Spaces:
Runtime error

Runtime error
Commit
•
86fe4f0
1
Parent(s):
5bfb5a7
Upload 631 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +1 -0
- .gitignore +5 -0
- LICENSE +107 -0
- README.md +71 -0
- checkpoints/README.txt +1 -0
- images/demo.png +3 -0
- images/workflow.png +0 -0
- ootd/inference_ootd.py +133 -0
- ootd/inference_ootd_dc.py +132 -0
- ootd/inference_ootd_hd.py +132 -0
- ootd/pipelines_ootd/attention_garm.py +402 -0
- ootd/pipelines_ootd/attention_vton.py +407 -0
- ootd/pipelines_ootd/pipeline_ootd.py +846 -0
- ootd/pipelines_ootd/transformer_garm_2d.py +449 -0
- ootd/pipelines_ootd/transformer_vton_2d.py +452 -0
- ootd/pipelines_ootd/unet_garm_2d_blocks.py +0 -0
- ootd/pipelines_ootd/unet_garm_2d_condition.py +1183 -0
- ootd/pipelines_ootd/unet_vton_2d_blocks.py +0 -0
- ootd/pipelines_ootd/unet_vton_2d_condition.py +1183 -0
- preprocess/humanparsing/datasets/__init__.py +0 -0
- preprocess/humanparsing/datasets/datasets.py +201 -0
- preprocess/humanparsing/datasets/simple_extractor_dataset.py +89 -0
- preprocess/humanparsing/datasets/target_generation.py +40 -0
- preprocess/humanparsing/mhp_extension/coco_style_annotation_creator/human_to_coco.py +166 -0
- preprocess/humanparsing/mhp_extension/coco_style_annotation_creator/pycococreatortools.py +114 -0
- preprocess/humanparsing/mhp_extension/coco_style_annotation_creator/test_human2coco_format.py +74 -0
- preprocess/humanparsing/mhp_extension/detectron2/.circleci/config.yml +179 -0
- preprocess/humanparsing/mhp_extension/detectron2/.clang-format +85 -0
- preprocess/humanparsing/mhp_extension/detectron2/.flake8 +9 -0
- preprocess/humanparsing/mhp_extension/detectron2/.github/CODE_OF_CONDUCT.md +5 -0
- preprocess/humanparsing/mhp_extension/detectron2/.github/CONTRIBUTING.md +49 -0
- preprocess/humanparsing/mhp_extension/detectron2/.github/Detectron2-Logo-Horz.svg +1 -0
- preprocess/humanparsing/mhp_extension/detectron2/.github/ISSUE_TEMPLATE.md +5 -0
- preprocess/humanparsing/mhp_extension/detectron2/.github/ISSUE_TEMPLATE/bugs.md +36 -0
- preprocess/humanparsing/mhp_extension/detectron2/.github/ISSUE_TEMPLATE/config.yml +9 -0
- preprocess/humanparsing/mhp_extension/detectron2/.github/ISSUE_TEMPLATE/feature-request.md +31 -0
- preprocess/humanparsing/mhp_extension/detectron2/.github/ISSUE_TEMPLATE/questions-help-support.md +26 -0
- preprocess/humanparsing/mhp_extension/detectron2/.github/ISSUE_TEMPLATE/unexpected-problems-bugs.md +45 -0
- preprocess/humanparsing/mhp_extension/detectron2/.github/pull_request_template.md +9 -0
- preprocess/humanparsing/mhp_extension/detectron2/.gitignore +46 -0
- preprocess/humanparsing/mhp_extension/detectron2/GETTING_STARTED.md +79 -0
- preprocess/humanparsing/mhp_extension/detectron2/INSTALL.md +184 -0
- preprocess/humanparsing/mhp_extension/detectron2/LICENSE +201 -0
- preprocess/humanparsing/mhp_extension/detectron2/MODEL_ZOO.md +903 -0
- preprocess/humanparsing/mhp_extension/detectron2/README.md +56 -0
- preprocess/humanparsing/mhp_extension/detectron2/configs/Base-RCNN-C4.yaml +18 -0
- preprocess/humanparsing/mhp_extension/detectron2/configs/Base-RCNN-DilatedC5.yaml +31 -0
- preprocess/humanparsing/mhp_extension/detectron2/configs/Base-RCNN-FPN.yaml +42 -0
- preprocess/humanparsing/mhp_extension/detectron2/configs/Base-RetinaNet.yaml +24 -0
- preprocess/humanparsing/mhp_extension/detectron2/configs/COCO-Detection/fast_rcnn_R_50_FPN_1x.yaml +17 -0
.gitattributes
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
images/demo.png filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.ckpt
|
| 2 |
+
__pycache__/
|
| 3 |
+
.vscode/
|
| 4 |
+
*.pyc
|
| 5 |
+
.uuid
|
LICENSE
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International
|
| 2 |
+
|
| 3 |
+
Creative Commons Corporation ("Creative Commons") is not a law firm and does not provide legal services or legal advice. Distribution of Creative Commons public licenses does not create a lawyer-client or other relationship. Creative Commons makes its licenses and related information available on an "as-is" basis. Creative Commons gives no warranties regarding its licenses, any material licensed under their terms and conditions, or any related information. Creative Commons disclaims all liability for damages resulting from their use to the fullest extent possible.
|
| 4 |
+
|
| 5 |
+
Using Creative Commons Public Licenses
|
| 6 |
+
|
| 7 |
+
Creative Commons public licenses provide a standard set of terms and conditions that creators and other rights holders may use to share original works of authorship and other material subject to copyright and certain other rights specified in the public license below. The following considerations are for informational purposes only, are not exhaustive, and do not form part of our licenses.
|
| 8 |
+
|
| 9 |
+
Considerations for licensors: Our public licenses are intended for use by those authorized to give the public permission to use material in ways otherwise restricted by copyright and certain other rights. Our licenses are irrevocable. Licensors should read and understand the terms and conditions of the license they choose before applying it. Licensors should also secure all rights necessary before applying our licenses so that the public can reuse the material as expected. Licensors should clearly mark any material not subject to the license. This includes other CC-licensed material, or material used under an exception or limitation to copyright. More considerations for licensors : wiki.creativecommons.org/Considerations_for_licensors
|
| 10 |
+
|
| 11 |
+
Considerations for the public: By using one of our public licenses, a licensor grants the public permission to use the licensed material under specified terms and conditions. If the licensor's permission is not necessary for any reason–for example, because of any applicable exception or limitation to copyright–then that use is not regulated by the license. Our licenses grant only permissions under copyright and certain other rights that a licensor has authority to grant. Use of the licensed material may still be restricted for other reasons, including because others have copyright or other rights in the material. A licensor may make special requests, such as asking that all changes be marked or described. Although not required by our licenses, you are encouraged to respect those requests where reasonable. More considerations for the public : wiki.creativecommons.org/Considerations_for_licensees
|
| 12 |
+
|
| 13 |
+
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International Public License
|
| 14 |
+
|
| 15 |
+
By exercising the Licensed Rights (defined below), You accept and agree to be bound by the terms and conditions of this Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International Public License ("Public License"). To the extent this Public License may be interpreted as a contract, You are granted the Licensed Rights in consideration of Your acceptance of these terms and conditions, and the Licensor grants You such rights in consideration of benefits the Licensor receives from making the Licensed Material available under these terms and conditions.
|
| 16 |
+
|
| 17 |
+
Section 1 – Definitions.
|
| 18 |
+
|
| 19 |
+
a. Adapted Material means material subject to Copyright and Similar Rights that is derived from or based upon the Licensed Material and in which the Licensed Material is translated, altered, arranged, transformed, or otherwise modified in a manner requiring permission under the Copyright and Similar Rights held by the Licensor. For purposes of this Public License, where the Licensed Material is a musical work, performance, or sound recording, Adapted Material is always produced where the Licensed Material is synched in timed relation with a moving image.
|
| 20 |
+
b. Adapter's License means the license You apply to Your Copyright and Similar Rights in Your contributions to Adapted Material in accordance with the terms and conditions of this Public License.
|
| 21 |
+
c. BY-NC-SA Compatible License means a license listed at creativecommons.org/compatiblelicenses, approved by Creative Commons as essentially the equivalent of this Public License.
|
| 22 |
+
d. Copyright and Similar Rights means copyright and/or similar rights closely related to copyright including, without limitation, performance, broadcast, sound recording, and Sui Generis Database Rights, without regard to how the rights are labeled or categorized. For purposes of this Public License, the rights specified in Section 2(b)(1)-(2) are not Copyright and Similar Rights.
|
| 23 |
+
e. Effective Technological Measures means those measures that, in the absence of proper authority, may not be circumvented under laws fulfilling obligations under Article 11 of the WIPO Copyright Treaty adopted on December 20, 1996, and/or similar international agreements.
|
| 24 |
+
f. Exceptions and Limitations means fair use, fair dealing, and/or any other exception or limitation to Copyright and Similar Rights that applies to Your use of the Licensed Material.
|
| 25 |
+
g. License Elements means the license attributes listed in the name of a Creative Commons Public License. The License Elements of this Public License are Attribution, NonCommercial, and ShareAlike.
|
| 26 |
+
h. Licensed Material means the artistic or literary work, database, or other material to which the Licensor applied this Public License.
|
| 27 |
+
i. Licensed Rights means the rights granted to You subject to the terms and conditions of this Public License, which are limited to all Copyright and Similar Rights that apply to Your use of the Licensed Material and that the Licensor has authority to license.
|
| 28 |
+
j. Licensor means the individual(s) or entity(ies) granting rights under this Public License.
|
| 29 |
+
k. NonCommercial means not primarily intended for or directed towards commercial advantage or monetary compensation. For purposes of this Public License, the exchange of the Licensed Material for other material subject to Copyright and Similar Rights by digital file-sharing or similar means is NonCommercial provided there is no payment of monetary compensation in connection with the exchange.
|
| 30 |
+
l. Share means to provide material to the public by any means or process that requires permission under the Licensed Rights, such as reproduction, public display, public performance, distribution, dissemination, communication, or importation, and to make material available to the public including in ways that members of the public may access the material from a place and at a time individually chosen by them.
|
| 31 |
+
m. Sui Generis Database Rights means rights other than copyright resulting from Directive 96/9/EC of the European Parliament and of the Council of 11 March 1996 on the legal protection of databases, as amended and/or succeeded, as well as other essentially equivalent rights anywhere in the world.
|
| 32 |
+
n. You means the individual or entity exercising the Licensed Rights under this Public License. Your has a corresponding meaning.
|
| 33 |
+
Section 2 – Scope.
|
| 34 |
+
|
| 35 |
+
a. License grant.
|
| 36 |
+
1. Subject to the terms and conditions of this Public License, the Licensor hereby grants You a worldwide, royalty-free, non-sublicensable, non-exclusive, irrevocable license to exercise the Licensed Rights in the Licensed Material to:
|
| 37 |
+
A. reproduce and Share the Licensed Material, in whole or in part, for NonCommercial purposes only; and
|
| 38 |
+
B. produce, reproduce, and Share Adapted Material for NonCommercial purposes only.
|
| 39 |
+
2. Exceptions and Limitations. For the avoidance of doubt, where Exceptions and Limitations apply to Your use, this Public License does not apply, and You do not need to comply with its terms and conditions.
|
| 40 |
+
3. Term. The term of this Public License is specified in Section 6(a).
|
| 41 |
+
4. Media and formats; technical modifications allowed. The Licensor authorizes You to exercise the Licensed Rights in all media and formats whether now known or hereafter created, and to make technical modifications necessary to do so. The Licensor waives and/or agrees not to assert any right or authority to forbid You from making technical modifications necessary to exercise the Licensed Rights, including technical modifications necessary to circumvent Effective Technological Measures. For purposes of this Public License, simply making modifications authorized by this Section 2(a)(4) never produces Adapted Material.
|
| 42 |
+
5. Downstream recipients.
|
| 43 |
+
A. Offer from the Licensor – Licensed Material. Every recipient of the Licensed Material automatically receives an offer from the Licensor to exercise the Licensed Rights under the terms and conditions of this Public License.
|
| 44 |
+
B. Additional offer from the Licensor – Adapted Material. Every recipient of Adapted Material from You automatically receives an offer from the Licensor to exercise the Licensed Rights in the Adapted Material under the conditions of the Adapter's License You apply.
|
| 45 |
+
C. No downstream restrictions. You may not offer or impose any additional or different terms or conditions on, or apply any Effective Technological Measures to, the Licensed Material if doing so restricts exercise of the Licensed Rights by any recipient of the Licensed Material.
|
| 46 |
+
6. No endorsement. Nothing in this Public License constitutes or may be construed as permission to assert or imply that You are, or that Your use of the Licensed Material is, connected with, or sponsored, endorsed, or granted official status by, the Licensor or others designated to receive attribution as provided in Section 3(a)(1)(A)(i).
|
| 47 |
+
b. Other rights.
|
| 48 |
+
1. Moral rights, such as the right of integrity, are not licensed under this Public License, nor are publicity, privacy, and/or other similar personality rights; however, to the extent possible, the Licensor waives and/or agrees not to assert any such rights held by the Licensor to the limited extent necessary to allow You to exercise the Licensed Rights, but not otherwise.
|
| 49 |
+
2. Patent and trademark rights are not licensed under this Public License.
|
| 50 |
+
3. To the extent possible, the Licensor waives any right to collect royalties from You for the exercise of the Licensed Rights, whether directly or through a collecting society under any voluntary or waivable statutory or compulsory licensing scheme. In all other cases the Licensor expressly reserves any right to collect such royalties, including when the Licensed Material is used other than for NonCommercial purposes.
|
| 51 |
+
Section 3 – License Conditions.
|
| 52 |
+
|
| 53 |
+
Your exercise of the Licensed Rights is expressly made subject to the following conditions.
|
| 54 |
+
|
| 55 |
+
a. Attribution.
|
| 56 |
+
1. If You Share the Licensed Material (including in modified form), You must:
|
| 57 |
+
A. retain the following if it is supplied by the Licensor with the Licensed Material:
|
| 58 |
+
i. identification of the creator(s) of the Licensed Material and any others designated to receive attribution, in any reasonable manner requested by the Licensor (including by pseudonym if designated);
|
| 59 |
+
ii. a copyright notice;
|
| 60 |
+
iii. a notice that refers to this Public License;
|
| 61 |
+
iv. a notice that refers to the disclaimer of warranties;
|
| 62 |
+
v. a URI or hyperlink to the Licensed Material to the extent reasonably practicable;
|
| 63 |
+
|
| 64 |
+
B. indicate if You modified the Licensed Material and retain an indication of any previous modifications; and
|
| 65 |
+
C. indicate the Licensed Material is licensed under this Public License, and include the text of, or the URI or hyperlink to, this Public License.
|
| 66 |
+
2. You may satisfy the conditions in Section 3(a)(1) in any reasonable manner based on the medium, means, and context in which You Share the Licensed Material. For example, it may be reasonable to satisfy the conditions by providing a URI or hyperlink to a resource that includes the required information.
|
| 67 |
+
3. If requested by the Licensor, You must remove any of the information required by Section 3(a)(1)(A) to the extent reasonably practicable.
|
| 68 |
+
b. ShareAlike.In addition to the conditions in Section 3(a), if You Share Adapted Material You produce, the following conditions also apply.
|
| 69 |
+
1. The Adapter's License You apply must be a Creative Commons license with the same License Elements, this version or later, or a BY-NC-SA Compatible License.
|
| 70 |
+
2. You must include the text of, or the URI or hyperlink to, the Adapter's License You apply. You may satisfy this condition in any reasonable manner based on the medium, means, and context in which You Share Adapted Material.
|
| 71 |
+
3. You may not offer or impose any additional or different terms or conditions on, or apply any Effective Technological Measures to, Adapted Material that restrict exercise of the rights granted under the Adapter's License You apply.
|
| 72 |
+
Section 4 – Sui Generis Database Rights.
|
| 73 |
+
|
| 74 |
+
Where the Licensed Rights include Sui Generis Database Rights that apply to Your use of the Licensed Material:
|
| 75 |
+
|
| 76 |
+
a. for the avoidance of doubt, Section 2(a)(1) grants You the right to extract, reuse, reproduce, and Share all or a substantial portion of the contents of the database for NonCommercial purposes only;
|
| 77 |
+
b. if You include all or a substantial portion of the database contents in a database in which You have Sui Generis Database Rights, then the database in which You have Sui Generis Database Rights (but not its individual contents) is Adapted Material, including for purposes of Section 3(b); and
|
| 78 |
+
c. You must comply with the conditions in Section 3(a) if You Share all or a substantial portion of the contents of the database.
|
| 79 |
+
For the avoidance of doubt, this Section 4 supplements and does not replace Your obligations under this Public License where the Licensed Rights include other Copyright and Similar Rights.
|
| 80 |
+
Section 5 – Disclaimer of Warranties and Limitation of Liability.
|
| 81 |
+
|
| 82 |
+
a. Unless otherwise separately undertaken by the Licensor, to the extent possible, the Licensor offers the Licensed Material as-is and as-available, and makes no representations or warranties of any kind concerning the Licensed Material, whether express, implied, statutory, or other. This includes, without limitation, warranties of title, merchantability, fitness for a particular purpose, non-infringement, absence of latent or other defects, accuracy, or the presence or absence of errors, whether or not known or discoverable. Where disclaimers of warranties are not allowed in full or in part, this disclaimer may not apply to You.
|
| 83 |
+
b. To the extent possible, in no event will the Licensor be liable to You on any legal theory (including, without limitation, negligence) or otherwise for any direct, special, indirect, incidental, consequential, punitive, exemplary, or other losses, costs, expenses, or damages arising out of this Public License or use of the Licensed Material, even if the Licensor has been advised of the possibility of such losses, costs, expenses, or damages. Where a limitation of liability is not allowed in full or in part, this limitation may not apply to You.
|
| 84 |
+
c. The disclaimer of warranties and limitation of liability provided above shall be interpreted in a manner that, to the extent possible, most closely approximates an absolute disclaimer and waiver of all liability.
|
| 85 |
+
Section 6 – Term and Termination.
|
| 86 |
+
|
| 87 |
+
a. This Public License applies for the term of the Copyright and Similar Rights licensed here. However, if You fail to comply with this Public License, then Your rights under this Public License terminate automatically.
|
| 88 |
+
b. Where Your right to use the Licensed Material has terminated under Section 6(a), it reinstates:
|
| 89 |
+
1. automatically as of the date the violation is cured, provided it is cured within 30 days of Your discovery of the violation; or
|
| 90 |
+
2. upon express reinstatement by the Licensor.
|
| 91 |
+
For the avoidance of doubt, this Section 6(b) does not affect any right the Licensor may have to seek remedies for Your violations of this Public License.
|
| 92 |
+
|
| 93 |
+
c. For the avoidance of doubt, the Licensor may also offer the Licensed Material under separate terms or conditions or stop distributing the Licensed Material at any time; however, doing so will not terminate this Public License.
|
| 94 |
+
d. Sections 1, 5, 6, 7, and 8 survive termination of this Public License.
|
| 95 |
+
Section 7 – Other Terms and Conditions.
|
| 96 |
+
|
| 97 |
+
a. The Licensor shall not be bound by any additional or different terms or conditions communicated by You unless expressly agreed.
|
| 98 |
+
b. Any arrangements, understandings, or agreements regarding the Licensed Material not stated herein are separate from and independent of the terms and conditions of this Public License.
|
| 99 |
+
Section 8 – Interpretation.
|
| 100 |
+
|
| 101 |
+
a. For the avoidance of doubt, this Public License does not, and shall not be interpreted to, reduce, limit, restrict, or impose conditions on any use of the Licensed Material that could lawfully be made without permission under this Public License.
|
| 102 |
+
b. To the extent possible, if any provision of this Public License is deemed unenforceable, it shall be automatically reformed to the minimum extent necessary to make it enforceable. If the provision cannot be reformed, it shall be severed from this Public License without affecting the enforceability of the remaining terms and conditions.
|
| 103 |
+
c. No term or condition of this Public License will be waived and no failure to comply consented to unless expressly agreed to by the Licensor.
|
| 104 |
+
d. Nothing in this Public License constitutes or may be interpreted as a limitation upon, or waiver of, any privileges and immunities that apply to the Licensor or You, including from the legal processes of any jurisdiction or authority.
|
| 105 |
+
Creative Commons is not a party to its public licenses. Notwithstanding, Creative Commons may elect to apply one of its public licenses to material it publishes and in those instances will be considered the "Licensor." The text of the Creative Commons public licenses is dedicated to the public domain under the CC0 Public Domain Dedication. Except for the limited purpose of indicating that material is shared under a Creative Commons public license or as otherwise permitted by the Creative Commons policies published at creativecommons.org/policies, Creative Commons does not authorize the use of the trademark "Creative Commons" or any other trademark or logo of Creative Commons without its prior written consent including, without limitation, in connection with any unauthorized modifications to any of its public licenses or any other arrangements, understandings, or agreements concerning use of licensed material. For the avoidance of doubt, this paragraph does not form part of the public licenses.
|
| 106 |
+
|
| 107 |
+
Creative Commons may be contacted at creativecommons.org.
|
README.md
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# OOTDiffusion
|
| 2 |
+
This repository is the official implementation of OOTDiffusion
|
| 3 |
+
|
| 4 |
+
🤗 [Try out OOTDiffusion](https://huggingface.co/spaces/levihsu/OOTDiffusion) (Thanks to [ZeroGPU](https://huggingface.co/zero-gpu-explorers) for providing A100 GPUs)
|
| 5 |
+
|
| 6 |
+
Or [try our own demo](https://ootd.ibot.cn/) on RTX 4090 GPUs
|
| 7 |
+
|
| 8 |
+
> **OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on** [[arXiv paper](https://arxiv.org/abs/2403.01779)]<br>
|
| 9 |
+
> [Yuhao Xu](http://levihsu.github.io/), [Tao Gu](https://github.com/T-Gu), [Weifeng Chen](https://github.com/ShineChen1024), [Chengcai Chen](https://www.researchgate.net/profile/Chengcai-Chen)<br>
|
| 10 |
+
> Xiao-i Research
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
Our model checkpoints trained on [VITON-HD](https://github.com/shadow2496/VITON-HD) (half-body) and [Dress Code](https://github.com/aimagelab/dress-code) (full-body) have been released
|
| 14 |
+
|
| 15 |
+
* 🤗 [Hugging Face link](https://huggingface.co/levihsu/OOTDiffusion)
|
| 16 |
+
* 📢📢 We support ONNX for [humanparsing](https://github.com/GoGoDuck912/Self-Correction-Human-Parsing) now. Most environmental issues should have been addressed : )
|
| 17 |
+
* Please download [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) into ***checkpoints*** folder
|
| 18 |
+
* We've only tested our code and models on Linux (Ubuntu 22.04)
|
| 19 |
+
|
| 20 |
+

|
| 21 |
+

|
| 22 |
+
|
| 23 |
+
## Installation
|
| 24 |
+
1. Clone the repository
|
| 25 |
+
|
| 26 |
+
```sh
|
| 27 |
+
git clone https://github.com/levihsu/OOTDiffusion
|
| 28 |
+
```
|
| 29 |
+
|
| 30 |
+
2. Create a conda environment and install the required packages
|
| 31 |
+
|
| 32 |
+
```sh
|
| 33 |
+
conda create -n ootd python==3.10
|
| 34 |
+
conda activate ootd
|
| 35 |
+
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2
|
| 36 |
+
pip install -r requirements.txt
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
## Inference
|
| 40 |
+
1. Half-body model
|
| 41 |
+
|
| 42 |
+
```sh
|
| 43 |
+
cd OOTDiffusion/run
|
| 44 |
+
python run_ootd.py --model_path <model-image-path> --cloth_path <cloth-image-path> --scale 2.0 --sample 4
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
2. Full-body model
|
| 48 |
+
|
| 49 |
+
> Garment category must be paired: 0 = upperbody; 1 = lowerbody; 2 = dress
|
| 50 |
+
|
| 51 |
+
```sh
|
| 52 |
+
cd OOTDiffusion/run
|
| 53 |
+
python run_ootd.py --model_path <model-image-path> --cloth_path <cloth-image-path> --model_type dc --category 2 --scale 2.0 --sample 4
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
## Citation
|
| 57 |
+
```
|
| 58 |
+
@article{xu2024ootdiffusion,
|
| 59 |
+
title={OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on},
|
| 60 |
+
author={Xu, Yuhao and Gu, Tao and Chen, Weifeng and Chen, Chengcai},
|
| 61 |
+
journal={arXiv preprint arXiv:2403.01779},
|
| 62 |
+
year={2024}
|
| 63 |
+
}
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
## TODO List
|
| 67 |
+
- [x] Paper
|
| 68 |
+
- [x] Gradio demo
|
| 69 |
+
- [x] Inference code
|
| 70 |
+
- [x] Model weights
|
| 71 |
+
- [ ] Training code
|
checkpoints/README.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Put checkpoints here, including ootd, humanparsing, openpose and clip-vit-large-patch14
|
images/demo.png
ADDED

|
Git LFS Details
|
images/workflow.png
ADDED
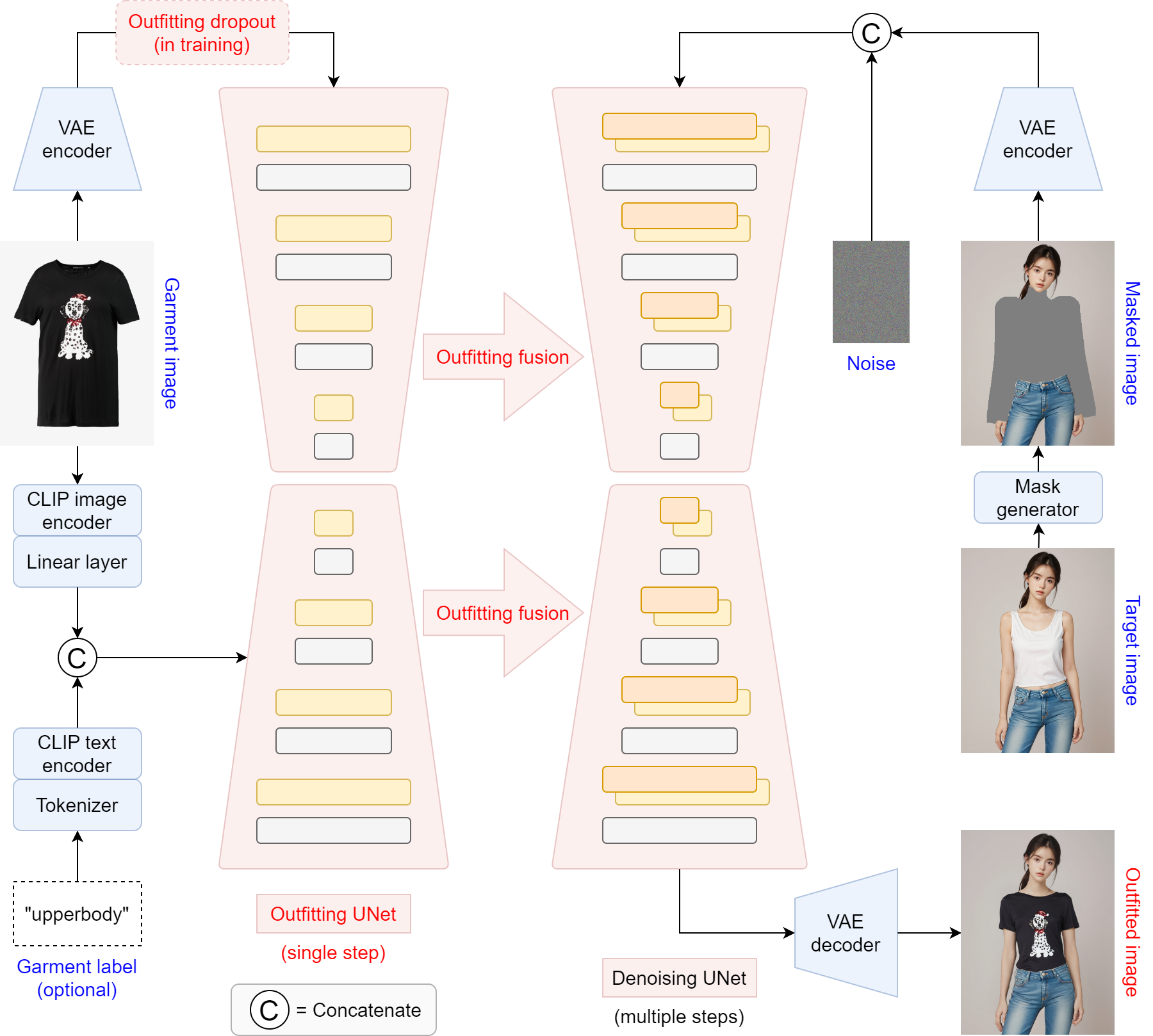
|
ootd/inference_ootd.py
ADDED
|
@@ -0,0 +1,133 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pdb
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
import sys
|
| 4 |
+
PROJECT_ROOT = Path(__file__).absolute().parents[0].absolute()
|
| 5 |
+
sys.path.insert(0, str(PROJECT_ROOT))
|
| 6 |
+
import os
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
import numpy as np
|
| 10 |
+
from PIL import Image
|
| 11 |
+
import cv2
|
| 12 |
+
|
| 13 |
+
import random
|
| 14 |
+
import time
|
| 15 |
+
import pdb
|
| 16 |
+
|
| 17 |
+
from pipelines_ootd.pipeline_ootd import OotdPipeline
|
| 18 |
+
from pipelines_ootd.unet_garm_2d_condition import UNetGarm2DConditionModel
|
| 19 |
+
from pipelines_ootd.unet_vton_2d_condition import UNetVton2DConditionModel
|
| 20 |
+
from diffusers import UniPCMultistepScheduler
|
| 21 |
+
from diffusers import AutoencoderKL
|
| 22 |
+
|
| 23 |
+
import torch.nn as nn
|
| 24 |
+
import torch.nn.functional as F
|
| 25 |
+
from transformers import AutoProcessor, CLIPVisionModelWithProjection
|
| 26 |
+
from transformers import CLIPTextModel, CLIPTokenizer
|
| 27 |
+
|
| 28 |
+
VIT_PATH = "../checkpoints/clip-vit-large-patch14"
|
| 29 |
+
VAE_PATH = "../checkpoints/ootd"
|
| 30 |
+
UNET_PATH = "../checkpoints/ootd/ootd_hd/checkpoint-36000"
|
| 31 |
+
MODEL_PATH = "../checkpoints/ootd"
|
| 32 |
+
|
| 33 |
+
class OOTDiffusion:
|
| 34 |
+
|
| 35 |
+
def __init__(self, gpu_id):
|
| 36 |
+
self.gpu_id = 'cuda:' + str(gpu_id)
|
| 37 |
+
|
| 38 |
+
vae = AutoencoderKL.from_pretrained(
|
| 39 |
+
VAE_PATH,
|
| 40 |
+
subfolder="vae",
|
| 41 |
+
torch_dtype=torch.float16,
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
unet_garm = UNetGarm2DConditionModel.from_pretrained(
|
| 45 |
+
UNET_PATH,
|
| 46 |
+
subfolder="unet_garm",
|
| 47 |
+
torch_dtype=torch.float16,
|
| 48 |
+
use_safetensors=True,
|
| 49 |
+
)
|
| 50 |
+
unet_vton = UNetVton2DConditionModel.from_pretrained(
|
| 51 |
+
UNET_PATH,
|
| 52 |
+
subfolder="unet_vton",
|
| 53 |
+
torch_dtype=torch.float16,
|
| 54 |
+
use_safetensors=True,
|
| 55 |
+
)
|
| 56 |
+
|
| 57 |
+
self.pipe = OotdPipeline.from_pretrained(
|
| 58 |
+
MODEL_PATH,
|
| 59 |
+
unet_garm=unet_garm,
|
| 60 |
+
unet_vton=unet_vton,
|
| 61 |
+
vae=vae,
|
| 62 |
+
torch_dtype=torch.float16,
|
| 63 |
+
variant="fp16",
|
| 64 |
+
use_safetensors=True,
|
| 65 |
+
safety_checker=None,
|
| 66 |
+
requires_safety_checker=False,
|
| 67 |
+
).to(self.gpu_id)
|
| 68 |
+
|
| 69 |
+
self.pipe.scheduler = UniPCMultistepScheduler.from_config(self.pipe.scheduler.config)
|
| 70 |
+
|
| 71 |
+
self.auto_processor = AutoProcessor.from_pretrained(VIT_PATH)
|
| 72 |
+
self.image_encoder = CLIPVisionModelWithProjection.from_pretrained(VIT_PATH).to(self.gpu_id)
|
| 73 |
+
|
| 74 |
+
self.tokenizer = CLIPTokenizer.from_pretrained(
|
| 75 |
+
MODEL_PATH,
|
| 76 |
+
subfolder="tokenizer",
|
| 77 |
+
)
|
| 78 |
+
self.text_encoder = CLIPTextModel.from_pretrained(
|
| 79 |
+
MODEL_PATH,
|
| 80 |
+
subfolder="text_encoder",
|
| 81 |
+
).to(self.gpu_id)
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
def tokenize_captions(self, captions, max_length):
|
| 85 |
+
inputs = self.tokenizer(
|
| 86 |
+
captions, max_length=max_length, padding="max_length", truncation=True, return_tensors="pt"
|
| 87 |
+
)
|
| 88 |
+
return inputs.input_ids
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def __call__(self,
|
| 92 |
+
model_type='hd',
|
| 93 |
+
category='upperbody',
|
| 94 |
+
image_garm=None,
|
| 95 |
+
image_vton=None,
|
| 96 |
+
mask=None,
|
| 97 |
+
image_ori=None,
|
| 98 |
+
num_samples=1,
|
| 99 |
+
num_steps=20,
|
| 100 |
+
image_scale=1.0,
|
| 101 |
+
seed=-1,
|
| 102 |
+
):
|
| 103 |
+
if seed == -1:
|
| 104 |
+
random.seed(time.time())
|
| 105 |
+
seed = random.randint(0, 2147483647)
|
| 106 |
+
print('Initial seed: ' + str(seed))
|
| 107 |
+
generator = torch.manual_seed(seed)
|
| 108 |
+
|
| 109 |
+
with torch.no_grad():
|
| 110 |
+
prompt_image = self.auto_processor(images=image_garm, return_tensors="pt").to(self.gpu_id)
|
| 111 |
+
prompt_image = self.image_encoder(prompt_image.data['pixel_values']).image_embeds
|
| 112 |
+
prompt_image = prompt_image.unsqueeze(1)
|
| 113 |
+
if model_type == 'hd':
|
| 114 |
+
prompt_embeds = self.text_encoder(self.tokenize_captions([""], 2).to(self.gpu_id))[0]
|
| 115 |
+
prompt_embeds[:, 1:] = prompt_image[:]
|
| 116 |
+
elif model_type == 'dc':
|
| 117 |
+
prompt_embeds = self.text_encoder(self.tokenize_captions([category], 3).to(self.gpu_id))[0]
|
| 118 |
+
prompt_embeds = torch.cat([prompt_embeds, prompt_image], dim=1)
|
| 119 |
+
else:
|
| 120 |
+
raise ValueError("model_type must be \'hd\' or \'dc\'!")
|
| 121 |
+
|
| 122 |
+
images = self.pipe(prompt_embeds=prompt_embeds,
|
| 123 |
+
image_garm=image_garm,
|
| 124 |
+
image_vton=image_vton,
|
| 125 |
+
mask=mask,
|
| 126 |
+
image_ori=image_ori,
|
| 127 |
+
num_inference_steps=num_steps,
|
| 128 |
+
image_guidance_scale=image_scale,
|
| 129 |
+
num_images_per_prompt=num_samples,
|
| 130 |
+
generator=generator,
|
| 131 |
+
).images
|
| 132 |
+
|
| 133 |
+
return images
|
ootd/inference_ootd_dc.py
ADDED
|
@@ -0,0 +1,132 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pdb
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
import sys
|
| 4 |
+
PROJECT_ROOT = Path(__file__).absolute().parents[0].absolute()
|
| 5 |
+
sys.path.insert(0, str(PROJECT_ROOT))
|
| 6 |
+
import os
|
| 7 |
+
import torch
|
| 8 |
+
import numpy as np
|
| 9 |
+
from PIL import Image
|
| 10 |
+
import cv2
|
| 11 |
+
|
| 12 |
+
import random
|
| 13 |
+
import time
|
| 14 |
+
import pdb
|
| 15 |
+
|
| 16 |
+
from pipelines_ootd.pipeline_ootd import OotdPipeline
|
| 17 |
+
from pipelines_ootd.unet_garm_2d_condition import UNetGarm2DConditionModel
|
| 18 |
+
from pipelines_ootd.unet_vton_2d_condition import UNetVton2DConditionModel
|
| 19 |
+
from diffusers import UniPCMultistepScheduler
|
| 20 |
+
from diffusers import AutoencoderKL
|
| 21 |
+
|
| 22 |
+
import torch.nn as nn
|
| 23 |
+
import torch.nn.functional as F
|
| 24 |
+
from transformers import AutoProcessor, CLIPVisionModelWithProjection
|
| 25 |
+
from transformers import CLIPTextModel, CLIPTokenizer
|
| 26 |
+
|
| 27 |
+
VIT_PATH = "../checkpoints/clip-vit-large-patch14"
|
| 28 |
+
VAE_PATH = "../checkpoints/ootd"
|
| 29 |
+
UNET_PATH = "../checkpoints/ootd/ootd_dc/checkpoint-36000"
|
| 30 |
+
MODEL_PATH = "../checkpoints/ootd"
|
| 31 |
+
|
| 32 |
+
class OOTDiffusionDC:
|
| 33 |
+
|
| 34 |
+
def __init__(self, gpu_id):
|
| 35 |
+
self.gpu_id = 'cuda:' + str(gpu_id)
|
| 36 |
+
|
| 37 |
+
vae = AutoencoderKL.from_pretrained(
|
| 38 |
+
VAE_PATH,
|
| 39 |
+
subfolder="vae",
|
| 40 |
+
torch_dtype=torch.float16,
|
| 41 |
+
)
|
| 42 |
+
|
| 43 |
+
unet_garm = UNetGarm2DConditionModel.from_pretrained(
|
| 44 |
+
UNET_PATH,
|
| 45 |
+
subfolder="unet_garm",
|
| 46 |
+
torch_dtype=torch.float16,
|
| 47 |
+
use_safetensors=True,
|
| 48 |
+
)
|
| 49 |
+
unet_vton = UNetVton2DConditionModel.from_pretrained(
|
| 50 |
+
UNET_PATH,
|
| 51 |
+
subfolder="unet_vton",
|
| 52 |
+
torch_dtype=torch.float16,
|
| 53 |
+
use_safetensors=True,
|
| 54 |
+
)
|
| 55 |
+
|
| 56 |
+
self.pipe = OotdPipeline.from_pretrained(
|
| 57 |
+
MODEL_PATH,
|
| 58 |
+
unet_garm=unet_garm,
|
| 59 |
+
unet_vton=unet_vton,
|
| 60 |
+
vae=vae,
|
| 61 |
+
torch_dtype=torch.float16,
|
| 62 |
+
variant="fp16",
|
| 63 |
+
use_safetensors=True,
|
| 64 |
+
safety_checker=None,
|
| 65 |
+
requires_safety_checker=False,
|
| 66 |
+
).to(self.gpu_id)
|
| 67 |
+
|
| 68 |
+
self.pipe.scheduler = UniPCMultistepScheduler.from_config(self.pipe.scheduler.config)
|
| 69 |
+
|
| 70 |
+
self.auto_processor = AutoProcessor.from_pretrained(VIT_PATH)
|
| 71 |
+
self.image_encoder = CLIPVisionModelWithProjection.from_pretrained(VIT_PATH).to(self.gpu_id)
|
| 72 |
+
|
| 73 |
+
self.tokenizer = CLIPTokenizer.from_pretrained(
|
| 74 |
+
MODEL_PATH,
|
| 75 |
+
subfolder="tokenizer",
|
| 76 |
+
)
|
| 77 |
+
self.text_encoder = CLIPTextModel.from_pretrained(
|
| 78 |
+
MODEL_PATH,
|
| 79 |
+
subfolder="text_encoder",
|
| 80 |
+
).to(self.gpu_id)
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def tokenize_captions(self, captions, max_length):
|
| 84 |
+
inputs = self.tokenizer(
|
| 85 |
+
captions, max_length=max_length, padding="max_length", truncation=True, return_tensors="pt"
|
| 86 |
+
)
|
| 87 |
+
return inputs.input_ids
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
def __call__(self,
|
| 91 |
+
model_type='hd',
|
| 92 |
+
category='upperbody',
|
| 93 |
+
image_garm=None,
|
| 94 |
+
image_vton=None,
|
| 95 |
+
mask=None,
|
| 96 |
+
image_ori=None,
|
| 97 |
+
num_samples=1,
|
| 98 |
+
num_steps=20,
|
| 99 |
+
image_scale=1.0,
|
| 100 |
+
seed=-1,
|
| 101 |
+
):
|
| 102 |
+
if seed == -1:
|
| 103 |
+
random.seed(time.time())
|
| 104 |
+
seed = random.randint(0, 2147483647)
|
| 105 |
+
print('Initial seed: ' + str(seed))
|
| 106 |
+
generator = torch.manual_seed(seed)
|
| 107 |
+
|
| 108 |
+
with torch.no_grad():
|
| 109 |
+
prompt_image = self.auto_processor(images=image_garm, return_tensors="pt").to(self.gpu_id)
|
| 110 |
+
prompt_image = self.image_encoder(prompt_image.data['pixel_values']).image_embeds
|
| 111 |
+
prompt_image = prompt_image.unsqueeze(1)
|
| 112 |
+
if model_type == 'hd':
|
| 113 |
+
prompt_embeds = self.text_encoder(self.tokenize_captions([""], 2).to(self.gpu_id))[0]
|
| 114 |
+
prompt_embeds[:, 1:] = prompt_image[:]
|
| 115 |
+
elif model_type == 'dc':
|
| 116 |
+
prompt_embeds = self.text_encoder(self.tokenize_captions([category], 3).to(self.gpu_id))[0]
|
| 117 |
+
prompt_embeds = torch.cat([prompt_embeds, prompt_image], dim=1)
|
| 118 |
+
else:
|
| 119 |
+
raise ValueError("model_type must be \'hd\' or \'dc\'!")
|
| 120 |
+
|
| 121 |
+
images = self.pipe(prompt_embeds=prompt_embeds,
|
| 122 |
+
image_garm=image_garm,
|
| 123 |
+
image_vton=image_vton,
|
| 124 |
+
mask=mask,
|
| 125 |
+
image_ori=image_ori,
|
| 126 |
+
num_inference_steps=num_steps,
|
| 127 |
+
image_guidance_scale=image_scale,
|
| 128 |
+
num_images_per_prompt=num_samples,
|
| 129 |
+
generator=generator,
|
| 130 |
+
).images
|
| 131 |
+
|
| 132 |
+
return images
|
ootd/inference_ootd_hd.py
ADDED
|
@@ -0,0 +1,132 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pdb
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
import sys
|
| 4 |
+
PROJECT_ROOT = Path(__file__).absolute().parents[0].absolute()
|
| 5 |
+
sys.path.insert(0, str(PROJECT_ROOT))
|
| 6 |
+
import os
|
| 7 |
+
import torch
|
| 8 |
+
import numpy as np
|
| 9 |
+
from PIL import Image
|
| 10 |
+
import cv2
|
| 11 |
+
|
| 12 |
+
import random
|
| 13 |
+
import time
|
| 14 |
+
import pdb
|
| 15 |
+
|
| 16 |
+
from pipelines_ootd.pipeline_ootd import OotdPipeline
|
| 17 |
+
from pipelines_ootd.unet_garm_2d_condition import UNetGarm2DConditionModel
|
| 18 |
+
from pipelines_ootd.unet_vton_2d_condition import UNetVton2DConditionModel
|
| 19 |
+
from diffusers import UniPCMultistepScheduler
|
| 20 |
+
from diffusers import AutoencoderKL
|
| 21 |
+
|
| 22 |
+
import torch.nn as nn
|
| 23 |
+
import torch.nn.functional as F
|
| 24 |
+
from transformers import AutoProcessor, CLIPVisionModelWithProjection
|
| 25 |
+
from transformers import CLIPTextModel, CLIPTokenizer
|
| 26 |
+
|
| 27 |
+
VIT_PATH = "../checkpoints/clip-vit-large-patch14"
|
| 28 |
+
VAE_PATH = "../checkpoints/ootd"
|
| 29 |
+
UNET_PATH = "../checkpoints/ootd/ootd_hd/checkpoint-36000"
|
| 30 |
+
MODEL_PATH = "../checkpoints/ootd"
|
| 31 |
+
|
| 32 |
+
class OOTDiffusionHD:
|
| 33 |
+
|
| 34 |
+
def __init__(self, gpu_id):
|
| 35 |
+
self.gpu_id = 'cuda:' + str(gpu_id)
|
| 36 |
+
|
| 37 |
+
vae = AutoencoderKL.from_pretrained(
|
| 38 |
+
VAE_PATH,
|
| 39 |
+
subfolder="vae",
|
| 40 |
+
torch_dtype=torch.float16,
|
| 41 |
+
)
|
| 42 |
+
|
| 43 |
+
unet_garm = UNetGarm2DConditionModel.from_pretrained(
|
| 44 |
+
UNET_PATH,
|
| 45 |
+
subfolder="unet_garm",
|
| 46 |
+
torch_dtype=torch.float16,
|
| 47 |
+
use_safetensors=True,
|
| 48 |
+
)
|
| 49 |
+
unet_vton = UNetVton2DConditionModel.from_pretrained(
|
| 50 |
+
UNET_PATH,
|
| 51 |
+
subfolder="unet_vton",
|
| 52 |
+
torch_dtype=torch.float16,
|
| 53 |
+
use_safetensors=True,
|
| 54 |
+
)
|
| 55 |
+
|
| 56 |
+
self.pipe = OotdPipeline.from_pretrained(
|
| 57 |
+
MODEL_PATH,
|
| 58 |
+
unet_garm=unet_garm,
|
| 59 |
+
unet_vton=unet_vton,
|
| 60 |
+
vae=vae,
|
| 61 |
+
torch_dtype=torch.float16,
|
| 62 |
+
variant="fp16",
|
| 63 |
+
use_safetensors=True,
|
| 64 |
+
safety_checker=None,
|
| 65 |
+
requires_safety_checker=False,
|
| 66 |
+
).to(self.gpu_id)
|
| 67 |
+
|
| 68 |
+
self.pipe.scheduler = UniPCMultistepScheduler.from_config(self.pipe.scheduler.config)
|
| 69 |
+
|
| 70 |
+
self.auto_processor = AutoProcessor.from_pretrained(VIT_PATH)
|
| 71 |
+
self.image_encoder = CLIPVisionModelWithProjection.from_pretrained(VIT_PATH).to(self.gpu_id)
|
| 72 |
+
|
| 73 |
+
self.tokenizer = CLIPTokenizer.from_pretrained(
|
| 74 |
+
MODEL_PATH,
|
| 75 |
+
subfolder="tokenizer",
|
| 76 |
+
)
|
| 77 |
+
self.text_encoder = CLIPTextModel.from_pretrained(
|
| 78 |
+
MODEL_PATH,
|
| 79 |
+
subfolder="text_encoder",
|
| 80 |
+
).to(self.gpu_id)
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def tokenize_captions(self, captions, max_length):
|
| 84 |
+
inputs = self.tokenizer(
|
| 85 |
+
captions, max_length=max_length, padding="max_length", truncation=True, return_tensors="pt"
|
| 86 |
+
)
|
| 87 |
+
return inputs.input_ids
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
def __call__(self,
|
| 91 |
+
model_type='hd',
|
| 92 |
+
category='upperbody',
|
| 93 |
+
image_garm=None,
|
| 94 |
+
image_vton=None,
|
| 95 |
+
mask=None,
|
| 96 |
+
image_ori=None,
|
| 97 |
+
num_samples=1,
|
| 98 |
+
num_steps=20,
|
| 99 |
+
image_scale=1.0,
|
| 100 |
+
seed=-1,
|
| 101 |
+
):
|
| 102 |
+
if seed == -1:
|
| 103 |
+
random.seed(time.time())
|
| 104 |
+
seed = random.randint(0, 2147483647)
|
| 105 |
+
print('Initial seed: ' + str(seed))
|
| 106 |
+
generator = torch.manual_seed(seed)
|
| 107 |
+
|
| 108 |
+
with torch.no_grad():
|
| 109 |
+
prompt_image = self.auto_processor(images=image_garm, return_tensors="pt").to(self.gpu_id)
|
| 110 |
+
prompt_image = self.image_encoder(prompt_image.data['pixel_values']).image_embeds
|
| 111 |
+
prompt_image = prompt_image.unsqueeze(1)
|
| 112 |
+
if model_type == 'hd':
|
| 113 |
+
prompt_embeds = self.text_encoder(self.tokenize_captions([""], 2).to(self.gpu_id))[0]
|
| 114 |
+
prompt_embeds[:, 1:] = prompt_image[:]
|
| 115 |
+
elif model_type == 'dc':
|
| 116 |
+
prompt_embeds = self.text_encoder(self.tokenize_captions([category], 3).to(self.gpu_id))[0]
|
| 117 |
+
prompt_embeds = torch.cat([prompt_embeds, prompt_image], dim=1)
|
| 118 |
+
else:
|
| 119 |
+
raise ValueError("model_type must be \'hd\' or \'dc\'!")
|
| 120 |
+
|
| 121 |
+
images = self.pipe(prompt_embeds=prompt_embeds,
|
| 122 |
+
image_garm=image_garm,
|
| 123 |
+
image_vton=image_vton,
|
| 124 |
+
mask=mask,
|
| 125 |
+
image_ori=image_ori,
|
| 126 |
+
num_inference_steps=num_steps,
|
| 127 |
+
image_guidance_scale=image_scale,
|
| 128 |
+
num_images_per_prompt=num_samples,
|
| 129 |
+
generator=generator,
|
| 130 |
+
).images
|
| 131 |
+
|
| 132 |
+
return images
|
ootd/pipelines_ootd/attention_garm.py
ADDED
|
@@ -0,0 +1,402 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# Modified by Yuhao Xu for OOTDiffusion (https://github.com/levihsu/OOTDiffusion)
|
| 16 |
+
from typing import Any, Dict, Optional
|
| 17 |
+
|
| 18 |
+
import torch
|
| 19 |
+
from torch import nn
|
| 20 |
+
|
| 21 |
+
from diffusers.utils import USE_PEFT_BACKEND
|
| 22 |
+
from diffusers.utils.torch_utils import maybe_allow_in_graph
|
| 23 |
+
from diffusers.models.activations import GEGLU, GELU, ApproximateGELU
|
| 24 |
+
from diffusers.models.attention_processor import Attention
|
| 25 |
+
from diffusers.models.embeddings import SinusoidalPositionalEmbedding
|
| 26 |
+
from diffusers.models.lora import LoRACompatibleLinear
|
| 27 |
+
from diffusers.models.normalization import AdaLayerNorm, AdaLayerNormZero
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
@maybe_allow_in_graph
|
| 31 |
+
class GatedSelfAttentionDense(nn.Module):
|
| 32 |
+
r"""
|
| 33 |
+
A gated self-attention dense layer that combines visual features and object features.
|
| 34 |
+
|
| 35 |
+
Parameters:
|
| 36 |
+
query_dim (`int`): The number of channels in the query.
|
| 37 |
+
context_dim (`int`): The number of channels in the context.
|
| 38 |
+
n_heads (`int`): The number of heads to use for attention.
|
| 39 |
+
d_head (`int`): The number of channels in each head.
|
| 40 |
+
"""
|
| 41 |
+
|
| 42 |
+
def __init__(self, query_dim: int, context_dim: int, n_heads: int, d_head: int):
|
| 43 |
+
super().__init__()
|
| 44 |
+
|
| 45 |
+
# we need a linear projection since we need cat visual feature and obj feature
|
| 46 |
+
self.linear = nn.Linear(context_dim, query_dim)
|
| 47 |
+
|
| 48 |
+
self.attn = Attention(query_dim=query_dim, heads=n_heads, dim_head=d_head)
|
| 49 |
+
self.ff = FeedForward(query_dim, activation_fn="geglu")
|
| 50 |
+
|
| 51 |
+
self.norm1 = nn.LayerNorm(query_dim)
|
| 52 |
+
self.norm2 = nn.LayerNorm(query_dim)
|
| 53 |
+
|
| 54 |
+
self.register_parameter("alpha_attn", nn.Parameter(torch.tensor(0.0)))
|
| 55 |
+
self.register_parameter("alpha_dense", nn.Parameter(torch.tensor(0.0)))
|
| 56 |
+
|
| 57 |
+
self.enabled = True
|
| 58 |
+
|
| 59 |
+
def forward(self, x: torch.Tensor, objs: torch.Tensor) -> torch.Tensor:
|
| 60 |
+
if not self.enabled:
|
| 61 |
+
return x
|
| 62 |
+
|
| 63 |
+
n_visual = x.shape[1]
|
| 64 |
+
objs = self.linear(objs)
|
| 65 |
+
|
| 66 |
+
x = x + self.alpha_attn.tanh() * self.attn(self.norm1(torch.cat([x, objs], dim=1)))[:, :n_visual, :]
|
| 67 |
+
x = x + self.alpha_dense.tanh() * self.ff(self.norm2(x))
|
| 68 |
+
|
| 69 |
+
return x
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
@maybe_allow_in_graph
|
| 73 |
+
class BasicTransformerBlock(nn.Module):
|
| 74 |
+
r"""
|
| 75 |
+
A basic Transformer block.
|
| 76 |
+
|
| 77 |
+
Parameters:
|
| 78 |
+
dim (`int`): The number of channels in the input and output.
|
| 79 |
+
num_attention_heads (`int`): The number of heads to use for multi-head attention.
|
| 80 |
+
attention_head_dim (`int`): The number of channels in each head.
|
| 81 |
+
dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
|
| 82 |
+
cross_attention_dim (`int`, *optional*): The size of the encoder_hidden_states vector for cross attention.
|
| 83 |
+
activation_fn (`str`, *optional*, defaults to `"geglu"`): Activation function to be used in feed-forward.
|
| 84 |
+
num_embeds_ada_norm (:
|
| 85 |
+
obj: `int`, *optional*): The number of diffusion steps used during training. See `Transformer2DModel`.
|
| 86 |
+
attention_bias (:
|
| 87 |
+
obj: `bool`, *optional*, defaults to `False`): Configure if the attentions should contain a bias parameter.
|
| 88 |
+
only_cross_attention (`bool`, *optional*):
|
| 89 |
+
Whether to use only cross-attention layers. In this case two cross attention layers are used.
|
| 90 |
+
double_self_attention (`bool`, *optional*):
|
| 91 |
+
Whether to use two self-attention layers. In this case no cross attention layers are used.
|
| 92 |
+
upcast_attention (`bool`, *optional*):
|
| 93 |
+
Whether to upcast the attention computation to float32. This is useful for mixed precision training.
|
| 94 |
+
norm_elementwise_affine (`bool`, *optional*, defaults to `True`):
|
| 95 |
+
Whether to use learnable elementwise affine parameters for normalization.
|
| 96 |
+
norm_type (`str`, *optional*, defaults to `"layer_norm"`):
|
| 97 |
+
The normalization layer to use. Can be `"layer_norm"`, `"ada_norm"` or `"ada_norm_zero"`.
|
| 98 |
+
final_dropout (`bool` *optional*, defaults to False):
|
| 99 |
+
Whether to apply a final dropout after the last feed-forward layer.
|
| 100 |
+
attention_type (`str`, *optional*, defaults to `"default"`):
|
| 101 |
+
The type of attention to use. Can be `"default"` or `"gated"` or `"gated-text-image"`.
|
| 102 |
+
positional_embeddings (`str`, *optional*, defaults to `None`):
|
| 103 |
+
The type of positional embeddings to apply to.
|
| 104 |
+
num_positional_embeddings (`int`, *optional*, defaults to `None`):
|
| 105 |
+
The maximum number of positional embeddings to apply.
|
| 106 |
+
"""
|
| 107 |
+
|
| 108 |
+
def __init__(
|
| 109 |
+
self,
|
| 110 |
+
dim: int,
|
| 111 |
+
num_attention_heads: int,
|
| 112 |
+
attention_head_dim: int,
|
| 113 |
+
dropout=0.0,
|
| 114 |
+
cross_attention_dim: Optional[int] = None,
|
| 115 |
+
activation_fn: str = "geglu",
|
| 116 |
+
num_embeds_ada_norm: Optional[int] = None,
|
| 117 |
+
attention_bias: bool = False,
|
| 118 |
+
only_cross_attention: bool = False,
|
| 119 |
+
double_self_attention: bool = False,
|
| 120 |
+
upcast_attention: bool = False,
|
| 121 |
+
norm_elementwise_affine: bool = True,
|
| 122 |
+
norm_type: str = "layer_norm", # 'layer_norm', 'ada_norm', 'ada_norm_zero', 'ada_norm_single'
|
| 123 |
+
norm_eps: float = 1e-5,
|
| 124 |
+
final_dropout: bool = False,
|
| 125 |
+
attention_type: str = "default",
|
| 126 |
+
positional_embeddings: Optional[str] = None,
|
| 127 |
+
num_positional_embeddings: Optional[int] = None,
|
| 128 |
+
):
|
| 129 |
+
super().__init__()
|
| 130 |
+
self.only_cross_attention = only_cross_attention
|
| 131 |
+
|
| 132 |
+
self.use_ada_layer_norm_zero = (num_embeds_ada_norm is not None) and norm_type == "ada_norm_zero"
|
| 133 |
+
self.use_ada_layer_norm = (num_embeds_ada_norm is not None) and norm_type == "ada_norm"
|
| 134 |
+
self.use_ada_layer_norm_single = norm_type == "ada_norm_single"
|
| 135 |
+
self.use_layer_norm = norm_type == "layer_norm"
|
| 136 |
+
|
| 137 |
+
if norm_type in ("ada_norm", "ada_norm_zero") and num_embeds_ada_norm is None:
|
| 138 |
+
raise ValueError(
|
| 139 |
+
f"`norm_type` is set to {norm_type}, but `num_embeds_ada_norm` is not defined. Please make sure to"
|
| 140 |
+
f" define `num_embeds_ada_norm` if setting `norm_type` to {norm_type}."
|
| 141 |
+
)
|
| 142 |
+
|
| 143 |
+
if positional_embeddings and (num_positional_embeddings is None):
|
| 144 |
+
raise ValueError(
|
| 145 |
+
"If `positional_embedding` type is defined, `num_positition_embeddings` must also be defined."
