
Upload 36 files
Browse files- .gitattributes +1 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/.gitignore +163 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/LICENSE +21 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/data/__init__.py +1 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/data/config.py +42 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/images/test.jpg +0 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/images/test.webp +0 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/layers/__init__.py +1 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/layers/functions/prior_box.py +34 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/models/__init__.py +0 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/models/net.py +137 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/models/retinaface.py +130 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/pytorch_retinaface.py +174 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/utils/__init__.py +0 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/utils/box_utils.py +330 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/utils/nms/__init__.py +0 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/utils/nms/py_cpu_nms.py +38 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/weights/mobilenet0.25_Final.pth +3 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/weights/mobilenetV1X0.25_pretrain.tar +3 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/README.md +41 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/__init__.py +177 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/images/Crop_Data.png +3 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/images/workflow-AutoCropFaces-Simple.png +0 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/images/workflow-AutoCropFaces-bottom.png +0 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/images/workflow-AutoCropFaces-with-Constrain.png +0 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/test.py +46 -0
- ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/tests/AutoCropFaces-Testing.json +1997 -0
- ComfyUI/custom_nodes/ComfyUI-Switch/README.md +6 -0
- ComfyUI/custom_nodes/ComfyUI-Switch/Switch.py +35 -0
- ComfyUI/custom_nodes/ComfyUI-Switch/__init__.py +3 -0
- ComfyUI/custom_nodes/example_node.py.example +128 -0
- ComfyUI/custom_nodes/image-resize-comfyui/LICENSE +21 -0
- ComfyUI/custom_nodes/image-resize-comfyui/README.md +51 -0
- ComfyUI/custom_nodes/image-resize-comfyui/__init__.py +3 -0
- ComfyUI/custom_nodes/image-resize-comfyui/image_resize.png +0 -0
- ComfyUI/custom_nodes/image-resize-comfyui/image_resize.py +163 -0
- ComfyUI/custom_nodes/websocket_image_save.py +45 -0
.gitattributes
CHANGED
|
@@ -40,3 +40,4 @@ ComfyUI/temp/ComfyUI_temp_zprxs_00002_.png filter=lfs diff=lfs merge=lfs -text
|
|
| 40 |
ComfyUI/custom_nodes/merge_cross_images/result3.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
ComfyUI/custom_nodes/comfyui_controlnet_aux/examples/example_mesh_graphormer.png filter=lfs diff=lfs merge=lfs -text
|
| 42 |
ComfyUI/custom_nodes/comfyui_controlnet_aux/src/controlnet_aux/mesh_graphormer/hand_landmarker.task filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 40 |
ComfyUI/custom_nodes/merge_cross_images/result3.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
ComfyUI/custom_nodes/comfyui_controlnet_aux/examples/example_mesh_graphormer.png filter=lfs diff=lfs merge=lfs -text
|
| 42 |
ComfyUI/custom_nodes/comfyui_controlnet_aux/src/controlnet_aux/mesh_graphormer/hand_landmarker.task filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/images/Crop_Data.png filter=lfs diff=lfs merge=lfs -text
|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/.gitignore
ADDED
|
@@ -0,0 +1,163 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
outputs/
|
| 2 |
+
**/Resnet50_Final.pth
|
| 3 |
+
|
| 4 |
+
# Byte-compiled / optimized / DLL files
|
| 5 |
+
__pycache__/
|
| 6 |
+
*.py[cod]
|
| 7 |
+
*$py.class
|
| 8 |
+
|
| 9 |
+
# C extensions
|
| 10 |
+
*.so
|
| 11 |
+
|
| 12 |
+
# Distribution / packaging
|
| 13 |
+
.Python
|
| 14 |
+
build/
|
| 15 |
+
develop-eggs/
|
| 16 |
+
dist/
|
| 17 |
+
downloads/
|
| 18 |
+
eggs/
|
| 19 |
+
.eggs/
|
| 20 |
+
lib/
|
| 21 |
+
lib64/
|
| 22 |
+
parts/
|
| 23 |
+
sdist/
|
| 24 |
+
var/
|
| 25 |
+
wheels/
|
| 26 |
+
share/python-wheels/
|
| 27 |
+
*.egg-info/
|
| 28 |
+
.installed.cfg
|
| 29 |
+
*.egg
|
| 30 |
+
MANIFEST
|
| 31 |
+
|
| 32 |
+
# PyInstaller
|
| 33 |
+
# Usually these files are written by a python script from a template
|
| 34 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 35 |
+
*.manifest
|
| 36 |
+
*.spec
|
| 37 |
+
|
| 38 |
+
# Installer logs
|
| 39 |
+
pip-log.txt
|
| 40 |
+
pip-delete-this-directory.txt
|
| 41 |
+
|
| 42 |
+
# Unit test / coverage reports
|
| 43 |
+
htmlcov/
|
| 44 |
+
.tox/
|
| 45 |
+
.nox/
|
| 46 |
+
.coverage
|
| 47 |
+
.coverage.*
|
| 48 |
+
.cache
|
| 49 |
+
nosetests.xml
|
| 50 |
+
coverage.xml
|
| 51 |
+
*.cover
|
| 52 |
+
*.py,cover
|
| 53 |
+
.hypothesis/
|
| 54 |
+
.pytest_cache/
|
| 55 |
+
cover/
|
| 56 |
+
|
| 57 |
+
# Translations
|
| 58 |
+
*.mo
|
| 59 |
+
*.pot
|
| 60 |
+
|
| 61 |
+
# Django stuff:
|
| 62 |
+
*.log
|
| 63 |
+
local_settings.py
|
| 64 |
+
db.sqlite3
|
| 65 |
+
db.sqlite3-journal
|
| 66 |
+
|
| 67 |
+
# Flask stuff:
|
| 68 |
+
instance/
|
| 69 |
+
.webassets-cache
|
| 70 |
+
|
| 71 |
+
# Scrapy stuff:
|
| 72 |
+
.scrapy
|
| 73 |
+
|
| 74 |
+
# Sphinx documentation
|
| 75 |
+
docs/_build/
|
| 76 |
+
|
| 77 |
+
# PyBuilder
|
| 78 |
+
.pybuilder/
|
| 79 |
+
target/
|
| 80 |
+
|
| 81 |
+
# Jupyter Notebook
|
| 82 |
+
.ipynb_checkpoints
|
| 83 |
+
|
| 84 |
+
# IPython
|
| 85 |
+
profile_default/
|
| 86 |
+
ipython_config.py
|
| 87 |
+
|
| 88 |
+
# pyenv
|
| 89 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 90 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 91 |
+
# .python-version
|
| 92 |
+
|
| 93 |
+
# pipenv
|
| 94 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 95 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 96 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 97 |
+
# install all needed dependencies.
|
| 98 |
+
#Pipfile.lock
|
| 99 |
+
|
| 100 |
+
# poetry
|
| 101 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 102 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 103 |
+
# commonly ignored for libraries.
|
| 104 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 105 |
+
#poetry.lock
|
| 106 |
+
|
| 107 |
+
# pdm
|
| 108 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 109 |
+
#pdm.lock
|
| 110 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 111 |
+
# in version control.
|
| 112 |
+
# https://pdm.fming.dev/#use-with-ide
|
| 113 |
+
.pdm.toml
|
| 114 |
+
|
| 115 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 116 |
+
__pypackages__/
|
| 117 |
+
|
| 118 |
+
# Celery stuff
|
| 119 |
+
celerybeat-schedule
|
| 120 |
+
celerybeat.pid
|
| 121 |
+
|
| 122 |
+
# SageMath parsed files
|
| 123 |
+
*.sage.py
|
| 124 |
+
|
| 125 |
+
# Environments
|
| 126 |
+
.env
|
| 127 |
+
.venv
|
| 128 |
+
env/
|
| 129 |
+
venv/
|
| 130 |
+
ENV/
|
| 131 |
+
env.bak/
|
| 132 |
+
venv.bak/
|
| 133 |
+
|
| 134 |
+
# Spyder project settings
|
| 135 |
+
.spyderproject
|
| 136 |
+
.spyproject
|
| 137 |
+
|
| 138 |
+
# Rope project settings
|
| 139 |
+
.ropeproject
|
| 140 |
+
|
| 141 |
+
# mkdocs documentation
|
| 142 |
+
/site
|
| 143 |
+
|
| 144 |
+
# mypy
|
| 145 |
+
.mypy_cache/
|
| 146 |
+
.dmypy.json
|
| 147 |
+
dmypy.json
|
| 148 |
+
|
| 149 |
+
# Pyre type checker
|
| 150 |
+
.pyre/
|
| 151 |
+
|
| 152 |
+
# pytype static type analyzer
|
| 153 |
+
.pytype/
|
| 154 |
+
|
| 155 |
+
# Cython debug symbols
|
| 156 |
+
cython_debug/
|
| 157 |
+
|
| 158 |
+
# PyCharm
|
| 159 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 160 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 161 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 162 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 163 |
+
#.idea/
|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2024 Liu Sida
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/data/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .config import *
|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/data/config.py
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# config.py
|
| 2 |
+
|
| 3 |
+
cfg_mnet = {
|
| 4 |
+
'name': 'mobilenet0.25',
|
| 5 |
+
'min_sizes': [[16, 32], [64, 128], [256, 512]],
|
| 6 |
+
'steps': [8, 16, 32],
|
| 7 |
+
'variance': [0.1, 0.2],
|
| 8 |
+
'clip': False,
|
| 9 |
+
'loc_weight': 2.0,
|
| 10 |
+
'gpu_train': True,
|
| 11 |
+
'batch_size': 32,
|
| 12 |
+
'ngpu': 1,
|
| 13 |
+
'epoch': 250,
|
| 14 |
+
'decay1': 190,
|
| 15 |
+
'decay2': 220,
|
| 16 |
+
'image_size': 640,
|
| 17 |
+
'pretrain': True,
|
| 18 |
+
'return_layers': {'stage1': 1, 'stage2': 2, 'stage3': 3},
|
| 19 |
+
'in_channel': 32,
|
| 20 |
+
'out_channel': 64
|
| 21 |
+
}
|
| 22 |
+
|
| 23 |
+
cfg_re50 = {
|
| 24 |
+
'name': 'Resnet50',
|
| 25 |
+
'min_sizes': [[16, 32], [64, 128], [256, 512]],
|
| 26 |
+
'steps': [8, 16, 32],
|
| 27 |
+
'variance': [0.1, 0.2],
|
| 28 |
+
'clip': False,
|
| 29 |
+
'loc_weight': 2.0,
|
| 30 |
+
'gpu_train': True,
|
| 31 |
+
'batch_size': 24,
|
| 32 |
+
'ngpu': 4,
|
| 33 |
+
'epoch': 100,
|
| 34 |
+
'decay1': 70,
|
| 35 |
+
'decay2': 90,
|
| 36 |
+
'image_size': 840,
|
| 37 |
+
'pretrain': True,
|
| 38 |
+
'return_layers': {'layer2': 1, 'layer3': 2, 'layer4': 3},
|
| 39 |
+
'in_channel': 256,
|
| 40 |
+
'out_channel': 256
|
| 41 |
+
}
|
| 42 |
+
|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/images/test.jpg
ADDED

|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/images/test.webp
ADDED

|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/layers/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .functions import *
|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/layers/functions/prior_box.py
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from itertools import product as product
|
| 3 |
+
import numpy as np
|
| 4 |
+
from math import ceil
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class PriorBox(object):
|
| 8 |
+
def __init__(self, cfg, image_size=None, phase='train'):
|
| 9 |
+
super(PriorBox, self).__init__()
|
| 10 |
+
self.min_sizes = cfg['min_sizes']
|
| 11 |
+
self.steps = cfg['steps']
|
| 12 |
+
self.clip = cfg['clip']
|
| 13 |
+
self.image_size = image_size
|
| 14 |
+
self.feature_maps = [[ceil(self.image_size[0]/step), ceil(self.image_size[1]/step)] for step in self.steps]
|
| 15 |
+
self.name = "s"
|
| 16 |
+
|
| 17 |
+
def forward(self):
|
| 18 |
+
anchors = []
|
| 19 |
+
for k, f in enumerate(self.feature_maps):
|
| 20 |
+
min_sizes = self.min_sizes[k]
|
| 21 |
+
for i, j in product(range(f[0]), range(f[1])):
|
| 22 |
+
for min_size in min_sizes:
|
| 23 |
+
s_kx = min_size / self.image_size[1]
|
| 24 |
+
s_ky = min_size / self.image_size[0]
|
| 25 |
+
dense_cx = [x * self.steps[k] / self.image_size[1] for x in [j + 0.5]]
|
| 26 |
+
dense_cy = [y * self.steps[k] / self.image_size[0] for y in [i + 0.5]]
|
| 27 |
+
for cy, cx in product(dense_cy, dense_cx):
|
| 28 |
+
anchors += [cx, cy, s_kx, s_ky]
|
| 29 |
+
|
| 30 |
+
# back to torch land
|
| 31 |
+
output = torch.Tensor(anchors).view(-1, 4)
|
| 32 |
+
if self.clip:
|
| 33 |
+
output.clamp_(max=1, min=0)
|
| 34 |
+
return output
|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/models/__init__.py
ADDED
|
File without changes
|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/models/net.py
ADDED
|
@@ -0,0 +1,137 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import time
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import torchvision.models._utils as _utils
|
| 5 |
+
import torchvision.models as models
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
from torch.autograd import Variable
|
| 8 |
+
|
| 9 |
+
def conv_bn(inp, oup, stride = 1, leaky = 0):
|
| 10 |
+
return nn.Sequential(
|
| 11 |
+
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
|
| 12 |
+
nn.BatchNorm2d(oup),
|
| 13 |
+
nn.LeakyReLU(negative_slope=leaky, inplace=True)
|
| 14 |
+
)
|
| 15 |
+
|
| 16 |
+
def conv_bn_no_relu(inp, oup, stride):
|
| 17 |
+
return nn.Sequential(
|
| 18 |
+
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
|
| 19 |
+
nn.BatchNorm2d(oup),
|
| 20 |
+
)
|
| 21 |
+
|
| 22 |
+
def conv_bn1X1(inp, oup, stride, leaky=0):
|
| 23 |
+
return nn.Sequential(
|
| 24 |
+
nn.Conv2d(inp, oup, 1, stride, padding=0, bias=False),
|
| 25 |
+
nn.BatchNorm2d(oup),
|
| 26 |
+
nn.LeakyReLU(negative_slope=leaky, inplace=True)
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
def conv_dw(inp, oup, stride, leaky=0.1):
|
| 30 |
+
return nn.Sequential(
|
| 31 |
+
nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),
|
| 32 |
+
nn.BatchNorm2d(inp),
|
| 33 |
+
nn.LeakyReLU(negative_slope= leaky,inplace=True),
|
| 34 |
+
|
| 35 |
+
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
|
| 36 |
+
nn.BatchNorm2d(oup),
|
| 37 |
+
nn.LeakyReLU(negative_slope= leaky,inplace=True),
|
| 38 |
+
)
|
| 39 |
+
|
| 40 |
+
class SSH(nn.Module):
|
| 41 |
+
def __init__(self, in_channel, out_channel):
|
| 42 |
+
super(SSH, self).__init__()
|
| 43 |
+
assert out_channel % 4 == 0
|
| 44 |
+
leaky = 0
|
| 45 |
+
if (out_channel <= 64):
|
| 46 |
+
leaky = 0.1
|
| 47 |
+
self.conv3X3 = conv_bn_no_relu(in_channel, out_channel//2, stride=1)
|
| 48 |
+
|
| 49 |
+
self.conv5X5_1 = conv_bn(in_channel, out_channel//4, stride=1, leaky = leaky)
|
| 50 |
+
self.conv5X5_2 = conv_bn_no_relu(out_channel//4, out_channel//4, stride=1)
|
| 51 |
+
|
| 52 |
+
self.conv7X7_2 = conv_bn(out_channel//4, out_channel//4, stride=1, leaky = leaky)
|
| 53 |
+
self.conv7x7_3 = conv_bn_no_relu(out_channel//4, out_channel//4, stride=1)
|
| 54 |
+
|
| 55 |
+
def forward(self, input):
|
| 56 |
+
conv3X3 = self.conv3X3(input)
|
| 57 |
+
|
| 58 |
+
conv5X5_1 = self.conv5X5_1(input)
|
| 59 |
+
conv5X5 = self.conv5X5_2(conv5X5_1)
|
| 60 |
+
|
| 61 |
+
conv7X7_2 = self.conv7X7_2(conv5X5_1)
|
| 62 |
+
conv7X7 = self.conv7x7_3(conv7X7_2)
|
| 63 |
+
|
| 64 |
+
out = torch.cat([conv3X3, conv5X5, conv7X7], dim=1)
|
| 65 |
+
out = F.relu(out)
|
| 66 |
+
return out
|
| 67 |
+
|
| 68 |
+
class FPN(nn.Module):
|
| 69 |
+
def __init__(self,in_channels_list,out_channels):
|
| 70 |
+
super(FPN,self).__init__()
|
| 71 |
+
leaky = 0
|
| 72 |
+
if (out_channels <= 64):
|
| 73 |
+
leaky = 0.1
|
| 74 |
+
self.output1 = conv_bn1X1(in_channels_list[0], out_channels, stride = 1, leaky = leaky)
|
| 75 |
+
self.output2 = conv_bn1X1(in_channels_list[1], out_channels, stride = 1, leaky = leaky)
|
| 76 |
+
self.output3 = conv_bn1X1(in_channels_list[2], out_channels, stride = 1, leaky = leaky)
|
| 77 |
+
|
| 78 |
+
self.merge1 = conv_bn(out_channels, out_channels, leaky = leaky)
|
| 79 |
+
self.merge2 = conv_bn(out_channels, out_channels, leaky = leaky)
|
| 80 |
+
|
| 81 |
+
def forward(self, input):
|
| 82 |
+
# names = list(input.keys())
|
| 83 |
+
input = list(input.values())
|
| 84 |
+
|
| 85 |
+
output1 = self.output1(input[0])
|
| 86 |
+
output2 = self.output2(input[1])
|
| 87 |
+
output3 = self.output3(input[2])
|
| 88 |
+
|
| 89 |
+
up3 = F.interpolate(output3, size=[output2.size(2), output2.size(3)], mode="nearest")
|
| 90 |
+
output2 = output2 + up3
|
| 91 |
+
output2 = self.merge2(output2)
|
| 92 |
+
|
| 93 |
+
up2 = F.interpolate(output2, size=[output1.size(2), output1.size(3)], mode="nearest")
|
| 94 |
+
output1 = output1 + up2
|
| 95 |
+
output1 = self.merge1(output1)
|
| 96 |
+
|
| 97 |
+
out = [output1, output2, output3]
|
| 98 |
+
return out
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
class MobileNetV1(nn.Module):
|
| 103 |
+
def __init__(self):
|
| 104 |
+
super(MobileNetV1, self).__init__()
|
| 105 |
+
self.stage1 = nn.Sequential(
|
| 106 |
+
conv_bn(3, 8, 2, leaky = 0.1), # 3
|
| 107 |
+
conv_dw(8, 16, 1), # 7
|
| 108 |
+
conv_dw(16, 32, 2), # 11
|
| 109 |
+
conv_dw(32, 32, 1), # 19
|
| 110 |
+
conv_dw(32, 64, 2), # 27
|
| 111 |
+
conv_dw(64, 64, 1), # 43
|
| 112 |
+
)
|
| 113 |
+
self.stage2 = nn.Sequential(
|
| 114 |
+
conv_dw(64, 128, 2), # 43 + 16 = 59
|
| 115 |
+
conv_dw(128, 128, 1), # 59 + 32 = 91
|
| 116 |
+
conv_dw(128, 128, 1), # 91 + 32 = 123
|
| 117 |
+
conv_dw(128, 128, 1), # 123 + 32 = 155
|
| 118 |
+
conv_dw(128, 128, 1), # 155 + 32 = 187
|
| 119 |
+
conv_dw(128, 128, 1), # 187 + 32 = 219
|
| 120 |
+
)
|
| 121 |
+
self.stage3 = nn.Sequential(
|
| 122 |
+
conv_dw(128, 256, 2), # 219 +3 2 = 241
|
| 123 |
+
conv_dw(256, 256, 1), # 241 + 64 = 301
|
| 124 |
+
)
|
| 125 |
+
self.avg = nn.AdaptiveAvgPool2d((1,1))
|
| 126 |
+
self.fc = nn.Linear(256, 1000)
|
| 127 |
+
|
| 128 |
+
def forward(self, x):
|
| 129 |
+
x = self.stage1(x)
|
| 130 |
+
x = self.stage2(x)
|
| 131 |
+
x = self.stage3(x)
|
| 132 |
+
x = self.avg(x)
|
| 133 |
+
# x = self.model(x)
|
| 134 |
+
x = x.view(-1, 256)
|
| 135 |
+
x = self.fc(x)
|
| 136 |
+
return x
|
| 137 |
+
|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/models/retinaface.py
ADDED
|
@@ -0,0 +1,130 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import torchvision.models.detection.backbone_utils as backbone_utils
|
| 5 |
+
import torchvision.models._utils as _utils
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
from collections import OrderedDict
|
| 8 |
+
|
| 9 |
+
from .net import MobileNetV1 as MobileNetV1
|
| 10 |
+
from .net import FPN as FPN
|
| 11 |
+
from .net import SSH as SSH
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class ClassHead(nn.Module):
|
| 16 |
+
def __init__(self,inchannels=512,num_anchors=3):
|
| 17 |
+
super(ClassHead,self).__init__()
|
| 18 |
+
self.num_anchors = num_anchors
|
| 19 |
+
self.conv1x1 = nn.Conv2d(inchannels,self.num_anchors*2,kernel_size=(1,1),stride=1,padding=0)
|
| 20 |
+
|
| 21 |
+
def forward(self,x):
|
| 22 |
+
out = self.conv1x1(x)
|
| 23 |
+
out = out.permute(0,2,3,1).contiguous()
|
| 24 |
+
|
| 25 |
+
return out.view(out.shape[0], -1, 2)
|
| 26 |
+
|
| 27 |
+
class BboxHead(nn.Module):
|
| 28 |
+
def __init__(self,inchannels=512,num_anchors=3):
|
| 29 |
+
super(BboxHead,self).__init__()
|
| 30 |
+
self.conv1x1 = nn.Conv2d(inchannels,num_anchors*4,kernel_size=(1,1),stride=1,padding=0)
|
| 31 |
+
|
| 32 |
+
def forward(self,x):
|
| 33 |
+
out = self.conv1x1(x)
|
| 34 |
+
out = out.permute(0,2,3,1).contiguous()
|
| 35 |
+
|
| 36 |
+
return out.view(out.shape[0], -1, 4)
|
| 37 |
+
|
| 38 |
+
class LandmarkHead(nn.Module):
|
| 39 |
+
def __init__(self,inchannels=512,num_anchors=3):
|
| 40 |
+
super(LandmarkHead,self).__init__()
|
| 41 |
+
self.conv1x1 = nn.Conv2d(inchannels,num_anchors*10,kernel_size=(1,1),stride=1,padding=0)
|
| 42 |
+
|
| 43 |
+
def forward(self,x):
|
| 44 |
+
out = self.conv1x1(x)
|
| 45 |
+
out = out.permute(0,2,3,1).contiguous()
|
| 46 |
+
|
| 47 |
+
return out.view(out.shape[0], -1, 10)
|
| 48 |
+
|
| 49 |
+
class RetinaFace(nn.Module):
|
| 50 |
+
def __init__(self, cfg = None, phase = 'train', weights_path='', device="cuda"):
|
| 51 |
+
"""
|
| 52 |
+
:param cfg: Network related settings.
|
| 53 |
+
:param phase: train or test.
