Spaces:
Runtime error

Runtime error
Commit
•
b863415
1
Parent(s):
09afafc
init commit
Browse files- AUTHORS +12 -0
- CONTRIBUTING.md +29 -0
- LICENSE +202 -0
- colabs/ithaca_inference.ipynb +0 -0
- example_input.txt +1 -0
- images/inscription.png +0 -0
- images/ithaca-arch.png +0 -0
- images/ithaca-logo.svg +16 -0
- inference_example.py +129 -0
- ithaca/__init__.py +13 -0
- ithaca/eval/__init__.py +13 -0
- ithaca/eval/inference.py +268 -0
- ithaca/models/__init__.py +13 -0
- ithaca/models/bigbird.py +110 -0
- ithaca/models/bigbird_attention.py +602 -0
- ithaca/models/common_layers.py +318 -0
- ithaca/models/model.py +243 -0
- ithaca/util/__init__.py +13 -0
- ithaca/util/alphabet.py +171 -0
- ithaca/util/dates.py +67 -0
- ithaca/util/eval.py +562 -0
- ithaca/util/loss.py +117 -0
- ithaca/util/optim.py +167 -0
- ithaca/util/region_names.py +44 -0
- ithaca/util/text.py +186 -0
- requirements.txt +8 -0
- setup.py +52 -0
- train/README.md +34 -0
- train/config.py +173 -0
- train/data/README +2 -0
- train/data/iphi-region-main.txt +15 -0
- train/data/iphi-region-sub.txt +88 -0
- train/data/iphi-wordlist.txt +0 -0
- train/dataloader.py +409 -0
- train/experiment.py +679 -0
- train/launch_local.sh +22 -0
AUTHORS
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This is the list of Ithaca authors for copyright purposes.
|
| 2 |
+
#
|
| 3 |
+
# This does not necessarily list everyone who has contributed code, since in
|
| 4 |
+
# some cases, their employer may be the copyright holder. To see the full list
|
| 5 |
+
# of contributors, see the revision history in source control.
|
| 6 |
+
DeepMind Technologies Limited
|
| 7 |
+
Google LLC
|
| 8 |
+
Thea Sommerschield
|
| 9 |
+
Jonathan Prag
|
| 10 |
+
Marita Chatzipanagiotou
|
| 11 |
+
John Pavlopoulos
|
| 12 |
+
Ion Androutsopoulos
|
CONTRIBUTING.md
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# How to Contribute
|
| 2 |
+
|
| 3 |
+
We'd love to accept your patches and contributions to this project. There are
|
| 4 |
+
just a few small guidelines you need to follow.
|
| 5 |
+
|
| 6 |
+
## Contributor License Agreement
|
| 7 |
+
|
| 8 |
+
Contributions to this project must be accompanied by a Contributor License
|
| 9 |
+
Agreement (CLA). You (or your employer) retain the copyright to your
|
| 10 |
+
contribution; this simply gives us permission to use and redistribute your
|
| 11 |
+
contributions as part of the project. Head over to
|
| 12 |
+
<https://cla.developers.google.com/> to see your current agreements on file or
|
| 13 |
+
to sign a new one.
|
| 14 |
+
|
| 15 |
+
You generally only need to submit a CLA once, so if you've already submitted one
|
| 16 |
+
(even if it was for a different project), you probably don't need to do it
|
| 17 |
+
again.
|
| 18 |
+
|
| 19 |
+
## Code reviews
|
| 20 |
+
|
| 21 |
+
All submissions, including submissions by project members, require review. We
|
| 22 |
+
use GitHub pull requests for this purpose. Consult
|
| 23 |
+
[GitHub Help](https://help.github.com/articles/about-pull-requests/) for more
|
| 24 |
+
information on using pull requests.
|
| 25 |
+
|
| 26 |
+
## Community Guidelines
|
| 27 |
+
|
| 28 |
+
This project follows
|
| 29 |
+
[Google's Open Source Community Guidelines](https://opensource.google/conduct/).
|
LICENSE
ADDED
|
@@ -0,0 +1,202 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
Apache License
|
| 3 |
+
Version 2.0, January 2004
|
| 4 |
+
http://www.apache.org/licenses/
|
| 5 |
+
|
| 6 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 7 |
+
|
| 8 |
+
1. Definitions.
|
| 9 |
+
|
| 10 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 11 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 12 |
+
|
| 13 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 14 |
+
the copyright owner that is granting the License.
|
| 15 |
+
|
| 16 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 17 |
+
other entities that control, are controlled by, or are under common
|
| 18 |
+
control with that entity. For the purposes of this definition,
|
| 19 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 20 |
+
direction or management of such entity, whether by contract or
|
| 21 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 22 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 23 |
+
|
| 24 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 25 |
+
exercising permissions granted by this License.
|
| 26 |
+
|
| 27 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 28 |
+
including but not limited to software source code, documentation
|
| 29 |
+
source, and configuration files.
|
| 30 |
+
|
| 31 |
+
"Object" form shall mean any form resulting from mechanical
|
| 32 |
+
transformation or translation of a Source form, including but
|
| 33 |
+
not limited to compiled object code, generated documentation,
|
| 34 |
+
and conversions to other media types.
|
| 35 |
+
|
| 36 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 37 |
+
Object form, made available under the License, as indicated by a
|
| 38 |
+
copyright notice that is included in or attached to the work
|
| 39 |
+
(an example is provided in the Appendix below).
|
| 40 |
+
|
| 41 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 42 |
+
form, that is based on (or derived from) the Work and for which the
|
| 43 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 44 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 45 |
+
of this License, Derivative Works shall not include works that remain
|
| 46 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 47 |
+
the Work and Derivative Works thereof.
|
| 48 |
+
|
| 49 |
+
"Contribution" shall mean any work of authorship, including
|
| 50 |
+
the original version of the Work and any modifications or additions
|
| 51 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 52 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 53 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 54 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 55 |
+
means any form of electronic, verbal, or written communication sent
|
| 56 |
+
to the Licensor or its representatives, including but not limited to
|
| 57 |
+
communication on electronic mailing lists, source code control systems,
|
| 58 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 59 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 60 |
+
excluding communication that is conspicuously marked or otherwise
|
| 61 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 62 |
+
|
| 63 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 64 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 65 |
+
subsequently incorporated within the Work.
|
| 66 |
+
|
| 67 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 68 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 69 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 70 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 71 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 72 |
+
Work and such Derivative Works in Source or Object form.
|
| 73 |
+
|
| 74 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 75 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 76 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 77 |
+
(except as stated in this section) patent license to make, have made,
|
| 78 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 79 |
+
where such license applies only to those patent claims licensable
|
| 80 |
+
by such Contributor that are necessarily infringed by their
|
| 81 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 82 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 83 |
+
institute patent litigation against any entity (including a
|
| 84 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 85 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 86 |
+
or contributory patent infringement, then any patent licenses
|
| 87 |
+
granted to You under this License for that Work shall terminate
|
| 88 |
+
as of the date such litigation is filed.
|
| 89 |
+
|
| 90 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 91 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 92 |
+
modifications, and in Source or Object form, provided that You
|
| 93 |
+
meet the following conditions:
|
| 94 |
+
|
| 95 |
+
(a) You must give any other recipients of the Work or
|
| 96 |
+
Derivative Works a copy of this License; and
|
| 97 |
+
|
| 98 |
+
(b) You must cause any modified files to carry prominent notices
|
| 99 |
+
stating that You changed the files; and
|
| 100 |
+
|
| 101 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 102 |
+
that You distribute, all copyright, patent, trademark, and
|
| 103 |
+
attribution notices from the Source form of the Work,
|
| 104 |
+
excluding those notices that do not pertain to any part of
|
| 105 |
+
the Derivative Works; and
|
| 106 |
+
|
| 107 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 108 |
+
distribution, then any Derivative Works that You distribute must
|
| 109 |
+
include a readable copy of the attribution notices contained
|
| 110 |
+
within such NOTICE file, excluding those notices that do not
|
| 111 |
+
pertain to any part of the Derivative Works, in at least one
|
| 112 |
+
of the following places: within a NOTICE text file distributed
|
| 113 |
+
as part of the Derivative Works; within the Source form or
|
| 114 |
+
documentation, if provided along with the Derivative Works; or,
|
| 115 |
+
within a display generated by the Derivative Works, if and
|
| 116 |
+
wherever such third-party notices normally appear. The contents
|
| 117 |
+
of the NOTICE file are for informational purposes only and
|
| 118 |
+
do not modify the License. You may add Your own attribution
|
| 119 |
+
notices within Derivative Works that You distribute, alongside
|
| 120 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 121 |
+
that such additional attribution notices cannot be construed
|
| 122 |
+
as modifying the License.
|
| 123 |
+
|
| 124 |
+
You may add Your own copyright statement to Your modifications and
|
| 125 |
+
may provide additional or different license terms and conditions
|
| 126 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 127 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 128 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 129 |
+
the conditions stated in this License.
|
| 130 |
+
|
| 131 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 132 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 133 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 134 |
+
this License, without any additional terms or conditions.
|
| 135 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 136 |
+
the terms of any separate license agreement you may have executed
|
| 137 |
+
with Licensor regarding such Contributions.
|
| 138 |
+
|
| 139 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 140 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 141 |
+
except as required for reasonable and customary use in describing the
|
| 142 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 143 |
+
|
| 144 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 145 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 146 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 147 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 148 |
+
implied, including, without limitation, any warranties or conditions
|
| 149 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 150 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 151 |
+
appropriateness of using or redistributing the Work and assume any
|
| 152 |
+
risks associated with Your exercise of permissions under this License.
|
| 153 |
+
|
| 154 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 155 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 156 |
+
unless required by applicable law (such as deliberate and grossly
|
| 157 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 158 |
+
liable to You for damages, including any direct, indirect, special,
|
| 159 |
+
incidental, or consequential damages of any character arising as a
|
| 160 |
+
result of this License or out of the use or inability to use the
|
| 161 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 162 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 163 |
+
other commercial damages or losses), even if such Contributor
|
| 164 |
+
has been advised of the possibility of such damages.
|
| 165 |
+
|
| 166 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 167 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 168 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 169 |
+
or other liability obligations and/or rights consistent with this
|
| 170 |
+
License. However, in accepting such obligations, You may act only
|
| 171 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 172 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 173 |
+
defend, and hold each Contributor harmless for any liability
|
| 174 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 175 |
+
of your accepting any such warranty or additional liability.
|
| 176 |
+
|
| 177 |
+
END OF TERMS AND CONDITIONS
|
| 178 |
+
|
| 179 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 180 |
+
|
| 181 |
+
To apply the Apache License to your work, attach the following
|
| 182 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 183 |
+
replaced with your own identifying information. (Don't include
|
| 184 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 185 |
+
comment syntax for the file format. We also recommend that a
|
| 186 |
+
file or class name and description of purpose be included on the
|
| 187 |
+
same "printed page" as the copyright notice for easier
|
| 188 |
+
identification within third-party archives.
|
| 189 |
+
|
| 190 |
+
Copyright [yyyy] [name of copyright owner]
|
| 191 |
+
|
| 192 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 193 |
+
you may not use this file except in compliance with the License.
|
| 194 |
+
You may obtain a copy of the License at
|
| 195 |
+
|
| 196 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 197 |
+
|
| 198 |
+
Unless required by applicable law or agreed to in writing, software
|
| 199 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 200 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 201 |
+
See the License for the specific language governing permissions and
|
| 202 |
+
limitations under the License.
|
colabs/ithaca_inference.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
example_input.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
ἔδοξεν τῆι βουλῆι καὶ τῶι δήμωι λυσίστρατος εἶπε- ἐπειδὴ διοφάνης ἀνὴρ ἀγαθὸς ὢν διατελεῖ περὶ δηλίους δεδόχθαι τῶι ----- διοφάνην καλλι-------- --ηναῖον πρόξενον εἶναι δ--------- αὐτὸγ καὶ ἐκγόνους κ-- εἶναι αὐτοῖς ἀτέλειαν ἐν δήλωι πάντων καὶ γῆς καὶ οἰκίας ἔγκτησιν καὶ πρόσοδον πρὸς τὴμ βουλὴγ καὶ τὸν δῆμον πρώτοις μετὰ τὰ ἱερὰ καὶ τὰ ἄλλα ὅσα καὶ τοῖς ἄλλοις προξένοις καὶ εὐεργέταις τοῦ ἱεροῦ δέδοται παρὰ ---ίων ἀναγράψαι δὲ τόδε ?????????α τὴν βουλὴν εἰς -----------ριον τοὺς -ὲ -----------------------.
|
images/inscription.png
ADDED

|
images/ithaca-arch.png
ADDED
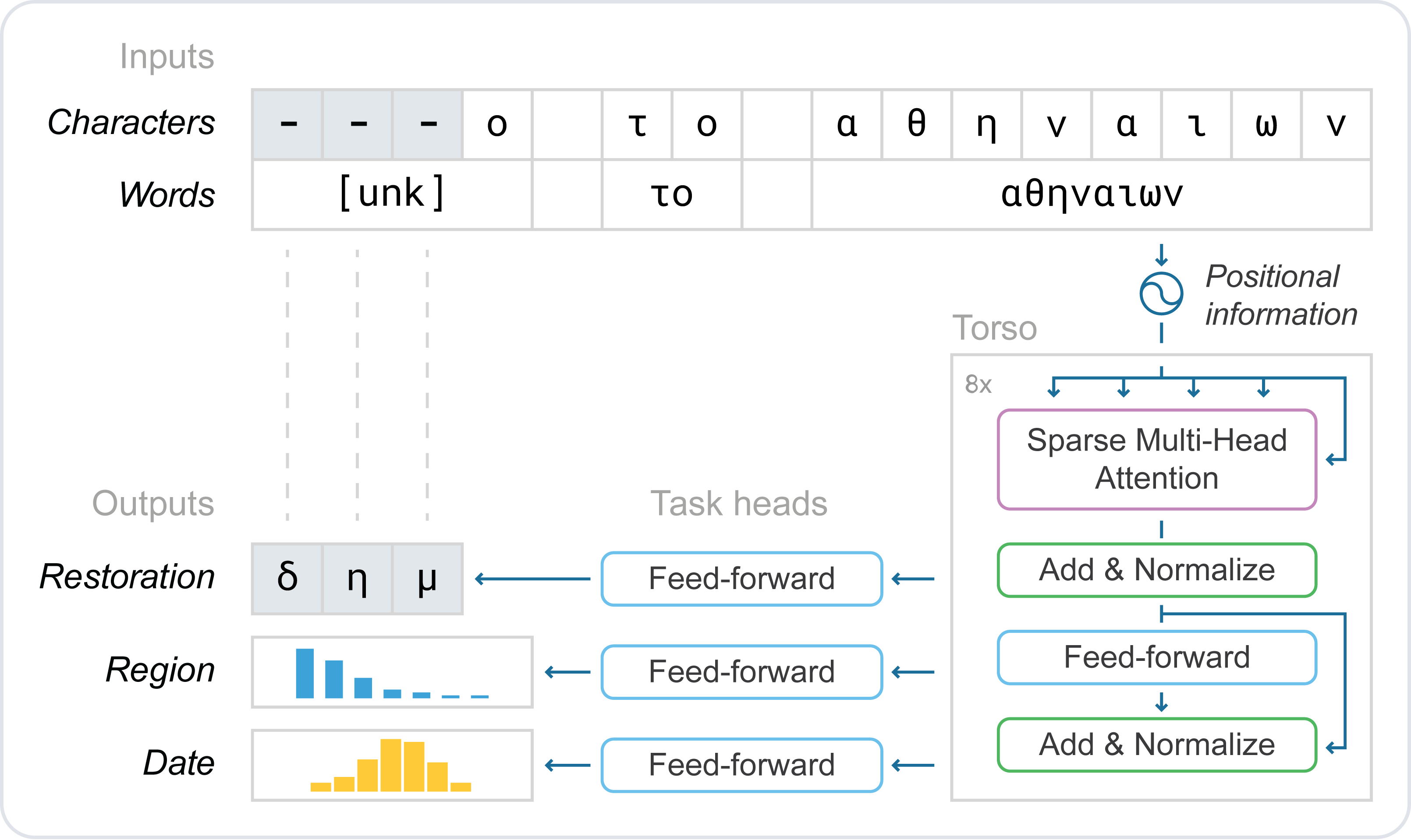
|
images/ithaca-logo.svg
ADDED
|
|
inference_example.py
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2021 the Ithaca Authors
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
"""Example for running inference. See also colab."""
|
| 15 |
+
|
| 16 |
+
import functools
|
| 17 |
+
import pickle
|
| 18 |
+
|
| 19 |
+
from absl import app
|
| 20 |
+
from absl import flags
|
| 21 |
+
from ithaca.eval import inference
|
| 22 |
+
from ithaca.models.model import Model
|
| 23 |
+
from ithaca.util.alphabet import GreekAlphabet
|
| 24 |
+
import jax
|
| 25 |
+
|
| 26 |
+
FLAGS = flags.FLAGS
|
| 27 |
+
|
| 28 |
+
flags.DEFINE_string(
|
| 29 |
+
'input', '', 'Text to directly pass to the model. Only one of --input and '
|
| 30 |
+
'--input_file can be specified.')
|
| 31 |
+
flags.DEFINE_string(
|
| 32 |
+
'input_file', '', 'File containing text to pass to the model. Only one of '
|
| 33 |
+
'--input and --input_file can be specified.')
|
| 34 |
+
flags.DEFINE_string('checkpoint_path', 'checkpoint.pkl',
|
| 35 |
+
'Path to model checkpoint pickle.')
|
| 36 |
+
flags.DEFINE_string('attribute_json', '', 'Path to save attribution JSON to.')
|
| 37 |
+
flags.DEFINE_string('restore_json', '', 'Path to save restoration JSON to.')
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def load_checkpoint(path):
|
| 41 |
+
"""Loads a checkpoint pickle.
|
| 42 |
+
|
| 43 |
+
Args:
|
| 44 |
+
path: path to checkpoint pickle
|
| 45 |
+
|
| 46 |
+
Returns:
|
| 47 |
+
a model config dictionary (arguments to the model's constructor), a dict of
|
| 48 |
+
dicts containing region mapping information, a GreekAlphabet instance with
|
| 49 |
+
indices and words populated from the checkpoint, a dict of Jax arrays
|
| 50 |
+
`params`, and a `forward` function.
|
| 51 |
+
"""
|
| 52 |
+
|
| 53 |
+
# Pickled checkpoint dict containing params and various config:
|
| 54 |
+
with open(path, 'rb') as f:
|
| 55 |
+
checkpoint = pickle.load(f)
|
| 56 |
+
|
| 57 |
+
# We reconstruct the model using the same arguments as during training, which
|
| 58 |
+
# are saved as a dict in the "model_config" key, and construct a `forward`
|
| 59 |
+
# function of the form required by attribute() and restore().
|
| 60 |
+
params = jax.device_put(checkpoint['params'])
|
| 61 |
+
model = Model(**checkpoint['model_config'])
|
| 62 |
+
forward = functools.partial(model.apply, params)
|
| 63 |
+
|
| 64 |
+
# Contains the mapping between region IDs and names:
|
| 65 |
+
region_map = checkpoint['region_map']
|
| 66 |
+
|
| 67 |
+
# Use vocabulary mapping from the checkpoint, the rest of the values in the
|
| 68 |
+
# class are fixed and constant e.g. the padding symbol
|
| 69 |
+
alphabet = GreekAlphabet()
|
| 70 |
+
alphabet.idx2word = checkpoint['alphabet']['idx2word']
|
| 71 |
+
alphabet.word2idx = checkpoint['alphabet']['word2idx']
|
| 72 |
+
|
| 73 |
+
return checkpoint['model_config'], region_map, alphabet, params, forward
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def main(argv):
|
| 77 |
+
if len(argv) > 1:
|
| 78 |
+
raise app.UsageError('Too many command-line arguments.')
|
| 79 |
+
|
| 80 |
+
if FLAGS.input and not FLAGS.input_file:
|
| 81 |
+
input_text = FLAGS.input
|
| 82 |
+
elif not FLAGS.input and FLAGS.input_file:
|
| 83 |
+
with open(FLAGS.input_file, 'r', encoding='utf8') as f:
|
| 84 |
+
input_text = f.read()
|
| 85 |
+
else:
|
| 86 |
+
raise app.UsageError('Specify exactly one of --input and --input_file.')
|
| 87 |
+
|
| 88 |
+
if not 50 <= len(input_text) <= 750:
|
| 89 |
+
raise app.UsageError(
|
| 90 |
+
f'Text should be between 50 and 750 chars long, but the input was '
|
| 91 |
+
f'{len(input_text)} characters')
|
| 92 |
+
|
| 93 |
+
# Load the checkpoint pickle and extract from it the pieces needed for calling
|
| 94 |
+
# the attribute() and restore() functions:
|
| 95 |
+
(model_config, region_map, alphabet, params,
|
| 96 |
+
forward) = load_checkpoint(FLAGS.checkpoint_path)
|
| 97 |
+
vocab_char_size = model_config['vocab_char_size']
|
| 98 |
+
vocab_word_size = model_config['vocab_word_size']
|
| 99 |
+
|
| 100 |
+
attribution = inference.attribute(
|
| 101 |
+
input_text,
|
| 102 |
+
forward=forward,
|
| 103 |
+
params=params,
|
| 104 |
+
alphabet=alphabet,
|
| 105 |
+
region_map=region_map,
|
| 106 |
+
vocab_char_size=vocab_char_size,
|
| 107 |
+
vocab_word_size=vocab_word_size)
|
| 108 |
+
if FLAGS.attribute_json:
|
| 109 |
+
with open(FLAGS.attribute_json, 'w') as f:
|
| 110 |
+
f.write(attribution.json(indent=2))
|
| 111 |
+
else:
|
| 112 |
+
print('Attribution:', attribution.json())
|
| 113 |
+
|
| 114 |
+
restoration = inference.restore(
|
| 115 |
+
input_text,
|
| 116 |
+
forward=forward,
|
| 117 |
+
params=params,
|
| 118 |
+
alphabet=alphabet,
|
| 119 |
+
vocab_char_size=vocab_char_size,
|
| 120 |
+
vocab_word_size=vocab_word_size)
|
| 121 |
+
if FLAGS.restore_json:
|
| 122 |
+
with open(FLAGS.restore_json, 'w') as f:
|
| 123 |
+
f.write(restoration.json(indent=2))
|
| 124 |
+
else:
|
| 125 |
+
print('Restoration:', restoration.json())
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
if __name__ == '__main__':
|
| 129 |
+
app.run(main)
|
ithaca/__init__.py
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2021 the Ithaca Authors
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
ithaca/eval/__init__.py
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2021 the Ithaca Authors
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
ithaca/eval/inference.py
ADDED
|
@@ -0,0 +1,268 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2021 the Ithaca Authors
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
"""Module for performing inference using Jax, including decoding.
|
| 15 |
+
|
| 16 |
+
The module is separated into two main entrypoints: attribute() and restore().
|
| 17 |
+
|
| 18 |
+
Both take a function called `forward`, a Jax function mapping from model inputs
|
| 19 |
+
(excluding parameters) to the model output tuple. Generated using
|
| 20 |
+
e.g. `functools.partial(exp.forward.apply, exp._params)`.
|
| 21 |
+
"""
|
| 22 |
+
|
| 23 |
+
import json
|
| 24 |
+
import math
|
| 25 |
+
import re
|
| 26 |
+
from typing import List, NamedTuple, Tuple
|
| 27 |
+
|
| 28 |
+
import ithaca.util.eval as eval_util
|
| 29 |
+
import ithaca.util.text as util_text
|
| 30 |
+
|
| 31 |
+
import jax
|
| 32 |
+
import numpy as np
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
class LocationPrediction(NamedTuple):
|
| 36 |
+
"""One location prediction and its associated probability."""
|
| 37 |
+
|
| 38 |
+
location_id: int
|
| 39 |
+
score: float
|
| 40 |
+
|
| 41 |
+
def build_json(self):
|
| 42 |
+
return {
|
| 43 |
+
'location_id': self.location_id,
|
| 44 |
+
'score': self.score,
|
| 45 |
+
}
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
class AttributionResults(NamedTuple):
|
| 49 |
+
"""Immediate model output attribution predictions and related information."""
|
| 50 |
+
|
| 51 |
+
input_text: str
|
| 52 |
+
|
| 53 |
+
# List of pairs of location ID and probability
|
| 54 |
+
locations: List[LocationPrediction]
|
| 55 |
+
|
| 56 |
+
# Probabilities over year range [-800, -790, -780, ..., 790, 800]
|
| 57 |
+
year_scores: List[float] # length 160
|
| 58 |
+
|
| 59 |
+
# Per-character saliency maps:
|
| 60 |
+
date_saliency: List[float]
|
| 61 |
+
location_saliency: List[float] # originally called subregion
|
| 62 |
+
|
| 63 |
+
def build_json(self):
|
| 64 |
+
return {
|
| 65 |
+
'input_text': self.input_text,
|
| 66 |
+
'locations': [l.build_json() for l in self.locations],
|
| 67 |
+
'year_scores': self.year_scores,
|
| 68 |
+
'date_saliency': self.date_saliency,
|
| 69 |
+
'location_saliency': self.location_saliency
|
| 70 |
+
}
|
| 71 |
+
|
| 72 |
+
def json(self, **kwargs):
|
| 73 |
+
return json.dumps(self.build_json(), **kwargs)
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
class Restoration(NamedTuple):
|
| 77 |
+
"""One restored candidate string from the beam search."""
|
| 78 |
+
text: str
|
| 79 |
+
score: float
|
| 80 |
+
|
| 81 |
+
def build_json(self):
|
| 82 |
+
return {'text': self.text, 'score': self.score}
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
class RestorationCharSaliency(NamedTuple):
|
| 86 |
+
"""Saliency entry for one predicted character of a prediction."""
|
| 87 |
+
text: str
|
| 88 |
+
restored_idx: int # which predicted character the saliency map corresponds to
|
| 89 |
+
saliency: List[float]
|
| 90 |
+
|
| 91 |
+
def build_json(self):
|
| 92 |
+
return {
|
| 93 |
+
'text': self.text,
|
| 94 |
+
'restored_idx': self.restored_idx,
|
| 95 |
+
'saliency': self.saliency
|
| 96 |
+
}
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
class RestorationResults(NamedTuple):
|
| 100 |
+
"""Contains all text-related restoration predictions."""
|
| 101 |
+
|
| 102 |
+
input_text: str
|
| 103 |
+
top_prediction: str
|
| 104 |
+
restored: List[int] # char indices that were missing (-)
|
| 105 |
+
|
| 106 |
+
# List of top N results from beam search:
|
| 107 |
+
predictions: List[Restoration]
|
| 108 |
+
|
| 109 |
+
# Saliency maps for each successive character of the best (greedy) prediction
|
| 110 |
+
prediction_saliency: List[RestorationCharSaliency]
|
| 111 |
+
|
| 112 |
+
def build_json(self):
|
| 113 |
+
return {
|
| 114 |
+
'input_text':
|
| 115 |
+
self.input_text,
|
| 116 |
+
'top_prediction':
|
| 117 |
+
self.top_prediction,
|
| 118 |
+
'restored':
|
| 119 |
+
self.restored,
|
| 120 |
+
'predictions': [r.build_json() for r in self.predictions],
|
| 121 |
+
'prediction_saliency': [
|
| 122 |
+
m.build_json() for m in self.prediction_saliency
|
| 123 |
+
],
|
| 124 |
+
}
|
| 125 |
+
|
| 126 |
+
def json(self, **kwargs):
|
| 127 |
+
return json.dumps(self.build_json(), **kwargs)
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
# These constants are fixed for all recent versions of the model.
|
| 131 |
+
MIN_TEXT_LEN = 50
|
| 132 |
+
TEXT_LEN = 768 # fixed model sequence length
|
| 133 |
+
DATE_MIN = -800
|
| 134 |
+
DATE_MAX = 800
|
| 135 |
+
DATE_INTERVAL = 10
|
| 136 |
+
RESTORATION_BEAM_WIDTH = 20
|
| 137 |
+
RESTORATION_TEMPERATURE = 1.
|
| 138 |
+
SEED = 1
|
| 139 |
+
ALPHABET_MISSING_RESTORE = '?' # missing characters to restore
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
def _prepare_text(
|
| 143 |
+
text, alphabet
|
| 144 |
+
) -> Tuple[str, str, str, np.ndarray, np.ndarray, List[int], np.ndarray,
|
| 145 |
+
List[int]]:
|
| 146 |
+
"""Adds start of sequence symbol, and padding.
|
| 147 |
+
|
| 148 |
+
Also strips accents if present, trims whitespace, and generates arrays ready
|
| 149 |
+
for input into the model.
|
| 150 |
+
|
| 151 |
+
Args:
|
| 152 |
+
text: Raw text input string, no padding or start of sequence symbol.
|
| 153 |
+
alphabet: GreekAlphabet object containing index/character mappings.
|
| 154 |
+
|
| 155 |
+
Returns:
|
| 156 |
+
Tuple of cleaned text (str), padded text (str), char indices (array of batch
|
| 157 |
+
size 1), word indices (array of batch size 1), text length (list of size 1)
|
| 158 |
+
"""
|
| 159 |
+
text = re.sub(r'\s+', ' ', text.strip())
|
| 160 |
+
text = util_text.strip_accents(text)
|
| 161 |
+
|
| 162 |
+
if len(text) < MIN_TEXT_LEN:
|
| 163 |
+
raise ValueError('Input text too short.')
|
| 164 |
+
|
| 165 |
+
if len(text) >= TEXT_LEN - 1:
|
| 166 |
+
raise ValueError('Input text too long.')
|
| 167 |
+
|
| 168 |
+
text_sos = alphabet.sos + text
|
| 169 |
+
text_len = [len(text_sos)] # includes SOS, but not padding
|
| 170 |
+
|
| 171 |
+
text_padded = text_sos + alphabet.pad * max(0, TEXT_LEN - len(text_sos))
|
| 172 |
+
|
| 173 |
+
restore_mask_idx = [
|
| 174 |
+
i for i, c in enumerate(text_padded) if c == ALPHABET_MISSING_RESTORE
|
| 175 |
+
]
|
| 176 |
+
text_padded = text_padded.replace(ALPHABET_MISSING_RESTORE, alphabet.missing)
|
| 177 |
+
|
| 178 |
+
text_char = util_text.text_to_idx(text_padded, alphabet).reshape(1, -1)
|
| 179 |
+
text_word = util_text.text_to_word_idx(text_padded, alphabet).reshape(1, -1)
|
| 180 |
+
padding = np.where(text_char > 0, 1, 0)
|
| 181 |
+
|
| 182 |
+
return (text, text_sos, text_padded, text_char, text_word, text_len, padding,
|
| 183 |
+
restore_mask_idx)
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
def attribute(text, forward, params, alphabet, vocab_char_size, vocab_word_size,
|
| 187 |
+
region_map) -> AttributionResults:
|
| 188 |
+
"""Computes predicted date and geographical region."""
|
| 189 |
+
|
| 190 |
+
(text, _, _, text_char, text_word, text_len, padding,
|
| 191 |
+
_) = _prepare_text(text, alphabet)
|
| 192 |
+
|
| 193 |
+
rng = jax.random.PRNGKey(SEED)
|
| 194 |
+
date_logits, subregion_logits, _, _ = forward(
|
| 195 |
+
text_char=text_char,
|
| 196 |
+
text_word=text_word,
|
| 197 |
+
rngs={'dropout': rng},
|
| 198 |
+
is_training=False)
|
| 199 |
+
|
| 200 |
+
# Generate subregion predictions:
|
| 201 |
+
subregion_logits = np.array(subregion_logits)
|
| 202 |
+
subregion_pred_probs = eval_util.softmax(subregion_logits[0]).tolist()
|
| 203 |
+
location_predictions = [
|
| 204 |
+
LocationPrediction(location_id=id, score=prob)
|
| 205 |
+
for prob, id in zip(subregion_pred_probs, region_map['sub']['ids'])
|
| 206 |
+
]
|
| 207 |
+
location_predictions.sort(key=lambda loc: loc.score, reverse=True)
|
| 208 |
+
|
| 209 |
+
# Generate date predictions:
|
| 210 |
+
date_pred_probs = eval_util.softmax(date_logits[0])
|
| 211 |
+
|
| 212 |
+
# Gradients for saliency maps
|
| 213 |
+
date_saliency, subregion_saliency = eval_util.compute_attribution_saliency_maps(
|
| 214 |
+
text_char, text_word, text_len, padding, forward, params, rng, alphabet,
|
| 215 |
+
vocab_char_size, vocab_word_size)
|
| 216 |
+
|
| 217 |
+
# Skip start of sequence symbol (first char) for text and saliency maps:
|
| 218 |
+
return AttributionResults(
|
| 219 |
+
input_text=text,
|
| 220 |
+
locations=location_predictions,
|
| 221 |
+
year_scores=date_pred_probs.tolist(),
|
| 222 |
+
date_saliency=date_saliency.tolist()[1:],
|
| 223 |
+
location_saliency=subregion_saliency.tolist()[1:])
|
| 224 |
+
|
| 225 |
+
|
| 226 |
+
def restore(text, forward, params, alphabet, vocab_char_size,
|
| 227 |
+
vocab_word_size) -> RestorationResults:
|
| 228 |
+
"""Performs search to compute text restoration. Slower, runs synchronously."""
