import gradio as gr
import os
from PIL import Image, ImageOps
import matplotlib.pyplot as plt
import numpy as np
import torch
import requests
from tqdm import tqdm
from io import BytesIO
from diffusers import StableDiffusionImg2ImgPipeline, StableDiffusionInpaintPipeline
import torchvision.transforms as T
from utils import preprocess,prepare_mask_and_masked_image, recover_image
to_pil = T.ToPILImage()
model_id_or_path = "runwayml/stable-diffusion-v1-5"
# model_id_or_path = "CompVis/stable-diffusion-v1-4"
# model_id_or_path = "CompVis/stable-diffusion-v1-3"
# model_id_or_path = "CompVis/stable-diffusion-v1-2"
# model_id_or_path = "CompVis/stable-diffusion-v1-1"
pipe_img2img = StableDiffusionImg2ImgPipeline.from_pretrained(
model_id_or_path,
revision="fp16",
torch_dtype=torch.float16,
)
pipe_img2img = pipe_img2img.to("cuda")
pipe_inpaint = StableDiffusionInpaintPipeline.from_pretrained(
"runwayml/stable-diffusion-inpainting",
revision="fp16",
torch_dtype=torch.float16,
)
pipe_inpaint = pipe_inpaint.to("cuda")
def pgd(X, model, eps=0.1, step_size=0.015, iters=40, clamp_min=0, clamp_max=1, mask=None):
X_adv = X.clone().detach() + (torch.rand(*X.shape)*2*eps-eps).cuda()
pbar = tqdm(range(iters))
for i in pbar:
actual_step_size = step_size - (step_size - step_size / 100) / iters * i
X_adv.requires_grad_(True)
loss = (model(X_adv).latent_dist.mean).norm()
pbar.set_description(f"[Running attack]: Loss {loss.item():.5f} | step size: {actual_step_size:.4}")
grad, = torch.autograd.grad(loss, [X_adv])
X_adv = X_adv - grad.detach().sign() * actual_step_size
X_adv = torch.minimum(torch.maximum(X_adv, X - eps), X + eps)
X_adv.data = torch.clamp(X_adv, min=clamp_min, max=clamp_max)
X_adv.grad = None
if mask is not None:
X_adv.data *= mask
return X_adv
def pgd_inpaint(X, target, model, criterion, eps=0.1, step_size=0.015, iters=40, clamp_min=0, clamp_max=1, mask=None):
X_adv = X.clone().detach() + (torch.rand(*X.shape)*2*eps-eps).cuda()
pbar = tqdm(range(iters))
for i in pbar:
actual_step_size = step_size - (step_size - step_size / 100) / iters * i
X_adv.requires_grad_(True)
loss = (model(X_adv).latent_dist.mean - target).norm()
pbar.set_description(f"[Running attack]: Loss {loss.item():.5f} | step size: {actual_step_size:.4}")
grad, = torch.autograd.grad(loss, [X_adv])
X_adv = X_adv - grad.detach().sign() * actual_step_size
X_adv = torch.minimum(torch.maximum(X_adv, X - eps), X + eps)
X_adv.data = torch.clamp(X_adv, min=clamp_min, max=clamp_max)
X_adv.grad = None
if mask is not None:
X_adv.data *= mask
return X_adv
def process_image_img2img(raw_image,prompt, scale, num_steps, seed):
resize = T.transforms.Resize(512)
center_crop = T.transforms.CenterCrop(512)
init_image = center_crop(resize(raw_image))
with torch.autocast('cuda'):
X = preprocess(init_image).half().cuda()
adv_X = pgd(X,
model=pipe_img2img.vae.encode,
clamp_min=-1,
clamp_max=1,
eps=0.06, # The higher, the less imperceptible the attack is
step_size=0.02, # Set smaller than eps
iters=100, # The higher, the stronger your attack will be
)
# convert pixels back to [0,1] range
adv_X = (adv_X / 2 + 0.5).clamp(0, 1)
adv_image = to_pil(adv_X[0]).convert("RGB")
# a good seed (uncomment the line below to generate new images)
SEED = seed# Default is 9222
# SEED = np.random.randint(low=0, high=10000)
# Play with these for improving generated image quality
STRENGTH = 0.5
