Spaces:
Paused

Paused
root
commited on
Commit
•
424a94c
1
Parent(s):
2d96aed
video-llama-2-test
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- LICENSE +28 -0
- LICENSE_Lavis.md +14 -0
- LICENSE_Minigpt4.md +14 -0
- README copy.md +244 -0
- README.md +249 -13
- Video-LLaMA-2-7B-Finetuned/AL_LLaMA_2_7B_Finetuned.pth +3 -0
- Video-LLaMA-2-7B-Finetuned/VL_LLaMA_2_7B_Finetuned.pth +3 -0
- Video-LLaMA-2-7B-Finetuned/imagebind_huge.pth +3 -0
- Video-LLaMA-2-7B-Finetuned/llama-2-7b-chat-hf/config.json +22 -0
- Video-LLaMA-2-7B-Finetuned/llama-2-7b-chat-hf/generation_config.json +7 -0
- Video-LLaMA-2-7B-Finetuned/llama-2-7b-chat-hf/pytorch_model-00001-of-00002.bin +3 -0
- Video-LLaMA-2-7B-Finetuned/llama-2-7b-chat-hf/pytorch_model-00002-of-00002.bin +3 -0
- Video-LLaMA-2-7B-Finetuned/llama-2-7b-chat-hf/pytorch_model.bin.index.json +330 -0
- Video-LLaMA-2-7B-Finetuned/llama-2-7b-chat-hf/special_tokens_map.json +23 -0
- Video-LLaMA-2-7B-Finetuned/llama-2-7b-chat-hf/tokenizer.json +0 -0
- Video-LLaMA-2-7B-Finetuned/llama-2-7b-chat-hf/tokenizer.model +3 -0
- Video-LLaMA-2-7B-Finetuned/llama-2-7b-chat-hf/tokenizer_config.json +33 -0
- app.py +237 -0
- apply_delta.py +49 -0
- demo_audiovideo.py +250 -0
- demo_video.py +247 -0
- environment.yml +70 -0
- eval_configs/video_llama_eval_only_vl.yaml +36 -0
- eval_configs/video_llama_eval_withaudio.yaml +35 -0
- figs/architecture.png +0 -0
- figs/architecture_v2.png +0 -0
- figs/video_llama_logo.jpg +0 -0
- prompts/alignment_image.txt +4 -0
- requirement.txt +13 -0
- setup.py +17 -0
- train.py +107 -0
- train_configs/audiobranch_stage1_pretrain.yaml +88 -0
- train_configs/audiobranch_stage2_finetune.yaml +120 -0
- train_configs/visionbranch_stage1_pretrain.yaml +87 -0
- train_configs/visionbranch_stage2_finetune.yaml +122 -0
- video_llama/__init__.py +31 -0
- video_llama/__pycache__/__init__.cpython-39.pyc +0 -0
- video_llama/common/__init__.py +0 -0
- video_llama/common/__pycache__/__init__.cpython-39.pyc +0 -0
- video_llama/common/__pycache__/config.cpython-39.pyc +0 -0
- video_llama/common/__pycache__/dist_utils.cpython-39.pyc +0 -0
- video_llama/common/__pycache__/logger.cpython-39.pyc +0 -0
- video_llama/common/__pycache__/registry.cpython-39.pyc +0 -0
- video_llama/common/__pycache__/utils.cpython-39.pyc +0 -0
- video_llama/common/config.py +468 -0
- video_llama/common/dist_utils.py +137 -0
- video_llama/common/gradcam.py +24 -0
- video_llama/common/logger.py +195 -0
- video_llama/common/optims.py +119 -0
- video_llama/common/registry.py +329 -0
LICENSE
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
BSD 3-Clause License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023, Multilingual NLP Team at Alibaba DAMO Academy
|
| 4 |
+
|
| 5 |
+
Redistribution and use in source and binary forms, with or without
|
| 6 |
+
modification, are permitted provided that the following conditions are met:
|
| 7 |
+
|
| 8 |
+
1. Redistributions of source code must retain the above copyright notice, this
|
| 9 |
+
list of conditions and the following disclaimer.
|
| 10 |
+
|
| 11 |
+
2. Redistributions in binary form must reproduce the above copyright notice,
|
| 12 |
+
this list of conditions and the following disclaimer in the documentation
|
| 13 |
+
and/or other materials provided with the distribution.
|
| 14 |
+
|
| 15 |
+
3. Neither the name of the copyright holder nor the names of its
|
| 16 |
+
contributors may be used to endorse or promote products derived from
|
| 17 |
+
this software without specific prior written permission.
|
| 18 |
+
|
| 19 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
|
| 20 |
+
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
|
| 21 |
+
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
|
| 22 |
+
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
|
| 23 |
+
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
|
| 24 |
+
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
|
| 25 |
+
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
|
| 26 |
+
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
|
| 27 |
+
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
| 28 |
+
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
LICENSE_Lavis.md
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
BSD 3-Clause License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2022 Salesforce, Inc.
|
| 4 |
+
All rights reserved.
|
| 5 |
+
|
| 6 |
+
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
|
| 7 |
+
|
| 8 |
+
1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
|
| 9 |
+
|
| 10 |
+
2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
|
| 11 |
+
|
| 12 |
+
3. Neither the name of Salesforce.com nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
|
| 13 |
+
|
| 14 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
LICENSE_Minigpt4.md
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
BSD 3-Clause License
|
| 2 |
+
|
| 3 |
+
Copyright 2023 Deyao Zhu
|
| 4 |
+
All rights reserved.
|
| 5 |
+
|
| 6 |
+
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
|
| 7 |
+
|
| 8 |
+
1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
|
| 9 |
+
|
| 10 |
+
2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
|
| 11 |
+
|
| 12 |
+
3. Neither the name of the copyright holder nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
|
| 13 |
+
|
| 14 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
README copy.md
ADDED
|
@@ -0,0 +1,244 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<p align="center" width="100%">
|
| 2 |
+
<a target="_blank"><img src="figs/video_llama_logo.jpg" alt="Video-LLaMA" style="width: 50%; min-width: 200px; display: block; margin: auto;"></a>
|
| 3 |
+
</p>
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
# Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
|
| 8 |
+
<!-- **Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding** -->
|
| 9 |
+
|
| 10 |
+
This is the repo for the Video-LLaMA project, which is working on empowering large language models with video and audio understanding capabilities.
|
| 11 |
+
|
| 12 |
+
<div style='display:flex; gap: 0.25rem; '>
|
| 13 |
+
<a href='https://huggingface.co/spaces/DAMO-NLP-SG/Video-LLaMA'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Demo-blue'></a>
|
| 14 |
+
<a href='https://modelscope.cn/studios/damo/video-llama/summary'><img src='https://img.shields.io/badge/ModelScope-Demo-blueviolet'></a>
|
| 15 |
+
<a href='https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Model-blue'></a>
|
| 16 |
+
<a href='https://arxiv.org/abs/2306.02858'><img src='https://img.shields.io/badge/Paper-PDF-red'></a>
|
| 17 |
+
</div>
|
| 18 |
+
|
| 19 |
+
## News
|
| 20 |
+
- [08.03] **NOTE**: Release the LLaMA-2-Chat version of **Video-LLaMA**, including its pre-trained and instruction-tuned checkpoints. We uploaded full weights on Huggingface ([7B-Pretrained](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-2-7B-Pretrained),[7B-Finetuned](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-2-7B-Finetuned),[13B-Pretrained](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-2-13B-Pretrained),[13B-Finetuned](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-2-13B-Finetuned)), just for your convenience and secondary development. Welcome to try.
|
| 21 |
+
- [06.14] **NOTE**: the current online interactive demo is primarily for English chatting and it may **NOT** be a good option to ask Chinese questions since Vicuna/LLaMA does not represent Chinese texts very well.
|
| 22 |
+
- [06.13] **NOTE**: the audio support is **ONLY** for Vicuna-7B by now although we have several VL checkpoints available for other decoders.
|
| 23 |
+
- [06.10] **NOTE**: we have NOT updated the HF demo yet because the whole framework (with audio branch) cannot run normally on A10-24G. The current running demo is still the previous version of Video-LLaMA. We will fix this issue soon.
|
| 24 |
+
- [06.08] 🚀🚀 Release the checkpoints of the audio-supported Video-LLaMA. Documentation and example outputs are also updated.
|
| 25 |
+
- [05.22] 🚀🚀 Interactive demo online, try our Video-LLaMA (with **Vicuna-7B** as language decoder) at [Hugging Face](https://huggingface.co/spaces/DAMO-NLP-SG/Video-LLaMA) and [ModelScope](https://pre.modelscope.cn/studios/damo/video-llama/summary)!!
|
| 26 |
+
- [05.22] ⭐️ Release **Video-LLaMA v2** built with Vicuna-7B
|
| 27 |
+
- [05.18] 🚀🚀 Support video-grounded chat in Chinese
|
| 28 |
+
- [**Video-LLaMA-BiLLA**](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/finetune-billa7b-zh.pth): we introduce [BiLLa-7B](https://huggingface.co/Neutralzz/BiLLa-7B-SFT) as language decoder and fine-tune the video-language aligned model (i.e., stage 1 model) with machine-translated [VideoChat](https://github.com/OpenGVLab/InternVideo/tree/main/Data/instruction_data) instructions.
|
| 29 |
+
- [**Video-LLaMA-Ziya**](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/finetune-ziya13b-zh.pth): same with Video-LLaMA-BiLLA but the language decoder is changed to [Ziya-13B](https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1).
|
| 30 |
+
- [05.18] ⭐️ Create a Hugging Face [repo](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series) to store the model weights of all the variants of our Video-LLaMA.
|
| 31 |
+
- [05.15] ⭐️ Release [**Video-LLaMA v2**](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/finetune-vicuna13b-v2.pth): we use the training data provided by [VideoChat](https://github.com/OpenGVLab/InternVideo/tree/main/Data/instruction_data) to further enhance the instruction-following capability of Video-LLaMA.
|
| 32 |
+
- [05.07] Release the initial version of **Video-LLaMA**, including its pre-trained and instruction-tuned checkpoints.
|
| 33 |
+
|
| 34 |
+
<p align="center" width="100%">
|
| 35 |
+
<a target="_blank"><img src="figs/architecture_v2.png" alt="Video-LLaMA" style="width: 80%; min-width: 200px; display: block; margin: auto;"></a>
|
| 36 |
+
</p>
|
| 37 |
+
|
| 38 |
+
## Introduction
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
- Video-LLaMA is built on top of [BLIP-2](https://github.com/salesforce/LAVIS/tree/main/projects/blip2) and [MiniGPT-4](https://github.com/Vision-CAIR/MiniGPT-4). It is composed of two core components: (1) Vision-Language (VL) Branch and (2) Audio-Language (AL) Branch.
|
| 42 |
+
- **VL Branch** (Visual encoder: ViT-G/14 + BLIP-2 Q-Former)
|
| 43 |
+
- A two-layer video Q-Former and a frame embedding layer (applied to the embeddings of each frame) are introduced to compute video representations.
|
| 44 |
+
- We train VL Branch on the Webvid-2M video caption dataset with a video-to-text generation task. We also add image-text pairs (~595K image captions from [LLaVA](https://github.com/haotian-liu/LLaVA)) into the pre-training dataset to enhance the understanding of static visual concepts.
|
| 45 |
+
- After pre-training, we further fine-tune our VL Branch using the instruction-tuning data from [MiniGPT-4](https://github.com/Vision-CAIR/MiniGPT-4), [LLaVA](https://github.com/haotian-liu/LLaVA) and [VideoChat](https://github.com/OpenGVLab/Ask-Anything).
|
| 46 |
+
- **AL Branch** (Audio encoder: ImageBind-Huge)
|
| 47 |
+
- A two-layer audio Q-Former and a audio segment embedding layer (applied to the embedding of each audio segment) are introduced to compute audio representations.
|
| 48 |
+
- As the used audio encoder (i.e., ImageBind) is already aligned across multiple modalities, we train AL Branch on video/image instrucaption data only, just to connect the output of ImageBind to language decoder.
|
| 49 |
+
- Note that only the Video/Audio Q-Former, positional embedding layers and the linear layers are trainable during cross-modal training.
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
## Example Outputs
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
- **Video with background sound**
|
| 57 |
+
|
| 58 |
+
<p float="left">
|
| 59 |
+
<img src="https://github.com/DAMO-NLP-SG/Video-LLaMA/assets/18526640/7f7bddb2-5cf1-4cf4-bce3-3fa67974cbb3" style="width: 45%; margin: auto;">
|
| 60 |
+
<img src="https://github.com/DAMO-NLP-SG/Video-LLaMA/assets/18526640/ec76be04-4aa9-4dde-bff2-0a232b8315e0" style="width: 45%; margin: auto;">
|
| 61 |
+
</p>
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
- **Video without sound effects**
|
| 65 |
+
<p float="left">
|
| 66 |
+
<img src="https://github.com/DAMO-NLP-SG/Video-LLaMA/assets/18526640/539ea3cc-360d-4b2c-bf86-5505096df2f7" style="width: 45%; margin: auto;">
|
| 67 |
+
<img src="https://github.com/DAMO-NLP-SG/Video-LLaMA/assets/18526640/7304ad6f-1009-46f1-aca4-7f861b636363" style="width: 45%; margin: auto;">
|
| 68 |
+
</p>
|
| 69 |
+
|
| 70 |
+
- **Static image**
|
| 71 |
+
<p float="left">
|
| 72 |
+
<img src="https://github.com/DAMO-NLP-SG/Video-LLaMA/assets/18526640/a146c169-8693-4627-96e6-f885ca22791f" style="width: 45%; margin: auto;">
|
| 73 |
+
<img src="https://github.com/DAMO-NLP-SG/Video-LLaMA/assets/18526640/66fc112d-e47e-4b66-b9bc-407f8d418b17" style="width: 45%; margin: auto;">
|
| 74 |
+
</p>
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
## Pre-trained & Fine-tuned Checkpoints
|
| 79 |
+
|
| 80 |
+
The following checkpoints store learnable parameters (positional embedding layers, Video/Audio Q-former and linear projection layers) only.
|
| 81 |
+
|
| 82 |
+
#### Vision-Language Branch
|
| 83 |
+
| Checkpoint | Link | Note |
|
| 84 |
+
|:------------|-------------|-------------|
|
| 85 |
+
| pretrain-vicuna7b | [link](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/pretrain_vicuna7b-v2.pth) | Pre-trained on WebVid (2.5M video-caption pairs) and LLaVA-CC3M (595k image-caption pairs) |
|
| 86 |
+
| finetune-vicuna7b-v2 | [link](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/finetune-vicuna7b-v2.pth) | Fine-tuned on the instruction-tuning data from [MiniGPT-4](https://github.com/Vision-CAIR/MiniGPT-4), [LLaVA](https://github.com/haotian-liu/LLaVA) and [VideoChat](https://github.com/OpenGVLab/Ask-Anything)|
|
| 87 |
+
| pretrain-vicuna13b | [link](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/pretrain-vicuna13b.pth) | Pre-trained on WebVid (2.5M video-caption pairs) and LLaVA-CC3M (595k image-caption pairs) |
|
| 88 |
+
| finetune-vicuna13b-v2 | [link](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/finetune-vicuna13b-v2.pth) | Fine-tuned on the instruction-tuning data from [MiniGPT-4](https://github.com/Vision-CAIR/MiniGPT-4), [LLaVA](https://github.com/haotian-liu/LLaVA) and [VideoChat](https://github.com/OpenGVLab/Ask-Anything)|
|
| 89 |
+
| pretrain-ziya13b-zh | [link](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/pretrain-ziya13b-zh.pth) | Pre-trained with Chinese LLM [Ziya-13B](https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1) |
|
| 90 |
+
| finetune-ziya13b-zh | [link](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/finetune-ziya13b-zh.pth) | Fine-tuned on machine-translated [VideoChat](https://github.com/OpenGVLab/Ask-Anything) instruction-following dataset (in Chinese)|
|
| 91 |
+
| pretrain-billa7b-zh | [link](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/pretrain-billa7b-zh.pth) | Pre-trained with Chinese LLM [BiLLA-7B](https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1) |
|
| 92 |
+
| finetune-billa7b-zh | [link](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/finetune-billa7b-zh.pth) | Fine-tuned on machine-translated [VideoChat](https://github.com/OpenGVLab/Ask-Anything) instruction-following dataset (in Chinese) |
|
| 93 |
+
|
| 94 |
+
#### Audio-Language Branch
|
| 95 |
+
| Checkpoint | Link | Note |
|
| 96 |
+
|:------------|-------------|-------------|
|
| 97 |
+
| pretrain-vicuna7b | [link](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/pretrain_vicuna7b_audiobranch.pth) | Pre-trained on WebVid (2.5M video-caption pairs) and LLaVA-CC3M (595k image-caption pairs) |
|
| 98 |
+
| finetune-vicuna7b-v2 | [link](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/finetune_vicuna7b_audiobranch.pth) | Fine-tuned on the instruction-tuning data from [MiniGPT-4](https://github.com/Vision-CAIR/MiniGPT-4), [LLaVA](https://github.com/haotian-liu/LLaVA) and [VideoChat](https://github.com/OpenGVLab/Ask-Anything)|
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
## Usage
|
| 102 |
+
#### Enviroment Preparation
|
| 103 |
+
|
| 104 |
+
First, install ffmpeg.
|
| 105 |
+
```
|
| 106 |
+
apt update
|
| 107 |
+
apt install ffmpeg
|
| 108 |
+
```
|
| 109 |
+
Then, create a conda environment:
|
| 110 |
+
```
|
| 111 |
+
conda env create -f environment.yml
|
| 112 |
+
conda activate videollama
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
## Prerequisites
|
| 117 |
+
|
| 118 |
+
Before using the repository, make sure you have obtained the following checkpoints:
|
| 119 |
+
|
| 120 |
+
#### Pre-trained Language Decoder
|
| 121 |
+
|
| 122 |
+
- Get the original LLaMA weights in the Hugging Face format by following the instructions [here](https://huggingface.co/docs/transformers/main/model_doc/llama).
|
| 123 |
+
- Download Vicuna delta weights :point_right: [[7B](https://huggingface.co/lmsys/vicuna-7b-delta-v0)][[13B](https://huggingface.co/lmsys/vicuna-13b-delta-v0)] (Note: we use **v0 weights** instead of v1.1 weights).
|
| 124 |
+
- Use the following command to add delta weights to the original LLaMA weights to obtain the Vicuna weights:
|
| 125 |
+
|
| 126 |
+
```
|
| 127 |
+
python apply_delta.py \
|
| 128 |
+
--base /path/to/llama-13b \
|
| 129 |
+
--target /output/path/to/vicuna-13b --delta /path/to/vicuna-13b-delta
|
| 130 |
+
```
|
| 131 |
+
|
| 132 |
+
#### Pre-trained Visual Encoder in Vision-Language Branch
|
| 133 |
+
- Download the MiniGPT-4 model (trained linear layer) from this [link](https://drive.google.com/file/d/1a4zLvaiDBr-36pasffmgpvH5P7CKmpze/view).
|
| 134 |
+
|
| 135 |
+
#### Pre-trained Audio Encoder in Audio-Language Branch
|
| 136 |
+
- Download the weight of ImageBind from this [link](https://github.com/facebookresearch/ImageBind).
|
| 137 |
+
|
| 138 |
+
## Download Learnable Weights
|
| 139 |
+
Use `git-lfs` to download the learnable weights of our Video-LLaMA (i.e., positional embedding layer + Q-Former + linear projection layer):
|
| 140 |
+
```bash
|
| 141 |
+
git lfs install
|
| 142 |
+
git clone https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series
|
| 143 |
+
```
|
| 144 |
+
The above commands will download the model weights of all the Video-LLaMA variants. For sure, you can choose to download the weights on demand. For example, if you want to run Video-LLaMA with Vicuna-7B as language decoder locally, then:
|
| 145 |
+
```bash
|
| 146 |
+
wget https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/finetune-vicuna7b-v2.pth
|
| 147 |
+
wget https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/finetune_vicuna7b_audiobranch.pth
|
| 148 |
+
```
|
| 149 |
+
should meet the requirement.
|
| 150 |
+
|
| 151 |
+
## How to Run Demo Locally
|
| 152 |
+
|
| 153 |
+
Firstly, set the `llama_model`, `imagebind_ckpt_path`, `ckpt` and `ckpt_2` in [eval_configs/video_llama_eval_withaudio.yaml](./eval_configs/video_llama_eval_withaudio.yaml).
|
| 154 |
+
Then run the script:
|
| 155 |
+
```
|
| 156 |
+
python demo_audiovideo.py \
|
| 157 |
+
--cfg-path eval_configs/video_llama_eval_withaudio.yaml --model_type vicuna --gpu-id 0
|
| 158 |
+
```
|
| 159 |
+
|
| 160 |
+
## Training
|
| 161 |
+
|
| 162 |
+
The training of each cross-modal branch (i.e., VL branch or AL branch) in Video-LLaMA consists of two stages,
|
| 163 |
+
|
| 164 |
+
1. Pre-training on the [Webvid-2.5M](https://github.com/m-bain/webvid) video caption dataset and [LLaVA-CC3M]((https://github.com/haotian-liu/LLaVA)) image caption dataset.
|
| 165 |
+
|
| 166 |
+
2. Fine-tuning using the image-based instruction-tuning data from [MiniGPT-4](https://github.com/Vision-CAIR/MiniGPT-4)/[LLaVA](https://github.com/haotian-liu/LLaVA) and the video-based instruction-tuning data from [VideoChat](https://github.com/OpenGVLab/Ask-Anything).
|
| 167 |
+
|
| 168 |
+
### 1. Pre-training
|
| 169 |
+
#### Data Preparation
|
| 170 |
+
Download the metadata and video following the instruction from the official Github repo of [Webvid](https://github.com/m-bain/webvid).
|
| 171 |
+
The folder structure of the dataset is shown below:
|
| 172 |
+
```
|
| 173 |
+
|webvid_train_data
|
| 174 |
+
|──filter_annotation
|
| 175 |
+
|────0.tsv
|
| 176 |
+
|──videos
|
| 177 |
+
|────000001_000050
|
| 178 |
+
|──────1066674784.mp4
|
| 179 |
+
```
|
| 180 |
+
```
|
| 181 |
+
|cc3m
|
| 182 |
+
|──filter_cap.json
|
| 183 |
+
|──image
|
| 184 |
+
|────GCC_train_000000000.jpg
|
| 185 |
+
|────...
|
| 186 |
+
```
|
| 187 |
+
#### Script
|
| 188 |
+
Config the the checkpoint and dataset paths in [video_llama_stage1_pretrain.yaml](./train_configs/video_llama_stage1_pretrain.yaml).
|
| 189 |
+
Run the script:
|
| 190 |
+
```
|
| 191 |
+
conda activate videollama
|
| 192 |
+
torchrun --nproc_per_node=8 train.py --cfg-path ./train_configs/video_llama_stage1_pretrain.yaml
|
| 193 |
+
```
|
| 194 |
+
|
| 195 |
+
### 2. Instruction Fine-tuning
|
| 196 |
+
#### Data
|
| 197 |
+
For now, the fine-tuning dataset consists of:
|
| 198 |
+
* 150K image-based instructions from LLaVA [[link](https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K/raw/main/llava_instruct_150k.json)]
|
| 199 |
+
* 3K image-based instructions from MiniGPT-4 [[link](https://github.com/Vision-CAIR/MiniGPT-4/blob/main/dataset/README_2_STAGE.md)]
|
| 200 |
+
* 11K video-based instructions from VideoChat [[link](https://github.com/OpenGVLab/InternVideo/tree/main/Data/instruction_data)]
|
| 201 |
+
|
| 202 |
+
#### Script
|
| 203 |
+
Config the checkpoint and dataset paths in [video_llama_stage2_finetune.yaml](./train_configs/video_llama_stage2_finetune.yaml).
|
| 204 |
+
```
|
| 205 |
+
conda activate videollama
|
| 206 |
+
torchrun --nproc_per_node=8 train.py --cfg-path ./train_configs/video_llama_stage2_finetune.yaml
|
| 207 |
+
```
|
| 208 |
+
|
| 209 |
+
## Recommended GPUs
|
| 210 |
+
* Pre-training: 8xA100 (80G)
|
| 211 |
+
* Instruction-tuning: 8xA100 (80G)
|
| 212 |
+
* Inference: 1xA100 (40G/80G) or 1xA6000
|
| 213 |
+
|
| 214 |
+
## Acknowledgement
|
| 215 |
+
We are grateful for the following awesome projects our Video-LLaMA arising from:
|
| 216 |
+
* [MiniGPT-4](https://github.com/Vision-CAIR/MiniGPT-4): Enhancing Vision-language Understanding with Advanced Large Language Models
|
| 217 |
+
* [FastChat](https://github.com/lm-sys/FastChat): An Open Platform for Training, Serving, and Evaluating Large Language Model based Chatbots
|
| 218 |
+
* [BLIP-2](https://github.com/salesforce/LAVIS/tree/main/projects/blip2): Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
|
| 219 |
+
* [EVA-CLIP](https://github.com/baaivision/EVA/tree/master/EVA-CLIP): Improved Training Techniques for CLIP at Scale
|
| 220 |
+
* [ImageBind](https://github.com/facebookresearch/ImageBind): One Embedding Space To Bind Them All
|
| 221 |
+
* [LLaMA](https://github.com/facebookresearch/llama): Open and Efficient Foundation Language Models
|
| 222 |
+
* [VideoChat](https://github.com/OpenGVLab/Ask-Anything): Chat-Centric Video Understanding
|
| 223 |
+
* [LLaVA](https://github.com/haotian-liu/LLaVA): Large Language and Vision Assistant
|
| 224 |
+
* [WebVid](https://github.com/m-bain/webvid): A Large-scale Video-Text dataset
|
| 225 |
+
* [mPLUG-Owl](https://github.com/X-PLUG/mPLUG-Owl/tree/main): Modularization Empowers Large Language Models with Multimodality
|
| 226 |
+
|
| 227 |
+
The logo of Video-LLaMA is generated by [Midjourney](https://www.midjourney.com/).
|
| 228 |
+
|
| 229 |
+
|
| 230 |
+
## Term of Use
|
| 231 |
+
Our Video-LLaMA is just a research preview intended for non-commercial use only. You must **NOT** use our Video-LLaMA for any illegal, harmful, violent, racist, or sexual purposes. You are strictly prohibited from engaging in any activity that will potentially violate these guidelines.
