Spaces:
Runtime error

Runtime error
Commit
•
9b6c8d0
1
Parent(s):
5539127
Add application file
Browse files- .gitattributes +1 -0
- Data/new_tracks.csv +3 -0
- Data/sc.sav +0 -0
- Data/streamlit.csv +3 -0
- README.md +1 -1
- Spotify/Spotify.yaml +2 -0
- Spotify/Spotify1.yaml +2 -0
- Spotify/Spotify2.yaml +2 -0
- Spotify/Spotify3.yaml +2 -0
- Spotify/Spotify4.yaml +2 -0
- Spotify/Spotify5.yaml +2 -0
- Spotify/Spotify6.yaml +2 -0
- main.py +293 -0
- model.py +481 -0
- requirements.txt +6 -0
- spotify_get_artist_url.png +0 -0
- spotify_get_playlist_url.png +0 -0
- spotify_get_song_url.png +0 -0
.gitattributes
CHANGED
|
@@ -32,3 +32,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*.csv filter=lfs diff=lfs merge=lfs -text
|
Data/new_tracks.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:691f1905395f220b953dc4e259a7bfbba8a17e4e75923ca955fe9d3561ff3626
|
| 3 |
+
size 22648
|
Data/sc.sav
ADDED
|
Binary file (1.09 kB). View file
|
|
|
Data/streamlit.csv
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c6a69e37d071948e19528b8b37eab0ac2c96dbf7ff846ddc630a5539dcded952
|
| 3 |
+
size 187020124
|
README.md
CHANGED
|
@@ -5,7 +5,7 @@ colorFrom: red
|
|
| 5 |
colorTo: gray
|
| 6 |
sdk: streamlit
|
| 7 |
sdk_version: 1.10.0
|
| 8 |
-
app_file:
|
| 9 |
pinned: false
|
| 10 |
---
|
| 11 |
|
|
|
|
| 5 |
colorTo: gray
|
| 6 |
sdk: streamlit
|
| 7 |
sdk_version: 1.10.0
|
| 8 |
+
app_file: main.py
|
| 9 |
pinned: false
|
| 10 |
---
|
| 11 |
|
Spotify/Spotify.yaml
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Client_id : 64049e33e24744f7a0a30e945e37be6c
|
| 2 |
+
client_secret : c9b30ec81f8d40ac81d5dd6aeec45ee4
|
Spotify/Spotify1.yaml
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Client_id : 28a753df0eb7494e8c2d1b212f20c590
|
| 2 |
+
client_secret : 9685313e8178455e9d4f05893ffe26e8
|
Spotify/Spotify2.yaml
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Client_id : e5d5709d13204cb9bdc3cae44bc6f39b
|
| 2 |
+
client_secret : f0f31bee6b584b7083fec26717707c69
|
Spotify/Spotify3.yaml
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Client_id : cc37f3ceb5ae47949933f41be465fbc8
|
| 2 |
+
client_secret : 1f8095e1e71f42848f00187132cb6e95
|
Spotify/Spotify4.yaml
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Client_id : aa397cd7e24e4c56a199f433692e48f3
|
| 2 |
+
client_secret : d85b2dfc58784376b5b33f94393b5d5e
|
Spotify/Spotify5.yaml
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Client_id : bfa5e7b3d8424aa28ef274c85e104c44
|
| 2 |
+
client_secret : 49e7e21f73ca4665be2294cfe10e66d3
|
Spotify/Spotify6.yaml
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Client_id : 65719a2ea2104545aa4b03a3ef622a6d
|
| 2 |
+
client_secret : a388bb9c73e34dcdad99814efa21a404
|
main.py
ADDED
|
@@ -0,0 +1,293 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_option_menu import option_menu
|
| 3 |
+
import streamlit.components.v1 as components
|
| 4 |
+
import time
|
| 5 |
+
from model import *
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
if 'model' not in st.session_state:
|
| 10 |
+
st.session_state.model = 'Model 1'
|
| 11 |
+
def update_radio2():
|
| 12 |
+
st.session_state.model=st.session_state.radio2
|
| 13 |
+
if 'genre' not in st.session_state:
|
| 14 |
+
st.session_state.genre=3
|
| 15 |
+
def update_num_genre():
|
| 16 |
+
st.session_state.genre=st.session_state.num_genre
|
| 17 |
+
if 'artist' not in st.session_state:
|
| 18 |
+
st.session_state.artist=5
|
| 19 |
+
def update_same_art():
|
| 20 |
+
st.session_state.artist=st.session_state.same_art
|
| 21 |
+
if 'model2' not in st.session_state:
|
| 22 |
+
st.session_state.model2= 'Spotify model'
|
| 23 |
+
def update_radio1():
|
| 24 |
+
st.session_state.model2 =st.session_state.radio1
|
| 25 |
+
|
| 26 |
+
if 'Region' not in st.session_state:
|
| 27 |
+
st.session_state.rg="US"
|
| 28 |
+
def update_Region():
|
| 29 |
+
st.session_state.rg=st.session_state.Region
|
| 30 |
+
if 'radio' not in st.session_state:
|
| 31 |
+
st.session_state.feature="Playlist"
|
| 32 |
+
def update_radio0():
|
| 33 |
+
st.session_state.feature=st.session_state.radio
|
| 34 |
+
|
| 35 |
+
if 'p_url' not in st.session_state:
|
| 36 |
+
st.session_state.p_url = 'Example: https://open.spotify.com/playlist/37i9dQZF1DX8FwnYE6PRvL?si=06ff6b38d4124af0'
|
| 37 |
+
def update_playlist_url():
|
| 38 |
+
st.session_state.p_url = st.session_state.playlist_url
|
| 39 |
+
|
| 40 |
+
if 's_url' not in st.session_state:
|
| 41 |
+
st.session_state.s_url = 'Example: https://open.spotify.com/track/5CQ30WqJwcep0pYcV4AMNc?si=ed4b04f153a24531'
|
| 42 |
+
def update_song_url():
|
| 43 |
+
st.session_state.s_url = st.session_state.song_url
|
| 44 |
+
|
| 45 |
+
if 'a_url' not in st.session_state:
|
| 46 |
+
st.session_state.a_url = 'Example: https://open.spotify.com/artist/3RNrq3jvMZxD9ZyoOZbQOD?si=UNAsX20kRpG89bxOO8o7ew'
|
| 47 |
+
def update_artist_url():
|
| 48 |
+
st.session_state.a_url = st.session_state.artist_url
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def play_recomm():
|
| 52 |
+
if 'rs' in st.session_state:
|
| 53 |
+
del st.session_state.rs,st.session_state.err
|
| 54 |
+
try:
|
| 55 |
+
if len(pd.read_csv('Data/new_tracks.csv')) >= 200:
|
| 56 |
+
with st.spinner('Updating the dataset...'):
|
| 57 |
+
x=update_dataset()
|
| 58 |
+
st.success('{} New tracks were added to the dataset.'.format(x))
|
| 59 |
+
except:
|
| 60 |
+
st.error("The dataset update failed. ")
|
| 61 |
+
with st.spinner('Getting Recommendations...'):
|
| 62 |
+
res,err = playlist_model(st.session_state.p_url,st.session_state.model,st.session_state.genre,st.session_state.artist)
|
| 63 |
+
st.session_state.rs=res
|
| 64 |
+
st.session_state.err=err
|
| 65 |
+
if len(st.session_state.rs)>=1:
|
| 66 |
+
if st.session_state.model == 'Model 1' or st.session_state.model == 'Model 2':
|
| 67 |
+
st.success('Go to the Result page to view the top {} recommendations'.format(len(st.session_state.rs)))
|
| 68 |
+
else:
|
| 69 |
+
st.success('Go to the Result page to view the Spotify recommendations')
|
| 70 |
+
else:
|
| 71 |
+
st.error('Model failed. Check the log for more information.')
|
| 72 |
+
|
| 73 |
+
def art_recomm():
|
| 74 |
+
if 'rs' in st.session_state:
|
| 75 |
+
del st.session_state.rs,st.session_state.err
|
| 76 |
+
with st.spinner('Getting Recommendations...'):
|
| 77 |
+
res,err = top_tracks(st.session_state.a_url,st.session_state.rg)
|
| 78 |
+
st.session_state.rs=res
|
| 79 |
+
st.session_state.err=err
|
| 80 |
+
if len(st.session_state.rs)>=1:
|
| 81 |
+
st.success("Go to the Result page to view the Artist's top tracks")
|
| 82 |
+
else:
|
| 83 |
+
st.error('Model failed. Check the log for more information.')
