"""A Gradio app for anonymizing text data using FHE."""
import base64
import os
import re
import subprocess
import time
import uuid
from typing import Dict, List
import gradio as gr
import numpy
import pandas as pd
import requests
from fhe_anonymizer import FHEAnonymizer
from openai import OpenAI
from utils_demo import *
from concrete.ml.deployment import FHEModelClient
# Ensure the directory is clean before starting processes or reading files
clean_directory()
anonymizer = FHEAnonymizer()
key=os.environ.get("openaikey")
client = OpenAI(api_key=key)
print(key)
# Start the Uvicorn server hosting the FastAPI app
subprocess.Popen(["uvicorn", "server:app"], cwd=CURRENT_DIR)
time.sleep(3)
# Load data from files required for the application
UUID_MAP = read_json(MAPPING_UUID_PATH)
ANONYMIZED_DOCUMENT = read_txt(ANONYMIZED_FILE_PATH)
MAPPING_ANONYMIZED_SENTENCES = read_pickle(MAPPING_ANONYMIZED_SENTENCES_PATH)
MAPPING_ENCRYPTED_SENTENCES = read_pickle(MAPPING_ENCRYPTED_SENTENCES_PATH)
ORIGINAL_DOCUMENT = read_txt(ORIGINAL_FILE_PATH).split("\n\n")
MAPPING_DOC_EMBEDDING = read_pickle(MAPPING_DOC_EMBEDDING_PATH)
print(f"{ORIGINAL_DOCUMENT=}\n")
print(f"{MAPPING_DOC_EMBEDDING.keys()=}")
# 4. Data Processing and Operations (No specific operations shown here, assuming it's part of anonymizer or client usage)
# 5. Utilizing External Services or APIs
# (Assuming client initialization and anonymizer setup are parts of using external services or application-specific logic)
# Generate a random user ID for this session
USER_ID = numpy.random.randint(0, 2**32)
def select_static_anonymized_sentences_fn(selected_sentences: List):
selected_sentences = [MAPPING_ANONYMIZED_SENTENCES[sentence] for sentence in selected_sentences]
anonymized_selected_sentence = sorted(selected_sentences, key=lambda x: x[0])
anonymized_selected_sentence = [sentence for _, sentence in anonymized_selected_sentence]
return "\n\n".join(anonymized_selected_sentence)
def key_gen_fn() -> Dict:
"""Generate keys for a given user."""
print("------------ Step 1: Key Generation:")
print(f"Your user ID is: {USER_ID}....")
client = FHEModelClient(path_dir=DEPLOYMENT_DIR, key_dir=KEYS_DIR / f"{USER_ID}")
client.load()
# Creates the private and evaluation keys on the client side
client.generate_private_and_evaluation_keys()
# Get the serialized evaluation keys
serialized_evaluation_keys = client.get_serialized_evaluation_keys()
assert isinstance(serialized_evaluation_keys, bytes)
# Save the evaluation key
evaluation_key_path = KEYS_DIR / f"{USER_ID}/evaluation_key"
write_bytes(evaluation_key_path, serialized_evaluation_keys)
# anonymizer.generate_key()
if not evaluation_key_path.is_file():
error_message = (
f"生成密钥时发生异常 {evaluation_key_path.is_file()=}"
)
print(error_message)
return {gen_key_btn: gr.update(value=error_message)}
else:
print("Keys have been generated ✅")
