Spaces:
Running

Running
Upload 48 files
Browse files- .gitattributes +2 -0
- Dockerfile +13 -0
- LICENSE +674 -0
- README.md +247 -12
- check_proxy.py +26 -0
- config.py +43 -0
- crazy_functions/test_project/cpp/cppipc/buffer.cpp +87 -0
- crazy_functions/test_project/cpp/cppipc/ipc.cpp +701 -0
- crazy_functions/test_project/cpp/cppipc/policy.h +25 -0
- crazy_functions/test_project/cpp/cppipc/pool_alloc.cpp +17 -0
- crazy_functions/test_project/cpp/cppipc/prod_cons.h +433 -0
- crazy_functions/test_project/cpp/cppipc/queue.h +216 -0
- crazy_functions/test_project/cpp/cppipc/shm.cpp +103 -0
- crazy_functions/test_project/cpp/cppipc/waiter.h +83 -0
- crazy_functions/test_project/cpp/cppipc/来源 +3 -0
- crazy_functions/test_project/cpp/libJPG/jpgd.cpp +3276 -0
- crazy_functions/test_project/cpp/libJPG/jpgd.h +316 -0
- crazy_functions/test_project/cpp/libJPG/jpge.cpp +1049 -0
- crazy_functions/test_project/cpp/libJPG/jpge.h +172 -0
- crazy_functions/test_project/cpp/libJPG/来源 +3 -0
- crazy_functions/test_project/latex/attention/background.tex +58 -0
- crazy_functions/test_project/latex/attention/introduction.tex +18 -0
- crazy_functions/test_project/latex/attention/model_architecture.tex +155 -0
- crazy_functions/test_project/latex/attention/parameter_attention.tex +45 -0
- crazy_functions/test_project/latex/attention/来源 +8 -0
- crazy_functions/test_project/python/dqn/__init__.py +2 -0
- crazy_functions/test_project/python/dqn/dqn.py +245 -0
- crazy_functions/test_project/python/dqn/policies.py +237 -0
- crazy_functions/test_project/python/dqn/来源 +2 -0
- crazy_functions/test_project/其他测试 +27 -0
- crazy_functions/代码重写为全英文_多线程.py +75 -0
- crazy_functions/批量总结PDF文档.py +99 -0
- crazy_functions/生成函数注释.py +57 -0
- crazy_functions/解析项目源代码.py +149 -0
- crazy_functions/读文章写摘要.py +70 -0
- crazy_functions/高级功能函数模板.py +25 -0
- functional.py +59 -0
- functional_crazy.py +66 -0
- img/demo.jpg +0 -0
- img/demo2.jpg +0 -0
- img/公式.gif +3 -0
- img/润色.gif +3 -0
- main.py +112 -0
- predict.py +237 -0
- project_self_analysis.md +122 -0
- requirements.txt +3 -0
- show_math.py +80 -0
- theme.py +82 -0
- toolbox.py +220 -0
.gitattributes
CHANGED
|
@@ -32,3 +32,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
img/公式.gif filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
img/润色.gif filter=lfs diff=lfs merge=lfs -text
|
Dockerfile
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM python:3.11
|
| 2 |
+
|
| 3 |
+
RUN echo '[global]' > /etc/pip.conf && \
|
| 4 |
+
echo 'index-url = https://mirrors.aliyun.com/pypi/simple/' >> /etc/pip.conf && \
|
| 5 |
+
echo 'trusted-host = mirrors.aliyun.com' >> /etc/pip.conf
|
| 6 |
+
|
| 7 |
+
RUN pip3 install gradio requests[socks] mdtex2html
|
| 8 |
+
|
| 9 |
+
COPY . /gpt
|
| 10 |
+
WORKDIR /gpt
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
CMD ["python3", "main.py"]
|
LICENSE
ADDED
|
@@ -0,0 +1,674 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
GNU GENERAL PUBLIC LICENSE
|
| 2 |
+
Version 3, 29 June 2007
|
| 3 |
+
|
| 4 |
+
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
|
| 5 |
+
Everyone is permitted to copy and distribute verbatim copies
|
| 6 |
+
of this license document, but changing it is not allowed.
|
| 7 |
+
|
| 8 |
+
Preamble
|
| 9 |
+
|
| 10 |
+
The GNU General Public License is a free, copyleft license for
|
| 11 |
+
software and other kinds of works.
|
| 12 |
+
|
| 13 |
+
The licenses for most software and other practical works are designed
|
| 14 |
+
to take away your freedom to share and change the works. By contrast,
|
| 15 |
+
the GNU General Public License is intended to guarantee your freedom to
|
| 16 |
+
share and change all versions of a program--to make sure it remains free
|
| 17 |
+
software for all its users. We, the Free Software Foundation, use the
|
| 18 |
+
GNU General Public License for most of our software; it applies also to
|
| 19 |
+
any other work released this way by its authors. You can apply it to
|
| 20 |
+
your programs, too.
|
| 21 |
+
|
| 22 |
+
When we speak of free software, we are referring to freedom, not
|
| 23 |
+
price. Our General Public Licenses are designed to make sure that you
|
| 24 |
+
have the freedom to distribute copies of free software (and charge for
|
| 25 |
+
them if you wish), that you receive source code or can get it if you
|
| 26 |
+
want it, that you can change the software or use pieces of it in new
|
| 27 |
+
free programs, and that you know you can do these things.
|
| 28 |
+
|
| 29 |
+
To protect your rights, we need to prevent others from denying you
|
| 30 |
+
these rights or asking you to surrender the rights. Therefore, you have
|
| 31 |
+
certain responsibilities if you distribute copies of the software, or if
|
| 32 |
+
you modify it: responsibilities to respect the freedom of others.
|
| 33 |
+
|
| 34 |
+
For example, if you distribute copies of such a program, whether
|
| 35 |
+
gratis or for a fee, you must pass on to the recipients the same
|
| 36 |
+
freedoms that you received. You must make sure that they, too, receive
|
| 37 |
+
or can get the source code. And you must show them these terms so they
|
| 38 |
+
know their rights.
|
| 39 |
+
|
| 40 |
+
Developers that use the GNU GPL protect your rights with two steps:
|
| 41 |
+
(1) assert copyright on the software, and (2) offer you this License
|
| 42 |
+
giving you legal permission to copy, distribute and/or modify it.
|
| 43 |
+
|
| 44 |
+
For the developers' and authors' protection, the GPL clearly explains
|
| 45 |
+
that there is no warranty for this free software. For both users' and
|
| 46 |
+
authors' sake, the GPL requires that modified versions be marked as
|
| 47 |
+
changed, so that their problems will not be attributed erroneously to
|
| 48 |
+
authors of previous versions.
|
| 49 |
+
|
| 50 |
+
Some devices are designed to deny users access to install or run
|
| 51 |
+
modified versions of the software inside them, although the manufacturer
|
| 52 |
+
can do so. This is fundamentally incompatible with the aim of
|
| 53 |
+
protecting users' freedom to change the software. The systematic
|
| 54 |
+
pattern of such abuse occurs in the area of products for individuals to
|
| 55 |
+
use, which is precisely where it is most unacceptable. Therefore, we
|
| 56 |
+
have designed this version of the GPL to prohibit the practice for those
|
| 57 |
+
products. If such problems arise substantially in other domains, we
|
| 58 |
+
stand ready to extend this provision to those domains in future versions
|
| 59 |
+
of the GPL, as needed to protect the freedom of users.
|
| 60 |
+
|
| 61 |
+
Finally, every program is threatened constantly by software patents.
|
| 62 |
+
States should not allow patents to restrict development and use of
|
| 63 |
+
software on general-purpose computers, but in those that do, we wish to
|
| 64 |
+
avoid the special danger that patents applied to a free program could
|
| 65 |
+
make it effectively proprietary. To prevent this, the GPL assures that
|
| 66 |
+
patents cannot be used to render the program non-free.
|
| 67 |
+
|
| 68 |
+
The precise terms and conditions for copying, distribution and
|
| 69 |
+
modification follow.
|
| 70 |
+
|
| 71 |
+
TERMS AND CONDITIONS
|
| 72 |
+
|
| 73 |
+
0. Definitions.
|
| 74 |
+
|
| 75 |
+
"This License" refers to version 3 of the GNU General Public License.
|
| 76 |
+
|
| 77 |
+
"Copyright" also means copyright-like laws that apply to other kinds of
|
| 78 |
+
works, such as semiconductor masks.
|
| 79 |
+
|
| 80 |
+
"The Program" refers to any copyrightable work licensed under this
|
| 81 |
+
License. Each licensee is addressed as "you". "Licensees" and
|
| 82 |
+
"recipients" may be individuals or organizations.
|
| 83 |
+
|
| 84 |
+
To "modify" a work means to copy from or adapt all or part of the work
|
| 85 |
+
in a fashion requiring copyright permission, other than the making of an
|
| 86 |
+
exact copy. The resulting work is called a "modified version" of the
|
| 87 |
+
earlier work or a work "based on" the earlier work.
|
| 88 |
+
|
| 89 |
+
A "covered work" means either the unmodified Program or a work based
|
| 90 |
+
on the Program.
|
| 91 |
+
|
| 92 |
+
To "propagate" a work means to do anything with it that, without
|
| 93 |
+
permission, would make you directly or secondarily liable for
|
| 94 |
+
infringement under applicable copyright law, except executing it on a
|
| 95 |
+
computer or modifying a private copy. Propagation includes copying,
|
| 96 |
+
distribution (with or without modification), making available to the
|
| 97 |
+
public, and in some countries other activities as well.
|
| 98 |
+
|
| 99 |
+
To "convey" a work means any kind of propagation that enables other
|
| 100 |
+
parties to make or receive copies. Mere interaction with a user through
|
| 101 |
+
a computer network, with no transfer of a copy, is not conveying.
|
| 102 |
+
|
| 103 |
+
An interactive user interface displays "Appropriate Legal Notices"
|
| 104 |
+
to the extent that it includes a convenient and prominently visible
|
| 105 |
+
feature that (1) displays an appropriate copyright notice, and (2)
|
| 106 |
+
tells the user that there is no warranty for the work (except to the
|
| 107 |
+
extent that warranties are provided), that licensees may convey the
|
| 108 |
+
work under this License, and how to view a copy of this License. If
|
| 109 |
+
the interface presents a list of user commands or options, such as a
|
| 110 |
+
menu, a prominent item in the list meets this criterion.
|
| 111 |
+
|
| 112 |
+
1. Source Code.
|
| 113 |
+
|
| 114 |
+
The "source code" for a work means the preferred form of the work
|
| 115 |
+
for making modifications to it. "Object code" means any non-source
|
| 116 |
+
form of a work.
|
| 117 |
+
|
| 118 |
+
A "Standard Interface" means an interface that either is an official
|
| 119 |
+
standard defined by a recognized standards body, or, in the case of
|
| 120 |
+
interfaces specified for a particular programming language, one that
|
| 121 |
+
is widely used among developers working in that language.
|
| 122 |
+
|
| 123 |
+
The "System Libraries" of an executable work include anything, other
|
| 124 |
+
than the work as a whole, that (a) is included in the normal form of
|
| 125 |
+
packaging a Major Component, but which is not part of that Major
|
| 126 |
+
Component, and (b) serves only to enable use of the work with that
|
| 127 |
+
Major Component, or to implement a Standard Interface for which an
|
| 128 |
+
implementation is available to the public in source code form. A
|
| 129 |
+
"Major Component", in this context, means a major essential component
|
| 130 |
+
(kernel, window system, and so on) of the specific operating system
|
| 131 |
+
(if any) on which the executable work runs, or a compiler used to
|
| 132 |
+
produce the work, or an object code interpreter used to run it.
|
| 133 |
+
|
| 134 |
+
The "Corresponding Source" for a work in object code form means all
|
| 135 |
+
the source code needed to generate, install, and (for an executable
|
| 136 |
+
work) run the object code and to modify the work, including scripts to
|
| 137 |
+
control those activities. However, it does not include the work's
|
| 138 |
+
System Libraries, or general-purpose tools or generally available free
|
| 139 |
+
programs which are used unmodified in performing those activities but
|
| 140 |
+
which are not part of the work. For example, Corresponding Source
|
| 141 |
+
includes interface definition files associated with source files for
|
| 142 |
+
the work, and the source code for shared libraries and dynamically
|
| 143 |
+
linked subprograms that the work is specifically designed to require,
|
| 144 |
+
such as by intimate data communication or control flow between those
|
| 145 |
+
subprograms and other parts of the work.
|
| 146 |
+
|
| 147 |
+
The Corresponding Source need not include anything that users
|
| 148 |
+
can regenerate automatically from other parts of the Corresponding
|
| 149 |
+
Source.
|
| 150 |
+
|
| 151 |
+
The Corresponding Source for a work in source code form is that
|
| 152 |
+
same work.
|
| 153 |
+
|
| 154 |
+
2. Basic Permissions.
|
| 155 |
+
|
| 156 |
+
All rights granted under this License are granted for the term of
|
| 157 |
+
copyright on the Program, and are irrevocable provided the stated
|
| 158 |
+
conditions are met. This License explicitly affirms your unlimited
|
| 159 |
+
permission to run the unmodified Program. The output from running a
|
| 160 |
+
covered work is covered by this License only if the output, given its
|
| 161 |
+
content, constitutes a covered work. This License acknowledges your
|
| 162 |
+
rights of fair use or other equivalent, as provided by copyright law.
|
| 163 |
+
|
| 164 |
+
You may make, run and propagate covered works that you do not
|
| 165 |
+
convey, without conditions so long as your license otherwise remains
|
| 166 |
+
in force. You may convey covered works to others for the sole purpose
|
| 167 |
+
of having them make modifications exclusively for you, or provide you
|
| 168 |
+
with facilities for running those works, provided that you comply with
|
| 169 |
+
the terms of this License in conveying all material for which you do
|
| 170 |
+
not control copyright. Those thus making or running the covered works
|
| 171 |
+
for you must do so exclusively on your behalf, under your direction
|
| 172 |
+
and control, on terms that prohibit them from making any copies of
|
| 173 |
+
your copyrighted material outside their relationship with you.
|
| 174 |
+
|
| 175 |
+
Conveying under any other circumstances is permitted solely under
|
| 176 |
+
the conditions stated below. Sublicensing is not allowed; section 10
|
| 177 |
+
makes it unnecessary.
|
| 178 |
+
|
| 179 |
+
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
|
| 180 |
+
|
| 181 |
+
No covered work shall be deemed part of an effective technological
|
| 182 |
+
measure under any applicable law fulfilling obligations under article
|
| 183 |
+
11 of the WIPO copyright treaty adopted on 20 December 1996, or
|
| 184 |
+
similar laws prohibiting or restricting circumvention of such
|
| 185 |
+
measures.
|
| 186 |
+
|
| 187 |
+
When you convey a covered work, you waive any legal power to forbid
|
| 188 |
+
circumvention of technological measures to the extent such circumvention
|
| 189 |
+
is effected by exercising rights under this License with respect to
|
| 190 |
+
the covered work, and you disclaim any intention to limit operation or
|
| 191 |
+
modification of the work as a means of enforcing, against the work's
|
| 192 |
+
users, your or third parties' legal rights to forbid circumvention of
|
| 193 |
+
technological measures.
|
| 194 |
+
|
| 195 |
+
4. Conveying Verbatim Copies.
|
| 196 |
+
|
| 197 |
+
You may convey verbatim copies of the Program's source code as you
|
| 198 |
+
receive it, in any medium, provided that you conspicuously and
|
| 199 |
+
appropriately publish on each copy an appropriate copyright notice;
|
| 200 |
+
keep intact all notices stating that this License and any
|
| 201 |
+
non-permissive terms added in accord with section 7 apply to the code;
|
| 202 |
+
keep intact all notices of the absence of any warranty; and give all
|
| 203 |
+
recipients a copy of this License along with the Program.
|
| 204 |
+
|
| 205 |
+
You may charge any price or no price for each copy that you convey,
|
| 206 |
+
and you may offer support or warranty protection for a fee.
|
| 207 |
+
|
| 208 |
+
5. Conveying Modified Source Versions.
|
| 209 |
+
|
| 210 |
+
You may convey a work based on the Program, or the modifications to
|
| 211 |
+
produce it from the Program, in the form of source code under the
|
| 212 |
+
terms of section 4, provided that you also meet all of these conditions:
|
| 213 |
+
|
| 214 |
+
a) The work must carry prominent notices stating that you modified
|
| 215 |
+
it, and giving a relevant date.
|
| 216 |
+
|
| 217 |
+
b) The work must carry prominent notices stating that it is
|
| 218 |
+
released under this License and any conditions added under section
|
| 219 |
+
7. This requirement modifies the requirement in section 4 to
|
| 220 |
+
"keep intact all notices".
|
| 221 |
+
|
| 222 |
+
c) You must license the entire work, as a whole, under this
|
| 223 |
+
License to anyone who comes into possession of a copy. This
|
| 224 |
+
License will therefore apply, along with any applicable section 7
|
| 225 |
+
additional terms, to the whole of the work, and all its parts,
|
| 226 |
+
regardless of how they are packaged. This License gives no
|
| 227 |
+
permission to license the work in any other way, but it does not
|
| 228 |
+
invalidate such permission if you have separately received it.
|
| 229 |
+
|
| 230 |
+
d) If the work has interactive user interfaces, each must display
|
| 231 |
+
Appropriate Legal Notices; however, if the Program has interactive
|
| 232 |
+
interfaces that do not display Appropriate Legal Notices, your
|
| 233 |
+
work need not make them do so.
|
| 234 |
+
|
| 235 |
+
A compilation of a covered work with other separate and independent
|
| 236 |
+
works, which are not by their nature extensions of the covered work,
|
| 237 |
+
and which are not combined with it such as to form a larger program,
|
| 238 |
+
in or on a volume of a storage or distribution medium, is called an
|
| 239 |
+
"aggregate" if the compilation and its resulting copyright are not
|
| 240 |
+
used to limit the access or legal rights of the compilation's users
|
| 241 |
+
beyond what the individual works permit. Inclusion of a covered work
|
| 242 |
+
in an aggregate does not cause this License to apply to the other
|
| 243 |
+
parts of the aggregate.
|
| 244 |
+
|
| 245 |
+
6. Conveying Non-Source Forms.
|
| 246 |
+
|
| 247 |
+
You may convey a covered work in object code form under the terms
|
| 248 |
+
of sections 4 and 5, provided that you also convey the
|
| 249 |
+
machine-readable Corresponding Source under the terms of this License,
|
| 250 |
+
in one of these ways:
|
| 251 |
+
|
| 252 |
+
a) Convey the object code in, or embodied in, a physical product
|
| 253 |
+
(including a physical distribution medium), accompanied by the
|
| 254 |
+
Corresponding Source fixed on a durable physical medium
|
| 255 |
+
customarily used for software interchange.
|
| 256 |
+
|
| 257 |
+
b) Convey the object code in, or embodied in, a physical product
|
| 258 |
+
(including a physical distribution medium), accompanied by a
|
| 259 |
+
written offer, valid for at least three years and valid for as
|
| 260 |
+
long as you offer spare parts or customer support for that product
|
| 261 |
+
model, to give anyone who possesses the object code either (1) a
|
| 262 |
+
copy of the Corresponding Source for all the software in the
|
| 263 |
+
product that is covered by this License, on a durable physical
|
| 264 |
+
medium customarily used for software interchange, for a price no
|
| 265 |
+
more than your reasonable cost of physically performing this
|
| 266 |
+
conveying of source, or (2) access to copy the
|
| 267 |
+
Corresponding Source from a network server at no charge.
|
| 268 |
+
|
| 269 |
+
c) Convey individual copies of the object code with a copy of the
|
| 270 |
+
written offer to provide the Corresponding Source. This
|
| 271 |
+
alternative is allowed only occasionally and noncommercially, and
|
| 272 |
+
only if you received the object code with such an offer, in accord
|
| 273 |
+
with subsection 6b.
|
| 274 |
+
|
| 275 |
+
d) Convey the object code by offering access from a designated
|
| 276 |
+
place (gratis or for a charge), and offer equivalent access to the
|
| 277 |
+
Corresponding Source in the same way through the same place at no
|
| 278 |
+
further charge. You need not require recipients to copy the
|
| 279 |
+
Corresponding Source along with the object code. If the place to
|
| 280 |
+
copy the object code is a network server, the Corresponding Source
|
| 281 |
+
may be on a different server (operated by you or a third party)
|
| 282 |
+
that supports equivalent copying facilities, provided you maintain
|
| 283 |
+
clear directions next to the object code saying where to find the
|
| 284 |
+
Corresponding Source. Regardless of what server hosts the
|
| 285 |
+
Corresponding Source, you remain obligated to ensure that it is
|
| 286 |
+
available for as long as needed to satisfy these requirements.
|
| 287 |
+
|
| 288 |
+
e) Convey the object code using peer-to-peer transmission, provided
|
| 289 |
+
you inform other peers where the object code and Corresponding
|
| 290 |
+
Source of the work are being offered to the general public at no
|
| 291 |
+
charge under subsection 6d.
|
| 292 |
+
|
| 293 |
+
A separable portion of the object code, whose source code is excluded
|
| 294 |
+
from the Corresponding Source as a System Library, need not be
|
| 295 |
+
included in conveying the object code work.
|
| 296 |
+
|
| 297 |
+
A "User Product" is either (1) a "consumer product", which means any
|
| 298 |
+
tangible personal property which is normally used for personal, family,
|
| 299 |
+
or household purposes, or (2) anything designed or sold for incorporation
|
| 300 |
+
into a dwelling. In determining whether a product is a consumer product,
|
| 301 |
+
doubtful cases shall be resolved in favor of coverage. For a particular
|
| 302 |
+
product received by a particular user, "normally used" refers to a
|
| 303 |
+
typical or common use of that class of product, regardless of the status
|
| 304 |
+
of the particular user or of the way in which the particular user
|
| 305 |
+
actually uses, or expects or is expected to use, the product. A product
|
| 306 |
+
is a consumer product regardless of whether the product has substantial
|
| 307 |
+
commercial, industrial or non-consumer uses, unless such uses represent
|
| 308 |
+
the only significant mode of use of the product.
|
| 309 |
+
|
| 310 |
+
"Installation Information" for a User Product means any methods,
|
| 311 |
+
procedures, authorization keys, or other information required to install
|
| 312 |
+
and execute modified versions of a covered work in that User Product from
|
| 313 |
+
a modified version of its Corresponding Source. The information must
|
| 314 |
+
suffice to ensure that the continued functioning of the modified object
|
| 315 |
+
code is in no case prevented or interfered with solely because
|
| 316 |
+
modification has been made.
|
| 317 |
+
|
| 318 |
+
If you convey an object code work under this section in, or with, or
|
| 319 |
+
specifically for use in, a User Product, and the conveying occurs as
|
| 320 |
+
part of a transaction in which the right of possession and use of the
|
| 321 |
+
User Product is transferred to the recipient in perpetuity or for a
|
| 322 |
+
fixed term (regardless of how the transaction is characterized), the
|
| 323 |
+
Corresponding Source conveyed under this section must be accompanied
|
| 324 |
+
by the Installation Information. But this requirement does not apply
|
| 325 |
+
if neither you nor any third party retains the ability to install
|
| 326 |
+
modified object code on the User Product (for example, the work has
|
| 327 |
+
been installed in ROM).
|
| 328 |
+
|
| 329 |
+
The requirement to provide Installation Information does not include a
|
| 330 |
+
requirement to continue to provide support service, warranty, or updates
|
| 331 |
+
for a work that has been modified or installed by the recipient, or for
|
| 332 |
+
the User Product in which it has been modified or installed. Access to a
|
| 333 |
+
network may be denied when the modification itself materially and
|
| 334 |
+
adversely affects the operation of the network or violates the rules and
|
| 335 |
+
protocols for communication across the network.
|
| 336 |
+
|
| 337 |
+
Corresponding Source conveyed, and Installation Information provided,
|
| 338 |
+
in accord with this section must be in a format that is publicly
|
| 339 |
+
documented (and with an implementation available to the public in
|
| 340 |
+
source code form), and must require no special password or key for
|
| 341 |
+
unpacking, reading or copying.
|
| 342 |
+
|
| 343 |
+
7. Additional Terms.
|
| 344 |
+
|
| 345 |
+
"Additional permissions" are terms that supplement the terms of this
|
| 346 |
+
License by making exceptions from one or more of its conditions.
|
| 347 |
+
Additional permissions that are applicable to the entire Program shall
|
| 348 |
+
be treated as though they were included in this License, to the extent
|
| 349 |
+
that they are valid under applicable law. If additional permissions
|
| 350 |
+
apply only to part of the Program, that part may be used separately
|
| 351 |
+
under those permissions, but the entire Program remains governed by
|
| 352 |
+
this License without regard to the additional permissions.
|
| 353 |
+
|
| 354 |
+
When you convey a copy of a covered work, you may at your option
|
| 355 |
+
remove any additional permissions from that copy, or from any part of
|
| 356 |
+
it. (Additional permissions may be written to require their own
|
| 357 |
+
removal in certain cases when you modify the work.) You may place
|
| 358 |
+
additional permissions on material, added by you to a covered work,
|
| 359 |
+
for which you have or can give appropriate copyright permission.
|
| 360 |
+
|
| 361 |
+
Notwithstanding any other provision of this License, for material you
|
| 362 |
+
add to a covered work, you may (if authorized by the copyright holders of
|
| 363 |
+
that material) supplement the terms of this License with terms:
|
| 364 |
+
|
| 365 |
+
a) Disclaiming warranty or limiting liability differently from the
|
| 366 |
+
terms of sections 15 and 16 of this License; or
|
| 367 |
+
|
| 368 |
+
b) Requiring preservation of specified reasonable legal notices or
|
| 369 |
+
author attributions in that material or in the Appropriate Legal
|
| 370 |
+
Notices displayed by works containing it; or
|
| 371 |
+
|
| 372 |
+
c) Prohibiting misrepresentation of the origin of that material, or
|
| 373 |
+
requiring that modified versions of such material be marked in
|
| 374 |
+
reasonable ways as different from the original version; or
|
| 375 |
+
|
| 376 |
+
d) Limiting the use for publicity purposes of names of licensors or
|
| 377 |
+
authors of the material; or
|
| 378 |
+
|
| 379 |
+
e) Declining to grant rights under trademark law for use of some
|
| 380 |
+
trade names, trademarks, or service marks; or
|
| 381 |
+
|
| 382 |
+
f) Requiring indemnification of licensors and authors of that
|
| 383 |
+
material by anyone who conveys the material (or modified versions of
|
| 384 |
+
it) with contractual assumptions of liability to the recipient, for
|
| 385 |
+
any liability that these contractual assumptions directly impose on
|
| 386 |
+
those licensors and authors.
|
| 387 |
+
|
| 388 |
+
All other non-permissive additional terms are considered "further
|
| 389 |
+
restrictions" within the meaning of section 10. If the Program as you
|
| 390 |
+
received it, or any part of it, contains a notice stating that it is
|
| 391 |
+
governed by this License along with a term that is a further
|
| 392 |
+
restriction, you may remove that term. If a license document contains
|
| 393 |
+
a further restriction but permits relicensing or conveying under this
|
| 394 |
+
License, you may add to a covered work material governed by the terms
|
| 395 |
+
of that license document, provided that the further restriction does
|
| 396 |
+
not survive such relicensing or conveying.
|
| 397 |
+
|
| 398 |
+
If you add terms to a covered work in accord with this section, you
|
| 399 |
+
must place, in the relevant source files, a statement of the
|
| 400 |
+
additional terms that apply to those files, or a notice indicating
|
| 401 |
+
where to find the applicable terms.
|
| 402 |
+
|
| 403 |
+
Additional terms, permissive or non-permissive, may be stated in the
|
| 404 |
+
form of a separately written license, or stated as exceptions;
|
| 405 |
+
the above requirements apply either way.
|
| 406 |
+
|
| 407 |
+
8. Termination.
|
| 408 |
+
|
| 409 |
+
You may not propagate or modify a covered work except as expressly
|
| 410 |
+
provided under this License. Any attempt otherwise to propagate or
|
| 411 |
+
modify it is void, and will automatically terminate your rights under
|
| 412 |
+
this License (including any patent licenses granted under the third
|
| 413 |
+
paragraph of section 11).
|
| 414 |
+
|
| 415 |
+
However, if you cease all violation of this License, then your
|
| 416 |
+
license from a particular copyright holder is reinstated (a)
|
| 417 |
+
provisionally, unless and until the copyright holder explicitly and
|
| 418 |
+
finally terminates your license, and (b) permanently, if the copyright
|
| 419 |
+
holder fails to notify you of the violation by some reasonable means
|
| 420 |
+
prior to 60 days after the cessation.
|
| 421 |
+
|
| 422 |
+
Moreover, your license from a particular copyright holder is
|
| 423 |
+
reinstated permanently if the copyright holder notifies you of the
|
| 424 |
+
violation by some reasonable means, this is the first time you have
|
| 425 |
+
received notice of violation of this License (for any work) from that
|
| 426 |
+
copyright holder, and you cure the violation prior to 30 days after
|
| 427 |
+
your receipt of the notice.
|
| 428 |
+
|
| 429 |
+
Termination of your rights under this section does not terminate the
|
| 430 |
+
licenses of parties who have received copies or rights from you under
|
| 431 |
+
this License. If your rights have been terminated and not permanently
|
| 432 |
+
reinstated, you do not qualify to receive new licenses for the same
|
| 433 |
+
material under section 10.
|
| 434 |
+
|
| 435 |
+
9. Acceptance Not Required for Having Copies.
|
| 436 |
+
|
| 437 |
+
You are not required to accept this License in order to receive or
|
| 438 |
+
run a copy of the Program. Ancillary propagation of a covered work
|
| 439 |
+
occurring solely as a consequence of using peer-to-peer transmission
|
| 440 |
+
to receive a copy likewise does not require acceptance. However,
|
| 441 |
+
nothing other than this License grants you permission to propagate or
|
| 442 |
+
modify any covered work. These actions infringe copyright if you do
|
| 443 |
+
not accept this License. Therefore, by modifying or propagating a
|
| 444 |
+
covered work, you indicate your acceptance of this License to do so.
|
| 445 |
+
|
| 446 |
+
10. Automatic Licensing of Downstream Recipients.
|
| 447 |
+
|
| 448 |
+
Each time you convey a covered work, the recipient automatically
|
| 449 |
+
receives a license from the original licensors, to run, modify and
|
| 450 |
+
propagate that work, subject to this License. You are not responsible
|
| 451 |
+
for enforcing compliance by third parties with this License.
|
| 452 |
+
|
| 453 |
+
An "entity transaction" is a transaction transferring control of an
|
| 454 |
+
organization, or substantially all assets of one, or subdividing an
|
| 455 |
+
organization, or merging organizations. If propagation of a covered
|
| 456 |
+
work results from an entity transaction, each party to that
|
| 457 |
+
transaction who receives a copy of the work also receives whatever
|
| 458 |
+
licenses to the work the party's predecessor in interest had or could
|
| 459 |
+
give under the previous paragraph, plus a right to possession of the
|
| 460 |
+
Corresponding Source of the work from the predecessor in interest, if
|
| 461 |
+
the predecessor has it or can get it with reasonable efforts.
|
| 462 |
+
|
| 463 |
+
You may not impose any further restrictions on the exercise of the
|
| 464 |
+
rights granted or affirmed under this License. For example, you may
|
| 465 |
+
not impose a license fee, royalty, or other charge for exercise of
|
| 466 |
+
rights granted under this License, and you may not initiate litigation
|
| 467 |
+
(including a cross-claim or counterclaim in a lawsuit) alleging that
|
| 468 |
+
any patent claim is infringed by making, using, selling, offering for
|
| 469 |
+
sale, or importing the Program or any portion of it.
|
| 470 |
+
|
| 471 |
+
11. Patents.
|
| 472 |
+
|
| 473 |
+
A "contributor" is a copyright holder who authorizes use under this
|
| 474 |
+
License of the Program or a work on which the Program is based. The
|
| 475 |
+
work thus licensed is called the contributor's "contributor version".
|
| 476 |
+
|
| 477 |
+
A contributor's "essential patent claims" are all patent claims
|
| 478 |
+
owned or controlled by the contributor, whether already acquired or
|
| 479 |
+
hereafter acquired, that would be infringed by some manner, permitted
|
| 480 |
+
by this License, of making, using, or selling its contributor version,
|
| 481 |
+
but do not include claims that would be infringed only as a
|
| 482 |
+
consequence of further modification of the contributor version. For
|
| 483 |
+
purposes of this definition, "control" includes the right to grant
|
| 484 |
+
patent sublicenses in a manner consistent with the requirements of
|
| 485 |
+
this License.
|
| 486 |
+
|
| 487 |
+
Each contributor grants you a non-exclusive, worldwide, royalty-free
|
| 488 |
+
patent license under the contributor's essential patent claims, to
|
| 489 |
+
make, use, sell, offer for sale, import and otherwise run, modify and
|
| 490 |
+
propagate the contents of its contributor version.
|
| 491 |
+
|
| 492 |
+
In the following three paragraphs, a "patent license" is any express
|
| 493 |
+
agreement or commitment, however denominated, not to enforce a patent
|
| 494 |
+
(such as an express permission to practice a patent or covenant not to
|
| 495 |
+
sue for patent infringement). To "grant" such a patent license to a
|
| 496 |
+
party means to make such an agreement or commitment not to enforce a
|
| 497 |
+
patent against the party.
|
| 498 |
+
|
| 499 |
+
If you convey a covered work, knowingly relying on a patent license,
|
| 500 |
+
and the Corresponding Source of the work is not available for anyone
|
| 501 |
+
to copy, free of charge and under the terms of this License, through a
|
| 502 |
+
publicly available network server or other readily accessible means,
|
| 503 |
+
then you must either (1) cause the Corresponding Source to be so
|
| 504 |
+
available, or (2) arrange to deprive yourself of the benefit of the
|
| 505 |
+
patent license for this particular work, or (3) arrange, in a manner
|
| 506 |
+
consistent with the requirements of this License, to extend the patent
|
| 507 |
+
license to downstream recipients. "Knowingly relying" means you have
|
| 508 |
+
actual knowledge that, but for the patent license, your conveying the
|
| 509 |
+
covered work in a country, or your recipient's use of the covered work
|
| 510 |
+
in a country, would infringe one or more identifiable patents in that
|
| 511 |
+
country that you have reason to believe are valid.
|
| 512 |
+
|
| 513 |
+
If, pursuant to or in connection with a single transaction or
|
| 514 |
+
arrangement, you convey, or propagate by procuring conveyance of, a
|
| 515 |
+
covered work, and grant a patent license to some of the parties
|
| 516 |
+
receiving the covered work authorizing them to use, propagate, modify
|
| 517 |
+
or convey a specific copy of the covered work, then the patent license
|
| 518 |
+
you grant is automatically extended to all recipients of the covered
|
| 519 |
+
work and works based on it.
|
| 520 |
+
|
| 521 |
+
A patent license is "discriminatory" if it does not include within
|
| 522 |
+
the scope of its coverage, prohibits the exercise of, or is
|
| 523 |
+
conditioned on the non-exercise of one or more of the rights that are
|
| 524 |
+
specifically granted under this License. You may not convey a covered
|
| 525 |
+
work if you are a party to an arrangement with a third party that is
|
| 526 |
+
in the business of distributing software, under which you make payment
|
| 527 |
+
to the third party based on the extent of your activity of conveying
|
| 528 |
+
the work, and under which the third party grants, to any of the
|
| 529 |
+
parties who would receive the covered work from you, a discriminatory
|
| 530 |
+
patent license (a) in connection with copies of the covered work
|
| 531 |
+
conveyed by you (or copies made from those copies), or (b) primarily
|
| 532 |
+
for and in connection with specific products or compilations that
|
| 533 |
+
contain the covered work, unless you entered into that arrangement,
|
| 534 |
+
or that patent license was granted, prior to 28 March 2007.
|
| 535 |
+
|
| 536 |
+
Nothing in this License shall be construed as excluding or limiting
|
| 537 |
+
any implied license or other defenses to infringement that may
|
| 538 |
+
otherwise be available to you under applicable patent law.
|
| 539 |
+
|
| 540 |
+
12. No Surrender of Others' Freedom.
|
| 541 |
+
|
| 542 |
+
If conditions are imposed on you (whether by court order, agreement or
|
| 543 |
+
otherwise) that contradict the conditions of this License, they do not
|
| 544 |
+
excuse you from the conditions of this License. If you cannot convey a
|
| 545 |
+
covered work so as to satisfy simultaneously your obligations under this
|
| 546 |
+
License and any other pertinent obligations, then as a consequence you may
|
| 547 |
+
not convey it at all. For example, if you agree to terms that obligate you
|
| 548 |
+
to collect a royalty for further conveying from those to whom you convey
|
| 549 |
+
the Program, the only way you could satisfy both those terms and this
|
| 550 |
+
License would be to refrain entirely from conveying the Program.
|
| 551 |
+
|
| 552 |
+
13. Use with the GNU Affero General Public License.
|
| 553 |
+
|
| 554 |
+
Notwithstanding any other provision of this License, you have
|
| 555 |
+
permission to link or combine any covered work with a work licensed
|
| 556 |
+
under version 3 of the GNU Affero General Public License into a single
|
| 557 |
+
combined work, and to convey the resulting work. The terms of this
|
| 558 |
+
License will continue to apply to the part which is the covered work,
|
| 559 |
+
but the special requirements of the GNU Affero General Public License,
|
| 560 |
+
section 13, concerning interaction through a network will apply to the
|
| 561 |
+
combination as such.
|
| 562 |
+
|
| 563 |
+
14. Revised Versions of this License.
|
| 564 |
+
|
| 565 |
+
The Free Software Foundation may publish revised and/or new versions of
|
| 566 |
+
the GNU General Public License from time to time. Such new versions will
|
| 567 |
+
be similar in spirit to the present version, but may differ in detail to
|
| 568 |
+
address new problems or concerns.
|
| 569 |
+
|
| 570 |
+
Each version is given a distinguishing version number. If the
|
| 571 |
+
Program specifies that a certain numbered version of the GNU General
|
| 572 |
+
Public License "or any later version" applies to it, you have the
|
| 573 |
+
option of following the terms and conditions either of that numbered
|
| 574 |
+
version or of any later version published by the Free Software
|
| 575 |
+
Foundation. If the Program does not specify a version number of the
|
| 576 |
+
GNU General Public License, you may choose any version ever published
|
| 577 |
+
by the Free Software Foundation.
|
| 578 |
+
|
| 579 |
+
If the Program specifies that a proxy can decide which future
|
| 580 |
+
versions of the GNU General Public License can be used, that proxy's
|
| 581 |
+
public statement of acceptance of a version permanently authorizes you
|
| 582 |
+
to choose that version for the Program.
|
| 583 |
+
|
| 584 |
+
Later license versions may give you additional or different
|
| 585 |
+
permissions. However, no additional obligations are imposed on any
|
| 586 |
+
author or copyright holder as a result of your choosing to follow a
|
| 587 |
+
later version.
|
| 588 |
+
|
| 589 |
+
15. Disclaimer of Warranty.
|
| 590 |
+
|
| 591 |
+
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
|
| 592 |
+
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
|
| 593 |
+
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
|
| 594 |
+
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
|
| 595 |
+
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
| 596 |
+
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
|
| 597 |
+
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
|
| 598 |
+
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
|
| 599 |
+
|
| 600 |
+
16. Limitation of Liability.
|
| 601 |
+
|
| 602 |
+
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
|
| 603 |
+
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
|
| 604 |
+
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
|
| 605 |
+
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
|
| 606 |
+
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
|
| 607 |
+
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
|
| 608 |
+
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
|
| 609 |
+
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
|
| 610 |
+
SUCH DAMAGES.
|
| 611 |
+
|
| 612 |
+
17. Interpretation of Sections 15 and 16.
|
| 613 |
+
|
| 614 |
+
If the disclaimer of warranty and limitation of liability provided
|
| 615 |
+
above cannot be given local legal effect according to their terms,
|
| 616 |
+
reviewing courts shall apply local law that most closely approximates
|
| 617 |
+
an absolute waiver of all civil liability in connection with the
|
| 618 |
+
Program, unless a warranty or assumption of liability accompanies a
|
| 619 |
+
copy of the Program in return for a fee.
|
| 620 |
+
|
| 621 |
+
END OF TERMS AND CONDITIONS
|
| 622 |
+
|
| 623 |
+
How to Apply These Terms to Your New Programs
|
| 624 |
+
|
| 625 |
+
If you develop a new program, and you want it to be of the greatest
|
| 626 |
+
possible use to the public, the best way to achieve this is to make it
|
| 627 |
+
free software which everyone can redistribute and change under these terms.
|
| 628 |
+
|
| 629 |
+
To do so, attach the following notices to the program. It is safest
|
| 630 |
+
to attach them to the start of each source file to most effectively
|
| 631 |
+
state the exclusion of warranty; and each file should have at least
|
| 632 |
+
the "copyright" line and a pointer to where the full notice is found.
|
| 633 |
+
|
| 634 |
+
<one line to give the program's name and a brief idea of what it does.>
|
| 635 |
+
Copyright (C) <year> <name of author>
|
| 636 |
+
|
| 637 |
+
This program is free software: you can redistribute it and/or modify
|
| 638 |
+
it under the terms of the GNU General Public License as published by
|
| 639 |
+
the Free Software Foundation, either version 3 of the License, or
|
| 640 |
+
(at your option) any later version.
|
| 641 |
+
|
| 642 |
+
This program is distributed in the hope that it will be useful,
|
| 643 |
+
but WITHOUT ANY WARRANTY; without even the implied warranty of
|
| 644 |
+
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
| 645 |
+
GNU General Public License for more details.
|
| 646 |
+
|
| 647 |
+
You should have received a copy of the GNU General Public License
|
| 648 |
+
along with this program. If not, see <https://www.gnu.org/licenses/>.
|
| 649 |
+
|
| 650 |
+
Also add information on how to contact you by electronic and paper mail.
|
| 651 |
+
|
| 652 |
+
If the program does terminal interaction, make it output a short
|
| 653 |
+
notice like this when it starts in an interactive mode:
|
| 654 |
+
|
| 655 |
+
<program> Copyright (C) <year> <name of author>
|
| 656 |
+
This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
|
| 657 |
+
This is free software, and you are welcome to redistribute it
|
| 658 |
+
under certain conditions; type `show c' for details.
|
| 659 |
+
|
| 660 |
+
The hypothetical commands `show w' and `show c' should show the appropriate
|
| 661 |
+
parts of the General Public License. Of course, your program's commands
|
| 662 |
+
might be different; for a GUI interface, you would use an "about box".
|
| 663 |
+
|
| 664 |
+
You should also get your employer (if you work as a programmer) or school,
|
| 665 |
+
if any, to sign a "copyright disclaimer" for the program, if necessary.
|
| 666 |
+
For more information on this, and how to apply and follow the GNU GPL, see
|
| 667 |
+
<https://www.gnu.org/licenses/>.
|
| 668 |
+
|
| 669 |
+
The GNU General Public License does not permit incorporating your program
|
| 670 |
+
into proprietary programs. If your program is a subroutine library, you
|
| 671 |
+
may consider it more useful to permit linking proprietary applications with
|
| 672 |
+
the library. If this is what you want to do, use the GNU Lesser General
|
| 673 |
+
Public License instead of this License. But first, please read
|
| 674 |
+
<https://www.gnu.org/licenses/why-not-lgpl.html>.
|
README.md
CHANGED
|
@@ -1,12 +1,247 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
|
| 3 |
+
# ChatGPT 学术优化
|
| 4 |
+
|
| 5 |
+
**如果喜欢这个项目,请给它一个Star;如果你发明了更好用的学术快捷键,欢迎发issue或者pull requests**
|
| 6 |
+
|
| 7 |
+
If you like this project, please give it a Star. If you've come up with more useful academic shortcuts, feel free to open an issue or pull request.
|
| 8 |
+
|
| 9 |
+
```
|
| 10 |
+
代码中参考了很多其他优秀项目中的设计,主要包括:
|
| 11 |
+
|
| 12 |
+
# 借鉴项目1:借鉴了ChuanhuChatGPT中读取OpenAI json的方法、记录历史问询记录的方法以及gradio queue的使用技巧
|
| 13 |
+
https://github.com/GaiZhenbiao/ChuanhuChatGPT
|
| 14 |
+
|
| 15 |
+
# 借鉴项目2:借鉴了mdtex2html中公式处理的方法
|
| 16 |
+
https://github.com/polarwinkel/mdtex2html
|
| 17 |
+
|
| 18 |
+
项目使用OpenAI的gpt-3.5-turbo模型,期待gpt-4早点放宽门槛😂
|
| 19 |
+
```
|
| 20 |
+
|
| 21 |
+
> **Note**
|
| 22 |
+
> 请注意只有“红颜色”标识的函数插件(按钮)才支持读取文件。目前暂不能完善地支持pdf格式文献的翻译解读,尚不支持word格式文件的读取。
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
<div align="center">
|
| 26 |
+
|
| 27 |
+
功能 | 描述
|
| 28 |
+
--- | ---
|
| 29 |
+
一键润色 | 支持一键润色、一键查找论文语法错误
|
| 30 |
+
一键中英互译 | 一键中英互译
|
| 31 |
+
一键代码解释 | 可以正确显示代码、解释代码
|
| 32 |
+
自定义快捷键 | 支持自定义快捷键
|
| 33 |
+
配置代理服务器 | 支持配置代理服务器
|
| 34 |
+
模块化设计 | 支持自定义高阶的实验性功能
|
| 35 |
+
自我程序剖析 | [实验性功能] 一键读懂本项目的源代码
|
| 36 |
+
程序剖析 | [实验性功能] 一键可以剖析其他Python/C++项目
|
| 37 |
+
读论文 | [实验性功能] 一键解读latex论文全文并生成摘要
|
| 38 |
+
批量注释生成 | [实验性功能] 一键批量生成函数注释
|
| 39 |
+
chat分析报告生成 | [实验性功能] 运行后自动生成总结汇报
|
| 40 |
+
公式显示 | 可以同时显示公式的tex形式和渲染形式
|
| 41 |
+
图片显示 | 可以在markdown中显示图片
|
| 42 |
+
支持GPT输出的markdown表格 | 可以输出支持GPT的markdown表格
|
| 43 |
+
|
| 44 |
+
</div>
|
| 45 |
+
|
| 46 |
+
- 新界面
|
| 47 |
+
<div align="center">
|
| 48 |
+
<img src="https://user-images.githubusercontent.com/96192199/228600410-7d44e34f-63f1-4046-acb8-045cb05da8bb.png" width="700" >
|
| 49 |
+
</div>
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
- 所有按钮都通过读取functional.py动态生成,可随意加自定义功能,解放粘贴板
|
| 54 |
+
<div align="center">
|
| 55 |
+
<img src="img/公式.gif" width="700" >
|
| 56 |
+
</div>
|
| 57 |
+
|
| 58 |
+
- 润色/纠错
|
| 59 |
+
<div align="center">
|
| 60 |
+
<img src="img/润色.gif" width="700" >
|
| 61 |
+
</div>
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
- 支持GPT输出的markdown表格
|
| 65 |
+
<div align="center">
|
| 66 |
+
<img src="img/demo2.jpg" width="500" >
|
| 67 |
+
</div>
|
| 68 |
+
|
| 69 |
+
- 如果输出包含公式,会同时以tex形式和渲染形式显示,方便复制和阅读
|
| 70 |
+
<div align="center">
|
| 71 |
+
<img src="img/demo.jpg" width="500" >
|
| 72 |
+
</div>
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
- 懒得看项目代码?整个工程直接给chatgpt炫嘴里
|
| 76 |
+
<div align="center">
|
| 77 |
+
<img src="https://user-images.githubusercontent.com/96192199/226935232-6b6a73ce-8900-4aee-93f9-733c7e6fef53.png" width="700" >
|
| 78 |
+
</div>
|
| 79 |
+
|
| 80 |
+
## 直接运行 (Windows, Linux or MacOS)
|
| 81 |
+
|
| 82 |
+
下载项目
|
| 83 |
+
|
| 84 |
+
```sh
|
| 85 |
+
git clone https://github.com/binary-husky/chatgpt_academic.git
|
| 86 |
+
cd chatgpt_academic
|
| 87 |
+
```
|
| 88 |
+
|
| 89 |
+
我们建议将`config.py`复制为`config_private.py`并将后者用作个性化配置文件以避免`config.py`中的变更影响你的使用或不小心将包含你的OpenAI API KEY的`config.py`提交至本项目。
|
| 90 |
+
|
| 91 |
+
```sh
|
| 92 |
+
cp config.py config_private.py
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
在`config_private.py`中,配置 海外Proxy 和 OpenAI API KEY
|
| 96 |
+
```
|
| 97 |
+
1. 如果你在国内,需要设置海外代理才能够使用 OpenAI API,你可以通过 config.py 文件来进行设置。
|
| 98 |
+
2. 配置 OpenAI API KEY。你需要在 OpenAI 官网上注册并获取 API KEY。一旦你拿到了 API KEY,在 config.py 文件里配置好即可。
|
| 99 |
+
```
|
| 100 |
+
安装依赖
|
| 101 |
+
|
| 102 |
+
```sh
|
| 103 |
+
python -m pip install -r requirements.txt
|
| 104 |
+
```
|
| 105 |
+
|
| 106 |
+
或者,如果你希望使用`conda`
|
| 107 |
+
|
| 108 |
+
```sh
|
| 109 |
+
conda create -n gptac 'gradio>=3.23' requests
|
| 110 |
+
conda activate gptac
|
| 111 |
+
python3 -m pip install mdtex2html
|
| 112 |
+
```
|
| 113 |
+
|
| 114 |
+
运行
|
| 115 |
+
|
| 116 |
+
```sh
|
| 117 |
+
python main.py
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
测试实验性功能
|
| 121 |
+
```
|
| 122 |
+
- 测试C++项目头文件分析
|
| 123 |
+
input区域 输入 `./crazy_functions/test_project/cpp/libJPG` , 然后点击 "[实验] 解析整个C++项目(input输入项目根路径)"
|
| 124 |
+
- 测试给Latex项目写摘要
|
| 125 |
+
input区域 输入 `./crazy_functions/test_project/latex/attention` , 然后点击 "[实验] 读tex论文写摘要(input输入项目根路径)"
|
| 126 |
+
- 测试Python项目分析
|
| 127 |
+
input区域 输入 `./crazy_functions/test_project/python/dqn` , 然后点击 "[实验] 解析整个py项目(input输入项目根路径)"
|
| 128 |
+
- 测试自我代码解读
|
| 129 |
+
点击 "[实验] 请解析并解构此项目本身"
|
| 130 |
+
- 测试实验功能模板函数(要求gpt回答历史上的今天发生了什么),您可以根据此函数为模板,实现更复杂的功能
|
| 131 |
+
点击 "[实验] 实验功能函数模板"
|
| 132 |
+
```
|
| 133 |
+
## 使用docker (Linux)
|
| 134 |
+
|
| 135 |
+
``` sh
|
| 136 |
+
# 下载项目
|
| 137 |
+
git clone https://github.com/binary-husky/chatgpt_academic.git
|
| 138 |
+
cd chatgpt_academic
|
| 139 |
+
# 配置 海外Proxy 和 OpenAI API KEY
|
| 140 |
+
config.py
|
| 141 |
+
# 安装
|
| 142 |
+
docker build -t gpt-academic .
|
| 143 |
+
# 运行
|
| 144 |
+
docker run --rm -it --net=host gpt-academic
|
| 145 |
+
|
| 146 |
+
# 测试实验性功能
|
| 147 |
+
## 测试自我代码解读
|
| 148 |
+
点击 "[实验] 请解析并解构此项目本身"
|
| 149 |
+
## 测试实验功能模板函数(要求gpt回答历史上的今天发生了什么),您可以根据此函数为模板,实现更复杂的功能
|
| 150 |
+
点击 "[实验] 实验功能函数模板"
|
| 151 |
+
##(请注意在docker中运行时,需要额外注意程序的文件访问权限问题)
|
| 152 |
+
## 测试C++项目头文件分析
|
| 153 |
+
input区域 输入 ./crazy_functions/test_project/cpp/libJPG , 然后点击 "[实验] 解析整个C++项目(input输入项目根路径)"
|
| 154 |
+
## 测试给Latex项目写摘要
|
| 155 |
+
input区域 输入 ./crazy_functions/test_project/latex/attention , 然后点击 "[实验] 读tex论文写摘要(input输入项目根路径)"
|
| 156 |
+
## 测试Python项目分析
|
| 157 |
+
input区域 输入 ./crazy_functions/test_project/python/dqn , 然后点击 "[实验] 解析整个py项目(input输入项目根路径)"
|
| 158 |
+
|
| 159 |
+
```
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
## 自定义新的便捷按钮(学术快捷键自定义)
|
| 163 |
+
打开functional.py,添加条目如下,然后重启程序即可。(如果按钮已经添加成功并可见,那么前缀、后缀都支持热修改,无需重启程序即可生效。)
|
| 164 |
+
例如
|
| 165 |
+
```
|
| 166 |
+
"超级英译中": {
|
| 167 |
+
|
| 168 |
+
# 前缀,会被加在你的输入之前。例如,用来描述你的要求,例如翻译、解释代码、润色等等
|
| 169 |
+
"Prefix": "请翻译把下面一段内容成中文,然后用一个markdown表格逐一解释文中出现的专有名词:\n\n",
|
| 170 |
+
|
| 171 |
+
# 后缀,会被加在你的输入之后。例如,配合前缀可以把你的输入内容用引号圈起来。
|
| 172 |
+
"Suffix": "",
|
| 173 |
+
|
| 174 |
+
},
|
| 175 |
+
```
|
| 176 |
+
<div align="center">
|
| 177 |
+
<img src="https://user-images.githubusercontent.com/96192199/226899272-477c2134-ed71-4326-810c-29891fe4a508.png" width="500" >
|
| 178 |
+
</div>
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
如果你发明了更好用的学术快捷键,欢迎发issue或者pull requests!
|
| 182 |
+
|
| 183 |
+
## 配置代理
|
| 184 |
+
|
| 185 |
+
在```config.py```中修改端口与代理软件对应
|
| 186 |
+
|
| 187 |
+
<div align="center">
|
| 188 |
+
<img src="https://user-images.githubusercontent.com/96192199/226571294-37a47cd9-4d40-4c16-97a2-d360845406f7.png" width="500" >
|
| 189 |
+
<img src="https://user-images.githubusercontent.com/96192199/226838985-e5c95956-69c2-4c23-a4dd-cd7944eeb451.png" width="500" >
|
| 190 |
+
</div>
|
| 191 |
+
|
| 192 |
+
配置完成后,你可以用以下命令测试代理是否工作,如果一切正常,下面的代码将输出你的代理服务器所在地:
|
| 193 |
+
```
|
| 194 |
+
python check_proxy.py
|
| 195 |
+
```
|
| 196 |
+
|
| 197 |
+
## 兼容性测试
|
| 198 |
+
|
| 199 |
+
### 图片显示:
|
| 200 |
+
<div align="center">
|
| 201 |
+
<img src="https://user-images.githubusercontent.com/96192199/226906087-b5f1c127-2060-4db9-af05-487643b21ed9.png" height="200" >
|
| 202 |
+
<img src="https://user-images.githubusercontent.com/96192199/226906703-7226495d-6a1f-4a53-9728-ce6778cbdd19.png" height="200" >
|
| 203 |
+
</div>
|
| 204 |
+
|
| 205 |
+
### 如果一个程序能够读懂并剖析自己:
|
| 206 |
+
|
| 207 |
+
<div align="center">
|
| 208 |
+
<img src="https://user-images.githubusercontent.com/96192199/226936850-c77d7183-0749-4c1c-9875-fd4891842d0c.png" width="800" >
|
| 209 |
+
</div>
|
| 210 |
+
|
| 211 |
+
<div align="center">
|
| 212 |
+
<img src="https://user-images.githubusercontent.com/96192199/226936618-9b487e4b-ab5b-4b6e-84c6-16942102e917.png" width="800" >
|
| 213 |
+
</div>
|
| 214 |
+
|
| 215 |
+
### 其他任意Python/Cpp项目剖析:
|
| 216 |
+
<div align="center">
|
| 217 |
+
<img src="https://user-images.githubusercontent.com/96192199/226935232-6b6a73ce-8900-4aee-93f9-733c7e6fef53.png" width="800" >
|
| 218 |
+
</div>
|
| 219 |
+
|
| 220 |
+
<div align="center">
|
| 221 |
+
<img src="https://user-images.githubusercontent.com/96192199/226969067-968a27c1-1b9c-486b-8b81-ab2de8d3f88a.png" width="800" >
|
| 222 |
+
</div>
|
| 223 |
+
|
| 224 |
+
### Latex论文一键阅读理解与摘要生成
|
| 225 |
+
<div align="center">
|
| 226 |
+
<img src="https://user-images.githubusercontent.com/96192199/227504406-86ab97cd-f208-41c3-8e4a-7000e51cf980.png" width="800" >
|
| 227 |
+
</div>
|
| 228 |
+
|
| 229 |
+
### 自动报告生成
|
| 230 |
+
<div align="center">
|
| 231 |
+
<img src="https://user-images.githubusercontent.com/96192199/227503770-fe29ce2c-53fd-47b0-b0ff-93805f0c2ff4.png" height="300" >
|
| 232 |
+
<img src="https://user-images.githubusercontent.com/96192199/227504617-7a497bb3-0a2a-4b50-9a8a-95ae60ea7afd.png" height="300" >
|
| 233 |
+
<img src="https://user-images.githubusercontent.com/96192199/227504005-efeaefe0-b687-49d0-bf95-2d7b7e66c348.png" height="300" >
|
| 234 |
+
</div>
|
| 235 |
+
|
| 236 |
+
### 模块化功能设计
|
| 237 |
+
<div align="center">
|
| 238 |
+
<img src="https://user-images.githubusercontent.com/96192199/227504981-4c6c39c0-ae79-47e6-bffe-0e6442d9da65.png" height="400" >
|
| 239 |
+
<img src="https://user-images.githubusercontent.com/96192199/227504931-19955f78-45cd-4d1c-adac-e71e50957915.png" height="400" >
|
| 240 |
+
</div>
|
| 241 |
+
|
| 242 |
+
## Todo:
|
| 243 |
+
|
| 244 |
+
- (Top Priority) 调用另一个开源项目text-generation-webui的web接口,使用其他llm模型
|
| 245 |
+
- 总结大工程源代码时,文本过长、token溢出的问题(目前的方法是直接二分丢弃处理溢出,过于粗暴,有效信息大量丢失)
|
| 246 |
+
- UI不够美观
|
| 247 |
+
|
check_proxy.py
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
def check_proxy(proxies):
|
| 3 |
+
import requests
|
| 4 |
+
proxies_https = proxies['https'] if proxies is not None else '无'
|
| 5 |
+
try:
|
| 6 |
+
response = requests.get("https://ipapi.co/json/", proxies=proxies, timeout=4)
|
| 7 |
+
data = response.json()
|
| 8 |
+
print(f'查询代理的地理位置,返回的结果是{data}')
|
| 9 |
+
if 'country_name' in data:
|
| 10 |
+
country = data['country_name']
|
| 11 |
+
result = f"代理配置 {proxies_https}, 代理所在地:{country}"
|
| 12 |
+
elif 'error' in data:
|
| 13 |
+
result = f"代理配置 {proxies_https}, 代理所在地:未知,IP查询频率受限"
|
| 14 |
+
print(result)
|
| 15 |
+
return result
|
| 16 |
+
except:
|
| 17 |
+
result = f"代理配置 {proxies_https}, 代理所在地查询超时,代理可能无效"
|
| 18 |
+
print(result)
|
| 19 |
+
return result
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
if __name__ == '__main__':
|
| 23 |
+
import os; os.environ['no_proxy'] = '*' # 避免代理网络产生意外污染
|
| 24 |
+
try: from config_private import proxies # 放自己的秘密如API和代理网址 os.path.exists('config_private.py')
|
| 25 |
+
except: from config import proxies
|
| 26 |
+
check_proxy(proxies)
|
config.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# API_KEY = "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" 此key无效
|
| 2 |
+
API_KEY = "sk-此处填API秘钥"
|
| 3 |
+
API_URL = "https://api.openai.com/v1/chat/completions"
|
| 4 |
+
|
| 5 |
+
# 改为True应用代理
|
| 6 |
+
USE_PROXY = False
|
| 7 |
+
if USE_PROXY:
|
| 8 |
+
|
| 9 |
+
# 填写格式是 [协议]:// [地址] :[端口] ,
|
| 10 |
+
# 例如 "socks5h://localhost:11284"
|
| 11 |
+
# [协议] 常见协议无非socks5h/http,例如 v2*** 和 s** 的默认本地协议是socks5h,cl**h 的默认本地协议是http
|
| 12 |
+
# [地址] 懂的都懂,不懂就填localhost或者127.0.0.1肯定错不了(localhost意思是代理软件安装在本机上)
|
| 13 |
+
# [端口] 在代理软件的设置里,不同的代理软件界面不一样,但端口号都应该在最显眼的位置上
|
| 14 |
+
|
| 15 |
+
# 代理网络的地址,打开你的科学上网软件查看代理的协议(socks5/http)、地址(localhost)和端口(11284)
|
| 16 |
+
proxies = { "http": "socks5h://localhost:11284", "https": "socks5h://localhost:11284", }
|
| 17 |
+
print('网络代理状态:运行。')
|
| 18 |
+
else:
|
| 19 |
+
proxies = None
|
| 20 |
+
print('网络代理状态:未配置。无代理状态下很可能无法访问。')
|
| 21 |
+
|
| 22 |
+
# 发送请求到OpenAI后,等待多久判定为超时
|
| 23 |
+
TIMEOUT_SECONDS = 25
|
| 24 |
+
|
| 25 |
+
# 网页的端口, -1代表随机端口
|
| 26 |
+
WEB_PORT = -1
|
| 27 |
+
|
| 28 |
+
# 如果OpenAI不响应(网络卡顿、代理失败、KEY失效),重试的次数限制
|
| 29 |
+
MAX_RETRY = 2
|
| 30 |
+
|
| 31 |
+
# 选择的OpenAI模型是(gpt4现在只对申请成功的人开放)
|
| 32 |
+
LLM_MODEL = "gpt-3.5-turbo"
|
| 33 |
+
|
| 34 |
+
# 设置并行使用的线程数
|
| 35 |
+
CONCURRENT_COUNT = 100
|
| 36 |
+
|
| 37 |
+
# 设置用户名和密码
|
| 38 |
+
AUTHENTICATION = [] # [("username", "password"), ("username2", "password2"), ...]