|
| 84 |
+
|
| 85 |
+
def song_recomm():
|
| 86 |
+
if 'rs' in st.session_state:
|
| 87 |
+
del st.session_state.rs,st.session_state.err
|
| 88 |
+
with st.spinner('Getting Recommendations...'):
|
| 89 |
+
res,err = song_model(st.session_state.s_url,st.session_state.model,st.session_state.genre,st.session_state.artist)
|
| 90 |
+
st.session_state.rs=res
|
| 91 |
+
st.session_state.err=err
|
| 92 |
+
if len(st.session_state.rs)>=1:
|
| 93 |
+
if st.session_state.model == 'Model 1' or st.session_state.model == 'Model 2':
|
| 94 |
+
st.success('Go to the Result page to view the top {} recommendations'.format(len(st.session_state.rs)))
|
| 95 |
+
else:
|
| 96 |
+
st.success('Go to the Result page to view the Spotify recommendations')
|
| 97 |
+
else:
|
| 98 |
+
st.error('Model failed. Check the log for more information.')
|
| 99 |
+
|
| 100 |
+
def playlist_page():
|
| 101 |
+
st.subheader("User Playlist")
|
| 102 |
+
st.markdown('---')
|
| 103 |
+
playlist_uri = (st.session_state.playlist_url).split('/')[-1].split('?')[0]
|
| 104 |
+
uri_link = 'https://open.spotify.com/embed/playlist/' + playlist_uri
|
| 105 |
+
components.iframe(uri_link, height=300)
|
| 106 |
+
return
|
| 107 |
+
|
| 108 |
+
def song_page():
|
| 109 |
+
st.subheader("User Song")
|
| 110 |
+
st.markdown('---')
|
| 111 |
+
song_uri = (st.session_state.song_url).split('/')[-1].split('?')[0]
|
| 112 |
+
uri_link = 'https://open.spotify.com/embed/track/' + song_uri
|
| 113 |
+
components.iframe(uri_link, height=100)
|
| 114 |
+
|
| 115 |
+
def artist_page():
|
| 116 |
+
st.subheader("User Artist")
|
| 117 |
+
st.markdown('---')
|
| 118 |
+
artist_uri = (st.session_state.artist_url).split('/')[-1].split('?')[0]
|
| 119 |
+
uri_link = 'https://open.spotify.com/embed/artist/' + artist_uri
|
| 120 |
+
components.iframe(uri_link, height=80)
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
def spr_sidebar():
|
| 124 |
+
menu=option_menu(
|
| 125 |
+
menu_title=None,
|
| 126 |
+
options=['Home','Result','About','Log'],
|
| 127 |
+
icons=['house','book','info-square','terminal'],
|
| 128 |
+
menu_icon='cast',
|
| 129 |
+
default_index=0,
|
| 130 |
+
orientation='horizontal'
|
| 131 |
+
)
|
| 132 |
+
if menu=='Home':
|
| 133 |
+
st.session_state.app_mode = 'Home'
|
| 134 |
+
elif menu=='Result':
|
| 135 |
+
st.session_state.app_mode = 'Result'
|
| 136 |
+
elif menu=='About':
|
| 137 |
+
st.session_state.app_mode = 'About'
|
| 138 |
+
elif menu=='Log':
|
| 139 |
+
st.session_state.app_mode = 'Log'
|
| 140 |
+
|
| 141 |
+
def home_page():
|
| 142 |
+
st.session_state.radio=st.session_state.feature
|
| 143 |
+
st.session_state.radio2=st.session_state.model
|
| 144 |
+
st.session_state.num_genre=st.session_state.genre
|
| 145 |
+
st.session_state.same_art=st.session_state.artist
|
| 146 |
+
st.session_state.Region=st.session_state.rg
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
st.title('Spotify Recommendation System')
|
| 150 |
+
col,col2,col3=st.columns([2,2,3])
|
| 151 |
+
radio=col.radio("Feature",options=("Playlist","Song","Artist Top Tracks"),key='radio',on_change=update_radio0)
|
| 152 |
+
if radio =="Artist Top Tracks":
|
| 153 |
+
radio1=col2.radio("Model",options=["Spotify model"],key='radio1',on_change=update_radio1)
|
| 154 |
+
Region=col3.selectbox("Please Choose Region",index=58,key='Region',on_change=update_Region,options=('AD', 'AR', 'AU', 'AT', 'BE', 'BO', 'BR', 'BG', 'CA', 'CL', 'CO', 'CR', 'CY', 'CZ', 'DK', 'DO', 'EC', 'SV', 'EE', 'FI', 'FR', 'DE', 'GR', 'GT', 'HN', 'HK', 'HU', 'IS', 'ID', 'IE', 'IT', 'JP', 'LV', 'LI', 'LT', 'LU', 'MY', 'MT', 'MX', 'MC', 'NL', 'NZ', 'NI', 'NO', 'PA', 'PY', 'PE', 'PH', 'PL', 'PT', 'SG', 'ES', 'SK', 'SE', 'CH', 'TW', 'TR', 'GB', 'US', 'UY'))
|
| 155 |
+
elif radio =="Playlist" or radio =="Song" :
|
| 156 |
+
radio2=col2.radio("Model",options=("Model 1","Model 2","Spotify Model"),key='radio2',on_change=update_radio2)
|
| 157 |
+
if st.session_state.radio2=="Model 1" or st.session_state.radio2=="Model 2":
|
| 158 |
+
num_genre=col3.selectbox("choose a number of genres to focus on",options=(1,2,3,4,5,6,7),index=2,key='num_genre',on_change=update_num_genre)
|
| 159 |
+
same_art=col3.selectbox("How many recommendations by the same artist",options=(1,2,3,4,5,7,10,15),index=3,key='same_art',on_change=update_same_art)
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
st.markdown("<br>", unsafe_allow_html=True)
|
| 163 |
+
|
| 164 |
+
if radio == "Playlist" :
|
| 165 |
+
st.session_state.playlist_url = st.session_state.p_url
|
| 166 |
+
Url = st.text_input(label="Playlist Url",key='playlist_url',on_change=update_playlist_url)
|
| 167 |
+
playlist_page()
|
| 168 |
+
state =st.button('Get Recommendations')
|
| 169 |
+
with st.expander("Here's how to find any Playlist URL in Spotify"):
|
| 170 |
+
st.write("""
|
| 171 |
+
- Search for Playlist on the Spotify app
|
| 172 |
+
- Right Click on the Playlist you like
|
| 173 |
+
- Click "Share"
|
| 174 |
+
- Choose "Copy link to playlist"
|
| 175 |
+
""")
|
| 176 |
+
st.markdown("<br>", unsafe_allow_html=True)
|
| 177 |
+
st.image('spotify_get_playlist_url.png')
|
| 178 |
+
if state:
|
| 179 |
+
play_recomm()
|
| 180 |
+
elif radio == "Song" :
|
| 181 |
+
st.session_state.song_url = st.session_state.s_url
|
| 182 |
+
Url = st.text_input(label="Song Url",key='song_url',on_change=update_song_url)
|
| 183 |
+
song_page()
|
| 184 |
+
state =st.button('Get Recommendations')
|
| 185 |
+
with st.expander("Here's how to find any Song URL in Spotify"):
|
| 186 |
+
st.write("""
|
| 187 |
+
- Search for Song on the Spotify app
|
| 188 |
+
- Right Click on the Song you like
|
| 189 |
+
- Click "Share"
|
| 190 |
+
- Choose "Copy link to Song"
|
| 191 |
+
""")
|
| 192 |
+
st.markdown("<br>", unsafe_allow_html=True)
|
| 193 |
+
st.image('spotify_get_song_url.png')
|
| 194 |
+
if state:
|
| 195 |
+
song_recomm()
|
| 196 |
+
elif radio == "Artist Top Tracks" :
|
| 197 |
+
st.session_state.artist_url = st.session_state.a_url
|
| 198 |
+
Url = st.text_input(label="Artist Url",key='artist_url',on_change=update_artist_url)
|
| 199 |
+
artist_page()
|
| 200 |
+
state =st.button('Get Recommendations')
|
| 201 |
+
with st.expander("Here's how to find any Artist URL in Spotify"):
|
| 202 |
+
st.write("""
|
| 203 |
+
- Search for Artist on the Spotify app
|
| 204 |
+
- Right Click on the Artist you like
|
| 205 |
+
- Click "Share"
|
| 206 |
+
- Choose "Copy link to Artist"
|
| 207 |
+
""")
|
| 208 |
+
st.markdown("<br>", unsafe_allow_html=True)
|
| 209 |
+
st.image('spotify_get_artist_url.png')
|
| 210 |
+
if state:
|
| 211 |
+
art_recomm()
|
| 212 |
+
|
| 213 |
+
def result_page():
|
| 214 |
+
if 'rs' not in st.session_state:
|
| 215 |
+
st.error('Please select a model on the Home page and run Get Recommendations')
|
| 216 |
+
else:
|
| 217 |
+
st.success('Top {} recommendations'.format(len(st.session_state.rs)))
|
| 218 |
+
i=0
|
| 219 |
+
for uri in st.session_state.rs:
|
| 220 |
+
uri_link = "https://open.spotify.com/embed/track/" + uri + "?utm_source=generator&theme=0"
|
| 221 |
+
components.iframe(uri_link, height=80)
|
| 222 |
+
i+=1
|
| 223 |
+
if i%5==0:
|
| 224 |
+
time.sleep(1)
|
| 225 |
+
def Log_page():
|
| 226 |
+
log=st.checkbox('Display Output', True, key='display_output')
|
| 227 |
+
if log == True:
|
| 228 |
+
if 'err' in st.session_state:
|
| 229 |
+
st.write(st.session_state.err)
|
| 230 |
+
with open('Data/new_tracks.csv') as f:
|
| 231 |
+
st.download_button('Download Dataset', f,file_name='new_tracks.csv')
|
| 232 |
+
def About_page():
|
| 233 |
+
st.header('Development')
|
| 234 |
+
"""
|
| 235 |
+
Check out the [repository](https://github.com/abdelrhmanelruby/Spotify-Recommendation-System) for the source code and approaches, and don't hesitate to contact me if you have any questions. I'm excited to read your review.
