

Upload 7 files
Browse files- .gitattributes +2 -0
- README.md +550 -0
- README_EN.md +533 -0
- assets/360Zhinao-7B-Chat-360K.en_score.png +0 -0
- assets/360Zhinao-7B-Chat-360K.zh_score.png +0 -0
- assets/WeChat.png +0 -0
- assets/cli_demo.gif +3 -0
- assets/web_demo.gif +3 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
assets/cli_demo.gif filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
assets/web_demo.gif filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,550 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
language:
|
| 4 |
+
- zh
|
| 5 |
+
- en
|
| 6 |
+
library_name: transformers
|
| 7 |
+
tags:
|
| 8 |
+
- qihoo360
|
| 9 |
+
- 奇虎360
|
| 10 |
+
- 360Zhinao
|
| 11 |
+
- pretrain
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
<div align="center">
|
| 15 |
+
<h1>
|
| 16 |
+
360智脑
|
| 17 |
+
</h1>
|
| 18 |
+
</div>
|
| 19 |
+
<div align="center">
|
| 20 |
+
🤖 <a href="https://www.modelscope.cn/profile/qihoo360">ModelScope</a>   |   
|
| 21 |
+
🔥 <a href="https://github.com/Qihoo360/360zhinao/blob/main/assets/WeChat.png">GitHub</a>   |   
|
| 22 |
+
💬 <a href="https://github.com/Qihoo360/360zhinao/blob/main/assets/WeChat.png">WeChat (微信)</a>  
|
| 23 |
+
</div>
|
| 24 |
+
<br>
|
| 25 |
+
<p align="center">
|
| 26 |
+
欢迎访问360智脑官网<a href="https://ai.360.com"> https://ai.360.com </a>体验更多更强大的功能。
|
| 27 |
+
</p>
|
| 28 |
+
|
| 29 |
+
<br>
|
| 30 |
+
|
| 31 |
+
# 模型介绍
|
| 32 |
+
🎉🎉🎉我们开源了360智脑大模型的系列工作,本次开源了以下模型:
|
| 33 |
+
- **360Zhinao-7B-Base**
|
| 34 |
+
- **360Zhinao-7B-Chat-4K**
|
| 35 |
+
- **360Zhinao-7B-Chat-32K**
|
| 36 |
+
- **360Zhinao-7B-Chat-360K**
|
| 37 |
+
|
| 38 |
+
360智脑大模型特点如下:
|
| 39 |
+
- **基础模型**:采用 3.4 万亿 Tokens 的高质量语料库训练,以中文、英文、代码为主,在相关基准评测中,同尺寸有竞争力。
|
| 40 |
+
- **对话模型**:具有强大的对话能力,开放4K、32K、360K三种不同文本长度。据了解,360K(约50万字)是当前国产开源模型文本长度最长的。
|
| 41 |
+
|
| 42 |
+
<br>
|
| 43 |
+
|
| 44 |
+
# 更新信息
|
| 45 |
+
- [2024.04.10] 我们发布了360Zhinao-7B 1.0版本,同时开放Base模型和4K、32K、360K三种文本长度的Chat模型。
|
| 46 |
+
|
| 47 |
+
<br>
|
| 48 |
+
|
| 49 |
+
# 目录
|
| 50 |
+
- [下载地址](#下载地址)
|
| 51 |
+
- [模型评估](#模型评估)
|
| 52 |
+
- [快速开始](#快速开始)
|
| 53 |
+
- [模型推理](#模型推理)
|
| 54 |
+
- [模型微调](#模型微调)
|
| 55 |
+
- [许可证](#许可证)
|
| 56 |
+
|
| 57 |
+
<br>
|
| 58 |
+
|
| 59 |
+
# 下载地址
|
| 60 |
+
本次发布版本和下载链接见下表:
|
| 61 |
+
| Size | Model | BF16 | Int4|
|
| 62 |
+
|:-:|-|:-:|:-:|
|
| 63 |
+
| 7B | 360Zhinao-7B-Base | <a href="https://www.modelscope.cn/models/qihoo360/360Zhinao-7B-Base/summary">🤖</a> <a href="https://huggingface.co/qihoo360/360Zhinao-7B-Base">🤗</a> | |
|
| 64 |
+
| 7B | 360Zhinao-7B-Chat-4K | <a href="https://www.modelscope.cn/models/qihoo360/360Zhinao-7B-Chat-4K/summary">🤖</a> <a href="https://huggingface.co/qihoo360/360Zhinao-7B-Chat-4K">🤗</a> | <a href="https://www.modelscope.cn/models/qihoo360/360Zhinao-7B-Chat-4K-Int4/summary">🤖</a> <a href="https://huggingface.co/qihoo360/360Zhinao-7B-Chat-4K-Int4">🤗</a> |
|
| 65 |
+
| 7B | 360Zhinao-7B-Chat-32K | <a href="https://www.modelscope.cn/models/qihoo360/360Zhinao-7B-Chat-32K/summary">🤖</a> <a href="https://huggingface.co/qihoo360/360Zhinao-7B-Chat-32K">🤗</a> | <a href="https://www.modelscope.cn/models/qihoo360/360Zhinao-7B-Chat-32K-Int4/summary">🤖</a> <a href="https://huggingface.co/qihoo360/360Zhinao-7B-Chat-32K-Int4">🤗</a> |
|
| 66 |
+
| 7B | 360Zhinao-7B-Chat-360K | <a href="https://www.modelscope.cn/models/qihoo360/360Zhinao-7B-Chat-360K/summary">🤖</a> <a href="https://huggingface.co/qihoo360/360Zhinao-7B-Chat-360K">🤗</a> | <a href="https://www.modelscope.cn/models/qihoo360/360Zhinao-7B-Chat-360K-Int4/summary">🤖</a> <a href="https://huggingface.co/qihoo360/360Zhinao-7B-Chat-360K-Int4">🤗</a> |
|
| 67 |
+
|
| 68 |
+
<br>
|
| 69 |
+
|
| 70 |
+
# 模型评估
|
| 71 |
+
|
| 72 |
+
## 基础模型
|
| 73 |
+
我们在OpenCompass的主流评测数据集上验证了我们的模型性能,包括C-Eval、AGIEval、MMLU、CMMLU、HellaSwag、MATH、GSM8K、HumanEval、MBPP、BBH、LAMBADA,考察的能力包括自然语言理解、知识、数学计算和推理、代码生成、逻辑推理等。
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
| <div style="width: 100pt">Model</div> | AVG | CEval | AGIEval | MMLU | CMMLU | HellaSwag | MATH | GSM8K | HumanEval | MBPP | BBH | LAMBADA |
|
| 77 |
+
|:----------------------|:---------:|:---------:|:---------:|:---------:|:---------:|:---------:|:---------:|:---------:|:---------:|:---------:|:---------:|:---------:|
|
| 78 |
+
| Baichuan2-7B | 41.49 | 56.3 | 34.6 | 54.7 | 57 | 67 | 5.4 | 24.6 | 17.7 | 24 | 41.8 | 73.3 |
|
| 79 |
+
| Baichuan-7B | 31.94 | 44.7 | 24.6 | 41.5 | 44.6 | 68.4 | 2.5 | 9.6 | 9.1 | 6.4 | 32.8 | 67.1 |
|
| 80 |
+
| ChatGLM3-6B | **58.67** | 67 | 47.4 | 62.8 | 66.5 | 76.5 | 19.2 | 61 | 44.5 | **57.2** | **66.2** | 77.1 |
|
| 81 |
+
| DeepSeek-7B | 39.8 | 45 | 24 | 49.3 | 46.8 | 73.4 | 4.2 | 18.3 | 25 | 36.4 | 42.8 | 72.6 |
|
| 82 |
+
| InternLM2-7B | 58.01 | 65.7 | 50.2 | 65.5 | 66.2 | 79.6 | 19.9 | **70.6** | 41.5 | 42.4 | 64.4 | 72.1 |
|
| 83 |
+
| InternLM-7B | 39.33 | 53.4 | 36.9 | 51 | 51.8 | 70.6 | 6.3 | 31.2 | 13.4 | 14 | 37 | 67 |
|
| 84 |
+
| LLaMA-2-7B | 33.27 | 32.5 | 21.8 | 46.8 | 31.8 | 74 | 3.3 | 16.7 | 12.8 | 14.8 | 38.2 | 73.3 |
|
| 85 |
+
| LLaMA-7B | 30.35 | 27.3 | 20.6 | 35.6 | 26.8 | 74.3 | 2.9 | 10 | 12.8 | 16.8 | 33.5 | 73.3 |
|
| 86 |
+
| Mistral-7B-v0.1 | 47.67 | 47.4 | 32.8 | 64.1 | 44.7 | 78.9 | 11.3 | 47.5 | 27.4 | 38.6 | 56.7 | 75 |
|
| 87 |
+
| MPT-7B | 30.06 | 23.5 | 21.3 | 27.5 | 25.9 | 75 | 2.9 | 9.1 | 17.1 | 22.8 | 35.6 | 70 |
|
| 88 |
+
| Qwen1.5-7B | 55.12 | 73.57 | **50.8** | 62.15 | 71.84 | 72.62 | **20.36** | 54.36 | **53.05** | 36.8 | 40.01 | 70.74 |
|
| 89 |
+
| Qwen-7B | 49.53 | 63.4 | 45.3 | 59.7 | 62.5 | 75 | 13.3 | 54.1 | 27.4 | 31.4 | 45.2 | 67.5 |
|
| 90 |
+
| XVERSE-7B | 34.27 | 61.1 | 39 | 58.4 | 60.8 | 73.7 | 2.2 | 11.7 | 4.9 | 10.2 | 31 | 24 |
|
| 91 |
+
| Yi-6B | 47.8 | 73 | 44.3 | 64 | **73.5** | 73.1 | 6.3 | 39.9 | 15.2 | 23.6 | 44.9 | 68 |
|
| 92 |
+
| **360Zhinao-7B** | 56.15 | **74.11** | 49.49 | **67.44** | 72.38 | **83.05** | 16.38 | 53.83 | 35.98 | 42.4 | 43.95 | **78.59** |
|
| 93 |
+
|
| 94 |
+
以上结果,在官方[Opencompass](https://rank.opencompass.org.cn/leaderboard-llm)上可查询或可复现。
|
| 95 |
+
|
| 96 |
+
## Chat模型
|
| 97 |
+
|
| 98 |
+
我们采用两阶段的方式训练长文本模型.