GUIDANCE = scale # Default is 7.5
NUM_STEPS = num_steps # Default is 50
with torch.autocast('cuda'):
torch.manual_seed(SEED)
image_nat = pipe_img2img(prompt=prompt, image=init_image, strength=STRENGTH, guidance_scale=GUIDANCE, num_inference_steps=NUM_STEPS).images[0]
torch.manual_seed(SEED)
image_adv = pipe_img2img(prompt=prompt, image=adv_image, strength=STRENGTH, guidance_scale=GUIDANCE, num_inference_steps=NUM_STEPS).images[0]
return [(init_image,"Source Image"), (adv_image, "Adv Image"), (image_nat,"Gen. Image Nat"), (image_adv, "Gen. Image Adv")]
def process_image_inpaint(raw_image,mask, prompt,scale, num_steps, seed):
init_image = raw_image.convert('RGB').resize((512,512))
mask_image = mask.convert('RGB')
mask_image = ImageOps.invert(mask_image).resize((512,512))
# Attack using embedding of random image from internet
target_url = "https://bostonglobe-prod.cdn.arcpublishing.com/resizer/2-ZvyQ3aRNl_VNo7ja51BM5-Kpk=/960x0/cloudfront-us-east-1.images.arcpublishing.com/bostonglobe/CZOXE32LQQX5UNAB42AOA3SUY4.jpg"
response = requests.get(target_url)
target_image = Image.open(BytesIO(response.content)).convert("RGB")
target_image = target_image.resize((512, 512))
with torch.autocast('cuda'):
mask, X = prepare_mask_and_masked_image(init_image, mask_image)
X = X.half().cuda()
mask = mask.half().cuda()
# Here we attack towards the embedding of a random target image. You can also simply attack towards an embedding of zeros!
target = pipe_inpaint.vae.encode(preprocess(target_image).half().cuda()).latent_dist.mean
adv_X = pgd_inpaint(X,
target = target,
model=pipe_inpaint.vae.encode,
criterion=torch.nn.MSELoss(),
clamp_min=-1,
clamp_max=1,
eps=0.06,
step_size=0.01,
iters=1000,
mask=1-mask
)
adv_X = (adv_X / 2 + 0.5).clamp(0, 1)
adv_image = to_pil(adv_X[0]).convert("RGB")
adv_image = recover_image(adv_image, init_image, mask_image, background=True)
# A good seed
SEED = seed #Default is 9209
# Uncomment the below to generated other images
# SEED = np.random.randint(low=0, high=100000)
torch.manual_seed(SEED)
print(SEED)
#strength = 0.7
guidance_scale = scale# Default is 7.5
num_inference_steps = num_steps # Default is 100
image_nat = pipe_inpaint(prompt=prompt,
image=init_image,
mask_image=mask_image,
eta=1,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale
#strength=strength
).images[0]
image_nat = recover_image(image_nat, init_image, mask_image)
torch.manual_seed(SEED)
image_adv = pipe_inpaint(prompt=prompt,
image=adv_image,
mask_image=mask_image,
eta=1,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale
#strength=strength
).images[0]
image_adv = recover_image(image_adv, init_image, mask_image)
return [(init_image,"Source Image"), (adv_image, "Adv Image"), (image_nat,"Gen. Image Nat"), (image_adv, "Gen. Image Adv")]
examples_list = [["dog.png", "dog under heavy rain and muddy ground real", 7.5, 50, 9222]]
with gr.Blocks() as demo:
gr.Markdown("""
## Interactive demo: Raising the Cost of Malicious AI-Powered Image Editing
""")
gr.HTML('''
This is an unofficial demo for Photoguard, which is an approach to safeguarding images against manipulation by ML-powered photo-editing models such as stable diffusion through immunization of images. The demo is based on the Github implementation provided by the authors.
