Spaces:
Paused

Paused

Commit
•
0fdb130
1
Parent(s):
691184b
created the updated web ui
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitignore +3 -0
- app.py +206 -0
- config.py +212 -0
- current_requirements.txt +225 -0
- embedding_mlp.pth +3 -0
- embedding_mlp.safetensors +3 -0
- gitattributes +35 -0
- requirements.txt +18 -0
- test_models/EDA.ipynb +106 -0
- test_models/create_setfit_model.py +99 -0
- test_models/financial-roberta/1_Pooling/config.json +7 -0
- test_models/financial-roberta/README.md +497 -0
- test_models/financial-roberta/config.json +28 -0
- test_models/financial-roberta/config_sentence_transformers.json +7 -0
- test_models/financial-roberta/merges.txt +0 -0
- test_models/financial-roberta/model.safetensors +3 -0
- test_models/financial-roberta/modules.json +20 -0
- test_models/financial-roberta/sentence_bert_config.json +4 -0
- test_models/financial-roberta/special_tokens_map.json +51 -0
- test_models/financial-roberta/tokenizer.json +0 -0
- test_models/financial-roberta/tokenizer_config.json +64 -0
- test_models/financial-roberta/vocab.json +0 -0
- test_models/get_embeddings.py +164 -0
- test_models/models/embedding_mlp_2023-12-07_13-41.pth +3 -0
- test_models/models/embedding_mlp_2023-12-07_13-41.safetensors +3 -0
- test_models/models/head.pth +3 -0
- test_models/models/head.safetensors +3 -0
- test_models/models/linear_head.pth +3 -0
- test_models/models/linear_head.safetensors +3 -0
- test_models/plots/confusion_matrix.png +0 -0
- test_models/plots/confusion_matrix_2023-12-06_17-53.png +0 -0
- test_models/plots/confusion_matrix_2023-12-06_17-55.png +0 -0
- test_models/plots/confusion_matrix_2023-12-06_17-56.png +0 -0
- test_models/plots/confusion_matrix_2023-12-06_17-58.png +0 -0
- test_models/plots/confusion_matrix_2023-12-06_18-06.png +0 -0
- test_models/plots/confusion_matrix_2023-12-06_18-07.png +0 -0
- test_models/plots/confusion_matrix_2023-12-06_18-08.png +0 -0
- test_models/plots/confusion_matrix_2023-12-06_18-10.png +0 -0
- test_models/plots/confusion_matrix_2023-12-06_18-15.png +0 -0
- test_models/plots/confusion_matrix_2023-12-06_18-17.png +0 -0
- test_models/plots/confusion_matrix_2023-12-06_18-18.png +0 -0
- test_models/plots/confusion_matrix_2023-12-06_18-35.png +0 -0
- test_models/plots/confusion_matrix_2023-12-06_18-36.png +0 -0
- test_models/plots/confusion_matrix_2023-12-06_18-37.png +0 -0
- test_models/plots/confusion_matrix_2023-12-06_18-38.png +0 -0
- test_models/plots/confusion_matrix_2023-12-06_18-39.png +0 -0
- test_models/plots/confusion_matrix_2023-12-06_18-40.png +0 -0
- test_models/plots/confusion_matrix_2023-12-07_12-15.png +0 -0
- test_models/plots/confusion_matrix_2023-12-07_12-16.png +0 -0
- test_models/plots/confusion_matrix_2023-12-07_12-17.png +0 -0
.gitignore
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.DS_Store
|
| 2 |
+
.ipynb_checkpoints/
|
| 3 |
+
__pycache__/
|
app.py
ADDED
|
@@ -0,0 +1,206 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
def read_and_split_file(filename, chunk_size=1200, chunk_overlap=200):
|
| 2 |
+
with open(filename, 'r') as f:
|
| 3 |
+
text = f.read()
|
| 4 |
+
|
| 5 |
+
text_splitter = RecursiveCharacterTextSplitter(
|
| 6 |
+
chunk_size=chunk_size, chunk_overlap=chunk_overlap,
|
| 7 |
+
length_function = len, separators=[" ", ",", "\n"]
|
| 8 |
+
)
|
| 9 |
+
|
| 10 |
+
# st.write(f'Financial report char len: {len(text)}')
|
| 11 |
+
texts = text_splitter.create_documents([text])
|
| 12 |
+
return texts
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def get_label_prediction(selected_predictor, texts):
|
| 16 |
+
predicted_labels = []
|
| 17 |
+
replies = []
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
emdedding_model_name = predictors[selected_predictor]['embedding_model']
|
| 21 |
+
emdedding_model = SentenceTransformer(emdedding_model_name)
|
| 22 |
+
|
| 23 |
+
texts_str = [text.page_content for text in texts]
|
| 24 |
+
embeddings = emdedding_model.encode(texts_str, show_progress_bar=True).tolist()
|
| 25 |
+
|
| 26 |
+
# dataset = load_dataset(predictors[selected_predictor]['dataset_name'])
|
| 27 |
+
label_encoder = LabelEncoder()
|
| 28 |
+
encoded_labels = label_encoder.fit_transform([label.upper() for label in labels])
|
| 29 |
+
|
| 30 |
+
input_size = predictors[selected_predictor]['embedding_dim']
|
| 31 |
+
hidden_size = 256
|
| 32 |
+
output_size = len(label_encoder.classes_)
|
| 33 |
+
dropout_rate = 0.5
|
| 34 |
+
batch_size = 8
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
model = MLP(input_size, hidden_size, output_size, dropout_rate)
|
| 38 |
+
load_model(model, predictors[selected_predictor]['mlp_model'])
|
| 39 |
+
|
| 40 |
+
embeddings_tensor = torch.tensor(embeddings)
|
| 41 |
+
|
| 42 |
+
data = TensorDataset(embeddings_tensor)
|
| 43 |
+
dataloader = DataLoader(data, batch_size=batch_size, shuffle=True)
|
| 44 |
+
|
| 45 |
+
with torch.no_grad():
|
| 46 |
+
model.eval()
|
| 47 |
+
for inputs in dataloader:
|
| 48 |
+
# st.write(inputs[0])
|
| 49 |
+
outputs = model(inputs[0])
|
| 50 |
+
|
| 51 |
+
# _, predicted = torch.max(outputs, 1)
|
| 52 |
+
|
| 53 |
+
probabilities = F.softmax(outputs, dim=1)
|
| 54 |
+
predicted_indices = torch.argmax(probabilities, dim=1).tolist()
|
| 55 |
+
predicted_labels_list = label_encoder.inverse_transform(predicted_indices)
|
| 56 |
+
for pred_label in predicted_labels_list:
|
| 57 |
+
predicted_labels.append(pred_label)
|
| 58 |
+
# st.write(pred_label)
|
| 59 |
+
|
| 60 |
+
predicted_labels_counter = Counter(predicted_labels)
|
| 61 |
+
predicted_label = predicted_labels_counter.most_common(1)[0][0]
|
| 62 |
+
return predicted_label
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
if __name__ == '__main__':
|
| 69 |
+
# Comments and ideas to implement:
|
| 70 |
+
# 1. Try sending list of inputs to the Inference API.
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
from config import (
|
| 75 |
+
labels, headers_inference_api, headers_inference_endpoint,
|
| 76 |
+
# summarization_prompt_template,
|
| 77 |
+
prompt_template,
|
| 78 |
+
# task_explain_for_predictor_model,
|
| 79 |
+
summarizers, predictors, summary_scores_template,
|
| 80 |
+
summarization_system_msg, summarization_user_prompt, prediction_user_prompt, prediction_system_msg,
|
| 81 |
+
# prediction_prompt,
|
| 82 |
+
chat_prompt, instruction_prompt
|
| 83 |
+
)
|
| 84 |
+
|
| 85 |
+
import streamlit as st
|
| 86 |
+
from sys import exit
|
| 87 |
+
from pprint import pprint
|
| 88 |
+
from collections import Counter
|
| 89 |
+
from itertools import zip_longest
|
| 90 |
+
from random import choice
|
| 91 |
+
import requests
|
| 92 |
+
from re import sub
|
| 93 |
+
from rouge import Rouge
|
| 94 |
+
from time import sleep, perf_counter
|
| 95 |
+
import os
|
| 96 |
+
from textwrap import wrap
|
| 97 |
+
from multiprocessing import Pool, freeze_support
|
| 98 |
+
from tqdm import tqdm
|
| 99 |
+
from stqdm import stqdm
|
| 100 |
+
from langchain.document_loaders import TextLoader
|
| 101 |
+
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
| 102 |
+
from langchain.schema.document import Document
|
| 103 |
+
# from langchain.schema import Document
|
| 104 |
+
from langchain.chat_models import ChatOpenAI
|
| 105 |
+
from langchain.llms import OpenAI
|
| 106 |
+
from langchain.schema import AIMessage, HumanMessage, SystemMessage
|
| 107 |
+
from langchain.prompts import PromptTemplate
|
| 108 |
+
from datasets import Dataset, load_dataset
|
| 109 |
+
from sklearn.preprocessing import LabelEncoder
|
| 110 |
+
from test_models.train_classificator import MLP
|
| 111 |
+
from safetensors.torch import load_model, save_model
|
| 112 |
+
from sentence_transformers import SentenceTransformer
|
| 113 |
+
from torch.utils.data import DataLoader, TensorDataset
|
| 114 |
+
import torch.nn.functional as F
|
| 115 |
+
import torch
|
| 116 |
+
import torch.nn as nn
|
| 117 |
+
import sys
|
| 118 |
+
|
| 119 |
+
sys.path.append(os.path.abspath(os.path.join(os.getcwd(), 'test_models/')))
|
| 120 |
+
sys.path.append(os.path.abspath(os.path.join(os.getcwd(), 'test_models/financial-roberta')))
|
| 121 |
+
|
| 122 |
+
st.set_page_config(
|
| 123 |
+
page_title="Financial advisor",
|
| 124 |
+
page_icon="💳💰",
|
| 125 |
+
layout="wide",
|
| 126 |
+
)
|
| 127 |
+
# st.session_state.summarized = False
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
with st.sidebar:
|
| 135 |
+
"# How to use🔍"
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
"""
|
| 139 |
+
✨This is a holiday version of the web-UI with the magic 🌐, allowing you to unwrap
|
| 140 |
+
label predictions for a company based on its financial report text! 📊✨ The prediction
|
| 141 |
+
enchantment is performed using the sophisticated embedding classifier approach. 🚀🔮
|
| 142 |
+
"""
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
center_style = "<h3 style='text-align: center; color: black;'>{} </h3>"
|
| 146 |
+
st.markdown(center_style.format('Load the financial report'), unsafe_allow_html=True)
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
upload_types = ['Text input', 'File upload']
|
| 150 |
+
upload_captions = ['Paste the text', 'Upload a text file']
|
| 151 |
+
upload_type = st.radio('Select how to upload the financial report', upload_types,
|
| 152 |
+
captions=upload_captions)
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
match upload_type:
|
| 156 |
+
case 'Text input':
|
| 157 |
+
financial_report_text = st.text_area('Something', label_visibility='collapsed',
|
| 158 |
+
placeholder='Financial report as TEXT')
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
case 'File upload':
|
| 162 |
+
uploaded_files = st.file_uploader("Choose a a text file", type=['.txt', '.docx'],
|
| 163 |
+
label_visibility='collapsed', accept_multiple_files=True)
|
| 164 |
+
|
| 165 |
+
if not bool(uploaded_files):
|
| 166 |
+
st.stop()
|
| 167 |
+
|
| 168 |
+
financial_report_text = ''
|
| 169 |
+
for uploaded_file in uploaded_files:
|
| 170 |
+
if uploaded_file.name.endswith("docx"):
|
| 171 |
+
document = Document(uploaded_file)
|
| 172 |
+
document.save('./utils/texts/' + uploaded_file.name)
|
| 173 |
+
document = Document(uploaded_file.name)
|
| 174 |
+
financial_report_text += "".join([paragraph.text for paragraph in document.paragraphs]) + '\n'
|
| 175 |
+
else:
|
| 176 |
+
financial_report_text += "".join([line.decode() for line in uploaded_file]) + '\n'
|
| 177 |
+
|
| 178 |
+
# with open('./utils/texts/financial_report_text.txt', 'w') as file:
|
| 179 |
+
# file.write(financial_report_text)
|
| 180 |
+
|
| 181 |
+
if st.button('Get label'):
|
| 182 |
+
with st.spinner("Thinking..."):
|
| 183 |
+
text_splitter = RecursiveCharacterTextSplitter(
|
| 184 |
+
chunk_size=3200, chunk_overlap=200,
|
| 185 |
+
length_function = len, separators=[" ", ",", "\n"]
|
| 186 |
+
)
|
| 187 |
+
|
| 188 |
+
# st.write(f'Financial report char len: {len(financial_report_text)}')
|
| 189 |
+
documents = text_splitter.create_documents([financial_report_text])
|
| 190 |
+
# st.write(f'Num chunks: {len(documents)}')
|
| 191 |
+
texts = [document.page_content for document in documents]
|
| 192 |
+
# st.write(f'Each chunk char length: {[len(text) for text in texts]}')
|
| 193 |
+
|
| 194 |
+
# predicted_label = get_label_prediction(texts)
|
| 195 |
+
from test_models.create_setfit_model import model
|
| 196 |
+
|
| 197 |
+
with torch.no_grad():
|
| 198 |
+
model.model_head.eval()
|
| 199 |
+
predicted_labels = model(texts)
|
| 200 |
+
# st.write(predicted_labels)
|
| 201 |
+
|
| 202 |
+
predicted_labels_counter = Counter(predicted_labels)
|
| 203 |
+
predicted_label = predicted_labels_counter.most_common(1)[0][0]
|
| 204 |
+
|
| 205 |
+
font_style = 'The predicted label is<span style="font-size: 32px"> **{}**</span>.'
|
| 206 |
+
st.markdown(font_style.format(predicted_label), unsafe_allow_html=True)
|
config.py
ADDED
|
@@ -0,0 +1,212 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from langchain.prompts import PromptTemplate
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
labels = ['buy', 'sell', 'hold']
|
| 6 |
+
headers_inference_api = {"Authorization": f"Bearer {os.environ['HG_api_key']}"}
|
| 7 |
+
# headers_inference_endpoint = {
|
| 8 |
+
# "Authorization": f"Bearer {os.environ['HG_api_key_personal']}",
|
| 9 |
+
# "Content-Type": "application/json"
|
| 10 |
+
#}
|
| 11 |
+
|
| 12 |
+
summarization_system_msg = """You are the best financial advisor and expert broker. You are \
|
| 13 |
+
reading Item 7 from Form 10-K of some company and you want to summarize it into 10 sentences the best as \
|
| 14 |
+
possible, so that then the human will analyze your summary and take on serious decisions, whether to \
|
| 15 |
+
buy, sell or hold the holdings of that company. There is no need to copy messages from the original text. \
|
| 16 |
+
Don't write general things, which aren't important to the investor. Include the most important parts, \
|
| 17 |
+
which describes the business growth, predictions for next years etc."""
|
| 18 |
+
summarization_user_msg = "Company's description: {company_description}"
|
| 19 |
+
|
| 20 |
+
summarization_user_prompt = PromptTemplate.from_template(
|
| 21 |
+
template=summarization_user_msg
|
| 22 |
+
)
|
| 23 |
+
|
| 24 |
+
# summarization_template = """<system> You are the best financial advisor and expert broker. You are \
|
| 25 |
+
# reading Item 7 from Form 10-K of some company and you want to summarize it into 2-3 sentences the best as \
|
| 26 |
+
# possible, so that then the human will analyze your summary and take on serious decisions, whether to \
|
| 27 |
+
# buy, sell or hold the holdings of that company. There is no need to copy messages from the original text</system>
|
| 28 |
+
|
| 29 |
+
# Company's description: {company_description}"""
|
| 30 |
+
|
| 31 |
+
# summarization_prompt_template = PromptTemplate.from_template(
|
| 32 |
+
# template=summarization_template
|
| 33 |
+
# )
|
| 34 |
+
|
| 35 |
+
prediction_system_msg = """You are the best financial advisor and expert broker. I am an investor, who seek \
|
| 36 |
+
for your help. Below is the description of one big company. You need to reply to me with a \
|
| 37 |
+
single word, either 'sell', 'buy' or 'hold'. This word should best describe your recommendation \
|
| 38 |
+
on what is the best action for me with the company's holdings."""
|
| 39 |
+
prediction_user_msg = """Company's description: {company_description}
|
| 40 |
+
|
| 41 |
+
So what do you think? Sell, buy or hold?"""
|
| 42 |
+
prediction_user_prompt = PromptTemplate.from_template(
|
| 43 |
+
template=prediction_user_msg
|
| 44 |
+
)
|
| 45 |
+
|
| 46 |
+
prediction_template = '<system> ' + prediction_system_msg + ' </system>\n\n' + prediction_user_msg
|
| 47 |
+
prediction_prompt = PromptTemplate.from_template(
|
| 48 |
+
template=prediction_template
|
| 49 |
+
)
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
template = """<system> You are the best financial advisor and expert broker. I am an investor, who seek \
|
| 56 |
+
for your help. Below is the description of one big company. You need to reply to me with a \
|
| 57 |
+
single word, either 'sell', 'buy' or 'hold'. This word should best describe your recommendation \
|
| 58 |
+
on what is the best action for me with the company's holdings. </system>
|
| 59 |
+
|
| 60 |
+
Company's description: {company_description}
|
| 61 |
+
|
| 62 |
+
So what do you think? Sell, buy or hold?"""
|
| 63 |
+
prompt_template = PromptTemplate.from_template(
|
| 64 |
+
template=template
|
| 65 |
+
)
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
chat_structure = """
|
| 69 |
+
### Instruction:
|
| 70 |
+
{instruction}
|
| 71 |
+
|
| 72 |
+
### Response:
|
| 73 |
+
"""
|
| 74 |
+
chat_prompt = PromptTemplate.from_template(
|
| 75 |
+
template=chat_structure
|
| 76 |
+
)
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