|
| 99 |
+
|
| 100 |
+
**第一阶段**:我们增大RoPE base,将上下文长度扩展至32K训练:
|
| 101 |
+
- 首先,对基础模型进行了约5B tokens的32K窗口继续预训练。
|
| 102 |
+
- 接着,SFT阶段使用了多种形式和来源的长文本数据,包括高质量的人工标注32K长文本数据。
|
| 103 |
+
|
| 104 |
+
**第二阶段**:我们将上下文长度扩展至360K进行训练,使用数据如下:
|
| 105 |
+
- 少量高质量人工标注数据。
|
| 106 |
+
- 由于带有标注的超长文本数据的稀缺性,我们构造了多种形式的合成数据:
|
| 107 |
+
- 多文档问答:类似[Ziya-Reader](https://arxiv.org/abs/2311.09198),我们基于360自有数据构造了多种类型的多文档问答数据,同时将问答改为多轮,显著提升长文本的训练效率。
|
| 108 |
+
- 单文档问答:类似[LLama2 Long](https://arxiv.org/abs/2309.16039),我们构造了基于超长文本各个片段的多轮问答数据。
|
| 109 |
+
|
| 110 |
+
我们在多种长度和多种任务的评测Benchmark上验证不同版本模型的性能。
|
| 111 |
+
|
| 112 |
+
- ### 360Zhinao-7B-Chat-32K模型长文本能力评测
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
我们使用LongBench验证长文本效果。[LongBench](https://github.com/THUDM/LongBench)是第一个多任务、中英双语、针对大语言模型长文本理解能力的评测基准。LongBench由六大类、二十一个不同的任务组成,我们选择其中与中文长文本应用最密切相关的中文单文档问答、多文档问答、摘要、Few-shot等任务进行评测。
|
| 116 |
+
|
| 117 |
+
| Model | Avg | 单文档QA | 多文档QA | 摘要 | Few-shot学习 | 代码补全 |
|
| 118 |
+
| :------------------------ |:---------:|:--------:|:---------:|:---------:|:------------:|:---------:|
|
| 119 |
+
| GPT-3.5-Turbo-16k | 37.84 | 61.2 | 28.7 | 16 | 29.2 | 54.1 |
|
| 120 |
+
| ChatGLM2-6B-32k | 37.16 | 51.6 | 37.6 | 16.2 | 27.7 | 52.7 |
|
| 121 |
+
| ChatGLM3-6B-32k | 44.62 | **62.3** | 44.8 | 17.8 | 42 | 56.2 |
|
| 122 |
+
| InternLM2-Chat-7B | 42.20 | 56.65 | 29.15 | **17.99** | 43.5 | **63.72** |
|
| 123 |
+
| Qwen1.5-Chat-7B | 36.75 | 52.85 | 30.08 | 14.28 | 32 | 54.55 |
|
| 124 |
+
| Qwen1.5-Chat-14B | 39.80 | 60.39 | 27.99 | 14.77 | 37 | 58.87 |
|
| 125 |
+
| 360Zhinao-7B-Chat-32K | **45.18** | 57.18 | **48.06** | 15.03 | **44** | 61.64 |
|
| 126 |
+
|
| 127 |
+
- ### 360Zhinao-7B-Chat-360K“大海捞针”测试
|
| 128 |
+
|
| 129 |
+
大海捞针测试([NeedleInAHaystack](https://github.com/gkamradt/LLMTest_NeedleInAHaystack))是将关键信息插入一段长文本的不同位置,再对该关键信息提问,从而测试大模型的长文本能力的一种方法。
|
| 130 |
+
|
| 131 |
+
360Zhinao-7B-Chat-360K在中英文大海捞针中都能达到98%以上的准确率。
|
| 132 |
+
|
| 133 |
+
- 英文"大海捞针"(和[NeedleInAHaystack](https://github.com/gkamradt/LLMTest_NeedleInAHaystack)相同)
|
| 134 |
+
|
| 135 |
+
<p align="center">
|
| 136 |
+
<img src="assets/360Zhinao-7B-Chat-360K.en_score.png" width="600" />
|
| 137 |
+
<p>
|
| 138 |
+
|
| 139 |
+
**针**:The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day.
|
| 140 |
+
|
| 141 |
+
**提问**:What is the best thing to do in San Francisco?
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
- 中文“大海捞针”
|
| 145 |
+
|
| 146 |
+
<p align="center">
|
| 147 |
+
<img src="assets/360Zhinao-7B-Chat-360K.zh_score.png" width="600" />
|
| 148 |
+
<p>
|
| 149 |
+
|
| 150 |
+
我们仿照[SuperCLUE-200K测评基准](https://mp.weixin.qq.com/s/QgoRf2LB-7vc3vTFOHJkpw)构造了中文大海捞针:
|
| 151 |
+
|
| 152 |
+
**海**:长篇小说。
|
| 153 |
+
|
| 154 |
+
**针**:王莽是一名勤奋的店员,他每天凌晨就起床,赶在第一缕阳光照亮大地之前到达店铺,为即将开始的一天做准备。他清扫店铺,整理货架,为顾客提供方便。他对五金的种类和用途了如指掌,无论顾客需要什么,他总能准确地找到。\n然而,他的老板刘秀却总是对他吹毛求疵。刘秀是个挑剔的人,他总能在王莽的工作中找出一些小错误,然后以此为由扣他的工资。他对王莽的工作要求非常严格,甚至有些过分。即使王莽做得再好,刘秀也总能找出一些小问题,让王莽感到非常沮丧。\n王莽虽然对此感到不满,但他并没有放弃。他知道,只有通过自己的努力,才能获得更好的生活。他坚持每天早起,尽管他知道那天可能会再次被刘秀扣工资。他始终保持微笑,尽管他知道刘秀可能会再次对他挑剔。
|
| 155 |
+
|
| 156 |
+
**提问**:王莽在谁的手下工作?
|
| 157 |
+
|
| 158 |
+
<br>
|
| 159 |
+
|
| 160 |
+
# 快速开始
|
| 161 |
+
简单的示例来说明如何利用🤖 ModelScope和🤗 Transformers快速使用360Zhinao-7B-Base和360Zhinao-7B-Chat
|
| 162 |
+
|
| 163 |
+
## 依赖安装
|
| 164 |
+
- python 3.8 and above
|
| 165 |
+
- pytorch 2.0 and above
|
| 166 |
+
- transformers 4.37.2 and above
|
| 167 |
+
- CUDA 11.4 and above are recommended.
