Spaces:
Runtime error

Runtime error
init
Browse files- .gitignore +11 -0
- LICENSE +21 -0
- app.py +67 -57
- attentions.py +303 -0
- commons.py +161 -0
- configs/ljs_base.json +52 -0
- configs/ljs_nosdp.json +53 -0
- configs/nan.json +52 -0
- configs/vctk_base.json +53 -0
- data_utils.py +392 -0
- filelists/train.txt +0 -0
- filelists/train.txt.cleaned +0 -0
- filelists/val.txt +63 -0
- filelists/val.txt.cleaned +63 -0
- inference.ipynb +200 -0
- log.log +5 -0
- losses.py +61 -0
- mel_processing.py +119 -0
- models.py +534 -0
- modules.py +390 -0
- monotonic_align/__init__.py +19 -0
- monotonic_align/core.pyx +42 -0
- monotonic_align/setup.py +9 -0
- preprocess.py +25 -0
- requirements.txt +10 -0
- resources/fig_1a.png +0 -0
- resources/fig_1b.png +0 -0
- resources/training.png +0 -0
- text/LICENSE +19 -0
- text/__init__.py +54 -0
- text/cleaners.py +203 -0
- text/symbols.py +2 -0
- train.py +290 -0
- train_ms.py +294 -0
- transforms.py +193 -0
- utils.py +258 -0
.gitignore
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
DUMMY1
|
| 2 |
+
DUMMY2
|
| 3 |
+
DUMMY3
|
| 4 |
+
logs
|
| 5 |
+
__pycache__
|
| 6 |
+
.ipynb_checkpoints
|
| 7 |
+
.*.swp
|
| 8 |
+
|
| 9 |
+
build
|
| 10 |
+
*.c
|
| 11 |
+
monotonic_align/monotonic_align
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2021 Jaehyeon Kim
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
app.py
CHANGED
|
@@ -1,92 +1,102 @@
|
|
| 1 |
import os
|
| 2 |
|
| 3 |
os.system('cd monotonic_align && python setup.py build_ext --inplace && cd ..')
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4 |
|
| 5 |
import librosa
|
| 6 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7 |
import torch
|
| 8 |
-
from torch import
|
|
|
|
|
|
|
|
|
|
| 9 |
import commons
|
| 10 |
import utils
|
| 11 |
-
import
|
| 12 |
from models import SynthesizerTrn
|
| 13 |
-
from text import
|
| 14 |
-
from
|
|
|
|
|
|
|
| 15 |
|
|
|
|
| 16 |
|
| 17 |
-
def get_text(text):
|
| 18 |
-
text_norm =
|
| 19 |
if hps.data.add_blank:
|
| 20 |
text_norm = commons.intersperse(text_norm, 0)
|
| 21 |
-
text_norm = LongTensor(text_norm)
|
| 22 |
return text_norm
|
|
|
|
| 23 |
|
| 24 |
|
| 25 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 26 |
if len(text) > 150:
|
| 27 |
return "Error: Text is too long", None
|
| 28 |
-
stn_tst = get_text(text)
|
| 29 |
-
with no_grad():
|
| 30 |
x_tst = stn_tst.unsqueeze(0)
|
| 31 |
-
x_tst_lengths = LongTensor([stn_tst.size(0)])
|
| 32 |
-
|
| 33 |
-
|
| 34 |
-
0, 0].data.cpu().float().numpy()
|
| 35 |
-
return "Success", (hps.data.sampling_rate, audio)
|
| 36 |
|
| 37 |
|
| 38 |
-
def
|
| 39 |
-
if
|
| 40 |
-
return "
|
| 41 |
-
|
| 42 |
-
|
| 43 |
-
|
| 44 |
-
|
| 45 |
-
|
| 46 |
-
if len(audio.shape) > 1:
|
| 47 |
-
audio = librosa.to_mono(audio.transpose(1, 0))
|
| 48 |
-
if sampling_rate != hps.data.sampling_rate:
|
| 49 |
-
audio = librosa.resample(audio, orig_sr=sampling_rate, target_sr=hps.data.sampling_rate)
|
| 50 |
-
y = torch.FloatTensor(audio)
|
| 51 |
-
y = y.unsqueeze(0)
|
| 52 |
-
spec = spectrogram_torch(y, hps.data.filter_length,
|
| 53 |
-
hps.data.sampling_rate, hps.data.hop_length, hps.data.win_length,
|
| 54 |
-
center=False)
|
| 55 |
-
spec_lengths = LongTensor([spec.size(-1)])
|
| 56 |
-
sid_src = LongTensor([original_speaker_id])
|
| 57 |
-
sid_tgt = LongTensor([target_speaker_id])
|
| 58 |
-
with no_grad():
|
| 59 |
-
audio = model.voice_conversion(spec, spec_lengths, sid_src=sid_src, sid_tgt=sid_tgt)[0][
|
| 60 |
0, 0].data.cpu().float().numpy()
|
| 61 |
return "Success", (hps.data.sampling_rate, audio)
|
| 62 |
|
| 63 |
|
| 64 |
if __name__ == '__main__':
|
| 65 |
-
|
| 66 |
-
model_path = "saved_model/model.pth"
|
| 67 |
-
hps = utils.get_hparams_from_file(config_path)
|
| 68 |
-
model = SynthesizerTrn(
|
| 69 |
-
len(hps.symbols),
|
| 70 |
-
hps.data.filter_length // 2 + 1,
|
| 71 |
-
hps.train.segment_size // hps.data.hop_length,
|
| 72 |
-
n_speakers=hps.data.n_speakers,
|
| 73 |
-
**hps.model)
|
| 74 |
-
utils.load_checkpoint(model_path, model, None)
|
| 75 |
-
model.eval()
|
| 76 |
|
| 77 |
app = gr.Blocks()
|
| 78 |
|
| 79 |
with app:
|
| 80 |
with gr.Tabs():
|
| 81 |
-
with gr.
|
| 82 |
-
|
| 83 |
-
|
| 84 |
-
|
| 85 |
-
|
| 86 |
-
tts_output1 = gr.Textbox(label="Output Message")
|
| 87 |
-
tts_output2 = gr.Audio(label="Output Audio")
|
| 88 |
|
| 89 |
tts_submit.click(tts_fn, [tts_input1, tts_input2], [tts_output1, tts_output2])
|
| 90 |
-
vc_submit.click(vc_fn, [vc_input1, vc_input2, vc_input3], [vc_output1, vc_output2])
|
| 91 |
|
| 92 |
app.launch()
|
|
|
|
| 1 |
import os
|
| 2 |
|
| 3 |
os.system('cd monotonic_align && python setup.py build_ext --inplace && cd ..')
|
| 4 |
+
os.system('pip install pypinyin Cython==0.29.21 librosa==0.8.0 matplotlib==3.3.1 numpy==1.18.5 phonemizer==2.2.1 scipy==1.5.2 Unidecode==1.1.1 >log.log')
|
| 5 |
+
os.system('sudo apt-get install espeak -y >log.log')
|
| 6 |
+
os.system('pip install gdown >log.log')
|
| 7 |
+
os.system('pip install pyopenjtalk janome > log.log')
|
| 8 |
+
os.system('pip install cloud-tpu-client > log.log')
|
| 9 |
+
|
| 10 |
+
import logging
|
| 11 |
+
|
| 12 |
+
numba_logger = logging.getLogger('numba')
|
| 13 |
+
numba_logger.setLevel(logging.WARNING)
|
| 14 |
|
| 15 |
import librosa
|
| 16 |
+
|
| 17 |
+
import matplotlib.pyplot as plt
|
| 18 |
+
import IPython.display as ipd
|
| 19 |
+
|
| 20 |
+
import os
|
| 21 |
+
import json
|
| 22 |
+
import math
|
| 23 |
import torch
|
| 24 |
+
from torch import nn
|
| 25 |
+
from torch.nn import functional as F
|
| 26 |
+
from torch.utils.data import DataLoader
|
| 27 |
+
|
| 28 |
import commons
|
| 29 |
import utils
|
| 30 |
+
from data_utils import TextAudioLoader, TextAudioCollate, TextAudioSpeakerLoader, TextAudioSpeakerCollate
|
| 31 |
from models import SynthesizerTrn
|
| 32 |
+
from text.symbols import symbols
|
| 33 |
+
from text.cleaners import japanese_phrase_cleaners
|
| 34 |
+
from text import cleaned_text_to_sequence
|
| 35 |
+
from pypinyin import lazy_pinyin, Style
|
| 36 |
|
| 37 |
+
from scipy.io.wavfile import write
|
| 38 |
|
| 39 |
+
def get_text(text, hps):
|
| 40 |
+
text_norm = cleaned_text_to_sequence(text)
|
| 41 |
if hps.data.add_blank:
|
| 42 |
text_norm = commons.intersperse(text_norm, 0)
|
| 43 |
+
text_norm = torch.LongTensor(text_norm)
|
| 44 |
return text_norm
|
| 45 |
+
# hps_ms = utils.get_hparams_from_file("./configs/vctk_base.json")
|
| 46 |
|
| 47 |
|
| 48 |
+
hps = utils.get_hparams_from_file("./configs/tokaiteio.json")
|
| 49 |
+
# net_g_ms = SynthesizerTrn(
|
| 50 |
+
# len(symbols),
|
| 51 |
+
# hps_ms.data.filter_length // 2 + 1,
|
| 52 |
+
# hps_ms.train.segment_size // hps.data.hop_length,
|
| 53 |
+
# n_speakers=hps_ms.data.n_speakers,
|
| 54 |
+
# **hps_ms.model)
|
| 55 |
+
|
| 56 |
+
net_g = SynthesizerTrn(
|
| 57 |
+
len(symbols),
|
| 58 |
+
hps.data.filter_length // 2 + 1,
|
| 59 |
+
hps.train.segment_size // hps.data.hop_length,
|
| 60 |
+
**hps.model)
|
| 61 |
+
_ = net_g.eval()
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def tts(text):
|
| 65 |
if len(text) > 150:
|
| 66 |
return "Error: Text is too long", None
|
| 67 |
+
stn_tst = get_text(text, hps)
|
| 68 |
+
with torch.no_grad():
|
| 69 |
x_tst = stn_tst.unsqueeze(0)
|
| 70 |
+
x_tst_lengths = torch.LongTensor([stn_tst.size(0)])
|
| 71 |
+
audio = net_g.infer(x_tst, x_tst_lengths, noise_scale=.667, noise_scale_w=0.8, length_scale=1)[0][0,0].data.float().numpy()
|
| 72 |
+
ipd.display(ipd.Audio(audio, rate=hps.data.sampling_rate))
|
|
|
|
|
|
|
| 73 |
|
| 74 |
|
| 75 |
+
def tts_fn(text, speaker_id):
|
| 76 |
+
if len(text) > 150:
|
| 77 |
+
return "Error: Text is too long", None
|
| 78 |
+
stn_tst = get_text(text, hps)
|
| 79 |
+
with torch.no_grad():
|
| 80 |
+
x_tst = stn_tst.unsqueeze(0)
|
| 81 |
+
x_tst_lengths = LongTensor([stn_tst.size(0)])
|
| 82 |
+
audio = net_g.infer(x_tst, x_tst_lengths, noise_scale=.667, noise_scale_w=0.8, length_scale=1)[0][
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 83 |
0, 0].data.cpu().float().numpy()
|
| 84 |
return "Success", (hps.data.sampling_rate, audio)
|
| 85 |
|
| 86 |
|
| 87 |
if __name__ == '__main__':
|
| 88 |
+
_ = utils.load_checkpoint("G_50000.pth", net_g, None)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 89 |
|
| 90 |
app = gr.Blocks()
|
| 91 |
|
| 92 |
with app:
|
| 93 |
with gr.Tabs():
|
| 94 |
+
with gr.Column():
|
| 95 |
+
tts_input1 = gr.TextArea(label="Text (150 words limitation)", value="こんにちは。")
|
| 96 |
+
tts_submit = gr.Button("Generate", variant="primary")
|
| 97 |
+
tts_output1 = gr.Textbox(label="Output Message")
|
| 98 |
+
tts_output2 = gr.Audio(label="Output Audio")
|
|
|
|
|
|
|
| 99 |
|
| 100 |
tts_submit.click(tts_fn, [tts_input1, tts_input2], [tts_output1, tts_output2])
|
|
|
|
| 101 |
|
| 102 |
app.launch()
|
attentions.py
ADDED
|
@@ -0,0 +1,303 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
import math
|
| 3 |
+
import numpy as np
|
| 4 |
+
import torch
|
| 5 |
+
from torch import nn
|
| 6 |
+
from torch.nn import functional as F
|
| 7 |
+
|
| 8 |
+
import commons
|
| 9 |
+
import modules
|
| 10 |
+
from modules import LayerNorm
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class Encoder(nn.Module):
|
| 14 |
+
def __init__(self, hidden_channels, filter_channels, n_heads, n_layers, kernel_size=1, p_dropout=0., window_size=4, **kwargs):
|
| 15 |
+
super().__init__()
|
| 16 |
+
self.hidden_channels = hidden_channels
|
| 17 |
+
self.filter_channels = filter_channels
|
| 18 |
+
self.n_heads = n_heads
|
| 19 |
+
self.n_layers = n_layers
|
| 20 |
+
self.kernel_size = kernel_size
|
| 21 |
+
self.p_dropout = p_dropout
|
| 22 |
+
self.window_size = window_size
|
| 23 |
+
|
| 24 |
+
self.drop = nn.Dropout(p_dropout)
|
| 25 |
+
self.attn_layers = nn.ModuleList()
|
| 26 |
+
self.norm_layers_1 = nn.ModuleList()
|
| 27 |
+
self.ffn_layers = nn.ModuleList()
|
| 28 |
+
self.norm_layers_2 = nn.ModuleList()
|
| 29 |
+
for i in range(self.n_layers):
|
| 30 |
+
self.attn_layers.append(MultiHeadAttention(hidden_channels, hidden_channels, n_heads, p_dropout=p_dropout, window_size=window_size))
|
| 31 |
+
self.norm_layers_1.append(LayerNorm(hidden_channels))
|
| 32 |
+
self.ffn_layers.append(FFN(hidden_channels, hidden_channels, filter_channels, kernel_size, p_dropout=p_dropout))
|
| 33 |
+
self.norm_layers_2.append(LayerNorm(hidden_channels))
|
| 34 |
+
|
| 35 |
+
def forward(self, x, x_mask):
|
| 36 |
+
attn_mask = x_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
|
| 37 |
+
x = x * x_mask
|
| 38 |
+
for i in range(self.n_layers):
|
| 39 |
+
y = self.attn_layers[i](x, x, attn_mask)
|
| 40 |
+
y = self.drop(y)
|
| 41 |
+
x = self.norm_layers_1[i](x + y)
|
| 42 |
+
|
| 43 |
+
y = self.ffn_layers[i](x, x_mask)
|
| 44 |
+
y = self.drop(y)
|
| 45 |
+
x = self.norm_layers_2[i](x + y)
|
| 46 |
+
x = x * x_mask
|
| 47 |
+
return x
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
class Decoder(nn.Module):
|
| 51 |
+
def __init__(self, hidden_channels, filter_channels, n_heads, n_layers, kernel_size=1, p_dropout=0., proximal_bias=False, proximal_init=True, **kwargs):
|
| 52 |
+
super().__init__()
|
| 53 |
+
self.hidden_channels = hidden_channels
|
| 54 |
+
self.filter_channels = filter_channels
|
| 55 |
+
self.n_heads = n_heads
|
| 56 |
+
self.n_layers = n_layers
|
| 57 |
+
self.kernel_size = kernel_size
|
| 58 |
+
self.p_dropout = p_dropout
|
| 59 |
+
self.proximal_bias = proximal_bias
|
| 60 |
+
self.proximal_init = proximal_init
|
| 61 |
+
|
| 62 |
+
self.drop = nn.Dropout(p_dropout)
|
| 63 |
+
self.self_attn_layers = nn.ModuleList()
|
| 64 |
+
self.norm_layers_0 = nn.ModuleList()
|
| 65 |
+
self.encdec_attn_layers = nn.ModuleList()
|
| 66 |
+
self.norm_layers_1 = nn.ModuleList()
|
| 67 |
+
self.ffn_layers = nn.ModuleList()
|
| 68 |
+
self.norm_layers_2 = nn.ModuleList()
|
| 69 |
+
for i in range(self.n_layers):
|
| 70 |
+
self.self_attn_layers.append(MultiHeadAttention(hidden_channels, hidden_channels, n_heads, p_dropout=p_dropout, proximal_bias=proximal_bias, proximal_init=proximal_init))
|
| 71 |
+
self.norm_layers_0.append(LayerNorm(hidden_channels))
|
| 72 |
+
self.encdec_attn_layers.append(MultiHeadAttention(hidden_channels, hidden_channels, n_heads, p_dropout=p_dropout))
|
| 73 |
+
self.norm_layers_1.append(LayerNorm(hidden_channels))
|
| 74 |
+
self.ffn_layers.append(FFN(hidden_channels, hidden_channels, filter_channels, kernel_size, p_dropout=p_dropout, causal=True))
|
| 75 |
+
self.norm_layers_2.append(LayerNorm(hidden_channels))
|
| 76 |
+
|
| 77 |
+
def forward(self, x, x_mask, h, h_mask):
|
| 78 |
+
"""
|
| 79 |
+
x: decoder input
|
| 80 |
+
h: encoder output
|
| 81 |
+
"""
|
| 82 |
+
self_attn_mask = commons.subsequent_mask(x_mask.size(2)).to(device=x.device, dtype=x.dtype)
|
| 83 |
+
encdec_attn_mask = h_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
|
| 84 |
+
x = x * x_mask
|
| 85 |
+
for i in range(self.n_layers):
|
| 86 |
+
y = self.self_attn_layers[i](x, x, self_attn_mask)
|
| 87 |
+
y = self.drop(y)
|
| 88 |
+
x = self.norm_layers_0[i](x + y)
|
| 89 |
+
|
| 90 |
+
y = self.encdec_attn_layers[i](x, h, encdec_attn_mask)
|
| 91 |
+
y = self.drop(y)
|
| 92 |
+
x = self.norm_layers_1[i](x + y)
|
| 93 |
+
|
| 94 |
+
y = self.ffn_layers[i](x, x_mask)
|
| 95 |
+
y = self.drop(y)
|
| 96 |
+
x = self.norm_layers_2[i](x + y)
|
| 97 |
+
x = x * x_mask
|
| 98 |
+
return x
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
class MultiHeadAttention(nn.Module):
|
| 102 |
+
def __init__(self, channels, out_channels, n_heads, p_dropout=0., window_size=None, heads_share=True, block_length=None, proximal_bias=False, proximal_init=False):
|
| 103 |
+
super().__init__()
|
| 104 |
+
assert channels % n_heads == 0
|
| 105 |
+
|
| 106 |
+
self.channels = channels
|
| 107 |
+
self.out_channels = out_channels
|
| 108 |
+
self.n_heads = n_heads
|
| 109 |
+
self.p_dropout = p_dropout
|
| 110 |
+
self.window_size = window_size
|
| 111 |
+
self.heads_share = heads_share
|
| 112 |
+
self.block_length = block_length
|
| 113 |
+
self.proximal_bias = proximal_bias
|
| 114 |
+
self.proximal_init = proximal_init
|
| 115 |
+
self.attn = None
|
| 116 |
+
|
| 117 |
+
self.k_channels = channels // n_heads
|
| 118 |
+
self.conv_q = nn.Conv1d(channels, channels, 1)
|
| 119 |
+
self.conv_k = nn.Conv1d(channels, channels, 1)
|
| 120 |
+
self.conv_v = nn.Conv1d(channels, channels, 1)
|
| 121 |
+
self.conv_o = nn.Conv1d(channels, out_channels, 1)
|
| 122 |
+
self.drop = nn.Dropout(p_dropout)
|
| 123 |
+
|
| 124 |
+
if window_size is not None:
|
| 125 |
+
n_heads_rel = 1 if heads_share else n_heads
|
| 126 |
+
rel_stddev = self.k_channels**-0.5
|
| 127 |
+
self.emb_rel_k = nn.Parameter(torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels) * rel_stddev)
|
| 128 |
+
self.emb_rel_v = nn.Parameter(torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels) * rel_stddev)
|
| 129 |
+
|
| 130 |
+
nn.init.xavier_uniform_(self.conv_q.weight)
|
| 131 |
+
nn.init.xavier_uniform_(self.conv_k.weight)
|
| 132 |
+
nn.init.xavier_uniform_(self.conv_v.weight)
|
| 133 |
+
if proximal_init:
|
| 134 |
+
with torch.no_grad():
|
| 135 |
+
self.conv_k.weight.copy_(self.conv_q.weight)
|
| 136 |
+
self.conv_k.bias.copy_(self.conv_q.bias)
|
| 137 |
+
|
| 138 |
+
def forward(self, x, c, attn_mask=None):
|
| 139 |
+
q = self.conv_q(x)
|
| 140 |
+
k = self.conv_k(c)
|
| 141 |
+
v = self.conv_v(c)
|
| 142 |
+
|
| 143 |
+
x, self.attn = self.attention(q, k, v, mask=attn_mask)
|
| 144 |
+
|
| 145 |
+
x = self.conv_o(x)
|
| 146 |
+
return x
|
| 147 |
+
|
| 148 |
+
def attention(self, query, key, value, mask=None):
|
| 149 |
+
# reshape [b, d, t] -> [b, n_h, t, d_k]
|
| 150 |
+
b, d, t_s, t_t = (*key.size(), query.size(2))
|
| 151 |
+
query = query.view(b, self.n_heads, self.k_channels, t_t).transpose(2, 3)
|
| 152 |
+
key = key.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
|
| 153 |
+
value = value.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
|
| 154 |
+
|
| 155 |
+
scores = torch.matmul(query / math.sqrt(self.k_channels), key.transpose(-2, -1))
|
| 156 |
+
if self.window_size is not None:
|
| 157 |
+
assert t_s == t_t, "Relative attention is only available for self-attention."
|
| 158 |
+
key_relative_embeddings = self._get_relative_embeddings(self.emb_rel_k, t_s)
|
| 159 |
+
rel_logits = self._matmul_with_relative_keys(query /math.sqrt(self.k_channels), key_relative_embeddings)
|
| 160 |
+
scores_local = self._relative_position_to_absolute_position(rel_logits)
|
| 161 |
+
scores = scores + scores_local
|
| 162 |
+
if self.proximal_bias:
|
| 163 |
+
assert t_s == t_t, "Proximal bias is only available for self-attention."
|
| 164 |
+
scores = scores + self._attention_bias_proximal(t_s).to(device=scores.device, dtype=scores.dtype)
|
| 165 |
+
if mask is not None:
|
| 166 |
+
scores = scores.masked_fill(mask == 0, -1e4)
|
| 167 |
+
if self.block_length is not None:
|
| 168 |
+
assert t_s == t_t, "Local attention is only available for self-attention."
|
| 169 |
+
block_mask = torch.ones_like(scores).triu(-self.block_length).tril(self.block_length)
|
| 170 |
+
scores = scores.masked_fill(block_mask == 0, -1e4)
|
| 171 |
+
p_attn = F.softmax(scores, dim=-1) # [b, n_h, t_t, t_s]
|
| 172 |
+
p_attn = self.drop(p_attn)
|
| 173 |
+
output = torch.matmul(p_attn, value)
|
| 174 |
+
if self.window_size is not None:
|
| 175 |
+
relative_weights = self._absolute_position_to_relative_position(p_attn)
|
| 176 |
+
value_relative_embeddings = self._get_relative_embeddings(self.emb_rel_v, t_s)
|
| 177 |
+
output = output + self._matmul_with_relative_values(relative_weights, value_relative_embeddings)
|
| 178 |
+
output = output.transpose(2, 3).contiguous().view(b, d, t_t) # [b, n_h, t_t, d_k] -> [b, d, t_t]
|
| 179 |
+
return output, p_attn
|
| 180 |
+
|
| 181 |
+
def _matmul_with_relative_values(self, x, y):
|
| 182 |
+
"""
|
| 183 |
+
x: [b, h, l, m]
|
| 184 |
+
y: [h or 1, m, d]
|
| 185 |
+
ret: [b, h, l, d]
|
| 186 |
+
"""
|
| 187 |
+
ret = torch.matmul(x, y.unsqueeze(0))
|
| 188 |
+
return ret
|
| 189 |
+
|
| 190 |
+
def _matmul_with_relative_keys(self, x, y):
|
| 191 |
+
"""
|
| 192 |
+
x: [b, h, l, d]
|
| 193 |
+
y: [h or 1, m, d]
|
| 194 |
+
ret: [b, h, l, m]
|
| 195 |
+
"""
|
| 196 |
+
ret = torch.matmul(x, y.unsqueeze(0).transpose(-2, -1))
|
| 197 |
+
return ret
|
| 198 |
+
|
| 199 |
+
def _get_relative_embeddings(self, relative_embeddings, length):
|
| 200 |
+
max_relative_position = 2 * self.window_size + 1
|
| 201 |
+
# Pad first before slice to avoid using cond ops.
|
| 202 |
+
pad_length = max(length - (self.window_size + 1), 0)
|
| 203 |
+
slice_start_position = max((self.window_size + 1) - length, 0)
|
| 204 |
+
slice_end_position = slice_start_position + 2 * length - 1
|
| 205 |
+
if pad_length > 0:
|
| 206 |
+
padded_relative_embeddings = F.pad(
|
| 207 |
+
relative_embeddings,
|
| 208 |
+
commons.convert_pad_shape([[0, 0], [pad_length, pad_length], [0, 0]]))
|
| 209 |
+
else:
|
| 210 |
+
padded_relative_embeddings = relative_embeddings
|
| 211 |
+
used_relative_embeddings = padded_relative_embeddings[:,slice_start_position:slice_end_position]
|
| 212 |
+
return used_relative_embeddings
|
| 213 |
+
|
| 214 |
+
def _relative_position_to_absolute_position(self, x):
|
| 215 |
+
"""
|
| 216 |
+
x: [b, h, l, 2*l-1]
|
| 217 |
+
ret: [b, h, l, l]
|
| 218 |
+
"""
|
| 219 |
+
batch, heads, length, _ = x.size()
|
| 220 |
+
# Concat columns of pad to shift from relative to absolute indexing.
|
| 221 |
+
x = F.pad(x, commons.convert_pad_shape([[0,0],[0,0],[0,0],[0,1]]))
|
| 222 |
+
|
| 223 |
+
# Concat extra elements so to add up to shape (len+1, 2*len-1).
|
| 224 |
+
x_flat = x.view([batch, heads, length * 2 * length])
|
| 225 |
+
x_flat = F.pad(x_flat, commons.convert_pad_shape([[0,0],[0,0],[0,length-1]]))
|
| 226 |
+
|
| 227 |
+
# Reshape and slice out the padded elements.
|
| 228 |
+
x_final = x_flat.view([batch, heads, length+1, 2*length-1])[:, :, :length, length-1:]
|
| 229 |
+
return x_final
|
| 230 |
+
|
| 231 |
+
def _absolute_position_to_relative_position(self, x):
|
| 232 |
+
"""
|
| 233 |
+
x: [b, h, l, l]
|
| 234 |
+
ret: [b, h, l, 2*l-1]
|
| 235 |
+
"""
|
| 236 |
+
batch, heads, length, _ = x.size()
|
| 237 |
+
# padd along column
|
| 238 |
+
x = F.pad(x, commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, length-1]]))
|
| 239 |
+
x_flat = x.view([batch, heads, length**2 + length*(length -1)])
|
| 240 |
+
# add 0's in the beginning that will skew the elements after reshape
|
| 241 |
+
x_flat = F.pad(x_flat, commons.convert_pad_shape([[0, 0], [0, 0], [length, 0]]))
|
| 242 |
+
x_final = x_flat.view([batch, heads, length, 2*length])[:,:,:,1:]
|
| 243 |
+
return x_final
|
| 244 |
+
|
| 245 |
+
def _attention_bias_proximal(self, length):
|
| 246 |
+
"""Bias for self-attention to encourage attention to close positions.
|
| 247 |
+
Args:
|
| 248 |
+
length: an integer scalar.
|
| 249 |
+
Returns:
|
| 250 |
+
a Tensor with shape [1, 1, length, length]
|
| 251 |
+
"""
|
| 252 |
+
r = torch.arange(length, dtype=torch.float32)
|
| 253 |
+
diff = torch.unsqueeze(r, 0) - torch.unsqueeze(r, 1)
|
| 254 |
+
return torch.unsqueeze(torch.unsqueeze(-torch.log1p(torch.abs(diff)), 0), 0)
|
| 255 |
+
|
| 256 |
+
|
| 257 |
+
class FFN(nn.Module):
|
| 258 |
+
def __init__(self, in_channels, out_channels, filter_channels, kernel_size, p_dropout=0., activation=None, causal=False):
|
| 259 |
+
super().__init__()
|
| 260 |
+
self.in_channels = in_channels
|
| 261 |
+
self.out_channels = out_channels
|
| 262 |
+
self.filter_channels = filter_channels
|
| 263 |
+
self.kernel_size = kernel_size
|
| 264 |
+
self.p_dropout = p_dropout
|
| 265 |
+
self.activation = activation
|
| 266 |
+
self.causal = causal
|
| 267 |
+
|
| 268 |
+
if causal:
|
| 269 |
+
self.padding = self._causal_padding
|
| 270 |
+
else:
|
| 271 |
+
self.padding = self._same_padding
|
| 272 |
+
|
| 273 |
+
self.conv_1 = nn.Conv1d(in_channels, filter_channels, kernel_size)
|
| 274 |
+
self.conv_2 = nn.Conv1d(filter_channels, out_channels, kernel_size)
|
| 275 |
+
self.drop = nn.Dropout(p_dropout)
|
| 276 |
+
|
| 277 |
+
def forward(self, x, x_mask):
|
| 278 |
+
x = self.conv_1(self.padding(x * x_mask))
|
| 279 |
+
if self.activation == "gelu":
|
| 280 |
+
x = x * torch.sigmoid(1.702 * x)
|
| 281 |
+
else:
|
| 282 |
+
x = torch.relu(x)
|
| 283 |
+
x = self.drop(x)
|
| 284 |
+
x = self.conv_2(self.padding(x * x_mask))
|
| 285 |
+
return x * x_mask
|
| 286 |
+
|
| 287 |
+
def _causal_padding(self, x):
|
| 288 |
+
if self.kernel_size == 1:
|
| 289 |
+
return x
|
| 290 |
+
pad_l = self.kernel_size - 1
|
| 291 |
+
pad_r = 0
|
| 292 |
+
padding = [[0, 0], [0, 0], [pad_l, pad_r]]
|
| 293 |
+
x = F.pad(x, commons.convert_pad_shape(padding))
|
| 294 |
+
return x
|
| 295 |
+
|
| 296 |
+
def _same_padding(self, x):
|
| 297 |
+
if self.kernel_size == 1:
|
| 298 |
+
return x
|
| 299 |
+
pad_l = (self.kernel_size - 1) // 2
|
| 300 |
+
pad_r = self.kernel_size // 2
|
| 301 |
+
padding = [[0, 0], [0, 0], [pad_l, pad_r]]
|
| 302 |
+
x = F.pad(x, commons.convert_pad_shape(padding))
|
| 303 |
+
return x
|
commons.py
ADDED
|
@@ -0,0 +1,161 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import numpy as np
|
| 3 |
+
import torch
|
| 4 |
+
from torch import nn
|
| 5 |
+
from torch.nn import functional as F
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def init_weights(m, mean=0.0, std=0.01):
|
| 9 |
+
classname = m.__class__.__name__
|
| 10 |
+
if classname.find("Conv") != -1:
|
| 11 |
+
m.weight.data.normal_(mean, std)
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def get_padding(kernel_size, dilation=1):
|
| 15 |
+
return int((kernel_size*dilation - dilation)/2)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def convert_pad_shape(pad_shape):
|
| 19 |
+
l = pad_shape[::-1]
|
| 20 |
+
pad_shape = [item for sublist in l for item in sublist]
|
| 21 |
+
return pad_shape
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def intersperse(lst, item):
|
| 25 |
+
result = [item] * (len(lst) * 2 + 1)
|
| 26 |
+
result[1::2] = lst
|
| 27 |
+
return result
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def kl_divergence(m_p, logs_p, m_q, logs_q):
|
| 31 |
+
"""KL(P||Q)"""
|
| 32 |
+
kl = (logs_q - logs_p) - 0.5
|
| 33 |
+
kl += 0.5 * (torch.exp(2. * logs_p) + ((m_p - m_q)**2)) * torch.exp(-2. * logs_q)
|
| 34 |
+
return kl
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def rand_gumbel(shape):
|
| 38 |
+
"""Sample from the Gumbel distribution, protect from overflows."""