instruction = """You are the best financial advisor and expert broker. I am an investor, who seek \
|
| 80 |
+
for your help. Below is the description of one big company. You need to reply to me with a \
|
| 81 |
+
single word, either 'sell', 'buy' or 'hold'. This word should best describe your recommendation \
|
| 82 |
+
on what is the best action for me with the company's holdings.
|
| 83 |
+
|
| 84 |
+
Company's description: {company_description}
|
| 85 |
+
|
| 86 |
+
So what do you think? Sell, buy or hold?"""
|
| 87 |
+
# text_gen_prompt = PromptTemplate.from_template(
|
| 88 |
+
# template=chat_prompt.format(instruction=instruction_prompt.format(company_description=text.page_content))
|
| 89 |
+
# )
|
| 90 |
+
instruction_prompt = PromptTemplate.from_template(
|
| 91 |
+
template=instruction
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
# predictor_system_message = """You are the preeminent financial advisor and expert broker,
|
| 99 |
+
# renowned for your unparalleled market acumen. As you meticulously analyze the summary of Item 7 from
|
| 100 |
+
# Form 10-K of some company, your task is to distill your profound insights into a single decisive word,
|
| 101 |
+
# choosing from the options: 'sell', 'buy', or 'hold'. This word reflects your beliefs about the company's
|
| 102 |
+
# future. Your selection should be astutely founded on a
|
| 103 |
+
# comprehensive understanding of all economic facets and nuanced considerations. Remember, your
|
| 104 |
+
# recommendation carries significant weight, influencing critical decisions on whether to divest, invest,
|
| 105 |
+
# or maintain positions in that company. If you predict "buy" it means that the company is a good investment
|
| 106 |
+
# option and is likely to grow in the next year. If you predict "sell" it means that you think that the
|
| 107 |
+
# company won't perform wellduring the upcoming year. Approach this task with the sagacity and expertise that
|
| 108 |
+
# has earned you your esteemed reputation. Please, don't include any warnings that it is difficult to make
|
| 109 |
+
# a definitive recommendation, based on the information provided. Please, don't include any additional text
|
| 110 |
+
# before your answer, don't write 'based on the information provided, I recommend ...'."""
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
summarizers = {
|
| 117 |
+
# 'financial-summarization-pegasus': {
|
| 118 |
+
# 'model_name': 'human-centered-summarization/financial-summarization-pegasus',
|
| 119 |
+
# 'api_url' : 'https://api-inference.huggingface.co/models/human-centered-summarization/financial-summarization-pegasus',
|
| 120 |
+
# 'chunk_size': 1_400,
|
| 121 |
+
# 'size': 'large'
|
| 122 |
+
# },
|
| 123 |
+
'bart-finance-pegasus': {
|
| 124 |
+
'model_name': 'amitesh11/bart-finance-pegasus',
|
| 125 |
+
'api_url': 'https://api-inference.huggingface.co/models/amitesh11/bart-finance-pegasus',
|
| 126 |
+
'chunk_size': 2_600,
|
| 127 |
+
'size': 'medium'
|
| 128 |
+
},
|
| 129 |
+
# 'financial-summary': {
|
| 130 |
+
# 'model_name': 'Spacetimetravel/autotrain-financial-conversation_financial-summary-90517144315',
|
| 131 |
+
# 'api_url' : "https://api-inference.huggingface.co/models/Spacetimetravel/autotrain-financial-conversation_financial-summary-90517144315",
|
| 132 |
+
# 'chunk_size': 1_800,
|
| 133 |
+
# 'size': 'small'
|
| 134 |
+
# },
|
| 135 |
+
'gpt-3.5-turbo': {
|
| 136 |
+
'model_name': 'gpt-3.5-turbo',
|
| 137 |
+
'api_url' : "",
|
| 138 |
+
'chunk_size': 6_000,
|
| 139 |
+
'size': ''
|
| 140 |
+
}
|
| 141 |
+
}
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
# There are 3 inference_types: chatGPT, Inference API and Inference Endpoint
|
| 146 |
+
# Add captions to display inference_type
|
| 147 |
+
predictors = {
|
| 148 |
+
'gpt-3.5-turbo': {
|
| 149 |
+
'model_name': 'OpenAI-gpt-3.5-turbo',
|
| 150 |
+
'inference_type': 'chatGPT',
|
| 151 |
+
'model_task': 'text-generation'
|
| 152 |
+
},
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
'blenderbot-3B': {
|
| 156 |
+
'model_name': 'facebook/blenderbot-3B',
|
| 157 |
+
'api_url' : 'https://api-inference.huggingface.co/models/facebook/blenderbot-3B',
|
| 158 |
+
'inference_type': 'Inference API',
|
| 159 |
+
'model_task': 'conversational'
|
| 160 |
+
},
|
| 161 |
+
'TinyLlama-1.1B': {
|
| 162 |
+
'model_name': 'tog/TinyLlama-1.1B-alpaca-chat-v1.0',
|
| 163 |
+
'api_url' : 'https://api-inference.huggingface.co/models/tog/TinyLlama-1.1B-alpaca-chat-v1.0',
|
| 164 |
+
'inference_type': 'Inference API',
|
| 165 |
+
'model_task': 'conversational'
|
| 166 |
+
},
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
'open-llama-7b-v2': {
|
| 170 |
+
'model_name': 'VMware/open-llama-7b-v2-open-instruct',
|
| 171 |
+
'api_url' : 'https://audqis4a3tk9s0li.us-east-1.aws.endpoints.huggingface.cloud',
|
| 172 |
+
'inference_type': 'Inference Endpoint',
|
| 173 |
+
'model_task': 'conversational'
|
| 174 |
+
},
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
'gpt2-xl': {
|
| 178 |
+
'model_name': 'gpt2-xl',
|
| 179 |
+
'api_url' : 'https://api-inference.huggingface.co/models/gpt2-xl',
|
| 180 |
+
'inference_type': 'Inference API',
|
| 181 |
+
'model_task': 'text-generation'
|
| 182 |
+
},
|
| 183 |
+
'distilgpt2-finance': {
|
| 184 |
+
'model_name': 'lxyuan/distilgpt2-finetuned-finance',
|
| 185 |
+
'api_url' : 'https://api-inference.huggingface.co/models/lxyuan/distilgpt2-finetuned-finance',
|
| 186 |
+
'inference_type': 'Inference API',
|
| 187 |
+
'model_task': 'text-generation'
|
| 188 |
+
},
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
'embedding_mlp_classifier': {
|
| 192 |
+
'dataset_name': 'CabraVC/vector_dataset_2023-12-02_00-32',
|
| 193 |
+
'embedding_model': 'all-distilroberta-v1',
|
| 194 |
+
'embedding_dim': 768,
|
| 195 |
+
'mlp_model': 'embedding_mlp.safetensors',
|
| 196 |
+
|
| 197 |
+
},
|
| 198 |
+
'embedding_mlp_classifier_gtr-t5-xxl': {
|
| 199 |
+
'dataset_name': 'CabraVC/vector_dataset_2023-12-02_00-32',
|
| 200 |
+
'embedding_model': 'gtr-t5-xxl',
|
| 201 |
+
'embedding_dim': 768,
|
| 202 |
+
'mlp_model': 'embedding_mlp.safetensors',
|
| 203 |
+
}
|
| 204 |
+
}
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
summary_scores_template = {
|
| 209 |
+
'rouge-1': [],
|
| 210 |
+
'rouge-2': [],
|
| 211 |
+
'rouge-l': []
|
| 212 |
+
}
|
current_requirements.txt
ADDED
|
@@ -0,0 +1,225 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
accelerate==0.24.1
|
| 2 |
+
aiohttp==3.9.0
|
| 3 |
+
aiosignal==1.3.1
|
| 4 |
+
altair==5.1.2
|
| 5 |
+
annotated-types==0.6.0
|
| 6 |
+
anyio==3.7.1
|
| 7 |
+
appnope==0.1.3
|
| 8 |
+
argcomplete @ file:///private/tmp/python-argcomplete-20231119-5267-f5ylk/argcomplete-3.1.6
|
| 9 |
+
argon2-cffi==23.1.0
|
| 10 |
+
argon2-cffi-bindings==21.2.0
|
| 11 |
+
arrow==1.3.0
|
| 12 |
+
asgiref==3.7.2
|
| 13 |
+
asttokens==2.4.1
|
| 14 |
+
async-lru==2.0.4
|
| 15 |
+
attrs==23.1.0
|
| 16 |
+
Babel==2.13.1
|
| 17 |
+
backoff==2.2.1
|
| 18 |
+
bcrypt==4.0.1
|
| 19 |
+
beautifulsoup4==4.12.2
|
| 20 |
+
bleach==6.1.0
|
| 21 |
+
blinker==1.7.0
|
| 22 |
+
cachetools==5.3.2
|
| 23 |
+
certifi==2023.11.17
|
| 24 |
+
cffi==1.15.1
|
| 25 |
+
charset-normalizer==3.3.2
|
| 26 |
+
chroma-hnswlib==0.7.3
|
| 27 |
+
chromadb==0.4.18
|
| 28 |
+
click==8.1.7
|
| 29 |
+
coloredlogs==15.0.1
|
| 30 |
+
comm==0.2.0
|
| 31 |
+
dataclasses-json==0.5.14
|
| 32 |
+
debugpy==1.8.0
|
| 33 |
+
decorator==5.1.1
|
| 34 |
+
defusedxml==0.7.1
|
| 35 |
+
Deprecated==1.2.14
|
| 36 |
+
distro==1.8.0
|
| 37 |
+
docutils==0.19
|
| 38 |
+
et-xmlfile==1.1.0
|
| 39 |
+
executing==2.0.1
|
| 40 |
+
fastapi==0.104.1
|
| 41 |
+
fastjsonschema==2.19.0
|
| 42 |
+
filelock==3.13.1
|
| 43 |
+
flatbuffers==23.5.26
|
| 44 |
+
fqdn==1.5.1
|
| 45 |
+
frozenlist==1.4.0
|
| 46 |
+
fsspec==2023.10.0
|
| 47 |
+
fvalues==0.0.3
|
| 48 |
+
gitdb==4.0.11
|
| 49 |
+
GitPython==3.1.40
|
| 50 |
+
google-auth==2.23.4
|
| 51 |
+
googleapis-common-protos==1.61.0
|
| 52 |
+
greenlet==3.0.1
|
| 53 |
+
grpcio==1.59.3
|
| 54 |
+
h11==0.14.0
|
| 55 |
+
httpcore==1.0.2
|
| 56 |
+
httptools==0.6.1
|
| 57 |
+
httpx==0.25.1
|
| 58 |
+
huggingface-hub==0.19.4
|
| 59 |
+
humanfriendly==10.0
|
| 60 |
+
idna==3.4
|
| 61 |
+
importlib-metadata==6.8.0
|
| 62 |
+
importlib-resources==6.1.1
|
| 63 |
+
ipykernel==6.26.0
|
| 64 |
+
ipython==8.17.2
|
| 65 |
+
ipywidgets==8.1.1
|
| 66 |
+
isoduration==20.11.0
|
| 67 |
+
jedi==0.19.1
|
| 68 |
+
Jinja2==3.1.2
|
| 69 |
+
json5==0.9.14
|
| 70 |
+
jsonpatch==1.33
|
| 71 |
+
jsonpointer==2.4
|
| 72 |
+
jsonschema==4.20.0
|
| 73 |
+
jsonschema-specifications==2023.11.1
|
| 74 |
+
jupyter-events==0.9.0
|
| 75 |
+
jupyter-lsp==2.2.0
|
| 76 |
+
jupyter_client==8.6.0
|
| 77 |
+
jupyter_core==5.5.0
|
| 78 |
+
jupyter_server==2.10.1
|
| 79 |
+
jupyter_server_terminals==0.4.4
|
| 80 |
+
jupyterlab==4.0.9
|
| 81 |
+
jupyterlab-pygments==0.2.2
|
| 82 |
+
jupyterlab-widgets==3.0.9
|
| 83 |
+
jupyterlab_server==2.25.2
|
| 84 |
+
kubernetes==28.1.0
|
| 85 |
+
langchain==0.0.281
|
| 86 |
+
langsmith==0.0.65
|
| 87 |
+
linkify-it-py==2.0.2
|
| 88 |
+
markdown-it-py==3.0.0
|
| 89 |
+
MarkupSafe==2.1.3
|
| 90 |
+
marshmallow==3.20.1
|
| 91 |
+
matplotlib-inline==0.1.6
|
| 92 |
+
mdit-py-plugins==0.4.0
|
| 93 |
+
mdurl==0.1.2
|
| 94 |
+
mistune==3.0.2
|
| 95 |
+
mmh3==4.0.1
|
| 96 |
+
monotonic==1.6
|
| 97 |
+
mpmath==1.3.0
|
| 98 |
+
multidict==6.0.4
|
| 99 |
+
mypy-extensions==1.0.0
|
| 100 |
+
nbclient==0.9.0
|
| 101 |
+
nbconvert==7.11.0
|
| 102 |
+
nbformat==5.9.2
|
| 103 |
+
nest-asyncio==1.5.8
|
| 104 |
+
networkx==3.2.1
|
| 105 |
+
notebook==7.0.6
|
| 106 |
+
notebook_shim==0.2.3
|
| 107 |
+
numexpr==2.8.7
|
| 108 |
+
numpy==1.26.2
|
| 109 |
+
oauthlib==3.2.2
|
| 110 |
+
onnxruntime==1.16.2
|
| 111 |
+
openai==0.28.1
|
| 112 |
+
openpyxl==3.1.2
|
| 113 |
+
opentelemetry-api==1.21.0
|
| 114 |
+
opentelemetry-exporter-otlp-proto-common==1.21.0
|
| 115 |
+
opentelemetry-exporter-otlp-proto-grpc==1.21.0
|
| 116 |
+
opentelemetry-instrumentation==0.42b0
|
| 117 |
+
opentelemetry-instrumentation-asgi==0.42b0
|
| 118 |
+
opentelemetry-instrumentation-fastapi==0.42b0
|
| 119 |
+
opentelemetry-proto==1.21.0
|
| 120 |
+
opentelemetry-sdk==1.21.0
|
| 121 |
+
opentelemetry-semantic-conventions==0.42b0
|
| 122 |
+
opentelemetry-util-http==0.42b0
|
| 123 |
+
outcome==1.3.0.post0
|
| 124 |
+
overrides==7.4.0
|
| 125 |
+
packaging==23.2
|
| 126 |
+
pandas==2.1.3
|
| 127 |
+
pandocfilters==1.5.0
|
| 128 |
+
parso==0.8.3
|
| 129 |
+
peft==0.6.2
|
| 130 |
+
pep8==1.7.1
|
| 131 |
+
pexpect==4.8.0
|
| 132 |
+
Pillow==10.1.0
|
| 133 |
+
platformdirs==4.0.0
|
| 134 |
+
posthog==3.0.2
|
| 135 |
+
prometheus-client==0.18.0
|
| 136 |
+
prompt-toolkit==3.0.41
|
| 137 |
+
protobuf==4.25.1
|
| 138 |
+
psutil==5.9.6
|
| 139 |
+
ptyprocess==0.7.0
|
| 140 |
+
pulsar-client==3.3.0
|
| 141 |
+
pure-eval==0.2.2
|
| 142 |
+
pyarrow==14.0.1
|
| 143 |
+
pyasn1==0.5.0
|
| 144 |
+
pyasn1-modules==0.3.0
|
| 145 |
+
pycparser==2.21
|
| 146 |
+
pydantic==1.10.13
|
| 147 |
+
pydantic_core==2.14.3
|
| 148 |
+
pydeck==0.8.1b0
|
| 149 |
+
Pygments==2.17.1
|
| 150 |
+
PyPika==0.48.9
|
| 151 |
+
PySocks==1.7.1
|
| 152 |
+
python-dateutil==2.8.2
|
| 153 |
+
python-dotenv==1.0.0
|
| 154 |
+
python-json-logger==2.0.7
|
| 155 |
+
pytz==2023.3.post1
|
| 156 |
+
PyYAML==6.0
|
| 157 |
+
pyzmq==25.1.1
|
| 158 |
+
recoverpy==2.1.4
|
| 159 |
+
referencing==0.31.0
|
| 160 |
+
regex==2023.10.3
|
| 161 |
+
requests==2.31.0
|
| 162 |
+
requests-oauthlib==1.3.1
|
| 163 |
+
rfc3339-validator==0.1.4
|
| 164 |
+
rfc3986-validator==0.1.1
|
| 165 |
+
rich==13.7.0
|
| 166 |
+
rouge==1.0.1
|
| 167 |
+
rpds-py==0.13.0
|
| 168 |
+
rsa==4.9
|
| 169 |
+
safetensors==0.4.0
|
| 170 |
+
selenium==4.15.2
|
| 171 |
+
Send2Trash==1.8.2
|
| 172 |
+
simple-term-menu==1.6.3
|
| 173 |
+
six==1.16.0
|
| 174 |
+
smmap==5.0.1
|
| 175 |
+
sniffio==1.3.0
|
| 176 |
+
sortedcontainers==2.4.0
|
| 177 |
+
soupsieve==2.5
|
| 178 |
+
SQLAlchemy==1.4.50
|
| 179 |
+
stack-data==0.6.3
|
| 180 |
+
starlette==0.27.0
|
| 181 |
+
stqdm==0.0.5
|
| 182 |
+
streamlit==1.28.2
|
| 183 |
+
sympy==1.12
|
| 184 |
+
tenacity==8.2.3
|
| 185 |
+
terminado==0.18.0
|
| 186 |
+
textual==0.42.0
|
| 187 |
+
tiktoken==0.5.1
|
| 188 |
+
tinycss2==1.2.1
|
| 189 |
+
tokenizers==0.15.0
|
| 190 |
+
toml==0.10.2
|
| 191 |
+
toolz==0.12.0
|
| 192 |
+
torch==2.1.1
|
| 193 |
+
torchaudio==2.1.1
|
| 194 |
+
torchvision==0.16.1
|
| 195 |
+
tornado==6.3.3
|
| 196 |
+
tqdm==4.66.1
|
| 197 |
+
traitlets==5.13.0
|
| 198 |
+
transformers==4.35.2
|
| 199 |
+
trio==0.23.1
|
| 200 |
+
trio-websocket==0.11.1
|
| 201 |
+
typer==0.9.0
|
| 202 |
+
types-python-dateutil==2.8.19.14
|
| 203 |
+
typing-inspect==0.9.0
|
| 204 |
+
typing_extensions==4.8.0
|
| 205 |
+
tzdata==2023.3
|
| 206 |
+
tzlocal==5.2
|
| 207 |
+
uc-micro-py==1.0.2
|
| 208 |
+
uri-template==1.3.0
|
| 209 |
+
urllib3==1.26.18
|
| 210 |
+
uvicorn==0.24.0.post1
|
| 211 |
+
uvloop==0.19.0
|
| 212 |
+
validators==0.22.0
|
| 213 |
+
watchdog==3.0.0
|
| 214 |
+
watchfiles==0.21.0
|
| 215 |
+
wcwidth==0.2.10
|
| 216 |
+
webcolors==1.13
|
| 217 |
+
webdriver-manager==4.0.1
|
| 218 |
+
webencodings==0.5.1
|
| 219 |
+
websocket-client==1.6.4
|
| 220 |
+
websockets==12.0
|
| 221 |
+
widgetsnbextension==4.0.9
|
| 222 |
+
wrapt==1.16.0
|
| 223 |
+
wsproto==1.2.0
|
| 224 |
+
yarl==1.9.2
|
| 225 |
+
zipp==3.17.0
|
embedding_mlp.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:07f9d57532b6a1d2f75dbbc24bf1cb07c00dad72115d709f1d69dda8a58167d5
|
| 3 |
+
size 792704
|
embedding_mlp.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6904be304f3772eea874d1354add73c90aa79f575ff7cd50fdb70555a4c0e90a
|
| 3 |
+
size 790836
|
gitattributes
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
requirements.txt
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
streamlit==1.28.2
|
| 2 |
+
transformers==4.35.2
|
| 3 |
+
sentence-transformers==2.2.2
|
| 4 |
+
datasets==2.15.0
|
| 5 |
+
torch==2.1.1
|
| 6 |
+
accelerate==0.24.1
|
| 7 |
+
openai==0.28.1
|
| 8 |
+
tiktoken==0.5.1
|
| 9 |
+
chromadb==0.4.18
|
| 10 |
+
langchain==0.0.281
|
| 11 |
+
stqdm==0.0.5
|
| 12 |
+
peft==0.6.2
|
| 13 |
+
rouge==1.0.1
|
| 14 |
+
watchdog==3.0.0
|
| 15 |
+
huggingface_hub==0.19.4
|
| 16 |
+
matplotlib==3.8.2
|
| 17 |
+
seaborn==0.13.0
|
| 18 |
+
setfit==1.0.1
|
test_models/EDA.ipynb
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": 7,
|
| 6 |
+
"id": "7d34f1af-07e7-4320-9cc8-085bc1848b2f",
|
| 7 |
+
"metadata": {},
|
| 8 |
+
"outputs": [],
|
| 9 |
+
"source": [
|
| 10 |
+
"import sys\n",
|
| 11 |
+
"from statistics import mean\n",
|
| 12 |
+
"import os\n",
|
| 13 |
+
"dataset_dir = os.path.abspath(os.path.join(os.getcwd(), '..', '..', 'financial_dataset'))\n",
|
| 14 |
+
"sys.path.append(dataset_dir)"
|
| 15 |
+
]
|
| 16 |
+
},
|
| 17 |
+
{
|
| 18 |
+
"cell_type": "code",
|
| 19 |
+
"execution_count": 8,
|
| 20 |
+
"id": "99b69912-8c9e-49b5-abf1-229217ac5e5e",
|
| 21 |
+
"metadata": {},
|
| 22 |
+
"outputs": [],
|
| 23 |
+
"source": [
|
| 24 |
+
"from load_test_data import get_labels_df, get_texts"
|
| 25 |
+
]
|
| 26 |
+
},
|
| 27 |
+
{
|
| 28 |
+
"cell_type": "code",
|
| 29 |
+
"execution_count": 9,
|
| 30 |
+
"id": "53b202a1-13c9-4ba0-9cba-bf6f207af9a1",
|
| 31 |
+
"metadata": {},
|
| 32 |
+
"outputs": [
|
| 33 |
+
{
|
| 34 |
+
"name": "stdout",
|
| 35 |
+
"output_type": "stream",
|
| 36 |
+
"text": [
|
| 37 |
+
"132 132\n",
|
| 38 |
+
"92249.56060606061\n"
|
| 39 |
+
]
|
| 40 |
+
}
|
| 41 |
+
],
|
| 42 |
+
"source": [
|
| 43 |
+
"labels_dir = dataset_dir + '/csvs/'\n",
|
| 44 |
+
"df = get_labels_df(labels_dir)\n",
|
| 45 |
+
"texts_dir = dataset_dir + '/txts/'\n",
|
| 46 |
+
"texts = get_texts(texts_dir)\n",
|
| 47 |
+
"print(len(df), len(texts))\n",
|
| 48 |
+
"print(mean(list(map(len, texts))))"
|
| 49 |
+
]
|
| 50 |
+
},
|
| 51 |
+
{
|
| 52 |
+
"cell_type": "code",
|
| 53 |
+
"execution_count": 17,
|
| 54 |
+
"id": "b1f8d856-8204-4a42-ab73-3af2ff7a728e",
|
| 55 |
