 2.0
**MiniCPM-V 2.8B** is a strong multimodal large language model for efficient end-side deployment. The model is built based on SigLip-400M and [MiniCPM-2.4B](https://github.com/OpenBMB/MiniCPM/), connected by a perceiver resampler. Our latest version, **MiniCPM-V 2.0** has several notable features.
- 🔥 **State-of-the-art Performance.**
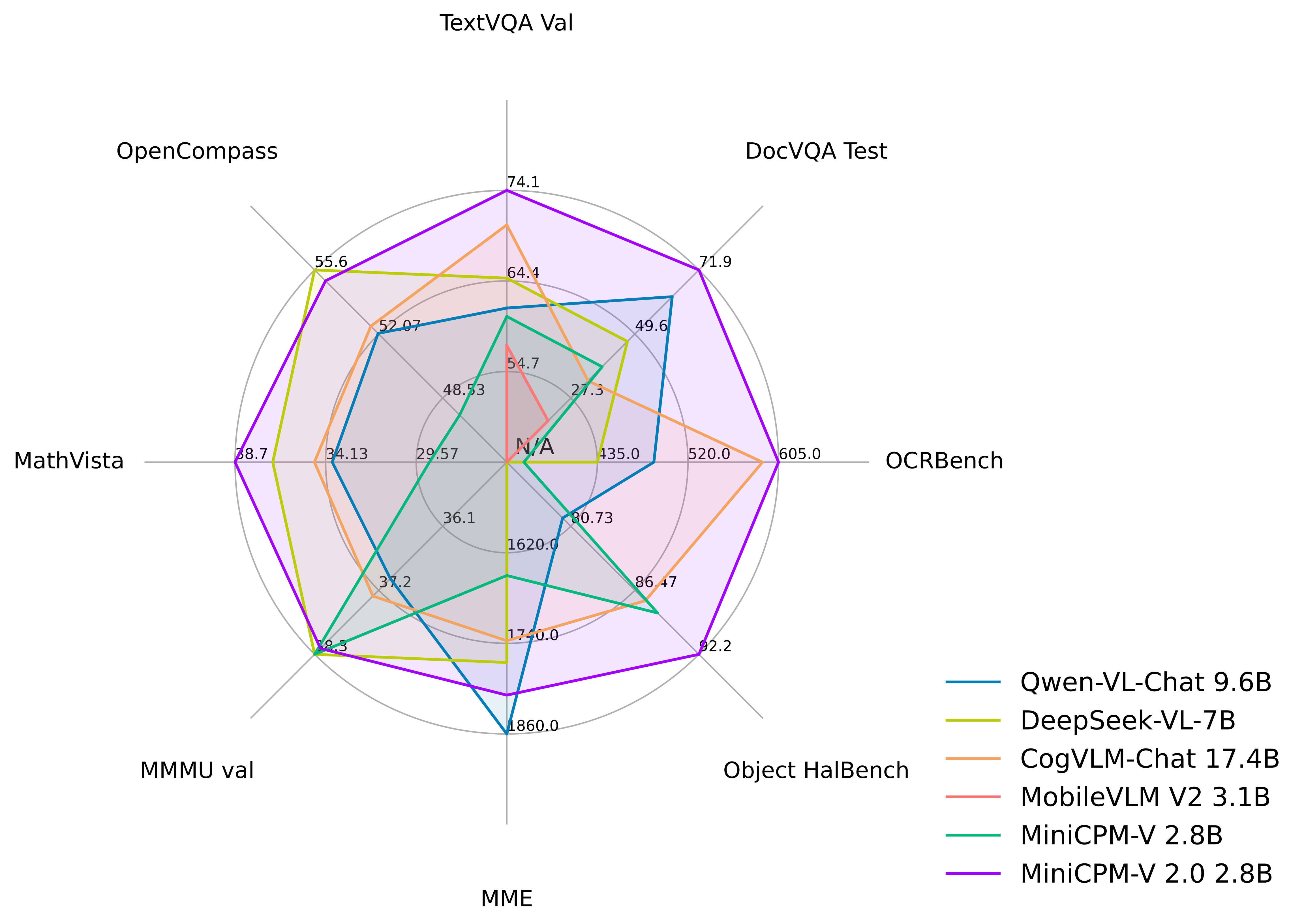
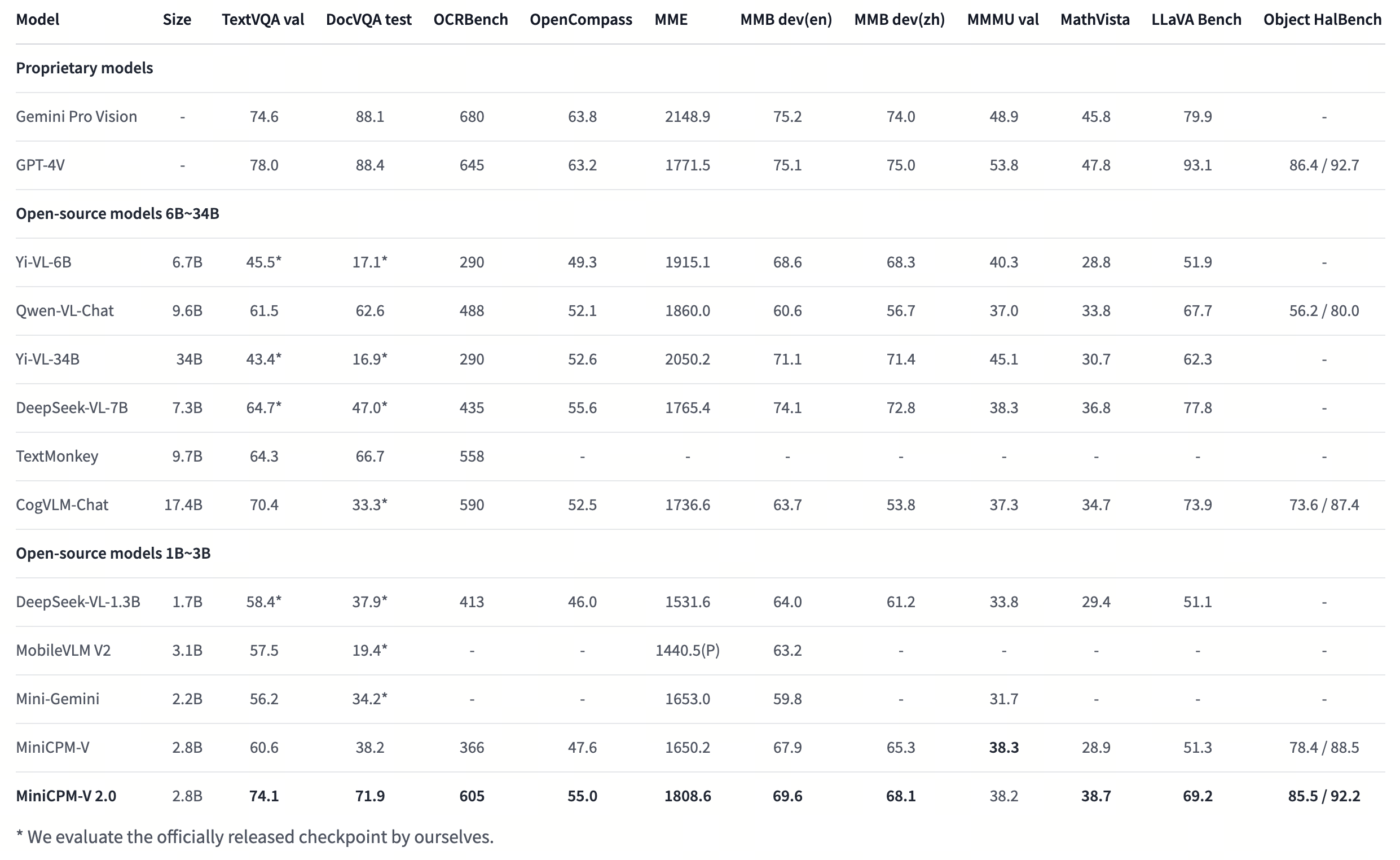
MiniCPM-V 2.0 achieves **state-of-the-art performance** on multiple benchmarks (including OCRBench, TextVQA, MME, MMB, MathVista, etc) among models under 7B parameters. It even **outperforms strong Qwen-VL-Chat 9.6B, CogVLM-Chat 17.4B, and Yi-VL 34B on OpenCompass, a comprehensive evaluation over 11 popular benchmarks**. Notably, MiniCPM-V 2.0 shows **strong OCR capability**, achieving **comparable performance to Gemini Pro in scene-text understanding**, and **state-of-the-art performance on OCRBench** among open-source models.