|
| 236 |
+
[Github](https://github.com/abdelrhmanelruby) [Linkedin](https://www.linkedin.com/in/abdelrhmanelruby/) Email : [email protected]
|
| 237 |
+
"""
|
| 238 |
+
st.subheader('Spotify Million Playlist Dataset')
|
| 239 |
+
"""
|
| 240 |
+
For this project, I'm using the Million Playlist Dataset, which, as its name implies, consists of one million playlists.
|
| 241 |
+
contains a number of songs, and some metadata is included as well, such as the name of the playlist, duration, number of songs, number of artists, etc.
|
| 242 |
+
"""
|
| 243 |
+
|
| 244 |
+
"""
|
| 245 |
+
It is created by sampling playlists from the billions of playlists that Spotify users have created over the years.
|
| 246 |
+
Playlists that meet the following criteria were selected at random:
|
| 247 |
+
- Created by a user that resides in the United States and is at least 13 years old
|
| 248 |
+
- Was a public playlist at the time the MPD was generated
|
| 249 |
+
- Contains at least 5 tracks
|
| 250 |
+
- Contains no more than 250 tracks
|
| 251 |
+
- Contains at least 3 unique artists
|
| 252 |
+
- Contains at least 2 unique albums
|
| 253 |
+
- Has no local tracks (local tracks are non-Spotify tracks that a user has on their local device
|
| 254 |
+
- Has at least one follower (not including the creator
|
| 255 |
+
- Was created after January 1, 2010 and before December 1, 2017
|
| 256 |
+
- Does not have an offensive title
|
| 257 |
+
- Does not have an adult-oriented title if the playlist was created by a user under 18 years of age
|
| 258 |
+
|
| 259 |
+
Information about the Dataset [here](https://www.aicrowd.com/challenges/spotify-million-playlist-dataset-challenge)
|
| 260 |
+
"""
|
| 261 |
+
st.subheader('Audio Features Explanation')
|
| 262 |
+
"""
|
| 263 |
+
| Variable | Description |
|
| 264 |
+
| :----: | :---: |
|
| 265 |
+
| Acousticness | A confidence measure from 0.0 to 1.0 of whether the track is acoustic. 1.0 represents high confidence the track is acoustic. |
|
| 266 |
+
| Danceability | Danceability describes how suitable a track is for dancing based on a combination of musical elements including tempo, rhythm stability, beat strength, and overall regularity. A value of 0.0 is least danceable and 1.0 is most danceable. |
|
| 267 |
+
| Energy | Energy is a measure from 0.0 to 1.0 and represents a perceptual measure of intensity and activity. Typically, energetic tracks feel fast, loud, and noisy. For example, death metal has high energy, while a Bach prelude scores low on the scale. Perceptual features contributing to this attribute include dynamic range, perceived loudness, timbre, onset rate, and general entropy. |
|
| 268 |
+
| Instrumentalness | Predicts whether a track contains no vocals. "Ooh" and "aah" sounds are treated as instrumental in this context. Rap or spoken word tracks are clearly "vocal". The closer the instrumentalness value is to 1.0, the greater likelihood the track contains no vocal content. Values above 0.5 are intended to represent instrumental tracks, but confidence is higher as the value approaches 1.0. |
|
| 269 |
+
| Key | The key the track is in. Integers map to pitches using standard Pitch Class notation. E.g. 0 = C, 1 = C♯/D♭, 2 = D, and so on. If no key was detected, the value is -1. |
|
| 270 |
+
| Liveness | Detects the presence of an audience in the recording. Higher liveness values represent an increased probability that the track was performed live. A value above 0.8 provides strong likelihood that the track is live. |
|
| 271 |
+
| Loudness | The overall loudness of a track in decibels (dB). Loudness values are averaged across the entire track and are useful for comparing relative loudness of tracks. Loudness is the quality of a sound that is the primary psychological correlate of physical strength (amplitude). Values typically range between -60 and 0 db. |
|
| 272 |
+
| Mode | Mode indicates the modality (major or minor) of a track, the type of scale from which its melodic content is derived. Major is represented by 1 and minor is 0. |
|
| 273 |
+
| Speechiness | Speechiness detects the presence of spoken words in a track. The more exclusively speech-like the recording (e.g. talk show, audio book, poetry), the closer to 1.0 the attribute value. Values above 0.66 describe tracks that are probably made entirely of spoken words. Values between 0.33 and 0.66 describe tracks that may contain both music and speech, either in sections or layered, including such cases as rap music. Values below 0.33 most likely represent music and other non-speech-like tracks. |
|
| 274 |
+
| Tempo | The overall estimated tempo of a track in beats per minute (BPM). In musical terminology, tempo is the speed or pace of a given piece and derives directly from the average beat duration. |
|
| 275 |
+
| Time Signature | An estimated time signature. The time signature (meter) is a notational convention to specify how many beats are in each bar (or measure). The time signature ranges from 3 to 7 indicating time signatures of "3/4", to "7/4". |
|
| 276 |
+
| Valence | A measure from 0.0 to 1.0 describing the musical positiveness conveyed by a track. Tracks with high valence sound more positive (e.g. happy, cheerful, euphoric), while tracks with low valence sound more negative (e.g. sad, depressed, angry). |
|
| 277 |
+
|
| 278 |
+
Information about features: [here](https://developer.spotify.com/documentation/web-api/reference/#/operations/get-audio-features)
|
| 279 |
+
"""
|
| 280 |
+
|
| 281 |
+
def main():
|
| 282 |
+
spr_sidebar()
|
| 283 |
+
if st.session_state.app_mode == 'Home':
|
| 284 |
+
home_page()
|
| 285 |
+
