Spaces:
Build error


Build error
This view is limited to 50 files because it contains too many changes.
See raw diff
- .gitignore +1 -1
- amt/src/.coverage +0 -0
- amt/src/.coveragerc +5 -0
- amt/src/config/.DS_Store +0 -0
- amt/src/config/config.py +272 -0
- amt/src/config/data_presets.py +811 -0
- amt/src/config/task.py +119 -0
- amt/src/config/vocabulary.py +384 -0
- amt/src/extras/.DS_Store +0 -0
- amt/src/extras/Dockerfile +18 -0
- amt/src/extras/check_drum_channel_slakh.py +24 -0
- amt/src/extras/dataset_mutable_var_sanity_check.py +81 -0
- amt/src/extras/datasets_eval_testing.py +42 -0
- amt/src/extras/demo_cross_augmentation.py +69 -0
- amt/src/extras/demo_intra_augmentation.py +52 -0
- amt/src/extras/download_mirst500.py +50 -0
- amt/src/extras/fig/label_smooth_interval_of_interest.png +0 -0
- amt/src/extras/fig/pitchshift_benchnmark.png +0 -0
- amt/src/extras/fig/pitchshift_stretch_and_resampler_process_time.png +0 -0
- amt/src/extras/inspecting_slakh_bass.py +34 -0
- amt/src/extras/install_deepspeed.md +28 -0
- amt/src/extras/label_smoothing.py +67 -0
- amt/src/extras/multi_channel_seqlen_stats.py +177 -0
- amt/src/extras/npy_speed_benchmark.py +187 -0
- amt/src/extras/perceivertf_inspect.py +640 -0
- amt/src/extras/perceivertf_multi_inspect.py +778 -0
- amt/src/extras/pitch_shift_benchmark.py +167 -0
- amt/src/extras/remove_silence_musicnet_midi.py +32 -0
- amt/src/extras/rotary_positional_embedding.py +191 -0
- amt/src/extras/run_spleeter_mir1k.sh +17 -0
- amt/src/extras/run_spleeter_mirst500.sh +13 -0
- amt/src/extras/run_spleeter_mirst500_cmedia.sh +13 -0
- amt/src/extras/swap_channel.py +122 -0
- amt/src/extras/t5_dev.py +41 -0
- amt/src/extras/t5perceiver.py +443 -0
- amt/src/extras/unimax_sampler/README.md +45 -0
- amt/src/extras/unimax_sampler/demo.py +15 -0
- amt/src/extras/unimax_sampler/unimax_sampler.py +168 -0
- amt/src/install_dataset.py +285 -0
- amt/src/model/RoPE/RoPE.py +306 -0
- amt/src/model/conformer_helper.py +169 -0
- amt/src/model/conformer_mod.py +439 -0
- amt/src/model/conv_block.py +217 -0
- amt/src/model/ff_layer.py +238 -0
- amt/src/model/init_train.py +281 -0
- amt/src/model/lm_head.py +40 -0
- amt/src/model/lr_scheduler.py +91 -0
- amt/src/model/ops.py +111 -0
- amt/src/model/optimizers.py +218 -0
- amt/src/model/perceiver_helper.py +290 -0
.gitignore
CHANGED
|
@@ -1,2 +1,2 @@
|
|
| 1 |
-
amt/
|
| 2 |
examples/
|
|
|
|
| 1 |
+
amt/logs/
|
| 2 |
examples/
|
amt/src/.coverage
ADDED
|
Binary file (53.2 kB). View file
|
|
|
amt/src/.coveragerc
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[run]
|
| 2 |
+
omit =
|
| 3 |
+
train.py
|
| 4 |
+
test.py
|
| 5 |
+
install*.py
|
amt/src/config/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
amt/src/config/config.py
ADDED
|
@@ -0,0 +1,272 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""config.py"""
|
| 2 |
+
import numpy as np
|
| 3 |
+
# yapf: disable
|
| 4 |
+
"""
|
| 5 |
+
audio_cfg:
|
| 6 |
+
- Used by 'ymt3' to create a spectrogram layer.
|
| 7 |
+
- Input shape of model is determined by audio_cfg.
|
| 8 |
+
- 'train.py' arguments can override these defaults.
|
| 9 |
+
"""
|
| 10 |
+
audio_cfg = {
|
| 11 |
+
# Overwrittable by args in train.py
|
| 12 |
+
"codec": "melspec", # {melspec, spec} melspec for MT3, spec for PerceiverTF
|
| 13 |
+
"hop_length": 128, # {128, 300} 128 for MT3, 300 for PerceiverTF
|
| 14 |
+
# Shared audio parameters
|
| 15 |
+
"audio_backend": "torchaudio", # {torchaudio, nnAudio}
|
| 16 |
+
"sample_rate": 16000,
|
| 17 |
+
"input_frames": 32767, # number of input frames (~=2.048 s), determining in-/output shape of front layers.
|
| 18 |
+
"n_fft": 2048,
|
| 19 |
+
"n_mels": 512, # only for melspec
|
| 20 |
+
"f_min": 50.0,
|
| 21 |
+
"f_max": 8000.0,
|
| 22 |
+
} # TODO: currently dataloader is not updated by "input_frames"
|
| 23 |
+
|
| 24 |
+
"""
|
| 25 |
+
model_cfg:
|
| 26 |
+
- Encoder type dictates use of T5_CFG or PERCEIVER_TF_CFG.
|
| 27 |
+
- 'train.py' arguments can override these defaults.
|
| 28 |
+
"""
|
| 29 |
+
model_cfg = {
|
| 30 |
+
"encoder_type": "t5", # {"t5", "perceiver-tf", "conformer"}
|
| 31 |
+
"decoder_type": "t5", # {"t5", "multi-t5"}
|
| 32 |
+
"pre_encoder_type": "default", # {None, "default", "conv", "conv1d", "conv2d_avpt"} by default, t5:None, perceiver:conv.
|
| 33 |
+
"pre_encoder_type_default": {"t5": None, "perceiver-tf": "conv", "conformer": None},
|
| 34 |
+
"pre_decoder_type": "default", # {None, 'linear', 'conv1', 'mlp', 'group_linear'} see model/projection_layer.py
|
| 35 |
+
"pre_decoder_type_default": { # [enc_type][dec_type]
|
| 36 |
+
"t5": {"t5": None,},
|
| 37 |
+
"perceiver-tf": {"t5": "linear", "multi-t5": "mc_shared_linear"},
|
| 38 |
+
"conformer": {"t5": None,},
|
| 39 |
+
},
|
| 40 |
+
"conv_out_channels": 128, # number of filters for 'conv' pre_encoder. Otherwise ignored.
|
| 41 |
+
"t5_basename": "google/t5-v1_1-small",
|
| 42 |
+
"pretrained": False, # bool, if True, load pretrained weights from t5_basename. Mismatched layers are ignored.
|
| 43 |
+
"use_task_conditional_encoder": True, # True by default, but default task is None. So not activated by default.
|
| 44 |
+
"use_task_conditional_decoder": True, # True by default, but default task is None. So not activated by default.
|
| 45 |
+
"d_feat": "auto", # Input audio feature dimension for encoder. Automatically inferred by audio_cfg and existence of pre_encoders.
|
| 46 |
+
"tie_word_embeddings": True, # If True, weights of embed_tokens and lm_head are tied for stabilizing gradients.
|
| 47 |
+
"vocab_size": "auto", # int or "auto", automatically inferred by task manager.
|
| 48 |
+
"num_max_positions": "auto", # int or "auto". Length of positional encoding. Automatically inferred by "feat_length", "event_length" and task_manager.max_task_token_length.
|
| 49 |
+
# 'vocab_size', 'tie_word_embeddings' and 'num_max_positions' are auto-copied to encoder and decoder configs in the below.
|
| 50 |
+
"encoder": {
|
| 51 |
+
"t5": {
|
| 52 |
+
"d_model": 512, # Hidden size of T5 encoder.
|
| 53 |
+
"num_heads": 6,
|
| 54 |
+
"num_layers": 8,
|
| 55 |
+
"dropout_rate": 0.05,
|
| 56 |
+
"position_encoding_type": "sinusoidal", # {'sinusoidal', 'trainable'}.
|
| 57 |
+
"ff_widening_factor": 2, # wideening factor for MLP/MoE layers. Default is 2 in T5.
|
| 58 |
+
"ff_layer_type": "t5_gmlp", # {'t5_gmlp', 'moe', 'mlp', 'gmlp'}. 'moe' for mixture of experts, 'mlp' for standard transformer dense layer, 'gmlp' for simple gated MLP.
|
| 59 |
+
},
|
| 60 |
+
"perceiver-tf": {
|
| 61 |
+
"num_latents": 24, # number of latents in Perceiver. 24 in perceiver-tf paper.
|
| 62 |
+
"d_latent": 128, # latent dimension of Perceiver. 128 in perceiver-tf paper.
|
| 63 |
+
"d_model": "q", # int or "q" or "kv". Inner-dim of sca and local/temporal self-att.
|
| 64 |
+
# "q" follows "latent_dim". "kv" follows "d_feat". Best practice is to inc-/decrease 'd_latent', instead of 'd_model'.
|
| 65 |
+
"num_blocks": 3, # number of Perceiver-TF blocks in encoder. L in the paper.
|
| 66 |
+
"num_local_transformers_per_block": 2, # N in the paper.
|
| 67 |
+
"num_temporal_transformers_per_block": 2, # M in the paper.
|
| 68 |
+
"sca_use_query_residual": False,
|
| 69 |
+
"dropout_rate": 0.1,
|
| 70 |
+
"position_encoding_type": "trainable", # {'trainable', 'rotary', 'alibi', 'alibit', None, 'tkd','td', 'tk', 'kdt'}. alibit is alibi with trainable slopes.
|
| 71 |
+
"attention_to_channel": True, # Whether to use channel attention in sca.
|
| 72 |
+
"layer_norm_type": "layer_norm", # {'layer_norm', 'rms_norm'}
|
| 73 |
+
"ff_layer_type": "mlp", # {'moe', 'mlp', gmlp}. 'moe' for mixture of experts, 'mlp' for standard transformer dense layer, 'gmlp' for simple gated MLP.
|
| 74 |
+
"ff_widening_factor": 1, # wideening factor for MLP/MoE layers. Default is 1.
|
| 75 |
+
"moe_num_experts": 4, # number of experts in MoE layer. Default is 4. Disabled if ff_layer_type is not 'moe'.
|
| 76 |
+
"moe_topk": 2, # top-k routing in MoE layer. Default is 2. Disabled if ff_layer_type is not 'moe'.
|
| 77 |
+
"hidden_act": 'gelu', # activation function in MLP/MoE layer. Default is 'gelu'. {'gelu', 'silu', 'relu'}
|
| 78 |
+
"rotary_type_sca": "pixel", # {'l'|'lang', 'p'|'pixel'}. Default is 'pixel'.
|
| 79 |
+
"rotary_type_latent": "pixel", # {'l'|'lang', 'p'|'pixel'}. Default is 'pixel'.
|
| 80 |
+
"rotary_type_temporal": "lang", # {'l'|'lang', 'p'|'pixel'}. Default is 'lang'.
|
| 81 |
+
"rotary_apply_to_keys": False, # Whether to apply rotary to keys. Default is False.
|
| 82 |
+
"rotary_partial_pe": False, # Whether to use partial positional encoding. Default is False.
|
| 83 |
+
},
|
| 84 |
+
"conformer": {
|
| 85 |
+
"d_model": 512, # Hidden size of T5 encoder.
|
| 86 |
+
"intermediate_size": 512, # or 2048. size of the intermediate feed forward layer in each T5Block
|
| 87 |
+
"num_heads": 8,
|
| 88 |
+
"num_layers": 8,
|
| 89 |
+
"dropout_rate": 0.1,
|
| 90 |
+
"layerdrop": 0.1, # see https://arxiv.org/abs/1909.11556
|
| 91 |
+
"position_encoding_type": "rotary", # {'rotary', 'relative'}.
|
| 92 |
+
"conv_dim": (512, 512, 512, 512, 512, 512, 512),
|
| 93 |
+
"conv_stride": (5, 2, 2, 2, 2, 2, 2),
|
| 94 |
+
"conv_kernel": (10, 3, 3, 3, 3, 3, 3),
|
| 95 |
+
"conv_depthwise_kernel_size": 31,
|
| 96 |
+
},
|
| 97 |
+
|
| 98 |
+
},
|
| 99 |
+
"decoder": {
|
| 100 |
+
"t5": {
|
| 101 |
+
"d_model": 512, # Hidden size of T5 encoder. If encoder has lower dim, it is projected to this dim for enc-dec cross att.
|
| 102 |
+
"num_heads": 6,
|
| 103 |
+
"num_layers": 8,
|
| 104 |
+
"dropout_rate": 0.05,
|
| 105 |
+
"position_encoding_type": "sinusoidal", # {'sinusoidal', 'trainable'}.
|
| 106 |
+
"ff_widening_factor": 2, # wideening factor for MLP/MoE layers. Default is 2 in T5.
|
| 107 |
+
"ff_layer_type": "t5_gmlp", # {'t5_gmlp', 'moe', 'mlp', 'gmlp'}. 'moe' for mixture of experts, 'mlp' for standard transformer dense layer, 'gmlp' for simple gated MLP.
|
| 108 |
+
},
|
| 109 |
+
"multi-t5": {
|
| 110 |
+
"d_model": 512, # Hidden size of T5 encoder. Recommended: {256 or 512}
|
| 111 |
+
"num_heads": 6,
|
| 112 |
+
"num_layers": 8,
|
| 113 |
+
"dropout_rate": 0.05,
|
| 114 |
+
"position_encoding_type": "sinusoidal", # {'sinusoidal', 'trainable'}.
|
| 115 |
+
"ff_widening_factor": 2, # wideening factor for MLP/MoE layers. Default is 2 in T5.
|
| 116 |
+
"ff_layer_type": "t5_gmlp", # {'t5_gmlp', 'moe', 'mlp', 'gmlp'}. 'moe' for mixture of experts, 'mlp' for standard transformer dense layer, 'gmlp' for simple gated MLP.
|
| 117 |
+
"num_channels": 13,
|
| 118 |
+
},
|
| 119 |
+
},
|
| 120 |
+
"feat_length": "auto", # Input audio feature length for encoder. Automatically inferred by audio_cfg.
|
| 121 |
+
# mt3: 256 time steps
|
| 122 |
+
"event_length": 1024, # max length of event tokens excluding task tokens <-- 128 for multi-t5
|
| 123 |
+
"init_factor": 1.0, # initialization factor for embedding layers
|
| 124 |
+
}
|
| 125 |
+
|
| 126 |
+
# yapf: enable
|
| 127 |
+
shared_cfg = {
|
| 128 |
+
"PATH": {
|
| 129 |
+
"data_home": "../../data", # path to the data directory. If using relative path, it is relative to /src directory.
|
| 130 |
+
},
|
| 131 |
+
"BSZ": { # global batch size is local_bsz * n_GPUs in DDP mode
|
| 132 |
+
"train_sub": 12, #20, # sub-batch size is per CPU worker
|
| 133 |
+
"train_local": 24, #40, # local batch size is per GPU in DDP mode
|
| 134 |
+
"validation": 64, # validation batch size is per GPU in DDP mode
|
| 135 |
+
"test": 64,
|
| 136 |
+
},
|
| 137 |
+
"AUGMENTATION": {
|
| 138 |
+
"train_random_amp_range": [0.8, 1.1], # min and max amplitude scaling factor
|
| 139 |
+
"train_stem_iaug_prob": 0.7, # probability of stem activation in intra-stem augmentation
|
| 140 |
+
"train_stem_xaug_policy": {
|
| 141 |
+
"max_k": 3,
|
| 142 |
+
"tau": 0.3,
|
| 143 |
+
"alpha": 1.0,
|
| 144 |
+
"max_subunit_stems": 12, # the number of subunit stems to be reduced to this number of stems
|
| 145 |
+
"p_include_singing": None, # NOT IMPLEMENTED; probability of including singing for cross augmented examples. if None, use base probaility.
|
| 146 |
+
"no_instr_overlap": True,
|
| 147 |
+
"no_drum_overlap": True,
|
| 148 |
+
"uhat_intra_stem_augment": True,
|
| 149 |
+
},
|
| 150 |
+
"train_pitch_shift_range": [-2, 2], # [min, max] in semitones. None or [0, 0] for no pitch shift.
|
| 151 |
+
},
|
| 152 |
+
"DATAIO": { # do not set `shuffle` here.
|
| 153 |
+
"num_workers": 4, # num_worker is per GPU in DDP mode
|
| 154 |
+
"prefetch_factor": 2, #2,
|
| 155 |
+
"pin_memory": True,
|
| 156 |
+
"persistent_workers": False,
|
| 157 |
+
},
|
| 158 |
+
"CHECKPOINT": {
|
| 159 |
+
"save_top_k": 4, # max top k checkpoints to save
|
| 160 |
+
"monitor": 'validation/macro_onset_f',
|
| 161 |
+
"mode": 'max',
|
| 162 |
+
# "every_n_epochs": 20, # only working when check_val_every_n_epoch is 0
|
| 163 |
+
"save_last": True, # save last model
|
| 164 |
+
"filename": "{epoch}-{step}",
|
| 165 |
+
},
|
| 166 |
+
"TRAINER": { # do not coverwrite args in this section
|
| 167 |
+
"limit_train_batches": 1.0, # How much of training dataset to check (float = fraction, int = num_batches)
|
| 168 |
+
"limit_val_batches": 1.0,
|
| 169 |
+
"limit_test_batches": 1.0,
|
| 170 |
+
"gradient_clip_val": 1.0, # {0 or None} means don't clip.
|
| 171 |
+
"accumulate_grad_batches": 1, #1, # Accumulates grads every k batches. If set to 1, no effect.
|
| 172 |
+
"check_val_every_n_epoch": 1, #5, 1 for very large dataset such as EGMD
|
| 173 |
+
"num_sanity_val_steps": 0,
|
| 174 |
+
},
|
| 175 |
+
"WANDB": {
|
| 176 |
+
"save_dir": "../logs",
|
| 177 |
+
"cache_dir": "../logs/.wandb_cache",
|
| 178 |
+
"resume": "allow",
|
| 179 |
+
"anonymous": "allow", # {never, allow, must}
|
| 180 |
+
"mode": "online", # {online, offline, disabled}
|
| 181 |
+
},
|
| 182 |
+
"LR_SCHEDULE": {
|
| 183 |
+
# "scheduler_type": "cosine", # {legacy, cosine, constant}
|
| 184 |
+
"warmup_steps": 1000, # only for cosine scheduler, legacy scheduler follows T5's legacy schedule
|
| 185 |
+
"total_steps": 100000, # argparser of train.py can overwrite this
|
| 186 |
+
"final_cosine": 1e-5, # only for cosine scheduler
|
| 187 |
+
},
|
| 188 |
+
"TOKENIZER": {
|
| 189 |
+
"max_shift_steps": "auto", # max number of shift steps in the model. (int) or "auto". If "auto", it is set by audio_cfg["input_frames"] and shift_steps_ms. 206 with default setup.
|
| 190 |
+
"shift_step_ms": 10, # shift step in ms
|
| 191 |
+
},
|
| 192 |
+
}
|
| 193 |
+
|
| 194 |
+
T5_BASE_CFG = {
|
| 195 |
+
"google/t5-v1_1-small": {
|
| 196 |
+
"architectures": ["T5ForConditionalGeneration"],
|
| 197 |
+
"d_ff":
|
| 198 |
+
1024, # size of the intermediate feed forward layer in each T5Block. Can be overwrten by ff_widening_factor in model_cfg.
|
| 199 |
+
"d_kv": 64, # d_kv has to be equal to d_model // num_heads.
|
| 200 |
+
# "d_model": 512, # encoder hiddnen size, defined by model_cfg
|
| 201 |
+
"decoder_start_token_id": 0,
|
| 202 |
+
"dense_act_fn": "gelu_new",
|
| 203 |
+
# "dropout_rate": 0.05, # can be overwritten by args in ymt3
|
| 204 |
+
"eos_token_id": 1,
|
| 205 |
+
"feed_forward_proj": "gated-gelu",
|
| 206 |
+
"initializer_factor": 1.0,
|
| 207 |
+
"is_encoder_decoder": True,
|
| 208 |
+
"is_gated_act": True,
|
| 209 |
+
"layer_norm_epsilon": 1e-06,
|
| 210 |
+
"model_type": "t5",
|
| 211 |
+
# "num_decoder_layers": 8, # defined by model_cfg
|
| 212 |
+
# "num_heads": 6, # defined by model_cfg
|
| 213 |
+
# "num_layers": 8, # defined by model_cfg
|
| 214 |
+
"output_past": True,
|
| 215 |
+
"pad_token_id": 0,
|
| 216 |
+
"relative_attention_num_buckets": 32,
|
| 217 |
+
# "tie_word_embeddings": True,
|
| 218 |
+
"use_cache": True,
|
| 219 |
+
# "vocab_size": 1391 # vocab_size is automatically set by the task manager...
|
| 220 |
+
},
|
| 221 |
+
"google/t5-efficient-small": {
|
| 222 |
+
"architectures": ["T5ForConditionalGeneration"],
|
| 223 |
+
"d_ff": 2048,
|
| 224 |
+
"d_kv": 64,
|
| 225 |
+
"d_model": 512,
|
| 226 |
+
"decoder_start_token_id": 0,
|
| 227 |
+
"dropout_rate": 0.1,
|
| 228 |
+
"eos_token_id": 1,
|
| 229 |
+
"feed_forward_proj": "relu",
|
| 230 |
+
"initializer_factor": 1.0,
|
| 231 |
+
"is_encoder_decoder": True,
|
| 232 |
+
"layer_norm_epsilon": 1e-06,
|
| 233 |
+
"model_type": "t5",
|
| 234 |
+
"num_decoder_layers": 6,
|
| 235 |
+
"num_heads": 8,
|
| 236 |
+
"num_layers": 6,
|
| 237 |
+
"pad_token_id": 0,
|
| 238 |
+
"relative_attention_num_buckets": 32,
|
| 239 |
+
"torch_dtype": "float32",
|
| 240 |
+
"transformers_version": "4.17.0.dev0",
|
| 241 |
+
"use_cache": True,
|
| 242 |
+
},
|
| 243 |
+
}
|
| 244 |
+
|
| 245 |
+
# yapf: enable
|
| 246 |
+
DEEPSPEED_CFG = {
|
| 247 |
+
"zero_allow_untested_optimizer": True,
|
| 248 |
+
"optimizer": {
|
| 249 |
+
"type": "adam",
|
| 250 |
+
"params": {
|
| 251 |
+
"lr": 1e-4,
|
| 252 |
+
"betas": [0.998, 0.999],
|
| 253 |
+
"eps": 1e-3,
|
| 254 |
+
"weight_decay": 0.001,
|
| 255 |
+
"adam_w_mode": True,
|
| 256 |
+
}
|
| 257 |
+
},
|
| 258 |
+
"scheduler": {
|
| 259 |
+
"type": "WarmupLR",
|
| 260 |
+
"params": {
|
| 261 |
+
"last_batch_iteration": -1,
|
| 262 |
+
"warmup_min_lr": 0,
|
| 263 |
+
"warmup_max_lr": 3e-5,
|
| 264 |
+
"warmup_num_steps": 100,
|
| 265 |
+
},
|
| 266 |
+
},
|
| 267 |
+
"zero_optimization": {
|
| 268 |
+
"stage": 0, #0,1,2,3
|
| 269 |
+
# "offload_optimizer":
|
| 270 |
+
# False, # Enable Offloading optimizer state/calculation to the host CPU
|
| 271 |
+
},
|
| 272 |
+
}
|
amt/src/config/data_presets.py
ADDED
|
@@ -0,0 +1,811 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
""" data.py:
|
| 2 |
+
Data presets for training and evaluation.
|
| 3 |
+
|
| 4 |
+
Single Presets:
|
| 5 |
+
musicnet_mt3
|
| 6 |
+
musicnet_em
|
| 7 |
+
musicnet_thickstun
|
| 8 |
+
slakh
|
| 9 |
+
guitarset
|
| 10 |
+
...
|
| 11 |
+
|
| 12 |
+
Multi Presets:
|
| 13 |
+
all_mmegs
|
| 14 |
+
...
|
| 15 |
+
|
| 16 |
+
"""
|
| 17 |
+
from config.vocabulary import *
|
| 18 |
+
from config.vocabulary import drum_vocab_presets, program_vocab_presets
|
| 19 |
+
from utils.utils import deduplicate_splits, merge_splits, merge_vocab
|
| 20 |
+
|
| 21 |
+
data_preset_single_cfg = {
|
| 22 |
+
"musicnet_mt3": {
|
| 23 |
+
"eval_vocab": [MUSICNET_INSTR_CLASS],
|
| 24 |
+
"dataset_name": "musicnet",
|
| 25 |
+
"train_split": "train_mt3",
|
| 26 |
+
"validation_split": "validation_mt3_acoustic",
|
| 27 |
+
"test_split": "test_mt3_acoustic",
|
| 28 |
+
"has_stem": False,
|
| 29 |
+
},
|
| 30 |
+
"musicnet_mt3_synth_only": { # sanity-check
|
| 31 |
+
"eval_vocab": [MUSICNET_INSTR_CLASS],
|
| 32 |
+
"dataset_name": "musicnet",
|
| 33 |
+
"train_split": "train_mt3_synth",
|
| 34 |
+
"validation_split": "validation_mt3_synth",
|
| 35 |
+
"test_split": "test_mt3_acoustic",
|
| 36 |
+
"has_stem": False,
|
| 37 |
+
},
|
| 38 |
+
"musicnet_mt3_em": {
|
| 39 |
+
"eval_vocab": [MUSICNET_INSTR_CLASS],
|
| 40 |
+
"dataset_name": "musicnet",
|
| 41 |
+
"train_split": "train_mt3_em",
|
| 42 |
+
"validation_split": "validation_mt3_em",
|
| 43 |
+
"test_split": "test_mt3_em",
|
| 44 |
+
"has_stem": False,
|
| 45 |
+
},
|
| 46 |
+
"musicnet_thickstun": { # exp4
|
| 47 |
+
"eval_vocab": [MUSICNET_INSTR_CLASS],
|
| 48 |
+
"dataset_name": "musicnet",
|
| 49 |
+
"train_split": "train_thickstun",
|
| 50 |
+
"validation_split": "test_thickstun",
|
| 51 |
+
"test_split": "test_thickstun",
|
| 52 |
+
"has_stem": False,
|
| 53 |
+
},
|
| 54 |
+
"musicnet_thickstun_em": { # NOTE: this is not the use of external 'synth' in the paper, but the use of 'synth' within the dataset
|
| 55 |
+
"eval_vocab": [MUSICNET_INSTR_CLASS],
|
| 56 |
+
"dataset_name": "musicnet",
|
| 57 |
+
"train_split": "train_thickstun_em",
|
| 58 |
+
"validation_split": "test_thickstun_em",
|
| 59 |
+
"test_split": "test_thickstun_em",
|
| 60 |
+
"has_stem": False,
|
| 61 |
+
},
|
| 62 |
+
"musicnet_thickstun_ext": { # exp4
|
| 63 |
+
"eval_vocab": [MUSICNET_INSTR_CLASS],
|
| 64 |
+
"dataset_name": "musicnet",
|
| 65 |
+
"train_split": "train_thickstun",
|
| 66 |
+
"validation_split": "test_thickstun_ext",
|
| 67 |
+
"test_split": "test_thickstun_ext",
|
| 68 |
+
"has_stem": False,
|
| 69 |
+
},
|
| 70 |
+
"musicnet_thickstun_ext_em": { # NOTE: this is not the use of external 'synth' in the paper, but the use of 'synth' within the dataset
|
| 71 |
+
"eval_vocab": [MUSICNET_INSTR_CLASS],
|
| 72 |
+
"dataset_name": "musicnet",
|
| 73 |
+
"train_split": "train_thickstun_em",
|
| 74 |
+
"validation_split": "test_thickstun_ext_em",
|
| 75 |
+
"test_split": "test_thickstun_ext_em",
|
| 76 |
+
"has_stem": False,
|
| 77 |
+
},
|
| 78 |
+
"maps_default": {
|
| 79 |
+
"eval_vocab": [PIANO_SOLO_CLASS],
|
| 80 |
+
"dataset_name": "maps",
|
| 81 |
+
"train_split": "train",
|
| 82 |
+
"validation_split": "test",
|
| 83 |
+
"test_split": "test",
|
| 84 |
+
"has_stem": False,
|
| 85 |
+
},
|
| 86 |
+
"maps_all": {
|
| 87 |
+
"eval_vocab": [None],
|
| 88 |
+
"dataset_name": "maps",
|
| 89 |
+
"train_split": "all",
|
| 90 |
+
"validation_split": None,
|
| 91 |
+
"test_split": None,
|
| 92 |
+
"has_stem": False,
|
| 93 |
+
},
|
| 94 |
+
"maestro": {
|
| 95 |
+
"eval_vocab": [PIANO_SOLO_CLASS],
|
| 96 |
+
"dataset_name": "maestro",
|
| 97 |
+
"train_split": "train",
|
| 98 |
+
"validation_split": "validation",
|
| 99 |
+
"test_split": "test",
|
| 100 |
+
"has_stem": False,
|
| 101 |
+
},
|
| 102 |
+
"maestro_final": {
|
| 103 |
+
"eval_vocab": [PIANO_SOLO_CLASS],
|
| 104 |
+
"dataset_name": "maestro",
|
| 105 |
+
"train_split": merge_splits(["train", "validation"], dataset_name="maestro"),
|
| 106 |
+
"validation_split": "test",
|
| 107 |
+
"test_split": "test",
|
| 108 |
+
"has_stem": False,
|
| 109 |
+
},
|
| 110 |
+
"guitarset": { # 4 random players for train, 1 for valid, and 1 for test
|
| 111 |
+
"eval_vocab": [GUITAR_SOLO_CLASS],
|
| 112 |
+
"dataset_name": "guitarset",
|
| 113 |
+
"train_split": "train",
|
| 114 |
+
"validation_split": "validation",
|
| 115 |
+
"test_split": "test",
|
| 116 |
+
"has_stem": False,
|
| 117 |
+
},
|
| 118 |
+
"guitarset_pshift": { # guitarset + pitch shift
|
| 119 |
+
"eval_vocab": [GUITAR_SOLO_CLASS],
|
| 120 |
+
"dataset_name": "guitarset",
|
| 121 |
+
"train_split": "train_pshift",
|
| 122 |
+
"validation_split": "validation",
|
| 123 |
+
"test_split": "test",
|
| 124 |
+
"has_stem": False,
|
| 125 |
+
},
|
| 126 |
+
"guitarset_progression": { # progression 1 and 2 as train, progression 3 as test
|
| 127 |
+
"eval_vocab": [GUITAR_SOLO_CLASS],
|
| 128 |
+
"dataset_name": "guitarset",
|
| 129 |
+
"train_split": merge_splits(["progression_1", "progression_2"], dataset_name="guitarset"),
|
| 130 |
+
"validation_split": "progression_3",
|
| 131 |
+
"test_split": "progression_3",
|
| 132 |
+
"has_stem": False,
|
| 133 |
+
},
|
| 134 |
+
"guitarset_progression_pshift": { # guuitarset_progression + pitch shift
|
| 135 |
+
"eval_vocab": [GUITAR_SOLO_CLASS],
|
| 136 |
+
"dataset_name": "guitarset",
|
| 137 |
+
"train_split": merge_splits(["progression_1_pshift", "progression_2_pshift"], dataset_name="guitarset"),
|
| 138 |
+
"validation_split": "progression_3",
|
| 139 |
+
"test_split": "progression_3",
|
| 140 |
+
"has_stem": False,
|
| 141 |
+
},
|
| 142 |
+
"guitarset_minus_bn": { # guuitarset_style + pitch shift
|
| 143 |
+
"eval_vocab": [GUITAR_SOLO_CLASS],
|
| 144 |
+
"dataset_name": "guitarset",
|
| 145 |
+
"train_split": merge_splits(["Funk_pshift", "SS_pshift", "Jazz_pshift", "Rock_pshift"],
|
| 146 |
+
dataset_name="guitarset"),
|
| 147 |
+
"validation_split": "BN",
|
| 148 |
+
"test_split": "BN",
|
| 149 |
+
"has_stem": False,
|
| 150 |
+
},
|
| 151 |
+
"guitarset_minus_funk": { # guuitarset_style + pitch shift
|
| 152 |
+
"eval_vocab": [GUITAR_SOLO_CLASS],
|
| 153 |
+
"dataset_name": "guitarset",
|
| 154 |
+
"train_split": merge_splits(["BN_pshift", "SS_pshift", "Jazz_pshift", "Rock_pshift"],
|
| 155 |
+
dataset_name="guitarset"),
|
| 156 |
+
"validation_split": "Funk",
|
| 157 |
+
"test_split": "Funk",
|
| 158 |
+
"has_stem": False,
|
| 159 |
+
},
|
| 160 |
+
"guitarset_minus_ss": { # guuitarset_style + pitch shift
|
| 161 |
+
"eval_vocab": GUITAR_SOLO_CLASS,
|
| 162 |
+
"dataset_name": "guitarset",
|
| 163 |
+
"train_split": merge_splits(["BN_pshift", "Funk_pshift", "Jazz_pshift", "Rock_pshift"],
|
| 164 |
+
dataset_name="guitarset"),
|
| 165 |
+
"validation_split": "SS",
|
| 166 |
+
"test_split": "SS",
|
| 167 |
+
"has_stem": False,
|
| 168 |
+
},
|
| 169 |
+
"guitarset_minus_jazz": { # guuitarset_style + pitch shift
|
| 170 |
+
"eval_vocab": [GUITAR_SOLO_CLASS],
|
| 171 |
+
"dataset_name": "guitarset",
|
| 172 |
+
"train_split": merge_splits(["BN_pshift", "Funk_pshift", "SS_pshift", "Rock_pshift"],
|
| 173 |
+
dataset_name="guitarset"),
|
| 174 |
+
"validation_split": "Jazz",
|
| 175 |
+
"test_split": "Jazz",
|
| 176 |
+
"has_stem": False,
|
| 177 |
+
},
|
| 178 |
+
"guitarset_minus_rock": { # guuitarset_style + pitch shift
|
| 179 |
+
"eval_vocab": [GUITAR_SOLO_CLASS],
|
| 180 |
+
"dataset_name": "guitarset",
|
| 181 |
+
"train_split": merge_splits(["BN_pshift", "Funk_pshift", "SS_pshift", "Jazz_pshift"],
|
| 182 |
+
dataset_name="guitarset"),
|
| 183 |
+
"validation_split": "Rock",
|
| 184 |
+
"test_split": "Rock",
|
| 185 |
+
"has_stem": False,
|
| 186 |
+
},
|
| 187 |
+
"guitarset_all": {
|
| 188 |
+
"eval_vocab": [None],
|
| 189 |
+
"dataset_name": "guitarset",
|
| 190 |
+
"train_split": "all",
|
| 191 |
+
"validation_split": None,
|
| 192 |
+
"test_split": None,
|
| 193 |
+
"has_stem": False,
|
| 194 |
+
},
|
| 195 |
+
"enstdrums_dtp": {
|
| 196 |
+
"eval_vocab": [None],
|
| 197 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"],
|
| 198 |
+
"dataset_name": "enstdrums",
|
| 199 |
+
"train_split": merge_splits(["drummer_1_dtp", "drummer_2_dtp", "drummer_1_dtp", "drummer_2_dtp"], dataset_name="enstdrums"),
|
| 200 |
+
"validation_split": "drummer_1_dtp", # for sanity check
|
| 201 |
+
"test_split": "drummer_3_dtp",
|
| 202 |
+
"has_stem": False,
|
| 203 |
+
},
|
| 204 |
+
"enstdrums_dtm": {
|
| 205 |
+
"eval_vocab": [None],
|
| 206 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"],
|
| 207 |
+
"dataset_name": "enstdrums",
|
| 208 |
+
"train_split": merge_splits(["drummer_1_dtm", "drummer_2_dtm", "drummer_1_dtp", "drummer_2_dtp"], dataset_name="enstdrums"),
|
| 209 |
+
"validation_split": "drummer_3_dtm_r2", # 0.6 * drum
|
| 210 |
+
"test_split": "drummer_3_dtm_r1", # 0.75 * drum
|
| 211 |
+
"has_stem": True,
|
| 212 |
+
},
|
| 213 |
+
"enstdrums_random_dtm": { # single dataset training as a denoising ADT model
|
| 214 |
+
"eval_vocab": [None],
|
| 215 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"],
|
| 216 |
+
"dataset_name": "enstdrums",
|
| 217 |
+
"train_split": "train_dtm",
|
| 218 |
+
"validation_split": "validation_dtm",
|
| 219 |
+
"test_split": "test_dtm",
|
| 220 |
+
"has_stem": True,
|
| 221 |
+
},
|
| 222 |
+
"enstdrums_random": { # multi dataset training with random split of 70:15:15
|
| 223 |
+
"eval_vocab": [None],
|
| 224 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"],
|
| 225 |
+
"dataset_name": "enstdrums",
|
| 226 |
+
"train_split": "train_dtp",
|
| 227 |
+
"validation_split": "test_dtm",
|
| 228 |
+
"test_split": "test_dtm",
|
| 229 |
+
"has_stem": True,
|
| 230 |
+
},
|
| 231 |
+
"enstdrums_random_plus_dtd": { # multi dataset training plus dtd
|
| 232 |
+
"eval_vocab": [None],
|
| 233 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"],
|
| 234 |
+
"dataset_name": "enstdrums",
|
| 235 |
+
"train_split": merge_splits(["train_dtp", "all_dtd"], dataset_name="enstdrums"),
|
| 236 |
+
"validation_split": "test_dtm",
|
| 237 |
+
"test_split": "test_dtm",
|
| 238 |
+
"has_stem": True,
|
| 239 |
+
},
|
| 240 |
+
"mir_st500": {
|
| 241 |
+
"eval_vocab": [SINGING_SOLO_CLASS],
|
| 242 |
+
"dataset_name": "mir_st500",
|
| 243 |
+
"train_split": "train_stem",
|
| 244 |
+
"validation_split": "test",
|
| 245 |
+
"test_split": "test",
|
| 246 |
+
"has_stem": True,
|
| 247 |
+
},
|
| 248 |
+
"mir_st500_voc": {
|
| 249 |
+
"eval_vocab": [SINGING_SOLO_CLASS],
|
| 250 |
+
"dataset_name": "mir_st500",
|
| 251 |
+
"train_split": "train_vocal",
|
| 252 |
+
"validation_split": "test_vocal",
|
| 253 |
+
"test_split": "test_vocal",
|
| 254 |
+
"has_stem": False,
|
| 255 |
+
},
|
| 256 |
+
"mir_st500_voc_debug": { # using train_vocal for test (for debugging)
|
| 257 |
+
"eval_vocab": [SINGING_SOLO_CLASS],
|
| 258 |
+
"dataset_name": "mir_st500",
|
| 259 |
+
"train_split": "train_vocal",
|
| 260 |
+
"validation_split": "test_vocal",
|
| 261 |
+
"test_split": "train_vocal",
|
| 262 |
+
"has_stem": False,
|
| 263 |
+
},
|
| 264 |
+
"slakh": {
|
| 265 |
+
"eval_vocab": [GM_INSTR_CLASS],
|
| 266 |
+
"eval_drum_vocab": drum_vocab_presets["gm"],
|
| 267 |
+
"dataset_name": "slakh",
|
| 268 |
+
"train_split": "train",
|
| 269 |
+
"validation_split": "validation",
|
| 270 |
+
"test_split": "test",
|
| 271 |
+
"has_stem": True,
|
| 272 |
+
},
|
| 273 |
+
"slakh_final": {
|
| 274 |
+
"eval_vocab": [GM_INSTR_CLASS],
|
| 275 |
+
"eval_drum_vocab": drum_vocab_presets["gm"],
|
| 276 |
+
"dataset_name": "slakh",
|
| 277 |
+
"train_split": merge_splits(["train", "validation"], dataset_name="slakh"),
|
| 278 |
+
"validation_split": "test",
|
| 279 |
+
"test_split": "test",
|
| 280 |
+
"has_stem": True,
|
| 281 |
+
},
|
| 282 |
+
"rwc_pop_bass": {
|
| 283 |
+
"eval_vocab": [BASS_SOLO_CLASS],
|
| 284 |
+
"add_pitch_class_metric": ["Bass"],
|
| 285 |
+
"dataset_name": "rwc_pop",
|
| 286 |
+
"train_split": None,
|
| 287 |
+
"validation_split": "bass",
|
| 288 |
+
"test_split": "bass",
|
| 289 |
+
"has_stem": False,
|
| 290 |
+
},
|
| 291 |
+
"rwc_pop_full": {
|
| 292 |
+
"eval_vocab": [GM_INSTR_CLASS_PLUS],
|
| 293 |
+
"add_pitch_class_metric": list(GM_INSTR_CLASS_PLUS.keys()),
|
| 294 |
+
"dataset_name": "rwc_pop",
|
| 295 |
+
"train_split": None,
|
| 296 |
+
"validation_split": "full",
|
| 297 |
+
"test_split": "full",
|
| 298 |
+
"has_stem": False,
|
| 299 |
+
},
|
| 300 |
+
"egmd": {
|
| 301 |
+
"eval_vocab": [None],
|
| 302 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"],
|
| 303 |
+
"dataset_name": "egmd",
|
| 304 |
+
"train_split": "train",
|
| 305 |
+
"validation_split": "validation",
|
| 306 |
+
"test_split": "test_reduced", # EGMD has 5000+ test files, so we reudce it to 200 files to save time
|
| 307 |
+
# "train_limit_num_files": 4402, #8804, # 17608, # limit the number of files for training to random choice of half.
|
| 308 |
+
"has_stem": False,
|
| 309 |
+
},
|
| 310 |
+
"urmp": {
|
| 311 |
+
"eval_vocab": [GM_INSTR_CLASS],
|
| 312 |
+
"dataset_name": "urmp",
|
| 313 |
+
"train_split": "train",
|
| 314 |
+
"validation_split": "test",
|
| 315 |
+
"test_split": "test",
|
| 316 |
+
"has_stem": True,
|
| 317 |
+
},
|
| 318 |
+
"cmedia": {
|
| 319 |
+
"eval_vocab": [SINGING_SOLO_CLASS],
|
| 320 |
+
"dataset_name": "cmedia",
|
| 321 |
+
"train_split": "train_stem",
|
| 322 |
+
"validation_split": "train",
|
| 323 |
+
"test_split": "train",
|
| 324 |
+
"has_stem": True,
|
| 325 |
+
},
|
| 326 |
+
"cmedia_voc": {
|
| 327 |
+
"eval_vocab": [SINGING_SOLO_CLASS],
|
| 328 |
+
"dataset_name": "cmedia",
|
| 329 |
+
"train_split": "train_vocal",
|
| 330 |
+
"validation_split": "train_vocal",
|
| 331 |
+
"test_split": "train_vocal",
|
| 332 |
+
"has_stem": False,
|
| 333 |
+
},
|
| 334 |
+
"idmt_smt_bass": {
|
| 335 |
+
"eval_vocab": [BASS_SOLO_CLASS],
|
| 336 |
+
"dataset_name": "idmt_smt_bass",
|
| 337 |
+
"train_split": "train",
|
| 338 |
+
"validation_split": "validation",
|
| 339 |
+
"test_split": "validation",
|
| 340 |
+
"has_stem": False,
|
| 341 |
+
},
|
| 342 |
+
"geerdes": { # full mix dataset for evaluation
|
| 343 |
+
"eval_vocab": [GM_INSTR_CLASS_PLUS],
|
| 344 |
+
"dataset_name": "geerdes",
|
| 345 |
+
"train_split": None,
|
| 346 |
+
"validation_split": None,
|
| 347 |
+
"test_split": "all",
|
| 348 |
+
"has_stem": False,
|
| 349 |
+
},
|
| 350 |
+
"geerdes_sep": { # Using vocal/accomp separation for evalutation
|
| 351 |
+
"eval_vocab": [GM_INSTR_CLASS_PLUS],
|
| 352 |
+
"dataset_name": "geerdes",
|
| 353 |
+
"train_split": None,
|
| 354 |
+
"validation_split": None,
|
| 355 |
+
"test_split": "all_sep",
|
| 356 |
+
"has_stem": False,
|
| 357 |
+
},
|
| 358 |
+
"geerdes_half": { # Using half dataset for train/val
|
| 359 |
+
"eval_vocab": [GM_INSTR_CLASS_PLUS],
|
| 360 |
+
"dataset_name": "geerdes",
|
| 361 |
+
"train_split": "train",
|
| 362 |
+
"validation_split": "validation",
|
| 363 |
+
"test_split": "validation",
|
| 364 |
+
"has_stem": False,
|
| 365 |
+
},
|
| 366 |
+
"geerdes_half_sep": { # Using half dataset with vocal/accomp separation for train/val
|
| 367 |
+
"eval_vocab": [GM_INSTR_CLASS_PLUS],
|
| 368 |
+
"dataset_name": "geerdes",
|
| 369 |
+
"train_split": "train_sep",
|
| 370 |
+
"validation_split": "validation_sep",
|
| 371 |
+
"test_split": "validation_sep",
|
| 372 |
+
"has_stem": False,
|
| 373 |
+
},
|
| 374 |
+
}
|
| 375 |
+
|
| 376 |
+
data_preset_multi_cfg = {
|
| 377 |
+
"musicnet_mt3_em_synth_plus_maps": {
|
| 378 |
+
"presets": ["musicnet_mt3_em_synth", "maps_all"],
|
| 379 |
+
"weights": [0.6, 0.4],
|
| 380 |
+
"eval_vocab": [MUSICNET_INSTR_CLASS],
|
| 381 |
+
},
|
| 382 |
+
"musicnet_em_synth_table2_plus_maps": {
|
| 383 |
+
"presets": ["musicnet_em_synth_table2", "maps_all"],
|
| 384 |
+
"weights": [0.6, 0.4],
|
| 385 |
+
"eval_vocab": [MUSICNET_INSTR_CLASS],
|
| 386 |
+
},
|
| 387 |
+
"musicnet_em_synth_table2_plus_maps_multi": {
|
| 388 |
+
"presets": ["musicnet_em_synth_table2", "maps_default"],
|
| 389 |
+
"weights": [0.6, 0.4],
|
| 390 |
+
"eval_vocab": [MUSICNET_INSTR_CLASS],
|
| 391 |
+
},
|
| 392 |
+
"guitarset_progression_plus_maps": {
|
| 393 |
+
"presets": ["guitarset_progression", "maps_all"],
|
| 394 |
+
"weights": [0.5, 0.5],
|
| 395 |
+
"eval_vocab": [GUITAR_SOLO_CLASS],
|
| 396 |
+
},
|
| 397 |
+
"guitarset_pshift_plus_maps": {
|
| 398 |
+
"presets": ["guitarset_pshift", "maps_default"],
|
| 399 |
+
"weights": [0.6, 0.4],
|
| 400 |
+
"eval_vocab": [merge_vocab([GUITAR_SOLO_CLASS, PIANO_SOLO_CLASS])],
|
| 401 |
+
},
|
| 402 |
+
"guitarset_pshift_plus_musicnet_thick": {
|
| 403 |
+
"presets": ["guitarset_pshift", "musicnet_thickstun_em"],
|
| 404 |
+
"weights": [0.5, 0.5],
|
| 405 |
+
"eval_vocab": [merge_vocab([GUITAR_SOLO_CLASS, PIANO_SOLO_CLASS])],
|
| 406 |
+
},
|
| 407 |
+
"multi_sanity_check": {
|
| 408 |
+
"presets": ["musicnet_mt3_synth_only", "musicnet_mt3_synth_only"],
|
| 409 |
+
"weights": [0.6, 0.4],
|
| 410 |
+
"eval_vocab": [MUSICNET_INSTR_CLASS],
|
| 411 |
+
},
|
| 412 |
+
"all_mmegs": {
|
| 413 |
+
"presets": [
|
| 414 |
+
"slakh", "musicnet_thickstun_em", "mir_st500_voc", "enstdrums_dtp", "guitarset_pshift"
|
| 415 |
+
],
|
| 416 |
+
"weights": [0.2, 0.2, 0.2, 0.2, 0.2],
|
| 417 |
+
"eval_vocab": [None] * 5, # None means instrument-agnostic F1 for each dataset
|
| 418 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 419 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 420 |
+
"test_max_num_files": None,
|
| 421 |
+
},
|
| 422 |
+
"all_gt_cv0": {
|
| 423 |
+
"presets": [
|
| 424 |
+
"slakh", "musicnet_thickstun_em", "mir_st500_voc", "enstdrums_dtp", "guitarset_minus_bn"
|
| 425 |
+
],
|
| 426 |
+
"weights": [0.2, 0.2, 0.2, 0.2, 0.2],
|
| 427 |
+
"eval_vocab": [None] * 5, # None means instrument-agnostic F1 for each dataset
|
| 428 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 429 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 430 |
+
"test_max_num_files": None,
|
| 431 |
+
},
|
| 432 |
+
"all_gt_cv1": {
|
| 433 |
+
"presets": [
|
| 434 |
+
"slakh", "musicnet_thickstun_em", "mir_st500_voc", "enstdrums_dtp",
|
| 435 |
+
"guitarset_minus_funk"
|
| 436 |
+
],
|
| 437 |
+
"weights": [0.2, 0.2, 0.2, 0.2, 0.2],
|
| 438 |
+
"eval_vocab": [None] * 5, # None means instrument-agnostic F1 for each dataset
|
| 439 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 440 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 441 |
+
"test_max_num_files": None,
|
| 442 |
+
},
|
| 443 |
+
"all_gt_cv2": {
|
| 444 |
+
"presets": [
|
| 445 |
+
"slakh", "musicnet_thickstun_em", "mir_st500_voc", "enstdrums_dtp", "guitarset_minus_ss"
|
| 446 |
+
],
|
| 447 |
+
"weights": [0.2, 0.2, 0.2, 0.2, 0.2],
|
| 448 |
+
"eval_vocab": [None] * 5, # None means instrument-agnostic F1 for each dataset
|
| 449 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 450 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 451 |
+
"test_max_num_files": None,
|
| 452 |
+
},
|
| 453 |
+
"all_gt_cv3": {
|
| 454 |
+
"presets": [
|
| 455 |
+
"slakh", "musicnet_thickstun_em", "mir_st500_voc", "enstdrums_dtp",
|
| 456 |
+
"guitarset_minus_rock"
|
| 457 |
+
],
|
| 458 |
+
"weights": [0.2, 0.2, 0.2, 0.2, 0.2],
|
| 459 |
+
"eval_vocab": [None] * 5, # None means instrument-agnostic F1 for each dataset
|
| 460 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 461 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 462 |
+
"test_max_num_files": None,
|
| 463 |
+
},
|
| 464 |
+
"all_gt_cv4": {
|
| 465 |
+
"presets": [
|
| 466 |
+
"slakh", "musicnet_thickstun_em", "mir_st500_voc", "enstdrums_dtp",
|
| 467 |
+
"guitarset_minus_jazz"
|
| 468 |
+
],
|
| 469 |
+
"weights": [0.2, 0.2, 0.2, 0.2, 0.2],
|
| 470 |
+
"eval_vocab": [None] * 5, # None means instrument-agnostic F1 for each dataset
|
| 471 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 472 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 473 |
+
"test_max_num_files": None,
|
| 474 |
+
},
|
| 475 |
+
"all_enstdrums_random": {
|
| 476 |
+
"presets": [
|
| 477 |
+
"slakh", "musicnet_thickstun_em", "mir_st500_voc", "enstdrums_random", "guitarset"
|
| 478 |
+
],
|
| 479 |
+
"weights": [0.2, 0.2, 0.2, 0.2, 0.2],
|
| 480 |
+
"eval_vocab": [None] * 5, # None means instrument-agnostic F1 for each dataset
|
| 481 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 482 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 483 |
+
"test_max_num_files": None,
|
| 484 |
+
},
|
| 485 |
+
"all_plus_egmd": {
|
| 486 |
+
"presets": [
|
| 487 |
+
"slakh", "musicnet_thickstun_em", "mir_st500_voc", "enstdrums_random_plus_dtd",
|
| 488 |
+
"guitarset", "egmd"
|
| 489 |
+
],
|
| 490 |
+
"weights": [0.2, 0.2, 0.2, 0.1, 0.1, 0.2],
|
| 491 |
+
"eval_vocab": [None] * 6, # None means instrument-agnostic F1 for each dataset
|
| 492 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 493 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 494 |
+
"test_max_num_files": None,
|
| 495 |
+
},
|
| 496 |
+
"all_dtp_egmd": {
|
| 497 |
+
"presets": [
|
| 498 |
+
"slakh", "musicnet_thickstun_em", "mir_st500_voc", "enstdrums_dtp", "guitarset", "egmd"
|
| 499 |
+
],
|
| 500 |
+
"weights": [0.2, 0.2, 0.2, 0.1, 0.1, 0.2],
|
| 501 |
+
"eval_vocab": [None] * 6, # None means instrument-agnostic F1 for each dataset
|
| 502 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 503 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 504 |
+
"test_max_num_files": None,
|
| 505 |
+
},
|
| 506 |
+
"all_weighted_slakh": {
|
| 507 |
+
"presets": [
|
| 508 |
+
"slakh", "musicnet_thickstun_em", "mir_st500_voc", "enstdrums_dtp", "guitarset_pshift", "egmd"
|
| 509 |
+
],
|
| 510 |
+
"weights": [0.5, 0.1, 0.1, 0.05, 0.05, 0.2],
|
| 511 |
+
"eval_vocab": [None] * 6, # None means instrument-agnostic F1 for each dataset
|
| 512 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 513 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 514 |
+
"test_max_num_files": None,
|
| 515 |
+
},
|
| 516 |
+
"all_weighted_mt3": { # for comparison with MT3
|
| 517 |
+
"presets": [
|
| 518 |
+
"slakh", "musicnet_mt3", "mir_st500_voc", "enstdrums_dtp",
|
| 519 |
+
"guitarset_progression_pshift", "egmd"
|
| 520 |
+
],
|
| 521 |
+
"weights": [0.5, 0.1, 0.1, 0.05, 0.05, 0.2],
|
| 522 |
+
"eval_vocab": [None] * 6, # None means instrument-agnostic F1 for each dataset
|
| 523 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 524 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 525 |
+
"test_max_num_files": None,
|
| 526 |
+
},
|
| 527 |
+
"all_weighted_mt3_em": { # musicnet_mt3_em
|
| 528 |
+
"presets": [
|
| 529 |
+
"slakh", "musicnet_mt3_em", "mir_st500_voc", "enstdrums_dtp",
|
| 530 |
+
"guitarset_progression_pshift", "egmd"
|
| 531 |
+
],
|
| 532 |
+
"weights": [0.5, 0.1, 0.1, 0.05, 0.05, 0.2],
|
| 533 |
+
"eval_vocab": [None] * 6, # None means instrument-agnoßstic F1 for each dataset
|
| 534 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 535 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 536 |
+
"test_max_num_files": None,
|
| 537 |
+
},
|
| 538 |
+
"all_urmp": {
|
| 539 |
+
"presets": [
|
| 540 |
+
"slakh", "musicnet_thickstun_em", "mir_st500_voc", "enstdrums_dtp",
|
| 541 |
+
"guitarset_pshift", "egmd", "urmp"
|
| 542 |
+
],
|
| 543 |
+
"weights": [0.5, 0.2, 0.1, 0.05, 0.05, 0.05, 0.1],
|
| 544 |
+
"eval_vocab": [None] * 7, # None means instrument-agnostic F1 for each dataset
|
| 545 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 546 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 547 |
+
"test_max_num_files": None,
|
| 548 |
+
},
|
| 549 |
+
"all_urmp_mt3": { # for comparison with MT3 including URMP
|
| 550 |
+
"presets": [
|
| 551 |
+
"slakh", "musicnet_mt3", "mir_st500_voc", "enstdrums_dtp",
|
| 552 |
+
"guitarset_progression", "egmd", "urmp"
|
| 553 |
+
],
|
| 554 |
+
"weights": [0.5, 0.2, 0.1, 0.05, 0.05, 0.0125, 0.1],
|
| 555 |
+
"eval_vocab": [None] * 7, # None means instrument-agnostic F1 for each dataset
|
| 556 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 557 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 558 |
+
"test_max_num_files": None,
|
| 559 |
+
},
|
| 560 |
+
"all_urmp_mt3_em": { # musicnet_mt3_em including URMP
|
| 561 |
+
"presets": [
|
| 562 |
+
"slakh", "musicnet_mt3_em", "mir_st500_voc", "enstdrums_dtp",
|
| 563 |
+
"guitarset_progression", "egmd", "urmp"
|
| 564 |
+
],
|
| 565 |
+
"weights": [0.5, 0.2, 0.1, 0.05, 0.05, 0.0125, 0.1],
|
| 566 |
+
"eval_vocab": [None] * 7, # None means instrument-agnostic F1 for each dataset
|
| 567 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 568 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 569 |
+
"test_max_num_files": None,
|
| 570 |
+
},
|
| 571 |
+
"all_maestro": { # including Mestro and URMP
|
| 572 |
+
"presets": [
|
| 573 |
+
"slakh", "musicnet_thickstun_em", "mir_st500_voc", "enstdrums_dtp",
|
| 574 |
+
"guitarset_pshift", "egmd", "urmp", "maestro"
|
| 575 |
+
],
|
| 576 |
+
"weights": [0.5, 0.1, 0.125, 0.075, 0.025, 0.01, 0.1, 0.1],
|
| 577 |
+
"eval_vocab": [None] * 8, # None means instrument-agnostic F1 for each dataset
|
| 578 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 579 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 580 |
+
"test_max_num_files": None,
|
| 581 |
+
},
|
| 582 |
+
"all_maestro_mt3": { # for comparison with MT3 including URMP
|
| 583 |
+
"presets": [
|
| 584 |
+
"slakh", "musicnet_mt3", "mir_st500_voc", "enstdrums_dtp",
|
| 585 |
+
"guitarset_progression", "egmd", "urmp", "maestro"
|
| 586 |
+
],
|
| 587 |
+
"weights": [0.5, 0.1, 0.1, 0.05, 0.05, 0.0125, 0.1, 0.1],
|
| 588 |
+
"eval_vocab": [None] * 8, # None means instrument-agnostic F1 for each dataset
|
| 589 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 590 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 591 |
+
"test_max_num_files": None,
|
| 592 |
+
},
|
| 593 |
+
"all_maestro_mt3_em": { # musicnet_mt3_em including URMP
|
| 594 |
+
"presets": [
|
| 595 |
+
"slakh", "musicnet_mt3_em", "mir_st500_voc", "enstdrums_dtp",
|
| 596 |
+
"guitarset_progression", "egmd", "urmp", "maestro"
|
| 597 |
+
],
|
| 598 |
+
"weights": [0.5, 0.1, 0.1, 0.05, 0.05, 0.0125, 0.1, 0.1],
|
| 599 |
+
"eval_vocab": [None] * 8, # None means instrument-agnostic F1 for each dataset
|
| 600 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 601 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 602 |
+
"test_max_num_files": None,
|
| 603 |
+
},
|
| 604 |
+
"singing_v1": { # slakh + mir_st500 without spleeter
|
| 605 |
+
"presets": ["slakh", "mir_st500"],
|
| 606 |
+
"weights": [0.8, 0.2],
|
| 607 |
+
"eval_vocab": [None, SINGING_SOLO_CLASS], # None means instrument-agnostic F1 for each dataset
|
| 608 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 609 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 610 |
+
"test_max_num_files": None,
|
| 611 |
+
},
|
| 612 |
+
"all_singing_v1": { # for singing-only task
|
| 613 |
+
"presets": [
|
| 614 |
+
"slakh", "musicnet_thickstun_em", "mir_st500_stem", "enstdrums_dtp",
|
| 615 |
+
"guitarset_pshift", "egmd", "urmp", "maestro"
|
| 616 |
+
],
|
| 617 |
+
"weights": [0.5, 0.1, 0.1, 0.05, 0.05, 0.0125, 0.1, 0.1],
|
| 618 |
+
"eval_vocab": [None, None, SINGING_SOLO_CLASS, None, None, None, None, None], # None means instrument-agnostic F1 for each dataset
|
| 619 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 620 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 621 |
+
"test_max_num_files": None,
|
| 622 |
+
},
|
| 623 |
+
"all_singing_drum_v1": { # for singing-only and drum-only tasks
|
| 624 |
+
"presets": [
|
| 625 |
+
"slakh", "musicnet_thickstun_em", "mir_st500_stem", "enstdrums_dtm",
|
| 626 |
+
"guitarset_pshift", "egmd", "urmp", "maestro"
|
| 627 |
+
],
|
| 628 |
+
"weights": [0.5, 0.1, 0.1, 0.05, 0.05, 0.0125, 0.1, 0.1],
|
| 629 |
+
"eval_vocab": [None, None, SINGING_SOLO_CLASS, None, None, None, None, None], # None means instrument-agnostic F1 for each dataset
|
| 630 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 631 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 632 |
+
"test_max_num_files": None,
|
| 633 |
+
},
|
| 634 |
+
"all_cross": { # including Mestro and URMP
|
| 635 |
+
"presets": [
|
| 636 |
+
"slakh", "musicnet_thickstun_em", "mir_st500_voc", "enstdrums_dtp",
|
| 637 |
+
"guitarset_pshift", "egmd", "urmp", "maestro"
|
| 638 |
+
],
|
| 639 |
+
"weights": [0.5, 0.1, 0.125, 0.075, 0.025, 0.01, 0.1, 0.1],
|
| 640 |
+
"eval_vocab": [None, None, SINGING_SOLO_CLASS, None, None, None, None, None], # None means instrument-agnostic F1 for each dataset
|
| 641 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 642 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 643 |
+
"test_max_num_files": None,
|
| 644 |
+
},
|
| 645 |
+
"all_cross_rebal": { # rebalanced for cross-augment, using spleeter
|
| 646 |
+
"presets": [
|
| 647 |
+
"slakh", "musicnet_thickstun_em", "mir_st500_voc", "enstdrums_dtp",
|
| 648 |
+
"guitarset_pshift", "egmd", "urmp", "maestro"
|
| 649 |
+
],
|
| 650 |
+
"weights": [0.4, 0.15, 0.15, 0.075, 0.025, 0.01, 0.1, 0.1],
|
| 651 |
+
"eval_vocab": [None, None, SINGING_SOLO_CLASS, None, None, None, None, None], # None means instrument-agnostic F1 for each dataset
|
| 652 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 653 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 654 |
+
"test_max_num_files": None,
|
| 655 |
+
},
|
| 656 |
+
"all_cross_rebal2": { # rebalanced for cross-augment, using spleeter
|
| 657 |
+
"presets": [
|
| 658 |
+
"slakh", "musicnet_thickstun_em", "mir_st500_voc", "enstdrums_dtp",
|
| 659 |
+
"guitarset_pshift", "egmd", "urmp", "maestro"
|
| 660 |
+
],
|
| 661 |
+
"weights": [0.275, 0.19, 0.19, 0.1, 0.025, 0.02, 0.1, 0.1],
|
| 662 |
+
"eval_vocab": [None, None, SINGING_SOLO_CLASS, None, None, None, None, None], # None means instrument-agnostic F1 for each dataset
|
| 663 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 664 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 665 |
+
"test_max_num_files": None,
|
| 666 |
+
},
|
| 667 |
+
"all_cross_rebal4": { # rebalanced for cross-augment, using spleeter
|
| 668 |
+
"presets": [
|
| 669 |
+
"slakh", "musicnet_thickstun_em", "mir_st500_voc", "enstdrums_dtp",
|
| 670 |
+
"guitarset_pshift", "egmd", "urmp", "maestro"
|
| 671 |
+
],
|
| 672 |
+
"weights": [0.258, 0.19, 0.2, 0.125, 0.022, 0.005, 0.1, 0.1],
|
| 673 |
+
"eval_vocab": [None, None, SINGING_SOLO_CLASS, None, None, None, None, None], # None means instrument-agnostic F1 for each dataset
|
| 674 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 675 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 676 |
+
"test_max_num_files": None,
|
| 677 |
+
},
|
| 678 |
+
"all_cross_rebal5": { # rebalanced for cross-augment, using spleeter
|
| 679 |
+
"presets": [
|
| 680 |
+
"slakh", "musicnet_thickstun_em", "mir_st500_voc", "enstdrums_dtp",
|
| 681 |
+
"guitarset_pshift", "egmd", "urmp", "maestro"
|
| 682 |
+
],
|
| 683 |
+
"weights": [0.295, 0.19, 0.24, 0.05, 0.02, 0.005, 0.1, 0.1],
|
| 684 |
+
"eval_vocab": [None, None, SINGING_SOLO_CLASS, None, None, None, None, None], # None means instrument-agnostic F1 for each dataset
|
| 685 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 686 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 687 |
+
"test_max_num_files": None,
|
| 688 |
+
},
|
| 689 |
+
"all_cross_stem": { # accomp stem for sub-task learning + rebalanced for cross-augment
|
| 690 |
+
"presets": [
|
| 691 |
+
"slakh", "musicnet_thickstun_em", "mir_st500_stem", "enstdrums_dtm",
|
| 692 |
+
"guitarset_pshift", "egmd", "urmp", "maestro"
|
| 693 |
+
],
|
| 694 |
+
"weights": [0.4, 0.15, 0.15, 0.075, 0.025, 0.01, 0.1, 0.1],
|
| 695 |
+
"eval_vocab": [None, None, SINGING_SOLO_CLASS, None, None, None, None, None], # None means instrument-agnostic F1 for each dataset
|
| 696 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 697 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 698 |
+
"test_max_num_files": None,
|
| 699 |
+
},
|
| 700 |
+
"all_cross_stem_rebal3": { # accomp stem for sub-task learning + rebalanced for cross-augment
|
| 701 |
+
"presets": [
|
| 702 |
+
"slakh", "musicnet_thickstun_em", "mir_st500_stem", "enstdrums_dtm",
|
| 703 |
+
"guitarset_pshift", "egmd", "urmp", "maestro"
|
| 704 |
+
],
|
| 705 |
+
"weights": [0.265, 0.18, 0.21, 0.1, 0.025, 0.02, 0.1, 0.1],
|
| 706 |
+
"eval_vocab": [None, None, SINGING_SOLO_CLASS, None, None, None, None, None], # None means instrument-agnostic F1 for each dataset
|
| 707 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 708 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 709 |
+
"test_max_num_files": None,
|
| 710 |
+
},
|
| 711 |
+
"all_cross_v6": { # +cmeida +idmt_smt_bass
|
| 712 |
+
"presets": [
|
| 713 |
+
"slakh", "musicnet_thickstun_em", "mir_st500_voc", "enstdrums_dtp",
|
| 714 |
+
"guitarset", "egmd", "urmp", "maestro", "idmt_smt_bass", "cmedia_voc",
|
| 715 |
+
],
|
| 716 |
+
"weights": [0.295, 0.19, 0.19, 0.05, 0.01, 0.005, 0.1, 0.1, 0.01, 0.05],
|
| 717 |
+
"eval_vocab": [None, None, SINGING_SOLO_CLASS, None, None, None, None, None, BASS_SOLO_CLASS, SINGING_SOLO_CLASS], # None means instrument-agnostic F1 for each dataset
|
| 718 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 719 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 720 |
+
"test_max_num_files": None,
|
| 721 |
+
},
|
| 722 |
+
"all_cross_v6_geerdes": { # +geerdes_half
|
| 723 |
+
"presets": [
|
| 724 |
+
"slakh", "musicnet_thickstun_em", "mir_st500_voc", "enstdrums_dtp",
|
| 725 |
+
"guitarset", "egmd", "urmp", "maestro", "idmt_smt_bass", "cmedia_voc",
|
| 726 |
+
"geerdes_half", "geerdes_half_sep"
|
| 727 |
+
],
|
| 728 |
+
"weights": [0.295, 0.19, 0.19, 0.05, 0.01, 0.005, 0.075, 0.075, 0.01, 0.05, 0.025, 0.025],
|
| 729 |
+
"eval_vocab": [None, None, SINGING_SOLO_CLASS, None, None, None, None, None, BASS_SOLO_CLASS,
|
| 730 |
+
SINGING_SOLO_CLASS, GM_INSTR_CLASS_PLUS, GM_INSTR_CLASS_PLUS], # None means instrument-agnostic F1 for each dataset
|
| 731 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 732 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 733 |
+
"test_max_num_files": None,
|
| 734 |
+
},
|
| 735 |
+
"all_cross_v6_geerdes_rebal": { # +geerdes_half
|
| 736 |
+
"presets": [
|
| 737 |
+
"slakh", "musicnet_thickstun_em", "mir_st500_voc", "enstdrums_dtp",
|
| 738 |
+
"guitarset", "egmd", "urmp", "maestro", "idmt_smt_bass", "cmedia_voc",
|
| 739 |
+
"geerdes_half", "geerdes_half_sep"
|
| 740 |
+
],
|
| 741 |
+
"weights": [0.245, 0.175, 0.19, 0.05, 0.01, 0.005, 0.075, 0.05, 0.01, 0.05, 0.075, 0.075],
|
| 742 |
+
"eval_vocab": [None, None, SINGING_SOLO_CLASS, None, None, None, None, None, BASS_SOLO_CLASS,
|
| 743 |
+
SINGING_SOLO_CLASS, GM_INSTR_EXT_CLASS_PLUS, GM_INSTR_EXT_CLASS_PLUS], # None means instrument-agnostic F1 for each dataset
|
| 744 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 745 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 746 |
+
"test_max_num_files": None,
|
| 747 |
+
},
|
| 748 |
+
"all_cross_v7": {
|
| 749 |
+
"presets": [
|
| 750 |
+
"slakh", "musicnet_thickstun_em", "mir_st500_voc", "enstdrums_dtp",
|
| 751 |
+
"guitarset_progression_pshift", "egmd", "urmp", "maestro", "idmt_smt_bass", "cmedia_voc",
|
| 752 |
+
],
|
| 753 |
+
"weights": [0.295, 0.19, 0.191, 0.05, 0.01, 0.004, 0.1, 0.1, 0.01, 0.05],
|
| 754 |
+
"eval_vocab": [None, None, SINGING_SOLO_CLASS, None, None, None, None, None, BASS_SOLO_CLASS, SINGING_SOLO_CLASS], # None means instrument-agnostic F1 for each dataset
|
| 755 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 756 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 757 |
+
"test_max_num_files": None,
|
| 758 |
+
},
|
| 759 |
+
"all_cross_final": {
|
| 760 |
+
"presets": [
|
| 761 |
+
"slakh_final", "musicnet_thickstun_em", "mir_st500_voc", "enstdrums_dtp",
|
| 762 |
+
"guitarset_progression_pshift", "egmd", "urmp", "maestro_final", "idmt_smt_bass", "cmedia_voc",
|
| 763 |
+
],
|
| 764 |
+
"weights": [0.295, 0.19, 0.191, 0.05, 0.01, 0.004, 0.1, 0.1, 0.01, 0.05],
|
| 765 |
+
"eval_vocab": [None, None, SINGING_SOLO_CLASS, None, None, None, None, None, BASS_SOLO_CLASS, SINGING_SOLO_CLASS], # None means instrument-agnostic F1 for each dataset
|
| 766 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 767 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 768 |
+
"test_max_num_files": None,
|
| 769 |
+
},
|
| 770 |
+
"all_eval_final": { # The final evaluation set
|
| 771 |
+
"presets": [
|
| 772 |
+
"slakh", "musicnet_thickstun", "musicnet_thickstun_em", "musicnet_thickstun_ext",
|
| 773 |
+
"musicnet_thickstun_ext_em", "mir_st500_voc", "mir_st500", "enstdrums_dtp",
|
| 774 |
+
"enstdrums_dtm", "guitarset_progression_pshift", "rwc_pop_bass", "maestro", "urmp",
|
| 775 |
+
"maps_default", "rwc_pop_full", # "geerdes", "geerdes_sep",
|
| 776 |
+
],
|
| 777 |
+
"eval_vocab": [
|
| 778 |
+
GM_INSTR_CLASS, MUSICNET_INSTR_CLASS, MUSICNET_INSTR_CLASS, MUSICNET_INSTR_CLASS,
|
| 779 |
+
MUSICNET_INSTR_CLASS, SINGING_SOLO_CLASS, SINGING_SOLO_CLASS, None,
|
| 780 |
+
None, None, BASS_SOLO_CLASS, PIANO_SOLO_CLASS, GM_INSTR_CLASS,
|
| 781 |
+
PIANO_SOLO_CLASS, GM_INSTR_CLASS_PLUS, # GM_INSTR_CLASS_PLUS, GM_INSTR_CLASS_PLUS
|
| 782 |
+
],
|
| 783 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"],
|
| 784 |
+
},
|
| 785 |
+
"geerdes_eval": { # Geerdes evaluation sets for models trained without Geerdes.