|
| 232 |
+
|
| 233 |
+
## Citation
|
| 234 |
+
If you find our project useful, hope you can star our repo and cite our paper as follows:
|
| 235 |
+
```
|
| 236 |
+
@article{damonlpsg2023videollama,
|
| 237 |
+
author = {Zhang, Hang and Li, Xin and Bing, Lidong},
|
| 238 |
+
title = {Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding},
|
| 239 |
+
year = 2023,
|
| 240 |
+
journal = {arXiv preprint arXiv:2306.02858},
|
| 241 |
+
url = {https://arxiv.org/abs/2306.02858}
|
| 242 |
+
}
|
| 243 |
+
```
|
| 244 |
+
|
README.md
CHANGED
|
@@ -1,13 +1,249 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<p align="center" width="100%">
|
| 2 |
+
<a target="_blank"><img src="figs/video_llama_logo.jpg" alt="Video-LLaMA" style="width: 50%; min-width: 200px; display: block; margin: auto;"></a>
|
| 3 |
+
</p>
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
# Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
|
| 8 |
+
<!-- **Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding** -->
|
| 9 |
+
|
| 10 |
+
This is the repo for the Video-LLaMA project, which is working on empowering large language models with video and audio understanding capabilities.
|
| 11 |
+
|
| 12 |
+
<div style='display:flex; gap: 0.25rem; '>
|
| 13 |
+
<a href='https://modelscope.cn/studios/damo/video-llama/summary'><img src='https://img.shields.io/badge/ModelScope-Demo-blueviolet'></a>
|
| 14 |
+
<a href='https://www.modelscope.cn/models/damo/videollama_7b_llama2_finetuned/summary'><img src='https://img.shields.io/badge/ModelScope-Checkpoint-blueviolet'></a>
|
| 15 |
+
<a href='https://huggingface.co/spaces/DAMO-NLP-SG/Video-LLaMA'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Demo-blue'></a>
|
| 16 |
+
<a href='https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-2-7B-Finetuned'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Checkpoint-blue'></a>
|
| 17 |
+
<a href='https://arxiv.org/abs/2306.02858'><img src='https://img.shields.io/badge/Paper-PDF-red'></a>
|
| 18 |
+
</div>
|
| 19 |
+
|
| 20 |
+
## News
|
| 21 |
+
- [08.03] 🚀🚀 Release **Video-LLaMA-2** with [Llama-2-7B/13B-Chat](https://huggingface.co/meta-llama) as language decoder
|
| 22 |
+
- **NO** delta weights and separate Q-former weights anymore, full weights to run Video-LLaMA are all here :point_right: [[7B](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-2-7B-Finetuned)][[13B](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-2-13B-Finetuned)]
|
| 23 |
+
- Allow further customization starting from our pre-trained checkpoints [[7B-Pretrained](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-2-7B-Pretrained)] [[13B-Pretrained](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-2-13B-Pretrained)]
|
| 24 |
+
- [06.14] **NOTE**: The current online interactive demo is primarily for English chatting and it may **NOT** be a good option to ask Chinese questions since Vicuna/LLaMA does not represent Chinese texts very well.
|
| 25 |
+
- [06.13] **NOTE**: The audio support is **ONLY** for Vicuna-7B by now although we have several VL checkpoints available for other decoders.
|
| 26 |
+
- [06.10] **NOTE**: We have NOT updated the HF demo yet because the whole framework (with the audio branch) cannot run normally on A10-24G. The current running demo is still the previous version of Video-LLaMA. We will fix this issue soon.
|
| 27 |
+
- [06.08] 🚀🚀 Release the checkpoints of the audio-supported Video-LLaMA. Documentation and example outputs are also updated.
|
| 28 |
+
- [05.22] 🚀🚀 Interactive demo online, try our Video-LLaMA (with **Vicuna-7B** as language decoder) at [Hugging Face](https://huggingface.co/spaces/DAMO-NLP-SG/Video-LLaMA) and [ModelScope](https://pre.modelscope.cn/studios/damo/video-llama/summary)!!
|
| 29 |
+
- [05.22] ⭐️ Release **Video-LLaMA v2** built with Vicuna-7B
|
| 30 |
+
- [05.18] 🚀🚀 Support video-grounded chat in Chinese
|
| 31 |
+
- [**Video-LLaMA-BiLLA**](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/finetune-billa7b-zh.pth): we introduce [BiLLa-7B-SFT](https://huggingface.co/Neutralzz/BiLLa-7B-SFT) as language decoder and fine-tune the video-language aligned model (i.e., stage 1 model) with machine-translated [VideoChat](https://github.com/OpenGVLab/InternVideo/tree/main/Data/instruction_data) instructions.
|
| 32 |
+
- [**Video-LLaMA-Ziya**](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/finetune-ziya13b-zh.pth): same with Video-LLaMA-BiLLA but the language decoder is changed to [Ziya-13B](https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1).
|
| 33 |
+
- [05.18] ⭐️ Create a Hugging Face [repo](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series) to store the model weights of all the variants of our Video-LLaMA.
|
| 34 |
+
- [05.15] ⭐️ Release [**Video-LLaMA v2**](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/finetune-vicuna13b-v2.pth): we use the training data provided by [VideoChat](https://github.com/OpenGVLab/InternVideo/tree/main/Data/instruction_data) to further enhance the instruction-following capability of Video-LLaMA.
|
| 35 |
+
- [05.07] Release the initial version of **Video-LLaMA**, including its pre-trained and instruction-tuned checkpoints.
|
| 36 |
+
|
| 37 |
+
<p align="center" width="100%">
|
| 38 |
+
<a target="_blank"><img src="figs/architecture_v2.png" alt="Video-LLaMA" style="width: 80%; min-width: 200px; display: block; margin: auto;"></a>
|
| 39 |
+
</p>
|
| 40 |
+
|
| 41 |
+
## Introduction
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
- Video-LLaMA is built on top of [BLIP-2](https://github.com/salesforce/LAVIS/tree/main/projects/blip2) and [MiniGPT-4](https://github.com/Vision-CAIR/MiniGPT-4). It is composed of two core components: (1) Vision-Language (VL) Branch and (2) Audio-Language (AL) Branch.
|
| 45 |
+
- **VL Branch** (Visual encoder: ViT-G/14 + BLIP-2 Q-Former)
|
| 46 |
+
- A two-layer video Q-Former and a frame embedding layer (applied to the embeddings of each frame) are introduced to compute video representations.
|
| 47 |
+
- We train VL Branch on the Webvid-2M video caption dataset with a video-to-text generation task. We also add image-text pairs (~595K image captions from [LLaVA](https://github.com/haotian-liu/LLaVA)) into the pre-training dataset to enhance the understanding of static visual concepts.
|
| 48 |
+
- After pre-training, we further fine-tune our VL Branch using the instruction-tuning data from [MiniGPT-4](https://github.com/Vision-CAIR/MiniGPT-4), [LLaVA](https://github.com/haotian-liu/LLaVA) and [VideoChat](https://github.com/OpenGVLab/Ask-Anything).
|
| 49 |
+
- **AL Branch** (Audio encoder: ImageBind-Huge)
|
| 50 |
+
- A two-layer audio Q-Former and an audio segment embedding layer (applied to the embedding of each audio segment) are introduced to compute audio representations.
|
| 51 |
+
- As the used audio encoder (i.e., ImageBind) is already aligned across multiple modalities, we train AL Branch on video/image instruction data only, just to connect the output of ImageBind to the language decoder.
|
| 52 |
+
- Only the Video/Audio Q-Former, positional embedding layers, and linear layers are trainable during cross-modal training.
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
## Example Outputs
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
- **Video with background sound**
|
| 60 |
+
|
| 61 |
+
<p float="left">
|
| 62 |
+
<img src="https://github.com/DAMO-NLP-SG/Video-LLaMA/assets/18526640/7f7bddb2-5cf1-4cf4-bce3-3fa67974cbb3" style="width: 45%; margin: auto;">
|
| 63 |
+
<img src="https://github.com/DAMO-NLP-SG/Video-LLaMA/assets/18526640/ec76be04-4aa9-4dde-bff2-0a232b8315e0" style="width: 45%; margin: auto;">
|
| 64 |
+
</p>
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
- **Video without sound effects**
|
| 68 |
+
<p float="left">
|
| 69 |
+
<img src="https://github.com/DAMO-NLP-SG/Video-LLaMA/assets/18526640/539ea3cc-360d-4b2c-bf86-5505096df2f7" style="width: 45%; margin: auto;">
|
| 70 |
+
<img src="https://github.com/DAMO-NLP-SG/Video-LLaMA/assets/18526640/7304ad6f-1009-46f1-aca4-7f861b636363" style="width: 45%; margin: auto;">
|
| 71 |
+
</p>
|
| 72 |
+
|
| 73 |
+
- **Static image**
|
| 74 |
+
<p float="left">
|
| 75 |
+
<img src="https://github.com/DAMO-NLP-SG/Video-LLaMA/assets/18526640/a146c169-8693-4627-96e6-f885ca22791f" style="width: 45%; margin: auto;">
|
| 76 |
+
<img src="https://github.com/DAMO-NLP-SG/Video-LLaMA/assets/18526640/66fc112d-e47e-4b66-b9bc-407f8d418b17" style="width: 45%; margin: auto;">
|
| 77 |
+
</p>
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
## Pre-trained & Fine-tuned Checkpoints
|
| 82 |
+
|
| 83 |
+
The following checkpoints store learnable parameters (positional embedding layers, Video/Audio Q-former, and linear projection layers) only.
|
| 84 |
+
|
| 85 |
+
#### Vision-Language Branch
|
| 86 |
+
| Checkpoint | Link | Note |
|
| 87 |
+
|:------------|-------------|-------------|
|
| 88 |
+
| pretrain-vicuna7b | [link](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/pretrain_vicuna7b-v2.pth) | Pre-trained on WebVid (2.5M video-caption pairs) and LLaVA-CC3M (595k image-caption pairs) |
|
| 89 |
+
| finetune-vicuna7b-v2 | [link](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/finetune-vicuna7b-v2.pth) | Fine-tuned on the instruction-tuning data from [MiniGPT-4](https://github.com/Vision-CAIR/MiniGPT-4), [LLaVA](https://github.com/haotian-liu/LLaVA) and [VideoChat](https://github.com/OpenGVLab/Ask-Anything)|
|
| 90 |
+
| pretrain-vicuna13b | [link](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/pretrain-vicuna13b.pth) | Pre-trained on WebVid (2.5M video-caption pairs) and LLaVA-CC3M (595k image-caption pairs) |
|
| 91 |
+
| finetune-vicuna13b-v2 | [link](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/finetune-vicuna13b-v2.pth) | Fine-tuned on the instruction-tuning data from [MiniGPT-4](https://github.com/Vision-CAIR/MiniGPT-4), [LLaVA](https://github.com/haotian-liu/LLaVA) and [VideoChat](https://github.com/OpenGVLab/Ask-Anything)|
|
| 92 |
+
| pretrain-ziya13b-zh | [link](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/pretrain-ziya13b-zh.pth) | Pre-trained with Chinese LLM [Ziya-13B](https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1) |
|
| 93 |
+
| finetune-ziya13b-zh | [link](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/finetune-ziya13b-zh.pth) | Fine-tuned on machine-translated [VideoChat](https://github.com/OpenGVLab/Ask-Anything) instruction-following dataset (in Chinese)|
|
| 94 |
+
| pretrain-billa7b-zh | [link](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/pretrain-billa7b-zh.pth) | Pre-trained with Chinese LLM [BiLLA-7B-SFT](https://huggingface.co/Neutralzz/BiLLa-7B-SFT) |
|
| 95 |
+
| finetune-billa7b-zh | [link](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/finetune-billa7b-zh.pth) | Fine-tuned on machine-translated [VideoChat](https://github.com/OpenGVLab/Ask-Anything) instruction-following dataset (in Chinese) |
|
| 96 |
+
|
| 97 |
+
#### Audio-Language Branch
|
| 98 |
+
| Checkpoint | Link | Note |
|
| 99 |
+
|:------------|-------------|-------------|
|
| 100 |
+
| pretrain-vicuna7b | [link](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/pretrain_vicuna7b_audiobranch.pth) | Pre-trained on WebVid (2.5M video-caption pairs) and LLaVA-CC3M (595k image-caption pairs) |
|
| 101 |
+
| finetune-vicuna7b-v2 | [link](https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/finetune_vicuna7b_audiobranch.pth) | Fine-tuned on the instruction-tuning data from [MiniGPT-4](https://github.com/Vision-CAIR/MiniGPT-4), [LLaVA](https://github.com/haotian-liu/LLaVA) and [VideoChat](https://github.com/OpenGVLab/Ask-Anything)|
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
## Usage
|
| 105 |
+
#### Enviroment Preparation
|
| 106 |
+
|
| 107 |
+
First, install ffmpeg.
|
| 108 |
+
```
|
| 109 |
+
apt update
|
| 110 |
+
apt install ffmpeg
|
| 111 |
+
```
|
| 112 |
+
Then, create a conda environment:
|
| 113 |
+
```
|
| 114 |
+
conda env create -f environment.yml
|
| 115 |
+
conda activate videollama
|
| 116 |
+
```
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
## Prerequisites
|
| 120 |
+
|
| 121 |
+
Before using the repository, make sure you have obtained the following checkpoints:
|
| 122 |
+
|
| 123 |
+
#### Pre-trained Language Decoder
|
| 124 |
+
|
| 125 |
+
- Get the original LLaMA weights in the Hugging Face format by following the instructions [here](https://huggingface.co/docs/transformers/main/model_doc/llama).
|
| 126 |
+
- Download Vicuna delta weights :point_right: [[7B](https://huggingface.co/lmsys/vicuna-7b-delta-v0)][[13B](https://huggingface.co/lmsys/vicuna-13b-delta-v0)] (Note: we use **v0 weights** instead of v1.1 weights).
|
| 127 |
+
- Use the following command to add delta weights to the original LLaMA weights to obtain the Vicuna weights:
|
| 128 |
+
|
| 129 |
+
```
|
| 130 |
+
python apply_delta.py \
|
| 131 |
+
--base /path/to/llama-13b \
|
| 132 |
+
--target /output/path/to/vicuna-13b --delta /path/to/vicuna-13b-delta
|
| 133 |
+
```
|
| 134 |
+
|
| 135 |
+
#### Pre-trained Visual Encoder in Vision-Language Branch
|
| 136 |
+
- Download the MiniGPT-4 model (trained linear layer) from this [link](https://drive.google.com/file/d/1a4zLvaiDBr-36pasffmgpvH5P7CKmpze/view).
|
| 137 |
+
|
| 138 |
+
#### Pre-trained Audio Encoder in Audio-Language Branch
|
| 139 |
+
- Download the weight of ImageBind from this [link](https://github.com/facebookresearch/ImageBind).
|
| 140 |
+
|
| 141 |
+
## Download Learnable Weights
|
| 142 |
+
Use `git-lfs` to download the learnable weights of our Video-LLaMA (i.e., positional embedding layer + Q-Former + linear projection layer):
|
| 143 |
+
```bash
|
| 144 |
+
git lfs install
|
| 145 |
+
git clone https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series
|
| 146 |
+
```
|
| 147 |
+
The above commands will download the model weights of all the Video-LLaMA variants. For sure, you can choose to download the weights on demand. For example, if you want to run Video-LLaMA with Vicuna-7B as language decoder locally, then:
|
| 148 |
+
```bash
|
| 149 |
+
wget https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/finetune-vicuna7b-v2.pth
|
| 150 |
+
wget https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series/resolve/main/finetune_vicuna7b_audiobranch.pth
|
| 151 |
+
```
|
| 152 |
+
should meet the requirement.
|
| 153 |
+
|
| 154 |
+
## How to Run Demo Locally
|
| 155 |
+
|
| 156 |
+
Firstly, set the `llama_model`, `imagebind_ckpt_path`, `ckpt` and `ckpt_2` in [eval_configs/video_llama_eval_withaudio.yaml](./eval_configs/video_llama_eval_withaudio.yaml).
|
| 157 |
+
Then run the script:
|
| 158 |
+
```
|
| 159 |
+
python demo_audiovideo.py \
|
| 160 |
+
--cfg-path eval_configs/video_llama_eval_withaudio.yaml \
|
| 161 |
+
--model_type llama_v2 \ # or vicuna
|
| 162 |
+
--gpu-id 0
|
| 163 |
+
```
|
| 164 |
+
|
| 165 |
+
## Training
|
| 166 |
+
|
| 167 |
+
The training of each cross-modal branch (i.e., VL branch or AL branch) in Video-LLaMA consists of two stages,
|
| 168 |
+
|
| 169 |
+
1. Pre-training on the [Webvid-2.5M](https://github.com/m-bain/webvid) video caption dataset and [LLaVA-CC3M]((https://github.com/haotian-liu/LLaVA)) image caption dataset.
|
| 170 |
+
|
| 171 |
+
2. Fine-tuning using the image-based instruction-tuning data from [MiniGPT-4](https://github.com/Vision-CAIR/MiniGPT-4)/[LLaVA](https://github.com/haotian-liu/LLaVA) and the video-based instruction-tuning data from [VideoChat](https://github.com/OpenGVLab/Ask-Anything).
|
| 172 |
+
|
| 173 |
+
### 1. Pre-training
|
| 174 |
+
#### Data Preparation
|
| 175 |
+
Download the metadata and video following the instructions from the official Github repo of [Webvid](https://github.com/m-bain/webvid).
|
| 176 |
+
The folder structure of the dataset is shown below:
|
| 177 |
+
```
|
| 178 |
+
|webvid_train_data
|
| 179 |
+
|──filter_annotation
|
| 180 |
+
|────0.tsv
|
| 181 |
+
|──videos
|
| 182 |
+
|────000001_000050
|
| 183 |
+
|──────1066674784.mp4
|
| 184 |
+
```
|
| 185 |
+
```
|
| 186 |
+
|cc3m
|
| 187 |
+
|──filter_cap.json
|
| 188 |
+
|──image
|
| 189 |
+
|────GCC_train_000000000.jpg
|
| 190 |
+
|────...
|
| 191 |
+
```
|
| 192 |
+
#### Script
|
| 193 |
+
Config the the checkpoint and dataset paths in [video_llama_stage1_pretrain.yaml](./train_configs/video_llama_stage1_pretrain.yaml).
|
| 194 |
+
Run the script:
|
| 195 |
+
```
|
| 196 |
+
conda activate videollama
|
| 197 |
+
torchrun --nproc_per_node=8 train.py --cfg-path ./train_configs/video_llama_stage1_pretrain.yaml
|
| 198 |
+
```
|
| 199 |
+
|
| 200 |
+
### 2. Instruction Fine-tuning
|
| 201 |
+
#### Data
|
| 202 |
+
For now, the fine-tuning dataset consists of:
|
| 203 |
+
* 150K image-based instructions from LLaVA [[link](https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K/raw/main/llava_instruct_150k.json)]
|
| 204 |
+
* 3K image-based instructions from MiniGPT-4 [[link](https://github.com/Vision-CAIR/MiniGPT-4/blob/main/dataset/README_2_STAGE.md)]
|
| 205 |
+
* 11K video-based instructions from VideoChat [[link](https://github.com/OpenGVLab/InternVideo/tree/main/Data/instruction_data)]
|
| 206 |
+
|
| 207 |
+
#### Script
|
| 208 |
+
Config the checkpoint and dataset paths in [video_llama_stage2_finetune.yaml](./train_configs/video_llama_stage2_finetune.yaml).
|
| 209 |
+
```
|
| 210 |
+
conda activate videollama
|
| 211 |
+
torchrun --nproc_per_node=8 train.py --cfg-path ./train_configs/video_llama_stage2_finetune.yaml
|
| 212 |
+
```
|
| 213 |
+
|
| 214 |
+
## Recommended GPUs
|
| 215 |
+
* Pre-training: 8xA100 (80G)
|
| 216 |
+
* Instruction-tuning: 8xA100 (80G)
|
| 217 |
+
* Inference: 1xA100 (40G/80G) or 1xA6000
|
| 218 |
+
|
| 219 |
+
## Acknowledgement
|
| 220 |
+
We are grateful for the following awesome projects our Video-LLaMA arising from:
|
| 221 |
+
* [MiniGPT-4](https://github.com/Vision-CAIR/MiniGPT-4): Enhancing Vision-language Understanding with Advanced Large Language Models
|
| 222 |
+
* [FastChat](https://github.com/lm-sys/FastChat): An Open Platform for Training, Serving, and Evaluating Large Language Model based Chatbots
|
| 223 |
+
* [BLIP-2](https://github.com/salesforce/LAVIS/tree/main/projects/blip2): Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
|
| 224 |
+
* [EVA-CLIP](https://github.com/baaivision/EVA/tree/master/EVA-CLIP): Improved Training Techniques for CLIP at Scale
|
| 225 |
+
* [ImageBind](https://github.com/facebookresearch/ImageBind): One Embedding Space To Bind Them All
|
| 226 |
+
* [LLaMA](https://github.com/facebookresearch/llama): Open and Efficient Foundation Language Models
|
| 227 |
+
* [VideoChat](https://github.com/OpenGVLab/Ask-Anything): Chat-Centric Video Understanding
|
| 228 |
+
* [LLaVA](https://github.com/haotian-liu/LLaVA): Large Language and Vision Assistant
|
| 229 |
+
* [WebVid](https://github.com/m-bain/webvid): A Large-scale Video-Text dataset
|
| 230 |
+
* [mPLUG-Owl](https://github.com/X-PLUG/mPLUG-Owl/tree/main): Modularization Empowers Large Language Models with Multimodality
|
| 231 |
+
|
| 232 |
+
The logo of Video-LLaMA is generated by [Midjourney](https://www.midjourney.com/).
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
## Term of Use
|
| 236 |
+
Our Video-LLaMA is just a research preview intended for non-commercial use only. You must **NOT** use our Video-LLaMA for any illegal, harmful, violent, racist, or sexual purposes. You are strictly prohibited from engaging in any activity that will potentially violate these guidelines.