|
| 229 |
+
|
| 230 |
+
if ALPHABET_MISSING_RESTORE not in text:
|
| 231 |
+
raise ValueError('At least one character must be missing.')
|
| 232 |
+
|
| 233 |
+
text, _, text_padded, _, _, text_len, _, restore_mask_idx = _prepare_text(
|
| 234 |
+
text, alphabet)
|
| 235 |
+
|
| 236 |
+
beam_result = eval_util.beam_search_batch_2d(
|
| 237 |
+
forward,
|
| 238 |
+
alphabet,
|
| 239 |
+
text_padded,
|
| 240 |
+
restore_mask_idx,
|
| 241 |
+
beam_width=RESTORATION_BEAM_WIDTH,
|
| 242 |
+
temperature=RESTORATION_TEMPERATURE,
|
| 243 |
+
rng=jax.random.PRNGKey(SEED))
|
| 244 |
+
|
| 245 |
+
# For visualization purposes, we strip out the SOS and padding, and adjust
|
| 246 |
+
# restored_indices accordingly
|
| 247 |
+
predictions = [
|
| 248 |
+
Restoration(
|
| 249 |
+
text=beam_entry.text_pred[1:].rstrip(alphabet.pad),
|
| 250 |
+
score=math.exp(beam_entry.pred_logprob)) for beam_entry in beam_result
|
| 251 |
+
]
|
| 252 |
+
restored_indices = [i - 1 for i in restore_mask_idx]
|
| 253 |
+
|
| 254 |
+
# Sequence of saliency maps for a greedy prediction:
|
| 255 |
+
saliency_steps = eval_util.sequential_restoration_saliency(
|
| 256 |
+
text_padded, text_len, forward, params, alphabet, restore_mask_idx,
|
| 257 |
+
vocab_char_size, vocab_word_size)
|
| 258 |
+
|
| 259 |
+
return RestorationResults(
|
| 260 |
+
input_text=text,
|
| 261 |
+
top_prediction=predictions[0].text,
|
| 262 |
+
restored=restored_indices,
|
| 263 |
+
predictions=predictions,
|
| 264 |
+
prediction_saliency=[
|
| 265 |
+
RestorationCharSaliency(step.text, int(step.pred_char_pos),
|
| 266 |
+
step.saliency_map.tolist())
|
| 267 |
+
for step in saliency_steps
|
| 268 |
+
])
|
ithaca/models/__init__.py
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2021 the Ithaca Authors
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
ithaca/models/bigbird.py
ADDED
|
@@ -0,0 +1,110 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2021 the Ithaca Authors
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
"""Transformer using BigBird (https://arxiv.org/abs/2007.14062).
|
| 15 |
+
|
| 16 |
+
This implementation is from the Long Range Arena:
|
| 17 |
+
https://github.com/google-research/long-range-arena/tree/main/lra_benchmarks/models/bigbird
|
| 18 |
+
"""
|
| 19 |
+
|
| 20 |
+
from typing import Any, Optional
|
| 21 |
+
|
| 22 |
+
from . import bigbird_attention
|
| 23 |
+
from . import common_layers
|
| 24 |
+
|
| 25 |
+
from flax import linen as nn
|
| 26 |
+
import jax.numpy as jnp
|
| 27 |
+
|
| 28 |
+
_DEFAULT_BLOCK_SIZE = 64
|
| 29 |
+
_DEFAULT_NUM_RAND_BLOCKS = 3
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
class BigBirdBlock(nn.Module):
|
| 33 |
+
"""BigBird layer (https://arxiv.org/abs/2007.14062).
|
| 34 |
+
|
| 35 |
+
Attributes:
|
| 36 |
+
qkv_dim: dimension of the query/key/value
|
| 37 |
+
mlp_dim: dimension of the mlp on top of attention block
|
| 38 |
+
num_heads: number of heads
|
| 39 |
+
dtype: the dtype of the computation (default: float32).
|
| 40 |
+
causal_mask: bool, mask future or not
|
| 41 |
+
dropout_rate: dropout rate
|
| 42 |
+
attention_dropout_rate: dropout rate for attention weights
|
| 43 |
+
deterministic: bool, deterministic or not (to apply dropout)
|
| 44 |
+
activation_fn: Activation function ("relu", "gelu")
|
| 45 |
+
block_size: Size of attention blocks.
|
| 46 |
+
num_rand_blocks: Number of random blocks.
|
| 47 |
+
connectivity_seed: Optional seed for random block sparse attention.
|
| 48 |
+
"""
|
| 49 |
+
|
| 50 |
+
qkv_dim: Any
|
| 51 |
+
mlp_dim: Any
|
| 52 |
+
num_heads: Any
|
| 53 |
+
dtype: Any = jnp.float32
|
| 54 |
+
causal_mask: bool = False
|
| 55 |
+
dropout_rate: float = 0.1
|
| 56 |
+
attention_dropout_rate: float = 0.1
|
| 57 |
+
deterministic: bool = False
|
| 58 |
+
activation_fn: str = 'relu'
|
| 59 |
+
block_size: int = _DEFAULT_BLOCK_SIZE
|
| 60 |
+
num_rand_blocks: int = _DEFAULT_NUM_RAND_BLOCKS
|
| 61 |
+
connectivity_seed: Optional[int] = None
|
| 62 |
+
|
| 63 |
+
@nn.compact
|
| 64 |
+
def __call__(self, inputs, inputs_segmentation=None, padding_mask=None):
|
| 65 |
+
"""Applies BigBirdBlock module.
|
| 66 |
+
|
| 67 |
+
Args:
|
| 68 |
+
inputs: input data
|
| 69 |
+
inputs_segmentation: input segmentation info for packed examples.
|
| 70 |
+
padding_mask: bool, mask padding tokens, [b, l, 1]
|
| 71 |
+
|
| 72 |
+
Returns:
|
| 73 |
+
output after transformer block.
|
| 74 |
+
|
| 75 |
+
"""
|
| 76 |
+
|
| 77 |
+
# Attention block.
|
| 78 |
+
assert inputs.ndim == 3
|
| 79 |
+
x = common_layers.LayerNorm(dtype=self.dtype)(inputs)
|
| 80 |
+
x = bigbird_attention.BigBirdSelfAttention(
|
| 81 |
+
num_heads=self.num_heads,
|
| 82 |
+
dtype=self.dtype,
|
| 83 |
+
qkv_features=self.qkv_dim,
|
| 84 |
+
kernel_init=nn.initializers.xavier_uniform(),
|
| 85 |
+
bias_init=nn.initializers.normal(stddev=1e-6),
|
| 86 |
+
use_bias=False,
|
| 87 |
+
broadcast_dropout=False,
|
| 88 |
+
dropout_rate=self.attention_dropout_rate,
|
| 89 |
+
deterministic=self.deterministic,
|
| 90 |
+
block_size=self.block_size,
|
| 91 |
+
num_rand_blocks=self.num_rand_blocks,
|
| 92 |
+
connectivity_seed=self.connectivity_seed)(
|
| 93 |
+
x,
|
| 94 |
+
segmentation=inputs_segmentation,
|
| 95 |
+
padding_mask=padding_mask,
|
| 96 |
+
)
|
| 97 |
+
x = nn.Dropout(rate=self.dropout_rate)(x, deterministic=self.deterministic)
|
| 98 |
+
x = x + inputs
|
| 99 |
+
|
| 100 |
+
# MLP block.
|
| 101 |
+
y = common_layers.LayerNorm(dtype=self.dtype)(x)
|
| 102 |
+
y = common_layers.MlpBlock(
|
| 103 |
+
mlp_dim=self.mlp_dim,
|
| 104 |
+
dtype=self.dtype,
|
| 105 |
+
dropout_rate=self.dropout_rate,
|
| 106 |
+
deterministic=self.deterministic,
|
| 107 |
+
activation_fn=self.activation_fn)(
|
| 108 |
+
y)
|
| 109 |
+
|
| 110 |
+
return x + y
|
ithaca/models/bigbird_attention.py
ADDED
|
@@ -0,0 +1,602 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2021 the Ithaca Authors
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
"""Big Bird attention mechanism.
|
| 15 |
+
|
| 16 |
+
See https://arxiv.org/abs/2007.14062.
|
| 17 |
+
|
| 18 |
+
This implementation is from the Long Range Arena:
|
| 19 |
+
https://github.com/google-research/long-range-arena/tree/main/lra_benchmarks/models/bigbird
|
| 20 |
+
"""
|
| 21 |
+
|
| 22 |
+
# pylint: disable=attribute-defined-outside-init,g-bare-generic
|
| 23 |
+
import functools
|
| 24 |
+
from typing import Any, Callable, Optional
|
| 25 |
+
from absl import logging
|
| 26 |
+
from flax import linen as nn
|
| 27 |
+
import jax
|
| 28 |
+
import jax.numpy as jnp
|
| 29 |
+
import numpy as np
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def get_block_rand_mask(m, n, wm, wn, r, last_idx=-1):
|
| 33 |
+
"""This function creates the m by n mask for random block sparse mask.
|
| 34 |
+
|
| 35 |
+
Args:
|
| 36 |
+
m: input size
|
| 37 |
+
n: output size
|
| 38 |
+
wm: block input size
|
| 39 |
+
wn: block output size
|
| 40 |
+
r: number of random block per row
|
| 41 |
+
last_idx: if -1 then r blocks are chosen throughout the n space, if
|
| 42 |
+
possitive then r blocks are chooses at random upto last_ids
|
| 43 |
+
|
| 44 |
+
Returns:
|
| 45 |
+
blocked mask of size m//wm -2 by r
|
| 46 |
+
"""
|
| 47 |
+
if (m // wm) != (n // wn):
|
| 48 |
+
logging.info('Error the number of blocks needs to be same')
|
| 49 |
+
rand_attn = np.zeros((m // wm - 2, r), dtype=jnp.int64)
|
| 50 |
+
a = np.array(range(1, n // wn - 1))
|
| 51 |
+
last = (m // wn) - 1
|
| 52 |
+
if last_idx > (2 * wn):
|
| 53 |
+
last = (last_idx // wn) - 1
|
| 54 |
+
for i in range(1, m // wm - 1):
|
| 55 |
+
start = i - 2
|
| 56 |
+
end = i
|
| 57 |
+
if i == 1:
|
| 58 |
+
rand_attn[i - 1, :] = np.random.permutation(a[2:last])[:r]
|
| 59 |
+
elif i == 2:
|
| 60 |
+
rand_attn[i - 1, :] = np.random.permutation(a[3:last])[:r]
|
| 61 |
+
elif i == m // wm - 3:
|
| 62 |
+
rand_attn[i - 1, :] = np.random.permutation(a[:last - 4])[:r]
|
| 63 |
+
elif i == m // wm - 2:
|
| 64 |
+
rand_attn[i - 1, :] = np.random.permutation(a[:last - 3])[:r]
|
| 65 |
+
else:
|
| 66 |
+
if start > last:
|
| 67 |
+
start = last
|
| 68 |
+
rand_attn[i - 1, :] = np.random.permutation(a[:start])[:r]
|
| 69 |
+
elif (end + 1) == last:
|
| 70 |
+
rand_attn[i - 1, :] = np.random.permutation(a[:start])[:r]
|
| 71 |
+
else:
|
| 72 |
+
rand_attn[i - 1, :] = np.random.permutation(
|
| 73 |
+
np.concatenate((a[:start], a[end + 1:last])))[:r]
|
| 74 |
+
return rand_attn
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def create_band_mask_from_inputs(from_blocked_mask, to_blocked_mask):
|
| 78 |
+
"""Create 3D attention mask from a 2D tensor mask.
|
| 79 |
+
|
| 80 |
+
Args:
|
| 81 |
+
from_blocked_mask: 2D Tensor of shape [batch_size,
|
| 82 |
+
from_seq_length//from_block_size, from_block_size].
|
| 83 |
+
to_blocked_mask: int32 Tensor of shape [batch_size,
|
| 84 |
+
to_seq_length//to_block_size, to_block_size].
|
| 85 |
+
|
| 86 |
+
Returns:
|
| 87 |
+
float Tensor of shape [batch_size, 1, from_seq_length//from_block_size-4,
|
| 88 |
+
from_block_size, 3*to_block_size].
|
| 89 |
+
"""
|
| 90 |
+
exp_blocked_to_pad = jnp.concatenate([
|
| 91 |
+
to_blocked_mask[:, 1:-3], to_blocked_mask[:, 2:-2], to_blocked_mask[:,
|
| 92 |
+
3:-1]
|
| 93 |
+
], 2)
|
| 94 |
+
band_pad = jnp.einsum('BLQ,BLK->BLQK', from_blocked_mask[:, 2:-2],
|
| 95 |
+
exp_blocked_to_pad)
|
| 96 |
+
band_pad = jnp.expand_dims(band_pad, 1)
|
| 97 |
+
return band_pad
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def create_rand_mask_from_inputs(from_blocked_mask, to_blocked_mask, rand_attn):
|
| 101 |
+
"""Create 3D attention mask from a 2D tensor mask.
|
| 102 |
+
|
| 103 |
+
Args:
|
| 104 |
+
from_blocked_mask: 2D Tensor of shape [batch_size,
|
| 105 |
+
from_seq_length//from_block_size, from_block_size].
|
| 106 |
+
to_blocked_mask: int32 Tensor of shape [batch_size,
|
| 107 |
+
to_seq_length//to_block_size, to_block_size].
|
| 108 |
+
rand_attn: [batch_size, num_attention_heads,
|
| 109 |
+
from_seq_length//from_block_size-2, rsize]
|
| 110 |
+
|
| 111 |
+
Returns:
|
| 112 |
+
float Tensor of shape [batch_size, num_attention_heads,
|
| 113 |
+
from_seq_length//from_block_size-2,
|
| 114 |
+
from_block_size, 3*to_block_size].
|
| 115 |
+
"""
|
| 116 |
+
|
| 117 |
+
# batch_size, num_attention_heads, num_windows, _ = get_shape_list(
|
| 118 |
+
# rand_attn, expected_rank=4)
|
| 119 |
+
batch_size, num_attention_heads, num_windows, _ = rand_attn.shape
|
| 120 |
+
rand_pad = jnp.reshape(
|
| 121 |
+
# Equivalent to tf.gather(to_blocked_mask, rand_attn, batch_dims=1)
|
| 122 |
+
gather_1(to_blocked_mask, rand_attn),
|
| 123 |
+
[batch_size, num_attention_heads, num_windows, -1])
|
| 124 |
+
rand_pad = jnp.einsum('BLQ,BHLK->BHLQK', from_blocked_mask[:, 1:-1], rand_pad)
|
| 125 |
+
return rand_pad
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
@jax.vmap
|
| 129 |
+
def gather_1(params, indices):
|
| 130 |
+
return jnp.take(params, indices, axis=0)
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
@jax.vmap
|
| 134 |
+
def gather_2(params, indices):
|
| 135 |
+
return gather_1(params, indices)
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
def band_start_block_rand_multi_attention_pad(query_matrix, key_matrix,
|
| 139 |
+
value_matrix, rand_attn, band_pad,
|
| 140 |
+
rand_pad, seq_m_pad, seq_n_pad, b,
|
| 141 |
+
h, m, wm, n, wn, r, d):
|
| 142 |
+
"""Applies sparse block band rand attention in hopefully efficient way.
|
| 143 |
+
|
| 144 |
+
Args:
|
| 145 |
+
query_matrix: b, h, n, d
|
| 146 |
+
key_matrix: b, h, n, d
|
| 147 |
+
value_matrix: b, h, n, d
|
| 148 |
+
rand_attn: b, h, m//wm-2, r
|
| 149 |
+
band_pad: b, 1, m//wm-4, wm, 3*wn
|
| 150 |
+
rand_pad: b, h, m//wm-2, wm, r*wn
|
| 151 |
+
seq_m_pad: b, 1, m, 1
|
| 152 |
+
seq_n_pad: b, 1, 1, n
|
| 153 |
+
b: batch size
|
| 154 |
+
h: number of head
|
| 155 |
+
m: from_length
|
| 156 |
+
wm: from window size
|
| 157 |
+
n: to length
|
| 158 |
+
wn: to window size
|
| 159 |
+
r: number of rand blocks
|
| 160 |
+
d: hidden dimension
|
| 161 |
+
|
| 162 |
+
Returns:
|
| 163 |
+
context layer. b, m, h, -1
|
| 164 |
+
attention weights. [b, h, m//wm-4, wm, (5+r)*wn]
|
| 165 |
+
"""
|
| 166 |
+
blocked_query_matrix = jnp.reshape(query_matrix, (b, h, m // wm, wm, -1))
|
| 167 |
+
blocked_key_matrix = jnp.reshape(key_matrix, (b, h, n // wn, wn, -1))
|
| 168 |
+
blocked_value_matrix = jnp.reshape(value_matrix, (b, h, n // wn, wn, -1))
|
| 169 |
+
# tf.gather(blocked_key_matrix, rand_attn, batch_dims=2, name='gather_key'),
|
| 170 |
+
gathered_key = jnp.reshape(
|
| 171 |
+
gather_2(blocked_key_matrix, rand_attn),
|
| 172 |
+
(b, h, m // wm - 2, r * wn, -1)) # [b, h, n//wn-2, r, wn, -1]
|
| 173 |
+
# tf.gather(
|
| 174 |
+
# blocked_value_matrix, rand_attn, batch_dims=2, name='gather_value')
|
| 175 |
+
gathered_value = jnp.reshape(
|
| 176 |
+
gather_2(blocked_value_matrix, rand_attn),
|
| 177 |
+
(b, h, m // wm - 2, r * wn, -1)) # [b, h, n//wn-2, r, wn, -1]
|
| 178 |
+
|
| 179 |
+
first_product = jnp.einsum(
|
| 180 |
+
'BHQD,BHKD->BHQK', blocked_query_matrix[:, :, 0],
|
| 181 |
+
key_matrix) # [b, h, wm, -1] x [b, h, n, -1] ==> [b, h, wm, n]
|
| 182 |
+
first_product = first_product / jnp.sqrt(d)
|
| 183 |
+
first_product += (1.0 - seq_n_pad) * -10000.0
|
| 184 |
+
first_attn_weights = jax.nn.softmax(first_product) # [b, h, wm, n]
|
| 185 |
+
first_context_layer = jnp.einsum(
|
| 186 |
+
'BHQK,BHKD->BHQD', first_attn_weights,
|
| 187 |
+
value_matrix) # [b, h, wm, n] x [b, h, n, -1] ==> [b, h, wm, -1]
|
| 188 |
+
first_context_layer = jnp.expand_dims(first_context_layer, 2)
|
| 189 |
+
|
| 190 |
+
second_key_mat = jnp.concatenate([
|
| 191 |
+
blocked_key_matrix[:, :, 0], blocked_key_matrix[:, :, 1],
|
| 192 |
+
blocked_key_matrix[:, :, 2], blocked_key_matrix[:, :,
|
| 193 |
+
-1], gathered_key[:, :, 0]
|
| 194 |
+
], 2) # [b, h, (4+r)*wn, -1]
|
| 195 |
+
second_value_mat = jnp.concatenate([
|
| 196 |
+
blocked_value_matrix[:, :, 0], blocked_value_matrix[:, :, 1],
|
| 197 |
+
blocked_value_matrix[:, :, 2], blocked_value_matrix[:, :, -1],
|
| 198 |
+
gathered_value[:, :, 0]
|
| 199 |
+
], 2) # [b, h, (4+r)*wn, -1]
|
| 200 |
+
second_product = jnp.einsum(
|
| 201 |
+
'BHQD,BHKD->BHQK', blocked_query_matrix[:, :, 1], second_key_mat
|
| 202 |
+
) # [b, h, wm, -1] x [b, h, (4+r)*wn, -1] ==> [b, h, wm, (4+r)*wn]
|
| 203 |
+
second_seq_pad = jnp.concatenate([
|
| 204 |
+
seq_n_pad[:, :, :, :3 * wn], seq_n_pad[:, :, :, -wn:],
|
| 205 |
+
jnp.ones([b, 1, 1, r * wn], dtype=jnp.float32)
|
| 206 |
+
], 3)
|
| 207 |
+
second_rand_pad = jnp.concatenate(
|
| 208 |
+
[jnp.ones([b, h, wm, 4 * wn], dtype=jnp.float32), rand_pad[:, :, 0]], 3)
|
| 209 |
+
second_product = second_product / jnp.sqrt(d)
|
| 210 |
+
second_product += (1.0 -
|
| 211 |
+
jnp.minimum(second_seq_pad, second_rand_pad)) * -10000.0
|
| 212 |
+
second_attn_weights = jax.nn.softmax(second_product) # [b , h, wm, (4+r)*wn]
|
| 213 |
+
second_context_layer = jnp.einsum(
|
| 214 |
+
'BHQK,BHKD->BHQD', second_attn_weights, second_value_mat
|
| 215 |
+
) # [b, h, wm, (4+r)*wn] x [b, h, (4+r)*wn, -1] ==> [b, h, wm, -1]
|
| 216 |
+
second_context_layer = jnp.expand_dims(second_context_layer, 2)
|
| 217 |
+
|
| 218 |
+
exp_blocked_key_matrix = jnp.concatenate([
|
| 219 |
+
blocked_key_matrix[:, :, 1:-3], blocked_key_matrix[:, :, 2:-2],
|
| 220 |
+
blocked_key_matrix[:, :, 3:-1]
|
| 221 |
+
], 3) # [b, h, m//wm-4, 3*wn, -1]
|
| 222 |
+
exp_blocked_value_matrix = jnp.concatenate([
|
| 223 |
+
blocked_value_matrix[:, :, 1:-3], blocked_value_matrix[:, :, 2:-2],
|
| 224 |
+
blocked_value_matrix[:, :, 3:-1]
|
| 225 |
+
], 3) # [b, h, m//wm-4, 3*wn, -1]
|
| 226 |
+
middle_query_matrix = blocked_query_matrix[:, :, 2:-2]
|
| 227 |
+
inner_band_product = jnp.einsum(
|
| 228 |
+
'BHLQD,BHLKD->BHLQK', middle_query_matrix, exp_blocked_key_matrix
|
| 229 |
+
) # [b, h, m//wm-4, wm, -1] x [b, h, m//wm-4, 3*wn, -1]
|
| 230 |
+
# ==> [b, h, m//wm-4, wm, 3*wn]
|
| 231 |
+
inner_band_product = inner_band_product / jnp.sqrt(d)
|
| 232 |
+
rand_band_product = jnp.einsum(
|
| 233 |
+
'BHLQD,BHLKD->BHLQK', middle_query_matrix,
|
| 234 |
+
gathered_key[:, :,
|
| 235 |
+
1:-1]) # [b, h, m//wm-4, wm, -1] x [b, h, m//wm-4, r*wn, -1]
|
| 236 |
+
# ==> [b, h, m//wm-4, wm, r*wn]
|
| 237 |
+
rand_band_product = rand_band_product / jnp.sqrt(d)
|
| 238 |
+
first_band_product = jnp.einsum(
|
| 239 |
+
'BHLQD,BHKD->BHLQK', middle_query_matrix, blocked_key_matrix[:, :, 0]
|
| 240 |
+
) # [b, h, m//wm-4, wm, -1] x [b, h, wn, -1] ==> [b, h, m//wm-4, wm, wn]
|
| 241 |
+
first_band_product = first_band_product / jnp.sqrt(d)
|
| 242 |
+
last_band_product = jnp.einsum(
|
| 243 |
+
'BHLQD,BHKD->BHLQK', middle_query_matrix, blocked_key_matrix[:, :, -1]
|
| 244 |
+
) # [b, h, m//wm-4, wm, -1] x [b, h, wn, -1] ==> [b, h, m//wm-4, wm, wn]
|
| 245 |
+
last_band_product = last_band_product / jnp.sqrt(d)
|
| 246 |
+
inner_band_product += (1.0 - band_pad) * -10000.0
|
| 247 |
+
first_band_product += (1.0 -
|
| 248 |
+
jnp.expand_dims(seq_n_pad[:, :, :, :wn], 3)) * -10000.0
|
| 249 |
+
last_band_product += (1.0 -
|
| 250 |
+
jnp.expand_dims(seq_n_pad[:, :, :, -wn:], 3)) * -10000.0
|
| 251 |
+
rand_band_product += (1.0 - rand_pad[:, :, 1:-1]) * -10000.0
|
| 252 |
+
band_product = jnp.concatenate([
|
| 253 |
+
first_band_product, inner_band_product, rand_band_product,
|
| 254 |
+
last_band_product
|
| 255 |
+
], -1) # [b, h, m//wm-4, wm, (5+r)*wn]
|
| 256 |
+
attn_weights = jax.nn.softmax(band_product) # [b, h, m//wm-4, wm, (5+r)*wn]
|
| 257 |
+
context_layer = jnp.einsum(
|
| 258 |
+
'BHLQK,BHLKD->BHLQD', attn_weights[:, :, :, :,
|
| 259 |
+
wn:4 * wn], exp_blocked_value_matrix
|
| 260 |
+
) # [b, h, m//wm-4, wm, 3*wn] x [b, h, m//wm-4, 3*wn, -1]
|
| 261 |
+
# ==> [b, h, m//wm-4, wm, -1]
|
| 262 |
+
context_layer += jnp.einsum(
|
| 263 |
+
'BHLQK,BHLKD->BHLQD', attn_weights[:, :, :, :,
|
| 264 |
+
4 * wn:-wn], gathered_value[:, :, 1:-1]
|
| 265 |
+
) # [b, h, m//wm-4, wm, r*wn] x [b, h, m//wm-4, r*wn, -1]
|
| 266 |
+
# ==> [b, h, m//wm-4, wm, -1]
|
| 267 |
+
context_layer += jnp.einsum(
|
| 268 |
+
'BHLQK,BHKD->BHLQD', attn_weights[:, :, :, :, :wn],
|
| 269 |
+
blocked_value_matrix[:, :, 0]
|
| 270 |
+
) # [b, h, m//wm-4, wm, wn] x [b, h, wn, -1] ==> [b, h, m//wm-4, wm, -1]
|
| 271 |
+
context_layer += jnp.einsum(
|
| 272 |
+
'BHLQK,BHKD->BHLQD', attn_weights[:, :, :, :,
|
| 273 |
+
-wn:], blocked_value_matrix[:, :, -1]
|
| 274 |
+
) # [b, h, m//wm-4, wm, wn] x [b, h, wn, -1] ==> [b, h, m//wm-4, wm, -1]
|
| 275 |
+
|
| 276 |
+
second_last_key_mat = jnp.concatenate([
|
| 277 |
+
blocked_key_matrix[:, :, 0], blocked_key_matrix[:, :, -3],
|
| 278 |
+
blocked_key_matrix[:, :, -2], blocked_key_matrix[:, :, -1],
|
| 279 |
+
gathered_key[:, :, -1]
|
| 280 |
+
], 2) # [b, h, (4+r)*wn, -1]
|
| 281 |
+
second_last_value_mat = jnp.concatenate([
|
| 282 |
+
blocked_value_matrix[:, :, 0], blocked_value_matrix[:, :, -3],
|
| 283 |
+
blocked_value_matrix[:, :, -2], blocked_value_matrix[:, :, -1],
|
| 284 |
+
gathered_value[:, :, -1]
|
| 285 |
+
], 2) # [b, h, (4+r)*wn, -1]
|
| 286 |
+
second_last_product = jnp.einsum(
|
| 287 |
+
'BHQD,BHKD->BHQK', blocked_query_matrix[:, :, -2], second_last_key_mat
|
| 288 |
+
) # [b, h, wm, -1] x [b, h, (4+r)*wn, -1] ==> [b, h, wm, (4+r)*wn]
|
| 289 |
+
second_last_seq_pad = jnp.concatenate([
|
| 290 |
+
seq_n_pad[:, :, :, :wn], seq_n_pad[:, :, :, -3 * wn:],
|
| 291 |
+
jnp.ones([b, 1, 1, r * wn], dtype=jnp.float32)
|
| 292 |
+
], 3)
|
| 293 |
+
second_last_rand_pad = jnp.concatenate(
|
| 294 |
+
[jnp.ones([b, h, wm, 4 * wn], dtype=jnp.float32), rand_pad[:, :, -1]], 3)
|
| 295 |
+
second_last_product = second_last_product / jnp.sqrt(d)
|
| 296 |
+
second_last_product += (
|
| 297 |
+
1.0 - jnp.minimum(second_last_seq_pad, second_last_rand_pad)) * -10000.0
|
| 298 |
+
second_last_attn_weights = jax.nn.softmax(
|
| 299 |
+
second_last_product) # [b, h, wm, (4+r)*wn]
|
| 300 |
+
second_last_context_layer = jnp.einsum(
|
| 301 |
+
'BHQK,BHKD->BHQD', second_last_attn_weights, second_last_value_mat
|
| 302 |
+
) # [b, h, wm, (4+r)*wn] x [b, h, (4+r)*wn, -1] ==> [b, h, wm, -1]
|
| 303 |
+
second_last_context_layer = jnp.expand_dims(second_last_context_layer, 2)
|
| 304 |
+
|
| 305 |
+
last_product = jnp.einsum(
|
| 306 |
+
'BHQD,BHKD->BHQK', blocked_query_matrix[:, :, -1],
|
| 307 |
+
key_matrix) # [b, h, wm, -1] x [b, h, n, -1] ==> [b, h, wm, n]
|
| 308 |
+
last_product = last_product / jnp.sqrt(d)
|
| 309 |
+
last_product += (1.0 - seq_n_pad) * -10000.0
|
| 310 |
+
last_attn_weights = jax.nn.softmax(last_product) # [b, h, wm, n]
|
| 311 |
+
last_context_layer = jnp.einsum(
|
| 312 |
+
'BHQK,BHKD->BHQD', last_attn_weights,
|
| 313 |
+
value_matrix) # [b, h, wm, n] x [b, h, n, -1] ==> [b, h, wm, -1]
|
| 314 |
+
last_context_layer = jnp.expand_dims(last_context_layer, 2)
|
| 315 |
+
|
| 316 |
+
context_layer = jnp.concatenate([
|
| 317 |
+
first_context_layer, second_context_layer, context_layer,
|
| 318 |
+
second_last_context_layer, last_context_layer
|
| 319 |
+
], 2)
|
| 320 |
+
context_layer = jnp.reshape(context_layer, (b, h, m, -1)) * seq_m_pad
|
| 321 |
+
context_layer = jnp.transpose(context_layer, (0, 2, 1, 3))
|
| 322 |
+
return context_layer, attn_weights
|
| 323 |
+
|
| 324 |
+
|
| 325 |
+
def sparse_dot_product_attention(queries,
|
| 326 |
+
keys,
|
| 327 |
+
values,
|
| 328 |
+
connectivity_seed,
|
| 329 |
+
input_mask=None,
|
| 330 |
+
block_size=64,
|
| 331 |
+
num_rand_blocks=3):
|
| 332 |
+
"""Implements sparse dot product attention given query, key, and value.
|
| 333 |
+
|
| 334 |
+
This is the core function for applying attention based on
|
| 335 |
+
https://arxiv.org/abs/1706.03762. It calculates the attention weights given
|
| 336 |
+
query and key and combines the values using the attention weights. This
|
| 337 |
+
function supports multi-dimensional inputs.