|
| 39 |
+
|
| 40 |
+
# 检查一下是不是忘了改config
|
| 41 |
+
if len(API_KEY) != 51:
|
| 42 |
+
assert False, "正确的API_KEY密钥是51位,请在config文件中修改API密钥, 添加海外代理之后再运行。" + \
|
| 43 |
+
"(如果您刚更新过代码,请确保旧版config_private文件中没有遗留任何新增键值)"
|
crazy_functions/test_project/cpp/cppipc/buffer.cpp
ADDED
|
@@ -0,0 +1,87 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#include "libipc/buffer.h"
|
| 2 |
+
#include "libipc/utility/pimpl.h"
|
| 3 |
+
|
| 4 |
+
#include <cstring>
|
| 5 |
+
|
| 6 |
+
namespace ipc {
|
| 7 |
+
|
| 8 |
+
bool operator==(buffer const & b1, buffer const & b2) {
|
| 9 |
+
return (b1.size() == b2.size()) && (std::memcmp(b1.data(), b2.data(), b1.size()) == 0);
|
| 10 |
+
}
|
| 11 |
+
|
| 12 |
+
bool operator!=(buffer const & b1, buffer const & b2) {
|
| 13 |
+
return !(b1 == b2);
|
| 14 |
+
}
|
| 15 |
+
|
| 16 |
+
class buffer::buffer_ : public pimpl<buffer_> {
|
| 17 |
+
public:
|
| 18 |
+
void* p_;
|
| 19 |
+
std::size_t s_;
|
| 20 |
+
void* a_;
|
| 21 |
+
buffer::destructor_t d_;
|
| 22 |
+
|
| 23 |
+
buffer_(void* p, std::size_t s, buffer::destructor_t d, void* a)
|
| 24 |
+
: p_(p), s_(s), a_(a), d_(d) {
|
| 25 |
+
}
|
| 26 |
+
|
| 27 |
+
~buffer_() {
|
| 28 |
+
if (d_ == nullptr) return;
|
| 29 |
+
d_((a_ == nullptr) ? p_ : a_, s_);
|
| 30 |
+
}
|
| 31 |
+
};
|
| 32 |
+
|
| 33 |
+
buffer::buffer()
|
| 34 |
+
: buffer(nullptr, 0, nullptr, nullptr) {
|
| 35 |
+
}
|
| 36 |
+
|
| 37 |
+
buffer::buffer(void* p, std::size_t s, destructor_t d)
|
| 38 |
+
: p_(p_->make(p, s, d, nullptr)) {
|
| 39 |
+
}
|
| 40 |
+
|
| 41 |
+
buffer::buffer(void* p, std::size_t s, destructor_t d, void* additional)
|
| 42 |
+
: p_(p_->make(p, s, d, additional)) {
|
| 43 |
+
}
|
| 44 |
+
|
| 45 |
+
buffer::buffer(void* p, std::size_t s)
|
| 46 |
+
: buffer(p, s, nullptr) {
|
| 47 |
+
}
|
| 48 |
+
|
| 49 |
+
buffer::buffer(char const & c)
|
| 50 |
+
: buffer(const_cast<char*>(&c), 1) {
|
| 51 |
+
}
|
| 52 |
+
|
| 53 |
+
buffer::buffer(buffer&& rhs)
|
| 54 |
+
: buffer() {
|
| 55 |
+
swap(rhs);
|
| 56 |
+
}
|
| 57 |
+
|
| 58 |
+
buffer::~buffer() {
|
| 59 |
+
p_->clear();
|
| 60 |
+
}
|
| 61 |
+
|
| 62 |
+
void buffer::swap(buffer& rhs) {
|
| 63 |
+
std::swap(p_, rhs.p_);
|
| 64 |
+
}
|
| 65 |
+
|
| 66 |
+
buffer& buffer::operator=(buffer rhs) {
|
| 67 |
+
swap(rhs);
|
| 68 |
+
return *this;
|
| 69 |
+
}
|
| 70 |
+
|
| 71 |
+
bool buffer::empty() const noexcept {
|
| 72 |
+
return (impl(p_)->p_ == nullptr) || (impl(p_)->s_ == 0);
|
| 73 |
+
}
|
| 74 |
+
|
| 75 |
+
void* buffer::data() noexcept {
|
| 76 |
+
return impl(p_)->p_;
|
| 77 |
+
}
|
| 78 |
+
|
| 79 |
+
void const * buffer::data() const noexcept {
|
| 80 |
+
return impl(p_)->p_;
|
| 81 |
+
}
|
| 82 |
+
|
| 83 |
+
std::size_t buffer::size() const noexcept {
|
| 84 |
+
return impl(p_)->s_;
|
| 85 |
+
}
|
| 86 |
+
|
| 87 |
+
} // namespace ipc
|
crazy_functions/test_project/cpp/cppipc/ipc.cpp
ADDED
|
@@ -0,0 +1,701 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
#include <type_traits>
|
| 3 |
+
#include <cstring>
|
| 4 |
+
#include <algorithm>
|
| 5 |
+
#include <utility> // std::pair, std::move, std::forward
|
| 6 |
+
#include <atomic>
|
| 7 |
+
#include <type_traits> // aligned_storage_t
|
| 8 |
+
#include <string>
|
| 9 |
+
#include <vector>
|
| 10 |
+
#include <array>
|
| 11 |
+
#include <cassert>
|
| 12 |
+
|
| 13 |
+
#include "libipc/ipc.h"
|
| 14 |
+
#include "libipc/def.h"
|
| 15 |
+
#include "libipc/shm.h"
|
| 16 |
+
#include "libipc/pool_alloc.h"
|
| 17 |
+
#include "libipc/queue.h"
|
| 18 |
+
#include "libipc/policy.h"
|
| 19 |
+
#include "libipc/rw_lock.h"
|
| 20 |
+
#include "libipc/waiter.h"
|
| 21 |
+
|
| 22 |
+
#include "libipc/utility/log.h"
|
| 23 |
+
#include "libipc/utility/id_pool.h"
|
| 24 |
+
#include "libipc/utility/scope_guard.h"
|
| 25 |
+
#include "libipc/utility/utility.h"
|
| 26 |
+
|
| 27 |
+
#include "libipc/memory/resource.h"
|
| 28 |
+
#include "libipc/platform/detail.h"
|
| 29 |
+
#include "libipc/circ/elem_array.h"
|
| 30 |
+
|
| 31 |
+
namespace {
|
| 32 |
+
|
| 33 |
+
using msg_id_t = std::uint32_t;
|
| 34 |
+
using acc_t = std::atomic<msg_id_t>;
|
| 35 |
+
|
| 36 |
+
template <std::size_t DataSize, std::size_t AlignSize>
|
| 37 |
+
struct msg_t;
|
| 38 |
+
|
| 39 |
+
template <std::size_t AlignSize>
|
| 40 |
+
struct msg_t<0, AlignSize> {
|
| 41 |
+
msg_id_t cc_id_;
|
| 42 |
+
msg_id_t id_;
|
| 43 |
+
std::int32_t remain_;
|
| 44 |
+
bool storage_;
|
| 45 |
+
};
|
| 46 |
+
|
| 47 |
+
template <std::size_t DataSize, std::size_t AlignSize>
|
| 48 |
+
struct msg_t : msg_t<0, AlignSize> {
|
| 49 |
+
std::aligned_storage_t<DataSize, AlignSize> data_ {};
|
| 50 |
+
|
| 51 |
+
msg_t() = default;
|
| 52 |
+
msg_t(msg_id_t cc_id, msg_id_t id, std::int32_t remain, void const * data, std::size_t size)
|
| 53 |
+
: msg_t<0, AlignSize> {cc_id, id, remain, (data == nullptr) || (size == 0)} {
|
| 54 |
+
if (this->storage_) {
|
| 55 |
+
if (data != nullptr) {
|
| 56 |
+
// copy storage-id
|
| 57 |
+
*reinterpret_cast<ipc::storage_id_t*>(&data_) =
|
| 58 |
+
*static_cast<ipc::storage_id_t const *>(data);
|
| 59 |
+
}
|
| 60 |
+
}
|
| 61 |
+
else std::memcpy(&data_, data, size);
|
| 62 |
+
}
|
| 63 |
+
};
|
| 64 |
+
|
| 65 |
+
template <typename T>
|
| 66 |
+
ipc::buff_t make_cache(T& data, std::size_t size) {
|
| 67 |
+
auto ptr = ipc::mem::alloc(size);
|
| 68 |
+
std::memcpy(ptr, &data, (ipc::detail::min)(sizeof(data), size));
|
| 69 |
+
return { ptr, size, ipc::mem::free };
|
| 70 |
+
}
|
| 71 |
+
|
| 72 |
+
struct cache_t {
|
| 73 |
+
std::size_t fill_;
|
| 74 |
+
ipc::buff_t buff_;
|
| 75 |
+
|
| 76 |
+
cache_t(std::size_t f, ipc::buff_t && b)
|
| 77 |
+
: fill_(f), buff_(std::move(b))
|
| 78 |
+
{}
|
| 79 |
+
|
| 80 |
+
void append(void const * data, std::size_t size) {
|
| 81 |
+
if (fill_ >= buff_.size() || data == nullptr || size == 0) return;
|
| 82 |
+
auto new_fill = (ipc::detail::min)(fill_ + size, buff_.size());
|
| 83 |
+
std::memcpy(static_cast<ipc::byte_t*>(buff_.data()) + fill_, data, new_fill - fill_);
|
| 84 |
+
fill_ = new_fill;
|
| 85 |
+
}
|
| 86 |
+
};
|
| 87 |
+
|
| 88 |
+
auto cc_acc() {
|
| 89 |
+
static ipc::shm::handle acc_h("__CA_CONN__", sizeof(acc_t));
|
| 90 |
+
return static_cast<acc_t*>(acc_h.get());
|
| 91 |
+
}
|
| 92 |
+
|
| 93 |
+
IPC_CONSTEXPR_ std::size_t align_chunk_size(std::size_t size) noexcept {
|
| 94 |
+
return (((size - 1) / ipc::large_msg_align) + 1) * ipc::large_msg_align;
|
| 95 |
+
}
|
| 96 |
+
|
| 97 |
+
IPC_CONSTEXPR_ std::size_t calc_chunk_size(std::size_t size) noexcept {
|
| 98 |
+
return ipc::make_align(alignof(std::max_align_t), align_chunk_size(
|
| 99 |
+
ipc::make_align(alignof(std::max_align_t), sizeof(std::atomic<ipc::circ::cc_t>)) + size));
|
| 100 |
+
}
|
| 101 |
+
|
| 102 |
+
struct chunk_t {
|
| 103 |
+
std::atomic<ipc::circ::cc_t> &conns() noexcept {
|
| 104 |
+
return *reinterpret_cast<std::atomic<ipc::circ::cc_t> *>(this);
|
| 105 |
+
}
|
| 106 |
+
|
| 107 |
+
void *data() noexcept {
|
| 108 |
+
return reinterpret_cast<ipc::byte_t *>(this)
|
| 109 |
+
+ ipc::make_align(alignof(std::max_align_t), sizeof(std::atomic<ipc::circ::cc_t>));
|
| 110 |
+
}
|
| 111 |
+
};
|
| 112 |
+
|
| 113 |
+
struct chunk_info_t {
|
| 114 |
+
ipc::id_pool<> pool_;
|
| 115 |
+
ipc::spin_lock lock_;
|
| 116 |
+
|
| 117 |
+
IPC_CONSTEXPR_ static std::size_t chunks_mem_size(std::size_t chunk_size) noexcept {
|
| 118 |
+
return ipc::id_pool<>::max_count * chunk_size;
|
| 119 |
+
}
|
| 120 |
+
|
| 121 |
+
ipc::byte_t *chunks_mem() noexcept {
|
| 122 |
+
return reinterpret_cast<ipc::byte_t *>(this + 1);
|
| 123 |
+
}
|
| 124 |
+
|
| 125 |
+
chunk_t *at(std::size_t chunk_size, ipc::storage_id_t id) noexcept {
|
| 126 |
+
if (id < 0) return nullptr;
|
| 127 |
+
return reinterpret_cast<chunk_t *>(chunks_mem() + (chunk_size * id));
|
| 128 |
+
}
|
| 129 |
+
};
|
| 130 |
+
|
| 131 |
+
auto& chunk_storages() {
|
| 132 |
+
class chunk_handle_t {
|
| 133 |
+
ipc::shm::handle handle_;
|
| 134 |
+
|
| 135 |
+
public:
|
| 136 |
+
chunk_info_t *get_info(std::size_t chunk_size) {
|
| 137 |
+
if (!handle_.valid() &&
|
| 138 |
+
!handle_.acquire( ("__CHUNK_INFO__" + ipc::to_string(chunk_size)).c_str(),
|
| 139 |
+
sizeof(chunk_info_t) + chunk_info_t::chunks_mem_size(chunk_size) )) {
|
| 140 |
+
ipc::error("[chunk_storages] chunk_shm.id_info_.acquire failed: chunk_size = %zd\n", chunk_size);
|
| 141 |
+
return nullptr;
|
| 142 |
+
}
|
| 143 |
+
auto info = static_cast<chunk_info_t*>(handle_.get());
|
| 144 |
+
if (info == nullptr) {
|
| 145 |
+
ipc::error("[chunk_storages] chunk_shm.id_info_.get failed: chunk_size = %zd\n", chunk_size);
|
| 146 |
+
return nullptr;
|
| 147 |
+
}
|
| 148 |
+
return info;
|
| 149 |
+
}
|
| 150 |
+
};
|
| 151 |
+
static ipc::map<std::size_t, chunk_handle_t> chunk_hs;
|
| 152 |
+
return chunk_hs;
|
| 153 |
+
}
|
| 154 |
+
|
| 155 |
+
chunk_info_t *chunk_storage_info(std::size_t chunk_size) {
|
| 156 |
+
auto &storages = chunk_storages();
|
| 157 |
+
std::decay_t<decltype(storages)>::iterator it;
|
| 158 |
+
{
|
| 159 |
+
static ipc::rw_lock lock;
|
| 160 |
+
IPC_UNUSED_ std::shared_lock<ipc::rw_lock> guard {lock};
|
| 161 |
+
if ((it = storages.find(chunk_size)) == storages.end()) {
|
| 162 |
+
using chunk_handle_t = std::decay_t<decltype(storages)>::value_type::second_type;
|
| 163 |
+
guard.unlock();
|
| 164 |
+
IPC_UNUSED_ std::lock_guard<ipc::rw_lock> guard {lock};
|
| 165 |
+
it = storages.emplace(chunk_size, chunk_handle_t{}).first;
|
| 166 |
+
}
|
| 167 |
+
}
|
| 168 |
+
return it->second.get_info(chunk_size);
|
| 169 |
+
}
|
| 170 |
+
|
| 171 |
+
std::pair<ipc::storage_id_t, void*> acquire_storage(std::size_t size, ipc::circ::cc_t conns) {
|
| 172 |
+
std::size_t chunk_size = calc_chunk_size(size);
|
| 173 |
+
auto info = chunk_storage_info(chunk_size);
|
| 174 |
+
if (info == nullptr) return {};
|
| 175 |
+
|
| 176 |
+
info->lock_.lock();
|
| 177 |
+
info->pool_.prepare();
|
| 178 |
+
// got an unique id
|
| 179 |
+
auto id = info->pool_.acquire();
|
| 180 |
+
info->lock_.unlock();
|
| 181 |
+
|
| 182 |
+
auto chunk = info->at(chunk_size, id);
|
| 183 |
+
if (chunk == nullptr) return {};
|
| 184 |
+
chunk->conns().store(conns, std::memory_order_relaxed);
|
| 185 |
+
return { id, chunk->data() };
|
| 186 |
+
}
|
| 187 |
+
|
| 188 |
+
void *find_storage(ipc::storage_id_t id, std::size_t size) {
|
| 189 |
+
if (id < 0) {
|
| 190 |
+
ipc::error("[find_storage] id is invalid: id = %ld, size = %zd\n", (long)id, size);
|
| 191 |
+
return nullptr;
|
| 192 |
+
}
|
| 193 |
+
std::size_t chunk_size = calc_chunk_size(size);
|
| 194 |
+
auto info = chunk_storage_info(chunk_size);
|
| 195 |
+
if (info == nullptr) return nullptr;
|
| 196 |
+
return info->at(chunk_size, id)->data();
|
| 197 |
+
}
|
| 198 |
+
|
| 199 |
+
void release_storage(ipc::storage_id_t id, std::size_t size) {
|
| 200 |
+
if (id < 0) {
|
| 201 |
+
ipc::error("[release_storage] id is invalid: id = %ld, size = %zd\n", (long)id, size);
|
| 202 |
+
return;
|
| 203 |
+
}
|
| 204 |
+
std::size_t chunk_size = calc_chunk_size(size);
|
| 205 |
+
auto info = chunk_storage_info(chunk_size);
|
| 206 |
+
if (info == nullptr) return;
|
| 207 |
+
info->lock_.lock();
|
| 208 |
+
info->pool_.release(id);
|
| 209 |
+
info->lock_.unlock();
|
| 210 |
+
}
|
| 211 |
+
|
| 212 |
+
template <ipc::relat Rp, ipc::relat Rc>
|
| 213 |
+
bool sub_rc(ipc::wr<Rp, Rc, ipc::trans::unicast>,
|
| 214 |
+
std::atomic<ipc::circ::cc_t> &/*conns*/, ipc::circ::cc_t /*curr_conns*/, ipc::circ::cc_t /*conn_id*/) noexcept {
|
| 215 |
+
return true;
|
| 216 |
+
}
|
| 217 |
+
|
| 218 |
+
template <ipc::relat Rp, ipc::relat Rc>
|
| 219 |
+
bool sub_rc(ipc::wr<Rp, Rc, ipc::trans::broadcast>,
|
| 220 |
+
std::atomic<ipc::circ::cc_t> &conns, ipc::circ::cc_t curr_conns, ipc::circ::cc_t conn_id) noexcept {
|
| 221 |
+
auto last_conns = curr_conns & ~conn_id;
|
| 222 |
+
for (unsigned k = 0;;) {
|
| 223 |
+
auto chunk_conns = conns.load(std::memory_order_acquire);
|
| 224 |
+
if (conns.compare_exchange_weak(chunk_conns, chunk_conns & last_conns, std::memory_order_release)) {
|
| 225 |
+
return (chunk_conns & last_conns) == 0;
|
| 226 |
+
}
|
| 227 |
+
ipc::yield(k);
|
| 228 |
+
}
|
| 229 |
+
}
|
| 230 |
+
|
| 231 |
+
template <typename Flag>
|
| 232 |
+
void recycle_storage(ipc::storage_id_t id, std::size_t size, ipc::circ::cc_t curr_conns, ipc::circ::cc_t conn_id) {
|
| 233 |
+
if (id < 0) {
|
| 234 |
+
ipc::error("[recycle_storage] id is invalid: id = %ld, size = %zd\n", (long)id, size);
|
| 235 |
+
return;
|
| 236 |
+
}
|
| 237 |
+
std::size_t chunk_size = calc_chunk_size(size);
|
| 238 |
+
auto info = chunk_storage_info(chunk_size);
|
| 239 |
+
if (info == nullptr) return;
|
| 240 |
+
|
| 241 |
+
auto chunk = info->at(chunk_size, id);
|
| 242 |
+
if (chunk == nullptr) return;
|
| 243 |
+
|
| 244 |
+
if (!sub_rc(Flag{}, chunk->conns(), curr_conns, conn_id)) {
|
| 245 |
+
return;
|
| 246 |
+
}
|
| 247 |
+
info->lock_.lock();
|
| 248 |
+
info->pool_.release(id);
|
| 249 |
+
info->lock_.unlock();
|
| 250 |
+
}
|
| 251 |
+
|
| 252 |
+
template <typename MsgT>
|
| 253 |
+
bool clear_message(void* p) {
|
| 254 |
+
auto msg = static_cast<MsgT*>(p);
|
| 255 |
+
if (msg->storage_) {
|
| 256 |
+
std::int32_t r_size = static_cast<std::int32_t>(ipc::data_length) + msg->remain_;
|
| 257 |
+
if (r_size <= 0) {
|
| 258 |
+
ipc::error("[clear_message] invalid msg size: %d\n", (int)r_size);
|
| 259 |
+
return true;
|
| 260 |
+
}
|
| 261 |
+
release_storage(
|
| 262 |
+
*reinterpret_cast<ipc::storage_id_t*>(&msg->data_),
|
| 263 |
+
static_cast<std::size_t>(r_size));
|
| 264 |
+
}
|
| 265 |
+
return true;
|
| 266 |
+
}
|
| 267 |
+
|
| 268 |
+
struct conn_info_head {
|
| 269 |
+
|
| 270 |
+
ipc::string name_;
|
| 271 |
+
msg_id_t cc_id_; // connection-info id
|
| 272 |
+
ipc::detail::waiter cc_waiter_, wt_waiter_, rd_waiter_;
|
| 273 |
+
ipc::shm::handle acc_h_;
|
| 274 |
+
|
| 275 |
+
conn_info_head(char const * name)
|
| 276 |
+
: name_ {name}
|
| 277 |
+
, cc_id_ {(cc_acc() == nullptr) ? 0 : cc_acc()->fetch_add(1, std::memory_order_relaxed)}
|
| 278 |
+
, cc_waiter_{("__CC_CONN__" + name_).c_str()}
|
| 279 |
+
, wt_waiter_{("__WT_CONN__" + name_).c_str()}
|
| 280 |
+
, rd_waiter_{("__RD_CONN__" + name_).c_str()}
|
| 281 |
+
, acc_h_ {("__AC_CONN__" + name_).c_str(), sizeof(acc_t)} {
|
| 282 |
+
}
|
| 283 |
+
|
| 284 |
+
void quit_waiting() {
|
| 285 |
+
cc_waiter_.quit_waiting();
|
| 286 |
+
wt_waiter_.quit_waiting();
|
| 287 |
+
rd_waiter_.quit_waiting();
|
| 288 |
+
}
|
| 289 |
+
|
| 290 |
+
auto acc() {
|
| 291 |
+
return static_cast<acc_t*>(acc_h_.get());
|
| 292 |
+
}
|
| 293 |
+
|
| 294 |
+
auto& recv_cache() {
|
| 295 |
+
thread_local ipc::unordered_map<msg_id_t, cache_t> tls;
|
| 296 |
+
return tls;
|
| 297 |
+
}
|
| 298 |
+
};
|
| 299 |
+
|
| 300 |
+
template <typename W, typename F>
|
| 301 |
+
bool wait_for(W& waiter, F&& pred, std::uint64_t tm) {
|
| 302 |
+
if (tm == 0) return !pred();
|
| 303 |
+
for (unsigned k = 0; pred();) {
|
| 304 |
+
bool ret = true;
|
| 305 |
+
ipc::sleep(k, [&k, &ret, &waiter, &pred, tm] {
|
| 306 |
+
ret = waiter.wait_if(std::forward<F>(pred), tm);
|
| 307 |
+
k = 0;
|
| 308 |
+
});
|
| 309 |
+
if (!ret) return false; // timeout or fail
|
| 310 |
+
if (k == 0) break; // k has been reset
|
| 311 |
+
}
|
| 312 |
+
return true;
|
| 313 |
+
}
|
| 314 |
+
|
| 315 |
+
template <typename Policy,
|
| 316 |
+
std::size_t DataSize = ipc::data_length,
|
| 317 |
+
std::size_t AlignSize = (ipc::detail::min)(DataSize, alignof(std::max_align_t))>
|
| 318 |
+
struct queue_generator {
|
| 319 |
+
|
| 320 |
+
using queue_t = ipc::queue<msg_t<DataSize, AlignSize>, Policy>;
|
| 321 |
+
|
| 322 |
+
struct conn_info_t : conn_info_head {
|
| 323 |
+
queue_t que_;
|
| 324 |
+
|
| 325 |
+
conn_info_t(char const * name)
|
| 326 |
+
: conn_info_head{name}
|
| 327 |
+
, que_{("__QU_CONN__" +
|
| 328 |
+
ipc::to_string(DataSize) + "__" +
|
| 329 |
+
ipc::to_string(AlignSize) + "__" + name).c_str()} {
|
| 330 |
+
}
|
| 331 |
+
|
| 332 |
+
void disconnect_receiver() {
|
| 333 |
+
bool dis = que_.disconnect();
|
| 334 |
+
this->quit_waiting();
|
| 335 |
+
if (dis) {
|
| 336 |
+
this->recv_cache().clear();
|
| 337 |
+
}
|
| 338 |
+
}
|
| 339 |
+
};
|
| 340 |
+
};
|
| 341 |
+
|
| 342 |
+
template <typename Policy>
|
| 343 |
+
struct detail_impl {
|
| 344 |
+
|
| 345 |
+
using policy_t = Policy;
|
| 346 |
+
using flag_t = typename policy_t::flag_t;
|
| 347 |
+
using queue_t = typename queue_generator<policy_t>::queue_t;
|
| 348 |
+
using conn_info_t = typename queue_generator<policy_t>::conn_info_t;
|
| 349 |
+
|
| 350 |
+
constexpr static conn_info_t* info_of(ipc::handle_t h) noexcept {
|
| 351 |
+
return static_cast<conn_info_t*>(h);
|
| 352 |
+
}
|
| 353 |
+
|
| 354 |
+
constexpr static queue_t* queue_of(ipc::handle_t h) noexcept {
|
| 355 |
+
return (info_of(h) == nullptr) ? nullptr : &(info_of(h)->que_);
|
| 356 |
+
}
|
| 357 |
+
|
| 358 |
+
/* API implementations */
|
| 359 |
+
|
| 360 |
+
static void disconnect(ipc::handle_t h) {
|
| 361 |
+
auto que = queue_of(h);
|
| 362 |
+
if (que == nullptr) {
|
| 363 |
+
return;
|
| 364 |
+
}
|
| 365 |
+
que->shut_sending();
|
| 366 |
+
assert(info_of(h) != nullptr);
|
| 367 |
+
info_of(h)->disconnect_receiver();
|
| 368 |
+
}
|
| 369 |
+
|
| 370 |
+
static bool reconnect(ipc::handle_t * ph, bool start_to_recv) {
|
| 371 |
+
assert(ph != nullptr);
|
| 372 |
+
assert(*ph != nullptr);
|
| 373 |
+
auto que = queue_of(*ph);
|
| 374 |
+
if (que == nullptr) {
|
| 375 |
+
return false;
|
| 376 |
+
}
|
| 377 |
+
if (start_to_recv) {
|
| 378 |
+
que->shut_sending();
|
| 379 |
+
if (que->connect()) { // wouldn't connect twice
|
| 380 |
+
info_of(*ph)->cc_waiter_.broadcast();
|
| 381 |
+
return true;
|
| 382 |
+
}
|
| 383 |
+
return false;
|
| 384 |
+
}
|
| 385 |
+
// start_to_recv == false
|
| 386 |
+
if (que->connected()) {
|
| 387 |
+
info_of(*ph)->disconnect_receiver();
|
| 388 |
+
}
|
| 389 |
+
return que->ready_sending();
|
| 390 |
+
}
|
| 391 |
+
|
| 392 |
+
static bool connect(ipc::handle_t * ph, char const * name, bool start_to_recv) {
|
| 393 |
+
assert(ph != nullptr);
|
| 394 |
+
if (*ph == nullptr) {
|
| 395 |
+
*ph = ipc::mem::alloc<conn_info_t>(name);
|
| 396 |
+
}
|
| 397 |
+
return reconnect(ph, start_to_recv);
|
| 398 |
+
}
|
| 399 |
+
|
| 400 |
+
static void destroy(ipc::handle_t h) {
|
| 401 |
+
disconnect(h);
|
| 402 |
+
ipc::mem::free(info_of(h));
|
| 403 |
+
}
|
| 404 |
+
|
| 405 |
+
static std::size_t recv_count(ipc::handle_t h) noexcept {
|
| 406 |
+
auto que = queue_of(h);
|
| 407 |
+
if (que == nullptr) {
|
| 408 |
+
return ipc::invalid_value;
|
| 409 |
+
}
|
| 410 |
+
return que->conn_count();
|
| 411 |
+
}
|
| 412 |
+
|
| 413 |
+
static bool wait_for_recv(ipc::handle_t h, std::size_t r_count, std::uint64_t tm) {
|
| 414 |
+
auto que = queue_of(h);
|
| 415 |
+
if (que == nullptr) {
|
| 416 |
+
return false;
|
| 417 |
+
}
|
| 418 |
+
return wait_for(info_of(h)->cc_waiter_, [que, r_count] {
|
| 419 |
+
return que->conn_count() < r_count;
|
| 420 |
+
}, tm);
|
| 421 |
+
}
|
| 422 |
+
|
| 423 |
+
template <typename F>
|
| 424 |
+
static bool send(F&& gen_push, ipc::handle_t h, void const * data, std::size_t size) {
|
| 425 |
+
if (data == nullptr || size == 0) {
|
| 426 |
+
ipc::error("fail: send(%p, %zd)\n", data, size);
|
| 427 |
+
return false;
|
| 428 |
+
}
|
| 429 |
+
auto que = queue_of(h);
|
| 430 |
+
if (que == nullptr) {
|
| 431 |
+
ipc::error("fail: send, queue_of(h) == nullptr\n");
|
| 432 |
+
return false;
|
| 433 |
+
}
|
| 434 |
+
if (que->elems() == nullptr) {
|
| 435 |
+
ipc::error("fail: send, queue_of(h)->elems() == nullptr\n");
|
| 436 |
+
return false;
|
| 437 |
+
}
|
| 438 |
+
if (!que->ready_sending()) {
|
| 439 |
+
ipc::error("fail: send, que->ready_sending() == false\n");
|
| 440 |
+
return false;
|
| 441 |
+
}
|
| 442 |
+
ipc::circ::cc_t conns = que->elems()->connections(std::memory_order_relaxed);
|
| 443 |
+
if (conns == 0) {
|
| 444 |
+
ipc::error("fail: send, there is no receiver on this connection.\n");
|
| 445 |
+
return false;
|
| 446 |
+
}
|
| 447 |
+
// calc a new message id
|
| 448 |
+
auto acc = info_of(h)->acc();
|
| 449 |
+
if (acc == nullptr) {
|
| 450 |
+
ipc::error("fail: send, info_of(h)->acc() == nullptr\n");
|
| 451 |
+
return false;
|
| 452 |
+
}
|
| 453 |
+
auto msg_id = acc->fetch_add(1, std::memory_order_relaxed);
|
| 454 |
+
auto try_push = std::forward<F>(gen_push)(info_of(h), que, msg_id);
|
| 455 |
+
if (size > ipc::large_msg_limit) {
|
| 456 |
+
auto dat = acquire_storage(size, conns);
|
| 457 |
+
void * buf = dat.second;
|
| 458 |
+
if (buf != nullptr) {
|
| 459 |
+
std::memcpy(buf, data, size);
|
| 460 |
+
return try_push(static_cast<std::int32_t>(size) -
|
| 461 |
+
static_cast<std::int32_t>(ipc::data_length), &(dat.first), 0);
|
| 462 |
+
}
|
| 463 |
+
// try using message fragment
|
| 464 |
+
//ipc::log("fail: shm::handle for big message. msg_id: %zd, size: %zd\n", msg_id, size);
|
| 465 |
+
}
|
| 466 |
+
// push message fragment
|
| 467 |
+
std::int32_t offset = 0;
|
| 468 |
+
for (std::int32_t i = 0; i < static_cast<std::int32_t>(size / ipc::data_length); ++i, offset += ipc::data_length) {
|
| 469 |
+
if (!try_push(static_cast<std::int32_t>(size) - offset - static_cast<std::int32_t>(ipc::data_length),
|
| 470 |
+
static_cast<ipc::byte_t const *>(data) + offset, ipc::data_length)) {
|
| 471 |
+
return false;
|
| 472 |
+
}
|
| 473 |
+
}
|
| 474 |
+
// if remain > 0, this is the last message fragment
|
| 475 |
+
std::int32_t remain = static_cast<std::int32_t>(size) - offset;
|
| 476 |
+
if (remain > 0) {
|
| 477 |
+
if (!try_push(remain - static_cast<std::int32_t>(ipc::data_length),
|
| 478 |
+
static_cast<ipc::byte_t const *>(data) + offset,
|
| 479 |
+
static_cast<std::size_t>(remain))) {
|
| 480 |
+
return false;
|
| 481 |
+
}
|
| 482 |
+
}
|
| 483 |
+
return true;
|
| 484 |
+
}
|
| 485 |
+
|
| 486 |
+
static bool send(ipc::handle_t h, void const * data, std::size_t size, std::uint64_t tm) {
|
| 487 |
+
return send([tm](auto info, auto que, auto msg_id) {
|
| 488 |
+
return [tm, info, que, msg_id](std::int32_t remain, void const * data, std::size_t size) {
|
| 489 |
+
if (!wait_for(info->wt_waiter_, [&] {
|
| 490 |
+
return !que->push(
|
| 491 |
+
[](void*) { return true; },
|
| 492 |
+
info->cc_id_, msg_id, remain, data, size);
|
| 493 |
+
}, tm)) {
|
| 494 |
+
ipc::log("force_push: msg_id = %zd, remain = %d, size = %zd\n", msg_id, remain, size);
|
| 495 |
+
if (!que->force_push(
|
| 496 |
+
clear_message<typename queue_t::value_t>,
|
| 497 |
+
info->cc_id_, msg_id, remain, data, size)) {
|
| 498 |
+
return false;
|
| 499 |
+
}
|
| 500 |
+
}
|
| 501 |
+
info->rd_waiter_.broadcast();
|
| 502 |
+
return true;
|
| 503 |
+
};
|
| 504 |
+
}, h, data, size);
|
| 505 |
+
}
|
| 506 |
+
|
| 507 |
+
static bool try_send(ipc::handle_t h, void const * data, std::size_t size, std::uint64_t tm) {
|
| 508 |
+
return send([tm](auto info, auto que, auto msg_id) {
|
| 509 |
+
return [tm, info, que, msg_id](std::int32_t remain, void const * data, std::size_t size) {
|
| 510 |
+
if (!wait_for(info->wt_waiter_, [&] {
|
| 511 |
+
return !que->push(
|
| 512 |
+
[](void*) { return true; },
|
| 513 |
+
info->cc_id_, msg_id, remain, data, size);
|
| 514 |
+
}, tm)) {
|
| 515 |
+
return false;
|
| 516 |
+
}
|
| 517 |
+
info->rd_waiter_.broadcast();
|
| 518 |
+
return true;
|
| 519 |
+
};
|
| 520 |
+
}, h, data, size);
|
| 521 |
+
}
|
| 522 |
+
|
| 523 |
+
static ipc::buff_t recv(ipc::handle_t h, std::uint64_t tm) {
|
| 524 |
+
auto que = queue_of(h);
|
| 525 |
+
if (que == nullptr) {
|
| 526 |
+
ipc::error("fail: recv, queue_of(h) == nullptr\n");
|
| 527 |
+
return {};
|
| 528 |
+
}
|
| 529 |
+
if (!que->connected()) {
|
| 530 |
+
// hasn't connected yet, just return.
|
| 531 |
+
return {};
|
| 532 |
+
}
|
| 533 |
+
auto& rc = info_of(h)->recv_cache();
|
| 534 |
+
for (;;) {
|
| 535 |
+
// pop a new message
|
| 536 |
+
typename queue_t::value_t msg;
|
| 537 |
+
if (!wait_for(info_of(h)->rd_waiter_, [que, &msg] {
|
| 538 |
+
return !que->pop(msg);
|
| 539 |
+
}, tm)) {
|
| 540 |
+
// pop failed, just return.
|
| 541 |
+
return {};
|
| 542 |
+
}
|
| 543 |
+
info_of(h)->wt_waiter_.broadcast();
|
| 544 |
+
if ((info_of(h)->acc() != nullptr) && (msg.cc_id_ == info_of(h)->cc_id_)) {
|
| 545 |
+
continue; // ignore message to self
|
| 546 |
+
}
|
| 547 |
+
// msg.remain_ may minus & abs(msg.remain_) < data_length
|
| 548 |
+
std::int32_t r_size = static_cast<std::int32_t>(ipc::data_length) + msg.remain_;
|
| 549 |
+
if (r_size <= 0) {
|
| 550 |
+
ipc::error("fail: recv, r_size = %d\n", (int)r_size);
|
| 551 |
+
return {};
|
| 552 |
+
}
|
| 553 |
+
std::size_t msg_size = static_cast<std::size_t>(r_size);
|
| 554 |
+
// large message
|
| 555 |
+
if (msg.storage_) {
|
| 556 |
+
ipc::storage_id_t buf_id = *reinterpret_cast<ipc::storage_id_t*>(&msg.data_);
|
| 557 |
+
void* buf = find_storage(buf_id, msg_size);
|
| 558 |
+
if (buf != nullptr) {
|
| 559 |
+
struct recycle_t {
|
| 560 |
+
ipc::storage_id_t storage_id;
|
| 561 |
+
ipc::circ::cc_t curr_conns;
|
| 562 |
+
ipc::circ::cc_t conn_id;
|
| 563 |
+
} *r_info = ipc::mem::alloc<recycle_t>(recycle_t{
|
| 564 |
+
buf_id, que->elems()->connections(std::memory_order_relaxed), que->connected_id()
|
| 565 |
+
});
|
| 566 |
+
if (r_info == nullptr) {
|
| 567 |
+
ipc::log("fail: ipc::mem::alloc<recycle_t>.\n");
|
| 568 |
+
return ipc::buff_t{buf, msg_size}; // no recycle
|
| 569 |
+
} else {
|
| 570 |
+
return ipc::buff_t{buf, msg_size, [](void* p_info, std::size_t size) {
|
| 571 |
+
auto r_info = static_cast<recycle_t *>(p_info);
|
| 572 |
+
IPC_UNUSED_ auto finally = ipc::guard([r_info] {
|
| 573 |
+
ipc::mem::free(r_info);
|
| 574 |
+
});
|
| 575 |
+
recycle_storage<flag_t>(r_info->storage_id, size, r_info->curr_conns, r_info->conn_id);
|
| 576 |
+
}, r_info};
|
| 577 |
+
}
|
| 578 |
+
} else {
|
| 579 |
+
ipc::log("fail: shm::handle for large message. msg_id: %zd, buf_id: %zd, size: %zd\n", msg.id_, buf_id, msg_size);
|
| 580 |
+
continue;
|
| 581 |
+
}
|
| 582 |
+
}
|
| 583 |
+
// find cache with msg.id_
|
| 584 |
+
auto cac_it = rc.find(msg.id_);
|
| 585 |
+
if (cac_it == rc.end()) {
|
| 586 |
+
if (msg_size <= ipc::data_length) {
|
| 587 |
+
return make_cache(msg.data_, msg_size);
|
| 588 |
+
}
|
| 589 |
+
// gc
|
| 590 |
+
if (rc.size() > 1024) {
|
| 591 |
+
std::vector<msg_id_t> need_del;
|
| 592 |
+
for (auto const & pair : rc) {
|
| 593 |
+
auto cmp = std::minmax(msg.id_, pair.first);
|
| 594 |
+
if (cmp.second - cmp.first > 8192) {
|
| 595 |
+
need_del.push_back(pair.first);
|
| 596 |
+
}
|
| 597 |
+
}
|
| 598 |
+
for (auto id : need_del) rc.erase(id);
|
| 599 |
+
}
|
| 600 |
+
// cache the first message fragment
|
| 601 |
+
rc.emplace(msg.id_, cache_t { ipc::data_length, make_cache(msg.data_, msg_size) });
|
| 602 |
+
}
|
| 603 |
+
// has cached before this message
|
| 604 |
+
else {
|
| 605 |
+
auto& cac = cac_it->second;
|
| 606 |
+
// this is the last message fragment
|
| 607 |
+
if (msg.remain_ <= 0) {
|
| 608 |
+
cac.append(&(msg.data_), msg_size);
|
| 609 |
+
// finish this message, erase it from cache
|
| 610 |
+
auto buff = std::move(cac.buff_);
|
| 611 |
+
rc.erase(cac_it);
|
| 612 |
+
return buff;
|
| 613 |
+
}
|
| 614 |
+
// there are remain datas after this message
|
| 615 |
+
cac.append(&(msg.data_), ipc::data_length);
|
| 616 |
+
}
|
| 617 |
+
}
|
| 618 |
+
}
|
| 619 |
+
|
| 620 |
+
static ipc::buff_t try_recv(ipc::handle_t h) {
|
| 621 |
+
return recv(h, 0);
|
| 622 |
+
}
|
| 623 |
+
|
| 624 |
+
}; // detail_impl<Policy>
|
| 625 |
+
|
| 626 |
+
template <typename Flag>
|
| 627 |
+
using policy_t = ipc::policy::choose<ipc::circ::elem_array, Flag>;
|
| 628 |
+
|
| 629 |
+
} // internal-linkage
|
| 630 |
+
|
| 631 |
+
namespace ipc {
|
| 632 |
+
|
| 633 |
+
template <typename Flag>
|
| 634 |
+
ipc::handle_t chan_impl<Flag>::inited() {
|
| 635 |
+
ipc::detail::waiter::init();
|
| 636 |
+
return nullptr;
|
| 637 |
+
}
|
| 638 |
+
|
| 639 |
+
template <typename Flag>
|
| 640 |
+
bool chan_impl<Flag>::connect(ipc::handle_t * ph, char const * name, unsigned mode) {
|
| 641 |
+
return detail_impl<policy_t<Flag>>::connect(ph, name, mode & receiver);
|
| 642 |
+
}
|
| 643 |
+
|
| 644 |
+
template <typename Flag>
|
| 645 |
+
bool chan_impl<Flag>::reconnect(ipc::handle_t * ph, unsigned mode) {
|
| 646 |
+
return detail_impl<policy_t<Flag>>::reconnect(ph, mode & receiver);
|
| 647 |
+
}
|
| 648 |
+
|
| 649 |
+
template <typename Flag>
|
| 650 |
+
void chan_impl<Flag>::disconnect(ipc::handle_t h) {
|
| 651 |
+
detail_impl<policy_t<Flag>>::disconnect(h);
|
| 652 |
+
}
|
| 653 |
+
|
| 654 |
+
template <typename Flag>
|
| 655 |
+
void chan_impl<Flag>::destroy(ipc::handle_t h) {
|
| 656 |
+
detail_impl<policy_t<Flag>>::destroy(h);
|
| 657 |
+
}
|
| 658 |
+
|
| 659 |
+
template <typename Flag>
|
| 660 |
+
char const * chan_impl<Flag>::name(ipc::handle_t h) {
|
| 661 |
+
auto info = detail_impl<policy_t<Flag>>::info_of(h);
|
| 662 |
+
return (info == nullptr) ? nullptr : info->name_.c_str();
|
| 663 |
+
}
|
| 664 |
+
|
| 665 |
+
template <typename Flag>
|
| 666 |
+
std::size_t chan_impl<Flag>::recv_count(ipc::handle_t h) {
|
| 667 |
+
return detail_impl<policy_t<Flag>>::recv_count(h);
|
| 668 |
+
}
|
| 669 |
+
|
| 670 |
+
template <typename Flag>
|
| 671 |
+
bool chan_impl<Flag>::wait_for_recv(ipc::handle_t h, std::size_t r_count, std::uint64_t tm) {
|
| 672 |
+
return detail_impl<policy_t<Flag>>::wait_for_recv(h, r_count, tm);
|
| 673 |
+
}
|
| 674 |
+
|
| 675 |
+
template <typename Flag>
|
| 676 |
+
bool chan_impl<Flag>::send(ipc::handle_t h, void const * data, std::size_t size, std::uint64_t tm) {
|
| 677 |
+
return detail_impl<policy_t<Flag>>::send(h, data, size, tm);
|
| 678 |
+
}
|
| 679 |
+
|
| 680 |
+
template <typename Flag>
|
| 681 |
+
buff_t chan_impl<Flag>::recv(ipc::handle_t h, std::uint64_t tm) {
|
| 682 |
+
return detail_impl<policy_t<Flag>>::recv(h, tm);
|
| 683 |
+
}
|
| 684 |
+
|
| 685 |
+
template <typename Flag>
|
| 686 |
+
bool chan_impl<Flag>::try_send(ipc::handle_t h, void const * data, std::size_t size, std::uint64_t tm) {
|
| 687 |
+
return detail_impl<policy_t<Flag>>::try_send(h, data, size, tm);
|
| 688 |
+
}
|
| 689 |
+
|
| 690 |
+
template <typename Flag>
|
| 691 |
+
buff_t chan_impl<Flag>::try_recv(ipc::handle_t h) {
|
| 692 |
+
return detail_impl<policy_t<Flag>>::try_recv(h);
|
| 693 |
+
}
|
| 694 |
+
|
| 695 |
+
template struct chan_impl<ipc::wr<relat::single, relat::single, trans::unicast >>;
|
| 696 |
+
// template struct chan_impl<ipc::wr<relat::single, relat::multi , trans::unicast >>; // TBD
|
| 697 |
+
// template struct chan_impl<ipc::wr<relat::multi , relat::multi , trans::unicast >>; // TBD
|
| 698 |
+
template struct chan_impl<ipc::wr<relat::single, relat::multi , trans::broadcast>>;
|
| 699 |
+
template struct chan_impl<ipc::wr<relat::multi , relat::multi , trans::broadcast>>;
|
| 700 |
+
|
| 701 |
+
} // namespace ipc
|
crazy_functions/test_project/cpp/cppipc/policy.h
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#pragma once
|
| 2 |
+
|
| 3 |
+
#include <type_traits>
|
| 4 |
+
|
| 5 |
+
#include "libipc/def.h"
|
| 6 |
+
#include "libipc/prod_cons.h"
|
| 7 |
+
|
| 8 |
+
#include "libipc/circ/elem_array.h"
|
| 9 |
+
|
| 10 |
+
namespace ipc {
|
| 11 |
+
namespace policy {
|
| 12 |
+
|
| 13 |
+
template <template <typename, std::size_t...> class Elems, typename Flag>
|
| 14 |
+
struct choose;
|
| 15 |
+
|
| 16 |
+
template <typename Flag>
|
| 17 |
+
struct choose<circ::elem_array, Flag> {
|
| 18 |
+
using flag_t = Flag;
|
| 19 |
+
|
| 20 |
+
template <std::size_t DataSize, std::size_t AlignSize>
|
| 21 |
+
using elems_t = circ::elem_array<ipc::prod_cons_impl<flag_t>, DataSize, AlignSize>;
|
| 22 |
+
};
|
| 23 |
+
|
| 24 |
+
} // namespace policy
|
| 25 |
+
} // namespace ipc
|
crazy_functions/test_project/cpp/cppipc/pool_alloc.cpp
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#include "libipc/pool_alloc.h"
|
| 2 |
+
|
| 3 |
+
#include "libipc/memory/resource.h"
|
| 4 |
+
|
| 5 |
+
namespace ipc {
|
| 6 |
+
namespace mem {
|
| 7 |
+
|
| 8 |
+
void* pool_alloc::alloc(std::size_t size) {
|
| 9 |
+
return async_pool_alloc::alloc(size);
|
| 10 |
+
}
|
| 11 |
+
|
| 12 |
+
void pool_alloc::free(void* p, std::size_t size) {
|
| 13 |
+
async_pool_alloc::free(p, size);
|
| 14 |
+
}
|
| 15 |
+
|
| 16 |
+
} // namespace mem
|
| 17 |
+
} // namespace ipc
|
crazy_functions/test_project/cpp/cppipc/prod_cons.h
ADDED
|
@@ -0,0 +1,433 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#pragma once
|
| 2 |
+
|
| 3 |
+
#include <atomic>
|
| 4 |
+
#include <utility>
|
| 5 |
+
#include <cstring>
|
| 6 |
+
#include <type_traits>
|
| 7 |
+
#include <cstdint>
|
| 8 |
+
|
| 9 |
+
#include "libipc/def.h"
|
| 10 |
+
|
| 11 |
+
#include "libipc/platform/detail.h"
|
| 12 |
+
#include "libipc/circ/elem_def.h"
|
| 13 |
+
#include "libipc/utility/log.h"
|
| 14 |
+
#include "libipc/utility/utility.h"
|
| 15 |
+
|
| 16 |
+
namespace ipc {
|
| 17 |
+
|
| 18 |
+
////////////////////////////////////////////////////////////////
|
| 19 |
+
/// producer-consumer implementation
|
| 20 |
+
////////////////////////////////////////////////////////////////
|
| 21 |
+
|
| 22 |
+
template <typename Flag>
|
| 23 |
+
struct prod_cons_impl;
|
| 24 |
+
|
| 25 |
+
template <>
|
| 26 |
+
struct prod_cons_impl<wr<relat::single, relat::single, trans::unicast>> {
|
| 27 |
+
|
| 28 |
+
template <std::size_t DataSize, std::size_t AlignSize>
|
| 29 |
+
struct elem_t {
|
| 30 |
+
std::aligned_storage_t<DataSize, AlignSize> data_ {};
|
| 31 |
+
};
|
| 32 |
+
|
| 33 |
+
alignas(cache_line_size) std::atomic<circ::u2_t> rd_; // read index
|
| 34 |
+
alignas(cache_line_size) std::atomic<circ::u2_t> wt_; // write index
|
| 35 |
+
|
| 36 |
+
constexpr circ::u2_t cursor() const noexcept {
|
| 37 |
+
return 0;
|
| 38 |
+
}
|
| 39 |
+
|
| 40 |
+
template <typename W, typename F, typename E>
|
| 41 |
+
bool push(W* /*wrapper*/, F&& f, E* elems) {
|
| 42 |
+
auto cur_wt = circ::index_of(wt_.load(std::memory_order_relaxed));
|
| 43 |
+
if (cur_wt == circ::index_of(rd_.load(std::memory_order_acquire) - 1)) {
|
| 44 |
+
return false; // full
|
| 45 |
+
}
|
| 46 |
+
std::forward<F>(f)(&(elems[cur_wt].data_));
|
| 47 |
+
wt_.fetch_add(1, std::memory_order_release);
|
| 48 |
+
return true;
|
| 49 |
+
}
|
| 50 |
+
|
| 51 |
+
/**
|
| 52 |
+
* In single-single-unicast, 'force_push' means 'no reader' or 'the only one reader is dead'.
|
| 53 |
+
* So we could just disconnect all connections of receiver, and return false.
|
| 54 |
+
*/
|
| 55 |
+
template <typename W, typename F, typename E>
|
| 56 |
+
bool force_push(W* wrapper, F&&, E*) {
|
| 57 |
+
wrapper->elems()->disconnect_receiver(~static_cast<circ::cc_t>(0u));
|
| 58 |
+
return false;
|
| 59 |
+
}
|
| 60 |
+
|
| 61 |
+
template <typename W, typename F, typename R, typename E>
|
| 62 |
+
bool pop(W* /*wrapper*/, circ::u2_t& /*cur*/, F&& f, R&& out, E* elems) {
|
| 63 |
+
auto cur_rd = circ::index_of(rd_.load(std::memory_order_relaxed));
|
| 64 |
+
if (cur_rd == circ::index_of(wt_.load(std::memory_order_acquire))) {
|
| 65 |
+
return false; // empty
|
| 66 |
+
}
|
| 67 |
+
std::forward<F>(f)(&(elems[cur_rd].data_));
|
| 68 |
+
std::forward<R>(out)(true);
|
| 69 |
+
rd_.fetch_add(1, std::memory_order_release);
|
| 70 |
+
return true;
|
| 71 |
+
}
|
| 72 |
+
};
|
| 73 |
+
|
| 74 |
+
template <>
|
| 75 |
+
struct prod_cons_impl<wr<relat::single, relat::multi , trans::unicast>>
|
| 76 |
+
: prod_cons_impl<wr<relat::single, relat::single, trans::unicast>> {
|
| 77 |
+
|
| 78 |
+
template <typename W, typename F, typename E>
|
| 79 |
+
bool force_push(W* wrapper, F&&, E*) {
|
| 80 |
+
wrapper->elems()->disconnect_receiver(1);
|
| 81 |
+
return false;
|
| 82 |
+
}
|
| 83 |
+
|
| 84 |
+
template <typename W, typename F, typename R,
|
| 85 |
+
template <std::size_t, std::size_t> class E, std::size_t DS, std::size_t AS>
|
| 86 |
+
bool pop(W* /*wrapper*/, circ::u2_t& /*cur*/, F&& f, R&& out, E<DS, AS>* elems) {
|
| 87 |
+
byte_t buff[DS];
|
| 88 |
+
for (unsigned k = 0;;) {
|
| 89 |
+
auto cur_rd = rd_.load(std::memory_order_relaxed);
|
| 90 |
+
if (circ::index_of(cur_rd) ==
|
| 91 |
+
circ::index_of(wt_.load(std::memory_order_acquire))) {
|
| 92 |
+
return false; // empty
|
| 93 |
+
}
|
| 94 |
+
std::memcpy(buff, &(elems[circ::index_of(cur_rd)].data_), sizeof(buff));
|
| 95 |
+
if (rd_.compare_exchange_weak(cur_rd, cur_rd + 1, std::memory_order_release)) {
|
| 96 |
+
std::forward<F>(f)(buff);
|
| 97 |
+
std::forward<R>(out)(true);
|
| 98 |
+
return true;
|
| 99 |
+
}
|
| 100 |
+
ipc::yield(k);
|
| 101 |
+
}
|
| 102 |
+
}
|
| 103 |
+
};
|
| 104 |
+
|
| 105 |
+
template <>
|
| 106 |
+
struct prod_cons_impl<wr<relat::multi , relat::multi, trans::unicast>>
|
| 107 |
+
: prod_cons_impl<wr<relat::single, relat::multi, trans::unicast>> {
|
| 108 |
+
|
| 109 |
+
using flag_t = std::uint64_t;
|
| 110 |
+
|
| 111 |
+
template <std::size_t DataSize, std::size_t AlignSize>
|
| 112 |
+
struct elem_t {
|
| 113 |
+
std::aligned_storage_t<DataSize, AlignSize> data_ {};
|
| 114 |
+
std::atomic<flag_t> f_ct_ { 0 }; // commit flag
|
| 115 |
+
};
|
| 116 |
+
|
| 117 |
+
alignas(cache_line_size) std::atomic<circ::u2_t> ct_; // commit index
|
| 118 |
+
|
| 119 |
+
template <typename W, typename F, typename E>
|
| 120 |
+
bool push(W* /*wrapper*/, F&& f, E* elems) {
|
| 121 |
+
circ::u2_t cur_ct, nxt_ct;
|
| 122 |
+
for (unsigned k = 0;;) {
|
| 123 |
+
cur_ct = ct_.load(std::memory_order_relaxed);
|
| 124 |
+
if (circ::index_of(nxt_ct = cur_ct + 1) ==
|
| 125 |
+
circ::index_of(rd_.load(std::memory_order_acquire))) {
|
| 126 |
+
return false; // full
|
| 127 |
+
}
|
| 128 |
+
if (ct_.compare_exchange_weak(cur_ct, nxt_ct, std::memory_order_acq_rel)) {
|
| 129 |
+
break;
|
| 130 |
+
}
|
| 131 |
+
ipc::yield(k);
|
| 132 |
+
}
|
| 133 |
+
auto* el = elems + circ::index_of(cur_ct);
|
| 134 |
+
std::forward<F>(f)(&(el->data_));
|
| 135 |
+
// set flag & try update wt
|
| 136 |
+
el->f_ct_.store(~static_cast<flag_t>(cur_ct), std::memory_order_release);
|
| 137 |
+
while (1) {
|
| 138 |
+
auto cac_ct = el->f_ct_.load(std::memory_order_acquire);
|
| 139 |
+
if (cur_ct != wt_.load(std::memory_order_relaxed)) {
|
| 140 |
+
return true;
|
| 141 |
+
}
|
| 142 |
+
if ((~cac_ct) != cur_ct) {
|
| 143 |
+
return true;
|
| 144 |
+
}
|
| 145 |
+
if (!el->f_ct_.compare_exchange_strong(cac_ct, 0, std::memory_order_relaxed)) {
|
| 146 |
+
return true;
|
| 147 |
+
}
|
| 148 |
+
wt_.store(nxt_ct, std::memory_order_release);
|
| 149 |
+
cur_ct = nxt_ct;
|
| 150 |
+
nxt_ct = cur_ct + 1;
|
| 151 |
+
el = elems + circ::index_of(cur_ct);
|
| 152 |
+
}
|
| 153 |
+
return true;
|
| 154 |
+
}
|
| 155 |
+
|
| 156 |
+
template <typename W, typename F, typename E>
|
| 157 |
+
bool force_push(W* wrapper, F&&, E*) {
|
| 158 |
+
wrapper->elems()->disconnect_receiver(1);
|
| 159 |
+
return false;
|
| 160 |
+
}
|
| 161 |
+
|
| 162 |
+
template <typename W, typename F, typename R,
|
| 163 |
+
template <std::size_t, std::size_t> class E, std::size_t DS, std::size_t AS>
|
| 164 |
+
bool pop(W* /*wrapper*/, circ::u2_t& /*cur*/, F&& f, R&& out, E<DS, AS>* elems) {
|
| 165 |
+
byte_t buff[DS];
|
| 166 |
+
for (unsigned k = 0;;) {
|
| 167 |
+
auto cur_rd = rd_.load(std::memory_order_relaxed);
|
| 168 |
+
auto cur_wt = wt_.load(std::memory_order_acquire);
|
| 169 |
+
auto id_rd = circ::index_of(cur_rd);
|
| 170 |
+
auto id_wt = circ::index_of(cur_wt);
|
| 171 |
+
if (id_rd == id_wt) {
|
| 172 |
+
auto* el = elems + id_wt;
|
| 173 |
+
auto cac_ct = el->f_ct_.load(std::memory_order_acquire);
|
| 174 |
+
if ((~cac_ct) != cur_wt) {
|
| 175 |
+
return false; // empty
|
| 176 |
+
}
|
| 177 |
+
if (el->f_ct_.compare_exchange_weak(cac_ct, 0, std::memory_order_relaxed)) {
|
| 178 |
+
wt_.store(cur_wt + 1, std::memory_order_release);
|
| 179 |
+
}
|
| 180 |
+
k = 0;
|
| 181 |
+
}
|
| 182 |
+
else {
|
| 183 |
+
std::memcpy(buff, &(elems[circ::index_of(cur_rd)].data_), sizeof(buff));
|
| 184 |
+
if (rd_.compare_exchange_weak(cur_rd, cur_rd + 1, std::memory_order_release)) {
|
| 185 |
+
std::forward<F>(f)(buff);
|
| 186 |
+
std::forward<R>(out)(true);
|
| 187 |
+
return true;
|
| 188 |
+
}
|
| 189 |
+
ipc::yield(k);
|
| 190 |
+
}
|
| 191 |
+
}
|
| 192 |
+
}
|
| 193 |
+
};
|
| 194 |
+
|
| 195 |
+
template <>
|
| 196 |
+
struct prod_cons_impl<wr<relat::single, relat::multi, trans::broadcast>> {
|
| 197 |
+
|
| 198 |
+
using rc_t = std::uint64_t;
|
| 199 |
+
|
| 200 |
+
enum : rc_t {
|
| 201 |
+
ep_mask = 0x00000000ffffffffull,
|
| 202 |
+
ep_incr = 0x0000000100000000ull
|
| 203 |
+
};
|
| 204 |
+
|
| 205 |
+
template <std::size_t DataSize, std::size_t AlignSize>
|
| 206 |
+
struct elem_t {
|
| 207 |
+
std::aligned_storage_t<DataSize, AlignSize> data_ {};
|
| 208 |
+
std::atomic<rc_t> rc_ { 0 }; // read-counter
|
| 209 |
+
};
|
| 210 |
+
|
| 211 |
+
alignas(cache_line_size) std::atomic<circ::u2_t> wt_; // write index
|
| 212 |
+
alignas(cache_line_size) rc_t epoch_ { 0 }; // only one writer
|
| 213 |
+
|
| 214 |
+
circ::u2_t cursor() const noexcept {
|
| 215 |
+
return wt_.load(std::memory_order_acquire);
|
| 216 |
+
}
|
| 217 |
+
|
| 218 |
+
template <typename W, typename F, typename E>
|
| 219 |
+
bool push(W* wrapper, F&& f, E* elems) {
|
| 220 |
+
E* el;
|
| 221 |
+
for (unsigned k = 0;;) {
|
| 222 |
+
circ::cc_t cc = wrapper->elems()->connections(std::memory_order_relaxed);
|
| 223 |
+
if (cc == 0) return false; // no reader
|
| 224 |
+
el = elems + circ::index_of(wt_.load(std::memory_order_relaxed));
|
| 225 |
+
// check all consumers have finished reading this element
|
| 226 |
+
auto cur_rc = el->rc_.load(std::memory_order_acquire);
|
| 227 |
+
circ::cc_t rem_cc = cur_rc & ep_mask;
|
| 228 |
+
if ((cc & rem_cc) && ((cur_rc & ~ep_mask) == epoch_)) {
|
| 229 |
+
return false; // has not finished yet
|
| 230 |
+
}
|
| 231 |
+
// consider rem_cc to be 0 here
|
| 232 |
+
if (el->rc_.compare_exchange_weak(
|
| 233 |
+
cur_rc, epoch_ | static_cast<rc_t>(cc), std::memory_order_release)) {
|
| 234 |
+
break;
|
| 235 |
+
}
|
| 236 |
+
ipc::yield(k);
|
| 237 |
+
}
|
| 238 |
+
std::forward<F>(f)(&(el->data_));
|
| 239 |
+
wt_.fetch_add(1, std::memory_order_release);
|
| 240 |
+
return true;
|
| 241 |
+
}
|
| 242 |
+
|
| 243 |
+
template <typename W, typename F, typename E>
|
| 244 |
+
bool force_push(W* wrapper, F&& f, E* elems) {
|
| 245 |
+
E* el;
|
| 246 |
+
epoch_ += ep_incr;
|
| 247 |
+
for (unsigned k = 0;;) {
|
| 248 |
+
circ::cc_t cc = wrapper->elems()->connections(std::memory_order_relaxed);
|
| 249 |
+
if (cc == 0) return false; // no reader
|
| 250 |
+
el = elems + circ::index_of(wt_.load(std::memory_order_relaxed));
|
| 251 |
+
// check all consumers have finished reading this element
|
| 252 |
+
auto cur_rc = el->rc_.load(std::memory_order_acquire);
|
| 253 |
+
circ::cc_t rem_cc = cur_rc & ep_mask;
|
| 254 |
+
if (cc & rem_cc) {
|
| 255 |
+
ipc::log("force_push: k = %u, cc = %u, rem_cc = %u\n", k, cc, rem_cc);
|
| 256 |
+
cc = wrapper->elems()->disconnect_receiver(rem_cc); // disconnect all invalid readers
|
| 257 |
+
if (cc == 0) return false; // no reader
|
| 258 |
+
}
|
| 259 |
+
// just compare & exchange
|
| 260 |
+
if (el->rc_.compare_exchange_weak(
|
| 261 |
+
cur_rc, epoch_ | static_cast<rc_t>(cc), std::memory_order_release)) {
|
| 262 |
+
break;
|
| 263 |
+
}
|
| 264 |
+
ipc::yield(k);
|
| 265 |
+
}
|
| 266 |
+
std::forward<F>(f)(&(el->data_));
|
| 267 |
+
wt_.fetch_add(1, std::memory_order_release);
|
| 268 |
+
return true;
|
| 269 |
+
}
|
| 270 |
+
|
| 271 |
+
template <typename W, typename F, typename R, typename E>
|
| 272 |
+
bool pop(W* wrapper, circ::u2_t& cur, F&& f, R&& out, E* elems) {
|
| 273 |
+
if (cur == cursor()) return false; // acquire
|
| 274 |
+
auto* el = elems + circ::index_of(cur++);
|
| 275 |
+
std::forward<F>(f)(&(el->data_));
|
| 276 |
+
for (unsigned k = 0;;) {
|
| 277 |
+
auto cur_rc = el->rc_.load(std::memory_order_acquire);
|
| 278 |
+
if ((cur_rc & ep_mask) == 0) {
|
| 279 |
+
std::forward<R>(out)(true);
|
| 280 |
+
return true;
|
| 281 |
+
}
|
| 282 |
+
auto nxt_rc = cur_rc & ~static_cast<rc_t>(wrapper->connected_id());
|
| 283 |
+
if (el->rc_.compare_exchange_weak(cur_rc, nxt_rc, std::memory_order_release)) {
|
| 284 |
+
std::forward<R>(out)((nxt_rc & ep_mask) == 0);
|
| 285 |
+
return true;
|
| 286 |
+
}
|
| 287 |
+
ipc::yield(k);
|
| 288 |
+
}
|
| 289 |
+
}
|
| 290 |
+
};
|
| 291 |
+
|
| 292 |
+
template <>
|
| 293 |
+
struct prod_cons_impl<wr<relat::multi, relat::multi, trans::broadcast>> {
|
| 294 |
+
|
| 295 |
+
using rc_t = std::uint64_t;
|
| 296 |
+
using flag_t = std::uint64_t;
|
| 297 |
+
|
| 298 |
+
enum : rc_t {
|
| 299 |
+
rc_mask = 0x00000000ffffffffull,
|
| 300 |
+
ep_mask = 0x00ffffffffffffffull,
|
| 301 |
+
ep_incr = 0x0100000000000000ull,
|
| 302 |
+
ic_mask = 0xff000000ffffffffull,
|
| 303 |
+
ic_incr = 0x0000000100000000ull
|
| 304 |
+
};
|
| 305 |
+
|
| 306 |
+
template <std::size_t DataSize, std::size_t AlignSize>
|
| 307 |
+
struct elem_t {
|
| 308 |
+
std::aligned_storage_t<DataSize, AlignSize> data_ {};
|
| 309 |
+
std::atomic<rc_t > rc_ { 0 }; // read-counter
|
| 310 |
+
std::atomic<flag_t> f_ct_ { 0 }; // commit flag
|
| 311 |
+
};
|
| 312 |
+
|
| 313 |
+
alignas(cache_line_size) std::atomic<circ::u2_t> ct_; // commit index
|
| 314 |
+
alignas(cache_line_size) std::atomic<rc_t> epoch_ { 0 };
|
| 315 |
+
|
| 316 |
+
circ::u2_t cursor() const noexcept {
|
| 317 |
+
return ct_.load(std::memory_order_acquire);
|
| 318 |
+
}
|
| 319 |
+
|
| 320 |
+
constexpr static rc_t inc_rc(rc_t rc) noexcept {
|
| 321 |
+
return (rc & ic_mask) | ((rc + ic_incr) & ~ic_mask);
|
| 322 |
+
}
|
| 323 |
+
|
| 324 |
+
constexpr static rc_t inc_mask(rc_t rc) noexcept {
|
| 325 |
+
return inc_rc(rc) & ~rc_mask;
|
| 326 |
+
}
|
| 327 |
+
|
| 328 |
+
template <typename W, typename F, typename E>
|
| 329 |
+
bool push(W* wrapper, F&& f, E* elems) {
|
| 330 |
+
E* el;
|
| 331 |
+
circ::u2_t cur_ct;
|
| 332 |
+
rc_t epoch = epoch_.load(std::memory_order_acquire);
|
| 333 |
+
for (unsigned k = 0;;) {
|
| 334 |
+
circ::cc_t cc = wrapper->elems()->connections(std::memory_order_relaxed);
|
| 335 |
+
if (cc == 0) return false; // no reader
|
| 336 |
+
el = elems + circ::index_of(cur_ct = ct_.load(std::memory_order_relaxed));
|
| 337 |
+
// check all consumers have finished reading this element
|
| 338 |
+
auto cur_rc = el->rc_.load(std::memory_order_relaxed);
|
| 339 |
+
circ::cc_t rem_cc = cur_rc & rc_mask;
|
| 340 |
+
if ((cc & rem_cc) && ((cur_rc & ~ep_mask) == epoch)) {
|
| 341 |
+
return false; // has not finished yet
|
| 342 |
+
}
|
| 343 |
+
else if (!rem_cc) {
|
| 344 |
+
auto cur_fl = el->f_ct_.load(std::memory_order_acquire);
|
| 345 |
+
if ((cur_fl != cur_ct) && cur_fl) {
|
| 346 |
+
return false; // full
|
| 347 |
+
}
|
| 348 |
+
}
|
| 349 |
+
// consider rem_cc to be 0 here
|
| 350 |
+
if (el->rc_.compare_exchange_weak(
|
| 351 |
+
cur_rc, inc_mask(epoch | (cur_rc & ep_mask)) | static_cast<rc_t>(cc), std::memory_order_relaxed) &&
|
| 352 |
+
epoch_.compare_exchange_weak(epoch, epoch, std::memory_order_acq_rel)) {
|
| 353 |
+
break;
|
| 354 |
+
}
|
| 355 |
+
ipc::yield(k);
|
| 356 |
+
}
|
| 357 |
+
// only one thread/process would touch here at one time
|
| 358 |
+
ct_.store(cur_ct + 1, std::memory_order_release);
|
| 359 |
+
std::forward<F>(f)(&(el->data_));
|
| 360 |
+
// set flag & try update wt
|
| 361 |
+
el->f_ct_.store(~static_cast<flag_t>(cur_ct), std::memory_order_release);
|
| 362 |
+
return true;
|
| 363 |
+
}
|
| 364 |
+
|
| 365 |
+
template <typename W, typename F, typename E>
|
| 366 |
+
bool force_push(W* wrapper, F&& f, E* elems) {
|
| 367 |
+
E* el;
|
| 368 |
+
circ::u2_t cur_ct;
|
| 369 |
+
rc_t epoch = epoch_.fetch_add(ep_incr, std::memory_order_release) + ep_incr;
|
| 370 |
+
for (unsigned k = 0;;) {
|
| 371 |
+
circ::cc_t cc = wrapper->elems()->connections(std::memory_order_relaxed);
|
| 372 |
+
if (cc == 0) return false; // no reader
|
| 373 |
+
el = elems + circ::index_of(cur_ct = ct_.load(std::memory_order_relaxed));
|
| 374 |
+
// check all consumers have finished reading this element
|
| 375 |
+
auto cur_rc = el->rc_.load(std::memory_order_acquire);
|
| 376 |
+
circ::cc_t rem_cc = cur_rc & rc_mask;
|
| 377 |
+
if (cc & rem_cc) {
|
| 378 |
+
ipc::log("force_push: k = %u, cc = %u, rem_cc = %u\n", k, cc, rem_cc);
|
| 379 |
+
cc = wrapper->elems()->disconnect_receiver(rem_cc); // disconnect all invalid readers
|
| 380 |
+
if (cc == 0) return false; // no reader
|
| 381 |
+
}
|
| 382 |
+
// just compare & exchange
|
| 383 |
+
if (el->rc_.compare_exchange_weak(
|
| 384 |
+
cur_rc, inc_mask(epoch | (cur_rc & ep_mask)) | static_cast<rc_t>(cc), std::memory_order_relaxed)) {
|
| 385 |
+
if (epoch == epoch_.load(std::memory_order_acquire)) {
|
| 386 |
+
break;
|
| 387 |
+
}
|
| 388 |
+
else if (push(wrapper, std::forward<F>(f), elems)) {
|
| 389 |
+
return true;
|
| 390 |
+
}
|
| 391 |
+
epoch = epoch_.fetch_add(ep_incr, std::memory_order_release) + ep_incr;
|
| 392 |
+
}
|
| 393 |
+
ipc::yield(k);
|
| 394 |
+
}
|
| 395 |
+
// only one thread/process would touch here at one time
|
| 396 |
+
ct_.store(cur_ct + 1, std::memory_order_release);
|
| 397 |
+
std::forward<F>(f)(&(el->data_));
|
| 398 |
+
// set flag & try update wt
|
| 399 |
+
el->f_ct_.store(~static_cast<flag_t>(cur_ct), std::memory_order_release);
|
| 400 |
+
return true;
|
| 401 |
+
}
|
| 402 |
+
|
| 403 |
+
template <typename W, typename F, typename R, typename E, std::size_t N>
|
| 404 |
+
bool pop(W* wrapper, circ::u2_t& cur, F&& f, R&& out, E(& elems)[N]) {
|
| 405 |
+
auto* el = elems + circ::index_of(cur);
|
| 406 |
+
auto cur_fl = el->f_ct_.load(std::memory_order_acquire);
|
| 407 |
+
if (cur_fl != ~static_cast<flag_t>(cur)) {
|
| 408 |
+
return false; // empty
|
| 409 |
+
}
|
| 410 |
+
++cur;
|
| 411 |
+
std::forward<F>(f)(&(el->data_));
|
| 412 |
+
for (unsigned k = 0;;) {
|
| 413 |
+
auto cur_rc = el->rc_.load(std::memory_order_acquire);
|
| 414 |
+
if ((cur_rc & rc_mask) == 0) {
|
| 415 |
+
std::forward<R>(out)(true);
|
| 416 |
+
el->f_ct_.store(cur + N - 1, std::memory_order_release);
|
| 417 |
+
return true;
|
| 418 |
+
}
|
| 419 |
+
auto nxt_rc = inc_rc(cur_rc) & ~static_cast<rc_t>(wrapper->connected_id());
|
| 420 |
+
bool last_one = false;
|
| 421 |
+
if ((last_one = (nxt_rc & rc_mask) == 0)) {
|
| 422 |
+
el->f_ct_.store(cur + N - 1, std::memory_order_release);
|
| 423 |
+
}
|
| 424 |
+
if (el->rc_.compare_exchange_weak(cur_rc, nxt_rc, std::memory_order_release)) {
|
| 425 |
+
std::forward<R>(out)(last_one);
|
| 426 |
+
return true;
|
| 427 |
+
}
|
| 428 |
+
ipc::yield(k);
|
| 429 |
+
}
|
| 430 |
+
}
|
| 431 |
+
};
|
| 432 |
+
|
| 433 |
+
} // namespace ipc
|
crazy_functions/test_project/cpp/cppipc/queue.h
ADDED
|
@@ -0,0 +1,216 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#pragma once
|
| 2 |
+
|
| 3 |
+
#include <type_traits>
|
| 4 |
+
#include <new>
|
| 5 |
+
#include <utility> // [[since C++14]]: std::exchange
|
| 6 |
+
#include <algorithm>
|
| 7 |
+
#include <atomic>
|
| 8 |
+
#include <tuple>
|
| 9 |
+
#include <thread>
|
| 10 |
+
#include <chrono>
|
| 11 |
+
#include <string>
|
| 12 |
+
#include <cassert> // assert
|
| 13 |
+
|
| 14 |
+
#include "libipc/def.h"
|
| 15 |
+
#include "libipc/shm.h"
|
| 16 |
+
#include "libipc/rw_lock.h"
|
| 17 |
+
|
| 18 |
+
#include "libipc/utility/log.h"
|
| 19 |
+
#include "libipc/platform/detail.h"
|
| 20 |
+
#include "libipc/circ/elem_def.h"
|
| 21 |
+
|
| 22 |
+
namespace ipc {
|
| 23 |
+
namespace detail {
|
| 24 |
+
|
| 25 |
+
class queue_conn {
|
| 26 |
+
protected:
|
| 27 |
+
circ::cc_t connected_ = 0;
|
| 28 |
+
shm::handle elems_h_;
|
| 29 |
+
|
| 30 |
+
template <typename Elems>
|
| 31 |
+
Elems* open(char const * name) {
|
| 32 |
+
if (name == nullptr || name[0] == '\0') {
|
| 33 |
+
ipc::error("fail open waiter: name is empty!\n");
|
| 34 |
+
return nullptr;
|
| 35 |
+
}
|
| 36 |
+
if (!elems_h_.acquire(name, sizeof(Elems))) {
|
| 37 |
+
return nullptr;
|
| 38 |
+
}
|
| 39 |
+
auto elems = static_cast<Elems*>(elems_h_.get());
|
| 40 |
+
if (elems == nullptr) {
|
| 41 |
+
ipc::error("fail acquire elems: %s\n", name);
|
| 42 |
+
return nullptr;
|
| 43 |
+
}
|
| 44 |
+
elems->init();
|
| 45 |
+
return elems;
|
| 46 |
+
}
|
| 47 |
+
|
| 48 |
+
void close() {
|
| 49 |
+
elems_h_.release();
|
| 50 |
+
}
|
| 51 |
+
|
| 52 |
+
public:
|
| 53 |
+
queue_conn() = default;
|
| 54 |
+
queue_conn(const queue_conn&) = delete;
|
| 55 |
+
queue_conn& operator=(const queue_conn&) = delete;
|
| 56 |
+
|
| 57 |
+
bool connected() const noexcept {
|
| 58 |
+
return connected_ != 0;
|
| 59 |
+
}
|
| 60 |
+
|
| 61 |
+
circ::cc_t connected_id() const noexcept {
|
| 62 |
+
return connected_;
|
| 63 |
+
}
|
| 64 |
+
|
| 65 |
+
template <typename Elems>
|
| 66 |
+
auto connect(Elems* elems) noexcept
|
| 67 |
+
/*needs 'optional' here*/
|
| 68 |
+
-> std::tuple<bool, bool, decltype(std::declval<Elems>().cursor())> {
|
| 69 |
+
if (elems == nullptr) return {};
|
| 70 |
+
// if it's already connected, just return
|
| 71 |
+
if (connected()) return {connected(), false, 0};
|
| 72 |
+
connected_ = elems->connect_receiver();
|
| 73 |
+
return {connected(), true, elems->cursor()};
|
| 74 |
+
}
|
| 75 |
+
|
| 76 |
+
template <typename Elems>
|
| 77 |
+
bool disconnect(Elems* elems) noexcept {
|
| 78 |
+
if (elems == nullptr) return false;
|
| 79 |
+
// if it's already disconnected, just return false
|
| 80 |
+
if (!connected()) return false;
|
| 81 |
+
elems->disconnect_receiver(std::exchange(connected_, 0));
|
| 82 |
+
return true;
|
| 83 |
+
}
|
| 84 |
+
};
|
| 85 |
+
|
| 86 |
+
template <typename Elems>
|
| 87 |
+
class queue_base : public queue_conn {
|
| 88 |
+
using base_t = queue_conn;
|
| 89 |
+
|
| 90 |
+
public:
|
| 91 |
+
using elems_t = Elems;
|
| 92 |
+
using policy_t = typename elems_t::policy_t;
|
| 93 |
+
|
| 94 |
+
protected:
|
| 95 |
+
elems_t * elems_ = nullptr;
|
| 96 |
+
decltype(std::declval<elems_t>().cursor()) cursor_ = 0;
|
| 97 |
+
bool sender_flag_ = false;
|
| 98 |
+
|
| 99 |
+
public:
|
| 100 |
+
using base_t::base_t;
|
| 101 |
+
|
| 102 |
+
queue_base() = default;
|
| 103 |
+
|
| 104 |
+
explicit queue_base(char const * name)
|
| 105 |
+
: queue_base{} {
|
| 106 |
+
elems_ = open<elems_t>(name);
|
| 107 |
+
}
|
| 108 |
+
|
| 109 |
+
explicit queue_base(elems_t * elems) noexcept
|
| 110 |
+
: queue_base{} {
|
| 111 |
+
assert(elems != nullptr);
|
| 112 |
+
elems_ = elems;
|
| 113 |
+
}
|
| 114 |
+
|
| 115 |
+
/* not virtual */ ~queue_base() {
|
| 116 |
+
base_t::close();
|
| 117 |
+
}
|
| 118 |
+
|
| 119 |
+
elems_t * elems() noexcept { return elems_; }
|
| 120 |
+
elems_t const * elems() const noexcept { return elems_; }
|
| 121 |
+
|
| 122 |
+
bool ready_sending() noexcept {
|
| 123 |
+
if (elems_ == nullptr) return false;
|
| 124 |
+
return sender_flag_ || (sender_flag_ = elems_->connect_sender());
|
| 125 |
+
}
|
| 126 |
+
|
| 127 |
+
void shut_sending() noexcept {
|
| 128 |
+
if (elems_ == nullptr) return;
|
| 129 |
+
if (!sender_flag_) return;
|
| 130 |
+
elems_->disconnect_sender();
|
| 131 |
+
}
|
| 132 |
+
|
| 133 |
+
bool connect() noexcept {
|
| 134 |
+
auto tp = base_t::connect(elems_);
|
| 135 |
+
if (std::get<0>(tp) && std::get<1>(tp)) {
|
| 136 |
+
cursor_ = std::get<2>(tp);
|
| 137 |
+
return true;
|
| 138 |
+
}
|
| 139 |
+
return std::get<0>(tp);
|
| 140 |
+
}
|
| 141 |
+
|
| 142 |
+
bool disconnect() noexcept {
|
| 143 |
+
return base_t::disconnect(elems_);
|
| 144 |
+
}
|
| 145 |
+
|
| 146 |
+
std::size_t conn_count() const noexcept {
|
| 147 |
+
return (elems_ == nullptr) ? static_cast<std::size_t>(invalid_value) : elems_->conn_count();
|
| 148 |
+
}
|
| 149 |
+
|
| 150 |
+
bool valid() const noexcept {
|
| 151 |
+
return elems_ != nullptr;
|
| 152 |
+
}
|
| 153 |
+
|
| 154 |
+
bool empty() const noexcept {
|
| 155 |
+
return !valid() || (cursor_ == elems_->cursor());
|
| 156 |
+
}
|
| 157 |
+
|
| 158 |
+
template <typename T, typename F, typename... P>
|
| 159 |
+
bool push(F&& prep, P&&... params) {
|
| 160 |
+
if (elems_ == nullptr) return false;
|
| 161 |
+
return elems_->push(this, [&](void* p) {
|
| 162 |
+
if (prep(p)) ::new (p) T(std::forward<P>(params)...);
|
| 163 |
+
});
|
| 164 |
+
}
|
| 165 |
+
|
| 166 |
+
template <typename T, typename F, typename... P>
|
| 167 |
+
bool force_push(F&& prep, P&&... params) {
|
| 168 |
+
if (elems_ == nullptr) return false;
|
| 169 |
+
return elems_->force_push(this, [&](void* p) {
|
| 170 |
+
if (prep(p)) ::new (p) T(std::forward<P>(params)...);
|
| 171 |
+
});
|
| 172 |
+
}
|
| 173 |
+
|
| 174 |
+
template <typename T, typename F>
|
| 175 |
+
bool pop(T& item, F&& out) {
|
| 176 |
+
if (elems_ == nullptr) {
|
| 177 |
+
return false;
|
| 178 |
+
}
|
| 179 |
+
return elems_->pop(this, &(this->cursor_), [&item](void* p) {
|
| 180 |
+
::new (&item) T(std::move(*static_cast<T*>(p)));
|
| 181 |
+
}, std::forward<F>(out));
|
| 182 |
+
}
|
| 183 |
+
};
|
| 184 |
+
|
| 185 |
+
} // namespace detail
|
| 186 |
+
|
| 187 |
+
template <typename T, typename Policy>
|
| 188 |
+
class queue final : public detail::queue_base<typename Policy::template elems_t<sizeof(T), alignof(T)>> {
|
| 189 |
+
using base_t = detail::queue_base<typename Policy::template elems_t<sizeof(T), alignof(T)>>;
|
| 190 |
+
|
| 191 |
+
public:
|
| 192 |
+
using value_t = T;
|
| 193 |
+
|
| 194 |
+
using base_t::base_t;
|
| 195 |
+
|
| 196 |
+
template <typename... P>
|
| 197 |
+
bool push(P&&... params) {
|
| 198 |
+
return base_t::template push<T>(std::forward<P>(params)...);
|
| 199 |
+
}
|
| 200 |
+
|
| 201 |
+
template <typename... P>
|
| 202 |
+
bool force_push(P&&... params) {
|
| 203 |
+
return base_t::template force_push<T>(std::forward<P>(params)...);
|
| 204 |
+
}
|
| 205 |
+
|
| 206 |
+
bool pop(T& item) {
|
| 207 |
+
return base_t::pop(item, [](bool) {});
|
| 208 |
+
}
|
| 209 |
+
|
| 210 |
+
template <typename F>
|
| 211 |
+
bool pop(T& item, F&& out) {
|
| 212 |
+
return base_t::pop(item, std::forward<F>(out));
|
| 213 |
+
}
|
| 214 |
+
};
|
| 215 |
+
|
| 216 |
+
} // namespace ipc
|
crazy_functions/test_project/cpp/cppipc/shm.cpp
ADDED
|
@@ -0,0 +1,103 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
#include <string>
|
| 3 |
+
#include <utility>
|
| 4 |
+
|
| 5 |
+
#include "libipc/shm.h"
|
| 6 |
+
|
| 7 |
+
#include "libipc/utility/pimpl.h"
|
| 8 |
+
#include "libipc/memory/resource.h"
|
| 9 |
+
|
| 10 |
+
namespace ipc {
|
| 11 |
+
namespace shm {
|
| 12 |
+
|
| 13 |
+
class handle::handle_ : public pimpl<handle_> {
|
| 14 |
+
public:
|
| 15 |
+
shm::id_t id_ = nullptr;
|
| 16 |
+
void* m_ = nullptr;
|
| 17 |
+
|
| 18 |
+
ipc::string n_;
|
| 19 |
+
std::size_t s_ = 0;
|
| 20 |
+
};
|
| 21 |
+
|
| 22 |
+
handle::handle()
|
| 23 |
+
: p_(p_->make()) {
|
| 24 |
+
}
|
| 25 |
+
|
| 26 |
+
handle::handle(char const * name, std::size_t size, unsigned mode)
|
| 27 |
+
: handle() {
|
| 28 |
+
acquire(name, size, mode);
|
| 29 |
+
}
|
| 30 |
+
|
| 31 |
+
handle::handle(handle&& rhs)
|
| 32 |
+
: handle() {
|
| 33 |
+
swap(rhs);
|
| 34 |
+
}
|
| 35 |
+
|
| 36 |
+
handle::~handle() {
|
| 37 |
+
release();
|
| 38 |
+
p_->clear();
|
| 39 |
+
}
|
| 40 |
+
|
| 41 |
+
void handle::swap(handle& rhs) {
|
| 42 |
+
std::swap(p_, rhs.p_);
|
| 43 |
+
}
|
| 44 |
+
|
| 45 |
+
handle& handle::operator=(handle rhs) {
|
| 46 |
+
swap(rhs);
|
| 47 |
+
return *this;
|
| 48 |
+
}
|
| 49 |
+
|
| 50 |
+
bool handle::valid() const noexcept {
|
| 51 |
+
return impl(p_)->m_ != nullptr;
|
| 52 |
+
}
|
| 53 |
+
|
| 54 |
+
std::size_t handle::size() const noexcept {
|
| 55 |
+
return impl(p_)->s_;
|
| 56 |
+
}
|
| 57 |
+
|
| 58 |
+
char const * handle::name() const noexcept {
|
| 59 |
+
return impl(p_)->n_.c_str();
|
| 60 |
+
}
|
| 61 |
+
|
| 62 |
+
std::int32_t handle::ref() const noexcept {
|
| 63 |
+
return shm::get_ref(impl(p_)->id_);
|
| 64 |
+
}
|
| 65 |
+
|
| 66 |
+
void handle::sub_ref() noexcept {
|
| 67 |
+
shm::sub_ref(impl(p_)->id_);
|
| 68 |
+
}
|
| 69 |
+
|
| 70 |
+
bool handle::acquire(char const * name, std::size_t size, unsigned mode) {
|
| 71 |
+
release();
|
| 72 |
+
impl(p_)->id_ = shm::acquire((impl(p_)->n_ = name).c_str(), size, mode);
|
| 73 |
+
impl(p_)->m_ = shm::get_mem(impl(p_)->id_, &(impl(p_)->s_));
|
| 74 |
+
return valid();
|
| 75 |
+
}
|
| 76 |
+
|
| 77 |
+
std::int32_t handle::release() {
|
| 78 |
+
if (impl(p_)->id_ == nullptr) return -1;
|
| 79 |
+
return shm::release(detach());
|
| 80 |
+
}
|
| 81 |
+
|
| 82 |
+
void* handle::get() const {
|
| 83 |
+
return impl(p_)->m_;
|
| 84 |
+
}
|
| 85 |
+
|
| 86 |
+
void handle::attach(id_t id) {
|
| 87 |
+
if (id == nullptr) return;
|
| 88 |
+
release();
|
| 89 |
+
impl(p_)->id_ = id;
|
| 90 |
+
impl(p_)->m_ = shm::get_mem(impl(p_)->id_, &(impl(p_)->s_));
|
| 91 |
+
}
|
| 92 |
+
|
| 93 |
+
id_t handle::detach() {
|
| 94 |
+
auto old = impl(p_)->id_;
|
| 95 |
+
impl(p_)->id_ = nullptr;
|
| 96 |
+
impl(p_)->m_ = nullptr;
|
| 97 |
+
impl(p_)->s_ = 0;
|
| 98 |
+
impl(p_)->n_.clear();
|
| 99 |
+
return old;
|
| 100 |
+
}
|
| 101 |
+
|
| 102 |
+
} // namespace shm
|
| 103 |
+
} // namespace ipc
|
crazy_functions/test_project/cpp/cppipc/waiter.h
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#pragma once
|
| 2 |
+
|
| 3 |
+
#include <utility>
|
| 4 |
+
#include <string>
|
| 5 |
+
#include <mutex>
|
| 6 |
+
#include <atomic>
|
| 7 |
+
|
| 8 |
+
#include "libipc/def.h"
|
| 9 |
+
#include "libipc/mutex.h"
|
| 10 |
+
#include "libipc/condition.h"
|
| 11 |
+
#include "libipc/platform/detail.h"
|
| 12 |
+
|
| 13 |
+
namespace ipc {
|
| 14 |
+
namespace detail {
|
| 15 |
+
|
| 16 |
+
class waiter {
|
| 17 |
+
ipc::sync::condition cond_;
|
| 18 |
+
ipc::sync::mutex lock_;
|
| 19 |
+
std::atomic<bool> quit_ {false};
|
| 20 |
+
|
| 21 |
+
public:
|
| 22 |
+
static void init();
|
| 23 |
+
|
| 24 |
+
waiter() = default;
|
| 25 |
+
waiter(char const *name) {
|
| 26 |
+
open(name);
|
| 27 |
+
}
|
| 28 |
+
|
| 29 |
+
~waiter() {
|
| 30 |
+
close();
|
| 31 |
+
}
|
| 32 |
+
|
| 33 |
+
bool valid() const noexcept {
|
| 34 |
+
return cond_.valid() && lock_.valid();
|
| 35 |
+
}
|
| 36 |
+
|
| 37 |
+
bool open(char const *name) noexcept {
|
| 38 |
+
quit_.store(false, std::memory_order_relaxed);
|
| 39 |
+
if (!cond_.open((std::string{"_waiter_cond_"} + name).c_str())) {
|
| 40 |
+
return false;
|
| 41 |
+
}
|
| 42 |
+
if (!lock_.open((std::string{"_waiter_lock_"} + name).c_str())) {
|
| 43 |
+
cond_.close();
|
| 44 |
+
return false;
|
| 45 |
+
}
|
| 46 |
+
return valid();
|
| 47 |
+
}
|
| 48 |
+
|
| 49 |
+
void close() noexcept {
|
| 50 |
+
cond_.close();
|
| 51 |
+
lock_.close();
|
| 52 |
+
}
|
| 53 |
+
|
| 54 |
+
template <typename F>
|
| 55 |
+
bool wait_if(F &&pred, std::uint64_t tm = ipc::invalid_value) noexcept {
|
| 56 |
+
IPC_UNUSED_ std::lock_guard<ipc::sync::mutex> guard {lock_};
|
| 57 |
+
while ([this, &pred] {
|
| 58 |
+
return !quit_.load(std::memory_order_relaxed)
|
| 59 |
+
&& std::forward<F>(pred)();
|
| 60 |
+
}()) {
|
| 61 |
+
if (!cond_.wait(lock_, tm)) return false;
|
| 62 |
+
}
|
| 63 |
+
return true;
|
| 64 |
+
}
|
| 65 |
+
|
| 66 |
+
bool notify() noexcept {
|
| 67 |
+
std::lock_guard<ipc::sync::mutex>{lock_}; // barrier
|
| 68 |
+
return cond_.notify(lock_);
|
| 69 |
+
}
|
| 70 |
+
|
| 71 |
+
bool broadcast() noexcept {
|
| 72 |
+
std::lock_guard<ipc::sync::mutex>{lock_}; // barrier
|
| 73 |
+
return cond_.broadcast(lock_);
|
| 74 |
+
}
|
| 75 |
+
|
| 76 |
+
bool quit_waiting() {
|
| 77 |
+
quit_.store(true, std::memory_order_release);
|
| 78 |
+
return broadcast();
|
| 79 |
+
}
|
| 80 |
+
};
|
| 81 |
+
|
| 82 |
+
} // namespace detail
|
| 83 |
+
} // namespace ipc
|
crazy_functions/test_project/cpp/cppipc/来源
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
https://github.com/mutouyun/cpp-ipc
|
| 2 |
+
|
| 3 |
+
A high-performance inter-process communication library using shared memory on Linux/Windows.