|
| 786 |
+
"presets": ["geerdes_sep", "geerdes"],
|
| 787 |
+
"eval_vocab": [GM_INSTR_CLASS_PLUS, GM_INSTR_CLASS_PLUS],
|
| 788 |
+
"eval_drum_vocab": drum_vocab_presets["gm"],
|
| 789 |
+
},
|
| 790 |
+
"geerdes_half_eval": { # Geerdes evaluation sets for models trained with Geerdes-half
|
| 791 |
+
"presets": ["geerdes_half_sep", "geerdes_half"],
|
| 792 |
+
"eval_vocab": [GM_INSTR_CLASS_PLUS, GM_INSTR_CLASS_PLUS],
|
| 793 |
+
"eval_drum_vocab": drum_vocab_presets["gm"],
|
| 794 |
+
},
|
| 795 |
+
"minimal": { # slakh + mir_st500 with spleeter
|
| 796 |
+
"presets": ["slakh", "mir_st500_voc"],
|
| 797 |
+
"weights": [0.8, 0.2],
|
| 798 |
+
"eval_vocab": [None, SINGING_SOLO_CLASS], # None means instrument-agnostic F1 for each dataset
|
| 799 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 800 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 801 |
+
"test_max_num_files": None,
|
| 802 |
+
},
|
| 803 |
+
"singing_debug": { # slakh + mir_st500 with spleeter
|
| 804 |
+
"presets": ["mir_st500_voc_debug"],
|
| 805 |
+
"weights": [1.0],
|
| 806 |
+
"eval_vocab": [SINGING_SOLO_CLASS], # None means instrument-agnostic F1 for each dataset
|
| 807 |
+
"eval_drum_vocab": drum_vocab_presets["ksh"], # for drums, kick-snare-hihat metric
|
| 808 |
+
"val_max_num_files": 20, # max 20 files per dataset
|
| 809 |
+
"test_max_num_files": None,
|
| 810 |
+
},
|
| 811 |
+
}
|
amt/src/config/task.py
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 The YourMT3 Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Please see the details in the LICENSE file.
|
| 10 |
+
"""task.py"""
|
| 11 |
+
from config.vocabulary import *
|
| 12 |
+
from utils.note_event_dataclasses import Event
|
| 13 |
+
|
| 14 |
+
task_cfg = {
|
| 15 |
+
"mt3_midi": { # 11 classes + drum class
|
| 16 |
+
"name": "mt3_midi",
|
| 17 |
+
"train_program_vocab": program_vocab_presets["mt3_midi"],
|
| 18 |
+
"train_drum_vocab": drum_vocab_presets["gm"],
|
| 19 |
+
},
|
| 20 |
+
"mt3_midi_plus": { # 11 classes + singing + drum class
|
| 21 |
+
"name": "mt3_midi_plus",
|
| 22 |
+
"train_program_vocab": program_vocab_presets["mt3_midi_plus"],
|
| 23 |
+
"train_drum_vocab": drum_vocab_presets["gm"],
|
| 24 |
+
},
|
| 25 |
+
"mt3_full": { # 34 classes (except drums) as in MT3 paper
|
| 26 |
+
"name": "mt3_full",
|
| 27 |
+
"train_program_vocab": program_vocab_presets["mt3_full"],
|
| 28 |
+
"train_drum_vocab": drum_vocab_presets["gm"],
|
| 29 |
+
},
|
| 30 |
+
"mt3_full_plus": { # 34 classes (except drums) as in MT3 paper + singing + drum class
|
| 31 |
+
"name": "mt3_full_plus",
|
| 32 |
+
"train_program_vocab": program_vocab_presets["mt3_full_plus"],
|
| 33 |
+
"train_drum_vocab": drum_vocab_presets["gm"],
|
| 34 |
+
},
|
| 35 |
+
"gm_ext_plus": { # 13 classes + singing + chorus (except drums)
|
| 36 |
+
"name": "gm_ext_plus",
|
| 37 |
+
"train_program_vocab": program_vocab_presets["gm_ext_plus"],
|
| 38 |
+
"train_drum_vocab": drum_vocab_presets["gm"],
|
| 39 |
+
},
|
| 40 |
+
"singing_v1": {
|
| 41 |
+
"name": "singing",
|
| 42 |
+
"train_program_vocab": program_vocab_presets["mt3_full_plus"],
|
| 43 |
+
"train_drum_vocab": drum_vocab_presets["gm"],
|
| 44 |
+
"subtask_tokens": ["task", "transcribe_singing", "transcribe_all"],
|
| 45 |
+
"ignore_decoding_tokens": ["task", "transcribe_singing", "transcribe_all"],
|
| 46 |
+
"max_task_token_length": 2,
|
| 47 |
+
"eval_subtask_prefix": {
|
| 48 |
+
"default": [Event("transcribe_all", 0), Event("task", 0)],
|
| 49 |
+
"singing-only": [Event("transcribe_singing", 0),
|
| 50 |
+
Event("task", 0)],
|
| 51 |
+
}
|
| 52 |
+
},
|
| 53 |
+
"singing_drum_v1": {
|
| 54 |
+
"name": "singing_drum",
|
| 55 |
+
"train_program_vocab": program_vocab_presets["mt3_full_plus"],
|
| 56 |
+
"train_drum_vocab": drum_vocab_presets["gm"],
|
| 57 |
+
"subtask_tokens": ["task", "transcribe_singing", "transcribe_drum", "transcribe_all"],
|
| 58 |
+
"ignore_decoding_tokens": [
|
| 59 |
+
"task", "transcribe_singing", "transcribe_drum", "transcribe_all"
|
| 60 |
+
],
|
| 61 |
+
"max_task_token_length": 2,
|
| 62 |
+
"eval_subtask_prefix": {
|
| 63 |
+
"default": [Event("transcribe_all", 0), Event("task", 0)],
|
| 64 |
+
"singing-only": [Event("transcribe_singing", 0),
|
| 65 |
+
Event("task", 0)],
|
| 66 |
+
"drum-only": [Event("transcribe_drum", 0),
|
| 67 |
+
Event("task", 0)],
|
| 68 |
+
}
|
| 69 |
+
},
|
| 70 |
+
"mc13": { # multi-channel decoding task of {11 classes + drums + singing}
|
| 71 |
+
"name": "mc13",
|
| 72 |
+
"train_program_vocab": program_vocab_presets["gm_plus"],
|
| 73 |
+
"train_drum_vocab": drum_vocab_presets["gm"],
|
| 74 |
+
"num_decoding_channels": len(program_vocab_presets["gm_plus"]) + 1, # 13
|
| 75 |
+
"max_note_token_length_per_ch": 512, # multi-channel decoding exclusive parameter
|
| 76 |
+
"mask_loss_strategy": None, # multi-channel decoding exclusive parameter
|
| 77 |
+
},
|
| 78 |
+
"mc13_256": { # multi-channel decoding task of {11 classes + drums + singing}
|
| 79 |
+
"name": "mc13_256",
|
| 80 |
+
"train_program_vocab": program_vocab_presets["gm_plus"],
|
| 81 |
+
"train_drum_vocab": drum_vocab_presets["gm"],
|
| 82 |
+
"num_decoding_channels": len(program_vocab_presets["gm_plus"]) + 1, # 13
|
| 83 |
+
"max_note_token_length_per_ch": 256, # multi-channel decoding exclusive parameter
|
| 84 |
+
"mask_loss_strategy": None, # multi-channel decoding exclusive parameter
|
| 85 |
+
},
|
| 86 |
+
"mc13_full_plus": { # multi-channel decoding task of {34 classes + drums + singing & chorus} mapped to 13 channels
|
| 87 |
+
"name": "mc13_full_plus",
|
| 88 |
+
"train_program_vocab": program_vocab_presets["mt3_full_plus"],
|
| 89 |
+
"train_drum_vocab": drum_vocab_presets["gm"],
|
| 90 |
+
"program2channel_vocab_source": program_vocab_presets["gm_plus"],
|
| 91 |
+
"num_decoding_channels": 13,
|
| 92 |
+
"max_note_token_length_per_ch": 512, # multi-channel decoding exclusive parameter
|
| 93 |
+
"mask_loss_strategy": None, # multi-channel decoding exclusive parameter
|
| 94 |
+
},
|
| 95 |
+
"mc13_full_plus_256": { # multi-channel decoding task of {34 classes + drums + singing & chorus} mapped to 13 channels
|
| 96 |
+
"name": "mc13_full_plus_256",
|
| 97 |
+
"train_program_vocab": program_vocab_presets["mt3_full_plus"],
|
| 98 |
+
"train_drum_vocab": drum_vocab_presets["gm"],
|
| 99 |
+
"program2channel_vocab_source": program_vocab_presets["gm_plus"],
|
| 100 |
+
"num_decoding_channels": 13,
|
| 101 |
+
"max_note_token_length_per_ch": 256, # multi-channel decoding exclusive parameter
|
| 102 |
+
"mask_loss_strategy": None, # multi-channel decoding exclusive parameter
|
| 103 |
+
},
|
| 104 |
+
"exc_v1": {
|
| 105 |
+
"name": "exclusive",
|
| 106 |
+
"train_program_vocab": program_vocab_presets["mt3_full_plus"],
|
| 107 |
+
"train_drum_vocab": drum_vocab_presets["gm"],
|
| 108 |
+
"subtask_tokens": ["transcribe", "all", ":"],
|
| 109 |
+
# "ignore_decoding_tokens": [
|
| 110 |
+
# "task", "transcribe_singing", "transcribe_drum", "transcribe_all"
|
| 111 |
+
# ],
|
| 112 |
+
# "max_task_token_length": 2,
|
| 113 |
+
"ignore_decoding_tokens_from_and_to": ["transcribe", ":"],
|
| 114 |
+
"eval_subtask_prefix": { # this is the main task that transcribe all instruments
|
| 115 |
+
"default": [Event("transcribe", 0), Event("all", 0), Event(":", 0)],
|
| 116 |
+
},
|
| 117 |
+
"shuffle_subtasks": True,
|
| 118 |
+
},
|
| 119 |
+
}
|
amt/src/config/vocabulary.py
ADDED
|
@@ -0,0 +1,384 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 The YourMT3 Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Please see the details in the LICENSE file.
|
| 10 |
+
"""vocabulary.py
|
| 11 |
+
|
| 12 |
+
Vocabulary for instrument classes. Vocabulary can be used as train_vocab
|
| 13 |
+
or test_vocab in data_presets.py or train.py arguments.
|
| 14 |
+
|
| 15 |
+
- When it is used as train_vocab, it maps the instrument classes to the first
|
| 16 |
+
program number of the class. For example, if you use 'GM_INSTR_CLASS' as
|
| 17 |
+
train_vocab, then the program number of 'Piano' is [0,1,2,3,4,5,6,7]. These
|
| 18 |
+
program numbers are trained as program [0] in the model.
|
| 19 |
+
|
| 20 |
+
- When it is used as eval_vocab, any program number in the instrument class
|
| 21 |
+
is considered as correct.
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
MUSICNET_INSTR_CLASS: 3 classes used for MusicNet benchmark
|
| 25 |
+
GM_INSTR_CLASS: equivalent to 'MIDI Class' defined by MT3.
|
| 26 |
+
GM_INSTR_CLASS_PLUS: GM_INSTR_CLASS + singing voice
|
| 27 |
+
GM_INSTR_FULL: 128 GM instruments, which is extended from 'MT3_FULL'
|
| 28 |
+
MT3_FULL: this matches the class names in Table 3 of MT3 paper
|
| 29 |
+
ENST_DRUM_NOTES: 20 drum notes used in ENST dataset
|
| 30 |
+
GM_DRUM_NOTES: 45 GM drum notes with percussions
|
| 31 |
+
|
| 32 |
+
Program 128 is reserved for 'drum' internally.
|
| 33 |
+
Program 129 is reserved for 'unannotated', internally.
|
| 34 |
+
Program 100 is reserved for 'singing voice (melody)' in GM_INSTR_CLASS_PLUS.
|
| 35 |
+
Program 101 is reserved for 'singing voice (chorus)' in GM_INSTR_CLASS_PLUS.
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
"""
|
| 39 |
+
# yapf: disable
|
| 40 |
+
import numpy as np
|
| 41 |
+
|
| 42 |
+
PIANO_SOLO_CLASS = {
|
| 43 |
+
"Piano": np.arange(0, 8),
|
| 44 |
+
}
|
| 45 |
+
|
| 46 |
+
GUITAR_SOLO_CLASS = {
|
| 47 |
+
"Guitar": np.arange(24, 32),
|
| 48 |
+
}
|
| 49 |
+
|
| 50 |
+
SINGING_SOLO_CLASS = {
|
| 51 |
+
"Singing Voice": [100, 101],
|
| 52 |
+
}
|
| 53 |
+
|
| 54 |
+
SINGING_CHORUS_SEP_CLASS = {
|
| 55 |
+
"Singing Voice": [100],
|
| 56 |
+
"Singing Voice (chorus)": [101],
|
| 57 |
+
}
|
| 58 |
+
|
| 59 |
+
BASS_SOLO_CLASS = {
|
| 60 |
+
"Bass": np.arange(32, 40),
|
| 61 |
+
}
|
| 62 |
+
|
| 63 |
+
MUSICNET_INSTR_CLASS = {
|
| 64 |
+
"Piano": np.arange(0, 8),
|
| 65 |
+
"Strings": np.arange(40, 52), # Solo strings + ensemble strings
|
| 66 |
+
"Winds": np.arange(64, 80), # Reed + Pipe
|
| 67 |
+
}
|
| 68 |
+
|
| 69 |
+
GM_INSTR_CLASS = {
|
| 70 |
+
"Piano": np.arange(0, 8),
|
| 71 |
+
"Chromatic Percussion": np.arange(8, 16),
|
| 72 |
+
"Organ": np.arange(16, 24),
|
| 73 |
+
"Guitar": np.arange(24, 32),
|
| 74 |
+
"Bass": np.arange(32, 40),
|
| 75 |
+
"Strings": np.arange(40, 56), # Strings + Ensemble
|
| 76 |
+
# "Strings": np.arange(40, 48),
|
| 77 |
+
# "Ensemble": np.arange(48, 56),
|
| 78 |
+
"Brass": np.arange(56, 64),
|
| 79 |
+
"Reed": np.arange(64, 72),
|
| 80 |
+
"Pipe": np.arange(72, 80),
|
| 81 |
+
"Synth Lead": np.arange(80, 88),
|
| 82 |
+
"Synth Pad": np.arange(88, 96),
|
| 83 |
+
}
|
| 84 |
+
|
| 85 |
+
GM_INSTR_CLASS_PLUS = GM_INSTR_CLASS.copy()
|
| 86 |
+
GM_INSTR_CLASS_PLUS["Singing Voice"] = [100, 101]
|
| 87 |
+
|
| 88 |
+
GM_INSTR_EXT_CLASS = { # Best for enjoyable MIDI file generation
|
| 89 |
+
"Acoustic Piano": [0, 1, 3, 6, 7],
|
| 90 |
+
"Electric Piano": [2, 4, 5],
|
| 91 |
+
"Chromatic Percussion": np.arange(8, 16),
|
| 92 |
+
"Organ": np.arange(16, 24),
|
| 93 |
+
"Guitar (clean)": np.arange(24, 28),
|
| 94 |
+
"Guitar (distortion)": [30, 28, 29, 31], # np.arange(28, 32),
|
| 95 |
+
"Bass": [33, 32, 34, 35, 36, 37, 38, 39], # np.arange(32, 40),
|
| 96 |
+
"Strings": [48, 40, 41, 42, 43, 44, 45, 46, 47, 49, 50, 51, 52, 53, 54, 55], # np.arange(40, 56),
|
| 97 |
+
"Brass": np.arange(56, 64),
|
| 98 |
+
"Reed": np.arange(64, 72),
|
| 99 |
+
"Pipe": np.arange(72, 80),
|
| 100 |
+
"Synth Lead": np.arange(80, 88),
|
| 101 |
+
"Synth Pad": np.arange(88, 96),
|
| 102 |
+
}
|
| 103 |
+
GM_INSTR_EXT_CLASS_PLUS = GM_INSTR_EXT_CLASS.copy()
|
| 104 |
+
GM_INSTR_EXT_CLASS_PLUS["Singing Voice"] = [100]
|
| 105 |
+
GM_INSTR_EXT_CLASS_PLUS["Singing Voice (chorus)"] = [101]
|
| 106 |
+
|
| 107 |
+
GM_INSTR_FULL = {
|
| 108 |
+
"Acoustic Grand Piano": [0],
|
| 109 |
+
"Bright Acoustic Piano": [1],
|
| 110 |
+
"Electric Grand Piano": [2],
|
| 111 |
+
"Honky-tonk Piano": [3],
|
| 112 |
+
"Electric Piano 1": [4],
|
| 113 |
+
"Electric Piano 2": [5],
|
| 114 |
+
"Harpsichord": [6],
|
| 115 |
+
"Clavinet": [7],
|
| 116 |
+
"Celesta": [8],
|
| 117 |
+
"Glockenspiel": [9],
|
| 118 |
+
"Music Box": [10],
|
| 119 |
+
"Vibraphone": [11],
|
| 120 |
+
"Marimba": [12],
|
| 121 |
+
"Xylophone": [13],
|
| 122 |
+
"Tubular Bells": [14],
|
| 123 |
+
"Dulcimer": [15],
|
| 124 |
+
"Drawbar Organ": [16],
|
| 125 |
+
"Percussive Organ": [17],
|
| 126 |
+
"Rock Organ": [18],
|
| 127 |
+
"Church Organ": [19],
|
| 128 |
+
"Reed Organ": [20],
|
| 129 |
+
"Accordion": [21],
|
| 130 |
+
"Harmonica": [22],
|
| 131 |
+
"Tango Accordion": [23],
|
| 132 |
+
"Acoustic Guitar (nylon)": [24],
|
| 133 |
+
"Acoustic Guitar (steel)": [25],
|
| 134 |
+
"Electric Guitar (jazz)": [26],
|
| 135 |
+
"Electric Guitar (clean)": [27],
|
| 136 |
+
"Electric Guitar (muted)": [28],
|
| 137 |
+
"Overdriven Guitar": [29],
|
| 138 |
+
"Distortion Guitar": [30],
|
| 139 |
+
"Guitar Harmonics": [31],
|
| 140 |
+
"Acoustic Bass": [32],
|
| 141 |
+
"Electric Bass (finger)": [33],
|
| 142 |
+
"Electric Bass (pick)": [34],
|
| 143 |
+
"Fretless Bass": [35],
|
| 144 |
+
"Slap Bass 1": [36],
|
| 145 |
+
"Slap Bass 2": [37],
|
| 146 |
+
"Synth Bass 1": [38],
|
| 147 |
+
"Synth Bass 2": [39],
|
| 148 |
+
"Violin": [40],
|
| 149 |
+
"Viola": [41],
|
| 150 |
+
"Cello": [42],
|
| 151 |
+
"Contrabass": [43],
|
| 152 |
+
"Tremolo Strings": [44],
|
| 153 |
+
"Pizzicato Strings": [45],
|
| 154 |
+
"Orchestral Harp": [46],
|
| 155 |
+
"Timpani": [47],
|
| 156 |
+
"String Ensemble 1": [48],
|
| 157 |
+
"String Ensemble 2": [49],
|
| 158 |
+
"Synth Strings 1": [50],
|
| 159 |
+
"Synth Strings 2": [51],
|
| 160 |
+
"Choir Aahs": [52],
|
| 161 |
+
"Voice Oohs": [53],
|
| 162 |
+
"Synth Choir": [54],
|
| 163 |
+
"Orchestra Hit": [55],
|
| 164 |
+
"Trumpet": [56],
|
| 165 |
+
"Trombone": [57],
|
| 166 |
+
"Tuba": [58],
|
| 167 |
+
"Muted Trumpet": [59],
|
| 168 |
+
"French Horn": [60],
|
| 169 |
+
"Brass Section": [61],
|
| 170 |
+
"Synth Brass 1": [62],
|
| 171 |
+
"Synth Brass 2": [63],
|
| 172 |
+
"Soprano Sax": [64],
|
| 173 |
+
"Alto Sax": [65],
|
| 174 |
+
"Tenor Sax": [66],
|
| 175 |
+
"Baritone Sax": [67],
|
| 176 |
+
"Oboe": [68],
|
| 177 |
+
"English Horn": [69],
|
| 178 |
+
"Bassoon": [70],
|
| 179 |
+
"Clarinet": [71],
|
| 180 |
+
"Piccolo": [72],
|
| 181 |
+
"Flute": [73],
|
| 182 |
+
"Recorder": [74],
|
| 183 |
+
"Pan Flute": [75],
|
| 184 |
+
"Bottle Blow": [76],
|
| 185 |
+
"Shakuhachi": [77],
|
| 186 |
+
"Whistle": [78],
|
| 187 |
+
"Ocarina": [79],
|
| 188 |
+
"Lead 1 (square)": [80],
|
| 189 |
+
"Lead 2 (sawtooth)": [81],
|
| 190 |
+
"Lead 3 (calliope)": [82],
|
| 191 |
+
"Lead 4 (chiff)": [83],
|
| 192 |
+
"Lead 5 (charang)": [84],
|
| 193 |
+
"Lead 6 (voice)": [85],
|
| 194 |
+
"Lead 7 (fifths)": [86],
|
| 195 |
+
"Lead 8 (bass + lead)": [87],
|
| 196 |
+
"Pad 1 (new age)": [88],
|
| 197 |
+
"Pad 2 (warm)": [89],
|
| 198 |
+
"Pad 3 (polysynth)": [90],
|
| 199 |
+
"Pad 4 (choir)": [91],
|
| 200 |
+
"Pad 5 (bowed)": [92],
|
| 201 |
+
"Pad 6 (metallic)": [93],
|
| 202 |
+
"Pad 7 (halo)": [94],
|
| 203 |
+
"Pad 8 (sweep)": [95],
|
| 204 |
+
# "FX 1 (rain)": [96],
|
| 205 |
+
# "FX 2 (soundtrack)": [97],
|
| 206 |
+
# "FX 3 (crystal)": [98],
|
| 207 |
+
# "FX 4 (atmosphere)": [99],
|
| 208 |
+
# "FX 5 (brightness)": [100],
|
| 209 |
+
# "FX 6 (goblins)": [101],
|
| 210 |
+
# "FX 7 (echoes)": [102],
|
| 211 |
+
# "FX 8 (sci-fi)": [103],
|
| 212 |
+
# "Sitar": [104],
|
| 213 |
+
# "Banjo": [105],
|
| 214 |
+
# "Shamisen": [106],
|
| 215 |
+
# "Koto": [107],
|
| 216 |
+
# "Kalimba": [108],
|
| 217 |
+
# "Bagpipe": [109],
|
| 218 |
+
# "Fiddle": [110],
|
| 219 |
+
# "Shanai": [111],
|
| 220 |
+
# "Tinkle Bell": [112],
|
| 221 |
+
# "Agogo": [113],
|
| 222 |
+
# "Steel Drums": [114],
|
| 223 |
+
# "Woodblock": [115],
|
| 224 |
+
# "Taiko Drum": [116],
|
| 225 |
+
# "Melodic Tom": [117],
|
| 226 |
+
# "Synth Drum": [118],
|
| 227 |
+
# "Reverse Cymbal": [119],
|
| 228 |
+
# "Guitar Fret Noise": [120],
|
| 229 |
+
# "Breath Noise": [121],
|
| 230 |
+
# "Seashore": [122],
|
| 231 |
+
# "Bird Tweet": [123],
|
| 232 |
+
# "Telephone Ring": [124],
|
| 233 |
+
# "Helicopter": [125],
|
| 234 |
+
# "Applause": [126],
|
| 235 |
+
# "Gunshot": [127]
|
| 236 |
+
}
|
| 237 |
+
|
| 238 |
+
MT3_FULL = { # this matches the class names in Table 3 of MT3 paper
|
| 239 |
+
"Acoustic Piano": [0, 1, 3, 6, 7],
|
| 240 |
+
"Electric Piano": [2, 4, 5],
|
| 241 |
+
"Chromatic Percussion": np.arange(8, 16),
|
| 242 |
+
"Organ": np.arange(16, 24),
|
| 243 |
+
"Acoustic Guitar": np.arange(24, 26),
|
| 244 |
+
"Clean Electric Guitar": np.arange(26, 29),
|
| 245 |
+
"Distorted Electric Guitar": np.arange(29, 32),
|
| 246 |
+
"Acoustic Bass": [32, 35],
|
| 247 |
+
"Electric Bass": [33, 34, 36, 37, 38, 39],
|
| 248 |
+
"Violin": [40],
|
| 249 |
+
"Viola": [41],
|
| 250 |
+
"Cello": [42],
|
| 251 |
+
"Contrabass": [43],
|
| 252 |
+
"Orchestral Harp": [46],
|
| 253 |
+
"Timpani": [47],
|
| 254 |
+
"String Ensemble": [48, 49, 44, 45],
|
| 255 |
+
"Synth Strings": [50, 51],
|
| 256 |
+
"Choir and Voice": [52, 53, 54],
|
| 257 |
+
"Orchestra Hit": [55],
|
| 258 |
+
"Trumpet": [56, 59],
|
| 259 |
+
"Trombone": [57],
|
| 260 |
+
"Tuba": [58],
|
| 261 |
+
"French Horn": [60],
|
| 262 |
+
"Brass Section": [61, 62, 63],
|
| 263 |
+
"Soprano/Alto Sax": [64, 65],
|
| 264 |
+
"Tenor Sax": [66],
|
| 265 |
+
"Baritone Sax": [67],
|
| 266 |
+
"Oboe": [68],
|
| 267 |
+
"English Horn": [69],
|
| 268 |
+
"Bassoon": [70],
|
| 269 |
+
"Clarinet": [71],
|
| 270 |
+
"Pipe": [73, 72, 74, 75, 76, 77, 78, 79],
|
| 271 |
+
"Synth Lead": np.arange(80, 88),
|
| 272 |
+
"Synth Pad": np.arange(88, 96),
|
| 273 |
+
}
|
| 274 |
+
|
| 275 |
+
MT3_FULL_PLUS = MT3_FULL.copy()
|
| 276 |
+
MT3_FULL_PLUS["Singing Voice"] = [100]
|
| 277 |
+
MT3_FULL_PLUS["Singing Voice (chorus)"] = [101]
|
| 278 |
+
|
| 279 |
+
ENST_DRUM_NOTES = {
|
| 280 |
+
"bd": [36], # Kick Drum
|
| 281 |
+
"sd": [38], # Snare Drum
|
| 282 |
+
"sweep": [0], # Brush sweep
|
| 283 |
+
"sticks": [1], # Sticks
|
| 284 |
+
"rs": [2], # Rim shot
|
| 285 |
+
"cs": [37], # X-stick
|
| 286 |
+
"chh": [42], # Closed Hi-Hat
|
| 287 |
+
"ohh": [46], # Open Hi-Hat
|
| 288 |
+
"cb": [56], # Cowbell
|
| 289 |
+
"c": [3], # Other Cymbals
|
| 290 |
+
"lmt": [47], # Low Mid Tom
|
| 291 |
+
"mt": [48], # Mid Tom
|
| 292 |
+
"mtr": [58], # Mid Tom Rim
|
| 293 |
+
"lt": [45], # Low Tom
|
| 294 |
+
"ltr": [50], # Low Tom Rim
|
| 295 |
+
"lft": [41], # Low Floor Tom
|
| 296 |
+
"rc": [51], # Ride Cymbal
|
| 297 |
+
"ch": [52], # Chinese Cymbal
|
| 298 |
+
"cr": [49], # Crash Cymbal
|
| 299 |
+
"spl": [55], # Splash Cymbal
|
| 300 |
+
}
|
| 301 |
+
|
| 302 |
+
EGMD_DRUM_NOTES = {
|
| 303 |
+
"Kick Drum": [36], # Listed by order of most common annotation
|
| 304 |
+
"Snare X-stick": [37], # Snare X-Stick, https://youtu.be/a2KFrrKaoYU?t=80
|
| 305 |
+
"Snare Drum": [38], # Snare (head) and Electric Snare
|
| 306 |
+
"Closed Hi-Hat": [42, 44, 22], # 44 is pedal hi-hat
|
| 307 |
+
"Open Hi-Hat": [46, 26],
|
| 308 |
+
"Cowbell": [56],
|
| 309 |
+
"High Floor Tom": [43],
|
| 310 |
+
"Low Floor Tom": [41], # Lowest Tom
|
| 311 |
+
"Low Tom": [45],
|
| 312 |
+
"Low-Mid Tom": [47],
|
| 313 |
+
"Mid Tom": [48],
|
| 314 |
+
"Low Tom (Rim)": [50], # TD-17: 47, 50, 58
|
| 315 |
+
"Mid Tom (Rim)": [58],
|
| 316 |
+
# "Ride Cymbal": [51, 53, 59],
|
| 317 |
+
"Ride": [51],
|
| 318 |
+
"Ride (Bell)": [53], # https://youtu.be/b94hZoM5s3k?t=323
|
| 319 |
+
"Ride (Edge)": [59],
|
| 320 |
+
"Chinese Cymbal": [52],
|
| 321 |
+
"Crash Cymbal": [49, 57],
|
| 322 |
+
"Splash Cymbal": [55],
|
| 323 |
+
}
|
| 324 |
+
|
| 325 |
+
# Inspired by Roland TD-17 MIDI note map, https://rolandus.zendesk.com/hc/en-us/articles/360005173411-TD-17-Default-Factory-MIDI-Note-Map
|
| 326 |
+
GM_DRUM_NOTES = {
|
| 327 |
+
"Kick Drum": [36, 35], # Listed by order of most common annotation
|
| 328 |
+
"Snare X-stick": [37, 2], # Snare X-Stick, https://youtu.be/a2KFrrKaoYU?t=80
|
| 329 |
+
"Snare Drum": [38, 40], # Snare (head) and Electric Snare
|
| 330 |
+
"Closed Hi-Hat": [42, 44, 22], # 44 is pedal hi-hat
|
| 331 |
+
"Open Hi-Hat": [46, 26],
|
| 332 |
+
"Cowbell": [56],
|
| 333 |
+
"High Floor Tom": [43],
|
| 334 |
+
"Low Floor Tom": [41], # Lowest Tom
|
| 335 |
+
"Low Tom": [45],
|
| 336 |
+
"Low-Mid Tom": [47],
|
| 337 |
+
"Mid Tom": [48],
|
| 338 |
+
"Low Tom (Rim)": [50], # TD-17: 47, 50, 58
|
| 339 |
+
"Mid Tom (Rim)": [58],
|
| 340 |
+
# "Ride Cymbal": [51, 53, 59],
|
| 341 |
+
"Ride": [51],
|
| 342 |
+
"Ride (Bell)": [53], # https://youtu.be/b94hZoM5s3k?t=323
|
| 343 |
+
"Ride (Edge)": [59],
|
| 344 |
+
"Chinese Cymbal": [52],
|
| 345 |
+
"Crash Cymbal": [49, 57],
|
| 346 |
+
"Splash Cymbal": [55],
|
| 347 |
+
}
|
| 348 |
+
|
| 349 |
+
KICK_SNARE_HIHAT = {
|
| 350 |
+
"Kick Drum": [36, 35],
|
| 351 |
+
"Snare Drum": [38, 40],
|
| 352 |
+
# "Snare Drum + X-Stick": [38, 40, 37, 2],
|
| 353 |
+
# "Snare X-stick": [37, 2], # Snare X-Stick, https://youtu.be/a2KFrrKaoYU?t=80
|
| 354 |
+
"Hi-Hat": [42, 44, 46, 22, 26],
|
| 355 |
+
# "Ride Cymbal": [51, 53, 59],
|
| 356 |
+
# "Hi-Hat + Ride": [42, 44, 46, 22, 26, 51, 53, 59],
|
| 357 |
+
# "HiHat + all Cymbals": [42, 44, 46, 22, 26, 51, 53, 59, 52, 49, 57, 55],
|
| 358 |
+
# "Kick Drum + Low Tom": [36, 35, 45],
|
| 359 |
+
# "All Cymbal": [51, 53, 59, 52, 49, 57, 55]
|
| 360 |
+
# "all": np.arange(30, 60)
|
| 361 |
+
}
|
| 362 |
+
|
| 363 |
+
drum_vocab_presets = {
|
| 364 |
+
"gm": GM_DRUM_NOTES,
|
| 365 |
+
"egmd": EGMD_DRUM_NOTES,
|
| 366 |
+
"enst": ENST_DRUM_NOTES,
|
| 367 |
+
"ksh": KICK_SNARE_HIHAT,
|
| 368 |
+
"kshr": {
|
| 369 |
+
"Kick Drum": [36, 35],
|
| 370 |
+
"Snare Drum": [38, 40],
|
| 371 |
+
"Hi-Hat": [42, 44, 46, 22, 26, 51, 53, 59],
|
| 372 |
+
}
|
| 373 |
+
}
|
| 374 |
+
|
| 375 |
+
program_vocab_presets = {
|
| 376 |
+
"gm_full": GM_INSTR_FULL, # 96 classes (except drums)
|
| 377 |
+
"mt3_full": MT3_FULL, # 34 classes (except drums) as in MT3 paper
|
| 378 |
+
"mt3_midi": GM_INSTR_CLASS, # 11 classes (except drums) as in MT3 paper
|
| 379 |
+
"mt3_midi_plus": GM_INSTR_CLASS_PLUS, # 11 classes + singing (except drums)
|
| 380 |
+
"mt3_full_plus": MT3_FULL_PLUS, # 34 classes (except drums) mt3_full + singing (except drums)
|
| 381 |
+
"gm": GM_INSTR_CLASS, # 11 classes (except drums)
|
| 382 |
+
"gm_plus": GM_INSTR_CLASS_PLUS, # 11 classes + singing (except drums)
|
| 383 |
+
"gm_ext_plus": GM_INSTR_EXT_CLASS_PLUS, # 13 classes + singing + chorus (except drums)
|
| 384 |
+
}
|
amt/src/extras/.DS_Store
ADDED
|
Binary file (10.2 kB). View file
|
|
|
amt/src/extras/Dockerfile
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM pytorch/pytorch:2.0.1-cuda11.7-cudnn8-devel
|
| 2 |
+
LABEL maintainer="https://github.com/mimbres/YourMT3"
|
| 3 |
+
|
| 4 |
+
ENV TZ=Europe/London \
|
| 5 |
+
DEBIAN_FRONTEND=noninteractive
|
| 6 |
+
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
|
| 7 |
+
|
| 8 |
+
RUN apt-get update
|
| 9 |
+
ENV LANG=C.UTF-8 LC_ALL=C.UTF-8
|
| 10 |
+
|
| 11 |
+
RUN apt-get update --fix-missing && apt-get install -y wget curl \
|
| 12 |
+
nano git ffmpeg sox tmux htop
|
| 13 |
+
RUN pip3 install --upgrade pip
|
| 14 |
+
RUN pip3 install mirdata mido git+https://github.com/craffel/mir_eval.git \
|
| 15 |
+
matplotlib lightning>=2.0.2 pytest-timeout pytest deprecated librosa \
|
| 16 |
+
einops transformers wandb
|
| 17 |
+
|
| 18 |
+
CMD [ "/bin/bash" ]
|
amt/src/extras/check_drum_channel_slakh.py
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from utils.mirdata_dev.datasets import slakh16k
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def check_drum_channel_slakh(data_home: str):
|
| 5 |
+
ds = slakh16k.Dataset(data_home, version='default')
|
| 6 |
+
for track_id in ds.track_ids:
|
| 7 |
+
is_drum = ds.track(track_id).is_drum
|
| 8 |
+
midi = MidiFile(ds.track(track_id).midi_path)
|
| 9 |
+
cnt = 0
|
| 10 |
+
for msg in midi:
|
| 11 |
+
if 'note' in msg.type:
|
| 12 |
+
if is_drum and (msg.channel != 9):
|
| 13 |
+
print('found drum track with channel != 9 in track_id: ',
|
| 14 |
+
track_id)
|
| 15 |
+
if not is_drum and (msg.channel == 9):
|
| 16 |
+
print(
|
| 17 |
+
'found non-drum track with channel == 9 in track_id: ',
|
| 18 |
+
track_id)
|
| 19 |
+
if is_drum and (msg.channel == 9):
|
| 20 |
+
cnt += 1
|
| 21 |
+
if cnt > 0:
|
| 22 |
+
print(f'found {cnt} notes in drum track with ch 9 in track_id: ',
|
| 23 |
+
track_id)
|
| 24 |
+
return
|
amt/src/extras/dataset_mutable_var_sanity_check.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
for n in range(1000):
|
| 2 |
+
sampled_data = ds.__getitem__(n)
|
| 3 |
+
|
| 4 |
+
a = deepcopy(sampled_data['note_event_segments'])
|
| 5 |
+
b = deepcopy(sampled_data['note_event_segments'])
|
| 6 |
+
|
| 7 |
+
for (note_events, tie_note_events, start_time) in list(zip(*b.values())):
|
| 8 |
+
note_events = pitch_shift_note_events(note_events, 2)
|
| 9 |
+
tie_note_events = pitch_shift_note_events(tie_note_events, 2)
|
| 10 |
+
|
| 11 |
+
# compare
|
| 12 |
+
for i, (note_events, tie_note_events, start_time) in enumerate(list(zip(*b.values()))):
|
| 13 |
+
for j, ne in enumerate(note_events):
|
| 14 |
+
if ne.is_drum is False:
|
| 15 |
+
if ne.pitch != a['note_events'][i][j].pitch + 2:
|
| 16 |
+
print(i, j)
|
| 17 |
+
assert ne.pitch == a['note_events'][i][j].pitch + 2
|
| 18 |
+
|
| 19 |
+
for k, tne in enumerate(tie_note_events):
|
| 20 |
+
assert tne.pitch == a['tie_note_events'][i][k].pitch + 2
|
| 21 |
+
|
| 22 |
+
print('test {} passed'.format(n))
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def assert_note_events_almost_equal(actual_note_events,
|
| 26 |
+
predicted_note_events,
|
| 27 |
+
ignore_time=False,
|
| 28 |
+
ignore_activity=True,
|
| 29 |
+
delta=5.1e-3):
|
| 30 |
+
"""
|
| 31 |
+
Asserts that the given lists of Note instances are equal up to a small
|
| 32 |
+
floating-point tolerance, similar to `assertAlmostEqual` of `unittest`.
|
| 33 |
+
Tolerance is 5e-3 by default, which is 5 ms for 100 ticks-per-second.
|
| 34 |
+
|
| 35 |
+
If `ignore_time` is True, then the time field is ignored. (useful for
|
| 36 |
+
comparing tie note events, default is False)
|
| 37 |
+
|
| 38 |
+
If `ignore_activity` is True, then the activity field is ignored (default
|
| 39 |
+
is True).
|
| 40 |
+
"""
|
| 41 |
+
assert len(actual_note_events) == len(predicted_note_events)
|
| 42 |
+
for j, (actual_note_event,
|
| 43 |
+
predicted_note_event) in enumerate(zip(actual_note_events, predicted_note_events)):
|
| 44 |
+
if ignore_time is False:
|
| 45 |
+
assert abs(actual_note_event.time - predicted_note_event.time) <= delta
|
| 46 |
+
assert actual_note_event.is_drum == predicted_note_event.is_drum
|
| 47 |
+
if actual_note_event.is_drum is False and predicted_note_event.is_drum is False:
|
| 48 |
+
assert actual_note_event.program == predicted_note_event.program
|
| 49 |
+
assert actual_note_event.pitch == predicted_note_event.pitch
|
| 50 |
+
assert actual_note_event.velocity == predicted_note_event.velocity
|
| 51 |
+
if ignore_activity is False:
|
| 52 |
+
assert actual_note_event.activity == predicted_note_event.activity
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
cache_old = deepcopy(dict(ds.cache))
|
| 56 |
+
for n in range(500):
|
| 57 |
+
sampled_data = ds.__getitem__(n)
|
| 58 |
+
cache_new = ds.cache
|
| 59 |
+
cnt = 0
|
| 60 |
+
for k, v in cache_new.items():
|
| 61 |
+
if k in cache_old:
|
| 62 |
+
cnt += 1
|
| 63 |
+
assert (cache_new[k]['programs'] == cache_old[k]['programs']).all()
|
| 64 |
+
assert (cache_new[k]['is_drum'] == cache_old[k]['is_drum']).all()
|
| 65 |
+
assert (cache_new[k]['has_stems'] == cache_old[k]['has_stems'])
|
| 66 |
+
assert (cache_new[k]['has_unannotated'] == cache_old[k]['has_unannotated'])
|
| 67 |
+
assert (cache_new[k]['audio_array'] == cache_old[k]['audio_array']).all()
|
| 68 |
+
|
| 69 |
+
for nes_new, nes_old in zip(cache_new[k]['note_event_segments']['note_events'],
|
| 70 |
+
cache_old[k]['note_event_segments']['note_events']):
|
| 71 |
+
assert_note_events_almost_equal(nes_new, nes_old)
|
| 72 |
+
|
| 73 |
+
for tnes_new, tnes_old in zip(cache_new[k]['note_event_segments']['tie_note_events'],
|
| 74 |
+
cache_old[k]['note_event_segments']['tie_note_events']):
|
| 75 |
+
assert_note_events_almost_equal(tnes_new, tnes_old, ignore_time=True)
|
| 76 |
+
|
| 77 |
+
for s_new, s_old in zip(cache_new[k]['note_event_segments']['start_times'],
|
| 78 |
+
cache_old[k]['note_event_segments']['start_times']):
|
| 79 |
+
assert s_new == s_old
|
| 80 |
+
cache_old = deepcopy(dict(ds.cache))
|
| 81 |
+
print(n, cnt)
|
amt/src/extras/datasets_eval_testing.py
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from utils.datasets_eval import AudioFileDataset
|
| 2 |
+
from torch.utils.data import DataLoader
|
| 3 |
+
import pytorch_lightning as pl
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def test():
|
| 7 |
+
|
| 8 |
+
ds = AudioFileDataset()
|
| 9 |
+
dl = DataLoader(
|
| 10 |
+
ds, batch_size=None, collate_fn=lambda k: k
|
| 11 |
+
) # empty collate_fn is required to use mixed types.
|
| 12 |
+
|
| 13 |
+
for x, y in dl:
|
| 14 |
+
break
|
| 15 |
+
|
| 16 |
+
class MyModel(pl.LightningModule):
|
| 17 |
+
|
| 18 |
+
def __init__(self, **kwargs):
|
| 19 |
+
super().__init__()
|
| 20 |
+
|
| 21 |
+
def forward(self, x):
|
| 22 |
+
return x
|
| 23 |
+
|
| 24 |
+
def training_step(self, batch, batch_idx):
|
| 25 |
+
return 0
|
| 26 |
+
|
| 27 |
+
def validation_step(self, batch, batch_idx):
|
| 28 |
+
print(batch)
|
| 29 |
+
return 0
|
| 30 |
+
|
| 31 |
+
def train_dataloader(self):
|
| 32 |
+
return dl
|
| 33 |
+
|
| 34 |
+
def val_dataloader(self):
|
| 35 |
+
return dl
|
| 36 |
+
|
| 37 |
+
def configure_optimizers(self):
|
| 38 |
+
return None
|
| 39 |
+
|
| 40 |
+
model = MyModel()
|
| 41 |
+
trainer = pl.Trainer()
|
| 42 |
+
trainer.validate(model)
|
amt/src/extras/demo_cross_augmentation.py
ADDED
|
@@ -0,0 +1,69 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 The YourMT3 Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Please see the details in the LICENSE file.
|
| 10 |
+
from typing import Dict, Tuple
|
| 11 |
+
from copy import deepcopy
|
| 12 |
+
import soundfile as sf
|
| 13 |
+
import torch
|
| 14 |
+
from utils.data_modules import AMTDataModule
|
| 15 |
+
from config.data_presets import data_preset_single_cfg, data_preset_multi_cfg
|
| 16 |
+
from utils.augment import intra_stem_augment_processor
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def get_ds(data_preset_multi: Dict, train_num_samples_per_epoch: int = 90000):
|
| 20 |
+
dm = AMTDataModule(data_preset_multi=data_preset_multi, train_num_samples_per_epoch=train_num_samples_per_epoch)
|
| 21 |
+
dm.setup('fit')
|
| 22 |
+
dl = dm.train_dataloader()
|
| 23 |
+
ds = dl.flattened[0].dataset
|
| 24 |
+
return ds
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def debug_func(num_segments: int = 10):
|
| 28 |
+
sampled_data, sampled_ids = ds._get_rand_segments_from_cache(num_segments)
|
| 29 |
+
ux_sampled_data, _ = ds._get_rand_segments_from_cache(ux_count_sum, False, sampled_ids)
|
| 30 |
+
s = deepcopy(sampled_data)
|
| 31 |
+
intra_stem_augment_processor(sampled_data, submix_audio=False)
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def gen_audio(index: int = 0):
|
| 35 |
+
# audio_arr: (b, 1, nframe), note_token_arr: (b, l), task_token_arr: (b, task_l)
|
| 36 |
+
audio_arr, note_token_arr, task_token_arr = ds.__getitem__(index)
|
| 37 |
+
|
| 38 |
+
# merge all the segments into one audio file
|
| 39 |
+
audio = audio_arr.permute(0, 2, 1).reshape(-1).squeeze().numpy()
|
| 40 |
+
|
| 41 |
+
# save the audio file
|
| 42 |
+
sf.write('xaug_demo_audio.wav', audio, 16000, subtype='PCM_16')
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
data_preset_multi = data_preset_multi_cfg["all_cross_rebal5"]
|
| 46 |
+
ds = get_ds(data_preset_multi)
|
| 47 |
+
ds.random_amp_range = [0.8, 1.1]
|
| 48 |
+
ds.stem_xaug_policy = {
|
| 49 |
+
"max_k": 5,
|
| 50 |
+
"tau": 0.3,
|
| 51 |
+
"alpha": 1.0,
|
| 52 |
+
"max_subunit_stems": 12,
|
| 53 |
+
"no_instr_overlap": True,
|
| 54 |
+
"no_drum_overlap": True,
|
| 55 |
+
"uhat_intra_stem_augment": True,
|
| 56 |
+
}
|
| 57 |
+
gen_audio(3)
|
| 58 |
+
|
| 59 |
+
# for k in ds.cache.keys():
|
| 60 |
+
# arr = ds.cache[k]['audio_array']
|
| 61 |
+
# arr = np.sum(arr, axis=1).reshape(-1)
|
| 62 |
+
# # sf.write(f'xxx/{k}.wav', arr, 16000, subtype='PCM_16')
|
| 63 |
+
# if np.min(arr) > -0.5:
|
| 64 |
+
# print(k)
|
| 65 |
+
|
| 66 |
+
# arr = ds.cache[52]['audio_array']
|
| 67 |
+
# for i in range(arr.shape[1]):
|
| 68 |
+
# a = arr[:, i, :].reshape(-1)
|
| 69 |
+
# sf.write(f'xxx52/52_{i}.wav', a, 16000, subtype='PCM_16')
|
amt/src/extras/demo_intra_augmentation.py
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 The YourMT3 Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Please see the details in the LICENSE file.
|
| 10 |
+
import numpy as np
|
| 11 |
+
import torch
|
| 12 |
+
import json
|
| 13 |
+
import soundfile as sf
|
| 14 |
+
from utils.datasets_train import get_cache_data_loader
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def get_filelist(track_id: int) -> dict:
|
| 18 |
+
filelist = '../../data/yourmt3_indexes/slakh_train_file_list.json'
|
| 19 |
+
with open(filelist, 'r') as f:
|
| 20 |
+
fl = json.load(f)
|
| 21 |
+
new_filelist = dict()
|
| 22 |
+
for key, value in fl.items():
|
| 23 |
+
if int(key) == track_id:
|
| 24 |
+
new_filelist[0] = value
|
| 25 |
+
return new_filelist
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def get_ds(track_id: int, random_amp_range: list = [1., 1.], stem_aug_prob: float = 0.8):
|
| 29 |
+
filelist = get_filelist(track_id)
|
| 30 |
+
dl = get_cache_data_loader(filelist,
|
| 31 |
+
'train',
|
| 32 |
+
1,
|
| 33 |
+
1,
|
| 34 |
+
random_amp_range=random_amp_range,
|
| 35 |
+
stem_aug_prob=stem_aug_prob,
|
| 36 |
+
shuffle=False)
|
| 37 |
+
ds = dl.dataset
|
| 38 |
+
return ds
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def gen_audio(track_id: int, n_segments: int = 30, random_amp_range: list = [1., 1.], stem_aug_prob: float = 0.8):
|
| 42 |
+
ds = get_ds(track_id, random_amp_range, stem_aug_prob)
|
| 43 |
+
audio = []
|
| 44 |
+
for i in range(n_segments):
|
| 45 |
+
audio.append(ds.__getitem__(0)[0])
|
| 46 |
+
# audio.append(ds.__getitem__(i)[0])
|
| 47 |
+
|
| 48 |
+
audio = torch.concat(audio, dim=2).numpy()[0, 0, :]
|
| 49 |
+
sf.write('audio.wav', audio, 16000, subtype='PCM_16')
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
gen_audio(1, 20)
|
amt/src/extras/download_mirst500.py
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import json
|
| 3 |
+
import numpy as np
|
| 4 |
+
from pytube import YouTube
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def downloadMp3(yt, idx, askPath=0):
|
| 8 |
+
# extract only audio
|
| 9 |
+
video = yt.streams.filter(only_audio=True).first()
|
| 10 |
+
|
| 11 |
+
destination = 'mp3File'
|
| 12 |
+
# check for destination to save file
|
| 13 |
+
if (askPath == 1):
|
| 14 |
+
print("Enter the destination (leave blank for default dir mp3File)")
|
| 15 |
+
destination = str(input(">> ")) or 'mp3File'
|
| 16 |
+
|
| 17 |
+
# download the file
|
| 18 |
+
out_file = video.download(output_path=destination)
|
| 19 |
+
|
| 20 |
+
# save the file
|
| 21 |
+
# base, ext = os.path.splitext(out_file)
|
| 22 |
+
dir_path, file_base = os.path.split(out_file)
|
| 23 |
+
|
| 24 |
+
new_file = os.path.join(dir_path, f'{idx}.mp3')
|
| 25 |
+
os.rename(out_file, new_file)
|
| 26 |
+
# result of success
|
| 27 |
+
print(yt.title + " has been successfully downloaded.")