|
| 338 |
+
|
| 339 |
+
|
| 340 |
+
Args:
|
| 341 |
+
queries: queries for calculating attention with shape of `[batch_size,
|
| 342 |
+
length, num_heads, mem_channels]`.
|
| 343 |
+
keys: keys for calculating attention with shape of `[batch_size, length,
|
| 344 |
+
num_heads, mem_channels]`.
|
| 345 |
+
values: values to be used in attention with shape of `[batch_size, length,
|
| 346 |
+
num_heads, value_channels]`.
|
| 347 |
+
connectivity_seed: Integer seed for generating connectivity graph.
|
| 348 |
+
input_mask: Optional mask for keys/values with shape `[batch_size, length]`
|
| 349 |
+
and the same dtype.
|
| 350 |
+
block_size: Size for local attention around diagonal of attention.
|
| 351 |
+
num_rand_blocks: int. Number of random chunks per row.
|
| 352 |
+
|
| 353 |
+
Returns:
|
| 354 |
+
Output of shape `[bs, length, num_heads, value_channels]`.
|
| 355 |
+
"""
|
| 356 |
+
(batch_size, to_seq_length, num_attention_heads, hidden_size) = keys.shape
|
| 357 |
+
from_seq_length = queries.shape[1]
|
| 358 |
+
seq_length = max(to_seq_length, from_seq_length)
|
| 359 |
+
queries = jnp.pad(queries,
|
| 360 |
+
((0, 0), (0, seq_length - from_seq_length), (0, 0), (0, 0)))
|
| 361 |
+
keys = jnp.pad(keys,
|
| 362 |
+
((0, 0), (0, seq_length - to_seq_length), (0, 0), (0, 0)))
|
| 363 |
+
values = jnp.pad(values,
|
| 364 |
+
((0, 0), (0, seq_length - to_seq_length), (0, 0), (0, 0)))
|
| 365 |
+
|
| 366 |
+
if input_mask is None:
|
| 367 |
+
input_mask = jnp.ones((batch_size, seq_length), dtype=keys.dtype)
|
| 368 |
+
else:
|
| 369 |
+
input_mask = jnp.pad(
|
| 370 |
+
input_mask,
|
| 371 |
+
tuple((0, seq_length - size) if i == 1 else (0, 0)
|
| 372 |
+
for i, size in enumerate(input_mask.shape)))
|
| 373 |
+
|
| 374 |
+
np.random.seed(connectivity_seed)
|
| 375 |
+
# pylint: disable=g-complex-comprehension
|
| 376 |
+
rand_attn = [
|
| 377 |
+
get_block_rand_mask(
|
| 378 |
+
seq_length,
|
| 379 |
+
seq_length,
|
| 380 |
+
block_size,
|
| 381 |
+
block_size,
|
| 382 |
+
num_rand_blocks,
|
| 383 |
+
last_idx=min(seq_length, 1024)) for _ in range(num_attention_heads)
|
| 384 |
+
]
|
| 385 |
+
# pylint: enable=g-complex-comprehension
|
| 386 |
+
rand_attn = jnp.stack(rand_attn, axis=0)
|
| 387 |
+
rand_attn = jnp.expand_dims(rand_attn, 0)
|
| 388 |
+
rand_attn = jnp.repeat(rand_attn, batch_size, 0)
|
| 389 |
+
|
| 390 |
+
# reshape and cast for blocking
|
| 391 |
+
blocked_input_mask = jnp.reshape(
|
| 392 |
+
input_mask, (batch_size, seq_length // block_size, block_size))
|
| 393 |
+
input_mask = jnp.reshape(input_mask, (batch_size, 1, seq_length, 1))
|
| 394 |
+
output_mask = jnp.reshape(input_mask, (batch_size, 1, 1, seq_length))
|
| 395 |
+
|
| 396 |
+
# create band padding
|
| 397 |
+
band_pad = create_band_mask_from_inputs(blocked_input_mask,
|
| 398 |
+
blocked_input_mask)
|
| 399 |
+
rand_pad = create_rand_mask_from_inputs(blocked_input_mask,
|
| 400 |
+
blocked_input_mask, rand_attn)
|
| 401 |
+
|
| 402 |
+
queries = jnp.transpose(queries, (0, 2, 1, 3))
|
| 403 |
+
keys = jnp.transpose(keys, (0, 2, 1, 3))
|
| 404 |
+
values = jnp.transpose(values, (0, 2, 1, 3))
|
| 405 |
+
|
| 406 |
+
# sparse mask
|
| 407 |
+
context_layer, _ = band_start_block_rand_multi_attention_pad(
|
| 408 |
+
queries, keys, values, rand_attn, band_pad, rand_pad, input_mask,
|
| 409 |
+
output_mask, batch_size, num_attention_heads, seq_length, block_size,
|
| 410 |
+
seq_length, block_size, num_rand_blocks, hidden_size)
|
| 411 |
+
|
| 412 |
+
return context_layer[:, :from_seq_length, ...]
|
| 413 |
+
|
| 414 |
+
|
| 415 |
+
class BigBirdAttention(nn.Module):
|
| 416 |
+
"""Multi-head dot-product attention.
|
| 417 |
+
|
| 418 |
+
Attributes:
|
| 419 |
+
num_heads: number of attention heads. Features (i.e. inputs_q.shape[-1])
|
| 420 |
+
should be divisible by the number of heads.
|
| 421 |
+
block_size: Size for local attention around diagonal of attention.
|
| 422 |
+
num_rand_blocks: int. Number of random chunks per row.
|
| 423 |
+
dtype: the dtype of the computation (default: float32)
|
| 424 |
+
qkv_features: dimension of the key, query, and value.
|
| 425 |
+
out_features: dimension of the last projection
|
| 426 |
+
broadcast_dropout: bool: use a broadcasted dropout along batch dims.
|
| 427 |
+
dropout_rate: dropout rate
|
| 428 |
+
deterministic: bool, deterministic or not (to apply dropout)
|
| 429 |
+
precision: numerical precision of the computation see `jax.lax.Precision`
|
| 430 |
+
for details.
|
| 431 |
+
kernel_init: initializer for the kernel of the Dense layers.
|
| 432 |
+
bias_init: initializer for the bias of the Dense layers.
|
| 433 |
+
use_bias: bool: whether pointwise QKVO dense transforms use bias.
|
| 434 |
+
connectivity_seed: Seed for random block sparse attention.
|
| 435 |
+
"""
|
| 436 |
+
|
| 437 |
+
num_heads: int
|
| 438 |
+
block_size: int = 64
|
| 439 |
+
num_rand_blocks: int = 3
|
| 440 |
+
dtype: Any = jnp.float32
|
| 441 |
+
qkv_features: Optional[int] = None
|
| 442 |
+
out_features: Optional[int] = None
|
| 443 |
+
broadcast_dropout: bool = True
|
| 444 |
+
dropout_rate: float = 0.
|
| 445 |
+
deterministic: bool = False
|
| 446 |
+
precision: Any = None
|
| 447 |
+
kernel_init: Callable = nn.linear.default_kernel_init
|
| 448 |
+
bias_init: Callable = nn.initializers.zeros
|
| 449 |
+
use_bias: bool = True
|
| 450 |
+
connectivity_seed: Optional[int] = None
|
| 451 |
+
|
| 452 |
+
@nn.compact
|
| 453 |
+
def __call__(self,
|
| 454 |
+
inputs_q,
|
| 455 |
+
inputs_kv,
|
| 456 |
+
padding_mask=None,
|
| 457 |
+
segmentation=None,
|
| 458 |
+
dropout_rng=None):
|
| 459 |
+
"""Applies multi-head dot product attention on the input data.
|
| 460 |
+
|
| 461 |
+
Projects the inputs into multi-headed query, key, and value vectors,
|
| 462 |
+
applies dot-product attention and project the results to an output vector.
|
| 463 |
+
|
| 464 |
+
This can be used for encoder-decoder attention by specifying both `inputs_q`
|
| 465 |
+
and `inputs_kv` orfor self-attention by only specifying `inputs_q` and
|
| 466 |
+
setting `inputs_kv` to None.
|
| 467 |
+
|
| 468 |
+
Args:
|
| 469 |
+
inputs_q: input queries of shape `[bs, length, features]`.
|
| 470 |
+
inputs_kv: key/values of shape `[bs, length, features]` or None for
|
| 471 |
+
self-attention, inn which case key/values will be derived from inputs_q.
|
| 472 |
+
padding_mask: boolean specifying query tokens that are pad token. [b, l,
|
| 473 |
+
1]
|
| 474 |
+
segmentation: segment indices for packed inputs_q data.
|
| 475 |
+
dropout_rng: JAX PRNGKey: to be used for dropout
|
| 476 |
+
|
| 477 |
+
Returns:
|
| 478 |
+
output of shape `[bs, length, features]`.
|
| 479 |
+
"""
|
| 480 |
+
|
| 481 |
+
orig_seqlen = inputs_q.shape[-2]
|
| 482 |
+
extra_len = self.block_size - (orig_seqlen % self.block_size)
|
| 483 |
+
pad_width = np.array([[0, 0], [0, extra_len], [0, 0]])
|
| 484 |
+
mask_pad = np.array([[0, 0], [0, extra_len], [0, 0]])
|
| 485 |
+
padding_mask = jnp.pad(padding_mask, mask_pad, constant_values=-1e9)
|
| 486 |
+
|
| 487 |
+
inputs_q = jnp.pad(inputs_q, pad_width)
|
| 488 |
+
if inputs_kv is not None:
|
| 489 |
+
inputs_kv = jnp.pad(inputs_kv, pad_width)
|
| 490 |
+
|
| 491 |
+
if inputs_kv is None:
|
| 492 |
+
inputs_kv = inputs_q
|
| 493 |
+
|
| 494 |
+
features = self.out_features or inputs_q.shape[-1]
|
| 495 |
+
qkv_features = self.qkv_features or inputs_q.shape[-1]
|
| 496 |
+
|
| 497 |
+
assert qkv_features % self.num_heads == 0, (
|
| 498 |
+
'Memory dimension must be divisible by number of heads.')
|
| 499 |
+
head_dim = qkv_features // self.num_heads
|
| 500 |
+
|
| 501 |
+
dense = functools.partial(
|
| 502 |
+
nn.DenseGeneral,
|
| 503 |
+
axis=-1,
|
| 504 |
+
features=(self.num_heads, head_dim),
|
| 505 |
+
kernel_init=self.kernel_init,
|
| 506 |
+
bias_init=self.bias_init,
|
| 507 |
+
use_bias=self.use_bias,
|
| 508 |
+
precision=self.precision)
|
| 509 |
+
# project inputs_q to multi-headed q/k/v
|
| 510 |
+
# dimensions are then [bs, dims..., n_heads, n_features_per_head]
|
| 511 |
+
query, key, value = (dense(dtype=self.dtype, name='query')(inputs_q),
|
| 512 |
+
dense(dtype=self.dtype, name='key')(inputs_kv),
|
| 513 |
+
dense(dtype=self.dtype, name='value')(inputs_kv))
|
| 514 |
+
|
| 515 |
+
if self.connectivity_seed is None:
|
| 516 |
+
path = self._get_construction_frame().path
|
| 517 |
+
connectivity_seed = hash(path) % 2**32
|
| 518 |
+
else:
|
| 519 |
+
connectivity_seed = self.connectivity_seed
|
| 520 |
+
# apply attention
|
| 521 |
+
input_mask = None
|
| 522 |
+
if padding_mask is not None:
|
| 523 |
+
input_mask = padding_mask.astype(key.dtype)
|
| 524 |
+
x = sparse_dot_product_attention(
|
| 525 |
+
query,
|
| 526 |
+
key,
|
| 527 |
+
value,
|
| 528 |
+
connectivity_seed=connectivity_seed,
|
| 529 |
+
input_mask=input_mask,
|
| 530 |
+
block_size=self.block_size,
|
| 531 |
+
num_rand_blocks=self.num_rand_blocks)
|
| 532 |
+
|
| 533 |
+
# back to the original inputs dimensions
|
| 534 |
+
out = nn.DenseGeneral(
|
| 535 |
+
features=features,
|
| 536 |
+
axis=(-2, -1),
|
| 537 |
+
kernel_init=self.kernel_init,
|
| 538 |
+
bias_init=self.bias_init,
|
| 539 |
+
use_bias=self.use_bias,
|
| 540 |
+
dtype=self.dtype,
|
| 541 |
+
precision=self.precision,
|
| 542 |
+
name='out')(
|
| 543 |
+
x)
|
| 544 |
+
|
| 545 |
+
out = out[:, :orig_seqlen, :]
|
| 546 |
+
|
| 547 |
+
return out
|
| 548 |
+
|
| 549 |
+
|
| 550 |
+
class BigBirdSelfAttention(BigBirdAttention):
|
| 551 |
+
"""Multi-head dot-product self-attention.
|
| 552 |
+
|
| 553 |
+
Attributes:
|
| 554 |
+
num_heads: number of attention heads. Features (i.e. inputs_q.shape[-1])
|
| 555 |
+
should be divisible by the number of heads.
|
| 556 |
+
block_size: Size for local attention around diagonal of attention.
|
| 557 |
+
num_rand_blocks: int. Number of random chunks per row.
|
| 558 |
+
dtype: the dtype of the computation (default: float32)
|
| 559 |
+
qkv_features: dimension of the key, query, and value.
|
| 560 |
+
out_features: dimension of the last projection
|
| 561 |
+
broadcast_dropout: bool: use a broadcasted dropout along batch dims.
|
| 562 |
+
dropout_rate: dropout rate
|
| 563 |
+
deterministic: bool, deterministic or not (to apply dropout)
|
| 564 |
+
precision: numerical precision of the computation see `jax.lax.Precision`
|
| 565 |
+
for details.
|
| 566 |
+
kernel_init: initializer for the kernel of the Dense layers.
|
| 567 |
+
bias_init: initializer for the bias of the Dense layers.
|
| 568 |
+
use_bias: bool: whether pointwise QKVO dense transforms use bias.
|
| 569 |
+
connectivity_seed: Seed for random block sparse attention.
|
| 570 |
+
"""
|
| 571 |
+
|
| 572 |
+
@nn.compact
|
| 573 |
+
def __call__(self,
|
| 574 |
+
inputs_q,
|
| 575 |
+
padding_mask=None,
|
| 576 |
+
segmentation=None,
|
| 577 |
+
dropout_rng=None):
|
| 578 |
+
"""Applies multi-head dot product attention on the input data.
|
| 579 |
+
|
| 580 |
+
Projects the inputs into multi-headed query, key, and value vectors,
|
| 581 |
+
applies dot-product attention and project the results to an output vector.
|
| 582 |
+
|
| 583 |
+
This can be used for encoder-decoder attention by specifying both `inputs_q`
|
| 584 |
+
and `inputs_kv` orfor self-attention by only specifying `inputs_q` and
|
| 585 |
+
setting `inputs_kv` to None.
|
| 586 |
+
|
| 587 |
+
Args:
|
| 588 |
+
inputs_q: input queries of shape `[bs, length, features]`.
|
| 589 |
+
padding_mask: boolean specifying query tokens that are pad token.
|
| 590 |
+
segmentation: segment indices for packed inputs_q data.
|
| 591 |
+
dropout_rng: JAX PRNGKey: to be used for dropout
|
| 592 |
+
|
| 593 |
+
Returns:
|
| 594 |
+
output of shape `[bs, length, features]`.
|
| 595 |
+
"""
|
| 596 |
+
return super().__call__(
|
| 597 |
+
inputs_q=inputs_q,
|
| 598 |
+
inputs_kv=None,
|
| 599 |
+
padding_mask=padding_mask,
|
| 600 |
+
segmentation=segmentation,
|
| 601 |
+
dropout_rng=dropout_rng,
|
| 602 |
+
)
|
ithaca/models/common_layers.py
ADDED
|
@@ -0,0 +1,318 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2021 the Ithaca Authors
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
"""Common layers used in models.
|
| 15 |
+
|
| 16 |
+
This implementation is from the Long Range Arena:
|
| 17 |
+
https://github.com/google-research/long-range-arena/tree/main/lra_benchmarks/models/bigbird
|
| 18 |
+
"""
|
| 19 |
+
|
| 20 |
+
# pylint: disable=attribute-defined-outside-init,g-bare-generic
|
| 21 |
+
from typing import Any, Callable, Iterable, Optional
|
| 22 |
+
|
| 23 |
+
from flax import linen as nn
|
| 24 |
+
from jax import lax
|
| 25 |
+
from jax.nn import initializers
|
| 26 |
+
import jax.numpy as jnp
|
| 27 |
+
import numpy as np
|
| 28 |
+
|
| 29 |
+
PRNGKey = Any
|
| 30 |
+
Array = Any
|
| 31 |
+
Shape = Iterable[int]
|
| 32 |
+
Dtype = Any # this could be a real type?
|
| 33 |
+
|
| 34 |
+
ACTIVATION_FN_DICT = {
|
| 35 |
+
'relu': nn.relu,
|
| 36 |
+
'gelu': nn.gelu,
|
| 37 |
+
}
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def grid_restack(all_vecs):
|
| 41 |
+
"""Grid restack for meta-performer.
|
| 42 |
+
|
| 43 |
+
Given multiple sequences (lists) of batch x len x dim,
|
| 44 |
+
reshape this such that all positions are side by side.
|
| 45 |
+
|
| 46 |
+
for example (for illustrative purposes):
|
| 47 |
+
|
| 48 |
+
inputs: [1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]
|
| 49 |
+
outputs: [1, 5, 9, 2, 6, 10, 3, 7, 11, 4, 8, 12]
|
| 50 |
+
|
| 51 |
+
Args:
|
| 52 |
+
all_vecs: list of sequences of batch x len x dim
|
| 53 |
+
|
| 54 |
+
Returns:
|
| 55 |
+
Array of batch x (length x num_items) x dim.
|
| 56 |
+
"""
|
| 57 |
+
cat_output = []
|
| 58 |
+
for pos in range(all_vecs[0].shape[1]):
|
| 59 |
+
pos_vecs = [x[:, None, pos, :] for x in all_vecs]
|
| 60 |
+
cat_output += pos_vecs
|
| 61 |
+
x2 = jnp.concatenate(cat_output, 1)
|
| 62 |
+
return x2
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def shift_right(x):
|
| 66 |
+
"""Shift the input to the right by padding on axis 1."""
|
| 67 |
+
pad_widths = [(0, 0)] * len(x.shape)
|
| 68 |
+
pad_widths[1] = (1, 0) # Padding on axis=1
|
| 69 |
+
padded = jnp.pad(
|
| 70 |
+
x, pad_widths, mode='constant', constant_values=x.dtype.type(0))
|
| 71 |
+
return padded[:, :-1]
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
class Embed(nn.Module):
|
| 75 |
+
"""Embedding Module.
|
| 76 |
+
|
| 77 |
+
A parameterized function from integers [0, n) to d-dimensional vectors.
|
| 78 |
+
|
| 79 |
+
Attributes:
|
| 80 |
+
mode: either 'input' or 'output' -> to share input/output embedding
|
| 81 |
+
emb_init: embedding initializer
|
| 82 |
+
"""
|
| 83 |
+
|
| 84 |
+
mode: str = 'input'
|
| 85 |
+
emb_init: Callable = nn.initializers.normal(stddev=1.0)
|
| 86 |
+
|
| 87 |
+
@nn.compact
|
| 88 |
+
def __call__(self, inputs, num_embeddings, features):
|
| 89 |
+
"""Applies Embed module.
|
| 90 |
+
|
| 91 |
+
Args:
|
| 92 |
+
inputs: input data
|
| 93 |
+
num_embeddings: number of embedding
|
| 94 |
+
features: size of the embedding dimension
|
| 95 |
+
|
| 96 |
+
Returns:
|
| 97 |
+
output which is embedded input data
|
| 98 |
+
"""
|
| 99 |
+
embedding = self.param('embedding', self.emb_init,
|
| 100 |
+
(num_embeddings, features))
|
| 101 |
+
if self.mode == 'input':
|
| 102 |
+
if inputs.dtype not in [jnp.int32, jnp.int64, jnp.uint32, jnp.uint64]:
|
| 103 |
+
raise ValueError('Input type must be an integer or unsigned integer.')
|
| 104 |
+
return jnp.take(embedding, inputs, axis=0)
|
| 105 |
+
if self.mode == 'output':
|
| 106 |
+
return jnp.einsum('bld,vd->blv', inputs, embedding)
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def sinusoidal_init(max_len=2048, replicate_tf=False):
|
| 110 |
+
"""1D Sinusoidal Position Embedding Initializer.
|
| 111 |
+
|
| 112 |
+
Args:
|
| 113 |
+
max_len: maximum possible length for the input
|
| 114 |
+
replicate_tf: replicate TF periodic encoding exactly
|
| 115 |
+
|
| 116 |
+
Returns:
|
| 117 |
+
output: init function returning `(1, max_len, d_feature)`
|
| 118 |
+
"""
|
| 119 |
+
|
| 120 |
+
def init(key, shape, dtype=np.float32):
|
| 121 |
+
"""Sinusoidal init."""
|
| 122 |
+
del key, dtype
|
| 123 |
+
d_feature = shape[-1]
|
| 124 |
+
pe = np.zeros((max_len, d_feature), dtype=np.float32)
|
| 125 |
+
position = np.arange(0, max_len)[:, np.newaxis]
|
| 126 |
+
if replicate_tf:
|
| 127 |
+
half_d_feature = d_feature // 2
|
| 128 |
+
div_term = np.exp(
|
| 129 |
+
np.arange(half_d_feature) * -(np.log(10000.0) / (half_d_feature - 1)))
|
| 130 |
+
pe[:, :half_d_feature] = np.sin(position * div_term)
|
| 131 |
+
pe[:, half_d_feature:] = np.cos(position * div_term)
|
| 132 |
+
else:
|
| 133 |
+
div_term = np.exp(
|
| 134 |
+
np.arange(0, d_feature, 2) * -(np.log(10000.0) / d_feature))
|
| 135 |
+
pe[:, 0::2] = np.sin(position * div_term)
|
| 136 |
+
pe[:, 1::2] = np.cos(position * div_term)
|
| 137 |
+
pe = pe[np.newaxis, :, :] # [1, max_len, d_feature]
|
| 138 |
+
return jnp.array(pe)
|
| 139 |
+
|
| 140 |
+
return init
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
class AddPositionEmbs(nn.Module):
|
| 144 |
+
"""Adds (optionally learned) positional embeddings to the inputs.
|
| 145 |
+
|
| 146 |
+
Attributes:
|
| 147 |
+
posemb_init: positional embedding initializer, if None, then use a fixed
|
| 148 |
+
(non-learned) sinusoidal embedding table.
|
| 149 |
+
max_len: maximum possible length for the input.
|
| 150 |
+
replicate_original: replicate original periodic encoding exactly
|
| 151 |
+
"""
|
| 152 |
+
|
| 153 |
+
posemb_init: Optional[Callable] = None
|
| 154 |
+
posemb_dim: Optional[int] = None
|
| 155 |
+
max_len: int = 512
|
| 156 |
+
combine_type: str = 'concat'
|
| 157 |
+
replicate_tf: bool = False
|
| 158 |
+
|
| 159 |
+
@nn.compact
|
| 160 |
+
def __call__(self, inputs, inputs_positions=None, cache=None):
|
| 161 |
+
"""Applies AddPositionEmbs module.
|
| 162 |
+
|
| 163 |
+
By default this layer uses a fixed sinusoidal embedding table. If a
|
| 164 |
+
learned position embedding is desired, pass an initializer to
|
| 165 |
+
posemb_init.
|
| 166 |
+
|
| 167 |
+
Args:
|
| 168 |
+
inputs: input data.
|
| 169 |
+
inputs_positions: input position indices for packed sequences.
|
| 170 |
+
cache: flax attention cache for fast decoding.
|
| 171 |
+
|
| 172 |
+
Returns:
|
| 173 |
+
output: `(bs, timesteps, in_dim)`
|
| 174 |
+
"""
|
| 175 |
+
# inputs.shape is (batch_size, seq_len, emb_dim)
|
| 176 |
+
assert inputs.ndim == 3, ('Number of dimensions should be 3,'
|
| 177 |
+
' but it is: %d' % inputs.ndim)
|
| 178 |
+
batch_size = inputs.shape[0]
|
| 179 |
+
length = inputs.shape[1]
|
| 180 |
+
if self.posemb_dim is None or self.combine_type == 'add':
|
| 181 |
+
self.posemb_dim = inputs.shape[-1]
|
| 182 |
+
pos_emb_shape = (1, self.max_len, self.posemb_dim)
|
| 183 |
+
if self.posemb_init is None:
|
| 184 |
+
# Use a fixed (non-learned) sinusoidal position embedding.
|
| 185 |
+
pos_embedding = sinusoidal_init(
|
| 186 |
+
max_len=self.max_len,
|
| 187 |
+
replicate_tf=self.replicate_tf,
|
| 188 |
+
)(None, pos_emb_shape, None)
|
| 189 |
+
else:
|
| 190 |
+
pos_embedding = self.param('pos_embedding', self.posemb_init,
|
| 191 |
+
pos_emb_shape)
|
| 192 |
+
pe = pos_embedding[:, :length, :]
|
| 193 |
+
# We abuse the same attention Cache mechanism to run positional embeddings
|
| 194 |
+
# in fast predict mode. We could use state variables instead, but this
|
| 195 |
+
# simplifies invocation with a single top-level cache context manager.
|
| 196 |
+
# We only use the cache's position index for tracking decoding position.
|
| 197 |
+
if cache:
|
| 198 |
+
if self.is_initializing():
|
| 199 |
+
cache.store(np.array((4, 1, 1), dtype=np.int32))
|
| 200 |
+
else:
|
| 201 |
+
cache_entry = cache.retrieve(None)
|
| 202 |
+
i = cache_entry.i
|
| 203 |
+
cache.store(cache_entry.replace(i=cache_entry.i + 1))
|
| 204 |
+
_, _, df = pos_embedding.shape
|
| 205 |
+
pe = lax.dynamic_slice(pos_embedding, jnp.array((0, i, 0)),
|
| 206 |
+
jnp.array((1, 1, df)))
|
| 207 |
+
if inputs_positions is None:
|
| 208 |
+
# normal unpacked case:
|
| 209 |
+
if self.combine_type == 'add':
|
| 210 |
+
return inputs + pe
|
| 211 |
+
elif self.combine_type == 'concat':
|
| 212 |
+
pe_broadcast = np.repeat(pe, batch_size, axis=0)
|
| 213 |
+
return lax.concatenate([inputs, pe_broadcast], 2)
|
| 214 |
+
else:
|
| 215 |
+
raise ValueError('Wrong type value.')
|
| 216 |
+
else:
|
| 217 |
+
# for packed data we need to use known position indices:
|
| 218 |
+
return inputs + jnp.take(pe[0], inputs_positions, axis=0)
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
class MlpBlock(nn.Module):
|
| 222 |
+
"""Transformer MLP block."""
|
| 223 |
+
|
| 224 |
+
mlp_dim: int
|
| 225 |
+
dtype: Any = jnp.float32
|
| 226 |
+
out_dim: Optional[int] = None
|
| 227 |
+
out_dropout: bool = True
|
| 228 |
+
dropout_rate: float = 0.1
|
| 229 |
+
deterministic: bool = False
|
| 230 |
+
kernel_init: Callable = nn.initializers.xavier_uniform()
|
| 231 |
+
bias_init: Callable = nn.initializers.normal(stddev=1e-6)
|
| 232 |
+
activation_fn: str = 'gelu'
|
| 233 |
+
|
| 234 |
+
@nn.compact
|
| 235 |
+
def __call__(self, inputs):
|
| 236 |
+
"""Applies Transformer MlpBlock module."""
|
| 237 |
+
actual_out_dim = inputs.shape[-1] if self.out_dim is None else self.out_dim
|
| 238 |
+
x = nn.Dense(
|
| 239 |
+
self.mlp_dim,
|
| 240 |
+
dtype=self.dtype,
|
| 241 |
+
kernel_init=self.kernel_init,
|
| 242 |
+
bias_init=self.bias_init)(
|
| 243 |
+
inputs)
|
| 244 |
+
x = ACTIVATION_FN_DICT[self.activation_fn](x)
|
| 245 |
+
x = nn.Dropout(rate=self.dropout_rate)(x, deterministic=self.deterministic)
|
| 246 |
+
output = nn.Dense(
|
| 247 |
+
actual_out_dim,
|
| 248 |
+
dtype=self.dtype,
|
| 249 |
+
kernel_init=self.kernel_init,
|
| 250 |
+
bias_init=self.bias_init)(
|
| 251 |
+
x)
|
| 252 |
+
if self.out_dropout:
|
| 253 |
+
output = nn.Dropout(rate=self.dropout_rate)(
|
| 254 |
+
output, deterministic=self.deterministic)
|
| 255 |
+
return output
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
def classifier_head(encoded, num_classes, mlp_dim, pooling_mode='MEAN'):
|
| 259 |
+
"""Classifier head.
|
| 260 |
+
|
| 261 |
+
We put this here just so that all models consistently call the same function.
|
| 262 |
+
|
| 263 |
+
Args:
|
| 264 |
+
encoded: tensor inputs are shape of [bs, len, dim].
|
| 265 |
+
num_classes: int, number of classes
|
| 266 |
+
mlp_dim: int, dim of intermediate MLP.
|
| 267 |
+
pooling_mode: str, string dictating pooling op {MEAN}
|
| 268 |
+
|
| 269 |
+
Returns:
|
| 270 |
+
tensor of shape [bs, num_classes]
|
| 271 |
+
|
| 272 |
+
"""
|
| 273 |
+
if pooling_mode == 'MEAN':
|
| 274 |
+
encoded = jnp.mean(encoded, axis=1)
|
| 275 |
+
elif pooling_mode == 'SUM':
|
| 276 |
+
encoded = jnp.sum(encoded, axis=1)
|
| 277 |
+
elif pooling_mode == 'FLATTEN':
|
| 278 |
+
encoded = encoded.reshape((encoded.shape[0], -1))
|
| 279 |
+
elif pooling_mode == 'CLS':
|
| 280 |
+
encoded = encoded[:, 0]
|
| 281 |
+
else:
|
| 282 |
+
raise NotImplementedError('Pooling not supported yet.')
|
| 283 |
+
encoded = nn.Dense(mlp_dim, name='mlp')(encoded)
|
| 284 |
+
encoded = nn.relu(encoded)
|
| 285 |
+
encoded = nn.Dense(num_classes, name='logits')(encoded)
|
| 286 |
+
return encoded
|
| 287 |
+
|
| 288 |
+
|
| 289 |
+
class LayerNorm(nn.Module):
|
| 290 |
+
"""Layer Norm to replicate tf.contrib."""
|
| 291 |
+
epsilon: Optional[float] = None
|
| 292 |
+
dtype: Any = jnp.float32
|
| 293 |
+
use_bias: bool = True
|
| 294 |
+
use_scale: bool = True
|
| 295 |
+
bias_init: Callable[[PRNGKey, Shape, Dtype], Array] = initializers.zeros
|
| 296 |
+
scale_init: Callable[[PRNGKey, Shape, Dtype], Array] = initializers.ones
|
| 297 |
+
|
| 298 |
+
@nn.compact
|
| 299 |
+
def __call__(self, x):
|
| 300 |
+
if self.epsilon is None:
|
| 301 |
+
epsilon = 1e-12 if self.dtype != jnp.float16 else 1e-3
|
| 302 |
+
else:
|
| 303 |
+
epsilon = self.epsilon
|
| 304 |
+
x = jnp.asarray(x, jnp.float32)
|
| 305 |
+
features = x.shape[-1]
|
| 306 |
+
mean = jnp.mean(x, axis=-1, keepdims=True)
|
| 307 |
+
mean2 = jnp.mean(lax.square(x), axis=-1, keepdims=True)
|
| 308 |
+
var = mean2 - lax.square(mean)
|
| 309 |
+
mul = lax.rsqrt(var + epsilon)
|
| 310 |
+
if self.use_scale:
|
| 311 |
+
mul = mul * jnp.asarray(
|
| 312 |
+
self.param('scale', self.scale_init, (features,)), self.dtype)
|
| 313 |
+
y = x * mul
|
| 314 |
+
if self.use_bias:
|
| 315 |
+
y = y + jnp.asarray(
|
| 316 |
+
self.param('bias', self.bias_init, (features,)), self.dtype)
|
| 317 |
+
y -= mean * mul
|
| 318 |
+
return jnp.asarray(y, self.dtype)
|
ithaca/models/model.py
ADDED
|
@@ -0,0 +1,243 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2021 the Ithaca Authors
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
"""Ithaca model."""