|
| 39 |
+
uniform_samples = torch.rand(shape) * 0.99998 + 0.00001
|
| 40 |
+
return -torch.log(-torch.log(uniform_samples))
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def rand_gumbel_like(x):
|
| 44 |
+
g = rand_gumbel(x.size()).to(dtype=x.dtype, device=x.device)
|
| 45 |
+
return g
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def slice_segments(x, ids_str, segment_size=4):
|
| 49 |
+
ret = torch.zeros_like(x[:, :, :segment_size])
|
| 50 |
+
for i in range(x.size(0)):
|
| 51 |
+
idx_str = ids_str[i]
|
| 52 |
+
idx_end = idx_str + segment_size
|
| 53 |
+
ret[i] = x[i, :, idx_str:idx_end]
|
| 54 |
+
return ret
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def rand_slice_segments(x, x_lengths=None, segment_size=4):
|
| 58 |
+
b, d, t = x.size()
|
| 59 |
+
if x_lengths is None:
|
| 60 |
+
x_lengths = t
|
| 61 |
+
ids_str_max = x_lengths - segment_size + 1
|
| 62 |
+
ids_str = (torch.rand([b]).to(device=x.device) * ids_str_max).to(dtype=torch.long)
|
| 63 |
+
ret = slice_segments(x, ids_str, segment_size)
|
| 64 |
+
return ret, ids_str
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def get_timing_signal_1d(
|
| 68 |
+
length, channels, min_timescale=1.0, max_timescale=1.0e4):
|
| 69 |
+
position = torch.arange(length, dtype=torch.float)
|
| 70 |
+
num_timescales = channels // 2
|
| 71 |
+
log_timescale_increment = (
|
| 72 |
+
math.log(float(max_timescale) / float(min_timescale)) /
|
| 73 |
+
(num_timescales - 1))
|
| 74 |
+
inv_timescales = min_timescale * torch.exp(
|
| 75 |
+
torch.arange(num_timescales, dtype=torch.float) * -log_timescale_increment)
|
| 76 |
+
scaled_time = position.unsqueeze(0) * inv_timescales.unsqueeze(1)
|
| 77 |
+
signal = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], 0)
|
| 78 |
+
signal = F.pad(signal, [0, 0, 0, channels % 2])
|
| 79 |
+
signal = signal.view(1, channels, length)
|
| 80 |
+
return signal
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def add_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4):
|
| 84 |
+
b, channels, length = x.size()
|
| 85 |
+
signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
|
| 86 |
+
return x + signal.to(dtype=x.dtype, device=x.device)
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def cat_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4, axis=1):
|
| 90 |
+
b, channels, length = x.size()
|
| 91 |
+
signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
|
| 92 |
+
return torch.cat([x, signal.to(dtype=x.dtype, device=x.device)], axis)
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def subsequent_mask(length):
|
| 96 |
+
mask = torch.tril(torch.ones(length, length)).unsqueeze(0).unsqueeze(0)
|
| 97 |
+
return mask
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
@torch.jit.script
|
| 101 |
+
def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels):
|
| 102 |
+
n_channels_int = n_channels[0]
|
| 103 |
+
in_act = input_a + input_b
|
| 104 |
+
t_act = torch.tanh(in_act[:, :n_channels_int, :])
|
| 105 |
+
s_act = torch.sigmoid(in_act[:, n_channels_int:, :])
|
| 106 |
+
acts = t_act * s_act
|
| 107 |
+
return acts
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def convert_pad_shape(pad_shape):
|
| 111 |
+
l = pad_shape[::-1]
|
| 112 |
+
pad_shape = [item for sublist in l for item in sublist]
|
| 113 |
+
return pad_shape
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
def shift_1d(x):
|
| 117 |
+
x = F.pad(x, convert_pad_shape([[0, 0], [0, 0], [1, 0]]))[:, :, :-1]
|
| 118 |
+
return x
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def sequence_mask(length, max_length=None):
|
| 122 |
+
if max_length is None:
|
| 123 |
+
max_length = length.max()
|
| 124 |
+
x = torch.arange(max_length, dtype=length.dtype, device=length.device)
|
| 125 |
+
return x.unsqueeze(0) < length.unsqueeze(1)
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
def generate_path(duration, mask):
|
| 129 |
+
"""
|
| 130 |
+
duration: [b, 1, t_x]
|
| 131 |
+
mask: [b, 1, t_y, t_x]
|
| 132 |
+
"""
|
| 133 |
+
device = duration.device
|
| 134 |
+
|
| 135 |
+
b, _, t_y, t_x = mask.shape
|
| 136 |
+
cum_duration = torch.cumsum(duration, -1)
|
| 137 |
+
|
| 138 |
+
cum_duration_flat = cum_duration.view(b * t_x)
|
| 139 |
+
path = sequence_mask(cum_duration_flat, t_y).to(mask.dtype)
|
| 140 |
+
path = path.view(b, t_x, t_y)
|
| 141 |
+
path = path - F.pad(path, convert_pad_shape([[0, 0], [1, 0], [0, 0]]))[:, :-1]
|
| 142 |
+
path = path.unsqueeze(1).transpose(2,3) * mask
|
| 143 |
+
return path
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def clip_grad_value_(parameters, clip_value, norm_type=2):
|
| 147 |
+
if isinstance(parameters, torch.Tensor):
|
| 148 |
+
parameters = [parameters]
|
| 149 |
+
parameters = list(filter(lambda p: p.grad is not None, parameters))
|
| 150 |
+
norm_type = float(norm_type)
|
| 151 |
+
if clip_value is not None:
|
| 152 |
+
clip_value = float(clip_value)
|
| 153 |
+
|
| 154 |
+
total_norm = 0
|
| 155 |
+
for p in parameters:
|
| 156 |
+
param_norm = p.grad.data.norm(norm_type)
|
| 157 |
+
total_norm += param_norm.item() ** norm_type
|
| 158 |
+
if clip_value is not None:
|
| 159 |
+
p.grad.data.clamp_(min=-clip_value, max=clip_value)
|
| 160 |
+
total_norm = total_norm ** (1. / norm_type)
|
| 161 |
+
return total_norm
|
configs/ljs_base.json
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"eval_interval": 1000,
|
| 5 |
+
"seed": 1234,
|
| 6 |
+
"epochs": 20000,
|
| 7 |
+
"learning_rate": 2e-4,
|
| 8 |
+
"betas": [0.8, 0.99],
|
| 9 |
+
"eps": 1e-9,
|
| 10 |
+
"batch_size": 64,
|
| 11 |
+
"fp16_run": true,
|
| 12 |
+
"lr_decay": 0.999875,
|
| 13 |
+
"segment_size": 8192,
|
| 14 |
+
"init_lr_ratio": 1,
|
| 15 |
+
"warmup_epochs": 0,
|
| 16 |
+
"c_mel": 45,
|
| 17 |
+
"c_kl": 1.0
|
| 18 |
+
},
|
| 19 |
+
"data": {
|
| 20 |
+
"training_files":"filelists/ljs_audio_text_train_filelist.txt.cleaned",
|
| 21 |
+
"validation_files":"filelists/ljs_audio_text_val_filelist.txt.cleaned",
|
| 22 |
+
"text_cleaners":["english_cleaners2"],
|
| 23 |
+
"max_wav_value": 32768.0,
|
| 24 |
+
"sampling_rate": 22050,
|
| 25 |
+
"filter_length": 1024,
|
| 26 |
+
"hop_length": 256,
|
| 27 |
+
"win_length": 1024,
|
| 28 |
+
"n_mel_channels": 80,
|
| 29 |
+
"mel_fmin": 0.0,
|
| 30 |
+
"mel_fmax": null,
|
| 31 |
+
"add_blank": true,
|
| 32 |
+
"n_speakers": 0,
|
| 33 |
+
"cleaned_text": true
|
| 34 |
+
},
|
| 35 |
+
"model": {
|
| 36 |
+
"inter_channels": 192,
|
| 37 |
+
"hidden_channels": 192,
|
| 38 |
+
"filter_channels": 768,
|
| 39 |
+
"n_heads": 2,
|
| 40 |
+
"n_layers": 6,
|
| 41 |
+
"kernel_size": 3,
|
| 42 |
+
"p_dropout": 0.1,
|
| 43 |
+
"resblock": "1",
|
| 44 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 45 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 46 |
+
"upsample_rates": [8,8,2,2],
|
| 47 |
+
"upsample_initial_channel": 512,
|
| 48 |
+
"upsample_kernel_sizes": [16,16,4,4],
|
| 49 |
+
"n_layers_q": 3,
|
| 50 |
+
"use_spectral_norm": false
|
| 51 |
+
}
|
| 52 |
+
}
|
configs/ljs_nosdp.json
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"eval_interval": 1000,
|
| 5 |
+
"seed": 1234,
|
| 6 |
+
"epochs": 20000,
|
| 7 |
+
"learning_rate": 2e-4,
|
| 8 |
+
"betas": [0.8, 0.99],
|
| 9 |
+
"eps": 1e-9,
|
| 10 |
+
"batch_size": 64,
|
| 11 |
+
"fp16_run": true,
|
| 12 |
+
"lr_decay": 0.999875,
|
| 13 |
+
"segment_size": 8192,
|
| 14 |
+
"init_lr_ratio": 1,
|
| 15 |
+
"warmup_epochs": 0,
|
| 16 |
+
"c_mel": 45,
|
| 17 |
+
"c_kl": 1.0
|
| 18 |
+
},
|
| 19 |
+
"data": {
|
| 20 |
+
"training_files":"filelists/ljs_audio_text_train_filelist.txt.cleaned",
|
| 21 |
+
"validation_files":"filelists/ljs_audio_text_val_filelist.txt.cleaned",
|
| 22 |
+
"text_cleaners":["english_cleaners2"],
|
| 23 |
+
"max_wav_value": 32768.0,
|
| 24 |
+
"sampling_rate": 22050,
|
| 25 |
+
"filter_length": 1024,
|
| 26 |
+
"hop_length": 256,
|
| 27 |
+
"win_length": 1024,
|
| 28 |
+
"n_mel_channels": 80,
|
| 29 |
+
"mel_fmin": 0.0,
|
| 30 |
+
"mel_fmax": null,
|
| 31 |
+
"add_blank": true,
|
| 32 |
+
"n_speakers": 0,
|
| 33 |
+
"cleaned_text": true
|
| 34 |
+
},
|
| 35 |
+
"model": {
|
| 36 |
+
"inter_channels": 192,
|
| 37 |
+
"hidden_channels": 192,
|
| 38 |
+
"filter_channels": 768,
|
| 39 |
+
"n_heads": 2,
|
| 40 |
+
"n_layers": 6,
|
| 41 |
+
"kernel_size": 3,
|
| 42 |
+
"p_dropout": 0.1,
|
| 43 |
+
"resblock": "1",
|
| 44 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 45 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 46 |
+
"upsample_rates": [8,8,2,2],
|
| 47 |
+
"upsample_initial_channel": 512,
|
| 48 |
+
"upsample_kernel_sizes": [16,16,4,4],
|
| 49 |
+
"n_layers_q": 3,
|
| 50 |
+
"use_spectral_norm": false,
|
| 51 |
+
"use_sdp": false
|
| 52 |
+
}
|
| 53 |
+
}
|
configs/nan.json
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 50,
|
| 4 |
+
"eval_interval": 500,
|
| 5 |
+
"seed": 1234,
|
| 6 |
+
"epochs": 20000,
|
| 7 |
+
"learning_rate": 2e-4,
|
| 8 |
+
"betas": [0.8, 0.99],
|
| 9 |
+
"eps": 1e-9,
|
| 10 |
+
"batch_size": 32,
|
| 11 |
+
"fp16_run": true,
|
| 12 |
+
"lr_decay": 0.999875,
|
| 13 |
+
"segment_size": 8192,
|
| 14 |
+
"init_lr_ratio": 1,
|
| 15 |
+
"warmup_epochs": 0,
|
| 16 |
+
"c_mel": 45,
|
| 17 |
+
"c_kl": 1.0
|
| 18 |
+
},
|
| 19 |
+
"data": {
|
| 20 |
+
"training_files":"filelists/train.txt.cleaned",
|
| 21 |
+
"validation_files":"filelists/val.txt.cleaned",
|
| 22 |
+
"text_cleaners":["japanese_phrase_cleaners"],
|
| 23 |
+
"max_wav_value": 32768.0,
|
| 24 |
+
"sampling_rate": 22050,
|
| 25 |
+
"filter_length": 1024,
|
| 26 |
+
"hop_length": 256,
|
| 27 |
+
"win_length": 1024,
|
| 28 |
+
"n_mel_channels": 80,
|
| 29 |
+
"mel_fmin": 0.0,
|
| 30 |
+
"mel_fmax": null,
|
| 31 |
+
"add_blank": true,
|
| 32 |
+
"n_speakers": 0,
|
| 33 |
+
"cleaned_text": true
|
| 34 |
+
},
|
| 35 |
+
"model": {
|
| 36 |
+
"inter_channels": 192,
|
| 37 |
+
"hidden_channels": 192,
|
| 38 |
+
"filter_channels": 768,
|
| 39 |
+
"n_heads": 2,
|
| 40 |
+
"n_layers": 6,
|
| 41 |
+
"kernel_size": 3,
|
| 42 |
+
"p_dropout": 0.1,
|
| 43 |
+
"resblock": "1",
|
| 44 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 45 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 46 |
+
"upsample_rates": [8,8,2,2],
|
| 47 |
+
"upsample_initial_channel": 512,
|
| 48 |
+
"upsample_kernel_sizes": [16,16,4,4],
|
| 49 |
+
"n_layers_q": 3,
|
| 50 |
+
"use_spectral_norm": false
|
| 51 |
+
}
|
| 52 |
+
}
|
configs/vctk_base.json
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"eval_interval": 1000,
|
| 5 |
+
"seed": 1234,
|
| 6 |
+
"epochs": 10000,
|
| 7 |
+
"learning_rate": 2e-4,
|
| 8 |
+
"betas": [0.8, 0.99],
|
| 9 |
+
"eps": 1e-9,
|
| 10 |
+
"batch_size": 64,
|
| 11 |
+
"fp16_run": true,
|
| 12 |
+
"lr_decay": 0.999875,
|
| 13 |
+
"segment_size": 8192,
|
| 14 |
+
"init_lr_ratio": 1,
|
| 15 |
+
"warmup_epochs": 0,
|
| 16 |
+
"c_mel": 45,
|
| 17 |
+
"c_kl": 1.0
|
| 18 |
+
},
|
| 19 |
+
"data": {
|
| 20 |
+
"training_files":"filelists/vctk_audio_sid_text_train_filelist.txt.cleaned",
|
| 21 |
+
"validation_files":"filelists/vctk_audio_sid_text_val_filelist.txt.cleaned",
|
| 22 |
+
"text_cleaners":["english_cleaners2"],
|
| 23 |
+
"max_wav_value": 32768.0,
|
| 24 |
+
"sampling_rate": 22050,
|
| 25 |
+
"filter_length": 1024,
|
| 26 |
+
"hop_length": 256,
|
| 27 |
+
"win_length": 1024,
|
| 28 |
+
"n_mel_channels": 80,
|
| 29 |
+
"mel_fmin": 0.0,
|
| 30 |
+
"mel_fmax": null,
|
| 31 |
+
"add_blank": true,
|
| 32 |
+
"n_speakers": 109,
|
| 33 |
+
"cleaned_text": true
|
| 34 |
+
},
|
| 35 |
+
"model": {
|
| 36 |
+
"inter_channels": 192,
|
| 37 |
+
"hidden_channels": 192,
|
| 38 |
+
"filter_channels": 768,
|
| 39 |
+
"n_heads": 2,
|
| 40 |
+
"n_layers": 6,
|
| 41 |
+
"kernel_size": 3,
|
| 42 |
+
"p_dropout": 0.1,
|
| 43 |
+
"resblock": "1",
|
| 44 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 45 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 46 |
+
"upsample_rates": [8,8,2,2],
|
| 47 |
+
"upsample_initial_channel": 512,
|
| 48 |
+
"upsample_kernel_sizes": [16,16,4,4],
|
| 49 |
+
"n_layers_q": 3,
|
| 50 |
+
"use_spectral_norm": false,
|
| 51 |
+
"gin_channels": 256
|
| 52 |
+
}
|
| 53 |
+
}
|
data_utils.py
ADDED
|
@@ -0,0 +1,392 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import time
|
| 2 |
+
import os
|
| 3 |
+
import random
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
import torch.utils.data
|
| 7 |
+
|
| 8 |
+
import commons
|
| 9 |
+
from mel_processing import spectrogram_torch
|
| 10 |
+
from utils import load_wav_to_torch, load_filepaths_and_text
|
| 11 |
+
from text import text_to_sequence, cleaned_text_to_sequence
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class TextAudioLoader(torch.utils.data.Dataset):
|
| 15 |
+
"""
|
| 16 |
+
1) loads audio, text pairs
|
| 17 |
+
2) normalizes text and converts them to sequences of integers
|
| 18 |
+
3) computes spectrograms from audio files.
|
| 19 |
+
"""
|
| 20 |
+
def __init__(self, audiopaths_and_text, hparams):
|
| 21 |
+
self.audiopaths_and_text = load_filepaths_and_text(audiopaths_and_text)
|
| 22 |
+
self.text_cleaners = hparams.text_cleaners
|
| 23 |
+
self.max_wav_value = hparams.max_wav_value
|
| 24 |
+
self.sampling_rate = hparams.sampling_rate
|
| 25 |
+
self.filter_length = hparams.filter_length
|
| 26 |
+
self.hop_length = hparams.hop_length
|
| 27 |
+
self.win_length = hparams.win_length
|
| 28 |
+
self.sampling_rate = hparams.sampling_rate
|
| 29 |
+
|
| 30 |
+
self.cleaned_text = getattr(hparams, "cleaned_text", False)
|
| 31 |
+
|
| 32 |
+
self.add_blank = hparams.add_blank
|
| 33 |
+
self.min_text_len = getattr(hparams, "min_text_len", 1)
|
| 34 |
+
self.max_text_len = getattr(hparams, "max_text_len", 190)
|
| 35 |
+
|
| 36 |
+
random.seed(1234)
|
| 37 |
+
random.shuffle(self.audiopaths_and_text)
|
| 38 |
+
self._filter()
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def _filter(self):
|
| 42 |
+
"""
|
| 43 |
+
Filter text & store spec lengths
|
| 44 |
+
"""
|
| 45 |
+
# Store spectrogram lengths for Bucketing
|
| 46 |
+
# wav_length ~= file_size / (wav_channels * Bytes per dim) = file_size / (1 * 2)
|
| 47 |
+
# spec_length = wav_length // hop_length
|
| 48 |
+
|
| 49 |
+
audiopaths_and_text_new = []
|
| 50 |
+
lengths = []
|
| 51 |
+
for audiopath, text in self.audiopaths_and_text:
|
| 52 |
+
if self.min_text_len <= len(text) and len(text) <= self.max_text_len:
|
| 53 |
+
audiopaths_and_text_new.append([audiopath, text])
|
| 54 |
+
lengths.append(os.path.getsize(audiopath) // (2 * self.hop_length))
|
| 55 |
+
self.audiopaths_and_text = audiopaths_and_text_new
|
| 56 |
+
self.lengths = lengths
|
| 57 |
+
|
| 58 |
+
def get_audio_text_pair(self, audiopath_and_text):
|
| 59 |
+
# separate filename and text
|
| 60 |
+
audiopath, text = audiopath_and_text[0], audiopath_and_text[1]
|
| 61 |
+
text = self.get_text(text)
|
| 62 |
+
spec, wav = self.get_audio(audiopath)
|
| 63 |
+
return (text, spec, wav)
|
| 64 |
+
|
| 65 |
+
def get_audio(self, filename):
|
| 66 |
+
audio, sampling_rate = load_wav_to_torch(filename)
|
| 67 |
+
if sampling_rate != self.sampling_rate:
|
| 68 |
+
raise ValueError("{} {} SR doesn't match target {} SR".format(
|
| 69 |
+
sampling_rate, self.sampling_rate))
|
| 70 |
+
audio_norm = audio / self.max_wav_value
|
| 71 |
+
audio_norm = audio_norm.unsqueeze(0)
|
| 72 |
+
spec_filename = filename.replace(".wav", ".spec.pt")
|
| 73 |
+
if os.path.exists(spec_filename):
|
| 74 |
+
spec = torch.load(spec_filename)
|
| 75 |
+
else:
|
| 76 |
+
spec = spectrogram_torch(audio_norm, self.filter_length,
|
| 77 |
+
self.sampling_rate, self.hop_length, self.win_length,
|
| 78 |
+
center=False)
|
| 79 |
+
spec = torch.squeeze(spec, 0)
|
| 80 |
+
torch.save(spec, spec_filename)
|
| 81 |
+
return spec, audio_norm
|
| 82 |
+
|
| 83 |
+
def get_text(self, text):
|
| 84 |
+
if self.cleaned_text:
|
| 85 |
+
text_norm = cleaned_text_to_sequence(text)
|
| 86 |
+
else:
|
| 87 |
+
text_norm = text_to_sequence(text, self.text_cleaners)
|
| 88 |
+
if self.add_blank:
|
| 89 |
+
text_norm = commons.intersperse(text_norm, 0)
|
| 90 |
+
text_norm = torch.LongTensor(text_norm)
|
| 91 |
+
return text_norm
|
| 92 |
+
|
| 93 |
+
def __getitem__(self, index):
|
| 94 |
+
return self.get_audio_text_pair(self.audiopaths_and_text[index])
|
| 95 |
+
|
| 96 |
+
def __len__(self):
|
| 97 |
+
return len(self.audiopaths_and_text)
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
class TextAudioCollate():
|
| 101 |
+
""" Zero-pads model inputs and targets
|
| 102 |
+
"""
|
| 103 |
+
def __init__(self, return_ids=False):
|
| 104 |
+
self.return_ids = return_ids
|
| 105 |
+
|
| 106 |
+
def __call__(self, batch):
|
| 107 |
+
"""Collate's training batch from normalized text and aduio
|
| 108 |
+
PARAMS
|
| 109 |
+
------
|
| 110 |
+
batch: [text_normalized, spec_normalized, wav_normalized]
|
| 111 |
+
"""
|
| 112 |
+
# Right zero-pad all one-hot text sequences to max input length
|
| 113 |
+
_, ids_sorted_decreasing = torch.sort(
|
| 114 |
+
torch.LongTensor([x[1].size(1) for x in batch]),
|
| 115 |
+
dim=0, descending=True)
|
| 116 |
+
|
| 117 |
+
max_text_len = max([len(x[0]) for x in batch])
|
| 118 |
+
max_spec_len = max([x[1].size(1) for x in batch])
|
| 119 |
+
max_wav_len = max([x[2].size(1) for x in batch])
|
| 120 |
+
|
| 121 |
+
text_lengths = torch.LongTensor(len(batch))
|
| 122 |
+
spec_lengths = torch.LongTensor(len(batch))
|
| 123 |
+
wav_lengths = torch.LongTensor(len(batch))
|
| 124 |
+
|
| 125 |
+
text_padded = torch.LongTensor(len(batch), max_text_len)
|
| 126 |
+
spec_padded = torch.FloatTensor(len(batch), batch[0][1].size(0), max_spec_len)
|
| 127 |
+
wav_padded = torch.FloatTensor(len(batch), 1, max_wav_len)
|
| 128 |
+
text_padded.zero_()
|
| 129 |
+
spec_padded.zero_()
|
| 130 |
+
wav_padded.zero_()
|
| 131 |
+
for i in range(len(ids_sorted_decreasing)):
|
| 132 |
+
row = batch[ids_sorted_decreasing[i]]
|
| 133 |
+
|
| 134 |
+
text = row[0]
|
| 135 |
+
text_padded[i, :text.size(0)] = text
|
| 136 |
+
text_lengths[i] = text.size(0)
|
| 137 |
+
|
| 138 |
+
spec = row[1]
|
| 139 |
+
spec_padded[i, :, :spec.size(1)] = spec
|
| 140 |
+
spec_lengths[i] = spec.size(1)
|
| 141 |
+
|
| 142 |
+
wav = row[2]
|
| 143 |
+
wav_padded[i, :, :wav.size(1)] = wav
|
| 144 |
+
wav_lengths[i] = wav.size(1)
|
| 145 |
+
|
| 146 |
+
if self.return_ids:
|
| 147 |
+
return text_padded, text_lengths, spec_padded, spec_lengths, wav_padded, wav_lengths, ids_sorted_decreasing
|
| 148 |
+
return text_padded, text_lengths, spec_padded, spec_lengths, wav_padded, wav_lengths
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
"""Multi speaker version"""
|
| 152 |
+
class TextAudioSpeakerLoader(torch.utils.data.Dataset):
|
| 153 |
+
"""
|
| 154 |
+
1) loads audio, speaker_id, text pairs
|
| 155 |
+
2) normalizes text and converts them to sequences of integers
|
| 156 |
+
3) computes spectrograms from audio files.