|
| 146 |
+
)
|
| 147 |
+
|
| 148 |
+
if positional_embeddings == "sinusoidal":
|
| 149 |
+
self.pos_embed = SinusoidalPositionalEmbedding(dim, max_seq_length=num_positional_embeddings)
|
| 150 |
+
else:
|
| 151 |
+
self.pos_embed = None
|
| 152 |
+
|
| 153 |
+
# Define 3 blocks. Each block has its own normalization layer.
|
| 154 |
+
# 1. Self-Attn
|
| 155 |
+
if self.use_ada_layer_norm:
|
| 156 |
+
self.norm1 = AdaLayerNorm(dim, num_embeds_ada_norm)
|
| 157 |
+
elif self.use_ada_layer_norm_zero:
|
| 158 |
+
self.norm1 = AdaLayerNormZero(dim, num_embeds_ada_norm)
|
| 159 |
+
else:
|
| 160 |
+
self.norm1 = nn.LayerNorm(dim, elementwise_affine=norm_elementwise_affine, eps=norm_eps)
|
| 161 |
+
|
| 162 |
+
self.attn1 = Attention(
|
| 163 |
+
query_dim=dim,
|
| 164 |
+
heads=num_attention_heads,
|
| 165 |
+
dim_head=attention_head_dim,
|
| 166 |
+
dropout=dropout,
|
| 167 |
+
bias=attention_bias,
|
| 168 |
+
cross_attention_dim=cross_attention_dim if only_cross_attention else None,
|
| 169 |
+
upcast_attention=upcast_attention,
|
| 170 |
+
)
|
| 171 |
+
|
| 172 |
+
# 2. Cross-Attn
|
| 173 |
+
if cross_attention_dim is not None or double_self_attention:
|
| 174 |
+
# We currently only use AdaLayerNormZero for self attention where there will only be one attention block.
|
| 175 |
+
# I.e. the number of returned modulation chunks from AdaLayerZero would not make sense if returned during
|
| 176 |
+
# the second cross attention block.
|
| 177 |
+
self.norm2 = (
|
| 178 |
+
AdaLayerNorm(dim, num_embeds_ada_norm)
|
| 179 |
+
if self.use_ada_layer_norm
|
| 180 |
+
else nn.LayerNorm(dim, elementwise_affine=norm_elementwise_affine, eps=norm_eps)
|
| 181 |
+
)
|
| 182 |
+
self.attn2 = Attention(
|
| 183 |
+
query_dim=dim,
|
| 184 |
+
cross_attention_dim=cross_attention_dim if not double_self_attention else None,
|
| 185 |
+
heads=num_attention_heads,
|
| 186 |
+
dim_head=attention_head_dim,
|
| 187 |
+
dropout=dropout,
|
| 188 |
+
bias=attention_bias,
|
| 189 |
+
upcast_attention=upcast_attention,
|
| 190 |
+
) # is self-attn if encoder_hidden_states is none
|
| 191 |
+
else:
|
| 192 |
+
self.norm2 = None
|
| 193 |
+
self.attn2 = None
|
| 194 |
+
|
| 195 |
+
# 3. Feed-forward
|
| 196 |
+
if not self.use_ada_layer_norm_single:
|
| 197 |
+
self.norm3 = nn.LayerNorm(dim, elementwise_affine=norm_elementwise_affine, eps=norm_eps)
|
| 198 |
+
|
| 199 |
+
self.ff = FeedForward(dim, dropout=dropout, activation_fn=activation_fn, final_dropout=final_dropout)
|
| 200 |
+
|
| 201 |
+
# 4. Fuser
|
| 202 |
+
if attention_type == "gated" or attention_type == "gated-text-image":
|
| 203 |
+
self.fuser = GatedSelfAttentionDense(dim, cross_attention_dim, num_attention_heads, attention_head_dim)
|
| 204 |
+
|
| 205 |
+
# 5. Scale-shift for PixArt-Alpha.
|
| 206 |
+
if self.use_ada_layer_norm_single:
|
| 207 |
+
self.scale_shift_table = nn.Parameter(torch.randn(6, dim) / dim**0.5)
|
| 208 |
+
|
| 209 |
+
# let chunk size default to None
|
| 210 |
+
self._chunk_size = None
|
| 211 |
+
self._chunk_dim = 0
|
| 212 |
+
|
| 213 |
+
def set_chunk_feed_forward(self, chunk_size: Optional[int], dim: int):
|
| 214 |
+
# Sets chunk feed-forward
|
| 215 |
+
self._chunk_size = chunk_size
|
| 216 |
+
self._chunk_dim = dim
|
| 217 |
+
|
| 218 |
+
def forward(
|
| 219 |
+
self,
|
| 220 |
+
hidden_states: torch.FloatTensor,
|
| 221 |
+
spatial_attn_inputs = [],
|
| 222 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 223 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 224 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 225 |
+
timestep: Optional[torch.LongTensor] = None,
|
| 226 |
+
cross_attention_kwargs: Dict[str, Any] = None,
|
| 227 |
+
class_labels: Optional[torch.LongTensor] = None,
|
| 228 |
+
) -> torch.FloatTensor:
|
| 229 |
+
# Notice that normalization is always applied before the real computation in the following blocks.
|
| 230 |
+
# 0. Self-Attention
|
| 231 |
+
batch_size = hidden_states.shape[0]
|
| 232 |
+
|
| 233 |
+
spatial_attn_input = hidden_states
|
| 234 |
+
spatial_attn_inputs.append(spatial_attn_input)
|
| 235 |
+
|
| 236 |
+
if self.use_ada_layer_norm:
|
| 237 |
+
norm_hidden_states = self.norm1(hidden_states, timestep)
|
| 238 |
+
elif self.use_ada_layer_norm_zero:
|
| 239 |
+
norm_hidden_states, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.norm1(
|
| 240 |
+
hidden_states, timestep, class_labels, hidden_dtype=hidden_states.dtype
|
| 241 |
+
)
|
| 242 |
+
elif self.use_layer_norm:
|
| 243 |
+
norm_hidden_states = self.norm1(hidden_states)
|
| 244 |
+
elif self.use_ada_layer_norm_single:
|
| 245 |
+
shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = (
|
| 246 |
+
self.scale_shift_table[None] + timestep.reshape(batch_size, 6, -1)
|
| 247 |
+
).chunk(6, dim=1)
|
| 248 |
+
norm_hidden_states = self.norm1(hidden_states)
|
| 249 |
+
norm_hidden_states = norm_hidden_states * (1 + scale_msa) + shift_msa
|
| 250 |
+
norm_hidden_states = norm_hidden_states.squeeze(1)
|
| 251 |
+
else:
|
| 252 |
+
raise ValueError("Incorrect norm used")
|
| 253 |
+
|
| 254 |
+
if self.pos_embed is not None:
|
| 255 |
+
norm_hidden_states = self.pos_embed(norm_hidden_states)
|
| 256 |
+
|
| 257 |
+
# 1. Retrieve lora scale.
|
| 258 |
+
lora_scale = cross_attention_kwargs.get("scale", 1.0) if cross_attention_kwargs is not None else 1.0
|
| 259 |
+
|
| 260 |
+
# 2. Prepare GLIGEN inputs
|
| 261 |
+
cross_attention_kwargs = cross_attention_kwargs.copy() if cross_attention_kwargs is not None else {}
|
| 262 |
+
gligen_kwargs = cross_attention_kwargs.pop("gligen", None)
|
| 263 |
+
|
| 264 |
+
attn_output = self.attn1(
|
| 265 |
+
norm_hidden_states,
|
| 266 |
+
encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None,
|
| 267 |
+
attention_mask=attention_mask,
|
| 268 |
+
**cross_attention_kwargs,
|
| 269 |
+
)
|
| 270 |
+
if self.use_ada_layer_norm_zero:
|
| 271 |
+
attn_output = gate_msa.unsqueeze(1) * attn_output
|
| 272 |
+
elif self.use_ada_layer_norm_single:
|
| 273 |
+
attn_output = gate_msa * attn_output
|
| 274 |
+
|
| 275 |
+
hidden_states = attn_output + hidden_states
|
| 276 |
+
if hidden_states.ndim == 4:
|
| 277 |
+
hidden_states = hidden_states.squeeze(1)
|
| 278 |
+
|
| 279 |
+
# 2.5 GLIGEN Control
|
| 280 |
+
if gligen_kwargs is not None:
|
| 281 |
+
hidden_states = self.fuser(hidden_states, gligen_kwargs["objs"])
|
| 282 |
+
|
| 283 |
+
# 3. Cross-Attention
|
| 284 |
+
if self.attn2 is not None:
|
| 285 |
+
if self.use_ada_layer_norm:
|
| 286 |
+
norm_hidden_states = self.norm2(hidden_states, timestep)
|
| 287 |
+
elif self.use_ada_layer_norm_zero or self.use_layer_norm:
|
| 288 |
+
norm_hidden_states = self.norm2(hidden_states)
|
| 289 |
+
elif self.use_ada_layer_norm_single:
|
| 290 |
+
# For PixArt norm2 isn't applied here:
|
| 291 |
+
# https://github.com/PixArt-alpha/PixArt-alpha/blob/0f55e922376d8b797edd44d25d0e7464b260dcab/diffusion/model/nets/PixArtMS.py#L70C1-L76C103
|
| 292 |
+
norm_hidden_states = hidden_states
|
| 293 |
+
else:
|
| 294 |
+
raise ValueError("Incorrect norm")
|
| 295 |
+
|
| 296 |
+
if self.pos_embed is not None and self.use_ada_layer_norm_single is False:
|
| 297 |
+
norm_hidden_states = self.pos_embed(norm_hidden_states)
|
| 298 |
+
|
| 299 |
+
attn_output = self.attn2(
|
| 300 |
+
norm_hidden_states,
|
| 301 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 302 |
+
attention_mask=encoder_attention_mask,
|
| 303 |
+
**cross_attention_kwargs,
|
| 304 |
+
)
|
| 305 |
+
hidden_states = attn_output + hidden_states
|
| 306 |
+
|
| 307 |
+
# 4. Feed-forward
|
| 308 |
+
if not self.use_ada_layer_norm_single:
|
| 309 |
+
norm_hidden_states = self.norm3(hidden_states)
|
| 310 |
+
|
| 311 |
+
if self.use_ada_layer_norm_zero:
|
| 312 |
+
norm_hidden_states = norm_hidden_states * (1 + scale_mlp[:, None]) + shift_mlp[:, None]
|
| 313 |
+
|
| 314 |
+
if self.use_ada_layer_norm_single:
|
| 315 |
+
norm_hidden_states = self.norm2(hidden_states)
|
| 316 |
+
norm_hidden_states = norm_hidden_states * (1 + scale_mlp) + shift_mlp
|
| 317 |
+
|
| 318 |
+
if self._chunk_size is not None:
|
| 319 |
+
# "feed_forward_chunk_size" can be used to save memory
|
| 320 |
+
if norm_hidden_states.shape[self._chunk_dim] % self._chunk_size != 0:
|
| 321 |
+
raise ValueError(
|
| 322 |
+
f"`hidden_states` dimension to be chunked: {norm_hidden_states.shape[self._chunk_dim]} has to be divisible by chunk size: {self._chunk_size}. Make sure to set an appropriate `chunk_size` when calling `unet.enable_forward_chunking`."
|
| 323 |
+
)
|
| 324 |
+
|
| 325 |
+
num_chunks = norm_hidden_states.shape[self._chunk_dim] // self._chunk_size
|
| 326 |
+
ff_output = torch.cat(
|
| 327 |
+
[
|
| 328 |
+
self.ff(hid_slice, scale=lora_scale)
|
| 329 |
+
for hid_slice in norm_hidden_states.chunk(num_chunks, dim=self._chunk_dim)
|
| 330 |
+
],
|
| 331 |
+
dim=self._chunk_dim,
|
| 332 |
+
)
|
| 333 |
+
else:
|
| 334 |
+
ff_output = self.ff(norm_hidden_states, scale=lora_scale)
|
| 335 |
+
|
| 336 |
+
if self.use_ada_layer_norm_zero:
|
| 337 |
+
ff_output = gate_mlp.unsqueeze(1) * ff_output
|
| 338 |
+
elif self.use_ada_layer_norm_single:
|
| 339 |
+
ff_output = gate_mlp * ff_output
|
| 340 |
+
|
| 341 |
+
hidden_states = ff_output + hidden_states
|
| 342 |
+
if hidden_states.ndim == 4:
|
| 343 |
+
hidden_states = hidden_states.squeeze(1)
|
| 344 |
+
|
| 345 |
+
return hidden_states, spatial_attn_inputs
|
| 346 |
+
|
| 347 |
+
|
| 348 |
+
class FeedForward(nn.Module):
|
| 349 |
+
r"""
|
| 350 |
+
A feed-forward layer.
|
| 351 |
+
|
| 352 |
+
Parameters:
|
| 353 |
+
dim (`int`): The number of channels in the input.
|
| 354 |
+
dim_out (`int`, *optional*): The number of channels in the output. If not given, defaults to `dim`.
|
| 355 |
+
mult (`int`, *optional*, defaults to 4): The multiplier to use for the hidden dimension.
|
| 356 |
+
dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
|
| 357 |
+
activation_fn (`str`, *optional*, defaults to `"geglu"`): Activation function to be used in feed-forward.
|
| 358 |
+
final_dropout (`bool` *optional*, defaults to False): Apply a final dropout.
|
| 359 |
+
"""
|
| 360 |
+
|
| 361 |
+
def __init__(
|
| 362 |
+
self,
|
| 363 |
+
dim: int,
|
| 364 |
+
dim_out: Optional[int] = None,
|
| 365 |
+
mult: int = 4,
|
| 366 |
+
dropout: float = 0.0,
|
| 367 |
+
activation_fn: str = "geglu",
|
| 368 |
+
final_dropout: bool = False,
|
| 369 |
+
):
|
| 370 |
+
super().__init__()
|
| 371 |
+
inner_dim = int(dim * mult)
|
| 372 |
+
dim_out = dim_out if dim_out is not None else dim
|
| 373 |
+
linear_cls = LoRACompatibleLinear if not USE_PEFT_BACKEND else nn.Linear
|
| 374 |
+
|
| 375 |
+
if activation_fn == "gelu":
|
| 376 |
+
act_fn = GELU(dim, inner_dim)
|
| 377 |
+
if activation_fn == "gelu-approximate":
|
| 378 |
+
act_fn = GELU(dim, inner_dim, approximate="tanh")
|
| 379 |
+
elif activation_fn == "geglu":
|
| 380 |
+
act_fn = GEGLU(dim, inner_dim)
|
| 381 |
+
elif activation_fn == "geglu-approximate":
|
| 382 |
+
act_fn = ApproximateGELU(dim, inner_dim)
|
| 383 |
+
|
| 384 |
+
self.net = nn.ModuleList([])
|
| 385 |
+
# project in
|
| 386 |
+
self.net.append(act_fn)
|
| 387 |
+
# project dropout
|
| 388 |
+
self.net.append(nn.Dropout(dropout))
|
| 389 |
+
# project out
|
| 390 |
+
self.net.append(linear_cls(inner_dim, dim_out))
|
| 391 |
+
# FF as used in Vision Transformer, MLP-Mixer, etc. have a final dropout
|
| 392 |
+
if final_dropout:
|
| 393 |
+
self.net.append(nn.Dropout(dropout))
|
| 394 |
+
|
| 395 |
+
def forward(self, hidden_states: torch.Tensor, scale: float = 1.0) -> torch.Tensor:
|
| 396 |
+
compatible_cls = (GEGLU,) if USE_PEFT_BACKEND else (GEGLU, LoRACompatibleLinear)
|
| 397 |
+
for module in self.net:
|
| 398 |
+
if isinstance(module, compatible_cls):
|
| 399 |
+
hidden_states = module(hidden_states, scale)
|
| 400 |
+
else:
|
| 401 |
+
hidden_states = module(hidden_states)
|
| 402 |
+
return hidden_states
|
ootd/pipelines_ootd/attention_vton.py
ADDED
|
@@ -0,0 +1,407 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# Modified by Yuhao Xu for OOTDiffusion (https://github.com/levihsu/OOTDiffusion)
|
| 16 |
+
from typing import Any, Dict, Optional
|
| 17 |
+
|
| 18 |
+
import torch
|
| 19 |
+
from torch import nn
|
| 20 |
+
|
| 21 |
+
from diffusers.utils import USE_PEFT_BACKEND
|
| 22 |
+
from diffusers.utils.torch_utils import maybe_allow_in_graph
|
| 23 |
+
from diffusers.models.activations import GEGLU, GELU, ApproximateGELU
|
| 24 |
+
from diffusers.models.attention_processor import Attention
|
| 25 |
+
from diffusers.models.embeddings import SinusoidalPositionalEmbedding
|
| 26 |
+
from diffusers.models.lora import LoRACompatibleLinear
|
| 27 |
+
from diffusers.models.normalization import AdaLayerNorm, AdaLayerNormZero
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
@maybe_allow_in_graph
|
| 31 |
+
class GatedSelfAttentionDense(nn.Module):
|
| 32 |
+
r"""
|
| 33 |
+
A gated self-attention dense layer that combines visual features and object features.
|
| 34 |
+
|
| 35 |
+
Parameters:
|
| 36 |
+
query_dim (`int`): The number of channels in the query.
|
| 37 |
+
context_dim (`int`): The number of channels in the context.
|
| 38 |
+
n_heads (`int`): The number of heads to use for attention.
|
| 39 |
+
d_head (`int`): The number of channels in each head.
|
| 40 |
+
"""
|
| 41 |
+
|
| 42 |
+
def __init__(self, query_dim: int, context_dim: int, n_heads: int, d_head: int):
|
| 43 |
+
super().__init__()
|
| 44 |
+
|
| 45 |
+
# we need a linear projection since we need cat visual feature and obj feature
|
| 46 |
+
self.linear = nn.Linear(context_dim, query_dim)
|
| 47 |
+
|
| 48 |
+
self.attn = Attention(query_dim=query_dim, heads=n_heads, dim_head=d_head)
|
| 49 |
+
self.ff = FeedForward(query_dim, activation_fn="geglu")
|
| 50 |
+
|
| 51 |
+
self.norm1 = nn.LayerNorm(query_dim)
|
| 52 |
+
self.norm2 = nn.LayerNorm(query_dim)
|
| 53 |
+
|
| 54 |
+
self.register_parameter("alpha_attn", nn.Parameter(torch.tensor(0.0)))
|
| 55 |
+
self.register_parameter("alpha_dense", nn.Parameter(torch.tensor(0.0)))
|
| 56 |
+
|
| 57 |
+
self.enabled = True
|
| 58 |
+
|
| 59 |
+
def forward(self, x: torch.Tensor, objs: torch.Tensor) -> torch.Tensor:
|
| 60 |
+
if not self.enabled:
|
| 61 |
+
return x
|
| 62 |
+
|
| 63 |
+
n_visual = x.shape[1]
|
| 64 |
+
objs = self.linear(objs)
|
| 65 |
+
|
| 66 |
+
x = x + self.alpha_attn.tanh() * self.attn(self.norm1(torch.cat([x, objs], dim=1)))[:, :n_visual, :]
|
| 67 |
+
x = x + self.alpha_dense.tanh() * self.ff(self.norm2(x))
|
| 68 |
+
|
| 69 |
+
return x
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
@maybe_allow_in_graph
|
| 73 |
+
class BasicTransformerBlock(nn.Module):
|
| 74 |
+
r"""
|
| 75 |
+
A basic Transformer block.
|
| 76 |
+
|
| 77 |
+
Parameters:
|
| 78 |
+
dim (`int`): The number of channels in the input and output.
|
| 79 |
+
num_attention_heads (`int`): The number of heads to use for multi-head attention.
|
| 80 |
+
attention_head_dim (`int`): The number of channels in each head.
|
| 81 |
+
dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
|
| 82 |
+
cross_attention_dim (`int`, *optional*): The size of the encoder_hidden_states vector for cross attention.
|
| 83 |
+
activation_fn (`str`, *optional*, defaults to `"geglu"`): Activation function to be used in feed-forward.
|
| 84 |
+
num_embeds_ada_norm (:
|
| 85 |
+
obj: `int`, *optional*): The number of diffusion steps used during training. See `Transformer2DModel`.
|
| 86 |
+
attention_bias (:
|
| 87 |
+
obj: `bool`, *optional*, defaults to `False`): Configure if the attentions should contain a bias parameter.
|
| 88 |
+
only_cross_attention (`bool`, *optional*):
|
| 89 |
+
Whether to use only cross-attention layers. In this case two cross attention layers are used.
|
| 90 |
+
double_self_attention (`bool`, *optional*):
|
| 91 |
+
Whether to use two self-attention layers. In this case no cross attention layers are used.
|
| 92 |
+
upcast_attention (`bool`, *optional*):
|
| 93 |
+
Whether to upcast the attention computation to float32. This is useful for mixed precision training.
|
| 94 |
+
norm_elementwise_affine (`bool`, *optional*, defaults to `True`):
|
| 95 |
+
Whether to use learnable elementwise affine parameters for normalization.
|
| 96 |
+
norm_type (`str`, *optional*, defaults to `"layer_norm"`):
|
| 97 |
+
The normalization layer to use. Can be `"layer_norm"`, `"ada_norm"` or `"ada_norm_zero"`.
|
| 98 |
+
final_dropout (`bool` *optional*, defaults to False):
|
| 99 |
+
Whether to apply a final dropout after the last feed-forward layer.
|
| 100 |
+
attention_type (`str`, *optional*, defaults to `"default"`):
|
| 101 |
+
The type of attention to use. Can be `"default"` or `"gated"` or `"gated-text-image"`.
|
| 102 |
+
positional_embeddings (`str`, *optional*, defaults to `None`):
|
| 103 |
+
The type of positional embeddings to apply to.
|
| 104 |
+
num_positional_embeddings (`int`, *optional*, defaults to `None`):
|
| 105 |
+
The maximum number of positional embeddings to apply.
|
| 106 |
+
"""
|
| 107 |
+
|
| 108 |
+
def __init__(
|
| 109 |
+
self,
|
| 110 |
+
dim: int,
|
| 111 |
+
num_attention_heads: int,
|
| 112 |
+
attention_head_dim: int,
|
| 113 |
+
dropout=0.0,
|
| 114 |
+
cross_attention_dim: Optional[int] = None,
|
| 115 |
+
activation_fn: str = "geglu",
|
| 116 |
+
num_embeds_ada_norm: Optional[int] = None,
|
| 117 |
+
attention_bias: bool = False,
|
| 118 |
+
only_cross_attention: bool = False,
|
| 119 |
+
double_self_attention: bool = False,
|
| 120 |
+
upcast_attention: bool = False,
|
| 121 |
+
norm_elementwise_affine: bool = True,
|
| 122 |
+
norm_type: str = "layer_norm", # 'layer_norm', 'ada_norm', 'ada_norm_zero', 'ada_norm_single'
|
| 123 |
+
norm_eps: float = 1e-5,
|
| 124 |
+
final_dropout: bool = False,
|
| 125 |
+
attention_type: str = "default",
|
| 126 |
+
positional_embeddings: Optional[str] = None,
|
| 127 |
+
num_positional_embeddings: Optional[int] = None,
|
| 128 |
+
):
|
| 129 |
+
super().__init__()
|
| 130 |
+
self.only_cross_attention = only_cross_attention
|
| 131 |
+
|
| 132 |
+
self.use_ada_layer_norm_zero = (num_embeds_ada_norm is not None) and norm_type == "ada_norm_zero"
|
| 133 |
+
self.use_ada_layer_norm = (num_embeds_ada_norm is not None) and norm_type == "ada_norm"
|
| 134 |
+
self.use_ada_layer_norm_single = norm_type == "ada_norm_single"
|
| 135 |
+
self.use_layer_norm = norm_type == "layer_norm"
|
| 136 |
+
|
| 137 |
+
if norm_type in ("ada_norm", "ada_norm_zero") and num_embeds_ada_norm is None:
|
| 138 |
+
raise ValueError(
|
| 139 |
+
f"`norm_type` is set to {norm_type}, but `num_embeds_ada_norm` is not defined. Please make sure to"
|
| 140 |
+
f" define `num_embeds_ada_norm` if setting `norm_type` to {norm_type}."
|
| 141 |
+
)
|
| 142 |
+
|
| 143 |
+
if positional_embeddings and (num_positional_embeddings is None):
|
| 144 |
+
raise ValueError(
|
| 145 |
+
"If `positional_embedding` type is defined, `num_positition_embeddings` must also be defined."
|
| 146 |
+
)
|
| 147 |
+
|
| 148 |
+
if positional_embeddings == "sinusoidal":
|
| 149 |
+
self.pos_embed = SinusoidalPositionalEmbedding(dim, max_seq_length=num_positional_embeddings)
|
| 150 |
+
else:
|
| 151 |
+
self.pos_embed = None
|
| 152 |
+
|
| 153 |
+
# Define 3 blocks. Each block has its own normalization layer.
|
| 154 |
+
# 1. Self-Attn
|
| 155 |
+
if self.use_ada_layer_norm:
|
| 156 |
+
self.norm1 = AdaLayerNorm(dim, num_embeds_ada_norm)
|
| 157 |
+
elif self.use_ada_layer_norm_zero:
|
| 158 |
+
self.norm1 = AdaLayerNormZero(dim, num_embeds_ada_norm)
|
| 159 |
+
else:
|
| 160 |
+
self.norm1 = nn.LayerNorm(dim, elementwise_affine=norm_elementwise_affine, eps=norm_eps)
|
| 161 |
+
|
| 162 |
+
self.attn1 = Attention(
|
| 163 |
+
query_dim=dim,
|
| 164 |
+
heads=num_attention_heads,
|
| 165 |
+
dim_head=attention_head_dim,
|
| 166 |
+
dropout=dropout,
|
| 167 |
+
bias=attention_bias,
|
| 168 |
+
cross_attention_dim=cross_attention_dim if only_cross_attention else None,
|
| 169 |
+
upcast_attention=upcast_attention,
|
| 170 |
+
)
|
| 171 |
+
|
| 172 |
+
# 2. Cross-Attn
|
| 173 |
+
if cross_attention_dim is not None or double_self_attention:
|
| 174 |
+
# We currently only use AdaLayerNormZero for self attention where there will only be one attention block.
|
| 175 |
+
# I.e. the number of returned modulation chunks from AdaLayerZero would not make sense if returned during
|
| 176 |
+
# the second cross attention block.
|
| 177 |
+
self.norm2 = (
|
| 178 |
+
AdaLayerNorm(dim, num_embeds_ada_norm)
|
| 179 |
+
if self.use_ada_layer_norm
|
| 180 |
+
else nn.LayerNorm(dim, elementwise_affine=norm_elementwise_affine, eps=norm_eps)
|
| 181 |
+
)
|
| 182 |
+
self.attn2 = Attention(
|
| 183 |
+
query_dim=dim,
|
| 184 |
+
cross_attention_dim=cross_attention_dim if not double_self_attention else None,
|
| 185 |
+
heads=num_attention_heads,
|
| 186 |
+
dim_head=attention_head_dim,
|
| 187 |
+
dropout=dropout,
|
| 188 |
+
bias=attention_bias,
|
| 189 |
+
upcast_attention=upcast_attention,
|
| 190 |
+
) # is self-attn if encoder_hidden_states is none
|
| 191 |
+
else:
|
| 192 |
+
self.norm2 = None
|
| 193 |
+
self.attn2 = None
|
| 194 |
+
|
| 195 |
+
# 3. Feed-forward
|
| 196 |
+
if not self.use_ada_layer_norm_single:
|
| 197 |
+
self.norm3 = nn.LayerNorm(dim, elementwise_affine=norm_elementwise_affine, eps=norm_eps)
|
| 198 |
+
|
| 199 |
+
self.ff = FeedForward(dim, dropout=dropout, activation_fn=activation_fn, final_dropout=final_dropout)
|
| 200 |
+
|
| 201 |
+
# 4. Fuser
|
| 202 |
+
if attention_type == "gated" or attention_type == "gated-text-image":
|
| 203 |
+
self.fuser = GatedSelfAttentionDense(dim, cross_attention_dim, num_attention_heads, attention_head_dim)
|
| 204 |
+
|
| 205 |
+
# 5. Scale-shift for PixArt-Alpha.
|
| 206 |
+
if self.use_ada_layer_norm_single:
|
| 207 |
+
self.scale_shift_table = nn.Parameter(torch.randn(6, dim) / dim**0.5)
|
| 208 |
+
|
| 209 |
+
# let chunk size default to None
|
| 210 |
+
self._chunk_size = None
|
| 211 |
+
self._chunk_dim = 0
|
| 212 |
+
|
| 213 |
+
def set_chunk_feed_forward(self, chunk_size: Optional[int], dim: int):
|
| 214 |
+
# Sets chunk feed-forward
|
| 215 |
+
self._chunk_size = chunk_size
|
| 216 |
+
self._chunk_dim = dim
|
| 217 |
+
|
| 218 |
+
def forward(
|
| 219 |
+
self,
|
| 220 |
+
hidden_states: torch.FloatTensor,
|
| 221 |
+
spatial_attn_inputs = [],
|
| 222 |
+
spatial_attn_idx = 0,
|
| 223 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 224 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 225 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 226 |
+
timestep: Optional[torch.LongTensor] = None,
|
| 227 |
+
cross_attention_kwargs: Dict[str, Any] = None,
|
| 228 |
+
class_labels: Optional[torch.LongTensor] = None,
|
| 229 |
+
) -> torch.FloatTensor:
|
| 230 |
+
# Notice that normalization is always applied before the real computation in the following blocks.
|
| 231 |
+
# 0. Self-Attention
|
| 232 |
+
batch_size = hidden_states.shape[0]
|
| 233 |
+
|
| 234 |
+
spatial_attn_input = spatial_attn_inputs[spatial_attn_idx]
|
| 235 |
+
spatial_attn_idx += 1
|
| 236 |
+
hidden_states = torch.cat((hidden_states, spatial_attn_input), dim=1)
|
| 237 |
+
|
| 238 |
+
if self.use_ada_layer_norm:
|
| 239 |
+
norm_hidden_states = self.norm1(hidden_states, timestep)
|
| 240 |
+
elif self.use_ada_layer_norm_zero:
|
| 241 |
+
norm_hidden_states, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.norm1(
|
| 242 |
+
hidden_states, timestep, class_labels, hidden_dtype=hidden_states.dtype
|
| 243 |
+
)
|
| 244 |
+
elif self.use_layer_norm:
|
| 245 |
+
norm_hidden_states = self.norm1(hidden_states)
|
| 246 |
+
elif self.use_ada_layer_norm_single:
|
| 247 |
+
shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = (
|
| 248 |
+
self.scale_shift_table[None] + timestep.reshape(batch_size, 6, -1)
|
| 249 |
+
).chunk(6, dim=1)
|
| 250 |
+
norm_hidden_states = self.norm1(hidden_states)
|
| 251 |
+
norm_hidden_states = norm_hidden_states * (1 + scale_msa) + shift_msa
|
| 252 |
+
norm_hidden_states = norm_hidden_states.squeeze(1)
|
| 253 |
+
else:
|
| 254 |
+
raise ValueError("Incorrect norm used")
|
| 255 |
+
|
| 256 |
+
if self.pos_embed is not None:
|
| 257 |
+
norm_hidden_states = self.pos_embed(norm_hidden_states)
|
| 258 |
+
|
| 259 |
+
# 1. Retrieve lora scale.
|
| 260 |
+
lora_scale = cross_attention_kwargs.get("scale", 1.0) if cross_attention_kwargs is not None else 1.0
|
| 261 |
+
|
| 262 |
+
# 2. Prepare GLIGEN inputs
|
| 263 |
+
cross_attention_kwargs = cross_attention_kwargs.copy() if cross_attention_kwargs is not None else {}
|
| 264 |
+
gligen_kwargs = cross_attention_kwargs.pop("gligen", None)
|
| 265 |
+
|
| 266 |
+
attn_output = self.attn1(
|
| 267 |
+
norm_hidden_states,
|
| 268 |
+
encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None,
|
| 269 |
+
attention_mask=attention_mask,
|
| 270 |
+
**cross_attention_kwargs,
|
| 271 |
+
)
|
| 272 |
+
if self.use_ada_layer_norm_zero:
|
| 273 |
+
attn_output = gate_msa.unsqueeze(1) * attn_output
|
| 274 |
+
elif self.use_ada_layer_norm_single:
|
| 275 |
+
attn_output = gate_msa * attn_output
|
| 276 |
+
|
| 277 |
+
|
| 278 |
+
hidden_states = attn_output + hidden_states
|
| 279 |
+
hidden_states, _ = hidden_states.chunk(2, dim=1)
|
| 280 |
+
|
| 281 |
+
if hidden_states.ndim == 4:
|
| 282 |
+
hidden_states = hidden_states.squeeze(1)
|
| 283 |
+
|
| 284 |
+
# 2.5 GLIGEN Control
|
| 285 |
+
if gligen_kwargs is not None:
|
| 286 |
+
hidden_states = self.fuser(hidden_states, gligen_kwargs["objs"])
|
| 287 |
+
|
| 288 |
+
# 3. Cross-Attention
|
| 289 |
+
if self.attn2 is not None:
|
| 290 |
+
if self.use_ada_layer_norm:
|
| 291 |
+
norm_hidden_states = self.norm2(hidden_states, timestep)
|
| 292 |
+
elif self.use_ada_layer_norm_zero or self.use_layer_norm:
|
| 293 |
+
norm_hidden_states = self.norm2(hidden_states)
|
| 294 |
+
elif self.use_ada_layer_norm_single:
|
| 295 |
+
# For PixArt norm2 isn't applied here:
|
| 296 |
+
# https://github.com/PixArt-alpha/PixArt-alpha/blob/0f55e922376d8b797edd44d25d0e7464b260dcab/diffusion/model/nets/PixArtMS.py#L70C1-L76C103
|
| 297 |
+
norm_hidden_states = hidden_states
|
| 298 |
+
else:
|
| 299 |
+
raise ValueError("Incorrect norm")
|
| 300 |
+
|
| 301 |
+
if self.pos_embed is not None and self.use_ada_layer_norm_single is False:
|
| 302 |
+
norm_hidden_states = self.pos_embed(norm_hidden_states)
|
| 303 |
+
|
| 304 |
+
attn_output = self.attn2(
|
| 305 |
+
norm_hidden_states,
|
| 306 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 307 |
+
attention_mask=encoder_attention_mask,
|
| 308 |
+
**cross_attention_kwargs,
|
| 309 |
+
)
|
| 310 |
+
hidden_states = attn_output + hidden_states
|
| 311 |
+
|
| 312 |
+
# 4. Feed-forward
|
| 313 |
+
if not self.use_ada_layer_norm_single:
|
| 314 |
+
norm_hidden_states = self.norm3(hidden_states)
|
| 315 |
+
|
| 316 |
+
if self.use_ada_layer_norm_zero:
|
| 317 |
+
norm_hidden_states = norm_hidden_states * (1 + scale_mlp[:, None]) + shift_mlp[:, None]
|
| 318 |
+
|
| 319 |
+
if self.use_ada_layer_norm_single:
|
| 320 |
+
norm_hidden_states = self.norm2(hidden_states)
|
| 321 |
+
norm_hidden_states = norm_hidden_states * (1 + scale_mlp) + shift_mlp
|
| 322 |
+
|
| 323 |
+
if self._chunk_size is not None:
|
| 324 |
+
# "feed_forward_chunk_size" can be used to save memory
|
| 325 |
+
if norm_hidden_states.shape[self._chunk_dim] % self._chunk_size != 0:
|
| 326 |
+
raise ValueError(
|
| 327 |
+
f"`hidden_states` dimension to be chunked: {norm_hidden_states.shape[self._chunk_dim]} has to be divisible by chunk size: {self._chunk_size}. Make sure to set an appropriate `chunk_size` when calling `unet.enable_forward_chunking`."
|
| 328 |
+
)
|
| 329 |
+
|
| 330 |
+
num_chunks = norm_hidden_states.shape[self._chunk_dim] // self._chunk_size
|
| 331 |
+
ff_output = torch.cat(
|
| 332 |
+
[
|
| 333 |
+
self.ff(hid_slice, scale=lora_scale)
|
| 334 |
+
for hid_slice in norm_hidden_states.chunk(num_chunks, dim=self._chunk_dim)
|
| 335 |
+
],
|
| 336 |
+
dim=self._chunk_dim,
|
| 337 |
+
)
|
| 338 |
+
else:
|
| 339 |
+
ff_output = self.ff(norm_hidden_states, scale=lora_scale)
|
| 340 |
+
|
| 341 |
+
if self.use_ada_layer_norm_zero:
|
| 342 |
+
ff_output = gate_mlp.unsqueeze(1) * ff_output
|
| 343 |
+
elif self.use_ada_layer_norm_single:
|
| 344 |
+
ff_output = gate_mlp * ff_output
|
| 345 |
+
|
| 346 |
+
hidden_states = ff_output + hidden_states
|
| 347 |
+
if hidden_states.ndim == 4:
|
| 348 |
+
hidden_states = hidden_states.squeeze(1)
|
| 349 |
+
|
| 350 |
+
return hidden_states, spatial_attn_inputs, spatial_attn_idx
|
| 351 |
+
|
| 352 |
+
|
| 353 |
+
class FeedForward(nn.Module):
|
| 354 |
+
r"""
|
| 355 |
+
A feed-forward layer.
|
| 356 |
+
|
| 357 |
+
Parameters:
|
| 358 |
+
dim (`int`): The number of channels in the input.
|
| 359 |
+
dim_out (`int`, *optional*): The number of channels in the output. If not given, defaults to `dim`.
|
| 360 |
+
mult (`int`, *optional*, defaults to 4): The multiplier to use for the hidden dimension.
|
| 361 |
+
dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
|
| 362 |
+
activation_fn (`str`, *optional*, defaults to `"geglu"`): Activation function to be used in feed-forward.
|
| 363 |
+
final_dropout (`bool` *optional*, defaults to False): Apply a final dropout.
|
| 364 |
+
"""
|
| 365 |
+
|
| 366 |
+
def __init__(
|
| 367 |
+
self,
|
| 368 |
+
dim: int,
|
| 369 |
+
dim_out: Optional[int] = None,
|
| 370 |
+
mult: int = 4,
|
| 371 |
+
dropout: float = 0.0,
|
| 372 |
+
activation_fn: str = "geglu",
|
| 373 |
+
final_dropout: bool = False,
|
| 374 |
+
):
|
| 375 |
+
super().__init__()
|
| 376 |
+
inner_dim = int(dim * mult)
|
| 377 |
+
dim_out = dim_out if dim_out is not None else dim
|
| 378 |
+
linear_cls = LoRACompatibleLinear if not USE_PEFT_BACKEND else nn.Linear
|
| 379 |
+
|
| 380 |
+
if activation_fn == "gelu":
|
| 381 |
+
act_fn = GELU(dim, inner_dim)
|
| 382 |
+
if activation_fn == "gelu-approximate":
|
| 383 |
+
act_fn = GELU(dim, inner_dim, approximate="tanh")
|
| 384 |
+
elif activation_fn == "geglu":
|
| 385 |
+
act_fn = GEGLU(dim, inner_dim)
|
| 386 |
+
elif activation_fn == "geglu-approximate":
|
| 387 |
+
act_fn = ApproximateGELU(dim, inner_dim)
|
| 388 |
+
|
| 389 |
+
self.net = nn.ModuleList([])
|
| 390 |
+
# project in
|
| 391 |
+
self.net.append(act_fn)
|
| 392 |
+
# project dropout
|
| 393 |
+
self.net.append(nn.Dropout(dropout))
|
| 394 |
+
# project out
|
| 395 |
+
self.net.append(linear_cls(inner_dim, dim_out))
|
| 396 |
+
# FF as used in Vision Transformer, MLP-Mixer, etc. have a final dropout
|
| 397 |
+
if final_dropout:
|
| 398 |
+
self.net.append(nn.Dropout(dropout))
|
| 399 |
+
|
| 400 |
+
def forward(self, hidden_states: torch.Tensor, scale: float = 1.0) -> torch.Tensor:
|
| 401 |
+
compatible_cls = (GEGLU,) if USE_PEFT_BACKEND else (GEGLU, LoRACompatibleLinear)
|
| 402 |
+
for module in self.net:
|
| 403 |
+
if isinstance(module, compatible_cls):
|
| 404 |
+
hidden_states = module(hidden_states, scale)
|
| 405 |
+
else:
|
| 406 |
+
hidden_states = module(hidden_states)
|
| 407 |
+
return hidden_states
|
ootd/pipelines_ootd/pipeline_ootd.py
ADDED
|
@@ -0,0 +1,846 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# Modified by Yuhao Xu for OOTDiffusion (https://github.com/levihsu/OOTDiffusion)
|
| 16 |
+
import inspect
|
| 17 |
+
from typing import Any, Callable, Dict, List, Optional, Union
|
| 18 |
+
|
| 19 |
+
import numpy as np
|
| 20 |
+
import PIL.Image
|
| 21 |
+
import torch
|
| 22 |
+
from packaging import version
|
| 23 |
+
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
|
| 24 |
+
|
| 25 |
+
from transformers import AutoProcessor, CLIPVisionModelWithProjection
|
| 26 |
+
|
| 27 |
+
from .unet_vton_2d_condition import UNetVton2DConditionModel
|
| 28 |
+
from .unet_garm_2d_condition import UNetGarm2DConditionModel
|
| 29 |
+
|
| 30 |
+
from diffusers.configuration_utils import FrozenDict
|
| 31 |
+
from diffusers.image_processor import PipelineImageInput, VaeImageProcessor
|
| 32 |
+
from diffusers.loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
|
| 33 |
+
from diffusers.models import AutoencoderKL, UNet2DConditionModel
|
| 34 |
+
from diffusers.models.lora import adjust_lora_scale_text_encoder
|
| 35 |
+
from diffusers.schedulers import KarrasDiffusionSchedulers
|
| 36 |
+
from diffusers.utils import (
|
| 37 |
+
PIL_INTERPOLATION,
|
| 38 |
+
USE_PEFT_BACKEND,
|
| 39 |
+
deprecate,
|
| 40 |
+
logging,
|
| 41 |
+
replace_example_docstring,
|
| 42 |
+
scale_lora_layers,
|
| 43 |
+
unscale_lora_layers,
|
| 44 |
+
)
|
| 45 |
+
from diffusers.utils.torch_utils import randn_tensor
|
| 46 |
+
from diffusers.pipelines.pipeline_utils import DiffusionPipeline
|
| 47 |
+
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
|
| 48 |
+
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.preprocess
|
| 55 |
+
def preprocess(image):
|
| 56 |
+
deprecation_message = "The preprocess method is deprecated and will be removed in diffusers 1.0.0. Please use VaeImageProcessor.preprocess(...) instead"
|
| 57 |
+
deprecate("preprocess", "1.0.0", deprecation_message, standard_warn=False)
|
| 58 |
+
if isinstance(image, torch.Tensor):
|
| 59 |
+
return image
|
| 60 |
+
elif isinstance(image, PIL.Image.Image):
|
| 61 |
+
image = [image]
|
| 62 |
+
|
| 63 |
+
if isinstance(image[0], PIL.Image.Image):
|
| 64 |
+
w, h = image[0].size
|
| 65 |
+
w, h = (x - x % 8 for x in (w, h)) # resize to integer multiple of 8
|
| 66 |
+
|
| 67 |
+
image = [np.array(i.resize((w, h), resample=PIL_INTERPOLATION["lanczos"]))[None, :] for i in image]
|
| 68 |
+
image = np.concatenate(image, axis=0)
|
| 69 |
+
image = np.array(image).astype(np.float32) / 255.0
|
| 70 |
+
image = image.transpose(0, 3, 1, 2)
|
| 71 |
+
image = 2.0 * image - 1.0
|
| 72 |
+
image = torch.from_numpy(image)
|
| 73 |
+
elif isinstance(image[0], torch.Tensor):
|
| 74 |
+
image = torch.cat(image, dim=0)
|
| 75 |
+
return image
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
class OotdPipeline(DiffusionPipeline, TextualInversionLoaderMixin, LoraLoaderMixin):
|
| 79 |
+
r"""
|
| 80 |
+
Args:
|
| 81 |
+
vae ([`AutoencoderKL`]):
|
| 82 |
+
Variational Auto-Encoder (VAE) model to encode and decode images to and from latent representations.
|
| 83 |
+
text_encoder ([`~transformers.CLIPTextModel`]):
|
| 84 |
+
Frozen text-encoder ([clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14)).
|
| 85 |
+
tokenizer ([`~transformers.CLIPTokenizer`]):
|
| 86 |
+
A `CLIPTokenizer` to tokenize text.
|
| 87 |
+
unet ([`UNet2DConditionModel`]):
|
| 88 |
+
A `UNet2DConditionModel` to denoise the encoded image latents.
|
| 89 |
+
scheduler ([`SchedulerMixin`]):
|
| 90 |
+
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
|
| 91 |
+
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
|
| 92 |
+
safety_checker ([`StableDiffusionSafetyChecker`]):
|
| 93 |
+
Classification module that estimates whether generated images could be considered offensive or harmful.
|
| 94 |
+
Please refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for more details
|
| 95 |
+
about a model's potential harms.
|
| 96 |
+
feature_extractor ([`~transformers.CLIPImageProcessor`]):
|
| 97 |
+
A `CLIPImageProcessor` to extract features from generated images; used as inputs to the `safety_checker`.
|
| 98 |
+
"""
|
| 99 |
+
model_cpu_offload_seq = "text_encoder->unet->vae"
|
| 100 |
+
_optional_components = ["safety_checker", "feature_extractor"]
|
| 101 |
+
_exclude_from_cpu_offload = ["safety_checker"]
|
| 102 |
+
_callback_tensor_inputs = ["latents", "prompt_embeds", "vton_latents"]
|
| 103 |
+
|
| 104 |
+
def __init__(
|
| 105 |
+
self,
|
| 106 |
+
vae: AutoencoderKL,
|
| 107 |
+
text_encoder: CLIPTextModel,
|
| 108 |
+
tokenizer: CLIPTokenizer,
|
| 109 |
+
unet_garm: UNetGarm2DConditionModel,
|
| 110 |
+
unet_vton: UNetVton2DConditionModel,
|
| 111 |
+
scheduler: KarrasDiffusionSchedulers,
|
| 112 |
+
safety_checker: StableDiffusionSafetyChecker,
|
| 113 |
+
feature_extractor: CLIPImageProcessor,
|
| 114 |
+
requires_safety_checker: bool = True,
|
| 115 |
+
):
|
| 116 |
+
super().__init__()
|
| 117 |
+
|
| 118 |
+
if safety_checker is None and requires_safety_checker:
|
| 119 |
+
logger.warning(
|
| 120 |
+
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
|
| 121 |
+
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
|
| 122 |
+
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
|
| 123 |
+
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
|
| 124 |
+
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
|
| 125 |
+
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
|
| 126 |
+
)
|
| 127 |
+
|
| 128 |
+
if safety_checker is not None and feature_extractor is None:
|
| 129 |
+
raise ValueError(
|
| 130 |
+
"Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
|
| 131 |
+
" checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
|
| 132 |
+
)
|
| 133 |
+
|
| 134 |
+
self.register_modules(
|
| 135 |
+
vae=vae,
|
| 136 |
+
text_encoder=text_encoder,
|
| 137 |
+
tokenizer=tokenizer,
|
| 138 |
+
unet_garm=unet_garm,
|
| 139 |
+
unet_vton=unet_vton,
|
| 140 |
+
scheduler=scheduler,
|
| 141 |
+
safety_checker=safety_checker,
|
| 142 |
+
feature_extractor=feature_extractor,
|
| 143 |
+
)
|
| 144 |
+
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
|
| 145 |
+
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
|
| 146 |
+
self.register_to_config(requires_safety_checker=requires_safety_checker)
|
| 147 |
+
|
| 148 |
+
@torch.no_grad()
|
| 149 |
+
def __call__(
|
| 150 |
+
self,
|
| 151 |
+
prompt: Union[str, List[str]] = None,
|
| 152 |
+
image_garm: PipelineImageInput = None,
|
| 153 |
+
image_vton: PipelineImageInput = None,
|
| 154 |
+
mask: PipelineImageInput = None,
|
| 155 |
+
image_ori: PipelineImageInput = None,
|
| 156 |
+
num_inference_steps: int = 100,
|
| 157 |
+
guidance_scale: float = 7.5,
|
| 158 |
+
image_guidance_scale: float = 1.5,
|
| 159 |
+
negative_prompt: Optional[Union[str, List[str]]] = None,
|
| 160 |
+
num_images_per_prompt: Optional[int] = 1,
|
| 161 |
+
eta: float = 0.0,
|
| 162 |
+
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
| 163 |
+
latents: Optional[torch.FloatTensor] = None,
|
| 164 |
+
prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 165 |
+
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 166 |
+
output_type: Optional[str] = "pil",
|
| 167 |
+
return_dict: bool = True,
|
| 168 |
+
callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
|
| 169 |
+
callback_on_step_end_tensor_inputs: List[str] = ["latents"],
|
| 170 |
+
**kwargs,
|
| 171 |
+
):
|
| 172 |
+
r"""
|
| 173 |
+
The call function to the pipeline for generation.
|
| 174 |
+
|
| 175 |
+
Args:
|
| 176 |
+
prompt (`str` or `List[str]`, *optional*):
|
| 177 |
+
The prompt or prompts to guide image generation. If not defined, you need to pass `prompt_embeds`.
|
| 178 |
+
image (`torch.FloatTensor` `np.ndarray`, `PIL.Image.Image`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, or `List[np.ndarray]`):
|
| 179 |
+
`Image` or tensor representing an image batch to be repainted according to `prompt`. Can also accept
|
| 180 |
+
image latents as `image`, but if passing latents directly it is not encoded again.
|
| 181 |
+
num_inference_steps (`int`, *optional*, defaults to 100):
|
| 182 |
+
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
|
| 183 |
+
expense of slower inference.
|
| 184 |
+
guidance_scale (`float`, *optional*, defaults to 7.5):
|
| 185 |
+
A higher guidance scale value encourages the model to generate images closely linked to the text
|
| 186 |
+
`prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
|
| 187 |
+
image_guidance_scale (`float`, *optional*, defaults to 1.5):
|
| 188 |
+
Push the generated image towards the initial `image`. Image guidance scale is enabled by setting
|
| 189 |
+
`image_guidance_scale > 1`. Higher image guidance scale encourages generated images that are closely
|
| 190 |
+
linked to the source `image`, usually at the expense of lower image quality. This pipeline requires a
|
| 191 |
+
value of at least `1`.
|
| 192 |
+
negative_prompt (`str` or `List[str]`, *optional*):
|
| 193 |
+
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
|
| 194 |
+
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
|
| 195 |
+
num_images_per_prompt (`int`, *optional*, defaults to 1):
|
| 196 |
+
The number of images to generate per prompt.
|
| 197 |
+
eta (`float`, *optional*, defaults to 0.0):
|
| 198 |
+
Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
|
| 199 |
+
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
|
| 200 |
+
generator (`torch.Generator`, *optional*):
|
| 201 |
+
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
|
| 202 |
+
generation deterministic.
|
| 203 |
+
latents (`torch.FloatTensor`, *optional*):
|
| 204 |
+
Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
|
| 205 |
+
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
|
| 206 |
+
tensor is generated by sampling using the supplied random `generator`.
|
| 207 |
+
prompt_embeds (`torch.FloatTensor`, *optional*):
|
| 208 |
+
Pre-generated text embeddings. Can be used to easily tweak text inputs (prompt weighting). If not
|
| 209 |
+
provided, text embeddings are generated from the `prompt` input argument.
|
| 210 |
+
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
|
| 211 |
+
Pre-generated negative text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
|
| 212 |
+
not provided, `negative_prompt_embeds` are generated from the `negative_prompt` input argument.
|
| 213 |
+
output_type (`str`, *optional*, defaults to `"pil"`):
|
| 214 |
+
The output format of the generated image. Choose between `PIL.Image` or `np.array`.
|
| 215 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 216 |
+
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
|
| 217 |
+
plain tuple.
|
| 218 |
+
callback_on_step_end (`Callable`, *optional*):
|
| 219 |
+
A function that calls at the end of each denoising steps during the inference. The function is called
|
| 220 |
+
with the following arguments: `callback_on_step_end(self: DiffusionPipeline, step: int, timestep: int,
|
| 221 |
+
callback_kwargs: Dict)`. `callback_kwargs` will include a list of all tensors as specified by
|
| 222 |
+
`callback_on_step_end_tensor_inputs`.
|
| 223 |
+
callback_on_step_end_tensor_inputs (`List`, *optional*):
|
| 224 |
+
The list of tensor inputs for the `callback_on_step_end` function. The tensors specified in the list
|
| 225 |
+
will be passed as `callback_kwargs` argument. You will only be able to include variables listed in the
|
| 226 |
+
`._callback_tensor_inputs` attribute of your pipeline class.
|
| 227 |
+
|
| 228 |
+
Returns:
|
| 229 |
+
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
|
| 230 |
+
If `return_dict` is `True`, [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] is returned,
|
| 231 |
+
otherwise a `tuple` is returned where the first element is a list with the generated images and the
|
| 232 |
+
second element is a list of `bool`s indicating whether the corresponding generated image contains
|
| 233 |
+
"not-safe-for-work" (nsfw) content.
|
| 234 |
+
"""
|
| 235 |
+
|
| 236 |
+
callback = kwargs.pop("callback", None)
|
| 237 |
+
callback_steps = kwargs.pop("callback_steps", None)
|
| 238 |
+
|
| 239 |
+
if callback is not None:
|
| 240 |
+
deprecate(
|
| 241 |
+
"callback",
|
| 242 |
+
"1.0.0",
|
| 243 |
+
"Passing `callback` as an input argument to `__call__` is deprecated, consider use `callback_on_step_end`",
|
| 244 |
+
)
|
| 245 |
+
if callback_steps is not None:
|
| 246 |
+
deprecate(
|
| 247 |
+
"callback_steps",
|
| 248 |
+
"1.0.0",
|
| 249 |
+
"Passing `callback_steps` as an input argument to `__call__` is deprecated, consider use `callback_on_step_end`",
|
| 250 |
+
)
|
| 251 |
+
|
| 252 |
+
# 0. Check inputs
|
| 253 |
+
self.check_inputs(
|
| 254 |
+
prompt,
|
| 255 |
+
callback_steps,
|
| 256 |
+
negative_prompt,
|
| 257 |
+
prompt_embeds,
|
| 258 |
+
negative_prompt_embeds,
|
| 259 |
+
callback_on_step_end_tensor_inputs,
|
| 260 |
+
)
|
| 261 |
+
self._guidance_scale = guidance_scale
|
| 262 |
+
self._image_guidance_scale = image_guidance_scale
|
| 263 |
+
|
| 264 |
+
if (image_vton is None) or (image_garm is None):
|
| 265 |
+
raise ValueError("`image` input cannot be undefined.")
|
| 266 |
+
|
| 267 |
+
# 1. Define call parameters
|
| 268 |
+
if prompt is not None and isinstance(prompt, str):
|
| 269 |
+
batch_size = 1
|
| 270 |
+
elif prompt is not None and isinstance(prompt, list):
|
| 271 |
+
batch_size = len(prompt)
|
| 272 |
+
else:
|
| 273 |
+
batch_size = prompt_embeds.shape[0]
|
| 274 |
+
|
| 275 |
+
device = self._execution_device
|
| 276 |
+
# check if scheduler is in sigmas space
|
| 277 |
+
scheduler_is_in_sigma_space = hasattr(self.scheduler, "sigmas")
|
| 278 |
+
|
| 279 |
+
# 2. Encode input prompt
|
| 280 |
+
prompt_embeds = self._encode_prompt(
|
| 281 |
+
prompt,
|
| 282 |
+
device,
|
| 283 |
+
num_images_per_prompt,
|
| 284 |
+
self.do_classifier_free_guidance,
|
| 285 |
+
negative_prompt,
|
| 286 |
+
prompt_embeds=prompt_embeds,
|
| 287 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 288 |
+
)
|
| 289 |
+
|
| 290 |
+
# 3. Preprocess image
|
| 291 |
+
image_garm = self.image_processor.preprocess(image_garm)
|
| 292 |
+
image_vton = self.image_processor.preprocess(image_vton)
|
| 293 |
+
image_ori = self.image_processor.preprocess(image_ori)
|
| 294 |
+
mask = np.array(mask)
|
| 295 |
+
mask[mask < 127] = 0
|
| 296 |
+
mask[mask >= 127] = 255
|
| 297 |
+
mask = torch.tensor(mask)
|
| 298 |
+
mask = mask / 255
|
| 299 |
+
mask = mask.reshape(-1, 1, mask.size(-2), mask.size(-1))
|
| 300 |
+
|
| 301 |
+
# 4. set timesteps
|
| 302 |
+
self.scheduler.set_timesteps(num_inference_steps, device=device)
|
| 303 |
+
timesteps = self.scheduler.timesteps
|
| 304 |
+
|
| 305 |
+
# 5. Prepare Image latents
|
| 306 |
+
garm_latents = self.prepare_garm_latents(
|
| 307 |
+
image_garm,
|
| 308 |
+
batch_size,
|
| 309 |
+
num_images_per_prompt,
|
| 310 |
+
prompt_embeds.dtype,
|
| 311 |
+
device,
|
| 312 |
+
self.do_classifier_free_guidance,
|
| 313 |
+
generator,
|
| 314 |
+
)
|
| 315 |
+
|
| 316 |
+
vton_latents, mask_latents, image_ori_latents = self.prepare_vton_latents(
|
| 317 |
+
image_vton,
|
| 318 |
+
mask,
|
| 319 |
+
image_ori,
|
| 320 |
+
batch_size,
|
| 321 |
+
num_images_per_prompt,
|
| 322 |
+
prompt_embeds.dtype,
|
| 323 |
+
device,
|
| 324 |
+
self.do_classifier_free_guidance,
|
| 325 |
+
generator,
|
| 326 |
+
)
|
| 327 |
+
|
| 328 |
+
height, width = vton_latents.shape[-2:]
|
| 329 |
+
height = height * self.vae_scale_factor
|
| 330 |
+
width = width * self.vae_scale_factor
|
| 331 |
+
|
| 332 |
+
# 6. Prepare latent variables
|
| 333 |
+
num_channels_latents = self.vae.config.latent_channels
|
| 334 |
+
latents = self.prepare_latents(
|
| 335 |
+
batch_size * num_images_per_prompt,
|
| 336 |
+
num_channels_latents,
|
| 337 |
+
height,
|
| 338 |
+
width,
|
| 339 |
+
prompt_embeds.dtype,
|
| 340 |
+
device,
|
| 341 |
+
generator,
|
| 342 |
+
latents,
|
| 343 |
+
)
|
| 344 |
+
|
| 345 |
+
noise = latents.clone()
|
| 346 |
+
|
| 347 |
+
# 8. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
|
| 348 |
+
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
|
| 349 |
+
|
| 350 |
+
# 9. Denoising loop
|
| 351 |
+
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
|
| 352 |
+
self._num_timesteps = len(timesteps)
|
| 353 |
+
|
| 354 |
+
_, spatial_attn_outputs = self.unet_garm(
|
| 355 |
+
garm_latents,
|
| 356 |
+
0,
|
| 357 |
+
encoder_hidden_states=prompt_embeds,
|
| 358 |
+
return_dict=False,
|
| 359 |
+
)
|
| 360 |
+
|
| 361 |
+
with self.progress_bar(total=num_inference_steps) as progress_bar:
|
| 362 |
+
for i, t in enumerate(timesteps):
|
| 363 |
+
latent_model_input = torch.cat([latents] * 2) if self.do_classifier_free_guidance else latents
|
| 364 |
+
|
| 365 |
+
# concat latents, image_latents in the channel dimension
|
| 366 |
+
scaled_latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
| 367 |
+
latent_vton_model_input = torch.cat([scaled_latent_model_input, vton_latents], dim=1)
|
| 368 |
+
# latent_vton_model_input = scaled_latent_model_input + vton_latents
|
| 369 |
+
|
| 370 |
+
spatial_attn_inputs = spatial_attn_outputs.copy()
|
| 371 |
+
|
| 372 |
+
# predict the noise residual
|
| 373 |
+
noise_pred = self.unet_vton(
|
| 374 |
+
latent_vton_model_input,
|
| 375 |
+
spatial_attn_inputs,
|
| 376 |
+
t,
|
| 377 |
+
encoder_hidden_states=prompt_embeds,
|
| 378 |
+
return_dict=False,
|
| 379 |
+
)[0]
|
| 380 |
+
|
| 381 |
+
# Hack:
|
| 382 |
+
# For karras style schedulers the model does classifer free guidance using the
|
| 383 |
+
# predicted_original_sample instead of the noise_pred. So we need to compute the
|
| 384 |
+
# predicted_original_sample here if we are using a karras style scheduler.
|
| 385 |
+
if scheduler_is_in_sigma_space:
|
| 386 |
+
step_index = (self.scheduler.timesteps == t).nonzero()[0].item()
|
| 387 |
+
sigma = self.scheduler.sigmas[step_index]
|
| 388 |
+
noise_pred = latent_model_input - sigma * noise_pred
|
| 389 |
+
|
| 390 |
+
# perform guidance
|
| 391 |
+
if self.do_classifier_free_guidance:
|
| 392 |
+
noise_pred_text_image, noise_pred_text = noise_pred.chunk(2)
|
| 393 |
+
noise_pred = (
|
| 394 |
+
noise_pred_text
|
| 395 |
+
+ self.image_guidance_scale * (noise_pred_text_image - noise_pred_text)
|
| 396 |
+
)
|
| 397 |
+
|
| 398 |
+
# Hack:
|
| 399 |
+
# For karras style schedulers the model does classifer free guidance using the
|
| 400 |
+
# predicted_original_sample instead of the noise_pred. But the scheduler.step function
|
| 401 |
+
# expects the noise_pred and computes the predicted_original_sample internally. So we
|
| 402 |
+
# need to overwrite the noise_pred here such that the value of the computed
|
| 403 |
+
# predicted_original_sample is correct.
|
| 404 |
+
if scheduler_is_in_sigma_space:
|
| 405 |
+
noise_pred = (noise_pred - latents) / (-sigma)
|
| 406 |
+
|
| 407 |
+
# compute the previous noisy sample x_t -> x_t-1
|
| 408 |
+
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
|
| 409 |
+
|
| 410 |
+
init_latents_proper = image_ori_latents * self.vae.config.scaling_factor
|
| 411 |
+
|
| 412 |
+
# repainting
|
| 413 |
+
if i < len(timesteps) - 1:
|
| 414 |
+
noise_timestep = timesteps[i + 1]
|
| 415 |
+
init_latents_proper = self.scheduler.add_noise(
|
| 416 |
+
init_latents_proper, noise, torch.tensor([noise_timestep])
|
| 417 |
+
)
|
| 418 |
+
|
| 419 |
+
latents = (1 - mask_latents) * init_latents_proper + mask_latents * latents
|
| 420 |
+
|
| 421 |
+
if callback_on_step_end is not None:
|
| 422 |
+
callback_kwargs = {}
|
| 423 |
+
for k in callback_on_step_end_tensor_inputs:
|
| 424 |
+
callback_kwargs[k] = locals()[k]
|
| 425 |
+
callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)
|
| 426 |
+
|
| 427 |
+
latents = callback_outputs.pop("latents", latents)
|
| 428 |
+
prompt_embeds = callback_outputs.pop("prompt_embeds", prompt_embeds)
|
| 429 |
+
negative_prompt_embeds = callback_outputs.pop("negative_prompt_embeds", negative_prompt_embeds)
|
| 430 |
+
vton_latents = callback_outputs.pop("vton_latents", vton_latents)
|
| 431 |
+
|
| 432 |
+
# call the callback, if provided
|
| 433 |
+
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
|
| 434 |
+
progress_bar.update()
|
| 435 |
+
if callback is not None and i % callback_steps == 0:
|
| 436 |
+
step_idx = i // getattr(self.scheduler, "order", 1)
|
| 437 |
+
callback(step_idx, t, latents)
|
| 438 |
+
|
| 439 |
+
if not output_type == "latent":
|
| 440 |
+
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
|
| 441 |
+
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
|
| 442 |
+
else:
|
| 443 |
+
image = latents
|
| 444 |
+
has_nsfw_concept = None
|
| 445 |
+
|
| 446 |
+
if has_nsfw_concept is None:
|
| 447 |
+
do_denormalize = [True] * image.shape[0]
|
| 448 |
+
else:
|
| 449 |
+
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
|
| 450 |
+
|
| 451 |
+
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
|
| 452 |
+
|
| 453 |
+
# Offload all models
|
| 454 |
+
self.maybe_free_model_hooks()
|
| 455 |
+
|
| 456 |
+
if not return_dict:
|
| 457 |
+
return (image, has_nsfw_concept)
|
| 458 |
+
|
| 459 |
+
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
|
| 460 |
+
|
| 461 |
+
def _encode_prompt(
|
| 462 |
+
self,
|
| 463 |
+
prompt,
|
| 464 |
+
device,
|
| 465 |
+
num_images_per_prompt,
|
| 466 |
+
do_classifier_free_guidance,
|
| 467 |
+
negative_prompt=None,
|
| 468 |
+
prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 469 |
+
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 470 |
+
):
|
| 471 |
+
r"""
|
| 472 |
+
Encodes the prompt into text encoder hidden states.
|
| 473 |
+
|
| 474 |
+
Args:
|
| 475 |
+
prompt (`str` or `List[str]`, *optional*):
|
| 476 |
+
prompt to be encoded
|
| 477 |
+
device: (`torch.device`):
|
| 478 |
+
torch device
|
| 479 |
+
num_images_per_prompt (`int`):
|
| 480 |
+
number of images that should be generated per prompt
|
| 481 |
+
do_classifier_free_guidance (`bool`):
|
| 482 |
+
whether to use classifier free guidance or not
|
| 483 |
+
negative_ prompt (`str` or `List[str]`, *optional*):
|
| 484 |
+
The prompt or prompts not to guide the image generation. If not defined, one has to pass
|
| 485 |
+
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
|
| 486 |
+
less than `1`).
|
| 487 |
+
prompt_embeds (`torch.FloatTensor`, *optional*):
|
| 488 |
+
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
|
| 489 |
+
provided, text embeddings will be generated from `prompt` input argument.
|
| 490 |
+
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
|
| 491 |
+
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
|
| 492 |
+
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
|
| 493 |
+
argument.
|
| 494 |
+
"""
|
| 495 |
+
if prompt is not None and isinstance(prompt, str):
|
| 496 |
+
batch_size = 1
|
| 497 |
+
elif prompt is not None and isinstance(prompt, list):
|
| 498 |
+
batch_size = len(prompt)
|
| 499 |
+
else:
|
| 500 |
+
batch_size = prompt_embeds.shape[0]
|
| 501 |
+
|
| 502 |
+
if prompt_embeds is None:
|
| 503 |
+
# textual inversion: procecss multi-vector tokens if necessary
|
| 504 |
+
if isinstance(self, TextualInversionLoaderMixin):
|
| 505 |
+
prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
|
| 506 |
+
|
| 507 |
+
text_inputs = self.tokenizer(
|
| 508 |
+
prompt,
|
| 509 |
+
padding="max_length",
|
| 510 |
+
max_length=self.tokenizer.model_max_length,
|
| 511 |
+
truncation=True,
|
| 512 |
+
return_tensors="pt",
|
| 513 |
+
)
|
| 514 |
+
text_input_ids = text_inputs.input_ids
|
| 515 |
+
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
|
| 516 |
+
|
| 517 |
+
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
|
| 518 |
+
text_input_ids, untruncated_ids
|
| 519 |
+
):
|
| 520 |
+
removed_text = self.tokenizer.batch_decode(
|
| 521 |
+
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
|
| 522 |
+
)
|
| 523 |
+
logger.warning(
|
| 524 |
+
"The following part of your input was truncated because CLIP can only handle sequences up to"
|
| 525 |
+
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
|
| 526 |
+
)
|
| 527 |
+
|
| 528 |
+
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
|
| 529 |
+
attention_mask = text_inputs.attention_mask.to(device)
|
| 530 |
+
else:
|
| 531 |
+
attention_mask = None
|
| 532 |
+
|
| 533 |
+
prompt_embeds = self.text_encoder(
|
| 534 |
+
text_input_ids.to(device),
|
| 535 |
+
attention_mask=attention_mask,
|
| 536 |
+
)
|
| 537 |
+
prompt_embeds = prompt_embeds[0]
|
| 538 |
+
|
| 539 |
+
prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
|
| 540 |
+
|
| 541 |
+
bs_embed, seq_len, _ = prompt_embeds.shape
|
| 542 |
+
# duplicate text embeddings for each generation per prompt, using mps friendly method
|
| 543 |
+
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
|
| 544 |
+
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
|
| 545 |
+
|
| 546 |
+
# get unconditional embeddings for classifier free guidance
|
| 547 |
+
if do_classifier_free_guidance and negative_prompt_embeds is None:
|
| 548 |
+
uncond_tokens: List[str]
|
| 549 |
+
if negative_prompt is None:
|
| 550 |
+
uncond_tokens = [""] * batch_size
|
| 551 |
+
elif type(prompt) is not type(negative_prompt):
|
| 552 |
+
raise TypeError(
|
| 553 |
+
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
|
| 554 |
+
f" {type(prompt)}."