if st.session_state.app_mode == 'Result':
|
| 286 |
+
result_page()
|
| 287 |
+
if st.session_state.app_mode == 'About' :
|
| 288 |
+
About_page()
|
| 289 |
+
if st.session_state.app_mode == 'Log':
|
| 290 |
+
Log_page()
|
| 291 |
+
# Run main()
|
| 292 |
+
if __name__ == '__main__':
|
| 293 |
+
main()
|
model.py
ADDED
|
@@ -0,0 +1,481 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pandas as pd
|
| 2 |
+
import spotipy
|
| 3 |
+
from spotipy.oauth2 import SpotifyOAuth, SpotifyClientCredentials
|
| 4 |
+
import yaml
|
| 5 |
+
import re
|
| 6 |
+
from sklearn.feature_extraction.text import TfidfVectorizer
|
| 7 |
+
from sklearn.metrics.pairwise import cosine_similarity
|
| 8 |
+
from sklearn.preprocessing import MinMaxScaler
|
| 9 |
+
import pickle
|
| 10 |
+
|
| 11 |
+
def playlist_model(url, model, max_gen=3, same_art=5):
|
| 12 |
+
log = []
|
| 13 |
+
Fresult = []
|
| 14 |
+
try:
|
| 15 |
+
log.append('Start logging')
|
| 16 |
+
uri = url.split('/')[-1].split('?')[0]
|
| 17 |
+
stream = open("Spotify/Spotify.yaml")
|
| 18 |
+
spotify_details = yaml.safe_load(stream)
|
| 19 |
+
auth_manager = SpotifyClientCredentials(
|
| 20 |
+
client_id=spotify_details['Client_id'], client_secret=spotify_details['client_secret'])
|
| 21 |
+
sp = spotipy.client.Spotify(auth_manager=auth_manager)
|
| 22 |
+
|
| 23 |
+
if model == 'Spotify Model':
|
| 24 |
+
def get_IDs(user, playlist_id):
|
| 25 |
+
try:
|
| 26 |
+
log.append('start playlist extraction')
|
| 27 |
+
track_ids = []
|
| 28 |
+
playlist = sp.user_playlist(user, playlist_id)
|
| 29 |
+
for item in playlist['tracks']['items']:
|
| 30 |
+
track = item['track']
|
| 31 |
+
track_ids.append(track['id'])
|
| 32 |
+
return track_ids
|
| 33 |
+
except Exception as e:
|
| 34 |
+
log.append('Failed to load the playlist')
|
| 35 |
+
log.append(e)
|
| 36 |
+
|
| 37 |
+
track_ids = get_IDs('Ruby', uri)
|
| 38 |
+
track_ids_uni = list(set(track_ids))
|
| 39 |
+
log.append('Starting Spotify Model')
|
| 40 |
+
Spotifyresult = pd.DataFrame()
|
| 41 |
+
for i in range(len(track_ids_uni)-5):
|
| 42 |
+
if len(Spotifyresult) >= 50:
|
| 43 |
+
break
|
| 44 |
+
try:
|
| 45 |
+
ff = sp.recommendations(seed_tracks=list(track_ids_uni[i:i+5]), limit=5)
|
| 46 |
+
except Exception as e:
|
| 47 |
+
log.append(e)
|
| 48 |
+
continue
|
| 49 |
+
for z in range(5):
|
| 50 |
+
result = pd.DataFrame([z+(5*i)+1])
|
| 51 |
+
result['uri'] = ff['tracks'][z]['id']
|
| 52 |
+
Spotifyresult = pd.concat([Spotifyresult, result], axis=0)
|
| 53 |
+
Spotifyresult.drop_duplicates(subset=['uri'], inplace=True,keep='first')
|
| 54 |
+
Fresult = Spotifyresult.uri[:50]
|
| 55 |
+
|
| 56 |
+
log.append('Model run successfully')
|
| 57 |
+
return Fresult, log
|
| 58 |
+
|
| 59 |
+
lendf=len(pd.read_csv('Data/streamlit.csv',usecols=['track_uri']))
|
| 60 |
+
dtypes = {'track_uri': 'object', 'artist_uri': 'object', 'album_uri': 'object', 'danceability': 'float16', 'energy': 'float16', 'key': 'float16',
|
| 61 |
+
'loudness': 'float16', 'mode': 'float16', 'speechiness': 'float16', 'acousticness': 'float16', 'instrumentalness': 'float16',
|
| 62 |
+
'liveness': 'float16', 'valence': 'float16', 'tempo': 'float16', 'duration_ms': 'float32', 'time_signature': 'float16',
|
| 63 |
+
'Track_release_date': 'int8', 'Track_pop': 'int8', 'Artist_pop': 'int8', 'Artist_genres': 'object'}
|
| 64 |
+
col_name= ['track_uri', 'artist_uri', 'album_uri', 'danceability', 'energy', 'key',
|
| 65 |
+
'loudness', 'mode', 'speechiness', 'acousticness', 'instrumentalness',
|
| 66 |
+
'liveness', 'valence', 'tempo', 'duration_ms', 'time_signature',
|
| 67 |
+
'Track_release_date', 'Track_pop', 'Artist_pop', 'Artist_genres']
|
| 68 |
+
|
| 69 |
+
try:
|
| 70 |
+
def get_IDs(user, playlist_id):
|
| 71 |
+
log.append('start playlist extraction')
|
| 72 |
+
track_ids = []
|
| 73 |
+
artist_id = []
|
| 74 |
+
playlist = sp.user_playlist(user, playlist_id)
|
| 75 |
+
for item in playlist['tracks']['items']:
|
| 76 |
+
track = item['track']
|
| 77 |
+
track_ids.append(track['id'])
|
| 78 |
+
artist = item['track']['artists']
|
| 79 |
+
artist_id.append(artist[0]['id'])
|
| 80 |
+
return track_ids, artist_id
|
| 81 |
+
except Exception as e:
|
| 82 |
+
log.append('Failed to load the playlist')
|
| 83 |
+
log.append(e)
|
| 84 |
+
|
| 85 |
+
track_ids, artist_id = get_IDs('Ruby', uri)
|
| 86 |
+
log.append("Number of Track : {}".format(len(track_ids)))
|
| 87 |
+
|
| 88 |
+
artist_id_uni = list(set(artist_id))
|
| 89 |
+
track_ids_uni = list(set(track_ids))
|
| 90 |
+
log.append("Number of unique Artists : {}".format(len(artist_id_uni)))
|
| 91 |
+
log.append("Number of unique Tracks : {}".format(len(track_ids_uni)))
|
| 92 |
+
|
| 93 |
+
def extract(track_ids_uni, artist_id_uni):
|
| 94 |
+
err = []
|
| 95 |
+
err.append('Start audio features extraction')
|
| 96 |
+
audio_features = pd.DataFrame()
|
| 97 |
+
for i in range(0, len(track_ids_uni), 25):
|
| 98 |
+
try:
|
| 99 |
+
track_feature = sp.audio_features(track_ids_uni[i:i+25])
|
| 100 |
+
track_df = pd.DataFrame(track_feature)
|
| 101 |
+
audio_features = pd.concat([audio_features, track_df], axis=0)
|
| 102 |
+
except Exception as e:
|
| 103 |
+
err.append(e)
|
| 104 |
+
continue
|
| 105 |
+
err.append('Start track features extraction')
|
| 106 |
+
track_ = pd.DataFrame()
|
| 107 |
+
for i in range(0, len(track_ids_uni), 25):
|
| 108 |
+
try:
|
| 109 |
+
track_features = sp.tracks(track_ids_uni[i:i+25])
|
| 110 |
+
for x in range(25):
|
| 111 |
+
track_pop = pd.DataFrame([track_ids_uni[i+x]], columns=['Track_uri'])
|
| 112 |
+
track_pop['Track_release_date'] = track_features['tracks'][x]['album']['release_date']
|
| 113 |
+
