Spaces:
Runtime error


Runtime error

Upload 34 files
Browse files- __init__.py +0 -0
- app.py +398 -0
- assets/mplug_owl2_logo.png +0 -0
- assets/mplug_owl2_radar.png +0 -0
- examples/Rebecca_(1939_poster)_Small.jpeg +0 -0
- examples/extreme_ironing.jpg +0 -0
- model_worker.py +143 -0
- mplug_owl2/__init__.py +1 -0
- mplug_owl2/constants.py +9 -0
- mplug_owl2/conversation.py +301 -0
- mplug_owl2/mm_utils.py +103 -0
- mplug_owl2/model/__init__.py +2 -0
- mplug_owl2/model/builder.py +118 -0
- mplug_owl2/model/configuration_mplug_owl2.py +332 -0
- mplug_owl2/model/convert_mplug_owl2_weight_to_hf.py +395 -0
- mplug_owl2/model/modeling_attn_mask_utils.py +247 -0
- mplug_owl2/model/modeling_llama2.py +486 -0
- mplug_owl2/model/modeling_mplug_owl2.py +329 -0
- mplug_owl2/model/utils.py +20 -0
- mplug_owl2/model/visual_encoder.py +928 -0
- mplug_owl2/serve/__init__.py +0 -0
- mplug_owl2/serve/cli.py +120 -0
- mplug_owl2/serve/controller.py +298 -0
- mplug_owl2/serve/examples/Rebecca_(1939_poster)_Small.jpeg +0 -0
- mplug_owl2/serve/examples/extreme_ironing.jpg +0 -0
- mplug_owl2/serve/gradio_web_server.py +460 -0
- mplug_owl2/serve/model_worker.py +278 -0
- mplug_owl2/serve/register_workers.py +26 -0
- mplug_owl2/train/llama_flash_attn_monkey_patch.py +117 -0
- mplug_owl2/train/mplug_owl2_trainer.py +243 -0
- mplug_owl2/train/train.py +848 -0
- mplug_owl2/train/train_mem.py +13 -0
- mplug_owl2/utils.py +126 -0
- requirements.txt +17 -0
__init__.py
ADDED
|
File without changes
|
app.py
ADDED
|
@@ -0,0 +1,398 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import datetime
|
| 3 |
+
import json
|
| 4 |
+
import os
|
| 5 |
+
import time
|
| 6 |
+
|
| 7 |
+
import gradio as gr
|
| 8 |
+
import requests
|
| 9 |
+
|
| 10 |
+
from mplug_owl2.conversation import (default_conversation, conv_templates,
|
| 11 |
+
SeparatorStyle)
|
| 12 |
+
from mplug_owl2.constants import LOGDIR
|
| 13 |
+
from mplug_owl2.utils import (build_logger, server_error_msg,
|
| 14 |
+
violates_moderation, moderation_msg)
|
| 15 |
+
from model_worker import ModelWorker
|
| 16 |
+
import hashlib
|
| 17 |
+
|
| 18 |
+
from modelscope.hub.snapshot_download import snapshot_download
|
| 19 |
+
model_dir = snapshot_download('damo/mPLUG-Owl2', cache_dir='./')
|
| 20 |
+
|
| 21 |
+
print(os.listdir('./'))
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
logger = build_logger("gradio_web_server_local", "gradio_web_server_local.log")
|
| 25 |
+
|
| 26 |
+
headers = {"User-Agent": "mPLUG-Owl2 Client"}
|
| 27 |
+
|
| 28 |
+
no_change_btn = gr.Button.update()
|
| 29 |
+
enable_btn = gr.Button.update(interactive=True)
|
| 30 |
+
disable_btn = gr.Button.update(interactive=False)
|
| 31 |
+
|
| 32 |
+
def get_conv_log_filename():
|
| 33 |
+
t = datetime.datetime.now()
|
| 34 |
+
name = os.path.join(LOGDIR, f"{t.year}-{t.month:02d}-{t.day:02d}-conv.json")
|
| 35 |
+
return name
|
| 36 |
+
|
| 37 |
+
get_window_url_params = """
|
| 38 |
+
function() {
|
| 39 |
+
const params = new URLSearchParams(window.location.search);
|
| 40 |
+
url_params = Object.fromEntries(params);
|
| 41 |
+
console.log(url_params);
|
| 42 |
+
return url_params;
|
| 43 |
+
}
|
| 44 |
+
"""
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def load_demo(url_params, request: gr.Request):
|
| 48 |
+
logger.info(f"load_demo. ip: {request.client.host}. params: {url_params}")
|
| 49 |
+
state = default_conversation.copy()
|
| 50 |
+
return state
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def vote_last_response(state, vote_type, request: gr.Request):
|
| 54 |
+
with open(get_conv_log_filename(), "a") as fout:
|
| 55 |
+
data = {
|
| 56 |
+
"tstamp": round(time.time(), 4),
|
| 57 |
+
"type": vote_type,
|
| 58 |
+
"state": state.dict(),
|
| 59 |
+
"ip": request.client.host,
|
| 60 |
+
}
|
| 61 |
+
fout.write(json.dumps(data) + "\n")
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def upvote_last_response(state, request: gr.Request):
|
| 65 |
+
logger.info(f"upvote. ip: {request.client.host}")
|
| 66 |
+
vote_last_response(state, "upvote", request)
|
| 67 |
+
return ("",) + (disable_btn,) * 3
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def downvote_last_response(state, request: gr.Request):
|
| 71 |
+
logger.info(f"downvote. ip: {request.client.host}")
|
| 72 |
+
vote_last_response(state, "downvote", request)
|
| 73 |
+
return ("",) + (disable_btn,) * 3
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def flag_last_response(state, request: gr.Request):
|
| 77 |
+
logger.info(f"flag. ip: {request.client.host}")
|
| 78 |
+
vote_last_response(state, "flag", request)
|
| 79 |
+
return ("",) + (disable_btn,) * 3
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def regenerate(state, image_process_mode, request: gr.Request):
|
| 83 |
+
logger.info(f"regenerate. ip: {request.client.host}")
|
| 84 |
+
state.messages[-1][-1] = None
|
| 85 |
+
prev_human_msg = state.messages[-2]
|
| 86 |
+
if type(prev_human_msg[1]) in (tuple, list):
|
| 87 |
+
prev_human_msg[1] = (*prev_human_msg[1][:2], image_process_mode)
|
| 88 |
+
state.skip_next = False
|
| 89 |
+
return (state, state.to_gradio_chatbot(), "", None) + (disable_btn,) * 5
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
def clear_history(request: gr.Request):
|
| 93 |
+
logger.info(f"clear_history. ip: {request.client.host}")
|
| 94 |
+
state = default_conversation.copy()
|
| 95 |
+
return (state, state.to_gradio_chatbot(), "", None) + (disable_btn,) * 5
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
def add_text(state, text, image, image_process_mode, request: gr.Request):
|
| 99 |
+
logger.info(f"add_text. ip: {request.client.host}. len: {len(text)}")
|
| 100 |
+
if len(text) <= 0 and image is None:
|
| 101 |
+
state.skip_next = True
|
| 102 |
+
return (state, state.to_gradio_chatbot(), "", None) + (no_change_btn,) * 5
|
| 103 |
+
if args.moderate:
|
| 104 |
+
flagged = violates_moderation(text)
|
| 105 |
+
if flagged:
|
| 106 |
+
state.skip_next = True
|
| 107 |
+
return (state, state.to_gradio_chatbot(), moderation_msg, None) + (
|
| 108 |
+
no_change_btn,) * 5
|
| 109 |
+
|
| 110 |
+
text = text[:3584] # Hard cut-off
|
| 111 |
+
if image is not None:
|
| 112 |
+
text = text[:3500] # Hard cut-off for images
|
| 113 |
+
if '<|image|>' not in text:
|
| 114 |
+
text = '<|image|>' + text
|
| 115 |
+
text = (text, image, image_process_mode)
|
| 116 |
+
if len(state.get_images(return_pil=True)) > 0:
|
| 117 |
+
state = default_conversation.copy()
|
| 118 |
+
state.append_message(state.roles[0], text)
|
| 119 |
+
state.append_message(state.roles[1], None)
|
| 120 |
+
state.skip_next = False
|
| 121 |
+
return (state, state.to_gradio_chatbot(), "", None) + (disable_btn,) * 5
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
def http_bot(state, temperature, top_p, max_new_tokens, request: gr.Request):
|
| 125 |
+
logger.info(f"http_bot. ip: {request.client.host}")
|
| 126 |
+
start_tstamp = time.time()
|
| 127 |
+
|
| 128 |
+
if state.skip_next:
|
| 129 |
+
# This generate call is skipped due to invalid inputs
|
| 130 |
+
yield (state, state.to_gradio_chatbot()) + (no_change_btn,) * 5
|
| 131 |
+
return
|
| 132 |
+
|
| 133 |
+
if len(state.messages) == state.offset + 2:
|
| 134 |
+
# First round of conversation
|
| 135 |
+
template_name = "mplug_owl2"
|
| 136 |
+
new_state = conv_templates[template_name].copy()
|
| 137 |
+
new_state.append_message(new_state.roles[0], state.messages[-2][1])
|
| 138 |
+
new_state.append_message(new_state.roles[1], None)
|
| 139 |
+
state = new_state
|
| 140 |
+
|
| 141 |
+
# Construct prompt
|
| 142 |
+
prompt = state.get_prompt()
|
| 143 |
+
|
| 144 |
+
all_images = state.get_images(return_pil=True)
|
| 145 |
+
all_image_hash = [hashlib.md5(image.tobytes()).hexdigest() for image in all_images]
|
| 146 |
+
for image, hash in zip(all_images, all_image_hash):
|
| 147 |
+
t = datetime.datetime.now()
|
| 148 |
+
filename = os.path.join(LOGDIR, "serve_images", f"{t.year}-{t.month:02d}-{t.day:02d}", f"{hash}.jpg")
|
| 149 |
+
if not os.path.isfile(filename):
|
| 150 |
+
os.makedirs(os.path.dirname(filename), exist_ok=True)
|
| 151 |
+
image.save(filename)
|
| 152 |
+
|
| 153 |
+
# Make requests
|
| 154 |
+
pload = {
|
| 155 |
+
"prompt": prompt,
|
| 156 |
+
"temperature": float(temperature),
|
| 157 |
+
"top_p": float(top_p),
|
| 158 |
+
"max_new_tokens": min(int(max_new_tokens), 2048),
|
| 159 |
+
"stop": state.sep if state.sep_style in [SeparatorStyle.SINGLE, SeparatorStyle.MPT] else state.sep2,
|
| 160 |
+
"images": f'List of {len(state.get_images())} images: {all_image_hash}',
|
| 161 |
+
}
|
| 162 |
+
logger.info(f"==== request ====\n{pload}")
|
| 163 |
+
|
| 164 |
+
pload['images'] = state.get_images()
|
| 165 |
+
|
| 166 |
+
state.messages[-1][-1] = "▌"
|
| 167 |
+
yield (state, state.to_gradio_chatbot()) + (disable_btn,) * 5
|
| 168 |
+
|
| 169 |
+
try:
|
| 170 |
+
# Stream output
|
| 171 |
+
# response = requests.post(worker_addr + "/worker_generate_stream",
|
| 172 |
+
# headers=headers, json=pload, stream=True, timeout=10)
|
| 173 |
+
# for chunk in response.iter_lines(decode_unicode=False, delimiter=b"\0"):
|
| 174 |
+
response = model.generate_stream_gate(pload)
|
| 175 |
+
for chunk in response:
|
| 176 |
+
if chunk:
|
| 177 |
+
data = json.loads(chunk.decode())
|
| 178 |
+
if data["error_code"] == 0:
|
| 179 |
+
output = data["text"][len(prompt):].strip()
|
| 180 |
+
state.messages[-1][-1] = output + "▌"
|
| 181 |
+
yield (state, state.to_gradio_chatbot()) + (disable_btn,) * 5
|
| 182 |
+
else:
|
| 183 |
+
output = data["text"] + f" (error_code: {data['error_code']})"
|
| 184 |
+
state.messages[-1][-1] = output
|
| 185 |
+
yield (state, state.to_gradio_chatbot()) + (disable_btn, disable_btn, disable_btn, enable_btn, enable_btn)
|
| 186 |
+
return
|
| 187 |
+
time.sleep(0.03)
|
| 188 |
+
except requests.exceptions.RequestException as e:
|
| 189 |
+
state.messages[-1][-1] = server_error_msg
|
| 190 |
+
yield (state, state.to_gradio_chatbot()) + (disable_btn, disable_btn, disable_btn, enable_btn, enable_btn)
|
| 191 |
+
return
|
| 192 |
+
|
| 193 |
+
state.messages[-1][-1] = state.messages[-1][-1][:-1]
|
| 194 |
+
yield (state, state.to_gradio_chatbot()) + (enable_btn,) * 5
|
| 195 |
+
|
| 196 |
+
finish_tstamp = time.time()
|
| 197 |
+
logger.info(f"{output}")
|
| 198 |
+
|
| 199 |
+
with open(get_conv_log_filename(), "a") as fout:
|
| 200 |
+
data = {
|
| 201 |
+
"tstamp": round(finish_tstamp, 4),
|
| 202 |
+
"type": "chat",
|
| 203 |
+
"start": round(start_tstamp, 4),
|
| 204 |
+
"finish": round(start_tstamp, 4),
|
| 205 |
+
"state": state.dict(),
|
| 206 |
+
"images": all_image_hash,
|
| 207 |
+
"ip": request.client.host,
|
| 208 |
+
}
|
| 209 |
+
fout.write(json.dumps(data) + "\n")
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
title_markdown = ("""
|
| 213 |
+
<h1 align="center"><a href="https://github.com/X-PLUG/mPLUG-Owl"><img src="https://z1.ax1x.com/2023/11/03/piM1rGQ.md.png", alt="mPLUG-Owl" border="0" style="margin: 0 auto; height: 200px;" /></a> </h1>
|
| 214 |
+
|
| 215 |
+
<h2 align="center"> mPLUG-Owl2: Revolutionizing Multi-modal Large Language Model with Modality Collaboration</h2>
|
| 216 |
+
|
| 217 |
+
<h5 align="center"> If you like our project, please give us a star ✨ on Github for latest update. </h2>
|
| 218 |
+
|
| 219 |
+
<div align="center">
|
| 220 |
+
<div style="display:flex; gap: 0.25rem;" align="center">
|
| 221 |
+
<a href='https://github.com/X-PLUG/mPLUG-Owl'><img src='https://img.shields.io/badge/Github-Code-blue'></a>
|
| 222 |
+
<a href="https://arxiv.org/abs/2304.14178"><img src="https://img.shields.io/badge/Arxiv-2304.14178-red"></a>
|
| 223 |
+
<a href='https://github.com/X-PLUG/mPLUG-Owl/stargazers'><img src='https://img.shields.io/github/stars/X-PLUG/mPLUG-Owl.svg?style=social'></a>
|
| 224 |
+
</div>
|
| 225 |
+
</div>
|
| 226 |
+
|
| 227 |
+
""")
|
| 228 |
+
|
| 229 |
+
|
| 230 |
+
tos_markdown = ("""
|
| 231 |
+
### Terms of use
|
| 232 |
+
By using this service, users are required to agree to the following terms:
|
| 233 |
+
The service is a research preview intended for non-commercial use only. It only provides limited safety measures and may generate offensive content. It must not be used for any illegal, harmful, violent, racist, or sexual purposes. The service may collect user dialogue data for future research.
|
| 234 |
+
Please click the "Flag" button if you get any inappropriate answer! We will collect those to keep improving our moderator.
|
| 235 |
+
For an optimal experience, please use desktop computers for this demo, as mobile devices may compromise its quality.
|
| 236 |
+
""")
|
| 237 |
+
|
| 238 |
+
|
| 239 |
+
learn_more_markdown = ("""
|
| 240 |
+
### License
|
| 241 |
+
The service is a research preview intended for non-commercial use only, subject to the model [License](https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md) of LLaMA, [Terms of Use](https://openai.com/policies/terms-of-use) of the data generated by OpenAI, and [Privacy Practices](https://chrome.google.com/webstore/detail/sharegpt-share-your-chatg/daiacboceoaocpibfodeljbdfacokfjb) of ShareGPT. Please contact us if you find any potential violation.
|
| 242 |
+
""")
|
| 243 |
+
|
| 244 |
+
block_css = """
|
| 245 |
+
|
| 246 |
+
#buttons button {
|
| 247 |
+
min-width: min(120px,100%);
|
| 248 |
+
}
|
| 249 |
+
|
| 250 |
+
"""
|
| 251 |
+
|
| 252 |
+
def build_demo(embed_mode):
|
| 253 |
+
textbox = gr.Textbox(show_label=False, placeholder="Enter text and press ENTER", container=False)
|
| 254 |
+
with gr.Blocks(title="mPLUG-Owl2", theme=gr.themes.Default(), css=block_css) as demo:
|
| 255 |
+
state = gr.State()
|
| 256 |
+
|
| 257 |
+
if not embed_mode:
|
| 258 |
+
gr.Markdown(title_markdown)
|
| 259 |
+
|
| 260 |
+
with gr.Row():
|
| 261 |
+
with gr.Column(scale=3):
|
| 262 |
+
imagebox = gr.Image(type="pil")
|
| 263 |
+
image_process_mode = gr.Radio(
|
| 264 |
+
["Crop", "Resize", "Pad", "Default"],
|
| 265 |
+
value="Default",
|
| 266 |
+
label="Preprocess for non-square image", visible=False)
|
| 267 |
+
|
| 268 |
+
cur_dir = os.path.dirname(os.path.abspath(__file__))
|
| 269 |
+
gr.Examples(examples=[
|
| 270 |
+
[f"{cur_dir}/examples/extreme_ironing.jpg", "What is unusual about this image?"],
|
| 271 |
+
[f"{cur_dir}/examples/Rebecca_(1939_poster)_Small.jpeg", "What is the name of the movie in the poster?"],
|
| 272 |
+
], inputs=[imagebox, textbox])
|
| 273 |
+
|
| 274 |
+
with gr.Accordion("Parameters", open=True) as parameter_row:
|
| 275 |
+
temperature = gr.Slider(minimum=0.0, maximum=1.0, value=0.2, step=0.1, interactive=True, label="Temperature",)
|
| 276 |
+
top_p = gr.Slider(minimum=0.0, maximum=1.0, value=0.7, step=0.1, interactive=True, label="Top P",)
|
| 277 |
+
max_output_tokens = gr.Slider(minimum=0, maximum=1024, value=512, step=64, interactive=True, label="Max output tokens",)
|
| 278 |
+
|
| 279 |
+
with gr.Column(scale=8):
|
| 280 |
+
chatbot = gr.Chatbot(elem_id="Chatbot", label="mPLUG-Owl2 Chatbot", height=600)
|
| 281 |
+
with gr.Row():
|
| 282 |
+
with gr.Column(scale=8):
|
| 283 |
+
textbox.render()
|
| 284 |
+
with gr.Column(scale=1, min_width=50):
|
| 285 |
+
submit_btn = gr.Button(value="Send", variant="primary")
|
| 286 |
+
with gr.Row(elem_id="buttons") as button_row:
|
| 287 |
+
upvote_btn = gr.Button(value="👍 Upvote", interactive=False)
|
| 288 |
+
downvote_btn = gr.Button(value="👎 Downvote", interactive=False)
|
| 289 |
+
flag_btn = gr.Button(value="⚠️ Flag", interactive=False)
|
| 290 |
+
#stop_btn = gr.Button(value="⏹️ Stop Generation", interactive=False)
|
| 291 |
+
regenerate_btn = gr.Button(value="🔄 Regenerate", interactive=False)
|
| 292 |
+
clear_btn = gr.Button(value="🗑️ Clear", interactive=False)
|
| 293 |
+
|
| 294 |
+
if not embed_mode:
|
| 295 |
+
gr.Markdown(tos_markdown)
|
| 296 |
+
gr.Markdown(learn_more_markdown)
|
| 297 |
+
url_params = gr.JSON(visible=False)
|
| 298 |
+
|
| 299 |
+
# Register listeners
|
| 300 |
+
btn_list = [upvote_btn, downvote_btn, flag_btn, regenerate_btn, clear_btn]
|
| 301 |
+
upvote_btn.click(
|
| 302 |
+
upvote_last_response,
|
| 303 |
+
state,
|
| 304 |
+
[textbox, upvote_btn, downvote_btn, flag_btn],
|
| 305 |
+
queue=False
|
| 306 |
+
)
|
| 307 |
+
downvote_btn.click(
|
| 308 |
+
downvote_last_response,
|
| 309 |
+
state,
|
| 310 |
+
[textbox, upvote_btn, downvote_btn, flag_btn],
|
| 311 |
+
queue=False
|
| 312 |
+
)
|
| 313 |
+
flag_btn.click(
|
| 314 |
+
flag_last_response,
|
| 315 |
+
state,
|
| 316 |
+
[textbox, upvote_btn, downvote_btn, flag_btn],
|
| 317 |
+
queue=False
|
| 318 |
+
)
|
| 319 |
+
|
| 320 |
+
regenerate_btn.click(
|
| 321 |
+
regenerate,
|
| 322 |
+
[state, image_process_mode],
|
| 323 |
+
[state, chatbot, textbox, imagebox] + btn_list,
|
| 324 |
+
queue=False
|
| 325 |
+
).then(
|
| 326 |
+
http_bot,
|
| 327 |
+
[state, temperature, top_p, max_output_tokens],
|
| 328 |
+
[state, chatbot] + btn_list
|
| 329 |
+
)
|
| 330 |
+
|
| 331 |
+
clear_btn.click(
|
| 332 |
+
clear_history,
|
| 333 |
+
None,
|
| 334 |
+
[state, chatbot, textbox, imagebox] + btn_list,
|
| 335 |
+
queue=False
|
| 336 |
+
)
|
| 337 |
+
|
| 338 |
+
textbox.submit(
|
| 339 |
+
add_text,
|
| 340 |
+
[state, textbox, imagebox, image_process_mode],
|
| 341 |
+
[state, chatbot, textbox, imagebox] + btn_list,
|
| 342 |
+
queue=False
|
| 343 |
+
).then(
|
| 344 |
+
http_bot,
|
| 345 |
+
[state, temperature, top_p, max_output_tokens],
|
| 346 |
+
[state, chatbot] + btn_list
|
| 347 |
+
)
|
| 348 |
+
|
| 349 |
+
submit_btn.click(
|
| 350 |
+
add_text,
|
| 351 |
+
[state, textbox, imagebox, image_process_mode],
|
| 352 |
+
[state, chatbot, textbox, imagebox] + btn_list,
|
| 353 |
+
queue=False
|
| 354 |
+
).then(
|
| 355 |
+
http_bot,
|
| 356 |
+
[state, temperature, top_p, max_output_tokens],
|
| 357 |
+
[state, chatbot] + btn_list
|
| 358 |
+
)
|
| 359 |
+
|
| 360 |
+
demo.load(
|
| 361 |
+
load_demo,
|
| 362 |
+
[url_params],
|
| 363 |
+
state,
|
| 364 |
+
_js=get_window_url_params,
|
| 365 |
+
queue=False
|
| 366 |
+
)
|
| 367 |
+
|
| 368 |
+
return demo
|
| 369 |
+
|
| 370 |
+
|
| 371 |
+
if __name__ == "__main__":
|
| 372 |
+
parser = argparse.ArgumentParser()
|
| 373 |
+
parser.add_argument("--host", type=str, default="0.0.0.0")
|
| 374 |
+
parser.add_argument("--port", type=int)
|
| 375 |
+
parser.add_argument("--concurrency-count", type=int, default=10)
|
| 376 |
+
parser.add_argument("--model-list-mode", type=str, default="once",
|
| 377 |
+
choices=["once", "reload"])
|
| 378 |
+
parser.add_argument("--model-path", type=str, default="./mPLUG-Owl2")
|
| 379 |
+
parser.add_argument("--device", type=str, default="cuda")
|
| 380 |
+
parser.add_argument("--load-8bit", action="store_true")
|
| 381 |
+
parser.add_argument("--load-4bit", action="store_true")
|
| 382 |
+
parser.add_argument("--moderate", action="store_true")
|
| 383 |
+
parser.add_argument("--embed", action="store_true")
|
| 384 |
+
args = parser.parse_args()
|
| 385 |
+
logger.info(f"args: {args}")
|
| 386 |
+
|
| 387 |
+
model = ModelWorker(args.model_path, None, None, args.load_8bit, args.load_4bit, args.device)
|
| 388 |
+
|
| 389 |
+
logger.info(args)
|
| 390 |
+
demo = build_demo(args.embed)
|
| 391 |
+
demo.queue(
|
| 392 |
+
concurrency_count=args.concurrency_count,
|
| 393 |
+
api_open=False
|
| 394 |
+
).launch(
|
| 395 |
+
server_name=args.host,
|
| 396 |
+
server_port=args.port,
|
| 397 |
+
share=False
|
| 398 |
+
)
|
assets/mplug_owl2_logo.png
ADDED
|
|
assets/mplug_owl2_radar.png
ADDED
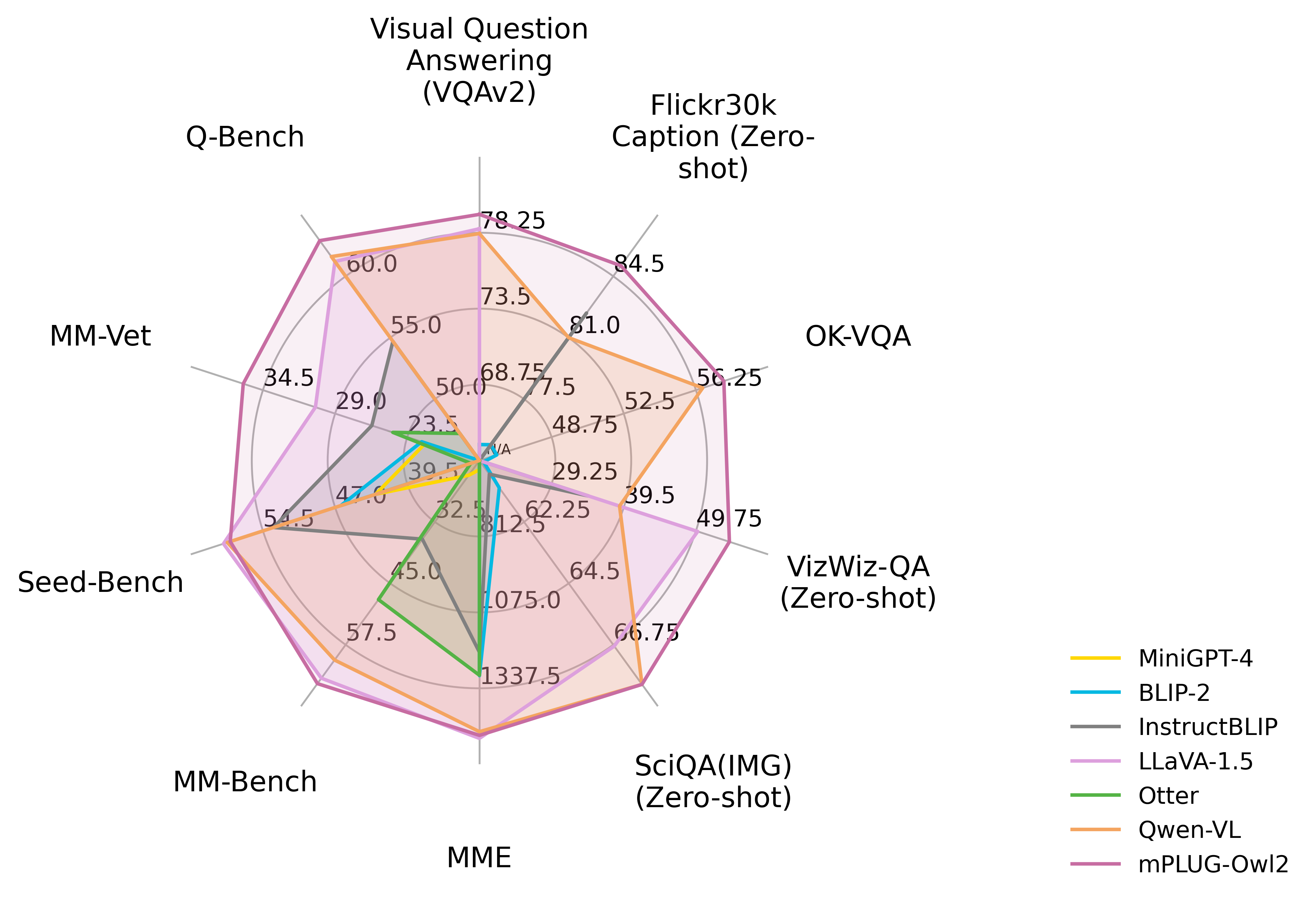
|
examples/Rebecca_(1939_poster)_Small.jpeg
ADDED
_Small.jpeg)
|
examples/extreme_ironing.jpg
ADDED

|
model_worker.py
ADDED
|
@@ -0,0 +1,143 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
A model worker executes the model.
|
| 3 |
+
"""
|
| 4 |
+
import argparse
|
| 5 |
+
import asyncio
|
| 6 |
+
import json
|
| 7 |
+
import time
|
| 8 |
+
import threading
|
| 9 |
+
import uuid
|
| 10 |
+
|
| 11 |
+
import requests
|
| 12 |
+
import torch
|
| 13 |
+
from functools import partial
|
| 14 |
+
|
| 15 |
+
from mplug_owl2.constants import WORKER_HEART_BEAT_INTERVAL
|
| 16 |
+
from mplug_owl2.utils import (build_logger, server_error_msg,
|
| 17 |
+
pretty_print_semaphore)
|
| 18 |
+
from mplug_owl2.model.builder import load_pretrained_model
|
| 19 |
+
from mplug_owl2.mm_utils import process_images, load_image_from_base64, tokenizer_image_token, KeywordsStoppingCriteria
|
| 20 |
+
from mplug_owl2.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN
|
| 21 |
+
from transformers import TextIteratorStreamer
|
| 22 |
+
from threading import Thread
|
| 23 |
+
|
| 24 |
+
GB = 1 << 30
|
| 25 |
+
|
| 26 |
+
worker_id = str(uuid.uuid4())[:6]
|
| 27 |
+
logger = build_logger("model_worker", f"model_worker_{worker_id}.log")
|
| 28 |
+
|
| 29 |
+
class ModelWorker:
|
| 30 |
+
def __init__(self, model_path, model_base, model_name, load_8bit, load_4bit, device):
|
| 31 |
+
self.worker_id = worker_id
|
| 32 |
+
if model_path.endswith("/"):
|
| 33 |
+
model_path = model_path[:-1]
|
| 34 |
+
if model_name is None:
|
| 35 |
+
model_paths = model_path.split("/")
|
| 36 |
+
if model_paths[-1].startswith('checkpoint-'):
|
| 37 |
+
self.model_name = model_paths[-2] + "_" + model_paths[-1]
|
| 38 |
+
else:
|
| 39 |
+
self.model_name = model_paths[-1]
|
| 40 |
+
else:
|
| 41 |
+
self.model_name = model_name
|
| 42 |
+
|
| 43 |
+
self.device = device
|
| 44 |
+
logger.info(f"Loading the model {self.model_name} on worker {worker_id} ...")
|
| 45 |
+
self.tokenizer, self.model, self.image_processor, self.context_len = load_pretrained_model(
|
| 46 |
+
model_path, model_base, self.model_name, load_8bit, load_4bit, device=self.device)
|
| 47 |
+
self.is_multimodal = True
|
| 48 |
+
|
| 49 |
+
@torch.inference_mode()
|
| 50 |
+
def generate_stream(self, params):
|
| 51 |
+
tokenizer, model, image_processor = self.tokenizer, self.model, self.image_processor
|
| 52 |
+
|
| 53 |
+
prompt = params["prompt"]
|
| 54 |
+
ori_prompt = prompt
|
| 55 |
+
images = params.get("images", None)
|
| 56 |
+
num_image_tokens = 0
|
| 57 |
+
if images is not None and len(images) > 0 and self.is_multimodal:
|
| 58 |
+
if len(images) > 0:
|
| 59 |
+
if len(images) != prompt.count(DEFAULT_IMAGE_TOKEN):
|
| 60 |
+
raise ValueError("Number of images does not match number of <|image|> tokens in prompt")
|
| 61 |
+
|
| 62 |
+
images = [load_image_from_base64(image) for image in images]
|
| 63 |
+
images = process_images(images, image_processor, model.config)
|
| 64 |
+
|
| 65 |
+
if type(images) is list:
|
| 66 |
+
images = [image.to(self.model.device, dtype=torch.float16) for image in images]
|
| 67 |
+
else:
|
| 68 |
+
images = images.to(self.model.device, dtype=torch.float16)
|
| 69 |
+
|
| 70 |
+
replace_token = DEFAULT_IMAGE_TOKEN
|
| 71 |
+
prompt = prompt.replace(DEFAULT_IMAGE_TOKEN, replace_token)
|
| 72 |
+
|
| 73 |
+
num_image_tokens = prompt.count(replace_token) * (model.get_model().visual_abstractor.config.num_learnable_queries + 1)
|
| 74 |
+
else:
|
| 75 |
+
images = None
|
| 76 |
+
image_args = {"images": images}
|
| 77 |
+
else:
|
| 78 |
+
images = None
|
| 79 |
+
image_args = {}
|
| 80 |
+
|
| 81 |
+
temperature = float(params.get("temperature", 1.0))
|
| 82 |
+
top_p = float(params.get("top_p", 1.0))
|
| 83 |
+
max_context_length = getattr(model.config, 'max_position_embeddings', 4096)
|
| 84 |
+
max_new_tokens = min(int(params.get("max_new_tokens", 256)), 1024)
|
| 85 |
+
stop_str = params.get("stop", None)
|
| 86 |
+
do_sample = True if temperature > 0.001 else False
|
| 87 |
+
|
| 88 |
+
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).to(self.device)
|
| 89 |
+
keywords = [stop_str]
|
| 90 |
+
stopping_criteria = KeywordsStoppingCriteria(keywords, tokenizer, input_ids)
|
| 91 |
+
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True, timeout=15)
|
| 92 |
+
|
| 93 |
+
max_new_tokens = min(max_new_tokens, max_context_length - input_ids.shape[-1] - num_image_tokens)
|
| 94 |
+
|
| 95 |
+
if max_new_tokens < 1:
|
| 96 |
+
yield json.dumps({"text": ori_prompt + "Exceeds max token length. Please start a new conversation, thanks.", "error_code": 0}).encode() + b"\0"
|
| 97 |
+
return
|
| 98 |
+
|
| 99 |
+
thread = Thread(target=model.generate, kwargs=dict(
|
| 100 |
+
inputs=input_ids,
|
| 101 |
+
do_sample=do_sample,
|
| 102 |
+
temperature=temperature,
|
| 103 |
+
top_p=top_p,
|
| 104 |
+
max_new_tokens=max_new_tokens,
|
| 105 |
+
streamer=streamer,
|
| 106 |
+
stopping_criteria=[stopping_criteria],
|
| 107 |
+
use_cache=True,
|
| 108 |
+
**image_args
|
| 109 |
+
))
|
| 110 |
+
thread.start()
|
| 111 |
+
|
| 112 |
+
generated_text = ori_prompt
|
| 113 |
+
for new_text in streamer:
|
| 114 |
+
generated_text += new_text
|
| 115 |
+
if generated_text.endswith(stop_str):
|
| 116 |
+
generated_text = generated_text[:-len(stop_str)]
|
| 117 |
+
yield json.dumps({"text": generated_text, "error_code": 0}).encode()
|
| 118 |
+
|
| 119 |
+
def generate_stream_gate(self, params):
|
| 120 |
+
try:
|
| 121 |
+
for x in self.generate_stream(params):
|
| 122 |
+
yield x
|
| 123 |
+
except ValueError as e:
|
| 124 |
+
print("Caught ValueError:", e)
|
| 125 |
+
ret = {
|
| 126 |
+
"text": server_error_msg,
|
| 127 |
+
"error_code": 1,
|
| 128 |
+
}
|
| 129 |
+
yield json.dumps(ret).encode()
|
| 130 |
+
except torch.cuda.CudaError as e:
|
| 131 |
+
print("Caught torch.cuda.CudaError:", e)
|
| 132 |
+
ret = {
|
| 133 |
+
"text": server_error_msg,
|
| 134 |
+
"error_code": 1,
|
| 135 |
+
}
|
| 136 |
+
yield json.dumps(ret).encode()
|
| 137 |
+
except Exception as e:
|
| 138 |
+
print("Caught Unknown Error", e)
|
| 139 |
+
ret = {
|
| 140 |
+
"text": server_error_msg,
|
| 141 |
+
"error_code": 1,
|
| 142 |
+
}
|
| 143 |
+
yield json.dumps(ret).encode()
|
mplug_owl2/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .model import MPLUGOwl2LlamaForCausalLM
|
mplug_owl2/constants.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
CONTROLLER_HEART_BEAT_EXPIRATION = 30
|
| 2 |
+
WORKER_HEART_BEAT_INTERVAL = 15
|
| 3 |
+
|
| 4 |
+
LOGDIR = "./demo_logs"
|
| 5 |
+
|
| 6 |
+
# Model Constants
|
| 7 |
+
IGNORE_INDEX = -100
|
| 8 |
+
IMAGE_TOKEN_INDEX = -200
|
| 9 |
+
DEFAULT_IMAGE_TOKEN = "<|image|>"
|
mplug_owl2/conversation.py
ADDED
|
@@ -0,0 +1,301 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import dataclasses
|
| 2 |
+
from enum import auto, Enum
|
| 3 |
+
from typing import List, Tuple
|
| 4 |
+
from mplug_owl2.constants import DEFAULT_IMAGE_TOKEN
|
| 5 |
+
|
| 6 |
+
class SeparatorStyle(Enum):
|
| 7 |
+
"""Different separator style."""
|
| 8 |
+
SINGLE = auto()
|
| 9 |
+
TWO = auto()
|
| 10 |
+
TWO_NO_SYS = auto()
|
| 11 |
+
MPT = auto()
|
| 12 |
+
PLAIN = auto()
|
| 13 |
+
LLAMA_2 = auto()
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
@dataclasses.dataclass
|
| 17 |
+
class Conversation:
|
| 18 |
+
"""A class that keeps all conversation history."""
|
| 19 |
+
system: str
|
| 20 |
+
roles: List[str]
|
| 21 |
+
messages: List[List[str]]
|
| 22 |
+
offset: int
|
| 23 |
+
sep_style: SeparatorStyle = SeparatorStyle.SINGLE
|
| 24 |
+
sep: str = "###"
|
| 25 |
+
sep2: str = None
|
| 26 |
+
version: str = "Unknown"
|
| 27 |
+
|
| 28 |
+
skip_next: bool = False
|
| 29 |
+
|
| 30 |
+
def get_prompt(self):
|
| 31 |
+
messages = self.messages
|
| 32 |
+
if len(messages) > 0 and type(messages[0][1]) is tuple:
|
| 33 |
+
messages = self.messages.copy()
|
| 34 |
+
init_role, init_msg = messages[0].copy()