+
"metadata": {},
|
| 56 |
+
"outputs": [
|
| 57 |
+
{
|
| 58 |
+
"data": {
|
| 59 |
+
"text/plain": [
|
| 60 |
+
"Label\n",
|
| 61 |
+
"SELL 53.8\n",
|
| 62 |
+
"HOLD 28.0\n",
|
| 63 |
+
"BUY 18.2\n",
|
| 64 |
+
"Name: proportion, dtype: float64"
|
| 65 |
+
]
|
| 66 |
+
},
|
| 67 |
+
"execution_count": 17,
|
| 68 |
+
"metadata": {},
|
| 69 |
+
"output_type": "execute_result"
|
| 70 |
+
}
|
| 71 |
+
],
|
| 72 |
+
"source": [
|
| 73 |
+
"df.Label.value_counts(normalize=True).round(3)s * 100"
|
| 74 |
+
]
|
| 75 |
+
},
|
| 76 |
+
{
|
| 77 |
+
"cell_type": "code",
|
| 78 |
+
"execution_count": null,
|
| 79 |
+
"id": "683fe2a9-6b9e-442b-a740-313482c96424",
|
| 80 |
+
"metadata": {},
|
| 81 |
+
"outputs": [],
|
| 82 |
+
"source": []
|
| 83 |
+
}
|
| 84 |
+
],
|
| 85 |
+
"metadata": {
|
| 86 |
+
"kernelspec": {
|
| 87 |
+
"display_name": "Python 3 (ipykernel)",
|
| 88 |
+
"language": "python",
|
| 89 |
+
"name": "python3"
|
| 90 |
+
},
|
| 91 |
+
"language_info": {
|
| 92 |
+
"codemirror_mode": {
|
| 93 |
+
"name": "ipython",
|
| 94 |
+
"version": 3
|
| 95 |
+
},
|
| 96 |
+
"file_extension": ".py",
|
| 97 |
+
"mimetype": "text/x-python",
|
| 98 |
+
"name": "python",
|
| 99 |
+
"nbconvert_exporter": "python",
|
| 100 |
+
"pygments_lexer": "ipython3",
|
| 101 |
+
"version": "3.11.6"
|
| 102 |
+
}
|
| 103 |
+
},
|
| 104 |
+
"nbformat": 4,
|
| 105 |
+
"nbformat_minor": 5
|
| 106 |
+
}
|
test_models/create_setfit_model.py
ADDED
|
@@ -0,0 +1,99 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch import nn
|
| 3 |
+
from sentence_transformers import SentenceTransformer
|
| 4 |
+
from datasets import load_dataset
|
| 5 |
+
from sklearn.utils.class_weight import compute_class_weight
|
| 6 |
+
from safetensors.torch import load_model
|
| 7 |
+
from setfit.__init__ import SetFitModel
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class MLP(nn.Module):
|
| 16 |
+
def __init__(self, input_size=768, output_size=3, dropout_rate=.2, class_weights=None):
|
| 17 |
+
super(MLP, self).__init__()
|
| 18 |
+
self.class_weights = class_weights
|
| 19 |
+
|
| 20 |
+
# self.bn1 = nn.BatchNorm1d(hidden_size)
|
| 21 |
+
self.dropout = nn.Dropout(dropout_rate)
|
| 22 |
+
|
| 23 |
+
self.linear = nn.Linear(input_size, output_size)
|
| 24 |
+
|
| 25 |
+
# nn.init.kaiming_normal_(self.fc1.weight, nonlinearity='relu')
|
| 26 |
+
# nn.init.kaiming_normal_(self.fc2.weight)
|
| 27 |
+
|
| 28 |
+
def forward(self, x):
|
| 29 |
+
# return self.linear(self.dropout(x))
|
| 30 |
+
return self.dropout(self.linear(x))
|
| 31 |
+
|
| 32 |
+
def predict(self, x):
|
| 33 |
+
_, predicted = torch.max(self.forward(x), 1)
|
| 34 |
+
return predicted
|
| 35 |
+
|
| 36 |
+
def predict_proba(self, x):
|
| 37 |
+
return self.forward(x)
|
| 38 |
+
|
| 39 |
+
def get_loss_fn(self):
|
| 40 |
+
return nn.CrossEntropyLoss(weight=self.class_weights, reduction='mean')
|
| 41 |
+
|
| 42 |
+
dataset = load_dataset("CabraVC/vector_dataset_roberta-fine-tuned")
|
| 43 |
+
|
| 44 |
+
class_weights = torch.tensor(compute_class_weight('balanced', classes=[0, 1, 2], y=dataset['train']['labels']), dtype=torch.float) ** .5
|
| 45 |
+
|
| 46 |
+
model_head = MLP(class_weights=class_weights)
|
| 47 |
+
|
| 48 |
+
if __name__ == '__main__' or __name__ == 'create_setfit_model':
|
| 49 |
+
model_body = SentenceTransformer('financial-roberta')
|
| 50 |
+
load_model(model_head, f'models/linear_head.pth')
|
| 51 |
+
elif __name__ == 'test_models.create_setfit_model':
|
| 52 |
+
model_body = SentenceTransformer('test_models/financial-roberta')
|
| 53 |
+
load_model(model_head, f'/test_models/models/linear_head.pth')
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
model = SetFitModel(model_body=model_body,
|
| 57 |
+
model_head=model_head,
|
| 58 |
+
labels=dataset['train'].features['labels'].names).to(DEVICE)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
if __name__ == '__main__':
|
| 62 |
+
from time import perf_counter
|
| 63 |
+
start = perf_counter()
|
| 64 |
+
test_sentences = [
|
| 65 |
+
"""Two thousand and six was a very good year for The Coca-Cola Company. We achieved our 52nd
|
| 66 |
+
consecutive year of unit case volume growth. Volume reached a record high of 2.4 billion unit cases.
|
| 67 |
+
Net operating revenues grew 4 percent to $24.billion, and operating income grew
|
| 68 |
+
4 percent to $6.3 billion. Our total return to shareowners was 23 percent, outperforming the Dow
|
| 69 |
+
Jones Industrial Average and the S&P 500. By virtually every measure, we met or exceeded our
|
| 70 |
+
objectives—a strong ending for the year with great momentum for entering 2007.""",
|
| 71 |
+
|
| 72 |
+
"""
|
| 73 |
+
The secret formula to our success in 2006? There is no one answer. Our inspiration comes from
|
| 74 |
+
many sources—our bottling partners, retail customers and consumers, as well as our critics. And the
|
| 75 |
+
men and women of The Coca-Cola Company have a passion for what they do that ignites this
|
| 76 |
+
inspiration every day, everywhere we do business. We remain fresh, relevant and original by knowing
|
| 77 |
+
what
|
| 78 |
+
to change without changing what we know. We are asking more questions, listening more closely and
|
| 79 |
+
collaborating more effectively with our bottling partners, suppliers and retail customers to give
|
| 80 |
+
consumers what they want.
|
| 81 |
+
""",
|
| 82 |
+
|
| 83 |
+
"""
|
| 84 |
+
And we continue to strengthen our bench, nurturing leaders and promoting from within our
|
| 85 |
+
organization. As 2006 came to a close, our Board of Directors elected Muhtar Kent as president and
|
| 86 |
+
chief operating officer of our Company. Muhtar is a 28-year veteran of the Coca-Cola system (the
|
| 87 |
+
Company and our bottling partners). Muhtar’s close working relationships with our bottling partners
|
| 88 |
+
will enable us to continue capturing marketplace opportunities and improving our business. Other
|
| 89 |
+
system veterans promoted and now leading operating groups include Ahmet Bozer, Eurasia; Sandy
|
| 90 |
+
Douglas, North America; and Glenn Jordan, Pacific. Combined, these leaders have 65 years of Coca-
|
| 91 |
+
Cola system experience.
|
| 92 |
+
"""
|
| 93 |
+
]
|
| 94 |
+
|
| 95 |
+
# for sentence in test_sentences:
|
| 96 |
+
# print(model(sentence))
|
| 97 |
+
# print('-' * 50)
|
| 98 |
+
print(model(test_sentences))
|
| 99 |
+
print(f'It took me: {(perf_counter() - start) // 60:.0f} mins {(perf_counter() - start) % 60:.0f} secs')
|
test_models/financial-roberta/1_Pooling/config.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"word_embedding_dimension": 768,
|
| 3 |
+
"pooling_mode_cls_token": false,
|
| 4 |
+
"pooling_mode_mean_tokens": true,
|
| 5 |
+
"pooling_mode_max_tokens": false,
|
| 6 |
+
"pooling_mode_mean_sqrt_len_tokens": false
|
| 7 |
+
}
|
test_models/financial-roberta/README.md
ADDED
|
@@ -0,0 +1,497 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: setfit
|
| 3 |
+
tags:
|
| 4 |
+
- setfit
|
| 5 |
+
- sentence-transformers
|
| 6 |
+
- text-classification
|
| 7 |
+
- generated_from_setfit_trainer
|
| 8 |
+
datasets:
|
| 9 |
+
- CabraVC/vector_dataset_stratified_ttv_split_2023-12-05_21-07
|
| 10 |
+
metrics:
|
| 11 |
+
- accuracy
|
| 12 |
+
widget:
|
| 13 |
+
- text: "30, 2006, we adopted the provisions of SFAS No. 123(R), which establishes\
|
| 14 |
+
\ accounting for stock-based awards exchanged for employee services. Accordingly,\
|
| 15 |
+
\ stock-based compensation cost is measured at grant date, based on the fair value\
|
| 16 |
+
\ of the awards, and is recognized as expense over the requisite employee service\
|
| 17 |
+
\ period. Stock-based compensation expense recognized during fiscal years 2008\
|
| 18 |
+
\ and 2007 was $133.4 million and $116.7 million, respectively, which consisted\
|
| 19 |
+
\ of stock-based compensation expense related to stock options and our employee\
|
| 20 |
+
\ stock purchase plan. Please refer to Note 2 of the Notes to Consolidated Financial\
|
| 21 |
+
\ Statements for further information.\n\n \n\n We elected to adopt the modified\
|
| 22 |
+
\ prospective application method beginning January 30, 2006 as provided by SFAS\
|
| 23 |
+
\ No. 123(R). We recognize stock-based compensation expense using the straight-line\
|
| 24 |
+
\ attribution method. We estimate the value of employee stock options on the date\
|
| 25 |
+
\ of grant using a binomial model. Prior to the adoption of SFAS No. 123(R), we\
|
| 26 |
+
\ recorded stock-based compensation expense equal to the amount that would have\
|
| 27 |
+
\ been recognized if the fair value method was used, for the purpose of the pro\
|
| 28 |
+
\ forma financial information provided in accordance with Statement of Financial\
|
| 29 |
+
\ Accounting Standards No. 123, or SFAS No. 123, Accounting for Stock-Based Compensation,\
|
| 30 |
+
\ as amended by SFAS No. 148, Accounting for Stock-Based Compensation - Transition\
|
| 31 |
+
\ and Disclosures.\n\n \n\n At the beginning of fiscal year 2006, we transitioned\
|
| 32 |
+
\ from a Black-Scholes model to a binomial model for calculating the estimated\
|
| 33 |
+
\ fair value of new stock-based compensation awards granted under our stock option\
|
| 34 |
+
\ plans. The determination of fair value of share-based payment awards on the\
|
| 35 |
+
\ date of grant using an option-pricing model is affected by our stock price as\
|
| 36 |
+
\ well as assumptions regarding a number of highly complex and subjective variables.\
|
| 37 |
+
\ These variables include, but are not limited to, the expected stock price volatility\
|
| 38 |
+
\ over the term of the awards, actual and projected employee stock option exercise\
|
| 39 |
+
\ behaviors, vesting schedules, death and disability probabilities, expected volatility\
|
| 40 |
+
\ and risk-free interest. Our management determined that the use of implied volatility\
|
| 41 |
+
\ is expected to be more reflective of market conditions and, therefore, could\
|
| 42 |
+
\ reasonably be expected to be a better indicator of our expected volatility than\
|
| 43 |
+
\ historical volatility. The risk-free interest rate assumption is based upon\
|
| 44 |
+
\ observed interest rates appropriate for the term of our employee stock options.\
|
| 45 |
+
\ The dividend yield assumption is based on the history and expectation of dividend\
|
| 46 |
+
\ payouts. We began segregating options into groups for employees with relatively\
|
| 47 |
+
\ homogeneous exercise behavior in order to calculate the best estimate of fair\
|
| 48 |
+
\ value using the binomial valuation model.\n\nUsing the binomial model, the fair\
|
| 49 |
+
\ value of the stock options granted under our stock option plans have been estimated\
|
| 50 |
+
\ using the following assumptions during the year ended January 27, 2008:\n\n\
|
| 51 |
+
\ \n\n For our employee stock purchase plan we continue to use the Black-Scholes\
|
| 52 |
+
\ model. The fair value of the shares issued under the employee stock purchase\
|
| 53 |
+
\ plan has"
|
| 54 |
+
- text: "local resources; help focus the bottler's sales and marketing programs; assist\
|
| 55 |
+
\ in the development of the bottler's business and information systems; and establish\
|
| 56 |
+
\ an appropriate capital structure for the bottler. \n\nOur Company has a long\
|
| 57 |
+
\ history of providing world-class customer service, demonstrating leadership\
|
| 58 |
+
\ in the marketplace and leveraging the talent of our global workforce. In addition,\
|
| 59 |
+
\ we have an experienced bottler management team. All of these factors are critical\
|
| 60 |
+
\ to build upon as we manage our growing bottling and distribution operations.\
|
| 61 |
+
\ \n\nThe Company has a deep commitment to continuously improving our business.\
|
| 62 |
+
\ This includes our efforts to develop innovative packaging and merchandising\
|
| 63 |
+
\ solutions which help drive demand for our beverages and meet the growing needs\
|
| 64 |
+
\ of our consumers. As we further transform the way we go to market, the Company\
|
| 65 |
+
\ continues to seek out ways to be more efficient. \n\nChallenges and Risks \n\
|
| 66 |
+
\nBeing global provides unique opportunities for our Company. Challenges and risks\
|
| 67 |
+
\ accompany those opportunities. Our management has identified certain challenges\
|
| 68 |
+
\ and risks that demand the attention of the nonalcoholic beverage segment of\
|
| 69 |
+
\ the commercial beverage industry and our Company. Of these, five key challenges\
|
| 70 |
+
\ and risks are discussed below. \n\nObesity and Inactive Lifestyles \n\nIncreasing\
|
| 71 |
+
\ concern among consumers, public health professionals and government agencies\
|
| 72 |
+
\ of the potential health problems associated with obesity and inactive lifestyles\
|
| 73 |
+
\ represents a significant challenge to our industry. We recognize that obesity\
|
| 74 |
+
\ is a complex public health problem and are committed to being a part of the\
|
| 75 |
+
\ solution. This commitment is reflected through our broad portfolio, with a beverage\
|
| 76 |
+
\ to suit every caloric and hydration need. \n\nAll of our beverages can be consumed\
|
| 77 |
+
\ as part of a balanced diet. Consumers who want to reduce the calories they consume\
|
| 78 |
+
\ from beverages can choose from our continuously expanding portfolio of more\
|
| 79 |
+
\ than 800 low- and no-calorie beverages, nearly 25 percent of our global portfolio,\
|
| 80 |
+
\ as well as our regular beverages in smaller portion sizes. We believe in the\
|
| 81 |
+
\ importance and power of “informed choice,” and we continue to support the fact-based\
|
| 82 |
+
\ nutrition labeling and education initiatives that encourage people to live active,\
|
| 83 |
+
\ healthy lifestyles. Our commitment also includes creating and adhering to responsible\
|
| 84 |
+
\ policies in schools and in the marketplace; supporting programs to encourage\
|
| 85 |
+
\ physical activity and promote nutrition education; and continuously meeting\
|
| 86 |
+
\ changing consumer needs through beverage innovation, choice and variety. We\
|
| 87 |
+
\ recognize the health of our business is interwoven with the well-being of our\
|
| 88 |
+
\ consumers, our employees and the communities we serve, and we are working in\
|
| 89 |
+
\ cooperation with governments, educators and consumers. \n\nWater Quality and\
|
| 90 |
+
\ Quantity \n\nWater quality and quantity is an issue that increasingly requires\
|
| 91 |
+
\ our Company's attention and collaboration with other companies, suppliers, governments,\
|
| 92 |
+
\ nongovernmental organizations and communities where we operate. Water is the\
|
| 93 |
+
\ main ingredient in substantially all of our products and is needed to produce\
|
| 94 |
+
\ the agricultural ingredients on"
|
| 95 |
+
- text: "over a fixed 17-year period and is calculated using an 8.85% interest rate.\
|
| 96 |
+
\ \n\n \n\nWhile the Pension Protection Act makes our funding obligations for\
|
| 97 |
+
\ these plans more predictable, factors outside our control continue to have an\
|
| 98 |
+
\ impact on the funding requirements. Estimates of future funding requirements\
|
| 99 |
+
\ are based on various assumptions and can vary materially from actual funding\
|
| 100 |
+
\ requirements. Assumptions include, among other things, the actual and projected\
|
| 101 |
+
\ market performance of assets; statutory requirements; and demographic data for\
|
| 102 |
+
\ participants. For additional information, see Note 10 of the Notes to the Consolidated\
|
| 103 |
+
\ Financial Statements. \n\n\n\nRecent Accounting Standards \n\n \n\nRevenue\
|
| 104 |
+
\ Arrangements with Multiple Deliverables. In October 2009, the Financial Accounting\
|
| 105 |
+
\ Standards Board (\"FASB\") issued ASU 200913. The standard (1) revises guidance\
|
| 106 |
+
\ on when individual deliverables may be treated as separate units of accounting,\