|
| 157 |
+
"""
|
| 158 |
+
def __init__(self, audiopaths_sid_text, hparams):
|
| 159 |
+
self.audiopaths_sid_text = load_filepaths_and_text(audiopaths_sid_text)
|
| 160 |
+
self.text_cleaners = hparams.text_cleaners
|
| 161 |
+
self.max_wav_value = hparams.max_wav_value
|
| 162 |
+
self.sampling_rate = hparams.sampling_rate
|
| 163 |
+
self.filter_length = hparams.filter_length
|
| 164 |
+
self.hop_length = hparams.hop_length
|
| 165 |
+
self.win_length = hparams.win_length
|
| 166 |
+
self.sampling_rate = hparams.sampling_rate
|
| 167 |
+
|
| 168 |
+
self.cleaned_text = getattr(hparams, "cleaned_text", False)
|
| 169 |
+
|
| 170 |
+
self.add_blank = hparams.add_blank
|
| 171 |
+
self.min_text_len = getattr(hparams, "min_text_len", 1)
|
| 172 |
+
self.max_text_len = getattr(hparams, "max_text_len", 190)
|
| 173 |
+
|
| 174 |
+
random.seed(1234)
|
| 175 |
+
random.shuffle(self.audiopaths_sid_text)
|
| 176 |
+
self._filter()
|
| 177 |
+
|
| 178 |
+
def _filter(self):
|
| 179 |
+
"""
|
| 180 |
+
Filter text & store spec lengths
|
| 181 |
+
"""
|
| 182 |
+
# Store spectrogram lengths for Bucketing
|
| 183 |
+
# wav_length ~= file_size / (wav_channels * Bytes per dim) = file_size / (1 * 2)
|
| 184 |
+
# spec_length = wav_length // hop_length
|
| 185 |
+
|
| 186 |
+
audiopaths_sid_text_new = []
|
| 187 |
+
lengths = []
|
| 188 |
+
for audiopath, sid, text in self.audiopaths_sid_text:
|
| 189 |
+
if self.min_text_len <= len(text) and len(text) <= self.max_text_len:
|
| 190 |
+
audiopaths_sid_text_new.append([audiopath, sid, text])
|
| 191 |
+
lengths.append(os.path.getsize(audiopath) // (2 * self.hop_length))
|
| 192 |
+
self.audiopaths_sid_text = audiopaths_sid_text_new
|
| 193 |
+
self.lengths = lengths
|
| 194 |
+
|
| 195 |
+
def get_audio_text_speaker_pair(self, audiopath_sid_text):
|
| 196 |
+
# separate filename, speaker_id and text
|
| 197 |
+
audiopath, sid, text = audiopath_sid_text[0], audiopath_sid_text[1], audiopath_sid_text[2]
|
| 198 |
+
text = self.get_text(text)
|
| 199 |
+
spec, wav = self.get_audio(audiopath)
|
| 200 |
+
sid = self.get_sid(sid)
|
| 201 |
+
return (text, spec, wav, sid)
|
| 202 |
+
|
| 203 |
+
def get_audio(self, filename):
|
| 204 |
+
audio, sampling_rate = load_wav_to_torch(filename)
|
| 205 |
+
if sampling_rate != self.sampling_rate:
|
| 206 |
+
raise ValueError("{} {} SR doesn't match target {} SR".format(
|
| 207 |
+
sampling_rate, self.sampling_rate))
|
| 208 |
+
audio_norm = audio / self.max_wav_value
|
| 209 |
+
audio_norm = audio_norm.unsqueeze(0)
|
| 210 |
+
spec_filename = filename.replace(".wav", ".spec.pt")
|
| 211 |
+
if os.path.exists(spec_filename):
|
| 212 |
+
spec = torch.load(spec_filename)
|
| 213 |
+
else:
|
| 214 |
+
spec = spectrogram_torch(audio_norm, self.filter_length,
|
| 215 |
+
self.sampling_rate, self.hop_length, self.win_length,
|
| 216 |
+
center=False)
|
| 217 |
+
spec = torch.squeeze(spec, 0)
|
| 218 |
+
torch.save(spec, spec_filename)
|
| 219 |
+
return spec, audio_norm
|
| 220 |
+
|
| 221 |
+
def get_text(self, text):
|
| 222 |
+
if self.cleaned_text:
|
| 223 |
+
text_norm = cleaned_text_to_sequence(text)
|
| 224 |
+
else:
|
| 225 |
+
text_norm = text_to_sequence(text, self.text_cleaners)
|
| 226 |
+
if self.add_blank:
|
| 227 |
+
text_norm = commons.intersperse(text_norm, 0)
|
| 228 |
+
text_norm = torch.LongTensor(text_norm)
|
| 229 |
+
return text_norm
|
| 230 |
+
|
| 231 |
+
def get_sid(self, sid):
|
| 232 |
+
sid = torch.LongTensor([int(sid)])
|
| 233 |
+
return sid
|
| 234 |
+
|
| 235 |
+
def __getitem__(self, index):
|
| 236 |
+
return self.get_audio_text_speaker_pair(self.audiopaths_sid_text[index])
|
| 237 |
+
|
| 238 |
+
def __len__(self):
|
| 239 |
+
return len(self.audiopaths_sid_text)
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
class TextAudioSpeakerCollate():
|
| 243 |
+
""" Zero-pads model inputs and targets
|
| 244 |
+
"""
|
| 245 |
+
def __init__(self, return_ids=False):
|
| 246 |
+
self.return_ids = return_ids
|
| 247 |
+
|
| 248 |
+
def __call__(self, batch):
|
| 249 |
+
"""Collate's training batch from normalized text, audio and speaker identities
|
| 250 |
+
PARAMS
|
| 251 |
+
------
|
| 252 |
+
batch: [text_normalized, spec_normalized, wav_normalized, sid]
|
| 253 |
+
"""
|
| 254 |
+
# Right zero-pad all one-hot text sequences to max input length
|
| 255 |
+
_, ids_sorted_decreasing = torch.sort(
|
| 256 |
+
torch.LongTensor([x[1].size(1) for x in batch]),
|
| 257 |
+
dim=0, descending=True)
|
| 258 |
+
|
| 259 |
+
max_text_len = max([len(x[0]) for x in batch])
|
| 260 |
+
max_spec_len = max([x[1].size(1) for x in batch])
|
| 261 |
+
max_wav_len = max([x[2].size(1) for x in batch])
|
| 262 |
+
|
| 263 |
+
text_lengths = torch.LongTensor(len(batch))
|
| 264 |
+
spec_lengths = torch.LongTensor(len(batch))
|
| 265 |
+
wav_lengths = torch.LongTensor(len(batch))
|
| 266 |
+
sid = torch.LongTensor(len(batch))
|
| 267 |
+
|
| 268 |
+
text_padded = torch.LongTensor(len(batch), max_text_len)
|
| 269 |
+
spec_padded = torch.FloatTensor(len(batch), batch[0][1].size(0), max_spec_len)
|
| 270 |
+
wav_padded = torch.FloatTensor(len(batch), 1, max_wav_len)
|
| 271 |
+
text_padded.zero_()
|
| 272 |
+
spec_padded.zero_()
|
| 273 |
+
wav_padded.zero_()
|
| 274 |
+
for i in range(len(ids_sorted_decreasing)):
|
| 275 |
+
row = batch[ids_sorted_decreasing[i]]
|
| 276 |
+
|
| 277 |
+
text = row[0]
|
| 278 |
+
text_padded[i, :text.size(0)] = text
|
| 279 |
+
text_lengths[i] = text.size(0)
|
| 280 |
+
|
| 281 |
+
spec = row[1]
|
| 282 |
+
spec_padded[i, :, :spec.size(1)] = spec
|
| 283 |
+
spec_lengths[i] = spec.size(1)
|
| 284 |
+
|
| 285 |
+
wav = row[2]
|
| 286 |
+
wav_padded[i, :, :wav.size(1)] = wav
|
| 287 |
+
wav_lengths[i] = wav.size(1)
|
| 288 |
+
|
| 289 |
+
sid[i] = row[3]
|
| 290 |
+
|
| 291 |
+
if self.return_ids:
|
| 292 |
+
return text_padded, text_lengths, spec_padded, spec_lengths, wav_padded, wav_lengths, sid, ids_sorted_decreasing
|
| 293 |
+
return text_padded, text_lengths, spec_padded, spec_lengths, wav_padded, wav_lengths, sid
|
| 294 |
+
|
| 295 |
+
|
| 296 |
+
class DistributedBucketSampler(torch.utils.data.distributed.DistributedSampler):
|
| 297 |
+
"""
|
| 298 |
+
Maintain similar input lengths in a batch.
|
| 299 |
+
Length groups are specified by boundaries.
|
| 300 |
+
Ex) boundaries = [b1, b2, b3] -> any batch is included either {x | b1 < length(x) <=b2} or {x | b2 < length(x) <= b3}.
|
| 301 |
+
|
| 302 |
+
It removes samples which are not included in the boundaries.
|
| 303 |
+
Ex) boundaries = [b1, b2, b3] -> any x s.t. length(x) <= b1 or length(x) > b3 are discarded.
|
| 304 |
+
"""
|
| 305 |
+
def __init__(self, dataset, batch_size, boundaries, num_replicas=None, rank=None, shuffle=True):
|
| 306 |
+
super().__init__(dataset, num_replicas=num_replicas, rank=rank, shuffle=shuffle)
|
| 307 |
+
self.lengths = dataset.lengths
|
| 308 |
+
self.batch_size = batch_size
|
| 309 |
+
self.boundaries = boundaries
|
| 310 |
+
|
| 311 |
+
self.buckets, self.num_samples_per_bucket = self._create_buckets()
|
| 312 |
+
self.total_size = sum(self.num_samples_per_bucket)
|
| 313 |
+
self.num_samples = self.total_size // self.num_replicas
|
| 314 |
+
|
| 315 |
+
def _create_buckets(self):
|
| 316 |
+
buckets = [[] for _ in range(len(self.boundaries) - 1)]
|
| 317 |
+
for i in range(len(self.lengths)):
|
| 318 |
+
length = self.lengths[i]
|
| 319 |
+
idx_bucket = self._bisect(length)
|
| 320 |
+
if idx_bucket != -1:
|
| 321 |
+
buckets[idx_bucket].append(i)
|
| 322 |
+
|
| 323 |
+
for i in range(len(buckets) - 1, 0, -1):
|
| 324 |
+
if len(buckets[i]) == 0:
|
| 325 |
+
buckets.pop(i)
|
| 326 |
+
self.boundaries.pop(i+1)
|
| 327 |
+
|
| 328 |
+
num_samples_per_bucket = []
|
| 329 |
+
for i in range(len(buckets)):
|
| 330 |
+
len_bucket = len(buckets[i])
|
| 331 |
+
total_batch_size = self.num_replicas * self.batch_size
|
| 332 |
+
rem = (total_batch_size - (len_bucket % total_batch_size)) % total_batch_size
|
| 333 |
+
num_samples_per_bucket.append(len_bucket + rem)
|
| 334 |
+
return buckets, num_samples_per_bucket
|
| 335 |
+
|
| 336 |
+
def __iter__(self):
|
| 337 |
+
# deterministically shuffle based on epoch
|
| 338 |
+
g = torch.Generator()
|
| 339 |
+
g.manual_seed(self.epoch)
|
| 340 |
+
|
| 341 |
+
indices = []
|
| 342 |
+
if self.shuffle:
|
| 343 |
+
for bucket in self.buckets:
|
| 344 |
+
indices.append(torch.randperm(len(bucket), generator=g).tolist())
|
| 345 |
+
else:
|
| 346 |
+
for bucket in self.buckets:
|
| 347 |
+
indices.append(list(range(len(bucket))))
|
| 348 |
+
|
| 349 |
+
batches = []
|
| 350 |
+
for i in range(len(self.buckets)):
|
| 351 |
+
bucket = self.buckets[i]
|
| 352 |
+
len_bucket = len(bucket)
|
| 353 |
+
ids_bucket = indices[i]
|
| 354 |
+
num_samples_bucket = self.num_samples_per_bucket[i]
|
| 355 |
+
|
| 356 |
+
# add extra samples to make it evenly divisible
|
| 357 |
+
rem = num_samples_bucket - len_bucket
|
| 358 |
+
ids_bucket = ids_bucket + ids_bucket * (rem // len_bucket) + ids_bucket[:(rem % len_bucket)]
|
| 359 |
+
|
| 360 |
+
# subsample
|
| 361 |
+
ids_bucket = ids_bucket[self.rank::self.num_replicas]
|
| 362 |
+
|
| 363 |
+
# batching
|
| 364 |
+
for j in range(len(ids_bucket) // self.batch_size):
|
| 365 |
+
batch = [bucket[idx] for idx in ids_bucket[j*self.batch_size:(j+1)*self.batch_size]]
|
| 366 |
+
batches.append(batch)
|
| 367 |
+
|
| 368 |
+
if self.shuffle:
|
| 369 |
+
batch_ids = torch.randperm(len(batches), generator=g).tolist()
|
| 370 |
+
batches = [batches[i] for i in batch_ids]
|
| 371 |
+
self.batches = batches
|
| 372 |
+
|
| 373 |
+
assert len(self.batches) * self.batch_size == self.num_samples
|
| 374 |
+
return iter(self.batches)
|
| 375 |
+
|
| 376 |
+
def _bisect(self, x, lo=0, hi=None):
|
| 377 |
+
if hi is None:
|
| 378 |
+
hi = len(self.boundaries) - 1
|
| 379 |
+
|
| 380 |
+
if hi > lo:
|
| 381 |
+
mid = (hi + lo) // 2
|
| 382 |
+
if self.boundaries[mid] < x and x <= self.boundaries[mid+1]:
|
| 383 |
+
return mid
|
| 384 |
+
elif x <= self.boundaries[mid]:
|
| 385 |
+
return self._bisect(x, lo, mid)
|
| 386 |
+
else:
|
| 387 |
+
return self._bisect(x, mid + 1, hi)
|
| 388 |
+
else:
|
| 389 |
+
return -1
|
| 390 |
+
|
| 391 |
+
def __len__(self):
|
| 392 |
+
return self.num_samples // self.batch_size
|
filelists/train.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
filelists/train.txt.cleaned
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
filelists/val.txt
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
wav/nen001_001.wav|はい?呼びました?
|
| 2 |
+
wav/nen001_002.wav|驚かせたならごめんなさい。通りかかったときにちょうど名前が聞こえてきたので
|
| 3 |
+
wav/nen001_003.wav|私に何か用ですか?
|
| 4 |
+
wav/nen001_004.wav|いえ、少し気になっただけですから、別に怒っているわけじゃないです。気にしないで下さい
|
| 5 |
+
wav/nen001_005.wav|それより仮屋さん、例の件ですが――
|
| 6 |
+
wav/nen001_006.wav|喜んでもらえたならなによりです
|
| 7 |
+
wav/nen001_007.wav|また何かあったら、いつでも部室に来て下さい
|
| 8 |
+
wav/nen001_008.wav|大したことじゃないので。それより体調の方はもういいんですか?
|
| 9 |
+
wav/nen001_009.wav|それはよかったです。他に困ったことはありますか?
|
| 10 |
+
wav/nen001_010.wav|何かあったらいつでも話して下さい。学院のことじゃなく、私事に関することでも何でも
|
| 11 |
+
wav/nen001_011.wav|はい、いつでもどうぞ
|
| 12 |
+
wav/nen001_012.wav|保科君も
|
| 13 |
+
wav/nen001_013.wav|もし何か困ったことがあれば、力になりますから
|
| 14 |
+
wav/nen001_014.wav|そうですか?私には、なにか悩み事があるように見えたりしましたけど……
|
| 15 |
+
wav/nen001_015.wav|――なんて、言ってみただけですから、深い意味はありませんよ
|
| 16 |
+
wav/nen001_016.wav|いえ、そういうわけじゃなくって……ただ何となく。そんな気がしただけですから
|
| 17 |
+
wav/nen001_017.wav|あ、いえ、絶対に秘密というわけじゃないので気にしないで下さい
|
| 18 |
+
wav/nen001_018.wav|好奇心だけで来られると困るので、本当に悩んでる人以外には、広めないようにお願いしているだけです
|
| 19 |
+
wav/nen001_019.wav|そんな仰々しい話じゃなく……私は、オカ研に所属しているんです
|
| 20 |
+
wav/nen001_020.wav|はい。そのオカ研です
|
| 21 |
+
wav/nen001_021.wav|そうですよ。実は私たちが入学する前からあった部活なんです。今は部員がいなくて、所属してるのは私一人ですが
|
| 22 |
+
wav/nen001_022.wav|なので最近は、学生会の方からは結構つつかれてて……活動も、発表などを意欲的にしているわけじゃありませんからね
|
| 23 |
+
wav/nen001_023.wav|いえ、私は占いを。オカルトと言っても幅は広いので。それに部には私しかいませんから、結構好きにできるんです
|
| 24 |
+
wav/nen001_024.wav|さすがに白蛇占いはできませんよ
|
| 25 |
+
wav/nen001_025.wav|一応。知ってはいますけど、私にできるのはタロットぐらいです。あくまで趣味程度ですから
|
| 26 |
+
wav/nen001_026.wav|あくまで占いの延長線上のものですから。人生相談なんていうほど大層な物じゃありません
|
| 27 |
+
wav/nen001_027.wav|でも……もし保科君も嫌いでなければ、いつでも部室に来て下さい
|
| 28 |
+
wav/nen001_028.wav|あ、はい。すぐに行きます
|
| 29 |
+
wav/nen001_029.wav|それじゃあ私はこれで
|
| 30 |
+
wav/nen001_030.wav|あの、先生
|
| 31 |
+
wav/nen001_031.wav|はい。気付いたらこんな時間になってしまって
|
| 32 |
+
wav/nen001_032.wav|図書室は……もう誰もいないんですか?
|
| 33 |
+
wav/nen001_033.wav|その前にちょっと調べ物をさせて欲しいんですが、鍵を貸してもらえませんか?
|
| 34 |
+
wav/nen001_034.wav|タロットカードのことで少々。時間はかかりません。5分……は無理かも……でも20分もあれば終わりますから……お願いします
|
| 35 |
+
wav/nen001_035.wav|わかりました。ありがとう……ございます
|
| 36 |
+
wav/nen001_036.wav|は、はい………気をつけます……ハァ、ハァ……
|
| 37 |
+
wav/nen001_037.wav|……ハァ……ハァ……
|
| 38 |
+
wav/nen001_038.wav|……大丈夫、ですよね……んっ……
|
| 39 |
+
wav/nen001_039.wav|……ハァ……ハァ……
|
| 40 |
+
wav/nen001_040.wav|んっ、んん……
|
| 41 |
+
wav/nen001_041.wav|あ……あっ、んっ……んんン、んッ、んッ、んぅぅッ……
|
| 42 |
+
wav/nen001_042.wav|んっ、ふぅぅ……はぁ、はぁ、あっ、ああぁぁ……ふぁぁぁ……
|
| 43 |
+
wav/nen001_043.wav|はぁ、はぁぁ……ん、ん、んっ……はぁぁ……ぁ、ぁ、ぁ……ぁぁ……ンッ……!
|
| 44 |
+
wav/nen001_044.wav|あぁ、もう……こ、んなの、最低ですッ……はぁ、はぁ……学院内で、おっ、オナニー……をするなんてっ、ん、んんっ
|
| 45 |
+
wav/nen001_045.wav|あっ、ああぁぁ……はぁ、はぁ、はぁぁぁ……ん、んンッッ
|
| 46 |
+
wav/nen001_046.wav|はぁ、はぁ……私、なんてこと……あっ、あぁぁ……でも、気持ちよくて止まりません……ん、んんッ、ふぁ、あ、あぁぁぁ……
|
| 47 |
+
wav/nen001_047.wav|うっ……あ、あ、あっ、あっ、ひあっ、ん、んはっ……はっ、はっ、んんぅぅッ
|
| 48 |
+
wav/nen001_048.wav|はぁ……はぁ……んっ、んんん……んぁ、んぁ、あっ……んっ、ぃぃぃッ
|
| 49 |
+
wav/nen001_049.wav|んっ、んっ、んくっ……ひっ、あっ、ぁっ、ぁっ、んんーーッ……
|
| 50 |
+
wav/nen001_050.wav|はぁぁぁ……はぁ、はぁ……んんっ、んっ、んんん、んぁ……んぁ、ぁ、ぁ、ぁぁぁぁ……ッ!
|
| 51 |
+
wav/nen001_051.wav|だめ、早く、しないと……先生が、戻って、きます……こんなところ、見られたら……んっ、んっ、んぁ、んぁ、あ、あ、あ、あ、あ……
|
| 52 |
+
wav/nen001_052.wav|あ、あ、ん、んんんッ……はっ、はぁ、はぁ、あぁぁもう、本当に、最低ですっ……
|
| 53 |
+
wav/nen001_053.wav|んッ……んはぁッ、はぁ、はぁ……ンン、んぁ、んぁぁ……あ、あ、あぁぁ……
|
| 54 |
+
wav/nen001_054.wav|はぁー、はぁーーぁぁ、気持ちいい……あっ、あぃ、あぃっ、いい……本当に……んん
|
| 55 |
+
wav/nen001_055.wav|早く……こんなこと、早く……先生が、また様子を……見に、きたりしない、内に……はぁ、はぁ、はぁ、はぁ
|
| 56 |
+
wav/nen001_056.wav|はぁ、はぁ、はぁっ、はぁぁぁ……ぁ、ぁ、ぁ……ぁぁ……ぁぁんッ、んっ、んーッ
|
| 57 |
+
wav/nen001_057.wav|んんッ、ん、んはぁぁぁーー……はぁ、はぁ、はぁァン、あッ、あん、あぁぁンッ
|
| 58 |
+
wav/nen001_058.wav|はぁ、はぁ、はぁぁ……ヨダレ、でちゃう……じゅる……んぁっ、はぁ、はぁぁ……はっ、はっ、はっ……じゅる
|
| 59 |
+
wav/nen001_059.wav|こんな、に、気持ちいいなんて、最低です……本当、図書室でオナニーなんて、最低すぎます……でも、でも
|
| 60 |
+
wav/nen001_060.wav|あああぁぁ……今は、止められなくて……じゅる……はぁ、はぁぁ……あぁぁぁあぁ……
|
| 61 |
+
wav/nen001_061.wav|はぁ、はぁ、はぁ……早く……あっ、あっ、あぁぁ……ぁぁぁ、早く、早く
|
| 62 |
+
wav/nen001_062.wav|早く、イきたい、イきたい……このままイきたいぃ……はぁ、はぁ、はぁ、ぁぁ、ぁっ、ぁっ、あっ、あっ、あぁッ!
|
| 63 |
+
wav/nen001_063.wav|あっ、あっ、ああぁぁ……痺れて、きたぁ……だめ、イきそう……んっ、だめじゃなくて、あっ、あっ、早く、このまま……早く早く早く
|
filelists/val.txt.cleaned
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
wav/nen001_001.wav|hai? yobimashIta?
|
| 2 |
+
wav/nen001_002.wav|odorokasetanara gomeNnasai. toorikakaclta tokini choodo namaega kIkoete kitanode.
|
| 3 |
+
wav/nen001_003.wav|watashini nanikayoodesUka?
|
| 4 |
+
wav/nen001_004.wav|ie, sUkoshI kini nacltadakedesUkara, betsuni okoclte iru wakejanaidesU. kini shinaide kudasai.
|
| 5 |
+
wav/nen001_005.wav|soreyori kariyasaN, reeno keNdesUga----
|
| 6 |
+
wav/nen001_006.wav|yorokoNde moraetanara naniyoridesU.
|
| 7 |
+
wav/nen001_007.wav|mata nanika acltara, itsudemo bushItsuni kite kudasai.
|
| 8 |
+
wav/nen001_008.wav|taishIta kotojanainode. soreyori taichoono hoowa moo ii NdesUka?
|
| 9 |
+
wav/nen001_009.wav|sorewa yokacltadesU. tani komaclta kotowa arimasUka?
|
| 10 |
+
wav/nen001_010.wav|nanika acltara itsudemo hanashIte kudasai. gakuiNno kotojanaku, shijini kaNsuru kotodemo nanidemo.
|
| 11 |
+
wav/nen001_011.wav|hai, itsudemo doozo.
|
| 12 |
+
wav/nen001_012.wav|hoshinakuNmo.
|
| 13 |
+
wav/nen001_013.wav|moshi nanika komaclta kotoga areba, chIkarani narimasUkara.
|
| 14 |
+
wav/nen001_014.wav|soodesUka? watashiniwa, nanika nayamigotoga aru yooni mietari shimashItakedo......
|
| 15 |
+
wav/nen001_015.wav|---- naNte, iclte mitadakedesUkara, fUkai imiwaarimaseNyo.
|
| 16 |
+
wav/nen001_016.wav|ie, sooyuu wakejanakuclte...... tada naNtonaku. soNna kiga shItadakedesUkara.
|
| 17 |
+
wav/nen001_017.wav|a, ie, zecltaini himitsUto iu wakejanainode kini shinaide kudasai.
|
| 18 |
+
wav/nen001_018.wav|kookIshiNdakede korareruto komarunode, hoNtooni nayaNde runiNigainiwa, hiromenai yooni onegai shIte irudakedesU.
|
| 19 |
+
wav/nen001_019.wav|soNna gyoogyooshii hanashijanaku...... watashiwa, okakeNni shozoku shIte iru NdesU.
|
| 20 |
+
wav/nen001_020.wav|hai. sono okakeNdesU.
|
| 21 |
+
wav/nen001_021.wav|soodesUyo. jitsuwa watashitachiga nyuugakU suru maekara aclta bukatsuna NdesU. imawa buiNga inakUte, shozoku shIteru nowa watashI hitoridesUga.
|
| 22 |
+
wav/nen001_022.wav|nanode saikiNwa, gakUseekaino hookarawa keclkoo tsUtsukaretete...... katsudoomo, haclpyoonadoo iyokutekini shIte iru wakejaarimaseNkarane.
|
| 23 |
+
wav/nen001_023.wav|ie, watashiwa uranaio. okarutoto icltemo habawa hiroinode. soreni buniwa watashIshika imaseNkara, keclkoo sUkini dekiru NdesU.
|
| 24 |
+
wav/nen001_024.wav|sasugani shirohebiuranaiwa dekimaseNyo.
|
| 25 |
+
wav/nen001_025.wav|ichioo. shiclte haimasUkedo, watashini dekiru nowa tarocltoguraidesU. akumade shumiteedodesUkara.
|
| 26 |
+
wav/nen001_026.wav|akumade uranaino eNchooseNjoono monodesUkara. jiNseesoodaNnaNte iuhodo taisoona monojaarimaseN.
|
| 27 |
+
wav/nen001_027.wav|demo...... moshI hoshinakuNmo kiraidenakereba, itsudemo bushItsuni kite kudasai.
|
| 28 |
+
wav/nen001_028.wav|a, hai. suguni ikimasU.
|
| 29 |
+
wav/nen001_029.wav|sorejaa watashiwa korede.
|
| 30 |
+
wav/nen001_030.wav|ano, seNsee.
|
| 31 |
+
wav/nen001_031.wav|hai. kizuitara koNna jikaNni naclte shimaclte.
|
| 32 |
+
wav/nen001_032.wav|toshoshItsuwa...... moo daremo inai NdesUka?
|
| 33 |
+
wav/nen001_033.wav|sono maeni choclto shirabebutsuo sasetehoshii NdesUga, kagio kashIte moraemaseNka?
|
| 34 |
+
wav/nen001_034.wav|tarocltokaadono kotode shooshoo. jikaNwa kakarimaseN. gofuN...... w a murikamo...... demo nijuclpuNmo areba owarimasUkara...... onegai shimasU.
|
| 35 |
+
wav/nen001_035.wav|wakarimashIta. arigatoo...... gozaimasU.
|
| 36 |
+
wav/nen001_036.wav|w a, hai......... kio tsUkemasU...... haa, haa......
|
| 37 |
+
wav/nen001_037.wav|...... haa...... haa......
|
| 38 |
+
wav/nen001_038.wav|...... daijoobu, desUyone...... Ncl......
|
| 39 |
+
wav/nen001_039.wav|...... haa...... haa......
|
| 40 |
+
wav/nen001_040.wav|Ncl, NN......
|
| 41 |
+
wav/nen001_041.wav|a...... acl, Ncl...... NN N, Ncl, Ncl, Nuucl......
|
| 42 |
+
wav/nen001_042.wav|Ncl, fuuu...... haa, haa, acl, aaaa...... faaa......
|
| 43 |
+
wav/nen001_043.wav|haa, haaa...... N, N, Ncl...... haaa...... a, a, a...... aa...... Ncl......!
|
| 44 |
+
wav/nen001_044.wav|aa, moo...... k o, Nna n o, saiteede sucl...... haa, haa...... gakuiNnaide, ocl, onanii...... o surunaNtecl, N, NNcl.
|
| 45 |
+
wav/nen001_045.wav|acl, aaaa...... haa, haa, haaaa...... N, NNclcl.
|
| 46 |
+
wav/nen001_046.wav|haa, haa...... watashi, naNte koto...... acl, aaa...... demo, kimochiyokUte tomarimaseN...... N, NNcl, f a, a, aaaa......
|
| 47 |
+
wav/nen001_047.wav|ucl...... a, a, acl, acl, hiacl, N, Nhacl...... hacl, hacl, NNuucl.
|
| 48 |
+
wav/nen001_048.wav|haa...... haa...... Ncl, NNN...... Na, Na, acl...... Ncl, iiicl.
|
| 49 |
+
wav/nen001_049.wav|Ncl, Ncl, N kucl...... hicl, acl, acl, acl, NNNNcl......
|
| 50 |
+
wav/nen001_050.wav|haaaa...... haa, haa...... NNcl, Ncl, NNN, Na...... Na, a, a, aaaa...... cl!
|
| 51 |
+
wav/nen001_051.wav|dame, hayaku, shinaito...... seNseega, modoclte, kimasU...... koNna tokoro, miraretara...... Ncl, Ncl, Na, Na, a, a, a, a, a......
|
| 52 |
+
wav/nen001_052.wav|a, a, N, NNN cl...... hacl, haa, haa, aaa moo, hoNtooni, saiteede sucl......
|
| 53 |
+
wav/nen001_053.wav|Ncl...... Nhaacl, haa, haa...... NN, Na, Naa...... a, a, aaa......
|
| 54 |
+
wav/nen001_054.wav|haaa, haaaaaa, kimochiii...... acl, ai, aicl, ii...... hoNtooni...... NN.
|
| 55 |
+
wav/nen001_055.wav|hayaku...... koNna koto, hayaku...... seNseega, mata yoosuo...... mini, kItarishinai, uchini...... haa, haa, haa, haa.
|
| 56 |
+
wav/nen001_056.wav|haa, haa, haacl, haaaa...... a, a, a...... aa...... aaNcl, Ncl, NNcl.
|
| 57 |
+
wav/nen001_057.wav|NNcl, N, Nhaaaaaa...... haa, haa, haaaN, acl, aN, aaaNcl.
|
| 58 |
+
wav/nen001_058.wav|haa, haa, haaa...... yodare, dechau...... juru...... Nacl, haa, haaa...... hacl, hacl, hacl...... juru.
|
| 59 |
+
wav/nen001_059.wav|koNna, n i, kimochiiinaNte, saiteedesU...... hoNtoo, toshoshItsude onaniinaNte, saitee sugimasU...... demo, demo.
|
| 60 |
+
wav/nen001_060.wav|aaaaa...... imawa, tomerarenakUte...... juru...... haa, haaa...... aaaaaa......
|
| 61 |
+
wav/nen001_061.wav|haa, haa, haa...... hayaku...... acl, acl, aaa...... aaa, hayaku, hayaku.
|
| 62 |
+
wav/nen001_062.wav|hayaku, ikitai, ikitai...... kono mamaikitaii...... haa, haa, haa, aa, acl, acl, acl, acl, aacl!
|
| 63 |
+
wav/nen001_063.wav|acl, acl, aaaa...... shibirete, kita a...... dame, ikIsou...... Ncl, damejanakUte, acl, acl, hayaku, kono mama...... hayakUhayakUhayaku.