|
| 168 |
+
|
| 169 |
+
```shell
|
| 170 |
+
pip install -r requirements.txt
|
| 171 |
+
```
|
| 172 |
+
我们推荐安装flash-attention(当前已支持flash attention 2)来提高你的运行效率以及降低显存占用。(flash-attention只是可选项,不安装也可正常运行该项目)
|
| 173 |
+
|
| 174 |
+
>flash-attn >= 2.3.6
|
| 175 |
+
```shell
|
| 176 |
+
FLASH_ATTENTION_FORCE_BUILD=TRUE pip install flash-attn==2.3.6
|
| 177 |
+
```
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
## 🤗 Transformers
|
| 181 |
+
### Base模型推理
|
| 182 |
+
|
| 183 |
+
此代码演示使用transformers快速使用360Zhinao-7B-Base模型进行推理
|
| 184 |
+
```python
|
| 185 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM
|
| 186 |
+
from transformers.generation import GenerationConfig
|
| 187 |
+
|
| 188 |
+
MODEL_NAME_OR_PATH = "qihoo360/360Zhinao-7B-Base"
|
| 189 |
+
|
| 190 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 191 |
+
MODEL_NAME_OR_PATH,
|
| 192 |
+
trust_remote_code=True)
|
| 193 |
+
|
| 194 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 195 |
+
MODEL_NAME_OR_PATH,
|
| 196 |
+
device_map="auto",
|
| 197 |
+
trust_remote_code=True)
|
| 198 |
+
|
| 199 |
+
generation_config = GenerationConfig.from_pretrained(
|
| 200 |
+
MODEL_NAME_OR_PATH,
|
| 201 |
+
trust_remote_code=True)
|
| 202 |
+
|
| 203 |
+
inputs = tokenizer('中国二十四节气\n1. 立春\n2. 雨水\n3. 惊蛰\n4. 春分\n5. 清明\n', return_tensors='pt')
|
| 204 |
+
inputs = inputs.to(model.device)
|
| 205 |
+
|
| 206 |
+
pred = model.generate(input_ids=inputs["input_ids"], generation_config=generation_config)
|
| 207 |
+
print("outputs:\n", tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
|
| 208 |
+
```
|
| 209 |
+
|
| 210 |
+
### Chat模型推理
|
| 211 |
+
|
| 212 |
+
此代码演示使用transformers快速使用360Zhinao-7B-Chat-4K模型进行推理
|
| 213 |
+
```python
|
| 214 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM
|
| 215 |
+
from transformers.generation import GenerationConfig
|
| 216 |
+
|
| 217 |
+
MODEL_NAME_OR_PATH = "qihoo360/360Zhinao-7B-Chat-4K"
|
| 218 |
+
|
| 219 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 220 |
+
MODEL_NAME_OR_PATH,
|
| 221 |
+
trust_remote_code=True)
|
| 222 |
+
|
| 223 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 224 |
+
MODEL_NAME_OR_PATH,
|
| 225 |
+
device_map="auto",
|
| 226 |
+
trust_remote_code=True)
|
| 227 |
+
|
| 228 |
+
generation_config = GenerationConfig.from_pretrained(
|
| 229 |
+
MODEL_NAME_OR_PATH,
|
| 230 |
+
trust_remote_code=True)
|
| 231 |
+
|
| 232 |
+
messages = []
|
| 233 |
+
#round-1
|
| 234 |
+
messages.append({"role": "user", "content": "介绍一下刘德华"})
|
| 235 |
+
response = model.chat(tokenizer=tokenizer, messages=messages, generation_config=generation_config)
|
| 236 |
+
messages.append({"role": "assistant", "content": response})
|
| 237 |
+
print(messages)
|
| 238 |
+
|
| 239 |
+
#round-2
|
| 240 |
+
messages.append({"role": "user", "content": "他有什么代表作?"})
|
| 241 |
+
response = model.chat(tokenizer=tokenizer, messages=messages, generation_config=generation_config)
|
| 242 |
+
messages.append({"role": "assistant", "content": response})
|
| 243 |
+
print(messages)
|
| 244 |
+
```
|
| 245 |
+
|
| 246 |
+
## 🤖 ModelScope
|
| 247 |
+
### Base模型推理
|
| 248 |
+
|
| 249 |
+
此代码演示使用ModelScope快速使用360Zhinao-7B-Base模型进行推理
|
| 250 |
+
|
| 251 |
+
|
| 252 |
+
```python
|
| 253 |
+
from modelscope import AutoModelForCausalLM, AutoTokenizer
|
| 254 |
+
from modelscope import GenerationConfig
|
| 255 |
+
|
| 256 |
+
MODEL_NAME_OR_PATH = "qihoo360/360Zhinao-7B-Base"
|
| 257 |
+
|
| 258 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 259 |
+
MODEL_NAME_OR_PATH,
|
| 260 |
+
trust_remote_code=True)
|
| 261 |
+
|
| 262 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 263 |
+
MODEL_NAME_OR_PATH,
|
| 264 |
+
device_map="auto",
|
| 265 |
+
trust_remote_code=True)
|
| 266 |
+
|
| 267 |
+
generation_config = GenerationConfig.from_pretrained(
|
| 268 |
+
MODEL_NAME_OR_PATH,
|
| 269 |
+
trust_remote_code=True)
|
| 270 |
+
|
| 271 |
+
inputs = tokenizer('中国二十四节气\n1. 立春\n2. 雨水\n3. 惊蛰\n4. 春分\n5. 清明\n', return_tensors='pt')
|
| 272 |
+
inputs = inputs.to(model.device)
|
| 273 |
+
|
| 274 |
+
pred = model.generate(input_ids=inputs["input_ids"], generation_config=generation_config)
|
| 275 |
+
print("outputs:\n", tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
|
| 276 |
+
```
|
| 277 |
+
|
| 278 |
+
### Chat模型推理
|
| 279 |
+
|
| 280 |
+
此代码演示使用ModelScope快速使用360Zhinao-7B-Chat-4K模型进行推理
|
| 281 |
+
```python
|
| 282 |
+
from modelscope import AutoModelForCausalLM, AutoTokenizer
|
| 283 |
+
from modelscope import GenerationConfig
|
| 284 |
+
|
| 285 |
+
MODEL_NAME_OR_PATH = "qihoo360/360Zhinao-7B-Chat-4K"
|
| 286 |
+
|
| 287 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 288 |
+
MODEL_NAME_OR_PATH,
|
| 289 |
+
trust_remote_code=True)
|
| 290 |
+
|
| 291 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 292 |
+
MODEL_NAME_OR_PATH,
|
| 293 |
+
device_map="auto",
|
| 294 |
+
trust_remote_code=True)
|
| 295 |
+
|
| 296 |
+
generation_config = GenerationConfig.from_pretrained(
|
| 297 |
+
MODEL_NAME_OR_PATH,
|
| 298 |
+
trust_remote_code=True)
|
| 299 |
+
|
| 300 |
+
messages = []
|
| 301 |
+
#round-1
|
| 302 |
+
messages.append({"role": "user", "content": "介绍一下刘德华"})
|
| 303 |
+
response = model.chat(tokenizer=tokenizer, messages=messages, generation_config=generation_config)
|
| 304 |
+
messages.append({"role": "assistant", "content": response})
|
| 305 |
+
print(messages)
|
| 306 |
+
|
| 307 |
+
#round-2
|
| 308 |
+
messages.append({"role": "user", "content": "他有什么代表作?"})
|
| 309 |
+
response = model.chat(tokenizer=tokenizer, messages=messages, generation_config=generation_config)
|
| 310 |
+
messages.append({"role": "assistant", "content": response})
|
| 311 |
+
print(messages)
|
| 312 |
+
```
|
| 313 |
+
|
| 314 |
+
## 终端 Demo
|
| 315 |
+
可使用终端交互实现快速体验
|
| 316 |
+
```shell
|
| 317 |
+
python cli_demo.py
|
| 318 |
+
```
|
| 319 |
+
<p align="center">
|
| 320 |
+
<img src="assets/cli_demo.gif" width="600" />
|
| 321 |
+
<p>
|
| 322 |
+
|
| 323 |
+
## 网页 Demo
|
| 324 |
+
也可使用网页交互实现快速体验
|
| 325 |
+
```shell
|
| 326 |
+
streamlit run web_demo.py
|
| 327 |
+
```
|
| 328 |
+
<p align="center">
|
| 329 |
+
<img src="assets/web_demo.gif" width="600" />
|
| 330 |
+
<p>
|
| 331 |
+
|
| 332 |
+
## API Demo
|
| 333 |
+
启动命令
|
| 334 |
+
```shell
|
| 335 |
+
python openai_api.py
|
| 336 |
+
```
|
| 337 |
+
|
| 338 |
+
请求参数
|
| 339 |
+
```shell
|
| 340 |
+
curl --location --request POST 'http://localhost:8360/v1/chat/completions' \
|
| 341 |
+
--header 'Content-Type: application/json' \
|
| 342 |
+
--data-raw '{
|
| 343 |
+
"max_new_tokens": 200,
|
| 344 |
+
"do_sample": true,
|
| 345 |
+
"top_k": 0,
|
| 346 |
+
"top_p": 0.8,
|
| 347 |
+
"temperature": 1.0,
|
| 348 |
+
"repetition_penalty": 1.0,
|
| 349 |
+
"messages": [
|
| 350 |
+
{
|
| 351 |
+
"role": "user",
|
| 352 |
+
"content": "你叫什么名字"
|
| 353 |
+
}
|
| 354 |
+
]
|
| 355 |
+
}'
|
| 356 |
+
```
|
| 357 |
+
|
| 358 |
+
<br>
|
| 359 |
+
|
| 360 |
+
# 模型推理
|
| 361 |
+
## 模型量化
|
| 362 |
+
我们提供了基于AutoGPTQ的量化方案,并开源了Int4量化模型。
|
| 363 |
+
|
| 364 |
+
## 模型部署
|
| 365 |
+
### vLLM安装环境
|
| 366 |
+
如希望部署及加速推理,我们建议你使用 `vLLM==0.3.3`。
|
| 367 |
+
|
| 368 |
+
如果你使用**CUDA 12.1和PyTorch 2.1**,可以直接使用以下命令安装vLLM。
|
| 369 |
+
```shell
|
| 370 |
+
pip install vllm==0.3.3
|
| 371 |
+
```
|
| 372 |
+
|
| 373 |
+
否则请参考vLLM官方的[安装说明](https://docs.vllm.ai/en/latest/getting_started/installation.html)。
|
| 374 |
+
|
| 375 |
+
>安装完成后,还需要以下操作~
|
| 376 |
+
1. 把vllm/zhinao.py文件复制到env环境对应的vllm/model_executor/models目录下。
|
| 377 |
+
2. 把vllm/serving_chat.py文件复制到env环境对应的vllm/entrypoints/openai目录下。
|
| 378 |
+
3. 然后在vllm/model_executor/models/\_\_init\_\_.py文件增加一行代码
|
| 379 |
+
|
| 380 |
+
```shell
|
| 381 |
+
"ZhinaoForCausalLM": ("zhinao", "ZhinaoForCausalLM"),
|
| 382 |
+
```
|
| 383 |
+
|
| 384 |
+
### vLLM服务启动
|
| 385 |
+
|
| 386 |
+
启动服务
|
| 387 |
+
```shell
|
| 388 |
+
python -m vllm.entrypoints.openai.api_server \
|
| 389 |
+
--served-model-name 360Zhinao-7B-Chat-4K \
|
| 390 |
+
--model qihoo360/360Zhinao-7B-Chat-4K \
|
| 391 |
+
--trust-remote-code \
|
| 392 |
+
--tensor-parallel-size 1 \
|
| 393 |
+
--max-model-len 4096 \
|
| 394 |
+
--host 0.0.0.0 \
|
| 395 |
+
--port 8360
|
| 396 |
+
```
|
| 397 |
+
|
| 398 |
+
使用curl请求服务
|
| 399 |
+
```shell
|
| 400 |
+
curl http://localhost:8360/v1/chat/completions \
|
| 401 |
+
-H "Content-Type: application/json" \
|
| 402 |
+
-d '{
|
| 403 |
+
"model": "360Zhinao-7B-Chat-4K",
|
| 404 |
+
"max_tokens": 200,
|
| 405 |
+
"top_k": -1,
|
| 406 |
+
"top_p": 0.8,
|
| 407 |
+
"temperature": 1.0,
|
| 408 |
+
"presence_penalty": 0.0,
|
| 409 |
+
"frequency_penalty": 0.0,
|
| 410 |
+
"messages": [
|
| 411 |
+
{"role": "system", "content": "You are a helpful assistant."},
|
| 412 |
+
{"role": "user", "content": "你好"}
|
| 413 |
+
],
|
| 414 |
+
"stop": [
|
| 415 |
+
"<eod>",
|
| 416 |
+
"<|im_end|>",
|
| 417 |
+
"<|im_start|>"
|
| 418 |
+
]
|
| 419 |
+
}'