|
| 107 |
+
\ (2) establishes a selling price hierarchy for determining the selling price\
|
| 108 |
+
\ of a deliverable, (3) eliminates the residual method for revenue recognition\
|
| 109 |
+
\ and (4) provides guidance on allocating consideration among separate deliverables.\
|
| 110 |
+
\ It applies only to contracts entered into or materially modified after December\
|
| 111 |
+
\ 31, 2010. We adopted this standard on a prospective basis beginning January\
|
| 112 |
+
\ 1, 2011. We determined that the only revenue arrangements impacted by the adoption\
|
| 113 |
+
\ of this standard are those associated with our SkyMiles Program. \n\n \n\n\
|
| 114 |
+
Fair Value Measurement and Disclosure Requirements. In May 2011, the FASB issued\
|
| 115 |
+
\ \"Amendments to Achieve Common Fair Value Measurement and Disclosure Requirements\
|
| 116 |
+
\ in U.S. GAAP and IFRSs.\" The standard revises guidance for fair value measurement\
|
| 117 |
+
\ and expands the disclosure requirements. It is effective prospectively for fiscal\
|
| 118 |
+
\ years beginning after December 15, 2011. We are currently evaluating the impact\
|
| 119 |
+
\ the adoption of this standard will have on our Consolidated Financial Statements.\
|
| 120 |
+
\ \n\n \n\nSupplemental Information \n\n \n\nWe sometimes use information that\
|
| 121 |
+
\ is derived from the Consolidated Financial Statements, but that is not presented\
|
| 122 |
+
\ in accordance with accounting principles generally accepted in the U.S. (“GAAP”).\
|
| 123 |
+
\ Certain of this information are considered to be “non-GAAP financial measures”\
|
| 124 |
+
\ under the U.S. Securities and Exchange Commission rules. The non-GAAP financial\
|
| 125 |
+
\ measures should be considered in addition to results prepared in accordance\
|
| 126 |
+
\ with GAAP, but should not be considered a substitute for or superior to GAAP\
|
| 127 |
+
\ results. \n\n \n\nThe following tables show reconciliations of non-GAAP financial\
|
| 128 |
+
\ measures to the most directly comparable GAAP financial measures. \n\n \n\n\
|
| 129 |
+
We exclude the following items from CASM to determine CASM-Ex: \n\n \n\n•\tAircraft\
|
| 130 |
+
\ fuel and related taxes. Management believes the volatility in fuel prices impacts\
|
| 131 |
+
\ the comparability of year-over-year financial performance. \n\n \n\n•\tAncillary\
|
| 132 |
+
\ businesses . Ancillary businesses are not related to the generation of a seat\
|
| 133 |
+
\ mile. These businesses include aircraft maintenance and staffing services we\
|
| 134 |
+
\ provide to third parties and our vacation wholesale operations. \n\n \n\n•\t\
|
| 135 |
+
Profit sharing. Management believes the exclusion of this item"
|
| 136 |
+
- text: 'Organic local-currency sales increased 4.0 percent and acquisitions added
|
| 137 |
+
1.4 percent. Acquisition growth was largely due to the October 2011 acquisition
|
| 138 |
+
of the do-it-yourself and professional business of GPI Group and the April 2010
|
| 139 |
+
acquisition of the A-One branded label business and related operations. A-One
|
| 140 |
+
is the largest branded label business in Asia and the second largest worldwide.
|
| 141 |
+
3M also acquired Hybrivet Systems Inc. in the first quarter of 2011, a provider
|
| 142 |
+
of instant-read products to detect lead and other contaminants and toxins. Foreign
|
| 143 |
+
currency impacts contributed 2.4 percent to sales growth in the Consumer and Office
|
| 144 |
+
segment.
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
On a geographic basis, sales increased in all regions, led by Asia Pacific, Latin
|
| 151 |
+
America/Canada and Europe, which all had sales growth rates in excess of 10 percent.
|
| 152 |
+
U.S. sales also grew, albeit at a slower rate.
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
Consumer and Office operating income was flat when comparing 2011 to 2010, reflecting
|
| 159 |
+
continued ongoing investments in developing economies in brand development and
|
| 160 |
+
marketing and sales coverage. Even with these investments, Consumer and Office
|
| 161 |
+
generated operating income margins of 20.2 percent.
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
Safety, Security and Protection Services Business (12.7% of consolidated sales):
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
The Safety, Security and Protection Services segment serves a broad range of markets
|
| 173 |
+
that increase the safety, security and productivity of workers, facilities and
|
| 174 |
+
systems. Major product offerings include personal protection products, cleaning
|
| 175 |
+
and protection products for commercial establishments, safety and security products
|
| 176 |
+
(including border and civil security solutions), roofing granules for asphalt
|
| 177 |
+
shingles, infrastructure protection products used in the oil and gas pipeline
|
| 178 |
+
markets, and track and trace solutions.
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
Year 2012 results:
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
Safety, Security and Protection Services sales totaled $3.8 billion, down 0.5
|
| 191 |
+
percent in U.S. dollars. Organic local-currency sales grew 2.2 percent and foreign
|
| 192 |
+
currency translation reduced sales by 2.7 percent. Organic local-currency sales
|
| 193 |
+
growth was led by infrastructure protection and personal safety, with growth also
|
| 194 |
+
in building and commercial services and roofing granules.
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
2012 organic local-currency sales declined 18 percent in security systems, as
|
| 201 |
+
government spending for security solutions has been declining over the last few
|
| 202 |
+
years. As discussed later in the “Critical Accounting Estimates” section, 3M will
|
| 203 |
+
continue to monitor this business to assess whether long-term expectations have
|
| 204 |
+
been significantly impacted such that an asset or goodwill impairment test would
|
| 205 |
+
be required. The Company completed its annual goodwill impairment test in the
|
| 206 |
+
fourth quarter of 2012, with no impairment indicated.
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
Geographically, organic local-currency sales increased 19 percent in Latin America/Canada.
|
| 213 |
+
Organic local-currency sales were flat in Asia Pacific and the United States,
|
| 214 |
+
and declined 2 percent in EMEA.
|
| 215 |
+
|
| 216 |
+
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
The combination of selling price increases and raw material cost reductions, plus
|
| 221 |
+
factory efficiencies, drove a 4.1 percent increase in operating income. Operating
|
| 222 |
+
income margins increased 1.0 percentage points to 22.3 percent.
|
| 223 |
+
|
| 224 |
+
|
| 225 |
+
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
Year 2011 results:
|
| 229 |
+
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
Safety,'
|
| 235 |
+
- text: "but are generally subject to refinement during the purchase price allocation\
|
| 236 |
+
\ period (generally within one year of the acquisition date). To estimate restructuring\
|
| 237 |
+
\ expenses, management utilizes assumptions of the number of employees that would\
|
| 238 |
+
\ be involuntarily terminated and of future costs to operate and eventually vacate\
|
| 239 |
+
\ duplicate facilities. Estimated restructuring expenses may change as management\
|
| 240 |
+
\ executes the approved plan. Decreases to the cost estimates of executing the\
|
| 241 |
+
\ currently approved plans associated with pre-merger activities of the companies\
|
| 242 |
+
\ we acquire are recorded as an adjustment to goodwill indefinitely, whereas increases\
|
| 243 |
+
\ to the estimates are recorded as an adjustment to goodwill during the purchase\
|
| 244 |
+
\ price allocation period and as operating expenses thereafter.\n\n \n\nFor a\
|
| 245 |
+
\ given acquisition, we may identify certain pre-acquisition contingencies. If,\
|
| 246 |
+
\ during the purchase price allocation period, we are able to determine the fair\
|
| 247 |
+
\ value of a pre-acquisition contingency, we will include that amount in the purchase\
|
| 248 |
+
\ price allocation. If, as of the end of the purchase price allocation period,\
|
| 249 |
+
\ we are unable to determine the fair value of a pre-acquisition contingency,\
|
| 250 |
+
\ we will evaluate whether to include an amount in the purchase price allocation\
|
| 251 |
+
\ based on whether it is probable a liability had been incurred and whether an\
|
| 252 |
+
\ amount can be reasonably estimated. Through fiscal 2009, after the end of the\
|
| 253 |
+
\ purchase price allocation period, any adjustment to amounts recorded for a pre-acquisition\
|
| 254 |
+
\ contingency, with the exception of unresolved income tax matters, were included\
|
| 255 |
+
\ in our operating results in the period in which the adjustment was determined.\n\
|
| 256 |
+
\n\n\nFiscal 2010\n\n \n\nIn fiscal 2010, we will adopt FASB Statement No. 141\
|
| 257 |
+
\ (revised 2007), Business Combinations . For any business combination that is\
|
| 258 |
+
\ consummated pursuant to Statement 141(R), including our proposed acquisition\
|
| 259 |
+
\ of Sun described above, we will recognize separately from goodwill, the identifiable\
|
| 260 |
+
\ assets acquired, the liabilities assumed, and any noncontrolling interests in\
|
| 261 |
+
\ the acquiree generally at their acquisition date fair values as defined by FASB\
|
| 262 |
+
\ Statement No. 157, Fair Value Measurements . Goodwill as of the acquisition\
|
| 263 |
+
\ date is measured as the excess of consideration transferred, which is also generally\
|
| 264 |
+
\ measured at fair value, and the net of the acquisition date amounts of the identifiable\
|
| 265 |
+
\ assets acquired and the liabilities assumed.\n\n \n\nThe determination of fair\
|
| 266 |
+
\ value will require our management to make significant estimates and assumptions,\
|
| 267 |
+
\ with respect to intangible assets acquired, support obligations assumed, and\
|
| 268 |
+
\ pre-acquisition contingencies. The assumptions and estimates used in determining\
|
| 269 |
+
\ the fair values of these items will be substantially similar upon our adoption\
|
| 270 |
+
\ of Statement 141(R) as they were under Statement 141 (see above).\n\n \n\nThe\
|
| 271 |
+
\ below discussion lists those areas of Statement 141(R) that we believe, upon\
|
| 272 |
+
\ our adoption, require us to apply additional, significant estimates and assumptions.\n\
|
| 273 |
+
\n \n\nUpon our adoption of Statement 141(R), any changes to deferred tax asset\
|
| 274 |
+
\ valuation allowances and liabilities related to uncertain tax positions will\
|
| 275 |
+
\ be recorded in current"
|
| 276 |
+
pipeline_tag: text-classification
|
| 277 |
+
inference: true
|
| 278 |
+
model-index:
|
| 279 |
+
- name: SetFit
|
| 280 |
+
results:
|
| 281 |
+
- task:
|
| 282 |
+
type: text-classification
|
| 283 |
+
name: Text Classification
|
| 284 |
+
dataset:
|
| 285 |
+
name: CabraVC/vector_dataset_stratified_ttv_split_2023-12-05_21-07
|
| 286 |
+
type: CabraVC/vector_dataset_stratified_ttv_split_2023-12-05_21-07
|
| 287 |
+
split: test
|
| 288 |
+
metrics:
|
| 289 |
+
- type: accuracy
|
| 290 |
+
value: 0.5833333333333334
|
| 291 |
+
name: Accuracy
|
| 292 |
+
---
|
| 293 |
+
|
| 294 |
+
# SetFit
|
| 295 |
+
|
| 296 |
+
This is a [SetFit](https://github.com/huggingface/setfit) model trained on the [CabraVC/vector_dataset_stratified_ttv_split_2023-12-05_21-07](https://huggingface.co/datasets/CabraVC/vector_dataset_stratified_ttv_split_2023-12-05_21-07) dataset that can be used for Text Classification. A [LogisticRegression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) instance is used for classification.
|
| 297 |
+
|
| 298 |
+
The model has been trained using an efficient few-shot learning technique that involves:
|
| 299 |
+
|
| 300 |
+
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
|
| 301 |
+
2. Training a classification head with features from the fine-tuned Sentence Transformer.
|
| 302 |
+
|
| 303 |
+
## Model Details
|
| 304 |
+
|
| 305 |
+
### Model Description
|
| 306 |
+
- **Model Type:** SetFit
|
| 307 |
+
<!-- - **Sentence Transformer:** [Unknown](https://huggingface.co/unknown) -->
|
| 308 |
+
- **Classification head:** a [LogisticRegression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) instance
|
| 309 |
+
- **Maximum Sequence Length:** 512 tokens
|
| 310 |
+
- **Number of Classes:** 3 classes
|
| 311 |
+
- **Training Dataset:** [CabraVC/vector_dataset_stratified_ttv_split_2023-12-05_21-07](https://huggingface.co/datasets/CabraVC/vector_dataset_stratified_ttv_split_2023-12-05_21-07)
|
| 312 |
+
<!-- - **Language:** Unknown -->
|
| 313 |
+
<!-- - **License:** Unknown -->
|
| 314 |
+
|
| 315 |
+
### Model Sources
|
| 316 |
+
|
| 317 |
+
- **Repository:** [SetFit on GitHub](https://github.com/huggingface/setfit)
|
| 318 |
+
- **Paper:** [Efficient Few-Shot Learning Without Prompts](https://arxiv.org/abs/2209.11055)
|
| 319 |
+
- **Blogpost:** [SetFit: Efficient Few-Shot Learning Without Prompts](https://huggingface.co/blog/setfit)
|
| 320 |
+
|
| 321 |
+
### Model Labels
|
| 322 |
+
| Label | Examples |
|
| 323 |
+
|:------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
| 324 |
+
| BUY | <ul><li>'mix, the mix of sales by us and by other sellers, our continuing focus on in-stock inventory availability, our investment in new geographies and product lines, and the extent to which we choose to utilize outsource fulfillment providers. Accounts payable days were 62, 57, and 53 for 2008, 2007 and 2006. We expect some variability in accounts payable days over time since they are affected by several factors, including the mix of product sales, the mix of sales by other sellers, the mix of suppliers, seasonality, and changes in payment terms over time, including the effect of balancing pricing and timing of payment terms with suppliers. \n\nWe expect spending in technology and content will increase over time as we add computer scientists, software engineers, and employees involved in category expansion, editorial content, buying, merchandising selection, and systems support. We seek to efficiently invest in several areas of technology and content, including seller platforms, web services, digital initiatives, and expansion of new and existing product categories, as well as in technology infrastructure to enhance the customer experience, improve our process efficiencies and support our infrastructure web services. We believe that advances in technology, specifically the speed and reduced cost of processing power, the improved consumer experience of the Internet outside of the workplace through lower-cost broadband service to the home, and the advances of wireless connectivity, will continue to improve the consumer experience on the Internet and increase its ubiquity in people’s lives. We are investing in Amazon Web Services, which provides technology services that give developers access to technology infrastructure that they can use to enable virtually any type of business. A continuing challenge will be to continue to build and deploy innovative and efficient software that will best take advantage of continued advances in technology. \n\nOur financial reporting currency is the U.S. Dollar and changes in exchange rates significantly affect our reported results and consolidated trends. For example, if the U.S. Dollar weakens year-over-year relative to currencies in our international locations, our consolidated net sales, gross profit, and operating expenses will be higher than if currencies had remained constant. Likewise, if the U.S. Dollar strengthens year-over-year relative to currencies in our international locations, our consolidated net sales, gross profit, and operating expenses will be lower than if currencies had remained constant. We believe that our increasing diversification beyond the U.S. economy through our growing international businesses benefits our shareholders over the long term. We also believe it is important to evaluate our operating results and growth rates before and after the effect of currency changes. \n\nIn addition, the remeasurement of our 6.875% PEACS and intercompany balances can result in significant gains and charges associated with the effect of movements in currency exchange rates. Currency volatilities may continue, which may significantly impact (either positively or negatively) our reported results and'</li><li>'equal to the entire difference between the debt instruments’ amortized cost basis and its fair value. For available-for-sale debt instruments that are considered other-than-temporarily impaired due to the existence of a credit loss, if we do not intend to sell and it is more likely than not that we will not be required to sell the instrument before recovery of its remaining amortized cost basis (amortized cost basis less any current-period credit loss), we separate the amount of the impairment into the amount that is credit related and the amount due to all other factors. The credit loss component is recognized in earnings.