|
| 35 |
+
# init_msg = init_msg[0].replace("<image>", "").strip()
|
| 36 |
+
# if 'mmtag' in self.version:
|
| 37 |
+
# messages[0] = (init_role, init_msg)
|
| 38 |
+
# messages.insert(0, (self.roles[0], "<Image><image></Image>"))
|
| 39 |
+
# messages.insert(1, (self.roles[1], "Received."))
|
| 40 |
+
# else:
|
| 41 |
+
# messages[0] = (init_role, "<image>\n" + init_msg)
|
| 42 |
+
init_msg = init_msg[0].replace(DEFAULT_IMAGE_TOKEN, "").strip()
|
| 43 |
+
messages[0] = (init_role, DEFAULT_IMAGE_TOKEN + init_msg)
|
| 44 |
+
|
| 45 |
+
if self.sep_style == SeparatorStyle.SINGLE:
|
| 46 |
+
ret = self.system + self.sep
|
| 47 |
+
for role, message in messages:
|
| 48 |
+
if message:
|
| 49 |
+
if type(message) is tuple:
|
| 50 |
+
message, _, _ = message
|
| 51 |
+
ret += role + ": " + message + self.sep
|
| 52 |
+
else:
|
| 53 |
+
ret += role + ":"
|
| 54 |
+
elif self.sep_style == SeparatorStyle.TWO:
|
| 55 |
+
seps = [self.sep, self.sep2]
|
| 56 |
+
ret = self.system + seps[0]
|
| 57 |
+
for i, (role, message) in enumerate(messages):
|
| 58 |
+
if message:
|
| 59 |
+
if type(message) is tuple:
|
| 60 |
+
message, _, _ = message
|
| 61 |
+
ret += role + ": " + message + seps[i % 2]
|
| 62 |
+
else:
|
| 63 |
+
ret += role + ":"
|
| 64 |
+
elif self.sep_style == SeparatorStyle.TWO_NO_SYS:
|
| 65 |
+
seps = [self.sep, self.sep2]
|
| 66 |
+
ret = ""
|
| 67 |
+
for i, (role, message) in enumerate(messages):
|
| 68 |
+
if message:
|
| 69 |
+
if type(message) is tuple:
|
| 70 |
+
message, _, _ = message
|
| 71 |
+
ret += role + ": " + message + seps[i % 2]
|
| 72 |
+
else:
|
| 73 |
+
ret += role + ":"
|
| 74 |
+
elif self.sep_style == SeparatorStyle.MPT:
|
| 75 |
+
ret = self.system + self.sep
|
| 76 |
+
for role, message in messages:
|
| 77 |
+
if message:
|
| 78 |
+
if type(message) is tuple:
|
| 79 |
+
message, _, _ = message
|
| 80 |
+
ret += role + message + self.sep
|
| 81 |
+
else:
|
| 82 |
+
ret += role
|
| 83 |
+
elif self.sep_style == SeparatorStyle.LLAMA_2:
|
| 84 |
+
wrap_sys = lambda msg: f"<<SYS>>\n{msg}\n<</SYS>>\n\n"
|
| 85 |
+
wrap_inst = lambda msg: f"[INST] {msg} [/INST]"
|
| 86 |
+
ret = ""
|
| 87 |
+
|
| 88 |
+
for i, (role, message) in enumerate(messages):
|
| 89 |
+
if i == 0:
|
| 90 |
+
assert message, "first message should not be none"
|
| 91 |
+
assert role == self.roles[0], "first message should come from user"
|
| 92 |
+
if message:
|
| 93 |
+
if type(message) is tuple:
|
| 94 |
+
message, _, _ = message
|
| 95 |
+
if i == 0: message = wrap_sys(self.system) + message
|
| 96 |
+
if i % 2 == 0:
|
| 97 |
+
message = wrap_inst(message)
|
| 98 |
+
ret += self.sep + message
|
| 99 |
+
else:
|
| 100 |
+
ret += " " + message + " " + self.sep2
|
| 101 |
+
else:
|
| 102 |
+
ret += ""
|
| 103 |
+
ret = ret.lstrip(self.sep)
|
| 104 |
+
elif self.sep_style == SeparatorStyle.PLAIN:
|
| 105 |
+
seps = [self.sep, self.sep2]
|
| 106 |
+
ret = self.system
|
| 107 |
+
for i, (role, message) in enumerate(messages):
|
| 108 |
+
if message:
|
| 109 |
+
if type(message) is tuple:
|
| 110 |
+
message, _, _ = message
|
| 111 |
+
ret += message + seps[i % 2]
|
| 112 |
+
else:
|
| 113 |
+
ret += ""
|
| 114 |
+
else:
|
| 115 |
+
raise ValueError(f"Invalid style: {self.sep_style}")
|
| 116 |
+
|
| 117 |
+
return ret
|
| 118 |
+
|
| 119 |
+
def append_message(self, role, message):
|
| 120 |
+
self.messages.append([role, message])
|
| 121 |
+
|
| 122 |
+
def get_images(self, return_pil=False):
|
| 123 |
+
images = []
|
| 124 |
+
for i, (role, msg) in enumerate(self.messages[self.offset:]):
|
| 125 |
+
if i % 2 == 0:
|
| 126 |
+
if type(msg) is tuple:
|
| 127 |
+
import base64
|
| 128 |
+
from io import BytesIO
|
| 129 |
+
from PIL import Image
|
| 130 |
+
msg, image, image_process_mode = msg
|
| 131 |
+
if image_process_mode == "Pad":
|
| 132 |
+
def expand2square(pil_img, background_color=(122, 116, 104)):
|
| 133 |
+
width, height = pil_img.size
|
| 134 |
+
if width == height:
|
| 135 |
+
return pil_img
|
| 136 |
+
elif width > height:
|
| 137 |
+
result = Image.new(pil_img.mode, (width, width), background_color)
|
| 138 |
+
result.paste(pil_img, (0, (width - height) // 2))
|
| 139 |
+
return result
|
| 140 |
+
else:
|
| 141 |
+
result = Image.new(pil_img.mode, (height, height), background_color)
|
| 142 |
+
result.paste(pil_img, ((height - width) // 2, 0))
|
| 143 |
+
return result
|
| 144 |
+
image = expand2square(image)
|
| 145 |
+
elif image_process_mode in ["Default", "Crop"]:
|
| 146 |
+
pass
|
| 147 |
+
elif image_process_mode == "Resize":
|
| 148 |
+
image = image.resize((336, 336))
|
| 149 |
+
else:
|
| 150 |
+
raise ValueError(f"Invalid image_process_mode: {image_process_mode}")
|
| 151 |
+
max_hw, min_hw = max(image.size), min(image.size)
|
| 152 |
+
aspect_ratio = max_hw / min_hw
|
| 153 |
+
max_len, min_len = 800, 400
|
| 154 |
+
shortest_edge = int(min(max_len / aspect_ratio, min_len, min_hw))
|
| 155 |
+
longest_edge = int(shortest_edge * aspect_ratio)
|
| 156 |
+
W, H = image.size
|
| 157 |
+
if longest_edge != max(image.size):
|
| 158 |
+
if H > W:
|
| 159 |
+
H, W = longest_edge, shortest_edge
|
| 160 |
+
else:
|
| 161 |
+
H, W = shortest_edge, longest_edge
|
| 162 |
+
image = image.resize((W, H))
|
| 163 |
+
if return_pil:
|
| 164 |
+
images.append(image)
|
| 165 |
+
else:
|
| 166 |
+
buffered = BytesIO()
|
| 167 |
+
image.save(buffered, format="PNG")
|
| 168 |
+
img_b64_str = base64.b64encode(buffered.getvalue()).decode()
|
| 169 |
+
images.append(img_b64_str)
|
| 170 |
+
return images
|
| 171 |
+
|
| 172 |
+
def to_gradio_chatbot(self):
|
| 173 |
+
ret = []
|
| 174 |
+
for i, (role, msg) in enumerate(self.messages[self.offset:]):
|
| 175 |
+
if i % 2 == 0:
|
| 176 |
+
if type(msg) is tuple:
|
| 177 |
+
import base64
|
| 178 |
+
from io import BytesIO
|
| 179 |
+
msg, image, image_process_mode = msg
|
| 180 |
+
max_hw, min_hw = max(image.size), min(image.size)
|
| 181 |
+
aspect_ratio = max_hw / min_hw
|
| 182 |
+
max_len, min_len = 800, 400
|
| 183 |
+
shortest_edge = int(min(max_len / aspect_ratio, min_len, min_hw))
|
| 184 |
+
longest_edge = int(shortest_edge * aspect_ratio)
|
| 185 |
+
W, H = image.size
|
| 186 |
+
if H > W:
|
| 187 |
+
H, W = longest_edge, shortest_edge
|
| 188 |
+
else:
|
| 189 |
+
H, W = shortest_edge, longest_edge
|
| 190 |
+
image = image.resize((W, H))
|
| 191 |
+
buffered = BytesIO()
|
| 192 |
+
image.save(buffered, format="JPEG")
|
| 193 |
+
img_b64_str = base64.b64encode(buffered.getvalue()).decode()
|
| 194 |
+
img_str = f'<img src="data:image/png;base64,{img_b64_str}" alt="user upload image" />'
|
| 195 |
+
msg = img_str + msg.replace('<|image|>', '').strip()
|
| 196 |
+
ret.append([msg, None])
|
| 197 |
+
else:
|
| 198 |
+
ret.append([msg, None])
|
| 199 |
+
else:
|
| 200 |
+
ret[-1][-1] = msg
|
| 201 |
+
return ret
|
| 202 |
+
|
| 203 |
+
def copy(self):
|
| 204 |
+
return Conversation(
|
| 205 |
+
system=self.system,
|
| 206 |
+
roles=self.roles,
|
| 207 |
+
messages=[[x, y] for x, y in self.messages],
|
| 208 |
+
offset=self.offset,
|
| 209 |
+
sep_style=self.sep_style,
|
| 210 |
+
sep=self.sep,
|
| 211 |
+
sep2=self.sep2,
|
| 212 |
+
version=self.version)
|
| 213 |
+
|
| 214 |
+
def dict(self):
|
| 215 |
+
if len(self.get_images()) > 0:
|
| 216 |
+
return {
|
| 217 |
+
"system": self.system,
|
| 218 |
+
"roles": self.roles,
|
| 219 |
+
"messages": [[x, y[0] if type(y) is tuple else y] for x, y in self.messages],
|
| 220 |
+
"offset": self.offset,
|
| 221 |
+
"sep": self.sep,
|
| 222 |
+
"sep2": self.sep2,
|
| 223 |
+
}
|
| 224 |
+
return {
|
| 225 |
+
"system": self.system,
|
| 226 |
+
"roles": self.roles,
|
| 227 |
+
"messages": self.messages,
|
| 228 |
+
"offset": self.offset,
|
| 229 |
+
"sep": self.sep,
|
| 230 |
+
"sep2": self.sep2,
|
| 231 |
+
}
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
conv_vicuna_v0 = Conversation(
|
| 235 |
+
system="A chat between a curious human and an artificial intelligence assistant. "
|
| 236 |
+
"The assistant gives helpful, detailed, and polite answers to the human's questions.",
|
| 237 |
+
roles=("Human", "Assistant"),
|
| 238 |
+
messages=(
|
| 239 |
+
("Human", "What are the key differences between renewable and non-renewable energy sources?"),
|
| 240 |
+
("Assistant",
|
| 241 |
+
"Renewable energy sources are those that can be replenished naturally in a relatively "
|
| 242 |
+
"short amount of time, such as solar, wind, hydro, geothermal, and biomass. "
|
| 243 |
+
"Non-renewable energy sources, on the other hand, are finite and will eventually be "
|
| 244 |
+
"depleted, such as coal, oil, and natural gas. Here are some key differences between "
|
| 245 |
+
"renewable and non-renewable energy sources:\n"
|
| 246 |
+
"1. Availability: Renewable energy sources are virtually inexhaustible, while non-renewable "
|
| 247 |
+
"energy sources are finite and will eventually run out.\n"
|
| 248 |
+
"2. Environmental impact: Renewable energy sources have a much lower environmental impact "
|
| 249 |
+
"than non-renewable sources, which can lead to air and water pollution, greenhouse gas emissions, "
|
| 250 |
+
"and other negative effects.\n"
|
| 251 |
+
"3. Cost: Renewable energy sources can be more expensive to initially set up, but they typically "
|
| 252 |
+
"have lower operational costs than non-renewable sources.\n"
|
| 253 |
+
"4. Reliability: Renewable energy sources are often more reliable and can be used in more remote "
|
| 254 |
+
"locations than non-renewable sources.\n"
|
| 255 |
+
"5. Flexibility: Renewable energy sources are often more flexible and can be adapted to different "
|
| 256 |
+
"situations and needs, while non-renewable sources are more rigid and inflexible.\n"
|
| 257 |
+
"6. Sustainability: Renewable energy sources are more sustainable over the long term, while "
|
| 258 |
+
"non-renewable sources are not, and their depletion can lead to economic and social instability.\n")
|
| 259 |
+
),
|
| 260 |
+
offset=2,
|
| 261 |
+
sep_style=SeparatorStyle.SINGLE,
|
| 262 |
+
sep="###",
|
| 263 |
+
)
|
| 264 |
+
|
| 265 |
+
conv_vicuna_v1 = Conversation(
|
| 266 |
+
system="A chat between a curious user and an artificial intelligence assistant. "
|
| 267 |
+
"The assistant gives helpful, detailed, and polite answers to the user's questions.",
|
| 268 |
+
roles=("USER", "ASSISTANT"),
|
| 269 |
+
version="v1",
|
| 270 |
+
messages=(),
|
| 271 |
+
offset=0,
|
| 272 |
+
sep_style=SeparatorStyle.TWO,
|
| 273 |
+
sep=" ",
|
| 274 |
+
sep2="</s>",
|
| 275 |
+
)
|
| 276 |
+
|
| 277 |
+
conv_mplug_owl2 = Conversation(
|
| 278 |
+
system="A chat between a curious human and an artificial intelligence assistant. "
|
| 279 |
+
"The assistant gives helpful, detailed, and polite answers to the human's questions.",
|
| 280 |
+
roles=("USER", "ASSISTANT"),
|
| 281 |
+
version="v1",
|
| 282 |
+
messages=(),
|
| 283 |
+
offset=0,
|
| 284 |
+
sep_style=SeparatorStyle.TWO_NO_SYS,
|
| 285 |
+
sep=" ",
|
| 286 |
+
sep2="</s>",
|
| 287 |
+
)
|
| 288 |
+
|
| 289 |
+
# default_conversation = conv_vicuna_v1
|
| 290 |
+
default_conversation = conv_mplug_owl2
|
| 291 |
+
conv_templates = {
|
| 292 |
+
"default": conv_vicuna_v0,
|
| 293 |
+
"v0": conv_vicuna_v0,
|
| 294 |
+
"v1": conv_vicuna_v1,
|
| 295 |
+
"vicuna_v1": conv_vicuna_v1,
|
| 296 |
+
"mplug_owl2": conv_mplug_owl2,
|
| 297 |
+
}
|
| 298 |
+
|
| 299 |
+
|
| 300 |
+
if __name__ == "__main__":
|
| 301 |
+
print(default_conversation.get_prompt())
|
mplug_owl2/mm_utils.py
ADDED
|
@@ -0,0 +1,103 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from PIL import Image
|
| 2 |
+
from io import BytesIO
|
| 3 |
+
import base64
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
from transformers import StoppingCriteria
|
| 7 |
+
from mplug_owl2.constants import IMAGE_TOKEN_INDEX,DEFAULT_IMAGE_TOKEN
|
| 8 |
+
from icecream import ic
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def load_image_from_base64(image):
|
| 12 |
+
return Image.open(BytesIO(base64.b64decode(image)))
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def expand2square(pil_img, background_color):
|
| 16 |
+
width, height = pil_img.size
|
| 17 |
+
if width == height:
|
| 18 |
+
return pil_img
|
| 19 |
+
elif width > height:
|
| 20 |
+
result = Image.new(pil_img.mode, (width, width), background_color)
|
| 21 |
+
result.paste(pil_img, (0, (width - height) // 2))
|
| 22 |
+
return result
|
| 23 |
+
else:
|
| 24 |
+
result = Image.new(pil_img.mode, (height, height), background_color)
|
| 25 |
+
result.paste(pil_img, ((height - width) // 2, 0))
|
| 26 |
+
return result
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def process_images(images, image_processor, model_cfg):
|
| 30 |
+
image_aspect_ratio = getattr(model_cfg, "image_aspect_ratio", None)
|
| 31 |
+
new_images = []
|
| 32 |
+
if image_aspect_ratio == 'pad':
|
| 33 |
+
for image in images:
|
| 34 |
+
image = expand2square(image, tuple(int(x*255) for x in image_processor.image_mean))
|
| 35 |
+
image = image_processor.preprocess(image, return_tensors='pt')['pixel_values'][0]
|
| 36 |
+
new_images.append(image)
|
| 37 |
+
else:
|
| 38 |
+
return image_processor(images, return_tensors='pt')['pixel_values']
|
| 39 |
+
if all(x.shape == new_images[0].shape for x in new_images):
|
| 40 |
+
new_images = torch.stack(new_images, dim=0)
|
| 41 |
+
return new_images
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def tokenizer_image_token(prompt, tokenizer, image_token_index=IMAGE_TOKEN_INDEX, return_tensors=None):
|
| 45 |
+
prompt_chunks = [tokenizer(chunk).input_ids for chunk in prompt.split(DEFAULT_IMAGE_TOKEN)]
|
| 46 |
+
|
| 47 |
+
def insert_separator(X, sep):
|
| 48 |
+
return [ele for sublist in zip(X, [sep]*len(X)) for ele in sublist][:-1]
|
| 49 |
+
|
| 50 |
+
input_ids = []
|
| 51 |
+
offset = 0
|
| 52 |
+
if len(prompt_chunks) > 0 and len(prompt_chunks[0]) > 0 and prompt_chunks[0][0] == tokenizer.bos_token_id:
|
| 53 |
+
offset = 1
|
| 54 |
+
input_ids.append(prompt_chunks[0][0])
|
| 55 |
+
|
| 56 |
+
for x in insert_separator(prompt_chunks, [image_token_index] * (offset + 1)):
|
| 57 |
+
input_ids.extend(x[offset:])
|
| 58 |
+
|
| 59 |
+
if return_tensors is not None:
|
| 60 |
+
if return_tensors == 'pt':
|
| 61 |
+
return torch.tensor(input_ids, dtype=torch.long)
|
| 62 |
+
raise ValueError(f'Unsupported tensor type: {return_tensors}')
|
| 63 |
+
return input_ids
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def get_model_name_from_path(model_path):
|
| 67 |
+
model_path = model_path.strip("/")
|
| 68 |
+
model_paths = model_path.split("/")
|
| 69 |
+
if model_paths[-1].startswith('checkpoint-'):
|
| 70 |
+
return model_paths[-2] + "_" + model_paths[-1]
|
| 71 |
+
else:
|
| 72 |
+
return model_paths[-1]
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
class KeywordsStoppingCriteria(StoppingCriteria):
|
| 78 |
+
def __init__(self, keywords, tokenizer, input_ids):
|
| 79 |
+
self.keywords = keywords
|
| 80 |
+
self.keyword_ids = []
|
| 81 |
+
self.max_keyword_len = 0
|
| 82 |
+
for keyword in keywords:
|
| 83 |
+
cur_keyword_ids = tokenizer(keyword).input_ids
|
| 84 |
+
if len(cur_keyword_ids) > 1 and cur_keyword_ids[0] == tokenizer.bos_token_id:
|
| 85 |
+
cur_keyword_ids = cur_keyword_ids[1:]
|
| 86 |
+
if len(cur_keyword_ids) > self.max_keyword_len:
|
| 87 |
+
self.max_keyword_len = len(cur_keyword_ids)
|
| 88 |
+
self.keyword_ids.append(torch.tensor(cur_keyword_ids))
|
| 89 |
+
self.tokenizer = tokenizer
|
| 90 |
+
self.start_len = input_ids.shape[1]
|
| 91 |
+
|
| 92 |
+
def __call__(self, output_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
|
| 93 |
+
assert output_ids.shape[0] == 1, "Only support batch size 1 (yet)" # TODO
|
| 94 |
+
offset = min(output_ids.shape[1] - self.start_len, self.max_keyword_len)
|
| 95 |
+
self.keyword_ids = [keyword_id.to(output_ids.device) for keyword_id in self.keyword_ids]
|
| 96 |
+
for keyword_id in self.keyword_ids:
|
| 97 |
+
if (output_ids[0, -keyword_id.shape[0]:] == keyword_id).all():
|
| 98 |
+
return True
|
| 99 |
+
outputs = self.tokenizer.batch_decode(output_ids[:, -offset:], skip_special_tokens=True)[0]
|
| 100 |
+
for keyword in self.keywords:
|
| 101 |
+
if keyword in outputs:
|
| 102 |
+
return True
|
| 103 |
+
return False
|
mplug_owl2/model/__init__.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .modeling_mplug_owl2 import MPLUGOwl2LlamaForCausalLM
|
| 2 |
+
from .configuration_mplug_owl2 import MPLUGOwl2Config
|
mplug_owl2/model/builder.py
ADDED
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 Haotian Liu
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
import os
|
| 17 |
+
import warnings
|
| 18 |
+
import shutil
|
| 19 |
+
|
| 20 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoConfig, BitsAndBytesConfig
|
| 21 |
+
from transformers.models.clip.image_processing_clip import CLIPImageProcessor
|
| 22 |
+
import torch
|
| 23 |
+
from mplug_owl2.model import *
|
| 24 |
+
from icecream import ic
|
| 25 |
+
def load_pretrained_model(model_path, model_base, model_name, load_8bit=False, load_4bit=False, device_map="auto", device="cuda"):
|
| 26 |
+
kwargs = {"device_map": device_map}
|
| 27 |
+
|
| 28 |
+
if device != "cuda":
|
| 29 |
+
kwargs['device_map'] = {"": device}
|
| 30 |
+
|
| 31 |
+
if load_8bit:
|
| 32 |
+
kwargs['load_in_8bit'] = True
|
| 33 |
+
elif load_4bit:
|
| 34 |
+
kwargs['load_in_4bit'] = True
|
| 35 |
+
kwargs['quantization_config'] = BitsAndBytesConfig(
|
| 36 |
+
load_in_4bit=True,
|
| 37 |
+
bnb_4bit_compute_dtype=torch.float16,
|
| 38 |
+
bnb_4bit_use_double_quant=True,
|
| 39 |
+
bnb_4bit_quant_type='nf4'
|
| 40 |
+
)
|
| 41 |
+
else:
|
| 42 |
+
kwargs['torch_dtype'] = torch.float16
|
| 43 |
+
if 'mplug_owl2' in model_name.lower():
|
| 44 |
+
# Load LLaVA model
|
| 45 |
+
if 'lora' in model_name.lower() and model_base is None:
|
| 46 |
+
warnings.warn('There is `lora` in model name but no `model_base` is provided. If you are loading a LoRA model, please provide the `model_base` argument. Detailed instruction: https://github.com/haotian-liu/LLaVA#launch-a-model-worker-lora-weights-unmerged.')
|
| 47 |
+
if 'lora' in model_name.lower() and model_base is not None:
|
| 48 |
+
lora_cfg_pretrained = AutoConfig.from_pretrained(model_path)
|
| 49 |
+
tokenizer = AutoTokenizer.from_pretrained(model_base, use_fast=False)
|
| 50 |
+
print('Loading mPLUG-Owl2 from base model...')
|
| 51 |
+
model = MPLUGOwl2LlamaForCausalLM.from_pretrained(model_base, low_cpu_mem_usage=True, config=lora_cfg_pretrained, **kwargs)
|
| 52 |
+
token_num, tokem_dim = model.lm_head.out_features, model.lm_head.in_features
|
| 53 |
+
if model.lm_head.weight.shape[0] != token_num:
|
| 54 |
+
model.lm_head.weight = torch.nn.Parameter(torch.empty(token_num, tokem_dim, device=model.device, dtype=model.dtype))
|
| 55 |
+
model.model.embed_tokens.weight = torch.nn.Parameter(torch.empty(token_num, tokem_dim, device=model.device, dtype=model.dtype))
|
| 56 |
+
|
| 57 |
+
print('Loading additional mPLUG-Owl2 weights...')
|
| 58 |
+
if os.path.exists(os.path.join(model_path, 'non_lora_trainables.bin')):
|
| 59 |
+
non_lora_trainables = torch.load(os.path.join(model_path, 'non_lora_trainables.bin'), map_location='cpu')
|
| 60 |
+
else:
|
| 61 |
+
# this is probably from HF Hub
|
| 62 |
+
from huggingface_hub import hf_hub_download
|
| 63 |
+
def load_from_hf(repo_id, filename, subfolder=None):
|
| 64 |
+
cache_file = hf_hub_download(
|
| 65 |
+
repo_id=repo_id,
|
| 66 |
+
filename=filename,
|
| 67 |
+
subfolder=subfolder)
|
| 68 |
+
return torch.load(cache_file, map_location='cpu')
|
| 69 |
+
non_lora_trainables = load_from_hf(model_path, 'non_lora_trainables.bin')
|
| 70 |
+
non_lora_trainables = {(k[11:] if k.startswith('base_model.') else k): v for k, v in non_lora_trainables.items()}
|
| 71 |
+
if any(k.startswith('model.model.') for k in non_lora_trainables):
|
| 72 |
+
non_lora_trainables = {(k[6:] if k.startswith('model.') else k): v for k, v in non_lora_trainables.items()}
|
| 73 |
+
model.load_state_dict(non_lora_trainables, strict=False)
|
| 74 |
+
|
| 75 |
+
from peft import PeftModel
|
| 76 |
+
print('Loading LoRA weights...')
|
| 77 |
+
model = PeftModel.from_pretrained(model, model_path)
|
| 78 |
+
print('Merging LoRA weights...')
|
| 79 |
+
model = model.merge_and_unload()
|
| 80 |
+
print('Model is loaded...')
|
| 81 |
+
elif model_base is not None:
|
| 82 |
+
# this may be mm projector only
|
| 83 |
+
print('Loading mPLUG-Owl2 from base model...')
|
| 84 |
+
tokenizer = AutoTokenizer.from_pretrained(model_base, use_fast=False)
|
| 85 |
+
cfg_pretrained = AutoConfig.from_pretrained(model_path)
|
| 86 |
+
model = MPLUGOwl2LlamaForCausalLM.from_pretrained(model_base, low_cpu_mem_usage=True, config=cfg_pretrained, **kwargs)
|
| 87 |
+
else:
|
| 88 |
+
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
|
| 89 |
+
model = MPLUGOwl2LlamaForCausalLM.from_pretrained(model_path, low_cpu_mem_usage=True, **kwargs)
|
| 90 |
+
else:
|
| 91 |
+
# Load language model
|
| 92 |
+
if model_base is not None:
|
| 93 |
+
# PEFT model
|
| 94 |
+
from peft import PeftModel
|
| 95 |
+
tokenizer = AutoTokenizer.from_pretrained(model_base, use_fast=False)
|
| 96 |
+
model = AutoModelForCausalLM.from_pretrained(model_base, low_cpu_mem_usage=True, **kwargs)
|
| 97 |
+
print(f"Loading LoRA weights from {model_path}")
|
| 98 |
+
model = PeftModel.from_pretrained(model, model_path)
|
| 99 |
+
print(f"Merging weights")
|
| 100 |
+
model = model.merge_and_unload()
|
| 101 |
+
print('Convert to FP16...')
|
| 102 |
+
model.to(torch.float16)
|
| 103 |
+
else:
|
| 104 |
+
use_fast = False
|
| 105 |
+
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
|
| 106 |
+
model = AutoModelForCausalLM.from_pretrained(model_path, low_cpu_mem_usage=True, **kwargs)
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
vision_tower = model.get_model().vision_model
|
| 110 |
+
vision_tower.to(device=device, dtype=torch.float16)
|
| 111 |
+
image_processor = CLIPImageProcessor.from_pretrained(model_path)
|
| 112 |
+
|
| 113 |
+
if hasattr(model.config, "max_sequence_length"):
|
| 114 |
+
context_len = model.config.max_sequence_length
|
| 115 |
+
else:
|
| 116 |
+
context_len = 2048
|
| 117 |
+
|
| 118 |
+
return tokenizer, model, image_processor, context_len
|
mplug_owl2/model/configuration_mplug_owl2.py
ADDED
|
@@ -0,0 +1,332 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Alibaba.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
import copy
|
| 6 |
+
import os
|
| 7 |
+
from typing import Union
|
| 8 |
+
|
| 9 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 10 |
+
from transformers.models.auto.modeling_auto import MODEL_FOR_CAUSAL_LM_MAPPING_NAMES
|
| 11 |
+
from transformers.utils import logging
|
| 12 |
+
from transformers.models.auto import CONFIG_MAPPING
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class LlamaConfig(PretrainedConfig):
|
| 16 |
+
r"""
|
| 17 |
+
This is the configuration class to store the configuration of a [`LlamaModel`]. It is used to instantiate an LLaMA
|
| 18 |
+
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
|
| 19 |
+
defaults will yield a similar configuration to that of the LLaMA-7B.
|
| 20 |
+
|
| 21 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 22 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
Args:
|
| 26 |
+
vocab_size (`int`, *optional*, defaults to 32000):
|
| 27 |
+
Vocabulary size of the LLaMA model. Defines the number of different tokens that can be represented by the
|
| 28 |
+
`inputs_ids` passed when calling [`LlamaModel`]
|
| 29 |
+
hidden_size (`int`, *optional*, defaults to 4096):
|
| 30 |
+
Dimension of the hidden representations.
|
| 31 |
+
intermediate_size (`int`, *optional*, defaults to 11008):
|
| 32 |
+
Dimension of the MLP representations.
|
| 33 |
+
num_hidden_layers (`int`, *optional*, defaults to 32):
|
| 34 |
+
Number of hidden layers in the Transformer decoder.
|
| 35 |
+
num_attention_heads (`int`, *optional*, defaults to 32):
|
| 36 |
+
Number of attention heads for each attention layer in the Transformer decoder.
|
| 37 |
+
num_key_value_heads (`int`, *optional*):
|
| 38 |
+
This is the number of key_value heads that should be used to implement Grouped Query Attention. If
|
| 39 |
+
`num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
|
| 40 |
+
`num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When
|
| 41 |
+
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
|
| 42 |
+
by meanpooling all the original heads within that group. For more details checkout [this
|
| 43 |
+
paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
|
| 44 |
+
`num_attention_heads`.
|
| 45 |
+
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
|
| 46 |
+
The non-linear activation function (function or string) in the decoder.
|
| 47 |
+
max_position_embeddings (`int`, *optional*, defaults to 2048):
|
| 48 |
+
The maximum sequence length that this model might ever be used with. Llama 1 supports up to 2048 tokens,
|
| 49 |
+
Llama 2 up to 4096, CodeLlama up to 16384.
|
| 50 |
+
initializer_range (`float`, *optional*, defaults to 0.02):
|
| 51 |
+
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
| 52 |
+
rms_norm_eps (`float`, *optional*, defaults to 1e-06):
|
| 53 |
+
The epsilon used by the rms normalization layers.
|
| 54 |
+
use_cache (`bool`, *optional*, defaults to `True`):
|
| 55 |
+
Whether or not the model should return the last key/values attentions (not used by all models). Only
|
| 56 |
+
relevant if `config.is_decoder=True`.
|
| 57 |
+
pad_token_id (`int`, *optional*):
|
| 58 |
+
Padding token id.
|
| 59 |
+
bos_token_id (`int`, *optional*, defaults to 1):
|
| 60 |
+
Beginning of stream token id.
|
| 61 |
+
eos_token_id (`int`, *optional*, defaults to 2):
|
| 62 |
+
End of stream token id.
|
| 63 |
+
pretraining_tp (`int`, *optional*, defaults to 1):
|
| 64 |
+
Experimental feature. Tensor parallelism rank used during pretraining. Please refer to [this
|
| 65 |
+
document](https://huggingface.co/docs/transformers/parallelism) to understand more about it. This value is
|
| 66 |
+
necessary to ensure exact reproducibility of the pretraining results. Please refer to [this
|
| 67 |
+
issue](https://github.com/pytorch/pytorch/issues/76232).
|
| 68 |
+
tie_word_embeddings (`bool`, *optional*, defaults to `False`):
|
| 69 |
+
Whether to tie weight embeddings
|
| 70 |
+
rope_theta (`float`, *optional*, defaults to 10000.0):
|
| 71 |
+
The base period of the RoPE embeddings.
|
| 72 |
+
rope_scaling (`Dict`, *optional*):
|
| 73 |
+
Dictionary containing the scaling configuration for the RoPE embeddings. Currently supports two scaling
|
| 74 |
+
strategies: linear and dynamic. Their scaling factor must be a float greater than 1. The expected format is
|
| 75 |
+
`{"type": strategy name, "factor": scaling factor}`. When using this flag, don't update
|
| 76 |
+
`max_position_embeddings` to the expected new maximum. See the following thread for more information on how
|
| 77 |
+
these scaling strategies behave:
|
| 78 |
+
https://www.reddit.com/r/LocalLLaMA/comments/14mrgpr/dynamically_scaled_rope_further_increases/. This is an
|
| 79 |
+
experimental feature, subject to breaking API changes in future versions.
|
| 80 |
+
attention_bias (`bool`, defaults to `False`, *optional*, defaults to `False`):
|
| 81 |
+
Whether to use a bias in the query, key, value and output projection layers during self-attention.
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
```python
|
| 85 |
+
>>> from transformers import LlamaModel, LlamaConfig
|
| 86 |
+
|
| 87 |
+
>>> # Initializing a LLaMA llama-7b style configuration
|
| 88 |
+
>>> configuration = LlamaConfig()
|
| 89 |
+
|
| 90 |
+
>>> # Initializing a model from the llama-7b style configuration
|
| 91 |
+
>>> model = LlamaModel(configuration)
|
| 92 |
+
|
| 93 |
+
>>> # Accessing the model configuration
|
| 94 |
+
>>> configuration = model.config
|
| 95 |
+
```"""
|
| 96 |
+
model_type = "llama"
|
| 97 |
+
keys_to_ignore_at_inference = ["past_key_values"]
|
| 98 |
+
|
| 99 |
+
def __init__(
|
| 100 |
+
self,
|
| 101 |
+
vocab_size=32000,
|
| 102 |
+
hidden_size=4096,
|
| 103 |
+
intermediate_size=11008,
|
| 104 |
+
num_hidden_layers=32,
|
| 105 |
+
num_attention_heads=32,
|
| 106 |
+
num_key_value_heads=None,
|
| 107 |
+
hidden_act="silu",
|
| 108 |
+
max_position_embeddings=2048,
|
| 109 |
+
initializer_range=0.02,
|
| 110 |
+
rms_norm_eps=1e-6,
|
| 111 |
+
use_cache=True,
|
| 112 |
+
pad_token_id=None,
|
| 113 |
+
bos_token_id=1,
|
| 114 |
+
eos_token_id=2,
|
| 115 |
+
pretraining_tp=1,
|
| 116 |
+
tie_word_embeddings=False,
|
| 117 |
+
rope_theta=10000.0,
|
| 118 |
+
rope_scaling=None,
|
| 119 |
+
attention_bias=False,
|
| 120 |
+
**kwargs,
|
| 121 |
+
):
|
| 122 |
+
self.vocab_size = vocab_size
|
| 123 |
+
self.max_position_embeddings = max_position_embeddings
|
| 124 |
+
self.hidden_size = hidden_size
|
| 125 |
+
self.intermediate_size = intermediate_size
|
| 126 |
+
self.num_hidden_layers = num_hidden_layers
|
| 127 |
+
self.num_attention_heads = num_attention_heads
|
| 128 |
+
|
| 129 |
+
# for backward compatibility
|
| 130 |
+
if num_key_value_heads is None:
|
| 131 |
+
num_key_value_heads = num_attention_heads
|
| 132 |
+
|
| 133 |
+
self.num_key_value_heads = num_key_value_heads
|
| 134 |
+
self.hidden_act = hidden_act
|
| 135 |
+
self.initializer_range = initializer_range
|
| 136 |
+
self.rms_norm_eps = rms_norm_eps
|
| 137 |
+
self.pretraining_tp = pretraining_tp
|
| 138 |
+
self.use_cache = use_cache
|
| 139 |
+
self.rope_theta = rope_theta
|
| 140 |
+
self.rope_scaling = rope_scaling
|
| 141 |
+
self._rope_scaling_validation()
|
| 142 |
+
self.attention_bias = attention_bias
|
| 143 |
+
|
| 144 |
+
super().__init__(
|
| 145 |
+
pad_token_id=pad_token_id,
|
| 146 |
+
bos_token_id=bos_token_id,
|
| 147 |
+
eos_token_id=eos_token_id,
|
| 148 |
+
tie_word_embeddings=tie_word_embeddings,
|
| 149 |
+
**kwargs,
|
| 150 |
+
)
|
| 151 |
+
|
| 152 |
+
def _rope_scaling_validation(self):
|
| 153 |
+
"""
|
| 154 |
+
Validate the `rope_scaling` configuration.
|
| 155 |
+
"""
|
| 156 |
+
if self.rope_scaling is None:
|
| 157 |
+
return
|
| 158 |
+
|
| 159 |
+
if not isinstance(self.rope_scaling, dict) or len(self.rope_scaling) != 2:
|
| 160 |
+
raise ValueError(
|
| 161 |
+
"`rope_scaling` must be a dictionary with with two fields, `type` and `factor`, "
|
| 162 |
+
f"got {self.rope_scaling}"
|
| 163 |
+
)
|
| 164 |
+
rope_scaling_type = self.rope_scaling.get("type", None)
|
| 165 |
+
rope_scaling_factor = self.rope_scaling.get("factor", None)
|
| 166 |
+
if rope_scaling_type is None or rope_scaling_type not in ["linear", "dynamic"]:
|
| 167 |
+
raise ValueError(
|
| 168 |
+
f"`rope_scaling`'s type field must be one of ['linear', 'dynamic'], got {rope_scaling_type}"
|
| 169 |
+
)
|
| 170 |
+
if rope_scaling_factor is None or not isinstance(rope_scaling_factor, float) or rope_scaling_factor <= 1.0:
|
| 171 |
+
raise ValueError(f"`rope_scaling`'s factor field must be a float > 1, got {rope_scaling_factor}")
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
class MplugOwlVisionConfig(PretrainedConfig):
|
| 175 |
+
r"""
|
| 176 |
+
This is the configuration class to store the configuration of a [`MplugOwlVisionModel`]. It is used to instantiate
|
| 177 |
+
a
|
| 178 |
+
mPLUG-Owl vision encoder according to the specified arguments, defining the model architecture. Instantiating a
|
| 179 |
+
configuration defaults will yield a similar configuration to that of the mPLUG-Owl
|
| 180 |
+
[x-plug/x_plug-llama-7b](https://huggingface.co/x-plug/x_plug-llama-7b) architecture.
|
| 181 |
+
|
| 182 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 183 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 184 |
+
|
| 185 |
+
Args:
|
| 186 |
+
hidden_size (`int`, *optional*, defaults to 768):
|
| 187 |
+
Dimensionality of the encoder layers and the pooler layer.
|
| 188 |
+
intermediate_size (`int`, *optional*, defaults to 3072):
|
| 189 |
+
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
|
| 190 |
+
num_hidden_layers (`int`, *optional*, defaults to 12):
|
| 191 |
+
Number of hidden layers in the Transformer encoder.
|
| 192 |
+
num_attention_heads (`int`, *optional*, defaults to 12):
|
| 193 |
+
Number of attention heads for each attention layer in the Transformer encoder.
|
| 194 |
+
image_size (`int`, *optional*, defaults to 224):
|
| 195 |
+
The size (resolution) of each image.
|
| 196 |
+
patch_size (`int`, *optional*, defaults to 32):
|
| 197 |
+
The size (resolution) of each patch.
|
| 198 |
+
hidden_act (`str` or `function`, *optional*, defaults to `"quick_gelu"`):
|
| 199 |
+
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
|
| 200 |
+
`"relu"`, `"selu"` and `"gelu_new"` ``"quick_gelu"` are supported.
|
| 201 |
+
layer_norm_eps (`float`, *optional*, defaults to 1e-5):
|
| 202 |
+
The epsilon used by the layer normalization layers.
|
| 203 |
+
attention_dropout (`float`, *optional*, defaults to 0.0):
|
| 204 |
+
The dropout ratio for the attention probabilities.
|
| 205 |
+
initializer_range (`float`, *optional*, defaults to 0.02):
|
| 206 |
+
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
| 207 |
+
initializer_factor (`float`, *optional*, defaults to 1):
|
| 208 |
+
A factor for initializing all weight matrices (should be kept to 1, used internally for initialization
|
| 209 |
+
testing).
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
```"""
|
| 213 |
+
|
| 214 |
+
model_type = "mplug_owl_vision_model"
|
| 215 |
+
|
| 216 |
+
def __init__(
|
| 217 |
+
self,
|
| 218 |
+
hidden_size=1024,
|
| 219 |
+
intermediate_size=4096,
|
| 220 |
+
projection_dim=768,
|
| 221 |
+
num_hidden_layers=24,
|
| 222 |
+
num_attention_heads=16,
|
| 223 |
+
num_channels=3,
|
| 224 |
+
image_size=448,
|
| 225 |
+
patch_size=14,
|
| 226 |
+
hidden_act="quick_gelu",
|
| 227 |
+
layer_norm_eps=1e-6,
|
| 228 |
+
attention_dropout=0.0,
|
| 229 |
+
initializer_range=0.02,
|
| 230 |
+
initializer_factor=1.0,
|
| 231 |
+
use_flash_attn=False,
|
| 232 |
+
**kwargs,
|
| 233 |
+
):
|
| 234 |
+
super().__init__(**kwargs)
|
| 235 |
+
self.hidden_size = hidden_size
|
| 236 |
+
self.intermediate_size = intermediate_size
|
| 237 |
+
self.projection_dim = projection_dim
|
| 238 |
+
self.num_hidden_layers = num_hidden_layers
|
| 239 |
+
self.num_attention_heads = num_attention_heads
|
| 240 |
+
self.num_channels = num_channels
|
| 241 |
+
self.patch_size = patch_size
|
| 242 |
+
self.image_size = image_size
|
| 243 |
+
self.initializer_range = initializer_range
|
| 244 |
+
self.initializer_factor = initializer_factor
|
| 245 |
+
self.attention_dropout = attention_dropout
|
| 246 |
+
self.layer_norm_eps = layer_norm_eps
|
| 247 |
+
self.hidden_act = hidden_act
|
| 248 |
+
self.use_flash_attn = use_flash_attn
|
| 249 |
+
|
| 250 |
+
@classmethod
|
| 251 |
+
def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> "PretrainedConfig":
|
| 252 |
+
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
|
| 253 |
+
|
| 254 |
+
# get the vision config dict if we are loading from MplugOwlConfig
|
| 255 |
+
if config_dict.get("model_type") == "mplug-owl":
|
| 256 |
+
config_dict = config_dict["vision_config"]
|
| 257 |
+
|
| 258 |
+
if "model_type" in config_dict and hasattr(cls, "model_type") and config_dict["model_type"] != cls.model_type:
|
| 259 |
+
logger.warning(
|
| 260 |
+
f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
|
| 261 |
+
f"{cls.model_type}. This is not supported for all configurations of models and can yield errors."
|
| 262 |
+
)
|
| 263 |
+
|
| 264 |
+
return cls.from_dict(config_dict, **kwargs)
|
| 265 |
+
|
| 266 |
+
|
| 267 |
+
class MplugOwlVisualAbstractorConfig(PretrainedConfig):
|
| 268 |
+
model_type = "mplug_owl_visual_abstract"
|
| 269 |
+
|
| 270 |
+
def __init__(
|
| 271 |
+
self,
|
| 272 |
+
num_learnable_queries=64,
|
| 273 |
+
hidden_size=1024,
|
| 274 |
+
num_hidden_layers=6,
|
| 275 |
+
num_attention_heads=16,
|
| 276 |
+
intermediate_size=2816,
|
| 277 |
+
attention_probs_dropout_prob=0.,
|
| 278 |
+
initializer_range=0.02,
|
| 279 |
+
layer_norm_eps=1e-6,
|
| 280 |
+
encoder_hidden_size=1024,
|
| 281 |
+
grid_size=None,
|
| 282 |
+
**kwargs,
|
| 283 |
+
):
|
| 284 |
+
super().__init__(**kwargs)
|
| 285 |
+
self.hidden_size = hidden_size
|
| 286 |
+
self.num_learnable_queries = num_learnable_queries
|
| 287 |
+
self.num_hidden_layers = num_hidden_layers
|
| 288 |
+
self.num_attention_heads = num_attention_heads
|
| 289 |
+
self.intermediate_size = intermediate_size
|
| 290 |
+
self.attention_probs_dropout_prob = attention_probs_dropout_prob
|
| 291 |
+
self.initializer_range = initializer_range
|
| 292 |
+
self.layer_norm_eps = layer_norm_eps
|
| 293 |
+
self.encoder_hidden_size = encoder_hidden_size
|
| 294 |
+
self.grid_size = grid_size if grid_size else 32
|
| 295 |
+
|
| 296 |
+
@classmethod
|
| 297 |
+
def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> "PretrainedConfig":
|
| 298 |
+
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
|
| 299 |
+
|
| 300 |
+
# get the visual_abstractor config dict if we are loading from MplugOwlConfig
|
| 301 |
+
if config_dict.get("model_type") == "mplug-owl":
|
| 302 |
+
config_dict = config_dict["abstractor_config"]
|
| 303 |
+
|
| 304 |
+
if "model_type" in config_dict and hasattr(cls, "model_type") and config_dict["model_type"] != cls.model_type:
|
| 305 |
+
logger.warning(
|
| 306 |
+
f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
|
| 307 |
+
f"{cls.model_type}. This is not supported for all configurations of models and can yield errors."
|
| 308 |
+
)
|
| 309 |
+
|
| 310 |
+
return cls.from_dict(config_dict, **kwargs)
|
| 311 |
+
|
| 312 |
+
|
| 313 |
+
|
| 314 |
+
DEFAULT_VISUAL_CONFIG = {
|
| 315 |
+
"visual_model": MplugOwlVisionConfig().to_dict(),
|
| 316 |
+
"visual_abstractor": MplugOwlVisualAbstractorConfig().to_dict()
|
| 317 |
+
}
|
| 318 |
+
|
| 319 |
+
class MPLUGOwl2Config(LlamaConfig):
|
| 320 |
+
model_type = "mplug_owl2"
|
| 321 |
+
def __init__(self, visual_config=None, **kwargs):
|
| 322 |
+
if visual_config is None:
|
| 323 |
+
self.visual_config = DEFAULT_VISUAL_CONFIG
|
| 324 |
+
else:
|
| 325 |
+
self.visual_config = visual_config
|
| 326 |
+
|
| 327 |
+
super().__init__(
|
| 328 |
+
**kwargs,
|
| 329 |
+
)
|
| 330 |
+
|
| 331 |
+
if __name__ == "__main__":
|
| 332 |
+
print(MplugOwlVisionConfig().to_dict())
|
mplug_owl2/model/convert_mplug_owl2_weight_to_hf.py
ADDED
|
@@ -0,0 +1,395 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 DAMO Academy and The HuggingFace Inc. team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
import argparse
|
| 15 |
+
import gc
|
| 16 |
+
import json
|
| 17 |
+
import math
|
| 18 |
+
import os
|
| 19 |
+
import shutil
|
| 20 |
+
import warnings
|
| 21 |
+
|
| 22 |
+
import torch
|
| 23 |
+
|
| 24 |
+
from transformers import LlamaConfig, LlamaForCausalLM, LlamaTokenizer
|
| 25 |
+
from .configuration_mplug_owl2 import MPLUGOwl2Config, MplugOwlVisionConfig, MplugOwlVisualAbstractorConfig
|
| 26 |
+
from .modeling_mplug_owl2 import MPLUGOwl2LlamaForCausalLM
|
| 27 |
+
|
| 28 |
+
try:
|
| 29 |
+
from transformers import LlamaTokenizerFast
|
| 30 |
+
except ImportError as e:
|
| 31 |
+
warnings.warn(e)
|
| 32 |
+
warnings.warn(
|
| 33 |
+
"The converted tokenizer will be the `slow` tokenizer. To use the fast, update your `tokenizers` library and re-run the tokenizer conversion"
|
| 34 |
+
)
|
| 35 |
+
LlamaTokenizerFast = None
|
| 36 |
+
|
| 37 |
+
"""
|
| 38 |
+
Sample usage:
|
| 39 |
+
|
| 40 |
+
```
|
| 41 |
+
python3 /pure-mlo-scratch/sfan/model-parallel-trainer/llama2megatron/convert_llama2hf.py \
|
| 42 |
+
--input_dir /pure-mlo-scratch/llama/ --model_size 7 --output_dir /pure-mlo-scratch/llama/converted_HF_7B
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
Thereafter, models can be loaded via:
|
| 46 |
+
|
| 47 |
+
```py
|
| 48 |
+
from transformers import LlamaForCausalLM, LlamaTokenizer
|
| 49 |
+
|
| 50 |
+
model = LlamaForCausalLM.from_pretrained("/output/path")
|
| 51 |
+
tokenizer = LlamaTokenizer.from_pretrained("/output/path")
|
| 52 |
+
```
|
| 53 |
+
|
| 54 |
+
Important note: you need to be able to host the whole model in RAM to execute this script (even if the biggest versions
|
| 55 |
+
come in several checkpoints they each contain a part of each weight of the model, so we need to load them all in RAM).
|
| 56 |
+
"""
|
| 57 |
+
|
| 58 |
+
llama_s2layer = {7: 32, 13: 40, 30: 60, 65: 80, 70: 80}
|
| 59 |
+
llama_s2heads = {7: 32, 13: 40, 30: 52, 65: 64, 70: 64}
|
| 60 |
+
llama_s2dense = {7: 11008, 13: 13824, 30: 17920, 65: 22016,
|
| 61 |
+
70: 28672} # should be (2/3)*4*d, but it isn't exaclty that
|
| 62 |
+
llama_s2hidden = {7: 4096, 13: 5120, 32: 6656, 65: 8192, 70: 8192}
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def compute_intermediate_size(n):
|
| 66 |
+
return int(math.ceil(n * 8 / 3) + 255) // 256 * 256
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def read_json(path):
|
| 70 |
+
with open(path, "r") as f:
|
| 71 |
+
return json.load(f)
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def write_json(text, path):
|
| 75 |
+
with open(path, "w") as f:
|
| 76 |
+
json.dump(text, f)
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
def write_model(model_path,
|
| 80 |
+
input_base_path,
|
| 81 |
+
model_size,
|
| 82 |
+
num_input_shards=1,
|
| 83 |
+
num_output_shards=2,
|
| 84 |
+
skip_permute=True,
|
| 85 |
+
norm_eps=1e-05):
|
| 86 |
+
# if os.path.exists(model_path):
|
| 87 |
+
# shutil.rmtree(model_path)
|
| 88 |
+
os.makedirs(model_path, exist_ok=True)
|
| 89 |
+
# tmp_model_path = os.path.join(model_path, "tmp")
|
| 90 |
+
tmp_model_path = model_path
|
| 91 |
+
os.makedirs(tmp_model_path, exist_ok=True)
|
| 92 |
+
|
| 93 |
+
num_shards = num_input_shards
|
| 94 |
+
n_layers = llama_s2layer[model_size]
|
| 95 |
+
n_heads = llama_s2heads[model_size]
|
| 96 |
+
n_heads_per_shard = n_heads // num_shards
|
| 97 |
+
n_dense = llama_s2dense[model_size]
|
| 98 |
+
n_hidden = llama_s2hidden[model_size]
|
| 99 |
+
hidden_per_head = n_hidden // n_heads
|
| 100 |
+
base = 10000.0
|
| 101 |
+
inv_freq = 1.0 / (base ** (torch.arange(0, hidden_per_head, 2).float() / hidden_per_head))
|
| 102 |
+
|
| 103 |
+
# permute for sliced rotary
|
| 104 |
+
def permute(w, skip_permute=skip_permute):
|
| 105 |
+
if skip_permute:
|
| 106 |
+
return w
|
| 107 |
+
return w.view(n_heads, n_hidden // n_heads // 2, 2, n_hidden).transpose(1, 2).reshape(n_hidden, n_hidden)
|
| 108 |
+
|
| 109 |
+
print(f"Fetching all parameters from the checkpoint at {input_base_path}.")