track_pop['Track_pop'] = track_features['tracks'][x]["popularity"]
|
| 114 |
+
track_pop['Artist_uri'] = track_features['tracks'][x]['artists'][0]['id']
|
| 115 |
+
track_pop['Album_uri'] = track_features['tracks'][x]['album']['id']
|
| 116 |
+
track_ = pd.concat([track_, track_pop], axis=0)
|
| 117 |
+
except Exception as e:
|
| 118 |
+
err.append(e)
|
| 119 |
+
continue
|
| 120 |
+
err.append('Start artist features extraction')
|
| 121 |
+
artist_ = pd.DataFrame()
|
| 122 |
+
for i in range(0, len(artist_id_uni), 25):
|
| 123 |
+
try:
|
| 124 |
+
artist_features = sp.artists(artist_id_uni[i:i+25])
|
| 125 |
+
for x in range(25):
|
| 126 |
+
artist_df = pd.DataFrame([artist_id_uni[i+x]], columns=['Artist_uri'])
|
| 127 |
+
artist_pop = artist_features['artists'][x]["popularity"]
|
| 128 |
+
artist_genres = artist_features['artists'][x]["genres"]
|
| 129 |
+
artist_df["Artist_pop"] = artist_pop
|
| 130 |
+
if artist_genres:
|
| 131 |
+
artist_df["genres"] = " ".join([re.sub(' ', '_', i) for i in artist_genres])
|
| 132 |
+
else:
|
| 133 |
+
artist_df["genres"] = "unknown"
|
| 134 |
+
artist_ = pd.concat([artist_, artist_df], axis=0)
|
| 135 |
+
except Exception as e:
|
| 136 |
+
err.append(e)
|
| 137 |
+
continue
|
| 138 |
+
try:
|
| 139 |
+
test = pd.DataFrame(
|
| 140 |
+
track_, columns=['Track_uri', 'Artist_uri', 'Album_uri'])
|
| 141 |
+
|
| 142 |
+
test.rename(columns={'Track_uri': 'track_uri',
|
| 143 |
+
'Artist_uri': 'artist_uri', 'Album_uri': 'album_uri'}, inplace=True)
|
| 144 |
+
|
| 145 |
+
audio_features.drop(
|
| 146 |
+
columns=['type', 'uri', 'track_href', 'analysis_url'], axis=1, inplace=True)
|
| 147 |
+
|
| 148 |
+
test = pd.merge(test, audio_features,
|
| 149 |
+
left_on="track_uri", right_on="id", how='outer')
|
| 150 |
+
test = pd.merge(test, track_, left_on="track_uri",
|
| 151 |
+
right_on="Track_uri", how='outer')
|
| 152 |
+
test = pd.merge(test, artist_, left_on="artist_uri",
|
| 153 |
+
right_on="Artist_uri", how='outer')
|
| 154 |
+
|
| 155 |
+
test.rename(columns={'genres': 'Artist_genres'}, inplace=True)
|
| 156 |
+
|
| 157 |
+
test.drop(columns=['Track_uri', 'Artist_uri_x',
|
| 158 |
+
'Artist_uri_y', 'Album_uri', 'id'], axis=1, inplace=True)
|
| 159 |
+
|
| 160 |
+
test.dropna(axis=0, inplace=True)
|
| 161 |
+
test['Track_pop'] = test['Track_pop'].apply(lambda x: int(x/5))
|
| 162 |
+
test['Artist_pop'] = test['Artist_pop'].apply(lambda x: int(x/5))
|
| 163 |
+
test['Track_release_date'] = test['Track_release_date'].apply(lambda x: x.split('-')[0])
|
| 164 |
+
test['Track_release_date'] = test['Track_release_date'].astype('int16')
|
| 165 |
+
test['Track_release_date'] = test['Track_release_date'].apply(lambda x: int(x/50))
|
| 166 |
+
|
| 167 |
+
test[['danceability', 'energy', 'key', 'loudness', 'mode', 'speechiness', 'acousticness', 'instrumentalness', 'liveness', 'valence', 'tempo', 'time_signature']] = test[[
|
| 168 |
+
'danceability', 'energy', 'key', 'loudness', 'mode', 'speechiness', 'acousticness', 'instrumentalness', 'liveness', 'valence', 'tempo', 'time_signature']].astype('float16')
|
| 169 |
+
test[['duration_ms']] = test[['duration_ms']].astype('float32')
|
| 170 |
+
test[['Track_release_date', 'Track_pop', 'Artist_pop']] = test[[
|
| 171 |
+
'Track_release_date', 'Track_pop', 'Artist_pop']].astype('int8')
|
| 172 |
+
except Exception as e:
|
| 173 |
+
err.append(e)
|
| 174 |
+
err.append('Finish extraction')
|
| 175 |
+
return test, err
|
| 176 |
+
test, err = extract(track_ids_uni, artist_id_uni)
|
| 177 |
+
|
| 178 |
+
for i in err:
|
| 179 |
+
log.append(i)
|
| 180 |
+
del err
|
| 181 |
+
grow = test.copy()
|
| 182 |
+
test['Artist_genres'] = test['Artist_genres'].apply(lambda x: x.split(" "))
|
| 183 |
+
tfidf = TfidfVectorizer(max_features=max_gen)
|
| 184 |
+
tfidf_matrix = tfidf.fit_transform(test['Artist_genres'].apply(lambda x: " ".join(x)))
|
| 185 |
+
genre_df = pd.DataFrame(tfidf_matrix.toarray())
|
| 186 |
+
genre_df.columns = ['genre' + "|" +i for i in tfidf.get_feature_names_out()]
|
| 187 |
+
genre_df = genre_df.astype('float16')
|
| 188 |
+
test.drop(columns=['Artist_genres'], axis=1, inplace=True)
|
| 189 |
+
test = pd.concat([test.reset_index(drop=True),genre_df.reset_index(drop=True)], axis=1)
|
| 190 |
+
Fresult = pd.DataFrame()
|
| 191 |
+
x = 1
|
| 192 |
+
for i in range(int(lendf/2), lendf+1, int(lendf/2)):
|
| 193 |
+
try:
|
| 194 |
+
df = pd.read_csv('Data/streamlit.csv',names= col_name,dtype=dtypes,skiprows=x,nrows=i)
|
| 195 |
+
log.append('reading data frame chunks from {} to {}'.format(x,i))
|
| 196 |
+
except Exception as e:
|
| 197 |
+
log.append('Failed to load grow')
|
| 198 |
+
log.append(e)
|
| 199 |
+
grow = grow[~grow['track_uri'].isin(df['track_uri'].values)]
|
| 200 |
+
df = df[~df['track_uri'].isin(test['track_uri'].values)]
|
| 201 |
+
df['Artist_genres'] = df['Artist_genres'].apply(lambda x: x.split(" "))
|
| 202 |
+
tfidf_matrix = tfidf.transform(df['Artist_genres'].apply(lambda x: " ".join(x)))
|
| 203 |
+
genre_df = pd.DataFrame(tfidf_matrix.toarray())
|
| 204 |
+
genre_df.columns = ['genre' + "|" +i for i in tfidf.get_feature_names_out()]
|
| 205 |
+
genre_df = genre_df.astype('float16')
|
| 206 |
+
df.drop(columns=['Artist_genres'], axis=1, inplace=True)
|
| 207 |
+
df = pd.concat([df.reset_index(drop=True),
|
| 208 |
+
genre_df.reset_index(drop=True)], axis=1)
|
| 209 |
+
del genre_df
|
| 210 |
+
try:
|
| 211 |
+
df.drop(columns=['genre|unknown'], axis=1, inplace=True)
|
| 212 |
+
test.drop(columns=['genre|unknown'], axis=1, inplace=True)
|
| 213 |
+
except:
|
| 214 |
+
log.append('genre|unknown not found')
|
| 215 |
+
log.append('Scaling the data .....')
