---
language:
- ca
base_model: BSC-LT/matcha-tts-cat-multispeaker
tags:
- matcha-tts
- acoustic modelling
- speech
- multispeaker
- tts
pipeline_tag: text-to-speech
license: cc-by-nc-4.0
---
# 🍵 Matxa-TTS (Matcha-TTS) Catalan Multiaccent
## Table of Contents
Click to expand
- [Model description](#model-description)
- [Intended uses and limitations](#intended-uses-and-limitations)
- [How to use](#how-to-use)
- [Training](#training)
- [Evaluation](#evaluation)
- [Citation](#citation)
- [Additional information](#additional-information)
## Summary
Here we present 🍵 Matxa, the first multispeaker, multidialectal neural TTS model. It works together with the vocoder model 🥑 alVoCat, to generate high quality and expressive speech efficiently in four dialects:
* Balear
* Central
* North-Occidental
* Valencian
Both models are trained with open data; 🍵 Matxa models are free (as in freedom) to use for non-comercial purposes, but for commercial purposes it needs licensing from the voice artist. To listen to the voices you can visit the [dedicated space](https://huggingface.co/spaces/projecte-aina/matxa-alvocat-tts-ca).
## Model Description
🍵 **Matxa-TTS** is based on **Matcha-TTS** that is an encoder-decoder architecture designed for fast acoustic modelling in TTS.
The encoder part is based on a text encoder and a phoneme duration prediction that together predict averaged acoustic features.
And the decoder has essentially a U-Net backbone inspired by [Grad-TTS](https://arxiv.org/pdf/2105.06337.pdf), which is based on the Transformer architecture.
In the latter, by replacing 2D CNNs by 1D CNNs, a large reduction in memory consumption and fast synthesis is achieved.
**Matxa-TTS** is a non-autorregressive model trained with optimal-transport conditional flow matching (OT-CFM).
This yields an ODE-based decoder capable of generating high output quality in fewer synthesis steps than models trained using score matching.
## Intended Uses and Limitations
This model is intended to serve as an acoustic feature generator for multispeaker text-to-speech systems for the Catalan language.
It has been finetuned using a Catalan phonemizer, therefore if the model is used for other languages it will not produce intelligible samples after mapping
its output into a speech waveform.
The quality of the samples can vary depending on the speaker.
This may be due to the sensitivity of the model in learning specific frequencies and also due to the quality of samples for each speaker.
As explained in the licenses section, the models can be used only for non-commercial purposes. Any parties interested in using them
commercially need to contact the rights holders, the voice artists for licensing their voices. For more information see the licenses section
under [Additional information](#additional-information).
## How to Get Started with the Model
### Installation
Models have been trained using the espeak-ng open source text-to-speech software.
The main [espeak-ng](https://github.com/espeak-ng/espeak-ng) now contains the Catalan phonemizer work started [here](https://github.com/projecte-aina/espeak-ng)
Create a virtual environment:
```bash
python -m venv /path/to/venv
source /path/to/venv/bin/activate
```
For training and synthesizing with Catalan Matxa-TTS you need to compile espeak-ng:
```bash
git clone https://github.com/espeak-ng/espeak-ng
export PYTHON=/path/to/env//bin/python
cd /path/to/espeak-ng
./autogen.sh
./configure --prefix=/path/to/espeak-ng
make
make install
```
Clone the repository:
```bash
git clone -b dev-cat https://github.com/langtech-bsc/Matcha-TTS.git
cd Matcha-TTS
```
Install the package from source:
```bash
pip install -e .
```
### For Inference
#### PyTorch
Speech end-to-end inference can be done together with **Catalan Matxa-TTS**.
Both models (Catalan Matxa-TTS and alVoCat) are loaded remotely from the HF hub.
First, export the following environment variables to include the installed espeak-ng version:
```bash
export PYTHON=/path/to/your/venv/bin/python
export ESPEAK_DATA_PATH=/path/to/espeak-ng/espeak-ng-data
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/espeak-ng/lib
export PATH="/path/to/espeak-ng/bin:$PATH"
```
Then you can run the inference script:
```bash
cd Matcha-TTS
python3 matcha_vocos_inference.py --output_path=/output/path --text_input="Bon dia Manel, avui anem a la muntanya."