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
MISSING_FILE_IDS = [
|
| 31 |
+
16, 26, 33, 38, 40, 50, 53, 55, 60, 81, 82, 98, 107, 122, 126, 127, 129, 141, 145, 150, 172,
|
| 32 |
+
201, 205, 206, 215, 216, 221, 226, 232, 240, 243, 245, 255, 257, 267, 273, 278, 279, 285, 287,
|
| 33 |
+
291, 304, 312, 319, 321, 325, 329, 332, 333, 336, 337, 342, 359, 375, 402, 417, 438, 445, 454,
|
| 34 |
+
498
|
| 35 |
+
]
|
| 36 |
+
|
| 37 |
+
data_link_file = '../../../data/mir_St500_yourmt3_16k/MIR-ST500_20210206/MIR-ST500_link.json'
|
| 38 |
+
data_link = json.load(open(data_link_file, 'r'))
|
| 39 |
+
download_fail = []
|
| 40 |
+
|
| 41 |
+
for i in MISSING_FILE_IDS:
|
| 42 |
+
print(f'Downloading {i}...')
|
| 43 |
+
yt = YouTube(data_link[str(i)])
|
| 44 |
+
try:
|
| 45 |
+
downloadMp3(yt, idx=i)
|
| 46 |
+
except:
|
| 47 |
+
download_fail.append(i)
|
| 48 |
+
print(f'Failed to download {i}.')
|
| 49 |
+
|
| 50 |
+
print(f'Failed to download {len(download_fail)} files: {download_fail}')
|
amt/src/extras/fig/label_smooth_interval_of_interest.png
ADDED
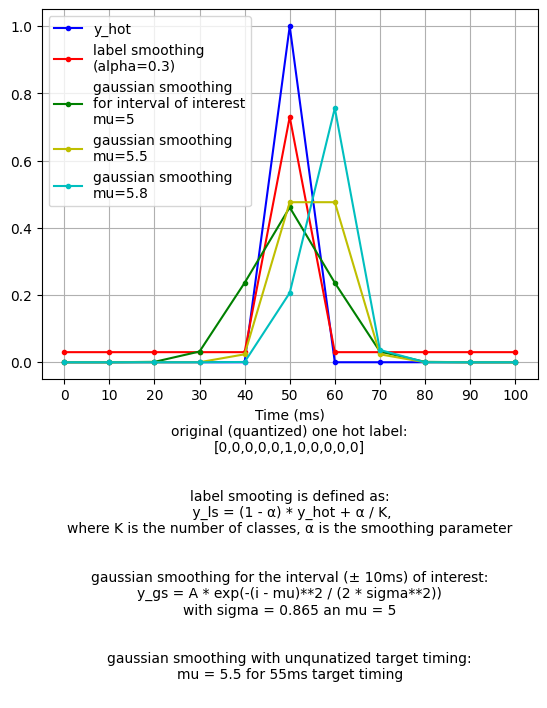
|
amt/src/extras/fig/pitchshift_benchnmark.png
ADDED
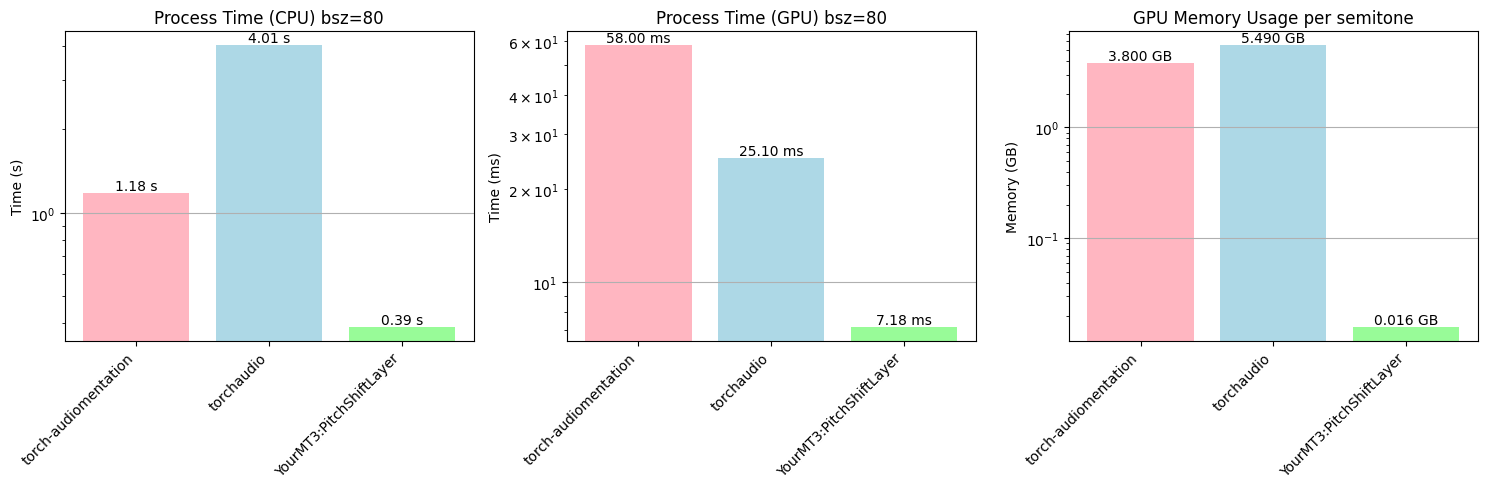
|
amt/src/extras/fig/pitchshift_stretch_and_resampler_process_time.png
ADDED

|
amt/src/extras/inspecting_slakh_bass.py
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import mirdata
|
| 2 |
+
from utils.mirdata_dev.datasets import slakh16k
|
| 3 |
+
|
| 4 |
+
ds = slakh16k.Dataset(data_home='../../data', version='2100-yourmt3-16k')
|
| 5 |
+
mtrack_ids = ds.mtrack_ids
|
| 6 |
+
|
| 7 |
+
# Collect plugin names
|
| 8 |
+
plugin_names = set()
|
| 9 |
+
cnt = 0
|
| 10 |
+
for mtrack_id in mtrack_ids:
|
| 11 |
+
mtrack = ds.multitrack(mtrack_id)
|
| 12 |
+
for track_id in mtrack.track_ids:
|
| 13 |
+
track = ds.track(track_id)
|
| 14 |
+
if track.instrument.lower() == 'bass':
|
| 15 |
+
if track.plugin_name == 'upright_bass.nkm':
|
| 16 |
+
print(f'{str(cnt)}: {track_id}: {track.plugin_name}')
|
| 17 |
+
# if track.plugin_name not in plugin_names:
|
| 18 |
+
# plugin_names.add(track.plugin_name)
|
| 19 |
+
# print(f'{str(cnt)}: {track_id}: {track.plugin_name}')
|
| 20 |
+
# cnt += 1
|
| 21 |
+
"""
|
| 22 |
+
0: Track00001-S03: scarbee_rickenbacker_bass_palm_muted.nkm
|
| 23 |
+
1: Track00002-S01: classic_bass.nkm
|
| 24 |
+
2: Track00004-S01: scarbee_rickenbacker_bass.nkm
|
| 25 |
+
3: Track00005-S04: scarbee_jay_bass_both.nkm
|
| 26 |
+
4: Track00006-S03: pop_bass.nkm
|
| 27 |
+
5: Track00008-S00: scarbee_pre_bass.nkm
|
| 28 |
+
6: Track00013-S00: jazz_upright.nkm
|
| 29 |
+
7: Track00014-S01: funk_bass.nkm
|
| 30 |
+
8: Track00016-S01: scarbee_mm_bass.nkm
|
| 31 |
+
9: Track00024-S07: upright_bass.nkm
|
| 32 |
+
10: Track00027-S03: scarbee_jay_bass_slap_both.nkm
|
| 33 |
+
11: Track00094-S08: upright_bass2.nkm
|
| 34 |
+
"""
|
amt/src/extras/install_deepspeed.md
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
|
| 3 |
+
# not required on pytorch 2.0:latest container
|
| 4 |
+
pip install cupy-cuda11x -f https://pip.cupy.dev/aarch64
|
| 5 |
+
|
| 6 |
+
apt-get update
|
| 7 |
+
apt-get install git
|
| 8 |
+
apt-get install libaio-dev
|
| 9 |
+
|
| 10 |
+
DS_BUILD_OPS=1 pip install deepspeed
|
| 11 |
+
ds_report
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
pip install deepspeed==0.7.7
|
| 15 |
+
|
| 16 |
+
git clone https://github.com/NVIDIA/apex
|
| 17 |
+
cd apex
|
| 18 |
+
pip install -v --disable-pip-version-check --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
|
| 19 |
+
|
| 20 |
+
In case you have trouble building apex from source we recommend using the NGC containers
|
| 21 |
+
from here which come with a pre-built PyTorch and apex release.
|
| 22 |
+
|
| 23 |
+
nvcr.io/nvidia/pytorch:23.01-py3
|
| 24 |
+
|
| 25 |
+
pip install deepspeed, pip install transformers[deepspeed]
|
| 26 |
+
https://www.deepspeed.ai/docs/config-json/#autotuning
|
| 27 |
+
|
| 28 |
+
"""
|
amt/src/extras/label_smoothing.py
ADDED
|
@@ -0,0 +1,67 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import numpy as np
|
| 3 |
+
import matplotlib.pyplot as plt
|
| 4 |
+
|
| 5 |
+
a = torch.signal.windows.gaussian(11, sym=True, std=3)
|
| 6 |
+
plt.plot(a)
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def gaussian_smoothing(y_hot, mu=5, sigma=0.865):
|
| 10 |
+
"""
|
| 11 |
+
y_hot: one-hot encoded array
|
| 12 |
+
"""
|
| 13 |
+
#sigma = np.sqrt(np.abs(np.log(0.05) / ((4 - mu)**2))) / 2
|
| 14 |
+
|
| 15 |
+
# Generate index array
|
| 16 |
+
i = np.arange(len(y_hot))
|
| 17 |
+
|
| 18 |
+
# Gaussian function
|
| 19 |
+
y_smooth = np.exp(-(i - mu)**2 / (2 * sigma**2))
|
| 20 |
+
|
| 21 |
+
# Normalize the resulting array
|
| 22 |
+
y_smooth /= y_smooth.sum()
|
| 23 |
+
return y_smooth, sigma
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
# y_ls = (1 - α) * y_hot + α / K, where K is the number of classes, alpha is the smoothing parameter
|
| 27 |
+
|
| 28 |
+
y_hot = torch.zeros(11)
|
| 29 |
+
y_hot[5] = 1
|
| 30 |
+
plt.plot(y_hot, 'b.-')
|
| 31 |
+
|
| 32 |
+
alpha = 0.3
|
| 33 |
+
y_ls = (1 - alpha) * y_hot + alpha / 10
|
| 34 |
+
plt.plot(y_ls, 'r.-')
|
| 35 |
+
|
| 36 |
+
y_gs, std = gaussian_smoothing(y_hot, A=0.5)
|
| 37 |
+
plt.plot(y_gs, 'g.-')
|
| 38 |
+
|
| 39 |
+
y_gst_a, std = gaussian_smoothing(y_hot, A=0.5, mu=5.5)
|
| 40 |
+
plt.plot(y_gst_a, 'y.-')
|
| 41 |
+
|
| 42 |
+
y_gst_b, std = gaussian_smoothing(y_hot, A=0.5, mu=5.8)
|
| 43 |
+
plt.plot(y_gst_b, 'c.-')
|
| 44 |
+
|
| 45 |
+
plt.legend([
|
| 46 |
+
'y_hot', 'label smoothing' + '\n' + '(alpha=0.3)',
|
| 47 |
+
'gaussian smoothing' + '\n' + 'for interval of interest' + '\n' + 'mu=5',
|
| 48 |
+
'gaussian smoothing' + '\n' + 'mu=5.5', 'gaussian smoothing' + '\n' + 'mu=5.8'
|
| 49 |
+
])
|
| 50 |
+
|
| 51 |
+
plt.grid()
|
| 52 |
+
plt.xticks(np.arange(11), np.arange(0, 110, 10))
|
| 53 |
+
plt.xlabel('''Time (ms)
|
| 54 |
+
original (quantized) one hot label:
|
| 55 |
+
[0,0,0,0,0,1,0,0,0,0,0]
|
| 56 |
+
\n
|
| 57 |
+
label smooting is defined as:
|
| 58 |
+
y_ls = (1 - α) * y_hot + α / K,
|
| 59 |
+
where K is the number of classes, α is the smoothing parameter
|
| 60 |
+
\n
|
| 61 |
+
gaussian smoothing for the interval (± 10ms) of interest:
|
| 62 |
+
y_gs = A * exp(-(i - mu)**2 / (2 * sigma**2))
|
| 63 |
+
with sigma = 0.865 an mu = 5
|
| 64 |
+
\n
|
| 65 |
+
gaussian smoothing with unqunatized target timing:
|
| 66 |
+
mu = 5.5 for 55ms target timing
|
| 67 |
+
''')
|
amt/src/extras/multi_channel_seqlen_stats.py
ADDED
|
@@ -0,0 +1,177 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 The YourMT3 Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Please see the details in the LICENSE file.
|
| 10 |
+
from typing import Dict, Tuple
|
| 11 |
+
from copy import deepcopy
|
| 12 |
+
from collections import Counter
|
| 13 |
+
import numpy as np
|
| 14 |
+
import torch
|
| 15 |
+
from utils.data_modules import AMTDataModule
|
| 16 |
+
from utils.task_manager import TaskManager
|
| 17 |
+
from config.data_presets import data_preset_single_cfg, data_preset_multi_cfg
|
| 18 |
+
from utils.augment import intra_stem_augment_processor
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def get_ds(data_preset_multi: Dict, task_name: str, train_num_samples_per_epoch: int = 90000):
|
| 22 |
+
tm = TaskManager(task_name=task_name)
|
| 23 |
+
tm.max_note_token_length_per_ch = 1024 # only to check the max length
|
| 24 |
+
dm = AMTDataModule(data_preset_multi=data_preset_multi,
|
| 25 |
+
task_manager=tm,
|
| 26 |
+
train_num_samples_per_epoch=train_num_samples_per_epoch)
|
| 27 |
+
dm.setup('fit')
|
| 28 |
+
dl = dm.train_dataloader()
|
| 29 |
+
ds = dl.flattened[0].dataset
|
| 30 |
+
return ds
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
data_preset_multi = data_preset_multi_cfg["all_cross_v6"]
|
| 34 |
+
task_name = "mc13" # "mt3_full_plus"
|
| 35 |
+
ds = get_ds(data_preset_multi, task_name=task_name)
|
| 36 |
+
ds.random_amp_range = [0.8, 1.1]
|
| 37 |
+
ds.stem_xaug_policy = {
|
| 38 |
+
"max_k": 5,
|
| 39 |
+
"tau": 0.3,
|
| 40 |
+
"alpha": 1.0,
|
| 41 |
+
"max_subunit_stems": 12,
|
| 42 |
+
"no_instr_overlap": True,
|
| 43 |
+
"no_drum_overlap": True,
|
| 44 |
+
"uhat_intra_stem_augment": True,
|
| 45 |
+
}
|
| 46 |
+
|
| 47 |
+
length_all = []
|
| 48 |
+
for i in range(40000):
|
| 49 |
+
if i % 5000 == 0:
|
| 50 |
+
print(i)
|
| 51 |
+
audio_arr, note_token_arr, task_totken_arr, pshift_steps = ds.__getitem__(i)
|
| 52 |
+
lengths = torch.sum(note_token_arr != 0, dim=2).flatten().cpu().tolist()
|
| 53 |
+
length_all.extend(lengths)
|
| 54 |
+
|
| 55 |
+
length_all = np.asarray(length_all)
|
| 56 |
+
|
| 57 |
+
# stats
|
| 58 |
+
empty_sequence = np.sum(length_all < 3) / len(length_all) * 100
|
| 59 |
+
print("empty_sequences:", f"{empty_sequence:.2f}", "%")
|
| 60 |
+
|
| 61 |
+
mean_except_empty = np.mean(length_all[length_all > 2])
|
| 62 |
+
print("mean_except_empty:", mean_except_empty)
|
| 63 |
+
|
| 64 |
+
median_except_empty = np.median(length_all[length_all > 2])
|
| 65 |
+
print("median_except_empty:", median_except_empty)
|
| 66 |
+
|
| 67 |
+
ch_less_than_768 = np.sum(length_all < 768) / len(length_all) * 100
|
| 68 |
+
print("ch_less_than_768:", f"{ch_less_than_768:.2f}", "%")
|
| 69 |
+
|
| 70 |
+
ch_larger_than_512 = np.sum(length_all > 512) / len(length_all) * 100
|
| 71 |
+
print("ch_larger_than_512:", f"{ch_larger_than_512:.6f}", "%")
|
| 72 |
+
|
| 73 |
+
ch_larger_than_256 = np.sum(length_all > 256) / len(length_all) * 100
|
| 74 |
+
print("ch_larger_than_256:", f"{ch_larger_than_256:.6f}", "%")
|
| 75 |
+
|
| 76 |
+
ch_larger_than_128 = np.sum(length_all > 128) / len(length_all) * 100
|
| 77 |
+
print("ch_larger_than_128:", f"{ch_larger_than_128:.6f}", "%")
|
| 78 |
+
|
| 79 |
+
ch_larger_than_64 = np.sum(length_all > 64) / len(length_all) * 100
|
| 80 |
+
print("ch_larger_than_64:", f"{ch_larger_than_64:.6f}", "%")
|
| 81 |
+
|
| 82 |
+
song_length_all = length_all.reshape(-1, 13)
|
| 83 |
+
song_larger_than_512 = 0
|
| 84 |
+
song_larger_than_256 = 0
|
| 85 |
+
song_larger_than_128 = 0
|
| 86 |
+
song_larger_than_64 = 0
|
| 87 |
+
for l in song_length_all:
|
| 88 |
+
if np.sum(l > 512) > 0:
|
| 89 |
+
song_larger_than_512 += 1
|
| 90 |
+
if np.sum(l > 256) > 0:
|
| 91 |
+
song_larger_than_256 += 1
|
| 92 |
+
if np.sum(l > 128) > 0:
|
| 93 |
+
song_larger_than_128 += 1
|
| 94 |
+
if np.sum(l > 64) > 0:
|
| 95 |
+
song_larger_than_64 += 1
|
| 96 |
+
num_songs = len(song_length_all)
|
| 97 |
+
print("song_larger_than_512:", f"{song_larger_than_512/num_songs*100:.4f}", "%")
|
| 98 |
+
print("song_larger_than_256:", f"{song_larger_than_256/num_songs*100:.4f}", "%")
|
| 99 |
+
print("song_larger_than_128:", f"{song_larger_than_128/num_songs*100:.4f}", "%")
|
| 100 |
+
print("song_larger_than_64:", f"{song_larger_than_64/num_songs*100:.4f}", "%")
|
| 101 |
+
|
| 102 |
+
instr_dict = {
|
| 103 |
+
0: "Piano",
|
| 104 |
+
1: "Chromatic Percussion",
|
| 105 |
+
2: "Organ",
|
| 106 |
+
3: "Guitar",
|
| 107 |
+
4: "Bass",
|
| 108 |
+
5: "Strings + Ensemble",
|
| 109 |
+
6: "Brass",
|
| 110 |
+
7: "Reed",
|
| 111 |
+
8: "Pipe",
|
| 112 |
+
9: "Synth Lead",
|
| 113 |
+
10: "Synth Pad",
|
| 114 |
+
11: "Singing",
|
| 115 |
+
12: "Drums",
|
| 116 |
+
}
|
| 117 |
+
cnt_larger_than_512 = Counter()
|
| 118 |
+
for i in np.where(length_all > 512)[0] % 13:
|
| 119 |
+
cnt_larger_than_512[i] += 1
|
| 120 |
+
print("larger_than_512:")
|
| 121 |
+
for k, v in cnt_larger_than_512.items():
|
| 122 |
+
print(f" - {instr_dict[k]}: {v}")
|
| 123 |
+
|
| 124 |
+
cnt_larger_than_256 = Counter()
|
| 125 |
+
for i in np.where(length_all > 256)[0] % 13:
|
| 126 |
+
cnt_larger_than_256[i] += 1
|
| 127 |
+
print("larger_than_256:")
|
| 128 |
+
for k, v in cnt_larger_than_256.items():
|
| 129 |
+
print(f" - {instr_dict[k]}: {v}")
|
| 130 |
+
|
| 131 |
+
cnt_larger_than_128 = Counter()
|
| 132 |
+
for i in np.where(length_all > 128)[0] % 13:
|
| 133 |
+
cnt_larger_than_128[i] += 1
|
| 134 |
+
print("larger_than_128:")
|
| 135 |
+
for k, v in cnt_larger_than_128.items():
|
| 136 |
+
print(f" - {instr_dict[k]}: {v}")
|
| 137 |
+
"""
|
| 138 |
+
empty_sequences: 91.06 %
|
| 139 |
+
mean_except_empty: 36.68976799156269
|
| 140 |
+
median_except_empty: 31.0
|
| 141 |
+
ch_less_than_768: 100.00 %
|
| 142 |
+
ch_larger_than_512: 0.000158 %
|
| 143 |
+
ch_larger_than_256: 0.015132 %
|
| 144 |
+
ch_larger_than_128: 0.192061 %
|
| 145 |
+
ch_larger_than_64: 0.661260 %
|
| 146 |
+
song_larger_than_512: 0.0021 %
|
| 147 |
+
song_larger_than_256: 0.1926 %
|
| 148 |
+
song_larger_than_128: 2.2280 %
|
| 149 |
+
song_larger_than_64: 6.1033 %
|
| 150 |
+
|
| 151 |
+
larger_than_512:
|
| 152 |
+
- Guitar: 7
|
| 153 |
+
- Strings + Ensemble: 3
|
| 154 |
+
larger_than_256:
|
| 155 |
+
- Piano: 177
|
| 156 |
+
- Guitar: 680
|
| 157 |
+
- Strings + Ensemble: 79
|
| 158 |
+
- Organ: 2
|
| 159 |
+
- Chromatic Percussion: 11
|
| 160 |
+
- Bass: 1
|
| 161 |
+
- Synth Lead: 2
|
| 162 |
+
- Brass: 1
|
| 163 |
+
- Reed: 5
|
| 164 |
+
larger_than_128:
|
| 165 |
+
- Guitar: 4711
|
| 166 |
+
- Strings + Ensemble: 1280
|
| 167 |
+
- Piano: 5548
|
| 168 |
+
- Bass: 211
|
| 169 |
+
- Synth Pad: 22
|
| 170 |
+
- Pipe: 18
|
| 171 |
+
- Chromatic Percussion: 55
|
| 172 |
+
- Synth Lead: 22
|
| 173 |
+
- Organ: 75
|
| 174 |
+
- Reed: 161
|
| 175 |
+
- Brass: 45
|
| 176 |
+
- Drums: 11
|
| 177 |
+
"""
|
amt/src/extras/npy_speed_benchmark.py
ADDED
|
@@ -0,0 +1,187 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from tasks.utils.event_codec import Event, EventRange
|
| 3 |
+
from tasks.utils import event_codec
|
| 4 |
+
|
| 5 |
+
ec = event_codec.Codec(
|
| 6 |
+
max_shift_steps=1000, # this means 0,1,...,1000
|
| 7 |
+
steps_per_second=100,
|
| 8 |
+
event_ranges=[
|
| 9 |
+
EventRange('pitch', min_value=0, max_value=127),
|
| 10 |
+
EventRange('velocity', min_value=0, max_value=1),
|
| 11 |
+
EventRange('tie', min_value=0, max_value=0),
|
| 12 |
+
EventRange('program', min_value=0, max_value=127),
|
| 13 |
+
EventRange('drum', min_value=0, max_value=127),
|
| 14 |
+
],
|
| 15 |
+
)
|
| 16 |
+
|
| 17 |
+
events = [
|
| 18 |
+
Event(type='shift', value=0), # actually not needed
|
| 19 |
+
Event(type='shift', value=1), # 10 ms shift
|
| 20 |
+
Event(type='shift', value=1000), # 10 s shift
|
| 21 |
+
Event(type='pitch', value=0), # lowest pitch 8.18 Hz
|
| 22 |
+
Event(type='pitch', value=60), # C4 or 261.63 Hz
|
| 23 |
+
Event(type='pitch', value=127), # highest pitch G9 or 12543.85 Hz
|
| 24 |
+
Event(type='velocity', value=0), # lowest velocity)
|
| 25 |
+
Event(type='velocity', value=1), # lowest velocity)
|
| 26 |
+
Event(type='tie', value=0), # tie
|
| 27 |
+
Event(type='program', value=0), # program
|
| 28 |
+
Event(type='program', value=127), # program
|
| 29 |
+
Event(type='drum', value=0), # drum
|
| 30 |
+
Event(type='drum', value=127), # drum
|
| 31 |
+
]
|
| 32 |
+
|
| 33 |
+
events = events * 100
|
| 34 |
+
tokens = [ec.encode_event(e) for e in events]
|
| 35 |
+
tokens = np.array(tokens, dtype=np.int16)
|
| 36 |
+
|
| 37 |
+
import csv
|
| 38 |
+
# Save events to a CSV file
|
| 39 |
+
with open('events.csv', 'w', newline='') as file:
|
| 40 |
+
writer = csv.writer(file)
|
| 41 |
+
for event in events:
|
| 42 |
+
writer.writerow([event.type, event.value])
|
| 43 |
+
|
| 44 |
+
# Load events from a CSV file
|
| 45 |
+
with open('events.csv', 'r') as file:
|
| 46 |
+
reader = csv.reader(file)
|
| 47 |
+
events2 = [Event(row[0], int(row[1])) for row in reader]
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
import json
|
| 51 |
+
# Save events to a JSON file
|
| 52 |
+
with open('events.json', 'w') as file:
|
| 53 |
+
json.dump([event.__dict__ for event in events], file)
|
| 54 |
+
|
| 55 |
+
# Load events from a JSON file
|
| 56 |
+
with open('events.json', 'r') as file:
|
| 57 |
+
events = [Event(**event_dict) for event_dict in json.load(file)]
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
"""----------------------------"""
|
| 63 |
+
# Write the tokens to a npy file
|
| 64 |
+
import numpy as np
|
| 65 |
+
np.save('tokens.npy', tokens)
|
| 66 |
+
|
| 67 |
+
def t_npy():
|
| 68 |
+
t = np.load('tokens.npy', allow_pickle=True) # allow pickle doesn't affect speed
|
| 69 |
+
|
| 70 |
+
os.makedirs('temp', exist_ok=True)
|
| 71 |
+
for i in range(2400):
|
| 72 |
+
np.save(f'temp/tokens{i}.npy', tokens)
|
| 73 |
+
|
| 74 |
+
def t_npy2400():
|
| 75 |
+
for i in range(2400):
|
| 76 |
+
t = np.load(f'temp/tokens{i}.npy')
|
| 77 |
+
def t_npy2400_take200():
|
| 78 |
+
for i in range(200):
|
| 79 |
+
t = np.load(f'temp/tokens{i}.npy')
|
| 80 |
+
|
| 81 |
+
import shutil
|
| 82 |
+
shutil.rmtree('temp', ignore_errors=True)
|
| 83 |
+
|
| 84 |
+
# Write the 2400 tokens to a single npy file
|
| 85 |
+
data = dict()
|
| 86 |
+
for i in range(2400):
|
| 87 |
+
data[f'arr{i}'] = tokens.copy()
|
| 88 |
+
np.save(f'tokens_2400x.npy', data)
|
| 89 |
+
def t_npy2400single():
|
| 90 |
+
t = np.load('tokens_2400x.npy', allow_pickle=True).item()
|
| 91 |
+
|
| 92 |
+
def t_mmap2400single():
|
| 93 |
+
t = np.load('tokens_2400x.npy', mmap_mode='r')
|
| 94 |
+
|
| 95 |
+
# Write the tokens to a npz file
|
| 96 |
+
np.savez('tokens.npz', arr0=tokens)
|
| 97 |
+
def t_npz():
|
| 98 |
+
npz_file = np.load('tokens.npz')
|
| 99 |
+
tt = npz_file['arr0']
|
| 100 |
+
|
| 101 |
+
data = dict()
|
| 102 |
+
for i in range(2400):
|
| 103 |
+
data[f'arr{i}'] = tokens
|
| 104 |
+
np.savez('tokens.npz', **data )
|
| 105 |
+
def t_npz2400():
|
| 106 |
+
npz_file = np.load('tokens.npz')
|
| 107 |
+
for i in range(2400):
|
| 108 |
+
tt = npz_file[f'arr{i}']
|
| 109 |
+
|
| 110 |
+
def t_npz2400_take200():
|
| 111 |
+
npz_file = np.load('tokens.npz')
|
| 112 |
+
# npz_file.files
|
| 113 |
+
for i in range(200):
|
| 114 |
+
tt = npz_file[f'arr{i}']
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
# Write the tokens to a txt file
|
| 118 |
+
with open('tokens.txt', 'w') as file:
|
| 119 |
+
file.write(' '.join(map(str, tokens)))
|
| 120 |
+
|
| 121 |
+
def t_txt():
|
| 122 |
+
# Read the tokens from the file
|
| 123 |
+
with open('tokens.txt', 'r') as file:
|
| 124 |
+
t = list(map(int, file.read().split()))
|
| 125 |
+
t = np.array(t)
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
# Write the tokens to a CSV file
|
| 129 |
+
with open('tokens.csv', 'w', newline='') as file:
|
| 130 |
+
writer = csv.writer(file)
|
| 131 |
+
writer.writerow(tokens)
|
| 132 |
+
|
| 133 |
+
def t_csv():
|
| 134 |
+
# Read the tokens from the CSV file
|
| 135 |
+
with open('tokens.csv', 'r') as file:
|
| 136 |
+
reader = csv.reader(file)
|
| 137 |
+
t = list(map(int, next(reader)))
|
| 138 |
+
t = np.array(t)
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
# Write the tokens to a JSON file
|
| 142 |
+
with open('tokens.json', 'w') as file:
|
| 143 |
+
json.dump(tokens, file)
|
| 144 |
+
|
| 145 |
+
def t_json():
|
| 146 |
+
# Read the tokens from the JSON file
|
| 147 |
+
with open('tokens.json', 'r') as file:
|
| 148 |
+
t = json.load(file)
|
| 149 |
+
t = np.array(t)
|
| 150 |
+
|
| 151 |
+
with open('tokens_2400x.json', 'w') as file:
|
| 152 |
+
json.dump(data, file)
|
| 153 |
+
|
| 154 |
+
def t_json2400single():
|
| 155 |
+
# Read the tokens from the JSON file
|
| 156 |
+
with open('tokens_2400x.json', 'r') as file:
|
| 157 |
+
t = json.load(file)
|
| 158 |
+
|
| 159 |
+
def t_mmap():
|
| 160 |
+
t = np.load('tokens.npy', mmap_mode='r')
|
| 161 |
+
|
| 162 |
+
# Write the tokens to bytes file
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
np.savetxt('tokens.ntxt', tokens)
|
| 168 |
+
def t_ntxt():
|
| 169 |
+
t = np.loadtxt('tokens.ntxt').astype(np.int32)
|
| 170 |
+
|
| 171 |
+
%timeit t_npz() # 139 us
|
| 172 |
+
%timeit t_mmap() # 3.12 ms
|
| 173 |
+
%timeit t_npy() # 87.8 us
|
| 174 |
+
%timeit t_txt() # 109 152 us
|
| 175 |
+
%timeit t_csv() # 145 190 us
|
| 176 |
+
%timeit t_json() # 72.8 119 us
|
| 177 |
+
%timeit t_ntxt() # 878 us
|
| 178 |
+
|
| 179 |
+
%timeit t_npy2400() # 212 ms; 2400 files in a folder
|
| 180 |
+
%timeit t_npz2400() # 296 ms; uncompreesed 1000 arrays in a single file
|
| 181 |
+
|
| 182 |
+
%timeit t_npy2400_take200() # 17.4 ms; 25 Mb
|
| 183 |
+
%timeit t_npz2400_take200() # 28.8 ms; 3.72 ms for 10 arrays; 25 Mb
|
| 184 |
+
%timeit t_npy2400single() # 4 ms; frozen dictionary containing 2400 arrays; 6.4 Mb; int16
|
| 185 |
+
%timeit t_mmap2400single() # dictionary is not supported
|
| 186 |
+
%timeit t_json2400single() # 175 ms; 17 Mb
|
| 187 |
+
# 2400 files from 100ms hop for 4 minutes
|
amt/src/extras/perceivertf_inspect.py
ADDED
|
@@ -0,0 +1,640 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def l2_normalize(matrix):
|
| 7 |
+
"""
|
| 8 |
+
L2 Normalize the matrix along its rows.
|
| 9 |
+
|
| 10 |
+
Parameters:
|
| 11 |
+
matrix (numpy.ndarray): The input matrix.
|
| 12 |
+
|
| 13 |
+
Returns:
|
| 14 |
+
numpy.ndarray: The L2 normalized matrix.
|
| 15 |
+
"""
|
| 16 |
+
l2_norms = np.linalg.norm(matrix, axis=1, keepdims=True)
|
| 17 |
+
normalized_matrix = matrix / l2_norms
|
| 18 |
+
return normalized_matrix
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def z_normalize(matrix):
|
| 22 |
+
"""
|
| 23 |
+
Z-normalize the matrix along its rows (mean=0 and std=1).
|
| 24 |
+
Z-normalization is also known as "standardization", and derives from z-score.
|
| 25 |
+
Z = (X - mean) / std
|
| 26 |
+
Z-nomarlized, each row has mean=0 and std=1.
|
| 27 |
+
|
| 28 |
+
Parameters:
|
| 29 |
+
matrix (numpy.ndarray): The input matrix.
|
| 30 |
+
|
| 31 |
+
Returns:
|
| 32 |
+
numpy.ndarray: The Z normalized matrix.
|
| 33 |
+
"""
|
| 34 |
+
mean = np.mean(matrix, axis=1, keepdims=True)
|
| 35 |
+
std = np.std(matrix, axis=1, keepdims=True)
|
| 36 |
+
normalized_matrix = (matrix - mean) / std
|
| 37 |
+
return normalized_matrix
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def l2_normalize_tensors(tensor_tuple):
|
| 41 |
+
"""
|
| 42 |
+
Applies L2 normalization on the last two dimensions for each tensor in a tuple.
|
| 43 |
+
|
| 44 |
+
Parameters:
|
| 45 |
+
tensor_tuple (tuple of torch.Tensor): A tuple containing N tensors, each of shape (1, k, 30, 30).
|
| 46 |
+
|
| 47 |
+
Returns:
|
| 48 |
+
tuple of torch.Tensor: A tuple containing N L2-normalized tensors.
|
| 49 |
+
"""
|
| 50 |
+
normalized_tensors = []
|
| 51 |
+
for tensor in tensor_tuple:
|
| 52 |
+
# Ensure the tensor is a floating-point type
|
| 53 |
+
tensor = tensor.float()
|
| 54 |
+
|
| 55 |
+
# Calculate L2 norm on the last two dimensions, keeping the dimensions using keepdim=True
|
| 56 |
+
l2_norm = torch.linalg.norm(tensor, dim=(-2, -1), keepdim=True)
|
| 57 |
+
|
| 58 |
+
# Apply L2 normalization
|
| 59 |
+
normalized_tensor = tensor / (
|
| 60 |
+
l2_norm + 1e-7) # Small value to avoid division by zero
|
| 61 |
+
|
| 62 |
+
normalized_tensors.append(normalized_tensor)
|
| 63 |
+
|
| 64 |
+
return tuple(normalized_tensors)
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def z_normalize_tensors(tensor_tuple):
|
| 68 |
+
"""
|
| 69 |
+
Applies Z-normalization on the last two dimensions for each tensor in a tuple.
|
| 70 |
+
|
| 71 |
+
Parameters:
|
| 72 |
+
tensor_tuple (tuple of torch.Tensor): A tuple containing N tensors, each of shape (1, k, 30, 30).
|
| 73 |
+
|
| 74 |
+
Returns:
|
| 75 |
+
tuple of torch.Tensor: A tuple containing N Z-normalized tensors.
|
| 76 |
+
"""
|
| 77 |
+
normalized_tensors = []
|
| 78 |
+
for tensor in tensor_tuple:
|
| 79 |
+
# Ensure the tensor is a floating-point type
|
| 80 |
+
tensor = tensor.float()
|
| 81 |
+
|
| 82 |
+
# Calculate mean and std on the last two dimensions
|
| 83 |
+
mean = tensor.mean(dim=(-2, -1), keepdim=True)
|
| 84 |
+
std = tensor.std(dim=(-2, -1), keepdim=True)
|
| 85 |
+
|
| 86 |
+
# Apply Z-normalization
|
| 87 |
+
normalized_tensor = (tensor - mean) / (
|
| 88 |
+
std + 1e-7) # Small value to avoid division by zero
|
| 89 |
+
|
| 90 |
+
normalized_tensors.append(normalized_tensor)
|
| 91 |
+
|
| 92 |
+
return tuple(normalized_tensors)
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def apply_temperature_to_attention_tensors(tensor_tuple, temperature=1.0):
|
| 96 |
+
"""
|
| 97 |
+
Applies temperature scaling to the attention weights in each tensor in a tuple.
|
| 98 |
+
|
| 99 |
+
Parameters:
|
| 100 |
+
tensor_tuple (tuple of torch.Tensor): A tuple containing N tensors,
|
| 101 |
+
each of shape (1, k, 30, 30).
|
| 102 |
+
temperature (float): Temperature parameter to control the sharpness
|
| 103 |
+
of the attention weights. Default is 1.0.
|
| 104 |
+
|
| 105 |
+
Returns:
|
| 106 |
+
tuple of torch.Tensor: A tuple containing N tensors with scaled attention weights.
|
| 107 |
+
"""
|
| 108 |
+
scaled_attention_tensors = []
|
| 109 |
+
|
| 110 |
+
for tensor in tensor_tuple:
|
| 111 |
+
# Ensure the tensor is a floating-point type
|
| 112 |
+
tensor = tensor.float()
|
| 113 |
+
|
| 114 |
+
# Flatten the last two dimensions
|
| 115 |
+
flattened_tensor = tensor.reshape(1, tensor.shape[1],
|
| 116 |
+
-1) # Modified line here
|
| 117 |
+
|
| 118 |
+
# Apply temperature scaling and softmax along the last dimension
|
| 119 |
+
scaled_attention = flattened_tensor / temperature
|
| 120 |
+
scaled_attention = F.softmax(scaled_attention, dim=-1)
|
| 121 |
+
|
| 122 |
+
# Reshape to original shape
|
| 123 |
+
scaled_attention = scaled_attention.view_as(tensor)
|
| 124 |
+
|
| 125 |
+
scaled_attention_tensors.append(scaled_attention)
|
| 126 |
+
|
| 127 |
+
return tuple(scaled_attention_tensors)
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
def shorten_att(tensor_tuple, length=30):
|
| 131 |
+
shortend_tensors = []
|
| 132 |
+
for tensor in tensor_tuple:
|
| 133 |
+
shortend_tensors.append(tensor[:, :, :length, :length])
|
| 134 |
+
return tuple(shortend_tensors)
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
def keep_top_k(matrix, k=6):
|
| 138 |
+
"""
|
| 139 |
+
Keep only the top k values in each row, set the rest to 0.
|
| 140 |
+
|
| 141 |
+
Parameters:
|
| 142 |
+
matrix (numpy.ndarray): The input matrix.
|
| 143 |
+
k (int): The number of top values to keep in each row.
|
| 144 |
+
|
| 145 |
+
Returns:
|
| 146 |
+
numpy.ndarray: The transformed matrix.
|
| 147 |
+
"""
|
| 148 |
+
topk_indices_per_row = np.argpartition(matrix, -k, axis=1)[:, -k:]
|
| 149 |
+
result_matrix = np.zeros_like(matrix)
|
| 150 |
+
|
| 151 |
+
for i in range(matrix.shape[0]):
|
| 152 |
+
result_matrix[i, topk_indices_per_row[i]] = matrix[
|
| 153 |
+
i, topk_indices_per_row[i]]
|
| 154 |
+
return result_matrix
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
def test_case_forward_enc_perceiver_tf_dec_t5():
|
| 158 |
+
import torch
|
| 159 |
+
from model.ymt3 import YourMT3
|
| 160 |
+
from config.config import audio_cfg, model_cfg, shared_cfg
|
| 161 |
+
model_cfg["encoder_type"] = "perceiver-tf"
|
| 162 |
+
model_cfg["encoder"]["perceiver-tf"]["attention_to_channel"] = True
|
| 163 |
+
model_cfg["encoder"]["perceiver-tf"]["num_latents"] = 24
|
| 164 |
+
model_cfg["decoder_type"] = "t5"
|
| 165 |
+
model_cfg["pre_decoder_type"] = "default"
|
| 166 |
+
|
| 167 |
+
audio_cfg["codec"] = "spec"
|
| 168 |
+
audio_cfg["hop_length"] = 300
|
| 169 |
+
model = YourMT3(audio_cfg=audio_cfg, model_cfg=model_cfg)
|
| 170 |
+
model.eval()
|
| 171 |
+
|
| 172 |
+
# x = torch.randn(2, 1, 32767)
|
| 173 |
+
# labels = torch.randint(0, 400, (2, 1024), requires_grad=False)
|
| 174 |
+
|
| 175 |
+
# # forward
|
| 176 |
+
# output = model.forward(x, labels)
|
| 177 |
+
|
| 178 |
+
# # inference
|
| 179 |
+
# result = model.inference(x, None)
|
| 180 |
+
|
| 181 |
+
# display latents
|
| 182 |
+
checkpoint = torch.load(
|
| 183 |
+
"../logs/ymt3/ptf_all_cross_rebal5_spec300_xk2_amp0811_edr_005_attend_c_full_plus_b52/checkpoints/model.ckpt",
|
| 184 |
+
map_location="cpu")
|
| 185 |
+
state_dict = checkpoint['state_dict']
|
| 186 |
+
new_state_dict = {
|
| 187 |
+
k: v
|
| 188 |
+
for k, v in state_dict.items() if 'pitchshift' not in k
|
| 189 |
+
}
|
| 190 |
+
model.load_state_dict(new_state_dict, strict=False)
|
| 191 |
+
|
| 192 |
+
latents = model.encoder.latent_array.latents.detach().numpy()
|
| 193 |
+
import matplotlib.pyplot as plt
|
| 194 |
+
import numpy as np
|
| 195 |
+
from sklearn.metrics.pairwise import cosine_similarity
|
| 196 |
+
cos = cosine_similarity(latents)
|
| 197 |
+
|
| 198 |
+
from utils.data_modules import AMTDataModule
|
| 199 |
+
from einops import rearrange
|
| 200 |
+
dm = AMTDataModule(data_preset_multi={"presets": ["slakh"]})
|
| 201 |
+
dm.setup("test")
|
| 202 |
+
dl = dm.test_dataloader()
|
| 203 |
+
ds = list(dl.values())[0].dataset
|
| 204 |
+
audio, notes, tokens, _ = ds.__getitem__(7)
|
| 205 |
+
x = audio[[16], ::]
|
| 206 |
+
label = tokens[[16], :]
|
| 207 |
+
# spectrogram
|
| 208 |
+
x_spec = model.spectrogram(x)
|
| 209 |
+
plt.imshow(x_spec[0].detach().numpy().T, aspect='auto', origin='lower')
|
| 210 |
+
plt.title("spectrogram")
|
| 211 |
+
plt.xlabel('time step')
|
| 212 |
+
plt.ylabel('frequency bin')
|
| 213 |
+
plt.show()
|
| 214 |
+
x_conv = model.pre_encoder(x_spec)
|
| 215 |
+
# Create a larger figure
|
| 216 |
+
plt.figure(
|
| 217 |
+
figsize=(15,
|
| 218 |
+
10)) # Adjust these numbers as needed for width and height
|
| 219 |
+
plt.subplot(2, 4, 1)
|
| 220 |
+
plt.imshow(x_spec[0].detach().numpy().T, aspect='auto', origin='lower')
|
| 221 |
+
plt.title("spectrogram")
|
| 222 |
+
plt.xlabel('time step')
|
| 223 |
+
plt.ylabel('frequency bin')
|
| 224 |
+
plt.subplot(2, 4, 2)
|
| 225 |
+
plt.imshow(x_conv[0][:, :, 0].detach().numpy().T,
|
| 226 |
+
aspect='auto',
|
| 227 |
+
origin='lower')
|
| 228 |
+
plt.title("conv(spec), ch=0")
|
| 229 |
+
plt.xlabel('time step')
|
| 230 |
+
plt.ylabel('F')
|
| 231 |
+
plt.subplot(2, 4, 3)
|
| 232 |
+
plt.imshow(x_conv[0][:, :, 42].detach().numpy().T,
|
| 233 |
+
aspect='auto',
|
| 234 |
+
origin='lower')
|
| 235 |
+
plt.title("ch=42")
|
| 236 |
+
plt.xlabel('time step')
|
| 237 |
+
plt.ylabel('F')
|
| 238 |
+
plt.subplot(2, 4, 4)
|
| 239 |
+
plt.imshow(x_conv[0][:, :, 80].detach().numpy().T,
|
| 240 |
+
aspect='auto',
|
| 241 |
+
origin='lower')
|
| 242 |
+
plt.title("ch=80")
|
| 243 |
+
plt.xlabel('time step')
|
| 244 |
+
plt.ylabel('F')
|
| 245 |
+
plt.subplot(2, 4, 5)
|
| 246 |
+
plt.imshow(x_conv[0][:, :, 11].detach().numpy().T,
|
| 247 |
+
aspect='auto',
|
| 248 |
+
origin='lower')
|
| 249 |
+
plt.title("ch=11")
|
| 250 |
+
plt.xlabel('time step')
|
| 251 |
+
plt.ylabel('F')
|
| 252 |
+
plt.subplot(2, 4, 6)
|
| 253 |
+
plt.imshow(x_conv[0][:, :, 20].detach().numpy().T,
|
| 254 |
+
aspect='auto',
|
| 255 |
+
origin='lower')
|
| 256 |
+
plt.title("ch=20")
|
| 257 |
+
plt.xlabel('time step')
|
| 258 |
+
plt.ylabel('F')
|
| 259 |
+
plt.subplot(2, 4, 7)
|
| 260 |
+
plt.imshow(x_conv[0][:, :, 77].detach().numpy().T,
|
| 261 |
+
aspect='auto',
|
| 262 |
+
origin='lower')
|
| 263 |
+
plt.title("ch=77")
|
| 264 |
+
plt.xlabel('time step')
|
| 265 |
+
plt.ylabel('F')
|
| 266 |
+
plt.subplot(2, 4, 8)
|
| 267 |
+
plt.imshow(x_conv[0][:, :, 90].detach().numpy().T,
|
| 268 |
+
aspect='auto',
|
| 269 |
+
origin='lower')
|
| 270 |
+
plt.title("ch=90")
|
| 271 |
+
plt.xlabel('time step')
|
| 272 |
+
plt.ylabel('F')
|
| 273 |
+
plt.tight_layout()
|
| 274 |
+
plt.show()
|
| 275 |
+
|
| 276 |
+
# encoding
|
| 277 |
+
output = model.encoder(inputs_embeds=x_conv,
|
| 278 |
+
output_hidden_states=True,
|
| 279 |
+
output_attentions=True)
|
| 280 |
+
enc_hs_all, att, catt = output["hidden_states"], output[
|
| 281 |
+
"attentions"], output["cross_attentions"]
|
| 282 |
+
enc_hs_last = enc_hs_all[2]
|
| 283 |
+
|
| 284 |
+
# enc_hs: time-varying encoder hidden state
|
| 285 |
+
plt.subplot(2, 3, 1)
|
| 286 |
+
plt.imshow(enc_hs_all[0][0][:, :, 21].detach().numpy().T)
|
| 287 |
+
plt.title('ENC_HS B0, d21')
|
| 288 |
+
plt.colorbar(orientation='horizontal')
|
| 289 |
+
plt.ylabel('latent k')
|
| 290 |
+
plt.xlabel('t')
|
| 291 |
+
plt.subplot(2, 3, 4)
|
| 292 |
+
plt.imshow(enc_hs_all[0][0][:, :, 127].detach().numpy().T)
|
| 293 |
+
plt.colorbar(orientation='horizontal')
|
| 294 |
+
plt.title('B0, d127')
|
| 295 |
+
plt.ylabel('latent k')
|
| 296 |
+
plt.xlabel('t')
|
| 297 |
+
plt.subplot(2, 3, 2)
|
| 298 |
+
plt.imshow(enc_hs_all[1][0][:, :, 21].detach().numpy().T)
|
| 299 |
+
plt.colorbar(orientation='horizontal')
|
| 300 |
+
plt.title('B1, d21')
|
| 301 |
+
plt.ylabel('latent k')
|
| 302 |
+
plt.xlabel('t')
|
| 303 |
+
plt.subplot(2, 3, 5)
|
| 304 |
+
plt.imshow(enc_hs_all[1][0][:, :, 127].detach().numpy().T)
|
| 305 |
+
plt.colorbar(orientation='horizontal')
|
| 306 |
+
plt.title('B1, d127')
|
| 307 |
+
plt.ylabel('latent k')
|
| 308 |
+
plt.xlabel('t')
|
| 309 |
+
plt.subplot(2, 3, 3)
|
| 310 |
+
plt.imshow(enc_hs_all[2][0][:, :, 21].detach().numpy().T)
|
| 311 |
+
plt.colorbar(orientation='horizontal')
|
| 312 |
+
plt.title('B2, d21')
|
| 313 |
+
plt.ylabel('latent k')
|
| 314 |
+
plt.xlabel('t')
|
| 315 |
+
plt.subplot(2, 3, 6)
|
| 316 |
+
plt.imshow(enc_hs_all[2][0][:, :, 127].detach().numpy().T)
|
| 317 |
+
plt.colorbar(orientation='horizontal')
|
| 318 |
+
plt.title('B2, d127')
|
| 319 |
+
plt.ylabel('latent k')
|
| 320 |
+
plt.xlabel('t')
|
| 321 |
+
plt.tight_layout()
|
| 322 |
+
plt.show()
|
| 323 |
+
|
| 324 |
+
enc_hs_proj = model.pre_decoder(enc_hs_last)
|
| 325 |
+
plt.imshow(enc_hs_proj[0].detach().numpy())
|
| 326 |
+
plt.title(
|
| 327 |
+
'ENC_HS_PROJ: linear projection of encoder output, which is used for enc-dec cross attention'
|
| 328 |
+
)
|
| 329 |
+
plt.colorbar(orientation='horizontal')
|
| 330 |
+
plt.ylabel('latent k')
|
| 331 |
+
plt.xlabel('d')
|
| 332 |
+
plt.show()
|
| 333 |
+
|
| 334 |
+
plt.subplot(221)
|
| 335 |
+
plt.imshow(enc_hs_all[2][0][0, :, :].detach().numpy(), aspect='auto')
|
| 336 |
+
plt.title('enc_hs, t=0')
|
| 337 |
+
plt.ylabel('latent k')
|
| 338 |
+
plt.xlabel('d')
|
| 339 |
+
plt.subplot(222)
|
| 340 |
+
plt.imshow(enc_hs_all[2][0][10, :, :].detach().numpy(), aspect='auto')
|
| 341 |
+
plt.title('enc_hs, t=10')
|
| 342 |
+
plt.ylabel('latent k')
|
| 343 |
+
plt.xlabel('d')
|
| 344 |
+
plt.subplot(223)
|
| 345 |
+
plt.imshow(enc_hs_all[2][0][20, :, :].detach().numpy(), aspect='auto')
|
| 346 |
+
plt.title('enc_hs, t=20')
|
| 347 |
+
plt.ylabel('latent k')
|
| 348 |
+
plt.xlabel('d')
|
| 349 |
+
plt.subplot(224)
|
| 350 |
+
plt.imshow(enc_hs_all[2][0][30, :, :].detach().numpy(), aspect='auto')
|
| 351 |
+
plt.title('enc_hs, t=30')
|
| 352 |
+
plt.ylabel('latent k')
|
| 353 |
+
plt.xlabel('d')
|
| 354 |
+
plt.tight_layout()
|
| 355 |
+
plt.show()
|
| 356 |
+
|
| 357 |
+
# enc_hs correlation: which dim has most unique info?
|
| 358 |
+
plt.subplot(1, 3, 1)
|
| 359 |
+
a = rearrange(enc_hs_last, '1 t k d -> t (k d)').detach().numpy()
|
| 360 |
+
plt.imshow(cosine_similarity(a))
|
| 361 |
+
plt.title("enc hs, t x t cos_sim")
|
| 362 |
+
plt.subplot(1, 3, 2)
|
| 363 |
+
b = rearrange(enc_hs_last, '1 t k d -> k (t d)').detach().numpy()
|
| 364 |
+
plt.imshow(cosine_similarity(b))
|
| 365 |
+
plt.title("enc hs, k x k cos_sim")
|
| 366 |
+
plt.subplot(1, 3, 3)
|
| 367 |
+
c = rearrange(enc_hs_last, '1 t k d -> d (k t)').detach().numpy()
|
| 368 |
+
plt.imshow(cosine_similarity(c))
|
| 369 |
+
plt.title("cross att, d x d cos_sim")
|
| 370 |
+
plt.tight_layout()
|
| 371 |
+
plt.show()
|
| 372 |
+
|
| 373 |
+
# enc latent
|
| 374 |
+
plt.imshow(model.encoder.latent_array.latents.detach().numpy())
|
| 375 |
+
plt.title('latent array')
|
| 376 |
+
plt.xlabel('d')
|
| 377 |
+
plt.ylabel('latent k')
|
| 378 |
+
plt.show()
|
| 379 |
+
|
| 380 |
+
# enc Spectral Cross Attention: (T x head x K x D). How latent K attends to conv channel C?
|
| 381 |
+
plt.subplot(311)
|
| 382 |
+
plt.imshow(
|
| 383 |
+
torch.sum(torch.sum(catt[0][0], axis=0), axis=0).detach().numpy())
|
| 384 |
+
plt.title('block=0')
|
| 385 |
+
plt.ylabel('latent k')
|
| 386 |
+
plt.xlabel('conv channel')
|
| 387 |
+
plt.subplot(312)
|
| 388 |
+
plt.imshow(
|
| 389 |
+
torch.sum(torch.sum(catt[1][0], axis=0), axis=0).detach().numpy())
|
| 390 |
+
plt.title('block=1')
|
| 391 |
+
plt.ylabel('latent k')
|
| 392 |
+
plt.xlabel('conv channel')
|
| 393 |
+
plt.subplot(313)
|
| 394 |
+
plt.imshow(
|
| 395 |
+
torch.sum(torch.sum(catt[2][0], axis=0), axis=0).detach().numpy())
|
| 396 |
+
plt.title('block=2')
|
| 397 |
+
plt.ylabel('latent k')
|
| 398 |
+
plt.xlabel('conv channel')
|
| 399 |
+
plt.tight_layout()
|
| 400 |
+
plt.show()