|
| 237 |
+
|
| 238 |
+
## Citation
|
| 239 |
+
If you find our project useful, hope you can star our repo and cite our paper as follows:
|
| 240 |
+
```
|
| 241 |
+
@article{damonlpsg2023videollama,
|
| 242 |
+
author = {Zhang, Hang and Li, Xin and Bing, Lidong},
|
| 243 |
+
title = {Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding},
|
| 244 |
+
year = 2023,
|
| 245 |
+
journal = {arXiv preprint arXiv:2306.02858},
|
| 246 |
+
url = {https://arxiv.org/abs/2306.02858}
|
| 247 |
+
}
|
| 248 |
+
```
|
| 249 |
+
|
Video-LLaMA-2-7B-Finetuned/AL_LLaMA_2_7B_Finetuned.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1ad66d3e0eb9eaef5392e7b67c4689166f5610088c92652b9ecdae332b8d5b6f
|
| 3 |
+
size 274578657
|
Video-LLaMA-2-7B-Finetuned/VL_LLaMA_2_7B_Finetuned.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3cec0e2979ed7656e08ecc5b185c2229a3c577b4b7a4721a94bd461ba0447c6e
|
| 3 |
+
size 265559201
|
Video-LLaMA-2-7B-Finetuned/imagebind_huge.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d6f6c22bedcc90708448d5d2fbb7b2db9c73f505dc89bd0b2e09b23af1b62157
|
| 3 |
+
size 4803584173
|
Video-LLaMA-2-7B-Finetuned/llama-2-7b-chat-hf/config.json
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"LlamaForCausalLM"
|
| 4 |
+
],
|
| 5 |
+
"bos_token_id": 1,
|
| 6 |
+
"eos_token_id": 2,
|
| 7 |
+
"hidden_act": "silu",
|
| 8 |
+
"hidden_size": 4096,
|
| 9 |
+
"initializer_range": 0.02,
|
| 10 |
+
"intermediate_size": 11008,
|
| 11 |
+
"max_position_embeddings": 2048,
|
| 12 |
+
"model_type": "llama",
|
| 13 |
+
"num_attention_heads": 32,
|
| 14 |
+
"num_hidden_layers": 32,
|
| 15 |
+
"pad_token_id": 0,
|
| 16 |
+
"rms_norm_eps": 1e-06,
|
| 17 |
+
"tie_word_embeddings": false,
|
| 18 |
+
"torch_dtype": "float16",
|
| 19 |
+
"transformers_version": "4.29.0.dev0",
|
| 20 |
+
"use_cache": true,
|
| 21 |
+
"vocab_size": 32000
|
| 22 |
+
}
|
Video-LLaMA-2-7B-Finetuned/llama-2-7b-chat-hf/generation_config.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 1,
|
| 4 |
+
"eos_token_id": 2,
|
| 5 |
+
"pad_token_id": 0,
|
| 6 |
+
"transformers_version": "4.29.0.dev0"
|
| 7 |
+
}
|
Video-LLaMA-2-7B-Finetuned/llama-2-7b-chat-hf/pytorch_model-00001-of-00002.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8f917a253ef631128743798d284a7e7a5a22ac1ad23ecd6a9da57550348317f5
|
| 3 |
+
size 9976634558
|
Video-LLaMA-2-7B-Finetuned/llama-2-7b-chat-hf/pytorch_model-00002-of-00002.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8e8fc22b2c138439c6bafb7331ac139585e683005407e016feb18a4feea18417
|
| 3 |
+
size 3500315539
|
Video-LLaMA-2-7B-Finetuned/llama-2-7b-chat-hf/pytorch_model.bin.index.json
ADDED
|
@@ -0,0 +1,330 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 13476839424
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "pytorch_model-00002-of-00002.bin",
|
| 7 |
+
"model.embed_tokens.weight": "pytorch_model-00001-of-00002.bin",
|
| 8 |
+
"model.layers.0.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 9 |
+
"model.layers.0.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 10 |
+
"model.layers.0.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 11 |
+
"model.layers.0.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 12 |
+
"model.layers.0.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 13 |
+
"model.layers.0.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 14 |
+
"model.layers.0.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 15 |
+
"model.layers.0.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 16 |
+
"model.layers.0.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 17 |
+
"model.layers.0.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 18 |
+
"model.layers.1.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 19 |
+
"model.layers.1.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 20 |
+
"model.layers.1.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 21 |
+
"model.layers.1.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 22 |
+
"model.layers.1.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 23 |
+
"model.layers.1.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 24 |
+
"model.layers.1.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 25 |
+
"model.layers.1.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 26 |
+
"model.layers.1.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 27 |
+
"model.layers.1.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 28 |
+
"model.layers.10.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 29 |
+
"model.layers.10.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 30 |
+
"model.layers.10.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 31 |
+
"model.layers.10.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 32 |
+
"model.layers.10.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 33 |
+
"model.layers.10.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 34 |
+
"model.layers.10.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 35 |
+
"model.layers.10.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 36 |
+
"model.layers.10.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 37 |
+
"model.layers.10.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 38 |
+
"model.layers.11.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 39 |
+
"model.layers.11.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 40 |
+
"model.layers.11.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 41 |
+
"model.layers.11.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 42 |
+
"model.layers.11.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 43 |
+
"model.layers.11.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 44 |
+
"model.layers.11.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 45 |
+
"model.layers.11.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 46 |
+
"model.layers.11.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 47 |
+
"model.layers.11.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 48 |
+
"model.layers.12.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 49 |
+
"model.layers.12.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 50 |
+
"model.layers.12.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 51 |
+
"model.layers.12.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 52 |
+
"model.layers.12.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 53 |
+
"model.layers.12.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 54 |
+
"model.layers.12.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 55 |
+
"model.layers.12.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 56 |
+
"model.layers.12.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 57 |
+
"model.layers.12.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 58 |
+
"model.layers.13.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 59 |
+
"model.layers.13.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 60 |
+
"model.layers.13.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 61 |
+
"model.layers.13.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 62 |
+
"model.layers.13.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 63 |
+
"model.layers.13.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 64 |
+
"model.layers.13.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 65 |
+
"model.layers.13.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 66 |
+
"model.layers.13.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 67 |
+
"model.layers.13.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 68 |
+
"model.layers.14.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 69 |
+
"model.layers.14.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 70 |
+
"model.layers.14.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 71 |
+
"model.layers.14.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 72 |
+
"model.layers.14.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 73 |
+
"model.layers.14.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 74 |
+
"model.layers.14.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 75 |
+
"model.layers.14.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 76 |
+
"model.layers.14.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 77 |
+
"model.layers.14.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 78 |
+
"model.layers.15.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 79 |
+
"model.layers.15.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 80 |
+
"model.layers.15.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 81 |
+
"model.layers.15.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 82 |
+
"model.layers.15.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 83 |
+
"model.layers.15.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 84 |
+
"model.layers.15.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 85 |
+
"model.layers.15.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 86 |
+
"model.layers.15.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 87 |
+
"model.layers.15.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 88 |
+
"model.layers.16.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 89 |
+
"model.layers.16.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 90 |
+
"model.layers.16.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 91 |
+
"model.layers.16.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 92 |
+
"model.layers.16.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 93 |
+
"model.layers.16.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 94 |
+
"model.layers.16.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 95 |
+
"model.layers.16.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 96 |
+
"model.layers.16.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 97 |
+
"model.layers.16.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 98 |
+
"model.layers.17.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 99 |
+
"model.layers.17.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 100 |
+
"model.layers.17.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 101 |
+
"model.layers.17.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 102 |
+
"model.layers.17.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 103 |
+
"model.layers.17.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 104 |
+
"model.layers.17.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 105 |
+
"model.layers.17.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 106 |
+
"model.layers.17.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 107 |
+
"model.layers.17.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 108 |
+
"model.layers.18.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 109 |
+
"model.layers.18.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 110 |
+
"model.layers.18.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 111 |
+
"model.layers.18.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 112 |
+
"model.layers.18.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 113 |
+
"model.layers.18.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 114 |
+
"model.layers.18.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 115 |
+
"model.layers.18.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 116 |
+
"model.layers.18.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 117 |
+
"model.layers.18.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 118 |
+
"model.layers.19.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 119 |
+
"model.layers.19.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 120 |
+
"model.layers.19.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 121 |
+
"model.layers.19.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 122 |
+
"model.layers.19.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 123 |
+
"model.layers.19.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 124 |
+
"model.layers.19.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 125 |
+
"model.layers.19.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 126 |
+
"model.layers.19.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 127 |
+
"model.layers.19.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 128 |
+
"model.layers.2.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 129 |
+
"model.layers.2.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 130 |
+
"model.layers.2.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 131 |
+
"model.layers.2.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 132 |
+
"model.layers.2.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 133 |
+
"model.layers.2.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 134 |
+
"model.layers.2.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 135 |
+
"model.layers.2.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 136 |
+
"model.layers.2.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 137 |
+
"model.layers.2.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 138 |
+
"model.layers.20.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 139 |
+
"model.layers.20.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 140 |
+
"model.layers.20.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 141 |
+
"model.layers.20.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 142 |
+
"model.layers.20.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 143 |
+
"model.layers.20.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 144 |
+
"model.layers.20.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 145 |
+
"model.layers.20.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 146 |
+
"model.layers.20.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 147 |
+
"model.layers.20.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 148 |
+
"model.layers.21.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 149 |
+
"model.layers.21.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 150 |
+
"model.layers.21.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 151 |
+
"model.layers.21.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 152 |
+
"model.layers.21.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 153 |
+
"model.layers.21.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 154 |
+
"model.layers.21.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 155 |
+
"model.layers.21.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 156 |
+
"model.layers.21.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 157 |
+
"model.layers.21.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 158 |
+
"model.layers.22.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 159 |
+
"model.layers.22.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 160 |
+
"model.layers.22.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 161 |
+
"model.layers.22.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 162 |
+
"model.layers.22.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 163 |
+
"model.layers.22.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 164 |
+
"model.layers.22.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 165 |
+
"model.layers.22.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 166 |
+
"model.layers.22.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 167 |
+
"model.layers.22.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 168 |
+
"model.layers.23.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 169 |
+
"model.layers.23.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 170 |
+
"model.layers.23.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 171 |
+
"model.layers.23.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 172 |
+
"model.layers.23.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 173 |
+
"model.layers.23.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 174 |
+
"model.layers.23.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 175 |
+
"model.layers.23.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 176 |
+
"model.layers.23.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 177 |
+
"model.layers.23.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 178 |
+
"model.layers.24.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 179 |
+
"model.layers.24.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 180 |
+
"model.layers.24.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 181 |
+
"model.layers.24.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 182 |
+
"model.layers.24.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 183 |
+
"model.layers.24.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 184 |
+
"model.layers.24.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 185 |
+
"model.layers.24.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 186 |
+
"model.layers.24.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
|
| 187 |
+
"model.layers.24.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 188 |
+
"model.layers.25.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 189 |
+
"model.layers.25.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 190 |
+
"model.layers.25.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 191 |
+
"model.layers.25.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 192 |
+
"model.layers.25.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 193 |
+
"model.layers.25.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 194 |
+
"model.layers.25.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 195 |
+
"model.layers.25.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 196 |
+
"model.layers.25.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
|
| 197 |
+
"model.layers.25.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 198 |
+
"model.layers.26.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 199 |
+
"model.layers.26.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 200 |
+
"model.layers.26.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 201 |
+
"model.layers.26.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 202 |
+
"model.layers.26.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 203 |
+
"model.layers.26.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 204 |
+
"model.layers.26.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 205 |
+
"model.layers.26.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 206 |
+
"model.layers.26.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
|
| 207 |
+
"model.layers.26.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 208 |
+
"model.layers.27.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 209 |
+
"model.layers.27.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 210 |
+
"model.layers.27.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 211 |
+
"model.layers.27.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 212 |
+
"model.layers.27.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 213 |
+
"model.layers.27.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 214 |
+
"model.layers.27.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 215 |
+
"model.layers.27.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 216 |
+
"model.layers.27.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
|
| 217 |
+
"model.layers.27.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 218 |
+
"model.layers.28.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 219 |
+
"model.layers.28.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 220 |
+
"model.layers.28.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 221 |
+
"model.layers.28.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 222 |
+
"model.layers.28.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 223 |
+
"model.layers.28.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 224 |
+
"model.layers.28.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 225 |
+
"model.layers.28.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 226 |
+
"model.layers.28.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
|
| 227 |
+
"model.layers.28.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 228 |
+
"model.layers.29.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 229 |
+
"model.layers.29.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 230 |
+
"model.layers.29.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 231 |
+
"model.layers.29.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 232 |
+
"model.layers.29.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 233 |
+
"model.layers.29.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 234 |
+
"model.layers.29.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 235 |
+
"model.layers.29.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 236 |
+
"model.layers.29.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
|
| 237 |
+
"model.layers.29.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 238 |
+
"model.layers.3.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 239 |
+
"model.layers.3.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 240 |
+
"model.layers.3.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 241 |
+
"model.layers.3.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 242 |
+
"model.layers.3.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 243 |
+
"model.layers.3.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 244 |
+
"model.layers.3.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 245 |
+
"model.layers.3.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 246 |
+
"model.layers.3.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 247 |
+
"model.layers.3.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 248 |
+
"model.layers.30.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 249 |
+
"model.layers.30.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 250 |
+
"model.layers.30.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 251 |
+
"model.layers.30.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 252 |
+
"model.layers.30.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 253 |
+
"model.layers.30.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 254 |
+
"model.layers.30.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 255 |
+
"model.layers.30.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 256 |
+
"model.layers.30.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
|
| 257 |
+
"model.layers.30.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 258 |
+
"model.layers.31.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 259 |
+
"model.layers.31.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 260 |
+
"model.layers.31.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 261 |
+
"model.layers.31.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 262 |
+
"model.layers.31.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
|
| 263 |
+
"model.layers.31.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 264 |
+
"model.layers.31.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 265 |
+
"model.layers.31.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 266 |
+
"model.layers.31.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
|
| 267 |
+
"model.layers.31.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
|
| 268 |
+
"model.layers.4.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 269 |
+
"model.layers.4.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 270 |
+
"model.layers.4.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 271 |
+
"model.layers.4.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 272 |
+
"model.layers.4.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 273 |
+
"model.layers.4.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 274 |
+
"model.layers.4.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 275 |
+
"model.layers.4.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 276 |
+
"model.layers.4.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 277 |
+
"model.layers.4.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 278 |
+
"model.layers.5.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 279 |
+
"model.layers.5.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 280 |
+
"model.layers.5.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 281 |
+
"model.layers.5.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 282 |
+
"model.layers.5.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 283 |
+
"model.layers.5.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 284 |
+
"model.layers.5.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 285 |
+
"model.layers.5.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 286 |
+
"model.layers.5.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 287 |
+
"model.layers.5.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 288 |
+
"model.layers.6.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 289 |
+
"model.layers.6.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 290 |
+
"model.layers.6.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 291 |
+
"model.layers.6.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 292 |
+
"model.layers.6.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 293 |
+
"model.layers.6.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 294 |
+
"model.layers.6.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 295 |
+
"model.layers.6.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 296 |
+
"model.layers.6.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 297 |
+
"model.layers.6.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 298 |
+
"model.layers.7.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 299 |
+
"model.layers.7.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 300 |
+
"model.layers.7.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 301 |
+
"model.layers.7.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 302 |
+
"model.layers.7.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 303 |
+
"model.layers.7.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 304 |
+
"model.layers.7.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 305 |
+
"model.layers.7.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 306 |
+
"model.layers.7.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 307 |
+
"model.layers.7.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 308 |
+
"model.layers.8.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 309 |
+
"model.layers.8.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 310 |
+
"model.layers.8.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 311 |
+
"model.layers.8.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 312 |
+
"model.layers.8.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 313 |
+
"model.layers.8.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 314 |
+
"model.layers.8.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 315 |
+
"model.layers.8.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 316 |
+
"model.layers.8.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 317 |
+
"model.layers.8.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 318 |
+
"model.layers.9.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 319 |
+
"model.layers.9.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 320 |
+
"model.layers.9.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 321 |
+
"model.layers.9.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 322 |
+
"model.layers.9.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
|
| 323 |
+
"model.layers.9.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 324 |
+
"model.layers.9.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 325 |
+
"model.layers.9.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 326 |
+
"model.layers.9.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
|
| 327 |
+
"model.layers.9.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
|
| 328 |
+
"model.norm.weight": "pytorch_model-00002-of-00002.bin"
|
| 329 |
+
}
|
| 330 |
+
}
|
Video-LLaMA-2-7B-Finetuned/llama-2-7b-chat-hf/special_tokens_map.json
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<s>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": true,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "</s>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": true,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"unk_token": {
|
| 17 |
+
"content": "<unk>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": true,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
}
|
| 23 |
+
}
|
Video-LLaMA-2-7B-Finetuned/llama-2-7b-chat-hf/tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Video-LLaMA-2-7B-Finetuned/llama-2-7b-chat-hf/tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9e556afd44213b6bd1be2b850ebbbd98f5481437a8021afaf58ee7fb1818d347
|
| 3 |
+
size 499723
|
Video-LLaMA-2-7B-Finetuned/llama-2-7b-chat-hf/tokenizer_config.json
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": true,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"bos_token": {
|
| 5 |
+
"__type": "AddedToken",
|
| 6 |
+
"content": "<s>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": true,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false
|
| 11 |
+
},
|
| 12 |
+
"clean_up_tokenization_spaces": false,
|
| 13 |
+
"eos_token": {
|
| 14 |
+
"__type": "AddedToken",
|
| 15 |
+
"content": "</s>",
|
| 16 |
+
"lstrip": false,
|
| 17 |
+
"normalized": true,
|
| 18 |
+
"rstrip": false,
|
| 19 |
+
"single_word": false
|
| 20 |
+
},
|
| 21 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 22 |
+
"pad_token": null,
|
| 23 |
+
"sp_model_kwargs": {},
|
| 24 |
+
"tokenizer_class": "LlamaTokenizer",
|
| 25 |
+
"unk_token": {
|
| 26 |
+
"__type": "AddedToken",
|
| 27 |
+
"content": "<unk>",
|
| 28 |
+
"lstrip": false,
|
| 29 |
+
"normalized": true,
|
| 30 |
+
"rstrip": false,
|
| 31 |
+
"single_word": false
|
| 32 |
+
}
|
| 33 |
+
}
|
app.py
ADDED
|
@@ -0,0 +1,237 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Adapted from: https://github.com/Vision-CAIR/MiniGPT-4/blob/main/demo.py
|
| 3 |
+
"""
|
| 4 |
+
import argparse
|
| 5 |
+
import os
|
| 6 |
+
import random
|
| 7 |
+
|
| 8 |
+
import numpy as np
|
| 9 |
+
import torch
|
| 10 |
+
import torch.backends.cudnn as cudnn
|
| 11 |
+
import gradio as gr
|
| 12 |
+
|
| 13 |
+
from video_llama.common.config import Config
|
| 14 |
+
from video_llama.common.dist_utils import get_rank
|
| 15 |
+
from video_llama.common.registry import registry
|
| 16 |
+
from video_llama.conversation.conversation_video import Chat, Conversation, default_conversation,SeparatorStyle,conv_llava_llama_2
|
| 17 |
+
import decord
|
| 18 |
+
decord.bridge.set_bridge('torch')
|
| 19 |
+
|
| 20 |
+
#%%
|
| 21 |
+
# imports modules for registration
|
| 22 |
+
from video_llama.datasets.builders import *
|
| 23 |
+
from video_llama.models import *
|
| 24 |
+
from video_llama.processors import *
|
| 25 |
+
from video_llama.runners import *
|
| 26 |
+
from video_llama.tasks import *
|
| 27 |
+
|
| 28 |
+
#%%
|
| 29 |
+
def parse_args():
|
| 30 |
+
parser = argparse.ArgumentParser(description="Demo")
|
| 31 |
+
parser.add_argument("--cfg-path", default='eval_configs/video_llama_eval_withaudio.yaml', help="path to configuration file.")
|
| 32 |
+
parser.add_argument("--gpu-id", type=int, default=0, help="specify the gpu to load the model.")
|
| 33 |
+
parser.add_argument("--model_type", type=str, default='vicuna', help="The type of LLM")
|
| 34 |
+
parser.add_argument(
|
| 35 |
+
"--options",
|
| 36 |
+
nargs="+",
|
| 37 |
+
help="override some settings in the used config, the key-value pair "
|
| 38 |
+
"in xxx=yyy format will be merged into config file (deprecate), "
|
| 39 |
+
"change to --cfg-options instead.",
|
| 40 |
+
)
|
| 41 |
+
args = parser.parse_args()
|
| 42 |
+
return args
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def setup_seeds(config):
|
| 46 |
+
seed = config.run_cfg.seed + get_rank()
|
| 47 |
+
|
| 48 |
+
random.seed(seed)
|
| 49 |
+
np.random.seed(seed)
|
| 50 |
+
torch.manual_seed(seed)
|
| 51 |
+
|
| 52 |
+
cudnn.benchmark = False
|
| 53 |
+
cudnn.deterministic = True
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
# ========================================
|
| 57 |
+
# Model Initialization
|
| 58 |
+
# ========================================
|
| 59 |
+
|
| 60 |
+
print('Initializing Chat')
|
| 61 |
+
args = parse_args()
|
| 62 |
+
cfg = Config(args)
|
| 63 |
+
|
| 64 |
+
model_config = cfg.model_cfg
|
| 65 |
+
model_config.device_8bit = args.gpu_id
|
| 66 |
+
model_cls = registry.get_model_class(model_config.arch)
|
| 67 |
+
model = model_cls.from_config(model_config).to('cuda:{}'.format(args.gpu_id))
|
| 68 |
+
model.eval()
|
| 69 |
+
vis_processor_cfg = cfg.datasets_cfg.webvid.vis_processor.train
|
| 70 |
+
vis_processor = registry.get_processor_class(vis_processor_cfg.name).from_config(vis_processor_cfg)
|
| 71 |
+
chat = Chat(model, vis_processor, device='cuda:{}'.format(args.gpu_id))
|
| 72 |
+
print('Initialization Finished')
|
| 73 |
+
|
| 74 |
+
# ========================================
|
| 75 |
+
# Gradio Setting
|
| 76 |
+
# ========================================
|
| 77 |
+
|
| 78 |
+
def gradio_reset(chat_state, img_list):
|
| 79 |
+
if chat_state is not None:
|
| 80 |
+
chat_state.messages = []
|
| 81 |
+
if img_list is not None:
|
| 82 |
+
img_list = []
|
| 83 |
+
return None, gr.update(value=None, interactive=True), gr.update(value=None, interactive=True), gr.update(placeholder='Please upload your video first', interactive=False),gr.update(value="Upload & Start Chat", interactive=True), chat_state, img_list
|
| 84 |
+
|
| 85 |
+
def upload_imgorvideo(gr_video, gr_img, text_input, chat_state,chatbot,audio_flag):
|
| 86 |
+
if args.model_type == 'vicuna':
|
| 87 |
+
chat_state = default_conversation.copy()
|
| 88 |
+
else:
|
| 89 |
+
chat_state = conv_llava_llama_2.copy()
|
| 90 |
+
if gr_img is None and gr_video is None:
|
| 91 |
+
return None, None, None, gr.update(interactive=True), chat_state, None
|
| 92 |
+
elif gr_img is not None and gr_video is None:
|
| 93 |
+
print(gr_img)
|
| 94 |
+
chatbot = chatbot + [((gr_img,), None)]
|
| 95 |
+
chat_state.system = "You are able to understand the visual content that the user provides. Follow the instructions carefully and explain your answers in detail."
|
| 96 |
+
img_list = []
|
| 97 |
+
llm_message = chat.upload_img(gr_img, chat_state, img_list)
|
| 98 |
+
return gr.update(interactive=False), gr.update(interactive=False), gr.update(interactive=True, placeholder='Type and press Enter'), gr.update(value="Start Chatting", interactive=False), chat_state, img_list,chatbot
|
| 99 |
+
elif gr_video is not None and gr_img is None:
|
| 100 |
+
print(gr_video)
|
| 101 |
+
chatbot = chatbot + [((gr_video,), None)]
|
| 102 |
+
chat_state.system = ""
|
| 103 |
+
img_list = []
|
| 104 |
+
if audio_flag:
|
| 105 |
+
llm_message = chat.upload_video(gr_video, chat_state, img_list)
|
| 106 |
+
else:
|
| 107 |
+
llm_message = chat.upload_video_without_audio(gr_video, chat_state, img_list)
|
| 108 |
+
return gr.update(interactive=False), gr.update(interactive=False), gr.update(interactive=True, placeholder='Type and press Enter'), gr.update(value="Start Chatting", interactive=False), chat_state, img_list,chatbot
|
| 109 |
+
else:
|
| 110 |
+
# img_list = []
|
| 111 |
+
return gr.update(interactive=False), gr.update(interactive=False, placeholder='Currently, only one input is supported'), gr.update(value="Currently, only one input is supported", interactive=False), chat_state, None,chatbot
|
| 112 |
+
|
| 113 |
+
def gradio_ask(user_message, chatbot, chat_state):
|
| 114 |
+
if len(user_message) == 0:
|
| 115 |
+
return gr.update(interactive=True, placeholder='Input should not be empty!'), chatbot, chat_state
|
| 116 |
+
chat.ask(user_message, chat_state)
|
| 117 |
+
chatbot = chatbot + [[user_message, None]]
|
| 118 |
+
return '', chatbot, chat_state
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def gradio_answer(chatbot, chat_state, img_list, num_beams, temperature):
|
| 122 |
+
llm_message = chat.answer(conv=chat_state,
|
| 123 |
+
img_list=img_list,
|
| 124 |
+
num_beams=num_beams,
|
| 125 |
+
temperature=temperature,
|
| 126 |
+
max_new_tokens=300,
|
| 127 |
+
max_length=2000)[0]
|
| 128 |
+
chatbot[-1][1] = llm_message
|
| 129 |
+
print(chat_state.get_prompt())
|
| 130 |
+
print(chat_state)
|
| 131 |
+
return chatbot, chat_state, img_list
|
| 132 |
+
|
| 133 |
+
title = """
|
| 134 |
+
<h1 align="center"><a href="https://github.com/DAMO-NLP-SG/Video-LLaMA"><img src="https://s1.ax1x.com/2023/05/22/p9oQ0FP.jpg", alt="Video-LLaMA" border="0" style="margin: 0 auto; height: 200px;" /></a> </h1>
|
| 135 |
+
|
| 136 |
+
<h1 align="center">Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding</h1>
|
| 137 |
+
|
| 138 |
+
<h5 align="center"> Introduction: Video-LLaMA is a multi-model large language model that achieves video-grounded conversations between humans and computers \
|
| 139 |
+
by connecting language decoder with off-the-shelf unimodal pre-trained models. </h5>
|
| 140 |
+
|
| 141 |
+
<div style='display:flex; gap: 0.25rem; '>
|
| 142 |
+
<a href='https://github.com/DAMO-NLP-SG/Video-LLaMA'><img src='https://img.shields.io/badge/Github-Code-success'></a>
|
| 143 |
+
<a href='https://huggingface.co/spaces/DAMO-NLP-SG/Video-LLaMA'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue'></a>
|
| 144 |
+
<a href='https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Model-blue'></a>
|
| 145 |
+
<a href='https://modelscope.cn/studios/damo/video-llama/summary'><img src='https://img.shields.io/badge/ModelScope-Demo-blueviolet'></a>
|
| 146 |
+
<a href='https://arxiv.org/abs/2306.02858'><img src='https://img.shields.io/badge/Paper-PDF-red'></a>
|
| 147 |
+
</div>
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
Thank you for using the Video-LLaMA Demo Page! If you have any questions or feedback, feel free to contact us.
|
| 151 |
+
|
| 152 |
+
If you find Video-LLaMA interesting, please give us a star on GitHub.
|
| 153 |
+
|
| 154 |
+
Current online demo uses the 7B version of Video-LLaMA due to resource limitations. We have released \
|
| 155 |
+
the 13B version on our GitHub repository.