''')
gr.HTML('''
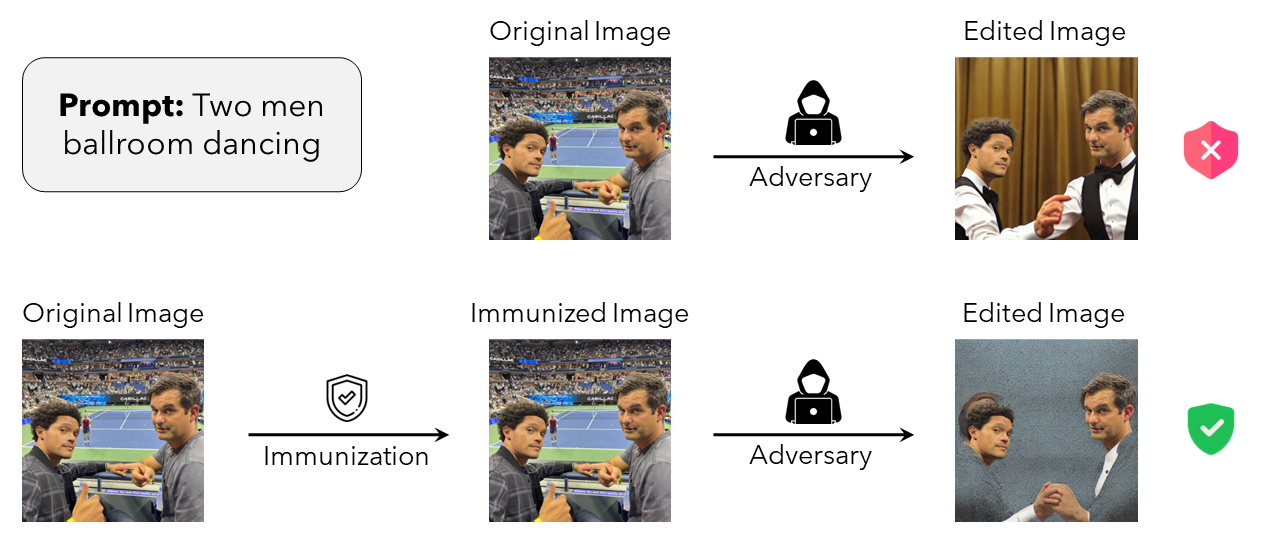
''')
gr.HTML('''
A malevolent actor might download
photos of people posted online and edit them maliciously using an off-the-shelf diffusion model. The adversary
describes via a textual prompt the desired changes and then uses a diffusion model to generate a realistic
image that matches the prompt (similar to the top row in the image). By immunizing the original image before the adversary can access it,
we disrupt their ability to successfully perform such edits forcing them to generate unrealistic images (similar to the bottom row in the image). For a more detailed explanation, please read the accompanying Paper or Blogpost
''')
with gr.Column():
with gr.Tab("Simple Image to Image"):
input_image_img2img = gr.Image(type="pil", label = "Source Image")
input_prompt_img2img = gr.Textbox(label="Prompt")
run_btn_img2img = gr.Button('Run')
with gr.Tab("Simple Inpainting"):
input_image_inpaint = gr.Image(type="pil", label = "Source Image")
mask_image_inpaint = gr.Image(type="pil", label = "Mask")
input_prompt_inpaint = gr.Textbox(label="Prompt")
run_btn_inpaint = gr.Button('Run')
with gr.Accordion("Advanced options", open=False):
scale = gr.Slider(label="Guidance Scale", minimum=0.1, maximum=30.0, value=7.5, step=0.1)
num_steps = gr.Slider(label="Number of Inference Steps", minimum=5, maximum=125, value=100, step=5)
seed = gr.Slider(label="Seed", minimum=0, maximum=2147483647, step=1, randomize=True)
with gr.Row():
result_gallery = gr.Gallery(
label="Generated images", show_label=False, elem_id="gallery"
).style(grid=[2], height="auto")
run_btn_img2img.click(process_image_img2img, inputs = [input_image_img2img,input_prompt_img2img, scale, num_steps, seed], outputs = [result_gallery])
examples = gr.Examples(examples=examples_list,inputs = [input_image_img2img,input_prompt_img2img,scale, num_steps, seed], outputs = [result_gallery], cache_examples = True, fn = process_image_img2img)
run_btn_inpaint.click(process_image_inpaint, inputs = [input_image_inpaint,mask_image_inpaint,input_prompt_inpaint,scale, num_steps, seed], outputs = [result_gallery])
demo.launch(debug=True)