Spaces:
Build error

Build error
Commit
•
4dbfce8
1
Parent(s):
e7d52ff
initial commit
Browse files- app.py +128 -0
- c_data.json +0 -0
- model.py +48 -0
- model_config.py +13 -0
app.py
ADDED
|
@@ -0,0 +1,128 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import transformers
|
| 3 |
+
import torch
|
| 4 |
+
import json
|
| 5 |
+
|
| 6 |
+
# load all models
|
| 7 |
+
pragformer = transformers.AutoModel.from_pretrained("Pragformer/PragFormer", trust_remote_code=True)
|
| 8 |
+
pragformer_private = transformers.AutoModel.from_pretrained("Pragformer/PragFormer_private", trust_remote_code=True)
|
| 9 |
+
pragformer_reduction = transformers.AutoModel.from_pretrained("Pragformer/PragFormer_reduction", trust_remote_code=True)
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
#Event Listeners
|
| 13 |
+
|
| 14 |
+
tokenizer = transformers.AutoTokenizer.from_pretrained('NTUYG/DeepSCC-RoBERTa')
|
| 15 |
+
|
| 16 |
+
with open('./HF_Pragformer/c_data.json', 'r') as f:
|
| 17 |
+
data = json.load(f)
|
| 18 |
+
|
| 19 |
+
def fill_code(code_pth):
|
| 20 |
+
return data[code_pth]['pragma'], data[code_pth]['code']
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def predict(code_txt):
|
| 24 |
+
code = code_txt.lstrip().rstrip()
|
| 25 |
+
tokenized = tokenizer.batch_encode_plus(
|
| 26 |
+
[code],
|
| 27 |
+
max_length = 150,
|
| 28 |
+
pad_to_max_length = True,
|
| 29 |
+
truncation = True
|
| 30 |
+
)
|
| 31 |
+
pred = pragformer(torch.tensor(tokenized['input_ids']), torch.tensor(tokenized['attention_mask']))
|
| 32 |
+
|
| 33 |
+
y_hat = torch.argmax(pred).item()
|
| 34 |
+
return 'With OpenMP' if y_hat==1 else 'Without OpenMP', torch.nn.Softmax(dim=1)(pred).squeeze()[y_hat].item()
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def is_private(code_txt):
|
| 38 |
+
code = code_txt.lstrip().rstrip()
|
| 39 |
+
tokenized = tokenizer.batch_encode_plus(
|
| 40 |
+
[code],
|
| 41 |
+
max_length = 150,
|
| 42 |
+
pad_to_max_length = True,
|
| 43 |
+
truncation = True
|
| 44 |
+
)
|
| 45 |
+
pred = pragformer_private(torch.tensor(tokenized['input_ids']), torch.tensor(tokenized['attention_mask']))
|
| 46 |
+
|
| 47 |
+
y_hat = torch.argmax(pred).item()
|
| 48 |
+
if y_hat == 0:
|
| 49 |
+
return gr.update(visible=False)
|
| 50 |
+
else:
|
| 51 |
+
return gr.update(value=f"Confidence: {torch.nn.Softmax(dim=1)(pred).squeeze()[y_hat].item()}", visible=True)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def is_reduction(code_txt):
|
| 55 |
+
code = code_txt.lstrip().rstrip()
|
| 56 |
+
tokenized = tokenizer.batch_encode_plus(
|
| 57 |
+
[code],
|
| 58 |
+
max_length = 150,
|
| 59 |
+
pad_to_max_length = True,
|
| 60 |
+
truncation = True
|
| 61 |
+
)
|
| 62 |
+
pred = pragformer_reduction(torch.tensor(tokenized['input_ids']), torch.tensor(tokenized['attention_mask']))
|
| 63 |
+
|
| 64 |
+
y_hat = torch.argmax(pred).item()
|
| 65 |
+
if y_hat == 0:
|
| 66 |
+
return gr.update(visible=False)
|
| 67 |
+
else:
|
| 68 |
+
return gr.update(value=f"Confidence: {torch.nn.Softmax(dim=1)(pred).squeeze()[y_hat].item()}", visible=True)
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
# Define GUI
|
| 72 |
+
|
| 73 |
+
with gr.Blocks() as pragformer_gui:
|
| 74 |
+
gr.Markdown(
|
| 75 |
+
"""
|
| 76 |
+
# PragFormer Pragma Classifiction
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
In past years, the world has switched to many-core and multi-core shared memory architectures.
|
| 80 |
+
As a result, there is a growing need to utilize these architectures by introducing shared memory parallelization schemes to software applications.
|
| 81 |
+
OpenMP is the most comprehensive API that implements such schemes, characterized by a readable interface.