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
"""
|
| 159 |
+
|
| 160 |
+
Note_markdown = ("""
|
| 161 |
+
### Note
|
| 162 |
+
Video-LLaMA is a prototype model and may have limitations in understanding complex scenes, long videos, or specific domains.
|
| 163 |
+
The output results may be influenced by input quality, limitations of the dataset, and the model's susceptibility to illusions. Please interpret the results with caution.
|
| 164 |
+
|
| 165 |
+
**Copyright 2023 Alibaba DAMO Academy.**
|
| 166 |
+
""")
|
| 167 |
+
|
| 168 |
+
cite_markdown = ("""
|
| 169 |
+
## Citation
|
| 170 |
+
If you find our project useful, hope you can star our repo and cite our paper as follows:
|
| 171 |
+
```
|
| 172 |
+
@article{damonlpsg2023videollama,
|
| 173 |
+
author = {Zhang, Hang and Li, Xin and Bing, Lidong},
|
| 174 |
+
title = {Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding},
|
| 175 |
+
year = 2023,
|
| 176 |
+
journal = {arXiv preprint arXiv:2306.02858}
|
| 177 |
+
url = {https://arxiv.org/abs/2306.02858}
|
| 178 |
+
}
|
| 179 |
+
""")
|
| 180 |
+
|
| 181 |
+
case_note_upload = ("""
|
| 182 |
+
### We provide some examples at the bottom of the page. Simply click on them to try them out directly.
|
| 183 |
+
""")
|
| 184 |
+
|
| 185 |
+
#TODO show examples below
|
| 186 |
+
|
| 187 |
+
with gr.Blocks() as demo:
|
| 188 |
+
gr.Markdown(title)
|
| 189 |
+
|
| 190 |
+
with gr.Row():
|
| 191 |
+
with gr.Column(scale=0.5):
|
| 192 |
+
video = gr.Video()
|
| 193 |
+
image = gr.Image(type="filepath")
|
| 194 |
+
gr.Markdown(case_note_upload)
|
| 195 |
+
|
| 196 |
+
upload_button = gr.Button(value="Upload & Start Chat", interactive=True, variant="primary")
|
| 197 |
+
clear = gr.Button("Restart")
|
| 198 |
+
|
| 199 |
+
num_beams = gr.Slider(
|
| 200 |
+
minimum=1,
|
| 201 |
+
maximum=10,
|
| 202 |
+
value=1,
|
| 203 |
+
step=1,
|
| 204 |
+
interactive=True,
|
| 205 |
+
label="beam search numbers)",
|
| 206 |
+
)
|
| 207 |
+
|
| 208 |
+
temperature = gr.Slider(
|
| 209 |
+
minimum=0.1,
|
| 210 |
+
maximum=2.0,
|
| 211 |
+
value=1.0,
|
| 212 |
+
step=0.1,
|
| 213 |
+
interactive=True,
|
| 214 |
+
label="Temperature",
|
| 215 |
+
)
|
| 216 |
+
|
| 217 |
+
audio = gr.Checkbox(interactive=True, value=False, label="Audio")
|
| 218 |
+
gr.Markdown(Note_markdown)
|
| 219 |
+
with gr.Column():
|
| 220 |
+
chat_state = gr.State()
|
| 221 |
+
img_list = gr.State()
|
| 222 |
+
chatbot = gr.Chatbot(label='Video-LLaMA')
|
| 223 |
+
text_input = gr.Textbox(label='User', placeholder='Upload your image/video first, or directly click the examples at the bottom of the page.', interactive=False)
|
| 224 |
+
|
| 225 |
+
|
| 226 |
+
gr.Markdown(cite_markdown)
|
| 227 |
+
upload_button.click(upload_imgorvideo, [video, image, text_input, chat_state,chatbot,audio], [video, image, text_input, upload_button, chat_state, img_list,chatbot])
|
| 228 |
+
|
| 229 |
+
text_input.submit(gradio_ask, [text_input, chatbot, chat_state], [text_input, chatbot, chat_state]).then(
|
| 230 |
+
gradio_answer, [chatbot, chat_state, img_list, num_beams, temperature], [chatbot, chat_state, img_list]
|
| 231 |
+
)
|
| 232 |
+
clear.click(gradio_reset, [chat_state, img_list], [chatbot, video, image, text_input, upload_button, chat_state, img_list], queue=False)
|
| 233 |
+
|
| 234 |
+
demo.launch(share=False, enable_queue=True)
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
# %%
|
apply_delta.py
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Apply the delta weights on top of a base model.
|
| 3 |
+
Adapted from: https://github.com/lm-sys/FastChat/blob/main/fastchat/model/apply_delta.py.
|
| 4 |
+
"""
|
| 5 |
+
import argparse
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def apply_delta(base_model_path, target_model_path, delta_path):
|
| 13 |
+
print(f"Loading the base model from {base_model_path}")
|
| 14 |
+
base = AutoModelForCausalLM.from_pretrained(
|
| 15 |
+
base_model_path, torch_dtype=torch.float16, low_cpu_mem_usage=True)
|
| 16 |
+
|
| 17 |
+
print(f"Loading the delta from {delta_path}")
|
| 18 |
+
delta = AutoModelForCausalLM.from_pretrained(delta_path, torch_dtype=torch.float16, low_cpu_mem_usage=True)
|
| 19 |
+
delta_tokenizer = AutoTokenizer.from_pretrained(delta_path, use_fast=False)
|
| 20 |
+
|
| 21 |
+
DEFAULT_PAD_TOKEN = "[PAD]"
|
| 22 |
+
base_tokenizer = AutoTokenizer.from_pretrained(base_model_path, use_fast=False)
|
| 23 |
+
num_new_tokens = base_tokenizer.add_special_tokens(dict(pad_token=DEFAULT_PAD_TOKEN))
|
| 24 |
+
|
| 25 |
+
base.resize_token_embeddings(len(base_tokenizer))
|
| 26 |
+
input_embeddings = base.get_input_embeddings().weight.data
|
| 27 |
+
output_embeddings = base.get_output_embeddings().weight.data
|
| 28 |
+
input_embeddings[-num_new_tokens:] = 0
|
| 29 |
+
output_embeddings[-num_new_tokens:] = 0
|
| 30 |
+
|
| 31 |
+
print("Applying the delta")
|
| 32 |
+
for name, param in tqdm(base.state_dict().items(), desc="Applying delta"):
|
| 33 |
+
assert name in delta.state_dict()
|
| 34 |
+
param.data += delta.state_dict()[name]
|
| 35 |
+
|
| 36 |
+
print(f"Saving the target model to {target_model_path}")
|
| 37 |
+
base.save_pretrained(target_model_path)
|
| 38 |
+
delta_tokenizer.save_pretrained(target_model_path)
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
if __name__ == "__main__":
|
| 42 |
+
parser = argparse.ArgumentParser()
|
| 43 |
+
parser.add_argument("--base-model-path", type=str, required=True)
|
| 44 |
+
parser.add_argument("--target-model-path", type=str, required=True)
|
| 45 |
+
parser.add_argument("--delta-path", type=str, required=True)
|
| 46 |
+
|
| 47 |
+
args = parser.parse_args()
|
| 48 |
+
|
| 49 |
+
apply_delta(args.base_model_path, args.target_model_path, args.delta_path)
|
demo_audiovideo.py
ADDED
|
@@ -0,0 +1,250 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Adapted from: https://github.com/Vision-CAIR/MiniGPT-4/blob/main/demo.py
|
| 3 |
+
"""
|
| 4 |
+
import argparse
|
| 5 |
+
import os
|
| 6 |
+
import random
|
| 7 |
+
|
| 8 |
+
import numpy as np
|
| 9 |
+
import torch
|
| 10 |
+
import torch.backends.cudnn as cudnn
|
| 11 |
+
import gradio as gr
|
| 12 |
+
|
| 13 |
+
from video_llama.common.config import Config
|
| 14 |
+
from video_llama.common.dist_utils import get_rank
|
| 15 |
+
from video_llama.common.registry import registry
|
| 16 |
+
from video_llama.conversation.conversation_video import Chat, Conversation, default_conversation,SeparatorStyle,conv_llava_llama_2
|
| 17 |
+
import decord
|
| 18 |
+
decord.bridge.set_bridge('torch')
|
| 19 |
+
|
| 20 |
+
#%%
|
| 21 |
+
# imports modules for registration
|
| 22 |
+
from video_llama.datasets.builders import *
|
| 23 |
+
from video_llama.models import *
|
| 24 |
+
from video_llama.processors import *
|
| 25 |
+
from video_llama.runners import *
|
| 26 |
+
from video_llama.tasks import *
|
| 27 |
+
|
| 28 |
+
#%%
|
| 29 |
+
def parse_args():
|
| 30 |
+
parser = argparse.ArgumentParser(description="Demo")
|
| 31 |
+
parser.add_argument("--cfg-path", default='eval_configs/video_llama_eval_withaudio.yaml', help="path to configuration file.")
|
| 32 |
+
parser.add_argument("--gpu-id", type=int, default=0, help="specify the gpu to load the model.")
|
| 33 |
+
parser.add_argument("--model_type", type=str, default='vicuna', help="The type of LLM")
|
| 34 |
+
parser.add_argument(
|
| 35 |
+
"--options",
|
| 36 |
+
nargs="+",
|
| 37 |
+
help="override some settings in the used config, the key-value pair "
|
| 38 |
+
"in xxx=yyy format will be merged into config file (deprecate), "
|
| 39 |
+
"change to --cfg-options instead.",
|
| 40 |
+
)
|
| 41 |
+
args = parser.parse_args()
|
| 42 |
+
return args
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def setup_seeds(config):
|
| 46 |
+
seed = config.run_cfg.seed + get_rank()
|
| 47 |
+
|
| 48 |
+
random.seed(seed)
|
| 49 |
+
np.random.seed(seed)
|
| 50 |
+
torch.manual_seed(seed)
|
| 51 |
+
|
| 52 |
+
cudnn.benchmark = False
|
| 53 |
+
cudnn.deterministic = True
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
# ========================================
|
| 57 |
+
# Model Initialization
|
| 58 |
+
# ========================================
|
| 59 |
+
|
| 60 |
+
print('Initializing Chat')
|
| 61 |
+
args = parse_args()
|
| 62 |
+
cfg = Config(args)
|
| 63 |
+
|
| 64 |
+
model_config = cfg.model_cfg
|
| 65 |
+
model_config.device_8bit = args.gpu_id
|
| 66 |
+
model_cls = registry.get_model_class(model_config.arch)
|
| 67 |
+
model = model_cls.from_config(model_config).to('cuda:{}'.format(args.gpu_id))
|
| 68 |
+
model.eval()
|
| 69 |
+
vis_processor_cfg = cfg.datasets_cfg.webvid.vis_processor.train
|
| 70 |
+
vis_processor = registry.get_processor_class(vis_processor_cfg.name).from_config(vis_processor_cfg)
|
| 71 |
+
chat = Chat(model, vis_processor, device='cuda:{}'.format(args.gpu_id))
|
| 72 |
+
print('Initialization Finished')
|
| 73 |
+
|
| 74 |
+
# ========================================
|
| 75 |
+
# Gradio Setting
|
| 76 |
+
# ========================================
|
| 77 |
+
|
| 78 |
+
def gradio_reset(chat_state, img_list):
|
| 79 |
+
if chat_state is not None:
|
| 80 |
+
chat_state.messages = []
|
| 81 |
+
if img_list is not None:
|
| 82 |
+
img_list = []
|
| 83 |
+
return None, gr.update(value=None, interactive=True), gr.update(value=None, interactive=True), gr.update(placeholder='Please upload your video first', interactive=False),gr.update(value="Upload & Start Chat", interactive=True), chat_state, img_list
|
| 84 |
+
|
| 85 |
+
def upload_imgorvideo(gr_video, gr_img, text_input, chat_state,chatbot,audio_flag):
|
| 86 |
+
if args.model_type == 'vicuna':
|
| 87 |
+
chat_state = default_conversation.copy()
|
| 88 |
+
else:
|
| 89 |
+
chat_state = conv_llava_llama_2.copy()
|
| 90 |
+
if gr_img is None and gr_video is None:
|
| 91 |
+
return None, None, None, gr.update(interactive=True), chat_state, None
|
| 92 |
+
elif gr_img is not None and gr_video is None:
|
| 93 |
+
print(gr_img)
|
| 94 |
+
chatbot = chatbot + [((gr_img,), None)]
|
| 95 |
+
chat_state.system = "You are able to understand the visual content that the user provides. Follow the instructions carefully and explain your answers in detail."
|
| 96 |
+
img_list = []
|
| 97 |
+
llm_message = chat.upload_img(gr_img, chat_state, img_list)
|
| 98 |
+
return gr.update(interactive=False), gr.update(interactive=False), gr.update(interactive=True, placeholder='Type and press Enter'), gr.update(value="Start Chatting", interactive=False), chat_state, img_list,chatbot
|
| 99 |
+
elif gr_video is not None and gr_img is None:
|
| 100 |
+
print(gr_video)
|
| 101 |
+
chatbot = chatbot + [((gr_video,), None)]
|
| 102 |
+
chat_state.system = ""
|
| 103 |
+
img_list = []
|
| 104 |
+
if audio_flag:
|
| 105 |
+
llm_message = chat.upload_video(gr_video, chat_state, img_list)
|
| 106 |
+
else:
|
| 107 |
+
llm_message = chat.upload_video_without_audio(gr_video, chat_state, img_list)
|
| 108 |
+
return gr.update(interactive=False), gr.update(interactive=False), gr.update(interactive=True, placeholder='Type and press Enter'), gr.update(value="Start Chatting", interactive=False), chat_state, img_list,chatbot
|
| 109 |
+
else:
|
| 110 |
+
# img_list = []
|
| 111 |
+
return gr.update(interactive=False), gr.update(interactive=False, placeholder='Currently, only one input is supported'), gr.update(value="Currently, only one input is supported", interactive=False), chat_state, None,chatbot
|
| 112 |
+
|
| 113 |
+
def gradio_ask(user_message, chatbot, chat_state):
|
| 114 |
+
if len(user_message) == 0:
|
| 115 |
+
return gr.update(interactive=True, placeholder='Input should not be empty!'), chatbot, chat_state
|
| 116 |
+
chat.ask(user_message, chat_state)
|
| 117 |
+
chatbot = chatbot + [[user_message, None]]
|
| 118 |
+
return '', chatbot, chat_state
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def gradio_answer(chatbot, chat_state, img_list, num_beams, temperature):
|
| 122 |
+
llm_message = chat.answer(conv=chat_state,
|
| 123 |
+
img_list=img_list,
|
| 124 |
+
num_beams=num_beams,
|
| 125 |
+
temperature=temperature,
|
| 126 |
+
max_new_tokens=300,
|
| 127 |
+
max_length=2000)[0]
|
| 128 |
+
chatbot[-1][1] = llm_message
|
| 129 |
+
print(chat_state.get_prompt())
|
| 130 |
+
print(chat_state)
|
| 131 |
+
return chatbot, chat_state, img_list
|
| 132 |
+
|
| 133 |
+
title = """
|
| 134 |
+
<h1 align="center"><a href="https://github.com/DAMO-NLP-SG/Video-LLaMA"><img src="https://s1.ax1x.com/2023/05/22/p9oQ0FP.jpg", alt="Video-LLaMA" border="0" style="margin: 0 auto; height: 200px;" /></a> </h1>
|
| 135 |
+
|
| 136 |
+
<h1 align="center">Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding</h1>
|
| 137 |
+
|
| 138 |
+
<h5 align="center"> Introduction: Video-LLaMA is a multi-model large language model that achieves video-grounded conversations between humans and computers \
|
| 139 |
+
by connecting language decoder with off-the-shelf unimodal pre-trained models. </h5>
|
| 140 |
+
|
| 141 |
+
<div style='display:flex; gap: 0.25rem; '>
|
| 142 |
+
<a href='https://github.com/DAMO-NLP-SG/Video-LLaMA'><img src='https://img.shields.io/badge/Github-Code-success'></a>
|
| 143 |
+
<a href='https://huggingface.co/spaces/DAMO-NLP-SG/Video-LLaMA'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue'></a>
|
| 144 |
+
<a href='https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Model-blue'></a>
|
| 145 |
+
<a href='https://modelscope.cn/studios/damo/video-llama/summary'><img src='https://img.shields.io/badge/ModelScope-Demo-blueviolet'></a>
|
| 146 |
+
<a href='https://arxiv.org/abs/2306.02858'><img src='https://img.shields.io/badge/Paper-PDF-red'></a>
|
| 147 |
+
</div>
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
Thank you for using the Video-LLaMA Demo Page! If you have any questions or feedback, feel free to contact us.
|
| 151 |
+
|
| 152 |
+
If you find Video-LLaMA interesting, please give us a star on GitHub.
|
| 153 |
+
|
| 154 |
+
Current online demo uses the 7B version of Video-LLaMA due to resource limitations. We have released \
|
| 155 |
+
the 13B version on our GitHub repository.
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
"""
|
| 159 |
+
|
| 160 |
+
Note_markdown = ("""
|
| 161 |
+
### Note
|
| 162 |
+
Video-LLaMA is a prototype model and may have limitations in understanding complex scenes, long videos, or specific domains.
|
| 163 |
+
The output results may be influenced by input quality, limitations of the dataset, and the model's susceptibility to illusions. Please interpret the results with caution.
|
| 164 |
+
|
| 165 |
+
**Copyright 2023 Alibaba DAMO Academy.**
|
| 166 |
+
""")
|
| 167 |
+
|
| 168 |
+
cite_markdown = ("""
|
| 169 |
+
## Citation
|
| 170 |
+
If you find our project useful, hope you can star our repo and cite our paper as follows:
|
| 171 |
+
```
|
| 172 |
+
@article{damonlpsg2023videollama,
|
| 173 |
+
author = {Zhang, Hang and Li, Xin and Bing, Lidong},
|
| 174 |
+
title = {Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding},
|
| 175 |
+
year = 2023,
|
| 176 |
+
journal = {arXiv preprint arXiv:2306.02858}
|
| 177 |
+
url = {https://arxiv.org/abs/2306.02858}
|
| 178 |
+
}
|
| 179 |
+
""")
|
| 180 |
+
|
| 181 |
+
case_note_upload = ("""
|
| 182 |
+
### We provide some examples at the bottom of the page. Simply click on them to try them out directly.
|
| 183 |
+
""")
|
| 184 |
+
|
| 185 |
+
#TODO show examples below
|
| 186 |
+
|
| 187 |
+
with gr.Blocks() as demo:
|
| 188 |
+
gr.Markdown(title)
|
| 189 |
+
|
| 190 |
+
with gr.Row():
|
| 191 |
+
with gr.Column(scale=0.5):
|
| 192 |
+
video = gr.Video()
|
| 193 |
+
image = gr.Image(type="filepath")
|
| 194 |
+
gr.Markdown(case_note_upload)
|
| 195 |
+
|
| 196 |
+
upload_button = gr.Button(value="Upload & Start Chat", interactive=True, variant="primary")
|
| 197 |
+
clear = gr.Button("Restart")
|
| 198 |
+
|
| 199 |
+
num_beams = gr.Slider(
|
| 200 |
+
minimum=1,
|
| 201 |
+
maximum=10,
|
| 202 |
+
value=1,
|
| 203 |
+
step=1,
|
| 204 |
+
interactive=True,
|
| 205 |
+
label="beam search numbers)",
|
| 206 |
+
)
|
| 207 |
+
|
| 208 |
+
temperature = gr.Slider(
|
| 209 |
+
minimum=0.1,
|
| 210 |
+
maximum=2.0,
|
| 211 |
+
value=1.0,
|
| 212 |
+
step=0.1,
|
| 213 |
+
interactive=True,
|
| 214 |
+
label="Temperature",
|
| 215 |
+
)
|
| 216 |
+
|
| 217 |
+
audio = gr.Checkbox(interactive=True, value=False, label="Audio")
|
| 218 |
+
gr.Markdown(Note_markdown)
|
| 219 |
+
with gr.Column():
|
| 220 |
+
chat_state = gr.State()
|
| 221 |
+
img_list = gr.State()
|
| 222 |
+
chatbot = gr.Chatbot(label='Video-LLaMA')
|
| 223 |
+
text_input = gr.Textbox(label='User', placeholder='Upload your image/video first, or directly click the examples at the bottom of the page.', interactive=False)
|
| 224 |
+
|
| 225 |
+
|
| 226 |
+
with gr.Column():
|
| 227 |
+
gr.Examples(examples=[
|
| 228 |
+
[f"examples/dog.jpg", "Which breed is this dog? "],
|
| 229 |
+
[f"examples/JonSnow.jpg", "Who's the man on the right? "],
|
| 230 |
+
[f"examples/Statue_of_Liberty.jpg", "Can you tell me about this building? "],
|
| 231 |
+
], inputs=[image, text_input])
|
| 232 |
+
|
| 233 |
+
gr.Examples(examples=[
|
| 234 |
+
[f"examples/skateboarding_dog.mp4", "What is the dog doing? "],
|
| 235 |
+
[f"examples/birthday.mp4", "What is the boy doing? "],
|
| 236 |
+
[f"examples/IronMan.mp4", "Is the guy in the video Iron Man? "],
|
| 237 |
+
], inputs=[video, text_input])
|
| 238 |
+
|
| 239 |
+
gr.Markdown(cite_markdown)
|
| 240 |
+
upload_button.click(upload_imgorvideo, [video, image, text_input, chat_state,chatbot,audio], [video, image, text_input, upload_button, chat_state, img_list,chatbot])
|
| 241 |
+
|
| 242 |
+
text_input.submit(gradio_ask, [text_input, chatbot, chat_state], [text_input, chatbot, chat_state]).then(
|
| 243 |
+
gradio_answer, [chatbot, chat_state, img_list, num_beams, temperature], [chatbot, chat_state, img_list]
|
| 244 |
+
)
|
| 245 |
+
clear.click(gradio_reset, [chat_state, img_list], [chatbot, video, image, text_input, upload_button, chat_state, img_list], queue=False)
|
| 246 |
+
|
| 247 |
+
demo.launch(share=False, enable_queue=True)
|
| 248 |
+
|
| 249 |
+
|
| 250 |
+
# %%
|
demo_video.py
ADDED
|
@@ -0,0 +1,247 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Adapted from: https://github.com/Vision-CAIR/MiniGPT-4/blob/main/demo.py
|
| 3 |
+
"""
|
| 4 |
+
import argparse
|
| 5 |
+
import os
|
| 6 |
+
import random
|
| 7 |
+
|
| 8 |
+
import numpy as np
|
| 9 |
+
import torch
|
| 10 |
+
import torch.backends.cudnn as cudnn
|
| 11 |
+
import gradio as gr
|
| 12 |
+
|
| 13 |
+
from video_llama.common.config import Config
|
| 14 |
+
from video_llama.common.dist_utils import get_rank
|
| 15 |
+
from video_llama.common.registry import registry
|
| 16 |
+
from video_llama.conversation.conversation_video import Chat, Conversation, default_conversation,SeparatorStyle,conv_llava_llama_2
|
| 17 |
+
import decord
|
| 18 |
+
decord.bridge.set_bridge('torch')
|
| 19 |
+
|
| 20 |
+
#%%
|
| 21 |
+
# imports modules for registration
|
| 22 |
+
from video_llama.datasets.builders import *
|
| 23 |
+
from video_llama.models import *
|
| 24 |
+
from video_llama.processors import *
|
| 25 |
+
from video_llama.runners import *
|
| 26 |
+
from video_llama.tasks import *
|
| 27 |
+
|
| 28 |
+
#%%
|
| 29 |
+
def parse_args():
|
| 30 |
+
parser = argparse.ArgumentParser(description="Demo")
|
| 31 |
+
parser.add_argument("--cfg-path", required=True, help="path to configuration file.")
|
| 32 |
+
parser.add_argument("--gpu-id", type=int, default=0, help="specify the gpu to load the model.")
|
| 33 |
+
parser.add_argument("--model_type", type=str, default='vicuna', help="The type of LLM")
|
| 34 |
+
parser.add_argument(
|
| 35 |
+
"--options",
|
| 36 |
+
nargs="+",
|
| 37 |
+
help="override some settings in the used config, the key-value pair "
|
| 38 |
+
"in xxx=yyy format will be merged into config file (deprecate), "
|
| 39 |
+
"change to --cfg-options instead.",
|
| 40 |
+
)
|
| 41 |
+
args = parser.parse_args()
|
| 42 |
+
return args
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def setup_seeds(config):
|
| 46 |
+
seed = config.run_cfg.seed + get_rank()
|
| 47 |
+
|
| 48 |
+
random.seed(seed)
|
| 49 |
+
np.random.seed(seed)
|
| 50 |
+
torch.manual_seed(seed)
|
| 51 |
+
|
| 52 |
+
cudnn.benchmark = False
|
| 53 |
+
cudnn.deterministic = True
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
# ========================================
|
| 57 |
+
# Model Initialization
|
| 58 |
+
# ========================================
|
| 59 |
+
|
| 60 |
+
print('Initializing Chat')
|
| 61 |
+
args = parse_args()
|
| 62 |
+
cfg = Config(args)
|
| 63 |
+
|
| 64 |
+
model_config = cfg.model_cfg
|
| 65 |
+
model_config.device_8bit = args.gpu_id
|
| 66 |
+
model_cls = registry.get_model_class(model_config.arch)
|
| 67 |
+
model = model_cls.from_config(model_config).to('cuda:{}'.format(args.gpu_id))
|
| 68 |
+
model.eval()
|
| 69 |
+
vis_processor_cfg = cfg.datasets_cfg.webvid.vis_processor.train
|
| 70 |
+
vis_processor = registry.get_processor_class(vis_processor_cfg.name).from_config(vis_processor_cfg)
|
| 71 |
+
chat = Chat(model, vis_processor, device='cuda:{}'.format(args.gpu_id))
|
| 72 |
+
print('Initialization Finished')
|
| 73 |
+
|
| 74 |
+
# ========================================
|
| 75 |
+
# Gradio Setting
|
| 76 |
+
# ========================================
|
| 77 |
+
|
| 78 |
+
def gradio_reset(chat_state, img_list):
|
| 79 |
+
if chat_state is not None:
|
| 80 |
+
chat_state.messages = []
|
| 81 |
+
if img_list is not None:
|
| 82 |
+
img_list = []
|
| 83 |
+
return None, gr.update(value=None, interactive=True), gr.update(value=None, interactive=True), gr.update(placeholder='Please upload your video first', interactive=False),gr.update(value="Upload & Start Chat", interactive=True), chat_state, img_list
|
| 84 |
+
|
| 85 |
+
def upload_imgorvideo(gr_video, gr_img, text_input, chat_state,chatbot):
|
| 86 |
+
if args.model_type == 'vicuna':
|
| 87 |
+
chat_state = default_conversation.copy()
|
| 88 |
+
else:
|
| 89 |
+
chat_state = conv_llava_llama_2.copy()
|
| 90 |
+
if gr_img is None and gr_video is None:
|
| 91 |
+
return None, None, None, gr.update(interactive=True), chat_state, None
|
| 92 |
+
elif gr_img is not None and gr_video is None:
|
| 93 |
+
print(gr_img)
|
| 94 |
+
chatbot = chatbot + [((gr_img,), None)]
|
| 95 |
+
chat_state.system = "You are able to understand the visual content that the user provides. Follow the instructions carefully and explain your answers in detail."
|
| 96 |
+
img_list = []
|
| 97 |
+
llm_message = chat.upload_img(gr_img, chat_state, img_list)
|
| 98 |
+
return gr.update(interactive=False), gr.update(interactive=False), gr.update(interactive=True, placeholder='Type and press Enter'), gr.update(value="Start Chatting", interactive=False), chat_state, img_list,chatbot
|
| 99 |
+
elif gr_video is not None and gr_img is None:
|
| 100 |
+
print(gr_video)
|
| 101 |
+
chatbot = chatbot + [((gr_video,), None)]
|
| 102 |
+
chat_state.system = "You are able to understand the visual content that the user provides. Follow the instructions carefully and explain your answers in detail."
|
| 103 |
+
img_list = []
|
| 104 |
+
llm_message = chat.upload_video_without_audio(gr_video, chat_state, img_list)
|
| 105 |
+
return gr.update(interactive=False), gr.update(interactive=False), gr.update(interactive=True, placeholder='Type and press Enter'), gr.update(value="Start Chatting", interactive=False), chat_state, img_list,chatbot
|
| 106 |
+
else:
|
| 107 |
+
# img_list = []
|
| 108 |
+
return gr.update(interactive=False), gr.update(interactive=False, placeholder='Currently, only one input is supported'), gr.update(value="Currently, only one input is supported", interactive=False), chat_state, None,chatbot
|
| 109 |
+
|
| 110 |
+
def gradio_ask(user_message, chatbot, chat_state):
|
| 111 |
+
if len(user_message) == 0:
|
| 112 |
+
return gr.update(interactive=True, placeholder='Input should not be empty!'), chatbot, chat_state
|
| 113 |
+
chat.ask(user_message, chat_state)
|
| 114 |
+
chatbot = chatbot + [[user_message, None]]
|
| 115 |
+
return '', chatbot, chat_state
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def gradio_answer(chatbot, chat_state, img_list, num_beams, temperature):
|
| 119 |
+
llm_message = chat.answer(conv=chat_state,
|
| 120 |
+
img_list=img_list,
|
| 121 |
+
num_beams=num_beams,
|
| 122 |
+
temperature=temperature,
|
| 123 |
+
max_new_tokens=300,
|
| 124 |
+
max_length=2000)[0]
|
| 125 |
+
chatbot[-1][1] = llm_message
|
| 126 |
+
print(chat_state.get_prompt())
|
| 127 |
+
print(chat_state)
|
| 128 |
+
return chatbot, chat_state, img_list
|
| 129 |
+
|
| 130 |
+
title = """
|
| 131 |
+
<h1 align="center"><a href="https://github.com/DAMO-NLP-SG/Video-LLaMA"><img src="https://s1.ax1x.com/2023/05/22/p9oQ0FP.jpg", alt="Video-LLaMA" border="0" style="margin: 0 auto; height: 200px;" /></a> </h1>
|
| 132 |
+
|
| 133 |
+
<h1 align="center">Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding</h1>
|
| 134 |
+
|
| 135 |
+
<h5 align="center"> Introduction: Video-LLaMA is a multi-model large language model that achieves video-grounded conversations between humans and computers \
|
| 136 |
+
by connecting language decoder with off-the-shelf unimodal pre-trained models. </h5>
|
| 137 |
+
|
| 138 |
+
<div style='display:flex; gap: 0.25rem; '>
|
| 139 |
+
<a href='https://github.com/DAMO-NLP-SG/Video-LLaMA'><img src='https://img.shields.io/badge/Github-Code-success'></a>
|
| 140 |
+
<a href='https://huggingface.co/spaces/DAMO-NLP-SG/Video-LLaMA'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue'></a>
|
| 141 |
+
<a href='https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-Series'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Model-blue'></a>
|
| 142 |
+
<a href='https://modelscope.cn/studios/damo/video-llama/summary'><img src='https://img.shields.io/badge/ModelScope-Demo-blueviolet'></a>
|
| 143 |
+
<a href='https://arxiv.org/abs/2306.02858'><img src='https://img.shields.io/badge/Paper-PDF-red'></a>
|
| 144 |
+
</div>
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
Thank you for using the Video-LLaMA Demo Page! If you have any questions or feedback, feel free to contact us.
|
| 148 |
+
|
| 149 |
+
If you find Video-LLaMA interesting, please give us a star on GitHub.
|
| 150 |
+
|
| 151 |
+
Current online demo uses the 7B version of Video-LLaMA due to resource limitations. We have released \
|
| 152 |
+
the 13B version on our GitHub repository.
