Spaces:
Build error

Build error
Commit
•
de59d95
1
Parent(s):
ec5cf45
Upload 30 files
Browse files- .gitattributes +3 -0
- fluxgym-main/.dockerignore +16 -0
- fluxgym-main/Dockerfile +53 -0
- fluxgym-main/Dockerfile.cuda12.4 +53 -0
- fluxgym-main/README.md +259 -0
- fluxgym-main/advanced.png +0 -0
- fluxgym-main/app-launch.sh +5 -0
- fluxgym-main/app.py +1119 -0
- fluxgym-main/docker-compose.yml +28 -0
- fluxgym-main/flags.png +0 -0
- fluxgym-main/flow.gif +3 -0
- fluxgym-main/icon.png +0 -0
- fluxgym-main/install.js +96 -0
- fluxgym-main/models.yaml +27 -0
- fluxgym-main/models/.gitkeep +0 -0
- fluxgym-main/models/clip/.gitkeep +0 -0
- fluxgym-main/models/unet/.gitkeep +0 -0
- fluxgym-main/models/vae/.gitkeep +0 -0
- fluxgym-main/outputs/.gitkeep +0 -0
- fluxgym-main/pinokio.js +95 -0
- fluxgym-main/pinokio_meta.json +38 -0
- fluxgym-main/publish_to_hf.png +0 -0
- fluxgym-main/requirements.txt +34 -0
- fluxgym-main/reset.js +13 -0
- fluxgym-main/sample.png +3 -0
- fluxgym-main/sample_fields.png +0 -0
- fluxgym-main/screenshot.png +0 -0
- fluxgym-main/seed.gif +3 -0
- fluxgym-main/start.js +37 -0
- fluxgym-main/torch.js +75 -0
- fluxgym-main/update.js +46 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
fluxgym-main/flow.gif filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
fluxgym-main/sample.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
fluxgym-main/seed.gif filter=lfs diff=lfs merge=lfs -text
|
fluxgym-main/.dockerignore
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.cache/
|
| 2 |
+
cudnn_windows/
|
| 3 |
+
bitsandbytes_windows/
|
| 4 |
+
bitsandbytes_windows_deprecated/
|
| 5 |
+
dataset/
|
| 6 |
+
__pycache__/
|
| 7 |
+
venv/
|
| 8 |
+
**/.hadolint.yml
|
| 9 |
+
**/*.log
|
| 10 |
+
**/.git
|
| 11 |
+
**/.gitignore
|
| 12 |
+
**/.env
|
| 13 |
+
**/.github
|
| 14 |
+
**/.vscode
|
| 15 |
+
**/*.ps1
|
| 16 |
+
sd-scripts/
|
fluxgym-main/Dockerfile
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Base image with CUDA 12.2
|
| 2 |
+
FROM nvidia/cuda:12.2.2-base-ubuntu22.04
|
| 3 |
+
|
| 4 |
+
# Install pip if not already installed
|
| 5 |
+
RUN apt-get update -y && apt-get install -y \
|
| 6 |
+
python3-pip \
|
| 7 |
+
python3-dev \
|
| 8 |
+
git \
|
| 9 |
+
build-essential # Install dependencies for building extensions
|
| 10 |
+
|
| 11 |
+
# Define environment variables for UID and GID and local timezone
|
| 12 |
+
ENV PUID=${PUID:-1000}
|
| 13 |
+
ENV PGID=${PGID:-1000}
|
| 14 |
+
|
| 15 |
+
# Create a group with the specified GID
|
| 16 |
+
RUN groupadd -g "${PGID}" appuser
|
| 17 |
+
# Create a user with the specified UID and GID
|
| 18 |
+
RUN useradd -m -s /bin/sh -u "${PUID}" -g "${PGID}" appuser
|
| 19 |
+
|
| 20 |
+
WORKDIR /app
|
| 21 |
+
|
| 22 |
+
# Get sd-scripts from kohya-ss and install them
|
| 23 |
+
RUN git clone -b sd3 https://github.com/kohya-ss/sd-scripts && \
|
| 24 |
+
cd sd-scripts && \
|
| 25 |
+
pip install --no-cache-dir -r ./requirements.txt
|
| 26 |
+
|
| 27 |
+
# Install main application dependencies
|
| 28 |
+
COPY ./requirements.txt ./requirements.txt
|
| 29 |
+
RUN pip install --no-cache-dir -r ./requirements.txt
|
| 30 |
+
|
| 31 |
+
# Install Torch, Torchvision, and Torchaudio for CUDA 12.2
|
| 32 |
+
RUN pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu122/torch_stable.html
|
| 33 |
+
|
| 34 |
+
RUN chown -R appuser:appuser /app
|
| 35 |
+
|
| 36 |
+
# delete redundant requirements.txt and sd-scripts directory within the container
|
| 37 |
+
RUN rm -r ./sd-scripts
|
| 38 |
+
RUN rm ./requirements.txt
|
| 39 |
+
|
| 40 |
+
#Run application as non-root
|
| 41 |
+
USER appuser
|
| 42 |
+
|
| 43 |
+
# Copy fluxgym application code
|
| 44 |
+
COPY . ./fluxgym
|
| 45 |
+
|
| 46 |
+
EXPOSE 7860
|
| 47 |
+
|
| 48 |
+
ENV GRADIO_SERVER_NAME="0.0.0.0"
|
| 49 |
+
|
| 50 |
+
WORKDIR /app/fluxgym
|
| 51 |
+
|
| 52 |
+
# Run fluxgym Python application
|
| 53 |
+
CMD ["python3", "./app.py"]
|
fluxgym-main/Dockerfile.cuda12.4
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Base image with CUDA 12.4
|
| 2 |
+
FROM nvidia/cuda:12.4.1-base-ubuntu22.04
|
| 3 |
+
|
| 4 |
+
# Install pip if not already installed
|
| 5 |
+
RUN apt-get update -y && apt-get install -y \
|
| 6 |
+
python3-pip \
|
| 7 |
+
python3-dev \
|
| 8 |
+
git \
|
| 9 |
+
build-essential # Install dependencies for building extensions
|
| 10 |
+
|
| 11 |
+
# Define environment variables for UID and GID and local timezone
|
| 12 |
+
ENV PUID=${PUID:-1000}
|
| 13 |
+
ENV PGID=${PGID:-1000}
|
| 14 |
+
|
| 15 |
+
# Create a group with the specified GID
|
| 16 |
+
RUN groupadd -g "${PGID}" appuser
|
| 17 |
+
# Create a user with the specified UID and GID
|
| 18 |
+
RUN useradd -m -s /bin/sh -u "${PUID}" -g "${PGID}" appuser
|
| 19 |
+
|
| 20 |
+
WORKDIR /app
|
| 21 |
+
|
| 22 |
+
# Get sd-scripts from kohya-ss and install them
|
| 23 |
+
RUN git clone -b sd3 https://github.com/kohya-ss/sd-scripts && \
|
| 24 |
+
cd sd-scripts && \
|
| 25 |
+
pip install --no-cache-dir -r ./requirements.txt
|
| 26 |
+
|
| 27 |
+
# Install main application dependencies
|
| 28 |
+
COPY ./requirements.txt ./requirements.txt
|
| 29 |
+
RUN pip install --no-cache-dir -r ./requirements.txt
|
| 30 |
+
|
| 31 |
+
# Install Torch, Torchvision, and Torchaudio for CUDA 12.4
|
| 32 |
+
RUN pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
|
| 33 |
+
|
| 34 |
+
RUN chown -R appuser:appuser /app
|
| 35 |
+
|
| 36 |
+
# delete redundant requirements.txt and sd-scripts directory within the container
|
| 37 |
+
RUN rm -r ./sd-scripts
|
| 38 |
+
RUN rm ./requirements.txt
|
| 39 |
+
|
| 40 |
+
#Run application as non-root
|
| 41 |
+
USER appuser
|
| 42 |
+
|
| 43 |
+
# Copy fluxgym application code
|
| 44 |
+
COPY . ./fluxgym
|
| 45 |
+
|
| 46 |
+
EXPOSE 7860
|
| 47 |
+
|
| 48 |
+
ENV GRADIO_SERVER_NAME="0.0.0.0"
|
| 49 |
+
|
| 50 |
+
WORKDIR /app/fluxgym
|
| 51 |
+
|
| 52 |
+
# Run fluxgym Python application
|
| 53 |
+
CMD ["python3", "./app.py"]
|
fluxgym-main/README.md
ADDED
|
@@ -0,0 +1,259 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Flux Gym
|
| 2 |
+
|
| 3 |
+
Dead simple web UI for training FLUX LoRA **with LOW VRAM (12GB/16GB/20GB) support.**
|
| 4 |
+
|
| 5 |
+
- **Frontend:** The WebUI forked from [AI-Toolkit](https://github.com/ostris/ai-toolkit) (Gradio UI created by https://x.com/multimodalart)
|
| 6 |
+
- **Backend:** The Training script powered by [Kohya Scripts](https://github.com/kohya-ss/sd-scripts)
|
| 7 |
+
|
| 8 |
+
FluxGym supports 100% of Kohya sd-scripts features through an [Advanced](#advanced) tab, which is hidden by default.
|
| 9 |
+
|
| 10 |
+

|
| 11 |
+
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
# What is this?
|
| 16 |
+
|
| 17 |
+
1. I wanted a super simple UI for training Flux LoRAs
|
| 18 |
+
2. The [AI-Toolkit](https://github.com/ostris/ai-toolkit) project is great, and the gradio UI contribution by [@multimodalart](https://x.com/multimodalart) is perfect, but the project only works for 24GB VRAM.
|
| 19 |
+
3. [Kohya Scripts](https://github.com/kohya-ss/sd-scripts) are very flexible and powerful for training FLUX, but you need to run in terminal.
|
| 20 |
+
4. What if you could have the simplicity of AI-Toolkit WebUI and the flexibility of Kohya Scripts?
|
| 21 |
+
5. Flux Gym was born. Supports 12GB, 16GB, 20GB VRAMs, and extensible since it uses Kohya Scripts underneath.
|
| 22 |
+
|
| 23 |
+
---
|
| 24 |
+
|
| 25 |
+
# News
|
| 26 |
+
|
| 27 |
+
- September 25: Docker support + Autodownload Models (No need to manually download models when setting up) + Support custom base models (not just flux-dev but anything, just need to include in the [models.yaml](models.yaml) file.
|
| 28 |
+
- September 16: Added "Publish to Huggingface" + 100% Kohya sd-scripts feature support: https://x.com/cocktailpeanut/status/1835719701172756592
|
| 29 |
+
- September 11: Automatic Sample Image Generation + Custom Resolution: https://x.com/cocktailpeanut/status/1833881392482066638
|
| 30 |
+
|
| 31 |
+
---
|
| 32 |
+
|
| 33 |
+
# Supported Models
|
| 34 |
+
|
| 35 |
+
1. Flux1-dev
|
| 36 |
+
2. Flux1-dev2pro (as explained here: https://medium.com/@zhiwangshi28/why-flux-lora-so-hard-to-train-and-how-to-overcome-it-a0c70bc59eaf)
|
| 37 |
+
3. Flux1-schnell (Couldn't get high quality results, so not really recommended, but feel free to experiment with it)
|
| 38 |
+
4. More?
|
| 39 |
+
|
| 40 |
+
The models are automatically downloaded when you start training with the model selected.
|
| 41 |
+
|
| 42 |
+
You can easily add more to the supported models list by editing the [models.yaml](models.yaml) file. If you want to share some interesting base models, please send a PR.
|
| 43 |
+
|
| 44 |
+
---
|
| 45 |
+
|
| 46 |
+
# How people are using Fluxgym
|
| 47 |
+
|
| 48 |
+
Here are people using Fluxgym to locally train Lora sharing their experience:
|
| 49 |
+
|
| 50 |
+
https://pinokio.computer/item?uri=https://github.com/cocktailpeanut/fluxgym
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
# More Info
|
| 54 |
+
|
| 55 |
+
To learn more, check out this X thread: https://x.com/cocktailpeanut/status/1832084951115972653
|
| 56 |
+
|
| 57 |
+
# Install
|
| 58 |
+
|
| 59 |
+
## 1. One-Click Install
|
| 60 |
+
|
| 61 |
+
You can automatically install and launch everything locally with Pinokio 1-click launcher: https://pinokio.computer/item?uri=https://github.com/cocktailpeanut/fluxgym
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
## 2. Install Manually
|
| 65 |
+
|
| 66 |
+
First clone Fluxgym and kohya-ss/sd-scripts:
|
| 67 |
+
|
| 68 |
+
```
|
| 69 |
+
git clone https://github.com/cocktailpeanut/fluxgym
|
| 70 |
+
cd fluxgym
|
| 71 |
+
git clone -b sd3 https://github.com/kohya-ss/sd-scripts
|
| 72 |
+
```
|
| 73 |
+
|
| 74 |
+
Your folder structure will look like this:
|
| 75 |
+
|
| 76 |
+
```
|
| 77 |
+
/fluxgym
|
| 78 |
+
app.py
|
| 79 |
+
requirements.txt
|
| 80 |
+
/sd-scripts
|
| 81 |
+
```
|
| 82 |
+
|
| 83 |
+
Now activate a venv from the root `fluxgym` folder:
|
| 84 |
+
|
| 85 |
+
If you're on Windows:
|
| 86 |
+
|
| 87 |
+
```
|
| 88 |
+
python -m venv env
|
| 89 |
+
env\Scripts\activate
|
| 90 |
+
```
|
| 91 |
+
|
| 92 |
+
If your're on Linux:
|
| 93 |
+
|
| 94 |
+
```
|
| 95 |
+
python -m venv env
|
| 96 |
+
source env/bin/activate
|
| 97 |
+
```
|
| 98 |
+
|
| 99 |
+
This will create an `env` folder right below the `fluxgym` folder:
|
| 100 |
+
|
| 101 |
+
```
|
| 102 |
+
/fluxgym
|
| 103 |
+
app.py
|
| 104 |
+
requirements.txt
|
| 105 |
+
/sd-scripts
|
| 106 |
+
/env
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
Now go to the `sd-scripts` folder and install dependencies to the activated environment:
|
| 110 |
+
|
| 111 |
+
```
|
| 112 |
+
cd sd-scripts
|
| 113 |
+
pip install -r requirements.txt
|
| 114 |
+
```
|
| 115 |
+
|
| 116 |
+
Now come back to the root folder and install the app dependencies:
|
| 117 |
+
|
| 118 |
+
```
|
| 119 |
+
cd ..
|
| 120 |
+
pip install -r requirements.txt
|
| 121 |
+
```
|
| 122 |
+
|
| 123 |
+
Finally, install pytorch Nightly:
|
| 124 |
+
|
| 125 |
+
```
|
| 126 |
+
pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
|
| 127 |
+
```
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
# Start
|
| 131 |
+
|
| 132 |
+
Go back to the root `fluxgym` folder, with the venv activated, run:
|
| 133 |
+
|
| 134 |
+
```
|
| 135 |
+
python app.py
|
| 136 |
+
```
|
| 137 |
+
|
| 138 |
+
> Make sure to have the venv activated before running `python app.py`.