|
| 15 |
+
|
| 16 |
+
from . import bigbird
|
| 17 |
+
from . import common_layers
|
| 18 |
+
|
| 19 |
+
import flax.linen as nn
|
| 20 |
+
import jax
|
| 21 |
+
import jax.numpy as jnp
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class Model(nn.Module):
|
| 25 |
+
"""Transformer Model for sequence tagging."""
|
| 26 |
+
vocab_char_size: int = 164
|
| 27 |
+
vocab_word_size: int = 100004
|
| 28 |
+
output_subregions: int = 85
|
| 29 |
+
output_date: int = 160
|
| 30 |
+
output_date_dist: bool = True
|
| 31 |
+
output_return_emb: bool = False
|
| 32 |
+
use_output_mlp: bool = True
|
| 33 |
+
num_heads: int = 8
|
| 34 |
+
num_layers: int = 6
|
| 35 |
+
word_char_emb_dim: int = 192
|
| 36 |
+
emb_dim: int = 512
|
| 37 |
+
qkv_dim: int = 512
|
| 38 |
+
mlp_dim: int = 2048
|
| 39 |
+
max_len: int = 1024
|
| 40 |
+
causal_mask: bool = False
|
| 41 |
+
feature_combine_type: str = 'concat'
|
| 42 |
+
posemb_combine_type: str = 'add'
|
| 43 |
+
region_date_pooling: str = 'first'
|
| 44 |
+
learn_pos_emb: bool = True
|
| 45 |
+
use_bfloat16: bool = False
|
| 46 |
+
dropout_rate: float = 0.1
|
| 47 |
+
attention_dropout_rate: float = 0.1
|
| 48 |
+
activation_fn: str = 'gelu'
|
| 49 |
+
model_type: str = 'bigbird'
|
| 50 |
+
|
| 51 |
+
def setup(self):
|
| 52 |
+
self.text_char_emb = nn.Embed(
|
| 53 |
+
num_embeddings=self.vocab_char_size,
|
| 54 |
+
features=self.word_char_emb_dim,
|
| 55 |
+
embedding_init=nn.initializers.normal(stddev=1.0),
|
| 56 |
+
name='char_embeddings')
|
| 57 |
+
self.text_word_emb = nn.Embed(
|
| 58 |
+
num_embeddings=self.vocab_word_size,
|
| 59 |
+
features=self.word_char_emb_dim,
|
| 60 |
+
embedding_init=nn.initializers.normal(stddev=1.0),
|
| 61 |
+
name='word_embeddings')
|
| 62 |
+
|
| 63 |
+
@nn.compact
|
| 64 |
+
def __call__(self,
|
| 65 |
+
text_char=None,
|
| 66 |
+
text_word=None,
|
| 67 |
+
text_char_onehot=None,
|
| 68 |
+
text_word_onehot=None,
|
| 69 |
+
text_char_emb=None,
|
| 70 |
+
text_word_emb=None,
|
| 71 |
+
padding=None,
|
| 72 |
+
is_training=True):
|
| 73 |
+
"""Applies Ithaca model on the inputs."""
|
| 74 |
+
|
| 75 |
+
if text_char is not None and padding is None:
|
| 76 |
+
padding = jnp.where(text_char > 0, 1, 0)
|
| 77 |
+
elif text_char_onehot is not None and padding is None:
|
| 78 |
+
padding = jnp.where(text_char_onehot.argmax(-1) > 0, 1, 0)
|
| 79 |
+
padding_mask = padding[..., jnp.newaxis]
|
| 80 |
+
text_len = jnp.sum(padding, 1)
|
| 81 |
+
|
| 82 |
+
if self.posemb_combine_type == 'add':
|
| 83 |
+
posemb_dim = None
|
| 84 |
+
elif self.posemb_combine_type == 'concat':
|
| 85 |
+
posemb_dim = self.word_char_emb_dim
|
| 86 |
+
else:
|
| 87 |
+
raise ValueError('Wrong feature_combine_type value.')
|
| 88 |
+
|
| 89 |
+
# Character embeddings
|
| 90 |
+
if text_char is not None:
|
| 91 |
+
x = self.text_char_emb(text_char)
|
| 92 |
+
elif text_char_onehot is not None:
|
| 93 |
+
x = self.text_char_emb.attend(text_char_onehot)
|
| 94 |
+
elif text_char_emb is not None:
|
| 95 |
+
x = text_char_emb
|
| 96 |
+
else:
|
| 97 |
+
raise ValueError('Wrong inputs.')
|
| 98 |
+
|
| 99 |
+
# Word embeddings
|
| 100 |
+
if text_word is not None:
|
| 101 |
+
text_word_emb_x = self.text_word_emb(text_word)
|
| 102 |
+
elif text_word_onehot is not None:
|
| 103 |
+
text_word_emb_x = self.text_word_emb.attend(text_word_onehot)
|
| 104 |
+
elif text_word_emb is not None:
|
| 105 |
+
text_word_emb_x = text_word_emb
|
| 106 |
+
else:
|
| 107 |
+
raise ValueError('Wrong inputs.')
|
| 108 |
+
|
| 109 |
+
if self.feature_combine_type == 'add':
|
| 110 |
+
x = x + text_word_emb_x
|
| 111 |
+
elif self.feature_combine_type == 'concat':
|
| 112 |
+
x = jax.lax.concatenate([x, text_word_emb_x], 2)
|
| 113 |
+
else:
|
| 114 |
+
raise ValueError('Wrong feature_combine_type value.')
|
| 115 |
+
|
| 116 |
+
# Positional embeddings
|
| 117 |
+
pe_init = common_layers.sinusoidal_init(
|
| 118 |
+
max_len=self.max_len) if self.learn_pos_emb else None
|
| 119 |
+
x = common_layers.AddPositionEmbs(
|
| 120 |
+
posemb_dim=posemb_dim,
|
| 121 |
+
posemb_init=pe_init,
|
| 122 |
+
max_len=self.max_len,
|
| 123 |
+
combine_type=self.posemb_combine_type,
|
| 124 |
+
name='posembed_input',
|
| 125 |
+
)(
|
| 126 |
+
x)
|
| 127 |
+
x = nn.Dropout(rate=self.dropout_rate)(x, deterministic=not is_training)
|
| 128 |
+
|
| 129 |
+
# Set floating point
|
| 130 |
+
if self.use_bfloat16:
|
| 131 |
+
x = x.astype(jnp.bfloat16)
|
| 132 |
+
dtype = jnp.bfloat16
|
| 133 |
+
else:
|
| 134 |
+
dtype = jnp.float32
|
| 135 |
+
|
| 136 |
+
if self.model_type == 'bigbird':
|
| 137 |
+
model_block = bigbird.BigBirdBlock
|
| 138 |
+
else:
|
| 139 |
+
raise ValueError('Wrong model type specified.')
|
| 140 |
+
|
| 141 |
+
for lyr in range(self.num_layers):
|
| 142 |
+
x = model_block(
|
| 143 |
+
qkv_dim=self.qkv_dim,
|
| 144 |
+
mlp_dim=self.mlp_dim,
|
| 145 |
+
num_heads=self.num_heads,
|
| 146 |
+
dtype=dtype,
|
| 147 |
+
causal_mask=self.causal_mask,
|
| 148 |
+
dropout_rate=self.dropout_rate,
|
| 149 |
+
attention_dropout_rate=self.attention_dropout_rate,
|
| 150 |
+
deterministic=not is_training,
|
| 151 |
+
activation_fn=self.activation_fn,
|
| 152 |
+
connectivity_seed=lyr,
|
| 153 |
+
name=f'encoderblock_{lyr}',
|
| 154 |
+
)(
|
| 155 |
+
x,
|
| 156 |
+
padding_mask=padding_mask,
|
| 157 |
+
)
|
| 158 |
+
x = common_layers.LayerNorm(dtype=dtype, name='encoder_norm')(x)
|
| 159 |
+
torso_output = x
|
| 160 |
+
|
| 161 |
+
# Bert logits
|
| 162 |
+
if self.use_output_mlp:
|
| 163 |
+
x_mask = common_layers.MlpBlock(
|
| 164 |
+
out_dim=self.word_char_emb_dim,
|
| 165 |
+
mlp_dim=self.emb_dim,
|
| 166 |
+
dtype=dtype,
|
| 167 |
+
out_dropout=False,
|
| 168 |
+
dropout_rate=self.dropout_rate,
|
| 169 |
+
deterministic=not is_training,
|
| 170 |
+
activation_fn=self.activation_fn)(
|
| 171 |
+
x)
|
| 172 |
+
else:
|
| 173 |
+
x_mask = nn.Dense(self.word_char_emb_dim)(x)
|
| 174 |
+
|
| 175 |
+
char_embeddings = self.text_char_emb.embedding
|
| 176 |
+
char_embeddings = nn.Dropout(rate=self.dropout_rate)(
|
| 177 |
+
char_embeddings, deterministic=not is_training)
|
| 178 |
+
logits_mask = jnp.matmul(x_mask, jnp.transpose(char_embeddings))
|
| 179 |
+
|
| 180 |
+
# Next sentence prediction
|
| 181 |
+
if self.use_output_mlp:
|
| 182 |
+
logits_nsp = common_layers.MlpBlock(
|
| 183 |
+
out_dim=2,
|
| 184 |
+
mlp_dim=self.emb_dim,
|
| 185 |
+
dtype=dtype,
|
| 186 |
+
out_dropout=False,
|
| 187 |
+
dropout_rate=self.dropout_rate,
|
| 188 |
+
deterministic=not is_training,
|
| 189 |
+
activation_fn=self.activation_fn)(
|
| 190 |
+
x)
|
| 191 |
+
else:
|
| 192 |
+
logits_nsp = nn.Dense(2)(x)
|
| 193 |
+
|
| 194 |
+
# Average over temporal dimension
|
| 195 |
+
if self.region_date_pooling == 'average':
|
| 196 |
+
x = jnp.multiply(padding_mask.astype(jnp.float32), x)
|
| 197 |
+
x = jnp.sum(x, 1) / text_len.astype(jnp.float32)[..., None]
|
| 198 |
+
elif self.region_date_pooling == 'sum':
|
| 199 |
+
x = jnp.multiply(padding_mask.astype(jnp.float32), x)
|
| 200 |
+
x = jnp.sum(x, 1)
|
| 201 |
+
elif self.region_date_pooling == 'first':
|
| 202 |
+
x = x[:, 0, :]
|
| 203 |
+
else:
|
| 204 |
+
raise ValueError('Wrong pooling type specified.')
|
| 205 |
+
|
| 206 |
+
# Date pred
|
| 207 |
+
if self.output_date_dist:
|
| 208 |
+
output_date_dim = self.output_date
|
| 209 |
+
else:
|
| 210 |
+
output_date_dim = 1
|
| 211 |
+
|
| 212 |
+
if self.use_output_mlp:
|
| 213 |
+
pred_date = common_layers.MlpBlock(
|
| 214 |
+
out_dim=output_date_dim,
|
| 215 |
+
mlp_dim=self.emb_dim,
|
| 216 |
+
dtype=dtype,
|
| 217 |
+
out_dropout=False,
|
| 218 |
+
dropout_rate=self.dropout_rate,
|
| 219 |
+
deterministic=not is_training,
|
| 220 |
+
activation_fn=self.activation_fn)(
|
| 221 |
+
x)
|
| 222 |
+
else:
|
| 223 |
+
pred_date = nn.Dense(output_date_dim)(x)
|
| 224 |
+
|
| 225 |
+
# Region logits
|
| 226 |
+
if self.use_output_mlp:
|
| 227 |
+
logits_subregion = common_layers.MlpBlock(
|
| 228 |
+
out_dim=self.output_subregions,
|
| 229 |
+
mlp_dim=self.emb_dim,
|
| 230 |
+
dtype=dtype,
|
| 231 |
+
out_dropout=False,
|
| 232 |
+
dropout_rate=self.dropout_rate,
|
| 233 |
+
deterministic=not is_training,
|
| 234 |
+
activation_fn=self.activation_fn)(
|
| 235 |
+
x)
|
| 236 |
+
else:
|
| 237 |
+
logits_subregion = nn.Dense(self.output_subregions)(x)
|
| 238 |
+
|
| 239 |
+
outputs = (pred_date, logits_subregion, logits_mask, logits_nsp)
|
| 240 |
+
if self.output_return_emb:
|
| 241 |
+
return outputs, torso_output
|
| 242 |
+
else:
|
| 243 |
+
return outputs
|
ithaca/util/__init__.py
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2021 the Ithaca Authors
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
ithaca/util/alphabet.py
ADDED
|
@@ -0,0 +1,171 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2021 the Ithaca Authors
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
"""Alphabet classes."""
|
| 15 |
+
|
| 16 |
+
import re
|
| 17 |
+
|
| 18 |
+
import numpy as np
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class Alphabet:
|
| 22 |
+
"""Generic alphabet class."""
|
| 23 |
+
|
| 24 |
+
def __init__(self,
|
| 25 |
+
alphabet,
|
| 26 |
+
numerals='0',
|
| 27 |
+
punctuation='.',
|
| 28 |
+
space=' ',
|
| 29 |
+
missing='-',
|
| 30 |
+
pad='#',
|
| 31 |
+
unk='^',
|
| 32 |
+
sos='<',
|
| 33 |
+
sog='[',
|
| 34 |
+
eog=']',
|
| 35 |
+
wordlist_file=None,
|
| 36 |
+
wordlist_size=100000):
|
| 37 |
+
self.alphabet = list(alphabet) # alph
|
| 38 |
+
self.numerals = list(numerals) # num
|
| 39 |
+
self.punctuation = list(punctuation) # punt
|
| 40 |
+
self.space = space # spacing
|
| 41 |
+
self.missing = missing # missing char
|
| 42 |
+
self.pad = pad # padding (spaces to right of string)
|
| 43 |
+
self.unk = unk # unknown char
|
| 44 |
+
self.sos = sos # start of sentence
|
| 45 |
+
self.sog = sog # start of guess
|
| 46 |
+
self.eog = eog # end of guess
|
| 47 |
+
|
| 48 |
+
# Define wordlist mapping
|
| 49 |
+
idx2word = [self.pad, self.sos, self.unk]
|
| 50 |
+
if wordlist_file:
|
| 51 |
+
idx2word += [
|
| 52 |
+
w_c.split(';')[0]
|
| 53 |
+
for w_c in wordlist_file.read().strip().split('\n')[:wordlist_size]
|
| 54 |
+
]
|
| 55 |
+
self.idx2word = np.array(idx2word)
|
| 56 |
+
self.word2idx = {self.idx2word[i]: i for i in range(len(self.idx2word))}
|
| 57 |
+
|
| 58 |
+
# Define vocab mapping
|
| 59 |
+
self.idx2char = np.array(
|
| 60 |
+
[self.pad, self.sos, self.unk, self.space, self.missing] +
|
| 61 |
+
self.alphabet + self.numerals + self.punctuation)
|
| 62 |
+
self.char2idx = {self.idx2char[i]: i for i in range(len(self.idx2char))}
|
| 63 |
+
|
| 64 |
+
# Define special character indices
|
| 65 |
+
self.pad_idx = self.char2idx[pad]
|
| 66 |
+
self.sos_idx = self.char2idx[sos]
|
| 67 |
+
self.unk_idx = self.char2idx[unk]
|
| 68 |
+
self.alphabet_start_idx = self.char2idx[self.alphabet[0]]
|
| 69 |
+
self.alphabet_end_idx = self.char2idx[self.numerals[-1]]
|
| 70 |
+
|
| 71 |
+
def filter(self, t):
|
| 72 |
+
return t
|
| 73 |
+
|
| 74 |
+
def size_char(self):
|
| 75 |
+
return len(self.idx2char)
|
| 76 |
+
|
| 77 |
+
def size_word(self):
|
| 78 |
+
return len(self.idx2word)
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
class GreekAlphabet(Alphabet):
|
| 82 |
+
"""Greek alphabet class."""
|
| 83 |
+
|
| 84 |
+
def __init__(self, wordlist_file=None, wordlist_size=100000):
|
| 85 |
+
greek_alphabet = 'αβγδεζηθικλμνξοπρςστυφχψωϙϛ'
|
| 86 |
+
|
| 87 |
+
super().__init__(
|
| 88 |
+
alphabet=greek_alphabet,
|
| 89 |
+
wordlist_file=wordlist_file,
|
| 90 |
+
wordlist_size=wordlist_size)
|
| 91 |
+
self.tonos_to_oxia = {
|
| 92 |
+
# tonos : #oxia
|
| 93 |
+
u'\u0386': u'\u1FBB', # capital letter alpha
|
| 94 |
+
u'\u0388': u'\u1FC9', # capital letter epsilon
|
| 95 |
+
u'\u0389': u'\u1FCB', # capital letter eta
|
| 96 |
+
u'\u038C': u'\u1FF9', # capital letter omicron
|
| 97 |
+
u'\u038A': u'\u1FDB', # capital letter iota
|
| 98 |
+
u'\u038E': u'\u1FF9', # capital letter upsilon
|
| 99 |
+
u'\u038F': u'\u1FFB', # capital letter omega
|
| 100 |
+
u'\u03AC': u'\u1F71', # small letter alpha
|
| 101 |
+
u'\u03AD': u'\u1F73', # small letter epsilon
|
| 102 |
+
u'\u03AE': u'\u1F75', # small letter eta
|
| 103 |
+
u'\u0390': u'\u1FD3', # small letter iota with dialytika and tonos/oxia
|
| 104 |
+
u'\u03AF': u'\u1F77', # small letter iota
|
| 105 |
+
u'\u03CC': u'\u1F79', # small letter omicron
|
| 106 |
+
u'\u03B0': u'\u1FE3',
|
| 107 |
+
# small letter upsilon with dialytika and tonos/oxia
|
| 108 |
+
u'\u03CD': u'\u1F7B', # small letter upsilon
|
| 109 |
+
u'\u03CE': u'\u1F7D' # small letter omega
|
| 110 |
+
}
|
| 111 |
+
self.oxia_to_tonos = {v: k for k, v in self.tonos_to_oxia.items()}
|
| 112 |
+
|
| 113 |
+
def filter(self, t): # override previous filter function
|
| 114 |
+
# lowercase
|
| 115 |
+
t = t.lower()
|
| 116 |
+
|
| 117 |
+
# replace dot below
|
| 118 |
+
t = t.replace(u'\u0323', '')
|
| 119 |
+
|
| 120 |
+
# replace perispomeni
|
| 121 |
+
t = t.replace(u'\u0342', '')
|
| 122 |
+
t = t.replace(u'\u02C9', '')
|
| 123 |
+
|
| 124 |
+
# replace ending sigma
|
| 125 |
+
t = re.sub(r'([\w\[\]])σ(?![\[\]])(\b)', r'\1ς\2', t)
|
| 126 |
+
|
| 127 |
+
# replace oxia with tonos
|
| 128 |
+
for oxia, tonos in self.oxia_to_tonos.items():
|
| 129 |
+
t = t.replace(oxia, tonos)
|
| 130 |
+
|
| 131 |
+
# replace h
|
| 132 |
+
h_patterns = {
|
| 133 |
+
# input: #target
|
| 134 |
+
'ε': 'ἑ',
|
| 135 |
+
'ὲ': 'ἓ',
|
| 136 |
+
'έ': 'ἕ',
|
| 137 |
+
'α': 'ἁ',
|
| 138 |
+
'ὰ': 'ἃ',
|
| 139 |
+
'ά': 'ἅ',
|
| 140 |
+
'ᾶ': 'ἇ',
|
| 141 |
+
'ι': 'ἱ',
|
| 142 |
+
'ὶ': 'ἳ',
|
| 143 |
+
'ί': 'ἵ',
|
| 144 |
+
'ῖ': 'ἷ',
|
| 145 |
+
'ο': 'ὁ',
|
| 146 |
+
'ό': 'ὅ',
|
| 147 |
+
'ὸ': 'ὃ',
|
| 148 |
+
'υ': 'ὑ',
|
| 149 |
+
'ὺ': 'ὓ',
|
| 150 |
+
'ύ': 'ὕ',
|
| 151 |
+
'ῦ': 'ὗ',
|
| 152 |
+
'ὴ': 'ἣ',
|
| 153 |
+
'η': 'ἡ',
|
| 154 |
+
'ή': 'ἥ',
|
| 155 |
+
'ῆ': 'ἧ',
|
| 156 |
+
'ὼ': 'ὣ',
|
| 157 |
+
'ώ': 'ὥ',
|
| 158 |
+
'ω': 'ὡ',
|
| 159 |
+
'ῶ': 'ὧ'
|
| 160 |
+
}
|
| 161 |
+
|
| 162 |
+
# iterate by keys
|
| 163 |
+
for h_in, h_tar in h_patterns.items():
|
| 164 |
+
# look up and replace h[ and h]
|
| 165 |
+
t = re.sub(r'ℎ(\[?){}'.format(h_in), r'\1{}'.format(h_tar), t)
|
| 166 |
+
t = re.sub(r'ℎ(\]?){}'.format(h_in), r'{}\1'.format(h_tar), t)
|
| 167 |
+
|
| 168 |
+
# any h left is an ἡ
|
| 169 |
+
t = re.sub(r'(\[?)ℎ(\]?)', r'\1ἡ\2', t)
|
| 170 |
+
|
| 171 |
+
return t
|
ithaca/util/dates.py
ADDED
|
@@ -0,0 +1,67 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2021 the Ithaca Authors
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
"""Date processing functions."""
|
| 15 |
+
import numpy as np
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def date_num_bins(date_min, date_max, date_interval, unknown_bin=True):
|
| 19 |
+
num_bins = (date_max - date_min - 1) // date_interval
|
| 20 |
+
if unknown_bin:
|
| 21 |
+
num_bins += 1 # +1 for unk
|
| 22 |
+
return num_bins
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def date_to_bin(date_cur, date_min, date_max, date_interval, date_bins):
|
| 26 |
+
if date_cur >= date_min and date_cur < date_max:
|
| 27 |
+
date_bin = np.digitize(
|
| 28 |
+
date_cur,
|
| 29 |
+
list(range(date_min + date_interval, date_max, date_interval)))
|
| 30 |
+
else:
|
| 31 |
+
date_bin = date_bins - 1
|
| 32 |
+
return date_bin
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def bin_to_date(date_cur_bin, date_min, date_interval):
|
| 36 |
+
return date_min + date_cur_bin * date_interval + date_interval // 2
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def date_range_to_dist(date_min_cur,
|
| 40 |
+
date_max_cur,
|
| 41 |
+
date_min,
|
| 42 |
+
date_max,
|
| 43 |
+
date_interval,
|
| 44 |
+
date_bins,
|
| 45 |
+
return_logits=True):
|
| 46 |
+
"""Converts a date range to a uniform distribution."""
|
| 47 |
+
dist = np.zeros(date_bins)
|
| 48 |
+
|
| 49 |
+
if (date_min_cur and date_max_cur and date_min_cur >= date_min and
|
| 50 |
+
date_max_cur < date_max and date_min_cur <= date_max_cur):
|
| 51 |
+
date_min_cur_bin = date_to_bin(date_min_cur, date_min, date_max,
|
| 52 |
+
date_interval, date_bins)
|
| 53 |
+
date_max_cur_bin = date_to_bin(date_max_cur, date_min, date_max,
|
| 54 |
+
date_interval, date_bins)
|
| 55 |
+
else:
|
| 56 |
+
date_min_cur_bin = date_bins - 1
|
| 57 |
+
date_max_cur_bin = date_bins - 1
|
| 58 |
+
|
| 59 |
+
date_bins_cur = date_max_cur_bin - date_min_cur_bin + 1
|
| 60 |
+
dist[date_min_cur_bin:date_max_cur_bin + 1] = 1. / date_bins_cur
|
| 61 |
+
|
| 62 |
+
if return_logits:
|
| 63 |
+
eps = 1e-6
|
| 64 |
+
dist = np.clip(dist, eps, 1. - eps)
|
| 65 |
+
dist = np.log(dist)
|
| 66 |
+
|
| 67 |
+
return dist
|
ithaca/util/eval.py
ADDED
|
@@ -0,0 +1,562 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2021 the Ithaca Authors
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
"""Eval utils."""
|
| 15 |
+
|
| 16 |
+
from typing import List, NamedTuple
|
| 17 |
+
|
| 18 |
+
import jax
|
| 19 |
+
import jax.numpy as jnp
|
| 20 |
+
import numpy as np
|
| 21 |
+
from .text import idx_to_text
|
| 22 |
+
from .text import text_to_idx
|
| 23 |
+
from .text import text_to_word_idx
|
| 24 |
+
import tqdm
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def date_loss_l1(pred, target_min, target_max):
|
| 28 |
+
"""L1 loss function for dates."""
|
| 29 |
+
loss = 0.
|
| 30 |
+
loss += np.abs(pred - target_min) * np.less(pred, target_min).astype(
|
| 31 |
+
pred.dtype)
|
| 32 |
+
loss += np.abs(pred - target_max) * np.greater(pred, target_max).astype(
|
| 33 |
+
pred.dtype)
|
| 34 |
+
return loss
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def grad_to_saliency_char(gradient_char, text_char_onehot, text_len, alphabet):
|
| 38 |
+
"""Generates saliency map."""
|
| 39 |
+
saliency_char = np.linalg.norm(gradient_char, axis=2)[0, :text_len[0]]
|
| 40 |
+
|
| 41 |
+
text_char = np.array(text_char_onehot).argmax(axis=-1)
|
| 42 |
+
idx_mask = np.logical_or(
|
| 43 |
+
text_char[0, :text_len[0]] > alphabet.alphabet_end_idx,
|
| 44 |
+
text_char[0, :text_len[0]] < alphabet.alphabet_start_idx)
|
| 45 |
+
idx_unmask = np.logical_not(idx_mask)
|
| 46 |
+
|
| 47 |
+
saliency_char_tmp = saliency_char.copy()
|
| 48 |
+
saliency_char_tmp[idx_mask] = 0.
|
| 49 |
+
if idx_unmask.any():
|
| 50 |
+
saliency_char_tmp[idx_unmask] = (saliency_char[idx_unmask] -
|
| 51 |
+
saliency_char[idx_unmask].min()) / (
|
| 52 |
+
saliency_char[idx_unmask].max() -
|
| 53 |
+
saliency_char[idx_unmask].min() + 1e-8)
|
| 54 |
+
return saliency_char_tmp
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def grad_to_saliency_word(gradient_word, text_word_onehot, text_len, alphabet):
|
| 58 |
+
"""Generates saliency map."""
|
| 59 |
+
saliency_word = np.linalg.norm(gradient_word, axis=2)[0, :text_len[0]]
|
| 60 |
+
text_word = np.array(text_word_onehot).argmax(axis=-1)
|
| 61 |
+
|
| 62 |
+
saliency_word = saliency_word.copy()
|
| 63 |
+
start_idx = None
|
| 64 |
+
for i in range(text_len[0]):
|
| 65 |
+
if text_word[0, i] == alphabet.unk_idx:
|
| 66 |
+
if start_idx is not None:
|
| 67 |
+
saliency_word[start_idx:i] = np.sum(saliency_word[start_idx:i])
|
| 68 |
+
start_idx = None
|
| 69 |
+
elif start_idx is None:
|
| 70 |
+
start_idx = i
|
| 71 |
+
|
| 72 |
+
idx_mask = text_word[0, :text_len[0]] == alphabet.unk_idx
|
| 73 |
+
idx_unmask = np.logical_not(idx_mask)
|
| 74 |
+
saliency_word_tmp = saliency_word.copy()
|
| 75 |
+
saliency_word_tmp[idx_mask] = 0.
|
| 76 |
+
if idx_unmask.any():
|
| 77 |
+
saliency_word_tmp[idx_unmask] = (
|
| 78 |
+
saliency_word[idx_unmask] - saliency_word[idx_unmask].min())
|
| 79 |
+
saliency_word_tmp[idx_unmask] = saliency_word_tmp[idx_unmask] / (
|
| 80 |
+
saliency_word[idx_unmask].max() - saliency_word[idx_unmask].min() +
|
| 81 |
+
1e-8)
|
| 82 |
+
return saliency_word_tmp
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def softmax(x, axis=-1):
|
| 86 |
+
"""Compute softmax values for each sets of scores in x."""
|
| 87 |
+
unnormalized = np.exp(x - x.max(axis, keepdims=True))
|
| 88 |
+
return unnormalized / unnormalized.sum(axis, keepdims=True)
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def log_softmax(x, axis=-1):
|
| 92 |
+
"""Log-Softmax function."""
|
| 93 |
+
shifted = x - x.max(axis, keepdims=True)
|
| 94 |
+
return shifted - np.log(np.sum(np.exp(shifted), axis, keepdims=True))
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
def nucleus_sample_inner(logits, top_p=0.95, temp=1.0):
|
| 98 |
+
"""Samples from the most likely tokens whose probability sums to top_p."""
|
| 99 |
+
sorted_logits = np.sort(logits)
|
| 100 |
+
sorted_probs = softmax(sorted_logits)
|
| 101 |
+
threshold_idx = np.argmax(np.cumsum(sorted_probs, -1) >= 1 - top_p)
|
| 102 |
+
threshold_largest_logits = sorted_logits[..., [threshold_idx]]
|
| 103 |
+
assert threshold_largest_logits.shape == logits.shape[:-1] + (1,)
|
| 104 |
+
mask = logits >= threshold_largest_logits
|
| 105 |
+
logits += (1 - mask) * -1e12 # Set unused logits to -inf.
|
| 106 |
+
logits /= np.maximum(temp, 1e-12)
|
| 107 |
+
return logits
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
class BeamEntry(NamedTuple):
|
| 111 |
+
text_pred: str
|
| 112 |
+
mask_idx: int
|
| 113 |
+
pred_len: int
|
| 114 |
+
pred_logprob: float
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def beam_search_batch_2d(forward,
|
| 118 |
+
alphabet,
|
| 119 |
+
text_pred,
|
| 120 |
+
mask_idx,
|
| 121 |
+
rng=None,
|
| 122 |
+
beam_width=20,
|
| 123 |
+
temperature=1.,
|
| 124 |
+
nucleus=False,
|
| 125 |
+
nucleus_top_p=0.8,
|
| 126 |
+
display_progress=False) -> List[BeamEntry]:
|
| 127 |
+
"""Non-sequential beam search."""
|
| 128 |
+
|
| 129 |
+
beam = [BeamEntry(text_pred, mask_idx, 0, 0.)]