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
"""
|
| 156 |
+
|
| 157 |
+
Note_markdown = ("""
|
| 158 |
+
### Note
|
| 159 |
+
Video-LLaMA is a prototype model and may have limitations in understanding complex scenes, long videos, or specific domains.
|
| 160 |
+
The output results may be influenced by input quality, limitations of the dataset, and the model's susceptibility to illusions. Please interpret the results with caution.
|
| 161 |
+
|
| 162 |
+
**Copyright 2023 Alibaba DAMO Academy.**
|
| 163 |
+
""")
|
| 164 |
+
|
| 165 |
+
cite_markdown = ("""
|
| 166 |
+
## Citation
|
| 167 |
+
If you find our project useful, hope you can star our repo and cite our paper as follows:
|
| 168 |
+
```
|
| 169 |
+
@article{damonlpsg2023videollama,
|
| 170 |
+
author = {Zhang, Hang and Li, Xin and Bing, Lidong},
|
| 171 |
+
title = {Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding},
|
| 172 |
+
year = 2023,
|
| 173 |
+
journal = {arXiv preprint arXiv:2306.02858}
|
| 174 |
+
url = {https://arxiv.org/abs/2306.02858}
|
| 175 |
+
}
|
| 176 |
+
""")
|
| 177 |
+
|
| 178 |
+
case_note_upload = ("""
|
| 179 |
+
### We provide some examples at the bottom of the page. Simply click on them to try them out directly.
|
| 180 |
+
""")
|
| 181 |
+
|
| 182 |
+
#TODO show examples below
|
| 183 |
+
|
| 184 |
+
with gr.Blocks() as demo:
|
| 185 |
+
gr.Markdown(title)
|
| 186 |
+
|
| 187 |
+
with gr.Row():
|
| 188 |
+
with gr.Column(scale=0.5):
|
| 189 |
+
video = gr.Video()
|
| 190 |
+
image = gr.Image(type="filepath")
|
| 191 |
+
gr.Markdown(case_note_upload)
|
| 192 |
+
|
| 193 |
+
upload_button = gr.Button(value="Upload & Start Chat", interactive=True, variant="primary")
|
| 194 |
+
clear = gr.Button("Restart")
|
| 195 |
+
|
| 196 |
+
num_beams = gr.Slider(
|
| 197 |
+
minimum=1,
|
| 198 |
+
maximum=10,
|
| 199 |
+
value=1,
|
| 200 |
+
step=1,
|
| 201 |
+
interactive=True,
|
| 202 |
+
label="beam search numbers)",
|
| 203 |
+
)
|
| 204 |
+
|
| 205 |
+
temperature = gr.Slider(
|
| 206 |
+
minimum=0.1,
|
| 207 |
+
maximum=2.0,
|
| 208 |
+
value=1.0,
|
| 209 |
+
step=0.1,
|
| 210 |
+
interactive=True,
|
| 211 |
+
label="Temperature",
|
| 212 |
+
)
|
| 213 |
+
|
| 214 |
+
audio = gr.Checkbox(interactive=True, value=False, label="Audio")
|
| 215 |
+
gr.Markdown(Note_markdown)
|
| 216 |
+
with gr.Column():
|
| 217 |
+
chat_state = gr.State()
|
| 218 |
+
img_list = gr.State()
|
| 219 |
+
chatbot = gr.Chatbot(label='Video-LLaMA')
|
| 220 |
+
text_input = gr.Textbox(label='User', placeholder='Upload your image/video first, or directly click the examples at the bottom of the page.', interactive=False)
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
with gr.Column():
|
| 224 |
+
gr.Examples(examples=[
|
| 225 |
+
[f"examples/dog.jpg", "Which breed is this dog? "],
|
| 226 |
+
[f"examples/JonSnow.jpg", "Who's the man on the right? "],
|
| 227 |
+
[f"examples/Statue_of_Liberty.jpg", "Can you tell me about this building? "],
|
| 228 |
+
], inputs=[image, text_input])
|
| 229 |
+
|
| 230 |
+
gr.Examples(examples=[
|
| 231 |
+
[f"examples/skateboarding_dog.mp4", "What is the dog doing? "],
|
| 232 |
+
[f"examples/birthday.mp4", "What is the boy doing? "],
|
| 233 |
+
[f"examples/IronMan.mp4", "Is the guy in the video Iron Man? "],
|
| 234 |
+
], inputs=[video, text_input])
|
| 235 |
+
|
| 236 |
+
gr.Markdown(cite_markdown)
|
| 237 |
+
upload_button.click(upload_imgorvideo, [video, image, text_input, chat_state,chatbot], [video, image, text_input, upload_button, chat_state, img_list,chatbot])
|
| 238 |
+
|
| 239 |
+
text_input.submit(gradio_ask, [text_input, chatbot, chat_state], [text_input, chatbot, chat_state]).then(
|
| 240 |
+
gradio_answer, [chatbot, chat_state, img_list, num_beams, temperature], [chatbot, chat_state, img_list]
|
| 241 |
+
)
|
| 242 |
+
clear.click(gradio_reset, [chat_state, img_list], [chatbot, video, image, text_input, upload_button, chat_state, img_list], queue=False)
|
| 243 |
+
|
| 244 |
+
demo.launch(share=False, enable_queue=True)
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
# %%
|
environment.yml
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: videollama
|
| 2 |
+
channels:
|
| 3 |
+
- pytorch
|
| 4 |
+
- defaults
|
| 5 |
+
- anaconda
|
| 6 |
+
dependencies:
|
| 7 |
+
- python=3.9
|
| 8 |
+
- cudatoolkit
|
| 9 |
+
- pip
|
| 10 |
+
- pytorch=1.12.1
|
| 11 |
+
- pytorch-mutex=1.0=cuda
|
| 12 |
+
- torchaudio=0.12.1
|
| 13 |
+
- torchvision=0.13.1
|
| 14 |
+
|
| 15 |
+
- pip:
|
| 16 |
+
- accelerate==0.16.0
|
| 17 |
+
- aiohttp==3.8.4
|
| 18 |
+
- aiosignal==1.3.1
|
| 19 |
+
- async-timeout==4.0.2
|
| 20 |
+
- attrs==22.2.0
|
| 21 |
+
- bitsandbytes==0.37.0
|
| 22 |
+
- cchardet==2.1.7
|
| 23 |
+
- chardet==5.1.0
|
| 24 |
+
- contourpy==1.0.7
|
| 25 |
+
- cycler==0.11.0
|
| 26 |
+
- filelock==3.9.0
|
| 27 |
+
- fonttools==4.38.0
|
| 28 |
+
- frozenlist==1.3.3
|
| 29 |
+
- huggingface-hub==0.13.4
|
| 30 |
+
- importlib-resources==5.12.0
|
| 31 |
+
- kiwisolver==1.4.4
|
| 32 |
+
- matplotlib==3.7.0
|
| 33 |
+
- multidict==6.0.4
|
| 34 |
+
- openai==0.27.0
|
| 35 |
+
- packaging==23.0
|
| 36 |
+
- psutil==5.9.4
|
| 37 |
+
- pycocotools==2.0.6
|
| 38 |
+
- pyparsing==3.0.9
|
| 39 |
+
- python-dateutil==2.8.2
|
| 40 |
+
- pyyaml==6.0
|
| 41 |
+
- regex==2022.10.31
|
| 42 |
+
- tokenizers==0.13.2
|
| 43 |
+
- tqdm==4.64.1
|
| 44 |
+
- transformers==4.28.0
|
| 45 |
+
- timm==0.6.13
|
| 46 |
+
- spacy==3.5.1
|
| 47 |
+
- webdataset==0.2.48
|
| 48 |
+
- scikit-learn==1.2.2
|
| 49 |
+
- scipy==1.10.1
|
| 50 |
+
- yarl==1.8.2
|
| 51 |
+
- zipp==3.14.0
|
| 52 |
+
- omegaconf==2.3.0
|
| 53 |
+
- opencv-python==4.7.0.72
|
| 54 |
+
- iopath==0.1.10
|
| 55 |
+
- decord==0.6.0
|
| 56 |
+
- tenacity==8.2.2
|
| 57 |
+
- peft
|
| 58 |
+
- pycocoevalcap
|
| 59 |
+
- sentence-transformers
|
| 60 |
+
- umap-learn
|
| 61 |
+
- notebook
|
| 62 |
+
- gradio==3.24.1
|
| 63 |
+
- gradio-client==0.0.8
|
| 64 |
+
- wandb
|
| 65 |
+
- einops
|
| 66 |
+
- SentencePiece
|
| 67 |
+
- ftfy
|
| 68 |
+
- pytorchvideo==0.1.5
|
| 69 |
+
|
| 70 |
+
|
eval_configs/video_llama_eval_only_vl.yaml
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
arch: video_llama
|
| 3 |
+
model_type: pretrain_vicuna
|
| 4 |
+
freeze_vit: True
|
| 5 |
+
freeze_qformer: True
|
| 6 |
+
max_txt_len: 512
|
| 7 |
+
end_sym: "###"
|
| 8 |
+
low_resource: False
|
| 9 |
+
|
| 10 |
+
frozen_llama_proj: False
|
| 11 |
+
|
| 12 |
+
# If you want use LLaMA-2-chat,
|
| 13 |
+
# some ckpts could be download from our provided huggingface repo
|
| 14 |
+
# i.e. https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-2-13B-Finetuned
|
| 15 |
+
llama_model: "ckpt/vicuna-13b/" or "ckpt/vicuna-7b/" or "ckpt/llama-2-7b-chat-hf" or "ckpt/llama-2-13b-chat-hf"
|
| 16 |
+
ckpt: 'path/pretrained_visual_branch_ckpt' # you can use our pretrained ckpt from https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-2-13B-Pretrained/
|
| 17 |
+
equip_audio_branch: False
|
| 18 |
+
|
| 19 |
+
fusion_head_layers: 2
|
| 20 |
+
max_frame_pos: 32
|
| 21 |
+
fusion_header_type: "seqTransf"
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
datasets:
|
| 25 |
+
webvid:
|
| 26 |
+
vis_processor:
|
| 27 |
+
train:
|
| 28 |
+
name: "alpro_video_eval"
|
| 29 |
+
n_frms: 8
|
| 30 |
+
image_size: 224
|
| 31 |
+
text_processor:
|
| 32 |
+
train:
|
| 33 |
+
name: "blip_caption"
|
| 34 |
+
|
| 35 |
+
run:
|
| 36 |
+
task: video_text_pretrain
|
eval_configs/video_llama_eval_withaudio.yaml
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
arch: video_llama
|
| 3 |
+
model_type: pretrain_vicuna
|
| 4 |
+
freeze_vit: True
|
| 5 |
+
freeze_qformer: True
|
| 6 |
+
max_txt_len: 512
|
| 7 |
+
end_sym: "###"
|
| 8 |
+
low_resource: False
|
| 9 |
+
|
| 10 |
+
frozen_llama_proj: False
|
| 11 |
+
|
| 12 |
+
llama_model: "Video-LLaMA-2-7B-Finetuned/llama-2-7b-chat-hf"
|
| 13 |
+
imagebind_ckpt_path: "Video-LLaMA-2-7B-Finetuned"
|
| 14 |
+
ckpt: "Video-LLaMA-2-7B-Finetuned/VL_LLaMA_2_7B_Finetuned.pth"
|
| 15 |
+
ckpt_2: "Video-LLaMA-2-7B-Finetuned/AL_LLaMA_2_7B_Finetuned.pth"
|
| 16 |
+
|
| 17 |
+
equip_audio_branch: True # whether equips the audio branch
|
| 18 |
+
fusion_head_layers: 2
|
| 19 |
+
max_frame_pos: 32
|
| 20 |
+
fusion_header_type: "seqTransf"
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
datasets:
|
| 24 |
+
webvid:
|
| 25 |
+
vis_processor:
|
| 26 |
+
train:
|
| 27 |
+
name: "alpro_video_eval"
|
| 28 |
+
n_frms: 8
|
| 29 |
+
image_size: 224
|
| 30 |
+
text_processor:
|
| 31 |
+
train:
|
| 32 |
+
name: "blip_caption"
|
| 33 |
+
|
| 34 |
+
run:
|
| 35 |
+
task: video_text_pretrain
|
figs/architecture.png
ADDED

|
figs/architecture_v2.png
ADDED
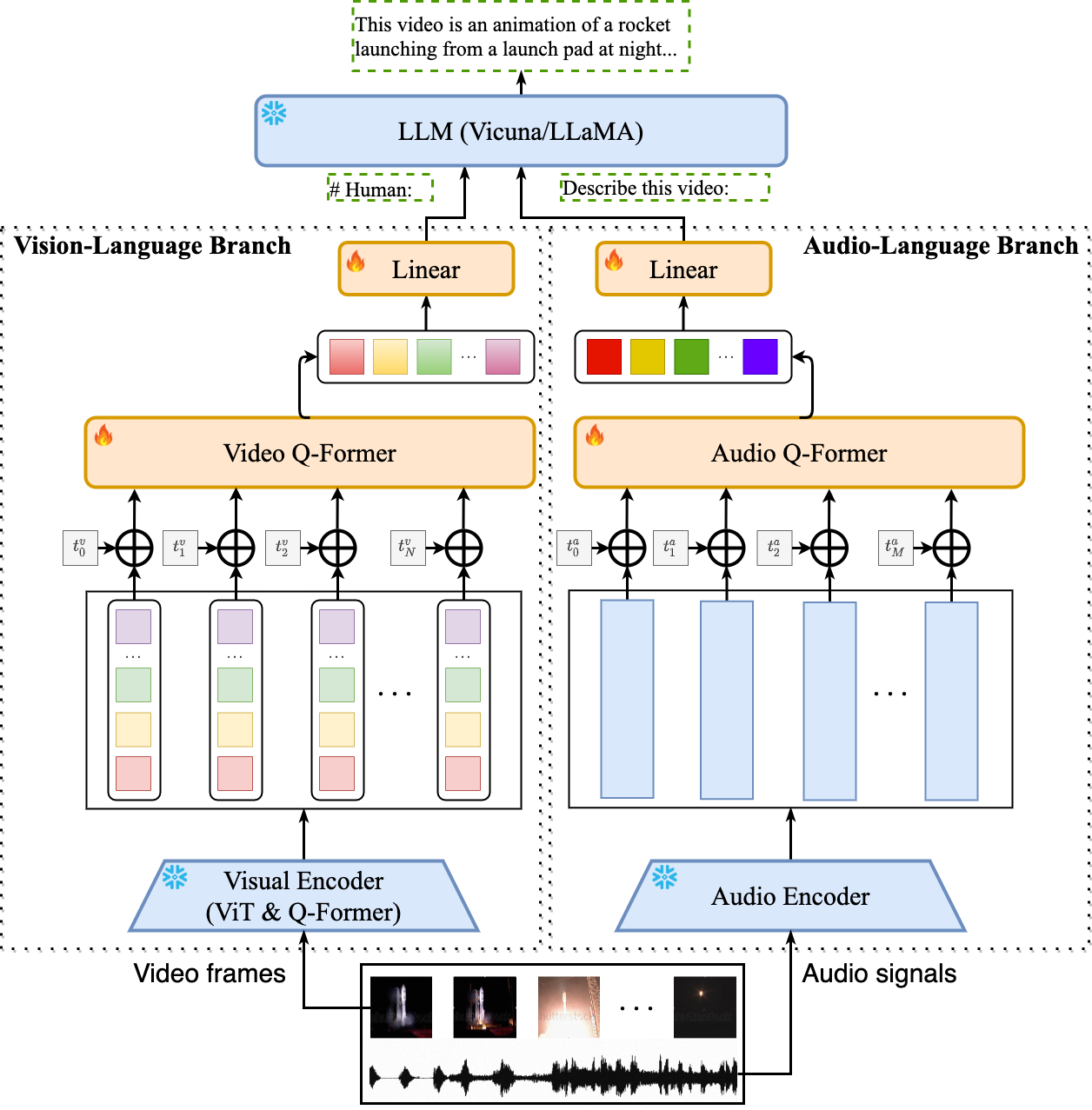
|
figs/video_llama_logo.jpg
ADDED
|
|
prompts/alignment_image.txt
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<Image><ImageHere></Image> Describe this image in detail.
|
| 2 |
+
<Image><ImageHere></Image> Take a look at this image and describe what you notice.
|
| 3 |
+
<Image><ImageHere></Image> Please provide a detailed description of the picture.
|
| 4 |
+
<Image><ImageHere></Image> Could you describe the contents of this image for me?
|
requirement.txt
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
--extra-index-url https://download.pytorch.org/whl/cu113
|
| 2 |
+
torch==1.12.1
|
| 3 |
+
torchvision==0.13.1
|
| 4 |
+
transformers==4.28.0
|
| 5 |
+
tqdm
|
| 6 |
+
decord
|
| 7 |
+
timm
|
| 8 |
+
einops
|
| 9 |
+
opencv_python
|
| 10 |
+
torchvision
|
| 11 |
+
|
| 12 |
+
salesforce-lavis
|
| 13 |
+
accelerate
|
setup.py
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from setuptools import setup, find_packages
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def _install_requirements():
|
| 5 |
+
with open('requirement.txt') as f:
|
| 6 |
+
packages = [line.strip() for line in f if not line.startswith('http')]
|
| 7 |
+
return packages
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
setup(
|
| 11 |
+
name='videollama',
|
| 12 |
+
version='0.1.0',
|
| 13 |
+
python_requires='>=3.8.0',
|
| 14 |
+
packages=find_packages(),
|
| 15 |
+
include_package_data=True,
|
| 16 |
+
install_requires=_install_requirements(),
|
| 17 |
+
)
|
train.py
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Adapted from salesforce@LAVIS and Vision-CAIR@MiniGPT-4. Below is the original copyright:
|
| 3 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 4 |
+
All rights reserved.
|
| 5 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 6 |
+
For full license text, see the LICENSE_Lavis file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 7 |
+
"""
|
| 8 |
+
|
| 9 |
+
import argparse
|
| 10 |
+
import os
|
| 11 |
+
import random
|
| 12 |
+
|
| 13 |
+
import numpy as np
|
| 14 |
+
import torch
|
| 15 |
+
import torch.backends.cudnn as cudnn
|
| 16 |
+
|
| 17 |
+
import video_llama.tasks as tasks
|
| 18 |
+
from video_llama.common.config import Config
|
| 19 |
+
from video_llama.common.dist_utils import get_rank, init_distributed_mode
|
| 20 |
+
from video_llama.common.logger import setup_logger
|
| 21 |
+
from video_llama.common.optims import (
|
| 22 |
+
LinearWarmupCosineLRScheduler,
|
| 23 |
+
LinearWarmupStepLRScheduler,
|
| 24 |
+
)
|
| 25 |
+
from video_llama.common.registry import registry
|
| 26 |
+
from video_llama.common.utils import now
|
| 27 |
+
|
| 28 |
+
# imports modules for registration
|
| 29 |
+
from video_llama.datasets.builders import *
|
| 30 |
+
from video_llama.models import *
|
| 31 |
+
from video_llama.processors import *
|
| 32 |
+
from video_llama.runners import *
|
| 33 |
+
from video_llama.tasks import *
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def parse_args():
|
| 37 |
+
parser = argparse.ArgumentParser(description="Training")
|
| 38 |
+
|
| 39 |
+
parser.add_argument("--cfg-path", required=True, help="path to configuration file.")
|
| 40 |
+
parser.add_argument(
|
| 41 |
+
"--options",
|
| 42 |
+
nargs="+",
|
| 43 |
+
help="override some settings in the used config, the key-value pair "
|
| 44 |
+
"in xxx=yyy format will be merged into config file (deprecate), "
|
| 45 |
+
"change to --cfg-options instead.",
|
| 46 |
+
)
|
| 47 |
+
|
| 48 |
+
args = parser.parse_args()
|
| 49 |
+
# if 'LOCAL_RANK' not in os.environ:
|
| 50 |
+
# os.environ['LOCAL_RANK'] = str(args.local_rank)
|
| 51 |
+
|
| 52 |
+
return args
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def setup_seeds(config):
|
| 56 |
+
seed = config.run_cfg.seed + get_rank()
|
| 57 |
+
|
| 58 |
+
random.seed(seed)
|
| 59 |
+
np.random.seed(seed)
|
| 60 |
+
torch.manual_seed(seed)
|
| 61 |
+
|
| 62 |
+
cudnn.benchmark = False
|
| 63 |
+
cudnn.deterministic = True
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def get_runner_class(cfg):
|
| 67 |
+
"""
|
| 68 |
+
Get runner class from config. Default to epoch-based runner.