|
| 54 |
+
"""
|
| 55 |
+
weights_path = os.path.join(os.path.dirname(os.path.dirname(os.path.abspath(__file__))), weights_path)
|
| 56 |
+
|
| 57 |
+
super(RetinaFace,self).__init__()
|
| 58 |
+
self.phase = phase
|
| 59 |
+
backbone = None
|
| 60 |
+
if cfg['name'] == 'mobilenet0.25':
|
| 61 |
+
backbone = MobileNetV1()
|
| 62 |
+
if cfg['pretrain']:
|
| 63 |
+
checkpoint = torch.load(weights_path, map_location=torch.device(device))
|
| 64 |
+
from collections import OrderedDict
|
| 65 |
+
new_state_dict = OrderedDict()
|
| 66 |
+
for k, v in checkpoint['state_dict'].items():
|
| 67 |
+
name = k[7:] # remove module.
|
| 68 |
+
new_state_dict[name] = v
|
| 69 |
+
# load params
|
| 70 |
+
backbone.load_state_dict(new_state_dict)
|
| 71 |
+
elif cfg['name'] == 'Resnet50':
|
| 72 |
+
import torchvision.models as models
|
| 73 |
+
backbone = models.resnet50(pretrained=cfg['pretrain'])
|
| 74 |
+
|
| 75 |
+
self.body = _utils.IntermediateLayerGetter(backbone, cfg['return_layers'])
|
| 76 |
+
in_channels_stage2 = cfg['in_channel']
|
| 77 |
+
in_channels_list = [
|
| 78 |
+
in_channels_stage2 * 2,
|
| 79 |
+
in_channels_stage2 * 4,
|
| 80 |
+
in_channels_stage2 * 8,
|
| 81 |
+
]
|
| 82 |
+
out_channels = cfg['out_channel']
|
| 83 |
+
self.fpn = FPN(in_channels_list,out_channels)
|
| 84 |
+
self.ssh1 = SSH(out_channels, out_channels)
|
| 85 |
+
self.ssh2 = SSH(out_channels, out_channels)
|
| 86 |
+
self.ssh3 = SSH(out_channels, out_channels)
|
| 87 |
+
|
| 88 |
+
self.ClassHead = self._make_class_head(fpn_num=3, inchannels=cfg['out_channel'])
|
| 89 |
+
self.BboxHead = self._make_bbox_head(fpn_num=3, inchannels=cfg['out_channel'])
|
| 90 |
+
self.LandmarkHead = self._make_landmark_head(fpn_num=3, inchannels=cfg['out_channel'])
|
| 91 |
+
|
| 92 |
+
def _make_class_head(self,fpn_num=3,inchannels=64,anchor_num=2):
|
| 93 |
+
classhead = nn.ModuleList()
|
| 94 |
+
for i in range(fpn_num):
|
| 95 |
+
classhead.append(ClassHead(inchannels,anchor_num))
|
| 96 |
+
return classhead
|
| 97 |
+
|
| 98 |
+
def _make_bbox_head(self,fpn_num=3,inchannels=64,anchor_num=2):
|
| 99 |
+
bboxhead = nn.ModuleList()
|
| 100 |
+
for i in range(fpn_num):
|
| 101 |
+
bboxhead.append(BboxHead(inchannels,anchor_num))
|
| 102 |
+
return bboxhead
|
| 103 |
+
|
| 104 |
+
def _make_landmark_head(self,fpn_num=3,inchannels=64,anchor_num=2):
|
| 105 |
+
landmarkhead = nn.ModuleList()
|
| 106 |
+
for i in range(fpn_num):
|
| 107 |
+
landmarkhead.append(LandmarkHead(inchannels,anchor_num))
|
| 108 |
+
return landmarkhead
|
| 109 |
+
|
| 110 |
+
def forward(self,inputs):
|
| 111 |
+
out = self.body(inputs)
|
| 112 |
+
|
| 113 |
+
# FPN
|
| 114 |
+
fpn = self.fpn(out)
|
| 115 |
+
|
| 116 |
+
# SSH
|
| 117 |
+
feature1 = self.ssh1(fpn[0])
|
| 118 |
+
feature2 = self.ssh2(fpn[1])
|
| 119 |
+
feature3 = self.ssh3(fpn[2])
|
| 120 |
+
features = [feature1, feature2, feature3]
|
| 121 |
+
|
| 122 |
+
bbox_regressions = torch.cat([self.BboxHead[i](feature) for i, feature in enumerate(features)], dim=1)
|
| 123 |
+
classifications = torch.cat([self.ClassHead[i](feature) for i, feature in enumerate(features)],dim=1)
|
| 124 |
+
ldm_regressions = torch.cat([self.LandmarkHead[i](feature) for i, feature in enumerate(features)], dim=1)
|
| 125 |
+
|
| 126 |
+
if self.phase == 'train':
|
| 127 |
+
output = (bbox_regressions, classifications, ldm_regressions)
|
| 128 |
+
else:
|
| 129 |
+
output = (bbox_regressions, F.softmax(classifications, dim=-1), ldm_regressions)
|
| 130 |
+
return output
|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/pytorch_retinaface.py
ADDED
|
@@ -0,0 +1,174 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import time
|
| 3 |
+
import math
|
| 4 |
+
import torch
|
| 5 |
+
import torch.backends.cudnn as cudnn
|
| 6 |
+
import numpy as np
|
| 7 |
+
|
| 8 |
+
from .data import cfg_mnet, cfg_re50
|
| 9 |
+
from .layers.functions.prior_box import PriorBox
|
| 10 |
+
from .utils.nms.py_cpu_nms import py_cpu_nms
|
| 11 |
+
from .models.retinaface import RetinaFace
|
| 12 |
+
from .utils.box_utils import decode, decode_landm
|
| 13 |
+
|
| 14 |
+
class Pytorch_RetinaFace:
|
| 15 |
+
def __init__(self, cfg="mobile0.25", pretrained_path="./weights/mobilenet0.25_Final.pth", weights_path="./weights/mobilenetV1X0.25_pretrain.tar", device="auto", vis_thres=0.6, top_k=5000, keep_top_k=750, nms_threshold=0.4, confidence_threshold=0.02):
|
| 16 |
+
self.vis_thres = vis_thres
|
| 17 |
+
self.top_k = top_k
|
| 18 |
+
self.keep_top_k = keep_top_k
|
| 19 |
+
self.nms_threshold = nms_threshold
|
| 20 |
+
self.confidence_threshold = confidence_threshold
|
| 21 |
+
self.cfg = cfg_mnet if cfg=="mobile0.25" else cfg_re50
|
| 22 |
+
|
| 23 |
+
if device == 'auto':
|
| 24 |
+
# Automatically choose the device
|
| 25 |
+
if torch.cuda.is_available():
|
| 26 |
+
self.device = torch.device("cuda")
|
| 27 |
+
elif torch.backends.mps.is_available():
|
| 28 |
+
self.device = torch.device("mps")
|
| 29 |
+
else:
|
| 30 |
+
self.device = torch.device("cpu")
|
| 31 |
+
else:
|
| 32 |
+
# Use the specified device
|
| 33 |
+
self.device = torch.device(device)
|
| 34 |
+
|
| 35 |
+
print("Using device:", self.device)
|
| 36 |
+
|
| 37 |
+
self.net = RetinaFace(cfg=self.cfg, weights_path=weights_path, phase='test', device=self.device).to(self.device)
|
| 38 |
+
self.load_model_weights(pretrained_path)
|
| 39 |
+
self.net.eval()
|
| 40 |
+
|
| 41 |
+
def check_keys(self, model, pretrained_state_dict):
|
| 42 |
+
ckpt_keys = set(pretrained_state_dict.keys())
|
| 43 |
+
model_keys = set(model.state_dict().keys())
|
| 44 |
+
used_pretrained_keys = model_keys & ckpt_keys
|
| 45 |
+
unused_pretrained_keys = ckpt_keys - model_keys
|
| 46 |
+
missing_keys = model_keys - ckpt_keys
|
| 47 |
+
print('Missing keys:{}'.format(len(missing_keys)))
|
| 48 |
+
print('Unused checkpoint keys:{}'.format(len(unused_pretrained_keys)))
|
| 49 |
+
print('Used keys:{}'.format(len(used_pretrained_keys)))
|
| 50 |
+
assert len(used_pretrained_keys) > 0, 'load NONE from pretrained checkpoint'
|
| 51 |
+
return True
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def remove_prefix(self, state_dict, prefix):
|
| 55 |
+
''' Old style model is stored with all names of parameters sharing common prefix 'module.' '''
|
| 56 |
+
print('remove prefix \'{}\''.format(prefix))
|
| 57 |
+
f = lambda x: x.split(prefix, 1)[-1] if x.startswith(prefix) else x
|
| 58 |
+
return {f(key): value for key, value in state_dict.items()}
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def load_model_weights(self, pretrained_path):
|
| 62 |
+
pretrained_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), pretrained_path)
|
| 63 |
+
print('Loading pretrained model from {}'.format(pretrained_path))
|
| 64 |
+
pretrained_dict = torch.load(pretrained_path, map_location=self.device)
|
| 65 |
+
if "state_dict" in pretrained_dict.keys():
|
| 66 |
+
pretrained_dict = self.remove_prefix(pretrained_dict['state_dict'], 'module.')
|
| 67 |
+
else:
|
| 68 |
+
pretrained_dict = self.remove_prefix(pretrained_dict, 'module.')
|
| 69 |
+
self.check_keys(self.net, pretrained_dict)
|
| 70 |
+
self.net.load_state_dict(pretrained_dict, strict=False)
|
| 71 |
+
self.net.to(self.device)
|
| 72 |
+
return self.net
|
| 73 |
+
|
| 74 |
+
def center_and_crop_rescale(self, image, dets, scale_factor=4, shift_factor=0.35, aspect_ratio=1.0):
|
| 75 |
+
cropped_imgs = []
|
| 76 |
+
bbox_infos = []
|
| 77 |
+
for index, bbox in enumerate(dets):
|
| 78 |
+
if bbox[4] < self.vis_thres:
|
| 79 |
+
continue
|
| 80 |
+
|
| 81 |
+
x1, y1, x2, y2 = map(int, bbox[:4])
|
| 82 |
+
face_width = x2 - x1
|
| 83 |
+
face_height = y2 - y1
|
| 84 |
+
|
| 85 |
+
default_area = face_width * face_height
|
| 86 |
+
default_area *= scale_factor
|
| 87 |
+
default_side = math.sqrt(default_area)
|
| 88 |
+
|
| 89 |
+
# New height and width based on aspect_ratio
|
| 90 |
+
new_face_width = int(default_side * math.sqrt(aspect_ratio))
|
| 91 |
+
new_face_height = int(default_side / math.sqrt(aspect_ratio))
|
| 92 |
+
|
| 93 |
+
# Center coordinates of the detected face
|
| 94 |
+
center_x = x1 + face_width // 2
|
| 95 |
+
center_y = y1 + face_height // 2 + int(new_face_height * (0.5 - shift_factor))
|
| 96 |
+
|
| 97 |
+
original_crop_x1 = center_x - new_face_width // 2
|
| 98 |
+
original_crop_x2 = center_x + new_face_width // 2
|
| 99 |
+
original_crop_y1 = center_y - new_face_height // 2
|
| 100 |
+
original_crop_y2 = center_y + new_face_height // 2
|
| 101 |
+
# Crop coordinates, adjusted to the image boundaries
|
| 102 |
+
crop_x1 = max(0, original_crop_x1)
|
| 103 |
+
crop_x2 = min(image.shape[1], original_crop_x2)
|
| 104 |
+
crop_y1 = max(0, original_crop_y1)
|
| 105 |
+
crop_y2 = min(image.shape[0], original_crop_y2)
|
| 106 |
+
|
| 107 |
+
# Crop the region and add padding to form a square
|
| 108 |
+
cropped_imgs.append(image[crop_y1:crop_y2, crop_x1:crop_x2])
|
| 109 |
+
bbox_infos.append((original_crop_x1, original_crop_y1, original_crop_x2, original_crop_y2))
|
| 110 |
+
return cropped_imgs, bbox_infos
|
| 111 |
+
|
| 112 |
+
def detect_faces(self, img):
|
| 113 |
+
resize = 1
|
| 114 |
+
|
| 115 |
+
if len(img.shape) == 4 and img.shape[0] == 1:
|
| 116 |
+
img = torch.squeeze(img, 0)
|
| 117 |
+
if isinstance(img, np.ndarray):
|
| 118 |
+
img = torch.from_numpy(img)
|
| 119 |
+
img = img.to(self.device)
|
| 120 |
+
|
| 121 |
+
im_height, im_width, _ = img.shape
|
| 122 |
+
scale = torch.Tensor([img.shape[1], img.shape[0], img.shape[1], img.shape[0]])
|
| 123 |
+
mean_values = torch.tensor([104, 117, 123], dtype=torch.float32).to(self.device)
|
| 124 |
+
mean_values = mean_values.view(1, 1, 3)
|
| 125 |
+
img -= mean_values
|
| 126 |
+
img = img.permute(2, 0, 1)
|
| 127 |
+
img = img.unsqueeze(0)
|
| 128 |
+
scale = scale.to(self.device)
|
| 129 |
+
|
| 130 |
+
tic = time.time()
|
| 131 |
+
with torch.no_grad():
|
| 132 |
+
loc, conf, landms = self.net(img) # forward pass
|
| 133 |
+
print('net forward time: {:.4f}'.format(time.time() - tic))
|
| 134 |
+
|
| 135 |
+
priorbox = PriorBox(self.cfg, image_size=(im_height, im_width))
|
| 136 |
+
priors = priorbox.forward()
|
| 137 |
+
priors = priors.to(self.device)
|
| 138 |
+
prior_data = priors.data
|
| 139 |
+
boxes = decode(loc.data.squeeze(0), prior_data, self.cfg['variance'])
|
| 140 |
+
boxes = boxes * scale / resize
|
| 141 |
+
boxes = boxes.cpu().numpy()
|
| 142 |
+
scores = conf.squeeze(0).data.cpu().numpy()[:, 1]
|
| 143 |
+
landms = decode_landm(landms.data.squeeze(0), prior_data, self.cfg['variance'])
|
| 144 |
+
scale1 = torch.Tensor([img.shape[3], img.shape[2], img.shape[3], img.shape[2],
|
| 145 |
+
img.shape[3], img.shape[2], img.shape[3], img.shape[2],
|
| 146 |
+
img.shape[3], img.shape[2]])
|
| 147 |
+
scale1 = scale1.to(self.device)
|
| 148 |
+
landms = landms * scale1 / resize
|
| 149 |
+
landms = landms.cpu().numpy()
|
| 150 |
+
|
| 151 |
+
# Ignore low scores
|
| 152 |
+
inds = np.where(scores > self.confidence_threshold)[0]
|
| 153 |
+
boxes = boxes[inds]
|
| 154 |
+
landms = landms[inds]
|
| 155 |
+
scores = scores[inds]
|
| 156 |
+
|
| 157 |
+
# Keep top-K before NMS
|
| 158 |
+
order = scores.argsort()[::-1][:self.top_k]
|
| 159 |
+
boxes = boxes[order]
|
| 160 |
+
landms = landms[order]
|
| 161 |
+
scores = scores[order]
|
| 162 |
+
|
| 163 |
+
# Perform NMS
|
| 164 |
+
dets = np.hstack((boxes, scores[:, np.newaxis])).astype(np.float32, copy=False)
|
| 165 |
+
keep = py_cpu_nms(dets, self.nms_threshold)
|
| 166 |
+
dets = dets[keep, :]
|
| 167 |
+
landms = landms[keep]
|
| 168 |
+
|
| 169 |
+
# Keep top-K faster NMS
|
| 170 |
+
dets = dets[:self.keep_top_k, :]
|
| 171 |
+
landms = landms[:self.keep_top_k, :]
|
| 172 |
+
|
| 173 |
+
dets = np.concatenate((dets, landms), axis=1)
|
| 174 |
+
return dets
|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/utils/__init__.py
ADDED
|
File without changes
|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/utils/box_utils.py
ADDED
|
@@ -0,0 +1,330 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import numpy as np
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def point_form(boxes):
|
| 6 |
+
""" Convert prior_boxes to (xmin, ymin, xmax, ymax)
|
| 7 |
+
representation for comparison to point form ground truth data.
|
| 8 |
+
Args:
|
| 9 |
+
boxes: (tensor) center-size default boxes from priorbox layers.
|
| 10 |
+
Return:
|
| 11 |
+
boxes: (tensor) Converted xmin, ymin, xmax, ymax form of boxes.
|
| 12 |
+
"""
|
| 13 |
+
return torch.cat((boxes[:, :2] - boxes[:, 2:]/2, # xmin, ymin
|
| 14 |
+
boxes[:, :2] + boxes[:, 2:]/2), 1) # xmax, ymax
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def center_size(boxes):
|
| 18 |
+
""" Convert prior_boxes to (cx, cy, w, h)
|
| 19 |
+
representation for comparison to center-size form ground truth data.
|
| 20 |
+
Args:
|
| 21 |
+
boxes: (tensor) point_form boxes
|
| 22 |
+
Return:
|
| 23 |
+
boxes: (tensor) Converted xmin, ymin, xmax, ymax form of boxes.
|
| 24 |
+
"""
|
| 25 |
+
return torch.cat((boxes[:, 2:] + boxes[:, :2])/2, # cx, cy
|
| 26 |
+
boxes[:, 2:] - boxes[:, :2], 1) # w, h
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def intersect(box_a, box_b):
|
| 30 |
+
""" We resize both tensors to [A,B,2] without new malloc:
|
| 31 |
+
[A,2] -> [A,1,2] -> [A,B,2]
|
| 32 |
+
[B,2] -> [1,B,2] -> [A,B,2]
|
| 33 |
+
Then we compute the area of intersect between box_a and box_b.
|
| 34 |
+
Args:
|
| 35 |
+
box_a: (tensor) bounding boxes, Shape: [A,4].
|
| 36 |
+
box_b: (tensor) bounding boxes, Shape: [B,4].
|
| 37 |
+
Return:
|
| 38 |
+
(tensor) intersection area, Shape: [A,B].
|
| 39 |
+
"""
|
| 40 |
+
A = box_a.size(0)
|
| 41 |
+
B = box_b.size(0)
|
| 42 |
+
max_xy = torch.min(box_a[:, 2:].unsqueeze(1).expand(A, B, 2),
|
| 43 |
+
box_b[:, 2:].unsqueeze(0).expand(A, B, 2))
|
| 44 |
+
min_xy = torch.max(box_a[:, :2].unsqueeze(1).expand(A, B, 2),
|
| 45 |
+
box_b[:, :2].unsqueeze(0).expand(A, B, 2))
|
| 46 |
+
inter = torch.clamp((max_xy - min_xy), min=0)
|
| 47 |
+
return inter[:, :, 0] * inter[:, :, 1]
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def jaccard(box_a, box_b):
|
| 51 |
+
"""Compute the jaccard overlap of two sets of boxes. The jaccard overlap
|
| 52 |
+
is simply the intersection over union of two boxes. Here we operate on
|
| 53 |
+
ground truth boxes and default boxes.
|
| 54 |
+
E.g.:
|
| 55 |
+
A ∩ B / A ∪ B = A ∩ B / (area(A) + area(B) - A ∩ B)
|
| 56 |
+
Args:
|
| 57 |
+
box_a: (tensor) Ground truth bounding boxes, Shape: [num_objects,4]
|
| 58 |
+
box_b: (tensor) Prior boxes from priorbox layers, Shape: [num_priors,4]
|
| 59 |
+
Return:
|
| 60 |
+
jaccard overlap: (tensor) Shape: [box_a.size(0), box_b.size(0)]
|
| 61 |
+
"""
|
| 62 |
+
inter = intersect(box_a, box_b)
|
| 63 |
+
area_a = ((box_a[:, 2]-box_a[:, 0]) *
|
| 64 |
+
(box_a[:, 3]-box_a[:, 1])).unsqueeze(1).expand_as(inter) # [A,B]
|
| 65 |
+
area_b = ((box_b[:, 2]-box_b[:, 0]) *
|
| 66 |
+
(box_b[:, 3]-box_b[:, 1])).unsqueeze(0).expand_as(inter) # [A,B]
|
| 67 |
+
union = area_a + area_b - inter
|
| 68 |
+
return inter / union # [A,B]
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def matrix_iou(a, b):
|
| 72 |
+
"""
|
| 73 |
+
return iou of a and b, numpy version for data augenmentation
|
| 74 |
+
"""
|
| 75 |
+
lt = np.maximum(a[:, np.newaxis, :2], b[:, :2])
|
| 76 |
+
rb = np.minimum(a[:, np.newaxis, 2:], b[:, 2:])
|
| 77 |
+
|
| 78 |
+
area_i = np.prod(rb - lt, axis=2) * (lt < rb).all(axis=2)
|
| 79 |
+
area_a = np.prod(a[:, 2:] - a[:, :2], axis=1)
|
| 80 |
+
area_b = np.prod(b[:, 2:] - b[:, :2], axis=1)
|
| 81 |
+
return area_i / (area_a[:, np.newaxis] + area_b - area_i)
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
def matrix_iof(a, b):
|
| 85 |
+
"""
|
| 86 |
+
return iof of a and b, numpy version for data augenmentation
|
| 87 |
+
"""
|
| 88 |
+
lt = np.maximum(a[:, np.newaxis, :2], b[:, :2])
|
| 89 |
+
rb = np.minimum(a[:, np.newaxis, 2:], b[:, 2:])
|
| 90 |
+
|
| 91 |
+
area_i = np.prod(rb - lt, axis=2) * (lt < rb).all(axis=2)
|
| 92 |
+
area_a = np.prod(a[:, 2:] - a[:, :2], axis=1)
|
| 93 |
+
return area_i / np.maximum(area_a[:, np.newaxis], 1)
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def match(threshold, truths, priors, variances, labels, landms, loc_t, conf_t, landm_t, idx):
|
| 97 |
+
"""Match each prior box with the ground truth box of the highest jaccard
|
| 98 |
+
overlap, encode the bounding boxes, then return the matched indices
|
| 99 |
+
corresponding to both confidence and location preds.
|
| 100 |
+
Args:
|
| 101 |
+
threshold: (float) The overlap threshold used when mathing boxes.
|
| 102 |
+
truths: (tensor) Ground truth boxes, Shape: [num_obj, 4].
|
| 103 |
+
priors: (tensor) Prior boxes from priorbox layers, Shape: [n_priors,4].
|
| 104 |
+
variances: (tensor) Variances corresponding to each prior coord,
|
| 105 |
+
Shape: [num_priors, 4].
|
| 106 |
+
labels: (tensor) All the class labels for the image, Shape: [num_obj].
|
| 107 |
+
landms: (tensor) Ground truth landms, Shape [num_obj, 10].
|
| 108 |
+
loc_t: (tensor) Tensor to be filled w/ endcoded location targets.
|
| 109 |
+
conf_t: (tensor) Tensor to be filled w/ matched indices for conf preds.
|
| 110 |
+
landm_t: (tensor) Tensor to be filled w/ endcoded landm targets.
|
| 111 |
+
idx: (int) current batch index
|
| 112 |
+
Return:
|
| 113 |
+
The matched indices corresponding to 1)location 2)confidence 3)landm preds.