|
| 401 |
+
# enc Latent Self-attention: How latent K attends to K?
|
| 402 |
+
plt.subplot(231)
|
| 403 |
+
plt.imshow(torch.sum(torch.sum(att[0][0], axis=1),
|
| 404 |
+
axis=0).detach().numpy(),
|
| 405 |
+
origin='upper')
|
| 406 |
+
plt.title('B0L0')
|
| 407 |
+
plt.xlabel('latent k')
|
| 408 |
+
plt.ylabel('latent k')
|
| 409 |
+
plt.subplot(234)
|
| 410 |
+
plt.imshow(torch.sum(torch.sum(att[0][1], axis=1),
|
| 411 |
+
axis=0).detach().numpy(),
|
| 412 |
+
origin='upper')
|
| 413 |
+
plt.title('B0L1')
|
| 414 |
+
plt.xlabel('latent k')
|
| 415 |
+
plt.ylabel('latent k')
|
| 416 |
+
plt.subplot(232)
|
| 417 |
+
plt.imshow(torch.sum(torch.sum(att[1][0], axis=1),
|
| 418 |
+
axis=0).detach().numpy(),
|
| 419 |
+
origin='upper')
|
| 420 |
+
plt.title('B1L0')
|
| 421 |
+
plt.xlabel('latent k')
|
| 422 |
+
plt.ylabel('latent k')
|
| 423 |
+
plt.subplot(235)
|
| 424 |
+
plt.imshow(torch.sum(torch.sum(att[1][1], axis=1),
|
| 425 |
+
axis=0).detach().numpy(),
|
| 426 |
+
origin='upper')
|
| 427 |
+
plt.title('B1L1')
|
| 428 |
+
plt.xlabel('latent k')
|
| 429 |
+
plt.ylabel('latent k')
|
| 430 |
+
plt.subplot(233)
|
| 431 |
+
plt.imshow(torch.sum(torch.sum(att[2][0], axis=1),
|
| 432 |
+
axis=0).detach().numpy(),
|
| 433 |
+
origin='upper')
|
| 434 |
+
plt.title('B2L0')
|
| 435 |
+
plt.xlabel('latent k')
|
| 436 |
+
plt.ylabel('latent k')
|
| 437 |
+
plt.subplot(236)
|
| 438 |
+
plt.imshow(torch.sum(torch.sum(att[2][1], axis=1),
|
| 439 |
+
axis=0).detach().numpy(),
|
| 440 |
+
origin='upper')
|
| 441 |
+
plt.title('B2L1')
|
| 442 |
+
plt.xlabel('latent k')
|
| 443 |
+
plt.ylabel('latent k')
|
| 444 |
+
plt.tight_layout()
|
| 445 |
+
plt.show()
|
| 446 |
+
# Time varying, different head for latent self-attention
|
| 447 |
+
plt.subplot(231)
|
| 448 |
+
plt.imshow(att[0][0][30, 3, :, :].detach().numpy())
|
| 449 |
+
plt.title('B0L0, t=30, Head=3')
|
| 450 |
+
plt.colorbar(orientation='horizontal')
|
| 451 |
+
plt.xlabel('k')
|
| 452 |
+
plt.ylabel('k')
|
| 453 |
+
plt.subplot(234)
|
| 454 |
+
plt.imshow(att[0][1][30, 3, :, :].detach().numpy())
|
| 455 |
+
plt.title('B0L1, t=30, Head=3')
|
| 456 |
+
plt.colorbar(orientation='horizontal')
|
| 457 |
+
plt.xlabel('k')
|
| 458 |
+
plt.ylabel('k')
|
| 459 |
+
plt.subplot(232)
|
| 460 |
+
plt.imshow(att[1][0][30, 3, :, :].detach().numpy())
|
| 461 |
+
plt.title('B1L0, t=30, Head=3')
|
| 462 |
+
plt.colorbar(orientation='horizontal')
|
| 463 |
+
plt.xlabel('k')
|
| 464 |
+
plt.ylabel('k')
|
| 465 |
+
plt.subplot(235)
|
| 466 |
+
plt.imshow(att[1][1][30, 3, :, :].detach().numpy())
|
| 467 |
+
plt.title('B1L1, t=30, Head=3')
|
| 468 |
+
plt.colorbar(orientation='horizontal')
|
| 469 |
+
plt.xlabel('k')
|
| 470 |
+
plt.ylabel('k')
|
| 471 |
+
plt.subplot(233)
|
| 472 |
+
plt.imshow(att[2][0][30, 3, :, :].detach().numpy())
|
| 473 |
+
plt.title('B2L0, t=30, Head=3')
|
| 474 |
+
plt.colorbar(orientation='horizontal')
|
| 475 |
+
plt.xlabel('k')
|
| 476 |
+
plt.ylabel('k')
|
| 477 |
+
plt.subplot(236)
|
| 478 |
+
plt.imshow(att[2][1][30, 3, :, :].detach().numpy())
|
| 479 |
+
plt.title('B2L1, t=30, Head=3')
|
| 480 |
+
plt.colorbar(orientation='horizontal')
|
| 481 |
+
plt.xlabel('k')
|
| 482 |
+
plt.ylabel('k')
|
| 483 |
+
plt.tight_layout()
|
| 484 |
+
plt.show()
|
| 485 |
+
plt.subplot(231)
|
| 486 |
+
plt.imshow(att[0][0][30, 5, :, :].detach().numpy())
|
| 487 |
+
plt.title('B0L0, t=30, Head=5')
|
| 488 |
+
plt.colorbar(orientation='horizontal')
|
| 489 |
+
plt.xlabel('k')
|
| 490 |
+
plt.ylabel('k')
|
| 491 |
+
plt.subplot(234)
|
| 492 |
+
plt.imshow(att[0][1][30, 5, :, :].detach().numpy())
|
| 493 |
+
plt.title('B0L1, t=30, Head=5')
|
| 494 |
+
plt.colorbar(orientation='horizontal')
|
| 495 |
+
plt.xlabel('k')
|
| 496 |
+
plt.ylabel('k')
|
| 497 |
+
plt.subplot(232)
|
| 498 |
+
plt.imshow(att[1][0][30, 5, :, :].detach().numpy())
|
| 499 |
+
plt.title('B1L0, t=30, Head=5')
|
| 500 |
+
plt.colorbar(orientation='horizontal')
|
| 501 |
+
plt.xlabel('k')
|
| 502 |
+
plt.ylabel('k')
|
| 503 |
+
plt.subplot(235)
|
| 504 |
+
plt.imshow(att[1][1][30, 5, :, :].detach().numpy())
|
| 505 |
+
plt.title('B1L1, t=30, Head=5')
|
| 506 |
+
plt.colorbar(orientation='horizontal')
|
| 507 |
+
plt.xlabel('k')
|
| 508 |
+
plt.ylabel('k')
|
| 509 |
+
plt.subplot(233)
|
| 510 |
+
plt.imshow(att[2][0][30, 5, :, :].detach().numpy())
|
| 511 |
+
plt.title('B2L0, t=30, Head=5')
|
| 512 |
+
plt.colorbar(orientation='horizontal')
|
| 513 |
+
plt.xlabel('k')
|
| 514 |
+
plt.ylabel('k')
|
| 515 |
+
plt.subplot(236)
|
| 516 |
+
plt.imshow(att[2][1][30, 5, :, :].detach().numpy())
|
| 517 |
+
plt.title('B2L1, t=30, Head=5')
|
| 518 |
+
plt.colorbar(orientation='horizontal')
|
| 519 |
+
plt.xlabel('k')
|
| 520 |
+
plt.ylabel('k')
|
| 521 |
+
plt.tight_layout()
|
| 522 |
+
plt.show()
|
| 523 |
+
|
| 524 |
+
# Temporal Self-attention: (K x H x T x T) How time t attends to time t?
|
| 525 |
+
plt.subplot(231)
|
| 526 |
+
plt.imshow(torch.sum(torch.sum(att[0][2], axis=1),
|
| 527 |
+
axis=0).detach().numpy(),
|
| 528 |
+
origin='upper')
|
| 529 |
+
plt.title('B0L2')
|
| 530 |
+
plt.xlabel('t')
|
| 531 |
+
plt.ylabel('t')
|
| 532 |
+
plt.subplot(234)
|
| 533 |
+
plt.imshow(torch.sum(torch.sum(att[0][3], axis=1),
|
| 534 |
+
axis=0).detach().numpy(),
|
| 535 |
+
origin='upper')
|
| 536 |
+
plt.title('B0L3')
|
| 537 |
+
plt.xlabel('t')
|
| 538 |
+
plt.ylabel('t')
|
| 539 |
+
plt.subplot(232)
|
| 540 |
+
plt.imshow(torch.sum(torch.sum(att[1][2], axis=1),
|
| 541 |
+
axis=0).detach().numpy(),
|
| 542 |
+
origin='upper')
|
| 543 |
+
plt.title('B1L2')
|
| 544 |
+
plt.xlabel('t')
|
| 545 |
+
plt.ylabel('t')
|
| 546 |
+
plt.subplot(235)
|
| 547 |
+
plt.imshow(torch.sum(torch.sum(att[1][3], axis=1),
|
| 548 |
+
axis=0).detach().numpy(),
|
| 549 |
+
origin='upper')
|
| 550 |
+
plt.title('B1L3')
|
| 551 |
+
plt.xlabel('t')
|
| 552 |
+
plt.ylabel('t')
|
| 553 |
+
plt.subplot(233)
|
| 554 |
+
plt.imshow(torch.sum(torch.sum(att[2][2], axis=1),
|
| 555 |
+
axis=0).detach().numpy(),
|
| 556 |
+
origin='upper')
|
| 557 |
+
plt.title('B2L2')
|
| 558 |
+
plt.xlabel('t')
|
| 559 |
+
plt.ylabel('t')
|
| 560 |
+
plt.subplot(236)
|
| 561 |
+
plt.imshow(torch.sum(torch.sum(att[2][3], axis=1),
|
| 562 |
+
axis=0).detach().numpy(),
|
| 563 |
+
origin='upper')
|
| 564 |
+
plt.title('B2L3')
|
| 565 |
+
plt.xlabel('t')
|
| 566 |
+
plt.ylabel('t')
|
| 567 |
+
plt.tight_layout()
|
| 568 |
+
plt.show()
|
| 569 |
+
|
| 570 |
+
# decoding
|
| 571 |
+
dec_input_ids = model.shift_right_fn(label)
|
| 572 |
+
dec_inputs_embeds = model.embed_tokens(dec_input_ids)
|
| 573 |
+
dec_output = model.decoder(inputs_embeds=dec_inputs_embeds,
|
| 574 |
+
encoder_hidden_states=enc_hs_proj,
|
| 575 |
+
output_attentions=True,
|
| 576 |
+
output_hidden_states=True,
|
| 577 |
+
return_dict=True)
|
| 578 |
+
dec_att, dec_catt = dec_output.attentions, dec_output.cross_attentions
|
| 579 |
+
dec_hs_all = dec_output.hidden_states
|
| 580 |
+
|
| 581 |
+
# dec att
|
| 582 |
+
plt.subplot(1, 2, 1)
|
| 583 |
+
plt.imshow(torch.sum(dec_att[0][0], axis=0).detach().numpy())
|
| 584 |
+
plt.title('decoder attention, layer0')
|
| 585 |
+
plt.xlabel('decoder time step')
|
| 586 |
+
plt.ylabel('decoder time step')
|
| 587 |
+
plt.subplot(1, 2, 2)
|
| 588 |
+
plt.imshow(torch.sum(dec_att[7][0], axis=0).detach().numpy())
|
| 589 |
+
plt.title('decoder attention, layer8')
|
| 590 |
+
plt.xlabel('decoder time step')
|
| 591 |
+
plt.show()
|
| 592 |
+
# dec catt
|
| 593 |
+
plt.imshow(np.rot90((torch.sum(dec_catt[7][0],
|
| 594 |
+
axis=0))[:1000, :].detach().numpy()),
|
| 595 |
+
origin='upper',
|
| 596 |
+
aspect='auto')
|
| 597 |
+
plt.colorbar()
|
| 598 |
+
plt.title('decoder cross att, layer8')
|
| 599 |
+
plt.xlabel('decoder time step')
|
| 600 |
+
plt.ylabel('encoder frame')
|
| 601 |
+
plt.show()
|
| 602 |
+
# dec catt by head with xxx
|
| 603 |
+
dec_att_z = z_normalize_tensors(shorten_att(dec_att))
|
| 604 |
+
plt.imshow(dec_att_z[0][0, 0, :, :].detach().numpy())
|
| 605 |
+
from bertviz import head_view
|
| 606 |
+
token = []
|
| 607 |
+
for i in label[0, :30]:
|
| 608 |
+
token.append(str(i))
|
| 609 |
+
head_view(dec_att_z, tokens)
|
| 610 |
+
|
| 611 |
+
# dec_hs
|
| 612 |
+
plt.subplot(1, 2, 1)
|
| 613 |
+
plt.imshow(dec_hs_all[0][0].detach().numpy(), origin='upper')
|
| 614 |
+
plt.colorbar(orientation='horizontal')
|
| 615 |
+
plt.title('decoder hidden state, layer1')
|
| 616 |
+
plt.xlabel('hidden dim')
|
| 617 |
+
plt.ylabel('time step')
|
| 618 |
+
plt.subplot(1, 2, 2)
|
| 619 |
+
plt.imshow(dec_hs_all[7][0].detach().numpy(), origin='upper')
|
| 620 |
+
plt.colorbar(orientation='horizontal')
|
| 621 |
+
plt.title('decoder hidden state, layer8')
|
| 622 |
+
plt.xlabel('hidden dim')
|
| 623 |
+
plt.show()
|
| 624 |
+
|
| 625 |
+
# lm head
|
| 626 |
+
logits = model.lm_head(dec_hs_all[0])
|
| 627 |
+
plt.imshow(logits[0][0:200, :].detach().numpy(), origin='upper')
|
| 628 |
+
plt.title('lm head softmax')
|
| 629 |
+
plt.xlabel('vocab dim')
|
| 630 |
+
plt.ylabel('time step')
|
| 631 |
+
plt.xlim([1000, 1350])
|
| 632 |
+
plt.show()
|
| 633 |
+
softmax = torch.nn.Softmax(dim=2)
|
| 634 |
+
logits_sm = softmax(logits)
|
| 635 |
+
plt.imshow(logits_sm[0][0:200, :].detach().numpy(), origin='upper')
|
| 636 |
+
plt.title('lm head softmax')
|
| 637 |
+
plt.xlabel('vocab dim')
|
| 638 |
+
plt.ylabel('time step')
|
| 639 |
+
plt.xlim([1000, 1350])
|
| 640 |
+
plt.show()
|
amt/src/extras/perceivertf_multi_inspect.py
ADDED
|
@@ -0,0 +1,778 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
import torchaudio
|
| 5 |
+
from matplotlib.animation import FuncAnimation
|
| 6 |
+
|
| 7 |
+
def l2_normalize(matrix):
|
| 8 |
+
"""
|
| 9 |
+
L2 Normalize the matrix along its rows.
|
| 10 |
+
|
| 11 |
+
Parameters:
|
| 12 |
+
matrix (numpy.ndarray): The input matrix.
|
| 13 |
+
|
| 14 |
+
Returns:
|
| 15 |
+
numpy.ndarray: The L2 normalized matrix.
|
| 16 |
+
"""
|
| 17 |
+
l2_norms = np.linalg.norm(matrix, axis=1, keepdims=True)
|
| 18 |
+
normalized_matrix = matrix / l2_norms
|
| 19 |
+
return normalized_matrix
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def z_normalize(matrix):
|
| 23 |
+
"""
|
| 24 |
+
Z-normalize the matrix along its rows (mean=0 and std=1).
|
| 25 |
+
Z-normalization is also known as "standardization", and derives from z-score.
|
| 26 |
+
Z = (X - mean) / std
|
| 27 |
+
Z-nomarlized, each row has mean=0 and std=1.
|
| 28 |
+
|
| 29 |
+
Parameters:
|
| 30 |
+
matrix (numpy.ndarray): The input matrix.
|
| 31 |
+
|
| 32 |
+
Returns:
|
| 33 |
+
numpy.ndarray: The Z normalized matrix.
|
| 34 |
+
"""
|
| 35 |
+
mean = np.mean(matrix, axis=1, keepdims=True)
|
| 36 |
+
std = np.std(matrix, axis=1, keepdims=True)
|
| 37 |
+
normalized_matrix = (matrix - mean) / std
|
| 38 |
+
return normalized_matrix
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def l2_normalize_tensors(tensor_tuple):
|
| 42 |
+
"""
|
| 43 |
+
Applies L2 normalization on the last two dimensions for each tensor in a tuple.
|
| 44 |
+
|
| 45 |
+
Parameters:
|
| 46 |
+
tensor_tuple (tuple of torch.Tensor): A tuple containing N tensors, each of shape (1, k, 30, 30).
|
| 47 |
+
|
| 48 |
+
Returns:
|
| 49 |
+
tuple of torch.Tensor: A tuple containing N L2-normalized tensors.
|
| 50 |
+
"""
|
| 51 |
+
normalized_tensors = []
|
| 52 |
+
for tensor in tensor_tuple:
|
| 53 |
+
# Ensure the tensor is a floating-point type
|
| 54 |
+
tensor = tensor.float()
|
| 55 |
+
|
| 56 |
+
# Calculate L2 norm on the last two dimensions, keeping the dimensions using keepdim=True
|
| 57 |
+
l2_norm = torch.linalg.norm(tensor, dim=(-2, -1), keepdim=True)
|
| 58 |
+
|
| 59 |
+
# Apply L2 normalization
|
| 60 |
+
normalized_tensor = tensor / (
|
| 61 |
+
l2_norm + 1e-7) # Small value to avoid division by zero
|
| 62 |
+
|
| 63 |
+
normalized_tensors.append(normalized_tensor)
|
| 64 |
+
|
| 65 |
+
return tuple(normalized_tensors)
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def z_normalize_tensors(tensor_tuple):
|
| 69 |
+
"""
|
| 70 |
+
Applies Z-normalization on the last two dimensions for each tensor in a tuple.
|
| 71 |
+
|
| 72 |
+
Parameters:
|
| 73 |
+
tensor_tuple (tuple of torch.Tensor): A tuple containing N tensors, each of shape (1, k, 30, 30).
|
| 74 |
+
|
| 75 |
+
Returns:
|
| 76 |
+
tuple of torch.Tensor: A tuple containing N Z-normalized tensors.
|
| 77 |
+
"""
|
| 78 |
+
normalized_tensors = []
|
| 79 |
+
for tensor in tensor_tuple:
|
| 80 |
+
# Ensure the tensor is a floating-point type
|
| 81 |
+
tensor = tensor.float()
|
| 82 |
+
|
| 83 |
+
# Calculate mean and std on the last two dimensions
|
| 84 |
+
mean = tensor.mean(dim=(-2, -1), keepdim=True)
|
| 85 |
+
std = tensor.std(dim=(-2, -1), keepdim=True)
|
| 86 |
+
|
| 87 |
+
# Apply Z-normalization
|
| 88 |
+
normalized_tensor = (tensor - mean) / (
|
| 89 |
+
std + 1e-7) # Small value to avoid division by zero
|
| 90 |
+
|
| 91 |
+
normalized_tensors.append(normalized_tensor)
|
| 92 |
+
|
| 93 |
+
return tuple(normalized_tensors)
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def apply_temperature_to_attention_tensors(tensor_tuple, temperature=1.0):
|
| 97 |
+
"""
|
| 98 |
+
Applies temperature scaling to the attention weights in each tensor in a tuple.
|
| 99 |
+
|
| 100 |
+
Parameters:
|
| 101 |
+
tensor_tuple (tuple of torch.Tensor): A tuple containing N tensors,
|
| 102 |
+
each of shape (1, k, 30, 30).
|
| 103 |
+
temperature (float): Temperature parameter to control the sharpness
|
| 104 |
+
of the attention weights. Default is 1.0.
|
| 105 |
+
|
| 106 |
+
Returns:
|
| 107 |
+
tuple of torch.Tensor: A tuple containing N tensors with scaled attention weights.
|
| 108 |
+
"""
|
| 109 |
+
scaled_attention_tensors = []
|
| 110 |
+
|
| 111 |
+
for tensor in tensor_tuple:
|
| 112 |
+
# Ensure the tensor is a floating-point type
|
| 113 |
+
tensor = tensor.float()
|
| 114 |
+
|
| 115 |
+
# Flatten the last two dimensions
|
| 116 |
+
flattened_tensor = tensor.reshape(1, tensor.shape[1],
|
| 117 |
+
-1) # Modified line here
|
| 118 |
+
|
| 119 |
+
# Apply temperature scaling and softmax along the last dimension
|
| 120 |
+
scaled_attention = flattened_tensor / temperature
|
| 121 |
+
scaled_attention = F.softmax(scaled_attention, dim=-1)
|
| 122 |
+
|
| 123 |
+
# Reshape to original shape
|
| 124 |
+
scaled_attention = scaled_attention.view_as(tensor)
|
| 125 |
+
|
| 126 |
+
scaled_attention_tensors.append(scaled_attention)
|
| 127 |
+
|
| 128 |
+
return tuple(scaled_attention_tensors)
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
def shorten_att(tensor_tuple, length=30):
|
| 132 |
+
shortend_tensors = []
|
| 133 |
+
for tensor in tensor_tuple:
|
| 134 |
+
shortend_tensors.append(tensor[:, :, :length, :length])
|
| 135 |
+
return tuple(shortend_tensors)
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
def keep_top_k(matrix, k=6):
|
| 139 |
+
"""
|
| 140 |
+
Keep only the top k values in each row, set the rest to 0.
|
| 141 |
+
|
| 142 |
+
Parameters:
|
| 143 |
+
matrix (numpy.ndarray): The input matrix.
|
| 144 |
+
k (int): The number of top values to keep in each row.
|
| 145 |
+
|
| 146 |
+
Returns:
|
| 147 |
+
numpy.ndarray: The transformed matrix.
|
| 148 |
+
"""
|
| 149 |
+
topk_indices_per_row = np.argpartition(matrix, -k, axis=1)[:, -k:]
|
| 150 |
+
result_matrix = np.zeros_like(matrix)
|
| 151 |
+
|
| 152 |
+
for i in range(matrix.shape[0]):
|
| 153 |
+
result_matrix[i, topk_indices_per_row[i]] = matrix[
|
| 154 |
+
i, topk_indices_per_row[i]]
|
| 155 |
+
return result_matrix
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
def test_case_forward_enc_perceiver_tf_dec_multi_t5():
|
| 159 |
+
import torch
|
| 160 |
+
from model.ymt3 import YourMT3
|
| 161 |
+
from config.config import audio_cfg, model_cfg, shared_cfg
|
| 162 |
+
model_cfg["encoder_type"] = "perceiver-tf"
|
| 163 |
+
|
| 164 |
+
model_cfg["encoder"]["perceiver-tf"]["attention_to_channel"] = True
|
| 165 |
+
model_cfg["encoder"]["perceiver-tf"]["num_latents"] = 26
|
| 166 |
+
|
| 167 |
+
model_cfg["decoder_type"] = "multi-t5"
|
| 168 |
+
|
| 169 |
+
audio_cfg["codec"] = "spec"
|
| 170 |
+
audio_cfg["hop_length"] = 300
|
| 171 |
+
model = YourMT3(audio_cfg=audio_cfg, model_cfg=model_cfg)
|
| 172 |
+
model.eval()
|
| 173 |
+
|
| 174 |
+
# x = torch.randn(2, 1, 32767)
|
| 175 |
+
# labels = torch.randint(0, 400, (2, 1024), requires_grad=False)
|
| 176 |
+
|
| 177 |
+
# # forward
|
| 178 |
+
# output = model.forward(x, labels)
|
| 179 |
+
|
| 180 |
+
# # inference
|
| 181 |
+
# result = model.inference(x, None)
|
| 182 |
+
|
| 183 |
+
# display latents
|
| 184 |
+
checkpoint = torch.load(
|
| 185 |
+
"../logs/ymt3/ptf_mc13_256_all_cross_v6_xk5_amp0811_edr005_attend_c_full_plus_2psn_nl26_sb_b26r_800k/checkpoints/model.ckpt",
|
| 186 |
+
map_location="cpu")
|
| 187 |
+
state_dict = checkpoint['state_dict']
|
| 188 |
+
new_state_dict = {
|
| 189 |
+
k: v
|
| 190 |
+
for k, v in state_dict.items() if 'pitchshift' not in k
|
| 191 |
+
}
|
| 192 |
+
model.load_state_dict(new_state_dict, strict=False)
|
| 193 |
+
|
| 194 |
+
latents = model.encoder.latent_array.latents.detach().numpy()
|
| 195 |
+
import matplotlib.pyplot as plt
|
| 196 |
+
import numpy as np
|
| 197 |
+
from sklearn.metrics.pairwise import cosine_similarity
|
| 198 |
+
cos = cosine_similarity(latents)
|
| 199 |
+
|
| 200 |
+
from utils.data_modules import AMTDataModule
|
| 201 |
+
from einops import rearrange
|
| 202 |
+
# dm = AMTDataModule(data_preset_multi={"presets": ["slakh"]})
|
| 203 |
+
#dm.setup("test")
|
| 204 |
+
# dl = dm.test_dataloader()
|
| 205 |
+
# ds = list(dl.values())[0].dataset
|
| 206 |
+
# audio, notes, tokens, _ = ds.__getitem__(7)
|
| 207 |
+
# x = audio[[16], ::]
|
| 208 |
+
# label = tokens[[16], :]
|
| 209 |
+
|
| 210 |
+
# from utils.task_manager import TaskManager
|
| 211 |
+
# tm = TaskManager(task_name='mc13_256')
|
| 212 |
+
# dm = AMTDataModule(data_preset_multi={"presets": ["slakh"]},
|
| 213 |
+
# task_manager=tm,
|
| 214 |
+
# train_stem_iaug_prob=None,
|
| 215 |
+
# train_stem_xaug_policy=None)
|
| 216 |
+
# dm.setup('fit')
|
| 217 |
+
# dl = dm.train_dataloader()
|
| 218 |
+
# ds = dl.flattened[0].dataset
|
| 219 |
+
# audio,tokens, _, _ = ds.__getitem__(67)
|
| 220 |
+
# x = audio[[5], ::]
|
| 221 |
+
# label = tokens[[5], :]
|
| 222 |
+
# save audio
|
| 223 |
+
# torchaudio.save("singing.wav", x[0, :, :], 16000)
|
| 224 |
+
|
| 225 |
+
x, _ = torchaudio.load('piano.wav')#'test.wav')
|
| 226 |
+
x = x.unsqueeze(0)
|
| 227 |
+
|
| 228 |
+
# spectrogram
|
| 229 |
+
x_spec = model.spectrogram(x)
|
| 230 |
+
x_conv = model.pre_encoder(x_spec)
|
| 231 |
+
# Create a larger figure
|
| 232 |
+
plt.figure(
|
| 233 |
+
figsize=(15,
|
| 234 |
+
10)) # Adjust these numbers as needed for width and height
|
| 235 |
+
plt.subplot(2, 4, 1)
|
| 236 |
+
plt.imshow(x_spec[0].detach().numpy().T, aspect='auto', origin='lower')
|
| 237 |
+
plt.title("spectrogram")
|
| 238 |
+
plt.xlabel('time step')
|
| 239 |
+
plt.ylabel('frequency bin')
|
| 240 |
+
plt.subplot(2, 4, 2)
|
| 241 |
+
plt.imshow(x_conv[0][:, :, 0].detach().numpy().T,
|
| 242 |
+
aspect='auto',
|
| 243 |
+
origin='lower')
|
| 244 |
+
plt.title("conv(spec), ch=0")
|
| 245 |
+
plt.xlabel('time step')
|
| 246 |
+
plt.ylabel('F')
|
| 247 |
+
plt.subplot(2, 4, 3)
|
| 248 |
+
plt.imshow(x_conv[0][:, :, 42].detach().numpy().T,
|
| 249 |
+
aspect='auto',
|
| 250 |
+
origin='lower')
|
| 251 |
+
plt.title("ch=42")
|
| 252 |
+
plt.xlabel('time step')
|
| 253 |
+
plt.ylabel('F')
|
| 254 |
+
plt.subplot(2, 4, 4)
|
| 255 |
+
plt.imshow(x_conv[0][:, :, 80].detach().numpy().T,
|
| 256 |
+
aspect='auto',
|
| 257 |
+
origin='lower')
|
| 258 |
+
plt.title("ch=80")
|
| 259 |
+
plt.xlabel('time step')
|
| 260 |
+
plt.ylabel('F')
|
| 261 |
+
plt.subplot(2, 4, 5)
|
| 262 |
+
plt.imshow(x_conv[0][:, :, 11].detach().numpy().T,
|
| 263 |
+
aspect='auto',
|
| 264 |
+
origin='lower')
|
| 265 |
+
plt.title("ch=11")
|
| 266 |
+
plt.xlabel('time step')
|
| 267 |
+
plt.ylabel('F')
|
| 268 |
+
plt.subplot(2, 4, 6)
|
| 269 |
+
plt.imshow(x_conv[0][:, :, 20].detach().numpy().T,
|
| 270 |
+
aspect='auto',
|
| 271 |
+
origin='lower')
|
| 272 |
+
plt.title("ch=20")
|
| 273 |
+
plt.xlabel('time step')
|
| 274 |
+
plt.ylabel('F')
|
| 275 |
+
plt.subplot(2, 4, 7)
|
| 276 |
+
plt.imshow(x_conv[0][:, :, 77].detach().numpy().T,
|
| 277 |
+
aspect='auto',
|
| 278 |
+
origin='lower')
|
| 279 |
+
plt.title("ch=77")
|
| 280 |
+
plt.xlabel('time step')
|
| 281 |
+
plt.ylabel('F')
|
| 282 |
+
plt.subplot(2, 4, 8)
|
| 283 |
+
plt.imshow(x_conv[0][:, :, 90].detach().numpy().T,
|
| 284 |
+
aspect='auto',
|
| 285 |
+
origin='lower')
|
| 286 |
+
plt.title("ch=90")
|
| 287 |
+
plt.xlabel('time step')
|
| 288 |
+
plt.ylabel('F')
|
| 289 |
+
plt.tight_layout()
|
| 290 |
+
plt.show()
|
| 291 |
+
|
| 292 |
+
# encoding
|
| 293 |
+
output = model.encoder(inputs_embeds=x_conv,
|
| 294 |
+
output_hidden_states=True,
|
| 295 |
+
output_attentions=True)
|
| 296 |
+
enc_hs_all, att, catt = output["hidden_states"], output[
|
| 297 |
+
"attentions"], output["cross_attentions"]
|
| 298 |
+
enc_hs_last = enc_hs_all[2]
|
| 299 |
+
|
| 300 |
+
# enc_hs: time-varying encoder hidden state
|
| 301 |
+
plt.subplot(2, 3, 1)
|
| 302 |
+
plt.imshow(enc_hs_all[0][0][:, :, 21].detach().numpy().T)
|
| 303 |
+
plt.title('ENC_HS B0, d21')
|
| 304 |
+
plt.colorbar(orientation='horizontal')
|
| 305 |
+
plt.ylabel('latent k')
|
| 306 |
+
plt.xlabel('t')
|
| 307 |
+
plt.subplot(2, 3, 4)
|
| 308 |
+
plt.imshow(enc_hs_all[0][0][:, :, 127].detach().numpy().T)
|
| 309 |
+
plt.colorbar(orientation='horizontal')
|
| 310 |
+
plt.title('B0, d127')
|
| 311 |
+
plt.ylabel('latent k')
|
| 312 |
+
plt.xlabel('t')
|
| 313 |
+
plt.subplot(2, 3, 2)
|
| 314 |
+
plt.imshow(enc_hs_all[1][0][:, :, 21].detach().numpy().T)
|
| 315 |
+
plt.colorbar(orientation='horizontal')
|
| 316 |
+
plt.title('B1, d21')
|
| 317 |
+
plt.ylabel('latent k')
|
| 318 |
+
plt.xlabel('t')
|
| 319 |
+
plt.subplot(2, 3, 5)
|
| 320 |
+
plt.imshow(enc_hs_all[1][0][:, :, 127].detach().numpy().T)
|
| 321 |
+
plt.colorbar(orientation='horizontal')
|
| 322 |
+
plt.title('B1, d127')
|
| 323 |
+
plt.ylabel('latent k')
|
| 324 |
+
plt.xlabel('t')
|
| 325 |
+
plt.subplot(2, 3, 3)
|
| 326 |
+
plt.imshow(enc_hs_all[2][0][:, :, 21].detach().numpy().T)
|
| 327 |
+
plt.colorbar(orientation='horizontal')
|
| 328 |
+
plt.title('B2, d21')
|
| 329 |
+
plt.ylabel('latent k')
|
| 330 |
+
plt.xlabel('t')
|
| 331 |
+
plt.subplot(2, 3, 6)
|
| 332 |
+
plt.imshow(enc_hs_all[2][0][:, :, 127].detach().numpy().T)
|
| 333 |
+
plt.colorbar(orientation='horizontal')
|
| 334 |
+
plt.title('B2, d127')
|
| 335 |
+
plt.ylabel('latent k')
|
| 336 |
+
plt.xlabel('t')
|
| 337 |
+
plt.tight_layout()
|
| 338 |
+
plt.show()
|
| 339 |
+
|
| 340 |
+
# enc_hs: time-varying encoder hidden state by k (block, 1, t, k, d)
|
| 341 |
+
# --> (t, d) for each k in last block
|
| 342 |
+
data = enc_hs_all[2][0].detach().numpy() # (T, K, D)
|
| 343 |
+
fig, axs = plt.subplots(
|
| 344 |
+
5, 5, figsize=(10, 9)) # 25 subplots arranged in 5 rows and 5 columns
|
| 345 |
+
axs = axs.flatten(
|
| 346 |
+
) # Flatten the 2D array of axes to 1D for easy iteration
|
| 347 |
+
|
| 348 |
+
for k in range(25): # Iterating through K indices from 0 to 24
|
| 349 |
+
axs[k].imshow(data[:, k, :].T,
|
| 350 |
+
cmap='viridis') # Transposing the matrix to swap T and D
|
| 351 |
+
axs[k].set_title(f'k={k}')
|
| 352 |
+
axs[k].set_xlabel('Time step')
|
| 353 |
+
axs[k].set_ylabel('Dim')
|
| 354 |
+
|
| 355 |
+
# Adjusting layout for better visibility
|
| 356 |
+
plt.tight_layout()
|
| 357 |
+
plt.show()
|
| 358 |
+
|
| 359 |
+
#!! Projected encoder hidden state for 13 channels, that is conditioning for decoder
|
| 360 |
+
enc_hs_proj = model.pre_decoder(enc_hs_last)
|
| 361 |
+
fig, axs = plt.subplots(1, 13, figsize=(26, 8)) # 13 subplots in a row
|
| 362 |
+
data = enc_hs_proj[0].detach().numpy()
|
| 363 |
+
for ch in range(13):
|
| 364 |
+
axs[ch].imshow(np.rot90(data[ch]), cmap='viridis') # Rotate 90 degrees
|
| 365 |
+
axs[ch].set_title(f'ch: {ch}')
|
| 366 |
+
axs[ch].set_xlabel('Time step')
|
| 367 |
+
axs[ch].set_ylabel('Dim')
|
| 368 |
+
plt.suptitle(
|
| 369 |
+
'linear projection of encoder outputs by channel, which is conditioning for enc-dec cross attention',
|
| 370 |
+
y=0.1,
|
| 371 |
+
fontsize=12)
|
| 372 |
+
plt.tight_layout(rect=[0, 0.1, 1, 1])
|
| 373 |
+
plt.show()
|
| 374 |
+
|
| 375 |
+
plt.subplot(221)
|
| 376 |
+
plt.imshow(enc_hs_all[2][0][0, :, :].detach().numpy(), aspect='auto')
|
| 377 |
+
plt.title('enc_hs, t=0')
|
| 378 |
+
plt.ylabel('latent k')
|
| 379 |
+
plt.xlabel('d')
|
| 380 |
+
plt.subplot(222)
|
| 381 |
+
plt.imshow(enc_hs_all[2][0][10, :, :].detach().numpy(), aspect='auto')
|
| 382 |
+
plt.title('enc_hs, t=10')
|
| 383 |
+
plt.ylabel('latent k')
|
| 384 |
+
plt.xlabel('d')
|
| 385 |
+
plt.subplot(223)
|
| 386 |
+
plt.imshow(enc_hs_all[2][0][20, :, :].detach().numpy(), aspect='auto')
|
| 387 |
+
plt.title('enc_hs, t=20')
|
| 388 |
+
plt.ylabel('latent k')
|
| 389 |
+
plt.xlabel('d')
|
| 390 |
+
plt.subplot(224)
|
| 391 |
+
plt.imshow(enc_hs_all[2][0][30, :, :].detach().numpy(), aspect='auto')
|
| 392 |
+
plt.title('enc_hs, t=30')
|
| 393 |
+
plt.ylabel('latent k')
|
| 394 |
+
plt.xlabel('d')
|
| 395 |
+
plt.tight_layout()
|
| 396 |
+
plt.show()
|
| 397 |
+
|
| 398 |
+
# enc_hs correlation: which dim has most unique info?
|
| 399 |
+
plt.subplot(1, 3, 1)
|
| 400 |
+
a = rearrange(enc_hs_last, '1 t k d -> t (k d)').detach().numpy()
|
| 401 |
+
plt.imshow(cosine_similarity(a))
|
| 402 |
+
plt.title("enc hs, t x t cos_sim")
|
| 403 |
+
plt.subplot(1, 3, 2)
|
| 404 |
+
b = rearrange(enc_hs_last, '1 t k d -> k (t d)').detach().numpy()
|
| 405 |
+
plt.imshow(cosine_similarity(b))
|
| 406 |
+
plt.title("enc hs, k x k cos_sim")
|
| 407 |
+
plt.subplot(1, 3, 3)
|
| 408 |
+
c = rearrange(enc_hs_last, '1 t k d -> d (k t)').detach().numpy()
|
| 409 |
+
plt.imshow(cosine_similarity(c))
|
| 410 |
+
plt.title("cross att, d x d cos_sim")
|
| 411 |
+
plt.tight_layout()
|
| 412 |
+
plt.show()
|
| 413 |
+
|
| 414 |
+
#!! enc latent
|
| 415 |
+
plt.imshow(model.encoder.latent_array.latents.detach().numpy())
|
| 416 |
+
plt.title('latent array')
|
| 417 |
+
plt.xlabel('d')
|
| 418 |
+
plt.ylabel('latent k')
|
| 419 |
+
plt.show()
|
| 420 |
+
|
| 421 |
+
#!! enc Spectral Cross Attention: (T x head x K x D). How latent K attends to conv channel C?
|
| 422 |
+
plt.subplot(311)
|
| 423 |
+
plt.imshow(
|
| 424 |
+
torch.sum(torch.sum(catt[0][0], axis=0), axis=0).detach().numpy())
|
| 425 |
+
plt.title('block=0')
|
| 426 |
+
plt.ylabel('latent k')
|
| 427 |
+
plt.xlabel('conv channel')
|
| 428 |
+
plt.subplot(312)
|
| 429 |
+
plt.imshow(
|
| 430 |
+
torch.sum(torch.sum(catt[1][0], axis=0), axis=0).detach().numpy())
|
| 431 |
+
plt.title('block=1')
|
| 432 |
+
plt.ylabel('latent k')
|
| 433 |
+
plt.xlabel('conv channel')
|
| 434 |
+
plt.subplot(313)
|
| 435 |
+
plt.imshow(
|
| 436 |
+
torch.sum(torch.sum(catt[2][0], axis=0), axis=0).detach().numpy())
|
| 437 |
+
plt.title('block=2')
|
| 438 |
+
plt.ylabel('latent k')
|
| 439 |
+
plt.xlabel('conv channel')
|
| 440 |
+
# f'spectral cross attention. T-C-F Model',
|
| 441 |
+
# y=0,
|
| 442 |
+
# fontsize=12)
|
| 443 |
+
plt.tight_layout()
|
| 444 |
+
plt.show()
|
| 445 |
+
|
| 446 |
+
#!! Animation of SCA for varying time, head in last block
|
| 447 |
+
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(10, 6)) # Adjusted figsize for better layout
|
| 448 |
+
|
| 449 |
+
# Function to update the plots for each frame in the animation
|
| 450 |
+
def update(t):
|
| 451 |
+
# Clear previous images
|
| 452 |
+
ax1.clear()
|
| 453 |
+
ax2.clear()
|
| 454 |
+
|
| 455 |
+
# Update subplot for h=3
|
| 456 |
+
ax1.imshow(catt[2][0][t, 3, :, :].detach().numpy())
|
| 457 |
+
ax1.set_title(f'block=2, t={t}, head=3')
|
| 458 |
+
ax1.set_ylabel('latent k'); ax1.set_xlabel('conv channel')
|
| 459 |
+
|
| 460 |
+
# Update subplot for h=5
|
| 461 |
+
ax2.imshow(catt[2][0][t, 5, :, :].detach().numpy())
|
| 462 |
+
ax2.set_title(f'block=2, t={t}, head=5')
|
| 463 |
+
ax2.set_ylabel('latent k'); ax2.set_xlabel('conv channel')
|
| 464 |
+
|
| 465 |
+
# Adjust layout
|
| 466 |
+
fig.tight_layout()
|
| 467 |
+
|
| 468 |
+
# Create the animation
|
| 469 |
+
anim = FuncAnimation(fig, update, frames=range(0, 110), interval=200)
|
| 470 |
+
anim.save('animation.gif', writer='pillow', fps=5)
|
| 471 |
+
|
| 472 |
+
|
| 473 |
+
|
| 474 |
+
fig, axs = plt.subplots(3, 1, figsize=(12, 18), gridspec_kw={'height_ratios': [1, 1, 0.5]}) # Adjusted for different subplot sizes
|
| 475 |
+
|
| 476 |
+
# Subplots for catt visualization (h=3 and h=5)
|
| 477 |
+
ax_catt3, ax_catt5, ax_att_row = axs
|
| 478 |
+
|
| 479 |
+
# Creating 8 subplots for att visualization within the third row
|
| 480 |
+
for i in range(8):
|
| 481 |
+
ax_att_row = fig.add_subplot(3, 8, 17 + i) # Adding subplots in the third row
|
| 482 |
+
|
| 483 |
+
# Update function for the combined animation
|
| 484 |
+
def combined_update_smaller_att(t):
|
| 485 |
+
# Update subplot for catt with h=3
|
| 486 |
+
ax_catt3.clear()
|
| 487 |
+
ax_catt3.imshow(catt[2][0][t, 3, :, :].detach().numpy())
|
| 488 |
+
ax_catt3.set_title(f'block=2, t={t}, head=3')
|
| 489 |
+
ax_catt3.set_ylabel('latent k'); ax_catt3.set_xlabel('conv channel')
|
| 490 |
+
|
| 491 |
+
# Update subplot for catt with h=5
|
| 492 |
+
ax_catt5.clear()
|
| 493 |
+
ax_catt5.imshow(catt[2][0][t, 5, :, :].detach().numpy())
|
| 494 |
+
ax_catt5.set_title(f'block=2, t={t}, head=5')
|
| 495 |
+
ax_catt5.set_ylabel('latent k'); ax_catt5.set_xlabel('conv channel')
|
| 496 |
+
|
| 497 |
+
# Update subplots for att (8 heads in one row)
|
| 498 |
+
for i in range(8):
|
| 499 |
+
ax = fig.add_subplot(3, 8, 17 + i)
|
| 500 |
+
ax.clear()
|
| 501 |
+
ax.imshow(att[0][1][t, i, :, :].detach().numpy(), cmap='viridis')
|
| 502 |
+
ax.set_title(f't={t}, head={i}')
|
| 503 |
+
ax.set_xlabel('k')
|
| 504 |
+
ax.set_ylabel('k')
|
| 505 |
+
ax.axis('square') # Make each subplot square-shaped
|
| 506 |
+
|
| 507 |
+
# Adjust layout
|
| 508 |
+
fig.tight_layout()
|
| 509 |
+
combined_anim_smaller_att = FuncAnimation(fig, combined_update_smaller_att, frames=range(0, 110), interval=200)
|
| 510 |
+
combined_anim_smaller_att.save('combined_animation_smaller_att.gif', writer='pillow', fps=5)
|
| 511 |
+
|
| 512 |
+
|
| 513 |
+
|
| 514 |
+
|
| 515 |
+
|
| 516 |
+
# enc Latent Self-attention: How latent K attends to K?
|
| 517 |
+
plt.subplot(231)
|
| 518 |
+
plt.imshow(torch.sum(torch.sum(att[0][0], axis=1),
|
| 519 |
+
axis=0).detach().numpy(),
|
| 520 |
+
origin='upper')
|
| 521 |
+
plt.title('B0L0')
|
| 522 |
+
plt.xlabel('latent k')
|
| 523 |
+
plt.ylabel('latent k')
|
| 524 |
+
plt.subplot(234)
|
| 525 |
+
plt.imshow(torch.sum(torch.sum(att[0][1], axis=1),
|
| 526 |
+
axis=0).detach().numpy(),
|
| 527 |
+
origin='upper')
|
| 528 |
+
plt.title('B0L1')
|
| 529 |
+
plt.xlabel('latent k')
|
| 530 |
+
plt.ylabel('latent k')
|
| 531 |
+
plt.subplot(232)
|
| 532 |
+
plt.imshow(torch.sum(torch.sum(att[1][0], axis=1),
|
| 533 |
+
axis=0).detach().numpy(),
|
| 534 |
+
origin='upper')
|
| 535 |
+
plt.title('B1L0')
|
| 536 |
+
plt.xlabel('latent k')
|
| 537 |
+
plt.ylabel('latent k')
|
| 538 |
+
plt.subplot(235)
|
| 539 |
+
plt.imshow(torch.sum(torch.sum(att[1][1], axis=1),
|
| 540 |
+
axis=0).detach().numpy(),
|
| 541 |
+
origin='upper')
|
| 542 |
+
plt.title('B1L1')
|
| 543 |
+
plt.xlabel('latent k')
|
| 544 |
+
plt.ylabel('latent k')
|
| 545 |
+
plt.subplot(233)
|
| 546 |
+
plt.imshow(torch.sum(torch.sum(att[2][0], axis=1),
|
| 547 |
+
axis=0).detach().numpy(),
|
| 548 |
+
origin='upper')
|
| 549 |
+
plt.title('B2L0')
|
| 550 |
+
plt.xlabel('latent k')
|
| 551 |
+
plt.ylabel('latent k')
|
| 552 |
+
plt.subplot(236)
|
| 553 |
+
plt.imshow(torch.sum(torch.sum(att[2][1], axis=1),
|
| 554 |
+
axis=0).detach().numpy(),
|
| 555 |
+
origin='upper')
|
| 556 |
+
plt.title('B2L1')
|
| 557 |
+
plt.xlabel('latent k')
|
| 558 |
+
plt.ylabel('latent k')
|
| 559 |
+
plt.tight_layout()
|
| 560 |
+
plt.show()
|
| 561 |
+
# Time varying, different head for latent self-attention
|
| 562 |
+
#!!! Display latent self-attention for each head
|
| 563 |
+
bl = 0 # first latent transformer block, last layer att
|
| 564 |
+
data = att[bl][1].detach().numpy()
|
| 565 |
+
time_steps = [30, 50, 100]
|
| 566 |
+
fig, axs = plt.subplots(
|
| 567 |
+
len(time_steps), 8,
|
| 568 |
+
figsize=(16, 6)) # Subplots for each time step and head
|
| 569 |
+
for i, t in enumerate(time_steps):
|
| 570 |
+
for head in range(8):
|
| 571 |
+
axs[i, head].imshow(data[t, head, :, :], cmap='viridis')
|
| 572 |
+
axs[i, head].set_title(f't={t}, head={head}')
|
| 573 |
+
axs[i, head].set_xlabel('k')
|
| 574 |
+
axs[i, head].set_ylabel('k')
|
| 575 |
+
plt.suptitle(
|
| 576 |
+
f'latent transformer block={bl}, last layer self-attention over time',
|
| 577 |
+
y=0,
|
| 578 |
+
fontsize=12)
|
| 579 |
+
plt.tight_layout()
|
| 580 |
+
plt.show()
|
| 581 |
+
|
| 582 |
+
bl = 1 # second latent transformer block, last layer att
|
| 583 |
+
data = att[bl][1].detach().numpy()
|
| 584 |
+
time_steps = [30, 50, 100]
|
| 585 |
+
fig, axs = plt.subplots(
|
| 586 |
+
len(time_steps), 8,
|
| 587 |
+
figsize=(16, 6)) # Subplots for each time step and head
|
| 588 |
+
for i, t in enumerate(time_steps):
|
| 589 |
+
for head in range(8):
|
| 590 |
+
axs[i, head].imshow(data[t, head, :, :], cmap='viridis')
|
| 591 |
+
axs[i, head].set_title(f't={t}, head={head}')
|
| 592 |
+
axs[i, head].set_xlabel('k')
|
| 593 |
+
axs[i, head].set_ylabel('k')
|
| 594 |
+
plt.suptitle(
|
| 595 |
+
f'latent transformer block={bl}, last layer self-attention over time',
|
| 596 |
+
y=0,
|
| 597 |
+
fontsize=12)
|
| 598 |
+
plt.tight_layout()
|
| 599 |
+
plt.show()
|
| 600 |
+
|
| 601 |
+
bl = 2 # last latent transformer block, last layer att
|
| 602 |
+
data = att[bl][1].detach().numpy()
|
| 603 |
+
time_steps = [30, 50, 100]
|
| 604 |
+
fig, axs = plt.subplots(
|
| 605 |
+
len(time_steps), 8,
|
| 606 |
+
figsize=(16, 6)) # Subplots for each time step and head
|
| 607 |
+
for i, t in enumerate(time_steps):
|
| 608 |
+
for head in range(8):
|
| 609 |
+
axs[i, head].imshow(data[t, head, :, :], cmap='viridis')
|
| 610 |
+
axs[i, head].set_title(f't={t}, head={head}')
|
| 611 |
+
axs[i, head].set_xlabel('k')
|
| 612 |
+
axs[i, head].set_ylabel('k')
|
| 613 |
+
plt.suptitle(
|
| 614 |
+
f'latent transformer block={bl}, last layer self-attention over time',
|
| 615 |
+
y=0,
|
| 616 |
+
fontsize=12)
|
| 617 |
+
plt.tight_layout()
|
| 618 |
+
plt.show()