|
| 69 |
+
"""
|
| 70 |
+
runner_cls = registry.get_runner_class(cfg.run_cfg.get("runner", "runner_base"))
|
| 71 |
+
|
| 72 |
+
return runner_cls
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def main():
|
| 76 |
+
# allow auto-dl completes on main process without timeout when using NCCL backend.
|
| 77 |
+
# os.environ["NCCL_BLOCKING_WAIT"] = "1"
|
| 78 |
+
|
| 79 |
+
# set before init_distributed_mode() to ensure the same job_id shared across all ranks.
|
| 80 |
+
job_id = now()
|
| 81 |
+
|
| 82 |
+
cfg = Config(parse_args())
|
| 83 |
+
|
| 84 |
+
init_distributed_mode(cfg.run_cfg)
|
| 85 |
+
|
| 86 |
+
setup_seeds(cfg)
|
| 87 |
+
|
| 88 |
+
# set after init_distributed_mode() to only log on master.
|
| 89 |
+
setup_logger()
|
| 90 |
+
|
| 91 |
+
cfg.pretty_print()
|
| 92 |
+
|
| 93 |
+
task = tasks.setup_task(cfg)
|
| 94 |
+
datasets = task.build_datasets(cfg)
|
| 95 |
+
|
| 96 |
+
# datasets['webvid']['train'][0]
|
| 97 |
+
# datasets
|
| 98 |
+
model = task.build_model(cfg)
|
| 99 |
+
|
| 100 |
+
runner = get_runner_class(cfg)(
|
| 101 |
+
cfg=cfg, job_id=job_id, task=task, model=model, datasets=datasets
|
| 102 |
+
)
|
| 103 |
+
runner.train()
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
if __name__ == "__main__":
|
| 107 |
+
main()
|
train_configs/audiobranch_stage1_pretrain.yaml
ADDED
|
@@ -0,0 +1,88 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
arch: video_llama
|
| 3 |
+
model_type: pretrain_vicuna
|
| 4 |
+
freeze_vit: True
|
| 5 |
+
freeze_qformer: True
|
| 6 |
+
low_resource: False
|
| 7 |
+
|
| 8 |
+
# Q-Former
|
| 9 |
+
num_query_token: 32
|
| 10 |
+
|
| 11 |
+
# If you want train models based on LLaMA-2-chat,
|
| 12 |
+
# some ckpts could be download from our provided huggingface repo
|
| 13 |
+
# i.e. https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-2-13B-Pretrained
|
| 14 |
+
llama_model: "ckpt/vicuna-13b/" or "ckpt/vicuna-7b/" or "ckpt/llama-2-7b-chat-hf" or "ckpt/llama-2-13b-chat-hf"
|
| 15 |
+
imagebind_ckpt_path: "ckpt/imagebind_path/"
|
| 16 |
+
llama_proj_model: 'ckpt/pretrained_minigpt4.pth' or '/mnt/workspace/ckpt/pretrained_minigpt4_7b.pth'
|
| 17 |
+
imagebind_ckpt_path: "ckpt/imagebind_path/"
|
| 18 |
+
|
| 19 |
+
# only train vision branch
|
| 20 |
+
equip_audio_branch: True # whether equips the audio branch
|
| 21 |
+
frozen_llama_proj: True
|
| 22 |
+
frozen_video_Qformer: True
|
| 23 |
+
frozen_audio_Qformer: False
|
| 24 |
+
|
| 25 |
+
fusion_head_layers: 2
|
| 26 |
+
max_frame_pos: 32
|
| 27 |
+
fusion_header_type: "seqTransf"
|
| 28 |
+
num_video_query_token: 32
|
| 29 |
+
|
| 30 |
+
datasets:
|
| 31 |
+
webvid:
|
| 32 |
+
data_type: video
|
| 33 |
+
build_info:
|
| 34 |
+
anno_dir: path/webvid/webvid_train_data/filter_annotations/
|
| 35 |
+
videos_dir: path/webvid/webvid_train_data/videos/
|
| 36 |
+
|
| 37 |
+
vis_processor:
|
| 38 |
+
train:
|
| 39 |
+
name: "alpro_video_train"
|
| 40 |
+
n_frms: 8
|
| 41 |
+
image_size: 224
|
| 42 |
+
text_processor:
|
| 43 |
+
train:
|
| 44 |
+
name: "blip_caption"
|
| 45 |
+
sample_ratio: 100
|
| 46 |
+
|
| 47 |
+
cc_sbu_align:
|
| 48 |
+
data_type: images
|
| 49 |
+
build_info:
|
| 50 |
+
storage: /path/LLaVA_cc3m
|
| 51 |
+
vis_processor:
|
| 52 |
+
train:
|
| 53 |
+
name: "blip2_image_train"
|
| 54 |
+
image_size: 224
|
| 55 |
+
text_processor:
|
| 56 |
+
train:
|
| 57 |
+
name: "blip_caption"
|
| 58 |
+
sample_ratio: 24
|
| 59 |
+
|
| 60 |
+
run:
|
| 61 |
+
task: video_text_pretrain
|
| 62 |
+
# optimizer
|
| 63 |
+
lr_sched: "linear_warmup_cosine_lr"
|
| 64 |
+
init_lr: 1e-4
|
| 65 |
+
min_lr: 8e-5
|
| 66 |
+
warmup_lr: 1e-6
|
| 67 |
+
|
| 68 |
+
weight_decay: 0.05
|
| 69 |
+
max_epoch: 5
|
| 70 |
+
batch_size_train: 32
|
| 71 |
+
batch_size_eval: 32
|
| 72 |
+
num_workers: 8
|
| 73 |
+
warmup_steps: 5000
|
| 74 |
+
iters_per_epoch: 5000
|
| 75 |
+
|
| 76 |
+
seed: 42
|
| 77 |
+
output_dir: "output/audiobranch_stage1_pretrain"
|
| 78 |
+
|
| 79 |
+
amp: True
|
| 80 |
+
resume_ckpt_path: null
|
| 81 |
+
|
| 82 |
+
evaluate: False
|
| 83 |
+
train_splits: ["train"]
|
| 84 |
+
|
| 85 |
+
device: "cuda"
|
| 86 |
+
world_size: 1
|
| 87 |
+
dist_url: "env://"
|
| 88 |
+
distributed: True
|
train_configs/audiobranch_stage2_finetune.yaml
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
arch: video_llama
|
| 3 |
+
model_type: pretrain_vicuna
|
| 4 |
+
freeze_vit: True
|
| 5 |
+
freeze_qformer: True
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
# Q-Former
|
| 9 |
+
num_query_token: 32
|
| 10 |
+
|
| 11 |
+
# If you want train models based on LLaMA-2-chat,
|
| 12 |
+
# some ckpts could be download from our provided huggingface repo
|
| 13 |
+
# i.e. https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-2-13B-Finetuned
|
| 14 |
+
llama_model: "ckpt/vicuna-13b/" or "ckpt/vicuna-7b/" or "ckpt/llama-2-7b-chat-hf" or "ckpt/llama-2-13b-chat-hf"
|
| 15 |
+
imagebind_ckpt_path: "ckpt/imagebind_path/"
|
| 16 |
+
# The ckpt of audio branch after stage1 pretrained,
|
| 17 |
+
ckpt: 'path/pretrained_visual_branch_ckpt' # you can use our pretrained ckpt from https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-2-13B-Pretrained/
|
| 18 |
+
ckpt_2: 'path/pretrained_audio_branch_ckpt'
|
| 19 |
+
|
| 20 |
+
# only train audio branch
|
| 21 |
+
equip_audio_branch: True # whether equips the audio branch
|
| 22 |
+
frozen_llama_proj: True
|
| 23 |
+
frozen_video_Qformer: True
|
| 24 |
+
frozen_audio_Qformer: False
|
| 25 |
+
|
| 26 |
+
fusion_head_layers: 2
|
| 27 |
+
max_frame_pos: 32
|
| 28 |
+
fusion_header_type: "seqTransf"
|
| 29 |
+
|
| 30 |
+
max_txt_len: 512
|
| 31 |
+
# vicuna and llama_2_chat use different template !!!!
|
| 32 |
+
|
| 33 |
+
# for llama_2_chat:
|
| 34 |
+
# end_sym: "</s>"
|
| 35 |
+
# prompt_path: "prompts/alignment_image.txt"
|
| 36 |
+
# prompt_template: '[INST] <<SYS>>\n \n<</SYS>>\n\n{} [/INST] '
|
| 37 |
+
|
| 38 |
+
# for vicuna:
|
| 39 |
+
end_sym: "###"
|
| 40 |
+
prompt_path: "prompts/alignment_image.txt"
|
| 41 |
+
prompt_template: '###Human: {} ###Assistant: '
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
datasets:
|
| 47 |
+
cc_sbu_align:
|
| 48 |
+
data_type: images
|
| 49 |
+
build_info:
|
| 50 |
+
storage: path/cc_sbu_align/
|
| 51 |
+
vis_processor:
|
| 52 |
+
train:
|
| 53 |
+
name: "blip2_image_train"
|
| 54 |
+
image_size: 224
|
| 55 |
+
text_processor:
|
| 56 |
+
train:
|
| 57 |
+
name: "blip_caption"
|
| 58 |
+
|
| 59 |
+
llava_instruct:
|
| 60 |
+
data_type: images
|
| 61 |
+
build_info:
|
| 62 |
+
anno_dir: path/llava_instruct_150k.json
|
| 63 |
+
videos_dir: path/train2014/
|
| 64 |
+
vis_processor:
|
| 65 |
+
train:
|
| 66 |
+
name: "blip2_image_train"
|
| 67 |
+
image_size: 224
|
| 68 |
+
text_processor:
|
| 69 |
+
train:
|
| 70 |
+
name: "blip_caption"
|
| 71 |
+
num_video_query_token: 8
|
| 72 |
+
tokenizer_name: "ckpt/vicuna-13b/" or "ckpt/vicuna-7b/" or "ckpt/llama-2-7b-chat-hf" or "ckpt/llama-2-13b-chat-hf"
|
| 73 |
+
model_type: "llama_v2" or "vicuna" # need to set, as vicuna and llama_2_chat use different template
|
| 74 |
+
|
| 75 |
+
webvid_instruct:
|
| 76 |
+
data_type: video
|
| 77 |
+
build_info:
|
| 78 |
+
anno_dir: path/videochat_instruct_11k.json
|
| 79 |
+
videos_dir: path/webvid_align/videos/
|
| 80 |
+
vis_processor:
|
| 81 |
+
train:
|
| 82 |
+
name: "alpro_video_train"
|
| 83 |
+
n_frms: 8
|
| 84 |
+
image_size: 224
|
| 85 |
+
text_processor:
|
| 86 |
+
train:
|
| 87 |
+
name: "blip_caption"
|
| 88 |
+
num_video_query_token: 8
|
| 89 |
+
tokenizer_name: "ckpt/vicuna-13b/" or "ckpt/vicuna-7b/" or "ckpt/llama-2-7b-chat-hf" or "ckpt/llama-2-13b-chat-hf"
|
| 90 |
+
model_type: "llama_v2" or "vicuna" # need to set, as vicuna and llama_2_chat use different template
|
| 91 |
+
|
| 92 |
+
run:
|
| 93 |
+
task: video_text_pretrain
|
| 94 |
+
# optimizer
|
| 95 |
+
lr_sched: "linear_warmup_cosine_lr"
|
| 96 |
+
init_lr: 3e-5
|
| 97 |
+
min_lr: 1e-5
|
| 98 |
+
warmup_lr: 1e-6
|
| 99 |
+
|
| 100 |
+
weight_decay: 0.05
|
| 101 |
+
max_epoch: 3
|
| 102 |
+
iters_per_epoch: 1000
|
| 103 |
+
batch_size_train: 4
|
| 104 |
+
batch_size_eval: 2
|
| 105 |
+
num_workers: 4
|
| 106 |
+
warmup_steps: 400
|
| 107 |
+
|
| 108 |
+
seed: 42
|
| 109 |
+
output_dir: "output/audiobranch_stage2_finetune"
|
| 110 |
+
|
| 111 |
+
amp: True
|
| 112 |
+
resume_ckpt_path: null
|
| 113 |
+
|
| 114 |
+
evaluate: False
|
| 115 |
+
train_splits: ["train"]
|
| 116 |
+
|
| 117 |
+
device: "cuda"
|
| 118 |
+
world_size: 1
|
| 119 |
+
dist_url: "env://"
|
| 120 |
+
distributed: True
|
train_configs/visionbranch_stage1_pretrain.yaml
ADDED
|
@@ -0,0 +1,87 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
arch: video_llama
|
| 3 |
+
model_type: pretrain_vicuna
|
| 4 |
+
freeze_vit: True
|
| 5 |
+
freeze_qformer: True
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
# Q-Former
|
| 9 |
+
num_query_token: 32
|
| 10 |
+
|
| 11 |
+
# If you want train models based on LLaMA-2-chat,
|
| 12 |
+
# some ckpts could be download from our provided huggingface repo
|
| 13 |
+
# i.e. https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-2-13B-Pretrained
|
| 14 |
+
llama_model: "ckpt/vicuna-13b/" or "ckpt/vicuna-7b/" or "ckpt/llama-2-7b-chat-hf" or "ckpt/llama-2-13b-chat-hf"
|
| 15 |
+
imagebind_ckpt_path: "ckpt/imagebind_path/"
|
| 16 |
+
llama_proj_model: 'ckpt/pretrained_minigpt4.pth' or '/mnt/workspace/ckpt/pretrained_minigpt4_7b.pth'
|
| 17 |
+
|
| 18 |
+
# only train vision branch
|
| 19 |
+
equip_audio_branch: False # whether equips the audio branch
|
| 20 |
+
frozen_llama_proj: False
|
| 21 |
+
frozen_video_Qformer: False
|
| 22 |
+
frozen_audio_Qformer: True
|
| 23 |
+
|
| 24 |
+
fusion_head_layers: 2
|
| 25 |
+
max_frame_pos: 32
|
| 26 |
+
fusion_header_type: "seqTransf"
|
| 27 |
+
num_video_query_token: 32
|
| 28 |
+
|
| 29 |
+
datasets:
|
| 30 |
+
webvid:
|
| 31 |
+
data_type: video
|
| 32 |
+
build_info:
|
| 33 |
+
anno_dir: path/webvid/webvid_train_data/filter_annotations/
|
| 34 |
+
videos_dir: path/webvid/webvid_train_data/videos/
|
| 35 |
+
|
| 36 |
+
vis_processor:
|
| 37 |
+
train:
|
| 38 |
+
name: "alpro_video_train"
|
| 39 |
+
n_frms: 8
|
| 40 |
+
image_size: 224
|
| 41 |
+
text_processor:
|
| 42 |
+
train:
|
| 43 |
+
name: "blip_caption"
|
| 44 |
+
sample_ratio: 100
|
| 45 |
+
|
| 46 |
+
cc_sbu_align:
|
| 47 |
+
data_type: images
|
| 48 |
+
build_info:
|
| 49 |
+
storage: /path/LLaVA_cc3m
|
| 50 |
+
vis_processor:
|
| 51 |
+
train:
|
| 52 |
+
name: "blip2_image_train"
|
| 53 |
+
image_size: 224
|
| 54 |
+
text_processor:
|
| 55 |
+
train:
|
| 56 |
+
name: "blip_caption"
|
| 57 |
+
sample_ratio: 24
|
| 58 |
+
|
| 59 |
+
run:
|
| 60 |
+
task: video_text_pretrain
|
| 61 |
+
# optimizer
|
| 62 |
+
lr_sched: "linear_warmup_cosine_lr"
|
| 63 |
+
init_lr: 1e-4
|
| 64 |
+
min_lr: 8e-5
|
| 65 |
+
warmup_lr: 1e-6
|
| 66 |
+
|
| 67 |
+
weight_decay: 0.05
|
| 68 |
+
max_epoch: 5
|
| 69 |
+
batch_size_train: 32
|
| 70 |
+
batch_size_eval: 32
|
| 71 |
+
num_workers: 8
|
| 72 |
+
warmup_steps: 2500
|
| 73 |
+
iters_per_epoch: 2500
|
| 74 |
+
|
| 75 |
+
seed: 42
|
| 76 |
+
output_dir: "output/videollama_stage1_pretrain"
|
| 77 |
+
|
| 78 |
+
amp: True
|
| 79 |
+
resume_ckpt_path: null
|
| 80 |
+
|
| 81 |
+
evaluate: False
|
| 82 |
+
train_splits: ["train"]
|
| 83 |
+
|
| 84 |
+
device: "cuda"
|
| 85 |
+
world_size: 1
|
| 86 |
+
dist_url: "env://"
|
| 87 |
+
distributed: True
|
train_configs/visionbranch_stage2_finetune.yaml
ADDED
|
@@ -0,0 +1,122 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
arch: video_llama
|
| 3 |
+
model_type: pretrain_vicuna
|
| 4 |
+
freeze_vit: True
|
| 5 |
+
freeze_qformer: True
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
# Q-Former
|
| 9 |
+
num_query_token: 32
|
| 10 |
+
|
| 11 |
+
# If you want train models based on LLaMA-2-chat,
|
| 12 |
+
# some ckpts could be download from our provided huggingface repo
|
| 13 |
+
# i.e. https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-2-13B-Finetuned
|
| 14 |
+
llama_model: "ckpt/vicuna-13b/" or "ckpt/vicuna-7b/" or "ckpt/llama-2-7b-chat-hf" or "ckpt/llama-2-13b-chat-hf"
|
| 15 |
+
imagebind_ckpt_path: "ckpt/imagebind_path/"
|
| 16 |
+
|
| 17 |
+
# The ckpt of vision branch after stage1 pretrained,
|
| 18 |
+
ckpt: 'path/pretrained_ckpt' # you can use our pretrained ckpt from https://huggingface.co/DAMO-NLP-SG/Video-LLaMA-2-13B-Pretrained/
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
# only train vision branch
|
| 22 |
+
equip_audio_branch: False # whether equips the audio branch
|
| 23 |
+
frozen_llama_proj: False
|
| 24 |
+
frozen_video_Qformer: False
|
| 25 |
+
frozen_audio_Qformer: True
|
| 26 |
+
|
| 27 |
+
fusion_head_layers: 2
|
| 28 |
+
max_frame_pos: 32
|
| 29 |
+
fusion_header_type: "seqTransf"
|
| 30 |
+
|
| 31 |
+
max_txt_len: 320
|
| 32 |
+
|
| 33 |
+
# vicuna and llama_2_chat use different template !!!
|
| 34 |
+
|
| 35 |
+
# for llama_2_chat:
|
| 36 |
+
# end_sym: "</s>"
|
| 37 |
+
# prompt_path: "prompts/alignment_image.txt"
|
| 38 |
+
# prompt_template: '[INST] <<SYS>>\n \n<</SYS>>\n\n{} [/INST] '
|
| 39 |
+
|
| 40 |
+
# for vicuna:
|
| 41 |
+
end_sym: "###"
|
| 42 |
+
prompt_path: "prompts/alignment_image.txt"
|
| 43 |
+
prompt_template: '###Human: {} ###Assistant: '
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
datasets:
|
| 49 |
+
cc_sbu_align:
|
| 50 |
+
data_type: images
|
| 51 |
+
build_info:
|
| 52 |
+
storage: path/cc_sbu_align/
|
| 53 |
+
vis_processor:
|
| 54 |
+
train:
|
| 55 |
+
name: "blip2_image_train"
|
| 56 |
+
image_size: 224
|
| 57 |
+
text_processor:
|
| 58 |
+
train:
|
| 59 |
+
name: "blip_caption"
|
| 60 |
+
|
| 61 |
+
llava_instruct:
|
| 62 |
+
data_type: images
|
| 63 |
+
build_info:
|
| 64 |
+
anno_dir: path/llava_instruct_150k.json
|
| 65 |
+
videos_dir: path/train2014/
|
| 66 |
+
vis_processor:
|
| 67 |
+
train:
|
| 68 |
+
name: "blip2_image_train"
|
| 69 |
+
image_size: 224
|
| 70 |
+
text_processor:
|
| 71 |
+
train:
|
| 72 |
+
name: "blip_caption"
|
| 73 |
+
num_video_query_token: 32
|
| 74 |
+
tokenizer_name: "ckpt/vicuna-13b/" or "ckpt/vicuna-7b/" or "ckpt/llama-2-7b-chat-hf" or "ckpt/llama-2-13b-chat-hf"
|
| 75 |
+
model_type: "llama_v2" or "vicuna" # need to set, as vicuna and llama_2_chat use different template
|
| 76 |
+
|
| 77 |
+
webvid_instruct:
|
| 78 |
+
data_type: video
|
| 79 |
+
build_info:
|
| 80 |
+
anno_dir: path/videochat_instruct_11k.json
|
| 81 |
+
videos_dir: path/webvid_align/videos/
|
| 82 |
+
vis_processor:
|
| 83 |
+
train:
|
| 84 |
+
name: "alpro_video_train"
|
| 85 |
+
n_frms: 8
|
| 86 |
+
image_size: 224
|
| 87 |
+
text_processor:
|
| 88 |
+
train:
|
| 89 |
+
name: "blip_caption"
|
| 90 |
+
num_video_query_token: 32
|
| 91 |
+
tokenizer_name: "ckpt/vicuna-13b/" or "ckpt/vicuna-7b/" or "ckpt/llama-2-7b-chat-hf" or "ckpt/llama-2-13b-chat-hf"
|
| 92 |
+
model_type: "llama_v2" or "vicuna" # need to set, as vicuna and llama_2_chat use different template
|
| 93 |
+
|
| 94 |
+
run:
|
| 95 |
+
task: video_text_pretrain
|
| 96 |
+
# optimizer
|
| 97 |
+
lr_sched: "linear_warmup_cosine_lr"
|
| 98 |
+
init_lr: 3e-5
|
| 99 |
+
min_lr: 1e-5
|
| 100 |
+
warmup_lr: 1e-6
|
| 101 |
+
|
| 102 |
+
weight_decay: 0.05
|
| 103 |
+
max_epoch: 3
|
| 104 |
+
iters_per_epoch: 1000
|
| 105 |
+
batch_size_train: 4
|
| 106 |
+
batch_size_eval: 4
|
| 107 |
+
num_workers: 4
|
| 108 |
+
warmup_steps: 1000
|
| 109 |
+
|
| 110 |
+
seed: 42
|
| 111 |
+
output_dir: "output/videollama_stage2_finetune"
|
| 112 |
+
|
| 113 |
+
amp: True
|
| 114 |
+
resume_ckpt_path: null
|
| 115 |
+
|
| 116 |
+
evaluate: False
|
| 117 |
+
train_splits: ["train"]
|
| 118 |
+
|
| 119 |
+
device: "cuda"
|
| 120 |
+
world_size: 1
|
| 121 |
+
dist_url: "env://"
|
| 122 |
+
distributed: True
|
video_llama/__init__.py
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE_Lavis file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import os
|
| 9 |
+
import sys
|
| 10 |
+
|
| 11 |
+
from omegaconf import OmegaConf
|
| 12 |
+
|
| 13 |
+
from video_llama.common.registry import registry
|
| 14 |
+
|
| 15 |
+
from video_llama.datasets.builders import *
|
| 16 |
+
from video_llama.models import *
|
| 17 |
+
from video_llama.processors import *
|
| 18 |
+
from video_llama.tasks import *
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
root_dir = os.path.dirname(os.path.abspath(__file__))
|
| 22 |
+
default_cfg = OmegaConf.load(os.path.join(root_dir, "configs/default.yaml"))
|
| 23 |
+
|
| 24 |
+
registry.register_path("library_root", root_dir)
|
| 25 |
+
repo_root = os.path.join(root_dir, "..")
|
| 26 |
+
registry.register_path("repo_root", repo_root)
|
| 27 |
+
cache_root = os.path.join(repo_root, default_cfg.env.cache_root)
|
| 28 |
+
registry.register_path("cache_root", cache_root)
|
| 29 |
+
|
| 30 |
+
registry.register("MAX_INT", sys.maxsize)
|
| 31 |
+
registry.register("SPLIT_NAMES", ["train", "val", "test"])
|
video_llama/__pycache__/__init__.cpython-39.pyc
ADDED
|
Binary file (1.02 kB). View file
|
|
|
video_llama/common/__init__.py
ADDED
|
File without changes
|
video_llama/common/__pycache__/__init__.cpython-39.pyc
ADDED
|
Binary file (144 Bytes). View file
|
|
|
video_llama/common/__pycache__/config.cpython-39.pyc
ADDED
|
Binary file (12.1 kB). View file
|
|
|
video_llama/common/__pycache__/dist_utils.cpython-39.pyc
ADDED
|
Binary file (3.77 kB). View file
|
|
|
video_llama/common/__pycache__/logger.cpython-39.pyc
ADDED
|
Binary file (6.4 kB). View file
|
|
|
video_llama/common/__pycache__/registry.cpython-39.pyc
ADDED
|
Binary file (9.03 kB). View file
|
|
|
video_llama/common/__pycache__/utils.cpython-39.pyc
ADDED
|
Binary file (12.6 kB). View file
|
|
|
video_llama/common/config.py
ADDED
|
@@ -0,0 +1,468 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE_Lavis file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import logging
|
| 9 |
+
import json
|
| 10 |
+
from typing import Dict
|
| 11 |
+
|
| 12 |
+
from omegaconf import OmegaConf
|
| 13 |
+
from video_llama.common.registry import registry
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class Config:
|
| 17 |
+
def __init__(self, args):
|
| 18 |
+
self.config = {}
|
| 19 |
+
|
| 20 |
+
self.args = args
|
| 21 |
+
|
| 22 |
+
# Register the config and configuration for setup
|
| 23 |
+
registry.register("configuration", self)
|
| 24 |
+
|
| 25 |
+
user_config = self._build_opt_list(self.args.options)
|
| 26 |
+
|
| 27 |
+
config = OmegaConf.load(self.args.cfg_path)
|
| 28 |
+
|
| 29 |
+
runner_config = self.build_runner_config(config)
|
| 30 |
+
model_config = self.build_model_config(config, **user_config)
|
| 31 |
+
dataset_config = self.build_dataset_config(config)
|
| 32 |
+
|
| 33 |
+
# Validate the user-provided runner configuration
|
| 34 |
+
# model and dataset configuration are supposed to be validated by the respective classes
|
| 35 |
+
# [TODO] validate the model/dataset configuration
|
| 36 |
+
# self._validate_runner_config(runner_config)
|
| 37 |
+
|
| 38 |
+
# Override the default configuration with user options.
|
| 39 |
+
self.config = OmegaConf.merge(
|
| 40 |
+
runner_config, model_config, dataset_config, user_config
|
| 41 |
+
)
|
| 42 |
+
|
| 43 |
+
def _validate_runner_config(self, runner_config):
|
| 44 |
+
"""
|
| 45 |
+
This method validates the configuration, such that
|
| 46 |
+
1) all the user specified options are valid;
|
| 47 |
+
2) no type mismatches between the user specified options and the config.
|
| 48 |
+
"""
|
| 49 |
+
runner_config_validator = create_runner_config_validator()
|
| 50 |
+
runner_config_validator.validate(runner_config)
|
| 51 |
+
|
| 52 |
+
def _build_opt_list(self, opts):
|
| 53 |
+
opts_dot_list = self._convert_to_dot_list(opts)
|
| 54 |
+
return OmegaConf.from_dotlist(opts_dot_list)
|
| 55 |
+
|
| 56 |
+
@staticmethod
|
| 57 |
+
def build_model_config(config, **kwargs):
|
| 58 |
+
model = config.get("model", None)
|
| 59 |
+
assert model is not None, "Missing model configuration file."
|
| 60 |
+
|
| 61 |
+
model_cls = registry.get_model_class(model.arch)
|
| 62 |
+
assert model_cls is not None, f"Model '{model.arch}' has not been registered."
|
| 63 |
+
|
| 64 |
+
model_type = kwargs.get("model.model_type", None)
|
| 65 |
+
if not model_type:
|
| 66 |
+
model_type = model.get("model_type", None)
|
| 67 |
+
# else use the model type selected by user.
|
| 68 |
+
|
| 69 |
+
assert model_type is not None, "Missing model_type."
|
| 70 |
+
|
| 71 |
+
model_config_path = model_cls.default_config_path(model_type=model_type)
|
| 72 |
+
|
| 73 |
+
model_config = OmegaConf.create()
|
| 74 |
+
# hierarchy override, customized config > default config
|
| 75 |
+
model_config = OmegaConf.merge(
|
| 76 |
+
model_config,
|
| 77 |
+
OmegaConf.load(model_config_path),
|
| 78 |
+
{"model": config["model"]},
|
| 79 |
+
)
|
| 80 |
+
|
| 81 |
+
return model_config
|
| 82 |
+
|
| 83 |
+
@staticmethod
|
| 84 |
+
def build_runner_config(config):
|
| 85 |
+
return {"run": config.run}
|
| 86 |
+
|
| 87 |
+
@staticmethod
|
| 88 |
+
def build_dataset_config(config):
|
| 89 |
+
datasets = config.get("datasets", None)
|
| 90 |
+
if datasets is None:
|
| 91 |
+
raise KeyError(
|
| 92 |
+
"Expecting 'datasets' as the root key for dataset configuration."