|
| 555 |
+
)
|
| 556 |
+
elif isinstance(negative_prompt, str):
|
| 557 |
+
uncond_tokens = [negative_prompt]
|
| 558 |
+
elif batch_size != len(negative_prompt):
|
| 559 |
+
raise ValueError(
|
| 560 |
+
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
|
| 561 |
+
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
|
| 562 |
+
" the batch size of `prompt`."
|
| 563 |
+
)
|
| 564 |
+
else:
|
| 565 |
+
uncond_tokens = negative_prompt
|
| 566 |
+
|
| 567 |
+
# textual inversion: procecss multi-vector tokens if necessary
|
| 568 |
+
if isinstance(self, TextualInversionLoaderMixin):
|
| 569 |
+
uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
|
| 570 |
+
|
| 571 |
+
max_length = prompt_embeds.shape[1]
|
| 572 |
+
uncond_input = self.tokenizer(
|
| 573 |
+
uncond_tokens,
|
| 574 |
+
padding="max_length",
|
| 575 |
+
max_length=max_length,
|
| 576 |
+
truncation=True,
|
| 577 |
+
return_tensors="pt",
|
| 578 |
+
)
|
| 579 |
+
|
| 580 |
+
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
|
| 581 |
+
attention_mask = uncond_input.attention_mask.to(device)
|
| 582 |
+
else:
|
| 583 |
+
attention_mask = None
|
| 584 |
+
|
| 585 |
+
if do_classifier_free_guidance:
|
| 586 |
+
prompt_embeds = torch.cat([prompt_embeds, prompt_embeds])
|
| 587 |
+
|
| 588 |
+
return prompt_embeds
|
| 589 |
+
|
| 590 |
+
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
|
| 591 |
+
def run_safety_checker(self, image, device, dtype):
|
| 592 |
+
if self.safety_checker is None:
|
| 593 |
+
has_nsfw_concept = None
|
| 594 |
+
else:
|
| 595 |
+
if torch.is_tensor(image):
|
| 596 |
+
feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
|
| 597 |
+
else:
|
| 598 |
+
feature_extractor_input = self.image_processor.numpy_to_pil(image)
|
| 599 |
+
safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
|
| 600 |
+
image, has_nsfw_concept = self.safety_checker(
|
| 601 |
+
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
|
| 602 |
+
)
|
| 603 |
+
return image, has_nsfw_concept
|
| 604 |
+
|
| 605 |
+
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
|
| 606 |
+
def prepare_extra_step_kwargs(self, generator, eta):
|
| 607 |
+
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
|
| 608 |
+
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
|
| 609 |
+
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
|
| 610 |
+
# and should be between [0, 1]
|
| 611 |
+
|
| 612 |
+
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
|
| 613 |
+
extra_step_kwargs = {}
|
| 614 |
+
if accepts_eta:
|
| 615 |
+
extra_step_kwargs["eta"] = eta
|
| 616 |
+
|
| 617 |
+
# check if the scheduler accepts generator
|
| 618 |
+
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
|
| 619 |
+
if accepts_generator:
|
| 620 |
+
extra_step_kwargs["generator"] = generator
|
| 621 |
+
return extra_step_kwargs
|
| 622 |
+
|
| 623 |
+
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
|
| 624 |
+
def decode_latents(self, latents):
|
| 625 |
+
deprecation_message = "The decode_latents method is deprecated and will be removed in 1.0.0. Please use VaeImageProcessor.postprocess(...) instead"
|
| 626 |
+
deprecate("decode_latents", "1.0.0", deprecation_message, standard_warn=False)
|
| 627 |
+
|
| 628 |
+
latents = 1 / self.vae.config.scaling_factor * latents
|
| 629 |
+
image = self.vae.decode(latents, return_dict=False)[0]
|
| 630 |
+
image = (image / 2 + 0.5).clamp(0, 1)
|
| 631 |
+
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
|
| 632 |
+
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
|
| 633 |
+
return image
|
| 634 |
+
|
| 635 |
+
def check_inputs(
|
| 636 |
+
self,
|
| 637 |
+
prompt,
|
| 638 |
+
callback_steps,
|
| 639 |
+
negative_prompt=None,
|
| 640 |
+
prompt_embeds=None,
|
| 641 |
+
negative_prompt_embeds=None,
|
| 642 |
+
callback_on_step_end_tensor_inputs=None,
|
| 643 |
+
):
|
| 644 |
+
if callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0):
|
| 645 |
+
raise ValueError(
|
| 646 |
+
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
|
| 647 |
+
f" {type(callback_steps)}."
|
| 648 |
+
)
|
| 649 |
+
|
| 650 |
+
if callback_on_step_end_tensor_inputs is not None and not all(
|
| 651 |
+
k in self._callback_tensor_inputs for k in callback_on_step_end_tensor_inputs
|
| 652 |
+
):
|
| 653 |
+
raise ValueError(
|
| 654 |
+
f"`callback_on_step_end_tensor_inputs` has to be in {self._callback_tensor_inputs}, but found {[k for k in callback_on_step_end_tensor_inputs if k not in self._callback_tensor_inputs]}"
|
| 655 |
+
)
|
| 656 |
+
|
| 657 |
+
if prompt is not None and prompt_embeds is not None:
|
| 658 |
+
raise ValueError(
|
| 659 |
+
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
|
| 660 |
+
" only forward one of the two."
|
| 661 |
+
)
|
| 662 |
+
elif prompt is None and prompt_embeds is None:
|
| 663 |
+
raise ValueError(
|
| 664 |
+
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
|
| 665 |
+
)
|
| 666 |
+
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
|
| 667 |
+
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
|
| 668 |
+
|
| 669 |
+
if negative_prompt is not None and negative_prompt_embeds is not None:
|
| 670 |
+
raise ValueError(
|
| 671 |
+
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
|
| 672 |
+
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
|
| 673 |
+
)
|
| 674 |
+
|
| 675 |
+
if prompt_embeds is not None and negative_prompt_embeds is not None:
|
| 676 |
+
if prompt_embeds.shape != negative_prompt_embeds.shape:
|
| 677 |
+
raise ValueError(
|
| 678 |
+
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
|
| 679 |
+
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
|
| 680 |
+
f" {negative_prompt_embeds.shape}."
|
| 681 |
+
)
|
| 682 |
+
|
| 683 |
+
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
|
| 684 |
+
def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
|
| 685 |
+
shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
|
| 686 |
+
if isinstance(generator, list) and len(generator) != batch_size:
|
| 687 |
+
raise ValueError(
|
| 688 |
+
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
|
| 689 |
+
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
|
| 690 |
+
)
|
| 691 |
+
|
| 692 |
+
if latents is None:
|
| 693 |
+
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
| 694 |
+
else:
|
| 695 |
+
latents = latents.to(device)
|
| 696 |
+
|
| 697 |
+
# scale the initial noise by the standard deviation required by the scheduler
|
| 698 |
+
latents = latents * self.scheduler.init_noise_sigma
|
| 699 |
+
return latents
|
| 700 |
+
|
| 701 |
+
def prepare_garm_latents(
|
| 702 |
+
self, image, batch_size, num_images_per_prompt, dtype, device, do_classifier_free_guidance, generator=None
|
| 703 |
+
):
|
| 704 |
+
if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)):
|
| 705 |
+
raise ValueError(
|
| 706 |
+
f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
|
| 707 |
+
)
|
| 708 |
+
|
| 709 |
+
image = image.to(device=device, dtype=dtype)
|
| 710 |
+
|
| 711 |
+
batch_size = batch_size * num_images_per_prompt
|
| 712 |
+
|
| 713 |
+
if image.shape[1] == 4:
|
| 714 |
+
image_latents = image
|
| 715 |
+
else:
|
| 716 |
+
if isinstance(generator, list) and len(generator) != batch_size:
|
| 717 |
+
raise ValueError(
|
| 718 |
+
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
|
| 719 |
+
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
|
| 720 |
+
)
|
| 721 |
+
|
| 722 |
+
if isinstance(generator, list):
|
| 723 |
+
image_latents = [self.vae.encode(image[i : i + 1]).latent_dist.mode() for i in range(batch_size)]
|
| 724 |
+
image_latents = torch.cat(image_latents, dim=0)
|
| 725 |
+
else:
|
| 726 |
+
image_latents = self.vae.encode(image).latent_dist.mode()
|
| 727 |
+
|
| 728 |
+
if batch_size > image_latents.shape[0] and batch_size % image_latents.shape[0] == 0:
|
| 729 |
+
additional_image_per_prompt = batch_size // image_latents.shape[0]
|
| 730 |
+
image_latents = torch.cat([image_latents] * additional_image_per_prompt, dim=0)
|
| 731 |
+
elif batch_size > image_latents.shape[0] and batch_size % image_latents.shape[0] != 0:
|
| 732 |
+
raise ValueError(
|
| 733 |
+
f"Cannot duplicate `image` of batch size {image_latents.shape[0]} to {batch_size} text prompts."
|
| 734 |
+
)
|
| 735 |
+
else:
|
| 736 |
+
image_latents = torch.cat([image_latents], dim=0)
|
| 737 |
+
|
| 738 |
+
if do_classifier_free_guidance:
|
| 739 |
+
uncond_image_latents = torch.zeros_like(image_latents)
|
| 740 |
+
image_latents = torch.cat([image_latents, uncond_image_latents], dim=0)
|
| 741 |
+
|
| 742 |
+
return image_latents
|
| 743 |
+
|
| 744 |
+
def prepare_vton_latents(
|
| 745 |
+
self, image, mask, image_ori, batch_size, num_images_per_prompt, dtype, device, do_classifier_free_guidance, generator=None
|
| 746 |
+
):
|
| 747 |
+
if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)):
|
| 748 |
+
raise ValueError(
|
| 749 |
+
f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
|
| 750 |
+
)
|
| 751 |
+
|
| 752 |
+
image = image.to(device=device, dtype=dtype)
|
| 753 |
+
image_ori = image_ori.to(device=device, dtype=dtype)
|
| 754 |
+
|
| 755 |
+
batch_size = batch_size * num_images_per_prompt
|
| 756 |
+
|
| 757 |
+
if image.shape[1] == 4:
|
| 758 |
+
image_latents = image
|
| 759 |
+
image_ori_latents = image_ori
|
| 760 |
+
else:
|
| 761 |
+
if isinstance(generator, list) and len(generator) != batch_size:
|
| 762 |
+
raise ValueError(
|
| 763 |
+
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
|
| 764 |
+
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
|
| 765 |
+
)
|
| 766 |
+
|
| 767 |
+
if isinstance(generator, list):
|
| 768 |
+
image_latents = [self.vae.encode(image[i : i + 1]).latent_dist.mode() for i in range(batch_size)]
|
| 769 |
+
image_latents = torch.cat(image_latents, dim=0)
|
| 770 |
+
image_ori_latents = [self.vae.encode(image_ori[i : i + 1]).latent_dist.mode() for i in range(batch_size)]
|
| 771 |
+
image_ori_latents = torch.cat(image_ori_latents, dim=0)
|
| 772 |
+
else:
|
| 773 |
+
image_latents = self.vae.encode(image).latent_dist.mode()
|
| 774 |
+
image_ori_latents = self.vae.encode(image_ori).latent_dist.mode()
|
| 775 |
+
|
| 776 |
+
mask = torch.nn.functional.interpolate(
|
| 777 |
+
mask, size=(image_latents.size(-2), image_latents.size(-1))
|
| 778 |
+
)
|
| 779 |
+
mask = mask.to(device=device, dtype=dtype)
|
| 780 |
+
|
| 781 |
+
if batch_size > image_latents.shape[0] and batch_size % image_latents.shape[0] == 0:
|
| 782 |
+
additional_image_per_prompt = batch_size // image_latents.shape[0]
|
| 783 |
+
image_latents = torch.cat([image_latents] * additional_image_per_prompt, dim=0)
|
| 784 |
+
mask = torch.cat([mask] * additional_image_per_prompt, dim=0)
|
| 785 |
+
image_ori_latents = torch.cat([image_ori_latents] * additional_image_per_prompt, dim=0)
|
| 786 |
+
elif batch_size > image_latents.shape[0] and batch_size % image_latents.shape[0] != 0:
|
| 787 |
+
raise ValueError(
|
| 788 |
+
f"Cannot duplicate `image` of batch size {image_latents.shape[0]} to {batch_size} text prompts."
|
| 789 |
+
)
|
| 790 |
+
else:
|
| 791 |
+
image_latents = torch.cat([image_latents], dim=0)
|
| 792 |
+
mask = torch.cat([mask], dim=0)
|
| 793 |
+
image_ori_latents = torch.cat([image_ori_latents], dim=0)
|
| 794 |
+
|
| 795 |
+
if do_classifier_free_guidance:
|
| 796 |
+
# uncond_image_latents = torch.zeros_like(image_latents)
|
| 797 |
+
image_latents = torch.cat([image_latents] * 2, dim=0)
|
| 798 |
+
|
| 799 |
+
return image_latents, mask, image_ori_latents
|
| 800 |
+
|
| 801 |
+
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_freeu
|
| 802 |
+
def enable_freeu(self, s1: float, s2: float, b1: float, b2: float):
|
| 803 |
+
r"""Enables the FreeU mechanism as in https://arxiv.org/abs/2309.11497.
|
| 804 |
+
|
| 805 |
+
The suffixes after the scaling factors represent the stages where they are being applied.
|
| 806 |
+
|
| 807 |
+
Please refer to the [official repository](https://github.com/ChenyangSi/FreeU) for combinations of the values
|
| 808 |
+
that are known to work well for different pipelines such as Stable Diffusion v1, v2, and Stable Diffusion XL.
|
| 809 |
+
|
| 810 |
+
Args:
|
| 811 |
+
s1 (`float`):
|
| 812 |
+
Scaling factor for stage 1 to attenuate the contributions of the skip features. This is done to
|
| 813 |
+
mitigate "oversmoothing effect" in the enhanced denoising process.
|
| 814 |
+
s2 (`float`):
|
| 815 |
+
Scaling factor for stage 2 to attenuate the contributions of the skip features. This is done to
|
| 816 |
+
mitigate "oversmoothing effect" in the enhanced denoising process.
|
| 817 |
+
b1 (`float`): Scaling factor for stage 1 to amplify the contributions of backbone features.
|
| 818 |
+
b2 (`float`): Scaling factor for stage 2 to amplify the contributions of backbone features.
|
| 819 |
+
"""
|
| 820 |
+
if not hasattr(self, "unet"):
|
| 821 |
+
raise ValueError("The pipeline must have `unet` for using FreeU.")
|
| 822 |
+
self.unet_vton.enable_freeu(s1=s1, s2=s2, b1=b1, b2=b2)
|
| 823 |
+
|
| 824 |
+
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_freeu
|
| 825 |
+
def disable_freeu(self):
|
| 826 |
+
"""Disables the FreeU mechanism if enabled."""
|
| 827 |
+
self.unet_vton.disable_freeu()
|
| 828 |
+
|
| 829 |
+
@property
|
| 830 |
+
def guidance_scale(self):
|
| 831 |
+
return self._guidance_scale
|
| 832 |
+
|
| 833 |
+
@property
|
| 834 |
+
def image_guidance_scale(self):
|
| 835 |
+
return self._image_guidance_scale
|
| 836 |
+
|
| 837 |
+
@property
|
| 838 |
+
def num_timesteps(self):
|
| 839 |
+
return self._num_timesteps
|
| 840 |
+
|
| 841 |
+
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
|
| 842 |
+
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
|
| 843 |
+
# corresponds to doing no classifier free guidance.
|
| 844 |
+
@property
|
| 845 |
+
def do_classifier_free_guidance(self):
|
| 846 |
+
return self.image_guidance_scale >= 1.0
|
ootd/pipelines_ootd/transformer_garm_2d.py
ADDED
|
@@ -0,0 +1,449 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# Modified by Yuhao Xu for OOTDiffusion (https://github.com/levihsu/OOTDiffusion)
|
| 16 |
+
from dataclasses import dataclass
|
| 17 |
+
from typing import Any, Dict, Optional
|
| 18 |
+
|
| 19 |
+
import torch
|
| 20 |
+
import torch.nn.functional as F
|
| 21 |
+
from torch import nn
|
| 22 |
+
|
| 23 |
+
from .attention_garm import BasicTransformerBlock
|
| 24 |
+
|
| 25 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 26 |
+
from diffusers.models.embeddings import ImagePositionalEmbeddings
|
| 27 |
+
from diffusers.utils import USE_PEFT_BACKEND, BaseOutput, deprecate
|
| 28 |
+
# from diffusers.models.attention import BasicTransformerBlock
|
| 29 |
+
from diffusers.models.embeddings import CaptionProjection, PatchEmbed
|
| 30 |
+
from diffusers.models.lora import LoRACompatibleConv, LoRACompatibleLinear
|
| 31 |
+
from diffusers.models.modeling_utils import ModelMixin
|
| 32 |
+
from diffusers.models.normalization import AdaLayerNormSingle
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
@dataclass
|
| 36 |
+
class Transformer2DModelOutput(BaseOutput):
|
| 37 |
+
"""
|
| 38 |
+
The output of [`Transformer2DModel`].
|
| 39 |
+
|
| 40 |
+
Args:
|
| 41 |
+
sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` or `(batch size, num_vector_embeds - 1, num_latent_pixels)` if [`Transformer2DModel`] is discrete):
|
| 42 |
+
The hidden states output conditioned on the `encoder_hidden_states` input. If discrete, returns probability
|
| 43 |
+
distributions for the unnoised latent pixels.
|
| 44 |
+
"""
|
| 45 |
+
|
| 46 |
+
sample: torch.FloatTensor
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
class Transformer2DModel(ModelMixin, ConfigMixin):
|
| 50 |
+
"""
|
| 51 |
+
A 2D Transformer model for image-like data.
|
| 52 |
+
|
| 53 |
+
Parameters:
|
| 54 |
+
num_attention_heads (`int`, *optional*, defaults to 16): The number of heads to use for multi-head attention.
|
| 55 |
+
attention_head_dim (`int`, *optional*, defaults to 88): The number of channels in each head.
|
| 56 |
+
in_channels (`int`, *optional*):
|
| 57 |
+
The number of channels in the input and output (specify if the input is **continuous**).
|
| 58 |
+
num_layers (`int`, *optional*, defaults to 1): The number of layers of Transformer blocks to use.
|
| 59 |
+
dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
|
| 60 |
+
cross_attention_dim (`int`, *optional*): The number of `encoder_hidden_states` dimensions to use.
|
| 61 |
+
sample_size (`int`, *optional*): The width of the latent images (specify if the input is **discrete**).
|
| 62 |
+
This is fixed during training since it is used to learn a number of position embeddings.
|
| 63 |
+
num_vector_embeds (`int`, *optional*):
|
| 64 |
+
The number of classes of the vector embeddings of the latent pixels (specify if the input is **discrete**).
|
| 65 |
+
Includes the class for the masked latent pixel.
|
| 66 |
+
activation_fn (`str`, *optional*, defaults to `"geglu"`): Activation function to use in feed-forward.
|
| 67 |
+
num_embeds_ada_norm ( `int`, *optional*):
|
| 68 |
+
The number of diffusion steps used during training. Pass if at least one of the norm_layers is
|
| 69 |
+
`AdaLayerNorm`. This is fixed during training since it is used to learn a number of embeddings that are
|
| 70 |
+
added to the hidden states.
|
| 71 |
+
|
| 72 |
+
During inference, you can denoise for up to but not more steps than `num_embeds_ada_norm`.
|
| 73 |
+
attention_bias (`bool`, *optional*):
|
| 74 |
+
Configure if the `TransformerBlocks` attention should contain a bias parameter.
|
| 75 |
+
"""
|
| 76 |
+
|
| 77 |
+
@register_to_config
|
| 78 |
+
def __init__(
|
| 79 |
+
self,
|
| 80 |
+
num_attention_heads: int = 16,
|
| 81 |
+
attention_head_dim: int = 88,
|
| 82 |
+
in_channels: Optional[int] = None,
|
| 83 |
+
out_channels: Optional[int] = None,
|
| 84 |
+
num_layers: int = 1,
|
| 85 |
+
dropout: float = 0.0,
|
| 86 |
+
norm_num_groups: int = 32,
|
| 87 |
+
cross_attention_dim: Optional[int] = None,
|
| 88 |
+
attention_bias: bool = False,
|
| 89 |
+
sample_size: Optional[int] = None,
|
| 90 |
+
num_vector_embeds: Optional[int] = None,
|
| 91 |
+
patch_size: Optional[int] = None,
|
| 92 |
+
activation_fn: str = "geglu",
|
| 93 |
+
num_embeds_ada_norm: Optional[int] = None,
|
| 94 |
+
use_linear_projection: bool = False,
|
| 95 |
+
only_cross_attention: bool = False,
|
| 96 |
+
double_self_attention: bool = False,
|
| 97 |
+
upcast_attention: bool = False,
|
| 98 |
+
norm_type: str = "layer_norm",
|
| 99 |
+
norm_elementwise_affine: bool = True,
|
| 100 |
+
norm_eps: float = 1e-5,
|
| 101 |
+
attention_type: str = "default",
|
| 102 |
+
caption_channels: int = None,
|
| 103 |
+
):
|
| 104 |
+
super().__init__()
|
| 105 |
+
self.use_linear_projection = use_linear_projection
|
| 106 |
+
self.num_attention_heads = num_attention_heads
|
| 107 |
+
self.attention_head_dim = attention_head_dim
|
| 108 |
+
inner_dim = num_attention_heads * attention_head_dim
|
| 109 |
+
|
| 110 |
+
conv_cls = nn.Conv2d if USE_PEFT_BACKEND else LoRACompatibleConv
|
| 111 |
+
linear_cls = nn.Linear if USE_PEFT_BACKEND else LoRACompatibleLinear
|
| 112 |
+
|
| 113 |
+
# 1. Transformer2DModel can process both standard continuous images of shape `(batch_size, num_channels, width, height)` as well as quantized image embeddings of shape `(batch_size, num_image_vectors)`
|
| 114 |
+
# Define whether input is continuous or discrete depending on configuration
|
| 115 |
+
self.is_input_continuous = (in_channels is not None) and (patch_size is None)
|
| 116 |
+
self.is_input_vectorized = num_vector_embeds is not None
|
| 117 |
+
self.is_input_patches = in_channels is not None and patch_size is not None
|
| 118 |
+
|
| 119 |
+
if norm_type == "layer_norm" and num_embeds_ada_norm is not None:
|
| 120 |
+
deprecation_message = (
|
| 121 |
+
f"The configuration file of this model: {self.__class__} is outdated. `norm_type` is either not set or"
|
| 122 |
+
" incorrectly set to `'layer_norm'`.Make sure to set `norm_type` to `'ada_norm'` in the config."
|
| 123 |
+
" Please make sure to update the config accordingly as leaving `norm_type` might led to incorrect"
|
| 124 |
+
" results in future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it"
|
| 125 |
+
" would be very nice if you could open a Pull request for the `transformer/config.json` file"
|
| 126 |
+
)
|
| 127 |
+
deprecate("norm_type!=num_embeds_ada_norm", "1.0.0", deprecation_message, standard_warn=False)
|
| 128 |
+
norm_type = "ada_norm"
|
| 129 |
+
|
| 130 |
+
if self.is_input_continuous and self.is_input_vectorized:
|
| 131 |
+
raise ValueError(
|
| 132 |
+
f"Cannot define both `in_channels`: {in_channels} and `num_vector_embeds`: {num_vector_embeds}. Make"
|
| 133 |
+
" sure that either `in_channels` or `num_vector_embeds` is None."
|
| 134 |
+
)
|
| 135 |
+
elif self.is_input_vectorized and self.is_input_patches:
|
| 136 |
+
raise ValueError(
|
| 137 |
+
f"Cannot define both `num_vector_embeds`: {num_vector_embeds} and `patch_size`: {patch_size}. Make"
|
| 138 |
+
" sure that either `num_vector_embeds` or `num_patches` is None."
|
| 139 |
+
)
|
| 140 |
+
elif not self.is_input_continuous and not self.is_input_vectorized and not self.is_input_patches:
|
| 141 |
+
raise ValueError(
|
| 142 |
+
f"Has to define `in_channels`: {in_channels}, `num_vector_embeds`: {num_vector_embeds}, or patch_size:"
|
| 143 |
+
f" {patch_size}. Make sure that `in_channels`, `num_vector_embeds` or `num_patches` is not None."
|
| 144 |
+
)
|
| 145 |
+
|
| 146 |
+
# 2. Define input layers
|
| 147 |
+
if self.is_input_continuous:
|
| 148 |
+
self.in_channels = in_channels
|
| 149 |
+
|
| 150 |
+
self.norm = torch.nn.GroupNorm(num_groups=norm_num_groups, num_channels=in_channels, eps=1e-6, affine=True)
|
| 151 |
+
if use_linear_projection:
|
| 152 |
+
self.proj_in = linear_cls(in_channels, inner_dim)
|
| 153 |
+
else:
|
| 154 |
+
self.proj_in = conv_cls(in_channels, inner_dim, kernel_size=1, stride=1, padding=0)
|
| 155 |
+
elif self.is_input_vectorized:
|
| 156 |
+
assert sample_size is not None, "Transformer2DModel over discrete input must provide sample_size"
|
| 157 |
+
assert num_vector_embeds is not None, "Transformer2DModel over discrete input must provide num_embed"
|
| 158 |
+
|
| 159 |
+
self.height = sample_size
|
| 160 |
+
self.width = sample_size
|
| 161 |
+
self.num_vector_embeds = num_vector_embeds
|
| 162 |
+
self.num_latent_pixels = self.height * self.width
|
| 163 |
+
|
| 164 |
+
self.latent_image_embedding = ImagePositionalEmbeddings(
|
| 165 |
+
num_embed=num_vector_embeds, embed_dim=inner_dim, height=self.height, width=self.width
|
| 166 |
+
)
|
| 167 |
+
elif self.is_input_patches:
|
| 168 |
+
assert sample_size is not None, "Transformer2DModel over patched input must provide sample_size"
|
| 169 |
+
|
| 170 |
+
self.height = sample_size
|
| 171 |
+
self.width = sample_size
|
| 172 |
+
|
| 173 |
+
self.patch_size = patch_size
|
| 174 |
+
interpolation_scale = self.config.sample_size // 64 # => 64 (= 512 pixart) has interpolation scale 1
|
| 175 |
+
interpolation_scale = max(interpolation_scale, 1)
|
| 176 |
+
self.pos_embed = PatchEmbed(
|
| 177 |
+
height=sample_size,
|
| 178 |
+
width=sample_size,
|
| 179 |
+
patch_size=patch_size,
|
| 180 |
+
in_channels=in_channels,
|
| 181 |
+
embed_dim=inner_dim,
|
| 182 |
+
interpolation_scale=interpolation_scale,
|
| 183 |
+
)
|
| 184 |
+
|
| 185 |
+
# 3. Define transformers blocks
|
| 186 |
+
self.transformer_blocks = nn.ModuleList(
|
| 187 |
+
[
|
| 188 |
+
BasicTransformerBlock(
|
| 189 |
+
inner_dim,
|
| 190 |
+
num_attention_heads,
|
| 191 |
+
attention_head_dim,
|
| 192 |
+
dropout=dropout,
|
| 193 |
+
cross_attention_dim=cross_attention_dim,
|
| 194 |
+
activation_fn=activation_fn,
|
| 195 |
+
num_embeds_ada_norm=num_embeds_ada_norm,
|
| 196 |
+
attention_bias=attention_bias,
|
| 197 |
+
only_cross_attention=only_cross_attention,
|
| 198 |
+
double_self_attention=double_self_attention,
|
| 199 |
+
upcast_attention=upcast_attention,
|
| 200 |
+
norm_type=norm_type,
|
| 201 |
+
norm_elementwise_affine=norm_elementwise_affine,
|
| 202 |
+
norm_eps=norm_eps,
|
| 203 |
+
attention_type=attention_type,
|
| 204 |
+
)
|
| 205 |
+
for d in range(num_layers)
|
| 206 |
+
]
|
| 207 |
+
)
|
| 208 |
+
|
| 209 |
+
# 4. Define output layers
|
| 210 |
+
self.out_channels = in_channels if out_channels is None else out_channels
|
| 211 |
+
if self.is_input_continuous:
|
| 212 |
+
# TODO: should use out_channels for continuous projections
|
| 213 |
+
if use_linear_projection:
|
| 214 |
+
self.proj_out = linear_cls(inner_dim, in_channels)
|
| 215 |
+
else:
|
| 216 |
+
self.proj_out = conv_cls(inner_dim, in_channels, kernel_size=1, stride=1, padding=0)
|
| 217 |
+
elif self.is_input_vectorized:
|
| 218 |
+
self.norm_out = nn.LayerNorm(inner_dim)
|
| 219 |
+
self.out = nn.Linear(inner_dim, self.num_vector_embeds - 1)
|
| 220 |
+
elif self.is_input_patches and norm_type != "ada_norm_single":
|
| 221 |
+
self.norm_out = nn.LayerNorm(inner_dim, elementwise_affine=False, eps=1e-6)
|
| 222 |
+
self.proj_out_1 = nn.Linear(inner_dim, 2 * inner_dim)
|
| 223 |
+
self.proj_out_2 = nn.Linear(inner_dim, patch_size * patch_size * self.out_channels)
|
| 224 |
+
elif self.is_input_patches and norm_type == "ada_norm_single":
|
| 225 |
+
self.norm_out = nn.LayerNorm(inner_dim, elementwise_affine=False, eps=1e-6)
|
| 226 |
+
self.scale_shift_table = nn.Parameter(torch.randn(2, inner_dim) / inner_dim**0.5)
|
| 227 |
+
self.proj_out = nn.Linear(inner_dim, patch_size * patch_size * self.out_channels)
|
| 228 |
+
|
| 229 |
+
# 5. PixArt-Alpha blocks.
|
| 230 |
+
self.adaln_single = None
|
| 231 |
+
self.use_additional_conditions = False
|
| 232 |
+
if norm_type == "ada_norm_single":
|
| 233 |
+
self.use_additional_conditions = self.config.sample_size == 128
|
| 234 |
+
# TODO(Sayak, PVP) clean this, for now we use sample size to determine whether to use
|
| 235 |
+
# additional conditions until we find better name
|
| 236 |
+
self.adaln_single = AdaLayerNormSingle(inner_dim, use_additional_conditions=self.use_additional_conditions)
|
| 237 |
+
|
| 238 |
+
self.caption_projection = None
|
| 239 |
+
if caption_channels is not None:
|
| 240 |
+
self.caption_projection = CaptionProjection(in_features=caption_channels, hidden_size=inner_dim)
|
| 241 |
+
|
| 242 |
+
self.gradient_checkpointing = False
|
| 243 |
+
|
| 244 |
+
def forward(
|
| 245 |
+
self,
|
| 246 |
+
hidden_states: torch.Tensor,
|
| 247 |
+
spatial_attn_inputs = [],
|
| 248 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 249 |
+
timestep: Optional[torch.LongTensor] = None,
|
| 250 |
+
added_cond_kwargs: Dict[str, torch.Tensor] = None,
|
| 251 |
+
class_labels: Optional[torch.LongTensor] = None,
|
| 252 |
+
cross_attention_kwargs: Dict[str, Any] = None,
|
| 253 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 254 |
+
encoder_attention_mask: Optional[torch.Tensor] = None,
|
| 255 |
+
return_dict: bool = True,
|
| 256 |
+
):
|
| 257 |
+
"""
|
| 258 |
+
The [`Transformer2DModel`] forward method.
|
| 259 |
+
|
| 260 |
+
Args:
|
| 261 |
+
hidden_states (`torch.LongTensor` of shape `(batch size, num latent pixels)` if discrete, `torch.FloatTensor` of shape `(batch size, channel, height, width)` if continuous):
|
| 262 |
+
Input `hidden_states`.
|
| 263 |
+
encoder_hidden_states ( `torch.FloatTensor` of shape `(batch size, sequence len, embed dims)`, *optional*):
|
| 264 |
+
Conditional embeddings for cross attention layer. If not given, cross-attention defaults to
|
| 265 |
+
self-attention.
|
| 266 |
+
timestep ( `torch.LongTensor`, *optional*):
|
| 267 |
+
Used to indicate denoising step. Optional timestep to be applied as an embedding in `AdaLayerNorm`.
|
| 268 |
+
class_labels ( `torch.LongTensor` of shape `(batch size, num classes)`, *optional*):
|
| 269 |
+
Used to indicate class labels conditioning. Optional class labels to be applied as an embedding in
|
| 270 |
+
`AdaLayerZeroNorm`.
|
| 271 |
+
cross_attention_kwargs ( `Dict[str, Any]`, *optional*):
|
| 272 |
+
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
| 273 |
+
`self.processor` in
|
| 274 |
+
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
|
| 275 |
+
attention_mask ( `torch.Tensor`, *optional*):
|
| 276 |
+
An attention mask of shape `(batch, key_tokens)` is applied to `encoder_hidden_states`. If `1` the mask
|
| 277 |
+
is kept, otherwise if `0` it is discarded. Mask will be converted into a bias, which adds large
|
| 278 |
+
negative values to the attention scores corresponding to "discard" tokens.
|
| 279 |
+
encoder_attention_mask ( `torch.Tensor`, *optional*):
|
| 280 |
+
Cross-attention mask applied to `encoder_hidden_states`. Two formats supported:
|
| 281 |
+
|
| 282 |
+
* Mask `(batch, sequence_length)` True = keep, False = discard.
|
| 283 |
+
* Bias `(batch, 1, sequence_length)` 0 = keep, -10000 = discard.
|
| 284 |
+
|
| 285 |
+
If `ndim == 2`: will be interpreted as a mask, then converted into a bias consistent with the format
|
| 286 |
+
above. This bias will be added to the cross-attention scores.
|
| 287 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 288 |
+
Whether or not to return a [`~models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain
|
| 289 |
+
tuple.
|
| 290 |
+
|
| 291 |
+
Returns:
|
| 292 |
+
If `return_dict` is True, an [`~models.transformer_2d.Transformer2DModelOutput`] is returned, otherwise a
|
| 293 |
+
`tuple` where the first element is the sample tensor.
|
| 294 |
+
"""
|
| 295 |
+
# ensure attention_mask is a bias, and give it a singleton query_tokens dimension.
|
| 296 |
+
# we may have done this conversion already, e.g. if we came here via UNet2DConditionModel#forward.
|
| 297 |
+
# we can tell by counting dims; if ndim == 2: it's a mask rather than a bias.
|
| 298 |
+
# expects mask of shape:
|
| 299 |
+
# [batch, key_tokens]
|
| 300 |
+
# adds singleton query_tokens dimension:
|
| 301 |
+
# [batch, 1, key_tokens]
|
| 302 |
+
# this helps to broadcast it as a bias over attention scores, which will be in one of the following shapes:
|
| 303 |
+
# [batch, heads, query_tokens, key_tokens] (e.g. torch sdp attn)
|
| 304 |
+
# [batch * heads, query_tokens, key_tokens] (e.g. xformers or classic attn)
|
| 305 |
+
if attention_mask is not None and attention_mask.ndim == 2:
|
| 306 |
+
# assume that mask is expressed as:
|
| 307 |
+
# (1 = keep, 0 = discard)
|
| 308 |
+
# convert mask into a bias that can be added to attention scores:
|
| 309 |
+
# (keep = +0, discard = -10000.0)
|
| 310 |
+
attention_mask = (1 - attention_mask.to(hidden_states.dtype)) * -10000.0
|
| 311 |
+
attention_mask = attention_mask.unsqueeze(1)
|
| 312 |
+
|
| 313 |
+
# convert encoder_attention_mask to a bias the same way we do for attention_mask
|
| 314 |
+
if encoder_attention_mask is not None and encoder_attention_mask.ndim == 2:
|
| 315 |
+
encoder_attention_mask = (1 - encoder_attention_mask.to(hidden_states.dtype)) * -10000.0
|
| 316 |
+
encoder_attention_mask = encoder_attention_mask.unsqueeze(1)
|
| 317 |
+
|
| 318 |
+
# Retrieve lora scale.
|
| 319 |
+
lora_scale = cross_attention_kwargs.get("scale", 1.0) if cross_attention_kwargs is not None else 1.0
|
| 320 |
+
|
| 321 |
+
# 1. Input
|
| 322 |
+
if self.is_input_continuous:
|
| 323 |
+
batch, _, height, width = hidden_states.shape
|
| 324 |
+
residual = hidden_states
|
| 325 |
+
|
| 326 |
+
hidden_states = self.norm(hidden_states)
|
| 327 |
+
if not self.use_linear_projection:
|
| 328 |
+
hidden_states = (
|
| 329 |
+
self.proj_in(hidden_states, scale=lora_scale)
|
| 330 |
+
if not USE_PEFT_BACKEND
|
| 331 |
+
else self.proj_in(hidden_states)
|
| 332 |
+
)
|
| 333 |
+
inner_dim = hidden_states.shape[1]
|
| 334 |
+
hidden_states = hidden_states.permute(0, 2, 3, 1).reshape(batch, height * width, inner_dim)
|
| 335 |
+
else:
|
| 336 |
+
inner_dim = hidden_states.shape[1]
|
| 337 |
+
hidden_states = hidden_states.permute(0, 2, 3, 1).reshape(batch, height * width, inner_dim)
|
| 338 |
+
hidden_states = (
|
| 339 |
+
self.proj_in(hidden_states, scale=lora_scale)
|
| 340 |
+
if not USE_PEFT_BACKEND
|
| 341 |
+
else self.proj_in(hidden_states)
|
| 342 |
+
)
|
| 343 |
+
|
| 344 |
+
elif self.is_input_vectorized:
|
| 345 |
+
hidden_states = self.latent_image_embedding(hidden_states)
|
| 346 |
+
elif self.is_input_patches:
|
| 347 |
+
height, width = hidden_states.shape[-2] // self.patch_size, hidden_states.shape[-1] // self.patch_size
|
| 348 |
+
hidden_states = self.pos_embed(hidden_states)
|
| 349 |
+
|
| 350 |
+
if self.adaln_single is not None:
|
| 351 |
+
if self.use_additional_conditions and added_cond_kwargs is None:
|
| 352 |
+
raise ValueError(
|
| 353 |
+
"`added_cond_kwargs` cannot be None when using additional conditions for `adaln_single`."
|
| 354 |
+
)
|
| 355 |
+
batch_size = hidden_states.shape[0]
|
| 356 |
+
timestep, embedded_timestep = self.adaln_single(
|
| 357 |
+
timestep, added_cond_kwargs, batch_size=batch_size, hidden_dtype=hidden_states.dtype
|
| 358 |
+
)
|
| 359 |
+
|
| 360 |
+
# 2. Blocks
|
| 361 |
+
if self.caption_projection is not None:
|
| 362 |
+
batch_size = hidden_states.shape[0]
|
| 363 |
+
encoder_hidden_states = self.caption_projection(encoder_hidden_states)
|
| 364 |
+
encoder_hidden_states = encoder_hidden_states.view(batch_size, -1, hidden_states.shape[-1])
|
| 365 |
+
|
| 366 |
+
for block in self.transformer_blocks:
|
| 367 |
+
if self.training and self.gradient_checkpointing:
|
| 368 |
+
hidden_states, spatial_attn_inputs = torch.utils.checkpoint.checkpoint(
|
| 369 |
+
block,
|
| 370 |
+
hidden_states,
|
| 371 |
+
spatial_attn_inputs,
|
| 372 |
+
attention_mask,
|
| 373 |
+
encoder_hidden_states,
|
| 374 |
+
encoder_attention_mask,
|
| 375 |
+
timestep,
|
| 376 |
+
cross_attention_kwargs,
|
| 377 |
+
class_labels,
|
| 378 |
+
use_reentrant=False,
|
| 379 |
+
)
|
| 380 |
+
else:
|
| 381 |
+
hidden_states, spatial_attn_inputs = block(
|
| 382 |
+
hidden_states,
|
| 383 |
+
spatial_attn_inputs,
|
| 384 |
+
attention_mask=attention_mask,
|
| 385 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 386 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 387 |
+
timestep=timestep,
|
| 388 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 389 |
+
class_labels=class_labels,
|
| 390 |
+
)
|
| 391 |
+
|
| 392 |
+
# 3. Output
|
| 393 |
+
if self.is_input_continuous:
|
| 394 |
+
if not self.use_linear_projection:
|
| 395 |
+
hidden_states = hidden_states.reshape(batch, height, width, inner_dim).permute(0, 3, 1, 2).contiguous()
|
| 396 |
+
hidden_states = (
|
| 397 |
+
self.proj_out(hidden_states, scale=lora_scale)
|
| 398 |
+
if not USE_PEFT_BACKEND
|
| 399 |
+
else self.proj_out(hidden_states)
|
| 400 |
+
)
|
| 401 |
+
else:
|
| 402 |
+
hidden_states = (
|
| 403 |
+
self.proj_out(hidden_states, scale=lora_scale)
|
| 404 |
+
if not USE_PEFT_BACKEND
|
| 405 |
+
else self.proj_out(hidden_states)
|
| 406 |
+
)
|
| 407 |
+
hidden_states = hidden_states.reshape(batch, height, width, inner_dim).permute(0, 3, 1, 2).contiguous()
|
| 408 |
+
|
| 409 |
+
output = hidden_states + residual
|
| 410 |
+
elif self.is_input_vectorized:
|
| 411 |
+
hidden_states = self.norm_out(hidden_states)
|
| 412 |
+
logits = self.out(hidden_states)
|
| 413 |
+
# (batch, self.num_vector_embeds - 1, self.num_latent_pixels)
|
| 414 |
+
logits = logits.permute(0, 2, 1)
|
| 415 |
+
|
| 416 |
+
# log(p(x_0))
|
| 417 |
+
output = F.log_softmax(logits.double(), dim=1).float()
|
| 418 |
+
|
| 419 |
+
if self.is_input_patches:
|
| 420 |
+
if self.config.norm_type != "ada_norm_single":
|
| 421 |
+
conditioning = self.transformer_blocks[0].norm1.emb(
|
| 422 |
+
timestep, class_labels, hidden_dtype=hidden_states.dtype
|
| 423 |
+
)
|
| 424 |
+
shift, scale = self.proj_out_1(F.silu(conditioning)).chunk(2, dim=1)
|
| 425 |
+
hidden_states = self.norm_out(hidden_states) * (1 + scale[:, None]) + shift[:, None]
|
| 426 |
+
hidden_states = self.proj_out_2(hidden_states)
|
| 427 |
+
elif self.config.norm_type == "ada_norm_single":
|
| 428 |
+
shift, scale = (self.scale_shift_table[None] + embedded_timestep[:, None]).chunk(2, dim=1)
|
| 429 |
+
hidden_states = self.norm_out(hidden_states)
|
| 430 |
+
# Modulation
|
| 431 |
+
hidden_states = hidden_states * (1 + scale) + shift
|
| 432 |
+
hidden_states = self.proj_out(hidden_states)
|
| 433 |
+
hidden_states = hidden_states.squeeze(1)
|
| 434 |
+
|
| 435 |
+
# unpatchify
|
| 436 |
+
if self.adaln_single is None:
|
| 437 |
+
height = width = int(hidden_states.shape[1] ** 0.5)
|
| 438 |
+
hidden_states = hidden_states.reshape(
|
| 439 |
+
shape=(-1, height, width, self.patch_size, self.patch_size, self.out_channels)
|
| 440 |
+
)
|
| 441 |
+
hidden_states = torch.einsum("nhwpqc->nchpwq", hidden_states)
|
| 442 |
+
output = hidden_states.reshape(
|
| 443 |
+
shape=(-1, self.out_channels, height * self.patch_size, width * self.patch_size)
|
| 444 |
+
)
|
| 445 |
+
|
| 446 |
+
if not return_dict:
|
| 447 |
+
return (output,), spatial_attn_inputs
|
| 448 |
+
|
| 449 |
+
return Transformer2DModelOutput(sample=output), spatial_attn_inputs
|
ootd/pipelines_ootd/transformer_vton_2d.py
ADDED
|
@@ -0,0 +1,452 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# Modified by Yuhao Xu for OOTDiffusion (https://github.com/levihsu/OOTDiffusion)
|
| 16 |
+
from dataclasses import dataclass
|
| 17 |
+
from typing import Any, Dict, Optional
|
| 18 |
+
|
| 19 |
+
import torch
|
| 20 |
+
import torch.nn.functional as F
|
| 21 |
+
from torch import nn
|
| 22 |
+
|
| 23 |
+
from .attention_vton import BasicTransformerBlock
|
| 24 |
+
|
| 25 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 26 |
+
from diffusers.models.embeddings import ImagePositionalEmbeddings
|
| 27 |
+
from diffusers.utils import USE_PEFT_BACKEND, BaseOutput, deprecate
|
| 28 |
+
# from diffusers.models.attention import BasicTransformerBlock
|
| 29 |
+
from diffusers.models.embeddings import CaptionProjection, PatchEmbed
|
| 30 |
+
from diffusers.models.lora import LoRACompatibleConv, LoRACompatibleLinear
|
| 31 |
+
from diffusers.models.modeling_utils import ModelMixin
|
| 32 |
+
from diffusers.models.normalization import AdaLayerNormSingle
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
@dataclass
|
| 36 |
+
class Transformer2DModelOutput(BaseOutput):
|
| 37 |
+
"""
|
| 38 |
+
The output of [`Transformer2DModel`].
|
| 39 |
+
|
| 40 |
+
Args:
|
| 41 |
+
sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` or `(batch size, num_vector_embeds - 1, num_latent_pixels)` if [`Transformer2DModel`] is discrete):
|
| 42 |
+
The hidden states output conditioned on the `encoder_hidden_states` input. If discrete, returns probability
|
| 43 |
+
distributions for the unnoised latent pixels.
|
| 44 |
+
"""
|
| 45 |
+
|
| 46 |
+
sample: torch.FloatTensor
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
class Transformer2DModel(ModelMixin, ConfigMixin):
|
| 50 |
+
"""
|
| 51 |
+
A 2D Transformer model for image-like data.
|
| 52 |
+
|
| 53 |
+
Parameters:
|
| 54 |
+
num_attention_heads (`int`, *optional*, defaults to 16): The number of heads to use for multi-head attention.
|
| 55 |
+
attention_head_dim (`int`, *optional*, defaults to 88): The number of channels in each head.
|
| 56 |
+
in_channels (`int`, *optional*):
|
| 57 |
+
The number of channels in the input and output (specify if the input is **continuous**).
|
| 58 |
+
num_layers (`int`, *optional*, defaults to 1): The number of layers of Transformer blocks to use.
|
| 59 |
+
dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
|
| 60 |
+
cross_attention_dim (`int`, *optional*): The number of `encoder_hidden_states` dimensions to use.
|
| 61 |
+
sample_size (`int`, *optional*): The width of the latent images (specify if the input is **discrete**).
|
| 62 |
+
This is fixed during training since it is used to learn a number of position embeddings.
|
| 63 |
+
num_vector_embeds (`int`, *optional*):
|
| 64 |
+
The number of classes of the vector embeddings of the latent pixels (specify if the input is **discrete**).
|
| 65 |
+
Includes the class for the masked latent pixel.
|
| 66 |
+
activation_fn (`str`, *optional*, defaults to `"geglu"`): Activation function to use in feed-forward.
|
| 67 |
+
num_embeds_ada_norm ( `int`, *optional*):
|
| 68 |
+
The number of diffusion steps used during training. Pass if at least one of the norm_layers is
|
| 69 |
+
`AdaLayerNorm`. This is fixed during training since it is used to learn a number of embeddings that are
|
| 70 |
+
added to the hidden states.
|
| 71 |
+
|
| 72 |
+
During inference, you can denoise for up to but not more steps than `num_embeds_ada_norm`.
|
| 73 |
+
attention_bias (`bool`, *optional*):
|
| 74 |
+
Configure if the `TransformerBlocks` attention should contain a bias parameter.
|
| 75 |
+
"""
|
| 76 |
+
|
| 77 |
+
@register_to_config
|
| 78 |
+
def __init__(
|
| 79 |
+
self,
|
| 80 |
+
num_attention_heads: int = 16,
|
| 81 |
+
attention_head_dim: int = 88,
|
| 82 |
+
in_channels: Optional[int] = None,
|
| 83 |
+
out_channels: Optional[int] = None,
|
| 84 |
+
num_layers: int = 1,
|
| 85 |
+
dropout: float = 0.0,
|
| 86 |
+
norm_num_groups: int = 32,
|
| 87 |
+
cross_attention_dim: Optional[int] = None,
|
| 88 |
+
attention_bias: bool = False,
|
| 89 |
+
sample_size: Optional[int] = None,
|
| 90 |
+
num_vector_embeds: Optional[int] = None,
|
| 91 |
+
patch_size: Optional[int] = None,
|
| 92 |
+
activation_fn: str = "geglu",
|
| 93 |
+
num_embeds_ada_norm: Optional[int] = None,
|
| 94 |
+
use_linear_projection: bool = False,
|
| 95 |
+
only_cross_attention: bool = False,
|
| 96 |
+
double_self_attention: bool = False,
|
| 97 |
+
upcast_attention: bool = False,
|
| 98 |
+
norm_type: str = "layer_norm",
|
| 99 |
+
norm_elementwise_affine: bool = True,
|
| 100 |
+
norm_eps: float = 1e-5,
|
| 101 |
+
attention_type: str = "default",
|
| 102 |
+
caption_channels: int = None,
|
| 103 |
+
):
|
| 104 |
+
super().__init__()
|
| 105 |
+
self.use_linear_projection = use_linear_projection
|
| 106 |
+
self.num_attention_heads = num_attention_heads
|
| 107 |
+
self.attention_head_dim = attention_head_dim
|
| 108 |
+
inner_dim = num_attention_heads * attention_head_dim
|
| 109 |
+
|
| 110 |
+
conv_cls = nn.Conv2d if USE_PEFT_BACKEND else LoRACompatibleConv
|
| 111 |
+
linear_cls = nn.Linear if USE_PEFT_BACKEND else LoRACompatibleLinear
|
| 112 |
+
|
| 113 |
+
# 1. Transformer2DModel can process both standard continuous images of shape `(batch_size, num_channels, width, height)` as well as quantized image embeddings of shape `(batch_size, num_image_vectors)`
|
| 114 |
+
# Define whether input is continuous or discrete depending on configuration
|
| 115 |
+
self.is_input_continuous = (in_channels is not None) and (patch_size is None)
|
| 116 |
+
self.is_input_vectorized = num_vector_embeds is not None
|
| 117 |
+
self.is_input_patches = in_channels is not None and patch_size is not None
|
| 118 |
+
|
| 119 |
+
if norm_type == "layer_norm" and num_embeds_ada_norm is not None:
|
| 120 |
+
deprecation_message = (
|
| 121 |
+
f"The configuration file of this model: {self.__class__} is outdated. `norm_type` is either not set or"
|
| 122 |
+
" incorrectly set to `'layer_norm'`.Make sure to set `norm_type` to `'ada_norm'` in the config."
|
| 123 |
+
" Please make sure to update the config accordingly as leaving `norm_type` might led to incorrect"
|
| 124 |
+
" results in future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it"
|
| 125 |
+
" would be very nice if you could open a Pull request for the `transformer/config.json` file"
|
| 126 |
+
)
|
| 127 |
+
deprecate("norm_type!=num_embeds_ada_norm", "1.0.0", deprecation_message, standard_warn=False)
|
| 128 |
+
norm_type = "ada_norm"
|
| 129 |
+
|
| 130 |
+
if self.is_input_continuous and self.is_input_vectorized:
|
| 131 |
+
raise ValueError(
|
| 132 |
+
f"Cannot define both `in_channels`: {in_channels} and `num_vector_embeds`: {num_vector_embeds}. Make"
|
| 133 |
+
" sure that either `in_channels` or `num_vector_embeds` is None."
|
| 134 |
+
)
|
| 135 |
+
elif self.is_input_vectorized and self.is_input_patches:
|
| 136 |
+
raise ValueError(
|
| 137 |
+
f"Cannot define both `num_vector_embeds`: {num_vector_embeds} and `patch_size`: {patch_size}. Make"
|
| 138 |
+
" sure that either `num_vector_embeds` or `num_patches` is None."
|
| 139 |
+
)
|
| 140 |
+
elif not self.is_input_continuous and not self.is_input_vectorized and not self.is_input_patches:
|
| 141 |
+
raise ValueError(
|
| 142 |
+
f"Has to define `in_channels`: {in_channels}, `num_vector_embeds`: {num_vector_embeds}, or patch_size:"
|
| 143 |
+
f" {patch_size}. Make sure that `in_channels`, `num_vector_embeds` or `num_patches` is not None."
|
| 144 |
+
)
|
| 145 |
+
|
| 146 |
+
# 2. Define input layers
|
| 147 |
+
if self.is_input_continuous:
|
| 148 |
+
self.in_channels = in_channels
|
| 149 |
+
|
| 150 |
+
self.norm = torch.nn.GroupNorm(num_groups=norm_num_groups, num_channels=in_channels, eps=1e-6, affine=True)
|
| 151 |
+
if use_linear_projection:
|
| 152 |
+
self.proj_in = linear_cls(in_channels, inner_dim)
|
| 153 |
+
else:
|
| 154 |
+
self.proj_in = conv_cls(in_channels, inner_dim, kernel_size=1, stride=1, padding=0)
|
| 155 |
+
elif self.is_input_vectorized:
|
| 156 |
+
assert sample_size is not None, "Transformer2DModel over discrete input must provide sample_size"
|
| 157 |
+
assert num_vector_embeds is not None, "Transformer2DModel over discrete input must provide num_embed"
|
| 158 |
+
|
| 159 |
+
self.height = sample_size
|
| 160 |
+
self.width = sample_size
|
| 161 |
+
self.num_vector_embeds = num_vector_embeds
|
| 162 |
+
self.num_latent_pixels = self.height * self.width
|
| 163 |
+
|
| 164 |
+
self.latent_image_embedding = ImagePositionalEmbeddings(
|
| 165 |
+
num_embed=num_vector_embeds, embed_dim=inner_dim, height=self.height, width=self.width
|
| 166 |
+
)
|
| 167 |
+
elif self.is_input_patches:
|
| 168 |
+
assert sample_size is not None, "Transformer2DModel over patched input must provide sample_size"
|
| 169 |
+
|
| 170 |
+
self.height = sample_size
|
| 171 |
+
self.width = sample_size
|
| 172 |
+
|
| 173 |
+
self.patch_size = patch_size
|
| 174 |
+
interpolation_scale = self.config.sample_size // 64 # => 64 (= 512 pixart) has interpolation scale 1
|
| 175 |
+
interpolation_scale = max(interpolation_scale, 1)
|
| 176 |
+
self.pos_embed = PatchEmbed(
|
| 177 |
+
height=sample_size,
|
| 178 |
+
width=sample_size,
|
| 179 |
+
patch_size=patch_size,
|
| 180 |
+
in_channels=in_channels,
|
| 181 |
+
embed_dim=inner_dim,
|
| 182 |
+
interpolation_scale=interpolation_scale,
|
| 183 |
+
)
|
| 184 |
+
|
| 185 |
+
# 3. Define transformers blocks
|
| 186 |
+
self.transformer_blocks = nn.ModuleList(
|
| 187 |
+
[
|
| 188 |
+
BasicTransformerBlock(
|
| 189 |
+
inner_dim,
|
| 190 |
+
num_attention_heads,
|
| 191 |
+
attention_head_dim,
|
| 192 |
+
dropout=dropout,
|
| 193 |
+
cross_attention_dim=cross_attention_dim,
|
| 194 |
+
activation_fn=activation_fn,
|
| 195 |
+
num_embeds_ada_norm=num_embeds_ada_norm,
|
| 196 |
+
attention_bias=attention_bias,
|
| 197 |
+
only_cross_attention=only_cross_attention,
|
| 198 |
+
double_self_attention=double_self_attention,
|
| 199 |
+
upcast_attention=upcast_attention,
|
| 200 |
+
norm_type=norm_type,
|
| 201 |
+
norm_elementwise_affine=norm_elementwise_affine,
|
| 202 |
+
norm_eps=norm_eps,
|
| 203 |
+
attention_type=attention_type,
|
| 204 |
+
)
|
| 205 |
+
for d in range(num_layers)
|
| 206 |
+
]
|
| 207 |
+
)
|
| 208 |
+
|
| 209 |
+
# 4. Define output layers
|
| 210 |
+
self.out_channels = in_channels if out_channels is None else out_channels
|
| 211 |
+
if self.is_input_continuous:
|
| 212 |
+
# TODO: should use out_channels for continuous projections
|
| 213 |
+
if use_linear_projection:
|
| 214 |
+
self.proj_out = linear_cls(inner_dim, in_channels)
|
| 215 |
+
else:
|
| 216 |
+
self.proj_out = conv_cls(inner_dim, in_channels, kernel_size=1, stride=1, padding=0)
|
| 217 |
+
elif self.is_input_vectorized:
|
| 218 |
+
self.norm_out = nn.LayerNorm(inner_dim)
|
| 219 |
+
self.out = nn.Linear(inner_dim, self.num_vector_embeds - 1)
|
| 220 |
+
elif self.is_input_patches and norm_type != "ada_norm_single":
|
| 221 |
+
self.norm_out = nn.LayerNorm(inner_dim, elementwise_affine=False, eps=1e-6)
|
| 222 |
+
self.proj_out_1 = nn.Linear(inner_dim, 2 * inner_dim)
|
| 223 |
+
self.proj_out_2 = nn.Linear(inner_dim, patch_size * patch_size * self.out_channels)
|
| 224 |
+
elif self.is_input_patches and norm_type == "ada_norm_single":
|
| 225 |
+
self.norm_out = nn.LayerNorm(inner_dim, elementwise_affine=False, eps=1e-6)
|
| 226 |
+
self.scale_shift_table = nn.Parameter(torch.randn(2, inner_dim) / inner_dim**0.5)
|
| 227 |
+
self.proj_out = nn.Linear(inner_dim, patch_size * patch_size * self.out_channels)
|
| 228 |
+
|
| 229 |
+
# 5. PixArt-Alpha blocks.
|
| 230 |
+
self.adaln_single = None
|
| 231 |
+
self.use_additional_conditions = False
|
| 232 |
+
if norm_type == "ada_norm_single":
|
| 233 |
+
self.use_additional_conditions = self.config.sample_size == 128
|
| 234 |
+
# TODO(Sayak, PVP) clean this, for now we use sample size to determine whether to use
|
| 235 |
+
# additional conditions until we find better name
|
| 236 |
+
self.adaln_single = AdaLayerNormSingle(inner_dim, use_additional_conditions=self.use_additional_conditions)
|
| 237 |
+
|
| 238 |
+
self.caption_projection = None
|
| 239 |
+
if caption_channels is not None:
|
| 240 |
+
self.caption_projection = CaptionProjection(in_features=caption_channels, hidden_size=inner_dim)
|
| 241 |
+
|
| 242 |
+
self.gradient_checkpointing = False
|
| 243 |
+
|
| 244 |
+
def forward(
|
| 245 |
+
self,
|
| 246 |
+
hidden_states: torch.Tensor,
|
| 247 |
+
spatial_attn_inputs = [],
|
| 248 |
+
spatial_attn_idx = 0,
|
| 249 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 250 |
+
timestep: Optional[torch.LongTensor] = None,
|
| 251 |
+
added_cond_kwargs: Dict[str, torch.Tensor] = None,
|
| 252 |
+
class_labels: Optional[torch.LongTensor] = None,
|
| 253 |
+
cross_attention_kwargs: Dict[str, Any] = None,
|
| 254 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 255 |
+
encoder_attention_mask: Optional[torch.Tensor] = None,
|
| 256 |
+
return_dict: bool = True,
|
| 257 |
+
):
|
| 258 |
+
"""
|
| 259 |
+
The [`Transformer2DModel`] forward method.
|
| 260 |
+
|
| 261 |
+
Args:
|
| 262 |
+
hidden_states (`torch.LongTensor` of shape `(batch size, num latent pixels)` if discrete, `torch.FloatTensor` of shape `(batch size, channel, height, width)` if continuous):
|
| 263 |
+
Input `hidden_states`.
|
| 264 |
+
encoder_hidden_states ( `torch.FloatTensor` of shape `(batch size, sequence len, embed dims)`, *optional*):
|
| 265 |
+
Conditional embeddings for cross attention layer. If not given, cross-attention defaults to
|
| 266 |
+
self-attention.
|
| 267 |
+
timestep ( `torch.LongTensor`, *optional*):
|
| 268 |
+
Used to indicate denoising step. Optional timestep to be applied as an embedding in `AdaLayerNorm`.
|
| 269 |
+
class_labels ( `torch.LongTensor` of shape `(batch size, num classes)`, *optional*):
|
| 270 |
+
Used to indicate class labels conditioning. Optional class labels to be applied as an embedding in
|
| 271 |
+
`AdaLayerZeroNorm`.
|
| 272 |
+
cross_attention_kwargs ( `Dict[str, Any]`, *optional*):
|
| 273 |
+
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
| 274 |
+
`self.processor` in
|
| 275 |
+
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
|
| 276 |
+
attention_mask ( `torch.Tensor`, *optional*):
|
| 277 |
+
An attention mask of shape `(batch, key_tokens)` is applied to `encoder_hidden_states`. If `1` the mask
|
| 278 |
+
is kept, otherwise if `0` it is discarded. Mask will be converted into a bias, which adds large
|
| 279 |
+
negative values to the attention scores corresponding to "discard" tokens.
|
| 280 |
+
encoder_attention_mask ( `torch.Tensor`, *optional*):
|
| 281 |
+
Cross-attention mask applied to `encoder_hidden_states`. Two formats supported:
|
| 282 |
+
|
| 283 |
+
* Mask `(batch, sequence_length)` True = keep, False = discard.
|
| 284 |
+
* Bias `(batch, 1, sequence_length)` 0 = keep, -10000 = discard.
|
| 285 |
+
|
| 286 |
+
If `ndim == 2`: will be interpreted as a mask, then converted into a bias consistent with the format
|
| 287 |
+
above. This bias will be added to the cross-attention scores.
|
| 288 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 289 |
+
Whether or not to return a [`~models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain
|
| 290 |
+
tuple.
|
| 291 |
+
|
| 292 |
+
Returns:
|
| 293 |
+
If `return_dict` is True, an [`~models.transformer_2d.Transformer2DModelOutput`] is returned, otherwise a
|
| 294 |
+
`tuple` where the first element is the sample tensor.