|
inference.ipynb
ADDED
|
@@ -0,0 +1,200 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": null,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [],
|
| 8 |
+
"source": [
|
| 9 |
+
"%matplotlib inline\n",
|
| 10 |
+
"import matplotlib.pyplot as plt\n",
|
| 11 |
+
"import IPython.display as ipd\n",
|
| 12 |
+
"\n",
|
| 13 |
+
"import os\n",
|
| 14 |
+
"import json\n",
|
| 15 |
+
"import math\n",
|
| 16 |
+
"import torch\n",
|
| 17 |
+
"from torch import nn\n",
|
| 18 |
+
"from torch.nn import functional as F\n",
|
| 19 |
+
"from torch.utils.data import DataLoader\n",
|
| 20 |
+
"\n",
|
| 21 |
+
"import commons\n",
|
| 22 |
+
"import utils\n",
|
| 23 |
+
"from data_utils import TextAudioLoader, TextAudioCollate, TextAudioSpeakerLoader, TextAudioSpeakerCollate\n",
|
| 24 |
+
"from models import SynthesizerTrn\n",
|
| 25 |
+
"from text.symbols import symbols\n",
|
| 26 |
+
"from text import text_to_sequence\n",
|
| 27 |
+
"\n",
|
| 28 |
+
"from scipy.io.wavfile import write\n",
|
| 29 |
+
"\n",
|
| 30 |
+
"\n",
|
| 31 |
+
"def get_text(text, hps):\n",
|
| 32 |
+
" text_norm = text_to_sequence(text, hps.data.text_cleaners)\n",
|
| 33 |
+
" if hps.data.add_blank:\n",
|
| 34 |
+
" text_norm = commons.intersperse(text_norm, 0)\n",
|
| 35 |
+
" text_norm = torch.LongTensor(text_norm)\n",
|
| 36 |
+
" return text_norm"
|
| 37 |
+
]
|
| 38 |
+
},
|
| 39 |
+
{
|
| 40 |
+
"cell_type": "markdown",
|
| 41 |
+
"metadata": {},
|
| 42 |
+
"source": [
|
| 43 |
+
"## LJ Speech"
|
| 44 |
+
]
|
| 45 |
+
},
|
| 46 |
+
{
|
| 47 |
+
"cell_type": "code",
|
| 48 |
+
"execution_count": null,
|
| 49 |
+
"metadata": {},
|
| 50 |
+
"outputs": [],
|
| 51 |
+
"source": [
|
| 52 |
+
"hps = utils.get_hparams_from_file(\"./configs/ljs_base.json\")"
|
| 53 |
+
]
|
| 54 |
+
},
|
| 55 |
+
{
|
| 56 |
+
"cell_type": "code",
|
| 57 |
+
"execution_count": null,
|
| 58 |
+
"metadata": {},
|
| 59 |
+
"outputs": [],
|
| 60 |
+
"source": [
|
| 61 |
+
"net_g = SynthesizerTrn(\n",
|
| 62 |
+
" len(symbols),\n",
|
| 63 |
+
" hps.data.filter_length // 2 + 1,\n",
|
| 64 |
+
" hps.train.segment_size // hps.data.hop_length,\n",
|
| 65 |
+
" **hps.model).cuda()\n",
|
| 66 |
+
"_ = net_g.eval()\n",
|
| 67 |
+
"\n",
|
| 68 |
+
"_ = utils.load_checkpoint(\"/path/to/pretrained_ljs.pth\", net_g, None)"
|
| 69 |
+
]
|
| 70 |
+
},
|
| 71 |
+
{
|
| 72 |
+
"cell_type": "code",
|
| 73 |
+
"execution_count": null,
|
| 74 |
+
"metadata": {},
|
| 75 |
+
"outputs": [],
|
| 76 |
+
"source": [
|
| 77 |
+
"stn_tst = get_text(\"VITS is Awesome!\", hps)\n",
|
| 78 |
+
"with torch.no_grad():\n",
|
| 79 |
+
" x_tst = stn_tst.cuda().unsqueeze(0)\n",
|
| 80 |
+
" x_tst_lengths = torch.LongTensor([stn_tst.size(0)]).cuda()\n",
|
| 81 |
+
" audio = net_g.infer(x_tst, x_tst_lengths, noise_scale=.667, noise_scale_w=0.8, length_scale=1)[0][0,0].data.cpu().float().numpy()\n",
|
| 82 |
+
"ipd.display(ipd.Audio(audio, rate=hps.data.sampling_rate, normalize=False))"
|
| 83 |
+
]
|
| 84 |
+
},
|
| 85 |
+
{
|
| 86 |
+
"cell_type": "markdown",
|
| 87 |
+
"metadata": {},
|
| 88 |
+
"source": [
|
| 89 |
+
"## VCTK"
|
| 90 |
+
]
|
| 91 |
+
},
|
| 92 |
+
{
|
| 93 |
+
"cell_type": "code",
|
| 94 |
+
"execution_count": null,
|
| 95 |
+
"metadata": {},
|
| 96 |
+
"outputs": [],
|
| 97 |
+
"source": [
|
| 98 |
+
"hps = utils.get_hparams_from_file(\"./configs/vctk_base.json\")"
|
| 99 |
+
]
|
| 100 |
+
},
|
| 101 |
+
{
|
| 102 |
+
"cell_type": "code",
|
| 103 |
+
"execution_count": null,
|
| 104 |
+
"metadata": {},
|
| 105 |
+
"outputs": [],
|
| 106 |
+
"source": [
|
| 107 |
+
"net_g = SynthesizerTrn(\n",
|
| 108 |
+
" len(symbols),\n",
|
| 109 |
+
" hps.data.filter_length // 2 + 1,\n",
|
| 110 |
+
" hps.train.segment_size // hps.data.hop_length,\n",
|
| 111 |
+
" n_speakers=hps.data.n_speakers,\n",
|
| 112 |
+
" **hps.model).cuda()\n",
|
| 113 |
+
"_ = net_g.eval()\n",
|
| 114 |
+
"\n",
|
| 115 |
+
"_ = utils.load_checkpoint(\"/path/to/pretrained_vctk.pth\", net_g, None)"
|
| 116 |
+
]
|
| 117 |
+
},
|
| 118 |
+
{
|
| 119 |
+
"cell_type": "code",
|
| 120 |
+
"execution_count": null,
|
| 121 |
+
"metadata": {},
|
| 122 |
+
"outputs": [],
|
| 123 |
+
"source": [
|
| 124 |
+
"stn_tst = get_text(\"VITS is Awesome!\", hps)\n",
|
| 125 |
+
"with torch.no_grad():\n",
|
| 126 |
+
" x_tst = stn_tst.cuda().unsqueeze(0)\n",
|
| 127 |
+
" x_tst_lengths = torch.LongTensor([stn_tst.size(0)]).cuda()\n",
|
| 128 |
+
" sid = torch.LongTensor([4]).cuda()\n",
|
| 129 |
+
" audio = net_g.infer(x_tst, x_tst_lengths, sid=sid, noise_scale=.667, noise_scale_w=0.8, length_scale=1)[0][0,0].data.cpu().float().numpy()\n",
|
| 130 |
+
"ipd.display(ipd.Audio(audio, rate=hps.data.sampling_rate, normalize=False))"
|
| 131 |
+
]
|
| 132 |
+
},
|
| 133 |
+
{
|
| 134 |
+
"cell_type": "markdown",
|
| 135 |
+
"metadata": {},
|
| 136 |
+
"source": [
|
| 137 |
+
"### Voice Conversion"
|
| 138 |
+
]
|
| 139 |
+
},
|
| 140 |
+
{
|
| 141 |
+
"cell_type": "code",
|
| 142 |
+
"execution_count": null,
|
| 143 |
+
"metadata": {},
|
| 144 |
+
"outputs": [],
|
| 145 |
+
"source": [
|
| 146 |
+
"dataset = TextAudioSpeakerLoader(hps.data.validation_files, hps.data)\n",
|
| 147 |
+
"collate_fn = TextAudioSpeakerCollate()\n",
|
| 148 |
+
"loader = DataLoader(dataset, num_workers=8, shuffle=False,\n",
|
| 149 |
+
" batch_size=1, pin_memory=True,\n",
|
| 150 |
+
" drop_last=True, collate_fn=collate_fn)\n",
|
| 151 |
+
"data_list = list(loader)"
|
| 152 |
+
]
|
| 153 |
+
},
|
| 154 |
+
{
|
| 155 |
+
"cell_type": "code",
|
| 156 |
+
"execution_count": null,
|
| 157 |
+
"metadata": {},
|
| 158 |
+
"outputs": [],
|
| 159 |
+
"source": [
|
| 160 |
+
"with torch.no_grad():\n",
|
| 161 |
+
" x, x_lengths, spec, spec_lengths, y, y_lengths, sid_src = [x.cuda() for x in data_list[0]]\n",
|
| 162 |
+
" sid_tgt1 = torch.LongTensor([1]).cuda()\n",
|
| 163 |
+
" sid_tgt2 = torch.LongTensor([2]).cuda()\n",
|
| 164 |
+
" sid_tgt3 = torch.LongTensor([4]).cuda()\n",
|
| 165 |
+
" audio1 = net_g.voice_conversion(spec, spec_lengths, sid_src=sid_src, sid_tgt=sid_tgt1)[0][0,0].data.cpu().float().numpy()\n",
|
| 166 |
+
" audio2 = net_g.voice_conversion(spec, spec_lengths, sid_src=sid_src, sid_tgt=sid_tgt2)[0][0,0].data.cpu().float().numpy()\n",
|
| 167 |
+
" audio3 = net_g.voice_conversion(spec, spec_lengths, sid_src=sid_src, sid_tgt=sid_tgt3)[0][0,0].data.cpu().float().numpy()\n",
|
| 168 |
+
"print(\"Original SID: %d\" % sid_src.item())\n",
|
| 169 |
+
"ipd.display(ipd.Audio(y[0].cpu().numpy(), rate=hps.data.sampling_rate, normalize=False))\n",
|
| 170 |
+
"print(\"Converted SID: %d\" % sid_tgt1.item())\n",
|
| 171 |
+
"ipd.display(ipd.Audio(audio1, rate=hps.data.sampling_rate, normalize=False))\n",
|
| 172 |
+
"print(\"Converted SID: %d\" % sid_tgt2.item())\n",
|
| 173 |
+
"ipd.display(ipd.Audio(audio2, rate=hps.data.sampling_rate, normalize=False))\n",
|
| 174 |
+
"print(\"Converted SID: %d\" % sid_tgt3.item())\n",
|
| 175 |
+
"ipd.display(ipd.Audio(audio3, rate=hps.data.sampling_rate, normalize=False))"
|
| 176 |
+
]
|
| 177 |
+
}
|
| 178 |
+
],
|
| 179 |
+
"metadata": {
|
| 180 |
+
"kernelspec": {
|
| 181 |
+
"display_name": "Python 3",
|
| 182 |
+
"language": "python",
|
| 183 |
+
"name": "python3"
|
| 184 |
+
},
|
| 185 |
+
"language_info": {
|
| 186 |
+
"codemirror_mode": {
|
| 187 |
+
"name": "ipython",
|
| 188 |
+
"version": 3
|
| 189 |
+
},
|
| 190 |
+
"file_extension": ".py",
|
| 191 |
+
"mimetype": "text/x-python",
|
| 192 |
+
"name": "python",
|
| 193 |
+
"nbconvert_exporter": "python",
|
| 194 |
+
"pygments_lexer": "ipython3",
|
| 195 |
+
"version": "3.7.7"
|
| 196 |
+
}
|
| 197 |
+
},
|
| 198 |
+
"nbformat": 4,
|
| 199 |
+
"nbformat_minor": 4
|
| 200 |
+
}
|
log.log
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Looking in indexes: http://mirrors.aliyun.com/pypi/simple/
|
| 2 |
+
Collecting pyopenjtalk
|
| 3 |
+
Downloading http://mirrors.aliyun.com/pypi/packages/11/7a/e09e39ad289300c252c9007045b87a60aceeb3f46e27522acc5a3caf4f0b/pyopenjtalk-0.2.0.tar.gz (1.5 MB)
|
| 4 |
+
Installing build dependencies: started
|
| 5 |
+
Installing build dependencies: finished with status 'canceled'
|
losses.py
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch.nn import functional as F
|
| 3 |
+
|
| 4 |
+
import commons
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def feature_loss(fmap_r, fmap_g):
|
| 8 |
+
loss = 0
|
| 9 |
+
for dr, dg in zip(fmap_r, fmap_g):
|
| 10 |
+
for rl, gl in zip(dr, dg):
|
| 11 |
+
rl = rl.float().detach()
|
| 12 |
+
gl = gl.float()
|
| 13 |
+
loss += torch.mean(torch.abs(rl - gl))
|
| 14 |
+
|
| 15 |
+
return loss * 2
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def discriminator_loss(disc_real_outputs, disc_generated_outputs):
|
| 19 |
+
loss = 0
|
| 20 |
+
r_losses = []
|
| 21 |
+
g_losses = []
|
| 22 |
+
for dr, dg in zip(disc_real_outputs, disc_generated_outputs):
|
| 23 |
+
dr = dr.float()
|
| 24 |
+
dg = dg.float()
|
| 25 |
+
r_loss = torch.mean((1-dr)**2)
|
| 26 |
+
g_loss = torch.mean(dg**2)
|
| 27 |
+
loss += (r_loss + g_loss)
|
| 28 |
+
r_losses.append(r_loss.item())
|
| 29 |
+
g_losses.append(g_loss.item())
|
| 30 |
+
|
| 31 |
+
return loss, r_losses, g_losses
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def generator_loss(disc_outputs):
|
| 35 |
+
loss = 0
|
| 36 |
+
gen_losses = []
|
| 37 |
+
for dg in disc_outputs:
|
| 38 |
+
dg = dg.float()
|
| 39 |
+
l = torch.mean((1-dg)**2)
|
| 40 |
+
gen_losses.append(l)
|
| 41 |
+
loss += l
|
| 42 |
+
|
| 43 |
+
return loss, gen_losses
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def kl_loss(z_p, logs_q, m_p, logs_p, z_mask):
|
| 47 |
+
"""
|
| 48 |
+
z_p, logs_q: [b, h, t_t]
|
| 49 |
+
m_p, logs_p: [b, h, t_t]
|
| 50 |
+
"""
|
| 51 |
+
z_p = z_p.float()
|
| 52 |
+
logs_q = logs_q.float()
|
| 53 |
+
m_p = m_p.float()
|
| 54 |
+
logs_p = logs_p.float()
|
| 55 |
+
z_mask = z_mask.float()
|
| 56 |
+
|
| 57 |
+
kl = logs_p - logs_q - 0.5
|
| 58 |
+
kl += 0.5 * ((z_p - m_p)**2) * torch.exp(-2. * logs_p)
|
| 59 |
+
kl = torch.sum(kl * z_mask)
|
| 60 |
+
l = kl / torch.sum(z_mask)
|
| 61 |
+
return l
|
mel_processing.py
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import os
|
| 3 |
+
import random
|
| 4 |
+
import torch
|
| 5 |
+
from torch import nn
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
import torch.utils.data
|
| 8 |
+
import numpy as np
|
| 9 |
+
|
| 10 |
+
import logging
|
| 11 |
+
|
| 12 |
+
numba_logger = logging.getLogger('numba')
|
| 13 |
+
numba_logger.setLevel(logging.WARNING)
|
| 14 |
+
import warnings
|
| 15 |
+
warnings.filterwarnings('ignore')
|
| 16 |
+
import librosa
|
| 17 |
+
import librosa.util as librosa_util
|
| 18 |
+
from librosa.util import normalize, pad_center, tiny
|
| 19 |
+
from scipy.signal import get_window
|
| 20 |
+
from scipy.io.wavfile import read
|
| 21 |
+
from librosa.filters import mel as librosa_mel_fn
|
| 22 |
+
|
| 23 |
+
MAX_WAV_VALUE = 32768.0
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def dynamic_range_compression_torch(x, C=1, clip_val=1e-5):
|
| 27 |
+
"""
|
| 28 |
+
PARAMS
|
| 29 |
+
------
|
| 30 |
+
C: compression factor
|
| 31 |
+
"""
|
| 32 |
+
return torch.log(torch.clamp(x, min=clip_val) * C)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def dynamic_range_decompression_torch(x, C=1):
|
| 36 |
+
"""
|
| 37 |
+
PARAMS
|
| 38 |
+
------
|
| 39 |
+
C: compression factor used to compress
|
| 40 |
+
"""
|
| 41 |
+
return torch.exp(x) / C
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def spectral_normalize_torch(magnitudes):
|
| 45 |
+
output = dynamic_range_compression_torch(magnitudes)
|
| 46 |
+
return output
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def spectral_de_normalize_torch(magnitudes):
|
| 50 |
+
output = dynamic_range_decompression_torch(magnitudes)
|
| 51 |
+
return output
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
mel_basis = {}
|
| 55 |
+
hann_window = {}
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def spectrogram_torch(y, n_fft, sampling_rate, hop_size, win_size, center=False):
|
| 59 |
+
if torch.min(y) < -1.:
|
| 60 |
+
print('min value is ', torch.min(y))
|
| 61 |
+
if torch.max(y) > 1.:
|
| 62 |
+
print('max value is ', torch.max(y))
|
| 63 |
+
|
| 64 |
+
global hann_window
|
| 65 |
+
dtype_device = str(y.dtype) + '_' + str(y.device)
|
| 66 |
+
wnsize_dtype_device = str(win_size) + '_' + dtype_device
|
| 67 |
+
if wnsize_dtype_device not in hann_window:
|
| 68 |
+
hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(dtype=y.dtype, device=y.device)
|
| 69 |
+
|
| 70 |
+
y = torch.nn.functional.pad(y.unsqueeze(1), (int((n_fft-hop_size)/2), int((n_fft-hop_size)/2)), mode='reflect')
|
| 71 |
+
y = y.squeeze(1)
|
| 72 |
+
|
| 73 |
+
spec = torch.stft(y, n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[wnsize_dtype_device],
|
| 74 |
+
center=center, pad_mode='reflect', normalized=False, onesided=True)
|
| 75 |
+
|
| 76 |
+
spec = torch.sqrt(spec.pow(2).sum(-1) + 1e-6)
|
| 77 |
+
return spec
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def spec_to_mel_torch(spec, n_fft, num_mels, sampling_rate, fmin, fmax):
|
| 81 |
+
global mel_basis
|
| 82 |
+
dtype_device = str(spec.dtype) + '_' + str(spec.device)
|
| 83 |
+
fmax_dtype_device = str(fmax) + '_' + dtype_device
|
| 84 |
+
if fmax_dtype_device not in mel_basis:
|
| 85 |
+
mel = librosa_mel_fn(sampling_rate, n_fft, num_mels, fmin, fmax)
|
| 86 |
+
mel_basis[fmax_dtype_device] = torch.from_numpy(mel).to(dtype=spec.dtype, device=spec.device)
|
| 87 |
+
spec = torch.matmul(mel_basis[fmax_dtype_device], spec)
|
| 88 |
+
spec = spectral_normalize_torch(spec)
|
| 89 |
+
return spec
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
def mel_spectrogram_torch(y, n_fft, num_mels, sampling_rate, hop_size, win_size, fmin, fmax, center=False):
|
| 93 |
+
if torch.min(y) < -1.:
|
| 94 |
+
print('min value is ', torch.min(y))
|
| 95 |
+
if torch.max(y) > 1.:
|
| 96 |
+
print('max value is ', torch.max(y))
|
| 97 |
+
|
| 98 |
+
global mel_basis, hann_window
|
| 99 |
+
dtype_device = str(y.dtype) + '_' + str(y.device)
|
| 100 |
+
fmax_dtype_device = str(fmax) + '_' + dtype_device
|
| 101 |
+
wnsize_dtype_device = str(win_size) + '_' + dtype_device
|
| 102 |
+
if fmax_dtype_device not in mel_basis:
|
| 103 |
+
mel = librosa_mel_fn(sampling_rate, n_fft, num_mels, fmin, fmax)
|
| 104 |
+
mel_basis[fmax_dtype_device] = torch.from_numpy(mel).to(dtype=y.dtype, device=y.device)
|
| 105 |
+
if wnsize_dtype_device not in hann_window:
|
| 106 |
+
hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(dtype=y.dtype, device=y.device)
|
| 107 |
+
|
| 108 |
+
y = torch.nn.functional.pad(y.unsqueeze(1), (int((n_fft-hop_size)/2), int((n_fft-hop_size)/2)), mode='reflect')
|
| 109 |
+
y = y.squeeze(1)
|
| 110 |
+
|
| 111 |
+
spec = torch.stft(y, n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[wnsize_dtype_device],
|
| 112 |
+
center=center, pad_mode='reflect', normalized=False, onesided=True)
|
| 113 |
+
|
| 114 |
+
spec = torch.sqrt(spec.pow(2).sum(-1) + 1e-6)
|
| 115 |
+
|
| 116 |
+
spec = torch.matmul(mel_basis[fmax_dtype_device], spec)
|
| 117 |
+
spec = spectral_normalize_torch(spec)
|
| 118 |
+
|
| 119 |
+
return spec
|
models.py
ADDED
|
@@ -0,0 +1,534 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
import math
|
| 3 |
+
import torch
|
| 4 |
+
from torch import nn
|
| 5 |
+
from torch.nn import functional as F
|
| 6 |
+
|
| 7 |
+
import commons
|
| 8 |
+
import modules
|
| 9 |
+
import attentions
|
| 10 |
+
import monotonic_align
|
| 11 |
+
|
| 12 |
+
from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
|
| 13 |
+
from torch.nn.utils import weight_norm, remove_weight_norm, spectral_norm
|
| 14 |
+
from commons import init_weights, get_padding
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class StochasticDurationPredictor(nn.Module):
|
| 18 |
+
def __init__(self, in_channels, filter_channels, kernel_size, p_dropout, n_flows=4, gin_channels=0):
|
| 19 |
+
super().__init__()
|
| 20 |
+
filter_channels = in_channels # it needs to be removed from future version.
|
| 21 |
+
self.in_channels = in_channels
|
| 22 |
+
self.filter_channels = filter_channels
|
| 23 |
+
self.kernel_size = kernel_size
|
| 24 |
+
self.p_dropout = p_dropout
|
| 25 |
+
self.n_flows = n_flows
|
| 26 |
+
self.gin_channels = gin_channels
|
| 27 |
+
|
| 28 |
+
self.log_flow = modules.Log()
|
| 29 |
+
self.flows = nn.ModuleList()
|
| 30 |
+
self.flows.append(modules.ElementwiseAffine(2))
|
| 31 |
+
for i in range(n_flows):
|
| 32 |
+
self.flows.append(modules.ConvFlow(2, filter_channels, kernel_size, n_layers=3))
|
| 33 |
+
self.flows.append(modules.Flip())
|
| 34 |
+
|
| 35 |
+
self.post_pre = nn.Conv1d(1, filter_channels, 1)
|
| 36 |
+
self.post_proj = nn.Conv1d(filter_channels, filter_channels, 1)
|
| 37 |
+
self.post_convs = modules.DDSConv(filter_channels, kernel_size, n_layers=3, p_dropout=p_dropout)
|
| 38 |
+
self.post_flows = nn.ModuleList()
|
| 39 |
+
self.post_flows.append(modules.ElementwiseAffine(2))
|
| 40 |
+
for i in range(4):
|
| 41 |
+
self.post_flows.append(modules.ConvFlow(2, filter_channels, kernel_size, n_layers=3))
|
| 42 |
+
self.post_flows.append(modules.Flip())
|
| 43 |
+
|
| 44 |
+
self.pre = nn.Conv1d(in_channels, filter_channels, 1)
|
| 45 |
+
self.proj = nn.Conv1d(filter_channels, filter_channels, 1)
|
| 46 |
+
self.convs = modules.DDSConv(filter_channels, kernel_size, n_layers=3, p_dropout=p_dropout)
|
| 47 |
+
if gin_channels != 0:
|
| 48 |
+
self.cond = nn.Conv1d(gin_channels, filter_channels, 1)
|
| 49 |
+
|
| 50 |
+
def forward(self, x, x_mask, w=None, g=None, reverse=False, noise_scale=1.0):
|
| 51 |
+
x = torch.detach(x)
|
| 52 |
+
x = self.pre(x)
|
| 53 |
+
if g is not None:
|
| 54 |
+
g = torch.detach(g)
|
| 55 |
+
x = x + self.cond(g)
|
| 56 |
+
x = self.convs(x, x_mask)
|
| 57 |
+
x = self.proj(x) * x_mask
|
| 58 |
+
|
| 59 |
+
if not reverse:
|
| 60 |
+
flows = self.flows
|
| 61 |
+
assert w is not None
|
| 62 |
+
|
| 63 |
+
logdet_tot_q = 0
|
| 64 |
+
h_w = self.post_pre(w)
|
| 65 |
+
h_w = self.post_convs(h_w, x_mask)
|
| 66 |
+
h_w = self.post_proj(h_w) * x_mask
|
| 67 |
+
e_q = torch.randn(w.size(0), 2, w.size(2)).to(device=x.device, dtype=x.dtype) * x_mask
|
| 68 |
+
z_q = e_q
|
| 69 |
+
for flow in self.post_flows:
|
| 70 |
+
z_q, logdet_q = flow(z_q, x_mask, g=(x + h_w))
|
| 71 |
+
logdet_tot_q += logdet_q
|
| 72 |
+
z_u, z1 = torch.split(z_q, [1, 1], 1)
|
| 73 |
+
u = torch.sigmoid(z_u) * x_mask
|
| 74 |
+
z0 = (w - u) * x_mask
|
| 75 |
+
logdet_tot_q += torch.sum((F.logsigmoid(z_u) + F.logsigmoid(-z_u)) * x_mask, [1,2])
|
| 76 |
+
logq = torch.sum(-0.5 * (math.log(2*math.pi) + (e_q**2)) * x_mask, [1,2]) - logdet_tot_q
|
| 77 |
+
|
| 78 |
+
logdet_tot = 0
|
| 79 |
+
z0, logdet = self.log_flow(z0, x_mask)
|
| 80 |
+
logdet_tot += logdet
|
| 81 |
+
z = torch.cat([z0, z1], 1)
|
| 82 |
+
for flow in flows:
|
| 83 |
+
z, logdet = flow(z, x_mask, g=x, reverse=reverse)
|
| 84 |
+
logdet_tot = logdet_tot + logdet
|
| 85 |
+
nll = torch.sum(0.5 * (math.log(2*math.pi) + (z**2)) * x_mask, [1,2]) - logdet_tot
|
| 86 |
+
return nll + logq # [b]
|
| 87 |
+
else:
|
| 88 |
+
flows = list(reversed(self.flows))
|
| 89 |
+
flows = flows[:-2] + [flows[-1]] # remove a useless vflow
|
| 90 |
+
z = torch.randn(x.size(0), 2, x.size(2)).to(device=x.device, dtype=x.dtype) * noise_scale
|
| 91 |
+
for flow in flows:
|
| 92 |
+
z = flow(z, x_mask, g=x, reverse=reverse)
|
| 93 |
+
z0, z1 = torch.split(z, [1, 1], 1)
|
| 94 |
+
logw = z0
|
| 95 |
+
return logw
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
class DurationPredictor(nn.Module):
|
| 99 |
+
def __init__(self, in_channels, filter_channels, kernel_size, p_dropout, gin_channels=0):
|
| 100 |
+
super().__init__()
|
| 101 |
+
|
| 102 |
+
self.in_channels = in_channels
|
| 103 |
+
self.filter_channels = filter_channels
|
| 104 |
+
self.kernel_size = kernel_size
|
| 105 |
+
self.p_dropout = p_dropout
|
| 106 |
+
self.gin_channels = gin_channels
|
| 107 |
+
|
| 108 |
+
self.drop = nn.Dropout(p_dropout)
|
| 109 |
+
self.conv_1 = nn.Conv1d(in_channels, filter_channels, kernel_size, padding=kernel_size//2)
|
| 110 |
+
self.norm_1 = modules.LayerNorm(filter_channels)
|
| 111 |
+
self.conv_2 = nn.Conv1d(filter_channels, filter_channels, kernel_size, padding=kernel_size//2)
|
| 112 |
+
self.norm_2 = modules.LayerNorm(filter_channels)
|
| 113 |
+
self.proj = nn.Conv1d(filter_channels, 1, 1)
|
| 114 |
+
|
| 115 |
+
if gin_channels != 0:
|
| 116 |
+
self.cond = nn.Conv1d(gin_channels, in_channels, 1)
|
| 117 |
+
|
| 118 |
+
def forward(self, x, x_mask, g=None):
|
| 119 |
+
x = torch.detach(x)
|
| 120 |
+
if g is not None:
|
| 121 |
+
g = torch.detach(g)
|
| 122 |
+
x = x + self.cond(g)
|
| 123 |
+
x = self.conv_1(x * x_mask)
|
| 124 |
+
x = torch.relu(x)
|
| 125 |
+
x = self.norm_1(x)
|
| 126 |
+
x = self.drop(x)
|
| 127 |
+
x = self.conv_2(x * x_mask)
|
| 128 |
+
x = torch.relu(x)
|
| 129 |
+
x = self.norm_2(x)
|
| 130 |
+
x = self.drop(x)
|
| 131 |
+
x = self.proj(x * x_mask)
|
| 132 |
+
return x * x_mask
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
class TextEncoder(nn.Module):
|
| 136 |
+
def __init__(self,
|
| 137 |
+
n_vocab,
|
| 138 |
+
out_channels,
|
| 139 |
+
hidden_channels,
|
| 140 |
+
filter_channels,
|
| 141 |
+
n_heads,
|
| 142 |
+
n_layers,
|
| 143 |
+
kernel_size,
|
| 144 |
+
p_dropout):
|
| 145 |
+
super().__init__()
|
| 146 |
+
self.n_vocab = n_vocab
|
| 147 |
+
self.out_channels = out_channels
|
| 148 |
+
self.hidden_channels = hidden_channels
|
| 149 |
+
self.filter_channels = filter_channels
|
| 150 |
+
self.n_heads = n_heads
|
| 151 |
+
self.n_layers = n_layers
|
| 152 |
+
self.kernel_size = kernel_size
|
| 153 |
+
self.p_dropout = p_dropout
|
| 154 |
+
|
| 155 |
+
self.emb = nn.Embedding(n_vocab, hidden_channels)
|
| 156 |
+
nn.init.normal_(self.emb.weight, 0.0, hidden_channels**-0.5)
|
| 157 |
+
|
| 158 |
+
self.encoder = attentions.Encoder(
|
| 159 |
+
hidden_channels,
|
| 160 |
+
filter_channels,
|
| 161 |
+
n_heads,
|
| 162 |
+
n_layers,
|
| 163 |
+
kernel_size,
|
| 164 |
+
p_dropout)
|
| 165 |
+
self.proj= nn.Conv1d(hidden_channels, out_channels * 2, 1)
|
| 166 |
+
|
| 167 |
+
def forward(self, x, x_lengths):
|
| 168 |
+
x = self.emb(x) * math.sqrt(self.hidden_channels) # [b, t, h]
|
| 169 |
+
x = torch.transpose(x, 1, -1) # [b, h, t]
|
| 170 |
+
x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype)
|
| 171 |
+
|
| 172 |
+
x = self.encoder(x * x_mask, x_mask)
|
| 173 |
+
stats = self.proj(x) * x_mask
|
| 174 |
+
|
| 175 |
+
m, logs = torch.split(stats, self.out_channels, dim=1)
|
| 176 |
+
return x, m, logs, x_mask
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
class ResidualCouplingBlock(nn.Module):
|
| 180 |
+
def __init__(self,
|
| 181 |
+
channels,
|
| 182 |
+
hidden_channels,
|
| 183 |
+
kernel_size,
|
| 184 |
+
dilation_rate,
|
| 185 |
+
n_layers,
|
| 186 |
+
n_flows=4,
|
| 187 |
+
gin_channels=0):
|
| 188 |
+
super().__init__()
|
| 189 |
+
self.channels = channels
|
| 190 |
+
self.hidden_channels = hidden_channels
|
| 191 |
+
self.kernel_size = kernel_size
|
| 192 |
+
self.dilation_rate = dilation_rate
|
| 193 |
+
self.n_layers = n_layers
|
| 194 |
+
self.n_flows = n_flows
|
| 195 |
+
self.gin_channels = gin_channels
|
| 196 |
+
|
| 197 |
+
self.flows = nn.ModuleList()
|
| 198 |
+
for i in range(n_flows):
|
| 199 |
+
self.flows.append(modules.ResidualCouplingLayer(channels, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=gin_channels, mean_only=True))
|
| 200 |
+
self.flows.append(modules.Flip())
|
| 201 |
+
|
| 202 |
+
def forward(self, x, x_mask, g=None, reverse=False):
|
| 203 |
+
if not reverse:
|
| 204 |
+
for flow in self.flows:
|
| 205 |
+
x, _ = flow(x, x_mask, g=g, reverse=reverse)
|
| 206 |
+
else:
|
| 207 |
+
for flow in reversed(self.flows):
|
| 208 |
+
x = flow(x, x_mask, g=g, reverse=reverse)
|
| 209 |
+
return x
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
class PosteriorEncoder(nn.Module):
|
| 213 |
+
def __init__(self,
|
| 214 |
+
in_channels,
|
| 215 |
+
out_channels,
|
| 216 |
+
hidden_channels,
|
| 217 |
+
kernel_size,
|
| 218 |
+
dilation_rate,
|
| 219 |
+
n_layers,
|
| 220 |
+
gin_channels=0):
|
| 221 |
+
super().__init__()
|
| 222 |
+
self.in_channels = in_channels
|
| 223 |
+
self.out_channels = out_channels
|
| 224 |
+
self.hidden_channels = hidden_channels
|
| 225 |
+
self.kernel_size = kernel_size
|
| 226 |
+
self.dilation_rate = dilation_rate
|
| 227 |
+
self.n_layers = n_layers
|
| 228 |
+
self.gin_channels = gin_channels
|
| 229 |
+
|
| 230 |
+
self.pre = nn.Conv1d(in_channels, hidden_channels, 1)
|
| 231 |
+
self.enc = modules.WN(hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=gin_channels)
|
| 232 |
+
self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
|
| 233 |
+
|
| 234 |
+
def forward(self, x, x_lengths, g=None):
|
| 235 |
+
x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype)
|
| 236 |
+
x = self.pre(x) * x_mask
|
| 237 |
+
x = self.enc(x, x_mask, g=g)
|
| 238 |
+
stats = self.proj(x) * x_mask
|
| 239 |
+
m, logs = torch.split(stats, self.out_channels, dim=1)
|
| 240 |
+
z = (m + torch.randn_like(m) * torch.exp(logs)) * x_mask
|
| 241 |
+
return z, m, logs, x_mask
|
| 242 |
+
|
| 243 |
+
|
| 244 |
+
class Generator(torch.nn.Module):
|
| 245 |
+
def __init__(self, initial_channel, resblock, resblock_kernel_sizes, resblock_dilation_sizes, upsample_rates, upsample_initial_channel, upsample_kernel_sizes, gin_channels=0):
|
| 246 |
+
super(Generator, self).__init__()
|
| 247 |
+
self.num_kernels = len(resblock_kernel_sizes)
|
| 248 |
+
self.num_upsamples = len(upsample_rates)
|
| 249 |
+
self.conv_pre = Conv1d(initial_channel, upsample_initial_channel, 7, 1, padding=3)
|
| 250 |
+
resblock = modules.ResBlock1 if resblock == '1' else modules.ResBlock2
|
| 251 |
+
|
| 252 |
+
self.ups = nn.ModuleList()
|
| 253 |
+
for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
|
| 254 |
+
self.ups.append(weight_norm(
|
| 255 |
+
ConvTranspose1d(upsample_initial_channel//(2**i), upsample_initial_channel//(2**(i+1)),
|
| 256 |
+
k, u, padding=(k-u)//2)))
|
| 257 |
+
|
| 258 |
+
self.resblocks = nn.ModuleList()
|
| 259 |
+
for i in range(len(self.ups)):
|
| 260 |
+
ch = upsample_initial_channel//(2**(i+1))
|
| 261 |
+
for j, (k, d) in enumerate(zip(resblock_kernel_sizes, resblock_dilation_sizes)):
|
| 262 |
+
self.resblocks.append(resblock(ch, k, d))
|
| 263 |
+
|
| 264 |
+
self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
|
| 265 |
+
self.ups.apply(init_weights)
|
| 266 |
+
|
| 267 |
+
if gin_channels != 0:
|
| 268 |
+
self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
|
| 269 |
+
|
| 270 |
+
def forward(self, x, g=None):
|
| 271 |
+
x = self.conv_pre(x)
|
| 272 |
+
if g is not None:
|
| 273 |
+
x = x + self.cond(g)
|
| 274 |
+
|
| 275 |
+
for i in range(self.num_upsamples):
|
| 276 |
+
x = F.leaky_relu(x, modules.LRELU_SLOPE)
|
| 277 |
+
x = self.ups[i](x)
|
| 278 |
+
xs = None
|
| 279 |
+
for j in range(self.num_kernels):
|
| 280 |
+
if xs is None:
|
| 281 |
+
xs = self.resblocks[i*self.num_kernels+j](x)
|
| 282 |
+
else:
|
| 283 |
+
xs += self.resblocks[i*self.num_kernels+j](x)
|
| 284 |
+
x = xs / self.num_kernels
|
| 285 |
+
x = F.leaky_relu(x)
|
| 286 |
+
x = self.conv_post(x)
|
| 287 |
+
x = torch.tanh(x)
|
| 288 |
+
|
| 289 |
+
return x
|
| 290 |
+
|
| 291 |
+
def remove_weight_norm(self):
|
| 292 |
+
print('Removing weight norm...')