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
dataset_config = OmegaConf.create()
|
| 96 |
+
|
| 97 |
+
for dataset_name in datasets:
|
| 98 |
+
builder_cls = registry.get_builder_class(dataset_name)
|
| 99 |
+
|
| 100 |
+
dataset_config_type = datasets[dataset_name].get("type", "default")
|
| 101 |
+
dataset_config_path = builder_cls.default_config_path(
|
| 102 |
+
type=dataset_config_type
|
| 103 |
+
)
|
| 104 |
+
|
| 105 |
+
# hierarchy override, customized config > default config
|
| 106 |
+
dataset_config = OmegaConf.merge(
|
| 107 |
+
dataset_config,
|
| 108 |
+
OmegaConf.load(dataset_config_path),
|
| 109 |
+
{"datasets": {dataset_name: config["datasets"][dataset_name]}},
|
| 110 |
+
)
|
| 111 |
+
|
| 112 |
+
return dataset_config
|
| 113 |
+
|
| 114 |
+
def _convert_to_dot_list(self, opts):
|
| 115 |
+
if opts is None:
|
| 116 |
+
opts = []
|
| 117 |
+
|
| 118 |
+
if len(opts) == 0:
|
| 119 |
+
return opts
|
| 120 |
+
|
| 121 |
+
has_equal = opts[0].find("=") != -1
|
| 122 |
+
|
| 123 |
+
if has_equal:
|
| 124 |
+
return opts
|
| 125 |
+
|
| 126 |
+
return [(opt + "=" + value) for opt, value in zip(opts[0::2], opts[1::2])]
|
| 127 |
+
|
| 128 |
+
def get_config(self):
|
| 129 |
+
return self.config
|
| 130 |
+
|
| 131 |
+
@property
|
| 132 |
+
def run_cfg(self):
|
| 133 |
+
return self.config.run
|
| 134 |
+
|
| 135 |
+
@property
|
| 136 |
+
def datasets_cfg(self):
|
| 137 |
+
return self.config.datasets
|
| 138 |
+
|
| 139 |
+
@property
|
| 140 |
+
def model_cfg(self):
|
| 141 |
+
return self.config.model
|
| 142 |
+
|
| 143 |
+
def pretty_print(self):
|
| 144 |
+
logging.info("\n===== Running Parameters =====")
|
| 145 |
+
logging.info(self._convert_node_to_json(self.config.run))
|
| 146 |
+
|
| 147 |
+
logging.info("\n====== Dataset Attributes ======")
|
| 148 |
+
datasets = self.config.datasets
|
| 149 |
+
|
| 150 |
+
for dataset in datasets:
|
| 151 |
+
if dataset in self.config.datasets:
|
| 152 |
+
logging.info(f"\n======== {dataset} =======")
|
| 153 |
+
dataset_config = self.config.datasets[dataset]
|
| 154 |
+
logging.info(self._convert_node_to_json(dataset_config))
|
| 155 |
+
else:
|
| 156 |
+
logging.warning(f"No dataset named '{dataset}' in config. Skipping")
|
| 157 |
+
|
| 158 |
+
logging.info(f"\n====== Model Attributes ======")
|
| 159 |
+
logging.info(self._convert_node_to_json(self.config.model))
|
| 160 |
+
|
| 161 |
+
def _convert_node_to_json(self, node):
|
| 162 |
+
container = OmegaConf.to_container(node, resolve=True)
|
| 163 |
+
return json.dumps(container, indent=4, sort_keys=True)
|
| 164 |
+
|
| 165 |
+
def to_dict(self):
|
| 166 |
+
return OmegaConf.to_container(self.config)
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
def node_to_dict(node):
|
| 170 |
+
return OmegaConf.to_container(node)
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
class ConfigValidator:
|
| 174 |
+
"""
|
| 175 |
+
This is a preliminary implementation to centralize and validate the configuration.
|
| 176 |
+
May be altered in the future.
|
| 177 |
+
|
| 178 |
+
A helper class to validate configurations from yaml file.
|
| 179 |
+
|
| 180 |
+
This serves the following purposes:
|
| 181 |
+
1. Ensure all the options in the yaml are defined, raise error if not.
|
| 182 |
+
2. when type mismatches are found, the validator will raise an error.
|
| 183 |
+
3. a central place to store and display helpful messages for supported configurations.
|
| 184 |
+
|
| 185 |
+
"""
|
| 186 |
+
|
| 187 |
+
class _Argument:
|
| 188 |
+
def __init__(self, name, choices=None, type=None, help=None):
|
| 189 |
+
self.name = name
|
| 190 |
+
self.val = None
|
| 191 |
+
self.choices = choices
|
| 192 |
+
self.type = type
|
| 193 |
+
self.help = help
|
| 194 |
+
|
| 195 |
+
def __str__(self):
|
| 196 |
+
s = f"{self.name}={self.val}"
|
| 197 |
+
if self.type is not None:
|
| 198 |
+
s += f", ({self.type})"
|
| 199 |
+
if self.choices is not None:
|
| 200 |
+
s += f", choices: {self.choices}"
|
| 201 |
+
if self.help is not None:
|
| 202 |
+
s += f", ({self.help})"
|
| 203 |
+
return s
|
| 204 |
+
|
| 205 |
+
def __init__(self, description):
|
| 206 |
+
self.description = description
|
| 207 |
+
|
| 208 |
+
self.arguments = dict()
|
| 209 |
+
|
| 210 |
+
self.parsed_args = None
|
| 211 |
+
|
| 212 |
+
def __getitem__(self, key):
|
| 213 |
+
assert self.parsed_args is not None, "No arguments parsed yet."
|
| 214 |
+
|
| 215 |
+
return self.parsed_args[key]
|
| 216 |
+
|
| 217 |
+
def __str__(self) -> str:
|
| 218 |
+
return self.format_help()
|
| 219 |
+
|
| 220 |
+
def add_argument(self, *args, **kwargs):
|
| 221 |
+
"""
|
| 222 |
+
Assume the first argument is the name of the argument.
|
| 223 |
+
"""
|
| 224 |
+
self.arguments[args[0]] = self._Argument(*args, **kwargs)
|
| 225 |
+
|
| 226 |
+
def validate(self, config=None):
|
| 227 |
+
"""
|
| 228 |
+
Convert yaml config (dict-like) to list, required by argparse.
|
| 229 |
+
"""
|
| 230 |
+
for k, v in config.items():
|
| 231 |
+
assert (
|
| 232 |
+
k in self.arguments
|
| 233 |
+
), f"""{k} is not a valid argument. Support arguments are {self.format_arguments()}."""
|
| 234 |
+
|
| 235 |
+
if self.arguments[k].type is not None:
|
| 236 |
+
try:
|
| 237 |
+
self.arguments[k].val = self.arguments[k].type(v)
|
| 238 |
+
except ValueError:
|
| 239 |
+
raise ValueError(f"{k} is not a valid {self.arguments[k].type}.")
|
| 240 |
+
|
| 241 |
+
if self.arguments[k].choices is not None:
|
| 242 |
+
assert (
|
| 243 |
+
v in self.arguments[k].choices
|
| 244 |
+
), f"""{k} must be one of {self.arguments[k].choices}."""
|
| 245 |
+
|
| 246 |
+
return config
|
| 247 |
+
|
| 248 |
+
def format_arguments(self):
|
| 249 |
+
return str([f"{k}" for k in sorted(self.arguments.keys())])
|
| 250 |
+
|
| 251 |
+
def format_help(self):
|
| 252 |
+
# description + key-value pair string for each argument
|
| 253 |
+
help_msg = str(self.description)
|
| 254 |
+
return help_msg + ", available arguments: " + self.format_arguments()
|
| 255 |
+
|
| 256 |
+
def print_help(self):
|
| 257 |
+
# display help message
|
| 258 |
+
print(self.format_help())
|
| 259 |
+
|
| 260 |
+
|
| 261 |
+
def create_runner_config_validator():
|
| 262 |
+
validator = ConfigValidator(description="Runner configurations")
|
| 263 |
+
|
| 264 |
+
validator.add_argument(
|
| 265 |
+
"runner",
|
| 266 |
+
type=str,
|
| 267 |
+
choices=["runner_base", "runner_iter"],
|
| 268 |
+
help="""Runner to use. The "runner_base" uses epoch-based training while iter-based
|
| 269 |
+
runner runs based on iters. Default: runner_base""",
|
| 270 |
+
)
|
| 271 |
+
# add argumetns for training dataset ratios
|
| 272 |
+
validator.add_argument(
|
| 273 |
+
"train_dataset_ratios",
|
| 274 |
+
type=Dict[str, float],
|
| 275 |
+
help="""Ratios of training dataset. This is used in iteration-based runner.
|
| 276 |
+
Do not support for epoch-based runner because how to define an epoch becomes tricky.
|
| 277 |
+
Default: None""",
|
| 278 |
+
)
|
| 279 |
+
validator.add_argument(
|
| 280 |
+
"max_iters",
|
| 281 |
+
type=float,
|
| 282 |
+
help="Maximum number of iterations to run.",
|
| 283 |
+
)
|
| 284 |
+
validator.add_argument(
|
| 285 |
+
"max_epoch",
|
| 286 |
+
type=int,
|
| 287 |
+
help="Maximum number of epochs to run.",
|
| 288 |
+
)
|
| 289 |
+
# add arguments for iters_per_inner_epoch
|
| 290 |
+
validator.add_argument(
|
| 291 |
+
"iters_per_inner_epoch",
|
| 292 |
+
type=float,
|
| 293 |
+
help="Number of iterations per inner epoch. This is required when runner is runner_iter.",
|
| 294 |
+
)
|
| 295 |
+
lr_scheds_choices = registry.list_lr_schedulers()
|
| 296 |
+
validator.add_argument(
|
| 297 |
+
"lr_sched",
|
| 298 |
+
type=str,
|
| 299 |
+
choices=lr_scheds_choices,
|
| 300 |
+
help="Learning rate scheduler to use, from {}".format(lr_scheds_choices),
|
| 301 |
+
)
|
| 302 |
+
task_choices = registry.list_tasks()
|
| 303 |
+
validator.add_argument(
|
| 304 |
+
"task",
|
| 305 |
+
type=str,
|
| 306 |
+
choices=task_choices,
|
| 307 |
+
help="Task to use, from {}".format(task_choices),
|
| 308 |
+
)
|
| 309 |
+
# add arguments for init_lr
|
| 310 |
+
validator.add_argument(
|
| 311 |
+
"init_lr",
|
| 312 |
+
type=float,
|
| 313 |
+
help="Initial learning rate. This will be the learning rate after warmup and before decay.",
|
| 314 |
+
)
|
| 315 |
+
# add arguments for min_lr
|
| 316 |
+
validator.add_argument(
|
| 317 |
+
"min_lr",
|
| 318 |
+
type=float,
|
| 319 |
+
help="Minimum learning rate (after decay).",
|
| 320 |
+
)
|
| 321 |
+
# add arguments for warmup_lr
|
| 322 |
+
validator.add_argument(
|
| 323 |
+
"warmup_lr",
|
| 324 |
+
type=float,
|
| 325 |
+
help="Starting learning rate for warmup.",
|
| 326 |
+
)
|
| 327 |
+
# add arguments for learning rate decay rate
|
| 328 |
+
validator.add_argument(
|
| 329 |
+
"lr_decay_rate",
|
| 330 |
+
type=float,
|
| 331 |
+
help="Learning rate decay rate. Required if using a decaying learning rate scheduler.",
|
| 332 |
+
)
|
| 333 |
+
# add arguments for weight decay
|
| 334 |
+
validator.add_argument(
|
| 335 |
+
"weight_decay",
|
| 336 |
+
type=float,
|
| 337 |
+
help="Weight decay rate.",
|
| 338 |
+
)
|
| 339 |
+
# add arguments for training batch size
|
| 340 |
+
validator.add_argument(
|
| 341 |
+
"batch_size_train",
|
| 342 |
+
type=int,
|
| 343 |
+
help="Training batch size.",
|
| 344 |
+
)
|
| 345 |
+
# add arguments for evaluation batch size
|
| 346 |
+
validator.add_argument(
|
| 347 |
+
"batch_size_eval",
|
| 348 |
+
type=int,
|
| 349 |
+
help="Evaluation batch size, including validation and testing.",
|
| 350 |
+
)
|
| 351 |
+
# add arguments for number of workers for data loading
|
| 352 |
+
validator.add_argument(
|
| 353 |
+
"num_workers",
|
| 354 |
+
help="Number of workers for data loading.",
|
| 355 |
+
)
|
| 356 |
+
# add arguments for warm up steps
|
| 357 |
+
validator.add_argument(
|
| 358 |
+
"warmup_steps",
|
| 359 |
+
type=int,
|
| 360 |
+
help="Number of warmup steps. Required if a warmup schedule is used.",
|
| 361 |
+
)
|
| 362 |
+
# add arguments for random seed
|
| 363 |
+
validator.add_argument(
|
| 364 |
+
"seed",
|
| 365 |
+
type=int,
|
| 366 |
+
help="Random seed.",
|
| 367 |
+
)
|
| 368 |
+
# add arguments for output directory
|
| 369 |
+
validator.add_argument(
|
| 370 |
+
"output_dir",
|
| 371 |
+
type=str,
|
| 372 |
+
help="Output directory to save checkpoints and logs.",
|
| 373 |
+
)
|
| 374 |
+
# add arguments for whether only use evaluation
|
| 375 |
+
validator.add_argument(
|
| 376 |
+
"evaluate",
|
| 377 |
+
help="Whether to only evaluate the model. If true, training will not be performed.",
|
| 378 |
+
)
|
| 379 |
+
# add arguments for splits used for training, e.g. ["train", "val"]
|
| 380 |
+
validator.add_argument(
|
| 381 |
+
"train_splits",
|
| 382 |
+
type=list,
|
| 383 |
+
help="Splits to use for training.",
|
| 384 |
+
)
|
| 385 |
+
# add arguments for splits used for validation, e.g. ["val"]
|
| 386 |
+
validator.add_argument(
|
| 387 |
+
"valid_splits",
|
| 388 |
+
type=list,
|
| 389 |
+
help="Splits to use for validation. If not provided, will skip the validation.",
|
| 390 |
+
)
|
| 391 |
+
# add arguments for splits used for testing, e.g. ["test"]
|
| 392 |
+
validator.add_argument(
|
| 393 |
+
"test_splits",
|
| 394 |
+
type=list,
|
| 395 |
+
help="Splits to use for testing. If not provided, will skip the testing.",
|
| 396 |
+
)
|
| 397 |
+
# add arguments for accumulating gradient for iterations
|
| 398 |
+
validator.add_argument(
|
| 399 |
+
"accum_grad_iters",
|
| 400 |
+
type=int,
|
| 401 |
+
help="Number of iterations to accumulate gradient for.",
|
| 402 |
+
)
|
| 403 |
+
|
| 404 |
+
# ====== distributed training ======
|
| 405 |
+
validator.add_argument(
|
| 406 |
+
"device",
|
| 407 |
+
type=str,
|
| 408 |
+
choices=["cpu", "cuda"],
|
| 409 |
+
help="Device to use. Support 'cuda' or 'cpu' as for now.",
|
| 410 |
+
)
|
| 411 |
+
validator.add_argument(
|
| 412 |
+
"world_size",
|
| 413 |
+
type=int,
|
| 414 |
+
help="Number of processes participating in the job.",
|
| 415 |
+
)
|
| 416 |
+
validator.add_argument("dist_url", type=str)
|
| 417 |
+
validator.add_argument("distributed", type=bool)
|
| 418 |
+
# add arguments to opt using distributed sampler during evaluation or not
|
| 419 |
+
validator.add_argument(
|
| 420 |
+
"use_dist_eval_sampler",
|
| 421 |
+
type=bool,
|
| 422 |
+
help="Whether to use distributed sampler during evaluation or not.",
|
| 423 |
+
)
|
| 424 |
+
|
| 425 |
+
# ====== task specific ======
|
| 426 |
+
# generation task specific arguments
|
| 427 |
+
# add arguments for maximal length of text output
|
| 428 |
+
validator.add_argument(
|
| 429 |
+
"max_len",
|
| 430 |
+
type=int,
|
| 431 |
+
help="Maximal length of text output.",
|
| 432 |
+
)
|
| 433 |
+
# add arguments for minimal length of text output
|
| 434 |
+
validator.add_argument(
|
| 435 |
+
"min_len",
|
| 436 |
+
type=int,
|
| 437 |
+
help="Minimal length of text output.",
|
| 438 |
+
)
|
| 439 |
+
# add arguments number of beams
|
| 440 |
+
validator.add_argument(
|
| 441 |
+
"num_beams",
|
| 442 |
+
type=int,
|
| 443 |
+
help="Number of beams used for beam search.",
|
| 444 |
+
)
|
| 445 |
+
|
| 446 |
+
# vqa task specific arguments
|
| 447 |
+
# add arguments for number of answer candidates
|
| 448 |
+
validator.add_argument(
|
| 449 |
+
"num_ans_candidates",
|
| 450 |
+
type=int,
|
| 451 |
+
help="""For ALBEF and BLIP, these models first rank answers according to likelihood to select answer candidates.""",
|
| 452 |
+
)
|
| 453 |
+
# add arguments for inference method
|
| 454 |
+
validator.add_argument(
|
| 455 |
+
"inference_method",
|
| 456 |
+
type=str,
|
| 457 |
+
choices=["genearte", "rank"],
|
| 458 |
+
help="""Inference method to use for question answering. If rank, requires a answer list.""",
|
| 459 |
+
)
|
| 460 |
+
|
| 461 |
+
# ====== model specific ======
|
| 462 |
+
validator.add_argument(
|
| 463 |
+
"k_test",
|
| 464 |
+
type=int,
|
| 465 |
+
help="Number of top k most similar samples from ITC/VTC selection to be tested.",
|
| 466 |
+
)
|
| 467 |
+
|
| 468 |
+
return validator
|
video_llama/common/dist_utils.py
ADDED
|
@@ -0,0 +1,137 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE_Lavis file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import datetime
|
| 9 |
+
import functools
|
| 10 |
+
import os
|
| 11 |
+
|
| 12 |
+
import torch
|
| 13 |
+
import torch.distributed as dist
|
| 14 |
+
import timm.models.hub as timm_hub
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def setup_for_distributed(is_master):
|
| 18 |
+
"""
|
| 19 |
+
This function disables printing when not in master process
|
| 20 |
+
"""
|
| 21 |
+
import builtins as __builtin__
|
| 22 |
+
|
| 23 |
+
builtin_print = __builtin__.print
|
| 24 |
+
|
| 25 |
+
def print(*args, **kwargs):
|
| 26 |
+
force = kwargs.pop("force", False)
|
| 27 |
+
if is_master or force:
|
| 28 |
+
builtin_print(*args, **kwargs)
|
| 29 |
+
|
| 30 |
+
__builtin__.print = print
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def is_dist_avail_and_initialized():
|
| 34 |
+
if not dist.is_available():
|
| 35 |
+
return False
|
| 36 |
+
if not dist.is_initialized():
|
| 37 |
+
return False
|
| 38 |
+
return True
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def get_world_size():
|
| 42 |
+
if not is_dist_avail_and_initialized():
|
| 43 |
+
return 1
|
| 44 |
+
return dist.get_world_size()
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def get_rank():
|
| 48 |
+
if not is_dist_avail_and_initialized():
|
| 49 |
+
return 0
|
| 50 |
+
return dist.get_rank()
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def is_main_process():
|
| 54 |
+
return get_rank() == 0
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def init_distributed_mode(args):
|
| 58 |
+
if "RANK" in os.environ and "WORLD_SIZE" in os.environ:
|
| 59 |
+
args.rank = int(os.environ["RANK"])
|
| 60 |
+
args.world_size = int(os.environ["WORLD_SIZE"])
|
| 61 |
+
args.gpu = int(os.environ["LOCAL_RANK"])
|
| 62 |
+
elif "SLURM_PROCID" in os.environ:
|
| 63 |
+
args.rank = int(os.environ["SLURM_PROCID"])
|
| 64 |
+
args.gpu = args.rank % torch.cuda.device_count()
|
| 65 |
+
else:
|
| 66 |
+
print("Not using distributed mode")
|
| 67 |
+
args.distributed = False
|
| 68 |
+
return
|
| 69 |
+
|
| 70 |
+
args.distributed = True
|
| 71 |
+
|
| 72 |
+
torch.cuda.set_device(args.gpu)
|
| 73 |
+
args.dist_backend = "nccl"
|
| 74 |
+
print(
|
| 75 |
+
"| distributed init (rank {}, world {}): {}".format(
|
| 76 |
+
args.rank, args.world_size, args.dist_url
|
| 77 |
+
),
|
| 78 |
+
flush=True,
|
| 79 |
+
)
|
| 80 |
+
torch.distributed.init_process_group(
|
| 81 |
+
backend=args.dist_backend,
|
| 82 |
+
init_method=args.dist_url,
|
| 83 |
+
world_size=args.world_size,
|
| 84 |
+
rank=args.rank,
|
| 85 |
+
timeout=datetime.timedelta(
|
| 86 |
+
days=365
|
| 87 |
+
), # allow auto-downloading and de-compressing
|
| 88 |
+
)
|
| 89 |
+
torch.distributed.barrier()
|
| 90 |
+
setup_for_distributed(args.rank == 0)
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def get_dist_info():
|
| 94 |
+
if torch.__version__ < "1.0":
|
| 95 |
+
initialized = dist._initialized
|
| 96 |
+
else:
|
| 97 |
+
initialized = dist.is_initialized()
|
| 98 |
+
if initialized:
|
| 99 |
+
rank = dist.get_rank()
|
| 100 |
+
world_size = dist.get_world_size()
|
| 101 |
+
else: # non-distributed training
|
| 102 |
+
rank = 0
|
| 103 |
+
world_size = 1
|
| 104 |
+
return rank, world_size
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
def main_process(func):
|
| 108 |
+
@functools.wraps(func)
|
| 109 |
+
def wrapper(*args, **kwargs):
|
| 110 |
+
rank, _ = get_dist_info()
|
| 111 |
+
if rank == 0:
|
| 112 |
+
return func(*args, **kwargs)
|
| 113 |
+
|
| 114 |
+
return wrapper
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def download_cached_file(url, check_hash=True, progress=False):
|
| 118 |
+
"""
|
| 119 |
+
Download a file from a URL and cache it locally. If the file already exists, it is not downloaded again.
|
| 120 |
+
If distributed, only the main process downloads the file, and the other processes wait for the file to be downloaded.
|
| 121 |
+
"""
|
| 122 |
+
|
| 123 |
+
def get_cached_file_path():
|
| 124 |
+
# a hack to sync the file path across processes
|
| 125 |
+
parts = torch.hub.urlparse(url)
|
| 126 |
+
filename = os.path.basename(parts.path)
|
| 127 |
+
cached_file = os.path.join(timm_hub.get_cache_dir(), filename)
|
| 128 |
+
|
| 129 |
+
return cached_file
|
| 130 |
+
|
| 131 |
+
if is_main_process():
|
| 132 |
+
timm_hub.download_cached_file(url, check_hash, progress)
|
| 133 |
+
|
| 134 |
+
if is_dist_avail_and_initialized():
|
| 135 |
+
dist.barrier()
|
| 136 |
+
|
| 137 |
+
return get_cached_file_path()
|
video_llama/common/gradcam.py
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
from matplotlib import pyplot as plt
|
| 3 |
+
from scipy.ndimage import filters
|
| 4 |
+
from skimage import transform as skimage_transform
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def getAttMap(img, attMap, blur=True, overlap=True):
|
| 8 |
+
attMap -= attMap.min()
|
| 9 |
+
if attMap.max() > 0:
|
| 10 |
+
attMap /= attMap.max()
|
| 11 |
+
attMap = skimage_transform.resize(attMap, (img.shape[:2]), order=3, mode="constant")
|
| 12 |
+
if blur:
|
| 13 |
+
attMap = filters.gaussian_filter(attMap, 0.02 * max(img.shape[:2]))
|
| 14 |
+
attMap -= attMap.min()
|
| 15 |
+
attMap /= attMap.max()
|
| 16 |
+
cmap = plt.get_cmap("jet")
|
| 17 |
+
attMapV = cmap(attMap)
|
| 18 |
+
attMapV = np.delete(attMapV, 3, 2)
|
| 19 |
+
if overlap:
|
| 20 |
+
attMap = (
|
| 21 |
+
1 * (1 - attMap**0.7).reshape(attMap.shape + (1,)) * img
|
| 22 |
+
+ (attMap**0.7).reshape(attMap.shape + (1,)) * attMapV
|
| 23 |
+
)
|
| 24 |
+
return attMap
|
video_llama/common/logger.py
ADDED
|
@@ -0,0 +1,195 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE_Lavis file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import datetime
|
| 9 |
+
import logging
|
| 10 |
+
import time
|
| 11 |
+
from collections import defaultdict, deque
|
| 12 |
+
|
| 13 |
+
import torch
|
| 14 |
+
import torch.distributed as dist
|
| 15 |
+
|
| 16 |
+
from video_llama.common import dist_utils
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class SmoothedValue(object):
|
| 20 |
+
"""Track a series of values and provide access to smoothed values over a
|
| 21 |
+
window or the global series average.