|
| 139 |
+
>
|
| 140 |
+
> Windows: `env/Scripts/activate`
|
| 141 |
+
> Linux: `source env/bin/activate`
|
| 142 |
+
|
| 143 |
+
## 3. Install via Docker
|
| 144 |
+
|
| 145 |
+
First clone Fluxgym and kohya-ss/sd-scripts:
|
| 146 |
+
|
| 147 |
+
```
|
| 148 |
+
git clone https://github.com/cocktailpeanut/fluxgym
|
| 149 |
+
cd fluxgym
|
| 150 |
+
git clone -b sd3 https://github.com/kohya-ss/sd-scripts
|
| 151 |
+
```
|
| 152 |
+
Check your `user id` and `group id` and change it if it's not 1000 via `environment variables` of `PUID` and `PGID`.
|
| 153 |
+
You can find out what these are in linux by running the following command: `id`
|
| 154 |
+
|
| 155 |
+
Now build the image and run it via `docker-compose`:
|
| 156 |
+
```
|
| 157 |
+
docker compose up -d --build
|
| 158 |
+
```
|
| 159 |
+
|
| 160 |
+
Open web browser and goto the IP address of the computer/VM: http://localhost:7860
|
| 161 |
+
|
| 162 |
+
# Usage
|
| 163 |
+
|
| 164 |
+
The usage is pretty straightforward:
|
| 165 |
+
|
| 166 |
+
1. Enter the lora info
|
| 167 |
+
2. Upload images and caption them (using the trigger word)
|
| 168 |
+
3. Click "start".
|
| 169 |
+
|
| 170 |
+
That's all!
|
| 171 |
+
|
| 172 |
+

|
| 173 |
+
|
| 174 |
+
# Configuration
|
| 175 |
+
|
| 176 |
+
## Sample Images
|
| 177 |
+
|
| 178 |
+
By default fluxgym doesn't generate any sample images during training.
|
| 179 |
+
|
| 180 |
+
You can however configure Fluxgym to automatically generate sample images for every N steps. Here's what it looks like:
|
| 181 |
+
|
| 182 |
+

|
| 183 |
+
|
| 184 |
+
To turn this on, just set the two fields:
|
| 185 |
+
|
| 186 |
+
1. **Sample Image Prompts:** These prompts will be used to automatically generate images during training. If you want multiple, separate teach prompt with new line.
|
| 187 |
+
2. **Sample Image Every N Steps:** If your "Expected training steps" is 960 and your "Sample Image Every N Steps" is 100, the images will be generated at step 100, 200, 300, 400, 500, 600, 700, 800, 900, for EACH prompt.
|
| 188 |
+
|
| 189 |
+

|
| 190 |
+
|
| 191 |
+
## Advanced Sample Images
|
| 192 |
+
|
| 193 |
+
Thanks to the built-in syntax from [kohya/sd-scripts](https://github.com/kohya-ss/sd-scripts?tab=readme-ov-file#sample-image-generation-during-training), you can control exactly how the sample images are generated during the training phase:
|
| 194 |
+
|
| 195 |
+
Let's say the trigger word is **hrld person.** Normally you would try sample prompts like:
|
| 196 |
+
|
| 197 |
+
```
|
| 198 |
+
hrld person is riding a bike
|
| 199 |
+
hrld person is a body builder
|
| 200 |
+
hrld person is a rock star
|
| 201 |
+
```
|
| 202 |
+
|
| 203 |
+
But for every prompt you can include **advanced flags** to fully control the image generation process. For example, the `--d` flag lets you specify the SEED.
|
| 204 |
+
|
| 205 |
+
Specifying a seed means every sample image will use that exact seed, which means you can literally see the LoRA evolve. Here's an example usage:
|
| 206 |
+
|
| 207 |
+
```
|
| 208 |
+
hrld person is riding a bike --d 42
|
| 209 |
+
hrld person is a body builder --d 42
|
| 210 |
+
hrld person is a rock star --d 42
|
| 211 |
+
```
|
| 212 |
+
|
| 213 |
+
Here's what it looks like in the UI:
|
| 214 |
+
|
| 215 |
+

|
| 216 |
+
|
| 217 |
+
And here are the results:
|
| 218 |
+
|
| 219 |
+

|
| 220 |
+
|
| 221 |
+
In addition to the `--d` flag, here are other flags you can use:
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
- `--n`: Negative prompt up to the next option.
|
| 225 |
+
- `--w`: Specifies the width of the generated image.
|
| 226 |
+
- `--h`: Specifies the height of the generated image.
|
| 227 |
+
- `--d`: Specifies the seed of the generated image.
|
| 228 |
+
- `--l`: Specifies the CFG scale of the generated image.
|
| 229 |
+
- `--s`: Specifies the number of steps in the generation.
|
| 230 |
+
|
| 231 |
+
The prompt weighting such as `( )` and `[ ]` also work. (Learn more about [Attention/Emphasis](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features#attentionemphasis))
|
| 232 |
+
|
| 233 |
+
## Publishing to Huggingface
|
| 234 |
+
|
| 235 |
+
1. Get your Huggingface Token from https://huggingface.co/settings/tokens
|
| 236 |
+
2. Enter the token in the "Huggingface Token" field and click "Login". This will save the token text in a local file named `HF_TOKEN` (All local and private).
|
| 237 |
+
3. Once you're logged in, you will be able to select a trained LoRA from the dropdown, edit the name if you want, and publish to Huggingface.
|
| 238 |
+
|
| 239 |
+

|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
## Advanced
|
| 243 |
+
|
| 244 |
+
The advanced tab is automatically constructed by parsing the launch flags available to the latest version of [kohya sd-scripts](https://github.com/kohya-ss/sd-scripts). This means Fluxgym is a full fledged UI for using the Kohya script.
|
| 245 |
+
|
| 246 |
+
> By default the advanced tab is hidden. You can click the "advanced" accordion to expand it.
|
| 247 |
+
|
| 248 |
+

|
| 249 |
+
|
| 250 |
+
|
| 251 |
+
## Advanced Features
|
| 252 |
+
|
| 253 |
+
### Uploading Caption Files
|
| 254 |
+
|
| 255 |
+
You can also upload the caption files along with the image files. You just need to follow the convention:
|
| 256 |
+
|
| 257 |
+
1. Every caption file must be a `.txt` file.
|
| 258 |
+
2. Each caption file needs to have a corresponding image file that has the same name.
|
| 259 |
+
3. For example, if you have an image file named `img0.png`, the corresponding caption file must be `img0.txt`.
|
fluxgym-main/advanced.png
ADDED

|
fluxgym-main/app-launch.sh
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env bash
|
| 2 |
+
|
| 3 |
+
cd "`dirname "$0"`" || exit 1
|
| 4 |
+
. env/bin/activate
|
| 5 |
+
python app.py
|
fluxgym-main/app.py
ADDED
|
@@ -0,0 +1,1119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "1"
|
| 4 |
+
os.environ['GRADIO_ANALYTICS_ENABLED'] = '0'
|
| 5 |
+
sys.path.insert(0, os.getcwd())
|
| 6 |
+
sys.path.append(os.path.join(os.path.dirname(__file__), 'sd-scripts'))
|
| 7 |
+
import subprocess
|
| 8 |
+
import gradio as gr
|
| 9 |
+
from PIL import Image
|
| 10 |
+
import torch
|
| 11 |
+
import uuid
|
| 12 |
+
import shutil
|
| 13 |
+
import json
|
| 14 |
+
import yaml
|
| 15 |
+
from slugify import slugify
|
| 16 |
+
from transformers import AutoProcessor, AutoModelForCausalLM
|
| 17 |
+
from gradio_logsview import LogsView, LogsViewRunner
|
| 18 |
+
from huggingface_hub import hf_hub_download, HfApi
|
| 19 |
+
from library import flux_train_utils, huggingface_util
|
| 20 |
+
from argparse import Namespace
|
| 21 |
+
import train_network
|
| 22 |
+
import toml
|
| 23 |
+
import re
|
| 24 |
+
MAX_IMAGES = 150
|
| 25 |
+
|
| 26 |
+
with open('models.yaml', 'r') as file:
|
| 27 |
+
models = yaml.safe_load(file)
|
| 28 |
+
|
| 29 |
+
def readme(base_model, lora_name, instance_prompt, sample_prompts):
|
| 30 |
+
|
| 31 |
+
# model license
|
| 32 |
+
model_config = models[base_model]
|
| 33 |
+
model_file = model_config["file"]
|
| 34 |
+
base_model_name = model_config["base"]
|
| 35 |
+
license = None
|
| 36 |
+
license_name = None
|
| 37 |
+
license_link = None
|
| 38 |
+
license_items = []
|
| 39 |
+
if "license" in model_config:
|
| 40 |
+
license = model_config["license"]
|
| 41 |
+
license_items.append(f"license: {license}")
|
| 42 |
+
if "license_name" in model_config:
|
| 43 |
+
license_name = model_config["license_name"]
|
| 44 |
+
license_items.append(f"license_name: {license_name}")
|
| 45 |
+
if "license_link" in model_config:
|
| 46 |
+
license_link = model_config["license_link"]
|
| 47 |
+
license_items.append(f"license_link: {license_link}")
|
| 48 |
+
license_str = "\n".join(license_items)
|
| 49 |
+
print(f"license_items={license_items}")
|
| 50 |
+
print(f"license_str = {license_str}")
|
| 51 |
+
|
| 52 |
+
# tags
|
| 53 |
+
tags = [ "text-to-image", "flux", "lora", "diffusers", "template:sd-lora", "fluxgym" ]
|
| 54 |
+
|
| 55 |
+
# widgets
|
| 56 |
+
widgets = []
|
| 57 |
+
sample_image_paths = []
|
| 58 |
+
output_name = slugify(lora_name)
|
| 59 |
+
samples_dir = resolve_path_without_quotes(f"outputs/{output_name}/sample")
|
| 60 |
+
try:
|
| 61 |
+
for filename in os.listdir(samples_dir):
|
| 62 |
+
# Filename Schema: [name]_[steps]_[index]_[timestamp].png
|
| 63 |
+
match = re.search(r"_(\d+)_(\d+)_(\d+)\.png$", filename)
|
| 64 |
+
if match:
|
| 65 |
+
steps, index, timestamp = int(match.group(1)), int(match.group(2)), int(match.group(3))
|
| 66 |
+
sample_image_paths.append((steps, index, f"sample/{filename}"))
|
| 67 |
+
|
| 68 |
+
# Sort by numeric index
|
| 69 |
+
sample_image_paths.sort(key=lambda x: x[0], reverse=True)
|
| 70 |
+
|
| 71 |
+
final_sample_image_paths = sample_image_paths[:len(sample_prompts)]
|
| 72 |
+
final_sample_image_paths.sort(key=lambda x: x[1])
|
| 73 |
+
for i, prompt in enumerate(sample_prompts):
|
| 74 |
+
_, _, image_path = final_sample_image_paths[i]
|
| 75 |
+
widgets.append(
|
| 76 |
+
{
|
| 77 |
+
"text": prompt,
|
| 78 |
+
"output": {
|
| 79 |
+
"url": image_path
|
| 80 |
+
},
|
| 81 |
+
}
|
| 82 |
+
)
|
| 83 |
+
except:
|
| 84 |
+
print(f"no samples")
|
| 85 |
+
dtype = "torch.bfloat16"
|
| 86 |
+
# Construct the README content
|
| 87 |
+
readme_content = f"""---
|
| 88 |
+
tags:
|
| 89 |
+
{yaml.dump(tags, indent=4).strip()}
|
| 90 |
+
{"widget:" if os.path.isdir(samples_dir) else ""}
|
| 91 |
+
{yaml.dump(widgets, indent=4).strip() if widgets else ""}
|
| 92 |
+
base_model: {base_model_name}
|
| 93 |
+
{"instance_prompt: " + instance_prompt if instance_prompt else ""}
|
| 94 |
+
{license_str}
|
| 95 |
+
---
|
| 96 |
+
|
| 97 |
+
# {lora_name}
|
| 98 |
+
|
| 99 |
+
A Flux LoRA trained on a local computer with [Fluxgym](https://github.com/cocktailpeanut/fluxgym)
|
| 100 |
+
|
| 101 |
+
<Gallery />
|
| 102 |
+
|
| 103 |
+
## Trigger words
|
| 104 |
+
|
| 105 |
+
{"You should use `" + instance_prompt + "` to trigger the image generation." if instance_prompt else "No trigger words defined."}
|
| 106 |
+
|
| 107 |
+
## Download model and use it with ComfyUI, AUTOMATIC1111, SD.Next, Invoke AI, Forge, etc.
|
| 108 |
+
|
| 109 |
+
Weights for this model are available in Safetensors format.