return {gen_key_btn: gr.update(value="密钥生成成功! ✅")}
def encrypt_doc_fn(doc):
print(f"\n------------ Step 2.1: Doc encryption: {doc=}")
if not (KEYS_DIR / f"{USER_ID}/evaluation_key").is_file():
return {encrypted_doc_box: gr.update(value="Error ❌: 请先生成密钥!", lines=10)}
# Retrieve the client API
client = FHEModelClient(path_dir=DEPLOYMENT_DIR, key_dir=KEYS_DIR / f"{USER_ID}")
client.load()
encrypted_tokens = []
tokens = re.findall(r"(\b[\w\.\/\-@]+\b|[\s,.!?;:'\"-]+|\$\d+(?:\.\d+)?|\€\d+(?:\.\d+)?)", ' '.join(doc))
for token in tokens:
if token.strip() and re.match(r"\w+", token):
emb_x = MAPPING_DOC_EMBEDDING[token]
assert emb_x.shape == (1, 1024)
encrypted_x = client.quantize_encrypt_serialize(emb_x)
assert isinstance(encrypted_x, bytes)
encrypted_tokens.append(encrypted_x)
print("Doc encrypted ✅ on Client Side")
# No need to save it
# write_bytes(KEYS_DIR / f"{USER_ID}/encrypted_doc", b"".join(encrypted_tokens))
encrypted_quant_tokens_hex = [token.hex()[500:510] for token in encrypted_tokens]
return {
encrypted_doc_box: gr.update(value=" ".join(encrypted_quant_tokens_hex), lines=10),
anonymized_doc_output: gr.update(visible=True, value=None),
}
def encrypt_query_fn(query):
print(f"\n------------ Step 2: Query encryption: {query=}")
if not (KEYS_DIR / f"{USER_ID}/evaluation_key").is_file():
return {output_encrypted_box: gr.update(value="Error ❌: 请先生成密钥!", lines=8)}
if is_user_query_valid(query):
return {
query_box: gr.update(
value=(
"不能执行 ❌: 请求超过了长度限制。修改查询后重试。 "
)
)
}
# Retrieve the client API
client = FHEModelClient(path_dir=DEPLOYMENT_DIR, key_dir=KEYS_DIR / f"{USER_ID}")
client.load()
encrypted_tokens = []
# Pattern to identify words and non-words (including punctuation, spaces, etc.)
tokens = re.findall(r"(\b[\w\.\/\-@]+\b|[\s,.!?;:'\"-]+)", query)
for token in tokens:
# 1- Ignore non-words tokens
if bool(re.match(r"^\s+$", token)):
continue
# 2- Directly append non-word tokens or whitespace to processed_tokens
# Prediction for each word
emb_x = get_batch_text_representation([token], EMBEDDINGS_MODEL, TOKENIZER)
encrypted_x = client.quantize_encrypt_serialize(emb_x)
assert isinstance(encrypted_x, bytes)
encrypted_tokens.append(encrypted_x)
print("数据已在客户端加密。 ✅")
assert len({len(token) for token in encrypted_tokens}) == 1
write_bytes(KEYS_DIR / f"{USER_ID}/encrypted_input", b"".join(encrypted_tokens))
write_bytes(
KEYS_DIR / f"{USER_ID}/encrypted_input_len", len(encrypted_tokens[0]).to_bytes(10, "big")
)
encrypted_quant_tokens_hex = [token.hex()[500:580] for token in encrypted_tokens]
return {
output_encrypted_box: gr.update(value=" ".join(encrypted_quant_tokens_hex), lines=8),
anonymized_query_output: gr.update(visible=True, value=None),
identified_words_output_df: gr.update(visible=False, value=None),
}
def send_input_fn(query) -> Dict:
"""Send the encrypted data and the evaluation key to the server."""