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
def __init__(self, window_size=20, fmt=None):
|
| 25 |
+
if fmt is None:
|
| 26 |
+
fmt = "{median:.4f} ({global_avg:.4f})"
|
| 27 |
+
self.deque = deque(maxlen=window_size)
|
| 28 |
+
self.total = 0.0
|
| 29 |
+
self.count = 0
|
| 30 |
+
self.fmt = fmt
|
| 31 |
+
|
| 32 |
+
def update(self, value, n=1):
|
| 33 |
+
self.deque.append(value)
|
| 34 |
+
self.count += n
|
| 35 |
+
self.total += value * n
|
| 36 |
+
|
| 37 |
+
def synchronize_between_processes(self):
|
| 38 |
+
"""
|
| 39 |
+
Warning: does not synchronize the deque!
|
| 40 |
+
"""
|
| 41 |
+
if not dist_utils.is_dist_avail_and_initialized():
|
| 42 |
+
return
|
| 43 |
+
t = torch.tensor([self.count, self.total], dtype=torch.float64, device="cuda")
|
| 44 |
+
dist.barrier()
|
| 45 |
+
dist.all_reduce(t)
|
| 46 |
+
t = t.tolist()
|
| 47 |
+
self.count = int(t[0])
|
| 48 |
+
self.total = t[1]
|
| 49 |
+
|
| 50 |
+
@property
|
| 51 |
+
def median(self):
|
| 52 |
+
d = torch.tensor(list(self.deque))
|
| 53 |
+
return d.median().item()
|
| 54 |
+
|
| 55 |
+
@property
|
| 56 |
+
def avg(self):
|
| 57 |
+
d = torch.tensor(list(self.deque), dtype=torch.float32)
|
| 58 |
+
return d.mean().item()
|
| 59 |
+
|
| 60 |
+
@property
|
| 61 |
+
def global_avg(self):
|
| 62 |
+
return self.total / self.count
|
| 63 |
+
|
| 64 |
+
@property
|
| 65 |
+
def max(self):
|
| 66 |
+
return max(self.deque)
|
| 67 |
+
|
| 68 |
+
@property
|
| 69 |
+
def value(self):
|
| 70 |
+
return self.deque[-1]
|
| 71 |
+
|
| 72 |
+
def __str__(self):
|
| 73 |
+
return self.fmt.format(
|
| 74 |
+
median=self.median,
|
| 75 |
+
avg=self.avg,
|
| 76 |
+
global_avg=self.global_avg,
|
| 77 |
+
max=self.max,
|
| 78 |
+
value=self.value,
|
| 79 |
+
)
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
class MetricLogger(object):
|
| 83 |
+
def __init__(self, delimiter="\t"):
|
| 84 |
+
self.meters = defaultdict(SmoothedValue)
|
| 85 |
+
self.delimiter = delimiter
|
| 86 |
+
|
| 87 |
+
def update(self, **kwargs):
|
| 88 |
+
for k, v in kwargs.items():
|
| 89 |
+
if isinstance(v, torch.Tensor):
|
| 90 |
+
v = v.item()
|
| 91 |
+
assert isinstance(v, (float, int))
|
| 92 |
+
self.meters[k].update(v)
|
| 93 |
+
|
| 94 |
+
def __getattr__(self, attr):
|
| 95 |
+
if attr in self.meters:
|
| 96 |
+
return self.meters[attr]
|
| 97 |
+
if attr in self.__dict__:
|
| 98 |
+
return self.__dict__[attr]
|
| 99 |
+
raise AttributeError(
|
| 100 |
+
"'{}' object has no attribute '{}'".format(type(self).__name__, attr)
|
| 101 |
+
)
|
| 102 |
+
|
| 103 |
+
def __str__(self):
|
| 104 |
+
loss_str = []
|
| 105 |
+
for name, meter in self.meters.items():
|
| 106 |
+
loss_str.append("{}: {}".format(name, str(meter)))
|
| 107 |
+
return self.delimiter.join(loss_str)
|
| 108 |
+
|
| 109 |
+
def global_avg(self):
|
| 110 |
+
loss_str = []
|
| 111 |
+
for name, meter in self.meters.items():
|
| 112 |
+
loss_str.append("{}: {:.4f}".format(name, meter.global_avg))
|
| 113 |
+
return self.delimiter.join(loss_str)
|
| 114 |
+
|
| 115 |
+
def synchronize_between_processes(self):
|
| 116 |
+
for meter in self.meters.values():
|
| 117 |
+
meter.synchronize_between_processes()
|
| 118 |
+
|
| 119 |
+
def add_meter(self, name, meter):
|
| 120 |
+
self.meters[name] = meter
|
| 121 |
+
|
| 122 |
+
def log_every(self, iterable, print_freq, header=None):
|
| 123 |
+
i = 0
|
| 124 |
+
if not header:
|
| 125 |
+
header = ""
|
| 126 |
+
start_time = time.time()
|
| 127 |
+
end = time.time()
|
| 128 |
+
iter_time = SmoothedValue(fmt="{avg:.4f}")
|
| 129 |
+
data_time = SmoothedValue(fmt="{avg:.4f}")
|
| 130 |
+
space_fmt = ":" + str(len(str(len(iterable)))) + "d"
|
| 131 |
+
log_msg = [
|
| 132 |
+
header,
|
| 133 |
+
"[{0" + space_fmt + "}/{1}]",
|
| 134 |
+
"eta: {eta}",
|
| 135 |
+
"{meters}",
|
| 136 |
+
"time: {time}",
|
| 137 |
+
"data: {data}",
|
| 138 |
+
]
|
| 139 |
+
if torch.cuda.is_available():
|
| 140 |
+
log_msg.append("max mem: {memory:.0f}")
|
| 141 |
+
log_msg = self.delimiter.join(log_msg)
|
| 142 |
+
MB = 1024.0 * 1024.0
|
| 143 |
+
for obj in iterable:
|
| 144 |
+
data_time.update(time.time() - end)
|
| 145 |
+
yield obj
|
| 146 |
+
iter_time.update(time.time() - end)
|
| 147 |
+
if i % print_freq == 0 or i == len(iterable) - 1:
|
| 148 |
+
eta_seconds = iter_time.global_avg * (len(iterable) - i)
|
| 149 |
+
eta_string = str(datetime.timedelta(seconds=int(eta_seconds)))
|
| 150 |
+
if torch.cuda.is_available():
|
| 151 |
+
print(
|
| 152 |
+
log_msg.format(
|
| 153 |
+
i,
|
| 154 |
+
len(iterable),
|
| 155 |
+
eta=eta_string,
|
| 156 |
+
meters=str(self),
|
| 157 |
+
time=str(iter_time),
|
| 158 |
+
data=str(data_time),
|
| 159 |
+
memory=torch.cuda.max_memory_allocated() / MB,
|
| 160 |
+
)
|
| 161 |
+
)
|
| 162 |
+
else:
|
| 163 |
+
print(
|
| 164 |
+
log_msg.format(
|
| 165 |
+
i,
|
| 166 |
+
len(iterable),
|
| 167 |
+
eta=eta_string,
|
| 168 |
+
meters=str(self),
|
| 169 |
+
time=str(iter_time),
|
| 170 |
+
data=str(data_time),
|
| 171 |
+
)
|
| 172 |
+
)
|
| 173 |
+
i += 1
|
| 174 |
+
end = time.time()
|
| 175 |
+
total_time = time.time() - start_time
|
| 176 |
+
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
|
| 177 |
+
print(
|
| 178 |
+
"{} Total time: {} ({:.4f} s / it)".format(
|
| 179 |
+
header, total_time_str, total_time / len(iterable)
|
| 180 |
+
)
|
| 181 |
+
)
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
class AttrDict(dict):
|
| 185 |
+
def __init__(self, *args, **kwargs):
|
| 186 |
+
super(AttrDict, self).__init__(*args, **kwargs)
|
| 187 |
+
self.__dict__ = self
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
def setup_logger():
|
| 191 |
+
logging.basicConfig(
|
| 192 |
+
level=logging.INFO if dist_utils.is_main_process() else logging.WARN,
|
| 193 |
+
format="%(asctime)s [%(levelname)s] %(message)s",
|
| 194 |
+
handlers=[logging.StreamHandler()],
|
| 195 |
+
)
|
video_llama/common/optims.py
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE_Lavis file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import math
|
| 9 |
+
|
| 10 |
+
from video_llama.common.registry import registry
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
@registry.register_lr_scheduler("linear_warmup_step_lr")
|
| 14 |
+
class LinearWarmupStepLRScheduler:
|
| 15 |
+
def __init__(
|
| 16 |
+
self,
|
| 17 |
+
optimizer,
|
| 18 |
+
max_epoch,
|
| 19 |
+
min_lr,
|
| 20 |
+
init_lr,
|
| 21 |
+
decay_rate=1,
|
| 22 |
+
warmup_start_lr=-1,
|
| 23 |
+
warmup_steps=0,
|
| 24 |
+
**kwargs
|
| 25 |
+
):
|
| 26 |
+
self.optimizer = optimizer
|
| 27 |
+
|
| 28 |
+
self.max_epoch = max_epoch
|
| 29 |
+
self.min_lr = min_lr
|
| 30 |
+
|
| 31 |
+
self.decay_rate = decay_rate
|
| 32 |
+
|
| 33 |
+
self.init_lr = init_lr
|
| 34 |
+
self.warmup_steps = warmup_steps
|
| 35 |
+
self.warmup_start_lr = warmup_start_lr if warmup_start_lr >= 0 else init_lr
|
| 36 |
+
|
| 37 |
+
def step(self, cur_epoch, cur_step):
|
| 38 |
+
if cur_epoch == 0:
|
| 39 |
+
warmup_lr_schedule(
|
| 40 |
+
step=cur_step,
|
| 41 |
+
optimizer=self.optimizer,
|
| 42 |
+
max_step=self.warmup_steps,
|
| 43 |
+
init_lr=self.warmup_start_lr,
|
| 44 |
+
max_lr=self.init_lr,
|
| 45 |
+
)
|
| 46 |
+
else:
|
| 47 |
+
step_lr_schedule(
|
| 48 |
+
epoch=cur_epoch,
|
| 49 |
+
optimizer=self.optimizer,
|
| 50 |
+
init_lr=self.init_lr,
|
| 51 |
+
min_lr=self.min_lr,
|
| 52 |
+
decay_rate=self.decay_rate,
|
| 53 |
+
)
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
@registry.register_lr_scheduler("linear_warmup_cosine_lr")
|
| 57 |
+
class LinearWarmupCosineLRScheduler:
|
| 58 |
+
def __init__(
|
| 59 |
+
self,
|
| 60 |
+
optimizer,
|
| 61 |
+
max_epoch,
|
| 62 |
+
iters_per_epoch,
|
| 63 |
+
min_lr,
|
| 64 |
+
init_lr,
|
| 65 |
+
warmup_steps=0,
|
| 66 |
+
warmup_start_lr=-1,
|
| 67 |
+
**kwargs
|
| 68 |
+
):
|
| 69 |
+
self.optimizer = optimizer
|
| 70 |
+
|
| 71 |
+
self.max_epoch = max_epoch
|
| 72 |
+
self.iters_per_epoch = iters_per_epoch
|
| 73 |
+
self.min_lr = min_lr
|
| 74 |
+
|
| 75 |
+
self.init_lr = init_lr
|
| 76 |
+
self.warmup_steps = warmup_steps
|
| 77 |
+
self.warmup_start_lr = warmup_start_lr if warmup_start_lr >= 0 else init_lr
|
| 78 |
+
|
| 79 |
+
def step(self, cur_epoch, cur_step):
|
| 80 |
+
total_cur_step = cur_epoch * self.iters_per_epoch + cur_step
|
| 81 |
+
if total_cur_step < self.warmup_steps:
|
| 82 |
+
warmup_lr_schedule(
|
| 83 |
+
step=cur_step,
|
| 84 |
+
optimizer=self.optimizer,
|
| 85 |
+
max_step=self.warmup_steps,
|
| 86 |
+
init_lr=self.warmup_start_lr,
|
| 87 |
+
max_lr=self.init_lr,
|
| 88 |
+
)
|
| 89 |
+
else:
|
| 90 |
+
cosine_lr_schedule(
|
| 91 |
+
epoch=total_cur_step,
|
| 92 |
+
optimizer=self.optimizer,
|
| 93 |
+
max_epoch=self.max_epoch * self.iters_per_epoch,
|
| 94 |
+
init_lr=self.init_lr,
|
| 95 |
+
min_lr=self.min_lr,
|
| 96 |
+
)
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def cosine_lr_schedule(optimizer, epoch, max_epoch, init_lr, min_lr):
|
| 100 |
+
"""Decay the learning rate"""
|
| 101 |
+
lr = (init_lr - min_lr) * 0.5 * (
|
| 102 |
+
1.0 + math.cos(math.pi * epoch / max_epoch)
|
| 103 |
+
) + min_lr
|
| 104 |
+
for param_group in optimizer.param_groups:
|
| 105 |
+
param_group["lr"] = lr
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
def warmup_lr_schedule(optimizer, step, max_step, init_lr, max_lr):
|
| 109 |
+
"""Warmup the learning rate"""
|
| 110 |
+
lr = min(max_lr, init_lr + (max_lr - init_lr) * step / max(max_step, 1))
|
| 111 |
+
for param_group in optimizer.param_groups:
|
| 112 |
+
param_group["lr"] = lr
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
def step_lr_schedule(optimizer, epoch, init_lr, min_lr, decay_rate):
|
| 116 |
+
"""Decay the learning rate"""
|
| 117 |
+
lr = max(min_lr, init_lr * (decay_rate**epoch))
|
| 118 |
+
for param_group in optimizer.param_groups:
|
| 119 |
+
param_group["lr"] = lr
|
video_llama/common/registry.py
ADDED
|
@@ -0,0 +1,329 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE_Lavis file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class Registry:
|
| 10 |
+
mapping = {
|
| 11 |
+
"builder_name_mapping": {},
|
| 12 |
+
"task_name_mapping": {},
|
| 13 |
+
"processor_name_mapping": {},
|
| 14 |
+
"model_name_mapping": {},
|
| 15 |
+
"lr_scheduler_name_mapping": {},
|
| 16 |
+
"runner_name_mapping": {},
|
| 17 |
+
"state": {},
|
| 18 |
+
"paths": {},
|
| 19 |
+
}
|
| 20 |
+
|
| 21 |
+
@classmethod
|
| 22 |
+
def register_builder(cls, name):
|
| 23 |
+
r"""Register a dataset builder to registry with key 'name'
|
| 24 |
+
|
| 25 |
+
Args:
|
| 26 |
+
name: Key with which the builder will be registered.
|
| 27 |
+
|
| 28 |
+
Usage:
|
| 29 |
+
|
| 30 |
+
from video_llama.common.registry import registry
|
| 31 |
+
from video_llama.datasets.base_dataset_builder import BaseDatasetBuilder
|
| 32 |
+
"""
|
| 33 |
+
|
| 34 |
+
def wrap(builder_cls):
|
| 35 |
+
from video_llama.datasets.builders.base_dataset_builder import BaseDatasetBuilder
|
| 36 |
+
|
| 37 |
+
assert issubclass(
|
| 38 |
+
builder_cls, BaseDatasetBuilder
|
| 39 |
+
), "All builders must inherit BaseDatasetBuilder class, found {}".format(
|
| 40 |
+
builder_cls
|
| 41 |
+
)
|
| 42 |
+
if name in cls.mapping["builder_name_mapping"]:
|
| 43 |
+
raise KeyError(
|
| 44 |
+
"Name '{}' already registered for {}.".format(
|
| 45 |
+
name, cls.mapping["builder_name_mapping"][name]
|
| 46 |
+
)
|
| 47 |
+
)
|
| 48 |
+
cls.mapping["builder_name_mapping"][name] = builder_cls
|
| 49 |
+
return builder_cls
|
| 50 |
+
|
| 51 |
+
return wrap
|
| 52 |
+
|
| 53 |
+
@classmethod
|
| 54 |
+
def register_task(cls, name):
|
| 55 |
+
r"""Register a task to registry with key 'name'
|
| 56 |
+
|
| 57 |
+
Args:
|
| 58 |
+
name: Key with which the task will be registered.
|
| 59 |
+
|
| 60 |
+
Usage:
|
| 61 |
+
|
| 62 |
+
from video_llama.common.registry import registry
|
| 63 |
+
"""
|
| 64 |
+
|
| 65 |
+
def wrap(task_cls):
|
| 66 |
+
from video_llama.tasks.base_task import BaseTask
|
| 67 |
+
|
| 68 |
+
assert issubclass(
|
| 69 |
+
task_cls, BaseTask
|
| 70 |
+
), "All tasks must inherit BaseTask class"
|
| 71 |
+
if name in cls.mapping["task_name_mapping"]:
|
| 72 |
+
raise KeyError(
|
| 73 |
+
"Name '{}' already registered for {}.".format(
|
| 74 |
+
name, cls.mapping["task_name_mapping"][name]
|
| 75 |
+
)
|
| 76 |
+
)
|
| 77 |
+
cls.mapping["task_name_mapping"][name] = task_cls
|
| 78 |
+
return task_cls
|
| 79 |
+
|
| 80 |
+
return wrap
|
| 81 |
+
|
| 82 |
+
@classmethod
|
| 83 |
+
def register_model(cls, name):
|
| 84 |
+
r"""Register a task to registry with key 'name'
|
| 85 |
+
|
| 86 |
+
Args:
|
| 87 |
+
name: Key with which the task will be registered.
|
| 88 |
+
|
| 89 |
+
Usage:
|
| 90 |
+
|
| 91 |
+
from video_llama.common.registry import registry
|
| 92 |
+
"""
|
| 93 |
+
|
| 94 |
+
def wrap(model_cls):
|
| 95 |
+
from video_llama.models import BaseModel
|
| 96 |
+
|
| 97 |
+
assert issubclass(
|
| 98 |
+
model_cls, BaseModel
|
| 99 |
+
), "All models must inherit BaseModel class"
|
| 100 |
+
if name in cls.mapping["model_name_mapping"]:
|
| 101 |
+
raise KeyError(
|
| 102 |
+
"Name '{}' already registered for {}.".format(
|
| 103 |
+
name, cls.mapping["model_name_mapping"][name]
|
| 104 |
+
)
|
| 105 |
+
)
|
| 106 |
+
cls.mapping["model_name_mapping"][name] = model_cls
|
| 107 |
+
return model_cls
|
| 108 |
+
|
| 109 |
+
return wrap
|
| 110 |
+
|
| 111 |
+
@classmethod
|
| 112 |
+
def register_processor(cls, name):
|
| 113 |
+
r"""Register a processor to registry with key 'name'
|
| 114 |
+
|
| 115 |
+
Args:
|
| 116 |
+
name: Key with which the task will be registered.
|
| 117 |
+
|
| 118 |
+
Usage:
|
| 119 |
+
|
| 120 |
+
from video_llama.common.registry import registry
|
| 121 |
+
"""
|
| 122 |
+
|
| 123 |
+
def wrap(processor_cls):
|
| 124 |
+
from video_llama.processors import BaseProcessor
|
| 125 |
+
|
| 126 |
+
assert issubclass(
|
| 127 |
+
processor_cls, BaseProcessor
|
| 128 |
+
), "All processors must inherit BaseProcessor class"
|
| 129 |
+
if name in cls.mapping["processor_name_mapping"]:
|
| 130 |
+
raise KeyError(
|
| 131 |
+
"Name '{}' already registered for {}.".format(
|
| 132 |
+
name, cls.mapping["processor_name_mapping"][name]
|
| 133 |
+
)
|
| 134 |
+
)
|
| 135 |
+
cls.mapping["processor_name_mapping"][name] = processor_cls
|
| 136 |
+
return processor_cls
|
| 137 |
+
|
| 138 |
+
return wrap
|
| 139 |
+
|
| 140 |
+
@classmethod
|
| 141 |
+
def register_lr_scheduler(cls, name):
|
| 142 |
+
r"""Register a model to registry with key 'name'
|
| 143 |
+
|
| 144 |
+
Args:
|
| 145 |
+
name: Key with which the task will be registered.
|
| 146 |
+
|
| 147 |
+
Usage:
|
| 148 |
+
|
| 149 |
+
from video_llama.common.registry import registry
|
| 150 |
+
"""
|
| 151 |
+
|
| 152 |
+
def wrap(lr_sched_cls):
|
| 153 |
+
if name in cls.mapping["lr_scheduler_name_mapping"]:
|
| 154 |
+
raise KeyError(
|
| 155 |
+
"Name '{}' already registered for {}.".format(
|
| 156 |
+
name, cls.mapping["lr_scheduler_name_mapping"][name]
|
| 157 |
+
)
|
| 158 |
+
)
|
| 159 |
+
cls.mapping["lr_scheduler_name_mapping"][name] = lr_sched_cls
|
| 160 |
+
return lr_sched_cls
|
| 161 |
+
|
| 162 |
+
return wrap
|
| 163 |
+
|
| 164 |
+
@classmethod
|
| 165 |
+
def register_runner(cls, name):
|
| 166 |
+
r"""Register a model to registry with key 'name'
|
| 167 |
+
|
| 168 |
+
Args:
|
| 169 |
+
name: Key with which the task will be registered.
|
| 170 |
+
|
| 171 |
+
Usage:
|
| 172 |
+
|
| 173 |
+
from video_llama.common.registry import registry
|
| 174 |
+
"""
|
| 175 |
+
|
| 176 |
+
def wrap(runner_cls):
|
| 177 |
+
if name in cls.mapping["runner_name_mapping"]:
|
| 178 |
+
raise KeyError(
|
| 179 |
+
"Name '{}' already registered for {}.".format(
|
| 180 |
+
name, cls.mapping["runner_name_mapping"][name]
|
| 181 |
+
)
|
| 182 |
+
)
|
| 183 |
+
cls.mapping["runner_name_mapping"][name] = runner_cls
|
| 184 |
+
return runner_cls
|
| 185 |
+
|
| 186 |
+
return wrap
|
| 187 |
+
|
| 188 |
+
@classmethod
|
| 189 |
+
def register_path(cls, name, path):
|
| 190 |
+
r"""Register a path to registry with key 'name'
|
| 191 |
+
|
| 192 |
+
Args:
|
| 193 |
+
name: Key with which the path will be registered.
|
| 194 |
+
|
| 195 |
+
Usage:
|
| 196 |
+
|
| 197 |
+
from video_llama.common.registry import registry
|
| 198 |
+
"""
|
| 199 |
+
assert isinstance(path, str), "All path must be str."
|
| 200 |
+
if name in cls.mapping["paths"]:
|
| 201 |
+
raise KeyError("Name '{}' already registered.".format(name))
|
| 202 |
+
cls.mapping["paths"][name] = path
|
| 203 |
+
|
| 204 |
+
@classmethod
|
| 205 |
+
def register(cls, name, obj):
|
| 206 |
+
r"""Register an item to registry with key 'name'
|
| 207 |
+
|
| 208 |
+
Args:
|
| 209 |
+
name: Key with which the item will be registered.
|
| 210 |
+
|
| 211 |
+
Usage::
|
| 212 |
+
|
| 213 |
+
from video_llama.common.registry import registry
|
| 214 |
+
|
| 215 |
+
registry.register("config", {})
|
| 216 |
+
"""
|
| 217 |
+
path = name.split(".")
|
| 218 |
+
current = cls.mapping["state"]
|
| 219 |
+
|
| 220 |
+
for part in path[:-1]:
|
| 221 |
+
if part not in current:
|
| 222 |
+
current[part] = {}
|
| 223 |
+
current = current[part]
|
| 224 |
+
|
| 225 |
+
current[path[-1]] = obj
|
| 226 |
+
|
| 227 |
+
# @classmethod
|
| 228 |
+
# def get_trainer_class(cls, name):
|
| 229 |
+
# return cls.mapping["trainer_name_mapping"].get(name, None)
|
| 230 |
+
|
| 231 |
+
@classmethod
|
| 232 |
+
def get_builder_class(cls, name):
|
| 233 |
+
return cls.mapping["builder_name_mapping"].get(name, None)
|
| 234 |
+
|
| 235 |
+
@classmethod
|
| 236 |
+
def get_model_class(cls, name):
|
| 237 |
+
return cls.mapping["model_name_mapping"].get(name, None)
|
| 238 |
+
|
| 239 |
+
@classmethod
|
| 240 |
+
def get_task_class(cls, name):
|
| 241 |
+
return cls.mapping["task_name_mapping"].get(name, None)
|
| 242 |
+
|
| 243 |
+
@classmethod
|
| 244 |
+
def get_processor_class(cls, name):
|
| 245 |
+
return cls.mapping["processor_name_mapping"].get(name, None)
|
| 246 |
+
|
| 247 |
+
@classmethod
|
| 248 |
+
def get_lr_scheduler_class(cls, name):
|
| 249 |
+
return cls.mapping["lr_scheduler_name_mapping"].get(name, None)
|
| 250 |
+
|
| 251 |
+
@classmethod
|
| 252 |
+
def get_runner_class(cls, name):
|
| 253 |
+
return cls.mapping["runner_name_mapping"].get(name, None)
|
| 254 |
+
|
| 255 |
+
@classmethod
|
| 256 |
+
def list_runners(cls):
|
| 257 |
+
return sorted(cls.mapping["runner_name_mapping"].keys())
|
| 258 |
+
|
| 259 |
+
@classmethod
|
| 260 |
+
def list_models(cls):
|
| 261 |
+
return sorted(cls.mapping["model_name_mapping"].keys())
|
| 262 |
+
|
| 263 |
+
@classmethod
|
| 264 |
+
def list_tasks(cls):
|
| 265 |
+
return sorted(cls.mapping["task_name_mapping"].keys())
|
| 266 |
+
|
| 267 |
+
@classmethod
|
| 268 |
+
def list_processors(cls):
|
| 269 |
+
return sorted(cls.mapping["processor_name_mapping"].keys())
|
| 270 |
+
|
| 271 |
+
@classmethod
|
| 272 |
+
def list_lr_schedulers(cls):
|
| 273 |
+
return sorted(cls.mapping["lr_scheduler_name_mapping"].keys())
|
| 274 |
+
|
| 275 |
+
@classmethod
|
| 276 |
+
def list_datasets(cls):
|
| 277 |
+
return sorted(cls.mapping["builder_name_mapping"].keys())
|
| 278 |
+
|
| 279 |
+
@classmethod
|
| 280 |
+
def get_path(cls, name):
|
| 281 |
+
return cls.mapping["paths"].get(name, None)
|
| 282 |
+
|
| 283 |
+
@classmethod
|
| 284 |
+
def get(cls, name, default=None, no_warning=False):
|
| 285 |
+
r"""Get an item from registry with key 'name'
|
| 286 |
+
|
| 287 |
+
Args:
|
| 288 |
+
name (string): Key whose value needs to be retrieved.
|
| 289 |
+
default: If passed and key is not in registry, default value will
|
| 290 |
+
be returned with a warning. Default: None
|
| 291 |
+
no_warning (bool): If passed as True, warning when key doesn't exist
|
| 292 |
+
will not be generated. Useful for MMF's
|
| 293 |
+
internal operations. Default: False
|
| 294 |
+
"""
|
| 295 |
+
original_name = name
|
| 296 |
+
name = name.split(".")
|
| 297 |
+
value = cls.mapping["state"]
|
| 298 |
+
for subname in name:
|
| 299 |
+
value = value.get(subname, default)
|
| 300 |
+
if value is default:
|
| 301 |
+
break
|
| 302 |
+
|
| 303 |
+
if (
|
| 304 |
+
"writer" in cls.mapping["state"]
|
| 305 |
+
and value == default
|
| 306 |
+
and no_warning is False
|
| 307 |
+
):
|
| 308 |
+
cls.mapping["state"]["writer"].warning(
|
| 309 |
+
"Key {} is not present in registry, returning default value "
|
| 310 |
+
"of {}".format(original_name, default)
|
| 311 |
+
)
|
| 312 |
+
return value
|
| 313 |
+
|
| 314 |
+
@classmethod
|
| 315 |
+
def unregister(cls, name):
|
| 316 |
+
r"""Remove an item from registry with key 'name'
|
| 317 |
+
|
| 318 |
+
Args:
|
| 319 |
+
name: Key which needs to be removed.
|
| 320 |
+
Usage::
|
| 321 |
+
|
| 322 |
+
from mmf.common.registry import registry
|
| 323 |
+
|
| 324 |
+
config = registry.unregister("config")
|
| 325 |
+
"""
|
| 326 |
+
return cls.mapping["state"].pop(name, None)
|
| 327 |
+
|
| 328 |
+
|
| 329 |
+
registry = Registry()
|