Spaces:
Running

Running

new stuff in readme.md
Browse files
readme.md
CHANGED
|
@@ -3,6 +3,7 @@
|
|
| 3 |
....
|
| 4 |
|
| 5 |
# Novel Contributions
|
|
|
|
| 6 |
The original CLIP model was trained on 400millions text-image pairs; this amount of data is not available for Italian and the only datasets for captioning in the literature are MSCOCO-IT (translated version of MSCOCO) and WIT. To get competitive results we follewed three directions: 1) more data 2) better augmentation and 3) better training.
|
| 7 |
|
| 8 |
## More Data
|
|
@@ -12,11 +13,13 @@ Thus, we opted for one choice, data of medium-high quality.
|
|
| 12 |
|
| 13 |
We considered three main sources of data:
|
| 14 |
|
| 15 |
-
+ WIT. Most of
|
| 16 |
However, this kind of text, without more information, is not useful to learn a good mapping between images and captions. On the other hand,
|
| 17 |
this text is written in Italian and it is good quality. To prevent polluting the data with captions that are not meaningful, we used POS tagging
|
| 18 |
on the data and removed all the captions that were composed for the 80% or more by PROPN.
|
|
|
|
| 19 |
+ MSCOCO-IT
|
|
|
|
| 20 |
+ CC
|
| 21 |
|
| 22 |
|
|
@@ -29,11 +32,12 @@ on the data and removed all the captions that were composed for the 80% or more
|
|
| 29 |
|
| 30 |
### Backbone Freezing
|
| 31 |
|
| 32 |
-