print("------------ Step 3.1: Send encrypted_data to the Server")
evaluation_key_path = KEYS_DIR / f"{USER_ID}/evaluation_key"
encrypted_input_path = KEYS_DIR / f"{USER_ID}/encrypted_input"
encrypted_input_len_path = KEYS_DIR / f"{USER_ID}/encrypted_input_len"
if not evaluation_key_path.is_file():
error_message = (
"发送数据到服务器时发生异常:"
f"密钥已经正常生成 - {evaluation_key_path.is_file()=}"
)
return {anonymized_query_output: gr.update(value=error_message)}
if not encrypted_input_path.is_file():
error_message = (
"发送数据到服务器时发生异常: 数据没有加密"
f"在客户端正确 - {encrypted_input_path.is_file()=}"
)
return {anonymized_query_output: gr.update(value=error_message)}
# Define the data and files to post
data = {"user_id": USER_ID, "input": query}
files = [
("files", open(evaluation_key_path, "rb")),
("files", open(encrypted_input_path, "rb")),
("files", open(encrypted_input_len_path, "rb")),
]
# Send the encrypted input and evaluation key to the server
url = SERVER_URL + "send_input"
with requests.post(
url=url,
data=data,
files=files,
) as resp:
print("数据发送到服务器。 ✅" if resp.ok else "发送到服务器时出现错误。 ❌ ")
def run_fhe_in_server_fn() -> Dict:
"""Run in FHE the anonymization of the query"""
print("------------ Step 3.2: Run in FHE on the Server Side")
evaluation_key_path = KEYS_DIR / f"{USER_ID}/evaluation_key"
encrypted_input_path = KEYS_DIR / f"{USER_ID}/encrypted_input"
if not evaluation_key_path.is_file():
error_message = (
"Error Encountered While Sending Data to the Server: "
f"The key has been generated correctly - {evaluation_key_path.is_file()=}"
)
return {anonymized_query_output: gr.update(value=error_message)}
if not encrypted_input_path.is_file():
error_message = (
"Error Encountered While Sending Data to the Server: The data has not been encrypted "
f"correctly on the client side - {encrypted_input_path.is_file()=}"
)
return {anonymized_query_output: gr.update(value=error_message)}
data = {
"user_id": USER_ID,
}
url = SERVER_URL + "run_fhe"
with requests.post(
url=url,
data=data,
) as response:
if not response.ok:
return {
anonymized_query_output: gr.update(
value=(
"⚠️ An error occurred on the Server Side. "
"Please check connectivity and data transmission."
),
),
}
else:
time.sleep(1)
print(f"匿名化查询在以每句柄{response.json():.2f} 秒的速率执行。")
def get_output_fn() -> Dict:
print("------------ Step 3.3: Get the output from the Server Side")
if not (KEYS_DIR / f"{USER_ID}/evaluation_key").is_file():
error_message = (
"Error Encountered While Sending Data to the Server: "
"The key has not been generated correctly"
)
return {anonymized_query_output: gr.update(value=error_message)}
if not (KEYS_DIR / f"{USER_ID}/encrypted_input").is_file():
error_message = (
"Error Encountered While Sending Data to the Server: "
"The data has not been encrypted correctly on the client side"
)
return {anonymized_query_output: gr.update(value=error_message)}
data = {
"user_id": USER_ID,
}
# Retrieve the encrypted output
url = SERVER_URL + "get_output"
with requests.post(
url=url,
data=data,
) as response:
if response.ok:
print("数据从远程服务器接收到。 ✅")
response_data = response.json()
encrypted_output_base64 = response_data["encrypted_output"]
length_encrypted_output_base64 = response_data["length"]
# Decode the base64 encoded data
encrypted_output = base64.b64decode(encrypted_output_base64)
length_encrypted_output = base64.b64decode(length_encrypted_output_base64)
# Save the encrypted output to bytes in a file as it is too large to pass through
# regular Gradio buttons (see https://github.com/gradio-app/gradio/issues/1877)
write_bytes(CLIENT_DIR / f"{USER_ID}_encrypted_output", encrypted_output)
write_bytes(CLIENT_DIR / f"{USER_ID}_encrypted_output_len", length_encrypted_output)
else:
print("Error ❌ in getting data to the server")
def decrypt_fn(text) -> Dict:
"""Dencrypt the data on the `Client Side`."""