|
| 114 |
+
"""
|
| 115 |
+
# jaccard index
|
| 116 |
+
overlaps = jaccard(
|
| 117 |
+
truths,
|
| 118 |
+
point_form(priors)
|
| 119 |
+
)
|
| 120 |
+
# (Bipartite Matching)
|
| 121 |
+
# [1,num_objects] best prior for each ground truth
|
| 122 |
+
best_prior_overlap, best_prior_idx = overlaps.max(1, keepdim=True)
|
| 123 |
+
|
| 124 |
+
# ignore hard gt
|
| 125 |
+
valid_gt_idx = best_prior_overlap[:, 0] >= 0.2
|
| 126 |
+
best_prior_idx_filter = best_prior_idx[valid_gt_idx, :]
|
| 127 |
+
if best_prior_idx_filter.shape[0] <= 0:
|
| 128 |
+
loc_t[idx] = 0
|
| 129 |
+
conf_t[idx] = 0
|
| 130 |
+
return
|
| 131 |
+
|
| 132 |
+
# [1,num_priors] best ground truth for each prior
|
| 133 |
+
best_truth_overlap, best_truth_idx = overlaps.max(0, keepdim=True)
|
| 134 |
+
best_truth_idx.squeeze_(0)
|
| 135 |
+
best_truth_overlap.squeeze_(0)
|
| 136 |
+
best_prior_idx.squeeze_(1)
|
| 137 |
+
best_prior_idx_filter.squeeze_(1)
|
| 138 |
+
best_prior_overlap.squeeze_(1)
|
| 139 |
+
best_truth_overlap.index_fill_(0, best_prior_idx_filter, 2) # ensure best prior
|
| 140 |
+
# TODO refactor: index best_prior_idx with long tensor
|
| 141 |
+
# ensure every gt matches with its prior of max overlap
|
| 142 |
+
for j in range(best_prior_idx.size(0)): # 判别此anchor是预测哪一个boxes
|
| 143 |
+
best_truth_idx[best_prior_idx[j]] = j
|
| 144 |
+
matches = truths[best_truth_idx] # Shape: [num_priors,4] 此处为每一个anchor对应的bbox取出来
|
| 145 |
+
conf = labels[best_truth_idx] # Shape: [num_priors] 此处为每一个anchor对应的label取出来
|
| 146 |
+
conf[best_truth_overlap < threshold] = 0 # label as background overlap<0.35的全部作为负样本
|
| 147 |
+
loc = encode(matches, priors, variances)
|
| 148 |
+
|
| 149 |
+
matches_landm = landms[best_truth_idx]
|
| 150 |
+
landm = encode_landm(matches_landm, priors, variances)
|
| 151 |
+
loc_t[idx] = loc # [num_priors,4] encoded offsets to learn
|
| 152 |
+
conf_t[idx] = conf # [num_priors] top class label for each prior
|
| 153 |
+
landm_t[idx] = landm
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
def encode(matched, priors, variances):
|
| 157 |
+
"""Encode the variances from the priorbox layers into the ground truth boxes
|
| 158 |
+
we have matched (based on jaccard overlap) with the prior boxes.
|
| 159 |
+
Args:
|
| 160 |
+
matched: (tensor) Coords of ground truth for each prior in point-form
|
| 161 |
+
Shape: [num_priors, 4].
|
| 162 |
+
priors: (tensor) Prior boxes in center-offset form
|
| 163 |
+
Shape: [num_priors,4].
|
| 164 |
+
variances: (list[float]) Variances of priorboxes
|
| 165 |
+
Return:
|
| 166 |
+
encoded boxes (tensor), Shape: [num_priors, 4]
|
| 167 |
+
"""
|
| 168 |
+
|
| 169 |
+
# dist b/t match center and prior's center
|
| 170 |
+
g_cxcy = (matched[:, :2] + matched[:, 2:])/2 - priors[:, :2]
|
| 171 |
+
# encode variance
|
| 172 |
+
g_cxcy /= (variances[0] * priors[:, 2:])
|
| 173 |
+
# match wh / prior wh
|
| 174 |
+
g_wh = (matched[:, 2:] - matched[:, :2]) / priors[:, 2:]
|
| 175 |
+
g_wh = torch.log(g_wh) / variances[1]
|
| 176 |
+
# return target for smooth_l1_loss
|
| 177 |
+
return torch.cat([g_cxcy, g_wh], 1) # [num_priors,4]
|
| 178 |
+
|
| 179 |
+
def encode_landm(matched, priors, variances):
|
| 180 |
+
"""Encode the variances from the priorbox layers into the ground truth boxes
|
| 181 |
+
we have matched (based on jaccard overlap) with the prior boxes.
|
| 182 |
+
Args:
|
| 183 |
+
matched: (tensor) Coords of ground truth for each prior in point-form
|
| 184 |
+
Shape: [num_priors, 10].
|
| 185 |
+
priors: (tensor) Prior boxes in center-offset form
|
| 186 |
+
Shape: [num_priors,4].
|
| 187 |
+
variances: (list[float]) Variances of priorboxes
|
| 188 |
+
Return:
|
| 189 |
+
encoded landm (tensor), Shape: [num_priors, 10]
|
| 190 |
+
"""
|
| 191 |
+
|
| 192 |
+
# dist b/t match center and prior's center
|
| 193 |
+
matched = torch.reshape(matched, (matched.size(0), 5, 2))
|
| 194 |
+
priors_cx = priors[:, 0].unsqueeze(1).expand(matched.size(0), 5).unsqueeze(2)
|
| 195 |
+
priors_cy = priors[:, 1].unsqueeze(1).expand(matched.size(0), 5).unsqueeze(2)
|
| 196 |
+
priors_w = priors[:, 2].unsqueeze(1).expand(matched.size(0), 5).unsqueeze(2)
|
| 197 |
+
priors_h = priors[:, 3].unsqueeze(1).expand(matched.size(0), 5).unsqueeze(2)
|
| 198 |
+
priors = torch.cat([priors_cx, priors_cy, priors_w, priors_h], dim=2)
|
| 199 |
+
g_cxcy = matched[:, :, :2] - priors[:, :, :2]
|
| 200 |
+
# encode variance
|
| 201 |
+
g_cxcy /= (variances[0] * priors[:, :, 2:])
|
| 202 |
+
# g_cxcy /= priors[:, :, 2:]
|
| 203 |
+
g_cxcy = g_cxcy.reshape(g_cxcy.size(0), -1)
|
| 204 |
+
# return target for smooth_l1_loss
|
| 205 |
+
return g_cxcy
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
# Adapted from https://github.com/Hakuyume/chainer-ssd
|
| 209 |
+
def decode(loc, priors, variances):
|
| 210 |
+
"""Decode locations from predictions using priors to undo
|
| 211 |
+
the encoding we did for offset regression at train time.
|
| 212 |
+
Args:
|
| 213 |
+
loc (tensor): location predictions for loc layers,
|
| 214 |
+
Shape: [num_priors,4]
|
| 215 |
+
priors (tensor): Prior boxes in center-offset form.
|
| 216 |
+
Shape: [num_priors,4].
|
| 217 |
+
variances: (list[float]) Variances of priorboxes
|
| 218 |
+
Return:
|
| 219 |
+
decoded bounding box predictions
|
| 220 |
+
"""
|
| 221 |
+
|
| 222 |
+
boxes = torch.cat((
|
| 223 |
+
priors[:, :2] + loc[:, :2] * variances[0] * priors[:, 2:],
|
| 224 |
+
priors[:, 2:] * torch.exp(loc[:, 2:] * variances[1])), 1)
|
| 225 |
+
boxes[:, :2] -= boxes[:, 2:] / 2
|
| 226 |
+
boxes[:, 2:] += boxes[:, :2]
|
| 227 |
+
return boxes
|
| 228 |
+
|
| 229 |
+
def decode_landm(pre, priors, variances):
|
| 230 |
+
"""Decode landm from predictions using priors to undo
|
| 231 |
+
the encoding we did for offset regression at train time.
|
| 232 |
+
Args:
|
| 233 |
+
pre (tensor): landm predictions for loc layers,
|
| 234 |
+
Shape: [num_priors,10]
|
| 235 |
+
priors (tensor): Prior boxes in center-offset form.
|
| 236 |
+
Shape: [num_priors,4].
|
| 237 |
+
variances: (list[float]) Variances of priorboxes
|
| 238 |
+
Return:
|
| 239 |
+
decoded landm predictions
|
| 240 |
+
"""
|
| 241 |
+
landms = torch.cat((priors[:, :2] + pre[:, :2] * variances[0] * priors[:, 2:],
|
| 242 |
+
priors[:, :2] + pre[:, 2:4] * variances[0] * priors[:, 2:],
|
| 243 |
+
priors[:, :2] + pre[:, 4:6] * variances[0] * priors[:, 2:],
|
| 244 |
+
priors[:, :2] + pre[:, 6:8] * variances[0] * priors[:, 2:],
|
| 245 |
+
priors[:, :2] + pre[:, 8:10] * variances[0] * priors[:, 2:],
|
| 246 |
+
), dim=1)
|
| 247 |
+
return landms
|
| 248 |
+
|
| 249 |
+
|
| 250 |
+
def log_sum_exp(x):
|
| 251 |
+
"""Utility function for computing log_sum_exp while determining
|
| 252 |
+
This will be used to determine unaveraged confidence loss across
|
| 253 |
+
all examples in a batch.
|
| 254 |
+
Args:
|
| 255 |
+
x (Variable(tensor)): conf_preds from conf layers
|
| 256 |
+
"""
|
| 257 |
+
x_max = x.data.max()
|
| 258 |
+
return torch.log(torch.sum(torch.exp(x-x_max), 1, keepdim=True)) + x_max
|
| 259 |
+
|
| 260 |
+
|
| 261 |
+
# Original author: Francisco Massa:
|
| 262 |
+
# https://github.com/fmassa/object-detection.torch
|
| 263 |
+
# Ported to PyTorch by Max deGroot (02/01/2017)
|
| 264 |
+
def nms(boxes, scores, overlap=0.5, top_k=200):
|
| 265 |
+
"""Apply non-maximum suppression at test time to avoid detecting too many
|
| 266 |
+
overlapping bounding boxes for a given object.
|
| 267 |
+
Args:
|
| 268 |
+
boxes: (tensor) The location preds for the img, Shape: [num_priors,4].
|
| 269 |
+
scores: (tensor) The class predscores for the img, Shape:[num_priors].
|
| 270 |
+
overlap: (float) The overlap thresh for suppressing unnecessary boxes.
|
| 271 |
+
top_k: (int) The Maximum number of box preds to consider.
|
| 272 |
+
Return:
|
| 273 |
+
The indices of the kept boxes with respect to num_priors.
|
| 274 |
+
"""
|
| 275 |
+
|
| 276 |
+
keep = torch.Tensor(scores.size(0)).fill_(0).long()
|
| 277 |
+
if boxes.numel() == 0:
|
| 278 |
+
return keep
|
| 279 |
+
x1 = boxes[:, 0]
|
| 280 |
+
y1 = boxes[:, 1]
|
| 281 |
+
x2 = boxes[:, 2]
|
| 282 |
+
y2 = boxes[:, 3]
|
| 283 |
+
area = torch.mul(x2 - x1, y2 - y1)
|
| 284 |
+
v, idx = scores.sort(0) # sort in ascending order
|
| 285 |
+
# I = I[v >= 0.01]
|
| 286 |
+
idx = idx[-top_k:] # indices of the top-k largest vals
|
| 287 |
+
xx1 = boxes.new()
|
| 288 |
+
yy1 = boxes.new()
|
| 289 |
+
xx2 = boxes.new()
|
| 290 |
+
yy2 = boxes.new()
|
| 291 |
+
w = boxes.new()
|
| 292 |
+
h = boxes.new()
|
| 293 |
+
|
| 294 |
+
# keep = torch.Tensor()
|
| 295 |
+
count = 0
|
| 296 |
+
while idx.numel() > 0:
|
| 297 |
+
i = idx[-1] # index of current largest val
|
| 298 |
+
# keep.append(i)
|
| 299 |
+
keep[count] = i
|
| 300 |
+
count += 1
|
| 301 |
+
if idx.size(0) == 1:
|
| 302 |
+
break
|
| 303 |
+
idx = idx[:-1] # remove kept element from view
|
| 304 |
+
# load bboxes of next highest vals
|
| 305 |
+
torch.index_select(x1, 0, idx, out=xx1)
|
| 306 |
+
torch.index_select(y1, 0, idx, out=yy1)
|
| 307 |
+
torch.index_select(x2, 0, idx, out=xx2)
|
| 308 |
+
torch.index_select(y2, 0, idx, out=yy2)
|
| 309 |
+
# store element-wise max with next highest score
|
| 310 |
+
xx1 = torch.clamp(xx1, min=x1[i])
|
| 311 |
+
yy1 = torch.clamp(yy1, min=y1[i])
|
| 312 |
+
xx2 = torch.clamp(xx2, max=x2[i])
|
| 313 |
+
yy2 = torch.clamp(yy2, max=y2[i])
|
| 314 |
+
w.resize_as_(xx2)
|
| 315 |
+
h.resize_as_(yy2)
|
| 316 |
+
w = xx2 - xx1
|
| 317 |
+
h = yy2 - yy1
|
| 318 |
+
# check sizes of xx1 and xx2.. after each iteration
|
| 319 |
+
w = torch.clamp(w, min=0.0)
|
| 320 |
+
h = torch.clamp(h, min=0.0)
|
| 321 |
+
inter = w*h
|
| 322 |
+
# IoU = i / (area(a) + area(b) - i)
|
| 323 |
+
rem_areas = torch.index_select(area, 0, idx) # load remaining areas)
|
| 324 |
+
union = (rem_areas - inter) + area[i]
|
| 325 |
+
IoU = inter/union # store result in iou
|
| 326 |
+
# keep only elements with an IoU <= overlap
|
| 327 |
+
idx = idx[IoU.le(overlap)]
|
| 328 |
+
return keep, count
|
| 329 |
+
|
| 330 |
+
|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/utils/nms/__init__.py
ADDED
|
File without changes
|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/utils/nms/py_cpu_nms.py
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# Fast R-CNN
|
| 3 |
+
# Copyright (c) 2015 Microsoft
|
| 4 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 5 |
+
# Written by Ross Girshick
|
| 6 |
+
# --------------------------------------------------------
|
| 7 |
+
|
| 8 |
+
import numpy as np
|
| 9 |
+
|
| 10 |
+
def py_cpu_nms(dets, thresh):
|
| 11 |
+
"""Pure Python NMS baseline."""
|
| 12 |
+
x1 = dets[:, 0]
|
| 13 |
+
y1 = dets[:, 1]
|
| 14 |
+
x2 = dets[:, 2]
|
| 15 |
+
y2 = dets[:, 3]
|
| 16 |
+
scores = dets[:, 4]
|
| 17 |
+
|
| 18 |
+
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
|
| 19 |
+
order = scores.argsort()[::-1]
|
| 20 |
+
|
| 21 |
+
keep = []
|
| 22 |
+
while order.size > 0:
|
| 23 |
+
i = order[0]
|
| 24 |
+
keep.append(i)
|
| 25 |
+
xx1 = np.maximum(x1[i], x1[order[1:]])
|
| 26 |
+
yy1 = np.maximum(y1[i], y1[order[1:]])
|
| 27 |
+
xx2 = np.minimum(x2[i], x2[order[1:]])
|
| 28 |
+
yy2 = np.minimum(y2[i], y2[order[1:]])
|
| 29 |
+
|
| 30 |
+
w = np.maximum(0.0, xx2 - xx1 + 1)
|
| 31 |
+
h = np.maximum(0.0, yy2 - yy1 + 1)
|
| 32 |
+
inter = w * h
|
| 33 |
+
ovr = inter / (areas[i] + areas[order[1:]] - inter)
|
| 34 |
+
|
| 35 |
+
inds = np.where(ovr <= thresh)[0]
|
| 36 |
+
order = order[inds + 1]
|
| 37 |
+
|
| 38 |
+
return keep
|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/weights/mobilenet0.25_Final.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2979b33ffafda5d74b6948cd7a5b9a7a62f62b949cef24e95fd15d2883a65220
|
| 3 |
+
size 1789735
|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/Pytorch_Retinaface/weights/mobilenetV1X0.25_pretrain.tar
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:75c37f8d438b7c6aed2e6b310fd0540c40dabf0dd820770bd7082668dfd7c1c1
|
| 3 |
+
size 3827150
|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/README.md
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ComfyUI-AutoCropFaces
|
| 2 |
+
Use RetinaFace to detect and automatically crop faces
|
| 3 |
+
|
| 4 |
+
Forked and modified from [biubug6/Pytorch_Retinaface](https://github.com/biubug6/Pytorch_Retinaface)
|
| 5 |
+
|
| 6 |
+
## Custom Nodes
|
| 7 |
+
|
| 8 |
+
### Auto Crop Faces
|
| 9 |
+
|
| 10 |
+
Detect faces and focus on one of them.
|
| 11 |
+
|
| 12 |
+
Sure, here is the updated documentation:
|
| 13 |
+
|
| 14 |
+
### Auto Crop Faces
|
| 15 |
+
|
| 16 |
+
Detect faces and focus on one of them.
|
| 17 |
+
|
| 18 |
+
* `number_of_faces`: How many faces would you like to detect in total? (default: 5, min: 1, max: 100)
|
| 19 |
+
|
| 20 |
+
* `start_index`: Which face would you like to start with? (default: 0, step: 1). The starting index of the detected faces list. If the start index is out of bounds, it wraps around in a circular fashion just like a Python list.
|
| 21 |
+
|
| 22 |
+
* `scale_factor`: How much padding would you like to add? 1 for no padding. (default: 1.5, min: 0.5, max: 10, step: 0.5)
|
| 23 |
+
|
| 24 |
+
* `shift_factor`: Where would you like the face to be placed in the output image? Set to 0 to place the face at the top edge, 0.5 to center it, and 1.0 to place it at the bottom edge. (default: 0.45, min: 0, max: 1, step: 0.01)
|
| 25 |
+
|
| 26 |
+
* `max_faces_per_image`: The maximum number of faces to detect for each image. (default: 50, min: 1, max: 1000, step: 1)
|
| 27 |
+
|
| 28 |
+
* `aspect_ratio`: The aspect ratio for cropping, specified as `width` : `height`. (default: 1:1)
|
| 29 |
+
|
| 30 |
+

|
| 31 |
+
|
| 32 |
+

|
| 33 |
+
|
| 34 |
+
Recommandation:
|
| 35 |
+
|
| 36 |
+
Users might upload extremely large images, so it would be a good idea to first pass through the ["Constrain Image"](https://github.com/pythongosssss/ComfyUI-Custom-Scripts#constrain-image) node.
|
| 37 |
+
|
| 38 |
+

|
| 39 |
+
|
| 40 |
+
It now supports CROP_DATA, which is compatible with [WAS node suite](https://github.com/WASasquatch/was-node-suite-comfyui).
|
| 41 |
+

|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/__init__.py
ADDED
|
@@ -0,0 +1,177 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import comfy.utils
|
| 3 |
+
from .Pytorch_Retinaface.pytorch_retinaface import Pytorch_RetinaFace
|
| 4 |
+
from comfy.model_management import get_torch_device
|
| 5 |
+
|
| 6 |
+
class AutoCropFaces:
|
| 7 |
+
def __init__(self):
|
| 8 |
+
pass
|
| 9 |
+
|
| 10 |
+
@classmethod
|
| 11 |
+
def INPUT_TYPES(s):
|
| 12 |
+
return {
|
| 13 |
+
"required": {
|
| 14 |
+
"image": ("IMAGE",),
|
| 15 |
+
"number_of_faces": ("INT", {
|
| 16 |
+
"default": 5,
|
| 17 |
+
"min": 1,
|
| 18 |
+
"max": 100,
|
| 19 |
+
"step": 1,
|
| 20 |
+
}),
|
| 21 |
+
"scale_factor": ("FLOAT", {
|
| 22 |
+
"default": 1.5,
|
| 23 |
+
"min": 0.5,
|
| 24 |
+
"max": 10,
|
| 25 |
+
"step": 0.5,
|
| 26 |
+
"display": "slider"
|
| 27 |
+
}),
|
| 28 |
+
"shift_factor": ("FLOAT", {
|
| 29 |
+
"default": 0.45,
|
| 30 |
+
"min": 0,
|
| 31 |
+
"max": 1,
|
| 32 |
+
"step": 0.01,
|
| 33 |
+
"display": "slider"
|
| 34 |
+
}),
|
| 35 |
+
"start_index": ("INT", {
|
| 36 |
+
"default": 0,
|
| 37 |
+
"step": 1,
|
| 38 |
+
"display": "number"
|
| 39 |
+
}),
|
| 40 |
+
"max_faces_per_image": ("INT", {
|
| 41 |
+
"default": 50,
|
| 42 |
+
"min": 1,
|
| 43 |
+
"max": 1000,
|
| 44 |
+
"step": 1,
|
| 45 |
+
}),
|
| 46 |
+
# "aspect_ratio": ("FLOAT", {
|
| 47 |
+
# "default": 1,
|
| 48 |
+
# "min": 0.2,
|
| 49 |
+
# "max": 5,
|
| 50 |
+
# "step": 0.1,
|
| 51 |
+
# }),
|
| 52 |
+
"aspect_ratio": (["9:16", "2:3", "3:4", "4:5", "1:1", "5:4", "4:3", "3:2", "16:9"], {
|
| 53 |
+
"default": "1:1",
|
| 54 |
+
}),
|
| 55 |
+
},
|
| 56 |
+
}
|
| 57 |
+
|
| 58 |
+
RETURN_TYPES = ("IMAGE", "CROP_DATA")
|
| 59 |
+
RETURN_NAMES = ("face",)
|
| 60 |
+
|
| 61 |
+
FUNCTION = "auto_crop_faces"
|
| 62 |
+
|
| 63 |
+
CATEGORY = "Faces"
|
| 64 |
+
|
| 65 |
+
def aspect_ratio_string_to_float(self, str_aspect_ratio="1:1"):
|
| 66 |
+
a, b = map(float, str_aspect_ratio.split(':'))
|
| 67 |
+
return a / b
|
| 68 |
+
|
| 69 |
+
def auto_crop_faces_in_image (self, image, max_number_of_faces, scale_factor, shift_factor, aspect_ratio, method='lanczos'):
|
| 70 |
+
image_255 = image * 255
|
| 71 |
+
rf = Pytorch_RetinaFace(top_k=50, keep_top_k=max_number_of_faces, device=get_torch_device())
|
| 72 |
+
dets = rf.detect_faces(image_255)
|
| 73 |
+
cropped_faces, bbox_info = rf.center_and_crop_rescale(image, dets, scale_factor=scale_factor, shift_factor=shift_factor, aspect_ratio=aspect_ratio)
|
| 74 |
+
|
| 75 |
+
# Add a batch dimension to each cropped face
|
| 76 |
+
cropped_faces_with_batch = [face.unsqueeze(0) for face in cropped_faces]
|
| 77 |
+
return cropped_faces_with_batch, bbox_info
|
| 78 |
+
|
| 79 |
+
def auto_crop_faces(self, image, number_of_faces, start_index, max_faces_per_image, scale_factor, shift_factor, aspect_ratio, method='lanczos'):
|
| 80 |
+
"""
|
| 81 |
+
"image" - Input can be one image or a batch of images with shape (batch, width, height, channel count)
|
| 82 |
+
"number_of_faces" - This is passed into PyTorch_RetinaFace which allows you to define a maximum number of faces to look for.
|
| 83 |
+
"start_index" - The starting index of which face you select out of the set of detected faces.
|
| 84 |
+
"scale_factor" - How much crop factor or padding do you want around each detected face.
|
| 85 |
+
"shift_factor" - Pan up or down relative to the face, 0.5 should be right in the center.
|
| 86 |
+
"aspect_ratio" - When we crop, you can have it crop down at a particular aspect ratio.
|
| 87 |
+
"method" - Scaling pixel sampling interpolation method.