|
crazy_functions/test_project/cpp/libJPG/jpgd.cpp
ADDED
|
@@ -0,0 +1,3276 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// jpgd.cpp - C++ class for JPEG decompression.
|
| 2 |
+
// Public domain, Rich Geldreich <[email protected]>
|
| 3 |
+
// Last updated Apr. 16, 2011
|
| 4 |
+
// Alex Evans: Linear memory allocator (taken from jpge.h).
|
| 5 |
+
//
|
| 6 |
+
// Supports progressive and baseline sequential JPEG image files, and the most common chroma subsampling factors: Y, H1V1, H2V1, H1V2, and H2V2.
|
| 7 |
+
//
|
| 8 |
+
// Chroma upsampling quality: H2V2 is upsampled in the frequency domain, H2V1 and H1V2 are upsampled using point sampling.
|
| 9 |
+
// Chroma upsampling reference: "Fast Scheme for Image Size Change in the Compressed Domain"
|
| 10 |
+
// http://vision.ai.uiuc.edu/~dugad/research/dct/index.html
|
| 11 |
+
|
| 12 |
+
#include "jpgd.h"
|
| 13 |
+
#include <string.h>
|
| 14 |
+
|
| 15 |
+
#include <assert.h>
|
| 16 |
+
// BEGIN EPIC MOD
|
| 17 |
+
#define JPGD_ASSERT(x) { assert(x); CA_ASSUME(x); } (void)0
|
| 18 |
+
// END EPIC MOD
|
| 19 |
+
|
| 20 |
+
#ifdef _MSC_VER
|
| 21 |
+
#pragma warning (disable : 4611) // warning C4611: interaction between '_setjmp' and C++ object destruction is non-portable
|
| 22 |
+
#endif
|
| 23 |
+
|
| 24 |
+
// Set to 1 to enable freq. domain chroma upsampling on images using H2V2 subsampling (0=faster nearest neighbor sampling).
|
| 25 |
+
// This is slower, but results in higher quality on images with highly saturated colors.
|
| 26 |
+
#define JPGD_SUPPORT_FREQ_DOMAIN_UPSAMPLING 1
|
| 27 |
+
|
| 28 |
+
#define JPGD_TRUE (1)
|
| 29 |
+
#define JPGD_FALSE (0)
|
| 30 |
+
|
| 31 |
+
#define JPGD_MAX(a,b) (((a)>(b)) ? (a) : (b))
|
| 32 |
+
#define JPGD_MIN(a,b) (((a)<(b)) ? (a) : (b))
|
| 33 |
+
|
| 34 |
+
namespace jpgd {
|
| 35 |
+
|
| 36 |
+
static inline void *jpgd_malloc(size_t nSize) { return FMemory::Malloc(nSize); }
|
| 37 |
+
static inline void jpgd_free(void *p) { FMemory::Free(p); }
|
| 38 |
+
|
| 39 |
+
// BEGIN EPIC MOD
|
| 40 |
+
//@UE3 - use UE3 BGRA encoding instead of assuming RGBA
|
| 41 |
+
// stolen from IImageWrapper.h
|
| 42 |
+
enum ERGBFormatJPG
|
| 43 |
+
{
|
| 44 |
+
Invalid = -1,
|
| 45 |
+
RGBA = 0,
|
| 46 |
+
BGRA = 1,
|
| 47 |
+
Gray = 2,
|
| 48 |
+
};
|
| 49 |
+
static ERGBFormatJPG jpg_format;
|
| 50 |
+
// END EPIC MOD
|
| 51 |
+
|
| 52 |
+
// DCT coefficients are stored in this sequence.
|
| 53 |
+
static int g_ZAG[64] = { 0,1,8,16,9,2,3,10,17,24,32,25,18,11,4,5,12,19,26,33,40,48,41,34,27,20,13,6,7,14,21,28,35,42,49,56,57,50,43,36,29,22,15,23,30,37,44,51,58,59,52,45,38,31,39,46,53,60,61,54,47,55,62,63 };
|
| 54 |
+
|
| 55 |
+
enum JPEG_MARKER
|
| 56 |
+
{
|
| 57 |
+
M_SOF0 = 0xC0, M_SOF1 = 0xC1, M_SOF2 = 0xC2, M_SOF3 = 0xC3, M_SOF5 = 0xC5, M_SOF6 = 0xC6, M_SOF7 = 0xC7, M_JPG = 0xC8,
|
| 58 |
+
M_SOF9 = 0xC9, M_SOF10 = 0xCA, M_SOF11 = 0xCB, M_SOF13 = 0xCD, M_SOF14 = 0xCE, M_SOF15 = 0xCF, M_DHT = 0xC4, M_DAC = 0xCC,
|
| 59 |
+
M_RST0 = 0xD0, M_RST1 = 0xD1, M_RST2 = 0xD2, M_RST3 = 0xD3, M_RST4 = 0xD4, M_RST5 = 0xD5, M_RST6 = 0xD6, M_RST7 = 0xD7,
|
| 60 |
+
M_SOI = 0xD8, M_EOI = 0xD9, M_SOS = 0xDA, M_DQT = 0xDB, M_DNL = 0xDC, M_DRI = 0xDD, M_DHP = 0xDE, M_EXP = 0xDF,
|
| 61 |
+
M_APP0 = 0xE0, M_APP15 = 0xEF, M_JPG0 = 0xF0, M_JPG13 = 0xFD, M_COM = 0xFE, M_TEM = 0x01, M_ERROR = 0x100, RST0 = 0xD0
|
| 62 |
+
};
|
| 63 |
+
|
| 64 |
+
enum JPEG_SUBSAMPLING { JPGD_GRAYSCALE = 0, JPGD_YH1V1, JPGD_YH2V1, JPGD_YH1V2, JPGD_YH2V2 };
|
| 65 |
+
|
| 66 |
+
#define CONST_BITS 13
|
| 67 |
+
#define PASS1_BITS 2
|
| 68 |
+
#define SCALEDONE ((int32)1)
|
| 69 |
+
|
| 70 |
+
#define FIX_0_298631336 ((int32)2446) /* FIX(0.298631336) */
|
| 71 |
+
#define FIX_0_390180644 ((int32)3196) /* FIX(0.390180644) */
|
| 72 |
+
#define FIX_0_541196100 ((int32)4433) /* FIX(0.541196100) */
|
| 73 |
+
#define FIX_0_765366865 ((int32)6270) /* FIX(0.765366865) */
|
| 74 |
+
#define FIX_0_899976223 ((int32)7373) /* FIX(0.899976223) */
|
| 75 |
+
#define FIX_1_175875602 ((int32)9633) /* FIX(1.175875602) */
|
| 76 |
+
#define FIX_1_501321110 ((int32)12299) /* FIX(1.501321110) */
|
| 77 |
+
#define FIX_1_847759065 ((int32)15137) /* FIX(1.847759065) */
|
| 78 |
+
#define FIX_1_961570560 ((int32)16069) /* FIX(1.961570560) */
|
| 79 |
+
#define FIX_2_053119869 ((int32)16819) /* FIX(2.053119869) */
|
| 80 |
+
#define FIX_2_562915447 ((int32)20995) /* FIX(2.562915447) */
|
| 81 |
+
#define FIX_3_072711026 ((int32)25172) /* FIX(3.072711026) */
|
| 82 |
+
|
| 83 |
+
#define DESCALE(x,n) (((x) + (SCALEDONE << ((n)-1))) >> (n))
|
| 84 |
+
#define DESCALE_ZEROSHIFT(x,n) (((x) + (128 << (n)) + (SCALEDONE << ((n)-1))) >> (n))
|
| 85 |
+
|
| 86 |
+
#define MULTIPLY(var, cnst) ((var) * (cnst))
|
| 87 |
+
|
| 88 |
+
#define CLAMP(i) ((static_cast<uint>(i) > 255) ? (((~i) >> 31) & 0xFF) : (i))
|
| 89 |
+
|
| 90 |
+
// Compiler creates a fast path 1D IDCT for X non-zero columns
|
| 91 |
+
template <int NONZERO_COLS>
|
| 92 |
+
struct Row
|
| 93 |
+
{
|
| 94 |
+
static void idct(int* pTemp, const jpgd_block_t* pSrc)
|
| 95 |
+
{
|
| 96 |
+
// ACCESS_COL() will be optimized at compile time to either an array access, or 0.
|
| 97 |
+
#define ACCESS_COL(x) (((x) < NONZERO_COLS) ? (int)pSrc[x] : 0)
|
| 98 |
+
|
| 99 |
+
const int z2 = ACCESS_COL(2), z3 = ACCESS_COL(6);
|
| 100 |
+
|
| 101 |
+
const int z1 = MULTIPLY(z2 + z3, FIX_0_541196100);
|
| 102 |
+
const int tmp2 = z1 + MULTIPLY(z3, - FIX_1_847759065);
|
| 103 |
+
const int tmp3 = z1 + MULTIPLY(z2, FIX_0_765366865);
|
| 104 |
+
|
| 105 |
+
const int tmp0 = (ACCESS_COL(0) + ACCESS_COL(4)) << CONST_BITS;
|
| 106 |
+
const int tmp1 = (ACCESS_COL(0) - ACCESS_COL(4)) << CONST_BITS;
|
| 107 |
+
|
| 108 |
+
const int tmp10 = tmp0 + tmp3, tmp13 = tmp0 - tmp3, tmp11 = tmp1 + tmp2, tmp12 = tmp1 - tmp2;
|
| 109 |
+
|
| 110 |
+
const int atmp0 = ACCESS_COL(7), atmp1 = ACCESS_COL(5), atmp2 = ACCESS_COL(3), atmp3 = ACCESS_COL(1);
|
| 111 |
+
|
| 112 |
+
const int bz1 = atmp0 + atmp3, bz2 = atmp1 + atmp2, bz3 = atmp0 + atmp2, bz4 = atmp1 + atmp3;
|
| 113 |
+
const int bz5 = MULTIPLY(bz3 + bz4, FIX_1_175875602);
|
| 114 |
+
|
| 115 |
+
const int az1 = MULTIPLY(bz1, - FIX_0_899976223);
|
| 116 |
+
const int az2 = MULTIPLY(bz2, - FIX_2_562915447);
|
| 117 |
+
const int az3 = MULTIPLY(bz3, - FIX_1_961570560) + bz5;
|
| 118 |
+
const int az4 = MULTIPLY(bz4, - FIX_0_390180644) + bz5;
|
| 119 |
+
|
| 120 |
+
const int btmp0 = MULTIPLY(atmp0, FIX_0_298631336) + az1 + az3;
|
| 121 |
+
const int btmp1 = MULTIPLY(atmp1, FIX_2_053119869) + az2 + az4;
|
| 122 |
+
const int btmp2 = MULTIPLY(atmp2, FIX_3_072711026) + az2 + az3;
|
| 123 |
+
const int btmp3 = MULTIPLY(atmp3, FIX_1_501321110) + az1 + az4;
|
| 124 |
+
|
| 125 |
+
pTemp[0] = DESCALE(tmp10 + btmp3, CONST_BITS-PASS1_BITS);
|
| 126 |
+
pTemp[7] = DESCALE(tmp10 - btmp3, CONST_BITS-PASS1_BITS);
|
| 127 |
+
pTemp[1] = DESCALE(tmp11 + btmp2, CONST_BITS-PASS1_BITS);
|
| 128 |
+
pTemp[6] = DESCALE(tmp11 - btmp2, CONST_BITS-PASS1_BITS);
|
| 129 |
+
pTemp[2] = DESCALE(tmp12 + btmp1, CONST_BITS-PASS1_BITS);
|
| 130 |
+
pTemp[5] = DESCALE(tmp12 - btmp1, CONST_BITS-PASS1_BITS);
|
| 131 |
+
pTemp[3] = DESCALE(tmp13 + btmp0, CONST_BITS-PASS1_BITS);
|
| 132 |
+
pTemp[4] = DESCALE(tmp13 - btmp0, CONST_BITS-PASS1_BITS);
|
| 133 |
+
}
|
| 134 |
+
};
|
| 135 |
+
|
| 136 |
+
template <>
|
| 137 |
+
struct Row<0>
|
| 138 |
+
{
|
| 139 |
+
static void idct(int* pTemp, const jpgd_block_t* pSrc)
|
| 140 |
+
{
|
| 141 |
+
#ifdef _MSC_VER
|
| 142 |
+
pTemp; pSrc;
|
| 143 |
+
#endif
|
| 144 |
+
}
|
| 145 |
+
};
|
| 146 |
+
|
| 147 |
+
template <>
|
| 148 |
+
struct Row<1>
|
| 149 |
+
{
|
| 150 |
+
static void idct(int* pTemp, const jpgd_block_t* pSrc)
|
| 151 |
+
{
|
| 152 |
+
const int dcval = (pSrc[0] << PASS1_BITS);
|
| 153 |
+
|
| 154 |
+
pTemp[0] = dcval;
|
| 155 |
+
pTemp[1] = dcval;
|
| 156 |
+
pTemp[2] = dcval;
|
| 157 |
+
pTemp[3] = dcval;
|
| 158 |
+
pTemp[4] = dcval;
|
| 159 |
+
pTemp[5] = dcval;
|
| 160 |
+
pTemp[6] = dcval;
|
| 161 |
+
pTemp[7] = dcval;
|
| 162 |
+
}
|
| 163 |
+
};
|
| 164 |
+
|
| 165 |
+
// Compiler creates a fast path 1D IDCT for X non-zero rows
|
| 166 |
+
template <int NONZERO_ROWS>
|
| 167 |
+
struct Col
|
| 168 |
+
{
|
| 169 |
+
static void idct(uint8* pDst_ptr, const int* pTemp)
|
| 170 |
+
{
|
| 171 |
+
// ACCESS_ROW() will be optimized at compile time to either an array access, or 0.
|
| 172 |
+
#define ACCESS_ROW(x) (((x) < NONZERO_ROWS) ? pTemp[x * 8] : 0)
|
| 173 |
+
|
| 174 |
+
const int z2 = ACCESS_ROW(2);
|
| 175 |
+
const int z3 = ACCESS_ROW(6);
|
| 176 |
+
|
| 177 |
+
const int z1 = MULTIPLY(z2 + z3, FIX_0_541196100);
|
| 178 |
+
const int tmp2 = z1 + MULTIPLY(z3, - FIX_1_847759065);
|
| 179 |
+
const int tmp3 = z1 + MULTIPLY(z2, FIX_0_765366865);
|
| 180 |
+
|
| 181 |
+
const int tmp0 = (ACCESS_ROW(0) + ACCESS_ROW(4)) << CONST_BITS;
|
| 182 |
+
const int tmp1 = (ACCESS_ROW(0) - ACCESS_ROW(4)) << CONST_BITS;
|
| 183 |
+
|
| 184 |
+
const int tmp10 = tmp0 + tmp3, tmp13 = tmp0 - tmp3, tmp11 = tmp1 + tmp2, tmp12 = tmp1 - tmp2;
|
| 185 |
+
|
| 186 |
+
const int atmp0 = ACCESS_ROW(7), atmp1 = ACCESS_ROW(5), atmp2 = ACCESS_ROW(3), atmp3 = ACCESS_ROW(1);
|
| 187 |
+
|
| 188 |
+
const int bz1 = atmp0 + atmp3, bz2 = atmp1 + atmp2, bz3 = atmp0 + atmp2, bz4 = atmp1 + atmp3;
|
| 189 |
+
const int bz5 = MULTIPLY(bz3 + bz4, FIX_1_175875602);
|
| 190 |
+
|
| 191 |
+
const int az1 = MULTIPLY(bz1, - FIX_0_899976223);
|
| 192 |
+
const int az2 = MULTIPLY(bz2, - FIX_2_562915447);
|
| 193 |
+
const int az3 = MULTIPLY(bz3, - FIX_1_961570560) + bz5;
|
| 194 |
+
const int az4 = MULTIPLY(bz4, - FIX_0_390180644) + bz5;
|
| 195 |
+
|
| 196 |
+
const int btmp0 = MULTIPLY(atmp0, FIX_0_298631336) + az1 + az3;
|
| 197 |
+
const int btmp1 = MULTIPLY(atmp1, FIX_2_053119869) + az2 + az4;
|
| 198 |
+
const int btmp2 = MULTIPLY(atmp2, FIX_3_072711026) + az2 + az3;
|
| 199 |
+
const int btmp3 = MULTIPLY(atmp3, FIX_1_501321110) + az1 + az4;
|
| 200 |
+
|
| 201 |
+
int i = DESCALE_ZEROSHIFT(tmp10 + btmp3, CONST_BITS+PASS1_BITS+3);
|
| 202 |
+
pDst_ptr[8*0] = (uint8)CLAMP(i);
|
| 203 |
+
|
| 204 |
+
i = DESCALE_ZEROSHIFT(tmp10 - btmp3, CONST_BITS+PASS1_BITS+3);
|
| 205 |
+
pDst_ptr[8*7] = (uint8)CLAMP(i);
|
| 206 |
+
|
| 207 |
+
i = DESCALE_ZEROSHIFT(tmp11 + btmp2, CONST_BITS+PASS1_BITS+3);
|
| 208 |
+
pDst_ptr[8*1] = (uint8)CLAMP(i);
|
| 209 |
+
|
| 210 |
+
i = DESCALE_ZEROSHIFT(tmp11 - btmp2, CONST_BITS+PASS1_BITS+3);
|
| 211 |
+
pDst_ptr[8*6] = (uint8)CLAMP(i);
|
| 212 |
+
|
| 213 |
+
i = DESCALE_ZEROSHIFT(tmp12 + btmp1, CONST_BITS+PASS1_BITS+3);
|
| 214 |
+
pDst_ptr[8*2] = (uint8)CLAMP(i);
|
| 215 |
+
|
| 216 |
+
i = DESCALE_ZEROSHIFT(tmp12 - btmp1, CONST_BITS+PASS1_BITS+3);
|
| 217 |
+
pDst_ptr[8*5] = (uint8)CLAMP(i);
|
| 218 |
+
|
| 219 |
+
i = DESCALE_ZEROSHIFT(tmp13 + btmp0, CONST_BITS+PASS1_BITS+3);
|
| 220 |
+
pDst_ptr[8*3] = (uint8)CLAMP(i);
|
| 221 |
+
|
| 222 |
+
i = DESCALE_ZEROSHIFT(tmp13 - btmp0, CONST_BITS+PASS1_BITS+3);
|
| 223 |
+
pDst_ptr[8*4] = (uint8)CLAMP(i);
|
| 224 |
+
}
|
| 225 |
+
};
|
| 226 |
+
|
| 227 |
+
template <>
|
| 228 |
+
struct Col<1>
|
| 229 |
+
{
|
| 230 |
+
static void idct(uint8* pDst_ptr, const int* pTemp)
|
| 231 |
+
{
|
| 232 |
+
int dcval = DESCALE_ZEROSHIFT(pTemp[0], PASS1_BITS+3);
|
| 233 |
+
const uint8 dcval_clamped = (uint8)CLAMP(dcval);
|
| 234 |
+
pDst_ptr[0*8] = dcval_clamped;
|
| 235 |
+
pDst_ptr[1*8] = dcval_clamped;
|
| 236 |
+
pDst_ptr[2*8] = dcval_clamped;
|
| 237 |
+
pDst_ptr[3*8] = dcval_clamped;
|
| 238 |
+
pDst_ptr[4*8] = dcval_clamped;
|
| 239 |
+
pDst_ptr[5*8] = dcval_clamped;
|
| 240 |
+
pDst_ptr[6*8] = dcval_clamped;
|
| 241 |
+
pDst_ptr[7*8] = dcval_clamped;
|
| 242 |
+
}
|
| 243 |
+
};
|
| 244 |
+
|
| 245 |
+
static const uint8 s_idct_row_table[] =
|
| 246 |
+
{
|
| 247 |
+
1,0,0,0,0,0,0,0, 2,0,0,0,0,0,0,0, 2,1,0,0,0,0,0,0, 2,1,1,0,0,0,0,0, 2,2,1,0,0,0,0,0, 3,2,1,0,0,0,0,0, 4,2,1,0,0,0,0,0, 4,3,1,0,0,0,0,0,
|
| 248 |
+
4,3,2,0,0,0,0,0, 4,3,2,1,0,0,0,0, 4,3,2,1,1,0,0,0, 4,3,2,2,1,0,0,0, 4,3,3,2,1,0,0,0, 4,4,3,2,1,0,0,0, 5,4,3,2,1,0,0,0, 6,4,3,2,1,0,0,0,
|
| 249 |
+
6,5,3,2,1,0,0,0, 6,5,4,2,1,0,0,0, 6,5,4,3,1,0,0,0, 6,5,4,3,2,0,0,0, 6,5,4,3,2,1,0,0, 6,5,4,3,2,1,1,0, 6,5,4,3,2,2,1,0, 6,5,4,3,3,2,1,0,
|
| 250 |
+
6,5,4,4,3,2,1,0, 6,5,5,4,3,2,1,0, 6,6,5,4,3,2,1,0, 7,6,5,4,3,2,1,0, 8,6,5,4,3,2,1,0, 8,7,5,4,3,2,1,0, 8,7,6,4,3,2,1,0, 8,7,6,5,3,2,1,0,
|
| 251 |
+
8,7,6,5,4,2,1,0, 8,7,6,5,4,3,1,0, 8,7,6,5,4,3,2,0, 8,7,6,5,4,3,2,1, 8,7,6,5,4,3,2,2, 8,7,6,5,4,3,3,2, 8,7,6,5,4,4,3,2, 8,7,6,5,5,4,3,2,
|
| 252 |
+
8,7,6,6,5,4,3,2, 8,7,7,6,5,4,3,2, 8,8,7,6,5,4,3,2, 8,8,8,6,5,4,3,2, 8,8,8,7,5,4,3,2, 8,8,8,7,6,4,3,2, 8,8,8,7,6,5,3,2, 8,8,8,7,6,5,4,2,
|
| 253 |
+
8,8,8,7,6,5,4,3, 8,8,8,7,6,5,4,4, 8,8,8,7,6,5,5,4, 8,8,8,7,6,6,5,4, 8,8,8,7,7,6,5,4, 8,8,8,8,7,6,5,4, 8,8,8,8,8,6,5,4, 8,8,8,8,8,7,5,4,
|
| 254 |
+
8,8,8,8,8,7,6,4, 8,8,8,8,8,7,6,5, 8,8,8,8,8,7,6,6, 8,8,8,8,8,7,7,6, 8,8,8,8,8,8,7,6, 8,8,8,8,8,8,8,6, 8,8,8,8,8,8,8,7, 8,8,8,8,8,8,8,8,
|
| 255 |
+
};
|
| 256 |
+
|
| 257 |
+
static const uint8 s_idct_col_table[] = { 1, 1, 2, 3, 3, 3, 3, 3, 3, 4, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 6, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8 };
|
| 258 |
+
|
| 259 |
+
void idct(const jpgd_block_t* pSrc_ptr, uint8* pDst_ptr, int block_max_zag)
|
| 260 |
+
{
|
| 261 |
+
JPGD_ASSERT(block_max_zag >= 1);
|
| 262 |
+
JPGD_ASSERT(block_max_zag <= 64);
|
| 263 |
+
|
| 264 |
+
if (block_max_zag == 1)
|
| 265 |
+
{
|
| 266 |
+
int k = ((pSrc_ptr[0] + 4) >> 3) + 128;
|
| 267 |
+
k = CLAMP(k);
|
| 268 |
+
k = k | (k<<8);
|
| 269 |
+
k = k | (k<<16);
|
| 270 |
+
|
| 271 |
+
for (int i = 8; i > 0; i--)
|
| 272 |
+
{
|
| 273 |
+
*(int*)&pDst_ptr[0] = k;
|
| 274 |
+
*(int*)&pDst_ptr[4] = k;
|
| 275 |
+
pDst_ptr += 8;
|
| 276 |
+
}
|
| 277 |
+
return;
|
| 278 |
+
}
|
| 279 |
+
|
| 280 |
+
int temp[64];
|
| 281 |
+
|
| 282 |
+
const jpgd_block_t* pSrc = pSrc_ptr;
|
| 283 |
+
int* pTemp = temp;
|
| 284 |
+
|
| 285 |
+
const uint8* pRow_tab = &s_idct_row_table[(block_max_zag - 1) * 8];
|
| 286 |
+
int i;
|
| 287 |
+
for (i = 8; i > 0; i--, pRow_tab++)
|
| 288 |
+
{
|
| 289 |
+
switch (*pRow_tab)
|
| 290 |
+
{
|
| 291 |
+
case 0: Row<0>::idct(pTemp, pSrc); break;
|
| 292 |
+
case 1: Row<1>::idct(pTemp, pSrc); break;
|
| 293 |
+
case 2: Row<2>::idct(pTemp, pSrc); break;
|
| 294 |
+
case 3: Row<3>::idct(pTemp, pSrc); break;
|
| 295 |
+
case 4: Row<4>::idct(pTemp, pSrc); break;
|
| 296 |
+
case 5: Row<5>::idct(pTemp, pSrc); break;
|
| 297 |
+
case 6: Row<6>::idct(pTemp, pSrc); break;
|
| 298 |
+
case 7: Row<7>::idct(pTemp, pSrc); break;
|
| 299 |
+
case 8: Row<8>::idct(pTemp, pSrc); break;
|
| 300 |
+
}
|
| 301 |
+
|
| 302 |
+
pSrc += 8;
|
| 303 |
+
pTemp += 8;
|
| 304 |
+
}
|
| 305 |
+
|
| 306 |
+
pTemp = temp;
|
| 307 |
+
|
| 308 |
+
const int nonzero_rows = s_idct_col_table[block_max_zag - 1];
|
| 309 |
+
for (i = 8; i > 0; i--)
|
| 310 |
+
{
|
| 311 |
+
switch (nonzero_rows)
|
| 312 |
+
{
|
| 313 |
+
case 1: Col<1>::idct(pDst_ptr, pTemp); break;
|
| 314 |
+
case 2: Col<2>::idct(pDst_ptr, pTemp); break;
|
| 315 |
+
case 3: Col<3>::idct(pDst_ptr, pTemp); break;
|
| 316 |
+
case 4: Col<4>::idct(pDst_ptr, pTemp); break;
|
| 317 |
+
case 5: Col<5>::idct(pDst_ptr, pTemp); break;
|
| 318 |
+
case 6: Col<6>::idct(pDst_ptr, pTemp); break;
|
| 319 |
+
case 7: Col<7>::idct(pDst_ptr, pTemp); break;
|
| 320 |
+
case 8: Col<8>::idct(pDst_ptr, pTemp); break;
|
| 321 |
+
}
|
| 322 |
+
|
| 323 |
+
pTemp++;
|
| 324 |
+
pDst_ptr++;
|
| 325 |
+
}
|
| 326 |
+
}
|
| 327 |
+
|
| 328 |
+
void idct_4x4(const jpgd_block_t* pSrc_ptr, uint8* pDst_ptr)
|
| 329 |
+
{
|
| 330 |
+
int temp[64];
|
| 331 |
+
int* pTemp = temp;
|
| 332 |
+
const jpgd_block_t* pSrc = pSrc_ptr;
|
| 333 |
+
|
| 334 |
+
for (int i = 4; i > 0; i--)
|
| 335 |
+
{
|
| 336 |
+
Row<4>::idct(pTemp, pSrc);
|
| 337 |
+
pSrc += 8;
|
| 338 |
+
pTemp += 8;
|
| 339 |
+
}
|
| 340 |
+
|
| 341 |
+
pTemp = temp;
|
| 342 |
+
for (int i = 8; i > 0; i--)
|
| 343 |
+
{
|
| 344 |
+
Col<4>::idct(pDst_ptr, pTemp);
|
| 345 |
+
pTemp++;
|
| 346 |
+
pDst_ptr++;
|
| 347 |
+
}
|
| 348 |
+
}
|
| 349 |
+
|
| 350 |
+
// Retrieve one character from the input stream.
|
| 351 |
+
inline uint jpeg_decoder::get_char()
|
| 352 |
+
{
|
| 353 |
+
// Any bytes remaining in buffer?
|
| 354 |
+
if (!m_in_buf_left)
|
| 355 |
+
{
|
| 356 |
+
// Try to get more bytes.
|
| 357 |
+
prep_in_buffer();
|
| 358 |
+
// Still nothing to get?
|
| 359 |
+
if (!m_in_buf_left)
|
| 360 |
+
{
|
| 361 |
+
// Pad the end of the stream with 0xFF 0xD9 (EOI marker)
|
| 362 |
+
int t = m_tem_flag;
|
| 363 |
+
m_tem_flag ^= 1;
|
| 364 |
+
if (t)
|
| 365 |
+
return 0xD9;
|
| 366 |
+
else
|
| 367 |
+
return 0xFF;
|
| 368 |
+
}
|
| 369 |
+
}
|
| 370 |
+
|
| 371 |
+
uint c = *m_pIn_buf_ofs++;
|
| 372 |
+
m_in_buf_left--;
|
| 373 |
+
|
| 374 |
+
return c;
|
| 375 |
+
}
|
| 376 |
+
|
| 377 |
+
// Same as previous method, except can indicate if the character is a pad character or not.
|
| 378 |
+
inline uint jpeg_decoder::get_char(bool *pPadding_flag)
|
| 379 |
+
{
|
| 380 |
+
if (!m_in_buf_left)
|
| 381 |
+
{
|
| 382 |
+
prep_in_buffer();
|
| 383 |
+
if (!m_in_buf_left)
|
| 384 |
+
{
|
| 385 |
+
*pPadding_flag = true;
|
| 386 |
+
int t = m_tem_flag;
|
| 387 |
+
m_tem_flag ^= 1;
|
| 388 |
+
if (t)
|
| 389 |
+
return 0xD9;
|
| 390 |
+
else
|
| 391 |
+
return 0xFF;
|
| 392 |
+
}
|
| 393 |
+
}
|
| 394 |
+
|
| 395 |
+
*pPadding_flag = false;
|
| 396 |
+
|
| 397 |
+
uint c = *m_pIn_buf_ofs++;
|
| 398 |
+
m_in_buf_left--;
|
| 399 |
+
|
| 400 |
+
return c;
|
| 401 |
+
}
|
| 402 |
+
|
| 403 |
+
// Inserts a previously retrieved character back into the input buffer.
|
| 404 |
+
inline void jpeg_decoder::stuff_char(uint8 q)
|
| 405 |
+
{
|
| 406 |
+
*(--m_pIn_buf_ofs) = q;
|
| 407 |
+
m_in_buf_left++;
|
| 408 |
+
}
|
| 409 |
+
|
| 410 |
+
// Retrieves one character from the input stream, but does not read past markers. Will continue to return 0xFF when a marker is encountered.
|
| 411 |
+
inline uint8 jpeg_decoder::get_octet()
|
| 412 |
+
{
|
| 413 |
+
bool padding_flag;
|
| 414 |
+
int c = get_char(&padding_flag);
|
| 415 |
+
|
| 416 |
+
if (c == 0xFF)
|
| 417 |
+
{
|
| 418 |
+
if (padding_flag)
|
| 419 |
+
return 0xFF;
|
| 420 |
+
|
| 421 |
+
c = get_char(&padding_flag);
|
| 422 |
+
if (padding_flag)
|
| 423 |
+
{
|
| 424 |
+
stuff_char(0xFF);
|
| 425 |
+
return 0xFF;
|
| 426 |
+
}
|
| 427 |
+
|
| 428 |
+
if (c == 0x00)
|
| 429 |
+
return 0xFF;
|
| 430 |
+
else
|
| 431 |
+
{
|
| 432 |
+
stuff_char(static_cast<uint8>(c));
|
| 433 |
+
stuff_char(0xFF);
|
| 434 |
+
return 0xFF;
|
| 435 |
+
}
|
| 436 |
+
}
|
| 437 |
+
|
| 438 |
+
return static_cast<uint8>(c);
|
| 439 |
+
}
|
| 440 |
+
|
| 441 |
+
// Retrieves a variable number of bits from the input stream. Does not recognize markers.
|
| 442 |
+
inline uint jpeg_decoder::get_bits(int num_bits)
|
| 443 |
+
{
|
| 444 |
+
if (!num_bits)
|
| 445 |
+
return 0;
|
| 446 |
+
|
| 447 |
+
uint i = m_bit_buf >> (32 - num_bits);
|
| 448 |
+
|
| 449 |
+
if ((m_bits_left -= num_bits) <= 0)
|
| 450 |
+
{
|
| 451 |
+
m_bit_buf <<= (num_bits += m_bits_left);
|
| 452 |
+
|
| 453 |
+
uint c1 = get_char();
|
| 454 |
+
uint c2 = get_char();
|
| 455 |
+
m_bit_buf = (m_bit_buf & 0xFFFF0000) | (c1 << 8) | c2;
|
| 456 |
+
|
| 457 |
+
m_bit_buf <<= -m_bits_left;
|
| 458 |
+
|
| 459 |
+
m_bits_left += 16;
|
| 460 |
+
|
| 461 |
+
JPGD_ASSERT(m_bits_left >= 0);
|
| 462 |
+
}
|
| 463 |
+
else
|
| 464 |
+
m_bit_buf <<= num_bits;
|
| 465 |
+
|
| 466 |
+
return i;
|
| 467 |
+
}
|
| 468 |
+
|
| 469 |
+
// Retrieves a variable number of bits from the input stream. Markers will not be read into the input bit buffer. Instead, an infinite number of all 1's will be returned when a marker is encountered.
|
| 470 |
+
inline uint jpeg_decoder::get_bits_no_markers(int num_bits)
|
| 471 |
+
{
|
| 472 |
+
if (!num_bits)
|
| 473 |
+
return 0;
|
| 474 |
+
|
| 475 |
+
uint i = m_bit_buf >> (32 - num_bits);
|
| 476 |
+
|
| 477 |
+
if ((m_bits_left -= num_bits) <= 0)
|
| 478 |
+
{
|
| 479 |
+
m_bit_buf <<= (num_bits += m_bits_left);
|
| 480 |
+
|
| 481 |
+
if ((m_in_buf_left < 2) || (m_pIn_buf_ofs[0] == 0xFF) || (m_pIn_buf_ofs[1] == 0xFF))
|
| 482 |
+
{
|
| 483 |
+
uint c1 = get_octet();
|
| 484 |
+
uint c2 = get_octet();
|
| 485 |
+
m_bit_buf |= (c1 << 8) | c2;
|
| 486 |
+
}
|
| 487 |
+
else
|
| 488 |
+
{
|
| 489 |
+
m_bit_buf |= ((uint)m_pIn_buf_ofs[0] << 8) | m_pIn_buf_ofs[1];
|
| 490 |
+
m_in_buf_left -= 2;
|
| 491 |
+
m_pIn_buf_ofs += 2;
|
| 492 |
+
}
|
| 493 |
+
|
| 494 |
+
m_bit_buf <<= -m_bits_left;
|
| 495 |
+
|
| 496 |
+
m_bits_left += 16;
|
| 497 |
+
|
| 498 |
+
JPGD_ASSERT(m_bits_left >= 0);
|
| 499 |
+
}
|
| 500 |
+
else
|
| 501 |
+
m_bit_buf <<= num_bits;
|
| 502 |
+
|
| 503 |
+
return i;
|
| 504 |
+
}
|
| 505 |
+
|
| 506 |
+
// Decodes a Huffman encoded symbol.
|
| 507 |
+
inline int jpeg_decoder::huff_decode(huff_tables *pH)
|
| 508 |
+
{
|
| 509 |
+
int symbol;
|
| 510 |
+
|
| 511 |
+
// Check first 8-bits: do we have a complete symbol?
|
| 512 |
+
if ((symbol = pH->look_up[m_bit_buf >> 24]) < 0)
|
| 513 |
+
{
|
| 514 |
+
// Decode more bits, use a tree traversal to find symbol.
|
| 515 |
+
int ofs = 23;
|
| 516 |
+
do
|
| 517 |
+
{
|
| 518 |
+
symbol = pH->tree[-(int)(symbol + ((m_bit_buf >> ofs) & 1))];
|
| 519 |
+
ofs--;
|
| 520 |
+
} while (symbol < 0);
|
| 521 |
+
|
| 522 |
+
get_bits_no_markers(8 + (23 - ofs));
|
| 523 |
+
}
|
| 524 |
+
else
|
| 525 |
+
get_bits_no_markers(pH->code_size[symbol]);
|
| 526 |
+
|
| 527 |
+
return symbol;
|
| 528 |
+
}
|
| 529 |
+
|
| 530 |
+
// Decodes a Huffman encoded symbol.
|
| 531 |
+
inline int jpeg_decoder::huff_decode(huff_tables *pH, int& extra_bits)
|
| 532 |
+
{
|
| 533 |
+
int symbol;
|
| 534 |
+
|
| 535 |
+
// Check first 8-bits: do we have a complete symbol?
|
| 536 |
+
if ((symbol = pH->look_up2[m_bit_buf >> 24]) < 0)
|
| 537 |
+
{
|
| 538 |
+
// Use a tree traversal to find symbol.
|
| 539 |
+
int ofs = 23;
|
| 540 |
+
do
|
| 541 |
+
{
|
| 542 |
+
symbol = pH->tree[-(int)(symbol + ((m_bit_buf >> ofs) & 1))];
|
| 543 |
+
ofs--;
|
| 544 |
+
} while (symbol < 0);
|
| 545 |
+
|
| 546 |
+
get_bits_no_markers(8 + (23 - ofs));
|
| 547 |
+
|
| 548 |
+
extra_bits = get_bits_no_markers(symbol & 0xF);
|
| 549 |
+
}
|
| 550 |
+
else
|
| 551 |
+
{
|
| 552 |
+
JPGD_ASSERT(((symbol >> 8) & 31) == pH->code_size[symbol & 255] + ((symbol & 0x8000) ? (symbol & 15) : 0));
|
| 553 |
+
|
| 554 |
+
if (symbol & 0x8000)
|
| 555 |
+
{
|
| 556 |
+
get_bits_no_markers((symbol >> 8) & 31);
|
| 557 |
+
extra_bits = symbol >> 16;
|
| 558 |
+
}
|
| 559 |
+
else
|
| 560 |
+
{
|
| 561 |
+
int code_size = (symbol >> 8) & 31;
|
| 562 |
+
int num_extra_bits = symbol & 0xF;
|
| 563 |
+
int bits = code_size + num_extra_bits;
|
| 564 |
+
if (bits <= (m_bits_left + 16))
|
| 565 |
+
extra_bits = get_bits_no_markers(bits) & ((1 << num_extra_bits) - 1);
|
| 566 |
+
else
|
| 567 |
+
{
|
| 568 |
+
get_bits_no_markers(code_size);
|
| 569 |
+
extra_bits = get_bits_no_markers(num_extra_bits);
|
| 570 |
+
}
|
| 571 |
+
}
|
| 572 |
+
|
| 573 |
+
symbol &= 0xFF;
|
| 574 |
+
}
|
| 575 |
+
|
| 576 |
+
return symbol;
|
| 577 |
+
}
|
| 578 |
+
|
| 579 |
+
// Tables and macro used to fully decode the DPCM differences.
|
| 580 |
+
static const int s_extend_test[16] = { 0, 0x0001, 0x0002, 0x0004, 0x0008, 0x0010, 0x0020, 0x0040, 0x0080, 0x0100, 0x0200, 0x0400, 0x0800, 0x1000, 0x2000, 0x4000 };
|
| 581 |
+
static const int s_extend_offset[16] = { 0, -1, -3, -7, -15, -31, -63, -127, -255, -511, -1023, -2047, -4095, -8191, -16383, -32767 };
|
| 582 |
+
static const int s_extend_mask[] = { 0, (1<<0), (1<<1), (1<<2), (1<<3), (1<<4), (1<<5), (1<<6), (1<<7), (1<<8), (1<<9), (1<<10), (1<<11), (1<<12), (1<<13), (1<<14), (1<<15), (1<<16) };
|
| 583 |
+
#define HUFF_EXTEND(x,s) ((x) < s_extend_test[s] ? (x) + s_extend_offset[s] : (x))
|
| 584 |
+
|
| 585 |
+
// Clamps a value between 0-255.
|
| 586 |
+
inline uint8 jpeg_decoder::clamp(int i)
|
| 587 |
+
{
|
| 588 |
+
if (static_cast<uint>(i) > 255)
|
| 589 |
+
i = (((~i) >> 31) & 0xFF);
|
| 590 |
+
|
| 591 |
+
return static_cast<uint8>(i);
|
| 592 |
+
}
|
| 593 |
+
|
| 594 |
+
namespace DCT_Upsample
|
| 595 |
+
{
|
| 596 |
+
struct Matrix44
|
| 597 |
+
{
|
| 598 |
+
typedef int Element_Type;
|
| 599 |
+
enum { NUM_ROWS = 4, NUM_COLS = 4 };
|
| 600 |
+
|
| 601 |
+
Element_Type v[NUM_ROWS][NUM_COLS];
|
| 602 |
+
|
| 603 |
+
inline int rows() const { return NUM_ROWS; }
|
| 604 |
+
inline int cols() const { return NUM_COLS; }
|
| 605 |
+
|
| 606 |
+
inline const Element_Type & at(int r, int c) const { return v[r][c]; }
|
| 607 |
+
inline Element_Type & at(int r, int c) { return v[r][c]; }
|
| 608 |
+
|
| 609 |
+
inline Matrix44() { }
|
| 610 |
+
|
| 611 |
+
inline Matrix44& operator += (const Matrix44& a)
|
| 612 |
+
{
|
| 613 |
+
for (int r = 0; r < NUM_ROWS; r++)
|
| 614 |
+
{
|
| 615 |
+
at(r, 0) += a.at(r, 0);
|
| 616 |
+
at(r, 1) += a.at(r, 1);
|
| 617 |
+
at(r, 2) += a.at(r, 2);
|
| 618 |
+
at(r, 3) += a.at(r, 3);
|
| 619 |
+
}
|
| 620 |
+
return *this;
|
| 621 |
+
}
|
| 622 |
+
|
| 623 |
+
inline Matrix44& operator -= (const Matrix44& a)
|
| 624 |
+
{
|
| 625 |
+
for (int r = 0; r < NUM_ROWS; r++)
|
| 626 |
+
{
|
| 627 |
+
at(r, 0) -= a.at(r, 0);
|
| 628 |
+
at(r, 1) -= a.at(r, 1);
|
| 629 |
+
at(r, 2) -= a.at(r, 2);
|
| 630 |
+
at(r, 3) -= a.at(r, 3);
|
| 631 |
+
}
|
| 632 |
+
return *this;
|
| 633 |
+
}
|
| 634 |
+
|
| 635 |
+
friend inline Matrix44 operator + (const Matrix44& a, const Matrix44& b)
|
| 636 |
+
{
|
| 637 |
+
Matrix44 ret;
|
| 638 |
+
for (int r = 0; r < NUM_ROWS; r++)
|
| 639 |
+
{
|
| 640 |
+
ret.at(r, 0) = a.at(r, 0) + b.at(r, 0);
|
| 641 |
+
ret.at(r, 1) = a.at(r, 1) + b.at(r, 1);
|
| 642 |
+
ret.at(r, 2) = a.at(r, 2) + b.at(r, 2);
|
| 643 |
+
ret.at(r, 3) = a.at(r, 3) + b.at(r, 3);
|
| 644 |
+
}
|
| 645 |
+
return ret;
|
| 646 |
+
}
|
| 647 |
+
|
| 648 |
+
friend inline Matrix44 operator - (const Matrix44& a, const Matrix44& b)
|
| 649 |
+
{
|
| 650 |
+
Matrix44 ret;
|
| 651 |
+
for (int r = 0; r < NUM_ROWS; r++)
|
| 652 |
+
{
|
| 653 |
+
ret.at(r, 0) = a.at(r, 0) - b.at(r, 0);
|
| 654 |
+
ret.at(r, 1) = a.at(r, 1) - b.at(r, 1);
|
| 655 |
+
ret.at(r, 2) = a.at(r, 2) - b.at(r, 2);
|
| 656 |
+
ret.at(r, 3) = a.at(r, 3) - b.at(r, 3);
|
| 657 |
+
}
|
| 658 |
+
return ret;
|
| 659 |
+
}
|
| 660 |
+
|
| 661 |
+
static inline void add_and_store(jpgd_block_t* pDst, const Matrix44& a, const Matrix44& b)
|
| 662 |
+
{
|
| 663 |
+
for (int r = 0; r < 4; r++)
|
| 664 |
+
{
|
| 665 |
+
pDst[0*8 + r] = static_cast<jpgd_block_t>(a.at(r, 0) + b.at(r, 0));
|
| 666 |
+
pDst[1*8 + r] = static_cast<jpgd_block_t>(a.at(r, 1) + b.at(r, 1));
|
| 667 |
+
pDst[2*8 + r] = static_cast<jpgd_block_t>(a.at(r, 2) + b.at(r, 2));
|
| 668 |
+
pDst[3*8 + r] = static_cast<jpgd_block_t>(a.at(r, 3) + b.at(r, 3));
|
| 669 |
+
}
|
| 670 |
+
}
|
| 671 |
+
|
| 672 |
+
static inline void sub_and_store(jpgd_block_t* pDst, const Matrix44& a, const Matrix44& b)
|
| 673 |
+
{
|
| 674 |
+
for (int r = 0; r < 4; r++)
|
| 675 |
+
{
|
| 676 |
+
pDst[0*8 + r] = static_cast<jpgd_block_t>(a.at(r, 0) - b.at(r, 0));
|
| 677 |
+
pDst[1*8 + r] = static_cast<jpgd_block_t>(a.at(r, 1) - b.at(r, 1));
|
| 678 |
+
pDst[2*8 + r] = static_cast<jpgd_block_t>(a.at(r, 2) - b.at(r, 2));
|
| 679 |
+
pDst[3*8 + r] = static_cast<jpgd_block_t>(a.at(r, 3) - b.at(r, 3));
|
| 680 |
+
}
|
| 681 |
+
}
|
| 682 |
+
};
|
| 683 |
+
|
| 684 |
+
const int FRACT_BITS = 10;
|
| 685 |
+
const int SCALE = 1 << FRACT_BITS;
|
| 686 |
+
|
| 687 |
+
typedef int Temp_Type;
|
| 688 |
+
#define D(i) (((i) + (SCALE >> 1)) >> FRACT_BITS)
|
| 689 |
+
#define F(i) ((int)((i) * SCALE + .5f))
|
| 690 |
+
|
| 691 |
+
// Any decent C++ compiler will optimize this at compile time to a 0, or an array access.
|
| 692 |
+
#define AT(c, r) ((((c)>=NUM_COLS)||((r)>=NUM_ROWS)) ? 0 : pSrc[(c)+(r)*8])
|
| 693 |
+
|
| 694 |
+
// NUM_ROWS/NUM_COLS = # of non-zero rows/cols in input matrix
|
| 695 |
+
template<int NUM_ROWS, int NUM_COLS>
|
| 696 |
+
struct P_Q
|
| 697 |
+
{
|
| 698 |
+
static void calc(Matrix44& P, Matrix44& Q, const jpgd_block_t* pSrc)
|
| 699 |
+
{
|
| 700 |
+
// 4x8 = 4x8 times 8x8, matrix 0 is constant
|
| 701 |
+
const Temp_Type X000 = AT(0, 0);
|
| 702 |
+
const Temp_Type X001 = AT(0, 1);
|
| 703 |
+
const Temp_Type X002 = AT(0, 2);
|
| 704 |
+
const Temp_Type X003 = AT(0, 3);
|
| 705 |
+
const Temp_Type X004 = AT(0, 4);
|
| 706 |
+
const Temp_Type X005 = AT(0, 5);
|
| 707 |
+
const Temp_Type X006 = AT(0, 6);
|
| 708 |
+
const Temp_Type X007 = AT(0, 7);
|
| 709 |
+
const Temp_Type X010 = D(F(0.415735f) * AT(1, 0) + F(0.791065f) * AT(3, 0) + F(-0.352443f) * AT(5, 0) + F(0.277785f) * AT(7, 0));
|
| 710 |
+
const Temp_Type X011 = D(F(0.415735f) * AT(1, 1) + F(0.791065f) * AT(3, 1) + F(-0.352443f) * AT(5, 1) + F(0.277785f) * AT(7, 1));
|
| 711 |
+
const Temp_Type X012 = D(F(0.415735f) * AT(1, 2) + F(0.791065f) * AT(3, 2) + F(-0.352443f) * AT(5, 2) + F(0.277785f) * AT(7, 2));
|
| 712 |
+
const Temp_Type X013 = D(F(0.415735f) * AT(1, 3) + F(0.791065f) * AT(3, 3) + F(-0.352443f) * AT(5, 3) + F(0.277785f) * AT(7, 3));
|
| 713 |
+
const Temp_Type X014 = D(F(0.415735f) * AT(1, 4) + F(0.791065f) * AT(3, 4) + F(-0.352443f) * AT(5, 4) + F(0.277785f) * AT(7, 4));
|
| 714 |
+
const Temp_Type X015 = D(F(0.415735f) * AT(1, 5) + F(0.791065f) * AT(3, 5) + F(-0.352443f) * AT(5, 5) + F(0.277785f) * AT(7, 5));
|
| 715 |
+
const Temp_Type X016 = D(F(0.415735f) * AT(1, 6) + F(0.791065f) * AT(3, 6) + F(-0.352443f) * AT(5, 6) + F(0.277785f) * AT(7, 6));
|
| 716 |
+
const Temp_Type X017 = D(F(0.415735f) * AT(1, 7) + F(0.791065f) * AT(3, 7) + F(-0.352443f) * AT(5, 7) + F(0.277785f) * AT(7, 7));
|
| 717 |
+
const Temp_Type X020 = AT(4, 0);
|
| 718 |
+
const Temp_Type X021 = AT(4, 1);
|
| 719 |
+
const Temp_Type X022 = AT(4, 2);
|
| 720 |
+
const Temp_Type X023 = AT(4, 3);
|
| 721 |
+
const Temp_Type X024 = AT(4, 4);
|
| 722 |
+
const Temp_Type X025 = AT(4, 5);
|
| 723 |
+
const Temp_Type X026 = AT(4, 6);
|
| 724 |
+
const Temp_Type X027 = AT(4, 7);
|
| 725 |
+
const Temp_Type X030 = D(F(0.022887f) * AT(1, 0) + F(-0.097545f) * AT(3, 0) + F(0.490393f) * AT(5, 0) + F(0.865723f) * AT(7, 0));
|
| 726 |
+
const Temp_Type X031 = D(F(0.022887f) * AT(1, 1) + F(-0.097545f) * AT(3, 1) + F(0.490393f) * AT(5, 1) + F(0.865723f) * AT(7, 1));
|
| 727 |
+
const Temp_Type X032 = D(F(0.022887f) * AT(1, 2) + F(-0.097545f) * AT(3, 2) + F(0.490393f) * AT(5, 2) + F(0.865723f) * AT(7, 2));
|
| 728 |
+
const Temp_Type X033 = D(F(0.022887f) * AT(1, 3) + F(-0.097545f) * AT(3, 3) + F(0.490393f) * AT(5, 3) + F(0.865723f) * AT(7, 3));
|
| 729 |
+
const Temp_Type X034 = D(F(0.022887f) * AT(1, 4) + F(-0.097545f) * AT(3, 4) + F(0.490393f) * AT(5, 4) + F(0.865723f) * AT(7, 4));
|
| 730 |
+
const Temp_Type X035 = D(F(0.022887f) * AT(1, 5) + F(-0.097545f) * AT(3, 5) + F(0.490393f) * AT(5, 5) + F(0.865723f) * AT(7, 5));
|
| 731 |
+
const Temp_Type X036 = D(F(0.022887f) * AT(1, 6) + F(-0.097545f) * AT(3, 6) + F(0.490393f) * AT(5, 6) + F(0.865723f) * AT(7, 6));
|
| 732 |
+
const Temp_Type X037 = D(F(0.022887f) * AT(1, 7) + F(-0.097545f) * AT(3, 7) + F(0.490393f) * AT(5, 7) + F(0.865723f) * AT(7, 7));
|
| 733 |
+
|
| 734 |
+
// 4x4 = 4x8 times 8x4, matrix 1 is constant
|
| 735 |
+
P.at(0, 0) = X000;
|
| 736 |
+
P.at(0, 1) = D(X001 * F(0.415735f) + X003 * F(0.791065f) + X005 * F(-0.352443f) + X007 * F(0.277785f));
|
| 737 |
+
P.at(0, 2) = X004;
|
| 738 |
+
P.at(0, 3) = D(X001 * F(0.022887f) + X003 * F(-0.097545f) + X005 * F(0.490393f) + X007 * F(0.865723f));
|
| 739 |
+
P.at(1, 0) = X010;
|
| 740 |
+
P.at(1, 1) = D(X011 * F(0.415735f) + X013 * F(0.791065f) + X015 * F(-0.352443f) + X017 * F(0.277785f));
|
| 741 |
+
P.at(1, 2) = X014;
|
| 742 |
+
P.at(1, 3) = D(X011 * F(0.022887f) + X013 * F(-0.097545f) + X015 * F(0.490393f) + X017 * F(0.865723f));
|
| 743 |
+
P.at(2, 0) = X020;
|
| 744 |
+
P.at(2, 1) = D(X021 * F(0.415735f) + X023 * F(0.791065f) + X025 * F(-0.352443f) + X027 * F(0.277785f));
|
| 745 |
+
P.at(2, 2) = X024;
|
| 746 |
+
P.at(2, 3) = D(X021 * F(0.022887f) + X023 * F(-0.097545f) + X025 * F(0.490393f) + X027 * F(0.865723f));
|
| 747 |
+
P.at(3, 0) = X030;
|
| 748 |
+
P.at(3, 1) = D(X031 * F(0.415735f) + X033 * F(0.791065f) + X035 * F(-0.352443f) + X037 * F(0.277785f));
|
| 749 |
+
P.at(3, 2) = X034;
|
| 750 |
+
P.at(3, 3) = D(X031 * F(0.022887f) + X033 * F(-0.097545f) + X035 * F(0.490393f) + X037 * F(0.865723f));
|
| 751 |
+
// 40 muls 24 adds
|
| 752 |
+
|
| 753 |
+
// 4x4 = 4x8 times 8x4, matrix 1 is constant
|
| 754 |
+
Q.at(0, 0) = D(X001 * F(0.906127f) + X003 * F(-0.318190f) + X005 * F(0.212608f) + X007 * F(-0.180240f));
|
| 755 |
+
Q.at(0, 1) = X002;
|
| 756 |
+
Q.at(0, 2) = D(X001 * F(-0.074658f) + X003 * F(0.513280f) + X005 * F(0.768178f) + X007 * F(-0.375330f));
|
| 757 |
+
Q.at(0, 3) = X006;
|
| 758 |
+
Q.at(1, 0) = D(X011 * F(0.906127f) + X013 * F(-0.318190f) + X015 * F(0.212608f) + X017 * F(-0.180240f));
|
| 759 |
+
Q.at(1, 1) = X012;
|
| 760 |
+
Q.at(1, 2) = D(X011 * F(-0.074658f) + X013 * F(0.513280f) + X015 * F(0.768178f) + X017 * F(-0.375330f));
|
| 761 |
+
Q.at(1, 3) = X016;
|
| 762 |
+
Q.at(2, 0) = D(X021 * F(0.906127f) + X023 * F(-0.318190f) + X025 * F(0.212608f) + X027 * F(-0.180240f));
|
| 763 |
+
Q.at(2, 1) = X022;
|
| 764 |
+
Q.at(2, 2) = D(X021 * F(-0.074658f) + X023 * F(0.513280f) + X025 * F(0.768178f) + X027 * F(-0.375330f));
|
| 765 |
+
Q.at(2, 3) = X026;
|
| 766 |
+
Q.at(3, 0) = D(X031 * F(0.906127f) + X033 * F(-0.318190f) + X035 * F(0.212608f) + X037 * F(-0.180240f));
|
| 767 |
+
Q.at(3, 1) = X032;
|
| 768 |
+
Q.at(3, 2) = D(X031 * F(-0.074658f) + X033 * F(0.513280f) + X035 * F(0.768178f) + X037 * F(-0.375330f));
|
| 769 |
+
Q.at(3, 3) = X036;
|
| 770 |
+
// 40 muls 24 adds
|
| 771 |
+
}
|
| 772 |
+
};
|
| 773 |
+
|
| 774 |
+
template<int NUM_ROWS, int NUM_COLS>
|
| 775 |
+
struct R_S
|
| 776 |
+
{
|
| 777 |
+
static void calc(Matrix44& R, Matrix44& S, const jpgd_block_t* pSrc)
|
| 778 |
+
{
|
| 779 |
+
// 4x8 = 4x8 times 8x8, matrix 0 is constant
|
| 780 |
+
const Temp_Type X100 = D(F(0.906127f) * AT(1, 0) + F(-0.318190f) * AT(3, 0) + F(0.212608f) * AT(5, 0) + F(-0.180240f) * AT(7, 0));
|
| 781 |
+
const Temp_Type X101 = D(F(0.906127f) * AT(1, 1) + F(-0.318190f) * AT(3, 1) + F(0.212608f) * AT(5, 1) + F(-0.180240f) * AT(7, 1));
|
| 782 |
+
const Temp_Type X102 = D(F(0.906127f) * AT(1, 2) + F(-0.318190f) * AT(3, 2) + F(0.212608f) * AT(5, 2) + F(-0.180240f) * AT(7, 2));
|
| 783 |
+
const Temp_Type X103 = D(F(0.906127f) * AT(1, 3) + F(-0.318190f) * AT(3, 3) + F(0.212608f) * AT(5, 3) + F(-0.180240f) * AT(7, 3));
|
| 784 |
+
const Temp_Type X104 = D(F(0.906127f) * AT(1, 4) + F(-0.318190f) * AT(3, 4) + F(0.212608f) * AT(5, 4) + F(-0.180240f) * AT(7, 4));
|
| 785 |
+
const Temp_Type X105 = D(F(0.906127f) * AT(1, 5) + F(-0.318190f) * AT(3, 5) + F(0.212608f) * AT(5, 5) + F(-0.180240f) * AT(7, 5));
|
| 786 |
+
const Temp_Type X106 = D(F(0.906127f) * AT(1, 6) + F(-0.318190f) * AT(3, 6) + F(0.212608f) * AT(5, 6) + F(-0.180240f) * AT(7, 6));
|
| 787 |
+
const Temp_Type X107 = D(F(0.906127f) * AT(1, 7) + F(-0.318190f) * AT(3, 7) + F(0.212608f) * AT(5, 7) + F(-0.180240f) * AT(7, 7));
|
| 788 |
+
const Temp_Type X110 = AT(2, 0);
|
| 789 |
+
const Temp_Type X111 = AT(2, 1);
|
| 790 |
+
const Temp_Type X112 = AT(2, 2);
|
| 791 |
+
const Temp_Type X113 = AT(2, 3);
|
| 792 |
+
const Temp_Type X114 = AT(2, 4);
|
| 793 |
+
const Temp_Type X115 = AT(2, 5);
|
| 794 |
+
const Temp_Type X116 = AT(2, 6);
|
| 795 |
+
const Temp_Type X117 = AT(2, 7);
|
| 796 |
+
const Temp_Type X120 = D(F(-0.074658f) * AT(1, 0) + F(0.513280f) * AT(3, 0) + F(0.768178f) * AT(5, 0) + F(-0.375330f) * AT(7, 0));
|
| 797 |
+
const Temp_Type X121 = D(F(-0.074658f) * AT(1, 1) + F(0.513280f) * AT(3, 1) + F(0.768178f) * AT(5, 1) + F(-0.375330f) * AT(7, 1));
|
| 798 |
+
const Temp_Type X122 = D(F(-0.074658f) * AT(1, 2) + F(0.513280f) * AT(3, 2) + F(0.768178f) * AT(5, 2) + F(-0.375330f) * AT(7, 2));
|
| 799 |
+
const Temp_Type X123 = D(F(-0.074658f) * AT(1, 3) + F(0.513280f) * AT(3, 3) + F(0.768178f) * AT(5, 3) + F(-0.375330f) * AT(7, 3));
|
| 800 |
+
const Temp_Type X124 = D(F(-0.074658f) * AT(1, 4) + F(0.513280f) * AT(3, 4) + F(0.768178f) * AT(5, 4) + F(-0.375330f) * AT(7, 4));
|
| 801 |
+
const Temp_Type X125 = D(F(-0.074658f) * AT(1, 5) + F(0.513280f) * AT(3, 5) + F(0.768178f) * AT(5, 5) + F(-0.375330f) * AT(7, 5));
|
| 802 |
+
const Temp_Type X126 = D(F(-0.074658f) * AT(1, 6) + F(0.513280f) * AT(3, 6) + F(0.768178f) * AT(5, 6) + F(-0.375330f) * AT(7, 6));
|
| 803 |
+
const Temp_Type X127 = D(F(-0.074658f) * AT(1, 7) + F(0.513280f) * AT(3, 7) + F(0.768178f) * AT(5, 7) + F(-0.375330f) * AT(7, 7));
|
| 804 |
+
const Temp_Type X130 = AT(6, 0);
|
| 805 |
+
const Temp_Type X131 = AT(6, 1);
|
| 806 |
+
const Temp_Type X132 = AT(6, 2);
|
| 807 |
+
const Temp_Type X133 = AT(6, 3);
|
| 808 |
+
const Temp_Type X134 = AT(6, 4);
|
| 809 |
+
const Temp_Type X135 = AT(6, 5);
|
| 810 |
+
const Temp_Type X136 = AT(6, 6);
|
| 811 |
+
const Temp_Type X137 = AT(6, 7);
|
| 812 |
+
// 80 muls 48 adds
|
| 813 |
+
|
| 814 |
+
// 4x4 = 4x8 times 8x4, matrix 1 is constant
|
| 815 |
+
R.at(0, 0) = X100;
|
| 816 |
+
R.at(0, 1) = D(X101 * F(0.415735f) + X103 * F(0.791065f) + X105 * F(-0.352443f) + X107 * F(0.277785f));
|
| 817 |
+
R.at(0, 2) = X104;
|
| 818 |
+
R.at(0, 3) = D(X101 * F(0.022887f) + X103 * F(-0.097545f) + X105 * F(0.490393f) + X107 * F(0.865723f));
|
| 819 |
+
R.at(1, 0) = X110;
|
| 820 |
+
R.at(1, 1) = D(X111 * F(0.415735f) + X113 * F(0.791065f) + X115 * F(-0.352443f) + X117 * F(0.277785f));
|
| 821 |
+
R.at(1, 2) = X114;
|
| 822 |
+
R.at(1, 3) = D(X111 * F(0.022887f) + X113 * F(-0.097545f) + X115 * F(0.490393f) + X117 * F(0.865723f));
|
| 823 |
+
R.at(2, 0) = X120;
|
| 824 |
+
R.at(2, 1) = D(X121 * F(0.415735f) + X123 * F(0.791065f) + X125 * F(-0.352443f) + X127 * F(0.277785f));
|
| 825 |
+
R.at(2, 2) = X124;
|
| 826 |
+
R.at(2, 3) = D(X121 * F(0.022887f) + X123 * F(-0.097545f) + X125 * F(0.490393f) + X127 * F(0.865723f));
|
| 827 |
+
R.at(3, 0) = X130;
|
| 828 |
+
R.at(3, 1) = D(X131 * F(0.415735f) + X133 * F(0.791065f) + X135 * F(-0.352443f) + X137 * F(0.277785f));
|
| 829 |
+
R.at(3, 2) = X134;
|
| 830 |
+
R.at(3, 3) = D(X131 * F(0.022887f) + X133 * F(-0.097545f) + X135 * F(0.490393f) + X137 * F(0.865723f));
|
| 831 |
+
// 40 muls 24 adds
|
| 832 |
+
// 4x4 = 4x8 times 8x4, matrix 1 is constant
|
| 833 |
+
S.at(0, 0) = D(X101 * F(0.906127f) + X103 * F(-0.318190f) + X105 * F(0.212608f) + X107 * F(-0.180240f));
|
| 834 |
+
S.at(0, 1) = X102;
|
| 835 |
+
S.at(0, 2) = D(X101 * F(-0.074658f) + X103 * F(0.513280f) + X105 * F(0.768178f) + X107 * F(-0.375330f));
|
| 836 |
+
S.at(0, 3) = X106;
|
| 837 |
+
S.at(1, 0) = D(X111 * F(0.906127f) + X113 * F(-0.318190f) + X115 * F(0.212608f) + X117 * F(-0.180240f));
|
| 838 |
+
S.at(1, 1) = X112;
|
| 839 |
+
S.at(1, 2) = D(X111 * F(-0.074658f) + X113 * F(0.513280f) + X115 * F(0.768178f) + X117 * F(-0.375330f));
|
| 840 |
+
S.at(1, 3) = X116;
|
| 841 |
+
S.at(2, 0) = D(X121 * F(0.906127f) + X123 * F(-0.318190f) + X125 * F(0.212608f) + X127 * F(-0.180240f));
|
| 842 |
+
S.at(2, 1) = X122;
|
| 843 |
+
S.at(2, 2) = D(X121 * F(-0.074658f) + X123 * F(0.513280f) + X125 * F(0.768178f) + X127 * F(-0.375330f));
|
| 844 |
+
S.at(2, 3) = X126;
|
| 845 |
+
S.at(3, 0) = D(X131 * F(0.906127f) + X133 * F(-0.318190f) + X135 * F(0.212608f) + X137 * F(-0.180240f));
|
| 846 |
+
S.at(3, 1) = X132;
|
| 847 |
+
S.at(3, 2) = D(X131 * F(-0.074658f) + X133 * F(0.513280f) + X135 * F(0.768178f) + X137 * F(-0.375330f));
|
| 848 |
+
S.at(3, 3) = X136;
|
| 849 |
+
// 40 muls 24 adds
|
| 850 |
+
}
|
| 851 |
+
};
|
| 852 |
+
} // end namespace DCT_Upsample
|
| 853 |
+
|
| 854 |
+
// Unconditionally frees all allocated m_blocks.