\n\n\n\nWe performed an impairment review of our investment portfolio as of January 25, 2015. We concluded that our investments were appropriately valued and that no other than temporary impairment charges were necessary on our portfolio of available-for-sale investments as of January 25, 2015.\n\n\n\nStock-based Compensation\n\n\n\nOur stock-based compensation expense is associated with stock options, restricted stock units, or RSUs, performance stock units, or PSUs, and our employee stock purchase plan, or ESPP.\n\n\n\nDuring fiscal year 2015, we shifted away from granting stock options and toward granting RSUs and PSUs to reflect changing market trends for equity incentives at our peer companies. The number of PSUs that will ultimately vest is contingent on the Company’s level of achievement compared with the corporate financial performance target established by our Compensation Committee in the beginning of each fiscal year. The number of shares of our stock to be received at vesting ranges from 0% to 200% of the target amount.\n\n\n\nWe use the closing trading price of our common stock on the date of grant, minus a dividend yield discount, as the fair value of awards of RSUs and PSUs. The compensation expense for RSUs is recognized using a straight-line attribution method over the requisite employee service period, while compensation expense for PSUs is recognized using an accelerated amortization model. We estimate the fair value of shares to be issued under our ESPP using the Black-Scholes model at the commencement of an offering period in March and September of each year. Stock-based compensation for our ESPP is expensed using an accelerated amortization model.\n\n\n\nOur RSU and PSU awards are not eligible for cash dividends prior to vesting; therefore, the fair value of RSUs and PSUs is discounted by the dividend yield. Additionally, we estimate forfeitures annually based on historical experience and revise the estimates of forfeiture in subsequent periods if actual forfeitures differ from those estimates. If factors change, the compensation expense that we record under these accounting standards may differ significantly from what we have recorded in the current period.\n\n\n\nLitigation, Investigation and Settlement Costs\n\n\n\nFrom time to time, we are involved in legal actions and/or investigations by regulatory bodies. We are aggressively defending our current litigation matters. However, there are many uncertainties associated with any litigation or investigations, and we cannot be certain that these actions or other third-party claims'</li><li>'local, and foreign tax authorities. Management believes that adequate provision has been made for any adjustments that may result from tax examinations. However, the outcome of tax audits cannot be predicted with certainty. If any issues addressed in the Company’s tax audits are resolved in a manner not consistent with management’s expectations, the Company could be required to adjust its provision for income taxes in the period such resolution occurs. \n\nAs of September 25, 2010, the Company had $51 billion in cash, cash equivalents and marketable securities, an increase of $17 billion from September 26, 2009. The principal component of this net increase was the cash generated by operating activities of $18.6 billion, which was partially offset by payments for acquisition of property, plant and equipment of $2 billion and payments made in connection with business acquisitions, net of cash acquired, of $638 million. \n\nThe Company’s marketable securities investment portfolio is invested primarily in highly rated securities, generally with a minimum rating of single-A or equivalent. As of September 25, 2010 and September 26, 2009, $30.8 billion and $17.4 billion, respectively, of the Company’s cash, cash equivalents and marketable securities were held by foreign subsidiaries and are generally based in U.S. dollar-denominated holdings. The Company believes its existing balances of cash, cash equivalents and marketable securities will be sufficient to satisfy its working capital needs, capital asset purchases, outstanding commitments and other liquidity requirements associated with its existing operations over the next 12 months. \n\nCapital Assets \n\nThe Company’s capital expenditures were $2.6 billion during 2010, consisting of approximately $404 million for retail store facilities and $2.2 billion for other capital expenditures, including product tooling and manufacturing process equipment and corporate facilities and infrastructure. The Company’s actual cash payments for capital expenditures during 2010 were $2 billion. \n\nThe Company anticipates utilizing approximately $4.0 billion for capital expenditures during 2011, including approximately $600 million for retail store facilities and approximately $3.4 billion for product tooling and manufacturing process equipment, and corporate facilities and infrastructure, including information systems hardware, software and enhancements. \n\nHistorically the Company has opened between 25 and 50 new retail stores per year. During 2011, the Company expects to open 40 to 50 new stores, over half of which are expected to be located outside of the U.S. \n\nOff-Balance Sheet Arrangements and Contractual Obligations \n\nThe Company has not entered into any transactions with unconsolidated entities whereby the Company has financial guarantees, subordinated retained interests, derivative instruments, or other contingent arrangements that expose the Company to material continuing risks, contingent liabilities, or any other obligation under a variable interest in an unconsolidated entity that provides financing, liquidity, market risk, or credit risk support to the Company. \n\nAs of September 25, 2010, the Company had'</li></ul> |
|
| 325 |
+
| SELL | <ul><li>'estimates and changes to these estimates will cause the fair values of our stock awards and related stock-based compensation expense that we record to vary.\n\nWe record deferred tax assets for stock-based compensation awards that result in deductions on our income tax returns, based on the amount of stock-based compensation recognized and the fair values attributable to the vested portion of stock awards assumed in connection with a business combination, at the statutory tax rate in the jurisdiction in which we will receive a tax deduction. Because the deferred tax assets we record are based upon the stock-based compensation expenses in a particular jurisdiction, the aforementioned inputs that affect the fair values of our stock awards may also indirectly affect our income tax expense. In addition, differences between the deferred tax assets recognized for financial reporting purposes and the actual tax deduction reported on our income tax returns are recorded in additional paid-in capital. If the tax deduction is less than the deferred tax asset, the calculated shortfall reduces our pool of excess tax benefits. If the pool of excess tax benefits is reduced to zero, then subsequent shortfalls would increase our income tax expense.\n\nTo the extent we change the terms of our employee stock-based compensation programs, experience market volatility in the pricing of our common stock that increases the implied volatility calculation of publicly traded options in our stock, refine different assumptions in future periods such as forfeiture rates that differ from our current estimates, or assume stock awards from acquired companies that are different in nature than our stock award arrangements, among other potential impacts, the stock-based compensation expense that we record in future periods and the tax benefits that we realize may differ significantly from what we have recorded in previous reporting periods.\n\nResults of Operations\n\nImpact of Acquisitions\n\nThe comparability of our operating results in fiscal 2014 compared to fiscal 2013 is impacted by our acquisitions, primarily our acquisitions of Responsys in the third quarter of fiscal 2014, Tekelec in the first quarter of fiscal 2014 and Acme Packet in the fourth quarter of fiscal 2013.\n\nThe comparability of our operating results in fiscal 2013 compared to fiscal 2012 is impacted by our acquisitions, primarily our acquisitions of Acme Packet in the fourth quarter of fiscal 2013, Taleo Corporation (Taleo) in the fourth quarter of fiscal 2012 and RightNow Technologies, Inc. (RightNow) during the third quarter of fiscal 2012.\n\nIn our discussion of changes in our results of operations from fiscal 2014 compared to fiscal 2013 and fiscal 2013 compared to fiscal 2012, we may qualitatively disclose the impacts of our acquired products (for the one year period subsequent to the acquisition date) to the growth in our new software licenses revenues, cloud SaaS and PaaS revenues, software license updates and product support revenues, hardware systems products revenues and hardware systems support revenues where such qualitative discussions would be meaningful for an understanding of the factors that'</li><li>'the share repurchase program for 2015.\n\nResults of Operations\n\nThe following section presents the results of operations and variances on an after-tax basis for the company’s business segments – Upstream and Downstream – as well as for “All Other.” Earnings are also presented for the U.S. and international geographic areas of the Upstream and Downstream business segments. Refer to Note 12, beginning on page FS-37, for a discussion of the company’s “reportable segments.” This section should also be read in conjunction with the discussion in “Business Environment and Outlook” on pages FS-2 through FS-5.\n\nU.S. upstream earnings of $3.3 billion in 2014 decreased $717 million from 2013, primarily due to lower crude oil prices of $950 million. Higher depreciation expenses of $440 million and higher operating expenses of $210 million also contributed to the decline. Partially offsetting the decrease were higher gains on asset sales of $700 million in the current period compared with $60 million in 2013, higher natural gas realizations of $150 million and higher crude oil production of $100 million.\n\nU.S. upstream earnings of $4.0 billion in 2013 decreased $1.3 billion from 2012, primarily due to higher operating, depreciation and exploration expenses of $420 million, $350 million, and $190 million, respectively, and lower crude oil production of $170 million. Higher natural gas realizations of approximately $200 million were mostly offset by lower crude oil realizations of $170 million.\n\nThe company’s average realization for U.S. crude oil and natural gas liquids in 2014 was $84.13 per barrel, compared with $93.46 in 2013 and $95.21 in 2012. The average natural gas realization was $3.90 per thousand cubic feet in 2014, compared with $3.37 and $2.64 in 2013 and 2012, respectively.\n\nNet oil-equivalent production in 2014 averaged 664,000 barrels per day, up 1 percent from both 2013 and 2012. Between 2014 and 2013, production increases in the Permian Basin in Texas and New Mexico and the Marcellus Shale in western Pennsylvania were partially offset by normal field declines. Between 2013 and 2012, new production in the Marcellus Shale in western Pennsylvania and the Delaware Basin in New Mexico, along with the absence of weather-related downtime in the Gulf of Mexico, was largely offset by normal field declines.\n\nThe net liquids component of oil-equivalent production for 2014 averaged 456,000 barrels per day, up 2 percent from 2013 and largely unchanged from 2012. Net natural gas production averaged about 1.3 billion cubic feet per day in 2014, largely unchanged from 2013 and up 4 percent from 2012. Refer to the “Selected Operating Data” table on page FS-11 for a three-year comparative of production volumes in the United States.\n\nInternational Upstream\n\nInternational upstream earnings were $13.6 billion in 2014 compared with $16.8 billion in 2013. The decrease between periods was primarily due to lower crude oil prices and sales volumes of $2.0 billion and $400 million, respectively. Also contributing to the decrease were higher depreciation expenses of $1.0 billion, mainly related to impairments and other asset writeoffs, and higher operating and tax'</li><li>'hypothetical royalties generated from using our tradename) or (4)\xa0projected discounted future cash flows. We recognize an impairment charge if the asset’s carrying value exceeds its estimated fair value.\n\n\xa0\xa0\xa0\xa0\xa0Changes in assumptions or circumstances could result in an additional impairment in the period in which the change occurs and in future years. Factors which could cause impairment include, but are not limited to, (1)\xa0negative trends in our market capitalization, (2)\xa0volatile fuel prices, (3)\xa0declining passenger mile yields, (4)\xa0lower passenger demand as a result of the weakened U.S. and global economy, (5)\xa0interruption to our operations due to an employee strike, terrorist attack, or other reasons, (6)\xa0changes to the regulatory environment and (7)\xa0consolidation of competitors in the industry.\n\n\xa0\xa0\xa0\xa0\xa0 Long-Lived Assets . Our flight equipment and other long-lived assets have a recorded value of $20.4\xa0billion on our Consolidated Balance Sheet at December\xa031, 2009. This value is based on various factors, including the assets’ estimated useful lives and their estimated salvage values. We record impairment losses on long-lived assets used in operations when events and circumstances indicate the assets may be impaired and the estimated future cash flows generated by those assets are less than their carrying amounts. If we decide to permanently remove flight equipment or other long-lived assets from operations, we will evaluate those assets for impairment. For long-lived assets held for sale, we record impairment losses when the carrying amount is greater than the fair value less the cost to sell. We discontinue depreciation of long-lived assets when these assets are classified as held for sale.\n\n\xa0\xa0\xa0\xa0\xa0To determine impairments for aircraft used in operations, we group assets at the fleet-type level (the lowest level for which there are identifiable cash flows) and then estimate future cash flows based on projections of capacity, passenger mile yield, fuel costs, labor costs and other relevant factors. If impairment occurs, the impairment loss recognized is the amount by which the aircraft’s carrying amount exceeds its estimated fair value. We estimate aircraft fair values using published sources, appraisals and bids received from third parties, as available. For additional information about our accounting policy for the impairment of long-lived assets, see Note 1 of the Notes to the Consolidated Financial Statements. \n\n\n\n\xa0\xa0\xa0\xa0\xa0 Income Tax Valuation Allowance and Contingencies . We periodically assess whether it is more likely than not that we will generate sufficient taxable income to realize our deferred income tax assets, and we establish valuation allowances if recovery is deemed not likely. In making this determination, we consider all available positive and negative evidence and make certain assumptions. We consider, among other things, our deferred tax liabilities, the overall business environment, our historical earnings and losses, our industry’s historically cyclical periods of earnings and losses and potential, current and future tax planning strategies. We cannot presently determine when we will be able to generate sufficient taxable'</li></ul> |