|
| 130 |
+
beam_top = {}
|
| 131 |
+
|
| 132 |
+
text_len = len(text_pred.rstrip(alphabet.pad))
|
| 133 |
+
|
| 134 |
+
# Initialise tqdm bar
|
| 135 |
+
if display_progress:
|
| 136 |
+
pbar = tqdm.tqdm(total=len(mask_idx))
|
| 137 |
+
|
| 138 |
+
while beam:
|
| 139 |
+
beam_tmp = []
|
| 140 |
+
beam_batch = []
|
| 141 |
+
|
| 142 |
+
text_chars = []
|
| 143 |
+
text_words = []
|
| 144 |
+
|
| 145 |
+
for text_pred, mask_idx, pred_len, pred_logprob in beam:
|
| 146 |
+
|
| 147 |
+
mask_idx = mask_idx.copy() # pytype: disable=attribute-error # strict_namedtuple_checks
|
| 148 |
+
text_char = text_to_idx(text_pred, alphabet).reshape(1, -1)
|
| 149 |
+
text_word = text_to_word_idx(text_pred, alphabet).reshape(1, -1)
|
| 150 |
+
text_chars.append(text_char)
|
| 151 |
+
text_words.append(text_word)
|
| 152 |
+
beam_batch.append(BeamEntry(text_pred, mask_idx, pred_len, pred_logprob))
|
| 153 |
+
text_chars = np.vstack(text_chars)
|
| 154 |
+
text_words = np.vstack(text_words)
|
| 155 |
+
|
| 156 |
+
_, _, mask_logits, _ = forward(
|
| 157 |
+
text_char=text_chars,
|
| 158 |
+
text_word=text_words,
|
| 159 |
+
text_char_onehot=None,
|
| 160 |
+
text_word_onehot=None,
|
| 161 |
+
rngs={'dropout': rng},
|
| 162 |
+
is_training=False)
|
| 163 |
+
mask_logits = mask_logits / temperature
|
| 164 |
+
mask_logits = np.array(mask_logits)
|
| 165 |
+
|
| 166 |
+
for batch_i in range(mask_logits.shape[0]):
|
| 167 |
+
text_pred, mask_idx, pred_len, pred_logprob = beam_batch[batch_i]
|
| 168 |
+
mask_logprob = log_softmax(mask_logits)[batch_i, :text_len]
|
| 169 |
+
mask_pred = softmax(mask_logits)[batch_i, :text_len]
|
| 170 |
+
mask_pred_argmax = np.dstack(
|
| 171 |
+
np.unravel_index(np.argsort(-mask_pred.ravel()), mask_pred.shape))[0]
|
| 172 |
+
|
| 173 |
+
# Keep only predictions for mask
|
| 174 |
+
for i in range(mask_pred_argmax.shape[0]):
|
| 175 |
+
if (mask_pred_argmax[i][0] in mask_idx and # pytype: disable=unsupported-operands # strict_namedtuple_checks
|
| 176 |
+
(mask_pred_argmax[i][1] == alphabet.char2idx[alphabet.space] or
|
| 177 |
+
(mask_pred_argmax[i][1] >= alphabet.alphabet_start_idx and
|
| 178 |
+
mask_pred_argmax[i][1] <=
|
| 179 |
+
alphabet.char2idx[alphabet.punctuation[-1]]))):
|
| 180 |
+
text_char_i = text_chars.copy()
|
| 181 |
+
text_char_i[batch_i, mask_pred_argmax[i][0]] = mask_pred_argmax[i][1]
|
| 182 |
+
text_pred_i = idx_to_text(
|
| 183 |
+
text_char_i[batch_i], alphabet, strip_sos=False, strip_pad=False)
|
| 184 |
+
|
| 185 |
+
mask_idx_i = mask_idx.copy() # pytype: disable=attribute-error # strict_namedtuple_checks
|
| 186 |
+
mask_idx_i.remove(mask_pred_argmax[i][0])
|
| 187 |
+
|
| 188 |
+
if nucleus:
|
| 189 |
+
mask_logits_i = mask_logits[batch_i, mask_pred_argmax[i][0]]
|
| 190 |
+
mask_logits_i = nucleus_sample_inner(mask_logits_i, nucleus_top_p)
|
| 191 |
+
mask_logprob_i = log_softmax(mask_logits_i)
|
| 192 |
+
|
| 193 |
+
# Skip expanding the beam if logprob too small
|
| 194 |
+
if mask_logits_i[mask_pred_argmax[i][1]] < -1e12:
|
| 195 |
+
continue
|
| 196 |
+
|
| 197 |
+
pred_logprob_i = pred_logprob + mask_logprob_i[mask_pred_argmax[i]
|
| 198 |
+
[1]]
|
| 199 |
+
else:
|
| 200 |
+
pred_logprob_i = pred_logprob + mask_logprob[mask_pred_argmax[i][0],
|
| 201 |
+
mask_pred_argmax[i][1]]
|
| 202 |
+
|
| 203 |
+
if not mask_idx_i:
|
| 204 |
+
if (text_pred_i
|
| 205 |
+
not in beam_top) or (text_pred_i in beam_top and
|
| 206 |
+
beam_top[text_pred_i][3] > pred_logprob_i):
|
| 207 |
+
beam_top[text_pred_i] = BeamEntry(text_pred_i, mask_idx_i,
|
| 208 |
+
pred_len + 1, pred_logprob_i)
|
| 209 |
+
else:
|
| 210 |
+
beam_tmp.append(
|
| 211 |
+
BeamEntry(text_pred_i, mask_idx_i, pred_len + 1,
|
| 212 |
+
pred_logprob_i))
|
| 213 |
+
|
| 214 |
+
# order all candidates by score
|
| 215 |
+
beam_tmp_kv = {}
|
| 216 |
+
for text_pred, mask_idx, pred_len, pred_logprob in beam_tmp:
|
| 217 |
+
if (text_pred not in beam_tmp_kv) or (
|
| 218 |
+
text_pred in beam_tmp_kv and
|
| 219 |
+
beam_tmp_kv[text_pred].pred_logprob > pred_logprob):
|
| 220 |
+
beam_tmp_kv[text_pred] = BeamEntry(text_pred, mask_idx, pred_len,
|
| 221 |
+
pred_logprob)
|
| 222 |
+
beam_tmp = sorted(
|
| 223 |
+
beam_tmp_kv.values(),
|
| 224 |
+
key=lambda entry: entry.pred_logprob,
|
| 225 |
+
reverse=True)
|
| 226 |
+
|
| 227 |
+
# select k best
|
| 228 |
+
beam = beam_tmp[:beam_width]
|
| 229 |
+
|
| 230 |
+
# update progress bar
|
| 231 |
+
if display_progress:
|
| 232 |
+
pbar.update(1)
|
| 233 |
+
|
| 234 |
+
# order all candidates by score
|
| 235 |
+
return sorted(
|
| 236 |
+
beam_top.values(), key=lambda entry: entry.pred_logprob,
|
| 237 |
+
reverse=True)[:beam_width]
|
| 238 |
+
|
| 239 |
+
|
| 240 |
+
def beam_search_batch_1d(forward,
|
| 241 |
+
alphabet,
|
| 242 |
+
text_pred,
|
| 243 |
+
mask_idx,
|
| 244 |
+
rng=None,
|
| 245 |
+
beam_width=20,
|
| 246 |
+
temperature=1.,
|
| 247 |
+
nucleus=False,
|
| 248 |
+
nucleus_top_p=0.8,
|
| 249 |
+
display_progress=False) -> List[BeamEntry]:
|
| 250 |
+
"""Sequential beam search."""
|
| 251 |
+
|
| 252 |
+
beam = [BeamEntry(text_pred, mask_idx, 0, 0.)]
|
| 253 |
+
beam_top = {}
|
| 254 |
+
|
| 255 |
+
# Initialise tqdm bar
|
| 256 |
+
if display_progress:
|
| 257 |
+
pbar = tqdm.tqdm(total=len(mask_idx))
|
| 258 |
+
|
| 259 |
+
while beam:
|
| 260 |
+
beam_tmp = []
|
| 261 |
+
beam_batch = []
|
| 262 |
+
|
| 263 |
+
text_chars = []
|
| 264 |
+
text_words = []
|
| 265 |
+
|
| 266 |
+
for text_pred, mask_idx, pred_len, pred_logprob in beam:
|
| 267 |
+
|
| 268 |
+
mask_idx = mask_idx.copy() # pytype: disable=attribute-error # strict_namedtuple_checks
|
| 269 |
+
text_char = text_to_idx(text_pred, alphabet).reshape(1, -1)
|
| 270 |
+
text_word = text_to_word_idx(text_pred, alphabet).reshape(1, -1)
|
| 271 |
+
text_chars.append(text_char)
|
| 272 |
+
text_words.append(text_word)
|
| 273 |
+
beam_batch.append(BeamEntry(text_pred, mask_idx, pred_len, pred_logprob))
|
| 274 |
+
text_chars = np.vstack(text_chars)
|
| 275 |
+
text_words = np.vstack(text_words)
|
| 276 |
+
|
| 277 |
+
_, _, mask_logits, _ = forward(
|
| 278 |
+
text_char=text_chars,
|
| 279 |
+
text_word=text_words,
|
| 280 |
+
text_char_onehot=None,
|
| 281 |
+
text_word_onehot=None,
|
| 282 |
+
rngs={'dropout': rng},
|
| 283 |
+
is_training=False)
|
| 284 |
+
mask_logits = mask_logits / temperature
|
| 285 |
+
mask_logits = np.array(mask_logits)
|
| 286 |
+
|
| 287 |
+
for batch_i in range(mask_logits.shape[0]):
|
| 288 |
+
text_pred, mask_idx, pred_len, pred_logprob = beam_batch[batch_i]
|
| 289 |
+
|
| 290 |
+
mask_logits_i = mask_logits[batch_i, mask_idx[0]] # pytype: disable=unsupported-operands # strict_namedtuple_checks
|
| 291 |
+
if nucleus:
|
| 292 |
+
mask_logits_i = nucleus_sample_inner(mask_logits_i, nucleus_top_p)
|
| 293 |
+
|
| 294 |
+
mask_logprob = log_softmax(mask_logits_i)
|
| 295 |
+
|
| 296 |
+
# Keep only predictions for mask
|
| 297 |
+
alphabet_chars = [alphabet.char2idx[alphabet.space]]
|
| 298 |
+
alphabet_chars += list(
|
| 299 |
+
range(alphabet.alphabet_start_idx,
|
| 300 |
+
alphabet.char2idx[alphabet.punctuation[-1]]))
|
| 301 |
+
for char_i in alphabet_chars:
|
| 302 |
+
# Skip expanding the beam if logprob too small
|
| 303 |
+
if nucleus and mask_logits_i[char_i] < -1e12:
|
| 304 |
+
continue
|
| 305 |
+
|
| 306 |
+
text_char_i = text_chars.copy()
|
| 307 |
+
text_char_i[batch_i, mask_idx[0]] = char_i # pytype: disable=unsupported-operands # strict_namedtuple_checks
|
| 308 |
+
|
| 309 |
+
text_pred_i = idx_to_text(
|
| 310 |
+
text_char_i[batch_i], alphabet, strip_sos=False, strip_pad=False)
|
| 311 |
+
|
| 312 |
+
mask_idx_i = mask_idx.copy() # pytype: disable=attribute-error # strict_namedtuple_checks
|
| 313 |
+
mask_idx_i.pop(0)
|
| 314 |
+
pred_logprob_i = pred_logprob + mask_logprob[char_i]
|
| 315 |
+
|
| 316 |
+
if not mask_idx_i:
|
| 317 |
+
if (text_pred_i
|
| 318 |
+
not in beam_top) or (text_pred_i in beam_top and
|
| 319 |
+
beam_top[text_pred_i][3] > pred_logprob_i):
|
| 320 |
+
beam_top[text_pred_i] = BeamEntry(text_pred_i, mask_idx_i,
|
| 321 |
+
pred_len + 1, pred_logprob_i)
|
| 322 |
+
else:
|
| 323 |
+
beam_tmp.append(
|
| 324 |
+
BeamEntry(text_pred_i, mask_idx_i, pred_len + 1, pred_logprob_i))
|
| 325 |
+
|
| 326 |
+
# order all candidates by score
|
| 327 |
+
beam_tmp_kv = {}
|
| 328 |
+
for text_pred, mask_idx, pred_len, pred_logprob in beam_tmp:
|
| 329 |
+
if (text_pred
|
| 330 |
+
not in beam_tmp_kv) or (text_pred in beam_tmp_kv and
|
| 331 |
+
beam_tmp_kv[text_pred][3] > pred_logprob):
|
| 332 |
+
beam_tmp_kv[text_pred] = BeamEntry(text_pred, mask_idx, pred_len,
|
| 333 |
+
pred_logprob)
|
| 334 |
+
beam_tmp = sorted(
|
| 335 |
+
beam_tmp_kv.values(),
|
| 336 |
+
key=lambda entry: entry.pred_logprob,
|
| 337 |
+
reverse=True)
|
| 338 |
+
|
| 339 |
+
# select k best
|
| 340 |
+
beam = beam_tmp[:beam_width]
|
| 341 |
+
|
| 342 |
+
# update progress bar
|
| 343 |
+
if display_progress:
|
| 344 |
+
pbar.update(1)
|
| 345 |
+
|
| 346 |
+
# order all candidates by score
|
| 347 |
+
return sorted(
|
| 348 |
+
beam_top.values(), key=lambda entry: entry.pred_logprob,
|
| 349 |
+
reverse=True)[:beam_width]
|
| 350 |
+
|
| 351 |
+
|
| 352 |
+
def saliency_loss_subregion(forward,
|
| 353 |
+
text_char_emb,
|
| 354 |
+
text_word_emb,
|
| 355 |
+
padding,
|
| 356 |
+
rng,
|
| 357 |
+
subregion=None):
|
| 358 |
+
"""Saliency map for subregion."""
|
| 359 |
+
|
| 360 |
+
_, subregion_logits, _, _ = forward(
|
| 361 |
+
text_char_emb=text_char_emb,
|
| 362 |
+
text_word_emb=text_word_emb,
|
| 363 |
+
padding=padding,
|
| 364 |
+
rngs={'dropout': rng},
|
| 365 |
+
is_training=False)
|
| 366 |
+
if subregion is None:
|
| 367 |
+
subregion = subregion_logits.argmax(axis=-1)[0]
|
| 368 |
+
return subregion_logits[0, subregion]
|
| 369 |
+
|
| 370 |
+
|
| 371 |
+
def saliency_loss_date(forward, text_char_emb, text_word_emb, padding, rng):
|
| 372 |
+
"""saliency_loss_date."""
|
| 373 |
+
|
| 374 |
+
date_pred, _, _, _ = forward(
|
| 375 |
+
text_char_emb=text_char_emb,
|
| 376 |
+
text_word_emb=text_word_emb,
|
| 377 |
+
padding=padding,
|
| 378 |
+
rngs={'dropout': rng},
|
| 379 |
+
is_training=False)
|
| 380 |
+
|
| 381 |
+
date_pred_argmax = date_pred.argmax(axis=-1)
|
| 382 |
+
return date_pred[0, date_pred_argmax[0]]
|
| 383 |
+
|
| 384 |
+
|
| 385 |
+
def predicted_dates(date_pred_probs, date_min, date_max, date_interval):
|
| 386 |
+
"""Returns mode and mean prediction."""
|
| 387 |
+
date_years = np.arange(date_min + date_interval / 2,
|
| 388 |
+
date_max + date_interval / 2, date_interval)
|
| 389 |
+
|
| 390 |
+
# Compute mode:
|
| 391 |
+
date_pred_argmax = (
|
| 392 |
+
date_pred_probs.argmax() * date_interval + date_min + date_interval // 2)
|
| 393 |
+
|
| 394 |
+
# Compute mean:
|
| 395 |
+
date_pred_avg = np.dot(date_pred_probs, date_years)
|
| 396 |
+
|
| 397 |
+
return date_pred_argmax, date_pred_avg
|
| 398 |
+
|
| 399 |
+
|
| 400 |
+
def compute_attribution_saliency_maps(text_char,
|
| 401 |
+
text_word,
|
| 402 |
+
text_len,
|
| 403 |
+
padding,
|
| 404 |
+
forward,
|
| 405 |
+
params,
|
| 406 |
+
rng,
|
| 407 |
+
alphabet,
|
| 408 |
+
vocab_char_size,
|
| 409 |
+
vocab_word_size,
|
| 410 |
+
subregion_loss_kwargs=None):
|
| 411 |
+
"""Compute saliency maps for subregions and dates."""
|
| 412 |
+
|
| 413 |
+
if subregion_loss_kwargs is None:
|
| 414 |
+
subregion_loss_kwargs = {}
|
| 415 |
+
|
| 416 |
+
# Get saliency gradients
|
| 417 |
+
dtype = params['params']['char_embeddings']['embedding'].dtype
|
| 418 |
+
text_char_onehot = jax.nn.one_hot(text_char, vocab_char_size).astype(dtype)
|
| 419 |
+
text_word_onehot = jax.nn.one_hot(text_word, vocab_word_size).astype(dtype)
|
| 420 |
+
text_char_emb = jnp.matmul(text_char_onehot,
|
| 421 |
+
params['params']['char_embeddings']['embedding'])
|
| 422 |
+
text_word_emb = jnp.matmul(text_word_onehot,
|
| 423 |
+
params['params']['word_embeddings']['embedding'])
|
| 424 |
+
gradient_subregion_char, gradient_subregion_word = jax.grad(
|
| 425 |
+
saliency_loss_subregion, (1, 2))(
|
| 426 |
+
forward,
|
| 427 |
+
text_char_emb,
|
| 428 |
+
text_word_emb,
|
| 429 |
+
padding,
|
| 430 |
+
rng=rng,
|
| 431 |
+
**subregion_loss_kwargs)
|
| 432 |
+
gradient_date_char, gradient_date_word = jax.grad(saliency_loss_date, (1, 2))(
|
| 433 |
+
forward, text_char_emb, text_word_emb, padding=padding, rng=rng)
|
| 434 |
+
|
| 435 |
+
# Generate saliency maps for subregions
|
| 436 |
+
input_grad_subregion_char = np.multiply(gradient_subregion_char,
|
| 437 |
+
text_char_emb) # grad x input
|
| 438 |
+
input_grad_subregion_word = np.multiply(gradient_subregion_word,
|
| 439 |
+
text_word_emb)
|
| 440 |
+
grad_char = grad_to_saliency_char(
|
| 441 |
+
input_grad_subregion_char,
|
| 442 |
+
text_char_onehot,
|
| 443 |
+
text_len=text_len,
|
| 444 |
+
alphabet=alphabet)
|
| 445 |
+
grad_word = grad_to_saliency_word(
|
| 446 |
+
input_grad_subregion_word,
|
| 447 |
+
text_word_onehot,
|
| 448 |
+
text_len=text_len,
|
| 449 |
+
alphabet=alphabet)
|
| 450 |
+
subregion_saliency = np.clip(grad_char + grad_word, 0, 1)
|
| 451 |
+
|
| 452 |
+
# Generate saliency maps for dates
|
| 453 |
+
input_grad_date_char = np.multiply(gradient_date_char,
|
| 454 |
+
text_char_emb) # grad x input
|
| 455 |
+
input_grad_date_word = np.multiply(gradient_date_word, text_word_emb)
|
| 456 |
+
grad_char = grad_to_saliency_char(
|
| 457 |
+
input_grad_date_char,
|
| 458 |
+
text_char_onehot,
|
| 459 |
+
text_len=text_len,
|
| 460 |
+
alphabet=alphabet)
|
| 461 |
+
grad_word = grad_to_saliency_word(
|
| 462 |
+
input_grad_date_word,
|
| 463 |
+
text_word_onehot,
|
| 464 |
+
text_len=text_len,
|
| 465 |
+
alphabet=alphabet)
|
| 466 |
+
date_saliency = np.clip(grad_char + grad_word, 0, 1)
|
| 467 |
+
|
| 468 |
+
return date_saliency, subregion_saliency
|
| 469 |
+
|
| 470 |
+
|
| 471 |
+
def saliency_loss_mask(forward, text_char_emb, text_word_emb, padding, rng,
|
| 472 |
+
char_pos, char_idx):
|
| 473 |
+
"""Saliency map for mask."""
|
| 474 |
+
|
| 475 |
+
_, _, mask_logits, _ = forward(
|
| 476 |
+
text_char_emb=text_char_emb,
|
| 477 |
+
text_word_emb=text_word_emb,
|
| 478 |
+
text_char_onehot=None,
|
| 479 |
+
text_word_onehot=None,
|
| 480 |
+
padding=padding,
|
| 481 |
+
rngs={'dropout': rng},
|
| 482 |
+
is_training=False)
|
| 483 |
+
return mask_logits[0, char_pos, char_idx]
|
| 484 |
+
|
| 485 |
+
|
| 486 |
+
class SequentialRestorationSaliencyResult(NamedTuple):
|
| 487 |
+
text: str # predicted text string so far
|
| 488 |
+
pred_char_pos: int # newly restored character's position
|
| 489 |
+
saliency_map: np.ndarray # saliency map for the newly added character
|
| 490 |
+
|
| 491 |
+
|
| 492 |
+
def sequential_restoration_saliency(text_str, text_len, forward, params,
|
| 493 |
+
alphabet, mask_idx, vocab_char_size,
|
| 494 |
+
vocab_word_size):
|
| 495 |
+
"""Greedily, non-sequentially restores, producing per-step saliency maps."""
|
| 496 |
+
text_len = text_len[0] if not isinstance(text_len, int) else text_len
|
| 497 |
+
rng = jax.random.PRNGKey(0) # dummy, no randomness in model
|
| 498 |
+
mask_idx = set(mask_idx)
|
| 499 |
+
while mask_idx:
|
| 500 |
+
text_char = text_to_idx(text_str, alphabet).reshape(1, -1)
|
| 501 |
+
padding = jnp.where(text_char > 0, 1, 0)
|
| 502 |
+
text_word = text_to_word_idx(text_str, alphabet).reshape(1, -1)
|
| 503 |
+
|
| 504 |
+
_, _, mask_logits, _ = forward(
|
| 505 |
+
text_char=text_char,
|
| 506 |
+
text_word=text_word,
|
| 507 |
+
text_char_onehot=None,
|
| 508 |
+
text_word_onehot=None,
|
| 509 |
+
rngs={'dropout': rng},
|
| 510 |
+
is_training=False)
|
| 511 |
+
mask_pred = jax.nn.softmax(mask_logits)[0, :text_len]
|
| 512 |
+
mask_pred_argmax = np.dstack(
|
| 513 |
+
np.unravel_index(np.argsort(-mask_pred.ravel()), mask_pred.shape))[0]
|
| 514 |
+
|
| 515 |
+
# Greedily, non-sequentially take the next highest probability prediction
|
| 516 |
+
# out of the characters that are to be restored
|
| 517 |
+
for i in range(mask_pred_argmax.shape[0]):
|
| 518 |
+
pred_char_pos, pred_char_idx = mask_pred_argmax[i]
|
| 519 |
+
if pred_char_pos in mask_idx:
|
| 520 |
+
break
|
| 521 |
+
|
| 522 |
+
# Update sequence
|
| 523 |
+
text_char[0, pred_char_pos] = pred_char_idx
|
| 524 |
+
text_str = idx_to_text(
|
| 525 |
+
text_char[0], alphabet, strip_sos=False, strip_pad=False)
|
| 526 |
+
mask_idx.remove(pred_char_pos)
|
| 527 |
+
|
| 528 |
+
# Gradients for saliency map
|
| 529 |
+
text_char_onehot = jax.nn.one_hot(text_char,
|
| 530 |
+
vocab_char_size).astype(jnp.float32)
|
| 531 |
+
text_word_onehot = jax.nn.one_hot(text_word,
|
| 532 |
+
vocab_word_size).astype(jnp.float32)
|
| 533 |
+
|
| 534 |
+
text_char_emb = jnp.matmul(text_char_onehot,
|
| 535 |
+
params['params']['char_embeddings']['embedding'])
|
| 536 |
+
text_word_emb = jnp.matmul(text_word_onehot,
|
| 537 |
+
params['params']['word_embeddings']['embedding'])
|
| 538 |
+
|
| 539 |
+
gradient_mask_char, gradient_mask_word = jax.grad(
|
| 540 |
+
saliency_loss_mask, (1, 2))(
|
| 541 |
+
forward,
|
| 542 |
+
text_char_emb,
|
| 543 |
+
text_word_emb,
|
| 544 |
+
padding,
|
| 545 |
+
rng=rng,
|
| 546 |
+
char_pos=pred_char_pos,
|
| 547 |
+
char_idx=pred_char_idx)
|
| 548 |
+
|
| 549 |
+
# Use gradient x input for visualizing saliency
|
| 550 |
+
input_grad_mask_char = np.multiply(gradient_mask_char, text_char_emb)
|
| 551 |
+
input_grad_mask_word = np.multiply(gradient_mask_word, text_word_emb)
|
| 552 |
+
|
| 553 |
+
# Return visualization-ready saliency maps
|
| 554 |
+
saliency_map = grad_to_saliency_char(
|
| 555 |
+
np.clip(input_grad_mask_char + input_grad_mask_word, 0, 1),
|
| 556 |
+
text_char_onehot, [text_len], alphabet) # normalize, etc.
|
| 557 |
+
result_text = idx_to_text(text_char[0], alphabet, strip_sos=False) # no pad
|
| 558 |
+
|
| 559 |
+
yield SequentialRestorationSaliencyResult(
|
| 560 |
+
text=result_text[1:],
|
| 561 |
+
pred_char_pos=pred_char_pos - 1,
|
| 562 |
+
saliency_map=saliency_map[1:])
|
ithaca/util/loss.py
ADDED
|
@@ -0,0 +1,117 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2021 the Ithaca Authors
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
"""Loss functions."""
|
| 15 |
+
import chex
|
| 16 |
+
from flax.deprecated import nn
|
| 17 |
+
import jax
|
| 18 |
+
import jax.numpy as jnp
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def smooth_labels(labels, num_classes, label_smoothing):
|
| 22 |
+
if not 0 <= label_smoothing < 1:
|
| 23 |
+
raise ValueError(
|
| 24 |
+
f"'label_smoothing is {label_smoothing} and should be in [0, 1)")
|
| 25 |
+
one = jax.lax.convert_element_type(1, labels.dtype)
|
| 26 |
+
label_smoothing = jax.lax.convert_element_type(label_smoothing,
|
| 27 |
+
labels.dtype)
|
| 28 |
+
num_classes = jax.lax.convert_element_type(num_classes, labels.dtype)
|
| 29 |
+
return (one - label_smoothing) * labels + (label_smoothing / num_classes)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def categorical_kl_divergence(p_logits, q_logits, temperature=1.):
|
| 33 |
+
"""Compute the KL between two categorical distributions from their logits.
|
| 34 |
+
|
| 35 |
+
Args:
|
| 36 |
+
p_logits: unnormalized logits for the first distribution.
|
| 37 |
+
q_logits: unnormalized logits for the second distribution.
|
| 38 |
+
temperature: the temperature for the softmax distribution, defaults at 1.
|
| 39 |
+
|
| 40 |
+
Returns:
|
| 41 |
+
the kl divergence between the distributions.
|
| 42 |
+
"""
|
| 43 |
+
chex.assert_type([p_logits, q_logits], float)
|
| 44 |
+
|
| 45 |
+
p_logits /= temperature
|
| 46 |
+
q_logits /= temperature
|
| 47 |
+
|
| 48 |
+
p = jax.nn.softmax(p_logits)
|
| 49 |
+
log_p = jax.nn.log_softmax(p_logits)
|
| 50 |
+
log_q = jax.nn.log_softmax(q_logits)
|
| 51 |
+
kl = jnp.sum(p * (log_p - log_q), axis=-1)
|
| 52 |
+
return jax.nn.relu(kl) # Guard against numerical issues giving negative KL.
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def cross_entropy_label_smoothing_loss(logits,
|
| 56 |
+
labels,
|
| 57 |
+
mask=None,
|
| 58 |
+
label_smoothing=0.1):
|
| 59 |
+
"""Cross entropy loss with label smoothing."""
|
| 60 |
+
|
| 61 |
+
num_classes = logits.shape[-1]
|
| 62 |
+
labels_onehot = jax.nn.one_hot(labels, num_classes, dtype=logits.dtype)
|
| 63 |
+
if label_smoothing > 0:
|
| 64 |
+
labels_onehot = smooth_labels(labels_onehot, num_classes, label_smoothing)
|
| 65 |
+
|
| 66 |
+
loss = -jnp.sum(labels_onehot * jax.nn.log_softmax(logits), axis=-1)
|
| 67 |
+
if mask is not None:
|
| 68 |
+
loss = jnp.multiply(loss, mask.astype(logits.dtype))
|
| 69 |
+
return loss
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
@jax.vmap
|
| 73 |
+
def cross_entropy_loss(logits, label):
|
| 74 |
+
logits = nn.log_softmax(logits)
|
| 75 |
+
return -logits[label]
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def cross_entropy_mask_loss(logits, label, mask):
|
| 79 |
+
nll = -nn.log_softmax(logits)[label]
|
| 80 |
+
loss = jnp.multiply(nll, mask.astype(logits.dtype))
|
| 81 |
+
return loss
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
def date_loss_l2(pred,
|
| 85 |
+
target_min,
|
| 86 |
+
target_max,
|
| 87 |
+
mask):
|
| 88 |
+
"""L2 loss function for dates."""
|
| 89 |
+
pred = jnp.squeeze(pred, 0)
|
| 90 |
+
|
| 91 |
+
loss = 0.
|
| 92 |
+
loss += (pred - target_min)**2 * jnp.less(pred, target_min).astype(
|
| 93 |
+
pred.dtype)
|
| 94 |
+
loss += (pred - target_max)**2 * jnp.greater(pred, target_max).astype(
|
| 95 |
+
pred.dtype)
|
| 96 |
+
|
| 97 |
+
# Mask loss
|
| 98 |
+
loss = jnp.multiply(loss, mask.astype(loss.dtype))
|
| 99 |
+
return loss
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def date_loss_l1(pred,
|
| 103 |
+
target_min,
|
| 104 |
+
target_max,
|
| 105 |
+
mask):
|
| 106 |
+
"""L1 loss function for dates."""
|
| 107 |
+
pred = jnp.squeeze(pred, 0)
|
| 108 |
+
|
| 109 |
+
loss = 0.
|
| 110 |
+
loss += jnp.abs(pred - target_min) * jnp.less(pred, target_min).astype(
|
| 111 |
+
pred.dtype)
|
| 112 |
+
loss += jnp.abs(pred - target_max) * jnp.greater(pred, target_max).astype(
|
| 113 |
+
pred.dtype)
|
| 114 |
+
|
| 115 |
+
# Mask loss
|
| 116 |
+
loss = jnp.multiply(loss, mask.astype(loss.dtype))
|
| 117 |
+
return loss
|
ithaca/util/optim.py
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2021 the Ithaca Authors
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
"""Optimizer utilities."""
|
| 15 |
+
|
| 16 |
+
from typing import Any, Callable, NamedTuple, Optional, Sequence, Tuple, Union
|
| 17 |
+
import jax
|
| 18 |
+
import jax.numpy as jnp
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def linear_weight(global_step, start, end):
|
| 22 |
+
"""Linear weight increase."""
|
| 23 |
+
if end <= 0:
|
| 24 |
+
return 1.
|
| 25 |
+
t = jnp.maximum(0., global_step - start)
|
| 26 |
+
w = t / (end - start)
|
| 27 |
+
w = jnp.minimum(w, 1.)
|
| 28 |
+
return w
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def linear_warmup_and_sqrt_decay(global_step, max_lr, warmup_steps):
|
| 32 |
+
"""Linear warmup and then an inverse square root decay of learning rate."""
|
| 33 |
+
linear_ratio = max_lr / warmup_steps
|
| 34 |
+
decay_ratio = jnp.power(warmup_steps * 1.0, 0.5) * max_lr
|
| 35 |
+
return jnp.minimum(linear_ratio * global_step,
|
| 36 |
+
decay_ratio * jnp.power(global_step, -0.5))
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def create_learning_rate_scheduler(
|
| 40 |
+
factors='constant * linear_warmup * rsqrt_decay',
|
| 41 |
+
base_learning_rate=0.5,
|
| 42 |
+
warmup_steps=1000,
|
| 43 |
+
decay_factor=0.5,
|
| 44 |
+
steps_per_decay=20000,
|
| 45 |
+
steps_per_cycle=100000):
|
| 46 |
+
"""Creates learning rate schedule.
|
| 47 |
+
|
| 48 |
+
Interprets factors in the factors string which can consist of:
|
| 49 |
+
* constant: interpreted as the constant value,
|
| 50 |
+
* linear_warmup: interpreted as linear warmup until warmup_steps,
|
| 51 |
+
* rsqrt_decay: divide by square root of max(step, warmup_steps)
|
| 52 |
+
* rsqrt_normalized_decay: divide by square root of max(step/warmup_steps, 1)
|
| 53 |
+
* decay_every: Every k steps decay the learning rate by decay_factor.
|
| 54 |
+
* cosine_decay: Cyclic cosine decay, uses steps_per_cycle parameter.
|
| 55 |
+
|
| 56 |
+
Args:
|
| 57 |
+
factors: string, factors separated by '*' that defines the schedule.
|
| 58 |
+
base_learning_rate: float, the starting constant for the lr schedule.
|
| 59 |
+
warmup_steps: int, how many steps to warm up for in the warmup schedule.
|
| 60 |
+
decay_factor: float, the amount to decay the learning rate by.
|
| 61 |
+
steps_per_decay: int, how often to decay the learning rate.
|
| 62 |
+
steps_per_cycle: int, steps per cycle when using cosine decay.
|
| 63 |
+
|
| 64 |
+
Returns:
|
| 65 |
+
a function learning_rate(step): float -> {'learning_rate': float}, the
|
| 66 |
+
step-dependent lr.
|
| 67 |
+
"""
|
| 68 |
+
factors = [n.strip() for n in factors.split('*')]
|
| 69 |
+
|
| 70 |
+
def step_fn(step):
|
| 71 |
+
"""Step to learning rate function."""
|
| 72 |
+
ret = 1.0
|
| 73 |
+
for name in factors:
|
| 74 |
+
if name == 'constant':
|
| 75 |
+
ret *= base_learning_rate
|
| 76 |
+
elif name == 'linear_warmup':
|
| 77 |
+
ret *= jnp.minimum(1.0, step / warmup_steps)
|
| 78 |
+
elif name == 'rsqrt_decay':
|
| 79 |
+
ret /= jnp.sqrt(jnp.maximum(step, warmup_steps))
|
| 80 |
+
elif name == 'rsqrt_normalized_decay':
|
| 81 |
+
ret *= jnp.sqrt(warmup_steps)
|
| 82 |
+
ret /= jnp.sqrt(jnp.maximum(step, warmup_steps))
|
| 83 |
+
elif name == 'decay_every':
|
| 84 |
+
ret *= (decay_factor**(step // steps_per_decay))
|
| 85 |
+
elif name == 'cosine_decay':
|
| 86 |
+
progress = jnp.maximum(0.0,
|
| 87 |
+
(step - warmup_steps) / float(steps_per_cycle))
|
| 88 |
+
ret *= jnp.maximum(0.0,
|
| 89 |
+
0.5 * (1.0 + jnp.cos(jnp.pi * (progress % 1.0))))
|
| 90 |
+
else:
|
| 91 |
+
raise ValueError('Unknown factor %s.' % name)
|
| 92 |
+
return jnp.asarray(ret, dtype=jnp.float32)
|
| 93 |
+
|
| 94 |
+
return step_fn
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
# pylint:disable=no-value-for-parameter
|
| 98 |
+
OptState = NamedTuple # Transformation states are (possibly empty) namedtuples.
|
| 99 |
+
Params = Any # Parameters are arbitrary nests of `jnp.ndarrays`.
|
| 100 |
+
Updates = Params # Gradient updates are of the same type as parameters.
