U-MATH: A University-Level Benchmark for Evaluating Mathematical Skills in LLMs
 cogwheelhead
cogwheelhead







Abstract
The current evaluation of mathematical skills in LLMs is limited, as existing benchmarks are either relatively small, primarily focus on elementary and high-school problems, or lack diversity in topics. Additionally, the inclusion of visual elements in tasks remains largely under-explored. To address these gaps, we introduce U-MATH, a novel benchmark of 1,100 unpublished open-ended university-level problems sourced from teaching materials. It is balanced across six core subjects, with 20% of multimodal problems. Given the open-ended nature of U-MATH problems, we employ an LLM to judge the correctness of generated solutions. To this end, we release mu-MATH, a dataset to evaluate the LLMs' capabilities in judging solutions. The evaluation of general domain, math-specific, and multimodal LLMs highlights the challenges presented by U-MATH. Our findings reveal that LLMs achieve a maximum accuracy of only 63% on text-based tasks, with even lower 45% on visual problems. The solution assessment proves challenging for LLMs, with the best LLM judge having an F1-score of 80% on mu-MATH.
Community
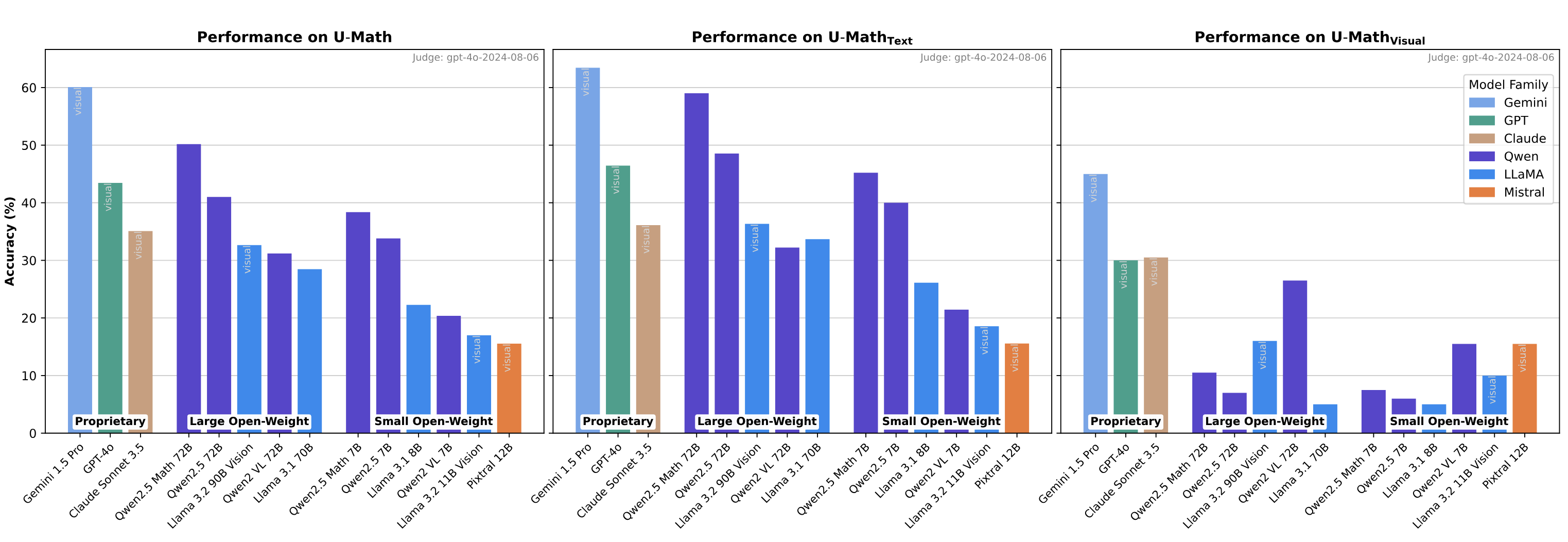
U-MATH is a comprehensive benchmark of 1,100 unpublished university-level problems sourced from real teaching materials.
It is designed to evaluate the mathematical reasoning capabilities of Large Language Models (LLMs).
The dataset is balanced across six core mathematical topics and includes 20% of multimodal problems (involving visual elements such as graphs and diagrams).
μ-MATH (Meta U-MATH) is a meta-evaluation dataset derived from the U-MATH benchmark.
It is intended to assess and rigorously study the ability of LLMs to judge free-form mathematical solutions.
The dataset includes 1,084 labeled samples generated from 271 U-MATH tasks, covering problems of varying assessment complexity.
- 📊 U-MATH benchmark at Huggingface
- 🔎 μ-MATH benchmark at Huggingface
- 🗞️ Paper at arXiv
- 👾 Evaluation Code at GitHub
The paper compares a number of different LLMs in terms of their math problem-solving and mathematical solution judgment performance across a number of different metrics and data slices
Some findings:
- Smaller open-weight specialized models are often able to outperform larger models, including large proprietary ones like GPT4-o
- Inclusion of visual elements considerably decreases the performance
- Continuous Pretraining proves effective at improving problem-solving skills
- Automatic evaluation with LLM-as-judge proves to be a challenging skill in its own right, with judgment performance being imperfect and also poorly correlated with problem-solving
- Judges exhibit strong prompt sensitivity, noticeable biases towards some models, and qualitatively different behavior patterns


This is an automated message from the Librarian Bot. I found the following papers similar to this paper.
The following papers were recommended by the Semantic Scholar API
- Automated Feedback in Math Education: A Comparative Analysis of LLMs for Open-Ended Responses (2024)
- Evaluating GPT-4 at Grading Handwritten Solutions in Math Exams (2024)
- Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Models (2024)
- Assessing the Creativity of LLMs in Proposing Novel Solutions to Mathematical Problems (2024)
- UTMath: Math Evaluation with Unit Test via Reasoning-to-Coding Thoughts (2024)
- HARDMath: A Benchmark Dataset for Challenging Problems in Applied Mathematics (2024)
- Curriculum Demonstration Selection for In-Context Learning (2024)
Please give a thumbs up to this comment if you found it helpful!
If you want recommendations for any Paper on Hugging Face checkout this Space
You can directly ask Librarian Bot for paper recommendations by tagging it in a comment:
@librarian-bot
recommend




Models citing this paper 0
No model linking this paper
Datasets citing this paper 2
Spaces citing this paper 0
No Space linking this paper