|
| 326 |
+
| HOLD | <ul><li>'both historical and projected future operating results, the reversal of existing taxable temporary differences, taxable income in prior carryback years (if permitted) and the availability of tax planning strategies. A valuation allowance is required to be established unless management determines that it is more likely than not that the Company will ultimately realize the tax benefit associated with a deferred tax asset. \n\nAdditionally, undistributed earnings of a subsidiary are accounted for as a temporary difference, except that deferred tax liabilities are not recorded for undistributed earnings of a foreign subsidiary that are deemed to be indefinitely reinvested in the foreign jurisdiction. The Company has formulated a specific plan for reinvestment of undistributed earnings of its foreign subsidiaries which demonstrates that such earnings will be indefinitely reinvested in the applicable tax jurisdictions. Should we change our plans, we would be required to record a significant amount of deferred tax liabilities. \n\nThe Company\'s effective tax rate is expected to be approximately 23.0 percent to 24.0 percent in 2009. This estimated tax rate does not reflect the impact of any unusual or special items that may affect our tax rate in 2009. \n\nContingencies \n\nOur Company is subject to various claims and contingencies, mostly related to legal proceedings and tax matters (both income taxes and indirect taxes). Due to their nature, such legal proceedings and tax matters involve inherent uncertainties including, but not limited to, court rulings, negotiations between affected parties and governmental actions. Management assesses the probability of loss for such contingencies and accrues a liability and/or discloses the relevant circumstances, as appropriate. Management believes that any liability to the Company that may arise as a result of currently pending legal proceedings, tax matters or other contingencies will not have a material adverse effect on the financial condition of the Company taken as a whole. Refer to Note 13 of Notes to Consolidated Financial Statements. \n\nRecent Accounting Standards and Pronouncements \n\nRefer to Note 1 of Notes to Consolidated Financial Statements for a discussion of recent accounting standards and pronouncements. \n\nOperations Review \n\nWe manufacture, distribute and market nonalcoholic beverage concentrates and syrups. We also manufacture, distribute and market finished beverages. Our organizational structure as of December 31, 2008, consisted of the following operating segments, the first six of which are sometimes referred to as "operating groups" or "groups": Eurasia and Africa; Europe; Latin America; North America; Pacific; Bottling Investments; and Corporate. We revised previously reported group information to conform to our operating structure in effect as of December 31, 2008. For further information regarding our operating segments, including a discussion of changes made to our operating segments effective July 1, 2008, refer to Note 21 of Notes to Consolidated Financial Statements. \n\nBeverage Volume \n\nWe measure our sales volume in two ways: (1) unit cases of finished products and (2) concentrate'</li><li>"the last month of each quarter, we may not be able to reduce our inventory purchase commitments in a timely manner in response to customer cancellations or deferrals.\n\n\n\nCharges to cost of sales for inventory provisions totaled $50.1 million, $89.9 million and $53.0 million, unfavorably impacting our gross margin by 1.2%, 2.1% and 1.3%, in fiscal years 2014, 2013 and 2012, respectively. Sales of inventory that was previously written-off or written-down totaled $43.4 million, $53.7 million and $71.1 million, favorably impacting our gross margin by 1.1%, 1.3% and 1.8% in fiscal years 2014, 2013 and 2012, respectively. As a result, the overall net effect on our gross margin from charges to cost of sales for inventory provisions and sales of items previously written-off or written-down was a 0.1% unfavorable impact in fiscal year 2014, a 0.8% unfavorable impact in fiscal year 2013 and a 0.5% favorable impact in fiscal year 2012.\n\nDuring fiscal years 2014, 2013 and 2012, the charges we took to cost of sales for inventory provisions were primarily related to the write-off of excess quantities of certain older generations of GPU and Tegra Processor products whose inventory levels were higher than our updated forecasts of future demand for those products. As a fabless semiconductor company, we must make commitments to purchase inventory based on forecasts of future customer demand. In doing so, we must account for our third-party manufacturers' lead times and constraints. We also adjust to other market factors, such as product offerings and pricing actions by our competitors, new product transitions, and macroeconomic conditions - all of which may impact demand for our products.\n\n\n\nPlease refer to the Gross Profit and Gross Margin discussion below in this Management's Discussion and Analysis for further discussion.\n\n\n\nWarranty Liabilities\n\n\n\nCost of revenue includes the estimated cost of product warranties that are calculated at the point of revenue recognition. Under limited circumstances, we may offer an extended limited warranty to customers for certain products. Our products are complex and may contain defects or experience failures due to any number of issues in design, fabrication, packaging, materials and/or use within a system. If any of our products or technologies contains a defect, compatibility issue or other error, we may have to invest additional research and development efforts to find and correct the issue. In addition, an error or defect in new products or releases or related software drivers after commencement of commercial shipments could result in failure to achieve market acceptance or loss of design wins. Also, we may be required to reimburse customers, including our customers’ costs to repair or replace products in the field.\n\n \n\nIncome Taxes\n\nWe recognize federal, state and foreign current tax liabilities or assets based on our estimate of taxes payable or refundable in the current fiscal year by tax jurisdiction. We recognize federal, state and foreign deferred tax assets or liabilities, as appropriate, for our estimate of future tax effects attributable to temporary differences and carryforwards; and we record a"</li><li>'the euro. The Europe segment represented approximately 23% and 26% of the Company’s total net sales for 2012 and 2011, respectively. \n\nNet sales in the Europe segment increased $9.1 billion or 49% during 2011 compared to 2010. The increase in net sales during 2011 was attributable primarily to the continued year-over-year increase in iPhone sales from carrier expansion and strong demand for iPhone 4, and increased sales of iPad and Mac, partially offset by a decrease in iPod sales. The Europe segment represented 26% and 29% of the Company’s total net sales for 2011 and 2010, respectively. \n\nJapan \n\nNet sales in the Japan segment increased $5.1 billion or 94% during 2012 compared to 2011. The growth in net sales during 2012 was primarily driven by increased demand for iPhone following the launches of iPhone 4S and iPhone 5, expanded distribution with a new iPhone carrier, strong demand for the new iPad and iPad 2, higher sales from the iTunes Store, and strength in the Japanese Yen relative to the U.S. dollar. The Japan segment represented approximately 7% and 5% of the Company’s total net sales for 2012 and 2011, respectively. \n\nNet sales in the Japan segment increased $1.5 billion or 37% during 2011 compared to 2010. The key contributors to Japan’s net sales growth were increased iPhone sales, strong sales of iPad, increased sales of Mac, and strength in the Japanese Yen relative to the U.S. dollar. The Japan segment represented 5% and 6% of the Company’s total net sales for 2011 and 2010, respectively. \n\nAsia-Pacific \n\nNet sales in the Asia-Pacific segment increased $10.7 billion or 47% during 2012 compared to 2011. The growth in net sales during 2012 was mainly due to increased demand for iPhone from the launch of iPhone 4S, strong demand for the new iPad and iPad 2, and higher Mac sales. Growth in the Asia Pacific segment was affected by the timing of iPhone and iPad product launches. iPhone 5 was launched in a limited number of countries in the Asia Pacific segment during the fourth quarter of 2012 and was not launched in China during 2012, and the new iPad that was introduced by the Company in March 2012 was not launched in China until the fourth quarter of 2012. The Asia-Pacific segment represented approximately 21% of the Company’s total net sales in both 2012 and 2011. \n\nNet sales in the Asia Pacific segment increased $14.3 billion or 174% during 2011 compared to 2010. The Company experienced particularly strong year-over-year net sales growth in its Asia Pacific segment during 2011, especially in Greater China, which includes Hong Kong and Taiwan. Korea and Australia also experienced strong year-over-year revenue growth. Higher net sales in the Asia Pacific segment were due mainly to the increase in iPhone sales primarily attributable to the strong demand for iPhone 4 and carrier expansion, strong sales of iPad, and increased Mac sales. The Asia Pacific segment represented 21% and 13% of the Company’s total net sales in 2011 and 2010, respectively. \n\nRetail \n\nNet sales in the Retail segment increased $4.7 billion or 33% during 2012 compared to 2011. The growth in net sales during 2012 was driven primarily by increased demand for'</li></ul> |
|
| 327 |
+
|
| 328 |
+
## Evaluation
|
| 329 |
+
|
| 330 |
+
### Metrics
|
| 331 |
+
| Label | Accuracy |
|
| 332 |
+
|:--------|:---------|
|
| 333 |
+
| **all** | 0.5833 |
|
| 334 |
+
|
| 335 |
+
## Uses
|
| 336 |
+
|
| 337 |
+
### Direct Use for Inference
|
| 338 |
+
|
| 339 |
+
First install the SetFit library:
|
| 340 |
+
|
| 341 |
+
```bash
|
| 342 |
+
pip install setfit
|
| 343 |
+
```
|
| 344 |
+
|
| 345 |
+
Then you can load this model and run inference.
|
| 346 |
+
|
| 347 |
+
```python
|
| 348 |
+
from setfit import SetFitModel
|
| 349 |
+
|
| 350 |
+
# Download from the 🤗 Hub
|
| 351 |
+
model = SetFitModel.from_pretrained("setfit_model_id")
|
| 352 |
+
# Run inference
|
| 353 |
+
preds = model("Organic local-currency sales increased 4.0 percent and acquisitions added 1.4 percent. Acquisition growth was largely due to the October 2011 acquisition of the do-it-yourself and professional business of GPI Group and the April 2010 acquisition of the A-One branded label business and related operations. A-One is the largest branded label business in Asia and the second largest worldwide. 3M also acquired Hybrivet Systems Inc. in the first quarter of 2011, a provider of instant-read products to detect lead and other contaminants and toxins. Foreign currency impacts contributed 2.4 percent to sales growth in the Consumer and Office segment.
|
| 354 |
+
|
| 355 |
+
|
| 356 |
+
|
| 357 |
+
On a geographic basis, sales increased in all regions, led by Asia Pacific, Latin America/Canada and Europe, which all had sales growth rates in excess of 10 percent. U.S. sales also grew, albeit at a slower rate.
|
| 358 |
+
|
| 359 |
+
|
| 360 |
+
|
| 361 |
+
Consumer and Office operating income was flat when comparing 2011 to 2010, reflecting continued ongoing investments in developing economies in brand development and marketing and sales coverage. Even with these investments, Consumer and Office generated operating income margins of 20.2 percent.
|
| 362 |
+
|
| 363 |
+
|
| 364 |
+
|
| 365 |
+
Safety, Security and Protection Services Business (12.7% of consolidated sales):
|
| 366 |
+
|
| 367 |
+
|
| 368 |
+
|
| 369 |
+
The Safety, Security and Protection Services segment serves a broad range of markets that increase the safety, security and productivity of workers, facilities and systems. Major product offerings include personal protection products, cleaning and protection products for commercial establishments, safety and security products (including border and civil security solutions), roofing granules for asphalt shingles, infrastructure protection products used in the oil and gas pipeline markets, and track and trace solutions.
|
| 370 |
+
|
| 371 |
+
|
| 372 |
+
|
| 373 |
+
Year 2012 results:
|
| 374 |
+
|
| 375 |
+
|
| 376 |
+
|
| 377 |
+
Safety, Security and Protection Services sales totaled $3.8 billion, down 0.5 percent in U.S. dollars. Organic local-currency sales grew 2.2 percent and foreign currency translation reduced sales by 2.7 percent. Organic local-currency sales growth was led by infrastructure protection and personal safety, with growth also in building and commercial services and roofing granules.
|
| 378 |
+
|
| 379 |
+
|
| 380 |
+
|
| 381 |
+
2012 organic local-currency sales declined 18 percent in security systems, as government spending for security solutions has been declining over the last few years. As discussed later in the “Critical Accounting Estimates” section, 3M will continue to monitor this business to assess whether long-term expectations have been significantly impacted such that an asset or goodwill impairment test would be required. The Company completed its annual goodwill impairment test in the fourth quarter of 2012, with no impairment indicated.
|
| 382 |
+
|
| 383 |
+
|
| 384 |
+
|
| 385 |
+
Geographically, organic local-currency sales increased 19 percent in Latin America/Canada. Organic local-currency sales were flat in Asia Pacific and the United States, and declined 2 percent in EMEA.
|
| 386 |
+
|
| 387 |
+
|
| 388 |
+
|
| 389 |
+
The combination of selling price increases and raw material cost reductions, plus factory efficiencies, drove a 4.1 percent increase in operating income. Operating income margins increased 1.0 percentage points to 22.3 percent.
|
| 390 |
+
|
| 391 |
+
|
| 392 |
+
|
| 393 |
+
Year 2011 results:
|
| 394 |
+
|
| 395 |
+
|
| 396 |
+
|
| 397 |
+
Safety,")
|
| 398 |
+
```
|
| 399 |
+
|
| 400 |
+
<!--
|
| 401 |
+
### Downstream Use
|
| 402 |
+
|
| 403 |
+
*List how someone could finetune this model on their own dataset.*
|
| 404 |
+
-->
|
| 405 |
+
|
| 406 |
+
<!--
|
| 407 |
+
### Out-of-Scope Use
|
| 408 |
+
|
| 409 |
+
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
|
| 410 |
+
-->
|
| 411 |
+
|
| 412 |
+
<!--
|
| 413 |
+
## Bias, Risks and Limitations
|
| 414 |
+
|
| 415 |
+
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
|
| 416 |
+
-->
|
| 417 |
+
|
| 418 |
+
<!--
|
| 419 |
+
### Recommendations
|
| 420 |
+
|
| 421 |
+
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
|
| 422 |
+
-->
|
| 423 |
+
|
| 424 |
+
## Training Details
|