print("------------ Step 4: Dencrypt the data on the `Client Side`")
# Get the encrypted output path
encrypted_output_path = CLIENT_DIR / f"{USER_ID}_encrypted_output"
if not encrypted_output_path.is_file():
error_message = """⚠️ Please ensure that: \n
- the connectivity \n
- the query has been submitted \n
- the evaluation key has been generated \n
- the server processed the encrypted data \n
- the Client received the data from the Server before decrypting the prediction
"""
print(error_message)
return error_message, None
# Retrieve the client API
client = FHEModelClient(path_dir=DEPLOYMENT_DIR, key_dir=KEYS_DIR / f"{USER_ID}")
client.load()
# Load the encrypted output as bytes
encrypted_output = read_bytes(CLIENT_DIR / f"{USER_ID}_encrypted_output")
length = int.from_bytes(read_bytes(CLIENT_DIR / f"{USER_ID}_encrypted_output_len"), "big")
tokens = re.findall(r"(\b[\w\.\/\-@]+\b|[\s,.!?;:'\"-]+)", text)
decrypted_output, identified_words_with_prob = [], []
i = 0
for token in tokens:
# Directly append non-word tokens or whitespace to processed_tokens
if bool(re.match(r"^\s+$", token)):
continue
else:
encrypted_token = encrypted_output[i : i + length]
prediction_proba = client.deserialize_decrypt_dequantize(encrypted_token)
probability = prediction_proba[0][1]
i += length
if probability >= 0.77:
identified_words_with_prob.append((token, probability))
# Use the existing UUID if available, otherwise generate a new one
tmp_uuid = UUID_MAP.get(token, str(uuid.uuid4())[:8])
decrypted_output.append(tmp_uuid)
UUID_MAP[token] = tmp_uuid
else:
decrypted_output.append(token)
# Update the UUID map with query.
write_json(MAPPING_UUID_PATH, UUID_MAP)
# Removing Spaces Before Punctuation:
anonymized_text = re.sub(r"\s([,.!?;:])", r"\1", " ".join(decrypted_output))
# Convert the list of identified words and probabilities into a DataFrame
if identified_words_with_prob:
identified_df = pd.DataFrame(
identified_words_with_prob, columns=["Identified Words", "Probability"]
)
else:
identified_df = pd.DataFrame(columns=["Identified Words", "Probability"])
print("在客户端完成了解密。 ✅")
return anonymized_text, identified_df
def anonymization_with_fn(selected_sentences, query):
encrypt_query_fn(query)
send_input_fn(query)
run_fhe_in_server_fn()
get_output_fn()
anonymized_text, identified_df = decrypt_fn(query)
return {
anonymized_doc_output: gr.update(value=select_static_anonymized_sentences_fn(selected_sentences)),
anonymized_query_output: gr.update(value=anonymized_text),
identified_words_output_df: gr.update(value=identified_df, visible=False),
}
def query_chatgpt_fn(anonymized_query, anonymized_document):
print("------------ Step 5: ChatGPT communication")
if not (KEYS_DIR / f"{USER_ID}/evaluation_key").is_file():
error_message = "Error ❌: Please generate the key first!"
return {chatgpt_response_anonymized: gr.update(value=error_message)}
if not (CLIENT_DIR / f"{USER_ID}_encrypted_output").is_file():
error_message = "Error ❌: Please encrypt your query first!"
return {chatgpt_response_anonymized: gr.update(value=error_message)}
context_prompt = read_txt(PROMPT_PATH)
# Prepare prompt
query = (
"Document content:\n```\n"
+ anonymized_document
+ "\n\n```"
+ "Query:\n```\n"
+ anonymized_query
+ "\n```"
)
print(f'Prompt of CHATGPT:\n{query}')
completion = client.chat.completions.create(
model="gpt-4o-mini-2024-07-18", # Replace with "gpt-4" if available
messages=[
{"role": "system", "content": context_prompt},
{"role": "user", "content": query},
],
)
anonymized_response = completion.choices[0].message.content
uuid_map = read_json(MAPPING_UUID_PATH)
inverse_uuid_map = {
v: k for k, v in uuid_map.items()