|
| 420 |
+
```
|
| 421 |
+
使用python请求服务
|
| 422 |
+
```python
|
| 423 |
+
from openai import OpenAI
|
| 424 |
+
# Set OpenAI's API key and API base to use vLLM's API server.
|
| 425 |
+
openai_api_key = "EMPTY"
|
| 426 |
+
openai_api_base = "http://localhost:8360/v1"
|
| 427 |
+
|
| 428 |
+
client = OpenAI(
|
| 429 |
+
api_key=openai_api_key,
|
| 430 |
+
base_url=openai_api_base,
|
| 431 |
+
)
|
| 432 |
+
|
| 433 |
+
chat_response = client.chat.completions.create(
|
| 434 |
+
model="360Zhinao-7B-Chat-4K",
|
| 435 |
+
messages=[
|
| 436 |
+
{"role": "system", "content": "You are a helpful assistant."},
|
| 437 |
+
{"role": "user", "content": "你好"},
|
| 438 |
+
],
|
| 439 |
+
stop=[
|
| 440 |
+
"<eod>",
|
| 441 |
+
"<|im_end|>",
|
| 442 |
+
"<|im_start|>"
|
| 443 |
+
],
|
| 444 |
+
presence_penalty=0.0,
|
| 445 |
+
frequency_penalty=0.0
|
| 446 |
+
)
|
| 447 |
+
print("Chat response:", chat_response)
|
| 448 |
+
```
|
| 449 |
+
|
| 450 |
+
> 注意:如需要开启重复惩罚,建议使用 *presence_penalty* 和 *frequency_penalty* 参数。
|
| 451 |
+
|
| 452 |
+
<br>
|
| 453 |
+
|
| 454 |
+
# 模型微调
|
| 455 |
+
## 训练数据
|
| 456 |
+
|
| 457 |
+
我们提供了微调训练样例数据 data/test.json,该样例数据是从 [multiturn_chat_0.8M](https://huggingface.co/datasets/BelleGroup/multiturn_chat_0.8M) 采样出 1 万条,并且做了格式转换。
|
| 458 |
+
|
| 459 |
+
数据格式:
|
| 460 |
+
```json
|
| 461 |
+
[
|
| 462 |
+
{
|
| 463 |
+
"id": 1,
|
| 464 |
+
"conversations": [
|
| 465 |
+
{
|
| 466 |
+
"from": "system",
|
| 467 |
+
"value": "You are a helpful assistant."
|
| 468 |
+
},
|
| 469 |
+
{
|
| 470 |
+
"from": "user",
|
| 471 |
+
"value": "您好啊"
|
| 472 |
+
},
|
| 473 |
+
{
|
| 474 |
+
"from": "assistant",
|
| 475 |
+
"value": "你好!我今天能为您做些什么?有什么问题或需要帮助吗? 我在这里为您提供服务。"
|
| 476 |
+
}
|
| 477 |
+
]
|
| 478 |
+
}
|
| 479 |
+
]
|
| 480 |
+
```
|
| 481 |
+
|
| 482 |
+
## 微调训练
|
| 483 |
+
训练脚本如下:
|
| 484 |
+
```shell
|
| 485 |
+
set -x
|
| 486 |
+
|
| 487 |
+
HOSTFILE=hostfile
|
| 488 |
+
DS_CONFIG=./finetune/ds_config_zero2.json
|
| 489 |
+
|
| 490 |
+
# PARAMS
|
| 491 |
+
LR=5e-6
|
| 492 |
+
EPOCHS=3
|
| 493 |
+
MAX_LEN=4096
|
| 494 |
+
BATCH_SIZE=4
|
| 495 |
+
NUM_NODES=1
|
| 496 |
+
NUM_GPUS=8
|
| 497 |
+
MASTER_PORT=29500
|
| 498 |
+
|
| 499 |
+
IS_CONCAT=False # 是否数据拼接到最大长度(MAX_LEN)
|
| 500 |
+
|
| 501 |
+
DATA_PATH="./data/training_data_sample.json"
|
| 502 |
+
MODEL_PATH="qihoo360/360Zhinao-7B-Base"
|
| 503 |
+
OUTPUT_DIR="./outputs/"
|
| 504 |
+
|
| 505 |
+
deepspeed --hostfile ${HOSTFILE} \
|
| 506 |
+
--master_port ${MASTER_PORT} \
|
| 507 |
+
--num_nodes ${NUM_NODES} \
|
| 508 |
+
--num_gpus ${NUM_GPUS} \
|
| 509 |
+
finetune.py \
|
| 510 |
+
--report_to "tensorboard" \
|
| 511 |
+
--data_path ${DATA_PATH} \
|
| 512 |
+
--model_name_or_path ${MODEL_PATH} \
|
| 513 |
+
--output_dir ${OUTPUT_DIR} \
|
| 514 |
+
--model_max_length ${MAX_LEN} \
|
| 515 |
+
--num_train_epochs ${EPOCHS} \
|
| 516 |
+
--per_device_train_batch_size ${BATCH_SIZE} \
|
| 517 |
+
--gradient_accumulation_steps 1 \
|
| 518 |
+
--save_strategy steps \
|
| 519 |
+
--save_steps 200 \
|
| 520 |
+
--learning_rate ${LR} \
|
| 521 |
+
--lr_scheduler_type cosine \
|
| 522 |
+
--adam_beta1 0.9 \
|
| 523 |
+
--adam_beta2 0.95 \
|
| 524 |
+
--adam_epsilon 1e-8 \
|
| 525 |
+
--max_grad_norm 1.0 \
|
| 526 |
+
--weight_decay 0.1 \
|
| 527 |
+
--warmup_ratio 0.01 \
|
| 528 |
+
--gradient_checkpointing True \
|
| 529 |
+
--bf16 True \
|
| 530 |
+
--tf32 True \
|
| 531 |
+
--deepspeed ${DS_CONFIG} \
|
| 532 |
+
--is_concat ${IS_CONCAT} \
|
| 533 |
+
--logging_steps 1 \
|
| 534 |
+
--log_on_each_node False
|
| 535 |
+
```
|
| 536 |
+
```shell
|
| 537 |
+
bash finetune/ds_finetune.sh
|
| 538 |
+
```
|
| 539 |
+
- 可通过配置hostfile,实现单机、多机训练。
|
| 540 |
+
- 可通过配置ds_config,实现zero2、zero3。
|
| 541 |
+
- 可通过配置fp16、bf16实现混合精度训练,建议使用bf16,与预训练模型保持一致。
|
| 542 |
+
- 可通过配置is_concat参数,控制训练数据是否拼接,当训练数据量级较大时,可通过拼接提升训练效率。
|
| 543 |
+
|
| 544 |
+
<br>
|
| 545 |
+
|
| 546 |
+
# 许可证
|
| 547 |
+
|
| 548 |
+
本仓库源码遵循开源许可证Apache 2.0。
|
| 549 |
+
|
| 550 |
+
360智脑开源模型支持商用,若需将本模型及衍生模型用于商业用途,请通过邮箱([email protected])联系进行申请, 具体许可协议请见[《360智脑开源模型许可证》](./360智脑开源模型许可证.txt)。
|
README_EN.md
ADDED
|
@@ -0,0 +1,533 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
<h1>
|
| 3 |
+
360Zhinao (360智脑)
|
| 4 |
+
</h1>
|
| 5 |
+
</div>
|
| 6 |
+
<div align="center">
|
| 7 |
+
🤖 <a href="https://www.modelscope.cn/profile/qihoo360">ModelScope</a>   |   
|
| 8 |
+
🔥 <a href="https://github.com/Qihoo360/360zhinao/blob/main/assets/WeChat.png">GitHub</a>   |   
|
| 9 |
+
💬 <a href="https://github.com/Qihoo360/360zhinao/tree/main/assets/WeChat.png">WeChat (微信)</a>  
|
| 10 |
+
</div>
|
| 11 |
+
<br>
|
| 12 |
+
<p align="center">
|
| 13 |
+
Feel free to visit 360Zhinao's official website<a href="https://ai.360.com"> https://ai.360.com</a> for more experience.
|
| 14 |
+
</p>
|
| 15 |
+
|
| 16 |
+
<br>
|
| 17 |
+
|
| 18 |
+
# Models Introduction
|
| 19 |
+
🎉🎉🎉We open-source the 360Zhinao model series:
|
| 20 |
+
- **360Zhinao-7B-Base**
|
| 21 |
+
- **360Zhinao-7B-Chat-4K**
|
| 22 |
+
- **360Zhinao-7B-Chat-32K**
|
| 23 |
+
- **360Zhinao-7B-Chat-360K**
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
The characteristics of the 360Zhinao open-source models are:
|
| 27 |
+
- **Base Model:** Leveraging a high-quality corpus of 3.4 trillion Tokens which mainly consist of Chinese, English and code, we achieved competitive performance on relevant benchmark evaluations of the same model scale.