| 425 |
+
|
| 426 |
+
### Training Set Metrics
|
| 427 |
+
| Training set | Min | Median | Max |
|
| 428 |
+
|:-------------|:----|:---------|:----|
|
| 429 |
+
| Word count | 431 | 475.4792 | 532 |
|
| 430 |
+
|
| 431 |
+
| Label | Training Sample Count |
|
| 432 |
+
|:------|:----------------------|
|
| 433 |
+
| BUY | 6 |
|
| 434 |
+
| HOLD | 12 |
|
| 435 |
+
| SELL | 30 |
|
| 436 |
+
|
| 437 |
+
### Training Hyperparameters
|
| 438 |
+
- batch_size: (6, 8)
|
| 439 |
+
- num_epochs: (0, 32)
|
| 440 |
+
- max_steps: -1
|
| 441 |
+
- sampling_strategy: oversampling
|
| 442 |
+
- body_learning_rate: (0.0, 0.0)
|
| 443 |
+
- head_learning_rate: 0.0002
|
| 444 |
+
- loss: CosineSimilarityLoss
|
| 445 |
+
- distance_metric: cosine_distance
|
| 446 |
+
- margin: 0.25
|
| 447 |
+
- end_to_end: False
|
| 448 |
+
- use_amp: False
|
| 449 |
+
- warmup_proportion: 0.1
|
| 450 |
+
- l2_weight: 0.08
|
| 451 |
+
- max_length: 512
|
| 452 |
+
- seed: 1003200212
|
| 453 |
+
- eval_max_steps: -1
|
| 454 |
+
- load_best_model_at_end: False
|
| 455 |
+
|
| 456 |
+
### Framework Versions
|
| 457 |
+
- Python: 3.11.6
|
| 458 |
+
- SetFit: 1.0.1
|
| 459 |
+
- Sentence Transformers: 2.2.2
|
| 460 |
+
- Transformers: 4.35.2
|
| 461 |
+
- PyTorch: 2.1.1
|
| 462 |
+
- Datasets: 2.15.0
|
| 463 |
+
- Tokenizers: 0.15.0
|
| 464 |
+
|
| 465 |
+
## Citation
|
| 466 |
+
|
| 467 |
+
### BibTeX
|
| 468 |
+
```bibtex
|
| 469 |
+
@article{https://doi.org/10.48550/arxiv.2209.11055,
|
| 470 |
+
doi = {10.48550/ARXIV.2209.11055},
|
| 471 |
+
url = {https://arxiv.org/abs/2209.11055},
|
| 472 |
+
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
|
| 473 |
+
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
|
| 474 |
+
title = {Efficient Few-Shot Learning Without Prompts},
|
| 475 |
+
publisher = {arXiv},
|
| 476 |
+
year = {2022},
|
| 477 |
+
copyright = {Creative Commons Attribution 4.0 International}
|
| 478 |
+
}
|
| 479 |
+
```
|
| 480 |
+
|
| 481 |
+
<!--
|
| 482 |
+
## Glossary
|
| 483 |
+
|
| 484 |
+
*Clearly define terms in order to be accessible across audiences.*
|
| 485 |
+
-->
|
| 486 |
+
|
| 487 |
+
<!--
|
| 488 |
+
## Model Card Authors
|
| 489 |
+
|
| 490 |
+
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
|
| 491 |
+
-->
|
| 492 |
+
|
| 493 |
+
<!--
|
| 494 |
+
## Model Card Contact
|
| 495 |
+
|
| 496 |
+
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
|
| 497 |
+
-->
|
test_models/financial-roberta/config.json
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "/root/.cache/torch/sentence_transformers/CabraVC_emb_classifier_model/",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"RobertaModel"
|
| 5 |
+
],
|
| 6 |
+
"attention_probs_dropout_prob": 0.1,
|
| 7 |
+
"bos_token_id": 0,
|
| 8 |
+
"classifier_dropout": null,
|
| 9 |
+
"eos_token_id": 2,
|
| 10 |
+
"gradient_checkpointing": false,
|
| 11 |
+
"hidden_act": "gelu",
|
| 12 |
+
"hidden_dropout_prob": 0.1,
|
| 13 |
+
"hidden_size": 768,
|
| 14 |
+
"initializer_range": 0.02,
|
| 15 |
+
"intermediate_size": 3072,
|
| 16 |
+
"layer_norm_eps": 1e-05,
|
| 17 |
+
"max_position_embeddings": 514,
|
| 18 |
+
"model_type": "roberta",
|
| 19 |
+
"num_attention_heads": 12,
|
| 20 |
+
"num_hidden_layers": 6,
|
| 21 |
+
"pad_token_id": 1,
|
| 22 |
+
"position_embedding_type": "absolute",
|
| 23 |
+
"torch_dtype": "float32",
|
| 24 |
+
"transformers_version": "4.36.1",
|
| 25 |
+
"type_vocab_size": 1,
|
| 26 |
+
"use_cache": true,
|
| 27 |
+
"vocab_size": 50265
|
| 28 |
+
}
|
test_models/financial-roberta/config_sentence_transformers.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"__version__": {
|
| 3 |
+
"sentence_transformers": "2.0.0",
|
| 4 |
+
"transformers": "4.6.1",
|
| 5 |
+
"pytorch": "1.8.1"
|
| 6 |
+
}
|
| 7 |
+
}
|
test_models/financial-roberta/merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
test_models/financial-roberta/model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:62937138265b78d1dc60d3bd3d4bf2939317223c02e21b6281187015cc7acb9a
|
| 3 |
+
size 328485128
|
test_models/financial-roberta/modules.json
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[
|
| 2 |
+
{
|
| 3 |
+
"idx": 0,
|
| 4 |
+
"name": "0",
|
| 5 |
+
"path": "",
|
| 6 |
+
"type": "sentence_transformers.models.Transformer"
|
| 7 |
+
},
|
| 8 |
+
{
|
| 9 |
+
"idx": 1,
|
| 10 |
+
"name": "1",
|
| 11 |
+
"path": "1_Pooling",
|
| 12 |
+
"type": "sentence_transformers.models.Pooling"
|
| 13 |
+
},
|
| 14 |
+
{
|
| 15 |
+
"idx": 2,
|
| 16 |
+
"name": "2",
|
| 17 |
+
"path": "2_Normalize",
|
| 18 |
+
"type": "sentence_transformers.models.Normalize"
|
| 19 |
+
}
|
| 20 |
+
]
|
test_models/financial-roberta/sentence_bert_config.json
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"max_seq_length": 512,
|
| 3 |
+
"do_lower_case": false
|
| 4 |
+
}
|
test_models/financial-roberta/special_tokens_map.json
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<s>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"cls_token": {
|
| 10 |
+
"content": "<s>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"eos_token": {
|
| 17 |
+
"content": "</s>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
},
|
| 23 |
+
"mask_token": {
|
| 24 |
+
"content": "<mask>",
|
| 25 |
+
"lstrip": true,
|
| 26 |
+
"normalized": false,
|
| 27 |
+
"rstrip": false,
|
| 28 |
+
"single_word": false
|
| 29 |
+
},
|
| 30 |
+
"pad_token": {
|
| 31 |
+
"content": "<pad>",
|
| 32 |
+
"lstrip": false,
|
| 33 |
+
"normalized": false,
|
| 34 |
+
"rstrip": false,
|
| 35 |
+
"single_word": false
|
| 36 |
+
},
|
| 37 |
+
"sep_token": {
|
| 38 |
+
"content": "</s>",
|
| 39 |
+
"lstrip": false,
|
| 40 |
+
"normalized": false,
|
| 41 |
+
"rstrip": false,
|
| 42 |
+
"single_word": false
|
| 43 |
+
},
|
| 44 |
+
"unk_token": {
|
| 45 |
+
"content": "<unk>",
|
| 46 |
+
"lstrip": false,
|
| 47 |
+
"normalized": false,
|
| 48 |
+
"rstrip": false,
|
| 49 |
+
"single_word": false
|
| 50 |
+
}
|
| 51 |
+
}
|
test_models/financial-roberta/tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
test_models/financial-roberta/tokenizer_config.json
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"0": {
|
| 5 |
+
"content": "<s>",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": false,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"1": {
|
| 13 |
+
"content": "<pad>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": false,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
},
|
| 20 |
+
"2": {
|
| 21 |
+
"content": "</s>",
|
| 22 |
+
"lstrip": false,
|
| 23 |
+
"normalized": false,
|
| 24 |
+
"rstrip": false,
|
| 25 |
+
"single_word": false,
|
| 26 |
+
"special": true
|
| 27 |
+
},
|
| 28 |
+
"3": {
|
| 29 |
+
"content": "<unk>",
|
| 30 |
+
"lstrip": false,
|
| 31 |
+
"normalized": false,
|
| 32 |
+
"rstrip": false,
|
| 33 |
+
"single_word": false,
|
| 34 |
+
"special": true
|
| 35 |
+
},
|
| 36 |
+
"50264": {
|
| 37 |
+
"content": "<mask>",
|
| 38 |
+
"lstrip": true,
|
| 39 |
+
"normalized": false,
|
| 40 |
+
"rstrip": false,
|
| 41 |
+
"single_word": false,
|
| 42 |
+
"special": true
|
| 43 |
+
}
|
| 44 |
+
},
|
| 45 |
+
"bos_token": "<s>",
|
| 46 |
+
"clean_up_tokenization_spaces": true,
|
| 47 |
+
"cls_token": "<s>",
|
| 48 |
+
"eos_token": "</s>",
|
| 49 |
+
"errors": "replace",
|
| 50 |
+
"mask_token": "<mask>",
|
| 51 |
+
"max_length": 128,
|
| 52 |
+
"model_max_length": 512,
|
| 53 |
+
"pad_to_multiple_of": null,
|
| 54 |
+
"pad_token": "<pad>",
|
| 55 |
+
"pad_token_type_id": 0,
|
| 56 |
+
"padding_side": "right",
|
| 57 |
+
"sep_token": "</s>",
|
| 58 |
+
"stride": 0,
|
| 59 |
+
"tokenizer_class": "RobertaTokenizer",
|
| 60 |
+
"trim_offsets": true,
|
| 61 |
+
"truncation_side": "right",
|
| 62 |
+
"truncation_strategy": "longest_first",
|
| 63 |
+
"unk_token": "<unk>"
|
| 64 |
+
}
|
test_models/financial-roberta/vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
test_models/get_embeddings.py
ADDED
|
@@ -0,0 +1,164 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch import nn
|
| 2 |
+
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix
|
| 3 |
+
|
| 4 |
+
def get_eval_metric(y_pred, y_test):
|
| 5 |
+
return {
|
| 6 |
+
'accuracy': accuracy_score(y_test, y_pred),
|
| 7 |
+
'precision': precision_score(y_test, y_pred, average='weighted'),
|
| 8 |
+
'recall': recall_score(y_test, y_pred, average='weighted'),
|
| 9 |
+
'f1': f1_score(y_test, y_pred, average='weighted'),
|
| 10 |
+
'confusion_mat': confusion_matrix(y_test, y_pred, normalize='true'),
|
| 11 |
+
}
|
| 12 |
+
|
| 13 |
+
class MLP(nn.Module):
|
| 14 |
+
def __init__(self, input_size=768, hidden_size=256, output_size=3, dropout_rate=.2, class_weights=None):
|
| 15 |
+
super(MLP, self).__init__()
|
| 16 |
+
self.class_weights = class_weights
|
| 17 |
+
|
| 18 |
+
self.activation = nn.ReLU()
|
| 19 |
+
self.bn1 = nn.BatchNorm1d(hidden_size)
|
| 20 |
+
self.dropout = nn.Dropout(dropout_rate)
|
| 21 |
+
|
| 22 |
+
self.fc1 = nn.Linear(input_size, hidden_size)
|
| 23 |
+
self.fc2 = nn.Linear(hidden_size, output_size)
|
| 24 |
+
|
| 25 |
+
def forward(self, x):
|
| 26 |
+
input_is_dict = False
|
| 27 |
+
if isinstance(x, dict):
|
| 28 |
+
assert "sentence_embedding" in x
|
| 29 |
+
input_is_dict = True
|
| 30 |
+
x = x['sentence_embedding']
|
| 31 |
+
|
| 32 |
+
x = self.fc1(x)
|
| 33 |
+
x = self.bn1(x)
|
| 34 |
+
x = self.activation(x)
|
| 35 |
+
x = self.dropout(x)
|
| 36 |
+
|
| 37 |
+
x = self.fc2(x)
|
| 38 |
+
|
| 39 |
+
if input_is_dict:
|
| 40 |
+
return {'logits': x}
|
| 41 |
+
return x
|
| 42 |
+
|
| 43 |
+
def predict(self, x):
|
| 44 |
+
_, predicted = torch.max(self.forward(x), 1)
|
| 45 |
+
print('I am predict')
|
| 46 |
+
return predicted
|
| 47 |
+
|
| 48 |
+
def predict_proba(self, x):
|
| 49 |
+
print('I am predict_proba')
|
| 50 |
+
return self.forward(x)
|
| 51 |
+
|
| 52 |
+
def get_loss_fn(self):
|
| 53 |
+
return nn.CrossEntropyLoss(weight=self.class_weights, reduction='mean')
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
if __name__ == '__main__':
|
| 61 |
+
from setfit.__init__ import SetFitModel, Trainer, TrainingArguments
|
| 62 |
+
from datasets import Dataset, load_dataset, DatasetDict
|
| 63 |
+
from sentence_transformers import SentenceTransformer, models, util
|
| 64 |
+
from sentence_transformers.losses import BatchAllTripletLoss, BatchHardSoftMarginTripletLoss, BatchHardTripletLoss, BatchSemiHardTripletLoss
|
| 65 |
+
from sklearn.linear_model import LogisticRegression
|
| 66 |
+
import sys
|
| 67 |
+
import os
|
| 68 |
+
import warnings
|
| 69 |
+
import torch
|
| 70 |
+
import torch.nn as nn
|
| 71 |
+
import torch.nn.functional as F
|
| 72 |
+
from datetime import datetime
|
| 73 |
+
import torch.optim as optim
|
| 74 |
+
from statistics import mean
|
| 75 |
+
from pprint import pprint
|
| 76 |
+
from torch.utils.data import DataLoader, TensorDataset
|
| 77 |
+
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
| 78 |
+
from safetensors.torch import load_model, save_model
|
| 79 |
+
from itertools import chain
|
| 80 |
+
from time import perf_counter
|
| 81 |
+
from tqdm import trange
|
| 82 |
+
from collections import Counter
|
| 83 |
+
from sklearn.utils.class_weight import compute_class_weight
|
| 84 |
+
import numpy as np
|
| 85 |
+
import matplotlib.pyplot as plt
|
| 86 |
+
|
| 87 |
+
warnings.filterwarnings("ignore")
|
| 88 |
+
|
| 89 |
+
SEED = 1003200212 + 1
|
| 90 |
+
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
|
| 91 |
+
print(DEVICE)
|
| 92 |
+
start = perf_counter()
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
sys.path.append(os.path.abspath(os.path.join(os.getcwd(), '..')))
|
| 97 |
+
dataset_dir = os.path.abspath(os.path.join(os.getcwd(), '..', '..', 'financial_dataset'))
|
| 98 |
+
sys.path.append(dataset_dir)
|
| 99 |
+
|
| 100 |
+
from load_test_data import get_labels_df, get_texts
|
| 101 |
+
from train_classificator import plot_labels_distribution
|
| 102 |
+
|
| 103 |
+
def split_text(text, chunk_size=1200, chunk_overlap=200):
|
| 104 |
+
text_splitter = RecursiveCharacterTextSplitter(
|
| 105 |
+
chunk_size=chunk_size, chunk_overlap=chunk_overlap,
|
| 106 |
+
length_function = len, separators=[" ", ",", "\n"]
|
| 107 |
+
)
|
| 108 |
+
|
| 109 |
+
text_chunks = text_splitter.create_documents([text])
|
| 110 |
+
return text_chunks
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
labels_dir = dataset_dir + '/csvs/'
|
| 114 |
+
df = get_labels_df(labels_dir)
|
| 115 |
+
texts_dir = dataset_dir + '/txts/'
|
| 116 |
+
texts = get_texts(texts_dir)
|
| 117 |
+
# df = df.iloc[[0, 13, 113], :]
|
| 118 |
+
# print(df.loc[:, 'Label'])
|
| 119 |
+
# texts = [texts[0]] + [texts[13]] + [texts[113]]
|
| 120 |
+
print(len(df), len(texts))
|
| 121 |
+
print(mean(list(map(len, texts))))
|
| 122 |
+
|
| 123 |
+
documents = [split_text(text, chunk_size=3_200, chunk_overlap=200) for text in texts]
|
| 124 |
+
docs_chunks = [[doc.page_content for doc in document] for document in documents]
|
| 125 |
+
# print([len(text_chunks)for text_chunks in docs_chunks])
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
model = SentenceTransformer('financial-roberta')
|
| 129 |
+
model = model.to('cuda:0')
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
# # Get sentence embeddings for each text
|
| 133 |
+
doc_embeddings = [model.encode(doc_chunks, show_progress_bar=True).tolist() for doc_chunks in docs_chunks]
|
| 134 |
+
embeddings = [embedding for doc_embedding in doc_embeddings for embedding in doc_embedding]
|
| 135 |
+
texts = [text for doc_chunks in docs_chunks for text in doc_chunks]
|
| 136 |
+
labels = np.repeat(df['Label'], [len(document) for document in documents]).tolist()
|
| 137 |
+
# print(df.loc[:, 'Label'])
|
| 138 |
+
# print([len(text) for text in texts])
|
| 139 |
+
# print([len(emb) for emb in embeddings])
|
| 140 |
+
# print(labels)
|
| 141 |
+
|
| 142 |
+
dataset = Dataset.from_dict({
|
| 143 |
+
'texts': texts,
|
| 144 |
+
'labels': labels,
|
| 145 |
+
'embeddings': embeddings,
|
| 146 |
+
})
|
| 147 |
+
print(len(dataset['texts']))
|
| 148 |
+
print(dataset['labels'])
|
| 149 |
+
|
| 150 |
+
dataset = dataset.class_encode_column('labels')
|
| 151 |
+
print(len(dataset))
|
| 152 |
+
|
| 153 |
+
train_test_dataset = dataset.train_test_split(test_size=.2, stratify_by_column='labels')
|
| 154 |
+
val_test_dataset = train_test_dataset['test'].train_test_split(test_size=.5, stratify_by_column='labels')
|
| 155 |
+
|
| 156 |
+
dataset = DatasetDict({
|
| 157 |
+
'train': train_test_dataset['train'],
|
| 158 |
+
'val': val_test_dataset['train'],
|
| 159 |
+
'test': val_test_dataset['test']
|
| 160 |
+
}
|
| 161 |
+
)
|
| 162 |
+
plot_labels_distribution(dataset, save_as_filename='plots/finetuned_st_label_distr.png')
|
| 163 |
+
dataset.push_to_hub("CabraVC/vector_dataset_roberta-fine-tuned", private=True)
|
| 164 |
+
|
test_models/models/embedding_mlp_2023-12-07_13-41.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0ed6cf5e052af7b9375ba7100b3160e7b7f15340eba90bd54bdd6a7c2fe11ee0
|
| 3 |
+
size 817138
|
test_models/models/embedding_mlp_2023-12-07_13-41.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:59e52e1aa3358ac631fdfa0340a3b60cb29634653848c5beb284fa0bafa04e21
|
| 3 |
+
size 812524
|
test_models/models/head.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:61ad77d2f34fa46f73f2eba4afacbcb288ddb4249e92b9519d59c8b69d402011
|
| 3 |
+
size 797589
|
test_models/models/head.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:219a7ab311c827493fde0d5d2e196f625c96a2ff6281ab4f9af363053da4eceb
|
| 3 |
+
size 795308
|
test_models/models/linear_head.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:044d8088a361e6cfc9b0ff61bf9cff2101d0222db35a844bf715ba541a88f412
|
| 3 |
+
size 10800
|
test_models/models/linear_head.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fe066efac931c13eb1fb42b4b8c9ea8a4ec0efefc716b7fa78a4530252d451bf
|
| 3 |
+
size 9380
|
test_models/plots/confusion_matrix.png
ADDED