|
| 110 |
+
|
| 111 |
+
"""
|
| 112 |
+
return readme_content
|
| 113 |
+
|
| 114 |
+
def account_hf():
|
| 115 |
+
try:
|
| 116 |
+
with open("HF_TOKEN", "r") as file:
|
| 117 |
+
token = file.read()
|
| 118 |
+
api = HfApi(token=token)
|
| 119 |
+
try:
|
| 120 |
+
account = api.whoami()
|
| 121 |
+
return { "token": token, "account": account['name'] }
|
| 122 |
+
except:
|
| 123 |
+
return None
|
| 124 |
+
except:
|
| 125 |
+
return None
|
| 126 |
+
|
| 127 |
+
"""
|
| 128 |
+
hf_logout.click(fn=logout_hf, outputs=[hf_token, hf_login, hf_logout, repo_owner])
|
| 129 |
+
"""
|
| 130 |
+
def logout_hf():
|
| 131 |
+
os.remove("HF_TOKEN")
|
| 132 |
+
global current_account
|
| 133 |
+
current_account = account_hf()
|
| 134 |
+
print(f"current_account={current_account}")
|
| 135 |
+
return gr.update(value=""), gr.update(visible=True), gr.update(visible=False), gr.update(value="", visible=False)
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
"""
|
| 139 |
+
hf_login.click(fn=login_hf, inputs=[hf_token], outputs=[hf_token, hf_login, hf_logout, repo_owner])
|
| 140 |
+
"""
|
| 141 |
+
def login_hf(hf_token):
|
| 142 |
+
api = HfApi(token=hf_token)
|
| 143 |
+
try:
|
| 144 |
+
account = api.whoami()
|
| 145 |
+
if account != None:
|
| 146 |
+
if "name" in account:
|
| 147 |
+
with open("HF_TOKEN", "w") as file:
|
| 148 |
+
file.write(hf_token)
|
| 149 |
+
global current_account
|
| 150 |
+
current_account = account_hf()
|
| 151 |
+
return gr.update(visible=True), gr.update(visible=False), gr.update(visible=True), gr.update(value=current_account["account"], visible=True)
|
| 152 |
+
return gr.update(), gr.update(), gr.update(), gr.update()
|
| 153 |
+
except:
|
| 154 |
+
print(f"incorrect hf_token")
|
| 155 |
+
return gr.update(), gr.update(), gr.update(), gr.update()
|
| 156 |
+
|
| 157 |
+
def upload_hf(base_model, lora_rows, repo_owner, repo_name, repo_visibility, hf_token):
|
| 158 |
+
src = lora_rows
|
| 159 |
+
repo_id = f"{repo_owner}/{repo_name}"
|
| 160 |
+
gr.Info(f"Uploading to Huggingface. Please Stand by...", duration=None)
|
| 161 |
+
args = Namespace(
|
| 162 |
+
huggingface_repo_id=repo_id,
|
| 163 |
+
huggingface_repo_type="model",
|
| 164 |
+
huggingface_repo_visibility=repo_visibility,
|
| 165 |
+
huggingface_path_in_repo="",
|
| 166 |
+
huggingface_token=hf_token,
|
| 167 |
+
async_upload=False
|
| 168 |
+
)
|
| 169 |
+
print(f"upload_hf args={args}")
|
| 170 |
+
huggingface_util.upload(args=args, src=src)
|
| 171 |
+
gr.Info(f"[Upload Complete] https://huggingface.co/{repo_id}", duration=None)
|
| 172 |
+
|
| 173 |
+
def load_captioning(uploaded_files, concept_sentence):
|
| 174 |
+
uploaded_images = [file for file in uploaded_files if not file.endswith('.txt')]
|
| 175 |
+
txt_files = [file for file in uploaded_files if file.endswith('.txt')]
|
| 176 |
+
txt_files_dict = {os.path.splitext(os.path.basename(txt_file))[0]: txt_file for txt_file in txt_files}
|
| 177 |
+
updates = []
|
| 178 |
+
if len(uploaded_images) <= 1:
|
| 179 |
+
raise gr.Error(
|
| 180 |
+
"Please upload at least 2 images to train your model (the ideal number with default settings is between 4-30)"
|
| 181 |
+
)
|
| 182 |
+
elif len(uploaded_images) > MAX_IMAGES:
|
| 183 |
+
raise gr.Error(f"For now, only {MAX_IMAGES} or less images are allowed for training")
|
| 184 |
+
# Update for the captioning_area
|
| 185 |
+
# for _ in range(3):
|
| 186 |
+
updates.append(gr.update(visible=True))
|
| 187 |
+
# Update visibility and image for each captioning row and image
|
| 188 |
+
for i in range(1, MAX_IMAGES + 1):
|
| 189 |
+
# Determine if the current row and image should be visible
|
| 190 |
+
visible = i <= len(uploaded_images)
|
| 191 |
+
|
| 192 |
+
# Update visibility of the captioning row
|
| 193 |
+
updates.append(gr.update(visible=visible))
|
| 194 |
+
|
| 195 |
+
# Update for image component - display image if available, otherwise hide
|
| 196 |
+
image_value = uploaded_images[i - 1] if visible else None
|
| 197 |
+
updates.append(gr.update(value=image_value, visible=visible))
|
| 198 |
+
|
| 199 |
+
corresponding_caption = False
|
| 200 |
+
if(image_value):
|
| 201 |
+
base_name = os.path.splitext(os.path.basename(image_value))[0]
|
| 202 |
+
if base_name in txt_files_dict:
|
| 203 |
+
with open(txt_files_dict[base_name], 'r') as file:
|
| 204 |
+
corresponding_caption = file.read()
|
| 205 |
+
|
| 206 |
+
# Update value of captioning area
|
| 207 |
+
text_value = corresponding_caption if visible and corresponding_caption else concept_sentence if visible and concept_sentence else None
|
| 208 |
+
updates.append(gr.update(value=text_value, visible=visible))
|
| 209 |
+
|
| 210 |
+
# Update for the sample caption area
|
| 211 |
+
updates.append(gr.update(visible=True))
|
| 212 |
+
updates.append(gr.update(visible=True))
|
| 213 |
+
|
| 214 |
+
return updates
|
| 215 |
+
|
| 216 |
+
def hide_captioning():
|
| 217 |
+
return gr.update(visible=False), gr.update(visible=False)
|
| 218 |
+
|
| 219 |
+
def resize_image(image_path, output_path, size):
|
| 220 |
+
with Image.open(image_path) as img:
|
| 221 |
+
width, height = img.size
|
| 222 |
+
if width < height:
|
| 223 |
+
new_width = size
|
| 224 |
+
new_height = int((size/width) * height)
|
| 225 |
+
else:
|
| 226 |
+
new_height = size
|
| 227 |
+
new_width = int((size/height) * width)
|
| 228 |
+
print(f"resize {image_path} : {new_width}x{new_height}")
|
| 229 |
+
img_resized = img.resize((new_width, new_height), Image.Resampling.LANCZOS)
|
| 230 |
+
img_resized.save(output_path)
|
| 231 |
+
|
| 232 |
+
def create_dataset(destination_folder, size, *inputs):
|
| 233 |
+
print("Creating dataset")
|
| 234 |
+
images = inputs[0]
|
| 235 |
+
if not os.path.exists(destination_folder):
|
| 236 |
+
os.makedirs(destination_folder)
|
| 237 |
+
|
| 238 |
+
for index, image in enumerate(images):
|
| 239 |
+
# copy the images to the datasets folder
|
| 240 |
+
new_image_path = shutil.copy(image, destination_folder)
|
| 241 |
+
|
| 242 |
+
# if it's a caption text file skip the next bit
|
| 243 |
+
ext = os.path.splitext(new_image_path)[-1].lower()
|
| 244 |
+
if ext == '.txt':
|
| 245 |
+
continue
|
| 246 |
+
|
| 247 |
+
# resize the images
|
| 248 |
+
resize_image(new_image_path, new_image_path, size)
|
| 249 |
+
|
| 250 |
+
# copy the captions
|
| 251 |
+
|
| 252 |
+
original_caption = inputs[index + 1]
|
| 253 |
+
|
| 254 |
+
image_file_name = os.path.basename(new_image_path)
|
| 255 |
+
caption_file_name = os.path.splitext(image_file_name)[0] + ".txt"
|
| 256 |
+
caption_path = resolve_path_without_quotes(os.path.join(destination_folder, caption_file_name))
|
| 257 |
+
print(f"image_path={new_image_path}, caption_path = {caption_path}, original_caption={original_caption}")
|
| 258 |
+
# if caption_path exists, do not write
|
| 259 |
+
if os.path.exists(caption_path):
|
| 260 |
+
print(f"{caption_path} already exists. use the existing .txt file")
|
| 261 |
+
else:
|
| 262 |
+
print(f"{caption_path} create a .txt caption file")
|
| 263 |
+
with open(caption_path, 'w') as file:
|
| 264 |
+
file.write(original_caption)
|
| 265 |
+
|
| 266 |
+
print(f"destination_folder {destination_folder}")
|
| 267 |
+
return destination_folder
|
| 268 |
+
|
| 269 |
+
|
| 270 |
+
def run_captioning(images, concept_sentence, *captions):
|
| 271 |
+
print(f"run_captioning")
|
| 272 |
+
print(f"concept sentence {concept_sentence}")
|
| 273 |
+
print(f"captions {captions}")
|
| 274 |
+
#Load internally to not consume resources for training
|
| 275 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 276 |
+
print(f"device={device}")
|
| 277 |
+
torch_dtype = torch.float16
|
| 278 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 279 |
+
"multimodalart/Florence-2-large-no-flash-attn", torch_dtype=torch_dtype, trust_remote_code=True
|
| 280 |
+
).to(device)
|
| 281 |
+
processor = AutoProcessor.from_pretrained("multimodalart/Florence-2-large-no-flash-attn", trust_remote_code=True)
|
| 282 |
+
|
| 283 |
+
captions = list(captions)
|
| 284 |
+
for i, image_path in enumerate(images):
|
| 285 |
+
print(captions[i])
|
| 286 |
+
if isinstance(image_path, str): # If image is a file path
|
| 287 |
+
image = Image.open(image_path).convert("RGB")
|
| 288 |
+
|
| 289 |
+
prompt = "<DETAILED_CAPTION>"
|
| 290 |
+
inputs = processor(text=prompt, images=image, return_tensors="pt").to(device, torch_dtype)
|
| 291 |
+
print(f"inputs {inputs}")
|
| 292 |
+
|
| 293 |
+
generated_ids = model.generate(
|
| 294 |
+
input_ids=inputs["input_ids"], pixel_values=inputs["pixel_values"], max_new_tokens=1024, num_beams=3
|
| 295 |
+
)
|
| 296 |
+
print(f"generated_ids {generated_ids}")
|
| 297 |
+
|
| 298 |
+
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=False)[0]
|
| 299 |
+
print(f"generated_text: {generated_text}")
|
| 300 |
+
parsed_answer = processor.post_process_generation(
|
| 301 |
+
generated_text, task=prompt, image_size=(image.width, image.height)
|
| 302 |
+
)
|
| 303 |
+
print(f"parsed_answer = {parsed_answer}")
|
| 304 |
+
caption_text = parsed_answer["<DETAILED_CAPTION>"].replace("The image shows ", "")
|
| 305 |
+
print(f"caption_text = {caption_text}, concept_sentence={concept_sentence}")
|
| 306 |
+
if concept_sentence:
|
| 307 |
+
caption_text = f"{concept_sentence} {caption_text}"
|
| 308 |
+
captions[i] = caption_text
|
| 309 |
+
|
| 310 |
+
yield captions
|
| 311 |
+
model.to("cpu")
|
| 312 |
+
del model
|
| 313 |
+
del processor
|
| 314 |
+
if torch.cuda.is_available():
|
| 315 |
+
torch.cuda.empty_cache()
|
| 316 |
+
|
| 317 |
+
def recursive_update(d, u):
|
| 318 |
+
for k, v in u.items():
|
| 319 |
+
if isinstance(v, dict) and v:
|
| 320 |
+
d[k] = recursive_update(d.get(k, {}), v)
|
| 321 |
+
else:
|
| 322 |
+
d[k] = v
|
| 323 |
+
return d
|
| 324 |
+
|
| 325 |
+
def download(base_model):
|
| 326 |
+
model = models[base_model]
|
| 327 |
+
model_file = model["file"]
|
| 328 |
+
repo = model["repo"]
|
| 329 |
+
|
| 330 |
+
# download unet
|
| 331 |
+
if base_model == "flux-dev" or base_model == "flux-schnell":
|
| 332 |
+
unet_folder = "models/unet"
|
| 333 |
+
else:
|
| 334 |
+
unet_folder = f"models/unet/{repo}"
|
| 335 |
+
unet_path = os.path.join(unet_folder, model_file)
|
| 336 |
+
if not os.path.exists(unet_path):
|
| 337 |
+
os.makedirs(unet_folder, exist_ok=True)
|
| 338 |
+
gr.Info(f"Downloading base model: {base_model}. Please wait. (You can check the terminal for the download progress)", duration=None)
|
| 339 |
+
print(f"download {base_model}")
|
| 340 |
+
hf_hub_download(repo_id=repo, local_dir=unet_folder, filename=model_file)
|
| 341 |
+
|
| 342 |
+
# download vae
|
| 343 |
+
vae_folder = "models/vae"
|
| 344 |
+
vae_path = os.path.join(vae_folder, "ae.sft")
|
| 345 |
+
if not os.path.exists(vae_path):
|
| 346 |
+
os.makedirs(vae_folder, exist_ok=True)
|
| 347 |
+
gr.Info(f"Downloading vae")
|
| 348 |
+
print(f"downloading ae.sft...")
|
| 349 |
+
hf_hub_download(repo_id="cocktailpeanut/xulf-dev", local_dir=vae_folder, filename="ae.sft")
|
| 350 |
+
|
| 351 |
+
# download clip
|
| 352 |
+
clip_folder = "models/clip"
|
| 353 |
+
clip_l_path = os.path.join(clip_folder, "clip_l.safetensors")
|
| 354 |
+
if not os.path.exists(clip_l_path):
|
| 355 |
+
os.makedirs(clip_folder, exist_ok=True)
|
| 356 |
+
gr.Info(f"Downloading clip...")
|
| 357 |
+
print(f"download clip_l.safetensors")
|
| 358 |
+
hf_hub_download(repo_id="comfyanonymous/flux_text_encoders", local_dir=clip_folder, filename="clip_l.safetensors")
|
| 359 |
+
|
| 360 |
+
# download t5xxl
|
| 361 |
+
t5xxl_path = os.path.join(clip_folder, "t5xxl_fp16.safetensors")
|
| 362 |
+
if not os.path.exists(t5xxl_path):
|
| 363 |
+
print(f"download t5xxl_fp16.safetensors")
|
| 364 |
+
gr.Info(f"Downloading t5xxl...")