|
| 110 |
+
# Load weights
|
| 111 |
+
if num_shards==1:
|
| 112 |
+
# Not sharded
|
| 113 |
+
# (The sharded implementation would also work, but this is simpler.)
|
| 114 |
+
# /pure-mlo-scratch/alhernan/megatron-data/checkpoints/llama2-7b-tp4-pp1-optim/release/mp_rank_00/model_optim_rng.pt
|
| 115 |
+
if os.path.exists(os.path.join(input_base_path, 'release')):
|
| 116 |
+
filename = os.path.join(input_base_path, 'release', 'mp_rank_00', 'model_optim_rng.pt')
|
| 117 |
+
elif input_base_path.split('/')[-1].startswith('iter_'):
|
| 118 |
+
iteration = eval(input_base_path.split('/')[-1].replace('iter_', '').lstrip('0'))
|
| 119 |
+
load_dir = '/'.join(input_base_path.split('/')[:-1])
|
| 120 |
+
filename = os.path.join(input_base_path, 'mp_rank_00', 'model_optim_rng.pt')
|
| 121 |
+
if not os.path.exists(filename):
|
| 122 |
+
filename = filename.replace('model_optim_rng.pt', 'model_rng.pt')
|
| 123 |
+
else:
|
| 124 |
+
tracker_filename = os.path.join(input_base_path, 'latest_checkpointed_iteration.txt')
|
| 125 |
+
with open(tracker_filename, 'r') as f:
|
| 126 |
+
metastring = f.read().strip()
|
| 127 |
+
iteration = 'iter_{:07d}'.format(int(metastring))
|
| 128 |
+
filename = os.path.join(input_base_path, iteration, 'mp_rank_00', 'model_optim_rng.pt')
|
| 129 |
+
if not os.path.exists(filename):
|
| 130 |
+
filename = filename.replace('model_optim_rng.pt', 'model_rng.pt')
|
| 131 |
+
original_filename = filename
|
| 132 |
+
loaded = torch.load(filename, map_location="cpu")['model']['language_model']
|
| 133 |
+
|
| 134 |
+
else:
|
| 135 |
+
# Sharded
|
| 136 |
+
filenames = []
|
| 137 |
+
for i in range(num_shards):
|
| 138 |
+
if os.path.exists(os.path.join(input_base_path, 'release')):
|
| 139 |
+
filename = os.path.join(input_base_path, 'release', f'mp_rank_{i:02d}', 'model_optim_rng.pt')
|
| 140 |
+
else:
|
| 141 |
+
tracker_filename = os.path.join(input_base_path, 'latest_checkpointed_iteration.txt')
|
| 142 |
+
with open(tracker_filename, 'r') as f:
|
| 143 |
+
metastring = f.read().strip()
|
| 144 |
+
iteration = 'iter_{:07d}'.format(int(metastring))
|
| 145 |
+
filename = os.path.join(input_base_path, iteration, f'mp_rank_{i:02d}', 'model_optim_rng.pt')
|
| 146 |
+
if not os.path.exists(filename):
|
| 147 |
+
filename = filename.replace('model_optim_rng.pt', 'model_rng.pt')
|
| 148 |
+
filenames.append(filename)
|
| 149 |
+
loaded = [
|
| 150 |
+
torch.load(filenames[i], map_location="cpu")['model']['language_model']
|
| 151 |
+
for i in range(num_shards)
|
| 152 |
+
]
|
| 153 |
+
|
| 154 |
+
print('Llama-Megatron Loaded!')
|
| 155 |
+
param_count = 0
|
| 156 |
+
index_dict = {"weight_map": {}}
|
| 157 |
+
|
| 158 |
+
print(f'Weighted Converting for {n_layers} layers...')
|
| 159 |
+
for layer_i in range(n_layers):
|
| 160 |
+
print(layer_i)
|
| 161 |
+
filename = f"pytorch_model-{layer_i + 1}-of-{n_layers + 1}.bin"
|
| 162 |
+
if num_shards == 1:
|
| 163 |
+
# Unsharded
|
| 164 |
+
state_dict = {
|
| 165 |
+
f"model.layers.{layer_i}.self_attn.q_proj.weight": loaded['encoder'][f"layers.{layer_i}.self_attention.q_proj.weight"],
|
| 166 |
+
f"model.layers.{layer_i}.self_attn.k_proj.multiway.0.weight": loaded['encoder'][f"layers.{layer_i}.self_attention.k_proj.multiway.0.weight"],
|
| 167 |
+
f"model.layers.{layer_i}.self_attn.v_proj.multiway.0.weight": loaded['encoder'][f"layers.{layer_i}.self_attention.v_proj.multiway.0.weight"],
|
| 168 |
+
f"model.layers.{layer_i}.self_attn.k_proj.multiway.1.weight": loaded['encoder'][f"layers.{layer_i}.self_attention.k_proj.multiway.1.weight"],
|
| 169 |
+
f"model.layers.{layer_i}.self_attn.v_proj.multiway.1.weight": loaded['encoder'][f"layers.{layer_i}.self_attention.v_proj.multiway.1.weight"],
|
| 170 |
+
f"model.layers.{layer_i}.self_attn.o_proj.weight": loaded['encoder'][f"layers.{layer_i}.self_attention.o_proj.weight"],
|
| 171 |
+
f"model.layers.{layer_i}.mlp.gate_proj.weight": loaded['encoder'][f"layers.{layer_i}.mlp.gate_proj.weight"],
|
| 172 |
+
f"model.layers.{layer_i}.mlp.down_proj.weight": loaded['encoder'][f"layers.{layer_i}.mlp.down_proj.weight"],
|
| 173 |
+
f"model.layers.{layer_i}.mlp.up_proj.weight": loaded['encoder'][f"layers.{layer_i}.mlp.up_proj.weight"],
|
| 174 |
+
f"model.layers.{layer_i}.input_layernorm.multiway.0.weight": loaded['encoder'][f"layers.{layer_i}.input_layernorm.multiway.0.weight"],
|
| 175 |
+
f"model.layers.{layer_i}.post_attention_layernorm.multiway.0.weight": loaded['encoder'][f"layers.{layer_i}.post_attention_layernorm.multiway.0.weight"],
|
| 176 |
+
f"model.layers.{layer_i}.input_layernorm.multiway.1.weight": loaded['encoder'][f"layers.{layer_i}.input_layernorm.multiway.1.weight"],
|
| 177 |
+
f"model.layers.{layer_i}.post_attention_layernorm.multiway.1.weight": loaded['encoder'][f"layers.{layer_i}.post_attention_layernorm.multiway.1.weight"],
|
| 178 |
+
}
|
| 179 |
+
else:
|
| 180 |
+
raise NotImplemented
|
| 181 |
+
# else:
|
| 182 |
+
# # Sharded
|
| 183 |
+
# # Note that attention.w{q,k,v,o}, feed_fordward.w[1,2,3], attention_norm.weight and ffn_norm.weight share
|
| 184 |
+
# # the same storage object, saving attention_norm and ffn_norm will save other weights too, which is
|
| 185 |
+
# # redundant as other weights will be stitched from multiple shards. To avoid that, they are cloned.
|
| 186 |
+
|
| 187 |
+
# state_dict = {
|
| 188 |
+
# f"model.layers.{layer_i}.input_layernorm.weight": loaded[0]['encoder'][
|
| 189 |
+
# f"layers.{layer_i}.input_layernorm.multiway.0.weight"
|
| 190 |
+
# ].clone(),
|
| 191 |
+
# f"model.layers.{layer_i}.post_attention_layernorm.weight": loaded[0]['encoder'][
|
| 192 |
+
# f"layers.{layer_i}.post_attention_layernorm.multiway.0.weight"
|
| 193 |
+
# ].clone(),
|
| 194 |
+
# }
|
| 195 |
+
|
| 196 |
+
# wqs, wks, wvs, ffn_w1s, ffn_w3s = [], [], [], [], []
|
| 197 |
+
# for shard_idx in range(num_shards):
|
| 198 |
+
# wqs.append(loaded[shard_idx]['encoder'][f"layers.{layer_i}.self_attention.q_proj.weight"])
|
| 199 |
+
# wks.append(loaded[shard_idx]['encoder'][f"layers.{layer_i}.self_attention.k_proj.multiway.0.weight"])
|
| 200 |
+
# wvs.append(loaded[shard_idx]['encoder'][f"layers.{layer_i}.self_attention.v_proj.multiway.0.weight"])
|
| 201 |
+
|
| 202 |
+
# state_dict[f"model.layers.{layer_i}.self_attn.q_proj.weight"] = permute(
|
| 203 |
+
# torch.cat(
|
| 204 |
+
# [
|
| 205 |
+
# wq.view(n_heads_per_shard, hidden_per_head, n_hidden)
|
| 206 |
+
# for wq in range(wqs)
|
| 207 |
+
# ],
|
| 208 |
+
# dim=0,
|
| 209 |
+
# ).reshape(n_hidden, n_hidden)
|
| 210 |
+
# )
|
| 211 |
+
# state_dict[f"model.layers.{layer_i}.self_attn.k_proj.weight"] = permute(
|
| 212 |
+
# torch.cat(
|
| 213 |
+
# [
|
| 214 |
+
# wk.view(n_heads_per_shard, hidden_per_head, n_hidden)
|
| 215 |
+
# for wk in range(wks)
|
| 216 |
+
# ],
|
| 217 |
+
# dim=0,
|
| 218 |
+
# ).reshape(n_hidden, n_hidden)
|
| 219 |
+
# )
|
| 220 |
+
# state_dict[f"model.layers.{layer_i}.self_attn.v_proj.weight"] = torch.cat(
|
| 221 |
+
# [
|
| 222 |
+
# wv.view(n_heads_per_shard, hidden_per_head, n_hidden)
|
| 223 |
+
# for wv in range(wvs)
|
| 224 |
+
# ],
|
| 225 |
+
# dim=0,
|
| 226 |
+
# ).reshape(n_hidden, n_hidden)
|
| 227 |
+
|
| 228 |
+
# state_dict[f"model.layers.{layer_i}.self_attn.o_proj.weight"] = torch.cat(
|
| 229 |
+
# [loaded[i]['encoder'][f"layers.{layer_i}.self_attention.o_proj.weight"] for i in range(num_shards)], dim=1
|
| 230 |
+
# )
|
| 231 |
+
# state_dict[f"model.layers.{layer_i}.mlp.gate_proj.weight"] = torch.cat(
|
| 232 |
+
# [loaded[i]['encoder'][f"layers.{layer_i}.mlp.gate_proj.weight"] for i in range(num_shards)], dim=0
|
| 233 |
+
# )
|
| 234 |
+
# state_dict[f"model.layers.{layer_i}.mlp.down_proj.weight"] = torch.cat(
|
| 235 |
+
# [loaded[i]['encoder'][f"layers.{layer_i}.mlp.down_proj.weight"] for i in range(num_shards)], dim=1
|
| 236 |
+
# )
|
| 237 |
+
# state_dict[f"model.layers.{layer_i}.mlp.up_proj.weight"] = torch.cat(
|
| 238 |
+
# [loaded[i]['encoder'][f"layers.{layer_i}.mlp.up_proj.weight"] for i in range(num_shards)], dim=0
|
| 239 |
+
# )
|
| 240 |
+
|
| 241 |
+
state_dict[f"model.layers.{layer_i}.self_attn.rotary_emb.inv_freq"] = inv_freq
|
| 242 |
+
for k, v in state_dict.items():
|
| 243 |
+
index_dict["weight_map"][k] = filename
|
| 244 |
+
param_count += v.numel()
|
| 245 |
+
torch.save(state_dict, os.path.join(tmp_model_path, filename))
|
| 246 |
+
print(f'Sharded file saved to {filename}')
|
| 247 |
+
|
| 248 |
+
filename = f"pytorch_model-{n_layers + 1}-of-{n_layers + 1}.bin"
|
| 249 |
+
if num_shards==1:
|
| 250 |
+
# Unsharded
|
| 251 |
+
state_dict = {
|
| 252 |
+
"model.embed_tokens.weight": loaded['embedding']['word_embeddings']['weight'],
|
| 253 |
+
"model.norm.weight": loaded['encoder']['norm.weight'],
|
| 254 |
+
"lm_head.weight": loaded['encoder']['lm_head.weight'],
|
| 255 |
+
}
|
| 256 |
+
else:
|
| 257 |
+
state_dict = {
|
| 258 |
+
"model.embed_tokens.weight": loaded[0]['embedding']['word_embeddings']['weight'],
|
| 259 |
+
"model.norm.weight": loaded[0]['encoder']['norm.weight'],
|
| 260 |
+
"lm_head.weight": loaded[0]['encoder']['lm_head.weight'],
|
| 261 |
+
}
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
loaded_all = torch.load(original_filename, map_location="cpu")['model']
|
| 265 |
+
# Vision Part
|
| 266 |
+
state_dict.update({
|
| 267 |
+
"model.vision_model.embeddings.cls_token": loaded_all['vision_model']['cls_token'],
|
| 268 |
+
"model.vision_model.embeddings.patch_embed.weight": loaded_all['vision_model']['patch_embed']['weight'],
|
| 269 |
+
"model.vision_model.embeddings.position_embedding": loaded_all['vision_model']['position_embeddings'],
|
| 270 |
+
"model.vision_model.embeddings.pre_layernorm.bias": loaded_all['vision_model']['pre_layernorm']['bias'],
|
| 271 |
+
"model.vision_model.embeddings.pre_layernorm.weight": loaded_all['vision_model']['pre_layernorm']['weight'],
|
| 272 |
+
"model.vision_model.post_layernorm.bias": loaded_all['vision_model']['transformer']['final_layernorm.bias'],
|
| 273 |
+
"model.vision_model.post_layernorm.weight": loaded_all['vision_model']['transformer']['final_layernorm.weight'],
|
| 274 |
+
})
|
| 275 |
+
for v_layer_idx in range(24):
|
| 276 |
+
state_dict.update({
|
| 277 |
+
f"model.vision_model.encoder.layers.{v_layer_idx}.input_layernorm.bias": loaded_all['vision_model']['transformer'][f'layers.{v_layer_idx}.input_layernorm.bias'],
|
| 278 |
+
f"model.vision_model.encoder.layers.{v_layer_idx}.input_layernorm.weight": loaded_all['vision_model']['transformer'][f'layers.{v_layer_idx}.input_layernorm.weight'],
|
| 279 |
+
f"model.vision_model.encoder.layers.{v_layer_idx}.mlp.fc1.bias": loaded_all['vision_model']['transformer'][f'layers.{v_layer_idx}.mlp.dense_h_to_4h.bias'],
|
| 280 |
+
f"model.vision_model.encoder.layers.{v_layer_idx}.mlp.fc1.weight": loaded_all['vision_model']['transformer'][f'layers.{v_layer_idx}.mlp.dense_h_to_4h.weight'],
|
| 281 |
+
f"model.vision_model.encoder.layers.{v_layer_idx}.mlp.fc2.bias": loaded_all['vision_model']['transformer'][f'layers.{v_layer_idx}.mlp.dense_4h_to_h.bias'],
|
| 282 |
+
f"model.vision_model.encoder.layers.{v_layer_idx}.mlp.fc2.weight": loaded_all['vision_model']['transformer'][f'layers.{v_layer_idx}.mlp.dense_4h_to_h.weight'],
|
| 283 |
+
f"model.vision_model.encoder.layers.{v_layer_idx}.post_attention_layernorm.bias": loaded_all['vision_model']['transformer'][f'layers.{v_layer_idx}.post_attention_layernorm.bias'],
|
| 284 |
+
f"model.vision_model.encoder.layers.{v_layer_idx}.post_attention_layernorm.weight": loaded_all['vision_model']['transformer'][f'layers.{v_layer_idx}.post_attention_layernorm.weight'],
|
| 285 |
+
f"model.vision_model.encoder.layers.{v_layer_idx}.self_attn.dense.bias": loaded_all['vision_model']['transformer'][f'layers.{v_layer_idx}.self_attention.dense.bias'],
|
| 286 |
+
f"model.vision_model.encoder.layers.{v_layer_idx}.self_attn.dense.weight": loaded_all['vision_model']['transformer'][f'layers.{v_layer_idx}.self_attention.dense.weight'],
|
| 287 |
+
f"model.vision_model.encoder.layers.{v_layer_idx}.self_attn.query_key_value.bias": loaded_all['vision_model']['transformer'][f'layers.{v_layer_idx}.self_attention.query_key_value.bias'],
|
| 288 |
+
f"model.vision_model.encoder.layers.{v_layer_idx}.self_attn.query_key_value.weight": loaded_all['vision_model']['transformer'][f'layers.{v_layer_idx}.self_attention.query_key_value.weight'],
|
| 289 |
+
})
|
| 290 |
+
|
| 291 |
+
# Abstractor Part
|
| 292 |
+
state_dict.update({
|
| 293 |
+
"model.visual_abstractor.query_embeds": loaded_all['vision_abstractor']['learnable_queries'],
|
| 294 |
+
"model.visual_abstractor.visual_fc.bias": loaded_all['vision_abstractor']['visual_fc']['bias'],
|
| 295 |
+
"model.visual_abstractor.visual_fc.weight": loaded_all['vision_abstractor']['visual_fc']['weight'],
|
| 296 |
+
"model.visual_abstractor.vit_eos": loaded_all['vision_abstractor']['vit_eos'],
|
| 297 |
+
})
|
| 298 |
+
for v_layer_idx in range(6):
|
| 299 |
+
state_dict.update({
|
| 300 |
+
# f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.attention.k_pos_embed":
|
| 301 |
+
f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.attention.key.bias": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.self_attention.k_proj.bias"],
|
| 302 |
+
f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.attention.key.weight": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.self_attention.k_proj.weight"],
|
| 303 |
+
# f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.attention.q_pos_embed": "pytorch_model-00004-of-00004.bin",
|
| 304 |
+
f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.attention.query.bias": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.self_attention.q_proj.bias"],
|
| 305 |
+
f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.attention.query.weight": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.self_attention.q_proj.weight"],
|
| 306 |
+
f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.attention.value.bias": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.self_attention.v_proj.bias"],
|
| 307 |
+
f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.attention.value.weight": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.self_attention.v_proj.weight"],
|
| 308 |
+
f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.norm1.bias": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.norm1.bias"],
|
| 309 |
+
f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.norm1.weight": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.norm1.weight"],
|
| 310 |
+
f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.normk.bias": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.normk.bias"],
|
| 311 |
+
f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.normk.weight": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.normk.weight"],
|
| 312 |
+
f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.output.mlp.ffn_ln.bias": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.mlp.ffn_ln.bias"],
|
| 313 |
+
f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.output.mlp.ffn_ln.weight": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.mlp.ffn_ln.weight"],
|
| 314 |
+
|
| 315 |
+
f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.output.mlp.w1.bias": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.mlp.w1.bias"],
|
| 316 |
+
f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.output.mlp.w1.weight": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.mlp.w1.weight"],
|
| 317 |
+
f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.output.mlp.w2.bias": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.mlp.w2.bias"],
|
| 318 |
+
f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.output.mlp.w2.weight": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.mlp.w2.weight"],
|
| 319 |
+
f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.output.mlp.w3.bias": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.mlp.w3.bias"],
|
| 320 |
+
f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.output.mlp.w3.weight": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.mlp.w3.weight"],
|
| 321 |
+
|
| 322 |
+
f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.output.norm2.bias": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.norm2.bias"],
|
| 323 |
+
f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.output.norm2.weight": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.norm2.weight"],
|
| 324 |
+
f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.output.out_proj.bias": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.self_attention.o_proj.bias"],
|
| 325 |
+
f"model.visual_abstractor.encoder.layers.{v_layer_idx}.crossattention.output.out_proj.weight": loaded_all['vision_abstractor']['transformer'][f"layers.{v_layer_idx}.self_attention.o_proj.weight"],
|
| 326 |
+
})
|
| 327 |
+
|
| 328 |
+
for k, v in state_dict.items():
|
| 329 |
+
index_dict["weight_map"][k] = filename
|
| 330 |
+
param_count += v.numel()
|
| 331 |
+
torch.save(state_dict, os.path.join(tmp_model_path, filename))
|
| 332 |
+
|
| 333 |
+
# Write configs
|
| 334 |
+
index_dict["metadata"] = {"total_size": param_count * 2}
|
| 335 |
+
write_json(index_dict, os.path.join(tmp_model_path, "pytorch_model.bin.index.json"))
|
| 336 |
+
|
| 337 |
+
config = MPLUGOwl2Config()
|
| 338 |
+
config.save_pretrained(tmp_model_path)
|
| 339 |
+
|
| 340 |
+
# Make space so we can load the model properly now.
|
| 341 |
+
del state_dict
|
| 342 |
+
del loaded
|
| 343 |
+
del loaded_all
|
| 344 |
+
gc.collect()
|
| 345 |
+
|
| 346 |
+
def write_tokenizer(tokenizer_path, input_tokenizer_path):
|
| 347 |
+
# Initialize the tokenizer based on the `spm` model
|
| 348 |
+
tokenizer_class = LlamaTokenizer if LlamaTokenizerFast is None else LlamaTokenizerFast
|
| 349 |
+
print(f"Saving a {tokenizer_class.__name__} to {tokenizer_path}.")
|
| 350 |
+
tokenizer = tokenizer_class(input_tokenizer_path)
|
| 351 |
+
tokenizer.save_pretrained(tokenizer_path)
|
| 352 |
+
|
| 353 |
+
|
| 354 |
+
def main():
|
| 355 |
+
parser = argparse.ArgumentParser()
|
| 356 |
+
parser.add_argument(
|
| 357 |
+
"--input_dir",
|
| 358 |
+
help="Location of LLaMA_Megatron weights",
|
| 359 |
+
)
|
| 360 |
+
parser.add_argument(
|
| 361 |
+
"--model_size",
|
| 362 |
+
type=int,
|
| 363 |
+
default=7,
|
| 364 |
+
choices=[7, 13, 30, 65, 70],
|
| 365 |
+
)
|
| 366 |
+
parser.add_argument(
|
| 367 |
+
"--num_input_shards",
|
| 368 |
+
type=int,
|
| 369 |
+
default=1,
|
| 370 |
+
)
|
| 371 |
+
parser.add_argument(
|
| 372 |
+
"--num_output_shards",
|
| 373 |
+
type=int,
|
| 374 |
+
default=1,
|
| 375 |
+
)
|
| 376 |
+
parser.add_argument('--skip_permute', action='store_true')
|
| 377 |
+
|
| 378 |
+
parser.add_argument(
|
| 379 |
+
"--output_dir",
|
| 380 |
+
help="Location to write HF model and tokenizer",
|
| 381 |
+
)
|
| 382 |
+
|
| 383 |
+
args = parser.parse_args()
|
| 384 |
+
write_model(
|
| 385 |
+
model_path=args.output_dir,
|
| 386 |
+
input_base_path=args.input_dir,
|
| 387 |
+
model_size=args.model_size,
|
| 388 |
+
num_input_shards=args.num_input_shards,
|
| 389 |
+
num_output_shards=args.num_output_shards,
|
| 390 |
+
skip_permute=args.skip_permute
|
| 391 |
+
)
|
| 392 |
+
|
| 393 |
+
|
| 394 |
+
if __name__ == "__main__":
|
| 395 |
+
main()
|
mplug_owl2/model/modeling_attn_mask_utils.py
ADDED
|
@@ -0,0 +1,247 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
from typing import List, Optional, Tuple, Union
|
| 15 |
+
|
| 16 |
+
import torch
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class AttentionMaskConverter:
|
| 20 |
+
"""
|
| 21 |
+
A utility attention mask class that allows one to:
|
| 22 |
+
- Create a causal 4d mask
|
| 23 |
+
- Create a causal 4d mask with slided window
|
| 24 |
+
- Convert a 2d attention mask (batch_size, query_length) to a 4d attention mask (batch_size, 1, query_length,
|
| 25 |
+
key_value_length) that can be multiplied with attention scores
|
| 26 |
+
|
| 27 |
+
Parameters:
|
| 28 |
+
is_causal (`bool`):
|
| 29 |
+
Whether the attention mask should be a uni-directional (causal) or bi-directional mask.
|
| 30 |
+
|
| 31 |
+
sliding_window (`int`, *optional*):
|
| 32 |
+
Optionally, the sliding window masks can be created if `sliding_window` is defined to a positive integer.
|
| 33 |
+
"""
|
| 34 |
+
|
| 35 |
+
def __init__(self, is_causal: bool, sliding_window: Optional[int] = None):
|
| 36 |
+
self.is_causal = is_causal
|
| 37 |
+
self.sliding_window = sliding_window
|
| 38 |
+
|
| 39 |
+
if self.sliding_window is not None and self.sliding_window <= 0:
|
| 40 |
+
raise ValueError(
|
| 41 |
+
f"Make sure that when passing `sliding_window` that its value is a strictly positive integer, not `{self.sliding_window}`"
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
def to_causal_4d(
|
| 45 |
+
self,
|
| 46 |
+
batch_size: int,
|
| 47 |
+
query_length: int,
|
| 48 |
+
key_value_length: int,
|
| 49 |
+
dtype: torch.dtype = torch.float32,
|
| 50 |
+
device: Union[torch.device, "str"] = "cpu",
|
| 51 |
+
) -> torch.Tensor:
|
| 52 |
+
"""
|
| 53 |
+
Creates a causal 4D mask of (bsz, head_dim=1, query_length, key_value_length) shape and adds large negative
|
| 54 |
+
bias to upper right hand triangular matrix (causal mask).
|
| 55 |
+
"""
|
| 56 |
+
if not self.is_causal:
|
| 57 |
+
raise ValueError(f"Please use `to_causal_4d` only if {self.__class__} has `is_causal` set to True.")
|
| 58 |
+
|
| 59 |
+
# If shape is not cached, create a new causal mask and cache it
|
| 60 |
+
input_shape = (batch_size, query_length)
|
| 61 |
+
past_key_values_length = key_value_length - query_length
|
| 62 |
+
|
| 63 |
+
# create causal mask
|
| 64 |
+
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
|
| 65 |
+
causal_4d_mask = None
|
| 66 |
+
if input_shape[-1] > 1 or self.sliding_window is not None:
|
| 67 |
+
causal_4d_mask = self._make_causal_mask(
|
| 68 |
+
input_shape,
|
| 69 |
+
dtype,
|
| 70 |
+
device=device,
|
| 71 |
+
past_key_values_length=past_key_values_length,
|
| 72 |
+
sliding_window=self.sliding_window,
|
| 73 |
+
)
|
| 74 |
+
|
| 75 |
+
return causal_4d_mask
|
| 76 |
+
|
| 77 |
+
def to_4d(
|
| 78 |
+
self,
|
| 79 |
+
attention_mask_2d: torch.Tensor,
|
| 80 |
+
query_length: int,
|
| 81 |
+
key_value_length: Optional[int] = None,
|
| 82 |
+
dtype: torch.dtype = torch.float32,
|
| 83 |
+
) -> torch.Tensor:
|
| 84 |
+
"""
|
| 85 |
+
Converts 2D attention mask to 4D attention mask by expanding mask to (bsz, head_dim=1, query_length,
|
| 86 |
+
key_value_length) shape and by adding a large negative bias to not-attended positions. If attention_mask is
|
| 87 |
+
causal, a causal mask will be added.
|
| 88 |
+
"""
|
| 89 |
+
input_shape = (attention_mask_2d.shape[0], query_length)
|
| 90 |
+
|
| 91 |
+
# create causal mask
|
| 92 |
+
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
|
| 93 |
+
causal_4d_mask = None
|
| 94 |
+
if (input_shape[-1] > 1 or self.sliding_window is not None) and self.is_causal:
|
| 95 |
+
if key_value_length is None:
|
| 96 |
+
raise ValueError(
|
| 97 |
+
"This attention mask converter is causal. Make sure to pass `key_value_length` to correctly create a causal mask."
|
| 98 |
+
)
|
| 99 |
+
|
| 100 |
+
past_key_values_length = key_value_length - query_length
|
| 101 |
+
causal_4d_mask = self._make_causal_mask(
|
| 102 |
+
input_shape,
|
| 103 |
+
dtype,
|
| 104 |
+
device=attention_mask_2d.device,
|
| 105 |
+
past_key_values_length=past_key_values_length,
|
| 106 |
+
sliding_window=self.sliding_window,
|
| 107 |
+
)
|
| 108 |
+
elif self.sliding_window is not None:
|
| 109 |
+
raise NotImplementedError("Sliding window is currently only implemented for causal masking")
|
| 110 |
+
|
| 111 |
+
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
|
| 112 |
+
expanded_attn_mask = self._expand_mask(attention_mask_2d, dtype, tgt_len=input_shape[-1]).to(
|
| 113 |
+
attention_mask_2d.device
|
| 114 |
+
)
|
| 115 |
+
expanded_4d_mask = expanded_attn_mask if causal_4d_mask is None else expanded_attn_mask + causal_4d_mask
|
| 116 |
+
|
| 117 |
+
return expanded_4d_mask
|
| 118 |
+
|
| 119 |
+
@staticmethod
|
| 120 |
+
def _make_causal_mask(
|
| 121 |
+
input_ids_shape: torch.Size,
|
| 122 |
+
dtype: torch.dtype,
|
| 123 |
+
device: torch.device,
|
| 124 |
+
past_key_values_length: int = 0,
|
| 125 |
+
sliding_window: Optional[int] = None,
|
| 126 |
+
):
|
| 127 |
+
"""
|
| 128 |
+
Make causal mask used for bi-directional self-attention.
|
| 129 |
+
"""
|
| 130 |
+
bsz, tgt_len = input_ids_shape
|
| 131 |
+
mask = torch.full((tgt_len, tgt_len), torch.finfo(dtype).min, device=device)
|
| 132 |
+
mask_cond = torch.arange(mask.size(-1), device=device)
|
| 133 |
+
mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)
|
| 134 |
+
|
| 135 |
+
mask = mask.to(dtype)
|
| 136 |
+
|
| 137 |
+
if past_key_values_length > 0:
|
| 138 |
+
mask = torch.cat([torch.zeros(tgt_len, past_key_values_length, dtype=dtype, device=device), mask], dim=-1)
|
| 139 |
+
|
| 140 |
+
# add lower triangular sliding window mask if necessary
|
| 141 |
+
if sliding_window is not None:
|
| 142 |
+
diagonal = past_key_values_length - sliding_window + 1
|
| 143 |
+
|
| 144 |
+
context_mask = 1 - torch.triu(torch.ones_like(mask, dtype=torch.int), diagonal=diagonal)
|
| 145 |
+
mask.masked_fill_(context_mask.bool(), torch.finfo(dtype).min)
|
| 146 |
+
|
| 147 |
+
return mask[None, None, :, :].expand(bsz, 1, tgt_len, tgt_len + past_key_values_length)
|
| 148 |
+
|
| 149 |
+
@staticmethod
|
| 150 |
+
def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
|
| 151 |
+
"""
|
| 152 |
+
Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
|
| 153 |
+
"""
|
| 154 |
+
bsz, src_len = mask.size()
|
| 155 |
+
tgt_len = tgt_len if tgt_len is not None else src_len
|
| 156 |
+
|
| 157 |
+
expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)
|
| 158 |
+
|
| 159 |
+
inverted_mask = 1.0 - expanded_mask
|
| 160 |
+
|
| 161 |
+
return inverted_mask.masked_fill(inverted_mask.to(torch.bool), torch.finfo(dtype).min)
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
def _prepare_4d_causal_attention_mask(
|
| 165 |
+
attention_mask: Optional[torch.Tensor],
|
| 166 |
+
input_shape: Union[torch.Size, Tuple, List],
|
| 167 |
+
inputs_embeds: torch.Tensor,
|
| 168 |
+
past_key_values_length: int,
|
| 169 |
+
sliding_window: Optional[int] = None,
|
| 170 |
+
):
|
| 171 |
+
"""
|
| 172 |
+
Creates a causal 4D mask of shape `(batch_size, 1, query_length, key_value_length)` from a 2D mask of shape
|
| 173 |
+
`(batch_size, key_value_length)`
|
| 174 |
+
|
| 175 |
+
Args:
|
| 176 |
+
attention_mask (`torch.Tensor` or `None`):
|
| 177 |
+
A 2D attention mask of shape `(batch_size, key_value_length)`
|
| 178 |
+
input_shape (`tuple(int)` or `list(int)` or `torch.Size`):
|
| 179 |
+
The input shape should be a tuple that defines `(batch_size, query_length)`.
|
| 180 |
+
inputs_embeds (`torch.Tensor`):
|
| 181 |
+
The embedded inputs as a torch Tensor.
|
| 182 |
+
past_key_values_length (`int`):
|
| 183 |
+
The length of the key value cache.
|
| 184 |
+
sliding_window (`int`, *optional*):
|
| 185 |
+
If the model uses windowed attention, a sliding window should be passed.
|
| 186 |
+
"""
|
| 187 |
+
attn_mask_converter = AttentionMaskConverter(is_causal=True, sliding_window=sliding_window)
|
| 188 |
+
|
| 189 |
+
key_value_length = input_shape[-1] + past_key_values_length
|
| 190 |
+
|
| 191 |
+
# 4d mask is passed through the layers
|
| 192 |
+
if attention_mask is not None:
|
| 193 |
+
attention_mask = attn_mask_converter.to_4d(
|
| 194 |
+
attention_mask, input_shape[-1], key_value_length, dtype=inputs_embeds.dtype
|
| 195 |
+
)
|
| 196 |
+
else:
|
| 197 |
+
attention_mask = attn_mask_converter.to_causal_4d(
|
| 198 |
+
input_shape[0], input_shape[-1], key_value_length, dtype=inputs_embeds.dtype, device=inputs_embeds.device
|
| 199 |
+
)
|
| 200 |
+
|
| 201 |
+
return attention_mask
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
def _prepare_4d_attention_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
|
| 205 |
+
"""
|
| 206 |
+
Creates a non-causal 4D mask of shape `(batch_size, 1, query_length, key_value_length)` from a 2D mask of shape
|
| 207 |
+
`(batch_size, key_value_length)`
|
| 208 |
+
|
| 209 |
+
Args:
|
| 210 |
+
mask (`torch.Tensor` or `None`):
|
| 211 |
+
A 2D attention mask of shape `(batch_size, key_value_length)`
|
| 212 |
+
dtype (`torch.dtype`):
|
| 213 |
+
The torch dtype the created mask shall have.
|
| 214 |
+
tgt_len (`int`):
|
| 215 |
+
The target length or query length the created mask shall have.
|
| 216 |
+
"""
|
| 217 |
+
return AttentionMaskConverter._expand_mask(mask=mask, dtype=dtype, tgt_len=tgt_len)
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
def _create_4d_causal_attention_mask(
|
| 221 |
+
input_shape: Union[torch.Size, Tuple, List],
|
| 222 |
+
dtype: torch.dtype,
|
| 223 |
+
device: torch.device,
|
| 224 |
+
past_key_values_length: int = 0,
|
| 225 |
+
sliding_window: Optional[int] = None,
|
| 226 |
+
):
|
| 227 |
+
"""
|
| 228 |
+
Creates a causal 4D mask of shape `(batch_size, 1, query_length, key_value_length)`
|
| 229 |
+
|
| 230 |
+
Args:
|
| 231 |
+
input_shape (`tuple(int)` or `list(int)` or `torch.Size`):
|
| 232 |
+
The input shape should be a tuple that defines `(batch_size, query_length)`.
|
| 233 |
+
dtype (`torch.dtype`):
|
| 234 |
+
The torch dtype the created mask shall have.
|
| 235 |
+
device (`int`):
|
| 236 |
+
The torch device the created mask shall have.
|
| 237 |
+
sliding_window (`int`, *optional*):
|
| 238 |
+
If the model uses windowed attention, a sliding window should be passed.
|
| 239 |
+
"""
|
| 240 |
+
attn_mask_converter = AttentionMaskConverter(is_causal=True, sliding_window=sliding_window)
|
| 241 |
+
|
| 242 |
+
key_value_length = past_key_values_length + input_shape[-1]
|
| 243 |
+
attention_mask = attn_mask_converter.to_causal_4d(
|
| 244 |
+
input_shape[0], input_shape[-1], key_value_length, dtype=dtype, device=device
|
| 245 |
+
)
|
| 246 |
+
|
| 247 |
+
return attention_mask
|
mplug_owl2/model/modeling_llama2.py
ADDED
|
@@ -0,0 +1,486 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import warnings
|
| 3 |
+
from functools import partial
|
| 4 |
+
from typing import List, Optional, Tuple, Union
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
import torch.nn.functional as F
|
| 8 |
+
import torch.utils.checkpoint
|
| 9 |
+
from torch import nn
|
| 10 |
+
|
| 11 |
+
import transformers
|
| 12 |
+
from transformers.models.llama.modeling_llama import *
|
| 13 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 14 |
+
from transformers.utils import logging
|
| 15 |
+
|
| 16 |
+
from .modeling_attn_mask_utils import _prepare_4d_causal_attention_mask
|
| 17 |
+
from .configuration_mplug_owl2 import LlamaConfig
|
| 18 |
+
|
| 19 |
+
class MultiwayNetwork(nn.Module):
|
| 20 |
+
|
| 21 |
+
def __init__(self, module_provider, num_multiway=2):
|
| 22 |
+
super(MultiwayNetwork, self).__init__()
|
| 23 |
+
|
| 24 |
+
self.multiway = torch.nn.ModuleList([module_provider() for _ in range(num_multiway)])
|
| 25 |
+
|
| 26 |
+
def forward(self, hidden_states, multiway_indices):
|
| 27 |
+
|
| 28 |
+
if len(self.multiway) == 1:
|
| 29 |
+
return self.multiway[0](hidden_states)
|
| 30 |
+
|
| 31 |
+
output_hidden_states = torch.empty_like(hidden_states)
|
| 32 |
+
|
| 33 |
+
for idx, subway in enumerate(self.multiway):
|
| 34 |
+
local_indices = multiway_indices.eq(idx).nonzero(as_tuple=True)
|
| 35 |
+
hidden = hidden_states[local_indices].unsqueeze(1).contiguous()
|
| 36 |
+
if hidden.numel():
|
| 37 |
+
output = subway(hidden)
|
| 38 |
+
if isinstance(output, tuple):
|
| 39 |
+
output = output[0]
|
| 40 |
+
output = output.squeeze(1)
|
| 41 |
+
output_hidden_states[local_indices] = output
|
| 42 |
+
|
| 43 |
+
return output_hidden_states.contiguous()
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
class LlamaAttention(nn.Module):
|
| 47 |
+
"""Multi-headed attention from 'Attention Is All You Need' paper"""
|
| 48 |
+
|
| 49 |
+
def __init__(self, config: LlamaConfig):
|
| 50 |
+
super().__init__()
|
| 51 |
+
self.config = config
|
| 52 |
+
self.hidden_size = config.hidden_size
|
| 53 |
+
self.num_heads = config.num_attention_heads
|
| 54 |
+
self.head_dim = self.hidden_size // self.num_heads
|
| 55 |
+
self.num_key_value_heads = config.num_key_value_heads
|
| 56 |
+
self.num_key_value_groups = self.num_heads // self.num_key_value_heads
|
| 57 |
+
self.max_position_embeddings = config.max_position_embeddings
|
| 58 |
+
self.rope_theta = config.rope_theta
|
| 59 |
+
|
| 60 |
+
if (self.head_dim * self.num_heads) != self.hidden_size:
|
| 61 |
+
raise ValueError(
|
| 62 |
+
f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"
|
| 63 |
+
f" and `num_heads`: {self.num_heads})."
|
| 64 |
+
)
|
| 65 |
+
self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=config.attention_bias)
|
| 66 |
+
self.k_proj = MultiwayNetwork(module_provider=partial(
|
| 67 |
+
nn.Linear, in_features=self.hidden_size, out_features=self.num_key_value_heads * self.head_dim, bias=config.attention_bias)
|
| 68 |
+
)
|
| 69 |
+
self.v_proj = MultiwayNetwork(module_provider=partial(
|
| 70 |
+
nn.Linear, in_features=self.hidden_size, out_features=self.num_key_value_heads * self.head_dim, bias=config.attention_bias)
|
| 71 |
+
)
|
| 72 |
+
self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=config.attention_bias)
|
| 73 |
+
self._init_rope()
|
| 74 |
+
|
| 75 |
+
def _init_rope(self):
|
| 76 |
+
if self.config.rope_scaling is None:
|
| 77 |
+
self.rotary_emb = LlamaRotaryEmbedding(
|
| 78 |
+
self.head_dim,
|
| 79 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 80 |
+
base=self.rope_theta,
|
| 81 |
+
)
|
| 82 |
+
else:
|
| 83 |
+
scaling_type = self.config.rope_scaling["type"]
|
| 84 |
+
scaling_factor = self.config.rope_scaling["factor"]
|
| 85 |
+
if scaling_type == "linear":
|
| 86 |
+
self.rotary_emb = LlamaLinearScalingRotaryEmbedding(
|
| 87 |
+
self.head_dim,
|
| 88 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 89 |
+
scaling_factor=scaling_factor,
|
| 90 |
+
base=self.rope_theta,
|
| 91 |
+
)
|
| 92 |
+
elif scaling_type == "dynamic":
|
| 93 |
+
self.rotary_emb = LlamaDynamicNTKScalingRotaryEmbedding(
|
| 94 |
+
self.head_dim,
|
| 95 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 96 |
+
scaling_factor=scaling_factor,
|
| 97 |
+
base=self.rope_theta,
|
| 98 |
+
)
|
| 99 |
+
else:
|
| 100 |
+
raise ValueError(f"Unknown RoPE scaling type {scaling_type}")
|
| 101 |
+
|
| 102 |
+
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
|
| 103 |
+
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
|
| 104 |
+
|
| 105 |
+
def forward(
|
| 106 |
+
self,
|
| 107 |
+
hidden_states: torch.Tensor,
|
| 108 |
+
modality_indicators: torch.Tensor,
|
| 109 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 110 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 111 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 112 |
+
output_attentions: bool = False,
|
| 113 |
+
use_cache: bool = False,
|
| 114 |
+
padding_mask: Optional[torch.LongTensor] = None,
|
| 115 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 116 |
+
bsz, q_len, _ = hidden_states.size()
|
| 117 |
+
|
| 118 |
+
query_states = self.q_proj(hidden_states, )
|
| 119 |
+
key_states = self.k_proj(hidden_states, modality_indicators)
|
| 120 |
+
value_states = self.v_proj(hidden_states, modality_indicators)
|
| 121 |
+
|
| 122 |
+
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 123 |
+
key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
| 124 |
+
value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
| 125 |
+
|
| 126 |
+
kv_seq_len = key_states.shape[-2]
|
| 127 |
+
if past_key_value is not None:
|
| 128 |
+
kv_seq_len += past_key_value[0].shape[-2]
|
| 129 |
+
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
| 130 |
+
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
|
| 131 |
+
|
| 132 |
+
if past_key_value is not None:
|
| 133 |
+
# reuse k, v, self_attention
|
| 134 |
+
key_states = torch.cat([past_key_value[0], key_states], dim=2)
|
| 135 |
+
value_states = torch.cat([past_key_value[1], value_states], dim=2)
|
| 136 |
+
|
| 137 |
+
past_key_value = (key_states, value_states) if use_cache else None
|
| 138 |
+
|
| 139 |
+
key_states = repeat_kv(key_states, self.num_key_value_groups)
|
| 140 |
+
value_states = repeat_kv(value_states, self.num_key_value_groups)
|
| 141 |
+
|
| 142 |
+
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
|
| 143 |
+
|
| 144 |
+
if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
|
| 145 |
+
raise ValueError(
|
| 146 |
+
f"Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is"
|
| 147 |
+
f" {attn_weights.size()}"
|
| 148 |
+
)
|
| 149 |
+
|
| 150 |
+
if attention_mask is not None:
|
| 151 |
+
if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
|
| 152 |
+
raise ValueError(
|
| 153 |
+
f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}"
|
| 154 |
+
)
|
| 155 |
+
attn_weights = attn_weights + attention_mask
|
| 156 |
+
|
| 157 |
+
# upcast attention to fp32
|
| 158 |
+
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
|
| 159 |
+
attn_output = torch.matmul(attn_weights, value_states)
|
| 160 |
+
|
| 161 |
+
if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
|
| 162 |
+
raise ValueError(
|
| 163 |
+
f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"
|
| 164 |
+
f" {attn_output.size()}"
|
| 165 |
+
)
|
| 166 |
+
|
| 167 |
+
attn_output = attn_output.transpose(1, 2).contiguous()
|
| 168 |
+
|
| 169 |
+
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
|
| 170 |
+
|
| 171 |
+
attn_output = self.o_proj(attn_output)
|
| 172 |
+
|
| 173 |
+
if not output_attentions:
|
| 174 |
+
attn_weights = None
|
| 175 |
+
|
| 176 |
+
return attn_output, attn_weights, past_key_value
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
class LlamaDecoderLayer(nn.Module):
|
| 181 |
+
def __init__(self, config: LlamaConfig):
|
| 182 |
+
super().__init__()
|
| 183 |
+
self.hidden_size = config.hidden_size
|
| 184 |
+
self.self_attn = LlamaAttention(config=config)
|
| 185 |
+
self.mlp = LlamaMLP(config)
|
| 186 |
+
self.input_layernorm = MultiwayNetwork(module_provider=partial(
|
| 187 |
+
LlamaRMSNorm, hidden_size=config.hidden_size, eps=config.rms_norm_eps
|
| 188 |
+
))
|
| 189 |
+
self.post_attention_layernorm = MultiwayNetwork(module_provider=partial(
|
| 190 |
+
LlamaRMSNorm, hidden_size=config.hidden_size, eps=config.rms_norm_eps
|
| 191 |
+
))
|
| 192 |
+
|
| 193 |
+
def forward(
|
| 194 |
+
self,
|
| 195 |
+
hidden_states: torch.Tensor,
|
| 196 |
+
modality_indicators: torch.Tensor = None,
|
| 197 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 198 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 199 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 200 |
+
output_attentions: Optional[bool] = False,
|
| 201 |
+
use_cache: Optional[bool] = False,
|
| 202 |
+
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
|
| 203 |
+
"""
|
| 204 |
+
Args:
|
| 205 |
+
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
|
| 206 |
+
attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
|
| 207 |
+
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
|
| 208 |
+
output_attentions (`bool`, *optional*):
|
| 209 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
| 210 |
+
returned tensors for more detail.