|
| 293 |
+
for l in self.ups:
|
| 294 |
+
remove_weight_norm(l)
|
| 295 |
+
for l in self.resblocks:
|
| 296 |
+
l.remove_weight_norm()
|
| 297 |
+
|
| 298 |
+
|
| 299 |
+
class DiscriminatorP(torch.nn.Module):
|
| 300 |
+
def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False):
|
| 301 |
+
super(DiscriminatorP, self).__init__()
|
| 302 |
+
self.period = period
|
| 303 |
+
self.use_spectral_norm = use_spectral_norm
|
| 304 |
+
norm_f = weight_norm if use_spectral_norm == False else spectral_norm
|
| 305 |
+
self.convs = nn.ModuleList([
|
| 306 |
+
norm_f(Conv2d(1, 32, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
|
| 307 |
+
norm_f(Conv2d(32, 128, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
|
| 308 |
+
norm_f(Conv2d(128, 512, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
|
| 309 |
+
norm_f(Conv2d(512, 1024, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
|
| 310 |
+
norm_f(Conv2d(1024, 1024, (kernel_size, 1), 1, padding=(get_padding(kernel_size, 1), 0))),
|
| 311 |
+
])
|
| 312 |
+
self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0)))
|
| 313 |
+
|
| 314 |
+
def forward(self, x):
|
| 315 |
+
fmap = []
|
| 316 |
+
|
| 317 |
+
# 1d to 2d
|
| 318 |
+
b, c, t = x.shape
|
| 319 |
+
if t % self.period != 0: # pad first
|
| 320 |
+
n_pad = self.period - (t % self.period)
|
| 321 |
+
x = F.pad(x, (0, n_pad), "reflect")
|
| 322 |
+
t = t + n_pad
|
| 323 |
+
x = x.view(b, c, t // self.period, self.period)
|
| 324 |
+
|
| 325 |
+
for l in self.convs:
|
| 326 |
+
x = l(x)
|
| 327 |
+
x = F.leaky_relu(x, modules.LRELU_SLOPE)
|
| 328 |
+
fmap.append(x)
|
| 329 |
+
x = self.conv_post(x)
|
| 330 |
+
fmap.append(x)
|
| 331 |
+
x = torch.flatten(x, 1, -1)
|
| 332 |
+
|
| 333 |
+
return x, fmap
|
| 334 |
+
|
| 335 |
+
|
| 336 |
+
class DiscriminatorS(torch.nn.Module):
|
| 337 |
+
def __init__(self, use_spectral_norm=False):
|
| 338 |
+
super(DiscriminatorS, self).__init__()
|
| 339 |
+
norm_f = weight_norm if use_spectral_norm == False else spectral_norm
|
| 340 |
+
self.convs = nn.ModuleList([
|
| 341 |
+
norm_f(Conv1d(1, 16, 15, 1, padding=7)),
|
| 342 |
+
norm_f(Conv1d(16, 64, 41, 4, groups=4, padding=20)),
|
| 343 |
+
norm_f(Conv1d(64, 256, 41, 4, groups=16, padding=20)),
|
| 344 |
+
norm_f(Conv1d(256, 1024, 41, 4, groups=64, padding=20)),
|
| 345 |
+
norm_f(Conv1d(1024, 1024, 41, 4, groups=256, padding=20)),
|
| 346 |
+
norm_f(Conv1d(1024, 1024, 5, 1, padding=2)),
|
| 347 |
+
])
|
| 348 |
+
self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1))
|
| 349 |
+
|
| 350 |
+
def forward(self, x):
|
| 351 |
+
fmap = []
|
| 352 |
+
|
| 353 |
+
for l in self.convs:
|
| 354 |
+
x = l(x)
|
| 355 |
+
x = F.leaky_relu(x, modules.LRELU_SLOPE)
|
| 356 |
+
fmap.append(x)
|
| 357 |
+
x = self.conv_post(x)
|
| 358 |
+
fmap.append(x)
|
| 359 |
+
x = torch.flatten(x, 1, -1)
|
| 360 |
+
|
| 361 |
+
return x, fmap
|
| 362 |
+
|
| 363 |
+
|
| 364 |
+
class MultiPeriodDiscriminator(torch.nn.Module):
|
| 365 |
+
def __init__(self, use_spectral_norm=False):
|
| 366 |
+
super(MultiPeriodDiscriminator, self).__init__()
|
| 367 |
+
periods = [2,3,5,7,11]
|
| 368 |
+
|
| 369 |
+
discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]
|
| 370 |
+
discs = discs + [DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods]
|
| 371 |
+
self.discriminators = nn.ModuleList(discs)
|
| 372 |
+
|
| 373 |
+
def forward(self, y, y_hat):
|
| 374 |
+
y_d_rs = []
|
| 375 |
+
y_d_gs = []
|
| 376 |
+
fmap_rs = []
|
| 377 |
+
fmap_gs = []
|
| 378 |
+
for i, d in enumerate(self.discriminators):
|
| 379 |
+
y_d_r, fmap_r = d(y)
|
| 380 |
+
y_d_g, fmap_g = d(y_hat)
|
| 381 |
+
y_d_rs.append(y_d_r)
|
| 382 |
+
y_d_gs.append(y_d_g)
|
| 383 |
+
fmap_rs.append(fmap_r)
|
| 384 |
+
fmap_gs.append(fmap_g)
|
| 385 |
+
|
| 386 |
+
return y_d_rs, y_d_gs, fmap_rs, fmap_gs
|
| 387 |
+
|
| 388 |
+
|
| 389 |
+
|
| 390 |
+
class SynthesizerTrn(nn.Module):
|
| 391 |
+
"""
|
| 392 |
+
Synthesizer for Training
|
| 393 |
+
"""
|
| 394 |
+
|
| 395 |
+
def __init__(self,
|
| 396 |
+
n_vocab,
|
| 397 |
+
spec_channels,
|
| 398 |
+
segment_size,
|
| 399 |
+
inter_channels,
|
| 400 |
+
hidden_channels,
|
| 401 |
+
filter_channels,
|
| 402 |
+
n_heads,
|
| 403 |
+
n_layers,
|
| 404 |
+
kernel_size,
|
| 405 |
+
p_dropout,
|
| 406 |
+
resblock,
|
| 407 |
+
resblock_kernel_sizes,
|
| 408 |
+
resblock_dilation_sizes,
|
| 409 |
+
upsample_rates,
|
| 410 |
+
upsample_initial_channel,
|
| 411 |
+
upsample_kernel_sizes,
|
| 412 |
+
n_speakers=0,
|
| 413 |
+
gin_channels=0,
|
| 414 |
+
use_sdp=True,
|
| 415 |
+
**kwargs):
|
| 416 |
+
|
| 417 |
+
super().__init__()
|
| 418 |
+
self.n_vocab = n_vocab
|
| 419 |
+
self.spec_channels = spec_channels
|
| 420 |
+
self.inter_channels = inter_channels
|
| 421 |
+
self.hidden_channels = hidden_channels
|
| 422 |
+
self.filter_channels = filter_channels
|
| 423 |
+
self.n_heads = n_heads
|
| 424 |
+
self.n_layers = n_layers
|
| 425 |
+
self.kernel_size = kernel_size
|
| 426 |
+
self.p_dropout = p_dropout
|
| 427 |
+
self.resblock = resblock
|
| 428 |
+
self.resblock_kernel_sizes = resblock_kernel_sizes
|
| 429 |
+
self.resblock_dilation_sizes = resblock_dilation_sizes
|
| 430 |
+
self.upsample_rates = upsample_rates
|
| 431 |
+
self.upsample_initial_channel = upsample_initial_channel
|
| 432 |
+
self.upsample_kernel_sizes = upsample_kernel_sizes
|
| 433 |
+
self.segment_size = segment_size
|
| 434 |
+
self.n_speakers = n_speakers
|
| 435 |
+
self.gin_channels = gin_channels
|
| 436 |
+
|
| 437 |
+
self.use_sdp = use_sdp
|
| 438 |
+
|
| 439 |
+
self.enc_p = TextEncoder(n_vocab,
|
| 440 |
+
inter_channels,
|
| 441 |
+
hidden_channels,
|
| 442 |
+
filter_channels,
|
| 443 |
+
n_heads,
|
| 444 |
+
n_layers,
|
| 445 |
+
kernel_size,
|
| 446 |
+
p_dropout)
|
| 447 |
+
self.dec = Generator(inter_channels, resblock, resblock_kernel_sizes, resblock_dilation_sizes, upsample_rates, upsample_initial_channel, upsample_kernel_sizes, gin_channels=gin_channels)
|
| 448 |
+
self.enc_q = PosteriorEncoder(spec_channels, inter_channels, hidden_channels, 5, 1, 16, gin_channels=gin_channels)
|
| 449 |
+
self.flow = ResidualCouplingBlock(inter_channels, hidden_channels, 5, 1, 4, gin_channels=gin_channels)
|
| 450 |
+
|
| 451 |
+
if use_sdp:
|
| 452 |
+
self.dp = StochasticDurationPredictor(hidden_channels, 192, 3, 0.5, 4, gin_channels=gin_channels)
|
| 453 |
+
else:
|
| 454 |
+
self.dp = DurationPredictor(hidden_channels, 256, 3, 0.5, gin_channels=gin_channels)
|
| 455 |
+
|
| 456 |
+
if n_speakers > 1:
|
| 457 |
+
self.emb_g = nn.Embedding(n_speakers, gin_channels)
|
| 458 |
+
|
| 459 |
+
def forward(self, x, x_lengths, y, y_lengths, sid=None):
|
| 460 |
+
|
| 461 |
+
x, m_p, logs_p, x_mask = self.enc_p(x, x_lengths)
|
| 462 |
+
if self.n_speakers > 0:
|
| 463 |
+
g = self.emb_g(sid).unsqueeze(-1) # [b, h, 1]
|
| 464 |
+
else:
|
| 465 |
+
g = None
|
| 466 |
+
|
| 467 |
+
z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
|
| 468 |
+
z_p = self.flow(z, y_mask, g=g)
|
| 469 |
+
|
| 470 |
+
with torch.no_grad():
|
| 471 |
+
# negative cross-entropy
|
| 472 |
+
s_p_sq_r = torch.exp(-2 * logs_p) # [b, d, t]
|
| 473 |
+
neg_cent1 = torch.sum(-0.5 * math.log(2 * math.pi) - logs_p, [1], keepdim=True) # [b, 1, t_s]
|
| 474 |
+
neg_cent2 = torch.matmul(-0.5 * (z_p ** 2).transpose(1, 2), s_p_sq_r) # [b, t_t, d] x [b, d, t_s] = [b, t_t, t_s]
|
| 475 |
+
neg_cent3 = torch.matmul(z_p.transpose(1, 2), (m_p * s_p_sq_r)) # [b, t_t, d] x [b, d, t_s] = [b, t_t, t_s]
|
| 476 |
+
neg_cent4 = torch.sum(-0.5 * (m_p ** 2) * s_p_sq_r, [1], keepdim=True) # [b, 1, t_s]
|
| 477 |
+
neg_cent = neg_cent1 + neg_cent2 + neg_cent3 + neg_cent4
|
| 478 |
+
|
| 479 |
+
attn_mask = torch.unsqueeze(x_mask, 2) * torch.unsqueeze(y_mask, -1)
|
| 480 |
+
attn = monotonic_align.maximum_path(neg_cent, attn_mask.squeeze(1)).unsqueeze(1).detach()
|
| 481 |
+
|
| 482 |
+
w = attn.sum(2)
|
| 483 |
+
if self.use_sdp:
|
| 484 |
+
l_length = self.dp(x, x_mask, w, g=g)
|
| 485 |
+
l_length = l_length / torch.sum(x_mask)
|
| 486 |
+
else:
|
| 487 |
+
logw_ = torch.log(w + 1e-6) * x_mask
|
| 488 |
+
logw = self.dp(x, x_mask, g=g)
|
| 489 |
+
l_length = torch.sum((logw - logw_)**2, [1,2]) / torch.sum(x_mask) # for averaging
|
| 490 |
+
|
| 491 |
+
# expand prior
|
| 492 |
+
m_p = torch.matmul(attn.squeeze(1), m_p.transpose(1, 2)).transpose(1, 2)
|
| 493 |
+
logs_p = torch.matmul(attn.squeeze(1), logs_p.transpose(1, 2)).transpose(1, 2)
|
| 494 |
+
|
| 495 |
+
z_slice, ids_slice = commons.rand_slice_segments(z, y_lengths, self.segment_size)
|
| 496 |
+
o = self.dec(z_slice, g=g)
|
| 497 |
+
return o, l_length, attn, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
|
| 498 |
+
|
| 499 |
+
def infer(self, x, x_lengths, sid=None, noise_scale=1, length_scale=1, noise_scale_w=1., max_len=None):
|
| 500 |
+
x, m_p, logs_p, x_mask = self.enc_p(x, x_lengths)
|
| 501 |
+
if self.n_speakers > 0:
|
| 502 |
+
g = self.emb_g(sid).unsqueeze(-1) # [b, h, 1]
|
| 503 |
+
else:
|
| 504 |
+
g = None
|
| 505 |
+
|
| 506 |
+
if self.use_sdp:
|
| 507 |
+
logw = self.dp(x, x_mask, g=g, reverse=True, noise_scale=noise_scale_w)
|
| 508 |
+
else:
|
| 509 |
+
logw = self.dp(x, x_mask, g=g)
|
| 510 |
+
w = torch.exp(logw) * x_mask * length_scale
|
| 511 |
+
w_ceil = torch.ceil(w)
|
| 512 |
+
y_lengths = torch.clamp_min(torch.sum(w_ceil, [1, 2]), 1).long()
|
| 513 |
+
y_mask = torch.unsqueeze(commons.sequence_mask(y_lengths, None), 1).to(x_mask.dtype)
|
| 514 |
+
attn_mask = torch.unsqueeze(x_mask, 2) * torch.unsqueeze(y_mask, -1)
|
| 515 |
+
attn = commons.generate_path(w_ceil, attn_mask)
|
| 516 |
+
|
| 517 |
+
m_p = torch.matmul(attn.squeeze(1), m_p.transpose(1, 2)).transpose(1, 2) # [b, t', t], [b, t, d] -> [b, d, t']
|
| 518 |
+
logs_p = torch.matmul(attn.squeeze(1), logs_p.transpose(1, 2)).transpose(1, 2) # [b, t', t], [b, t, d] -> [b, d, t']
|
| 519 |
+
|
| 520 |
+
z_p = m_p + torch.randn_like(m_p) * torch.exp(logs_p) * noise_scale
|
| 521 |
+
z = self.flow(z_p, y_mask, g=g, reverse=True)
|
| 522 |
+
o = self.dec((z * y_mask)[:,:,:max_len], g=g)
|
| 523 |
+
return o, attn, y_mask, (z, z_p, m_p, logs_p)
|
| 524 |
+
|
| 525 |
+
def voice_conversion(self, y, y_lengths, sid_src, sid_tgt):
|
| 526 |
+
assert self.n_speakers > 0, "n_speakers have to be larger than 0."
|
| 527 |
+
g_src = self.emb_g(sid_src).unsqueeze(-1)
|
| 528 |
+
g_tgt = self.emb_g(sid_tgt).unsqueeze(-1)
|
| 529 |
+
z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g_src)
|
| 530 |
+
z_p = self.flow(z, y_mask, g=g_src)
|
| 531 |
+
z_hat = self.flow(z_p, y_mask, g=g_tgt, reverse=True)
|
| 532 |
+
o_hat = self.dec(z_hat * y_mask, g=g_tgt)
|
| 533 |
+
return o_hat, y_mask, (z, z_p, z_hat)
|
| 534 |
+
|
modules.py
ADDED
|
@@ -0,0 +1,390 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
import math
|
| 3 |
+
import numpy as np
|
| 4 |
+
import scipy
|
| 5 |
+
import torch
|
| 6 |
+
from torch import nn
|
| 7 |
+
from torch.nn import functional as F
|
| 8 |
+
|
| 9 |
+
from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
|
| 10 |
+
from torch.nn.utils import weight_norm, remove_weight_norm
|
| 11 |
+
|
| 12 |
+
import commons
|
| 13 |
+
from commons import init_weights, get_padding
|
| 14 |
+
from transforms import piecewise_rational_quadratic_transform
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
LRELU_SLOPE = 0.1
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class LayerNorm(nn.Module):
|
| 21 |
+
def __init__(self, channels, eps=1e-5):
|
| 22 |
+
super().__init__()
|
| 23 |
+
self.channels = channels
|
| 24 |
+
self.eps = eps
|
| 25 |
+
|
| 26 |
+
self.gamma = nn.Parameter(torch.ones(channels))
|
| 27 |
+
self.beta = nn.Parameter(torch.zeros(channels))
|
| 28 |
+
|
| 29 |
+
def forward(self, x):
|
| 30 |
+
x = x.transpose(1, -1)
|
| 31 |
+
x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)
|
| 32 |
+
return x.transpose(1, -1)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
class ConvReluNorm(nn.Module):
|
| 36 |
+
def __init__(self, in_channels, hidden_channels, out_channels, kernel_size, n_layers, p_dropout):
|
| 37 |
+
super().__init__()
|
| 38 |
+
self.in_channels = in_channels
|
| 39 |
+
self.hidden_channels = hidden_channels
|
| 40 |
+
self.out_channels = out_channels
|
| 41 |
+
self.kernel_size = kernel_size
|
| 42 |
+
self.n_layers = n_layers
|
| 43 |
+
self.p_dropout = p_dropout
|
| 44 |
+
assert n_layers > 1, "Number of layers should be larger than 0."
|
| 45 |
+
|
| 46 |
+
self.conv_layers = nn.ModuleList()
|
| 47 |
+
self.norm_layers = nn.ModuleList()
|
| 48 |
+
self.conv_layers.append(nn.Conv1d(in_channels, hidden_channels, kernel_size, padding=kernel_size//2))
|
| 49 |
+
self.norm_layers.append(LayerNorm(hidden_channels))
|
| 50 |
+
self.relu_drop = nn.Sequential(
|
| 51 |
+
nn.ReLU(),
|
| 52 |
+
nn.Dropout(p_dropout))
|
| 53 |
+
for _ in range(n_layers-1):
|
| 54 |
+
self.conv_layers.append(nn.Conv1d(hidden_channels, hidden_channels, kernel_size, padding=kernel_size//2))
|
| 55 |
+
self.norm_layers.append(LayerNorm(hidden_channels))
|
| 56 |
+
self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
|
| 57 |
+
self.proj.weight.data.zero_()
|
| 58 |
+
self.proj.bias.data.zero_()
|
| 59 |
+
|
| 60 |
+
def forward(self, x, x_mask):
|
| 61 |
+
x_org = x
|
| 62 |
+
for i in range(self.n_layers):
|
| 63 |
+
x = self.conv_layers[i](x * x_mask)
|
| 64 |
+
x = self.norm_layers[i](x)
|
| 65 |
+
x = self.relu_drop(x)
|
| 66 |
+
x = x_org + self.proj(x)
|
| 67 |
+
return x * x_mask
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
class DDSConv(nn.Module):
|
| 71 |
+
"""
|
| 72 |
+
Dialted and Depth-Separable Convolution
|
| 73 |
+
"""
|
| 74 |
+
def __init__(self, channels, kernel_size, n_layers, p_dropout=0.):
|
| 75 |
+
super().__init__()
|
| 76 |
+
self.channels = channels
|
| 77 |
+
self.kernel_size = kernel_size
|
| 78 |
+
self.n_layers = n_layers
|
| 79 |
+
self.p_dropout = p_dropout
|
| 80 |
+
|
| 81 |
+
self.drop = nn.Dropout(p_dropout)
|
| 82 |
+
self.convs_sep = nn.ModuleList()
|
| 83 |
+
self.convs_1x1 = nn.ModuleList()
|
| 84 |
+
self.norms_1 = nn.ModuleList()
|
| 85 |
+
self.norms_2 = nn.ModuleList()
|
| 86 |
+
for i in range(n_layers):
|
| 87 |
+
dilation = kernel_size ** i
|
| 88 |
+
padding = (kernel_size * dilation - dilation) // 2
|
| 89 |
+
self.convs_sep.append(nn.Conv1d(channels, channels, kernel_size,
|
| 90 |
+
groups=channels, dilation=dilation, padding=padding
|
| 91 |
+
))
|
| 92 |
+
self.convs_1x1.append(nn.Conv1d(channels, channels, 1))
|
| 93 |
+
self.norms_1.append(LayerNorm(channels))
|
| 94 |
+
self.norms_2.append(LayerNorm(channels))
|
| 95 |
+
|
| 96 |
+
def forward(self, x, x_mask, g=None):
|
| 97 |
+
if g is not None:
|
| 98 |
+
x = x + g
|
| 99 |
+
for i in range(self.n_layers):
|
| 100 |
+
y = self.convs_sep[i](x * x_mask)
|
| 101 |
+
y = self.norms_1[i](y)
|
| 102 |
+
y = F.gelu(y)
|
| 103 |
+
y = self.convs_1x1[i](y)
|
| 104 |
+
y = self.norms_2[i](y)
|
| 105 |
+
y = F.gelu(y)
|
| 106 |
+
y = self.drop(y)
|
| 107 |
+
x = x + y
|
| 108 |
+
return x * x_mask
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
class WN(torch.nn.Module):
|
| 112 |
+
def __init__(self, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=0, p_dropout=0):
|
| 113 |
+
super(WN, self).__init__()
|
| 114 |
+
assert(kernel_size % 2 == 1)
|
| 115 |
+
self.hidden_channels =hidden_channels
|
| 116 |
+
self.kernel_size = kernel_size,
|
| 117 |
+
self.dilation_rate = dilation_rate
|
| 118 |
+
self.n_layers = n_layers
|
| 119 |
+
self.gin_channels = gin_channels
|
| 120 |
+
self.p_dropout = p_dropout
|
| 121 |
+
|
| 122 |
+
self.in_layers = torch.nn.ModuleList()
|
| 123 |
+
self.res_skip_layers = torch.nn.ModuleList()
|
| 124 |
+
self.drop = nn.Dropout(p_dropout)
|
| 125 |
+
|
| 126 |
+
if gin_channels != 0:
|
| 127 |
+
cond_layer = torch.nn.Conv1d(gin_channels, 2*hidden_channels*n_layers, 1)
|
| 128 |
+
self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name='weight')
|
| 129 |
+
|
| 130 |
+
for i in range(n_layers):
|
| 131 |
+
dilation = dilation_rate ** i
|
| 132 |
+
padding = int((kernel_size * dilation - dilation) / 2)
|
| 133 |
+
in_layer = torch.nn.Conv1d(hidden_channels, 2*hidden_channels, kernel_size,
|
| 134 |
+
dilation=dilation, padding=padding)
|
| 135 |
+
in_layer = torch.nn.utils.weight_norm(in_layer, name='weight')
|
| 136 |
+
self.in_layers.append(in_layer)
|
| 137 |
+
|
| 138 |
+
# last one is not necessary
|
| 139 |
+
if i < n_layers - 1:
|
| 140 |
+
res_skip_channels = 2 * hidden_channels
|
| 141 |
+
else:
|
| 142 |
+
res_skip_channels = hidden_channels
|
| 143 |
+
|
| 144 |
+
res_skip_layer = torch.nn.Conv1d(hidden_channels, res_skip_channels, 1)
|
| 145 |
+
res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name='weight')
|
| 146 |
+
self.res_skip_layers.append(res_skip_layer)
|
| 147 |
+
|
| 148 |
+
def forward(self, x, x_mask, g=None, **kwargs):
|
| 149 |
+
output = torch.zeros_like(x)
|
| 150 |
+
n_channels_tensor = torch.IntTensor([self.hidden_channels])
|
| 151 |
+
|
| 152 |
+
if g is not None:
|
| 153 |
+
g = self.cond_layer(g)
|
| 154 |
+
|
| 155 |
+
for i in range(self.n_layers):
|
| 156 |
+
x_in = self.in_layers[i](x)
|
| 157 |
+
if g is not None:
|
| 158 |
+
cond_offset = i * 2 * self.hidden_channels
|
| 159 |
+
g_l = g[:,cond_offset:cond_offset+2*self.hidden_channels,:]
|
| 160 |
+
else:
|
| 161 |
+
g_l = torch.zeros_like(x_in)
|
| 162 |
+
|
| 163 |
+
acts = commons.fused_add_tanh_sigmoid_multiply(
|
| 164 |
+
x_in,
|
| 165 |
+
g_l,
|
| 166 |
+
n_channels_tensor)
|
| 167 |
+
acts = self.drop(acts)
|
| 168 |
+
|
| 169 |
+
res_skip_acts = self.res_skip_layers[i](acts)
|
| 170 |
+
if i < self.n_layers - 1:
|
| 171 |
+
res_acts = res_skip_acts[:,:self.hidden_channels,:]
|
| 172 |
+
x = (x + res_acts) * x_mask
|
| 173 |
+
output = output + res_skip_acts[:,self.hidden_channels:,:]
|
| 174 |
+
else:
|
| 175 |
+
output = output + res_skip_acts
|
| 176 |
+
return output * x_mask
|
| 177 |
+
|
| 178 |
+
def remove_weight_norm(self):
|
| 179 |
+
if self.gin_channels != 0:
|
| 180 |
+
torch.nn.utils.remove_weight_norm(self.cond_layer)
|
| 181 |
+
for l in self.in_layers:
|
| 182 |
+
torch.nn.utils.remove_weight_norm(l)
|
| 183 |
+
for l in self.res_skip_layers:
|
| 184 |
+
torch.nn.utils.remove_weight_norm(l)
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
class ResBlock1(torch.nn.Module):
|
| 188 |
+
def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):
|
| 189 |
+
super(ResBlock1, self).__init__()
|
| 190 |
+
self.convs1 = nn.ModuleList([
|
| 191 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
|
| 192 |
+
padding=get_padding(kernel_size, dilation[0]))),
|
| 193 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
|
| 194 |
+
padding=get_padding(kernel_size, dilation[1]))),
|
| 195 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2],
|
| 196 |
+
padding=get_padding(kernel_size, dilation[2])))
|
| 197 |
+
])
|
| 198 |
+
self.convs1.apply(init_weights)
|
| 199 |
+
|
| 200 |
+
self.convs2 = nn.ModuleList([
|
| 201 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
|
| 202 |
+
padding=get_padding(kernel_size, 1))),
|
| 203 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
|
| 204 |
+
padding=get_padding(kernel_size, 1))),
|
| 205 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
|
| 206 |
+
padding=get_padding(kernel_size, 1)))
|
| 207 |
+
])
|
| 208 |
+
self.convs2.apply(init_weights)
|
| 209 |
+
|
| 210 |
+
def forward(self, x, x_mask=None):
|
| 211 |
+
for c1, c2 in zip(self.convs1, self.convs2):
|
| 212 |
+
xt = F.leaky_relu(x, LRELU_SLOPE)
|
| 213 |
+
if x_mask is not None:
|
| 214 |
+
xt = xt * x_mask
|
| 215 |
+
xt = c1(xt)
|
| 216 |
+
xt = F.leaky_relu(xt, LRELU_SLOPE)
|
| 217 |
+
if x_mask is not None:
|
| 218 |
+
xt = xt * x_mask
|
| 219 |
+
xt = c2(xt)
|
| 220 |
+
x = xt + x
|
| 221 |
+
if x_mask is not None:
|
| 222 |
+
x = x * x_mask
|
| 223 |
+
return x
|
| 224 |
+
|
| 225 |
+
def remove_weight_norm(self):
|
| 226 |
+
for l in self.convs1:
|
| 227 |
+
remove_weight_norm(l)
|
| 228 |
+
for l in self.convs2:
|
| 229 |
+
remove_weight_norm(l)
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
class ResBlock2(torch.nn.Module):
|
| 233 |
+
def __init__(self, channels, kernel_size=3, dilation=(1, 3)):
|
| 234 |
+
super(ResBlock2, self).__init__()
|
| 235 |
+
self.convs = nn.ModuleList([
|
| 236 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
|
| 237 |
+
padding=get_padding(kernel_size, dilation[0]))),
|
| 238 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
|
| 239 |
+
padding=get_padding(kernel_size, dilation[1])))
|
| 240 |
+
])
|
| 241 |
+
self.convs.apply(init_weights)
|
| 242 |
+
|
| 243 |
+
def forward(self, x, x_mask=None):
|
| 244 |
+
for c in self.convs:
|
| 245 |
+
xt = F.leaky_relu(x, LRELU_SLOPE)
|
| 246 |
+
if x_mask is not None:
|
| 247 |
+
xt = xt * x_mask
|
| 248 |
+
xt = c(xt)
|
| 249 |
+
x = xt + x
|
| 250 |
+
if x_mask is not None:
|
| 251 |
+
x = x * x_mask
|
| 252 |
+
return x
|
| 253 |
+
|
| 254 |
+
def remove_weight_norm(self):
|
| 255 |
+
for l in self.convs:
|
| 256 |
+
remove_weight_norm(l)
|
| 257 |
+
|
| 258 |
+
|
| 259 |
+
class Log(nn.Module):
|
| 260 |
+
def forward(self, x, x_mask, reverse=False, **kwargs):
|
| 261 |
+
if not reverse:
|
| 262 |
+
y = torch.log(torch.clamp_min(x, 1e-5)) * x_mask
|
| 263 |
+
logdet = torch.sum(-y, [1, 2])
|
| 264 |
+
return y, logdet
|
| 265 |
+
else:
|
| 266 |
+
x = torch.exp(x) * x_mask
|
| 267 |
+
return x
|
| 268 |
+
|
| 269 |
+
|
| 270 |
+
class Flip(nn.Module):
|
| 271 |
+
def forward(self, x, *args, reverse=False, **kwargs):
|
| 272 |
+
x = torch.flip(x, [1])
|
| 273 |
+
if not reverse:
|
| 274 |
+
logdet = torch.zeros(x.size(0)).to(dtype=x.dtype, device=x.device)
|
| 275 |
+
return x, logdet
|
| 276 |
+
else:
|
| 277 |
+
return x
|
| 278 |
+
|
| 279 |
+
|
| 280 |
+
class ElementwiseAffine(nn.Module):
|
| 281 |
+
def __init__(self, channels):
|
| 282 |
+
super().__init__()
|
| 283 |
+
self.channels = channels
|
| 284 |
+
self.m = nn.Parameter(torch.zeros(channels,1))
|
| 285 |
+
self.logs = nn.Parameter(torch.zeros(channels,1))
|
| 286 |
+
|
| 287 |
+
def forward(self, x, x_mask, reverse=False, **kwargs):
|
| 288 |
+
if not reverse:
|
| 289 |
+
y = self.m + torch.exp(self.logs) * x
|
| 290 |
+
y = y * x_mask
|
| 291 |
+
logdet = torch.sum(self.logs * x_mask, [1,2])
|
| 292 |
+
return y, logdet
|
| 293 |
+
else:
|
| 294 |
+
x = (x - self.m) * torch.exp(-self.logs) * x_mask
|
| 295 |
+
return x
|
| 296 |
+
|
| 297 |
+
|
| 298 |
+
class ResidualCouplingLayer(nn.Module):
|
| 299 |
+
def __init__(self,
|
| 300 |
+
channels,
|
| 301 |
+
hidden_channels,
|
| 302 |
+
kernel_size,
|
| 303 |
+
dilation_rate,
|
| 304 |
+
n_layers,
|
| 305 |
+
p_dropout=0,
|
| 306 |
+
gin_channels=0,
|
| 307 |
+
mean_only=False):
|
| 308 |
+
assert channels % 2 == 0, "channels should be divisible by 2"
|
| 309 |
+
super().__init__()
|
| 310 |
+
self.channels = channels
|
| 311 |
+
self.hidden_channels = hidden_channels
|
| 312 |
+
self.kernel_size = kernel_size
|
| 313 |
+
self.dilation_rate = dilation_rate
|
| 314 |
+
self.n_layers = n_layers
|
| 315 |
+
self.half_channels = channels // 2
|
| 316 |
+
self.mean_only = mean_only
|
| 317 |
+
|
| 318 |
+
self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)
|
| 319 |
+
self.enc = WN(hidden_channels, kernel_size, dilation_rate, n_layers, p_dropout=p_dropout, gin_channels=gin_channels)
|
| 320 |
+
self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)
|
| 321 |
+
self.post.weight.data.zero_()
|
| 322 |
+
self.post.bias.data.zero_()
|
| 323 |
+
|
| 324 |
+
def forward(self, x, x_mask, g=None, reverse=False):
|
| 325 |
+
x0, x1 = torch.split(x, [self.half_channels]*2, 1)
|
| 326 |
+
h = self.pre(x0) * x_mask
|
| 327 |
+
h = self.enc(h, x_mask, g=g)
|
| 328 |
+
stats = self.post(h) * x_mask
|
| 329 |
+
if not self.mean_only:
|
| 330 |
+
m, logs = torch.split(stats, [self.half_channels]*2, 1)
|
| 331 |
+
else:
|
| 332 |
+
m = stats
|
| 333 |
+
logs = torch.zeros_like(m)
|
| 334 |
+
|
| 335 |
+
if not reverse:
|
| 336 |
+
x1 = m + x1 * torch.exp(logs) * x_mask
|
| 337 |
+
x = torch.cat([x0, x1], 1)
|
| 338 |
+
logdet = torch.sum(logs, [1,2])
|
| 339 |
+
return x, logdet
|
| 340 |
+
else:
|
| 341 |
+
x1 = (x1 - m) * torch.exp(-logs) * x_mask
|
| 342 |
+
x = torch.cat([x0, x1], 1)
|
| 343 |
+
return x
|
| 344 |
+
|
| 345 |
+
|
| 346 |
+
class ConvFlow(nn.Module):
|
| 347 |
+
def __init__(self, in_channels, filter_channels, kernel_size, n_layers, num_bins=10, tail_bound=5.0):
|
| 348 |
+
super().__init__()
|
| 349 |
+
self.in_channels = in_channels
|
| 350 |
+
self.filter_channels = filter_channels
|
| 351 |
+
self.kernel_size = kernel_size
|
| 352 |
+
self.n_layers = n_layers
|
| 353 |
+
self.num_bins = num_bins
|
| 354 |
+
self.tail_bound = tail_bound
|
| 355 |
+
self.half_channels = in_channels // 2
|
| 356 |
+
|
| 357 |
+
self.pre = nn.Conv1d(self.half_channels, filter_channels, 1)
|
| 358 |
+
self.convs = DDSConv(filter_channels, kernel_size, n_layers, p_dropout=0.)