|
| 33 |
|
| 34 |
|
| 35 |
|
| 36 |
# Scientific Validity
|
|
|
|
| 37 |
Those images are definitely cool and interesting, but a model is nothing without validation.
|
| 38 |
To better understand how well our clip-italian model works we run an experimental evaluation. Since this is the first clip-based model in Italian, we used the multilingual CLIP model as a comparison baseline.
|
| 39 |
|
|
@@ -46,7 +50,7 @@ We selected two different tasks:
|
|
| 46 |
+ zero-shot classification
|
| 47 |
|
| 48 |
|
| 49 |
-
|
| 50 |
|
| 51 |
| MRR | CLIP-Italian | mCLIP |
|
| 52 |
| --------------- | ------------ |-------|
|
|
@@ -55,7 +59,7 @@ We selected two different tasks:
|
|
| 55 |
| MRR@10 | | |
|
| 56 |
|
| 57 |
|
| 58 |
-
|
| 59 |
|
| 60 |
| Accuracy | CLIP-Italian | mCLIP |
|
| 61 |
| --------------- | ------------ |-------|
|
|
@@ -68,5 +72,5 @@ We selected two different tasks:
|
|
| 68 |
|
| 69 |
|
| 70 |
|
| 71 |
-
|
| 72 |
This readme has been designed using resources from Flaticon.com
|
|
|
|
| 3 |
....
|
| 4 |
|
| 5 |
# Novel Contributions
|
| 6 |
+
|
| 7 |
The original CLIP model was trained on 400millions text-image pairs; this amount of data is not available for Italian and the only datasets for captioning in the literature are MSCOCO-IT (translated version of MSCOCO) and WIT. To get competitive results we follewed three directions: 1) more data 2) better augmentation and 3) better training.
|
| 8 |
|
| 9 |
## More Data
|
|
|
|
| 13 |
|
| 14 |
We considered three main sources of data:
|
| 15 |
|
| 16 |
+
+ WIT. Most of these captions describe ontological knowledge and encyclopedic facts (e.g., Roberto Baggio in 1994).
|
| 17 |
However, this kind of text, without more information, is not useful to learn a good mapping between images and captions. On the other hand,
|
| 18 |
this text is written in Italian and it is good quality. To prevent polluting the data with captions that are not meaningful, we used POS tagging
|
| 19 |
on the data and removed all the captions that were composed for the 80% or more by PROPN.
|
| 20 |
+
|
| 21 |
+ MSCOCO-IT
|
| 22 |
+
|
| 23 |
+ CC
|
| 24 |
|
| 25 |
|
|
|
|
| 32 |
|
| 33 |
### Backbone Freezing
|
| 34 |
|
| 35 |
+
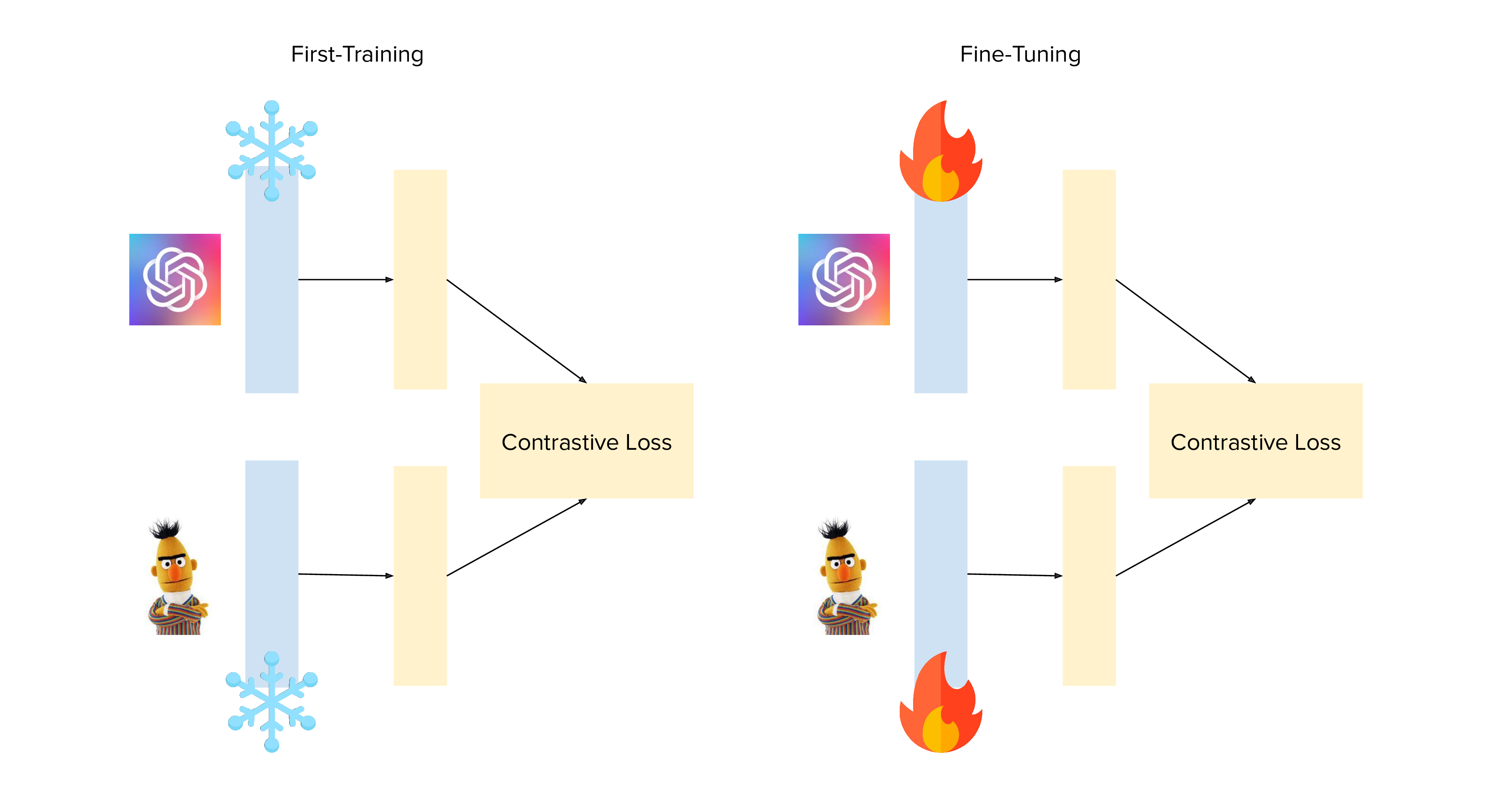
|
| 36 |
|
| 37 |
|
| 38 |
|
| 39 |
# Scientific Validity
|
| 40 |
+
|
| 41 |
Those images are definitely cool and interesting, but a model is nothing without validation.
|
| 42 |
To better understand how well our clip-italian model works we run an experimental evaluation. Since this is the first clip-based model in Italian, we used the multilingual CLIP model as a comparison baseline.
|
| 43 |
|
|
|
|
| 50 |
+ zero-shot classification
|
| 51 |
|
| 52 |
|
| 53 |
+
### Image Retrieval
|
| 54 |
|
| 55 |
| MRR | CLIP-Italian | mCLIP |
|
| 56 |
| --------------- | ------------ |-------|
|
|
|
|
| 59 |
| MRR@10 | | |
|
| 60 |
|
| 61 |
|
| 62 |
+
### Zero-shot classification
|
| 63 |
|
| 64 |
| Accuracy | CLIP-Italian | mCLIP |
|
| 65 |
| --------------- | ------------ |-------|
|
|
|
|
| 72 |
|
| 73 |
|
| 74 |
|
| 75 |
+
# Other Notes
|
| 76 |
This readme has been designed using resources from Flaticon.com
|