|
| 295 |
+
"""
|
| 296 |
+
# ensure attention_mask is a bias, and give it a singleton query_tokens dimension.
|
| 297 |
+
# we may have done this conversion already, e.g. if we came here via UNet2DConditionModel#forward.
|
| 298 |
+
# we can tell by counting dims; if ndim == 2: it's a mask rather than a bias.
|
| 299 |
+
# expects mask of shape:
|
| 300 |
+
# [batch, key_tokens]
|
| 301 |
+
# adds singleton query_tokens dimension:
|
| 302 |
+
# [batch, 1, key_tokens]
|
| 303 |
+
# this helps to broadcast it as a bias over attention scores, which will be in one of the following shapes:
|
| 304 |
+
# [batch, heads, query_tokens, key_tokens] (e.g. torch sdp attn)
|
| 305 |
+
# [batch * heads, query_tokens, key_tokens] (e.g. xformers or classic attn)
|
| 306 |
+
if attention_mask is not None and attention_mask.ndim == 2:
|
| 307 |
+
# assume that mask is expressed as:
|
| 308 |
+
# (1 = keep, 0 = discard)
|
| 309 |
+
# convert mask into a bias that can be added to attention scores:
|
| 310 |
+
# (keep = +0, discard = -10000.0)
|
| 311 |
+
attention_mask = (1 - attention_mask.to(hidden_states.dtype)) * -10000.0
|
| 312 |
+
attention_mask = attention_mask.unsqueeze(1)
|
| 313 |
+
|
| 314 |
+
# convert encoder_attention_mask to a bias the same way we do for attention_mask
|
| 315 |
+
if encoder_attention_mask is not None and encoder_attention_mask.ndim == 2:
|
| 316 |
+
encoder_attention_mask = (1 - encoder_attention_mask.to(hidden_states.dtype)) * -10000.0
|
| 317 |
+
encoder_attention_mask = encoder_attention_mask.unsqueeze(1)
|
| 318 |
+
|
| 319 |
+
# Retrieve lora scale.
|
| 320 |
+
lora_scale = cross_attention_kwargs.get("scale", 1.0) if cross_attention_kwargs is not None else 1.0
|
| 321 |
+
|
| 322 |
+
# 1. Input
|
| 323 |
+
if self.is_input_continuous:
|
| 324 |
+
batch, _, height, width = hidden_states.shape
|
| 325 |
+
residual = hidden_states
|
| 326 |
+
|
| 327 |
+
hidden_states = self.norm(hidden_states)
|
| 328 |
+
if not self.use_linear_projection:
|
| 329 |
+
hidden_states = (
|
| 330 |
+
self.proj_in(hidden_states, scale=lora_scale)
|
| 331 |
+
if not USE_PEFT_BACKEND
|
| 332 |
+
else self.proj_in(hidden_states)
|
| 333 |
+
)
|
| 334 |
+
inner_dim = hidden_states.shape[1]
|
| 335 |
+
hidden_states = hidden_states.permute(0, 2, 3, 1).reshape(batch, height * width, inner_dim)
|
| 336 |
+
else:
|
| 337 |
+
inner_dim = hidden_states.shape[1]
|
| 338 |
+
hidden_states = hidden_states.permute(0, 2, 3, 1).reshape(batch, height * width, inner_dim)
|
| 339 |
+
hidden_states = (
|
| 340 |
+
self.proj_in(hidden_states, scale=lora_scale)
|
| 341 |
+
if not USE_PEFT_BACKEND
|
| 342 |
+
else self.proj_in(hidden_states)
|
| 343 |
+
)
|
| 344 |
+
|
| 345 |
+
elif self.is_input_vectorized:
|
| 346 |
+
hidden_states = self.latent_image_embedding(hidden_states)
|
| 347 |
+
elif self.is_input_patches:
|
| 348 |
+
height, width = hidden_states.shape[-2] // self.patch_size, hidden_states.shape[-1] // self.patch_size
|
| 349 |
+
hidden_states = self.pos_embed(hidden_states)
|
| 350 |
+
|
| 351 |
+
if self.adaln_single is not None:
|
| 352 |
+
if self.use_additional_conditions and added_cond_kwargs is None:
|
| 353 |
+
raise ValueError(
|
| 354 |
+
"`added_cond_kwargs` cannot be None when using additional conditions for `adaln_single`."
|
| 355 |
+
)
|
| 356 |
+
batch_size = hidden_states.shape[0]
|
| 357 |
+
timestep, embedded_timestep = self.adaln_single(
|
| 358 |
+
timestep, added_cond_kwargs, batch_size=batch_size, hidden_dtype=hidden_states.dtype
|
| 359 |
+
)
|
| 360 |
+
|
| 361 |
+
# 2. Blocks
|
| 362 |
+
if self.caption_projection is not None:
|
| 363 |
+
batch_size = hidden_states.shape[0]
|
| 364 |
+
encoder_hidden_states = self.caption_projection(encoder_hidden_states)
|
| 365 |
+
encoder_hidden_states = encoder_hidden_states.view(batch_size, -1, hidden_states.shape[-1])
|
| 366 |
+
|
| 367 |
+
for block in self.transformer_blocks:
|
| 368 |
+
if self.training and self.gradient_checkpointing:
|
| 369 |
+
hidden_states, spatial_attn_inputs, spatial_attn_idx = torch.utils.checkpoint.checkpoint(
|
| 370 |
+
block,
|
| 371 |
+
hidden_states,
|
| 372 |
+
spatial_attn_inputs,
|
| 373 |
+
spatial_attn_idx,
|
| 374 |
+
attention_mask,
|
| 375 |
+
encoder_hidden_states,
|
| 376 |
+
encoder_attention_mask,
|
| 377 |
+
timestep,
|
| 378 |
+
cross_attention_kwargs,
|
| 379 |
+
class_labels,
|
| 380 |
+
use_reentrant=False,
|
| 381 |
+
)
|
| 382 |
+
else:
|
| 383 |
+
hidden_states, spatial_attn_inputs, spatial_attn_idx = block(
|
| 384 |
+
hidden_states,
|
| 385 |
+
spatial_attn_inputs,
|
| 386 |
+
spatial_attn_idx,
|
| 387 |
+
attention_mask=attention_mask,
|
| 388 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 389 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 390 |
+
timestep=timestep,
|
| 391 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 392 |
+
class_labels=class_labels,
|
| 393 |
+
)
|
| 394 |
+
|
| 395 |
+
# 3. Output
|
| 396 |
+
if self.is_input_continuous:
|
| 397 |
+
if not self.use_linear_projection:
|
| 398 |
+
hidden_states = hidden_states.reshape(batch, height, width, inner_dim).permute(0, 3, 1, 2).contiguous()
|
| 399 |
+
hidden_states = (
|
| 400 |
+
self.proj_out(hidden_states, scale=lora_scale)
|
| 401 |
+
if not USE_PEFT_BACKEND
|
| 402 |
+
else self.proj_out(hidden_states)
|
| 403 |
+
)
|
| 404 |
+
else:
|
| 405 |
+
hidden_states = (
|
| 406 |
+
self.proj_out(hidden_states, scale=lora_scale)
|
| 407 |
+
if not USE_PEFT_BACKEND
|
| 408 |
+
else self.proj_out(hidden_states)
|
| 409 |
+
)
|
| 410 |
+
hidden_states = hidden_states.reshape(batch, height, width, inner_dim).permute(0, 3, 1, 2).contiguous()
|
| 411 |
+
|
| 412 |
+
output = hidden_states + residual
|
| 413 |
+
elif self.is_input_vectorized:
|
| 414 |
+
hidden_states = self.norm_out(hidden_states)
|
| 415 |
+
logits = self.out(hidden_states)
|
| 416 |
+
# (batch, self.num_vector_embeds - 1, self.num_latent_pixels)
|
| 417 |
+
logits = logits.permute(0, 2, 1)
|
| 418 |
+
|
| 419 |
+
# log(p(x_0))
|
| 420 |
+
output = F.log_softmax(logits.double(), dim=1).float()
|
| 421 |
+
|
| 422 |
+
if self.is_input_patches:
|
| 423 |
+
if self.config.norm_type != "ada_norm_single":
|
| 424 |
+
conditioning = self.transformer_blocks[0].norm1.emb(
|
| 425 |
+
timestep, class_labels, hidden_dtype=hidden_states.dtype
|
| 426 |
+
)
|
| 427 |
+
shift, scale = self.proj_out_1(F.silu(conditioning)).chunk(2, dim=1)
|
| 428 |
+
hidden_states = self.norm_out(hidden_states) * (1 + scale[:, None]) + shift[:, None]
|
| 429 |
+
hidden_states = self.proj_out_2(hidden_states)
|
| 430 |
+
elif self.config.norm_type == "ada_norm_single":
|
| 431 |
+
shift, scale = (self.scale_shift_table[None] + embedded_timestep[:, None]).chunk(2, dim=1)
|
| 432 |
+
hidden_states = self.norm_out(hidden_states)
|
| 433 |
+
# Modulation
|
| 434 |
+
hidden_states = hidden_states * (1 + scale) + shift
|
| 435 |
+
hidden_states = self.proj_out(hidden_states)
|
| 436 |
+
hidden_states = hidden_states.squeeze(1)
|
| 437 |
+
|
| 438 |
+
# unpatchify
|
| 439 |
+
if self.adaln_single is None:
|
| 440 |
+
height = width = int(hidden_states.shape[1] ** 0.5)
|
| 441 |
+
hidden_states = hidden_states.reshape(
|
| 442 |
+
shape=(-1, height, width, self.patch_size, self.patch_size, self.out_channels)
|
| 443 |
+
)
|
| 444 |
+
hidden_states = torch.einsum("nhwpqc->nchpwq", hidden_states)
|
| 445 |
+
output = hidden_states.reshape(
|
| 446 |
+
shape=(-1, self.out_channels, height * self.patch_size, width * self.patch_size)
|
| 447 |
+
)
|
| 448 |
+
|
| 449 |
+
if not return_dict:
|
| 450 |
+
return (output,), spatial_attn_inputs, spatial_attn_idx
|
| 451 |
+
|
| 452 |
+
return Transformer2DModelOutput(sample=output), spatial_attn_inputs, spatial_attn_idx
|
ootd/pipelines_ootd/unet_garm_2d_blocks.py
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
ootd/pipelines_ootd/unet_garm_2d_condition.py
ADDED
|
@@ -0,0 +1,1183 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# Modified by Yuhao Xu for OOTDiffusion (https://github.com/levihsu/OOTDiffusion)
|
| 16 |
+
from dataclasses import dataclass
|
| 17 |
+
from typing import Any, Dict, List, Optional, Tuple, Union
|
| 18 |
+
|
| 19 |
+
import torch
|
| 20 |
+
import torch.nn as nn
|
| 21 |
+
import torch.utils.checkpoint
|
| 22 |
+
|
| 23 |
+
from .unet_garm_2d_blocks import (
|
| 24 |
+
UNetMidBlock2D,
|
| 25 |
+
UNetMidBlock2DCrossAttn,
|
| 26 |
+
UNetMidBlock2DSimpleCrossAttn,
|
| 27 |
+
get_down_block,
|
| 28 |
+
get_up_block,
|
| 29 |
+
)
|
| 30 |
+
|
| 31 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 32 |
+
from diffusers.loaders import UNet2DConditionLoadersMixin
|
| 33 |
+
from diffusers.utils import USE_PEFT_BACKEND, BaseOutput, deprecate, logging, scale_lora_layers, unscale_lora_layers
|
| 34 |
+
from diffusers.models.activations import get_activation
|
| 35 |
+
from diffusers.models.attention_processor import (
|
| 36 |
+
ADDED_KV_ATTENTION_PROCESSORS,
|
| 37 |
+
CROSS_ATTENTION_PROCESSORS,
|
| 38 |
+
AttentionProcessor,
|
| 39 |
+
AttnAddedKVProcessor,
|
| 40 |
+
AttnProcessor,
|
| 41 |
+
)
|
| 42 |
+
from diffusers.models.embeddings import (
|
| 43 |
+
GaussianFourierProjection,
|
| 44 |
+
ImageHintTimeEmbedding,
|
| 45 |
+
ImageProjection,
|
| 46 |
+
ImageTimeEmbedding,
|
| 47 |
+
PositionNet,
|
| 48 |
+
TextImageProjection,
|
| 49 |
+
TextImageTimeEmbedding,
|
| 50 |
+
TextTimeEmbedding,
|
| 51 |
+
TimestepEmbedding,
|
| 52 |
+
Timesteps,
|
| 53 |
+
)
|
| 54 |
+
from diffusers.models.modeling_utils import ModelMixin
|
| 55 |
+
# from diffusers.models.unet_2d_blocks import (
|
| 56 |
+
# UNetMidBlock2D,
|
| 57 |
+
# UNetMidBlock2DCrossAttn,
|
| 58 |
+
# UNetMidBlock2DSimpleCrossAttn,
|
| 59 |
+
# get_down_block,
|
| 60 |
+
# get_up_block,
|
| 61 |
+
# )
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
@dataclass
|
| 68 |
+
class UNet2DConditionOutput(BaseOutput):
|
| 69 |
+
"""
|
| 70 |
+
The output of [`UNet2DConditionModel`].
|
| 71 |
+
|
| 72 |
+
Args:
|
| 73 |
+
sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
|
| 74 |
+
The hidden states output conditioned on `encoder_hidden_states` input. Output of last layer of model.
|
| 75 |
+
"""
|
| 76 |
+
|
| 77 |
+
sample: torch.FloatTensor = None
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
class UNetGarm2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin):
|
| 81 |
+
r"""
|
| 82 |
+
A conditional 2D UNet model that takes a noisy sample, conditional state, and a timestep and returns a sample
|
| 83 |
+
shaped output.
|
| 84 |
+
|
| 85 |
+
This model inherits from [`ModelMixin`]. Check the superclass documentation for it's generic methods implemented
|
| 86 |
+
for all models (such as downloading or saving).
|
| 87 |
+
|
| 88 |
+
Parameters:
|
| 89 |
+
sample_size (`int` or `Tuple[int, int]`, *optional*, defaults to `None`):
|
| 90 |
+
Height and width of input/output sample.
|
| 91 |
+
in_channels (`int`, *optional*, defaults to 4): Number of channels in the input sample.
|
| 92 |
+
out_channels (`int`, *optional*, defaults to 4): Number of channels in the output.
|
| 93 |
+
center_input_sample (`bool`, *optional*, defaults to `False`): Whether to center the input sample.
|
| 94 |
+
flip_sin_to_cos (`bool`, *optional*, defaults to `False`):
|
| 95 |
+
Whether to flip the sin to cos in the time embedding.
|
| 96 |
+
freq_shift (`int`, *optional*, defaults to 0): The frequency shift to apply to the time embedding.
|
| 97 |
+
down_block_types (`Tuple[str]`, *optional*, defaults to `("CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D")`):
|
| 98 |
+
The tuple of downsample blocks to use.
|
| 99 |
+
mid_block_type (`str`, *optional*, defaults to `"UNetMidBlock2DCrossAttn"`):
|
| 100 |
+
Block type for middle of UNet, it can be one of `UNetMidBlock2DCrossAttn`, `UNetMidBlock2D`, or
|
| 101 |
+
`UNetMidBlock2DSimpleCrossAttn`. If `None`, the mid block layer is skipped.
|
| 102 |
+
up_block_types (`Tuple[str]`, *optional*, defaults to `("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D")`):
|
| 103 |
+
The tuple of upsample blocks to use.
|
| 104 |
+
only_cross_attention(`bool` or `Tuple[bool]`, *optional*, default to `False`):
|
| 105 |
+
Whether to include self-attention in the basic transformer blocks, see
|
| 106 |
+
[`~models.attention.BasicTransformerBlock`].
|
| 107 |
+
block_out_channels (`Tuple[int]`, *optional*, defaults to `(320, 640, 1280, 1280)`):
|
| 108 |
+
The tuple of output channels for each block.
|
| 109 |
+
layers_per_block (`int`, *optional*, defaults to 2): The number of layers per block.
|
| 110 |
+
downsample_padding (`int`, *optional*, defaults to 1): The padding to use for the downsampling convolution.
|
| 111 |
+
mid_block_scale_factor (`float`, *optional*, defaults to 1.0): The scale factor to use for the mid block.
|
| 112 |
+
dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
|
| 113 |
+
act_fn (`str`, *optional*, defaults to `"silu"`): The activation function to use.
|
| 114 |
+
norm_num_groups (`int`, *optional*, defaults to 32): The number of groups to use for the normalization.
|
| 115 |
+
If `None`, normalization and activation layers is skipped in post-processing.
|
| 116 |
+
norm_eps (`float`, *optional*, defaults to 1e-5): The epsilon to use for the normalization.
|
| 117 |
+
cross_attention_dim (`int` or `Tuple[int]`, *optional*, defaults to 1280):
|
| 118 |
+
The dimension of the cross attention features.
|
| 119 |
+
transformer_layers_per_block (`int`, `Tuple[int]`, or `Tuple[Tuple]` , *optional*, defaults to 1):
|
| 120 |
+
The number of transformer blocks of type [`~models.attention.BasicTransformerBlock`]. Only relevant for
|
| 121 |
+
[`~models.unet_2d_blocks.CrossAttnDownBlock2D`], [`~models.unet_2d_blocks.CrossAttnUpBlock2D`],
|
| 122 |
+
[`~models.unet_2d_blocks.UNetMidBlock2DCrossAttn`].
|
| 123 |
+
reverse_transformer_layers_per_block : (`Tuple[Tuple]`, *optional*, defaults to None):
|
| 124 |
+
The number of transformer blocks of type [`~models.attention.BasicTransformerBlock`], in the upsampling
|
| 125 |
+
blocks of the U-Net. Only relevant if `transformer_layers_per_block` is of type `Tuple[Tuple]` and for
|
| 126 |
+
[`~models.unet_2d_blocks.CrossAttnDownBlock2D`], [`~models.unet_2d_blocks.CrossAttnUpBlock2D`],
|
| 127 |
+
[`~models.unet_2d_blocks.UNetMidBlock2DCrossAttn`].
|
| 128 |
+
encoder_hid_dim (`int`, *optional*, defaults to None):
|
| 129 |
+
If `encoder_hid_dim_type` is defined, `encoder_hidden_states` will be projected from `encoder_hid_dim`
|
| 130 |
+
dimension to `cross_attention_dim`.
|
| 131 |
+
encoder_hid_dim_type (`str`, *optional*, defaults to `None`):
|
| 132 |
+
If given, the `encoder_hidden_states` and potentially other embeddings are down-projected to text
|
| 133 |
+
embeddings of dimension `cross_attention` according to `encoder_hid_dim_type`.
|
| 134 |
+
attention_head_dim (`int`, *optional*, defaults to 8): The dimension of the attention heads.
|
| 135 |
+
num_attention_heads (`int`, *optional*):
|
| 136 |
+
The number of attention heads. If not defined, defaults to `attention_head_dim`
|
| 137 |
+
resnet_time_scale_shift (`str`, *optional*, defaults to `"default"`): Time scale shift config
|
| 138 |
+
for ResNet blocks (see [`~models.resnet.ResnetBlock2D`]). Choose from `default` or `scale_shift`.
|
| 139 |
+
class_embed_type (`str`, *optional*, defaults to `None`):
|
| 140 |
+
The type of class embedding to use which is ultimately summed with the time embeddings. Choose from `None`,
|
| 141 |
+
`"timestep"`, `"identity"`, `"projection"`, or `"simple_projection"`.
|
| 142 |
+
addition_embed_type (`str`, *optional*, defaults to `None`):
|
| 143 |
+
Configures an optional embedding which will be summed with the time embeddings. Choose from `None` or
|
| 144 |
+
"text". "text" will use the `TextTimeEmbedding` layer.
|
| 145 |
+
addition_time_embed_dim: (`int`, *optional*, defaults to `None`):
|
| 146 |
+
Dimension for the timestep embeddings.
|
| 147 |
+
num_class_embeds (`int`, *optional*, defaults to `None`):
|
| 148 |
+
Input dimension of the learnable embedding matrix to be projected to `time_embed_dim`, when performing
|
| 149 |
+
class conditioning with `class_embed_type` equal to `None`.
|
| 150 |
+
time_embedding_type (`str`, *optional*, defaults to `positional`):
|
| 151 |
+
The type of position embedding to use for timesteps. Choose from `positional` or `fourier`.
|
| 152 |
+
time_embedding_dim (`int`, *optional*, defaults to `None`):
|
| 153 |
+
An optional override for the dimension of the projected time embedding.
|
| 154 |
+
time_embedding_act_fn (`str`, *optional*, defaults to `None`):
|
| 155 |
+
Optional activation function to use only once on the time embeddings before they are passed to the rest of
|
| 156 |
+
the UNet. Choose from `silu`, `mish`, `gelu`, and `swish`.
|
| 157 |
+
timestep_post_act (`str`, *optional*, defaults to `None`):
|
| 158 |
+
The second activation function to use in timestep embedding. Choose from `silu`, `mish` and `gelu`.
|
| 159 |
+
time_cond_proj_dim (`int`, *optional*, defaults to `None`):
|
| 160 |
+
The dimension of `cond_proj` layer in the timestep embedding.
|
| 161 |
+
conv_in_kernel (`int`, *optional*, default to `3`): The kernel size of `conv_in` layer. conv_out_kernel (`int`,
|
| 162 |
+
*optional*, default to `3`): The kernel size of `conv_out` layer. projection_class_embeddings_input_dim (`int`,
|
| 163 |
+
*optional*): The dimension of the `class_labels` input when
|
| 164 |
+
`class_embed_type="projection"`. Required when `class_embed_type="projection"`.
|
| 165 |
+
class_embeddings_concat (`bool`, *optional*, defaults to `False`): Whether to concatenate the time
|
| 166 |
+
embeddings with the class embeddings.
|
| 167 |
+
mid_block_only_cross_attention (`bool`, *optional*, defaults to `None`):
|
| 168 |
+
Whether to use cross attention with the mid block when using the `UNetMidBlock2DSimpleCrossAttn`. If
|
| 169 |
+
`only_cross_attention` is given as a single boolean and `mid_block_only_cross_attention` is `None`, the
|
| 170 |
+
`only_cross_attention` value is used as the value for `mid_block_only_cross_attention`. Default to `False`
|
| 171 |
+
otherwise.
|
| 172 |
+
"""
|
| 173 |
+
|
| 174 |
+
_supports_gradient_checkpointing = True
|
| 175 |
+
|
| 176 |
+
@register_to_config
|
| 177 |
+
def __init__(
|
| 178 |
+
self,
|
| 179 |
+
sample_size: Optional[int] = None,
|
| 180 |
+
in_channels: int = 4,
|
| 181 |
+
out_channels: int = 4,
|
| 182 |
+
center_input_sample: bool = False,
|
| 183 |
+
flip_sin_to_cos: bool = True,
|
| 184 |
+
freq_shift: int = 0,
|
| 185 |
+
down_block_types: Tuple[str] = (
|
| 186 |
+
"CrossAttnDownBlock2D",
|
| 187 |
+
"CrossAttnDownBlock2D",
|
| 188 |
+
"CrossAttnDownBlock2D",
|
| 189 |
+
"DownBlock2D",
|
| 190 |
+
),
|
| 191 |
+
mid_block_type: Optional[str] = "UNetMidBlock2DCrossAttn",
|
| 192 |
+
up_block_types: Tuple[str] = ("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D"),
|
| 193 |
+
only_cross_attention: Union[bool, Tuple[bool]] = False,
|
| 194 |
+
block_out_channels: Tuple[int] = (320, 640, 1280, 1280),
|
| 195 |
+
layers_per_block: Union[int, Tuple[int]] = 2,
|
| 196 |
+
downsample_padding: int = 1,
|
| 197 |
+
mid_block_scale_factor: float = 1,
|
| 198 |
+
dropout: float = 0.0,
|
| 199 |
+
act_fn: str = "silu",
|
| 200 |
+
norm_num_groups: Optional[int] = 32,
|
| 201 |
+
norm_eps: float = 1e-5,
|
| 202 |
+
cross_attention_dim: Union[int, Tuple[int]] = 1280,
|
| 203 |
+
transformer_layers_per_block: Union[int, Tuple[int], Tuple[Tuple]] = 1,
|
| 204 |
+
reverse_transformer_layers_per_block: Optional[Tuple[Tuple[int]]] = None,
|
| 205 |
+
encoder_hid_dim: Optional[int] = None,
|
| 206 |
+
encoder_hid_dim_type: Optional[str] = None,
|
| 207 |
+
attention_head_dim: Union[int, Tuple[int]] = 8,
|
| 208 |
+
num_attention_heads: Optional[Union[int, Tuple[int]]] = None,
|
| 209 |
+
dual_cross_attention: bool = False,
|
| 210 |
+
use_linear_projection: bool = False,
|
| 211 |
+
class_embed_type: Optional[str] = None,
|
| 212 |
+
addition_embed_type: Optional[str] = None,
|
| 213 |
+
addition_time_embed_dim: Optional[int] = None,
|
| 214 |
+
num_class_embeds: Optional[int] = None,
|
| 215 |
+
upcast_attention: bool = False,
|
| 216 |
+
resnet_time_scale_shift: str = "default",
|
| 217 |
+
resnet_skip_time_act: bool = False,
|
| 218 |
+
resnet_out_scale_factor: int = 1.0,
|
| 219 |
+
time_embedding_type: str = "positional",
|
| 220 |
+
time_embedding_dim: Optional[int] = None,
|
| 221 |
+
time_embedding_act_fn: Optional[str] = None,
|
| 222 |
+
timestep_post_act: Optional[str] = None,
|
| 223 |
+
time_cond_proj_dim: Optional[int] = None,
|
| 224 |
+
conv_in_kernel: int = 3,
|
| 225 |
+
conv_out_kernel: int = 3,
|
| 226 |
+
projection_class_embeddings_input_dim: Optional[int] = None,
|
| 227 |
+
attention_type: str = "default",
|
| 228 |
+
class_embeddings_concat: bool = False,
|
| 229 |
+
mid_block_only_cross_attention: Optional[bool] = None,
|
| 230 |
+
cross_attention_norm: Optional[str] = None,
|
| 231 |
+
addition_embed_type_num_heads=64,
|
| 232 |
+
):
|
| 233 |
+
super().__init__()
|
| 234 |
+
|
| 235 |
+
self.sample_size = sample_size
|
| 236 |
+
|
| 237 |
+
if num_attention_heads is not None:
|
| 238 |
+
raise ValueError(
|
| 239 |
+
"At the moment it is not possible to define the number of attention heads via `num_attention_heads` because of a naming issue as described in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131. Passing `num_attention_heads` will only be supported in diffusers v0.19."
|
| 240 |
+
)
|
| 241 |
+
|
| 242 |
+
# If `num_attention_heads` is not defined (which is the case for most models)
|
| 243 |
+
# it will default to `attention_head_dim`. This looks weird upon first reading it and it is.
|
| 244 |
+
# The reason for this behavior is to correct for incorrectly named variables that were introduced
|
| 245 |
+
# when this library was created. The incorrect naming was only discovered much later in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131
|
| 246 |
+
# Changing `attention_head_dim` to `num_attention_heads` for 40,000+ configurations is too backwards breaking
|
| 247 |
+
# which is why we correct for the naming here.
|
| 248 |
+
num_attention_heads = num_attention_heads or attention_head_dim
|
| 249 |
+
|
| 250 |
+
# Check inputs
|
| 251 |
+
if len(down_block_types) != len(up_block_types):
|
| 252 |
+
raise ValueError(
|
| 253 |
+
f"Must provide the same number of `down_block_types` as `up_block_types`. `down_block_types`: {down_block_types}. `up_block_types`: {up_block_types}."
|
| 254 |
+
)
|
| 255 |
+
|
| 256 |
+
if len(block_out_channels) != len(down_block_types):
|
| 257 |
+
raise ValueError(
|
| 258 |
+
f"Must provide the same number of `block_out_channels` as `down_block_types`. `block_out_channels`: {block_out_channels}. `down_block_types`: {down_block_types}."
|
| 259 |
+
)
|
| 260 |
+
|
| 261 |
+
if not isinstance(only_cross_attention, bool) and len(only_cross_attention) != len(down_block_types):
|
| 262 |
+
raise ValueError(
|
| 263 |
+
f"Must provide the same number of `only_cross_attention` as `down_block_types`. `only_cross_attention`: {only_cross_attention}. `down_block_types`: {down_block_types}."
|
| 264 |
+
)
|
| 265 |
+
|
| 266 |
+
if not isinstance(num_attention_heads, int) and len(num_attention_heads) != len(down_block_types):
|
| 267 |
+
raise ValueError(
|
| 268 |
+
f"Must provide the same number of `num_attention_heads` as `down_block_types`. `num_attention_heads`: {num_attention_heads}. `down_block_types`: {down_block_types}."
|
| 269 |
+
)
|
| 270 |
+
|
| 271 |
+
if not isinstance(attention_head_dim, int) and len(attention_head_dim) != len(down_block_types):
|
| 272 |
+
raise ValueError(
|
| 273 |
+
f"Must provide the same number of `attention_head_dim` as `down_block_types`. `attention_head_dim`: {attention_head_dim}. `down_block_types`: {down_block_types}."
|
| 274 |
+
)
|
| 275 |
+
|
| 276 |
+
if isinstance(cross_attention_dim, list) and len(cross_attention_dim) != len(down_block_types):
|
| 277 |
+
raise ValueError(
|
| 278 |
+
f"Must provide the same number of `cross_attention_dim` as `down_block_types`. `cross_attention_dim`: {cross_attention_dim}. `down_block_types`: {down_block_types}."
|
| 279 |
+
)
|
| 280 |
+
|
| 281 |
+
if not isinstance(layers_per_block, int) and len(layers_per_block) != len(down_block_types):
|
| 282 |
+
raise ValueError(
|
| 283 |
+
f"Must provide the same number of `layers_per_block` as `down_block_types`. `layers_per_block`: {layers_per_block}. `down_block_types`: {down_block_types}."
|
| 284 |
+
)
|
| 285 |
+
if isinstance(transformer_layers_per_block, list) and reverse_transformer_layers_per_block is None:
|
| 286 |
+
for layer_number_per_block in transformer_layers_per_block:
|
| 287 |
+
if isinstance(layer_number_per_block, list):
|
| 288 |
+
raise ValueError("Must provide 'reverse_transformer_layers_per_block` if using asymmetrical UNet.")
|
| 289 |
+
|
| 290 |
+
# input
|
| 291 |
+
conv_in_padding = (conv_in_kernel - 1) // 2
|
| 292 |
+
self.conv_in = nn.Conv2d(
|
| 293 |
+
in_channels, block_out_channels[0], kernel_size=conv_in_kernel, padding=conv_in_padding
|
| 294 |
+
)
|
| 295 |
+
|
| 296 |
+
# time
|
| 297 |
+
if time_embedding_type == "fourier":
|
| 298 |
+
time_embed_dim = time_embedding_dim or block_out_channels[0] * 2
|
| 299 |
+
if time_embed_dim % 2 != 0:
|
| 300 |
+
raise ValueError(f"`time_embed_dim` should be divisible by 2, but is {time_embed_dim}.")
|
| 301 |
+
self.time_proj = GaussianFourierProjection(
|
| 302 |
+
time_embed_dim // 2, set_W_to_weight=False, log=False, flip_sin_to_cos=flip_sin_to_cos
|
| 303 |
+
)
|
| 304 |
+
timestep_input_dim = time_embed_dim
|
| 305 |
+
elif time_embedding_type == "positional":
|
| 306 |
+
time_embed_dim = time_embedding_dim or block_out_channels[0] * 4
|
| 307 |
+
|
| 308 |
+
self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
|
| 309 |
+
timestep_input_dim = block_out_channels[0]
|
| 310 |
+
else:
|
| 311 |
+
raise ValueError(
|
| 312 |
+
f"{time_embedding_type} does not exist. Please make sure to use one of `fourier` or `positional`."
|
| 313 |
+
)
|
| 314 |
+
|
| 315 |
+
self.time_embedding = TimestepEmbedding(
|
| 316 |
+
timestep_input_dim,
|
| 317 |
+
time_embed_dim,
|
| 318 |
+
act_fn=act_fn,
|
| 319 |
+
post_act_fn=timestep_post_act,
|
| 320 |
+
cond_proj_dim=time_cond_proj_dim,
|
| 321 |
+
)
|
| 322 |
+
|
| 323 |
+
if encoder_hid_dim_type is None and encoder_hid_dim is not None:
|
| 324 |
+
encoder_hid_dim_type = "text_proj"
|
| 325 |
+
self.register_to_config(encoder_hid_dim_type=encoder_hid_dim_type)
|
| 326 |
+
logger.info("encoder_hid_dim_type defaults to 'text_proj' as `encoder_hid_dim` is defined.")
|
| 327 |
+
|
| 328 |
+
if encoder_hid_dim is None and encoder_hid_dim_type is not None:
|
| 329 |
+
raise ValueError(
|
| 330 |
+
f"`encoder_hid_dim` has to be defined when `encoder_hid_dim_type` is set to {encoder_hid_dim_type}."
|
| 331 |
+
)
|
| 332 |
+
|
| 333 |
+
if encoder_hid_dim_type == "text_proj":
|
| 334 |
+
self.encoder_hid_proj = nn.Linear(encoder_hid_dim, cross_attention_dim)
|
| 335 |
+
elif encoder_hid_dim_type == "text_image_proj":
|
| 336 |
+
# image_embed_dim DOESN'T have to be `cross_attention_dim`. To not clutter the __init__ too much
|
| 337 |
+
# they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
|
| 338 |
+
# case when `addition_embed_type == "text_image_proj"` (Kadinsky 2.1)`
|
| 339 |
+
self.encoder_hid_proj = TextImageProjection(
|
| 340 |
+
text_embed_dim=encoder_hid_dim,
|
| 341 |
+
image_embed_dim=cross_attention_dim,
|
| 342 |
+
cross_attention_dim=cross_attention_dim,
|
| 343 |
+
)
|
| 344 |
+
elif encoder_hid_dim_type == "image_proj":
|
| 345 |
+
# Kandinsky 2.2
|
| 346 |
+
self.encoder_hid_proj = ImageProjection(
|
| 347 |
+
image_embed_dim=encoder_hid_dim,
|
| 348 |
+
cross_attention_dim=cross_attention_dim,
|
| 349 |
+
)
|
| 350 |
+
elif encoder_hid_dim_type is not None:
|
| 351 |
+
raise ValueError(
|
| 352 |
+
f"encoder_hid_dim_type: {encoder_hid_dim_type} must be None, 'text_proj' or 'text_image_proj'."
|
| 353 |
+
)
|
| 354 |
+
else:
|
| 355 |
+
self.encoder_hid_proj = None
|
| 356 |
+
|
| 357 |
+
# class embedding
|
| 358 |
+
if class_embed_type is None and num_class_embeds is not None:
|
| 359 |
+
self.class_embedding = nn.Embedding(num_class_embeds, time_embed_dim)
|
| 360 |
+
elif class_embed_type == "timestep":
|
| 361 |
+
self.class_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim, act_fn=act_fn)
|
| 362 |
+
elif class_embed_type == "identity":
|
| 363 |
+
self.class_embedding = nn.Identity(time_embed_dim, time_embed_dim)
|
| 364 |
+
elif class_embed_type == "projection":
|
| 365 |
+
if projection_class_embeddings_input_dim is None:
|
| 366 |
+
raise ValueError(
|
| 367 |
+
"`class_embed_type`: 'projection' requires `projection_class_embeddings_input_dim` be set"
|
| 368 |
+
)
|
| 369 |
+
# The projection `class_embed_type` is the same as the timestep `class_embed_type` except
|
| 370 |
+
# 1. the `class_labels` inputs are not first converted to sinusoidal embeddings
|
| 371 |
+
# 2. it projects from an arbitrary input dimension.
|
| 372 |
+
#
|
| 373 |
+
# Note that `TimestepEmbedding` is quite general, being mainly linear layers and activations.
|
| 374 |
+
# When used for embedding actual timesteps, the timesteps are first converted to sinusoidal embeddings.
|
| 375 |
+
# As a result, `TimestepEmbedding` can be passed arbitrary vectors.
|
| 376 |
+
self.class_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
|
| 377 |
+
elif class_embed_type == "simple_projection":
|
| 378 |
+
if projection_class_embeddings_input_dim is None:
|
| 379 |
+
raise ValueError(
|
| 380 |
+
"`class_embed_type`: 'simple_projection' requires `projection_class_embeddings_input_dim` be set"
|
| 381 |
+
)
|
| 382 |
+
self.class_embedding = nn.Linear(projection_class_embeddings_input_dim, time_embed_dim)
|
| 383 |
+
else:
|
| 384 |
+
self.class_embedding = None
|
| 385 |
+
|
| 386 |
+
if addition_embed_type == "text":
|
| 387 |
+
if encoder_hid_dim is not None:
|
| 388 |
+
text_time_embedding_from_dim = encoder_hid_dim
|
| 389 |
+
else:
|
| 390 |
+
text_time_embedding_from_dim = cross_attention_dim
|
| 391 |
+
|
| 392 |
+
self.add_embedding = TextTimeEmbedding(
|
| 393 |
+
text_time_embedding_from_dim, time_embed_dim, num_heads=addition_embed_type_num_heads
|
| 394 |
+
)
|
| 395 |
+
elif addition_embed_type == "text_image":
|
| 396 |
+
# text_embed_dim and image_embed_dim DON'T have to be `cross_attention_dim`. To not clutter the __init__ too much
|
| 397 |
+
# they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
|
| 398 |
+
# case when `addition_embed_type == "text_image"` (Kadinsky 2.1)`
|
| 399 |
+
self.add_embedding = TextImageTimeEmbedding(
|
| 400 |
+
text_embed_dim=cross_attention_dim, image_embed_dim=cross_attention_dim, time_embed_dim=time_embed_dim
|
| 401 |
+
)
|
| 402 |
+
elif addition_embed_type == "text_time":
|
| 403 |
+
self.add_time_proj = Timesteps(addition_time_embed_dim, flip_sin_to_cos, freq_shift)
|
| 404 |
+
self.add_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
|
| 405 |
+
elif addition_embed_type == "image":
|
| 406 |
+
# Kandinsky 2.2
|
| 407 |
+
self.add_embedding = ImageTimeEmbedding(image_embed_dim=encoder_hid_dim, time_embed_dim=time_embed_dim)
|
| 408 |
+
elif addition_embed_type == "image_hint":
|
| 409 |
+
# Kandinsky 2.2 ControlNet
|
| 410 |
+
self.add_embedding = ImageHintTimeEmbedding(image_embed_dim=encoder_hid_dim, time_embed_dim=time_embed_dim)
|
| 411 |
+
elif addition_embed_type is not None:
|
| 412 |
+
raise ValueError(f"addition_embed_type: {addition_embed_type} must be None, 'text' or 'text_image'.")
|
| 413 |
+
|
| 414 |
+
if time_embedding_act_fn is None:
|
| 415 |
+
self.time_embed_act = None
|
| 416 |
+
else:
|
| 417 |
+
self.time_embed_act = get_activation(time_embedding_act_fn)
|
| 418 |
+
|
| 419 |
+
self.down_blocks = nn.ModuleList([])
|
| 420 |
+
self.up_blocks = nn.ModuleList([])
|
| 421 |
+
|
| 422 |
+
if isinstance(only_cross_attention, bool):
|
| 423 |
+
if mid_block_only_cross_attention is None:
|
| 424 |
+
mid_block_only_cross_attention = only_cross_attention
|
| 425 |
+
|
| 426 |
+
only_cross_attention = [only_cross_attention] * len(down_block_types)
|
| 427 |
+
|
| 428 |
+
if mid_block_only_cross_attention is None:
|
| 429 |
+
mid_block_only_cross_attention = False
|
| 430 |
+
|
| 431 |
+
if isinstance(num_attention_heads, int):
|
| 432 |
+
num_attention_heads = (num_attention_heads,) * len(down_block_types)
|
| 433 |
+
|
| 434 |
+
if isinstance(attention_head_dim, int):
|
| 435 |
+
attention_head_dim = (attention_head_dim,) * len(down_block_types)
|
| 436 |
+
|
| 437 |
+
if isinstance(cross_attention_dim, int):
|
| 438 |
+
cross_attention_dim = (cross_attention_dim,) * len(down_block_types)
|
| 439 |
+
|
| 440 |
+
if isinstance(layers_per_block, int):
|
| 441 |
+
layers_per_block = [layers_per_block] * len(down_block_types)
|
| 442 |
+
|
| 443 |
+
if isinstance(transformer_layers_per_block, int):
|
| 444 |
+
transformer_layers_per_block = [transformer_layers_per_block] * len(down_block_types)
|
| 445 |
+
|
| 446 |
+
if class_embeddings_concat:
|
| 447 |
+
# The time embeddings are concatenated with the class embeddings. The dimension of the
|
| 448 |
+
# time embeddings passed to the down, middle, and up blocks is twice the dimension of the
|
| 449 |
+
# regular time embeddings
|
| 450 |
+
blocks_time_embed_dim = time_embed_dim * 2
|
| 451 |
+
else:
|
| 452 |
+
blocks_time_embed_dim = time_embed_dim
|
| 453 |
+
|
| 454 |
+
# down
|
| 455 |
+
output_channel = block_out_channels[0]
|
| 456 |
+
for i, down_block_type in enumerate(down_block_types):
|
| 457 |
+
input_channel = output_channel
|
| 458 |
+
output_channel = block_out_channels[i]
|
| 459 |
+
is_final_block = i == len(block_out_channels) - 1
|
| 460 |
+
|
| 461 |
+
down_block = get_down_block(
|
| 462 |
+
down_block_type,
|
| 463 |
+
num_layers=layers_per_block[i],
|
| 464 |
+
transformer_layers_per_block=transformer_layers_per_block[i],
|
| 465 |
+
in_channels=input_channel,
|
| 466 |
+
out_channels=output_channel,
|
| 467 |
+
temb_channels=blocks_time_embed_dim,
|
| 468 |
+
add_downsample=not is_final_block,
|
| 469 |
+
resnet_eps=norm_eps,
|
| 470 |
+
resnet_act_fn=act_fn,
|
| 471 |
+
resnet_groups=norm_num_groups,
|
| 472 |
+
cross_attention_dim=cross_attention_dim[i],
|
| 473 |
+
num_attention_heads=num_attention_heads[i],
|
| 474 |
+
downsample_padding=downsample_padding,
|
| 475 |
+
dual_cross_attention=dual_cross_attention,
|
| 476 |
+
use_linear_projection=use_linear_projection,
|
| 477 |
+
only_cross_attention=only_cross_attention[i],
|
| 478 |
+
upcast_attention=upcast_attention,
|
| 479 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 480 |
+
attention_type=attention_type,
|
| 481 |
+
resnet_skip_time_act=resnet_skip_time_act,
|
| 482 |
+
resnet_out_scale_factor=resnet_out_scale_factor,
|
| 483 |
+
cross_attention_norm=cross_attention_norm,
|
| 484 |
+
attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
|
| 485 |
+
dropout=dropout,
|
| 486 |
+
)
|
| 487 |
+
self.down_blocks.append(down_block)
|
| 488 |
+
|
| 489 |
+
# mid
|
| 490 |
+
if mid_block_type == "UNetMidBlock2DCrossAttn":
|
| 491 |
+
self.mid_block = UNetMidBlock2DCrossAttn(
|
| 492 |
+
transformer_layers_per_block=transformer_layers_per_block[-1],
|
| 493 |
+
in_channels=block_out_channels[-1],
|
| 494 |
+
temb_channels=blocks_time_embed_dim,
|
| 495 |
+
dropout=dropout,
|
| 496 |
+
resnet_eps=norm_eps,
|
| 497 |
+
resnet_act_fn=act_fn,
|
| 498 |
+
output_scale_factor=mid_block_scale_factor,
|
| 499 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 500 |
+
cross_attention_dim=cross_attention_dim[-1],
|
| 501 |
+
num_attention_heads=num_attention_heads[-1],
|
| 502 |
+
resnet_groups=norm_num_groups,
|
| 503 |
+
dual_cross_attention=dual_cross_attention,
|
| 504 |
+
use_linear_projection=use_linear_projection,
|
| 505 |
+
upcast_attention=upcast_attention,
|
| 506 |
+
attention_type=attention_type,
|
| 507 |
+
)
|
| 508 |
+
elif mid_block_type == "UNetMidBlock2DSimpleCrossAttn":
|
| 509 |
+
self.mid_block = UNetMidBlock2DSimpleCrossAttn(
|
| 510 |
+
in_channels=block_out_channels[-1],
|
| 511 |
+
temb_channels=blocks_time_embed_dim,
|
| 512 |
+
dropout=dropout,
|
| 513 |
+
resnet_eps=norm_eps,
|
| 514 |
+
resnet_act_fn=act_fn,
|
| 515 |
+
output_scale_factor=mid_block_scale_factor,
|
| 516 |
+
cross_attention_dim=cross_attention_dim[-1],
|
| 517 |
+
attention_head_dim=attention_head_dim[-1],
|
| 518 |
+
resnet_groups=norm_num_groups,
|
| 519 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 520 |
+
skip_time_act=resnet_skip_time_act,
|
| 521 |
+
only_cross_attention=mid_block_only_cross_attention,
|
| 522 |
+
cross_attention_norm=cross_attention_norm,
|
| 523 |
+
)
|
| 524 |
+
elif mid_block_type == "UNetMidBlock2D":
|
| 525 |
+
self.mid_block = UNetMidBlock2D(
|
| 526 |
+
in_channels=block_out_channels[-1],
|
| 527 |
+
temb_channels=blocks_time_embed_dim,
|
| 528 |
+
dropout=dropout,
|
| 529 |
+
num_layers=0,
|
| 530 |
+
resnet_eps=norm_eps,
|
| 531 |
+
resnet_act_fn=act_fn,
|
| 532 |
+
output_scale_factor=mid_block_scale_factor,
|
| 533 |
+
resnet_groups=norm_num_groups,
|
| 534 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 535 |
+
add_attention=False,
|
| 536 |
+
)
|
| 537 |
+
elif mid_block_type is None:
|
| 538 |
+
self.mid_block = None
|
| 539 |
+
else:
|
| 540 |
+
raise ValueError(f"unknown mid_block_type : {mid_block_type}")
|
| 541 |
+
|
| 542 |
+
# count how many layers upsample the images
|
| 543 |
+
self.num_upsamplers = 0
|
| 544 |
+
|
| 545 |
+
# up
|
| 546 |
+
reversed_block_out_channels = list(reversed(block_out_channels))
|
| 547 |
+
reversed_num_attention_heads = list(reversed(num_attention_heads))
|
| 548 |
+
reversed_layers_per_block = list(reversed(layers_per_block))
|
| 549 |
+
reversed_cross_attention_dim = list(reversed(cross_attention_dim))
|
| 550 |
+
reversed_transformer_layers_per_block = (
|
| 551 |
+
list(reversed(transformer_layers_per_block))
|
| 552 |
+
if reverse_transformer_layers_per_block is None
|
| 553 |
+
else reverse_transformer_layers_per_block
|
| 554 |
+
)
|
| 555 |
+
only_cross_attention = list(reversed(only_cross_attention))
|
| 556 |
+
|
| 557 |
+
output_channel = reversed_block_out_channels[0]
|
| 558 |
+
for i, up_block_type in enumerate(up_block_types):
|
| 559 |
+
is_final_block = i == len(block_out_channels) - 1
|
| 560 |
+
|
| 561 |
+
prev_output_channel = output_channel
|
| 562 |
+
output_channel = reversed_block_out_channels[i]
|
| 563 |
+
input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
|
| 564 |
+
|
| 565 |
+
# add upsample block for all BUT final layer
|
| 566 |
+
if not is_final_block:
|
| 567 |
+
add_upsample = True
|
| 568 |
+
self.num_upsamplers += 1
|
| 569 |
+
else:
|
| 570 |
+
add_upsample = False
|
| 571 |
+
|
| 572 |
+
up_block = get_up_block(
|
| 573 |
+
up_block_type,
|
| 574 |
+
num_layers=reversed_layers_per_block[i] + 1,
|
| 575 |
+
transformer_layers_per_block=reversed_transformer_layers_per_block[i],
|
| 576 |
+
in_channels=input_channel,
|
| 577 |
+
out_channels=output_channel,
|
| 578 |
+
prev_output_channel=prev_output_channel,
|
| 579 |
+
temb_channels=blocks_time_embed_dim,
|
| 580 |
+
add_upsample=add_upsample,
|
| 581 |
+
resnet_eps=norm_eps,
|
| 582 |
+
resnet_act_fn=act_fn,
|
| 583 |
+
resolution_idx=i,
|
| 584 |
+
resnet_groups=norm_num_groups,
|
| 585 |
+
cross_attention_dim=reversed_cross_attention_dim[i],
|
| 586 |
+
num_attention_heads=reversed_num_attention_heads[i],
|
| 587 |
+
dual_cross_attention=dual_cross_attention,
|
| 588 |
+
use_linear_projection=use_linear_projection,
|
| 589 |
+
only_cross_attention=only_cross_attention[i],
|
| 590 |
+
upcast_attention=upcast_attention,
|
| 591 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 592 |
+
attention_type=attention_type,
|
| 593 |
+
resnet_skip_time_act=resnet_skip_time_act,
|
| 594 |
+
resnet_out_scale_factor=resnet_out_scale_factor,
|
| 595 |
+
cross_attention_norm=cross_attention_norm,
|
| 596 |
+
attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
|
| 597 |
+
dropout=dropout,
|
| 598 |
+
)
|
| 599 |
+
self.up_blocks.append(up_block)
|
| 600 |
+
prev_output_channel = output_channel
|
| 601 |
+
|
| 602 |
+
# out
|
| 603 |
+
if norm_num_groups is not None:
|
| 604 |
+
self.conv_norm_out = nn.GroupNorm(
|
| 605 |
+
num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=norm_eps
|
| 606 |
+
)
|
| 607 |
+
|
| 608 |
+
self.conv_act = get_activation(act_fn)
|
| 609 |
+
|
| 610 |
+
else:
|
| 611 |
+
self.conv_norm_out = None
|
| 612 |
+
self.conv_act = None
|
| 613 |
+
|
| 614 |
+
conv_out_padding = (conv_out_kernel - 1) // 2
|
| 615 |
+
self.conv_out = nn.Conv2d(
|
| 616 |
+
block_out_channels[0], out_channels, kernel_size=conv_out_kernel, padding=conv_out_padding
|
| 617 |
+
)
|
| 618 |
+
|
| 619 |
+
if attention_type in ["gated", "gated-text-image"]:
|
| 620 |
+
positive_len = 768
|
| 621 |
+
if isinstance(cross_attention_dim, int):
|
| 622 |
+
positive_len = cross_attention_dim
|
| 623 |
+
elif isinstance(cross_attention_dim, tuple) or isinstance(cross_attention_dim, list):
|
| 624 |
+
positive_len = cross_attention_dim[0]
|
| 625 |
+
|
| 626 |
+
feature_type = "text-only" if attention_type == "gated" else "text-image"
|
| 627 |
+
self.position_net = PositionNet(
|
| 628 |
+
positive_len=positive_len, out_dim=cross_attention_dim, feature_type=feature_type
|
| 629 |
+
)
|
| 630 |
+
|
| 631 |
+
@property
|
| 632 |
+
def attn_processors(self) -> Dict[str, AttentionProcessor]:
|
| 633 |
+
r"""
|
| 634 |
+
Returns:
|
| 635 |
+
`dict` of attention processors: A dictionary containing all attention processors used in the model with
|
| 636 |
+
indexed by its weight name.
|
| 637 |
+
"""
|
| 638 |
+
# set recursively
|
| 639 |
+
processors = {}
|
| 640 |
+
|
| 641 |
+
def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
|
| 642 |
+
if hasattr(module, "get_processor"):
|
| 643 |
+
processors[f"{name}.processor"] = module.get_processor(return_deprecated_lora=True)
|
| 644 |
+
|
| 645 |
+
for sub_name, child in module.named_children():
|
| 646 |
+
fn_recursive_add_processors(f"{name}.{sub_name}", child, processors)
|
| 647 |
+
|
| 648 |
+
return processors
|
| 649 |
+
|
| 650 |
+
for name, module in self.named_children():
|
| 651 |
+
fn_recursive_add_processors(name, module, processors)
|
| 652 |
+
|
| 653 |
+
return processors
|
| 654 |
+
|
| 655 |
+
def set_attn_processor(
|
| 656 |
+
self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]], _remove_lora=False
|
| 657 |
+
):
|
| 658 |
+
r"""
|
| 659 |
+
Sets the attention processor to use to compute attention.
|
| 660 |
+
|
| 661 |
+
Parameters:
|
| 662 |
+
processor (`dict` of `AttentionProcessor` or only `AttentionProcessor`):
|
| 663 |
+
The instantiated processor class or a dictionary of processor classes that will be set as the processor
|
| 664 |
+
for **all** `Attention` layers.
|
| 665 |
+
|
| 666 |
+
If `processor` is a dict, the key needs to define the path to the corresponding cross attention
|
| 667 |
+
processor. This is strongly recommended when setting trainable attention processors.
|
| 668 |
+
|
| 669 |
+
"""
|
| 670 |
+
count = len(self.attn_processors.keys())
|
| 671 |
+
|
| 672 |
+
if isinstance(processor, dict) and len(processor) != count:
|
| 673 |
+
raise ValueError(
|
| 674 |
+
f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
|
| 675 |
+
f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
|
| 676 |
+
)
|
| 677 |
+
|
| 678 |
+
def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
|
| 679 |
+
if hasattr(module, "set_processor"):
|
| 680 |
+
if not isinstance(processor, dict):
|
| 681 |
+
module.set_processor(processor, _remove_lora=_remove_lora)
|
| 682 |
+
else:
|
| 683 |
+
module.set_processor(processor.pop(f"{name}.processor"), _remove_lora=_remove_lora)
|
| 684 |
+
|
| 685 |
+
for sub_name, child in module.named_children():
|
| 686 |
+
fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor)
|
| 687 |
+
|
| 688 |
+
for name, module in self.named_children():
|
| 689 |
+
fn_recursive_attn_processor(name, module, processor)
|
| 690 |
+
|
| 691 |
+
def set_default_attn_processor(self):
|
| 692 |
+
"""
|
| 693 |
+
Disables custom attention processors and sets the default attention implementation.
|
| 694 |
+
"""
|
| 695 |
+
if all(proc.__class__ in ADDED_KV_ATTENTION_PROCESSORS for proc in self.attn_processors.values()):
|
| 696 |
+
processor = AttnAddedKVProcessor()
|
| 697 |
+
elif all(proc.__class__ in CROSS_ATTENTION_PROCESSORS for proc in self.attn_processors.values()):
|
| 698 |
+
processor = AttnProcessor()
|
| 699 |
+
else:
|
| 700 |
+
raise ValueError(
|
| 701 |
+
f"Cannot call `set_default_attn_processor` when attention processors are of type {next(iter(self.attn_processors.values()))}"
|
| 702 |
+
)
|
| 703 |
+
|
| 704 |
+
self.set_attn_processor(processor, _remove_lora=True)
|
| 705 |
+
|
| 706 |
+
def set_attention_slice(self, slice_size):
|
| 707 |
+
r"""
|
| 708 |
+
Enable sliced attention computation.
|
| 709 |
+
|
| 710 |
+
When this option is enabled, the attention module splits the input tensor in slices to compute attention in
|
| 711 |
+
several steps. This is useful for saving some memory in exchange for a small decrease in speed.
|
| 712 |
+
|
| 713 |
+
Args:
|
| 714 |
+
slice_size (`str` or `int` or `list(int)`, *optional*, defaults to `"auto"`):
|
| 715 |
+
When `"auto"`, input to the attention heads is halved, so attention is computed in two steps. If
|
| 716 |
+
`"max"`, maximum amount of memory is saved by running only one slice at a time. If a number is
|
| 717 |
+
provided, uses as many slices as `attention_head_dim // slice_size`. In this case, `attention_head_dim`
|
| 718 |
+
must be a multiple of `slice_size`.
|
| 719 |
+
"""
|
| 720 |
+
sliceable_head_dims = []
|
| 721 |
+
|
| 722 |
+
def fn_recursive_retrieve_sliceable_dims(module: torch.nn.Module):
|
| 723 |
+
if hasattr(module, "set_attention_slice"):
|
| 724 |
+
sliceable_head_dims.append(module.sliceable_head_dim)
|
| 725 |
+
|
| 726 |
+
for child in module.children():
|
| 727 |
+
fn_recursive_retrieve_sliceable_dims(child)
|
| 728 |
+
|
| 729 |
+
# retrieve number of attention layers
|
| 730 |
+
for module in self.children():
|
| 731 |
+
fn_recursive_retrieve_sliceable_dims(module)
|
| 732 |
+
|
| 733 |
+
num_sliceable_layers = len(sliceable_head_dims)
|
| 734 |
+
|
| 735 |
+
if slice_size == "auto":
|
| 736 |
+
# half the attention head size is usually a good trade-off between
|
| 737 |
+
# speed and memory
|
| 738 |
+
slice_size = [dim // 2 for dim in sliceable_head_dims]
|
| 739 |
+
elif slice_size == "max":
|
| 740 |
+
# make smallest slice possible
|
| 741 |
+
slice_size = num_sliceable_layers * [1]
|
| 742 |
+
|
| 743 |
+
slice_size = num_sliceable_layers * [slice_size] if not isinstance(slice_size, list) else slice_size
|
| 744 |
+
|
| 745 |
+
if len(slice_size) != len(sliceable_head_dims):
|
| 746 |
+
raise ValueError(
|
| 747 |
+
f"You have provided {len(slice_size)}, but {self.config} has {len(sliceable_head_dims)} different"
|
| 748 |
+
f" attention layers. Make sure to match `len(slice_size)` to be {len(sliceable_head_dims)}."
|
| 749 |
+
)
|
| 750 |
+
|
| 751 |
+
for i in range(len(slice_size)):
|
| 752 |
+
size = slice_size[i]
|
| 753 |
+
dim = sliceable_head_dims[i]
|
| 754 |
+
if size is not None and size > dim:
|
| 755 |
+
raise ValueError(f"size {size} has to be smaller or equal to {dim}.")
|
| 756 |
+
|
| 757 |
+
# Recursively walk through all the children.
|
| 758 |
+
# Any children which exposes the set_attention_slice method
|
| 759 |
+
# gets the message
|
| 760 |
+
def fn_recursive_set_attention_slice(module: torch.nn.Module, slice_size: List[int]):
|
| 761 |
+
if hasattr(module, "set_attention_slice"):
|
| 762 |
+
module.set_attention_slice(slice_size.pop())
|
| 763 |
+
|
| 764 |
+
for child in module.children():
|
| 765 |
+
fn_recursive_set_attention_slice(child, slice_size)
|
| 766 |
+
|
| 767 |
+
reversed_slice_size = list(reversed(slice_size))
|
| 768 |
+
for module in self.children():
|
| 769 |
+
fn_recursive_set_attention_slice(module, reversed_slice_size)
|
| 770 |
+
|
| 771 |
+
def _set_gradient_checkpointing(self, module, value=False):
|
| 772 |
+
if hasattr(module, "gradient_checkpointing"):
|
| 773 |
+
module.gradient_checkpointing = value
|
| 774 |
+
|
| 775 |
+
def enable_freeu(self, s1, s2, b1, b2):
|
| 776 |
+
r"""Enables the FreeU mechanism from https://arxiv.org/abs/2309.11497.
|
| 777 |
+
|
| 778 |
+
The suffixes after the scaling factors represent the stage blocks where they are being applied.
|
| 779 |
+
|
| 780 |
+
Please refer to the [official repository](https://github.com/ChenyangSi/FreeU) for combinations of values that
|
| 781 |
+
are known to work well for different pipelines such as Stable Diffusion v1, v2, and Stable Diffusion XL.
|
| 782 |
+
|
| 783 |
+
Args:
|
| 784 |
+
s1 (`float`):
|
| 785 |
+
Scaling factor for stage 1 to attenuate the contributions of the skip features. This is done to
|
| 786 |
+
mitigate the "oversmoothing effect" in the enhanced denoising process.
|
| 787 |
+
s2 (`float`):
|
| 788 |
+
Scaling factor for stage 2 to attenuate the contributions of the skip features. This is done to
|
| 789 |
+
mitigate the "oversmoothing effect" in the enhanced denoising process.
|
| 790 |
+
b1 (`float`): Scaling factor for stage 1 to amplify the contributions of backbone features.
|
| 791 |
+
b2 (`float`): Scaling factor for stage 2 to amplify the contributions of backbone features.
|
| 792 |
+
"""
|
| 793 |
+
for i, upsample_block in enumerate(self.up_blocks):
|
| 794 |
+
setattr(upsample_block, "s1", s1)
|
| 795 |
+
setattr(upsample_block, "s2", s2)
|
| 796 |
+
setattr(upsample_block, "b1", b1)
|
| 797 |
+
setattr(upsample_block, "b2", b2)
|
| 798 |
+
|
| 799 |
+
def disable_freeu(self):
|
| 800 |
+
"""Disables the FreeU mechanism."""
|
| 801 |
+
freeu_keys = {"s1", "s2", "b1", "b2"}
|
| 802 |
+
for i, upsample_block in enumerate(self.up_blocks):
|
| 803 |
+
for k in freeu_keys:
|
| 804 |
+
if hasattr(upsample_block, k) or getattr(upsample_block, k, None) is not None:
|
| 805 |
+
setattr(upsample_block, k, None)
|
| 806 |
+
|
| 807 |
+
def forward(
|
| 808 |
+
self,
|
| 809 |
+
sample: torch.FloatTensor,
|
| 810 |
+
timestep: Union[torch.Tensor, float, int],
|
| 811 |
+
encoder_hidden_states: torch.Tensor,
|
| 812 |
+
class_labels: Optional[torch.Tensor] = None,
|
| 813 |
+
timestep_cond: Optional[torch.Tensor] = None,
|
| 814 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 815 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 816 |
+
added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
|
| 817 |
+
down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
|
| 818 |
+
mid_block_additional_residual: Optional[torch.Tensor] = None,
|
| 819 |
+
down_intrablock_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
|
| 820 |
+
encoder_attention_mask: Optional[torch.Tensor] = None,
|
| 821 |
+
return_dict: bool = True,
|
| 822 |
+
) -> Union[UNet2DConditionOutput, Tuple]:
|
| 823 |
+
r"""
|
| 824 |
+
The [`UNet2DConditionModel`] forward method.
|
| 825 |
+
|
| 826 |
+
Args:
|
| 827 |
+
sample (`torch.FloatTensor`):
|
| 828 |
+
The noisy input tensor with the following shape `(batch, channel, height, width)`.
|
| 829 |
+
timestep (`torch.FloatTensor` or `float` or `int`): The number of timesteps to denoise an input.
|
| 830 |
+
encoder_hidden_states (`torch.FloatTensor`):
|
| 831 |
+
The encoder hidden states with shape `(batch, sequence_length, feature_dim)`.
|
| 832 |
+
class_labels (`torch.Tensor`, *optional*, defaults to `None`):
|
| 833 |
+
Optional class labels for conditioning. Their embeddings will be summed with the timestep embeddings.
|
| 834 |
+
timestep_cond: (`torch.Tensor`, *optional*, defaults to `None`):
|
| 835 |
+
Conditional embeddings for timestep. If provided, the embeddings will be summed with the samples passed
|
| 836 |
+
through the `self.time_embedding` layer to obtain the timestep embeddings.
|
| 837 |
+
attention_mask (`torch.Tensor`, *optional*, defaults to `None`):
|
| 838 |
+
An attention mask of shape `(batch, key_tokens)` is applied to `encoder_hidden_states`. If `1` the mask
|
| 839 |
+
is kept, otherwise if `0` it is discarded. Mask will be converted into a bias, which adds large
|
| 840 |
+
negative values to the attention scores corresponding to "discard" tokens.
|
| 841 |
+
cross_attention_kwargs (`dict`, *optional*):
|
| 842 |
+
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
| 843 |
+
`self.processor` in
|
| 844 |
+
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
|
| 845 |
+
added_cond_kwargs: (`dict`, *optional*):
|
| 846 |
+
A kwargs dictionary containing additional embeddings that if specified are added to the embeddings that
|
| 847 |
+
are passed along to the UNet blocks.
|
| 848 |
+
down_block_additional_residuals: (`tuple` of `torch.Tensor`, *optional*):
|
| 849 |
+
A tuple of tensors that if specified are added to the residuals of down unet blocks.
|
| 850 |
+
mid_block_additional_residual: (`torch.Tensor`, *optional*):
|
| 851 |
+
A tensor that if specified is added to the residual of the middle unet block.