|
| 359 |
+
self.proj = nn.Conv1d(filter_channels, self.half_channels * (num_bins * 3 - 1), 1)
|
| 360 |
+
self.proj.weight.data.zero_()
|
| 361 |
+
self.proj.bias.data.zero_()
|
| 362 |
+
|
| 363 |
+
def forward(self, x, x_mask, g=None, reverse=False):
|
| 364 |
+
x0, x1 = torch.split(x, [self.half_channels]*2, 1)
|
| 365 |
+
h = self.pre(x0)
|
| 366 |
+
h = self.convs(h, x_mask, g=g)
|
| 367 |
+
h = self.proj(h) * x_mask
|
| 368 |
+
|
| 369 |
+
b, c, t = x0.shape
|
| 370 |
+
h = h.reshape(b, c, -1, t).permute(0, 1, 3, 2) # [b, cx?, t] -> [b, c, t, ?]
|
| 371 |
+
|
| 372 |
+
unnormalized_widths = h[..., :self.num_bins] / math.sqrt(self.filter_channels)
|
| 373 |
+
unnormalized_heights = h[..., self.num_bins:2*self.num_bins] / math.sqrt(self.filter_channels)
|
| 374 |
+
unnormalized_derivatives = h[..., 2 * self.num_bins:]
|
| 375 |
+
|
| 376 |
+
x1, logabsdet = piecewise_rational_quadratic_transform(x1,
|
| 377 |
+
unnormalized_widths,
|
| 378 |
+
unnormalized_heights,
|
| 379 |
+
unnormalized_derivatives,
|
| 380 |
+
inverse=reverse,
|
| 381 |
+
tails='linear',
|
| 382 |
+
tail_bound=self.tail_bound
|
| 383 |
+
)
|
| 384 |
+
|
| 385 |
+
x = torch.cat([x0, x1], 1) * x_mask
|
| 386 |
+
logdet = torch.sum(logabsdet * x_mask, [1,2])
|
| 387 |
+
if not reverse:
|
| 388 |
+
return x, logdet
|
| 389 |
+
else:
|
| 390 |
+
return x
|
monotonic_align/__init__.py
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch
|
| 3 |
+
from .monotonic_align.core import maximum_path_c
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def maximum_path(neg_cent, mask):
|
| 7 |
+
""" Cython optimized version.
|
| 8 |
+
neg_cent: [b, t_t, t_s]
|
| 9 |
+
mask: [b, t_t, t_s]
|
| 10 |
+
"""
|
| 11 |
+
device = neg_cent.device
|
| 12 |
+
dtype = neg_cent.dtype
|
| 13 |
+
neg_cent = neg_cent.data.cpu().numpy().astype(np.float32)
|
| 14 |
+
path = np.zeros(neg_cent.shape, dtype=np.int32)
|
| 15 |
+
|
| 16 |
+
t_t_max = mask.sum(1)[:, 0].data.cpu().numpy().astype(np.int32)
|
| 17 |
+
t_s_max = mask.sum(2)[:, 0].data.cpu().numpy().astype(np.int32)
|
| 18 |
+
maximum_path_c(path, neg_cent, t_t_max, t_s_max)
|
| 19 |
+
return torch.from_numpy(path).to(device=device, dtype=dtype)
|
monotonic_align/core.pyx
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
cimport cython
|
| 2 |
+
from cython.parallel import prange
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
@cython.boundscheck(False)
|
| 6 |
+
@cython.wraparound(False)
|
| 7 |
+
cdef void maximum_path_each(int[:,::1] path, float[:,::1] value, int t_y, int t_x, float max_neg_val=-1e9) nogil:
|
| 8 |
+
cdef int x
|
| 9 |
+
cdef int y
|
| 10 |
+
cdef float v_prev
|
| 11 |
+
cdef float v_cur
|
| 12 |
+
cdef float tmp
|
| 13 |
+
cdef int index = t_x - 1
|
| 14 |
+
|
| 15 |
+
for y in range(t_y):
|
| 16 |
+
for x in range(max(0, t_x + y - t_y), min(t_x, y + 1)):
|
| 17 |
+
if x == y:
|
| 18 |
+
v_cur = max_neg_val
|
| 19 |
+
else:
|
| 20 |
+
v_cur = value[y-1, x]
|
| 21 |
+
if x == 0:
|
| 22 |
+
if y == 0:
|
| 23 |
+
v_prev = 0.
|
| 24 |
+
else:
|
| 25 |
+
v_prev = max_neg_val
|
| 26 |
+
else:
|
| 27 |
+
v_prev = value[y-1, x-1]
|
| 28 |
+
value[y, x] += max(v_prev, v_cur)
|
| 29 |
+
|
| 30 |
+
for y in range(t_y - 1, -1, -1):
|
| 31 |
+
path[y, index] = 1
|
| 32 |
+
if index != 0 and (index == y or value[y-1, index] < value[y-1, index-1]):
|
| 33 |
+
index = index - 1
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
@cython.boundscheck(False)
|
| 37 |
+
@cython.wraparound(False)
|
| 38 |
+
cpdef void maximum_path_c(int[:,:,::1] paths, float[:,:,::1] values, int[::1] t_ys, int[::1] t_xs) nogil:
|
| 39 |
+
cdef int b = paths.shape[0]
|
| 40 |
+
cdef int i
|
| 41 |
+
for i in prange(b, nogil=True):
|
| 42 |
+
maximum_path_each(paths[i], values[i], t_ys[i], t_xs[i])
|
monotonic_align/setup.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from distutils.core import setup
|
| 2 |
+
from Cython.Build import cythonize
|
| 3 |
+
import numpy
|
| 4 |
+
|
| 5 |
+
setup(
|
| 6 |
+
name = 'monotonic_align',
|
| 7 |
+
ext_modules = cythonize("core.pyx"),
|
| 8 |
+
include_dirs=[numpy.get_include()]
|
| 9 |
+
)
|
preprocess.py
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import text
|
| 3 |
+
from utils import load_filepaths_and_text
|
| 4 |
+
|
| 5 |
+
if __name__ == '__main__':
|
| 6 |
+
parser = argparse.ArgumentParser()
|
| 7 |
+
parser.add_argument("--out_extension", default="cleaned")
|
| 8 |
+
parser.add_argument("--text_index", default=1, type=int)
|
| 9 |
+
parser.add_argument("--filelists", nargs="+", default=["filelists/ljs_audio_text_val_filelist.txt", "filelists/ljs_audio_text_test_filelist.txt"])
|
| 10 |
+
parser.add_argument("--text_cleaners", nargs="+", default=["english_cleaners2"])
|
| 11 |
+
|
| 12 |
+
args = parser.parse_args()
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
for filelist in args.filelists:
|
| 16 |
+
print("START:", filelist)
|
| 17 |
+
filepaths_and_text = load_filepaths_and_text(filelist)
|
| 18 |
+
for i in range(len(filepaths_and_text)):
|
| 19 |
+
original_text = filepaths_and_text[i][args.text_index]
|
| 20 |
+
cleaned_text = text._clean_text(original_text, args.text_cleaners)
|
| 21 |
+
filepaths_and_text[i][args.text_index] = cleaned_text
|
| 22 |
+
|
| 23 |
+
new_filelist = filelist + "." + args.out_extension
|
| 24 |
+
with open(new_filelist, "w", encoding="utf-8") as f:
|
| 25 |
+
f.writelines(["|".join(x) + "\n" for x in filepaths_and_text])
|
requirements.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Cython==0.29.21
|
| 2 |
+
librosa==0.8.0
|
| 3 |
+
matplotlib==3.3.1
|
| 4 |
+
numpy==1.18.5
|
| 5 |
+
phonemizer==2.2.1
|
| 6 |
+
scipy==1.5.2
|
| 7 |
+
tensorboard==2.3.0
|
| 8 |
+
torch==1.6.0
|
| 9 |
+
torchvision==0.7.0
|
| 10 |
+
Unidecode==1.1.1
|
resources/fig_1a.png
ADDED
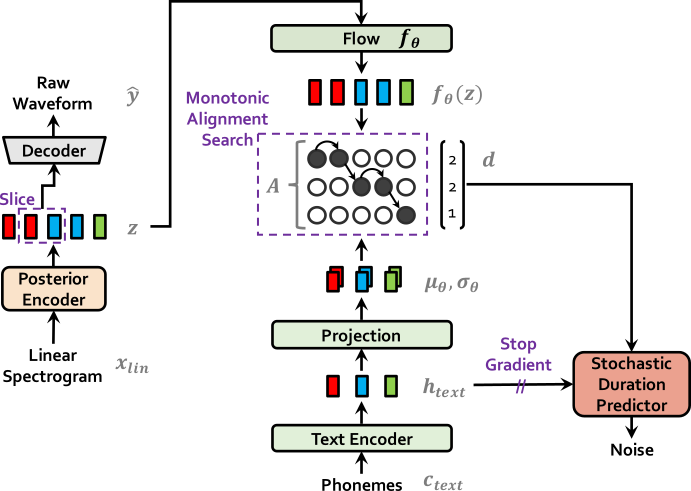
|
resources/fig_1b.png
ADDED
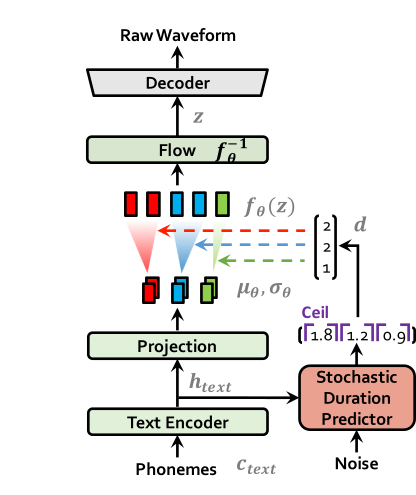
|
resources/training.png
ADDED
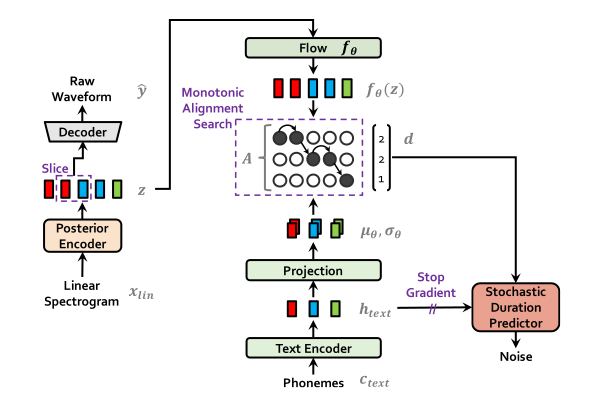
|
text/LICENSE
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Copyright (c) 2017 Keith Ito
|
| 2 |
+
|
| 3 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 4 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 5 |
+
in the Software without restriction, including without limitation the rights
|
| 6 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 7 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 8 |
+
furnished to do so, subject to the following conditions:
|
| 9 |
+
|
| 10 |
+
The above copyright notice and this permission notice shall be included in
|
| 11 |
+
all copies or substantial portions of the Software.
|
| 12 |
+
|
| 13 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 15 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 16 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 17 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 18 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
|
| 19 |
+
THE SOFTWARE.
|
text/__init__.py
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
""" from https://github.com/keithito/tacotron """
|
| 2 |
+
from text import cleaners
|
| 3 |
+
from text.symbols import symbols
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
# Mappings from symbol to numeric ID and vice versa:
|
| 7 |
+
_symbol_to_id = {s: i for i, s in enumerate(symbols)}
|
| 8 |
+
_id_to_symbol = {i: s for i, s in enumerate(symbols)}
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def text_to_sequence(text, cleaner_names):
|
| 12 |
+
'''Converts a string of text to a sequence of IDs corresponding to the symbols in the text.
|
| 13 |
+
Args:
|
| 14 |
+
text: string to convert to a sequence
|
| 15 |
+
cleaner_names: names of the cleaner functions to run the text through
|
| 16 |
+
Returns:
|
| 17 |
+
List of integers corresponding to the symbols in the text
|
| 18 |
+
'''
|
| 19 |
+
sequence = []
|
| 20 |
+
|
| 21 |
+
clean_text = _clean_text(text, cleaner_names)
|
| 22 |
+
for symbol in clean_text:
|
| 23 |
+
symbol_id = _symbol_to_id[symbol]
|
| 24 |
+
sequence += [symbol_id]
|
| 25 |
+
return sequence
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def cleaned_text_to_sequence(cleaned_text):
|
| 29 |
+
'''Converts a string of text to a sequence of IDs corresponding to the symbols in the text.
|
| 30 |
+
Args:
|
| 31 |
+
text: string to convert to a sequence
|
| 32 |
+
Returns:
|
| 33 |
+
List of integers corresponding to the symbols in the text
|
| 34 |
+
'''
|
| 35 |
+
sequence = [_symbol_to_id[symbol] for symbol in cleaned_text]
|
| 36 |
+
return sequence
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def sequence_to_text(sequence):
|
| 40 |
+
'''Converts a sequence of IDs back to a string'''
|
| 41 |
+
result = ''
|
| 42 |
+
for symbol_id in sequence:
|
| 43 |
+
s = _id_to_symbol[symbol_id]
|
| 44 |
+
result += s
|
| 45 |
+
return result
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def _clean_text(text, cleaner_names):
|
| 49 |
+
for name in cleaner_names:
|
| 50 |
+
cleaner = getattr(cleaners, name)
|
| 51 |
+
if not cleaner:
|
| 52 |
+
raise Exception('Unknown cleaner: %s' % name)
|
| 53 |
+
text = cleaner(text)
|
| 54 |
+
return text
|
text/cleaners.py
ADDED
|
@@ -0,0 +1,203 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
""" from https://github.com/keithito/tacotron """
|
| 2 |
+
|
| 3 |
+
'''
|
| 4 |
+
Cleaners are transformations that run over the input text at both training and eval time.
|
| 5 |
+
|
| 6 |
+
Cleaners can be selected by passing a comma-delimited list of cleaner names as the "cleaners"
|
| 7 |
+
hyperparameter. Some cleaners are English-specific. You'll typically want to use:
|
| 8 |
+
1. "english_cleaners" for English text
|
| 9 |
+
2. "transliteration_cleaners" for non-English text that can be transliterated to ASCII using
|
| 10 |
+
the Unidecode library (https://pypi.python.org/pypi/Unidecode)
|
| 11 |
+
3. "basic_cleaners" if you do not want to transliterate (in this case, you should also update
|
| 12 |
+
the symbols in symbols.py to match your data).
|
| 13 |
+
'''
|
| 14 |
+
|
| 15 |
+
import re
|
| 16 |
+
from unidecode import unidecode
|
| 17 |
+
import pyopenjtalk
|
| 18 |
+
from janome.tokenizer import Tokenizer
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
# Regular expression matching whitespace:
|
| 22 |
+
_whitespace_re = re.compile(r'\s+')
|
| 23 |
+
|
| 24 |
+
# List of (regular expression, replacement) pairs for abbreviations:
|
| 25 |
+
_abbreviations = [(re.compile('\\b%s\\.' % x[0], re.IGNORECASE), x[1]) for x in [
|
| 26 |
+
('mrs', 'misess'),
|
| 27 |
+
('mr', 'mister'),
|
| 28 |
+
('dr', 'doctor'),
|
| 29 |
+
('st', 'saint'),
|
| 30 |
+
('co', 'company'),
|
| 31 |
+
('jr', 'junior'),
|
| 32 |
+
('maj', 'major'),
|
| 33 |
+
('gen', 'general'),
|
| 34 |
+
('drs', 'doctors'),
|
| 35 |
+
('rev', 'reverend'),
|
| 36 |
+
('lt', 'lieutenant'),
|
| 37 |
+
('hon', 'honorable'),
|
| 38 |
+
('sgt', 'sergeant'),
|
| 39 |
+
('capt', 'captain'),
|
| 40 |
+
('esq', 'esquire'),
|
| 41 |
+
('ltd', 'limited'),
|
| 42 |
+
('col', 'colonel'),
|
| 43 |
+
('ft', 'fort'),
|
| 44 |
+
]]
|
| 45 |
+
|
| 46 |
+
# Regular expression matching Japanese without punctuation marks:
|
| 47 |
+
_japanese_characters = re.compile(r'[A-Za-z\d\u3005\u3040-\u30ff\u4e00-\u9fff\uff11-\uff19\uff21-\uff3a\uff41-\uff5a\uff66-\uff9d]')
|
| 48 |
+
|
| 49 |
+
# Regular expression matching non-Japanese characters or punctuation marks:
|
| 50 |
+
_japanese_marks = re.compile(r'[^A-Za-z\d\u3005\u3040-\u30ff\u4e00-\u9fff\uff11-\uff19\uff21-\uff3a\uff41-\uff5a\uff66-\uff9d]')
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
# Tokenizer for Japanese
|
| 54 |
+
tokenizer = Tokenizer()
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def expand_abbreviations(text):
|
| 58 |
+
for regex, replacement in _abbreviations:
|
| 59 |
+
text = re.sub(regex, replacement, text)
|
| 60 |
+
return text
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def lowercase(text):
|
| 66 |
+
return text.lower()
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def collapse_whitespace(text):
|
| 70 |
+
return re.sub(_whitespace_re, ' ', text)
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def convert_to_ascii(text):
|
| 74 |
+
return unidecode(text)
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def basic_cleaners(text):
|
| 78 |
+
'''Basic pipeline that lowercases and collapses whitespace without transliteration.'''
|
| 79 |
+
text = lowercase(text)
|
| 80 |
+
text = collapse_whitespace(text)
|
| 81 |
+
return text
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
def transliteration_cleaners(text):
|
| 85 |
+
'''Pipeline for non-English text that transliterates to ASCII.'''
|
| 86 |
+
text = convert_to_ascii(text)
|
| 87 |
+
text = lowercase(text)
|
| 88 |
+
text = collapse_whitespace(text)
|
| 89 |
+
return text
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def japanese_cleaners(text):
|
| 94 |
+
'''Pipeline for Japanese text.'''
|
| 95 |
+
sentences = re.split(_japanese_marks, text)
|
| 96 |
+
marks = re.findall(_japanese_marks, text)
|
| 97 |
+
text = ''
|
| 98 |
+
for i, mark in enumerate(marks):
|
| 99 |
+
if re.match(_japanese_characters, sentences[i]):
|
| 100 |
+
text += pyopenjtalk.g2p(sentences[i], kana=False).replace('pau','').replace(' ','')
|
| 101 |
+
text += unidecode(mark).replace(' ','')
|
| 102 |
+
if re.match(_japanese_characters, sentences[-1]):
|
| 103 |
+
text += pyopenjtalk.g2p(sentences[-1], kana=False).replace('pau','').replace(' ','')
|
| 104 |
+
if re.match('[A-Za-z]',text[-1]):
|
| 105 |
+
text += '.'
|
| 106 |
+
return text
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def japanese_tokenization_cleaners(text):
|
| 110 |
+
'''Pipeline for tokenizing Japanese text.'''
|
| 111 |
+
words = []
|
| 112 |
+
for token in tokenizer.tokenize(text):
|
| 113 |
+
if token.phonetic!='*':
|
| 114 |
+
words.append(token.phonetic)
|
| 115 |
+
else:
|
| 116 |
+
words.append(token.surface)
|
| 117 |
+
text = ''
|
| 118 |
+
for word in words:
|
| 119 |
+
if re.match(_japanese_characters, word):
|
| 120 |
+
if word[0] == '\u30fc':
|
| 121 |
+
continue
|
| 122 |
+
if len(text)>0:
|
| 123 |
+
text += ' '
|
| 124 |
+
text += pyopenjtalk.g2p(word, kana=False).replace(' ','')
|
| 125 |
+
else:
|
| 126 |
+
text += unidecode(word).replace(' ','')
|
| 127 |
+
if re.match('[A-Za-z]',text[-1]):
|
| 128 |
+
text += '.'
|
| 129 |
+
return text
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
def japanese_accent_cleaners(text):
|
| 133 |
+
'''Pipeline for notating accent in Japanese text.'''
|
| 134 |
+
'''Reference https://r9y9.github.io/ttslearn/latest/notebooks/ch10_Recipe-Tacotron.html'''
|
| 135 |
+
sentences = re.split(_japanese_marks, text)
|
| 136 |
+
marks = re.findall(_japanese_marks, text)
|
| 137 |
+
text = ''
|
| 138 |
+
for i, sentence in enumerate(sentences):
|
| 139 |
+
if re.match(_japanese_characters, sentence):
|
| 140 |
+
text += ':'
|
| 141 |
+
labels = pyopenjtalk.extract_fullcontext(sentence)
|
| 142 |
+
for n, label in enumerate(labels):
|
| 143 |
+
phoneme = re.search(r'\-([^\+]*)\+', label).group(1)
|
| 144 |
+
if phoneme not in ['sil','pau']:
|
| 145 |
+
text += phoneme
|
| 146 |
+
else:
|
| 147 |
+
continue
|
| 148 |
+
n_moras = int(re.search(r'/F:(\d+)_', label).group(1))
|
| 149 |
+
a1 = int(re.search(r"/A:(\-?[0-9]+)\+", label).group(1))
|
| 150 |
+
a2 = int(re.search(r"\+(\d+)\+", label).group(1))
|
| 151 |
+
a3 = int(re.search(r"\+(\d+)/", label).group(1))
|
| 152 |
+
if re.search(r'\-([^\+]*)\+', labels[n + 1]).group(1) in ['sil','pau']:
|
| 153 |
+
a2_next=-1
|
| 154 |
+
else:
|
| 155 |
+
a2_next = int(re.search(r"\+(\d+)\+", labels[n + 1]).group(1))
|
| 156 |
+
# Accent phrase boundary
|
| 157 |
+
if a3 == 1 and a2_next == 1:
|
| 158 |
+
text += ' '
|
| 159 |
+
# Falling
|
| 160 |
+
elif a1 == 0 and a2_next == a2 + 1 and a2 != n_moras:
|
| 161 |
+
text += ')'
|
| 162 |
+
# Rising
|
| 163 |
+
elif a2 == 1 and a2_next == 2:
|
| 164 |
+
text += '('
|
| 165 |
+
if i<len(marks):
|
| 166 |
+
text += unidecode(marks[i]).replace(' ','')
|
| 167 |
+
if re.match('[A-Za-z]',text[-1]):
|
| 168 |
+
text += '.'
|
| 169 |
+
return text
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
def japanese_phrase_cleaners(text):
|
| 173 |
+
'''Pipeline for dividing Japanese text into phrases.'''
|
| 174 |
+
sentences = re.split(_japanese_marks, text)
|
| 175 |
+
marks = re.findall(_japanese_marks, text)
|
| 176 |
+
text = ''
|
| 177 |
+
for i, sentence in enumerate(sentences):
|
| 178 |
+
if re.match(_japanese_characters, sentence):
|
| 179 |
+
if text != '':
|
| 180 |
+
text += ' '
|
| 181 |
+
labels = pyopenjtalk.extract_fullcontext(sentence)
|
| 182 |
+
for n, label in enumerate(labels):
|
| 183 |
+
phoneme = re.search(r'\-([^\+]*)\+', label).group(1)
|
| 184 |
+
if phoneme not in ['sil','pau']:
|
| 185 |
+
text += phoneme
|
| 186 |
+
else:
|
| 187 |
+
continue
|
| 188 |
+
a3 = int(re.search(r"\+(\d+)/", label).group(1))
|
| 189 |
+
if re.search(r'\-([^\+]*)\+', labels[n + 1]).group(1) in ['sil','pau']:
|
| 190 |
+
a2_next=-1
|
| 191 |
+
else:
|
| 192 |
+
a2_next = int(re.search(r"\+(\d+)\+", labels[n + 1]).group(1))
|
| 193 |
+
# Accent phrase boundary
|
| 194 |
+
if a3 == 1 and a2_next == 1:
|
| 195 |
+
text += ' '
|
| 196 |
+
if i<len(marks):
|
| 197 |
+
text += unidecode(marks[i]).replace(' ','')
|
| 198 |
+
if re.match('[A-Za-z]',text[-1]):
|
| 199 |
+
text += '.'
