import os
import re
import zipfile
import torch
import gradio as gr
print('hello', gr.__version__)
import numpy as np
import time
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, DDPMScheduler, StableDiffusionPipeline, UNet2DConditionModel, DiffusionPipeline
from tqdm import tqdm
from PIL import Image
from PIL import Image, ImageDraw, ImageFont
import random
import copy
import string
alphabet = string.digits + string.ascii_lowercase + string.ascii_uppercase + string.punctuation + ' ' # len(aphabet) = 95
'''alphabet
0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~
'''
if not os.path.exists('images2'):
os.system('wget https://huggingface.co/datasets/JingyeChen22/TextDiffuser/resolve/main/images2.zip')
with zipfile.ZipFile('images2.zip', 'r') as zip_ref:
zip_ref.extractall('.')
# os.system('nvidia-smi')
os.system('ls')
#### import diffusion models
text_encoder = CLIPTextModel.from_pretrained(
'JingyeChen22/textdiffuser2-full-ft-inpainting', subfolder="text_encoder"
).cuda().half()
tokenizer = CLIPTokenizer.from_pretrained(
'botp/stable-diffusion-v1-5', subfolder="tokenizer"
)
#### additional tokens are introduced, including coordinate tokens and character tokens
print('***************')
print(len(tokenizer))
for i in range(520):
tokenizer.add_tokens(['l' + str(i) ]) # left
tokenizer.add_tokens(['t' + str(i) ]) # top
tokenizer.add_tokens(['r' + str(i) ]) # width
tokenizer.add_tokens(['b' + str(i) ]) # height
for c in alphabet:
tokenizer.add_tokens([f'[{c}]'])
print(len(tokenizer))
print('***************')
vae = AutoencoderKL.from_pretrained('botp/stable-diffusion-v1-5', subfolder="vae").half().cuda()
unet = UNet2DConditionModel.from_pretrained(
'JingyeChen22/textdiffuser2-full-ft-inpainting', subfolder="unet"
).half().cuda()
text_encoder.resize_token_embeddings(len(tokenizer))
global_dict = {}
#### for interactive
# stack = []
# state = 0
font = ImageFont.truetype("./Arial.ttf", 20)
def skip_fun(i, t, guest_id):
global_dict[guest_id]['state'] = 0
# global state
# state = 0
def exe_undo(i, orig_i, t, guest_id):
global_dict[guest_id]['stack'] = []
global_dict[guest_id]['state'] = 0
return copy.deepcopy(orig_i)
def exe_redo(i, orig_i, t, guest_id):
print('redo ',orig_i)
if type(orig_i) == str:
orig_i = Image.open(orig_i)
# global state
# state = 0
global_dict[guest_id]['state'] = 0
if len(global_dict[guest_id]['stack']) > 0:
global_dict[guest_id]['stack'].pop()
image = copy.deepcopy(orig_i)
draw = ImageDraw.Draw(image)
for items in global_dict[guest_id]['stack']:
# print('now', items)
text_position, t = items
if len(text_position) == 2:
x, y = text_position
text_color = (255, 0, 0)
draw.text((x+2, y), t, font=font, fill=text_color)
r = 4
leftUpPoint = (x-r, y-r)
rightDownPoint = (x+r, y+r)
draw.ellipse((leftUpPoint,rightDownPoint), fill='red')
elif len(text_position) == 4:
x0, y0, x1, y1 = text_position
text_color = (255, 0, 0)
draw.text((x0+2, y0), t, font=font, fill=text_color)
r = 4
leftUpPoint = (x0-r, y0-r)
rightDownPoint = (x0+r, y0+r)
draw.ellipse((leftUpPoint,rightDownPoint), fill='red')
draw.rectangle((x0,y0,x1,y1), outline=(255, 0, 0) )
print('stack', global_dict[guest_id]['stack'])
return image
def get_pixels(i, orig_i, radio, t, guest_id, evt: gr.SelectData):