|
| 852 |
+
encoder_attention_mask (`torch.Tensor`):
|
| 853 |
+
A cross-attention mask of shape `(batch, sequence_length)` is applied to `encoder_hidden_states`. If
|
| 854 |
+
`True` the mask is kept, otherwise if `False` it is discarded. Mask will be converted into a bias,
|
| 855 |
+
which adds large negative values to the attention scores corresponding to "discard" tokens.
|
| 856 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 857 |
+
Whether or not to return a [`~models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain
|
| 858 |
+
tuple.
|
| 859 |
+
cross_attention_kwargs (`dict`, *optional*):
|
| 860 |
+
A kwargs dictionary that if specified is passed along to the [`AttnProcessor`].
|
| 861 |
+
added_cond_kwargs: (`dict`, *optional*):
|
| 862 |
+
A kwargs dictionary containin additional embeddings that if specified are added to the embeddings that
|
| 863 |
+
are passed along to the UNet blocks.
|
| 864 |
+
down_block_additional_residuals (`tuple` of `torch.Tensor`, *optional*):
|
| 865 |
+
additional residuals to be added to UNet long skip connections from down blocks to up blocks for
|
| 866 |
+
example from ControlNet side model(s)
|
| 867 |
+
mid_block_additional_residual (`torch.Tensor`, *optional*):
|
| 868 |
+
additional residual to be added to UNet mid block output, for example from ControlNet side model
|
| 869 |
+
down_intrablock_additional_residuals (`tuple` of `torch.Tensor`, *optional*):
|
| 870 |
+
additional residuals to be added within UNet down blocks, for example from T2I-Adapter side model(s)
|
| 871 |
+
|
| 872 |
+
Returns:
|
| 873 |
+
[`~models.unet_2d_condition.UNet2DConditionOutput`] or `tuple`:
|
| 874 |
+
If `return_dict` is True, an [`~models.unet_2d_condition.UNet2DConditionOutput`] is returned, otherwise
|
| 875 |
+
a `tuple` is returned where the first element is the sample tensor.
|
| 876 |
+
"""
|
| 877 |
+
# By default samples have to be AT least a multiple of the overall upsampling factor.
|
| 878 |
+
# The overall upsampling factor is equal to 2 ** (# num of upsampling layers).
|
| 879 |
+
# However, the upsampling interpolation output size can be forced to fit any upsampling size
|
| 880 |
+
# on the fly if necessary.
|
| 881 |
+
default_overall_up_factor = 2**self.num_upsamplers
|
| 882 |
+
|
| 883 |
+
# upsample size should be forwarded when sample is not a multiple of `default_overall_up_factor`
|
| 884 |
+
forward_upsample_size = False
|
| 885 |
+
upsample_size = None
|
| 886 |
+
|
| 887 |
+
for dim in sample.shape[-2:]:
|
| 888 |
+
if dim % default_overall_up_factor != 0:
|
| 889 |
+
# Forward upsample size to force interpolation output size.
|
| 890 |
+
forward_upsample_size = True
|
| 891 |
+
break
|
| 892 |
+
|
| 893 |
+
# ensure attention_mask is a bias, and give it a singleton query_tokens dimension
|
| 894 |
+
# expects mask of shape:
|
| 895 |
+
# [batch, key_tokens]
|
| 896 |
+
# adds singleton query_tokens dimension:
|
| 897 |
+
# [batch, 1, key_tokens]
|
| 898 |
+
# this helps to broadcast it as a bias over attention scores, which will be in one of the following shapes:
|
| 899 |
+
# [batch, heads, query_tokens, key_tokens] (e.g. torch sdp attn)
|
| 900 |
+
# [batch * heads, query_tokens, key_tokens] (e.g. xformers or classic attn)
|
| 901 |
+
if attention_mask is not None:
|
| 902 |
+
# assume that mask is expressed as:
|
| 903 |
+
# (1 = keep, 0 = discard)
|
| 904 |
+
# convert mask into a bias that can be added to attention scores:
|
| 905 |
+
# (keep = +0, discard = -10000.0)
|
| 906 |
+
attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0
|
| 907 |
+
attention_mask = attention_mask.unsqueeze(1)
|
| 908 |
+
|
| 909 |
+
# convert encoder_attention_mask to a bias the same way we do for attention_mask
|
| 910 |
+
if encoder_attention_mask is not None:
|
| 911 |
+
encoder_attention_mask = (1 - encoder_attention_mask.to(sample.dtype)) * -10000.0
|
| 912 |
+
encoder_attention_mask = encoder_attention_mask.unsqueeze(1)
|
| 913 |
+
|
| 914 |
+
# 0. center input if necessary
|
| 915 |
+
if self.config.center_input_sample:
|
| 916 |
+
sample = 2 * sample - 1.0
|
| 917 |
+
|
| 918 |
+
# 1. time
|
| 919 |
+
timesteps = timestep
|
| 920 |
+
if not torch.is_tensor(timesteps):
|
| 921 |
+
# TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
|
| 922 |
+
# This would be a good case for the `match` statement (Python 3.10+)
|
| 923 |
+
is_mps = sample.device.type == "mps"
|
| 924 |
+
if isinstance(timestep, float):
|
| 925 |
+
dtype = torch.float32 if is_mps else torch.float64
|
| 926 |
+
else:
|
| 927 |
+
dtype = torch.int32 if is_mps else torch.int64
|
| 928 |
+
timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
|
| 929 |
+
elif len(timesteps.shape) == 0:
|
| 930 |
+
timesteps = timesteps[None].to(sample.device)
|
| 931 |
+
|
| 932 |
+
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
| 933 |
+
timesteps = timesteps.expand(sample.shape[0])
|
| 934 |
+
|
| 935 |
+
t_emb = self.time_proj(timesteps)
|
| 936 |
+
|
| 937 |
+
# `Timesteps` does not contain any weights and will always return f32 tensors
|
| 938 |
+
# but time_embedding might actually be running in fp16. so we need to cast here.
|
| 939 |
+
# there might be better ways to encapsulate this.
|
| 940 |
+
t_emb = t_emb.to(dtype=sample.dtype)
|
| 941 |
+
|
| 942 |
+
emb = self.time_embedding(t_emb, timestep_cond)
|
| 943 |
+
aug_emb = None
|
| 944 |
+
|
| 945 |
+
if self.class_embedding is not None:
|
| 946 |
+
if class_labels is None:
|
| 947 |
+
raise ValueError("class_labels should be provided when num_class_embeds > 0")
|
| 948 |
+
|
| 949 |
+
if self.config.class_embed_type == "timestep":
|
| 950 |
+
class_labels = self.time_proj(class_labels)
|
| 951 |
+
|
| 952 |
+
# `Timesteps` does not contain any weights and will always return f32 tensors
|
| 953 |
+
# there might be better ways to encapsulate this.
|
| 954 |
+
class_labels = class_labels.to(dtype=sample.dtype)
|
| 955 |
+
|
| 956 |
+
class_emb = self.class_embedding(class_labels).to(dtype=sample.dtype)
|
| 957 |
+
|
| 958 |
+
if self.config.class_embeddings_concat:
|
| 959 |
+
emb = torch.cat([emb, class_emb], dim=-1)
|
| 960 |
+
else:
|
| 961 |
+
emb = emb + class_emb
|
| 962 |
+
|
| 963 |
+
if self.config.addition_embed_type == "text":
|
| 964 |
+
aug_emb = self.add_embedding(encoder_hidden_states)
|
| 965 |
+
elif self.config.addition_embed_type == "text_image":
|
| 966 |
+
# Kandinsky 2.1 - style
|
| 967 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 968 |
+
raise ValueError(
|
| 969 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'text_image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
|
| 970 |
+
)
|
| 971 |
+
|
| 972 |
+
image_embs = added_cond_kwargs.get("image_embeds")
|
| 973 |
+
text_embs = added_cond_kwargs.get("text_embeds", encoder_hidden_states)
|
| 974 |
+
aug_emb = self.add_embedding(text_embs, image_embs)
|
| 975 |
+
elif self.config.addition_embed_type == "text_time":
|
| 976 |
+
# SDXL - style
|
| 977 |
+
if "text_embeds" not in added_cond_kwargs:
|
| 978 |
+
raise ValueError(
|
| 979 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `text_embeds` to be passed in `added_cond_kwargs`"
|
| 980 |
+
)
|
| 981 |
+
text_embeds = added_cond_kwargs.get("text_embeds")
|
| 982 |
+
if "time_ids" not in added_cond_kwargs:
|
| 983 |
+
raise ValueError(
|
| 984 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `time_ids` to be passed in `added_cond_kwargs`"
|
| 985 |
+
)
|
| 986 |
+
time_ids = added_cond_kwargs.get("time_ids")
|
| 987 |
+
time_embeds = self.add_time_proj(time_ids.flatten())
|
| 988 |
+
time_embeds = time_embeds.reshape((text_embeds.shape[0], -1))
|
| 989 |
+
add_embeds = torch.concat([text_embeds, time_embeds], dim=-1)
|
| 990 |
+
add_embeds = add_embeds.to(emb.dtype)
|
| 991 |
+
aug_emb = self.add_embedding(add_embeds)
|
| 992 |
+
elif self.config.addition_embed_type == "image":
|
| 993 |
+
# Kandinsky 2.2 - style
|
| 994 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 995 |
+
raise ValueError(
|
| 996 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
|
| 997 |
+
)
|
| 998 |
+
image_embs = added_cond_kwargs.get("image_embeds")
|
| 999 |
+
aug_emb = self.add_embedding(image_embs)
|
| 1000 |
+
elif self.config.addition_embed_type == "image_hint":
|
| 1001 |
+
# Kandinsky 2.2 - style
|
| 1002 |
+
if "image_embeds" not in added_cond_kwargs or "hint" not in added_cond_kwargs:
|
| 1003 |
+
raise ValueError(
|
| 1004 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'image_hint' which requires the keyword arguments `image_embeds` and `hint` to be passed in `added_cond_kwargs`"
|
| 1005 |
+
)
|
| 1006 |
+
image_embs = added_cond_kwargs.get("image_embeds")
|
| 1007 |
+
hint = added_cond_kwargs.get("hint")
|
| 1008 |
+
aug_emb, hint = self.add_embedding(image_embs, hint)
|
| 1009 |
+
sample = torch.cat([sample, hint], dim=1)
|
| 1010 |
+
|
| 1011 |
+
emb = emb + aug_emb if aug_emb is not None else emb
|
| 1012 |
+
|
| 1013 |
+
if self.time_embed_act is not None:
|
| 1014 |
+
emb = self.time_embed_act(emb)
|
| 1015 |
+
|
| 1016 |
+
if self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_proj":
|
| 1017 |
+
encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states)
|
| 1018 |
+
elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_image_proj":
|
| 1019 |
+
# Kadinsky 2.1 - style
|
| 1020 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 1021 |
+
raise ValueError(
|
| 1022 |
+
f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'text_image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
|
| 1023 |
+
)
|
| 1024 |
+
|
| 1025 |
+
image_embeds = added_cond_kwargs.get("image_embeds")
|
| 1026 |
+
encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states, image_embeds)
|
| 1027 |
+
elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "image_proj":
|
| 1028 |
+
# Kandinsky 2.2 - style
|
| 1029 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 1030 |
+
raise ValueError(
|
| 1031 |
+
f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
|
| 1032 |
+
)
|
| 1033 |
+
image_embeds = added_cond_kwargs.get("image_embeds")
|
| 1034 |
+
encoder_hidden_states = self.encoder_hid_proj(image_embeds)
|
| 1035 |
+
# 2. pre-process
|
| 1036 |
+
sample = self.conv_in(sample)
|
| 1037 |
+
|
| 1038 |
+
# 2.5 GLIGEN position net
|
| 1039 |
+
if cross_attention_kwargs is not None and cross_attention_kwargs.get("gligen", None) is not None:
|
| 1040 |
+
cross_attention_kwargs = cross_attention_kwargs.copy()
|
| 1041 |
+
gligen_args = cross_attention_kwargs.pop("gligen")
|
| 1042 |
+
cross_attention_kwargs["gligen"] = {"objs": self.position_net(**gligen_args)}
|
| 1043 |
+
|
| 1044 |
+
# For Vton
|
| 1045 |
+
spatial_attn_inputs = []
|
| 1046 |
+
|
| 1047 |
+
# 3. down
|
| 1048 |
+
lora_scale = cross_attention_kwargs.get("scale", 1.0) if cross_attention_kwargs is not None else 1.0
|
| 1049 |
+
if USE_PEFT_BACKEND:
|
| 1050 |
+
# weight the lora layers by setting `lora_scale` for each PEFT layer
|
| 1051 |
+
scale_lora_layers(self, lora_scale)
|
| 1052 |
+
|
| 1053 |
+
is_controlnet = mid_block_additional_residual is not None and down_block_additional_residuals is not None
|
| 1054 |
+
# using new arg down_intrablock_additional_residuals for T2I-Adapters, to distinguish from controlnets
|
| 1055 |
+
is_adapter = down_intrablock_additional_residuals is not None
|
| 1056 |
+
# maintain backward compatibility for legacy usage, where
|
| 1057 |
+
# T2I-Adapter and ControlNet both use down_block_additional_residuals arg
|
| 1058 |
+
# but can only use one or the other
|
| 1059 |
+
if not is_adapter and mid_block_additional_residual is None and down_block_additional_residuals is not None:
|
| 1060 |
+
deprecate(
|
| 1061 |
+
"T2I should not use down_block_additional_residuals",
|
| 1062 |
+
"1.3.0",
|
| 1063 |
+
"Passing intrablock residual connections with `down_block_additional_residuals` is deprecated \
|
| 1064 |
+
and will be removed in diffusers 1.3.0. `down_block_additional_residuals` should only be used \
|
| 1065 |
+
for ControlNet. Please make sure use `down_intrablock_additional_residuals` instead. ",
|
| 1066 |
+
standard_warn=False,
|
| 1067 |
+
)
|
| 1068 |
+
down_intrablock_additional_residuals = down_block_additional_residuals
|
| 1069 |
+
is_adapter = True
|
| 1070 |
+
|
| 1071 |
+
down_block_res_samples = (sample,)
|
| 1072 |
+
for downsample_block in self.down_blocks:
|
| 1073 |
+
if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
|
| 1074 |
+
# For t2i-adapter CrossAttnDownBlock2D
|
| 1075 |
+
additional_residuals = {}
|
| 1076 |
+
if is_adapter and len(down_intrablock_additional_residuals) > 0:
|
| 1077 |
+
additional_residuals["additional_residuals"] = down_intrablock_additional_residuals.pop(0)
|
| 1078 |
+
|
| 1079 |
+
sample, res_samples, spatial_attn_inputs = downsample_block(
|
| 1080 |
+
hidden_states=sample,
|
| 1081 |
+
spatial_attn_inputs=spatial_attn_inputs,
|
| 1082 |
+
temb=emb,
|
| 1083 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1084 |
+
attention_mask=attention_mask,
|
| 1085 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 1086 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1087 |
+
**additional_residuals,
|
| 1088 |
+
)
|
| 1089 |
+
else:
|
| 1090 |
+
sample, res_samples = downsample_block(
|
| 1091 |
+
hidden_states=sample,
|
| 1092 |
+
temb=emb,
|
| 1093 |
+
scale=lora_scale,
|
| 1094 |
+
)
|
| 1095 |
+
if is_adapter and len(down_intrablock_additional_residuals) > 0:
|
| 1096 |
+
sample += down_intrablock_additional_residuals.pop(0)
|
| 1097 |
+
|
| 1098 |
+
down_block_res_samples += res_samples
|
| 1099 |
+
|
| 1100 |
+
# if is_controlnet:
|
| 1101 |
+
# new_down_block_res_samples = ()
|
| 1102 |
+
|
| 1103 |
+
# for down_block_res_sample, down_block_additional_residual in zip(
|
| 1104 |
+
# down_block_res_samples, down_block_additional_residuals
|
| 1105 |
+
# ):
|
| 1106 |
+
# down_block_res_sample = down_block_res_sample + down_block_additional_residual
|
| 1107 |
+
# new_down_block_res_samples = new_down_block_res_samples + (down_block_res_sample,)
|
| 1108 |
+
|
| 1109 |
+
# down_block_res_samples = new_down_block_res_samples
|
| 1110 |
+
|
| 1111 |
+
# 4. mid
|
| 1112 |
+
if self.mid_block is not None:
|
| 1113 |
+
if hasattr(self.mid_block, "has_cross_attention") and self.mid_block.has_cross_attention:
|
| 1114 |
+
sample, spatial_attn_inputs = self.mid_block(
|
| 1115 |
+
sample,
|
| 1116 |
+
spatial_attn_inputs=spatial_attn_inputs,
|
| 1117 |
+
temb=emb,
|
| 1118 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1119 |
+
attention_mask=attention_mask,
|
| 1120 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 1121 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1122 |
+
)
|
| 1123 |
+
else:
|
| 1124 |
+
sample = self.mid_block(sample, emb)
|
| 1125 |
+
|
| 1126 |
+
# To support T2I-Adapter-XL
|
| 1127 |
+
if (
|
| 1128 |
+
is_adapter
|
| 1129 |
+
and len(down_intrablock_additional_residuals) > 0
|
| 1130 |
+
and sample.shape == down_intrablock_additional_residuals[0].shape
|
| 1131 |
+
):
|
| 1132 |
+
sample += down_intrablock_additional_residuals.pop(0)
|
| 1133 |
+
|
| 1134 |
+
if is_controlnet:
|
| 1135 |
+
sample = sample + mid_block_additional_residual
|
| 1136 |
+
|
| 1137 |
+
# 5. up
|
| 1138 |
+
for i, upsample_block in enumerate(self.up_blocks):
|
| 1139 |
+
is_final_block = i == len(self.up_blocks) - 1
|
| 1140 |
+
|
| 1141 |
+
res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
|
| 1142 |
+
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
|
| 1143 |
+
|
| 1144 |
+
# if we have not reached the final block and need to forward the
|
| 1145 |
+
# upsample size, we do it here
|
| 1146 |
+
if not is_final_block and forward_upsample_size:
|
| 1147 |
+
upsample_size = down_block_res_samples[-1].shape[2:]
|
| 1148 |
+
|
| 1149 |
+
if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
|
| 1150 |
+
sample, spatial_attn_inputs = upsample_block(
|
| 1151 |
+
hidden_states=sample,
|
| 1152 |
+
spatial_attn_inputs=spatial_attn_inputs,
|
| 1153 |
+
temb=emb,
|
| 1154 |
+
res_hidden_states_tuple=res_samples,
|
| 1155 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1156 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 1157 |
+
upsample_size=upsample_size,
|
| 1158 |
+
attention_mask=attention_mask,
|
| 1159 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1160 |
+
)
|
| 1161 |
+
else:
|
| 1162 |
+
sample = upsample_block(
|
| 1163 |
+
hidden_states=sample,
|
| 1164 |
+
temb=emb,
|
| 1165 |
+
res_hidden_states_tuple=res_samples,
|
| 1166 |
+
upsample_size=upsample_size,
|
| 1167 |
+
scale=lora_scale,
|
| 1168 |
+
)
|
| 1169 |
+
|
| 1170 |
+
# 6. post-process
|
| 1171 |
+
if self.conv_norm_out:
|
| 1172 |
+
sample = self.conv_norm_out(sample)
|
| 1173 |
+
sample = self.conv_act(sample)
|
| 1174 |
+
sample = self.conv_out(sample)
|
| 1175 |
+
|
| 1176 |
+
if USE_PEFT_BACKEND:
|
| 1177 |
+
# remove `lora_scale` from each PEFT layer
|
| 1178 |
+
unscale_lora_layers(self, lora_scale)
|
| 1179 |
+
|
| 1180 |
+
if not return_dict:
|
| 1181 |
+
return (sample,), spatial_attn_inputs
|
| 1182 |
+
|
| 1183 |
+
return UNet2DConditionOutput(sample=sample), spatial_attn_inputs
|
ootd/pipelines_ootd/unet_vton_2d_blocks.py
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
ootd/pipelines_ootd/unet_vton_2d_condition.py
ADDED
|
@@ -0,0 +1,1183 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# Modified by Yuhao Xu for OOTDiffusion (https://github.com/levihsu/OOTDiffusion)
|
| 16 |
+
from dataclasses import dataclass
|
| 17 |
+
from typing import Any, Dict, List, Optional, Tuple, Union
|
| 18 |
+
|
| 19 |
+
import torch
|
| 20 |
+
import torch.nn as nn
|
| 21 |
+
import torch.utils.checkpoint
|
| 22 |
+
|
| 23 |
+
from .unet_vton_2d_blocks import (
|
| 24 |
+
UNetMidBlock2D,
|
| 25 |
+
UNetMidBlock2DCrossAttn,
|
| 26 |
+
UNetMidBlock2DSimpleCrossAttn,
|
| 27 |
+
get_down_block,
|
| 28 |
+
get_up_block,
|
| 29 |
+
)
|
| 30 |
+
|
| 31 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 32 |
+
from diffusers.loaders import UNet2DConditionLoadersMixin
|
| 33 |
+
from diffusers.utils import USE_PEFT_BACKEND, BaseOutput, deprecate, logging, scale_lora_layers, unscale_lora_layers
|
| 34 |
+
from diffusers.models.activations import get_activation
|
| 35 |
+
from diffusers.models.attention_processor import (
|
| 36 |
+
ADDED_KV_ATTENTION_PROCESSORS,
|
| 37 |
+
CROSS_ATTENTION_PROCESSORS,
|
| 38 |
+
AttentionProcessor,
|
| 39 |
+
AttnAddedKVProcessor,
|
| 40 |
+
AttnProcessor,
|
| 41 |
+
)
|
| 42 |
+
from diffusers.models.embeddings import (
|
| 43 |
+
GaussianFourierProjection,
|
| 44 |
+
ImageHintTimeEmbedding,
|
| 45 |
+
ImageProjection,
|
| 46 |
+
ImageTimeEmbedding,
|
| 47 |
+
PositionNet,
|
| 48 |
+
TextImageProjection,
|
| 49 |
+
TextImageTimeEmbedding,
|
| 50 |
+
TextTimeEmbedding,
|
| 51 |
+
TimestepEmbedding,
|
| 52 |
+
Timesteps,
|
| 53 |
+
)
|
| 54 |
+
from diffusers.models.modeling_utils import ModelMixin
|
| 55 |
+
# from ..diffusers.src.diffusers.models.unet_2d_blocks import (
|
| 56 |
+
# UNetMidBlock2D,
|
| 57 |
+
# UNetMidBlock2DCrossAttn,
|
| 58 |
+
# UNetMidBlock2DSimpleCrossAttn,
|
| 59 |
+
# get_down_block,
|
| 60 |
+
# get_up_block,
|
| 61 |
+
# )
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
@dataclass
|
| 68 |
+
class UNet2DConditionOutput(BaseOutput):
|
| 69 |
+
"""
|
| 70 |
+
The output of [`UNet2DConditionModel`].
|
| 71 |
+
|
| 72 |
+
Args:
|
| 73 |
+
sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
|
| 74 |
+
The hidden states output conditioned on `encoder_hidden_states` input. Output of last layer of model.
|
| 75 |
+
"""
|
| 76 |
+
|
| 77 |
+
sample: torch.FloatTensor = None
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
class UNetVton2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin):
|
| 81 |
+
r"""
|
| 82 |
+
A conditional 2D UNet model that takes a noisy sample, conditional state, and a timestep and returns a sample
|
| 83 |
+
shaped output.
|
| 84 |
+
|
| 85 |
+
This model inherits from [`ModelMixin`]. Check the superclass documentation for it's generic methods implemented
|
| 86 |
+
for all models (such as downloading or saving).
|
| 87 |
+
|
| 88 |
+
Parameters:
|
| 89 |
+
sample_size (`int` or `Tuple[int, int]`, *optional*, defaults to `None`):
|
| 90 |
+
Height and width of input/output sample.
|
| 91 |
+
in_channels (`int`, *optional*, defaults to 4): Number of channels in the input sample.
|
| 92 |
+
out_channels (`int`, *optional*, defaults to 4): Number of channels in the output.
|
| 93 |
+
center_input_sample (`bool`, *optional*, defaults to `False`): Whether to center the input sample.
|
| 94 |
+
flip_sin_to_cos (`bool`, *optional*, defaults to `False`):
|
| 95 |
+
Whether to flip the sin to cos in the time embedding.
|
| 96 |
+
freq_shift (`int`, *optional*, defaults to 0): The frequency shift to apply to the time embedding.
|
| 97 |
+
down_block_types (`Tuple[str]`, *optional*, defaults to `("CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D")`):
|
| 98 |
+
The tuple of downsample blocks to use.
|
| 99 |
+
mid_block_type (`str`, *optional*, defaults to `"UNetMidBlock2DCrossAttn"`):
|
| 100 |
+
Block type for middle of UNet, it can be one of `UNetMidBlock2DCrossAttn`, `UNetMidBlock2D`, or
|
| 101 |
+
`UNetMidBlock2DSimpleCrossAttn`. If `None`, the mid block layer is skipped.
|
| 102 |
+
up_block_types (`Tuple[str]`, *optional*, defaults to `("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D")`):
|
| 103 |
+
The tuple of upsample blocks to use.
|
| 104 |
+
only_cross_attention(`bool` or `Tuple[bool]`, *optional*, default to `False`):
|
| 105 |
+
Whether to include self-attention in the basic transformer blocks, see
|
| 106 |
+
[`~models.attention.BasicTransformerBlock`].
|
| 107 |
+
block_out_channels (`Tuple[int]`, *optional*, defaults to `(320, 640, 1280, 1280)`):
|
| 108 |
+
The tuple of output channels for each block.
|
| 109 |
+
layers_per_block (`int`, *optional*, defaults to 2): The number of layers per block.
|
| 110 |
+
downsample_padding (`int`, *optional*, defaults to 1): The padding to use for the downsampling convolution.
|
| 111 |
+
mid_block_scale_factor (`float`, *optional*, defaults to 1.0): The scale factor to use for the mid block.
|
| 112 |
+
dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
|
| 113 |
+
act_fn (`str`, *optional*, defaults to `"silu"`): The activation function to use.
|
| 114 |
+
norm_num_groups (`int`, *optional*, defaults to 32): The number of groups to use for the normalization.
|
| 115 |
+
If `None`, normalization and activation layers is skipped in post-processing.
|
| 116 |
+
norm_eps (`float`, *optional*, defaults to 1e-5): The epsilon to use for the normalization.
|
| 117 |
+
cross_attention_dim (`int` or `Tuple[int]`, *optional*, defaults to 1280):
|
| 118 |
+
The dimension of the cross attention features.
|
| 119 |
+
transformer_layers_per_block (`int`, `Tuple[int]`, or `Tuple[Tuple]` , *optional*, defaults to 1):
|
| 120 |
+
The number of transformer blocks of type [`~models.attention.BasicTransformerBlock`]. Only relevant for
|
| 121 |
+
[`~models.unet_2d_blocks.CrossAttnDownBlock2D`], [`~models.unet_2d_blocks.CrossAttnUpBlock2D`],
|
| 122 |
+
[`~models.unet_2d_blocks.UNetMidBlock2DCrossAttn`].
|
| 123 |
+
reverse_transformer_layers_per_block : (`Tuple[Tuple]`, *optional*, defaults to None):
|
| 124 |
+
The number of transformer blocks of type [`~models.attention.BasicTransformerBlock`], in the upsampling
|
| 125 |
+
blocks of the U-Net. Only relevant if `transformer_layers_per_block` is of type `Tuple[Tuple]` and for
|
| 126 |
+
[`~models.unet_2d_blocks.CrossAttnDownBlock2D`], [`~models.unet_2d_blocks.CrossAttnUpBlock2D`],
|
| 127 |
+
[`~models.unet_2d_blocks.UNetMidBlock2DCrossAttn`].
|
| 128 |
+
encoder_hid_dim (`int`, *optional*, defaults to None):
|
| 129 |
+
If `encoder_hid_dim_type` is defined, `encoder_hidden_states` will be projected from `encoder_hid_dim`
|
| 130 |
+
dimension to `cross_attention_dim`.
|
| 131 |
+
encoder_hid_dim_type (`str`, *optional*, defaults to `None`):
|
| 132 |
+
If given, the `encoder_hidden_states` and potentially other embeddings are down-projected to text
|
| 133 |
+
embeddings of dimension `cross_attention` according to `encoder_hid_dim_type`.
|
| 134 |
+
attention_head_dim (`int`, *optional*, defaults to 8): The dimension of the attention heads.
|
| 135 |
+
num_attention_heads (`int`, *optional*):
|
| 136 |
+
The number of attention heads. If not defined, defaults to `attention_head_dim`
|
| 137 |
+
resnet_time_scale_shift (`str`, *optional*, defaults to `"default"`): Time scale shift config
|
| 138 |
+
for ResNet blocks (see [`~models.resnet.ResnetBlock2D`]). Choose from `default` or `scale_shift`.
|
| 139 |
+
class_embed_type (`str`, *optional*, defaults to `None`):
|
| 140 |
+
The type of class embedding to use which is ultimately summed with the time embeddings. Choose from `None`,
|
| 141 |
+
`"timestep"`, `"identity"`, `"projection"`, or `"simple_projection"`.
|
| 142 |
+
addition_embed_type (`str`, *optional*, defaults to `None`):
|
| 143 |
+
Configures an optional embedding which will be summed with the time embeddings. Choose from `None` or
|
| 144 |
+
"text". "text" will use the `TextTimeEmbedding` layer.
|
| 145 |
+
addition_time_embed_dim: (`int`, *optional*, defaults to `None`):
|
| 146 |
+
Dimension for the timestep embeddings.
|
| 147 |
+
num_class_embeds (`int`, *optional*, defaults to `None`):
|
| 148 |
+
Input dimension of the learnable embedding matrix to be projected to `time_embed_dim`, when performing
|
| 149 |
+
class conditioning with `class_embed_type` equal to `None`.
|
| 150 |
+
time_embedding_type (`str`, *optional*, defaults to `positional`):
|
| 151 |
+
The type of position embedding to use for timesteps. Choose from `positional` or `fourier`.
|
| 152 |
+
time_embedding_dim (`int`, *optional*, defaults to `None`):
|
| 153 |
+
An optional override for the dimension of the projected time embedding.
|
| 154 |
+
time_embedding_act_fn (`str`, *optional*, defaults to `None`):
|
| 155 |
+
Optional activation function to use only once on the time embeddings before they are passed to the rest of
|
| 156 |
+
the UNet. Choose from `silu`, `mish`, `gelu`, and `swish`.
|
| 157 |
+
timestep_post_act (`str`, *optional*, defaults to `None`):
|
| 158 |
+
The second activation function to use in timestep embedding. Choose from `silu`, `mish` and `gelu`.
|
| 159 |
+
time_cond_proj_dim (`int`, *optional*, defaults to `None`):
|
| 160 |
+
The dimension of `cond_proj` layer in the timestep embedding.
|
| 161 |
+
conv_in_kernel (`int`, *optional*, default to `3`): The kernel size of `conv_in` layer. conv_out_kernel (`int`,
|
| 162 |
+
*optional*, default to `3`): The kernel size of `conv_out` layer. projection_class_embeddings_input_dim (`int`,
|
| 163 |
+
*optional*): The dimension of the `class_labels` input when
|
| 164 |
+
`class_embed_type="projection"`. Required when `class_embed_type="projection"`.
|
| 165 |
+
class_embeddings_concat (`bool`, *optional*, defaults to `False`): Whether to concatenate the time
|
| 166 |
+
embeddings with the class embeddings.
|
| 167 |
+
mid_block_only_cross_attention (`bool`, *optional*, defaults to `None`):
|
| 168 |
+
Whether to use cross attention with the mid block when using the `UNetMidBlock2DSimpleCrossAttn`. If
|
| 169 |
+
`only_cross_attention` is given as a single boolean and `mid_block_only_cross_attention` is `None`, the
|
| 170 |
+
`only_cross_attention` value is used as the value for `mid_block_only_cross_attention`. Default to `False`
|
| 171 |
+
otherwise.
|
| 172 |
+
"""
|
| 173 |
+
|
| 174 |
+
_supports_gradient_checkpointing = True
|
| 175 |
+
|
| 176 |
+
@register_to_config
|
| 177 |
+
def __init__(
|
| 178 |
+
self,
|
| 179 |
+
sample_size: Optional[int] = None,
|
| 180 |
+
in_channels: int = 4,
|
| 181 |
+
out_channels: int = 4,
|
| 182 |
+
center_input_sample: bool = False,
|
| 183 |
+
flip_sin_to_cos: bool = True,
|
| 184 |
+
freq_shift: int = 0,
|
| 185 |
+
down_block_types: Tuple[str] = (
|
| 186 |
+
"CrossAttnDownBlock2D",
|
| 187 |
+
"CrossAttnDownBlock2D",
|
| 188 |
+
"CrossAttnDownBlock2D",
|
| 189 |
+
"DownBlock2D",
|
| 190 |
+
),
|
| 191 |
+
mid_block_type: Optional[str] = "UNetMidBlock2DCrossAttn",
|
| 192 |
+
up_block_types: Tuple[str] = ("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D"),
|
| 193 |
+
only_cross_attention: Union[bool, Tuple[bool]] = False,
|
| 194 |
+
block_out_channels: Tuple[int] = (320, 640, 1280, 1280),
|
| 195 |
+
layers_per_block: Union[int, Tuple[int]] = 2,
|
| 196 |
+
downsample_padding: int = 1,
|
| 197 |
+
mid_block_scale_factor: float = 1,
|
| 198 |
+
dropout: float = 0.0,
|
| 199 |
+
act_fn: str = "silu",
|
| 200 |
+
norm_num_groups: Optional[int] = 32,
|
| 201 |
+
norm_eps: float = 1e-5,
|
| 202 |
+
cross_attention_dim: Union[int, Tuple[int]] = 1280,
|
| 203 |
+
transformer_layers_per_block: Union[int, Tuple[int], Tuple[Tuple]] = 1,
|
| 204 |
+
reverse_transformer_layers_per_block: Optional[Tuple[Tuple[int]]] = None,
|
| 205 |
+
encoder_hid_dim: Optional[int] = None,
|
| 206 |
+
encoder_hid_dim_type: Optional[str] = None,
|
| 207 |
+
attention_head_dim: Union[int, Tuple[int]] = 8,
|
| 208 |
+
num_attention_heads: Optional[Union[int, Tuple[int]]] = None,
|
| 209 |
+
dual_cross_attention: bool = False,
|
| 210 |
+
use_linear_projection: bool = False,
|
| 211 |
+
class_embed_type: Optional[str] = None,
|
| 212 |
+
addition_embed_type: Optional[str] = None,
|
| 213 |
+
addition_time_embed_dim: Optional[int] = None,
|
| 214 |
+
num_class_embeds: Optional[int] = None,
|
| 215 |
+
upcast_attention: bool = False,
|
| 216 |
+
resnet_time_scale_shift: str = "default",
|
| 217 |
+
resnet_skip_time_act: bool = False,
|
| 218 |
+
resnet_out_scale_factor: int = 1.0,
|
| 219 |
+
time_embedding_type: str = "positional",
|
| 220 |
+
time_embedding_dim: Optional[int] = None,
|
| 221 |
+
time_embedding_act_fn: Optional[str] = None,
|
| 222 |
+
timestep_post_act: Optional[str] = None,
|
| 223 |
+
time_cond_proj_dim: Optional[int] = None,
|
| 224 |
+
conv_in_kernel: int = 3,
|
| 225 |
+
conv_out_kernel: int = 3,
|
| 226 |
+
projection_class_embeddings_input_dim: Optional[int] = None,
|
| 227 |
+
attention_type: str = "default",
|
| 228 |
+
class_embeddings_concat: bool = False,
|
| 229 |
+
mid_block_only_cross_attention: Optional[bool] = None,
|
| 230 |
+
cross_attention_norm: Optional[str] = None,
|
| 231 |
+
addition_embed_type_num_heads=64,
|
| 232 |
+
):
|
| 233 |
+
super().__init__()
|
| 234 |
+
|
| 235 |
+
self.sample_size = sample_size
|
| 236 |
+
|
| 237 |
+
if num_attention_heads is not None:
|
| 238 |
+
raise ValueError(
|
| 239 |
+
"At the moment it is not possible to define the number of attention heads via `num_attention_heads` because of a naming issue as described in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131. Passing `num_attention_heads` will only be supported in diffusers v0.19."
|
| 240 |
+
)
|
| 241 |
+
|
| 242 |
+
# If `num_attention_heads` is not defined (which is the case for most models)
|
| 243 |
+
# it will default to `attention_head_dim`. This looks weird upon first reading it and it is.
|
| 244 |
+
# The reason for this behavior is to correct for incorrectly named variables that were introduced
|
| 245 |
+
# when this library was created. The incorrect naming was only discovered much later in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131
|
| 246 |
+
# Changing `attention_head_dim` to `num_attention_heads` for 40,000+ configurations is too backwards breaking
|
| 247 |
+
# which is why we correct for the naming here.
|
| 248 |
+
num_attention_heads = num_attention_heads or attention_head_dim
|
| 249 |
+
|
| 250 |
+
# Check inputs
|
| 251 |
+
if len(down_block_types) != len(up_block_types):
|
| 252 |
+
raise ValueError(
|
| 253 |
+
f"Must provide the same number of `down_block_types` as `up_block_types`. `down_block_types`: {down_block_types}. `up_block_types`: {up_block_types}."
|
| 254 |
+
)
|
| 255 |
+
|
| 256 |
+
if len(block_out_channels) != len(down_block_types):
|
| 257 |
+
raise ValueError(
|
| 258 |
+
f"Must provide the same number of `block_out_channels` as `down_block_types`. `block_out_channels`: {block_out_channels}. `down_block_types`: {down_block_types}."
|
| 259 |
+
)
|
| 260 |
+
|
| 261 |
+
if not isinstance(only_cross_attention, bool) and len(only_cross_attention) != len(down_block_types):
|
| 262 |
+
raise ValueError(
|
| 263 |
+
f"Must provide the same number of `only_cross_attention` as `down_block_types`. `only_cross_attention`: {only_cross_attention}. `down_block_types`: {down_block_types}."
|
| 264 |
+
)
|
| 265 |
+
|
| 266 |
+
if not isinstance(num_attention_heads, int) and len(num_attention_heads) != len(down_block_types):
|
| 267 |
+
raise ValueError(
|
| 268 |
+
f"Must provide the same number of `num_attention_heads` as `down_block_types`. `num_attention_heads`: {num_attention_heads}. `down_block_types`: {down_block_types}."
|
| 269 |
+
)
|
| 270 |
+
|
| 271 |
+
if not isinstance(attention_head_dim, int) and len(attention_head_dim) != len(down_block_types):
|
| 272 |
+
raise ValueError(
|
| 273 |
+
f"Must provide the same number of `attention_head_dim` as `down_block_types`. `attention_head_dim`: {attention_head_dim}. `down_block_types`: {down_block_types}."
|
| 274 |
+
)
|
| 275 |
+
|
| 276 |
+
if isinstance(cross_attention_dim, list) and len(cross_attention_dim) != len(down_block_types):
|
| 277 |
+
raise ValueError(
|
| 278 |
+
f"Must provide the same number of `cross_attention_dim` as `down_block_types`. `cross_attention_dim`: {cross_attention_dim}. `down_block_types`: {down_block_types}."
|
| 279 |
+
)
|
| 280 |
+
|
| 281 |
+
if not isinstance(layers_per_block, int) and len(layers_per_block) != len(down_block_types):
|
| 282 |
+
raise ValueError(
|
| 283 |
+
f"Must provide the same number of `layers_per_block` as `down_block_types`. `layers_per_block`: {layers_per_block}. `down_block_types`: {down_block_types}."
|
| 284 |
+
)
|
| 285 |
+
if isinstance(transformer_layers_per_block, list) and reverse_transformer_layers_per_block is None:
|
| 286 |
+
for layer_number_per_block in transformer_layers_per_block:
|
| 287 |
+
if isinstance(layer_number_per_block, list):
|
| 288 |
+
raise ValueError("Must provide 'reverse_transformer_layers_per_block` if using asymmetrical UNet.")
|
| 289 |
+
|
| 290 |
+
# input
|
| 291 |
+
conv_in_padding = (conv_in_kernel - 1) // 2
|
| 292 |
+
self.conv_in = nn.Conv2d(
|
| 293 |
+
in_channels, block_out_channels[0], kernel_size=conv_in_kernel, padding=conv_in_padding
|
| 294 |
+
)
|
| 295 |
+
|
| 296 |
+
# time
|
| 297 |
+
if time_embedding_type == "fourier":
|
| 298 |
+
time_embed_dim = time_embedding_dim or block_out_channels[0] * 2
|
| 299 |
+
if time_embed_dim % 2 != 0:
|
| 300 |
+
raise ValueError(f"`time_embed_dim` should be divisible by 2, but is {time_embed_dim}.")
|
| 301 |
+
self.time_proj = GaussianFourierProjection(
|
| 302 |
+
time_embed_dim // 2, set_W_to_weight=False, log=False, flip_sin_to_cos=flip_sin_to_cos
|
| 303 |
+
)
|
| 304 |
+
timestep_input_dim = time_embed_dim
|
| 305 |
+
elif time_embedding_type == "positional":
|
| 306 |
+
time_embed_dim = time_embedding_dim or block_out_channels[0] * 4
|
| 307 |
+
|
| 308 |
+
self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
|
| 309 |
+
timestep_input_dim = block_out_channels[0]
|
| 310 |
+
else:
|
| 311 |
+
raise ValueError(
|
| 312 |
+
f"{time_embedding_type} does not exist. Please make sure to use one of `fourier` or `positional`."
|
| 313 |
+
)
|
| 314 |
+
|
| 315 |
+
self.time_embedding = TimestepEmbedding(
|
| 316 |
+
timestep_input_dim,
|
| 317 |
+
time_embed_dim,
|
| 318 |
+
act_fn=act_fn,
|
| 319 |
+
post_act_fn=timestep_post_act,
|
| 320 |
+
cond_proj_dim=time_cond_proj_dim,
|
| 321 |
+
)
|
| 322 |
+
|
| 323 |
+
if encoder_hid_dim_type is None and encoder_hid_dim is not None:
|
| 324 |
+
encoder_hid_dim_type = "text_proj"
|
| 325 |
+
self.register_to_config(encoder_hid_dim_type=encoder_hid_dim_type)
|
| 326 |
+
logger.info("encoder_hid_dim_type defaults to 'text_proj' as `encoder_hid_dim` is defined.")
|
| 327 |
+
|
| 328 |
+
if encoder_hid_dim is None and encoder_hid_dim_type is not None:
|
| 329 |
+
raise ValueError(
|
| 330 |
+
f"`encoder_hid_dim` has to be defined when `encoder_hid_dim_type` is set to {encoder_hid_dim_type}."
|
| 331 |
+
)
|
| 332 |
+
|
| 333 |
+
if encoder_hid_dim_type == "text_proj":
|
| 334 |
+
self.encoder_hid_proj = nn.Linear(encoder_hid_dim, cross_attention_dim)
|
| 335 |
+
elif encoder_hid_dim_type == "text_image_proj":
|
| 336 |
+
# image_embed_dim DOESN'T have to be `cross_attention_dim`. To not clutter the __init__ too much
|
| 337 |
+
# they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
|
| 338 |
+
# case when `addition_embed_type == "text_image_proj"` (Kadinsky 2.1)`
|
| 339 |
+
self.encoder_hid_proj = TextImageProjection(
|
| 340 |
+
text_embed_dim=encoder_hid_dim,
|
| 341 |
+
image_embed_dim=cross_attention_dim,
|
| 342 |
+
cross_attention_dim=cross_attention_dim,
|
| 343 |
+
)
|
| 344 |
+
elif encoder_hid_dim_type == "image_proj":
|
| 345 |
+
# Kandinsky 2.2
|
| 346 |
+
self.encoder_hid_proj = ImageProjection(
|
| 347 |
+
image_embed_dim=encoder_hid_dim,
|
| 348 |
+
cross_attention_dim=cross_attention_dim,
|
| 349 |
+
)
|
| 350 |
+
elif encoder_hid_dim_type is not None:
|
| 351 |
+
raise ValueError(
|
| 352 |
+
f"encoder_hid_dim_type: {encoder_hid_dim_type} must be None, 'text_proj' or 'text_image_proj'."
|
| 353 |
+
)
|
| 354 |
+
else:
|
| 355 |
+
self.encoder_hid_proj = None
|
| 356 |
+
|
| 357 |
+
# class embedding
|
| 358 |
+
if class_embed_type is None and num_class_embeds is not None:
|
| 359 |
+
self.class_embedding = nn.Embedding(num_class_embeds, time_embed_dim)
|
| 360 |
+
elif class_embed_type == "timestep":
|
| 361 |
+
self.class_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim, act_fn=act_fn)
|
| 362 |
+
elif class_embed_type == "identity":
|
| 363 |
+
self.class_embedding = nn.Identity(time_embed_dim, time_embed_dim)
|
| 364 |
+
elif class_embed_type == "projection":
|
| 365 |
+
if projection_class_embeddings_input_dim is None:
|
| 366 |
+
raise ValueError(
|
| 367 |
+
"`class_embed_type`: 'projection' requires `projection_class_embeddings_input_dim` be set"
|
| 368 |
+
)
|
| 369 |
+
# The projection `class_embed_type` is the same as the timestep `class_embed_type` except
|
| 370 |
+
# 1. the `class_labels` inputs are not first converted to sinusoidal embeddings
|
| 371 |
+
# 2. it projects from an arbitrary input dimension.
|
| 372 |
+
#
|
| 373 |
+
# Note that `TimestepEmbedding` is quite general, being mainly linear layers and activations.
|
| 374 |
+
# When used for embedding actual timesteps, the timesteps are first converted to sinusoidal embeddings.
|
| 375 |
+
# As a result, `TimestepEmbedding` can be passed arbitrary vectors.
|
| 376 |
+
self.class_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
|
| 377 |
+
elif class_embed_type == "simple_projection":
|
| 378 |
+
if projection_class_embeddings_input_dim is None:
|
| 379 |
+
raise ValueError(
|
| 380 |
+
"`class_embed_type`: 'simple_projection' requires `projection_class_embeddings_input_dim` be set"
|
| 381 |
+
)
|
| 382 |
+
self.class_embedding = nn.Linear(projection_class_embeddings_input_dim, time_embed_dim)
|
| 383 |
+
else:
|
| 384 |
+
self.class_embedding = None
|
| 385 |
+
|
| 386 |
+
if addition_embed_type == "text":
|
| 387 |
+
if encoder_hid_dim is not None:
|
| 388 |
+
text_time_embedding_from_dim = encoder_hid_dim
|
| 389 |
+
else:
|
| 390 |
+
text_time_embedding_from_dim = cross_attention_dim
|
| 391 |
+
|
| 392 |
+
self.add_embedding = TextTimeEmbedding(
|
| 393 |
+
text_time_embedding_from_dim, time_embed_dim, num_heads=addition_embed_type_num_heads
|
| 394 |
+
)
|
| 395 |
+
elif addition_embed_type == "text_image":
|
| 396 |
+
# text_embed_dim and image_embed_dim DON'T have to be `cross_attention_dim`. To not clutter the __init__ too much
|
| 397 |
+
# they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
|
| 398 |
+
# case when `addition_embed_type == "text_image"` (Kadinsky 2.1)`
|
| 399 |
+
self.add_embedding = TextImageTimeEmbedding(
|
| 400 |
+
text_embed_dim=cross_attention_dim, image_embed_dim=cross_attention_dim, time_embed_dim=time_embed_dim
|
| 401 |
+
)
|
| 402 |
+
elif addition_embed_type == "text_time":
|
| 403 |
+
self.add_time_proj = Timesteps(addition_time_embed_dim, flip_sin_to_cos, freq_shift)
|
| 404 |
+
self.add_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
|
| 405 |
+
elif addition_embed_type == "image":
|
| 406 |
+
# Kandinsky 2.2
|
| 407 |
+
self.add_embedding = ImageTimeEmbedding(image_embed_dim=encoder_hid_dim, time_embed_dim=time_embed_dim)
|
| 408 |
+
elif addition_embed_type == "image_hint":
|
| 409 |
+
# Kandinsky 2.2 ControlNet
|
| 410 |
+
self.add_embedding = ImageHintTimeEmbedding(image_embed_dim=encoder_hid_dim, time_embed_dim=time_embed_dim)
|
| 411 |
+
elif addition_embed_type is not None:
|
| 412 |
+
raise ValueError(f"addition_embed_type: {addition_embed_type} must be None, 'text' or 'text_image'.")
|
| 413 |
+
|
| 414 |
+
if time_embedding_act_fn is None:
|
| 415 |
+
self.time_embed_act = None
|
| 416 |
+
else:
|
| 417 |
+
self.time_embed_act = get_activation(time_embedding_act_fn)
|
| 418 |
+
|
| 419 |
+
self.down_blocks = nn.ModuleList([])
|
| 420 |
+
self.up_blocks = nn.ModuleList([])
|
| 421 |
+
|
| 422 |
+
if isinstance(only_cross_attention, bool):
|
| 423 |
+
if mid_block_only_cross_attention is None:
|
| 424 |
+
mid_block_only_cross_attention = only_cross_attention
|
| 425 |
+
|
| 426 |
+
only_cross_attention = [only_cross_attention] * len(down_block_types)
|
| 427 |
+
|
| 428 |
+
if mid_block_only_cross_attention is None:
|
| 429 |
+
mid_block_only_cross_attention = False
|
| 430 |
+
|
| 431 |
+
if isinstance(num_attention_heads, int):
|
| 432 |
+
num_attention_heads = (num_attention_heads,) * len(down_block_types)
|
| 433 |
+
|
| 434 |
+
if isinstance(attention_head_dim, int):
|
| 435 |
+
attention_head_dim = (attention_head_dim,) * len(down_block_types)
|
| 436 |
+
|
| 437 |
+
if isinstance(cross_attention_dim, int):
|
| 438 |
+
cross_attention_dim = (cross_attention_dim,) * len(down_block_types)
|
| 439 |
+
|
| 440 |
+
if isinstance(layers_per_block, int):
|
| 441 |
+
layers_per_block = [layers_per_block] * len(down_block_types)
|
| 442 |
+
|
| 443 |
+
if isinstance(transformer_layers_per_block, int):
|
| 444 |
+
transformer_layers_per_block = [transformer_layers_per_block] * len(down_block_types)
|
| 445 |
+
|
| 446 |
+
if class_embeddings_concat:
|
| 447 |
+
# The time embeddings are concatenated with the class embeddings. The dimension of the
|
| 448 |
+
# time embeddings passed to the down, middle, and up blocks is twice the dimension of the
|
| 449 |
+
# regular time embeddings
|
| 450 |
+
blocks_time_embed_dim = time_embed_dim * 2
|
| 451 |
+
else:
|
| 452 |
+
blocks_time_embed_dim = time_embed_dim
|
| 453 |
+
|
| 454 |
+
# down
|
| 455 |
+
output_channel = block_out_channels[0]
|
| 456 |
+
for i, down_block_type in enumerate(down_block_types):
|
| 457 |
+
input_channel = output_channel
|
| 458 |
+
output_channel = block_out_channels[i]
|
| 459 |
+
is_final_block = i == len(block_out_channels) - 1
|
| 460 |
+
|
| 461 |
+
down_block = get_down_block(
|
| 462 |
+
down_block_type,
|
| 463 |
+
num_layers=layers_per_block[i],
|
| 464 |
+
transformer_layers_per_block=transformer_layers_per_block[i],
|
| 465 |
+
in_channels=input_channel,
|
| 466 |
+
out_channels=output_channel,
|
| 467 |
+
temb_channels=blocks_time_embed_dim,
|
| 468 |
+
add_downsample=not is_final_block,
|
| 469 |
+
resnet_eps=norm_eps,
|
| 470 |
+
resnet_act_fn=act_fn,
|
| 471 |
+
resnet_groups=norm_num_groups,
|
| 472 |
+
cross_attention_dim=cross_attention_dim[i],
|
| 473 |
+
num_attention_heads=num_attention_heads[i],
|
| 474 |
+
downsample_padding=downsample_padding,
|
| 475 |
+
dual_cross_attention=dual_cross_attention,
|
| 476 |
+
use_linear_projection=use_linear_projection,
|
| 477 |
+
only_cross_attention=only_cross_attention[i],
|
| 478 |
+
upcast_attention=upcast_attention,
|
| 479 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 480 |
+
attention_type=attention_type,
|
| 481 |
+
resnet_skip_time_act=resnet_skip_time_act,
|
| 482 |
+
resnet_out_scale_factor=resnet_out_scale_factor,
|
| 483 |
+
cross_attention_norm=cross_attention_norm,
|
| 484 |
+
attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
|
| 485 |
+
dropout=dropout,
|
| 486 |
+
)
|
| 487 |
+
self.down_blocks.append(down_block)
|
| 488 |
+
|
| 489 |
+
# mid
|
| 490 |
+
if mid_block_type == "UNetMidBlock2DCrossAttn":
|
| 491 |
+
self.mid_block = UNetMidBlock2DCrossAttn(
|
| 492 |
+
transformer_layers_per_block=transformer_layers_per_block[-1],
|
| 493 |
+
in_channels=block_out_channels[-1],
|
| 494 |
+
temb_channels=blocks_time_embed_dim,
|
| 495 |
+
dropout=dropout,
|
| 496 |
+
resnet_eps=norm_eps,
|
| 497 |
+
resnet_act_fn=act_fn,
|
| 498 |
+
output_scale_factor=mid_block_scale_factor,
|
| 499 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 500 |
+
cross_attention_dim=cross_attention_dim[-1],
|
| 501 |
+
num_attention_heads=num_attention_heads[-1],
|
| 502 |
+
resnet_groups=norm_num_groups,
|
| 503 |
+
dual_cross_attention=dual_cross_attention,
|
| 504 |
+
use_linear_projection=use_linear_projection,
|
| 505 |
+
upcast_attention=upcast_attention,
|
| 506 |
+
attention_type=attention_type,
|
| 507 |
+
)
|
| 508 |
+
elif mid_block_type == "UNetMidBlock2DSimpleCrossAttn":
|
| 509 |
+
self.mid_block = UNetMidBlock2DSimpleCrossAttn(
|
| 510 |
+
in_channels=block_out_channels[-1],
|
| 511 |
+
temb_channels=blocks_time_embed_dim,
|
| 512 |
+
dropout=dropout,
|
| 513 |
+
resnet_eps=norm_eps,
|
| 514 |
+
resnet_act_fn=act_fn,
|
| 515 |
+
output_scale_factor=mid_block_scale_factor,
|
| 516 |
+
cross_attention_dim=cross_attention_dim[-1],
|
| 517 |
+
attention_head_dim=attention_head_dim[-1],
|
| 518 |
+
resnet_groups=norm_num_groups,
|
| 519 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 520 |
+
skip_time_act=resnet_skip_time_act,
|
| 521 |
+
only_cross_attention=mid_block_only_cross_attention,
|
| 522 |
+
cross_attention_norm=cross_attention_norm,
|
| 523 |
+
)
|
| 524 |
+
elif mid_block_type == "UNetMidBlock2D":
|
| 525 |
+
self.mid_block = UNetMidBlock2D(
|
| 526 |
+
in_channels=block_out_channels[-1],
|
| 527 |
+
temb_channels=blocks_time_embed_dim,
|
| 528 |
+
dropout=dropout,
|
| 529 |
+
num_layers=0,
|
| 530 |
+
resnet_eps=norm_eps,
|
| 531 |
+
resnet_act_fn=act_fn,
|
| 532 |
+
output_scale_factor=mid_block_scale_factor,
|
| 533 |
+
resnet_groups=norm_num_groups,
|
| 534 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 535 |
+
add_attention=False,
|
| 536 |
+
)
|
| 537 |
+
elif mid_block_type is None:
|
| 538 |
+
self.mid_block = None
|
| 539 |
+
else:
|
| 540 |
+
raise ValueError(f"unknown mid_block_type : {mid_block_type}")
|
| 541 |
+
|
| 542 |
+
# count how many layers upsample the images
|
| 543 |
+
self.num_upsamplers = 0
|
| 544 |
+
|
| 545 |
+
# up
|
| 546 |
+
reversed_block_out_channels = list(reversed(block_out_channels))
|
| 547 |
+
reversed_num_attention_heads = list(reversed(num_attention_heads))
|
| 548 |
+
reversed_layers_per_block = list(reversed(layers_per_block))
|
| 549 |
+
reversed_cross_attention_dim = list(reversed(cross_attention_dim))
|
| 550 |
+
reversed_transformer_layers_per_block = (
|
| 551 |
+
list(reversed(transformer_layers_per_block))
|
| 552 |
+
if reverse_transformer_layers_per_block is None
|
| 553 |
+
else reverse_transformer_layers_per_block
|
| 554 |
+
)
|
| 555 |
+
only_cross_attention = list(reversed(only_cross_attention))
|
| 556 |
+
|
| 557 |
+
output_channel = reversed_block_out_channels[0]
|
| 558 |
+
for i, up_block_type in enumerate(up_block_types):
|
| 559 |
+
is_final_block = i == len(block_out_channels) - 1
|
| 560 |
+
|
| 561 |
+
prev_output_channel = output_channel
|
| 562 |
+
output_channel = reversed_block_out_channels[i]
|
| 563 |
+
input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
|
| 564 |
+
|
| 565 |
+
# add upsample block for all BUT final layer
|
| 566 |
+
if not is_final_block:
|
| 567 |
+
add_upsample = True
|
| 568 |
+
self.num_upsamplers += 1
|
| 569 |
+
else:
|
| 570 |
+
add_upsample = False
|
| 571 |
+
|
| 572 |
+
up_block = get_up_block(
|
| 573 |
+
up_block_type,
|
| 574 |
+
num_layers=reversed_layers_per_block[i] + 1,
|
| 575 |
+
transformer_layers_per_block=reversed_transformer_layers_per_block[i],
|
| 576 |
+
in_channels=input_channel,
|
| 577 |
+
out_channels=output_channel,
|
| 578 |
+
prev_output_channel=prev_output_channel,
|
| 579 |
+
temb_channels=blocks_time_embed_dim,
|
| 580 |
+
add_upsample=add_upsample,
|
| 581 |
+
resnet_eps=norm_eps,
|
| 582 |
+
resnet_act_fn=act_fn,
|
| 583 |
+
resolution_idx=i,
|
| 584 |
+
resnet_groups=norm_num_groups,
|
| 585 |
+
cross_attention_dim=reversed_cross_attention_dim[i],
|
| 586 |
+
num_attention_heads=reversed_num_attention_heads[i],
|
| 587 |
+
dual_cross_attention=dual_cross_attention,
|
| 588 |
+
use_linear_projection=use_linear_projection,
|
| 589 |
+
only_cross_attention=only_cross_attention[i],
|
| 590 |
+
upcast_attention=upcast_attention,
|
| 591 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 592 |
+
attention_type=attention_type,
|
| 593 |
+
resnet_skip_time_act=resnet_skip_time_act,
|
| 594 |
+
resnet_out_scale_factor=resnet_out_scale_factor,
|
| 595 |
+
cross_attention_norm=cross_attention_norm,
|
| 596 |
+
attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
|
| 597 |
+
dropout=dropout,
|
| 598 |
+
)
|
| 599 |
+
self.up_blocks.append(up_block)
|
| 600 |
+
prev_output_channel = output_channel
|
| 601 |
+
|
| 602 |
+
# out
|
| 603 |
+
if norm_num_groups is not None:
|
| 604 |
+
self.conv_norm_out = nn.GroupNorm(
|
| 605 |
+
num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=norm_eps
|
| 606 |
+
)
|
| 607 |
+
|
| 608 |
+
self.conv_act = get_activation(act_fn)
|
| 609 |
+
|
| 610 |
+
else:
|
| 611 |
+
self.conv_norm_out = None
|
| 612 |
+
self.conv_act = None
|
| 613 |
+
|
| 614 |
+
conv_out_padding = (conv_out_kernel - 1) // 2
|
| 615 |
+
self.conv_out = nn.Conv2d(
|
| 616 |
+
block_out_channels[0], out_channels, kernel_size=conv_out_kernel, padding=conv_out_padding
|
| 617 |
+
)
|
| 618 |
+
|
| 619 |
+
if attention_type in ["gated", "gated-text-image"]:
|
| 620 |
+
positive_len = 768
|
| 621 |
+
if isinstance(cross_attention_dim, int):
|
| 622 |
+
positive_len = cross_attention_dim
|
| 623 |
+
elif isinstance(cross_attention_dim, tuple) or isinstance(cross_attention_dim, list):
|
| 624 |
+
positive_len = cross_attention_dim[0]
|
| 625 |
+
|
| 626 |
+
feature_type = "text-only" if attention_type == "gated" else "text-image"
|
| 627 |
+
self.position_net = PositionNet(
|
| 628 |
+
positive_len=positive_len, out_dim=cross_attention_dim, feature_type=feature_type
|
| 629 |
+
)
|
| 630 |
+
|
| 631 |
+
@property
|
| 632 |
+
def attn_processors(self) -> Dict[str, AttentionProcessor]:
|
| 633 |
+
r"""
|
| 634 |
+
Returns:
|
| 635 |
+
`dict` of attention processors: A dictionary containing all attention processors used in the model with
|
| 636 |
+
indexed by its weight name.
|
| 637 |
+
"""
|
| 638 |
+
# set recursively
|
| 639 |
+
processors = {}
|
| 640 |
+
|
| 641 |
+
def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
|
| 642 |
+
if hasattr(module, "get_processor"):
|
| 643 |
+
processors[f"{name}.processor"] = module.get_processor(return_deprecated_lora=True)
|
| 644 |
+
|
| 645 |
+
for sub_name, child in module.named_children():
|
| 646 |
+
fn_recursive_add_processors(f"{name}.{sub_name}", child, processors)
|
| 647 |
+
|
| 648 |
+
return processors
|
| 649 |
+
|
| 650 |
+
for name, module in self.named_children():
|
| 651 |
+
fn_recursive_add_processors(name, module, processors)
|
| 652 |
+
|
| 653 |
+
return processors
|
| 654 |
+
|
| 655 |
+
def set_attn_processor(
|
| 656 |
+
self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]], _remove_lora=False
|
| 657 |
+
):
|
| 658 |
+
r"""
|
| 659 |
+
Sets the attention processor to use to compute attention.
|
| 660 |
+
|
| 661 |
+
Parameters:
|
| 662 |
+
processor (`dict` of `AttentionProcessor` or only `AttentionProcessor`):
|
| 663 |
+
The instantiated processor class or a dictionary of processor classes that will be set as the processor
|
| 664 |
+
for **all** `Attention` layers.
|
| 665 |
+
|
| 666 |
+
If `processor` is a dict, the key needs to define the path to the corresponding cross attention
|
| 667 |
+
processor. This is strongly recommended when setting trainable attention processors.
|
| 668 |
+
|
| 669 |
+
"""
|
| 670 |
+
count = len(self.attn_processors.keys())
|
| 671 |
+
|
| 672 |
+
if isinstance(processor, dict) and len(processor) != count:
|
| 673 |
+
raise ValueError(
|
| 674 |
+
f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
|
| 675 |
+
f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
|
| 676 |
+
)
|
| 677 |
+
|
| 678 |
+
def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
|
| 679 |
+
if hasattr(module, "set_processor"):
|
| 680 |
+
if not isinstance(processor, dict):
|
| 681 |
+
module.set_processor(processor, _remove_lora=_remove_lora)
|
| 682 |
+
else:
|
| 683 |
+
module.set_processor(processor.pop(f"{name}.processor"), _remove_lora=_remove_lora)
|
| 684 |
+
|
| 685 |
+
for sub_name, child in module.named_children():
|
| 686 |
+
fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor)
|
| 687 |
+
|
| 688 |
+
for name, module in self.named_children():
|
| 689 |
+
fn_recursive_attn_processor(name, module, processor)
|
| 690 |
+
|
| 691 |
+
def set_default_attn_processor(self):
|
| 692 |
+
"""
|
| 693 |
+
Disables custom attention processors and sets the default attention implementation.
