Spaces:
Runtime error


Runtime error
SingleZombie
commited on
Commit
•
0825d29
1
Parent(s):
9fd841c
update readme
Browse files
README.md
CHANGED
|
@@ -1,208 +1,8 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
**Abstract:** *The remarkable efficacy of text-to-image diffusion models has motivated extensive exploration of their potential application in video domains.
|
| 10 |
-
Zero-shot methods seek to extend image diffusion models to videos without necessitating model training.
|
| 11 |
-
Recent methods mainly focus on incorporating inter-frame correspondence into attention mechanisms. However, the soft constraint imposed on determining where to attend to valid features can sometimes be insufficient, resulting in temporal inconsistency.
|
| 12 |
-
In this paper, we introduce FRESCO, intra-frame correspondence alongside inter-frame correspondence to establish a more robust spatial-temporal constraint. This enhancement ensures a more consistent transformation of semantically similar content across frames. Beyond mere attention guidance, our approach involves an explicit update of features to achieve high spatial-temporal consistency with the input video, significantly improving the visual coherence of the resulting translated videos.
|
| 13 |
-
Extensive experiments demonstrate the effectiveness of our proposed framework in producing high-quality, coherent videos, marking a notable improvement over existing zero-shot methods.*
|
| 14 |
-
|
| 15 |
-
**Features**:<br>
|
| 16 |
-
- **Temporal consistency**: use intra-and inter-frame constraint with better consistency and coverage than optical flow alone.
|
| 17 |
-
- Compared with our previous work [Rerender-A-Video](https://github.com/williamyang1991/Rerender_A_Video), FRESCO is more robust to large and quick motion.
|
| 18 |
-
- **Zero-shot**: no training or fine-tuning required.
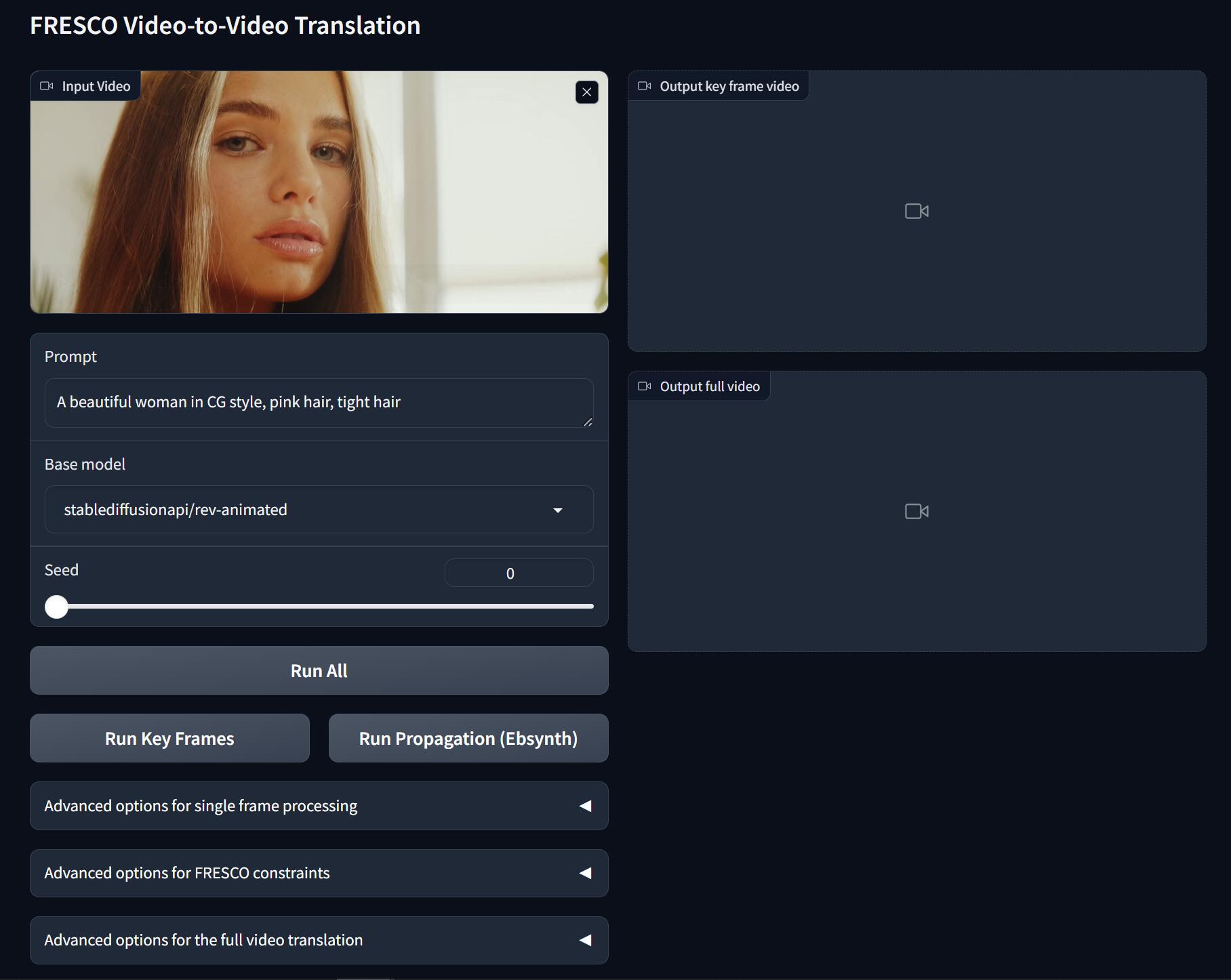
|
| 19 |
-
- **Flexibility**: compatible with off-the-shelf models (e.g., [ControlNet](https://github.com/lllyasviel/ControlNet), [LoRA](https://civitai.com/)) for customized translation.