|
| 619 |
+
|
| 620 |
+
# Temporal Self-attention: (K x H x T x T) How time t attends to time t?
|
| 621 |
+
plt.subplot(231)
|
| 622 |
+
plt.imshow(torch.sum(torch.sum(att[0][2], axis=1),
|
| 623 |
+
axis=0).detach().numpy(),
|
| 624 |
+
origin='upper')
|
| 625 |
+
plt.title('B0L2')
|
| 626 |
+
plt.xlabel('t')
|
| 627 |
+
plt.ylabel('t')
|
| 628 |
+
plt.subplot(234)
|
| 629 |
+
plt.imshow(torch.sum(torch.sum(att[0][3], axis=1),
|
| 630 |
+
axis=0).detach().numpy(),
|
| 631 |
+
origin='upper')
|
| 632 |
+
plt.title('B0L3')
|
| 633 |
+
plt.xlabel('t')
|
| 634 |
+
plt.ylabel('t')
|
| 635 |
+
plt.subplot(232)
|
| 636 |
+
plt.imshow(torch.sum(torch.sum(att[1][2], axis=1),
|
| 637 |
+
axis=0).detach().numpy(),
|
| 638 |
+
origin='upper')
|
| 639 |
+
plt.title('B1L2')
|
| 640 |
+
plt.xlabel('t')
|
| 641 |
+
plt.ylabel('t')
|
| 642 |
+
plt.subplot(235)
|
| 643 |
+
plt.imshow(torch.sum(torch.sum(att[1][3], axis=1),
|
| 644 |
+
axis=0).detach().numpy(),
|
| 645 |
+
origin='upper')
|
| 646 |
+
plt.title('B1L3')
|
| 647 |
+
plt.xlabel('t')
|
| 648 |
+
plt.ylabel('t')
|
| 649 |
+
plt.subplot(233)
|
| 650 |
+
plt.imshow(torch.sum(torch.sum(att[2][2], axis=1),
|
| 651 |
+
axis=0).detach().numpy(),
|
| 652 |
+
origin='upper')
|
| 653 |
+
plt.title('B2L2')
|
| 654 |
+
plt.xlabel('t')
|
| 655 |
+
plt.ylabel('t')
|
| 656 |
+
plt.subplot(236)
|
| 657 |
+
plt.imshow(torch.sum(torch.sum(att[2][3], axis=1),
|
| 658 |
+
axis=0).detach().numpy(),
|
| 659 |
+
origin='upper')
|
| 660 |
+
plt.title('B2L3')
|
| 661 |
+
plt.xlabel('t')
|
| 662 |
+
plt.ylabel('t')
|
| 663 |
+
plt.tight_layout()
|
| 664 |
+
plt.show()
|
| 665 |
+
|
| 666 |
+
# decoding
|
| 667 |
+
dec_input_ids = model.shift_right_fn(label)
|
| 668 |
+
dec_inputs_embeds = model.embed_tokens(dec_input_ids)
|
| 669 |
+
dec_output = model.decoder(inputs_embeds=dec_inputs_embeds,
|
| 670 |
+
encoder_hidden_states=enc_hs_proj,
|
| 671 |
+
output_attentions=True,
|
| 672 |
+
output_hidden_states=True,
|
| 673 |
+
return_dict=True)
|
| 674 |
+
dec_att, dec_catt = dec_output.attentions, dec_output.cross_attentions
|
| 675 |
+
dec_hs_all = dec_output.hidden_states
|
| 676 |
+
dec_last_hs = dec_output.last_hidden_state
|
| 677 |
+
|
| 678 |
+
# lm head
|
| 679 |
+
logits = model.lm_head(dec_last_hs)
|
| 680 |
+
|
| 681 |
+
# pred ids
|
| 682 |
+
pred_ids = torch.argmax(logits, dim=3)
|
| 683 |
+
|
| 684 |
+
# dec att
|
| 685 |
+
plt.subplot(1, 2, 1)
|
| 686 |
+
plt.imshow(torch.sum(dec_att[5][0], axis=0).detach().numpy())
|
| 687 |
+
plt.title('decoder attention, layer0')
|
| 688 |
+
plt.xlabel('decoder time step')
|
| 689 |
+
plt.ylabel('decoder time step')
|
| 690 |
+
plt.subplot(1, 2, 2)
|
| 691 |
+
plt.imshow(torch.sum(dec_att[7][0], axis=0).detach().numpy())
|
| 692 |
+
plt.title('decoder attention, final layer')
|
| 693 |
+
plt.xlabel('decoder step')
|
| 694 |
+
plt.show()
|
| 695 |
+
|
| 696 |
+
|
| 697 |
+
# dec catt
|
| 698 |
+
def remove_values_after_eos(catt_np, pred_ids, max_k):
|
| 699 |
+
# catt_np: (k, head, t, t)
|
| 700 |
+
# pred_ids: (1, k, t))
|
| 701 |
+
max_length = pred_ids.shape[-1]
|
| 702 |
+
seq_lengths = np.zeros((max_k), dtype=np.int32)
|
| 703 |
+
for k in range(max_k):
|
| 704 |
+
for t in range(max_length):
|
| 705 |
+
if pred_ids[0, k, t] == 1:
|
| 706 |
+
break
|
| 707 |
+
catt_np[k, :, t+1:, :] = 0
|
| 708 |
+
# catt_np[k, :, :, t+1:] = 0
|
| 709 |
+
seq_lengths[k] = t+1
|
| 710 |
+
return catt_np, seq_lengths
|
| 711 |
+
|
| 712 |
+
# data = dec_catt[1].detach().numpy() # last layer's cross attention
|
| 713 |
+
l = 4
|
| 714 |
+
data = dec_catt[l].detach().numpy()
|
| 715 |
+
data, seq_lengths = remove_values_after_eos(data, pred_ids, max_k=13)
|
| 716 |
+
seq_lengths[:]= 256
|
| 717 |
+
|
| 718 |
+
fig, axs = plt.subplots(13, 6, figsize=(21, 39)) # 13 rows (for k=0:12) and 7 columns (for head=0:6)
|
| 719 |
+
for k in range(13):
|
| 720 |
+
s = seq_lengths[k]
|
| 721 |
+
for head in range(6):
|
| 722 |
+
axs[k, head].imshow(data[k, head, :s, :].T, aspect='auto', cmap='viridis')
|
| 723 |
+
axs[k, head].set_title(f'Layer {l}, k={k}, head={head}')
|
| 724 |
+
axs[k, head].set_xlabel('Decoder step')
|
| 725 |
+
axs[k, head].set_ylabel('Encoder frame')
|
| 726 |
+
plt.tight_layout()
|
| 727 |
+
plt.show()
|
| 728 |
+
|
| 729 |
+
|
| 730 |
+
# # dec catt by head with xxx
|
| 731 |
+
# dec_att_z = z_normalize_tensors(shorten_att(dec_att))
|
| 732 |
+
# plt.imshow(dec_att_z[0][0, 0, :, :].detach().numpy())
|
| 733 |
+
# from bertviz import head_view
|
| 734 |
+
# token = []
|
| 735 |
+
# for i in label[0, :30]:
|
| 736 |
+
# token.append(str(i))
|
| 737 |
+
# head_view(dec_att_z, tokens)
|
| 738 |
+
|
| 739 |
+
# dec_hs
|
| 740 |
+
plt.subplot(1, 2, 1)
|
| 741 |
+
k=2
|
| 742 |
+
plt.imshow(dec_last_hs[0][k].detach().numpy(), origin='upper')
|
| 743 |
+
plt.colorbar(orientation='horizontal')
|
| 744 |
+
plt.title('decoder last hidden state, k=0')
|
| 745 |
+
plt.xlabel('hidden dim')
|
| 746 |
+
plt.ylabel('time step')
|
| 747 |
+
plt.subplot(1, 2, 2)
|
| 748 |
+
k=12
|
| 749 |
+
plt.imshow(dec_last_hs[0][k].detach().numpy(), origin='upper')
|
| 750 |
+
plt.colorbar(orientation='horizontal')
|
| 751 |
+
plt.title('decoder last hidden state, k=12')
|
| 752 |
+
plt.xlabel('hidden dim')
|
| 753 |
+
plt.show()
|
| 754 |
+
|
| 755 |
+
# lm head
|
| 756 |
+
logits = model.lm_head(dec_last_hs)
|
| 757 |
+
k=6
|
| 758 |
+
plt.imshow(logits[0][k][0:200, :].detach().numpy().T, origin='upper')
|
| 759 |
+
plt.title('lm head output')
|
| 760 |
+
plt.xlabel('vocab dim')
|
| 761 |
+
plt.ylabel('time step')
|
| 762 |
+
plt.show()
|
| 763 |
+
softmax = torch.nn.Softmax(dim=3)
|
| 764 |
+
logits_sm = softmax(logits) # B, K, T, V
|
| 765 |
+
k=6
|
| 766 |
+
plt.imshow(logits_sm[0][k][:255, :].detach().numpy().T, origin='upper')
|
| 767 |
+
plt.title('lm head softmax')
|
| 768 |
+
plt.xlabel('vocab dim')
|
| 769 |
+
plt.ylabel('time step')
|
| 770 |
+
# plt.xlim([1000, 1350])
|
| 771 |
+
plt.show()
|
| 772 |
+
|
| 773 |
+
k = 10
|
| 774 |
+
print(torch.argmax(logits, dim=3)[0,k,:])
|
| 775 |
+
|
| 776 |
+
|
| 777 |
+
|
| 778 |
+
|
amt/src/extras/pitch_shift_benchmark.py
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
""" Test the speed of the augmentation """
|
| 2 |
+
import torch
|
| 3 |
+
import torchaudio
|
| 4 |
+
|
| 5 |
+
# Device
|
| 6 |
+
device = torch.device("cuda")
|
| 7 |
+
# device = torch.device("cpu")
|
| 8 |
+
|
| 9 |
+
# Music
|
| 10 |
+
# x, _ = torchaudio.load("music.wav")
|
| 11 |
+
# slice_length = 32767
|
| 12 |
+
# n_slices = 80
|
| 13 |
+
# slices = [x[0, i * slice_length:(i + 1) * slice_length] for i in range(n_slices)]
|
| 14 |
+
# x = torch.stack(slices) # (80, 32767)
|
| 15 |
+
# Sine wave
|
| 16 |
+
t = torch.arange(0, 2.0479, 1 / 16000) # 2.05 seconds at 16kHz
|
| 17 |
+
x = torch.sin(2 * torch.pi * 440 * t) * 0.5
|
| 18 |
+
x = x.reshape(1, 1, 32767).tile(80, 1, 1)
|
| 19 |
+
x = x.to(device)
|
| 20 |
+
|
| 21 |
+
############################################################################################
|
| 22 |
+
# torch-audiomentation: https://github.com/asteroid-team/torch-audiomentation
|
| 23 |
+
#
|
| 24 |
+
# process time <CPU>: 1.18 s ± 5.35 ms
|
| 25 |
+
# process time <GPU>: 58 ms
|
| 26 |
+
# GPU memory usage: 3.8 GB per 1 semitone
|
| 27 |
+
############################################################################################
|
| 28 |
+
import torch
|
| 29 |
+
from torch_audiomentations import Compose, PitchShift, Gain, PolarityInversion
|
| 30 |
+
|
| 31 |
+
apply_augmentation = Compose(transforms=[
|
| 32 |
+
# Gain(
|
| 33 |
+
# min_gain_in_db=-15.0,
|
| 34 |
+
# max_gain_in_db=5.0,
|
| 35 |
+
# p=0.5,
|
| 36 |
+
# ),
|
| 37 |
+
# PolarityInversion(p=0.5)
|
| 38 |
+
PitchShift(
|
| 39 |
+
min_transpose_semitones=0,
|
| 40 |
+
max_transpose_semitones=2.2,
|
| 41 |
+
mode="per_batch", #"per_example",
|
| 42 |
+
p=1.0,
|
| 43 |
+
p_mode="per_batch",
|
| 44 |
+
sample_rate=16000,
|
| 45 |
+
target_rate=16000)
|
| 46 |
+
])
|
| 47 |
+
x_am = apply_augmentation(x, sample_rate=16000)
|
| 48 |
+
|
| 49 |
+
############################################################################################
|
| 50 |
+
# torchaudio:
|
| 51 |
+
#
|
| 52 |
+
# process time <CPU>: 4.01 s ± 19.6 ms per loop
|
| 53 |
+
# process time <GPU>: 25.1 ms ± 161 µs per loop
|
| 54 |
+
# memory usage <GPU>: 1.2 (growth to 5.49) GB per 1 semitone
|
| 55 |
+
############################################################################################
|
| 56 |
+
from torchaudio import transforms
|
| 57 |
+
|
| 58 |
+
ta_transform = transforms.PitchShift(16000, n_steps=2).to(device)
|
| 59 |
+
x_ta = ta_transform(x)
|
| 60 |
+
|
| 61 |
+
############################################################################################
|
| 62 |
+
# YourMT3 pitch_shift_layer:
|
| 63 |
+
#
|
| 64 |
+
# process time <CPU>: 389ms ± 22ms, (stretch=143 ms, resampler=245 ms)
|
| 65 |
+
# process time <GPU>: 7.18 ms ± 17.3 µs (stretch=6.47 ms, resampler=0.71 ms)
|
| 66 |
+
# memory usage: 16 MB per 1 semitone (average)
|
| 67 |
+
############################################################################################
|
| 68 |
+
from model.pitchshift_layer import PitchShiftLayer
|
| 69 |
+
|
| 70 |
+
ps_ymt3 = PitchShiftLayer(pshift_range=[2, 2], fs=16000, min_gcd=16, n_fft=2048).to(device)
|
| 71 |
+
x_ymt3 = ps_ymt3(x, 2)
|
| 72 |
+
|
| 73 |
+
############################################################################################
|
| 74 |
+
# Plot 1: Comparison of Process Time and GPU Memory Usage for 3 Pitch Shifting Methods
|
| 75 |
+
############################################################################################
|
| 76 |
+
import matplotlib.pyplot as plt
|
| 77 |
+
|
| 78 |
+
# Model names
|
| 79 |
+
models = ['torch-audiomentation', 'torchaudio', 'YourMT3:PitchShiftLayer']
|
| 80 |
+
|
| 81 |
+
# Process time (CPU) in seconds
|
| 82 |
+
cpu_time = [1.18, 4.01, 0.389]
|
| 83 |
+
|
| 84 |
+
# Process time (GPU) in milliseconds
|
| 85 |
+
gpu_time = [58, 25.1, 7.18]
|
| 86 |
+
|
| 87 |
+
# GPU memory usage in GB
|
| 88 |
+
gpu_memory = [3.8, 5.49, 0.016]
|
| 89 |
+
|
| 90 |
+
# Creating subplots
|
| 91 |
+
fig, axs = plt.subplots(1, 3, figsize=(15, 5))
|
| 92 |
+
|
| 93 |
+
# Creating bar charts
|
| 94 |
+
bar1 = axs[0].bar(models, cpu_time, color=['#FFB6C1', '#ADD8E6', '#98FB98'])
|
| 95 |
+
bar2 = axs[1].bar(models, gpu_time, color=['#FFB6C1', '#ADD8E6', '#98FB98'])
|
| 96 |
+
bar3 = axs[2].bar(models, gpu_memory, color=['#FFB6C1', '#ADD8E6', '#98FB98'])
|
| 97 |
+
|
| 98 |
+
# Adding labels and titles
|
| 99 |
+
axs[0].set_ylabel('Time (s)')
|
| 100 |
+
axs[0].set_title('Process Time (CPU) bsz=80')
|
| 101 |
+
axs[1].set_ylabel('Time (ms)')
|
| 102 |
+
axs[1].set_title('Process Time (GPU) bsz=80')
|
| 103 |
+
axs[2].set_ylabel('Memory (GB)')
|
| 104 |
+
axs[2].set_title('GPU Memory Usage per semitone')
|
| 105 |
+
|
| 106 |
+
# Adding grid for better readability of the plots
|
| 107 |
+
for ax in axs:
|
| 108 |
+
ax.grid(axis='y')
|
| 109 |
+
ax.set_yscale('log')
|
| 110 |
+
ax.set_xticklabels(models, rotation=45, ha="right")
|
| 111 |
+
|
| 112 |
+
# Adding text labels above the bars
|
| 113 |
+
for i, rect in enumerate(bar1):
|
| 114 |
+
axs[0].text(
|
| 115 |
+
rect.get_x() + rect.get_width() / 2,
|
| 116 |
+
rect.get_height(),
|
| 117 |
+
f'{cpu_time[i]:.2f} s',
|
| 118 |
+
ha='center',
|
| 119 |
+
va='bottom')
|
| 120 |
+
for i, rect in enumerate(bar2):
|
| 121 |
+
axs[1].text(
|
| 122 |
+
rect.get_x() + rect.get_width() / 2,
|
| 123 |
+
rect.get_height(),
|
| 124 |
+
f'{gpu_time[i]:.2f} ms',
|
| 125 |
+
ha='center',
|
| 126 |
+
va='bottom')
|
| 127 |
+
for i, rect in enumerate(bar3):
|
| 128 |
+
axs[2].text(
|
| 129 |
+
rect.get_x() + rect.get_width() / 2,
|
| 130 |
+
rect.get_height(),
|
| 131 |
+
f'{gpu_memory[i]:.3f} GB',
|
| 132 |
+
ha='center',
|
| 133 |
+
va='bottom')
|
| 134 |
+
plt.tight_layout()
|
| 135 |
+
plt.show()
|
| 136 |
+
|
| 137 |
+
############################################################################################
|
| 138 |
+
# Plot 2: Stretch and Resampler Processing Time Contribution
|
| 139 |
+
############################################################################################
|
| 140 |
+
# Data
|
| 141 |
+
processing_type = ['Stretch (Phase Vocoder)', 'Resampler (Conv1D)']
|
| 142 |
+
cpu_times = [143, 245] # [Stretch, Resampler] times for CPU in milliseconds
|
| 143 |
+
gpu_times = [6.47, 0.71] # [Stretch, Resampler] times for GPU in milliseconds
|
| 144 |
+
|
| 145 |
+
# Creating subplots
|
| 146 |
+
fig, axs = plt.subplots(1, 2, figsize=(12, 6))
|
| 147 |
+
|
| 148 |
+
# Plotting bar charts
|
| 149 |
+
axs[0].bar(processing_type, cpu_times, color=['#ADD8E6', '#98FB98'])
|
| 150 |
+
axs[1].bar(processing_type, gpu_times, color=['#ADD8E6', '#98FB98'])
|
| 151 |
+
|
| 152 |
+
# Adding labels and titles
|
| 153 |
+
axs[0].set_ylabel('Time (ms)')
|
| 154 |
+
axs[0].set_title('Contribution of CPU Processing Time: YMT3-PS (BSZ=80)')
|
| 155 |
+
axs[1].set_title('Contribution of GPU Processing Time: YMT3-PS (BSZ=80)')
|
| 156 |
+
|
| 157 |
+
# Adding grid for better readability of the plots
|
| 158 |
+
for ax in axs:
|
| 159 |
+
ax.grid(axis='y')
|
| 160 |
+
ax.set_yscale('log') # Log scale to better visualize the smaller values
|
| 161 |
+
|
| 162 |
+
# Adding values on top of the bars
|
| 163 |
+
for ax, times in zip(axs, [cpu_times, gpu_times]):
|
| 164 |
+
for idx, time in enumerate(times):
|
| 165 |
+
ax.text(idx, time, f"{time:.2f} ms", ha='center', va='bottom', fontsize=8)
|
| 166 |
+
plt.tight_layout()
|
| 167 |
+
plt.show()
|
amt/src/extras/remove_silence_musicnet_midi.py
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import glob
|
| 3 |
+
|
| 4 |
+
from utils.midi import midi2note
|
| 5 |
+
from utils.note2event import note2note_event
|
| 6 |
+
from utils.note_event_dataclasses import Note
|
| 7 |
+
from utils.note_event_dataclasses import NoteEvent
|
| 8 |
+
from utils.midi import note_event2midi
|
| 9 |
+
|
| 10 |
+
data_home = '../../data'
|
| 11 |
+
dataset_name = 'musicnet'
|
| 12 |
+
base_dir = os.path.join(data_home, dataset_name + '_yourmt3_16k')
|
| 13 |
+
mid_pattern = os.path.join(base_dir, '*_midi', '*.mid')
|
| 14 |
+
mid_files = glob.glob(mid_pattern, recursive=True)
|
| 15 |
+
|
| 16 |
+
for mid_file in mid_files:
|
| 17 |
+
notes, _ = midi2note(mid_file)
|
| 18 |
+
first_onset_time = notes[0].onset
|
| 19 |
+
fixed_notes = []
|
| 20 |
+
for note in notes:
|
| 21 |
+
fixed_notes.append(
|
| 22 |
+
Note(
|
| 23 |
+
is_drum=note.is_drum,
|
| 24 |
+
program=note.program,
|
| 25 |
+
onset=note.onset - first_onset_time,
|
| 26 |
+
offset=note.offset - first_onset_time,
|
| 27 |
+
pitch=note.pitch,
|
| 28 |
+
velocity=note.velocity))
|
| 29 |
+
assert len(notes) == len(fixed_notes)
|
| 30 |
+
fixed_note_events = note2note_event(fixed_notes, return_activity=False)
|
| 31 |
+
note_event2midi(fixed_note_events, mid_file)
|
| 32 |
+
print(f'Overwriting {mid_file}')
|
amt/src/extras/rotary_positional_embedding.py
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""rotary_positional_embedding.py - Rotary Positional Embedding
|
| 2 |
+
|
| 3 |
+
code from github.com/lucidrains/rotary-embedding-torch
|
| 4 |
+
|
| 5 |
+
MIT License
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
from math import pi, log
|
| 9 |
+
import torch
|
| 10 |
+
from torch import nn, einsum
|
| 11 |
+
from einops import rearrange, repeat
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def exists(val):
|
| 15 |
+
return val is not None
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def broadcat(tensors, dim=-1):
|
| 19 |
+
num_tensors = len(tensors)
|
| 20 |
+
shape_lens = set(list(map(lambda t: len(t.shape), tensors)))
|
| 21 |
+
assert len(shape_lens) == 1, 'tensors must all have the same number of dimensions'
|
| 22 |
+
shape_len = list(shape_lens)[0]
|
| 23 |
+
|
| 24 |
+
dim = (dim + shape_len) if dim < 0 else dim
|
| 25 |
+
dims = list(zip(*map(lambda t: list(t.shape), tensors)))
|
| 26 |
+
|
| 27 |
+
expandable_dims = [(i, val) for i, val in enumerate(dims) if i != dim]
|
| 28 |
+
assert all([*map(lambda t: len(set(t[1])) <= 2, expandable_dims)
|
| 29 |
+
]), 'invalid dimensions for broadcastable concatentation'
|
| 30 |
+
max_dims = list(map(lambda t: (t[0], max(t[1])), expandable_dims))
|
| 31 |
+
expanded_dims = list(map(lambda t: (t[0], (t[1],) * num_tensors), max_dims))
|
| 32 |
+
expanded_dims.insert(dim, (dim, dims[dim]))
|
| 33 |
+
expandable_shapes = list(zip(*map(lambda t: t[1], expanded_dims)))
|
| 34 |
+
tensors = list(map(lambda t: t[0].expand(*t[1]), zip(tensors, expandable_shapes)))
|
| 35 |
+
return torch.cat(tensors, dim=dim)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
# rotary embedding helper functions
|
| 39 |
+
def rotate_half(x):
|
| 40 |
+
x = rearrange(x, '... (d r) -> ... d r', r=2)
|
| 41 |
+
x1, x2 = x.unbind(dim=-1)
|
| 42 |
+
x = torch.stack((-x2, x1), dim=-1)
|
| 43 |
+
return rearrange(x, '... d r -> ... (d r)')
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def apply_rotary_emb(freqs, t, start_index=0, scale=1.):
|
| 47 |
+
rot_dim, seq_len = freqs.shape[-1], t.shape[-2]
|
| 48 |
+
freqs = freqs[-seq_len:, :]
|
| 49 |
+
|
| 50 |
+
freqs = freqs.to(t)
|
| 51 |
+
end_index = start_index + rot_dim
|
| 52 |
+
assert rot_dim <= t.shape[
|
| 53 |
+
-1], f'feature dimension {t.shape[-1]} is not of sufficient size to rotate in all the positions {rot_dim}'
|
| 54 |
+
t_left, t, t_right = t[..., :start_index], t[..., start_index:end_index], t[..., end_index:]
|
| 55 |
+
t = (t * freqs.cos() * scale) + (rotate_half(t) * freqs.sin() * scale)
|
| 56 |
+
return torch.cat((t_left, t, t_right), dim=-1)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
# learned rotation helpers
|
| 60 |
+
def apply_learned_rotations(rotations, t, start_index=0, freq_ranges=None):
|
| 61 |
+
if exists(freq_ranges):
|
| 62 |
+
rotations = einsum('..., f -> ... f', rotations, freq_ranges)
|
| 63 |
+
rotations = rearrange(rotations, '... r f -> ... (r f)')
|
| 64 |
+
|
| 65 |
+
rotations = repeat(rotations, '... n -> ... (n r)', r=2)
|
| 66 |
+
return apply_rotary_emb(rotations, t, start_index=start_index)
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
# classes
|
| 70 |
+
class RotaryEmbedding(nn.Module):
|
| 71 |
+
|
| 72 |
+
def __init__(self,
|
| 73 |
+
dim,
|
| 74 |
+
custom_freqs=None,
|
| 75 |
+
freqs_for='lang',
|
| 76 |
+
theta=10000,
|
| 77 |
+
max_freq=10,
|
| 78 |
+
num_freqs=1,
|
| 79 |
+
learned_freq=False,
|
| 80 |
+
use_xpos=False,
|
| 81 |
+
xpos_scale_base=512,
|
| 82 |
+
interpolate_factor=1.,
|
| 83 |
+
theta_rescale_factor=1.):
|
| 84 |
+
super().__init__()
|
| 85 |
+
# proposed by reddit user bloc97, to rescale rotary embeddings to longer sequence length without fine-tuning
|
| 86 |
+
# has some connection to NTK literature
|
| 87 |
+
# https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama_models_to_have/
|
| 88 |
+
theta *= theta_rescale_factor**(dim / (dim - 2))
|
| 89 |
+
|
| 90 |
+
if exists(custom_freqs):
|
| 91 |
+
freqs = custom_freqs
|
| 92 |
+
elif freqs_for == 'lang':
|
| 93 |
+
freqs = 1. / (theta**(torch.arange(0, dim, 2)[:(dim // 2)].float() / dim))
|
| 94 |
+
elif freqs_for == 'pixel':
|
| 95 |
+
freqs = torch.linspace(1., max_freq / 2, dim // 2) * pi
|
| 96 |
+
elif freqs_for == 'constant':
|
| 97 |
+
freqs = torch.ones(num_freqs).float()
|
| 98 |
+
else:
|
| 99 |
+
raise ValueError(f'unknown modality {freqs_for}')
|
| 100 |
+
|
| 101 |
+
self.cache = dict()
|
| 102 |
+
self.cache_scale = dict()
|
| 103 |
+
self.freqs = nn.Parameter(freqs, requires_grad=learned_freq)
|
| 104 |
+
|
| 105 |
+
# interpolation factors
|
| 106 |
+
|
| 107 |
+
assert interpolate_factor >= 1.
|
| 108 |
+
self.interpolate_factor = interpolate_factor
|
| 109 |
+
|
| 110 |
+
# xpos
|
| 111 |
+
|
| 112 |
+
self.use_xpos = use_xpos
|
| 113 |
+
if not use_xpos:
|
| 114 |
+
self.register_buffer('scale', None)
|
| 115 |
+
return
|
| 116 |
+
|
| 117 |
+
scale = (torch.arange(0, dim, 2) + 0.4 * dim) / (1.4 * dim)
|
| 118 |
+
self.scale_base = xpos_scale_base
|
| 119 |
+
self.register_buffer('scale', scale)
|
| 120 |
+
|
| 121 |
+
def get_seq_pos(self, seq_len, device, dtype, offset=0):
|
| 122 |
+
return (torch.arange(seq_len, device=device, dtype=dtype) +
|
| 123 |
+
offset) / self.interpolate_factor
|
| 124 |
+
|
| 125 |
+
def rotate_queries_or_keys(self, t, seq_dim=-2, offset=0, freq_seq_len=None):
|
| 126 |
+
assert not self.use_xpos, 'you must use `.rotate_queries_and_keys` method instead and pass in both queries and keys, for length extrapolatable rotary embeddings'
|
| 127 |
+
|
| 128 |
+
device, dtype, seq_len = t.device, t.dtype, t.shape[seq_dim]
|
| 129 |
+
|
| 130 |
+
if exists(freq_seq_len):
|
| 131 |
+
assert freq_seq_len >= seq_len
|
| 132 |
+
seq_len = freq_seq_len
|
| 133 |
+
|
| 134 |
+
freqs = self.forward(
|
| 135 |
+
lambda: self.get_seq_pos(seq_len, device=device, dtype=dtype, offset=offset),
|
| 136 |
+
cache_key=f'freqs:{seq_len}|offset:{offset}')
|
| 137 |
+
return apply_rotary_emb(freqs, t)
|
| 138 |
+
|
| 139 |
+
def rotate_queries_with_cached_keys(self, q, k, seq_dim=-2):
|
| 140 |
+
q_len, k_len = q.shape[seq_dim], k.shape[seq_dim]
|
| 141 |
+
assert q_len <= k_len
|
| 142 |
+
q = self.rotate_queries_or_keys(q, seq_dim=seq_dim, freq_seq_len=k_len)
|
| 143 |
+
k = self.rotate_queries_or_keys(k, seq_dim=seq_dim)
|
| 144 |
+
return q, k
|
| 145 |
+
|
| 146 |
+
def rotate_queries_and_keys(self, q, k, seq_dim=-2):
|
| 147 |
+
assert self.use_xpos
|
| 148 |
+
device, dtype, seq_len = q.device, q.dtype, q.shape[seq_dim]
|
| 149 |
+
seq = self.get_seq_pos(seq_len, dtype=dtype, device=device)
|
| 150 |
+
freqs = self.forward(lambda: seq, cache_key=f'freqs:{seq_len}')
|
| 151 |
+
scale = self.get_scale(lambda: seq, cache_key=f'scale:{seq_len}').to(dtype)
|
| 152 |
+
rotated_q = apply_rotary_emb(freqs, q, scale=scale)
|
| 153 |
+
rotated_k = apply_rotary_emb(freqs, k, scale=scale**-1)
|
| 154 |
+
return rotated_q, rotated_k
|
| 155 |
+
|
| 156 |
+
def get_scale(self, t, cache_key=None):
|
| 157 |
+
assert self.use_xpos
|
| 158 |
+
|
| 159 |
+
if exists(cache_key) and cache_key in self.cache:
|
| 160 |
+
return self.cache[cache_key]
|
| 161 |
+
|
| 162 |
+
if callable(t):
|
| 163 |
+
t = t()
|
| 164 |
+
|
| 165 |
+
scale = 1.
|
| 166 |
+
if self.use_xpos:
|
| 167 |
+
power = (t - len(t) // 2) / self.scale_base
|
| 168 |
+
scale = self.scale**rearrange(power, 'n -> n 1')
|
| 169 |
+
scale = torch.cat((scale, scale), dim=-1)
|
| 170 |
+
|
| 171 |
+
if exists(cache_key):
|
| 172 |
+
self.cache[cache_key] = scale
|
| 173 |
+
|
| 174 |
+
return scale
|
| 175 |
+
|
| 176 |
+
def forward(self, t, cache_key=None):
|
| 177 |
+
if exists(cache_key) and cache_key in self.cache:
|
| 178 |
+
return self.cache[cache_key]
|
| 179 |
+
|
| 180 |
+
if callable(t):
|
| 181 |
+
t = t()
|
| 182 |
+
|
| 183 |
+
freqs = self.freqs
|
| 184 |
+
|
| 185 |
+
freqs = einsum('..., f -> ... f', t.type(freqs.dtype), freqs)
|
| 186 |
+
freqs = repeat(freqs, '... n -> ... (n r)', r=2)
|
| 187 |
+
|
| 188 |
+
if exists(cache_key):
|
| 189 |
+
self.cache[cache_key] = freqs
|
| 190 |
+
|
| 191 |
+
return freqs
|
amt/src/extras/run_spleeter_mir1k.sh
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
shopt -s globstar
|
| 3 |
+
for file in "$1"/**/*.wav; do
|
| 4 |
+
echo $file
|
| 5 |
+
output_dir="tmp"
|
| 6 |
+
spleeter separate -b 256k -B tensorflow -p spleeter:2stems -o $output_dir $file -f {instrument}.{codec}
|
| 7 |
+
sox --ignore-length tmp/accompaniment.wav -r 16000 -c 1 -b 16 tmp/accompaniment_16k.wav
|
| 8 |
+
sox --ignore-length tmp/vocals.wav -r 16000 -c 1 -b 16 tmp/vocals_16k.wav
|
| 9 |
+
acc_file="${file//.wav/_accompaniment.wav}"
|
| 10 |
+
voc_file="${file//.wav/_vocals.wav}"
|
| 11 |
+
mv -f "tmp/accompaniment_16k.wav" $acc_file
|
| 12 |
+
mv -f "tmp/vocals_16k.wav" $voc_file
|
| 13 |
+
echo $acc_file
|
| 14 |
+
echo $voc_file
|
| 15 |
+
rm -rf tmp
|
| 16 |
+
done
|
| 17 |
+
rm -rf pretrained_models
|
amt/src/extras/run_spleeter_mirst500.sh
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
shopt -s globstar
|
| 3 |
+
for file in "$1"/**/*.wav; do
|
| 4 |
+
output_dir="${file%/*}"
|
| 5 |
+
input_file="$output_dir/converted_Mixture.wav"
|
| 6 |
+
spleeter separate -p spleeter:2stems -o $output_dir $input_file -f {instrument}.{codec}
|
| 7 |
+
ffmpeg -i "$output_dir/vocals.wav" -acodec pcm_s16le -ac 1 -ar 16000 -y "$output_dir/vocals_16k.wav"
|
| 8 |
+
ffmpeg -i "$output_dir/accompaniment.wav" -acodec pcm_s16le -ac 1 -ar 16000 -y "$output_dir/accompaniment_16k.wav"
|
| 9 |
+
rm "$output_dir/vocals.wav"
|
| 10 |
+
rm "$output_dir/accompaniment.wav"
|
| 11 |
+
mv "$output_dir/vocals_16k.wav" "$output_dir/vocals.wav"
|
| 12 |
+
mv "$output_dir/accompaniment_16k.wav" "$output_dir/accompaniment.wav"
|
| 13 |
+
done
|
amt/src/extras/run_spleeter_mirst500_cmedia.sh
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
shopt -s globstar
|
| 3 |
+
for file in "$1"/**/*.wav; do
|
| 4 |
+
output_dir="${file%/*}"
|
| 5 |
+
input_file="$output_dir/converted_Mixture.wav"
|
| 6 |
+
spleeter separate -p spleeter:2stems -o $output_dir $input_file -f {instrument}.{codec}
|
| 7 |
+
ffmpeg -i "$output_dir/vocals.wav" -acodec pcm_s16le -ac 1 -ar 16000 -y "$output_dir/vocals_16k.wav"
|
| 8 |
+
ffmpeg -i "$output_dir/accompaniment.wav" -acodec pcm_s16le -ac 1 -ar 16000 -y "$output_dir/accompaniment_16k.wav"
|
| 9 |
+
rm "$output_dir/vocals.wav"
|
| 10 |
+
rm "$output_dir/accompaniment.wav"
|
| 11 |
+
mv "$output_dir/vocals_16k.wav" "$output_dir/vocals.wav"
|
| 12 |
+
mv "$output_dir/accompaniment_16k.wav" "$output_dir/accompaniment.wav"
|
| 13 |
+
done
|
amt/src/extras/swap_channel.py
ADDED
|
@@ -0,0 +1,122 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
|
| 3 |
+
a = np.arange(12).reshape(2, 3, 2) # (batch, channel, dim)
|
| 4 |
+
print(a)
|
| 5 |
+
array([[[0, 1], [2, 3], [4, 5]], [[6, 7], [8, 9], [10, 11]]])
|
| 6 |
+
|
| 7 |
+
swap_mat = create_swap_channel_mat(input_shape, swap_channel=(1, 2))
|
| 8 |
+
|
| 9 |
+
# will swap channel 1 and 2 of batch 0 with channel 1 and 2 of batch 1
|
| 10 |
+
b = a @ swap_mat
|
| 11 |
+
print(b)
|
| 12 |
+
# expected output
|
| 13 |
+
array([[[0, 1], [8, 9], [10, 11]], [[6, 7], [2, 3], [4, 5]]])
|
| 14 |
+
|
| 15 |
+
import torch
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def swap_channels_between_batches(a_tensor, swap_channels):
|
| 19 |
+
# Copy the tensor to avoid modifying the original tensor
|
| 20 |
+
result_tensor = a_tensor.clone()
|
| 21 |
+
|
| 22 |
+
# Unpack the channels to be swapped
|
| 23 |
+
ch1, ch2 = swap_channels
|
| 24 |
+
|
| 25 |
+
# Swap the specified channels between batches
|
| 26 |
+
result_tensor[0, ch1, :], result_tensor[1, ch1, :] = a_tensor[1, ch1, :].clone(), a_tensor[0, ch1, :].clone()
|
| 27 |
+
result_tensor[0, ch2, :], result_tensor[1, ch2, :] = a_tensor[1, ch2, :].clone(), a_tensor[0, ch2, :].clone()
|
| 28 |
+
|
| 29 |
+
return result_tensor
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
# Define a sample tensor 'a_tensor'
|
| 33 |
+
a_tensor = torch.tensor([[[0, 1], [2, 3], [4, 5]], [[6, 7], [8, 9], [10, 11]]], dtype=torch.float32)
|
| 34 |
+
|
| 35 |
+
# Define channels to swap
|
| 36 |
+
swap_channels = (1, 2) # Channels to swap between batches
|
| 37 |
+
|
| 38 |
+
# Swap the channels between batches
|
| 39 |
+
swapped_tensor = swap_channels_between_batches(a_tensor, swap_channels)
|
| 40 |
+
|
| 41 |
+
# Print the original tensor and the tensor after swapping channels between batches
|
| 42 |
+
print("Original Tensor 'a_tensor':")
|
| 43 |
+
print(a_tensor)
|
| 44 |
+
print("\nTensor after swapping channels between batches:")
|
| 45 |
+
print(swapped_tensor)
|
| 46 |
+
|
| 47 |
+
#-------------------------------------------------
|
| 48 |
+
|
| 49 |
+
import torch
|
| 50 |
+
from einops import rearrange
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def shift(arr, num, fill_value=np.nan):
|
| 54 |
+
result = np.empty_like(arr)
|
| 55 |
+
if num > 0:
|
| 56 |
+
result[:num] = fill_value
|
| 57 |
+
result[num:] = arr[:-num]
|
| 58 |
+
elif num < 0:
|
| 59 |
+
result[num:] = fill_value
|
| 60 |
+
result[:num] = arr[-num:]
|
| 61 |
+
else:
|
| 62 |
+
result[:] = arr
|
| 63 |
+
return result
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def create_batch_swap_matrix(batch_size, channels, swap_channels):
|
| 67 |
+
swap_mat = np.eye(batch_size * channels)
|
| 68 |
+
|
| 69 |
+
for c in swap_channels:
|
| 70 |
+
idx1 = c # 첫 번째 배치의 교환할 채널 인덱스
|
| 71 |
+
idx2 = c + channels # 두 번째 배치의 교환할 채널 인덱스
|
| 72 |
+
|
| 73 |
+
swap_mat[idx1, idx1], swap_mat[idx2, idx2] = 0, 0 # 대각선 값을 0으로 설정
|
| 74 |
+
swap_mat[idx1, idx2], swap_mat[idx2, idx1] = 1, 1 # 해당 채널을 교환
|
| 75 |
+
return swap_mat
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def create_batch_swap_matrix(batch_size, channels, swap_channels):
|
| 79 |
+
swap_mat = np.eye(batch_size * channels)
|
| 80 |
+
|
| 81 |
+
# 모든 채널에 대해 교환 수행
|
| 82 |
+
for c in swap_channels:
|
| 83 |
+
idx1 = np.arange(c, batch_size * channels, channels) # 현재 채널의 모든 배치 인덱스
|
| 84 |
+
idx2 = (idx1 + channels) % (batch_size * channels) # 순환을 위해 modulo 사용
|
| 85 |
+
|
| 86 |
+
swap_mat[idx1, idx1] = 0
|
| 87 |
+
swap_mat[idx2, idx2] = 0
|
| 88 |
+
swap_mat[idx1, idx2] = 1
|
| 89 |
+
swap_mat[idx2, idx1] = 1
|
| 90 |
+
|
| 91 |
+
return swap_mat
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def swap_channels_between_batches(input_tensor, swap_matrix):
|
| 95 |
+
reshaped_tensor = rearrange(input_tensor, 'b c d -> (b c) d')
|
| 96 |
+
swapped_tensor = swap_matrix @ reshaped_tensor
|
| 97 |
+
return rearrange(swapped_tensor, '(b c) d -> b c d', b=input_tensor.shape[0])
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
# 예제 파라미터
|
| 101 |
+
batch_size = 2
|
| 102 |
+
channels = 3
|
| 103 |
+
# swap_info = {
|
| 104 |
+
# : [1, 2] # batch_index: [channel_indices]
|
| 105 |
+
# }
|
| 106 |
+
swap_channels = [1, 2] # 교환할 채널
|
| 107 |
+
|
| 108 |
+
# 예제 텐서 생성
|
| 109 |
+
input_tensor = torch.tensor([[[0, 1], [2, 3], [4, 5]], [[6, 7], [8, 9], [10, 11]]], dtype=torch.float32)
|
| 110 |
+
|
| 111 |
+
# swap matrix 생성
|
| 112 |
+
swap_matrix = create_batch_swap_matrix(batch_size, channels, swap_channels)
|
| 113 |
+
swap_matrix = torch.Tensor(swap_matrix)
|
| 114 |
+
|
| 115 |
+
# 채널 교환 수행
|
| 116 |
+
swapped_tensor = swap_channels_between_batches(input_tensor, swap_matrix)
|
| 117 |
+
|
| 118 |
+
# 결과 출력
|
| 119 |
+
print("Original Tensor:")
|
| 120 |
+
print(input_tensor)
|
| 121 |
+
print("\nSwapped Tensor:")
|
| 122 |
+
print(swapped_tensor)
|
amt/src/extras/t5_dev.py
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from transformers import T5Config
|
| 3 |
+
from model.t5mod import T5ForConditionalGeneration
|
| 4 |
+
|
| 5 |
+
a = {
|
| 6 |
+
"architectures": ["T5ForConditionalGeneration"],
|
| 7 |
+
"d_ff": 1024, # size of the intermediate feed forward layer in each T5Block
|
| 8 |
+
"d_kv": 64, # d_kv has to be equal to d_model // num_heads.
|
| 9 |
+
# "d_model": 512, # encoder hiddnen size, defined by model_cfg
|
| 10 |
+
"decoder_start_token_id": 0,
|
| 11 |
+
"dense_act_fn": "gelu_new",
|
| 12 |
+
# "dropout_rate": 0.05, # can be overwritten by args in ymt3
|
| 13 |
+
"eos_token_id": 1,
|
| 14 |
+
"feed_forward_proj": "gated-gelu",
|
| 15 |
+
"initializer_factor": 1.0,
|
| 16 |
+
# "is_encoder_decoder": True,
|
| 17 |
+
"is_gated_act": True,
|
| 18 |
+
"layer_norm_epsilon": 1e-06,
|
| 19 |
+
"model_type": "t5",
|
| 20 |
+
# "num_decoder_layers": 8,
|
| 21 |
+
"num_heads": 6,
|
| 22 |
+
"num_layers": 8,
|
| 23 |
+
"output_past": True,
|
| 24 |
+
"pad_token_id": 0,
|
| 25 |
+
"relative_attention_num_buckets": 32,
|
| 26 |
+
"use_cache": True,
|
| 27 |
+
"vocab_size": 1391 # vocab_size is automatically set by the task manager...
|
| 28 |
+
}
|
| 29 |
+
cfg = T5Config(**a)
|
| 30 |
+
cfg.num_decoder_layers = 4
|
| 31 |
+
cfg.num_layers = 0
|
| 32 |
+
|
| 33 |
+
model = T5ForConditionalGeneration(cfg)
|
| 34 |
+
print(model)
|
| 35 |
+
|
| 36 |
+
x = torch.rand(((2, 256, 512)))
|
| 37 |
+
out = model.encoder.forward(inputs_embeds=x)
|
| 38 |
+
|
| 39 |
+
enc_hs = torch.rand((2, 256, 512))
|
| 40 |
+
labels = torch.randint(0, 1391, (2, 256))
|
| 41 |
+
pred = model(encoder_outputs=(enc_hs,), labels=labels) # important (enc_hs,) comma!
|
amt/src/extras/t5perceiver.py
ADDED
|
@@ -0,0 +1,443 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 The YourMT3 Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Please see the details in the LICENSE file.
|
| 10 |
+
""" Bare wrapper of HF PyTorch T5 and Perceiver with the following modifications:
|
| 11 |
+
- PerceiverTF encoder
|
| 12 |
+
- ResConv pre-encoder
|
| 13 |
+
- Projection layers for dynamic dimension matching
|
| 14 |
+
- Sinusoidal absolute positional embeddings
|
| 15 |
+
- Positional embeddings from Perceiver implementation
|
| 16 |
+
- Task conditioning on encoder and decoder by input tokens
|
| 17 |
+
"""
|
| 18 |
+
import copy
|
| 19 |
+
import warnings
|
| 20 |
+
from typing import Optional, Tuple, Union
|
| 21 |
+
|
| 22 |
+
import torch
|
| 23 |
+
from torch import nn
|
| 24 |
+
from torch.nn import CrossEntropyLoss
|
| 25 |
+
from torch.utils.checkpoint import checkpoint
|
| 26 |
+
|
| 27 |
+
from transformers.utils import logging
|
| 28 |
+
from transformers.utils.model_parallel_utils import assert_device_map, get_device_map
|
| 29 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 30 |
+
from transformers.models.t5.modeling_t5 import (T5LayerNorm, T5Block, PARALLELIZE_DOCSTRING, DEPARALLELIZE_DOCSTRING,
|
| 31 |
+
T5_START_DOCSTRING, T5_INPUTS_DOCSTRING, _CONFIG_FOR_DOC,
|
| 32 |
+
__HEAD_MASK_WARNING_MSG)
|
| 33 |
+
from transformers.modeling_outputs import (Seq2SeqLMOutput, BaseModelOutput, BaseModelOutputWithPastAndCrossAttentions)
|
| 34 |
+
from transformers import T5Config #, T5PreTrainedModel
|
| 35 |
+
from model.ops import FixedSinusoidalPositionalEmbedding
|
| 36 |
+
|
| 37 |
+
# additional imports
|
| 38 |
+
from model.t5mod import T5Stack
|
| 39 |
+
from transformers.models.t5.modeling_t5 import (T5Model, T5ForConditionalGeneration, T5EncoderModel, T5DenseActDense,
|
| 40 |
+
T5DenseGatedActDense, T5Attention, load_tf_weights_in_t5,
|
| 41 |
+
is_torch_fx_proxy)
|
| 42 |
+
|
| 43 |
+
from transformers.utils import (DUMMY_INPUTS, DUMMY_MASK)
|
| 44 |
+
|
| 45 |
+
logger = logging.get_logger(__name__)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
class T5PerceiverPreTrainedModel(PreTrainedModel):
|
| 49 |
+
"""
|
| 50 |
+
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
|
| 51 |
+
models.
|
| 52 |
+
"""
|
| 53 |
+
|
| 54 |
+
config_class = None
|
| 55 |
+
load_tf_weights = load_tf_weights_in_t5
|
| 56 |
+
base_model_prefix = "transformer"
|
| 57 |
+
is_parallelizable = True
|
| 58 |
+
supports_gradient_checkpointing = True
|
| 59 |
+
_no_split_modules = ["T5Block"]
|
| 60 |
+
_keep_in_fp32_modules = ["wo"]
|
| 61 |
+
|
| 62 |
+
@property
|
| 63 |
+
def dummy_inputs(self):
|
| 64 |
+
input_ids = torch.tensor(DUMMY_INPUTS)
|
| 65 |
+
input_mask = torch.tensor(DUMMY_MASK)
|
| 66 |
+
dummy_inputs = {
|
| 67 |
+
"decoder_input_ids": input_ids,
|
| 68 |
+
"input_ids": input_ids,
|
| 69 |
+
"decoder_attention_mask": input_mask,
|
| 70 |
+
}
|
| 71 |
+
return dummy_inputs
|
| 72 |
+
|
| 73 |
+
def _init_weights(self, module):
|
| 74 |
+
"""Initialize the weights"""
|
| 75 |
+
factor = self.config.initializer_factor # Used for testing weights initialization
|
| 76 |
+
if isinstance(module, T5LayerNorm):
|
| 77 |
+
module.weight.data.fill_(factor * 1.0)
|
| 78 |
+
elif isinstance(module, (T5Model, T5ForConditionalGeneration, T5EncoderModel)):
|
| 79 |
+
# Mesh TensorFlow embeddings initialization
|
| 80 |
+
# See https://github.com/tensorflow/mesh/blob/fa19d69eafc9a482aff0b59ddd96b025c0cb207d/mesh_tensorflow/layers.py#L1624
|
| 81 |
+
module.shared.weight.data.normal_(mean=0.0, std=factor * 1.0)
|
| 82 |
+
if hasattr(module, "lm_head") and not self.config.tie_word_embeddings:
|
| 83 |
+
module.lm_head.weight.data.normal_(mean=0.0, std=factor * 1.0)
|
| 84 |
+
elif isinstance(module, T5DenseActDense):
|
| 85 |
+
# Mesh TensorFlow FF initialization
|
| 86 |
+
# See https://github.com/tensorflow/mesh/blob/master/mesh_tensorflow/transformer/transformer_layers.py#L56
|
| 87 |
+
# and https://github.com/tensorflow/mesh/blob/fa19d69eafc9a482aff0b59ddd96b025c0cb207d/mesh_tensorflow/layers.py#L89
|
| 88 |
+
module.wi.weight.data.normal_(mean=0.0, std=factor * ((self.config.d_model)**-0.5))
|
| 89 |
+
if hasattr(module.wi, "bias") and module.wi.bias is not None:
|
| 90 |
+
module.wi.bias.data.zero_()
|
| 91 |
+
module.wo.weight.data.normal_(mean=0.0, std=factor * ((self.config.d_ff)**-0.5))
|
| 92 |
+
if hasattr(module.wo, "bias") and module.wo.bias is not None:
|
| 93 |
+
module.wo.bias.data.zero_()
|
| 94 |
+
elif isinstance(module, T5DenseGatedActDense):
|
| 95 |
+
module.wi_0.weight.data.normal_(mean=0.0, std=factor * ((self.config.d_model)**-0.5))
|
| 96 |
+
if hasattr(module.wi_0, "bias") and module.wi_0.bias is not None:
|
| 97 |
+
module.wi_0.bias.data.zero_()
|
| 98 |
+
module.wi_1.weight.data.normal_(mean=0.0, std=factor * ((self.config.d_model)**-0.5))
|
| 99 |
+
if hasattr(module.wi_1, "bias") and module.wi_1.bias is not None:
|
| 100 |
+
module.wi_1.bias.data.zero_()
|
| 101 |
+
module.wo.weight.data.normal_(mean=0.0, std=factor * ((self.config.d_ff)**-0.5))
|
| 102 |
+
if hasattr(module.wo, "bias") and module.wo.bias is not None:
|
| 103 |
+
module.wo.bias.data.zero_()
|
| 104 |
+
elif isinstance(module, T5Attention):
|
| 105 |
+
# Mesh TensorFlow attention initialization to avoid scaling before softmax
|
| 106 |
+
# See https://github.com/tensorflow/mesh/blob/fa19d69eafc9a482aff0b59ddd96b025c0cb207d/mesh_tensorflow/transformer/attention.py#L136
|
| 107 |
+
d_model = self.config.d_model
|
| 108 |
+
key_value_proj_dim = self.config.d_kv
|
| 109 |
+
n_heads = self.config.num_heads
|
| 110 |
+
module.q.weight.data.normal_(mean=0.0, std=factor * ((d_model * key_value_proj_dim)**-0.5))
|
| 111 |
+
module.k.weight.data.normal_(mean=0.0, std=factor * (d_model**-0.5))
|
| 112 |
+
module.v.weight.data.normal_(mean=0.0, std=factor * (d_model**-0.5))
|
| 113 |
+
module.o.weight.data.normal_(mean=0.0, std=factor * ((n_heads * key_value_proj_dim)**-0.5))
|
| 114 |
+
if module.has_relative_attention_bias:
|
| 115 |
+
module.relative_attention_bias.weight.data.normal_(mean=0.0, std=factor * ((d_model)**-0.5))
|
| 116 |
+
|
| 117 |
+
def _set_gradient_checkpointing(self, module, value=False):
|
| 118 |
+
if isinstance(module, (T5Attention, T5Stack)):
|
| 119 |
+
module.gradient_checkpointing = value
|
| 120 |
+
|
| 121 |
+
def _shift_right(self, input_ids):
|
| 122 |
+
decoder_start_token_id = self.config.decoder_start_token_id
|
| 123 |
+
pad_token_id = self.config.pad_token_id
|
| 124 |
+
|
| 125 |
+
assert decoder_start_token_id is not None, (
|
| 126 |
+
"self.model.config.decoder_start_token_id has to be defined. In T5 it is usually set to the pad_token_id."
|
| 127 |
+
" See T5 docs for more information")
|
| 128 |
+
|
| 129 |
+
# shift inputs to the right
|
| 130 |
+
if is_torch_fx_proxy(input_ids):
|
| 131 |
+
# Item assignment is not supported natively for proxies.
|
| 132 |
+
shifted_input_ids = torch.full(input_ids.shape[:-1] + (1,), decoder_start_token_id)
|
| 133 |
+
shifted_input_ids = torch.cat([shifted_input_ids, input_ids[..., :-1]], dim=-1)
|
| 134 |
+
else:
|
| 135 |
+
shifted_input_ids = input_ids.new_zeros(input_ids.shape)
|
| 136 |
+
shifted_input_ids[..., 1:] = input_ids[..., :-1].clone()
|
| 137 |
+
shifted_input_ids[..., 0] = decoder_start_token_id
|
| 138 |
+
|
| 139 |
+
assert pad_token_id is not None, "self.model.config.pad_token_id has to be defined."
|
| 140 |
+
# replace possible -100 values in labels by `pad_token_id`
|
| 141 |
+
shifted_input_ids.masked_fill_(shifted_input_ids == -100, pad_token_id)
|
| 142 |
+
|
| 143 |
+
return shifted_input_ids
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
class T5PerceiverForConditionalGeneration(T5PerceiverPreTrainedModel):
|
| 147 |
+
config_class = None
|
| 148 |
+
load_tf_weights = load_tf_weights_in_t5
|
| 149 |
+
base_model_prefix = "transformer"
|
| 150 |
+
is_parallelizable = True
|
| 151 |
+
supports_gradient_checkpointing = True
|
| 152 |
+
_no_split_modules = ["T5Block"]
|
| 153 |
+
_keep_in_fp32_modules = ["wo"]
|
| 154 |
+
|
| 155 |
+
@property
|
| 156 |
+
def dummy_inputs(self):
|
| 157 |
+
input_ids = torch.tensor(DUMMY_INPUTS)
|
| 158 |
+
input_mask = torch.tensor(DUMMY_MASK)
|
| 159 |
+
dummy_inputs = {
|
| 160 |
+
"decoder_input_ids": input_ids,
|
| 161 |
+
"input_ids": input_ids,
|
| 162 |
+
"decoder_attention_mask": input_mask,
|
| 163 |
+
}
|
| 164 |
+
return dummy_inputs
|
| 165 |
+
|
| 166 |
+
def __init__(
|
| 167 |
+
self,
|
| 168 |
+
model_cfg: dict,
|
| 169 |
+
# config: T5Config,
|
| 170 |
+
# use_fixed_absolute_pe: bool = True,
|
| 171 |
+
# num_max_positions: int = 1025
|
| 172 |
+
):
|
| 173 |
+
super().__init__(config)
|
| 174 |
+
self.model_dim = config.d_model
|
| 175 |
+
""" mod: absolute position embedding """
|
| 176 |
+
self.use_fixed_absolute_pe = use_fixed_absolute_pe
|
| 177 |
+
|
| 178 |
+
self.shared = nn.Embedding(config.vocab_size, config.d_model)
|
| 179 |
+
|
| 180 |
+
encoder_config = copy.deepcopy(config)
|
| 181 |
+
encoder_config.is_decoder = False
|
| 182 |
+
encoder_config.use_cache = False
|
| 183 |
+
encoder_config.is_encoder_decoder = False
|
| 184 |
+
self.encoder = T5Stack(encoder_config,
|
| 185 |
+
self.shared,
|
| 186 |
+
use_fixed_absolute_pe=use_fixed_absolute_pe,
|
| 187 |
+
num_max_positions=num_max_positions)
|
| 188 |
+
|
| 189 |
+
decoder_config = copy.deepcopy(config)
|
| 190 |
+
decoder_config.is_decoder = True
|
| 191 |
+
decoder_config.is_encoder_decoder = False
|
| 192 |
+
decoder_config.num_layers = config.num_decoder_layers
|
| 193 |
+
self.decoder = T5Stack(decoder_config,
|
| 194 |
+
self.shared,
|
| 195 |
+
use_fixed_absolute_pe=use_fixed_absolute_pe,
|
| 196 |
+
num_max_positions=num_max_positions)
|
| 197 |
+
|
| 198 |
+
self.lm_head = nn.Linear(config.d_model, config.vocab_size, bias=False)
|
| 199 |
+
|
| 200 |
+
# Initialize weights and apply final processing
|
| 201 |
+
self.post_init()
|
| 202 |
+
|
| 203 |
+
# Model parallel
|
| 204 |
+
self.model_parallel = False
|
| 205 |
+
self.device_map = None
|
| 206 |
+
|
| 207 |
+
def get_input_embeddings(self):
|
| 208 |
+
return self.shared
|
| 209 |
+
|
| 210 |
+
def set_input_embeddings(self, new_embeddings):
|
| 211 |
+
self.shared = new_embeddings
|
| 212 |
+
self.encoder.set_input_embeddings(new_embeddings)
|
| 213 |
+
self.decoder.set_input_embeddings(new_embeddings)
|
| 214 |
+
|
| 215 |
+
def set_output_embeddings(self, new_embeddings):
|
| 216 |
+
self.lm_head = new_embeddings
|
| 217 |
+
|
| 218 |
+
def get_output_embeddings(self):
|
| 219 |
+
return self.lm_head
|
| 220 |
+
|
| 221 |
+
def get_encoder(self):
|
| 222 |
+
return self.encoder
|
| 223 |
+
|
| 224 |
+
def get_decoder(self):
|
| 225 |
+
return self.decoder
|
| 226 |
+
|
| 227 |
+
def forward(
|
| 228 |
+
self,
|
| 229 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 230 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 231 |
+
decoder_input_ids: Optional[torch.LongTensor] = None,
|
| 232 |
+
decoder_attention_mask: Optional[torch.BoolTensor] = None,
|
| 233 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 234 |
+
decoder_head_mask: Optional[torch.FloatTensor] = None,
|
| 235 |
+
cross_attn_head_mask: Optional[torch.Tensor] = None,
|
| 236 |
+
encoder_outputs: Optional[Tuple[Tuple[torch.Tensor]]] = None,
|
| 237 |
+
past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
|
| 238 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 239 |
+
decoder_inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 240 |
+
labels: Optional[torch.LongTensor] = None,
|
| 241 |
+
use_cache: Optional[bool] = None,
|
| 242 |
+
output_attentions: Optional[bool] = None,
|
| 243 |
+
output_hidden_states: Optional[bool] = None,
|
| 244 |
+
return_dict: Optional[bool] = None,
|
| 245 |
+
) -> Union[Tuple[torch.FloatTensor], Seq2SeqLMOutput]:
|
| 246 |
+
r"""
|
| 247 |
+
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
|
| 248 |
+
Labels for computing the sequence classification/regression loss. Indices should be in `[-100, 0, ...,
|
| 249 |
+
config.vocab_size - 1]`. All labels set to `-100` are ignored (masked), the loss is only computed for
|
| 250 |
+
labels in `[0, ..., config.vocab_size]`
|
| 251 |
+
|
| 252 |
+
Returns:
|
| 253 |
+
|
| 254 |
+
Examples:
|
| 255 |
+
|
| 256 |
+
```python
|
| 257 |
+
>>> from transformers import AutoTokenizer, T5ForConditionalGeneration
|
| 258 |
+
|
| 259 |
+
>>> tokenizer = AutoTokenizer.from_pretrained("t5-small")
|
| 260 |
+
>>> model = T5ForConditionalGeneration.from_pretrained("t5-small")
|
| 261 |
+
|
| 262 |
+
>>> # training
|
| 263 |
+
>>> input_ids = tokenizer("The <extra_id_0> walks in <extra_id_1> park", return_tensors="pt").input_ids
|
| 264 |
+
>>> labels = tokenizer("<extra_id_0> cute dog <extra_id_1> the <extra_id_2>", return_tensors="pt").input_ids
|
| 265 |
+
>>> outputs = model(input_ids=input_ids, labels=labels)
|
| 266 |
+
>>> loss = outputs.loss
|
| 267 |
+
>>> logits = outputs.logits
|
| 268 |
+
|
| 269 |
+
>>> # inference
|
| 270 |
+
>>> input_ids = tokenizer(
|
| 271 |
+
... "summarize: studies have shown that owning a dog is good for you", return_tensors="pt"
|
| 272 |
+
... ).input_ids # Batch size 1
|
| 273 |
+
>>> outputs = model.generate(input_ids)
|
| 274 |
+
>>> print(tokenizer.decode(outputs[0], skip_special_tokens=True))
|
| 275 |
+
>>> # studies have shown that owning a dog is good for you.
|
| 276 |
+
```"""
|
| 277 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 278 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 279 |
+
|
| 280 |
+
# FutureWarning: head_mask was separated into two input args - head_mask, decoder_head_mask
|
| 281 |
+
if head_mask is not None and decoder_head_mask is None:
|
| 282 |
+
if self.config.num_layers == self.config.num_decoder_layers:
|
| 283 |
+
warnings.warn(__HEAD_MASK_WARNING_MSG, FutureWarning)
|
| 284 |
+
decoder_head_mask = head_mask
|
| 285 |
+
|
| 286 |
+
# Encode if needed (training, first prediction pass)
|
| 287 |
+
if encoder_outputs is None:
|
| 288 |
+
# Convert encoder inputs in embeddings if needed
|
| 289 |
+
encoder_outputs = self.encoder(
|
| 290 |
+
input_ids=input_ids,
|
| 291 |
+
attention_mask=attention_mask,
|
| 292 |
+
inputs_embeds=inputs_embeds,
|
| 293 |
+
head_mask=head_mask,
|
| 294 |
+
output_attentions=output_attentions,
|
| 295 |
+
output_hidden_states=output_hidden_states,
|
| 296 |
+
return_dict=return_dict,
|
| 297 |
+
)
|
| 298 |
+
elif return_dict and not isinstance(encoder_outputs, BaseModelOutput):
|
| 299 |
+
encoder_outputs = BaseModelOutput(
|
| 300 |
+
last_hidden_state=encoder_outputs[0],
|
| 301 |
+
hidden_states=encoder_outputs[1] if len(encoder_outputs) > 1 else None,
|
| 302 |
+
attentions=encoder_outputs[2] if len(encoder_outputs) > 2 else None,
|
| 303 |
+
)
|
| 304 |
+
|
| 305 |
+
hidden_states = encoder_outputs[0]
|
| 306 |
+
|
| 307 |
+
if self.model_parallel:
|
| 308 |
+
torch.cuda.set_device(self.decoder.first_device)
|
| 309 |
+
|
| 310 |
+
if labels is not None and decoder_input_ids is None and decoder_inputs_embeds is None:
|
| 311 |
+
# get decoder inputs from shifting lm labels to the right
|
| 312 |
+
decoder_input_ids = self._shift_right(labels)
|
| 313 |
+
|
| 314 |
+
# Set device for model parallelism
|
| 315 |
+
if self.model_parallel:
|
| 316 |
+
torch.cuda.set_device(self.decoder.first_device)
|
| 317 |
+
hidden_states = hidden_states.to(self.decoder.first_device)
|
| 318 |
+
if decoder_input_ids is not None:
|
| 319 |
+
decoder_input_ids = decoder_input_ids.to(self.decoder.first_device)
|
| 320 |
+
if attention_mask is not None:
|
| 321 |
+
attention_mask = attention_mask.to(self.decoder.first_device)
|
| 322 |
+
if decoder_attention_mask is not None:
|
| 323 |
+
decoder_attention_mask = decoder_attention_mask.to(self.decoder.first_device)
|
| 324 |
+
|
| 325 |
+
# Decode
|
| 326 |
+
decoder_outputs = self.decoder(
|
| 327 |
+
input_ids=decoder_input_ids,
|
| 328 |
+
attention_mask=decoder_attention_mask,
|
| 329 |
+
inputs_embeds=decoder_inputs_embeds,
|
| 330 |
+
past_key_values=past_key_values,
|
| 331 |
+
encoder_hidden_states=hidden_states,
|
| 332 |
+
encoder_attention_mask=attention_mask,
|
| 333 |
+
head_mask=decoder_head_mask,
|
| 334 |
+
cross_attn_head_mask=cross_attn_head_mask,
|
| 335 |
+
use_cache=use_cache,
|
| 336 |
+
output_attentions=output_attentions,
|
| 337 |
+
output_hidden_states=output_hidden_states,
|
| 338 |
+
return_dict=return_dict,
|
| 339 |
+
)
|
| 340 |
+
|
| 341 |
+
sequence_output = decoder_outputs[0]
|
| 342 |
+
|
| 343 |
+
# Set device for model parallelism
|
| 344 |
+
if self.model_parallel:
|
| 345 |
+
torch.cuda.set_device(self.encoder.first_device)
|
| 346 |
+
self.lm_head = self.lm_head.to(self.encoder.first_device)
|
| 347 |
+
sequence_output = sequence_output.to(self.lm_head.weight.device)
|
| 348 |
+
|
| 349 |
+
if self.config.tie_word_embeddings:
|
| 350 |
+
# Rescale output before projecting on vocab
|
| 351 |
+
# See https://github.com/tensorflow/mesh/blob/fa19d69eafc9a482aff0b59ddd96b025c0cb207d/mesh_tensorflow/transformer/transformer.py#L586
|
| 352 |
+
sequence_output = sequence_output * (self.model_dim**-0.5)
|
| 353 |
+
|
| 354 |
+
lm_logits = self.lm_head(sequence_output)
|
| 355 |
+
|
| 356 |
+
loss = None
|
| 357 |
+
if labels is not None:
|
| 358 |
+
loss_fct = CrossEntropyLoss(ignore_index=-100)
|
| 359 |
+
# move labels to correct device to enable PP
|
| 360 |
+
labels = labels.to(lm_logits.device)
|
| 361 |
+
loss = loss_fct(lm_logits.view(-1, lm_logits.size(-1)), labels.view(-1))
|
| 362 |
+
# TODO(thom): Add z_loss https://github.com/tensorflow/mesh/blob/fa19d69eafc9a482aff0b59ddd96b025c0cb207d/mesh_tensorflow/layers.py#L666
|
| 363 |
+
|
| 364 |
+
if not return_dict:
|
| 365 |
+
output = (lm_logits,) + decoder_outputs[1:] + encoder_outputs
|
| 366 |
+
return ((loss,) + output) if loss is not None else output
|
| 367 |
+
|
| 368 |
+
return Seq2SeqLMOutput(
|
| 369 |
+
loss=loss,
|
| 370 |
+
logits=lm_logits,
|
| 371 |
+
past_key_values=decoder_outputs.past_key_values,
|
| 372 |
+
decoder_hidden_states=decoder_outputs.hidden_states,
|
| 373 |
+
decoder_attentions=decoder_outputs.attentions,
|
| 374 |
+
cross_attentions=decoder_outputs.cross_attentions,
|
| 375 |
+
encoder_last_hidden_state=encoder_outputs.last_hidden_state,
|
| 376 |
+
encoder_hidden_states=encoder_outputs.hidden_states,
|
| 377 |
+
encoder_attentions=encoder_outputs.attentions,
|
| 378 |
+
)
|
| 379 |
+
|
| 380 |
+
def prepare_inputs_for_generation(
|
| 381 |
+
self,
|
| 382 |
+
input_ids,
|
| 383 |
+
past_key_values=None,
|
| 384 |
+
attention_mask=None,
|
| 385 |
+
head_mask=None,
|
| 386 |
+
decoder_head_mask=None,
|
| 387 |
+
cross_attn_head_mask=None,
|
| 388 |
+
use_cache=None,
|
| 389 |
+
encoder_outputs=None,
|
| 390 |
+
**kwargs,
|
| 391 |
+
):
|
| 392 |
+
# cut decoder_input_ids if past is used
|
| 393 |
+
if past_key_values is not None:
|
| 394 |
+
input_ids = input_ids[:, -1:]
|
| 395 |
+
|
| 396 |
+
return {
|
| 397 |
+
"decoder_input_ids": input_ids,
|
| 398 |
+
"past_key_values": past_key_values,
|
| 399 |
+
"encoder_outputs": encoder_outputs,
|
| 400 |
+
"attention_mask": attention_mask,
|
| 401 |
+
"head_mask": head_mask,
|
| 402 |
+
"decoder_head_mask": decoder_head_mask,
|
| 403 |
+
"cross_attn_head_mask": cross_attn_head_mask,
|
| 404 |
+
"use_cache": use_cache,
|
| 405 |
+
}
|
| 406 |
+
|
| 407 |
+
def prepare_decoder_input_ids_from_labels(self, labels: torch.Tensor):
|
| 408 |
+
return self._shift_right(labels)
|
| 409 |
+
|
| 410 |
+
def _reorder_cache(self, past_key_values, beam_idx):
|
| 411 |
+
# if decoder past is not included in output
|
| 412 |
+
# speedy decoding is disabled and no need to reorder
|
| 413 |
+
if past_key_values is None:
|
| 414 |
+
logger.warning("You might want to consider setting `use_cache=True` to speed up decoding")
|
| 415 |
+
return past_key_values
|
| 416 |
+
|
| 417 |
+
reordered_decoder_past = ()
|
| 418 |
+
for layer_past_states in past_key_values:
|
| 419 |
+
# get the correct batch idx from layer past batch dim
|
| 420 |
+
# batch dim of `past` is at 2nd position
|
| 421 |
+
reordered_layer_past_states = ()
|
| 422 |
+
for layer_past_state in layer_past_states:
|
| 423 |
+
# need to set correct `past` for each of the four key / value states
|
| 424 |
+
reordered_layer_past_states = reordered_layer_past_states + (layer_past_state.index_select(
|
| 425 |
+
0, beam_idx.to(layer_past_state.device)),)
|
| 426 |
+
|
| 427 |
+
assert reordered_layer_past_states[0].shape == layer_past_states[0].shape
|
| 428 |
+
assert len(reordered_layer_past_states) == len(layer_past_states)
|
| 429 |
+
|
| 430 |
+
reordered_decoder_past = reordered_decoder_past + (reordered_layer_past_states,)
|
| 431 |
+
return reordered_decoder_past
|
| 432 |
+
|
| 433 |
+
|
| 434 |
+
from transformers import PreTrainedModel, PretrainedConfig
|
| 435 |
+
from transformers import AutoModel, AutoConfig
|
| 436 |
+
|
| 437 |
+
|
| 438 |
+
class MyConfig(T5Config, PerceiverConfig):
|
| 439 |
+
model_type = 'mymodel'
|
| 440 |
+
|
| 441 |
+
def __init__(self, important_param=42, **kwargs):
|
| 442 |
+
super().__init__(**kwargs)
|
| 443 |
+
self.important_param = important_param
|
amt/src/extras/unimax_sampler/README.md
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# UniMax Language Dataset Sampler with DDP support
|
| 2 |
+
|
| 3 |
+
This repository contains an unofficial implementation of the UNIMAX sampling algorithm using PyTorch. The UNIMAX algorithm ["UniMax: Fairer and more Effective Language Sampling for Large-Scale Multilingual Pretraining" by HW Chung et al. (ICLR 2023)](https://arxiv.org/abs/2304.09151) is used to generate a sampling distribution of languages based on their character counts, a total character budget, and a specified number of epochs per language. This can be useful for training language models on datasets with imbalanced language distribution.