- 🏆 **Trustworthy Behavior.**
LMMs are known for suffering from hallucination, often generating text not factually grounded in images. MiniCPM-V 2.0 is **the first end-side LMM aligned via multimodal RLHF for trustworthy behavior** (using the recent [RLHF-V](https://rlhf-v.github.io/) [CVPR'24] series technique). This allows the model to **match GPT-4V in preventing hallucinations** on Object HalBench.
- 🌟 **High-Resolution Images at Any Aspect Raito.**
MiniCPM-V 2.0 can accept **1.8 million pixels (e.g., 1344x1344) images at any aspect ratio**. This enables better perception of fine-grained visual information such as small objects and optical characters, which is achieved via a recent technique from [LLaVA-UHD](https://arxiv.org/pdf/2403.11703.pdf).
- ⚡️ **High Efficiency.**
MiniCPM-V 2.0 can be **efficiently deployed on most GPU cards and personal computers**, and **even on end devices such as mobile phones**. For visual encoding, we compress the image representations into much fewer tokens via a perceiver resampler. This allows MiniCPM-V 2.0 to operate with **favorable memory cost and speed during inference even when dealing with high-resolution images**.
- 🙌 **Bilingual Support.**
MiniCPM-V 2.0 **supports strong bilingual multimodal capabilities in both English and Chinese**. This is enabled by generalizing multimodal capabilities across languages, a technique from [VisCPM](https://arxiv.org/abs/2308.12038) [ICLR'24].
## Evaluation
Results on TextVQA, DocVQA, OCRBench, OpenCompass, MME, MMBench, MMMU, MathVista, LLaVA Bench, Object HalBench.
## Examples
We deploy MiniCPM-V 2.0 on end devices. The demo video is the raw screen recording on a Xiaomi 14 Pro without edition.
## Demo
Click here to try out the Demo of [MiniCPM-V 2.0](http://120.92.209.146:80).
## Deployment on Mobile Phone
MiniCPM-V 2.0 can be deployed on mobile phones with Android and Harmony operating systems. 🚀 Try it out [here](https://github.com/OpenBMB/mlc-MiniCPM).
## Usage
Inference using Huggingface transformers on Nivdia GPUs or Mac with MPS (Apple silicon or AMD GPUs). Requirements tested on python 3.10:
```
Pillow==10.1.0
timm==0.9.10
torch==2.1.2
torchvision==0.16.2
transformers==4.36.0
sentencepiece==0.1.99
```
```python
# test.py
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-2.0', trust_remote_code=True, torch_dtype=torch.bfloat16)
# For Nvidia GPUs support BF16 (like A100, H100, RTX3090)
model = model.to(device='cuda', dtype=torch.bfloat16)
# For Nvidia GPUs do NOT support BF16 (like V100, T4, RTX2080)
#model = model.to(device='cuda', dtype=torch.float16)
# For Mac with MPS (Apple silicon or AMD GPUs).
# Run with `PYTORCH_ENABLE_MPS_FALLBACK=1 python test.py`
#model = model.to(device='mps', dtype=torch.float16)
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-2.0', trust_remote_code=True)
model.eval()
image = Image.open('xx.jpg').convert('RGB')
question = 'What is in the image?'
msgs = [{'role': 'user', 'content': question}]
res, context, _ = model.chat(
image=image,
msgs=msgs,
context=None,
tokenizer=tokenizer,
sampling=True,
temperature=0.7
)
print(res)
```
Please look at [GitHub](https://github.com/OpenBMB/MiniCPM-V) for more detail about usage.
## MiniCPM-V 1.0
Please see the info about MiniCPM-V 1.0 [here](https://huggingface.co/openbmb/MiniCPM-V).
## License
#### Model License
* The code in this repo is released according to [Apache-2.0](https://github.com/OpenBMB/MiniCPM/blob/main/LICENSE)
* The usage of MiniCPM-V 2.0's parameters is subject to ["General Model License Agreement - Source Notes - Publicity Restrictions - Commercial License"](https://github.com/OpenBMB/General-Model-License/blob/main/)
* The parameters are fully open to acedemic research
* Please contact cpm@modelbest.cn to obtain a written authorization for commercial uses. Free commercial use is also allowed after registration.
#### Statement
* As a LLM, MiniCPM-V 2.0 generates contents by learning a large mount of texts, but it cannot comprehend, express personal opinions or make value judgement. Anything generated by MiniCPM-V 2.0 does not represent the views and positions of the model developers
* We will not be liable for any problems arising from the use of the MinCPM-V open Source model, including but not limited to data security issues, risk of public opinion, or any risks and problems arising from the misdirection, misuse, dissemination or misuse of the model.