|
| 28 |
+
- **Chat Model:** Powerful chat capabilities and three different sequence lengths of 4K, 32K and 360K. 360K (about 500k Chinese characters) is the longest sequcence length among open-sourced Chinese models until now.
|
| 29 |
+
|
| 30 |
+
<br>
|
| 31 |
+
|
| 32 |
+
# News and Updates
|
| 33 |
+
- 2024.04.11 We release **360Zhinao-7B** 1.0 version, include the base model and three chat model with sequence lengths of 4K, 32K adn 360K.
|
| 34 |
+
|
| 35 |
+
<br>
|
| 36 |
+
|
| 37 |
+
# Table of contents
|
| 38 |
+
- [Download URL](#Download-URL)
|
| 39 |
+
- [Model Evaluation](#Model-Evaluation)
|
| 40 |
+
- [Quickstart](#Quickstart)
|
| 41 |
+
- [Model Inference](#Model-Inference)
|
| 42 |
+
- [Model Finetune](#Model-Finetune)
|
| 43 |
+
- [License](#License)
|
| 44 |
+
|
| 45 |
+
<br>
|
| 46 |
+
|
| 47 |
+
# Download URL
|
| 48 |
+
See the following table for this release and download links:
|
| 49 |
+
| Size | Model | BF16 | Int4|
|
| 50 |
+
|-|-|-|-|
|
| 51 |
+
| 7B | 360Zhinao-7B-Base | <a href="https://www.modelscope.cn/models/qihoo360/360Zhinao-7B-Base/summary">🤖</a> <a href="https://huggingface.co/qihoo360/360Zhinao-7B-Base">🤗</a> | |
|
| 52 |
+
| 7B | 360Zhinao-7B-Chat-4K | <a href="https://www.modelscope.cn/models/qihoo360/360Zhinao-7B-Chat-4K/summary">🤖</a> <a href="https://huggingface.co/qihoo360/360Zhinao-7B-Chat-4K">🤗</a> | <a href="https://www.modelscope.cn/models/qihoo360/360Zhinao-7B-Chat-4K-Int4/summary">🤖</a> <a href="https://huggingface.co/qihoo360/360Zhinao-7B-Chat-4K-Int4">🤗</a> |
|
| 53 |
+
| 7B | 360Zhinao-7B-Chat-32K | <a href="https://www.modelscope.cn/models/qihoo360/360Zhinao-7B-Chat-32K/summary">🤖</a> <a href="https://huggingface.co/qihoo360/360Zhinao-7B-Chat-32K">🤗</a> | <a href="https://www.modelscope.cn/models/qihoo360/360Zhinao-7B-Chat-32K-Int4/summary">🤖</a> <a href="https://huggingface.co/qihoo360/360Zhinao-7B-Chat-32K-Int4">🤗</a> |
|
| 54 |
+
| 7B | 360Zhinao-7B-Chat-360K | <a href="https://www.modelscope.cn/models/qihoo360/360Zhinao-7B-Chat-360K/summary">🤖</a> <a href="https://huggingface.co/qihoo360/360Zhinao-7B-Chat-360K">🤗</a> | <a href="https://www.modelscope.cn/models/qihoo360/360Zhinao-7B-Chat-360K-Int4/summary">🤖</a> <a href="https://huggingface.co/qihoo360/360Zhinao-7B-Chat-360K-Int4">🤗</a> |
|
| 55 |
+
|
| 56 |
+
<br>
|
| 57 |
+
|
| 58 |
+
# Model Evaluation
|
| 59 |
+
## Base Model
|
| 60 |
+
We evaluate the performance of our model on the OpenCompass evaluation datasets, including C-Eval, AGIEval, MMLU, CMMLU, HellaSwag, MATH, GSM8K, HumanEval, MBPP, BBH, LAMBADA. The ablity evaluated of model include natural language understanding, knowledge, mathematical computation and reasoning, code generation, logical reasoning, etc.
|
| 61 |
+
|
| 62 |
+
| <div style="width: 100pt">Model</div> | AVG | CEval | AGIEval | MMLU | CMMLU | HellaSwag | MATH | GSM8K | HumanEval | MBPP | BBH | LAMBADA |
|
| 63 |
+
|:----------------------|:---------:|:---------:|:---------:|:---------:|:---------:|:---------:|:---------:|:---------:|:---------:|:---------:|:---------:|:---------:|
|
| 64 |
+
| Baichuan2-7B | 41.49 | 56.3 | 34.6 | 54.7 | 57 | 67 | 5.4 | 24.6 | 17.7 | 24 | 41.8 | 73.3 |
|
| 65 |
+
| Baichuan-7B | 31.94 | 44.7 | 24.6 | 41.5 | 44.6 | 68.4 | 2.5 | 9.6 | 9.1 | 6.4 | 32.8 | 67.1 |
|
| 66 |
+
| ChatGLM3-6B | **58.67** | 67 | 47.4 | 62.8 | 66.5 | 76.5 | 19.2 | 61 | 44.5 | **57.2** | **66.2** | 77.1 |
|
| 67 |
+
| DeepSeek-7B | 39.8 | 45 | 24 | 49.3 | 46.8 | 73.4 | 4.2 | 18.3 | 25 | 36.4 | 42.8 | 72.6 |
|
| 68 |
+
| InternLM2-7B | 58.01 | 65.7 | 50.2 | 65.5 | 66.2 | 79.6 | 19.9 | **70.6** | 41.5 | 42.4 | 64.4 | 72.1 |
|
| 69 |
+
| InternLM-7B | 39.33 | 53.4 | 36.9 | 51 | 51.8 | 70.6 | 6.3 | 31.2 | 13.4 | 14 | 37 | 67 |
|
| 70 |
+
| LLaMA-2-7B | 33.27 | 32.5 | 21.8 | 46.8 | 31.8 | 74 | 3.3 | 16.7 | 12.8 | 14.8 | 38.2 | 73.3 |
|
| 71 |
+
| LLaMA-7B | 30.35 | 27.3 | 20.6 | 35.6 | 26.8 | 74.3 | 2.9 | 10 | 12.8 | 16.8 | 33.5 | 73.3 |
|
| 72 |
+
| Mistral-7B-v0.1 | 47.67 | 47.4 | 32.8 | 64.1 | 44.7 | 78.9 | 11.3 | 47.5 | 27.4 | 38.6 | 56.7 | 75 |
|
| 73 |
+
| MPT-7B | 30.06 | 23.5 | 21.3 | 27.5 | 25.9 | 75 | 2.9 | 9.1 | 17.1 | 22.8 | 35.6 | 70 |
|
| 74 |
+
| Qwen1.5-7B | 55.12 | 73.57 | **50.8** | 62.15 | 71.84 | 72.62 | **20.36** | 54.36 | **53.05** | 36.8 | 40.01 | 70.74 |
|
| 75 |
+
| Qwen-7B | 49.53 | 63.4 | 45.3 | 59.7 | 62.5 | 75 | 13.3 | 54.1 | 27.4 | 31.4 | 45.2 | 67.5 |
|
| 76 |
+
| XVERSE-7B | 34.27 | 61.1 | 39 | 58.4 | 60.8 | 73.7 | 2.2 | 11.7 | 4.9 | 10.2 | 31 | 24 |
|
| 77 |
+
| Yi-6B | 47.8 | 73 | 44.3 | 64 | **73.5** | 73.1 | 6.3 | 39.9 | 15.2 | 23.6 | 44.9 | 68 |
|
| 78 |
+
| **360Zhinao-7B** | 56.15 | **74.11** | 49.49 | **67.44** | 72.38 | **83.05** | 16.38 | 53.83 | 35.98 | 42.4 | 43.95 | **78.59** |
|
| 79 |
+
|
| 80 |
+
The above results could be viewed or reproduced on [Opencompass](https://rank.opencompass.org.cn/leaderboard-llm).
|
| 81 |
+
|
| 82 |
+
## Chat Models
|
| 83 |
+
|
| 84 |
+
We adopted a two-stage approach to train the long context models.
|
| 85 |
+
|
| 86 |
+
**First stage**: We increased RoPE base and extended the context length to 32K.
|
| 87 |
+
- Firstly, we performed Continual Pretraining on approximately 5B tokens with a 32K context window.
|
| 88 |
+
- Then during the SFT stage, we fine-tuned the model using long data from various sources, including high-quality human-labeled 32K data.
|
| 89 |
+
|
| 90 |
+
**Second stage**: We extended the context length to 360K, training with the following data:
|
| 91 |
+
- A small amount of high-quality human-labeled super-long data.
|
| 92 |
+
- Due to the scarcity of annotated super-long data, we constructed various forms of synthetic data.
|
| 93 |
+
- Multi-Doc QA: Similar to [Ziya-Reader](https://arxiv.org/abs/2311.09198), we generated multi-document QA pairs based on 360's database. Multiple QA pairs are constructed for one row of Multi-Doc QA data input, resulting in a multi-turn format and significantly improving the training efficiency.
|
| 94 |
+
- Single-Doc QA: Similar to [LLama2 Long](https://arxiv.org/abs/2309.16039), we constructed multi-turn QA data based on different segments within one row of long-text input.
|
| 95 |
+
|
| 96 |
+
We evaluated our models across various lengths and benchmarks.
|
| 97 |
+
|
| 98 |
+
- ### Long Context Benchmarks
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
We evaluated our 32K and 360K models on [LongBench](https://github.com/THUDM/LongBench), a multi-task bilingual benchmark for long contexts. We report results on Chinese tasks that are the most relevant to downstream applications: Single/Multi-Doc QA, Summarization, Few-Shot Learning and Code Completion.