|
| 694 |
+
"""
|
| 695 |
+
if all(proc.__class__ in ADDED_KV_ATTENTION_PROCESSORS for proc in self.attn_processors.values()):
|
| 696 |
+
processor = AttnAddedKVProcessor()
|
| 697 |
+
elif all(proc.__class__ in CROSS_ATTENTION_PROCESSORS for proc in self.attn_processors.values()):
|
| 698 |
+
processor = AttnProcessor()
|
| 699 |
+
else:
|
| 700 |
+
raise ValueError(
|
| 701 |
+
f"Cannot call `set_default_attn_processor` when attention processors are of type {next(iter(self.attn_processors.values()))}"
|
| 702 |
+
)
|
| 703 |
+
|
| 704 |
+
self.set_attn_processor(processor, _remove_lora=True)
|
| 705 |
+
|
| 706 |
+
def set_attention_slice(self, slice_size):
|
| 707 |
+
r"""
|
| 708 |
+
Enable sliced attention computation.
|
| 709 |
+
|
| 710 |
+
When this option is enabled, the attention module splits the input tensor in slices to compute attention in
|
| 711 |
+
several steps. This is useful for saving some memory in exchange for a small decrease in speed.
|
| 712 |
+
|
| 713 |
+
Args:
|
| 714 |
+
slice_size (`str` or `int` or `list(int)`, *optional*, defaults to `"auto"`):
|
| 715 |
+
When `"auto"`, input to the attention heads is halved, so attention is computed in two steps. If
|
| 716 |
+
`"max"`, maximum amount of memory is saved by running only one slice at a time. If a number is
|
| 717 |
+
provided, uses as many slices as `attention_head_dim // slice_size`. In this case, `attention_head_dim`
|
| 718 |
+
must be a multiple of `slice_size`.
|
| 719 |
+
"""
|
| 720 |
+
sliceable_head_dims = []
|
| 721 |
+
|
| 722 |
+
def fn_recursive_retrieve_sliceable_dims(module: torch.nn.Module):
|
| 723 |
+
if hasattr(module, "set_attention_slice"):
|
| 724 |
+
sliceable_head_dims.append(module.sliceable_head_dim)
|
| 725 |
+
|
| 726 |
+
for child in module.children():
|
| 727 |
+
fn_recursive_retrieve_sliceable_dims(child)
|
| 728 |
+
|
| 729 |
+
# retrieve number of attention layers
|
| 730 |
+
for module in self.children():
|
| 731 |
+
fn_recursive_retrieve_sliceable_dims(module)
|
| 732 |
+
|
| 733 |
+
num_sliceable_layers = len(sliceable_head_dims)
|
| 734 |
+
|
| 735 |
+
if slice_size == "auto":
|
| 736 |
+
# half the attention head size is usually a good trade-off between
|
| 737 |
+
# speed and memory
|
| 738 |
+
slice_size = [dim // 2 for dim in sliceable_head_dims]
|
| 739 |
+
elif slice_size == "max":
|
| 740 |
+
# make smallest slice possible
|
| 741 |
+
slice_size = num_sliceable_layers * [1]
|
| 742 |
+
|
| 743 |
+
slice_size = num_sliceable_layers * [slice_size] if not isinstance(slice_size, list) else slice_size
|
| 744 |
+
|
| 745 |
+
if len(slice_size) != len(sliceable_head_dims):
|
| 746 |
+
raise ValueError(
|
| 747 |
+
f"You have provided {len(slice_size)}, but {self.config} has {len(sliceable_head_dims)} different"
|
| 748 |
+
f" attention layers. Make sure to match `len(slice_size)` to be {len(sliceable_head_dims)}."
|
| 749 |
+
)
|
| 750 |
+
|
| 751 |
+
for i in range(len(slice_size)):
|
| 752 |
+
size = slice_size[i]
|
| 753 |
+
dim = sliceable_head_dims[i]
|
| 754 |
+
if size is not None and size > dim:
|
| 755 |
+
raise ValueError(f"size {size} has to be smaller or equal to {dim}.")
|
| 756 |
+
|
| 757 |
+
# Recursively walk through all the children.
|
| 758 |
+
# Any children which exposes the set_attention_slice method
|
| 759 |
+
# gets the message
|
| 760 |
+
def fn_recursive_set_attention_slice(module: torch.nn.Module, slice_size: List[int]):
|
| 761 |
+
if hasattr(module, "set_attention_slice"):
|
| 762 |
+
module.set_attention_slice(slice_size.pop())
|
| 763 |
+
|
| 764 |
+
for child in module.children():
|
| 765 |
+
fn_recursive_set_attention_slice(child, slice_size)
|
| 766 |
+
|
| 767 |
+
reversed_slice_size = list(reversed(slice_size))
|
| 768 |
+
for module in self.children():
|
| 769 |
+
fn_recursive_set_attention_slice(module, reversed_slice_size)
|
| 770 |
+
|
| 771 |
+
def _set_gradient_checkpointing(self, module, value=False):
|
| 772 |
+
if hasattr(module, "gradient_checkpointing"):
|
| 773 |
+
module.gradient_checkpointing = value
|
| 774 |
+
|
| 775 |
+
def enable_freeu(self, s1, s2, b1, b2):
|
| 776 |
+
r"""Enables the FreeU mechanism from https://arxiv.org/abs/2309.11497.
|
| 777 |
+
|
| 778 |
+
The suffixes after the scaling factors represent the stage blocks where they are being applied.
|
| 779 |
+
|
| 780 |
+
Please refer to the [official repository](https://github.com/ChenyangSi/FreeU) for combinations of values that
|
| 781 |
+
are known to work well for different pipelines such as Stable Diffusion v1, v2, and Stable Diffusion XL.
|
| 782 |
+
|
| 783 |
+
Args:
|
| 784 |
+
s1 (`float`):
|
| 785 |
+
Scaling factor for stage 1 to attenuate the contributions of the skip features. This is done to
|
| 786 |
+
mitigate the "oversmoothing effect" in the enhanced denoising process.
|
| 787 |
+
s2 (`float`):
|
| 788 |
+
Scaling factor for stage 2 to attenuate the contributions of the skip features. This is done to
|
| 789 |
+
mitigate the "oversmoothing effect" in the enhanced denoising process.
|
| 790 |
+
b1 (`float`): Scaling factor for stage 1 to amplify the contributions of backbone features.
|
| 791 |
+
b2 (`float`): Scaling factor for stage 2 to amplify the contributions of backbone features.
|
| 792 |
+
"""
|
| 793 |
+
for i, upsample_block in enumerate(self.up_blocks):
|
| 794 |
+
setattr(upsample_block, "s1", s1)
|
| 795 |
+
setattr(upsample_block, "s2", s2)
|
| 796 |
+
setattr(upsample_block, "b1", b1)
|
| 797 |
+
setattr(upsample_block, "b2", b2)
|
| 798 |
+
|
| 799 |
+
def disable_freeu(self):
|
| 800 |
+
"""Disables the FreeU mechanism."""
|
| 801 |
+
freeu_keys = {"s1", "s2", "b1", "b2"}
|
| 802 |
+
for i, upsample_block in enumerate(self.up_blocks):
|
| 803 |
+
for k in freeu_keys:
|
| 804 |
+
if hasattr(upsample_block, k) or getattr(upsample_block, k, None) is not None:
|
| 805 |
+
setattr(upsample_block, k, None)
|
| 806 |
+
|
| 807 |
+
def forward(
|
| 808 |
+
self,
|
| 809 |
+
sample: torch.FloatTensor,
|
| 810 |
+
spatial_attn_inputs,
|
| 811 |
+
timestep: Union[torch.Tensor, float, int],
|
| 812 |
+
encoder_hidden_states: torch.Tensor,
|
| 813 |
+
class_labels: Optional[torch.Tensor] = None,
|
| 814 |
+
timestep_cond: Optional[torch.Tensor] = None,
|
| 815 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 816 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 817 |
+
added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
|
| 818 |
+
down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
|
| 819 |
+
mid_block_additional_residual: Optional[torch.Tensor] = None,
|
| 820 |
+
down_intrablock_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
|
| 821 |
+
encoder_attention_mask: Optional[torch.Tensor] = None,
|
| 822 |
+
return_dict: bool = True,
|
| 823 |
+
) -> Union[UNet2DConditionOutput, Tuple]:
|
| 824 |
+
r"""
|
| 825 |
+
The [`UNet2DConditionModel`] forward method.
|
| 826 |
+
|
| 827 |
+
Args:
|
| 828 |
+
sample (`torch.FloatTensor`):
|
| 829 |
+
The noisy input tensor with the following shape `(batch, channel, height, width)`.
|
| 830 |
+
timestep (`torch.FloatTensor` or `float` or `int`): The number of timesteps to denoise an input.
|
| 831 |
+
encoder_hidden_states (`torch.FloatTensor`):
|
| 832 |
+
The encoder hidden states with shape `(batch, sequence_length, feature_dim)`.
|
| 833 |
+
class_labels (`torch.Tensor`, *optional*, defaults to `None`):
|
| 834 |
+
Optional class labels for conditioning. Their embeddings will be summed with the timestep embeddings.
|
| 835 |
+
timestep_cond: (`torch.Tensor`, *optional*, defaults to `None`):
|
| 836 |
+
Conditional embeddings for timestep. If provided, the embeddings will be summed with the samples passed
|
| 837 |
+
through the `self.time_embedding` layer to obtain the timestep embeddings.
|
| 838 |
+
attention_mask (`torch.Tensor`, *optional*, defaults to `None`):
|
| 839 |
+
An attention mask of shape `(batch, key_tokens)` is applied to `encoder_hidden_states`. If `1` the mask
|
| 840 |
+
is kept, otherwise if `0` it is discarded. Mask will be converted into a bias, which adds large
|
| 841 |
+
negative values to the attention scores corresponding to "discard" tokens.
|
| 842 |
+
cross_attention_kwargs (`dict`, *optional*):
|
| 843 |
+
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
| 844 |
+
`self.processor` in
|
| 845 |
+
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
|
| 846 |
+
added_cond_kwargs: (`dict`, *optional*):
|
| 847 |
+
A kwargs dictionary containing additional embeddings that if specified are added to the embeddings that
|
| 848 |
+
are passed along to the UNet blocks.
|
| 849 |
+
down_block_additional_residuals: (`tuple` of `torch.Tensor`, *optional*):
|
| 850 |
+
A tuple of tensors that if specified are added to the residuals of down unet blocks.
|
| 851 |
+
mid_block_additional_residual: (`torch.Tensor`, *optional*):
|
| 852 |
+
A tensor that if specified is added to the residual of the middle unet block.
|
| 853 |
+
encoder_attention_mask (`torch.Tensor`):
|
| 854 |
+
A cross-attention mask of shape `(batch, sequence_length)` is applied to `encoder_hidden_states`. If
|
| 855 |
+
`True` the mask is kept, otherwise if `False` it is discarded. Mask will be converted into a bias,
|
| 856 |
+
which adds large negative values to the attention scores corresponding to "discard" tokens.
|
| 857 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 858 |
+
Whether or not to return a [`~models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain
|
| 859 |
+
tuple.
|
| 860 |
+
cross_attention_kwargs (`dict`, *optional*):
|
| 861 |
+
A kwargs dictionary that if specified is passed along to the [`AttnProcessor`].
|
| 862 |
+
added_cond_kwargs: (`dict`, *optional*):
|
| 863 |
+
A kwargs dictionary containin additional embeddings that if specified are added to the embeddings that
|
| 864 |
+
are passed along to the UNet blocks.
|
| 865 |
+
down_block_additional_residuals (`tuple` of `torch.Tensor`, *optional*):
|
| 866 |
+
additional residuals to be added to UNet long skip connections from down blocks to up blocks for
|
| 867 |
+
example from ControlNet side model(s)
|
| 868 |
+
mid_block_additional_residual (`torch.Tensor`, *optional*):
|
| 869 |
+
additional residual to be added to UNet mid block output, for example from ControlNet side model
|
| 870 |
+
down_intrablock_additional_residuals (`tuple` of `torch.Tensor`, *optional*):
|
| 871 |
+
additional residuals to be added within UNet down blocks, for example from T2I-Adapter side model(s)
|
| 872 |
+
|
| 873 |
+
Returns:
|
| 874 |
+
[`~models.unet_2d_condition.UNet2DConditionOutput`] or `tuple`:
|
| 875 |
+
If `return_dict` is True, an [`~models.unet_2d_condition.UNet2DConditionOutput`] is returned, otherwise
|
| 876 |
+
a `tuple` is returned where the first element is the sample tensor.
|
| 877 |
+
"""
|
| 878 |
+
# By default samples have to be AT least a multiple of the overall upsampling factor.
|
| 879 |
+
# The overall upsampling factor is equal to 2 ** (# num of upsampling layers).
|
| 880 |
+
# However, the upsampling interpolation output size can be forced to fit any upsampling size
|
| 881 |
+
# on the fly if necessary.
|
| 882 |
+
default_overall_up_factor = 2**self.num_upsamplers
|
| 883 |
+
|
| 884 |
+
# upsample size should be forwarded when sample is not a multiple of `default_overall_up_factor`
|
| 885 |
+
forward_upsample_size = False
|
| 886 |
+
upsample_size = None
|
| 887 |
+
|
| 888 |
+
for dim in sample.shape[-2:]:
|
| 889 |
+
if dim % default_overall_up_factor != 0:
|
| 890 |
+
# Forward upsample size to force interpolation output size.
|
| 891 |
+
forward_upsample_size = True
|
| 892 |
+
break
|
| 893 |
+
|
| 894 |
+
# ensure attention_mask is a bias, and give it a singleton query_tokens dimension
|
| 895 |
+
# expects mask of shape:
|
| 896 |
+
# [batch, key_tokens]
|
| 897 |
+
# adds singleton query_tokens dimension:
|
| 898 |
+
# [batch, 1, key_tokens]
|
| 899 |
+
# this helps to broadcast it as a bias over attention scores, which will be in one of the following shapes:
|
| 900 |
+
# [batch, heads, query_tokens, key_tokens] (e.g. torch sdp attn)
|
| 901 |
+
# [batch * heads, query_tokens, key_tokens] (e.g. xformers or classic attn)
|
| 902 |
+
if attention_mask is not None:
|
| 903 |
+
# assume that mask is expressed as:
|
| 904 |
+
# (1 = keep, 0 = discard)
|
| 905 |
+
# convert mask into a bias that can be added to attention scores:
|
| 906 |
+
# (keep = +0, discard = -10000.0)
|
| 907 |
+
attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0
|
| 908 |
+
attention_mask = attention_mask.unsqueeze(1)
|
| 909 |
+
|
| 910 |
+
# convert encoder_attention_mask to a bias the same way we do for attention_mask
|
| 911 |
+
if encoder_attention_mask is not None:
|
| 912 |
+
encoder_attention_mask = (1 - encoder_attention_mask.to(sample.dtype)) * -10000.0
|
| 913 |
+
encoder_attention_mask = encoder_attention_mask.unsqueeze(1)
|
| 914 |
+
|
| 915 |
+
# 0. center input if necessary
|
| 916 |
+
if self.config.center_input_sample:
|
| 917 |
+
sample = 2 * sample - 1.0
|
| 918 |
+
|
| 919 |
+
# 1. time
|
| 920 |
+
timesteps = timestep
|
| 921 |
+
if not torch.is_tensor(timesteps):
|
| 922 |
+
# TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
|
| 923 |
+
# This would be a good case for the `match` statement (Python 3.10+)
|
| 924 |
+
is_mps = sample.device.type == "mps"
|
| 925 |
+
if isinstance(timestep, float):
|
| 926 |
+
dtype = torch.float32 if is_mps else torch.float64
|
| 927 |
+
else:
|
| 928 |
+
dtype = torch.int32 if is_mps else torch.int64
|
| 929 |
+
timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
|
| 930 |
+
elif len(timesteps.shape) == 0:
|
| 931 |
+
timesteps = timesteps[None].to(sample.device)
|
| 932 |
+
|
| 933 |
+
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
| 934 |
+
timesteps = timesteps.expand(sample.shape[0])
|
| 935 |
+
|
| 936 |
+
t_emb = self.time_proj(timesteps)
|
| 937 |
+
|
| 938 |
+
# `Timesteps` does not contain any weights and will always return f32 tensors
|
| 939 |
+
# but time_embedding might actually be running in fp16. so we need to cast here.
|
| 940 |
+
# there might be better ways to encapsulate this.
|
| 941 |
+
t_emb = t_emb.to(dtype=sample.dtype)
|
| 942 |
+
|
| 943 |
+
emb = self.time_embedding(t_emb, timestep_cond)
|
| 944 |
+
aug_emb = None
|
| 945 |
+
|
| 946 |
+
if self.class_embedding is not None:
|
| 947 |
+
if class_labels is None:
|
| 948 |
+
raise ValueError("class_labels should be provided when num_class_embeds > 0")
|
| 949 |
+
|
| 950 |
+
if self.config.class_embed_type == "timestep":
|
| 951 |
+
class_labels = self.time_proj(class_labels)
|
| 952 |
+
|
| 953 |
+
# `Timesteps` does not contain any weights and will always return f32 tensors
|
| 954 |
+
# there might be better ways to encapsulate this.
|
| 955 |
+
class_labels = class_labels.to(dtype=sample.dtype)
|
| 956 |
+
|
| 957 |
+
class_emb = self.class_embedding(class_labels).to(dtype=sample.dtype)
|
| 958 |
+
|
| 959 |
+
if self.config.class_embeddings_concat:
|
| 960 |
+
emb = torch.cat([emb, class_emb], dim=-1)
|
| 961 |
+
else:
|
| 962 |
+
emb = emb + class_emb
|
| 963 |
+
|
| 964 |
+
if self.config.addition_embed_type == "text":
|
| 965 |
+
aug_emb = self.add_embedding(encoder_hidden_states)
|
| 966 |
+
elif self.config.addition_embed_type == "text_image":
|
| 967 |
+
# Kandinsky 2.1 - style
|
| 968 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 969 |
+
raise ValueError(
|
| 970 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'text_image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
|
| 971 |
+
)
|
| 972 |
+
|
| 973 |
+
image_embs = added_cond_kwargs.get("image_embeds")
|
| 974 |
+
text_embs = added_cond_kwargs.get("text_embeds", encoder_hidden_states)
|
| 975 |
+
aug_emb = self.add_embedding(text_embs, image_embs)
|
| 976 |
+
elif self.config.addition_embed_type == "text_time":
|
| 977 |
+
# SDXL - style
|
| 978 |
+
if "text_embeds" not in added_cond_kwargs:
|
| 979 |
+
raise ValueError(
|
| 980 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `text_embeds` to be passed in `added_cond_kwargs`"
|
| 981 |
+
)
|
| 982 |
+
text_embeds = added_cond_kwargs.get("text_embeds")
|
| 983 |
+
if "time_ids" not in added_cond_kwargs:
|
| 984 |
+
raise ValueError(
|
| 985 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `time_ids` to be passed in `added_cond_kwargs`"
|
| 986 |
+
)
|
| 987 |
+
time_ids = added_cond_kwargs.get("time_ids")
|
| 988 |
+
time_embeds = self.add_time_proj(time_ids.flatten())
|
| 989 |
+
time_embeds = time_embeds.reshape((text_embeds.shape[0], -1))
|
| 990 |
+
add_embeds = torch.concat([text_embeds, time_embeds], dim=-1)
|
| 991 |
+
add_embeds = add_embeds.to(emb.dtype)
|
| 992 |
+
aug_emb = self.add_embedding(add_embeds)
|
| 993 |
+
elif self.config.addition_embed_type == "image":
|
| 994 |
+
# Kandinsky 2.2 - style
|
| 995 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 996 |
+
raise ValueError(
|
| 997 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
|
| 998 |
+
)
|
| 999 |
+
image_embs = added_cond_kwargs.get("image_embeds")
|
| 1000 |
+
aug_emb = self.add_embedding(image_embs)
|
| 1001 |
+
elif self.config.addition_embed_type == "image_hint":
|
| 1002 |
+
# Kandinsky 2.2 - style
|
| 1003 |
+
if "image_embeds" not in added_cond_kwargs or "hint" not in added_cond_kwargs:
|
| 1004 |
+
raise ValueError(
|
| 1005 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'image_hint' which requires the keyword arguments `image_embeds` and `hint` to be passed in `added_cond_kwargs`"
|
| 1006 |
+
)
|
| 1007 |
+
image_embs = added_cond_kwargs.get("image_embeds")
|
| 1008 |
+
hint = added_cond_kwargs.get("hint")
|
| 1009 |
+
aug_emb, hint = self.add_embedding(image_embs, hint)
|
| 1010 |
+
sample = torch.cat([sample, hint], dim=1)
|
| 1011 |
+
|
| 1012 |
+
emb = emb + aug_emb if aug_emb is not None else emb
|
| 1013 |
+
|
| 1014 |
+
if self.time_embed_act is not None:
|
| 1015 |
+
emb = self.time_embed_act(emb)
|
| 1016 |
+
|
| 1017 |
+
if self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_proj":
|
| 1018 |
+
encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states)
|
| 1019 |
+
elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_image_proj":
|
| 1020 |
+
# Kadinsky 2.1 - style
|
| 1021 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 1022 |
+
raise ValueError(
|
| 1023 |
+
f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'text_image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
|
| 1024 |
+
)
|
| 1025 |
+
|
| 1026 |
+
image_embeds = added_cond_kwargs.get("image_embeds")
|
| 1027 |
+
encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states, image_embeds)
|
| 1028 |
+
elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "image_proj":
|
| 1029 |
+
# Kandinsky 2.2 - style
|
| 1030 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 1031 |
+
raise ValueError(
|
| 1032 |
+
f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
|
| 1033 |
+
)
|
| 1034 |
+
image_embeds = added_cond_kwargs.get("image_embeds")
|
| 1035 |
+
encoder_hidden_states = self.encoder_hid_proj(image_embeds)
|
| 1036 |
+
# 2. pre-process
|
| 1037 |
+
sample = self.conv_in(sample)
|
| 1038 |
+
|
| 1039 |
+
# 2.5 GLIGEN position net
|
| 1040 |
+
if cross_attention_kwargs is not None and cross_attention_kwargs.get("gligen", None) is not None:
|
| 1041 |
+
cross_attention_kwargs = cross_attention_kwargs.copy()
|
| 1042 |
+
gligen_args = cross_attention_kwargs.pop("gligen")
|
| 1043 |
+
cross_attention_kwargs["gligen"] = {"objs": self.position_net(**gligen_args)}
|
| 1044 |
+
|
| 1045 |
+
# for spatial attention
|
| 1046 |
+
spatial_attn_idx = 0
|
| 1047 |
+
|
| 1048 |
+
# 3. down
|
| 1049 |
+
lora_scale = cross_attention_kwargs.get("scale", 1.0) if cross_attention_kwargs is not None else 1.0
|
| 1050 |
+
if USE_PEFT_BACKEND:
|
| 1051 |
+
# weight the lora layers by setting `lora_scale` for each PEFT layer
|
| 1052 |
+
scale_lora_layers(self, lora_scale)
|
| 1053 |
+
|
| 1054 |
+
is_controlnet = mid_block_additional_residual is not None and down_block_additional_residuals is not None
|
| 1055 |
+
# using new arg down_intrablock_additional_residuals for T2I-Adapters, to distinguish from controlnets
|
| 1056 |
+
is_adapter = down_intrablock_additional_residuals is not None
|
| 1057 |
+
# maintain backward compatibility for legacy usage, where
|
| 1058 |
+
# T2I-Adapter and ControlNet both use down_block_additional_residuals arg
|
| 1059 |
+
# but can only use one or the other
|
| 1060 |
+
if not is_adapter and mid_block_additional_residual is None and down_block_additional_residuals is not None:
|
| 1061 |
+
deprecate(
|
| 1062 |
+
"T2I should not use down_block_additional_residuals",
|
| 1063 |
+
"1.3.0",
|
| 1064 |
+
"Passing intrablock residual connections with `down_block_additional_residuals` is deprecated \
|
| 1065 |
+
and will be removed in diffusers 1.3.0. `down_block_additional_residuals` should only be used \
|
| 1066 |
+
for ControlNet. Please make sure use `down_intrablock_additional_residuals` instead. ",
|
| 1067 |
+
standard_warn=False,
|
| 1068 |
+
)
|
| 1069 |
+
down_intrablock_additional_residuals = down_block_additional_residuals
|
| 1070 |
+
is_adapter = True
|
| 1071 |
+
|
| 1072 |
+
down_block_res_samples = (sample,)
|
| 1073 |
+
for downsample_block in self.down_blocks:
|
| 1074 |
+
if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
|
| 1075 |
+
# For t2i-adapter CrossAttnDownBlock2D
|
| 1076 |
+
additional_residuals = {}
|
| 1077 |
+
if is_adapter and len(down_intrablock_additional_residuals) > 0:
|
| 1078 |
+
additional_residuals["additional_residuals"] = down_intrablock_additional_residuals.pop(0)
|
| 1079 |
+
|
| 1080 |
+
sample, res_samples, spatial_attn_inputs, spatial_attn_idx = downsample_block(
|
| 1081 |
+
hidden_states=sample,
|
| 1082 |
+
spatial_attn_inputs=spatial_attn_inputs,
|
| 1083 |
+
spatial_attn_idx=spatial_attn_idx,
|
| 1084 |
+
temb=emb,
|
| 1085 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1086 |
+
attention_mask=attention_mask,
|
| 1087 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 1088 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1089 |
+
**additional_residuals,
|
| 1090 |
+
)
|
| 1091 |
+
else:
|
| 1092 |
+
sample, res_samples = downsample_block(hidden_states=sample, temb=emb, scale=lora_scale)
|
| 1093 |
+
if is_adapter and len(down_intrablock_additional_residuals) > 0:
|
| 1094 |
+
sample += down_intrablock_additional_residuals.pop(0)
|
| 1095 |
+
|
| 1096 |
+
down_block_res_samples += res_samples
|
| 1097 |
+
|
| 1098 |
+
if is_controlnet:
|
| 1099 |
+
new_down_block_res_samples = ()
|
| 1100 |
+
|
| 1101 |
+
for down_block_res_sample, down_block_additional_residual in zip(
|
| 1102 |
+
down_block_res_samples, down_block_additional_residuals
|
| 1103 |
+
):
|
| 1104 |
+
down_block_res_sample = down_block_res_sample + down_block_additional_residual
|
| 1105 |
+
new_down_block_res_samples = new_down_block_res_samples + (down_block_res_sample,)
|
| 1106 |
+
|
| 1107 |
+
down_block_res_samples = new_down_block_res_samples
|
| 1108 |
+
|
| 1109 |
+
# 4. mid
|
| 1110 |
+
if self.mid_block is not None:
|
| 1111 |
+
if hasattr(self.mid_block, "has_cross_attention") and self.mid_block.has_cross_attention:
|
| 1112 |
+
sample, spatial_attn_inputs, spatial_attn_idx = self.mid_block(
|
| 1113 |
+
sample,
|
| 1114 |
+
spatial_attn_inputs=spatial_attn_inputs,
|
| 1115 |
+
spatial_attn_idx=spatial_attn_idx,
|
| 1116 |
+
temb=emb,
|
| 1117 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1118 |
+
attention_mask=attention_mask,
|
| 1119 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 1120 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1121 |
+
)
|
| 1122 |
+
else:
|
| 1123 |
+
sample = self.mid_block(sample, emb)
|
| 1124 |
+
|
| 1125 |
+
# To support T2I-Adapter-XL
|
| 1126 |
+
if (
|
| 1127 |
+
is_adapter
|
| 1128 |
+
and len(down_intrablock_additional_residuals) > 0
|
| 1129 |
+
and sample.shape == down_intrablock_additional_residuals[0].shape
|
| 1130 |
+
):
|
| 1131 |
+
sample += down_intrablock_additional_residuals.pop(0)
|
| 1132 |
+
|
| 1133 |
+
if is_controlnet:
|
| 1134 |
+
sample = sample + mid_block_additional_residual
|
| 1135 |
+
|
| 1136 |
+
# 5. up
|
| 1137 |
+
for i, upsample_block in enumerate(self.up_blocks):
|
| 1138 |
+
is_final_block = i == len(self.up_blocks) - 1
|
| 1139 |
+
|
| 1140 |
+
res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
|
| 1141 |
+
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
|
| 1142 |
+
|
| 1143 |
+
# if we have not reached the final block and need to forward the
|
| 1144 |
+
# upsample size, we do it here
|
| 1145 |
+
if not is_final_block and forward_upsample_size:
|
| 1146 |
+
upsample_size = down_block_res_samples[-1].shape[2:]
|
| 1147 |
+
|
| 1148 |
+
if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
|
| 1149 |
+
sample, spatial_attn_inputs, spatial_attn_idx = upsample_block(
|
| 1150 |
+
hidden_states=sample,
|
| 1151 |
+
spatial_attn_inputs=spatial_attn_inputs,
|
| 1152 |
+
spatial_attn_idx=spatial_attn_idx,
|
| 1153 |
+
temb=emb,
|
| 1154 |
+
res_hidden_states_tuple=res_samples,
|
| 1155 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1156 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 1157 |
+
upsample_size=upsample_size,
|
| 1158 |
+
attention_mask=attention_mask,
|
| 1159 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1160 |
+
)
|
| 1161 |
+
else:
|
| 1162 |
+
sample = upsample_block(
|
| 1163 |
+
hidden_states=sample,
|
| 1164 |
+
temb=emb,
|
| 1165 |
+
res_hidden_states_tuple=res_samples,
|
| 1166 |
+
upsample_size=upsample_size,
|
| 1167 |
+
scale=lora_scale,
|
| 1168 |
+
)
|
| 1169 |
+
|
| 1170 |
+
# 6. post-process
|
| 1171 |
+
if self.conv_norm_out:
|
| 1172 |
+
sample = self.conv_norm_out(sample)
|
| 1173 |
+
sample = self.conv_act(sample)
|
| 1174 |
+
sample = self.conv_out(sample)
|
| 1175 |
+
|
| 1176 |
+
if USE_PEFT_BACKEND:
|
| 1177 |
+
# remove `lora_scale` from each PEFT layer
|
| 1178 |
+
unscale_lora_layers(self, lora_scale)
|
| 1179 |
+
|
| 1180 |
+
if not return_dict:
|
| 1181 |
+
return (sample,)
|
| 1182 |
+
|
| 1183 |
+
return UNet2DConditionOutput(sample=sample)
|
preprocess/humanparsing/datasets/__init__.py
ADDED
|
File without changes
|
preprocess/humanparsing/datasets/datasets.py
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- encoding: utf-8 -*-
|
| 3 |
+
|
| 4 |
+
"""
|
| 5 |
+
@Author : Peike Li
|
| 6 |
+
@Contact : [email protected]
|
| 7 |
+
@File : datasets.py
|
| 8 |
+
@Time : 8/4/19 3:35 PM
|
| 9 |
+
@Desc :
|
| 10 |
+
@License : This source code is licensed under the license found in the
|
| 11 |
+
LICENSE file in the root directory of this source tree.
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
import os
|
| 15 |
+
import numpy as np
|
| 16 |
+
import random
|
| 17 |
+
import torch
|
| 18 |
+
import cv2
|
| 19 |
+
from torch.utils import data
|
| 20 |
+
from utils.transforms import get_affine_transform
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
class LIPDataSet(data.Dataset):
|
| 24 |
+
def __init__(self, root, dataset, crop_size=[473, 473], scale_factor=0.25,
|
| 25 |
+
rotation_factor=30, ignore_label=255, transform=None):
|
| 26 |
+
self.root = root
|
| 27 |
+
self.aspect_ratio = crop_size[1] * 1.0 / crop_size[0]
|
| 28 |
+
self.crop_size = np.asarray(crop_size)
|
| 29 |
+
self.ignore_label = ignore_label
|
| 30 |
+
self.scale_factor = scale_factor
|
| 31 |
+
self.rotation_factor = rotation_factor
|
| 32 |
+
self.flip_prob = 0.5
|
| 33 |
+
self.transform = transform
|
| 34 |
+
self.dataset = dataset
|
| 35 |
+
|
| 36 |
+
list_path = os.path.join(self.root, self.dataset + '_id.txt')
|
| 37 |
+
train_list = [i_id.strip() for i_id in open(list_path)]
|
| 38 |
+
|
| 39 |
+
self.train_list = train_list
|
| 40 |
+
self.number_samples = len(self.train_list)
|
| 41 |
+
|
| 42 |
+
def __len__(self):
|
| 43 |
+
return self.number_samples
|
| 44 |
+
|
| 45 |
+
def _box2cs(self, box):
|
| 46 |
+
x, y, w, h = box[:4]
|
| 47 |
+
return self._xywh2cs(x, y, w, h)
|
| 48 |
+
|
| 49 |
+
def _xywh2cs(self, x, y, w, h):
|
| 50 |
+
center = np.zeros((2), dtype=np.float32)
|
| 51 |
+
center[0] = x + w * 0.5
|
| 52 |
+
center[1] = y + h * 0.5
|
| 53 |
+
if w > self.aspect_ratio * h:
|
| 54 |
+
h = w * 1.0 / self.aspect_ratio
|
| 55 |
+
elif w < self.aspect_ratio * h:
|
| 56 |
+
w = h * self.aspect_ratio
|
| 57 |
+
scale = np.array([w * 1.0, h * 1.0], dtype=np.float32)
|
| 58 |
+
return center, scale
|
| 59 |
+
|
| 60 |
+
def __getitem__(self, index):
|
| 61 |
+
train_item = self.train_list[index]
|
| 62 |
+
|
| 63 |
+
im_path = os.path.join(self.root, self.dataset + '_images', train_item + '.jpg')
|
| 64 |
+
parsing_anno_path = os.path.join(self.root, self.dataset + '_segmentations', train_item + '.png')
|
| 65 |
+
|
| 66 |
+
im = cv2.imread(im_path, cv2.IMREAD_COLOR)
|
| 67 |
+
h, w, _ = im.shape
|
| 68 |
+
parsing_anno = np.zeros((h, w), dtype=np.long)
|
| 69 |
+
|
| 70 |
+
# Get person center and scale
|
| 71 |
+
person_center, s = self._box2cs([0, 0, w - 1, h - 1])
|
| 72 |
+
r = 0
|
| 73 |
+
|
| 74 |
+
if self.dataset != 'test':
|
| 75 |
+
# Get pose annotation
|
| 76 |
+
parsing_anno = cv2.imread(parsing_anno_path, cv2.IMREAD_GRAYSCALE)
|
| 77 |
+
if self.dataset == 'train' or self.dataset == 'trainval':
|
| 78 |
+
sf = self.scale_factor
|
| 79 |
+
rf = self.rotation_factor
|
| 80 |
+
s = s * np.clip(np.random.randn() * sf + 1, 1 - sf, 1 + sf)
|
| 81 |
+
r = np.clip(np.random.randn() * rf, -rf * 2, rf * 2) if random.random() <= 0.6 else 0
|
| 82 |
+
|
| 83 |
+
if random.random() <= self.flip_prob:
|
| 84 |
+
im = im[:, ::-1, :]
|
| 85 |
+
parsing_anno = parsing_anno[:, ::-1]
|
| 86 |
+
person_center[0] = im.shape[1] - person_center[0] - 1
|
| 87 |
+
right_idx = [15, 17, 19]
|
| 88 |
+
left_idx = [14, 16, 18]
|
| 89 |
+
for i in range(0, 3):
|
| 90 |
+
right_pos = np.where(parsing_anno == right_idx[i])
|
| 91 |
+
left_pos = np.where(parsing_anno == left_idx[i])
|
| 92 |
+
parsing_anno[right_pos[0], right_pos[1]] = left_idx[i]
|
| 93 |
+
parsing_anno[left_pos[0], left_pos[1]] = right_idx[i]
|
| 94 |
+
|
| 95 |
+
trans = get_affine_transform(person_center, s, r, self.crop_size)
|
| 96 |
+
input = cv2.warpAffine(
|
| 97 |
+
im,
|
| 98 |
+
trans,
|
| 99 |
+
(int(self.crop_size[1]), int(self.crop_size[0])),
|
| 100 |
+
flags=cv2.INTER_LINEAR,
|
| 101 |
+
borderMode=cv2.BORDER_CONSTANT,
|
| 102 |
+
borderValue=(0, 0, 0))
|
| 103 |
+
|
| 104 |
+
if self.transform:
|
| 105 |
+
input = self.transform(input)
|
| 106 |
+
|
| 107 |
+
meta = {
|
| 108 |
+
'name': train_item,
|
| 109 |
+
'center': person_center,
|
| 110 |
+
'height': h,
|
| 111 |
+
'width': w,
|
| 112 |
+
'scale': s,
|
| 113 |
+
'rotation': r
|
| 114 |
+
}
|
| 115 |
+
|
| 116 |
+
if self.dataset == 'val' or self.dataset == 'test':
|
| 117 |
+
return input, meta
|
| 118 |
+
else:
|
| 119 |
+
label_parsing = cv2.warpAffine(
|
| 120 |
+
parsing_anno,
|
| 121 |
+
trans,
|
| 122 |
+
(int(self.crop_size[1]), int(self.crop_size[0])),
|
| 123 |
+
flags=cv2.INTER_NEAREST,
|
| 124 |
+
borderMode=cv2.BORDER_CONSTANT,
|
| 125 |
+
borderValue=(255))
|
| 126 |
+
|
| 127 |
+
label_parsing = torch.from_numpy(label_parsing)
|
| 128 |
+
|
| 129 |
+
return input, label_parsing, meta
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
class LIPDataValSet(data.Dataset):
|
| 133 |
+
def __init__(self, root, dataset='val', crop_size=[473, 473], transform=None, flip=False):
|
| 134 |
+
self.root = root
|
| 135 |
+
self.crop_size = crop_size
|
| 136 |
+
self.transform = transform
|
| 137 |
+
self.flip = flip
|
| 138 |
+
self.dataset = dataset
|
| 139 |
+
self.root = root
|
| 140 |
+
self.aspect_ratio = crop_size[1] * 1.0 / crop_size[0]
|
| 141 |
+
self.crop_size = np.asarray(crop_size)
|
| 142 |
+
|
| 143 |
+
list_path = os.path.join(self.root, self.dataset + '_id.txt')
|
| 144 |
+
val_list = [i_id.strip() for i_id in open(list_path)]
|
| 145 |
+
|
| 146 |
+
self.val_list = val_list
|
| 147 |
+
self.number_samples = len(self.val_list)
|
| 148 |
+
|
| 149 |
+
def __len__(self):
|
| 150 |
+
return len(self.val_list)
|
| 151 |
+
|
| 152 |
+
def _box2cs(self, box):
|
| 153 |
+
x, y, w, h = box[:4]
|
| 154 |
+
return self._xywh2cs(x, y, w, h)
|
| 155 |
+
|
| 156 |
+
def _xywh2cs(self, x, y, w, h):
|
| 157 |
+
center = np.zeros((2), dtype=np.float32)
|
| 158 |
+
center[0] = x + w * 0.5
|
| 159 |
+
center[1] = y + h * 0.5
|
| 160 |
+
if w > self.aspect_ratio * h:
|
| 161 |
+
h = w * 1.0 / self.aspect_ratio
|
| 162 |
+
elif w < self.aspect_ratio * h:
|
| 163 |
+
w = h * self.aspect_ratio
|
| 164 |
+
scale = np.array([w * 1.0, h * 1.0], dtype=np.float32)
|
| 165 |
+
|
| 166 |
+
return center, scale
|
| 167 |
+
|
| 168 |
+
def __getitem__(self, index):
|
| 169 |
+
val_item = self.val_list[index]
|
| 170 |
+
# Load training image
|
| 171 |
+
im_path = os.path.join(self.root, self.dataset + '_images', val_item + '.jpg')
|
| 172 |
+
im = cv2.imread(im_path, cv2.IMREAD_COLOR)
|
| 173 |
+
h, w, _ = im.shape
|
| 174 |
+
# Get person center and scale
|
| 175 |
+
person_center, s = self._box2cs([0, 0, w - 1, h - 1])
|
| 176 |
+
r = 0
|
| 177 |
+
trans = get_affine_transform(person_center, s, r, self.crop_size)
|
| 178 |
+
input = cv2.warpAffine(
|
| 179 |
+
im,
|
| 180 |
+
trans,
|
| 181 |
+
(int(self.crop_size[1]), int(self.crop_size[0])),
|
| 182 |
+
flags=cv2.INTER_LINEAR,
|
| 183 |
+
borderMode=cv2.BORDER_CONSTANT,
|
| 184 |
+
borderValue=(0, 0, 0))
|
| 185 |
+
input = self.transform(input)
|
| 186 |
+
flip_input = input.flip(dims=[-1])
|
| 187 |
+
if self.flip:
|
| 188 |
+
batch_input_im = torch.stack([input, flip_input])
|
| 189 |
+
else:
|
| 190 |
+
batch_input_im = input
|
| 191 |
+
|
| 192 |
+
meta = {
|
| 193 |
+
'name': val_item,
|
| 194 |
+
'center': person_center,
|
| 195 |
+
'height': h,
|
| 196 |
+
'width': w,
|
| 197 |
+
'scale': s,
|
| 198 |
+
'rotation': r
|
| 199 |
+
}
|
| 200 |
+
|
| 201 |
+
return batch_input_im, meta
|
preprocess/humanparsing/datasets/simple_extractor_dataset.py
ADDED
|
@@ -0,0 +1,89 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- encoding: utf-8 -*-
|
| 3 |
+
|
| 4 |
+
"""
|
| 5 |
+
@Author : Peike Li
|
| 6 |
+
@Contact : [email protected]
|
| 7 |
+
@File : dataset.py
|
| 8 |
+
@Time : 8/30/19 9:12 PM
|
| 9 |
+
@Desc : Dataset Definition
|
| 10 |
+
@License : This source code is licensed under the license found in the
|
| 11 |
+
LICENSE file in the root directory of this source tree.
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
import os
|
| 15 |
+
import pdb
|
| 16 |
+
|
| 17 |
+
import cv2
|
| 18 |
+
import numpy as np
|
| 19 |
+
from PIL import Image
|
| 20 |
+
from torch.utils import data
|
| 21 |
+
from utils.transforms import get_affine_transform
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class SimpleFolderDataset(data.Dataset):
|
| 25 |
+
def __init__(self, root, input_size=[512, 512], transform=None):
|
| 26 |
+
self.root = root
|
| 27 |
+
self.input_size = input_size
|
| 28 |
+
self.transform = transform
|
| 29 |
+
self.aspect_ratio = input_size[1] * 1.0 / input_size[0]
|
| 30 |
+
self.input_size = np.asarray(input_size)
|
| 31 |
+
self.is_pil_image = False
|
| 32 |
+
if isinstance(root, Image.Image):
|
| 33 |
+
self.file_list = [root]
|
| 34 |
+
self.is_pil_image = True
|
| 35 |
+
elif os.path.isfile(root):
|
| 36 |
+
self.file_list = [os.path.basename(root)]
|
| 37 |
+
self.root = os.path.dirname(root)
|
| 38 |
+
else:
|
| 39 |
+
self.file_list = os.listdir(self.root)
|
| 40 |
+
|
| 41 |
+
def __len__(self):
|
| 42 |
+
return len(self.file_list)
|
| 43 |
+
|
| 44 |
+
def _box2cs(self, box):
|
| 45 |
+
x, y, w, h = box[:4]
|
| 46 |
+
return self._xywh2cs(x, y, w, h)
|
| 47 |
+
|
| 48 |
+
def _xywh2cs(self, x, y, w, h):
|
| 49 |
+
center = np.zeros((2), dtype=np.float32)
|
| 50 |
+
center[0] = x + w * 0.5
|
| 51 |
+
center[1] = y + h * 0.5
|
| 52 |
+
if w > self.aspect_ratio * h:
|
| 53 |
+
h = w * 1.0 / self.aspect_ratio
|
| 54 |
+
elif w < self.aspect_ratio * h:
|
| 55 |
+
w = h * self.aspect_ratio
|
| 56 |
+
scale = np.array([w, h], dtype=np.float32)
|
| 57 |
+
return center, scale
|
| 58 |
+
|
| 59 |
+
def __getitem__(self, index):
|
| 60 |
+
if self.is_pil_image:
|
| 61 |
+
img = np.asarray(self.file_list[index])[:, :, [2, 1, 0]]
|
| 62 |
+
else:
|
| 63 |
+
img_name = self.file_list[index]
|
| 64 |
+
img_path = os.path.join(self.root, img_name)
|
| 65 |
+
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
|
| 66 |
+
h, w, _ = img.shape
|
| 67 |
+
|
| 68 |
+
# Get person center and scale
|
| 69 |
+
person_center, s = self._box2cs([0, 0, w - 1, h - 1])
|
| 70 |
+
r = 0
|
| 71 |
+
trans = get_affine_transform(person_center, s, r, self.input_size)
|
| 72 |
+
input = cv2.warpAffine(
|
| 73 |
+
img,
|
| 74 |
+
trans,
|
| 75 |
+
(int(self.input_size[1]), int(self.input_size[0])),
|
| 76 |
+
flags=cv2.INTER_LINEAR,
|
| 77 |
+
borderMode=cv2.BORDER_CONSTANT,
|
| 78 |
+
borderValue=(0, 0, 0))
|
| 79 |
+
|
| 80 |
+
input = self.transform(input)
|
| 81 |
+
meta = {
|
| 82 |
+
'center': person_center,
|
| 83 |
+
'height': h,
|
| 84 |
+
'width': w,
|
| 85 |
+
'scale': s,
|
| 86 |
+
'rotation': r
|
| 87 |
+
}
|
| 88 |
+
|
| 89 |
+
return input, meta
|
preprocess/humanparsing/datasets/target_generation.py
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch.nn import functional as F
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def generate_edge_tensor(label, edge_width=3):
|
| 6 |
+
label = label.type(torch.cuda.FloatTensor)
|
| 7 |
+
if len(label.shape) == 2:
|
| 8 |
+
label = label.unsqueeze(0)
|
| 9 |
+
n, h, w = label.shape
|
| 10 |
+
edge = torch.zeros(label.shape, dtype=torch.float).cuda()
|
| 11 |
+
# right
|
| 12 |
+
edge_right = edge[:, 1:h, :]
|
| 13 |
+
edge_right[(label[:, 1:h, :] != label[:, :h - 1, :]) & (label[:, 1:h, :] != 255)
|
| 14 |
+
& (label[:, :h - 1, :] != 255)] = 1
|
| 15 |
+
|
| 16 |
+
# up
|
| 17 |
+
edge_up = edge[:, :, :w - 1]
|
| 18 |
+
edge_up[(label[:, :, :w - 1] != label[:, :, 1:w])
|
| 19 |
+
& (label[:, :, :w - 1] != 255)
|
| 20 |
+
& (label[:, :, 1:w] != 255)] = 1
|
| 21 |
+
|
| 22 |
+
# upright
|
| 23 |
+
edge_upright = edge[:, :h - 1, :w - 1]
|
| 24 |
+
edge_upright[(label[:, :h - 1, :w - 1] != label[:, 1:h, 1:w])
|
| 25 |
+
& (label[:, :h - 1, :w - 1] != 255)
|
| 26 |
+
& (label[:, 1:h, 1:w] != 255)] = 1
|
| 27 |
+
|
| 28 |
+
# bottomright
|
| 29 |
+
edge_bottomright = edge[:, :h - 1, 1:w]
|
| 30 |
+
edge_bottomright[(label[:, :h - 1, 1:w] != label[:, 1:h, :w - 1])
|
| 31 |
+
& (label[:, :h - 1, 1:w] != 255)
|
| 32 |
+
& (label[:, 1:h, :w - 1] != 255)] = 1
|
| 33 |
+
|
| 34 |
+
kernel = torch.ones((1, 1, edge_width, edge_width), dtype=torch.float).cuda()
|
| 35 |
+
with torch.no_grad():
|
| 36 |
+
edge = edge.unsqueeze(1)
|
| 37 |
+
edge = F.conv2d(edge, kernel, stride=1, padding=1)
|
| 38 |
+
edge[edge!=0] = 1
|
| 39 |
+
edge = edge.squeeze()
|
| 40 |
+
return edge
|
preprocess/humanparsing/mhp_extension/coco_style_annotation_creator/human_to_coco.py
ADDED
|
@@ -0,0 +1,166 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import datetime
|
| 3 |
+
import json
|
| 4 |
+
import os
|
| 5 |
+
from PIL import Image
|
| 6 |
+
import numpy as np
|
| 7 |
+
|
| 8 |
+
import pycococreatortools
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def get_arguments():
|
| 12 |
+
parser = argparse.ArgumentParser(description="transform mask annotation to coco annotation")
|
| 13 |
+
parser.add_argument("--dataset", type=str, default='CIHP', help="name of dataset (CIHP, MHPv2 or VIP)")
|
| 14 |
+
parser.add_argument("--json_save_dir", type=str, default='../data/msrcnn_finetune_annotations',
|
| 15 |
+
help="path to save coco-style annotation json file")
|
| 16 |
+
parser.add_argument("--use_val", type=bool, default=False,
|
| 17 |
+
help="use train+val set for finetuning or not")
|
| 18 |
+
parser.add_argument("--train_img_dir", type=str, default='../data/instance-level_human_parsing/Training/Images',
|
| 19 |
+
help="train image path")
|
| 20 |
+
parser.add_argument("--train_anno_dir", type=str,
|
| 21 |
+
default='../data/instance-level_human_parsing/Training/Human_ids',
|
| 22 |
+
help="train human mask path")
|
| 23 |
+
parser.add_argument("--val_img_dir", type=str, default='../data/instance-level_human_parsing/Validation/Images',
|
| 24 |
+
help="val image path")
|
| 25 |
+
parser.add_argument("--val_anno_dir", type=str,
|
| 26 |
+
default='../data/instance-level_human_parsing/Validation/Human_ids',
|
| 27 |
+
help="val human mask path")
|
| 28 |
+
return parser.parse_args()
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def main(args):
|
| 32 |
+
INFO = {
|
| 33 |
+
"description": args.split_name + " Dataset",
|
| 34 |
+
"url": "",
|
| 35 |
+
"version": "",
|
| 36 |
+
"year": 2019,
|
| 37 |
+
"contributor": "xyq",
|
| 38 |
+
"date_created": datetime.datetime.utcnow().isoformat(' ')
|
| 39 |
+
}
|
| 40 |
+
|
| 41 |
+
LICENSES = [
|
| 42 |
+
{
|
| 43 |
+
"id": 1,
|
| 44 |
+
"name": "",
|
| 45 |
+
"url": ""
|
| 46 |
+
}
|
| 47 |
+
]
|
| 48 |
+
|
| 49 |
+
CATEGORIES = [
|
| 50 |
+
{
|
| 51 |
+
'id': 1,
|
| 52 |
+
'name': 'person',
|
| 53 |
+
'supercategory': 'person',
|
| 54 |
+
},
|
| 55 |
+
]
|
| 56 |
+
|
| 57 |
+
coco_output = {
|
| 58 |
+
"info": INFO,
|
| 59 |
+
"licenses": LICENSES,
|
| 60 |
+
"categories": CATEGORIES,
|
| 61 |
+
"images": [],
|
| 62 |
+
"annotations": []
|
| 63 |
+
}
|
| 64 |
+
|
| 65 |
+
image_id = 1
|
| 66 |
+
segmentation_id = 1
|
| 67 |
+
|
| 68 |
+
for image_name in os.listdir(args.train_img_dir):
|
| 69 |
+
image = Image.open(os.path.join(args.train_img_dir, image_name))
|
| 70 |
+
image_info = pycococreatortools.create_image_info(
|
| 71 |
+
image_id, image_name, image.size
|
| 72 |
+
)
|
| 73 |
+
coco_output["images"].append(image_info)
|
| 74 |
+
|
| 75 |
+
human_mask_name = os.path.splitext(image_name)[0] + '.png'
|
| 76 |
+
human_mask = np.asarray(Image.open(os.path.join(args.train_anno_dir, human_mask_name)))
|
| 77 |
+
human_gt_labels = np.unique(human_mask)
|
| 78 |
+
|
| 79 |
+
for i in range(1, len(human_gt_labels)):
|
| 80 |
+
category_info = {'id': 1, 'is_crowd': 0}
|
| 81 |
+
binary_mask = np.uint8(human_mask == i)
|
| 82 |
+
annotation_info = pycococreatortools.create_annotation_info(
|
| 83 |
+
segmentation_id, image_id, category_info, binary_mask,
|
| 84 |
+
image.size, tolerance=10
|
| 85 |
+
)
|
| 86 |
+
if annotation_info is not None:
|
| 87 |
+
coco_output["annotations"].append(annotation_info)
|
| 88 |
+
|
| 89 |
+
segmentation_id += 1
|
| 90 |
+
image_id += 1
|
| 91 |
+
|
| 92 |
+
if not os.path.exists(args.json_save_dir):
|
| 93 |
+
os.makedirs(args.json_save_dir)
|
| 94 |
+
if not args.use_val:
|
| 95 |
+
with open('{}/{}_train.json'.format(args.json_save_dir, args.split_name), 'w') as output_json_file:
|
| 96 |
+
json.dump(coco_output, output_json_file)
|
| 97 |
+
else:
|
| 98 |
+
for image_name in os.listdir(args.val_img_dir):
|
| 99 |
+
image = Image.open(os.path.join(args.val_img_dir, image_name))
|
| 100 |
+
image_info = pycococreatortools.create_image_info(
|
| 101 |
+
image_id, image_name, image.size
|
| 102 |
+
)
|
| 103 |
+
coco_output["images"].append(image_info)
|
| 104 |
+
|
| 105 |
+
human_mask_name = os.path.splitext(image_name)[0] + '.png'
|
| 106 |
+
human_mask = np.asarray(Image.open(os.path.join(args.val_anno_dir, human_mask_name)))
|
| 107 |
+
human_gt_labels = np.unique(human_mask)
|
| 108 |
+
|
| 109 |
+
for i in range(1, len(human_gt_labels)):
|
| 110 |
+
category_info = {'id': 1, 'is_crowd': 0}
|
| 111 |
+
binary_mask = np.uint8(human_mask == i)
|
| 112 |
+
annotation_info = pycococreatortools.create_annotation_info(
|
| 113 |
+
segmentation_id, image_id, category_info, binary_mask,
|
| 114 |
+
image.size, tolerance=10
|
| 115 |
+
)
|
| 116 |
+
if annotation_info is not None:
|
| 117 |
+
coco_output["annotations"].append(annotation_info)
|
| 118 |
+
|
| 119 |
+
segmentation_id += 1
|
| 120 |
+
image_id += 1
|
| 121 |
+
|
| 122 |
+
with open('{}/{}_trainval.json'.format(args.json_save_dir, args.split_name), 'w') as output_json_file:
|
| 123 |
+
json.dump(coco_output, output_json_file)
|
| 124 |
+
|
| 125 |
+
coco_output_val = {
|
| 126 |
+
"info": INFO,
|
| 127 |
+
"licenses": LICENSES,
|
| 128 |
+
"categories": CATEGORIES,
|
| 129 |
+
"images": [],
|
| 130 |
+
"annotations": []
|
| 131 |
+
}
|
| 132 |
+
|
| 133 |
+
image_id_val = 1
|
| 134 |
+
segmentation_id_val = 1
|
| 135 |
+
|
| 136 |
+
for image_name in os.listdir(args.val_img_dir):
|
| 137 |
+
image = Image.open(os.path.join(args.val_img_dir, image_name))
|
| 138 |
+
image_info = pycococreatortools.create_image_info(
|
| 139 |
+
image_id_val, image_name, image.size
|
| 140 |
+
)
|
| 141 |
+
coco_output_val["images"].append(image_info)
|
| 142 |
+
|
| 143 |
+
human_mask_name = os.path.splitext(image_name)[0] + '.png'
|
| 144 |
+
human_mask = np.asarray(Image.open(os.path.join(args.val_anno_dir, human_mask_name)))
|
| 145 |
+
human_gt_labels = np.unique(human_mask)
|
| 146 |
+
|
| 147 |
+
for i in range(1, len(human_gt_labels)):
|
| 148 |
+
category_info = {'id': 1, 'is_crowd': 0}
|
| 149 |
+
binary_mask = np.uint8(human_mask == i)
|
| 150 |
+
annotation_info = pycococreatortools.create_annotation_info(
|
| 151 |
+
segmentation_id_val, image_id_val, category_info, binary_mask,
|
| 152 |
+
image.size, tolerance=10
|
| 153 |
+
)
|
| 154 |
+
if annotation_info is not None:
|
| 155 |
+
coco_output_val["annotations"].append(annotation_info)
|
| 156 |
+
|
| 157 |
+
segmentation_id_val += 1
|
| 158 |
+
image_id_val += 1
|
| 159 |
+
|
| 160 |
+
with open('{}/{}_val.json'.format(args.json_save_dir, args.split_name), 'w') as output_json_file_val:
|
| 161 |
+
json.dump(coco_output_val, output_json_file_val)
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
if __name__ == "__main__":
|
| 165 |
+
args = get_arguments()
|
| 166 |
+
main(args)
|
preprocess/humanparsing/mhp_extension/coco_style_annotation_creator/pycococreatortools.py
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
import datetime
|
| 3 |
+
import numpy as np
|
| 4 |
+
from itertools import groupby
|
| 5 |
+
from skimage import measure
|
| 6 |
+
from PIL import Image
|
| 7 |
+
from pycocotools import mask
|
| 8 |
+
|
| 9 |
+
convert = lambda text: int(text) if text.isdigit() else text.lower()
|
| 10 |
+
natrual_key = lambda key: [convert(c) for c in re.split('([0-9]+)', key)]
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def resize_binary_mask(array, new_size):
|
| 14 |
+
image = Image.fromarray(array.astype(np.uint8) * 255)
|
| 15 |
+
image = image.resize(new_size)
|
| 16 |
+
return np.asarray(image).astype(np.bool_)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def close_contour(contour):
|
| 20 |
+
if not np.array_equal(contour[0], contour[-1]):
|
| 21 |
+
contour = np.vstack((contour, contour[0]))
|
| 22 |
+
return contour
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def binary_mask_to_rle(binary_mask):
|
| 26 |
+
rle = {'counts': [], 'size': list(binary_mask.shape)}
|
| 27 |
+
counts = rle.get('counts')
|
| 28 |
+
for i, (value, elements) in enumerate(groupby(binary_mask.ravel(order='F'))):
|
| 29 |
+
if i == 0 and value == 1:
|
| 30 |
+
counts.append(0)
|
| 31 |
+
counts.append(len(list(elements)))
|
| 32 |
+
|
| 33 |
+
return rle
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def binary_mask_to_polygon(binary_mask, tolerance=0):
|
| 37 |
+
"""Converts a binary mask to COCO polygon representation
|
| 38 |
+
Args:
|
| 39 |
+
binary_mask: a 2D binary numpy array where '1's represent the object
|
| 40 |
+
tolerance: Maximum distance from original points of polygon to approximated
|
| 41 |
+
polygonal chain. If tolerance is 0, the original coordinate array is returned.