# print('hi1 ', i)
# print('hi2 ', orig_i)
width, height = Image.open(i).size
# register
if guest_id == '-1': # register for the first time
seed = str(int(time.time()))
global_dict[str(seed)] = {
'state': 0,
'stack': [],
'image_id': [list(Image.open(i).resize((512,512)).getdata())] # an image has been recorded
}
guest_id = str(seed)
else:
seed = guest_id
if type(i) == str:
i = Image.open(i)
i = i.resize((512,512))
images = global_dict[str(seed)]['image_id']
flag = False
for image in images:
if image == list(i.getdata()):
print('find it')
flag = True
break
if not flag:
global_dict[str(seed)]['image_id'] = [list(i.getdata())]
global_dict[str(seed)]['stack'] = []
global_dict[str(seed)]['state'] = 0
orig_i = i
else:
if orig_i is not None:
orig_i = Image.open(orig_i)
orig_i = orig_i.resize((512,512))
else:
orig_i = i
global_dict[guest_id]['stack'] = []
global_dict[guest_id]['state'] = 0
text_position = evt.index
print('hello ', text_position)
if radio == 'Two Points':
if global_dict[guest_id]['state'] == 0:
global_dict[guest_id]['stack'].append(
(text_position, t)
)
print(text_position, global_dict[guest_id]['stack'])
global_dict[guest_id]['state'] = 1
else:
(_, t) = global_dict[guest_id]['stack'].pop()
x, y = _
global_dict[guest_id]['stack'].append(
((x,y,text_position[0],text_position[1]), t)
)
global_dict[guest_id]['state'] = 0
image = copy.deepcopy(orig_i)
draw = ImageDraw.Draw(image)
for items in global_dict[guest_id]['stack']:
text_position, t = items
if len(text_position) == 2:
x, y = text_position
x = int(512 * x / width)
y = int(512 * y / height)
text_color = (255, 0, 0)
draw.text((x+2, y), t, font=font, fill=text_color)
r = 4
leftUpPoint = (x-r, y-r)
rightDownPoint = (x+r, y+r)
draw.ellipse((leftUpPoint,rightDownPoint), fill='red')
elif len(text_position) == 4:
x0, y0, x1, y1 = text_position
x0 = int(512 * x0 / width)
x1 = int(512 * x1 / width)
y0 = int(512 * y0 / height)
y1 = int(512 * y1 / height)
text_color = (255, 0, 0)
draw.text((x0+2, y0), t, font=font, fill=text_color)
r = 4
leftUpPoint = (x0-r, y0-r)
rightDownPoint = (x0+r, y0+r)
draw.ellipse((leftUpPoint,rightDownPoint), fill='red')
draw.rectangle((x0,y0,x1,y1), outline=(255, 0, 0) )
elif radio == 'Four Points':
if global_dict[guest_id]['state'] == 0:
global_dict[guest_id]['stack'].append(
(text_position, t)
)
print(text_position, global_dict[guest_id]['stack'])
global_dict[guest_id]['state'] = 1
elif global_dict[guest_id]['state'] == 1:
(_, t) = global_dict[guest_id]['stack'].pop()
x, y = _
global_dict[guest_id]['stack'].append(
((x,y,text_position[0],text_position[1]), t)
)
global_dict[guest_id]['state'] = 2
elif global_dict[guest_id]['state'] == 2:
(_, t) = global_dict[guest_id]['stack'].pop()
x0, y0, x1, y1 = _
global_dict[guest_id]['stack'].append(
((x0, y0, x1, y1,text_position[0],text_position[1]), t)
)
global_dict[guest_id]['state'] = 3
elif global_dict[guest_id]['state'] == 3:
(_, t) = global_dict[guest_id]['stack'].pop()
x0, y0, x1, y1, x2, y2 = _
global_dict[guest_id]['stack'].append(
((x0, y0, x1, y1, x2, y2,text_position[0],text_position[1]), t)
)
global_dict[guest_id]['state'] = 0
image = copy.deepcopy(orig_i)
draw = ImageDraw.Draw(image)
for items in global_dict[guest_id]['stack']:
text_position, t = items
if len(text_position) == 2:
x, y = text_position
x = int(512 * x / width)
y = int(512 * y / height)
text_color = (255, 0, 0)
draw.text((x+2, y), t, font=font, fill=text_color)
r = 4
leftUpPoint = (x-r, y-r)
rightDownPoint = (x+r, y+r)
draw.ellipse((leftUpPoint,rightDownPoint), fill='red')
elif len(text_position) == 4:
x0, y0, x1, y1 = text_position
text_color = (255, 0, 0)
draw.text((x0+2, y0), t, font=font, fill=text_color)
r = 4
leftUpPoint = (x0-r, y0-r)
rightDownPoint = (x0+r, y0+r)
draw.ellipse((leftUpPoint,rightDownPoint), fill='red')
draw.line(((x0,y0),(x1,y1)), fill=(255, 0, 0) )
elif len(text_position) == 6:
x0, y0, x1, y1, x2, y2 = text_position
text_color = (255, 0, 0)
draw.text((x0+2, y0), t, font=font, fill=text_color)
r = 4
leftUpPoint = (x0-r, y0-r)
rightDownPoint = (x0+r, y0+r)
draw.ellipse((leftUpPoint,rightDownPoint), fill='red')
draw.line(((x0,y0),(x1,y1)), fill=(255, 0, 0) )
draw.line(((x1,y1),(x2,y2)), fill=(255, 0, 0) )
elif len(text_position) == 8:
x0, y0, x1, y1, x2, y2, x3, y3 = text_position
text_color = (255, 0, 0)
draw.text((x0+2, y0), t, font=font, fill=text_color)
r = 4
leftUpPoint = (x0-r, y0-r)
rightDownPoint = (x0+r, y0+r)
draw.ellipse((leftUpPoint,rightDownPoint), fill='red')
draw.line(((x0,y0),(x1,y1)), fill=(255, 0, 0) )
draw.line(((x1,y1),(x2,y2)), fill=(255, 0, 0) )
draw.line(((x2,y2),(x3,y3)), fill=(255, 0, 0) )
draw.line(((x3,y3),(x0,y0)), fill=(255, 0, 0) )
print('stack', global_dict[guest_id]['stack'])
global_dict[str(seed)]['image_id'].append(list(image.getdata()))
return image, orig_i, seed
font_layout = ImageFont.truetype('./Arial.ttf', 16)
def get_layout_image(ocrs):
blank = Image.new('RGB', (256,256), (0,0,0))
draw = ImageDraw.ImageDraw(blank)
for line in ocrs.split('\n'):
line = line.strip()
if len(line) == 0:
break
pred = ' '.join(line.split()[:-1])
box = line.split()[-1]
l, t, r, b = [int(i)*2 for i in box.split(',')] # the size of canvas is 256x256
draw.rectangle([(l, t), (r, b)], outline ="red")
draw.text((l, t), pred, font=font_layout)
return blank
def to_tensor(image):
if isinstance(image, Image.Image):
image = np.array(image)
elif not isinstance(image, np.ndarray):
raise TypeError("Error")
image = image.astype(np.float32) / 255.0
image = np.transpose(image, (2, 0, 1))
tensor = torch.from_numpy(image)
return tensor
def test_fn(x,y):
print('hello')
def text_to_image(guest_id, i, orig_i, prompt,keywords,positive_prompt,radio,slider_step,slider_guidance,slider_batch,slider_temperature,slider_natural):
# print(type(i))
# exit(0)
print(f'[info] Prompt: {prompt} | Keywords: {keywords} | Radio: {radio} | Steps: {slider_step} | Guidance: {slider_guidance} | Natural: {slider_natural}')
# global stack
# global state
if len(positive_prompt.strip()) != 0:
prompt += positive_prompt
with torch.no_grad():
time1 = time.time()
user_prompt = prompt
if slider_natural:
user_prompt = f'{user_prompt}'
composed_prompt = user_prompt
prompt = tokenizer.encode(user_prompt)
layout_image = None
else:
if guest_id not in global_dict or len(global_dict[guest_id]['stack']) == 0:
if len(keywords.strip()) == 0:
template = f'Given a prompt that will be used to generate an image, plan the layout of visual text for the image. The size of the image is 128x128. Therefore, all properties of the positions should not exceed 128, including the coordinates of top, left, right, and bottom. All keywords are included in the caption. You dont need to specify the details of font styles. At each line, the format should be keyword left, top, right, bottom. So let us begin. Prompt: {user_prompt}'
else:
keywords = keywords.split('/')
keywords = [i.strip() for i in keywords]
template = f'Given a prompt that will be used to generate an image, plan the layout of visual text for the image. The size of the image is 128x128. Therefore, all properties of the positions should not exceed 128, including the coordinates of top, left, right, and bottom. In addition, we also provide all keywords at random order for reference. You dont need to specify the details of font styles. At each line, the format should be keyword left, top, right, bottom. So let us begin. Prompt: {prompt}. Keywords: {str(keywords)}'
msg = template
conv = get_conversation_template(m1_model_path)
conv.append_message(conv.roles[0], msg)
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
inputs = m1_tokenizer([prompt], return_token_type_ids=False)
inputs = {k: torch.tensor(v).to('cuda') for k, v in inputs.items()}
output_ids = m1_model.generate(
**inputs,
do_sample=True,
temperature=slider_temperature,
repetition_penalty=1.0,
max_new_tokens=512,
)
if m1_model.config.is_encoder_decoder:
output_ids = output_ids[0]
else:
output_ids = output_ids[0][len(inputs["input_ids"][0]) :]
outputs = m1_tokenizer.decode(
output_ids, skip_special_tokens=True, spaces_between_special_tokens=False
)
print(f"[{conv.roles[0]}]\n{msg}")
print(f"[{conv.roles[1]}]\n{outputs}")
layout_image = get_layout_image(outputs)
ocrs = outputs.split('\n')
time2 = time.time()
print(time2-time1)
# user_prompt = prompt
current_ocr = ocrs
ocr_ids = []
print('user_prompt', user_prompt)
print('current_ocr', current_ocr)
for ocr in current_ocr:
ocr = ocr.strip()
if len(ocr) == 0 or '###' in ocr or '.com' in ocr:
continue
items = ocr.split()
pred = ' '.join(items[:-1])
box = items[-1]
l,t,r,b = box.split(',')
l,t,r,b = int(l), int(t), int(r), int(b)
ocr_ids.extend(['l'+str(l), 't'+str(t), 'r'+str(r), 'b'+str(b)])
char_list = list(pred)
char_list = [f'[{i}]' for i in char_list]
ocr_ids.extend(char_list)
ocr_ids.append(tokenizer.eos_token_id)
caption_ids = tokenizer(
user_prompt, truncation=True, return_tensors="pt"
).input_ids[0].tolist()
try:
ocr_ids = tokenizer.encode(ocr_ids)
prompt = caption_ids + ocr_ids
except:
prompt = caption_ids
user_prompt = tokenizer.decode(prompt)
composed_prompt = tokenizer.decode(prompt)
else:
user_prompt += ' <|endoftext|><|startoftext|>'
layout_image = None
image_mask = Image.new('L', (512,512), 0)
draw = ImageDraw.Draw(image_mask)
for items in global_dict[guest_id]['stack']:
position, text = items
# feature_mask
# masked_feature
if len(position) == 2:
x, y = position
x = x // 4
y = y // 4
text_str = ' '.join([f'[{c}]' for c in list(text)])
user_prompt += f' l{x} t{y} {text_str} <|endoftext|>'
elif len(position) == 4:
x0, y0, x1, y1 = position
x0 = x0 // 4
y0 = y0 // 4
x1 = x1 // 4
y1 = y1 // 4
text_str = ' '.join([f'[{c}]' for c in list(text)])