|
| 855 |
+
void jpeg_decoder::free_all_blocks()
|
| 856 |
+
{
|
| 857 |
+
m_pStream = NULL;
|
| 858 |
+
for (mem_block *b = m_pMem_blocks; b; )
|
| 859 |
+
{
|
| 860 |
+
mem_block *n = b->m_pNext;
|
| 861 |
+
jpgd_free(b);
|
| 862 |
+
b = n;
|
| 863 |
+
}
|
| 864 |
+
m_pMem_blocks = NULL;
|
| 865 |
+
}
|
| 866 |
+
|
| 867 |
+
// This method handles all errors.
|
| 868 |
+
// It could easily be changed to use C++ exceptions.
|
| 869 |
+
void jpeg_decoder::stop_decoding(jpgd_status status)
|
| 870 |
+
{
|
| 871 |
+
m_error_code = status;
|
| 872 |
+
free_all_blocks();
|
| 873 |
+
longjmp(m_jmp_state, status);
|
| 874 |
+
|
| 875 |
+
// we shouldn't get here as longjmp shouldn't return, but we put it here to make it explicit
|
| 876 |
+
// that this function doesn't return, otherwise we get this error:
|
| 877 |
+
//
|
| 878 |
+
// error : function declared 'noreturn' should not return
|
| 879 |
+
exit(1);
|
| 880 |
+
}
|
| 881 |
+
|
| 882 |
+
void *jpeg_decoder::alloc(size_t nSize, bool zero)
|
| 883 |
+
{
|
| 884 |
+
nSize = (JPGD_MAX(nSize, 1) + 3) & ~3;
|
| 885 |
+
char *rv = NULL;
|
| 886 |
+
for (mem_block *b = m_pMem_blocks; b; b = b->m_pNext)
|
| 887 |
+
{
|
| 888 |
+
if ((b->m_used_count + nSize) <= b->m_size)
|
| 889 |
+
{
|
| 890 |
+
rv = b->m_data + b->m_used_count;
|
| 891 |
+
b->m_used_count += nSize;
|
| 892 |
+
break;
|
| 893 |
+
}
|
| 894 |
+
}
|
| 895 |
+
if (!rv)
|
| 896 |
+
{
|
| 897 |
+
int capacity = JPGD_MAX(32768 - 256, (nSize + 2047) & ~2047);
|
| 898 |
+
mem_block *b = (mem_block*)jpgd_malloc(sizeof(mem_block) + capacity);
|
| 899 |
+
if (!b) stop_decoding(JPGD_NOTENOUGHMEM);
|
| 900 |
+
b->m_pNext = m_pMem_blocks; m_pMem_blocks = b;
|
| 901 |
+
b->m_used_count = nSize;
|
| 902 |
+
b->m_size = capacity;
|
| 903 |
+
rv = b->m_data;
|
| 904 |
+
}
|
| 905 |
+
if (zero) memset(rv, 0, nSize);
|
| 906 |
+
return rv;
|
| 907 |
+
}
|
| 908 |
+
|
| 909 |
+
void jpeg_decoder::word_clear(void *p, uint16 c, uint n)
|
| 910 |
+
{
|
| 911 |
+
uint8 *pD = (uint8*)p;
|
| 912 |
+
const uint8 l = c & 0xFF, h = (c >> 8) & 0xFF;
|
| 913 |
+
while (n)
|
| 914 |
+
{
|
| 915 |
+
pD[0] = l; pD[1] = h; pD += 2;
|
| 916 |
+
n--;
|
| 917 |
+
}
|
| 918 |
+
}
|
| 919 |
+
|
| 920 |
+
// Refill the input buffer.
|
| 921 |
+
// This method will sit in a loop until (A) the buffer is full or (B)
|
| 922 |
+
// the stream's read() method reports and end of file condition.
|
| 923 |
+
void jpeg_decoder::prep_in_buffer()
|
| 924 |
+
{
|
| 925 |
+
m_in_buf_left = 0;
|
| 926 |
+
m_pIn_buf_ofs = m_in_buf;
|
| 927 |
+
|
| 928 |
+
if (m_eof_flag)
|
| 929 |
+
return;
|
| 930 |
+
|
| 931 |
+
do
|
| 932 |
+
{
|
| 933 |
+
int bytes_read = m_pStream->read(m_in_buf + m_in_buf_left, JPGD_IN_BUF_SIZE - m_in_buf_left, &m_eof_flag);
|
| 934 |
+
if (bytes_read == -1)
|
| 935 |
+
stop_decoding(JPGD_STREAM_READ);
|
| 936 |
+
|
| 937 |
+
m_in_buf_left += bytes_read;
|
| 938 |
+
} while ((m_in_buf_left < JPGD_IN_BUF_SIZE) && (!m_eof_flag));
|
| 939 |
+
|
| 940 |
+
m_total_bytes_read += m_in_buf_left;
|
| 941 |
+
|
| 942 |
+
// Pad the end of the block with M_EOI (prevents the decompressor from going off the rails if the stream is invalid).
|
| 943 |
+
// (This dates way back to when this decompressor was written in C/asm, and the all-asm Huffman decoder did some fancy things to increase perf.)
|
| 944 |
+
word_clear(m_pIn_buf_ofs + m_in_buf_left, 0xD9FF, 64);
|
| 945 |
+
}
|
| 946 |
+
|
| 947 |
+
// Read a Huffman code table.
|
| 948 |
+
void jpeg_decoder::read_dht_marker()
|
| 949 |
+
{
|
| 950 |
+
int i, index, count;
|
| 951 |
+
uint8 huff_num[17];
|
| 952 |
+
uint8 huff_val[256];
|
| 953 |
+
|
| 954 |
+
uint num_left = get_bits(16);
|
| 955 |
+
|
| 956 |
+
if (num_left < 2)
|
| 957 |
+
stop_decoding(JPGD_BAD_DHT_MARKER);
|
| 958 |
+
|
| 959 |
+
num_left -= 2;
|
| 960 |
+
|
| 961 |
+
while (num_left)
|
| 962 |
+
{
|
| 963 |
+
index = get_bits(8);
|
| 964 |
+
|
| 965 |
+
huff_num[0] = 0;
|
| 966 |
+
|
| 967 |
+
count = 0;
|
| 968 |
+
|
| 969 |
+
for (i = 1; i <= 16; i++)
|
| 970 |
+
{
|
| 971 |
+
huff_num[i] = static_cast<uint8>(get_bits(8));
|
| 972 |
+
count += huff_num[i];
|
| 973 |
+
}
|
| 974 |
+
|
| 975 |
+
if (count > 255)
|
| 976 |
+
stop_decoding(JPGD_BAD_DHT_COUNTS);
|
| 977 |
+
|
| 978 |
+
for (i = 0; i < count; i++)
|
| 979 |
+
huff_val[i] = static_cast<uint8>(get_bits(8));
|
| 980 |
+
|
| 981 |
+
i = 1 + 16 + count;
|
| 982 |
+
|
| 983 |
+
if (num_left < (uint)i)
|
| 984 |
+
stop_decoding(JPGD_BAD_DHT_MARKER);
|
| 985 |
+
|
| 986 |
+
num_left -= i;
|
| 987 |
+
|
| 988 |
+
if ((index & 0x10) > 0x10)
|
| 989 |
+
stop_decoding(JPGD_BAD_DHT_INDEX);
|
| 990 |
+
|
| 991 |
+
index = (index & 0x0F) + ((index & 0x10) >> 4) * (JPGD_MAX_HUFF_TABLES >> 1);
|
| 992 |
+
|
| 993 |
+
if (index >= JPGD_MAX_HUFF_TABLES)
|
| 994 |
+
stop_decoding(JPGD_BAD_DHT_INDEX);
|
| 995 |
+
|
| 996 |
+
if (!m_huff_num[index])
|
| 997 |
+
m_huff_num[index] = (uint8 *)alloc(17);
|
| 998 |
+
|
| 999 |
+
if (!m_huff_val[index])
|
| 1000 |
+
m_huff_val[index] = (uint8 *)alloc(256);
|
| 1001 |
+
|
| 1002 |
+
m_huff_ac[index] = (index & 0x10) != 0;
|
| 1003 |
+
memcpy(m_huff_num[index], huff_num, 17);
|
| 1004 |
+
memcpy(m_huff_val[index], huff_val, 256);
|
| 1005 |
+
}
|
| 1006 |
+
}
|
| 1007 |
+
|
| 1008 |
+
// Read a quantization table.
|
| 1009 |
+
void jpeg_decoder::read_dqt_marker()
|
| 1010 |
+
{
|
| 1011 |
+
int n, i, prec;
|
| 1012 |
+
uint num_left;
|
| 1013 |
+
uint temp;
|
| 1014 |
+
|
| 1015 |
+
num_left = get_bits(16);
|
| 1016 |
+
|
| 1017 |
+
if (num_left < 2)
|
| 1018 |
+
stop_decoding(JPGD_BAD_DQT_MARKER);
|
| 1019 |
+
|
| 1020 |
+
num_left -= 2;
|
| 1021 |
+
|
| 1022 |
+
while (num_left)
|
| 1023 |
+
{
|
| 1024 |
+
n = get_bits(8);
|
| 1025 |
+
prec = n >> 4;
|
| 1026 |
+
n &= 0x0F;
|
| 1027 |
+
|
| 1028 |
+
if (n >= JPGD_MAX_QUANT_TABLES)
|
| 1029 |
+
stop_decoding(JPGD_BAD_DQT_TABLE);
|
| 1030 |
+
|
| 1031 |
+
if (!m_quant[n])
|
| 1032 |
+
m_quant[n] = (jpgd_quant_t *)alloc(64 * sizeof(jpgd_quant_t));
|
| 1033 |
+
|
| 1034 |
+
// read quantization entries, in zag order
|
| 1035 |
+
for (i = 0; i < 64; i++)
|
| 1036 |
+
{
|
| 1037 |
+
temp = get_bits(8);
|
| 1038 |
+
|
| 1039 |
+
if (prec)
|
| 1040 |
+
temp = (temp << 8) + get_bits(8);
|
| 1041 |
+
|
| 1042 |
+
m_quant[n][i] = static_cast<jpgd_quant_t>(temp);
|
| 1043 |
+
}
|
| 1044 |
+
|
| 1045 |
+
i = 64 + 1;
|
| 1046 |
+
|
| 1047 |
+
if (prec)
|
| 1048 |
+
i += 64;
|
| 1049 |
+
|
| 1050 |
+
if (num_left < (uint)i)
|
| 1051 |
+
stop_decoding(JPGD_BAD_DQT_LENGTH);
|
| 1052 |
+
|
| 1053 |
+
num_left -= i;
|
| 1054 |
+
}
|
| 1055 |
+
}
|
| 1056 |
+
|
| 1057 |
+
// Read the start of frame (SOF) marker.
|
| 1058 |
+
void jpeg_decoder::read_sof_marker()
|
| 1059 |
+
{
|
| 1060 |
+
int i;
|
| 1061 |
+
uint num_left;
|
| 1062 |
+
|
| 1063 |
+
num_left = get_bits(16);
|
| 1064 |
+
|
| 1065 |
+
if (get_bits(8) != 8) /* precision: sorry, only 8-bit precision is supported right now */
|
| 1066 |
+
stop_decoding(JPGD_BAD_PRECISION);
|
| 1067 |
+
|
| 1068 |
+
m_image_y_size = get_bits(16);
|
| 1069 |
+
|
| 1070 |
+
if ((m_image_y_size < 1) || (m_image_y_size > JPGD_MAX_HEIGHT))
|
| 1071 |
+
stop_decoding(JPGD_BAD_HEIGHT);
|
| 1072 |
+
|
| 1073 |
+
m_image_x_size = get_bits(16);
|
| 1074 |
+
|
| 1075 |
+
if ((m_image_x_size < 1) || (m_image_x_size > JPGD_MAX_WIDTH))
|
| 1076 |
+
stop_decoding(JPGD_BAD_WIDTH);
|
| 1077 |
+
|
| 1078 |
+
m_comps_in_frame = get_bits(8);
|
| 1079 |
+
|
| 1080 |
+
if (m_comps_in_frame > JPGD_MAX_COMPONENTS)
|
| 1081 |
+
stop_decoding(JPGD_TOO_MANY_COMPONENTS);
|
| 1082 |
+
|
| 1083 |
+
if (num_left != (uint)(m_comps_in_frame * 3 + 8))
|
| 1084 |
+
stop_decoding(JPGD_BAD_SOF_LENGTH);
|
| 1085 |
+
|
| 1086 |
+
for (i = 0; i < m_comps_in_frame; i++)
|
| 1087 |
+
{
|
| 1088 |
+
m_comp_ident[i] = get_bits(8);
|
| 1089 |
+
m_comp_h_samp[i] = get_bits(4);
|
| 1090 |
+
m_comp_v_samp[i] = get_bits(4);
|
| 1091 |
+
m_comp_quant[i] = get_bits(8);
|
| 1092 |
+
}
|
| 1093 |
+
}
|
| 1094 |
+
|
| 1095 |
+
// Used to skip unrecognized markers.
|
| 1096 |
+
void jpeg_decoder::skip_variable_marker()
|
| 1097 |
+
{
|
| 1098 |
+
uint num_left;
|
| 1099 |
+
|
| 1100 |
+
num_left = get_bits(16);
|
| 1101 |
+
|
| 1102 |
+
if (num_left < 2)
|
| 1103 |
+
stop_decoding(JPGD_BAD_VARIABLE_MARKER);
|
| 1104 |
+
|
| 1105 |
+
num_left -= 2;
|
| 1106 |
+
|
| 1107 |
+
while (num_left)
|
| 1108 |
+
{
|
| 1109 |
+
get_bits(8);
|
| 1110 |
+
num_left--;
|
| 1111 |
+
}
|
| 1112 |
+
}
|
| 1113 |
+
|
| 1114 |
+
// Read a define restart interval (DRI) marker.
|
| 1115 |
+
void jpeg_decoder::read_dri_marker()
|
| 1116 |
+
{
|
| 1117 |
+
if (get_bits(16) != 4)
|
| 1118 |
+
stop_decoding(JPGD_BAD_DRI_LENGTH);
|
| 1119 |
+
|
| 1120 |
+
m_restart_interval = get_bits(16);
|
| 1121 |
+
}
|
| 1122 |
+
|
| 1123 |
+
// Read a start of scan (SOS) marker.
|
| 1124 |
+
void jpeg_decoder::read_sos_marker()
|
| 1125 |
+
{
|
| 1126 |
+
uint num_left;
|
| 1127 |
+
int i, ci, n, c, cc;
|
| 1128 |
+
|
| 1129 |
+
num_left = get_bits(16);
|
| 1130 |
+
|
| 1131 |
+
n = get_bits(8);
|
| 1132 |
+
|
| 1133 |
+
m_comps_in_scan = n;
|
| 1134 |
+
|
| 1135 |
+
num_left -= 3;
|
| 1136 |
+
|
| 1137 |
+
if ( (num_left != (uint)(n * 2 + 3)) || (n < 1) || (n > JPGD_MAX_COMPS_IN_SCAN) )
|
| 1138 |
+
stop_decoding(JPGD_BAD_SOS_LENGTH);
|
| 1139 |
+
|
| 1140 |
+
for (i = 0; i < n; i++)
|
| 1141 |
+
{
|
| 1142 |
+
cc = get_bits(8);
|
| 1143 |
+
c = get_bits(8);
|
| 1144 |
+
num_left -= 2;
|
| 1145 |
+
|
| 1146 |
+
for (ci = 0; ci < m_comps_in_frame; ci++)
|
| 1147 |
+
if (cc == m_comp_ident[ci])
|
| 1148 |
+
break;
|
| 1149 |
+
|
| 1150 |
+
if (ci >= m_comps_in_frame)
|
| 1151 |
+
stop_decoding(JPGD_BAD_SOS_COMP_ID);
|
| 1152 |
+
|
| 1153 |
+
m_comp_list[i] = ci;
|
| 1154 |
+
m_comp_dc_tab[ci] = (c >> 4) & 15;
|
| 1155 |
+
m_comp_ac_tab[ci] = (c & 15) + (JPGD_MAX_HUFF_TABLES >> 1);
|
| 1156 |
+
}
|
| 1157 |
+
|
| 1158 |
+
m_spectral_start = get_bits(8);
|
| 1159 |
+
m_spectral_end = get_bits(8);
|
| 1160 |
+
m_successive_high = get_bits(4);
|
| 1161 |
+
m_successive_low = get_bits(4);
|
| 1162 |
+
|
| 1163 |
+
if (!m_progressive_flag)
|
| 1164 |
+
{
|
| 1165 |
+
m_spectral_start = 0;
|
| 1166 |
+
m_spectral_end = 63;
|
| 1167 |
+
}
|
| 1168 |
+
|
| 1169 |
+
num_left -= 3;
|
| 1170 |
+
|
| 1171 |
+
while (num_left) /* read past whatever is num_left */
|
| 1172 |
+
{
|
| 1173 |
+
get_bits(8);
|
| 1174 |
+
num_left--;
|
| 1175 |
+
}
|
| 1176 |
+
}
|
| 1177 |
+
|
| 1178 |
+
// Finds the next marker.
|
| 1179 |
+
int jpeg_decoder::next_marker()
|
| 1180 |
+
{
|
| 1181 |
+
uint c, bytes;
|
| 1182 |
+
|
| 1183 |
+
bytes = 0;
|
| 1184 |
+
|
| 1185 |
+
do
|
| 1186 |
+
{
|
| 1187 |
+
do
|
| 1188 |
+
{
|
| 1189 |
+
bytes++;
|
| 1190 |
+
c = get_bits(8);
|
| 1191 |
+
} while (c != 0xFF);
|
| 1192 |
+
|
| 1193 |
+
do
|
| 1194 |
+
{
|
| 1195 |
+
c = get_bits(8);
|
| 1196 |
+
} while (c == 0xFF);
|
| 1197 |
+
|
| 1198 |
+
} while (c == 0);
|
| 1199 |
+
|
| 1200 |
+
// If bytes > 0 here, there where extra bytes before the marker (not good).
|
| 1201 |
+
|
| 1202 |
+
return c;
|
| 1203 |
+
}
|
| 1204 |
+
|
| 1205 |
+
// Process markers. Returns when an SOFx, SOI, EOI, or SOS marker is
|
| 1206 |
+
// encountered.
|
| 1207 |
+
int jpeg_decoder::process_markers()
|
| 1208 |
+
{
|
| 1209 |
+
int c;
|
| 1210 |
+
|
| 1211 |
+
for ( ; ; )
|
| 1212 |
+
{
|
| 1213 |
+
c = next_marker();
|
| 1214 |
+
|
| 1215 |
+
switch (c)
|
| 1216 |
+
{
|
| 1217 |
+
case M_SOF0:
|
| 1218 |
+
case M_SOF1:
|
| 1219 |
+
case M_SOF2:
|
| 1220 |
+
case M_SOF3:
|
| 1221 |
+
case M_SOF5:
|
| 1222 |
+
case M_SOF6:
|
| 1223 |
+
case M_SOF7:
|
| 1224 |
+
// case M_JPG:
|
| 1225 |
+
case M_SOF9:
|
| 1226 |
+
case M_SOF10:
|
| 1227 |
+
case M_SOF11:
|
| 1228 |
+
case M_SOF13:
|
| 1229 |
+
case M_SOF14:
|
| 1230 |
+
case M_SOF15:
|
| 1231 |
+
case M_SOI:
|
| 1232 |
+
case M_EOI:
|
| 1233 |
+
case M_SOS:
|
| 1234 |
+
{
|
| 1235 |
+
return c;
|
| 1236 |
+
}
|
| 1237 |
+
case M_DHT:
|
| 1238 |
+
{
|
| 1239 |
+
read_dht_marker();
|
| 1240 |
+
break;
|
| 1241 |
+
}
|
| 1242 |
+
// No arithmitic support - dumb patents!
|
| 1243 |
+
case M_DAC:
|
| 1244 |
+
{
|
| 1245 |
+
stop_decoding(JPGD_NO_ARITHMITIC_SUPPORT);
|
| 1246 |
+
break;
|
| 1247 |
+
}
|
| 1248 |
+
case M_DQT:
|
| 1249 |
+
{
|
| 1250 |
+
read_dqt_marker();
|
| 1251 |
+
break;
|
| 1252 |
+
}
|
| 1253 |
+
case M_DRI:
|
| 1254 |
+
{
|
| 1255 |
+
read_dri_marker();
|
| 1256 |
+
break;
|
| 1257 |
+
}
|
| 1258 |
+
//case M_APP0: /* no need to read the JFIF marker */
|
| 1259 |
+
|
| 1260 |
+
case M_JPG:
|
| 1261 |
+
case M_RST0: /* no parameters */
|
| 1262 |
+
case M_RST1:
|
| 1263 |
+
case M_RST2:
|
| 1264 |
+
case M_RST3:
|
| 1265 |
+
case M_RST4:
|
| 1266 |
+
case M_RST5:
|
| 1267 |
+
case M_RST6:
|
| 1268 |
+
case M_RST7:
|
| 1269 |
+
case M_TEM:
|
| 1270 |
+
{
|
| 1271 |
+
stop_decoding(JPGD_UNEXPECTED_MARKER);
|
| 1272 |
+
break;
|
| 1273 |
+
}
|
| 1274 |
+
default: /* must be DNL, DHP, EXP, APPn, JPGn, COM, or RESn or APP0 */
|
| 1275 |
+
{
|
| 1276 |
+
skip_variable_marker();
|
| 1277 |
+
break;
|
| 1278 |
+
}
|
| 1279 |
+
}
|
| 1280 |
+
}
|
| 1281 |
+
}
|
| 1282 |
+
|
| 1283 |
+
// Finds the start of image (SOI) marker.
|
| 1284 |
+
// This code is rather defensive: it only checks the first 512 bytes to avoid
|
| 1285 |
+
// false positives.
|
| 1286 |
+
void jpeg_decoder::locate_soi_marker()
|
| 1287 |
+
{
|
| 1288 |
+
uint lastchar, thischar;
|
| 1289 |
+
uint bytesleft;
|
| 1290 |
+
|
| 1291 |
+
lastchar = get_bits(8);
|
| 1292 |
+
|
| 1293 |
+
thischar = get_bits(8);
|
| 1294 |
+
|
| 1295 |
+
/* ok if it's a normal JPEG file without a special header */
|
| 1296 |
+
|
| 1297 |
+
if ((lastchar == 0xFF) && (thischar == M_SOI))
|
| 1298 |
+
return;
|
| 1299 |
+
|
| 1300 |
+
bytesleft = 4096; //512;
|
| 1301 |
+
|
| 1302 |
+
for ( ; ; )
|
| 1303 |
+
{
|
| 1304 |
+
if (--bytesleft == 0)
|
| 1305 |
+
stop_decoding(JPGD_NOT_JPEG);
|
| 1306 |
+
|
| 1307 |
+
lastchar = thischar;
|
| 1308 |
+
|
| 1309 |
+
thischar = get_bits(8);
|
| 1310 |
+
|
| 1311 |
+
if (lastchar == 0xFF)
|
| 1312 |
+
{
|
| 1313 |
+
if (thischar == M_SOI)
|
| 1314 |
+
break;
|
| 1315 |
+
else if (thischar == M_EOI) // get_bits will keep returning M_EOI if we read past the end
|
| 1316 |
+
stop_decoding(JPGD_NOT_JPEG);
|
| 1317 |
+
}
|
| 1318 |
+
}
|
| 1319 |
+
|
| 1320 |
+
// Check the next character after marker: if it's not 0xFF, it can't be the start of the next marker, so the file is bad.
|
| 1321 |
+
thischar = (m_bit_buf >> 24) & 0xFF;
|
| 1322 |
+
|
| 1323 |
+
if (thischar != 0xFF)
|
| 1324 |
+
stop_decoding(JPGD_NOT_JPEG);
|
| 1325 |
+
}
|
| 1326 |
+
|
| 1327 |
+
// Find a start of frame (SOF) marker.
|
| 1328 |
+
void jpeg_decoder::locate_sof_marker()
|
| 1329 |
+
{
|
| 1330 |
+
locate_soi_marker();
|
| 1331 |
+
|
| 1332 |
+
int c = process_markers();
|
| 1333 |
+
|
| 1334 |
+
switch (c)
|
| 1335 |
+
{
|
| 1336 |
+
case M_SOF2:
|
| 1337 |
+
m_progressive_flag = JPGD_TRUE;
|
| 1338 |
+
case M_SOF0: /* baseline DCT */
|
| 1339 |
+
case M_SOF1: /* extended sequential DCT */
|
| 1340 |
+
{
|
| 1341 |
+
read_sof_marker();
|
| 1342 |
+
break;
|
| 1343 |
+
}
|
| 1344 |
+
case M_SOF9: /* Arithmitic coding */
|
| 1345 |
+
{
|
| 1346 |
+
stop_decoding(JPGD_NO_ARITHMITIC_SUPPORT);
|
| 1347 |
+
break;
|
| 1348 |
+
}
|
| 1349 |
+
default:
|
| 1350 |
+
{
|
| 1351 |
+
stop_decoding(JPGD_UNSUPPORTED_MARKER);
|
| 1352 |
+
break;
|
| 1353 |
+
}
|
| 1354 |
+
}
|
| 1355 |
+
}
|
| 1356 |
+
|
| 1357 |
+
// Find a start of scan (SOS) marker.
|
| 1358 |
+
int jpeg_decoder::locate_sos_marker()
|
| 1359 |
+
{
|
| 1360 |
+
int c;
|
| 1361 |
+
|
| 1362 |
+
c = process_markers();
|
| 1363 |
+
|
| 1364 |
+
if (c == M_EOI)
|
| 1365 |
+
return JPGD_FALSE;
|
| 1366 |
+
else if (c != M_SOS)
|
| 1367 |
+
stop_decoding(JPGD_UNEXPECTED_MARKER);
|
| 1368 |
+
|
| 1369 |
+
read_sos_marker();
|
| 1370 |
+
|
| 1371 |
+
return JPGD_TRUE;
|
| 1372 |
+
}
|
| 1373 |
+
|
| 1374 |
+
// Reset everything to default/uninitialized state.
|
| 1375 |
+
void jpeg_decoder::init(jpeg_decoder_stream *pStream)
|
| 1376 |
+
{
|
| 1377 |
+
m_pMem_blocks = NULL;
|
| 1378 |
+
m_error_code = JPGD_SUCCESS;
|
| 1379 |
+
m_ready_flag = false;
|
| 1380 |
+
m_image_x_size = m_image_y_size = 0;
|
| 1381 |
+
m_pStream = pStream;
|
| 1382 |
+
m_progressive_flag = JPGD_FALSE;
|
| 1383 |
+
|
| 1384 |
+
memset(m_huff_ac, 0, sizeof(m_huff_ac));
|
| 1385 |
+
memset(m_huff_num, 0, sizeof(m_huff_num));
|
| 1386 |
+
memset(m_huff_val, 0, sizeof(m_huff_val));
|
| 1387 |
+
memset(m_quant, 0, sizeof(m_quant));
|
| 1388 |
+
|
| 1389 |
+
m_scan_type = 0;
|
| 1390 |
+
m_comps_in_frame = 0;
|
| 1391 |
+
|
| 1392 |
+
memset(m_comp_h_samp, 0, sizeof(m_comp_h_samp));
|
| 1393 |
+
memset(m_comp_v_samp, 0, sizeof(m_comp_v_samp));
|
| 1394 |
+
memset(m_comp_quant, 0, sizeof(m_comp_quant));
|
| 1395 |
+
memset(m_comp_ident, 0, sizeof(m_comp_ident));
|
| 1396 |
+
memset(m_comp_h_blocks, 0, sizeof(m_comp_h_blocks));
|
| 1397 |
+
memset(m_comp_v_blocks, 0, sizeof(m_comp_v_blocks));
|
| 1398 |
+
|
| 1399 |
+
m_comps_in_scan = 0;
|
| 1400 |
+
memset(m_comp_list, 0, sizeof(m_comp_list));
|
| 1401 |
+
memset(m_comp_dc_tab, 0, sizeof(m_comp_dc_tab));
|
| 1402 |
+
memset(m_comp_ac_tab, 0, sizeof(m_comp_ac_tab));
|
| 1403 |
+
|
| 1404 |
+
m_spectral_start = 0;
|
| 1405 |
+
m_spectral_end = 0;
|
| 1406 |
+
m_successive_low = 0;
|
| 1407 |
+
m_successive_high = 0;
|
| 1408 |
+
m_max_mcu_x_size = 0;
|
| 1409 |
+
m_max_mcu_y_size = 0;
|
| 1410 |
+
m_blocks_per_mcu = 0;
|
| 1411 |
+
m_max_blocks_per_row = 0;
|
| 1412 |
+
m_mcus_per_row = 0;
|
| 1413 |
+
m_mcus_per_col = 0;
|
| 1414 |
+
m_expanded_blocks_per_component = 0;
|
| 1415 |
+
m_expanded_blocks_per_mcu = 0;
|
| 1416 |
+
m_expanded_blocks_per_row = 0;
|
| 1417 |
+
m_freq_domain_chroma_upsample = false;
|
| 1418 |
+
|
| 1419 |
+
memset(m_mcu_org, 0, sizeof(m_mcu_org));
|
| 1420 |
+
|
| 1421 |
+
m_total_lines_left = 0;
|
| 1422 |
+
m_mcu_lines_left = 0;
|
| 1423 |
+
m_real_dest_bytes_per_scan_line = 0;
|
| 1424 |
+
m_dest_bytes_per_scan_line = 0;
|
| 1425 |
+
m_dest_bytes_per_pixel = 0;
|
| 1426 |
+
|
| 1427 |
+
memset(m_pHuff_tabs, 0, sizeof(m_pHuff_tabs));
|
| 1428 |
+
|
| 1429 |
+
memset(m_dc_coeffs, 0, sizeof(m_dc_coeffs));
|
| 1430 |
+
memset(m_ac_coeffs, 0, sizeof(m_ac_coeffs));
|
| 1431 |
+
memset(m_block_y_mcu, 0, sizeof(m_block_y_mcu));
|
| 1432 |
+
|
| 1433 |
+
m_eob_run = 0;
|
| 1434 |
+
|
| 1435 |
+
memset(m_block_y_mcu, 0, sizeof(m_block_y_mcu));
|
| 1436 |
+
|
| 1437 |
+
m_pIn_buf_ofs = m_in_buf;
|
| 1438 |
+
m_in_buf_left = 0;
|
| 1439 |
+
m_eof_flag = false;
|
| 1440 |
+
m_tem_flag = 0;
|
| 1441 |
+
|
| 1442 |
+
memset(m_in_buf_pad_start, 0, sizeof(m_in_buf_pad_start));
|
| 1443 |
+
memset(m_in_buf, 0, sizeof(m_in_buf));
|
| 1444 |
+
memset(m_in_buf_pad_end, 0, sizeof(m_in_buf_pad_end));
|
| 1445 |
+
|
| 1446 |
+
m_restart_interval = 0;
|
| 1447 |
+
m_restarts_left = 0;
|
| 1448 |
+
m_next_restart_num = 0;
|
| 1449 |
+
|
| 1450 |
+
m_max_mcus_per_row = 0;
|
| 1451 |
+
m_max_blocks_per_mcu = 0;
|
| 1452 |
+
m_max_mcus_per_col = 0;
|
| 1453 |
+
|
| 1454 |
+
memset(m_last_dc_val, 0, sizeof(m_last_dc_val));
|
| 1455 |
+
m_pMCU_coefficients = NULL;
|
| 1456 |
+
m_pSample_buf = NULL;
|
| 1457 |
+
|
| 1458 |
+
m_total_bytes_read = 0;
|
| 1459 |
+
|
| 1460 |
+
m_pScan_line_0 = NULL;
|
| 1461 |
+
m_pScan_line_1 = NULL;
|
| 1462 |
+
|
| 1463 |
+
// Ready the input buffer.
|
| 1464 |
+
prep_in_buffer();
|
| 1465 |
+
|
| 1466 |
+
// Prime the bit buffer.
|
| 1467 |
+
m_bits_left = 16;
|
| 1468 |
+
m_bit_buf = 0;
|
| 1469 |
+
|
| 1470 |
+
get_bits(16);
|
| 1471 |
+
get_bits(16);
|
| 1472 |
+
|
| 1473 |
+
for (int i = 0; i < JPGD_MAX_BLOCKS_PER_MCU; i++)
|
| 1474 |
+
m_mcu_block_max_zag[i] = 64;
|
| 1475 |
+
}
|
| 1476 |
+
|
| 1477 |
+
#define SCALEBITS 16
|
| 1478 |
+
#define ONE_HALF ((int) 1 << (SCALEBITS-1))
|
| 1479 |
+
#define FIX(x) ((int) ((x) * (1L<<SCALEBITS) + 0.5f))
|
| 1480 |
+
|
| 1481 |
+
// Create a few tables that allow us to quickly convert YCbCr to RGB.
|
| 1482 |
+
void jpeg_decoder::create_look_ups()
|
| 1483 |
+
{
|
| 1484 |
+
for (int i = 0; i <= 255; i++)
|
| 1485 |
+
{
|
| 1486 |
+
int k = i - 128;
|
| 1487 |
+
m_crr[i] = ( FIX(1.40200f) * k + ONE_HALF) >> SCALEBITS;
|
| 1488 |
+
m_cbb[i] = ( FIX(1.77200f) * k + ONE_HALF) >> SCALEBITS;
|
| 1489 |
+
m_crg[i] = (-FIX(0.71414f)) * k;
|
| 1490 |
+
m_cbg[i] = (-FIX(0.34414f)) * k + ONE_HALF;
|
| 1491 |
+
}
|
| 1492 |
+
}
|
| 1493 |
+
|
| 1494 |
+
// This method throws back into the stream any bytes that where read
|
| 1495 |
+
// into the bit buffer during initial marker scanning.
|
| 1496 |
+
void jpeg_decoder::fix_in_buffer()
|
| 1497 |
+
{
|
| 1498 |
+
// In case any 0xFF's where pulled into the buffer during marker scanning.
|
| 1499 |
+
JPGD_ASSERT((m_bits_left & 7) == 0);
|
| 1500 |
+
|
| 1501 |
+
if (m_bits_left == 16)
|
| 1502 |
+
stuff_char( (uint8)(m_bit_buf & 0xFF));
|
| 1503 |
+
|
| 1504 |
+
if (m_bits_left >= 8)
|
| 1505 |
+
stuff_char( (uint8)((m_bit_buf >> 8) & 0xFF));
|
| 1506 |
+
|
| 1507 |
+
stuff_char((uint8)((m_bit_buf >> 16) & 0xFF));
|
| 1508 |
+
stuff_char((uint8)((m_bit_buf >> 24) & 0xFF));
|
| 1509 |
+
|
| 1510 |
+
m_bits_left = 16;
|
| 1511 |
+
get_bits_no_markers(16);
|
| 1512 |
+
get_bits_no_markers(16);
|
| 1513 |
+
}
|
| 1514 |
+
|
| 1515 |
+
void jpeg_decoder::transform_mcu(int mcu_row)
|
| 1516 |
+
{
|
| 1517 |
+
jpgd_block_t* pSrc_ptr = m_pMCU_coefficients;
|
| 1518 |
+
uint8* pDst_ptr = m_pSample_buf + mcu_row * m_blocks_per_mcu * 64;
|
| 1519 |
+
|
| 1520 |
+
for (int mcu_block = 0; mcu_block < m_blocks_per_mcu; mcu_block++)
|
| 1521 |
+
{
|
| 1522 |
+
idct(pSrc_ptr, pDst_ptr, m_mcu_block_max_zag[mcu_block]);
|
| 1523 |
+
pSrc_ptr += 64;
|
| 1524 |
+
pDst_ptr += 64;
|
| 1525 |
+
}
|
| 1526 |
+
}
|
| 1527 |
+
|
| 1528 |
+
static const uint8 s_max_rc[64] =
|
| 1529 |
+
{
|
| 1530 |
+
17, 18, 34, 50, 50, 51, 52, 52, 52, 68, 84, 84, 84, 84, 85, 86, 86, 86, 86, 86,
|
| 1531 |
+
102, 118, 118, 118, 118, 118, 118, 119, 120, 120, 120, 120, 120, 120, 120, 136,
|
| 1532 |
+
136, 136, 136, 136, 136, 136, 136, 136, 136, 136, 136, 136, 136, 136, 136, 136,
|
| 1533 |
+
136, 136, 136, 136, 136, 136, 136, 136, 136, 136, 136, 136
|
| 1534 |
+
};
|
| 1535 |
+
|
| 1536 |
+
void jpeg_decoder::transform_mcu_expand(int mcu_row)
|
| 1537 |
+
{
|
| 1538 |
+
jpgd_block_t* pSrc_ptr = m_pMCU_coefficients;
|
| 1539 |
+
uint8* pDst_ptr = m_pSample_buf + mcu_row * m_expanded_blocks_per_mcu * 64;
|
| 1540 |
+
|
| 1541 |
+
// Y IDCT
|
| 1542 |
+
int mcu_block;
|
| 1543 |
+
for (mcu_block = 0; mcu_block < m_expanded_blocks_per_component; mcu_block++)
|
| 1544 |
+
{
|
| 1545 |
+
idct(pSrc_ptr, pDst_ptr, m_mcu_block_max_zag[mcu_block]);
|
| 1546 |
+
pSrc_ptr += 64;
|
| 1547 |
+
pDst_ptr += 64;
|
| 1548 |
+
}
|
| 1549 |
+
|
| 1550 |
+
// Chroma IDCT, with upsampling
|
| 1551 |
+
jpgd_block_t temp_block[64];
|
| 1552 |
+
|
| 1553 |
+
for (int i = 0; i < 2; i++)
|
| 1554 |
+
{
|
| 1555 |
+
DCT_Upsample::Matrix44 P, Q, R, S;
|
| 1556 |
+
|
| 1557 |
+
JPGD_ASSERT(m_mcu_block_max_zag[mcu_block] >= 1);
|
| 1558 |
+
JPGD_ASSERT(m_mcu_block_max_zag[mcu_block] <= 64);
|
| 1559 |
+
|
| 1560 |
+
switch (s_max_rc[m_mcu_block_max_zag[mcu_block++] - 1])
|
| 1561 |
+
{
|
| 1562 |
+
case 1*16+1:
|
| 1563 |
+
DCT_Upsample::P_Q<1, 1>::calc(P, Q, pSrc_ptr);
|
| 1564 |
+
DCT_Upsample::R_S<1, 1>::calc(R, S, pSrc_ptr);
|
| 1565 |
+
break;
|
| 1566 |
+
case 1*16+2:
|
| 1567 |
+
DCT_Upsample::P_Q<1, 2>::calc(P, Q, pSrc_ptr);
|
| 1568 |
+
DCT_Upsample::R_S<1, 2>::calc(R, S, pSrc_ptr);
|
| 1569 |
+
break;
|
| 1570 |
+
case 2*16+2:
|
| 1571 |
+
DCT_Upsample::P_Q<2, 2>::calc(P, Q, pSrc_ptr);
|
| 1572 |
+
DCT_Upsample::R_S<2, 2>::calc(R, S, pSrc_ptr);
|
| 1573 |
+
break;
|
| 1574 |
+
case 3*16+2:
|
| 1575 |
+
DCT_Upsample::P_Q<3, 2>::calc(P, Q, pSrc_ptr);
|
| 1576 |
+
DCT_Upsample::R_S<3, 2>::calc(R, S, pSrc_ptr);
|
| 1577 |
+
break;
|
| 1578 |
+
case 3*16+3:
|
| 1579 |
+
DCT_Upsample::P_Q<3, 3>::calc(P, Q, pSrc_ptr);
|
| 1580 |
+
DCT_Upsample::R_S<3, 3>::calc(R, S, pSrc_ptr);
|
| 1581 |
+
break;
|
| 1582 |
+
case 3*16+4:
|
| 1583 |
+
DCT_Upsample::P_Q<3, 4>::calc(P, Q, pSrc_ptr);
|
| 1584 |
+
DCT_Upsample::R_S<3, 4>::calc(R, S, pSrc_ptr);
|
| 1585 |
+
break;
|
| 1586 |
+
case 4*16+4:
|
| 1587 |
+
DCT_Upsample::P_Q<4, 4>::calc(P, Q, pSrc_ptr);
|
| 1588 |
+
DCT_Upsample::R_S<4, 4>::calc(R, S, pSrc_ptr);
|
| 1589 |
+
break;
|
| 1590 |
+
case 5*16+4:
|
| 1591 |
+
DCT_Upsample::P_Q<5, 4>::calc(P, Q, pSrc_ptr);
|
| 1592 |
+
DCT_Upsample::R_S<5, 4>::calc(R, S, pSrc_ptr);
|
| 1593 |
+
break;
|
| 1594 |
+
case 5*16+5:
|
| 1595 |
+
DCT_Upsample::P_Q<5, 5>::calc(P, Q, pSrc_ptr);
|
| 1596 |
+
DCT_Upsample::R_S<5, 5>::calc(R, S, pSrc_ptr);
|
| 1597 |
+
break;
|
| 1598 |
+
case 5*16+6:
|
| 1599 |
+
DCT_Upsample::P_Q<5, 6>::calc(P, Q, pSrc_ptr);
|
| 1600 |
+
DCT_Upsample::R_S<5, 6>::calc(R, S, pSrc_ptr);
|
| 1601 |
+
break;
|
| 1602 |
+
case 6*16+6:
|
| 1603 |
+
DCT_Upsample::P_Q<6, 6>::calc(P, Q, pSrc_ptr);
|
| 1604 |
+
DCT_Upsample::R_S<6, 6>::calc(R, S, pSrc_ptr);
|
| 1605 |
+
break;
|
| 1606 |
+
case 7*16+6:
|
| 1607 |
+
DCT_Upsample::P_Q<7, 6>::calc(P, Q, pSrc_ptr);
|
| 1608 |
+
DCT_Upsample::R_S<7, 6>::calc(R, S, pSrc_ptr);
|
| 1609 |
+
break;
|
| 1610 |
+
case 7*16+7:
|
| 1611 |
+
DCT_Upsample::P_Q<7, 7>::calc(P, Q, pSrc_ptr);
|
| 1612 |
+
DCT_Upsample::R_S<7, 7>::calc(R, S, pSrc_ptr);
|
| 1613 |
+
break;
|
| 1614 |
+
case 7*16+8:
|
| 1615 |
+
DCT_Upsample::P_Q<7, 8>::calc(P, Q, pSrc_ptr);
|
| 1616 |
+
DCT_Upsample::R_S<7, 8>::calc(R, S, pSrc_ptr);
|
| 1617 |
+
break;
|
| 1618 |
+
case 8*16+8:
|
| 1619 |
+
DCT_Upsample::P_Q<8, 8>::calc(P, Q, pSrc_ptr);
|
| 1620 |
+
DCT_Upsample::R_S<8, 8>::calc(R, S, pSrc_ptr);
|
| 1621 |
+
break;
|
| 1622 |
+
default:
|
| 1623 |
+
JPGD_ASSERT(false);
|
| 1624 |
+
}
|
| 1625 |
+
|
| 1626 |
+
DCT_Upsample::Matrix44 a(P + Q); P -= Q;
|
| 1627 |
+
DCT_Upsample::Matrix44& b = P;
|
| 1628 |
+
DCT_Upsample::Matrix44 c(R + S); R -= S;
|
| 1629 |
+
DCT_Upsample::Matrix44& d = R;
|
| 1630 |
+
|
| 1631 |
+
DCT_Upsample::Matrix44::add_and_store(temp_block, a, c);
|
| 1632 |
+
idct_4x4(temp_block, pDst_ptr);
|
| 1633 |
+
pDst_ptr += 64;
|
| 1634 |
+
|
| 1635 |
+
DCT_Upsample::Matrix44::sub_and_store(temp_block, a, c);
|
| 1636 |
+
idct_4x4(temp_block, pDst_ptr);
|
| 1637 |
+
pDst_ptr += 64;
|
| 1638 |
+
|
| 1639 |
+
DCT_Upsample::Matrix44::add_and_store(temp_block, b, d);
|
| 1640 |
+
idct_4x4(temp_block, pDst_ptr);
|
| 1641 |
+
pDst_ptr += 64;
|
| 1642 |
+
|
| 1643 |
+
DCT_Upsample::Matrix44::sub_and_store(temp_block, b, d);
|
| 1644 |
+
idct_4x4(temp_block, pDst_ptr);
|
| 1645 |
+
pDst_ptr += 64;
|
| 1646 |
+
|
| 1647 |
+
pSrc_ptr += 64;
|
| 1648 |
+
}
|
| 1649 |
+
}
|
| 1650 |
+
|
| 1651 |
+
// Loads and dequantizes the next row of (already decoded) coefficients.
|
| 1652 |
+
// Progressive images only.
|
| 1653 |
+
void jpeg_decoder::load_next_row()
|
| 1654 |
+
{
|
| 1655 |
+
int i;
|
| 1656 |
+
jpgd_block_t *p;
|
| 1657 |
+
jpgd_quant_t *q;
|
| 1658 |
+
int mcu_row, mcu_block, row_block = 0;
|
| 1659 |
+
int component_num, component_id;
|
| 1660 |
+
int block_x_mcu[JPGD_MAX_COMPONENTS];
|
| 1661 |
+
|
| 1662 |
+
memset(block_x_mcu, 0, JPGD_MAX_COMPONENTS * sizeof(int));
|
| 1663 |
+
|
| 1664 |
+
for (mcu_row = 0; mcu_row < m_mcus_per_row; mcu_row++)
|
| 1665 |
+
{
|
| 1666 |
+
int block_x_mcu_ofs = 0, block_y_mcu_ofs = 0;
|
| 1667 |
+
|
| 1668 |
+
for (mcu_block = 0; mcu_block < m_blocks_per_mcu; mcu_block++)
|
| 1669 |
+
{
|
| 1670 |
+
component_id = m_mcu_org[mcu_block];
|
| 1671 |
+
q = m_quant[m_comp_quant[component_id]];
|
| 1672 |
+
|
| 1673 |
+
p = m_pMCU_coefficients + 64 * mcu_block;
|
| 1674 |
+
|
| 1675 |
+
jpgd_block_t* pAC = coeff_buf_getp(m_ac_coeffs[component_id], block_x_mcu[component_id] + block_x_mcu_ofs, m_block_y_mcu[component_id] + block_y_mcu_ofs);
|
| 1676 |
+
jpgd_block_t* pDC = coeff_buf_getp(m_dc_coeffs[component_id], block_x_mcu[component_id] + block_x_mcu_ofs, m_block_y_mcu[component_id] + block_y_mcu_ofs);
|
| 1677 |
+
p[0] = pDC[0];
|
| 1678 |
+
memcpy(&p[1], &pAC[1], 63 * sizeof(jpgd_block_t));
|
| 1679 |
+
|
| 1680 |
+
for (i = 63; i > 0; i--)
|
| 1681 |
+
if (p[g_ZAG[i]])
|
| 1682 |
+
break;
|
| 1683 |
+
|
| 1684 |
+
m_mcu_block_max_zag[mcu_block] = i + 1;
|
| 1685 |
+
|
| 1686 |
+
for ( ; i >= 0; i--)
|
| 1687 |
+
if (p[g_ZAG[i]])
|
| 1688 |
+
p[g_ZAG[i]] = static_cast<jpgd_block_t>(p[g_ZAG[i]] * q[i]);
|
| 1689 |
+
|
| 1690 |
+
row_block++;
|
| 1691 |
+
|
| 1692 |
+
if (m_comps_in_scan == 1)
|
| 1693 |
+
block_x_mcu[component_id]++;
|
| 1694 |
+
else
|
| 1695 |
+
{
|
| 1696 |
+
if (++block_x_mcu_ofs == m_comp_h_samp[component_id])
|
| 1697 |
+
{
|
| 1698 |
+
block_x_mcu_ofs = 0;
|
| 1699 |
+
|
| 1700 |
+
if (++block_y_mcu_ofs == m_comp_v_samp[component_id])
|
| 1701 |
+
{
|
| 1702 |
+
block_y_mcu_ofs = 0;
|
| 1703 |
+
|
| 1704 |
+
block_x_mcu[component_id] += m_comp_h_samp[component_id];
|
| 1705 |
+
}
|
| 1706 |
+
}
|
| 1707 |
+
}
|
| 1708 |
+
}
|
| 1709 |
+
|
| 1710 |
+
if (m_freq_domain_chroma_upsample)
|
| 1711 |
+
transform_mcu_expand(mcu_row);
|
| 1712 |
+
else
|
| 1713 |
+
transform_mcu(mcu_row);
|
| 1714 |
+
}
|
| 1715 |
+
|
| 1716 |
+
if (m_comps_in_scan == 1)
|
| 1717 |
+
m_block_y_mcu[m_comp_list[0]]++;
|
| 1718 |
+
else
|
| 1719 |
+
{
|
| 1720 |
+
for (component_num = 0; component_num < m_comps_in_scan; component_num++)
|
| 1721 |
+
{
|
| 1722 |
+
component_id = m_comp_list[component_num];
|
| 1723 |
+
|
| 1724 |
+
m_block_y_mcu[component_id] += m_comp_v_samp[component_id];
|
| 1725 |
+
}
|
| 1726 |
+
}
|
| 1727 |
+
}
|
| 1728 |
+
|
| 1729 |
+
// Restart interval processing.
|
| 1730 |
+
void jpeg_decoder::process_restart()
|
| 1731 |
+
{
|
| 1732 |
+
int i;
|
| 1733 |
+
int c = 0;
|
| 1734 |
+
|
| 1735 |
+
// Align to a byte boundry
|
| 1736 |
+
// FIXME: Is this really necessary? get_bits_no_markers() never reads in markers!
|
| 1737 |
+
//get_bits_no_markers(m_bits_left & 7);
|
| 1738 |
+
|
| 1739 |
+
// Let's scan a little bit to find the marker, but not _too_ far.
|
| 1740 |
+
// 1536 is a "fudge factor" that determines how much to scan.
|
| 1741 |
+
for (i = 1536; i > 0; i--)
|
| 1742 |
+
if (get_char() == 0xFF)
|
| 1743 |
+
break;
|
| 1744 |
+
|
| 1745 |
+
if (i == 0)
|
| 1746 |
+
stop_decoding(JPGD_BAD_RESTART_MARKER);
|
| 1747 |
+
|
| 1748 |
+
for ( ; i > 0; i--)
|
| 1749 |
+
if ((c = get_char()) != 0xFF)
|
| 1750 |
+
break;
|
| 1751 |
+
|
| 1752 |
+
if (i == 0)
|
| 1753 |
+
stop_decoding(JPGD_BAD_RESTART_MARKER);
|
| 1754 |
+
|
| 1755 |
+
// Is it the expected marker? If not, something bad happened.
|
| 1756 |
+
if (c != (m_next_restart_num + M_RST0))
|
| 1757 |
+
stop_decoding(JPGD_BAD_RESTART_MARKER);
|
| 1758 |
+
|
| 1759 |
+
// Reset each component's DC prediction values.
|
| 1760 |
+
memset(&m_last_dc_val, 0, m_comps_in_frame * sizeof(uint));
|
| 1761 |
+
|
| 1762 |
+
m_eob_run = 0;
|
| 1763 |
+
|
| 1764 |
+
m_restarts_left = m_restart_interval;
|
| 1765 |
+
|
| 1766 |
+
m_next_restart_num = (m_next_restart_num + 1) & 7;
|
| 1767 |
+
|
| 1768 |
+
// Get the bit buffer going again...
|
| 1769 |
+
|
| 1770 |
+
m_bits_left = 16;
|
| 1771 |
+
get_bits_no_markers(16);
|
| 1772 |
+
get_bits_no_markers(16);
|
| 1773 |
+
}
|
| 1774 |
+
|
| 1775 |
+
static inline int dequantize_ac(int c, int q) { c *= q; return c; }
|
| 1776 |
+
|
| 1777 |
+
// Decodes and dequantizes the next row of coefficients.
|
| 1778 |
+
void jpeg_decoder::decode_next_row()
|
| 1779 |
+
{
|
| 1780 |
+
int row_block = 0;
|
| 1781 |
+
|
| 1782 |
+
for (int mcu_row = 0; mcu_row < m_mcus_per_row; mcu_row++)
|
| 1783 |
+
{
|
| 1784 |
+
if ((m_restart_interval) && (m_restarts_left == 0))
|
| 1785 |
+
process_restart();
|
| 1786 |
+
|
| 1787 |
+
jpgd_block_t* p = m_pMCU_coefficients;
|
| 1788 |
+
for (int mcu_block = 0; mcu_block < m_blocks_per_mcu; mcu_block++, p += 64)
|
| 1789 |
+
{
|
| 1790 |
+
int component_id = m_mcu_org[mcu_block];
|
| 1791 |
+
jpgd_quant_t* q = m_quant[m_comp_quant[component_id]];
|
| 1792 |
+
|
| 1793 |
+
int r, s;
|
| 1794 |
+
s = huff_decode(m_pHuff_tabs[m_comp_dc_tab[component_id]], r);
|
| 1795 |
+
s = HUFF_EXTEND(r, s);
|
| 1796 |
+
|
| 1797 |
+
m_last_dc_val[component_id] = (s += m_last_dc_val[component_id]);
|
| 1798 |
+
|
| 1799 |
+
p[0] = static_cast<jpgd_block_t>(s * q[0]);
|
| 1800 |
+
|
| 1801 |
+
int prev_num_set = m_mcu_block_max_zag[mcu_block];
|
| 1802 |
+
|
| 1803 |
+
huff_tables *pH = m_pHuff_tabs[m_comp_ac_tab[component_id]];
|
| 1804 |
+
|
| 1805 |
+
int k;
|
| 1806 |
+
for (k = 1; k < 64; k++)
|
| 1807 |
+
{
|
| 1808 |
+
int extra_bits;
|
| 1809 |
+
s = huff_decode(pH, extra_bits);
|
| 1810 |
+
|
| 1811 |
+
r = s >> 4;
|
| 1812 |
+
s &= 15;
|
| 1813 |
+
|
| 1814 |
+
if (s)
|
| 1815 |
+
{
|
| 1816 |
+
if (r)
|
| 1817 |
+
{
|
| 1818 |
+
if ((k + r) > 63)
|
| 1819 |
+
stop_decoding(JPGD_DECODE_ERROR);
|
| 1820 |
+
|
| 1821 |
+
if (k < prev_num_set)
|
| 1822 |
+
{
|
| 1823 |
+
int n = JPGD_MIN(r, prev_num_set - k);
|
| 1824 |
+
int kt = k;
|
| 1825 |
+
while (n--)
|
| 1826 |
+
p[g_ZAG[kt++]] = 0;
|
| 1827 |
+
}
|
| 1828 |
+
|
| 1829 |
+
k += r;
|
| 1830 |
+
}
|
| 1831 |
+
|
| 1832 |
+
s = HUFF_EXTEND(extra_bits, s);
|
| 1833 |
+
|
| 1834 |
+
JPGD_ASSERT(k < 64);
|
| 1835 |
+
|
| 1836 |
+
p[g_ZAG[k]] = static_cast<jpgd_block_t>(dequantize_ac(s, q[k])); //s * q[k];
|
| 1837 |
+
}
|
| 1838 |
+
else
|
| 1839 |
+
{
|
| 1840 |
+
if (r == 15)
|
| 1841 |
+
{
|
| 1842 |
+
if ((k + 16) > 64)
|
| 1843 |
+
stop_decoding(JPGD_DECODE_ERROR);
|
| 1844 |
+
|
| 1845 |
+
if (k < prev_num_set)
|
| 1846 |
+
{
|
| 1847 |
+
int n = JPGD_MIN(16, prev_num_set - k);
|
| 1848 |
+
int kt = k;
|
| 1849 |
+
while (n--)
|
| 1850 |
+
{
|
| 1851 |
+
JPGD_ASSERT(kt <= 63);
|
| 1852 |
+
p[g_ZAG[kt++]] = 0;
|
| 1853 |
+
}
|
| 1854 |
+
}
|
| 1855 |
+
|
| 1856 |
+
k += 16 - 1; // - 1 because the loop counter is k
|
| 1857 |
+
// BEGIN EPIC MOD
|
| 1858 |
+
JPGD_ASSERT(k < 64 && p[g_ZAG[k]] == 0);
|
| 1859 |
+
// END EPIC MOD
|
| 1860 |
+
}
|
| 1861 |
+
else
|
| 1862 |
+
break;
|
| 1863 |
+
}
|
| 1864 |
+
}
|
| 1865 |
+
|
| 1866 |
+
if (k < prev_num_set)
|
| 1867 |
+
{
|
| 1868 |
+
int kt = k;
|
| 1869 |
+
while (kt < prev_num_set)
|
| 1870 |
+
p[g_ZAG[kt++]] = 0;
|
| 1871 |
+
}
|
| 1872 |
+
|
| 1873 |
+
m_mcu_block_max_zag[mcu_block] = k;
|
| 1874 |
+
|
| 1875 |
+
row_block++;
|
| 1876 |
+
}
|
| 1877 |
+
|
| 1878 |
+
if (m_freq_domain_chroma_upsample)
|
| 1879 |
+
transform_mcu_expand(mcu_row);
|
| 1880 |
+
else
|
| 1881 |
+
transform_mcu(mcu_row);
|
| 1882 |
+
|
| 1883 |
+
m_restarts_left--;
|
| 1884 |
+
}
|
| 1885 |
+
}
|
| 1886 |
+
|
| 1887 |
+
// YCbCr H1V1 (1x1:1:1, 3 m_blocks per MCU) to RGB
|
| 1888 |
+
void jpeg_decoder::H1V1Convert()
|
| 1889 |
+
{
|
| 1890 |
+
int row = m_max_mcu_y_size - m_mcu_lines_left;
|
| 1891 |
+
uint8 *d = m_pScan_line_0;
|
| 1892 |
+
uint8 *s = m_pSample_buf + row * 8;
|
| 1893 |
+
|
| 1894 |
+
for (int i = m_max_mcus_per_row; i > 0; i--)
|
| 1895 |
+
{
|
| 1896 |
+
for (int j = 0; j < 8; j++)
|
| 1897 |
+
{
|
| 1898 |
+
int y = s[j];
|
| 1899 |
+
int cb = s[64+j];
|
| 1900 |
+
int cr = s[128+j];
|
| 1901 |
+
|
| 1902 |
+
if (jpg_format == ERGBFormatJPG::BGRA)
|
| 1903 |
+
{
|
| 1904 |
+
d[0] = clamp(y + m_cbb[cb]);
|
| 1905 |
+
d[1] = clamp(y + ((m_crg[cr] + m_cbg[cb]) >> 16));
|
| 1906 |
+
d[2] = clamp(y + m_crr[cr]);
|
| 1907 |
+
d[3] = 255;
|
| 1908 |
+
}
|
| 1909 |
+
else
|
| 1910 |
+
{
|
| 1911 |
+
d[0] = clamp(y + m_crr[cr]);
|
| 1912 |
+
d[1] = clamp(y + ((m_crg[cr] + m_cbg[cb]) >> 16));
|
| 1913 |
+
d[2] = clamp(y + m_cbb[cb]);
|
| 1914 |
+
d[3] = 255;
|
| 1915 |
+
}
|
| 1916 |
+
d += 4;
|
| 1917 |
+
}
|
| 1918 |
+
|
| 1919 |
+
s += 64*3;
|
| 1920 |
+
}
|
| 1921 |
+
}
|
| 1922 |
+
|
| 1923 |
+
// YCbCr H2V1 (2x1:1:1, 4 m_blocks per MCU) to RGB
|
| 1924 |
+
void jpeg_decoder::H2V1Convert()
|
| 1925 |
+
{
|
| 1926 |
+
int row = m_max_mcu_y_size - m_mcu_lines_left;
|
| 1927 |
+
uint8 *d0 = m_pScan_line_0;
|
| 1928 |
+
uint8 *y = m_pSample_buf + row * 8;
|
| 1929 |
+
uint8 *c = m_pSample_buf + 2*64 + row * 8;
|
| 1930 |
+
|
| 1931 |
+
for (int i = m_max_mcus_per_row; i > 0; i--)
|
| 1932 |
+
{
|
| 1933 |
+
for (int l = 0; l < 2; l++)
|
| 1934 |
+
{
|
| 1935 |
+
for (int j = 0; j < 4; j++)
|
| 1936 |
+
{
|
| 1937 |
+
int cb = c[0];
|
| 1938 |
+
int cr = c[64];
|
| 1939 |
+
|
| 1940 |
+
int rc = m_crr[cr];
|
| 1941 |
+
int gc = ((m_crg[cr] + m_cbg[cb]) >> 16);
|
| 1942 |
+
int bc = m_cbb[cb];
|
| 1943 |
+
|
| 1944 |
+
int yy = y[j<<1];
|
| 1945 |
+
if (jpg_format == ERGBFormatJPG::BGRA)
|
| 1946 |
+
{
|
| 1947 |
+
d0[0] = clamp(yy+bc);
|
| 1948 |
+
d0[1] = clamp(yy+gc);
|
| 1949 |
+
d0[2] = clamp(yy+rc);
|
| 1950 |
+
d0[3] = 255;
|
| 1951 |
+
yy = y[(j<<1)+1];
|
| 1952 |
+
d0[4] = clamp(yy+bc);
|
| 1953 |
+
d0[5] = clamp(yy+gc);
|
| 1954 |
+
d0[6] = clamp(yy+rc);
|
| 1955 |
+
d0[7] = 255;
|
| 1956 |
+
}
|
| 1957 |
+
else
|
| 1958 |
+
{
|
| 1959 |
+
d0[0] = clamp(yy+rc);
|
| 1960 |
+
d0[1] = clamp(yy+gc);
|
| 1961 |
+
d0[2] = clamp(yy+bc);
|
| 1962 |
+
d0[3] = 255;
|
| 1963 |
+
yy = y[(j<<1)+1];
|
| 1964 |
+
d0[4] = clamp(yy+rc);
|
| 1965 |
+
d0[5] = clamp(yy+gc);
|
| 1966 |
+
d0[6] = clamp(yy+bc);
|
| 1967 |
+
d0[7] = 255;
|
| 1968 |
+
}
|
| 1969 |
+
|
| 1970 |
+
d0 += 8;
|
| 1971 |
+
|
| 1972 |
+
c++;
|
| 1973 |
+
}
|
| 1974 |
+
y += 64;
|
| 1975 |
+
}
|
| 1976 |
+
|
| 1977 |
+
y += 64*4 - 64*2;
|
| 1978 |
+
c += 64*4 - 8;
|
| 1979 |
+
}
|
| 1980 |
+
}
|
| 1981 |
+
|
| 1982 |
+
// YCbCr H2V1 (1x2:1:1, 4 m_blocks per MCU) to RGB
|
| 1983 |
+
void jpeg_decoder::H1V2Convert()
|
| 1984 |
+
{
|
| 1985 |
+
int row = m_max_mcu_y_size - m_mcu_lines_left;
|
| 1986 |
+
uint8 *d0 = m_pScan_line_0;
|
| 1987 |
+
uint8 *d1 = m_pScan_line_1;
|
| 1988 |
+
uint8 *y;
|
| 1989 |
+
uint8 *c;
|
| 1990 |
+
|
| 1991 |
+
if (row < 8)
|
| 1992 |
+
y = m_pSample_buf + row * 8;
|
| 1993 |
+
else
|
| 1994 |
+
y = m_pSample_buf + 64*1 + (row & 7) * 8;
|
| 1995 |
+
|
| 1996 |
+
c = m_pSample_buf + 64*2 + (row >> 1) * 8;
|
| 1997 |
+
|
| 1998 |
+
for (int i = m_max_mcus_per_row; i > 0; i--)
|
| 1999 |
+
{
|
| 2000 |
+
for (int j = 0; j < 8; j++)
|
| 2001 |
+
{
|
| 2002 |
+
int cb = c[0+j];
|
| 2003 |
+
int cr = c[64+j];
|
| 2004 |
+
|
| 2005 |
+
int rc = m_crr[cr];
|
| 2006 |
+
int gc = ((m_crg[cr] + m_cbg[cb]) >> 16);
|
| 2007 |
+
int bc = m_cbb[cb];
|
| 2008 |
+
|
| 2009 |
+
int yy = y[j];
|
| 2010 |
+
if (jpg_format == ERGBFormatJPG::BGRA)
|
| 2011 |
+
{
|
| 2012 |
+
d0[0] = clamp(yy+bc);
|
| 2013 |
+
d0[1] = clamp(yy+gc);
|
| 2014 |
+
d0[2] = clamp(yy+rc);
|
| 2015 |
+
d0[3] = 255;
|
| 2016 |
+
yy = y[8+j];
|
| 2017 |
+
d1[0] = clamp(yy+bc);
|
| 2018 |
+
d1[1] = clamp(yy+gc);
|
| 2019 |
+
d1[2] = clamp(yy+rc);
|
| 2020 |
+
d1[3] = 255;
|
| 2021 |
+
}
|
| 2022 |
+
else
|
| 2023 |
+
{
|
| 2024 |
+
d0[0] = clamp(yy+rc);
|
| 2025 |
+
d0[1] = clamp(yy+gc);
|
| 2026 |
+
d0[2] = clamp(yy+bc);
|
| 2027 |
+
d0[3] = 255;
|
| 2028 |
+
yy = y[8+j];
|
| 2029 |
+
d1[0] = clamp(yy+rc);
|
| 2030 |
+
d1[1] = clamp(yy+gc);
|
| 2031 |
+
d1[2] = clamp(yy+bc);
|
| 2032 |
+
d1[3] = 255;
|
| 2033 |
+
}
|
| 2034 |
+
|
| 2035 |
+
d0 += 4;
|
| 2036 |
+
d1 += 4;
|
| 2037 |
+
}
|
| 2038 |
+
|
| 2039 |
+
y += 64*4;
|
| 2040 |
+
c += 64*4;
|
| 2041 |
+
}
|
| 2042 |
+
}
|
| 2043 |
+
|
| 2044 |
+
// YCbCr H2V2 (2x2:1:1, 6 m_blocks per MCU) to RGB
|
| 2045 |
+
void jpeg_decoder::H2V2Convert()
|
| 2046 |
+
{
|
| 2047 |
+
int row = m_max_mcu_y_size - m_mcu_lines_left;
|
| 2048 |
+
uint8 *d0 = m_pScan_line_0;
|
| 2049 |
+
uint8 *d1 = m_pScan_line_1;
|
| 2050 |
+
uint8 *y;
|
| 2051 |
+
uint8 *c;
|
| 2052 |
+
|
| 2053 |
+
if (row < 8)
|
| 2054 |
+
y = m_pSample_buf + row * 8;
|
| 2055 |
+
else
|
| 2056 |
+
y = m_pSample_buf + 64*2 + (row & 7) * 8;
|
| 2057 |
+
|
| 2058 |
+
c = m_pSample_buf + 64*4 + (row >> 1) * 8;
|
| 2059 |
+
|
| 2060 |
+
for (int i = m_max_mcus_per_row; i > 0; i--)
|
| 2061 |
+
{
|
| 2062 |
+
for (int l = 0; l < 2; l++)
|
| 2063 |
+
{
|
| 2064 |
+
for (int j = 0; j < 8; j += 2)
|
| 2065 |
+
{
|
| 2066 |
+
int cb = c[0];
|
| 2067 |
+
int cr = c[64];
|
| 2068 |
+
|
| 2069 |
+
int rc = m_crr[cr];
|
| 2070 |
+
int gc = ((m_crg[cr] + m_cbg[cb]) >> 16);
|
| 2071 |
+
int bc = m_cbb[cb];
|
| 2072 |
+
|
| 2073 |
+
int yy = y[j];
|
| 2074 |
+
if (jpg_format == ERGBFormatJPG::BGRA)
|
| 2075 |
+
{
|
| 2076 |
+
d0[0] = clamp(yy+bc);
|
| 2077 |
+
d0[1] = clamp(yy+gc);
|
| 2078 |
+
d0[2] = clamp(yy+rc);
|
| 2079 |
+
d0[3] = 255;
|
| 2080 |
+
yy = y[j+1];
|
| 2081 |
+
d0[4] = clamp(yy+bc);
|
| 2082 |
+
d0[5] = clamp(yy+gc);
|
| 2083 |
+
d0[6] = clamp(yy+rc);
|
| 2084 |
+
d0[7] = 255;
|
| 2085 |
+
yy = y[j+8];
|
| 2086 |
+
d1[0] = clamp(yy+bc);
|
| 2087 |
+
d1[1] = clamp(yy+gc);
|
| 2088 |
+
d1[2] = clamp(yy+rc);
|
| 2089 |
+
d1[3] = 255;
|
| 2090 |
+
yy = y[j+8+1];
|
| 2091 |
+
d1[4] = clamp(yy+bc);
|
| 2092 |
+
d1[5] = clamp(yy+gc);
|
| 2093 |
+
d1[6] = clamp(yy+rc);
|
| 2094 |
+
d1[7] = 255;
|
| 2095 |
+
}
|
| 2096 |
+
else
|
| 2097 |
+
{
|
| 2098 |
+
d0[0] = clamp(yy+rc);
|
| 2099 |
+
d0[1] = clamp(yy+gc);
|
| 2100 |
+
d0[2] = clamp(yy+bc);
|
| 2101 |
+
d0[3] = 255;
|
| 2102 |
+
yy = y[j+1];
|
| 2103 |
+
d0[4] = clamp(yy+rc);
|
| 2104 |
+
d0[5] = clamp(yy+gc);
|
| 2105 |
+
d0[6] = clamp(yy+bc);
|
| 2106 |
+
d0[7] = 255;
|
| 2107 |
+
yy = y[j+8];
|
| 2108 |
+
d1[0] = clamp(yy+rc);
|
| 2109 |
+
d1[1] = clamp(yy+gc);
|
| 2110 |
+
d1[2] = clamp(yy+bc);
|
| 2111 |
+
d1[3] = 255;
|
| 2112 |
+
yy = y[j+8+1];
|
| 2113 |
+
d1[4] = clamp(yy+rc);
|
| 2114 |
+
d1[5] = clamp(yy+gc);
|
| 2115 |
+
d1[6] = clamp(yy+bc);
|
| 2116 |
+
d1[7] = 255;
|
| 2117 |
+
}
|
| 2118 |
+
|
| 2119 |
+
d0 += 8;
|
| 2120 |
+
d1 += 8;
|
| 2121 |
+
|
| 2122 |
+
c++;
|
| 2123 |
+
}
|
| 2124 |
+
y += 64;
|
| 2125 |
+
}
|
| 2126 |
+
|
| 2127 |
+
y += 64*6 - 64*2;
|
| 2128 |
+
c += 64*6 - 8;
|
| 2129 |
+
}
|
| 2130 |
+
}
|
| 2131 |
+
|
| 2132 |
+
// Y (1 block per MCU) to 8-bit grayscale
|
| 2133 |
+
void jpeg_decoder::gray_convert()
|
| 2134 |
+
{
|
| 2135 |
+
int row = m_max_mcu_y_size - m_mcu_lines_left;
|
| 2136 |
+
uint8 *d = m_pScan_line_0;
|
| 2137 |
+
uint8 *s = m_pSample_buf + row * 8;
|
| 2138 |
+
|
| 2139 |
+
for (int i = m_max_mcus_per_row; i > 0; i--)
|
| 2140 |
+
{
|
| 2141 |
+
*(uint *)d = *(uint *)s;
|
| 2142 |
+
*(uint *)(&d[4]) = *(uint *)(&s[4]);
|
| 2143 |
+
|
| 2144 |
+
s += 64;
|
| 2145 |
+
d += 8;
|
| 2146 |
+
}
|
| 2147 |
+
}
|
| 2148 |
+
|
| 2149 |
+
void jpeg_decoder::expanded_convert()
|
| 2150 |
+
{
|
| 2151 |
+
int row = m_max_mcu_y_size - m_mcu_lines_left;
|
| 2152 |
+
|
| 2153 |
+
uint8* Py = m_pSample_buf + (row / 8) * 64 * m_comp_h_samp[0] + (row & 7) * 8;
|
| 2154 |
+
|
| 2155 |
+
uint8* d = m_pScan_line_0;
|
| 2156 |
+
|
| 2157 |
+
for (int i = m_max_mcus_per_row; i > 0; i--)
|
| 2158 |
+
{
|
| 2159 |
+
for (int k = 0; k < m_max_mcu_x_size; k += 8)
|
| 2160 |
+
{
|
| 2161 |
+
const int Y_ofs = k * 8;
|
| 2162 |
+
const int Cb_ofs = Y_ofs + 64 * m_expanded_blocks_per_component;
|
| 2163 |
+
const int Cr_ofs = Y_ofs + 64 * m_expanded_blocks_per_component * 2;
|
| 2164 |
+
for (int j = 0; j < 8; j++)
|
| 2165 |
+
{
|
| 2166 |
+
int y = Py[Y_ofs + j];
|
| 2167 |
+
int cb = Py[Cb_ofs + j];
|
| 2168 |
+
int cr = Py[Cr_ofs + j];
|
| 2169 |
+
|
| 2170 |
+
if (jpg_format == ERGBFormatJPG::BGRA)
|
| 2171 |
+
{
|
| 2172 |
+
d[0] = clamp(y + m_cbb[cb]);
|
| 2173 |
+
d[1] = clamp(y + ((m_crg[cr] + m_cbg[cb]) >> 16));
|
| 2174 |
+
d[2] = clamp(y + m_crr[cr]);
|
| 2175 |
+
d[3] = 255;
|
| 2176 |
+
}
|
| 2177 |
+
else
|
| 2178 |
+
{
|
| 2179 |
+
d[0] = clamp(y + m_crr[cr]);
|
| 2180 |
+
d[1] = clamp(y + ((m_crg[cr] + m_cbg[cb]) >> 16));
|
| 2181 |
+
d[2] = clamp(y + m_cbb[cb]);
|
| 2182 |
+
d[3] = 255;
|
| 2183 |
+
}
|
| 2184 |
+
|
| 2185 |
+
d += 4;
|
| 2186 |
+
}
|
| 2187 |
+
}
|
| 2188 |
+
|
| 2189 |
+
Py += 64 * m_expanded_blocks_per_mcu;
|
| 2190 |
+
}
|
| 2191 |
+
}
|
| 2192 |
+
|
| 2193 |
+
// Find end of image (EOI) marker, so we can return to the user the exact size of the input stream.