|
test_models/plots/confusion_matrix_2023-12-06_17-53.png
ADDED

|
test_models/plots/confusion_matrix_2023-12-06_17-55.png
ADDED

|
test_models/plots/confusion_matrix_2023-12-06_17-56.png
ADDED

|
test_models/plots/confusion_matrix_2023-12-06_17-58.png
ADDED

|
test_models/plots/confusion_matrix_2023-12-06_18-06.png
ADDED

|
test_models/plots/confusion_matrix_2023-12-06_18-07.png
ADDED

|
test_models/plots/confusion_matrix_2023-12-06_18-08.png
ADDED

|
test_models/plots/confusion_matrix_2023-12-06_18-10.png
ADDED

|
test_models/plots/confusion_matrix_2023-12-06_18-15.png
ADDED

|
test_models/plots/confusion_matrix_2023-12-06_18-17.png
ADDED

|
test_models/plots/confusion_matrix_2023-12-06_18-18.png
ADDED

|
test_models/plots/confusion_matrix_2023-12-06_18-35.png
ADDED
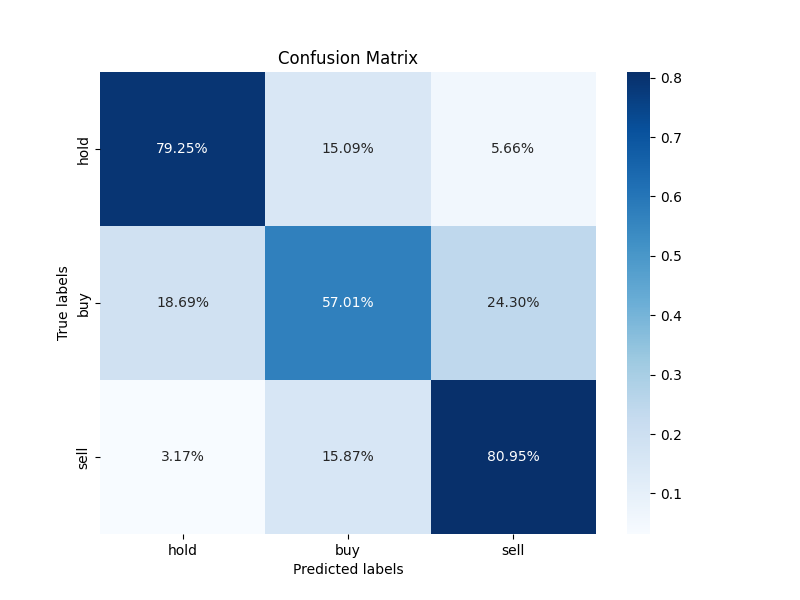
|
test_models/plots/confusion_matrix_2023-12-06_18-36.png
ADDED

|
test_models/plots/confusion_matrix_2023-12-06_18-37.png
ADDED
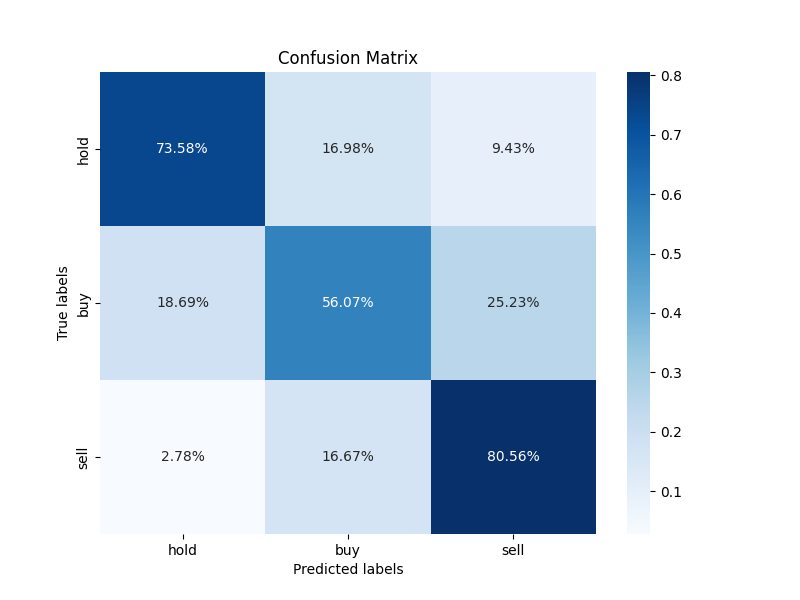
|
test_models/plots/confusion_matrix_2023-12-06_18-38.png
ADDED
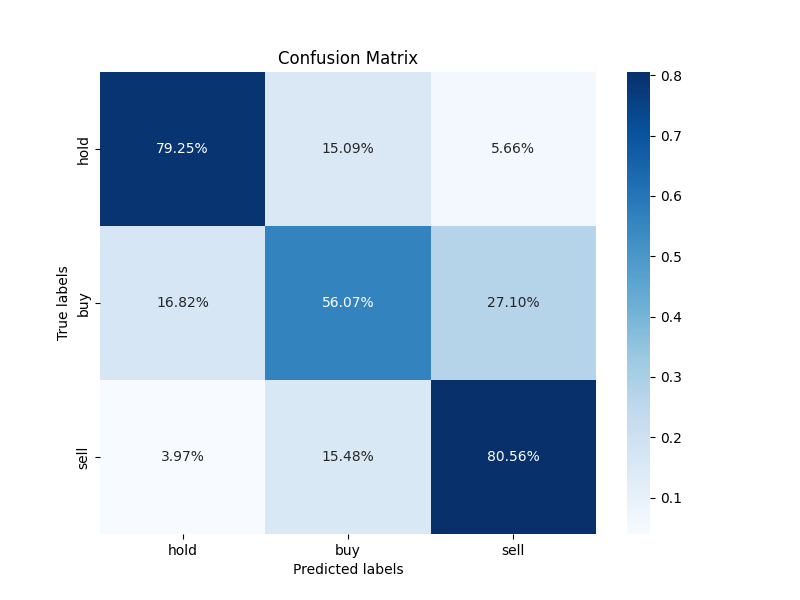
|
test_models/plots/confusion_matrix_2023-12-06_18-39.png
ADDED

|
test_models/plots/confusion_matrix_2023-12-06_18-40.png
ADDED

|
test_models/plots/confusion_matrix_2023-12-07_12-15.png
ADDED
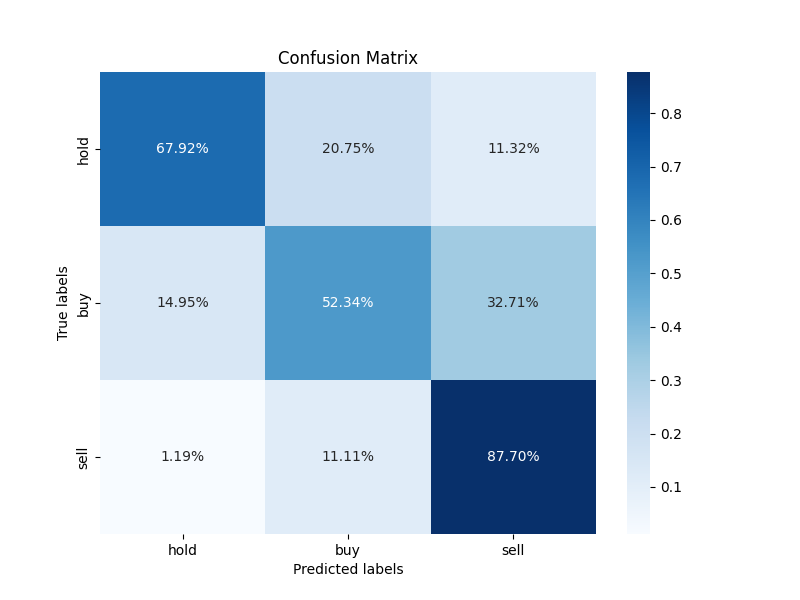
|
test_models/plots/confusion_matrix_2023-12-07_12-16.png
ADDED

|
test_models/plots/confusion_matrix_2023-12-07_12-17.png
ADDED

|