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
class GradientTransformation(NamedTuple):
|
| 104 |
+
"""Optax transformations consists of a function pair: (initialise, update)."""
|
| 105 |
+
init: Callable[ # Function used to initialise the transformation's state.
|
| 106 |
+
[Params], Union[OptState, Sequence[OptState]]]
|
| 107 |
+
update: Callable[ # Function used to apply a transformation.
|
| 108 |
+
[Updates, OptState, Optional[Params]], Tuple[Updates, OptState]]
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
class ClipByGlobalNormState(OptState):
|
| 112 |
+
"""The `clip_by_global_norm` transformation is stateless."""
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
def unitwise_norm(x):
|
| 116 |
+
"""Computes norms of each output unit separately."""
|
| 117 |
+
if len(jnp.squeeze(x).shape) <= 1: # Scalars and vectors
|
| 118 |
+
axis = None
|
| 119 |
+
keepdims = False
|
| 120 |
+
elif len(x.shape) in [2, 3]: # Linear layers of shape IO or multihead linear
|
| 121 |
+
axis = 0
|
| 122 |
+
keepdims = True
|
| 123 |
+
elif len(x.shape) == 4: # Conv kernels of shape HWIO
|
| 124 |
+
axis = [0, 1, 2,]
|
| 125 |
+
keepdims = True
|
| 126 |
+
else:
|
| 127 |
+
raise ValueError(f'Got a parameter with shape not in [1, 2, 3, 4]! {x}')
|
| 128 |
+
return jnp.sum(x ** 2, axis=axis, keepdims=keepdims) ** 0.5
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
def unitwise_clip(g_norm, max_norm, grad):
|
| 132 |
+
"""Applies gradient clipping unit-wise."""
|
| 133 |
+
trigger = g_norm < max_norm
|
| 134 |
+
# This little max(., 1e-6) is distinct from the normal eps and just prevents
|
| 135 |
+
# division by zero. It technically should be impossible to engage.
|
| 136 |
+
clipped_grad = grad * (max_norm / jnp.maximum(g_norm, 1e-6))
|
| 137 |
+
return jnp.where(trigger, grad, clipped_grad)
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
def adaptive_grad_clip(clipping, eps=1e-3) -> GradientTransformation:
|
| 141 |
+
"""Clip updates to be at most clipping * parameter_norm, unit-wise.
|
| 142 |
+
|
| 143 |
+
References:
|
| 144 |
+
[Brock, Smith, De, Simonyan 2021] High-Performance Large-Scale Image
|
| 145 |
+
Recognition Without Normalization. (https://arxiv.org/abs/2102.06171)
|
| 146 |
+
|
| 147 |
+
Args:
|
| 148 |
+
clipping: Maximum allowed ratio of update norm to parameter norm.
|
| 149 |
+
eps: epsilon term to prevent clipping of zero-initialized params.
|
| 150 |
+
|
| 151 |
+
Returns:
|
| 152 |
+
An (init_fn, update_fn) tuple.
|
| 153 |
+
"""
|
| 154 |
+
|
| 155 |
+
def init_fn(_):
|
| 156 |
+
return ClipByGlobalNormState()
|
| 157 |
+
|
| 158 |
+
def update_fn(updates, state, params):
|
| 159 |
+
g_norm = jax.tree_map(unitwise_norm, updates)
|
| 160 |
+
p_norm = jax.tree_map(unitwise_norm, params)
|
| 161 |
+
# Maximum allowable norm
|
| 162 |
+
max_norm = jax.tree_map(lambda x: clipping * jnp.maximum(x, eps), p_norm)
|
| 163 |
+
# If grad norm > clipping * param_norm, rescale
|
| 164 |
+
updates = jax.tree_multimap(unitwise_clip, g_norm, max_norm, updates)
|
| 165 |
+
return updates, state
|
| 166 |
+
|
| 167 |
+
return GradientTransformation(init_fn, update_fn)
|
ithaca/util/region_names.py
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2021 the Ithaca Authors
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
"""Subregion mapping used to train the model.
|
| 15 |
+
|
| 16 |
+
The subregion IDs originate from the I.PHI generator and may be subject to
|
| 17 |
+
change in future versions of the PHI dataset.
|
| 18 |
+
"""
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def load_region_maps(region_file):
|
| 22 |
+
"""Extracts creates a map from PHI region id to a continuous region id."""
|
| 23 |
+
region_ids = [] # Used mainly for eval
|
| 24 |
+
region_ids_inv = {} # Used in data loader
|
| 25 |
+
region_names_inv = {} # Used in eval
|
| 26 |
+
for l in region_file.read().strip().split('\n'):
|
| 27 |
+
tok_name_id, _ = l.strip().split(';') # second field is frequency, unused
|
| 28 |
+
region_name, region_id = tok_name_id.split('_')
|
| 29 |
+
region_name = region_name.strip()
|
| 30 |
+
region_id = int(region_id)
|
| 31 |
+
# Ignore unknown regions:
|
| 32 |
+
if ((region_name == 'Unknown Provenances' and region_id == 884) or
|
| 33 |
+
(region_name == 'unspecified subregion' and region_id == 885) or
|
| 34 |
+
(region_name == 'unspecified subregion' and region_id == 1439)):
|
| 35 |
+
continue
|
| 36 |
+
region_ids.append(region_id)
|
| 37 |
+
region_ids_inv[region_id] = len(region_ids_inv)
|
| 38 |
+
region_names_inv[len(region_names_inv)] = region_name
|
| 39 |
+
|
| 40 |
+
return {
|
| 41 |
+
'ids': region_ids,
|
| 42 |
+
'ids_inv': region_ids_inv,
|
| 43 |
+
'names_inv': region_names_inv
|
| 44 |
+
}
|
ithaca/util/text.py
ADDED
|
@@ -0,0 +1,186 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2021 the Ithaca Authors
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
"""Text processing functions."""
|
| 15 |
+
|
| 16 |
+
import random
|
| 17 |
+
import re
|
| 18 |
+
import unicodedata
|
| 19 |
+
|
| 20 |
+
import numpy as np
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def idx_to_text(idxs, alphabet, strip_sos=True, strip_pad=True):
|
| 24 |
+
"""Converts a list of indices to a string."""
|
| 25 |
+
idxs = np.array(idxs)
|
| 26 |
+
out = ''
|
| 27 |
+
for i in range(idxs.size):
|
| 28 |
+
idx = idxs[i]
|
| 29 |
+
if strip_pad and idx == alphabet.pad_idx:
|
| 30 |
+
break
|
| 31 |
+
elif strip_sos and idx == alphabet.sos_idx:
|
| 32 |
+
pass
|
| 33 |
+
else:
|
| 34 |
+
out += alphabet.idx2char[idx]
|
| 35 |
+
return out
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def idx_to_text_batch(idxs, alphabet, lengths=None):
|
| 39 |
+
"""Converts batched lists of indices to strings."""
|
| 40 |
+
b = []
|
| 41 |
+
for i in range(idxs.shape[0]):
|
| 42 |
+
idxs_i = idxs[i]
|
| 43 |
+
if lengths:
|
| 44 |
+
idxs_i = idxs_i[:lengths[i]]
|
| 45 |
+
b.append(idx_to_text(idxs_i, alphabet))
|
| 46 |
+
return b
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def random_mask_span(t, geometric_p=0.2, limit_chars=None):
|
| 50 |
+
"""Masks a span of sequential words."""
|
| 51 |
+
|
| 52 |
+
# Obtain span indexes (indlusive)
|
| 53 |
+
span_idx = [(ele.start(), ele.end()) for ele in re.finditer(r'[\w\s]+', t)]
|
| 54 |
+
if not span_idx:
|
| 55 |
+
return []
|
| 56 |
+
|
| 57 |
+
# Select a span to mask
|
| 58 |
+
span_start, span_end = random.choice(span_idx)
|
| 59 |
+
|
| 60 |
+
# Sample a random span length using a geomteric distribution
|
| 61 |
+
if geometric_p and limit_chars:
|
| 62 |
+
span_len = np.clip(
|
| 63 |
+
np.random.geometric(geometric_p),
|
| 64 |
+
1, min(limit_chars, span_end - span_start))
|
| 65 |
+
elif geometric_p:
|
| 66 |
+
span_len = np.clip(
|
| 67 |
+
np.random.geometric(geometric_p),
|
| 68 |
+
1, span_end - span_start)
|
| 69 |
+
elif limit_chars:
|
| 70 |
+
span_len = min(limit_chars, span_end - span_start)
|
| 71 |
+
else:
|
| 72 |
+
raise ValueError('geometric_p or limit_chars should be set.')
|
| 73 |
+
|
| 74 |
+
# Pick a random start index
|
| 75 |
+
span_start = np.random.randint(span_start, span_end - span_len + 1)
|
| 76 |
+
assert span_start + span_len <= span_end
|
| 77 |
+
|
| 78 |
+
# Clip to limit chars
|
| 79 |
+
if limit_chars is not None and span_len >= limit_chars:
|
| 80 |
+
span_len = limit_chars
|
| 81 |
+
|
| 82 |
+
# Create mask indices
|
| 83 |
+
mask_idx = list(range(span_start, span_start + span_len))
|
| 84 |
+
|
| 85 |
+
return mask_idx
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def random_sentence_swap(sentences, p):
|
| 89 |
+
"""Swaps sentences with probability p."""
|
| 90 |
+
|
| 91 |
+
def swap_sentence(s):
|
| 92 |
+
idx_1 = random.randint(0, len(s) - 1)
|
| 93 |
+
idx_2 = idx_1
|
| 94 |
+
counter = 0
|
| 95 |
+
|
| 96 |
+
while idx_2 == idx_1:
|
| 97 |
+
idx_2 = random.randint(0, len(s) - 1)
|
| 98 |
+
counter += 1
|
| 99 |
+
if counter > 3:
|
| 100 |
+
return s
|
| 101 |
+
|
| 102 |
+
s[idx_1], s[idx_2] = s[idx_2], s[idx_1]
|
| 103 |
+
return s
|
| 104 |
+
|
| 105 |
+
new_sentences = sentences.copy()
|
| 106 |
+
n = int(p * len(sentences))
|
| 107 |
+
for _ in range(n):
|
| 108 |
+
new_sentences = swap_sentence(new_sentences)
|
| 109 |
+
|
| 110 |
+
return new_sentences
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
def random_word_delete(sentence, p):
|
| 114 |
+
"""Deletes a word from a sentence with probability p."""
|
| 115 |
+
|
| 116 |
+
words = sentence.split(' ')
|
| 117 |
+
|
| 118 |
+
# Return if one word.
|
| 119 |
+
if len(words) == 1:
|
| 120 |
+
return words[0]
|
| 121 |
+
|
| 122 |
+
# Randomly delete words.
|
| 123 |
+
new_words = []
|
| 124 |
+
for word in words:
|
| 125 |
+
if random.uniform(0, 1) > p:
|
| 126 |
+
new_words.append(word)
|
| 127 |
+
|
| 128 |
+
# If all words are removed return one.
|
| 129 |
+
if not new_words:
|
| 130 |
+
rand_int = random.randint(0, len(words) - 1)
|
| 131 |
+
return words[rand_int]
|
| 132 |
+
|
| 133 |
+
sentence = ' '.join(new_words)
|
| 134 |
+
|
| 135 |
+
return sentence
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
def random_word_swap(sentence, p):
|
| 139 |
+
"""Swaps words from a sentence with probability p."""
|
| 140 |
+
|
| 141 |
+
def swap_word(new_words):
|
| 142 |
+
idx_1 = random.randint(0, len(new_words) - 1)
|
| 143 |
+
idx_2 = idx_1
|
| 144 |
+
counter = 0
|
| 145 |
+
|
| 146 |
+
while idx_2 == idx_1:
|
| 147 |
+
idx_2 = random.randint(0, len(new_words) - 1)
|
| 148 |
+
counter += 1
|
| 149 |
+
|
| 150 |
+
if counter > 3:
|
| 151 |
+
return new_words
|
| 152 |
+
|
| 153 |
+
new_words[idx_1], new_words[idx_2] = new_words[idx_2], new_words[idx_1]
|
| 154 |
+
return new_words
|
| 155 |
+
|
| 156 |
+
words = sentence.split(' ')
|
| 157 |
+
|
| 158 |
+
new_words = words.copy()
|
| 159 |
+
n = int(p * len(words))
|
| 160 |
+
for _ in range(n):
|
| 161 |
+
new_words = swap_word(new_words)
|
| 162 |
+
|
| 163 |
+
sentence = ' '.join(new_words)
|
| 164 |
+
|
| 165 |
+
return sentence
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
def strip_accents(s):
|
| 169 |
+
return ''.join(
|
| 170 |
+
c for c in unicodedata.normalize('NFD', s)
|
| 171 |
+
if unicodedata.category(c) != 'Mn')
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
def text_to_idx(t, alphabet):
|
| 175 |
+
"""Converts a string to character indices."""
|
| 176 |
+
return np.array([alphabet.char2idx[c] for c in t], dtype=np.int32)
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
def text_to_word_idx(t, alphabet):
|
| 180 |
+
"""Converts a string to word indices."""
|
| 181 |
+
out = np.full(len(t), alphabet.word2idx[alphabet.unk], dtype=np.int32)
|
| 182 |
+
for m in re.finditer(r'\w+', t):
|
| 183 |
+
if m.group() in alphabet.word2idx:
|
| 184 |
+
out[m.start():m.end()] = alphabet.word2idx[m.group()]
|
| 185 |
+
return out
|
| 186 |
+
|
requirements.txt
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
absl-py==0.13.0
|
| 2 |
+
chex==0.0.8
|
| 3 |
+
flax==0.3.6
|
| 4 |
+
dm-haiku==0.0.5
|
| 5 |
+
jax==0.2.21
|
| 6 |
+
ml-collections==0.1.1
|
| 7 |
+
numpy>=1.18.0
|
| 8 |
+
tqdm>=4.62.2
|
setup.py
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2021 the Ithaca Authors
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
"""Setup module for Ithaca.
|
| 15 |
+
|
| 16 |
+
Only installs the inference components.
|
| 17 |
+
|
| 18 |
+
See README.md for more details.
|
| 19 |
+
"""
|
| 20 |
+
|
| 21 |
+
import pathlib
|
| 22 |
+
import setuptools
|
| 23 |
+
|
| 24 |
+
here = pathlib.Path(__file__).parent.resolve()
|
| 25 |
+
long_description = (here / 'README.md').read_text(encoding='utf-8')
|
| 26 |
+
setuptools.setup(
|
| 27 |
+
name='ithaca',
|
| 28 |
+
author='Ithaca team',
|
| 29 |
+
author_email='[email protected]',
|
| 30 |
+
version='0.1.0',
|
| 31 |
+
license='Apache License, Version 2.0',
|
| 32 |
+
description='Ithaca library for ancient text restoration and attribution.',
|
| 33 |
+
long_description=long_description,
|
| 34 |
+
long_description_content_type='text/markdown',
|
| 35 |
+
packages=setuptools.find_packages(exclude=('train',)),
|
| 36 |
+
package_data={'': ['*.txt']},
|
| 37 |
+
install_requires=(here / 'requirements.txt').read_text().splitlines(),
|
| 38 |
+
extras_require={
|
| 39 |
+
'train': [
|
| 40 |
+
'optax',
|
| 41 |
+
'jaxline==0.0.5',
|
| 42 |
+
'tensorflow-datasets',
|
| 43 |
+
]
|
| 44 |
+
},
|
| 45 |
+
classifiers=[
|
| 46 |
+
'Development Status :: 4 - Beta',
|
| 47 |
+
'Intended Audience :: Developers',
|
| 48 |
+
'Intended Audience :: Science/Research',
|
| 49 |
+
'License :: OSI Approved :: Apache Software License',
|
| 50 |
+
'Topic :: Scientific/Engineering :: Artificial Intelligence',
|
| 51 |
+
],
|
| 52 |
+
)
|
train/README.md
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Ithaca training code
|
| 2 |
+
|
| 3 |
+
We recommend creating and activating a `conda` environment to ensure a clean
|
| 4 |
+
environment where the correct package versions are installed below.
|
| 5 |
+
```sh
|
| 6 |
+
# Optional but recommended:
|
| 7 |
+
conda create -n ithaca python==3.9
|
| 8 |
+
conda activate ithaca
|
| 9 |
+
```
|
| 10 |
+
|
| 11 |
+
Clone this repository and enter its root directory. Install the full `ithaca`
|
| 12 |
+
dependencies (including training), via:
|
| 13 |
+
```sh
|
| 14 |
+
git clone https://github.com/deepmind/ithaca
|
| 15 |
+
cd ithaca
|
| 16 |
+
pip install --editable .[train]
|
| 17 |
+
cd train/
|
| 18 |
+
```
|
| 19 |
+
The `--editable` option links the `ithaca` installation to this repository, so
|
| 20 |
+
that `import ithaca` will reflect any local modifications to the source code.
|
| 21 |
+
|
| 22 |
+
Then, ensure you have TensorFlow installed. If you do not, install either the CPU or GPU version following the [instructions on the TensorFlow website](https://www.tensorflow.org/install/pip).
|
| 23 |
+
While we use [Jax](https://github.com/google/jax) for training, TensorFlow is still needed for dataset loading.
|
| 24 |
+
|
| 25 |
+
Next, ensure you have placed the dataset in `data/iphi.json`, note the wordlist and region mappings are also in that directory and may need to be replaced if they change in an updated version of the dataset. The dataset can be obtained from [I.PHI dataset](https://github.com/sommerschield/iphi).
|
| 26 |
+
|
| 27 |
+
Finally, to run training, run:
|
| 28 |
+
```sh
|
| 29 |
+
./launch_local.sh
|
| 30 |
+
```
|
| 31 |
+
Alternatively, you can manually run:
|
| 32 |
+
```sh
|
| 33 |
+
python experiment.py --config=config.py --jaxline_mode=train --logtostderr
|
| 34 |
+
```
|
train/config.py
ADDED
|
@@ -0,0 +1,173 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2021 the Ithaca Authors
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
"""Config for a Ithaca experiment."""
|
| 15 |
+
|
| 16 |
+
from jaxline import base_config
|
| 17 |
+
from ml_collections import config_dict
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def get_config():
|
| 21 |
+
"""Return config object for training."""
|
| 22 |
+
|
| 23 |
+
config = base_config.get_base_config()
|
| 24 |
+
|
| 25 |
+
# Experiment config.
|
| 26 |
+
# Modify this to adapt to your custom distributed learning setup
|
| 27 |
+
local_batch_size = 1
|
| 28 |
+
num_devices = 1
|
| 29 |
+
config.train_batch_size = local_batch_size * num_devices
|
| 30 |
+
|
| 31 |
+
# Experiment config.
|
| 32 |
+
config.macros = config_dict.ConfigDict(
|
| 33 |
+
dict(
|
| 34 |
+
wordlist_size=35884, # Keeping words with freq >10
|
| 35 |
+
context_char_max=768,
|
| 36 |
+
date_max=800,
|
| 37 |
+
date_min=-800,
|
| 38 |
+
date_interval=10,
|
| 39 |
+
date_bins=160,
|
| 40 |
+
))
|
| 41 |
+
cm = config.macros # Alias.
|
| 42 |
+
|
| 43 |
+
config.experiment_kwargs = config_dict.ConfigDict(
|
| 44 |
+
dict(
|
| 45 |
+
config=dict(
|
| 46 |
+
random_seed=4,
|
| 47 |
+
random_mode_train=config.get_ref('random_mode_train'),
|
| 48 |
+
random_mode_eval=config.get_ref('random_mode_eval'),
|
| 49 |
+
optimizer=dict(
|
| 50 |
+
name='lamb',
|
| 51 |
+
kwargs=dict(
|
| 52 |
+
learning_rate=3e-4,
|
| 53 |
+
weight_decay=0.,
|
| 54 |
+
b2=0.999,
|
| 55 |
+
),
|
| 56 |
+
# Set up the learning rate schedule.
|
| 57 |
+
# factors='constant * linear_warmup * rsqrt_decay',
|
| 58 |
+
warmup=4000,
|
| 59 |
+
clip_adaptive=False,
|
| 60 |
+
clip_level=0.,
|
| 61 |
+
),
|
| 62 |
+
training=dict(
|
| 63 |
+
batch_size=config.get_oneway_ref('train_batch_size')),
|
| 64 |
+
alphabet=dict(
|
| 65 |
+
wordlist_path='data/iphi-wordlist.txt',
|
| 66 |
+
wordlist_size=cm.get_ref('wordlist_size'),
|
| 67 |
+
),
|
| 68 |
+
dataset=dict(
|
| 69 |
+
dataset_path='data/iphi.json',
|
| 70 |
+
region_main_path='data/iphi-region-main.txt',
|
| 71 |
+
region_sub_path='data/iphi-region-sub.txt',
|
| 72 |
+
context_char_min=50,
|
| 73 |
+
context_char_max=cm.get_ref('context_char_max'),
|
| 74 |
+
context_char_random=True,
|
| 75 |
+
char_use_guess=True,
|
| 76 |
+
char_mask_rate_min=0.,
|
| 77 |
+
char_mask_rate_max=0.5,
|
| 78 |
+
span_mask_eval_len=10,
|
| 79 |
+
span_mask_ratio=0.15,
|
| 80 |
+
span_mask_geometric_p=0.1,
|
| 81 |
+
random_sentence_swap=0.25,
|
| 82 |
+
random_word_delete=0.2,
|
| 83 |
+
random_word_swap=0.,
|
| 84 |
+
date_min=cm.get_ref('date_min'),
|
| 85 |
+
date_max=cm.get_ref('date_max'),
|
| 86 |
+
date_interval=cm.get_ref('date_interval'),
|
| 87 |
+
date_bins=cm.get_ref('date_bins'),
|
| 88 |
+
prepend_sos=1,
|
| 89 |
+
repeat_train=-1,
|
| 90 |
+
repeat_eval=10,
|
| 91 |
+
black_list=[
|
| 92 |
+
# 2334, 10, 293931, 14, 293752, 15, 293753, 16, 11,
|
| 93 |
+
# 294468, 229647, 12, 291324, 291317, 17, 232697, 293754,
|
| 94 |
+
# 1682, 1675, 1676, 1677, 1678, 1679, 1680, 1681, 291118,
|
| 95 |
+
# 291320, 291319, 292366, 34, 291960, 35, 32, 346490, 27,
|
| 96 |
+
# 292187, 291318, 19, 18, 37, 291321, 292189, 293756, 42,
|
| 97 |
+
# 46, 232710, 39, 40, 41, 291322, 293757, 293327, 28,
|
| 98 |
+
# 292194, 293326, 21, 293755, 291319, 291117, 38, 291959,
|
| 99 |
+
# 31, 232705
|
| 100 |
+
],
|
| 101 |
+
white_list=[]),
|
| 102 |
+
model=dict(
|
| 103 |
+
word_char_emb_dim=256,
|
| 104 |
+
emb_dim=512,
|
| 105 |
+
mlp_dim=2048,
|
| 106 |
+
num_layers=8,
|
| 107 |
+
num_heads=4,
|
| 108 |
+
vocab_char_size=34,
|
| 109 |
+
vocab_word_size=cm.get_ref('wordlist_size') + 4,
|
| 110 |
+
output_subregions=85,
|
| 111 |
+
output_date=cm.get_ref('date_bins'),
|
| 112 |
+
output_date_dist=True,
|
| 113 |
+
region_date_pooling='first',
|
| 114 |
+
use_output_mlp=True,
|
| 115 |
+
max_len=cm.get_ref('context_char_max'),
|
| 116 |
+
dropout_rate=0.1,
|
| 117 |
+
attention_dropout_rate=0.1,
|
| 118 |
+
use_bfloat16=False,
|
| 119 |
+
model_type='bigbird',
|
| 120 |
+
feature_combine_type='concat',
|
| 121 |
+
posemb_combine_type='concat',
|
| 122 |
+
),
|
| 123 |
+
loss=dict(
|
| 124 |
+
date=dict(
|
| 125 |
+
enabled=True,
|
| 126 |
+
type='dist',
|
| 127 |
+
weight_dist=1.25,
|
| 128 |
+
weight_l1=0.,
|
| 129 |
+
label_smoothing=0.,
|
| 130 |
+
step_start=0,
|
| 131 |
+
step_end=0,
|
| 132 |
+
),
|
| 133 |
+
region=dict(
|
| 134 |
+
enabled=True,
|
| 135 |
+
weight=2.,
|
| 136 |
+
label_smoothing=0.1,
|
| 137 |
+
step_start=0,
|
| 138 |
+
step_end=0,
|
| 139 |
+
),
|
| 140 |
+
mask=dict(
|
| 141 |
+
enabled=True,
|
| 142 |
+
weight=3.,
|
| 143 |
+
label_smoothing=0.05,
|
| 144 |
+
step_start=0,
|
| 145 |
+
step_end=0,
|
| 146 |
+
),
|
| 147 |
+
nsp=dict(
|
| 148 |
+
enabled=True,
|
| 149 |
+
weight=0.01,
|
| 150 |
+
step_start=0,
|
| 151 |
+
step_end=0,
|
| 152 |
+
)),
|
| 153 |
+
evaluation=dict(
|
| 154 |
+
use_jit=True,
|
| 155 |
+
batch_size=1,
|
| 156 |
+
mode='valid',
|
| 157 |
+
store_model_log=False,
|
| 158 |
+
store_model_log_steps=100,
|
| 159 |
+
),
|
| 160 |
+
),))
|
| 161 |
+
|
| 162 |
+
# Training loop config.
|
| 163 |
+
config.training_steps = 1_000_000
|
| 164 |
+
config.log_train_data_interval = 10
|
| 165 |
+
config.save_checkpoint_interval = 300
|
| 166 |
+
config.best_model_eval_metric = 'score/eval'
|
| 167 |
+
config.checkpoint_dir = '/tmp/ithaca_checkpoints'
|
| 168 |
+
config.train_checkpoint_all_hosts = False
|
| 169 |
+
|
| 170 |
+
# Prevents accidentally setting keys that aren't recognized (e.g. in tests).
|
| 171 |
+
config.lock()
|
| 172 |
+
|
| 173 |
+
return config
|
train/data/README
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Put iphi.json in this directory before training.
|
| 2 |
+
See train/README.md for details.
|
train/data/iphi-region-main.txt
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Asia Minor_1702;48510
|
| 2 |
+
Attica (IG I-III)_1701;27215
|
| 3 |
+
Aegean Islands, incl. Crete (IG XI-[XIII])_1699;25309
|
| 4 |
+
Central Greece (IG VII-IX)_1698;14789
|
| 5 |
+
Egypt, Nubia and Cyrenaïca_1695;12384
|
| 6 |
+
Sicily, Italy, and the West (IG XIV)_1696;10108
|
| 7 |
+
Greater Syria and the East_1693;9191
|
| 8 |
+
Thrace and the Lower Danube (IG X)_1697;8456
|
| 9 |
+
Northern Greece (IG X)_1692;7932
|
| 10 |
+
Peloponnesos (IG IV-[VI])_1690;6393
|
| 11 |
+
Cyprus ([IG XV])_1680;4056
|
| 12 |
+
North Shore of the Black Sea_1683;3687
|
| 13 |
+
North Africa_1614;287
|
| 14 |
+
Upper Danube_1644;232
|
| 15 |
+
Unknown Provenances_884;2
|
train/data/iphi-region-sub.txt
ADDED
|
@@ -0,0 +1,88 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Attica_1700;25595
|
| 2 |
+
Egypt and Nubia_1694;11654
|
| 3 |
+
Ionia_1688;10566
|
| 4 |
+
Caria _1682;6214
|
| 5 |
+
Megaris, Oropia, and Boiotia (IG VII) _1691;5576
|
| 6 |
+
Macedonia _1485;5552
|
| 7 |
+
Italy, incl. Magna Graecia_1689;5365
|
| 8 |
+
Thrace and Moesia Inferior _1687;5257
|
| 9 |
+
Rhodes and S. Dodecanese (IG XII,1) _1627;4957
|
| 10 |
+
Cos and Calymna (IG XII,4)_1646;4487
|
| 11 |
+
Phrygia_1679;4278
|
| 12 |
+
Delphi _1272;4159
|
| 13 |
+
unspecified subregion_1681;4056
|
| 14 |
+
Sicily, Sardinia, and neighboring Islands_1686;4041
|
| 15 |
+
unspecified subregion_1684;3687
|
| 16 |
+
Lydia_1654;3621
|
| 17 |
+
Thessaly (IG IX,2) _899;3586
|
| 18 |
+
Syria and Phoenicia_1676;3444
|
| 19 |
+
Delos (IG XI and ID) _1672;3431
|
| 20 |
+
Mysia [Kaïkos], Pergamon_1674;3301
|
| 21 |
+
Pisidia_1671;3110
|
| 22 |
+
Arabia_1668;3064
|
| 23 |
+
Scythia Minor _1675;2842
|
| 24 |
+
Lycia_1669;2687
|
| 25 |
+
Crete _474;2652
|
| 26 |
+
Cilicia and Isauria_1662;2423
|
| 27 |
+
Epeiros, Illyria, and Dalmatia _1463;2380
|
| 28 |
+
Bithynia_1666;2253
|
| 29 |
+
Samos (IG XII,6) _1665;1853
|
| 30 |
+
Pamphylia_1651;1797
|
| 31 |
+
Euboia (IG XII,9) _1653;1792
|
| 32 |
+
Galatia_1663;1772
|
| 33 |
+
Lycaonia_1661;1693
|
| 34 |
+
Saronic Gulf, Corinthia, and the Argolid (IG IV) _1667;1620
|
| 35 |
+
Lakonia and Messenia (IG V,1) _1658;1575
|
| 36 |
+
Doric Sporades (IG XII,3) _1547;1529
|
| 37 |
+
Cyclades, excl. Delos (IG XII,5) _1585;1526
|
| 38 |
+
Mysia_1656;1475
|
| 39 |
+
Phokis, Lokris, Aitolia, Akarnania, and Ionian Islands (IG IX,1) _1659;1449
|
| 40 |
+
Pontus and Paphlagonia_1377;1369
|
| 41 |
+
Palaestina_1657;1363
|
| 42 |
+
Epidauria (IG IV²,1) _1643;1119
|
| 43 |
+
Northern Aegean (IG XII,8) _1596;1099
|
| 44 |
+
Elis _1647;1069
|
| 45 |
+
Lesbos, Nesos, and Tenedos (IG XII,2) _1554;870
|
| 46 |
+
Eleusis_1640;846
|
| 47 |
+
Rhamnous_1639;774
|
| 48 |
+
Mesopotamia_1626;740
|
| 49 |
+
Cyrenaïca_1633;730
|
| 50 |
+
Arkadia (IG V,2) _1632;702
|
| 51 |
+
Troas_1631;583
|
| 52 |
+
Amorgos and vicinity (IG XII,7) _1443;565
|
| 53 |
+
Chios _1624;548
|
| 54 |
+
Caria, Rhodian Peraia _1617;518
|
| 55 |
+
Gallia_1635;451
|
| 56 |
+
Aeolis_1012;396
|
| 57 |
+
Dacia _1673;357
|
| 58 |
+
Cappadocia_1607;344
|
| 59 |
+
Achaia_1621;308
|
| 60 |
+
Commagene_1590;229
|
| 61 |
+
Africa Proconsularis_1589;189
|
| 62 |
+
Hispania and Lusitania_1595;160
|
| 63 |
+
Raetia, Noricum, and Pannonia _1574;116
|
| 64 |
+
Moesia Superior _1641;116
|
| 65 |
+
Bactria, Sogdiana_1558;104
|
| 66 |
+
Babylonia_1535;77
|
| 67 |
+
Tripolitania_1578;68
|
| 68 |
+
Mysia [Upper Kaïkos] / Lydia_1482;50
|
| 69 |
+
Susiana_1480;45
|
| 70 |
+
Unknown Provenance_1477;43
|
| 71 |
+
Germania_1502;42
|
| 72 |
+
Armenia _1497;41
|
| 73 |
+
Arabian Peninsula_1453;34
|
| 74 |
+
unspecified subregion_1439;27
|
| 75 |
+
Britannia_1445;22
|
| 76 |
+
Doris_1434;19
|
| 77 |
+
Iberia and Colchis_1421;19
|
| 78 |
+
Arachosia, Drangiana_1417;17
|
| 79 |
+
Persis_1399;15
|
| 80 |
+
Mauretania Caesariensis_1381;14
|
| 81 |
+
Media_1324;12
|
| 82 |
+
Byzacena_1474;9
|
| 83 |
+
Mauretania Tingitana_1090;4
|
| 84 |
+
Numidia_1147;3
|
| 85 |
+
unspecified subregion_885;2
|
| 86 |
+
Hyrcania, Parthia_1146;2
|
| 87 |
+
Osrhoene_634;1
|
| 88 |
+
Carmania_881;1
|
train/data/iphi-wordlist.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
train/dataloader.py
ADDED
|
@@ -0,0 +1,409 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2021 the Ithaca Authors
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
"""Dataloader functions."""