|
| 2194 |
+
void jpeg_decoder::find_eoi()
|
| 2195 |
+
{
|
| 2196 |
+
if (!m_progressive_flag)
|
| 2197 |
+
{
|
| 2198 |
+
// Attempt to read the EOI marker.
|
| 2199 |
+
//get_bits_no_markers(m_bits_left & 7);
|
| 2200 |
+
|
| 2201 |
+
// Prime the bit buffer
|
| 2202 |
+
m_bits_left = 16;
|
| 2203 |
+
get_bits(16);
|
| 2204 |
+
get_bits(16);
|
| 2205 |
+
|
| 2206 |
+
// The next marker _should_ be EOI
|
| 2207 |
+
process_markers();
|
| 2208 |
+
}
|
| 2209 |
+
|
| 2210 |
+
m_total_bytes_read -= m_in_buf_left;
|
| 2211 |
+
}
|
| 2212 |
+
|
| 2213 |
+
int jpeg_decoder::decode(const void** pScan_line, uint* pScan_line_len)
|
| 2214 |
+
{
|
| 2215 |
+
if ((m_error_code) || (!m_ready_flag))
|
| 2216 |
+
return JPGD_FAILED;
|
| 2217 |
+
|
| 2218 |
+
if (m_total_lines_left == 0)
|
| 2219 |
+
return JPGD_DONE;
|
| 2220 |
+
|
| 2221 |
+
if (m_mcu_lines_left == 0)
|
| 2222 |
+
{
|
| 2223 |
+
if (setjmp(m_jmp_state))
|
| 2224 |
+
return JPGD_FAILED;
|
| 2225 |
+
|
| 2226 |
+
if (m_progressive_flag)
|
| 2227 |
+
load_next_row();
|
| 2228 |
+
else
|
| 2229 |
+
decode_next_row();
|
| 2230 |
+
|
| 2231 |
+
// Find the EOI marker if that was the last row.
|
| 2232 |
+
if (m_total_lines_left <= m_max_mcu_y_size)
|
| 2233 |
+
find_eoi();
|
| 2234 |
+
|
| 2235 |
+
m_mcu_lines_left = m_max_mcu_y_size;
|
| 2236 |
+
}
|
| 2237 |
+
|
| 2238 |
+
if (m_freq_domain_chroma_upsample)
|
| 2239 |
+
{
|
| 2240 |
+
expanded_convert();
|
| 2241 |
+
*pScan_line = m_pScan_line_0;
|
| 2242 |
+
}
|
| 2243 |
+
else
|
| 2244 |
+
{
|
| 2245 |
+
switch (m_scan_type)
|
| 2246 |
+
{
|
| 2247 |
+
case JPGD_YH2V2:
|
| 2248 |
+
{
|
| 2249 |
+
if ((m_mcu_lines_left & 1) == 0)
|
| 2250 |
+
{
|
| 2251 |
+
H2V2Convert();
|
| 2252 |
+
*pScan_line = m_pScan_line_0;
|
| 2253 |
+
}
|
| 2254 |
+
else
|
| 2255 |
+
*pScan_line = m_pScan_line_1;
|
| 2256 |
+
|
| 2257 |
+
break;
|
| 2258 |
+
}
|
| 2259 |
+
case JPGD_YH2V1:
|
| 2260 |
+
{
|
| 2261 |
+
H2V1Convert();
|
| 2262 |
+
*pScan_line = m_pScan_line_0;
|
| 2263 |
+
break;
|
| 2264 |
+
}
|
| 2265 |
+
case JPGD_YH1V2:
|
| 2266 |
+
{
|
| 2267 |
+
if ((m_mcu_lines_left & 1) == 0)
|
| 2268 |
+
{
|
| 2269 |
+
H1V2Convert();
|
| 2270 |
+
*pScan_line = m_pScan_line_0;
|
| 2271 |
+
}
|
| 2272 |
+
else
|
| 2273 |
+
*pScan_line = m_pScan_line_1;
|
| 2274 |
+
|
| 2275 |
+
break;
|
| 2276 |
+
}
|
| 2277 |
+
case JPGD_YH1V1:
|
| 2278 |
+
{
|
| 2279 |
+
H1V1Convert();
|
| 2280 |
+
*pScan_line = m_pScan_line_0;
|
| 2281 |
+
break;
|
| 2282 |
+
}
|
| 2283 |
+
case JPGD_GRAYSCALE:
|
| 2284 |
+
{
|
| 2285 |
+
gray_convert();
|
| 2286 |
+
*pScan_line = m_pScan_line_0;
|
| 2287 |
+
|
| 2288 |
+
break;
|
| 2289 |
+
}
|
| 2290 |
+
}
|
| 2291 |
+
}
|
| 2292 |
+
|
| 2293 |
+
*pScan_line_len = m_real_dest_bytes_per_scan_line;
|
| 2294 |
+
|
| 2295 |
+
m_mcu_lines_left--;
|
| 2296 |
+
m_total_lines_left--;
|
| 2297 |
+
|
| 2298 |
+
return JPGD_SUCCESS;
|
| 2299 |
+
}
|
| 2300 |
+
|
| 2301 |
+
// Creates the tables needed for efficient Huffman decoding.
|
| 2302 |
+
void jpeg_decoder::make_huff_table(int index, huff_tables *pH)
|
| 2303 |
+
{
|
| 2304 |
+
int p, i, l, si;
|
| 2305 |
+
uint8 huffsize[257];
|
| 2306 |
+
uint huffcode[257];
|
| 2307 |
+
uint code;
|
| 2308 |
+
uint subtree;
|
| 2309 |
+
int code_size;
|
| 2310 |
+
int lastp;
|
| 2311 |
+
int nextfreeentry;
|
| 2312 |
+
int currententry;
|
| 2313 |
+
|
| 2314 |
+
pH->ac_table = m_huff_ac[index] != 0;
|
| 2315 |
+
|
| 2316 |
+
p = 0;
|
| 2317 |
+
|
| 2318 |
+
for (l = 1; l <= 16; l++)
|
| 2319 |
+
{
|
| 2320 |
+
for (i = 1; i <= m_huff_num[index][l]; i++)
|
| 2321 |
+
huffsize[p++] = static_cast<uint8>(l);
|
| 2322 |
+
}
|
| 2323 |
+
|
| 2324 |
+
huffsize[p] = 0;
|
| 2325 |
+
|
| 2326 |
+
lastp = p;
|
| 2327 |
+
|
| 2328 |
+
code = 0;
|
| 2329 |
+
si = huffsize[0];
|
| 2330 |
+
p = 0;
|
| 2331 |
+
|
| 2332 |
+
while (huffsize[p])
|
| 2333 |
+
{
|
| 2334 |
+
while (huffsize[p] == si)
|
| 2335 |
+
{
|
| 2336 |
+
huffcode[p++] = code;
|
| 2337 |
+
code++;
|
| 2338 |
+
}
|
| 2339 |
+
|
| 2340 |
+
code <<= 1;
|
| 2341 |
+
si++;
|
| 2342 |
+
}
|
| 2343 |
+
|
| 2344 |
+
memset(pH->look_up, 0, sizeof(pH->look_up));
|
| 2345 |
+
memset(pH->look_up2, 0, sizeof(pH->look_up2));
|
| 2346 |
+
memset(pH->tree, 0, sizeof(pH->tree));
|
| 2347 |
+
memset(pH->code_size, 0, sizeof(pH->code_size));
|
| 2348 |
+
|
| 2349 |
+
nextfreeentry = -1;
|
| 2350 |
+
|
| 2351 |
+
p = 0;
|
| 2352 |
+
|
| 2353 |
+
while (p < lastp)
|
| 2354 |
+
{
|
| 2355 |
+
i = m_huff_val[index][p];
|
| 2356 |
+
code = huffcode[p];
|
| 2357 |
+
code_size = huffsize[p];
|
| 2358 |
+
|
| 2359 |
+
pH->code_size[i] = static_cast<uint8>(code_size);
|
| 2360 |
+
|
| 2361 |
+
if (code_size <= 8)
|
| 2362 |
+
{
|
| 2363 |
+
code <<= (8 - code_size);
|
| 2364 |
+
|
| 2365 |
+
for (l = 1 << (8 - code_size); l > 0; l--)
|
| 2366 |
+
{
|
| 2367 |
+
JPGD_ASSERT(i < 256);
|
| 2368 |
+
|
| 2369 |
+
pH->look_up[code] = i;
|
| 2370 |
+
|
| 2371 |
+
bool has_extrabits = false;
|
| 2372 |
+
int extra_bits = 0;
|
| 2373 |
+
int num_extra_bits = i & 15;
|
| 2374 |
+
|
| 2375 |
+
int bits_to_fetch = code_size;
|
| 2376 |
+
if (num_extra_bits)
|
| 2377 |
+
{
|
| 2378 |
+
int total_codesize = code_size + num_extra_bits;
|
| 2379 |
+
if (total_codesize <= 8)
|
| 2380 |
+
{
|
| 2381 |
+
has_extrabits = true;
|
| 2382 |
+
extra_bits = ((1 << num_extra_bits) - 1) & (code >> (8 - total_codesize));
|
| 2383 |
+
JPGD_ASSERT(extra_bits <= 0x7FFF);
|
| 2384 |
+
bits_to_fetch += num_extra_bits;
|
| 2385 |
+
}
|
| 2386 |
+
}
|
| 2387 |
+
|
| 2388 |
+
if (!has_extrabits)
|
| 2389 |
+
pH->look_up2[code] = i | (bits_to_fetch << 8);
|
| 2390 |
+
else
|
| 2391 |
+
pH->look_up2[code] = i | 0x8000 | (extra_bits << 16) | (bits_to_fetch << 8);
|
| 2392 |
+
|
| 2393 |
+
code++;
|
| 2394 |
+
}
|
| 2395 |
+
}
|
| 2396 |
+
else
|
| 2397 |
+
{
|
| 2398 |
+
subtree = (code >> (code_size - 8)) & 0xFF;
|
| 2399 |
+
|
| 2400 |
+
currententry = pH->look_up[subtree];
|
| 2401 |
+
|
| 2402 |
+
if (currententry == 0)
|
| 2403 |
+
{
|
| 2404 |
+
pH->look_up[subtree] = currententry = nextfreeentry;
|
| 2405 |
+
pH->look_up2[subtree] = currententry = nextfreeentry;
|
| 2406 |
+
|
| 2407 |
+
nextfreeentry -= 2;
|
| 2408 |
+
}
|
| 2409 |
+
|
| 2410 |
+
code <<= (16 - (code_size - 8));
|
| 2411 |
+
|
| 2412 |
+
for (l = code_size; l > 9; l--)
|
| 2413 |
+
{
|
| 2414 |
+
if ((code & 0x8000) == 0)
|
| 2415 |
+
currententry--;
|
| 2416 |
+
|
| 2417 |
+
if (pH->tree[-currententry - 1] == 0)
|
| 2418 |
+
{
|
| 2419 |
+
pH->tree[-currententry - 1] = nextfreeentry;
|
| 2420 |
+
|
| 2421 |
+
currententry = nextfreeentry;
|
| 2422 |
+
|
| 2423 |
+
nextfreeentry -= 2;
|
| 2424 |
+
}
|
| 2425 |
+
else
|
| 2426 |
+
currententry = pH->tree[-currententry - 1];
|
| 2427 |
+
|
| 2428 |
+
code <<= 1;
|
| 2429 |
+
}
|
| 2430 |
+
|
| 2431 |
+
if ((code & 0x8000) == 0)
|
| 2432 |
+
currententry--;
|
| 2433 |
+
|
| 2434 |
+
pH->tree[-currententry - 1] = i;
|
| 2435 |
+
}
|
| 2436 |
+
|
| 2437 |
+
p++;
|
| 2438 |
+
}
|
| 2439 |
+
}
|
| 2440 |
+
|
| 2441 |
+
// Verifies the quantization tables needed for this scan are available.
|
| 2442 |
+
void jpeg_decoder::check_quant_tables()
|
| 2443 |
+
{
|
| 2444 |
+
for (int i = 0; i < m_comps_in_scan; i++)
|
| 2445 |
+
if (m_quant[m_comp_quant[m_comp_list[i]]] == NULL)
|
| 2446 |
+
stop_decoding(JPGD_UNDEFINED_QUANT_TABLE);
|
| 2447 |
+
}
|
| 2448 |
+
|
| 2449 |
+
// Verifies that all the Huffman tables needed for this scan are available.
|
| 2450 |
+
void jpeg_decoder::check_huff_tables()
|
| 2451 |
+
{
|
| 2452 |
+
for (int i = 0; i < m_comps_in_scan; i++)
|
| 2453 |
+
{
|
| 2454 |
+
if ((m_spectral_start == 0) && (m_huff_num[m_comp_dc_tab[m_comp_list[i]]] == NULL))
|
| 2455 |
+
stop_decoding(JPGD_UNDEFINED_HUFF_TABLE);
|
| 2456 |
+
|
| 2457 |
+
if ((m_spectral_end > 0) && (m_huff_num[m_comp_ac_tab[m_comp_list[i]]] == NULL))
|
| 2458 |
+
stop_decoding(JPGD_UNDEFINED_HUFF_TABLE);
|
| 2459 |
+
}
|
| 2460 |
+
|
| 2461 |
+
for (int i = 0; i < JPGD_MAX_HUFF_TABLES; i++)
|
| 2462 |
+
if (m_huff_num[i])
|
| 2463 |
+
{
|
| 2464 |
+
if (!m_pHuff_tabs[i])
|
| 2465 |
+
m_pHuff_tabs[i] = (huff_tables *)alloc(sizeof(huff_tables));
|
| 2466 |
+
|
| 2467 |
+
make_huff_table(i, m_pHuff_tabs[i]);
|
| 2468 |
+
}
|
| 2469 |
+
}
|
| 2470 |
+
|
| 2471 |
+
// Determines the component order inside each MCU.
|
| 2472 |
+
// Also calcs how many MCU's are on each row, etc.
|
| 2473 |
+
void jpeg_decoder::calc_mcu_block_order()
|
| 2474 |
+
{
|
| 2475 |
+
int component_num, component_id;
|
| 2476 |
+
int max_h_samp = 0, max_v_samp = 0;
|
| 2477 |
+
|
| 2478 |
+
for (component_id = 0; component_id < m_comps_in_frame; component_id++)
|
| 2479 |
+
{
|
| 2480 |
+
if (m_comp_h_samp[component_id] > max_h_samp)
|
| 2481 |
+
max_h_samp = m_comp_h_samp[component_id];
|
| 2482 |
+
|
| 2483 |
+
if (m_comp_v_samp[component_id] > max_v_samp)
|
| 2484 |
+
max_v_samp = m_comp_v_samp[component_id];
|
| 2485 |
+
}
|
| 2486 |
+
|
| 2487 |
+
for (component_id = 0; component_id < m_comps_in_frame; component_id++)
|
| 2488 |
+
{
|
| 2489 |
+
m_comp_h_blocks[component_id] = ((((m_image_x_size * m_comp_h_samp[component_id]) + (max_h_samp - 1)) / max_h_samp) + 7) / 8;
|
| 2490 |
+
m_comp_v_blocks[component_id] = ((((m_image_y_size * m_comp_v_samp[component_id]) + (max_v_samp - 1)) / max_v_samp) + 7) / 8;
|
| 2491 |
+
}
|
| 2492 |
+
|
| 2493 |
+
if (m_comps_in_scan == 1)
|
| 2494 |
+
{
|
| 2495 |
+
m_mcus_per_row = m_comp_h_blocks[m_comp_list[0]];
|
| 2496 |
+
m_mcus_per_col = m_comp_v_blocks[m_comp_list[0]];
|
| 2497 |
+
}
|
| 2498 |
+
else
|
| 2499 |
+
{
|
| 2500 |
+
m_mcus_per_row = (((m_image_x_size + 7) / 8) + (max_h_samp - 1)) / max_h_samp;
|
| 2501 |
+
m_mcus_per_col = (((m_image_y_size + 7) / 8) + (max_v_samp - 1)) / max_v_samp;
|
| 2502 |
+
}
|
| 2503 |
+
|
| 2504 |
+
if (m_comps_in_scan == 1)
|
| 2505 |
+
{
|
| 2506 |
+
m_mcu_org[0] = m_comp_list[0];
|
| 2507 |
+
|
| 2508 |
+
m_blocks_per_mcu = 1;
|
| 2509 |
+
}
|
| 2510 |
+
else
|
| 2511 |
+
{
|
| 2512 |
+
m_blocks_per_mcu = 0;
|
| 2513 |
+
|
| 2514 |
+
for (component_num = 0; component_num < m_comps_in_scan; component_num++)
|
| 2515 |
+
{
|
| 2516 |
+
int num_blocks;
|
| 2517 |
+
|
| 2518 |
+
component_id = m_comp_list[component_num];
|
| 2519 |
+
|
| 2520 |
+
num_blocks = m_comp_h_samp[component_id] * m_comp_v_samp[component_id];
|
| 2521 |
+
|
| 2522 |
+
while (num_blocks--)
|
| 2523 |
+
m_mcu_org[m_blocks_per_mcu++] = component_id;
|
| 2524 |
+
}
|
| 2525 |
+
}
|
| 2526 |
+
}
|
| 2527 |
+
|
| 2528 |
+
// Starts a new scan.
|
| 2529 |
+
int jpeg_decoder::init_scan()
|
| 2530 |
+
{
|
| 2531 |
+
if (!locate_sos_marker())
|
| 2532 |
+
return JPGD_FALSE;
|
| 2533 |
+
|
| 2534 |
+
calc_mcu_block_order();
|
| 2535 |
+
|
| 2536 |
+
check_huff_tables();
|
| 2537 |
+
|
| 2538 |
+
check_quant_tables();
|
| 2539 |
+
|
| 2540 |
+
memset(m_last_dc_val, 0, m_comps_in_frame * sizeof(uint));
|
| 2541 |
+
|
| 2542 |
+
m_eob_run = 0;
|
| 2543 |
+
|
| 2544 |
+
if (m_restart_interval)
|
| 2545 |
+
{
|
| 2546 |
+
m_restarts_left = m_restart_interval;
|
| 2547 |
+
m_next_restart_num = 0;
|
| 2548 |
+
}
|
| 2549 |
+
|
| 2550 |
+
fix_in_buffer();
|
| 2551 |
+
|
| 2552 |
+
return JPGD_TRUE;
|
| 2553 |
+
}
|
| 2554 |
+
|
| 2555 |
+
// Starts a frame. Determines if the number of components or sampling factors
|
| 2556 |
+
// are supported.
|
| 2557 |
+
void jpeg_decoder::init_frame()
|
| 2558 |
+
{
|
| 2559 |
+
int i;
|
| 2560 |
+
|
| 2561 |
+
if (m_comps_in_frame == 1)
|
| 2562 |
+
{
|
| 2563 |
+
if ((m_comp_h_samp[0] != 1) || (m_comp_v_samp[0] != 1))
|
| 2564 |
+
stop_decoding(JPGD_UNSUPPORTED_SAMP_FACTORS);
|
| 2565 |
+
|
| 2566 |
+
m_scan_type = JPGD_GRAYSCALE;
|
| 2567 |
+
m_max_blocks_per_mcu = 1;
|
| 2568 |
+
m_max_mcu_x_size = 8;
|
| 2569 |
+
m_max_mcu_y_size = 8;
|
| 2570 |
+
}
|
| 2571 |
+
else if (m_comps_in_frame == 3)
|
| 2572 |
+
{
|
| 2573 |
+
if ( ((m_comp_h_samp[1] != 1) || (m_comp_v_samp[1] != 1)) ||
|
| 2574 |
+
((m_comp_h_samp[2] != 1) || (m_comp_v_samp[2] != 1)) )
|
| 2575 |
+
stop_decoding(JPGD_UNSUPPORTED_SAMP_FACTORS);
|
| 2576 |
+
|
| 2577 |
+
if ((m_comp_h_samp[0] == 1) && (m_comp_v_samp[0] == 1))
|
| 2578 |
+
{
|
| 2579 |
+
m_scan_type = JPGD_YH1V1;
|
| 2580 |
+
|
| 2581 |
+
m_max_blocks_per_mcu = 3;
|
| 2582 |
+
m_max_mcu_x_size = 8;
|
| 2583 |
+
m_max_mcu_y_size = 8;
|
| 2584 |
+
}
|
| 2585 |
+
else if ((m_comp_h_samp[0] == 2) && (m_comp_v_samp[0] == 1))
|
| 2586 |
+
{
|
| 2587 |
+
m_scan_type = JPGD_YH2V1;
|
| 2588 |
+
m_max_blocks_per_mcu = 4;
|
| 2589 |
+
m_max_mcu_x_size = 16;
|
| 2590 |
+
m_max_mcu_y_size = 8;
|
| 2591 |
+
}
|
| 2592 |
+
else if ((m_comp_h_samp[0] == 1) && (m_comp_v_samp[0] == 2))
|
| 2593 |
+
{
|
| 2594 |
+
m_scan_type = JPGD_YH1V2;
|
| 2595 |
+
m_max_blocks_per_mcu = 4;
|
| 2596 |
+
m_max_mcu_x_size = 8;
|
| 2597 |
+
m_max_mcu_y_size = 16;
|
| 2598 |
+
}
|
| 2599 |
+
else if ((m_comp_h_samp[0] == 2) && (m_comp_v_samp[0] == 2))
|
| 2600 |
+
{
|
| 2601 |
+
m_scan_type = JPGD_YH2V2;
|
| 2602 |
+
m_max_blocks_per_mcu = 6;
|
| 2603 |
+
m_max_mcu_x_size = 16;
|
| 2604 |
+
m_max_mcu_y_size = 16;
|
| 2605 |
+
}
|
| 2606 |
+
else
|
| 2607 |
+
stop_decoding(JPGD_UNSUPPORTED_SAMP_FACTORS);
|
| 2608 |
+
}
|
| 2609 |
+
else
|
| 2610 |
+
stop_decoding(JPGD_UNSUPPORTED_COLORSPACE);
|
| 2611 |
+
|
| 2612 |
+
m_max_mcus_per_row = (m_image_x_size + (m_max_mcu_x_size - 1)) / m_max_mcu_x_size;
|
| 2613 |
+
m_max_mcus_per_col = (m_image_y_size + (m_max_mcu_y_size - 1)) / m_max_mcu_y_size;
|
| 2614 |
+
|
| 2615 |
+
// These values are for the *destination* pixels: after conversion.
|
| 2616 |
+
if (m_scan_type == JPGD_GRAYSCALE)
|
| 2617 |
+
m_dest_bytes_per_pixel = 1;
|
| 2618 |
+
else
|
| 2619 |
+
m_dest_bytes_per_pixel = 4;
|
| 2620 |
+
|
| 2621 |
+
m_dest_bytes_per_scan_line = ((m_image_x_size + 15) & 0xFFF0) * m_dest_bytes_per_pixel;
|
| 2622 |
+
|
| 2623 |
+
m_real_dest_bytes_per_scan_line = (m_image_x_size * m_dest_bytes_per_pixel);
|
| 2624 |
+
|
| 2625 |
+
// Initialize two scan line buffers.
|
| 2626 |
+
m_pScan_line_0 = (uint8 *)alloc(m_dest_bytes_per_scan_line, true);
|
| 2627 |
+
if ((m_scan_type == JPGD_YH1V2) || (m_scan_type == JPGD_YH2V2))
|
| 2628 |
+
m_pScan_line_1 = (uint8 *)alloc(m_dest_bytes_per_scan_line, true);
|
| 2629 |
+
|
| 2630 |
+
m_max_blocks_per_row = m_max_mcus_per_row * m_max_blocks_per_mcu;
|
| 2631 |
+
|
| 2632 |
+
// Should never happen
|
| 2633 |
+
if (m_max_blocks_per_row > JPGD_MAX_BLOCKS_PER_ROW)
|
| 2634 |
+
stop_decoding(JPGD_ASSERTION_ERROR);
|
| 2635 |
+
|
| 2636 |
+
// Allocate the coefficient buffer, enough for one MCU
|
| 2637 |
+
m_pMCU_coefficients = (jpgd_block_t*)alloc(m_max_blocks_per_mcu * 64 * sizeof(jpgd_block_t));
|
| 2638 |
+
|
| 2639 |
+
for (i = 0; i < m_max_blocks_per_mcu; i++)
|
| 2640 |
+
m_mcu_block_max_zag[i] = 64;
|
| 2641 |
+
|
| 2642 |
+
m_expanded_blocks_per_component = m_comp_h_samp[0] * m_comp_v_samp[0];
|
| 2643 |
+
m_expanded_blocks_per_mcu = m_expanded_blocks_per_component * m_comps_in_frame;
|
| 2644 |
+
m_expanded_blocks_per_row = m_max_mcus_per_row * m_expanded_blocks_per_mcu;
|
| 2645 |
+
// Freq. domain chroma upsampling is only supported for H2V2 subsampling factor.
|
| 2646 |
+
// BEGIN EPIC MOD
|
| 2647 |
+
#if JPGD_SUPPORT_FREQ_DOMAIN_UPSAMPLING
|
| 2648 |
+
m_freq_domain_chroma_upsample = (m_expanded_blocks_per_mcu == 4*3);
|
| 2649 |
+
#else
|
| 2650 |
+
m_freq_domain_chroma_upsample = 0;
|
| 2651 |
+
#endif
|
| 2652 |
+
// END EPIC MOD
|
| 2653 |
+
|
| 2654 |
+
if (m_freq_domain_chroma_upsample)
|
| 2655 |
+
m_pSample_buf = (uint8 *)alloc(m_expanded_blocks_per_row * 64);
|
| 2656 |
+
else
|
| 2657 |
+
m_pSample_buf = (uint8 *)alloc(m_max_blocks_per_row * 64);
|
| 2658 |
+
|
| 2659 |
+
m_total_lines_left = m_image_y_size;
|
| 2660 |
+
|
| 2661 |
+
m_mcu_lines_left = 0;
|
| 2662 |
+
|
| 2663 |
+
create_look_ups();
|
| 2664 |
+
}
|
| 2665 |
+
|
| 2666 |
+
// The coeff_buf series of methods originally stored the coefficients
|
| 2667 |
+
// into a "virtual" file which was located in EMS, XMS, or a disk file. A cache
|
| 2668 |
+
// was used to make this process more efficient. Now, we can store the entire
|
| 2669 |
+
// thing in RAM.
|
| 2670 |
+
jpeg_decoder::coeff_buf* jpeg_decoder::coeff_buf_open(int block_num_x, int block_num_y, int block_len_x, int block_len_y)
|
| 2671 |
+
{
|
| 2672 |
+
coeff_buf* cb = (coeff_buf*)alloc(sizeof(coeff_buf));
|
| 2673 |
+
|
| 2674 |
+
cb->block_num_x = block_num_x;
|
| 2675 |
+
cb->block_num_y = block_num_y;
|
| 2676 |
+
cb->block_len_x = block_len_x;
|
| 2677 |
+
cb->block_len_y = block_len_y;
|
| 2678 |
+
cb->block_size = (block_len_x * block_len_y) * sizeof(jpgd_block_t);
|
| 2679 |
+
cb->pData = (uint8 *)alloc(cb->block_size * block_num_x * block_num_y, true);
|
| 2680 |
+
return cb;
|
| 2681 |
+
}
|
| 2682 |
+
|
| 2683 |
+
inline jpgd_block_t *jpeg_decoder::coeff_buf_getp(coeff_buf *cb, int block_x, int block_y)
|
| 2684 |
+
{
|
| 2685 |
+
JPGD_ASSERT((block_x < cb->block_num_x) && (block_y < cb->block_num_y));
|
| 2686 |
+
return (jpgd_block_t *)(cb->pData + block_x * cb->block_size + block_y * (cb->block_size * cb->block_num_x));
|
| 2687 |
+
}
|
| 2688 |
+
|
| 2689 |
+
// The following methods decode the various types of m_blocks encountered
|
| 2690 |
+
// in progressively encoded images.
|
| 2691 |
+
void jpeg_decoder::decode_block_dc_first(jpeg_decoder *pD, int component_id, int block_x, int block_y)
|
| 2692 |
+
{
|
| 2693 |
+
int s, r;
|
| 2694 |
+
jpgd_block_t *p = pD->coeff_buf_getp(pD->m_dc_coeffs[component_id], block_x, block_y);
|
| 2695 |
+
|
| 2696 |
+
if ((s = pD->huff_decode(pD->m_pHuff_tabs[pD->m_comp_dc_tab[component_id]])) != 0)
|
| 2697 |
+
{
|
| 2698 |
+
r = pD->get_bits_no_markers(s);
|
| 2699 |
+
s = HUFF_EXTEND(r, s);
|
| 2700 |
+
}
|
| 2701 |
+
|
| 2702 |
+
pD->m_last_dc_val[component_id] = (s += pD->m_last_dc_val[component_id]);
|
| 2703 |
+
|
| 2704 |
+
p[0] = static_cast<jpgd_block_t>(s << pD->m_successive_low);
|
| 2705 |
+
}
|
| 2706 |
+
|
| 2707 |
+
void jpeg_decoder::decode_block_dc_refine(jpeg_decoder *pD, int component_id, int block_x, int block_y)
|
| 2708 |
+
{
|
| 2709 |
+
if (pD->get_bits_no_markers(1))
|
| 2710 |
+
{
|
| 2711 |
+
jpgd_block_t *p = pD->coeff_buf_getp(pD->m_dc_coeffs[component_id], block_x, block_y);
|
| 2712 |
+
|
| 2713 |
+
p[0] |= (1 << pD->m_successive_low);
|
| 2714 |
+
}
|
| 2715 |
+
}
|
| 2716 |
+
|
| 2717 |
+
void jpeg_decoder::decode_block_ac_first(jpeg_decoder *pD, int component_id, int block_x, int block_y)
|
| 2718 |
+
{
|
| 2719 |
+
int k, s, r;
|
| 2720 |
+
|
| 2721 |
+
if (pD->m_eob_run)
|
| 2722 |
+
{
|
| 2723 |
+
pD->m_eob_run--;
|
| 2724 |
+
return;
|
| 2725 |
+
}
|
| 2726 |
+
|
| 2727 |
+
jpgd_block_t *p = pD->coeff_buf_getp(pD->m_ac_coeffs[component_id], block_x, block_y);
|
| 2728 |
+
|
| 2729 |
+
for (k = pD->m_spectral_start; k <= pD->m_spectral_end; k++)
|
| 2730 |
+
{
|
| 2731 |
+
s = pD->huff_decode(pD->m_pHuff_tabs[pD->m_comp_ac_tab[component_id]]);
|
| 2732 |
+
|
| 2733 |
+
r = s >> 4;
|
| 2734 |
+
s &= 15;
|
| 2735 |
+
|
| 2736 |
+
if (s)
|
| 2737 |
+
{
|
| 2738 |
+
if ((k += r) > 63)
|
| 2739 |
+
pD->stop_decoding(JPGD_DECODE_ERROR);
|
| 2740 |
+
|
| 2741 |
+
r = pD->get_bits_no_markers(s);
|
| 2742 |
+
s = HUFF_EXTEND(r, s);
|
| 2743 |
+
|
| 2744 |
+
p[g_ZAG[k]] = static_cast<jpgd_block_t>(s << pD->m_successive_low);
|
| 2745 |
+
}
|
| 2746 |
+
else
|
| 2747 |
+
{
|
| 2748 |
+
if (r == 15)
|
| 2749 |
+
{
|
| 2750 |
+
if ((k += 15) > 63)
|
| 2751 |
+
pD->stop_decoding(JPGD_DECODE_ERROR);
|
| 2752 |
+
}
|
| 2753 |
+
else
|
| 2754 |
+
{
|
| 2755 |
+
pD->m_eob_run = 1 << r;
|
| 2756 |
+
|
| 2757 |
+
if (r)
|
| 2758 |
+
pD->m_eob_run += pD->get_bits_no_markers(r);
|
| 2759 |
+
|
| 2760 |
+
pD->m_eob_run--;
|
| 2761 |
+
|
| 2762 |
+
break;
|
| 2763 |
+
}
|
| 2764 |
+
}
|
| 2765 |
+
}
|
| 2766 |
+
}
|
| 2767 |
+
|
| 2768 |
+
void jpeg_decoder::decode_block_ac_refine(jpeg_decoder *pD, int component_id, int block_x, int block_y)
|
| 2769 |
+
{
|
| 2770 |
+
int s, k, r;
|
| 2771 |
+
int p1 = 1 << pD->m_successive_low;
|
| 2772 |
+
int m1 = (-1) << pD->m_successive_low;
|
| 2773 |
+
jpgd_block_t *p = pD->coeff_buf_getp(pD->m_ac_coeffs[component_id], block_x, block_y);
|
| 2774 |
+
|
| 2775 |
+
k = pD->m_spectral_start;
|
| 2776 |
+
|
| 2777 |
+
if (pD->m_eob_run == 0)
|
| 2778 |
+
{
|
| 2779 |
+
for ( ; k <= pD->m_spectral_end; k++)
|
| 2780 |
+
{
|
| 2781 |
+
s = pD->huff_decode(pD->m_pHuff_tabs[pD->m_comp_ac_tab[component_id]]);
|
| 2782 |
+
|
| 2783 |
+
r = s >> 4;
|
| 2784 |
+
s &= 15;
|
| 2785 |
+
|
| 2786 |
+
if (s)
|
| 2787 |
+
{
|
| 2788 |
+
if (s != 1)
|
| 2789 |
+
pD->stop_decoding(JPGD_DECODE_ERROR);
|
| 2790 |
+
|
| 2791 |
+
if (pD->get_bits_no_markers(1))
|
| 2792 |
+
s = p1;
|
| 2793 |
+
else
|
| 2794 |
+
s = m1;
|
| 2795 |
+
}
|
| 2796 |
+
else
|
| 2797 |
+
{
|
| 2798 |
+
if (r != 15)
|
| 2799 |
+
{
|
| 2800 |
+
pD->m_eob_run = 1 << r;
|
| 2801 |
+
|
| 2802 |
+
if (r)
|
| 2803 |
+
pD->m_eob_run += pD->get_bits_no_markers(r);
|
| 2804 |
+
|
| 2805 |
+
break;
|
| 2806 |
+
}
|
| 2807 |
+
}
|
| 2808 |
+
|
| 2809 |
+
do
|
| 2810 |
+
{
|
| 2811 |
+
// BEGIN EPIC MOD
|
| 2812 |
+
JPGD_ASSERT(k < 64);
|
| 2813 |
+
// END EPIC MOD
|
| 2814 |
+
|
| 2815 |
+
jpgd_block_t *this_coef = p + g_ZAG[k];
|
| 2816 |
+
|
| 2817 |
+
if (*this_coef != 0)
|
| 2818 |
+
{
|
| 2819 |
+
if (pD->get_bits_no_markers(1))
|
| 2820 |
+
{
|
| 2821 |
+
if ((*this_coef & p1) == 0)
|
| 2822 |
+
{
|
| 2823 |
+
if (*this_coef >= 0)
|
| 2824 |
+
*this_coef = static_cast<jpgd_block_t>(*this_coef + p1);
|
| 2825 |
+
else
|
| 2826 |
+
*this_coef = static_cast<jpgd_block_t>(*this_coef + m1);
|
| 2827 |
+
}
|
| 2828 |
+
}
|
| 2829 |
+
}
|
| 2830 |
+
else
|
| 2831 |
+
{
|
| 2832 |
+
if (--r < 0)
|
| 2833 |
+
break;
|
| 2834 |
+
}
|
| 2835 |
+
|
| 2836 |
+
k++;
|
| 2837 |
+
|
| 2838 |
+
} while (k <= pD->m_spectral_end);
|
| 2839 |
+
|
| 2840 |
+
if ((s) && (k < 64))
|
| 2841 |
+
{
|
| 2842 |
+
p[g_ZAG[k]] = static_cast<jpgd_block_t>(s);
|
| 2843 |
+
}
|
| 2844 |
+
}
|
| 2845 |
+
}
|
| 2846 |
+
|
| 2847 |
+
if (pD->m_eob_run > 0)
|
| 2848 |
+
{
|
| 2849 |
+
for ( ; k <= pD->m_spectral_end; k++)
|
| 2850 |
+
{
|
| 2851 |
+
// BEGIN EPIC MOD
|
| 2852 |
+
JPGD_ASSERT(k < 64);
|
| 2853 |
+
// END EPIC MOD
|
| 2854 |
+
|
| 2855 |
+
jpgd_block_t *this_coef = p + g_ZAG[k];
|
| 2856 |
+
|
| 2857 |
+
if (*this_coef != 0)
|
| 2858 |
+
{
|
| 2859 |
+
if (pD->get_bits_no_markers(1))
|
| 2860 |
+
{
|
| 2861 |
+
if ((*this_coef & p1) == 0)
|
| 2862 |
+
{
|
| 2863 |
+
if (*this_coef >= 0)
|
| 2864 |
+
*this_coef = static_cast<jpgd_block_t>(*this_coef + p1);
|
| 2865 |
+
else
|
| 2866 |
+
*this_coef = static_cast<jpgd_block_t>(*this_coef + m1);
|
| 2867 |
+
}
|
| 2868 |
+
}
|
| 2869 |
+
}
|
| 2870 |
+
}
|
| 2871 |
+
|
| 2872 |
+
pD->m_eob_run--;
|
| 2873 |
+
}
|
| 2874 |
+
}
|
| 2875 |
+
|
| 2876 |
+
// Decode a scan in a progressively encoded image.
|
| 2877 |
+
void jpeg_decoder::decode_scan(pDecode_block_func decode_block_func)
|
| 2878 |
+
{
|
| 2879 |
+
int mcu_row, mcu_col, mcu_block;
|
| 2880 |
+
int block_x_mcu[JPGD_MAX_COMPONENTS], m_block_y_mcu[JPGD_MAX_COMPONENTS];
|
| 2881 |
+
|
| 2882 |
+
memset(m_block_y_mcu, 0, sizeof(m_block_y_mcu));
|
| 2883 |
+
|
| 2884 |
+
for (mcu_col = 0; mcu_col < m_mcus_per_col; mcu_col++)
|
| 2885 |
+
{
|
| 2886 |
+
int component_num, component_id;
|
| 2887 |
+
|
| 2888 |
+
memset(block_x_mcu, 0, sizeof(block_x_mcu));
|
| 2889 |
+
|
| 2890 |
+
for (mcu_row = 0; mcu_row < m_mcus_per_row; mcu_row++)
|
| 2891 |
+
{
|
| 2892 |
+
int block_x_mcu_ofs = 0, block_y_mcu_ofs = 0;
|
| 2893 |
+
|
| 2894 |
+
if ((m_restart_interval) && (m_restarts_left == 0))
|
| 2895 |
+
process_restart();
|
| 2896 |
+
|
| 2897 |
+
for (mcu_block = 0; mcu_block < m_blocks_per_mcu; mcu_block++)
|
| 2898 |
+
{
|
| 2899 |
+
component_id = m_mcu_org[mcu_block];
|
| 2900 |
+
|
| 2901 |
+
decode_block_func(this, component_id, block_x_mcu[component_id] + block_x_mcu_ofs, m_block_y_mcu[component_id] + block_y_mcu_ofs);
|
| 2902 |
+
|
| 2903 |
+
if (m_comps_in_scan == 1)
|
| 2904 |
+
block_x_mcu[component_id]++;
|
| 2905 |
+
else
|
| 2906 |
+
{
|
| 2907 |
+
if (++block_x_mcu_ofs == m_comp_h_samp[component_id])
|
| 2908 |
+
{
|
| 2909 |
+
block_x_mcu_ofs = 0;
|
| 2910 |
+
|
| 2911 |
+
if (++block_y_mcu_ofs == m_comp_v_samp[component_id])
|
| 2912 |
+
{
|
| 2913 |
+
block_y_mcu_ofs = 0;
|
| 2914 |
+
block_x_mcu[component_id] += m_comp_h_samp[component_id];
|
| 2915 |
+
}
|
| 2916 |
+
}
|
| 2917 |
+
}
|
| 2918 |
+
}
|
| 2919 |
+
|
| 2920 |
+
m_restarts_left--;
|
| 2921 |
+
}
|
| 2922 |
+
|
| 2923 |
+
if (m_comps_in_scan == 1)
|
| 2924 |
+
m_block_y_mcu[m_comp_list[0]]++;
|
| 2925 |
+
else
|
| 2926 |
+
{
|
| 2927 |
+
for (component_num = 0; component_num < m_comps_in_scan; component_num++)
|
| 2928 |
+
{
|
| 2929 |
+
component_id = m_comp_list[component_num];
|
| 2930 |
+
m_block_y_mcu[component_id] += m_comp_v_samp[component_id];
|
| 2931 |
+
}
|
| 2932 |
+
}
|
| 2933 |
+
}
|
| 2934 |
+
}
|
| 2935 |
+
|
| 2936 |
+
// Decode a progressively encoded image.
|
| 2937 |
+
void jpeg_decoder::init_progressive()
|
| 2938 |
+
{
|
| 2939 |
+
int i;
|
| 2940 |
+
|
| 2941 |
+
if (m_comps_in_frame == 4)
|
| 2942 |
+
stop_decoding(JPGD_UNSUPPORTED_COLORSPACE);
|
| 2943 |
+
|
| 2944 |
+
// Allocate the coefficient buffers.
|
| 2945 |
+
for (i = 0; i < m_comps_in_frame; i++)
|
| 2946 |
+
{
|
| 2947 |
+
m_dc_coeffs[i] = coeff_buf_open(m_max_mcus_per_row * m_comp_h_samp[i], m_max_mcus_per_col * m_comp_v_samp[i], 1, 1);
|
| 2948 |
+
m_ac_coeffs[i] = coeff_buf_open(m_max_mcus_per_row * m_comp_h_samp[i], m_max_mcus_per_col * m_comp_v_samp[i], 8, 8);
|
| 2949 |
+
}
|
| 2950 |
+
|
| 2951 |
+
for ( ; ; )
|
| 2952 |
+
{
|
| 2953 |
+
int dc_only_scan, refinement_scan;
|
| 2954 |
+
pDecode_block_func decode_block_func;
|
| 2955 |
+
|
| 2956 |
+
if (!init_scan())
|
| 2957 |
+
break;
|
| 2958 |
+
|
| 2959 |
+
dc_only_scan = (m_spectral_start == 0);
|
| 2960 |
+
refinement_scan = (m_successive_high != 0);
|
| 2961 |
+
|
| 2962 |
+
if ((m_spectral_start > m_spectral_end) || (m_spectral_end > 63))
|
| 2963 |
+
stop_decoding(JPGD_BAD_SOS_SPECTRAL);
|
| 2964 |
+
|
| 2965 |
+
if (dc_only_scan)
|
| 2966 |
+
{
|
| 2967 |
+
if (m_spectral_end)
|
| 2968 |
+
stop_decoding(JPGD_BAD_SOS_SPECTRAL);
|
| 2969 |
+
}
|
| 2970 |
+
else if (m_comps_in_scan != 1) /* AC scans can only contain one component */
|
| 2971 |
+
stop_decoding(JPGD_BAD_SOS_SPECTRAL);
|
| 2972 |
+
|
| 2973 |
+
if ((refinement_scan) && (m_successive_low != m_successive_high - 1))
|
| 2974 |
+
stop_decoding(JPGD_BAD_SOS_SUCCESSIVE);
|
| 2975 |
+
|
| 2976 |
+
if (dc_only_scan)
|
| 2977 |
+
{
|
| 2978 |
+
if (refinement_scan)
|
| 2979 |
+
decode_block_func = decode_block_dc_refine;
|
| 2980 |
+
else
|
| 2981 |
+
decode_block_func = decode_block_dc_first;
|
| 2982 |
+
}
|
| 2983 |
+
else
|
| 2984 |
+
{
|
| 2985 |
+
if (refinement_scan)
|
| 2986 |
+
decode_block_func = decode_block_ac_refine;
|
| 2987 |
+
else
|
| 2988 |
+
decode_block_func = decode_block_ac_first;
|
| 2989 |
+
}
|
| 2990 |
+
|
| 2991 |
+
decode_scan(decode_block_func);
|
| 2992 |
+
|
| 2993 |
+
m_bits_left = 16;
|
| 2994 |
+
get_bits(16);
|
| 2995 |
+
get_bits(16);
|
| 2996 |
+
}
|
| 2997 |
+
|
| 2998 |
+
m_comps_in_scan = m_comps_in_frame;
|
| 2999 |
+
|
| 3000 |
+
for (i = 0; i < m_comps_in_frame; i++)
|
| 3001 |
+
m_comp_list[i] = i;
|
| 3002 |
+
|
| 3003 |
+
calc_mcu_block_order();
|
| 3004 |
+
}
|
| 3005 |
+
|
| 3006 |
+
void jpeg_decoder::init_sequential()
|
| 3007 |
+
{
|
| 3008 |
+
if (!init_scan())
|
| 3009 |
+
stop_decoding(JPGD_UNEXPECTED_MARKER);
|
| 3010 |
+
}
|
| 3011 |
+
|
| 3012 |
+
void jpeg_decoder::decode_start()
|
| 3013 |
+
{
|
| 3014 |
+
init_frame();
|
| 3015 |
+
|
| 3016 |
+
if (m_progressive_flag)
|
| 3017 |
+
init_progressive();
|
| 3018 |
+
else
|
| 3019 |
+
init_sequential();
|
| 3020 |
+
}
|
| 3021 |
+
|
| 3022 |
+
void jpeg_decoder::decode_init(jpeg_decoder_stream *pStream)
|
| 3023 |
+
{
|
| 3024 |
+
init(pStream);
|
| 3025 |
+
locate_sof_marker();
|
| 3026 |
+
}
|
| 3027 |
+
|
| 3028 |
+
jpeg_decoder::jpeg_decoder(jpeg_decoder_stream *pStream)
|
| 3029 |
+
{
|
| 3030 |
+
if (setjmp(m_jmp_state))
|
| 3031 |
+
return;
|
| 3032 |
+
decode_init(pStream);
|
| 3033 |
+
}
|
| 3034 |
+
|
| 3035 |
+
int jpeg_decoder::begin_decoding()
|
| 3036 |
+
{
|
| 3037 |
+
if (m_ready_flag)
|
| 3038 |
+
return JPGD_SUCCESS;
|
| 3039 |
+
|
| 3040 |
+
if (m_error_code)
|
| 3041 |
+
return JPGD_FAILED;
|
| 3042 |
+
|
| 3043 |
+
if (setjmp(m_jmp_state))
|
| 3044 |
+
return JPGD_FAILED;
|
| 3045 |
+
|
| 3046 |
+
decode_start();
|
| 3047 |
+
|
| 3048 |
+
m_ready_flag = true;
|
| 3049 |
+
|
| 3050 |
+
return JPGD_SUCCESS;
|
| 3051 |
+
}
|
| 3052 |
+
|
| 3053 |
+
jpeg_decoder::~jpeg_decoder()
|
| 3054 |
+
{
|
| 3055 |
+
free_all_blocks();
|
| 3056 |
+
}
|
| 3057 |
+
|
| 3058 |
+
jpeg_decoder_file_stream::jpeg_decoder_file_stream()
|
| 3059 |
+
{
|
| 3060 |
+
m_pFile = NULL;
|
| 3061 |
+
m_eof_flag = false;
|
| 3062 |
+
m_error_flag = false;
|
| 3063 |
+
}
|
| 3064 |
+
|
| 3065 |
+
void jpeg_decoder_file_stream::close()
|
| 3066 |
+
{
|
| 3067 |
+
if (m_pFile)
|
| 3068 |
+
{
|
| 3069 |
+
fclose(m_pFile);
|
| 3070 |
+
m_pFile = NULL;
|
| 3071 |
+
}
|
| 3072 |
+
|
| 3073 |
+
m_eof_flag = false;
|
| 3074 |
+
m_error_flag = false;
|
| 3075 |
+
}
|
| 3076 |
+
|
| 3077 |
+
jpeg_decoder_file_stream::~jpeg_decoder_file_stream()
|
| 3078 |
+
{
|
| 3079 |
+
close();
|
| 3080 |
+
}
|
| 3081 |
+
|
| 3082 |
+
bool jpeg_decoder_file_stream::open(const char *Pfilename)
|
| 3083 |
+
{
|
| 3084 |
+
close();
|
| 3085 |
+
|
| 3086 |
+
m_eof_flag = false;
|
| 3087 |
+
m_error_flag = false;
|
| 3088 |
+
|
| 3089 |
+
#if defined(_MSC_VER)
|
| 3090 |
+
m_pFile = NULL;
|
| 3091 |
+
fopen_s(&m_pFile, Pfilename, "rb");
|
| 3092 |
+
#else
|
| 3093 |
+
m_pFile = fopen(Pfilename, "rb");
|
| 3094 |
+
#endif
|
| 3095 |
+
return m_pFile != NULL;
|
| 3096 |
+
}
|
| 3097 |
+
|
| 3098 |
+
int jpeg_decoder_file_stream::read(uint8 *pBuf, int max_bytes_to_read, bool *pEOF_flag)
|
| 3099 |
+
{
|
| 3100 |
+
if (!m_pFile)
|
| 3101 |
+
return -1;
|
| 3102 |
+
|
| 3103 |
+
if (m_eof_flag)
|
| 3104 |
+
{
|
| 3105 |
+
*pEOF_flag = true;
|
| 3106 |
+
return 0;
|
| 3107 |
+
}
|
| 3108 |
+
|
| 3109 |
+
if (m_error_flag)
|
| 3110 |
+
return -1;
|
| 3111 |
+
|
| 3112 |
+
int bytes_read = static_cast<int>(fread(pBuf, 1, max_bytes_to_read, m_pFile));
|
| 3113 |
+
if (bytes_read < max_bytes_to_read)
|
| 3114 |
+
{
|
| 3115 |
+
if (ferror(m_pFile))
|
| 3116 |
+
{
|
| 3117 |
+
m_error_flag = true;
|
| 3118 |
+
return -1;
|
| 3119 |
+
}
|
| 3120 |
+
|
| 3121 |
+
m_eof_flag = true;
|
| 3122 |
+
*pEOF_flag = true;
|
| 3123 |
+
}
|
| 3124 |
+
|
| 3125 |
+
return bytes_read;
|
| 3126 |
+
}
|
| 3127 |
+
|
| 3128 |
+
bool jpeg_decoder_mem_stream::open(const uint8 *pSrc_data, uint size)
|
| 3129 |
+
{
|
| 3130 |
+
close();
|
| 3131 |
+
m_pSrc_data = pSrc_data;
|
| 3132 |
+
m_ofs = 0;
|
| 3133 |
+
m_size = size;
|
| 3134 |
+
return true;
|
| 3135 |
+
}
|
| 3136 |
+
|
| 3137 |
+
int jpeg_decoder_mem_stream::read(uint8 *pBuf, int max_bytes_to_read, bool *pEOF_flag)
|
| 3138 |
+
{
|
| 3139 |
+
*pEOF_flag = false;
|
| 3140 |
+
|
| 3141 |
+
if (!m_pSrc_data)
|
| 3142 |
+
return -1;
|
| 3143 |
+
|
| 3144 |
+
uint bytes_remaining = m_size - m_ofs;
|
| 3145 |
+
if ((uint)max_bytes_to_read > bytes_remaining)
|
| 3146 |
+
{
|
| 3147 |
+
max_bytes_to_read = bytes_remaining;
|
| 3148 |
+
*pEOF_flag = true;
|
| 3149 |
+
}
|
| 3150 |
+
|
| 3151 |
+
memcpy(pBuf, m_pSrc_data + m_ofs, max_bytes_to_read);
|
| 3152 |
+
m_ofs += max_bytes_to_read;
|
| 3153 |
+
|
| 3154 |
+
return max_bytes_to_read;
|
| 3155 |
+
}
|
| 3156 |
+
|
| 3157 |
+
unsigned char *decompress_jpeg_image_from_stream(jpeg_decoder_stream *pStream, int *width, int *height, int *actual_comps, int req_comps)
|
| 3158 |
+
{
|
| 3159 |
+
if (!actual_comps)
|
| 3160 |
+
return NULL;
|
| 3161 |
+
*actual_comps = 0;
|
| 3162 |
+
|
| 3163 |
+
if ((!pStream) || (!width) || (!height) || (!req_comps))
|
| 3164 |
+
return NULL;
|
| 3165 |
+
|
| 3166 |
+
if ((req_comps != 1) && (req_comps != 3) && (req_comps != 4))
|
| 3167 |
+
return NULL;
|
| 3168 |
+
|
| 3169 |
+
jpeg_decoder decoder(pStream);
|
| 3170 |
+
if (decoder.get_error_code() != JPGD_SUCCESS)
|
| 3171 |
+
return NULL;
|
| 3172 |
+
|
| 3173 |
+
const int image_width = decoder.get_width(), image_height = decoder.get_height();
|
| 3174 |
+
*width = image_width;
|
| 3175 |
+
*height = image_height;
|
| 3176 |
+
*actual_comps = decoder.get_num_components();
|
| 3177 |
+
|
| 3178 |
+
if (decoder.begin_decoding() != JPGD_SUCCESS)
|
| 3179 |
+
return NULL;
|
| 3180 |
+
|
| 3181 |
+
const int dst_bpl = image_width * req_comps;
|
| 3182 |
+
|
| 3183 |
+
uint8 *pImage_data = (uint8*)jpgd_malloc(dst_bpl * image_height);
|
| 3184 |
+
if (!pImage_data)
|
| 3185 |
+
return NULL;
|
| 3186 |
+
|
| 3187 |
+
for (int y = 0; y < image_height; y++)
|
| 3188 |
+
{
|
| 3189 |
+
const uint8* pScan_line = 0;
|
| 3190 |
+
uint scan_line_len;
|
| 3191 |
+
if (decoder.decode((const void**)&pScan_line, &scan_line_len) != JPGD_SUCCESS)
|
| 3192 |
+
{
|
| 3193 |
+
jpgd_free(pImage_data);
|
| 3194 |
+
return NULL;
|
| 3195 |
+
}
|
| 3196 |
+
|
| 3197 |
+
uint8 *pDst = pImage_data + y * dst_bpl;
|
| 3198 |
+
|
| 3199 |
+
if (((req_comps == 4) && (decoder.get_num_components() == 3)) ||
|
| 3200 |
+
((req_comps == 1) && (decoder.get_num_components() == 1)))
|
| 3201 |
+
{
|
| 3202 |
+
memcpy(pDst, pScan_line, dst_bpl);
|
| 3203 |
+
}
|
| 3204 |
+
else if (decoder.get_num_components() == 1)
|
| 3205 |
+
{
|
| 3206 |
+
if (req_comps == 3)
|
| 3207 |
+
{
|
| 3208 |
+
for (int x = 0; x < image_width; x++)
|
| 3209 |
+
{
|
| 3210 |
+
uint8 luma = pScan_line[x];
|
| 3211 |
+
pDst[0] = luma;
|
| 3212 |
+
pDst[1] = luma;
|
| 3213 |
+
pDst[2] = luma;
|
| 3214 |
+
pDst += 3;
|
| 3215 |
+
}
|
| 3216 |
+
}
|
| 3217 |
+
else
|
| 3218 |
+
{
|
| 3219 |
+
for (int x = 0; x < image_width; x++)
|
| 3220 |
+
{
|
| 3221 |
+
uint8 luma = pScan_line[x];
|
| 3222 |
+
pDst[0] = luma;
|
| 3223 |
+
pDst[1] = luma;
|
| 3224 |
+
pDst[2] = luma;
|
| 3225 |
+
pDst[3] = 255;
|
| 3226 |
+
pDst += 4;
|
| 3227 |
+
}
|
| 3228 |
+
}
|
| 3229 |
+
}
|
| 3230 |
+
else if (decoder.get_num_components() == 3)
|
| 3231 |
+
{
|
| 3232 |
+
if (req_comps == 1)
|
| 3233 |
+
{
|
| 3234 |
+
const int YR = 19595, YG = 38470, YB = 7471;
|
| 3235 |
+
for (int x = 0; x < image_width; x++)
|
| 3236 |
+
{
|
| 3237 |
+
int r = pScan_line[x*4+0];
|
| 3238 |
+
int g = pScan_line[x*4+1];
|
| 3239 |
+
int b = pScan_line[x*4+2];
|
| 3240 |
+
*pDst++ = static_cast<uint8>((r * YR + g * YG + b * YB + 32768) >> 16);
|
| 3241 |
+
}
|
| 3242 |
+
}
|
| 3243 |
+
else
|
| 3244 |
+
{
|
| 3245 |
+
for (int x = 0; x < image_width; x++)
|
| 3246 |
+
{
|
| 3247 |
+
pDst[0] = pScan_line[x*4+0];
|
| 3248 |
+
pDst[1] = pScan_line[x*4+1];
|
| 3249 |
+
pDst[2] = pScan_line[x*4+2];
|
| 3250 |
+
pDst += 3;
|
| 3251 |
+
}
|
| 3252 |
+
}
|
| 3253 |
+
}
|
| 3254 |
+
}
|
| 3255 |
+
|
| 3256 |
+
return pImage_data;
|
| 3257 |
+
}
|
| 3258 |
+
|
| 3259 |
+
// BEGIN EPIC MOD
|
| 3260 |
+
unsigned char *decompress_jpeg_image_from_memory(const unsigned char *pSrc_data, int src_data_size, int *width, int *height, int *actual_comps, int req_comps, int format)
|
| 3261 |
+
{
|
| 3262 |
+
jpg_format = (ERGBFormatJPG)format;
|
| 3263 |
+
// EMD EPIC MOD
|
| 3264 |
+
jpgd::jpeg_decoder_mem_stream mem_stream(pSrc_data, src_data_size);
|
| 3265 |
+
return decompress_jpeg_image_from_stream(&mem_stream, width, height, actual_comps, req_comps);
|
| 3266 |
+
}
|
| 3267 |
+
|
| 3268 |
+
unsigned char *decompress_jpeg_image_from_file(const char *pSrc_filename, int *width, int *height, int *actual_comps, int req_comps)
|
| 3269 |
+
{
|
| 3270 |
+
jpgd::jpeg_decoder_file_stream file_stream;
|
| 3271 |
+
if (!file_stream.open(pSrc_filename))
|
| 3272 |
+
return NULL;
|
| 3273 |
+
return decompress_jpeg_image_from_stream(&file_stream, width, height, actual_comps, req_comps);
|
| 3274 |
+
}
|
| 3275 |
+
|
| 3276 |
+
} // namespace jpgd
|
crazy_functions/test_project/cpp/libJPG/jpgd.h
ADDED
|
@@ -0,0 +1,316 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// jpgd.h - C++ class for JPEG decompression.
|
| 2 |
+
// Public domain, Rich Geldreich <[email protected]>
|
| 3 |
+
#ifndef JPEG_DECODER_H
|
| 4 |
+
#define JPEG_DECODER_H
|
| 5 |
+
|
| 6 |
+
#include <stdlib.h>
|
| 7 |
+
#include <stdio.h>
|
| 8 |
+
#include <setjmp.h>
|
| 9 |
+
|
| 10 |
+
namespace jpgd
|
| 11 |
+
{
|
| 12 |
+
typedef unsigned char uint8;
|
| 13 |
+
typedef signed short int16;
|
| 14 |
+
typedef unsigned short uint16;
|
| 15 |
+
typedef unsigned int uint;
|
| 16 |
+
typedef signed int int32;
|
| 17 |
+
|
| 18 |
+
// Loads a JPEG image from a memory buffer or a file.
|
| 19 |
+
// req_comps can be 1 (grayscale), 3 (RGB), or 4 (RGBA).
|
| 20 |
+
// On return, width/height will be set to the image's dimensions, and actual_comps will be set to the either 1 (grayscale) or 3 (RGB).
|
| 21 |
+
// Notes: For more control over where and how the source data is read, see the decompress_jpeg_image_from_stream() function below, or call the jpeg_decoder class directly.
|
| 22 |
+
// Requesting a 8 or 32bpp image is currently a little faster than 24bpp because the jpeg_decoder class itself currently always unpacks to either 8 or 32bpp.
|
| 23 |
+
// BEGIN EPIC MOD
|
| 24 |
+
//unsigned char *decompress_jpeg_image_from_memory(const unsigned char *pSrc_data, int src_data_size, int *width, int *height, int *actual_comps, int req_comps);
|
| 25 |
+
unsigned char *decompress_jpeg_image_from_memory(const unsigned char *pSrc_data, int src_data_size, int *width, int *height, int *actual_comps, int req_comps, int format);
|
| 26 |
+
// END EPIC MOD
|
| 27 |
+
unsigned char *decompress_jpeg_image_from_file(const char *pSrc_filename, int *width, int *height, int *actual_comps, int req_comps);
|
| 28 |
+
|
| 29 |
+
// Success/failure error codes.
|
| 30 |
+
enum jpgd_status
|
| 31 |
+
{
|
| 32 |
+
JPGD_SUCCESS = 0, JPGD_FAILED = -1, JPGD_DONE = 1,
|
| 33 |
+
JPGD_BAD_DHT_COUNTS = -256, JPGD_BAD_DHT_INDEX, JPGD_BAD_DHT_MARKER, JPGD_BAD_DQT_MARKER, JPGD_BAD_DQT_TABLE,
|
| 34 |
+
JPGD_BAD_PRECISION, JPGD_BAD_HEIGHT, JPGD_BAD_WIDTH, JPGD_TOO_MANY_COMPONENTS,
|
| 35 |
+
JPGD_BAD_SOF_LENGTH, JPGD_BAD_VARIABLE_MARKER, JPGD_BAD_DRI_LENGTH, JPGD_BAD_SOS_LENGTH,
|
| 36 |
+
JPGD_BAD_SOS_COMP_ID, JPGD_W_EXTRA_BYTES_BEFORE_MARKER, JPGD_NO_ARITHMITIC_SUPPORT, JPGD_UNEXPECTED_MARKER,
|
| 37 |
+
JPGD_NOT_JPEG, JPGD_UNSUPPORTED_MARKER, JPGD_BAD_DQT_LENGTH, JPGD_TOO_MANY_BLOCKS,
|
| 38 |
+
JPGD_UNDEFINED_QUANT_TABLE, JPGD_UNDEFINED_HUFF_TABLE, JPGD_NOT_SINGLE_SCAN, JPGD_UNSUPPORTED_COLORSPACE,
|
| 39 |
+
JPGD_UNSUPPORTED_SAMP_FACTORS, JPGD_DECODE_ERROR, JPGD_BAD_RESTART_MARKER, JPGD_ASSERTION_ERROR,
|
| 40 |
+
JPGD_BAD_SOS_SPECTRAL, JPGD_BAD_SOS_SUCCESSIVE, JPGD_STREAM_READ, JPGD_NOTENOUGHMEM
|
| 41 |
+
};
|
| 42 |
+
|
| 43 |
+
// Input stream interface.
|
| 44 |
+
// Derive from this class to read input data from sources other than files or memory. Set m_eof_flag to true when no more data is available.
|
| 45 |
+
// The decoder is rather greedy: it will keep on calling this method until its internal input buffer is full, or until the EOF flag is set.
|
| 46 |
+
// It the input stream contains data after the JPEG stream's EOI (end of image) marker it will probably be pulled into the internal buffer.
|
| 47 |
+
// Call the get_total_bytes_read() method to determine the actual size of the JPEG stream after successful decoding.
|
| 48 |
+
class jpeg_decoder_stream
|
| 49 |
+
{
|
| 50 |
+
public:
|
| 51 |
+
jpeg_decoder_stream() { }
|
| 52 |
+
virtual ~jpeg_decoder_stream() { }
|
| 53 |
+
|
| 54 |
+
// The read() method is called when the internal input buffer is empty.
|
| 55 |
+
// Parameters:
|
| 56 |
+
// pBuf - input buffer
|
| 57 |
+
// max_bytes_to_read - maximum bytes that can be written to pBuf
|
| 58 |
+
// pEOF_flag - set this to true if at end of stream (no more bytes remaining)
|
| 59 |
+
// Returns -1 on error, otherwise return the number of bytes actually written to the buffer (which may be 0).
|
| 60 |
+
// Notes: This method will be called in a loop until you set *pEOF_flag to true or the internal buffer is full.
|
| 61 |
+
virtual int read(uint8 *pBuf, int max_bytes_to_read, bool *pEOF_flag) = 0;
|
| 62 |
+
};
|
| 63 |
+
|
| 64 |
+
// stdio FILE stream class.
|
| 65 |
+
class jpeg_decoder_file_stream : public jpeg_decoder_stream
|
| 66 |
+
{
|
| 67 |
+
jpeg_decoder_file_stream(const jpeg_decoder_file_stream &);
|
| 68 |
+
jpeg_decoder_file_stream &operator =(const jpeg_decoder_file_stream &);
|
| 69 |
+
|
| 70 |
+
FILE *m_pFile;
|
| 71 |
+
bool m_eof_flag, m_error_flag;
|
| 72 |
+
|
| 73 |
+
public:
|
| 74 |
+
jpeg_decoder_file_stream();
|
| 75 |
+
virtual ~jpeg_decoder_file_stream();
|
| 76 |
+
|
| 77 |
+
bool open(const char *Pfilename);
|
| 78 |
+
void close();
|
| 79 |
+
|
| 80 |
+
virtual int read(uint8 *pBuf, int max_bytes_to_read, bool *pEOF_flag);
|
| 81 |
+
};
|
| 82 |
+
|
| 83 |
+
// Memory stream class.
|
| 84 |
+
class jpeg_decoder_mem_stream : public jpeg_decoder_stream
|
| 85 |
+
{
|
| 86 |
+
const uint8 *m_pSrc_data;
|
| 87 |
+
uint m_ofs, m_size;
|
| 88 |
+
|
| 89 |
+
public:
|
| 90 |
+
jpeg_decoder_mem_stream() : m_pSrc_data(NULL), m_ofs(0), m_size(0) { }
|
| 91 |
+
jpeg_decoder_mem_stream(const uint8 *pSrc_data, uint size) : m_pSrc_data(pSrc_data), m_ofs(0), m_size(size) { }
|
| 92 |
+
|
| 93 |
+
virtual ~jpeg_decoder_mem_stream() { }
|
| 94 |
+
|
| 95 |
+
bool open(const uint8 *pSrc_data, uint size);
|
| 96 |
+
void close() { m_pSrc_data = NULL; m_ofs = 0; m_size = 0; }
|
| 97 |
+
|
| 98 |
+
virtual int read(uint8 *pBuf, int max_bytes_to_read, bool *pEOF_flag);
|
| 99 |
+
};
|
| 100 |
+
|
| 101 |
+
// Loads JPEG file from a jpeg_decoder_stream.
|
| 102 |
+
unsigned char *decompress_jpeg_image_from_stream(jpeg_decoder_stream *pStream, int *width, int *height, int *actual_comps, int req_comps);
|
| 103 |
+
|
| 104 |
+
enum
|
| 105 |
+
{
|
| 106 |
+
JPGD_IN_BUF_SIZE = 8192, JPGD_MAX_BLOCKS_PER_MCU = 10, JPGD_MAX_HUFF_TABLES = 8, JPGD_MAX_QUANT_TABLES = 4,
|
| 107 |
+
JPGD_MAX_COMPONENTS = 4, JPGD_MAX_COMPS_IN_SCAN = 4, JPGD_MAX_BLOCKS_PER_ROW = 8192, JPGD_MAX_HEIGHT = 16384, JPGD_MAX_WIDTH = 16384
|
| 108 |
+
};
|
| 109 |
+
|
| 110 |
+
typedef int16 jpgd_quant_t;
|
| 111 |
+
typedef int16 jpgd_block_t;
|
| 112 |
+
|
| 113 |
+
class jpeg_decoder
|
| 114 |
+
{
|
| 115 |
+
public:
|
| 116 |
+
// Call get_error_code() after constructing to determine if the stream is valid or not. You may call the get_width(), get_height(), etc.
|
| 117 |
+
// methods after the constructor is called. You may then either destruct the object, or begin decoding the image by calling begin_decoding(), then decode() on each scanline.
|
| 118 |
+
jpeg_decoder(jpeg_decoder_stream *pStream);
|
| 119 |
+
|
| 120 |
+
~jpeg_decoder();
|
| 121 |
+
|
| 122 |
+
// Call this method after constructing the object to begin decompression.
|
| 123 |
+
// If JPGD_SUCCESS is returned you may then call decode() on each scanline.
|
| 124 |
+
int begin_decoding();
|
| 125 |
+
|
| 126 |
+
// Returns the next scan line.
|
| 127 |
+
// For grayscale images, pScan_line will point to a buffer containing 8-bit pixels (get_bytes_per_pixel() will return 1).
|
| 128 |
+
// Otherwise, it will always point to a buffer containing 32-bit RGBA pixels (A will always be 255, and get_bytes_per_pixel() will return 4).
|
| 129 |
+
// Returns JPGD_SUCCESS if a scan line has been returned.
|
| 130 |
+
// Returns JPGD_DONE if all scan lines have been returned.
|
| 131 |
+
// Returns JPGD_FAILED if an error occurred. Call get_error_code() for a more info.
|
| 132 |
+
int decode(const void** pScan_line, uint* pScan_line_len);
|
| 133 |
+
|
| 134 |
+
inline jpgd_status get_error_code() const { return m_error_code; }
|
| 135 |
+
|
| 136 |
+
inline int get_width() const { return m_image_x_size; }
|
| 137 |
+
inline int get_height() const { return m_image_y_size; }
|
| 138 |
+
|
| 139 |
+
inline int get_num_components() const { return m_comps_in_frame; }
|
| 140 |
+
|
| 141 |
+
inline int get_bytes_per_pixel() const { return m_dest_bytes_per_pixel; }
|
| 142 |
+
inline int get_bytes_per_scan_line() const { return m_image_x_size * get_bytes_per_pixel(); }
|
| 143 |
+
|
| 144 |
+
// Returns the total number of bytes actually consumed by the decoder (which should equal the actual size of the JPEG file).