|
| 88 |
+
"""
|
| 89 |
+
|
| 90 |
+
# Turn aspect ratio to float value
|
| 91 |
+
aspect_ratio = self.aspect_ratio_string_to_float(aspect_ratio)
|
| 92 |
+
|
| 93 |
+
selected_faces, detected_cropped_faces = [], []
|
| 94 |
+
selected_crop_data, detected_crop_data = [], []
|
| 95 |
+
original_images = []
|
| 96 |
+
|
| 97 |
+
# Loop through the input batches. Even if there is only one input image, it's still considered a batch.
|
| 98 |
+
for i in range(image.shape[0]):
|
| 99 |
+
|
| 100 |
+
original_images.append(image[i].unsqueeze(0)) # Temporarily the image, but insure it still has the batch dimension.
|
| 101 |
+
# Detect the faces in the image, this will return multiple images and crop data for it.
|
| 102 |
+
cropped_images, infos = self.auto_crop_faces_in_image(
|
| 103 |
+
image[i],
|
| 104 |
+
max_faces_per_image,
|
| 105 |
+
scale_factor,
|
| 106 |
+
shift_factor,
|
| 107 |
+
aspect_ratio,
|
| 108 |
+
method)
|
| 109 |
+
|
| 110 |
+
detected_cropped_faces.extend(cropped_images)
|
| 111 |
+
detected_crop_data.extend(infos)
|
| 112 |
+
|
| 113 |
+
# If we haven't detected anything, just return the original images, and default crop data.
|
| 114 |
+
if not detected_cropped_faces or len(detected_cropped_faces) == 0:
|
| 115 |
+
selected_crop_data = [(0, 0, img.shape[3], img.shape[2]) for img in original_images]
|
| 116 |
+
return (image, selected_crop_data)
|
| 117 |
+
|
| 118 |
+
# Circular index calculation
|
| 119 |
+
start_index = start_index % len(detected_cropped_faces)
|
| 120 |
+
|
| 121 |
+
if number_of_faces >= len(detected_cropped_faces):
|
| 122 |
+
selected_faces = detected_cropped_faces[start_index:] + detected_cropped_faces[:start_index]
|
| 123 |
+
selected_crop_data = detected_crop_data[start_index:] + detected_crop_data[:start_index]
|
| 124 |
+
else:
|
| 125 |
+
end_index = (start_index + number_of_faces) % len(detected_cropped_faces)
|
| 126 |
+
if start_index < end_index:
|
| 127 |
+
selected_faces = detected_cropped_faces[start_index:end_index]
|
| 128 |
+
selected_crop_data = detected_crop_data[start_index:end_index]
|
| 129 |
+
else:
|
| 130 |
+
selected_faces = detected_cropped_faces[start_index:] + detected_cropped_faces[:end_index]
|
| 131 |
+
selected_crop_data = detected_crop_data[start_index:] + detected_crop_data[:end_index]
|
| 132 |
+
|
| 133 |
+
# If we haven't selected anything, then return original images.
|
| 134 |
+
if len(selected_faces) == 0:
|
| 135 |
+
selected_crop_data = [(0, 0, img.shape[3], img.shape[2]) for img in original_images]
|
| 136 |
+
return (image, selected_crop_data)
|
| 137 |
+
|
| 138 |
+
# If there is only one detected face in batch of images, just return that one.
|
| 139 |
+
elif len(selected_faces) <= 1:
|
| 140 |
+
out = selected_faces[0]
|
| 141 |
+
return (out, selected_crop_data)
|
| 142 |
+
|
| 143 |
+
# Determine the index of the face with the maximum width
|
| 144 |
+
max_width_index = max(range(len(selected_faces)), key=lambda i: selected_faces[i].shape[1])
|
| 145 |
+
|
| 146 |
+
# Determine the maximum width
|
| 147 |
+
max_width = selected_faces[max_width_index].shape[1]
|
| 148 |
+
max_height = selected_faces[max_width_index].shape[2]
|
| 149 |
+
shape = (max_height, max_width)
|
| 150 |
+
|
| 151 |
+
out = None
|
| 152 |
+
# All images need to have the same width/height to fit into the tensor such that we can output as image batches.
|
| 153 |
+
for face_image in selected_faces:
|
| 154 |
+
if shape != face_image.shape[1:3]: # Determine whether cropped face image size matches largest cropped face image.
|
| 155 |
+
face_image = comfy.utils.common_upscale( # This method expects (batch, channel, height, width)
|
| 156 |
+
face_image.movedim(-1, 1), # Move channel dimension to width dimension
|
| 157 |
+
max_height, # Height
|
| 158 |
+
max_width, # Width
|
| 159 |
+
method, # Pixel sampling method.
|
| 160 |
+
"" # Only "center" is implemented right now, and we don't want to use that.
|
| 161 |
+
).movedim(1, -1)
|
| 162 |
+
# Append the fitted image into the tensor.
|
| 163 |
+
if out is None:
|
| 164 |
+
out = face_image
|
| 165 |
+
else:
|
| 166 |
+
out = torch.cat((out, face_image), dim=0)
|
| 167 |
+
|
| 168 |
+
return (out, selected_crop_data)
|
| 169 |
+
|
| 170 |
+
NODE_CLASS_MAPPINGS = {
|
| 171 |
+
"AutoCropFaces": AutoCropFaces
|
| 172 |
+
}
|
| 173 |
+
|
| 174 |
+
# A dictionary that contains the friendly/humanly readable titles for the nodes
|
| 175 |
+
NODE_DISPLAY_NAME_MAPPINGS = {
|
| 176 |
+
"AutoCropFaces": "Auto Crop Faces"
|
| 177 |
+
}
|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/images/Crop_Data.png
ADDED
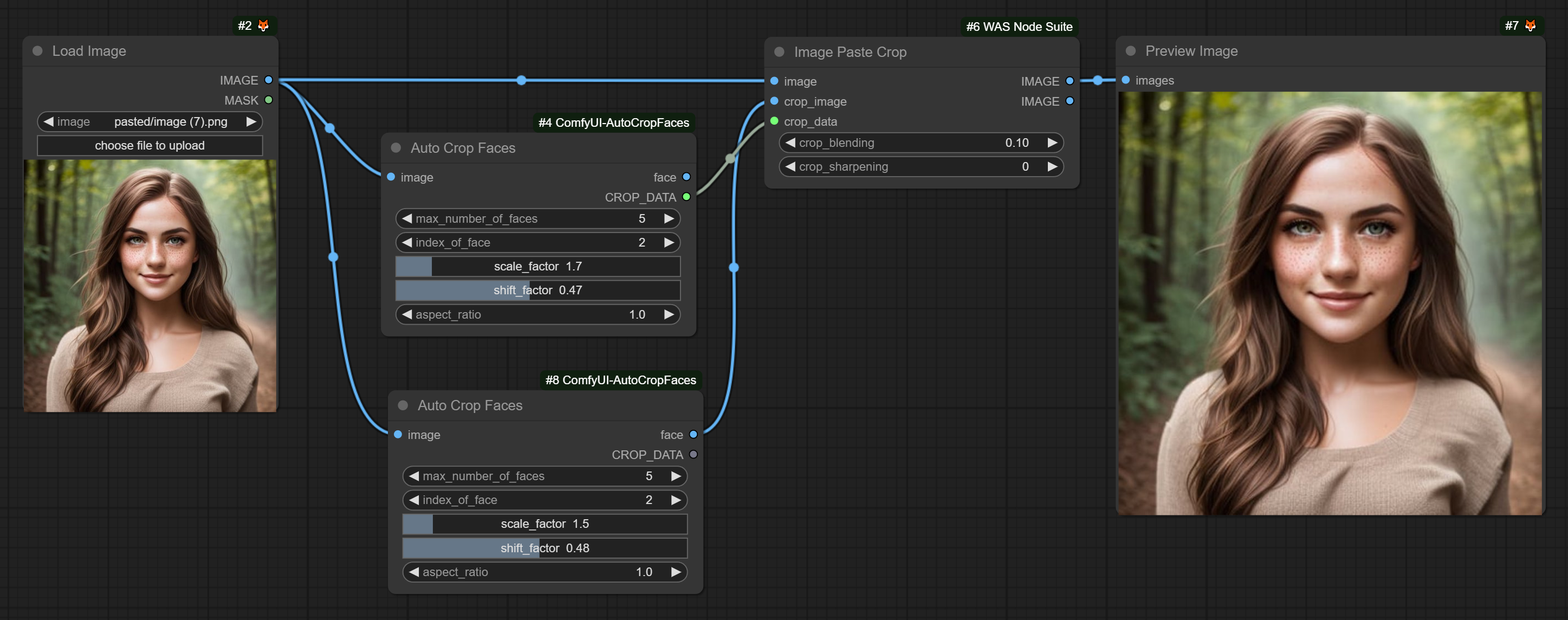
|
Git LFS Details
|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/images/workflow-AutoCropFaces-Simple.png
ADDED
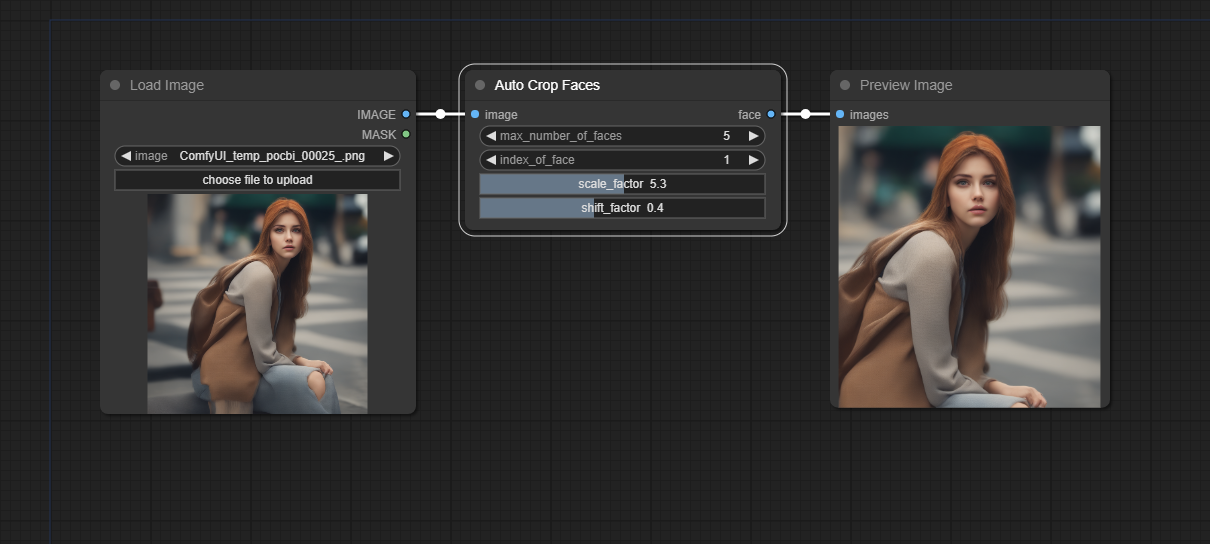
|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/images/workflow-AutoCropFaces-bottom.png
ADDED

|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/images/workflow-AutoCropFaces-with-Constrain.png
ADDED

|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/test.py
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from __future__ import print_function
|
| 2 |
+
import os
|
| 3 |
+
import argparse
|
| 4 |
+
import numpy as np
|
| 5 |
+
import cv2
|
| 6 |
+
from Pytorch_Retinaface.pytorch_retinaface import Pytorch_RetinaFace
|
| 7 |
+
|
| 8 |
+
parser = argparse.ArgumentParser(description='Retinaface')
|
| 9 |
+
|
| 10 |
+
parser.add_argument('-m', '--trained_model', default='./weights/mobilenet0.25_Final.pth',
|
| 11 |
+
type=str, help='Trained state_dict file path to open')
|
| 12 |
+
parser.add_argument('--network', default='mobile0.25', help='Backbone network mobile0.25 or resnet50')
|
| 13 |
+
parser.add_argument('--cpu', action="store_true", default=False, help='Use cpu inference')
|
| 14 |
+
parser.add_argument('--confidence_threshold', default=0.02, type=float, help='confidence_threshold')
|
| 15 |
+
parser.add_argument('--top_k', default=5000, type=int, help='top_k')
|
| 16 |
+
parser.add_argument('--nms_threshold', default=0.4, type=float, help='nms_threshold')
|
| 17 |
+
parser.add_argument('--keep_top_k', default=750, type=int, help='keep_top_k')
|
| 18 |
+
parser.add_argument('-s', '--save_image', action="store_true", default=True, help='show detection results')
|
| 19 |
+
parser.add_argument('--vis_thres', default=0.6, type=float, help='visualization_threshold')
|
| 20 |
+
args = parser.parse_args()
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def main():
|
| 24 |
+
rf = Pytorch_RetinaFace()
|
| 25 |
+
current_dir = os.path.dirname(os.path.abspath(__file__))
|
| 26 |
+
output_dir = os.path.join(current_dir, "./Pytorch_Retinaface/outputs")
|
| 27 |
+
|
| 28 |
+
image_path = os.path.join(current_dir, "./Pytorch_Retinaface/images/test.webp")
|
| 29 |
+
if not os.path.exists(image_path):
|
| 30 |
+
raise FileNotFoundError
|
| 31 |
+
img_raw = cv2.imread(image_path, cv2.IMREAD_COLOR)
|
| 32 |
+
|
| 33 |
+
img = np.float32(img_raw)
|
| 34 |
+
|
| 35 |
+
dets = rf.detect_faces(img)
|
| 36 |
+
|
| 37 |
+
# Crop and save each detected face
|
| 38 |
+
cropped_imgs = rf.center_and_crop_rescale(img_raw, dets)
|
| 39 |
+
for index, cropped_img in enumerate(cropped_imgs[0]):
|
| 40 |
+
# Save the final image
|
| 41 |
+
os.makedirs(output_dir, exist_ok=True)
|
| 42 |
+
cv2.imwrite(os.path.join(output_dir, f"cropped_face_{index}.jpg"), cropped_img)
|
| 43 |
+
print(f"Saved: cropped_face_{index}.jpg")
|
| 44 |
+
|
| 45 |
+
if __name__ == '__main__':
|
| 46 |
+
main()
|
ComfyUI/custom_nodes/ComfyUI-AutoCropFaces/tests/AutoCropFaces-Testing.json
ADDED
|
@@ -0,0 +1,1997 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"last_node_id": 91,
|
| 3 |
+
"last_link_id": 141,
|
| 4 |
+
"nodes": [
|
| 5 |
+
{
|
| 6 |
+
"id": 54,
|
| 7 |
+
"type": "VAEDecode",
|
| 8 |
+
"pos": [
|
| 9 |
+
2550,
|
| 10 |
+
2240
|
| 11 |
+
],
|
| 12 |
+
"size": {
|
| 13 |
+
"0": 210,
|
| 14 |
+
"1": 46
|
| 15 |
+
},
|
| 16 |
+
"flags": {},
|
| 17 |
+
"order": 18,
|
| 18 |
+
"mode": 0,
|
| 19 |
+
"inputs": [
|
| 20 |
+
{
|
| 21 |
+
"name": "samples",
|
| 22 |
+
"type": "LATENT",
|
| 23 |
+
"link": 78
|
| 24 |
+
},
|
| 25 |
+
{
|
| 26 |
+
"name": "vae",
|
| 27 |
+
"type": "VAE",
|
| 28 |
+
"link": 120
|
| 29 |
+
}
|
| 30 |
+
],
|
| 31 |
+
"outputs": [
|
| 32 |
+
{
|
| 33 |
+
"name": "IMAGE",
|
| 34 |
+
"type": "IMAGE",
|
| 35 |
+
"links": [
|
| 36 |
+
80
|
| 37 |
+
],
|
| 38 |
+
"slot_index": 0
|
| 39 |
+
}
|
| 40 |
+
],
|
| 41 |
+
"properties": {
|
| 42 |
+
"Node name for S&R": "VAEDecode"
|
| 43 |
+
}
|
| 44 |
+
},
|
| 45 |
+
{
|
| 46 |
+
"id": 52,
|
| 47 |
+
"type": "KSampler",
|
| 48 |
+
"pos": [
|
| 49 |
+
2150,
|
| 50 |
+
2370
|
| 51 |
+
],
|
| 52 |
+
"size": {
|
| 53 |
+
"0": 315,
|
| 54 |
+
"1": 262
|
| 55 |
+
},
|
| 56 |
+
"flags": {},
|
| 57 |
+
"order": 12,
|
| 58 |
+
"mode": 0,
|
| 59 |
+
"inputs": [
|
| 60 |
+
{
|
| 61 |
+
"name": "model",
|
| 62 |
+
"type": "MODEL",
|
| 63 |
+
"link": 73
|
| 64 |
+
},
|
| 65 |
+
{
|
| 66 |
+
"name": "positive",
|
| 67 |
+
"type": "CONDITIONING",
|
| 68 |
+
"link": 74
|
| 69 |
+
},
|
| 70 |
+
{
|
| 71 |
+
"name": "negative",
|
| 72 |
+
"type": "CONDITIONING",
|
| 73 |
+
"link": 75
|
| 74 |
+
},
|
| 75 |
+
{
|
| 76 |
+
"name": "latent_image",
|
| 77 |
+
"type": "LATENT",
|
| 78 |
+
"link": 76
|
| 79 |
+
}
|
| 80 |
+
],
|
| 81 |
+
"outputs": [
|
| 82 |
+
{
|
| 83 |
+
"name": "LATENT",
|
| 84 |
+
"type": "LATENT",
|
| 85 |
+
"links": [
|
| 86 |
+
78
|
| 87 |
+
],
|
| 88 |
+
"slot_index": 0
|
| 89 |
+
}
|
| 90 |
+
],
|
| 91 |
+
"properties": {
|
| 92 |
+
"Node name for S&R": "KSampler"
|
| 93 |
+
},
|
| 94 |
+
"widgets_values": [
|
| 95 |
+
444793366152418,
|
| 96 |
+
"fixed",
|
| 97 |
+
50,
|
| 98 |
+
8,
|
| 99 |
+
"euler",
|
| 100 |
+
"normal",
|
| 101 |
+
1
|
| 102 |
+
]
|
| 103 |
+
},
|
| 104 |
+
{
|
| 105 |
+
"id": 51,
|
| 106 |
+
"type": "PreviewImage",
|
| 107 |
+
"pos": [
|
| 108 |
+
3120,
|
| 109 |
+
2360
|
| 110 |
+
],
|
| 111 |
+
"size": {
|
| 112 |
+
"0": 210,
|
| 113 |
+
"1": 246
|
| 114 |
+
},
|
| 115 |
+
"flags": {},
|
| 116 |
+
"order": 29,
|
| 117 |
+
"mode": 0,
|
| 118 |
+
"inputs": [
|
| 119 |
+
{
|
| 120 |
+
"name": "images",
|
| 121 |
+
"type": "IMAGE",
|
| 122 |
+
"link": 82
|
| 123 |
+
}
|
| 124 |
+
],
|
| 125 |
+
"properties": {
|
| 126 |
+
"Node name for S&R": "PreviewImage"
|
| 127 |
+
}
|
| 128 |
+
},
|
| 129 |
+
{
|
| 130 |
+
"id": 44,
|
| 131 |
+
"type": "KSampler",
|
| 132 |
+
"pos": [
|
| 133 |
+
2150,
|
| 134 |
+
2060
|
| 135 |
+
],
|
| 136 |
+
"size": {
|
| 137 |
+
"0": 315,
|
| 138 |
+
"1": 262
|
| 139 |
+
},
|
| 140 |
+
"flags": {},
|
| 141 |
+
"order": 11,
|
| 142 |
+
"mode": 0,
|
| 143 |
+
"inputs": [
|
| 144 |
+
{
|
| 145 |
+
"name": "model",
|
| 146 |
+
"type": "MODEL",
|
| 147 |
+
"link": 62
|
| 148 |
+
},
|
| 149 |
+
{
|
| 150 |
+
"name": "positive",
|
| 151 |
+
"type": "CONDITIONING",
|
| 152 |
+
"link": 63
|
| 153 |
+
},
|
| 154 |
+
{
|
| 155 |
+
"name": "negative",
|
| 156 |
+
"type": "CONDITIONING",
|
| 157 |
+
"link": 64
|
| 158 |
+
},
|
| 159 |
+
{
|
| 160 |
+
"name": "latent_image",
|
| 161 |
+
"type": "LATENT",
|
| 162 |
+
"link": 65
|
| 163 |
+
}
|
| 164 |
+
],
|
| 165 |
+
"outputs": [
|
| 166 |
+
{
|
| 167 |
+
"name": "LATENT",
|
| 168 |
+
"type": "LATENT",
|
| 169 |
+
"links": [
|
| 170 |
+
68
|
| 171 |
+
],
|
| 172 |
+
"slot_index": 0
|
| 173 |
+
}
|
| 174 |
+
],
|
| 175 |
+
"properties": {
|
| 176 |
+
"Node name for S&R": "KSampler"
|
| 177 |
+
},
|
| 178 |
+
"widgets_values": [
|
| 179 |
+
444793366152274,
|
| 180 |
+
"fixed",
|
| 181 |
+
50,
|
| 182 |
+
8,
|
| 183 |
+
"euler",
|
| 184 |
+
"normal",
|
| 185 |
+
1
|
| 186 |
+
]
|
| 187 |
+
},
|
| 188 |
+
{
|
| 189 |
+
"id": 49,
|
| 190 |
+
"type": "VAEDecode",
|
| 191 |
+
"pos": [
|
| 192 |
+
2540,
|
| 193 |
+
2090
|
| 194 |
+
],
|
| 195 |
+
"size": {
|
| 196 |
+
"0": 210,
|
| 197 |
+
"1": 46
|
| 198 |
+
},
|
| 199 |
+
"flags": {},
|
| 200 |
+
"order": 17,
|
| 201 |
+
"mode": 0,
|
| 202 |
+
"inputs": [
|
| 203 |
+
{
|
| 204 |
+
"name": "samples",
|
| 205 |
+
"type": "LATENT",
|
| 206 |
+
"link": 68
|
| 207 |
+
},
|
| 208 |
+
{
|
| 209 |
+
"name": "vae",
|
| 210 |
+
"type": "VAE",
|
| 211 |
+
"link": 121
|
| 212 |
+
}
|
| 213 |
+
],
|
| 214 |
+
"outputs": [
|
| 215 |
+
{
|
| 216 |
+
"name": "IMAGE",
|
| 217 |
+
"type": "IMAGE",
|
| 218 |
+
"links": [
|
| 219 |
+
79
|
| 220 |
+
],
|
| 221 |
+
"slot_index": 0
|
| 222 |
+
}
|
| 223 |
+
],
|
| 224 |
+
"properties": {
|
| 225 |
+
"Node name for S&R": "VAEDecode"
|
| 226 |
+
}
|
| 227 |
+
},
|
| 228 |
+
{
|
| 229 |
+
"id": 61,
|
| 230 |
+
"type": "KSampler",
|
| 231 |
+
"pos": [
|
| 232 |
+
2210,
|
| 233 |
+
1270
|
| 234 |
+
],
|
| 235 |
+
"size": {
|
| 236 |
+
"0": 315,
|
| 237 |
+
"1": 262
|
| 238 |
+
},
|
| 239 |
+
"flags": {},
|
| 240 |
+
"order": 13,
|
| 241 |
+
"mode": 0,
|
| 242 |
+
"inputs": [
|
| 243 |
+
{
|
| 244 |
+
"name": "model",
|
| 245 |
+
"type": "MODEL",
|
| 246 |
+
"link": 105
|
| 247 |
+
},
|
| 248 |
+
{
|
| 249 |
+
"name": "positive",
|
| 250 |
+
"type": "CONDITIONING",
|
| 251 |
+
"link": 87
|
| 252 |
+
},
|
| 253 |
+
{
|
| 254 |
+
"name": "negative",
|
| 255 |
+
"type": "CONDITIONING",
|
| 256 |
+
"link": 84
|
| 257 |
+
},
|
| 258 |
+
{
|
| 259 |
+
"name": "latent_image",
|
| 260 |
+
"type": "LATENT",
|
| 261 |
+
"link": 85
|
| 262 |
+
}
|
| 263 |
+
],
|
| 264 |
+
"outputs": [
|
| 265 |
+
{
|
| 266 |
+
"name": "LATENT",
|
| 267 |
+
"type": "LATENT",
|
| 268 |
+
"links": [
|
| 269 |
+
89
|
| 270 |
+
],
|
| 271 |
+
"slot_index": 0
|
| 272 |
+
}
|
| 273 |
+
],
|
| 274 |
+
"properties": {
|
| 275 |
+
"Node name for S&R": "KSampler"
|
| 276 |
+
},
|
| 277 |
+
"widgets_values": [
|
| 278 |
+
444793366152274,
|
| 279 |
+
"fixed",
|
| 280 |
+
50,
|
| 281 |
+
8,
|
| 282 |
+
"euler",
|
| 283 |
+
"normal",
|
| 284 |
+
1
|
| 285 |
+
]
|
| 286 |
+
},
|
| 287 |
+
{
|
| 288 |
+
"id": 56,
|
| 289 |
+
"type": "ImageBatch",
|
| 290 |
+
"pos": [
|
| 291 |
+
2840,
|
| 292 |
+
2170
|
| 293 |
+
],
|
| 294 |
+
"size": {
|
| 295 |
+
"0": 210,
|
| 296 |
+
"1": 46
|
| 297 |
+
},
|
| 298 |
+
"flags": {},
|
| 299 |
+
"order": 23,
|
| 300 |
+
"mode": 0,
|
| 301 |
+
"inputs": [
|
| 302 |
+
{
|
| 303 |
+
"name": "image1",
|
| 304 |
+
"type": "IMAGE",
|
| 305 |
+
"link": 79
|
| 306 |
+
},
|
| 307 |
+
{
|
| 308 |
+
"name": "image2",
|
| 309 |
+
"type": "IMAGE",
|
| 310 |
+
"link": 80