|
| 102 |
+
|
| 103 |
+
| Model | Avg | 单文档QA | 多文档QA | 摘要 | Few-shot学习 | 代码补全 |
|
| 104 |
+
| :------------------------ |:---------:|:--------:|:---------:|:---------:|:------------:|:---------:|
|
| 105 |
+
| GPT-3.5-Turbo-16k | 37.84 | 61.2 | 28.7 | 16 | 29.2 | 54.1 |
|
| 106 |
+
| ChatGLM2-6B-32k | 37.16 | 51.6 | 37.6 | 16.2 | 27.7 | 52.7 |
|
| 107 |
+
| ChatGLM3-6B-32k | 44.62 | **62.3** | 44.8 | 17.8 | 42 | 56.2 |
|
| 108 |
+
| InternLM2-Chat-7B | 42.20 | 56.65 | 29.15 | **17.99** | 43.5 | **63.72** |
|
| 109 |
+
| Qwen1.5-Chat-7B | 36.75 | 52.85 | 30.08 | 14.28 | 32 | 54.55 |
|
| 110 |
+
| Qwen1.5-Chat-14B | 39.80 | 60.39 | 27.99 | 14.77 | 37 | 58.87 |
|
| 111 |
+
| 360Zhinao-7B-Chat-32K | **45.18** | 57.18 | **48.06** | 15.03 | **44** | 61.64 |
|
| 112 |
+
|
| 113 |
+
- ### 360Zhinao-7B-Chat-360K on "NeedleInAHaystack"
|
| 114 |
+
|
| 115 |
+
[NeedleInAHaystack](https://github.com/gkamradt/LLMTest_NeedleInAHaystack) places one small piece of information in different positions of long text and queries this information as a test of LLM's long-context capabilities.
|
| 116 |
+
|
| 117 |
+
360Zhinao-7B-Chat-360K could achieve over 98% accuracy on both English and Chinese NeedleInAHaystack tasks.
|
| 118 |
+
|
| 119 |
+
- English version(same as [NeedleInAHaystack](https://github.com/gkamradt/LLMTest_NeedleInAHaystack))
|
| 120 |
+
|
| 121 |
+
<p align="center">
|
| 122 |
+
<img src="assets/360Zhinao-7B-Chat-360K.en_score.png" width="600" />
|
| 123 |
+
<p>
|
| 124 |
+
|
| 125 |
+
**needle**:The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day.
|
| 126 |
+
|
| 127 |
+
**query**:What is the best thing to do in San Francisco?
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
- Chinese version
|
| 131 |
+
|
| 132 |
+
<p align="center">
|
| 133 |
+
<img src="assets/360Zhinao-7B-Chat-360K.zh_score.png" width="600" />
|
| 134 |
+
<p>
|
| 135 |
+
|
| 136 |
+
We constructed the Chinese version following the [SuperCLUE-200K benchmark](https://mp.weixin.qq.com/s/QgoRf2LB-7vc3vTFOHJkpw):
|
| 137 |
+
|
| 138 |
+
**haystack**:Chinese novels.
|
| 139 |
+
|
| 140 |
+
**needle**:(in Chinese) 王莽是一名勤奋的店员,他每天凌晨就起床,赶在第一缕阳光照亮大地之前到达店铺,为即将开始的一天做准备。他清扫店铺,整理货架,为顾客提供方便。他对五金的种类和用途了如指掌,无论顾客需要什么,他总能准确地找到。\n然而,他的老板刘秀却总是对他吹毛求疵。刘秀是个挑剔的人,他总能在王莽的工作中找出一些小错误,然后以此为由扣他的工资。他对王莽的工作要求非常严格,甚至有些过分。即使王莽做得再好,刘秀也总能找出一些小问题,让王莽感到非常沮丧。\n王莽虽然对此感到不满,但他并没有放弃。他知道,只有通过自己的努力,才能获得更好的生活。他坚持每天早起,尽管他知道那天可能会再次被刘秀扣工资。他始终保持微笑,尽管他知道刘秀可能会再次对他挑剔。
|
| 141 |
+
|
| 142 |
+
**query**:(in Chinese) 王莽在谁的手下工作?
|
| 143 |
+
|
| 144 |
+
<br>
|
| 145 |
+
|
| 146 |
+
# Quickstart
|
| 147 |
+
Simple examples to illustrate how to use 360Zhinao-7B-Base and 360Zhinao-7B-Chat quickly using 🤖 ModelScope and 🤗 Transformers
|
| 148 |
+
|
| 149 |
+
## Dependency Installation
|
| 150 |
+
- python 3.8 and above
|
| 151 |
+
- pytorch 2.0 and above
|
| 152 |
+
- transformers 4.37.2 and above
|
| 153 |
+
- CUDA 11.4 and above are recommended.
|
| 154 |
+
|
| 155 |
+
```shell
|
| 156 |
+
pip install -r requirements.txt
|
| 157 |
+
```
|
| 158 |
+
We recommend installing Flash-Attention (which currently supports flash attention 2) to increase your performance and reduce your memory footprint. (flash-attention is optional and will work without installation)
|
| 159 |
+
|
| 160 |
+
>flash-attn >= 2.3.6
|
| 161 |
+
```shell
|
| 162 |
+
FLASH_ATTENTION_FORCE_BUILD=TRUE pip install flash-attn==2.3.6
|
| 163 |
+
```
|
| 164 |
+
|
| 165 |
+
## 🤗 Transformers
|
| 166 |
+
### Demonstration of Base Model Inference
|
| 167 |
+
|
| 168 |
+
This code demonstrates fast inference with 360Zhinao-7B-Base models using transformers.
|
| 169 |
+
```python
|
| 170 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM
|
| 171 |
+
from transformers.generation import GenerationConfig
|
| 172 |
+
|
| 173 |
+
MODEL_NAME_OR_PATH = "qihoo360/360Zhinao-7B-Base"
|
| 174 |
+
|
| 175 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 176 |
+
MODEL_NAME_OR_PATH,
|
| 177 |
+
trust_remote_code=True)
|
| 178 |
+
|
| 179 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 180 |
+
MODEL_NAME_OR_PATH,
|
| 181 |
+
device_map="auto",
|
| 182 |
+
trust_remote_code=True)
|
| 183 |
+
|
| 184 |
+
generation_config = GenerationConfig.from_pretrained(
|
| 185 |
+
MODEL_NAME_OR_PATH,
|
| 186 |
+
trust_remote_code=True)
|
| 187 |
+
|
| 188 |
+
inputs = tokenizer('中国二十四节气\n1. 立春\n2. 雨水\n3. 惊蛰\n4. 春分\n5. 清明\n', return_tensors='pt')
|
| 189 |
+
inputs = inputs.to(model.device)
|
| 190 |
+
|
| 191 |
+
pred = model.generate(input_ids=inputs["input_ids"], generation_config=generation_config)
|
| 192 |
+
print("outputs:\n", tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
|
| 193 |
+
```
|
| 194 |
+
### Demonstration of Chat Model Inference
|
| 195 |
+
|
| 196 |
+
This code demo uses transformers to quickly use the 360Zhinao-7B-Chat-4K model for inference.
|
| 197 |
+
```python
|
| 198 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM
|
| 199 |
+
from transformers.generation import GenerationConfig
|
| 200 |
+
|
| 201 |
+
MODEL_NAME_OR_PATH = "qihoo360/360Zhinao-7B-Chat-4K"
|
| 202 |
+
|
| 203 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 204 |
+
MODEL_NAME_OR_PATH,
|
| 205 |
+
trust_remote_code=True)
|
| 206 |
+
|
| 207 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 208 |
+
MODEL_NAME_OR_PATH,
|
| 209 |
+
device_map="auto",
|
| 210 |
+
trust_remote_code=True)
|
| 211 |
+
|
| 212 |
+
generation_config = GenerationConfig.from_pretrained(
|
| 213 |
+
MODEL_NAME_OR_PATH,
|
| 214 |
+
trust_remote_code=True)
|
| 215 |
+
|
| 216 |
+
messages = []
|
| 217 |
+
#round-1
|
| 218 |
+
messages.append({"role": "user", "content": "介绍一下刘德华"})
|
| 219 |
+
response = model.chat(tokenizer=tokenizer, messages=messages, generation_config=generation_config)
|
| 220 |
+
messages.append({"role": "assistant", "content": response})
|
| 221 |
+
print(messages)
|
| 222 |
+
|
| 223 |
+
#round-2
|
| 224 |
+
messages.append({"role": "user", "content": "他有什么代表作?"})
|
| 225 |
+
response = model.chat(tokenizer=tokenizer, messages=messages, generation_config=generation_config)
|
| 226 |
+
messages.append({"role": "assistant", "content": response})
|
| 227 |
+
print(messages)
|
| 228 |
+
```
|
| 229 |
+
|
| 230 |
+
## 🤖 ModelScope
|
| 231 |
+
### Demonstration of Base Model Inference
|
| 232 |
+
|
| 233 |
+
This code demonstrates using ModelScope to quickly use the 360Zhinao-7B-Base model for inference.