|
| 15 |
+
|
| 16 |
+
import json
|
| 17 |
+
import random
|
| 18 |
+
import re
|
| 19 |
+
|
| 20 |
+
from absl import logging
|
| 21 |
+
from ithaca.util.dates import date_range_to_dist
|
| 22 |
+
from ithaca.util.text import random_mask_span
|
| 23 |
+
from ithaca.util.text import random_sentence_swap
|
| 24 |
+
from ithaca.util.text import random_word_delete
|
| 25 |
+
from ithaca.util.text import random_word_swap
|
| 26 |
+
from ithaca.util.text import text_to_idx
|
| 27 |
+
from ithaca.util.text import text_to_word_idx
|
| 28 |
+
import numpy as np
|
| 29 |
+
import tensorflow.compat.v1 as tf
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def generate_sample(config, alphabet, region_map, sample, mode='train'):
|
| 33 |
+
"""Generates a new TF dataset sample."""
|
| 34 |
+
|
| 35 |
+
# Get text
|
| 36 |
+
text = sample['text']
|
| 37 |
+
|
| 38 |
+
# Next sentence prediction
|
| 39 |
+
sentences = text.split('.')
|
| 40 |
+
# Strip spaces
|
| 41 |
+
sentences = list(map(str.strip, sentences))
|
| 42 |
+
# Filter blank sentences
|
| 43 |
+
sentences = list(filter(None, sentences))
|
| 44 |
+
# Generate indexes
|
| 45 |
+
sentence_idx = np.arange(len(sentences), dtype=np.int32)
|
| 46 |
+
|
| 47 |
+
# Random sentence shuffling
|
| 48 |
+
if (mode == 'train' and config.random_sentence_swap > 0):
|
| 49 |
+
# Shuffle indexes
|
| 50 |
+
sentence_idx = random_sentence_swap(sentence_idx,
|
| 51 |
+
config.random_sentence_swap)
|
| 52 |
+
# Reshuffle sentences
|
| 53 |
+
sentences = np.array(sentences)[sentence_idx].tolist()
|
| 54 |
+
|
| 55 |
+
# Random word swap
|
| 56 |
+
if mode == 'train' and config.random_word_swap > 0:
|
| 57 |
+
sentences = [
|
| 58 |
+
random_word_swap(s, config.random_word_swap) for s in sentences
|
| 59 |
+
]
|
| 60 |
+
|
| 61 |
+
# Random word delete
|
| 62 |
+
if mode == 'train' and config.random_word_delete > 0:
|
| 63 |
+
sentences = [
|
| 64 |
+
random_word_delete(s, config.random_word_delete) for s in sentences
|
| 65 |
+
]
|
| 66 |
+
|
| 67 |
+
# Join text
|
| 68 |
+
text = '. '.join(sentences) + '.'
|
| 69 |
+
|
| 70 |
+
# Generate mask and labels
|
| 71 |
+
next_sentence_dots = np.array(
|
| 72 |
+
[pos for pos, char in enumerate(text[:-1]) if char == '.'],
|
| 73 |
+
dtype=np.int32)
|
| 74 |
+
next_sentence_mask = np.zeros(len(text), dtype=bool)
|
| 75 |
+
next_sentence_label = np.zeros(len(text), dtype=np.int32)
|
| 76 |
+
if sentence_idx.size > 1:
|
| 77 |
+
next_sentence_mask[next_sentence_dots] = True
|
| 78 |
+
next_sentence_label[next_sentence_dots] = (
|
| 79 |
+
sentence_idx[:-1] == (sentence_idx[1:] - 1))
|
| 80 |
+
|
| 81 |
+
# Computer start for prepending start of sentence character
|
| 82 |
+
start_sample_idx = int(config.prepend_sos)
|
| 83 |
+
|
| 84 |
+
if (mode in ['train', 'valid'] and config.context_char_random and
|
| 85 |
+
len(text) >= config.context_char_min):
|
| 86 |
+
# During training pick random context length
|
| 87 |
+
context_char_len = np.random.randint(
|
| 88 |
+
config.context_char_min,
|
| 89 |
+
min(len(text), config.context_char_max - start_sample_idx) + 1)
|
| 90 |
+
|
| 91 |
+
start_idx = 0
|
| 92 |
+
if context_char_len < len(text):
|
| 93 |
+
start_idx = np.random.randint(0, len(text) - context_char_len + 1)
|
| 94 |
+
text = text[start_idx:start_idx + context_char_len - start_sample_idx]
|
| 95 |
+
next_sentence_mask = next_sentence_mask[start_idx:start_idx +
|
| 96 |
+
context_char_len - start_sample_idx]
|
| 97 |
+
next_sentence_label = next_sentence_label[start_idx:start_idx +
|
| 98 |
+
context_char_len -
|
| 99 |
+
start_sample_idx]
|
| 100 |
+
elif (config.context_char_max and len(text) >
|
| 101 |
+
(config.context_char_max - start_sample_idx)):
|
| 102 |
+
# Clip text by maximum length
|
| 103 |
+
start_idx = np.random.randint(
|
| 104 |
+
0,
|
| 105 |
+
len(text) - (config.context_char_max - start_sample_idx) + 1)
|
| 106 |
+
text = text[start_idx:start_idx + config.context_char_max -
|
| 107 |
+
start_sample_idx]
|
| 108 |
+
next_sentence_mask = next_sentence_mask[start_idx:start_idx +
|
| 109 |
+
config.context_char_max -
|
| 110 |
+
start_sample_idx]
|
| 111 |
+
next_sentence_label = next_sentence_label[start_idx:start_idx +
|
| 112 |
+
config.context_char_max -
|
| 113 |
+
start_sample_idx]
|
| 114 |
+
|
| 115 |
+
# Prepend start of sentence character
|
| 116 |
+
if config.prepend_sos:
|
| 117 |
+
text = alphabet.sos + text
|
| 118 |
+
next_sentence_mask = [False] + next_sentence_mask
|
| 119 |
+
next_sentence_label = [0] + next_sentence_label
|
| 120 |
+
|
| 121 |
+
# Unmasked text
|
| 122 |
+
text_unmasked_idx = text_to_idx(text, alphabet)
|
| 123 |
+
text_unmasked_word_idx = text_to_word_idx(text, alphabet)
|
| 124 |
+
|
| 125 |
+
# Mask text
|
| 126 |
+
text_mask = np.zeros(len(text), dtype=bool)
|
| 127 |
+
if mode in ['train', 'valid']:
|
| 128 |
+
text_list = list(text)
|
| 129 |
+
|
| 130 |
+
# Non missing idx (avoid removing start of sentence character)
|
| 131 |
+
non_missing_idx = []
|
| 132 |
+
for i in range(start_sample_idx, len(text_list)):
|
| 133 |
+
if text_list[i] not in [alphabet.missing] + alphabet.punctuation:
|
| 134 |
+
non_missing_idx.append(i)
|
| 135 |
+
|
| 136 |
+
# Skip sample if there are no usable characters
|
| 137 |
+
if not non_missing_idx:
|
| 138 |
+
return
|
| 139 |
+
|
| 140 |
+
char_mask_idx = []
|
| 141 |
+
if config.char_mask_rate_max > 0.:
|
| 142 |
+
# Compute rate
|
| 143 |
+
char_mask_rate = np.random.uniform(config.char_mask_rate_min,
|
| 144 |
+
config.char_mask_rate_max)
|
| 145 |
+
|
| 146 |
+
# Fix masking in valid mode for comparing experiments
|
| 147 |
+
span_mask_geometric_p = config.span_mask_geometric_p
|
| 148 |
+
mask_num_total = int(char_mask_rate * len(non_missing_idx))
|
| 149 |
+
mask_num_span = int(mask_num_total * config.span_mask_ratio)
|
| 150 |
+
if mode == 'valid' and config.span_mask_eval_len > 0:
|
| 151 |
+
span_mask_geometric_p = None
|
| 152 |
+
mask_num_total = min(config.span_mask_eval_len, len(non_missing_idx))
|
| 153 |
+
mask_num_span = mask_num_total
|
| 154 |
+
mask_num_char = mask_num_total - mask_num_span
|
| 155 |
+
|
| 156 |
+
# Mask random indices
|
| 157 |
+
if mask_num_char > 0:
|
| 158 |
+
char_mask_idx = np.random.choice(
|
| 159 |
+
non_missing_idx, mask_num_char, replace=False).tolist()
|
| 160 |
+
|
| 161 |
+
# Mask random spans
|
| 162 |
+
if mask_num_span > 0:
|
| 163 |
+
count_span = 0
|
| 164 |
+
span_mask_idx = []
|
| 165 |
+
while (len(span_mask_idx) < mask_num_span and count_span < 10000):
|
| 166 |
+
span_mask_idx.extend(
|
| 167 |
+
random_mask_span(
|
| 168 |
+
text,
|
| 169 |
+
geometric_p=span_mask_geometric_p,
|
| 170 |
+
limit_chars=mask_num_span - len(span_mask_idx)))
|
| 171 |
+
count_span += 1
|
| 172 |
+
char_mask_idx.extend(span_mask_idx)
|
| 173 |
+
|
| 174 |
+
# Mask text
|
| 175 |
+
for idx in set(char_mask_idx):
|
| 176 |
+
text_mask[idx] = True
|
| 177 |
+
text_list[idx] = alphabet.missing
|
| 178 |
+
text = ''.join(text_list)
|
| 179 |
+
|
| 180 |
+
# Text missing mask
|
| 181 |
+
text_missing_mask = np.array(list(text)) == alphabet.missing
|
| 182 |
+
|
| 183 |
+
# Convert to indices
|
| 184 |
+
text_idx = text_to_idx(text, alphabet)
|
| 185 |
+
text_idx_len = len(text_idx)
|
| 186 |
+
text_word_idx = text_to_word_idx(text, alphabet)
|
| 187 |
+
text_word_idx_len = len(text_word_idx)
|
| 188 |
+
assert text_idx_len == text_word_idx_len
|
| 189 |
+
|
| 190 |
+
# PHI id
|
| 191 |
+
phi_id = int(sample['id'])
|
| 192 |
+
|
| 193 |
+
# Map region ids to local ids
|
| 194 |
+
region_main_id = region_map['main']['ids_inv'][int(sample['region_main_id'])]
|
| 195 |
+
region_sub_id = region_map['sub']['ids_inv'][int(sample['region_sub_id'])]
|
| 196 |
+
|
| 197 |
+
# Dates
|
| 198 |
+
if (sample['date_min'] and sample['date_max'] and
|
| 199 |
+
int(sample['date_min']) <= int(sample['date_max']) and
|
| 200 |
+
int(sample['date_min']) >= config.date_min and
|
| 201 |
+
int(sample['date_max']) < config.date_max):
|
| 202 |
+
date_available = True
|
| 203 |
+
date_min = float(sample['date_min'])
|
| 204 |
+
date_max = float(sample['date_max'])
|
| 205 |
+
date_dist = date_range_to_dist(date_min, date_max, config.date_min,
|
| 206 |
+
config.date_max, config.date_interval,
|
| 207 |
+
config.date_bins)
|
| 208 |
+
else:
|
| 209 |
+
date_available = False
|
| 210 |
+
date_min = 0.
|
| 211 |
+
date_max = 0.
|
| 212 |
+
date_dist = date_range_to_dist(None, None, config.date_min, config.date_max,
|
| 213 |
+
config.date_interval, config.date_bins)
|
| 214 |
+
|
| 215 |
+
return {
|
| 216 |
+
'id': phi_id, # 'text_str': text,
|
| 217 |
+
'text_char': text_idx,
|
| 218 |
+
'text_mask': text_mask,
|
| 219 |
+
'text_missing_mask': text_missing_mask,
|
| 220 |
+
'text_word': text_word_idx,
|
| 221 |
+
'text_len': text_idx_len,
|
| 222 |
+
'text_unmasked': text_unmasked_idx,
|
| 223 |
+
'text_unmasked_word': text_unmasked_word_idx,
|
| 224 |
+
'next_sentence_mask': next_sentence_mask,
|
| 225 |
+
'next_sentence_label': next_sentence_label,
|
| 226 |
+
'region_main_id': region_main_id,
|
| 227 |
+
'region_sub_id': region_sub_id,
|
| 228 |
+
'date_available': date_available,
|
| 229 |
+
'date_min': date_min,
|
| 230 |
+
'date_max': date_max,
|
| 231 |
+
'date_dist': date_dist,
|
| 232 |
+
}
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
def loader_tf(batch_size,
|
| 236 |
+
config,
|
| 237 |
+
region_map,
|
| 238 |
+
alphabet=None,
|
| 239 |
+
dataset_file=None,
|
| 240 |
+
mode='train'):
|
| 241 |
+
"""TF dataloader."""
|
| 242 |
+
# Load dataset
|
| 243 |
+
dataset_tmp = {int(d['id']): d for d in json.load(dataset_file)}
|
| 244 |
+
logging.info('Loaded dataset inscriptions: %d.', len(dataset_tmp))
|
| 245 |
+
|
| 246 |
+
# Check if white_list enabled
|
| 247 |
+
if hasattr(config, 'white_list') and config.white_list:
|
| 248 |
+
dataset = []
|
| 249 |
+
for d in dataset_tmp.values():
|
| 250 |
+
if int(d['id']) in config.white_list:
|
| 251 |
+
dataset.append(d)
|
| 252 |
+
del dataset_tmp
|
| 253 |
+
else:
|
| 254 |
+
# Find duplicate inscriptions
|
| 255 |
+
rev_dataset = {}
|
| 256 |
+
black_list = set()
|
| 257 |
+
if hasattr(config, 'black_list') and config.black_list:
|
| 258 |
+
logging.info('Ignore list inscriptions: %d.', len(config.black_list))
|
| 259 |
+
black_list.update(config.black_list)
|
| 260 |
+
|
| 261 |
+
for key in sorted(dataset_tmp.keys()):
|
| 262 |
+
value = dataset_tmp[key]
|
| 263 |
+
rev_dataset.setdefault(value['text'], set()).add(key)
|
| 264 |
+
if len(rev_dataset[value['text']]) > 1:
|
| 265 |
+
black_list.add(int(value['id']))
|
| 266 |
+
del rev_dataset
|
| 267 |
+
logging.info('Inscriptions filtered: %d.', len(black_list))
|
| 268 |
+
|
| 269 |
+
# Create deduplicated dataset
|
| 270 |
+
dataset = []
|
| 271 |
+
for d in dataset_tmp.values():
|
| 272 |
+
if int(d['id']) not in black_list:
|
| 273 |
+
dataset.append(d)
|
| 274 |
+
del dataset_tmp
|
| 275 |
+
del black_list
|
| 276 |
+
|
| 277 |
+
logging.info('Final dataset inscriptions: %d.', len(dataset))
|
| 278 |
+
|
| 279 |
+
# Breaks dataset correlated order.
|
| 280 |
+
random.shuffle(dataset)
|
| 281 |
+
|
| 282 |
+
# Sample generator function
|
| 283 |
+
def generate_samples():
|
| 284 |
+
|
| 285 |
+
dataset_idxs = list(range(len(dataset)))
|
| 286 |
+
random.shuffle(dataset_idxs)
|
| 287 |
+
for dataset_i in dataset_idxs:
|
| 288 |
+
sample = dataset[dataset_i]
|
| 289 |
+
|
| 290 |
+
# Skip if region does not exist in map
|
| 291 |
+
if (int(sample['region_main_id']) not in region_map['main']['ids_inv'] or
|
| 292 |
+
int(sample['region_sub_id']) not in region_map['sub']['ids_inv']):
|
| 293 |
+
continue
|
| 294 |
+
|
| 295 |
+
# Replace guess signs with missing chars
|
| 296 |
+
if hasattr(config, 'char_use_guess') and not config.char_use_guess:
|
| 297 |
+
sample['text'] = re.sub(r'\[(.*?)\]', lambda m: '-' * len(m.group(1)),
|
| 298 |
+
sample['text'])
|
| 299 |
+
sample['text'] = sample['text'].replace(alphabet.sog,
|
| 300 |
+
'').replace(alphabet.eog, '')
|
| 301 |
+
|
| 302 |
+
# Filter by text length
|
| 303 |
+
if len(sample['text'].replace(alphabet.missing,
|
| 304 |
+
'')) < config.context_char_min:
|
| 305 |
+
continue
|
| 306 |
+
|
| 307 |
+
# Last digit 3 -> test, 4 -> valid, the rest are the training set
|
| 308 |
+
sample_id = int(sample['id'])
|
| 309 |
+
if ((sample_id % 10 == 3 and mode == 'test') or
|
| 310 |
+
(sample_id % 10 == 4 and mode == 'valid') or
|
| 311 |
+
(sample_id % 10 != 3 and sample_id % 10 != 4 and mode == 'train') or
|
| 312 |
+
(hasattr(config, 'white_list') and config.white_list)):
|
| 313 |
+
s = generate_sample(config, alphabet, region_map, sample, mode=mode)
|
| 314 |
+
if s:
|
| 315 |
+
yield s
|
| 316 |
+
|
| 317 |
+
# Create dataset from generator.
|
| 318 |
+
with tf.device('/cpu:0'):
|
| 319 |
+
ds = tf.data.Dataset.from_generator(
|
| 320 |
+
generate_samples,
|
| 321 |
+
output_signature={
|
| 322 |
+
'id':
|
| 323 |
+
tf.TensorSpec(shape=(), dtype=tf.int32),
|
| 324 |
+
'text_char':
|
| 325 |
+
tf.TensorSpec(shape=(None), dtype=tf.int32),
|
| 326 |
+
'text_mask':
|
| 327 |
+
tf.TensorSpec(shape=(None), dtype=tf.bool),
|
| 328 |
+
'text_missing_mask':
|
| 329 |
+
tf.TensorSpec(shape=(None), dtype=tf.bool),
|
| 330 |
+
'text_word':
|
| 331 |
+
tf.TensorSpec(shape=(None), dtype=tf.int32),
|
| 332 |
+
'text_unmasked':
|
| 333 |
+
tf.TensorSpec(shape=(None), dtype=tf.int32),
|
| 334 |
+
'text_unmasked_word':
|
| 335 |
+
tf.TensorSpec(shape=(None), dtype=tf.int32),
|
| 336 |
+
'next_sentence_mask':
|
| 337 |
+
tf.TensorSpec(shape=(None), dtype=tf.bool),
|
| 338 |
+
'next_sentence_label':
|
| 339 |
+
tf.TensorSpec(shape=(None), dtype=tf.int32),
|
| 340 |
+
'text_len':
|
| 341 |
+
tf.TensorSpec(shape=(), dtype=tf.int32),
|
| 342 |
+
'region_main_id':
|
| 343 |
+
tf.TensorSpec(shape=(), dtype=tf.int32),
|
| 344 |
+
'region_sub_id':
|
| 345 |
+
tf.TensorSpec(shape=(), dtype=tf.int32),
|
| 346 |
+
'date_available':
|
| 347 |
+
tf.TensorSpec(shape=(), dtype=tf.bool),
|
| 348 |
+
'date_min':
|
| 349 |
+
tf.TensorSpec(shape=(), dtype=tf.float32),
|
| 350 |
+
'date_max':
|
| 351 |
+
tf.TensorSpec(shape=(), dtype=tf.float32),
|
| 352 |
+
'date_dist':
|
| 353 |
+
tf.TensorSpec(shape=(config.date_bins), dtype=tf.float32),
|
| 354 |
+
})
|
| 355 |
+
|
| 356 |
+
# Shuffle and repeat.
|
| 357 |
+
if mode == 'train':
|
| 358 |
+
if config.repeat_train == -1:
|
| 359 |
+
ds = ds.repeat()
|
| 360 |
+
elif config.repeat_train >= 1:
|
| 361 |
+
ds = ds.repeat(config.repeat_train)
|
| 362 |
+
else:
|
| 363 |
+
if config.repeat_eval == -1:
|
| 364 |
+
ds = ds.repeat()
|
| 365 |
+
elif config.repeat_eval >= 1:
|
| 366 |
+
ds = ds.repeat(config.repeat_eval)
|
| 367 |
+
|
| 368 |
+
# Batch and pad.
|
| 369 |
+
max_len = config.context_char_max
|
| 370 |
+
ds = ds.padded_batch(
|
| 371 |
+
batch_size,
|
| 372 |
+
padded_shapes={
|
| 373 |
+
'id': [],
|
| 374 |
+
'text_char': [max_len],
|
| 375 |
+
'text_mask': [max_len],
|
| 376 |
+
'text_missing_mask': [max_len],
|
| 377 |
+
'text_word': [max_len],
|
| 378 |
+
'text_unmasked': [max_len],
|
| 379 |
+
'text_unmasked_word': [max_len],
|
| 380 |
+
'next_sentence_mask': [max_len],
|
| 381 |
+
'next_sentence_label': [max_len],
|
| 382 |
+
'text_len': [],
|
| 383 |
+
'region_main_id': [],
|
| 384 |
+
'region_sub_id': [],
|
| 385 |
+
'date_available': [],
|
| 386 |
+
'date_min': [],
|
| 387 |
+
'date_max': [],
|
| 388 |
+
'date_dist': [config.date_bins]
|
| 389 |
+
},
|
| 390 |
+
padding_values={
|
| 391 |
+
'id': 0,
|
| 392 |
+
'text_char': alphabet.pad_idx,
|
| 393 |
+
'text_mask': False,
|
| 394 |
+
'text_missing_mask': True,
|
| 395 |
+
'text_word': alphabet.pad_idx,
|
| 396 |
+
'text_unmasked': alphabet.pad_idx,
|
| 397 |
+
'text_unmasked_word': alphabet.pad_idx,
|
| 398 |
+
'next_sentence_mask': False,
|
| 399 |
+
'next_sentence_label': 0,
|
| 400 |
+
'text_len': 0,
|
| 401 |
+
'region_main_id': 0,
|
| 402 |
+
'region_sub_id': 0,
|
| 403 |
+
'date_available': False,
|
| 404 |
+
'date_min': 0.,
|
| 405 |
+
'date_max': 0.,
|
| 406 |
+
'date_dist': 0.
|
| 407 |
+
})
|
| 408 |
+
|
| 409 |
+
return ds
|
train/experiment.py
ADDED
|
@@ -0,0 +1,679 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2021 the Ithaca Authors
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
"""Ithaca: Restoring and attributing ancient texts with deep neural networks."""
|
| 15 |
+
|
| 16 |
+
import bz2
|
| 17 |
+
import distutils
|
| 18 |
+
import functools
|
| 19 |
+
import glob
|
| 20 |
+
import os
|
| 21 |
+
import pickle
|
| 22 |
+
|
| 23 |
+
from absl import app
|
| 24 |
+
from absl import flags
|
| 25 |
+
from absl import logging
|
| 26 |
+
import dataloader
|
| 27 |
+
from ithaca.models.model import Model
|
| 28 |
+
from ithaca.util.alphabet import GreekAlphabet
|
| 29 |
+
from ithaca.util.loss import categorical_kl_divergence
|
| 30 |
+
from ithaca.util.loss import cross_entropy_label_smoothing_loss
|
| 31 |
+
from ithaca.util.loss import cross_entropy_loss
|
| 32 |
+
from ithaca.util.loss import cross_entropy_mask_loss
|
| 33 |
+
from ithaca.util.loss import date_loss_l1
|
| 34 |
+
from ithaca.util.optim import adaptive_grad_clip
|
| 35 |
+
from ithaca.util.optim import linear_warmup_and_sqrt_decay
|
| 36 |
+
from ithaca.util.optim import linear_weight
|
| 37 |
+
from ithaca.util.region_names import load_region_maps
|
| 38 |
+
import jax
|
| 39 |
+
import jax.numpy as jnp
|
| 40 |
+
from jaxline import experiment
|
| 41 |
+
from jaxline import platform
|
| 42 |
+
from jaxline import utils as jl_utils
|
| 43 |
+
import numpy as np
|
| 44 |
+
import optax
|
| 45 |
+
import tensorflow_datasets.public_api as tfds
|
| 46 |
+
|
| 47 |
+
FLAGS = flags.FLAGS
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
class Experiment(experiment.AbstractExperiment):
|
| 51 |
+
"""Ithaca experiment."""
|
| 52 |
+
|
| 53 |
+
# Holds a map from object properties that will be checkpointed to their name
|
| 54 |
+
# within a checkpoint. Currently it is assume that these are all sharded
|
| 55 |
+
# device arrays.
|
| 56 |
+
CHECKPOINT_ATTRS = {
|
| 57 |
+
'_params': 'params',
|
| 58 |
+
'_opt_state': 'opt_state',
|
| 59 |
+
}
|
| 60 |
+
|
| 61 |
+
def __init__(self, mode, init_rng, config):
|
| 62 |
+
"""Initializes experiment."""
|
| 63 |
+
|
| 64 |
+
super(Experiment, self).__init__(mode=mode)
|
| 65 |
+
self.mode = mode
|
| 66 |
+
self.init_rng = init_rng
|
| 67 |
+
self.config = config
|
| 68 |
+
|
| 69 |
+
# Same random key on each device.
|
| 70 |
+
self._rng_key = jl_utils.bcast_local_devices(self.init_rng)
|
| 71 |
+
|
| 72 |
+
# Checkpointed experiment state.
|
| 73 |
+
self._params = None
|
| 74 |
+
self._opt_state = None
|
| 75 |
+
|
| 76 |
+
# Input pipelines.
|
| 77 |
+
self._train_input = None
|
| 78 |
+
self._eval_input = None
|
| 79 |
+
|
| 80 |
+
# Forward and update functions.
|
| 81 |
+
self.forward = Model(**self.config.model)
|
| 82 |
+
self._update_func = jax.pmap(
|
| 83 |
+
self._update_func, axis_name='i', donate_argnums=(0, 1))
|
| 84 |
+
|
| 85 |
+
self._learning_rate_fn = functools.partial(
|
| 86 |
+
linear_warmup_and_sqrt_decay,
|
| 87 |
+
max_lr=self.config.optimizer.kwargs.learning_rate,
|
| 88 |
+
warmup_steps=self.config.optimizer.warmup)
|
| 89 |
+
|
| 90 |
+
self._opt_init, self._opt_update = self.optimizer()
|
| 91 |
+
|
| 92 |
+
if 'use_jit' in self.config.evaluation and self.config.evaluation.use_jit:
|
| 93 |
+
self._eval_batch = jax.jit(self._eval_batch)
|
| 94 |
+
|
| 95 |
+
# Create alphabet
|
| 96 |
+
alphabet_kwargs = dict(self.config.alphabet)
|
| 97 |
+
wordlist_path = alphabet_kwargs.pop('wordlist_path')
|
| 98 |
+
with open(wordlist_path, 'r') as f:
|
| 99 |
+
self._alphabet = GreekAlphabet(wordlist_file=f, **alphabet_kwargs)
|
| 100 |
+
|
| 101 |
+
# Create region mapping
|
| 102 |
+
self._region_map = {'main': None, 'sub': None}
|
| 103 |
+
if self.config.dataset.region_main_path:
|
| 104 |
+
with open(self.config.dataset.region_main_path, 'r') as f:
|
| 105 |
+
self._region_map['main'] = load_region_maps(f)
|
| 106 |
+
if self.config.dataset.region_sub_path:
|
| 107 |
+
with open(self.config.dataset.region_sub_path, 'r') as f:
|
| 108 |
+
self._region_map['sub'] = load_region_maps(f)
|
| 109 |
+
|
| 110 |
+
def optimizer(self):
|
| 111 |
+
config_opt = self.config.optimizer
|
| 112 |
+
|
| 113 |
+
kwargs = config_opt.kwargs.to_dict()
|
| 114 |
+
kwargs['learning_rate'] = self._learning_rate_fn
|
| 115 |
+
opt = getattr(optax, config_opt.name)(**kwargs)
|
| 116 |
+
|
| 117 |
+
if hasattr(config_opt, 'clip_adaptive') and config_opt.clip_adaptive:
|
| 118 |
+
if config_opt.clip_level > 0.:
|
| 119 |
+
opt = optax.chain(adaptive_grad_clip(config_opt.clip_level), opt)
|
| 120 |
+
elif config_opt.clip_level > 0.:
|
| 121 |
+
opt = optax.chain(optax.clip_by_global_norm(config_opt.clip_level), opt)
|
| 122 |
+
return opt
|
| 123 |
+
|
| 124 |
+
# _ _
|
| 125 |
+
# | |_ _ __ __ _(_)_ __
|
| 126 |
+
# | __| '__/ _` | | '_ \
|
| 127 |
+
# | |_| | | (_| | | | | |
|
| 128 |
+
# \__|_| \__,_|_|_| |_|
|
| 129 |
+
#
|
| 130 |
+
|
| 131 |
+
def step(self, global_step, rng, **unused_args):
|
| 132 |
+
"""See base class."""
|
| 133 |
+
|
| 134 |
+
if self._train_input is None:
|
| 135 |
+
self._initialize_train(rng)
|
| 136 |
+
|
| 137 |
+
batch = next(self._train_input)
|
| 138 |
+
(self._params, self._opt_state, scalars) = (
|
| 139 |
+
self._update_func(self._params, self._opt_state, global_step, batch,
|
| 140 |
+
rng))
|
| 141 |
+
|
| 142 |
+
scalars = jl_utils.get_first(scalars)
|
| 143 |
+
return scalars
|
| 144 |
+
|
| 145 |
+
def _initialize_train(self, rng):
|
| 146 |
+
# Check we haven't already restored params
|
| 147 |
+
if self._params is None:
|
| 148 |
+
logging.info(
|
| 149 |
+
'Initializing parameters rather than restoring from checkpoint.')