|
| 365 |
+
hf_hub_download(repo_id="comfyanonymous/flux_text_encoders", local_dir=clip_folder, filename="t5xxl_fp16.safetensors")
|
| 366 |
+
|
| 367 |
+
|
| 368 |
+
def resolve_path(p):
|
| 369 |
+
current_dir = os.path.dirname(os.path.abspath(__file__))
|
| 370 |
+
norm_path = os.path.normpath(os.path.join(current_dir, p))
|
| 371 |
+
return f"\"{norm_path}\""
|
| 372 |
+
def resolve_path_without_quotes(p):
|
| 373 |
+
current_dir = os.path.dirname(os.path.abspath(__file__))
|
| 374 |
+
norm_path = os.path.normpath(os.path.join(current_dir, p))
|
| 375 |
+
return norm_path
|
| 376 |
+
|
| 377 |
+
def gen_sh(
|
| 378 |
+
base_model,
|
| 379 |
+
output_name,
|
| 380 |
+
resolution,
|
| 381 |
+
seed,
|
| 382 |
+
workers,
|
| 383 |
+
learning_rate,
|
| 384 |
+
network_dim,
|
| 385 |
+
max_train_epochs,
|
| 386 |
+
save_every_n_epochs,
|
| 387 |
+
timestep_sampling,
|
| 388 |
+
guidance_scale,
|
| 389 |
+
vram,
|
| 390 |
+
sample_prompts,
|
| 391 |
+
sample_every_n_steps,
|
| 392 |
+
*advanced_components
|
| 393 |
+
):
|
| 394 |
+
|
| 395 |
+
print(f"gen_sh: network_dim:{network_dim}, max_train_epochs={max_train_epochs}, save_every_n_epochs={save_every_n_epochs}, timestep_sampling={timestep_sampling}, guidance_scale={guidance_scale}, vram={vram}, sample_prompts={sample_prompts}, sample_every_n_steps={sample_every_n_steps}")
|
| 396 |
+
|
| 397 |
+
output_dir = resolve_path(f"outputs/{output_name}")
|
| 398 |
+
sample_prompts_path = resolve_path(f"outputs/{output_name}/sample_prompts.txt")
|
| 399 |
+
|
| 400 |
+
line_break = "\\"
|
| 401 |
+
file_type = "sh"
|
| 402 |
+
if sys.platform == "win32":
|
| 403 |
+
line_break = "^"
|
| 404 |
+
file_type = "bat"
|
| 405 |
+
|
| 406 |
+
############# Sample args ########################
|
| 407 |
+
sample = ""
|
| 408 |
+
if len(sample_prompts) > 0 and sample_every_n_steps > 0:
|
| 409 |
+
sample = f"""--sample_prompts={sample_prompts_path} --sample_every_n_steps="{sample_every_n_steps}" {line_break}"""
|
| 410 |
+
|
| 411 |
+
|
| 412 |
+
############# Optimizer args ########################
|
| 413 |
+
# if vram == "8G":
|
| 414 |
+
# optimizer = f"""--optimizer_type adafactor {line_break}
|
| 415 |
+
# --optimizer_args "relative_step=False" "scale_parameter=False" "warmup_init=False" {line_break}
|
| 416 |
+
# --split_mode {line_break}
|
| 417 |
+
# --network_args "train_blocks=single" {line_break}
|
| 418 |
+
# --lr_scheduler constant_with_warmup {line_break}
|
| 419 |
+
# --max_grad_norm 0.0 {line_break}"""
|
| 420 |
+
if vram == "16G":
|
| 421 |
+
# 16G VRAM
|
| 422 |
+
optimizer = f"""--optimizer_type adafactor {line_break}
|
| 423 |
+
--optimizer_args "relative_step=False" "scale_parameter=False" "warmup_init=False" {line_break}
|
| 424 |
+
--lr_scheduler constant_with_warmup {line_break}
|
| 425 |
+
--max_grad_norm 0.0 {line_break}"""
|
| 426 |
+
elif vram == "12G":
|
| 427 |
+
# 12G VRAM
|
| 428 |
+
optimizer = f"""--optimizer_type adafactor {line_break}
|
| 429 |
+
--optimizer_args "relative_step=False" "scale_parameter=False" "warmup_init=False" {line_break}
|
| 430 |
+
--split_mode {line_break}
|
| 431 |
+
--network_args "train_blocks=single" {line_break}
|
| 432 |
+
--lr_scheduler constant_with_warmup {line_break}
|
| 433 |
+
--max_grad_norm 0.0 {line_break}"""
|
| 434 |
+
else:
|
| 435 |
+
# 20G+ VRAM
|
| 436 |
+
optimizer = f"--optimizer_type adamw8bit {line_break}"
|
| 437 |
+
|
| 438 |
+
|
| 439 |
+
#######################################################
|
| 440 |
+
model_config = models[base_model]
|
| 441 |
+
model_file = model_config["file"]
|
| 442 |
+
repo = model_config["repo"]
|
| 443 |
+
if base_model == "flux-dev" or base_model == "flux-schnell":
|
| 444 |
+
model_folder = "models/unet"
|
| 445 |
+
else:
|
| 446 |
+
model_folder = f"models/unet/{repo}"
|
| 447 |
+
model_path = os.path.join(model_folder, model_file)
|
| 448 |
+
pretrained_model_path = resolve_path(model_path)
|
| 449 |
+
|
| 450 |
+
clip_path = resolve_path("models/clip/clip_l.safetensors")
|
| 451 |
+
t5_path = resolve_path("models/clip/t5xxl_fp16.safetensors")
|
| 452 |
+
ae_path = resolve_path("models/vae/ae.sft")
|
| 453 |
+
sh = f"""accelerate launch {line_break}
|
| 454 |
+
--mixed_precision bf16 {line_break}
|
| 455 |
+
--num_cpu_threads_per_process 1 {line_break}
|
| 456 |
+
sd-scripts/flux_train_network.py {line_break}
|
| 457 |
+
--pretrained_model_name_or_path {pretrained_model_path} {line_break}
|
| 458 |
+
--clip_l {clip_path} {line_break}
|
| 459 |
+
--t5xxl {t5_path} {line_break}
|
| 460 |
+
--ae {ae_path} {line_break}
|
| 461 |
+
--cache_latents_to_disk {line_break}
|
| 462 |
+
--save_model_as safetensors {line_break}
|
| 463 |
+
--sdpa --persistent_data_loader_workers {line_break}
|
| 464 |
+
--max_data_loader_n_workers {workers} {line_break}
|
| 465 |
+
--seed {seed} {line_break}
|
| 466 |
+
--gradient_checkpointing {line_break}
|
| 467 |
+
--mixed_precision bf16 {line_break}
|
| 468 |
+
--save_precision bf16 {line_break}
|
| 469 |
+
--network_module networks.lora_flux {line_break}
|
| 470 |
+
--network_dim {network_dim} {line_break}
|
| 471 |
+
{optimizer}{sample}
|
| 472 |
+
--learning_rate {learning_rate} {line_break}
|
| 473 |
+
--cache_text_encoder_outputs {line_break}
|
| 474 |
+
--cache_text_encoder_outputs_to_disk {line_break}
|
| 475 |
+
--fp8_base {line_break}
|
| 476 |
+
--highvram {line_break}
|
| 477 |
+
--max_train_epochs {max_train_epochs} {line_break}
|
| 478 |
+
--save_every_n_epochs {save_every_n_epochs} {line_break}
|
| 479 |
+
--dataset_config {resolve_path(f"outputs/{output_name}/dataset.toml")} {line_break}
|
| 480 |
+
--output_dir {output_dir} {line_break}
|
| 481 |
+
--output_name {output_name} {line_break}
|
| 482 |
+
--timestep_sampling {timestep_sampling} {line_break}
|
| 483 |
+
--discrete_flow_shift 3.1582 {line_break}
|
| 484 |
+
--model_prediction_type raw {line_break}
|
| 485 |
+
--guidance_scale {guidance_scale} {line_break}
|
| 486 |
+
--loss_type l2 {line_break}"""
|
| 487 |
+
|
| 488 |
+
|
| 489 |
+
|
| 490 |
+
############# Advanced args ########################
|
| 491 |
+
global advanced_component_ids
|
| 492 |
+
global original_advanced_component_values
|
| 493 |
+
|
| 494 |
+
# check dirty
|
| 495 |
+
print(f"original_advanced_component_values = {original_advanced_component_values}")
|
| 496 |
+
advanced_flags = []
|
| 497 |
+
for i, current_value in enumerate(advanced_components):
|
| 498 |
+
# print(f"compare {advanced_component_ids[i]}: old={original_advanced_component_values[i]}, new={current_value}")
|
| 499 |
+
if original_advanced_component_values[i] != current_value:
|
| 500 |
+
# dirty
|
| 501 |
+
if current_value == True:
|
| 502 |
+
# Boolean
|
| 503 |
+
advanced_flags.append(advanced_component_ids[i])
|
| 504 |
+
else:
|
| 505 |
+
# string
|
| 506 |
+
advanced_flags.append(f"{advanced_component_ids[i]} {current_value}")
|
| 507 |
+
|
| 508 |
+
if len(advanced_flags) > 0:
|
| 509 |
+
advanced_flags_str = f" {line_break}\n ".join(advanced_flags)
|
| 510 |
+
sh = sh + "\n " + advanced_flags_str
|
| 511 |
+
|
| 512 |
+
return sh
|
| 513 |
+
|
| 514 |
+
def gen_toml(
|
| 515 |
+
dataset_folder,
|
| 516 |
+
resolution,
|
| 517 |
+
class_tokens,
|
| 518 |
+
num_repeats
|
| 519 |
+
):
|
| 520 |
+
toml = f"""[general]
|
| 521 |
+
shuffle_caption = false
|
| 522 |
+
caption_extension = '.txt'
|
| 523 |
+
keep_tokens = 1
|
| 524 |
+
|
| 525 |
+
[[datasets]]
|
| 526 |
+
resolution = {resolution}
|
| 527 |
+
batch_size = 1
|
| 528 |
+
keep_tokens = 1
|
| 529 |
+
|
| 530 |
+
[[datasets.subsets]]
|
| 531 |
+
image_dir = '{resolve_path_without_quotes(dataset_folder)}'
|
| 532 |
+
class_tokens = '{class_tokens}'
|
| 533 |
+
num_repeats = {num_repeats}"""
|
| 534 |
+
return toml
|
| 535 |
+
|
| 536 |
+
def update_total_steps(max_train_epochs, num_repeats, images):
|
| 537 |
+
try:
|
| 538 |
+
num_images = len(images)
|
| 539 |
+
total_steps = max_train_epochs * num_images * num_repeats
|
| 540 |
+
print(f"max_train_epochs={max_train_epochs} num_images={num_images}, num_repeats={num_repeats}, total_steps={total_steps}")
|
| 541 |
+
return gr.update(value = total_steps)
|
| 542 |
+
except:
|
| 543 |
+
print("")
|
| 544 |
+
|
| 545 |
+
def set_repo(lora_rows):
|
| 546 |
+
selected_name = os.path.basename(lora_rows)
|
| 547 |
+
return gr.update(value=selected_name)
|
| 548 |
+
|
| 549 |
+
def get_loras():
|
| 550 |
+
try:
|
| 551 |
+
outputs_path = resolve_path_without_quotes(f"outputs")
|
| 552 |
+
files = os.listdir(outputs_path)
|
| 553 |
+
folders = [os.path.join(outputs_path, item) for item in files if os.path.isdir(os.path.join(outputs_path, item)) and item != "sample"]
|
| 554 |
+
folders.sort(key=lambda file: os.path.getctime(file), reverse=True)
|
| 555 |
+
return folders
|
| 556 |
+
except Exception as e:
|
| 557 |
+
return []
|
| 558 |
+
|
| 559 |
+
def get_samples(lora_name):
|
| 560 |
+
output_name = slugify(lora_name)
|
| 561 |
+
try:
|
| 562 |
+
samples_path = resolve_path_without_quotes(f"outputs/{output_name}/sample")
|
| 563 |
+
files = [os.path.join(samples_path, file) for file in os.listdir(samples_path)]
|
| 564 |
+
files.sort(key=lambda file: os.path.getctime(file), reverse=True)
|
| 565 |
+
return files
|
| 566 |
+
except:
|
| 567 |
+
return []
|
| 568 |
+
|
| 569 |
+
def start_training(
|
| 570 |
+
base_model,
|
| 571 |
+
lora_name,
|
| 572 |
+
train_script,
|
| 573 |
+
train_config,
|
| 574 |
+
sample_prompts,
|
| 575 |
+
):
|
| 576 |
+
# write custom script and toml
|
| 577 |
+
if not os.path.exists("models"):
|
| 578 |
+
os.makedirs("models", exist_ok=True)
|
| 579 |
+
if not os.path.exists("outputs"):
|
| 580 |
+
os.makedirs("outputs", exist_ok=True)
|
| 581 |
+
output_name = slugify(lora_name)
|
| 582 |
+
output_dir = resolve_path_without_quotes(f"outputs/{output_name}")
|
| 583 |
+
if not os.path.exists(output_dir):
|
| 584 |
+
os.makedirs(output_dir, exist_ok=True)
|
| 585 |
+
|
| 586 |
+
download(base_model)
|
| 587 |
+
|
| 588 |
+
file_type = "sh"
|
| 589 |
+
if sys.platform == "win32":
|
| 590 |
+
file_type = "bat"
|
| 591 |
+
|
| 592 |
+
sh_filename = f"train.{file_type}"
|
| 593 |
+
sh_filepath = resolve_path_without_quotes(f"outputs/{output_name}/{sh_filename}")
|
| 594 |
+
with open(sh_filepath, 'w', encoding="utf-8") as file:
|
| 595 |
+
file.write(train_script)
|
| 596 |
+
gr.Info(f"Generated train script at {sh_filename}")
|
| 597 |
+
|
| 598 |
+
|
| 599 |
+
dataset_path = resolve_path_without_quotes(f"outputs/{output_name}/dataset.toml")
|
| 600 |
+
with open(dataset_path, 'w', encoding="utf-8") as file:
|
| 601 |
+
file.write(train_config)
|
| 602 |
+
gr.Info(f"Generated dataset.toml")
|
| 603 |
+
|
| 604 |
+
sample_prompts_path = resolve_path_without_quotes(f"outputs/{output_name}/sample_prompts.txt")
|
| 605 |
+
with open(sample_prompts_path, 'w', encoding='utf-8') as file:
|
| 606 |
+
file.write(sample_prompts)
|
| 607 |
+
gr.Info(f"Generated sample_prompts.txt")
|
| 608 |
+
|
| 609 |
+
# Train
|
| 610 |
+
if sys.platform == "win32":
|
| 611 |
+
command = sh_filepath
|
| 612 |
+
else:
|
| 613 |
+
command = f"bash \"{sh_filepath}\""
|
| 614 |
+
|
| 615 |
+
# Use Popen to run the command and capture output in real-time
|
| 616 |
+
env = os.environ.copy()
|
| 617 |
+