|
| 211 |
+
use_cache (`bool`, *optional*):
|
| 212 |
+
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
|
| 213 |
+
(see `past_key_values`).
|
| 214 |
+
past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
|
| 215 |
+
"""
|
| 216 |
+
|
| 217 |
+
residual = hidden_states
|
| 218 |
+
|
| 219 |
+
hidden_states = self.input_layernorm(hidden_states, modality_indicators)
|
| 220 |
+
|
| 221 |
+
# Self Attention
|
| 222 |
+
hidden_states, self_attn_weights, present_key_value = self.self_attn(
|
| 223 |
+
hidden_states=hidden_states,
|
| 224 |
+
modality_indicators=modality_indicators,
|
| 225 |
+
attention_mask=attention_mask,
|
| 226 |
+
position_ids=position_ids,
|
| 227 |
+
past_key_value=past_key_value,
|
| 228 |
+
output_attentions=output_attentions,
|
| 229 |
+
use_cache=use_cache,
|
| 230 |
+
)
|
| 231 |
+
hidden_states = residual + hidden_states
|
| 232 |
+
|
| 233 |
+
# Fully Connected
|
| 234 |
+
residual = hidden_states
|
| 235 |
+
hidden_states = self.post_attention_layernorm(hidden_states, modality_indicators)
|
| 236 |
+
hidden_states = self.mlp(hidden_states)
|
| 237 |
+
hidden_states = residual + hidden_states
|
| 238 |
+
|
| 239 |
+
outputs = (hidden_states,)
|
| 240 |
+
|
| 241 |
+
if output_attentions:
|
| 242 |
+
outputs += (self_attn_weights,)
|
| 243 |
+
|
| 244 |
+
if use_cache:
|
| 245 |
+
outputs += (present_key_value,)
|
| 246 |
+
|
| 247 |
+
return outputs
|
| 248 |
+
|
| 249 |
+
|
| 250 |
+
def model_forward(
|
| 251 |
+
self,
|
| 252 |
+
input_ids: torch.LongTensor = None,
|
| 253 |
+
modality_indicators: torch.Tensor = None,
|
| 254 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 255 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 256 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 257 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 258 |
+
use_cache: Optional[bool] = None,
|
| 259 |
+
output_attentions: Optional[bool] = None,
|
| 260 |
+
output_hidden_states: Optional[bool] = None,
|
| 261 |
+
return_dict: Optional[bool] = None,
|
| 262 |
+
) -> Union[Tuple, BaseModelOutputWithPast]:
|
| 263 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 264 |
+
output_hidden_states = (
|
| 265 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 266 |
+
)
|
| 267 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 268 |
+
|
| 269 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 270 |
+
|
| 271 |
+
# retrieve input_ids and inputs_embeds
|
| 272 |
+
if input_ids is not None and inputs_embeds is not None:
|
| 273 |
+
raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
|
| 274 |
+
elif input_ids is not None:
|
| 275 |
+
batch_size, seq_length = input_ids.shape
|
| 276 |
+
elif inputs_embeds is not None:
|
| 277 |
+
batch_size, seq_length, _ = inputs_embeds.shape
|
| 278 |
+
else:
|
| 279 |
+
raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
|
| 280 |
+
|
| 281 |
+
seq_length_with_past = seq_length
|
| 282 |
+
past_key_values_length = 0
|
| 283 |
+
|
| 284 |
+
if past_key_values is not None:
|
| 285 |
+
past_key_values_length = past_key_values[0][0].shape[2]
|
| 286 |
+
seq_length_with_past = seq_length_with_past + past_key_values_length
|
| 287 |
+
|
| 288 |
+
if position_ids is None:
|
| 289 |
+
device = input_ids.device if input_ids is not None else inputs_embeds.device
|
| 290 |
+
position_ids = torch.arange(
|
| 291 |
+
past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
|
| 292 |
+
)
|
| 293 |
+
position_ids = position_ids.unsqueeze(0).view(-1, seq_length)
|
| 294 |
+
else:
|
| 295 |
+
position_ids = position_ids.view(-1, seq_length).long()
|
| 296 |
+
|
| 297 |
+
if inputs_embeds is None:
|
| 298 |
+
inputs_embeds = self.embed_tokens(input_ids)
|
| 299 |
+
# embed positions
|
| 300 |
+
if attention_mask is None:
|
| 301 |
+
attention_mask = torch.ones(
|
| 302 |
+
(batch_size, seq_length_with_past), dtype=torch.bool, device=inputs_embeds.device
|
| 303 |
+
)
|
| 304 |
+
attention_mask = self._prepare_decoder_attention_mask(
|
| 305 |
+
attention_mask, (batch_size, seq_length), inputs_embeds, past_key_values_length
|
| 306 |
+
)
|
| 307 |
+
|
| 308 |
+
hidden_states = inputs_embeds
|
| 309 |
+
|
| 310 |
+
if self.gradient_checkpointing and self.training:
|
| 311 |
+
if use_cache:
|
| 312 |
+
logger.warning_once(
|
| 313 |
+
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
| 314 |
+
)
|
| 315 |
+
use_cache = False
|
| 316 |
+
|
| 317 |
+
# decoder layers
|
| 318 |
+
all_hidden_states = () if output_hidden_states else None
|
| 319 |
+
all_self_attns = () if output_attentions else None
|
| 320 |
+
next_decoder_cache = () if use_cache else None
|
| 321 |
+
|
| 322 |
+
for idx, decoder_layer in enumerate(self.layers):
|
| 323 |
+
if output_hidden_states:
|
| 324 |
+
all_hidden_states += (hidden_states,)
|
| 325 |
+
|
| 326 |
+
past_key_value = past_key_values[idx] if past_key_values is not None else None
|
| 327 |
+
|
| 328 |
+
if self.gradient_checkpointing and self.training:
|
| 329 |
+
|
| 330 |
+
def create_custom_forward(module):
|
| 331 |
+
def custom_forward(*inputs):
|
| 332 |
+
# None for past_key_value
|
| 333 |
+
return module(*inputs, past_key_value, output_attentions)
|
| 334 |
+
|
| 335 |
+
return custom_forward
|
| 336 |
+
|
| 337 |
+
layer_outputs = torch.utils.checkpoint.checkpoint(
|
| 338 |
+
create_custom_forward(decoder_layer),
|
| 339 |
+
hidden_states,
|
| 340 |
+
modality_indicators,
|
| 341 |
+
attention_mask,
|
| 342 |
+
position_ids,
|
| 343 |
+
)
|
| 344 |
+
else:
|
| 345 |
+
layer_outputs = decoder_layer(
|
| 346 |
+
hidden_states,
|
| 347 |
+
modality_indicators=modality_indicators,
|
| 348 |
+
attention_mask=attention_mask,
|
| 349 |
+
position_ids=position_ids,
|
| 350 |
+
past_key_value=past_key_value,
|
| 351 |
+
output_attentions=output_attentions,
|
| 352 |
+
use_cache=use_cache,
|
| 353 |
+
)
|
| 354 |
+
|
| 355 |
+
hidden_states = layer_outputs[0]
|
| 356 |
+
|
| 357 |
+
if use_cache:
|
| 358 |
+
next_decoder_cache += (layer_outputs[2 if output_attentions else 1],)
|
| 359 |
+
|
| 360 |
+
if output_attentions:
|
| 361 |
+
all_self_attns += (layer_outputs[1],)
|
| 362 |
+
|
| 363 |
+
hidden_states = self.norm(hidden_states)
|
| 364 |
+
|
| 365 |
+
# add hidden states from the last decoder layer
|
| 366 |
+
if output_hidden_states:
|
| 367 |
+
all_hidden_states += (hidden_states,)
|
| 368 |
+
|
| 369 |
+
next_cache = next_decoder_cache if use_cache else None
|
| 370 |
+
if not return_dict:
|
| 371 |
+
return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
|
| 372 |
+
return BaseModelOutputWithPast(
|
| 373 |
+
last_hidden_state=hidden_states,
|
| 374 |
+
past_key_values=next_cache,
|
| 375 |
+
hidden_states=all_hidden_states,
|
| 376 |
+
attentions=all_self_attns,
|
| 377 |
+
)
|
| 378 |
+
|
| 379 |
+
|
| 380 |
+
def causal_model_forward(
|
| 381 |
+
self,
|
| 382 |
+
input_ids: torch.LongTensor = None,
|
| 383 |
+
modality_indicators: torch.Tensor = None,
|
| 384 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 385 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 386 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 387 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 388 |
+
labels: Optional[torch.LongTensor] = None,
|
| 389 |
+
use_cache: Optional[bool] = None,
|
| 390 |
+
output_attentions: Optional[bool] = None,
|
| 391 |
+
output_hidden_states: Optional[bool] = None,
|
| 392 |
+
return_dict: Optional[bool] = None,
|
| 393 |
+
) -> Union[Tuple, CausalLMOutputWithPast]:
|
| 394 |
+
r"""
|
| 395 |
+
Args:
|
| 396 |
+
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 397 |
+
Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
|
| 398 |
+
config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
|
| 399 |
+
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
|
| 400 |
+
|
| 401 |
+
Returns:
|
| 402 |
+
|
| 403 |
+
Example:
|
| 404 |
+
|
| 405 |
+
```python
|
| 406 |
+
>>> from transformers import AutoTokenizer, LlamaForCausalLM
|
| 407 |
+
|
| 408 |
+
>>> model = LlamaForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
|
| 409 |
+
>>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
|
| 410 |
+
|
| 411 |
+
>>> prompt = "Hey, are you conscious? Can you talk to me?"
|
| 412 |
+
>>> inputs = tokenizer(prompt, return_tensors="pt")
|
| 413 |
+
|
| 414 |
+
>>> # Generate
|
| 415 |
+
>>> generate_ids = model.generate(inputs.input_ids, max_length=30)
|
| 416 |
+
>>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
|
| 417 |
+
"Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."
|
| 418 |
+
```"""
|
| 419 |
+
|
| 420 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 421 |
+
output_hidden_states = (
|
| 422 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 423 |
+
)
|
| 424 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 425 |
+
|
| 426 |
+
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
|
| 427 |
+
outputs = self.model(
|
| 428 |
+
input_ids=input_ids,
|
| 429 |
+
modality_indicators=modality_indicators,
|
| 430 |
+
attention_mask=attention_mask,
|
| 431 |
+
position_ids=position_ids,
|
| 432 |
+
past_key_values=past_key_values,
|
| 433 |
+
inputs_embeds=inputs_embeds,
|
| 434 |
+
use_cache=use_cache,
|
| 435 |
+
output_attentions=output_attentions,
|
| 436 |
+
output_hidden_states=output_hidden_states,
|
| 437 |
+
return_dict=return_dict,
|
| 438 |
+
)
|
| 439 |
+
|
| 440 |
+
hidden_states = outputs[0]
|
| 441 |
+
if self.config.pretraining_tp > 1:
|
| 442 |
+
lm_head_slices = self.lm_head.weight.split(self.vocab_size // self.config.pretraining_tp, dim=0)
|
| 443 |
+
logits = [F.linear(hidden_states, lm_head_slices[i]) for i in range(self.config.pretraining_tp)]
|
| 444 |
+
logits = torch.cat(logits, dim=-1)
|
| 445 |
+
else:
|
| 446 |
+
logits = self.lm_head(hidden_states)
|
| 447 |
+
logits = logits.float()
|
| 448 |
+
|
| 449 |
+
loss = None
|
| 450 |
+
if labels is not None:
|
| 451 |
+
# Shift so that tokens < n predict n
|
| 452 |
+
shift_logits = logits[..., :-1, :].contiguous()
|
| 453 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 454 |
+
# Flatten the tokens
|
| 455 |
+
loss_fct = CrossEntropyLoss()
|
| 456 |
+
shift_logits = shift_logits.view(-1, self.config.vocab_size)
|
| 457 |
+
shift_labels = shift_labels.view(-1)
|
| 458 |
+
# Enable model parallelism
|
| 459 |
+
shift_labels = shift_labels.to(shift_logits.device)
|
| 460 |
+
loss = loss_fct(shift_logits, shift_labels)
|
| 461 |
+
|
| 462 |
+
if not return_dict:
|
| 463 |
+
output = (logits,) + outputs[1:]
|
| 464 |
+
return (loss,) + output if loss is not None else output
|
| 465 |
+
|
| 466 |
+
return CausalLMOutputWithPast(
|
| 467 |
+
loss=loss,
|
| 468 |
+
logits=logits,
|
| 469 |
+
past_key_values=outputs.past_key_values,
|
| 470 |
+
hidden_states=outputs.hidden_states,
|
| 471 |
+
attentions=outputs.attentions,
|
| 472 |
+
)
|
| 473 |
+
|
| 474 |
+
def replace_llama_modality_adaptive():
|
| 475 |
+
transformers.models.llama.configuration_llama.LlamaConfig = LlamaConfig
|
| 476 |
+
transformers.models.llama.modeling_llama.LlamaAttention = LlamaAttention
|
| 477 |
+
transformers.models.llama.modeling_llama.LlamaDecoderLayer = LlamaDecoderLayer
|
| 478 |
+
transformers.models.llama.modeling_llama.LlamaModel.forward = model_forward
|
| 479 |
+
transformers.models.llama.modeling_llama.LlamaForCausalLM.forward = causal_model_forward
|
| 480 |
+
|
| 481 |
+
|
| 482 |
+
if __name__ == "__main__":
|
| 483 |
+
replace_llama_modality_adaptive()
|
| 484 |
+
config = transformers.LlamaConfig.from_pretrained('/cpfs01/shared/public/test/vicuna-7b-v1.5/')
|
| 485 |
+
model = transformers.LlamaForCausalLM(config)
|
| 486 |
+
print(model)
|
mplug_owl2/model/modeling_mplug_owl2.py
ADDED
|
@@ -0,0 +1,329 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 Haotian Liu & Qinghao Ye (Modified from LLaVA)
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
from abc import ABC, abstractmethod
|
| 16 |
+
from typing import List, Optional, Tuple, Union
|
| 17 |
+
|
| 18 |
+
import torch
|
| 19 |
+
import torch.nn as nn
|
| 20 |
+
from torch.nn import CrossEntropyLoss
|
| 21 |
+
|
| 22 |
+
from transformers import AutoConfig, AutoModelForCausalLM, LlamaConfig, LlamaModel, LlamaForCausalLM
|
| 23 |
+
from transformers.modeling_outputs import CausalLMOutputWithPast
|
| 24 |
+
|
| 25 |
+
from .configuration_mplug_owl2 import MPLUGOwl2Config, MplugOwlVisionConfig, MplugOwlVisualAbstractorConfig
|
| 26 |
+
from .visual_encoder import MplugOwlVisionModel, MplugOwlVisualAbstractorModel
|
| 27 |
+
from .modeling_llama2 import replace_llama_modality_adaptive
|
| 28 |
+
from mplug_owl2.constants import IMAGE_TOKEN_INDEX, IGNORE_INDEX
|
| 29 |
+
from icecream import ic
|
| 30 |
+
|
| 31 |
+
class MPLUGOwl2MetaModel:
|
| 32 |
+
def __init__(self, config):
|
| 33 |
+
super(MPLUGOwl2MetaModel, self).__init__(config)
|
| 34 |
+
self.vision_model = MplugOwlVisionModel(
|
| 35 |
+
MplugOwlVisionConfig(**config.visual_config["visual_model"])
|
| 36 |
+
)
|
| 37 |
+
self.visual_abstractor = MplugOwlVisualAbstractorModel(
|
| 38 |
+
MplugOwlVisualAbstractorConfig(**config.visual_config["visual_abstractor"]), config.hidden_size
|
| 39 |
+
)
|
| 40 |
+
|
| 41 |
+
def get_vision_tower(self):
|
| 42 |
+
vision_model = getattr(self, 'vision_model', None)
|
| 43 |
+
if type(vision_model) is list:
|
| 44 |
+
vision_model = vision_model[0]
|
| 45 |
+
return vision_model
|
| 46 |
+
|
| 47 |
+
def get_visual_abstractor(self):
|
| 48 |
+
visual_abstractor = getattr(self, 'visual_abstractor', None)
|
| 49 |
+
if type(visual_abstractor) is list:
|
| 50 |
+
visual_abstractor = visual_abstractor[0]
|
| 51 |
+
return visual_abstractor
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
class MPLUGOwl2MetaForCausalLM(ABC):
|
| 55 |
+
@abstractmethod
|
| 56 |
+
def get_model(self):
|
| 57 |
+
pass
|
| 58 |
+
|
| 59 |
+
def encode_images(self, images):
|
| 60 |
+
image_features = self.get_model().vision_model(images).last_hidden_state
|
| 61 |
+
image_features = self.get_model().visual_abstractor(encoder_hidden_states=image_features).last_hidden_state
|
| 62 |
+
return image_features
|
| 63 |
+
|
| 64 |
+
def prepare_inputs_labels_for_multimodal(
|
| 65 |
+
self, input_ids, attention_mask, past_key_values, labels, images
|
| 66 |
+
):
|
| 67 |
+
if images is None or input_ids.shape[1] == 1:
|
| 68 |
+
if past_key_values is not None and images is not None and input_ids.shape[1] == 1:
|
| 69 |
+
attention_mask = torch.ones((attention_mask.shape[0], past_key_values[-1][-1].shape[-2] + 1), dtype=attention_mask.dtype, device=attention_mask.device)
|
| 70 |
+
multiway_indices = torch.zeros_like(input_ids).long().to(self.device)
|
| 71 |
+
return input_ids, multiway_indices, attention_mask, past_key_values, None, labels
|
| 72 |
+
|
| 73 |
+
if type(images) is list or images.ndim == 5:
|
| 74 |
+
concat_images = torch.cat([image for image in images], dim=0)
|
| 75 |
+
image_features = self.encode_images(concat_images)
|
| 76 |
+
split_sizes = [image.shape[0] for image in images]
|
| 77 |
+
image_features = torch.split(image_features, split_sizes, dim=0)
|
| 78 |
+
image_features = [x.flatten(0, 1) for x in image_features]
|
| 79 |
+
else:
|
| 80 |
+
image_features = self.encode_images(images)
|
| 81 |
+
|
| 82 |
+
new_input_embeds = []
|
| 83 |
+
new_modality_indicators = []
|
| 84 |
+
new_labels = [] if labels is not None else None
|
| 85 |
+
cur_image_idx = 0
|
| 86 |
+
for batch_idx, cur_input_ids in enumerate(input_ids):
|
| 87 |
+
if (cur_input_ids == IMAGE_TOKEN_INDEX).sum() == 0:
|
| 88 |
+
# multimodal LLM, but the current sample is not multimodal
|
| 89 |
+
# FIXME: this is a hacky fix, for deepspeed zero3 to work
|
| 90 |
+
half_len = cur_input_ids.shape[0] // 2
|
| 91 |
+
cur_image_features = image_features[cur_image_idx]
|
| 92 |
+
cur_input_embeds_1 = self.get_model().embed_tokens(cur_input_ids[:half_len])
|
| 93 |
+
cur_input_embeds_2 = self.get_model().embed_tokens(cur_input_ids[half_len:])
|
| 94 |
+
cur_input_embeds = torch.cat([cur_input_embeds_1, cur_image_features[0:0], cur_input_embeds_2], dim=0)
|
| 95 |
+
new_input_embeds.append(cur_input_embeds)
|
| 96 |
+
|
| 97 |
+
cur_modality_indicators = torch.zeros(len(cur_input_embeds)).long().to(self.device)
|
| 98 |
+
new_modality_indicators.append(cur_modality_indicators)
|
| 99 |
+
if labels is not None:
|
| 100 |
+
new_labels.append(labels[batch_idx])
|
| 101 |
+
cur_image_idx += 1
|
| 102 |
+
continue
|
| 103 |
+
image_token_indices = torch.where(cur_input_ids == IMAGE_TOKEN_INDEX)[0]
|
| 104 |
+
cur_new_input_embeds = []
|
| 105 |
+
cur_modality_indicators = []
|
| 106 |
+
if labels is not None:
|
| 107 |
+
cur_labels = labels[batch_idx]
|
| 108 |
+
cur_new_labels = []
|
| 109 |
+
assert cur_labels.shape == cur_input_ids.shape
|
| 110 |
+
while image_token_indices.numel() > 0:
|
| 111 |
+
cur_image_features = image_features[cur_image_idx]
|
| 112 |
+
image_token_start = image_token_indices[0]
|
| 113 |
+
cur_new_input_embeds.append(self.get_model().embed_tokens(cur_input_ids[:image_token_start]))
|
| 114 |
+
cur_new_input_embeds.append(cur_image_features)
|
| 115 |
+
|
| 116 |
+
# Add modality indicator
|
| 117 |
+
assert image_token_start == len(cur_input_ids[:image_token_start])
|
| 118 |
+
cur_modality_indicators.append(torch.zeros(len(cur_input_ids[:image_token_start])).long())
|
| 119 |
+
cur_modality_indicators.append(torch.ones(len(cur_image_features)).long())
|
| 120 |
+
|
| 121 |
+
if labels is not None:
|
| 122 |
+
cur_new_labels.append(cur_labels[:image_token_start])
|
| 123 |
+
cur_new_labels.append(torch.full((cur_image_features.shape[0],), IGNORE_INDEX, device=labels.device, dtype=labels.dtype))
|
| 124 |
+
cur_labels = cur_labels[image_token_start+1:]
|
| 125 |
+
cur_image_idx += 1
|
| 126 |
+
cur_input_ids = cur_input_ids[image_token_start+1:]
|
| 127 |
+
image_token_indices = torch.where(cur_input_ids == IMAGE_TOKEN_INDEX)[0]
|
| 128 |
+
if cur_input_ids.numel() > 0:
|
| 129 |
+
cur_new_input_embeds.append(self.get_model().embed_tokens(cur_input_ids))
|
| 130 |
+
cur_modality_indicators.append(torch.zeros(len(cur_input_ids)).long())
|
| 131 |
+
if labels is not None:
|
| 132 |
+
cur_new_labels.append(cur_labels)
|
| 133 |
+
cur_new_input_embeds = [x.to(device=self.device) for x in cur_new_input_embeds]
|
| 134 |
+
cur_new_input_embeds = torch.cat(cur_new_input_embeds, dim=0)
|
| 135 |
+
new_input_embeds.append(cur_new_input_embeds)
|
| 136 |
+
|
| 137 |
+
# Modality
|
| 138 |
+
cur_modality_indicators = [x.to(device=self.device) for x in cur_modality_indicators]
|
| 139 |
+
cur_modality_indicators = torch.cat(cur_modality_indicators, dim=0)
|
| 140 |
+
new_modality_indicators.append(cur_modality_indicators)
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
if labels is not None:
|
| 144 |
+
cur_new_labels = torch.cat(cur_new_labels, dim=0)
|
| 145 |
+
new_labels.append(cur_new_labels)
|
| 146 |
+
|
| 147 |
+
if any(x.shape != new_input_embeds[0].shape for x in new_input_embeds):
|
| 148 |
+
max_len = max(x.shape[0] for x in new_input_embeds)
|
| 149 |
+
|
| 150 |
+
# Embedding
|
| 151 |
+
new_input_embeds_align = []
|
| 152 |
+
for cur_new_embed in new_input_embeds:
|
| 153 |
+
cur_new_embed = torch.cat((cur_new_embed, torch.zeros((max_len - cur_new_embed.shape[0], cur_new_embed.shape[1]), dtype=cur_new_embed.dtype, device=cur_new_embed.device)), dim=0)
|
| 154 |
+
new_input_embeds_align.append(cur_new_embed)
|
| 155 |
+
new_input_embeds = torch.stack(new_input_embeds_align, dim=0)
|
| 156 |
+
|
| 157 |
+
# Modality
|
| 158 |
+
new_modality_indicators_align = []
|
| 159 |
+
for cur_modality_indicator in new_modality_indicators:
|
| 160 |
+
cur_new_embed = torch.cat((cur_modality_indicator, torch.zeros(max_len - cur_modality_indicator.shape[0], dtype=cur_modality_indicator.dtype, device=cur_modality_indicator.device)), dim=0)
|
| 161 |
+
new_modality_indicators_align.append(cur_new_embed)
|
| 162 |
+
new_modality_indicators = torch.stack(new_modality_indicators_align, dim=0)
|
| 163 |
+
|
| 164 |
+
# Label
|
| 165 |
+
if labels is not None:
|
| 166 |
+
new_labels_align = []
|
| 167 |
+
_new_labels = new_labels
|
| 168 |
+
for cur_new_label in new_labels:
|
| 169 |
+
cur_new_label = torch.cat((cur_new_label, torch.full((max_len - cur_new_label.shape[0],), IGNORE_INDEX, dtype=cur_new_label.dtype, device=cur_new_label.device)), dim=0)
|
| 170 |
+
new_labels_align.append(cur_new_label)
|
| 171 |
+
new_labels = torch.stack(new_labels_align, dim=0)
|
| 172 |
+
|
| 173 |
+
# Attention Mask
|
| 174 |
+
if attention_mask is not None:
|
| 175 |
+
new_attention_mask = []
|
| 176 |
+
for cur_attention_mask, cur_new_labels, cur_new_labels_align in zip(attention_mask, _new_labels, new_labels):
|
| 177 |
+
new_attn_mask_pad_left = torch.full((cur_new_labels.shape[0] - labels.shape[1],), True, dtype=attention_mask.dtype, device=attention_mask.device)
|
| 178 |
+
new_attn_mask_pad_right = torch.full((cur_new_labels_align.shape[0] - cur_new_labels.shape[0],), False, dtype=attention_mask.dtype, device=attention_mask.device)
|
| 179 |
+
cur_new_attention_mask = torch.cat((new_attn_mask_pad_left, cur_attention_mask, new_attn_mask_pad_right), dim=0)
|
| 180 |
+
new_attention_mask.append(cur_new_attention_mask)
|
| 181 |
+
attention_mask = torch.stack(new_attention_mask, dim=0)
|
| 182 |
+
assert attention_mask.shape == new_labels.shape
|
| 183 |
+
else:
|
| 184 |
+
new_input_embeds = torch.stack(new_input_embeds, dim=0)
|
| 185 |
+
new_modality_indicators = torch.stack(new_modality_indicators, dim=0)
|
| 186 |
+
if labels is not None:
|
| 187 |
+
new_labels = torch.stack(new_labels, dim=0)
|
| 188 |
+
|
| 189 |
+
if attention_mask is not None:
|
| 190 |
+
new_attn_mask_pad_left = torch.full((attention_mask.shape[0], new_input_embeds.shape[1] - input_ids.shape[1]), True, dtype=attention_mask.dtype, device=attention_mask.device)
|
| 191 |
+
attention_mask = torch.cat((new_attn_mask_pad_left, attention_mask), dim=1)
|
| 192 |
+
assert attention_mask.shape == new_input_embeds.shape[:2]
|
| 193 |
+
return None, new_modality_indicators, attention_mask, past_key_values, new_input_embeds, new_labels
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
class MPLUGOwl2LlamaModel(MPLUGOwl2MetaModel, LlamaModel):
|
| 198 |
+
config_class = MPLUGOwl2Config
|
| 199 |
+
|
| 200 |
+
def __init__(self, config: MPLUGOwl2Config):
|
| 201 |
+
super(MPLUGOwl2LlamaModel, self).__init__(config)
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
class MPLUGOwl2LlamaForCausalLM(LlamaForCausalLM, MPLUGOwl2MetaForCausalLM):
|
| 205 |
+
config_class = MPLUGOwl2Config
|
| 206 |
+
|
| 207 |
+
def __init__(self, config):
|
| 208 |
+
super(LlamaForCausalLM, self).__init__(config)
|
| 209 |
+
self.model = MPLUGOwl2LlamaModel(config)
|
| 210 |
+
|
| 211 |
+
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
| 212 |
+
|
| 213 |
+
# Initialize weights and apply final processing
|
| 214 |
+
self.post_init()
|
| 215 |
+
|
| 216 |
+
def get_model(self):
|
| 217 |
+
return self.model
|
| 218 |
+
|
| 219 |
+
def forward(
|
| 220 |
+
self,
|
| 221 |
+
input_ids: torch.LongTensor = None,
|
| 222 |
+
# modality_indicators: torch.LongTensor = None,
|
| 223 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 224 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 225 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 226 |
+
labels: Optional[torch.LongTensor] = None,
|
| 227 |
+
use_cache: Optional[bool] = None,
|
| 228 |
+
output_attentions: Optional[bool] = None,
|
| 229 |
+
output_hidden_states: Optional[bool] = None,
|
| 230 |
+
images: Optional[torch.FloatTensor] = None,
|
| 231 |
+
return_dict: Optional[bool] = None,
|
| 232 |
+
) -> Union[Tuple, CausalLMOutputWithPast]:
|
| 233 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 234 |
+
output_hidden_states = (
|
| 235 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 236 |
+
)
|
| 237 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 238 |
+
input_ids, modality_indicators, attention_mask, past_key_values, inputs_embeds, labels = \
|
| 239 |
+
self.prepare_inputs_labels_for_multimodal(input_ids, attention_mask, past_key_values, labels, images)
|
| 240 |
+
|
| 241 |
+
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
|
| 242 |
+
outputs = self.model(
|
| 243 |
+
input_ids=input_ids,
|
| 244 |
+
modality_indicators=modality_indicators,
|
| 245 |
+
attention_mask=attention_mask,
|
| 246 |
+
past_key_values=past_key_values,
|
| 247 |
+
inputs_embeds=inputs_embeds,
|
| 248 |
+
use_cache=use_cache,
|
| 249 |
+
output_attentions=output_attentions,
|
| 250 |
+
output_hidden_states=output_hidden_states,
|
| 251 |
+
return_dict=return_dict
|
| 252 |
+
)
|
| 253 |
+
|
| 254 |
+
hidden_states = outputs[0]
|
| 255 |
+
logits = self.lm_head(hidden_states)
|
| 256 |
+
|
| 257 |
+
loss = None
|
| 258 |
+
if labels is not None:
|
| 259 |
+
# Shift so that tokens < n predict n
|
| 260 |
+
shift_logits = logits[..., :-1, :].contiguous()
|
| 261 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 262 |
+
# Flatten the tokens
|
| 263 |
+
loss_fct = CrossEntropyLoss()
|
| 264 |
+
shift_logits = shift_logits.view(-1, self.config.vocab_size)
|
| 265 |
+
shift_labels = shift_labels.view(-1)
|
| 266 |
+
# Enable model/pipeline parallelism
|
| 267 |
+
shift_labels = shift_labels.to(shift_logits.device)
|
| 268 |
+
loss = loss_fct(shift_logits, shift_labels)
|
| 269 |
+
|
| 270 |
+
if not return_dict:
|
| 271 |
+
output = (logits,) + outputs[1:]
|
| 272 |
+
return (loss,) + output if loss is not None else output
|
| 273 |
+
|
| 274 |
+
return CausalLMOutputWithPast(
|
| 275 |
+
loss=loss,
|
| 276 |
+
logits=logits,
|
| 277 |
+
past_key_values=outputs.past_key_values,
|
| 278 |
+
hidden_states=outputs.hidden_states,
|
| 279 |
+
attentions=outputs.attentions,
|
| 280 |
+
)
|
| 281 |
+
|
| 282 |
+
def prepare_inputs_for_generation(
|
| 283 |
+
self, input_ids, past_key_values=None, attention_mask=None, inputs_embeds=None, **kwargs
|
| 284 |
+
):
|
| 285 |
+
if past_key_values:
|
| 286 |
+
input_ids = input_ids[:, -1:]
|
| 287 |
+
|
| 288 |
+
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
|
| 289 |
+
if inputs_embeds is not None and past_key_values is None:
|
| 290 |
+
model_inputs = {"inputs_embeds": inputs_embeds}
|
| 291 |
+
else:
|
| 292 |
+
model_inputs = {"input_ids": input_ids}
|
| 293 |
+
|
| 294 |
+
model_inputs.update(
|
| 295 |
+
{
|
| 296 |
+
"past_key_values": past_key_values,
|
| 297 |
+
"use_cache": kwargs.get("use_cache"),
|
| 298 |
+
"attention_mask": attention_mask,
|
| 299 |
+
"images": kwargs.get("images", None),
|
| 300 |
+
}
|
| 301 |
+
)
|
| 302 |
+
return model_inputs
|
| 303 |
+
|
| 304 |
+
AutoConfig.register("mplug_owl2", MPLUGOwl2Config)
|
| 305 |
+
AutoModelForCausalLM.register(MPLUGOwl2Config, MPLUGOwl2LlamaForCausalLM)
|
| 306 |
+
|
| 307 |
+
replace_llama_modality_adaptive()
|
| 308 |
+
|
| 309 |
+
if __name__ == "__main__":
|
| 310 |
+
config = MPLUGOwl2Config.from_pretrained('/cpfs01/shared/public/test/vicuna-7b-v1.5/')
|
| 311 |
+
from icecream import ic
|
| 312 |
+
# config = MPLUGOwl2Config()
|
| 313 |
+
model = MPLUGOwl2LlamaForCausalLM(config)
|
| 314 |
+
|
| 315 |
+
images = torch.randn(2, 3, 448, 448)
|
| 316 |
+
input_ids = torch.cat([
|
| 317 |
+
torch.ones(8).long(), torch.tensor([-1]*1).long(), torch.ones(8).long(), torch.tensor([-1]*1).long(), torch.ones(8).long()
|
| 318 |
+
], dim=0).unsqueeze(0)
|
| 319 |
+
labels = input_ids.clone()
|
| 320 |
+
labels[labels < 0] = -100
|
| 321 |
+
|
| 322 |
+
# image_feature = model.encode_images(images)
|
| 323 |
+
# ic(image_feature.shape)
|
| 324 |
+
|
| 325 |
+
output = model(images=images, input_ids=input_ids, labels=labels)
|
| 326 |
+
ic(output.loss)
|
| 327 |
+
ic(output.logits.shape)
|
| 328 |
+
|
| 329 |
+
model.save_pretrained('/cpfs01/shared/public/test/tmp_owl')
|
mplug_owl2/model/utils.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import AutoConfig
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def auto_upgrade(config):
|
| 5 |
+
cfg = AutoConfig.from_pretrained(config)
|
| 6 |
+
if 'mplug_owl2' in config and 'mplug_owl2' not in cfg.model_type:
|
| 7 |
+
assert cfg.model_type == 'mplug_owl2'
|
| 8 |
+
print("You are using newer LLaVA code base, while the checkpoint of v0 is from older code base.")
|
| 9 |
+
print("You must upgrade the checkpoint to the new code base (this can be done automatically).")
|
| 10 |
+
confirm = input("Please confirm that you want to upgrade the checkpoint. [Y/N]")
|
| 11 |
+
if confirm.lower() in ["y", "yes"]:
|
| 12 |
+
print("Upgrading checkpoint...")
|
| 13 |
+
assert len(cfg.architectures) == 1
|
| 14 |
+
setattr(cfg.__class__, "model_type", "mplug_owl2")
|
| 15 |
+
cfg.architectures[0] = 'LlavaLlamaForCausalLM'
|
| 16 |
+
cfg.save_pretrained(config)
|
| 17 |
+
print("Checkpoint upgraded.")
|
| 18 |
+
else:
|
| 19 |
+
print("Checkpoint upgrade aborted.")
|
| 20 |
+
exit(1)
|
mplug_owl2/model/visual_encoder.py
ADDED
|
@@ -0,0 +1,928 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
from typing import Any, Optional, Tuple, Union
|
| 3 |
+
|
| 4 |
+
from transformers.modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling, BaseModelOutputWithPastAndCrossAttentions
|
| 5 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 6 |
+
from transformers.pytorch_utils import find_pruneable_heads_and_indices, prune_linear_layer
|
| 7 |
+
|
| 8 |
+
import numpy as np
|
| 9 |
+
import torch
|
| 10 |
+
import torch.nn as nn
|
| 11 |
+
import torch.utils.checkpoint
|
| 12 |
+
from icecream import ic
|
| 13 |
+
|
| 14 |
+
def get_abs_pos(abs_pos, tgt_size):
|
| 15 |
+
# abs_pos: L, C
|
| 16 |
+
# tgt_size: M
|
| 17 |
+
# return: M, C
|
| 18 |
+
src_size = int(math.sqrt(abs_pos.size(0)))
|
| 19 |
+
tgt_size = int(math.sqrt(tgt_size))
|
| 20 |
+
dtype = abs_pos.dtype
|
| 21 |
+
|
| 22 |
+
if src_size != tgt_size:
|
| 23 |
+
return F.interpolate(
|
| 24 |
+
abs_pos.float().reshape(1, src_size, src_size, -1).permute(0, 3, 1, 2),
|
| 25 |
+
size=(tgt_size, tgt_size),
|
| 26 |
+
mode="bicubic",
|
| 27 |
+
align_corners=False,
|
| 28 |
+
).permute(0, 2, 3, 1).flatten(0, 2).to(dtype=dtype)
|
| 29 |
+
else:
|
| 30 |
+
return abs_pos
|
| 31 |
+
|
| 32 |
+
# https://github.com/facebookresearch/mae/blob/efb2a8062c206524e35e47d04501ed4f544c0ae8/util/pos_embed.py#L20
|
| 33 |
+
def get_2d_sincos_pos_embed(embed_dim, grid_size, cls_token=False):
|
| 34 |
+
"""
|
| 35 |
+
grid_size: int of the grid height and width
|
| 36 |
+
return:
|
| 37 |
+
pos_embed: [grid_size*grid_size, embed_dim] or [1+grid_size*grid_size, embed_dim] (w/ or w/o cls_token)
|
| 38 |
+
"""
|
| 39 |
+
grid_h = np.arange(grid_size, dtype=np.float32)
|
| 40 |
+
grid_w = np.arange(grid_size, dtype=np.float32)
|
| 41 |
+
grid = np.meshgrid(grid_w, grid_h) # here w goes first
|
| 42 |
+
grid = np.stack(grid, axis=0)
|
| 43 |
+
|
| 44 |
+
grid = grid.reshape([2, 1, grid_size, grid_size])
|
| 45 |
+
pos_embed = get_2d_sincos_pos_embed_from_grid(embed_dim, grid)
|
| 46 |
+
if cls_token:
|
| 47 |
+
pos_embed = np.concatenate([np.zeros([1, embed_dim]), pos_embed], axis=0)
|
| 48 |
+
return pos_embed
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def get_2d_sincos_pos_embed_from_grid(embed_dim, grid):
|
| 52 |
+
assert embed_dim % 2 == 0
|
| 53 |
+
|
| 54 |
+
# use half of dimensions to encode grid_h
|
| 55 |
+
emb_h = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[0]) # (H*W, D/2)
|
| 56 |
+
emb_w = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[1]) # (H*W, D/2)
|
| 57 |
+
|
| 58 |
+
emb = np.concatenate([emb_h, emb_w], axis=1) # (H*W, D)
|
| 59 |
+
return emb
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def get_1d_sincos_pos_embed_from_grid(embed_dim, pos):
|
| 63 |
+
"""
|
| 64 |
+
embed_dim: output dimension for each position
|
| 65 |
+
pos: a list of positions to be encoded: size (M,)
|
| 66 |
+
out: (M, D)
|
| 67 |
+
"""
|
| 68 |
+
assert embed_dim % 2 == 0
|
| 69 |
+
omega = np.arange(embed_dim // 2, dtype=np.float32)
|
| 70 |
+
omega /= embed_dim / 2.
|
| 71 |
+
omega = 1. / 10000**omega # (D/2,)
|
| 72 |
+
|
| 73 |
+
pos = pos.reshape(-1) # (M,)
|
| 74 |
+
out = np.einsum('m,d->md', pos, omega) # (M, D/2), outer product
|
| 75 |
+
|
| 76 |
+
emb_sin = np.sin(out) # (M, D/2)
|
| 77 |
+
emb_cos = np.cos(out) # (M, D/2)
|
| 78 |
+
|
| 79 |
+
emb = np.concatenate([emb_sin, emb_cos], axis=1) # (M, D)
|
| 80 |
+
return emb
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
class MplugOwlVisionEmbeddings(nn.Module):
|
| 85 |
+
def __init__(self, config):
|
| 86 |
+
super().__init__()
|
| 87 |
+
self.config = config
|
| 88 |
+
self.hidden_size = config.hidden_size
|
| 89 |
+
self.image_size = config.image_size
|
| 90 |
+
self.patch_size = config.patch_size
|
| 91 |
+
|
| 92 |
+
self.cls_token = nn.Parameter(torch.randn(1, 1, self.hidden_size))
|
| 93 |
+
|
| 94 |
+
self.patch_embed = nn.Conv2d(
|
| 95 |
+
in_channels=3,
|
| 96 |
+
out_channels=self.hidden_size,
|
| 97 |
+
kernel_size=self.patch_size,
|
| 98 |
+
stride=self.patch_size,
|
| 99 |
+
bias=False,
|
| 100 |
+
)
|
| 101 |
+
|
| 102 |
+
self.num_patches = (self.image_size // self.patch_size) ** 2
|
| 103 |
+
|
| 104 |
+
self.position_embedding = nn.Parameter(torch.randn(1, self.num_patches + 1, self.hidden_size))
|
| 105 |
+
|
| 106 |
+
self.pre_layernorm = nn.LayerNorm(self.hidden_size, eps=config.layer_norm_eps)
|
| 107 |
+
|
| 108 |
+
def forward(self, pixel_values: torch.FloatTensor) -> torch.Tensor:
|
| 109 |
+
batch_size = pixel_values.size(0)
|
| 110 |
+
image_embeds = self.patch_embed(pixel_values)
|
| 111 |
+
image_embeds = image_embeds.flatten(2).transpose(1, 2)
|
| 112 |
+
|
| 113 |
+
class_embeds = self.cls_token.expand(batch_size, 1, -1).to(image_embeds.dtype)
|
| 114 |
+
embeddings = torch.cat([class_embeds, image_embeds], dim=1)
|
| 115 |
+
embeddings = embeddings + self.position_embedding[:, : embeddings.size(1)].to(image_embeds.dtype)
|
| 116 |
+
embeddings = self.pre_layernorm(embeddings)
|
| 117 |
+
return embeddings
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
class MplugOwlVisionAttention(nn.Module):
|
| 122 |
+
"""Multi-headed attention from 'Attention Is All You Need' paper"""
|
| 123 |
+
|
| 124 |
+
def __init__(self, config):
|
| 125 |
+
super().__init__()
|
| 126 |
+
self.config = config
|
| 127 |
+
self.hidden_size = config.hidden_size
|
| 128 |
+
self.num_heads = config.num_attention_heads
|
| 129 |
+
self.head_dim = self.hidden_size // self.num_heads
|
| 130 |
+
if self.head_dim * self.num_heads != self.hidden_size:
|
| 131 |
+
raise ValueError(
|
| 132 |
+
f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size} and `num_heads`:"
|
| 133 |
+
f" {self.num_heads})."