|
| 150 |
+
batch = next(self._build_train_input())
|
| 151 |
+
|
| 152 |
+
rng = jl_utils.get_first(rng)
|
| 153 |
+
params_rng, dropout_rng = jax.random.split(rng)
|
| 154 |
+
params_rng = jl_utils.bcast_local_devices(params_rng)
|
| 155 |
+
dropout_rng = jl_utils.bcast_local_devices(dropout_rng)
|
| 156 |
+
init_net = jax.pmap(
|
| 157 |
+
functools.partial(self.forward.init, is_training=True))
|
| 158 |
+
self._params = init_net({
|
| 159 |
+
'params': params_rng,
|
| 160 |
+
'dropout': dropout_rng
|
| 161 |
+
},
|
| 162 |
+
text_char=batch['text_char'],
|
| 163 |
+
text_word=batch['text_word'])
|
| 164 |
+
|
| 165 |
+
init_opt = jax.pmap(self._opt_init)
|
| 166 |
+
self._opt_state = init_opt(self._params)
|
| 167 |
+
|
| 168 |
+
self._train_input = jl_utils.py_prefetch(self._build_train_input)
|
| 169 |
+
self._train_input = jl_utils.double_buffer_on_gpu(self._train_input)
|
| 170 |
+
|
| 171 |
+
def _build_train_input(self):
|
| 172 |
+
"""See base class."""
|
| 173 |
+
num_devices = jax.device_count()
|
| 174 |
+
global_batch_size = self.config.training.batch_size
|
| 175 |
+
per_device_batch_size, ragged = divmod(global_batch_size, num_devices)
|
| 176 |
+
logging.info(
|
| 177 |
+
'num_devices: %d, per_device_batch_size: %d, global_batch_size: %d',
|
| 178 |
+
num_devices, per_device_batch_size, global_batch_size)
|
| 179 |
+
|
| 180 |
+
if ragged:
|
| 181 |
+
raise ValueError(
|
| 182 |
+
f'Global batch size {global_batch_size} must be divisible by '
|
| 183 |
+
f'num devices {num_devices}')
|
| 184 |
+
|
| 185 |
+
config_dataset = self.config.dataset
|
| 186 |
+
with open(config_dataset.dataset_path) as dataset_file:
|
| 187 |
+
ds = dataloader.loader_tf(
|
| 188 |
+
per_device_batch_size,
|
| 189 |
+
config_dataset,
|
| 190 |
+
self._region_map,
|
| 191 |
+
alphabet=self._alphabet,
|
| 192 |
+
dataset_file=dataset_file,
|
| 193 |
+
mode='train')
|
| 194 |
+
|
| 195 |
+
ds = ds.batch(jax.local_device_count())
|
| 196 |
+
return iter(tfds.as_numpy(ds))
|
| 197 |
+
|
| 198 |
+
def _loss_fn(self, params, batch, global_step, rng):
|
| 199 |
+
text_char = batch['text_char']
|
| 200 |
+
text_word = batch['text_word']
|
| 201 |
+
text_unmasked = batch['text_unmasked']
|
| 202 |
+
text_mask = batch['text_mask']
|
| 203 |
+
next_sentence_mask = batch['next_sentence_mask']
|
| 204 |
+
next_sentence_label = batch['next_sentence_label']
|
| 205 |
+
subregion = batch['region_sub_id']
|
| 206 |
+
date_min = batch['date_min']
|
| 207 |
+
date_max = batch['date_max']
|
| 208 |
+
date_dist = batch['date_dist']
|
| 209 |
+
date_available = batch['date_available']
|
| 210 |
+
eps = 1e-6
|
| 211 |
+
|
| 212 |
+
(date_pred, subregion_logits, mask_logits, nsp_logits) = self.forward.apply(
|
| 213 |
+
params,
|
| 214 |
+
text_char=text_char,
|
| 215 |
+
text_word=text_word,
|
| 216 |
+
text_char_onehot=None,
|
| 217 |
+
text_word_onehot=None,
|
| 218 |
+
is_training=True,
|
| 219 |
+
rngs={'dropout': rng})
|
| 220 |
+
|
| 221 |
+
date_loss = 0.
|
| 222 |
+
subregion_loss = 0.
|
| 223 |
+
subregion_accuracy = 0.
|
| 224 |
+
mask_loss = 0.
|
| 225 |
+
mask_accuracy = 0.
|
| 226 |
+
nsp_loss = 0.
|
| 227 |
+
nsp_accuracy = 0.
|
| 228 |
+
|
| 229 |
+
# Date loss
|
| 230 |
+
if self.config.loss.date.enabled:
|
| 231 |
+
if self.config.loss.date.label_smoothing > 0:
|
| 232 |
+
date_dist_prob = jnp.exp(date_dist) # logprob to prob
|
| 233 |
+
date_dist_prob_smooth = date_dist_prob * jax.random.uniform(
|
| 234 |
+
rng,
|
| 235 |
+
shape=date_dist_prob.shape,
|
| 236 |
+
dtype=date_dist_prob.dtype,
|
| 237 |
+
minval=1 - self.config.loss.date.label_smoothing,
|
| 238 |
+
maxval=1 + self.config.loss.date.label_smoothing)
|
| 239 |
+
date_dist_prob_smooth /= date_dist_prob_smooth.sum(axis=-1)[:,
|
| 240 |
+
jnp.newaxis]
|
| 241 |
+
|
| 242 |
+
date_dist_prob_smooth = jnp.clip(date_dist_prob_smooth, 1e-6, 1)
|
| 243 |
+
date_dist = jnp.log(date_dist_prob_smooth)
|
| 244 |
+
|
| 245 |
+
date_loss = 0.
|
| 246 |
+
if 'l1' in self.config.loss.date.type.split('+'):
|
| 247 |
+
date_pred_x = jnp.arange(
|
| 248 |
+
self.config.dataset.date_min +
|
| 249 |
+
self.config.dataset.date_interval / 2,
|
| 250 |
+
self.config.dataset.date_max +
|
| 251 |
+
self.config.dataset.date_interval / 2,
|
| 252 |
+
self.config.dataset.date_interval).reshape(-1, 1)
|
| 253 |
+
date_pred_val = jnp.dot(jax.nn.softmax(date_pred, axis=-1), date_pred_x)
|
| 254 |
+
date_loss_l1_ = jax.vmap(date_loss_l1)(date_pred_val, date_min,
|
| 255 |
+
date_max, date_available)
|
| 256 |
+
jnp.nan_to_num(date_loss_l1_, copy=False)
|
| 257 |
+
date_loss += (
|
| 258 |
+
jnp.mean(date_loss_l1_, axis=0) * self.config.loss.date.weight_l1)
|
| 259 |
+
|
| 260 |
+
if 'dist' in self.config.loss.date.type.split('+'):
|
| 261 |
+
date_loss_dist_ = categorical_kl_divergence(date_dist, date_pred)
|
| 262 |
+
date_loss_dist_ *= date_available
|
| 263 |
+
jnp.nan_to_num(date_loss_dist_, copy=False)
|
| 264 |
+
date_loss += (
|
| 265 |
+
jnp.mean(date_loss_dist_, axis=0) *
|
| 266 |
+
self.config.loss.date.weight_dist)
|
| 267 |
+
|
| 268 |
+
date_loss *= linear_weight(global_step, self.config.loss.date.step_start,
|
| 269 |
+
self.config.loss.date.step_end)
|
| 270 |
+
|
| 271 |
+
# Region and subregion loss
|
| 272 |
+
if self.config.loss.region.enabled:
|
| 273 |
+
subregion_loss = jnp.mean(
|
| 274 |
+
cross_entropy_label_smoothing_loss(
|
| 275 |
+
subregion_logits,
|
| 276 |
+
subregion,
|
| 277 |
+
label_smoothing=self.config.loss.region.label_smoothing), 0)
|
| 278 |
+
jnp.nan_to_num(subregion_loss, copy=False)
|
| 279 |
+
subregion_loss *= self.config.loss.region.weight
|
| 280 |
+
subregion_accuracy = jnp.mean(
|
| 281 |
+
jnp.argmax(subregion_logits, -1) == subregion)
|
| 282 |
+
|
| 283 |
+
w = linear_weight(global_step, self.config.loss.region.step_start,
|
| 284 |
+
self.config.loss.region.step_end)
|
| 285 |
+
subregion_loss *= w
|
| 286 |
+
|
| 287 |
+
# Mask loss
|
| 288 |
+
if self.config.loss.mask.enabled:
|
| 289 |
+
mask_loss = jnp.sum(
|
| 290 |
+
cross_entropy_label_smoothing_loss(
|
| 291 |
+
mask_logits,
|
| 292 |
+
text_unmasked,
|
| 293 |
+
text_mask,
|
| 294 |
+
label_smoothing=self.config.loss.mask.label_smoothing), 1) # [B]
|
| 295 |
+
assert mask_loss.ndim == 1
|
| 296 |
+
jnp.nan_to_num(mask_loss, copy=False)
|
| 297 |
+
mask_loss = jnp.mean(mask_loss, 0) * self.config.loss.mask.weight # []
|
| 298 |
+
mask_all_accuracy = (jnp.argmax(mask_logits, -1) == text_unmasked).astype(
|
| 299 |
+
mask_logits.dtype)
|
| 300 |
+
mask_accuracy = jnp.divide(
|
| 301 |
+
jnp.sum(
|
| 302 |
+
jnp.multiply(mask_all_accuracy,
|
| 303 |
+
text_mask.astype(mask_logits.dtype))),
|
| 304 |
+
jnp.sum(text_mask) + eps)
|
| 305 |
+
|
| 306 |
+
mask_loss *= linear_weight(global_step, self.config.loss.mask.step_start,
|
| 307 |
+
self.config.loss.mask.step_end)
|
| 308 |
+
|
| 309 |
+
# NSP loss
|
| 310 |
+
if self.config.loss.nsp.enabled:
|
| 311 |
+
nsp_loss = jnp.sum(
|
| 312 |
+
jax.vmap(jax.vmap(cross_entropy_mask_loss))(nsp_logits,
|
| 313 |
+
next_sentence_label,
|
| 314 |
+
next_sentence_mask),
|
| 315 |
+
1) # [B]
|
| 316 |
+
assert nsp_loss.ndim == 1
|
| 317 |
+
jnp.nan_to_num(nsp_loss, copy=False)
|
| 318 |
+
nsp_loss = jnp.mean(nsp_loss, 0) * self.config.loss.nsp.weight
|
| 319 |
+
nsp_all_accuracy = (jnp.argmax(
|
| 320 |
+
nsp_logits, -1) == next_sentence_label).astype(nsp_logits.dtype)
|
| 321 |
+
nsp_accuracy = jnp.divide(
|
| 322 |
+
jnp.sum(
|
| 323 |
+
jnp.multiply(nsp_all_accuracy,
|
| 324 |
+
next_sentence_mask.astype(nsp_logits.dtype))),
|
| 325 |
+
jnp.sum(next_sentence_mask) + eps)
|
| 326 |
+
nsp_loss *= linear_weight(global_step, self.config.loss.nsp.step_start,
|
| 327 |
+
self.config.loss.nsp.step_end)
|
| 328 |
+
|
| 329 |
+
loss = date_loss + subregion_loss + mask_loss + nsp_loss
|
| 330 |
+
scaled_loss = loss / jax.device_count()
|
| 331 |
+
# NOTE: We use scaled_loss for grads and unscaled for logging.
|
| 332 |
+
return scaled_loss, (loss, date_loss, subregion_loss, subregion_accuracy,
|
| 333 |
+
mask_loss, mask_accuracy, nsp_loss, nsp_accuracy)
|
| 334 |
+
|
| 335 |
+
def _update_func(self, params, opt_state, global_step, batch, rng):
|
| 336 |
+
"""Applies an update to parameters and returns new state."""
|
| 337 |
+
# This function computes the gradient of the first output of loss_fn and
|
| 338 |
+
# passes through the other arguments unchanged.
|
| 339 |
+
grad_loss_fn = jax.grad(self._loss_fn, has_aux=True)
|
| 340 |
+
scaled_grads, (loss, date_loss, subregion_loss, subregion_accuracy,
|
| 341 |
+
mask_loss, mask_accuracy, nsp_loss,
|
| 342 |
+
nsp_accuracy) = grad_loss_fn(params, batch, global_step, rng)
|
| 343 |
+
|
| 344 |
+
scaled_grads = jax.tree_map(jnp.nan_to_num, scaled_grads)
|
| 345 |
+
grads = jl_utils.tree_psum(scaled_grads, axis_name='i')
|
| 346 |
+
|
| 347 |
+
# Compute and apply updates via our optimizer.
|
| 348 |
+
learning_rate = self._learning_rate_fn(global_step)
|
| 349 |
+
updates, opt_state = self._opt_update(grads, opt_state, params=params)
|
| 350 |
+
params = optax.apply_updates(params, updates)
|
| 351 |
+
|
| 352 |
+
# Scalars to log (note: we log the mean across all hosts/devices).
|
| 353 |
+
scalars = {
|
| 354 |
+
'loss/train': loss,
|
| 355 |
+
'loss/date': date_loss,
|
| 356 |
+
'loss/subregion': subregion_loss,
|
| 357 |
+
'loss/mask': mask_loss,
|
| 358 |
+
'loss/nsp': nsp_loss,
|
| 359 |
+
'accuracy/subregion': subregion_accuracy,
|
| 360 |
+
'accuracy/mask': mask_accuracy,
|
| 361 |
+
'accuracy/nsp': nsp_accuracy,
|
| 362 |
+
'opt/learning_rate': learning_rate,
|
| 363 |
+
'opt/grad_norm': optax.global_norm(grads),
|
| 364 |
+
'opt/param_norm': optax.global_norm(params),
|
| 365 |
+
}
|
| 366 |
+
scalars = jax.lax.pmean(scalars, axis_name='i')
|
| 367 |
+
|
| 368 |
+
return params, opt_state, scalars
|
| 369 |
+
|
| 370 |
+
# _
|
| 371 |
+
# _____ ____ _| |
|
| 372 |
+
# / _ \ \ / / _` | |
|
| 373 |
+
# | __/\ V / (_| | |
|
| 374 |
+
# \___| \_/ \__,_|_|
|
| 375 |
+
#
|
| 376 |
+
|
| 377 |
+
def evaluate(self, global_step, rng, **unused_kwargs):
|
| 378 |
+
"""See base class."""
|
| 379 |
+
|
| 380 |
+
if self._eval_input is None:
|
| 381 |
+
self._initialize_eval()
|
| 382 |
+
|
| 383 |
+
global_step = np.array(jl_utils.get_first(global_step))
|
| 384 |
+
summary, outputs = self._eval_epoch(jl_utils.get_first(rng))
|
| 385 |
+
|
| 386 |
+
for k, v in summary.items():
|
| 387 |
+
summary[k] = np.array(v)
|
| 388 |
+
|
| 389 |
+
score = summary['score/eval']
|
| 390 |
+
logging.info('[Step %d] eval_score=%.2f', global_step, score)
|
| 391 |
+
|
| 392 |
+
# Log outputs
|
| 393 |
+
checkpoint_dir = jl_utils.get_checkpoint_dir(FLAGS.config,
|
| 394 |
+
jax.process_index())
|
| 395 |
+
outputs_path = os.path.join(checkpoint_dir, 'best_outputs.pkl.bz2')
|
| 396 |
+
score_path = os.path.join(checkpoint_dir, 'best_score.txt')
|
| 397 |
+
model_log_path = os.path.join(checkpoint_dir, 'model_log')
|
| 398 |
+
best_model_log_path = os.path.join(checkpoint_dir, 'best_model_log')
|
| 399 |
+
|
| 400 |
+
# Check for preexisting outputs
|
| 401 |
+
best_score = None
|
| 402 |
+
best_step = None
|
| 403 |
+
if os.path.exists(score_path):
|
| 404 |
+
with open(score_path, 'r') as f:
|
| 405 |
+
tok = f.read().strip().split(' ')
|
| 406 |
+
best_step = int(tok[0])
|
| 407 |
+
best_score = float(tok[1])
|
| 408 |
+
|
| 409 |
+
# Store outputs if score is better
|
| 410 |
+
if best_score is None or (score > best_score and global_step > best_step):
|
| 411 |
+
best_score = score
|
| 412 |
+
|
| 413 |
+
with open(score_path, 'w') as f:
|
| 414 |
+
f.write(f'{global_step} {best_score}')
|
| 415 |
+
|
| 416 |
+
with open(outputs_path, 'wb') as f:
|
| 417 |
+
outputs_pkl = pickle.dumps(outputs, protocol=2)
|
| 418 |
+
outputs_pkl_bz2 = bz2.compress(outputs_pkl)
|
| 419 |
+
f.write(outputs_pkl_bz2)
|
| 420 |
+
|
| 421 |
+
if self.config.evaluation.store_model_log:
|
| 422 |
+
if os.path.isdir(best_model_log_path):
|
| 423 |
+
map(os.remove, glob.glob(best_model_log_path + '/*'))
|
| 424 |
+
else:
|
| 425 |
+
os.makedirs(best_model_log_path)
|
| 426 |
+
distutils.dir_util.copy_tree(model_log_path, best_model_log_path)
|
| 427 |
+
|
| 428 |
+
logging.info('[Step %d] Writing eval outputs: %s.', global_step,
|
| 429 |
+
outputs_path)
|
| 430 |
+
|
| 431 |
+
# Log best score
|
| 432 |
+
summary['score/eval_best'] = best_score
|
| 433 |
+
|
| 434 |
+
return summary
|
| 435 |
+
|
| 436 |
+
def _initialize_eval(self):
|
| 437 |
+
self._eval_input = jl_utils.py_prefetch(self._build_eval_input)
|
| 438 |
+
|
| 439 |
+
def _build_eval_input(self):
|
| 440 |
+
"""Builds the evaluation input pipeline."""
|
| 441 |
+
config_dataset = self.config.dataset
|
| 442 |
+
with open(config_dataset.dataset_path) as dataset_file:
|
| 443 |
+
ds = dataloader.loader_tf(
|
| 444 |
+
self.config.evaluation.batch_size,
|
| 445 |
+
config_dataset,
|
| 446 |
+
self._region_map,
|
| 447 |
+
alphabet=self._alphabet,
|
| 448 |
+
dataset_file=dataset_file,
|
| 449 |
+
mode=self.config.evaluation.mode)
|
| 450 |
+
|
| 451 |
+
return iter(tfds.as_numpy(ds))
|
| 452 |
+
|
| 453 |
+
def _eval_batch(self, params, batch, rng):
|
| 454 |
+
"""Evaluates a batch."""
|
| 455 |
+
phi_id = batch['id']
|
| 456 |
+
text_char = batch['text_char']
|
| 457 |
+
text_word = batch['text_word']
|
| 458 |
+
text_unmasked = batch['text_unmasked']
|
| 459 |
+
text_mask = batch['text_mask']
|
| 460 |
+
next_sentence_mask = batch['next_sentence_mask']
|
| 461 |
+
next_sentence_label = batch['next_sentence_label']
|
| 462 |
+
subregion = batch['region_sub_id']
|
| 463 |
+
date_min = batch['date_min']
|
| 464 |
+
date_max = batch['date_max']
|
| 465 |
+
date_dist = batch['date_dist']
|
| 466 |
+
date_available = batch['date_available']
|
| 467 |
+
|
| 468 |
+
# with hlogging.context() as log:
|
| 469 |
+
(date_pred, subregion_logits, mask_logits, nsp_logits) = self.forward.apply(
|
| 470 |
+
params,
|
| 471 |
+
text_char=text_char,
|
| 472 |
+
text_word=text_word,
|
| 473 |
+
text_char_onehot=None,
|
| 474 |
+
text_word_onehot=None,
|
| 475 |
+
is_training=False,
|
| 476 |
+
rngs={'dropout': rng})
|
| 477 |
+
|
| 478 |
+
# Log model weights
|
| 479 |
+
model_log = {}
|
| 480 |
+
|
| 481 |
+
subregion_loss = 0.
|
| 482 |
+
subregion_accuracy = 0.
|
| 483 |
+
date_loss = 0.
|
| 484 |
+
date_l1_loss = 0.
|
| 485 |
+
nsp_loss = 0.
|
| 486 |
+
nsp_accuracy = 0.
|
| 487 |
+
# eps = 1e-6
|
| 488 |
+
|
| 489 |
+
date_count = 0
|
| 490 |
+
mask_count = 0
|
| 491 |
+
nsp_count = 0
|
| 492 |
+
|
| 493 |
+
# Date loss
|
| 494 |
+
if self.config.loss.date.enabled:
|
| 495 |
+
date_pred_x = jnp.arange(
|
| 496 |
+
self.config.dataset.date_min + self.config.dataset.date_interval / 2,
|
| 497 |
+
self.config.dataset.date_max + self.config.dataset.date_interval / 2,
|
| 498 |
+
self.config.dataset.date_interval).reshape(-1, 1)
|
| 499 |
+
date_pred_val = jnp.dot(jax.nn.softmax(date_pred, axis=-1), date_pred_x)
|
| 500 |
+
date_l1_loss = jnp.sum(
|
| 501 |
+
jax.vmap(date_loss_l1)(date_pred_val, date_min, date_max,
|
| 502 |
+
date_available),
|
| 503 |
+
axis=0)
|
| 504 |
+
|
| 505 |
+
if 'l1' in self.config.loss.date.type.split('+'):
|
| 506 |
+
date_loss += date_l1_loss * self.config.loss.date.weight_l1
|
| 507 |
+
|
| 508 |
+
if 'dist' in self.config.loss.date.type.split('+'):
|
| 509 |
+
date_loss_dist_ = categorical_kl_divergence(date_dist, date_pred)
|
| 510 |
+
date_loss_dist_ *= date_available
|
| 511 |
+
date_loss += (
|
| 512 |
+
jnp.sum(date_loss_dist_, axis=0) *
|
| 513 |
+
self.config.loss.date.weight_dist)
|
| 514 |
+
|
| 515 |
+
date_count = jnp.sum(date_available)
|
| 516 |
+
|
| 517 |
+
# Region and subregion loss
|
| 518 |
+
if self.config.loss.region.enabled:
|
| 519 |
+
subregion_loss = jnp.sum(
|
| 520 |
+
cross_entropy_loss(subregion_logits, subregion), 0)
|
| 521 |
+
subregion_loss *= self.config.loss.region.weight
|
| 522 |
+
subregion_accuracy = jnp.mean(
|
| 523 |
+
jnp.argmax(subregion_logits, -1) == subregion)
|
| 524 |
+
|
| 525 |
+
# Mask loss
|
| 526 |
+
if self.config.loss.mask.enabled:
|
| 527 |
+
mask_loss = jnp.sum(
|
| 528 |
+
cross_entropy_label_smoothing_loss(
|
| 529 |
+
mask_logits, text_unmasked, text_mask, label_smoothing=0),
|
| 530 |
+
1) # [B]
|
| 531 |
+
# mask_loss /= jnp.sum(text_mask, axis=1) + eps # [B]
|
| 532 |
+
assert mask_loss.ndim == 1
|
| 533 |
+
mask_loss = jnp.mean(mask_loss, 0) * self.config.loss.mask.weight # []
|
| 534 |
+
|
| 535 |
+
mask_all_accuracy = (jnp.argmax(mask_logits, -1) == text_unmasked).astype(
|
| 536 |
+
mask_logits.dtype)
|
| 537 |
+
mask_accuracy = jnp.sum(
|
| 538 |
+
jnp.multiply(mask_all_accuracy, text_mask.astype(mask_logits.dtype)))
|
| 539 |
+
mask_count = jnp.sum(text_mask)
|
| 540 |
+
|
| 541 |
+
# NSP loss
|
| 542 |
+
if self.config.loss.nsp.enabled:
|
| 543 |
+
nsp_loss = jnp.sum(
|
| 544 |
+
jax.vmap(jax.vmap(cross_entropy_mask_loss))(nsp_logits,
|
| 545 |
+
next_sentence_label,
|
| 546 |
+
next_sentence_mask),
|
| 547 |
+
1) # [B]
|
| 548 |
+
assert nsp_loss.ndim == 1
|
| 549 |
+
nsp_loss = jnp.sum(nsp_loss, 0) * self.config.loss.nsp.weight
|
| 550 |
+
nsp_all_accuracy = (jnp.argmax(
|
| 551 |
+
nsp_logits, -1) == next_sentence_label).astype(nsp_logits.dtype)
|
| 552 |
+
nsp_accuracy = jnp.sum(
|
| 553 |
+
jnp.multiply(nsp_all_accuracy,
|
| 554 |
+
next_sentence_mask.astype(nsp_logits.dtype)))
|
| 555 |
+
nsp_count = jnp.sum(next_sentence_mask)
|
| 556 |
+
|
| 557 |
+
# Outputs
|
| 558 |
+
scalars = {
|
| 559 |
+
'score/eval':
|
| 560 |
+
(mask_accuracy + subregion_accuracy - date_l1_loss * 0.01),
|
| 561 |
+
'loss/eval': mask_loss + date_loss + subregion_loss,
|
| 562 |
+
'loss/date': date_loss,
|
| 563 |
+
'loss/date_l1': date_l1_loss,
|
| 564 |
+
'loss/subregion': subregion_loss,
|
| 565 |
+
'loss/mask': mask_loss,
|
| 566 |
+
'loss/nsp': nsp_loss,
|
| 567 |
+
'count/date': date_count,
|
| 568 |
+
'count/nsp': nsp_count,
|
| 569 |
+
'count/mask': mask_count,
|
| 570 |
+
'accuracy/subregion': subregion_accuracy,
|
| 571 |
+
'accuracy/mask': mask_accuracy,
|
| 572 |
+
'accuracy/nsp': nsp_accuracy,
|
| 573 |
+
}
|
| 574 |
+
|
| 575 |
+
outputs = {
|
| 576 |
+
'outputs/id': phi_id,
|
| 577 |
+
'outputs/date_pred': date_pred.astype('float16'),
|
| 578 |
+
'outputs/date_min': date_min,
|
| 579 |
+
'outputs/date_max': date_max,
|
| 580 |
+
'outputs/date_dist': date_dist.astype('float16'),
|
| 581 |
+
'outputs/date_available': date_available,
|
| 582 |
+
'outputs/subregion_logits': subregion_logits.astype('float16'),
|
| 583 |
+
'outputs/subregion': subregion,
|
| 584 |
+
}
|
| 585 |
+
|
| 586 |
+
return scalars, outputs, model_log
|
| 587 |
+
|
| 588 |
+
def _eval_epoch(self, rng):
|
| 589 |
+
"""Evaluates an epoch."""
|
| 590 |
+
summary = {}
|
| 591 |
+
outputs = {}
|
| 592 |
+
total_num_sequences = 0
|
| 593 |
+
|
| 594 |
+
# Prepare directories for storing model log
|
| 595 |
+
checkpoint_dir = jl_utils.get_checkpoint_dir(FLAGS.config,
|
| 596 |
+
jax.process_index())
|
| 597 |
+
model_log_path = os.path.join(checkpoint_dir, 'model_log')
|
| 598 |
+
if self.config.evaluation.store_model_log:
|
| 599 |
+
if os.path.isdir(model_log_path):
|
| 600 |
+
map(os.remove, glob.glob(model_log_path + '/*'))
|
| 601 |
+
else:
|
| 602 |
+
os.makedirs(model_log_path)
|
| 603 |
+
|
| 604 |
+
# Checkpoints broadcast for each local device
|
| 605 |
+
params = jl_utils.get_first(self._params)
|
| 606 |
+
|
| 607 |
+
# Model log buffer initialisation
|
| 608 |
+
model_log_buffer = []
|
| 609 |
+
|
| 610 |
+
def _flush_model_log_buffer(model_log_buffer):
|
| 611 |
+
"""Writes model log to bz2 pickle files."""
|
| 612 |
+
while model_log_buffer:
|
| 613 |
+
model_log_batch_path, model_log_pkl_bz2 = model_log_buffer.pop(0)
|
| 614 |
+
with open(model_log_batch_path, 'wb') as f:
|
| 615 |
+
f.write(model_log_pkl_bz2)
|
| 616 |
+
|
| 617 |
+
# Converting to numpy here allows us to reset the generator
|
| 618 |
+
for batch in self._eval_input():
|
| 619 |
+
# Make sure that the input has batch_dim=1
|
| 620 |
+
assert batch['text_char'].shape[0] == 1
|
| 621 |
+
|
| 622 |
+
summary_batch, outputs_batch, model_log_batch = self._eval_batch(
|
| 623 |
+
params, batch, rng)
|
| 624 |
+
|
| 625 |
+
# Append batch values to dictionary
|
| 626 |
+
for k, v in summary_batch.items():
|
| 627 |
+
summary[k] = summary.get(k, 0) + v
|
| 628 |
+
for k, v in outputs_batch.items():
|
| 629 |
+
outputs.setdefault(k, []).append(v)
|
| 630 |
+
|
| 631 |
+
total_num_sequences += self.config.evaluation.batch_size
|
| 632 |
+
|
| 633 |
+
# Store model log per batch
|
| 634 |
+
if self.config.evaluation.store_model_log:
|
| 635 |
+
# Append to buffer
|
| 636 |
+
model_log_batch_path = os.path.join(
|
| 637 |
+
model_log_path,
|
| 638 |
+
str(outputs_batch['outputs/id'][0]) + '.pkl.bz2')
|
| 639 |
+
model_log_pkl = pickle.dumps(model_log_batch, protocol=2)
|
| 640 |
+
model_log_pkl_bz2 = bz2.compress(model_log_pkl)
|
| 641 |
+
model_log_buffer += [(model_log_batch_path, model_log_pkl_bz2)]
|
| 642 |
+
|
| 643 |
+
# Flush model log buffer
|
| 644 |
+
if (len(model_log_buffer) %
|
| 645 |
+
self.config.evaluation.store_model_log_steps == 0):
|
| 646 |
+
_flush_model_log_buffer(model_log_buffer)
|
| 647 |
+
|
| 648 |
+
# Flush remaining model log buffer
|
| 649 |
+
if self.config.evaluation.store_model_log:
|
| 650 |
+
_flush_model_log_buffer(model_log_buffer)
|
| 651 |
+
|
| 652 |
+
# Normalise and concatenate
|
| 653 |
+
summary['loss/date'] /= summary['count/date']
|
| 654 |
+
summary['loss/date_l1'] /= summary['count/date']
|
| 655 |
+
|
| 656 |
+
summary['loss/mask'] /= summary['count/mask']
|
| 657 |
+
summary['accuracy/mask'] /= summary['count/mask']
|
| 658 |
+
|
| 659 |
+
summary['loss/nsp'] /= summary['count/nsp']
|
| 660 |
+
summary['accuracy/nsp'] /= summary['count/nsp']
|
| 661 |
+
|
| 662 |
+
summary['loss/subregion'] /= total_num_sequences
|
| 663 |
+
summary['accuracy/subregion'] /= total_num_sequences
|
| 664 |
+
|
| 665 |
+
summary['score/eval'] = (
|
| 666 |
+
summary['accuracy/mask'] + summary['accuracy/subregion'] -
|
| 667 |
+
summary['loss/date_l1'] * 0.01)
|
| 668 |
+
summary['loss/eval'] = (
|
| 669 |
+
summary['loss/mask'] + summary['loss/date'] + summary['loss/subregion'])
|
| 670 |
+
|
| 671 |
+
for k, v in outputs.items():
|
| 672 |
+
outputs[k] = np.concatenate(v, axis=0)
|
| 673 |
+
|
| 674 |
+
return summary, outputs
|
| 675 |
+
|
| 676 |
+
|
| 677 |
+
if __name__ == '__main__':
|
| 678 |
+
flags.mark_flag_as_required('config')
|
| 679 |
+
app.run(functools.partial(platform.main, Experiment))
|
train/launch_local.sh
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
# Copyright 2021 the Ithaca Authors
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
|
| 17 |
+
# Command for running training script. Run from within train/ directory
|
| 18 |
+
# after first installing the ithaca package.
|
| 19 |
+
#
|
| 20 |
+
# See README.md in this train/ directory for details.
|
| 21 |
+
|
| 22 |
+
python experiment.py --config=config.py --jaxline_mode=train --logtostderr
|