|
| 82 |
+
Nevertheless, introducing OpenMP into code, especially legacy code, is challenging due to pervasive pitfalls in management of parallel shared memory.
|
| 83 |
+
To facilitate the performance of this task, many source-to-source (S2S) compilers have been created over the years, tasked with inserting OpenMP directives into
|
| 84 |
+
code automatically.
|
| 85 |
+
In addition to having limited robustness to their input format, these compilers still do not achieve satisfactory coverage and precision in locating parallelizable
|
| 86 |
+
code and generating appropriate directives.
|
| 87 |
+
In this work, we propose leveraging recent advances in machine learning techniques, specifically in natural language processing (NLP), to replace S2S compilers altogether.
|
| 88 |
+
We create a database (corpus), OpenMP-OMP specifically for this goal.
|
| 89 |
+
OpenMP-OMP contains over 28,000 code snippets, half of which contain OpenMP directives while the other half do not need parallelization at all with high probability.
|
| 90 |
+
We use the corpus to train systems to automatically classify code segments in need of parallelization, as well as suggest individual OpenMP clauses.
|
| 91 |
+
We train several transformer models, named PragFormer, for these tasks, and show that they outperform statistically-trained baselines and automatic S2S parallelization
|
| 92 |
+
compilers in both classifying the overall need for an OpenMP directive and the introduction of private and reduction clauses.
|
| 93 |
+
|
| 94 |
+
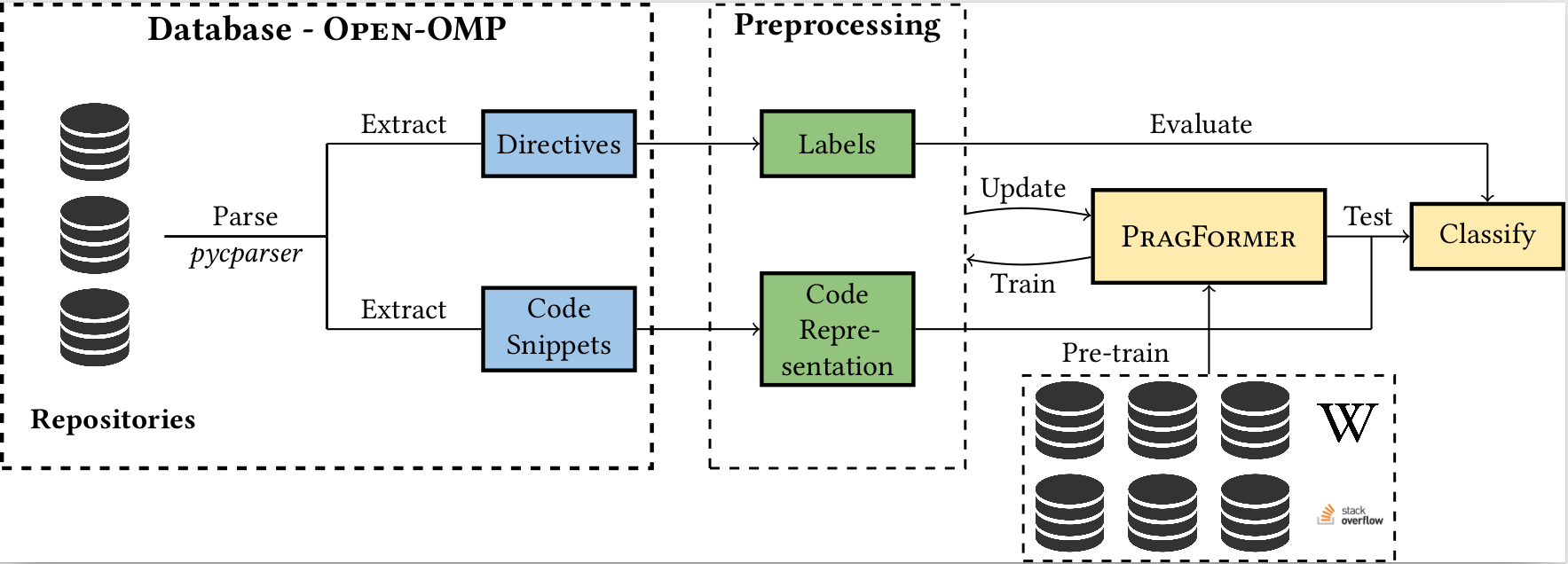
|
| 95 |
+
|
| 96 |
+
Link to [PragFormer](https://arxiv.org/abs/2204.12835) Paper
|
| 97 |
+
""")
|
| 98 |
+
|
| 99 |
+
with gr.Row(equal_height=True):
|
| 100 |
+
|
| 101 |
+
with gr.Column():
|
| 102 |
+
gr.Markdown("## Input")
|
| 103 |
+
with gr.Row():
|
| 104 |
+
with gr.Column():
|
| 105 |
+
drop = gr.Dropdown(list(data.keys()), label="Random Code Snippet")
|
| 106 |
+
sample_btn = gr.Button("Sample")
|
| 107 |
+
|
| 108 |
+
pragma = gr.Textbox(label="Pragma")
|
| 109 |
+
|
| 110 |
+
code_in = gr.Textbox(lines=5, label="Write some code and see if it should be parallelized with OpenMP")
|
| 111 |
+
submit_btn = gr.Button("Submit")
|
| 112 |
+
with gr.Column():
|
| 113 |
+
gr.Markdown("## Results")
|
| 114 |
+
label_out = gr.Textbox(label="Label")
|
| 115 |
+
confidence_out = gr.Textbox(label="Confidence")
|
| 116 |
+
|
| 117 |
+
with gr.Row():
|
| 118 |
+
private = gr.Textbox(label="Private", visible=False)
|
| 119 |
+
reduction = gr.Textbox(label="Reduction", visible=False)
|
| 120 |
+
|
| 121 |
+
submit_btn.click(fn=predict, inputs=code_in, outputs=[label_out, confidence_out])