} # TODO load the inverse mapping from disk for efficiency
# Pattern to identify words and non-words (including punctuation, spaces, etc.)
tokens = re.findall(r"(\b[\w\.\/\-@]+\b|[\s,.!?;:'\"-]+)", anonymized_response)
processed_tokens = []
for token in tokens:
# Directly append non-word tokens or whitespace to processed_tokens
if not token.strip() or not re.match(r"\w+", token):
processed_tokens.append(token)
continue
if token in inverse_uuid_map:
processed_tokens.append(inverse_uuid_map[token])
else:
processed_tokens.append(token)
deanonymized_response = "".join(processed_tokens)
return {chatgpt_response_anonymized: gr.update(value=anonymized_response),
chatgpt_response_deanonymized: gr.update(value=deanonymized_response)}
demo = gr.Blocks(css=".markdown-body { font-size: 18px; }")
with demo:
gr.Markdown(
"""

""")
gr.Markdown(
"""
使用全同态加密实现加密匿名化
"""
)
gr.Markdown(
"""
匿名化是为了保护个人隐私从文档中删除个人身份信息 (PII) 数据的过程。
通常的匿名化会删除隐私数据或者用没有意义的字符代替,这就使得数据失去了价值。而加密匿名化使用完全同态加密 (FHE) 对文档中的个人身份信息 (PII) 进行加密实现匿名化,从而可以对加密后的数据执行其他计算。
在本示例中,我们展示了如何利用加密匿名化以保护隐私的方式使用ChatGPT等LLM服务。
"""
)
gr.Markdown(
"""
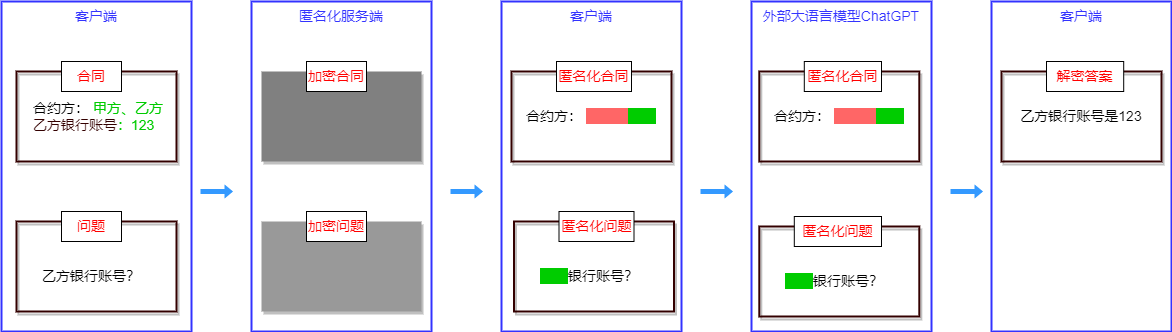
"""
)
########################## Key Gen Part ##########################
gr.Markdown(
"## 第1步: 生成密钥\n\n"
"""在全同态加密 (FHE) 方法中,会创建两种类型的密钥。第一种称为私钥,用于加密和解密用户的数据。第二种称为计算密钥,使服务器能够在不查看实际数据的情况下处理加密数据。
"""
)
gen_key_btn = gr.Button("生成私钥和评估密钥")
gen_key_btn.click(
key_gen_fn,
inputs=[],
outputs=[gen_key_btn],
)
########################## Main document Part ##########################
gr.Markdown("
")
gr.Markdown("## 第2.1步: 选择要加密的文档\n\n"
"""为了演示步骤的简单,预先编译了这个文档,但是你可以选择任意部分使用。
"""
)
with gr.Row():
with gr.Column(scale=5):
original_sentences_box = gr.CheckboxGroup(
ORIGINAL_DOCUMENT,
value=ORIGINAL_DOCUMENT,
label="合同文件:",
show_label=True,
)
with gr.Column(scale=1, min_width=6):
gr.HTML("")
encrypt_doc_btn = gr.Button("加密文档")
with gr.Column(scale=5):
encrypted_doc_box = gr.Textbox(
label="加密后的文档:", show_label=True, interactive=False, lines=10
)
########################## User Query Part ##########################
gr.Markdown("
")
gr.Markdown("## 第2.2步: 选择要加密的查询问题\n\n"
"""请从以下预先定义的选择
“示例问题”或者输入自己的问题”输入问题“文本输入框。
请保持问题的上下文相关性。任何无关的问题都不会处理。""")
with gr.Row():
with gr.Column(scale=5):
with gr.Column(scale=5):