|
| 4 |
+
|
| 5 |
+
## Contents
|
| 6 |
+
|
| 7 |
+
1. `unimax_sampler.py`: This Python file contains the `UnimaxSampler` class, a PyTorch `Sampler` that uses the UNIMAX algorithm.
|
| 8 |
+
|
| 9 |
+
2. `test_unimax_sampler.py`: This Python file contains a unit test for the `UnimaxSampler` class to ensure its correct functionality.
|
| 10 |
+
|
| 11 |
+
## Usage
|
| 12 |
+
|
| 13 |
+
```python
|
| 14 |
+
from torch.utils.data import Dataset, DataLoader
|
| 15 |
+
from unimax_sampler import UnimaxSampler
|
| 16 |
+
|
| 17 |
+
# Define your parameters
|
| 18 |
+
language_character_counts = [100, 200, 300, 400, 500]
|
| 19 |
+
total_character_budget = 1000
|
| 20 |
+
num_epochs = 2
|
| 21 |
+
|
| 22 |
+
# Create the UnimaxSampler
|
| 23 |
+
unimax_sampler = UnimaxSampler(language_character_counts, total_character_budget, num_epochs)
|
| 24 |
+
```
|
| 25 |
+
|
| 26 |
+
Then, use the sampler as the sampler argument when creating a DataLoader.
|
| 27 |
+
|
| 28 |
+
```python
|
| 29 |
+
# Disable shuffle when using custom sampler...
|
| 30 |
+
data_loader = DataLoader(my_dataset, batch_size=2, shuffle=None, sampler=unimax_sampler)
|
| 31 |
+
```
|
| 32 |
+
|
| 33 |
+
For DDP,
|
| 34 |
+
```python
|
| 35 |
+
if torch.distributed.is_initialized():
|
| 36 |
+
sampler = DistributedUnimaxSampler(...)
|
| 37 |
+
else:
|
| 38 |
+
return unimax_sampler(...)
|
| 39 |
+
```
|
| 40 |
+
|
| 41 |
+
## Note
|
| 42 |
+
The initial version of this code was created by [Chat GPT-4](https://chat.openai.com/), based on the pseudocode provided in the [UNIMAX](https://arxiv.org/abs/2304.09151) paper. Subsequently, the code was manually revised for `PyTorch` Distributed Data Parallel ([DDP](https://pytorch.org/docs/stable/notes/ddp.html)) framework. The DistributedSamplerWrapper implementation is derived from an earlier version found in the [Catalyst](https://github.com/catalyst-team/catalyst) project.
|
| 43 |
+
|
| 44 |
+
## License
|
| 45 |
+
This project is licensed under the MIT License.
|
amt/src/extras/unimax_sampler/demo.py
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from utils.unimax_sampler.unimax_sampler import UnimaxSampler
|
| 2 |
+
|
| 3 |
+
language_character_counts = [100, 200, 300, 400, 500]
|
| 4 |
+
total_character_budget = 1000
|
| 5 |
+
num_epochs = 2
|
| 6 |
+
|
| 7 |
+
# Create the UnimaxSampler.
|
| 8 |
+
sampler = UnimaxSampler(language_character_counts, total_character_budget, num_epochs)
|
| 9 |
+
|
| 10 |
+
# Define the expected output. This will depend on your specific implementation of Unimax.
|
| 11 |
+
expected_output = torch.tensor([0.1, 0.2, 0.3, 0.2, 0.2])
|
| 12 |
+
|
| 13 |
+
# Use PyTorch's allclose function to compare the computed and expected outputs.
|
| 14 |
+
# The absolute tolerance parameter atol specifies the maximum difference allowed for the test to pass.
|
| 15 |
+
self.assertTrue(torch.allclose(sampler.p, expected_output, atol=1e-6))
|
amt/src/extras/unimax_sampler/unimax_sampler.py
ADDED
|
@@ -0,0 +1,168 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch.utils.data import DistributedSampler
|
| 3 |
+
from torch.utils.data import Dataset, Sampler
|
| 4 |
+
from torch.utils.data import RandomSampler
|
| 5 |
+
from operator import itemgetter
|
| 6 |
+
from typing import List, Union, Iterator, Optional
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class DatasetFromSampler(Dataset):
|
| 10 |
+
"""Dataset to create indexes from `Sampler`. From catalyst library.
|
| 11 |
+
|
| 12 |
+
Args:
|
| 13 |
+
sampler: PyTorch sampler
|
| 14 |
+
"""
|
| 15 |
+
|
| 16 |
+
def __init__(self, sampler: Sampler):
|
| 17 |
+
"""Initialisation for DatasetFromSampler."""
|
| 18 |
+
self.sampler = sampler
|
| 19 |
+
self.sampler_list = None
|
| 20 |
+
|
| 21 |
+
def __getitem__(self, index: int):
|
| 22 |
+
"""Gets element of the dataset.
|
| 23 |
+
|
| 24 |
+
Args:
|
| 25 |
+
index: index of the element in the dataset
|
| 26 |
+
|
| 27 |
+
Returns:
|
| 28 |
+
Single element by index
|
| 29 |
+
"""
|
| 30 |
+
if self.sampler_list is None:
|
| 31 |
+
self.sampler_list = list(self.sampler)
|
| 32 |
+
return self.sampler_list[index]
|
| 33 |
+
|
| 34 |
+
def __len__(self) -> int:
|
| 35 |
+
"""
|
| 36 |
+
Returns:
|
| 37 |
+
int: length of the dataset
|
| 38 |
+
"""
|
| 39 |
+
return len(self.sampler)
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
class DistributedSamplerWrapper(DistributedSampler):
|
| 43 |
+
"""
|
| 44 |
+
Wrapper over `Sampler` for distributed training.
|
| 45 |
+
Allows you to use any sampler in distributed mode.
|
| 46 |
+
From https://github.com/catalyst-team/catalyst/blob/master/catalyst/data/sampler.py
|
| 47 |
+
|
| 48 |
+
It is especially useful in conjunction with
|
| 49 |
+
`torch.nn.parallel.DistributedDataParallel`. In such case, each
|
| 50 |
+
process can pass a DistributedSamplerWrapper instance as a DataLoader
|
| 51 |
+
sampler, and load a subset of subsampled data of the original dataset
|
| 52 |
+
that is exclusive to it.
|
| 53 |
+
|
| 54 |
+
.. note::
|
| 55 |
+
Sampler is assumed to be of constant size.
|
| 56 |
+
"""
|
| 57 |
+
|
| 58 |
+
def __init__(
|
| 59 |
+
self,
|
| 60 |
+
sampler,
|
| 61 |
+
num_replicas: Optional[int] = None,
|
| 62 |
+
rank: Optional[int] = None,
|
| 63 |
+
shuffle: bool = True,
|
| 64 |
+
):
|
| 65 |
+
"""
|
| 66 |
+
|
| 67 |
+
Args:
|
| 68 |
+
sampler: Sampler used for subsampling
|
| 69 |
+
num_replicas (int, optional): Number of processes participating in
|
| 70 |
+
distributed training
|
| 71 |
+
rank (int, optional): Rank of the current process
|
| 72 |
+
within ``num_replicas``
|
| 73 |
+
shuffle (bool, optional): If true (default),
|
| 74 |
+
sampler will shuffle the indices
|
| 75 |
+
"""
|
| 76 |
+
super(DistributedSamplerWrapper, self).__init__(
|
| 77 |
+
DatasetFromSampler(sampler),
|
| 78 |
+
num_replicas=num_replicas,
|
| 79 |
+
rank=rank,
|
| 80 |
+
shuffle=shuffle,
|
| 81 |
+
)
|
| 82 |
+
self.sampler = sampler
|
| 83 |
+
|
| 84 |
+
def __iter__(self) -> Iterator[int]:
|
| 85 |
+
"""Iterate over sampler.
|
| 86 |
+
|
| 87 |
+
Returns:
|
| 88 |
+
python iterator
|
| 89 |
+
"""
|
| 90 |
+
self.dataset = DatasetFromSampler(self.sampler)
|
| 91 |
+
indexes_of_indexes = super().__iter__()
|
| 92 |
+
subsampler_indexes = self.dataset
|
| 93 |
+
return iter(itemgetter(*indexes_of_indexes)(subsampler_indexes))
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
class UnimaxSampler(Sampler):
|
| 97 |
+
# Initialize the sampler with the character counts for each language,
|
| 98 |
+
# the total character budget, and the number of epochs per language.
|
| 99 |
+
def __init__(self, language_character_counts: List[int], total_character_budget: int,
|
| 100 |
+
num_epochs: int) -> None:
|
| 101 |
+
self.language_character_counts = torch.tensor(language_character_counts)
|
| 102 |
+
self.total_character_budget = total_character_budget
|
| 103 |
+
self.num_epochs = num_epochs
|
| 104 |
+
# Compute the sampling distribution p.
|
| 105 |
+
self.p = self._unimax()
|
| 106 |
+
|
| 107 |
+
# Define how to iterate over the data. We'll use PyTorch's multinomial
|
| 108 |
+
# function to generate indices according to the distribution p.
|
| 109 |
+
def __iter__(self) -> iter:
|
| 110 |
+
return iter(torch.multinomial(self.p, len(self.p), replacement=True).tolist())
|
| 111 |
+
|
| 112 |
+
# Define the length of the sampler as the number of languages.
|
| 113 |
+
def __len__(self) -> int:
|
| 114 |
+
return len(self.p)
|
| 115 |
+
|
| 116 |
+
# Implement the UNIMAX algorithm to compute the sampling distribution p.
|
| 117 |
+
def _unimax(self) -> torch.Tensor:
|
| 118 |
+
# Sort languages by character count.
|
| 119 |
+
L, indices = torch.sort(self.language_character_counts)
|
| 120 |
+
# Initialize the remaining budget to the total character budget.
|
| 121 |
+
B = float(self.total_character_budget)
|
| 122 |
+
i = 0
|
| 123 |
+
# Initialize the budget per language.
|
| 124 |
+
U = torch.zeros_like(L)
|
| 125 |
+
# For each language...
|
| 126 |
+
for idx in indices:
|
| 127 |
+
# Compute the remaining budget per-language.
|
| 128 |
+
bl = B / (len(L) - i)
|
| 129 |
+
cl = L[idx]
|
| 130 |
+
# If per-language budget exceeds N epochs of the language, use N epochs.
|
| 131 |
+
if bl > cl * self.num_epochs:
|
| 132 |
+
Ul = cl * self.num_epochs
|
| 133 |
+
# Otherwise use uniform per-language budget.
|
| 134 |
+
else:
|
| 135 |
+
Ul = bl
|
| 136 |
+
# Store the computed budget.
|
| 137 |
+
U[idx] = Ul
|
| 138 |
+
# Update the remaining budget.
|
| 139 |
+
B -= Ul
|
| 140 |
+
# Move to the next language.
|
| 141 |
+
i += 1
|
| 142 |
+
# Normalize the budget to create a distribution.
|
| 143 |
+
p = U / U.sum()
|
| 144 |
+
# Return the computed distribution.
|
| 145 |
+
return p
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
class DistributedUnimaxSampler(UnimaxSampler):
|
| 149 |
+
|
| 150 |
+
def __init__(self,
|
| 151 |
+
language_character_counts: List[int],
|
| 152 |
+
total_character_budget: int,
|
| 153 |
+
num_epochs: int,
|
| 154 |
+
num_replicas: Optional[int] = None,
|
| 155 |
+
rank: Optional[int] = None,
|
| 156 |
+
shuffle: bool = True) -> None:
|
| 157 |
+
|
| 158 |
+
super().__init__(language_character_counts, total_character_budget, num_epochs)
|
| 159 |
+
self.distributed_sampler = DistributedSamplerWrapper(self, num_replicas, rank, shuffle)
|
| 160 |
+
|
| 161 |
+
def __iter__(self):
|
| 162 |
+
return iter(self.distributed_sampler)
|
| 163 |
+
|
| 164 |
+
def __len__(self):
|
| 165 |
+
return len(self.distributed_sampler)
|
| 166 |
+
|
| 167 |
+
def set_epoch(self, epoch):
|
| 168 |
+
self.distributed_sampler.set_epoch(epoch)
|
amt/src/install_dataset.py
ADDED
|
@@ -0,0 +1,285 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 The YourMT3 Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Please see the details in the LICENSE file.
|
| 10 |
+
""" install_dataset.py """
|
| 11 |
+
import os
|
| 12 |
+
import argparse
|
| 13 |
+
import mirdata
|
| 14 |
+
from typing import Optional, Tuple, Union
|
| 15 |
+
from utils.preprocess.generate_dataset_stats import generate_dataset_stats_for_all_datasets, update_dataset_stats_for_new_dataset
|
| 16 |
+
from utils.mirdata_dev.datasets import slakh16k
|
| 17 |
+
from utils.preprocess.preprocess_slakh import preprocess_slakh16k, add_program_and_is_drum_info_to_file_list
|
| 18 |
+
from utils.preprocess.preprocess_musicnet import preprocess_musicnet16k
|
| 19 |
+
from utils.preprocess.preprocess_maps import preprocess_maps16k
|
| 20 |
+
from utils.preprocess.preprocess_maestro import preprocess_maestro16k
|
| 21 |
+
from utils.preprocess.preprocess_guitarset import preprocess_guitarset16k, create_filelist_by_style_guitarset16k
|
| 22 |
+
from utils.preprocess.preprocess_enstdrums import preprocess_enstdrums16k, create_filelist_dtm_random_enstdrums16k
|
| 23 |
+
from utils.preprocess.preprocess_mir_st500 import preprocess_mir_st500_16k
|
| 24 |
+
from utils.preprocess.preprocess_cmedia import preprocess_cmedia_16k
|
| 25 |
+
from utils.preprocess.preprocess_rwc_pop_full import preprocess_rwc_pop_full16k
|
| 26 |
+
from utils.preprocess.preprocess_rwc_pop import preprocess_rwc_pop16k
|
| 27 |
+
from utils.preprocess.preprocess_egmd import preprocess_egmd16k
|
| 28 |
+
from utils.preprocess.preprocess_mir1k import preprocess_mir1k_16k
|
| 29 |
+
from utils.preprocess.preprocess_urmp import preprocess_urmp16k
|
| 30 |
+
from utils.preprocess.preprocess_idmt_smt_bass import preprocess_idmt_smt_bass_16k
|
| 31 |
+
from utils.preprocess.preprocess_geerdes import preprocess_geerdes16k
|
| 32 |
+
from utils.utils import download_and_extract #, download_and_extract_zenodo_restricted
|
| 33 |
+
|
| 34 |
+
# zenodo_token = "eyJhbGciOiJIUzUxMiIsImlhdCI6MTcxMDE1MDYzNywiZXhwIjoxNzEyNzA3MTk5fQ.eyJpZCI6ImRmODA5NzZlLTBjM2QtNDk5NS05YjM0LWFiNGM4NzJhMmZhMSIsImRhdGEiOnt9LCJyYW5kb20iOiIwMzY5ZDcxZjc2NTMyN2UyYmVmN2ExYjJkMmMyYTRhNSJ9.0aHnNC-7ivWQO6l8twjLR0NDH4boC0uOolAAmogVt7XRi2PHU5MEKBQoK7-wgDdnmWEIqEIvoLO6p8KTnsY9dg"
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def install_slakh(data_home=os.PathLike, no_down=False) -> None:
|
| 38 |
+
if not no_down:
|
| 39 |
+
ds = slakh16k.Dataset(data_home, version='2100-yourmt3-16k')
|
| 40 |
+
ds.download(partial_download=['2100-yourmt3-16k', 'index'])
|
| 41 |
+
del (ds)
|
| 42 |
+
preprocess_slakh16k(data_home, delete_source_files=False, fix_bass_octave=True)
|
| 43 |
+
add_program_and_is_drum_info_to_file_list(data_home)
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def install_musicnet(data_home=os.PathLike, no_down=False) -> None:
|
| 47 |
+
if not no_down:
|
| 48 |
+
url = "https://zenodo.org/record/7811639/files/musicnet_yourmt3_16k.tar.gz?download=1"
|
| 49 |
+
checksum = "a2da7c169e26d452a4e8b9bef498b3d7"
|
| 50 |
+
download_and_extract(data_home, url, remove_tar_file=True, check_sum=checksum)
|
| 51 |
+
preprocess_musicnet16k(data_home, dataset_name='musicnet')
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def install_maps(data_home=os.PathLike, no_down=False, sanity_check=False) -> None:
|
| 55 |
+
if not no_down:
|
| 56 |
+
url = "https://zenodo.org/record/7812075/files/maps_yourmt3_16k.tar.gz?download=1"
|
| 57 |
+
checksum = "6b070d162c931cd5e69c16ef2398a649"
|
| 58 |
+
download_and_extract(data_home, url, remove_tar_file=True, check_sum=checksum)
|
| 59 |
+
preprocess_maps16k(data_home, dataset_name='maps', ignore_pedal=False, sanity_check=sanity_check)
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def install_maestro(data_home=os.PathLike, no_down=False, sanity_check=False) -> None:
|
| 63 |
+
if not no_down:
|
| 64 |
+
url = "https://zenodo.org/record/7852176/files/maestro_yourmt3_16k.tar.gz?download=1"
|
| 65 |
+
checksum = "c17c6a188d936e5ff3870ef27144d397"
|
| 66 |
+
download_and_extract(data_home, url, remove_tar_file=True, check_sum=checksum)
|
| 67 |
+
preprocess_maestro16k(data_home, dataset_name='maestro', ignore_pedal=False, sanity_check=sanity_check)
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def install_guitarset(data_home=os.PathLike, no_down=False) -> None:
|
| 71 |
+
if not no_down:
|
| 72 |
+
url = "https://zenodo.org/record/7831843/files/guitarset_yourmt3_16k.tar.gz?download=1"
|
| 73 |
+
checksum = "e3cfe0cc9394d91d9c290ce888821360"
|
| 74 |
+
download_and_extract(data_home, url, remove_tar_file=True, check_sum=checksum)
|
| 75 |
+
preprocess_guitarset16k(data_home, dataset_name='guitarset')
|
| 76 |
+
create_filelist_by_style_guitarset16k(data_home, dataset_name='guitarset')
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
def install_enstdrums(data_home, no_down=False) -> None:
|
| 80 |
+
if not no_down:
|
| 81 |
+
url = "https://zenodo.org/record/7831843/files/enstdrums_yourmt3_16k.tar.gz?download=1"
|
| 82 |
+
checksum = "7e28c2a923e4f4162b3d83877cedb5eb"
|
| 83 |
+
download_and_extract(data_home, url, remove_tar_file=True, check_sum=checksum)
|
| 84 |
+
preprocess_enstdrums16k(data_home, dataset_name='enstdrums')
|
| 85 |
+
create_filelist_dtm_random_enstdrums16k(data_home, dataset_name='enstdrums')
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def install_egmd(data_home, no_down=False) -> None:
|
| 89 |
+
if not no_down:
|
| 90 |
+
url = "https://zenodo.org/record/7831072/files/egmc_yourmt3_16k.tar.gz?download=1"
|
| 91 |
+
checksum = "4f615157ea4c52a64c6c9dcf68bf2bde"
|
| 92 |
+
download_and_extract(data_home, url, remove_tar_file=True, check_sum=checksum)
|
| 93 |
+
preprocess_egmd16k(data_home, dataset_name='egmd')
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def install_mirst500(data_home, zenodo_token, no_down=False, sanity_check=True, apply_correction=False) -> None:
|
| 97 |
+
""" Update Oct 2023: MIR-ST500 with FULL audio files"""
|
| 98 |
+
if not no_down:
|
| 99 |
+
url = "https://zenodo.org/records/10016397/files/mir_st500_yourmt3_16k.tar.gz?download=1"
|
| 100 |
+
checksum = "98eb52eb2456ce4034e21750f309da13"
|
| 101 |
+
download_and_extract(data_home, url, check_sum=checksum, zenodo_token=zenodo_token)
|
| 102 |
+
preprocess_mir_st500_16k(data_home, dataset_name='mir_st500', sanity_check=sanity_check)
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
def install_cmedia(data_home, zenodo_token, no_down=False, sanity_check=True) -> None:
|
| 106 |
+
if not no_down:
|
| 107 |
+
url = "https://zenodo.org/records/10016397/files/cmedia_yourmt3_16k.tar.gz?download=1"
|
| 108 |
+
checksum = "e6cca23577ba7588e9ed9711a398f7cf"
|
| 109 |
+
download_and_extract(data_home, url, check_sum=checksum, zenodo_token=zenodo_token)
|
| 110 |
+
preprocess_cmedia_16k(data_home, dataset_name='cmedia', sanity_check=sanity_check, apply_correction=True)
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
def install_rwc_pop(data_home, zenodo_token, no_down=False) -> None:
|
| 114 |
+
if not no_down:
|
| 115 |
+
url = "https://zenodo.org/records/10016397/files/rwc_pop_yourmt3_16k.tar.gz?download=1"
|
| 116 |
+
checksum = "ad459f9fa1b6b87676b2fb37c0ba5dfc"
|
| 117 |
+
download_and_extract(data_home, url, check_sum=checksum, zenodo_token=zenodo_token)
|
| 118 |
+
preprocess_rwc_pop16k(data_home, dataset_name='rwc_pop') # bass transcriptions
|
| 119 |
+
preprocess_rwc_pop_full16k(data_home, dataset_name='rwc_pop') # full transcriptions
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def install_mir1k(data_home, no_down=False) -> None:
|
| 123 |
+
if not no_down:
|
| 124 |
+
url = "https://zenodo.org/record/7955481/files/mir1k_yourmt3_16k.tar.gz?download=1"
|
| 125 |
+
checksum = "4cbac56a4e971432ca807efd5cb76d67"
|
| 126 |
+
download_and_extract(data_home, url, remove_tar_file=True, check_sum=checksum)
|
| 127 |
+
# preprocess_mir1k_16k(data_home, dataset_name='mir1k')
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
def install_urmp(data_home, no_down=False) -> None:
|
| 131 |
+
if not no_down:
|
| 132 |
+
url = "https://zenodo.org/record/8021437/files/urmp_yourmt3_16k.tar.gz?download=1"
|
| 133 |
+
checksum = "4f539c71678a77ba34f6dfca41072102"
|
| 134 |
+
download_and_extract(data_home, url, remove_tar_file=True, check_sum=checksum)
|
| 135 |
+
preprocess_urmp16k(data_home, dataset_name='urmp')
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
def install_idmt_smt_bass(data_home, no_down=False) -> None:
|
| 139 |
+
if not no_down:
|
| 140 |
+
url = "https://zenodo.org/records/10009959/files/idmt_smt_bass_yourmt3_16k.tar.gz?download=1"
|
| 141 |
+
checksum = "0c95f91926a1e95b1f5d075c05b7eb76"
|
| 142 |
+
download_and_extract(data_home, url, remove_tar_file=True, check_sum=checksum)
|
| 143 |
+
preprocess_idmt_smt_bass_16k(data_home, dataset_name='idmt_smt_bass', sanity_check=True,
|
| 144 |
+
edit_audio=False) # the donwloaded audio has already been edited
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
def install_random_nsynth(data_home, no_down=False) -> None:
|
| 148 |
+
return
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
def install_geerdes(data_home) -> None:
|
| 152 |
+
try:
|
| 153 |
+
preprocess_geerdes16k(data_home, dataset_name='geerdes', sanity_check=False)
|
| 154 |
+
except Exception as e:
|
| 155 |
+
print(e)
|
| 156 |
+
print("Geerdes dataset is not available for download. Please contact the dataset provider.")
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
def regenerate_dataset_stats(data_home) -> None:
|
| 160 |
+
generate_dataset_stats_for_all_datasets(data_home)
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
def get_cached_zenodo_token() -> str:
|
| 164 |
+
# check if cached token exists
|
| 165 |
+
if not os.path.exists('.cached_zenodo_token'):
|
| 166 |
+
raise Exception("Cached Zenodo token not found. Please enter your Zenodo token.")
|
| 167 |
+
# read cached token
|
| 168 |
+
with open('.cached_zenodo_token', 'r') as f:
|
| 169 |
+
zenodo_token = f.read().strip()
|
| 170 |
+
print(f"Using cached Zenodo token: {zenodo_token}")
|
| 171 |
+
return zenodo_token
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
def cache_zenodo_token(zenodo_token: str) -> None:
|
| 175 |
+
with open('.cached_zenodo_token', 'w') as f:
|
| 176 |
+
f.write(zenodo_token)
|
| 177 |
+
print("Your Zenodo token is cached.")
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
def option_prompt(data_home: os.PathLike, no_download: bool = False) -> None:
|
| 181 |
+
print("Select the dataset(s) to install (enter comma-separated numbers):")
|
| 182 |
+
print("1. Slakh")
|
| 183 |
+
print("2. MusicNet")
|
| 184 |
+
print("3. MAPS")
|
| 185 |
+
print("4. Maestro")
|
| 186 |
+
print("5. GuitarSet")
|
| 187 |
+
print("6. ENST-drums")
|
| 188 |
+
print("7. EGMD")
|
| 189 |
+
print("8. MIR-ST500 ** Restricted Access **")
|
| 190 |
+
print("9. CMedia ** Restricted Access **")
|
| 191 |
+
print("10. RWC-Pop (Bass and Full) ** Restricted Access **")
|
| 192 |
+
print("11. MIR-1K (NOT SUPPORTED)")
|
| 193 |
+
print("12. URMP")
|
| 194 |
+
print("13. IDMT-SMT-Bass")
|
| 195 |
+
print("14. Random-NSynth")
|
| 196 |
+
print("15. Geerdes")
|
| 197 |
+
print("16. Regenerate Dataset Stats (experimental)")
|
| 198 |
+
print("17. Request Token for ** Restricted Access **")
|
| 199 |
+
print("18. Exit")
|
| 200 |
+
|
| 201 |
+
choice = input("Enter your choices (multiple choices with comma): ")
|
| 202 |
+
choices = [c.strip() for c in choice.split(',')]
|
| 203 |
+
|
| 204 |
+
if "18" in choices:
|
| 205 |
+
print("Exiting.")
|
| 206 |
+
else:
|
| 207 |
+
# ask for Zenodo token
|
| 208 |
+
for c in choices:
|
| 209 |
+
if int(c) in [8, 9, 10]:
|
| 210 |
+
if no_download is True:
|
| 211 |
+
zenodo_token = None
|
| 212 |
+
else:
|
| 213 |
+
zenodo_token = input("Enter Zenodo token, or press enter to use the cached token:")
|
| 214 |
+
if zenodo_token == "":
|
| 215 |
+
zenodo_token = get_cached_zenodo_token()
|
| 216 |
+
else:
|
| 217 |
+
cache_zenodo_token(zenodo_token)
|
| 218 |
+
break
|
| 219 |
+
|
| 220 |
+
if "1" in choices:
|
| 221 |
+
install_slakh(data_home, no_down=no_download)
|
| 222 |
+
if "2" in choices:
|
| 223 |
+
install_musicnet(data_home, no_down=no_download)
|
| 224 |
+
if "3" in choices:
|
| 225 |
+
install_maps(data_home, no_down=no_download)
|
| 226 |
+
if "4" in choices:
|
| 227 |
+
install_maestro(data_home, no_down=no_download)
|
| 228 |
+
if "5" in choices:
|
| 229 |
+
install_guitarset(data_home, no_down=no_download)
|
| 230 |
+
if "6" in choices:
|
| 231 |
+
install_enstdrums(data_home, no_down=no_download)
|
| 232 |
+
if "7" in choices:
|
| 233 |
+
install_egmd(data_home, no_down=no_download)
|
| 234 |
+
if "8" in choices:
|
| 235 |
+
install_mirst500(data_home, zenodo_token, no_down=no_download)
|
| 236 |
+
if "9" in choices:
|
| 237 |
+
install_cmedia(data_home, zenodo_token, no_down=no_download)
|
| 238 |
+
if "10" in choices:
|
| 239 |
+
install_rwc_pop(data_home, zenodo_token, no_down=no_download)
|
| 240 |
+
if "11" in choices:
|
| 241 |
+
install_mir1k(data_home, no_down=no_download)
|
| 242 |
+
if "12" in choices:
|
| 243 |
+
install_urmp(data_home, no_down=no_download)
|
| 244 |
+
if "13" in choices:
|
| 245 |
+
install_idmt_smt_bass(data_home, no_down=no_download)
|
| 246 |
+
if "14" in choices:
|
| 247 |
+
install_random_nsynth(data_home, no_down=no_download)
|
| 248 |
+
if "15" in choices:
|
| 249 |
+
install_geerdes(data_home) # not available for download
|
| 250 |
+
if "16" in choices:
|
| 251 |
+
regenerate_dataset_stats(data_home, no_down=no_download)
|
| 252 |
+
if "17" in choices:
|
| 253 |
+
print("\nPlease visit https://zenodo.org/records/10016397 to request a Zenodo token.")
|
| 254 |
+
print("Upon submitting your request, you will receive an email with a link labeled 'Access the record'.")
|
| 255 |
+
print("Copy the token that follows 'token=' in that link.")
|
| 256 |
+
if not any(int(c) in range(16) for c in choices):
|
| 257 |
+
print("Invalid choice(s). Please enter valid numbers separated by commas.")
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
if __name__ == "__main__":
|
| 261 |
+
|
| 262 |
+
parser = argparse.ArgumentParser(description='Dataset installer script.')
|
| 263 |
+
# data home dir
|
| 264 |
+
parser.add_argument(
|
| 265 |
+
'data_home',
|
| 266 |
+
type=str,
|
| 267 |
+
nargs='?',
|
| 268 |
+
default=None,
|
| 269 |
+
help='Path to data home directory. If None, use the default path defined in src/config/config.py')
|
| 270 |
+
# `no_download` option
|
| 271 |
+
parser.add_argument('--nodown',
|
| 272 |
+
'-nd',
|
| 273 |
+
action='store_true',
|
| 274 |
+
help='Flag to control downloading. If set, no downloading will occur.')
|
| 275 |
+
args = parser.parse_args()
|
| 276 |
+
|
| 277 |
+
if args.data_home is None:
|
| 278 |
+
from config.config import shared_cfg
|
| 279 |
+
data_home = shared_cfg["PATH"]["data_home"]
|
| 280 |
+
else:
|
| 281 |
+
data_home = args.data_home
|
| 282 |
+
os.makedirs(data_home, exist_ok=True)
|
| 283 |
+
no_download = args.nodown
|
| 284 |
+
|
| 285 |
+
option_prompt(data_home, no_download)
|
amt/src/model/RoPE/RoPE.py
ADDED
|
@@ -0,0 +1,306 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""rotary_embedding.py - Rotary Embedding based on https://github.com/lucidrains/rotary-embedding-torch"""
|
| 2 |
+
from typing import Literal, Union, Optional
|
| 3 |
+
from math import pi, log
|
| 4 |
+
from einops import rearrange, repeat
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
from torch.nn import Module, ModuleList
|
| 8 |
+
from torch.cuda.amp import autocast
|
| 9 |
+
from torch import nn, einsum, broadcast_tensors, Tensor
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
# helper functions
|
| 13 |
+
def exists(val):
|
| 14 |
+
return val is not None
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def default(val, d):
|
| 18 |
+
return val if exists(val) else d
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
# broadcat, as tortoise-tts was using it
|
| 22 |
+
def broadcat(tensors, dim=-1):
|
| 23 |
+
broadcasted_tensors = broadcast_tensors(*tensors)
|
| 24 |
+
return torch.cat(broadcasted_tensors, dim=dim)
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
# rotary embedding helper functions
|
| 28 |
+
def rotate_half(x):
|
| 29 |
+
x = rearrange(x, '... (d r) -> ... d r', r=2)
|
| 30 |
+
x1, x2 = x.unbind(dim=-1)
|
| 31 |
+
x = torch.stack((-x2, x1), dim=-1)
|
| 32 |
+
return rearrange(x, '... d r -> ... (d r)')
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
@autocast(enabled=False)
|
| 36 |
+
def apply_rotary_emb(freqs, t, start_index=0, scale=1., seq_dim=-2):
|
| 37 |
+
"""Applies rotary embedding for pixels."""
|
| 38 |
+
if t.ndim == 3:
|
| 39 |
+
seq_len = t.shape[seq_dim]
|
| 40 |
+
freqs = freqs[-seq_len:].to(t)
|
| 41 |
+
|
| 42 |
+
rot_dim = freqs.shape[-1]
|
| 43 |
+
end_index = start_index + rot_dim
|
| 44 |
+
|
| 45 |
+
assert rot_dim <= t.shape[
|
| 46 |
+
-1], f'feature dimension {t.shape[-1]} is not of sufficient size to rotate in all the positions {rot_dim}'
|
| 47 |
+
|
| 48 |
+
t_left, t, t_right = t[..., :start_index], t[..., start_index:end_index], t[..., end_index:]
|
| 49 |
+
t = (t * freqs.cos() * scale) + (rotate_half(t) * freqs.sin() * scale)
|
| 50 |
+
return torch.cat((t_left, t, t_right), dim=-1)
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
# learned rotation helpers
|
| 54 |
+
def apply_learned_rotations(rotations, t, start_index=0, freq_ranges=None):
|
| 55 |
+
if exists(freq_ranges):
|
| 56 |
+
rotations = einsum('..., f -> ... f', rotations, freq_ranges)
|
| 57 |
+
rotations = rearrange(rotations, '... r f -> ... (r f)')
|
| 58 |
+
|
| 59 |
+
rotations = repeat(rotations, '... n -> ... (n r)', r=2)
|
| 60 |
+
return apply_rotary_emb(rotations, t, start_index=start_index)
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
# classes
|
| 64 |
+
class RotaryEmbedding(Module):
|
| 65 |
+
|
| 66 |
+
def __init__(self,
|
| 67 |
+
dim,
|
| 68 |
+
custom_freqs: Optional[Tensor] = None,
|
| 69 |
+
freqs_for: Union[Literal['lang'], Literal['pixel'], Literal['constant']] = 'lang',
|
| 70 |
+
theta=10000,
|
| 71 |
+
max_freq=10,
|
| 72 |
+
num_freqs=1,
|
| 73 |
+
learned_freq=False,
|
| 74 |
+
use_xpos=False,
|
| 75 |
+
xpos_scale_base=512,
|
| 76 |
+
interpolate_factor=1.,
|
| 77 |
+
theta_rescale_factor=1.,
|
| 78 |
+
seq_before_head_dim=False,
|
| 79 |
+
cache_if_possible=True):
|
| 80 |
+
super().__init__()
|
| 81 |
+
# proposed by reddit user bloc97, to rescale rotary embeddings to longer sequence length without fine-tuning
|
| 82 |
+
# has some connection to NTK literature
|
| 83 |
+
# https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama_models_to_have/
|
| 84 |
+
|
| 85 |
+
theta *= theta_rescale_factor**(dim / (dim - 2))
|
| 86 |
+
|
| 87 |
+
self.freqs_for = freqs_for
|
| 88 |
+
|
| 89 |
+
if exists(custom_freqs):
|
| 90 |
+
freqs = custom_freqs
|
| 91 |
+
elif freqs_for == 'lang':
|
| 92 |
+
freqs = 1. / (theta**(torch.arange(0, dim, 2)[:(dim // 2)].float() / dim))
|
| 93 |
+
elif freqs_for == 'pixel':
|
| 94 |
+
freqs = torch.linspace(1., max_freq / 2, dim // 2) * pi
|
| 95 |
+
elif freqs_for == 'constant':
|
| 96 |
+
freqs = torch.ones(num_freqs).float()
|
| 97 |
+
|
| 98 |
+
self.cache_if_possible = cache_if_possible
|
| 99 |
+
|
| 100 |
+
self.tmp_store('cached_freqs', None)
|
| 101 |
+
self.tmp_store('cached_scales', None)
|
| 102 |
+
|
| 103 |
+
self.freqs = nn.Parameter(freqs, requires_grad=learned_freq)
|
| 104 |
+
|
| 105 |
+
self.learned_freq = learned_freq
|
| 106 |
+
|
| 107 |
+
# dummy for device
|
| 108 |
+
|
| 109 |
+
self.tmp_store('dummy', torch.tensor(0))
|
| 110 |
+
|
| 111 |
+
# default sequence dimension
|
| 112 |
+
|
| 113 |
+
self.seq_before_head_dim = seq_before_head_dim
|
| 114 |
+
self.default_seq_dim = -3 if seq_before_head_dim else -2
|
| 115 |
+
|
| 116 |
+
# interpolation factors
|
| 117 |
+
|
| 118 |
+
assert interpolate_factor >= 1.
|
| 119 |
+
self.interpolate_factor = interpolate_factor
|
| 120 |
+
|
| 121 |
+
# xpos
|
| 122 |
+
|
| 123 |
+
self.use_xpos = use_xpos
|
| 124 |
+
if not use_xpos:
|
| 125 |
+
self.tmp_store('scale', None)
|
| 126 |
+
return
|
| 127 |
+
|
| 128 |
+
scale = (torch.arange(0, dim, 2) + 0.4 * dim) / (1.4 * dim)
|
| 129 |
+
self.scale_base = xpos_scale_base
|
| 130 |
+
self.tmp_store('scale', scale)
|
| 131 |
+
|
| 132 |
+
@property
|
| 133 |
+
def device(self):
|
| 134 |
+
return self.dummy.device
|
| 135 |
+
|
| 136 |
+
def tmp_store(self, key, value):
|
| 137 |
+
self.register_buffer(key, value, persistent=False)
|
| 138 |
+
|
| 139 |
+
def get_seq_pos(self, seq_len, device, dtype, offset=0):
|
| 140 |
+
return (torch.arange(seq_len, device=device, dtype=dtype) + offset) / self.interpolate_factor
|
| 141 |
+
|
| 142 |
+
def rotate_queries_or_keys(self, t, seq_dim=None, offset=0, freq_seq_len=None):
|
| 143 |
+
seq_dim = default(seq_dim, self.default_seq_dim)
|
| 144 |
+
|
| 145 |
+
assert not self.use_xpos, 'you must use `.rotate_queries_and_keys` method instead and pass in both queries and keys, for length extrapolatable rotary embeddings'
|
| 146 |
+
|
| 147 |
+
device, dtype, seq_len = t.device, t.dtype, t.shape[seq_dim]
|
| 148 |
+
|
| 149 |
+
if exists(freq_seq_len):
|
| 150 |
+
assert freq_seq_len >= seq_len
|
| 151 |
+
seq_len = freq_seq_len
|
| 152 |
+
|
| 153 |
+
freqs = self.forward(self.get_seq_pos(seq_len, device=device, dtype=dtype, offset=offset),
|
| 154 |
+
seq_len=seq_len,
|
| 155 |
+
offset=offset)
|
| 156 |
+
|
| 157 |
+
if seq_dim == -3:
|
| 158 |
+
freqs = rearrange(freqs, 'n d -> n 1 d')
|
| 159 |
+
|
| 160 |
+
return apply_rotary_emb(freqs, t, seq_dim=seq_dim)
|
| 161 |
+
|
| 162 |
+
def rotate_queries_with_cached_keys(self, q, k, seq_dim=None, offset=0):
|
| 163 |
+
seq_dim = default(seq_dim, self.default_seq_dim)
|
| 164 |
+
|
| 165 |
+
q_len, k_len = q.shape[seq_dim], k.shape[seq_dim]
|
| 166 |
+
assert q_len <= k_len
|
| 167 |
+
rotated_q = self.rotate_queries_or_keys(q, seq_dim=seq_dim, freq_seq_len=k_len)
|
| 168 |
+
rotated_k = self.rotate_queries_or_keys(k, seq_dim=seq_dim)
|
| 169 |
+
|
| 170 |
+
rotated_q = rotated_q.type(q.dtype)
|
| 171 |
+
rotated_k = rotated_k.type(k.dtype)
|
| 172 |
+
|
| 173 |
+
return rotated_q, rotated_k
|
| 174 |
+
|
| 175 |
+
def rotate_queries_and_keys(self, q, k, seq_dim=None):
|
| 176 |
+
seq_dim = default(seq_dim, self.default_seq_dim)
|
| 177 |
+
|
| 178 |
+
assert self.use_xpos
|
| 179 |
+
device, dtype, seq_len = q.device, q.dtype, q.shape[seq_dim]
|
| 180 |
+
|
| 181 |
+
seq = self.get_seq_pos(seq_len, dtype=dtype, device=device)
|
| 182 |
+
|
| 183 |
+
freqs = self.forward(seq, seq_len=seq_len)
|
| 184 |
+
scale = self.get_scale(seq, seq_len=seq_len).to(dtype)
|
| 185 |
+
|
| 186 |
+
if seq_dim == -3:
|
| 187 |
+
freqs = rearrange(freqs, 'n d -> n 1 d')
|
| 188 |
+
scale = rearrange(scale, 'n d -> n 1 d')
|
| 189 |
+
|
| 190 |
+
rotated_q = apply_rotary_emb(freqs, q, scale=scale, seq_dim=seq_dim)
|
| 191 |
+
rotated_k = apply_rotary_emb(freqs, k, scale=scale**-1, seq_dim=seq_dim)
|
| 192 |
+
|
| 193 |
+
rotated_q = rotated_q.type(q.dtype)
|
| 194 |
+
rotated_k = rotated_k.type(k.dtype)
|
| 195 |
+
|
| 196 |
+
return rotated_q, rotated_k
|
| 197 |
+
|
| 198 |
+
def get_scale(self, t: Tensor, seq_len: Optional[int] = None, offset=0):
|
| 199 |
+
assert self.use_xpos
|
| 200 |
+
|
| 201 |
+
should_cache = (self.cache_if_possible and exists(seq_len))
|
| 202 |
+
|
| 203 |
+
if (
|
| 204 |
+
should_cache and \
|
| 205 |
+
exists(self.cached_scales) and \
|
| 206 |
+
(seq_len + offset) <= self.cached_scales.shape[0]
|
| 207 |
+
):
|
| 208 |
+
return self.cached_scales[offset:(offset + seq_len)]
|
| 209 |
+
|
| 210 |
+
scale = 1.
|
| 211 |
+
if self.use_xpos:
|
| 212 |
+
power = (t - len(t) // 2) / self.scale_base
|
| 213 |
+
scale = self.scale**rearrange(power, 'n -> n 1')
|
| 214 |
+
scale = torch.cat((scale, scale), dim=-1)
|
| 215 |
+
|
| 216 |
+
if should_cache:
|
| 217 |
+
self.tmp_store('cached_scales', scale)
|
| 218 |
+
|
| 219 |
+
return scale
|
| 220 |
+
|
| 221 |
+
def get_axial_freqs(self, *dims):
|
| 222 |
+
Colon = slice(None)
|
| 223 |
+
all_freqs = []
|
| 224 |
+
|
| 225 |
+
for ind, dim in enumerate(dims):
|
| 226 |
+
if self.freqs_for == 'pixel':
|
| 227 |
+
pos = torch.linspace(-1, 1, steps=dim, device=self.device)
|
| 228 |
+
else:
|
| 229 |
+
pos = torch.arange(dim, device=self.device)
|
| 230 |
+
|
| 231 |
+
freqs = self.forward(pos, seq_len=dim)
|
| 232 |
+
|
| 233 |
+
all_axis = [None] * len(dims)
|
| 234 |
+
all_axis[ind] = Colon
|
| 235 |
+
|
| 236 |
+
new_axis_slice = (Ellipsis, *all_axis, Colon)
|
| 237 |
+
all_freqs.append(freqs[new_axis_slice])
|
| 238 |
+
|
| 239 |
+
all_freqs = broadcast_tensors(*all_freqs)
|
| 240 |
+
return torch.cat(all_freqs, dim=-1)
|
| 241 |
+
|
| 242 |
+
@autocast(enabled=False)
|
| 243 |
+
def forward(self, t: Tensor, seq_len=None, offset=0):
|
| 244 |
+
should_cache = (
|
| 245 |
+
self.cache_if_possible and \
|
| 246 |
+
not self.learned_freq and \
|
| 247 |
+
exists(seq_len) and \
|
| 248 |
+
self.freqs_for != 'pixel'
|
| 249 |
+
)
|
| 250 |
+
|
| 251 |
+
if (
|
| 252 |
+
should_cache and \
|
| 253 |
+
exists(self.cached_freqs) and \
|
| 254 |
+
(offset + seq_len) <= self.cached_freqs.shape[0]
|
| 255 |
+
):
|
| 256 |
+
return self.cached_freqs[offset:(offset + seq_len)].detach()
|
| 257 |
+
|
| 258 |
+
freqs = self.freqs
|
| 259 |
+
|
| 260 |
+
freqs = einsum('..., f -> ... f', t.type(freqs.dtype), freqs)
|
| 261 |
+
freqs = repeat(freqs, '... n -> ... (n r)', r=2)
|
| 262 |
+
|
| 263 |
+
if should_cache:
|
| 264 |
+
self.tmp_store('cached_freqs', freqs.detach())
|
| 265 |
+
|
| 266 |
+
return freqs
|
| 267 |
+
|
| 268 |
+
# custom method for applying rotary embeddings
|
| 269 |
+
@torch.compiler.disable
|
| 270 |
+
def apply_rotary_custom(self, t: torch.Tensor):
|
| 271 |
+
"""Apply rotary embeddings to queries and keys, if k is None, only q is rotated.
|
| 272 |
+
Depending on the freqs type, the rotation will be different."""
|
| 273 |
+
if self.freqs_for == 'lang':
|
| 274 |
+
return self.rotate_queries_or_keys(t, seq_dim=-2)
|
| 275 |
+
elif self.freqs_for == 'pixel':
|
| 276 |
+
return apply_rotary_emb(self.get_axial_freqs(t.shape[-2]), t)
|
| 277 |
+
else:
|
| 278 |
+
raise ValueError(f"freqs_for must be 'lang' or 'pixel', but got {self.freqs_for}")
|
| 279 |
+
|
| 280 |
+
|
| 281 |
+
def test_rotary_embedding_lang():
|
| 282 |
+
d = 32 # d by head
|
| 283 |
+
q = torch.ones(1, 4, 110, 32) # (B, H, T, D) for multi-head attention
|
| 284 |
+
rdim = d // 2 # will do a partial rotation on half, or d
|
| 285 |
+
|
| 286 |
+
rotary = RotaryEmbedding(dim=rdim, freqs_for="lang")
|
| 287 |
+
q = rotary.rotate_queries_or_keys(q, seq_dim=-2)
|
| 288 |
+
|
| 289 |
+
# visualize
|
| 290 |
+
import matplotlib.pyplot as plt
|
| 291 |
+
plt.imshow(q[0, 0, :, :].numpy().T, origin='lower')
|
| 292 |
+
|
| 293 |
+
|
| 294 |
+
def test_rotary_embedding_pixel():
|
| 295 |
+
d = 32 # d by head
|
| 296 |
+
q = torch.ones(1, 4, 128, 32) # (B*T, H, F, C/H) for multi-head attention
|
| 297 |
+
rdim = d // 2 # will do a partial rotation on half
|
| 298 |
+
|
| 299 |
+
rotary = RotaryEmbedding(dim=rdim, freqs_for="pixel", max_freq=10)
|
| 300 |
+
freqs = rotary.get_axial_freqs(128)
|
| 301 |
+
|
| 302 |
+
q = apply_rotary_emb(freqs, q) # also k, if needed
|
| 303 |
+
|
| 304 |
+
# visualize
|
| 305 |
+
import matplotlib.pyplot as plt
|
| 306 |
+
plt.imshow(q[0, 0, :, :].numpy().T, origin='lower')
|
amt/src/model/conformer_helper.py
ADDED
|
@@ -0,0 +1,169 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 The YourMT3 Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Please see the details in the LICENSE file.
|
| 10 |
+
import math
|
| 11 |
+
from typing import Optional, Union
|
| 12 |
+
|
| 13 |
+
from torch import nn
|
| 14 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 15 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class ConformerYMT3Config(PretrainedConfig):
|
| 19 |
+
r"""
|
| 20 |
+
This is the configuration class to store the configuration of a [`ConformerYMT3Encoder`]. It is used to
|
| 21 |
+
instantiate an ConformerYMT3Encoder according to the specified arguments, defining the model architecture.
|
| 22 |
+
Instantiating a configuration with the defaults will yield a similar configuration to that of the Wav2Vec2Conformer
|
| 23 |
+
[facebook/wav2vec2-conformer-rel-pos-large](https://huggingface.co/facebook/wav2vec2-conformer-rel-pos-large)
|
| 24 |
+
architecture.
|
| 25 |
+
|
| 26 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 27 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
Args:
|
| 31 |
+
d_model (`int`, *optional*, defaults to 512):
|
| 32 |
+
Dimensionality of the encoder layers and the pooler layer.
|
| 33 |
+
num_layers (`int`, *optional*, defaults to 12):
|
| 34 |
+
Number of hidden layers in the Transformer encoder.
|
| 35 |
+
num_heads (`int`, *optional*, defaults to 12):
|
| 36 |
+
Number of attention heads for each attention layer in the Transformer encoder.
|
| 37 |
+
intermediate_size (`int`, *optional*, defaults to 2048):
|
| 38 |
+
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
|
| 39 |
+
hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
|
| 40 |
+
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
|
| 41 |
+
`"relu"`, `"selu"` and `"gelu_new"` are supported.
|
| 42 |
+
dropout_rate (`float`, *optional*, defaults to 0.05):
|
| 43 |
+
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
|
| 44 |
+
layerdrop (`float`, *optional*, defaults to 0.1):
|
| 45 |
+
The LayerDrop probability. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556) for more
|
| 46 |
+
details.
|
| 47 |
+
initializer_range (`float`, *optional*, defaults to 0.02):
|
| 48 |
+
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
| 49 |
+
layer_norm_eps (`float`, *optional*, defaults to 1e-12):
|
| 50 |
+
The epsilon used by the layer normalization layers.
|
| 51 |
+
conv_dim (`Tuple[int]` or `List[int]`, *optional*, defaults to `(512, 512, 512, 512, 512, 512, 512)`):
|
| 52 |
+
A tuple of integers defining the number of input and output channels of each 1D convolutional layer in the
|
| 53 |
+
feature encoder. The length of *conv_dim* defines the number of 1D convolutional layers.
|
| 54 |
+
conv_stride (`Tuple[int]` or `List[int]`, *optional*, defaults to `(5, 2, 2, 2, 2, 2, 2)`):
|
| 55 |
+
A tuple of integers defining the stride of each 1D convolutional layer in the feature encoder. The length
|
| 56 |
+
of *conv_stride* defines the number of convolutional layers and has to match the length of *conv_dim*.
|
| 57 |
+
conv_kernel (`Tuple[int]` or `List[int]`, *optional*, defaults to `(10, 3, 3, 3, 3, 3, 3)`):
|
| 58 |
+
A tuple of integers defining the kernel size of each 1D convolutional layer in the feature encoder. The
|
| 59 |
+
length of *conv_kernel* defines the number of convolutional layers and has to match the length of
|
| 60 |
+
*conv_dim*.
|
| 61 |
+
conv_bias (`bool`, *optional*, defaults to `False`):
|
| 62 |
+
Whether the 1D convolutional layers have a bias.
|
| 63 |
+
output_hidden_size (`int`, *optional*):
|
| 64 |
+
Dimensionality of the encoder output layer. If not defined, this defaults to *hidden-size*. Only relevant
|
| 65 |
+
if `add_adapter is True`.
|
| 66 |
+
position_encoding_type (`str`, *optional*, defaults to `"relative"`):
|
| 67 |
+
Can be specified to `relative` or `rotary` for relative or rotary position embeddings respectively. If left
|
| 68 |
+
`None` no relative position embedding is applied.
|
| 69 |
+
rotary_embedding_base (`int`, *optional*, defaults to 10000):
|
| 70 |
+
If `"rotary"` position embeddings are used, defines the size of the embedding base.
|
| 71 |
+
num_max_positions (`int`, *optional*, defaults to 5000):
|
| 72 |
+
if `"relative"` position embeddings are used, defines the maximum source input positions.
|
| 73 |
+
conv_depthwise_kernel_size (`int`, defaults to 31):
|
| 74 |
+
Kernel size of convolutional depthwise 1D layer in Conformer blocks.
|
| 75 |
+
|
| 76 |
+
Example:
|
| 77 |
+
|
| 78 |
+
```python
|
| 79 |
+
>>> from transformers import ConformerYMT3Config, ConformerYMT3Encoder
|
| 80 |
+
|
| 81 |
+
>>> # Initializing a ConformerYMT3Encoder configuration
|
| 82 |
+
>>> configuration = ConformerYMT3Config()
|
| 83 |
+
|
| 84 |
+
>>> # Initializing a model (with random weights) from the facebook/wav2vec2-conformer-rel-pos-large style configuration
|
| 85 |
+
>>> model = ConformerYMT3Encoder(configuration)
|
| 86 |
+
|
| 87 |
+
>>> # Accessing the model configuration
|
| 88 |
+
>>> configuration = model.config
|
| 89 |
+
```"""
|
| 90 |
+
model_type = "conformer-ymt3"
|
| 91 |
+
|
| 92 |
+
def __init__(
|
| 93 |
+
self,
|
| 94 |
+
d_model=512, # 768
|
| 95 |
+
num_layers=8, # ConformerYMT3Encoder
|
| 96 |
+
num_heads=8, # ConformerYMT3SelfAttention
|
| 97 |
+
intermediate_size=2048, # 3072,# used in intermediate_dense of ConformerYMT3FeedForward
|
| 98 |
+
hidden_act="gelu", # used in intermediate_act_fn of ConformerYMT3FeedForward
|
| 99 |
+
dropout_rate=0.1,
|
| 100 |
+
layerdrop=0.1,
|
| 101 |
+
initializer_range=0.02,
|
| 102 |
+
layer_norm_eps=1e-5,
|
| 103 |
+
conv_dim=(512, 512, 512, 512, 512, 512, 512),
|
| 104 |
+
conv_stride=(5, 2, 2, 2, 2, 2, 2),
|
| 105 |
+
conv_kernel=(10, 3, 3, 3, 3, 3, 3),
|
| 106 |
+
conv_bias=False,
|
| 107 |
+
position_encoding_type="rotary",
|
| 108 |
+
rotary_embedding_base=10000,
|
| 109 |
+
num_max_positions=1024,
|
| 110 |
+
conv_depthwise_kernel_size=31,
|
| 111 |
+
**kwargs,
|
| 112 |
+
):
|
| 113 |
+
super().__init__(**kwargs)
|
| 114 |
+
self.d_model = d_model
|
| 115 |
+
self.conv_dim = list(conv_dim)
|
| 116 |
+
self.conv_stride = list(conv_stride)
|
| 117 |
+
self.conv_kernel = list(conv_kernel)
|
| 118 |
+
self.conv_bias = conv_bias
|
| 119 |
+
self.num_layers = num_layers
|
| 120 |
+
self.intermediate_size = intermediate_size
|
| 121 |
+
self.hidden_act = hidden_act
|
| 122 |
+
self.num_heads = num_heads
|
| 123 |
+
self.dropout_rate = dropout_rate
|
| 124 |
+
|
| 125 |
+
self.layerdrop = layerdrop
|
| 126 |
+
self.layer_norm_eps = layer_norm_eps
|
| 127 |
+
self.initializer_range = initializer_range
|
| 128 |
+
self.num_max_positions = num_max_positions
|
| 129 |
+
self.position_encoding_type = position_encoding_type
|
| 130 |
+
self.rotary_embedding_base = rotary_embedding_base
|
| 131 |
+
|
| 132 |
+
# Conformer-block related
|
| 133 |
+
self.conv_depthwise_kernel_size = conv_depthwise_kernel_size
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
class ConformerYMT3PreTrainedModel(PreTrainedModel):
|
| 137 |
+
"""
|
| 138 |
+
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
|
| 139 |
+
models.