env['PYTHONIOENCODING'] = 'utf-8'
|
| 618 |
+
env['LOG_LEVEL'] = 'DEBUG'
|
| 619 |
+
runner = LogsViewRunner()
|
| 620 |
+
cwd = os.path.dirname(os.path.abspath(__file__))
|
| 621 |
+
gr.Info(f"Started training")
|
| 622 |
+
yield from runner.run_command([command], cwd=cwd)
|
| 623 |
+
yield runner.log(f"Runner: {runner}")
|
| 624 |
+
|
| 625 |
+
# Generate Readme
|
| 626 |
+
config = toml.loads(train_config)
|
| 627 |
+
concept_sentence = config['datasets'][0]['subsets'][0]['class_tokens']
|
| 628 |
+
print(f"concept_sentence={concept_sentence}")
|
| 629 |
+
print(f"lora_name {lora_name}, concept_sentence={concept_sentence}, output_name={output_name}")
|
| 630 |
+
sample_prompts_path = resolve_path_without_quotes(f"outputs/{output_name}/sample_prompts.txt")
|
| 631 |
+
with open(sample_prompts_path, "r", encoding="utf-8") as f:
|
| 632 |
+
lines = f.readlines()
|
| 633 |
+
sample_prompts = [line.strip() for line in lines if len(line.strip()) > 0 and line[0] != "#"]
|
| 634 |
+
md = readme(base_model, lora_name, concept_sentence, sample_prompts)
|
| 635 |
+
readme_path = resolve_path_without_quotes(f"outputs/{output_name}/README.md")
|
| 636 |
+
with open(readme_path, "w", encoding="utf-8") as f:
|
| 637 |
+
f.write(md)
|
| 638 |
+
|
| 639 |
+
gr.Info(f"Training Complete. Check the outputs folder for the LoRA files.", duration=None)
|
| 640 |
+
|
| 641 |
+
|
| 642 |
+
def update(
|
| 643 |
+
base_model,
|
| 644 |
+
lora_name,
|
| 645 |
+
resolution,
|
| 646 |
+
seed,
|
| 647 |
+
workers,
|
| 648 |
+
class_tokens,
|
| 649 |
+
learning_rate,
|
| 650 |
+
network_dim,
|
| 651 |
+
max_train_epochs,
|
| 652 |
+
save_every_n_epochs,
|
| 653 |
+
timestep_sampling,
|
| 654 |
+
guidance_scale,
|
| 655 |
+
vram,
|
| 656 |
+
num_repeats,
|
| 657 |
+
sample_prompts,
|
| 658 |
+
sample_every_n_steps,
|
| 659 |
+
*advanced_components,
|
| 660 |
+
):
|
| 661 |
+
output_name = slugify(lora_name)
|
| 662 |
+
dataset_folder = str(f"datasets/{output_name}")
|
| 663 |
+
sh = gen_sh(
|
| 664 |
+
base_model,
|
| 665 |
+
output_name,
|
| 666 |
+
resolution,
|
| 667 |
+
seed,
|
| 668 |
+
workers,
|
| 669 |
+
learning_rate,
|
| 670 |
+
network_dim,
|
| 671 |
+
max_train_epochs,
|
| 672 |
+
save_every_n_epochs,
|
| 673 |
+
timestep_sampling,
|
| 674 |
+
guidance_scale,
|
| 675 |
+
vram,
|
| 676 |
+
sample_prompts,
|
| 677 |
+
sample_every_n_steps,
|
| 678 |
+
*advanced_components,
|
| 679 |
+
)
|
| 680 |
+
toml = gen_toml(
|
| 681 |
+
dataset_folder,
|
| 682 |
+
resolution,
|
| 683 |
+
class_tokens,
|
| 684 |
+
num_repeats
|
| 685 |
+
)
|
| 686 |
+
return gr.update(value=sh), gr.update(value=toml), dataset_folder
|
| 687 |
+
|
| 688 |
+
"""
|
| 689 |
+
demo.load(fn=loaded, js=js, outputs=[hf_token, hf_login, hf_logout, hf_account])
|
| 690 |
+
"""
|
| 691 |
+
def loaded():
|
| 692 |
+
global current_account
|
| 693 |
+
current_account = account_hf()
|
| 694 |
+
print(f"current_account={current_account}")
|
| 695 |
+
if current_account != None:
|
| 696 |
+
return gr.update(value=current_account["token"]), gr.update(visible=False), gr.update(visible=True), gr.update(value=current_account["account"], visible=True)
|
| 697 |
+
else:
|
| 698 |
+
return gr.update(value=""), gr.update(visible=True), gr.update(visible=False), gr.update(value="", visible=False)
|
| 699 |
+
|
| 700 |
+
def update_sample(concept_sentence):
|
| 701 |
+
return gr.update(value=concept_sentence)
|
| 702 |
+
|
| 703 |
+
def refresh_publish_tab():
|
| 704 |
+
loras = get_loras()
|
| 705 |
+
return gr.Dropdown(label="Trained LoRAs", choices=loras)
|
| 706 |
+
|
| 707 |
+
def init_advanced():
|
| 708 |
+
# if basic_args
|
| 709 |
+
basic_args = {
|
| 710 |
+
'pretrained_model_name_or_path',
|
| 711 |
+
'clip_l',
|
| 712 |
+
't5xxl',
|
| 713 |
+
'ae',
|
| 714 |
+
'cache_latents_to_disk',
|
| 715 |
+
'save_model_as',
|
| 716 |
+
'sdpa',
|
| 717 |
+
'persistent_data_loader_workers',
|
| 718 |
+
'max_data_loader_n_workers',
|
| 719 |
+
'seed',
|
| 720 |
+
'gradient_checkpointing',
|
| 721 |
+
'mixed_precision',
|
| 722 |
+
'save_precision',
|
| 723 |
+
'network_module',
|
| 724 |
+
'network_dim',
|
| 725 |
+
'learning_rate',
|
| 726 |
+
'cache_text_encoder_outputs',
|
| 727 |
+
'cache_text_encoder_outputs_to_disk',
|
| 728 |
+
'fp8_base',
|
| 729 |
+
'highvram',
|
| 730 |
+
'max_train_epochs',
|
| 731 |
+
'save_every_n_epochs',
|
| 732 |
+
'dataset_config',
|
| 733 |
+
'output_dir',
|
| 734 |
+
'output_name',
|
| 735 |
+
'timestep_sampling',
|
| 736 |
+
'discrete_flow_shift',
|
| 737 |
+
'model_prediction_type',
|
| 738 |
+
'guidance_scale',
|
| 739 |
+
'loss_type',
|
| 740 |
+
'optimizer_type',
|
| 741 |
+
'optimizer_args',
|
| 742 |
+
'lr_scheduler',
|
| 743 |
+
'sample_prompts',
|
| 744 |
+
'sample_every_n_steps',
|
| 745 |
+
'max_grad_norm',
|
| 746 |
+
'split_mode',
|
| 747 |
+
'network_args'
|
| 748 |
+
}
|
| 749 |
+
|
| 750 |
+
# generate a UI config
|
| 751 |
+
# if not in basic_args, create a simple form
|
| 752 |
+
parser = train_network.setup_parser()
|
| 753 |
+
flux_train_utils.add_flux_train_arguments(parser)
|
| 754 |
+
args_info = {}
|
| 755 |
+
for action in parser._actions:
|
| 756 |
+
if action.dest != 'help': # Skip the default help argument
|
| 757 |
+
# if the dest is included in basic_args
|
| 758 |
+
args_info[action.dest] = {
|
| 759 |
+
"action": action.option_strings, # Option strings like '--use_8bit_adam'
|
| 760 |
+
"type": action.type, # Type of the argument
|
| 761 |
+
"help": action.help, # Help message
|
| 762 |
+
"default": action.default, # Default value, if any
|
| 763 |
+
"required": action.required # Whether the argument is required
|
| 764 |
+
}
|
| 765 |
+
temp = []
|
| 766 |
+
for key in args_info:
|
| 767 |
+
temp.append({ 'key': key, 'action': args_info[key] })
|
| 768 |
+
temp.sort(key=lambda x: x['key'])
|
| 769 |
+
advanced_component_ids = []
|
| 770 |
+
advanced_components = []
|
| 771 |
+
for item in temp:
|
| 772 |
+
key = item['key']
|
| 773 |
+
action = item['action']
|
| 774 |
+
if key in basic_args:
|
| 775 |
+
print("")
|
| 776 |
+
else:
|
| 777 |
+
action_type = str(action['type'])
|
| 778 |
+
component = None
|
| 779 |
+
with gr.Column(min_width=300):
|
| 780 |
+
if action_type == "None":
|
| 781 |
+
# radio
|
| 782 |
+
component = gr.Checkbox()
|
| 783 |
+
# elif action_type == "<class 'str'>":
|
| 784 |
+
# component = gr.Textbox()
|
| 785 |
+
# elif action_type == "<class 'int'>":
|
| 786 |
+
# component = gr.Number(precision=0)
|
| 787 |
+
# elif action_type == "<class 'float'>":
|
| 788 |
+
# component = gr.Number()
|
| 789 |
+
# elif "int_or_float" in action_type:
|
| 790 |
+
# component = gr.Number()
|
| 791 |
+
else:
|
| 792 |
+
component = gr.Textbox(value="")
|
| 793 |
+
if component != None:
|
| 794 |
+
component.interactive = True
|
| 795 |
+
component.elem_id = action['action'][0]
|
| 796 |
+
component.label = component.elem_id
|
| 797 |
+
component.elem_classes = ["advanced"]
|
| 798 |
+
if action['help'] != None:
|
| 799 |
+
component.info = action['help']
|
| 800 |
+
advanced_components.append(component)
|
| 801 |
+
advanced_component_ids.append(component.elem_id)
|
| 802 |
+
return advanced_components, advanced_component_ids
|
| 803 |
+
|
| 804 |
+
|
| 805 |
+
theme = gr.themes.Monochrome(
|
| 806 |
+
text_size=gr.themes.Size(lg="18px", md="15px", sm="13px", xl="22px", xs="12px", xxl="24px", xxs="9px"),
|
| 807 |
+
font=[gr.themes.GoogleFont("Source Sans Pro"), "ui-sans-serif", "system-ui", "sans-serif"],
|
| 808 |
+
)
|
| 809 |
+
css = """
|
| 810 |
+
@keyframes rotate {
|
| 811 |
+
0% {
|
| 812 |
+
transform: rotate(0deg);
|
| 813 |
+
}
|
| 814 |
+
100% {
|
| 815 |
+
transform: rotate(360deg);
|
| 816 |
+
}
|
| 817 |
+
}
|
| 818 |
+
#advanced_options .advanced:nth-child(even) { background: rgba(0,0,100,0.04) !important; }
|
| 819 |
+
h1{font-family: georgia; font-style: italic; font-weight: bold; font-size: 30px; letter-spacing: -1px;}
|
| 820 |
+
h3{margin-top: 0}
|
| 821 |
+
.tabitem{border: 0px}
|
| 822 |
+
.group_padding{}
|
| 823 |
+
nav{position: fixed; top: 0; left: 0; right: 0; z-index: 1000; text-align: center; padding: 10px; box-sizing: border-box; display: flex; align-items: center; backdrop-filter: blur(10px); }
|
| 824 |
+
nav button { background: none; color: firebrick; font-weight: bold; border: 2px solid firebrick; padding: 5px 10px; border-radius: 5px; font-size: 14px; }
|
| 825 |
+
nav img { height: 40px; width: 40px; border-radius: 40px; }
|
| 826 |
+
nav img.rotate { animation: rotate 2s linear infinite; }
|
| 827 |
+
.flexible { flex-grow: 1; }
|
| 828 |
+
.tast-details { margin: 10px 0 !important; }
|
| 829 |
+
.toast-wrap { bottom: var(--size-4) !important; top: auto !important; border: none !important; backdrop-filter: blur(10px); }
|
| 830 |
+
.toast-title, .toast-text, .toast-icon, .toast-close { color: black !important; font-size: 14px; }
|
| 831 |
+
.toast-body { border: none !important; }
|
| 832 |
+
#terminal { box-shadow: none !important; margin-bottom: 25px; background: rgba(0,0,0,0.03); }
|
| 833 |
+
#terminal .generating { border: none !important; }
|
| 834 |
+
#terminal label { position: absolute !important; }
|
| 835 |
+
.tabs { margin-top: 50px; }
|
| 836 |
+
.hidden { display: none !important; }
|
| 837 |
+
.codemirror-wrapper .cm-line { font-size: 12px !important; }
|
| 838 |
+
label { font-weight: bold !important; }
|
| 839 |
+
#start_training.clicked { background: silver; color: black; }
|
| 840 |
+
"""
|
| 841 |
+
|
| 842 |
+
js = """
|
| 843 |
+
function() {
|
| 844 |
+
let autoscroll = document.querySelector("#autoscroll")
|
| 845 |
+
if (window.iidxx) {
|
| 846 |
+
window.clearInterval(window.iidxx);
|
| 847 |
+
}
|
| 848 |
+
window.iidxx = window.setInterval(function() {
|
| 849 |
+
let text=document.querySelector(".codemirror-wrapper .cm-line").innerText.trim()
|
| 850 |
+
let img = document.querySelector("#logo")
|
| 851 |
+
if (text.length > 0) {
|
| 852 |
+
autoscroll.classList.remove("hidden")
|
| 853 |
+
if (autoscroll.classList.contains("on")) {
|
| 854 |
+
autoscroll.textContent = "Autoscroll ON"
|
| 855 |
+
window.scrollTo(0, document.body.scrollHeight, { behavior: "smooth" });
|
| 856 |
+
img.classList.add("rotate")
|
| 857 |
+
} else {
|
| 858 |
+
autoscroll.textContent = "Autoscroll OFF"
|
| 859 |
+
img.classList.remove("rotate")
|
| 860 |
+
}
|
| 861 |
+
}
|
| 862 |
+
}, 500);
|
| 863 |
+
console.log("autoscroll", autoscroll)
|
| 864 |
+
autoscroll.addEventListener("click", (e) => {
|
| 865 |
+
autoscroll.classList.toggle("on")
|
| 866 |
+
})
|
| 867 |
+
function debounce(fn, delay) {
|
| 868 |
+
let timeoutId;
|
| 869 |
+
return function(...args) {
|
| 870 |
+
clearTimeout(timeoutId);
|
| 871 |
+
timeoutId = setTimeout(() => fn(...args), delay);
|
| 872 |
+
};
|
| 873 |
+
}
|
| 874 |
+
|
| 875 |
+
function handleClick() {
|
| 876 |
+
console.log("refresh")
|
| 877 |
+
document.querySelector("#refresh").click();
|
| 878 |
+
}
|
| 879 |
+
const debouncedClick = debounce(handleClick, 1000);
|
| 880 |
+
document.addEventListener("input", debouncedClick);
|
| 881 |
+
|
| 882 |
+
document.querySelector("#start_training").addEventListener("click", (e) => {
|
| 883 |
+
e.target.classList.add("clicked")
|
| 884 |
+
e.target.innerHTML = "Training..."