user_prompt += f' l{x0} t{y0} r{x1} b{y1} {text_str} <|endoftext|>'
draw.rectangle((x0*4, y0*4, x1*4, y1*4), fill=1)
print('prompt ', user_prompt)
elif len(position) == 8: # four points
x0, y0, x1, y1, x2, y2, x3, y3 = position
draw.polygon([(x0, y0), (x1, y1), (x2, y2), (x3, y3)], fill=1)
x0 = x0 // 4
y0 = y0 // 4
x1 = x1 // 4
y1 = y1 // 4
x2 = x2 // 4
y2 = y2 // 4
x3 = x3 // 4
y3 = y3 // 4
xmin = min(x0, x1, x2, x3)
ymin = min(y0, y1, y2, y3)
xmax = max(x0, x1, x2, x3)
ymax = max(y0, y1, y2, y3)
text_str = ' '.join([f'[{c}]' for c in list(text)])
user_prompt += f' l{xmin} t{ymin} r{xmax} b{ymax} {text_str} <|endoftext|>'
print('prompt ', user_prompt)
prompt = tokenizer.encode(user_prompt)
composed_prompt = tokenizer.decode(prompt)
prompt = prompt[:77]
while len(prompt) < 77:
prompt.append(tokenizer.pad_token_id)
prompts_cond = prompt
prompts_nocond = [tokenizer.pad_token_id]*77
prompts_cond = [prompts_cond] * slider_batch
prompts_nocond = [prompts_nocond] * slider_batch
prompts_cond = torch.Tensor(prompts_cond).long().cuda()
prompts_nocond = torch.Tensor(prompts_nocond).long().cuda()
scheduler = DDPMScheduler.from_pretrained('botp/stable-diffusion-v1-5', subfolder="scheduler")
scheduler.set_timesteps(slider_step)
noise = torch.randn((slider_batch, 4, 64, 64)).to("cuda").half()
input = noise
encoder_hidden_states_cond = text_encoder(prompts_cond)[0].half()
encoder_hidden_states_nocond = text_encoder(prompts_nocond)[0].half()
image_mask = torch.Tensor(np.array(image_mask)).float().half().cuda()
image_mask = image_mask.unsqueeze(0).unsqueeze(0).repeat(slider_batch, 1, 1, 1)
image = Image.open(orig_i).resize((512,512))
image_tensor = to_tensor(image).unsqueeze(0).cuda().sub_(0.5).div_(0.5)
# print(f'image_tensor.shape {image_tensor.shape}')
masked_image = image_tensor * (1-image_mask)
masked_feature = vae.encode(masked_image.half()).latent_dist.sample()
masked_feature = masked_feature * vae.config.scaling_factor
masked_feature = masked_feature.half()
# print(f'masked_feature.shape {masked_feature.shape}')
feature_mask = torch.nn.functional.interpolate(image_mask, size=(64,64), mode='nearest').cuda()
for t in tqdm(scheduler.timesteps):
with torch.no_grad(): # classifier free guidance
noise_pred_cond = unet(sample=input, timestep=t, encoder_hidden_states=encoder_hidden_states_cond[:slider_batch],feature_mask=feature_mask, masked_feature=masked_feature).sample # b, 4, 64, 64
noise_pred_uncond = unet(sample=input, timestep=t, encoder_hidden_states=encoder_hidden_states_nocond[:slider_batch],feature_mask=feature_mask, masked_feature=masked_feature).sample # b, 4, 64, 64
noisy_residual = noise_pred_uncond + slider_guidance * (noise_pred_cond - noise_pred_uncond) # b, 4, 64, 64
input = scheduler.step(noisy_residual, t, input).prev_sample
del noise_pred_cond
del noise_pred_uncond
torch.cuda.empty_cache()
# decode
input = 1 / vae.config.scaling_factor * input
images = vae.decode(input, return_dict=False)[0]
width, height = 512, 512
results = []
new_image = Image.new('RGB', (2*width, 2*height))
for index, image in enumerate(images.cpu().float()):
image = (image / 2 + 0.5).clamp(0, 1).unsqueeze(0)
image = image.cpu().permute(0, 2, 3, 1).numpy()[0]