|
| 140 |
+
"""
|
| 141 |
+
|
| 142 |
+
config_class = ConformerYMT3Config
|
| 143 |
+
base_model_prefix = "wav2vec2_conformer"
|
| 144 |
+
main_input_name = "input_values"
|
| 145 |
+
supports_gradient_checkpointing = True
|
| 146 |
+
|
| 147 |
+
def _init_weights(self, module):
|
| 148 |
+
"""Initialize the weights"""
|
| 149 |
+
if module.__class__.__name__ == "ConformerYMT3SelfAttention":
|
| 150 |
+
if hasattr(module, "pos_bias_u"):
|
| 151 |
+
nn.init.xavier_uniform_(module.pos_bias_u)
|
| 152 |
+
if hasattr(module, "pos_bias_v"):
|
| 153 |
+
nn.init.xavier_uniform_(module.pos_bias_v)
|
| 154 |
+
elif isinstance(module, nn.Linear):
|
| 155 |
+
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
|
| 156 |
+
if module.bias is not None:
|
| 157 |
+
module.bias.data.zero_()
|
| 158 |
+
elif isinstance(module, (nn.LayerNorm, nn.GroupNorm)):
|
| 159 |
+
module.bias.data.zero_()
|
| 160 |
+
module.weight.data.fill_(1.0)
|
| 161 |
+
elif isinstance(module, nn.Conv1d):
|
| 162 |
+
nn.init.kaiming_normal_(module.weight)
|
| 163 |
+
if module.bias is not None:
|
| 164 |
+
k = math.sqrt(module.groups / (module.in_channels * module.kernel_size[0]))
|
| 165 |
+
nn.init.uniform_(module.bias, a=-k, b=k)
|
| 166 |
+
|
| 167 |
+
def _set_gradient_checkpointing(self, module, value=False):
|
| 168 |
+
if module.__class__.__name__ == "ConformerYMT3Encoder":
|
| 169 |
+
module.gradient_checkpointing = value
|
amt/src/model/conformer_mod.py
ADDED
|
@@ -0,0 +1,439 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 The YourMT3 Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Please see the details in the LICENSE file.
|
| 10 |
+
from typing import Tuple, Literal, Any, Optional
|
| 11 |
+
import math
|
| 12 |
+
|
| 13 |
+
import torch
|
| 14 |
+
from torch import nn
|
| 15 |
+
from transformers.activations import ACT2FN
|
| 16 |
+
from transformers.modeling_outputs import BaseModelOutput
|
| 17 |
+
|
| 18 |
+
from model.conformer_helper import ConformerYMT3Config, ConformerYMT3PreTrainedModel
|
| 19 |
+
from model.positional_encoding import (Wav2Vec2ConformerRelPositionalEmbedding,
|
| 20 |
+
Wav2Vec2ConformerRotaryPositionalEmbedding)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
class ConformerYMT3FeedForward(nn.Module):
|
| 24 |
+
|
| 25 |
+
def __init__(self, config):
|
| 26 |
+
super().__init__()
|
| 27 |
+
self.intermediate_dropout = nn.Dropout(config.dropout_rate)
|
| 28 |
+
|
| 29 |
+
self.intermediate_dense = nn.Linear(config.d_model, config.intermediate_size)
|
| 30 |
+
if isinstance(config.hidden_act, str):
|
| 31 |
+
self.intermediate_act_fn = ACT2FN[config.hidden_act]
|
| 32 |
+
else:
|
| 33 |
+
self.intermediate_act_fn = config.hidden_act
|
| 34 |
+
|
| 35 |
+
self.output_dense = nn.Linear(config.intermediate_size, config.d_model)
|
| 36 |
+
self.output_dropout = nn.Dropout(config.dropout_rate)
|
| 37 |
+
|
| 38 |
+
def forward(self, hidden_states):
|
| 39 |
+
hidden_states = self.intermediate_dense(hidden_states)
|
| 40 |
+
hidden_states = self.intermediate_act_fn(hidden_states)
|
| 41 |
+
hidden_states = self.intermediate_dropout(hidden_states)
|
| 42 |
+
|
| 43 |
+
hidden_states = self.output_dense(hidden_states)
|
| 44 |
+
hidden_states = self.output_dropout(hidden_states)
|
| 45 |
+
return hidden_states
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
class ConformerYMT3ConvolutionModule(nn.Module):
|
| 49 |
+
"""Convolution block used in the conformer block"""
|
| 50 |
+
|
| 51 |
+
def __init__(self, config):
|
| 52 |
+
super().__init__()
|
| 53 |
+
if (config.conv_depthwise_kernel_size - 1) % 2 == 1:
|
| 54 |
+
raise ValueError("`config.conv_depthwise_kernel_size` should be a odd number for 'SAME' padding")
|
| 55 |
+
self.layer_norm = nn.LayerNorm(config.d_model)
|
| 56 |
+
self.pointwise_conv1 = torch.nn.Conv1d(
|
| 57 |
+
config.d_model,
|
| 58 |
+
2 * config.d_model,
|
| 59 |
+
kernel_size=1,
|
| 60 |
+
stride=1,
|
| 61 |
+
padding=0,
|
| 62 |
+
bias=False,
|
| 63 |
+
)
|
| 64 |
+
self.glu = torch.nn.GLU(dim=1)
|
| 65 |
+
self.depthwise_conv = torch.nn.Conv1d(
|
| 66 |
+
config.d_model,
|
| 67 |
+
config.d_model,
|
| 68 |
+
config.conv_depthwise_kernel_size,
|
| 69 |
+
stride=1,
|
| 70 |
+
padding=(config.conv_depthwise_kernel_size - 1) // 2,
|
| 71 |
+
groups=config.d_model,
|
| 72 |
+
bias=False,
|
| 73 |
+
)
|
| 74 |
+
self.batch_norm = torch.nn.BatchNorm1d(config.d_model)
|
| 75 |
+
self.activation = ACT2FN[config.hidden_act]
|
| 76 |
+
self.pointwise_conv2 = torch.nn.Conv1d(
|
| 77 |
+
config.d_model,
|
| 78 |
+
config.d_model,
|
| 79 |
+
kernel_size=1,
|
| 80 |
+
stride=1,
|
| 81 |
+
padding=0,
|
| 82 |
+
bias=False,
|
| 83 |
+
)
|
| 84 |
+
self.dropout = torch.nn.Dropout(config.dropout_rate)
|
| 85 |
+
|
| 86 |
+
def forward(self, hidden_states):
|
| 87 |
+
hidden_states = self.layer_norm(hidden_states)
|
| 88 |
+
# exchange the temporal dimension and the feature dimension
|
| 89 |
+
hidden_states = hidden_states.transpose(1, 2)
|
| 90 |
+
|
| 91 |
+
# GLU mechanism
|
| 92 |
+
# => (batch, 2*channel, dim)
|
| 93 |
+
hidden_states = self.pointwise_conv1(hidden_states)
|
| 94 |
+
# => (batch, channel, dim)
|
| 95 |
+
hidden_states = self.glu(hidden_states)
|
| 96 |
+
|
| 97 |
+
# 1D Depthwise Conv
|
| 98 |
+
hidden_states = self.depthwise_conv(hidden_states)
|
| 99 |
+
hidden_states = self.batch_norm(hidden_states)
|
| 100 |
+
hidden_states = self.activation(hidden_states)
|
| 101 |
+
|
| 102 |
+
hidden_states = self.pointwise_conv2(hidden_states)
|
| 103 |
+
hidden_states = self.dropout(hidden_states)
|
| 104 |
+
hidden_states = hidden_states.transpose(1, 2)
|
| 105 |
+
return hidden_states
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
class ConformerYMT3SelfAttention(nn.Module):
|
| 109 |
+
"""Construct a ConformerSelfAttention object.
|
| 110 |
+
Can be enhanced with rotary or relative position embeddings.
|
| 111 |
+
"""
|
| 112 |
+
|
| 113 |
+
def __init__(self, config):
|
| 114 |
+
super().__init__()
|
| 115 |
+
|
| 116 |
+
self.head_size = config.d_model // config.num_heads
|
| 117 |
+
self.num_heads = config.num_heads
|
| 118 |
+
self.position_encoding_type = config.position_encoding_type
|
| 119 |
+
|
| 120 |
+
self.linear_q = nn.Linear(config.d_model, config.d_model)
|
| 121 |
+
self.linear_k = nn.Linear(config.d_model, config.d_model)
|
| 122 |
+
self.linear_v = nn.Linear(config.d_model, config.d_model)
|
| 123 |
+
self.linear_out = nn.Linear(config.d_model, config.d_model)
|
| 124 |
+
|
| 125 |
+
self.dropout = nn.Dropout(p=config.dropout_rate)
|
| 126 |
+
|
| 127 |
+
if self.position_encoding_type == "relative":
|
| 128 |
+
# linear transformation for positional encoding
|
| 129 |
+
self.linear_pos = nn.Linear(config.d_model, config.d_model, bias=False)
|
| 130 |
+
# these two learnable bias are used in matrix c and matrix d
|
| 131 |
+
# as described in https://arxiv.org/abs/1901.02860 Section 3.3
|
| 132 |
+
self.pos_bias_u = nn.Parameter(torch.zeros(self.num_heads, self.head_size))
|
| 133 |
+
self.pos_bias_v = nn.Parameter(torch.zeros(self.num_heads, self.head_size))
|
| 134 |
+
|
| 135 |
+
def forward(
|
| 136 |
+
self,
|
| 137 |
+
hidden_states: torch.Tensor,
|
| 138 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 139 |
+
relative_position_embeddings: Optional[torch.Tensor] = None,
|
| 140 |
+
output_attentions: bool = False,
|
| 141 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 142 |
+
# self-attention mechanism
|
| 143 |
+
batch_size, sequence_length, d_model = hidden_states.size()
|
| 144 |
+
|
| 145 |
+
# make sure query/key states can be != value states
|
| 146 |
+
query_key_states = hidden_states
|
| 147 |
+
value_states = hidden_states
|
| 148 |
+
|
| 149 |
+
if self.position_encoding_type == "rotary":
|
| 150 |
+
if relative_position_embeddings is None:
|
| 151 |
+
raise ValueError(
|
| 152 |
+
"`relative_position_embeddings` has to be defined when `self.position_encoding_type == 'rotary'")
|
| 153 |
+
query_key_states = self._apply_rotary_embedding(query_key_states, relative_position_embeddings)
|
| 154 |
+
|
| 155 |
+
# project query_key_states and value_states
|
| 156 |
+
query = self.linear_q(query_key_states).view(batch_size, -1, self.num_heads, self.head_size)
|
| 157 |
+
key = self.linear_k(query_key_states).view(batch_size, -1, self.num_heads, self.head_size)
|
| 158 |
+
value = self.linear_v(value_states).view(batch_size, -1, self.num_heads, self.head_size)
|
| 159 |
+
|
| 160 |
+
# => (batch, head, time1, d_k)
|
| 161 |
+
query = query.transpose(1, 2)
|
| 162 |
+
key = key.transpose(1, 2)
|
| 163 |
+
value = value.transpose(1, 2)
|
| 164 |
+
|
| 165 |
+
if self.position_encoding_type == "relative":
|
| 166 |
+
if relative_position_embeddings is None:
|
| 167 |
+
raise ValueError("`relative_position_embeddings` has to be defined when `self.position_encoding_type =="
|
| 168 |
+
" 'relative'")
|
| 169 |
+
# apply relative_position_embeddings to qk scores
|
| 170 |
+
# as proposed in Transformer_XL: https://arxiv.org/abs/1901.02860
|
| 171 |
+
scores = self._apply_relative_embeddings(query=query,
|
| 172 |
+
key=key,
|
| 173 |
+
relative_position_embeddings=relative_position_embeddings)
|
| 174 |
+
else:
|
| 175 |
+
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(self.head_size)
|
| 176 |
+
|
| 177 |
+
# apply attention_mask if necessary
|
| 178 |
+
if attention_mask is not None:
|
| 179 |
+
scores = scores + attention_mask
|
| 180 |
+
|
| 181 |
+
# => (batch, head, time1, time2)
|
| 182 |
+
probs = torch.softmax(scores, dim=-1)
|
| 183 |
+
probs = self.dropout(probs)
|
| 184 |
+
|
| 185 |
+
# => (batch, head, time1, d_k)
|
| 186 |
+
hidden_states = torch.matmul(probs, value)
|
| 187 |
+
|
| 188 |
+
# => (batch, time1, d_model)
|
| 189 |
+
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, self.num_heads * self.head_size)
|
| 190 |
+
hidden_states = self.linear_out(hidden_states)
|
| 191 |
+
|
| 192 |
+
return hidden_states, probs
|
| 193 |
+
|
| 194 |
+
def _apply_rotary_embedding(self, hidden_states, relative_position_embeddings):
|
| 195 |
+
batch_size, sequence_length, d_model = hidden_states.size()
|
| 196 |
+
hidden_states = hidden_states.view(batch_size, sequence_length, self.num_heads, self.head_size)
|
| 197 |
+
|
| 198 |
+
cos = relative_position_embeddings[0, :sequence_length, ...]
|
| 199 |
+
sin = relative_position_embeddings[1, :sequence_length, ...]
|
| 200 |
+
|
| 201 |
+
# rotate hidden_states with rotary embeddings
|
| 202 |
+
hidden_states = hidden_states.transpose(0, 1)
|
| 203 |
+
rotated_states_begin = hidden_states[..., :self.head_size // 2]
|
| 204 |
+
rotated_states_end = hidden_states[..., self.head_size // 2:]
|
| 205 |
+
rotated_states = torch.cat((-rotated_states_end, rotated_states_begin), dim=rotated_states_begin.ndim - 1)
|
| 206 |
+
hidden_states = (hidden_states * cos) + (rotated_states * sin)
|
| 207 |
+
hidden_states = hidden_states.transpose(0, 1)
|
| 208 |
+
|
| 209 |
+
hidden_states = hidden_states.view(batch_size, sequence_length, self.num_heads * self.head_size)
|
| 210 |
+
|
| 211 |
+
return hidden_states
|
| 212 |
+
|
| 213 |
+
def _apply_relative_embeddings(self, query, key, relative_position_embeddings):
|
| 214 |
+
# 1. project positional embeddings
|
| 215 |
+
# => (batch, head, 2*time1-1, d_k)
|
| 216 |
+
proj_relative_position_embeddings = self.linear_pos(relative_position_embeddings)
|
| 217 |
+
proj_relative_position_embeddings = proj_relative_position_embeddings.view(relative_position_embeddings.size(0),
|
| 218 |
+
-1, self.num_heads, self.head_size)
|
| 219 |
+
proj_relative_position_embeddings = proj_relative_position_embeddings.transpose(1, 2)
|
| 220 |
+
proj_relative_position_embeddings = proj_relative_position_embeddings.transpose(2, 3)
|
| 221 |
+
|
| 222 |
+
# 2. Add bias to query
|
| 223 |
+
# => (batch, head, time1, d_k)
|
| 224 |
+
query = query.transpose(1, 2)
|
| 225 |
+
q_with_bias_u = (query + self.pos_bias_u).transpose(1, 2)
|
| 226 |
+
q_with_bias_v = (query + self.pos_bias_v).transpose(1, 2)
|
| 227 |
+
|
| 228 |
+
# 3. attention score: first compute matrix a and matrix c
|
| 229 |
+
# as described in https://arxiv.org/abs/1901.02860 Section 3.3
|
| 230 |
+
# => (batch, head, time1, time2)
|
| 231 |
+
scores_ac = torch.matmul(q_with_bias_u, key.transpose(-2, -1))
|
| 232 |
+
|
| 233 |
+
# 4. then compute matrix b and matrix d
|
| 234 |
+
# => (batch, head, time1, 2*time1-1)
|
| 235 |
+
scores_bd = torch.matmul(q_with_bias_v, proj_relative_position_embeddings)
|
| 236 |
+
|
| 237 |
+
# 5. shift matrix b and matrix d
|
| 238 |
+
zero_pad = torch.zeros((*scores_bd.size()[:3], 1), device=scores_bd.device, dtype=scores_bd.dtype)
|
| 239 |
+
scores_bd_padded = torch.cat([zero_pad, scores_bd], dim=-1)
|
| 240 |
+
scores_bd_padded_shape = scores_bd.size()[:2] + (scores_bd.shape[3] + 1, scores_bd.shape[2])
|
| 241 |
+
scores_bd_padded = scores_bd_padded.view(*scores_bd_padded_shape)
|
| 242 |
+
scores_bd = scores_bd_padded[:, :, 1:].view_as(scores_bd)
|
| 243 |
+
scores_bd = scores_bd[:, :, :, :scores_bd.size(-1) // 2 + 1]
|
| 244 |
+
|
| 245 |
+
# 6. sum matrices
|
| 246 |
+
# => (batch, head, time1, time2)
|
| 247 |
+
scores = (scores_ac + scores_bd) / math.sqrt(self.head_size)
|
| 248 |
+
|
| 249 |
+
return scores
|
| 250 |
+
|
| 251 |
+
|
| 252 |
+
class ConformerYMT3EncoderLayer(nn.Module):
|
| 253 |
+
"""Conformer block based on https://arxiv.org/abs/2005.08100."""
|
| 254 |
+
|
| 255 |
+
def __init__(self, config):
|
| 256 |
+
super().__init__()
|
| 257 |
+
embed_dim = config.d_model
|
| 258 |
+
dropout = config.dropout_rate
|
| 259 |
+
|
| 260 |
+
# Feed-forward 1
|
| 261 |
+
self.ffn1_layer_norm = nn.LayerNorm(embed_dim)
|
| 262 |
+
self.ffn1 = ConformerYMT3FeedForward(config)
|
| 263 |
+
|
| 264 |
+
# Self-Attention
|
| 265 |
+
self.self_attn_layer_norm = nn.LayerNorm(embed_dim)
|
| 266 |
+
self.self_attn_dropout = torch.nn.Dropout(dropout)
|
| 267 |
+
self.self_attn = ConformerYMT3SelfAttention(config)
|
| 268 |
+
|
| 269 |
+
# Conformer Convolution
|
| 270 |
+
self.conv_module = ConformerYMT3ConvolutionModule(config)
|
| 271 |
+
|
| 272 |
+
# Feed-forward 2
|
| 273 |
+
self.ffn2_layer_norm = nn.LayerNorm(embed_dim)
|
| 274 |
+
self.ffn2 = ConformerYMT3FeedForward(config)
|
| 275 |
+
self.final_layer_norm = nn.LayerNorm(embed_dim)
|
| 276 |
+
|
| 277 |
+
def forward(
|
| 278 |
+
self,
|
| 279 |
+
hidden_states,
|
| 280 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 281 |
+
relative_position_embeddings: Optional[torch.Tensor] = None,
|
| 282 |
+
output_attentions: bool = False,
|
| 283 |
+
):
|
| 284 |
+
hidden_states = hidden_states
|
| 285 |
+
|
| 286 |
+
# 1. Feed-Forward 1 layer
|
| 287 |
+
residual = hidden_states
|
| 288 |
+
hidden_states = self.ffn1_layer_norm(hidden_states)
|
| 289 |
+
hidden_states = self.ffn1(hidden_states)
|
| 290 |
+
hidden_states = hidden_states * 0.5 + residual
|
| 291 |
+
residual = hidden_states
|
| 292 |
+
|
| 293 |
+
# 2. Self-Attention layer
|
| 294 |
+
hidden_states = self.self_attn_layer_norm(hidden_states)
|
| 295 |
+
hidden_states, attn_weigts = self.self_attn(
|
| 296 |
+
hidden_states=hidden_states,
|
| 297 |
+
attention_mask=attention_mask,
|
| 298 |
+
relative_position_embeddings=relative_position_embeddings,
|
| 299 |
+
output_attentions=output_attentions,
|
| 300 |
+
)
|
| 301 |
+
hidden_states = self.self_attn_dropout(hidden_states)
|
| 302 |
+
hidden_states = hidden_states + residual
|
| 303 |
+
|
| 304 |
+
# 3. Convolutional Layer
|
| 305 |
+
residual = hidden_states
|
| 306 |
+
hidden_states = self.conv_module(hidden_states)
|
| 307 |
+
hidden_states = residual + hidden_states
|
| 308 |
+
|
| 309 |
+
# 4. Feed-Forward 2 Layer
|
| 310 |
+
residual = hidden_states
|
| 311 |
+
hidden_states = self.ffn2_layer_norm(hidden_states)
|
| 312 |
+
hidden_states = self.ffn2(hidden_states)
|
| 313 |
+
hidden_states = hidden_states * 0.5 + residual
|
| 314 |
+
hidden_states = self.final_layer_norm(hidden_states)
|
| 315 |
+
|
| 316 |
+
return hidden_states, attn_weigts
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
class ConformerYMT3Encoder(nn.Module):
|
| 320 |
+
|
| 321 |
+
def __init__(self, config):
|
| 322 |
+
super().__init__()
|
| 323 |
+
self.config = config
|
| 324 |
+
|
| 325 |
+
if config.position_encoding_type == "relative":
|
| 326 |
+
self.embed_positions = Wav2Vec2ConformerRelPositionalEmbedding(config)
|
| 327 |
+
elif config.position_encoding_type == "rotary":
|
| 328 |
+
self.embed_positions = Wav2Vec2ConformerRotaryPositionalEmbedding(config)
|
| 329 |
+
else:
|
| 330 |
+
self.embed_positions = None
|
| 331 |
+
|
| 332 |
+
# self.pos_conv_embed = Wav2Vec2ConformerPositionalConvEmbedding(config)
|
| 333 |
+
self.layer_norm = nn.LayerNorm(config.d_model, eps=config.layer_norm_eps)
|
| 334 |
+
self.dropout = nn.Dropout(config.dropout_rate)
|
| 335 |
+
self.layers = nn.ModuleList([ConformerYMT3EncoderLayer(config) for _ in range(config.num_layers)])
|
| 336 |
+
self.gradient_checkpointing = False
|
| 337 |
+
|
| 338 |
+
def forward(
|
| 339 |
+
self,
|
| 340 |
+
inputs_embeds: torch.FloatTensor, # (B, T, D)
|
| 341 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 342 |
+
output_attentions: Optional[bool] = False,
|
| 343 |
+
output_hidden_states: Optional[bool] = False,
|
| 344 |
+
return_dict: Optional[bool] = True,
|
| 345 |
+
):
|
| 346 |
+
if output_attentions is None:
|
| 347 |
+
output_attentions = self.config.output_attentions
|
| 348 |
+
if output_hidden_states is None:
|
| 349 |
+
output_hidden_states = self.config.output_hidden_states
|
| 350 |
+
if return_dict is None:
|
| 351 |
+
return_dict = self.config.use_return_dict
|
| 352 |
+
all_hidden_states = () if output_hidden_states else None
|
| 353 |
+
all_self_attentions = () if output_attentions else None
|
| 354 |
+
|
| 355 |
+
# inputs_embeds as hidden_states
|
| 356 |
+
hidden_states = inputs_embeds
|
| 357 |
+
|
| 358 |
+
if attention_mask is not None:
|
| 359 |
+
# make sure padded tokens output 0
|
| 360 |
+
hidden_states[~attention_mask] = 0.0
|
| 361 |
+
|
| 362 |
+
# extend attention_mask
|
| 363 |
+
attention_mask = 1.0 - attention_mask[:, None, None, :].to(dtype=hidden_states.dtype)
|
| 364 |
+
attention_mask = attention_mask * torch.finfo(hidden_states.dtype).min
|
| 365 |
+
attention_mask = attention_mask.expand(attention_mask.shape[0], 1, attention_mask.shape[-1],
|
| 366 |
+
attention_mask.shape[-1])
|
| 367 |
+
|
| 368 |
+
hidden_states = self.dropout(hidden_states)
|
| 369 |
+
|
| 370 |
+
if self.embed_positions is not None:
|
| 371 |
+
relative_position_embeddings = self.embed_positions(hidden_states)
|
| 372 |
+
else:
|
| 373 |
+
relative_position_embeddings = None
|
| 374 |
+
|
| 375 |
+
for i, layer in enumerate(self.layers):
|
| 376 |
+
if output_hidden_states:
|
| 377 |
+
all_hidden_states = all_hidden_states + (hidden_states,)
|
| 378 |
+
|
| 379 |
+
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
|
| 380 |
+
dropout_probability = torch.rand([])
|
| 381 |
+
|
| 382 |
+
skip_the_layer = True if self.training and (dropout_probability < self.config.layerdrop) else False
|
| 383 |
+
if not skip_the_layer:
|
| 384 |
+
# under deepspeed zero3 all gpus must run in sync
|
| 385 |
+
if self.gradient_checkpointing and self.training:
|
| 386 |
+
# create gradient checkpointing function
|
| 387 |
+
def create_custom_forward(module):
|
| 388 |
+
|
| 389 |
+
def custom_forward(*inputs):
|
| 390 |
+
return module(*inputs, output_attentions)
|
| 391 |
+
|
| 392 |
+
return custom_forward
|
| 393 |
+
|
| 394 |
+
layer_outputs = torch.utils.checkpoint.checkpoint(
|
| 395 |
+
create_custom_forward(layer),
|
| 396 |
+
hidden_states,
|
| 397 |
+
attention_mask,
|
| 398 |
+
relative_position_embeddings,
|
| 399 |
+
)
|
| 400 |
+
else:
|
| 401 |
+
layer_outputs = layer(
|
| 402 |
+
hidden_states,
|
| 403 |
+
attention_mask=attention_mask,
|
| 404 |
+
relative_position_embeddings=relative_position_embeddings,
|
| 405 |
+
output_attentions=output_attentions,
|
| 406 |
+
)
|
| 407 |
+
hidden_states = layer_outputs[0]
|
| 408 |
+
|
| 409 |
+
if skip_the_layer:
|
| 410 |
+
layer_outputs = (None, None)
|
| 411 |
+
|
| 412 |
+
if output_attentions:
|
| 413 |
+
all_self_attentions = all_self_attentions + (layer_outputs[1],)
|
| 414 |
+
|
| 415 |
+
hidden_states = self.layer_norm(hidden_states)
|
| 416 |
+
if output_hidden_states:
|
| 417 |
+
all_hidden_states = all_hidden_states + (hidden_states,)
|
| 418 |
+
|
| 419 |
+
if not return_dict:
|
| 420 |
+
return tuple(v for v in [hidden_states, all_hidden_states, all_self_attentions] if v is not None)
|
| 421 |
+
return BaseModelOutput(
|
| 422 |
+
last_hidden_state=hidden_states,
|
| 423 |
+
hidden_states=all_hidden_states,
|
| 424 |
+
attentions=all_self_attentions,
|
| 425 |
+
)
|
| 426 |
+
|
| 427 |
+
|
| 428 |
+
def test():
|
| 429 |
+
import torch
|
| 430 |
+
from model.conformer_mod import ConformerYMT3Encoder
|
| 431 |
+
from model.conformer_helper import ConformerYMT3Config
|
| 432 |
+
from model.ops import count_parameters
|
| 433 |
+
config = ConformerYMT3Config()
|
| 434 |
+
encoder = ConformerYMT3Encoder(config)
|
| 435 |
+
encoder.eval()
|
| 436 |
+
# num params: 48,468,992 w/ intermediate_size=2048
|
| 437 |
+
# num params: 23,278,592 w/ intermediate_size=512
|
| 438 |
+
x = torch.randn(2, 256, 512) # (B, T, D)
|
| 439 |
+
enc_hs = encoder.forward(inputs_embeds=x)['last_hidden_state'] # (B, T, D)
|
amt/src/model/conv_block.py
ADDED
|
@@ -0,0 +1,217 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 The YourMT3 Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Please see the details in the LICENSE file.
|
| 10 |
+
from typing import Literal
|
| 11 |
+
import torch
|
| 12 |
+
import torch.nn as nn
|
| 13 |
+
import torch.nn.functional as F
|
| 14 |
+
from einops import rearrange
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def init_layer(layer: nn.Module) -> None:
|
| 18 |
+
"""Initialize a Linear or Convolutional layer."""
|
| 19 |
+
nn.init.xavier_uniform_(layer.weight)
|
| 20 |
+
if hasattr(layer, "bias") and layer.bias is not None:
|
| 21 |
+
layer.bias.data.zero_()
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def init_bn(bn: nn.Module) -> None:
|
| 25 |
+
"""Initialize a Batchnorm layer."""
|
| 26 |
+
bn.bias.data.zero_()
|
| 27 |
+
bn.weight.data.fill_(1.0)
|
| 28 |
+
bn.running_mean.data.zero_()
|
| 29 |
+
bn.running_var.data.fill_(1.0)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def act(x: torch.Tensor, activation: str) -> torch.Tensor:
|
| 33 |
+
"""Activation function."""
|
| 34 |
+
funcs = {"relu": F.relu_, "leaky_relu": lambda x: F.leaky_relu_(x, 0.01), "swish": lambda x: x * torch.sigmoid(x)}
|
| 35 |
+
return funcs.get(activation, lambda x: Exception("Incorrect activation!"))(x)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
class Res2DAVPBlock(nn.Module):
|
| 39 |
+
|
| 40 |
+
def __init__(self, in_channels, out_channels, kernel_size, avp_kernel_size, activation):
|
| 41 |
+
"""Convolutional residual block modified fromr bytedance/music_source_separation."""
|
| 42 |
+
super().__init__()
|
| 43 |
+
|
| 44 |
+
padding = kernel_size[0] // 2, kernel_size[1] // 2
|
| 45 |
+
|
| 46 |
+
self.activation = activation
|
| 47 |
+
self.bn1, self.bn2 = nn.BatchNorm2d(out_channels), nn.BatchNorm2d(out_channels)
|
| 48 |
+
|
| 49 |
+
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size, padding=padding, bias=False)
|
| 50 |
+
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size, padding=padding, bias=False)
|
| 51 |
+
|
| 52 |
+
self.is_shortcut = in_channels != out_channels
|
| 53 |
+
if self.is_shortcut:
|
| 54 |
+
self.shortcut = nn.Conv2d(in_channels, out_channels, kernel_size=(1, 1))
|
| 55 |
+
|
| 56 |
+
self.avp = nn.AvgPool2d(avp_kernel_size)
|
| 57 |
+
self.init_weights()
|
| 58 |
+
|
| 59 |
+
def init_weights(self):
|
| 60 |
+
for m in [self.conv1, self.conv2] + ([self.shortcut] if self.is_shortcut else []):
|
| 61 |
+
init_layer(m)
|
| 62 |
+
for m in [self.bn1, self.bn2]:
|
| 63 |
+
init_bn(m)
|
| 64 |
+
|
| 65 |
+
def forward(self, x):
|
| 66 |
+
origin = x
|
| 67 |
+
x = act(self.bn1(self.conv1(x)), self.activation)
|
| 68 |
+
x = self.bn2(self.conv2(x))
|
| 69 |
+
x += self.shortcut(origin) if self.is_shortcut else origin
|
| 70 |
+
x = act(x, self.activation)
|
| 71 |
+
return self.avp(x)
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
class PreEncoderBlockRes3B(nn.Module):
|
| 75 |
+
|
| 76 |
+
def __init__(self, in_channels, out_channels, kernel_size=(3, 3), avp_kernerl_size=(1, 2), activation='relu'):
|
| 77 |
+
"""Pre-Encoder with 3 Res2DAVPBlocks."""
|
| 78 |
+
super().__init__()
|
| 79 |
+
|
| 80 |
+
self.blocks = nn.ModuleList([
|
| 81 |
+
Res2DAVPBlock(in_channels if i == 0 else out_channels, out_channels, kernel_size, avp_kernerl_size,
|
| 82 |
+
activation) for i in range(3)
|
| 83 |
+
])
|
| 84 |
+
|
| 85 |
+
def forward(self, x): # (B, T, F)
|
| 86 |
+
x = rearrange(x, 'b t f -> b 1 t f')
|
| 87 |
+
for block in self.blocks:
|
| 88 |
+
x = block(x)
|
| 89 |
+
return rearrange(x, 'b c t f -> b t f c')
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
def test_res3b():
|
| 93 |
+
# mel-spec input
|
| 94 |
+
x = torch.randn(2, 256, 512) # (B, T, F)
|
| 95 |
+
pre = PreEncoderBlockRes3B(in_channels=1, out_channels=128)
|
| 96 |
+
x = pre(x) # (2, 256, 64, 128): B T,F,C
|
| 97 |
+
|
| 98 |
+
x = torch.randn(2, 110, 1024) # (B, T, F)
|
| 99 |
+
pre = PreEncoderBlockRes3B(in_channels=1, out_channels=128)
|
| 100 |
+
x = pre(x) # (2, 110, 128, 128): B,T,F,C
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
# ====================================================================================================================
|
| 104 |
+
# PreEncoderBlockHFTT: hFT-Transformer-like Pre-encoder
|
| 105 |
+
# ====================================================================================================================
|
| 106 |
+
class PreEncoderBlockHFTT(nn.Module):
|
| 107 |
+
|
| 108 |
+
def __init__(self, margin_pre=15, margin_post=16) -> None:
|
| 109 |
+
"""Pre-Encoder with hFT-Transformer-like convolutions."""
|
| 110 |
+
super().__init__()
|
| 111 |
+
|
| 112 |
+
self.margin_pre, self.margin_post = margin_pre, margin_post
|
| 113 |
+
self.conv = nn.Conv2d(1, 4, kernel_size=(1, 5), padding='same', padding_mode='zeros')
|
| 114 |
+
self.emb_freq = nn.Linear(128, 128)
|
| 115 |
+
|
| 116 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 117 |
+
# x: (B, T, F)
|
| 118 |
+
x = rearrange(x, 'b t f -> b 1 f t') # (B, 1, F, T) or (2, 1, 128, 110)
|
| 119 |
+
x = F.pad(x, (self.margin_pre, self.margin_post), value=1e-7) # (B, 1, F, T+margin) or (2,1,128,141)
|
| 120 |
+
x = self.conv(x) # (B, C, F, T+margin) or (2, 4, 128, 141)
|
| 121 |
+
x = x.unfold(dimension=3, size=32, step=1) # (B, c1, T, F, c2) or (2, 4, 128, 110, 32)
|
| 122 |
+
x = rearrange(x, 'b c1 f t c2 -> b t f (c1 c2)') # (B, T, F, C) or (2, 110, 128, 128)
|
| 123 |
+
return self.emb_freq(x) # (B, T, F, C) or (2, 110, 128, 128)
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
def test_hftt():
|
| 127 |
+
# from model.spectrogram import get_spectrogram_layer_from_audio_cfg
|
| 128 |
+
# from config.config import audio_cfg as default_audio_cfg
|
| 129 |
+
# audio_cfg = default_audio_cfg
|
| 130 |
+
# audio_cfg['codec'] = 'melspec'
|
| 131 |
+
# audio_cfg['hop_length'] = 300
|
| 132 |
+
# audio_cfg['n_mels'] = 128
|
| 133 |
+
# x = torch.randn(2, 1, 32767)
|
| 134 |
+
# mspec, _ = get_spectrogram_layer_from_audio_cfg(audio_cfg)
|
| 135 |
+
# x = mspec(x)
|
| 136 |
+
x = torch.randn(2, 110, 128) # (B, T, F)
|
| 137 |
+
pre_enc_hftt = PreEncoderBlockHFTT()
|
| 138 |
+
y = pre_enc_hftt(x) # (2, 110, 128, 128): B, T, F, C
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
# ====================================================================================================================
|
| 142 |
+
# PreEncoderBlockRes3BHFTT: hFT-Transformer-like Pre-encoder with Res2DAVPBlock and spec input
|
| 143 |
+
# ====================================================================================================================
|
| 144 |
+
class PreEncoderBlockRes3BHFTT(nn.Module):
|
| 145 |
+
|
| 146 |
+
def __init__(self, margin_pre: int = 15, margin_post: int = 16) -> None:
|
| 147 |
+
"""Pre-Encoder with hFT-Transformer-like convolutions.
|
| 148 |
+
|
| 149 |
+
Args:
|
| 150 |
+
margin_pre (int): padding before the input
|
| 151 |
+
margin_post (int): padding after the input
|
| 152 |
+
stack_dim (Literal['c', 'f']): stack dimension. channel or frequency
|
| 153 |
+
|
| 154 |
+
"""
|
| 155 |
+
super().__init__()
|
| 156 |
+
self.margin_pre, self.margin_post = margin_pre, margin_post
|
| 157 |
+
self.res3b = PreEncoderBlockRes3B(in_channels=1, out_channels=4)
|
| 158 |
+
self.emb_freq = nn.Linear(128, 128)
|
| 159 |
+
|
| 160 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 161 |
+
# x: (B, T, F) or (2, 110, 1024), input spectrogram
|
| 162 |
+
x = rearrange(x, 'b t f -> b f t') # (2, 1024, 110): B,F,T
|
| 163 |
+
x = F.pad(x, (self.margin_pre, self.margin_post), value=1e-7) # (2, 1024, 141): B,F,T+margin
|
| 164 |
+
x = rearrange(x, 'b f t -> b t f') # (2, 141, 1024): B,T+margin,F
|
| 165 |
+
x = self.res3b(x) # (2, 141, 128, 4): B,T+margin,F,C
|
| 166 |
+
x = x.unfold(dimension=1, size=32, step=1) # (B, T, F, C1, C2) or (2, 110, 128, 4, 32)
|
| 167 |
+
x = rearrange(x, 'b t f c1 c2 -> b t f (c1 c2)') # (B, T, F, C) or (2, 110, 128, 128)
|
| 168 |
+
return self.emb_freq(x) # (B, T, F, C) or (2, 110, 128, 128)
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
def test_res3b_hftt():
|
| 172 |
+
# from model.spectrogram import get_spectrogram_layer_from_audio_cfg
|
| 173 |
+
# from config.config import audio_cfg as default_audio_cfg
|
| 174 |
+
# audio_cfg = default_audio_cfg
|
| 175 |
+
# audio_cfg['codec'] = 'spec'
|
| 176 |
+
# audio_cfg['hop_length'] = 300
|
| 177 |
+
# x = torch.randn(2, 1, 32767)
|
| 178 |
+
# spec, _ = get_spectrogram_layer_from_audio_cfg(audio_cfg)
|
| 179 |
+
# x = spec(x) # (2, 110, 1024): B,T,F
|
| 180 |
+
x = torch.randn(2, 110, 1024) # (B, T, F)
|
| 181 |
+
pre_enc_res3b_hftt = PreEncoderBlockRes3BHFTT()
|
| 182 |
+
y = pre_enc_res3b_hftt(x) # (2, 110, 128, 128): B, T, F, C
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
# # ====================================================================================================================
|
| 186 |
+
# # PreEncoderBlockConv1D: Pre-encoder without activation, with Melspec input
|
| 187 |
+
# # ====================================================================================================================
|
| 188 |
+
# class PreEncoderBlockConv1D(nn.Module):
|
| 189 |
+
|
| 190 |
+
# def __init__(self,
|
| 191 |
+
# in_channels,
|
| 192 |
+
# out_channels,
|
| 193 |
+
# kernel_size=3) -> None:
|
| 194 |
+
# """Pre-Encoder with 1D convolution."""
|
| 195 |
+
# super().__init__()
|
| 196 |
+
# self.conv1 = nn.Conv1d(in_channels, out_channels, kernel_size=kernel_size, stride=1)
|
| 197 |
+
# self.conv2 = nn.Conv1d(out_channels, out_channels, kernel_size=kernel_size, stride=1)
|
| 198 |
+
|
| 199 |
+
# def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 200 |
+
# # x: (B, T, F) or (2, 128, 256), input melspec
|
| 201 |
+
# x = rearrange(x, 'b t f -> b f t') # (2, 256, 128): B,F,T
|
| 202 |
+
# x = self.conv1(x) # (2, 128, 128): B,F,T
|
| 203 |
+
# return rearrange(x, 'b f t -> b t f') # (2, 110, 128): B,T,F
|
| 204 |
+
|
| 205 |
+
# def test_conv1d():
|
| 206 |
+
# # from model.spectrogram import get_spectrogram_layer_from_audio_cfg
|
| 207 |
+
# # from config.config import audio_cfg as default_audio_cfg
|
| 208 |
+
# # audio_cfg = default_audio_cfg
|
| 209 |
+
# # audio_cfg['codec'] = 'melspec'
|
| 210 |
+
# # audio_cfg['hop_length'] = 256
|
| 211 |
+
# # audio_cfg['n_mels'] = 512
|
| 212 |
+
# # x = torch.randn(2, 1, 32767)
|
| 213 |
+
# # mspec, _ = get_spectrogram_layer_from_audio_cfg(audio_cfg)
|
| 214 |
+
# # x = mspec(x)
|
| 215 |
+
# x = torch.randn(2, 128, 128) # (B, T, F)
|
| 216 |
+
# pre_enc_conv1d = PreEncoderBlockConv1D(in_channels=1, out_channels=128)
|
| 217 |
+
# y = pre_enc_conv1d(x) # (2, 110, 128, 128): B, T, F, C
|
amt/src/model/ff_layer.py
ADDED
|
@@ -0,0 +1,238 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 The YourMT3 Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Please see the details in the LICENSE file.
|
| 10 |
+
"""ff_layer.py
|
| 11 |
+
|
| 12 |
+
This module contains the implementation of the feedforward layers.
|
| 13 |
+
|
| 14 |
+
Supported ff_layer_type:
|
| 15 |
+
'mlp': Multi-Layer Perceptron
|
| 16 |
+
'gmlp': Gated Multi-Layer Perceptron, simplified version of Mixtral Expert with num_experts=1 and top_k=1.
|
| 17 |
+
This is not the spatial gating MLP (https://arxiv.org/abs/2105.08050).
|
| 18 |
+
'moe': Mixtral of Experts, modified from the original source code:
|
| 19 |
+
https://github.com/huggingface/transformers/blob/v4.38.2/src/transformers/models/mixtral/modeling_mixtral.py
|
| 20 |
+
|
| 21 |
+
Usage:
|
| 22 |
+
from model.ff_layer import get_ff_layer
|
| 23 |
+
|
| 24 |
+
config = PerceiverTFConfig() # or any type of PretrainedConfig()
|
| 25 |
+
config.ff_layer_type = 'moe' # or 'mlp'
|
| 26 |
+
config.moe_num_experts = 4
|
| 27 |
+
config.moe_topk = 2
|
| 28 |
+
config.hidden_act = 'gelu' # or any type of activation function, e.g., 'silu'
|
| 29 |
+
|
| 30 |
+
ff_layer = get_ff_layer(config, input_size, widening_factor)
|
| 31 |
+
|
| 32 |
+
What ff_layer returns:
|
| 33 |
+
- It returns (hidden_states, router_logits) for MoE and (hidden_states, None) for MLP.
|
| 34 |
+
- router_logits has the shape of (batch_size * sequence_length, n_experts) for MoE.
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
"""
|
| 38 |
+
from typing import Any, Tuple
|
| 39 |
+
import torch
|
| 40 |
+
import torch.nn as nn
|
| 41 |
+
import torch.nn.functional as F
|
| 42 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 43 |
+
from transformers.activations import ACT2FN
|
| 44 |
+
from model.ops import get_layer_norm
|
| 45 |
+
from model.ops import optional_compiler_disable, optional_compiler_dynamic
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
class MixtralBlockSparseTop2MLP(nn.Module):
|
| 49 |
+
"""
|
| 50 |
+
The Gated Multilayer Perceptron (GMLP) used in Mixtral of Experts (MoE).
|
| 51 |
+
|
| 52 |
+
"""
|
| 53 |
+
|
| 54 |
+
def __init__(self, config: PretrainedConfig, input_size: int, widening_factor: int):
|
| 55 |
+
super().__init__()
|
| 56 |
+
self.hidden_dim = input_size
|
| 57 |
+
self.ffn_dim = int(input_size * widening_factor)
|
| 58 |
+
|
| 59 |
+
self.w1 = nn.Linear(self.hidden_dim, self.ffn_dim, bias=False)
|
| 60 |
+
self.w2 = nn.Linear(self.ffn_dim, self.hidden_dim, bias=False)
|
| 61 |
+
self.gate = nn.Linear(self.hidden_dim, self.ffn_dim, bias=False)
|
| 62 |
+
self.act_fn = ACT2FN[config.hidden_act]
|
| 63 |
+
|
| 64 |
+
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
|
| 65 |
+
current_hidden_states = self.act_fn(self.w1(hidden_states)) * self.gate(hidden_states)
|
| 66 |
+
current_hidden_states = self.w2(current_hidden_states)
|
| 67 |
+
return current_hidden_states
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
class MixtralSparseMoeBlock(nn.Module):
|
| 71 |
+
"""
|
| 72 |
+
This implementation is
|
| 73 |
+
strictly equivalent to standard MoE with full capacity (no
|
| 74 |
+
dropped tokens). It's faster since it formulates MoE operations
|
| 75 |
+
in terms of block-sparse operations to accomodate imbalanced
|
| 76 |
+
assignments of tokens to experts, whereas standard MoE either
|
| 77 |
+
(1) drop tokens at the cost of reduced performance or (2) set
|
| 78 |
+
capacity factor to number of experts and thus waste computation
|
| 79 |
+
and memory on padding.
|
| 80 |
+
"""
|
| 81 |
+
|
| 82 |
+
def __init__(self, config, input_size: int, widening_factor: int):
|
| 83 |
+
super().__init__()
|
| 84 |
+
self.hidden_dim = input_size
|
| 85 |
+
self.widening_factor = widening_factor
|
| 86 |
+
self.num_experts = config.moe_num_experts
|
| 87 |
+
self.top_k = config.moe_topk
|
| 88 |
+
|
| 89 |
+
# gating
|
| 90 |
+
self.gate = nn.Linear(self.hidden_dim, self.num_experts, bias=False)
|
| 91 |
+
self.experts = nn.ModuleList(
|
| 92 |
+
[MixtralBlockSparseTop2MLP(config, self.hidden_dim, self.widening_factor) for _ in range(self.num_experts)])
|
| 93 |
+
|
| 94 |
+
@optional_compiler_disable
|
| 95 |
+
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
|
| 96 |
+
""" """
|
| 97 |
+
batch_size, sequence_length, hidden_dim = hidden_states.shape
|
| 98 |
+
hidden_states = hidden_states.view(-1, hidden_dim)
|
| 99 |
+
# router_logits: (batch * sequence_length, n_experts)
|
| 100 |
+
router_logits = self.gate(hidden_states)
|
| 101 |
+
|
| 102 |
+
routing_weights = F.softmax(router_logits, dim=1, dtype=torch.float)
|
| 103 |
+
routing_weights, selected_experts = torch.topk(routing_weights, self.top_k, dim=-1)
|
| 104 |
+
routing_weights /= routing_weights.sum(dim=-1, keepdim=True)
|
| 105 |
+
# we cast back to the input dtype
|
| 106 |
+
routing_weights = routing_weights.to(hidden_states.dtype)
|
| 107 |
+
|
| 108 |
+
final_hidden_states = torch.zeros((batch_size * sequence_length, hidden_dim),
|
| 109 |
+
dtype=hidden_states.dtype,
|
| 110 |
+
device=hidden_states.device)
|
| 111 |
+
|
| 112 |
+
# One hot encode the selected experts to create an expert mask
|
| 113 |
+
# this will be used to easily index which expert is going to be sollicitated
|
| 114 |
+
expert_mask = torch.nn.functional.one_hot(selected_experts, num_classes=self.num_experts).permute(2, 1, 0)
|
| 115 |
+
|
| 116 |
+
# Loop over all available experts in the model and perform the computation on each expert
|
| 117 |
+
for expert_idx in range(self.num_experts):
|
| 118 |
+
expert_layer = self.experts[expert_idx]
|
| 119 |
+
idx, top_x = torch.where(expert_mask[expert_idx])
|
| 120 |
+
|
| 121 |
+
if top_x.shape[0] == 0:
|
| 122 |
+
continue
|
| 123 |
+
|
| 124 |
+
# in torch it is faster to index using lists than torch tensors
|
| 125 |
+
top_x_list = top_x.tolist()
|
| 126 |
+
idx_list = idx.tolist()
|
| 127 |
+
|
| 128 |
+
# Index the correct hidden states and compute the expert hidden state for
|
| 129 |
+
# the current expert. We need to make sure to multiply the output hidden
|
| 130 |
+
# states by `routing_weights` on the corresponding tokens (top-1 and top-2)
|
| 131 |
+
current_state = hidden_states[None, top_x_list].reshape(-1, hidden_dim)
|
| 132 |
+
current_hidden_states = expert_layer(current_state) * routing_weights[top_x_list, idx_list, None]
|
| 133 |
+
|
| 134 |
+
# However `index_add_` only support torch tensors for indexing so we'll use
|
| 135 |
+
# the `top_x` tensor here.
|
| 136 |
+
final_hidden_states.index_add_(0, top_x, current_hidden_states.to(hidden_states.dtype))
|
| 137 |
+
final_hidden_states = final_hidden_states.reshape(batch_size, sequence_length, hidden_dim)
|
| 138 |
+
return final_hidden_states, router_logits
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
class MLP(nn.Module):
|
| 142 |
+
"""A Standard Transformer-style dense module to follow attention."""
|
| 143 |
+
|
| 144 |
+
def __init__(self, config: PretrainedConfig, input_size: int, widening_factor: int):
|
| 145 |
+
super().__init__()
|
| 146 |
+
self.dense1 = nn.Linear(input_size, widening_factor * input_size)
|
| 147 |
+
self.dense2 = nn.Linear(widening_factor * input_size, input_size)
|
| 148 |
+
|
| 149 |
+
if isinstance(config.hidden_act, str):
|
| 150 |
+
self.intermediate_act_fn = ACT2FN[config.hidden_act]
|
| 151 |
+
else:
|
| 152 |
+
self.intermediate_act_fn = config.hidden_act
|
| 153 |
+
|
| 154 |
+
def forward(self, hidden_states: torch.Tensor) -> Tuple[torch.Tensor, Any]:
|
| 155 |
+
hidden_states = self.dense1(hidden_states)
|
| 156 |
+
hidden_states = self.intermediate_act_fn(hidden_states)
|
| 157 |
+
hidden_states = self.dense2(hidden_states)
|
| 158 |
+
return hidden_states, None
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
class SimpleGMLP(nn.Module):
|
| 162 |
+
"""A Simple Gated Multilayer Perceptron (aka. 'gmlp'), without the spatial gating mechanism.
|
| 163 |
+
|
| 164 |
+
Note that this is not the spatial gating MLP (https://arxiv.org/abs/2105.08050).
|
| 165 |
+
- A simplified MLP w/ gating mechanism adapted from Mixtral Expert, as when
|
| 166 |
+
the number of experts and top_k are both set to 1.)
|
| 167 |
+
- Added a dropout layer.
|
| 168 |
+
- This was also used in T5 v1.1.
|
| 169 |
+
"""
|
| 170 |
+
|
| 171 |
+
def __init__(self, config: PretrainedConfig, input_size: int, widening_factor: int):
|
| 172 |
+
super().__init__()
|
| 173 |
+
self.hidden_dim = input_size
|
| 174 |
+
self.ffn_dim = int(input_size * widening_factor)
|
| 175 |
+
|
| 176 |
+
self.w1 = nn.Linear(self.hidden_dim, self.ffn_dim, bias=False)
|
| 177 |
+
self.w2 = nn.Linear(self.ffn_dim, self.hidden_dim, bias=False)
|
| 178 |
+
self.gate = nn.Linear(self.hidden_dim, self.ffn_dim, bias=False)
|
| 179 |
+
self.act_fn = ACT2FN[config.hidden_act]
|
| 180 |
+
self.dropout1 = nn.Dropout(config.dropout_rate)
|
| 181 |
+
self.dropout2 = nn.Dropout(config.dropout_rate)
|
| 182 |
+
|
| 183 |
+
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
|
| 184 |
+
current_hidden_states = self.act_fn(self.w1(hidden_states)) * self.gate(hidden_states)
|
| 185 |
+
current_hidden_states = self.dropout1(current_hidden_states)
|
| 186 |
+
current_hidden_states = self.w2(current_hidden_states)
|
| 187 |
+
current_hidden_states = self.dropout2(
|
| 188 |
+
current_hidden_states) # Residual connection is applied outside of this module.
|
| 189 |
+
return current_hidden_states, None
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
def get_ff_layer(config: PretrainedConfig, input_size: int, widening_factor: int):
|
| 193 |
+
if config.ff_layer_type == 'moe':
|
| 194 |
+
assert hasattr(config, 'moe_num_experts') and hasattr(config, 'moe_topk') and hasattr(config, 'hidden_act')
|
| 195 |
+
return MixtralSparseMoeBlock(config, input_size, widening_factor)
|
| 196 |
+
elif config.ff_layer_type == 'mlp':
|
| 197 |
+
assert hasattr(config, 'hidden_act')
|
| 198 |
+
return MLP(config, input_size, widening_factor)
|
| 199 |
+
elif config.ff_layer_type == 'gmlp':
|
| 200 |
+
assert hasattr(config, 'hidden_act')
|
| 201 |
+
return SimpleGMLP(config, input_size, widening_factor)
|
| 202 |
+
else:
|
| 203 |
+
raise ValueError(
|
| 204 |
+
f"Unsupported ff_layer_type: {config.ff_layer_type}. Supported types are 'moe', 'mlp' and 'gmlp'.")