|
| 885 |
+
})
|
| 886 |
+
|
| 887 |
+
}
|
| 888 |
+
"""
|
| 889 |
+
|
| 890 |
+
current_account = account_hf()
|
| 891 |
+
print(f"current_account={current_account}")
|
| 892 |
+
|
| 893 |
+
with gr.Blocks(elem_id="app", theme=theme, css=css, fill_width=True) as demo:
|
| 894 |
+
with gr.Tabs() as tabs:
|
| 895 |
+
with gr.TabItem("Gym"):
|
| 896 |
+
output_components = []
|
| 897 |
+
with gr.Row():
|
| 898 |
+
gr.HTML("""<nav>
|
| 899 |
+
<img id='logo' src='/file=icon.png' width='80' height='80'>
|
| 900 |
+
<div class='flexible'></div>
|
| 901 |
+
<button id='autoscroll' class='on hidden'></button>
|
| 902 |
+
</nav>
|
| 903 |
+
""")
|
| 904 |
+
with gr.Row(elem_id='container'):
|
| 905 |
+
with gr.Column():
|
| 906 |
+
gr.Markdown(
|
| 907 |
+
"""# Step 1. LoRA Info
|
| 908 |
+
<p style="margin-top:0">Configure your LoRA train settings.</p>
|
| 909 |
+
""", elem_classes="group_padding")
|
| 910 |
+
lora_name = gr.Textbox(
|
| 911 |
+
label="The name of your LoRA",
|
| 912 |
+
info="This has to be a unique name",
|
| 913 |
+
placeholder="e.g.: Persian Miniature Painting style, Cat Toy",
|
| 914 |
+
)
|
| 915 |
+
concept_sentence = gr.Textbox(
|
| 916 |
+
elem_id="--concept_sentence",
|
| 917 |
+
label="Trigger word/sentence",
|
| 918 |
+
info="Trigger word or sentence to be used",
|
| 919 |
+
placeholder="uncommon word like p3rs0n or trtcrd, or sentence like 'in the style of CNSTLL'",
|
| 920 |
+
interactive=True,
|
| 921 |
+
)
|
| 922 |
+
model_names = list(models.keys())
|
| 923 |
+
print(f"model_names={model_names}")
|
| 924 |
+
base_model = gr.Dropdown(label="Base model (edit the models.yaml file to add more to this list)", choices=model_names, value=model_names[0])
|
| 925 |
+
vram = gr.Radio(["20G", "16G", "12G" ], value="20G", label="VRAM", interactive=True)
|
| 926 |
+
num_repeats = gr.Number(value=10, precision=0, label="Repeat trains per image", interactive=True)
|
| 927 |
+
max_train_epochs = gr.Number(label="Max Train Epochs", value=16, interactive=True)
|
| 928 |
+
total_steps = gr.Number(0, interactive=False, label="Expected training steps")
|
| 929 |
+
sample_prompts = gr.Textbox("", lines=5, label="Sample Image Prompts (Separate with new lines)", interactive=True)
|
| 930 |
+
sample_every_n_steps = gr.Number(0, precision=0, label="Sample Image Every N Steps", interactive=True)
|
| 931 |
+
resolution = gr.Number(value=512, precision=0, label="Resize dataset images")
|
| 932 |
+
with gr.Column():
|
| 933 |
+
gr.Markdown(
|
| 934 |
+
"""# Step 2. Dataset
|
| 935 |
+
<p style="margin-top:0">Make sure the captions include the trigger word.</p>
|
| 936 |
+
""", elem_classes="group_padding")
|
| 937 |
+
with gr.Group():
|
| 938 |
+
images = gr.File(
|
| 939 |
+
file_types=["image", ".txt"],
|
| 940 |
+
label="Upload your images",
|
| 941 |
+
#info="If you want, you can also manually upload caption files that match the image names (example: img0.png => img0.txt)",
|
| 942 |
+
file_count="multiple",
|
| 943 |
+
interactive=True,
|
| 944 |
+
visible=True,
|
| 945 |
+
scale=1,
|
| 946 |
+
)
|
| 947 |
+
with gr.Group(visible=False) as captioning_area:
|
| 948 |
+
do_captioning = gr.Button("Add AI captions with Florence-2")
|
| 949 |
+
output_components.append(captioning_area)
|
| 950 |
+
#output_components = [captioning_area]
|
| 951 |
+
caption_list = []
|
| 952 |
+
for i in range(1, MAX_IMAGES + 1):
|
| 953 |
+
locals()[f"captioning_row_{i}"] = gr.Row(visible=False)
|
| 954 |
+
with locals()[f"captioning_row_{i}"]:
|
| 955 |
+
locals()[f"image_{i}"] = gr.Image(
|
| 956 |
+
type="filepath",
|
| 957 |
+
width=111,
|
| 958 |
+
height=111,
|
| 959 |
+
min_width=111,
|
| 960 |
+
interactive=False,
|
| 961 |
+
scale=2,
|
| 962 |
+
show_label=False,
|
| 963 |
+
show_share_button=False,
|
| 964 |
+
show_download_button=False,
|
| 965 |
+
)
|
| 966 |
+
locals()[f"caption_{i}"] = gr.Textbox(
|
| 967 |
+
label=f"Caption {i}", scale=15, interactive=True
|
| 968 |
+
)
|
| 969 |
+
|
| 970 |
+
output_components.append(locals()[f"captioning_row_{i}"])
|
| 971 |
+
output_components.append(locals()[f"image_{i}"])
|
| 972 |
+
output_components.append(locals()[f"caption_{i}"])
|
| 973 |
+
caption_list.append(locals()[f"caption_{i}"])
|
| 974 |
+
with gr.Column():
|
| 975 |
+
gr.Markdown(
|
| 976 |
+
"""# Step 3. Train
|
| 977 |
+
<p style="margin-top:0">Press start to start training.</p>
|
| 978 |
+
""", elem_classes="group_padding")
|
| 979 |
+
refresh = gr.Button("Refresh", elem_id="refresh", visible=False)
|
| 980 |
+
start = gr.Button("Start training", visible=False, elem_id="start_training")
|
| 981 |
+
output_components.append(start)
|
| 982 |
+
train_script = gr.Textbox(label="Train script", max_lines=100, interactive=True)
|
| 983 |
+
train_config = gr.Textbox(label="Train config", max_lines=100, interactive=True)
|
| 984 |
+
with gr.Accordion("Advanced options", elem_id='advanced_options', open=False):
|
| 985 |
+
with gr.Row():
|
| 986 |
+
with gr.Column(min_width=300):
|
| 987 |
+
seed = gr.Number(label="--seed", info="Seed", value=42, interactive=True)
|
| 988 |
+
with gr.Column(min_width=300):
|
| 989 |
+
workers = gr.Number(label="--max_data_loader_n_workers", info="Number of Workers", value=2, interactive=True)
|
| 990 |
+
with gr.Column(min_width=300):
|
| 991 |
+
learning_rate = gr.Textbox(label="--learning_rate", info="Learning Rate", value="8e-4", interactive=True)
|
| 992 |
+
with gr.Column(min_width=300):
|
| 993 |
+
save_every_n_epochs = gr.Number(label="--save_every_n_epochs", info="Save every N epochs", value=4, interactive=True)
|
| 994 |
+
with gr.Column(min_width=300):
|
| 995 |
+
guidance_scale = gr.Number(label="--guidance_scale", info="Guidance Scale", value=1.0, interactive=True)
|
| 996 |
+
with gr.Column(min_width=300):
|
| 997 |
+
timestep_sampling = gr.Textbox(label="--timestep_sampling", info="Timestep Sampling", value="shift", interactive=True)
|
| 998 |
+
with gr.Column(min_width=300):
|
| 999 |
+
network_dim = gr.Number(label="--network_dim", info="LoRA Rank", value=4, minimum=4, maximum=128, step=4, interactive=True)
|
| 1000 |
+
advanced_components, advanced_component_ids = init_advanced()
|
| 1001 |
+
with gr.Row():
|
| 1002 |
+
terminal = LogsView(label="Train log", elem_id="terminal")
|
| 1003 |
+
with gr.Row():
|
| 1004 |
+
gallery = gr.Gallery(get_samples, inputs=[lora_name], label="Samples", every=10, columns=6)
|
| 1005 |
+
|
| 1006 |
+
with gr.TabItem("Publish") as publish_tab:
|
| 1007 |
+
hf_token = gr.Textbox(label="Huggingface Token")
|
| 1008 |
+
hf_login = gr.Button("Login")
|
| 1009 |
+
hf_logout = gr.Button("Logout")
|
| 1010 |
+
with gr.Row() as row:
|
| 1011 |
+
gr.Markdown("**LoRA**")
|
| 1012 |
+
gr.Markdown("**Upload**")
|
| 1013 |
+
loras = get_loras()
|
| 1014 |
+
with gr.Row():
|
| 1015 |
+
lora_rows = refresh_publish_tab()
|
| 1016 |
+
with gr.Column():
|
| 1017 |
+
with gr.Row():
|
| 1018 |
+
repo_owner = gr.Textbox(label="Account", interactive=False)
|
| 1019 |
+
repo_name = gr.Textbox(label="Repository Name")
|
| 1020 |
+
repo_visibility = gr.Textbox(label="Repository Visibility ('public' or 'private')", value="public")
|
| 1021 |
+
upload_button = gr.Button("Upload to HuggingFace")
|
| 1022 |
+
upload_button.click(
|
| 1023 |
+
fn=upload_hf,
|
| 1024 |
+
inputs=[
|
| 1025 |
+
base_model,
|
| 1026 |
+
lora_rows,
|
| 1027 |
+
repo_owner,
|
| 1028 |
+
repo_name,
|
| 1029 |
+
repo_visibility,
|
| 1030 |
+
hf_token,
|
| 1031 |
+
]
|
| 1032 |
+
)
|
| 1033 |
+
hf_login.click(fn=login_hf, inputs=[hf_token], outputs=[hf_token, hf_login, hf_logout, repo_owner])
|
| 1034 |
+
hf_logout.click(fn=logout_hf, outputs=[hf_token, hf_login, hf_logout, repo_owner])
|
| 1035 |
+
|
| 1036 |
+
|
| 1037 |
+
publish_tab.select(refresh_publish_tab, outputs=lora_rows)
|
| 1038 |
+
lora_rows.select(fn=set_repo, inputs=[lora_rows], outputs=[repo_name])
|
| 1039 |
+
|
| 1040 |
+
dataset_folder = gr.State()
|
| 1041 |
+
|
| 1042 |
+
listeners = [
|
| 1043 |
+
base_model,
|
| 1044 |
+
lora_name,
|
| 1045 |
+
resolution,
|
| 1046 |
+
seed,
|
| 1047 |
+
workers,
|
| 1048 |
+
concept_sentence,
|
| 1049 |
+
learning_rate,
|
| 1050 |
+
network_dim,
|
| 1051 |
+
max_train_epochs,
|
| 1052 |
+
save_every_n_epochs,
|
| 1053 |
+
timestep_sampling,
|
| 1054 |
+
guidance_scale,
|
| 1055 |
+
vram,
|
| 1056 |
+
num_repeats,
|
| 1057 |
+
sample_prompts,
|
| 1058 |
+
sample_every_n_steps,
|
| 1059 |
+
*advanced_components
|
| 1060 |
+
]
|
| 1061 |
+
advanced_component_ids = [x.elem_id for x in advanced_components]
|
| 1062 |
+
original_advanced_component_values = [comp.value for comp in advanced_components]
|
| 1063 |
+
images.upload(
|
| 1064 |
+
load_captioning,
|
| 1065 |
+
inputs=[images, concept_sentence],
|
| 1066 |
+
outputs=output_components
|
| 1067 |
+
)
|
| 1068 |
+
images.delete(
|
| 1069 |
+
load_captioning,
|
| 1070 |
+
inputs=[images, concept_sentence],
|
| 1071 |
+
outputs=output_components
|
| 1072 |
+
)
|
| 1073 |
+
images.clear(
|
| 1074 |
+
hide_captioning,
|
| 1075 |
+
outputs=[captioning_area, start]
|
| 1076 |
+
)
|
| 1077 |
+
max_train_epochs.change(
|
| 1078 |
+
fn=update_total_steps,
|
| 1079 |
+
inputs=[max_train_epochs, num_repeats, images],
|
| 1080 |
+
outputs=[total_steps]
|
| 1081 |
+
)
|
| 1082 |
+
num_repeats.change(
|
| 1083 |
+
fn=update_total_steps,
|
| 1084 |
+
inputs=[max_train_epochs, num_repeats, images],
|
| 1085 |
+
outputs=[total_steps]
|
| 1086 |
+
)
|
| 1087 |
+
images.upload(
|
| 1088 |
+
fn=update_total_steps,
|
| 1089 |
+
inputs=[max_train_epochs, num_repeats, images],
|
| 1090 |
+
outputs=[total_steps]
|
| 1091 |
+
)
|
| 1092 |
+
images.delete(
|
| 1093 |
+
fn=update_total_steps,
|
| 1094 |
+
inputs=[max_train_epochs, num_repeats, images],
|
| 1095 |
+
outputs=[total_steps]
|
| 1096 |
+
)
|
| 1097 |
+
images.clear(
|
| 1098 |
+
fn=update_total_steps,
|
| 1099 |
+
inputs=[max_train_epochs, num_repeats, images],
|
| 1100 |
+
outputs=[total_steps]
|
| 1101 |
+
)
|
| 1102 |
+
concept_sentence.change(fn=update_sample, inputs=[concept_sentence], outputs=sample_prompts)
|
| 1103 |
+
start.click(fn=create_dataset, inputs=[dataset_folder, resolution, images] + caption_list, outputs=dataset_folder).then(
|
| 1104 |
+
fn=start_training,
|
| 1105 |
+
inputs=[
|
| 1106 |
+
base_model,
|
| 1107 |
+
lora_name,
|
| 1108 |
+
train_script,
|
| 1109 |
+
train_config,
|
| 1110 |
+
sample_prompts,
|
| 1111 |
+
],
|
| 1112 |
+
outputs=terminal,
|
| 1113 |
+
)
|
| 1114 |
+
do_captioning.click(fn=run_captioning, inputs=[images, concept_sentence] + caption_list, outputs=caption_list)
|
| 1115 |
+
demo.load(fn=loaded, js=js, outputs=[hf_token, hf_login, hf_logout, repo_owner])
|
| 1116 |
+
refresh.click(update, inputs=listeners, outputs=[train_script, train_config, dataset_folder])
|
| 1117 |
+
if __name__ == "__main__":
|
| 1118 |
+
cwd = os.path.dirname(os.path.abspath(__file__))
|
| 1119 |
+
demo.launch(debug=True, show_error=True, allowed_paths=[cwd])
|
fluxgym-main/docker-compose.yml
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
services:
|
| 2 |
+
|
| 3 |
+
fluxgym:
|
| 4 |
+
build:
|
| 5 |
+
context: .