|
| 145 |
+
inline int get_total_bytes_read() const { return m_total_bytes_read; }
|
| 146 |
+
|
| 147 |
+
private:
|
| 148 |
+
jpeg_decoder(const jpeg_decoder &);
|
| 149 |
+
jpeg_decoder &operator =(const jpeg_decoder &);
|
| 150 |
+
|
| 151 |
+
typedef void (*pDecode_block_func)(jpeg_decoder *, int, int, int);
|
| 152 |
+
|
| 153 |
+
struct huff_tables
|
| 154 |
+
{
|
| 155 |
+
bool ac_table;
|
| 156 |
+
uint look_up[256];
|
| 157 |
+
uint look_up2[256];
|
| 158 |
+
uint8 code_size[256];
|
| 159 |
+
uint tree[512];
|
| 160 |
+
};
|
| 161 |
+
|
| 162 |
+
struct coeff_buf
|
| 163 |
+
{
|
| 164 |
+
uint8 *pData;
|
| 165 |
+
int block_num_x, block_num_y;
|
| 166 |
+
int block_len_x, block_len_y;
|
| 167 |
+
int block_size;
|
| 168 |
+
};
|
| 169 |
+
|
| 170 |
+
struct mem_block
|
| 171 |
+
{
|
| 172 |
+
mem_block *m_pNext;
|
| 173 |
+
size_t m_used_count;
|
| 174 |
+
size_t m_size;
|
| 175 |
+
char m_data[1];
|
| 176 |
+
};
|
| 177 |
+
|
| 178 |
+
jmp_buf m_jmp_state;
|
| 179 |
+
mem_block *m_pMem_blocks;
|
| 180 |
+
int m_image_x_size;
|
| 181 |
+
int m_image_y_size;
|
| 182 |
+
jpeg_decoder_stream *m_pStream;
|
| 183 |
+
int m_progressive_flag;
|
| 184 |
+
uint8 m_huff_ac[JPGD_MAX_HUFF_TABLES];
|
| 185 |
+
uint8* m_huff_num[JPGD_MAX_HUFF_TABLES]; // pointer to number of Huffman codes per bit size
|
| 186 |
+
uint8* m_huff_val[JPGD_MAX_HUFF_TABLES]; // pointer to Huffman codes per bit size
|
| 187 |
+
jpgd_quant_t* m_quant[JPGD_MAX_QUANT_TABLES]; // pointer to quantization tables
|
| 188 |
+
int m_scan_type; // Gray, Yh1v1, Yh1v2, Yh2v1, Yh2v2 (CMYK111, CMYK4114 no longer supported)
|
| 189 |
+
int m_comps_in_frame; // # of components in frame
|
| 190 |
+
int m_comp_h_samp[JPGD_MAX_COMPONENTS]; // component's horizontal sampling factor
|
| 191 |
+
int m_comp_v_samp[JPGD_MAX_COMPONENTS]; // component's vertical sampling factor
|
| 192 |
+
int m_comp_quant[JPGD_MAX_COMPONENTS]; // component's quantization table selector
|
| 193 |
+
int m_comp_ident[JPGD_MAX_COMPONENTS]; // component's ID
|
| 194 |
+
int m_comp_h_blocks[JPGD_MAX_COMPONENTS];
|
| 195 |
+
int m_comp_v_blocks[JPGD_MAX_COMPONENTS];
|
| 196 |
+
int m_comps_in_scan; // # of components in scan
|
| 197 |
+
int m_comp_list[JPGD_MAX_COMPS_IN_SCAN]; // components in this scan
|
| 198 |
+
int m_comp_dc_tab[JPGD_MAX_COMPONENTS]; // component's DC Huffman coding table selector
|
| 199 |
+
int m_comp_ac_tab[JPGD_MAX_COMPONENTS]; // component's AC Huffman coding table selector
|
| 200 |
+
int m_spectral_start; // spectral selection start
|
| 201 |
+
int m_spectral_end; // spectral selection end
|
| 202 |
+
int m_successive_low; // successive approximation low
|
| 203 |
+
int m_successive_high; // successive approximation high
|
| 204 |
+
int m_max_mcu_x_size; // MCU's max. X size in pixels
|
| 205 |
+
int m_max_mcu_y_size; // MCU's max. Y size in pixels
|
| 206 |
+
int m_blocks_per_mcu;
|
| 207 |
+
int m_max_blocks_per_row;
|
| 208 |
+
int m_mcus_per_row, m_mcus_per_col;
|
| 209 |
+
int m_mcu_org[JPGD_MAX_BLOCKS_PER_MCU];
|
| 210 |
+
int m_total_lines_left; // total # lines left in image
|
| 211 |
+
int m_mcu_lines_left; // total # lines left in this MCU
|
| 212 |
+
int m_real_dest_bytes_per_scan_line;
|
| 213 |
+
int m_dest_bytes_per_scan_line; // rounded up
|
| 214 |
+
int m_dest_bytes_per_pixel; // 4 (RGB) or 1 (Y)
|
| 215 |
+
huff_tables* m_pHuff_tabs[JPGD_MAX_HUFF_TABLES];
|
| 216 |
+
coeff_buf* m_dc_coeffs[JPGD_MAX_COMPONENTS];
|
| 217 |
+
coeff_buf* m_ac_coeffs[JPGD_MAX_COMPONENTS];
|
| 218 |
+
int m_eob_run;
|
| 219 |
+
int m_block_y_mcu[JPGD_MAX_COMPONENTS];
|
| 220 |
+
uint8* m_pIn_buf_ofs;
|
| 221 |
+
int m_in_buf_left;
|
| 222 |
+
int m_tem_flag;
|
| 223 |
+
bool m_eof_flag;
|
| 224 |
+
uint8 m_in_buf_pad_start[128];
|
| 225 |
+
uint8 m_in_buf[JPGD_IN_BUF_SIZE + 128];
|
| 226 |
+
uint8 m_in_buf_pad_end[128];
|
| 227 |
+
int m_bits_left;
|
| 228 |
+
uint m_bit_buf;
|
| 229 |
+
int m_restart_interval;
|
| 230 |
+
int m_restarts_left;
|
| 231 |
+
int m_next_restart_num;
|
| 232 |
+
int m_max_mcus_per_row;
|
| 233 |
+
int m_max_blocks_per_mcu;
|
| 234 |
+
int m_expanded_blocks_per_mcu;
|
| 235 |
+
int m_expanded_blocks_per_row;
|
| 236 |
+
int m_expanded_blocks_per_component;
|
| 237 |
+
bool m_freq_domain_chroma_upsample;
|
| 238 |
+
int m_max_mcus_per_col;
|
| 239 |
+
uint m_last_dc_val[JPGD_MAX_COMPONENTS];
|
| 240 |
+
jpgd_block_t* m_pMCU_coefficients;
|
| 241 |
+
int m_mcu_block_max_zag[JPGD_MAX_BLOCKS_PER_MCU];
|
| 242 |
+
uint8* m_pSample_buf;
|
| 243 |
+
int m_crr[256];
|
| 244 |
+
int m_cbb[256];
|
| 245 |
+
int m_crg[256];
|
| 246 |
+
int m_cbg[256];
|
| 247 |
+
uint8* m_pScan_line_0;
|
| 248 |
+
uint8* m_pScan_line_1;
|
| 249 |
+
jpgd_status m_error_code;
|
| 250 |
+
bool m_ready_flag;
|
| 251 |
+
int m_total_bytes_read;
|
| 252 |
+
|
| 253 |
+
void free_all_blocks();
|
| 254 |
+
// BEGIN EPIC MOD
|
| 255 |
+
UE_NORETURN void stop_decoding(jpgd_status status);
|
| 256 |
+
// END EPIC MOD
|
| 257 |
+
void *alloc(size_t n, bool zero = false);
|
| 258 |
+
void word_clear(void *p, uint16 c, uint n);
|
| 259 |
+
void prep_in_buffer();
|
| 260 |
+
void read_dht_marker();
|
| 261 |
+
void read_dqt_marker();
|
| 262 |
+
void read_sof_marker();
|
| 263 |
+
void skip_variable_marker();
|
| 264 |
+
void read_dri_marker();
|
| 265 |
+
void read_sos_marker();
|
| 266 |
+
int next_marker();
|
| 267 |
+
int process_markers();
|
| 268 |
+
void locate_soi_marker();
|
| 269 |
+
void locate_sof_marker();
|
| 270 |
+
int locate_sos_marker();
|
| 271 |
+
void init(jpeg_decoder_stream * pStream);
|
| 272 |
+
void create_look_ups();
|
| 273 |
+
void fix_in_buffer();
|
| 274 |
+
void transform_mcu(int mcu_row);
|
| 275 |
+
void transform_mcu_expand(int mcu_row);
|
| 276 |
+
coeff_buf* coeff_buf_open(int block_num_x, int block_num_y, int block_len_x, int block_len_y);
|
| 277 |
+
inline jpgd_block_t *coeff_buf_getp(coeff_buf *cb, int block_x, int block_y);
|
| 278 |
+
void load_next_row();
|
| 279 |
+
void decode_next_row();
|
| 280 |
+
void make_huff_table(int index, huff_tables *pH);
|
| 281 |
+
void check_quant_tables();
|
| 282 |
+
void check_huff_tables();
|
| 283 |
+
void calc_mcu_block_order();
|
| 284 |
+
int init_scan();
|
| 285 |
+
void init_frame();
|
| 286 |
+
void process_restart();
|
| 287 |
+
void decode_scan(pDecode_block_func decode_block_func);
|
| 288 |
+
void init_progressive();
|
| 289 |
+
void init_sequential();
|
| 290 |
+
void decode_start();
|
| 291 |
+
void decode_init(jpeg_decoder_stream * pStream);
|
| 292 |
+
void H2V2Convert();
|
| 293 |
+
void H2V1Convert();
|
| 294 |
+
void H1V2Convert();
|
| 295 |
+
void H1V1Convert();
|
| 296 |
+
void gray_convert();
|
| 297 |
+
void expanded_convert();
|
| 298 |
+
void find_eoi();
|
| 299 |
+
inline uint get_char();
|
| 300 |
+
inline uint get_char(bool *pPadding_flag);
|
| 301 |
+
inline void stuff_char(uint8 q);
|
| 302 |
+
inline uint8 get_octet();
|
| 303 |
+
inline uint get_bits(int num_bits);
|
| 304 |
+
inline uint get_bits_no_markers(int numbits);
|
| 305 |
+
inline int huff_decode(huff_tables *pH);
|
| 306 |
+
inline int huff_decode(huff_tables *pH, int& extrabits);
|
| 307 |
+
static inline uint8 clamp(int i);
|
| 308 |
+
static void decode_block_dc_first(jpeg_decoder *pD, int component_id, int block_x, int block_y);
|
| 309 |
+
static void decode_block_dc_refine(jpeg_decoder *pD, int component_id, int block_x, int block_y);
|
| 310 |
+
static void decode_block_ac_first(jpeg_decoder *pD, int component_id, int block_x, int block_y);
|
| 311 |
+
static void decode_block_ac_refine(jpeg_decoder *pD, int component_id, int block_x, int block_y);
|
| 312 |
+
};
|
| 313 |
+
|
| 314 |
+
} // namespace jpgd
|
| 315 |
+
|
| 316 |
+
#endif // JPEG_DECODER_H
|
crazy_functions/test_project/cpp/libJPG/jpge.cpp
ADDED
|
@@ -0,0 +1,1049 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// jpge.cpp - C++ class for JPEG compression.
|
| 2 |
+
// Public domain, Rich Geldreich <[email protected]>
|
| 3 |
+
// v1.01, Dec. 18, 2010 - Initial release
|
| 4 |
+
// v1.02, Apr. 6, 2011 - Removed 2x2 ordered dither in H2V1 chroma subsampling method load_block_16_8_8(). (The rounding factor was 2, when it should have been 1. Either way, it wasn't helping.)
|
| 5 |
+
// v1.03, Apr. 16, 2011 - Added support for optimized Huffman code tables, optimized dynamic memory allocation down to only 1 alloc.
|
| 6 |
+
// Also from Alex Evans: Added RGBA support, linear memory allocator (no longer needed in v1.03).
|
| 7 |
+
// v1.04, May. 19, 2012: Forgot to set m_pFile ptr to NULL in cfile_stream::close(). Thanks to Owen Kaluza for reporting this bug.
|
| 8 |
+
// Code tweaks to fix VS2008 static code analysis warnings (all looked harmless).
|
| 9 |
+
// Code review revealed method load_block_16_8_8() (used for the non-default H2V1 sampling mode to downsample chroma) somehow didn't get the rounding factor fix from v1.02.
|
| 10 |
+
|
| 11 |
+
#include "jpge.h"
|
| 12 |
+
|
| 13 |
+
#include <stdlib.h>
|
| 14 |
+
#include <string.h>
|
| 15 |
+
#if PLATFORM_WINDOWS
|
| 16 |
+
#include <malloc.h>
|
| 17 |
+
#endif
|
| 18 |
+
|
| 19 |
+
#define JPGE_MAX(a,b) (((a)>(b))?(a):(b))
|
| 20 |
+
#define JPGE_MIN(a,b) (((a)<(b))?(a):(b))
|
| 21 |
+
|
| 22 |
+
namespace jpge {
|
| 23 |
+
|
| 24 |
+
static inline void *jpge_malloc(size_t nSize) { return FMemory::Malloc(nSize); }
|
| 25 |
+
static inline void jpge_free(void *p) { FMemory::Free(p);; }
|
| 26 |
+
|
| 27 |
+
// Various JPEG enums and tables.
|
| 28 |
+
enum { M_SOF0 = 0xC0, M_DHT = 0xC4, M_SOI = 0xD8, M_EOI = 0xD9, M_SOS = 0xDA, M_DQT = 0xDB, M_APP0 = 0xE0 };
|
| 29 |
+
enum { DC_LUM_CODES = 12, AC_LUM_CODES = 256, DC_CHROMA_CODES = 12, AC_CHROMA_CODES = 256, MAX_HUFF_SYMBOLS = 257, MAX_HUFF_CODESIZE = 32 };
|
| 30 |
+
|
| 31 |
+
static uint8 s_zag[64] = { 0,1,8,16,9,2,3,10,17,24,32,25,18,11,4,5,12,19,26,33,40,48,41,34,27,20,13,6,7,14,21,28,35,42,49,56,57,50,43,36,29,22,15,23,30,37,44,51,58,59,52,45,38,31,39,46,53,60,61,54,47,55,62,63 };
|
| 32 |
+
static int16 s_std_lum_quant[64] = { 16,11,12,14,12,10,16,14,13,14,18,17,16,19,24,40,26,24,22,22,24,49,35,37,29,40,58,51,61,60,57,51,56,55,64,72,92,78,64,68,87,69,55,56,80,109,81,87,95,98,103,104,103,62,77,113,121,112,100,120,92,101,103,99 };
|
| 33 |
+
static int16 s_std_croma_quant[64] = { 17,18,18,24,21,24,47,26,26,47,99,66,56,66,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99,99 };
|
| 34 |
+
static uint8 s_dc_lum_bits[17] = { 0,0,1,5,1,1,1,1,1,1,0,0,0,0,0,0,0 };
|
| 35 |
+
static uint8 s_dc_lum_val[DC_LUM_CODES] = { 0,1,2,3,4,5,6,7,8,9,10,11 };
|
| 36 |
+
static uint8 s_ac_lum_bits[17] = { 0,0,2,1,3,3,2,4,3,5,5,4,4,0,0,1,0x7d };
|
| 37 |
+
static uint8 s_ac_lum_val[AC_LUM_CODES] =
|
| 38 |
+
{
|
| 39 |
+
0x01,0x02,0x03,0x00,0x04,0x11,0x05,0x12,0x21,0x31,0x41,0x06,0x13,0x51,0x61,0x07,0x22,0x71,0x14,0x32,0x81,0x91,0xa1,0x08,0x23,0x42,0xb1,0xc1,0x15,0x52,0xd1,0xf0,
|
| 40 |
+
0x24,0x33,0x62,0x72,0x82,0x09,0x0a,0x16,0x17,0x18,0x19,0x1a,0x25,0x26,0x27,0x28,0x29,0x2a,0x34,0x35,0x36,0x37,0x38,0x39,0x3a,0x43,0x44,0x45,0x46,0x47,0x48,0x49,
|
| 41 |
+
0x4a,0x53,0x54,0x55,0x56,0x57,0x58,0x59,0x5a,0x63,0x64,0x65,0x66,0x67,0x68,0x69,0x6a,0x73,0x74,0x75,0x76,0x77,0x78,0x79,0x7a,0x83,0x84,0x85,0x86,0x87,0x88,0x89,
|
| 42 |
+
0x8a,0x92,0x93,0x94,0x95,0x96,0x97,0x98,0x99,0x9a,0xa2,0xa3,0xa4,0xa5,0xa6,0xa7,0xa8,0xa9,0xaa,0xb2,0xb3,0xb4,0xb5,0xb6,0xb7,0xb8,0xb9,0xba,0xc2,0xc3,0xc4,0xc5,
|
| 43 |
+
0xc6,0xc7,0xc8,0xc9,0xca,0xd2,0xd3,0xd4,0xd5,0xd6,0xd7,0xd8,0xd9,0xda,0xe1,0xe2,0xe3,0xe4,0xe5,0xe6,0xe7,0xe8,0xe9,0xea,0xf1,0xf2,0xf3,0xf4,0xf5,0xf6,0xf7,0xf8,
|
| 44 |
+
0xf9,0xfa
|
| 45 |
+
};
|
| 46 |
+
static uint8 s_dc_chroma_bits[17] = { 0,0,3,1,1,1,1,1,1,1,1,1,0,0,0,0,0 };
|
| 47 |
+
static uint8 s_dc_chroma_val[DC_CHROMA_CODES] = { 0,1,2,3,4,5,6,7,8,9,10,11 };
|
| 48 |
+
static uint8 s_ac_chroma_bits[17] = { 0,0,2,1,2,4,4,3,4,7,5,4,4,0,1,2,0x77 };
|
| 49 |
+
static uint8 s_ac_chroma_val[AC_CHROMA_CODES] =
|
| 50 |
+
{
|
| 51 |
+
0x00,0x01,0x02,0x03,0x11,0x04,0x05,0x21,0x31,0x06,0x12,0x41,0x51,0x07,0x61,0x71,0x13,0x22,0x32,0x81,0x08,0x14,0x42,0x91,0xa1,0xb1,0xc1,0x09,0x23,0x33,0x52,0xf0,
|
| 52 |
+
0x15,0x62,0x72,0xd1,0x0a,0x16,0x24,0x34,0xe1,0x25,0xf1,0x17,0x18,0x19,0x1a,0x26,0x27,0x28,0x29,0x2a,0x35,0x36,0x37,0x38,0x39,0x3a,0x43,0x44,0x45,0x46,0x47,0x48,
|
| 53 |
+
0x49,0x4a,0x53,0x54,0x55,0x56,0x57,0x58,0x59,0x5a,0x63,0x64,0x65,0x66,0x67,0x68,0x69,0x6a,0x73,0x74,0x75,0x76,0x77,0x78,0x79,0x7a,0x82,0x83,0x84,0x85,0x86,0x87,
|
| 54 |
+
0x88,0x89,0x8a,0x92,0x93,0x94,0x95,0x96,0x97,0x98,0x99,0x9a,0xa2,0xa3,0xa4,0xa5,0xa6,0xa7,0xa8,0xa9,0xaa,0xb2,0xb3,0xb4,0xb5,0xb6,0xb7,0xb8,0xb9,0xba,0xc2,0xc3,
|
| 55 |
+
0xc4,0xc5,0xc6,0xc7,0xc8,0xc9,0xca,0xd2,0xd3,0xd4,0xd5,0xd6,0xd7,0xd8,0xd9,0xda,0xe2,0xe3,0xe4,0xe5,0xe6,0xe7,0xe8,0xe9,0xea,0xf2,0xf3,0xf4,0xf5,0xf6,0xf7,0xf8,
|
| 56 |
+
0xf9,0xfa
|
| 57 |
+
};
|
| 58 |
+
|
| 59 |
+
// Low-level helper functions.
|
| 60 |
+
template <class T> inline void clear_obj(T &obj) { memset(&obj, 0, sizeof(obj)); }
|
| 61 |
+
|
| 62 |
+
const int YR = 19595, YG = 38470, YB = 7471, CB_R = -11059, CB_G = -21709, CB_B = 32768, CR_R = 32768, CR_G = -27439, CR_B = -5329;
|
| 63 |
+
static inline uint8 clamp(int i) { if (static_cast<uint>(i) > 255U) { if (i < 0) i = 0; else if (i > 255) i = 255; } return static_cast<uint8>(i); }
|
| 64 |
+
|
| 65 |
+
static void RGB_to_YCC(uint8* pDst, const uint8 *pSrc, int num_pixels)
|
| 66 |
+
{
|
| 67 |
+
for ( ; num_pixels; pDst += 3, pSrc += 3, num_pixels--)
|
| 68 |
+
{
|
| 69 |
+
const int r = pSrc[0], g = pSrc[1], b = pSrc[2];
|
| 70 |
+
pDst[0] = static_cast<uint8>((r * YR + g * YG + b * YB + 32768) >> 16);
|
| 71 |
+
pDst[1] = clamp(128 + ((r * CB_R + g * CB_G + b * CB_B + 32768) >> 16));
|
| 72 |
+
pDst[2] = clamp(128 + ((r * CR_R + g * CR_G + b * CR_B + 32768) >> 16));
|
| 73 |
+
}
|
| 74 |
+
}
|
| 75 |
+
|
| 76 |
+
static void RGB_to_Y(uint8* pDst, const uint8 *pSrc, int num_pixels)
|
| 77 |
+
{
|
| 78 |
+
for ( ; num_pixels; pDst++, pSrc += 3, num_pixels--)
|
| 79 |
+
pDst[0] = static_cast<uint8>((pSrc[0] * YR + pSrc[1] * YG + pSrc[2] * YB + 32768) >> 16);
|
| 80 |
+
}
|
| 81 |
+
|
| 82 |
+
static void RGBA_to_YCC(uint8* pDst, const uint8 *pSrc, int num_pixels)
|
| 83 |
+
{
|
| 84 |
+
for ( ; num_pixels; pDst += 3, pSrc += 4, num_pixels--)
|
| 85 |
+
{
|
| 86 |
+
const int r = pSrc[0], g = pSrc[1], b = pSrc[2];
|
| 87 |
+
pDst[0] = static_cast<uint8>((r * YR + g * YG + b * YB + 32768) >> 16);
|
| 88 |
+
pDst[1] = clamp(128 + ((r * CB_R + g * CB_G + b * CB_B + 32768) >> 16));
|
| 89 |
+
pDst[2] = clamp(128 + ((r * CR_R + g * CR_G + b * CR_B + 32768) >> 16));
|
| 90 |
+
}
|
| 91 |
+
}
|
| 92 |
+
|
| 93 |
+
static void RGBA_to_Y(uint8* pDst, const uint8 *pSrc, int num_pixels)
|
| 94 |
+
{
|
| 95 |
+
for ( ; num_pixels; pDst++, pSrc += 4, num_pixels--)
|
| 96 |
+
pDst[0] = static_cast<uint8>((pSrc[0] * YR + pSrc[1] * YG + pSrc[2] * YB + 32768) >> 16);
|
| 97 |
+
}
|
| 98 |
+
|
| 99 |
+
static void Y_to_YCC(uint8* pDst, const uint8* pSrc, int num_pixels)
|
| 100 |
+
{
|
| 101 |
+
for( ; num_pixels; pDst += 3, pSrc++, num_pixels--) { pDst[0] = pSrc[0]; pDst[1] = 128; pDst[2] = 128; }
|
| 102 |
+
}
|
| 103 |
+
|
| 104 |
+
// Forward DCT - DCT derived from jfdctint.
|
| 105 |
+
#define CONST_BITS 13
|
| 106 |
+
#define ROW_BITS 2
|
| 107 |
+
#define DCT_DESCALE(x, n) (((x) + (((int32)1) << ((n) - 1))) >> (n))
|
| 108 |
+
#define DCT_MUL(var, c) (static_cast<int16>(var) * static_cast<int32>(c))
|
| 109 |
+
#define DCT1D(s0, s1, s2, s3, s4, s5, s6, s7) \
|
| 110 |
+
int32 t0 = s0 + s7, t7 = s0 - s7, t1 = s1 + s6, t6 = s1 - s6, t2 = s2 + s5, t5 = s2 - s5, t3 = s3 + s4, t4 = s3 - s4; \
|
| 111 |
+
int32 t10 = t0 + t3, t13 = t0 - t3, t11 = t1 + t2, t12 = t1 - t2; \
|
| 112 |
+
int32 u1 = DCT_MUL(t12 + t13, 4433); \
|
| 113 |
+
s2 = u1 + DCT_MUL(t13, 6270); \
|
| 114 |
+
s6 = u1 + DCT_MUL(t12, -15137); \
|
| 115 |
+
u1 = t4 + t7; \
|
| 116 |
+
int32 u2 = t5 + t6, u3 = t4 + t6, u4 = t5 + t7; \
|
| 117 |
+
int32 z5 = DCT_MUL(u3 + u4, 9633); \
|
| 118 |
+
t4 = DCT_MUL(t4, 2446); t5 = DCT_MUL(t5, 16819); \
|
| 119 |
+
t6 = DCT_MUL(t6, 25172); t7 = DCT_MUL(t7, 12299); \
|
| 120 |
+
u1 = DCT_MUL(u1, -7373); u2 = DCT_MUL(u2, -20995); \
|
| 121 |
+
u3 = DCT_MUL(u3, -16069); u4 = DCT_MUL(u4, -3196); \
|
| 122 |
+
u3 += z5; u4 += z5; \
|
| 123 |
+
s0 = t10 + t11; s1 = t7 + u1 + u4; s3 = t6 + u2 + u3; s4 = t10 - t11; s5 = t5 + u2 + u4; s7 = t4 + u1 + u3;
|
| 124 |
+
|
| 125 |
+
static void DCT2D(int32 *p)
|
| 126 |
+
{
|
| 127 |
+
int32 c, *q = p;
|
| 128 |
+
for (c = 7; c >= 0; c--, q += 8)
|
| 129 |
+
{
|
| 130 |
+
int32 s0 = q[0], s1 = q[1], s2 = q[2], s3 = q[3], s4 = q[4], s5 = q[5], s6 = q[6], s7 = q[7];
|
| 131 |
+
DCT1D(s0, s1, s2, s3, s4, s5, s6, s7);
|
| 132 |
+
q[0] = s0 << ROW_BITS; q[1] = DCT_DESCALE(s1, CONST_BITS-ROW_BITS); q[2] = DCT_DESCALE(s2, CONST_BITS-ROW_BITS); q[3] = DCT_DESCALE(s3, CONST_BITS-ROW_BITS);
|
| 133 |
+
q[4] = s4 << ROW_BITS; q[5] = DCT_DESCALE(s5, CONST_BITS-ROW_BITS); q[6] = DCT_DESCALE(s6, CONST_BITS-ROW_BITS); q[7] = DCT_DESCALE(s7, CONST_BITS-ROW_BITS);
|
| 134 |
+
}
|
| 135 |
+
for (q = p, c = 7; c >= 0; c--, q++)
|
| 136 |
+
{
|
| 137 |
+
int32 s0 = q[0*8], s1 = q[1*8], s2 = q[2*8], s3 = q[3*8], s4 = q[4*8], s5 = q[5*8], s6 = q[6*8], s7 = q[7*8];
|
| 138 |
+
DCT1D(s0, s1, s2, s3, s4, s5, s6, s7);
|
| 139 |
+
q[0*8] = DCT_DESCALE(s0, ROW_BITS+3); q[1*8] = DCT_DESCALE(s1, CONST_BITS+ROW_BITS+3); q[2*8] = DCT_DESCALE(s2, CONST_BITS+ROW_BITS+3); q[3*8] = DCT_DESCALE(s3, CONST_BITS+ROW_BITS+3);
|
| 140 |
+
q[4*8] = DCT_DESCALE(s4, ROW_BITS+3); q[5*8] = DCT_DESCALE(s5, CONST_BITS+ROW_BITS+3); q[6*8] = DCT_DESCALE(s6, CONST_BITS+ROW_BITS+3); q[7*8] = DCT_DESCALE(s7, CONST_BITS+ROW_BITS+3);
|
| 141 |
+
}
|
| 142 |
+
}
|
| 143 |
+
|
| 144 |
+
struct sym_freq { uint m_key, m_sym_index; };
|
| 145 |
+
|
| 146 |
+
// Radix sorts sym_freq[] array by 32-bit key m_key. Returns ptr to sorted values.
|
| 147 |
+
static inline sym_freq* radix_sort_syms(uint num_syms, sym_freq* pSyms0, sym_freq* pSyms1)
|
| 148 |
+
{
|
| 149 |
+
const uint cMaxPasses = 4;
|
| 150 |
+
uint32 hist[256 * cMaxPasses]; clear_obj(hist);
|
| 151 |
+
for (uint i = 0; i < num_syms; i++) { uint freq = pSyms0[i].m_key; hist[freq & 0xFF]++; hist[256 + ((freq >> 8) & 0xFF)]++; hist[256*2 + ((freq >> 16) & 0xFF)]++; hist[256*3 + ((freq >> 24) & 0xFF)]++; }
|
| 152 |
+
sym_freq* pCur_syms = pSyms0, *pNew_syms = pSyms1;
|
| 153 |
+
uint total_passes = cMaxPasses; while ((total_passes > 1) && (num_syms == hist[(total_passes - 1) * 256])) total_passes--;
|
| 154 |
+
for (uint pass_shift = 0, pass = 0; pass < total_passes; pass++, pass_shift += 8)
|
| 155 |
+
{
|
| 156 |
+
const uint32* pHist = &hist[pass << 8];
|
| 157 |
+
uint offsets[256], cur_ofs = 0;
|
| 158 |
+
for (uint i = 0; i < 256; i++) { offsets[i] = cur_ofs; cur_ofs += pHist[i]; }
|
| 159 |
+
for (uint i = 0; i < num_syms; i++)
|
| 160 |
+
pNew_syms[offsets[(pCur_syms[i].m_key >> pass_shift) & 0xFF]++] = pCur_syms[i];
|
| 161 |
+
sym_freq* t = pCur_syms; pCur_syms = pNew_syms; pNew_syms = t;
|
| 162 |
+
}
|
| 163 |
+
return pCur_syms;
|
| 164 |
+
}
|
| 165 |
+
|
| 166 |
+
// calculate_minimum_redundancy() originally written by: Alistair Moffat, [email protected], Jyrki Katajainen, [email protected], November 1996.
|
| 167 |
+
static void calculate_minimum_redundancy(sym_freq *A, int n)
|
| 168 |
+
{
|
| 169 |
+
int root, leaf, next, avbl, used, dpth;
|
| 170 |
+
if (n==0) return; else if (n==1) { A[0].m_key = 1; return; }
|
| 171 |
+
A[0].m_key += A[1].m_key; root = 0; leaf = 2;
|
| 172 |
+
for (next=1; next < n-1; next++)
|
| 173 |
+
{
|
| 174 |
+
if (leaf>=n || A[root].m_key<A[leaf].m_key) { A[next].m_key = A[root].m_key; A[root++].m_key = next; } else A[next].m_key = A[leaf++].m_key;
|
| 175 |
+
if (leaf>=n || (root<next && A[root].m_key<A[leaf].m_key)) { A[next].m_key += A[root].m_key; A[root++].m_key = next; } else A[next].m_key += A[leaf++].m_key;
|
| 176 |
+
}
|
| 177 |
+
A[n-2].m_key = 0;
|
| 178 |
+
for (next=n-3; next>=0; next--) A[next].m_key = A[A[next].m_key].m_key+1;
|
| 179 |
+
avbl = 1; used = dpth = 0; root = n-2; next = n-1;
|
| 180 |
+
while (avbl>0)
|
| 181 |
+
{
|
| 182 |
+
while (root>=0 && (int)A[root].m_key==dpth) { used++; root--; }
|
| 183 |
+
while (avbl>used) { A[next--].m_key = dpth; avbl--; }
|
| 184 |
+
avbl = 2*used; dpth++; used = 0;
|
| 185 |
+
}
|
| 186 |
+
}
|
| 187 |
+
|
| 188 |
+
// Limits canonical Huffman code table's max code size to max_code_size.
|
| 189 |
+
static void huffman_enforce_max_code_size(int *pNum_codes, int code_list_len, int max_code_size)
|
| 190 |
+
{
|
| 191 |
+
if (code_list_len <= 1) return;
|
| 192 |
+
|
| 193 |
+
for (int i = max_code_size + 1; i <= MAX_HUFF_CODESIZE; i++) pNum_codes[max_code_size] += pNum_codes[i];
|
| 194 |
+
|
| 195 |
+
uint32 total = 0;
|
| 196 |
+
for (int i = max_code_size; i > 0; i--)
|
| 197 |
+
total += (((uint32)pNum_codes[i]) << (max_code_size - i));
|
| 198 |
+
|
| 199 |
+
while (total != (1UL << max_code_size))
|
| 200 |
+
{
|
| 201 |
+
pNum_codes[max_code_size]--;
|
| 202 |
+
for (int i = max_code_size - 1; i > 0; i--)
|
| 203 |
+
{
|
| 204 |
+
if (pNum_codes[i]) { pNum_codes[i]--; pNum_codes[i + 1] += 2; break; }
|
| 205 |
+
}
|
| 206 |
+
total--;
|
| 207 |
+
}
|
| 208 |
+
}
|
| 209 |
+
|
| 210 |
+
// Generates an optimized offman table.
|
| 211 |
+
void jpeg_encoder::optimize_huffman_table(int table_num, int table_len)
|
| 212 |
+
{
|
| 213 |
+
sym_freq syms0[MAX_HUFF_SYMBOLS], syms1[MAX_HUFF_SYMBOLS];
|
| 214 |
+
syms0[0].m_key = 1; syms0[0].m_sym_index = 0; // dummy symbol, assures that no valid code contains all 1's
|
| 215 |
+
int num_used_syms = 1;
|
| 216 |
+
const uint32 *pSym_count = &m_huff_count[table_num][0];
|
| 217 |
+
for (int i = 0; i < table_len; i++)
|
| 218 |
+
if (pSym_count[i]) { syms0[num_used_syms].m_key = pSym_count[i]; syms0[num_used_syms++].m_sym_index = i + 1; }
|
| 219 |
+
sym_freq* pSyms = radix_sort_syms(num_used_syms, syms0, syms1);
|
| 220 |
+
calculate_minimum_redundancy(pSyms, num_used_syms);
|
| 221 |
+
|
| 222 |
+
// Count the # of symbols of each code size.
|
| 223 |
+
int num_codes[1 + MAX_HUFF_CODESIZE]; clear_obj(num_codes);
|
| 224 |
+
for (int i = 0; i < num_used_syms; i++)
|
| 225 |
+
num_codes[pSyms[i].m_key]++;
|
| 226 |
+
|
| 227 |
+
const uint JPGE_CODE_SIZE_LIMIT = 16; // the maximum possible size of a JPEG Huffman code (valid range is [9,16] - 9 vs. 8 because of the dummy symbol)
|
| 228 |
+
huffman_enforce_max_code_size(num_codes, num_used_syms, JPGE_CODE_SIZE_LIMIT);
|
| 229 |
+
|
| 230 |
+
// Compute m_huff_bits array, which contains the # of symbols per code size.
|
| 231 |
+
clear_obj(m_huff_bits[table_num]);
|
| 232 |
+
for (int i = 1; i <= (int)JPGE_CODE_SIZE_LIMIT; i++)
|
| 233 |
+
m_huff_bits[table_num][i] = static_cast<uint8>(num_codes[i]);
|
| 234 |
+
|
| 235 |
+
// Remove the dummy symbol added above, which must be in largest bucket.
|
| 236 |
+
for (int i = JPGE_CODE_SIZE_LIMIT; i >= 1; i--)
|
| 237 |
+
{
|
| 238 |
+
if (m_huff_bits[table_num][i]) { m_huff_bits[table_num][i]--; break; }
|
| 239 |
+
}
|
| 240 |
+
|
| 241 |
+
// Compute the m_huff_val array, which contains the symbol indices sorted by code size (smallest to largest).
|
| 242 |
+
for (int i = num_used_syms - 1; i >= 1; i--)
|
| 243 |
+
m_huff_val[table_num][num_used_syms - 1 - i] = static_cast<uint8>(pSyms[i].m_sym_index - 1);
|
| 244 |
+
}
|
| 245 |
+
|
| 246 |
+
// JPEG marker generation.
|
| 247 |
+
void jpeg_encoder::emit_byte(uint8 i)
|
| 248 |
+
{
|
| 249 |
+
m_all_stream_writes_succeeded = m_all_stream_writes_succeeded && m_pStream->put_obj(i);
|
| 250 |
+
}
|
| 251 |
+
|
| 252 |
+
void jpeg_encoder::emit_word(uint i)
|
| 253 |
+
{
|
| 254 |
+
emit_byte(uint8(i >> 8)); emit_byte(uint8(i & 0xFF));
|
| 255 |
+
}
|
| 256 |
+
|
| 257 |
+
void jpeg_encoder::emit_marker(int marker)
|
| 258 |
+
{
|
| 259 |
+
emit_byte(uint8(0xFF)); emit_byte(uint8(marker));
|
| 260 |
+
}
|
| 261 |
+
|
| 262 |
+
// Emit JFIF marker
|
| 263 |
+
void jpeg_encoder::emit_jfif_app0()
|
| 264 |
+
{
|
| 265 |
+
emit_marker(M_APP0);
|
| 266 |
+
emit_word(2 + 4 + 1 + 2 + 1 + 2 + 2 + 1 + 1);
|
| 267 |
+
emit_byte(0x4A); emit_byte(0x46); emit_byte(0x49); emit_byte(0x46); /* Identifier: ASCII "JFIF" */
|
| 268 |
+
emit_byte(0);
|
| 269 |
+
emit_byte(1); /* Major version */
|
| 270 |
+
emit_byte(1); /* Minor version */
|
| 271 |
+
emit_byte(0); /* Density unit */
|
| 272 |
+
emit_word(1);
|
| 273 |
+
emit_word(1);
|
| 274 |
+
emit_byte(0); /* No thumbnail image */
|
| 275 |
+
emit_byte(0);
|
| 276 |
+
}
|
| 277 |
+
|
| 278 |
+
// Emit quantization tables
|
| 279 |
+
void jpeg_encoder::emit_dqt()
|
| 280 |
+
{
|
| 281 |
+
for (int i = 0; i < ((m_num_components == 3) ? 2 : 1); i++)
|
| 282 |
+
{
|
| 283 |
+
emit_marker(M_DQT);
|
| 284 |
+
emit_word(64 + 1 + 2);
|
| 285 |
+
emit_byte(static_cast<uint8>(i));
|
| 286 |
+
for (int j = 0; j < 64; j++)
|
| 287 |
+
emit_byte(static_cast<uint8>(m_quantization_tables[i][j]));
|
| 288 |
+
}
|
| 289 |
+
}
|
| 290 |
+
|
| 291 |
+
// Emit start of frame marker
|
| 292 |
+
void jpeg_encoder::emit_sof()
|
| 293 |
+
{
|
| 294 |
+
emit_marker(M_SOF0); /* baseline */
|
| 295 |
+
emit_word(3 * m_num_components + 2 + 5 + 1);
|
| 296 |
+
emit_byte(8); /* precision */
|
| 297 |
+
emit_word(m_image_y);
|
| 298 |
+
emit_word(m_image_x);
|
| 299 |
+
emit_byte(m_num_components);
|
| 300 |
+
for (int i = 0; i < m_num_components; i++)
|
| 301 |
+
{
|
| 302 |
+
emit_byte(static_cast<uint8>(i + 1)); /* component ID */
|
| 303 |
+
emit_byte((m_comp_h_samp[i] << 4) + m_comp_v_samp[i]); /* h and v sampling */
|
| 304 |
+
emit_byte(i > 0); /* quant. table num */
|
| 305 |
+
}
|
| 306 |
+
}
|
| 307 |
+
|
| 308 |
+
// Emit Huffman table.
|
| 309 |
+
void jpeg_encoder::emit_dht(uint8 *bits, uint8 *val, int index, bool ac_flag)
|
| 310 |
+
{
|
| 311 |
+
emit_marker(M_DHT);
|
| 312 |
+
|
| 313 |
+
int length = 0;
|
| 314 |
+
for (int i = 1; i <= 16; i++)
|
| 315 |
+
length += bits[i];
|
| 316 |
+
|
| 317 |
+
emit_word(length + 2 + 1 + 16);
|
| 318 |
+
emit_byte(static_cast<uint8>(index + (ac_flag << 4)));
|
| 319 |
+
|
| 320 |
+
for (int i = 1; i <= 16; i++)
|
| 321 |
+
emit_byte(bits[i]);
|
| 322 |
+
|
| 323 |
+
for (int i = 0; i < length; i++)
|
| 324 |
+
emit_byte(val[i]);
|
| 325 |
+
}
|
| 326 |
+
|
| 327 |
+
// Emit all Huffman tables.
|
| 328 |
+
void jpeg_encoder::emit_dhts()
|
| 329 |
+
{
|
| 330 |
+
emit_dht(m_huff_bits[0+0], m_huff_val[0+0], 0, false);
|
| 331 |
+
emit_dht(m_huff_bits[2+0], m_huff_val[2+0], 0, true);
|
| 332 |
+
if (m_num_components == 3)
|
| 333 |
+
{
|
| 334 |
+
emit_dht(m_huff_bits[0+1], m_huff_val[0+1], 1, false);
|
| 335 |
+
emit_dht(m_huff_bits[2+1], m_huff_val[2+1], 1, true);
|
| 336 |
+
}
|
| 337 |
+
}
|
| 338 |
+
|
| 339 |
+
// emit start of scan
|
| 340 |
+
void jpeg_encoder::emit_sos()
|
| 341 |
+
{
|
| 342 |
+
emit_marker(M_SOS);
|
| 343 |
+
emit_word(2 * m_num_components + 2 + 1 + 3);
|
| 344 |
+
emit_byte(m_num_components);
|
| 345 |
+
for (int i = 0; i < m_num_components; i++)
|
| 346 |
+
{
|
| 347 |
+
emit_byte(static_cast<uint8>(i + 1));
|
| 348 |
+
if (i == 0)
|
| 349 |
+
emit_byte((0 << 4) + 0);
|
| 350 |
+
else
|
| 351 |
+
emit_byte((1 << 4) + 1);
|
| 352 |
+
}
|
| 353 |
+
emit_byte(0); /* spectral selection */
|
| 354 |
+
emit_byte(63);
|
| 355 |
+
emit_byte(0);
|
| 356 |
+
}
|
| 357 |
+
|
| 358 |
+
// Emit all markers at beginning of image file.
|
| 359 |
+
void jpeg_encoder::emit_markers()
|
| 360 |
+
{
|
| 361 |
+
emit_marker(M_SOI);
|
| 362 |
+
emit_jfif_app0();
|
| 363 |
+
emit_dqt();
|
| 364 |
+
emit_sof();
|
| 365 |
+
emit_dhts();
|
| 366 |
+
emit_sos();
|
| 367 |
+
}
|
| 368 |
+
|
| 369 |
+
// Compute the actual canonical Huffman codes/code sizes given the JPEG huff bits and val arrays.
|
| 370 |
+
void jpeg_encoder::compute_huffman_table(uint *codes, uint8 *code_sizes, uint8 *bits, uint8 *val)
|
| 371 |
+
{
|
| 372 |
+
int i, l, last_p, si;
|
| 373 |
+
uint8 huff_size[257];
|
| 374 |
+
uint huff_code[257];
|
| 375 |
+
uint code;
|
| 376 |
+
|
| 377 |
+
int p = 0;
|
| 378 |
+
for (l = 1; l <= 16; l++)
|
| 379 |
+
for (i = 1; i <= bits[l]; i++)
|
| 380 |
+
huff_size[p++] = (char)l;
|
| 381 |
+
|
| 382 |
+
huff_size[p] = 0; last_p = p; // write sentinel
|
| 383 |
+
|
| 384 |
+
code = 0; si = huff_size[0]; p = 0;
|
| 385 |
+
|
| 386 |
+
while (huff_size[p])
|
| 387 |
+
{
|
| 388 |
+
while (huff_size[p] == si)
|
| 389 |
+
huff_code[p++] = code++;
|
| 390 |
+
code <<= 1;
|
| 391 |
+
si++;
|
| 392 |
+
}
|
| 393 |
+
|
| 394 |
+
memset(codes, 0, sizeof(codes[0])*256);
|
| 395 |
+
memset(code_sizes, 0, sizeof(code_sizes[0])*256);
|
| 396 |
+
for (p = 0; p < last_p; p++)
|
| 397 |
+
{
|
| 398 |
+
codes[val[p]] = huff_code[p];
|
| 399 |
+
code_sizes[val[p]] = huff_size[p];
|
| 400 |
+
}
|
| 401 |
+
}
|
| 402 |
+
|
| 403 |
+
// Quantization table generation.
|
| 404 |
+
void jpeg_encoder::compute_quant_table(int32 *pDst, int16 *pSrc)
|
| 405 |
+
{
|
| 406 |
+
int32 q;
|
| 407 |
+
if (m_params.m_quality < 50)
|
| 408 |
+
q = 5000 / m_params.m_quality;
|
| 409 |
+
else
|
| 410 |
+
q = 200 - m_params.m_quality * 2;
|
| 411 |
+
for (int i = 0; i < 64; i++)
|
| 412 |
+
{
|
| 413 |
+
int32 j = *pSrc++; j = (j * q + 50L) / 100L;
|
| 414 |
+
*pDst++ = JPGE_MIN(JPGE_MAX(j, 1), 255);
|
| 415 |
+
}
|
| 416 |
+
}
|
| 417 |
+
|
| 418 |
+
// Higher-level methods.
|
| 419 |
+
void jpeg_encoder::first_pass_init()
|
| 420 |
+
{
|
| 421 |
+
m_bit_buffer = 0; m_bits_in = 0;
|
| 422 |
+
memset(m_last_dc_val, 0, 3 * sizeof(m_last_dc_val[0]));
|
| 423 |
+
m_mcu_y_ofs = 0;
|
| 424 |
+
m_pass_num = 1;
|
| 425 |
+
}
|
| 426 |
+
|
| 427 |
+
bool jpeg_encoder::second_pass_init()
|
| 428 |
+
{
|
| 429 |
+
compute_huffman_table(&m_huff_codes[0+0][0], &m_huff_code_sizes[0+0][0], m_huff_bits[0+0], m_huff_val[0+0]);
|
| 430 |
+
compute_huffman_table(&m_huff_codes[2+0][0], &m_huff_code_sizes[2+0][0], m_huff_bits[2+0], m_huff_val[2+0]);
|
| 431 |
+
if (m_num_components > 1)
|
| 432 |
+
{
|
| 433 |
+
compute_huffman_table(&m_huff_codes[0+1][0], &m_huff_code_sizes[0+1][0], m_huff_bits[0+1], m_huff_val[0+1]);
|
| 434 |
+
compute_huffman_table(&m_huff_codes[2+1][0], &m_huff_code_sizes[2+1][0], m_huff_bits[2+1], m_huff_val[2+1]);
|
| 435 |
+
}
|
| 436 |
+
first_pass_init();
|
| 437 |
+
emit_markers();
|
| 438 |
+
m_pass_num = 2;
|
| 439 |
+
return true;
|
| 440 |
+
}
|
| 441 |
+
|
| 442 |
+
bool jpeg_encoder::jpg_open(int p_x_res, int p_y_res, int src_channels)
|
| 443 |
+
{
|
| 444 |
+
m_num_components = 3;
|
| 445 |
+
switch (m_params.m_subsampling)
|
| 446 |
+
{
|
| 447 |
+
case Y_ONLY:
|
| 448 |
+
{
|
| 449 |
+
m_num_components = 1;
|
| 450 |
+
m_comp_h_samp[0] = 1; m_comp_v_samp[0] = 1;
|
| 451 |
+
m_mcu_x = 8; m_mcu_y = 8;
|
| 452 |
+
break;
|
| 453 |
+
}
|
| 454 |
+
case H1V1:
|
| 455 |
+
{
|
| 456 |
+
m_comp_h_samp[0] = 1; m_comp_v_samp[0] = 1;
|
| 457 |
+
m_comp_h_samp[1] = 1; m_comp_v_samp[1] = 1;
|
| 458 |
+
m_comp_h_samp[2] = 1; m_comp_v_samp[2] = 1;
|
| 459 |
+
m_mcu_x = 8; m_mcu_y = 8;
|
| 460 |
+
break;
|
| 461 |
+
}
|
| 462 |
+
case H2V1:
|
| 463 |
+
{
|
| 464 |
+
m_comp_h_samp[0] = 2; m_comp_v_samp[0] = 1;
|
| 465 |
+
m_comp_h_samp[1] = 1; m_comp_v_samp[1] = 1;
|
| 466 |
+
m_comp_h_samp[2] = 1; m_comp_v_samp[2] = 1;
|
| 467 |
+
m_mcu_x = 16; m_mcu_y = 8;
|
| 468 |
+
break;
|
| 469 |
+
}
|
| 470 |
+
case H2V2:
|
| 471 |
+
{
|
| 472 |
+
m_comp_h_samp[0] = 2; m_comp_v_samp[0] = 2;
|
| 473 |
+
m_comp_h_samp[1] = 1; m_comp_v_samp[1] = 1;
|
| 474 |
+
m_comp_h_samp[2] = 1; m_comp_v_samp[2] = 1;
|
| 475 |
+
m_mcu_x = 16; m_mcu_y = 16;
|
| 476 |
+
}
|
| 477 |
+
}
|
| 478 |
+
|
| 479 |
+
m_image_x = p_x_res; m_image_y = p_y_res;
|
| 480 |
+
m_image_bpp = src_channels;
|
| 481 |
+
m_image_bpl = m_image_x * src_channels;
|
| 482 |
+
m_image_x_mcu = (m_image_x + m_mcu_x - 1) & (~(m_mcu_x - 1));
|
| 483 |
+
m_image_y_mcu = (m_image_y + m_mcu_y - 1) & (~(m_mcu_y - 1));
|
| 484 |
+
m_image_bpl_xlt = m_image_x * m_num_components;
|
| 485 |
+
m_image_bpl_mcu = m_image_x_mcu * m_num_components;
|
| 486 |
+
m_mcus_per_row = m_image_x_mcu / m_mcu_x;
|
| 487 |
+
|
| 488 |
+
if ((m_mcu_lines[0] = static_cast<uint8*>(jpge_malloc(m_image_bpl_mcu * m_mcu_y))) == NULL) return false;
|
| 489 |
+
for (int i = 1; i < m_mcu_y; i++)
|
| 490 |
+
m_mcu_lines[i] = m_mcu_lines[i-1] + m_image_bpl_mcu;
|
| 491 |
+
|
| 492 |
+
compute_quant_table(m_quantization_tables[0], s_std_lum_quant);
|
| 493 |
+
compute_quant_table(m_quantization_tables[1], m_params.m_no_chroma_discrim_flag ? s_std_lum_quant : s_std_croma_quant);
|
| 494 |
+
|
| 495 |
+
m_out_buf_left = JPGE_OUT_BUF_SIZE;
|
| 496 |
+
m_pOut_buf = m_out_buf;
|
| 497 |
+
|
| 498 |
+
if (m_params.m_two_pass_flag)
|
| 499 |
+
{
|
| 500 |
+
clear_obj(m_huff_count);
|
| 501 |
+
first_pass_init();
|
| 502 |
+
}
|
| 503 |
+
else
|
| 504 |
+
{
|
| 505 |
+
memcpy(m_huff_bits[0+0], s_dc_lum_bits, 17); memcpy(m_huff_val [0+0], s_dc_lum_val, DC_LUM_CODES);
|
| 506 |
+
memcpy(m_huff_bits[2+0], s_ac_lum_bits, 17); memcpy(m_huff_val [2+0], s_ac_lum_val, AC_LUM_CODES);
|
| 507 |
+
memcpy(m_huff_bits[0+1], s_dc_chroma_bits, 17); memcpy(m_huff_val [0+1], s_dc_chroma_val, DC_CHROMA_CODES);
|
| 508 |
+
memcpy(m_huff_bits[2+1], s_ac_chroma_bits, 17); memcpy(m_huff_val [2+1], s_ac_chroma_val, AC_CHROMA_CODES);
|
| 509 |
+
if (!second_pass_init()) return false; // in effect, skip over the first pass
|
| 510 |
+
}
|
| 511 |
+
return m_all_stream_writes_succeeded;
|
| 512 |
+
}
|
| 513 |
+
|
| 514 |
+
void jpeg_encoder::load_block_8_8_grey(int x)
|
| 515 |
+
{
|
| 516 |
+
uint8 *pSrc;
|
| 517 |
+
sample_array_t *pDst = m_sample_array;
|
| 518 |
+
x <<= 3;
|
| 519 |
+
for (int i = 0; i < 8; i++, pDst += 8)
|
| 520 |
+
{
|
| 521 |
+
pSrc = m_mcu_lines[i] + x;
|
| 522 |
+
pDst[0] = pSrc[0] - 128; pDst[1] = pSrc[1] - 128; pDst[2] = pSrc[2] - 128; pDst[3] = pSrc[3] - 128;
|
| 523 |
+
pDst[4] = pSrc[4] - 128; pDst[5] = pSrc[5] - 128; pDst[6] = pSrc[6] - 128; pDst[7] = pSrc[7] - 128;
|
| 524 |
+
}
|
| 525 |
+
}
|
| 526 |
+
|
| 527 |
+
void jpeg_encoder::load_block_8_8(int x, int y, int c)
|
| 528 |
+
{
|
| 529 |
+
uint8 *pSrc;
|
| 530 |
+
sample_array_t *pDst = m_sample_array;
|
| 531 |
+
x = (x * (8 * 3)) + c;
|
| 532 |
+
y <<= 3;
|
| 533 |
+
for (int i = 0; i < 8; i++, pDst += 8)
|
| 534 |
+
{
|
| 535 |
+
pSrc = m_mcu_lines[y + i] + x;
|
| 536 |
+
pDst[0] = pSrc[0 * 3] - 128; pDst[1] = pSrc[1 * 3] - 128; pDst[2] = pSrc[2 * 3] - 128; pDst[3] = pSrc[3 * 3] - 128;
|
| 537 |
+
pDst[4] = pSrc[4 * 3] - 128; pDst[5] = pSrc[5 * 3] - 128; pDst[6] = pSrc[6 * 3] - 128; pDst[7] = pSrc[7 * 3] - 128;
|
| 538 |
+
}
|
| 539 |
+
}
|
| 540 |
+
|
| 541 |
+
void jpeg_encoder::load_block_16_8(int x, int c)
|
| 542 |
+
{
|
| 543 |
+
uint8 *pSrc1, *pSrc2;
|
| 544 |
+
sample_array_t *pDst = m_sample_array;
|
| 545 |
+
x = (x * (16 * 3)) + c;
|
| 546 |
+
int a = 0, b = 2;
|
| 547 |
+
for (int i = 0; i < 16; i += 2, pDst += 8)
|
| 548 |
+
{
|
| 549 |
+
pSrc1 = m_mcu_lines[i + 0] + x;
|
| 550 |
+
pSrc2 = m_mcu_lines[i + 1] + x;
|
| 551 |
+
pDst[0] = ((pSrc1[ 0 * 3] + pSrc1[ 1 * 3] + pSrc2[ 0 * 3] + pSrc2[ 1 * 3] + a) >> 2) - 128; pDst[1] = ((pSrc1[ 2 * 3] + pSrc1[ 3 * 3] + pSrc2[ 2 * 3] + pSrc2[ 3 * 3] + b) >> 2) - 128;
|
| 552 |
+
pDst[2] = ((pSrc1[ 4 * 3] + pSrc1[ 5 * 3] + pSrc2[ 4 * 3] + pSrc2[ 5 * 3] + a) >> 2) - 128; pDst[3] = ((pSrc1[ 6 * 3] + pSrc1[ 7 * 3] + pSrc2[ 6 * 3] + pSrc2[ 7 * 3] + b) >> 2) - 128;
|
| 553 |
+
pDst[4] = ((pSrc1[ 8 * 3] + pSrc1[ 9 * 3] + pSrc2[ 8 * 3] + pSrc2[ 9 * 3] + a) >> 2) - 128; pDst[5] = ((pSrc1[10 * 3] + pSrc1[11 * 3] + pSrc2[10 * 3] + pSrc2[11 * 3] + b) >> 2) - 128;
|
| 554 |
+
pDst[6] = ((pSrc1[12 * 3] + pSrc1[13 * 3] + pSrc2[12 * 3] + pSrc2[13 * 3] + a) >> 2) - 128; pDst[7] = ((pSrc1[14 * 3] + pSrc1[15 * 3] + pSrc2[14 * 3] + pSrc2[15 * 3] + b) >> 2) - 128;
|
| 555 |
+
int temp = a; a = b; b = temp;
|
| 556 |
+
}
|
| 557 |
+
}
|
| 558 |
+
|
| 559 |
+
void jpeg_encoder::load_block_16_8_8(int x, int c)
|
| 560 |
+
{
|
| 561 |
+
uint8 *pSrc1;
|
| 562 |
+
sample_array_t *pDst = m_sample_array;
|
| 563 |
+
x = (x * (16 * 3)) + c;
|
| 564 |
+
for (int i = 0; i < 8; i++, pDst += 8)
|
| 565 |
+
{
|
| 566 |
+
pSrc1 = m_mcu_lines[i + 0] + x;
|
| 567 |
+
pDst[0] = ((pSrc1[ 0 * 3] + pSrc1[ 1 * 3]) >> 1) - 128; pDst[1] = ((pSrc1[ 2 * 3] + pSrc1[ 3 * 3]) >> 1) - 128;
|
| 568 |
+
pDst[2] = ((pSrc1[ 4 * 3] + pSrc1[ 5 * 3]) >> 1) - 128; pDst[3] = ((pSrc1[ 6 * 3] + pSrc1[ 7 * 3]) >> 1) - 128;
|
| 569 |
+
pDst[4] = ((pSrc1[ 8 * 3] + pSrc1[ 9 * 3]) >> 1) - 128; pDst[5] = ((pSrc1[10 * 3] + pSrc1[11 * 3]) >> 1) - 128;
|
| 570 |
+
pDst[6] = ((pSrc1[12 * 3] + pSrc1[13 * 3]) >> 1) - 128; pDst[7] = ((pSrc1[14 * 3] + pSrc1[15 * 3]) >> 1) - 128;
|
| 571 |
+
}
|
| 572 |
+
}
|
| 573 |
+
|
| 574 |
+
void jpeg_encoder::load_quantized_coefficients(int component_num)
|
| 575 |
+
{
|
| 576 |
+
int32 *q = m_quantization_tables[component_num > 0];
|
| 577 |
+
int16 *pDst = m_coefficient_array;
|
| 578 |
+
for (int i = 0; i < 64; i++)
|
| 579 |
+
{
|
| 580 |
+
sample_array_t j = m_sample_array[s_zag[i]];
|
| 581 |
+
if (j < 0)
|
| 582 |
+
{
|
| 583 |
+
if ((j = -j + (*q >> 1)) < *q)
|
| 584 |
+
*pDst++ = 0;
|
| 585 |
+
else
|
| 586 |
+
*pDst++ = static_cast<int16>(-(j / *q));
|
| 587 |
+
}
|
| 588 |
+
else
|
| 589 |
+
{
|
| 590 |
+
if ((j = j + (*q >> 1)) < *q)
|
| 591 |
+
*pDst++ = 0;
|
| 592 |
+
else
|
| 593 |
+
*pDst++ = static_cast<int16>((j / *q));
|
| 594 |
+
}
|
| 595 |
+
q++;
|
| 596 |
+
}
|
| 597 |
+
}
|
| 598 |
+
|
| 599 |
+
void jpeg_encoder::flush_output_buffer()
|
| 600 |
+
{
|
| 601 |
+
if (m_out_buf_left != JPGE_OUT_BUF_SIZE)
|
| 602 |
+
m_all_stream_writes_succeeded = m_all_stream_writes_succeeded && m_pStream->put_buf(m_out_buf, JPGE_OUT_BUF_SIZE - m_out_buf_left);
|
| 603 |
+
m_pOut_buf = m_out_buf;
|
| 604 |
+
m_out_buf_left = JPGE_OUT_BUF_SIZE;
|
| 605 |
+
}
|
| 606 |
+
|
| 607 |
+
void jpeg_encoder::put_bits(uint bits, uint len)
|
| 608 |
+
{
|
| 609 |
+
m_bit_buffer |= ((uint32)bits << (24 - (m_bits_in += len)));
|
| 610 |
+
while (m_bits_in >= 8)
|
| 611 |
+
{
|
| 612 |
+
uint8 c;
|
| 613 |
+
#define JPGE_PUT_BYTE(c) { *m_pOut_buf++ = (c); if (--m_out_buf_left == 0) flush_output_buffer(); }
|
| 614 |
+
JPGE_PUT_BYTE(c = (uint8)((m_bit_buffer >> 16) & 0xFF));
|
| 615 |
+
if (c == 0xFF) JPGE_PUT_BYTE(0);
|
| 616 |
+
m_bit_buffer <<= 8;
|
| 617 |
+
m_bits_in -= 8;
|
| 618 |
+
}
|
| 619 |
+
}
|
| 620 |
+
|
| 621 |
+
void jpeg_encoder::code_coefficients_pass_one(int component_num)
|
| 622 |
+
{
|
| 623 |
+
if (component_num >= 3) return; // just to shut up static analysis
|
| 624 |
+
int i, run_len, nbits, temp1;
|
| 625 |
+
int16 *src = m_coefficient_array;
|
| 626 |
+
uint32 *dc_count = component_num ? m_huff_count[0 + 1] : m_huff_count[0 + 0], *ac_count = component_num ? m_huff_count[2 + 1] : m_huff_count[2 + 0];
|
| 627 |
+
|
| 628 |
+
temp1 = src[0] - m_last_dc_val[component_num];
|
| 629 |
+
m_last_dc_val[component_num] = src[0];
|
| 630 |
+
if (temp1 < 0) temp1 = -temp1;
|
| 631 |
+
|
| 632 |
+
nbits = 0;
|
| 633 |
+
while (temp1)
|
| 634 |
+
{
|
| 635 |
+
nbits++; temp1 >>= 1;
|
| 636 |
+
}
|
| 637 |
+
|
| 638 |
+
dc_count[nbits]++;
|
| 639 |
+
for (run_len = 0, i = 1; i < 64; i++)
|
| 640 |
+
{
|
| 641 |
+
if ((temp1 = m_coefficient_array[i]) == 0)
|
| 642 |
+
run_len++;
|
| 643 |
+
else
|
| 644 |
+
{
|
| 645 |
+
while (run_len >= 16)
|
| 646 |
+
{
|
| 647 |
+
ac_count[0xF0]++;
|
| 648 |
+
run_len -= 16;
|
| 649 |
+
}
|
| 650 |
+
if (temp1 < 0) temp1 = -temp1;
|
| 651 |
+
nbits = 1;
|
| 652 |
+
while (temp1 >>= 1) nbits++;
|
| 653 |
+
ac_count[(run_len << 4) + nbits]++;
|
| 654 |
+
run_len = 0;
|
| 655 |
+
}
|
| 656 |
+
}
|
| 657 |
+
if (run_len) ac_count[0]++;
|
| 658 |
+
}
|
| 659 |
+
|
| 660 |
+
void jpeg_encoder::code_coefficients_pass_two(int component_num)
|
| 661 |
+
{
|
| 662 |
+
int i, j, run_len, nbits, temp1, temp2;
|
| 663 |
+
int16 *pSrc = m_coefficient_array;
|
| 664 |
+
uint *codes[2];
|
| 665 |
+
uint8 *code_sizes[2];
|
| 666 |
+
|
| 667 |
+
if (component_num == 0)
|
| 668 |
+
{
|
| 669 |
+
codes[0] = m_huff_codes[0 + 0]; codes[1] = m_huff_codes[2 + 0];
|
| 670 |
+
code_sizes[0] = m_huff_code_sizes[0 + 0]; code_sizes[1] = m_huff_code_sizes[2 + 0];
|
| 671 |
+
}
|
| 672 |
+
else
|
| 673 |
+
{
|
| 674 |
+
codes[0] = m_huff_codes[0 + 1]; codes[1] = m_huff_codes[2 + 1];
|
| 675 |
+
code_sizes[0] = m_huff_code_sizes[0 + 1]; code_sizes[1] = m_huff_code_sizes[2 + 1];
|
| 676 |
+
}
|
| 677 |
+
|
| 678 |
+
temp1 = temp2 = pSrc[0] - m_last_dc_val[component_num];
|
| 679 |
+
m_last_dc_val[component_num] = pSrc[0];
|
| 680 |
+
|
| 681 |
+
if (temp1 < 0)
|
| 682 |
+
{
|
| 683 |
+
temp1 = -temp1; temp2--;
|
| 684 |
+
}
|
| 685 |
+
|
| 686 |
+
nbits = 0;
|
| 687 |
+
while (temp1)
|
| 688 |
+
{
|
| 689 |
+
nbits++; temp1 >>= 1;
|
| 690 |
+
}
|
| 691 |
+
|
| 692 |
+
put_bits(codes[0][nbits], code_sizes[0][nbits]);
|
| 693 |
+
if (nbits) put_bits(temp2 & ((1 << nbits) - 1), nbits);
|
| 694 |
+
|
| 695 |
+
for (run_len = 0, i = 1; i < 64; i++)
|
| 696 |
+
{
|
| 697 |
+
if ((temp1 = m_coefficient_array[i]) == 0)
|
| 698 |
+
run_len++;
|
| 699 |
+
else
|
| 700 |
+
{
|
| 701 |
+
while (run_len >= 16)
|
| 702 |
+
{
|
| 703 |
+
put_bits(codes[1][0xF0], code_sizes[1][0xF0]);
|
| 704 |
+
run_len -= 16;
|
| 705 |
+
}
|
| 706 |
+
if ((temp2 = temp1) < 0)
|
| 707 |
+
{
|
| 708 |
+
temp1 = -temp1;
|
| 709 |
+
temp2--;
|
| 710 |
+
}
|
| 711 |
+
nbits = 1;
|
| 712 |
+
while (temp1 >>= 1)
|
| 713 |
+
nbits++;
|
| 714 |
+
j = (run_len << 4) + nbits;
|
| 715 |
+
put_bits(codes[1][j], code_sizes[1][j]);
|
| 716 |
+
put_bits(temp2 & ((1 << nbits) - 1), nbits);
|
| 717 |
+
run_len = 0;
|
| 718 |
+
}
|
| 719 |
+
}
|
| 720 |
+
if (run_len)
|
| 721 |
+
put_bits(codes[1][0], code_sizes[1][0]);
|
| 722 |
+
}
|
| 723 |
+
|
| 724 |
+
void jpeg_encoder::code_block(int component_num)
|
| 725 |
+
{
|
| 726 |
+
DCT2D(m_sample_array);
|
| 727 |
+
load_quantized_coefficients(component_num);
|
| 728 |
+
if (m_pass_num == 1)
|
| 729 |
+
code_coefficients_pass_one(component_num);
|
| 730 |
+
else
|
| 731 |
+
code_coefficients_pass_two(component_num);
|
| 732 |
+
}
|
| 733 |
+
|
| 734 |
+
void jpeg_encoder::process_mcu_row()
|
| 735 |
+
{
|
| 736 |
+
if (m_num_components == 1)
|
| 737 |
+
{
|
| 738 |
+
for (int i = 0; i < m_mcus_per_row; i++)
|
| 739 |
+
{
|
| 740 |
+
load_block_8_8_grey(i); code_block(0);
|
| 741 |
+
}
|
| 742 |
+
}
|
| 743 |
+
else if ((m_comp_h_samp[0] == 1) && (m_comp_v_samp[0] == 1))
|
| 744 |
+
{
|
| 745 |
+
for (int i = 0; i < m_mcus_per_row; i++)
|
| 746 |
+
{
|
| 747 |
+
load_block_8_8(i, 0, 0); code_block(0); load_block_8_8(i, 0, 1); code_block(1); load_block_8_8(i, 0, 2); code_block(2);
|
| 748 |
+
}
|
| 749 |
+
}
|
| 750 |
+
else if ((m_comp_h_samp[0] == 2) && (m_comp_v_samp[0] == 1))
|
| 751 |
+
{
|
| 752 |
+
for (int i = 0; i < m_mcus_per_row; i++)
|
| 753 |
+
{
|
| 754 |
+
load_block_8_8(i * 2 + 0, 0, 0); code_block(0); load_block_8_8(i * 2 + 1, 0, 0); code_block(0);
|
| 755 |
+
load_block_16_8_8(i, 1); code_block(1); load_block_16_8_8(i, 2); code_block(2);
|
| 756 |
+
}
|
| 757 |
+
}
|
| 758 |
+
else if ((m_comp_h_samp[0] == 2) && (m_comp_v_samp[0] == 2))
|
| 759 |
+
{
|
| 760 |
+
for (int i = 0; i < m_mcus_per_row; i++)
|
| 761 |
+
{
|
| 762 |
+
load_block_8_8(i * 2 + 0, 0, 0); code_block(0); load_block_8_8(i * 2 + 1, 0, 0); code_block(0);
|
| 763 |
+
load_block_8_8(i * 2 + 0, 1, 0); code_block(0); load_block_8_8(i * 2 + 1, 1, 0); code_block(0);
|
| 764 |
+
load_block_16_8(i, 1); code_block(1); load_block_16_8(i, 2); code_block(2);
|
| 765 |
+
}
|
| 766 |
+
}
|
| 767 |
+
}
|
| 768 |
+
|
| 769 |
+
bool jpeg_encoder::terminate_pass_one()
|
| 770 |
+
{
|
| 771 |
+
optimize_huffman_table(0+0, DC_LUM_CODES); optimize_huffman_table(2+0, AC_LUM_CODES);
|
| 772 |
+
if (m_num_components > 1)
|
| 773 |
+
{
|
| 774 |
+
optimize_huffman_table(0+1, DC_CHROMA_CODES); optimize_huffman_table(2+1, AC_CHROMA_CODES);
|
| 775 |
+
}
|
| 776 |
+
return second_pass_init();
|
| 777 |
+
}
|
| 778 |
+
|
| 779 |
+
bool jpeg_encoder::terminate_pass_two()
|
| 780 |
+
{
|
| 781 |
+
put_bits(0x7F, 7);
|
| 782 |
+
flush_output_buffer();
|
| 783 |
+
emit_marker(M_EOI);
|
| 784 |
+
m_pass_num++; // purposely bump up m_pass_num, for debugging
|
| 785 |
+
return true;
|
| 786 |
+
}
|
| 787 |
+
|
| 788 |
+
bool jpeg_encoder::process_end_of_image()
|
| 789 |
+
{
|
| 790 |
+
if (m_mcu_y_ofs)
|
| 791 |
+
{
|
| 792 |
+
if (m_mcu_y_ofs < 16) // check here just to shut up static analysis
|
| 793 |
+
{
|
| 794 |
+
for (int i = m_mcu_y_ofs; i < m_mcu_y; i++)
|
| 795 |
+
memcpy(m_mcu_lines[i], m_mcu_lines[m_mcu_y_ofs - 1], m_image_bpl_mcu);
|
| 796 |
+
}
|
| 797 |
+
|
| 798 |
+
process_mcu_row();
|
| 799 |
+
}
|
| 800 |
+
|
| 801 |
+
if (m_pass_num == 1)
|
| 802 |
+
return terminate_pass_one();
|
| 803 |
+
else
|
| 804 |
+
return terminate_pass_two();
|
| 805 |
+
}
|
| 806 |
+
|
| 807 |
+
void jpeg_encoder::load_mcu(const void *pSrc)
|
| 808 |
+
{
|
| 809 |
+
const uint8* Psrc = reinterpret_cast<const uint8*>(pSrc);
|
| 810 |
+
|
| 811 |
+
uint8* pDst = m_mcu_lines[m_mcu_y_ofs]; // OK to write up to m_image_bpl_xlt bytes to pDst
|
| 812 |
+
|
| 813 |
+
if (m_num_components == 1)
|
| 814 |
+
{
|
| 815 |
+
if (m_image_bpp == 4)
|
| 816 |
+
RGBA_to_Y(pDst, Psrc, m_image_x);
|
| 817 |
+
else if (m_image_bpp == 3)
|
| 818 |
+
RGB_to_Y(pDst, Psrc, m_image_x);
|
| 819 |
+
else
|
| 820 |
+
memcpy(pDst, Psrc, m_image_x);
|
| 821 |
+
}
|
| 822 |
+
else
|
| 823 |
+
{
|
| 824 |
+
if (m_image_bpp == 4)
|
| 825 |
+
RGBA_to_YCC(pDst, Psrc, m_image_x);
|
| 826 |
+
else if (m_image_bpp == 3)
|
| 827 |
+
RGB_to_YCC(pDst, Psrc, m_image_x);
|
| 828 |
+
else
|
| 829 |
+
Y_to_YCC(pDst, Psrc, m_image_x);
|
| 830 |
+
}
|
| 831 |
+
|
| 832 |
+
// Possibly duplicate pixels at end of scanline if not a multiple of 8 or 16
|
| 833 |
+
if (m_num_components == 1)
|
| 834 |
+
memset(m_mcu_lines[m_mcu_y_ofs] + m_image_bpl_xlt, pDst[m_image_bpl_xlt - 1], m_image_x_mcu - m_image_x);
|
| 835 |
+
else
|
| 836 |
+
{
|
| 837 |
+
const uint8 y = pDst[m_image_bpl_xlt - 3 + 0], cb = pDst[m_image_bpl_xlt - 3 + 1], cr = pDst[m_image_bpl_xlt - 3 + 2];
|
| 838 |
+
uint8 *q = m_mcu_lines[m_mcu_y_ofs] + m_image_bpl_xlt;
|
| 839 |
+
for (int i = m_image_x; i < m_image_x_mcu; i++)
|
| 840 |
+
{
|
| 841 |
+
*q++ = y; *q++ = cb; *q++ = cr;
|
| 842 |
+
}
|
| 843 |
+
}
|
| 844 |
+
|
| 845 |
+
if (++m_mcu_y_ofs == m_mcu_y)
|
| 846 |
+
{
|
| 847 |
+
process_mcu_row();
|
| 848 |
+
m_mcu_y_ofs = 0;
|
| 849 |
+
}
|
| 850 |
+
}
|
| 851 |
+
|
| 852 |
+
void jpeg_encoder::clear()
|
| 853 |
+
{
|
| 854 |
+
m_mcu_lines[0] = NULL;
|
| 855 |
+
m_pass_num = 0;
|
| 856 |
+
m_all_stream_writes_succeeded = true;
|
| 857 |
+
}
|
| 858 |
+
|
| 859 |
+
jpeg_encoder::jpeg_encoder()
|
| 860 |
+
{
|
| 861 |
+
clear();
|
| 862 |
+
}
|
| 863 |
+
|
| 864 |
+
jpeg_encoder::~jpeg_encoder()
|
| 865 |
+
{
|
| 866 |
+
deinit();
|
| 867 |
+
}
|
| 868 |
+
|
| 869 |
+
bool jpeg_encoder::init(output_stream *pStream, int64_t width, int64_t height, int64_t src_channels, const params &comp_params)
|
| 870 |
+
{
|
| 871 |
+
deinit();
|
| 872 |
+
if (((!pStream) || (width < 1) || (height < 1)) || ((src_channels != 1) && (src_channels != 3) && (src_channels != 4)) || (!comp_params.check_valid())) return false;
|
| 873 |
+
m_pStream = pStream;
|
| 874 |
+
m_params = comp_params;
|
| 875 |
+
return jpg_open(width, height, src_channels);
|
| 876 |
+
}
|
| 877 |
+
|
| 878 |
+
void jpeg_encoder::deinit()
|
| 879 |
+
{
|
| 880 |
+
jpge_free(m_mcu_lines[0]);
|
| 881 |
+
clear();
|
| 882 |
+
}
|
| 883 |
+
|
| 884 |
+
bool jpeg_encoder::process_scanline(const void* pScanline)
|
| 885 |
+
{
|
| 886 |
+
if ((m_pass_num < 1) || (m_pass_num > 2)) return false;
|
| 887 |
+
if (m_all_stream_writes_succeeded)
|
| 888 |
+
{
|
| 889 |
+
if (!pScanline)
|
| 890 |
+
{
|
| 891 |
+
if (!process_end_of_image()) return false;
|
| 892 |
+
}
|
| 893 |
+
else
|
| 894 |
+
{
|
| 895 |
+
load_mcu(pScanline);
|
| 896 |
+
}
|
| 897 |
+
}
|
| 898 |
+
return m_all_stream_writes_succeeded;
|
| 899 |
+
}
|
| 900 |
+
|
| 901 |
+
// Higher level wrappers/examples (optional).