|
| 122 |
+
submit_btn.click(fn=is_private, inputs=code_in, outputs=private)
|
| 123 |
+
submit_btn.click(fn=is_reduction, inputs=code_in, outputs=reduction)
|
| 124 |
+
sample_btn.click(fn=fill_code, inputs=drop, outputs=[pragma, code_in])
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
# pragformer_gui.launch()
|
| 128 |
+
|
c_data.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model.py
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import AutoModel, AutoConfig
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
from transformers import BertPreTrainedModel, AutoModel, PreTrainedModel
|
| 4 |
+
from model_config import PragFormerConfig
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class BERT_Arch(PreTrainedModel): #(BertPreTrainedModel):
|
| 9 |
+
config_class = PragFormerConfig
|
| 10 |
+
|
| 11 |
+
def __init__(self, config):
|
| 12 |
+
super().__init__(config)
|
| 13 |
+
print(config.bert)
|
| 14 |
+
self.bert = AutoModel.from_pretrained(config.bert['_name_or_path'])
|
| 15 |
+
|
| 16 |
+
# dropout layer
|
| 17 |
+
self.dropout = nn.Dropout(config.dropout)
|
| 18 |
+
|
| 19 |
+
# relu activation function
|
| 20 |
+
self.relu = nn.ReLU()
|
| 21 |
+
|
| 22 |
+
# dense layer 1
|
| 23 |
+
self.fc1 = nn.Linear(self.config.bert['hidden_size'], config.fc1)
|
| 24 |
+
# self.fc1 = nn.Linear(768, 512)
|
| 25 |
+
|
| 26 |
+
# dense layer 2 (Output layer)
|
| 27 |
+
self.fc2 = nn.Linear(config.fc1, config.fc2)
|
| 28 |
+
|
| 29 |
+
# softmax activation function
|
| 30 |
+
self.softmax = nn.LogSoftmax(dim = config.softmax_dim)
|
| 31 |
+
|
| 32 |
+
# define the forward pass
|
| 33 |
+
def forward(self, input_ids, attention_mask):
|
| 34 |
+
# pass the inputs to the model
|
| 35 |
+
_, cls_hs = self.bert(input_ids, attention_mask = attention_mask, return_dict=False)
|
| 36 |
+
|
| 37 |
+
x = self.fc1(cls_hs)
|
| 38 |
+
|
| 39 |
+
x = self.relu(x)
|
| 40 |
+
|
| 41 |
+
x = self.dropout(x)
|
| 42 |
+
|
| 43 |
+
# output layer
|
| 44 |
+
x = self.fc2(x)
|
| 45 |
+
|
| 46 |
+
# apply softmax activation
|
| 47 |
+
x = self.softmax(x)
|
| 48 |
+
return x
|
model_config.py
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import PretrainedConfig
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class PragFormerConfig(PretrainedConfig):
|
| 5 |
+
model_type = "pragformer"
|
| 6 |
+
|
| 7 |
+
def __init__(self, bert=None, dropout=0.2, fc1=512, fc2=2, softmax_dim=1, **kwargs):
|
| 8 |
+
self.bert = bert
|
| 9 |
+
self.dropout = dropout
|
| 10 |
+
self.fc1 = fc1
|
| 11 |
+
self.fc2 = fc2
|
| 12 |
+
self.softmax_dim = softmax_dim
|
| 13 |
+
super().__init__(**kwargs)
|