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
def test_get_ff_layer():
|
| 208 |
+
from model.ff_layer import get_ff_layer
|
| 209 |
+
from model.perceiver_helper import PerceiverTFConfig
|
| 210 |
+
input_size = 32
|
| 211 |
+
widening_factor = 1
|
| 212 |
+
|
| 213 |
+
# Test for MoE
|
| 214 |
+
config = PerceiverTFConfig() # or any type of PretrainedConfig()
|
| 215 |
+
config.ff_layer_type = 'moe'
|
| 216 |
+
config.moe_num_experts = 4
|
| 217 |
+
config.moe_topk = 2
|
| 218 |
+
config.hidden_act = 'silu'
|
| 219 |
+
|
| 220 |
+
ff_layer = get_ff_layer(config, input_size, widening_factor)
|
| 221 |
+
x = torch.rand(2, 8, input_size)
|
| 222 |
+
hidden_states, router_logits = ff_layer(x)
|
| 223 |
+
print(hidden_states.shape, router_logits.shape) # (2, 8, 32), (2*8, 4)
|
| 224 |
+
|
| 225 |
+
# Test for MLP
|
| 226 |
+
config.ff_layer_type = 'mlp'
|
| 227 |
+
config.hidden_act = 'gelu'
|
| 228 |
+
|
| 229 |
+
ff_layer = get_ff_layer(config, input_size, widening_factor)
|
| 230 |
+
hidden_states, _ = ff_layer(x)
|
| 231 |
+
print(hidden_states.shape) # (2, 8, 32)
|
| 232 |
+
|
| 233 |
+
# Test for (simple)gMLP
|
| 234 |
+
config.ff_layer_type = 'gmlp'
|
| 235 |
+
config.hidden_act = 'silu'
|
| 236 |
+
ff_layer = get_ff_layer(config, input_size, widening_factor)
|
| 237 |
+
hidden_states, _ = ff_layer(x)
|
| 238 |
+
print(hidden_states.shape) # (2, 8, 32)
|
amt/src/model/init_train.py
ADDED
|
@@ -0,0 +1,281 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 The YourMT3 Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Please see the details in the LICENSE file.
|
| 10 |
+
"""init_train.py"""
|
| 11 |
+
from typing import Tuple, Literal, Any
|
| 12 |
+
from copy import deepcopy
|
| 13 |
+
import os
|
| 14 |
+
import argparse
|
| 15 |
+
import pytorch_lightning as pl
|
| 16 |
+
from pytorch_lightning.loggers import WandbLogger
|
| 17 |
+
from pytorch_lightning.callbacks import ModelCheckpoint
|
| 18 |
+
from pytorch_lightning.callbacks import LearningRateMonitor
|
| 19 |
+
from pytorch_lightning.utilities import rank_zero_only
|
| 20 |
+
from config.config import shared_cfg as default_shared_cfg
|
| 21 |
+
from config.config import audio_cfg as default_audio_cfg
|
| 22 |
+
from config.config import model_cfg as default_model_cfg
|
| 23 |
+
from config.config import DEEPSPEED_CFG
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def initialize_trainer(args: argparse.Namespace,
|
| 27 |
+
stage: Literal['train', 'test'] = 'train') -> Tuple[pl.Trainer, WandbLogger, dict]:
|
| 28 |
+
"""Initialize trainer and logger"""
|
| 29 |
+
shared_cfg = deepcopy(default_shared_cfg)
|
| 30 |
+
|
| 31 |
+
# create save dir
|
| 32 |
+
os.makedirs(shared_cfg["WANDB"]["save_dir"], exist_ok=True)
|
| 33 |
+
|
| 34 |
+
# collecting specific checkpoint from exp_id with extension (@xxx where xxx is checkpoint name)
|
| 35 |
+
if "@" in args.exp_id:
|
| 36 |
+
args.exp_id, checkpoint_name = args.exp_id.split("@")
|
| 37 |
+
else:
|
| 38 |
+
checkpoint_name = "last.ckpt"
|
| 39 |
+
|
| 40 |
+
# checkpoint dir
|
| 41 |
+
lightning_dir = os.path.join(shared_cfg["WANDB"]["save_dir"], args.project, args.exp_id)
|
| 42 |
+
|
| 43 |
+
# create logger
|
| 44 |
+
if args.wandb_mode is not None:
|
| 45 |
+
shared_cfg["WANDB"]["mode"] = str(args.wandb_mode)
|
| 46 |
+
if shared_cfg["WANDB"].get("cache_dir", None) is not None:
|
| 47 |
+
os.environ["WANDB_CACHE_DIR"] = shared_cfg["WANDB"].get("cache_dir")
|
| 48 |
+
del shared_cfg["WANDB"]["cache_dir"] # remove cache_dir from shared_cfg
|
| 49 |
+
wandb_logger = WandbLogger(log_model="all",
|
| 50 |
+
project=args.project,
|
| 51 |
+
id=args.exp_id,
|
| 52 |
+
allow_val_change=True,
|
| 53 |
+
**shared_cfg['WANDB'])
|
| 54 |
+
|
| 55 |
+
# check if any checkpoint exists
|
| 56 |
+
last_ckpt_path = os.path.join(lightning_dir, "checkpoints", checkpoint_name)
|
| 57 |
+
if os.path.exists(os.path.join(last_ckpt_path)):
|
| 58 |
+
print(f'Resuming from {last_ckpt_path}')
|
| 59 |
+
elif stage == 'train':
|
| 60 |
+
print(f'No checkpoint found in {last_ckpt_path}. Starting from scratch')
|
| 61 |
+
last_ckpt_path = None
|
| 62 |
+
else:
|
| 63 |
+
raise ValueError(f'No checkpoint found in {last_ckpt_path}. Quit...')
|
| 64 |
+
|
| 65 |
+
# add info
|
| 66 |
+
dir_info = dict(lightning_dir=lightning_dir, last_ckpt_path=last_ckpt_path)
|
| 67 |
+
|
| 68 |
+
# define checkpoint callback
|
| 69 |
+
checkpoint_callback = ModelCheckpoint(**shared_cfg["CHECKPOINT"],)
|
| 70 |
+
|
| 71 |
+
# define lr scheduler monitor callback
|
| 72 |
+
lr_monitor = LearningRateMonitor(logging_interval='step')
|
| 73 |
+
|
| 74 |
+
# deepspeed strategy
|
| 75 |
+
if args.strategy == 'deepspeed':
|
| 76 |
+
strategy = pl.strategies.DeepSpeedStrategy(config=DEEPSPEED_CFG)
|
| 77 |
+
|
| 78 |
+
# validation interval
|
| 79 |
+
if stage == 'train' and args.val_interval is not None:
|
| 80 |
+
shared_cfg["TRAINER"]["check_val_every_n_epoch"] = None
|
| 81 |
+
shared_cfg["TRAINER"]["val_check_interval"] = int(args.val_interval)
|
| 82 |
+
|
| 83 |
+
# define trainer
|
| 84 |
+
sync_batchnorm = False
|
| 85 |
+
if stage == 'train':
|
| 86 |
+
# train batch size
|
| 87 |
+
if args.train_batch_size is not None:
|
| 88 |
+
train_sub_bsz = int(args.train_batch_size[0])
|
| 89 |
+
train_local_bsz = int(args.train_batch_size[1])
|
| 90 |
+
if train_local_bsz % train_sub_bsz == 0:
|
| 91 |
+
shared_cfg["BSZ"]["train_sub"] = train_sub_bsz
|
| 92 |
+
shared_cfg["BSZ"]["train_local"] = train_local_bsz
|
| 93 |
+
else:
|
| 94 |
+
raise ValueError(
|
| 95 |
+
f'Local batch size {train_local_bsz} must be divisible by sub batch size {train_sub_bsz}')
|
| 96 |
+
|
| 97 |
+
# ddp strategy
|
| 98 |
+
if args.strategy == 'ddp':
|
| 99 |
+
args.strategy = 'ddp_find_unused_parameters_true' # fix for conformer or pitchshifter having unused parameter issue
|
| 100 |
+
|
| 101 |
+
# sync-batchnorm
|
| 102 |
+
if args.sync_batchnorm is True:
|
| 103 |
+
sync_batchnorm = True
|
| 104 |
+
|
| 105 |
+
train_params = dict(**shared_cfg["TRAINER"],
|
| 106 |
+
devices=args.num_gpus if args.num_gpus == 'auto' else int(args.num_gpus),
|
| 107 |
+
num_nodes=int(args.num_nodes),
|
| 108 |
+
strategy=strategy if args.strategy == 'deepspeed' else args.strategy,
|
| 109 |
+
precision=args.precision,
|
| 110 |
+
max_epochs=args.max_epochs if stage == 'train' else None,
|
| 111 |
+
max_steps=args.max_steps if stage == 'train' else -1,
|
| 112 |
+
logger=wandb_logger,
|
| 113 |
+
callbacks=[checkpoint_callback, lr_monitor],
|
| 114 |
+
sync_batchnorm=sync_batchnorm)
|
| 115 |
+
trainer = pl.trainer.trainer.Trainer(**train_params)
|
| 116 |
+
|
| 117 |
+
# Update wandb logger (for DDP)
|
| 118 |
+
if trainer.global_rank == 0:
|
| 119 |
+
wandb_logger.experiment.config.update(args, allow_val_change=True)
|
| 120 |
+
|
| 121 |
+
return trainer, wandb_logger, dir_info, shared_cfg
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
def update_config(args, shared_cfg, stage: Literal['train', 'test'] = 'train'):
|
| 125 |
+
"""Update audio/model/shared configurations with args"""
|
| 126 |
+
audio_cfg = default_audio_cfg
|
| 127 |
+
model_cfg = default_model_cfg
|
| 128 |
+
|
| 129 |
+
# Only update config when training
|
| 130 |
+
if stage == 'train':
|
| 131 |
+
# Augmentation parameters
|
| 132 |
+
if args.random_amp_range is not None:
|
| 133 |
+
shared_cfg["AUGMENTATION"]["train_random_amp_range"] = list(
|
| 134 |
+
(float(args.random_amp_range[0]), float(args.random_amp_range[1])))
|
| 135 |
+
if args.stem_iaug_prob is not None:
|
| 136 |
+
shared_cfg["AUGMENTATION"]["train_stem_iaug_prob"] = float(args.stem_iaug_prob)
|
| 137 |
+
|
| 138 |
+
if args.xaug_max_k is not None:
|
| 139 |
+
shared_cfg["AUGMENTATION"]["train_stem_xaug_policy"]["max_k"] = int(args.xaug_max_k)
|
| 140 |
+
if args.xaug_tau is not None:
|
| 141 |
+
shared_cfg["AUGMENTATION"]["train_stem_xaug_policy"]["tau"] = float(args.xaug_tau)
|
| 142 |
+
if args.xaug_alpha is not None:
|
| 143 |
+
shared_cfg["AUGMENTATION"]["train_stem_xaug_policy"]["alpha"] = float(args.xaug_alpha)
|
| 144 |
+
if args.xaug_no_instr_overlap is not None:
|
| 145 |
+
shared_cfg["AUGMENTATION"]["train_stem_xaug_policy"]["no_instr_overlap"] = bool(args.xaug_no_instr_overlap)
|
| 146 |
+
if args.xaug_no_drum_overlap is not None:
|
| 147 |
+
shared_cfg["AUGMENTATION"]["train_stem_xaug_policy"]["no_drum_overlap"] = bool(args.xaug_no_drum_overlap)
|
| 148 |
+
if args.uhat_intra_stem_augment is not None:
|
| 149 |
+
shared_cfg["AUGMENTATION"]["train_stem_xaug_policy"]["uhat_intra_stem_augment"] = bool(
|
| 150 |
+
args.uhat_intra_stem_augment)
|
| 151 |
+
|
| 152 |
+
if args.pitch_shift_range is not None:
|
| 153 |
+
if args.pitch_shift_range in [["0", "0"], [0, 0]]:
|
| 154 |
+
shared_cfg["AUGMENTATION"]["train_pitch_shift_range"] = None
|
| 155 |
+
else:
|
| 156 |
+
shared_cfg["AUGMENTATION"]["train_pitch_shift_range"] = list(
|
| 157 |
+
(int(args.pitch_shift_range[0]), int(args.pitch_shift_range[1])))
|
| 158 |
+
|
| 159 |
+
train_stem_iaug_prob = shared_cfg["AUGMENTATION"]["train_stem_iaug_prob"]
|
| 160 |
+
random_amp_range = shared_cfg["AUGMENTATION"]["train_random_amp_range"]
|
| 161 |
+
train_stem_xaug_policy = shared_cfg["AUGMENTATION"]["train_stem_xaug_policy"]
|
| 162 |
+
print(f'Random amp range: {random_amp_range}\n' +
|
| 163 |
+
f'Intra-stem augmentation probability: {train_stem_iaug_prob}\n' +
|
| 164 |
+
f'Stem augmentation policy: {train_stem_xaug_policy}\n' +
|
| 165 |
+
f'Pitch shift range: {shared_cfg["AUGMENTATION"]["train_pitch_shift_range"]}\n')
|
| 166 |
+
|
| 167 |
+
# Update audio config
|
| 168 |
+
if args.audio_codec != None:
|
| 169 |
+
assert args.audio_codec in ['spec', 'melspec']
|
| 170 |
+
audio_cfg["codec"] = str(args.audio_codec)
|
| 171 |
+
if args.hop_length != None:
|
| 172 |
+
audio_cfg["hop_length"] = int(args.hop_length)
|
| 173 |
+
if args.n_mels != None:
|
| 174 |
+
audio_cfg["n_mels"] = int(args.n_mels)
|
| 175 |
+
if args.input_frames != None:
|
| 176 |
+
audio_cfg["input_frames"] = int(args.input_frames)
|
| 177 |
+
|
| 178 |
+
# Update shared config
|
| 179 |
+
if shared_cfg["TOKENIZER"]["max_shift_steps"] == "auto":
|
| 180 |
+
shift_steps_ms = shared_cfg["TOKENIZER"]["shift_step_ms"]
|
| 181 |
+
input_frames = audio_cfg["input_frames"]
|
| 182 |
+
fs = audio_cfg["sample_rate"]
|
| 183 |
+
max_shift_steps = (input_frames / fs) // (shift_steps_ms / 1000) + 2 # 206 by default
|
| 184 |
+
shared_cfg["TOKENIZER"]["max_shift_steps"] = int(max_shift_steps)
|
| 185 |
+
|
| 186 |
+
# Update model config
|
| 187 |
+
if args.encoder_type != None:
|
| 188 |
+
model_cfg["encoder_type"] = str(args.encoder_type)
|
| 189 |
+
if args.decoder_type != None:
|
| 190 |
+
model_cfg["decoder_type"] = str(args.decoder_type)
|
| 191 |
+
if args.pre_encoder_type != "default":
|
| 192 |
+
model_cfg["pre_encoder_type"] = str(args.pre_encoder_type)
|
| 193 |
+
if args.pre_decoder_type != 'default':
|
| 194 |
+
model_cfg["pre_decoder_type"] = str(args.pre_decoder_type)
|
| 195 |
+
if args.conv_out_channels != None:
|
| 196 |
+
model_cfg["conv_out_channels"] = int(args.conv_out_channels)
|
| 197 |
+
assert isinstance(args.task_cond_decoder, bool) and isinstance(args.task_cond_encoder, bool)
|
| 198 |
+
model_cfg["use_task_conditional_encoder"] = args.task_cond_encoder
|
| 199 |
+
model_cfg["use_task_conditional_decoder"] = args.task_cond_decoder
|
| 200 |
+
|
| 201 |
+
if args.encoder_position_encoding_type != 'default':
|
| 202 |
+
if args.encoder_position_encoding_type in ['None', 'none', '0']:
|
| 203 |
+
model_cfg["encoder"][model_cfg["encoder_type"]]["position_encoding_type"] = None
|
| 204 |
+
elif args.encoder_position_encoding_type in [
|
| 205 |
+
'sinusoidal', 'rope', 'trainable', 'alibi', 'alibit', 'tkd', 'td', 'tk', 'kdt'
|
| 206 |
+
]:
|
| 207 |
+
model_cfg["encoder"][model_cfg["encoder_type"]]["position_encoding_type"] = str(
|
| 208 |
+
args.encoder_position_encoding_type)
|
| 209 |
+
else:
|
| 210 |
+
raise ValueError(f'Encoder PE type {args.encoder_position_encoding_type} not supported')
|
| 211 |
+
if args.decoder_position_encoding_type != 'default':
|
| 212 |
+
if args.decoder_position_encoding_type in ['None', 'none', '0']:
|
| 213 |
+
raise ValueError('Decoder PE type cannot be None')
|
| 214 |
+
elif args.decoder_position_encoding_type in ['sinusoidal', 'trainable']:
|
| 215 |
+
model_cfg["decoder"][model_cfg["decoder_type"]]["position_encoding_type"] = str(
|
| 216 |
+
args.decoder_position_encoding_type)
|
| 217 |
+
else:
|
| 218 |
+
raise ValueError(f'Decoder PE {args.decoder_position_encoding_type} not supported')
|
| 219 |
+
|
| 220 |
+
if args.tie_word_embedding is not None:
|
| 221 |
+
model_cfg["tie_word_embedding"] = bool(args.tie_word_embedding)
|
| 222 |
+
|
| 223 |
+
if args.d_feat != None:
|
| 224 |
+
model_cfg["d_feat"] = int(args.d_feat)
|
| 225 |
+
if args.d_latent != None:
|
| 226 |
+
model_cfg['encoder']['perceiver-tf']["d_latent"] = int(args.d_latent)
|
| 227 |
+
if args.num_latents != None:
|
| 228 |
+
model_cfg['encoder']['perceiver-tf']['num_latents'] = int(args.num_latents)
|
| 229 |
+
if args.perceiver_tf_d_model != None:
|
| 230 |
+
model_cfg['encoder']['perceiver-tf']['d_model'] = int(args.perceiver_tf_d_model)
|
| 231 |
+
if args.num_perceiver_tf_blocks != None:
|
| 232 |
+
model_cfg["encoder"]["perceiver-tf"]["num_blocks"] = int(args.num_perceiver_tf_blocks)
|
| 233 |
+
if args.num_perceiver_tf_local_transformers_per_block != None:
|
| 234 |
+
model_cfg["encoder"]["perceiver-tf"]["num_local_transformers_per_block"] = int(
|
| 235 |
+
args.num_perceiver_tf_local_transformers_per_block)
|
| 236 |
+
if args.num_perceiver_tf_temporal_transformers_per_block != None:
|
| 237 |
+
model_cfg["encoder"]["perceiver-tf"]["num_temporal_transformers_per_block"] = int(
|
| 238 |
+
args.num_perceiver_tf_temporal_transformers_per_block)
|
| 239 |
+
if args.attention_to_channel != None:
|
| 240 |
+
model_cfg["encoder"]["perceiver-tf"]["attention_to_channel"] = bool(args.attention_to_channel)
|
| 241 |
+
if args.sca_use_query_residual != None:
|
| 242 |
+
model_cfg["encoder"]["perceiver-tf"]["sca_use_query_residual"] = bool(args.sca_use_query_residual)
|
| 243 |
+
if args.layer_norm_type != None:
|
| 244 |
+
model_cfg["encoder"]["perceiver-tf"]["layer_norm"] = str(args.layer_norm_type)
|
| 245 |
+
if args.ff_layer_type != None:
|
| 246 |
+
model_cfg["encoder"]["perceiver-tf"]["ff_layer_type"] = str(args.ff_layer_type)
|
| 247 |
+
if args.ff_widening_factor != None:
|
| 248 |
+
model_cfg["encoder"]["perceiver-tf"]["ff_widening_factor"] = int(args.ff_widening_factor)
|
| 249 |
+
if args.moe_num_experts != None:
|
| 250 |
+
model_cfg["encoder"]["perceiver-tf"]["moe_num_experts"] = int(args.moe_num_experts)
|
| 251 |
+
if args.moe_topk != None:
|
| 252 |
+
model_cfg["encoder"]["perceiver-tf"]["moe_topk"] = int(args.moe_topk)
|
| 253 |
+
if args.hidden_act != None:
|
| 254 |
+
model_cfg["encoder"]["perceiver-tf"]["hidden_act"] = str(args.hidden_act)
|
| 255 |
+
if args.rotary_type != None:
|
| 256 |
+
assert len(
|
| 257 |
+
args.rotary_type
|
| 258 |
+
) == 3, "rotary_type must be a 3-letter string (e.g. 'ppl': 'pixel' for SCA, 'pixel' for latent, 'lang' for temporal transformer)"
|
| 259 |
+
model_cfg["encoder"]["perceiver-tf"]["rotary_type_sca"] = str(args.rotary_type)[0]
|
| 260 |
+
model_cfg["encoder"]["perceiver-tf"]["rotary_type_latent"] = str(args.rotary_type)[1]
|
| 261 |
+
model_cfg["encoder"]["perceiver-tf"]["rotary_type_temporal"] = str(args.rotary_type)[2]
|
| 262 |
+
if args.rope_apply_to_keys != None:
|
| 263 |
+
model_cfg["encoder"]["perceiver-tf"]["rope_apply_to_keys"] = bool(args.rope_apply_to_keys)
|
| 264 |
+
if args.rope_partial_pe != None:
|
| 265 |
+
model_cfg["encoder"]["perceiver-tf"]["rope_partial_pe"] = bool(args.rope_partial_pe)
|
| 266 |
+
|
| 267 |
+
if args.decoder_ff_layer_type != None:
|
| 268 |
+
model_cfg["decoder"][model_cfg["decoder_type"]]["ff_layer_type"] = str(args.decoder_ff_layer_type)
|
| 269 |
+
if args.decoder_ff_widening_factor != None:
|
| 270 |
+
model_cfg["decoder"][model_cfg["decoder_type"]]["ff_widening_factor"] = int(args.decoder_ff_widening_factor)
|
| 271 |
+
|
| 272 |
+
if args.event_length != None:
|
| 273 |
+
model_cfg["event_length"] = int(args.event_length)
|
| 274 |
+
|
| 275 |
+
if stage == 'train':
|
| 276 |
+
if args.encoder_dropout_rate != None:
|
| 277 |
+
model_cfg["encoder"][model_cfg["encoder_type"]]["dropout_rate"] = float(args.encoder_dropout_rate)
|
| 278 |
+
if args.decoder_dropout_rate != None:
|
| 279 |
+
model_cfg["decoder"][model_cfg["decoder_type"]]["dropout_rate"] = float(args.decoder_dropout_rate)
|
| 280 |
+
|
| 281 |
+
return shared_cfg, audio_cfg, model_cfg # return updated configs
|
amt/src/model/lm_head.py
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 The YourMT3 Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Please see the details in the LICENSE file.
|
| 10 |
+
"""lm_head.py"""
|
| 11 |
+
import torch
|
| 12 |
+
from torch import nn
|
| 13 |
+
from typing import Optional, Dict
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class LMHead(nn.Module):
|
| 17 |
+
"""Language Model Head with tied weights."""
|
| 18 |
+
|
| 19 |
+
def __init__(self, decoder_config: Dict, init_factor: float = 1.0, tie_word_embeddings: bool = True):
|
| 20 |
+
|
| 21 |
+
super().__init__()
|
| 22 |
+
self.d_model = decoder_config["d_model"]
|
| 23 |
+
self.init_factor = init_factor
|
| 24 |
+
self.tie_word_embeddings = tie_word_embeddings
|
| 25 |
+
|
| 26 |
+
self.lm_head = nn.Linear(decoder_config["d_model"], decoder_config["vocab_size"], bias=False)
|
| 27 |
+
self._init_weights()
|
| 28 |
+
|
| 29 |
+
def _init_weights(self):
|
| 30 |
+
if self.tie_word_embeddings is False:
|
| 31 |
+
self.lm_head.weight.data.normal_(mean=0.0, std=self.init_factor * 1.0)
|
| 32 |
+
|
| 33 |
+
def forward(self, decoder_hs: torch.FloatTensor) -> torch.FloatTensor:
|
| 34 |
+
if self.tie_word_embeddings is True:
|
| 35 |
+
# Rescale output before projecting on vocab
|
| 36 |
+
# See https://github.com/tensorflow/mesh/blob/fa19d69eafc9a482aff0b59ddd96b025c0cb207d/mesh_tensorflow/transformer/transformer.py#L586
|
| 37 |
+
decoder_hs = decoder_hs * (self.d_model**-0.5)
|
| 38 |
+
|
| 39 |
+
lm_logits = self.lm_head(decoder_hs)
|
| 40 |
+
return lm_logits
|
amt/src/model/lr_scheduler.py
ADDED
|
@@ -0,0 +1,91 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 The YourMT3 Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Please see the details in the LICENSE file.
|
| 10 |
+
"""lr_schedule.py"""
|
| 11 |
+
import torch
|
| 12 |
+
from typing import Dict, Optional
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def get_lr_scheduler(optimizer: torch.optim.Optimizer, scheduler_name: str, base_lr: float, scheduler_cfg: Dict):
|
| 16 |
+
|
| 17 |
+
if scheduler_name.lower() == 'cosine':
|
| 18 |
+
from torch.optim.lr_scheduler import (
|
| 19 |
+
SequentialLR,
|
| 20 |
+
LinearLR,
|
| 21 |
+
CosineAnnealingLR,
|
| 22 |
+
)
|
| 23 |
+
|
| 24 |
+
scheduler1 = LinearLR(
|
| 25 |
+
optimizer,
|
| 26 |
+
start_factor=0.5,
|
| 27 |
+
end_factor=1,
|
| 28 |
+
total_iters=scheduler_cfg["warmup_steps"],
|
| 29 |
+
last_epoch=-1,
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
scheduler2 = CosineAnnealingLR(
|
| 33 |
+
optimizer,
|
| 34 |
+
T_max=scheduler_cfg["total_steps"] - scheduler_cfg["warmup_steps"],
|
| 35 |
+
eta_min=scheduler_cfg["final_cosine"],
|
| 36 |
+
)
|
| 37 |
+
|
| 38 |
+
lr_scheduler = SequentialLR(optimizer,
|
| 39 |
+
schedulers=[scheduler1, scheduler2],
|
| 40 |
+
milestones=[scheduler_cfg["warmup_steps"]])
|
| 41 |
+
elif scheduler_name.lower() == 'legacy':
|
| 42 |
+
import math
|
| 43 |
+
from torch.optim.lr_scheduler import (
|
| 44 |
+
SequentialLR,
|
| 45 |
+
LinearLR,
|
| 46 |
+
LambdaLR,
|
| 47 |
+
)
|
| 48 |
+
|
| 49 |
+
msg = "You are using T5 legacy LR Schedule, it's independent from the optim.base_lr"
|
| 50 |
+
print(msg)
|
| 51 |
+
|
| 52 |
+
num_steps_optimizer1 = math.ceil(scheduler_cfg["total_steps"] * 0.9)
|
| 53 |
+
iters_left_for_optimizer2 = scheduler_cfg["total_steps"] - num_steps_optimizer1
|
| 54 |
+
|
| 55 |
+
scheduler1 = LambdaLR(optimizer, lambda step: min(base_lr, 1.0 / math.sqrt(step)) / base_lr
|
| 56 |
+
if step else base_lr / base_lr)
|
| 57 |
+
|
| 58 |
+
scheduler2 = LinearLR(optimizer,
|
| 59 |
+
start_factor=(min(base_lr, 1.0 / math.sqrt(num_steps_optimizer1)) / base_lr),
|
| 60 |
+
end_factor=0,
|
| 61 |
+
total_iters=iters_left_for_optimizer2,
|
| 62 |
+
last_epoch=-1)
|
| 63 |
+
|
| 64 |
+
lr_scheduler = SequentialLR(
|
| 65 |
+
optimizer,
|
| 66 |
+
schedulers=[scheduler1, scheduler2],
|
| 67 |
+
milestones=[num_steps_optimizer1],
|
| 68 |
+
)
|
| 69 |
+
elif scheduler_name.lower() == 'constant':
|
| 70 |
+
from transformers import get_scheduler
|
| 71 |
+
lr_scheduler = get_scheduler(
|
| 72 |
+
name=scheduler_name.lower(),
|
| 73 |
+
optimizer=optimizer,
|
| 74 |
+
)
|
| 75 |
+
else:
|
| 76 |
+
raise NotImplementedError
|
| 77 |
+
|
| 78 |
+
return lr_scheduler
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def extra_stats(args, model, optimizer):
|
| 82 |
+
stats = {}
|
| 83 |
+
|
| 84 |
+
if args.logging.weights_l2:
|
| 85 |
+
weights_l2 = sum(p.detach().norm(2).item()**2 for p in model.parameters())**0.5
|
| 86 |
+
stats['weights_l2'] = weights_l2
|
| 87 |
+
|
| 88 |
+
cur_lr = optimizer.param_groups[0]['lr']
|
| 89 |
+
stats['lr'] = cur_lr
|
| 90 |
+
|
| 91 |
+
return stats
|
amt/src/model/ops.py
ADDED
|
@@ -0,0 +1,111 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 The YourMT3 Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Please see the details in the LICENSE file.
|
| 10 |
+
""" op.py """
|
| 11 |
+
import math
|
| 12 |
+
from packaging.version import parse as VersionParse
|
| 13 |
+
|
| 14 |
+
import torch
|
| 15 |
+
import torch.nn as nn
|
| 16 |
+
import torch.nn.functional as F
|
| 17 |
+
from einops import rearrange
|
| 18 |
+
from transformers.models.t5.modeling_t5 import T5LayerNorm as RMSNorm
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def get_layer_norm(dim: int, layer_norm_type: str = "layer_norm", layer_norm_eps: float = 1e-5):
|
| 22 |
+
"""Get layer normalization layer.
|
| 23 |
+
Args:
|
| 24 |
+
dim (int): Feature dimension
|
| 25 |
+
layer_norm_type (str): "layer_norm" or "rms_norm"
|
| 26 |
+
layer_norm_eps (float): Epsilon value for numerical stability
|
| 27 |
+
|
| 28 |
+
Returns:
|
| 29 |
+
nn.Module: Layer normalization layer
|
| 30 |
+
"""
|
| 31 |
+
if layer_norm_type == "rms_norm":
|
| 32 |
+
# T5LayerNorm is equivalent to RMSNorm. https://arxiv.org/abs/1910.07467
|
| 33 |
+
return RMSNorm(hidden_size=dim, eps=layer_norm_eps)
|
| 34 |
+
else:
|
| 35 |
+
return nn.LayerNorm(normalized_shape=dim, eps=layer_norm_eps)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def check_all_elements_equal(x: torch.Tensor) -> bool:
|
| 39 |
+
return x.eq(x[0]).all().item()
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def minmax_normalize(x: torch.Tensor, eps: float = 0.008) -> torch.FloatTensor:
|
| 43 |
+
"""Min-max normalization:
|
| 44 |
+
|
| 45 |
+
x_norm = (x - x_min) / (x_max - x_min + eps)
|
| 46 |
+
|
| 47 |
+
Args:
|
| 48 |
+
x (torch.Tensor): (B, T, F)
|
| 49 |
+
Returns:
|
| 50 |
+
torch.Tensor: (B, T, F) with output range of [0, 1]
|
| 51 |
+
"""
|
| 52 |
+
x_max = rearrange(x, "b t f -> b (t f)").max(1, keepdim=True)[0]
|
| 53 |
+
x_min = rearrange(x, "b t f -> b (f t)").min(1, keepdim=True)[0]
|
| 54 |
+
x_max = x_max[:, None, :] # (B,1,1)
|
| 55 |
+
x_min = x_min[:, None, :] # (B,1,1)
|
| 56 |
+
return (x - x_min) / (x_max - x_min + eps)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
def count_parameters(model):
|
| 60 |
+
num_trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
|
| 61 |
+
num_params = sum(p.numel() for p in model.parameters())
|
| 62 |
+
return num_trainable_params, num_params
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def adjust_b_to_gcd(a, b, min_gcd=16):
|
| 66 |
+
"""
|
| 67 |
+
Adjust the value of b to ensure the GCD(a, b) is at least min_gcd with minimum change to b.
|
| 68 |
+
|
| 69 |
+
Parameters:
|
| 70 |
+
- a (int): A positive integer
|
| 71 |
+
- b (int): A positive integer
|
| 72 |
+
- min_gcd (int): The minimum desired GCD
|
| 73 |
+
|
| 74 |
+
Returns:
|
| 75 |
+
- int: The adjusted value of b
|
| 76 |
+
"""
|
| 77 |
+
current_gcd = math.gcd(a, b)
|
| 78 |
+
|
| 79 |
+
# If current GCD is already greater than or equal to min_gcd, return b as it is.
|
| 80 |
+
if current_gcd >= min_gcd:
|
| 81 |
+
return b
|
| 82 |
+
|
| 83 |
+
# If a is less than min_gcd, then it's impossible to get a GCD of at least min_gcd.
|
| 84 |
+
if a < min_gcd:
|
| 85 |
+
raise ValueError("a must be at least as large as min_gcd.")
|
| 86 |
+
|
| 87 |
+
# Adjust b by trying increments and decrements, preferring the smallest absolute change.
|
| 88 |
+
adjusted_b_up = b
|
| 89 |
+
adjusted_b_down = b
|
| 90 |
+
|
| 91 |
+
while True:
|
| 92 |
+
adjusted_b_up += 1
|
| 93 |
+
adjusted_b_down -= 1
|
| 94 |
+
|
| 95 |
+
if math.gcd(a, adjusted_b_up) >= min_gcd:
|
| 96 |
+
return adjusted_b_up
|
| 97 |
+
elif math.gcd(a, adjusted_b_down) >= min_gcd:
|
| 98 |
+
return adjusted_b_down
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def optional_compiler_disable(func):
|
| 102 |
+
if VersionParse(torch.__version__) >= VersionParse("2.1"):
|
| 103 |
+
# If the version is 2.1 or higher, apply the torch.compiler.disable decorator.
|
| 104 |
+
return torch.compiler.disable(func)
|
| 105 |
+
else:
|
| 106 |
+
# If the version is below 2.1, return the original function.
|
| 107 |
+
return func
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def optional_compiler_dynamic(func):
|
| 111 |
+
return torch.compile(func, dynamic=True)
|
amt/src/model/optimizers.py
ADDED
|
@@ -0,0 +1,218 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
""" optimizers.py
|
| 2 |
+
|
| 3 |
+
Code based on nanoT5 project:
|
| 4 |
+
https://github.com/PiotrNawrot/nanoT5/blob/main/nanoT5/utils/copied_utils.py
|
| 5 |
+
|
| 6 |
+
+ D-adapt Adam from https://github.com/facebookresearch/dadaptation
|
| 7 |
+
"""
|
| 8 |
+
import importlib
|
| 9 |
+
import math
|
| 10 |
+
import torch
|
| 11 |
+
|
| 12 |
+
from typing import Iterable, Tuple
|
| 13 |
+
from torch import nn
|
| 14 |
+
from torch.optim import Optimizer
|
| 15 |
+
from transformers import Adafactor
|
| 16 |
+
from torch.optim import AdamW
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class AdamWScale(Optimizer):
|
| 20 |
+
"""
|
| 21 |
+
This AdamW implementation is copied from Huggingface.
|
| 22 |
+
We modified it with Adagrad scaling by rms of a weight tensor
|
| 23 |
+
|
| 24 |
+
Implements Adam algorithm with weight decay fix as introduced in [Decoupled Weight Decay
|
| 25 |
+
Regularization](https://arxiv.org/abs/1711.05101).
|
| 26 |
+
|
| 27 |
+
Parameters:
|
| 28 |
+
params (`Iterable[nn.parameter.Parameter]`):
|
| 29 |
+
Iterable of parameters to optimize or dictionaries defining parameter groups.
|
| 30 |
+
lr (`float`, *optional*, defaults to 1e-3):
|
| 31 |
+
The learning rate to use.
|
| 32 |
+
betas (`Tuple[float,float]`, *optional*, defaults to (0.9, 0.999)):
|
| 33 |
+
Adam's betas parameters (b1, b2).
|
| 34 |
+
eps (`float`, *optional*, defaults to 1e-6):
|
| 35 |
+
Adam's epsilon for numerical stability.
|
| 36 |
+
weight_decay (`float`, *optional*, defaults to 0):
|
| 37 |
+
Decoupled weight decay to apply.
|
| 38 |
+
correct_bias (`bool`, *optional*, defaults to `True`):
|
| 39 |
+
Whether or not to correct bias in Adam (for instance, in Bert TF repository they use `False`).
|
| 40 |
+
no_deprecation_warning (`bool`, *optional*, defaults to `False`):
|
| 41 |
+
A flag used to disable the deprecation warning (set to `True` to disable the warning).
|
| 42 |
+
"""
|
| 43 |
+
|
| 44 |
+
def __init__(
|
| 45 |
+
self,
|
| 46 |
+
params: Iterable[nn.parameter.Parameter],
|
| 47 |
+
lr: float = 1e-3,
|
| 48 |
+
betas: Tuple[float, float] = (0.9, 0.999),
|
| 49 |
+
eps: float = 1e-6,
|
| 50 |
+
weight_decay: float = 0.0,
|
| 51 |
+
correct_bias: bool = True,
|
| 52 |
+
):
|
| 53 |
+
if lr < 0.0:
|
| 54 |
+
raise ValueError(f"Invalid learning rate: {lr} - should be >= 0.0")
|
| 55 |
+
if not 0.0 <= betas[0] < 1.0:
|
| 56 |
+
raise ValueError(f"Invalid beta parameter: {betas[0]} - should be in [0.0, 1.0)")
|
| 57 |
+
if not 0.0 <= betas[1] < 1.0:
|
| 58 |
+
raise ValueError(f"Invalid beta parameter: {betas[1]} - should be in [0.0, 1.0)")
|
| 59 |
+
if not 0.0 <= eps:
|
| 60 |
+
raise ValueError(f"Invalid epsilon value: {eps} - should be >= 0.0")
|
| 61 |
+
defaults = dict(
|
| 62 |
+
lr=lr, betas=betas, eps=eps, weight_decay=weight_decay, correct_bias=correct_bias)
|
| 63 |
+
super().__init__(params, defaults)
|
| 64 |
+
|
| 65 |
+
@staticmethod
|
| 66 |
+
def _rms(tensor):
|
| 67 |
+
return tensor.norm(2) / (tensor.numel()**0.5)
|
| 68 |
+
|
| 69 |
+
def step(self, closure=None):
|
| 70 |
+
"""
|
| 71 |
+
Performs a single optimization step.
|
| 72 |
+
|
| 73 |
+
Arguments:
|
| 74 |
+
closure (`Callable`, *optional*): A closure that reevaluates the model and returns the loss.
|
| 75 |
+
"""
|
| 76 |
+
loss = None
|
| 77 |
+
if closure is not None:
|
| 78 |
+
loss = closure()
|
| 79 |
+
|
| 80 |
+
for group in self.param_groups:
|
| 81 |
+
for p in group["params"]:
|
| 82 |
+
if p.grad is None:
|
| 83 |
+
continue
|
| 84 |
+
grad = p.grad.data
|
| 85 |
+
if grad.is_sparse:
|
| 86 |
+
raise RuntimeError(
|
| 87 |
+
"Adam does not support sparse gradients, please consider SparseAdam instead"
|
| 88 |
+
)
|
| 89 |
+
|
| 90 |
+
state = self.state[p]
|
| 91 |
+
beta1, beta2 = group["betas"]
|
| 92 |
+
|
| 93 |
+
# State initialization
|
| 94 |
+
if len(state) == 0:
|
| 95 |
+
state["step"] = 0
|
| 96 |
+
# Exponential moving average of gradient values
|
| 97 |
+
state["exp_avg"] = torch.zeros_like(p.data)
|
| 98 |
+
# Exponential moving average of squared gradient values
|
| 99 |
+
state["exp_avg_sq"] = torch.zeros_like(p.data)
|
| 100 |
+
|
| 101 |
+
exp_avg, exp_avg_sq = state["exp_avg"], state["exp_avg_sq"]
|
| 102 |
+
|
| 103 |
+
state["step"] += 1
|
| 104 |
+
|
| 105 |
+
# Decay the first and second moment running average coefficient
|
| 106 |
+
# In-place operations to update the averages at the same time
|
| 107 |
+
exp_avg.mul_(beta1).add_(grad, alpha=(1.0 - beta1))
|
| 108 |
+
exp_avg_sq.mul_(beta2).addcmul_(grad, grad, value=1.0 - beta2)
|
| 109 |
+
denom = exp_avg_sq.sqrt().add_(group["eps"])
|
| 110 |
+
|
| 111 |
+
step_size = group["lr"]
|
| 112 |
+
if group["correct_bias"]: # No bias correction for Bert
|
| 113 |
+
bias_correction1 = 1.0 - beta1**state["step"]
|
| 114 |
+
bias_correction2 = 1.0 - beta2**state["step"]
|
| 115 |
+
step_size = step_size * math.sqrt(bias_correction2) / bias_correction1
|
| 116 |
+
|
| 117 |
+
# /Adapt Step from Adagrad
|
| 118 |
+
step_size = step_size * max(1e-3, self._rms(p.data))
|
| 119 |
+
# /Adapt Step from Adagrad
|
| 120 |
+
|
| 121 |
+
p.data.addcdiv_(exp_avg, denom, value=-step_size)
|
| 122 |
+
|
| 123 |
+
# Just adding the square of the weights to the loss function is *not*
|
| 124 |
+
# the correct way of using L2 regularization/weight decay with Adam,
|
| 125 |
+
# since that will interact with the m and v parameters in strange ways.
|
| 126 |
+
#
|
| 127 |
+
# Instead we want to decay the weights in a manner that doesn't interact
|
| 128 |
+
# with the m/v parameters. This is equivalent to adding the square
|
| 129 |
+
# of the weights to the loss with plain (non-momentum) SGD.
|
| 130 |
+
# Add weight decay at the end (fixed version)
|
| 131 |
+
if group["weight_decay"] > 0.0:
|
| 132 |
+
p.data.add_(p.data, alpha=(-group["lr"] * group["weight_decay"]))
|
| 133 |
+
|
| 134 |
+
return loss
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
# def get_optimizer(models_dict: nn.ModuleDict,
|
| 138 |
+
# optimizer_name: str,
|
| 139 |
+
# base_lr: float,
|
| 140 |
+
# weight_decay: float = 0.):
|
| 141 |
+
|
| 142 |
+
# no_decay = [
|
| 143 |
+
# "bias", "LayerNorm", "layernorm", "layer_norm", "ln", "BatchNorm", "bn", "batch_norm",
|
| 144 |
+
# "batchnorm"
|
| 145 |
+
# ]
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
# optimizer_grouped_parameters = []
|
| 149 |
+
# for name, current_model in models_dict.items():
|
| 150 |
+
# if current_model is None:
|
| 151 |
+
# continue
|
| 152 |
+
# optimizer_grouped_parameters += [
|
| 153 |
+
# {
|
| 154 |
+
# "params": [
|
| 155 |
+
# p for n, p in current_model.named_parameters()
|
| 156 |
+
# if not any(nd in n for nd in no_decay)
|
| 157 |
+
# ],
|
| 158 |
+
# "weight_decay": weight_decay,
|
| 159 |
+
# },
|
| 160 |
+
# {
|
| 161 |
+
# "params": [
|
| 162 |
+
# p for n, p in current_model.named_parameters()
|
| 163 |
+
# if any(nd in n for nd in no_decay)
|
| 164 |
+
# ],
|
| 165 |
+
# "weight_decay": 0.0,
|
| 166 |
+
# },
|
| 167 |
+
# ]
|
| 168 |
+
def get_optimizer(models_dict: nn.ModuleDict,
|
| 169 |
+
optimizer_name: str,
|
| 170 |
+
base_lr: float,
|
| 171 |
+
weight_decay: float = 0.):
|
| 172 |
+
|
| 173 |
+
no_decay = [
|
| 174 |
+
"bias", "LayerNorm", "layernorm", "layer_norm", "ln", "BatchNorm", "bn", "batch_norm",
|
| 175 |
+
"batchnorm"
|
| 176 |
+
]
|
| 177 |
+
optimizer_grouped_parameters = []
|
| 178 |
+
for n, p in models_dict:
|
| 179 |
+
# drop pitch shifter
|
| 180 |
+
if 'pshifters' in n:
|
| 181 |
+
continue
|
| 182 |
+
# no decay
|
| 183 |
+
if n in no_decay:
|
| 184 |
+
optimizer_grouped_parameters.append({"params": [p], "weight_decay": 0.0})
|
| 185 |
+
else:
|
| 186 |
+
optimizer_grouped_parameters.append({"params": [p], "weight_decay": weight_decay})
|
| 187 |
+
|
| 188 |
+
if optimizer_name.lower() == 'adamw':
|
| 189 |
+
base_lr = 1e-03 if base_lr == None else float(base_lr)
|
| 190 |
+
opt = AdamW(optimizer_grouped_parameters, lr=base_lr)
|
| 191 |
+
elif optimizer_name.lower() == 'adafactor':
|
| 192 |
+
if base_lr == None:
|
| 193 |
+
opt = Adafactor(
|
| 194 |
+
optimizer_grouped_parameters,
|
| 195 |
+
lr=None,
|
| 196 |
+
scale_parameter=True,
|
| 197 |
+
relative_step=True,
|
| 198 |
+
warmup_init=True)
|
| 199 |
+
else:
|
| 200 |
+
opt = Adafactor(optimizer_grouped_parameters, lr=base_lr, relative_step=False)
|
| 201 |
+
elif optimizer_name.lower() == 'adamwscale':
|
| 202 |
+
base_lr = 1e-02 if base_lr == None else float(base_lr)
|
| 203 |
+
opt = AdamWScale(
|
| 204 |
+
optimizer_grouped_parameters,
|
| 205 |
+
lr=base_lr,
|
| 206 |
+
)
|
| 207 |
+
elif optimizer_name.lower() == 'cpuadam':
|
| 208 |
+
dspd = importlib.import_module('deepspeed')
|
| 209 |
+
base_lr = 1e-03 if base_lr == None else float(base_lr)
|
| 210 |
+
opt = dspd.ops.adam.cpu_adam.DeepSpeedCPUAdam(optimizer_grouped_parameters, lr=base_lr)
|
| 211 |
+
elif optimizer_name.lower() == 'dadaptadam':
|
| 212 |
+
dadaptation = importlib.import_module('dadaptation')
|
| 213 |
+
base_lr = 1.0 if base_lr == None else float(base_lr)
|
| 214 |
+
opt = dadaptation.DAdaptAdam(optimizer_grouped_parameters, lr=base_lr)
|
| 215 |
+
else:
|
| 216 |
+
raise NotImplementedError(optimizer_name)
|
| 217 |
+
|
| 218 |
+
return opt, base_lr
|
amt/src/model/perceiver_helper.py
ADDED
|
@@ -0,0 +1,290 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 The YourMT3 Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Please see the details in the LICENSE file.
|
| 10 |
+
from dataclasses import dataclass
|
| 11 |
+
from typing import Optional, Tuple
|
| 12 |
+
import torch
|
| 13 |
+
from torch import nn
|
| 14 |
+
from transformers.utils import ModelOutput
|
| 15 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 16 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 17 |
+
# from transformers.models.perceiver.modeling_perceiver import (PerceiverAbstractPositionEncoding,
|
| 18 |
+
# PerceiverTrainablePositionEncoding,
|
| 19 |
+
# PerceiverFourierPositionEncoding)
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class PerceiverTFConfig(PretrainedConfig):
|
| 23 |
+
r"""
|
| 24 |
+
This is the configuration class to store the configuration of a [`PerceiverTF`]. It is used to instantiate an
|
| 25 |
+
Perceiver model according to the specified arguments, defining the model architecture. Instantiating a
|
| 26 |
+
configuration with the defaults will yield a similar configuration to that of the Perceiver
|
| 27 |
+
[deepmind/language-perceiver](https://huggingface.co/deepmind/language-perceiver) architecture.
|
| 28 |
+
|
| 29 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 30 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 31 |
+
|
| 32 |
+
Args:
|
| 33 |
+
num_latents (`int`, *optional*, defaults to 256):
|
| 34 |
+
The number of latents.
|
| 35 |
+
d_latents (`int`, *optional*, defaults to 1280):
|
| 36 |
+
Dimension of the latent embeddings.
|
| 37 |
+
d_model (`int`, *optional*, defaults to 768):
|
| 38 |
+
Dimension of the inputs. Should only be provided in case [*PerceiverTextPreprocessor*] is used or no
|
| 39 |
+
preprocessor is provided.
|
| 40 |
+
kv_dim (`int`, *optional*, defaults to 128):
|
| 41 |
+
num_blocks (`int`, *optional*, defaults to 1):
|
| 42 |
+
Number of blocks in the Transformer encoder.
|
| 43 |
+
num_self_attention_heads (`int`, *optional*, defaults to 8):
|
| 44 |
+
Number of attention heads for each self-attention layer in the Transformer encoder.
|
| 45 |
+
num_cross_attention_heads (`int`, *optional*, defaults to 8):
|
| 46 |
+
Number of attention heads for each cross-attention layer in the Transformer encoder.
|
| 47 |
+
num_local_transformers_per_block (`int`, *optional*, defaults to 2):
|
| 48 |
+
Number of local Transformer layers per Transformer block in the Transformer encoder.
|
| 49 |
+
num_temporal_transformers_per_block (`int`, *optional*, defaults to 2):
|
| 50 |
+
Number of temporal Transformer layers per Transformer block in the Transformer encoder.
|
| 51 |
+
shared_parallel_temporal_transformers (`bool`, *optional*, defaults to `False`):
|
| 52 |
+
Whether to share the parameters across the K parallel temporal Transformers in each block.
|
| 53 |
+
qk_channels (`int`, *optional*):
|
| 54 |
+
Dimension to project the queries + keys before applying attention in the cross-attention and self-attention
|
| 55 |
+
layers of the encoder. Will default to preserving the dimension of the queries if not specified.
|
| 56 |
+
v_channels (`int`, *optional*):
|
| 57 |
+
Dimension to project the values before applying attention in the cross-attention and self-attention layers
|
| 58 |
+
of the encoder. Will default to preserving the dimension of the queries if not specified.
|
| 59 |
+
** DEPRECATED ** cross_attention_shape_for_attention (`str`, *optional*, defaults to `'kv'`):
|
| 60 |
+
Dimension to use when downsampling the queries and keys in the cross-attention layer of the encoder.
|
| 61 |
+
** DEPRECATED ** self_attention_widening_factor (`int`, *optional*, defaults to 1):
|
| 62 |
+
Dimension of the feed-forward layer in the cross-attention layer of the Transformer encoder.
|
| 63 |
+
cross_attention_widening_factor (`int`, *optional*, defaults to 1):
|
| 64 |
+
Dimension of the feed-forward layer in the self-attention layers of the Transformer encoder.
|
| 65 |
+
hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
|
| 66 |
+
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
|
| 67 |
+
`"relu"`, `"selu"` and `"gelu_new"` are supported.
|
| 68 |
+
dropout_rate (`float`, *optional*, defaults to 0.1):
|
| 69 |
+
The dropout ratio for the attention probabilities.
|
| 70 |
+
initializer_range (`float`, *optional*, defaults to 0.02):
|
| 71 |
+
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
| 72 |
+
layer_norm_type (`str`, *optional*, defaults to `'layer_norm'`):
|
| 73 |
+
The type of layer normalization to use. Can be one of {'layer_norm', 'rms_norm'}.
|
| 74 |
+
layer_norm_eps (`float`, *optional*, defaults to 1e-5):
|
| 75 |
+
The epsilon used by the layer normalization layers.
|
| 76 |
+
sca_use_query_residual (`bool`, *optional*, defaults to `True`):
|
| 77 |
+
Whether to add a query residual in the spectral cross attention (SCA) layer of the encoder.
|
| 78 |
+
use_query_residual (`float`, *optional*, defaults to `True`):
|
| 79 |
+
Whether to add a query residual in the cross-attention layer of the encoder.
|
| 80 |
+
position_encoding_type (`str`, *optional*, defaults to `'trainable'`):
|
| 81 |
+
Type of position encoding to use. Can be one of {'trainable', 'alibi', 'alibit', 'rope', None}.
|
| 82 |
+
num_max_positions (`int`, *optional*, defaults to 331):
|
| 83 |
+
Maximum number of positions to use for the position encoding.
|
| 84 |
+
vocab_size (`int`, *optional*, defaults to 262):
|
| 85 |
+
Vocabulary size for the masked language modeling model.
|
| 86 |
+
attention_to_channel (`bool`, defaults to `False`):
|
| 87 |
+
Whether SCA should attend to the channel dimension. If False, attention to frequency bin dimension.
|
| 88 |
+
ff_layer_type (`str`, *optional*, defaults to `'mlp'`):
|
| 89 |
+
Type of feed-forward layer to use. Can be one of {'mlp', 'moe'}.
|
| 90 |
+
ff_widening_factor (`int`, *optional*, defaults to 1):
|
| 91 |
+
Widening factor for the feed-forward layers in the MLP/MoE.
|
| 92 |
+
moe_num_experts (`int`, *optional*, defaults to 4):
|
| 93 |
+
Number of experts to use in the mixture of experts (MoE) feed-forward layer.
|
| 94 |
+
Only used if `ff_layer_type` is set to `'moe'`.
|
| 95 |
+
moe_topk (`int`, *optional*, defaults to 2):
|
| 96 |
+
Number of top experts to use in the mixture of experts (MoE) feed-forward layer.
|
| 97 |
+
Only used if `ff_layer_type` is set to `'moe'`.
|
| 98 |
+
rope_type_sca (`str`, *optional*, defaults to `pixel`): Can be one of {'l'|lang', 'p'|'pixel', None}.
|
| 99 |
+
RoPE index type for SCA. Only used if `position_encoding_type` is set to `rope`.
|
| 100 |
+
rope_type_latent (`str`, *optional*, defaults to `pixel`): Can be one of {'l'|'lang', 'p'|'pixel', None}.
|
| 101 |
+
RoPE index type for Latent Transformer. Only used if `position_encoding_type` is set to `'rope'`.
|
| 102 |
+
rope_type_temporal (`str`, *optional*, defaults to `lang`): Can be one of {'l'|'lang', 'p'|'pixel', None}.
|
| 103 |
+
RoPE index type for Temporal Transformer. Only used if `position_encoding_type` is set to `'rope'`.
|
| 104 |
+
rope_apply_to_keys (`bool`, *optional*, defaults to `False`): Whether to apply RoPE to the keys in the
|
| 105 |
+
self/cross-attention layers. Only used if `position_encoding_type` is set to `'rope'`.
|
| 106 |
+
rope_partial_pe (`bool`, *optional*, defaults to `False`): Whether to use partial RoPE in the self/cross-attention.
|
| 107 |
+
Only used if `position_encoding_type` is set to `'rope'`.
|
| 108 |
+
rope_trainable (`bool`, *optional*, defaults to `False`): Whether to make the RoPE trainable. Only used if
|
| 109 |
+
|
| 110 |
+
Example:
|
| 111 |
+
|
| 112 |
+
```python
|
| 113 |
+
>>> from model.perceiver_mod import PerceiverTFEncodel, PerceiverTFConfig
|
| 114 |
+
|
| 115 |
+
>>> # Initializing a Perceiver deepmind/language-perceiver style configuration
|
| 116 |
+
>>> configuration = PerceiverTFConfig()
|
| 117 |
+
|
| 118 |
+
>>> # Initializing a model from the deepmind/language-perceiver style configuration
|
| 119 |
+
>>> model = PerceiverTFEncoder(configuration)
|
| 120 |
+
|
| 121 |
+
>>> # Accessing the model configuration
|
| 122 |
+
>>> configuration = model.config
|
| 123 |
+
```"""
|
| 124 |
+
model_type = "perceivertf"
|
| 125 |
+
|
| 126 |
+
def __init__(
|
| 127 |
+
self,
|
| 128 |
+
num_latents=24,
|
| 129 |
+
d_latents=128,
|
| 130 |
+
d_model=128,
|
| 131 |
+
kv_dim=128,
|
| 132 |
+
num_blocks=3,
|
| 133 |
+
num_self_attention_heads=8,
|
| 134 |
+
num_cross_attention_heads=8,
|
| 135 |
+
num_local_transformers_per_block=2,
|
| 136 |
+
num_temporal_transformers_per_block=2,
|
| 137 |
+
qk_channels=128,
|
| 138 |
+
v_channels=128,
|
| 139 |
+
cross_attention_shape_for_attention="q",
|
| 140 |
+
# self_attention_widening_factor=1, ** DEPRECATED **
|
| 141 |
+
# cross_attention_widening_factor=1, ** DEPRECATED **
|
| 142 |
+
hidden_act="gelu",
|
| 143 |
+
dropout_rate=0.1,
|
| 144 |
+
initializer_range=0.02,
|
| 145 |
+
layer_norm_type="layer_norm",
|
| 146 |
+
layer_norm_eps=1e-5,
|
| 147 |
+
sca_use_query_residual=True,
|
| 148 |
+
use_query_residual=True,
|
| 149 |
+
position_encoding_type="trainable",
|
| 150 |
+
num_max_positions=330,
|
| 151 |
+
vocab_size=1391,
|
| 152 |
+
attention_to_channel=False,
|
| 153 |
+
ff_layer_type="mlp",
|
| 154 |
+
ff_widening_factor=1,
|
| 155 |
+
moe_num_experts=4,
|
| 156 |
+
moe_topk=2,
|
| 157 |
+
rope_type_sca="pixel",
|
| 158 |
+
rope_type_latent="pixel",
|
| 159 |
+
rope_type_temporal="lang",
|
| 160 |
+
rope_apply_to_keys=False,
|
| 161 |
+
rope_partial_pe=False,
|
| 162 |
+
rope_trainable=False,
|
| 163 |
+
**kwargs,
|
| 164 |
+
):
|
| 165 |
+
super().__init__(**kwargs)
|
| 166 |
+
|
| 167 |
+
self.num_latents = num_latents
|
| 168 |
+
self.d_latents = d_latents
|
| 169 |
+
self.d_model = d_model
|
| 170 |
+
self.kv_dim = kv_dim
|
| 171 |
+
self.qk_channels = qk_channels
|
| 172 |
+
self.v_channels = v_channels
|
| 173 |
+
|
| 174 |
+
self.num_blocks = num_blocks
|
| 175 |
+
self.num_self_attention_heads = num_self_attention_heads
|
| 176 |
+
self.num_cross_attention_heads = num_cross_attention_heads
|
| 177 |
+
self.num_local_transformers_per_block = num_local_transformers_per_block
|
| 178 |
+
self.num_temporal_transformers_per_block = num_temporal_transformers_per_block
|
| 179 |
+
self.sca_use_query_residual = sca_use_query_residual
|
| 180 |
+
self.use_query_residual = use_query_residual
|
| 181 |
+
self.position_encoding_type = position_encoding_type
|
| 182 |
+
self.num_max_positions = num_max_positions
|
| 183 |
+
# self.self_attention_widening_factor = self_attention_widening_factor
|
| 184 |
+
# self.cross_attention_widening_factor = cross_attention_widening_factor
|
| 185 |
+
self.cross_attention_shape_for_attention = cross_attention_shape_for_attention
|
| 186 |
+
self.attention_to_channel = attention_to_channel
|
| 187 |
+
self.ff_layer_type = ff_layer_type
|
| 188 |
+
self.ff_widening_factor = ff_widening_factor
|
| 189 |
+
self.moe_num_experts = moe_num_experts
|
| 190 |
+
self.moe_topk = moe_topk
|
| 191 |
+
self.rope_type_sca = rope_type_sca
|
| 192 |
+
self.rope_type_latent = rope_type_latent
|
| 193 |
+
self.rope_type_temporal = rope_type_temporal
|
| 194 |
+
self.rope_apply_to_keys = rope_apply_to_keys
|
| 195 |
+
self.rope_partial_pe = rope_partial_pe
|
| 196 |
+
self.rope_trainable = rope_trainable
|
| 197 |
+
|
| 198 |
+
self.hidden_act = hidden_act
|
| 199 |
+
self.dropout_rate = dropout_rate
|
| 200 |
+
self.initializer_range = initializer_range
|
| 201 |
+
self.layer_norm_type = layer_norm_type
|
| 202 |
+
self.layer_norm_eps = layer_norm_eps
|
| 203 |
+
|
| 204 |
+
# masked language modeling attributes
|
| 205 |
+
self.vocab_size = vocab_size
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
class PerceiverTFPreTrainedModel(PreTrainedModel):
|
| 209 |
+
"""
|
| 210 |
+
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
|
| 211 |
+
models.
|
| 212 |
+
"""
|
| 213 |
+
|
| 214 |
+
config_class = PerceiverTFConfig
|
| 215 |
+
base_model_prefix = "perceivertf"
|
| 216 |
+
main_input_name = "inputs"
|
| 217 |
+
|
| 218 |
+
def _init_weights(self, module):
|
| 219 |
+
"""Initialize the weights"""
|
| 220 |
+
if isinstance(module, (nn.Linear, nn.Conv2d)):
|
| 221 |
+
# Slightly different from the TF version which uses truncated_normal for initialization
|
| 222 |
+
# cf https://github.com/pytorch/pytorch/pull/5617
|
| 223 |
+
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
|
| 224 |
+
if module.bias is not None:
|
| 225 |
+
module.bias.data.zero_()
|
| 226 |
+
elif hasattr(module, "latents"):
|
| 227 |
+
module.latents.data.normal_(mean=0.0, std=self.config.initializer_range)
|
| 228 |
+
elif hasattr(module, "_pos_emb") and isinstance(module._pos_emb, nn.Parameter):
|
| 229 |
+
# initialize PerceiverTFTrainablePE
|
| 230 |
+
module._pos_emb.data.normal_(mean=0.0, std=self.config.initializer_range)
|
| 231 |
+
elif hasattr(module, "_pos_emb_temporal"):
|
| 232 |
+
# initialize PerceiverTFTrainablePE
|
| 233 |
+
module._pos_emb_temporal.data.normal_(mean=0.0, std=self.config.initializer_range)
|
| 234 |
+
elif hasattr(module, "slopes") and isinstance(module.slopes, nn.Parameter):
|
| 235 |
+
# initialize AlibiPositionalBias
|
| 236 |
+
module.reset_parameters()
|
| 237 |
+
elif isinstance(module, nn.ParameterDict):
|
| 238 |
+
for modality in module.keys():
|
| 239 |
+
module[modality].data.normal_(mean=0.0, std=self.config.initializer_range)
|
| 240 |
+
elif isinstance(module, nn.Embedding):
|
| 241 |
+
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
|
| 242 |
+
if module.padding_idx is not None:
|
| 243 |
+
module.weight.data[module.padding_idx].zero_()
|
| 244 |
+
elif isinstance(module, nn.LayerNorm):
|
| 245 |
+
module.bias.data.zero_()
|
| 246 |
+
module.weight.data.fill_(1.0)
|
| 247 |
+
# elif hasattr(module, "position_embeddings") and isinstance(
|
| 248 |
+
# module, PerceiverTrainablePositionEncoding):
|
| 249 |
+
# module.position_embeddings.data.normal_(mean=0.0, std=self.config.initializer_range)
|
| 250 |
+
|
| 251 |
+
|
| 252 |
+
# Replace the 'ModelOutputWithCrossAttentions' with 'MoEModelOutputWithCrossAttentions' for MoE
|
| 253 |
+
@dataclass
|
| 254 |
+
class MoEModelOutputWithCrossAttentions(ModelOutput):
|
| 255 |
+
"""
|
| 256 |
+
Base class for model's outputs, with potential hidden states and attentions.
|
| 257 |
+
Plus, router_probs for Mixture of Experts models.
|
| 258 |
+
|
| 259 |
+
Args:
|
| 260 |
+
last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
|
| 261 |
+
Sequence of hidden-states at the output of the last layer of the model.
|
| 262 |
+
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
|
| 263 |
+
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
|
| 264 |
+
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
|
| 265 |
+
|
| 266 |
+
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
|
| 267 |
+
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
|
| 268 |
+
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
|
| 269 |
+
sequence_length)`.
|
| 270 |
+
|
| 271 |
+
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
|
| 272 |
+
heads.
|
| 273 |
+
cross_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` and `config.add_cross_attention=True` is passed or when `config.output_attentions=True`):
|
| 274 |
+
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
|
| 275 |
+
sequence_length)`.
|
| 276 |
+
|
| 277 |
+
Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
|
| 278 |
+
weighted average in the cross-attention heads.
|
| 279 |
+
router_probs (`tuple(torch.FloatTensor)`, *optional*, returned when `output_router_probs=True` and `config.add_router_probs=True` is passed or when `config.output_router_probs=True`):
|
| 280 |
+
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, sequence_length, num_experts)`.
|
| 281 |
+
|
| 282 |
+
Raw router probabilities that are computed by MoE routers, these terms are used to compute the auxiliary
|
| 283 |
+
loss and the z_loss for Mixture of Experts models.
|
| 284 |
+
"""
|
| 285 |
+
|
| 286 |
+
last_hidden_state: torch.FloatTensor = None
|
| 287 |
+
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
|
| 288 |
+
attentions: Optional[Tuple[torch.FloatTensor]] = None
|
| 289 |
+
cross_attentions: Optional[Tuple[torch.FloatTensor]] = None
|
| 290 |
+
router_logits: Optional[Tuple[torch.FloatTensor]] = None
|