|
| 234 |
+
|
| 235 |
+
```python
|
| 236 |
+
from modelscope import AutoModelForCausalLM, AutoTokenizer
|
| 237 |
+
from modelscope import GenerationConfig
|
| 238 |
+
|
| 239 |
+
MODEL_NAME_OR_PATH = "qihoo360/360Zhinao-7B-Base"
|
| 240 |
+
|
| 241 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 242 |
+
MODEL_NAME_OR_PATH,
|
| 243 |
+
trust_remote_code=True)
|
| 244 |
+
|
| 245 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 246 |
+
MODEL_NAME_OR_PATH,
|
| 247 |
+
device_map="auto",
|
| 248 |
+
trust_remote_code=True)
|
| 249 |
+
|
| 250 |
+
generation_config = GenerationConfig.from_pretrained(
|
| 251 |
+
MODEL_NAME_OR_PATH,
|
| 252 |
+
trust_remote_code=True)
|
| 253 |
+
|
| 254 |
+
inputs = tokenizer('中国二十四节气\n1. 立春\n2. 雨水\n3. 惊蛰\n4. 春分\n5. 清明\n', return_tensors='pt')
|
| 255 |
+
inputs = inputs.to(model.device)
|
| 256 |
+
|
| 257 |
+
pred = model.generate(input_ids=inputs["input_ids"], generation_config=generation_config)
|
| 258 |
+
print("outputs:\n", tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
|
| 259 |
+
```
|
| 260 |
+
|
| 261 |
+
### Demonstration of Chat Model Inference
|
| 262 |
+
|
| 263 |
+
This code demonstrates using ModelScope to quickly use the 360Zhinao-7B-Chat-4K model for inference.
|
| 264 |
+
|
| 265 |
+
```python
|
| 266 |
+
from modelscope import AutoModelForCausalLM, AutoTokenizer
|
| 267 |
+
from modelscope import GenerationConfig
|
| 268 |
+
|
| 269 |
+
MODEL_NAME_OR_PATH = "qihoo360/360Zhinao-7B-Chat-4K"
|
| 270 |
+
|
| 271 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 272 |
+
MODEL_NAME_OR_PATH,
|
| 273 |
+
trust_remote_code=True)
|
| 274 |
+
|
| 275 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 276 |
+
MODEL_NAME_OR_PATH,
|
| 277 |
+
device_map="auto",
|
| 278 |
+
trust_remote_code=True)
|
| 279 |
+
|
| 280 |
+
generation_config = GenerationConfig.from_pretrained(
|
| 281 |
+
MODEL_NAME_OR_PATH,
|
| 282 |
+
trust_remote_code=True)
|
| 283 |
+
|
| 284 |
+
messages = []
|
| 285 |
+
#round-1
|
| 286 |
+
messages.append({"role": "user", "content": "介绍一下刘德华"})
|
| 287 |
+
response = model.chat(tokenizer=tokenizer, messages=messages, generation_config=generation_config)
|
| 288 |
+
messages.append({"role": "assistant", "content": response})
|
| 289 |
+
print(messages)
|
| 290 |
+
|
| 291 |
+
#round-2
|
| 292 |
+
messages.append({"role": "user", "content": "他有什么代表作?"})
|
| 293 |
+
response = model.chat(tokenizer=tokenizer, messages=messages, generation_config=generation_config)
|
| 294 |
+
messages.append({"role": "assistant", "content": response})
|
| 295 |
+
print(messages)
|
| 296 |
+
```
|
| 297 |
+
|
| 298 |
+
## CLI Demo
|
| 299 |
+
Use terminal interaction for a fast experience
|
| 300 |
+
```shell
|
| 301 |
+
python cli_demo.py
|
| 302 |
+
```
|
| 303 |
+
<p align="center">
|
| 304 |
+
<img src="assets/cli_demo.gif" width="600" />
|
| 305 |
+
<p>
|
| 306 |
+
|
| 307 |
+
## Web Demo
|
| 308 |
+
You can also use web interaction for a quick experience
|
| 309 |
+
```shell
|
| 310 |
+
streamlit run web_demo.py
|
| 311 |
+
```
|
| 312 |
+
<p align="center">
|
| 313 |
+
<img src="assets/web_demo.gif" width="600" />
|
| 314 |
+
<p>
|
| 315 |
+
|
| 316 |
+
## API Demo
|
| 317 |
+
Start command
|
| 318 |
+
```shell
|
| 319 |
+
python openai_api.py
|
| 320 |
+
```
|
| 321 |
+
|
| 322 |
+
Request parameter
|
| 323 |
+
```shell
|
| 324 |
+
curl --location --request POST 'http://localhost:8360/v1/chat/completions' \
|
| 325 |
+
--header 'Content-Type: application/json' \
|
| 326 |
+
--data-raw '{
|
| 327 |
+
"max_new_tokens": 200,
|
| 328 |
+
"do_sample": true,
|
| 329 |
+
"top_k": 0,
|
| 330 |
+
"top_p": 0.8,
|
| 331 |
+
"temperature": 1.0,
|
| 332 |
+
"repetition_penalty": 1.0,
|
| 333 |
+
"messages": [
|
| 334 |
+
{
|
| 335 |
+
"role": "user",
|
| 336 |
+
"content": "你叫什么名字?"
|
| 337 |
+
}
|
| 338 |
+
]
|
| 339 |
+
}'
|
| 340 |
+
```
|
| 341 |
+
|
| 342 |
+
<br>
|
| 343 |
+
|
| 344 |
+
# Model Inference
|
| 345 |
+
## Quantization
|
| 346 |
+
We provide quantization schemes based on AutoGPTQ and open source the Int4 quantization models.
|
| 347 |
+
|
| 348 |
+
## Deployment
|
| 349 |
+
### vLLM Installation
|
| 350 |
+
If you want to deploy and accelerate inference, we recommend using `vLLM==0.3.3`。
|
| 351 |
+
|
| 352 |
+
If you are using **CUDA 12.1 and PyTorch 2.1**, you can install vLLM directly with the following command.
|
| 353 |
+
```shell
|
| 354 |
+
pip install vllm==0.3.3
|
| 355 |
+
```
|
| 356 |
+
|
| 357 |
+
Otherwise, please refer to the official vLLM [Installation Instructions](https://docs.vllm.ai/en/latest/getting_started/installation.html)。
|
| 358 |
+
|
| 359 |
+
>Once the installation is complete, you will need to do the following
|
| 360 |
+
1. Copy the vllm/zhinao.py file to the vllm/model_executor/models directory corresponding to your env environment.
|
| 361 |
+
2. Copy the vllm/serving_chat.py file to the vllm/entrypoints/openai corresponding to your env environment.
|
| 362 |
+
3. Then add a line to vllm/model_executor/models/\_\_init\_\_.py
|
| 363 |
+
|
| 364 |
+
```shell
|
| 365 |
+
"ZhinaoForCausalLM": ("zhinao", "ZhinaoForCausalLM"),
|
| 366 |
+
```
|
| 367 |
+
|
| 368 |
+
### vLLM Service Start
|
| 369 |
+
|
| 370 |
+
Starting the service
|
| 371 |
+
```shell
|
| 372 |
+
python -m vllm.entrypoints.openai.api_server \
|
| 373 |
+
--served-model-name 360Zhinao-7B-Chat-4K \
|
| 374 |
+
--model qihoo360/360Zhinao-7B-Chat-4K \
|
| 375 |
+
--trust-remote-code \
|
| 376 |
+
--tensor-parallel-size 1 \
|
| 377 |
+
--max-model-len 4096 \
|
| 378 |
+
--host 0.0.0.0 \
|
| 379 |
+
--port 8360
|
| 380 |
+
```
|
| 381 |
+
|
| 382 |
+
Use curl to request the service
|
| 383 |
+
```shell
|
| 384 |
+
curl http://localhost:8360/v1/chat/completions \
|
| 385 |
+
-H "Content-Type: application/json" \
|
| 386 |
+
-d '{
|
| 387 |
+
"model": "360Zhinao-7B-Chat-4K",
|
| 388 |
+
"max_tokens": 200,
|
| 389 |
+
"top_k": -1,
|
| 390 |
+
"top_p": 0.8,
|
| 391 |
+
"temperature": 1.0,
|
| 392 |
+
"presence_penalty": 0.0,
|
| 393 |
+
"frequency_penalty": 0.0,
|
| 394 |
+
"messages": [
|
| 395 |
+
{"role": "system", "content": "You are a helpful assistant."},
|
| 396 |
+
{"role": "user", "content": "你好"}
|
| 397 |
+
],
|
| 398 |
+
"stop": [
|
| 399 |
+
"<eod>",
|
| 400 |
+
"<|im_end|>",
|
| 401 |
+
"<|im_start|>"
|
| 402 |
+
]
|
| 403 |
+
}'
|
| 404 |
+
```
|
| 405 |
+
Use python to request the service
|
| 406 |
+
```python
|
| 407 |
+
from openai import OpenAI
|
| 408 |
+
openai_api_key = "EMPTY"
|
| 409 |
+
openai_api_base = "http://localhost:8360/v1"
|
| 410 |
+
|
| 411 |
+
client = OpenAI(
|
| 412 |
+
api_key=openai_api_key,
|
| 413 |
+
base_url=openai_api_base,
|
| 414 |
+
)
|
| 415 |
+
|
| 416 |
+
chat_response = client.chat.completions.create(
|
| 417 |
+
model="360Zhinao-7B-Chat-4K",
|
| 418 |
+
messages=[
|
| 419 |
+
{"role": "system", "content": "You are a helpful assistant."},
|
| 420 |
+
{"role": "user", "content": "你好"},
|
| 421 |
+
],
|
| 422 |
+
stop=[
|
| 423 |
+
"<eod>",
|
| 424 |
+
"<|im_end|>",
|
| 425 |
+
"<|im_start|>"
|
| 426 |
+
],
|
| 427 |
+
presence_penalty=0.0,
|
| 428 |
+
frequency_penalty=0.0
|
| 429 |
+
)
|
| 430 |
+
print("Chat response:", chat_response)
|
| 431 |
+
```
|
| 432 |
+
|
| 433 |
+
> Notice: If you need to enable repetition penalty, recommended to use *presence_penalty* and *frequency_penalty* parameters.