|
| 20 |
-
|
| 21 |
-
https://github.com/williamyang1991/FRESCO/assets/18130694/aad358af-4d27-4f18-b069-89a1abd94d38
|
| 22 |
-
|
| 23 |
-
|
| 24 |
-
## Updates
|
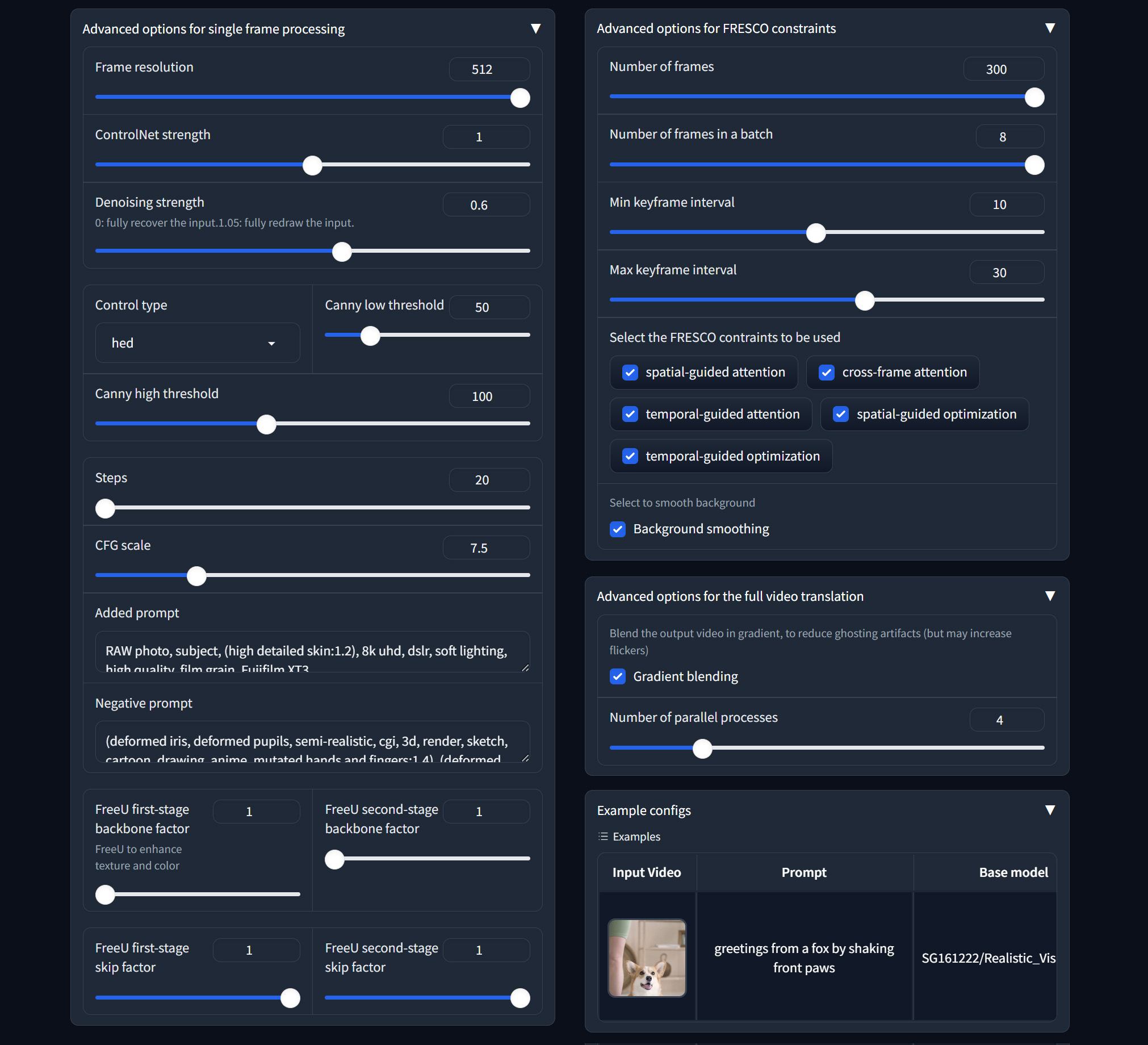
| 25 |
-
- [03/2023] Paper is released.