```
You can also modify the length scale (speech rate) and the temperature of the generated sample:
```bash
python3 matcha_vocos_inference.py --output_path=/output/path --text_input="Bon dia Manel, avui anem a la muntanya." --length_scale=0.8 --temperature=0.7
```
Additionally you can choose the speaker id from the following table
```bash
python3 matcha_vocos_inference.py --output_path=/output/path --text_input="Bon dia Manel, avui anem a la muntanya." --length_scale=0.8 --temperature=0.7 --speaker_id 3
```
| accent | Name | speaker_id |
|-----------------|------|------------|
| balear | quim | 0 |
| balear | olga | 1 |
| central | grau | 2 |
| central | elia | 3 |
| nord-occidental | pere | 4 |
| nord-occidental | emma | 5 |
| valencia | lluc | 6 |
| valencia | gina | 7 |
Be aware that depending on the accent you should choose the proper text cleaner as an argument, by default it uses the catalan central cleaner.
```bash
python3 matcha_vocos_inference.py --output_path=/output/path --text_input="Bon dia Manel, avui anem a la muntanya." --length_scale=0.8 --temperature=0.7 --speaker_id 0 --cleaner "catalan_balear_cleaners"
```
| accent | cleaner |
|-----------------|---------------------------|
| balear | catalan_balear_cleaners |
| central | catalan_cleaners(default) |
| nord-occidental | catalan_occidental_cleaners|
| valencia | catalan_valencia_cleaners |
#### ONNX
We also release ONNXs version of the models, you can use it via the OVOS plugins.
Just install the plugin from pypi.
```bash
pip install ovos-tts-plugin-matxa-multispeaker-cat
```
and synthesize
```python
from ovos_tts_plugin_matxa_multispeaker_cat import MatxaCatalanTTSPlugin
sent = "Això és una prova de síntesi de veu."
tts = MatxaCatalanTTSPlugin()
tts.get_tts(sent, "test.wav", voice="valencia/gina")
```
### For Training
See the [repo instructions](https://github.com/langtech-bsc/Matcha-TTS/tree/dev-cat)
## Training Details
### Training data
The model was trained on a **Multiaccent Catalan** speech dataset
| Dataset | Language | Hours | Num. Speakers |
|---------|----------|-------|---------------|
| [LaFrescat](https://huggingface.co/datasets/projecte-aina/LaFrescat) | ca | 3.5 | 8 |
### Training procedure
***Matxa Multiaccent Catalan*** is finetuned from a Catalan Matxa-base model. This Matxa-base model was finetuned from the English multispeaker checkpoint, using a 100h subset of the Catalan CommonVoice v.16 database. The selection of this small set of samples was made by using the UTMOS system, a predictor of values of the metric Mean Opinion Score (MOS) a score usually set by human evaluators according to their subjective perception of speech quality.
The embedding layer was initialized with the number of catalan speakers per accent (in total 8) and the original hyperparameters were kept.
### Training Hyperparameters
* batch size: 32 (x2 GPUs)
* learning rate: 1e-4
* number of speakers: 2
* n_fft: 1024
* n_feats: 80
* sample_rate: 22050
* hop_length: 256
* win_length: 1024
* f_min: 0
* f_max: 8000
* data_statistics:
* mel_mean: -6578195
* mel_std: 2.538758
* number of samples: 13340
## Evaluation
Validation values obtained from tensorboard from epoch 2399*:
* val_dur_loss_epoch: 0.38
* val_prior_loss_epoch: 0.97
* val_diff_loss_epoch: 2.195
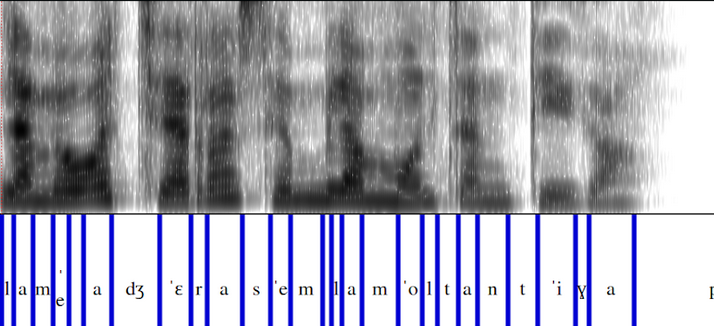
## Analyzing Multi-Accented Inferences
Here we show aligned spectrograms with phonemes from the same inference generated with the four accents. The following spectrograms correspond to the sentence *La seva gerra sembla molt antiga*.