|
| 434 |
+
|
| 435 |
+
>
|
| 436 |
+
|
| 437 |
+
<br>
|
| 438 |
+
|
| 439 |
+
# Model Finetune
|
| 440 |
+
## Training data
|
| 441 |
+
|
| 442 |
+
Training Data: data/training_data_sample.json. The sample data is 10,000 pieces sampled from [multiturn_chat_0.8M](https://huggingface.co/datasets/BelleGroup/multiturn_chat_0.8M) and format converted.
|
| 443 |
+
|
| 444 |
+
Data Format:
|
| 445 |
+
```json
|
| 446 |
+
[
|
| 447 |
+
{
|
| 448 |
+
"id": 1,
|
| 449 |
+
"conversations": [
|
| 450 |
+
{
|
| 451 |
+
"from": "system",
|
| 452 |
+
"value": "You are a helpful assistant."
|
| 453 |
+
},
|
| 454 |
+
{
|
| 455 |
+
"from": "user",
|
| 456 |
+
"value": "您���啊"
|
| 457 |
+
},
|
| 458 |
+
{
|
| 459 |
+
"from": "assistant",
|
| 460 |
+
"value": "你好!我今天能为您做些什么?有什么问题或需要帮助吗? 我在这里为您提供服务。"
|
| 461 |
+
}
|
| 462 |
+
]
|
| 463 |
+
}
|
| 464 |
+
]
|
| 465 |
+
```
|
| 466 |
+
## Fine-tuning scripts
|
| 467 |
+
```shell
|
| 468 |
+
set -x
|
| 469 |
+
|
| 470 |
+
HOSTFILE=hostfile
|
| 471 |
+
DS_CONFIG=./finetune/ds_config_zero2.json
|
| 472 |
+
|
| 473 |
+
# PARAMS
|
| 474 |
+
LR=5e-6
|
| 475 |
+
EPOCHS=3
|
| 476 |
+
MAX_LEN=4096
|
| 477 |
+
BATCH_SIZE=4
|
| 478 |
+
NUM_NODES=1
|
| 479 |
+
NUM_GPUS=8
|
| 480 |
+
MASTER_PORT=29500
|
| 481 |
+
|
| 482 |
+
IS_CONCAT=False # Whether to concatenate to maximum length (MAX_LEN)
|
| 483 |
+
|
| 484 |
+
DATA_PATH="./data/training_data_sample.json"
|
| 485 |
+
MODEL_PATH="qihoo360/360Zhinao-7B-Base"
|
| 486 |
+
OUTPUT_DIR="./outputs/"
|
| 487 |
+
|
| 488 |
+
deepspeed --hostfile ${HOSTFILE} \
|
| 489 |
+
--master_port ${MASTER_PORT} \
|
| 490 |
+
--num_nodes ${NUM_NODES} \
|
| 491 |
+
--num_gpus ${NUM_GPUS} \
|
| 492 |
+
finetune.py \
|
| 493 |
+
--report_to "tensorboard" \
|
| 494 |
+
--data_path ${DATA_PATH} \
|
| 495 |
+
--model_name_or_path ${MODEL_PATH} \
|
| 496 |
+
--output_dir ${OUTPUT_DIR} \
|
| 497 |
+
--model_max_length ${MAX_LEN} \
|
| 498 |
+
--num_train_epochs ${EPOCHS} \
|
| 499 |
+
--per_device_train_batch_size ${BATCH_SIZE} \
|
| 500 |
+
--gradient_accumulation_steps 1 \
|
| 501 |
+
--save_strategy steps \
|
| 502 |
+
--save_steps 200 \
|
| 503 |
+
--learning_rate ${LR} \
|
| 504 |
+
--lr_scheduler_type cosine \
|
| 505 |
+
--adam_beta1 0.9 \
|
| 506 |
+
--adam_beta2 0.95 \
|
| 507 |
+
--adam_epsilon 1e-8 \
|
| 508 |
+
--max_grad_norm 1.0 \
|
| 509 |
+
--weight_decay 0.1 \
|
| 510 |
+
--warmup_ratio 0.01 \
|
| 511 |
+
--gradient_checkpointing True \
|
| 512 |
+
--bf16 True \
|
| 513 |
+
--tf32 True \
|
| 514 |
+
--deepspeed ${DS_CONFIG} \
|
| 515 |
+
--is_concat ${IS_CONCAT} \
|
| 516 |
+
--logging_steps 1 \
|
| 517 |
+
--log_on_each_node False
|
| 518 |
+
```
|
| 519 |
+
```shell
|
| 520 |
+
bash finetune/ds_finetune.sh
|
| 521 |
+
```
|
| 522 |
+
- By configuring the **hostfile**, single-machine and multi-machine training can be realized.
|
| 523 |
+
- By configuring **ds_config**, realize zero2 and zero3 training
|
| 524 |
+
- By configuring the **fp16**、**bf16** realize mixed precision training, bf16 is recommended to be consistent with the pre-trained model.
|
| 525 |
+
- By configuring **is_concat**, Whether the training data is concatenated or not is controlled. When the magnitude of the training data is large, the training efficiency can be improved by concatenation.
|
| 526 |
+
|
| 527 |
+
<br>
|
| 528 |
+
|
| 529 |
+
# License
|
| 530 |
+
|
| 531 |
+
The source code of this warehouse follows the open source license Apache 2.0.
|
| 532 |
+
|
| 533 |
+
The 360 Zhinao open source model supports commercial use. If you need to use this model and its derivative models for commercial purposes, please contact us via email ([email protected]) to apply. For the specific license agreement, please see [《360 Zhinao Open Source Model License》](./360智脑开源模型许可证.txt).
|
assets/360Zhinao-7B-Chat-360K.en_score.png
ADDED
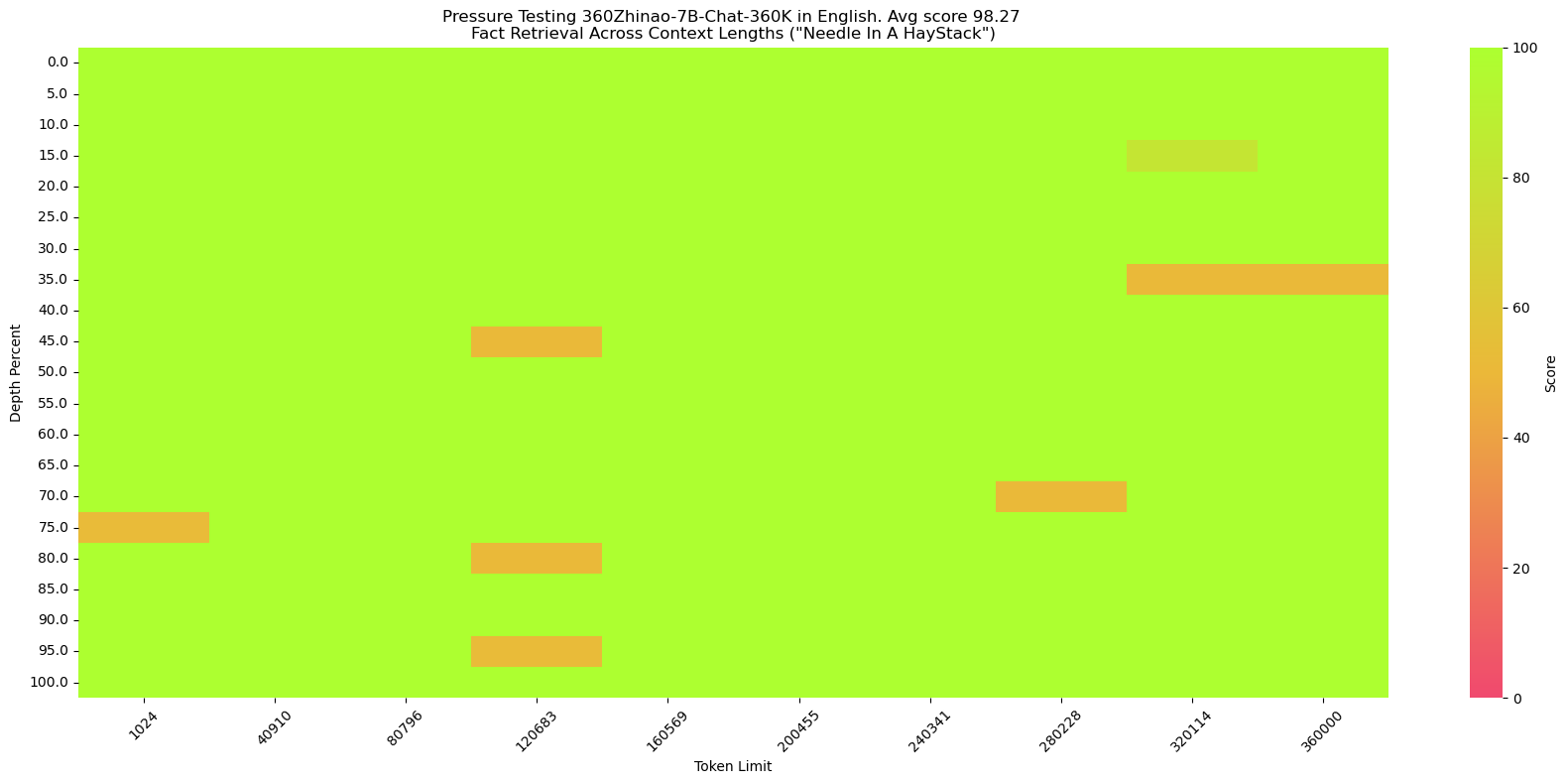
|
assets/360Zhinao-7B-Chat-360K.zh_score.png
ADDED

|
assets/WeChat.png
ADDED

|
assets/cli_demo.gif
ADDED

|
Git LFS Details
|
assets/web_demo.gif
ADDED

|
Git LFS Details
|