|
| 311 |
+
}
|
| 312 |
+
],
|
| 313 |
+
"outputs": [
|
| 314 |
+
{
|
| 315 |
+
"name": "IMAGE",
|
| 316 |
+
"type": "IMAGE",
|
| 317 |
+
"links": [
|
| 318 |
+
81,
|
| 319 |
+
82
|
| 320 |
+
],
|
| 321 |
+
"shape": 3,
|
| 322 |
+
"slot_index": 0
|
| 323 |
+
}
|
| 324 |
+
],
|
| 325 |
+
"properties": {
|
| 326 |
+
"Node name for S&R": "ImageBatch"
|
| 327 |
+
}
|
| 328 |
+
},
|
| 329 |
+
{
|
| 330 |
+
"id": 58,
|
| 331 |
+
"type": "AutoCropFaces",
|
| 332 |
+
"pos": [
|
| 333 |
+
2860,
|
| 334 |
+
1340
|
| 335 |
+
],
|
| 336 |
+
"size": {
|
| 337 |
+
"0": 315,
|
| 338 |
+
"1": 198
|
| 339 |
+
},
|
| 340 |
+
"flags": {},
|
| 341 |
+
"order": 24,
|
| 342 |
+
"mode": 0,
|
| 343 |
+
"inputs": [
|
| 344 |
+
{
|
| 345 |
+
"name": "image",
|
| 346 |
+
"type": "IMAGE",
|
| 347 |
+
"link": 90
|
| 348 |
+
}
|
| 349 |
+
],
|
| 350 |
+
"outputs": [
|
| 351 |
+
{
|
| 352 |
+
"name": "face",
|
| 353 |
+
"type": "IMAGE",
|
| 354 |
+
"links": [
|
| 355 |
+
91
|
| 356 |
+
],
|
| 357 |
+
"shape": 3,
|
| 358 |
+
"slot_index": 0
|
| 359 |
+
},
|
| 360 |
+
{
|
| 361 |
+
"name": "CROP_DATA",
|
| 362 |
+
"type": "CROP_DATA",
|
| 363 |
+
"links": null,
|
| 364 |
+
"shape": 3,
|
| 365 |
+
"slot_index": 1
|
| 366 |
+
}
|
| 367 |
+
],
|
| 368 |
+
"properties": {
|
| 369 |
+
"Node name for S&R": "AutoCropFaces"
|
| 370 |
+
},
|
| 371 |
+
"widgets_values": [
|
| 372 |
+
5,
|
| 373 |
+
0,
|
| 374 |
+
-1,
|
| 375 |
+
1.5,
|
| 376 |
+
0.5,
|
| 377 |
+
1
|
| 378 |
+
]
|
| 379 |
+
},
|
| 380 |
+
{
|
| 381 |
+
"id": 72,
|
| 382 |
+
"type": "AutoCropFaces",
|
| 383 |
+
"pos": [
|
| 384 |
+
3080,
|
| 385 |
+
540
|
| 386 |
+
],
|
| 387 |
+
"size": {
|
| 388 |
+
"0": 315,
|
| 389 |
+
"1": 198
|
| 390 |
+
},
|
| 391 |
+
"flags": {},
|
| 392 |
+
"order": 31,
|
| 393 |
+
"mode": 0,
|
| 394 |
+
"inputs": [
|
| 395 |
+
{
|
| 396 |
+
"name": "image",
|
| 397 |
+
"type": "IMAGE",
|
| 398 |
+
"link": 117
|
| 399 |
+
}
|
| 400 |
+
],
|
| 401 |
+
"outputs": [
|
| 402 |
+
{
|
| 403 |
+
"name": "face",
|
| 404 |
+
"type": "IMAGE",
|
| 405 |
+
"links": [
|
| 406 |
+
102
|
| 407 |
+
],
|
| 408 |
+
"shape": 3,
|
| 409 |
+
"slot_index": 0
|
| 410 |
+
},
|
| 411 |
+
{
|
| 412 |
+
"name": "CROP_DATA",
|
| 413 |
+
"type": "CROP_DATA",
|
| 414 |
+
"links": null,
|
| 415 |
+
"shape": 3,
|
| 416 |
+
"slot_index": 1
|
| 417 |
+
}
|
| 418 |
+
],
|
| 419 |
+
"properties": {
|
| 420 |
+
"Node name for S&R": "AutoCropFaces"
|
| 421 |
+
},
|
| 422 |
+
"widgets_values": [
|
| 423 |
+
5,
|
| 424 |
+
0,
|
| 425 |
+
-1,
|
| 426 |
+
1.5,
|
| 427 |
+
0.5,
|
| 428 |
+
1
|
| 429 |
+
]
|
| 430 |
+
},
|
| 431 |
+
{
|
| 432 |
+
"id": 67,
|
| 433 |
+
"type": "PreviewImage",
|
| 434 |
+
"pos": [
|
| 435 |
+
3230,
|
| 436 |
+
1140
|
| 437 |
+
],
|
| 438 |
+
"size": {
|
| 439 |
+
"0": 210,
|
| 440 |
+
"1": 246
|
| 441 |
+
},
|
| 442 |
+
"flags": {},
|
| 443 |
+
"order": 25,
|
| 444 |
+
"mode": 0,
|
| 445 |
+
"inputs": [
|
| 446 |
+
{
|
| 447 |
+
"name": "images",
|
| 448 |
+
"type": "IMAGE",
|
| 449 |
+
"link": 92
|
| 450 |
+
}
|
| 451 |
+
],
|
| 452 |
+
"properties": {
|
| 453 |
+
"Node name for S&R": "PreviewImage"
|
| 454 |
+
}
|
| 455 |
+
},
|
| 456 |
+
{
|
| 457 |
+
"id": 65,
|
| 458 |
+
"type": "VAEDecode",
|
| 459 |
+
"pos": [
|
| 460 |
+
2610,
|
| 461 |
+
1290
|
| 462 |
+
],
|
| 463 |
+
"size": {
|
| 464 |
+
"0": 210,
|
| 465 |
+
"1": 46
|
| 466 |
+
},
|
| 467 |
+
"flags": {},
|
| 468 |
+
"order": 19,
|
| 469 |
+
"mode": 0,
|
| 470 |
+
"inputs": [
|
| 471 |
+
{
|
| 472 |
+
"name": "samples",
|
| 473 |
+
"type": "LATENT",
|
| 474 |
+
"link": 89
|
| 475 |
+
},
|
| 476 |
+
{
|
| 477 |
+
"name": "vae",
|
| 478 |
+
"type": "VAE",
|
| 479 |
+
"link": 109
|
| 480 |
+
}
|
| 481 |
+
],
|
| 482 |
+
"outputs": [
|
| 483 |
+
{
|
| 484 |
+
"name": "IMAGE",
|
| 485 |
+
"type": "IMAGE",
|
| 486 |
+
"links": [
|
| 487 |
+
90,
|
| 488 |
+
92
|
| 489 |
+
],
|
| 490 |
+
"slot_index": 0
|
| 491 |
+
}
|
| 492 |
+
],
|
| 493 |
+
"properties": {
|
| 494 |
+
"Node name for S&R": "VAEDecode"
|
| 495 |
+
}
|
| 496 |
+
},
|
| 497 |
+
{
|
| 498 |
+
"id": 66,
|
| 499 |
+
"type": "PreviewImage",
|
| 500 |
+
"pos": [
|
| 501 |
+
3230,
|
| 502 |
+
1430
|
| 503 |
+
],
|
| 504 |
+
"size": {
|
| 505 |
+
"0": 210,
|
| 506 |
+
"1": 246
|
| 507 |
+
},
|
| 508 |
+
"flags": {},
|
| 509 |
+
"order": 30,
|
| 510 |
+
"mode": 0,
|
| 511 |
+
"inputs": [
|
| 512 |
+
{
|
| 513 |
+
"name": "images",
|
| 514 |
+
"type": "IMAGE",
|
| 515 |
+
"link": 91
|
| 516 |
+
}
|
| 517 |
+
],
|
| 518 |
+
"properties": {
|
| 519 |
+
"Node name for S&R": "PreviewImage"
|
| 520 |
+
}
|
| 521 |
+
},
|
| 522 |
+
{
|
| 523 |
+
"id": 73,
|
| 524 |
+
"type": "PreviewImage",
|
| 525 |
+
"pos": [
|
| 526 |
+
3460,
|
| 527 |
+
540
|
| 528 |
+
],
|
| 529 |
+
"size": {
|
| 530 |
+
"0": 210,
|
| 531 |
+
"1": 246
|
| 532 |
+
},
|
| 533 |
+
"flags": {},
|
| 534 |
+
"order": 35,
|
| 535 |
+
"mode": 0,
|
| 536 |
+
"inputs": [
|
| 537 |
+
{
|
| 538 |
+
"name": "images",
|
| 539 |
+
"type": "IMAGE",
|
| 540 |
+
"link": 102
|
| 541 |
+
}
|
| 542 |
+
],
|
| 543 |
+
"properties": {
|
| 544 |
+
"Node name for S&R": "PreviewImage"
|
| 545 |
+
}
|
| 546 |
+
},
|
| 547 |
+
{
|
| 548 |
+
"id": 68,
|
| 549 |
+
"type": "KSampler",
|
| 550 |
+
"pos": [
|
| 551 |
+
2190,
|
| 552 |
+
260
|
| 553 |
+
],
|
| 554 |
+
"size": {
|
| 555 |
+
"0": 315,
|
| 556 |
+
"1": 262
|
| 557 |
+
},
|
| 558 |
+
"flags": {},
|
| 559 |
+
"order": 14,
|
| 560 |
+
"mode": 0,
|
| 561 |
+
"inputs": [
|
| 562 |
+
{
|
| 563 |
+
"name": "model",
|
| 564 |
+
"type": "MODEL",
|
| 565 |
+
"link": 93
|
| 566 |
+
},
|
| 567 |
+
{
|
| 568 |
+
"name": "positive",
|
| 569 |
+
"type": "CONDITIONING",
|
| 570 |
+
"link": 94
|
| 571 |
+
},
|
| 572 |
+
{
|
| 573 |
+
"name": "negative",
|
| 574 |
+
"type": "CONDITIONING",
|
| 575 |
+
"link": 95
|
| 576 |
+
},
|
| 577 |
+
{
|
| 578 |
+
"name": "latent_image",
|
| 579 |
+
"type": "LATENT",
|
| 580 |
+
"link": 96
|
| 581 |
+
}
|
| 582 |
+
],
|
| 583 |
+
"outputs": [
|
| 584 |
+
{
|
| 585 |
+
"name": "LATENT",
|
| 586 |
+
"type": "LATENT",
|
| 587 |
+
"links": [
|
| 588 |
+
99
|
| 589 |
+
],
|
| 590 |
+
"slot_index": 0
|
| 591 |
+
}
|
| 592 |
+
],
|
| 593 |
+
"properties": {
|
| 594 |
+
"Node name for S&R": "KSampler"
|
| 595 |
+
},
|
| 596 |
+
"widgets_values": [
|
| 597 |
+
444793366152274,
|
| 598 |
+
"fixed",
|
| 599 |
+
50,
|
| 600 |
+
8,
|
| 601 |
+
"euler",
|
| 602 |
+
"normal",
|
| 603 |
+
1
|
| 604 |
+
]
|
| 605 |
+
},
|
| 606 |
+
{
|
| 607 |
+
"id": 70,
|
| 608 |
+
"type": "VAEDecode",
|
| 609 |
+
"pos": [
|
| 610 |
+
2530,
|
| 611 |
+
280
|
| 612 |
+
],
|
| 613 |
+
"size": {
|
| 614 |
+
"0": 210,
|
| 615 |
+
"1": 46
|
| 616 |
+
},
|
| 617 |
+
"flags": {},
|
| 618 |
+
"order": 20,
|
| 619 |
+
"mode": 0,
|
| 620 |
+
"inputs": [
|
| 621 |
+
{
|
| 622 |
+
"name": "samples",
|
| 623 |
+
"type": "LATENT",
|
| 624 |
+
"link": 99
|
| 625 |
+
},
|
| 626 |
+
{
|
| 627 |
+
"name": "vae",
|
| 628 |
+
"type": "VAE",
|
| 629 |
+
"link": 107
|
| 630 |
+
}
|
| 631 |
+
],
|
| 632 |
+
"outputs": [
|
| 633 |
+
{
|
| 634 |
+
"name": "IMAGE",
|
| 635 |
+
"type": "IMAGE",
|
| 636 |
+
"links": [
|
| 637 |
+
116
|
| 638 |
+
],
|
| 639 |
+
"slot_index": 0
|
| 640 |
+
}
|
| 641 |
+
],
|
| 642 |
+
"properties": {
|
| 643 |
+
"Node name for S&R": "VAEDecode"
|
| 644 |
+
}
|
| 645 |
+
},
|
| 646 |
+
{
|
| 647 |
+
"id": 69,
|
| 648 |
+
"type": "CLIPTextEncode",
|
| 649 |
+
"pos": [
|
| 650 |
+
1630,
|
| 651 |
+
270
|
| 652 |
+
],
|
| 653 |
+
"size": {
|
| 654 |
+
"0": 422.84503173828125,
|
| 655 |
+
"1": 164.31304931640625
|
| 656 |
+
},
|
| 657 |
+
"flags": {},
|
| 658 |
+
"order": 5,
|
| 659 |
+
"mode": 0,
|
| 660 |
+
"inputs": [
|
| 661 |
+
{
|
| 662 |
+
"name": "clip",
|
| 663 |
+
"type": "CLIP",
|
| 664 |
+
"link": 97
|
| 665 |
+
}
|
| 666 |
+
],
|
| 667 |
+
"outputs": [
|
| 668 |
+
{
|
| 669 |
+
"name": "CONDITIONING",
|
| 670 |
+
"type": "CONDITIONING",
|
| 671 |
+
"links": [
|
| 672 |
+
94,
|
| 673 |
+
111
|
| 674 |
+
],
|
| 675 |
+
"slot_index": 0
|
| 676 |
+
}
|
| 677 |
+
],
|
| 678 |
+
"properties": {
|
| 679 |
+
"Node name for S&R": "CLIPTextEncode"
|
| 680 |
+
},
|
| 681 |
+
"widgets_values": [
|
| 682 |
+
"Beautiful forest"
|
| 683 |
+
]
|
| 684 |
+
},
|
| 685 |
+
{
|
| 686 |
+
"id": 77,
|
| 687 |
+
"type": "Reroute",
|
| 688 |
+
"pos": [
|
| 689 |
+
1970,
|
| 690 |
+
440
|
| 691 |
+
],
|
| 692 |
+
"size": [
|
| 693 |
+
75,
|
| 694 |
+
26
|
| 695 |
+
],
|
| 696 |
+
"flags": {},
|
| 697 |
+
"order": 7,
|
| 698 |
+
"mode": 0,
|
| 699 |
+
"inputs": [
|
| 700 |
+
{
|
| 701 |
+
"name": "",
|
| 702 |
+
"type": "*",
|
| 703 |
+
"link": 106
|
| 704 |
+
}
|
| 705 |
+
],
|
| 706 |
+
"outputs": [
|
| 707 |
+
{
|
| 708 |
+
"name": "",
|
| 709 |
+
"type": "VAE",
|
| 710 |
+
"links": [
|
| 711 |
+
107,
|
| 712 |
+
118
|
| 713 |
+
],
|
| 714 |
+
"slot_index": 0
|
| 715 |
+
}
|
| 716 |
+
],
|
| 717 |
+
"properties": {
|
| 718 |
+
"showOutputText": false,
|
| 719 |
+
"horizontal": false
|
| 720 |
+
}
|
| 721 |
+
},
|
| 722 |
+
{
|
| 723 |
+
"id": 46,
|
| 724 |
+
"type": "EmptyLatentImage",
|
| 725 |
+
"pos": [
|
| 726 |
+
501,
|
| 727 |
+
1441
|
| 728 |
+
],
|
| 729 |
+
"size": {
|
| 730 |
+
"0": 315,
|
| 731 |
+
"1": 106
|
| 732 |
+
},
|
| 733 |
+
"flags": {},
|
| 734 |
+
"order": 0,
|
| 735 |
+
"mode": 0,
|
| 736 |
+
"outputs": [
|
| 737 |
+
{
|
| 738 |
+
"name": "LATENT",
|
| 739 |
+
"type": "LATENT",
|
| 740 |
+
"links": [
|
| 741 |
+
65,
|
| 742 |
+
76,
|
| 743 |
+
85,
|
| 744 |
+
96,
|
| 745 |
+
113,
|
| 746 |
+
126
|
| 747 |
+
],
|
| 748 |
+
"slot_index": 0
|
| 749 |
+
}
|
| 750 |
+
],
|
| 751 |
+
"properties": {
|
| 752 |
+
"Node name for S&R": "EmptyLatentImage"
|
| 753 |
+
},
|
| 754 |
+
"widgets_values": [
|
| 755 |
+
1024,
|
| 756 |
+
1024,
|
| 757 |
+
1
|
| 758 |
+
]
|
| 759 |
+
},
|
| 760 |
+
{
|
| 761 |
+
"id": 78,
|
| 762 |
+
"type": "Reroute",
|
| 763 |
+
"pos": [
|
| 764 |
+
2009,
|
| 765 |
+
1378
|
| 766 |
+
],
|
| 767 |
+
"size": [
|
| 768 |
+
75,
|
| 769 |
+
26
|
| 770 |
+
],
|
| 771 |
+
"flags": {},
|
| 772 |
+
"order": 8,
|
| 773 |
+
"mode": 0,
|
| 774 |
+
"inputs": [
|
| 775 |
+
{
|
| 776 |
+
"name": "",
|
| 777 |
+
"type": "*",
|
| 778 |
+
"link": 108
|
| 779 |
+
}
|
| 780 |
+
],
|
| 781 |
+
"outputs": [
|
| 782 |
+
{
|
| 783 |
+
"name": "",
|
| 784 |
+
"type": "VAE",
|
| 785 |
+
"links": [
|
| 786 |
+
109
|
| 787 |
+
],
|
| 788 |
+
"slot_index": 0
|
| 789 |
+
}
|
| 790 |
+
],
|
| 791 |
+
"properties": {
|
| 792 |
+
"showOutputText": false,
|
| 793 |
+
"horizontal": false
|
| 794 |
+
}
|
| 795 |
+
},
|
| 796 |
+
{
|
| 797 |
+
"id": 82,
|
| 798 |
+
"type": "Reroute",
|
| 799 |
+
"pos": [
|
| 800 |
+
2030,
|
| 801 |
+
2490
|
| 802 |
+
],
|
| 803 |
+
"size": [
|
| 804 |
+
75,
|
| 805 |
+
26
|
| 806 |
+
],
|
| 807 |
+
"flags": {},
|
| 808 |
+
"order": 9,
|
| 809 |
+
"mode": 0,
|
| 810 |
+
"inputs": [
|
| 811 |
+
{
|
| 812 |
+
"name": "",
|
| 813 |
+
"type": "*",
|
| 814 |
+
"link": 119
|
| 815 |
+
}
|
| 816 |
+
],
|
| 817 |
+
"outputs": [
|
| 818 |
+
{
|
| 819 |
+
"name": "",
|
| 820 |
+
"type": "VAE",
|
| 821 |
+
"links": [
|
| 822 |
+
120,
|
| 823 |
+
121
|
| 824 |
+
],
|
| 825 |
+
"slot_index": 0
|
| 826 |
+
}
|
| 827 |
+
],
|
| 828 |
+
"properties": {
|
| 829 |
+
"showOutputText": false,
|
| 830 |
+
"horizontal": false
|
| 831 |
+
}
|
| 832 |
+
},
|
| 833 |
+
{
|
| 834 |
+
"id": 48,
|
| 835 |
+
"type": "CLIPTextEncode",
|
| 836 |
+
"pos": [
|
| 837 |
+
1247,
|
| 838 |
+
1461
|
| 839 |
+
],
|
| 840 |
+
"size": {
|
| 841 |
+
"0": 425.27801513671875,
|
| 842 |
+
"1": 180.6060791015625
|
| 843 |
+
},
|
| 844 |
+
"flags": {},
|
| 845 |
+
"order": 3,
|
| 846 |
+
"mode": 0,
|
| 847 |
+
"inputs": [
|
| 848 |
+
{
|
| 849 |
+
"name": "clip",
|
| 850 |
+
"type": "CLIP",
|
| 851 |
+
"link": 67
|
| 852 |
+
}
|
| 853 |
+
],
|
| 854 |
+
"outputs": [
|
| 855 |
+
{
|
| 856 |
+
"name": "CONDITIONING",
|
| 857 |
+
"type": "CONDITIONING",
|
| 858 |
+
"links": [
|
| 859 |
+
64,
|
| 860 |
+
75,
|
| 861 |
+
84,
|
| 862 |
+
95,
|
| 863 |
+
112,
|
| 864 |
+
125
|
| 865 |
+
],
|
| 866 |
+
"slot_index": 0
|
| 867 |
+
}
|
| 868 |
+
],
|
| 869 |
+
"properties": {
|
| 870 |
+
"Node name for S&R": "CLIPTextEncode"
|
| 871 |
+
},
|
| 872 |
+
"widgets_values": [
|
| 873 |
+
"text, watermark"
|
| 874 |
+
]
|
| 875 |
+
},
|
| 876 |
+
{
|
| 877 |
+
"id": 45,
|
| 878 |
+
"type": "CheckpointLoaderSimple",
|
| 879 |
+
"pos": [
|
| 880 |
+
507,
|
| 881 |
+
1591
|
| 882 |
+
],
|
| 883 |
+
"size": {
|
| 884 |
+
"0": 315,
|
| 885 |
+
"1": 98
|
| 886 |
+
},
|
| 887 |
+
"flags": {},
|
| 888 |
+
"order": 1,
|
| 889 |
+
"mode": 0,
|
| 890 |
+
"outputs": [
|
| 891 |
+
{
|
| 892 |
+
"name": "MODEL",
|
| 893 |
+
"type": "MODEL",
|
| 894 |
+
"links": [
|
| 895 |
+
62,
|
| 896 |
+
73,
|
| 897 |
+
93,
|
| 898 |
+
105,
|
| 899 |
+
110,
|
| 900 |
+
123
|
| 901 |
+
],
|
| 902 |
+
"slot_index": 0
|
| 903 |
+
},
|
| 904 |
+
{
|
| 905 |
+
"name": "CLIP",
|
| 906 |
+
"type": "CLIP",
|
| 907 |
+
"links": [
|
| 908 |
+
66,
|
| 909 |
+
67,
|
| 910 |
+
86,
|
| 911 |
+
97,
|
| 912 |
+
127
|
| 913 |
+
],
|
| 914 |
+
"slot_index": 1
|
| 915 |
+
},
|
| 916 |
+
{
|
| 917 |
+
"name": "VAE",
|
| 918 |
+
"type": "VAE",
|
| 919 |
+
"links": [
|
| 920 |
+
106,
|
| 921 |
+
108,
|
| 922 |
+
119,
|
| 923 |
+
131
|
| 924 |
+
],
|
| 925 |
+
"slot_index": 2
|
| 926 |
+
}
|
| 927 |
+
],
|
| 928 |
+
"properties": {
|
| 929 |
+
"Node name for S&R": "CheckpointLoaderSimple"
|
| 930 |
+
},
|
| 931 |
+
"widgets_values": [
|
| 932 |
+
"sd_xl_base_1.0.safetensors"
|
| 933 |
+
]
|
| 934 |
+
},
|
| 935 |
+
{
|
| 936 |
+
"id": 47,
|
| 937 |
+
"type": "CLIPTextEncode",
|
| 938 |
+
"pos": [
|
| 939 |
+
1630,
|
| 940 |
+
2220
|
| 941 |
+
],
|
| 942 |
+
"size": {
|
| 943 |
+
"0": 422.84503173828125,
|
| 944 |
+
"1": 164.31304931640625
|
| 945 |
+
},
|
| 946 |
+
"flags": {},
|
| 947 |
+
"order": 2,
|
| 948 |
+
"mode": 0,
|
| 949 |
+
"inputs": [
|
| 950 |
+
{
|
| 951 |
+
"name": "clip",
|
| 952 |
+
"type": "CLIP",
|
| 953 |
+
"link": 66
|
| 954 |
+
}
|
| 955 |
+
],
|
| 956 |
+
"outputs": [
|
| 957 |
+
{
|
| 958 |
+
"name": "CONDITIONING",
|
| 959 |
+
"type": "CONDITIONING",
|
| 960 |
+
"links": [
|
| 961 |
+
63,
|
| 962 |
+
74
|
| 963 |
+
],
|
| 964 |
+
"slot_index": 0
|
| 965 |
+
}
|
| 966 |
+
],
|
| 967 |
+
"properties": {
|
| 968 |
+
"Node name for S&R": "CLIPTextEncode"
|
| 969 |
+
},
|
| 970 |
+
"widgets_values": [
|
| 971 |
+
"Large crowd of people all facing the camera posing for a company photo."