|
| 6 |
+
# change the dockerfile to Dockerfile.cuda12.4 if you are running CUDA 12.4 drivers otherwise leave as is
|
| 7 |
+
dockerfile: Dockerfile
|
| 8 |
+
image: fluxgym
|
| 9 |
+
container_name: fluxgym
|
| 10 |
+
ports:
|
| 11 |
+
- 7860:7860
|
| 12 |
+
environment:
|
| 13 |
+
- PUID=${PUID:-1000}
|
| 14 |
+
- PGID=${PGID:-1000}
|
| 15 |
+
volumes:
|
| 16 |
+
- /etc/localtime:/etc/localtime:ro
|
| 17 |
+
- /etc/timezone:/etc/timezone:ro
|
| 18 |
+
- ./:/app/fluxgym
|
| 19 |
+
stop_signal: SIGKILL
|
| 20 |
+
tty: true
|
| 21 |
+
deploy:
|
| 22 |
+
resources:
|
| 23 |
+
reservations:
|
| 24 |
+
devices:
|
| 25 |
+
- driver: nvidia
|
| 26 |
+
count: all
|
| 27 |
+
capabilities: [gpu]
|
| 28 |
+
restart: unless-stopped
|
fluxgym-main/flags.png
ADDED

|
fluxgym-main/flow.gif
ADDED

|
Git LFS Details
|
fluxgym-main/icon.png
ADDED
|
|
fluxgym-main/install.js
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
module.exports = {
|
| 2 |
+
run: [
|
| 3 |
+
{
|
| 4 |
+
method: "shell.run",
|
| 5 |
+
params: {
|
| 6 |
+
venv: "env",
|
| 7 |
+
message: [
|
| 8 |
+
"git config --global --add safe.directory '*'",
|
| 9 |
+
"git clone -b sd3 https://github.com/kohya-ss/sd-scripts"
|
| 10 |
+
]
|
| 11 |
+
}
|
| 12 |
+
},
|
| 13 |
+
{
|
| 14 |
+
method: "shell.run",
|
| 15 |
+
params: {
|
| 16 |
+
path: "sd-scripts",
|
| 17 |
+
venv: "../env",
|
| 18 |
+
message: [
|
| 19 |
+
"pip install -r requirements.txt",
|
| 20 |
+
]
|
| 21 |
+
}
|
| 22 |
+
},
|
| 23 |
+
{
|
| 24 |
+
method: "shell.run",
|
| 25 |
+
params: {
|
| 26 |
+
venv: "env",
|
| 27 |
+
message: [
|
| 28 |
+
"pip uninstall -y diffusers[torch] torch torchaudio torchvision",
|
| 29 |
+
"pip install -r requirements.txt",
|
| 30 |
+
]
|
| 31 |
+
}
|
| 32 |
+
},
|
| 33 |
+
{
|
| 34 |
+
method: "script.start",
|
| 35 |
+
params: {
|
| 36 |
+
uri: "torch.js",
|
| 37 |
+
params: {
|
| 38 |
+
venv: "env",
|
| 39 |
+
// xformers: true // uncomment this line if your project requires xformers
|
| 40 |
+
}
|
| 41 |
+
}
|
| 42 |
+
},
|
| 43 |
+
{
|
| 44 |
+
method: "fs.link",
|
| 45 |
+
params: {
|
| 46 |
+
drive: {
|
| 47 |
+
vae: "models/vae",
|
| 48 |
+
clip: "models/clip",
|
| 49 |
+
unet: "models/unet",
|
| 50 |
+
loras: "outputs",
|
| 51 |
+
},
|
| 52 |
+
peers: [
|
| 53 |
+
"https://github.com/pinokiofactory/stable-diffusion-webui-forge.git",
|
| 54 |
+
"https://github.com/pinokiofactory/comfy.git",
|
| 55 |
+
"https://github.com/cocktailpeanutlabs/comfyui.git",
|
| 56 |
+
"https://github.com/cocktailpeanutlabs/fooocus.git",
|
| 57 |
+
"https://github.com/cocktailpeanutlabs/automatic1111.git",
|
| 58 |
+
]
|
| 59 |
+
}
|
| 60 |
+
},
|
| 61 |
+
// {
|
| 62 |
+
// method: "fs.download",
|
| 63 |
+
// params: {
|
| 64 |
+
// uri: [
|
| 65 |
+
// "https://huggingface.co/comfyanonymous/flux_text_encoders/resolve/main/clip_l.safetensors?download=true",
|
| 66 |
+
// "https://huggingface.co/comfyanonymous/flux_text_encoders/resolve/main/t5xxl_fp16.safetensors?download=true",
|
| 67 |
+
// ],
|
| 68 |
+
// dir: "models/clip"
|
| 69 |
+
// }
|
| 70 |
+
// },
|
| 71 |
+
// {
|
| 72 |
+
// method: "fs.download",
|
| 73 |
+
// params: {
|
| 74 |
+
// uri: [
|
| 75 |
+
// "https://huggingface.co/cocktailpeanut/xulf-dev/resolve/main/ae.sft?download=true",
|
| 76 |
+
// ],
|
| 77 |
+
// dir: "models/vae"
|
| 78 |
+
// }
|
| 79 |
+
// },
|
| 80 |
+
// {
|
| 81 |
+
// method: "fs.download",
|
| 82 |
+
// params: {
|
| 83 |
+
// uri: [
|
| 84 |
+
// "https://huggingface.co/cocktailpeanut/xulf-dev/resolve/main/flux1-dev.sft?download=true",
|
| 85 |
+
// ],
|
| 86 |
+
// dir: "models/unet"
|
| 87 |
+
// }
|
| 88 |
+
// },
|
| 89 |
+
{
|
| 90 |
+
method: "fs.link",
|
| 91 |
+
params: {
|
| 92 |
+
venv: "env"
|
| 93 |
+
}
|
| 94 |
+
}
|
| 95 |
+
]
|
| 96 |
+
}
|
fluxgym-main/models.yaml
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Add your own model here
|
| 2 |
+
# <name that will show up on the dropdown>:
|
| 3 |
+
# repo: <the huggingface repo ID to pull from>
|
| 4 |
+
# base: <the model used to run inference with (The Huggingface "Inference API" widget will use this to generate demo images)>
|
| 5 |
+
# license: <follow the other examples. Any model inherited from DEV should use the dev license, schenll is apache-2.0>
|
| 6 |
+
# license_name: <follow the other examples. only needed for dev inherited models>
|
| 7 |
+
# license_link: <follow the other examples. only needed for dev inherited models>
|
| 8 |
+
# file: <the file name within the huggingface repo>
|
| 9 |
+
flux-dev:
|
| 10 |
+
repo: cocktailpeanut/xulf-dev
|
| 11 |
+
base: black-forest-labs/FLUX.1-dev
|
| 12 |
+
license: other
|
| 13 |
+
license_name: flux-1-dev-non-commercial-license
|
| 14 |
+
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
|
| 15 |
+
file: flux1-dev.sft
|
| 16 |
+
flux-schnell:
|
| 17 |
+
repo: black-forest-labs/FLUX.1-schnell
|
| 18 |
+
base: black-forest-labs/FLUX.1-schnell
|
| 19 |
+
license: apache-2.0
|
| 20 |
+
file: flux1-schnell.safetensors
|
| 21 |
+
bdsqlsz/flux1-dev2pro-single:
|
| 22 |
+
repo: bdsqlsz/flux1-dev2pro-single
|
| 23 |
+
base: black-forest-labs/FLUX.1-dev
|
| 24 |
+
license: other
|
| 25 |
+
license_name: flux-1-dev-non-commercial-license
|
| 26 |
+
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
|
| 27 |
+
file: flux1-dev2pro.safetensors
|
fluxgym-main/models/.gitkeep
ADDED
|
File without changes
|
fluxgym-main/models/clip/.gitkeep
ADDED
|
File without changes
|
fluxgym-main/models/unet/.gitkeep
ADDED
|
File without changes
|
fluxgym-main/models/vae/.gitkeep
ADDED
|
File without changes
|
fluxgym-main/outputs/.gitkeep
ADDED
|
File without changes
|
fluxgym-main/pinokio.js
ADDED
|
@@ -0,0 +1,95 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
const path = require('path')
|
| 2 |
+
module.exports = {
|
| 3 |
+
version: "2.1",
|
| 4 |
+
title: "fluxgym",
|
| 5 |
+
description: "[NVIDIA Only] Dead simple web UI for training FLUX LoRA with LOW VRAM support (From 12GB)",
|
| 6 |
+
icon: "icon.png",
|
| 7 |
+
menu: async (kernel, info) => {
|
| 8 |
+
let installed = info.exists("env")
|
| 9 |
+
let running = {
|
| 10 |
+
install: info.running("install.js"),
|
| 11 |
+
start: info.running("start.js"),
|
| 12 |
+
update: info.running("update.js"),
|
| 13 |
+
reset: info.running("reset.js")
|
| 14 |
+
}
|
| 15 |
+
if (running.install) {
|
| 16 |
+
return [{
|
| 17 |
+
default: true,
|
| 18 |
+
icon: "fa-solid fa-plug",
|
| 19 |
+
text: "Installing",
|
| 20 |
+
href: "install.js",
|
| 21 |
+
}]
|
| 22 |
+
} else if (installed) {
|
| 23 |
+
if (running.start) {
|
| 24 |
+
let local = info.local("start.js")
|
| 25 |
+
if (local && local.url) {
|
| 26 |
+
return [{
|
| 27 |
+
default: true,
|
| 28 |
+
icon: "fa-solid fa-rocket",
|
| 29 |
+
text: "Open Web UI",
|
| 30 |
+
href: local.url,
|
| 31 |
+
}, {
|
| 32 |
+
icon: 'fa-solid fa-terminal',
|
| 33 |
+
text: "Terminal",
|
| 34 |
+
href: "start.js",
|
| 35 |
+
}, {
|
| 36 |
+
icon: "fa-solid fa-flask",
|
| 37 |
+
text: "Outputs",
|
| 38 |
+
href: "outputs?fs"
|
| 39 |
+
}]
|
| 40 |
+
} else {
|
| 41 |
+
return [{
|
| 42 |
+
default: true,
|
| 43 |
+
icon: 'fa-solid fa-terminal',
|
| 44 |
+
text: "Terminal",
|
| 45 |
+
href: "start.js",
|
| 46 |
+
}]
|
| 47 |
+
}
|
| 48 |
+
} else if (running.update) {
|
| 49 |
+
return [{
|
| 50 |
+
default: true,
|
| 51 |
+
icon: 'fa-solid fa-terminal',
|
| 52 |
+
text: "Updating",
|
| 53 |
+
href: "update.js",
|
| 54 |
+
}]
|
| 55 |
+
} else if (running.reset) {
|
| 56 |
+
return [{
|
| 57 |
+
default: true,
|
| 58 |
+
icon: 'fa-solid fa-terminal',
|
| 59 |
+
text: "Resetting",
|
| 60 |
+
href: "reset.js",
|
| 61 |
+
}]
|
| 62 |
+
} else {
|
| 63 |
+
return [{
|
| 64 |
+
default: true,
|
| 65 |
+
icon: "fa-solid fa-power-off",
|
| 66 |
+
text: "Start",
|
| 67 |
+
href: "start.js",
|
| 68 |
+
}, {
|
| 69 |
+
icon: "fa-solid fa-flask",
|
| 70 |
+
text: "Outputs",
|
| 71 |
+
href: "sd-scripts/fluxgym/outputs?fs"
|
| 72 |
+
}, {
|
| 73 |
+
icon: "fa-solid fa-plug",
|
| 74 |
+
text: "Update",
|
| 75 |
+
href: "update.js",
|
| 76 |
+
}, {
|
| 77 |
+
icon: "fa-solid fa-plug",
|
| 78 |
+
text: "Install",
|
| 79 |
+
href: "install.js",
|
| 80 |
+
}, {
|
| 81 |
+
icon: "fa-regular fa-circle-xmark",
|
| 82 |
+
text: "Reset",
|
| 83 |
+
href: "reset.js",
|
| 84 |
+
}]
|
| 85 |
+
}
|
| 86 |
+
} else {
|
| 87 |
+
return [{
|
| 88 |
+
default: true,
|
| 89 |
+
icon: "fa-solid fa-plug",
|
| 90 |
+
text: "Install",
|
| 91 |
+
href: "install.js",
|
| 92 |
+
}]
|
| 93 |
+
}
|
| 94 |
+
}
|
| 95 |
+
}
|
fluxgym-main/pinokio_meta.json
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"posts": [
|
| 3 |
+
"https://x.com/cocktailpeanut/status/1835719701172756592",
|
| 4 |
+
"https://x.com/LikeToasters/status/1834258975384092858",
|
| 5 |
+
"https://x.com/cocktailpeanut/status/1834245329627009295",
|
| 6 |
+
"https://x.com/jkch0205/status/1834003420132614450",
|
| 7 |
+
"https://x.com/huwhitememes/status/1834074992209699132",
|
| 8 |
+
"https://x.com/GorillaRogueGam/status/1834148656791888139",
|
| 9 |
+
"https://x.com/cocktailpeanut/status/1833964839519068303",
|
| 10 |
+
