## OmniLMM-12B
> OmniLMM-12B is released at early time of this project. We recommond you to use our [recently released models](./README_en.md), for better performance and efficiency.
> Archieve at: 2024-05-19
**OmniLMM-12B** is the most capable version. The model is built based on EVA02-5B and Zephyr-7B-β, connected with a perceiver resampler layer, and trained on multimodal data in a curriculum fashion. The model has three notable features:
- 🔥 **Strong Performance.**
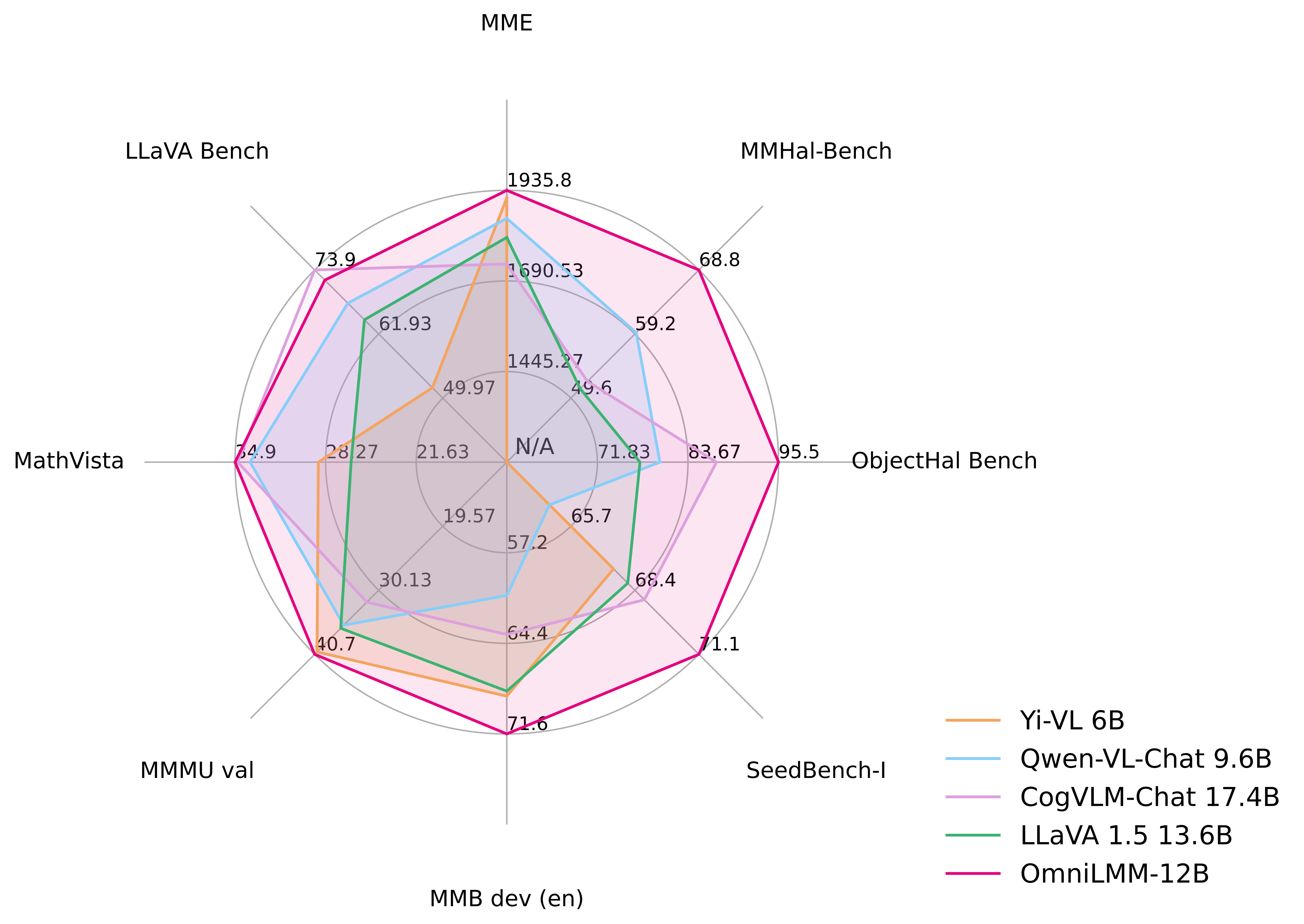
OmniLMM-12B achieves **leading performance** among models with comparable sizes, surpassing established LMMs on multiple benchmarks (including MME, MMBench, SEED-Bench, etc). The model also endows rich multi-modal world knowledge.