|
| 972 |
+
]
|
| 973 |
+
},
|
| 974 |
+
{
|
| 975 |
+
"id": 64,
|
| 976 |
+
"type": "CLIPTextEncode",
|
| 977 |
+
"pos": [
|
| 978 |
+
1737,
|
| 979 |
+
1195
|
| 980 |
+
],
|
| 981 |
+
"size": {
|
| 982 |
+
"0": 422.84503173828125,
|
| 983 |
+
"1": 164.31304931640625
|
| 984 |
+
},
|
| 985 |
+
"flags": {},
|
| 986 |
+
"order": 4,
|
| 987 |
+
"mode": 0,
|
| 988 |
+
"inputs": [
|
| 989 |
+
{
|
| 990 |
+
"name": "clip",
|
| 991 |
+
"type": "CLIP",
|
| 992 |
+
"link": 86
|
| 993 |
+
}
|
| 994 |
+
],
|
| 995 |
+
"outputs": [
|
| 996 |
+
{
|
| 997 |
+
"name": "CONDITIONING",
|
| 998 |
+
"type": "CONDITIONING",
|
| 999 |
+
"links": [
|
| 1000 |
+
87
|
| 1001 |
+
],
|
| 1002 |
+
"slot_index": 0
|
| 1003 |
+
}
|
| 1004 |
+
],
|
| 1005 |
+
"properties": {
|
| 1006 |
+
"Node name for S&R": "CLIPTextEncode"
|
| 1007 |
+
},
|
| 1008 |
+
"widgets_values": [
|
| 1009 |
+
"Female model posing looking at the camera"
|
| 1010 |
+
]
|
| 1011 |
+
},
|
| 1012 |
+
{
|
| 1013 |
+
"id": 79,
|
| 1014 |
+
"type": "KSampler",
|
| 1015 |
+
"pos": [
|
| 1016 |
+
2190,
|
| 1017 |
+
560
|
| 1018 |
+
],
|
| 1019 |
+
"size": {
|
| 1020 |
+
"0": 315,
|
| 1021 |
+
"1": 262
|
| 1022 |
+
},
|
| 1023 |
+
"flags": {},
|
| 1024 |
+
"order": 15,
|
| 1025 |
+
"mode": 0,
|
| 1026 |
+
"inputs": [
|
| 1027 |
+
{
|
| 1028 |
+
"name": "model",
|
| 1029 |
+
"type": "MODEL",
|
| 1030 |
+
"link": 110
|
| 1031 |
+
},
|
| 1032 |
+
{
|
| 1033 |
+
"name": "positive",
|
| 1034 |
+
"type": "CONDITIONING",
|
| 1035 |
+
"link": 111
|
| 1036 |
+
},
|
| 1037 |
+
{
|
| 1038 |
+
"name": "negative",
|
| 1039 |
+
"type": "CONDITIONING",
|
| 1040 |
+
"link": 112
|
| 1041 |
+
},
|
| 1042 |
+
{
|
| 1043 |
+
"name": "latent_image",
|
| 1044 |
+
"type": "LATENT",
|
| 1045 |
+
"link": 113
|
| 1046 |
+
}
|
| 1047 |
+
],
|
| 1048 |
+
"outputs": [
|
| 1049 |
+
{
|
| 1050 |
+
"name": "LATENT",
|
| 1051 |
+
"type": "LATENT",
|
| 1052 |
+
"links": [
|
| 1053 |
+
114
|
| 1054 |
+
],
|
| 1055 |
+
"slot_index": 0
|
| 1056 |
+
}
|
| 1057 |
+
],
|
| 1058 |
+
"properties": {
|
| 1059 |
+
"Node name for S&R": "KSampler"
|
| 1060 |
+
},
|
| 1061 |
+
"widgets_values": [
|
| 1062 |
+
444793366152415,
|
| 1063 |
+
"fixed",
|
| 1064 |
+
50,
|
| 1065 |
+
8,
|
| 1066 |
+
"euler",
|
| 1067 |
+
"normal",
|
| 1068 |
+
1
|
| 1069 |
+
]
|
| 1070 |
+
},
|
| 1071 |
+
{
|
| 1072 |
+
"id": 81,
|
| 1073 |
+
"type": "VAEDecode",
|
| 1074 |
+
"pos": [
|
| 1075 |
+
2540,
|
| 1076 |
+
570
|
| 1077 |
+
],
|
| 1078 |
+
"size": {
|
| 1079 |
+
"0": 210,
|
| 1080 |
+
"1": 46
|
| 1081 |
+
},
|
| 1082 |
+
"flags": {},
|
| 1083 |
+
"order": 21,
|
| 1084 |
+
"mode": 0,
|
| 1085 |
+
"inputs": [
|
| 1086 |
+
{
|
| 1087 |
+
"name": "samples",
|
| 1088 |
+
"type": "LATENT",
|
| 1089 |
+
"link": 114
|
| 1090 |
+
},
|
| 1091 |
+
{
|
| 1092 |
+
"name": "vae",
|
| 1093 |
+
"type": "VAE",
|
| 1094 |
+
"link": 118
|
| 1095 |
+
}
|
| 1096 |
+
],
|
| 1097 |
+
"outputs": [
|
| 1098 |
+
{
|
| 1099 |
+
"name": "IMAGE",
|
| 1100 |
+
"type": "IMAGE",
|
| 1101 |
+
"links": [
|
| 1102 |
+
115
|
| 1103 |
+
],
|
| 1104 |
+
"slot_index": 0
|
| 1105 |
+
}
|
| 1106 |
+
],
|
| 1107 |
+
"properties": {
|
| 1108 |
+
"Node name for S&R": "VAEDecode"
|
| 1109 |
+
}
|
| 1110 |
+
},
|
| 1111 |
+
{
|
| 1112 |
+
"id": 80,
|
| 1113 |
+
"type": "ImageBatch",
|
| 1114 |
+
"pos": [
|
| 1115 |
+
2810,
|
| 1116 |
+
580
|
| 1117 |
+
],
|
| 1118 |
+
"size": {
|
| 1119 |
+
"0": 210,
|
| 1120 |
+
"1": 46
|
| 1121 |
+
},
|
| 1122 |
+
"flags": {},
|
| 1123 |
+
"order": 26,
|
| 1124 |
+
"mode": 0,
|
| 1125 |
+
"inputs": [
|
| 1126 |
+
{
|
| 1127 |
+
"name": "image1",
|
| 1128 |
+
"type": "IMAGE",
|
| 1129 |
+
"link": 116
|
| 1130 |
+
},
|
| 1131 |
+
{
|
| 1132 |
+
"name": "image2",
|
| 1133 |
+
"type": "IMAGE",
|
| 1134 |
+
"link": 115
|
| 1135 |
+
}
|
| 1136 |
+
],
|
| 1137 |
+
"outputs": [
|
| 1138 |
+
{
|
| 1139 |
+
"name": "IMAGE",
|
| 1140 |
+
"type": "IMAGE",
|
| 1141 |
+
"links": [
|
| 1142 |
+
117,
|
| 1143 |
+
122
|
| 1144 |
+
],
|
| 1145 |
+
"shape": 3,
|
| 1146 |
+
"slot_index": 0
|
| 1147 |
+
}
|
| 1148 |
+
],
|
| 1149 |
+
"properties": {
|
| 1150 |
+
"Node name for S&R": "ImageBatch"
|
| 1151 |
+
}
|
| 1152 |
+
},
|
| 1153 |
+
{
|
| 1154 |
+
"id": 40,
|
| 1155 |
+
"type": "PreviewImage",
|
| 1156 |
+
"pos": [
|
| 1157 |
+
3530,
|
| 1158 |
+
2070
|
| 1159 |
+
],
|
| 1160 |
+
"size": [
|
| 1161 |
+
140.9676944827229,
|
| 1162 |
+
232.36873662566404
|
| 1163 |
+
],
|
| 1164 |
+
"flags": {},
|
| 1165 |
+
"order": 34,
|
| 1166 |
+
"mode": 0,
|
| 1167 |
+
"inputs": [
|
| 1168 |
+
{
|
| 1169 |
+
"name": "images",
|
| 1170 |
+
"type": "IMAGE",
|
| 1171 |
+
"link": 53
|
| 1172 |
+
}
|
| 1173 |
+
],
|
| 1174 |
+
"properties": {
|
| 1175 |
+
"Node name for S&R": "PreviewImage"
|
| 1176 |
+
}
|
| 1177 |
+
},
|
| 1178 |
+
{
|
| 1179 |
+
"id": 87,
|
| 1180 |
+
"type": "Reroute",
|
| 1181 |
+
"pos": [
|
| 1182 |
+
1990,
|
| 1183 |
+
-170
|
| 1184 |
+
],
|
| 1185 |
+
"size": [
|
| 1186 |
+
75,
|
| 1187 |
+
26
|
| 1188 |
+
],
|
| 1189 |
+
"flags": {},
|
| 1190 |
+
"order": 10,
|
| 1191 |
+
"mode": 0,
|
| 1192 |
+
"inputs": [
|
| 1193 |
+
{
|
| 1194 |
+
"name": "",
|
| 1195 |
+
"type": "*",
|
| 1196 |
+
"link": 131
|
| 1197 |
+
}
|
| 1198 |
+
],
|
| 1199 |
+
"outputs": [
|
| 1200 |
+
{
|
| 1201 |
+
"name": "",
|
| 1202 |
+
"type": "VAE",
|
| 1203 |
+
"links": [
|
| 1204 |
+
129
|
| 1205 |
+
]
|
| 1206 |
+
}
|
| 1207 |
+
],
|
| 1208 |
+
"properties": {
|
| 1209 |
+
"showOutputText": false,
|
| 1210 |
+
"horizontal": false
|
| 1211 |
+
}
|
| 1212 |
+
},
|
| 1213 |
+
{
|
| 1214 |
+
"id": 84,
|
| 1215 |
+
"type": "CLIPTextEncode",
|
| 1216 |
+
"pos": [
|
| 1217 |
+
1650,
|
| 1218 |
+
-340
|
| 1219 |
+
],
|
| 1220 |
+
"size": {
|
| 1221 |
+
"0": 422.84503173828125,
|
| 1222 |
+
"1": 164.31304931640625
|
| 1223 |
+
},
|
| 1224 |
+
"flags": {},
|
| 1225 |
+
"order": 6,
|
| 1226 |
+
"mode": 0,
|
| 1227 |
+
"inputs": [
|
| 1228 |
+
{
|
| 1229 |
+
"name": "clip",
|
| 1230 |
+
"type": "CLIP",
|
| 1231 |
+
"link": 127
|
| 1232 |
+
}
|
| 1233 |
+
],
|
| 1234 |
+
"outputs": [
|
| 1235 |
+
{
|
| 1236 |
+
"name": "CONDITIONING",
|
| 1237 |
+
"type": "CONDITIONING",
|
| 1238 |
+
"links": [
|
| 1239 |
+
124
|
| 1240 |
+
],
|
| 1241 |
+
"slot_index": 0
|
| 1242 |
+
}
|
| 1243 |
+
],
|
| 1244 |
+
"properties": {
|
| 1245 |
+
"Node name for S&R": "CLIPTextEncode"
|
| 1246 |
+
},
|
| 1247 |
+
"widgets_values": [
|
| 1248 |
+
"Beautiful forest"
|
| 1249 |
+
]
|
| 1250 |
+
},
|
| 1251 |
+
{
|
| 1252 |
+
"id": 86,
|
| 1253 |
+
"type": "AutoCropFaces",
|
| 1254 |
+
"pos": [
|
| 1255 |
+
3050,
|
| 1256 |
+
-320
|
| 1257 |
+
],
|
| 1258 |
+
"size": {
|
| 1259 |
+
"0": 315,
|
| 1260 |
+
"1": 198
|
| 1261 |
+
},
|
| 1262 |
+
"flags": {},
|
| 1263 |
+
"order": 27,
|
| 1264 |
+
"mode": 0,
|
| 1265 |
+
"inputs": [
|
| 1266 |
+
{
|
| 1267 |
+
"name": "image",
|
| 1268 |
+
"type": "IMAGE",
|
| 1269 |
+
"link": 141
|
| 1270 |
+
}
|
| 1271 |
+
],
|
| 1272 |
+
"outputs": [
|
| 1273 |
+
{
|
| 1274 |
+
"name": "face",
|
| 1275 |
+
"type": "IMAGE",
|
| 1276 |
+
"links": [
|
| 1277 |
+
140
|
| 1278 |
+
],
|
| 1279 |
+
"shape": 3,
|
| 1280 |
+
"slot_index": 0
|
| 1281 |
+
},
|
| 1282 |
+
{
|
| 1283 |
+
"name": "CROP_DATA",
|
| 1284 |
+
"type": "CROP_DATA",
|
| 1285 |
+
"links": null,
|
| 1286 |
+
"shape": 3,
|
| 1287 |
+
"slot_index": 1
|
| 1288 |
+
}
|
| 1289 |
+
],
|
| 1290 |
+
"properties": {
|
| 1291 |
+
"Node name for S&R": "AutoCropFaces"
|
| 1292 |
+
},
|
| 1293 |
+
"widgets_values": [
|
| 1294 |
+
5,
|
| 1295 |
+
0,
|
| 1296 |
+
-1,
|
| 1297 |
+
1.5,
|
| 1298 |
+
0.5,
|
| 1299 |
+
1
|
| 1300 |
+
]
|
| 1301 |
+
},
|
| 1302 |
+
{
|
| 1303 |
+
"id": 91,
|
| 1304 |
+
"type": "PreviewImage",
|
| 1305 |
+
"pos": [
|
| 1306 |
+
3410,
|
| 1307 |
+
-320
|
| 1308 |
+
],
|
| 1309 |
+
"size": {
|
| 1310 |
+
"0": 210,
|
| 1311 |
+
"1": 246
|
| 1312 |
+
},
|
| 1313 |
+
"flags": {},
|
| 1314 |
+
"order": 33,
|
| 1315 |
+
"mode": 0,
|
| 1316 |
+
"inputs": [
|
| 1317 |
+
{
|
| 1318 |
+
"name": "images",
|
| 1319 |
+
"type": "IMAGE",
|
| 1320 |
+
"link": 140
|
| 1321 |
+
}
|
| 1322 |
+
],
|
| 1323 |
+
"properties": {
|
| 1324 |
+
"Node name for S&R": "PreviewImage"
|
| 1325 |
+
}
|
| 1326 |
+
},
|
| 1327 |
+
{
|
| 1328 |
+
"id": 71,
|
| 1329 |
+
"type": "PreviewImage",
|
| 1330 |
+
"pos": [
|
| 1331 |
+
3450,
|
| 1332 |
+
260
|
| 1333 |
+
],
|
| 1334 |
+
"size": {
|
| 1335 |
+
"0": 210,
|
| 1336 |
+
"1": 246
|
| 1337 |
+
},
|
| 1338 |
+
"flags": {},
|
| 1339 |
+
"order": 32,
|
| 1340 |
+
"mode": 0,
|
| 1341 |
+
"inputs": [
|
| 1342 |
+
{
|
| 1343 |
+
"name": "images",
|
| 1344 |
+
"type": "IMAGE",
|
| 1345 |
+
"link": 122
|
| 1346 |
+
}
|
| 1347 |
+
],
|
| 1348 |
+
"properties": {
|
| 1349 |
+
"Node name for S&R": "PreviewImage"
|
| 1350 |
+
}
|
| 1351 |
+
},
|
| 1352 |
+
{
|
| 1353 |
+
"id": 36,
|
| 1354 |
+
"type": "AutoCropFaces",
|
| 1355 |
+
"pos": [
|
| 1356 |
+
3120,
|
| 1357 |
+
2130
|
| 1358 |
+
],
|
| 1359 |
+
"size": {
|
| 1360 |
+
"0": 315,
|
| 1361 |
+
"1": 198
|
| 1362 |
+
},
|
| 1363 |
+
"flags": {},
|
| 1364 |
+
"order": 28,
|
| 1365 |
+
"mode": 0,
|
| 1366 |
+
"inputs": [
|
| 1367 |
+
{
|
| 1368 |
+
"name": "image",
|
| 1369 |
+
"type": "IMAGE",
|
| 1370 |
+
"link": 81
|
| 1371 |
+
}
|
| 1372 |
+
],
|
| 1373 |
+
"outputs": [
|
| 1374 |
+
{
|
| 1375 |
+
"name": "face",
|
| 1376 |
+
"type": "IMAGE",
|
| 1377 |
+
"links": [
|
| 1378 |
+
53
|
| 1379 |
+
],
|
| 1380 |
+
"shape": 3,
|
| 1381 |
+
"slot_index": 0
|
| 1382 |
+
},
|
| 1383 |
+
{
|
| 1384 |
+
"name": "CROP_DATA",
|
| 1385 |
+
"type": "CROP_DATA",
|
| 1386 |
+
"links": null,
|
| 1387 |
+
"shape": 3,
|
| 1388 |
+
"slot_index": 1
|
| 1389 |
+
}
|
| 1390 |
+
],
|
| 1391 |
+
"properties": {
|
| 1392 |
+
"Node name for S&R": "AutoCropFaces"
|
| 1393 |
+
},
|
| 1394 |
+
"widgets_values": [
|
| 1395 |
+
50,
|
| 1396 |
+
5,
|
| 1397 |
+
15,
|
| 1398 |
+
1.5,
|
| 1399 |
+
0.5,
|
| 1400 |
+
1
|
| 1401 |
+
]
|
| 1402 |
+
},
|
| 1403 |
+
{
|
| 1404 |
+
"id": 85,
|
| 1405 |
+
"type": "VAEDecode",
|
| 1406 |
+
"pos": [
|
| 1407 |
+
2550,
|
| 1408 |
+
-330
|
| 1409 |
+
],
|
| 1410 |
+
"size": {
|
| 1411 |
+
"0": 210,
|
| 1412 |
+
"1": 46
|
| 1413 |
+
},
|
| 1414 |
+
"flags": {},
|
| 1415 |
+
"order": 22,
|
| 1416 |
+
"mode": 0,
|
| 1417 |
+
"inputs": [
|
| 1418 |
+
{
|
| 1419 |
+
"name": "samples",
|
| 1420 |
+
"type": "LATENT",
|
| 1421 |
+
"link": 128
|
| 1422 |
+
},
|
| 1423 |
+
{
|
| 1424 |
+
"name": "vae",
|
| 1425 |
+
"type": "VAE",
|
| 1426 |
+
"link": 129
|
| 1427 |
+
}
|
| 1428 |
+
],
|
| 1429 |
+
"outputs": [
|
| 1430 |
+
{
|
| 1431 |
+
"name": "IMAGE",
|
| 1432 |
+
"type": "IMAGE",
|
| 1433 |
+
"links": [
|
| 1434 |
+
141
|
| 1435 |
+
],
|
| 1436 |
+
"slot_index": 0
|
| 1437 |
+
}
|
| 1438 |
+
],
|
| 1439 |
+
"properties": {
|
| 1440 |
+
"Node name for S&R": "VAEDecode"
|
| 1441 |
+
}
|
| 1442 |
+
},
|
| 1443 |
+
{
|
| 1444 |
+
"id": 83,
|
| 1445 |
+
"type": "KSampler",
|
| 1446 |
+
"pos": [
|
| 1447 |
+
2200,
|
| 1448 |
+
-350
|
| 1449 |
+
],
|
| 1450 |
+
"size": {
|
| 1451 |
+
"0": 315,
|
| 1452 |
+
"1": 262
|
| 1453 |
+
},
|
| 1454 |
+
"flags": {},
|
| 1455 |
+
"order": 16,
|
| 1456 |
+
"mode": 0,
|
| 1457 |
+
"inputs": [
|
| 1458 |
+
{
|
| 1459 |
+
"name": "model",
|
| 1460 |
+
"type": "MODEL",
|
| 1461 |
+
"link": 123
|
| 1462 |
+
},
|
| 1463 |
+
{
|
| 1464 |
+
"name": "positive",
|
| 1465 |
+
"type": "CONDITIONING",
|
| 1466 |
+
"link": 124
|
| 1467 |
+
},
|
| 1468 |
+
{
|
| 1469 |
+
"name": "negative",
|
| 1470 |
+
"type": "CONDITIONING",
|
| 1471 |
+
"link": 125
|
| 1472 |
+
},
|
| 1473 |
+
{
|
| 1474 |
+
"name": "latent_image",
|
| 1475 |
+
"type": "LATENT",
|
| 1476 |
+
"link": 126
|
| 1477 |
+
}
|
| 1478 |
+
],
|
| 1479 |
+
"outputs": [
|
| 1480 |
+
{
|
| 1481 |
+
"name": "LATENT",
|
| 1482 |
+
"type": "LATENT",
|
| 1483 |
+
"links": [
|
| 1484 |
+
128
|
| 1485 |
+
],
|
| 1486 |
+
"slot_index": 0
|
| 1487 |
+
}
|
| 1488 |
+
],
|
| 1489 |
+
"properties": {
|
| 1490 |
+
"Node name for S&R": "KSampler"
|
| 1491 |
+
},
|
| 1492 |
+
"widgets_values": [
|
| 1493 |
+
444793366152357,
|
| 1494 |
+
"fixed",
|
| 1495 |
+
50,
|
| 1496 |
+
8,
|
| 1497 |
+
"euler",
|
| 1498 |
+
"normal",
|
| 1499 |
+
1
|
| 1500 |
+
]
|
| 1501 |
+
}
|
| 1502 |
+
],
|
| 1503 |
+
"links": [
|
| 1504 |
+
[
|
| 1505 |
+
53,
|
| 1506 |
+
36,
|
| 1507 |
+
0,
|
| 1508 |
+
40,
|
| 1509 |
+
0,
|
| 1510 |
+
"IMAGE"
|
| 1511 |
+
],
|
| 1512 |
+
[
|
| 1513 |
+
62,
|
| 1514 |
+
45,
|
| 1515 |