|
| 26 |
-
- [03/2023] Code is released.
|
| 27 |
-
- [03/2024] This website is created.
|
| 28 |
-
|
| 29 |
-
### TODO
|
| 30 |
-
- [ ] Integrate into Diffusers
|
| 31 |
-
- [ ] Add Huggingface web demo
|
| 32 |
-
- [x] ~~Add webUI.~~
|
| 33 |
-
- [x] ~~Update readme~~
|
| 34 |
-
- [x] ~~Upload paper to arXiv, release related material~~
|
| 35 |
-
|
| 36 |
-
## Installation
|
| 37 |
-
|
| 38 |
-
1. Clone the repository.
|
| 39 |
-
|
| 40 |
-
```shell
|
| 41 |
-
git clone https://github.com/williamyang1991/FRESCO.git
|
| 42 |
-
cd FRESCO
|
| 43 |
-
```
|
| 44 |
-
|
| 45 |
-
2. You can simply set up the environment with pip based on [requirements.txt](https://github.com/williamyang1991/FRESCO/blob/main/requirements.txt)
|
| 46 |
-
- Create a conda environment and install torch >= 2.0.0. Here is an example script to install torch 2.0.0 + CUDA 11.8 :
|
| 47 |
-
```
|
| 48 |
-
conda create --name diffusers python==3.8.5
|
| 49 |
-
conda activate diffusers
|
| 50 |
-
pip install torch==2.0.0 torchvision==0.15.1 --index-url https://download.pytorch.org/whl/cu118
|
| 51 |
-
```
|
| 52 |
-
- Run `pip install -r requirements.txt` in an environment where torch is installed.
|
| 53 |
-
- We have tested on torch 2.0.0/2.1.0 and diffusers 0.19.3
|
| 54 |
-
- If you use new versions of diffusers, you need to modify [my_forward()](https://github.com/williamyang1991/FRESCO/blob/fb991262615665de88f7a8f2cc903d9539e1b234/src/diffusion_hacked.py#L496)
|
| 55 |
-
|
| 56 |
-
3. Run the installation script. The required models will be downloaded in `./model`, `./src/ControlNet/annotator` and `./src/ebsynth/deps/ebsynth/bin`.
|
| 57 |
-
- Requires access to huggingface.co
|
| 58 |
-
|
| 59 |
-
```shell
|
| 60 |
-
python install.py
|
| 61 |
-
```
|
| 62 |
-
|
| 63 |
-
4. You can run the demo with `run_fresco.py`
|
| 64 |
-
|
| 65 |
-
```shell
|
| 66 |
-
python run_fresco.py ./config/config_music.yaml
|
| 67 |
-
```
|
| 68 |
-
|
| 69 |
-
5. For issues with Ebsynth, please refer to [issues](https://github.com/williamyang1991/Rerender_A_Video#issues)
|
| 70 |
-
|
| 71 |
-
|
| 72 |
-
## (1) Inference
|
| 73 |
-
|
| 74 |
-
### WebUI (recommended)
|
| 75 |
-
|
| 76 |
-
```
|
| 77 |
-
python webUI.py
|
| 78 |
-
```
|
| 79 |
-
The Gradio app also allows you to flexibly change the inference options. Just try it for more details.
|
| 80 |
-
|
| 81 |
-
Upload your video, input the prompt, select the model and seed, and hit:
|
| 82 |
-
- **Run Key Frames**: detect keyframes, translate all keyframes.