|
| 134 |
+
)
|
| 135 |
+
self.scale = self.head_dim**-0.5
|
| 136 |
+
self.dropout = nn.Dropout(config.attention_dropout)
|
| 137 |
+
|
| 138 |
+
self.query_key_value = nn.Linear(self.hidden_size, 3 * self.hidden_size)
|
| 139 |
+
self.dense = nn.Linear(self.hidden_size, self.hidden_size)
|
| 140 |
+
|
| 141 |
+
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
|
| 142 |
+
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
|
| 143 |
+
|
| 144 |
+
def forward(
|
| 145 |
+
self,
|
| 146 |
+
hidden_states: torch.Tensor,
|
| 147 |
+
head_mask: Optional[torch.Tensor] = None,
|
| 148 |
+
output_attentions: Optional[bool] = False,
|
| 149 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 150 |
+
"""Input shape: Batch x Time x Channel"""
|
| 151 |
+
|
| 152 |
+
bsz, seq_len, embed_dim = hidden_states.size()
|
| 153 |
+
|
| 154 |
+
mixed_qkv = self.query_key_value(hidden_states)
|
| 155 |
+
|
| 156 |
+
mixed_qkv = mixed_qkv.reshape(bsz, seq_len, self.num_heads, 3, embed_dim // self.num_heads).permute(
|
| 157 |
+
3, 0, 2, 1, 4
|
| 158 |
+
) # [3, b, np, sq, hn]
|
| 159 |
+
query_states, key_states, value_states = (
|
| 160 |
+
mixed_qkv[0],
|
| 161 |
+
mixed_qkv[1],
|
| 162 |
+
mixed_qkv[2],
|
| 163 |
+
)
|
| 164 |
+
# if self.config.use_flash_attn and flash_attn_func is not None:
|
| 165 |
+
if False:
|
| 166 |
+
# [b*sq, np, hn]
|
| 167 |
+
query_states = query_states.permute(0, 2, 1, 3).contiguous()
|
| 168 |
+
query_states = query_states.view(query_states.size(0) * query_states.size(1), query_states.size(2), -1)
|
| 169 |
+
|
| 170 |
+
key_states = key_states.permute(0, 2, 1, 3).contiguous()
|
| 171 |
+
key_states = key_states.view(key_states.size(0) * key_states.size(1), key_states.size(2), -1)
|
| 172 |
+
|
| 173 |
+
value_states = value_states.permute(0, 2, 1, 3).contiguous()
|
| 174 |
+
value_states = value_states.view(value_states.size(0) * value_states.size(1), value_states.size(2), -1)
|
| 175 |
+
|
| 176 |
+
cu_seqlens = torch.arange(
|
| 177 |
+
0, (bsz + 1) * seq_len, step=seq_len, dtype=torch.int32, device=query_states.device
|
| 178 |
+
)
|
| 179 |
+
|
| 180 |
+
context_layer = flash_attn_func(
|
| 181 |
+
query_states,
|
| 182 |
+
key_states,
|
| 183 |
+
value_states,
|
| 184 |
+
cu_seqlens,
|
| 185 |
+
cu_seqlens,
|
| 186 |
+
seq_len,
|
| 187 |
+
seq_len,
|
| 188 |
+
self.dropout if self.training else 0.0,
|
| 189 |
+
softmax_scale=self.scale,
|
| 190 |
+
causal=False,
|
| 191 |
+
return_attn_probs=False,
|
| 192 |
+
)
|
| 193 |
+
# [b*sq, np, hn] => [b, sq, np, hn]
|
| 194 |
+
context_layer = context_layer.view(bsz, seq_len, context_layer.size(1), context_layer.size(2))
|
| 195 |
+
else:
|
| 196 |
+
# Take the dot product between "query" and "key" to get the raw attention scores.
|
| 197 |
+
attention_scores = torch.matmul(query_states, key_states.transpose(-1, -2))
|
| 198 |
+
|
| 199 |
+
attention_scores = attention_scores * self.scale
|
| 200 |
+
|
| 201 |
+
# Normalize the attention scores to probabilities.
|
| 202 |
+
attention_probs = torch.softmax(attention_scores, dim=-1)
|
| 203 |
+
|
| 204 |
+
# This is actually dropping out entire tokens to attend to, which might
|
| 205 |
+
# seem a bit unusual, but is taken from the original Transformer paper.
|
| 206 |
+
attention_probs = self.dropout(attention_probs)
|
| 207 |
+
|
| 208 |
+
# Mask heads if we want to
|
| 209 |
+
if head_mask is not None:
|
| 210 |
+
attention_probs = attention_probs * head_mask
|
| 211 |
+
|
| 212 |
+
context_layer = torch.matmul(attention_probs, value_states).permute(0, 2, 1, 3)
|
| 213 |
+
|
| 214 |
+
new_context_layer_shape = context_layer.size()[:-2] + (self.hidden_size,)
|
| 215 |
+
context_layer = context_layer.reshape(new_context_layer_shape)
|
| 216 |
+
|
| 217 |
+
output = self.dense(context_layer)
|
| 218 |
+
|
| 219 |
+
outputs = (output, attention_probs) if output_attentions else (output, None)
|
| 220 |
+
|
| 221 |
+
return outputs
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
class QuickGELU(nn.Module):
|
| 225 |
+
def forward(self, x: torch.Tensor):
|
| 226 |
+
return x * torch.sigmoid(1.702 * x)
|
| 227 |
+
|
| 228 |
+
|
| 229 |
+
class MplugOwlMLP(nn.Module):
|
| 230 |
+
def __init__(self, config):
|
| 231 |
+
super().__init__()
|
| 232 |
+
self.config = config
|
| 233 |
+
self.activation_fn = QuickGELU()
|
| 234 |
+
self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
|
| 235 |
+
self.fc2 = nn.Linear(config.intermediate_size, config.hidden_size)
|
| 236 |
+
|
| 237 |
+
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
|
| 238 |
+
hidden_states = self.fc1(hidden_states)
|
| 239 |
+
hidden_states = self.activation_fn(hidden_states)
|
| 240 |
+
hidden_states = self.fc2(hidden_states)
|
| 241 |
+
return hidden_states
|
| 242 |
+
|
| 243 |
+
|
| 244 |
+
class MplugOwlVisionEncoderLayer(nn.Module):
|
| 245 |
+
def __init__(self, config):
|
| 246 |
+
super().__init__()
|
| 247 |
+
self.hidden_size = config.hidden_size
|
| 248 |
+
self.self_attn = MplugOwlVisionAttention(config)
|
| 249 |
+
self.input_layernorm = nn.LayerNorm(self.hidden_size, eps=config.layer_norm_eps)
|
| 250 |
+
self.mlp = MplugOwlMLP(config)
|
| 251 |
+
self.post_attention_layernorm = nn.LayerNorm(self.hidden_size, eps=config.layer_norm_eps)
|
| 252 |
+
|
| 253 |
+
def forward(
|
| 254 |
+
self,
|
| 255 |
+
hidden_states: torch.Tensor,
|
| 256 |
+
attention_mask: torch.Tensor,
|
| 257 |
+
output_attentions: Optional[bool] = False,
|
| 258 |
+
) -> Tuple[torch.FloatTensor]:
|
| 259 |
+
"""
|
| 260 |
+
Args:
|
| 261 |
+
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
|
| 262 |
+
attention_mask (`torch.FloatTensor`): attention mask of size
|
| 263 |
+
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
|
| 264 |
+
`(config.encoder_attention_heads,)`.
|
| 265 |
+
output_attentions (`bool`, *optional*):
|
| 266 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
| 267 |
+
returned tensors for more detail.
|
| 268 |
+
"""
|
| 269 |
+
residual = hidden_states
|
| 270 |
+
|
| 271 |
+
hidden_states = self.input_layernorm(hidden_states)
|
| 272 |
+
hidden_states, attn_weights = self.self_attn(
|
| 273 |
+
hidden_states=hidden_states,
|
| 274 |
+
head_mask=attention_mask,
|
| 275 |
+
output_attentions=output_attentions,
|
| 276 |
+
)
|
| 277 |
+
hidden_states = hidden_states + residual
|
| 278 |
+
residual = hidden_states
|
| 279 |
+
hidden_states = self.post_attention_layernorm(hidden_states)
|
| 280 |
+
hidden_states = self.mlp(hidden_states)
|
| 281 |
+
|
| 282 |
+
hidden_states = hidden_states + residual
|
| 283 |
+
|
| 284 |
+
outputs = (hidden_states,)
|
| 285 |
+
|
| 286 |
+
if output_attentions:
|
| 287 |
+
outputs += (attn_weights,)
|
| 288 |
+
|
| 289 |
+
return outputs
|
| 290 |
+
|
| 291 |
+
|
| 292 |
+
class MplugOwlVisionEncoder(nn.Module):
|
| 293 |
+
"""
|
| 294 |
+
Transformer encoder consisting of `config.num_hidden_layers` self attention layers. Each layer is a
|
| 295 |
+
[`MplugOwlVisionEncoderLayer`].
|
| 296 |
+
|
| 297 |
+
Args:
|
| 298 |
+
config (`MplugOwlVisionConfig`):
|
| 299 |
+
The corresponding vision configuration for the `MplugOwlEncoder`.
|
| 300 |
+
"""
|
| 301 |
+
|
| 302 |
+
def __init__(self, config):
|
| 303 |
+
super().__init__()
|
| 304 |
+
self.config = config
|
| 305 |
+
self.layers = nn.ModuleList([MplugOwlVisionEncoderLayer(config) for _ in range(config.num_hidden_layers)])
|
| 306 |
+
self.gradient_checkpointing = True
|
| 307 |
+
|
| 308 |
+
def forward(
|
| 309 |
+
self,
|
| 310 |
+
inputs_embeds,
|
| 311 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 312 |
+
output_attentions: Optional[bool] = None,
|
| 313 |
+
output_hidden_states: Optional[bool] = None,
|
| 314 |
+
return_dict: Optional[bool] = None,
|
| 315 |
+
) -> Union[Tuple, BaseModelOutput]:
|
| 316 |
+
r"""
|
| 317 |
+
Args:
|
| 318 |
+
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
|
| 319 |
+
Embedded representation of the inputs. Should be float, not int tokens.
|
| 320 |
+
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 321 |
+
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
|
| 322 |
+
|
| 323 |
+
- 1 for tokens that are **not masked**,
|
| 324 |
+
- 0 for tokens that are **masked**.
|
| 325 |
+
|
| 326 |
+
[What are attention masks?](../glossary#attention-mask)
|
| 327 |
+
output_attentions (`bool`, *optional*):
|
| 328 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
| 329 |
+
returned tensors for more detail.
|
| 330 |
+
output_hidden_states (`bool`, *optional*):
|
| 331 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
|
| 332 |
+
for more detail.
|
| 333 |
+
return_dict (`bool`, *optional*):
|
| 334 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 335 |
+
"""
|
| 336 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 337 |
+
output_hidden_states = (
|
| 338 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 339 |
+
)
|
| 340 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 341 |
+
|
| 342 |
+
encoder_states = () if output_hidden_states else None
|
| 343 |
+
all_attentions = () if output_attentions else None
|
| 344 |
+
|
| 345 |
+
hidden_states = inputs_embeds
|
| 346 |
+
for idx, encoder_layer in enumerate(self.layers):
|
| 347 |
+
if output_hidden_states:
|
| 348 |
+
encoder_states = encoder_states + (hidden_states,)
|
| 349 |
+
if self.gradient_checkpointing and self.training:
|
| 350 |
+
|
| 351 |
+
def create_custom_forward(module):
|
| 352 |
+
def custom_forward(*inputs):
|
| 353 |
+
return module(*inputs, output_attentions)
|
| 354 |
+
|
| 355 |
+
return custom_forward
|
| 356 |
+
|
| 357 |
+
layer_outputs = torch.utils.checkpoint.checkpoint(
|
| 358 |
+
create_custom_forward(encoder_layer),
|
| 359 |
+
hidden_states,
|
| 360 |
+
attention_mask,
|
| 361 |
+
)
|
| 362 |
+
else:
|
| 363 |
+
layer_outputs = encoder_layer(
|
| 364 |
+
hidden_states,
|
| 365 |
+
attention_mask,
|
| 366 |
+
output_attentions=output_attentions,
|
| 367 |
+
)
|
| 368 |
+
|
| 369 |
+
hidden_states = layer_outputs[0]
|
| 370 |
+
|
| 371 |
+
if output_attentions:
|
| 372 |
+
all_attentions = all_attentions + (layer_outputs[1],)
|
| 373 |
+
|
| 374 |
+
if output_hidden_states:
|
| 375 |
+
encoder_states = encoder_states + (hidden_states,)
|
| 376 |
+
|
| 377 |
+
if not return_dict:
|
| 378 |
+
return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
|
| 379 |
+
return BaseModelOutput(
|
| 380 |
+
last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
|
| 381 |
+
)
|
| 382 |
+
|
| 383 |
+
|
| 384 |
+
class MplugOwlVisionModel(PreTrainedModel):
|
| 385 |
+
main_input_name = "pixel_values"
|
| 386 |
+
|
| 387 |
+
def __init__(self, config):
|
| 388 |
+
super().__init__(config)
|
| 389 |
+
self.config = config
|
| 390 |
+
self.hidden_size = config.hidden_size
|
| 391 |
+
|
| 392 |
+
self.embeddings = MplugOwlVisionEmbeddings(config)
|
| 393 |
+
self.encoder = MplugOwlVisionEncoder(config)
|
| 394 |
+
self.post_layernorm = nn.LayerNorm(self.hidden_size, eps=config.layer_norm_eps)
|
| 395 |
+
|
| 396 |
+
self.post_init()
|
| 397 |
+
|
| 398 |
+
|
| 399 |
+
def forward(
|
| 400 |
+
self,
|
| 401 |
+
pixel_values: Optional[torch.FloatTensor] = None,
|
| 402 |
+
output_attentions: Optional[bool] = None,
|
| 403 |
+
output_hidden_states: Optional[bool] = None,
|
| 404 |
+
return_dict: Optional[bool] = None,
|
| 405 |
+
) -> Union[Tuple, BaseModelOutputWithPooling]:
|
| 406 |
+
r"""
|
| 407 |
+
Returns:
|
| 408 |
+
|
| 409 |
+
"""
|
| 410 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 411 |
+
output_hidden_states = (
|
| 412 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 413 |
+
)
|
| 414 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 415 |
+
|
| 416 |
+
if pixel_values is None:
|
| 417 |
+
raise ValueError("You have to specify pixel_values")
|
| 418 |
+
|
| 419 |
+
hidden_states = self.embeddings(pixel_values)
|
| 420 |
+
|
| 421 |
+
encoder_outputs = self.encoder(
|
| 422 |
+
inputs_embeds=hidden_states,
|
| 423 |
+
output_attentions=output_attentions,
|
| 424 |
+
output_hidden_states=output_hidden_states,
|
| 425 |
+
return_dict=return_dict,
|
| 426 |
+
)
|
| 427 |
+
|
| 428 |
+
last_hidden_state = encoder_outputs[0]
|
| 429 |
+
last_hidden_state = self.post_layernorm(last_hidden_state)
|
| 430 |
+
|
| 431 |
+
pooled_output = last_hidden_state[:, 0, :]
|
| 432 |
+
pooled_output = self.post_layernorm(pooled_output)
|
| 433 |
+
|
| 434 |
+
if not return_dict:
|
| 435 |
+
return (last_hidden_state, pooled_output) + encoder_outputs[1:]
|
| 436 |
+
|
| 437 |
+
return BaseModelOutputWithPooling(
|
| 438 |
+
last_hidden_state=last_hidden_state,
|
| 439 |
+
pooler_output=pooled_output,
|
| 440 |
+
hidden_states=encoder_outputs.hidden_states,
|
| 441 |
+
attentions=encoder_outputs.attentions,
|
| 442 |
+
)
|
| 443 |
+
|
| 444 |
+
def get_input_embeddings(self):
|
| 445 |
+
return self.embeddings
|
| 446 |
+
|
| 447 |
+
|
| 448 |
+
class MplugOwlVisualAbstractorMLP(nn.Module):
|
| 449 |
+
def __init__(self, config):
|
| 450 |
+
super().__init__()
|
| 451 |
+
self.config = config
|
| 452 |
+
in_features = config.hidden_size
|
| 453 |
+
self.act = nn.SiLU()
|
| 454 |
+
|
| 455 |
+
self.w1 = nn.Linear(in_features, config.intermediate_size)
|
| 456 |
+
self.w2 = nn.Linear(config.intermediate_size, in_features)
|
| 457 |
+
self.w3 = nn.Linear(in_features, config.intermediate_size)
|
| 458 |
+
self.ffn_ln = nn.LayerNorm(config.intermediate_size, eps=config.layer_norm_eps)
|
| 459 |
+
|
| 460 |
+
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
|
| 461 |
+
hidden_states = self.act(self.w1(hidden_states)) * self.w3(hidden_states)
|
| 462 |
+
hidden_states = self.ffn_ln(hidden_states)
|
| 463 |
+
hidden_states = self.w2(hidden_states)
|
| 464 |
+
return hidden_states
|
| 465 |
+
|
| 466 |
+
|
| 467 |
+
class MplugOwlVisualAbstractorMultiHeadAttention(nn.Module):
|
| 468 |
+
def __init__(self, config):
|
| 469 |
+
super().__init__()
|
| 470 |
+
self.config = config
|
| 471 |
+
if config.hidden_size % config.num_attention_heads != 0:
|
| 472 |
+
raise ValueError(
|
| 473 |
+
"The hidden size (%d) is not a multiple of the number of attention heads (%d)"
|
| 474 |
+
% (config.hidden_size, config.num_attention_heads)
|
| 475 |
+
)
|
| 476 |
+
|
| 477 |
+
self.num_attention_heads = config.num_attention_heads
|
| 478 |
+
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
|
| 479 |
+
self.all_head_size = self.num_attention_heads * self.attention_head_size
|
| 480 |
+
|
| 481 |
+
self.query = nn.Linear(config.hidden_size, self.all_head_size)
|
| 482 |
+
self.key = nn.Linear(config.encoder_hidden_size, self.all_head_size)
|
| 483 |
+
self.value = nn.Linear(config.encoder_hidden_size, self.all_head_size)
|
| 484 |
+
|
| 485 |
+
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
|
| 486 |
+
self.save_attention = False
|
| 487 |
+
|
| 488 |
+
# self.q_pos_embed = nn.Parameter(
|
| 489 |
+
# torch.from_numpy(get_1d_sincos_pos_embed_from_grid(config.hidden_size, np.arange(config.num_learnable_queries, dtype=np.float32))).float()
|
| 490 |
+
# ).requires_grad_(False)
|
| 491 |
+
# grids = config.grid_size
|
| 492 |
+
# self.k_pos_embed = nn.Parameter(
|
| 493 |
+
# torch.from_numpy(get_2d_sincos_pos_embed(config.hidden_size, grids, cls_token=True)).float()
|
| 494 |
+
# ).requires_grad_(False)
|
| 495 |
+
grids = config.grid_size
|
| 496 |
+
self.register_buffer(
|
| 497 |
+
'q_pos_embed',
|
| 498 |
+
torch.from_numpy(get_1d_sincos_pos_embed_from_grid(config.hidden_size, np.arange(config.num_learnable_queries, dtype=np.float32))).float()
|
| 499 |
+
)
|
| 500 |
+
self.register_buffer(
|
| 501 |
+
'k_pos_embed',
|
| 502 |
+
torch.from_numpy(get_2d_sincos_pos_embed(config.hidden_size, grids, cls_token=True)).float()
|
| 503 |
+
)
|
| 504 |
+
|
| 505 |
+
|
| 506 |
+
def save_attn_gradients(self, attn_gradients):
|
| 507 |
+
self.attn_gradients = attn_gradients
|
| 508 |
+
|
| 509 |
+
def get_attn_gradients(self):
|
| 510 |
+
return self.attn_gradients
|
| 511 |
+
|
| 512 |
+
def save_attention_map(self, attention_map):
|
| 513 |
+
self.attention_map = attention_map
|
| 514 |
+
|
| 515 |
+
def get_attention_map(self):
|
| 516 |
+
return self.attention_map
|
| 517 |
+
|
| 518 |
+
def transpose_for_scores(self, x):
|
| 519 |
+
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
|
| 520 |
+
x = x.view(*new_x_shape)
|
| 521 |
+
return x.permute(0, 2, 1, 3)
|
| 522 |
+
|
| 523 |
+
def forward(
|
| 524 |
+
self,
|
| 525 |
+
hidden_states,
|
| 526 |
+
attention_mask=None,
|
| 527 |
+
head_mask=None,
|
| 528 |
+
encoder_hidden_states=None,
|
| 529 |
+
encoder_attention_mask=None,
|
| 530 |
+
past_key_value=None,
|
| 531 |
+
output_attentions=False,
|
| 532 |
+
):
|
| 533 |
+
# If this is instantiated as a cross-attention module, the keys
|
| 534 |
+
# and values come from an encoder; the attention mask needs to be
|
| 535 |
+
# such that the encoder's padding tokens are not attended to.
|
| 536 |
+
|
| 537 |
+
qk_pos_embed = torch.cat([self.q_pos_embed, self.k_pos_embed], dim = 0).unsqueeze(0).to(dtype=hidden_states.dtype)
|
| 538 |
+
|
| 539 |
+
key_layer = self.transpose_for_scores(self.key(encoder_hidden_states + qk_pos_embed))
|
| 540 |
+
value_layer = self.transpose_for_scores(self.value(encoder_hidden_states))
|
| 541 |
+
attention_mask = encoder_attention_mask
|
| 542 |
+
|
| 543 |
+
mixed_query_layer = self.query(hidden_states + self.q_pos_embed.unsqueeze(0).to(dtype=hidden_states.dtype))
|
| 544 |
+
|
| 545 |
+
query_layer = self.transpose_for_scores(mixed_query_layer)
|
| 546 |
+
|
| 547 |
+
past_key_value = (key_layer, value_layer)
|
| 548 |
+
|
| 549 |
+
# Take the dot product between "query" and "key" to get the raw attention scores.
|
| 550 |
+
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
|
| 551 |
+
|
| 552 |
+
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
|
| 553 |
+
|
| 554 |
+
if attention_mask is not None:
|
| 555 |
+
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
|
| 556 |
+
attention_scores = attention_scores + attention_mask
|
| 557 |
+
|
| 558 |
+
# Normalize the attention scores to probabilities.
|
| 559 |
+
attention_probs = nn.Softmax(dim=-1)(attention_scores)
|
| 560 |
+
|
| 561 |
+
if self.save_attention:
|
| 562 |
+
self.save_attention_map(attention_probs)
|
| 563 |
+
attention_probs.register_hook(self.save_attn_gradients)
|
| 564 |
+
|
| 565 |
+
# This is actually dropping out entire tokens to attend to, which might
|
| 566 |
+
# seem a bit unusual, but is taken from the original Transformer paper.
|
| 567 |
+
attention_probs_dropped = self.dropout(attention_probs)
|
| 568 |
+
|
| 569 |
+
# Mask heads if we want to
|
| 570 |
+
if head_mask is not None:
|
| 571 |
+
attention_probs_dropped = attention_probs_dropped * head_mask
|
| 572 |
+
|
| 573 |
+
context_layer = torch.matmul(attention_probs_dropped, value_layer)
|
| 574 |
+
|
| 575 |
+
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
|
| 576 |
+
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
|
| 577 |
+
context_layer = context_layer.view(*new_context_layer_shape)
|
| 578 |
+
|
| 579 |
+
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
|
| 580 |
+
|
| 581 |
+
outputs = outputs + (past_key_value,)
|
| 582 |
+
return outputs
|
| 583 |
+
|
| 584 |
+
|
| 585 |
+
class MplugOwlVisualAbstractorCrossOutput(nn.Module):
|
| 586 |
+
def __init__(self, config):
|
| 587 |
+
super().__init__()
|
| 588 |
+
dim = config.hidden_size
|
| 589 |
+
self.out_proj = nn.Linear(dim, dim, bias=True)
|
| 590 |
+
self.norm2 = nn.LayerNorm(dim)
|
| 591 |
+
self.mlp = MplugOwlVisualAbstractorMLP(config)
|
| 592 |
+
|
| 593 |
+
def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
|
| 594 |
+
input_tensor = input_tensor + self.out_proj(hidden_states)
|
| 595 |
+
input_tensor = input_tensor + self.mlp(self.norm2(input_tensor))
|
| 596 |
+
return input_tensor
|
| 597 |
+
|
| 598 |
+
|
| 599 |
+
class MplugOwlVisualAbstractorAttention(nn.Module):
|
| 600 |
+
def __init__(self, config):
|
| 601 |
+
super().__init__()
|
| 602 |
+
self.attention = MplugOwlVisualAbstractorMultiHeadAttention(config)
|
| 603 |
+
self.output = MplugOwlVisualAbstractorCrossOutput(config)
|
| 604 |
+
self.pruned_heads = set()
|
| 605 |
+
self.norm1 = nn.LayerNorm(config.hidden_size)
|
| 606 |
+
self.normk = nn.LayerNorm(config.hidden_size)
|
| 607 |
+
|
| 608 |
+
def prune_heads(self, heads):
|
| 609 |
+
if len(heads) == 0:
|
| 610 |
+
return
|
| 611 |
+
heads, index = find_pruneable_heads_and_indices(
|
| 612 |
+
heads, self.attention.num_attention_heads, self.attention.attention_head_size, self.pruned_heads
|
| 613 |
+
)
|
| 614 |
+
|
| 615 |
+
# Prune linear layers
|
| 616 |
+
self.attention.query = prune_linear_layer(self.attention.query, index)
|
| 617 |
+
self.attention.key = prune_linear_layer(self.attention.key, index)
|
| 618 |
+
self.attention.value = prune_linear_layer(self.attention.value, index)
|
| 619 |
+
self.output.dense = prune_linear_layer(self.output.out_proj, index, dim=1)
|
| 620 |
+
|
| 621 |
+
# Update hyper params and store pruned heads
|
| 622 |
+
self.attention.num_attention_heads = self.attention.num_attention_heads - len(heads)
|
| 623 |
+
self.attention.all_head_size = self.attention.attention_head_size * self.attention.num_attention_heads
|
| 624 |
+
self.pruned_heads = self.pruned_heads.union(heads)
|
| 625 |
+
|
| 626 |
+
def forward(
|
| 627 |
+
self,
|
| 628 |
+
hidden_states: torch.Tensor,
|
| 629 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 630 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 631 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 632 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 633 |
+
past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
|
| 634 |
+
output_attentions: Optional[bool] = False,
|
| 635 |
+
) -> Tuple[torch.Tensor]:
|
| 636 |
+
# HACK we apply norm on q and k
|
| 637 |
+
hidden_states = self.norm1(hidden_states)
|
| 638 |
+
encoder_hidden_states = self.normk(encoder_hidden_states)
|
| 639 |
+
encoder_hidden_states = torch.cat([hidden_states, encoder_hidden_states], dim=1)
|
| 640 |
+
encoder_attention_mask = torch.cat([attention_mask, encoder_attention_mask], dim=-1)
|
| 641 |
+
self_outputs = self.attention(
|
| 642 |
+
hidden_states,
|
| 643 |
+
attention_mask,
|
| 644 |
+
head_mask,
|
| 645 |
+
encoder_hidden_states,
|
| 646 |
+
encoder_attention_mask,
|
| 647 |
+
past_key_value,
|
| 648 |
+
output_attentions,
|
| 649 |
+
)
|
| 650 |
+
attention_output = self.output(self_outputs[0], hidden_states)
|
| 651 |
+
# add attentions if we output them
|
| 652 |
+
outputs = (attention_output,) + self_outputs[1:]
|
| 653 |
+
return outputs
|
| 654 |
+
|
| 655 |
+
|
| 656 |
+
class MplugOwlVisualAbstractorLayer(nn.Module):
|
| 657 |
+
def __init__(self, config, layer_idx):
|
| 658 |
+
super().__init__()
|
| 659 |
+
self.chunk_size_feed_forward = config.chunk_size_feed_forward
|
| 660 |
+
self.seq_len_dim = 1
|
| 661 |
+
|
| 662 |
+
self.layer_idx = layer_idx
|
| 663 |
+
|
| 664 |
+
self.crossattention = MplugOwlVisualAbstractorAttention(config)
|
| 665 |
+
self.has_cross_attention = True
|
| 666 |
+
|
| 667 |
+
def forward(
|
| 668 |
+
self,
|
| 669 |
+
hidden_states,
|
| 670 |
+
attention_mask=None,
|
| 671 |
+
head_mask=None,
|
| 672 |
+
encoder_hidden_states=None,
|
| 673 |
+
encoder_attention_mask=None,
|
| 674 |
+
output_attentions=False,
|
| 675 |
+
):
|
| 676 |
+
if encoder_hidden_states is None:
|
| 677 |
+
raise ValueError("encoder_hidden_states must be given for cross-attention layers")
|
| 678 |
+
cross_attention_outputs = self.crossattention(
|
| 679 |
+
hidden_states,
|
| 680 |
+
attention_mask,
|
| 681 |
+
head_mask,
|
| 682 |
+
encoder_hidden_states,
|
| 683 |
+
encoder_attention_mask,
|
| 684 |
+
output_attentions=output_attentions,
|
| 685 |
+
)
|
| 686 |
+
query_attention_output = cross_attention_outputs[0]
|
| 687 |
+
|
| 688 |
+
outputs = (query_attention_output,)
|
| 689 |
+
return outputs
|
| 690 |
+
|
| 691 |
+
|
| 692 |
+
class MplugOwlVisualAbstractorEncoder(nn.Module):
|
| 693 |
+
def __init__(self, config):
|
| 694 |
+
super().__init__()
|
| 695 |
+
self.config = config
|
| 696 |
+
self.layers = nn.ModuleList(
|
| 697 |
+
[MplugOwlVisualAbstractorLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
|
| 698 |
+
)
|
| 699 |
+
self.gradient_checkpointing = True
|
| 700 |
+
|
| 701 |
+
def forward(
|
| 702 |
+
self,
|
| 703 |
+
hidden_states,
|
| 704 |
+
attention_mask=None,
|
| 705 |
+
head_mask=None,
|
| 706 |
+
encoder_hidden_states=None,
|
| 707 |
+
encoder_attention_mask=None,
|
| 708 |
+
past_key_values=None,
|
| 709 |
+
output_attentions=False,
|
| 710 |
+
output_hidden_states=False,
|
| 711 |
+
return_dict=True,
|
| 712 |
+
):
|
| 713 |
+
all_hidden_states = () if output_hidden_states else None
|
| 714 |
+
|
| 715 |
+
for i in range(self.config.num_hidden_layers):
|
| 716 |
+
layer_module = self.layers[i]
|
| 717 |
+
if output_hidden_states:
|
| 718 |
+
all_hidden_states = all_hidden_states + (hidden_states,)
|
| 719 |
+
|
| 720 |
+
layer_head_mask = head_mask[i] if head_mask is not None else None
|
| 721 |
+
past_key_value = past_key_values[i] if past_key_values is not None else None
|
| 722 |
+
|
| 723 |
+
if getattr(self.config, "gradient_checkpointing", False) and self.training:
|
| 724 |
+
|
| 725 |
+
def create_custom_forward(module):
|
| 726 |
+
def custom_forward(*inputs):
|
| 727 |
+
return module(*inputs, past_key_value, output_attentions)
|
| 728 |
+
|
| 729 |
+
return custom_forward
|
| 730 |
+
|
| 731 |
+
layer_outputs = torch.utils.checkpoint.checkpoint(
|
| 732 |
+
create_custom_forward(layer_module),
|
| 733 |
+
hidden_states,
|
| 734 |
+
attention_mask,
|
| 735 |
+
layer_head_mask,
|
| 736 |
+
encoder_hidden_states,
|
| 737 |
+
encoder_attention_mask,
|
| 738 |
+
)
|
| 739 |
+
else:
|
| 740 |
+
layer_outputs = layer_module(
|
| 741 |
+
hidden_states,
|
| 742 |
+
attention_mask,
|
| 743 |
+
layer_head_mask,
|
| 744 |
+
encoder_hidden_states,
|
| 745 |
+
encoder_attention_mask,
|
| 746 |
+
output_attentions,
|
| 747 |
+
)
|
| 748 |
+
|
| 749 |
+
hidden_states = layer_outputs[0]
|
| 750 |
+
|
| 751 |
+
return BaseModelOutput(
|
| 752 |
+
last_hidden_state=hidden_states,
|
| 753 |
+
)
|
| 754 |
+
|
| 755 |
+
|
| 756 |
+
class MplugOwlVisualAbstractorModel(PreTrainedModel):
|
| 757 |
+
def __init__(self, config, language_hidden_size):
|
| 758 |
+
super().__init__(config)
|
| 759 |
+
self.config = config
|
| 760 |
+
|
| 761 |
+
self.encoder = MplugOwlVisualAbstractorEncoder(config)
|
| 762 |
+
self.visual_fc = torch.nn.Linear(config.hidden_size, language_hidden_size)
|
| 763 |
+
self.query_embeds = torch.nn.Parameter(torch.randn(1, config.num_learnable_queries, config.hidden_size))
|
| 764 |
+
self.vit_eos = torch.nn.Parameter(torch.randn(1, 1, language_hidden_size))
|
| 765 |
+
|
| 766 |
+
self.post_init()
|
| 767 |
+
|
| 768 |
+
def _prune_heads(self, heads_to_prune):
|
| 769 |
+
"""
|
| 770 |
+
Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
|
| 771 |
+
class PreTrainedModel
|
| 772 |
+
"""
|
| 773 |
+
for layer, heads in heads_to_prune.items():
|
| 774 |
+
self.encoder.layer[layer].attention.prune_heads(heads)
|
| 775 |
+
|
| 776 |
+
def get_extended_attention_mask(
|
| 777 |
+
self,
|
| 778 |
+
attention_mask: torch.Tensor,
|
| 779 |
+
input_shape: Tuple[int],
|
| 780 |
+
device: torch.device,
|
| 781 |
+
) -> torch.Tensor:
|
| 782 |
+
"""
|
| 783 |
+
Makes broadcastable attention and causal masks so that future and masked tokens are ignored.
|
| 784 |
+
|
| 785 |
+
Arguments:
|
| 786 |
+
attention_mask (`torch.Tensor`):
|
| 787 |
+
Mask with ones indicating tokens to attend to, zeros for tokens to ignore.
|
| 788 |
+
input_shape (`Tuple[int]`):
|
| 789 |
+
The shape of the input to the model.
|
| 790 |
+
device: (`torch.device`):
|
| 791 |
+
The device of the input to the model.
|
| 792 |
+
|
| 793 |
+
Returns:
|
| 794 |
+
`torch.Tensor` The extended attention mask, with a the same dtype as `attention_mask.dtype`.
|
| 795 |
+
"""
|
| 796 |
+
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
|
| 797 |
+
# ourselves in which case we just need to make it broadcastable to all heads.
|
| 798 |
+
if attention_mask.dim() == 3:
|
| 799 |
+
extended_attention_mask = attention_mask[:, None, :, :]
|
| 800 |
+
elif attention_mask.dim() == 2:
|
| 801 |
+
# Provided a padding mask of dimensions [batch_size, seq_length]
|
| 802 |
+
# - the model is an encoder, so make the mask broadcastable to [batch_size, num_heads, seq_length, seq_length]
|
| 803 |
+
extended_attention_mask = attention_mask[:, None, None, :]
|
| 804 |
+
else:
|
| 805 |
+
raise ValueError(
|
| 806 |
+
"Wrong shape for input_ids (shape {}) or attention_mask (shape {})".format(
|
| 807 |
+
input_shape, attention_mask.shape
|
| 808 |
+
)
|
| 809 |
+
)
|
| 810 |
+
|
| 811 |
+
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
|
| 812 |
+
# masked positions, this operation will create a tensor which is 0.0 for
|
| 813 |
+
# positions we want to attend and -10000.0 for masked positions.
|
| 814 |
+
# Since we are adding it to the raw scores before the softmax, this is
|
| 815 |
+
# effectively the same as removing these entirely.
|
| 816 |
+
extended_attention_mask = extended_attention_mask.to(dtype=self.dtype) # fp16 compatibility
|
| 817 |
+
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
|
| 818 |
+
return extended_attention_mask
|
| 819 |
+
|
| 820 |
+
def forward(
|
| 821 |
+
self,
|
| 822 |
+
attention_mask=None,
|
| 823 |
+
head_mask=None,
|
| 824 |
+
encoder_hidden_states=None,
|
| 825 |
+
encoder_attention_mask=None,
|
| 826 |
+
past_key_values=None,
|
| 827 |
+
output_attentions=None,
|
| 828 |
+
output_hidden_states=None,
|
| 829 |
+
return_dict=None,
|
| 830 |
+
):
|
| 831 |
+
r"""
|
| 832 |
+
encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, `optional`):
|
| 833 |
+
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
|
| 834 |
+
the model is configured as a decoder.
|
| 835 |
+
encoder_attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, `optional`):
|
| 836 |
+
Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
|
| 837 |
+
the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
|
| 838 |
+
- 1 for tokens that are **not masked**,
|
| 839 |
+
- 0 for tokens that are **masked**.
|
| 840 |
+
past_key_values (`tuple(tuple(torch.FloatTensor))` of length `config.n_layers` with each tuple having 4 tensors of:
|
| 841 |
+
shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`): Contains precomputed key and
|
| 842 |
+
value hidden states of the attention blocks. Can be used to speed up decoding. If `past_key_values` are
|
| 843 |
+
used, the user can optionally input only the last `decoder_input_ids` (those that don't have their past key
|
| 844 |
+
value states given to this model) of shape `(batch_size, 1)` instead of all `decoder_input_ids` of shape
|
| 845 |
+
`(batch_size, sequence_length)`.
|
| 846 |
+
"""
|
| 847 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 848 |
+
output_hidden_states = (
|
| 849 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 850 |
+
)
|
| 851 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 852 |
+
|
| 853 |
+
query_embeds = self.query_embeds.repeat(encoder_hidden_states.shape[0], 1, 1)
|
| 854 |
+
embedding_output = query_embeds
|
| 855 |
+
input_shape = embedding_output.size()[:-1]
|
| 856 |
+
batch_size, seq_length = input_shape
|
| 857 |
+
device = embedding_output.device
|
| 858 |
+
|
| 859 |
+
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
|
| 860 |
+
# ourselves in which case we just need to make it broadcastable to all heads.
|
| 861 |
+
if attention_mask is None:
|
| 862 |
+
attention_mask = torch.ones(
|
| 863 |
+
(query_embeds.shape[0], query_embeds.shape[1]), dtype=torch.long, device=query_embeds.device
|
| 864 |
+
)
|
| 865 |
+
extended_attention_mask = self.get_extended_attention_mask(attention_mask, input_shape, device)
|
| 866 |
+
|
| 867 |
+
# If a 2D or 3D attention mask is provided for the cross-attention
|
| 868 |
+
# we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
|
| 869 |
+
if encoder_hidden_states is not None:
|
| 870 |
+
if type(encoder_hidden_states) == list:
|
| 871 |
+
encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states[0].size()
|
| 872 |
+
else:
|
| 873 |
+
(
|
| 874 |
+
encoder_batch_size,
|
| 875 |
+
encoder_sequence_length,
|
| 876 |
+
_,
|
| 877 |
+
) = encoder_hidden_states.size()
|
| 878 |
+
encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
|
| 879 |
+
|
| 880 |
+
if type(encoder_attention_mask) == list:
|
| 881 |
+
encoder_extended_attention_mask = [self.invert_attention_mask(mask) for mask in encoder_attention_mask]
|
| 882 |
+
elif encoder_attention_mask is None:
|
| 883 |
+
encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
|
| 884 |
+
encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
|
| 885 |
+
else:
|
| 886 |
+
encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
|
| 887 |
+
else:
|
| 888 |
+
encoder_extended_attention_mask = None
|
| 889 |
+
|
| 890 |
+
# Prepare head mask if needed
|
| 891 |
+
# 1.0 in head_mask indicate we keep the head
|
| 892 |
+
# attention_probs has shape bsz x n_heads x N x N
|
| 893 |
+
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
|
| 894 |
+
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
|
| 895 |
+
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
|
| 896 |
+
|
| 897 |
+
encoder_outputs = self.encoder(
|
| 898 |
+
embedding_output,
|
| 899 |
+
attention_mask=extended_attention_mask,
|
| 900 |
+
head_mask=head_mask,
|
| 901 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 902 |
+
encoder_attention_mask=encoder_extended_attention_mask,
|
| 903 |
+
past_key_values=past_key_values,
|
| 904 |
+
output_attentions=output_attentions,
|
| 905 |
+
output_hidden_states=output_hidden_states,
|
| 906 |
+
return_dict=return_dict,
|
| 907 |
+
)
|
| 908 |
+
sequence_output = encoder_outputs[0]
|
| 909 |
+
pooled_output = sequence_output[:, 0, :]
|
| 910 |
+
|
| 911 |
+
sequence_output = self.visual_fc(sequence_output)
|
| 912 |
+
sequence_output = torch.cat([sequence_output, self.vit_eos.repeat(sequence_output.shape[0], 1, 1)], dim=1)
|
| 913 |
+
|
| 914 |
+
return BaseModelOutputWithPooling(
|
| 915 |
+
last_hidden_state=sequence_output,
|
| 916 |
+
pooler_output=pooled_output,
|
| 917 |
+
hidden_states=encoder_outputs.hidden_states,
|
| 918 |
+
)
|
| 919 |
+
|
| 920 |
+
|
| 921 |
+
if __name__ == "__main__":
|
| 922 |
+
from configuration_mplug_owl2 import MPLUGOwl2Config
|
| 923 |
+
config = MPLUGOwl2Config()
|
| 924 |
+
visual_model = MplugOwlVisionModel(config.visual_config["visual_model"])
|
| 925 |
+
print(visual_model)
|
| 926 |
+
|
| 927 |
+
abstractor_module = MplugOwlVisualAbstractorModel(config.visual_config["visual_abstractor"], config.hidden_size)
|
| 928 |
+
print(abstractor_module)
|
mplug_owl2/serve/__init__.py
ADDED
|
File without changes
|
mplug_owl2/serve/cli.py
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
from mplug_owl2.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN
|
| 5 |
+
from mplug_owl2.conversation import conv_templates, SeparatorStyle
|
| 6 |
+
from mplug_owl2.model.builder import load_pretrained_model
|
| 7 |
+
from mplug_owl2.mm_utils import process_images, tokenizer_image_token, get_model_name_from_path, KeywordsStoppingCriteria
|
| 8 |
+
|
| 9 |
+
from PIL import Image
|
| 10 |
+
|
| 11 |
+
import requests
|
| 12 |
+
from PIL import Image
|
| 13 |
+
from io import BytesIO
|
| 14 |
+
from transformers import TextStreamer
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def disable_torch_init():
|
| 18 |
+
"""
|
| 19 |
+
Disable the redundant torch default initialization to accelerate model creation.
|
| 20 |
+
"""
|
| 21 |
+
import torch
|
| 22 |
+
setattr(torch.nn.Linear, "reset_parameters", lambda self: None)
|
| 23 |
+
setattr(torch.nn.LayerNorm, "reset_parameters", lambda self: None)
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def load_image(image_file):
|
| 27 |
+
if image_file.startswith('http://') or image_file.startswith('https://'):
|
| 28 |
+
response = requests.get(image_file)
|
| 29 |
+
image = Image.open(BytesIO(response.content)).convert('RGB')
|
| 30 |
+
else:
|
| 31 |
+
image = Image.open(image_file).convert('RGB')
|
| 32 |
+
return image
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def main(args):
|
| 36 |
+
# Model
|
| 37 |
+
disable_torch_init()
|
| 38 |
+
|
| 39 |
+
model_name = get_model_name_from_path(args.model_path)
|
| 40 |
+
tokenizer, model, image_processor, context_len = load_pretrained_model(args.model_path, args.model_base, model_name, args.load_8bit, args.load_4bit, device=args.device)
|
| 41 |
+
|
| 42 |
+
conv_mode = "mplug_owl2"
|
| 43 |
+
|
| 44 |
+
if args.conv_mode is not None and conv_mode != args.conv_mode:
|
| 45 |
+
print('[WARNING] the auto inferred conversation mode is {}, while `--conv-mode` is {}, using {}'.format(conv_mode, args.conv_mode, args.conv_mode))
|
| 46 |
+
else:
|
| 47 |
+
args.conv_mode = conv_mode
|
| 48 |
+
|
| 49 |
+
conv = conv_templates[args.conv_mode].copy()
|
| 50 |
+
roles = conv.roles
|
| 51 |
+
|
| 52 |
+
image = load_image(args.image_file)
|
| 53 |
+
# Similar operation in model_worker.py
|
| 54 |
+
image_tensor = process_images([image], image_processor, args)
|
| 55 |
+
if type(image_tensor) is list:
|
| 56 |
+
image_tensor = [image.to(model.device, dtype=torch.float16) for image in image_tensor]
|
| 57 |
+
else:
|
| 58 |
+
image_tensor = image_tensor.to(model.device, dtype=torch.float16)
|
| 59 |
+
|
| 60 |
+
while True:
|
| 61 |
+
try:
|
| 62 |
+
inp = input(f"{roles[0]}: ")
|
| 63 |
+
except EOFError:
|
| 64 |
+
inp = ""
|
| 65 |
+
if not inp:
|
| 66 |
+
print("exit...")