"https://x.com/cocktailpeanut/status/1833935061907079521",
|
| 11 |
+
"https://x.com/cocktailpeanut/status/1833940728881242135",
|
| 12 |
+
"https://x.com/cocktailpeanut/status/1833881392482066638",
|
| 13 |
+
"https://x.com/Alone1Moon/status/1833348850662445369",
|
| 14 |
+
"https://x.com/_f_ai_9/status/1833485349995397167",
|
| 15 |
+
"https://x.com/intocryptoast/status/1833061082862412186",
|
| 16 |
+
"https://x.com/cocktailpeanut/status/1833888423716827321",
|
| 17 |
+
"https://x.com/cocktailpeanut/status/1833884852992516596",
|
| 18 |
+
"https://x.com/cocktailpeanut/status/1833885335077417046",
|
| 19 |
+
"https://x.com/NiwonArt/status/1833565746624139650",
|
| 20 |
+
"https://x.com/cocktailpeanut/status/1833884361986380117",
|
| 21 |
+
"https://x.com/NiwonArt/status/1833599399764889685",
|
| 22 |
+
"https://x.com/LikeToasters/status/1832934391217045913",
|
| 23 |
+
"https://x.com/cocktailpeanut/status/1832924887456817415",
|
| 24 |
+
"https://x.com/cocktailpeanut/status/1832927154536902897",
|
| 25 |
+
"https://x.com/YabaiHamster/status/1832697724690386992",
|
| 26 |
+
"https://x.com/cocktailpeanut/status/1832747889497366706",
|
| 27 |
+
"https://x.com/PhotogenicWeekE/status/1832720544959185202",
|
| 28 |
+
"https://x.com/zuzaritt/status/1832748542164652390",
|
| 29 |
+
"https://x.com/foxyy4i/status/1832764883710185880",
|
| 30 |
+
"https://x.com/waynedahlberg/status/1832226132999213095",
|
| 31 |
+
"https://x.com/PhotoGarrido/status/1832214644515041770",
|
| 32 |
+
"https://x.com/cocktailpeanut/status/1832787205774786710",
|
| 33 |
+
"https://x.com/cocktailpeanut/status/1832151307198541961",
|
| 34 |
+
"https://x.com/cocktailpeanut/status/1832145996014612735",
|
| 35 |
+
"https://x.com/cocktailpeanut/status/1832084951115972653",
|
| 36 |
+
"https://x.com/cocktailpeanut/status/1832091112086843684"
|
| 37 |
+
]
|
| 38 |
+
}
|
fluxgym-main/publish_to_hf.png
ADDED
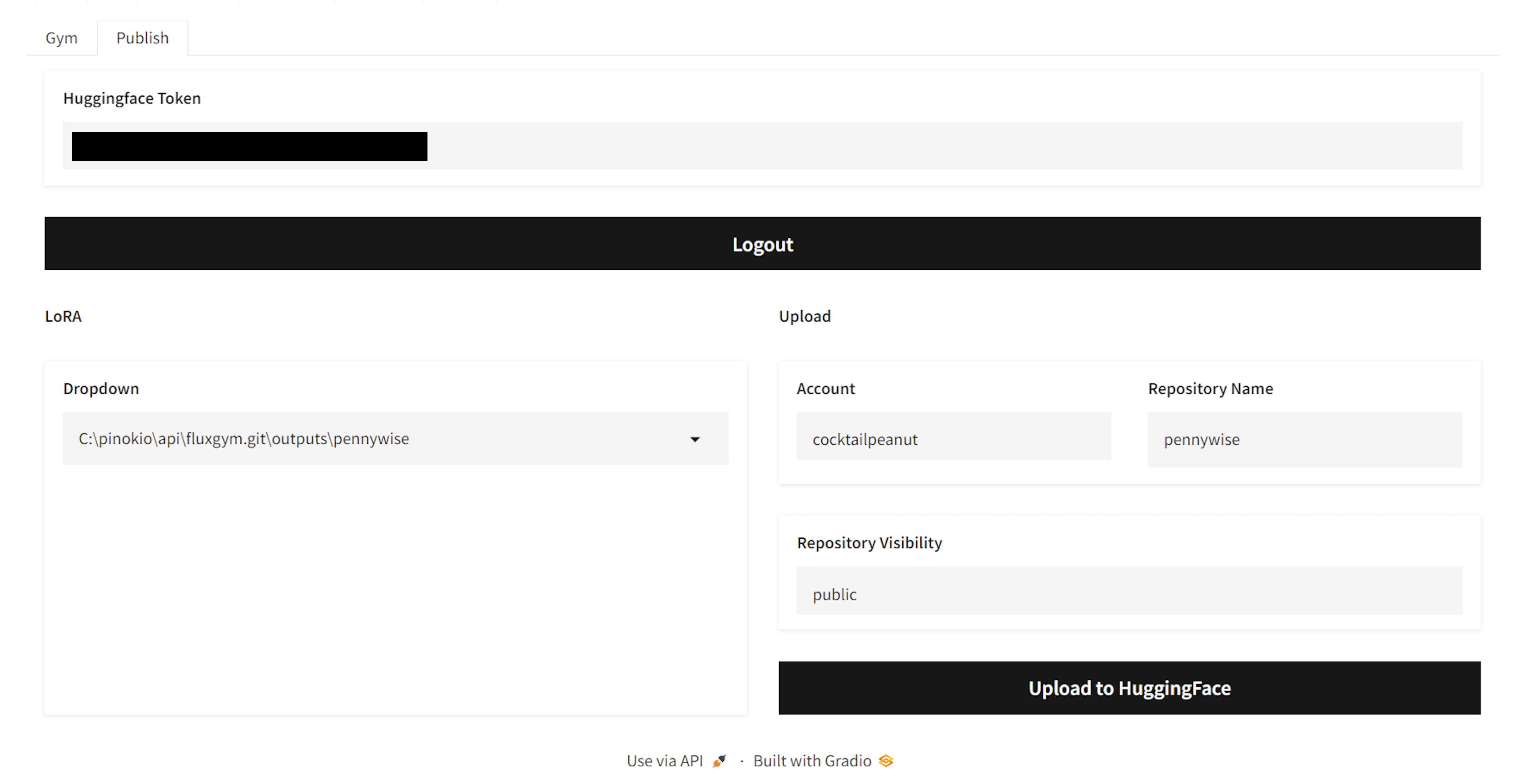
|
fluxgym-main/requirements.txt
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
safetensors
|
| 2 |
+
git+https://github.com/huggingface/diffusers.git
|
| 3 |
+
gradio_logsview@https://huggingface.co/spaces/cocktailpeanut/gradio_logsview/resolve/main/gradio_logsview-0.0.17-py3-none-any.whl
|
| 4 |
+
transformers
|
| 5 |
+
lycoris-lora==1.8.3
|
| 6 |
+
flatten_json
|
| 7 |
+
pyyaml
|
| 8 |
+
oyaml
|
| 9 |
+
tensorboard
|
| 10 |
+
kornia
|
| 11 |
+
invisible-watermark
|
| 12 |
+
einops
|
| 13 |
+
accelerate
|
| 14 |
+
toml
|
| 15 |
+
albumentations
|
| 16 |
+
pydantic
|
| 17 |
+
omegaconf
|
| 18 |
+
k-diffusion
|
| 19 |
+
open_clip_torch
|
| 20 |
+
timm
|
| 21 |
+
prodigyopt
|
| 22 |
+
controlnet_aux==0.0.7
|
| 23 |
+
python-dotenv
|
| 24 |
+
bitsandbytes
|
| 25 |
+
hf_transfer
|
| 26 |
+
lpips
|
| 27 |
+
pytorch_fid
|
| 28 |
+
optimum-quanto
|
| 29 |
+
sentencepiece
|
| 30 |
+
huggingface_hub
|
| 31 |
+
peft
|
| 32 |
+
gradio
|
| 33 |
+
python-slugify
|
| 34 |
+
imagesize
|
fluxgym-main/reset.js
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
module.exports = {
|
| 2 |
+
run: [{
|
| 3 |
+
method: "fs.rm",
|
| 4 |
+
params: {
|
| 5 |
+
path: "sd-scripts"
|
| 6 |
+
}
|
| 7 |
+
}, {
|
| 8 |
+
method: "fs.rm",
|
| 9 |
+
params: {
|
| 10 |
+
path: "env"
|
| 11 |
+
}
|
| 12 |
+
}]
|
| 13 |
+
}
|
fluxgym-main/sample.png
ADDED

|
Git LFS Details
|
fluxgym-main/sample_fields.png
ADDED

|
fluxgym-main/screenshot.png
ADDED
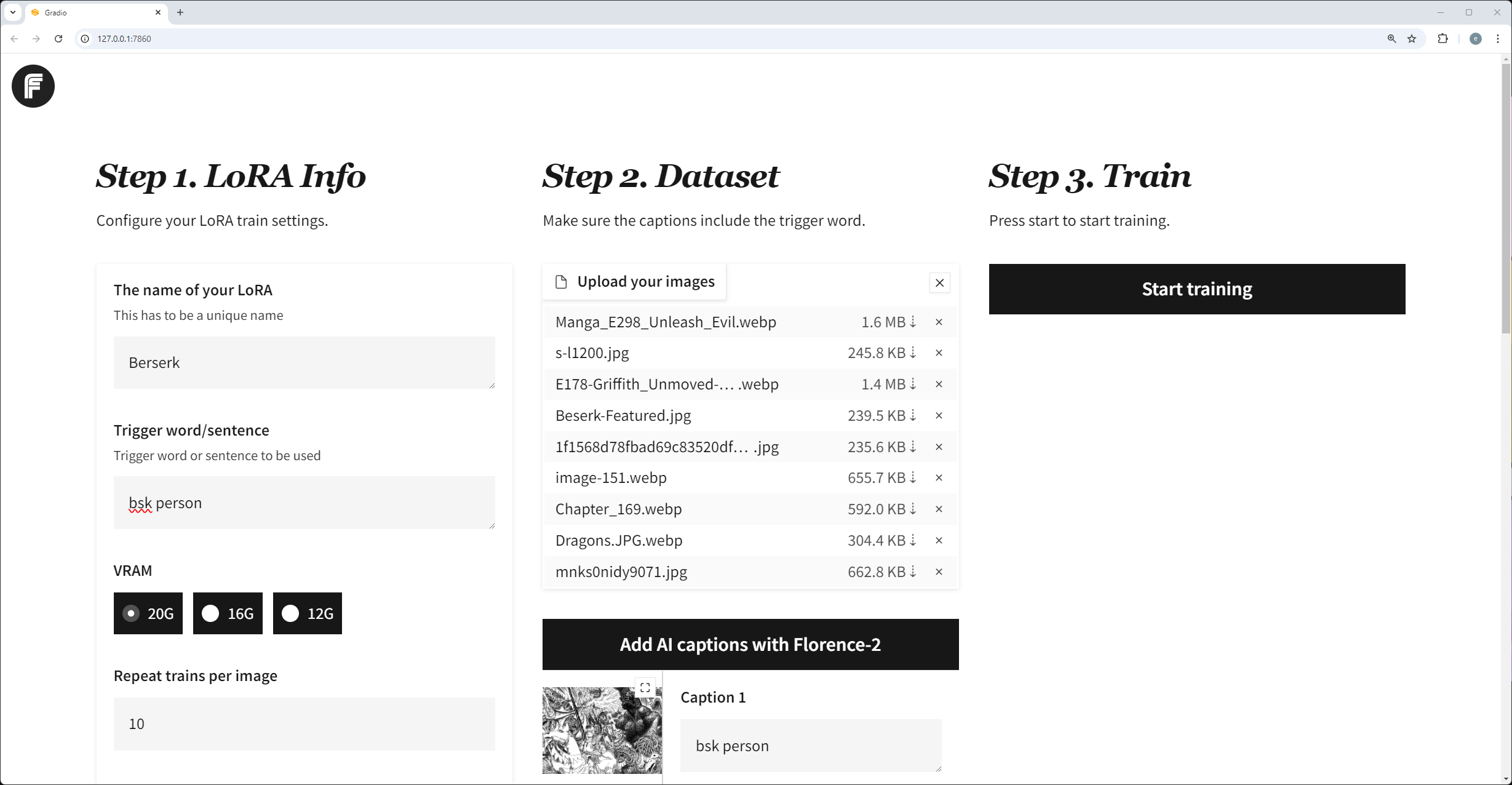
|
fluxgym-main/seed.gif
ADDED

|
Git LFS Details
|
fluxgym-main/start.js
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
module.exports = {
|
| 2 |
+
daemon: true,
|
| 3 |
+
run: [
|
| 4 |
+
{
|
| 5 |
+
method: "shell.run",
|
| 6 |
+
params: {
|
| 7 |
+
venv: "env", // Edit this to customize the venv folder path
|
| 8 |
+
env: {
|
| 9 |
+
LOG_LEVEL: "DEBUG",
|
| 10 |
+
CUDA_VISIBLE_DEVICES: "0"
|
| 11 |
+
}, // Edit this to customize environment variables (see documentation)
|
| 12 |
+
message: [
|
| 13 |
+
"python app.py", // Edit with your custom commands
|
| 14 |
+
],
|
| 15 |
+
on: [{
|
| 16 |
+
// The regular expression pattern to monitor.
|
| 17 |
+
// When this pattern occurs in the shell terminal, the shell will return,
|
| 18 |
+
// and the script will go onto the next step.
|
| 19 |
+
"event": "/http:\/\/\\S+/",
|
| 20 |
+
|
| 21 |
+
// "done": true will move to the next step while keeping the shell alive.
|
| 22 |
+
// "kill": true will move to the next step after killing the shell.
|
| 23 |
+
"done": true
|
| 24 |
+
}]
|
| 25 |
+
}
|
| 26 |
+
},
|
| 27 |
+
{
|
| 28 |
+
// This step sets the local variable 'url'.
|
| 29 |
+
// This local variable will be used in pinokio.js to display the "Open WebUI" tab when the value is set.
|
| 30 |
+
method: "local.set",
|
| 31 |
+
params: {
|
| 32 |
+
// the input.event is the regular expression match object from the previous step
|
| 33 |
+
url: "{{input.event[0]}}"
|
| 34 |
+
}
|
| 35 |
+
}
|
| 36 |
+
]
|
| 37 |
+
}
|
fluxgym-main/torch.js
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
module.exports = {
|
| 2 |
+
run: [
|
| 3 |
+
// windows nvidia
|
| 4 |
+
{
|
| 5 |
+
"when": "{{platform === 'win32' && gpu === 'nvidia'}}",
|
| 6 |
+
"method": "shell.run",
|
| 7 |
+
"params": {
|
| 8 |
+
"venv": "{{args && args.venv ? args.venv : null}}",
|
| 9 |
+
"path": "{{args && args.path ? args.path : '.'}}",
|
| 10 |
+
"message": "pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121"
|
| 11 |
+
|
| 12 |
+
}
|
| 13 |
+
},
|
| 14 |
+
// windows amd
|
| 15 |
+
{
|
| 16 |
+
"when": "{{platform === 'win32' && gpu === 'amd'}}",
|
| 17 |
+
"method": "shell.run",
|
| 18 |
+
"params": {
|
| 19 |
+
"venv": "{{args && args.venv ? args.venv : null}}",
|
| 20 |
+
"path": "{{args && args.path ? args.path : '.'}}",
|
| 21 |
+
"message": "pip install torch-directml torchaudio torchvision"
|
| 22 |
+
}
|
| 23 |
+
},
|
| 24 |
+
// windows cpu
|
| 25 |
+
{
|
| 26 |
+
"when": "{{platform === 'win32' && (gpu !== 'nvidia' && gpu !== 'amd')}}",
|
| 27 |
+
"method": "shell.run",
|
| 28 |
+
"params": {
|
| 29 |
+
"venv": "{{args && args.venv ? args.venv : null}}",
|
| 30 |
+
"path": "{{args && args.path ? args.path : '.'}}",
|
| 31 |
+
"message": "pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu"
|
| 32 |
+
}
|
| 33 |
+
},
|
| 34 |
+
// mac
|
| 35 |
+
{
|
| 36 |
+
"when": "{{platform === 'darwin'}}",
|
| 37 |
+
"method": "shell.run",
|
| 38 |
+
"params": {
|
| 39 |
+
"venv": "{{args && args.venv ? args.venv : null}}",
|
| 40 |
+
"path": "{{args && args.path ? args.path : '.'}}",
|
| 41 |
+
"message": "pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu"
|
| 42 |
+
}
|
| 43 |
+
},
|
| 44 |
+
// linux nvidia
|
| 45 |
+
{
|
| 46 |
+
"when": "{{platform === 'linux' && gpu === 'nvidia'}}",
|
| 47 |
+
"method": "shell.run",
|
| 48 |
+
"params": {
|
| 49 |
+
"venv": "{{args && args.venv ? args.venv : null}}",
|
| 50 |
+
"path": "{{args && args.path ? args.path : '.'}}",
|
| 51 |
+
"message": "pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121"
|
| 52 |
+
}
|
| 53 |
+
},
|
| 54 |
+
// linux rocm (amd)
|
| 55 |
+
{
|
| 56 |
+
"when": "{{platform === 'linux' && gpu === 'amd'}}",
|
| 57 |
+
"method": "shell.run",
|
| 58 |
+
"params": {
|
| 59 |
+
"venv": "{{args && args.venv ? args.venv : null}}",
|
| 60 |
+
"path": "{{args && args.path ? args.path : '.'}}",
|
| 61 |
+
"message": "pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm6.1"
|
| 62 |
+
}
|
| 63 |
+
},
|
| 64 |
+
// linux cpu
|
| 65 |
+
{
|
| 66 |
+
"when": "{{platform === 'linux' && (gpu !== 'amd' && gpu !=='nvidia')}}",
|
| 67 |
+
"method": "shell.run",
|
| 68 |
+
"params": {
|
| 69 |
+
"venv": "{{args && args.venv ? args.venv : null}}",
|
| 70 |
+
"path": "{{args && args.path ? args.path : '.'}}",
|
| 71 |
+
"message": "pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu"
|
| 72 |
+
}
|
| 73 |
+
}
|
| 74 |
+
]
|
| 75 |
+
}
|
fluxgym-main/update.js
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
module.exports = {
|
| 2 |
+
run: [{
|
| 3 |
+
method: "shell.run",
|
| 4 |
+
params: {
|
| 5 |
+
message: "git pull"
|
| 6 |
+
}
|
| 7 |
+
}, {
|
| 8 |
+
method: "shell.run",
|
| 9 |
+
params: {
|
| 10 |
+
path: "sd-scripts",
|
| 11 |
+
message: "git pull"
|
| 12 |
+
}
|
| 13 |
+
}, {
|
| 14 |
+
method: "shell.run",
|
| 15 |
+
params: {
|
| 16 |
+
path: "sd-scripts",
|
| 17 |
+
venv: "../env",
|
| 18 |
+
message: [
|
| 19 |
+
"pip install -r requirements.txt",
|
| 20 |
+
]
|
| 21 |
+
}
|
| 22 |
+
}, {
|
| 23 |
+
method: "shell.run",
|
| 24 |
+
params: {
|
| 25 |
+
venv: "env",
|
| 26 |
+
message: [
|
| 27 |
+
"pip uninstall -y diffusers[torch] torch torchaudio torchvision",
|
| 28 |
+
"pip install -r requirements.txt",
|
| 29 |
+
]
|
| 30 |
+
}
|
| 31 |
+
}, {
|
| 32 |
+
method: "script.start",
|
| 33 |
+
params: {
|
| 34 |
+
uri: "torch.js",
|
| 35 |
+
params: {
|
| 36 |
+
venv: "env",
|
| 37 |
+
// xformers: true // uncomment this line if your project requires xformers
|
| 38 |
+
}
|
| 39 |
+
}
|
| 40 |
+
}, {
|
| 41 |
+
method: "fs.link",
|
| 42 |
+
params: {
|
| 43 |
+
venv: "env"
|
| 44 |
+
}
|
| 45 |
+
}]
|
| 46 |
+
}
|