|
| 83 |
-
- **Run Propagation**: propagate the keyframes to other frames for full video translation
|
| 84 |
-
- **Run All**: **Run Key Frames** and **Run Propagation**
|
| 85 |
-
|
| 86 |
-
Select the model:
|
| 87 |
-
- **Base model**: base Stable Diffusion model (SD 1.5)
|
| 88 |
-
- Stable Diffusion 1.5: official model
|
| 89 |
-
- [rev-Animated](https://huggingface.co/stablediffusionapi/rev-animated): a semi-realistic (2.5D) model
|
| 90 |
-
- [realistic-Vision](https://huggingface.co/SG161222/Realistic_Vision_V2.0): a photo-realistic model
|
| 91 |
-
- [flat2d-animerge](https://huggingface.co/stablediffusionapi/flat-2d-animerge): a cartoon model
|
| 92 |
-
- You can add other models on huggingface.co by modifying this [line](https://github.com/williamyang1991/FRESCO/blob/1afcca9c7b1bc1ac68254f900be9bd768fbb6988/webUI.py#L362)
|
| 93 |
-
|
| 94 |
-
|
| 95 |
-
|
| 96 |
-
We provide abundant advanced options to play with
|
| 97 |
-
|
| 98 |
-
</details>
|
| 99 |
-
|
| 100 |
-
<details id="option1">
|
| 101 |
-
<summary> <b>Advanced options for single frame processing</b></summary>
|
| 102 |
-
|
| 103 |
-
1. **Frame resolution**: resize the short side of the video to 512.
|
| 104 |
-
2. ControlNet related:
|
| 105 |
-
- **ControlNet strength**: how well the output matches the input control edges
|
| 106 |
-
- **Control type**: HED edge, Canny edge, Depth map
|
| 107 |
-
- **Canny low/high threshold**: low values for more edge details
|
| 108 |
-
3. SDEdit related:
|
| 109 |
-
- **Denoising strength**: repaint degree (low value to make the output look more like the original video)
|
| 110 |
-
- **Preserve color**: preserve the color of the original video
|
| 111 |
-
4. SD related:
|
| 112 |
-
- **Steps**: denoising step
|
| 113 |
-
- **CFG scale**: how well the output matches the prompt
|
| 114 |
-
- **Added prompt/Negative prompt**: supplementary prompts
|
| 115 |
-
5. FreeU related:
|
| 116 |
-
- **FreeU first/second-stage backbone factor**: =1 do nothing; >1 enhance output color and details
|
| 117 |
-
- **FreeU first/second-stage skip factor**: =1 do nothing; <1 enhance output color and details
|
| 118 |
-
|
| 119 |
-
</details>
|
| 120 |
-
|
| 121 |
-
<details id="option2">
|
| 122 |
-
<summary> <b>Advanced options for FRESCO constraints</b></summary>
|
| 123 |
-
|
| 124 |
-
1. Keyframe related
|
| 125 |
-
- **Number of frames**: Total frames to be translated
|
| 126 |
-
- **Number of frames in a batch**: To avoid out-of-memory, use small batch size
|
| 127 |
-
- **Min keyframe interval (s_min)**: The keyframes will be detected at least every s_min frames
|
| 128 |
-
- **Max keyframe interval (s_max)**: The keyframes will be detected at most every s_max frames
|
| 129 |
-
2. FRESCO constraints
|
| 130 |
-
- FRESCO-guided Attention:
|
| 131 |
-
- **spatial-guided attention**: Check to enable spatial-guided attention
|
| 132 |
-
- **cross-frame attention**: Check to enable efficient cross-frame attention
|
| 133 |
-
- **temporal-guided attention**: Check to enable temporal-guided attention
|
| 134 |
-
- FRESCO-guided optimization:
|
| 135 |
-
- **spatial-guided optimization**: Check to enable spatial-guided optimization
|
| 136 |
-
- **temporal-guided optimization**: Check to enable temporal-guided optimization
|
| 137 |
-
3. **Background smoothing**: Check to enable background smoothing (best for static background)
|
| 138 |
-
|
| 139 |
-
</details>
|
| 140 |
-
|
| 141 |
-
<details id="option3">
|
| 142 |
-
<summary> <b>Advanced options for the full video translation</b></summary>
|
| 143 |
-
|
| 144 |
-
1. **Gradient blending**: apply Poisson Blending to reduce ghosting artifacts. May slow the process and increase flickers.
|
| 145 |
-
2. **Number of parallel processes**: multiprocessing to speed up the process. Large value (4) is recommended.
|
| 146 |
-
</details>
|
| 147 |
-
|
| 148 |
-
|
| 149 |
-
|
| 150 |
-
### Command Line
|
| 151 |
-
|
| 152 |
-
We provide a flexible script `run_fresco.py` to run our method.