|
| 216 |
+
if x == 1:
|
| 217 |
+
sc = pickle.load(open('Data/sc.sav','rb'))
|
| 218 |
+
df.iloc[:, 3:19] = sc.transform(df.iloc[:, 3:19])
|
| 219 |
+
test.iloc[:, 3:19] = sc.transform(test.iloc[:, 3:19])
|
| 220 |
+
log.append("Creating playlist vector")
|
| 221 |
+
playvec = pd.DataFrame(test.sum(axis=0)).T
|
| 222 |
+
else:
|
| 223 |
+
df.iloc[:, 3:19] = sc.transform(df.iloc[:, 3:19])
|
| 224 |
+
x = i
|
| 225 |
+
if model == 'Model 1':
|
| 226 |
+
df['sim']=cosine_similarity(df.drop(['track_uri', 'artist_uri', 'album_uri'], axis = 1),playvec.drop(['track_uri', 'artist_uri', 'album_uri'], axis = 1))
|
| 227 |
+
df['sim2']=cosine_similarity(df.iloc[:,16:-1],playvec.iloc[:,16:])
|
| 228 |
+
df['sim3']=cosine_similarity(df.iloc[:,19:-2],playvec.iloc[:,19:])
|
| 229 |
+
df = df.sort_values(['sim3','sim2','sim'],ascending = False,kind='stable').groupby('artist_uri').head(same_art).head(50)
|
| 230 |
+
Fresult = pd.concat([Fresult, df], axis=0)
|
| 231 |
+
Fresult = Fresult.sort_values(['sim3', 'sim2', 'sim'],ascending=False,kind='stable')
|
| 232 |
+
Fresult.drop_duplicates(subset=['track_uri'], inplace=True,keep='first')
|
| 233 |
+
Fresult = Fresult.groupby('artist_uri').head(same_art).head(50)
|
| 234 |
+
elif model == 'Model 2':
|
| 235 |
+
df['sim'] = cosine_similarity(df.iloc[:, 3:16], playvec.iloc[:, 3:16])
|
| 236 |
+
df['sim2'] = cosine_similarity(df.loc[:, df.columns.str.startswith('T') | df.columns.str.startswith('A')], playvec.loc[:, playvec.columns.str.startswith('T') | playvec.columns.str.startswith('A')])
|
| 237 |
+
df['sim3'] = cosine_similarity(df.loc[:, df.columns.str.startswith('genre')], playvec.loc[:, playvec.columns.str.startswith('genre')])
|
| 238 |
+
df['sim4'] = (df['sim']+df['sim2']+df['sim3'])/3
|
| 239 |
+
df = df.sort_values(['sim4'], ascending=False,kind='stable').groupby('artist_uri').head(same_art).head(50)
|
| 240 |
+
Fresult = pd.concat([Fresult, df], axis=0)
|
| 241 |
+
Fresult = Fresult.sort_values(['sim4'], ascending=False,kind='stable')
|
| 242 |
+
Fresult.drop_duplicates(subset=['track_uri'], inplace=True,keep='first')
|
| 243 |
+
Fresult = Fresult.groupby('artist_uri').head(same_art).head(50)
|
| 244 |
+
del test
|
| 245 |
+
try:
|
| 246 |
+
del df
|
| 247 |
+
log.append('Getting Result')
|
| 248 |
+
except:
|
| 249 |
+
log.append('Getting Result')
|
| 250 |
+
if model == 'Model 1':
|
| 251 |
+
Fresult = Fresult.sort_values(['sim3', 'sim2', 'sim'],ascending=False,kind='stable')
|
| 252 |
+
Fresult.drop_duplicates(subset=['track_uri'], inplace=True,keep='first')
|
| 253 |
+
Fresult = Fresult.groupby('artist_uri').head(same_art).track_uri.head(50)
|
| 254 |
+
elif model == 'Model 2':
|
| 255 |
+
Fresult = Fresult.sort_values(['sim4'], ascending=False,kind='stable')
|
| 256 |
+
Fresult.drop_duplicates(subset=['track_uri'], inplace=True,keep='first')
|
| 257 |
+
Fresult = Fresult.groupby('artist_uri').head(same_art).track_uri.head(50)
|
| 258 |
+
log.append('{} New Tracks Found'.format(len(grow)))
|
| 259 |
+
if(len(grow)>=1):
|
| 260 |
+
try:
|
| 261 |
+
new=pd.read_csv('Data/new_tracks.csv',dtype=dtypes)
|
| 262 |
+
new=pd.concat([new, grow], axis=0)
|
| 263 |
+
new=new[new.Track_pop >0]
|
| 264 |
+
new.drop_duplicates(subset=['track_uri'], inplace=True,keep='last')
|
| 265 |
+
new.to_csv('Data/new_tracks.csv',index=False)
|
| 266 |
+
except:
|
| 267 |
+
grow.to_csv('Data/new_tracks.csv', index=False)
|
| 268 |
+
log.append('Model run successfully')
|
| 269 |
+
except Exception as e:
|
| 270 |
+
log.append("Model Failed")
|
| 271 |
+
log.append(e)
|
| 272 |
+
return Fresult, log
|
| 273 |
+
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
def top_tracks(url,region):
|
| 277 |
+
uri = url.split('/')[-1].split('?')[0]
|
| 278 |
+
stream= open("Spotify/Spotify.yaml")
|
| 279 |
+
spotify_details = yaml.safe_load(stream)
|
| 280 |
+
auth_manager = SpotifyClientCredentials(client_id=spotify_details['Client_id'],client_secret=spotify_details['client_secret'])
|
| 281 |
+
sp = spotipy.client.Spotify(auth_manager=auth_manager)
|
| 282 |
+
log = []
|
| 283 |
+
Fresult = []
|
| 284 |
+
try:
|
| 285 |
+
log.append('Starting Spotify Model')
|
| 286 |
+
top=sp.artist_top_tracks(uri,country=region)
|
| 287 |
+
for i in range(10) :
|
| 288 |
+
Fresult.append(top['tracks'][i]['id'])
|
| 289 |
+
log.append('Model run successfully')
|
| 290 |
+
except Exception as e:
|
| 291 |
+
log.append("Model Failed")
|
| 292 |
+
log.append(e)
|
| 293 |
+
return Fresult,log
|
| 294 |
+
|
| 295 |
+
def song_model(url, model, max_gen=3, same_art=5):
|
| 296 |
+
log = []
|
| 297 |
+
Fresult = []
|
| 298 |
+
try:
|
| 299 |
+
log.append('Start logging')
|
| 300 |
+
uri = url.split('/')[-1].split('?')[0]
|
| 301 |
+
stream = open("Spotify/Spotify.yaml")
|
| 302 |
+
spotify_details = yaml.safe_load(stream)
|
| 303 |
+
auth_manager = SpotifyClientCredentials(
|
| 304 |
+
client_id=spotify_details['Client_id'], client_secret=spotify_details['client_secret'])
|
| 305 |
+
sp = spotipy.client.Spotify(auth_manager=auth_manager)
|
| 306 |
+
|
| 307 |
+
if model == 'Spotify Model':
|
| 308 |
+
log.append('Starting Spotify Model')
|
| 309 |
+
aa=sp.recommendations(seed_tracks=[uri], limit=25)
|
| 310 |
+
for i in range(25):
|
| 311 |
+
Fresult.append(aa['tracks'][i]['id'])
|
| 312 |
+
log.append('Model run successfully')
|
| 313 |
+
return Fresult, log
|
| 314 |
+
lendf=len(pd.read_csv('Data/streamlit.csv',usecols=['track_uri']))
|
| 315 |
+
dtypes = {'track_uri': 'object', 'artist_uri': 'object', 'album_uri': 'object', 'danceability': 'float16', 'energy': 'float16', 'key': 'float16',
|
| 316 |
+
'loudness': 'float16', 'mode': 'float16', 'speechiness': 'float16', 'acousticness': 'float16', 'instrumentalness': 'float16',
|
| 317 |
+