default_query_box = gr.Dropdown(
list(DEFAULT_QUERIES.values()), label="问题示例:"
)
gr.Markdown("或者")
query_box = gr.Textbox(
value="Kate的国际银行账号是什么?", label="自定义问题:", interactive=True
)
default_query_box.change(
fn=lambda default_query_box: default_query_box,
inputs=[default_query_box],
outputs=[query_box],
)
with gr.Column(scale=1, min_width=6):
gr.HTML("")
encrypt_query_btn = gr.Button("加密的问题")
# gr.HTML("")
with gr.Column(scale=5):
output_encrypted_box = gr.Textbox(
label="加密后的问题将发送给匿名化服务器:",
lines=8,
)
########################## FHE processing Part ##########################
gr.Markdown("
")
gr.Markdown("## 第3步: 使用全同态加密匿名化文件和问题")
gr.Markdown(
"""客户端在本地对文件和问题进行加密后,会将其发送到远程服务器对加密数据进行匿名化处理。计算完成后,服务器会将结果返回给客户端进行解密。
"""
)
run_fhe_btn = gr.Button("使用全同态加密匿名化")
with gr.Row():
with gr.Column(scale=5):
anonymized_doc_output = gr.Textbox(
label="解密和匿名化文件", lines=10, interactive=True
)
with gr.Column(scale=5):
anonymized_query_output = gr.Textbox(
label="解密和匿名化问题", lines=10, interactive=True
)
identified_words_output_df = gr.Dataframe(label="已识别单词:", visible=False)
encrypt_doc_btn.click(
fn=encrypt_doc_fn,
inputs=[original_sentences_box],
outputs=[encrypted_doc_box, anonymized_doc_output],
)
encrypt_query_btn.click(
fn=encrypt_query_fn,
inputs=[query_box],
outputs=[
query_box,
output_encrypted_box,
anonymized_query_output,
identified_words_output_df,
],
)
run_fhe_btn.click(
anonymization_with_fn,
inputs=[original_sentences_box, query_box],
outputs=[anonymized_doc_output, anonymized_query_output, identified_words_output_df],
)
########################## ChatGpt Part ##########################
gr.Markdown("
")
gr.Markdown("## 第4步: 发送匿名化后的问题给ChatGPT")
gr.Markdown(
"""使用FHE安全地匿名化查询问题后,您可以将其转发给ChatGPT而不必担心信息泄露。"""
)
chatgpt_button = gr.Button("查询ChatGPT")
with gr.Row():
chatgpt_response_anonymized = gr.Textbox(label="ChatGPT的匿名化响应:", lines=5)
chatgpt_response_deanonymized = gr.Textbox(
label="ChatGPT的去匿名化响应", lines=5
)
chatgpt_button.click(
query_chatgpt_fn,
inputs=[anonymized_query_output, anonymized_doc_output],
outputs=[chatgpt_response_anonymized, chatgpt_response_deanonymized],
)
gr.Markdown(
"""**请注意**: 由于此应用仅用于演示目的,匿名化算法可能会遗漏一些私人信息。请在将查询发送到ChatGPT之前对其进行复核。
"""
)
# Launch the app
demo.launch(share=False)