|
| 42 |
+
"""
|
| 43 |
+
polygons = []
|
| 44 |
+
# pad mask to close contours of shapes which start and end at an edge
|
| 45 |
+
padded_binary_mask = np.pad(binary_mask, pad_width=1, mode='constant', constant_values=0)
|
| 46 |
+
contours = measure.find_contours(padded_binary_mask, 0.5)
|
| 47 |
+
contours = np.subtract(contours, 1)
|
| 48 |
+
for contour in contours:
|
| 49 |
+
contour = close_contour(contour)
|
| 50 |
+
contour = measure.approximate_polygon(contour, tolerance)
|
| 51 |
+
if len(contour) < 3:
|
| 52 |
+
continue
|
| 53 |
+
contour = np.flip(contour, axis=1)
|
| 54 |
+
segmentation = contour.ravel().tolist()
|
| 55 |
+
# after padding and subtracting 1 we may get -0.5 points in our segmentation
|
| 56 |
+
segmentation = [0 if i < 0 else i for i in segmentation]
|
| 57 |
+
polygons.append(segmentation)
|
| 58 |
+
|
| 59 |
+
return polygons
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def create_image_info(image_id, file_name, image_size,
|
| 63 |
+
date_captured=datetime.datetime.utcnow().isoformat(' '),
|
| 64 |
+
license_id=1, coco_url="", flickr_url=""):
|
| 65 |
+
image_info = {
|
| 66 |
+
"id": image_id,
|
| 67 |
+
"file_name": file_name,
|
| 68 |
+
"width": image_size[0],
|
| 69 |
+
"height": image_size[1],
|
| 70 |
+
"date_captured": date_captured,
|
| 71 |
+
"license": license_id,
|
| 72 |
+
"coco_url": coco_url,
|
| 73 |
+
"flickr_url": flickr_url
|
| 74 |
+
}
|
| 75 |
+
|
| 76 |
+
return image_info
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
def create_annotation_info(annotation_id, image_id, category_info, binary_mask,
|
| 80 |
+
image_size=None, tolerance=2, bounding_box=None):
|
| 81 |
+
if image_size is not None:
|
| 82 |
+
binary_mask = resize_binary_mask(binary_mask, image_size)
|
| 83 |
+
|
| 84 |
+
binary_mask_encoded = mask.encode(np.asfortranarray(binary_mask.astype(np.uint8)))
|
| 85 |
+
|
| 86 |
+
area = mask.area(binary_mask_encoded)
|
| 87 |
+
if area < 1:
|
| 88 |
+
return None
|
| 89 |
+
|
| 90 |
+
if bounding_box is None:
|
| 91 |
+
bounding_box = mask.toBbox(binary_mask_encoded)
|
| 92 |
+
|
| 93 |
+
if category_info["is_crowd"]:
|
| 94 |
+
is_crowd = 1
|
| 95 |
+
segmentation = binary_mask_to_rle(binary_mask)
|
| 96 |
+
else:
|
| 97 |
+
is_crowd = 0
|
| 98 |
+
segmentation = binary_mask_to_polygon(binary_mask, tolerance)
|
| 99 |
+
if not segmentation:
|
| 100 |
+
return None
|
| 101 |
+
|
| 102 |
+
annotation_info = {
|
| 103 |
+
"id": annotation_id,
|
| 104 |
+
"image_id": image_id,
|
| 105 |
+
"category_id": category_info["id"],
|
| 106 |
+
"iscrowd": is_crowd,
|
| 107 |
+
"area": area.tolist(),
|
| 108 |
+
"bbox": bounding_box.tolist(),
|
| 109 |
+
"segmentation": segmentation,
|
| 110 |
+
"width": binary_mask.shape[1],
|
| 111 |
+
"height": binary_mask.shape[0],
|
| 112 |
+
}
|
| 113 |
+
|
| 114 |
+
return annotation_info
|
preprocess/humanparsing/mhp_extension/coco_style_annotation_creator/test_human2coco_format.py
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import datetime
|
| 3 |
+
import json
|
| 4 |
+
import os
|
| 5 |
+
from PIL import Image
|
| 6 |
+
|
| 7 |
+
import pycococreatortools
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def get_arguments():
|
| 11 |
+
parser = argparse.ArgumentParser(description="transform mask annotation to coco annotation")
|
| 12 |
+
parser.add_argument("--dataset", type=str, default='CIHP', help="name of dataset (CIHP, MHPv2 or VIP)")
|
| 13 |
+
parser.add_argument("--json_save_dir", type=str, default='../data/CIHP/annotations',
|
| 14 |
+
help="path to save coco-style annotation json file")
|
| 15 |
+
parser.add_argument("--test_img_dir", type=str, default='../data/CIHP/Testing/Images',
|
| 16 |
+
help="test image path")
|
| 17 |
+
return parser.parse_args()
|
| 18 |
+
|
| 19 |
+
args = get_arguments()
|
| 20 |
+
|
| 21 |
+
INFO = {
|
| 22 |
+
"description": args.dataset + "Dataset",
|
| 23 |
+
"url": "",
|
| 24 |
+
"version": "",
|
| 25 |
+
"year": 2020,
|
| 26 |
+
"contributor": "yunqiuxu",
|
| 27 |
+
"date_created": datetime.datetime.utcnow().isoformat(' ')
|
| 28 |
+
}
|
| 29 |
+
|
| 30 |
+
LICENSES = [
|
| 31 |
+
{
|
| 32 |
+
"id": 1,
|
| 33 |
+
"name": "",
|
| 34 |
+
"url": ""
|
| 35 |
+
}
|
| 36 |
+
]
|
| 37 |
+
|
| 38 |
+
CATEGORIES = [
|
| 39 |
+
{
|
| 40 |
+
'id': 1,
|
| 41 |
+
'name': 'person',
|
| 42 |
+
'supercategory': 'person',
|
| 43 |
+
},
|
| 44 |
+
]
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def main(args):
|
| 48 |
+
coco_output = {
|
| 49 |
+
"info": INFO,
|
| 50 |
+
"licenses": LICENSES,
|
| 51 |
+
"categories": CATEGORIES,
|
| 52 |
+
"images": [],
|
| 53 |
+
"annotations": []
|
| 54 |
+
}
|
| 55 |
+
|
| 56 |
+
image_id = 1
|
| 57 |
+
|
| 58 |
+
for image_name in os.listdir(args.test_img_dir):
|
| 59 |
+
image = Image.open(os.path.join(args.test_img_dir, image_name))
|
| 60 |
+
image_info = pycococreatortools.create_image_info(
|
| 61 |
+
image_id, image_name, image.size
|
| 62 |
+
)
|
| 63 |
+
coco_output["images"].append(image_info)
|
| 64 |
+
image_id += 1
|
| 65 |
+
|
| 66 |
+
if not os.path.exists(os.path.join(args.json_save_dir)):
|
| 67 |
+
os.mkdir(os.path.join(args.json_save_dir))
|
| 68 |
+
|
| 69 |
+
with open('{}/{}.json'.format(args.json_save_dir, args.dataset), 'w') as output_json_file:
|
| 70 |
+
json.dump(coco_output, output_json_file)
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
if __name__ == "__main__":
|
| 74 |
+
main(args)
|
preprocess/humanparsing/mhp_extension/detectron2/.circleci/config.yml
ADDED
|
@@ -0,0 +1,179 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Python CircleCI 2.0 configuration file
|
| 2 |
+
#
|
| 3 |
+
# Check https://circleci.com/docs/2.0/language-python/ for more details
|
| 4 |
+
#
|
| 5 |
+
version: 2
|
| 6 |
+
|
| 7 |
+
# -------------------------------------------------------------------------------------
|
| 8 |
+
# Environments to run the jobs in
|
| 9 |
+
# -------------------------------------------------------------------------------------
|
| 10 |
+
cpu: &cpu
|
| 11 |
+
docker:
|
| 12 |
+
- image: circleci/python:3.6.8-stretch
|
| 13 |
+
resource_class: medium
|
| 14 |
+
|
| 15 |
+
gpu: &gpu
|
| 16 |
+
machine:
|
| 17 |
+
image: ubuntu-1604:201903-01
|
| 18 |
+
docker_layer_caching: true
|
| 19 |
+
resource_class: gpu.small
|
| 20 |
+
|
| 21 |
+
# -------------------------------------------------------------------------------------
|
| 22 |
+
# Re-usable commands
|
| 23 |
+
# -------------------------------------------------------------------------------------
|
| 24 |
+
install_python: &install_python
|
| 25 |
+
- run:
|
| 26 |
+
name: Install Python
|
| 27 |
+
working_directory: ~/
|
| 28 |
+
command: |
|
| 29 |
+
pyenv install 3.6.1
|
| 30 |
+
pyenv global 3.6.1
|
| 31 |
+
|
| 32 |
+
setup_venv: &setup_venv
|
| 33 |
+
- run:
|
| 34 |
+
name: Setup Virtual Env
|
| 35 |
+
working_directory: ~/
|
| 36 |
+
command: |
|
| 37 |
+
python -m venv ~/venv
|
| 38 |
+
echo ". ~/venv/bin/activate" >> $BASH_ENV
|
| 39 |
+
. ~/venv/bin/activate
|
| 40 |
+
python --version
|
| 41 |
+
which python
|
| 42 |
+
which pip
|
| 43 |
+
pip install --upgrade pip
|
| 44 |
+
|
| 45 |
+
install_dep: &install_dep
|
| 46 |
+
- run:
|
| 47 |
+
name: Install Dependencies
|
| 48 |
+
command: |
|
| 49 |
+
pip install --progress-bar off -U 'git+https://github.com/facebookresearch/fvcore'
|
| 50 |
+
pip install --progress-bar off cython opencv-python
|
| 51 |
+
pip install --progress-bar off 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'
|
| 52 |
+
pip install --progress-bar off torch torchvision
|
| 53 |
+
|
| 54 |
+
install_detectron2: &install_detectron2
|
| 55 |
+
- run:
|
| 56 |
+
name: Install Detectron2
|
| 57 |
+
command: |
|
| 58 |
+
gcc --version
|
| 59 |
+
pip install -U --progress-bar off -e .[dev]
|
| 60 |
+
python -m detectron2.utils.collect_env
|
| 61 |
+
|
| 62 |
+
install_nvidia_driver: &install_nvidia_driver
|
| 63 |
+
- run:
|
| 64 |
+
name: Install nvidia driver
|
| 65 |
+
working_directory: ~/
|
| 66 |
+
command: |
|
| 67 |
+
wget -q 'https://s3.amazonaws.com/ossci-linux/nvidia_driver/NVIDIA-Linux-x86_64-430.40.run'
|
| 68 |
+
sudo /bin/bash ./NVIDIA-Linux-x86_64-430.40.run -s --no-drm
|
| 69 |
+
nvidia-smi
|
| 70 |
+
|
| 71 |
+
run_unittests: &run_unittests
|
| 72 |
+
- run:
|
| 73 |
+
name: Run Unit Tests
|
| 74 |
+
command: |
|
| 75 |
+
python -m unittest discover -v -s tests
|
| 76 |
+
|
| 77 |
+
# -------------------------------------------------------------------------------------
|
| 78 |
+
# Jobs to run
|
| 79 |
+
# -------------------------------------------------------------------------------------
|
| 80 |
+
jobs:
|
| 81 |
+
cpu_tests:
|
| 82 |
+
<<: *cpu
|
| 83 |
+
|
| 84 |
+
working_directory: ~/detectron2
|
| 85 |
+
|
| 86 |
+
steps:
|
| 87 |
+
- checkout
|
| 88 |
+
- <<: *setup_venv
|
| 89 |
+
|
| 90 |
+
# Cache the venv directory that contains dependencies
|
| 91 |
+
- restore_cache:
|
| 92 |
+
keys:
|
| 93 |
+
- cache-key-{{ .Branch }}-ID-20200425
|
| 94 |
+
|
| 95 |
+
- <<: *install_dep
|
| 96 |
+
|
| 97 |
+
- save_cache:
|
| 98 |
+
paths:
|
| 99 |
+
- ~/venv
|
| 100 |
+
key: cache-key-{{ .Branch }}-ID-20200425
|
| 101 |
+
|
| 102 |
+
- <<: *install_detectron2
|
| 103 |
+
|
| 104 |
+
- run:
|
| 105 |
+
name: isort
|
| 106 |
+
command: |
|
| 107 |
+
isort -c -sp .
|
| 108 |
+
- run:
|
| 109 |
+
name: black
|
| 110 |
+
command: |
|
| 111 |
+
black --check -l 100 .
|
| 112 |
+
- run:
|
| 113 |
+
name: flake8
|
| 114 |
+
command: |
|
| 115 |
+
flake8 .
|
| 116 |
+
|
| 117 |
+
- <<: *run_unittests
|
| 118 |
+
|
| 119 |
+
gpu_tests:
|
| 120 |
+
<<: *gpu
|
| 121 |
+
|
| 122 |
+
working_directory: ~/detectron2
|
| 123 |
+
|
| 124 |
+
steps:
|
| 125 |
+
- checkout
|
| 126 |
+
- <<: *install_nvidia_driver
|
| 127 |
+
|
| 128 |
+
- run:
|
| 129 |
+
name: Install nvidia-docker
|
| 130 |
+
working_directory: ~/
|
| 131 |
+
command: |
|
| 132 |
+
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
|
| 133 |
+
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
|
| 134 |
+
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | \
|
| 135 |
+
sudo tee /etc/apt/sources.list.d/nvidia-docker.list
|
| 136 |
+
sudo apt-get update && sudo apt-get install -y nvidia-docker2
|
| 137 |
+
# reload the docker daemon configuration
|
| 138 |
+
sudo pkill -SIGHUP dockerd
|
| 139 |
+
|
| 140 |
+
- run:
|
| 141 |
+
name: Launch docker
|
| 142 |
+
working_directory: ~/detectron2/docker
|
| 143 |
+
command: |
|
| 144 |
+
nvidia-docker build -t detectron2:v0 -f Dockerfile-circleci .
|
| 145 |
+
nvidia-docker run -itd --name d2 detectron2:v0
|
| 146 |
+
docker exec -it d2 nvidia-smi
|
| 147 |
+
|
| 148 |
+
- run:
|
| 149 |
+
name: Build Detectron2
|
| 150 |
+
command: |
|
| 151 |
+
docker exec -it d2 pip install 'git+https://github.com/facebookresearch/fvcore'
|
| 152 |
+
docker cp ~/detectron2 d2:/detectron2
|
| 153 |
+
# This will build d2 for the target GPU arch only
|
| 154 |
+
docker exec -it d2 pip install -e /detectron2
|
| 155 |
+
docker exec -it d2 python3 -m detectron2.utils.collect_env
|
| 156 |
+
docker exec -it d2 python3 -c 'import torch; assert(torch.cuda.is_available())'
|
| 157 |
+
|
| 158 |
+
- run:
|
| 159 |
+
name: Run Unit Tests
|
| 160 |
+
command: |
|
| 161 |
+
docker exec -e CIRCLECI=true -it d2 python3 -m unittest discover -v -s /detectron2/tests
|
| 162 |
+
|
| 163 |
+
workflows:
|
| 164 |
+
version: 2
|
| 165 |
+
regular_test:
|
| 166 |
+
jobs:
|
| 167 |
+
- cpu_tests
|
| 168 |
+
- gpu_tests
|
| 169 |
+
|
| 170 |
+
#nightly_test:
|
| 171 |
+
#jobs:
|
| 172 |
+
#- gpu_tests
|
| 173 |
+
#triggers:
|
| 174 |
+
#- schedule:
|
| 175 |
+
#cron: "0 0 * * *"
|
| 176 |
+
#filters:
|
| 177 |
+
#branches:
|
| 178 |
+
#only:
|
| 179 |
+
#- master
|
preprocess/humanparsing/mhp_extension/detectron2/.clang-format
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
AccessModifierOffset: -1
|
| 2 |
+
AlignAfterOpenBracket: AlwaysBreak
|
| 3 |
+
AlignConsecutiveAssignments: false
|
| 4 |
+
AlignConsecutiveDeclarations: false
|
| 5 |
+
AlignEscapedNewlinesLeft: true
|
| 6 |
+
AlignOperands: false
|
| 7 |
+
AlignTrailingComments: false
|
| 8 |
+
AllowAllParametersOfDeclarationOnNextLine: false
|
| 9 |
+
AllowShortBlocksOnASingleLine: false
|
| 10 |
+
AllowShortCaseLabelsOnASingleLine: false
|
| 11 |
+
AllowShortFunctionsOnASingleLine: Empty
|
| 12 |
+
AllowShortIfStatementsOnASingleLine: false
|
| 13 |
+
AllowShortLoopsOnASingleLine: false
|
| 14 |
+
AlwaysBreakAfterReturnType: None
|
| 15 |
+
AlwaysBreakBeforeMultilineStrings: true
|
| 16 |
+
AlwaysBreakTemplateDeclarations: true
|
| 17 |
+
BinPackArguments: false
|
| 18 |
+
BinPackParameters: false
|
| 19 |
+
BraceWrapping:
|
| 20 |
+
AfterClass: false
|
| 21 |
+
AfterControlStatement: false
|
| 22 |
+
AfterEnum: false
|
| 23 |
+
AfterFunction: false
|
| 24 |
+
AfterNamespace: false
|
| 25 |
+
AfterObjCDeclaration: false
|
| 26 |
+
AfterStruct: false
|
| 27 |
+
AfterUnion: false
|
| 28 |
+
BeforeCatch: false
|
| 29 |
+
BeforeElse: false
|
| 30 |
+
IndentBraces: false
|
| 31 |
+
BreakBeforeBinaryOperators: None
|
| 32 |
+
BreakBeforeBraces: Attach
|
| 33 |
+
BreakBeforeTernaryOperators: true
|
| 34 |
+
BreakConstructorInitializersBeforeComma: false
|
| 35 |
+
BreakAfterJavaFieldAnnotations: false
|
| 36 |
+
BreakStringLiterals: false
|
| 37 |
+
ColumnLimit: 80
|
| 38 |
+
CommentPragmas: '^ IWYU pragma:'
|
| 39 |
+
ConstructorInitializerAllOnOneLineOrOnePerLine: true
|
| 40 |
+
ConstructorInitializerIndentWidth: 4
|
| 41 |
+
ContinuationIndentWidth: 4
|
| 42 |
+
Cpp11BracedListStyle: true
|
| 43 |
+
DerivePointerAlignment: false
|
| 44 |
+
DisableFormat: false
|
| 45 |
+
ForEachMacros: [ FOR_EACH, FOR_EACH_ENUMERATE, FOR_EACH_KV, FOR_EACH_R, FOR_EACH_RANGE, ]
|
| 46 |
+
IncludeCategories:
|
| 47 |
+
- Regex: '^<.*\.h(pp)?>'
|
| 48 |
+
Priority: 1
|
| 49 |
+
- Regex: '^<.*'
|
| 50 |
+
Priority: 2
|
| 51 |
+
- Regex: '.*'
|
| 52 |
+
Priority: 3
|
| 53 |
+
IndentCaseLabels: true
|
| 54 |
+
IndentWidth: 2
|
| 55 |
+
IndentWrappedFunctionNames: false
|
| 56 |
+
KeepEmptyLinesAtTheStartOfBlocks: false
|
| 57 |
+
MacroBlockBegin: ''
|
| 58 |
+
MacroBlockEnd: ''
|
| 59 |
+
MaxEmptyLinesToKeep: 1
|
| 60 |
+
NamespaceIndentation: None
|
| 61 |
+
ObjCBlockIndentWidth: 2
|
| 62 |
+
ObjCSpaceAfterProperty: false
|
| 63 |
+
ObjCSpaceBeforeProtocolList: false
|
| 64 |
+
PenaltyBreakBeforeFirstCallParameter: 1
|
| 65 |
+
PenaltyBreakComment: 300
|
| 66 |
+
PenaltyBreakFirstLessLess: 120
|
| 67 |
+
PenaltyBreakString: 1000
|
| 68 |
+
PenaltyExcessCharacter: 1000000
|
| 69 |
+
PenaltyReturnTypeOnItsOwnLine: 200
|
| 70 |
+
PointerAlignment: Left
|
| 71 |
+
ReflowComments: true
|
| 72 |
+
SortIncludes: true
|
| 73 |
+
SpaceAfterCStyleCast: false
|
| 74 |
+
SpaceBeforeAssignmentOperators: true
|
| 75 |
+
SpaceBeforeParens: ControlStatements
|
| 76 |
+
SpaceInEmptyParentheses: false
|
| 77 |
+
SpacesBeforeTrailingComments: 1
|
| 78 |
+
SpacesInAngles: false
|
| 79 |
+
SpacesInContainerLiterals: true
|
| 80 |
+
SpacesInCStyleCastParentheses: false
|
| 81 |
+
SpacesInParentheses: false
|
| 82 |
+
SpacesInSquareBrackets: false
|
| 83 |
+
Standard: Cpp11
|
| 84 |
+
TabWidth: 8
|
| 85 |
+
UseTab: Never
|
preprocess/humanparsing/mhp_extension/detectron2/.flake8
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This is an example .flake8 config, used when developing *Black* itself.
|
| 2 |
+
# Keep in sync with setup.cfg which is used for source packages.
|
| 3 |
+
|
| 4 |
+
[flake8]
|
| 5 |
+
ignore = W503, E203, E221, C901, C408, E741
|
| 6 |
+
max-line-length = 100
|
| 7 |
+
max-complexity = 18
|
| 8 |
+
select = B,C,E,F,W,T4,B9
|
| 9 |
+
exclude = build,__init__.py
|
preprocess/humanparsing/mhp_extension/detectron2/.github/CODE_OF_CONDUCT.md
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Code of Conduct
|
| 2 |
+
|
| 3 |
+
Facebook has adopted a Code of Conduct that we expect project participants to adhere to.
|
| 4 |
+
Please read the [full text](https://code.fb.com/codeofconduct/)
|
| 5 |
+
so that you can understand what actions will and will not be tolerated.
|
preprocess/humanparsing/mhp_extension/detectron2/.github/CONTRIBUTING.md
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Contributing to detectron2
|
| 2 |
+
|
| 3 |
+
## Issues
|
| 4 |
+
We use GitHub issues to track public bugs and questions.
|
| 5 |
+
Please make sure to follow one of the
|
| 6 |
+
[issue templates](https://github.com/facebookresearch/detectron2/issues/new/choose)
|
| 7 |
+
when reporting any issues.
|
| 8 |
+
|
| 9 |
+
Facebook has a [bounty program](https://www.facebook.com/whitehat/) for the safe
|
| 10 |
+
disclosure of security bugs. In those cases, please go through the process
|
| 11 |
+
outlined on that page and do not file a public issue.
|
| 12 |
+
|
| 13 |
+
## Pull Requests
|
| 14 |
+
We actively welcome your pull requests.
|
| 15 |
+
|
| 16 |
+
However, if you're adding any significant features (e.g. > 50 lines), please
|
| 17 |
+
make sure to have a corresponding issue to discuss your motivation and proposals,
|
| 18 |
+
before sending a PR. We do not always accept new features, and we take the following
|
| 19 |
+
factors into consideration:
|
| 20 |
+
|
| 21 |
+
1. Whether the same feature can be achieved without modifying detectron2.
|
| 22 |
+
Detectron2 is designed so that you can implement many extensions from the outside, e.g.
|
| 23 |
+
those in [projects](https://github.com/facebookresearch/detectron2/tree/master/projects).
|
| 24 |
+
If some part is not as extensible, you can also bring up the issue to make it more extensible.
|
| 25 |
+
2. Whether the feature is potentially useful to a large audience, or only to a small portion of users.
|
| 26 |
+
3. Whether the proposed solution has a good design / interface.
|
| 27 |
+
4. Whether the proposed solution adds extra mental/practical overhead to users who don't
|
| 28 |
+
need such feature.
|
| 29 |
+
5. Whether the proposed solution breaks existing APIs.
|
| 30 |
+
|
| 31 |
+
When sending a PR, please do:
|
| 32 |
+
|
| 33 |
+
1. If a PR contains multiple orthogonal changes, split it to several PRs.
|
| 34 |
+
2. If you've added code that should be tested, add tests.
|
| 35 |
+
3. For PRs that need experiments (e.g. adding a new model or new methods),
|
| 36 |
+
you don't need to update model zoo, but do provide experiment results in the description of the PR.
|
| 37 |
+
4. If APIs are changed, update the documentation.
|
| 38 |
+
5. Make sure your code lints with `./dev/linter.sh`.
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
## Contributor License Agreement ("CLA")
|
| 42 |
+
In order to accept your pull request, we need you to submit a CLA. You only need
|
| 43 |
+
to do this once to work on any of Facebook's open source projects.
|
| 44 |
+
|
| 45 |
+
Complete your CLA here: <https://code.facebook.com/cla>
|
| 46 |
+
|
| 47 |
+
## License
|
| 48 |
+
By contributing to detectron2, you agree that your contributions will be licensed
|
| 49 |
+
under the LICENSE file in the root directory of this source tree.
|
preprocess/humanparsing/mhp_extension/detectron2/.github/Detectron2-Logo-Horz.svg
ADDED
|
|
preprocess/humanparsing/mhp_extension/detectron2/.github/ISSUE_TEMPLATE.md
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
Please select an issue template from
|
| 3 |
+
https://github.com/facebookresearch/detectron2/issues/new/choose .
|
| 4 |
+
|
| 5 |
+
Otherwise your issue will be closed.
|
preprocess/humanparsing/mhp_extension/detectron2/.github/ISSUE_TEMPLATE/bugs.md
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
name: "🐛 Bugs"
|
| 3 |
+
about: Report bugs in detectron2
|
| 4 |
+
title: Please read & provide the following
|
| 5 |
+
|
| 6 |
+
---
|
| 7 |
+
|
| 8 |
+
## Instructions To Reproduce the 🐛 Bug:
|
| 9 |
+
|
| 10 |
+
1. what changes you made (`git diff`) or what code you wrote
|
| 11 |
+
```
|
| 12 |
+
<put diff or code here>
|
| 13 |
+
```
|
| 14 |
+
2. what exact command you run:
|
| 15 |
+
3. what you observed (including __full logs__):
|
| 16 |
+
```
|
| 17 |
+
<put logs here>
|
| 18 |
+
```
|
| 19 |
+
4. please simplify the steps as much as possible so they do not require additional resources to
|
| 20 |
+
run, such as a private dataset.
|
| 21 |
+
|
| 22 |
+
## Expected behavior:
|
| 23 |
+
|
| 24 |
+
If there are no obvious error in "what you observed" provided above,
|
| 25 |
+
please tell us the expected behavior.
|
| 26 |
+
|
| 27 |
+
## Environment:
|
| 28 |
+
|
| 29 |
+
Provide your environment information using the following command:
|
| 30 |
+
```
|
| 31 |
+
wget -nc -q https://github.com/facebookresearch/detectron2/raw/master/detectron2/utils/collect_env.py && python collect_env.py
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
If your issue looks like an installation issue / environment issue,
|
| 35 |
+
please first try to solve it yourself with the instructions in
|
| 36 |
+
https://detectron2.readthedocs.io/tutorials/install.html#common-installation-issues
|
preprocess/humanparsing/mhp_extension/detectron2/.github/ISSUE_TEMPLATE/config.yml
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# require an issue template to be chosen
|
| 2 |
+
blank_issues_enabled: false
|
| 3 |
+
|
| 4 |
+
# Unexpected behaviors & bugs are split to two templates.
|
| 5 |
+
# When they are one template, users think "it's not a bug" and don't choose the template.
|
| 6 |
+
#
|
| 7 |
+
# But the file name is still "unexpected-problems-bugs.md" so that old references
|
| 8 |
+
# to this issue template still works.
|
| 9 |
+
# It's ok since this template should be a superset of "bugs.md" (unexpected behaviors is a superset of bugs)
|
preprocess/humanparsing/mhp_extension/detectron2/.github/ISSUE_TEMPLATE/feature-request.md
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
name: "\U0001F680Feature Request"
|
| 3 |
+
about: Submit a proposal/request for a new detectron2 feature
|
| 4 |
+
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
## 🚀 Feature
|
| 8 |
+
A clear and concise description of the feature proposal.
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
## Motivation & Examples
|
| 12 |
+
|
| 13 |
+
Tell us why the feature is useful.
|
| 14 |
+
|
| 15 |
+
Describe what the feature would look like, if it is implemented.
|
| 16 |
+
Best demonstrated using **code examples** in addition to words.
|
| 17 |
+
|
| 18 |
+
## Note
|
| 19 |
+
|
| 20 |
+
We only consider adding new features if they are relevant to many users.
|
| 21 |
+
|
| 22 |
+
If you request implementation of research papers --
|
| 23 |
+
we only consider papers that have enough significance and prevalance in the object detection field.
|
| 24 |
+
|
| 25 |
+
We do not take requests for most projects in the `projects/` directory,
|
| 26 |
+
because they are research code release that is mainly for other researchers to reproduce results.
|
| 27 |
+
|
| 28 |
+
Instead of adding features inside detectron2,
|
| 29 |
+
you can implement many features by [extending detectron2](https://detectron2.readthedocs.io/tutorials/extend.html).
|
| 30 |
+
The [projects/](https://github.com/facebookresearch/detectron2/tree/master/projects/) directory contains many of such examples.
|
| 31 |
+
|
preprocess/humanparsing/mhp_extension/detectron2/.github/ISSUE_TEMPLATE/questions-help-support.md
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
name: "❓How to do something?"
|
| 3 |
+
about: How to do something using detectron2? What does an API do?
|
| 4 |
+
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
## ❓ How to do something using detectron2
|
| 8 |
+
|
| 9 |
+
Describe what you want to do, including:
|
| 10 |
+
1. what inputs you will provide, if any:
|
| 11 |
+
2. what outputs you are expecting:
|
| 12 |
+
|
| 13 |
+
## ❓ What does an API do and how to use it?
|
| 14 |
+
Please link to which API or documentation you're asking about from
|
| 15 |
+
https://detectron2.readthedocs.io/
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
NOTE:
|
| 19 |
+
|
| 20 |
+
1. Only general answers are provided.
|
| 21 |
+
If you want to ask about "why X did not work", please use the
|
| 22 |
+
[Unexpected behaviors](https://github.com/facebookresearch/detectron2/issues/new/choose) issue template.
|
| 23 |
+
|
| 24 |
+
2. About how to implement new models / new dataloader / new training logic, etc., check documentation first.
|
| 25 |
+
|
| 26 |
+
3. We do not answer general machine learning / computer vision questions that are not specific to detectron2, such as how a model works, how to improve your training/make it converge, or what algorithm/methods can be used to achieve X.
|
preprocess/humanparsing/mhp_extension/detectron2/.github/ISSUE_TEMPLATE/unexpected-problems-bugs.md
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
name: "Unexpected behaviors"
|
| 3 |
+
about: Run into unexpected behaviors when using detectron2
|
| 4 |
+
title: Please read & provide the following
|
| 5 |
+
|
| 6 |
+
---
|
| 7 |
+
|
| 8 |
+
If you do not know the root cause of the problem, and wish someone to help you, please
|
| 9 |
+
post according to this template:
|
| 10 |
+
|
| 11 |
+
## Instructions To Reproduce the Issue:
|
| 12 |
+
|
| 13 |
+
1. what changes you made (`git diff`) or what code you wrote
|
| 14 |
+
```
|
| 15 |
+
<put diff or code here>
|
| 16 |
+
```
|
| 17 |
+
2. what exact command you run:
|
| 18 |
+
3. what you observed (including __full logs__):
|
| 19 |
+
```
|
| 20 |
+
<put logs here>
|
| 21 |
+
```
|
| 22 |
+
4. please simplify the steps as much as possible so they do not require additional resources to
|
| 23 |
+
run, such as a private dataset.
|
| 24 |
+
|
| 25 |
+
## Expected behavior:
|
| 26 |
+
|
| 27 |
+
If there are no obvious error in "what you observed" provided above,
|
| 28 |
+
please tell us the expected behavior.
|
| 29 |
+
|
| 30 |
+
If you expect the model to converge / work better, note that we do not give suggestions
|
| 31 |
+
on how to train a new model.
|
| 32 |
+
Only in one of the two conditions we will help with it:
|
| 33 |
+
(1) You're unable to reproduce the results in detectron2 model zoo.
|
| 34 |
+
(2) It indicates a detectron2 bug.
|
| 35 |
+
|
| 36 |
+
## Environment:
|
| 37 |
+
|
| 38 |
+
Provide your environment information using the following command:
|
| 39 |
+
```
|
| 40 |
+
wget -nc -q https://github.com/facebookresearch/detectron2/raw/master/detectron2/utils/collect_env.py && python collect_env.py
|
| 41 |
+
```
|
| 42 |
+
|
| 43 |
+
If your issue looks like an installation issue / environment issue,
|
| 44 |
+
please first try to solve it yourself with the instructions in
|
| 45 |
+
https://detectron2.readthedocs.io/tutorials/install.html#common-installation-issues
|
preprocess/humanparsing/mhp_extension/detectron2/.github/pull_request_template.md
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Thanks for your contribution!
|
| 2 |
+
|
| 3 |
+
If you're sending a large PR (e.g., >50 lines),
|
| 4 |
+
please open an issue first about the feature / bug, and indicate how you want to contribute.
|
| 5 |
+
|
| 6 |
+
Before submitting a PR, please run `dev/linter.sh` to lint the code.
|
| 7 |
+
|
| 8 |
+
See https://detectron2.readthedocs.io/notes/contributing.html#pull-requests
|
| 9 |
+
about how we handle PRs.
|
preprocess/humanparsing/mhp_extension/detectron2/.gitignore
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# output dir
|
| 2 |
+
output
|
| 3 |
+
instant_test_output
|
| 4 |
+
inference_test_output
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
*.jpg
|
| 8 |
+
*.png
|
| 9 |
+
*.txt
|
| 10 |
+
*.json
|
| 11 |
+
*.diff
|
| 12 |
+
|
| 13 |
+
# compilation and distribution
|
| 14 |
+
__pycache__
|
| 15 |
+
_ext
|
| 16 |
+
*.pyc
|
| 17 |
+
*.so
|
| 18 |
+
detectron2.egg-info/
|
| 19 |
+
build/
|
| 20 |
+
dist/
|
| 21 |
+
wheels/
|
| 22 |
+
|
| 23 |
+
# pytorch/python/numpy formats
|
| 24 |
+
*.pth
|
| 25 |
+
*.pkl
|
| 26 |
+
*.npy
|
| 27 |
+
|
| 28 |
+
# ipython/jupyter notebooks
|
| 29 |
+
*.ipynb
|
| 30 |
+
**/.ipynb_checkpoints/
|
| 31 |
+
|
| 32 |
+
# Editor temporaries
|
| 33 |
+
*.swn
|
| 34 |
+
*.swo
|
| 35 |
+
*.swp
|
| 36 |
+
*~
|
| 37 |
+
|
| 38 |
+
# editor settings
|
| 39 |
+
.idea
|
| 40 |
+
.vscode
|
| 41 |
+
|
| 42 |
+
# project dirs
|
| 43 |
+
/detectron2/model_zoo/configs
|
| 44 |
+
/datasets
|
| 45 |
+
/projects/*/datasets
|
| 46 |
+
/models
|
preprocess/humanparsing/mhp_extension/detectron2/GETTING_STARTED.md
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Getting Started with Detectron2
|
| 2 |
+
|
| 3 |
+
This document provides a brief intro of the usage of builtin command-line tools in detectron2.
|
| 4 |
+
|
| 5 |
+
For a tutorial that involves actual coding with the API,
|
| 6 |
+
see our [Colab Notebook](https://colab.research.google.com/drive/16jcaJoc6bCFAQ96jDe2HwtXj7BMD_-m5)
|
| 7 |
+
which covers how to run inference with an
|
| 8 |
+
existing model, and how to train a builtin model on a custom dataset.
|
| 9 |
+
|
| 10 |
+
For more advanced tutorials, refer to our [documentation](https://detectron2.readthedocs.io/tutorials/extend.html).
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
### Inference Demo with Pre-trained Models
|
| 14 |
+
|
| 15 |
+
1. Pick a model and its config file from
|
| 16 |
+
[model zoo](MODEL_ZOO.md),
|
| 17 |
+
for example, `mask_rcnn_R_50_FPN_3x.yaml`.
|
| 18 |
+
2. We provide `demo.py` that is able to run builtin standard models. Run it with:
|
| 19 |
+
```
|
| 20 |
+
cd demo/
|
| 21 |
+
python demo.py --config-file ../configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml \
|
| 22 |
+
--input input1.jpg input2.jpg \
|
| 23 |
+
[--other-options]
|
| 24 |
+
--opts MODEL.WEIGHTS detectron2://COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl
|
| 25 |
+
```
|
| 26 |
+
The configs are made for training, therefore we need to specify `MODEL.WEIGHTS` to a model from model zoo for evaluation.
|
| 27 |
+
This command will run the inference and show visualizations in an OpenCV window.
|
| 28 |
+
|
| 29 |
+
For details of the command line arguments, see `demo.py -h` or look at its source code
|
| 30 |
+
to understand its behavior. Some common arguments are:
|
| 31 |
+
* To run __on your webcam__, replace `--input files` with `--webcam`.
|
| 32 |
+
* To run __on a video__, replace `--input files` with `--video-input video.mp4`.
|
| 33 |
+
* To run __on cpu__, add `MODEL.DEVICE cpu` after `--opts`.
|
| 34 |
+
* To save outputs to a directory (for images) or a file (for webcam or video), use `--output`.
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
### Training & Evaluation in Command Line
|
| 38 |
+
|
| 39 |
+
We provide a script in "tools/{,plain_}train_net.py", that is made to train
|
| 40 |
+
all the configs provided in detectron2.
|
| 41 |
+
You may want to use it as a reference to write your own training script.
|
| 42 |
+
|
| 43 |
+
To train a model with "train_net.py", first
|
| 44 |
+
setup the corresponding datasets following
|
| 45 |
+
[datasets/README.md](./datasets/README.md),
|
| 46 |
+
then run:
|
| 47 |
+
```
|
| 48 |
+
cd tools/
|
| 49 |
+
./train_net.py --num-gpus 8 \
|
| 50 |
+
--config-file ../configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
The configs are made for 8-GPU training.
|
| 54 |
+
To train on 1 GPU, you may need to [change some parameters](https://arxiv.org/abs/1706.02677), e.g.:
|
| 55 |
+
```
|
| 56 |
+
./train_net.py \
|
| 57 |
+
--config-file ../configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml \
|
| 58 |
+
--num-gpus 1 SOLVER.IMS_PER_BATCH 2 SOLVER.BASE_LR 0.0025
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
For most models, CPU training is not supported.
|
| 62 |
+
|
| 63 |
+
To evaluate a model's performance, use
|
| 64 |
+
```
|
| 65 |
+
./train_net.py \
|
| 66 |
+
--config-file ../configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml \
|
| 67 |
+
--eval-only MODEL.WEIGHTS /path/to/checkpoint_file
|
| 68 |
+
```
|
| 69 |
+
For more options, see `./train_net.py -h`.
|
| 70 |
+
|
| 71 |
+
### Use Detectron2 APIs in Your Code
|
| 72 |
+
|
| 73 |
+
See our [Colab Notebook](https://colab.research.google.com/drive/16jcaJoc6bCFAQ96jDe2HwtXj7BMD_-m5)
|
| 74 |
+
to learn how to use detectron2 APIs to:
|
| 75 |
+
1. run inference with an existing model
|
| 76 |
+
2. train a builtin model on a custom dataset
|
| 77 |
+
|
| 78 |
+
See [detectron2/projects](https://github.com/facebookresearch/detectron2/tree/master/projects)
|
| 79 |
+
for more ways to build your project on detectron2.
|
preprocess/humanparsing/mhp_extension/detectron2/INSTALL.md
ADDED
|
@@ -0,0 +1,184 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Installation
|
| 2 |
+
|
| 3 |
+
Our [Colab Notebook](https://colab.research.google.com/drive/16jcaJoc6bCFAQ96jDe2HwtXj7BMD_-m5)
|
| 4 |
+
has step-by-step instructions that install detectron2.
|
| 5 |
+
The [Dockerfile](docker)
|
| 6 |
+
also installs detectron2 with a few simple commands.
|
| 7 |
+
|
| 8 |
+
### Requirements
|
| 9 |
+
- Linux or macOS with Python ≥ 3.6
|
| 10 |
+
- PyTorch ≥ 1.4
|
| 11 |
+
- [torchvision](https://github.com/pytorch/vision/) that matches the PyTorch installation.
|
| 12 |
+
You can install them together at [pytorch.org](https://pytorch.org) to make sure of this.
|
| 13 |
+
- OpenCV, optional, needed by demo and visualization
|
| 14 |
+
- pycocotools: `pip install cython; pip install -U 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'`
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
### Build Detectron2 from Source
|
| 18 |
+
|
| 19 |
+
gcc & g++ ≥ 5 are required. [ninja](https://ninja-build.org/) is recommended for faster build.
|
| 20 |
+
After having them, run:
|
| 21 |
+
```
|
| 22 |
+
python -m pip install 'git+https://github.com/facebookresearch/detectron2.git'
|
| 23 |
+
# (add --user if you don't have permission)
|
| 24 |
+
|
| 25 |
+
# Or, to install it from a local clone:
|
| 26 |
+
git clone https://github.com/facebookresearch/detectron2.git
|
| 27 |
+
python -m pip install -e detectron2
|
| 28 |
+
|
| 29 |
+
# Or if you are on macOS
|
| 30 |
+
# CC=clang CXX=clang++ python -m pip install -e .
|
| 31 |
+
```
|
| 32 |
+
|
| 33 |
+
To __rebuild__ detectron2 that's built from a local clone, use `rm -rf build/ **/*.so` to clean the
|
| 34 |
+
old build first. You often need to rebuild detectron2 after reinstalling PyTorch.
|
| 35 |
+
|
| 36 |
+
### Install Pre-Built Detectron2 (Linux only)
|
| 37 |
+
```
|
| 38 |
+
# for CUDA 10.1:
|
| 39 |
+
python -m pip install detectron2 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu101/index.html
|
| 40 |
+
```
|
| 41 |
+
You can replace cu101 with "cu{100,92}" or "cpu".
|
| 42 |
+
|
| 43 |
+
Note that:
|
| 44 |
+
1. Such installation has to be used with certain version of official PyTorch release.
|
| 45 |
+
See [releases](https://github.com/facebookresearch/detectron2/releases) for requirements.
|
| 46 |
+
It will not work with a different version of PyTorch or a non-official build of PyTorch.
|
| 47 |
+
2. Such installation is out-of-date w.r.t. master branch of detectron2. It may not be
|
| 48 |
+
compatible with the master branch of a research project that uses detectron2 (e.g. those in
|
| 49 |
+
[projects](projects) or [meshrcnn](https://github.com/facebookresearch/meshrcnn/)).
|
| 50 |
+
|
| 51 |
+
### Common Installation Issues
|
| 52 |
+
|
| 53 |
+
If you met issues using the pre-built detectron2, please uninstall it and try building it from source.
|
| 54 |
+
|
| 55 |
+
Click each issue for its solutions:
|
| 56 |
+
|
| 57 |
+
<details>
|
| 58 |
+
<summary>
|
| 59 |
+
Undefined torch/aten/caffe2 symbols, or segmentation fault immediately when running the library.
|
| 60 |
+
</summary>
|
| 61 |
+
<br/>
|
| 62 |
+
|
| 63 |
+
This usually happens when detectron2 or torchvision is not
|
| 64 |
+
compiled with the version of PyTorch you're running.
|
| 65 |
+
|
| 66 |
+
Pre-built torchvision or detectron2 has to work with the corresponding official release of pytorch.
|
| 67 |
+
If the error comes from a pre-built torchvision, uninstall torchvision and pytorch and reinstall them
|
| 68 |
+
following [pytorch.org](http://pytorch.org). So the versions will match.
|
| 69 |
+
|
| 70 |
+
If the error comes from a pre-built detectron2, check [release notes](https://github.com/facebookresearch/detectron2/releases)
|
| 71 |
+
to see the corresponding pytorch version required for each pre-built detectron2.
|
| 72 |
+
|
| 73 |
+
If the error comes from detectron2 or torchvision that you built manually from source,
|
| 74 |
+
remove files you built (`build/`, `**/*.so`) and rebuild it so it can pick up the version of pytorch currently in your environment.
|
| 75 |
+
|
| 76 |
+
If you cannot resolve this problem, please include the output of `gdb -ex "r" -ex "bt" -ex "quit" --args python -m detectron2.utils.collect_env`
|
| 77 |
+
in your issue.
|
| 78 |
+
</details>
|
| 79 |
+
|
| 80 |
+
<details>
|
| 81 |
+
<summary>
|
| 82 |
+
Undefined C++ symbols (e.g. `GLIBCXX`) or C++ symbols not found.
|
| 83 |
+
</summary>
|
| 84 |
+
<br/>
|
| 85 |
+
Usually it's because the library is compiled with a newer C++ compiler but run with an old C++ runtime.
|
| 86 |
+
|
| 87 |
+
This often happens with old anaconda.
|
| 88 |
+
Try `conda update libgcc`. Then rebuild detectron2.
|
| 89 |
+
|
| 90 |
+
The fundamental solution is to run the code with proper C++ runtime.
|
| 91 |
+
One way is to use `LD_PRELOAD=/path/to/libstdc++.so`.
|
| 92 |
+
|
| 93 |
+
</details>
|
| 94 |
+
|
| 95 |
+
<details>
|
| 96 |
+
<summary>
|
| 97 |
+
"Not compiled with GPU support" or "Detectron2 CUDA Compiler: not available".
|
| 98 |
+
</summary>
|
| 99 |
+
<br/>
|
| 100 |
+
CUDA is not found when building detectron2.
|
| 101 |
+
You should make sure
|
| 102 |
+
|
| 103 |
+
```
|
| 104 |
+
python -c 'import torch; from torch.utils.cpp_extension import CUDA_HOME; print(torch.cuda.is_available(), CUDA_HOME)'
|
| 105 |
+
```
|
| 106 |
+
|
| 107 |
+
print valid outputs at the time you build detectron2.
|
| 108 |
+
|
| 109 |
+
Most models can run inference (but not training) without GPU support. To use CPUs, set `MODEL.DEVICE='cpu'` in the config.
|
| 110 |
+
</details>
|
| 111 |
+
|
| 112 |
+
<details>
|
| 113 |
+
<summary>
|
| 114 |
+
"invalid device function" or "no kernel image is available for execution".
|
| 115 |
+
</summary>
|
| 116 |
+
<br/>
|
| 117 |
+
Two possibilities:
|
| 118 |
+
|
| 119 |
+
* You build detectron2 with one version of CUDA but run it with a different version.
|
| 120 |
+
|
| 121 |
+
To check whether it is the case,
|
| 122 |
+
use `python -m detectron2.utils.collect_env` to find out inconsistent CUDA versions.
|
| 123 |
+
In the output of this command, you should expect "Detectron2 CUDA Compiler", "CUDA_HOME", "PyTorch built with - CUDA"
|
| 124 |
+
to contain cuda libraries of the same version.
|
| 125 |
+
|
| 126 |
+
When they are inconsistent,
|
| 127 |
+
you need to either install a different build of PyTorch (or build by yourself)
|
| 128 |
+
to match your local CUDA installation, or install a different version of CUDA to match PyTorch.
|
| 129 |
+
|
| 130 |
+
* Detectron2 or PyTorch/torchvision is not built for the correct GPU architecture (compute compatibility).
|
| 131 |
+
|
| 132 |
+
The GPU architecture for PyTorch/detectron2/torchvision is available in the "architecture flags" in
|
| 133 |
+
`python -m detectron2.utils.collect_env`.
|
| 134 |
+
|
| 135 |
+
The GPU architecture flags of detectron2/torchvision by default matches the GPU model detected
|
| 136 |
+
during compilation. This means the compiled code may not work on a different GPU model.
|
| 137 |
+
To overwrite the GPU architecture for detectron2/torchvision, use `TORCH_CUDA_ARCH_LIST` environment variable during compilation.
|
| 138 |
+
|
| 139 |
+
For example, `export TORCH_CUDA_ARCH_LIST=6.0,7.0` makes it compile for both P100s and V100s.
|
| 140 |
+
Visit [developer.nvidia.com/cuda-gpus](https://developer.nvidia.com/cuda-gpus) to find out
|
| 141 |
+
the correct compute compatibility number for your device.
|
| 142 |
+
|
| 143 |
+
</details>
|
| 144 |
+
|
| 145 |
+
<details>
|
| 146 |
+
<summary>
|
| 147 |
+
Undefined CUDA symbols; cannot open libcudart.so; other nvcc failures.
|
| 148 |
+
</summary>
|
| 149 |
+
<br/>
|
| 150 |
+
The version of NVCC you use to build detectron2 or torchvision does
|
| 151 |
+
not match the version of CUDA you are running with.
|
| 152 |
+
This often happens when using anaconda's CUDA runtime.
|
| 153 |
+
|
| 154 |
+
Use `python -m detectron2.utils.collect_env` to find out inconsistent CUDA versions.
|
| 155 |
+
In the output of this command, you should expect "Detectron2 CUDA Compiler", "CUDA_HOME", "PyTorch built with - CUDA"
|
| 156 |
+
to contain cuda libraries of the same version.
|
| 157 |
+
|
| 158 |
+
When they are inconsistent,
|
| 159 |
+
you need to either install a different build of PyTorch (or build by yourself)
|
| 160 |
+
to match your local CUDA installation, or install a different version of CUDA to match PyTorch.
|
| 161 |
+
</details>
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
<details>
|
| 165 |
+
<summary>
|
| 166 |
+
"ImportError: cannot import name '_C'".
|
| 167 |
+
</summary>
|
| 168 |
+
<br/>
|
| 169 |
+
Please build and install detectron2 following the instructions above.
|
| 170 |
+
|
| 171 |
+
If you are running code from detectron2's root directory, `cd` to a different one.
|
| 172 |
+
Otherwise you may not import the code that you installed.
|
| 173 |
+
</details>
|
| 174 |
+
|
| 175 |
+
<details>
|
| 176 |
+
<summary>
|
| 177 |
+
ONNX conversion segfault after some "TraceWarning".
|
| 178 |
+
</summary>
|
| 179 |
+
<br/>
|
| 180 |
+
The ONNX package is compiled with too old compiler.
|
| 181 |
+
|
| 182 |
+
Please build and install ONNX from its source code using a compiler
|
| 183 |
+
whose version is closer to what's used by PyTorch (available in `torch.__config__.show()`).
|
| 184 |
+
</details>
|
preprocess/humanparsing/mhp_extension/detectron2/LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright 2019 - present, Facebook, Inc
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
preprocess/humanparsing/mhp_extension/detectron2/MODEL_ZOO.md
ADDED
|
@@ -0,0 +1,903 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Detectron2 Model Zoo and Baselines
|
| 2 |
+
|
| 3 |
+
## Introduction
|
| 4 |
+
|
| 5 |
+
This file documents a large collection of baselines trained
|
| 6 |
+
with detectron2 in Sep-Oct, 2019.
|
| 7 |
+
All numbers were obtained on [Big Basin](https://engineering.fb.com/data-center-engineering/introducing-big-basin-our-next-generation-ai-hardware/)
|
| 8 |
+
servers with 8 NVIDIA V100 GPUs & NVLink. The software in use were PyTorch 1.3, CUDA 9.2, cuDNN 7.4.2 or 7.6.3.
|
| 9 |
+
You can access these models from code using [detectron2.model_zoo](https://detectron2.readthedocs.io/modules/model_zoo.html) APIs.
|
| 10 |
+
|
| 11 |
+
In addition to these official baseline models, you can find more models in [projects/](projects/).
|
| 12 |
+
|
| 13 |
+
#### How to Read the Tables
|
| 14 |
+
* The "Name" column contains a link to the config file. Running `tools/train_net.py` with this config file
|
| 15 |
+
and 8 GPUs will reproduce the model.
|
| 16 |
+
* Training speed is averaged across the entire training.
|
| 17 |
+
We keep updating the speed with latest version of detectron2/pytorch/etc.,
|
| 18 |
+
so they might be different from the `metrics` file.
|
| 19 |
+
Training speed for multi-machine jobs is not provided.
|
| 20 |
+
* Inference speed is measured by `tools/train_net.py --eval-only`, or [inference_on_dataset()](https://detectron2.readthedocs.io/modules/evaluation.html#detectron2.evaluation.inference_on_dataset),
|
| 21 |
+
with batch size 1 in detectron2 directly.
|
| 22 |
+
Measuring it with your own code will likely introduce other overhead.
|
| 23 |
+
Actual deployment in production should in general be faster than the given inference
|
| 24 |
+
speed due to more optimizations.
|
| 25 |
+
* The *model id* column is provided for ease of reference.
|
| 26 |
+
To check downloaded file integrity, any model on this page contains its md5 prefix in its file name.
|
| 27 |
+
* Training curves and other statistics can be found in `metrics` for each model.
|
| 28 |
+
|
| 29 |
+
#### Common Settings for COCO Models
|
| 30 |
+
* All COCO models were trained on `train2017` and evaluated on `val2017`.
|
| 31 |
+
* The default settings are __not directly comparable__ with Detectron's standard settings.
|
| 32 |
+
For example, our default training data augmentation uses scale jittering in addition to horizontal flipping.
|
| 33 |
+
|
| 34 |
+
To make fair comparisons with Detectron's settings, see
|
| 35 |
+
[Detectron1-Comparisons](configs/Detectron1-Comparisons/) for accuracy comparison,
|
| 36 |
+
and [benchmarks](https://detectron2.readthedocs.io/notes/benchmarks.html)
|
| 37 |
+
for speed comparison.
|
| 38 |
+
* For Faster/Mask R-CNN, we provide baselines based on __3 different backbone combinations__:
|
| 39 |
+
* __FPN__: Use a ResNet+FPN backbone with standard conv and FC heads for mask and box prediction,
|
| 40 |
+
respectively. It obtains the best
|
| 41 |
+
speed/accuracy tradeoff, but the other two are still useful for research.
|
| 42 |
+
* __C4__: Use a ResNet conv4 backbone with conv5 head. The original baseline in the Faster R-CNN paper.
|
| 43 |
+
* __DC5__ (Dilated-C5): Use a ResNet conv5 backbone with dilations in conv5, and standard conv and FC heads
|
| 44 |
+
for mask and box prediction, respectively.
|
| 45 |
+
This is used by the Deformable ConvNet paper.
|
| 46 |
+
* Most models are trained with the 3x schedule (~37 COCO epochs).
|
| 47 |
+
Although 1x models are heavily under-trained, we provide some ResNet-50 models with the 1x (~12 COCO epochs)
|
| 48 |
+
training schedule for comparison when doing quick research iteration.
|
| 49 |
+
|
| 50 |
+
#### ImageNet Pretrained Models
|
| 51 |
+
|
| 52 |
+
We provide backbone models pretrained on ImageNet-1k dataset.
|
| 53 |
+
These models have __different__ format from those provided in Detectron: we do not fuse BatchNorm into an affine layer.
|
| 54 |
+
* [R-50.pkl](https://dl.fbaipublicfiles.com/detectron2/ImageNetPretrained/MSRA/R-50.pkl): converted copy of [MSRA's original ResNet-50](https://github.com/KaimingHe/deep-residual-networks) model.
|
| 55 |
+
* [R-101.pkl](https://dl.fbaipublicfiles.com/detectron2/ImageNetPretrained/MSRA/R-101.pkl): converted copy of [MSRA's original ResNet-101](https://github.com/KaimingHe/deep-residual-networks) model.
|
| 56 |
+
* [X-101-32x8d.pkl](https://dl.fbaipublicfiles.com/detectron2/ImageNetPretrained/FAIR/X-101-32x8d.pkl): ResNeXt-101-32x8d model trained with Caffe2 at FB.
|
| 57 |
+
|
| 58 |
+
Pretrained models in Detectron's format can still be used. For example:
|
| 59 |
+
* [X-152-32x8d-IN5k.pkl](https://dl.fbaipublicfiles.com/detectron/ImageNetPretrained/25093814/X-152-32x8d-IN5k.pkl):
|
| 60 |
+
ResNeXt-152-32x8d model trained on ImageNet-5k with Caffe2 at FB (see ResNeXt paper for details on ImageNet-5k).
|
| 61 |
+
* [R-50-GN.pkl](https://dl.fbaipublicfiles.com/detectron/ImageNetPretrained/47261647/R-50-GN.pkl):
|
| 62 |
+
ResNet-50 with Group Normalization.
|
| 63 |
+
* [R-101-GN.pkl](https://dl.fbaipublicfiles.com/detectron/ImageNetPretrained/47592356/R-101-GN.pkl):
|
| 64 |
+
ResNet-101 with Group Normalization.
|
| 65 |
+
|
| 66 |
+
Torchvision's ResNet models can be used after converted by [this script](tools/convert-torchvision-to-d2.py).
|
| 67 |
+
|
| 68 |
+
#### License
|
| 69 |
+
|
| 70 |
+
All models available for download through this document are licensed under the
|
| 71 |
+
[Creative Commons Attribution-ShareAlike 3.0 license](https://creativecommons.org/licenses/by-sa/3.0/).