'liveness': 'float16', 'valence': 'float16', 'tempo': 'float16', 'duration_ms': 'float32', 'time_signature': 'float16',
|
| 318 |
+
'Track_release_date': 'int8', 'Track_pop': 'int8', 'Artist_pop': 'int8', 'Artist_genres': 'object'}
|
| 319 |
+
col_name= ['track_uri', 'artist_uri', 'album_uri', 'danceability', 'energy', 'key',
|
| 320 |
+
'loudness', 'mode', 'speechiness', 'acousticness', 'instrumentalness',
|
| 321 |
+
'liveness', 'valence', 'tempo', 'duration_ms', 'time_signature',
|
| 322 |
+
'Track_release_date', 'Track_pop', 'Artist_pop', 'Artist_genres']
|
| 323 |
+
log.append('Start audio features extraction')
|
| 324 |
+
audio_features = pd.DataFrame(sp.audio_features([uri]))
|
| 325 |
+
log.append('Start track features extraction')
|
| 326 |
+
track_ = pd.DataFrame()
|
| 327 |
+
track_features = sp.tracks([uri])
|
| 328 |
+
track_pop = pd.DataFrame([uri], columns=['Track_uri'])
|
| 329 |
+
track_pop['Track_release_date'] = track_features['tracks'][0]['album']['release_date']
|
| 330 |
+
track_pop['Track_pop'] = track_features['tracks'][0]["popularity"]
|
| 331 |
+
track_pop['Artist_uri'] = track_features['tracks'][0]['artists'][0]['id']
|
| 332 |
+
track_pop['Album_uri'] = track_features['tracks'][0]['album']['id']
|
| 333 |
+
track_ = pd.concat([track_, track_pop], axis=0)
|
| 334 |
+
log.append('Start artist features extraction')
|
| 335 |
+
artist_id_uni=list(track_['Artist_uri'])
|
| 336 |
+
artist_ = pd.DataFrame()
|
| 337 |
+
artist_features = sp.artists(artist_id_uni)
|
| 338 |
+
artist_df = pd.DataFrame(artist_id_uni, columns=['Artist_uri'])
|
| 339 |
+
artist_pop = artist_features['artists'][0]["popularity"]
|
| 340 |
+
artist_genres = artist_features['artists'][0]["genres"]
|
| 341 |
+
artist_df["Artist_pop"] = artist_pop
|
| 342 |
+
if artist_genres:
|
| 343 |
+
artist_df["genres"] = " ".join([re.sub(' ', '_', i) for i in artist_genres])
|
| 344 |
+
else:
|
| 345 |
+
artist_df["genres"] = "unknown"
|
| 346 |
+
artist_ = pd.concat([artist_, artist_df], axis=0)
|
| 347 |
+
try:
|
| 348 |
+
test = pd.DataFrame(track_, columns=['Track_uri', 'Artist_uri', 'Album_uri'])
|
| 349 |
+
test.rename(columns={'Track_uri': 'track_uri','Artist_uri': 'artist_uri', 'Album_uri': 'album_uri'}, inplace=True)
|
| 350 |
+
audio_features.drop(columns=['type', 'uri', 'track_href', 'analysis_url'], axis=1, inplace=True)
|
| 351 |
+
test = pd.merge(test, audio_features,left_on="track_uri", right_on="id", how='outer')
|
| 352 |
+
test = pd.merge(test, track_, left_on="track_uri",right_on="Track_uri", how='outer')
|
| 353 |
+
test = pd.merge(test, artist_, left_on="artist_uri",right_on="Artist_uri", how='outer')
|
| 354 |
+
test.rename(columns={'genres': 'Artist_genres'}, inplace=True)
|
| 355 |
+
test.drop(columns=['Track_uri', 'Artist_uri_x','Artist_uri_y', 'Album_uri', 'id'], axis=1, inplace=True)
|
| 356 |
+
test.dropna(axis=0, inplace=True)
|
| 357 |
+
test['Track_pop'] = test['Track_pop'].apply(lambda x: int(x/5))
|
| 358 |
+
test['Artist_pop'] = test['Artist_pop'].apply(lambda x: int(x/5))
|
| 359 |
+
test['Track_release_date'] = test['Track_release_date'].apply(lambda x: x.split('-')[0])
|
| 360 |
+
test['Track_release_date'] = test['Track_release_date'].astype('int16')
|
| 361 |
+
test['Track_release_date'] = test['Track_release_date'].apply(lambda x: int(x/50))
|
| 362 |
+
test[['danceability', 'energy', 'key', 'loudness', 'mode', 'speechiness', 'acousticness', 'instrumentalness', 'liveness', 'valence', 'tempo', 'time_signature']] = test[['danceability', 'energy', 'key', 'loudness', 'mode', 'speechiness', 'acousticness', 'instrumentalness', 'liveness', 'valence', 'tempo', 'time_signature']].astype('float16')
|
| 363 |
+
test[['duration_ms']] = test[['duration_ms']].astype('float32')
|
| 364 |
+
test[['Track_release_date', 'Track_pop', 'Artist_pop']] = test[['Track_release_date', 'Track_pop', 'Artist_pop']].astype('int8')
|
| 365 |
+
except Exception as e:
|
| 366 |
+
log.append(e)
|
| 367 |
+
log.append('Finish extraction')
|
| 368 |
+
grow = test.copy()
|
| 369 |
+
test['Artist_genres'] = test['Artist_genres'].apply(lambda x: x.split(" "))
|
| 370 |
+
tfidf = TfidfVectorizer(max_features=max_gen)
|
| 371 |
+
tfidf_matrix = tfidf.fit_transform(test['Artist_genres'].apply(lambda x: " ".join(x)))
|
| 372 |
+
genre_df = pd.DataFrame(tfidf_matrix.toarray())
|
| 373 |
+
genre_df.columns = ['genre' + "|" +i for i in tfidf.get_feature_names_out()]
|
| 374 |
+
genre_df = genre_df.astype('float16')
|
| 375 |
+
test.drop(columns=['Artist_genres'], axis=1, inplace=True)
|
| 376 |
+
test = pd.concat([test.reset_index(drop=True),genre_df.reset_index(drop=True)], axis=1)
|
| 377 |
+
Fresult = pd.DataFrame()
|
| 378 |
+
x = 1
|
| 379 |
+
for i in range(int(lendf/2), lendf+1, int(lendf/2)):
|
| 380 |
+
try:
|
| 381 |
+
df = pd.read_csv('Data/streamlit.csv',names= col_name,dtype=dtypes,skiprows=x,nrows=i)
|
| 382 |
+
log.append('reading data frame chunks from {} to {}'.format(x,i))
|
| 383 |
+
except Exception as e:
|
| 384 |
+
log.append('Failed to load grow')
|
| 385 |
+
log.append(e)
|
| 386 |
+
grow = grow[~grow['track_uri'].isin(df['track_uri'].values)]
|
| 387 |
+
df = df[~df['track_uri'].isin(test['track_uri'].values)]
|
| 388 |
+
df['Artist_genres'] = df['Artist_genres'].apply(lambda x: x.split(" "))
|
| 389 |
+
tfidf_matrix = tfidf.transform(df['Artist_genres'].apply(lambda x: " ".join(x)))
|
| 390 |
+
genre_df = pd.DataFrame(tfidf_matrix.toarray())
|
| 391 |
+
genre_df.columns = ['genre' + "|" +i for i in tfidf.get_feature_names_out()]
|
| 392 |
+
genre_df = genre_df.astype('float16')
|
| 393 |
+
df.drop(columns=['Artist_genres'], axis=1, inplace=True)
|
| 394 |
+
df = pd.concat([df.reset_index(drop=True),
|
| 395 |
+
genre_df.reset_index(drop=True)], axis=1)
|
| 396 |
+
del genre_df
|
| 397 |
+
try:
|
| 398 |
+