|
| 153 |
-
|
| 154 |
-
Set the options via a config file. For example,
|
| 155 |
-
```shell
|
| 156 |
-
python run_fresco.py ./config/config_music.yaml
|
| 157 |
-
```
|
| 158 |
-
We provide some examples of the config in `config` directory.
|
| 159 |
-
Most options in the config is the same as those in WebUI.
|
| 160 |
-
Please check the explanations in the WebUI section.
|
| 161 |
-
|
| 162 |
-
We provide a separate Ebsynth python script `video_blend.py` with the temporal blending algorithm introduced in
|
| 163 |
-
[Stylizing Video by Example](https://dcgi.fel.cvut.cz/home/sykorad/ebsynth.html) for interpolating style between key frames.
|
| 164 |
-
It can work on your own stylized key frames independently of our FRESCO algorithm.
|
| 165 |
-
For the details, please refer to our previous work [Rerender-A-Video](https://github.com/williamyang1991/Rerender_A_Video/tree/main?tab=readme-ov-file#our-ebsynth-implementation)
|
| 166 |
-
|
| 167 |
-
## (2) Results
|
| 168 |
-
|
| 169 |
-
### Key frame translation
|
| 170 |
-
|
| 171 |
-
<table class="center">
|
| 172 |
-
<tr>
|
| 173 |
-
<td><img src="https://github.com/williamyang1991/FRESCO/assets/18130694/e8d5776a-37c5-49ae-8ab4-15669df6f572" raw=true></td>
|
| 174 |
-
<td><img src="https://github.com/williamyang1991/FRESCO/assets/18130694/8a792af6-555c-4e82-ac1e-5c2e1ee35fdb" raw=true></td>
|
| 175 |
-
<td><img src="https://github.com/williamyang1991/FRESCO/assets/18130694/10f9a964-85ac-4433-84c5-1611a6c2c434" raw=true></td>
|
| 176 |
-
<td><img src="https://github.com/williamyang1991/FRESCO/assets/18130694/0ec0fbf9-90dd-4d8b-964d-945b5f6687c2" raw=true></td>
|
| 177 |
-
</tr>
|
| 178 |
-
<tr>
|
| 179 |
-
<td width=26.5% align="center">a red car turns in the winter</td>
|
| 180 |
-
<td width=26.5% align="center">an African American boxer wearing black boxing gloves punches towards the camera, cartoon style</td>
|
| 181 |
-
<td width=26.5% align="center">a cartoon spiderman in black suit, black shoes and white gloves is dancing</td>
|
| 182 |
-
<td width=20.5% align="center">a beautiful woman holding her glasses in CG style</td>
|
| 183 |
-
</tr>
|
| 184 |
-
</table>
|
| 185 |
-
|
| 186 |
-
|
| 187 |
-
### Full video translation
|
| 188 |
-
|
| 189 |
-
https://github.com/williamyang1991/FRESCO/assets/18130694/bf8bfb82-5cb7-4b2f-8169-cf8dbf408b54
|
| 190 |
-
|
| 191 |
-
## Citation
|
| 192 |
-
|
| 193 |
-
If you find this work useful for your research, please consider citing our paper:
|
| 194 |
-
|
| 195 |
-
```bibtex
|
| 196 |
-
@inproceedings{yang2024fresco,
|
| 197 |
-
title = {FRESCO: Spatial-Temporal Correspondence for Zero-Shot Video Translation},
|
| 198 |
-
author = {Yang, Shuai and Zhou, Yifan and Liu, Ziwei and and Loy, Chen Change},
|
| 199 |
-
booktitle = {CVPR},
|
| 200 |
-
year = {2024},
|
| 201 |
-
}
|
| 202 |
-
```
|
| 203 |
-
|
| 204 |
-
## Acknowledgments
|
| 205 |
-
|
| 206 |
-
The code is mainly developed based on [Rerender-A-Video](https://github.com/williamyang1991/Rerender_A_Video), [ControlNet](https://github.com/lllyasviel/ControlNet), [Stable Diffusion](https://github.com/Stability-AI/stablediffusion), [GMFlow](https://github.com/haofeixu/gmflow) and [Ebsynth](https://github.com/jamriska/ebsynth).
|
| 207 |
-
|
| 208 |
-
|
|
|
|
| 1 |
+
title: FRESCO
|
| 2 |
+
emoji: ⚡
|
| 3 |
+
colorFrom: green
|
| 4 |
+
colorTo: indigo
|
| 5 |
+
sdk: gradio
|
| 6 |
+
sdk_version: 3.44.4
|
| 7 |
+
app_file: app.py
|
| 8 |
+
pinned: false
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|