|
| 67 |
+
break
|
| 68 |
+
|
| 69 |
+
print(f"{roles[1]}: ", end="")
|
| 70 |
+
|
| 71 |
+
if image is not None:
|
| 72 |
+
# first message
|
| 73 |
+
inp = DEFAULT_IMAGE_TOKEN + inp
|
| 74 |
+
conv.append_message(conv.roles[0], inp)
|
| 75 |
+
image = None
|
| 76 |
+
else:
|
| 77 |
+
# later messages
|
| 78 |
+
conv.append_message(conv.roles[0], inp)
|
| 79 |
+
conv.append_message(conv.roles[1], None)
|
| 80 |
+
prompt = conv.get_prompt()
|
| 81 |
+
|
| 82 |
+
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).to(model.device)
|
| 83 |
+
stop_str = conv.sep if conv.sep_style not in [SeparatorStyle.TWO, SeparatorStyle.TWO_NO_SYS] else conv.sep2
|
| 84 |
+
keywords = [stop_str]
|
| 85 |
+
stopping_criteria = KeywordsStoppingCriteria(keywords, tokenizer, input_ids)
|
| 86 |
+
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
|
| 87 |
+
|
| 88 |
+
with torch.inference_mode():
|
| 89 |
+
output_ids = model.generate(
|
| 90 |
+
input_ids,
|
| 91 |
+
images=image_tensor,
|
| 92 |
+
do_sample=True,
|
| 93 |
+
temperature=args.temperature,
|
| 94 |
+
max_new_tokens=args.max_new_tokens,
|
| 95 |
+
streamer=streamer,
|
| 96 |
+
use_cache=True,
|
| 97 |
+
stopping_criteria=[stopping_criteria])
|
| 98 |
+
|
| 99 |
+
outputs = tokenizer.decode(output_ids[0, input_ids.shape[1]:]).strip()
|
| 100 |
+
conv.messages[-1][-1] = outputs
|
| 101 |
+
|
| 102 |
+
if args.debug:
|
| 103 |
+
print("\n", {"prompt": prompt, "outputs": outputs}, "\n")
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
if __name__ == "__main__":
|
| 107 |
+
parser = argparse.ArgumentParser()
|
| 108 |
+
parser.add_argument("--model-path", type=str, default="facebook/opt-350m")
|
| 109 |
+
parser.add_argument("--model-base", type=str, default=None)
|
| 110 |
+
parser.add_argument("--image-file", type=str, required=True)
|
| 111 |
+
parser.add_argument("--device", type=str, default="cuda")
|
| 112 |
+
parser.add_argument("--conv-mode", type=str, default=None)
|
| 113 |
+
parser.add_argument("--temperature", type=float, default=0.2)
|
| 114 |
+
parser.add_argument("--max-new-tokens", type=int, default=512)
|
| 115 |
+
parser.add_argument("--load-8bit", action="store_true")
|
| 116 |
+
parser.add_argument("--load-4bit", action="store_true")
|
| 117 |
+
parser.add_argument("--debug", action="store_true")
|
| 118 |
+
parser.add_argument("--image-aspect-ratio", type=str, default='pad')
|
| 119 |
+
args = parser.parse_args()
|
| 120 |
+
main(args)
|
mplug_owl2/serve/controller.py
ADDED
|
@@ -0,0 +1,298 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
A controller manages distributed workers.
|
| 3 |
+
It sends worker addresses to clients.
|
| 4 |
+
"""
|
| 5 |
+
import argparse
|
| 6 |
+
import asyncio
|
| 7 |
+
import dataclasses
|
| 8 |
+
from enum import Enum, auto
|
| 9 |
+
import json
|
| 10 |
+
import logging
|
| 11 |
+
import time
|
| 12 |
+
from typing import List, Union
|
| 13 |
+
import threading
|
| 14 |
+
|
| 15 |
+
from fastapi import FastAPI, Request
|
| 16 |
+
from fastapi.responses import StreamingResponse
|
| 17 |
+
import numpy as np
|
| 18 |
+
import requests
|
| 19 |
+
import uvicorn
|
| 20 |
+
|
| 21 |
+
from mplug_owl2.constants import CONTROLLER_HEART_BEAT_EXPIRATION
|
| 22 |
+
from mplug_owl2.utils import build_logger, server_error_msg
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
logger = build_logger("controller", "controller.log")
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class DispatchMethod(Enum):
|
| 29 |
+
LOTTERY = auto()
|
| 30 |
+
SHORTEST_QUEUE = auto()
|
| 31 |
+
|
| 32 |
+
@classmethod
|
| 33 |
+
def from_str(cls, name):
|
| 34 |
+
if name == "lottery":
|
| 35 |
+
return cls.LOTTERY
|
| 36 |
+
elif name == "shortest_queue":
|
| 37 |
+
return cls.SHORTEST_QUEUE
|
| 38 |
+
else:
|
| 39 |
+
raise ValueError(f"Invalid dispatch method")
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
@dataclasses.dataclass
|
| 43 |
+
class WorkerInfo:
|
| 44 |
+
model_names: List[str]
|
| 45 |
+
speed: int
|
| 46 |
+
queue_length: int
|
| 47 |
+
check_heart_beat: bool
|
| 48 |
+
last_heart_beat: str
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def heart_beat_controller(controller):
|
| 52 |
+
while True:
|
| 53 |
+
time.sleep(CONTROLLER_HEART_BEAT_EXPIRATION)
|
| 54 |
+
controller.remove_stable_workers_by_expiration()
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
class Controller:
|
| 58 |
+
def __init__(self, dispatch_method: str):
|
| 59 |
+
# Dict[str -> WorkerInfo]
|
| 60 |
+
self.worker_info = {}
|
| 61 |
+
self.dispatch_method = DispatchMethod.from_str(dispatch_method)
|
| 62 |
+
|
| 63 |
+
self.heart_beat_thread = threading.Thread(
|
| 64 |
+
target=heart_beat_controller, args=(self,))
|
| 65 |
+
self.heart_beat_thread.start()
|
| 66 |
+
|
| 67 |
+
logger.info("Init controller")
|
| 68 |
+
|
| 69 |
+
def register_worker(self, worker_name: str, check_heart_beat: bool,
|
| 70 |
+
worker_status: dict):
|
| 71 |
+
if worker_name not in self.worker_info:
|
| 72 |
+
logger.info(f"Register a new worker: {worker_name}")
|
| 73 |
+
else:
|
| 74 |
+
logger.info(f"Register an existing worker: {worker_name}")
|
| 75 |
+
|
| 76 |
+
if not worker_status:
|
| 77 |
+
worker_status = self.get_worker_status(worker_name)
|
| 78 |
+
if not worker_status:
|
| 79 |
+
return False
|
| 80 |
+
|
| 81 |
+
self.worker_info[worker_name] = WorkerInfo(
|
| 82 |
+
worker_status["model_names"], worker_status["speed"], worker_status["queue_length"],
|
| 83 |
+
check_heart_beat, time.time())
|
| 84 |
+
|
| 85 |
+
logger.info(f"Register done: {worker_name}, {worker_status}")
|
| 86 |
+
return True
|
| 87 |
+
|
| 88 |
+
def get_worker_status(self, worker_name: str):
|
| 89 |
+
try:
|
| 90 |
+
r = requests.post(worker_name + "/worker_get_status", timeout=5)
|
| 91 |
+
except requests.exceptions.RequestException as e:
|
| 92 |
+
logger.error(f"Get status fails: {worker_name}, {e}")
|
| 93 |
+
return None
|
| 94 |
+
|
| 95 |
+
if r.status_code != 200:
|
| 96 |
+
logger.error(f"Get status fails: {worker_name}, {r}")
|
| 97 |
+
return None
|
| 98 |
+
|
| 99 |
+
return r.json()
|
| 100 |
+
|
| 101 |
+
def remove_worker(self, worker_name: str):
|
| 102 |
+
del self.worker_info[worker_name]
|
| 103 |
+
|
| 104 |
+
def refresh_all_workers(self):
|
| 105 |
+
old_info = dict(self.worker_info)
|
| 106 |
+
self.worker_info = {}
|
| 107 |
+
|
| 108 |
+
for w_name, w_info in old_info.items():
|
| 109 |
+
if not self.register_worker(w_name, w_info.check_heart_beat, None):
|
| 110 |
+
logger.info(f"Remove stale worker: {w_name}")
|
| 111 |
+
|
| 112 |
+
def list_models(self):
|
| 113 |
+
model_names = set()
|
| 114 |
+
|
| 115 |
+
for w_name, w_info in self.worker_info.items():
|
| 116 |
+
model_names.update(w_info.model_names)
|
| 117 |
+
|
| 118 |
+
return list(model_names)
|
| 119 |
+
|
| 120 |
+
def get_worker_address(self, model_name: str):
|
| 121 |
+
if self.dispatch_method == DispatchMethod.LOTTERY:
|
| 122 |
+
worker_names = []
|
| 123 |
+
worker_speeds = []
|
| 124 |
+
for w_name, w_info in self.worker_info.items():
|
| 125 |
+
if model_name in w_info.model_names:
|
| 126 |
+
worker_names.append(w_name)
|
| 127 |
+
worker_speeds.append(w_info.speed)
|
| 128 |
+
worker_speeds = np.array(worker_speeds, dtype=np.float32)
|
| 129 |
+
norm = np.sum(worker_speeds)
|
| 130 |
+
if norm < 1e-4:
|
| 131 |
+
return ""
|
| 132 |
+
worker_speeds = worker_speeds / norm
|
| 133 |
+
if True: # Directly return address
|
| 134 |
+
pt = np.random.choice(np.arange(len(worker_names)),
|
| 135 |
+
p=worker_speeds)
|
| 136 |
+
worker_name = worker_names[pt]
|
| 137 |
+
return worker_name
|
| 138 |
+
|
| 139 |
+
# Check status before returning
|
| 140 |
+
while True:
|
| 141 |
+
pt = np.random.choice(np.arange(len(worker_names)),
|
| 142 |
+
p=worker_speeds)
|
| 143 |
+
worker_name = worker_names[pt]
|
| 144 |
+
|
| 145 |
+
if self.get_worker_status(worker_name):
|
| 146 |
+
break
|
| 147 |
+
else:
|
| 148 |
+
self.remove_worker(worker_name)
|
| 149 |
+
worker_speeds[pt] = 0
|
| 150 |
+
norm = np.sum(worker_speeds)
|
| 151 |
+
if norm < 1e-4:
|
| 152 |
+
return ""
|
| 153 |
+
worker_speeds = worker_speeds / norm
|
| 154 |
+
continue
|
| 155 |
+
return worker_name
|
| 156 |
+
elif self.dispatch_method == DispatchMethod.SHORTEST_QUEUE:
|
| 157 |
+
worker_names = []
|
| 158 |
+
worker_qlen = []
|
| 159 |
+
for w_name, w_info in self.worker_info.items():
|
| 160 |
+
if model_name in w_info.model_names:
|
| 161 |
+
worker_names.append(w_name)
|
| 162 |
+
worker_qlen.append(w_info.queue_length / w_info.speed)
|
| 163 |
+
if len(worker_names) == 0:
|
| 164 |
+
return ""
|
| 165 |
+
min_index = np.argmin(worker_qlen)
|
| 166 |
+
w_name = worker_names[min_index]
|
| 167 |
+
self.worker_info[w_name].queue_length += 1
|
| 168 |
+
logger.info(f"names: {worker_names}, queue_lens: {worker_qlen}, ret: {w_name}")
|
| 169 |
+
return w_name
|
| 170 |
+
else:
|
| 171 |
+
raise ValueError(f"Invalid dispatch method: {self.dispatch_method}")
|
| 172 |
+
|
| 173 |
+
def receive_heart_beat(self, worker_name: str, queue_length: int):
|
| 174 |
+
if worker_name not in self.worker_info:
|
| 175 |
+
logger.info(f"Receive unknown heart beat. {worker_name}")
|
| 176 |
+
return False
|
| 177 |
+
|
| 178 |
+
self.worker_info[worker_name].queue_length = queue_length
|
| 179 |
+
self.worker_info[worker_name].last_heart_beat = time.time()
|
| 180 |
+
logger.info(f"Receive heart beat. {worker_name}")
|
| 181 |
+
return True
|
| 182 |
+
|
| 183 |
+
def remove_stable_workers_by_expiration(self):
|
| 184 |
+
expire = time.time() - CONTROLLER_HEART_BEAT_EXPIRATION
|
| 185 |
+
to_delete = []
|
| 186 |
+
for worker_name, w_info in self.worker_info.items():
|
| 187 |
+
if w_info.check_heart_beat and w_info.last_heart_beat < expire:
|
| 188 |
+
to_delete.append(worker_name)
|
| 189 |
+
|
| 190 |
+
for worker_name in to_delete:
|
| 191 |
+
self.remove_worker(worker_name)
|
| 192 |
+
|
| 193 |
+
def worker_api_generate_stream(self, params):
|
| 194 |
+
worker_addr = self.get_worker_address(params["model"])
|
| 195 |
+
if not worker_addr:
|
| 196 |
+
logger.info(f"no worker: {params['model']}")
|
| 197 |
+
ret = {
|
| 198 |
+
"text": server_error_msg,
|
| 199 |
+
"error_code": 2,
|
| 200 |
+
}
|
| 201 |
+
yield json.dumps(ret).encode() + b"\0"
|
| 202 |
+
|
| 203 |
+
try:
|
| 204 |
+
response = requests.post(worker_addr + "/worker_generate_stream",
|
| 205 |
+
json=params, stream=True, timeout=5)
|
| 206 |
+
for chunk in response.iter_lines(decode_unicode=False, delimiter=b"\0"):
|
| 207 |
+
if chunk:
|
| 208 |
+
yield chunk + b"\0"
|
| 209 |
+
except requests.exceptions.RequestException as e:
|
| 210 |
+
logger.info(f"worker timeout: {worker_addr}")
|
| 211 |
+
ret = {
|
| 212 |
+
"text": server_error_msg,
|
| 213 |
+
"error_code": 3,
|
| 214 |
+
}
|
| 215 |
+
yield json.dumps(ret).encode() + b"\0"
|
| 216 |
+
|
| 217 |
+
|
| 218 |
+
# Let the controller act as a worker to achieve hierarchical
|
| 219 |
+
# management. This can be used to connect isolated sub networks.
|
| 220 |
+
def worker_api_get_status(self):
|
| 221 |
+
model_names = set()
|
| 222 |
+
speed = 0
|
| 223 |
+
queue_length = 0
|
| 224 |
+
|
| 225 |
+
for w_name in self.worker_info:
|
| 226 |
+
worker_status = self.get_worker_status(w_name)
|
| 227 |
+
if worker_status is not None:
|
| 228 |
+
model_names.update(worker_status["model_names"])
|
| 229 |
+
speed += worker_status["speed"]
|
| 230 |
+
queue_length += worker_status["queue_length"]
|
| 231 |
+
|
| 232 |
+
return {
|
| 233 |
+
"model_names": list(model_names),
|
| 234 |
+
"speed": speed,
|
| 235 |
+
"queue_length": queue_length,
|
| 236 |
+
}
|
| 237 |
+
|
| 238 |
+
|
| 239 |
+
app = FastAPI()
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
@app.post("/register_worker")
|
| 243 |
+
async def register_worker(request: Request):
|
| 244 |
+
data = await request.json()
|
| 245 |
+
controller.register_worker(
|
| 246 |
+
data["worker_name"], data["check_heart_beat"],
|
| 247 |
+
data.get("worker_status", None))
|
| 248 |
+
|
| 249 |
+
|
| 250 |
+
@app.post("/refresh_all_workers")
|
| 251 |
+
async def refresh_all_workers():
|
| 252 |
+
models = controller.refresh_all_workers()
|
| 253 |
+
|
| 254 |
+
|
| 255 |
+
@app.post("/list_models")
|
| 256 |
+
async def list_models():
|
| 257 |
+
models = controller.list_models()
|
| 258 |
+
return {"models": models}
|
| 259 |
+
|
| 260 |
+
|
| 261 |
+
@app.post("/get_worker_address")
|
| 262 |
+
async def get_worker_address(request: Request):
|
| 263 |
+
data = await request.json()
|
| 264 |
+
addr = controller.get_worker_address(data["model"])
|
| 265 |
+
return {"address": addr}
|
| 266 |
+
|
| 267 |
+
|
| 268 |
+
@app.post("/receive_heart_beat")
|
| 269 |
+
async def receive_heart_beat(request: Request):
|
| 270 |
+
data = await request.json()
|
| 271 |
+
exist = controller.receive_heart_beat(
|
| 272 |
+
data["worker_name"], data["queue_length"])
|
| 273 |
+
return {"exist": exist}
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
@app.post("/worker_generate_stream")
|
| 277 |
+
async def worker_api_generate_stream(request: Request):
|
| 278 |
+
params = await request.json()
|
| 279 |
+
generator = controller.worker_api_generate_stream(params)
|
| 280 |
+
return StreamingResponse(generator)
|
| 281 |
+
|
| 282 |
+
|
| 283 |
+
@app.post("/worker_get_status")
|
| 284 |
+
async def worker_api_get_status(request: Request):
|
| 285 |
+
return controller.worker_api_get_status()
|
| 286 |
+
|
| 287 |
+
|
| 288 |
+
if __name__ == "__main__":
|
| 289 |
+
parser = argparse.ArgumentParser()
|
| 290 |
+
parser.add_argument("--host", type=str, default="localhost")
|
| 291 |
+
parser.add_argument("--port", type=int, default=21001)
|
| 292 |
+
parser.add_argument("--dispatch-method", type=str, choices=[
|
| 293 |
+
"lottery", "shortest_queue"], default="shortest_queue")
|
| 294 |
+
args = parser.parse_args()
|
| 295 |
+
logger.info(f"args: {args}")
|
| 296 |
+
|
| 297 |
+
controller = Controller(args.dispatch_method)
|
| 298 |
+
uvicorn.run(app, host=args.host, port=args.port, log_level="info")
|
mplug_owl2/serve/examples/Rebecca_(1939_poster)_Small.jpeg
ADDED
_Small.jpeg)
|
mplug_owl2/serve/examples/extreme_ironing.jpg
ADDED

|
mplug_owl2/serve/gradio_web_server.py
ADDED
|
@@ -0,0 +1,460 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import datetime
|
| 3 |
+
import json
|
| 4 |
+
import os
|
| 5 |
+
import time
|
| 6 |
+
|
| 7 |
+
import gradio as gr
|
| 8 |
+
import requests
|
| 9 |
+
|
| 10 |
+
from mplug_owl2.conversation import (default_conversation, conv_templates,
|
| 11 |
+
SeparatorStyle)
|
| 12 |
+
from mplug_owl2.constants import LOGDIR
|
| 13 |
+
from mplug_owl2.utils import (build_logger, server_error_msg,
|
| 14 |
+
violates_moderation, moderation_msg)
|
| 15 |
+
import hashlib
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
logger = build_logger("gradio_web_server", "gradio_web_server.log")
|
| 19 |
+
|
| 20 |
+
headers = {"User-Agent": "mPLUG-Owl2 Client"}
|
| 21 |
+
|
| 22 |
+
no_change_btn = gr.Button.update()
|
| 23 |
+
enable_btn = gr.Button.update(interactive=True)
|
| 24 |
+
disable_btn = gr.Button.update(interactive=False)
|
| 25 |
+
|
| 26 |
+
priority = {
|
| 27 |
+
"vicuna-13b": "aaaaaaa",
|
| 28 |
+
"koala-13b": "aaaaaab",
|
| 29 |
+
}
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def get_conv_log_filename():
|
| 33 |
+
t = datetime.datetime.now()
|
| 34 |
+
name = os.path.join(LOGDIR, f"{t.year}-{t.month:02d}-{t.day:02d}-conv.json")
|
| 35 |
+
return name
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def get_model_list():
|
| 39 |
+
ret = requests.post(args.controller_url + "/refresh_all_workers")
|
| 40 |
+
assert ret.status_code == 200
|
| 41 |
+
ret = requests.post(args.controller_url + "/list_models")
|
| 42 |
+
models = ret.json()["models"]
|
| 43 |
+
models.sort(key=lambda x: priority.get(x, x))
|
| 44 |
+
logger.info(f"Models: {models}")
|
| 45 |
+
return models
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
get_window_url_params = """
|
| 49 |
+
function() {
|
| 50 |
+
const params = new URLSearchParams(window.location.search);
|
| 51 |
+
url_params = Object.fromEntries(params);
|
| 52 |
+
console.log(url_params);
|
| 53 |
+
return url_params;
|
| 54 |
+
}
|
| 55 |
+
"""
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def load_demo(url_params, request: gr.Request):
|
| 59 |
+
logger.info(f"load_demo. ip: {request.client.host}. params: {url_params}")
|
| 60 |
+
|
| 61 |
+
dropdown_update = gr.Dropdown.update(visible=True)
|
| 62 |
+
if "model" in url_params:
|
| 63 |
+
model = url_params["model"]
|
| 64 |
+
if model in models:
|
| 65 |
+
dropdown_update = gr.Dropdown.update(
|
| 66 |
+
value=model, visible=True)
|
| 67 |
+
|
| 68 |
+
state = default_conversation.copy()
|
| 69 |
+
return state, dropdown_update
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def load_demo_refresh_model_list(request: gr.Request):
|
| 73 |
+
logger.info(f"load_demo. ip: {request.client.host}")
|
| 74 |
+
models = get_model_list()
|
| 75 |
+
state = default_conversation.copy()
|
| 76 |
+
dropdown_update = gr.Dropdown.update(
|
| 77 |
+
choices=models,
|
| 78 |
+
value=models[0] if len(models) > 0 else ""
|
| 79 |
+
)
|
| 80 |
+
return state, dropdown_update
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def vote_last_response(state, vote_type, model_selector, request: gr.Request):
|
| 84 |
+
with open(get_conv_log_filename(), "a") as fout:
|
| 85 |
+
data = {
|
| 86 |
+
"tstamp": round(time.time(), 4),
|
| 87 |
+
"type": vote_type,
|
| 88 |
+
"model": model_selector,
|
| 89 |
+
"state": state.dict(),
|
| 90 |
+
"ip": request.client.host,
|
| 91 |
+
}
|
| 92 |
+
fout.write(json.dumps(data) + "\n")
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def upvote_last_response(state, model_selector, request: gr.Request):
|
| 96 |
+
logger.info(f"upvote. ip: {request.client.host}")
|
| 97 |
+
vote_last_response(state, "upvote", model_selector, request)
|
| 98 |
+
return ("",) + (disable_btn,) * 3
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def downvote_last_response(state, model_selector, request: gr.Request):
|
| 102 |
+
logger.info(f"downvote. ip: {request.client.host}")
|
| 103 |
+
vote_last_response(state, "downvote", model_selector, request)
|
| 104 |
+
return ("",) + (disable_btn,) * 3
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
def flag_last_response(state, model_selector, request: gr.Request):
|
| 108 |
+
logger.info(f"flag. ip: {request.client.host}")
|
| 109 |
+
vote_last_response(state, "flag", model_selector, request)
|
| 110 |
+
return ("",) + (disable_btn,) * 3
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
def regenerate(state, image_process_mode, request: gr.Request):
|
| 114 |
+
logger.info(f"regenerate. ip: {request.client.host}")
|
| 115 |
+
state.messages[-1][-1] = None
|
| 116 |
+
prev_human_msg = state.messages[-2]
|
| 117 |
+
if type(prev_human_msg[1]) in (tuple, list):
|
| 118 |
+
prev_human_msg[1] = (*prev_human_msg[1][:2], image_process_mode)
|
| 119 |
+
state.skip_next = False
|
| 120 |
+
return (state, state.to_gradio_chatbot(), "", None) + (disable_btn,) * 5
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
def clear_history(request: gr.Request):
|
| 124 |
+
logger.info(f"clear_history. ip: {request.client.host}")
|
| 125 |
+
state = default_conversation.copy()
|
| 126 |
+
return (state, state.to_gradio_chatbot(), "", None) + (disable_btn,) * 5
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
def add_text(state, text, image, image_process_mode, request: gr.Request):
|
| 130 |
+
logger.info(f"add_text. ip: {request.client.host}. len: {len(text)}")
|
| 131 |
+
if len(text) <= 0 and image is None:
|
| 132 |
+
state.skip_next = True
|
| 133 |
+
return (state, state.to_gradio_chatbot(), "", None) + (no_change_btn,) * 5
|
| 134 |
+
if args.moderate:
|
| 135 |
+
flagged = violates_moderation(text)
|
| 136 |
+
if flagged:
|
| 137 |
+
state.skip_next = True
|
| 138 |
+
return (state, state.to_gradio_chatbot(), moderation_msg, None) + (
|
| 139 |
+
no_change_btn,) * 5
|
| 140 |
+
|
| 141 |
+
text = text[:1536] # Hard cut-off
|
| 142 |
+
if image is not None:
|
| 143 |
+
text = text[:1200] # Hard cut-off for images
|
| 144 |
+
if '<|image|>' not in text:
|
| 145 |
+
# text = text + '<|image|>'
|
| 146 |
+
text = '<|image|>' + text
|
| 147 |
+
text = (text, image, image_process_mode)
|
| 148 |
+
if len(state.get_images(return_pil=True)) > 0:
|
| 149 |
+
state = default_conversation.copy()
|
| 150 |
+
state.append_message(state.roles[0], text)
|
| 151 |
+
state.append_message(state.roles[1], None)
|
| 152 |
+
state.skip_next = False
|
| 153 |
+
return (state, state.to_gradio_chatbot(), "", None) + (disable_btn,) * 5
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
def http_bot(state, model_selector, temperature, top_p, max_new_tokens, request: gr.Request):
|
| 157 |
+
logger.info(f"http_bot. ip: {request.client.host}")
|
| 158 |
+
start_tstamp = time.time()
|
| 159 |
+
model_name = model_selector
|
| 160 |
+
|
| 161 |
+
if state.skip_next:
|
| 162 |
+
# This generate call is skipped due to invalid inputs
|
| 163 |
+
yield (state, state.to_gradio_chatbot()) + (no_change_btn,) * 5
|
| 164 |
+
return
|
| 165 |
+
|
| 166 |
+
if len(state.messages) == state.offset + 2:
|
| 167 |
+
# First round of conversation
|
| 168 |
+
template_name = "mplug_owl2"
|
| 169 |
+
new_state = conv_templates[template_name].copy()
|
| 170 |
+
new_state.append_message(new_state.roles[0], state.messages[-2][1])
|
| 171 |
+
new_state.append_message(new_state.roles[1], None)
|
| 172 |
+
state = new_state
|
| 173 |
+
|
| 174 |
+
# Query worker address
|
| 175 |
+
controller_url = args.controller_url
|
| 176 |
+
ret = requests.post(controller_url + "/get_worker_address",
|
| 177 |
+
json={"model": model_name})
|
| 178 |
+
worker_addr = ret.json()["address"]
|
| 179 |
+
logger.info(f"model_name: {model_name}, worker_addr: {worker_addr}")
|
| 180 |
+
|
| 181 |
+
# No available worker
|
| 182 |
+
if worker_addr == "":
|
| 183 |
+
state.messages[-1][-1] = server_error_msg
|
| 184 |
+
yield (state, state.to_gradio_chatbot(), disable_btn, disable_btn, disable_btn, enable_btn, enable_btn)
|
| 185 |
+
return
|
| 186 |
+
|
| 187 |
+
# Construct prompt
|
| 188 |
+
prompt = state.get_prompt()
|
| 189 |
+
|
| 190 |
+
all_images = state.get_images(return_pil=True)
|
| 191 |
+
all_image_hash = [hashlib.md5(image.tobytes()).hexdigest() for image in all_images]
|
| 192 |
+
for image, hash in zip(all_images, all_image_hash):
|
| 193 |
+
t = datetime.datetime.now()
|
| 194 |
+
filename = os.path.join(LOGDIR, "serve_images", f"{t.year}-{t.month:02d}-{t.day:02d}", f"{hash}.jpg")
|
| 195 |
+
if not os.path.isfile(filename):
|
| 196 |
+
os.makedirs(os.path.dirname(filename), exist_ok=True)
|
| 197 |
+
image.save(filename)
|
| 198 |
+
|
| 199 |
+
# Make requests
|
| 200 |
+
pload = {
|
| 201 |
+
"model": model_name,
|
| 202 |
+
"prompt": prompt,
|
| 203 |
+
"temperature": float(temperature),
|
| 204 |
+
"top_p": float(top_p),
|
| 205 |
+
"max_new_tokens": min(int(max_new_tokens), 1536),
|
| 206 |
+
"stop": state.sep if state.sep_style in [SeparatorStyle.SINGLE, SeparatorStyle.MPT] else state.sep2,
|
| 207 |
+
"images": f'List of {len(state.get_images())} images: {all_image_hash}',
|
| 208 |
+
}
|
| 209 |
+
logger.info(f"==== request ====\n{pload}")
|
| 210 |
+
|
| 211 |
+
pload['images'] = state.get_images()
|
| 212 |
+
|
| 213 |
+
state.messages[-1][-1] = "▌"
|
| 214 |
+
yield (state, state.to_gradio_chatbot()) + (disable_btn,) * 5
|
| 215 |
+
|
| 216 |
+
try:
|
| 217 |
+
# Stream output
|
| 218 |
+
response = requests.post(worker_addr + "/worker_generate_stream",
|
| 219 |
+
headers=headers, json=pload, stream=True, timeout=10)
|
| 220 |
+
for chunk in response.iter_lines(decode_unicode=False, delimiter=b"\0"):
|
| 221 |
+
if chunk:
|
| 222 |
+
data = json.loads(chunk.decode())
|
| 223 |
+
if data["error_code"] == 0:
|
| 224 |
+
output = data["text"][len(prompt):].strip()
|
| 225 |
+
state.messages[-1][-1] = output + "▌"
|
| 226 |
+
yield (state, state.to_gradio_chatbot()) + (disable_btn,) * 5
|
| 227 |
+
else:
|
| 228 |
+
output = data["text"] + f" (error_code: {data['error_code']})"
|
| 229 |
+
state.messages[-1][-1] = output
|
| 230 |
+
yield (state, state.to_gradio_chatbot()) + (disable_btn, disable_btn, disable_btn, enable_btn, enable_btn)
|
| 231 |
+
return
|
| 232 |
+
time.sleep(0.03)
|
| 233 |
+
except requests.exceptions.RequestException as e:
|
| 234 |
+
state.messages[-1][-1] = server_error_msg
|
| 235 |
+
yield (state, state.to_gradio_chatbot()) + (disable_btn, disable_btn, disable_btn, enable_btn, enable_btn)
|
| 236 |
+
return
|
| 237 |
+
|
| 238 |
+
state.messages[-1][-1] = state.messages[-1][-1][:-1]
|
| 239 |
+
yield (state, state.to_gradio_chatbot()) + (enable_btn,) * 5
|
| 240 |
+
|
| 241 |
+
finish_tstamp = time.time()
|
| 242 |
+
logger.info(f"{output}")
|
| 243 |
+
|
| 244 |
+
with open(get_conv_log_filename(), "a") as fout:
|
| 245 |
+
data = {
|
| 246 |
+
"tstamp": round(finish_tstamp, 4),
|
| 247 |
+
"type": "chat",
|
| 248 |
+
"model": model_name,
|
| 249 |
+
"start": round(start_tstamp, 4),
|
| 250 |
+
"finish": round(start_tstamp, 4),
|
| 251 |
+
"state": state.dict(),
|
| 252 |
+
"images": all_image_hash,
|
| 253 |
+
"ip": request.client.host,
|
| 254 |
+
}
|
| 255 |
+
fout.write(json.dumps(data) + "\n")
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
title_markdown = ("""
|
| 259 |
+
<h1 align="center"><a href="https://github.com/X-PLUG/mPLUG-Owl"><img src="https://z1.ax1x.com/2023/11/03/piM1rGQ.md.png", alt="mPLUG-Owl" border="0" style="margin: 0 auto; height: 200px;" /></a> </h1>
|
| 260 |
+
|
| 261 |
+
<h2 align="center"> mPLUG-Owl2: Revolutionizing Multi-modal Large Language Model with Modality Collaboration</h2>
|
| 262 |
+
|
| 263 |
+
<h5 align="center"> If you like our project, please give us a star ✨ on Github for latest update. </h2>
|
| 264 |
+
|
| 265 |
+
<div align="center">
|
| 266 |
+
<div style="display:flex; gap: 0.25rem;" align="center">
|
| 267 |
+
<a href='https://github.com/X-PLUG/mPLUG-Owl'><img src='https://img.shields.io/badge/Github-Code-blue'></a>
|
| 268 |
+
<a href="https://arxiv.org/abs/2304.14178"><img src="https://img.shields.io/badge/Arxiv-2304.14178-red"></a>
|
| 269 |
+
<a href='https://github.com/X-PLUG/mPLUG-Owl/stargazers'><img src='https://img.shields.io/github/stars/X-PLUG/mPLUG-Owl.svg?style=social'></a>
|
| 270 |
+
</div>
|
| 271 |
+
</div>
|
| 272 |
+
|
| 273 |
+
""")
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
tos_markdown = ("""
|
| 277 |
+
### Terms of use
|
| 278 |
+
By using this service, users are required to agree to the following terms:
|
| 279 |
+
The service is a research preview intended for non-commercial use only. It only provides limited safety measures and may generate offensive content. It must not be used for any illegal, harmful, violent, racist, or sexual purposes. The service may collect user dialogue data for future research.
|
| 280 |
+
Please click the "Flag" button if you get any inappropriate answer! We will collect those to keep improving our moderator.
|
| 281 |
+
For an optimal experience, please use desktop computers for this demo, as mobile devices may compromise its quality.
|
| 282 |
+
""")
|
| 283 |
+
|
| 284 |
+
|
| 285 |
+
learn_more_markdown = ("""
|
| 286 |
+
### License
|
| 287 |
+
The service is a research preview intended for non-commercial use only, subject to the model [License](https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md) of LLaMA, [Terms of Use](https://openai.com/policies/terms-of-use) of the data generated by OpenAI, and [Privacy Practices](https://chrome.google.com/webstore/detail/sharegpt-share-your-chatg/daiacboceoaocpibfodeljbdfacokfjb) of ShareGPT. Please contact us if you find any potential violation.
|
| 288 |
+
""")
|
| 289 |
+
|
| 290 |
+
block_css = """
|
| 291 |
+
|
| 292 |
+
#buttons button {
|
| 293 |
+
min-width: min(120px,100%);
|
| 294 |
+
}
|
| 295 |
+
|
| 296 |
+
"""
|
| 297 |
+
|
| 298 |
+
def build_demo(embed_mode):
|
| 299 |
+
textbox = gr.Textbox(show_label=False, placeholder="Enter text and press ENTER", container=False)
|
| 300 |
+
with gr.Blocks(title="mPLUG-Owl2", theme=gr.themes.Default(), css=block_css) as demo:
|
| 301 |
+
state = gr.State()
|
| 302 |
+
|
| 303 |
+
if not embed_mode:
|
| 304 |
+
gr.Markdown(title_markdown)
|
| 305 |
+
|
| 306 |
+
with gr.Row():
|
| 307 |
+
with gr.Column(scale=3):
|
| 308 |
+
with gr.Row(elem_id="model_selector_row"):
|
| 309 |
+
model_selector = gr.Dropdown(
|
| 310 |
+
choices=models,
|
| 311 |
+
value=models[0] if len(models) > 0 else "",
|
| 312 |
+
interactive=True,
|
| 313 |
+
show_label=False,
|
| 314 |
+
container=False)
|
| 315 |
+
|
| 316 |
+
imagebox = gr.Image(type="pil")
|
| 317 |
+
image_process_mode = gr.Radio(
|
| 318 |
+
["Crop", "Resize", "Pad", "Default"],
|
| 319 |
+
value="Default",
|
| 320 |
+
label="Preprocess for non-square image", visible=False)
|
| 321 |
+
|
| 322 |
+
cur_dir = os.path.dirname(os.path.abspath(__file__))
|
| 323 |
+
gr.Examples(examples=[
|
| 324 |
+
[f"{cur_dir}/examples/extreme_ironing.jpg", "What is unusual about this image?"],
|
| 325 |
+
[f"{cur_dir}/examples/Rebecca_(1939_poster)_Small.jpeg", "What is the name of the movie in the poster?"],
|
| 326 |
+
], inputs=[imagebox, textbox])
|
| 327 |
+
|
| 328 |
+
with gr.Accordion("Parameters", open=True) as parameter_row:
|
| 329 |
+
temperature = gr.Slider(minimum=0.0, maximum=1.0, value=0.2, step=0.1, interactive=True, label="Temperature",)
|
| 330 |
+
top_p = gr.Slider(minimum=0.0, maximum=1.0, value=0.7, step=0.1, interactive=True, label="Top P",)
|
| 331 |
+
max_output_tokens = gr.Slider(minimum=0, maximum=1024, value=512, step=64, interactive=True, label="Max output tokens",)
|
| 332 |
+
|
| 333 |
+
with gr.Column(scale=8):
|
| 334 |
+
chatbot = gr.Chatbot(elem_id="Chatbot", label="mPLUG-Owl2 Chatbot", height=600)
|
| 335 |
+
with gr.Row():
|
| 336 |
+
with gr.Column(scale=8):
|
| 337 |
+
textbox.render()
|
| 338 |
+
with gr.Column(scale=1, min_width=50):
|
| 339 |
+
submit_btn = gr.Button(value="Send", variant="primary")
|
| 340 |
+
with gr.Row(elem_id="buttons") as button_row:
|
| 341 |
+
upvote_btn = gr.Button(value="👍 Upvote", interactive=False)
|
| 342 |
+
downvote_btn = gr.Button(value="👎 Downvote", interactive=False)
|
| 343 |
+
flag_btn = gr.Button(value="⚠️ Flag", interactive=False)
|
| 344 |
+
#stop_btn = gr.Button(value="⏹️ Stop Generation", interactive=False)
|
| 345 |
+
regenerate_btn = gr.Button(value="🔄 Regenerate", interactive=False)
|
| 346 |
+
clear_btn = gr.Button(value="🗑️ Clear", interactive=False)
|
| 347 |
+
|
| 348 |
+
if not embed_mode:
|
| 349 |
+
gr.Markdown(tos_markdown)
|
| 350 |
+
gr.Markdown(learn_more_markdown)
|
| 351 |
+
url_params = gr.JSON(visible=False)
|
| 352 |
+
|
| 353 |
+
# Register listeners
|
| 354 |
+
btn_list = [upvote_btn, downvote_btn, flag_btn, regenerate_btn, clear_btn]
|
| 355 |
+
upvote_btn.click(
|
| 356 |
+
upvote_last_response,
|
| 357 |
+
[state, model_selector],
|
| 358 |
+
[textbox, upvote_btn, downvote_btn, flag_btn],
|
| 359 |
+
queue=False
|
| 360 |
+
)
|
| 361 |
+
downvote_btn.click(
|
| 362 |
+
downvote_last_response,
|
| 363 |
+
[state, model_selector],
|
| 364 |
+
[textbox, upvote_btn, downvote_btn, flag_btn],
|
| 365 |
+
queue=False
|
| 366 |
+
)
|
| 367 |
+
flag_btn.click(
|
| 368 |
+
flag_last_response,
|
| 369 |
+
[state, model_selector],
|
| 370 |
+
[textbox, upvote_btn, downvote_btn, flag_btn],
|
| 371 |
+
queue=False
|
| 372 |
+
)
|
| 373 |
+
|
| 374 |
+
regenerate_btn.click(
|
| 375 |
+
regenerate,
|
| 376 |
+
[state, image_process_mode],
|
| 377 |
+
[state, chatbot, textbox, imagebox] + btn_list,
|
| 378 |
+
queue=False
|
| 379 |
+
).then(
|
| 380 |
+
http_bot,
|
| 381 |
+
[state, model_selector, temperature, top_p, max_output_tokens],
|
| 382 |
+
[state, chatbot] + btn_list
|
| 383 |
+
)
|
| 384 |
+
|
| 385 |
+
clear_btn.click(
|
| 386 |
+
clear_history,
|
| 387 |
+
None,
|
| 388 |
+
[state, chatbot, textbox, imagebox] + btn_list,
|
| 389 |
+
queue=False
|
| 390 |
+
)
|
| 391 |
+
|
| 392 |
+
textbox.submit(
|
| 393 |
+
add_text,
|
| 394 |
+
[state, textbox, imagebox, image_process_mode],
|
| 395 |
+
[state, chatbot, textbox, imagebox] + btn_list,
|
| 396 |
+
queue=False
|
| 397 |
+
).then(
|
| 398 |
+
http_bot,
|
| 399 |
+
[state, model_selector, temperature, top_p, max_output_tokens],
|
| 400 |
+
[state, chatbot] + btn_list
|
| 401 |
+
)
|
| 402 |
+
|
| 403 |
+
submit_btn.click(
|
| 404 |
+
add_text,
|
| 405 |
+
[state, textbox, imagebox, image_process_mode],
|
| 406 |
+
[state, chatbot, textbox, imagebox] + btn_list,
|
| 407 |
+
queue=False
|
| 408 |
+
).then(
|
| 409 |
+
http_bot,
|
| 410 |
+
[state, model_selector, temperature, top_p, max_output_tokens],
|
| 411 |
+
[state, chatbot] + btn_list
|
| 412 |
+
)
|
| 413 |
+
|
| 414 |
+
if args.model_list_mode == "once":
|
| 415 |
+
demo.load(
|
| 416 |
+
load_demo,
|
| 417 |
+
[url_params],
|
| 418 |
+
[state, model_selector],
|
| 419 |
+
_js=get_window_url_params,
|
| 420 |
+
queue=False
|
| 421 |
+
)
|
| 422 |
+
elif args.model_list_mode == "reload":
|
| 423 |
+
demo.load(
|
| 424 |
+
load_demo_refresh_model_list,
|
| 425 |
+
None,
|
| 426 |
+
[state, model_selector],
|
| 427 |
+
queue=False
|
| 428 |
+
)
|
| 429 |
+
else:
|
| 430 |
+
raise ValueError(f"Unknown model list mode: {args.model_list_mode}")
|
| 431 |
+
|
| 432 |
+
return demo
|
| 433 |
+
|
| 434 |
+
|
| 435 |
+
if __name__ == "__main__":
|
| 436 |
+
parser = argparse.ArgumentParser()
|
| 437 |
+
parser.add_argument("--host", type=str, default="0.0.0.0")
|
| 438 |
+
parser.add_argument("--port", type=int)
|
| 439 |
+
parser.add_argument("--controller-url", type=str, default="http://localhost:21001")
|
| 440 |
+
parser.add_argument("--concurrency-count", type=int, default=10)
|
| 441 |
+
parser.add_argument("--model-list-mode", type=str, default="once",
|
| 442 |
+
choices=["once", "reload"])
|
| 443 |
+
parser.add_argument("--share", action="store_true")
|
| 444 |
+
parser.add_argument("--moderate", action="store_true")
|
| 445 |
+
parser.add_argument("--embed", action="store_true")
|
| 446 |
+
args = parser.parse_args()
|
| 447 |
+
logger.info(f"args: {args}")
|
| 448 |
+
|
| 449 |
+
models = get_model_list()
|
| 450 |
+
|
| 451 |
+
logger.info(args)
|
| 452 |
+
demo = build_demo(args.embed)
|
| 453 |
+
demo.queue(
|
| 454 |
+
concurrency_count=args.concurrency_count,
|
| 455 |
+
api_open=False
|
| 456 |
+
).launch(
|
| 457 |
+
server_name=args.host,
|
| 458 |
+
server_port=args.port,
|
| 459 |
+
share=False
|
| 460 |
+
)
|
mplug_owl2/serve/model_worker.py
ADDED
|
@@ -0,0 +1,278 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
A model worker executes the model.
|
| 3 |
+
"""
|
| 4 |
+
import argparse
|
| 5 |
+
import asyncio
|
| 6 |
+
import json
|
| 7 |
+
import time
|
| 8 |
+
import threading
|
| 9 |
+
import uuid
|
| 10 |
+
|
| 11 |
+
from fastapi import FastAPI, Request, BackgroundTasks
|
| 12 |
+
from fastapi.responses import StreamingResponse
|
| 13 |
+
import requests
|
| 14 |
+
import torch
|
| 15 |
+
import uvicorn
|
| 16 |
+
from functools import partial
|
| 17 |
+
|
| 18 |
+
from mplug_owl2.constants import WORKER_HEART_BEAT_INTERVAL
|
| 19 |
+
from mplug_owl2.utils import (build_logger, server_error_msg,
|
| 20 |
+
pretty_print_semaphore)
|
| 21 |
+
from mplug_owl2.model.builder import load_pretrained_model
|
| 22 |
+
from mplug_owl2.mm_utils import process_images, load_image_from_base64, tokenizer_image_token, KeywordsStoppingCriteria
|
| 23 |
+
from mplug_owl2.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN
|
| 24 |
+
from transformers import TextIteratorStreamer
|
| 25 |
+
from threading import Thread
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
GB = 1 << 30
|
| 29 |
+
|
| 30 |
+
worker_id = str(uuid.uuid4())[:6]
|
| 31 |
+
logger = build_logger("model_worker", f"model_worker_{worker_id}.log")
|
| 32 |
+
global_counter = 0
|
| 33 |
+
|
| 34 |
+
model_semaphore = None
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def heart_beat_worker(controller):
|
| 38 |
+
|
| 39 |
+
while True:
|
| 40 |
+
time.sleep(WORKER_HEART_BEAT_INTERVAL)
|
| 41 |
+
controller.send_heart_beat()
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
class ModelWorker:
|
| 45 |
+
def __init__(self, controller_addr, worker_addr,
|
| 46 |
+
worker_id, no_register,
|
| 47 |
+
model_path, model_base, model_name,
|
| 48 |
+
load_8bit, load_4bit, device):
|
| 49 |
+
self.controller_addr = controller_addr
|
| 50 |
+
self.worker_addr = worker_addr
|
| 51 |
+
self.worker_id = worker_id
|
| 52 |
+
if model_path.endswith("/"):
|
| 53 |
+
model_path = model_path[:-1]
|
| 54 |
+
if model_name is None:
|
| 55 |
+
model_paths = model_path.split("/")
|
| 56 |
+
if model_paths[-1].startswith('checkpoint-'):
|
| 57 |
+
self.model_name = model_paths[-2] + "_" + model_paths[-1]
|
| 58 |
+
else:
|
| 59 |
+
self.model_name = model_paths[-1]
|
| 60 |
+
else:
|
| 61 |
+
self.model_name = model_name
|
| 62 |
+
|
| 63 |
+
self.device = device
|
| 64 |
+
logger.info(f"Loading the model {self.model_name} on worker {worker_id} ...")