image = Image.fromarray((image * 255).round().astype("uint8")).convert('RGB')
results.append(image)
row = index // 2
col = index % 2
new_image.paste(image, (col*width, row*height))
# os.system('nvidia-smi')
torch.cuda.empty_cache()
# os.system('nvidia-smi')
return tuple(results), composed_prompt
with gr.Blocks() as demo:
gr.HTML(
"""
TextDiffuser-2: Unleashing the Power of Language Models for Text Rendering
(Demo for Text Inpainting 🖼️🖌️)
HKUST, Sun Yat-sen University, Microsoft Research
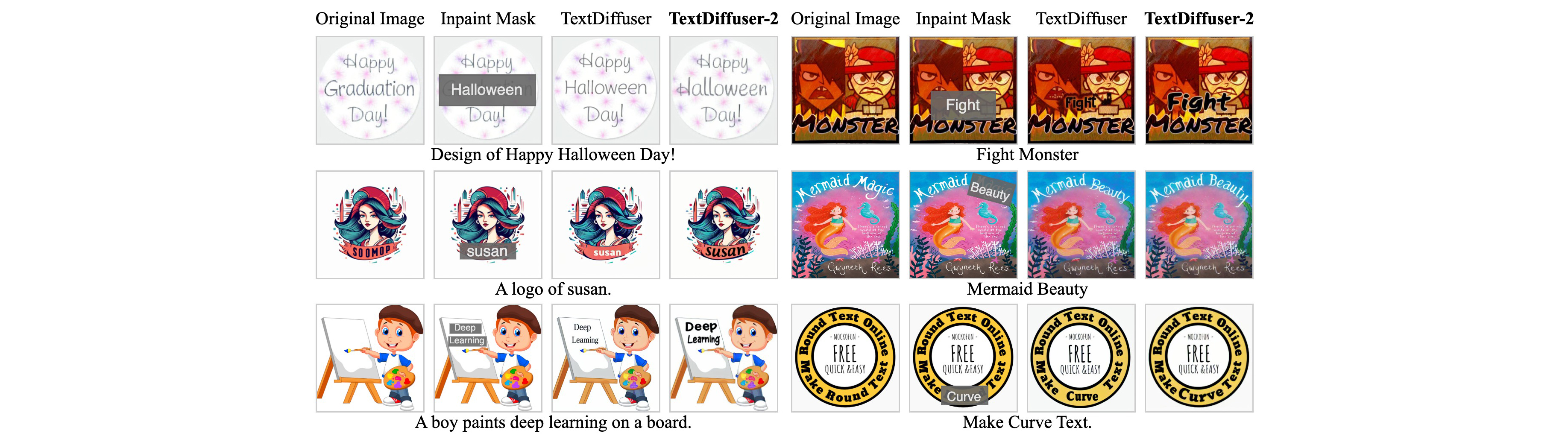
TextDiffuser-2 leverages language models to enhance text rendering, achieving greater flexibility. Different from text editing, the text inpainting task aims to add or modify text guided by users, ensuring that the inpainted text has a reasonable style (i.e., no need to match the style of the original text during modification exactly) and is coherent with backgrounds. TextDiffuser-2 offers an improved user experience. Specifically, users only need to type the text they wish to inpaint into the provided input box and then select key points on the Canvas.
👀 Tips for using this demo: (1) Please carefully read the disclaimer in the below. Current verison can only support English. (2) The prompt is optional. If provided, the generated image may be more accurate. (3) Redo is used to cancel the last keyword, and undo is used to clear all keywords. (4) Current version only supports input image with resolution 512x512. (5) You can use either two points or four points to specify the text box. Using four points can better represent the perspective boxes. (6) Leave "Text to be inpaintd" empty can function as the text removal task. (7) Classifier-free guidance is set to a small value in default. It is noticed that a larger cfg may result in chromatic aberration against the background. (8) You can inpaint many text regions at one time. (9) Thanks for reading these tips, shall we start now?
""")
with gr.Tab("Text Inpainting"):
with gr.Row():
with gr.Column():
keywords = gr.Textbox(label="(Optional) Keywords. Should be seperated by / (e.g., keyword1/keyword2/...)", placeholder="keyword1/keyword2", visible=False)
positive_prompt = gr.Textbox(label="(Optional) Positive prompt", value="", visible=False)
i = gr.Image(label="Image", type='filepath', value='https://raw.githubusercontent.com/JingyeChen/jingyechen.github.io/master/textdiffuser2/static/images/example11.jpg')
orig_i = gr.Image(label="Placeholder", type='filepath', height=512, width=512, visible=False)
radio = gr.Radio(["Two Points", "Four Points"], label="Number of points to represent the text box.", value="Two Points", visible=True)
with gr.Row():
t = gr.Textbox(label="Text to be inpainted", value='Test')
prompt = gr.Textbox(label="(Optional) Prompt.")
with gr.Row():
redo = gr.Button(value='Redo - Cancel the last keyword')
undo = gr.Button(value='Undo - Clear the canvas')
# skip_button = gr.Button(value='Skip - Operate the next keyword')
slider_natural = gr.Checkbox(label="Natural image generation", value=False, info="The text position and content info will not be incorporated.", visible=False)
slider_step = gr.Slider(minimum=1, maximum=50, value=20, step=1, label="Sampling step", info="The sampling step for TextDiffuser-2.")