+
0,
|
| 1516 |
+
44,
|
| 1517 |
+
0,
|
| 1518 |
+
"MODEL"
|
| 1519 |
+
],
|
| 1520 |
+
[
|
| 1521 |
+
63,
|
| 1522 |
+
47,
|
| 1523 |
+
0,
|
| 1524 |
+
44,
|
| 1525 |
+
1,
|
| 1526 |
+
"CONDITIONING"
|
| 1527 |
+
],
|
| 1528 |
+
[
|
| 1529 |
+
64,
|
| 1530 |
+
48,
|
| 1531 |
+
0,
|
| 1532 |
+
44,
|
| 1533 |
+
2,
|
| 1534 |
+
"CONDITIONING"
|
| 1535 |
+
],
|
| 1536 |
+
[
|
| 1537 |
+
65,
|
| 1538 |
+
46,
|
| 1539 |
+
0,
|
| 1540 |
+
44,
|
| 1541 |
+
3,
|
| 1542 |
+
"LATENT"
|
| 1543 |
+
],
|
| 1544 |
+
[
|
| 1545 |
+
66,
|
| 1546 |
+
45,
|
| 1547 |
+
1,
|
| 1548 |
+
47,
|
| 1549 |
+
0,
|
| 1550 |
+
"CLIP"
|
| 1551 |
+
],
|
| 1552 |
+
[
|
| 1553 |
+
67,
|
| 1554 |
+
45,
|
| 1555 |
+
1,
|
| 1556 |
+
48,
|
| 1557 |
+
0,
|
| 1558 |
+
"CLIP"
|
| 1559 |
+
],
|
| 1560 |
+
[
|
| 1561 |
+
68,
|
| 1562 |
+
44,
|
| 1563 |
+
0,
|
| 1564 |
+
49,
|
| 1565 |
+
0,
|
| 1566 |
+
"LATENT"
|
| 1567 |
+
],
|
| 1568 |
+
[
|
| 1569 |
+
73,
|
| 1570 |
+
45,
|
| 1571 |
+
0,
|
| 1572 |
+
52,
|
| 1573 |
+
0,
|
| 1574 |
+
"MODEL"
|
| 1575 |
+
],
|
| 1576 |
+
[
|
| 1577 |
+
74,
|
| 1578 |
+
47,
|
| 1579 |
+
0,
|
| 1580 |
+
52,
|
| 1581 |
+
1,
|
| 1582 |
+
"CONDITIONING"
|
| 1583 |
+
],
|
| 1584 |
+
[
|
| 1585 |
+
75,
|
| 1586 |
+
48,
|
| 1587 |
+
0,
|
| 1588 |
+
52,
|
| 1589 |
+
2,
|
| 1590 |
+
"CONDITIONING"
|
| 1591 |
+
],
|
| 1592 |
+
[
|
| 1593 |
+
76,
|
| 1594 |
+
46,
|
| 1595 |
+
0,
|
| 1596 |
+
52,
|
| 1597 |
+
3,
|
| 1598 |
+
"LATENT"
|
| 1599 |
+
],
|
| 1600 |
+
[
|
| 1601 |
+
78,
|
| 1602 |
+
52,
|
| 1603 |
+
0,
|
| 1604 |
+
54,
|
| 1605 |
+
0,
|
| 1606 |
+
"LATENT"
|
| 1607 |
+
],
|
| 1608 |
+
[
|
| 1609 |
+
79,
|
| 1610 |
+
49,
|
| 1611 |
+
0,
|
| 1612 |
+
56,
|
| 1613 |
+
0,
|
| 1614 |
+
"IMAGE"
|
| 1615 |
+
],
|
| 1616 |
+
[
|
| 1617 |
+
80,
|
| 1618 |
+
54,
|
| 1619 |
+
0,
|
| 1620 |
+
56,
|
| 1621 |
+
1,
|
| 1622 |
+
"IMAGE"
|
| 1623 |
+
],
|
| 1624 |
+
[
|
| 1625 |
+
81,
|
| 1626 |
+
56,
|
| 1627 |
+
0,
|
| 1628 |
+
36,
|
| 1629 |
+
0,
|
| 1630 |
+
"IMAGE"
|
| 1631 |
+
],
|
| 1632 |
+
[
|
| 1633 |
+
82,
|
| 1634 |
+
56,
|
| 1635 |
+
0,
|
| 1636 |
+
51,
|
| 1637 |
+
0,
|
| 1638 |
+
"IMAGE"
|
| 1639 |
+
],
|
| 1640 |
+
[
|
| 1641 |
+
84,
|
| 1642 |
+
48,
|
| 1643 |
+
0,
|
| 1644 |
+
61,
|
| 1645 |
+
2,
|
| 1646 |
+
"CONDITIONING"
|
| 1647 |
+
],
|
| 1648 |
+
[
|
| 1649 |
+
85,
|
| 1650 |
+
46,
|
| 1651 |
+
0,
|
| 1652 |
+
61,
|
| 1653 |
+
3,
|
| 1654 |
+
"LATENT"
|
| 1655 |
+
],
|
| 1656 |
+
[
|
| 1657 |
+
86,
|
| 1658 |
+
45,
|
| 1659 |
+
1,
|
| 1660 |
+
64,
|
| 1661 |
+
0,
|
| 1662 |
+
"CLIP"
|
| 1663 |
+
],
|
| 1664 |
+
[
|
| 1665 |
+
87,
|
| 1666 |
+
64,
|
| 1667 |
+
0,
|
| 1668 |
+
61,
|
| 1669 |
+
1,
|
| 1670 |
+
"CONDITIONING"
|
| 1671 |
+
],
|
| 1672 |
+
[
|
| 1673 |
+
89,
|
| 1674 |
+
61,
|
| 1675 |
+
0,
|
| 1676 |
+
65,
|
| 1677 |
+
0,
|
| 1678 |
+
"LATENT"
|
| 1679 |
+
],
|
| 1680 |
+
[
|
| 1681 |
+
90,
|
| 1682 |
+
65,
|
| 1683 |
+
0,
|
| 1684 |
+
58,
|
| 1685 |
+
0,
|
| 1686 |
+
"IMAGE"
|
| 1687 |
+
],
|
| 1688 |
+
[
|
| 1689 |
+
91,
|
| 1690 |
+
58,
|
| 1691 |
+
0,
|
| 1692 |
+
66,
|
| 1693 |
+
0,
|
| 1694 |
+
"IMAGE"
|
| 1695 |
+
],
|
| 1696 |
+
[
|
| 1697 |
+
92,
|
| 1698 |
+
65,
|
| 1699 |
+
0,
|
| 1700 |
+
67,
|
| 1701 |
+
0,
|
| 1702 |
+
"IMAGE"
|
| 1703 |
+
],
|
| 1704 |
+
[
|
| 1705 |
+
93,
|
| 1706 |
+
45,
|
| 1707 |
+
0,
|
| 1708 |
+
68,
|
| 1709 |
+
0,
|
| 1710 |
+
"MODEL"
|
| 1711 |
+
],
|
| 1712 |
+
[
|
| 1713 |
+
94,
|
| 1714 |
+
69,
|
| 1715 |
+
0,
|
| 1716 |
+
68,
|
| 1717 |
+
1,
|
| 1718 |
+
"CONDITIONING"
|
| 1719 |
+
],
|
| 1720 |
+
[
|
| 1721 |
+
95,
|
| 1722 |
+
48,
|
| 1723 |
+
0,
|
| 1724 |
+
68,
|
| 1725 |
+
2,
|
| 1726 |
+
"CONDITIONING"
|
| 1727 |
+
],
|
| 1728 |
+
[
|
| 1729 |
+
96,
|
| 1730 |
+
46,
|
| 1731 |
+
0,
|
| 1732 |
+
68,
|
| 1733 |
+
3,
|
| 1734 |
+
"LATENT"
|
| 1735 |
+
],
|
| 1736 |
+
[
|
| 1737 |
+
97,
|
| 1738 |
+
45,
|
| 1739 |
+
1,
|
| 1740 |
+
69,
|
| 1741 |
+
0,
|
| 1742 |
+
"CLIP"
|
| 1743 |
+
],
|
| 1744 |
+
[
|
| 1745 |
+
99,
|
| 1746 |
+
68,
|
| 1747 |
+
0,
|
| 1748 |
+
70,
|
| 1749 |
+
0,
|
| 1750 |
+
"LATENT"
|
| 1751 |
+
],
|
| 1752 |
+
[
|
| 1753 |
+
102,
|
| 1754 |
+
72,
|
| 1755 |
+
0,
|
| 1756 |
+
73,
|
| 1757 |
+
0,
|
| 1758 |
+
"IMAGE"
|
| 1759 |
+
],
|
| 1760 |
+
[
|
| 1761 |
+
105,
|
| 1762 |
+
45,
|
| 1763 |
+
0,
|
| 1764 |
+
61,
|
| 1765 |
+
0,
|
| 1766 |
+
"MODEL"
|
| 1767 |
+
],
|
| 1768 |
+
[
|
| 1769 |
+
106,
|
| 1770 |
+
45,
|
| 1771 |
+
2,
|
| 1772 |
+
77,
|
| 1773 |
+
0,
|
| 1774 |
+
"*"
|
| 1775 |
+
],
|
| 1776 |
+
[
|
| 1777 |
+
107,
|
| 1778 |
+
77,
|
| 1779 |
+
0,
|
| 1780 |
+
70,
|
| 1781 |
+
1,
|
| 1782 |
+
"VAE"
|
| 1783 |
+
],
|
| 1784 |
+
[
|
| 1785 |
+
108,
|
| 1786 |
+
45,
|
| 1787 |
+
2,
|
| 1788 |
+
78,
|
| 1789 |
+
0,
|
| 1790 |
+
"*"
|
| 1791 |
+
],
|
| 1792 |
+
[
|
| 1793 |
+
109,
|
| 1794 |
+
78,
|
| 1795 |
+
0,
|
| 1796 |
+
65,
|
| 1797 |
+
1,
|
| 1798 |
+
"VAE"
|
| 1799 |
+
],
|
| 1800 |
+
[
|
| 1801 |
+
110,
|
| 1802 |
+
45,
|
| 1803 |
+
0,
|
| 1804 |
+
79,
|
| 1805 |
+
0,
|
| 1806 |
+
"MODEL"
|
| 1807 |
+
],
|
| 1808 |
+
[
|
| 1809 |
+
111,
|
| 1810 |
+
69,
|
| 1811 |
+
0,
|
| 1812 |
+
79,
|
| 1813 |
+
1,
|
| 1814 |
+
"CONDITIONING"
|
| 1815 |
+
],
|
| 1816 |
+
[
|
| 1817 |
+
112,
|
| 1818 |
+
48,
|
| 1819 |
+
0,
|
| 1820 |
+
79,
|
| 1821 |
+
2,
|
| 1822 |
+
"CONDITIONING"
|
| 1823 |
+
],
|
| 1824 |
+
[
|
| 1825 |
+
113,
|
| 1826 |
+
46,
|
| 1827 |
+
0,
|
| 1828 |
+
79,
|
| 1829 |
+
3,
|
| 1830 |
+
"LATENT"
|
| 1831 |
+
],
|
| 1832 |
+
[
|
| 1833 |
+
114,
|
| 1834 |
+
79,
|
| 1835 |
+
0,
|
| 1836 |
+
81,
|
| 1837 |
+
0,
|
| 1838 |
+
"LATENT"
|
| 1839 |
+
],
|
| 1840 |
+
[
|
| 1841 |
+
115,
|
| 1842 |
+
81,
|
| 1843 |
+
0,
|
| 1844 |
+
80,
|
| 1845 |
+
1,
|
| 1846 |
+
"IMAGE"
|
| 1847 |
+
],
|
| 1848 |
+
[
|
| 1849 |
+
116,
|
| 1850 |
+
70,
|
| 1851 |
+
0,
|
| 1852 |
+
80,
|
| 1853 |
+
0,
|
| 1854 |
+
"IMAGE"
|
| 1855 |
+
],
|
| 1856 |
+
[
|
| 1857 |
+
117,
|
| 1858 |
+
80,
|
| 1859 |
+
0,
|
| 1860 |
+
72,
|
| 1861 |
+
0,
|
| 1862 |
+
"IMAGE"
|
| 1863 |
+
],
|
| 1864 |
+
[
|
| 1865 |
+
118,
|
| 1866 |
+
77,
|
| 1867 |
+
0,
|
| 1868 |
+
81,
|
| 1869 |
+
1,
|
| 1870 |
+
"VAE"
|
| 1871 |
+
],
|
| 1872 |
+
[
|
| 1873 |
+
119,
|
| 1874 |
+
45,
|
| 1875 |
+
2,
|
| 1876 |
+
82,
|
| 1877 |
+
0,
|
| 1878 |
+
"*"
|
| 1879 |
+
],
|
| 1880 |
+
[
|
| 1881 |
+
120,
|
| 1882 |
+
82,
|
| 1883 |
+
0,
|
| 1884 |
+
54,
|
| 1885 |
+
1,
|
| 1886 |
+
"VAE"
|
| 1887 |
+
],
|
| 1888 |
+
[
|
| 1889 |
+
121,
|
| 1890 |
+
82,
|
| 1891 |
+
0,
|
| 1892 |
+
49,
|
| 1893 |
+
1,
|
| 1894 |
+
"VAE"
|
| 1895 |
+
],
|
| 1896 |
+
[
|
| 1897 |
+
122,
|
| 1898 |
+
80,
|
| 1899 |
+
0,
|
| 1900 |
+
71,
|
| 1901 |
+
0,
|
| 1902 |
+
"IMAGE"
|
| 1903 |
+
],
|
| 1904 |
+
[
|
| 1905 |
+
123,
|
| 1906 |
+
45,
|
| 1907 |
+
0,
|
| 1908 |
+
83,
|
| 1909 |
+
0,
|
| 1910 |
+
"MODEL"
|
| 1911 |
+
],
|
| 1912 |
+
[
|
| 1913 |
+
124,
|
| 1914 |
+
84,
|
| 1915 |
+
0,
|
| 1916 |
+
83,
|
| 1917 |
+
1,
|
| 1918 |
+
"CONDITIONING"
|
| 1919 |
+
],
|
| 1920 |
+
[
|
| 1921 |
+
125,
|
| 1922 |
+
48,
|
| 1923 |
+
0,
|
| 1924 |
+
83,
|
| 1925 |
+
2,
|
| 1926 |
+
"CONDITIONING"
|
| 1927 |
+
],
|
| 1928 |
+
[
|
| 1929 |
+
126,
|
| 1930 |
+
46,
|
| 1931 |
+
0,
|
| 1932 |
+
83,
|
| 1933 |
+
3,
|
| 1934 |
+
"LATENT"
|
| 1935 |
+
],
|
| 1936 |
+
[
|
| 1937 |
+
127,
|
| 1938 |
+
45,
|
| 1939 |
+
1,
|
| 1940 |
+
84,
|
| 1941 |
+
0,
|
| 1942 |
+
"CLIP"
|
| 1943 |
+
],
|
| 1944 |
+
[
|
| 1945 |
+
128,
|
| 1946 |
+
83,
|
| 1947 |
+
0,
|
| 1948 |
+
85,
|
| 1949 |
+
0,
|
| 1950 |
+
"LATENT"
|
| 1951 |
+
],
|
| 1952 |
+
[
|
| 1953 |
+
129,
|
| 1954 |
+
87,
|
| 1955 |
+
0,
|
| 1956 |
+
85,
|
| 1957 |
+
1,
|
| 1958 |
+
"VAE"
|
| 1959 |
+
],
|
| 1960 |
+
[
|
| 1961 |
+
131,
|
| 1962 |
+
45,
|
| 1963 |
+
2,
|
| 1964 |
+
87,
|
| 1965 |
+
0,
|
| 1966 |
+
"*"
|
| 1967 |
+
],
|
| 1968 |
+
[
|
| 1969 |
+
140,
|
| 1970 |
+
86,
|
| 1971 |
+
0,
|
| 1972 |
+
91,
|
| 1973 |
+
0,
|
| 1974 |
+
"IMAGE"
|
| 1975 |
+
],
|
| 1976 |
+
[
|
| 1977 |
+
141,
|
| 1978 |
+
85,
|
| 1979 |
+
0,
|
| 1980 |
+
86,
|
| 1981 |
+
0,
|
| 1982 |
+
"IMAGE"
|
| 1983 |
+
]
|
| 1984 |
+
],
|
| 1985 |
+
"groups": [],
|
| 1986 |
+
"config": {},
|
| 1987 |
+
"extra": {
|
| 1988 |
+
"ds": {
|
| 1989 |
+
"scale": 0.5730855330116886,
|
| 1990 |
+
"offset": [
|
| 1991 |
+
-309.80067971195854,
|
| 1992 |
+
-137.54286569310958
|
| 1993 |
+
]
|
| 1994 |
+
}
|
| 1995 |
+
},
|
| 1996 |
+
"version": 0.4
|
| 1997 |
+
}
|
ComfyUI/custom_nodes/ComfyUI-Switch/README.md
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ComfyUI Node Switcher
|
| 2 |
+
|
| 3 |
+
그냥 두개 똑딱 바로 하게끔 쓰기위해서
|
| 4 |
+
|
| 5 |
+

|
| 6 |
+
|
ComfyUI/custom_nodes/ComfyUI-Switch/Switch.py
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 와일드 카드를 속이는 용도? 임팩트팩에서 가져옴
|
| 2 |
+
class AnyType(str):
|
| 3 |
+
def __ne__(self, __value: object) -> bool:
|
| 4 |
+
return False
|
| 5 |
+
|
| 6 |
+
any_typ = AnyType("*")
|
| 7 |
+
|
| 8 |
+
class NodeSwitch:
|
| 9 |
+
def __init__(self):
|
| 10 |
+
pass
|
| 11 |
+
|
| 12 |
+
@classmethod
|
| 13 |
+
def INPUT_TYPES(self):
|
| 14 |
+
return {
|
| 15 |
+
"required": {
|
| 16 |
+
"DeTK": ("BOOLEAN", { "default": True, "label_on": "case1", "label_off": "case2" }),
|
| 17 |
+
},
|
| 18 |
+
"optional": {
|
| 19 |
+
"case1": (any_typ,),
|
| 20 |
+
"case2": (any_typ,)
|
| 21 |
+
}
|
| 22 |
+
}
|
| 23 |
+
CATEGORY = "Switch"
|
| 24 |
+
FUNCTION = "run"
|
| 25 |
+
RETURN_TYPES = (any_typ,)
|
| 26 |
+
|
| 27 |
+
def run(self, DeTK, case1, case2):
|
| 28 |
+
return ((case1 if DeTK else case2),)
|
| 29 |
+
|
| 30 |
+
NODE_CLASS_MAPPINGS = {
|
| 31 |
+
"NodeSwitch": NodeSwitch
|
| 32 |
+
}
|
| 33 |
+
NODE_DISPLAY_NAME_MAPPINGS = {
|
| 34 |
+
"NodeSwitch": "NodeSwitch",
|
| 35 |
+
}
|
ComfyUI/custom_nodes/ComfyUI-Switch/__init__.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .Switch import NODE_CLASS_MAPPINGS
|
| 2 |
+
|
| 3 |
+
__all__ = ['NODE_CLASS_MAPPINGS']
|
ComfyUI/custom_nodes/example_node.py.example
ADDED
|
@@ -0,0 +1,128 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
class Example:
|
| 2 |
+
"""
|
| 3 |
+
A example node
|
| 4 |
+
|
| 5 |
+
Class methods
|
| 6 |
+
-------------
|
| 7 |
+
INPUT_TYPES (dict):
|
| 8 |
+
Tell the main program input parameters of nodes.
|
| 9 |
+
IS_CHANGED:
|
| 10 |
+
optional method to control when the node is re executed.
|
| 11 |
+
|
| 12 |
+
Attributes
|
| 13 |
+
----------
|
| 14 |
+
RETURN_TYPES (`tuple`):
|
| 15 |
+
The type of each element in the output tuple.
|
| 16 |
+
RETURN_NAMES (`tuple`):
|
| 17 |
+
Optional: The name of each output in the output tuple.
|
| 18 |
+
FUNCTION (`str`):
|
| 19 |
+
The name of the entry-point method. For example, if `FUNCTION = "execute"` then it will run Example().execute()
|
| 20 |
+
OUTPUT_NODE ([`bool`]):
|
| 21 |
+
If this node is an output node that outputs a result/image from the graph. The SaveImage node is an example.
|
| 22 |
+
The backend iterates on these output nodes and tries to execute all their parents if their parent graph is properly connected.
|
| 23 |
+
Assumed to be False if not present.
|
| 24 |
+
CATEGORY (`str`):
|
| 25 |
+
The category the node should appear in the UI.
|
| 26 |
+
execute(s) -> tuple || None:
|
| 27 |
+
The entry point method. The name of this method must be the same as the value of property `FUNCTION`.
|
| 28 |
+
For example, if `FUNCTION = "execute"` then this method's name must be `execute`, if `FUNCTION = "foo"` then it must be `foo`.
|
| 29 |
+
"""
|
| 30 |
+
def __init__(self):
|
| 31 |
+
pass
|
| 32 |
+
|
| 33 |
+
@classmethod
|
| 34 |
+
def INPUT_TYPES(s):
|
| 35 |
+
"""
|
| 36 |
+
Return a dictionary which contains config for all input fields.
|
| 37 |
+
Some types (string): "MODEL", "VAE", "CLIP", "CONDITIONING", "LATENT", "IMAGE", "INT", "STRING", "FLOAT".
|
| 38 |
+
Input types "INT", "STRING" or "FLOAT" are special values for fields on the node.
|
| 39 |
+
The type can be a list for selection.
|
| 40 |
+
|
| 41 |
+
Returns: `dict`:
|
| 42 |
+
- Key input_fields_group (`string`): Can be either required, hidden or optional. A node class must have property `required`
|
| 43 |
+
- Value input_fields (`dict`): Contains input fields config:
|
| 44 |
+
* Key field_name (`string`): Name of a entry-point method's argument
|
| 45 |
+
* Value field_config (`tuple`):
|
| 46 |
+
+ First value is a string indicate the type of field or a list for selection.
|
| 47 |
+
+ Second value is a config for type "INT", "STRING" or "FLOAT".