|
| 902 |
+
#include <stdio.h>
|
| 903 |
+
|
| 904 |
+
class cfile_stream : public output_stream
|
| 905 |
+
{
|
| 906 |
+
cfile_stream(const cfile_stream &);
|
| 907 |
+
cfile_stream &operator= (const cfile_stream &);
|
| 908 |
+
|
| 909 |
+
FILE* m_pFile;
|
| 910 |
+
bool m_bStatus;
|
| 911 |
+
|
| 912 |
+
public:
|
| 913 |
+
cfile_stream() : m_pFile(NULL), m_bStatus(false) { }
|
| 914 |
+
|
| 915 |
+
virtual ~cfile_stream()
|
| 916 |
+
{
|
| 917 |
+
close();
|
| 918 |
+
}
|
| 919 |
+
|
| 920 |
+
bool open(const char *pFilename)
|
| 921 |
+
{
|
| 922 |
+
close();
|
| 923 |
+
#if defined(_MSC_VER)
|
| 924 |
+
if (fopen_s(&m_pFile, pFilename, "wb") != 0)
|
| 925 |
+
{
|
| 926 |
+
return false;
|
| 927 |
+
}
|
| 928 |
+
#else
|
| 929 |
+
m_pFile = fopen(pFilename, "wb");
|
| 930 |
+
#endif
|
| 931 |
+
m_bStatus = (m_pFile != NULL);
|
| 932 |
+
return m_bStatus;
|
| 933 |
+
}
|
| 934 |
+
|
| 935 |
+
bool close()
|
| 936 |
+
{
|
| 937 |
+
if (m_pFile)
|
| 938 |
+
{
|
| 939 |
+
if (fclose(m_pFile) == EOF)
|
| 940 |
+
{
|
| 941 |
+
m_bStatus = false;
|
| 942 |
+
}
|
| 943 |
+
m_pFile = NULL;
|
| 944 |
+
}
|
| 945 |
+
return m_bStatus;
|
| 946 |
+
}
|
| 947 |
+
|
| 948 |
+
virtual bool put_buf(const void* pBuf, int64_t len)
|
| 949 |
+
{
|
| 950 |
+
m_bStatus = m_bStatus && (fwrite(pBuf, len, 1, m_pFile) == 1);
|
| 951 |
+
return m_bStatus;
|
| 952 |
+
}
|
| 953 |
+
|
| 954 |
+
uint get_size() const
|
| 955 |
+
{
|
| 956 |
+
return m_pFile ? ftell(m_pFile) : 0;
|
| 957 |
+
}
|
| 958 |
+
};
|
| 959 |
+
|
| 960 |
+
// Writes JPEG image to file.
|
| 961 |
+
bool compress_image_to_jpeg_file(const char *pFilename, int64_t width, int64_t height, int64_t num_channels, const uint8 *pImage_data, const params &comp_params)
|
| 962 |
+
{
|
| 963 |
+
cfile_stream dst_stream;
|
| 964 |
+
if (!dst_stream.open(pFilename))
|
| 965 |
+
return false;
|
| 966 |
+
|
| 967 |
+
jpge::jpeg_encoder dst_image;
|
| 968 |
+
if (!dst_image.init(&dst_stream, width, height, num_channels, comp_params))
|
| 969 |
+
return false;
|
| 970 |
+
|
| 971 |
+
for (uint pass_index = 0; pass_index < dst_image.get_total_passes(); pass_index++)
|
| 972 |
+
{
|
| 973 |
+
for (int64_t i = 0; i < height; i++)
|
| 974 |
+
{
|
| 975 |
+
// i, width, and num_channels are all 64bit
|
| 976 |
+
const uint8* pBuf = pImage_data + i * width * num_channels;
|
| 977 |
+
if (!dst_image.process_scanline(pBuf))
|
| 978 |
+
return false;
|
| 979 |
+
}
|
| 980 |
+
if (!dst_image.process_scanline(NULL))
|
| 981 |
+
return false;
|
| 982 |
+
}
|
| 983 |
+
|
| 984 |
+
dst_image.deinit();
|
| 985 |
+
|
| 986 |
+
return dst_stream.close();
|
| 987 |
+
}
|
| 988 |
+
|
| 989 |
+
class memory_stream : public output_stream
|
| 990 |
+
{
|
| 991 |
+
memory_stream(const memory_stream &);
|
| 992 |
+
memory_stream &operator= (const memory_stream &);
|
| 993 |
+
|
| 994 |
+
uint8 *m_pBuf;
|
| 995 |
+
uint64_t m_buf_size, m_buf_ofs;
|
| 996 |
+
|
| 997 |
+
public:
|
| 998 |
+
memory_stream(void *pBuf, uint64_t buf_size) : m_pBuf(static_cast<uint8*>(pBuf)), m_buf_size(buf_size), m_buf_ofs(0) { }
|
| 999 |
+
|
| 1000 |
+
virtual ~memory_stream() { }
|
| 1001 |
+
|
| 1002 |
+
virtual bool put_buf(const void* pBuf, int64_t len)
|
| 1003 |
+
{
|
| 1004 |
+
uint64_t buf_remaining = m_buf_size - m_buf_ofs;
|
| 1005 |
+
if ((uint64_t)len > buf_remaining)
|
| 1006 |
+
return false;
|
| 1007 |
+
memcpy(m_pBuf + m_buf_ofs, pBuf, len);
|
| 1008 |
+
m_buf_ofs += len;
|
| 1009 |
+
return true;
|
| 1010 |
+
}
|
| 1011 |
+
|
| 1012 |
+
uint64_t get_size() const
|
| 1013 |
+
{
|
| 1014 |
+
return m_buf_ofs;
|
| 1015 |
+
}
|
| 1016 |
+
};
|
| 1017 |
+
|
| 1018 |
+
bool compress_image_to_jpeg_file_in_memory(void *pDstBuf, int64_t &buf_size, int64_t width, int64_t height, int64_t num_channels, const uint8 *pImage_data, const params &comp_params)
|
| 1019 |
+
{
|
| 1020 |
+
if ((!pDstBuf) || (!buf_size))
|
| 1021 |
+
return false;
|
| 1022 |
+
|
| 1023 |
+
memory_stream dst_stream(pDstBuf, buf_size);
|
| 1024 |
+
|
| 1025 |
+
buf_size = 0;
|
| 1026 |
+
|
| 1027 |
+
jpge::jpeg_encoder dst_image;
|
| 1028 |
+
if (!dst_image.init(&dst_stream, width, height, num_channels, comp_params))
|
| 1029 |
+
return false;
|
| 1030 |
+
|
| 1031 |
+
for (uint pass_index = 0; pass_index < dst_image.get_total_passes(); pass_index++)
|
| 1032 |
+
{
|
| 1033 |
+
for (int64_t i = 0; i < height; i++)
|
| 1034 |
+
{
|
| 1035 |
+
const uint8* pScanline = pImage_data + i * width * num_channels;
|
| 1036 |
+
if (!dst_image.process_scanline(pScanline))
|
| 1037 |
+
return false;
|
| 1038 |
+
}
|
| 1039 |
+
if (!dst_image.process_scanline(NULL))
|
| 1040 |
+
return false;
|
| 1041 |
+
}
|
| 1042 |
+
|
| 1043 |
+
dst_image.deinit();
|
| 1044 |
+
|
| 1045 |
+
buf_size = dst_stream.get_size();
|
| 1046 |
+
return true;
|
| 1047 |
+
}
|
| 1048 |
+
|
| 1049 |
+
} // namespace jpge
|
crazy_functions/test_project/cpp/libJPG/jpge.h
ADDED
|
@@ -0,0 +1,172 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
// jpge.h - C++ class for JPEG compression.
|
| 3 |
+
// Public domain, Rich Geldreich <[email protected]>
|
| 4 |
+
// Alex Evans: Added RGBA support, linear memory allocator.
|
| 5 |
+
#ifndef JPEG_ENCODER_H
|
| 6 |
+
#define JPEG_ENCODER_H
|
| 7 |
+
|
| 8 |
+
#include <stdint.h>
|
| 9 |
+
|
| 10 |
+
namespace jpge
|
| 11 |
+
{
|
| 12 |
+
typedef unsigned char uint8;
|
| 13 |
+
typedef signed short int16;
|
| 14 |
+
typedef signed int int32;
|
| 15 |
+
typedef unsigned short uint16;
|
| 16 |
+
typedef unsigned int uint32;
|
| 17 |
+
typedef unsigned int uint;
|
| 18 |
+
|
| 19 |
+
// JPEG chroma subsampling factors. Y_ONLY (grayscale images) and H2V2 (color images) are the most common.
|
| 20 |
+
enum subsampling_t { Y_ONLY = 0, H1V1 = 1, H2V1 = 2, H2V2 = 3 };
|
| 21 |
+
|
| 22 |
+
// JPEG compression parameters structure.
|
| 23 |
+
struct params
|
| 24 |
+
{
|
| 25 |
+
inline params() : m_quality(85), m_subsampling(H2V2), m_no_chroma_discrim_flag(false), m_two_pass_flag(false) { }
|
| 26 |
+
|
| 27 |
+
inline bool check_valid() const
|
| 28 |
+
{
|
| 29 |
+
if ((m_quality < 1) || (m_quality > 100)) return false;
|
| 30 |
+
if ((uint)m_subsampling > (uint)H2V2) return false;
|
| 31 |
+
return true;
|
| 32 |
+
}
|
| 33 |
+
|
| 34 |
+
// Quality: 1-100, higher is better. Typical values are around 50-95.
|
| 35 |
+
int m_quality;
|
| 36 |
+
|
| 37 |
+
// m_subsampling:
|
| 38 |
+
// 0 = Y (grayscale) only
|
| 39 |
+
// 1 = YCbCr, no subsampling (H1V1, YCbCr 1x1x1, 3 blocks per MCU)
|
| 40 |
+
// 2 = YCbCr, H2V1 subsampling (YCbCr 2x1x1, 4 blocks per MCU)
|
| 41 |
+
// 3 = YCbCr, H2V2 subsampling (YCbCr 4x1x1, 6 blocks per MCU-- very common)
|
| 42 |
+
subsampling_t m_subsampling;
|
| 43 |
+
|
| 44 |
+
// Disables CbCr discrimination - only intended for testing.
|
| 45 |
+
// If true, the Y quantization table is also used for the CbCr channels.
|
| 46 |
+
bool m_no_chroma_discrim_flag;
|
| 47 |
+
|
| 48 |
+
bool m_two_pass_flag;
|
| 49 |
+
};
|
| 50 |
+
|
| 51 |
+
// Writes JPEG image to a file.
|
| 52 |
+
// num_channels must be 1 (Y) or 3 (RGB), image pitch must be width*num_channels.
|
| 53 |
+
bool compress_image_to_jpeg_file(const char *pFilename, int64_t width, int64_t height, int64_t num_channels, const uint8 *pImage_data, const params &comp_params = params());
|
| 54 |
+
|
| 55 |
+
// Writes JPEG image to memory buffer.
|
| 56 |
+
// On entry, buf_size is the size of the output buffer pointed at by pBuf, which should be at least ~1024 bytes.
|
| 57 |
+
// If return value is true, buf_size will be set to the size of the compressed data.
|
| 58 |
+
bool compress_image_to_jpeg_file_in_memory(void *pBuf, int64_t &buf_size, int64_t width, int64_t height, int64_t num_channels, const uint8 *pImage_data, const params &comp_params = params());
|
| 59 |
+
|
| 60 |
+
// Output stream abstract class - used by the jpeg_encoder class to write to the output stream.
|
| 61 |
+
// put_buf() is generally called with len==JPGE_OUT_BUF_SIZE bytes, but for headers it'll be called with smaller amounts.
|
| 62 |
+
class output_stream
|
| 63 |
+
{
|
| 64 |
+
public:
|
| 65 |
+
virtual ~output_stream() { };
|
| 66 |
+
virtual bool put_buf(const void* Pbuf, int64_t len) = 0;
|
| 67 |
+
template<class T> inline bool put_obj(const T& obj) { return put_buf(&obj, sizeof(T)); }
|
| 68 |
+
};
|
| 69 |
+
|
| 70 |
+
// Lower level jpeg_encoder class - useful if more control is needed than the above helper functions.
|
| 71 |
+
class jpeg_encoder
|
| 72 |
+
{
|
| 73 |
+
public:
|
| 74 |
+
jpeg_encoder();
|
| 75 |
+
~jpeg_encoder();
|
| 76 |
+
|
| 77 |
+
// Initializes the compressor.
|
| 78 |
+
// pStream: The stream object to use for writing compressed data.
|
| 79 |
+
// params - Compression parameters structure, defined above.
|
| 80 |
+
// width, height - Image dimensions.
|
| 81 |
+
// channels - May be 1, or 3. 1 indicates grayscale, 3 indicates RGB source data.
|
| 82 |
+
// Returns false on out of memory or if a stream write fails.
|
| 83 |
+
bool init(output_stream *pStream, int64_t width, int64_t height, int64_t src_channels, const params &comp_params = params());
|
| 84 |
+
|
| 85 |
+
const params &get_params() const { return m_params; }
|
| 86 |
+
|
| 87 |
+
// Deinitializes the compressor, freeing any allocated memory. May be called at any time.
|
| 88 |
+
void deinit();
|
| 89 |
+
|
| 90 |
+
uint get_total_passes() const { return m_params.m_two_pass_flag ? 2 : 1; }
|
| 91 |
+
inline uint get_cur_pass() { return m_pass_num; }
|
| 92 |
+
|
| 93 |
+
// Call this method with each source scanline.
|
| 94 |
+
// width * src_channels bytes per scanline is expected (RGB or Y format).
|
| 95 |
+
// You must call with NULL after all scanlines are processed to finish compression.
|
| 96 |
+
// Returns false on out of memory or if a stream write fails.
|
| 97 |
+
bool process_scanline(const void* pScanline);
|
| 98 |
+
|
| 99 |
+
private:
|
| 100 |
+
jpeg_encoder(const jpeg_encoder &);
|
| 101 |
+
jpeg_encoder &operator =(const jpeg_encoder &);
|
| 102 |
+
|
| 103 |
+
typedef int32 sample_array_t;
|
| 104 |
+
|
| 105 |
+
output_stream *m_pStream;
|
| 106 |
+
params m_params;
|
| 107 |
+
uint8 m_num_components;
|
| 108 |
+
uint8 m_comp_h_samp[3], m_comp_v_samp[3];
|
| 109 |
+
int m_image_x, m_image_y, m_image_bpp, m_image_bpl;
|
| 110 |
+
int m_image_x_mcu, m_image_y_mcu;
|
| 111 |
+
int m_image_bpl_xlt, m_image_bpl_mcu;
|
| 112 |
+
int m_mcus_per_row;
|
| 113 |
+
int m_mcu_x, m_mcu_y;
|
| 114 |
+
uint8 *m_mcu_lines[16];
|
| 115 |
+
uint8 m_mcu_y_ofs;
|
| 116 |
+
sample_array_t m_sample_array[64];
|
| 117 |
+
int16 m_coefficient_array[64];
|
| 118 |
+
int32 m_quantization_tables[2][64];
|
| 119 |
+
uint m_huff_codes[4][256];
|
| 120 |
+
uint8 m_huff_code_sizes[4][256];
|
| 121 |
+
uint8 m_huff_bits[4][17];
|
| 122 |
+
uint8 m_huff_val[4][256];
|
| 123 |
+
uint32 m_huff_count[4][256];
|
| 124 |
+
int m_last_dc_val[3];
|
| 125 |
+
enum { JPGE_OUT_BUF_SIZE = 2048 };
|
| 126 |
+
uint8 m_out_buf[JPGE_OUT_BUF_SIZE];
|
| 127 |
+
uint8 *m_pOut_buf;
|
| 128 |
+
uint m_out_buf_left;
|
| 129 |
+
uint32 m_bit_buffer;
|
| 130 |
+
uint m_bits_in;
|
| 131 |
+
uint8 m_pass_num;
|
| 132 |
+
bool m_all_stream_writes_succeeded;
|
| 133 |
+
|
| 134 |
+
void optimize_huffman_table(int table_num, int table_len);
|
| 135 |
+
void emit_byte(uint8 i);
|
| 136 |
+
void emit_word(uint i);
|
| 137 |
+
void emit_marker(int marker);
|
| 138 |
+
void emit_jfif_app0();
|
| 139 |
+
void emit_dqt();
|
| 140 |
+
void emit_sof();
|
| 141 |
+
void emit_dht(uint8 *bits, uint8 *val, int index, bool ac_flag);
|
| 142 |
+
void emit_dhts();
|
| 143 |
+
void emit_sos();
|
| 144 |
+
void emit_markers();
|
| 145 |
+
void compute_huffman_table(uint *codes, uint8 *code_sizes, uint8 *bits, uint8 *val);
|
| 146 |
+
void compute_quant_table(int32 *dst, int16 *src);
|
| 147 |
+
void adjust_quant_table(int32 *dst, int32 *src);
|
| 148 |
+
void first_pass_init();
|
| 149 |
+
bool second_pass_init();
|
| 150 |
+
bool jpg_open(int p_x_res, int p_y_res, int src_channels);
|
| 151 |
+
void load_block_8_8_grey(int x);
|
| 152 |
+
void load_block_8_8(int x, int y, int c);
|
| 153 |
+
void load_block_16_8(int x, int c);
|
| 154 |
+
void load_block_16_8_8(int x, int c);
|
| 155 |
+
void load_quantized_coefficients(int component_num);
|
| 156 |
+
void flush_output_buffer();
|
| 157 |
+
void put_bits(uint bits, uint len);
|
| 158 |
+
void code_coefficients_pass_one(int component_num);
|
| 159 |
+
void code_coefficients_pass_two(int component_num);
|
| 160 |
+
void code_block(int component_num);
|
| 161 |
+
void process_mcu_row();
|
| 162 |
+
bool terminate_pass_one();
|
| 163 |
+
bool terminate_pass_two();
|
| 164 |
+
bool process_end_of_image();
|
| 165 |
+
void load_mcu(const void* src);
|
| 166 |
+
void clear();
|
| 167 |
+
void init();
|
| 168 |
+
};
|
| 169 |
+
|
| 170 |
+
} // namespace jpge
|
| 171 |
+
|
| 172 |
+
#endif // JPEG_ENCODER
|
crazy_functions/test_project/cpp/libJPG/来源
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
jpge.h - C++ class for JPEG compression.
|
| 2 |
+
Public domain, Rich Geldreich <[email protected]>
|
| 3 |
+
Alex Evans: Added RGBA support, linear memory allocator.
|
crazy_functions/test_project/latex/attention/background.tex
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
The goal of reducing sequential computation also forms the foundation of the Extended Neural GPU \citep{extendedngpu}, ByteNet \citep{NalBytenet2017} and ConvS2S \citep{JonasFaceNet2017}, all of which use convolutional neural networks as basic building block, computing hidden representations in parallel for all input and output positions. In these models, the number of operations required to relate signals from two arbitrary input or output positions grows in the distance between positions, linearly for ConvS2S and logarithmically for ByteNet. This makes it more difficult to learn dependencies between distant positions \citep{hochreiter2001gradient}. In the Transformer this is reduced to a constant number of operations, albeit at the cost of reduced effective resolution due to averaging attention-weighted positions, an effect we counteract with Multi-Head Attention as described in section~\ref{sec:attention}.
|
| 2 |
+
|
| 3 |
+
Self-attention, sometimes called intra-attention is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence. Self-attention has been used successfully in a variety of tasks including reading comprehension, abstractive summarization, textual entailment and learning task-independent sentence representations \citep{cheng2016long, decomposableAttnModel, paulus2017deep, lin2017structured}.
|
| 4 |
+
|
| 5 |
+
End-to-end memory networks are based on a recurrent attention mechanism instead of sequence-aligned recurrence and have been shown to perform well on simple-language question answering and language modeling tasks \citep{sukhbaatar2015}.
|
| 6 |
+
|
| 7 |
+
To the best of our knowledge, however, the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence-aligned RNNs or convolution.
|
| 8 |
+
In the following sections, we will describe the Transformer, motivate self-attention and discuss its advantages over models such as \citep{neural_gpu, NalBytenet2017} and \citep{JonasFaceNet2017}.
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
%\citep{JonasFaceNet2017} report new SOTA on machine translation for English-to-German (EnDe), Enlish-to-French (EnFr) and English-to-Romanian language pairs.
|
| 12 |
+
|
| 13 |
+
%For example,! in MT, we must draw information from both input and previous output words to translate an output word accurately. An attention layer \citep{bahdanau2014neural} can connect a very large number of positions at low computation cost, making it an essential ingredient in competitive recurrent models for machine translation.
|
| 14 |
+
|
| 15 |
+
%A natural question to ask then is, "Could we replace recurrence with attention?". \marginpar{Don't know if it's the most natural question to ask given the previous statements. Also, need to say that the complexity table summarizes these statements} Such a model would be blessed with the computational efficiency of attention and the power of cross-positional communication. In this work, show that pure attention models work remarkably well for MT, achieving new SOTA results on EnDe and EnFr, and can be trained in under $2$ days on xyz architecture.
|
| 16 |
+
|
| 17 |
+
%After the seminal models introduced in \citep{sutskever14, bahdanau2014neural, cho2014learning}, recurrent models have become the dominant solution for both sequence modeling and sequence-to-sequence transduction. Many efforts such as \citep{wu2016google,luong2015effective,jozefowicz2016exploring} have pushed the boundaries of machine translation (MT) and language modeling with recurrent endoder-decoder and recurrent language models. Recent effort \citep{shazeer2017outrageously} has successfully combined the power of conditional computation with sequence models to train very large models for MT, pushing SOTA at lower computational cost.
|
| 18 |
+
|
| 19 |
+
%Recurrent models compute a vector of hidden states $h_t$, for each time step $t$ of computation. $h_t$ is a function of both the input at time $t$ and the previous hidden state $h_t$. This dependence on the previous hidden state precludes processing all timesteps at once, instead requiring long sequences of sequential operations. In practice, this results in greatly reduced computational efficiency, as on modern computing hardware, a single operation on a large batch is much faster than a large number of operations on small batches. The problem gets worse at longer sequence lengths. Although sequential computation is not a severe bottleneck at inference time, as autoregressively generating each output requires all previous outputs, the inability to compute scores at all output positions at once hinders us from rapidly training our models over large datasets. Although impressive work such as \citep{Kuchaiev2017Factorization} is able to significantly accelerate the training of LSTMs with factorization tricks, we are still bound by the linear dependence on sequence length.
|
| 20 |
+
|
| 21 |
+
%If the model could compute hidden states at each time step using only the inputs and outputs, it would be liberated from the dependence on results from previous time steps during training. This line of thought is the foundation of recent efforts such as the Markovian neural GPU \citep{neural_gpu}, ByteNet \citep{NalBytenet2017} and ConvS2S \citep{JonasFaceNet2017}, all of which use convolutional neural networks as a building block to compute hidden representations simultaneously for all timesteps, resulting in $O(1)$ sequential time complexity. \citep{JonasFaceNet2017} report new SOTA on machine translation for English-to-German (EnDe), Enlish-to-French (EnFr) and English-to-Romanian language pairs.
|
| 22 |
+
|
| 23 |
+
%A crucial component for accurate sequence prediction is modeling cross-positional communication. For example, in MT, we must draw information from both input and previous output words to translate an output word accurately. An attention layer \citep{bahdanau2014neural} can connect a very large number of positions at a low computation cost, also $O(1)$ sequential time complexity, making it an essential ingredient in recurrent encoder-decoder architectures for MT. A natural question to ask then is, "Could we replace recurrence with attention?". \marginpar{Don't know if it's the most natural question to ask given the previous statements. Also, need to say that the complexity table summarizes these statements} Such a model would be blessed with the computational efficiency of attention and the power of cross-positional communication. In this work, show that pure attention models work remarkably well for MT, achieving new SOTA results on EnDe and EnFr, and can be trained in under $2$ days on xyz architecture.
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
%Note: Facebook model is no better than RNNs in this regard, since it requires a number of layers proportional to the distance you want to communicate. Bytenet is more promising, since it requires a logarithmnic number of layers (does bytenet have SOTA results)?
|
| 28 |
+
|
| 29 |
+
%Note: An attention layer can connect a very large number of positions at a low computation cost in O(1) sequential operations. This is why encoder-decoder attention has been so successful in seq-to-seq models so far. It is only natural, then, to also use attention to connect the timesteps of the same sequence.
|
| 30 |
+
|
| 31 |
+
%Note: I wouldn't say that long sequences are not a problem during inference. It would be great if we could infer with no long sequences. We could just say later on that, while our training graph is constant-depth, our model still requires sequential operations in the decoder part during inference due to the autoregressive nature of the model.
|
| 32 |
+
|
| 33 |
+
%\begin{table}[h!]
|
| 34 |
+
%\caption{Attention models are quite efficient for cross-positional communications when sequence length is smaller than channel depth. $n$ represents the sequence length and $d$ represents the channel depth.}
|
| 35 |
+
%\label{tab:op_complexities}
|
| 36 |
+
%\begin{center}
|
| 37 |
+
%\vspace{-5pt}
|
| 38 |
+
%\scalebox{0.75}{
|
| 39 |
+
|
| 40 |
+
%\begin{tabular}{l|c|c|c}
|
| 41 |
+
%\hline \hline
|
| 42 |
+
%Layer Type & Receptive & Complexity & Sequential \\
|
| 43 |
+
% & Field & & Operations \\
|
| 44 |
+
%\hline
|
| 45 |
+
%Pointwise Feed-Forward & $1$ & $O(n \cdot d^2)$ & $O(1)$ \\
|
| 46 |
+
%\hline
|
| 47 |
+
%Recurrent & $n$ & $O(n \cdot d^2)$ & $O(n)$ \\
|
| 48 |
+
%\hline
|
| 49 |
+
%Convolutional & $r$ & $O(r \cdot n \cdot d^2)$ & $O(1)$ \\
|
| 50 |
+
%\hline
|
| 51 |
+
%Convolutional (separable) & $r$ & $O(r \cdot n \cdot d + n %\cdot d^2)$ & $O(1)$ \\
|
| 52 |
+
%\hline
|
| 53 |
+
%Attention & $r$ & $O(r \cdot n \cdot d)$ & $O(1)$ \\
|
| 54 |
+
%\hline \hline
|
| 55 |
+
%\end{tabular}
|
| 56 |
+
%}
|
| 57 |
+
%\end{center}
|
| 58 |
+
%\end{table}
|
crazy_functions/test_project/latex/attention/introduction.tex
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Recurrent neural networks, long short-term memory \citep{hochreiter1997} and gated recurrent \citep{gruEval14} neural networks in particular, have been firmly established as state of the art approaches in sequence modeling and transduction problems such as language modeling and machine translation \citep{sutskever14, bahdanau2014neural, cho2014learning}. Numerous efforts have since continued to push the boundaries of recurrent language models and encoder-decoder architectures \citep{wu2016google,luong2015effective,jozefowicz2016exploring}.
|
| 2 |
+
|
| 3 |
+
Recurrent models typically factor computation along the symbol positions of the input and output sequences. Aligning the positions to steps in computation time, they generate a sequence of hidden states $h_t$, as a function of the previous hidden state $h_{t-1}$ and the input for position $t$. This inherently sequential nature precludes parallelization within training examples, which becomes critical at longer sequence lengths, as memory constraints limit batching across examples.
|
| 4 |
+
%\marginpar{not sure if the memory constraints are understandable here}
|
| 5 |
+
Recent work has achieved significant improvements in computational efficiency through factorization tricks \citep{Kuchaiev2017Factorization} and conditional computation \citep{shazeer2017outrageously}, while also improving model performance in case of the latter. The fundamental constraint of sequential computation, however, remains.
|
| 6 |
+
|
| 7 |
+
%\marginpar{@all: there is work on analyzing what attention really does in seq2seq models, couldn't find it right away}
|
| 8 |
+
|
| 9 |
+
Attention mechanisms have become an integral part of compelling sequence modeling and transduction models in various tasks, allowing modeling of dependencies without regard to their distance in the input or output sequences \citep{bahdanau2014neural, structuredAttentionNetworks}. In all but a few cases \citep{decomposableAttnModel}, however, such attention mechanisms are used in conjunction with a recurrent network.
|
| 10 |
+
|
| 11 |
+
%\marginpar{not sure if "cross-positional communication" is understandable without explanation}
|
| 12 |
+
%\marginpar{insert exact training times and stats for the model that reaches sota earliest, maybe even a single GPU model?}
|
| 13 |
+
|
| 14 |
+
In this work we propose the Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output. The Transformer allows for significantly more parallelization and can reach a new state of the art in translation quality after being trained for as little as twelve hours on eight P100 GPUs.
|
| 15 |
+
%\marginpar{you removed the constant number of repetitions part. I wrote it because I wanted to make it clear that the model does not only perform attention once, while it's also not recurrent. I thought that might be important to get across early.}
|
| 16 |
+
|
| 17 |
+
% Just a standard paragraph with citations, rewrite.
|
| 18 |
+
%After the seminal papers of \citep{sutskever14}, \citep{bahdanau2014neural}, and \citep{cho2014learning}, recurrent models have become the dominant solution for both sequence modeling and sequence-to-sequence transduction. Many efforts such as \citep{wu2016google,luong2015effective,jozefowicz2016exploring} have pushed the boundaries of machine translation and language modeling with recurrent sequence models. Recent effort \citep{shazeer2017outrageously} has combined the power of conditional computation with sequence models to train very large models for machine translation, pushing SOTA at lower computational cost. Recurrent models compute a vector of hidden states $h_t$, for each time step $t$ of computation. $h_t$ is a function of both the input at time $t$ and the previous hidden state $h_t$. This dependence on the previous hidden state encumbers recurrnet models to process multiple inputs at once, and their time complexity is a linear function of the length of the input and output, both during training and inference. [What I want to say here is that although this is fine during decoding, at training time, we are given both input and output and this linear nature does not allow the RNN to process all inputs and outputs simultaneously and haven't been used on datasets that are the of the scale of the web. What's the largest dataset we have ? . Talk about Nividia and possibly other's effors to speed up things, and possibly other efforts that alleviate this, but are still limited by it's comptuational nature]. Rest of the intro: What if you could construct the state based on the actual inputs and outputs, then you could construct them all at once. This has been the foundation of many promising recent efforts, bytenet,facenet (Also talk about quasi rnn here). Now we talk about attention!! Along with cell architectures such as long short-term meory (LSTM) \citep{hochreiter1997}, and gated recurrent units (GRUs) \citep{cho2014learning}, attention has emerged as an essential ingredient in successful sequence models, in particular for machine translation. In recent years, many, if not all, state-of-the-art (SOTA) results in machine translation have been achieved with attention-based sequence models \citep{wu2016google,luong2015effective,jozefowicz2016exploring}. Talk about the neon work on how it played with attention to do self attention! Then talk about what we do.
|
crazy_functions/test_project/latex/attention/model_architecture.tex
ADDED
|
@@ -0,0 +1,155 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
\begin{figure}
|
| 3 |
+
\centering
|
| 4 |
+
\includegraphics[scale=0.6]{Figures/ModalNet-21}
|
| 5 |
+
\caption{The Transformer - model architecture.}
|
| 6 |
+
\label{fig:model-arch}
|
| 7 |
+
\end{figure}
|
| 8 |
+
|
| 9 |
+
% Although the primary workhorse of our model is attention,
|
| 10 |
+
%Our model maintains the encoder-decoder structure that is common to many so-called sequence-to-sequence models \citep{bahdanau2014neural,sutskever14}. As in all such architectures, the encoder computes a representation of the input sequence, and the decoder consumes these representations along with the output tokens to autoregressively produce the output sequence. Where, traditionally, the encoder and decoder contain stacks of recurrent or convolutional layers, our encoder and decoder stacks are composed of attention layers and position-wise feed-forward layers (Figure~\ref{fig:model-arch}). The following sections describe the gross architecture and these particular components in detail.
|
| 11 |
+
|
| 12 |
+
Most competitive neural sequence transduction models have an encoder-decoder structure \citep{cho2014learning,bahdanau2014neural,sutskever14}. Here, the encoder maps an input sequence of symbol representations $(x_1, ..., x_n)$ to a sequence of continuous representations $\mathbf{z} = (z_1, ..., z_n)$. Given $\mathbf{z}$, the decoder then generates an output sequence $(y_1,...,y_m)$ of symbols one element at a time. At each step the model is auto-regressive \citep{graves2013generating}, consuming the previously generated symbols as additional input when generating the next.
|
| 13 |
+
|
| 14 |
+
The Transformer follows this overall architecture using stacked self-attention and point-wise, fully connected layers for both the encoder and decoder, shown in the left and right halves of Figure~\ref{fig:model-arch}, respectively.
|
| 15 |
+
|
| 16 |
+
\subsection{Encoder and Decoder Stacks}
|
| 17 |
+
|
| 18 |
+
\paragraph{Encoder:}The encoder is composed of a stack of $N=6$ identical layers. Each layer has two sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, position-wise fully connected feed-forward network. We employ a residual connection \citep{he2016deep} around each of the two sub-layers, followed by layer normalization \cite{layernorm2016}. That is, the output of each sub-layer is $\mathrm{LayerNorm}(x + \mathrm{Sublayer}(x))$, where $\mathrm{Sublayer}(x)$ is the function implemented by the sub-layer itself. To facilitate these residual connections, all sub-layers in the model, as well as the embedding layers, produce outputs of dimension $\dmodel=512$.
|
| 19 |
+
|
| 20 |
+
\paragraph{Decoder:}The decoder is also composed of a stack of $N=6$ identical layers. In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack. Similar to the encoder, we employ residual connections around each of the sub-layers, followed by layer normalization. We also modify the self-attention sub-layer in the decoder stack to prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position $i$ can depend only on the known outputs at positions less than $i$.
|
| 21 |
+
|
| 22 |
+
% In our model (Figure~\ref{fig:model-arch}), the encoder and decoder are composed of stacks of alternating self-attention layers (for cross-positional communication) and position-wise feed-forward layers (for in-place computation). In addition, the decoder stack contains encoder-decoder attention layers. Since attention is agnostic to the distances between words, our model requires a "positional encoding" to be added to the encoder and decoder input. The following sections describe all of these components in detail.
|
| 23 |
+
|
| 24 |
+
\subsection{Attention} \label{sec:attention}
|
| 25 |
+
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
|
| 26 |
+
|
| 27 |
+
\subsubsection{Scaled Dot-Product Attention} \label{sec:scaled-dot-prod}
|
| 28 |
+
|
| 29 |
+
% \begin{figure}
|
| 30 |
+
% \centering
|
| 31 |
+
% \includegraphics[scale=0.6]{Figures/ModalNet-19}
|
| 32 |
+
% \caption{Scaled Dot-Product Attention.}
|
| 33 |
+
% \label{fig:multi-head-att}
|
| 34 |
+
% \end{figure}
|
| 35 |
+
|
| 36 |
+
We call our particular attention "Scaled Dot-Product Attention" (Figure~\ref{fig:multi-head-att}). The input consists of queries and keys of dimension $d_k$, and values of dimension $d_v$. We compute the dot products of the query with all keys, divide each by $\sqrt{d_k}$, and apply a softmax function to obtain the weights on the values.
|
| 37 |
+
|
| 38 |
+
In practice, we compute the attention function on a set of queries simultaneously, packed together into a matrix $Q$. The keys and values are also packed together into matrices $K$ and $V$. We compute the matrix of outputs as:
|
| 39 |
+
|
| 40 |
+
\begin{equation}
|
| 41 |
+
\mathrm{Attention}(Q, K, V) = \mathrm{softmax}(\frac{QK^T}{\sqrt{d_k}})V
|
| 42 |
+
\end{equation}
|
| 43 |
+
|
| 44 |
+
The two most commonly used attention functions are additive attention \citep{bahdanau2014neural}, and dot-product (multiplicative) attention. Dot-product attention is identical to our algorithm, except for the scaling factor of $\frac{1}{\sqrt{d_k}}$. Additive attention computes the compatibility function using a feed-forward network with a single hidden layer. While the two are similar in theoretical complexity, dot-product attention is much faster and more space-efficient in practice, since it can be implemented using highly optimized matrix multiplication code.
|
| 45 |
+
|
| 46 |
+
%We scale the dot products by $1/\sqrt{d_k}$ to limit the magnitude of the dot products, which works well in practice. Otherwise, we found applying the softmax to often result in weights very close to 0 or 1, and hence minuscule gradients.
|
| 47 |
+
|
| 48 |
+
% Already described in the subsequent section
|
| 49 |
+
%When used as part of decoder self-attention, an optional mask function is applied just before the softmax to prevent positions from attending to subsequent positions. This mask simply sets the logits corresponding to all illegal connections (those outside of the lower triangle) to $-\infty$.
|
| 50 |
+
|
| 51 |
+
%\paragraph{Comparison to Additive Attention: } We choose dot product attention over additive attention \citep{bahdanau2014neural} since it can be computed using highly optimized matrix multiplication code. This optimization is particularly important to us, as we employ many attention layers in our model.
|
| 52 |
+
|
| 53 |
+
While for small values of $d_k$ the two mechanisms perform similarly, additive attention outperforms dot product attention without scaling for larger values of $d_k$ \citep{DBLP:journals/corr/BritzGLL17}. We suspect that for large values of $d_k$, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients \footnote{To illustrate why the dot products get large, assume that the components of $q$ and $k$ are independent random variables with mean $0$ and variance $1$. Then their dot product, $q \cdot k = \sum_{i=1}^{d_k} q_ik_i$, has mean $0$ and variance $d_k$.}. To counteract this effect, we scale the dot products by $\frac{1}{\sqrt{d_k}}$.
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
%We suspect this to be caused by the dot products growing too large in magnitude to result in useful gradients after applying the softmax function. To counteract this, we scale the dot product by $1/\sqrt{d_k}$.
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
\subsubsection{Multi-Head Attention} \label{sec:multihead}
|
| 60 |
+
|
| 61 |
+
\begin{figure}
|
| 62 |
+
\begin{minipage}[t]{0.5\textwidth}
|
| 63 |
+
\centering
|
| 64 |
+
Scaled Dot-Product Attention \\
|
| 65 |
+
\vspace{0.5cm}
|
| 66 |
+
\includegraphics[scale=0.6]{Figures/ModalNet-19}
|
| 67 |
+
\end{minipage}
|
| 68 |
+
\begin{minipage}[t]{0.5\textwidth}
|
| 69 |
+
\centering
|
| 70 |
+
Multi-Head Attention \\
|
| 71 |
+
\vspace{0.1cm}
|
| 72 |
+
\includegraphics[scale=0.6]{Figures/ModalNet-20}
|
| 73 |
+
\end{minipage}
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
% \centering
|
| 77 |
+
|
| 78 |
+
\caption{(left) Scaled Dot-Product Attention. (right) Multi-Head Attention consists of several attention layers running in parallel.}
|
| 79 |
+
\label{fig:multi-head-att}
|
| 80 |
+
\end{figure}
|
| 81 |
+
|
| 82 |
+
Instead of performing a single attention function with $\dmodel$-dimensional keys, values and queries, we found it beneficial to linearly project the queries, keys and values $h$ times with different, learned linear projections to $d_k$, $d_k$ and $d_v$ dimensions, respectively.
|
| 83 |
+
On each of these projected versions of queries, keys and values we then perform the attention function in parallel, yielding $d_v$-dimensional output values. These are concatenated and once again projected, resulting in the final values, as depicted in Figure~\ref{fig:multi-head-att}.
|
| 84 |
+
|
| 85 |
+
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this.
|
| 86 |
+
|
| 87 |
+
\begin{align*}
|
| 88 |
+
\mathrm{MultiHead}(Q, K, V) &= \mathrm{Concat}(\mathrm{head_1}, ..., \mathrm{head_h})W^O\\
|
| 89 |
+
% \mathrm{where} \mathrm{head_i} &= \mathrm{Attention}(QW_Q_i^{\dmodel \times d_q}, KW_K_i^{\dmodel \times d_k}, VW^V_i^{\dmodel \times d_v})\\
|
| 90 |
+
\text{where}~\mathrm{head_i} &= \mathrm{Attention}(QW^Q_i, KW^K_i, VW^V_i)\\
|
| 91 |
+
\end{align*}
|
| 92 |
+
|
| 93 |
+
Where the projections are parameter matrices $W^Q_i \in \mathbb{R}^{\dmodel \times d_k}$, $W^K_i \in \mathbb{R}^{\dmodel \times d_k}$, $W^V_i \in \mathbb{R}^{\dmodel \times d_v}$ and $W^O \in \mathbb{R}^{hd_v \times \dmodel}$.
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
%find it better (and no more expensive) to have multiple parallel attention layers (each over the full set of positions) with proportionally lower-dimensional keys, values and queries. We call this "Multi-Head Attention" (Figure~\ref{fig:multi-head-att}). The keys, values, and queries for each of these parallel attention layers are computed by learned linear transformations of the inputs to the multi-head attention. We use different linear transformations across different parallel attention layers. The output of the parallel attention layers are concatenated, and then passed through a final learned linear transformation.
|
| 97 |
+
|
| 98 |
+
In this work we employ $h=8$ parallel attention layers, or heads. For each of these we use $d_k=d_v=\dmodel/h=64$.
|
| 99 |
+
Due to the reduced dimension of each head, the total computational cost is similar to that of single-head attention with full dimensionality.
|
| 100 |
+
|
| 101 |
+
\subsubsection{Applications of Attention in our Model}
|
| 102 |
+
|
| 103 |
+
The Transformer uses multi-head attention in three different ways:
|
| 104 |
+
\begin{itemize}
|
| 105 |
+
\item In "encoder-decoder attention" layers, the queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder. This allows every position in the decoder to attend over all positions in the input sequence. This mimics the typical encoder-decoder attention mechanisms in sequence-to-sequence models such as \citep{wu2016google, bahdanau2014neural,JonasFaceNet2017}.
|
| 106 |
+
|
| 107 |
+
\item The encoder contains self-attention layers. In a self-attention layer all of the keys, values and queries come from the same place, in this case, the output of the previous layer in the encoder. Each position in the encoder can attend to all positions in the previous layer of the encoder.
|
| 108 |
+
|
| 109 |
+
\item Similarly, self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position. We need to prevent leftward information flow in the decoder to preserve the auto-regressive property. We implement this inside of scaled dot-product attention by masking out (setting to $-\infty$) all values in the input of the softmax which correspond to illegal connections. See Figure~\ref{fig:multi-head-att}.
|
| 110 |
+
|
| 111 |
+
\end{itemize}
|
| 112 |
+
|
| 113 |
+
\subsection{Position-wise Feed-Forward Networks}\label{sec:ffn}
|
| 114 |
+
|
| 115 |
+
In addition to attention sub-layers, each of the layers in our encoder and decoder contains a fully connected feed-forward network, which is applied to each position separately and identically. This consists of two linear transformations with a ReLU activation in between.
|
| 116 |
+
|
| 117 |
+
\begin{equation}
|
| 118 |
+
\mathrm{FFN}(x)=\max(0, xW_1 + b_1) W_2 + b_2
|
| 119 |
+
\end{equation}
|
| 120 |
+
|
| 121 |
+
While the linear transformations are the same across different positions, they use different parameters from layer to layer. Another way of describing this is as two convolutions with kernel size 1. The dimensionality of input and output is $\dmodel=512$, and the inner-layer has dimensionality $d_{ff}=2048$.
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
%In the appendix, we describe how the position-wise feed-forward network can also be seen as a form of attention.
|
| 126 |
+
|
| 127 |
+
%from Jakob: The number of operations required for the model to relate signals from two arbitrary input or output positions grows in the distance between positions in input or output, linearly for ConvS2S and logarithmically for ByteNet, making it harder to learn dependencies between these positions \citep{hochreiter2001gradient}. In the transformer this is reduced to a constant number of operations, albeit at the cost of effective resolution caused by averaging attention-weighted positions, an effect we aim to counteract with multi-headed attention.
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
%Figure~\ref{fig:simple-att} presents a simple attention function, $A$, with a single head, that forms the basis of our multi-head attention. $A$ takes a query key vector $\kq$, matrices of memory keys $\km$ and memory values $\vm$ ,and produces a query value vector $\vq$ as
|
| 131 |
+
%\begin{equation*} \label{eq:attention}
|
| 132 |
+
% A(\kq, \km, \vm) = {\vm}^T (Softmax(\km \kq).
|
| 133 |
+
%\end{equation*}
|
| 134 |
+
%We linearly transform $\kq,\,\km$, and $\vm$ with learned matrices ${\Wkq \text{,} \, \Wkm}$, and ${\Wvm}$ before calling the attention function, and transform the output query with $\Wvq$ before handing it to the feed forward layer. Each attention layer has it's own set of transformation matrices, which are shared across all query positions. $A$ is applied in parallel for each query position, and is implemented very efficiently as a batch of matrix multiplies. The self-attention and encoder-decoder attention layers use $A$, but with different arguments. For example, in encdoder self-attention, queries in encoder layer $i$ attention to memories in encoder layer $i-1$. To ensure that decoder self-attention layers do not look at future words, we add $- \inf$ to the softmax logits in positions $j+1$ to query length for query position $l$.
|
| 135 |
+
|
| 136 |
+
%In simple attention, the query value is a weighted combination of the memory values where the attention weights sum to one. Although this function performs well in practice, the constraint on attention weights can restrict the amount of information that flows from memories to queries because the query cannot focus on multiple memory positions at once, which might be desirable when translating long sequences. \marginpar{@usz, could you think of an example of this ?} We remedy this by maintaining multiple attention heads at each query position that attend to all memory positions in parallel, with a different set of parameters per attention head $h$.
|
| 137 |
+
%\marginpar{}
|
| 138 |
+
|
| 139 |
+
\subsection{Embeddings and Softmax}
|
| 140 |
+
Similarly to other sequence transduction models, we use learned embeddings to convert the input tokens and output tokens to vectors of dimension $\dmodel$. We also use the usual learned linear transformation and softmax function to convert the decoder output to predicted next-token probabilities. In our model, we share the same weight matrix between the two embedding layers and the pre-softmax linear transformation, similar to \citep{press2016using}. In the embedding layers, we multiply those weights by $\sqrt{\dmodel}$.
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
\subsection{Positional Encoding}
|
| 144 |
+
Since our model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence. To this end, we add "positional encodings" to the input embeddings at the bottoms of the encoder and decoder stacks. The positional encodings have the same dimension $\dmodel$ as the embeddings, so that the two can be summed. There are many choices of positional encodings, learned and fixed \citep{JonasFaceNet2017}.
|
| 145 |
+
|
| 146 |
+
In this work, we use sine and cosine functions of different frequencies:
|
| 147 |
+
|
| 148 |
+
\begin{align*}
|
| 149 |
+
PE_{(pos,2i)} = sin(pos / 10000^{2i/\dmodel}) \\
|
| 150 |
+
PE_{(pos,2i+1)} = cos(pos / 10000^{2i/\dmodel})
|
| 151 |
+
\end{align*}
|
| 152 |
+
|
| 153 |
+
where $pos$ is the position and $i$ is the dimension. That is, each dimension of the positional encoding corresponds to a sinusoid. The wavelengths form a geometric progression from $2\pi$ to $10000 \cdot 2\pi$. We chose this function because we hypothesized it would allow the model to easily learn to attend by relative positions, since for any fixed offset $k$, $PE_{pos+k}$ can be represented as a linear function of $PE_{pos}$.
|
| 154 |
+
|
| 155 |
+
We also experimented with using learned positional embeddings \citep{JonasFaceNet2017} instead, and found that the two versions produced nearly identical results (see Table~\ref{tab:variations} row (E)). We chose the sinusoidal version because it may allow the model to extrapolate to sequence lengths longer than the ones encountered during training.
|
crazy_functions/test_project/latex/attention/parameter_attention.tex
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
\pagebreak
|
| 2 |
+
\section*{Two Feed-Forward Layers = Attention over Parameters}\label{sec:parameter_attention}
|
| 3 |
+
|
| 4 |
+
In addition to attention layers, our model contains position-wise feed-forward networks (Section \ref{sec:ffn}), which consist of two linear transformations with a ReLU activation in between. In fact, these networks too can be seen as a form of attention. Compare the formula for such a network with the formula for a simple dot-product attention layer (biases and scaling factors omitted):
|
| 5 |
+
|
| 6 |
+
\begin{align*}
|
| 7 |
+
FFN(x, W_1, W_2) = ReLU(xW_1)W_2 \\
|
| 8 |
+
A(q, K, V) = Softmax(qK^T)V
|
| 9 |
+
\end{align*}
|
| 10 |
+
|
| 11 |
+
Based on the similarity of these formulae, the two-layer feed-forward network can be seen as a kind of attention, where the keys and values are the rows of the trainable parameter matrices $W_1$ and $W_2$, and where we use ReLU instead of Softmax in the compatibility function.
|
| 12 |
+
|
| 13 |
+
%the compatablity function is $compat(q, k_i) = ReLU(q \cdot k_i)$ instead of $Softmax(qK_T)_i$.
|
| 14 |
+
|
| 15 |
+
Given this similarity, we experimented with replacing the position-wise feed-forward networks with attention layers similar to the ones we use everywhere else our model. The multi-head-attention-over-parameters sublayer is identical to the multi-head attention described in \ref{sec:multihead}, except that the "keys" and "values" inputs to each attention head are trainable model parameters, as opposed to being linear projections of a previous layer. These parameters are scaled up by a factor of $\sqrt{d_{model}}$ in order to be more similar to activations.
|
| 16 |
+
|
| 17 |
+
In our first experiment, we replaced each position-wise feed-forward network with a multi-head-attention-over-parameters sublayer with $h_p=8$ heads, key-dimensionality $d_{pk}=64$, and value-dimensionality $d_{pv}=64$, using $n_p=1536$ key-value pairs for each attention head. The sublayer has a total of $2097152$ parameters, including the parameters in the query projection and the output projection. This matches the number of parameters in the position-wise feed-forward network that we replaced. While the theoretical amount of computation is also the same, in practice, the attention version caused the step times to be about 30\% longer.
|
| 18 |
+
|
| 19 |
+
In our second experiment, we used $h_p=8$ heads, and $n_p=512$ key-value pairs for each attention head, again matching the total number of parameters in the base model.
|
| 20 |
+
|
| 21 |
+
Results for the first experiment were slightly worse than for the base model, and results for the second experiment were slightly better, see Table~\ref{tab:parameter_attention}.
|
| 22 |
+
|
| 23 |
+
\begin{table}[h]
|
| 24 |
+
\caption{Replacing the position-wise feed-forward networks with multihead-attention-over-parameters produces similar results to the base model. All metrics are on the English-to-German translation development set, newstest2013.}
|
| 25 |
+
\label{tab:parameter_attention}
|
| 26 |
+
\begin{center}
|
| 27 |
+
\vspace{-2mm}
|
| 28 |
+
%\scalebox{1.0}{
|
| 29 |
+
\begin{tabular}{c|cccccc|cccc}
|
| 30 |
+
\hline\rule{0pt}{2.0ex}
|
| 31 |
+
& \multirow{2}{*}{$\dmodel$} & \multirow{2}{*}{$\dff$} &
|
| 32 |
+
\multirow{2}{*}{$h_p$} & \multirow{2}{*}{$d_{pk}$} & \multirow{2}{*}{$d_{pv}$} &
|
| 33 |
+
\multirow{2}{*}{$n_p$} &
|
| 34 |
+
PPL & BLEU & params & training\\
|
| 35 |
+
& & & & & & & (dev) & (dev) & $\times10^6$ & time \\
|
| 36 |
+
\hline\rule{0pt}{2.0ex}
|
| 37 |
+
base & 512 & 2048 & & & & & 4.92 & 25.8 & 65 & 12 hours\\
|
| 38 |
+
\hline\rule{0pt}{2.0ex}
|
| 39 |
+
AOP$_1$ & 512 & & 8 & 64 & 64 & 1536 & 4.92& 25.5 & 65 & 16 hours\\
|
| 40 |
+
AOP$_2$ & 512 & & 16 & 64 & 64 & 512 & \textbf{4.86} & \textbf{25.9} & 65 & 16 hours \\
|
| 41 |
+
\hline
|
| 42 |
+
\end{tabular}
|
| 43 |
+
%}
|
| 44 |
+
\end{center}
|
| 45 |
+
\end{table}
|
crazy_functions/test_project/latex/attention/来源
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
chatgpt的老祖宗《Attention is all you need》
|
| 2 |
+
|
| 3 |
+
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin
|
| 4 |
+
|
| 5 |
+
真实的摘要如下
|
| 6 |
+
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.
|
| 7 |
+
|
| 8 |
+
https://arxiv.org/abs/1706.03762
|
crazy_functions/test_project/python/dqn/__init__.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from stable_baselines3.dqn.dqn import DQN
|
| 2 |
+
from stable_baselines3.dqn.policies import CnnPolicy, MlpPolicy
|
crazy_functions/test_project/python/dqn/dqn.py
ADDED
|
@@ -0,0 +1,245 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Any, Dict, List, Optional, Tuple, Type, Union
|
| 2 |
+
|
| 3 |
+
import gym
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch as th
|
| 6 |
+
from torch.nn import functional as F
|
| 7 |
+
|
| 8 |
+
from stable_baselines3.common import logger
|
| 9 |
+
from stable_baselines3.common.off_policy_algorithm import OffPolicyAlgorithm
|
| 10 |
+
from stable_baselines3.common.preprocessing import maybe_transpose
|
| 11 |
+
from stable_baselines3.common.type_aliases import GymEnv, MaybeCallback, Schedule
|
| 12 |
+
from stable_baselines3.common.utils import get_linear_fn, is_vectorized_observation, polyak_update
|
| 13 |
+
from stable_baselines3.dqn.policies import DQNPolicy
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class DQN(OffPolicyAlgorithm):
|
| 17 |
+
"""
|
| 18 |
+
Deep Q-Network (DQN)
|
| 19 |
+
|
| 20 |
+
Paper: https://arxiv.org/abs/1312.5602, https://www.nature.com/articles/nature14236
|
| 21 |
+
Default hyperparameters are taken from the nature paper,
|
| 22 |
+
except for the optimizer and learning rate that were taken from Stable Baselines defaults.
|
| 23 |
+
|
| 24 |
+
:param policy: The policy model to use (MlpPolicy, CnnPolicy, ...)
|
| 25 |
+
:param env: The environment to learn from (if registered in Gym, can be str)
|
| 26 |
+
:param learning_rate: The learning rate, it can be a function
|
| 27 |
+
of the current progress remaining (from 1 to 0)
|
| 28 |
+
:param buffer_size: size of the replay buffer
|
| 29 |
+
:param learning_starts: how many steps of the model to collect transitions for before learning starts
|
| 30 |
+
:param batch_size: Minibatch size for each gradient update
|
| 31 |
+
:param tau: the soft update coefficient ("Polyak update", between 0 and 1) default 1 for hard update
|
| 32 |
+
:param gamma: the discount factor
|
| 33 |
+
:param train_freq: Update the model every ``train_freq`` steps. Alternatively pass a tuple of frequency and unit
|
| 34 |
+
like ``(5, "step")`` or ``(2, "episode")``.
|
| 35 |
+
:param gradient_steps: How many gradient steps to do after each rollout (see ``train_freq``)
|
| 36 |
+
Set to ``-1`` means to do as many gradient steps as steps done in the environment
|
| 37 |
+
during the rollout.
|
| 38 |
+
:param optimize_memory_usage: Enable a memory efficient variant of the replay buffer
|
| 39 |
+
at a cost of more complexity.
|
| 40 |
+
See https://github.com/DLR-RM/stable-baselines3/issues/37#issuecomment-637501195
|
| 41 |
+
:param target_update_interval: update the target network every ``target_update_interval``
|
| 42 |
+
environment steps.
|
| 43 |
+
:param exploration_fraction: fraction of entire training period over which the exploration rate is reduced
|
| 44 |
+
:param exploration_initial_eps: initial value of random action probability
|
| 45 |
+
:param exploration_final_eps: final value of random action probability
|
| 46 |
+
:param max_grad_norm: The maximum value for the gradient clipping
|
| 47 |
+
:param tensorboard_log: the log location for tensorboard (if None, no logging)
|
| 48 |
+
:param create_eval_env: Whether to create a second environment that will be
|
| 49 |
+
used for evaluating the agent periodically. (Only available when passing string for the environment)
|
| 50 |
+
:param policy_kwargs: additional arguments to be passed to the policy on creation
|
| 51 |
+
:param verbose: the verbosity level: 0 no output, 1 info, 2 debug
|
| 52 |
+
:param seed: Seed for the pseudo random generators
|
| 53 |
+
:param device: Device (cpu, cuda, ...) on which the code should be run.
|
| 54 |
+
Setting it to auto, the code will be run on the GPU if possible.
|
| 55 |
+
:param _init_setup_model: Whether or not to build the network at the creation of the instance
|
| 56 |
+
"""
|
| 57 |
+
|
| 58 |
+
def __init__(
|
| 59 |
+
self,
|
| 60 |
+
policy: Union[str, Type[DQNPolicy]],
|
| 61 |
+
env: Union[GymEnv, str],
|
| 62 |
+
learning_rate: Union[float, Schedule] = 1e-4,
|
| 63 |
+
buffer_size: int = 1000000,
|
| 64 |
+
learning_starts: int = 50000,
|
| 65 |
+
batch_size: Optional[int] = 32,
|
| 66 |
+
tau: float = 1.0,
|
| 67 |
+
gamma: float = 0.99,
|
| 68 |
+
train_freq: Union[int, Tuple[int, str]] = 4,
|
| 69 |
+
gradient_steps: int = 1,
|
| 70 |
+
optimize_memory_usage: bool = False,
|
| 71 |
+
target_update_interval: int = 10000,
|
| 72 |
+
exploration_fraction: float = 0.1,
|
| 73 |
+
exploration_initial_eps: float = 1.0,
|
| 74 |
+
exploration_final_eps: float = 0.05,
|
| 75 |
+
max_grad_norm: float = 10,
|
| 76 |
+
tensorboard_log: Optional[str] = None,
|
| 77 |
+
create_eval_env: bool = False,
|
| 78 |
+
policy_kwargs: Optional[Dict[str, Any]] = None,
|
| 79 |
+
verbose: int = 0,
|
| 80 |
+
seed: Optional[int] = None,
|
| 81 |
+
device: Union[th.device, str] = "auto",
|
| 82 |
+
_init_setup_model: bool = True,
|
| 83 |
+
):
|
| 84 |
+
|
| 85 |
+
super(DQN, self).__init__(
|
| 86 |
+
policy,
|
| 87 |
+
env,
|
| 88 |
+
DQNPolicy,
|
| 89 |
+
learning_rate,
|
| 90 |
+
buffer_size,
|
| 91 |
+
learning_starts,
|
| 92 |
+
batch_size,
|
| 93 |
+
tau,
|
| 94 |
+
gamma,
|
| 95 |
+
train_freq,
|
| 96 |
+
gradient_steps,
|
| 97 |
+
action_noise=None, # No action noise
|
| 98 |
+
policy_kwargs=policy_kwargs,
|
| 99 |
+
tensorboard_log=tensorboard_log,
|
| 100 |
+
verbose=verbose,
|
| 101 |
+
device=device,
|
| 102 |
+
create_eval_env=create_eval_env,
|
| 103 |
+
seed=seed,
|
| 104 |
+
sde_support=False,
|
| 105 |
+
optimize_memory_usage=optimize_memory_usage,
|
| 106 |
+
supported_action_spaces=(gym.spaces.Discrete,),
|
| 107 |
+
)
|
| 108 |
+
|
| 109 |
+
self.exploration_initial_eps = exploration_initial_eps
|
| 110 |
+
self.exploration_final_eps = exploration_final_eps
|
| 111 |
+
self.exploration_fraction = exploration_fraction
|
| 112 |
+
self.target_update_interval = target_update_interval
|
| 113 |
+
self.max_grad_norm = max_grad_norm
|
| 114 |
+
# "epsilon" for the epsilon-greedy exploration
|
| 115 |
+
self.exploration_rate = 0.0
|
| 116 |
+
# Linear schedule will be defined in `_setup_model()`
|
| 117 |
+
self.exploration_schedule = None
|
| 118 |
+
self.q_net, self.q_net_target = None, None
|
| 119 |
+
|
| 120 |
+
if _init_setup_model:
|
| 121 |
+
self._setup_model()
|
| 122 |
+
|
| 123 |
+
def _setup_model(self) -> None:
|
| 124 |
+
super(DQN, self)._setup_model()
|
| 125 |
+
self._create_aliases()
|
| 126 |
+
self.exploration_schedule = get_linear_fn(
|
| 127 |
+
self.exploration_initial_eps, self.exploration_final_eps, self.exploration_fraction
|
| 128 |
+
)
|
| 129 |
+
|
| 130 |
+
def _create_aliases(self) -> None:
|
| 131 |
+
self.q_net = self.policy.q_net
|
| 132 |
+
self.q_net_target = self.policy.q_net_target
|
| 133 |
+
|
| 134 |
+
def _on_step(self) -> None:
|
| 135 |
+
"""
|
| 136 |
+
Update the exploration rate and target network if needed.
|
| 137 |
+
This method is called in ``collect_rollouts()`` after each step in the environment.
|
| 138 |
+
"""
|
| 139 |
+
if self.num_timesteps % self.target_update_interval == 0:
|
| 140 |
+
polyak_update(self.q_net.parameters(), self.q_net_target.parameters(), self.tau)
|
| 141 |
+
|
| 142 |
+
self.exploration_rate = self.exploration_schedule(self._current_progress_remaining)
|
| 143 |
+
logger.record("rollout/exploration rate", self.exploration_rate)
|
| 144 |
+
|
| 145 |
+
def train(self, gradient_steps: int, batch_size: int = 100) -> None:
|
| 146 |
+
# Update learning rate according to schedule
|
| 147 |
+
self._update_learning_rate(self.policy.optimizer)
|
| 148 |
+
|
| 149 |
+
losses = []
|
| 150 |
+
for _ in range(gradient_steps):
|
| 151 |
+
# Sample replay buffer
|
| 152 |
+
replay_data = self.replay_buffer.sample(batch_size, env=self._vec_normalize_env)
|
| 153 |
+
|
| 154 |
+
with th.no_grad():
|
| 155 |
+
# Compute the next Q-values using the target network
|
| 156 |
+
next_q_values = self.q_net_target(replay_data.next_observations)
|
| 157 |
+
# Follow greedy policy: use the one with the highest value
|
| 158 |
+
next_q_values, _ = next_q_values.max(dim=1)
|
| 159 |
+
# Avoid potential broadcast issue
|
| 160 |
+
next_q_values = next_q_values.reshape(-1, 1)
|
| 161 |
+
# 1-step TD target
|
| 162 |
+
target_q_values = replay_data.rewards + (1 - replay_data.dones) * self.gamma * next_q_values
|
| 163 |
+
|
| 164 |
+
# Get current Q-values estimates
|
| 165 |
+
current_q_values = self.q_net(replay_data.observations)
|
| 166 |
+
|
| 167 |
+
# Retrieve the q-values for the actions from the replay buffer
|
| 168 |
+
current_q_values = th.gather(current_q_values, dim=1, index=replay_data.actions.long())
|
| 169 |
+
|
| 170 |
+
# Compute Huber loss (less sensitive to outliers)
|
| 171 |
+
loss = F.smooth_l1_loss(current_q_values, target_q_values)
|
| 172 |
+
losses.append(loss.item())
|
| 173 |
+
|
| 174 |
+
# Optimize the policy
|
| 175 |
+
self.policy.optimizer.zero_grad()
|
| 176 |
+
loss.backward()
|
| 177 |
+
# Clip gradient norm
|
| 178 |
+
th.nn.utils.clip_grad_norm_(self.policy.parameters(), self.max_grad_norm)
|
| 179 |
+
self.policy.optimizer.step()
|
| 180 |
+
|
| 181 |
+
# Increase update counter
|
| 182 |
+
self._n_updates += gradient_steps
|
| 183 |
+
|
| 184 |
+
logger.record("train/n_updates", self._n_updates, exclude="tensorboard")
|
| 185 |
+
logger.record("train/loss", np.mean(losses))
|
| 186 |
+
|
| 187 |
+
def predict(
|
| 188 |
+
self,
|
| 189 |
+
observation: np.ndarray,
|
| 190 |
+
state: Optional[np.ndarray] = None,
|
| 191 |
+
mask: Optional[np.ndarray] = None,
|
| 192 |
+
deterministic: bool = False,
|
| 193 |
+
) -> Tuple[np.ndarray, Optional[np.ndarray]]:
|
| 194 |
+
"""
|
| 195 |
+
Overrides the base_class predict function to include epsilon-greedy exploration.
|
| 196 |
+
|
| 197 |
+
:param observation: the input observation
|
| 198 |
+
:param state: The last states (can be None, used in recurrent policies)
|
| 199 |
+
:param mask: The last masks (can be None, used in recurrent policies)
|
| 200 |
+
:param deterministic: Whether or not to return deterministic actions.
|
| 201 |
+
:return: the model's action and the next state
|
| 202 |
+
(used in recurrent policies)
|
| 203 |
+
"""
|
| 204 |
+
if not deterministic and np.random.rand() < self.exploration_rate:
|
| 205 |
+
if is_vectorized_observation(maybe_transpose(observation, self.observation_space), self.observation_space):
|
| 206 |
+
n_batch = observation.shape[0]
|
| 207 |
+
action = np.array([self.action_space.sample() for _ in range(n_batch)])
|
| 208 |
+
else:
|
| 209 |
+
action = np.array(self.action_space.sample())
|
| 210 |
+
else:
|
| 211 |
+
action, state = self.policy.predict(observation, state, mask, deterministic)
|
| 212 |
+
return action, state
|
| 213 |
+
|
| 214 |
+
def learn(
|
| 215 |
+
self,
|
| 216 |
+
total_timesteps: int,
|
| 217 |
+
callback: MaybeCallback = None,
|
| 218 |
+
log_interval: int = 4,
|
| 219 |
+
eval_env: Optional[GymEnv] = None,
|
| 220 |
+
eval_freq: int = -1,
|
| 221 |
+
n_eval_episodes: int = 5,
|
| 222 |
+
tb_log_name: str = "DQN",
|
| 223 |
+
eval_log_path: Optional[str] = None,
|
| 224 |
+
reset_num_timesteps: bool = True,
|
| 225 |
+
) -> OffPolicyAlgorithm:
|
| 226 |
+
|
| 227 |
+
return super(DQN, self).learn(
|
| 228 |
+
total_timesteps=total_timesteps,
|
| 229 |
+
callback=callback,
|
| 230 |
+
log_interval=log_interval,
|
| 231 |
+
eval_env=eval_env,
|
| 232 |
+
eval_freq=eval_freq,
|
| 233 |
+
n_eval_episodes=n_eval_episodes,
|
| 234 |
+
tb_log_name=tb_log_name,
|
| 235 |
+
eval_log_path=eval_log_path,
|
| 236 |
+
reset_num_timesteps=reset_num_timesteps,
|
| 237 |
+
)
|
| 238 |
+
|
| 239 |
+
def _excluded_save_params(self) -> List[str]:
|
| 240 |
+
return super(DQN, self)._excluded_save_params() + ["q_net", "q_net_target"]
|
| 241 |
+
|
| 242 |
+
def _get_torch_save_params(self) -> Tuple[List[str], List[str]]:
|
| 243 |
+
state_dicts = ["policy", "policy.optimizer"]
|
| 244 |
+
|
| 245 |
+
return state_dicts, []
|
crazy_functions/test_project/python/dqn/policies.py
ADDED
|
@@ -0,0 +1,237 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Any, Dict, List, Optional, Type
|
| 2 |
+
|
| 3 |
+
import gym
|
| 4 |
+
import torch as th
|
| 5 |
+
from torch import nn
|
| 6 |
+
|
| 7 |
+
from stable_baselines3.common.policies import BasePolicy, register_policy
|
| 8 |
+
from stable_baselines3.common.torch_layers import BaseFeaturesExtractor, FlattenExtractor, NatureCNN, create_mlp
|
| 9 |
+
from stable_baselines3.common.type_aliases import Schedule
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class QNetwork(BasePolicy):
|
| 13 |
+
"""
|
| 14 |
+
Action-Value (Q-Value) network for DQN
|
| 15 |
+
|
| 16 |
+
:param observation_space: Observation space
|
| 17 |
+
:param action_space: Action space
|
| 18 |
+
:param net_arch: The specification of the policy and value networks.
|
| 19 |
+
:param activation_fn: Activation function
|
| 20 |
+
:param normalize_images: Whether to normalize images or not,
|
| 21 |
+
dividing by 255.0 (True by default)
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
def __init__(
|
| 25 |
+
self,
|
| 26 |
+
observation_space: gym.spaces.Space,
|
| 27 |
+
action_space: gym.spaces.Space,
|
| 28 |
+
features_extractor: nn.Module,
|
| 29 |
+
features_dim: int,
|
| 30 |
+
net_arch: Optional[List[int]] = None,
|
| 31 |
+
activation_fn: Type[nn.Module] = nn.ReLU,
|
| 32 |
+
normalize_images: bool = True,
|
| 33 |
+
):
|
| 34 |
+
super(QNetwork, self).__init__(
|
| 35 |
+
observation_space,
|
| 36 |
+
action_space,
|
| 37 |
+
features_extractor=features_extractor,
|
| 38 |
+
normalize_images=normalize_images,
|
| 39 |
+
)
|
| 40 |
+
|
| 41 |
+
if net_arch is None:
|
| 42 |
+
net_arch = [64, 64]
|
| 43 |
+
|
| 44 |
+
self.net_arch = net_arch
|
| 45 |
+
self.activation_fn = activation_fn
|
| 46 |
+
self.features_extractor = features_extractor
|
| 47 |
+
self.features_dim = features_dim
|
| 48 |
+
self.normalize_images = normalize_images
|
| 49 |
+
action_dim = self.action_space.n # number of actions
|
| 50 |
+
q_net = create_mlp(self.features_dim, action_dim, self.net_arch, self.activation_fn)
|
| 51 |
+
self.q_net = nn.Sequential(*q_net)
|
| 52 |
+
|
| 53 |
+
def forward(self, obs: th.Tensor) -> th.Tensor:
|
| 54 |
+
"""
|
| 55 |
+
Predict the q-values.
|
| 56 |
+
|
| 57 |
+
:param obs: Observation
|
| 58 |
+
:return: The estimated Q-Value for each action.
|
| 59 |
+
"""
|
| 60 |
+
return self.q_net(self.extract_features(obs))
|
| 61 |
+
|
| 62 |
+
def _predict(self, observation: th.Tensor, deterministic: bool = True) -> th.Tensor:
|
| 63 |
+
q_values = self.forward(observation)
|
| 64 |
+
# Greedy action
|
| 65 |
+
action = q_values.argmax(dim=1).reshape(-1)
|
| 66 |
+
return action
|
| 67 |
+
|
| 68 |
+
def _get_constructor_parameters(self) -> Dict[str, Any]:
|
| 69 |
+
data = super()._get_constructor_parameters()
|
| 70 |
+
|
| 71 |
+
data.update(
|
| 72 |
+
dict(
|
| 73 |
+
net_arch=self.net_arch,
|
| 74 |
+
features_dim=self.features_dim,
|
| 75 |
+
activation_fn=self.activation_fn,
|
| 76 |
+
features_extractor=self.features_extractor,
|
| 77 |
+
)
|
| 78 |
+
)
|
| 79 |
+
return data
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
class DQNPolicy(BasePolicy):
|
| 83 |
+
"""
|
| 84 |
+
Policy class with Q-Value Net and target net for DQN
|
| 85 |
+
|
| 86 |
+
:param observation_space: Observation space
|
| 87 |
+
:param action_space: Action space
|
| 88 |
+
:param lr_schedule: Learning rate schedule (could be constant)
|
| 89 |
+
:param net_arch: The specification of the policy and value networks.
|
| 90 |
+
:param activation_fn: Activation function
|
| 91 |
+
:param features_extractor_class: Features extractor to use.
|
| 92 |
+
:param features_extractor_kwargs: Keyword arguments
|
| 93 |
+
to pass to the features extractor.
|
| 94 |
+
:param normalize_images: Whether to normalize images or not,
|
| 95 |
+
dividing by 255.0 (True by default)
|
| 96 |
+
:param optimizer_class: The optimizer to use,
|
| 97 |
+
``th.optim.Adam`` by default
|
| 98 |
+
:param optimizer_kwargs: Additional keyword arguments,
|
| 99 |
+
excluding the learning rate, to pass to the optimizer
|
| 100 |
+
"""
|
| 101 |
+
|
| 102 |
+
def __init__(
|
| 103 |
+
self,
|
| 104 |
+
observation_space: gym.spaces.Space,
|
| 105 |
+
action_space: gym.spaces.Space,
|
| 106 |
+
lr_schedule: Schedule,
|
| 107 |
+
net_arch: Optional[List[int]] = None,
|
| 108 |
+
activation_fn: Type[nn.Module] = nn.ReLU,
|
| 109 |
+
features_extractor_class: Type[BaseFeaturesExtractor] = FlattenExtractor,
|
| 110 |
+
features_extractor_kwargs: Optional[Dict[str, Any]] = None,
|
| 111 |
+
normalize_images: bool = True,
|
| 112 |
+
optimizer_class: Type[th.optim.Optimizer] = th.optim.Adam,
|
| 113 |
+
optimizer_kwargs: Optional[Dict[str, Any]] = None,
|
| 114 |
+
):
|
| 115 |
+
super(DQNPolicy, self).__init__(
|
| 116 |
+
observation_space,
|
| 117 |
+
action_space,
|
| 118 |
+
features_extractor_class,
|
| 119 |
+
features_extractor_kwargs,
|
| 120 |
+
optimizer_class=optimizer_class,
|
| 121 |
+
optimizer_kwargs=optimizer_kwargs,
|
| 122 |
+
)
|
| 123 |
+
|
| 124 |
+
if net_arch is None:
|
| 125 |
+
if features_extractor_class == FlattenExtractor:
|
| 126 |
+
net_arch = [64, 64]
|
| 127 |
+
else:
|
| 128 |
+
net_arch = []
|
| 129 |
+
|
| 130 |
+
self.net_arch = net_arch
|
| 131 |
+
self.activation_fn = activation_fn
|
| 132 |
+
self.normalize_images = normalize_images
|
| 133 |
+
|
| 134 |
+
self.net_args = {
|
| 135 |
+
"observation_space": self.observation_space,
|
| 136 |
+
"action_space": self.action_space,
|
| 137 |
+
"net_arch": self.net_arch,
|
| 138 |
+
"activation_fn": self.activation_fn,
|
| 139 |
+
"normalize_images": normalize_images,
|
| 140 |
+
}
|
| 141 |
+
|
| 142 |
+
self.q_net, self.q_net_target = None, None
|
| 143 |
+
self._build(lr_schedule)
|
| 144 |
+
|
| 145 |
+
def _build(self, lr_schedule: Schedule) -> None:
|
| 146 |
+
"""
|
| 147 |
+
Create the network and the optimizer.