|
| 200 |
+
return text
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
|
text/symbols.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
symbols = list(' !"&*,-.?ABCINU[]abcdefghijklmnoprstuwyz{}~')
|
| 2 |
+
SPACE_ID = symbols.index(" ")
|
train.py
ADDED
|
@@ -0,0 +1,290 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import json
|
| 3 |
+
import argparse
|
| 4 |
+
import itertools
|
| 5 |
+
import math
|
| 6 |
+
import torch
|
| 7 |
+
from torch import nn, optim
|
| 8 |
+
from torch.nn import functional as F
|
| 9 |
+
from torch.utils.data import DataLoader
|
| 10 |
+
from torch.utils.tensorboard import SummaryWriter
|
| 11 |
+
import torch.multiprocessing as mp
|
| 12 |
+
import torch.distributed as dist
|
| 13 |
+
from torch.nn.parallel import DistributedDataParallel as DDP
|
| 14 |
+
from torch.cuda.amp import autocast, GradScaler
|
| 15 |
+
|
| 16 |
+
import commons
|
| 17 |
+
import utils
|
| 18 |
+
from data_utils import (
|
| 19 |
+
TextAudioLoader,
|
| 20 |
+
TextAudioCollate,
|
| 21 |
+
DistributedBucketSampler
|
| 22 |
+
)
|
| 23 |
+
from models import (
|
| 24 |
+
SynthesizerTrn,
|
| 25 |
+
MultiPeriodDiscriminator,
|
| 26 |
+
)
|
| 27 |
+
from losses import (
|
| 28 |
+
generator_loss,
|
| 29 |
+
discriminator_loss,
|
| 30 |
+
feature_loss,
|
| 31 |
+
kl_loss
|
| 32 |
+
)
|
| 33 |
+
from mel_processing import mel_spectrogram_torch, spec_to_mel_torch
|
| 34 |
+
from text.symbols import symbols
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
torch.backends.cudnn.benchmark = True
|
| 38 |
+
global_step = 0
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def main():
|
| 42 |
+
"""Assume Single Node Multi GPUs Training Only"""
|
| 43 |
+
assert torch.cuda.is_available(), "CPU training is not allowed."
|
| 44 |
+
|
| 45 |
+
n_gpus = torch.cuda.device_count()
|
| 46 |
+
os.environ['MASTER_ADDR'] = 'localhost'
|
| 47 |
+
os.environ['MASTER_PORT'] = '80000'
|
| 48 |
+
|
| 49 |
+
hps = utils.get_hparams()
|
| 50 |
+
mp.spawn(run, nprocs=n_gpus, args=(n_gpus, hps,))
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def run(rank, n_gpus, hps):
|
| 54 |
+
global global_step
|
| 55 |
+
if rank == 0:
|
| 56 |
+
logger = utils.get_logger(hps.model_dir)
|
| 57 |
+
logger.info(hps)
|
| 58 |
+
utils.check_git_hash(hps.model_dir)
|
| 59 |
+
writer = SummaryWriter(log_dir=hps.model_dir)
|
| 60 |
+
writer_eval = SummaryWriter(log_dir=os.path.join(hps.model_dir, "eval"))
|
| 61 |
+
|
| 62 |
+
dist.init_process_group(backend='nccl', init_method='env://', world_size=n_gpus, rank=rank)
|
| 63 |
+
torch.manual_seed(hps.train.seed)
|
| 64 |
+
torch.cuda.set_device(rank)
|
| 65 |
+
|
| 66 |
+
train_dataset = TextAudioLoader(hps.data.training_files, hps.data)
|
| 67 |
+
train_sampler = DistributedBucketSampler(
|
| 68 |
+
train_dataset,
|
| 69 |
+
hps.train.batch_size,
|
| 70 |
+
[32,300,400,500,600,700,800,900,1000],
|
| 71 |
+
num_replicas=n_gpus,
|
| 72 |
+
rank=rank,
|
| 73 |
+
shuffle=True)
|
| 74 |
+
collate_fn = TextAudioCollate()
|
| 75 |
+
train_loader = DataLoader(train_dataset, num_workers=8, shuffle=False, pin_memory=True,
|
| 76 |
+
collate_fn=collate_fn, batch_sampler=train_sampler)
|
| 77 |
+
if rank == 0:
|
| 78 |
+
eval_dataset = TextAudioLoader(hps.data.validation_files, hps.data)
|
| 79 |
+
eval_loader = DataLoader(eval_dataset, num_workers=8, shuffle=False,
|
| 80 |
+
batch_size=hps.train.batch_size, pin_memory=True,
|
| 81 |
+
drop_last=False, collate_fn=collate_fn)
|
| 82 |
+
|
| 83 |
+
net_g = SynthesizerTrn(
|
| 84 |
+
len(symbols),
|
| 85 |
+
hps.data.filter_length // 2 + 1,
|
| 86 |
+
hps.train.segment_size // hps.data.hop_length,
|
| 87 |
+
**hps.model).cuda(rank)
|
| 88 |
+
net_d = MultiPeriodDiscriminator(hps.model.use_spectral_norm).cuda(rank)
|
| 89 |
+
optim_g = torch.optim.AdamW(
|
| 90 |
+
net_g.parameters(),
|
| 91 |
+
hps.train.learning_rate,
|
| 92 |
+
betas=hps.train.betas,
|
| 93 |
+
eps=hps.train.eps)
|
| 94 |
+
optim_d = torch.optim.AdamW(
|
| 95 |
+
net_d.parameters(),
|
| 96 |
+
hps.train.learning_rate,
|
| 97 |
+
betas=hps.train.betas,
|
| 98 |
+
eps=hps.train.eps)
|
| 99 |
+
net_g = DDP(net_g, device_ids=[rank])
|
| 100 |
+
net_d = DDP(net_d, device_ids=[rank])
|
| 101 |
+
|
| 102 |
+
try:
|
| 103 |
+
_, _, _, epoch_str = utils.load_checkpoint(utils.latest_checkpoint_path(hps.model_dir, "G_*.pth"), net_g, optim_g)
|
| 104 |
+
_, _, _, epoch_str = utils.load_checkpoint(utils.latest_checkpoint_path(hps.model_dir, "D_*.pth"), net_d, optim_d)
|
| 105 |
+
global_step = (epoch_str - 1) * len(train_loader)
|
| 106 |
+
except:
|
| 107 |
+
epoch_str = 1
|
| 108 |
+
global_step = 0
|
| 109 |
+
|
| 110 |
+
scheduler_g = torch.optim.lr_scheduler.ExponentialLR(optim_g, gamma=hps.train.lr_decay, last_epoch=epoch_str-2)
|
| 111 |
+
scheduler_d = torch.optim.lr_scheduler.ExponentialLR(optim_d, gamma=hps.train.lr_decay, last_epoch=epoch_str-2)
|
| 112 |
+
|
| 113 |
+
scaler = GradScaler(enabled=hps.train.fp16_run)
|
| 114 |
+
|
| 115 |
+
for epoch in range(epoch_str, hps.train.epochs + 1):
|
| 116 |
+
if rank==0:
|
| 117 |
+
train_and_evaluate(rank, epoch, hps, [net_g, net_d], [optim_g, optim_d], [scheduler_g, scheduler_d], scaler, [train_loader, eval_loader], logger, [writer, writer_eval])
|
| 118 |
+
else:
|
| 119 |
+
train_and_evaluate(rank, epoch, hps, [net_g, net_d], [optim_g, optim_d], [scheduler_g, scheduler_d], scaler, [train_loader, None], None, None)
|
| 120 |
+
scheduler_g.step()
|
| 121 |
+
scheduler_d.step()
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
def train_and_evaluate(rank, epoch, hps, nets, optims, schedulers, scaler, loaders, logger, writers):
|
| 125 |
+
net_g, net_d = nets
|
| 126 |
+
optim_g, optim_d = optims
|
| 127 |
+
scheduler_g, scheduler_d = schedulers
|
| 128 |
+
train_loader, eval_loader = loaders
|
| 129 |
+
if writers is not None:
|
| 130 |
+
writer, writer_eval = writers
|
| 131 |
+
|
| 132 |
+
train_loader.batch_sampler.set_epoch(epoch)
|
| 133 |
+
global global_step
|
| 134 |
+
|
| 135 |
+
net_g.train()
|
| 136 |
+
net_d.train()
|
| 137 |
+
for batch_idx, (x, x_lengths, spec, spec_lengths, y, y_lengths) in enumerate(train_loader):
|
| 138 |
+
x, x_lengths = x.cuda(rank, non_blocking=True), x_lengths.cuda(rank, non_blocking=True)
|
| 139 |
+
spec, spec_lengths = spec.cuda(rank, non_blocking=True), spec_lengths.cuda(rank, non_blocking=True)
|
| 140 |
+
y, y_lengths = y.cuda(rank, non_blocking=True), y_lengths.cuda(rank, non_blocking=True)
|
| 141 |
+
|
| 142 |
+
with autocast(enabled=hps.train.fp16_run):
|
| 143 |
+
y_hat, l_length, attn, ids_slice, x_mask, z_mask,\
|
| 144 |
+
(z, z_p, m_p, logs_p, m_q, logs_q) = net_g(x, x_lengths, spec, spec_lengths)
|
| 145 |
+
|
| 146 |
+
mel = spec_to_mel_torch(
|
| 147 |
+
spec,
|
| 148 |
+
hps.data.filter_length,
|
| 149 |
+
hps.data.n_mel_channels,
|
| 150 |
+
hps.data.sampling_rate,
|
| 151 |
+
hps.data.mel_fmin,
|
| 152 |
+
hps.data.mel_fmax)
|
| 153 |
+
y_mel = commons.slice_segments(mel, ids_slice, hps.train.segment_size // hps.data.hop_length)
|
| 154 |
+
y_hat_mel = mel_spectrogram_torch(
|
| 155 |
+
y_hat.squeeze(1),
|
| 156 |
+
hps.data.filter_length,
|
| 157 |
+
hps.data.n_mel_channels,
|
| 158 |
+
hps.data.sampling_rate,
|
| 159 |
+
hps.data.hop_length,
|
| 160 |
+
hps.data.win_length,
|
| 161 |
+
hps.data.mel_fmin,
|
| 162 |
+
hps.data.mel_fmax
|
| 163 |
+
)
|
| 164 |
+
|
| 165 |
+
y = commons.slice_segments(y, ids_slice * hps.data.hop_length, hps.train.segment_size) # slice
|
| 166 |
+
|
| 167 |
+
# Discriminator
|
| 168 |
+
y_d_hat_r, y_d_hat_g, _, _ = net_d(y, y_hat.detach())
|
| 169 |
+
with autocast(enabled=False):
|
| 170 |
+
loss_disc, losses_disc_r, losses_disc_g = discriminator_loss(y_d_hat_r, y_d_hat_g)
|
| 171 |
+
loss_disc_all = loss_disc
|
| 172 |
+
optim_d.zero_grad()
|
| 173 |
+
scaler.scale(loss_disc_all).backward()
|
| 174 |
+
scaler.unscale_(optim_d)
|
| 175 |
+
grad_norm_d = commons.clip_grad_value_(net_d.parameters(), None)
|
| 176 |
+
scaler.step(optim_d)
|
| 177 |
+
|
| 178 |
+
with autocast(enabled=hps.train.fp16_run):
|
| 179 |
+
# Generator
|
| 180 |
+
y_d_hat_r, y_d_hat_g, fmap_r, fmap_g = net_d(y, y_hat)
|
| 181 |
+
with autocast(enabled=False):
|
| 182 |
+
loss_dur = torch.sum(l_length.float())
|
| 183 |
+
loss_mel = F.l1_loss(y_mel, y_hat_mel) * hps.train.c_mel
|
| 184 |
+
loss_kl = kl_loss(z_p, logs_q, m_p, logs_p, z_mask) * hps.train.c_kl
|
| 185 |
+
|
| 186 |
+
loss_fm = feature_loss(fmap_r, fmap_g)
|
| 187 |
+
loss_gen, losses_gen = generator_loss(y_d_hat_g)
|
| 188 |
+
loss_gen_all = loss_gen + loss_fm + loss_mel + loss_dur + loss_kl
|
| 189 |
+
optim_g.zero_grad()
|
| 190 |
+
scaler.scale(loss_gen_all).backward()
|
| 191 |
+
scaler.unscale_(optim_g)
|
| 192 |
+
grad_norm_g = commons.clip_grad_value_(net_g.parameters(), None)
|
| 193 |
+
scaler.step(optim_g)
|
| 194 |
+
scaler.update()
|
| 195 |
+
|
| 196 |
+
if rank==0:
|
| 197 |
+
if global_step % hps.train.log_interval == 0:
|
| 198 |
+
lr = optim_g.param_groups[0]['lr']
|
| 199 |
+
losses = [loss_disc, loss_gen, loss_fm, loss_mel, loss_dur, loss_kl]
|
| 200 |
+
logger.info('Train Epoch: {} [{:.0f}%]'.format(
|
| 201 |
+
epoch,
|
| 202 |
+
100. * batch_idx / len(train_loader)))
|
| 203 |
+
logger.info([x.item() for x in losses] + [global_step, lr])
|
| 204 |
+
|
| 205 |
+
scalar_dict = {"loss/g/total": loss_gen_all, "loss/d/total": loss_disc_all, "learning_rate": lr, "grad_norm_d": grad_norm_d, "grad_norm_g": grad_norm_g}
|
| 206 |
+
scalar_dict.update({"loss/g/fm": loss_fm, "loss/g/mel": loss_mel, "loss/g/dur": loss_dur, "loss/g/kl": loss_kl})
|
| 207 |
+
|
| 208 |
+
scalar_dict.update({"loss/g/{}".format(i): v for i, v in enumerate(losses_gen)})
|
| 209 |
+
scalar_dict.update({"loss/d_r/{}".format(i): v for i, v in enumerate(losses_disc_r)})
|
| 210 |
+
scalar_dict.update({"loss/d_g/{}".format(i): v for i, v in enumerate(losses_disc_g)})
|
| 211 |
+
image_dict = {
|
| 212 |
+
"slice/mel_org": utils.plot_spectrogram_to_numpy(y_mel[0].data.cpu().numpy()),
|
| 213 |
+
"slice/mel_gen": utils.plot_spectrogram_to_numpy(y_hat_mel[0].data.cpu().numpy()),
|
| 214 |
+
"all/mel": utils.plot_spectrogram_to_numpy(mel[0].data.cpu().numpy()),
|
| 215 |
+
"all/attn": utils.plot_alignment_to_numpy(attn[0,0].data.cpu().numpy())
|
| 216 |
+
}
|
| 217 |
+
utils.summarize(
|
| 218 |
+
writer=writer,
|
| 219 |
+
global_step=global_step,
|
| 220 |
+
images=image_dict,
|
| 221 |
+
scalars=scalar_dict)
|
| 222 |
+
|
| 223 |
+
if global_step % hps.train.eval_interval == 0:
|
| 224 |
+
evaluate(hps, net_g, eval_loader, writer_eval)
|
| 225 |
+
utils.save_checkpoint(net_g, optim_g, hps.train.learning_rate, epoch, os.path.join(hps.model_dir, "G_{}.pth".format(global_step)))
|
| 226 |
+
utils.save_checkpoint(net_d, optim_d, hps.train.learning_rate, epoch, os.path.join(hps.model_dir, "D_{}.pth".format(global_step)))
|
| 227 |
+
global_step += 1
|
| 228 |
+
|
| 229 |
+
if rank == 0:
|
| 230 |
+
logger.info('====> Epoch: {}'.format(epoch))
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
def evaluate(hps, generator, eval_loader, writer_eval):
|
| 234 |
+
generator.eval()
|
| 235 |
+
with torch.no_grad():
|
| 236 |
+
for batch_idx, (x, x_lengths, spec, spec_lengths, y, y_lengths) in enumerate(eval_loader):
|
| 237 |
+
x, x_lengths = x.cuda(0), x_lengths.cuda(0)
|
| 238 |
+
spec, spec_lengths = spec.cuda(0), spec_lengths.cuda(0)
|
| 239 |
+
y, y_lengths = y.cuda(0), y_lengths.cuda(0)
|
| 240 |
+
|
| 241 |
+
# remove else
|
| 242 |
+
x = x[:1]
|
| 243 |
+
x_lengths = x_lengths[:1]
|
| 244 |
+
spec = spec[:1]
|
| 245 |
+
spec_lengths = spec_lengths[:1]
|
| 246 |
+
y = y[:1]
|
| 247 |
+
y_lengths = y_lengths[:1]
|
| 248 |
+
break
|
| 249 |
+
y_hat, attn, mask, *_ = generator.module.infer(x, x_lengths, max_len=1000)
|
| 250 |
+
y_hat_lengths = mask.sum([1,2]).long() * hps.data.hop_length
|
| 251 |
+
|
| 252 |
+
mel = spec_to_mel_torch(
|
| 253 |
+
spec,
|
| 254 |
+
hps.data.filter_length,
|
| 255 |
+
hps.data.n_mel_channels,
|
| 256 |
+
hps.data.sampling_rate,
|
| 257 |
+
hps.data.mel_fmin,
|
| 258 |
+
hps.data.mel_fmax)
|
| 259 |
+
y_hat_mel = mel_spectrogram_torch(
|
| 260 |
+
y_hat.squeeze(1).float(),
|
| 261 |
+
hps.data.filter_length,
|
| 262 |
+
hps.data.n_mel_channels,
|
| 263 |
+
hps.data.sampling_rate,
|
| 264 |
+
hps.data.hop_length,
|
| 265 |
+
hps.data.win_length,
|
| 266 |
+
hps.data.mel_fmin,
|
| 267 |
+
hps.data.mel_fmax
|
| 268 |
+
)
|
| 269 |
+
image_dict = {
|
| 270 |
+
"gen/mel": utils.plot_spectrogram_to_numpy(y_hat_mel[0].cpu().numpy())
|
| 271 |
+
}
|
| 272 |
+
audio_dict = {
|
| 273 |
+
"gen/audio": y_hat[0,:,:y_hat_lengths[0]]
|
| 274 |
+
}
|
| 275 |
+
if global_step == 0:
|
| 276 |
+
image_dict.update({"gt/mel": utils.plot_spectrogram_to_numpy(mel[0].cpu().numpy())})
|
| 277 |
+
audio_dict.update({"gt/audio": y[0,:,:y_lengths[0]]})
|
| 278 |
+
|
| 279 |
+
utils.summarize(
|
| 280 |
+
writer=writer_eval,
|
| 281 |
+
global_step=global_step,
|
| 282 |
+
images=image_dict,
|
| 283 |
+
audios=audio_dict,
|
| 284 |
+
audio_sampling_rate=hps.data.sampling_rate
|
| 285 |
+
)
|
| 286 |
+
generator.train()
|
| 287 |
+
|
| 288 |
+
|
| 289 |
+
if __name__ == "__main__":
|
| 290 |
+
main()
|
train_ms.py
ADDED
|
@@ -0,0 +1,294 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import json
|
| 3 |
+
import argparse
|
| 4 |
+
import itertools
|
| 5 |
+
import math
|
| 6 |
+
import torch
|
| 7 |
+
from torch import nn, optim
|
| 8 |
+
from torch.nn import functional as F
|
| 9 |
+
from torch.utils.data import DataLoader
|
| 10 |
+
from torch.utils.tensorboard import SummaryWriter
|
| 11 |
+
import torch.multiprocessing as mp
|
| 12 |
+
import torch.distributed as dist
|
| 13 |
+
from torch.nn.parallel import DistributedDataParallel as DDP
|
| 14 |
+
from torch.cuda.amp import autocast, GradScaler
|
| 15 |
+
|
| 16 |
+
import commons
|
| 17 |
+
import utils
|
| 18 |
+
from data_utils import (
|
| 19 |
+
TextAudioSpeakerLoader,
|
| 20 |
+
TextAudioSpeakerCollate,
|
| 21 |
+
DistributedBucketSampler
|
| 22 |
+
)
|
| 23 |
+
from models import (
|
| 24 |
+
SynthesizerTrn,
|
| 25 |
+
MultiPeriodDiscriminator,
|
| 26 |
+
)
|
| 27 |
+
from losses import (
|
| 28 |
+
generator_loss,
|
| 29 |
+
discriminator_loss,
|
| 30 |
+
feature_loss,
|
| 31 |
+
kl_loss
|
| 32 |
+
)
|
| 33 |
+
from mel_processing import mel_spectrogram_torch, spec_to_mel_torch
|
| 34 |
+
from text.symbols import symbols
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
torch.backends.cudnn.benchmark = True
|
| 38 |
+
global_step = 0
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def main():
|
| 42 |
+
"""Assume Single Node Multi GPUs Training Only"""
|
| 43 |
+
assert torch.cuda.is_available(), "CPU training is not allowed."
|
| 44 |
+
|
| 45 |
+
n_gpus = torch.cuda.device_count()
|
| 46 |
+
os.environ['MASTER_ADDR'] = 'localhost'
|
| 47 |
+
os.environ['MASTER_PORT'] = '80000'
|
| 48 |
+
|
| 49 |
+
hps = utils.get_hparams()
|
| 50 |
+
mp.spawn(run, nprocs=n_gpus, args=(n_gpus, hps,))
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def run(rank, n_gpus, hps):
|
| 54 |
+
global global_step
|
| 55 |
+
if rank == 0:
|
| 56 |
+
logger = utils.get_logger(hps.model_dir)
|
| 57 |
+
logger.info(hps)
|
| 58 |
+
utils.check_git_hash(hps.model_dir)
|
| 59 |
+
writer = SummaryWriter(log_dir=hps.model_dir)
|
| 60 |
+
writer_eval = SummaryWriter(log_dir=os.path.join(hps.model_dir, "eval"))
|
| 61 |
+
|
| 62 |
+
dist.init_process_group(backend='nccl', init_method='env://', world_size=n_gpus, rank=rank)
|
| 63 |
+
torch.manual_seed(hps.train.seed)
|
| 64 |
+
torch.cuda.set_device(rank)
|
| 65 |
+
|
| 66 |
+
train_dataset = TextAudioSpeakerLoader(hps.data.training_files, hps.data)
|
| 67 |
+
train_sampler = DistributedBucketSampler(
|
| 68 |
+
train_dataset,
|
| 69 |
+
hps.train.batch_size,
|
| 70 |
+
[32,300,400,500,600,700,800,900,1000],
|
| 71 |
+
num_replicas=n_gpus,
|
| 72 |
+
rank=rank,
|
| 73 |
+
shuffle=True)
|
| 74 |
+
collate_fn = TextAudioSpeakerCollate()
|
| 75 |
+
train_loader = DataLoader(train_dataset, num_workers=8, shuffle=False, pin_memory=True,
|
| 76 |
+
collate_fn=collate_fn, batch_sampler=train_sampler)
|
| 77 |
+
if rank == 0:
|
| 78 |
+
eval_dataset = TextAudioSpeakerLoader(hps.data.validation_files, hps.data)
|
| 79 |
+
eval_loader = DataLoader(eval_dataset, num_workers=8, shuffle=False,
|
| 80 |
+
batch_size=hps.train.batch_size, pin_memory=True,
|
| 81 |
+
drop_last=False, collate_fn=collate_fn)
|
| 82 |
+
|
| 83 |
+
net_g = SynthesizerTrn(
|
| 84 |
+
len(symbols),
|
| 85 |
+
hps.data.filter_length // 2 + 1,
|
| 86 |
+
hps.train.segment_size // hps.data.hop_length,
|
| 87 |
+
n_speakers=hps.data.n_speakers,
|
| 88 |
+
**hps.model).cuda(rank)
|
| 89 |
+
net_d = MultiPeriodDiscriminator(hps.model.use_spectral_norm).cuda(rank)
|
| 90 |
+
optim_g = torch.optim.AdamW(
|
| 91 |
+
net_g.parameters(),
|
| 92 |
+
hps.train.learning_rate,
|
| 93 |
+
betas=hps.train.betas,
|
| 94 |
+
eps=hps.train.eps)
|
| 95 |
+
optim_d = torch.optim.AdamW(
|
| 96 |
+
net_d.parameters(),
|
| 97 |
+
hps.train.learning_rate,
|
| 98 |
+
betas=hps.train.betas,
|
| 99 |
+
eps=hps.train.eps)
|
| 100 |
+
net_g = DDP(net_g, device_ids=[rank])
|
| 101 |
+
net_d = DDP(net_d, device_ids=[rank])
|
| 102 |
+
|
| 103 |
+
try:
|
| 104 |
+
_, _, _, epoch_str = utils.load_checkpoint(utils.latest_checkpoint_path(hps.model_dir, "G_*.pth"), net_g, optim_g)
|
| 105 |
+
_, _, _, epoch_str = utils.load_checkpoint(utils.latest_checkpoint_path(hps.model_dir, "D_*.pth"), net_d, optim_d)
|
| 106 |
+
global_step = (epoch_str - 1) * len(train_loader)
|
| 107 |
+
except:
|
| 108 |
+
epoch_str = 1
|
| 109 |
+
global_step = 0
|
| 110 |
+
|
| 111 |
+
scheduler_g = torch.optim.lr_scheduler.ExponentialLR(optim_g, gamma=hps.train.lr_decay, last_epoch=epoch_str-2)
|
| 112 |
+
scheduler_d = torch.optim.lr_scheduler.ExponentialLR(optim_d, gamma=hps.train.lr_decay, last_epoch=epoch_str-2)
|
| 113 |
+
|
| 114 |
+
scaler = GradScaler(enabled=hps.train.fp16_run)
|
| 115 |
+
|
| 116 |
+
for epoch in range(epoch_str, hps.train.epochs + 1):
|
| 117 |
+
if rank==0:
|
| 118 |
+
train_and_evaluate(rank, epoch, hps, [net_g, net_d], [optim_g, optim_d], [scheduler_g, scheduler_d], scaler, [train_loader, eval_loader], logger, [writer, writer_eval])
|
| 119 |
+
else:
|
| 120 |
+
train_and_evaluate(rank, epoch, hps, [net_g, net_d], [optim_g, optim_d], [scheduler_g, scheduler_d], scaler, [train_loader, None], None, None)
|
| 121 |
+
scheduler_g.step()
|
| 122 |
+
scheduler_d.step()
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
def train_and_evaluate(rank, epoch, hps, nets, optims, schedulers, scaler, loaders, logger, writers):
|
| 126 |
+
net_g, net_d = nets
|
| 127 |
+
optim_g, optim_d = optims
|
| 128 |
+
scheduler_g, scheduler_d = schedulers
|
| 129 |
+
train_loader, eval_loader = loaders
|
| 130 |
+
if writers is not None:
|
| 131 |
+
writer, writer_eval = writers
|
| 132 |
+
|
| 133 |
+
train_loader.batch_sampler.set_epoch(epoch)
|
| 134 |
+
global global_step
|
| 135 |
+
|
| 136 |
+
net_g.train()
|
| 137 |
+
net_d.train()
|
| 138 |
+
for batch_idx, (x, x_lengths, spec, spec_lengths, y, y_lengths, speakers) in enumerate(train_loader):
|
| 139 |
+
x, x_lengths = x.cuda(rank, non_blocking=True), x_lengths.cuda(rank, non_blocking=True)
|
| 140 |
+
spec, spec_lengths = spec.cuda(rank, non_blocking=True), spec_lengths.cuda(rank, non_blocking=True)
|
| 141 |
+
y, y_lengths = y.cuda(rank, non_blocking=True), y_lengths.cuda(rank, non_blocking=True)
|
| 142 |
+
speakers = speakers.cuda(rank, non_blocking=True)
|
| 143 |
+
|
| 144 |
+
with autocast(enabled=hps.train.fp16_run):
|
| 145 |
+
y_hat, l_length, attn, ids_slice, x_mask, z_mask,\
|
| 146 |
+
(z, z_p, m_p, logs_p, m_q, logs_q) = net_g(x, x_lengths, spec, spec_lengths, speakers)
|
| 147 |
+
|
| 148 |
+
mel = spec_to_mel_torch(
|
| 149 |
+
spec,
|
| 150 |
+
hps.data.filter_length,
|
| 151 |
+
hps.data.n_mel_channels,
|
| 152 |
+
hps.data.sampling_rate,
|
| 153 |
+
hps.data.mel_fmin,
|
| 154 |
+
hps.data.mel_fmax)
|
| 155 |
+
y_mel = commons.slice_segments(mel, ids_slice, hps.train.segment_size // hps.data.hop_length)
|
| 156 |
+
y_hat_mel = mel_spectrogram_torch(
|
| 157 |
+
y_hat.squeeze(1),
|
| 158 |
+
hps.data.filter_length,
|
| 159 |
+
hps.data.n_mel_channels,
|
| 160 |
+
hps.data.sampling_rate,
|
| 161 |
+
hps.data.hop_length,
|
| 162 |
+
hps.data.win_length,
|
| 163 |
+
hps.data.mel_fmin,
|
| 164 |
+
hps.data.mel_fmax
|
| 165 |
+
)
|
| 166 |
+
|
| 167 |
+
y = commons.slice_segments(y, ids_slice * hps.data.hop_length, hps.train.segment_size) # slice
|
| 168 |
+
|
| 169 |
+
# Discriminator
|
| 170 |
+
y_d_hat_r, y_d_hat_g, _, _ = net_d(y, y_hat.detach())
|
| 171 |
+
with autocast(enabled=False):
|
| 172 |
+
loss_disc, losses_disc_r, losses_disc_g = discriminator_loss(y_d_hat_r, y_d_hat_g)
|
| 173 |
+
loss_disc_all = loss_disc
|
| 174 |
+
optim_d.zero_grad()
|
| 175 |
+
scaler.scale(loss_disc_all).backward()
|
| 176 |
+
scaler.unscale_(optim_d)
|
| 177 |
+
grad_norm_d = commons.clip_grad_value_(net_d.parameters(), None)
|
| 178 |
+
scaler.step(optim_d)
|
| 179 |
+
|
| 180 |
+
with autocast(enabled=hps.train.fp16_run):
|
| 181 |
+
# Generator
|
| 182 |
+
y_d_hat_r, y_d_hat_g, fmap_r, fmap_g = net_d(y, y_hat)
|
| 183 |
+
with autocast(enabled=False):
|
| 184 |
+
loss_dur = torch.sum(l_length.float())
|
| 185 |
+
loss_mel = F.l1_loss(y_mel, y_hat_mel) * hps.train.c_mel
|
| 186 |
+
loss_kl = kl_loss(z_p, logs_q, m_p, logs_p, z_mask) * hps.train.c_kl
|
| 187 |
+
|
| 188 |
+
loss_fm = feature_loss(fmap_r, fmap_g)
|
| 189 |
+
loss_gen, losses_gen = generator_loss(y_d_hat_g)
|
| 190 |
+
loss_gen_all = loss_gen + loss_fm + loss_mel + loss_dur + loss_kl
|
| 191 |
+
optim_g.zero_grad()
|
| 192 |
+
scaler.scale(loss_gen_all).backward()
|
| 193 |
+
scaler.unscale_(optim_g)
|
| 194 |
+
grad_norm_g = commons.clip_grad_value_(net_g.parameters(), None)
|
| 195 |
+
scaler.step(optim_g)
|
| 196 |
+
scaler.update()
|
| 197 |
+
|
| 198 |
+
if rank==0:
|
| 199 |
+
if global_step % hps.train.log_interval == 0:
|
| 200 |
+
lr = optim_g.param_groups[0]['lr']
|
| 201 |
+
losses = [loss_disc, loss_gen, loss_fm, loss_mel, loss_dur, loss_kl]
|
| 202 |
+
logger.info('Train Epoch: {} [{:.0f}%]'.format(
|
| 203 |
+
epoch,
|
| 204 |
+
100. * batch_idx / len(train_loader)))
|
| 205 |
+
logger.info([x.item() for x in losses] + [global_step, lr])
|
| 206 |
+
|
| 207 |
+