This utterances shows three phonetic particularities that differentiate the Catalan variants.
In the Balearic and Valencian accents, [t] is pronounced, whereas it is not pronounced in the other two accents.
It can be seen that the **-v-** in *seva* is pronounced as [β] in Central accent while as [w] in Valencian.
Also, it is observed that the /ʒ/ in *gerra* has an affricate pronunciation ([d͡ʒ]) in Valencian.
*Balearic inference*
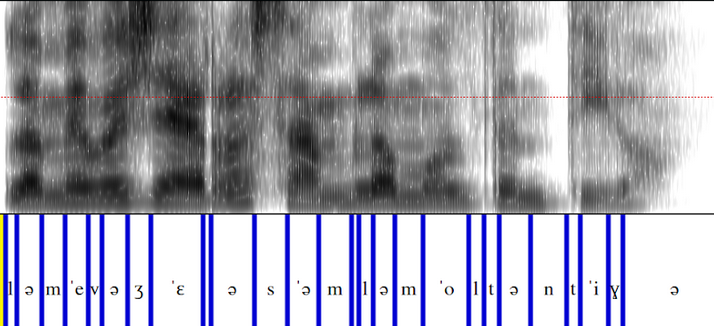
*Central inference*

*North-Western inference*
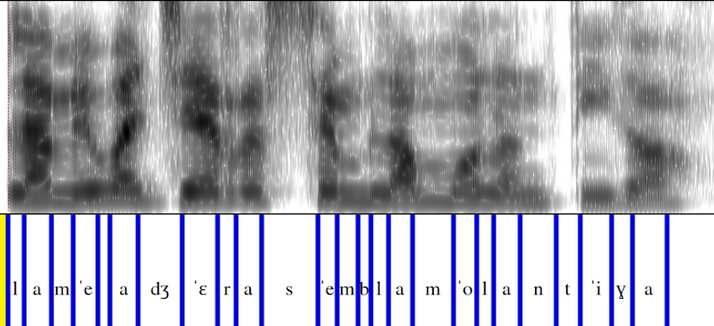
*Valencian inference*
## Citation
If this code contributes to your research, please cite the work:
```
@misc{mehta2024matchatts,
title={Matcha-TTS: A fast TTS architecture with conditional flow matching},
author={Shivam Mehta and Ruibo Tu and Jonas Beskow and Éva Székely and Gustav Eje Henter},
year={2024},
eprint={2309.03199},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
```
## Additional Information
### Author
The Language Technologies Unit from Barcelona Supercomputing Center.
### Contact
For further information, please send an email to .
### Copyright
Copyright(c) 2023 by Language Technologies Unit, Barcelona Supercomputing Center.
### License
[Creative Commons Attribution Non-commercial 4.0](https://www.creativecommons.org/licenses/by-nc/4.0/)
These models are free to use for non-commercial and research purposes. Commercial use is only possible through licensing by
the voice artists. For further information, contact and .
### Funding
This work has been promoted and financed by the Generalitat de Catalunya through the [Aina project](https://projecteaina.cat/).
Part of the training of the model was possible thanks to the compute time given by Galician Supercomputing Center CESGA
([Centro de Supercomputación de Galicia](https://www.cesga.es/)), and also by [Barcelona Supercomputing Center](https://www.bsc.es/) in MareNostrum 5.