|
| 65 |
+
self.tokenizer, self.model, self.image_processor, self.context_len = load_pretrained_model(
|
| 66 |
+
model_path, model_base, self.model_name, load_8bit, load_4bit, device=self.device)
|
| 67 |
+
self.is_multimodal = True
|
| 68 |
+
|
| 69 |
+
if not no_register:
|
| 70 |
+
self.register_to_controller()
|
| 71 |
+
self.heart_beat_thread = threading.Thread(
|
| 72 |
+
target=heart_beat_worker, args=(self,))
|
| 73 |
+
self.heart_beat_thread.start()
|
| 74 |
+
|
| 75 |
+
def register_to_controller(self):
|
| 76 |
+
logger.info("Register to controller")
|
| 77 |
+
|
| 78 |
+
url = self.controller_addr + "/register_worker"
|
| 79 |
+
data = {
|
| 80 |
+
"worker_name": self.worker_addr,
|
| 81 |
+
"check_heart_beat": True,
|
| 82 |
+
"worker_status": self.get_status()
|
| 83 |
+
}
|
| 84 |
+
r = requests.post(url, json=data)
|
| 85 |
+
assert r.status_code == 200
|
| 86 |
+
|
| 87 |
+
def send_heart_beat(self):
|
| 88 |
+
logger.info(f"Send heart beat. Models: {[self.model_name]}. "
|
| 89 |
+
f"Semaphore: {pretty_print_semaphore(model_semaphore)}. "
|
| 90 |
+
f"global_counter: {global_counter}")
|
| 91 |
+
|
| 92 |
+
url = self.controller_addr + "/receive_heart_beat"
|
| 93 |
+
|
| 94 |
+
while True:
|
| 95 |
+
try:
|
| 96 |
+
ret = requests.post(url, json={
|
| 97 |
+
"worker_name": self.worker_addr,
|
| 98 |
+
"queue_length": self.get_queue_length()}, timeout=5)
|
| 99 |
+
exist = ret.json()["exist"]
|
| 100 |
+
break
|
| 101 |
+
except requests.exceptions.RequestException as e:
|
| 102 |
+
logger.error(f"heart beat error: {e}")
|
| 103 |
+
time.sleep(5)
|
| 104 |
+
|
| 105 |
+
if not exist:
|
| 106 |
+
self.register_to_controller()
|
| 107 |
+
|
| 108 |
+
def get_queue_length(self):
|
| 109 |
+
if model_semaphore is None:
|
| 110 |
+
return 0
|
| 111 |
+
else:
|
| 112 |
+
return args.limit_model_concurrency - model_semaphore._value + (len(
|
| 113 |
+
model_semaphore._waiters) if model_semaphore._waiters is not None else 0)
|
| 114 |
+
|
| 115 |
+
def get_status(self):
|
| 116 |
+
return {
|
| 117 |
+
"model_names": [self.model_name],
|
| 118 |
+
"speed": 1,
|
| 119 |
+
"queue_length": self.get_queue_length(),
|
| 120 |
+
}
|
| 121 |
+
|
| 122 |
+
@torch.inference_mode()
|
| 123 |
+
def generate_stream(self, params):
|
| 124 |
+
tokenizer, model, image_processor = self.tokenizer, self.model, self.image_processor
|
| 125 |
+
|
| 126 |
+
prompt = params["prompt"]
|
| 127 |
+
ori_prompt = prompt
|
| 128 |
+
images = params.get("images", None)
|
| 129 |
+
num_image_tokens = 0
|
| 130 |
+
if images is not None and len(images) > 0 and self.is_multimodal:
|
| 131 |
+
if len(images) > 0:
|
| 132 |
+
if len(images) != prompt.count(DEFAULT_IMAGE_TOKEN):
|
| 133 |
+
raise ValueError("Number of images does not match number of <|image|> tokens in prompt")
|
| 134 |
+
|
| 135 |
+
images = [load_image_from_base64(image) for image in images]
|
| 136 |
+
images = process_images(images, image_processor, model.config)
|
| 137 |
+
|
| 138 |
+
if type(images) is list:
|
| 139 |
+
images = [image.to(self.model.device, dtype=torch.float16) for image in images]
|
| 140 |
+
else:
|
| 141 |
+
images = images.to(self.model.device, dtype=torch.float16)
|
| 142 |
+
|
| 143 |
+
replace_token = DEFAULT_IMAGE_TOKEN
|
| 144 |
+
prompt = prompt.replace(DEFAULT_IMAGE_TOKEN, replace_token)
|
| 145 |
+
|
| 146 |
+
num_image_tokens = prompt.count(replace_token) * (model.get_model().visual_abstractor.config.num_learnable_queries + 1)
|
| 147 |
+
else:
|
| 148 |
+
images = None
|
| 149 |
+
image_args = {"images": images}
|
| 150 |
+
else:
|
| 151 |
+
images = None
|
| 152 |
+
image_args = {}
|
| 153 |
+
|
| 154 |
+
temperature = float(params.get("temperature", 1.0))
|
| 155 |
+
top_p = float(params.get("top_p", 1.0))
|
| 156 |
+
max_context_length = getattr(model.config, 'max_position_embeddings', 4096)
|
| 157 |
+
max_new_tokens = min(int(params.get("max_new_tokens", 256)), 1024)
|
| 158 |
+
stop_str = params.get("stop", None)
|
| 159 |
+
do_sample = True if temperature > 0.001 else False
|
| 160 |
+
|
| 161 |
+
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).to(self.device)
|
| 162 |
+
keywords = [stop_str]
|
| 163 |
+
stopping_criteria = KeywordsStoppingCriteria(keywords, tokenizer, input_ids)
|
| 164 |
+
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True, timeout=15)
|
| 165 |
+
|
| 166 |
+
max_new_tokens = min(max_new_tokens, max_context_length - input_ids.shape[-1] - num_image_tokens)
|
| 167 |
+
|
| 168 |
+
if max_new_tokens < 1:
|
| 169 |
+
yield json.dumps({"text": ori_prompt + "Exceeds max token length. Please start a new conversation, thanks.", "error_code": 0}).encode() + b"\0"
|
| 170 |
+
return
|
| 171 |
+
|
| 172 |
+
thread = Thread(target=model.generate, kwargs=dict(
|
| 173 |
+
inputs=input_ids,
|
| 174 |
+
do_sample=do_sample,
|
| 175 |
+
temperature=temperature,
|
| 176 |
+
top_p=top_p,
|
| 177 |
+
max_new_tokens=max_new_tokens,
|
| 178 |
+
streamer=streamer,
|
| 179 |
+
stopping_criteria=[stopping_criteria],
|
| 180 |
+
use_cache=True,
|
| 181 |
+
**image_args
|
| 182 |
+
))
|
| 183 |
+
thread.start()
|
| 184 |
+
|
| 185 |
+
generated_text = ori_prompt
|
| 186 |
+
for new_text in streamer:
|
| 187 |
+
generated_text += new_text
|
| 188 |
+
if generated_text.endswith(stop_str):
|
| 189 |
+
generated_text = generated_text[:-len(stop_str)]
|
| 190 |
+
yield json.dumps({"text": generated_text, "error_code": 0}).encode() + b"\0"
|
| 191 |
+
|
| 192 |
+
def generate_stream_gate(self, params):
|
| 193 |
+
try:
|
| 194 |
+
for x in self.generate_stream(params):
|
| 195 |
+
yield x
|
| 196 |
+
except ValueError as e:
|
| 197 |
+
print("Caught ValueError:", e)
|
| 198 |
+
ret = {
|
| 199 |
+
"text": server_error_msg,
|
| 200 |
+
"error_code": 1,
|
| 201 |
+
}
|
| 202 |
+
yield json.dumps(ret).encode() + b"\0"
|
| 203 |
+
except torch.cuda.CudaError as e:
|
| 204 |
+
print("Caught torch.cuda.CudaError:", e)
|
| 205 |
+
ret = {
|
| 206 |
+
"text": server_error_msg,
|
| 207 |
+
"error_code": 1,
|
| 208 |
+
}
|
| 209 |
+
yield json.dumps(ret).encode() + b"\0"
|
| 210 |
+
except Exception as e:
|
| 211 |
+
print("Caught Unknown Error", e)
|
| 212 |
+
ret = {
|
| 213 |
+
"text": server_error_msg,
|
| 214 |
+
"error_code": 1,
|
| 215 |
+
}
|
| 216 |
+
yield json.dumps(ret).encode() + b"\0"
|
| 217 |
+
|
| 218 |
+
app = FastAPI()
|
| 219 |
+
|
| 220 |
+
def release_model_semaphore(fn=None):
|
| 221 |
+
model_semaphore.release()
|
| 222 |
+
if fn is not None:
|
| 223 |
+
fn()
|
| 224 |
+
|
| 225 |
+
|
| 226 |
+
@app.post("/worker_generate_stream")
|
| 227 |
+
async def generate_stream(request: Request):
|
| 228 |
+
global model_semaphore, global_counter
|
| 229 |
+
global_counter += 1
|
| 230 |
+
params = await request.json()
|
| 231 |
+
|
| 232 |
+
if model_semaphore is None:
|
| 233 |
+
model_semaphore = asyncio.Semaphore(args.limit_model_concurrency)
|
| 234 |
+
await model_semaphore.acquire()
|
| 235 |
+
worker.send_heart_beat()
|
| 236 |
+
generator = worker.generate_stream_gate(params)
|
| 237 |
+
background_tasks = BackgroundTasks()
|
| 238 |
+
background_tasks.add_task(partial(release_model_semaphore, fn=worker.send_heart_beat))
|
| 239 |
+
return StreamingResponse(generator, background=background_tasks)
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
@app.post("/worker_get_status")
|
| 243 |
+
async def get_status(request: Request):
|
| 244 |
+
return worker.get_status()
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
if __name__ == "__main__":
|
| 248 |
+
parser = argparse.ArgumentParser()
|
| 249 |
+
parser.add_argument("--host", type=str, default="localhost")
|
| 250 |
+
parser.add_argument("--port", type=int, default=21002)
|
| 251 |
+
parser.add_argument("--worker-address", type=str,
|
| 252 |
+
default="http://localhost:21002")
|
| 253 |
+
parser.add_argument("--controller-address", type=str,
|
| 254 |
+
default="http://localhost:21001")
|
| 255 |
+
parser.add_argument("--model-path", type=str, default="facebook/opt-350m")
|
| 256 |
+
parser.add_argument("--model-base", type=str, default=None)
|
| 257 |
+
parser.add_argument("--model-name", type=str)
|
| 258 |
+
parser.add_argument("--device", type=str, default="cuda")
|
| 259 |
+
parser.add_argument("--limit-model-concurrency", type=int, default=5)
|
| 260 |
+
parser.add_argument("--stream-interval", type=int, default=1)
|
| 261 |
+
parser.add_argument("--no-register", action="store_true")
|
| 262 |
+
parser.add_argument("--load-8bit", action="store_true")
|
| 263 |
+
parser.add_argument("--load-4bit", action="store_true")
|
| 264 |
+
args = parser.parse_args()
|
| 265 |
+
logger.info(f"args: {args}")
|
| 266 |
+
|
| 267 |
+
|
| 268 |
+
worker = ModelWorker(args.controller_address,
|
| 269 |
+
args.worker_address,
|
| 270 |
+
worker_id,
|
| 271 |
+
args.no_register,
|
| 272 |
+
args.model_path,
|
| 273 |
+
args.model_base,
|
| 274 |
+
args.model_name,
|
| 275 |
+
args.load_8bit,
|
| 276 |
+
args.load_4bit,
|
| 277 |
+
args.device)
|
| 278 |
+
uvicorn.run(app, host=args.host, port=args.port, log_level="info")
|
mplug_owl2/serve/register_workers.py
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Manually register workers.
|
| 3 |
+
|
| 4 |
+
Usage:
|
| 5 |
+
python3 -m fastchat.serve.register_worker --controller http://localhost:21001 --worker-name http://localhost:21002
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import argparse
|
| 9 |
+
|
| 10 |
+
import requests
|
| 11 |
+
|
| 12 |
+
if __name__ == "__main__":
|
| 13 |
+
parser = argparse.ArgumentParser()
|
| 14 |
+
parser.add_argument("--controller-address", type=str)
|
| 15 |
+
parser.add_argument("--worker-name", type=str)
|
| 16 |
+
parser.add_argument("--check-heart-beat", action="store_true")
|
| 17 |
+
args = parser.parse_args()
|
| 18 |
+
|
| 19 |
+
url = args.controller_address + "/register_worker"
|
| 20 |
+
data = {
|
| 21 |
+
"worker_name": args.worker_name,
|
| 22 |
+
"check_heart_beat": args.check_heart_beat,
|
| 23 |
+
"worker_status": None,
|
| 24 |
+
}
|
| 25 |
+
r = requests.post(url, json=data)
|
| 26 |
+
assert r.status_code == 200
|
mplug_owl2/train/llama_flash_attn_monkey_patch.py
ADDED
|
@@ -0,0 +1,117 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Optional, Tuple
|
| 2 |
+
import warnings
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
|
| 6 |
+
import transformers
|
| 7 |
+
from transformers.models.llama.modeling_llama import apply_rotary_pos_emb, repeat_kv
|
| 8 |
+
|
| 9 |
+
try:
|
| 10 |
+
from flash_attn.flash_attn_interface import flash_attn_unpadded_qkvpacked_func
|
| 11 |
+
except ImportError:
|
| 12 |
+
from flash_attn.flash_attn_interface import flash_attn_varlen_qkvpacked_func as flash_attn_unpadded_qkvpacked_func
|
| 13 |
+
from flash_attn.bert_padding import unpad_input, pad_input
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def forward(
|
| 17 |
+
self,
|
| 18 |
+
hidden_states: torch.Tensor,
|
| 19 |
+
modality_indicators: torch.Tensor,
|
| 20 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 21 |
+
position_ids: Optional[torch.Tensor] = None,
|
| 22 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 23 |
+
output_attentions: bool = False,
|
| 24 |
+
use_cache: bool = False,
|
| 25 |
+
padding_mask: bool = None,
|
| 26 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 27 |
+
if output_attentions:
|
| 28 |
+
warnings.warn(
|
| 29 |
+
"Output attentions is not supported for patched `LlamaAttention`, returning `None` instead."
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
bsz, q_len, _ = hidden_states.size()
|
| 33 |
+
|
| 34 |
+
query_states = (
|
| 35 |
+
self.q_proj(hidden_states)
|
| 36 |
+
.view(bsz, q_len, self.num_heads, self.head_dim)
|
| 37 |
+
.transpose(1, 2)
|
| 38 |
+
)
|
| 39 |
+
key_states = (
|
| 40 |
+
self.k_proj(hidden_states, modality_indicators)
|
| 41 |
+
.view(bsz, q_len, self.num_key_value_heads, self.head_dim)
|
| 42 |
+
.transpose(1, 2)
|
| 43 |
+
)
|
| 44 |
+
value_states = (
|
| 45 |
+
self.v_proj(hidden_states, modality_indicators)
|
| 46 |
+
.view(bsz, q_len, self.num_key_value_heads, self.head_dim)
|
| 47 |
+
.transpose(1, 2)
|
| 48 |
+
) # shape: (b, num_heads, s, head_dim)
|
| 49 |
+
|
| 50 |
+
kv_seq_len = key_states.shape[-2]
|
| 51 |
+
if past_key_value is not None:
|
| 52 |
+
kv_seq_len += past_key_value[0].shape[-2]
|
| 53 |
+
|
| 54 |
+
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
| 55 |
+
query_states, key_states = apply_rotary_pos_emb(
|
| 56 |
+
query_states, key_states, cos, sin, position_ids
|
| 57 |
+
)
|
| 58 |
+
|
| 59 |
+
if past_key_value is not None:
|
| 60 |
+
# reuse k, v
|
| 61 |
+
key_states = torch.cat([past_key_value[0], key_states], dim=2)
|
| 62 |
+
value_states = torch.cat([past_key_value[1], value_states], dim=2)
|
| 63 |
+
|
| 64 |
+
past_key_value = (key_states, value_states) if use_cache else None
|
| 65 |
+
|
| 66 |
+
# repeat k/v heads if n_kv_heads < n_heads
|
| 67 |
+
key_states = repeat_kv(key_states, self.num_key_value_groups)
|
| 68 |
+
value_states = repeat_kv(value_states, self.num_key_value_groups)
|
| 69 |
+
|
| 70 |
+
# Transform the data into the format required by flash attention
|
| 71 |
+
qkv = torch.stack([query_states, key_states, value_states], dim=2)
|
| 72 |
+
qkv = qkv.transpose(1, 3) # shape: [b, s, 3, num_heads, head_dim]
|
| 73 |
+
key_padding_mask = attention_mask
|
| 74 |
+
|
| 75 |
+
if key_padding_mask is None:
|
| 76 |
+
qkv = qkv.reshape(-1, 3, self.num_heads, self.head_dim)
|
| 77 |
+
cu_q_lens = torch.arange(
|
| 78 |
+
0, (bsz + 1) * q_len, step=q_len, dtype=torch.int32, device=qkv.device
|
| 79 |
+
)
|
| 80 |
+
max_s = q_len
|
| 81 |
+
output = flash_attn_unpadded_qkvpacked_func(
|
| 82 |
+
qkv, cu_q_lens, max_s, 0.0, softmax_scale=None, causal=True
|
| 83 |
+
)
|
| 84 |
+
output = output.view(bsz, q_len, -1)
|
| 85 |
+
else:
|
| 86 |
+
qkv = qkv.reshape(bsz, q_len, -1)
|
| 87 |
+
qkv, indices, cu_q_lens, max_s = unpad_input(qkv, key_padding_mask)
|
| 88 |
+
qkv = qkv.view(-1, 3, self.num_heads, self.head_dim)
|
| 89 |
+
output_unpad = flash_attn_unpadded_qkvpacked_func(
|
| 90 |
+
qkv, cu_q_lens, max_s, 0.0, softmax_scale=None, causal=True
|
| 91 |
+
)
|
| 92 |
+
output_unpad = output_unpad.reshape(-1, self.num_heads * self.head_dim)
|
| 93 |
+
output = pad_input(output_unpad, indices, bsz, q_len)
|
| 94 |
+
|
| 95 |
+
return self.o_proj(output), None, past_key_value
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
# Disable the transformation of the attention mask in LlamaModel as the flash attention
|
| 99 |
+
# requires the attention mask to be the same as the key_padding_mask
|
| 100 |
+
def _prepare_decoder_attention_mask(
|
| 101 |
+
self, attention_mask, input_shape, inputs_embeds, past_key_values_length
|
| 102 |
+
):
|
| 103 |
+
# [bsz, seq_len]
|
| 104 |
+
return attention_mask
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
def replace_llama_attn_with_flash_attn():
|
| 108 |
+
cuda_major, cuda_minor = torch.cuda.get_device_capability()
|
| 109 |
+
if cuda_major < 8:
|
| 110 |
+
warnings.warn(
|
| 111 |
+
"Flash attention is only supported on A100 or H100 GPU during training due to head dim > 64 backward."
|
| 112 |
+
"ref: https://github.com/HazyResearch/flash-attention/issues/190#issuecomment-1523359593"
|
| 113 |
+
)
|
| 114 |
+
transformers.models.llama.modeling_llama.LlamaModel._prepare_decoder_attention_mask = (
|
| 115 |
+
_prepare_decoder_attention_mask
|
| 116 |
+
)
|
| 117 |
+
transformers.models.llama.modeling_llama.LlamaAttention.forward = forward
|
mplug_owl2/train/mplug_owl2_trainer.py
ADDED
|
@@ -0,0 +1,243 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
from torch.utils.data import Sampler
|
| 5 |
+
|
| 6 |
+
from transformers import Trainer
|
| 7 |
+
from transformers.trainer import (
|
| 8 |
+
is_sagemaker_mp_enabled,
|
| 9 |
+
get_parameter_names,
|
| 10 |
+
has_length,
|
| 11 |
+
ALL_LAYERNORM_LAYERS,
|
| 12 |
+
ShardedDDPOption,
|
| 13 |
+
logger,
|
| 14 |
+
)
|
| 15 |
+
from typing import List, Optional
|
| 16 |
+
from icecream import ic
|
| 17 |
+
|
| 18 |
+
def maybe_zero_3(param, ignore_status=False, name=None):
|
| 19 |
+
from deepspeed import zero
|
| 20 |
+
from deepspeed.runtime.zero.partition_parameters import ZeroParamStatus
|
| 21 |
+
if hasattr(param, "ds_id"):
|
| 22 |
+
if param.ds_status == ZeroParamStatus.NOT_AVAILABLE:
|
| 23 |
+
if not ignore_status:
|
| 24 |
+
print(name, 'no ignore status')
|
| 25 |
+
with zero.GatheredParameters([param]):
|
| 26 |
+
param = param.data.detach().cpu().clone()
|
| 27 |
+
else:
|
| 28 |
+
param = param.detach().cpu().clone()
|
| 29 |
+
return param
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def get_mm_adapter_state_maybe_zero_3(named_params, keys_to_match):
|
| 33 |
+
to_return = {k: t for k, t in named_params if any(key_match in k for key_match in keys_to_match)}
|
| 34 |
+
to_return = {k: maybe_zero_3(v, ignore_status=True, name=k).cpu() for k, v in to_return.items()}
|
| 35 |
+
return to_return
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def split_to_even_chunks(indices, lengths, num_chunks):
|
| 39 |
+
"""
|
| 40 |
+
Split a list of indices into `chunks` chunks of roughly equal lengths.
|
| 41 |
+
"""
|
| 42 |
+
|
| 43 |
+
if len(indices) % num_chunks != 0:
|
| 44 |
+
return [indices[i::num_chunks] for i in range(num_chunks)]
|
| 45 |
+
|
| 46 |
+
num_indices_per_chunk = len(indices) // num_chunks
|
| 47 |
+
|
| 48 |
+
chunks = [[] for _ in range(num_chunks)]
|
| 49 |
+
chunks_lengths = [0 for _ in range(num_chunks)]
|
| 50 |
+
for index in indices:
|
| 51 |
+
shortest_chunk = chunks_lengths.index(min(chunks_lengths))
|
| 52 |
+
chunks[shortest_chunk].append(index)
|
| 53 |
+
chunks_lengths[shortest_chunk] += lengths[index]
|
| 54 |
+
if len(chunks[shortest_chunk]) == num_indices_per_chunk:
|
| 55 |
+
chunks_lengths[shortest_chunk] = float("inf")
|
| 56 |
+
|
| 57 |
+
return chunks
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def get_modality_length_grouped_indices(lengths, batch_size, world_size, generator=None):
|
| 61 |
+
# We need to use torch for the random part as a distributed sampler will set the random seed for torch.
|
| 62 |
+
assert all(l != 0 for l in lengths), "Should not have zero length."
|
| 63 |
+
if all(l > 0 for l in lengths) or all(l < 0 for l in lengths):
|
| 64 |
+
# all samples are in the same modality
|
| 65 |
+
return get_length_grouped_indices(lengths, batch_size, world_size, generator=generator)
|
| 66 |
+
mm_indices, mm_lengths = zip(*[(i, l) for i, l in enumerate(lengths) if l > 0])
|
| 67 |
+
lang_indices, lang_lengths = zip(*[(i, -l) for i, l in enumerate(lengths) if l < 0])
|
| 68 |
+
|
| 69 |
+
mm_shuffle = [mm_indices[i] for i in get_length_grouped_indices(mm_lengths, batch_size, world_size, generator=None)]
|
| 70 |
+
lang_shuffle = [lang_indices[i] for i in get_length_grouped_indices(lang_lengths, batch_size, world_size, generator=None)]
|
| 71 |
+
megabatch_size = world_size * batch_size
|
| 72 |
+
mm_megabatches = [mm_shuffle[i : i + megabatch_size] for i in range(0, len(mm_shuffle), megabatch_size)]
|
| 73 |
+
lang_megabatches = [lang_shuffle[i : i + megabatch_size] for i in range(0, len(lang_shuffle), megabatch_size)]
|
| 74 |
+
|
| 75 |
+
last_mm = mm_megabatches[-1]
|
| 76 |
+
last_lang = lang_megabatches[-1]
|
| 77 |
+
additional_batch = last_mm + last_lang
|
| 78 |
+
megabatches = mm_megabatches[:-1] + lang_megabatches[:-1]
|
| 79 |
+
megabatch_indices = torch.randperm(len(megabatches), generator=generator)
|
| 80 |
+
megabatches = [megabatches[i] for i in megabatch_indices]
|
| 81 |
+
|
| 82 |
+
if len(additional_batch) > 0:
|
| 83 |
+
megabatches.append(sorted(additional_batch))
|
| 84 |
+
|
| 85 |
+
return [i for megabatch in megabatches for i in megabatch]
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def get_length_grouped_indices(lengths, batch_size, world_size, generator=None, merge=True):
|
| 89 |
+
# We need to use torch for the random part as a distributed sampler will set the random seed for torch.
|
| 90 |
+
indices = torch.randperm(len(lengths), generator=generator)
|
| 91 |
+
megabatch_size = world_size * batch_size
|
| 92 |
+
megabatches = [indices[i : i + megabatch_size].tolist() for i in range(0, len(lengths), megabatch_size)]
|
| 93 |
+
megabatches = [sorted(megabatch, key=lambda i: lengths[i], reverse=True) for megabatch in megabatches]
|
| 94 |
+
megabatches = [split_to_even_chunks(megabatch, lengths, world_size) for megabatch in megabatches]
|
| 95 |
+
|
| 96 |
+
return [i for megabatch in megabatches for batch in megabatch for i in batch]
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
class LengthGroupedSampler(Sampler):
|
| 100 |
+
r"""
|
| 101 |
+
Sampler that samples indices in a way that groups together features of the dataset of roughly the same length while
|
| 102 |
+
keeping a bit of randomness.
|
| 103 |
+
"""
|
| 104 |
+
|
| 105 |
+
def __init__(
|
| 106 |
+
self,
|
| 107 |
+
batch_size: int,
|
| 108 |
+
world_size: int,
|
| 109 |
+
lengths: Optional[List[int]] = None,
|
| 110 |
+
generator=None,
|
| 111 |
+
group_by_modality: bool = False,
|
| 112 |
+
):
|
| 113 |
+
if lengths is None:
|
| 114 |
+
raise ValueError("Lengths must be provided.")
|
| 115 |
+
|
| 116 |
+
self.batch_size = batch_size
|
| 117 |
+
self.world_size = world_size
|
| 118 |
+
self.lengths = lengths
|
| 119 |
+
self.generator = generator
|
| 120 |
+
self.group_by_modality = group_by_modality
|
| 121 |
+
|
| 122 |
+
def __len__(self):
|
| 123 |
+
return len(self.lengths)
|
| 124 |
+
|
| 125 |
+
def __iter__(self):
|
| 126 |
+
if self.group_by_modality:
|
| 127 |
+
indices = get_modality_length_grouped_indices(self.lengths, self.batch_size, self.world_size, generator=self.generator)
|
| 128 |
+
else:
|
| 129 |
+
indices = get_length_grouped_indices(self.lengths, self.batch_size, self.world_size, generator=self.generator)
|
| 130 |
+
return iter(indices)
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
class MPLUGOwl2Trainer(Trainer):
|
| 134 |
+
|
| 135 |
+
def _get_train_sampler(self) -> Optional[torch.utils.data.Sampler]:
|
| 136 |
+
if self.train_dataset is None or not has_length(self.train_dataset):
|
| 137 |
+
return None
|
| 138 |
+
|
| 139 |
+
if self.args.group_by_modality_length:
|
| 140 |
+
lengths = self.train_dataset.modality_lengths
|
| 141 |
+
return LengthGroupedSampler(
|
| 142 |
+
self.args.train_batch_size,
|
| 143 |
+
world_size=self.args.world_size * self.args.gradient_accumulation_steps,
|
| 144 |
+
lengths=lengths,
|
| 145 |
+
group_by_modality=True,
|
| 146 |
+
)
|
| 147 |
+
else:
|
| 148 |
+
return super()._get_train_sampler()
|
| 149 |
+
|
| 150 |
+
def create_optimizer(self):
|
| 151 |
+
"""
|
| 152 |
+
Setup the optimizer.
|
| 153 |
+
|
| 154 |
+
We provide a reasonable default that works well. If you want to use something else, you can pass a tuple in the
|
| 155 |
+
Trainer's init through `optimizers`, or subclass and override this method in a subclass.
|
| 156 |
+
"""
|
| 157 |
+
if is_sagemaker_mp_enabled():
|
| 158 |
+
return super().create_optimizer()
|
| 159 |
+
if self.sharded_ddp == ShardedDDPOption.SIMPLE:
|
| 160 |
+
return super().create_optimizer()
|
| 161 |
+
|
| 162 |
+
opt_model = self.model
|
| 163 |
+
|
| 164 |
+
if self.optimizer is None:
|
| 165 |
+
decay_parameters = get_parameter_names(opt_model, ALL_LAYERNORM_LAYERS)
|
| 166 |
+
decay_parameters = [name for name in decay_parameters if "bias" not in name]
|
| 167 |
+
if self.args.visual_abstractor_lr is not None:
|
| 168 |
+
projector_parameters = [name for name, _ in opt_model.named_parameters() if "visual_abstractor_lr" in name]
|
| 169 |
+
optimizer_grouped_parameters = [
|
| 170 |
+
{
|
| 171 |
+
"params": [
|
| 172 |
+
p for n, p in opt_model.named_parameters() if (n in decay_parameters and n not in projector_parameters and p.requires_grad)
|
| 173 |
+
],
|
| 174 |
+
"weight_decay": self.args.weight_decay,
|
| 175 |
+
},
|
| 176 |
+
{
|
| 177 |
+
"params": [
|
| 178 |
+
p for n, p in opt_model.named_parameters() if (n not in decay_parameters and n not in projector_parameters and p.requires_grad)
|
| 179 |
+
],
|
| 180 |
+
"weight_decay": 0.0,
|
| 181 |
+
},
|
| 182 |
+
{
|
| 183 |
+
"params": [
|
| 184 |
+
p for n, p in opt_model.named_parameters() if (n in decay_parameters and n in projector_parameters and p.requires_grad)
|
| 185 |
+
],
|
| 186 |
+
"weight_decay": self.args.weight_decay,
|
| 187 |
+
"lr": self.args.visual_abstractor_lr,
|
| 188 |
+
},
|
| 189 |
+
{
|
| 190 |
+
"params": [
|
| 191 |
+
p for n, p in opt_model.named_parameters() if (n not in decay_parameters and n in projector_parameters and p.requires_grad)
|
| 192 |
+
],
|
| 193 |
+
"weight_decay": 0.0,
|
| 194 |
+
"lr": self.args.visual_abstractor_lr,
|
| 195 |
+
},
|
| 196 |
+
]
|
| 197 |
+
else:
|
| 198 |
+
optimizer_grouped_parameters = [
|
| 199 |
+
{
|
| 200 |
+
"params": [
|
| 201 |
+
p for n, p in opt_model.named_parameters() if (n in decay_parameters and p.requires_grad)
|
| 202 |
+
],
|
| 203 |
+
"weight_decay": self.args.weight_decay,
|
| 204 |
+
},
|
| 205 |
+
{
|
| 206 |
+
"params": [
|
| 207 |
+
p for n, p in opt_model.named_parameters() if (n not in decay_parameters and p.requires_grad)
|
| 208 |
+
],
|
| 209 |
+
"weight_decay": 0.0,
|
| 210 |
+
},
|
| 211 |
+
]
|
| 212 |
+
ic(len(optimizer_grouped_parameters[0]['params']),len(optimizer_grouped_parameters[1]['params']))
|
| 213 |
+
optimizer_cls, optimizer_kwargs = Trainer.get_optimizer_cls_and_kwargs(self.args)
|
| 214 |
+
|
| 215 |
+
if self.sharded_ddp == ShardedDDPOption.SIMPLE:
|
| 216 |
+
self.optimizer = OSS(
|
| 217 |
+
params=optimizer_grouped_parameters,
|
| 218 |
+
optim=optimizer_cls,
|
| 219 |
+
**optimizer_kwargs,
|
| 220 |
+
)
|
| 221 |
+
else:
|
| 222 |
+
self.optimizer = optimizer_cls(optimizer_grouped_parameters, **optimizer_kwargs)
|
| 223 |
+
if optimizer_cls.__name__ == "Adam8bit":
|
| 224 |
+
import bitsandbytes
|
| 225 |
+
|
| 226 |
+
manager = bitsandbytes.optim.GlobalOptimManager.get_instance()
|
| 227 |
+
|
| 228 |
+
skipped = 0
|
| 229 |
+
for module in opt_model.modules():
|
| 230 |
+
if isinstance(module, nn.Embedding):
|
| 231 |
+
skipped += sum({p.data_ptr(): p.numel() for p in module.parameters()}.values())
|
| 232 |
+
logger.info(f"skipped {module}: {skipped/2**20}M params")
|
| 233 |
+
manager.register_module_override(module, "weight", {"optim_bits": 32})
|
| 234 |
+
logger.debug(f"bitsandbytes: will optimize {module} in fp32")
|
| 235 |
+
logger.info(f"skipped: {skipped/2**20}M params")
|
| 236 |
+
|
| 237 |
+
return self.optimizer
|
| 238 |
+
|
| 239 |
+
def _save_checkpoint(self, model, trial, metrics=None):
|
| 240 |
+
super(MPLUGOwl2Trainer, self)._save_checkpoint(model, trial, metrics)
|
| 241 |
+
|
| 242 |
+
def _save(self, output_dir: Optional[str] = None, state_dict=None):
|
| 243 |
+
super(MPLUGOwl2Trainer, self)._save(output_dir, state_dict)
|
mplug_owl2/train/train.py
ADDED
|
@@ -0,0 +1,848 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Adopted from https://github.com/lm-sys/FastChat. Below is the original copyright:
|
| 2 |
+
# Adopted from tatsu-lab@stanford_alpaca. Below is the original copyright:
|
| 3 |
+
# Copyright 2023 Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
|
| 17 |
+
import os
|
| 18 |
+
import copy
|
| 19 |
+
from dataclasses import dataclass, field
|
| 20 |
+
import json
|
| 21 |
+
import logging
|
| 22 |
+
import pathlib
|
| 23 |
+
from typing import Dict, Optional, Sequence, List
|
| 24 |
+
|
| 25 |
+
import torch
|
| 26 |
+
|
| 27 |
+
import transformers
|
| 28 |
+
from transformers.models.clip.image_processing_clip import CLIPImageProcessor
|
| 29 |
+
|
| 30 |
+
from torch.utils.data import Dataset
|
| 31 |
+
from mplug_owl2.train.mplug_owl2_trainer import MPLUGOwl2Trainer
|
| 32 |
+
from mplug_owl2.constants import IGNORE_INDEX, IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN
|
| 33 |
+
|
| 34 |
+
from mplug_owl2 import conversation as conversation_lib
|
| 35 |
+
from mplug_owl2.model import *
|
| 36 |
+
from mplug_owl2.mm_utils import tokenizer_image_token
|
| 37 |
+
|
| 38 |
+
from PIL import Image
|
| 39 |
+
from icecream import ic
|
| 40 |
+
|
| 41 |
+
local_rank = None
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def rank0_print(*args):
|
| 45 |
+
if local_rank == 0:
|
| 46 |
+
print(*args)
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
@dataclass
|
| 50 |
+
class ModelArguments:
|
| 51 |
+
model_name_or_path: Optional[str] = field(default="facebook/opt-125m")
|
| 52 |
+
version: Optional[str] = field(default="v0")
|
| 53 |
+
freeze_backbone: bool = field(default=False)
|
| 54 |
+
tune_mm_mlp_adapter: bool = field(default=False)
|
| 55 |
+
# vision_tower: Optional[str] = field(default=None)
|
| 56 |
+
# mm_vision_select_layer: Optional[int] = field(default=-1) # default to the last layer
|
| 57 |
+
# pretrain_mm_mlp_adapter: Optional[str] = field(default=None)
|
| 58 |
+
# mm_projector_type: Optional[str] = field(default='linear')
|
| 59 |
+
# mm_use_im_start_end: bool = field(default=False)
|
| 60 |
+
# mm_use_im_patch_token: bool = field(default=True)
|
| 61 |
+
# mm_vision_select_feature: Optional[str] = field(default="patch")
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
@dataclass
|
| 65 |
+
class DataArguments:
|
| 66 |
+
data_path: str = field(default=None,
|
| 67 |
+
metadata={"help": "Path to the training data."})
|
| 68 |
+
lazy_preprocess: bool = False
|
| 69 |
+
is_multimodal: bool = False
|
| 70 |
+
image_folder: Optional[str] = field(default=None)
|
| 71 |
+
image_aspect_ratio: str = 'square'
|
| 72 |
+
image_grid_pinpoints: Optional[str] = field(default=None)
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
@dataclass
|
| 76 |
+
class TrainingArguments(transformers.TrainingArguments):
|
| 77 |
+
cache_dir: Optional[str] = field(default=None)
|
| 78 |
+
optim: str = field(default="adamw_torch")
|
| 79 |
+
remove_unused_columns: bool = field(default=False)
|
| 80 |
+
|
| 81 |
+
tune_visual_abstractor: bool = field(default=True)
|
| 82 |
+
freeze_vision_model: bool = field(default=True)
|
| 83 |
+
# freeze_mm_mlp_adapter: bool = field(default=False)
|
| 84 |
+
# mpt_attn_impl: Optional[str] = field(default="triton")
|
| 85 |
+
model_max_length: int = field(
|
| 86 |
+
default=512,
|
| 87 |
+
metadata={
|
| 88 |
+
"help":
|
| 89 |
+
"Maximum sequence length. Sequences will be right padded (and possibly truncated)."
|
| 90 |
+
},
|
| 91 |
+
)
|
| 92 |
+
double_quant: bool = field(
|
| 93 |
+
default=True,
|
| 94 |
+
metadata={"help": "Compress the quantization statistics through double quantization."}
|
| 95 |
+
)
|
| 96 |
+
quant_type: str = field(
|
| 97 |
+
default="nf4",
|
| 98 |
+
metadata={"help": "Quantization data type to use. Should be one of `fp4` or `nf4`."}
|
| 99 |
+
)
|
| 100 |
+
bits: int = field(
|
| 101 |
+
default=16,
|
| 102 |
+
metadata={"help": "How many bits to use."}
|
| 103 |
+
)
|
| 104 |
+
lora_enable: bool = False
|
| 105 |
+
lora_r: int = 64
|
| 106 |
+
lora_alpha: int = 16
|
| 107 |
+
lora_dropout: float = 0.05
|
| 108 |
+
lora_weight_path: str = ""
|
| 109 |
+
lora_bias: str = "none"
|
| 110 |
+
visual_abstractor_lr: Optional[float] = None
|
| 111 |
+
group_by_modality_length: bool = field(default=False)
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
def maybe_zero_3(param, ignore_status=False, name=None):
|
| 115 |
+
from deepspeed import zero
|
| 116 |
+
from deepspeed.runtime.zero.partition_parameters import ZeroParamStatus
|
| 117 |
+
if hasattr(param, "ds_id"):
|
| 118 |
+
if param.ds_status == ZeroParamStatus.NOT_AVAILABLE:
|
| 119 |
+
if not ignore_status:
|
| 120 |
+
logging.warning(f"{name}: param.ds_status != ZeroParamStatus.NOT_AVAILABLE: {param.ds_status}")
|
| 121 |
+
with zero.GatheredParameters([param]):
|
| 122 |
+
param = param.data.detach().cpu().clone()
|
| 123 |
+
else:
|
| 124 |
+
param = param.detach().cpu().clone()
|
| 125 |
+
return param
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
# Borrowed from peft.utils.get_peft_model_state_dict
|
| 129 |
+
def get_peft_state_maybe_zero_3(named_params, bias):
|
| 130 |
+
if bias == "none":
|
| 131 |
+
to_return = {k: t for k, t in named_params if "lora_" in k}
|
| 132 |
+
elif bias == "all":
|
| 133 |
+
to_return = {k: t for k, t in named_params if "lora_" in k or "bias" in k}
|
| 134 |
+
elif bias == "lora_only":
|
| 135 |
+
to_return = {}
|
| 136 |
+
maybe_lora_bias = {}
|
| 137 |
+
lora_bias_names = set()
|
| 138 |
+
for k, t in named_params:
|
| 139 |
+
if "lora_" in k:
|
| 140 |
+
to_return[k] = t
|
| 141 |
+
bias_name = k.split("lora_")[0] + "bias"
|
| 142 |
+
lora_bias_names.add(bias_name)
|
| 143 |
+
elif "bias" in k:
|
| 144 |
+
maybe_lora_bias[k] = t
|
| 145 |
+
for k, t in maybe_lora_bias:
|
| 146 |
+
if bias_name in lora_bias_names:
|
| 147 |
+
to_return[bias_name] = t
|
| 148 |
+
else:
|
| 149 |
+
raise NotImplementedError
|
| 150 |
+
to_return = {k: maybe_zero_3(v, ignore_status=True) for k, v in to_return.items()}
|
| 151 |
+
return to_return
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
def get_peft_state_non_lora_maybe_zero_3(named_params, require_grad_only=True):
|
| 155 |
+
to_return = {k: t for k, t in named_params if "lora_" not in k}
|
| 156 |
+
if require_grad_only:
|
| 157 |
+
to_return = {k: t for k, t in to_return.items() if t.requires_grad}
|
| 158 |
+
to_return = {k: maybe_zero_3(v, ignore_status=True).cpu() for k, v in to_return.items()}
|
| 159 |
+
return to_return
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
def get_mm_adapter_state_maybe_zero_3(named_params, keys_to_match):
|
| 163 |
+
to_return = {k: t for k, t in named_params if any(key_match in k for key_match in keys_to_match)}
|
| 164 |
+
to_return = {k: maybe_zero_3(v, ignore_status=True).cpu() for k, v in to_return.items()}
|
| 165 |
+
return to_return
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
def find_all_linear_names(model):
|
| 169 |
+
cls = torch.nn.Linear
|
| 170 |
+
lora_module_names = set()
|
| 171 |
+
multimodal_keywords = ['vision_model', 'visual_abstractor']
|
| 172 |
+
for name, module in model.named_modules():
|
| 173 |
+
if any(mm_keyword in name for mm_keyword in multimodal_keywords):
|
| 174 |
+
continue
|
| 175 |
+
if isinstance(module, cls):
|
| 176 |
+
lora_module_names.add(name)
|
| 177 |
+
|
| 178 |
+
if 'lm_head' in lora_module_names: # needed for 16-bit
|
| 179 |
+
lora_module_names.remove('lm_head')
|
| 180 |
+
return list(lora_module_names)
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
def safe_save_model_for_hf_trainer(trainer: transformers.Trainer,
|
| 184 |
+
output_dir: str):
|
| 185 |
+
"""Collects the state dict and dump to disk."""
|
| 186 |
+
|
| 187 |
+
if trainer.deepspeed:
|
| 188 |
+
torch.cuda.synchronize()
|
| 189 |
+
trainer.save_model(output_dir)
|
| 190 |
+
return
|
| 191 |
+
|
| 192 |
+
state_dict = trainer.model.state_dict()
|
| 193 |
+
if trainer.args.should_save:
|
| 194 |
+
cpu_state_dict = {
|
| 195 |
+
key: value.cpu()
|
| 196 |
+
for key, value in state_dict.items()
|
| 197 |
+
}
|
| 198 |
+
del state_dict
|
| 199 |
+
trainer._save(output_dir, state_dict=cpu_state_dict) # noqa
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
def smart_tokenizer_and_embedding_resize(
|
| 203 |
+
special_tokens_dict: Dict,
|
| 204 |
+
tokenizer: transformers.PreTrainedTokenizer,
|
| 205 |
+
model: transformers.PreTrainedModel,
|
| 206 |
+
):
|
| 207 |
+
"""Resize tokenizer and embedding.
|
| 208 |
+
|
| 209 |
+
Note: This is the unoptimized version that may make your embedding size not be divisible by 64.