slider_guidance = gr.Slider(minimum=1, maximum=13, value=2.5, step=0.5, label="Scale of classifier-free guidance", info="The scale of cfg. Smaller cfg produce stable results.")
slider_batch = gr.Slider(minimum=1, maximum=6, value=4, step=1, label="Batch size", info="The number of images to be sampled.")
slider_temperature = gr.Slider(minimum=0.1, maximum=2, value=1.4, step=0.1, label="Temperature", info="Control the diversity of layout planner. Higher value indicates more diversity.", visible=False)
# slider_seed = gr.Slider(minimum=1, maximum=10000, label="Seed", randomize=True)
button = gr.Button("Generate")
guest_id_box = gr.Textbox(label="guest_id", value=f"-1", visible=False)
i.select(get_pixels,[i,orig_i,radio,t,guest_id_box],[i,orig_i,guest_id_box])
redo.click(exe_redo, [i,orig_i,t,guest_id_box],[i])
undo.click(exe_undo, [i,orig_i,t,guest_id_box],[i])
# skip_button.click(skip_fun, [i,t,guest_id_box])
with gr.Column():
output = gr.Gallery(label='Generated image', rows=2, height=768)
with gr.Accordion("Intermediate results", open=False, visible=False):
gr.Markdown("Composed prompt")
composed_prompt = gr.Textbox(label='')
# gr.Markdown("Layout visualization")
# layout = gr.Image(height=256, width=256)
button.click(text_to_image, inputs=[guest_id_box, i, orig_i, prompt,keywords,positive_prompt, radio,slider_step,slider_guidance,slider_batch,slider_temperature,slider_natural], outputs=[output, composed_prompt])
gr.Markdown("## Image Examples")
template = None
gr.Examples(
[
["https://raw.githubusercontent.com/JingyeChen/jingyechen.github.io/master/textdiffuser2/static/images/example1.jpg"],
["https://raw.githubusercontent.com/JingyeChen/jingyechen.github.io/master/textdiffuser2/static/images/example2.jpg"],
["https://raw.githubusercontent.com/JingyeChen/jingyechen.github.io/master/textdiffuser2/static/images/example3.jpg"],
["https://raw.githubusercontent.com/JingyeChen/jingyechen.github.io/master/textdiffuser2/static/images/example4.jpg"],
["https://raw.githubusercontent.com/JingyeChen/jingyechen.github.io/master/textdiffuser2/static/images/example5.jpg"],
["https://raw.githubusercontent.com/JingyeChen/jingyechen.github.io/master/textdiffuser2/static/images/example7.jpg"],
["https://raw.githubusercontent.com/JingyeChen/jingyechen.github.io/master/textdiffuser2/static/images/example8.jpg"],
["https://raw.githubusercontent.com/JingyeChen/jingyechen.github.io/master/textdiffuser2/static/images/example11.jpg"],
["https://raw.githubusercontent.com/JingyeChen/jingyechen.github.io/master/textdiffuser2/static/images/example12.jpg"],
["https://raw.githubusercontent.com/JingyeChen/jingyechen.github.io/master/textdiffuser2/static/images/example13.jpg"],
["https://raw.githubusercontent.com/JingyeChen/jingyechen.github.io/master/textdiffuser2/static/images/example14.jpg"],
["https://raw.githubusercontent.com/JingyeChen/jingyechen.github.io/master/textdiffuser2/static/images/example15.jpg"],
],
[
i
],
examples_per_page=25,
)
gr.HTML(
"""
Version: 1.0
Contact:
For help or issues using TextDiffuser-2, please email Jingye Chen (qwerty.chen@connect.ust.hk), Yupan Huang (huangyp28@mail2.sysu.edu.cn) or submit a GitHub issue. For other communications related to TextDiffuser-2, please contact Lei Cui (lecu@microsoft.com) or Furu Wei (fuwei@microsoft.com).
Disclaimer:
Please note that the demo is intended for academic and research purposes ONLY. Any use of the demo for generating inappropriate content is strictly prohibited. The responsibility for any misuse or inappropriate use of the demo lies solely with the users who generated such content, and this demo shall not be held liable for any such use.
"""
)
demo.launch()