scalar_dict = {"loss/g/total": loss_gen_all, "loss/d/total": loss_disc_all, "learning_rate": lr, "grad_norm_d": grad_norm_d, "grad_norm_g": grad_norm_g}
|
| 208 |
+
scalar_dict.update({"loss/g/fm": loss_fm, "loss/g/mel": loss_mel, "loss/g/dur": loss_dur, "loss/g/kl": loss_kl})
|
| 209 |
+
|
| 210 |
+
scalar_dict.update({"loss/g/{}".format(i): v for i, v in enumerate(losses_gen)})
|
| 211 |
+
scalar_dict.update({"loss/d_r/{}".format(i): v for i, v in enumerate(losses_disc_r)})
|
| 212 |
+
scalar_dict.update({"loss/d_g/{}".format(i): v for i, v in enumerate(losses_disc_g)})
|
| 213 |
+
image_dict = {
|
| 214 |
+
"slice/mel_org": utils.plot_spectrogram_to_numpy(y_mel[0].data.cpu().numpy()),
|
| 215 |
+
"slice/mel_gen": utils.plot_spectrogram_to_numpy(y_hat_mel[0].data.cpu().numpy()),
|
| 216 |
+
"all/mel": utils.plot_spectrogram_to_numpy(mel[0].data.cpu().numpy()),
|
| 217 |
+
"all/attn": utils.plot_alignment_to_numpy(attn[0,0].data.cpu().numpy())
|
| 218 |
+
}
|
| 219 |
+
utils.summarize(
|
| 220 |
+
writer=writer,
|
| 221 |
+
global_step=global_step,
|
| 222 |
+
images=image_dict,
|
| 223 |
+
scalars=scalar_dict)
|
| 224 |
+
|
| 225 |
+
if global_step % hps.train.eval_interval == 0:
|
| 226 |
+
evaluate(hps, net_g, eval_loader, writer_eval)
|
| 227 |
+
utils.save_checkpoint(net_g, optim_g, hps.train.learning_rate, epoch, os.path.join(hps.model_dir, "G_{}.pth".format(global_step)))
|
| 228 |
+
utils.save_checkpoint(net_d, optim_d, hps.train.learning_rate, epoch, os.path.join(hps.model_dir, "D_{}.pth".format(global_step)))
|
| 229 |
+
global_step += 1
|
| 230 |
+
|
| 231 |
+
if rank == 0:
|
| 232 |
+
logger.info('====> Epoch: {}'.format(epoch))
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
def evaluate(hps, generator, eval_loader, writer_eval):
|
| 236 |
+
generator.eval()
|
| 237 |
+
with torch.no_grad():
|
| 238 |
+
for batch_idx, (x, x_lengths, spec, spec_lengths, y, y_lengths, speakers) in enumerate(eval_loader):
|
| 239 |
+
x, x_lengths = x.cuda(0), x_lengths.cuda(0)
|
| 240 |
+
spec, spec_lengths = spec.cuda(0), spec_lengths.cuda(0)
|
| 241 |
+
y, y_lengths = y.cuda(0), y_lengths.cuda(0)
|
| 242 |
+
speakers = speakers.cuda(0)
|
| 243 |
+
|
| 244 |
+
# remove else
|
| 245 |
+
x = x[:1]
|
| 246 |
+
x_lengths = x_lengths[:1]
|
| 247 |
+
spec = spec[:1]
|
| 248 |
+
spec_lengths = spec_lengths[:1]
|
| 249 |
+
y = y[:1]
|
| 250 |
+
y_lengths = y_lengths[:1]
|
| 251 |
+
speakers = speakers[:1]
|
| 252 |
+
break
|
| 253 |
+
y_hat, attn, mask, *_ = generator.module.infer(x, x_lengths, speakers, max_len=1000)
|
| 254 |
+
y_hat_lengths = mask.sum([1,2]).long() * hps.data.hop_length
|
| 255 |
+
|
| 256 |
+
mel = spec_to_mel_torch(
|
| 257 |
+
spec,
|
| 258 |
+
hps.data.filter_length,
|
| 259 |
+
hps.data.n_mel_channels,
|
| 260 |
+
hps.data.sampling_rate,
|
| 261 |
+
hps.data.mel_fmin,
|
| 262 |
+
hps.data.mel_fmax)
|
| 263 |
+
y_hat_mel = mel_spectrogram_torch(
|
| 264 |
+
y_hat.squeeze(1).float(),
|
| 265 |
+
hps.data.filter_length,
|
| 266 |
+
hps.data.n_mel_channels,
|
| 267 |
+
hps.data.sampling_rate,
|
| 268 |
+
hps.data.hop_length,
|
| 269 |
+
hps.data.win_length,
|
| 270 |
+
hps.data.mel_fmin,
|
| 271 |
+
hps.data.mel_fmax
|
| 272 |
+
)
|
| 273 |
+
image_dict = {
|
| 274 |
+
"gen/mel": utils.plot_spectrogram_to_numpy(y_hat_mel[0].cpu().numpy())
|
| 275 |
+
}
|
| 276 |
+
audio_dict = {
|
| 277 |
+
"gen/audio": y_hat[0,:,:y_hat_lengths[0]]
|
| 278 |
+
}
|
| 279 |
+
if global_step == 0:
|
| 280 |
+
image_dict.update({"gt/mel": utils.plot_spectrogram_to_numpy(mel[0].cpu().numpy())})
|
| 281 |
+
audio_dict.update({"gt/audio": y[0,:,:y_lengths[0]]})
|
| 282 |
+
|
| 283 |
+
utils.summarize(
|
| 284 |
+
writer=writer_eval,
|
| 285 |
+
global_step=global_step,
|
| 286 |
+
images=image_dict,
|
| 287 |
+
audios=audio_dict,
|
| 288 |
+
audio_sampling_rate=hps.data.sampling_rate
|
| 289 |
+
)
|
| 290 |
+
generator.train()
|
| 291 |
+
|
| 292 |
+
|
| 293 |
+
if __name__ == "__main__":
|
| 294 |
+
main()
|
transforms.py
ADDED
|
@@ -0,0 +1,193 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch.nn import functional as F
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
DEFAULT_MIN_BIN_WIDTH = 1e-3
|
| 8 |
+
DEFAULT_MIN_BIN_HEIGHT = 1e-3
|
| 9 |
+
DEFAULT_MIN_DERIVATIVE = 1e-3
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def piecewise_rational_quadratic_transform(inputs,
|
| 13 |
+
unnormalized_widths,
|
| 14 |
+
unnormalized_heights,
|
| 15 |
+
unnormalized_derivatives,
|
| 16 |
+
inverse=False,
|
| 17 |
+
tails=None,
|
| 18 |
+
tail_bound=1.,
|
| 19 |
+
min_bin_width=DEFAULT_MIN_BIN_WIDTH,
|
| 20 |
+
min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
|
| 21 |
+
min_derivative=DEFAULT_MIN_DERIVATIVE):
|
| 22 |
+
|
| 23 |
+
if tails is None:
|
| 24 |
+
spline_fn = rational_quadratic_spline
|
| 25 |
+
spline_kwargs = {}
|
| 26 |
+
else:
|
| 27 |
+
spline_fn = unconstrained_rational_quadratic_spline
|
| 28 |
+
spline_kwargs = {
|
| 29 |
+
'tails': tails,
|
| 30 |
+
'tail_bound': tail_bound
|
| 31 |
+
}
|
| 32 |
+
|
| 33 |
+
outputs, logabsdet = spline_fn(
|
| 34 |
+
inputs=inputs,
|
| 35 |
+
unnormalized_widths=unnormalized_widths,
|
| 36 |
+
unnormalized_heights=unnormalized_heights,
|
| 37 |
+
unnormalized_derivatives=unnormalized_derivatives,
|
| 38 |
+
inverse=inverse,
|
| 39 |
+
min_bin_width=min_bin_width,
|
| 40 |
+
min_bin_height=min_bin_height,
|
| 41 |
+
min_derivative=min_derivative,
|
| 42 |
+
**spline_kwargs
|
| 43 |
+
)
|
| 44 |
+
return outputs, logabsdet
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def searchsorted(bin_locations, inputs, eps=1e-6):
|
| 48 |
+
bin_locations[..., -1] += eps
|
| 49 |
+
return torch.sum(
|
| 50 |
+
inputs[..., None] >= bin_locations,
|
| 51 |
+
dim=-1
|
| 52 |
+
) - 1
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def unconstrained_rational_quadratic_spline(inputs,
|
| 56 |
+
unnormalized_widths,
|
| 57 |
+
unnormalized_heights,
|
| 58 |
+
unnormalized_derivatives,
|
| 59 |
+
inverse=False,
|
| 60 |
+
tails='linear',
|
| 61 |
+
tail_bound=1.,
|
| 62 |
+
min_bin_width=DEFAULT_MIN_BIN_WIDTH,
|
| 63 |
+
min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
|
| 64 |
+
min_derivative=DEFAULT_MIN_DERIVATIVE):
|
| 65 |
+
inside_interval_mask = (inputs >= -tail_bound) & (inputs <= tail_bound)
|
| 66 |
+
outside_interval_mask = ~inside_interval_mask
|
| 67 |
+
|
| 68 |
+
outputs = torch.zeros_like(inputs)
|
| 69 |
+
logabsdet = torch.zeros_like(inputs)
|
| 70 |
+
|
| 71 |
+
if tails == 'linear':
|
| 72 |
+
unnormalized_derivatives = F.pad(unnormalized_derivatives, pad=(1, 1))
|
| 73 |
+
constant = np.log(np.exp(1 - min_derivative) - 1)
|
| 74 |
+
unnormalized_derivatives[..., 0] = constant
|
| 75 |
+
unnormalized_derivatives[..., -1] = constant
|
| 76 |
+
|
| 77 |
+
outputs[outside_interval_mask] = inputs[outside_interval_mask]
|
| 78 |
+
logabsdet[outside_interval_mask] = 0
|
| 79 |
+
else:
|
| 80 |
+
raise RuntimeError('{} tails are not implemented.'.format(tails))
|
| 81 |
+
|
| 82 |
+
outputs[inside_interval_mask], logabsdet[inside_interval_mask] = rational_quadratic_spline(
|
| 83 |
+
inputs=inputs[inside_interval_mask],
|
| 84 |
+
unnormalized_widths=unnormalized_widths[inside_interval_mask, :],
|
| 85 |
+
unnormalized_heights=unnormalized_heights[inside_interval_mask, :],
|
| 86 |
+
unnormalized_derivatives=unnormalized_derivatives[inside_interval_mask, :],
|
| 87 |
+
inverse=inverse,
|
| 88 |
+
left=-tail_bound, right=tail_bound, bottom=-tail_bound, top=tail_bound,
|
| 89 |
+
min_bin_width=min_bin_width,
|
| 90 |
+
min_bin_height=min_bin_height,
|
| 91 |
+
min_derivative=min_derivative
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
return outputs, logabsdet
|
| 95 |
+
|
| 96 |
+
def rational_quadratic_spline(inputs,
|
| 97 |
+
unnormalized_widths,
|
| 98 |
+
unnormalized_heights,
|
| 99 |
+
unnormalized_derivatives,
|
| 100 |
+
inverse=False,
|
| 101 |
+
left=0., right=1., bottom=0., top=1.,
|
| 102 |
+
min_bin_width=DEFAULT_MIN_BIN_WIDTH,
|
| 103 |
+
min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
|
| 104 |
+
min_derivative=DEFAULT_MIN_DERIVATIVE):
|
| 105 |
+
if torch.min(inputs) < left or torch.max(inputs) > right:
|
| 106 |
+
raise ValueError('Input to a transform is not within its domain')
|
| 107 |
+
|
| 108 |
+
num_bins = unnormalized_widths.shape[-1]
|
| 109 |
+
|
| 110 |
+
if min_bin_width * num_bins > 1.0:
|
| 111 |
+
raise ValueError('Minimal bin width too large for the number of bins')
|
| 112 |
+
if min_bin_height * num_bins > 1.0:
|
| 113 |
+
raise ValueError('Minimal bin height too large for the number of bins')
|
| 114 |
+
|
| 115 |
+
widths = F.softmax(unnormalized_widths, dim=-1)
|
| 116 |
+
widths = min_bin_width + (1 - min_bin_width * num_bins) * widths
|
| 117 |
+
cumwidths = torch.cumsum(widths, dim=-1)
|
| 118 |
+
cumwidths = F.pad(cumwidths, pad=(1, 0), mode='constant', value=0.0)
|
| 119 |
+
cumwidths = (right - left) * cumwidths + left
|
| 120 |
+
cumwidths[..., 0] = left
|
| 121 |
+
cumwidths[..., -1] = right
|
| 122 |
+
widths = cumwidths[..., 1:] - cumwidths[..., :-1]
|
| 123 |
+
|
| 124 |
+
derivatives = min_derivative + F.softplus(unnormalized_derivatives)
|
| 125 |
+
|
| 126 |
+
heights = F.softmax(unnormalized_heights, dim=-1)
|
| 127 |
+
heights = min_bin_height + (1 - min_bin_height * num_bins) * heights
|
| 128 |
+
cumheights = torch.cumsum(heights, dim=-1)
|
| 129 |
+
cumheights = F.pad(cumheights, pad=(1, 0), mode='constant', value=0.0)
|
| 130 |
+
cumheights = (top - bottom) * cumheights + bottom
|
| 131 |
+
cumheights[..., 0] = bottom
|
| 132 |
+
cumheights[..., -1] = top
|
| 133 |
+
heights = cumheights[..., 1:] - cumheights[..., :-1]
|
| 134 |
+
|
| 135 |
+
if inverse:
|
| 136 |
+
bin_idx = searchsorted(cumheights, inputs)[..., None]
|
| 137 |
+
else:
|
| 138 |
+
bin_idx = searchsorted(cumwidths, inputs)[..., None]
|
| 139 |
+
|
| 140 |
+
input_cumwidths = cumwidths.gather(-1, bin_idx)[..., 0]
|
| 141 |
+
input_bin_widths = widths.gather(-1, bin_idx)[..., 0]
|
| 142 |
+
|
| 143 |
+
input_cumheights = cumheights.gather(-1, bin_idx)[..., 0]
|
| 144 |
+
delta = heights / widths
|
| 145 |
+
input_delta = delta.gather(-1, bin_idx)[..., 0]
|
| 146 |
+
|
| 147 |
+
input_derivatives = derivatives.gather(-1, bin_idx)[..., 0]
|
| 148 |
+
input_derivatives_plus_one = derivatives[..., 1:].gather(-1, bin_idx)[..., 0]
|
| 149 |
+
|
| 150 |
+
input_heights = heights.gather(-1, bin_idx)[..., 0]
|
| 151 |
+
|
| 152 |
+
if inverse:
|
| 153 |
+
a = (((inputs - input_cumheights) * (input_derivatives
|
| 154 |
+
+ input_derivatives_plus_one
|
| 155 |
+
- 2 * input_delta)
|
| 156 |
+
+ input_heights * (input_delta - input_derivatives)))
|
| 157 |
+
b = (input_heights * input_derivatives
|
| 158 |
+
- (inputs - input_cumheights) * (input_derivatives
|
| 159 |
+
+ input_derivatives_plus_one
|
| 160 |
+
- 2 * input_delta))
|
| 161 |
+
c = - input_delta * (inputs - input_cumheights)
|
| 162 |
+
|
| 163 |
+
discriminant = b.pow(2) - 4 * a * c
|
| 164 |
+
assert (discriminant >= 0).all()
|
| 165 |
+
|
| 166 |
+
root = (2 * c) / (-b - torch.sqrt(discriminant))
|
| 167 |
+
outputs = root * input_bin_widths + input_cumwidths
|
| 168 |
+
|
| 169 |
+
theta_one_minus_theta = root * (1 - root)
|
| 170 |
+
denominator = input_delta + ((input_derivatives + input_derivatives_plus_one - 2 * input_delta)
|
| 171 |
+
* theta_one_minus_theta)
|
| 172 |
+
derivative_numerator = input_delta.pow(2) * (input_derivatives_plus_one * root.pow(2)
|
| 173 |
+
+ 2 * input_delta * theta_one_minus_theta
|
| 174 |
+
+ input_derivatives * (1 - root).pow(2))
|
| 175 |
+
logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator)
|
| 176 |
+
|
| 177 |
+
return outputs, -logabsdet
|
| 178 |
+
else:
|
| 179 |
+
theta = (inputs - input_cumwidths) / input_bin_widths
|
| 180 |
+
theta_one_minus_theta = theta * (1 - theta)
|
| 181 |
+
|
| 182 |
+
numerator = input_heights * (input_delta * theta.pow(2)
|
| 183 |
+
+ input_derivatives * theta_one_minus_theta)
|
| 184 |
+
denominator = input_delta + ((input_derivatives + input_derivatives_plus_one - 2 * input_delta)
|
| 185 |
+
* theta_one_minus_theta)
|
| 186 |
+
outputs = input_cumheights + numerator / denominator
|
| 187 |
+
|
| 188 |
+
derivative_numerator = input_delta.pow(2) * (input_derivatives_plus_one * theta.pow(2)
|
| 189 |
+
+ 2 * input_delta * theta_one_minus_theta
|
| 190 |
+
+ input_derivatives * (1 - theta).pow(2))
|
| 191 |
+
logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator)
|
| 192 |
+
|
| 193 |
+
return outputs, logabsdet
|
utils.py
ADDED
|
@@ -0,0 +1,258 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import glob
|
| 3 |
+
import sys
|
| 4 |
+
import argparse
|
| 5 |
+
import logging
|
| 6 |
+
import json
|
| 7 |
+
import subprocess
|
| 8 |
+
import numpy as np
|
| 9 |
+
from scipy.io.wavfile import read
|
| 10 |
+
import torch
|
| 11 |
+
|
| 12 |
+
MATPLOTLIB_FLAG = False
|
| 13 |
+
|
| 14 |
+
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
|
| 15 |
+
logger = logging
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def load_checkpoint(checkpoint_path, model, optimizer=None):
|
| 19 |
+
assert os.path.isfile(checkpoint_path)
|
| 20 |
+
checkpoint_dict = torch.load(checkpoint_path, map_location='cpu')
|
| 21 |
+
iteration = checkpoint_dict['iteration']
|
| 22 |
+
learning_rate = checkpoint_dict['learning_rate']
|
| 23 |
+
if optimizer is not None:
|
| 24 |
+
optimizer.load_state_dict(checkpoint_dict['optimizer'])
|
| 25 |
+
saved_state_dict = checkpoint_dict['model']
|
| 26 |
+
if hasattr(model, 'module'):
|
| 27 |
+
state_dict = model.module.state_dict()
|
| 28 |
+
else:
|
| 29 |
+
state_dict = model.state_dict()
|
| 30 |
+
new_state_dict= {}
|
| 31 |
+
for k, v in state_dict.items():
|
| 32 |
+
try:
|
| 33 |
+
new_state_dict[k] = saved_state_dict[k]
|
| 34 |
+
except:
|
| 35 |
+
logger.info("%s is not in the checkpoint" % k)
|
| 36 |
+
new_state_dict[k] = v
|
| 37 |
+
if hasattr(model, 'module'):
|
| 38 |
+
model.module.load_state_dict(new_state_dict)
|
| 39 |
+
else:
|
| 40 |
+
model.load_state_dict(new_state_dict)
|
| 41 |
+
logger.info("Loaded checkpoint '{}' (iteration {})" .format(
|
| 42 |
+
checkpoint_path, iteration))
|
| 43 |
+
return model, optimizer, learning_rate, iteration
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def save_checkpoint(model, optimizer, learning_rate, iteration, checkpoint_path):
|
| 47 |
+
logger.info("Saving model and optimizer state at iteration {} to {}".format(
|
| 48 |
+
iteration, checkpoint_path))
|
| 49 |
+
if hasattr(model, 'module'):
|
| 50 |
+
state_dict = model.module.state_dict()
|
| 51 |
+
else:
|
| 52 |
+
state_dict = model.state_dict()
|
| 53 |
+
torch.save({'model': state_dict,
|
| 54 |
+
'iteration': iteration,
|
| 55 |
+
'optimizer': optimizer.state_dict(),
|
| 56 |
+
'learning_rate': learning_rate}, checkpoint_path)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
def summarize(writer, global_step, scalars={}, histograms={}, images={}, audios={}, audio_sampling_rate=22050):
|
| 60 |
+
for k, v in scalars.items():
|
| 61 |
+
writer.add_scalar(k, v, global_step)
|
| 62 |
+
for k, v in histograms.items():
|
| 63 |
+
writer.add_histogram(k, v, global_step)
|
| 64 |
+
for k, v in images.items():
|
| 65 |
+
writer.add_image(k, v, global_step, dataformats='HWC')
|
| 66 |
+
for k, v in audios.items():
|
| 67 |
+
writer.add_audio(k, v, global_step, audio_sampling_rate)
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def latest_checkpoint_path(dir_path, regex="G_*.pth"):
|
| 71 |
+
f_list = glob.glob(os.path.join(dir_path, regex))
|
| 72 |
+
f_list.sort(key=lambda f: int("".join(filter(str.isdigit, f))))
|
| 73 |
+
x = f_list[-1]
|
| 74 |
+
print(x)
|
| 75 |
+
return x
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def plot_spectrogram_to_numpy(spectrogram):
|
| 79 |
+
global MATPLOTLIB_FLAG
|
| 80 |
+
if not MATPLOTLIB_FLAG:
|
| 81 |
+
import matplotlib
|
| 82 |
+
matplotlib.use("Agg")
|
| 83 |
+
MATPLOTLIB_FLAG = True
|
| 84 |
+
mpl_logger = logging.getLogger('matplotlib')
|
| 85 |
+
mpl_logger.setLevel(logging.WARNING)
|
| 86 |
+
import matplotlib.pylab as plt
|
| 87 |
+
import numpy as np
|
| 88 |
+
|
| 89 |
+
fig, ax = plt.subplots(figsize=(10,2))
|
| 90 |
+
im = ax.imshow(spectrogram, aspect="auto", origin="lower",
|
| 91 |
+
interpolation='none')
|
| 92 |
+
plt.colorbar(im, ax=ax)
|
| 93 |
+
plt.xlabel("Frames")
|
| 94 |
+
plt.ylabel("Channels")
|
| 95 |
+
plt.tight_layout()
|
| 96 |
+
|
| 97 |
+
fig.canvas.draw()
|
| 98 |
+
data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='')
|
| 99 |
+
data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
|
| 100 |
+
plt.close()
|
| 101 |
+
return data
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
def plot_alignment_to_numpy(alignment, info=None):
|
| 105 |
+
global MATPLOTLIB_FLAG
|
| 106 |
+
if not MATPLOTLIB_FLAG:
|
| 107 |
+
import matplotlib
|
| 108 |
+
matplotlib.use("Agg")
|
| 109 |
+
MATPLOTLIB_FLAG = True
|
| 110 |
+
mpl_logger = logging.getLogger('matplotlib')
|
| 111 |
+
mpl_logger.setLevel(logging.WARNING)
|
| 112 |
+
import matplotlib.pylab as plt
|
| 113 |
+
import numpy as np
|
| 114 |
+
|
| 115 |
+
fig, ax = plt.subplots(figsize=(6, 4))
|
| 116 |
+
im = ax.imshow(alignment.transpose(), aspect='auto', origin='lower',
|
| 117 |
+
interpolation='none')
|
| 118 |
+
fig.colorbar(im, ax=ax)
|
| 119 |
+
xlabel = 'Decoder timestep'
|
| 120 |
+
if info is not None:
|
| 121 |
+
xlabel += '\n\n' + info
|
| 122 |
+
plt.xlabel(xlabel)
|
| 123 |
+
plt.ylabel('Encoder timestep')
|
| 124 |
+
plt.tight_layout()
|
| 125 |
+
|
| 126 |
+
fig.canvas.draw()
|
| 127 |
+
data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='')
|
| 128 |
+
data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
|
| 129 |
+
plt.close()
|
| 130 |
+
return data
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
def load_wav_to_torch(full_path):
|
| 134 |
+
sampling_rate, data = read(full_path)
|
| 135 |
+
return torch.FloatTensor(data.astype(np.float32)), sampling_rate
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
def load_filepaths_and_text(filename, split="|"):
|
| 139 |
+
with open(filename, encoding='utf-8') as f:
|
| 140 |
+
filepaths_and_text = [line.strip().split(split) for line in f]
|
| 141 |
+
return filepaths_and_text
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
def get_hparams(init=True):
|
| 145 |
+
parser = argparse.ArgumentParser()
|
| 146 |
+
parser.add_argument('-c', '--config', type=str, default="./configs/base.json",
|
| 147 |
+
help='JSON file for configuration')
|
| 148 |
+
parser.add_argument('-m', '--model', type=str, required=True,
|
| 149 |
+
help='Model name')
|
| 150 |
+
|
| 151 |
+
args = parser.parse_args()
|
| 152 |
+
model_dir = os.path.join("./logs", args.model)
|
| 153 |
+
|
| 154 |
+
if not os.path.exists(model_dir):
|
| 155 |
+
os.makedirs(model_dir)
|
| 156 |
+
|
| 157 |
+
config_path = args.config
|
| 158 |
+
config_save_path = os.path.join(model_dir, "config.json")
|
| 159 |
+
if init:
|
| 160 |
+
with open(config_path, "r") as f:
|
| 161 |
+
data = f.read()
|
| 162 |
+
with open(config_save_path, "w") as f:
|
| 163 |
+
f.write(data)
|
| 164 |
+
else:
|
| 165 |
+
with open(config_save_path, "r") as f:
|
| 166 |
+
data = f.read()
|
| 167 |
+
config = json.loads(data)
|
| 168 |
+
|
| 169 |
+
hparams = HParams(**config)
|
| 170 |
+
hparams.model_dir = model_dir
|
| 171 |
+
return hparams
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
def get_hparams_from_dir(model_dir):
|
| 175 |
+
config_save_path = os.path.join(model_dir, "config.json")
|
| 176 |
+
with open(config_save_path, "r") as f:
|
| 177 |
+
data = f.read()
|
| 178 |
+
config = json.loads(data)
|
| 179 |
+
|
| 180 |
+
hparams =HParams(**config)
|
| 181 |
+
hparams.model_dir = model_dir
|
| 182 |
+
return hparams
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
def get_hparams_from_file(config_path):
|
| 186 |
+
with open(config_path, "r") as f:
|
| 187 |
+
data = f.read()
|
| 188 |
+
config = json.loads(data)
|
| 189 |
+
|
| 190 |
+
hparams =HParams(**config)
|
| 191 |
+
return hparams
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
def check_git_hash(model_dir):
|
| 195 |
+
source_dir = os.path.dirname(os.path.realpath(__file__))
|
| 196 |
+
if not os.path.exists(os.path.join(source_dir, ".git")):
|
| 197 |
+
logger.warn("{} is not a git repository, therefore hash value comparison will be ignored.".format(
|
| 198 |
+
source_dir
|
| 199 |
+
))
|
| 200 |
+
return
|
| 201 |
+
|
| 202 |
+
cur_hash = subprocess.getoutput("git rev-parse HEAD")
|
| 203 |
+
|
| 204 |
+
path = os.path.join(model_dir, "githash")
|
| 205 |
+
if os.path.exists(path):
|
| 206 |
+
saved_hash = open(path).read()
|
| 207 |
+
if saved_hash != cur_hash:
|
| 208 |
+
logger.warn("git hash values are different. {}(saved) != {}(current)".format(
|
| 209 |
+
saved_hash[:8], cur_hash[:8]))
|
| 210 |
+
else:
|
| 211 |
+
open(path, "w").write(cur_hash)
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
def get_logger(model_dir, filename="train.log"):
|
| 215 |
+
global logger
|
| 216 |
+
logger = logging.getLogger(os.path.basename(model_dir))
|
| 217 |
+
logger.setLevel(logging.DEBUG)
|
| 218 |
+
|
| 219 |
+
formatter = logging.Formatter("%(asctime)s\t%(name)s\t%(levelname)s\t%(message)s")
|
| 220 |
+
if not os.path.exists(model_dir):
|
| 221 |
+
os.makedirs(model_dir)
|
| 222 |
+
h = logging.FileHandler(os.path.join(model_dir, filename))
|
| 223 |
+
h.setLevel(logging.DEBUG)
|
| 224 |
+
h.setFormatter(formatter)
|
| 225 |
+
logger.addHandler(h)
|
| 226 |
+
return logger
|
| 227 |
+
|
| 228 |
+
|
| 229 |
+
class HParams():
|
| 230 |
+
def __init__(self, **kwargs):
|
| 231 |
+
for k, v in kwargs.items():
|
| 232 |
+
if type(v) == dict:
|
| 233 |
+
v = HParams(**v)
|
| 234 |
+
self[k] = v
|
| 235 |
+
|
| 236 |
+
def keys(self):
|
| 237 |
+
return self.__dict__.keys()
|
| 238 |
+
|
| 239 |
+
def items(self):
|
| 240 |
+
return self.__dict__.items()
|
| 241 |
+
|
| 242 |
+
def values(self):
|
| 243 |
+
return self.__dict__.values()
|
| 244 |
+
|
| 245 |
+
def __len__(self):
|
| 246 |
+
return len(self.__dict__)
|
| 247 |
+
|
| 248 |
+
def __getitem__(self, key):
|
| 249 |
+
return getattr(self, key)
|
| 250 |
+
|
| 251 |
+
def __setitem__(self, key, value):
|
| 252 |
+
return setattr(self, key, value)
|
| 253 |
+
|
| 254 |
+
def __contains__(self, key):
|
| 255 |
+
return key in self.__dict__
|
| 256 |
+
|
| 257 |
+
def __repr__(self):
|
| 258 |
+
return self.__dict__.__repr__()
|