|
| 210 |
+
"""
|
| 211 |
+
num_new_tokens = tokenizer.add_special_tokens(special_tokens_dict)
|
| 212 |
+
model.resize_token_embeddings(len(tokenizer))
|
| 213 |
+
|
| 214 |
+
if num_new_tokens > 0:
|
| 215 |
+
input_embeddings = model.get_input_embeddings().weight.data
|
| 216 |
+
output_embeddings = model.get_output_embeddings().weight.data
|
| 217 |
+
|
| 218 |
+
input_embeddings_avg = input_embeddings[:-num_new_tokens].mean(
|
| 219 |
+
dim=0, keepdim=True)
|
| 220 |
+
output_embeddings_avg = output_embeddings[:-num_new_tokens].mean(
|
| 221 |
+
dim=0, keepdim=True)
|
| 222 |
+
|
| 223 |
+
input_embeddings[-num_new_tokens:] = input_embeddings_avg
|
| 224 |
+
output_embeddings[-num_new_tokens:] = output_embeddings_avg
|
| 225 |
+
|
| 226 |
+
|
| 227 |
+
def _tokenize_fn(strings: Sequence[str],
|
| 228 |
+
tokenizer: transformers.PreTrainedTokenizer) -> Dict:
|
| 229 |
+
"""Tokenize a list of strings."""
|
| 230 |
+
tokenized_list = [
|
| 231 |
+
tokenizer(
|
| 232 |
+
text,
|
| 233 |
+
return_tensors="pt",
|
| 234 |
+
padding="longest",
|
| 235 |
+
max_length=tokenizer.model_max_length,
|
| 236 |
+
truncation=True,
|
| 237 |
+
) for text in strings
|
| 238 |
+
]
|
| 239 |
+
input_ids = labels = [
|
| 240 |
+
tokenized.input_ids[0] for tokenized in tokenized_list
|
| 241 |
+
]
|
| 242 |
+
input_ids_lens = labels_lens = [
|
| 243 |
+
tokenized.input_ids.ne(tokenizer.pad_token_id).sum().item()
|
| 244 |
+
for tokenized in tokenized_list
|
| 245 |
+
]
|
| 246 |
+
return dict(
|
| 247 |
+
input_ids=input_ids,
|
| 248 |
+
labels=labels,
|
| 249 |
+
input_ids_lens=input_ids_lens,
|
| 250 |
+
labels_lens=labels_lens,
|
| 251 |
+
)
|
| 252 |
+
|
| 253 |
+
|
| 254 |
+
def _mask_targets(target, tokenized_lens, speakers):
|
| 255 |
+
# cur_idx = 0
|
| 256 |
+
cur_idx = tokenized_lens[0]
|
| 257 |
+
tokenized_lens = tokenized_lens[1:]
|
| 258 |
+
target[:cur_idx] = IGNORE_INDEX
|
| 259 |
+
for tokenized_len, speaker in zip(tokenized_lens, speakers):
|
| 260 |
+
if speaker == "human":
|
| 261 |
+
target[cur_idx+2:cur_idx + tokenized_len] = IGNORE_INDEX
|
| 262 |
+
cur_idx += tokenized_len
|
| 263 |
+
|
| 264 |
+
|
| 265 |
+
def _add_speaker_and_signal(header, source, get_conversation=True):
|
| 266 |
+
"""Add speaker and start/end signal on each round."""
|
| 267 |
+
BEGIN_SIGNAL = "### "
|
| 268 |
+
END_SIGNAL = "\n"
|
| 269 |
+
conversation = header
|
| 270 |
+
for sentence in source:
|
| 271 |
+
from_str = sentence["from"]
|
| 272 |
+
if from_str.lower() == "human":
|
| 273 |
+
from_str = conversation_lib.default_conversation.roles[0]
|
| 274 |
+
elif from_str.lower() == "gpt":
|
| 275 |
+
from_str = conversation_lib.default_conversation.roles[1]
|
| 276 |
+
else:
|
| 277 |
+
from_str = 'unknown'
|
| 278 |
+
sentence["value"] = (BEGIN_SIGNAL + from_str + ": " +
|
| 279 |
+
sentence["value"] + END_SIGNAL)
|
| 280 |
+
if get_conversation:
|
| 281 |
+
conversation += sentence["value"]
|
| 282 |
+
conversation += BEGIN_SIGNAL
|
| 283 |
+
return conversation
|
| 284 |
+
|
| 285 |
+
|
| 286 |
+
def preprocess_multimodal(
|
| 287 |
+
sources: Sequence[str],
|
| 288 |
+
data_args: DataArguments
|
| 289 |
+
) -> Dict:
|
| 290 |
+
is_multimodal = data_args.is_multimodal
|
| 291 |
+
if not is_multimodal:
|
| 292 |
+
return sources
|
| 293 |
+
|
| 294 |
+
for source in sources:
|
| 295 |
+
for sentence in source:
|
| 296 |
+
if DEFAULT_IMAGE_TOKEN in sentence['value']:
|
| 297 |
+
sentence['value'] = sentence['value'].replace(DEFAULT_IMAGE_TOKEN, '').strip()
|
| 298 |
+
sentence['value'] = DEFAULT_IMAGE_TOKEN + '\n' + sentence['value']
|
| 299 |
+
sentence['value'] = sentence['value'].strip()
|
| 300 |
+
|
| 301 |
+
replace_token = DEFAULT_IMAGE_TOKEN
|
| 302 |
+
sentence["value"] = sentence["value"].replace(DEFAULT_IMAGE_TOKEN, replace_token)
|
| 303 |
+
|
| 304 |
+
return sources
|
| 305 |
+
|
| 306 |
+
|
| 307 |
+
def preprocess_v1(
|
| 308 |
+
sources,
|
| 309 |
+
tokenizer: transformers.PreTrainedTokenizer,
|
| 310 |
+
has_image: bool = False
|
| 311 |
+
) -> Dict:
|
| 312 |
+
conv = conversation_lib.default_conversation.copy()
|
| 313 |
+
roles = {"human": conv.roles[0], "gpt": conv.roles[1]}
|
| 314 |
+
|
| 315 |
+
# Apply prompt templates
|
| 316 |
+
conversations = []
|
| 317 |
+
for i, source in enumerate(sources):
|
| 318 |
+
if roles[source[0]["from"]] != conv.roles[0]:
|
| 319 |
+
# Skip the first one if it is not from human
|
| 320 |
+
source = source[1:]
|
| 321 |
+
|
| 322 |
+
conv.messages = []
|
| 323 |
+
for j, sentence in enumerate(source):
|
| 324 |
+
role = roles[sentence["from"]]
|
| 325 |
+
assert role == conv.roles[j % 2], f"{i}"
|
| 326 |
+
conv.append_message(role, sentence["value"])
|
| 327 |
+
conversations.append(conv.get_prompt())
|
| 328 |
+
|
| 329 |
+
# Tokenize conversations
|
| 330 |
+
|
| 331 |
+
if has_image:
|
| 332 |
+
input_ids = torch.stack([tokenizer_image_token(prompt, tokenizer, return_tensors='pt') for prompt in conversations], dim=0)
|
| 333 |
+
else:
|
| 334 |
+
input_ids = tokenizer(
|
| 335 |
+
conversations,
|
| 336 |
+
return_tensors="pt",
|
| 337 |
+
padding="longest",
|
| 338 |
+
max_length=tokenizer.model_max_length,
|
| 339 |
+
truncation=True,
|
| 340 |
+
).input_ids
|
| 341 |
+
|
| 342 |
+
targets = input_ids.clone()
|
| 343 |
+
|
| 344 |
+
assert conv.sep_style == conversation_lib.SeparatorStyle.TWO or conv.sep_style == conversation_lib.SeparatorStyle.TWO_NO_SYS
|
| 345 |
+
|
| 346 |
+
# Mask targets
|
| 347 |
+
sep = conv.sep + conv.roles[1] + ": "
|
| 348 |
+
for conversation, target in zip(conversations, targets):
|
| 349 |
+
total_len = int(target.ne(tokenizer.pad_token_id).sum())
|
| 350 |
+
|
| 351 |
+
rounds = conversation.split(conv.sep2)
|
| 352 |
+
cur_len = 1
|
| 353 |
+
target[:cur_len] = IGNORE_INDEX
|
| 354 |
+
for i, rou in enumerate(rounds):
|
| 355 |
+
if rou == "":
|
| 356 |
+
break
|
| 357 |
+
|
| 358 |
+
parts = rou.split(sep)
|
| 359 |
+
if len(parts) != 2:
|
| 360 |
+
break
|
| 361 |
+
parts[0] += sep
|
| 362 |
+
|
| 363 |
+
if has_image:
|
| 364 |
+
round_len = len(tokenizer_image_token(rou, tokenizer))
|
| 365 |
+
instruction_len = len(tokenizer_image_token(parts[0], tokenizer)) - 2
|
| 366 |
+
else:
|
| 367 |
+
round_len = len(tokenizer(rou).input_ids)
|
| 368 |
+
instruction_len = len(tokenizer(parts[0]).input_ids) - 2
|
| 369 |
+
|
| 370 |
+
target[cur_len : cur_len + instruction_len] = IGNORE_INDEX
|
| 371 |
+
|
| 372 |
+
cur_len += round_len
|
| 373 |
+
target[cur_len:] = IGNORE_INDEX
|
| 374 |
+
|
| 375 |
+
if cur_len < tokenizer.model_max_length:
|
| 376 |
+
if cur_len != total_len:
|
| 377 |
+
target[:] = IGNORE_INDEX
|
| 378 |
+
print(
|
| 379 |
+
f"WARNING: tokenization mismatch: {cur_len} vs. {total_len}."
|
| 380 |
+
f" (ignored)"
|
| 381 |
+
)
|
| 382 |
+
|
| 383 |
+
return dict(
|
| 384 |
+
input_ids=input_ids,
|
| 385 |
+
labels=targets,
|
| 386 |
+
)
|
| 387 |
+
|
| 388 |
+
|
| 389 |
+
def preprocess_plain(
|
| 390 |
+
sources: Sequence[str],
|
| 391 |
+
tokenizer: transformers.PreTrainedTokenizer,
|
| 392 |
+
) -> Dict:
|
| 393 |
+
# add end signal and concatenate together
|
| 394 |
+
conversations = []
|
| 395 |
+
for source in sources:
|
| 396 |
+
assert len(source) == 2
|
| 397 |
+
assert DEFAULT_IMAGE_TOKEN in source[0]['value']
|
| 398 |
+
source[0]['value'] = DEFAULT_IMAGE_TOKEN
|
| 399 |
+
conversation = source[0]['value'] + source[1]['value'] + conversation_lib.default_conversation.sep
|
| 400 |
+
conversations.append(conversation)
|
| 401 |
+
# tokenize conversations
|
| 402 |
+
input_ids = [tokenizer_image_token(prompt, tokenizer, return_tensors='pt') for prompt in conversations]
|
| 403 |
+
targets = copy.deepcopy(input_ids)
|
| 404 |
+
for target, source in zip(targets, sources):
|
| 405 |
+
tokenized_len = len(tokenizer_image_token(source[0]['value'], tokenizer))
|
| 406 |
+
target[:tokenized_len] = IGNORE_INDEX
|
| 407 |
+
|
| 408 |
+
return dict(input_ids=input_ids, labels=targets)
|
| 409 |
+
|
| 410 |
+
|
| 411 |
+
def preprocess(
|
| 412 |
+
sources: Sequence[str],
|
| 413 |
+
tokenizer: transformers.PreTrainedTokenizer,
|
| 414 |
+
has_image: bool = False
|
| 415 |
+
) -> Dict:
|
| 416 |
+
"""
|
| 417 |
+
Given a list of sources, each is a conversation list. This transform:
|
| 418 |
+
1. Add signal '### ' at the beginning each sentence, with end signal '\n';
|
| 419 |
+
2. Concatenate conversations together;
|
| 420 |
+
3. Tokenize the concatenated conversation;
|
| 421 |
+
4. Make a deepcopy as the target. Mask human words with IGNORE_INDEX.
|
| 422 |
+
"""
|
| 423 |
+
if conversation_lib.default_conversation.sep_style == conversation_lib.SeparatorStyle.PLAIN:
|
| 424 |
+
return preprocess_plain(sources, tokenizer)
|
| 425 |
+
if conversation_lib.default_conversation.version.startswith("v1"):
|
| 426 |
+
return preprocess_v1(sources, tokenizer, has_image=has_image)
|
| 427 |
+
# add end signal and concatenate together
|
| 428 |
+
conversations = []
|
| 429 |
+
for source in sources:
|
| 430 |
+
header = f"{conversation_lib.default_conversation.system}\n\n"
|
| 431 |
+
conversation = _add_speaker_and_signal(header, source)
|
| 432 |
+
conversations.append(conversation)
|
| 433 |
+
# tokenize conversations
|
| 434 |
+
def get_tokenize_len(prompts):
|
| 435 |
+
return [len(tokenizer_image_token(prompt, tokenizer)) for prompt in prompts]
|
| 436 |
+
if has_image:
|
| 437 |
+
input_ids = [tokenizer_image_token(prompt, tokenizer, return_tensors='pt') for prompt in conversations]
|
| 438 |
+
else:
|
| 439 |
+
conversations_tokenized = _tokenize_fn(conversations, tokenizer)
|
| 440 |
+
input_ids = conversations_tokenized["input_ids"]
|
| 441 |
+
|
| 442 |
+
targets = copy.deepcopy(input_ids)
|
| 443 |
+
for target, source in zip(targets, sources):
|
| 444 |
+
if has_image:
|
| 445 |
+
tokenized_lens = get_tokenize_len([header] + [s["value"] for s in source])
|
| 446 |
+
else:
|
| 447 |
+
tokenized_lens = _tokenize_fn([header] + [s["value"] for s in source], tokenizer)["input_ids_lens"]
|
| 448 |
+
speakers = [sentence["from"] for sentence in source]
|
| 449 |
+
_mask_targets(target, tokenized_lens, speakers)
|
| 450 |
+
|
| 451 |
+
return dict(input_ids=input_ids, labels=targets)
|
| 452 |
+
|
| 453 |
+
|
| 454 |
+
class LazySupervisedDataset(Dataset):
|
| 455 |
+
"""Dataset for supervised fine-tuning."""
|
| 456 |
+
|
| 457 |
+
def __init__(self, data_path: str,
|
| 458 |
+
tokenizer: transformers.PreTrainedTokenizer,
|
| 459 |
+
data_args: DataArguments):
|
| 460 |
+
super(LazySupervisedDataset, self).__init__()
|
| 461 |
+
list_data_dict = json.load(open(data_path, "r"))
|
| 462 |
+
|
| 463 |
+
rank0_print("Formatting inputs...Skip in lazy mode")
|
| 464 |
+
self.tokenizer = tokenizer
|
| 465 |
+
self.list_data_dict = list_data_dict
|
| 466 |
+
self.data_args = data_args
|
| 467 |
+
|
| 468 |
+
def __len__(self):
|
| 469 |
+
return len(self.list_data_dict)
|
| 470 |
+
|
| 471 |
+
@property
|
| 472 |
+
def lengths(self):
|
| 473 |
+
length_list = []
|
| 474 |
+
for sample in self.list_data_dict:
|
| 475 |
+
img_tokens = 128 if 'image' in sample else 0
|
| 476 |
+
length_list.append(sum(len(conv['value'].split()) for conv in sample['conversations']) + img_tokens)
|
| 477 |
+
return length_list
|
| 478 |
+
|
| 479 |
+
|
| 480 |
+
@property
|
| 481 |
+
def modality_lengths(self):
|
| 482 |
+
length_list = []
|
| 483 |
+
for sample in self.list_data_dict:
|
| 484 |
+
cur_len = sum(len(conv['value'].split()) for conv in sample['conversations'])
|
| 485 |
+
cur_len = cur_len if 'image' in sample else -cur_len
|
| 486 |
+
length_list.append(cur_len)
|
| 487 |
+
return length_list
|
| 488 |
+
|
| 489 |
+
# def __getitem__(self, i) -> Dict[str, torch.Tensor]:
|
| 490 |
+
# sources = self.list_data_dict[i]
|
| 491 |
+
# if isinstance(i, int):
|
| 492 |
+
# sources = [sources]
|
| 493 |
+
# assert len(sources) == 1, "Don't know why it is wrapped to a list" # FIXME
|
| 494 |
+
# if 'image' in sources[0]:
|
| 495 |
+
# image_file = self.list_data_dict[i]['image']
|
| 496 |
+
# image_folder = self.data_args.image_folder
|
| 497 |
+
# processor = self.data_args.image_processor
|
| 498 |
+
# image = Image.open(os.path.join(image_folder, image_file)).convert('RGB')
|
| 499 |
+
# if self.data_args.image_aspect_ratio == 'pad':
|
| 500 |
+
# def expand2square(pil_img, background_color):
|
| 501 |
+
# width, height = pil_img.size
|
| 502 |
+
# if width == height:
|
| 503 |
+
# return pil_img
|
| 504 |
+
# elif width > height:
|
| 505 |
+
# result = Image.new(pil_img.mode, (width, width), background_color)
|
| 506 |
+
# result.paste(pil_img, (0, (width - height) // 2))
|
| 507 |
+
# return result
|
| 508 |
+
# else:
|
| 509 |
+
# result = Image.new(pil_img.mode, (height, height), background_color)
|
| 510 |
+
# result.paste(pil_img, ((height - width) // 2, 0))
|
| 511 |
+
# return result
|
| 512 |
+
# image = expand2square(image, tuple(int(x*255) for x in processor.image_mean))
|
| 513 |
+
# image = processor.preprocess(image, return_tensors='pt')['pixel_values'][0]
|
| 514 |
+
# else:
|
| 515 |
+
# image = processor.preprocess(image, return_tensors='pt')['pixel_values'][0]
|
| 516 |
+
# sources = preprocess_multimodal(
|
| 517 |
+
# copy.deepcopy([e["conversations"] for e in sources]),
|
| 518 |
+
# self.data_args)
|
| 519 |
+
# else:
|
| 520 |
+
# sources = copy.deepcopy([e["conversations"] for e in sources])
|
| 521 |
+
# data_dict = preprocess(
|
| 522 |
+
# sources,
|
| 523 |
+
# self.tokenizer,
|
| 524 |
+
# has_image=('image' in self.list_data_dict[i]))
|
| 525 |
+
# if isinstance(i, int):
|
| 526 |
+
# data_dict = dict(input_ids=data_dict["input_ids"][0],
|
| 527 |
+
# labels=data_dict["labels"][0])
|
| 528 |
+
|
| 529 |
+
# # image exist in the data
|
| 530 |
+
# if 'image' in self.list_data_dict[i]:
|
| 531 |
+
# data_dict['image'] = image
|
| 532 |
+
# elif self.data_args.is_multimodal:
|
| 533 |
+
# # image does not exist in the data, but the model is multimodal
|
| 534 |
+
# crop_size = self.data_args.image_processor.crop_size
|
| 535 |
+
# data_dict['image'] = torch.zeros(3, crop_size['height'], crop_size['width'])
|
| 536 |
+
# return data_dict
|
| 537 |
+
|
| 538 |
+
def next_rand(self):
|
| 539 |
+
import random
|
| 540 |
+
return random.randint(0,len(self)-1)
|
| 541 |
+
|
| 542 |
+
def __getitem__(self, i) -> Dict[str, torch.Tensor]:
|
| 543 |
+
while True:
|
| 544 |
+
sources = self.list_data_dict[i]
|
| 545 |
+
if isinstance(i, int):
|
| 546 |
+
sources = [sources]
|
| 547 |
+
assert len(sources) == 1, "Don't know why it is wrapped to a list" # FIXME
|
| 548 |
+
if 'image' in sources[0]:
|
| 549 |
+
|
| 550 |
+
image_file = self.list_data_dict[i]['image']
|
| 551 |
+
image_folder = self.data_args.image_folder
|
| 552 |
+
processor = self.data_args.image_processor
|
| 553 |
+
from pathlib import Path
|
| 554 |
+
if not Path(os.path.join(image_folder, image_file)).exists():
|
| 555 |
+
i = self.next_rand()
|
| 556 |
+
continue
|
| 557 |
+
image = Image.open(os.path.join(image_folder, image_file)).convert('RGB')
|
| 558 |
+
if self.data_args.image_aspect_ratio == 'pad':
|
| 559 |
+
def expand2square(pil_img, background_color):
|
| 560 |
+
width, height = pil_img.size
|
| 561 |
+
if width == height:
|
| 562 |
+
return pil_img
|
| 563 |
+
elif width > height:
|
| 564 |
+
result = Image.new(pil_img.mode, (width, width), background_color)
|
| 565 |
+
result.paste(pil_img, (0, (width - height) // 2))
|
| 566 |
+
return result
|
| 567 |
+
else:
|
| 568 |
+
result = Image.new(pil_img.mode, (height, height), background_color)
|
| 569 |
+
result.paste(pil_img, ((height - width) // 2, 0))
|
| 570 |
+
return result
|
| 571 |
+
image = expand2square(image, tuple(int(x*255) for x in processor.image_mean))
|
| 572 |
+
image = processor.preprocess(image, return_tensors='pt')['pixel_values'][0]
|
| 573 |
+
else:
|
| 574 |
+
image = processor.preprocess(image, return_tensors='pt')['pixel_values'][0]
|
| 575 |
+
sources = preprocess_multimodal(
|
| 576 |
+
copy.deepcopy([e["conversations"] for e in sources]),
|
| 577 |
+
self.data_args)
|
| 578 |
+
else:
|
| 579 |
+
|
| 580 |
+
sources = copy.deepcopy([e["conversations"] for e in sources])
|
| 581 |
+
data_dict = preprocess(
|
| 582 |
+
sources,
|
| 583 |
+
self.tokenizer,
|
| 584 |
+
has_image=('image' in self.list_data_dict[i]))
|
| 585 |
+
if isinstance(i, int):
|
| 586 |
+
data_dict = dict(input_ids=data_dict["input_ids"][0],
|
| 587 |
+
labels=data_dict["labels"][0])
|
| 588 |
+
|
| 589 |
+
# image exist in the data
|
| 590 |
+
if 'image' in self.list_data_dict[i]:
|
| 591 |
+
data_dict['image'] = image
|
| 592 |
+
elif self.data_args.is_multimodal:
|
| 593 |
+
# image does not exist in the data, but the model is multimodal
|
| 594 |
+
crop_size = self.data_args.image_processor.crop_size
|
| 595 |
+
data_dict['image'] = torch.zeros(3, crop_size['height'], crop_size['width'])
|
| 596 |
+
return data_dict
|
| 597 |
+
|
| 598 |
+
|
| 599 |
+
@dataclass
|
| 600 |
+
class DataCollatorForSupervisedDataset(object):
|
| 601 |
+
"""Collate examples for supervised fine-tuning."""
|
| 602 |
+
|
| 603 |
+
tokenizer: transformers.PreTrainedTokenizer
|
| 604 |
+
|
| 605 |
+
def __call__(self, instances: Sequence[Dict]) -> Dict[str, torch.Tensor]:
|
| 606 |
+
input_ids, labels = tuple([instance[key] for instance in instances]
|
| 607 |
+
for key in ("input_ids", "labels"))
|
| 608 |
+
input_ids = torch.nn.utils.rnn.pad_sequence(
|
| 609 |
+
input_ids,
|
| 610 |
+
batch_first=True,
|
| 611 |
+
padding_value=self.tokenizer.pad_token_id)
|
| 612 |
+
labels = torch.nn.utils.rnn.pad_sequence(labels,
|
| 613 |
+
batch_first=True,
|
| 614 |
+
padding_value=IGNORE_INDEX)
|
| 615 |
+
input_ids = input_ids[:, :self.tokenizer.model_max_length]
|
| 616 |
+
labels = labels[:, :self.tokenizer.model_max_length]
|
| 617 |
+
batch = dict(
|
| 618 |
+
input_ids=input_ids,
|
| 619 |
+
labels=labels,
|
| 620 |
+
attention_mask=input_ids.ne(self.tokenizer.pad_token_id),
|
| 621 |
+
)
|
| 622 |
+
|
| 623 |
+
if 'image' in instances[0]:
|
| 624 |
+
images = [instance['image'] for instance in instances]
|
| 625 |
+
if all(x is not None and x.shape == images[0].shape for x in images):
|
| 626 |
+
batch['images'] = torch.stack(images)
|
| 627 |
+
else:
|
| 628 |
+
batch['images'] = images
|
| 629 |
+
|
| 630 |
+
return batch
|
| 631 |
+
|
| 632 |
+
|
| 633 |
+
def make_supervised_data_module(tokenizer: transformers.PreTrainedTokenizer,
|
| 634 |
+
data_args) -> Dict:
|
| 635 |
+
"""Make dataset and collator for supervised fine-tuning."""
|
| 636 |
+
train_dataset = LazySupervisedDataset(tokenizer=tokenizer,
|
| 637 |
+
data_path=data_args.data_path,
|
| 638 |
+
data_args=data_args)
|
| 639 |
+
data_collator = DataCollatorForSupervisedDataset(tokenizer=tokenizer)
|
| 640 |
+
return dict(train_dataset=train_dataset,
|
| 641 |
+
eval_dataset=None,
|
| 642 |
+
data_collator=data_collator)
|
| 643 |
+
|
| 644 |
+
|
| 645 |
+
def train():
|
| 646 |
+
global local_rank
|
| 647 |
+
|
| 648 |
+
parser = transformers.HfArgumentParser(
|
| 649 |
+
(ModelArguments, DataArguments, TrainingArguments))
|
| 650 |
+
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
|
| 651 |
+
local_rank = training_args.local_rank
|
| 652 |
+
compute_dtype = (torch.float16 if training_args.fp16 else (torch.bfloat16 if training_args.bf16 else torch.float32))
|
| 653 |
+
|
| 654 |
+
bnb_model_from_pretrained_args = {}
|
| 655 |
+
if training_args.bits in [4, 8]:
|
| 656 |
+
from transformers import BitsAndBytesConfig
|
| 657 |
+
bnb_model_from_pretrained_args.update(dict(
|
| 658 |
+
device_map={"": training_args.device},
|
| 659 |
+
load_in_4bit=training_args.bits == 4,
|
| 660 |
+
load_in_8bit=training_args.bits == 8,
|
| 661 |
+
quantization_config=BitsAndBytesConfig(
|
| 662 |
+
load_in_4bit=training_args.bits == 4,
|
| 663 |
+
load_in_8bit=training_args.bits == 8,
|
| 664 |
+
llm_int8_threshold=6.0,
|
| 665 |
+
llm_int8_has_fp16_weight=False,
|
| 666 |
+
bnb_4bit_compute_dtype=compute_dtype,
|
| 667 |
+
bnb_4bit_use_double_quant=training_args.double_quant,
|
| 668 |
+
bnb_4bit_quant_type=training_args.quant_type # {'fp4', 'nf4'}
|
| 669 |
+
)
|
| 670 |
+
))
|
| 671 |
+
|
| 672 |
+
model = MPLUGOwl2LlamaForCausalLM.from_pretrained(
|
| 673 |
+
model_args.model_name_or_path,
|
| 674 |
+
cache_dir=training_args.cache_dir,
|
| 675 |
+
**bnb_model_from_pretrained_args
|
| 676 |
+
)
|
| 677 |
+
model.config.use_cache = False
|
| 678 |
+
|
| 679 |
+
if model_args.freeze_backbone:
|
| 680 |
+
model.model.requires_grad_(False)
|
| 681 |
+
|
| 682 |
+
if training_args.bits in [4, 8]:
|
| 683 |
+
from peft import prepare_model_for_kbit_training
|
| 684 |
+
model.config.torch_dtype=(torch.float32 if training_args.fp16 else (torch.bfloat16 if training_args.bf16 else torch.float32))
|
| 685 |
+
model = prepare_model_for_kbit_training(model, use_gradient_checkpointing=training_args.gradient_checkpointing)
|
| 686 |
+
|
| 687 |
+
if training_args.gradient_checkpointing:
|
| 688 |
+
if hasattr(model, "enable_input_require_grads"):
|
| 689 |
+
model.enable_input_require_grads()
|
| 690 |
+
else:
|
| 691 |
+
def make_inputs_require_grad(module, input, output):
|
| 692 |
+
output.requires_grad_(True)
|
| 693 |
+
model.get_input_embeddings().register_forward_hook(make_inputs_require_grad)
|
| 694 |
+
|
| 695 |
+
if training_args.lora_enable:
|
| 696 |
+
from peft import LoraConfig, get_peft_model
|
| 697 |
+
lora_config = LoraConfig(
|
| 698 |
+
r=training_args.lora_r,
|
| 699 |
+
lora_alpha=training_args.lora_alpha,
|
| 700 |
+
target_modules=find_all_linear_names(model),
|
| 701 |
+
lora_dropout=training_args.lora_dropout,
|
| 702 |
+
bias=training_args.lora_bias,
|
| 703 |
+
task_type="CAUSAL_LM",
|
| 704 |
+
)
|
| 705 |
+
if training_args.bits == 16:
|
| 706 |
+
if training_args.bf16:
|
| 707 |
+
model.to(torch.bfloat16)
|
| 708 |
+
if training_args.fp16:
|
| 709 |
+
model.to(torch.float16)
|
| 710 |
+
rank0_print("Adding LoRA adapters...")
|
| 711 |
+
model = get_peft_model(model, lora_config)
|
| 712 |
+
|
| 713 |
+
tokenizer = transformers.AutoTokenizer.from_pretrained(
|
| 714 |
+
model_args.model_name_or_path,
|
| 715 |
+
cache_dir=training_args.cache_dir,
|
| 716 |
+
model_max_length=training_args.model_max_length,
|
| 717 |
+
padding_side="right",
|
| 718 |
+
use_fast=False,
|
| 719 |
+
)
|
| 720 |
+
|
| 721 |
+
|
| 722 |
+
tokenizer.pad_token = tokenizer.unk_token
|
| 723 |
+
if model_args.version in conversation_lib.conv_templates:
|
| 724 |
+
conversation_lib.default_conversation = conversation_lib.conv_templates[model_args.version]
|
| 725 |
+
else:
|
| 726 |
+
conversation_lib.default_conversation = conversation_lib.conv_templates["vicuna_v1"]
|
| 727 |
+
|
| 728 |
+
# if model_args.vision_tower is not None:
|
| 729 |
+
# model.get_model().initialize_vision_modules(
|
| 730 |
+
# model_args=model_args,
|
| 731 |
+
# fsdp=training_args.fsdp
|
| 732 |
+
# )
|
| 733 |
+
|
| 734 |
+
# vision_tower = model.get_vision_tower()
|
| 735 |
+
# vision_tower.to(dtype=torch.bfloat16 if training_args.bf16 else torch.float16, device=training_args.device)
|
| 736 |
+
|
| 737 |
+
# data_args.image_processor = vision_tower.image_processor
|
| 738 |
+
# data_args.is_multimodal = True
|
| 739 |
+
|
| 740 |
+
# model.config.image_aspect_ratio = data_args.image_aspect_ratio
|
| 741 |
+
# model.config.image_grid_pinpoints = data_args.image_grid_pinpoints
|
| 742 |
+
|
| 743 |
+
# model.config.tune_mm_mlp_adapter = training_args.tune_mm_mlp_adapter = model_args.tune_mm_mlp_adapter
|
| 744 |
+
# if model_args.tune_mm_mlp_adapter:
|
| 745 |
+
# model.requires_grad_(False)
|
| 746 |
+
# for p in model.get_model().mm_projector.parameters():
|
| 747 |
+
# p.requires_grad = True
|
| 748 |
+
|
| 749 |
+
# model.config.freeze_mm_mlp_adapter = training_args.freeze_mm_mlp_adapter
|
| 750 |
+
# if training_args.freeze_mm_mlp_adapter:
|
| 751 |
+
# for p in model.get_model().mm_projector.parameters():
|
| 752 |
+
# p.requires_grad = False
|
| 753 |
+
|
| 754 |
+
# if training_args.bits in [4, 8]:
|
| 755 |
+
# model.get_model().mm_projector.to(dtype=compute_dtype, device=training_args.device)
|
| 756 |
+
|
| 757 |
+
# model.config.mm_use_im_start_end = data_args.mm_use_im_start_end = model_args.mm_use_im_start_end
|
| 758 |
+
# model.config.mm_projector_lr = training_args.mm_projector_lr
|
| 759 |
+
# training_args.use_im_start_end = model_args.mm_use_im_start_end
|
| 760 |
+
# model.config.mm_use_im_patch_token = model_args.mm_use_im_patch_token
|
| 761 |
+
# model.initialize_vision_tokenizer(model_args, tokenizer=tokenizer)
|
| 762 |
+
|
| 763 |
+
# data_args.image_processor = vision_tower.image_processor
|
| 764 |
+
|
| 765 |
+
if not training_args.freeze_vision_model and training_args.bits in [4, 8]:
|
| 766 |
+
model.get_model().vision_model.to(dtype=compute_dtype, device=training_args.device)
|
| 767 |
+
else:
|
| 768 |
+
vision_tower = model.get_model().vision_model
|
| 769 |
+
vision_tower.to(dtype=torch.bfloat16 if training_args.bf16 else torch.float16, device=training_args.device)
|
| 770 |
+
|
| 771 |
+
if training_args.tune_visual_abstractor and training_args.bits in [4, 8]:
|
| 772 |
+
model.get_model().visual_abstractor.to(dtype=compute_dtype, device=training_args.device)
|
| 773 |
+
else:
|
| 774 |
+
visual_abstractor = model.get_model().visual_abstractor
|
| 775 |
+
visual_abstractor.to(dtype=torch.bfloat16 if training_args.bf16 else torch.float16, device=training_args.device)
|
| 776 |
+
|
| 777 |
+
data_args.image_processor = CLIPImageProcessor.from_pretrained(model_args.model_name_or_path)
|
| 778 |
+
data_args.is_multimodal = True
|
| 779 |
+
|
| 780 |
+
model.config.image_aspect_ratio = data_args.image_aspect_ratio
|
| 781 |
+
model.config.image_grid_pinpoints = data_args.image_grid_pinpoints
|
| 782 |
+
model.config.tune_visual_abstractor = model_args.tune_visual_abstractor = training_args.tune_visual_abstractor
|
| 783 |
+
ic(training_args.tune_visual_abstractor)
|
| 784 |
+
model.requires_grad_(True)
|
| 785 |
+
if training_args.tune_visual_abstractor:
|
| 786 |
+
# model.requires_grad_(False)
|
| 787 |
+
for p in model.get_model().visual_abstractor.parameters():
|
| 788 |
+
p.requires_grad = True
|
| 789 |
+
|
| 790 |
+
model.config.freeze_vision_model = training_args.freeze_vision_model
|
| 791 |
+
ic(training_args.freeze_vision_model)
|
| 792 |
+
if training_args.freeze_vision_model:
|
| 793 |
+
for p in model.get_model().vision_model.parameters():
|
| 794 |
+
p.requires_grad = False
|
| 795 |
+
|
| 796 |
+
model.config.visual_abstractor_lr = training_args.visual_abstractor_lr
|
| 797 |
+
|
| 798 |
+
|
| 799 |
+
if training_args.bits in [4, 8]:
|
| 800 |
+
from peft.tuners.lora import LoraLayer
|
| 801 |
+
for name, module in model.named_modules():
|
| 802 |
+
if isinstance(module, LoraLayer):
|
| 803 |
+
if training_args.bf16:
|
| 804 |
+
module = module.to(torch.bfloat16)
|
| 805 |
+
if 'norm' in name:
|
| 806 |
+
module = module.to(torch.float32)
|
| 807 |
+
if 'lm_head' in name or 'embed_tokens' in name:
|
| 808 |
+
if hasattr(module, 'weight'):
|
| 809 |
+
if training_args.bf16 and module.weight.dtype == torch.float32:
|
| 810 |
+
module = module.to(torch.bfloat16)
|
| 811 |
+
|
| 812 |
+
data_module = make_supervised_data_module(tokenizer=tokenizer,
|
| 813 |
+
data_args=data_args)
|
| 814 |
+
trainer = MPLUGOwl2Trainer(model=model,
|
| 815 |
+
tokenizer=tokenizer,
|
| 816 |
+
args=training_args,
|
| 817 |
+
**data_module)
|
| 818 |
+
|
| 819 |
+
# if list(pathlib.Path(training_args.output_dir).glob("checkpoint-*")):
|
| 820 |
+
# trainer.train(resume_from_checkpoint=True)
|
| 821 |
+
# else:
|
| 822 |
+
# trainer.train()
|
| 823 |
+
|
| 824 |
+
# TODO I dont like auto resume << REMOVE IT AND UNCOMMENT THE ABOVE CODE
|
| 825 |
+
trainer.train()
|
| 826 |
+
|
| 827 |
+
trainer.save_state()
|
| 828 |
+
|
| 829 |
+
model.config.use_cache = True
|
| 830 |
+
|
| 831 |
+
if training_args.lora_enable:
|
| 832 |
+
state_dict = get_peft_state_maybe_zero_3(
|
| 833 |
+
model.named_parameters(), training_args.lora_bias
|
| 834 |
+
)
|
| 835 |
+
non_lora_state_dict = get_peft_state_non_lora_maybe_zero_3(
|
| 836 |
+
model.named_parameters()
|
| 837 |
+
)
|
| 838 |
+
if training_args.local_rank == 0 or training_args.local_rank == -1:
|
| 839 |
+
model.config.save_pretrained(training_args.output_dir)
|
| 840 |
+
model.save_pretrained(training_args.output_dir, state_dict=state_dict)
|
| 841 |
+
torch.save(non_lora_state_dict, os.path.join(training_args.output_dir, 'non_lora_trainables.bin'))
|
| 842 |
+
else:
|
| 843 |
+
safe_save_model_for_hf_trainer(trainer=trainer,
|
| 844 |
+
output_dir=training_args.output_dir)
|
| 845 |
+
|
| 846 |
+
|
| 847 |
+
if __name__ == "__main__":
|
| 848 |
+
train()
|
mplug_owl2/train/train_mem.py
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Adopted from https://github.com/lm-sys/FastChat. Below is the original copyright:
|
| 2 |
+
# Adopted from tatsu-lab@stanford_alpaca. Below is the original copyright:
|
| 3 |
+
# Make it more memory efficient by monkey patching the LLaMA model with FlashAttn.
|
| 4 |
+
|
| 5 |
+
# Need to call this before importing transformers.
|
| 6 |
+
from mplug_owl2.train.llama_flash_attn_monkey_patch import replace_llama_attn_with_flash_attn
|
| 7 |
+
|
| 8 |
+
replace_llama_attn_with_flash_attn()
|
| 9 |
+
|
| 10 |
+
from mplug_owl2.train.train import train
|
| 11 |
+
|
| 12 |
+
if __name__ == "__main__":
|
| 13 |
+
train()
|
mplug_owl2/utils.py
ADDED
|
@@ -0,0 +1,126 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import datetime
|
| 2 |
+
import logging
|
| 3 |
+
import logging.handlers
|
| 4 |
+
import os
|
| 5 |
+
import sys
|
| 6 |
+
|
| 7 |
+
import requests
|
| 8 |
+
|
| 9 |
+
from mplug_owl2.constants import LOGDIR
|
| 10 |
+
|
| 11 |
+
server_error_msg = "**NETWORK ERROR DUE TO HIGH TRAFFIC. PLEASE REGENERATE OR REFRESH THIS PAGE.**"
|
| 12 |
+
moderation_msg = "YOUR INPUT VIOLATES OUR CONTENT MODERATION GUIDELINES. PLEASE TRY AGAIN."
|
| 13 |
+
|
| 14 |
+
handler = None
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def build_logger(logger_name, logger_filename):
|
| 18 |
+
global handler
|
| 19 |
+
|
| 20 |
+
formatter = logging.Formatter(
|
| 21 |
+
fmt="%(asctime)s | %(levelname)s | %(name)s | %(message)s",
|
| 22 |
+
datefmt="%Y-%m-%d %H:%M:%S",
|
| 23 |
+
)
|
| 24 |
+
|
| 25 |
+
# Set the format of root handlers
|
| 26 |
+
if not logging.getLogger().handlers:
|
| 27 |
+
logging.basicConfig(level=logging.INFO)
|
| 28 |
+
logging.getLogger().handlers[0].setFormatter(formatter)
|
| 29 |
+
|
| 30 |
+
# Redirect stdout and stderr to loggers
|
| 31 |
+
stdout_logger = logging.getLogger("stdout")
|
| 32 |
+
stdout_logger.setLevel(logging.INFO)
|
| 33 |
+
sl = StreamToLogger(stdout_logger, logging.INFO)
|
| 34 |
+
sys.stdout = sl
|
| 35 |
+
|
| 36 |
+
stderr_logger = logging.getLogger("stderr")
|
| 37 |
+
stderr_logger.setLevel(logging.ERROR)
|
| 38 |
+
sl = StreamToLogger(stderr_logger, logging.ERROR)
|
| 39 |
+
sys.stderr = sl
|
| 40 |
+
|
| 41 |
+
# Get logger
|
| 42 |
+
logger = logging.getLogger(logger_name)
|
| 43 |
+
logger.setLevel(logging.INFO)
|
| 44 |
+
|
| 45 |
+
# Add a file handler for all loggers
|
| 46 |
+
if handler is None:
|
| 47 |
+
os.makedirs(LOGDIR, exist_ok=True)
|
| 48 |
+
filename = os.path.join(LOGDIR, logger_filename)
|
| 49 |
+
handler = logging.handlers.TimedRotatingFileHandler(
|
| 50 |
+
filename, when='D', utc=True)
|
| 51 |
+
handler.setFormatter(formatter)
|
| 52 |
+
|
| 53 |
+
for name, item in logging.root.manager.loggerDict.items():
|
| 54 |
+
if isinstance(item, logging.Logger):
|
| 55 |
+
item.addHandler(handler)
|
| 56 |
+
|
| 57 |
+
return logger
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
class StreamToLogger(object):
|
| 61 |
+
"""
|
| 62 |
+
Fake file-like stream object that redirects writes to a logger instance.
|
| 63 |
+
"""
|
| 64 |
+
def __init__(self, logger, log_level=logging.INFO):
|
| 65 |
+
self.terminal = sys.stdout
|
| 66 |
+
self.logger = logger
|
| 67 |
+
self.log_level = log_level
|
| 68 |
+
self.linebuf = ''
|
| 69 |
+
|
| 70 |
+
def __getattr__(self, attr):
|
| 71 |
+
return getattr(self.terminal, attr)
|
| 72 |
+
|
| 73 |
+
def write(self, buf):
|
| 74 |
+
temp_linebuf = self.linebuf + buf
|
| 75 |
+
self.linebuf = ''
|
| 76 |
+
for line in temp_linebuf.splitlines(True):
|
| 77 |
+
# From the io.TextIOWrapper docs:
|
| 78 |
+
# On output, if newline is None, any '\n' characters written
|
| 79 |
+
# are translated to the system default line separator.
|
| 80 |
+
# By default sys.stdout.write() expects '\n' newlines and then
|
| 81 |
+
# translates them so this is still cross platform.
|
| 82 |
+
if line[-1] == '\n':
|
| 83 |
+
self.logger.log(self.log_level, line.rstrip())
|
| 84 |
+
else:
|
| 85 |
+
self.linebuf += line
|
| 86 |
+
|
| 87 |
+
def flush(self):
|
| 88 |
+
if self.linebuf != '':
|
| 89 |
+
self.logger.log(self.log_level, self.linebuf.rstrip())
|
| 90 |
+
self.linebuf = ''
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def disable_torch_init():
|
| 94 |
+
"""
|
| 95 |
+
Disable the redundant torch default initialization to accelerate model creation.
|
| 96 |
+
"""
|
| 97 |
+
import torch
|
| 98 |
+
setattr(torch.nn.Linear, "reset_parameters", lambda self: None)
|
| 99 |
+
setattr(torch.nn.LayerNorm, "reset_parameters", lambda self: None)
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def violates_moderation(text):
|
| 103 |
+
"""
|
| 104 |
+
Check whether the text violates OpenAI moderation API.
|
| 105 |
+
"""
|
| 106 |
+
url = "https://api.openai.com/v1/moderations"
|
| 107 |
+
headers = {"Content-Type": "application/json",
|
| 108 |
+
"Authorization": "Bearer " + os.environ["OPENAI_API_KEY"]}
|
| 109 |
+
text = text.replace("\n", "")
|
| 110 |
+
data = "{" + '"input": ' + f'"{text}"' + "}"
|
| 111 |
+
data = data.encode("utf-8")
|
| 112 |
+
try:
|
| 113 |
+
ret = requests.post(url, headers=headers, data=data, timeout=5)
|
| 114 |
+
flagged = ret.json()["results"][0]["flagged"]
|
| 115 |
+
except requests.exceptions.RequestException as e:
|
| 116 |
+
flagged = False
|
| 117 |
+
except KeyError as e:
|
| 118 |
+
flagged = False
|
| 119 |
+
|
| 120 |
+
return flagged
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
def pretty_print_semaphore(semaphore):
|
| 124 |
+
if semaphore is None:
|
| 125 |
+
return "None"
|
| 126 |
+
return f"Semaphore(value={semaphore._value}, locked={semaphore.locked()})"
|
requirements.txt
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
icecream
|
| 2 |
+
markdown2
|
| 3 |
+
pydantic
|
| 4 |
+
accelerate==0.21.0
|
| 5 |
+
transformers==4.31.0
|
| 6 |
+
tokenizers==0.12.1
|
| 7 |
+
sentencepiece==0.1.99
|
| 8 |
+
shortuuid
|
| 9 |
+
bitsandbytes==0.41.0
|
| 10 |
+
timm==0.6.13
|
| 11 |
+
requests
|
| 12 |
+
httpx==0.24.0
|
| 13 |
+
uvicorn
|
| 14 |
+
einops-exts==0.0.4
|
| 15 |
+
einops==0.6.1
|
| 16 |
+
scikit-learn==1.2.2
|
| 17 |
+
numpy
|