|
| 72 |
+
|
| 73 |
+
### COCO Object Detection Baselines
|
| 74 |
+
|
| 75 |
+
#### Faster R-CNN:
|
| 76 |
+
<!--
|
| 77 |
+
(fb only) To update the table in vim:
|
| 78 |
+
1. Remove the old table: d}
|
| 79 |
+
2. Copy the below command to the place of the table
|
| 80 |
+
3. :.!bash
|
| 81 |
+
|
| 82 |
+
./gen_html_table.py --config 'COCO-Detection/faster*50*'{1x,3x}'*' 'COCO-Detection/faster*101*' --name R50-C4 R50-DC5 R50-FPN R50-C4 R50-DC5 R50-FPN R101-C4 R101-DC5 R101-FPN X101-FPN --fields lr_sched train_speed inference_speed mem box_AP
|
| 83 |
+
-->
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
<table><tbody>
|
| 87 |
+
<!-- START TABLE -->
|
| 88 |
+
<!-- TABLE HEADER -->
|
| 89 |
+
<th valign="bottom">Name</th>
|
| 90 |
+
<th valign="bottom">lr<br/>sched</th>
|
| 91 |
+
<th valign="bottom">train<br/>time<br/>(s/iter)</th>
|
| 92 |
+
<th valign="bottom">inference<br/>time<br/>(s/im)</th>
|
| 93 |
+
<th valign="bottom">train<br/>mem<br/>(GB)</th>
|
| 94 |
+
<th valign="bottom">box<br/>AP</th>
|
| 95 |
+
<th valign="bottom">model id</th>
|
| 96 |
+
<th valign="bottom">download</th>
|
| 97 |
+
<!-- TABLE BODY -->
|
| 98 |
+
<!-- ROW: faster_rcnn_R_50_C4_1x -->
|
| 99 |
+
<tr><td align="left"><a href="configs/COCO-Detection/faster_rcnn_R_50_C4_1x.yaml">R50-C4</a></td>
|
| 100 |
+
<td align="center">1x</td>
|
| 101 |
+
<td align="center">0.551</td>
|
| 102 |
+
<td align="center">0.102</td>
|
| 103 |
+
<td align="center">4.8</td>
|
| 104 |
+
<td align="center">35.7</td>
|
| 105 |
+
<td align="center">137257644</td>
|
| 106 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_C4_1x/137257644/model_final_721ade.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_C4_1x/137257644/metrics.json">metrics</a></td>
|
| 107 |
+
</tr>
|
| 108 |
+
<!-- ROW: faster_rcnn_R_50_DC5_1x -->
|
| 109 |
+
<tr><td align="left"><a href="configs/COCO-Detection/faster_rcnn_R_50_DC5_1x.yaml">R50-DC5</a></td>
|
| 110 |
+
<td align="center">1x</td>
|
| 111 |
+
<td align="center">0.380</td>
|
| 112 |
+
<td align="center">0.068</td>
|
| 113 |
+
<td align="center">5.0</td>
|
| 114 |
+
<td align="center">37.3</td>
|
| 115 |
+
<td align="center">137847829</td>
|
| 116 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_DC5_1x/137847829/model_final_51d356.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_DC5_1x/137847829/metrics.json">metrics</a></td>
|
| 117 |
+
</tr>
|
| 118 |
+
<!-- ROW: faster_rcnn_R_50_FPN_1x -->
|
| 119 |
+
<tr><td align="left"><a href="configs/COCO-Detection/faster_rcnn_R_50_FPN_1x.yaml">R50-FPN</a></td>
|
| 120 |
+
<td align="center">1x</td>
|
| 121 |
+
<td align="center">0.210</td>
|
| 122 |
+
<td align="center">0.038</td>
|
| 123 |
+
<td align="center">3.0</td>
|
| 124 |
+
<td align="center">37.9</td>
|
| 125 |
+
<td align="center">137257794</td>
|
| 126 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_FPN_1x/137257794/model_final_b275ba.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_FPN_1x/137257794/metrics.json">metrics</a></td>
|
| 127 |
+
</tr>
|
| 128 |
+
<!-- ROW: faster_rcnn_R_50_C4_3x -->
|
| 129 |
+
<tr><td align="left"><a href="configs/COCO-Detection/faster_rcnn_R_50_C4_3x.yaml">R50-C4</a></td>
|
| 130 |
+
<td align="center">3x</td>
|
| 131 |
+
<td align="center">0.543</td>
|
| 132 |
+
<td align="center">0.104</td>
|
| 133 |
+
<td align="center">4.8</td>
|
| 134 |
+
<td align="center">38.4</td>
|
| 135 |
+
<td align="center">137849393</td>
|
| 136 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_C4_3x/137849393/model_final_f97cb7.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_C4_3x/137849393/metrics.json">metrics</a></td>
|
| 137 |
+
</tr>
|
| 138 |
+
<!-- ROW: faster_rcnn_R_50_DC5_3x -->
|
| 139 |
+
<tr><td align="left"><a href="configs/COCO-Detection/faster_rcnn_R_50_DC5_3x.yaml">R50-DC5</a></td>
|
| 140 |
+
<td align="center">3x</td>
|
| 141 |
+
<td align="center">0.378</td>
|
| 142 |
+
<td align="center">0.070</td>
|
| 143 |
+
<td align="center">5.0</td>
|
| 144 |
+
<td align="center">39.0</td>
|
| 145 |
+
<td align="center">137849425</td>
|
| 146 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_DC5_3x/137849425/model_final_68d202.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_DC5_3x/137849425/metrics.json">metrics</a></td>
|
| 147 |
+
</tr>
|
| 148 |
+
<!-- ROW: faster_rcnn_R_50_FPN_3x -->
|
| 149 |
+
<tr><td align="left"><a href="configs/COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml">R50-FPN</a></td>
|
| 150 |
+
<td align="center">3x</td>
|
| 151 |
+
<td align="center">0.209</td>
|
| 152 |
+
<td align="center">0.038</td>
|
| 153 |
+
<td align="center">3.0</td>
|
| 154 |
+
<td align="center">40.2</td>
|
| 155 |
+
<td align="center">137849458</td>
|
| 156 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_FPN_3x/137849458/model_final_280758.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_50_FPN_3x/137849458/metrics.json">metrics</a></td>
|
| 157 |
+
</tr>
|
| 158 |
+
<!-- ROW: faster_rcnn_R_101_C4_3x -->
|
| 159 |
+
<tr><td align="left"><a href="configs/COCO-Detection/faster_rcnn_R_101_C4_3x.yaml">R101-C4</a></td>
|
| 160 |
+
<td align="center">3x</td>
|
| 161 |
+
<td align="center">0.619</td>
|
| 162 |
+
<td align="center">0.139</td>
|
| 163 |
+
<td align="center">5.9</td>
|
| 164 |
+
<td align="center">41.1</td>
|
| 165 |
+
<td align="center">138204752</td>
|
| 166 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_101_C4_3x/138204752/model_final_298dad.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_101_C4_3x/138204752/metrics.json">metrics</a></td>
|
| 167 |
+
</tr>
|
| 168 |
+
<!-- ROW: faster_rcnn_R_101_DC5_3x -->
|
| 169 |
+
<tr><td align="left"><a href="configs/COCO-Detection/faster_rcnn_R_101_DC5_3x.yaml">R101-DC5</a></td>
|
| 170 |
+
<td align="center">3x</td>
|
| 171 |
+
<td align="center">0.452</td>
|
| 172 |
+
<td align="center">0.086</td>
|
| 173 |
+
<td align="center">6.1</td>
|
| 174 |
+
<td align="center">40.6</td>
|
| 175 |
+
<td align="center">138204841</td>
|
| 176 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_101_DC5_3x/138204841/model_final_3e0943.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_101_DC5_3x/138204841/metrics.json">metrics</a></td>
|
| 177 |
+
</tr>
|
| 178 |
+
<!-- ROW: faster_rcnn_R_101_FPN_3x -->
|
| 179 |
+
<tr><td align="left"><a href="configs/COCO-Detection/faster_rcnn_R_101_FPN_3x.yaml">R101-FPN</a></td>
|
| 180 |
+
<td align="center">3x</td>
|
| 181 |
+
<td align="center">0.286</td>
|
| 182 |
+
<td align="center">0.051</td>
|
| 183 |
+
<td align="center">4.1</td>
|
| 184 |
+
<td align="center">42.0</td>
|
| 185 |
+
<td align="center">137851257</td>
|
| 186 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_101_FPN_3x/137851257/model_final_f6e8b1.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_R_101_FPN_3x/137851257/metrics.json">metrics</a></td>
|
| 187 |
+
</tr>
|
| 188 |
+
<!-- ROW: faster_rcnn_X_101_32x8d_FPN_3x -->
|
| 189 |
+
<tr><td align="left"><a href="configs/COCO-Detection/faster_rcnn_X_101_32x8d_FPN_3x.yaml">X101-FPN</a></td>
|
| 190 |
+
<td align="center">3x</td>
|
| 191 |
+
<td align="center">0.638</td>
|
| 192 |
+
<td align="center">0.098</td>
|
| 193 |
+
<td align="center">6.7</td>
|
| 194 |
+
<td align="center">43.0</td>
|
| 195 |
+
<td align="center">139173657</td>
|
| 196 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_X_101_32x8d_FPN_3x/139173657/model_final_68b088.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/faster_rcnn_X_101_32x8d_FPN_3x/139173657/metrics.json">metrics</a></td>
|
| 197 |
+
</tr>
|
| 198 |
+
</tbody></table>
|
| 199 |
+
|
| 200 |
+
#### RetinaNet:
|
| 201 |
+
<!--
|
| 202 |
+
./gen_html_table.py --config 'COCO-Detection/retina*50*' 'COCO-Detection/retina*101*' --name R50 R50 R101 --fields lr_sched train_speed inference_speed mem box_AP
|
| 203 |
+
-->
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
<table><tbody>
|
| 207 |
+
<!-- START TABLE -->
|
| 208 |
+
<!-- TABLE HEADER -->
|
| 209 |
+
<th valign="bottom">Name</th>
|
| 210 |
+
<th valign="bottom">lr<br/>sched</th>
|
| 211 |
+
<th valign="bottom">train<br/>time<br/>(s/iter)</th>
|
| 212 |
+
<th valign="bottom">inference<br/>time<br/>(s/im)</th>
|
| 213 |
+
<th valign="bottom">train<br/>mem<br/>(GB)</th>
|
| 214 |
+
<th valign="bottom">box<br/>AP</th>
|
| 215 |
+
<th valign="bottom">model id</th>
|
| 216 |
+
<th valign="bottom">download</th>
|
| 217 |
+
<!-- TABLE BODY -->
|
| 218 |
+
<!-- ROW: retinanet_R_50_FPN_1x -->
|
| 219 |
+
<tr><td align="left"><a href="configs/COCO-Detection/retinanet_R_50_FPN_1x.yaml">R50</a></td>
|
| 220 |
+
<td align="center">1x</td>
|
| 221 |
+
<td align="center">0.200</td>
|
| 222 |
+
<td align="center">0.055</td>
|
| 223 |
+
<td align="center">3.9</td>
|
| 224 |
+
<td align="center">36.5</td>
|
| 225 |
+
<td align="center">137593951</td>
|
| 226 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/retinanet_R_50_FPN_1x/137593951/model_final_b796dc.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/retinanet_R_50_FPN_1x/137593951/metrics.json">metrics</a></td>
|
| 227 |
+
</tr>
|
| 228 |
+
<!-- ROW: retinanet_R_50_FPN_3x -->
|
| 229 |
+
<tr><td align="left"><a href="configs/COCO-Detection/retinanet_R_50_FPN_3x.yaml">R50</a></td>
|
| 230 |
+
<td align="center">3x</td>
|
| 231 |
+
<td align="center">0.201</td>
|
| 232 |
+
<td align="center">0.055</td>
|
| 233 |
+
<td align="center">3.9</td>
|
| 234 |
+
<td align="center">37.9</td>
|
| 235 |
+
<td align="center">137849486</td>
|
| 236 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/retinanet_R_50_FPN_3x/137849486/model_final_4cafe0.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/retinanet_R_50_FPN_3x/137849486/metrics.json">metrics</a></td>
|
| 237 |
+
</tr>
|
| 238 |
+
<!-- ROW: retinanet_R_101_FPN_3x -->
|
| 239 |
+
<tr><td align="left"><a href="configs/COCO-Detection/retinanet_R_101_FPN_3x.yaml">R101</a></td>
|
| 240 |
+
<td align="center">3x</td>
|
| 241 |
+
<td align="center">0.280</td>
|
| 242 |
+
<td align="center">0.068</td>
|
| 243 |
+
<td align="center">5.1</td>
|
| 244 |
+
<td align="center">39.9</td>
|
| 245 |
+
<td align="center">138363263</td>
|
| 246 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/retinanet_R_101_FPN_3x/138363263/model_final_59f53c.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/retinanet_R_101_FPN_3x/138363263/metrics.json">metrics</a></td>
|
| 247 |
+
</tr>
|
| 248 |
+
</tbody></table>
|
| 249 |
+
|
| 250 |
+
#### RPN & Fast R-CNN:
|
| 251 |
+
<!--
|
| 252 |
+
./gen_html_table.py --config 'COCO-Detection/rpn*' 'COCO-Detection/fast_rcnn*' --name "RPN R50-C4" "RPN R50-FPN" "Fast R-CNN R50-FPN" --fields lr_sched train_speed inference_speed mem box_AP prop_AR
|
| 253 |
+
-->
|
| 254 |
+
|
| 255 |
+
<table><tbody>
|
| 256 |
+
<!-- START TABLE -->
|
| 257 |
+
<!-- TABLE HEADER -->
|
| 258 |
+
<th valign="bottom">Name</th>
|
| 259 |
+
<th valign="bottom">lr<br/>sched</th>
|
| 260 |
+
<th valign="bottom">train<br/>time<br/>(s/iter)</th>
|
| 261 |
+
<th valign="bottom">inference<br/>time<br/>(s/im)</th>
|
| 262 |
+
<th valign="bottom">train<br/>mem<br/>(GB)</th>
|
| 263 |
+
<th valign="bottom">box<br/>AP</th>
|
| 264 |
+
<th valign="bottom">prop.<br/>AR</th>
|
| 265 |
+
<th valign="bottom">model id</th>
|
| 266 |
+
<th valign="bottom">download</th>
|
| 267 |
+
<!-- TABLE BODY -->
|
| 268 |
+
<!-- ROW: rpn_R_50_C4_1x -->
|
| 269 |
+
<tr><td align="left"><a href="configs/COCO-Detection/rpn_R_50_C4_1x.yaml">RPN R50-C4</a></td>
|
| 270 |
+
<td align="center">1x</td>
|
| 271 |
+
<td align="center">0.130</td>
|
| 272 |
+
<td align="center">0.034</td>
|
| 273 |
+
<td align="center">1.5</td>
|
| 274 |
+
<td align="center"></td>
|
| 275 |
+
<td align="center">51.6</td>
|
| 276 |
+
<td align="center">137258005</td>
|
| 277 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/rpn_R_50_C4_1x/137258005/model_final_450694.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/rpn_R_50_C4_1x/137258005/metrics.json">metrics</a></td>
|
| 278 |
+
</tr>
|
| 279 |
+
<!-- ROW: rpn_R_50_FPN_1x -->
|
| 280 |
+
<tr><td align="left"><a href="configs/COCO-Detection/rpn_R_50_FPN_1x.yaml">RPN R50-FPN</a></td>
|
| 281 |
+
<td align="center">1x</td>
|
| 282 |
+
<td align="center">0.186</td>
|
| 283 |
+
<td align="center">0.032</td>
|
| 284 |
+
<td align="center">2.7</td>
|
| 285 |
+
<td align="center"></td>
|
| 286 |
+
<td align="center">58.0</td>
|
| 287 |
+
<td align="center">137258492</td>
|
| 288 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/rpn_R_50_FPN_1x/137258492/model_final_02ce48.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/rpn_R_50_FPN_1x/137258492/metrics.json">metrics</a></td>
|
| 289 |
+
</tr>
|
| 290 |
+
<!-- ROW: fast_rcnn_R_50_FPN_1x -->
|
| 291 |
+
<tr><td align="left"><a href="configs/COCO-Detection/fast_rcnn_R_50_FPN_1x.yaml">Fast R-CNN R50-FPN</a></td>
|
| 292 |
+
<td align="center">1x</td>
|
| 293 |
+
<td align="center">0.140</td>
|
| 294 |
+
<td align="center">0.029</td>
|
| 295 |
+
<td align="center">2.6</td>
|
| 296 |
+
<td align="center">37.8</td>
|
| 297 |
+
<td align="center"></td>
|
| 298 |
+
<td align="center">137635226</td>
|
| 299 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/fast_rcnn_R_50_FPN_1x/137635226/model_final_e5f7ce.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Detection/fast_rcnn_R_50_FPN_1x/137635226/metrics.json">metrics</a></td>
|
| 300 |
+
</tr>
|
| 301 |
+
</tbody></table>
|
| 302 |
+
|
| 303 |
+
### COCO Instance Segmentation Baselines with Mask R-CNN
|
| 304 |
+
<!--
|
| 305 |
+
./gen_html_table.py --config 'COCO-InstanceSegmentation/mask*50*'{1x,3x}'*' 'COCO-InstanceSegmentation/mask*101*' --name R50-C4 R50-DC5 R50-FPN R50-C4 R50-DC5 R50-FPN R101-C4 R101-DC5 R101-FPN X101-FPN --fields lr_sched train_speed inference_speed mem box_AP mask_AP
|
| 306 |
+
-->
|
| 307 |
+
|
| 308 |
+
|
| 309 |
+
|
| 310 |
+
<table><tbody>
|
| 311 |
+
<!-- START TABLE -->
|
| 312 |
+
<!-- TABLE HEADER -->
|
| 313 |
+
<th valign="bottom">Name</th>
|
| 314 |
+
<th valign="bottom">lr<br/>sched</th>
|
| 315 |
+
<th valign="bottom">train<br/>time<br/>(s/iter)</th>
|
| 316 |
+
<th valign="bottom">inference<br/>time<br/>(s/im)</th>
|
| 317 |
+
<th valign="bottom">train<br/>mem<br/>(GB)</th>
|
| 318 |
+
<th valign="bottom">box<br/>AP</th>
|
| 319 |
+
<th valign="bottom">mask<br/>AP</th>
|
| 320 |
+
<th valign="bottom">model id</th>
|
| 321 |
+
<th valign="bottom">download</th>
|
| 322 |
+
<!-- TABLE BODY -->
|
| 323 |
+
<!-- ROW: mask_rcnn_R_50_C4_1x -->
|
| 324 |
+
<tr><td align="left"><a href="configs/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_1x.yaml">R50-C4</a></td>
|
| 325 |
+
<td align="center">1x</td>
|
| 326 |
+
<td align="center">0.584</td>
|
| 327 |
+
<td align="center">0.110</td>
|
| 328 |
+
<td align="center">5.2</td>
|
| 329 |
+
<td align="center">36.8</td>
|
| 330 |
+
<td align="center">32.2</td>
|
| 331 |
+
<td align="center">137259246</td>
|
| 332 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_1x/137259246/model_final_9243eb.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_1x/137259246/metrics.json">metrics</a></td>
|
| 333 |
+
</tr>
|
| 334 |
+
<!-- ROW: mask_rcnn_R_50_DC5_1x -->
|
| 335 |
+
<tr><td align="left"><a href="configs/COCO-InstanceSegmentation/mask_rcnn_R_50_DC5_1x.yaml">R50-DC5</a></td>
|
| 336 |
+
<td align="center">1x</td>
|
| 337 |
+
<td align="center">0.471</td>
|
| 338 |
+
<td align="center">0.076</td>
|
| 339 |
+
<td align="center">6.5</td>
|
| 340 |
+
<td align="center">38.3</td>
|
| 341 |
+
<td align="center">34.2</td>
|
| 342 |
+
<td align="center">137260150</td>
|
| 343 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_DC5_1x/137260150/model_final_4f86c3.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_DC5_1x/137260150/metrics.json">metrics</a></td>
|
| 344 |
+
</tr>
|
| 345 |
+
<!-- ROW: mask_rcnn_R_50_FPN_1x -->
|
| 346 |
+
<tr><td align="left"><a href="configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml">R50-FPN</a></td>
|
| 347 |
+
<td align="center">1x</td>
|
| 348 |
+
<td align="center">0.261</td>
|
| 349 |
+
<td align="center">0.043</td>
|
| 350 |
+
<td align="center">3.4</td>
|
| 351 |
+
<td align="center">38.6</td>
|
| 352 |
+
<td align="center">35.2</td>
|
| 353 |
+
<td align="center">137260431</td>
|
| 354 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x/137260431/model_final_a54504.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x/137260431/metrics.json">metrics</a></td>
|
| 355 |
+
</tr>
|
| 356 |
+
<!-- ROW: mask_rcnn_R_50_C4_3x -->
|
| 357 |
+
<tr><td align="left"><a href="configs/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_3x.yaml">R50-C4</a></td>
|
| 358 |
+
<td align="center">3x</td>
|
| 359 |
+
<td align="center">0.575</td>
|
| 360 |
+
<td align="center">0.111</td>
|
| 361 |
+
<td align="center">5.2</td>
|
| 362 |
+
<td align="center">39.8</td>
|
| 363 |
+
<td align="center">34.4</td>
|
| 364 |
+
<td align="center">137849525</td>
|
| 365 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_3x/137849525/model_final_4ce675.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_C4_3x/137849525/metrics.json">metrics</a></td>
|
| 366 |
+
</tr>
|
| 367 |
+
<!-- ROW: mask_rcnn_R_50_DC5_3x -->
|
| 368 |
+
<tr><td align="left"><a href="configs/COCO-InstanceSegmentation/mask_rcnn_R_50_DC5_3x.yaml">R50-DC5</a></td>
|
| 369 |
+
<td align="center">3x</td>
|
| 370 |
+
<td align="center">0.470</td>
|
| 371 |
+
<td align="center">0.076</td>
|
| 372 |
+
<td align="center">6.5</td>
|
| 373 |
+
<td align="center">40.0</td>
|
| 374 |
+
<td align="center">35.9</td>
|
| 375 |
+
<td align="center">137849551</td>
|
| 376 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_DC5_3x/137849551/model_final_84107b.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_DC5_3x/137849551/metrics.json">metrics</a></td>
|
| 377 |
+
</tr>
|
| 378 |
+
<!-- ROW: mask_rcnn_R_50_FPN_3x -->
|
| 379 |
+
<tr><td align="left"><a href="configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml">R50-FPN</a></td>
|
| 380 |
+
<td align="center">3x</td>
|
| 381 |
+
<td align="center">0.261</td>
|
| 382 |
+
<td align="center">0.043</td>
|
| 383 |
+
<td align="center">3.4</td>
|
| 384 |
+
<td align="center">41.0</td>
|
| 385 |
+
<td align="center">37.2</td>
|
| 386 |
+
<td align="center">137849600</td>
|
| 387 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/metrics.json">metrics</a></td>
|
| 388 |
+
</tr>
|
| 389 |
+
<!-- ROW: mask_rcnn_R_101_C4_3x -->
|
| 390 |
+
<tr><td align="left"><a href="configs/COCO-InstanceSegmentation/mask_rcnn_R_101_C4_3x.yaml">R101-C4</a></td>
|
| 391 |
+
<td align="center">3x</td>
|
| 392 |
+
<td align="center">0.652</td>
|
| 393 |
+
<td align="center">0.145</td>
|
| 394 |
+
<td align="center">6.3</td>
|
| 395 |
+
<td align="center">42.6</td>
|
| 396 |
+
<td align="center">36.7</td>
|
| 397 |
+
<td align="center">138363239</td>
|
| 398 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_101_C4_3x/138363239/model_final_a2914c.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_101_C4_3x/138363239/metrics.json">metrics</a></td>
|
| 399 |
+
</tr>
|
| 400 |
+
<!-- ROW: mask_rcnn_R_101_DC5_3x -->
|
| 401 |
+
<tr><td align="left"><a href="configs/COCO-InstanceSegmentation/mask_rcnn_R_101_DC5_3x.yaml">R101-DC5</a></td>
|
| 402 |
+
<td align="center">3x</td>
|
| 403 |
+
<td align="center">0.545</td>
|
| 404 |
+
<td align="center">0.092</td>
|
| 405 |
+
<td align="center">7.6</td>
|
| 406 |
+
<td align="center">41.9</td>
|
| 407 |
+
<td align="center">37.3</td>
|
| 408 |
+
<td align="center">138363294</td>
|
| 409 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_101_DC5_3x/138363294/model_final_0464b7.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_101_DC5_3x/138363294/metrics.json">metrics</a></td>
|
| 410 |
+
</tr>
|
| 411 |
+
<!-- ROW: mask_rcnn_R_101_FPN_3x -->
|
| 412 |
+
<tr><td align="left"><a href="configs/COCO-InstanceSegmentation/mask_rcnn_R_101_FPN_3x.yaml">R101-FPN</a></td>
|
| 413 |
+
<td align="center">3x</td>
|
| 414 |
+
<td align="center">0.340</td>
|
| 415 |
+
<td align="center">0.056</td>
|
| 416 |
+
<td align="center">4.6</td>
|
| 417 |
+
<td align="center">42.9</td>
|
| 418 |
+
<td align="center">38.6</td>
|
| 419 |
+
<td align="center">138205316</td>
|
| 420 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_101_FPN_3x/138205316/model_final_a3ec72.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_101_FPN_3x/138205316/metrics.json">metrics</a></td>
|
| 421 |
+
</tr>
|
| 422 |
+
<!-- ROW: mask_rcnn_X_101_32x8d_FPN_3x -->
|
| 423 |
+
<tr><td align="left"><a href="configs/COCO-InstanceSegmentation/mask_rcnn_X_101_32x8d_FPN_3x.yaml">X101-FPN</a></td>
|
| 424 |
+
<td align="center">3x</td>
|
| 425 |
+
<td align="center">0.690</td>
|
| 426 |
+
<td align="center">0.103</td>
|
| 427 |
+
<td align="center">7.2</td>
|
| 428 |
+
<td align="center">44.3</td>
|
| 429 |
+
<td align="center">39.5</td>
|
| 430 |
+
<td align="center">139653917</td>
|
| 431 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_X_101_32x8d_FPN_3x/139653917/model_final_2d9806.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_X_101_32x8d_FPN_3x/139653917/metrics.json">metrics</a></td>
|
| 432 |
+
</tr>
|
| 433 |
+
</tbody></table>
|
| 434 |
+
|
| 435 |
+
### COCO Person Keypoint Detection Baselines with Keypoint R-CNN
|
| 436 |
+
<!--
|
| 437 |
+
./gen_html_table.py --config 'COCO-Keypoints/*50*' 'COCO-Keypoints/*101*' --name R50-FPN R50-FPN R101-FPN X101-FPN --fields lr_sched train_speed inference_speed mem box_AP keypoint_AP
|
| 438 |
+
-->
|
| 439 |
+
|
| 440 |
+
|
| 441 |
+
<table><tbody>
|
| 442 |
+
<!-- START TABLE -->
|
| 443 |
+
<!-- TABLE HEADER -->
|
| 444 |
+
<th valign="bottom">Name</th>
|
| 445 |
+
<th valign="bottom">lr<br/>sched</th>
|
| 446 |
+
<th valign="bottom">train<br/>time<br/>(s/iter)</th>
|
| 447 |
+
<th valign="bottom">inference<br/>time<br/>(s/im)</th>
|
| 448 |
+
<th valign="bottom">train<br/>mem<br/>(GB)</th>
|
| 449 |
+
<th valign="bottom">box<br/>AP</th>
|
| 450 |
+
<th valign="bottom">kp.<br/>AP</th>
|
| 451 |
+
<th valign="bottom">model id</th>
|
| 452 |
+
<th valign="bottom">download</th>
|
| 453 |
+
<!-- TABLE BODY -->
|
| 454 |
+
<!-- ROW: keypoint_rcnn_R_50_FPN_1x -->
|
| 455 |
+
<tr><td align="left"><a href="configs/COCO-Keypoints/keypoint_rcnn_R_50_FPN_1x.yaml">R50-FPN</a></td>
|
| 456 |
+
<td align="center">1x</td>
|
| 457 |
+
<td align="center">0.315</td>
|
| 458 |
+
<td align="center">0.072</td>
|
| 459 |
+
<td align="center">5.0</td>
|
| 460 |
+
<td align="center">53.6</td>
|
| 461 |
+
<td align="center">64.0</td>
|
| 462 |
+
<td align="center">137261548</td>
|
| 463 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Keypoints/keypoint_rcnn_R_50_FPN_1x/137261548/model_final_04e291.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Keypoints/keypoint_rcnn_R_50_FPN_1x/137261548/metrics.json">metrics</a></td>
|
| 464 |
+
</tr>
|
| 465 |
+
<!-- ROW: keypoint_rcnn_R_50_FPN_3x -->
|
| 466 |
+
<tr><td align="left"><a href="configs/COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml">R50-FPN</a></td>
|
| 467 |
+
<td align="center">3x</td>
|
| 468 |
+
<td align="center">0.316</td>
|
| 469 |
+
<td align="center">0.066</td>
|
| 470 |
+
<td align="center">5.0</td>
|
| 471 |
+
<td align="center">55.4</td>
|
| 472 |
+
<td align="center">65.5</td>
|
| 473 |
+
<td align="center">137849621</td>
|
| 474 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x/137849621/model_final_a6e10b.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x/137849621/metrics.json">metrics</a></td>
|
| 475 |
+
</tr>
|
| 476 |
+
<!-- ROW: keypoint_rcnn_R_101_FPN_3x -->
|
| 477 |
+
<tr><td align="left"><a href="configs/COCO-Keypoints/keypoint_rcnn_R_101_FPN_3x.yaml">R101-FPN</a></td>
|
| 478 |
+
<td align="center">3x</td>
|
| 479 |
+
<td align="center">0.390</td>
|
| 480 |
+
<td align="center">0.076</td>
|
| 481 |
+
<td align="center">6.1</td>
|
| 482 |
+
<td align="center">56.4</td>
|
| 483 |
+
<td align="center">66.1</td>
|
| 484 |
+
<td align="center">138363331</td>
|
| 485 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Keypoints/keypoint_rcnn_R_101_FPN_3x/138363331/model_final_997cc7.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Keypoints/keypoint_rcnn_R_101_FPN_3x/138363331/metrics.json">metrics</a></td>
|
| 486 |
+
</tr>
|
| 487 |
+
<!-- ROW: keypoint_rcnn_X_101_32x8d_FPN_3x -->
|
| 488 |
+
<tr><td align="left"><a href="configs/COCO-Keypoints/keypoint_rcnn_X_101_32x8d_FPN_3x.yaml">X101-FPN</a></td>
|
| 489 |
+
<td align="center">3x</td>
|
| 490 |
+
<td align="center">0.738</td>
|
| 491 |
+
<td align="center">0.121</td>
|
| 492 |
+
<td align="center">8.7</td>
|
| 493 |
+
<td align="center">57.3</td>
|
| 494 |
+
<td align="center">66.0</td>
|
| 495 |
+
<td align="center">139686956</td>
|
| 496 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Keypoints/keypoint_rcnn_X_101_32x8d_FPN_3x/139686956/model_final_5ad38f.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-Keypoints/keypoint_rcnn_X_101_32x8d_FPN_3x/139686956/metrics.json">metrics</a></td>
|
| 497 |
+
</tr>
|
| 498 |
+
</tbody></table>
|
| 499 |
+
|
| 500 |
+
### COCO Panoptic Segmentation Baselines with Panoptic FPN
|
| 501 |
+
<!--
|
| 502 |
+
./gen_html_table.py --config 'COCO-PanopticSegmentation/*50*' 'COCO-PanopticSegmentation/*101*' --name R50-FPN R50-FPN R101-FPN --fields lr_sched train_speed inference_speed mem box_AP mask_AP PQ
|
| 503 |
+
-->
|
| 504 |
+
|
| 505 |
+
|
| 506 |
+
<table><tbody>
|
| 507 |
+
<!-- START TABLE -->
|
| 508 |
+
<!-- TABLE HEADER -->
|
| 509 |
+
<th valign="bottom">Name</th>
|
| 510 |
+
<th valign="bottom">lr<br/>sched</th>
|
| 511 |
+
<th valign="bottom">train<br/>time<br/>(s/iter)</th>
|
| 512 |
+
<th valign="bottom">inference<br/>time<br/>(s/im)</th>
|
| 513 |
+
<th valign="bottom">train<br/>mem<br/>(GB)</th>
|
| 514 |
+
<th valign="bottom">box<br/>AP</th>
|
| 515 |
+
<th valign="bottom">mask<br/>AP</th>
|
| 516 |
+
<th valign="bottom">PQ</th>
|
| 517 |
+
<th valign="bottom">model id</th>
|
| 518 |
+
<th valign="bottom">download</th>
|
| 519 |
+
<!-- TABLE BODY -->
|
| 520 |
+
<!-- ROW: panoptic_fpn_R_50_1x -->
|
| 521 |
+
<tr><td align="left"><a href="configs/COCO-PanopticSegmentation/panoptic_fpn_R_50_1x.yaml">R50-FPN</a></td>
|
| 522 |
+
<td align="center">1x</td>
|
| 523 |
+
<td align="center">0.304</td>
|
| 524 |
+
<td align="center">0.053</td>
|
| 525 |
+
<td align="center">4.8</td>
|
| 526 |
+
<td align="center">37.6</td>
|
| 527 |
+
<td align="center">34.7</td>
|
| 528 |
+
<td align="center">39.4</td>
|
| 529 |
+
<td align="center">139514544</td>
|
| 530 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-PanopticSegmentation/panoptic_fpn_R_50_1x/139514544/model_final_dbfeb4.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-PanopticSegmentation/panoptic_fpn_R_50_1x/139514544/metrics.json">metrics</a></td>
|
| 531 |
+
</tr>
|
| 532 |
+
<!-- ROW: panoptic_fpn_R_50_3x -->
|
| 533 |
+
<tr><td align="left"><a href="configs/COCO-PanopticSegmentation/panoptic_fpn_R_50_3x.yaml">R50-FPN</a></td>
|
| 534 |
+
<td align="center">3x</td>
|
| 535 |
+
<td align="center">0.302</td>
|
| 536 |
+
<td align="center">0.053</td>
|
| 537 |
+
<td align="center">4.8</td>
|
| 538 |
+
<td align="center">40.0</td>
|
| 539 |
+
<td align="center">36.5</td>
|
| 540 |
+
<td align="center">41.5</td>
|
| 541 |
+
<td align="center">139514569</td>
|
| 542 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-PanopticSegmentation/panoptic_fpn_R_50_3x/139514569/model_final_c10459.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-PanopticSegmentation/panoptic_fpn_R_50_3x/139514569/metrics.json">metrics</a></td>
|
| 543 |
+
</tr>
|
| 544 |
+
<!-- ROW: panoptic_fpn_R_101_3x -->
|
| 545 |
+
<tr><td align="left"><a href="configs/COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml">R101-FPN</a></td>
|
| 546 |
+
<td align="center">3x</td>
|
| 547 |
+
<td align="center">0.392</td>
|
| 548 |
+
<td align="center">0.066</td>
|
| 549 |
+
<td align="center">6.0</td>
|
| 550 |
+
<td align="center">42.4</td>
|
| 551 |
+
<td align="center">38.5</td>
|
| 552 |
+
<td align="center">43.0</td>
|
| 553 |
+
<td align="center">139514519</td>
|
| 554 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-PanopticSegmentation/panoptic_fpn_R_101_3x/139514519/model_final_cafdb1.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-PanopticSegmentation/panoptic_fpn_R_101_3x/139514519/metrics.json">metrics</a></td>
|
| 555 |
+
</tr>
|
| 556 |
+
</tbody></table>
|
| 557 |
+
|
| 558 |
+
|
| 559 |
+
### LVIS Instance Segmentation Baselines with Mask R-CNN
|
| 560 |
+
|
| 561 |
+
Mask R-CNN baselines on the [LVIS dataset](https://lvisdataset.org), v0.5.
|
| 562 |
+
These baselines are described in Table 3(c) of the [LVIS paper](https://arxiv.org/abs/1908.03195).
|
| 563 |
+
|
| 564 |
+
NOTE: the 1x schedule here has the same amount of __iterations__ as the COCO 1x baselines.
|
| 565 |
+
They are roughly 24 epochs of LVISv0.5 data.
|
| 566 |
+
The final results of these configs have large variance across different runs.
|
| 567 |
+
|
| 568 |
+
<!--
|
| 569 |
+
./gen_html_table.py --config 'LVIS-InstanceSegmentation/mask*50*' 'LVIS-InstanceSegmentation/mask*101*' --name R50-FPN R101-FPN X101-FPN --fields lr_sched train_speed inference_speed mem box_AP mask_AP
|
| 570 |
+
-->
|
| 571 |
+
|
| 572 |
+
|
| 573 |
+
<table><tbody>
|
| 574 |
+
<!-- START TABLE -->
|
| 575 |
+
<!-- TABLE HEADER -->
|
| 576 |
+
<th valign="bottom">Name</th>
|
| 577 |
+
<th valign="bottom">lr<br/>sched</th>
|
| 578 |
+
<th valign="bottom">train<br/>time<br/>(s/iter)</th>
|
| 579 |
+
<th valign="bottom">inference<br/>time<br/>(s/im)</th>
|
| 580 |
+
<th valign="bottom">train<br/>mem<br/>(GB)</th>
|
| 581 |
+
<th valign="bottom">box<br/>AP</th>
|
| 582 |
+
<th valign="bottom">mask<br/>AP</th>
|
| 583 |
+
<th valign="bottom">model id</th>
|
| 584 |
+
<th valign="bottom">download</th>
|
| 585 |
+
<!-- TABLE BODY -->
|
| 586 |
+
<!-- ROW: mask_rcnn_R_50_FPN_1x -->
|
| 587 |
+
<tr><td align="left"><a href="configs/LVIS-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml">R50-FPN</a></td>
|
| 588 |
+
<td align="center">1x</td>
|
| 589 |
+
<td align="center">0.292</td>
|
| 590 |
+
<td align="center">0.107</td>
|
| 591 |
+
<td align="center">7.1</td>
|
| 592 |
+
<td align="center">23.6</td>
|
| 593 |
+
<td align="center">24.4</td>
|
| 594 |
+
<td align="center">144219072</td>
|
| 595 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/LVIS-InstanceSegmentation/mask_rcnn_R_50_FPN_1x/144219072/model_final_571f7c.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/LVIS-InstanceSegmentation/mask_rcnn_R_50_FPN_1x/144219072/metrics.json">metrics</a></td>
|
| 596 |
+
</tr>
|
| 597 |
+
<!-- ROW: mask_rcnn_R_101_FPN_1x -->
|
| 598 |
+
<tr><td align="left"><a href="configs/LVIS-InstanceSegmentation/mask_rcnn_R_101_FPN_1x.yaml">R101-FPN</a></td>
|
| 599 |
+
<td align="center">1x</td>
|
| 600 |
+
<td align="center">0.371</td>
|
| 601 |
+
<td align="center">0.114</td>
|
| 602 |
+
<td align="center">7.8</td>
|
| 603 |
+
<td align="center">25.6</td>
|
| 604 |
+
<td align="center">25.9</td>
|
| 605 |
+
<td align="center">144219035</td>
|
| 606 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/LVIS-InstanceSegmentation/mask_rcnn_R_101_FPN_1x/144219035/model_final_824ab5.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/LVIS-InstanceSegmentation/mask_rcnn_R_101_FPN_1x/144219035/metrics.json">metrics</a></td>
|
| 607 |
+
</tr>
|
| 608 |
+
<!-- ROW: mask_rcnn_X_101_32x8d_FPN_1x -->
|
| 609 |
+
<tr><td align="left"><a href="configs/LVIS-InstanceSegmentation/mask_rcnn_X_101_32x8d_FPN_1x.yaml">X101-FPN</a></td>
|
| 610 |
+
<td align="center">1x</td>
|
| 611 |
+
<td align="center">0.712</td>
|
| 612 |
+
<td align="center">0.151</td>
|
| 613 |
+
<td align="center">10.2</td>
|
| 614 |
+
<td align="center">26.7</td>
|
| 615 |
+
<td align="center">27.1</td>
|
| 616 |
+
<td align="center">144219108</td>
|
| 617 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/LVIS-InstanceSegmentation/mask_rcnn_X_101_32x8d_FPN_1x/144219108/model_final_5e3439.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/LVIS-InstanceSegmentation/mask_rcnn_X_101_32x8d_FPN_1x/144219108/metrics.json">metrics</a></td>
|
| 618 |
+
</tr>
|
| 619 |
+
</tbody></table>
|
| 620 |
+
|
| 621 |
+
|
| 622 |
+
|
| 623 |
+
### Cityscapes & Pascal VOC Baselines
|
| 624 |
+
|
| 625 |
+
Simple baselines for
|
| 626 |
+
* Mask R-CNN on Cityscapes instance segmentation (initialized from COCO pre-training, then trained on Cityscapes fine annotations only)
|
| 627 |
+
* Faster R-CNN on PASCAL VOC object detection (trained on VOC 2007 train+val + VOC 2012 train+val, tested on VOC 2007 using 11-point interpolated AP)
|
| 628 |
+
|
| 629 |
+
<!--
|
| 630 |
+
./gen_html_table.py --config 'Cityscapes/*' 'PascalVOC-Detection/*' --name "R50-FPN, Cityscapes" "R50-C4, VOC" --fields train_speed inference_speed mem box_AP box_AP50 mask_AP
|
| 631 |
+
-->
|
| 632 |
+
|
| 633 |
+
|
| 634 |
+
<table><tbody>
|
| 635 |
+
<!-- START TABLE -->
|
| 636 |
+
<!-- TABLE HEADER -->
|
| 637 |
+
<th valign="bottom">Name</th>
|
| 638 |
+
<th valign="bottom">train<br/>time<br/>(s/iter)</th>
|
| 639 |
+
<th valign="bottom">inference<br/>time<br/>(s/im)</th>
|
| 640 |
+
<th valign="bottom">train<br/>mem<br/>(GB)</th>
|
| 641 |
+
<th valign="bottom">box<br/>AP</th>
|
| 642 |
+
<th valign="bottom">box<br/>AP50</th>
|
| 643 |
+
<th valign="bottom">mask<br/>AP</th>
|
| 644 |
+
<th valign="bottom">model id</th>
|
| 645 |
+
<th valign="bottom">download</th>
|
| 646 |
+
<!-- TABLE BODY -->
|
| 647 |
+
<!-- ROW: mask_rcnn_R_50_FPN -->
|
| 648 |
+
<tr><td align="left"><a href="configs/Cityscapes/mask_rcnn_R_50_FPN.yaml">R50-FPN, Cityscapes</a></td>
|
| 649 |
+
<td align="center">0.240</td>
|
| 650 |
+
<td align="center">0.078</td>
|
| 651 |
+
<td align="center">4.4</td>
|
| 652 |
+
<td align="center"></td>
|
| 653 |
+
<td align="center"></td>
|
| 654 |
+
<td align="center">36.5</td>
|
| 655 |
+
<td align="center">142423278</td>
|
| 656 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/Cityscapes/mask_rcnn_R_50_FPN/142423278/model_final_af9cf5.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/Cityscapes/mask_rcnn_R_50_FPN/142423278/metrics.json">metrics</a></td>
|
| 657 |
+
</tr>
|
| 658 |
+
<!-- ROW: faster_rcnn_R_50_C4 -->
|
| 659 |
+
<tr><td align="left"><a href="configs/PascalVOC-Detection/faster_rcnn_R_50_C4.yaml">R50-C4, VOC</a></td>
|
| 660 |
+
<td align="center">0.537</td>
|
| 661 |
+
<td align="center">0.081</td>
|
| 662 |
+
<td align="center">4.8</td>
|
| 663 |
+
<td align="center">51.9</td>
|
| 664 |
+
<td align="center">80.3</td>
|
| 665 |
+
<td align="center"></td>
|
| 666 |
+
<td align="center">142202221</td>
|
| 667 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/PascalVOC-Detection/faster_rcnn_R_50_C4/142202221/model_final_b1acc2.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/PascalVOC-Detection/faster_rcnn_R_50_C4/142202221/metrics.json">metrics</a></td>
|
| 668 |
+
</tr>
|
| 669 |
+
</tbody></table>
|
| 670 |
+
|
| 671 |
+
|
| 672 |
+
|
| 673 |
+
### Other Settings
|
| 674 |
+
|
| 675 |
+
Ablations for Deformable Conv and Cascade R-CNN:
|
| 676 |
+
|
| 677 |
+
<!--
|
| 678 |
+
./gen_html_table.py --config 'COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml' 'Misc/*R_50_FPN_1x_dconv*' 'Misc/cascade*1x.yaml' 'COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml' 'Misc/*R_50_FPN_3x_dconv*' 'Misc/cascade*3x.yaml' --name "Baseline R50-FPN" "Deformable Conv" "Cascade R-CNN" "Baseline R50-FPN" "Deformable Conv" "Cascade R-CNN" --fields lr_sched train_speed inference_speed mem box_AP mask_AP
|
| 679 |
+
-->
|
| 680 |
+
|
| 681 |
+
|
| 682 |
+
<table><tbody>
|
| 683 |
+
<!-- START TABLE -->
|
| 684 |
+
<!-- TABLE HEADER -->
|
| 685 |
+
<th valign="bottom">Name</th>
|
| 686 |
+
<th valign="bottom">lr<br/>sched</th>
|
| 687 |
+
<th valign="bottom">train<br/>time<br/>(s/iter)</th>
|
| 688 |
+
<th valign="bottom">inference<br/>time<br/>(s/im)</th>
|
| 689 |
+
<th valign="bottom">train<br/>mem<br/>(GB)</th>
|
| 690 |
+
<th valign="bottom">box<br/>AP</th>
|
| 691 |
+
<th valign="bottom">mask<br/>AP</th>
|
| 692 |
+
<th valign="bottom">model id</th>
|
| 693 |
+
<th valign="bottom">download</th>
|
| 694 |
+
<!-- TABLE BODY -->
|
| 695 |
+
<!-- ROW: mask_rcnn_R_50_FPN_1x -->
|
| 696 |
+
<tr><td align="left"><a href="configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x.yaml">Baseline R50-FPN</a></td>
|
| 697 |
+
<td align="center">1x</td>
|
| 698 |
+
<td align="center">0.261</td>
|
| 699 |
+
<td align="center">0.043</td>
|
| 700 |
+
<td align="center">3.4</td>
|
| 701 |
+
<td align="center">38.6</td>
|
| 702 |
+
<td align="center">35.2</td>
|
| 703 |
+
<td align="center">137260431</td>
|
| 704 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x/137260431/model_final_a54504.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_1x/137260431/metrics.json">metrics</a></td>
|
| 705 |
+
</tr>
|
| 706 |
+
<!-- ROW: mask_rcnn_R_50_FPN_1x_dconv_c3-c5 -->
|
| 707 |
+
<tr><td align="left"><a href="configs/Misc/mask_rcnn_R_50_FPN_1x_dconv_c3-c5.yaml">Deformable Conv</a></td>
|
| 708 |
+
<td align="center">1x</td>
|
| 709 |
+
<td align="center">0.342</td>
|
| 710 |
+
<td align="center">0.048</td>
|
| 711 |
+
<td align="center">3.5</td>
|
| 712 |
+
<td align="center">41.5</td>
|
| 713 |
+
<td align="center">37.5</td>
|
| 714 |
+
<td align="center">138602867</td>
|
| 715 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/Misc/mask_rcnn_R_50_FPN_1x_dconv_c3-c5/138602867/model_final_65c703.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/Misc/mask_rcnn_R_50_FPN_1x_dconv_c3-c5/138602867/metrics.json">metrics</a></td>
|
| 716 |
+
</tr>
|
| 717 |
+
<!-- ROW: cascade_mask_rcnn_R_50_FPN_1x -->
|
| 718 |
+
<tr><td align="left"><a href="configs/Misc/cascade_mask_rcnn_R_50_FPN_1x.yaml">Cascade R-CNN</a></td>
|
| 719 |
+
<td align="center">1x</td>
|
| 720 |
+
<td align="center">0.317</td>
|
| 721 |
+
<td align="center">0.052</td>
|
| 722 |
+
<td align="center">4.0</td>
|
| 723 |
+
<td align="center">42.1</td>
|
| 724 |
+
<td align="center">36.4</td>
|
| 725 |
+
<td align="center">138602847</td>
|
| 726 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/Misc/cascade_mask_rcnn_R_50_FPN_1x/138602847/model_final_e9d89b.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/Misc/cascade_mask_rcnn_R_50_FPN_1x/138602847/metrics.json">metrics</a></td>
|
| 727 |
+
</tr>
|
| 728 |
+
<!-- ROW: mask_rcnn_R_50_FPN_3x -->
|
| 729 |
+
<tr><td align="left"><a href="configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml">Baseline R50-FPN</a></td>
|
| 730 |
+
<td align="center">3x</td>
|
| 731 |
+
<td align="center">0.261</td>
|
| 732 |
+
<td align="center">0.043</td>
|
| 733 |
+
<td align="center">3.4</td>
|
| 734 |
+
<td align="center">41.0</td>
|
| 735 |
+
<td align="center">37.2</td>
|
| 736 |
+
<td align="center">137849600</td>
|
| 737 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/metrics.json">metrics</a></td>
|
| 738 |
+
</tr>
|
| 739 |
+
<!-- ROW: mask_rcnn_R_50_FPN_3x_dconv_c3-c5 -->
|
| 740 |
+
<tr><td align="left"><a href="configs/Misc/mask_rcnn_R_50_FPN_3x_dconv_c3-c5.yaml">Deformable Conv</a></td>
|
| 741 |
+
<td align="center">3x</td>
|
| 742 |
+
<td align="center">0.349</td>
|
| 743 |
+
<td align="center">0.047</td>
|
| 744 |
+
<td align="center">3.5</td>
|
| 745 |
+
<td align="center">42.7</td>
|
| 746 |
+
<td align="center">38.5</td>
|
| 747 |
+
<td align="center">144998336</td>
|
| 748 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/Misc/mask_rcnn_R_50_FPN_3x_dconv_c3-c5/144998336/model_final_821d0b.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/Misc/mask_rcnn_R_50_FPN_3x_dconv_c3-c5/144998336/metrics.json">metrics</a></td>
|
| 749 |
+
</tr>
|
| 750 |
+
<!-- ROW: cascade_mask_rcnn_R_50_FPN_3x -->
|
| 751 |
+
<tr><td align="left"><a href="configs/Misc/cascade_mask_rcnn_R_50_FPN_3x.yaml">Cascade R-CNN</a></td>
|
| 752 |
+
<td align="center">3x</td>
|
| 753 |
+
<td align="center">0.328</td>
|
| 754 |
+
<td align="center">0.053</td>
|
| 755 |
+
<td align="center">4.0</td>
|
| 756 |
+
<td align="center">44.3</td>
|
| 757 |
+
<td align="center">38.5</td>
|
| 758 |
+
<td align="center">144998488</td>
|
| 759 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/Misc/cascade_mask_rcnn_R_50_FPN_3x/144998488/model_final_480dd8.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/Misc/cascade_mask_rcnn_R_50_FPN_3x/144998488/metrics.json">metrics</a></td>
|
| 760 |
+
</tr>
|
| 761 |
+
</tbody></table>
|
| 762 |
+
|
| 763 |
+
|
| 764 |
+
Ablations for normalization methods, and a few models trained from scratch following [Rethinking ImageNet Pre-training](https://arxiv.org/abs/1811.08883).
|
| 765 |
+
(Note: The baseline uses `2fc` head while the others use [`4conv1fc` head](https://arxiv.org/abs/1803.08494))
|
| 766 |
+
<!--
|
| 767 |
+
./gen_html_table.py --config 'COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml' 'Misc/mask*50_FPN_3x_gn.yaml' 'Misc/mask*50_FPN_3x_syncbn.yaml' 'Misc/scratch*' --name "Baseline R50-FPN" "GN" "SyncBN" "GN (from scratch)" "GN (from scratch)" "SyncBN (from scratch)" --fields lr_sched train_speed inference_speed mem box_AP mask_AP
|
| 768 |
+
-->
|
| 769 |
+
|
| 770 |
+
|
| 771 |
+
<table><tbody>
|
| 772 |
+
<!-- START TABLE -->
|
| 773 |
+
<!-- TABLE HEADER -->
|
| 774 |
+
<th valign="bottom">Name</th>
|
| 775 |
+
<th valign="bottom">lr<br/>sched</th>
|
| 776 |
+
<th valign="bottom">train<br/>time<br/>(s/iter)</th>
|
| 777 |
+
<th valign="bottom">inference<br/>time<br/>(s/im)</th>
|
| 778 |
+
<th valign="bottom">train<br/>mem<br/>(GB)</th>
|
| 779 |
+
<th valign="bottom">box<br/>AP</th>
|
| 780 |
+
<th valign="bottom">mask<br/>AP</th>
|
| 781 |
+
<th valign="bottom">model id</th>
|
| 782 |
+
<th valign="bottom">download</th>
|
| 783 |
+
<!-- TABLE BODY -->
|
| 784 |
+
<!-- ROW: mask_rcnn_R_50_FPN_3x -->
|
| 785 |
+
<tr><td align="left"><a href="configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml">Baseline R50-FPN</a></td>
|
| 786 |
+
<td align="center">3x</td>
|
| 787 |
+
<td align="center">0.261</td>
|
| 788 |
+
<td align="center">0.043</td>
|
| 789 |
+
<td align="center">3.4</td>
|
| 790 |
+
<td align="center">41.0</td>
|
| 791 |
+
<td align="center">37.2</td>
|
| 792 |
+
<td align="center">137849600</td>
|
| 793 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/metrics.json">metrics</a></td>
|
| 794 |
+
</tr>
|
| 795 |
+
<!-- ROW: mask_rcnn_R_50_FPN_3x_gn -->
|
| 796 |
+
<tr><td align="left"><a href="configs/Misc/mask_rcnn_R_50_FPN_3x_gn.yaml">GN</a></td>
|
| 797 |
+
<td align="center">3x</td>
|
| 798 |
+
<td align="center">0.356</td>
|
| 799 |
+
<td align="center">0.069</td>
|
| 800 |
+
<td align="center">7.3</td>
|
| 801 |
+
<td align="center">42.6</td>
|
| 802 |
+
<td align="center">38.6</td>
|
| 803 |
+
<td align="center">138602888</td>
|
| 804 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/Misc/mask_rcnn_R_50_FPN_3x_gn/138602888/model_final_dc5d9e.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/Misc/mask_rcnn_R_50_FPN_3x_gn/138602888/metrics.json">metrics</a></td>
|
| 805 |
+
</tr>
|
| 806 |
+
<!-- ROW: mask_rcnn_R_50_FPN_3x_syncbn -->
|
| 807 |
+
<tr><td align="left"><a href="configs/Misc/mask_rcnn_R_50_FPN_3x_syncbn.yaml">SyncBN</a></td>
|
| 808 |
+
<td align="center">3x</td>
|
| 809 |
+
<td align="center">0.371</td>
|
| 810 |
+
<td align="center">0.053</td>
|
| 811 |
+
<td align="center">5.5</td>
|
| 812 |
+
<td align="center">41.9</td>
|
| 813 |
+
<td align="center">37.8</td>
|
| 814 |
+
<td align="center">169527823</td>
|
| 815 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/Misc/mask_rcnn_R_50_FPN_3x_syncbn/169527823/model_final_3b3c51.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/Misc/mask_rcnn_R_50_FPN_3x_syncbn/169527823/metrics.json">metrics</a></td>
|
| 816 |
+
</tr>
|
| 817 |
+
<!-- ROW: scratch_mask_rcnn_R_50_FPN_3x_gn -->
|
| 818 |
+
<tr><td align="left"><a href="configs/Misc/scratch_mask_rcnn_R_50_FPN_3x_gn.yaml">GN (from scratch)</a></td>
|
| 819 |
+
<td align="center">3x</td>
|
| 820 |
+
<td align="center">0.400</td>
|
| 821 |
+
<td align="center">0.069</td>
|
| 822 |
+
<td align="center">9.8</td>
|
| 823 |
+
<td align="center">39.9</td>
|
| 824 |
+
<td align="center">36.6</td>
|
| 825 |
+
<td align="center">138602908</td>
|
| 826 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/Misc/scratch_mask_rcnn_R_50_FPN_3x_gn/138602908/model_final_01ca85.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/Misc/scratch_mask_rcnn_R_50_FPN_3x_gn/138602908/metrics.json">metrics</a></td>
|
| 827 |
+
</tr>
|
| 828 |
+
<!-- ROW: scratch_mask_rcnn_R_50_FPN_9x_gn -->
|
| 829 |
+
<tr><td align="left"><a href="configs/Misc/scratch_mask_rcnn_R_50_FPN_9x_gn.yaml">GN (from scratch)</a></td>
|
| 830 |
+
<td align="center">9x</td>
|
| 831 |
+
<td align="center">N/A</td>
|
| 832 |
+
<td align="center">0.070</td>
|
| 833 |
+
<td align="center">9.8</td>
|
| 834 |
+
<td align="center">43.7</td>
|
| 835 |
+
<td align="center">39.6</td>
|
| 836 |
+
<td align="center">183808979</td>
|
| 837 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/Misc/scratch_mask_rcnn_R_50_FPN_9x_gn/183808979/model_final_da7b4c.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/Misc/scratch_mask_rcnn_R_50_FPN_9x_gn/183808979/metrics.json">metrics</a></td>
|
| 838 |
+
</tr>
|
| 839 |
+
<!-- ROW: scratch_mask_rcnn_R_50_FPN_9x_syncbn -->
|
| 840 |
+
<tr><td align="left"><a href="configs/Misc/scratch_mask_rcnn_R_50_FPN_9x_syncbn.yaml">SyncBN (from scratch)</a></td>
|
| 841 |
+
<td align="center">9x</td>
|
| 842 |
+
<td align="center">N/A</td>
|
| 843 |
+
<td align="center">0.055</td>
|
| 844 |
+
<td align="center">7.2</td>
|
| 845 |
+
<td align="center">43.6</td>
|
| 846 |
+
<td align="center">39.3</td>
|
| 847 |
+
<td align="center">184226666</td>
|
| 848 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/Misc/scratch_mask_rcnn_R_50_FPN_9x_syncbn/184226666/model_final_5ce33e.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/Misc/scratch_mask_rcnn_R_50_FPN_9x_syncbn/184226666/metrics.json">metrics</a></td>
|
| 849 |
+
</tr>
|
| 850 |
+
</tbody></table>
|
| 851 |
+
|
| 852 |
+
|
| 853 |
+
A few very large models trained for a long time, for demo purposes. They are trained using multiple machines:
|
| 854 |
+
|
| 855 |
+
<!--
|
| 856 |
+
./gen_html_table.py --config 'Misc/panoptic_*dconv*' 'Misc/cascade_*152*' --name "Panoptic FPN R101" "Mask R-CNN X152" --fields inference_speed mem box_AP mask_AP PQ
|
| 857 |
+
# manually add TTA results
|
| 858 |
+
-->
|
| 859 |
+
|
| 860 |
+
|
| 861 |
+
<table><tbody>
|
| 862 |
+
<!-- START TABLE -->
|
| 863 |
+
<!-- TABLE HEADER -->
|
| 864 |
+
<th valign="bottom">Name</th>
|
| 865 |
+
<th valign="bottom">inference<br/>time<br/>(s/im)</th>
|
| 866 |
+
<th valign="bottom">train<br/>mem<br/>(GB)</th>
|
| 867 |
+
<th valign="bottom">box<br/>AP</th>
|
| 868 |
+
<th valign="bottom">mask<br/>AP</th>
|
| 869 |
+
<th valign="bottom">PQ</th>
|
| 870 |
+
<th valign="bottom">model id</th>
|
| 871 |
+
<th valign="bottom">download</th>
|
| 872 |
+
<!-- TABLE BODY -->
|
| 873 |
+
<!-- ROW: panoptic_fpn_R_101_dconv_cascade_gn_3x -->
|
| 874 |
+
<tr><td align="left"><a href="configs/Misc/panoptic_fpn_R_101_dconv_cascade_gn_3x.yaml">Panoptic FPN R101</a></td>
|
| 875 |
+
<td align="center">0.107</td>
|
| 876 |
+
<td align="center">11.4</td>
|
| 877 |
+
<td align="center">47.4</td>
|
| 878 |
+
<td align="center">41.3</td>
|
| 879 |
+
<td align="center">46.1</td>
|
| 880 |
+
<td align="center">139797668</td>
|
| 881 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/Misc/panoptic_fpn_R_101_dconv_cascade_gn_3x/139797668/model_final_be35db.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/Misc/panoptic_fpn_R_101_dconv_cascade_gn_3x/139797668/metrics.json">metrics</a></td>
|
| 882 |
+
</tr>
|
| 883 |
+
<!-- ROW: cascade_mask_rcnn_X_152_32x8d_FPN_IN5k_gn_dconv -->
|
| 884 |
+
<tr><td align="left"><a href="configs/Misc/cascade_mask_rcnn_X_152_32x8d_FPN_IN5k_gn_dconv.yaml">Mask R-CNN X152</a></td>
|
| 885 |
+
<td align="center">0.242</td>
|
| 886 |
+
<td align="center">15.1</td>
|
| 887 |
+
<td align="center">50.2</td>
|
| 888 |
+
<td align="center">44.0</td>
|
| 889 |
+
<td align="center"></td>
|
| 890 |
+
<td align="center">18131413</td>
|
| 891 |
+
<td align="center"><a href="https://dl.fbaipublicfiles.com/detectron2/Misc/cascade_mask_rcnn_X_152_32x8d_FPN_IN5k_gn_dconv/18131413/model_0039999_e76410.pkl">model</a> | <a href="https://dl.fbaipublicfiles.com/detectron2/Misc/cascade_mask_rcnn_X_152_32x8d_FPN_IN5k_gn_dconv/18131413/metrics.json">metrics</a></td>
|
| 892 |
+
</tr>
|
| 893 |
+
<!-- ROW: TTA cascade_mask_rcnn_X_152_32x8d_FPN_IN5k_gn_dconv -->
|
| 894 |
+
<tr><td align="left">above + test-time aug.</td>
|
| 895 |
+
<td align="center"></td>
|
| 896 |
+
<td align="center"></td>
|
| 897 |
+
<td align="center">51.9</td>
|
| 898 |
+
<td align="center">45.9</td>
|
| 899 |
+
<td align="center"></td>
|
| 900 |
+
<td align="center"></td>
|
| 901 |
+
<td align="center"></td>
|
| 902 |
+
</tr>
|
| 903 |
+
</tbody></table>
|
preprocess/humanparsing/mhp_extension/detectron2/README.md
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<img src=".github/Detectron2-Logo-Horz.svg" width="300" >
|
| 2 |
+
|
| 3 |
+
Detectron2 is Facebook AI Research's next generation software system
|
| 4 |
+
that implements state-of-the-art object detection algorithms.
|
| 5 |
+
It is a ground-up rewrite of the previous version,
|
| 6 |
+
[Detectron](https://github.com/facebookresearch/Detectron/),
|
| 7 |
+
and it originates from [maskrcnn-benchmark](https://github.com/facebookresearch/maskrcnn-benchmark/).
|
| 8 |
+
|
| 9 |
+
<div align="center">
|
| 10 |
+
<img src="https://user-images.githubusercontent.com/1381301/66535560-d3422200-eace-11e9-9123-5535d469db19.png"/>
|
| 11 |
+
</div>
|
| 12 |
+
|
| 13 |
+
### What's New
|
| 14 |
+
* It is powered by the [PyTorch](https://pytorch.org) deep learning framework.
|
| 15 |
+
* Includes more features such as panoptic segmentation, densepose, Cascade R-CNN, rotated bounding boxes, etc.
|
| 16 |
+
* Can be used as a library to support [different projects](projects/) on top of it.
|
| 17 |
+
We'll open source more research projects in this way.
|
| 18 |
+
* It [trains much faster](https://detectron2.readthedocs.io/notes/benchmarks.html).
|
| 19 |
+
|
| 20 |
+
See our [blog post](https://ai.facebook.com/blog/-detectron2-a-pytorch-based-modular-object-detection-library-/)
|
| 21 |
+
to see more demos and learn about detectron2.
|
| 22 |
+
|
| 23 |
+
## Installation
|
| 24 |
+
|
| 25 |
+
See [INSTALL.md](INSTALL.md).
|
| 26 |
+
|
| 27 |
+
## Quick Start
|
| 28 |
+
|
| 29 |
+
See [GETTING_STARTED.md](GETTING_STARTED.md),
|
| 30 |
+
or the [Colab Notebook](https://colab.research.google.com/drive/16jcaJoc6bCFAQ96jDe2HwtXj7BMD_-m5).
|
| 31 |
+
|
| 32 |
+
Learn more at our [documentation](https://detectron2.readthedocs.org).
|
| 33 |
+
And see [projects/](projects/) for some projects that are built on top of detectron2.
|
| 34 |
+
|
| 35 |
+
## Model Zoo and Baselines
|
| 36 |
+
|
| 37 |
+
We provide a large set of baseline results and trained models available for download in the [Detectron2 Model Zoo](MODEL_ZOO.md).
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
## License
|
| 41 |
+
|
| 42 |
+
Detectron2 is released under the [Apache 2.0 license](LICENSE).
|
| 43 |
+
|
| 44 |
+
## Citing Detectron2
|
| 45 |
+
|
| 46 |
+
If you use Detectron2 in your research or wish to refer to the baseline results published in the [Model Zoo](MODEL_ZOO.md), please use the following BibTeX entry.
|
| 47 |
+
|
| 48 |
+
```BibTeX
|
| 49 |
+
@misc{wu2019detectron2,
|
| 50 |
+
author = {Yuxin Wu and Alexander Kirillov and Francisco Massa and
|
| 51 |
+
Wan-Yen Lo and Ross Girshick},
|
| 52 |
+
title = {Detectron2},
|
| 53 |
+
howpublished = {\url{https://github.com/facebookresearch/detectron2}},
|
| 54 |
+
year = {2019}
|
| 55 |
+
}
|
| 56 |
+
```
|
preprocess/humanparsing/mhp_extension/detectron2/configs/Base-RCNN-C4.yaml
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MODEL:
|
| 2 |
+
META_ARCHITECTURE: "GeneralizedRCNN"
|
| 3 |
+
RPN:
|
| 4 |
+
PRE_NMS_TOPK_TEST: 6000
|
| 5 |
+
POST_NMS_TOPK_TEST: 1000
|
| 6 |
+
ROI_HEADS:
|
| 7 |
+
NAME: "Res5ROIHeads"
|
| 8 |
+
DATASETS:
|
| 9 |
+
TRAIN: ("coco_2017_train",)
|
| 10 |
+
TEST: ("coco_2017_val",)
|
| 11 |
+
SOLVER:
|
| 12 |
+
IMS_PER_BATCH: 16
|
| 13 |
+
BASE_LR: 0.02
|
| 14 |
+
STEPS: (60000, 80000)
|
| 15 |
+
MAX_ITER: 90000
|
| 16 |
+
INPUT:
|
| 17 |
+
MIN_SIZE_TRAIN: (640, 672, 704, 736, 768, 800)
|
| 18 |
+
VERSION: 2
|
preprocess/humanparsing/mhp_extension/detectron2/configs/Base-RCNN-DilatedC5.yaml
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MODEL:
|
| 2 |
+
META_ARCHITECTURE: "GeneralizedRCNN"
|
| 3 |
+
RESNETS:
|
| 4 |
+
OUT_FEATURES: ["res5"]
|
| 5 |
+
RES5_DILATION: 2
|
| 6 |
+
RPN:
|
| 7 |
+
IN_FEATURES: ["res5"]
|
| 8 |
+
PRE_NMS_TOPK_TEST: 6000
|
| 9 |
+
POST_NMS_TOPK_TEST: 1000
|
| 10 |
+
ROI_HEADS:
|
| 11 |
+
NAME: "StandardROIHeads"
|
| 12 |
+
IN_FEATURES: ["res5"]
|
| 13 |
+
ROI_BOX_HEAD:
|
| 14 |
+
NAME: "FastRCNNConvFCHead"
|
| 15 |
+
NUM_FC: 2
|
| 16 |
+
POOLER_RESOLUTION: 7
|
| 17 |
+
ROI_MASK_HEAD:
|
| 18 |
+
NAME: "MaskRCNNConvUpsampleHead"
|
| 19 |
+
NUM_CONV: 4
|
| 20 |
+
POOLER_RESOLUTION: 14
|
| 21 |
+
DATASETS:
|
| 22 |
+
TRAIN: ("coco_2017_train",)
|
| 23 |
+
TEST: ("coco_2017_val",)
|
| 24 |
+
SOLVER:
|
| 25 |
+
IMS_PER_BATCH: 16
|
| 26 |
+
BASE_LR: 0.02
|
| 27 |
+
STEPS: (60000, 80000)
|
| 28 |
+
MAX_ITER: 90000
|
| 29 |
+
INPUT:
|
| 30 |
+
MIN_SIZE_TRAIN: (640, 672, 704, 736, 768, 800)
|
| 31 |
+
VERSION: 2
|
preprocess/humanparsing/mhp_extension/detectron2/configs/Base-RCNN-FPN.yaml
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MODEL:
|
| 2 |
+
META_ARCHITECTURE: "GeneralizedRCNN"
|
| 3 |
+
BACKBONE:
|
| 4 |
+
NAME: "build_resnet_fpn_backbone"
|
| 5 |
+
RESNETS:
|
| 6 |
+
OUT_FEATURES: ["res2", "res3", "res4", "res5"]
|
| 7 |
+
FPN:
|
| 8 |
+
IN_FEATURES: ["res2", "res3", "res4", "res5"]
|
| 9 |
+
ANCHOR_GENERATOR:
|
| 10 |
+
SIZES: [[32], [64], [128], [256], [512]] # One size for each in feature map
|
| 11 |
+
ASPECT_RATIOS: [[0.5, 1.0, 2.0]] # Three aspect ratios (same for all in feature maps)
|
| 12 |
+
RPN:
|
| 13 |
+
IN_FEATURES: ["p2", "p3", "p4", "p5", "p6"]
|
| 14 |
+
PRE_NMS_TOPK_TRAIN: 2000 # Per FPN level
|
| 15 |
+
PRE_NMS_TOPK_TEST: 1000 # Per FPN level
|
| 16 |
+
# Detectron1 uses 2000 proposals per-batch,
|
| 17 |
+
# (See "modeling/rpn/rpn_outputs.py" for details of this legacy issue)
|
| 18 |
+
# which is approximately 1000 proposals per-image since the default batch size for FPN is 2.
|
| 19 |
+
POST_NMS_TOPK_TRAIN: 1000
|
| 20 |
+
POST_NMS_TOPK_TEST: 1000
|
| 21 |
+
ROI_HEADS:
|
| 22 |
+
NAME: "StandardROIHeads"
|
| 23 |
+
IN_FEATURES: ["p2", "p3", "p4", "p5"]
|
| 24 |
+
ROI_BOX_HEAD:
|
| 25 |
+
NAME: "FastRCNNConvFCHead"
|
| 26 |
+
NUM_FC: 2
|
| 27 |
+
POOLER_RESOLUTION: 7
|
| 28 |
+
ROI_MASK_HEAD:
|
| 29 |
+
NAME: "MaskRCNNConvUpsampleHead"
|
| 30 |
+
NUM_CONV: 4
|
| 31 |
+
POOLER_RESOLUTION: 14
|
| 32 |
+
DATASETS:
|
| 33 |
+
TRAIN: ("coco_2017_train",)
|
| 34 |
+
TEST: ("coco_2017_val",)
|
| 35 |
+
SOLVER:
|
| 36 |
+
IMS_PER_BATCH: 16
|
| 37 |
+
BASE_LR: 0.02
|
| 38 |
+
STEPS: (60000, 80000)
|
| 39 |
+
MAX_ITER: 90000
|
| 40 |
+
INPUT:
|
| 41 |
+
MIN_SIZE_TRAIN: (640, 672, 704, 736, 768, 800)
|
| 42 |
+
VERSION: 2
|
preprocess/humanparsing/mhp_extension/detectron2/configs/Base-RetinaNet.yaml
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MODEL:
|
| 2 |
+
META_ARCHITECTURE: "RetinaNet"
|
| 3 |
+
BACKBONE:
|
| 4 |
+
NAME: "build_retinanet_resnet_fpn_backbone"
|
| 5 |
+
RESNETS:
|
| 6 |
+
OUT_FEATURES: ["res3", "res4", "res5"]
|
| 7 |
+
ANCHOR_GENERATOR:
|
| 8 |
+
SIZES: !!python/object/apply:eval ["[[x, x * 2**(1.0/3), x * 2**(2.0/3) ] for x in [32, 64, 128, 256, 512 ]]"]
|
| 9 |
+
FPN:
|
| 10 |
+
IN_FEATURES: ["res3", "res4", "res5"]
|
| 11 |
+
RETINANET:
|
| 12 |
+
IOU_THRESHOLDS: [0.4, 0.5]
|
| 13 |
+
IOU_LABELS: [0, -1, 1]
|
| 14 |
+
DATASETS:
|
| 15 |
+
TRAIN: ("coco_2017_train",)
|
| 16 |
+
TEST: ("coco_2017_val",)
|
| 17 |
+
SOLVER:
|
| 18 |
+
IMS_PER_BATCH: 16
|
| 19 |
+
BASE_LR: 0.01 # Note that RetinaNet uses a different default learning rate
|
| 20 |
+
STEPS: (60000, 80000)
|
| 21 |
+
MAX_ITER: 90000
|
| 22 |
+
INPUT:
|
| 23 |
+
MIN_SIZE_TRAIN: (640, 672, 704, 736, 768, 800)
|
| 24 |
+
VERSION: 2
|
preprocess/humanparsing/mhp_extension/detectron2/configs/COCO-Detection/fast_rcnn_R_50_FPN_1x.yaml
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: "../Base-RCNN-FPN.yaml"
|
| 2 |
+
MODEL:
|
| 3 |
+
WEIGHTS: "detectron2://ImageNetPretrained/MSRA/R-50.pkl"
|
| 4 |
+
MASK_ON: False
|
| 5 |
+
LOAD_PROPOSALS: True
|
| 6 |
+
RESNETS:
|
| 7 |
+
DEPTH: 50
|
| 8 |
+
PROPOSAL_GENERATOR:
|
| 9 |
+
NAME: "PrecomputedProposals"
|
| 10 |
+
DATASETS:
|
| 11 |
+
TRAIN: ("coco_2017_train",)
|
| 12 |
+
PROPOSAL_FILES_TRAIN: ("detectron2://COCO-Detection/rpn_R_50_FPN_1x/137258492/coco_2017_train_box_proposals_21bc3a.pkl", )
|
| 13 |
+
TEST: ("coco_2017_val",)
|
| 14 |
+
PROPOSAL_FILES_TEST: ("detectron2://COCO-Detection/rpn_R_50_FPN_1x/137258492/coco_2017_val_box_proposals_ee0dad.pkl", )
|
| 15 |
+
DATALOADER:
|
| 16 |
+
# proposals are part of the dataset_dicts, and take a lot of RAM
|
| 17 |
+
NUM_WORKERS: 2
|