- 🏆 **Trustworthy Behavior.**
LMMs are known for suffering from hallucination, often generating text that is not factually grounded in images (e.g., faithfully describing non-existing objects in images). OmniLMM-12B is **the first state-of-the-art open-source LMM aligned via multimodal RLHF for trustworthy behavior** (using the recent [RLHF-V](https://rlhf-v.github.io/) technique). It **ranks #1** among open-source models on [MMHal-Bench](https://huggingface.co/datasets/Shengcao1006/MMHal-Bench), and **outperforms GPT-4V** on [Object HalBench](https://arxiv.org/abs/2312.00849).
- 🕹 **Real-time Multimodal Interaction.**
We combine the OmniLMM-12B and GPT-3.5 (text-only) into a **real-time multimodal interactive assistant**. The assistant accepts video streams from the camera and speech streams from the microphone and emits speech output. While still primary, we find the model can **replicate some of the fun cases shown in the Gemini Demo video, without any video edition**.
### Evaluation
Click to view results on MME, MMBench, MMMU, MMBench, MMHal-Bench, Object HalBench, SeedBench, LLaVA Bench, MathVista.
| Model |
Size |
MME |
MMB dev (en) |
MMMU val |
MMHal-Bench |
Object HalBench |
SeedBench-I |
MathVista |
LLaVA Bench |
| GPT-4V† |
- |
1771.5 |
75.1 |
56.8 |
3.53 / 70.8 |
86.4 / 92.7 |
71.6 |
47.8 |
93.1 |
| Qwen-VL-Plus† |
- |
2183.4 |
66.2 |
45.2 |
- |
- |
65.7 |
36.0 |
73.7 |
| Yi-VL 6B |
6.7B |
1915.1 |
68.6 |
40.3 |
- |
- |
67.5 |
28.8 |
51.9 |
| Qwen-VL-Chat |
9.6B |
1860.0 |
60.6 |
35.9 |
2.93 / 59.4 |
56.2 / 80.0 |
64.8 |
33.8 |
67.7 |
| CogVLM-Chat |
17.4B |
1736.6 |
63.7 |
32.1 |
2.68 / 52.1 |
73.6 / 87.4 |
68.8 |
34.7 |
73.9 |
| LLaVA 1.5 |
13.6B |
1808.4 |
68.2 |
36.4 |
2.71 / 51.0 |
53.7 / 77.4 |
68.1 |
26.4 |
64.6 |
| OmniLMM-12B |
11.6B |
1935.8 |
71.6 |
40.7 |
3.45 / 68.8 |
90.3 / 95.5 |
71.1 |
34.9 |
72.0 |
†: Proprietary models
### Examples
We combine the OmniLMM-12B and GPT-3.5 (text-only) into a **real-time multimodal interactive assistant**. Video frames are described in text using OmniLMM-12B, and ChatGPT 3.5 (text-only) is employed to generate response according to the descriptions and user prompts. The demo video is a raw recording without edition.
### Model Zoo
| Model | Description | Download Link |
|:----------------------|:-------------------|:---------------:|
| OmniLMM-12B | The most capable version with leading performance. | [🤗](https://huggingface.co/openbmb/OmniLMM-12B) [ ](https://modelscope.cn/models/OpenBMB/OmniLMM-12B/files) |
](https://modelscope.cn/models/OpenBMB/OmniLMM-12B/files) |