|
| 48 |
+
"""
|
| 49 |
+
return {
|
| 50 |
+
"required": {
|
| 51 |
+
"image": ("IMAGE",),
|
| 52 |
+
"int_field": ("INT", {
|
| 53 |
+
"default": 0,
|
| 54 |
+
"min": 0, #Minimum value
|
| 55 |
+
"max": 4096, #Maximum value
|
| 56 |
+
"step": 64, #Slider's step
|
| 57 |
+
"display": "number" # Cosmetic only: display as "number" or "slider"
|
| 58 |
+
}),
|
| 59 |
+
"float_field": ("FLOAT", {
|
| 60 |
+
"default": 1.0,
|
| 61 |
+
"min": 0.0,
|
| 62 |
+
"max": 10.0,
|
| 63 |
+
"step": 0.01,
|
| 64 |
+
"round": 0.001, #The value representing the precision to round to, will be set to the step value by default. Can be set to False to disable rounding.
|
| 65 |
+
"display": "number"}),
|
| 66 |
+
"print_to_screen": (["enable", "disable"],),
|
| 67 |
+
"string_field": ("STRING", {
|
| 68 |
+
"multiline": False, #True if you want the field to look like the one on the ClipTextEncode node
|
| 69 |
+
"default": "Hello World!"
|
| 70 |
+
}),
|
| 71 |
+
},
|
| 72 |
+
}
|
| 73 |
+
|
| 74 |
+
RETURN_TYPES = ("IMAGE",)
|
| 75 |
+
#RETURN_NAMES = ("image_output_name",)
|
| 76 |
+
|
| 77 |
+
FUNCTION = "test"
|
| 78 |
+
|
| 79 |
+
#OUTPUT_NODE = False
|
| 80 |
+
|
| 81 |
+
CATEGORY = "Example"
|
| 82 |
+
|
| 83 |
+
def test(self, image, string_field, int_field, float_field, print_to_screen):
|
| 84 |
+
if print_to_screen == "enable":
|
| 85 |
+
print(f"""Your input contains:
|
| 86 |
+
string_field aka input text: {string_field}
|
| 87 |
+
int_field: {int_field}
|
| 88 |
+
float_field: {float_field}
|
| 89 |
+
""")
|
| 90 |
+
#do some processing on the image, in this example I just invert it
|
| 91 |
+
image = 1.0 - image
|
| 92 |
+
return (image,)
|
| 93 |
+
|
| 94 |
+
"""
|
| 95 |
+
The node will always be re executed if any of the inputs change but
|
| 96 |
+
this method can be used to force the node to execute again even when the inputs don't change.
|
| 97 |
+
You can make this node return a number or a string. This value will be compared to the one returned the last time the node was
|
| 98 |
+
executed, if it is different the node will be executed again.
|
| 99 |
+
This method is used in the core repo for the LoadImage node where they return the image hash as a string, if the image hash
|
| 100 |
+
changes between executions the LoadImage node is executed again.
|
| 101 |
+
"""
|
| 102 |
+
#@classmethod
|
| 103 |
+
#def IS_CHANGED(s, image, string_field, int_field, float_field, print_to_screen):
|
| 104 |
+
# return ""
|
| 105 |
+
|
| 106 |
+
# Set the web directory, any .js file in that directory will be loaded by the frontend as a frontend extension
|
| 107 |
+
# WEB_DIRECTORY = "./somejs"
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
# Add custom API routes, using router
|
| 111 |
+
from aiohttp import web
|
| 112 |
+
from server import PromptServer
|
| 113 |
+
|
| 114 |
+
@PromptServer.instance.routes.get("/hello")
|
| 115 |
+
async def get_hello(request):
|
| 116 |
+
return web.json_response("hello")
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
# A dictionary that contains all nodes you want to export with their names
|
| 120 |
+
# NOTE: names should be globally unique
|
| 121 |
+
NODE_CLASS_MAPPINGS = {
|
| 122 |
+
"Example": Example
|
| 123 |
+
}
|
| 124 |
+
|
| 125 |
+
# A dictionary that contains the friendly/humanly readable titles for the nodes
|
| 126 |
+
NODE_DISPLAY_NAME_MAPPINGS = {
|
| 127 |
+
"Example": "Example Node"
|
| 128 |
+
}
|
ComfyUI/custom_nodes/image-resize-comfyui/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023 Wladimir Palant
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
ComfyUI/custom_nodes/image-resize-comfyui/README.md
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Image Resize for ComfyUI
|
| 2 |
+
|
| 3 |
+
This custom node provides various tools for resizing images. The goal is resizing without distorting proportions, yet without having to perform any calculations with the size of the original image. If a mask is present, it is resized and modified along with the image.
|
| 4 |
+
|
| 5 |
+

|
| 6 |
+
|
| 7 |
+
## Installation
|
| 8 |
+
|
| 9 |
+
To install, clone this repository into `ComfyUI/custom_nodes` folder with `git clone https://github.com/palant/image-resize-comfyui` and restart ComfyUI.
|
| 10 |
+
|
| 11 |
+
## Node configuration
|
| 12 |
+
|
| 13 |
+
### action
|
| 14 |
+
|
| 15 |
+
In the `resize only` mode, the image will only be resized while keeping its side ratio. The `side_ratio` setting is ignored then.
|
| 16 |
+
|
| 17 |
+
In the `crop to ratio` mode, parts of the image will be removed after resizing as necessary to make its side ratio match `side_ratio` setting.
|
| 18 |
+
|
| 19 |
+
In the `pad to ratio` mode, transparent padding will be added to the image after resizing as necessary to make its side ratio match `side_ratio` setting.
|
| 20 |
+
|
| 21 |
+
### smaller_side, larger_side, scale_factor
|
| 22 |
+
|
| 23 |
+
These settings determine the image’s target size. Only one of these settings can be enabled (set to a non-zero value).
|
| 24 |
+
|
| 25 |
+
With `smaller_side` set, the target size is determined by the smaller side of the image. E.g. with the `action` being `resize only` and the original image being 512x768 pixels large, `smaller_side` set to 1024 will resize the image to 1024x1536 pixels.
|
| 26 |
+
|
| 27 |
+
With `larger_side` set, the target size is determined by the larger side of the image. E.g. with the `action` being `resize only` and the original image being 512x768 pixels large, `larger_side` set to 1024 will resize the image to 683x1024 pixels.
|
| 28 |
+
|
| 29 |
+
Finally, `scale_factor` can be set as an explicit scaling factor. Values below 1.0 will reduce image size, above 1.0 increase it.
|
| 30 |
+
|
| 31 |
+
If neither setting is set, the image is not resized but merely cropped/padded as necessary.
|
| 32 |
+
|
| 33 |
+
### resize_mode
|
| 34 |
+
|
| 35 |
+
In the `reduce size only` mode, images already smaller than the target size will not be resized. In the `increase size only` mode, images already larger than the target size will not be resized. The `any` mode causes the image to be always resized, regardless of whether downscaling or upscaling is required.
|
| 36 |
+
|
| 37 |
+
### side_ratio
|
| 38 |
+
|
| 39 |
+
If the `action` setting enables cropping or padding of the image, this setting determines the required side ratio of the image. The format is `width:height`, e.g. `4:3` or `2:3`.
|
| 40 |
+
|
| 41 |
+
In case you want to resize the image to an explicit size, you can also set this size here, e.g. `512:768`. You then set `smaller_side` setting to `512` and the resulting image will always be 512x768 pixels large.
|
| 42 |
+
|
| 43 |
+
### crop_pad_position
|
| 44 |
+
|
| 45 |
+
If the image is cropped, this setting determines which side is cropped. The value `0.0` means that only the right/bottom side is cropped. The value `1.0` means that only left/top side is cropped. The value `0.3` means that 30% are being cropped on the left/top side and 70% on the right/top side.
|
| 46 |
+
|
| 47 |
+
If the image is padded, this setting determines where the padding is being inserted. The value `0.0` means that all padding is inserted on the right/bottom side. The value `1.0` means that all padding is inserted on the left/top side. The value `0.3` means that 30% of the padding are inserted on the left/top side and 70% on the right/top side.
|
| 48 |
+
|
| 49 |
+
### pad_feathering
|
| 50 |
+
|
| 51 |
+
If the image is padded, this setting causes mask transparency to partially expand into the original image for the given number of pixels. This helps avoid borders if the image is later inpainted.
|
ComfyUI/custom_nodes/image-resize-comfyui/__init__.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .image_resize import NODE_CLASS_MAPPINGS, NODE_DISPLAY_NAME_MAPPINGS
|
| 2 |
+
|
| 3 |
+
__all__ = ['NODE_CLASS_MAPPINGS', 'NODE_DISPLAY_NAME_MAPPINGS']
|
ComfyUI/custom_nodes/image-resize-comfyui/image_resize.png
ADDED
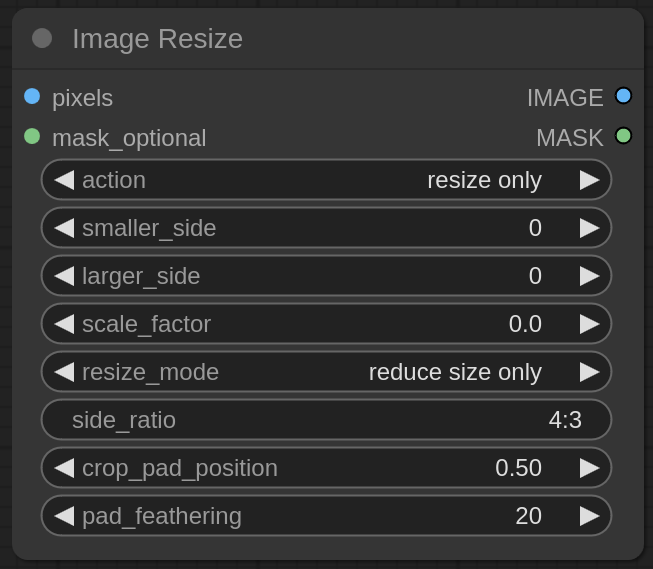
|
ComfyUI/custom_nodes/image-resize-comfyui/image_resize.py
ADDED
|
@@ -0,0 +1,163 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
|
| 3 |
+
class ImageResize:
|
| 4 |
+
def __init__(self):
|
| 5 |
+
pass
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
ACTION_TYPE_RESIZE = "resize only"
|
| 9 |
+
ACTION_TYPE_CROP = "crop to ratio"
|
| 10 |
+
ACTION_TYPE_PAD = "pad to ratio"
|
| 11 |
+
RESIZE_MODE_DOWNSCALE = "reduce size only"
|
| 12 |
+
RESIZE_MODE_UPSCALE = "increase size only"
|
| 13 |
+
RESIZE_MODE_ANY = "any"
|
| 14 |
+
RETURN_TYPES = ("IMAGE", "MASK",)
|
| 15 |
+
FUNCTION = "resize"
|
| 16 |
+
CATEGORY = "image"
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
@classmethod
|
| 20 |
+
def INPUT_TYPES(s):
|
| 21 |
+
return {
|
| 22 |
+
"required": {
|
| 23 |
+
"pixels": ("IMAGE",),
|
| 24 |
+
"action": ([s.ACTION_TYPE_RESIZE, s.ACTION_TYPE_CROP, s.ACTION_TYPE_PAD],),
|
| 25 |
+
"smaller_side": ("INT", {"default": 0, "min": 0, "max": 8192, "step": 8}),
|
| 26 |
+
"larger_side": ("INT", {"default": 0, "min": 0, "max": 8192, "step": 8}),
|
| 27 |
+
"scale_factor": ("FLOAT", {"default": 0.0, "min": 0.0, "max": 10.0, "step": 0.1}),
|
| 28 |
+
"resize_mode": ([s.RESIZE_MODE_DOWNSCALE, s.RESIZE_MODE_UPSCALE, s.RESIZE_MODE_ANY],),
|
| 29 |
+
"side_ratio": ("STRING", {"default": "4:3"}),
|
| 30 |
+
"crop_pad_position": ("FLOAT", {"default": 0.5, "min": 0.0, "max": 1.0, "step": 0.01}),
|
| 31 |
+
"pad_feathering": ("INT", {"default": 20, "min": 0, "max": 8192, "step": 1}),
|
| 32 |
+
},
|
| 33 |
+
"optional": {
|
| 34 |
+
"mask_optional": ("MASK",),
|
| 35 |
+
},
|
| 36 |
+
}
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
@classmethod
|
| 40 |
+
def VALIDATE_INPUTS(s, action, smaller_side, larger_side, scale_factor, resize_mode, side_ratio, **_):
|
| 41 |
+
if side_ratio is not None:
|
| 42 |
+
if action != s.ACTION_TYPE_RESIZE and s.parse_side_ratio(side_ratio) is None:
|
| 43 |
+
return f"Invalid side ratio: {side_ratio}"
|
| 44 |
+
|
| 45 |
+
if smaller_side is not None and larger_side is not None and scale_factor is not None:
|
| 46 |
+
if int(smaller_side > 0) + int(larger_side > 0) + int(scale_factor > 0) > 1:
|
| 47 |
+
return f"At most one scaling rule (smaller_side, larger_side, scale_factor) should be enabled by setting a non-zero value"
|
| 48 |
+
|
| 49 |
+
if scale_factor is not None:
|
| 50 |
+
if resize_mode == s.RESIZE_MODE_DOWNSCALE and scale_factor > 1.0:
|
| 51 |
+
return f"For resize_mode {s.RESIZE_MODE_DOWNSCALE}, scale_factor should be less than one but got {scale_factor}"
|
| 52 |
+
if resize_mode == s.RESIZE_MODE_UPSCALE and scale_factor > 0.0 and scale_factor < 1.0:
|
| 53 |
+
return f"For resize_mode {s.RESIZE_MODE_UPSCALE}, scale_factor should be larger than one but got {scale_factor}"
|
| 54 |
+
|
| 55 |
+
return True
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
@classmethod
|
| 59 |
+
def parse_side_ratio(s, side_ratio):
|
| 60 |
+
try:
|
| 61 |
+
x, y = map(int, side_ratio.split(":", 1))
|
| 62 |
+
if x < 1 or y < 1:
|
| 63 |
+
raise Exception("Ratio factors have to be positive numbers")
|
| 64 |
+
return float(x) / float(y)
|
| 65 |
+
except:
|
| 66 |
+
return None
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def resize(self, pixels, action, smaller_side, larger_side, scale_factor, resize_mode, side_ratio, crop_pad_position, pad_feathering, mask_optional=None):
|
| 70 |
+
validity = self.VALIDATE_INPUTS(action, smaller_side, larger_side, scale_factor, resize_mode, side_ratio)
|
| 71 |
+
if validity is not True:
|
| 72 |
+
raise Exception(validity)
|
| 73 |
+
|
| 74 |
+
height, width = pixels.shape[1:3]
|
| 75 |
+
if mask_optional is None:
|
| 76 |
+
mask = torch.zeros(1, height, width, dtype=torch.float32)
|
| 77 |
+
else:
|
| 78 |
+
mask = mask_optional
|
| 79 |
+
if mask.shape[1] != height or mask.shape[2] != width:
|
| 80 |
+
mask = torch.nn.functional.interpolate(mask.unsqueeze(0), size=(height, width), mode="bicubic").squeeze(0).clamp(0.0, 1.0)
|
| 81 |
+
|
| 82 |
+
crop_x, crop_y, pad_x, pad_y = (0.0, 0.0, 0.0, 0.0)
|
| 83 |
+
if action == self.ACTION_TYPE_CROP:
|
| 84 |
+
target_ratio = self.parse_side_ratio(side_ratio)
|
| 85 |
+
if height * target_ratio < width:
|
| 86 |
+
crop_x = width - height * target_ratio
|
| 87 |
+
else:
|
| 88 |
+
crop_y = height - width / target_ratio
|
| 89 |
+
elif action == self.ACTION_TYPE_PAD:
|
| 90 |
+
target_ratio = self.parse_side_ratio(side_ratio)
|
| 91 |
+
if height * target_ratio > width:
|
| 92 |
+
pad_x = height * target_ratio - width
|
| 93 |
+
else:
|
| 94 |
+
pad_y = width / target_ratio - height
|
| 95 |
+
|
| 96 |
+
if smaller_side > 0:
|
| 97 |
+
if width + pad_x - crop_x > height + pad_y - crop_y:
|
| 98 |
+
scale_factor = float(smaller_side) / (height + pad_y - crop_y)
|
| 99 |
+
else:
|
| 100 |
+
scale_factor = float(smaller_side) / (width + pad_x - crop_x)
|
| 101 |
+
if larger_side > 0:
|
| 102 |
+
if width + pad_x - crop_x > height + pad_y - crop_y:
|
| 103 |
+
scale_factor = float(larger_side) / (width + pad_x - crop_x)
|
| 104 |
+
else:
|
| 105 |
+
scale_factor = float(larger_side) / (height + pad_y - crop_y)
|
| 106 |
+
|
| 107 |
+
if (resize_mode == self.RESIZE_MODE_DOWNSCALE and scale_factor >= 1.0) or (resize_mode == self.RESIZE_MODE_UPSCALE and scale_factor <= 1.0):
|
| 108 |
+
scale_factor = 0.0
|
| 109 |
+
|
| 110 |
+
if scale_factor > 0.0:
|
| 111 |
+
pixels = torch.nn.functional.interpolate(pixels.movedim(-1, 1), scale_factor=scale_factor, mode="bicubic", antialias=True).movedim(1, -1).clamp(0.0, 1.0)
|
| 112 |
+
mask = torch.nn.functional.interpolate(mask.unsqueeze(0), scale_factor=scale_factor, mode="bicubic", antialias=True).squeeze(0).clamp(0.0, 1.0)
|
| 113 |
+
height, width = pixels.shape[1:3]
|
| 114 |
+
|
| 115 |
+
crop_x *= scale_factor
|
| 116 |
+
crop_y *= scale_factor
|
| 117 |
+
pad_x *= scale_factor
|
| 118 |
+
pad_y *= scale_factor
|
| 119 |
+
|
| 120 |
+
if crop_x > 0.0 or crop_y > 0.0:
|
| 121 |
+
remove_x = (round(crop_x * crop_pad_position), round(crop_x * (1 - crop_pad_position))) if crop_x > 0.0 else (0, 0)
|
| 122 |
+
remove_y = (round(crop_y * crop_pad_position), round(crop_y * (1 - crop_pad_position))) if crop_y > 0.0 else (0, 0)
|
| 123 |
+
pixels = pixels[:, remove_y[0]:height - remove_y[1], remove_x[0]:width - remove_x[1], :]
|
| 124 |
+
mask = mask[:, remove_y[0]:height - remove_y[1], remove_x[0]:width - remove_x[1]]
|
| 125 |
+
elif pad_x > 0.0 or pad_y > 0.0:
|
| 126 |
+
add_x = (round(pad_x * crop_pad_position), round(pad_x * (1 - crop_pad_position))) if pad_x > 0.0 else (0, 0)
|
| 127 |
+
add_y = (round(pad_y * crop_pad_position), round(pad_y * (1 - crop_pad_position))) if pad_y > 0.0 else (0, 0)
|
| 128 |
+
|
| 129 |
+
new_pixels = torch.zeros(pixels.shape[0], height + add_y[0] + add_y[1], width + add_x[0] + add_x[1], pixels.shape[3], dtype=torch.float32)
|
| 130 |
+
new_pixels[:, add_y[0]:height + add_y[0], add_x[0]:width + add_x[0], :] = pixels
|
| 131 |
+
pixels = new_pixels
|
| 132 |
+
|
| 133 |
+
new_mask = torch.ones(mask.shape[0], height + add_y[0] + add_y[1], width + add_x[0] + add_x[1], dtype=torch.float32)
|
| 134 |
+
new_mask[:, add_y[0]:height + add_y[0], add_x[0]:width + add_x[0]] = mask
|
| 135 |
+
mask = new_mask
|
| 136 |
+
|
| 137 |
+
if pad_feathering > 0:
|
| 138 |
+
for i in range(mask.shape[0]):
|
| 139 |
+
for j in range(pad_feathering):
|
| 140 |
+
feather_strength = (1 - j / pad_feathering) * (1 - j / pad_feathering)
|
| 141 |
+
if add_x[0] > 0 and j < width:
|
| 142 |
+
for k in range(height):
|
| 143 |
+
mask[i, k, add_x[0] + j] = max(mask[i, k, add_x[0] + j], feather_strength)
|
| 144 |
+
if add_x[1] > 0 and j < width:
|
| 145 |
+
for k in range(height):
|
| 146 |
+
mask[i, k, width + add_x[0] - j - 1] = max(mask[i, k, width + add_x[0] - j - 1], feather_strength)
|
| 147 |
+
if add_y[0] > 0 and j < height:
|
| 148 |
+
for k in range(width):
|
| 149 |
+
mask[i, add_y[0] + j, k] = max(mask[i, add_y[0] + j, k], feather_strength)
|
| 150 |
+
if add_y[1] > 0 and j < height:
|
| 151 |
+
for k in range(width):
|
| 152 |
+
mask[i, height + add_y[0] - j - 1, k] = max(mask[i, height + add_y[0] - j - 1, k], feather_strength)
|
| 153 |
+
|
| 154 |
+
return (pixels, mask)
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
NODE_CLASS_MAPPINGS = {
|
| 158 |
+
"ImageResize": ImageResize
|
| 159 |
+
}
|
| 160 |
+
|
| 161 |
+
NODE_DISPLAY_NAME_MAPPINGS = {
|
| 162 |
+
"ImageResize": "Image Resize"
|
| 163 |
+
}
|
ComfyUI/custom_nodes/websocket_image_save.py
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from PIL import Image, ImageOps
|
| 2 |
+
from io import BytesIO
|
| 3 |
+
import numpy as np
|
| 4 |
+
import struct
|
| 5 |
+
import comfy.utils
|
| 6 |
+
import time
|
| 7 |
+
|
| 8 |
+
#You can use this node to save full size images through the websocket, the
|
| 9 |
+
#images will be sent in exactly the same format as the image previews: as
|
| 10 |
+
#binary images on the websocket with a 8 byte header indicating the type
|
| 11 |
+
#of binary message (first 4 bytes) and the image format (next 4 bytes).
|
| 12 |
+
|
| 13 |
+
#Note that no metadata will be put in the images saved with this node.
|
| 14 |
+
|
| 15 |
+
class SaveImageWebsocket:
|
| 16 |
+
@classmethod
|
| 17 |
+
def INPUT_TYPES(s):
|
| 18 |
+
return {"required":
|
| 19 |
+
{"images": ("IMAGE", ),}
|
| 20 |
+
}
|
| 21 |
+
|
| 22 |
+
RETURN_TYPES = ()
|
| 23 |
+
FUNCTION = "save_images"
|
| 24 |
+
|
| 25 |
+
OUTPUT_NODE = True
|
| 26 |
+
|
| 27 |
+
CATEGORY = "api/image"
|
| 28 |
+
|
| 29 |
+
def save_images(self, images):
|
| 30 |
+
pbar = comfy.utils.ProgressBar(images.shape[0])
|
| 31 |
+
step = 0
|
| 32 |
+
for image in images:
|
| 33 |
+
i = 255. * image.cpu().numpy()
|
| 34 |
+
img = Image.fromarray(np.clip(i, 0, 255).astype(np.uint8))
|
| 35 |
+
pbar.update_absolute(step, images.shape[0], ("PNG", img, None))
|
| 36 |
+
step += 1
|
| 37 |
+
|
| 38 |
+
return {}
|
| 39 |
+
|
| 40 |
+
def IS_CHANGED(s, images):
|
| 41 |
+
return time.time()
|
| 42 |
+
|
| 43 |
+
NODE_CLASS_MAPPINGS = {
|
| 44 |
+
"SaveImageWebsocket": SaveImageWebsocket,
|
| 45 |
+
}
|