df.drop(columns=['genre|unknown'], axis=1, inplace=True)
|
| 399 |
+
test.drop(columns=['genre|unknown'], axis=1, inplace=True)
|
| 400 |
+
except:
|
| 401 |
+
log.append('genre|unknown not found')
|
| 402 |
+
log.append('Scaling the data .....')
|
| 403 |
+
if x == 1:
|
| 404 |
+
sc = pickle.load(open('Data/sc.sav','rb'))
|
| 405 |
+
df.iloc[:, 3:19] = sc.transform(df.iloc[:, 3:19])
|
| 406 |
+
test.iloc[:, 3:19] = sc.transform(test.iloc[:, 3:19])
|
| 407 |
+
log.append("Creating playlist vector")
|
| 408 |
+
playvec = pd.DataFrame(test.sum(axis=0)).T
|
| 409 |
+
else:
|
| 410 |
+
df.iloc[:, 3:19] = sc.transform(df.iloc[:, 3:19])
|
| 411 |
+
x = i
|
| 412 |
+
if model == 'Model 1':
|
| 413 |
+
df['sim']=cosine_similarity(df.drop(['track_uri', 'artist_uri', 'album_uri'], axis = 1),playvec.drop(['track_uri', 'artist_uri', 'album_uri'], axis = 1))
|
| 414 |
+
df['sim2']=cosine_similarity(df.iloc[:,16:-1],playvec.iloc[:,16:])
|
| 415 |
+
df['sim3']=cosine_similarity(df.iloc[:,19:-2],playvec.iloc[:,19:])
|
| 416 |
+
df = df.sort_values(['sim3','sim2','sim'],ascending = False,kind='stable').groupby('artist_uri').head(same_art).head(50)
|
| 417 |
+
Fresult = pd.concat([Fresult, df], axis=0)
|
| 418 |
+
Fresult = Fresult.sort_values(['sim3', 'sim2', 'sim'],ascending=False,kind='stable')
|
| 419 |
+
Fresult.drop_duplicates(subset=['track_uri'], inplace=True,keep='first')
|
| 420 |
+
Fresult = Fresult.groupby('artist_uri').head(same_art).head(50)
|
| 421 |
+
elif model == 'Model 2':
|
| 422 |
+
df['sim'] = cosine_similarity(df.iloc[:, 3:16], playvec.iloc[:, 3:16])
|
| 423 |
+
df['sim2'] = cosine_similarity(df.loc[:, df.columns.str.startswith('T') | df.columns.str.startswith('A')], playvec.loc[:, playvec.columns.str.startswith('T') | playvec.columns.str.startswith('A')])
|
| 424 |
+
df['sim3'] = cosine_similarity(df.loc[:, df.columns.str.startswith('genre')], playvec.loc[:, playvec.columns.str.startswith('genre')])
|
| 425 |
+
df['sim4'] = (df['sim']+df['sim2']+df['sim3'])/3
|
| 426 |
+
df = df.sort_values(['sim4'], ascending=False,kind='stable').groupby('artist_uri').head(same_art).head(50)
|
| 427 |
+
Fresult = pd.concat([Fresult, df], axis=0)
|
| 428 |
+
Fresult = Fresult.sort_values(['sim4'], ascending=False,kind='stable')
|
| 429 |
+
Fresult.drop_duplicates(subset=['track_uri'], inplace=True,keep='first')
|
| 430 |
+
Fresult = Fresult.groupby('artist_uri').head(same_art).head(50)
|
| 431 |
+
del test
|
| 432 |
+
try:
|
| 433 |
+
del df
|
| 434 |
+
log.append('Getting Result')
|
| 435 |
+
except:
|
| 436 |
+
log.append('Getting Result')
|
| 437 |
+
if model == 'Model 1':
|
| 438 |
+
Fresult = Fresult.sort_values(['sim3', 'sim2', 'sim'],ascending=False,kind='stable')
|
| 439 |
+
Fresult.drop_duplicates(subset=['track_uri'], inplace=True,keep='first')
|
| 440 |
+
Fresult = Fresult.groupby('artist_uri').head(same_art).track_uri.head(50)
|
| 441 |
+
elif model == 'Model 2':
|
| 442 |
+
Fresult = Fresult.sort_values(['sim4'], ascending=False,kind='stable')
|
| 443 |
+
Fresult.drop_duplicates(subset=['track_uri'], inplace=True,keep='first')
|
| 444 |
+
Fresult = Fresult.groupby('artist_uri').head(same_art).track_uri.head(50)
|
| 445 |
+
log.append('{} New Tracks Found'.format(len(grow)))
|
| 446 |
+
if(len(grow)>=1):
|
| 447 |
+
try:
|
| 448 |
+
new=pd.read_csv('Data/new_tracks.csv',dtype=dtypes)
|
| 449 |
+
new=pd.concat([new, grow], axis=0)
|
| 450 |
+
new=new[new.Track_pop >0]
|
| 451 |
+
new.drop_duplicates(subset=['track_uri'], inplace=True,keep='last')
|
| 452 |
+
new.to_csv('Data/new_tracks.csv',index=False)
|
| 453 |
+
except:
|
| 454 |
+
grow.to_csv('Data/new_tracks.csv', index=False)
|
| 455 |
+
log.append('Model run successfully')
|
| 456 |
+
except Exception as e:
|
| 457 |
+
log.append("Model Failed")
|
| 458 |
+
log.append(e)
|
| 459 |
+
return Fresult, log
|
| 460 |
+
|
| 461 |
+
def update_dataset():
|
| 462 |
+
col_name= ['track_uri', 'artist_uri', 'album_uri', 'danceability', 'energy', 'key',
|
| 463 |
+
'loudness', 'mode', 'speechiness', 'acousticness', 'instrumentalness',
|
| 464 |
+
'liveness', 'valence', 'tempo', 'duration_ms', 'time_signature',
|
| 465 |
+
'Track_release_date', 'Track_pop', 'Artist_pop', 'Artist_genres']
|
| 466 |
+
dtypes = {'track_uri': 'object', 'artist_uri': 'object', 'album_uri': 'object', 'danceability': 'float16', 'energy': 'float16', 'key': 'float16',
|
| 467 |
+
'loudness': 'float16', 'mode': 'float16', 'speechiness': 'float16', 'acousticness': 'float16', 'instrumentalness': 'float16',
|
| 468 |
+
'liveness': 'float16', 'valence': 'float16', 'tempo': 'float16', 'duration_ms': 'float32', 'time_signature': 'float16',
|
| 469 |
+
'Track_release_date': 'int8', 'Track_pop': 'int8', 'Artist_pop': 'int8', 'Artist_genres': 'object'}
|
| 470 |
+
df = pd.read_csv('Data/streamlit.csv',dtype=dtypes)
|
| 471 |
+
grow = pd.read_csv('Data/new_tracks.csv',dtype=dtypes)
|
| 472 |
+
cur = len(df)
|
| 473 |
+
df=pd.concat([df,grow],axis=0)
|
| 474 |
+
grow=pd.DataFrame(columns=col_name)
|
| 475 |
+
grow.to_csv('Data/new_tracks.csv',index=False)
|
| 476 |
+
df=df[df.Track_pop >0]
|
| 477 |
+
df.drop_duplicates(subset=['track_uri'],inplace=True,keep='last')
|
| 478 |
+
df.dropna(axis=0,inplace=True)
|
| 479 |
+
df.to_csv('Data/streamlit.csv',index=False)
|
| 480 |
+
return (len(df)-cur)
|
| 481 |
+
|
requirements.txt
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
pandas==1.4.4
|
| 2 |
+
PyYAML==6.0
|
| 3 |
+
scikit_learn==1.1.3
|
| 4 |
+
spotipy==2.20.0
|
| 5 |
+
streamlit==1.14.0
|
| 6 |
+
streamlit_option_menu==0.3.2
|
spotify_get_artist_url.png
ADDED
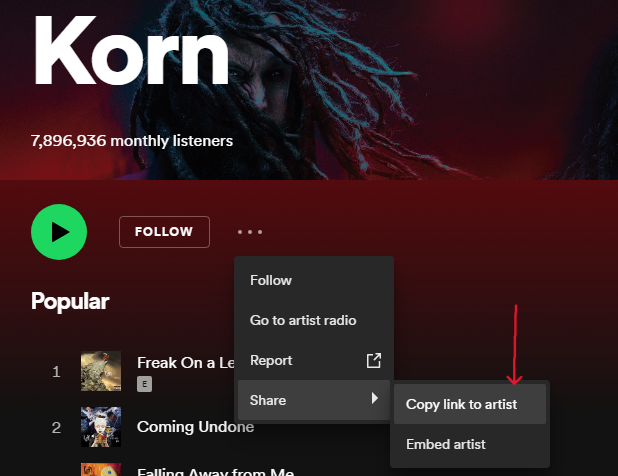
|
spotify_get_playlist_url.png
ADDED
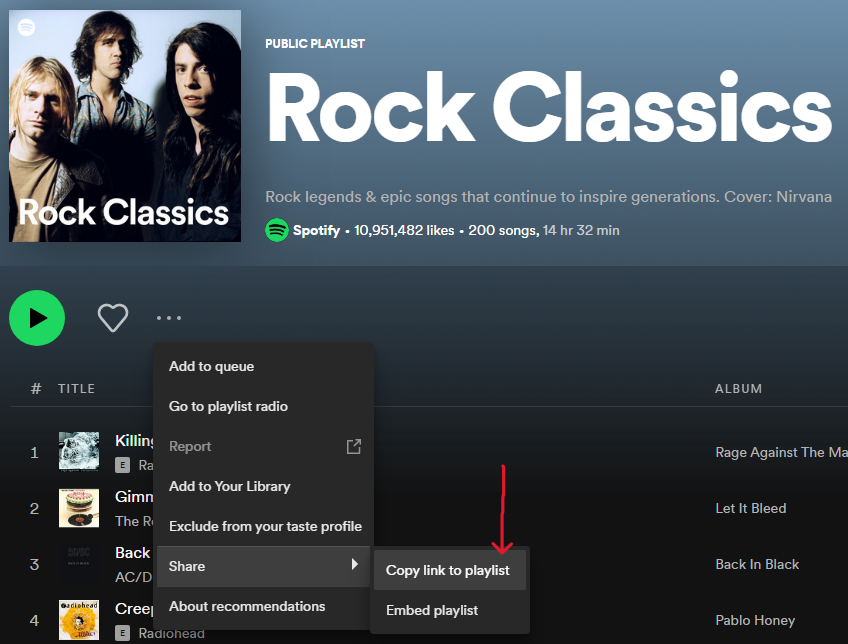
|
spotify_get_song_url.png
ADDED
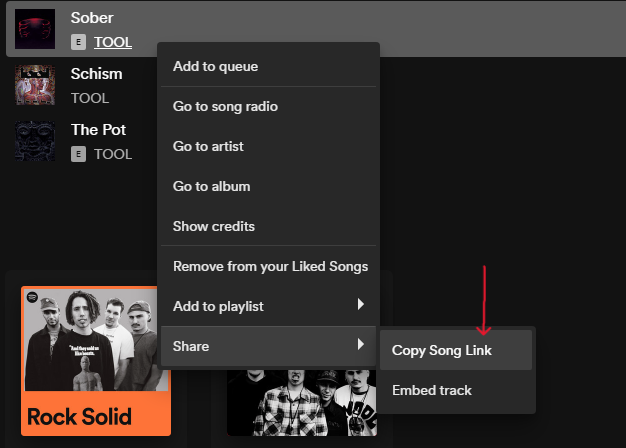
|