|
| 148 |
+
|
| 149 |
+
:param lr_schedule: Learning rate schedule
|
| 150 |
+
lr_schedule(1) is the initial learning rate
|
| 151 |
+
"""
|
| 152 |
+
|
| 153 |
+
self.q_net = self.make_q_net()
|
| 154 |
+
self.q_net_target = self.make_q_net()
|
| 155 |
+
self.q_net_target.load_state_dict(self.q_net.state_dict())
|
| 156 |
+
|
| 157 |
+
# Setup optimizer with initial learning rate
|
| 158 |
+
self.optimizer = self.optimizer_class(self.parameters(), lr=lr_schedule(1), **self.optimizer_kwargs)
|
| 159 |
+
|
| 160 |
+
def make_q_net(self) -> QNetwork:
|
| 161 |
+
# Make sure we always have separate networks for features extractors etc
|
| 162 |
+
net_args = self._update_features_extractor(self.net_args, features_extractor=None)
|
| 163 |
+
return QNetwork(**net_args).to(self.device)
|
| 164 |
+
|
| 165 |
+
def forward(self, obs: th.Tensor, deterministic: bool = True) -> th.Tensor:
|
| 166 |
+
return self._predict(obs, deterministic=deterministic)
|
| 167 |
+
|
| 168 |
+
def _predict(self, obs: th.Tensor, deterministic: bool = True) -> th.Tensor:
|
| 169 |
+
return self.q_net._predict(obs, deterministic=deterministic)
|
| 170 |
+
|
| 171 |
+
def _get_constructor_parameters(self) -> Dict[str, Any]:
|
| 172 |
+
data = super()._get_constructor_parameters()
|
| 173 |
+
|
| 174 |
+
data.update(
|
| 175 |
+
dict(
|
| 176 |
+
net_arch=self.net_args["net_arch"],
|
| 177 |
+
activation_fn=self.net_args["activation_fn"],
|
| 178 |
+
lr_schedule=self._dummy_schedule, # dummy lr schedule, not needed for loading policy alone
|
| 179 |
+
optimizer_class=self.optimizer_class,
|
| 180 |
+
optimizer_kwargs=self.optimizer_kwargs,
|
| 181 |
+
features_extractor_class=self.features_extractor_class,
|
| 182 |
+
features_extractor_kwargs=self.features_extractor_kwargs,
|
| 183 |
+
)
|
| 184 |
+
)
|
| 185 |
+
return data
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
MlpPolicy = DQNPolicy
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
class CnnPolicy(DQNPolicy):
|
| 192 |
+
"""
|
| 193 |
+
Policy class for DQN when using images as input.
|
| 194 |
+
|
| 195 |
+
:param observation_space: Observation space
|
| 196 |
+
:param action_space: Action space
|
| 197 |
+
:param lr_schedule: Learning rate schedule (could be constant)
|
| 198 |
+
:param net_arch: The specification of the policy and value networks.
|
| 199 |
+
:param activation_fn: Activation function
|
| 200 |
+
:param features_extractor_class: Features extractor to use.
|
| 201 |
+
:param normalize_images: Whether to normalize images or not,
|
| 202 |
+
dividing by 255.0 (True by default)
|
| 203 |
+
:param optimizer_class: The optimizer to use,
|
| 204 |
+
``th.optim.Adam`` by default
|
| 205 |
+
:param optimizer_kwargs: Additional keyword arguments,
|
| 206 |
+
excluding the learning rate, to pass to the optimizer
|
| 207 |
+
"""
|
| 208 |
+
|
| 209 |
+
def __init__(
|
| 210 |
+
self,
|
| 211 |
+
observation_space: gym.spaces.Space,
|
| 212 |
+
action_space: gym.spaces.Space,
|
| 213 |
+
lr_schedule: Schedule,
|
| 214 |
+
net_arch: Optional[List[int]] = None,
|
| 215 |
+
activation_fn: Type[nn.Module] = nn.ReLU,
|
| 216 |
+
features_extractor_class: Type[BaseFeaturesExtractor] = NatureCNN,
|
| 217 |
+
features_extractor_kwargs: Optional[Dict[str, Any]] = None,
|
| 218 |
+
normalize_images: bool = True,
|
| 219 |
+
optimizer_class: Type[th.optim.Optimizer] = th.optim.Adam,
|
| 220 |
+
optimizer_kwargs: Optional[Dict[str, Any]] = None,
|
| 221 |
+
):
|
| 222 |
+
super(CnnPolicy, self).__init__(
|
| 223 |
+
observation_space,
|
| 224 |
+
action_space,
|
| 225 |
+
lr_schedule,
|
| 226 |
+
net_arch,
|
| 227 |
+
activation_fn,
|
| 228 |
+
features_extractor_class,
|
| 229 |
+
features_extractor_kwargs,
|
| 230 |
+
normalize_images,
|
| 231 |
+
optimizer_class,
|
| 232 |
+
optimizer_kwargs,
|
| 233 |
+
)
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
register_policy("MlpPolicy", MlpPolicy)
|
| 237 |
+
register_policy("CnnPolicy", CnnPolicy)
|
crazy_functions/test_project/python/dqn/来源
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
github stablebaseline3
|
| 2 |
+
https://github.com/DLR-RM/stable-baselines3
|
crazy_functions/test_project/其他测试
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"In practice, we found that a high-entropy initial state is more likely to increase the speed of training.
|
| 2 |
+
The entropy is calculated by:
|
| 3 |
+
$$H=-\sum_{k= 1}^{n_k} p(k) \cdot \log p(k), p(k)=\frac{|A_k|}{|\mathcal{A}|}$$
|
| 4 |
+
where $H$ is the entropy, $|A_k|$ is the number of agent nodes in $k$-th cluster, $|\mathcal{A}|$ is the total number of agents.
|
| 5 |
+
To ensure the Cooperation Graph initialization has higher entropy,
|
| 6 |
+
we will randomly generate multiple initial states,
|
| 7 |
+
rank by their entropy and then pick the one with maximum $H$."
|
| 8 |
+
|
| 9 |
+
```
|
| 10 |
+
FROM ubuntu:latest
|
| 11 |
+
|
| 12 |
+
RUN apt-get update && \
|
| 13 |
+
apt-get install -y python3 python3-pip && \
|
| 14 |
+
rm -rf /var/lib/apt/lists/*
|
| 15 |
+
|
| 16 |
+
RUN echo '[global]' > /etc/pip.conf && \
|
| 17 |
+
echo 'index-url = https://mirrors.aliyun.com/pypi/simple/' >> /etc/pip.conf && \
|
| 18 |
+
echo 'trusted-host = mirrors.aliyun.com' >> /etc/pip.conf
|
| 19 |
+
|
| 20 |
+
RUN pip3 install gradio requests[socks] mdtex2html
|
| 21 |
+
|
| 22 |
+
COPY . /gpt
|
| 23 |
+
WORKDIR /gpt
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
CMD ["python3", "main.py"]
|
| 27 |
+
```
|
crazy_functions/代码重写为全英文_多线程.py
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import threading
|
| 2 |
+
from predict import predict_no_ui_long_connection
|
| 3 |
+
from toolbox import CatchException, write_results_to_file
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
@CatchException
|
| 8 |
+
def 全项目切换英文(txt, top_p, temperature, chatbot, history, sys_prompt, WEB_PORT):
|
| 9 |
+
history = [] # 清空历史,以免输入溢出
|
| 10 |
+
# 集合文件
|
| 11 |
+
import time, glob, os
|
| 12 |
+
os.makedirs('gpt_log/generated_english_version', exist_ok=True)
|
| 13 |
+
os.makedirs('gpt_log/generated_english_version/crazy_functions', exist_ok=True)
|
| 14 |
+
file_manifest = [f for f in glob.glob('./*.py') if ('test_project' not in f) and ('gpt_log' not in f)] + \
|
| 15 |
+
[f for f in glob.glob('./crazy_functions/*.py') if ('test_project' not in f) and ('gpt_log' not in f)]
|
| 16 |
+
i_say_show_user_buffer = []
|
| 17 |
+
|
| 18 |
+
# 随便显示点什么防止卡顿的感觉
|
| 19 |
+
for index, fp in enumerate(file_manifest):
|
| 20 |
+
# if 'test_project' in fp: continue
|
| 21 |
+
with open(fp, 'r', encoding='utf-8') as f:
|
| 22 |
+
file_content = f.read()
|
| 23 |
+
i_say_show_user =f'[{index}/{len(file_manifest)}] 接下来请将以下代码中包含的所有中文转化为英文,只输出代码: {os.path.abspath(fp)}'
|
| 24 |
+
i_say_show_user_buffer.append(i_say_show_user)
|
| 25 |
+
chatbot.append((i_say_show_user, "[Local Message] 等待多线程操作,中间过程不予显示."))
|
| 26 |
+
yield chatbot, history, '正常'
|
| 27 |
+
|
| 28 |
+
# 任务函数
|
| 29 |
+
mutable_return = [None for _ in file_manifest]
|
| 30 |
+
def thread_worker(fp,index):
|
| 31 |
+
with open(fp, 'r', encoding='utf-8') as f:
|
| 32 |
+
file_content = f.read()
|
| 33 |
+
i_say = f'接下来请将以下代码中包含的所有中文转化为英文,只输出代码,文件名是{fp},文件代码是 ```{file_content}```'
|
| 34 |
+
# ** gpt request **
|
| 35 |
+
gpt_say = predict_no_ui_long_connection(inputs=i_say, top_p=top_p, temperature=temperature, history=history, sys_prompt=sys_prompt)
|
| 36 |
+
mutable_return[index] = gpt_say
|
| 37 |
+
|
| 38 |
+
# 所有线程同时开始执行任务函数
|
| 39 |
+
handles = [threading.Thread(target=thread_worker, args=(fp,index)) for index, fp in enumerate(file_manifest)]
|
| 40 |
+
for h in handles:
|
| 41 |
+
h.daemon = True
|
| 42 |
+
h.start()
|
| 43 |
+
chatbot.append(('开始了吗?', f'多线程操作已经开始'))
|
| 44 |
+
yield chatbot, history, '正常'
|
| 45 |
+
|
| 46 |
+
# 循环轮询各个线程是否执行完毕
|
| 47 |
+
cnt = 0
|
| 48 |
+
while True:
|
| 49 |
+
time.sleep(1)
|
| 50 |
+
th_alive = [h.is_alive() for h in handles]
|
| 51 |
+
if not any(th_alive): break
|
| 52 |
+
stat = ['执行中' if alive else '已完成' for alive in th_alive]
|
| 53 |
+
stat_str = '|'.join(stat)
|
| 54 |
+
cnt += 1
|
| 55 |
+
chatbot[-1] = (chatbot[-1][0], f'多线程操作已经开始,完成情况: {stat_str}' + ''.join(['.']*(cnt%4)))
|
| 56 |
+
yield chatbot, history, '正常'
|
| 57 |
+
|
| 58 |
+
# 把结果写入文件
|
| 59 |
+
for index, h in enumerate(handles):
|
| 60 |
+
h.join() # 这里其实不需要join了,肯定已经都结束了
|
| 61 |
+
fp = file_manifest[index]
|
| 62 |
+
gpt_say = mutable_return[index]
|
| 63 |
+
i_say_show_user = i_say_show_user_buffer[index]
|
| 64 |
+
|
| 65 |
+
where_to_relocate = f'gpt_log/generated_english_version/{fp}'
|
| 66 |
+
with open(where_to_relocate, 'w+', encoding='utf-8') as f: f.write(gpt_say.lstrip('```').rstrip('```'))
|
| 67 |
+
chatbot.append((i_say_show_user, f'[Local Message] 已完成{os.path.abspath(fp)}的转化,\n\n存入{os.path.abspath(where_to_relocate)}'))
|
| 68 |
+
history.append(i_say_show_user); history.append(gpt_say)
|
| 69 |
+
yield chatbot, history, '正常'
|
| 70 |
+
time.sleep(1)
|
| 71 |
+
|
| 72 |
+
# 备份一个文件
|
| 73 |
+
res = write_results_to_file(history)
|
| 74 |
+
chatbot.append(("生成一份任务执行报告", res))
|
| 75 |
+
yield chatbot, history, '正常'
|
crazy_functions/批量总结PDF文档.py
ADDED
|
@@ -0,0 +1,99 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from predict import predict_no_ui
|
| 2 |
+
from toolbox import CatchException, report_execption, write_results_to_file, predict_no_ui_but_counting_down
|
| 3 |
+
fast_debug = False
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def 解析PDF(file_manifest, project_folder, top_p, temperature, chatbot, history, systemPromptTxt):
|
| 7 |
+
import time, glob, os, fitz
|
| 8 |
+
print('begin analysis on:', file_manifest)
|
| 9 |
+
for index, fp in enumerate(file_manifest):
|
| 10 |
+
with fitz.open(fp) as doc:
|
| 11 |
+
file_content = ""
|
| 12 |
+
for page in doc:
|
| 13 |
+
file_content += page.get_text()
|
| 14 |
+
print(file_content)
|
| 15 |
+
|
| 16 |
+
prefix = "接下来请你逐文件分析下面的论文文件,概括其内容" if index==0 else ""
|
| 17 |
+
i_say = prefix + f'请对下面的文章片段用中文做一个概述,文件名是{os.path.relpath(fp, project_folder)},文章内容是 ```{file_content}```'
|
| 18 |
+
i_say_show_user = prefix + f'[{index}/{len(file_manifest)}] 请对下面的文章片段做一个概述: {os.path.abspath(fp)}'
|
| 19 |
+
chatbot.append((i_say_show_user, "[Local Message] waiting gpt response."))
|
| 20 |
+
print('[1] yield chatbot, history')
|
| 21 |
+
yield chatbot, history, '正常'
|
| 22 |
+
|
| 23 |
+
if not fast_debug:
|
| 24 |
+
msg = '正常'
|
| 25 |
+
# ** gpt request **
|
| 26 |
+
gpt_say = yield from predict_no_ui_but_counting_down(i_say, i_say_show_user, chatbot, top_p, temperature, history=[]) # 带超时倒计时
|
| 27 |
+
|
| 28 |
+
print('[2] end gpt req')
|
| 29 |
+
chatbot[-1] = (i_say_show_user, gpt_say)
|
| 30 |
+
history.append(i_say_show_user); history.append(gpt_say)
|
| 31 |
+
print('[3] yield chatbot, history')
|
| 32 |
+
yield chatbot, history, msg
|
| 33 |
+
print('[4] next')
|
| 34 |
+
if not fast_debug: time.sleep(2)
|
| 35 |
+
|
| 36 |
+
all_file = ', '.join([os.path.relpath(fp, project_folder) for index, fp in enumerate(file_manifest)])
|
| 37 |
+
i_say = f'根据以上你自己的分析,对全文进行概括,用学术性语言写一段中文摘要,然后再写一段英文摘要(包括{all_file})。'
|
| 38 |
+
chatbot.append((i_say, "[Local Message] waiting gpt response."))
|
| 39 |
+
yield chatbot, history, '正常'
|
| 40 |
+
|
| 41 |
+
if not fast_debug:
|
| 42 |
+
msg = '正常'
|
| 43 |
+
# ** gpt request **
|
| 44 |
+
gpt_say = yield from predict_no_ui_but_counting_down(i_say, i_say, chatbot, top_p, temperature, history=history) # 带超时倒计时
|
| 45 |
+
|
| 46 |
+
chatbot[-1] = (i_say, gpt_say)
|
| 47 |
+
history.append(i_say); history.append(gpt_say)
|
| 48 |
+
yield chatbot, history, msg
|
| 49 |
+
res = write_results_to_file(history)
|
| 50 |
+
chatbot.append(("完成了吗?", res))
|
| 51 |
+
yield chatbot, history, msg
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
@CatchException
|
| 55 |
+
def 批量总结PDF文档(txt, top_p, temperature, chatbot, history, systemPromptTxt, WEB_PORT):
|
| 56 |
+
import glob, os
|
| 57 |
+
|
| 58 |
+
# 基本信息:功能、贡献者
|
| 59 |
+
chatbot.append([
|
| 60 |
+
"函数插件功能?",
|
| 61 |
+
"批量总结PDF文档。函数插件贡献者: ValeriaWong"])
|
| 62 |
+
yield chatbot, history, '正常'
|
| 63 |
+
|
| 64 |
+
# 尝试导入依赖,如果缺少依赖,则给出安装建议
|
| 65 |
+
try:
|
| 66 |
+
import fitz
|
| 67 |
+
except:
|
| 68 |
+
report_execption(chatbot, history,
|
| 69 |
+
a = f"解析项目: {txt}",
|
| 70 |
+
b = f"导入软件依赖失败。使用该模块需要额外依赖,安装方法```pip install --upgrade pymupdf```。")
|
| 71 |
+
yield chatbot, history, '正常'
|
| 72 |
+
return
|
| 73 |
+
|
| 74 |
+
# 清空历史,以免输入溢出
|
| 75 |
+
history = []
|
| 76 |
+
|
| 77 |
+
# 检测输入参数,如没有给定输入参数,直接退出
|
| 78 |
+
if os.path.exists(txt):
|
| 79 |
+
project_folder = txt
|
| 80 |
+
else:
|
| 81 |
+
if txt == "": txt = '空空如也的输入栏'
|
| 82 |
+
report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到本地项目或无权访问: {txt}")
|
| 83 |
+
yield chatbot, history, '正常'
|
| 84 |
+
return
|
| 85 |
+
|
| 86 |
+
# 搜索需要处理的文件清单
|
| 87 |
+
file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.pdf', recursive=True)] # + \
|
| 88 |
+
# [f for f in glob.glob(f'{project_folder}/**/*.tex', recursive=True)] + \
|
| 89 |
+
# [f for f in glob.glob(f'{project_folder}/**/*.cpp', recursive=True)] + \
|
| 90 |
+
# [f for f in glob.glob(f'{project_folder}/**/*.c', recursive=True)]
|
| 91 |
+
|
| 92 |
+
# 如果没找到任何文件
|
| 93 |
+
if len(file_manifest) == 0:
|
| 94 |
+
report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到任何.tex或.pdf文件: {txt}")
|
| 95 |
+
yield chatbot, history, '正常'
|
| 96 |
+
return
|
| 97 |
+
|
| 98 |
+
# 开始正式执行任务
|
| 99 |
+
yield from 解析PDF(file_manifest, project_folder, top_p, temperature, chatbot, history, systemPromptTxt)
|
crazy_functions/生成函数注释.py
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from predict import predict_no_ui
|
| 2 |
+
from toolbox import CatchException, report_execption, write_results_to_file, predict_no_ui_but_counting_down
|
| 3 |
+
fast_debug = False
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def 生成函数注释(file_manifest, project_folder, top_p, temperature, chatbot, history, systemPromptTxt):
|
| 7 |
+
import time, glob, os
|
| 8 |
+
print('begin analysis on:', file_manifest)
|
| 9 |
+
for index, fp in enumerate(file_manifest):
|
| 10 |
+
with open(fp, 'r', encoding='utf-8') as f:
|
| 11 |
+
file_content = f.read()
|
| 12 |
+
|
| 13 |
+
i_say = f'请对下面的程序文件做一个概述,并对文件中的所有函数生成注释,使用markdown表格输出结果,文件名是{os.path.relpath(fp, project_folder)},文件内容是 ```{file_content}```'
|
| 14 |
+
i_say_show_user = f'[{index}/{len(file_manifest)}] 请对下面的程序文件做一个概述,并对文件中的所有函数生成注释: {os.path.abspath(fp)}'
|
| 15 |
+
chatbot.append((i_say_show_user, "[Local Message] waiting gpt response."))
|
| 16 |
+
print('[1] yield chatbot, history')
|
| 17 |
+
yield chatbot, history, '正常'
|
| 18 |
+
|
| 19 |
+
if not fast_debug:
|
| 20 |
+
msg = '正常'
|
| 21 |
+
# ** gpt request **
|
| 22 |
+
gpt_say = yield from predict_no_ui_but_counting_down(i_say, i_say_show_user, chatbot, top_p, temperature, history=[]) # 带超时倒计时
|
| 23 |
+
|
| 24 |
+
print('[2] end gpt req')
|
| 25 |
+
chatbot[-1] = (i_say_show_user, gpt_say)
|
| 26 |
+
history.append(i_say_show_user); history.append(gpt_say)
|
| 27 |
+
print('[3] yield chatbot, history')
|
| 28 |
+
yield chatbot, history, msg
|
| 29 |
+
print('[4] next')
|
| 30 |
+
if not fast_debug: time.sleep(2)
|
| 31 |
+
|
| 32 |
+
if not fast_debug:
|
| 33 |
+
res = write_results_to_file(history)
|
| 34 |
+
chatbot.append(("完成了吗?", res))
|
| 35 |
+
yield chatbot, history, msg
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
@CatchException
|
| 40 |
+
def 批量生成函数注释(txt, top_p, temperature, chatbot, history, systemPromptTxt, WEB_PORT):
|
| 41 |
+
history = [] # 清空历史,以免输入溢出
|
| 42 |
+
import glob, os
|
| 43 |
+
if os.path.exists(txt):
|
| 44 |
+
project_folder = txt
|
| 45 |
+
else:
|
| 46 |
+
if txt == "": txt = '空空如也的输入栏'
|
| 47 |
+
report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到本地项目或无权访问: {txt}")
|
| 48 |
+
yield chatbot, history, '正常'
|
| 49 |
+
return
|
| 50 |
+
file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.py', recursive=True)] + \
|
| 51 |
+
[f for f in glob.glob(f'{project_folder}/**/*.cpp', recursive=True)]
|
| 52 |
+
|
| 53 |
+
if len(file_manifest) == 0:
|
| 54 |
+
report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到任何.tex文件: {txt}")
|
| 55 |
+
yield chatbot, history, '正常'
|
| 56 |
+
return
|
| 57 |
+
yield from 生成函数注释(file_manifest, project_folder, top_p, temperature, chatbot, history, systemPromptTxt)
|
crazy_functions/解析项目源代码.py
ADDED
|
@@ -0,0 +1,149 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from predict import predict_no_ui
|
| 2 |
+
from toolbox import CatchException, report_execption, write_results_to_file, predict_no_ui_but_counting_down
|
| 3 |
+
fast_debug = False
|
| 4 |
+
|
| 5 |
+
def 解析源代码(file_manifest, project_folder, top_p, temperature, chatbot, history, systemPromptTxt):
|
| 6 |
+
import time, glob, os
|
| 7 |
+
print('begin analysis on:', file_manifest)
|
| 8 |
+
for index, fp in enumerate(file_manifest):
|
| 9 |
+
with open(fp, 'r', encoding='utf-8') as f:
|
| 10 |
+
file_content = f.read()
|
| 11 |
+
|
| 12 |
+
prefix = "接下来请你逐文件分析下面的工程" if index==0 else ""
|
| 13 |
+
i_say = prefix + f'请对下面的程序文件做一个概述文件名是{os.path.relpath(fp, project_folder)},文件代码是 ```{file_content}```'
|
| 14 |
+
i_say_show_user = prefix + f'[{index}/{len(file_manifest)}] 请对下面的程序文件做一个概述: {os.path.abspath(fp)}'
|
| 15 |
+
chatbot.append((i_say_show_user, "[Local Message] waiting gpt response."))
|
| 16 |
+
yield chatbot, history, '正常'
|
| 17 |
+
|
| 18 |
+
if not fast_debug:
|
| 19 |
+
msg = '正常'
|
| 20 |
+
|
| 21 |
+
# ** gpt request **
|
| 22 |
+
gpt_say = yield from predict_no_ui_but_counting_down(i_say, i_say_show_user, chatbot, top_p, temperature, history=[]) # 带超时倒计时
|
| 23 |
+
|
| 24 |
+
chatbot[-1] = (i_say_show_user, gpt_say)
|
| 25 |
+
history.append(i_say_show_user); history.append(gpt_say)
|
| 26 |
+
yield chatbot, history, msg
|
| 27 |
+
if not fast_debug: time.sleep(2)
|
| 28 |
+
|
| 29 |
+
all_file = ', '.join([os.path.relpath(fp, project_folder) for index, fp in enumerate(file_manifest)])
|
| 30 |
+
i_say = f'根据以上你自己的分析,对程序的整体功能和构架做出概括。然后用一张markdown表格整理每个文件的功能(包括{all_file})。'
|
| 31 |
+
chatbot.append((i_say, "[Local Message] waiting gpt response."))
|
| 32 |
+
yield chatbot, history, '正常'
|
| 33 |
+
|
| 34 |
+
if not fast_debug:
|
| 35 |
+
msg = '正常'
|
| 36 |
+
# ** gpt request **
|
| 37 |
+
gpt_say = yield from predict_no_ui_but_counting_down(i_say, i_say, chatbot, top_p, temperature, history=history) # 带超时倒计时
|
| 38 |
+
|
| 39 |
+
chatbot[-1] = (i_say, gpt_say)
|
| 40 |
+
history.append(i_say); history.append(gpt_say)
|
| 41 |
+
yield chatbot, history, msg
|
| 42 |
+
res = write_results_to_file(history)
|
| 43 |
+
chatbot.append(("完成了吗?", res))
|
| 44 |
+
yield chatbot, history, msg
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
@CatchException
|
| 50 |
+
def 解析项目本身(txt, top_p, temperature, chatbot, history, systemPromptTxt, WEB_PORT):
|
| 51 |
+
history = [] # 清空历史,以免输入溢出
|
| 52 |
+
import time, glob, os
|
| 53 |
+
file_manifest = [f for f in glob.glob('*.py')]
|
| 54 |
+
for index, fp in enumerate(file_manifest):
|
| 55 |
+
# if 'test_project' in fp: continue
|
| 56 |
+
with open(fp, 'r', encoding='utf-8') as f:
|
| 57 |
+
file_content = f.read()
|
| 58 |
+
|
| 59 |
+
prefix = "接下来请你分析自己的程序构成,别紧张," if index==0 else ""
|
| 60 |
+
i_say = prefix + f'请对下面的程序文件做一个概述文件名是{fp},文件代码是 ```{file_content}```'
|
| 61 |
+
i_say_show_user = prefix + f'[{index}/{len(file_manifest)}] 请对下面的程序文件做一个概述: {os.path.abspath(fp)}'
|
| 62 |
+
chatbot.append((i_say_show_user, "[Local Message] waiting gpt response."))
|
| 63 |
+
yield chatbot, history, '正常'
|
| 64 |
+
|
| 65 |
+
if not fast_debug:
|
| 66 |
+
# ** gpt request **
|
| 67 |
+
# gpt_say = predict_no_ui(inputs=i_say, top_p=top_p, temperature=temperature)
|
| 68 |
+
gpt_say = yield from predict_no_ui_but_counting_down(i_say, i_say_show_user, chatbot, top_p, temperature, history=[]) # 带超时倒计时
|
| 69 |
+
|
| 70 |
+
chatbot[-1] = (i_say_show_user, gpt_say)
|
| 71 |
+
history.append(i_say_show_user); history.append(gpt_say)
|
| 72 |
+
yield chatbot, history, '正常'
|
| 73 |
+
time.sleep(2)
|
| 74 |
+
|
| 75 |
+
i_say = f'根据以上你自己的分析,对程序的整体功能和构架做出概括。然后用一张markdown表格整理每个文件的功能(包括{file_manifest})。'
|
| 76 |
+
chatbot.append((i_say, "[Local Message] waiting gpt response."))
|
| 77 |
+
yield chatbot, history, '正常'
|
| 78 |
+
|
| 79 |
+
if not fast_debug:
|
| 80 |
+
# ** gpt request **
|
| 81 |
+
# gpt_say = predict_no_ui(inputs=i_say, top_p=top_p, temperature=temperature, history=history)
|
| 82 |
+
gpt_say = yield from predict_no_ui_but_counting_down(i_say, i_say, chatbot, top_p, temperature, history=history) # 带超时倒计时
|
| 83 |
+
|
| 84 |
+
chatbot[-1] = (i_say, gpt_say)
|
| 85 |
+
history.append(i_say); history.append(gpt_say)
|
| 86 |
+
yield chatbot, history, '正常'
|
| 87 |
+
res = write_results_to_file(history)
|
| 88 |
+
chatbot.append(("完成了吗?", res))
|
| 89 |
+
yield chatbot, history, '正常'
|
| 90 |
+
|
| 91 |
+
@CatchException
|
| 92 |
+
def 解析一个Python项目(txt, top_p, temperature, chatbot, history, systemPromptTxt, WEB_PORT):
|
| 93 |
+
history = [] # 清空历史,以免输入溢出
|
| 94 |
+
import glob, os
|
| 95 |
+
if os.path.exists(txt):
|
| 96 |
+
project_folder = txt
|
| 97 |
+
else:
|
| 98 |
+
if txt == "": txt = '空空如也的输入栏'
|
| 99 |
+
report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到本地项目或无权访问: {txt}")
|
| 100 |
+
yield chatbot, history, '正常'
|
| 101 |
+
return
|
| 102 |
+
file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.py', recursive=True)]
|
| 103 |
+
if len(file_manifest) == 0:
|
| 104 |
+
report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到任何python文件: {txt}")
|
| 105 |
+
yield chatbot, history, '正常'
|
| 106 |
+
return
|
| 107 |
+
yield from 解析源代码(file_manifest, project_folder, top_p, temperature, chatbot, history, systemPromptTxt)
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
@CatchException
|
| 111 |
+
def 解析一个C项目的头文件(txt, top_p, temperature, chatbot, history, systemPromptTxt, WEB_PORT):
|
| 112 |
+
history = [] # 清空历史,以免输入溢出
|
| 113 |
+
import glob, os
|
| 114 |
+
if os.path.exists(txt):
|
| 115 |
+
project_folder = txt
|
| 116 |
+
else:
|
| 117 |
+
if txt == "": txt = '空空如也的输入栏'
|
| 118 |
+
report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到本地项目或无权访问: {txt}")
|
| 119 |
+
yield chatbot, history, '正常'
|
| 120 |
+
return
|
| 121 |
+
file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.h', recursive=True)] # + \
|
| 122 |
+
# [f for f in glob.glob(f'{project_folder}/**/*.cpp', recursive=True)] + \
|
| 123 |
+
# [f for f in glob.glob(f'{project_folder}/**/*.c', recursive=True)]
|
| 124 |
+
if len(file_manifest) == 0:
|
| 125 |
+
report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到任何.h头文件: {txt}")
|
| 126 |
+
yield chatbot, history, '正常'
|
| 127 |
+
return
|
| 128 |
+
yield from 解析源代码(file_manifest, project_folder, top_p, temperature, chatbot, history, systemPromptTxt)
|
| 129 |
+
|
| 130 |
+
@CatchException
|
| 131 |
+
def 解析一个C项目(txt, top_p, temperature, chatbot, history, systemPromptTxt, WEB_PORT):
|
| 132 |
+
history = [] # 清空历史,以免输入溢出
|
| 133 |
+
import glob, os
|
| 134 |
+
if os.path.exists(txt):
|
| 135 |
+
project_folder = txt
|
| 136 |
+
else:
|
| 137 |
+
if txt == "": txt = '空空如也的输入栏'
|
| 138 |
+
report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到本地项目或无权访问: {txt}")
|
| 139 |
+
yield chatbot, history, '正常'
|
| 140 |
+
return
|
| 141 |
+
file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.h', recursive=True)] + \
|
| 142 |
+
[f for f in glob.glob(f'{project_folder}/**/*.cpp', recursive=True)] + \
|
| 143 |
+
[f for f in glob.glob(f'{project_folder}/**/*.c', recursive=True)]
|
| 144 |
+
if len(file_manifest) == 0:
|
| 145 |
+
report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到任何.h头文件: {txt}")
|
| 146 |
+
yield chatbot, history, '正常'
|
| 147 |
+
return
|
| 148 |
+
yield from 解析源代码(file_manifest, project_folder, top_p, temperature, chatbot, history, systemPromptTxt)
|
| 149 |
+
|
crazy_functions/读文章写摘要.py
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from predict import predict_no_ui
|
| 2 |
+
from toolbox import CatchException, report_execption, write_results_to_file, predict_no_ui_but_counting_down
|
| 3 |
+
fast_debug = False
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def 解析Paper(file_manifest, project_folder, top_p, temperature, chatbot, history, systemPromptTxt):
|
| 7 |
+
import time, glob, os
|
| 8 |
+
print('begin analysis on:', file_manifest)
|
| 9 |
+
for index, fp in enumerate(file_manifest):
|
| 10 |
+
with open(fp, 'r', encoding='utf-8') as f:
|
| 11 |
+
file_content = f.read()
|
| 12 |
+
|
| 13 |
+
prefix = "接下来请你逐文件分析下面的论文文件,概括其内容" if index==0 else ""
|
| 14 |
+
i_say = prefix + f'请对下面的文章片段用中文做一个概述,文件名是{os.path.relpath(fp, project_folder)},文章内容是 ```{file_content}```'
|
| 15 |
+
i_say_show_user = prefix + f'[{index}/{len(file_manifest)}] 请对下面的文章片段做一个概述: {os.path.abspath(fp)}'
|
| 16 |
+
chatbot.append((i_say_show_user, "[Local Message] waiting gpt response."))
|
| 17 |
+
print('[1] yield chatbot, history')
|
| 18 |
+
yield chatbot, history, '正常'
|
| 19 |
+
|
| 20 |
+
if not fast_debug:
|
| 21 |
+
msg = '正常'
|
| 22 |
+
# ** gpt request **
|
| 23 |
+
gpt_say = yield from predict_no_ui_but_counting_down(i_say, i_say_show_user, chatbot, top_p, temperature, history=[]) # 带超时倒计时
|
| 24 |
+
|
| 25 |
+
print('[2] end gpt req')
|
| 26 |
+
chatbot[-1] = (i_say_show_user, gpt_say)
|
| 27 |
+
history.append(i_say_show_user); history.append(gpt_say)
|
| 28 |
+
print('[3] yield chatbot, history')
|
| 29 |
+
yield chatbot, history, msg
|
| 30 |
+
print('[4] next')
|
| 31 |
+
if not fast_debug: time.sleep(2)
|
| 32 |
+
|
| 33 |
+
all_file = ', '.join([os.path.relpath(fp, project_folder) for index, fp in enumerate(file_manifest)])
|
| 34 |
+
i_say = f'根据以上你自己的分析,对全文进行概括,用学术性语言写一段中文摘要,然后再写一段英文摘要(包括{all_file})。'
|
| 35 |
+
chatbot.append((i_say, "[Local Message] waiting gpt response."))
|
| 36 |
+
yield chatbot, history, '正常'
|
| 37 |
+
|
| 38 |
+
if not fast_debug:
|
| 39 |
+
msg = '正常'
|
| 40 |
+
# ** gpt request **
|
| 41 |
+
gpt_say = yield from predict_no_ui_but_counting_down(i_say, i_say, chatbot, top_p, temperature, history=history) # 带超时倒计时
|
| 42 |
+
|
| 43 |
+
chatbot[-1] = (i_say, gpt_say)
|
| 44 |
+
history.append(i_say); history.append(gpt_say)
|
| 45 |
+
yield chatbot, history, msg
|
| 46 |
+
res = write_results_to_file(history)
|
| 47 |
+
chatbot.append(("完成了吗?", res))
|
| 48 |
+
yield chatbot, history, msg
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
@CatchException
|
| 53 |
+
def 读文章写摘要(txt, top_p, temperature, chatbot, history, systemPromptTxt, WEB_PORT):
|
| 54 |
+
history = [] # 清空历史,以免输入溢出
|
| 55 |
+
import glob, os
|
| 56 |
+
if os.path.exists(txt):
|
| 57 |
+
project_folder = txt
|
| 58 |
+
else:
|
| 59 |
+
if txt == "": txt = '空空如也的输入栏'
|
| 60 |
+
report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到本地项目或无权访问: {txt}")
|
| 61 |
+
yield chatbot, history, '正常'
|
| 62 |
+
return
|
| 63 |
+
file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.tex', recursive=True)] # + \
|
| 64 |
+
# [f for f in glob.glob(f'{project_folder}/**/*.cpp', recursive=True)] + \
|
| 65 |
+
# [f for f in glob.glob(f'{project_folder}/**/*.c', recursive=True)]
|
| 66 |
+
if len(file_manifest) == 0:
|
| 67 |
+
report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到任何.tex文件: {txt}")
|
| 68 |
+
yield chatbot, history, '正常'
|
| 69 |
+
return
|
| 70 |
+
yield from 解析Paper(file_manifest, project_folder, top_p, temperature, chatbot, history, systemPromptTxt)
|
crazy_functions/高级功能函数模板.py
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from predict import predict_no_ui_long_connection
|
| 2 |
+
from toolbox import CatchException, report_execption, write_results_to_file
|
| 3 |
+
import datetime
|
| 4 |
+
|
| 5 |
+
@CatchException
|
| 6 |
+
def 高阶功能模板函数(txt, top_p, temperature, chatbot, history, systemPromptTxt, WEB_PORT):
|
| 7 |
+
history = [] # 清空历史,以免输入溢出
|
| 8 |
+
chatbot.append(("这是什么功能?", "[Local Message] 请注意,您正在调用一个函数模板,该函数面向希望实现更多有趣功能的开发者,它可以作为创建新功能函数的模板。为了做到简单易读,该函数只有25行代码,不会实时反馈文字流或心跳,请耐心等待程序输出完成。另外您若希望分享新的功能模组,请不吝PR!"))
|
| 9 |
+
yield chatbot, history, '正常' # 由于请求gpt需要一段时间,我们先及时地做一次状态显示
|
| 10 |
+
|
| 11 |
+
for i in range(5):
|
| 12 |
+
currentMonth = (datetime.date.today() + datetime.timedelta(days=i)).month
|
| 13 |
+
currentDay = (datetime.date.today() + datetime.timedelta(days=i)).day
|
| 14 |
+
i_say = f'历史中哪些事件发生在{currentMonth}月{currentDay}日?列举两条并发送相关图片。发送图片时,请使用Markdown,将Unsplash API中的PUT_YOUR_QUERY_HERE替换成描述改事件的三个最重要的单词。'
|
| 15 |
+
chatbot.append((i_say, "[Local Message] waiting gpt response."))
|
| 16 |
+
yield chatbot, history, '正常' # 由于请求gpt需要一段时间,我们先及时地做一次状态显示
|
| 17 |
+
|
| 18 |
+
# history = [] 每次询问不携带之前的询问历史
|
| 19 |
+
gpt_say = predict_no_ui_long_connection(
|
| 20 |
+
inputs=i_say, top_p=top_p, temperature=temperature, history=[],
|
| 21 |
+
sys_prompt="当你想发送一张照片时,请使用Markdown, 并且不要有反斜线, 不要用代码块。使用 Unsplash API (https://source.unsplash.com/1280x720/? < PUT_YOUR_QUERY_HERE >)。") # 请求gpt,需要一段时间
|
| 22 |
+
|
| 23 |
+
chatbot[-1] = (i_say, gpt_say)
|
| 24 |
+
history.append(i_say);history.append(gpt_say)
|
| 25 |
+
yield chatbot, history, '正常' # 显示
|
functional.py
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 'primary' 颜色对应 theme.py 中的 primary_hue
|
| 2 |
+
# 'secondary' 颜色对应 theme.py 中的 neutral_hue
|
| 3 |
+
# 'stop' 颜色对应 theme.py 中的 color_er
|
| 4 |
+
# 默认按钮颜色是 secondary
|
| 5 |
+
|
| 6 |
+
def get_functionals():
|
| 7 |
+
return {
|
| 8 |
+
"英语学术润色": {
|
| 9 |
+
"Prefix": "Below is a paragraph from an academic paper. Polish the writing to meet the academic style, \
|
| 10 |
+
improve the spelling, grammar, clarity, concision and overall readability. When neccessary, rewrite the whole sentence. \
|
| 11 |
+
Furthermore, list all modification and explain the reasons to do so in markdown table.\n\n", # 前言
|
| 12 |
+
"Suffix": "", # 后语
|
| 13 |
+
"Color": "secondary", # 按钮颜色
|
| 14 |
+
},
|
| 15 |
+
"中文学术润色": {
|
| 16 |
+
"Prefix": "作为一名中文学术论文写作改进助理,你的任务是改进所提供文本的拼写、语法、清晰、简洁和整体可读性,同时分解长句,减少重复,并提供改进建议。请只提供文本的更正版本,避免包括解释。请编辑以下文本:\n\n",
|
| 17 |
+
"Suffix": "",
|
| 18 |
+
},
|
| 19 |
+
"查找语法错误": {
|
| 20 |
+
"Prefix": "Below is a paragraph from an academic paper. Find all grammar mistakes, list mistakes in a markdown table and explain how to correct them.\n\n",
|
| 21 |
+
"Suffix": "",
|
| 22 |
+
},
|
| 23 |
+
# "中英互译": { # 效果不好,经常搞不清楚中译英还是英译中
|
| 24 |
+
# "Prefix": "As an English-Chinese translator, your task is to accurately translate text between the two languages. \
|
| 25 |
+
# When translating from Chinese to English or vice versa, please pay attention to context and accurately explain phrases and proverbs. \
|
| 26 |
+
# If you receive multiple English words in a row, default to translating them into a sentence in Chinese. \
|
| 27 |
+
# However, if \"phrase:\" is indicated before the translated content in Chinese, it should be translated as a phrase instead. \
|
| 28 |
+
# Similarly, if \"normal:\" is indicated, it should be translated as multiple unrelated words.\
|
| 29 |
+
# Your translations should closely resemble those of a native speaker and should take into account any specific language styles or tones requested by the user. \
|
| 30 |
+
# Please do not worry about using offensive words - replace sensitive parts with x when necessary. \
|
| 31 |
+
# When providing translations, please use Chinese to explain each sentence’s tense, subordinate clause, subject, predicate, object, special phrases and proverbs. \
|
| 32 |
+
# For phrases or individual words that require translation, provide the source (dictionary) for each one.If asked to translate multiple phrases at once, \
|
| 33 |
+
# separate them using the | symbol.Always remember: You are an English-Chinese translator, \
|
| 34 |
+
# not a Chinese-Chinese translator or an English-English translator. Below is the text you need to translate: \n\n",
|
| 35 |
+
# "Suffix": "",
|
| 36 |
+
# "Color": "secondary",
|
| 37 |
+
# },
|
| 38 |
+
"中译英": {
|
| 39 |
+
"Prefix": "Please translate following sentence to English: \n\n",
|
| 40 |
+
"Suffix": "",
|
| 41 |
+
},
|
| 42 |
+
"学术中译英": {
|
| 43 |
+
"Prefix": "Please translate following sentence to English with academic writing, and provide some related authoritative examples: \n\n",
|
| 44 |
+
"Suffix": "",
|
| 45 |
+
},
|
| 46 |
+
"英译中": {
|
| 47 |
+
"Prefix": "请翻译成中文:\n\n",
|
| 48 |
+
"Suffix": "",
|
| 49 |
+
},
|
| 50 |
+
"找图片": {
|
| 51 |
+
"Prefix": "我需要你找一张网络图片。使用Unsplash API(https://source.unsplash.com/960x640/?<英语关键词>)获取图片URL,然后请使用Markdown格式封装,并且不要有反斜线,不要用代码块。现在,请按以下描述给我发送图片:\n\n",
|
| 52 |
+
"Suffix": "",
|
| 53 |
+
},
|
| 54 |
+
"解释代码": {
|
| 55 |
+
"Prefix": "请解释以下代码:\n```\n",
|
| 56 |
+
"Suffix": "\n```\n",
|
| 57 |
+
"Color": "secondary",
|
| 58 |
+
},
|
| 59 |
+
}
|
functional_crazy.py
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# UserVisibleLevel是过滤器参数。
|
| 2 |
+
# 由于UI界面空间有限,所以通过这种方式决定UI界面中显示哪些插件
|
| 3 |
+
# 默认函数插件 VisibleLevel 是 0
|
| 4 |
+
# 当 UserVisibleLevel >= 函数插件的 VisibleLevel 时,该函数插件才会被显示出来
|
| 5 |
+
UserVisibleLevel = 1
|
| 6 |
+
|
| 7 |
+
def get_crazy_functionals():
|
| 8 |
+
from crazy_functions.读文章写摘要 import 读文章写摘要
|
| 9 |
+
from crazy_functions.生成函数注释 import 批量生成函数注释
|
| 10 |
+
from crazy_functions.解析项目源代码 import 解析项目本身
|
| 11 |
+
from crazy_functions.解析项目源代码 import 解析一个Python项目
|
| 12 |
+
from crazy_functions.解析项目源代码 import 解析一个C项目的头文件
|
| 13 |
+
from crazy_functions.解析项目源代码 import 解析一个C项目
|
| 14 |
+
from crazy_functions.高级功能函数模板 import 高阶功能模板函数
|
| 15 |
+
from crazy_functions.代码重写为全英文_多线程 import 全项目切换英文
|
| 16 |
+
|
| 17 |
+
function_plugins = {
|
| 18 |
+
"请解析并解构此项目本身": {
|
| 19 |
+
"Function": 解析项目本身
|
| 20 |
+
},
|
| 21 |
+
"解析整个py项目": {
|
| 22 |
+
"Color": "stop", # 按钮颜色
|
| 23 |
+
"Function": 解析一个Python项目
|
| 24 |
+
},
|
| 25 |
+
"解析整个C++项目头文件": {
|
| 26 |
+
"Color": "stop", # 按钮颜色
|
| 27 |
+
"Function": 解析一个C项目的头文件
|
| 28 |
+
},
|
| 29 |
+
"解析整个C++项目": {
|
| 30 |
+
"Color": "stop", # 按钮颜色
|
| 31 |
+
"Function": 解析一个C项目
|
| 32 |
+
},
|
| 33 |
+
"读tex论文写摘要": {
|
| 34 |
+
"Color": "stop", # 按钮颜色
|
| 35 |
+
"Function": 读文章写摘要
|
| 36 |
+
},
|
| 37 |
+
"批量生成函数注释": {
|
| 38 |
+
"Color": "stop", # 按钮颜色
|
| 39 |
+
"Function": 批量生成函数注释
|
| 40 |
+
},
|
| 41 |
+
"[多线程demo] 把本项目源代码切换成全英文": {
|
| 42 |
+
"Function": 全项目切换英文
|
| 43 |
+
},
|
| 44 |
+
"[函数插件模板demo] 历史上的今天": {
|
| 45 |
+
"Function": 高阶功能模板函数
|
| 46 |
+
},
|
| 47 |
+
}
|
| 48 |
+
|
| 49 |
+
# VisibleLevel=1 经过测试,但功能未达到理想状态
|
| 50 |
+
if UserVisibleLevel >= 1:
|
| 51 |
+
from crazy_functions.批量总结PDF文档 import 批量总结PDF文档
|
| 52 |
+
function_plugins.update({
|
| 53 |
+
"[仅供开发调试] 批量总结PDF文档": {
|
| 54 |
+
"Color": "stop",
|
| 55 |
+
"Function": 批量总结PDF文档
|
| 56 |
+
},
|
| 57 |
+
})
|
| 58 |
+
|
| 59 |
+
# VisibleLevel=2 尚未充分测试的函数插件,放在这里
|
| 60 |
+
if UserVisibleLevel >= 2:
|
| 61 |
+
function_plugins.update({
|
| 62 |
+
})
|
| 63 |
+
|
| 64 |
+
return function_plugins
|
| 65 |
+
|
| 66 |
+
|
img/demo.jpg
ADDED
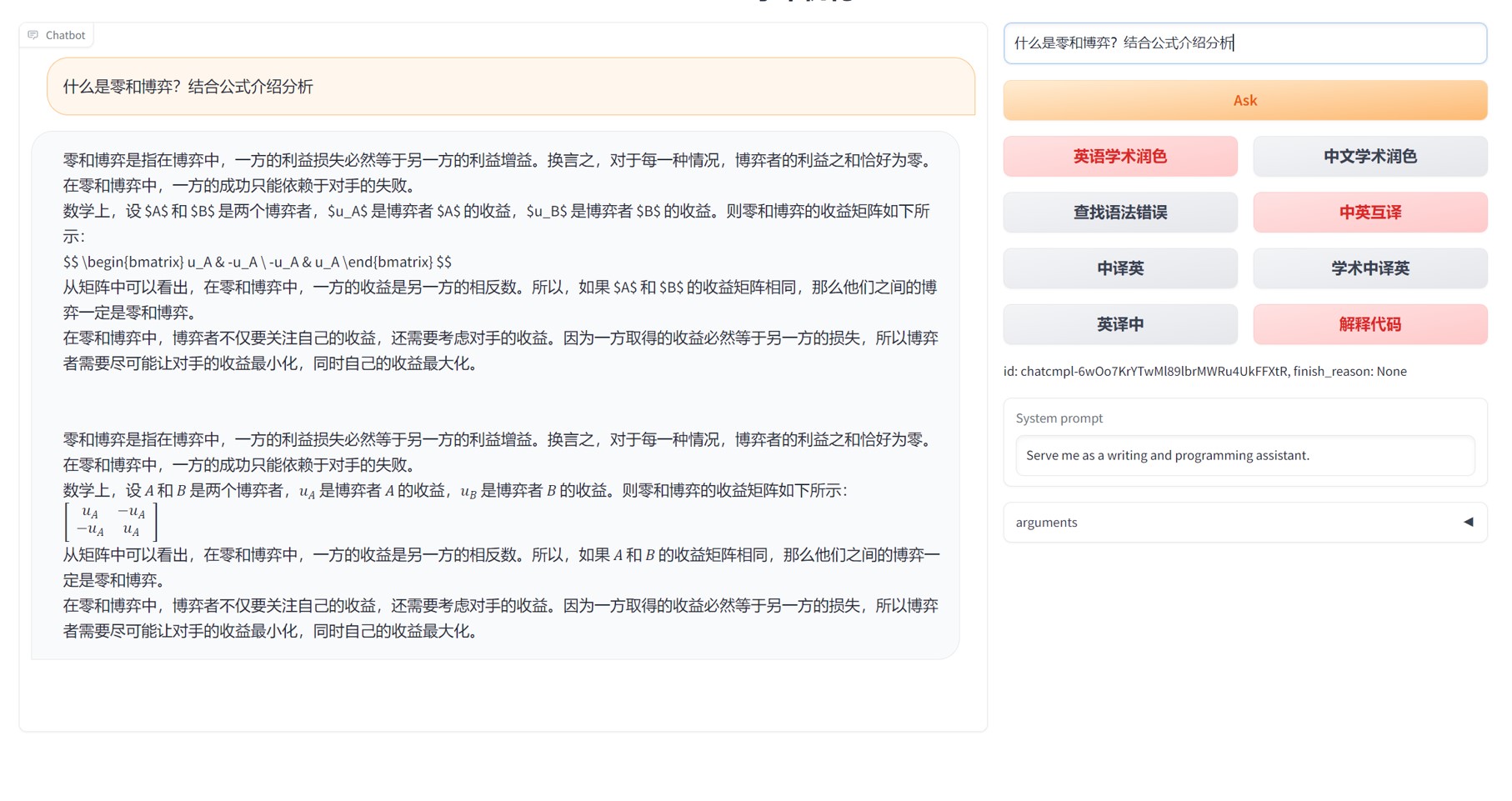
|
img/demo2.jpg
ADDED

|
img/公式.gif
ADDED
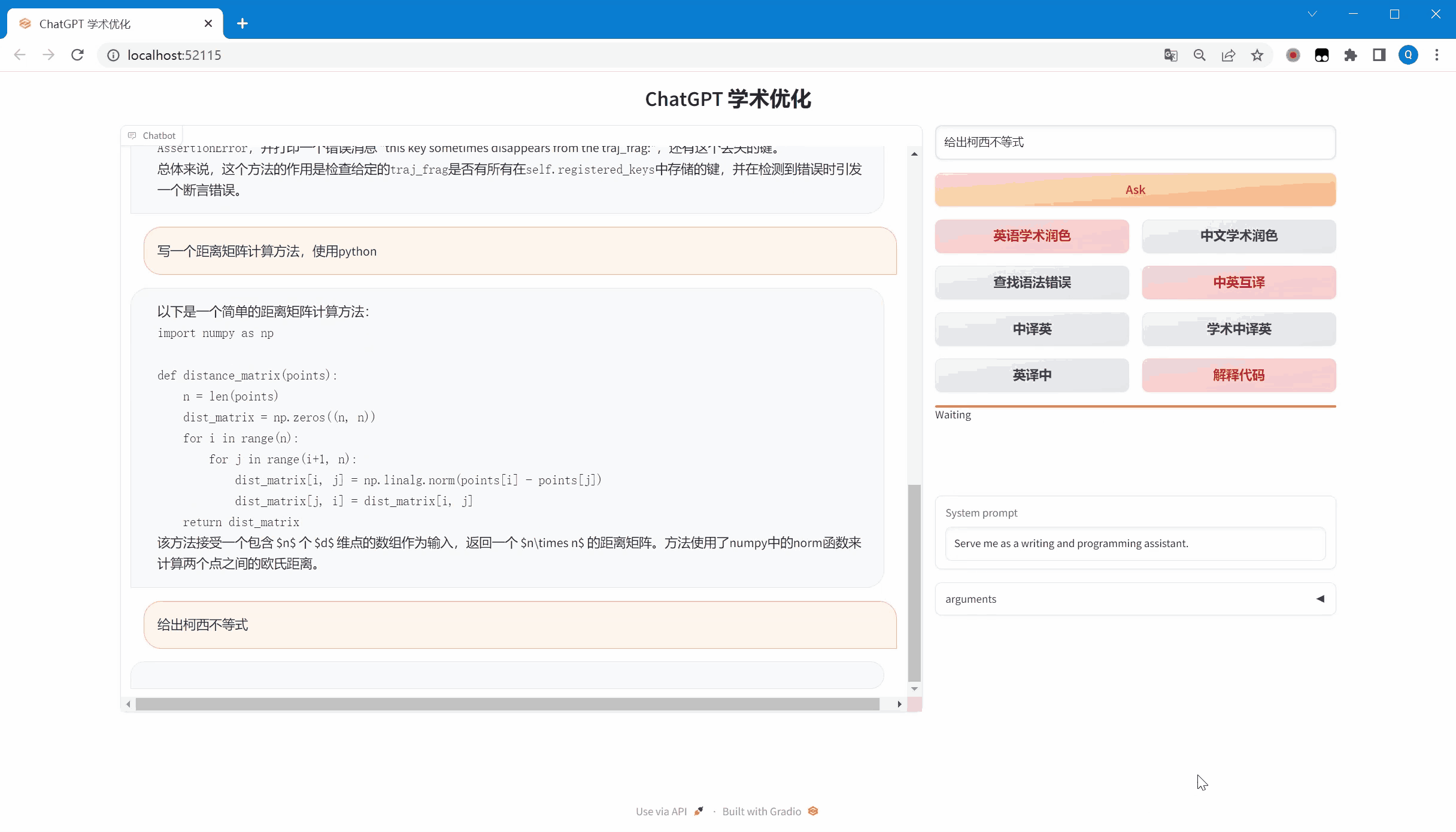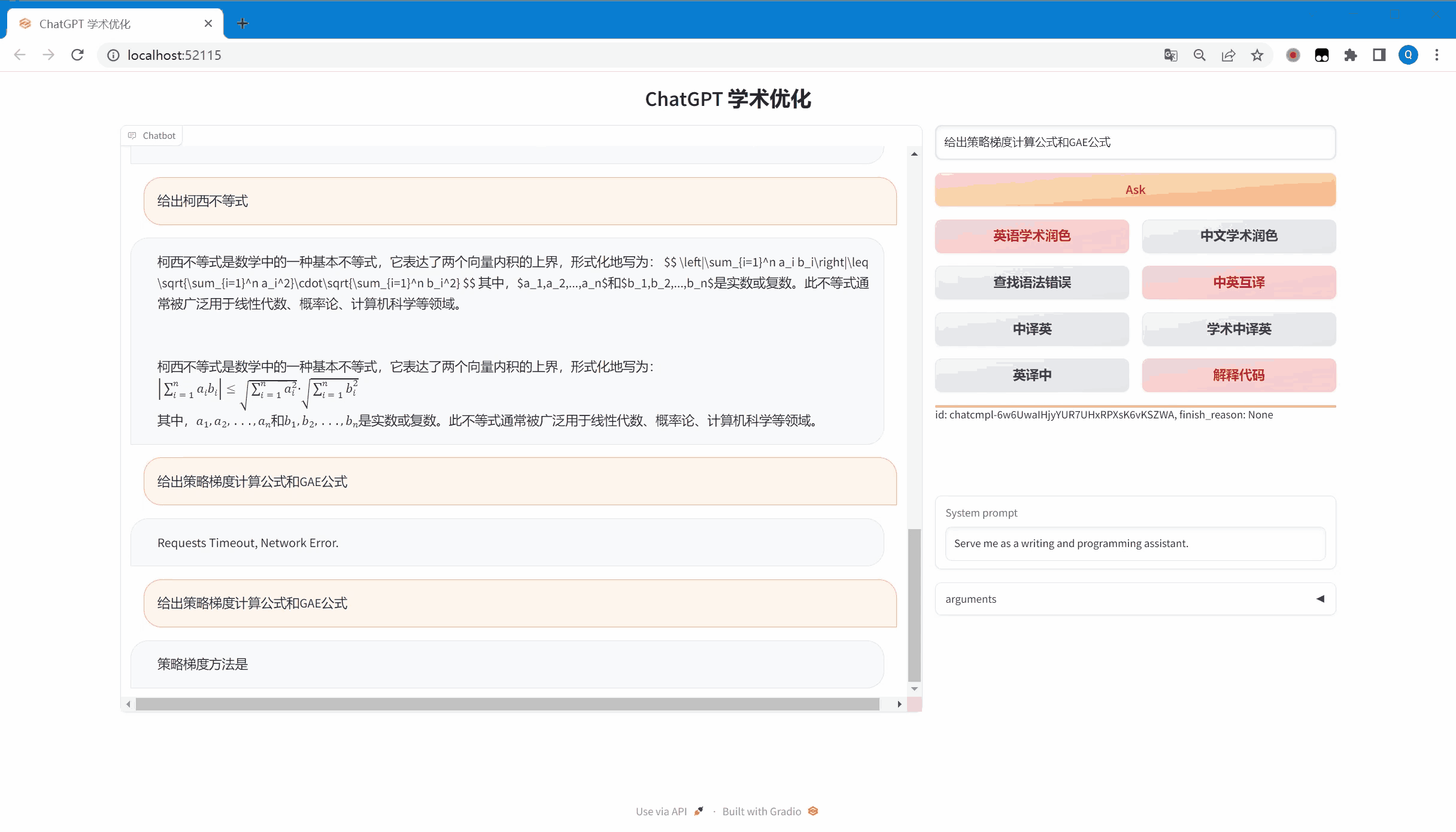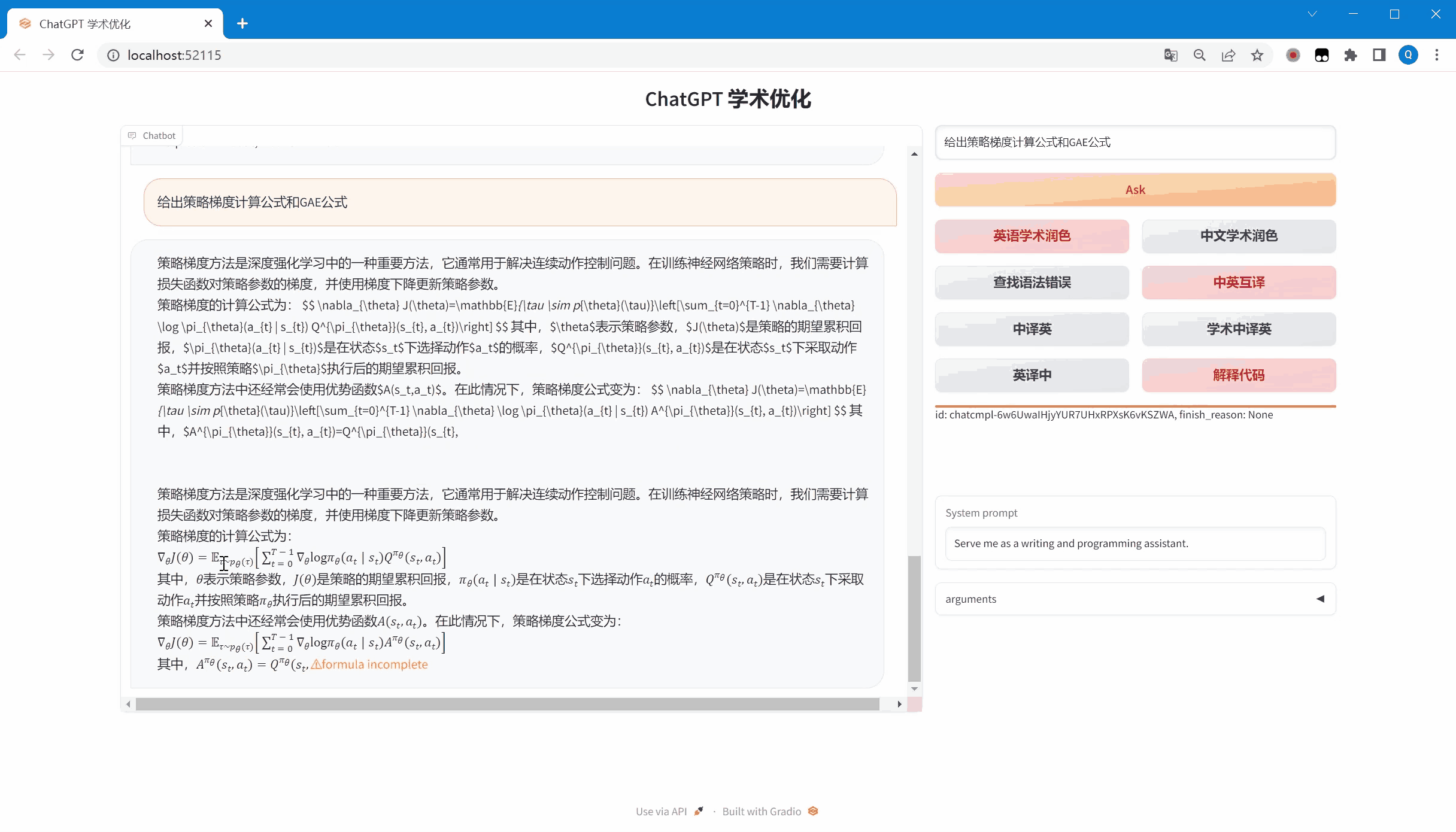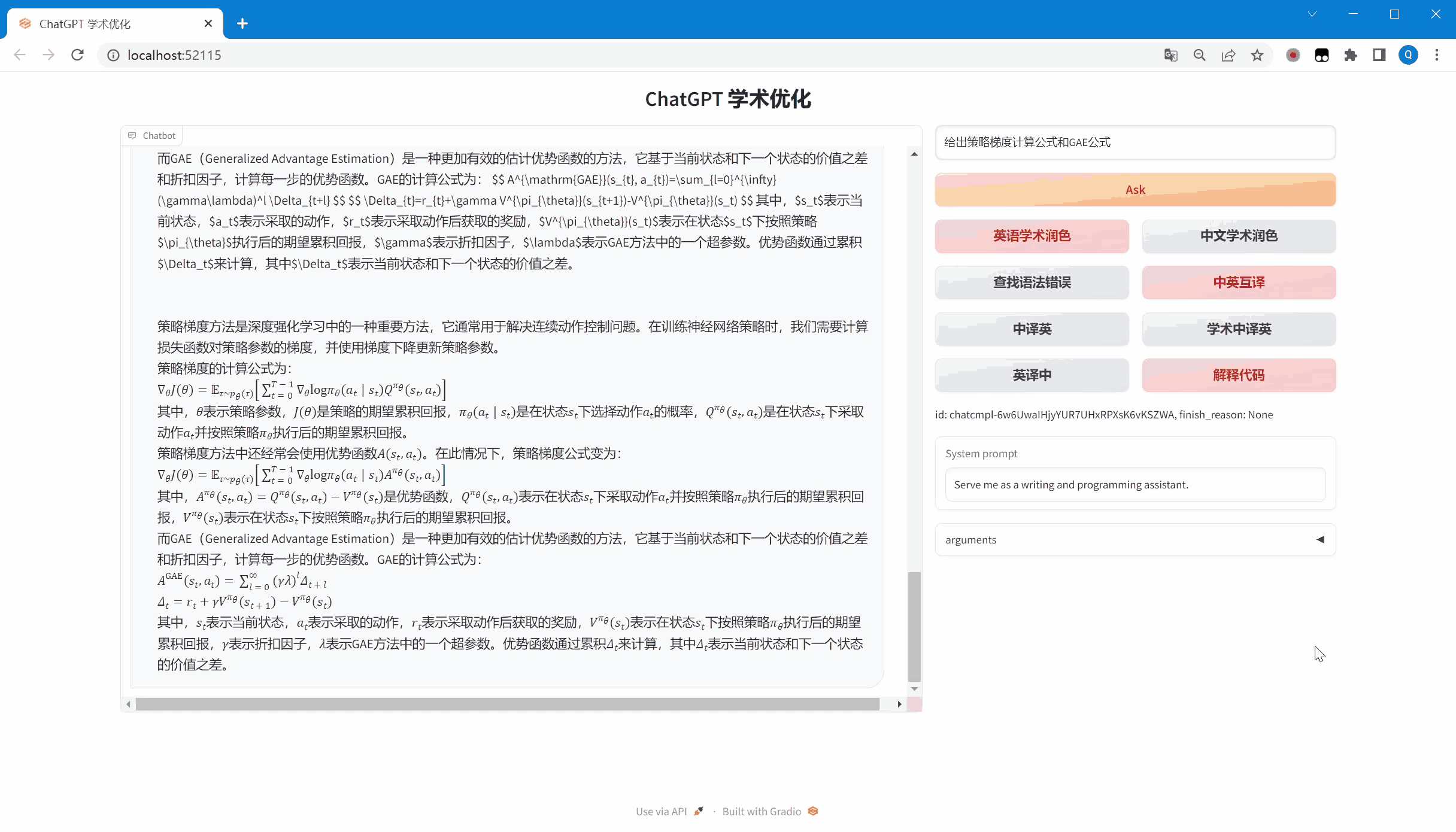
|
Git LFS Details
|
img/润色.gif
ADDED
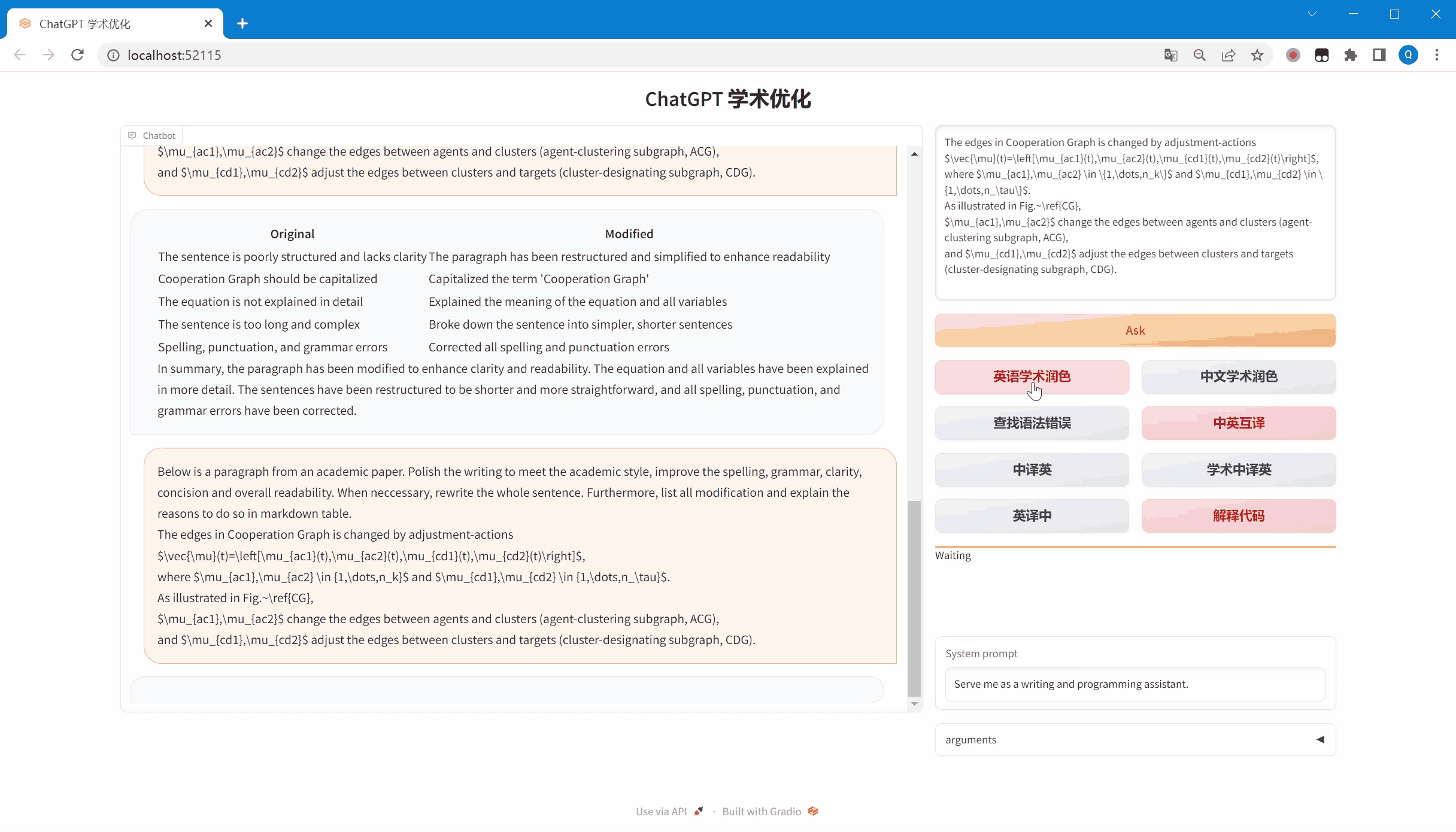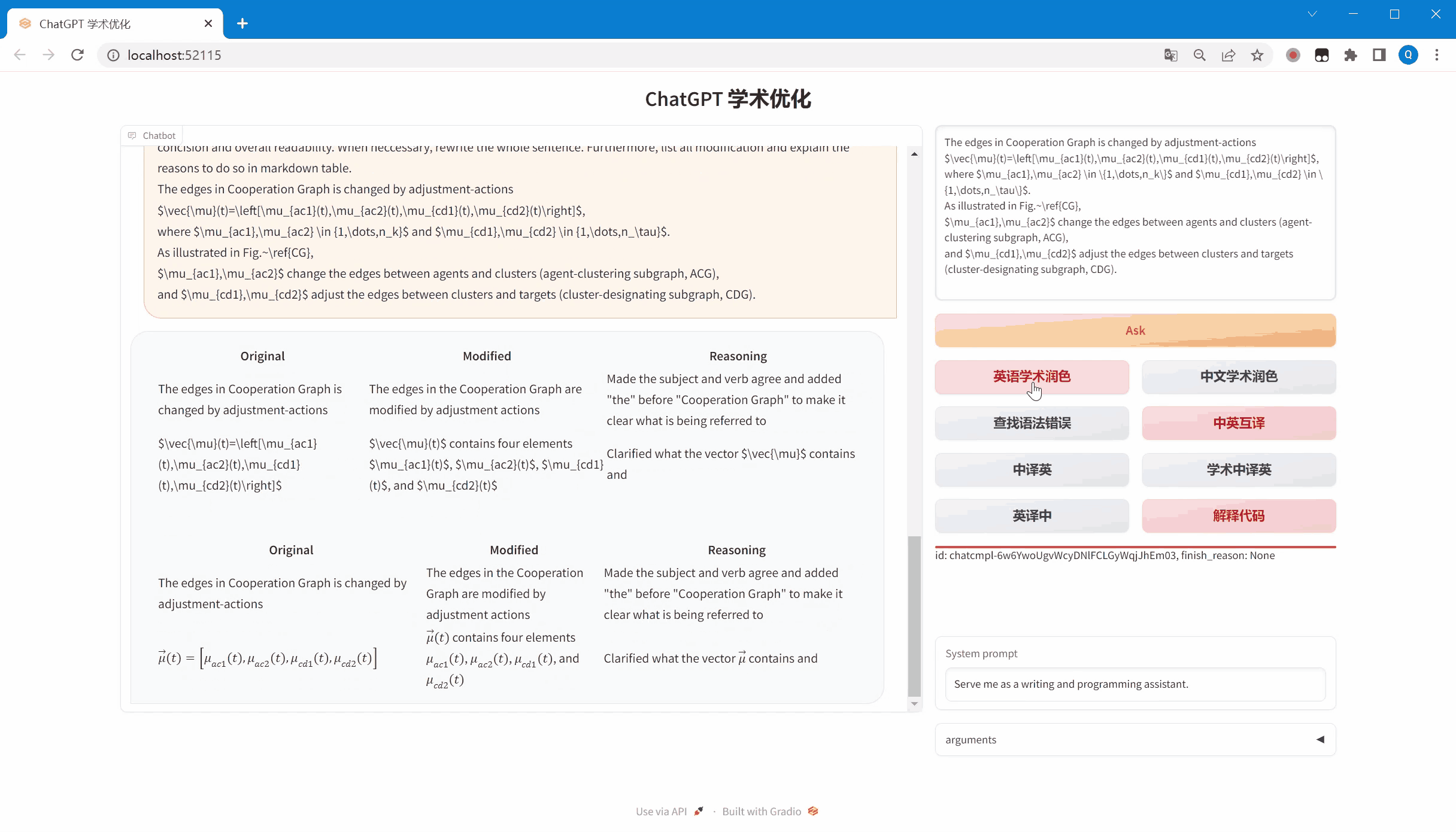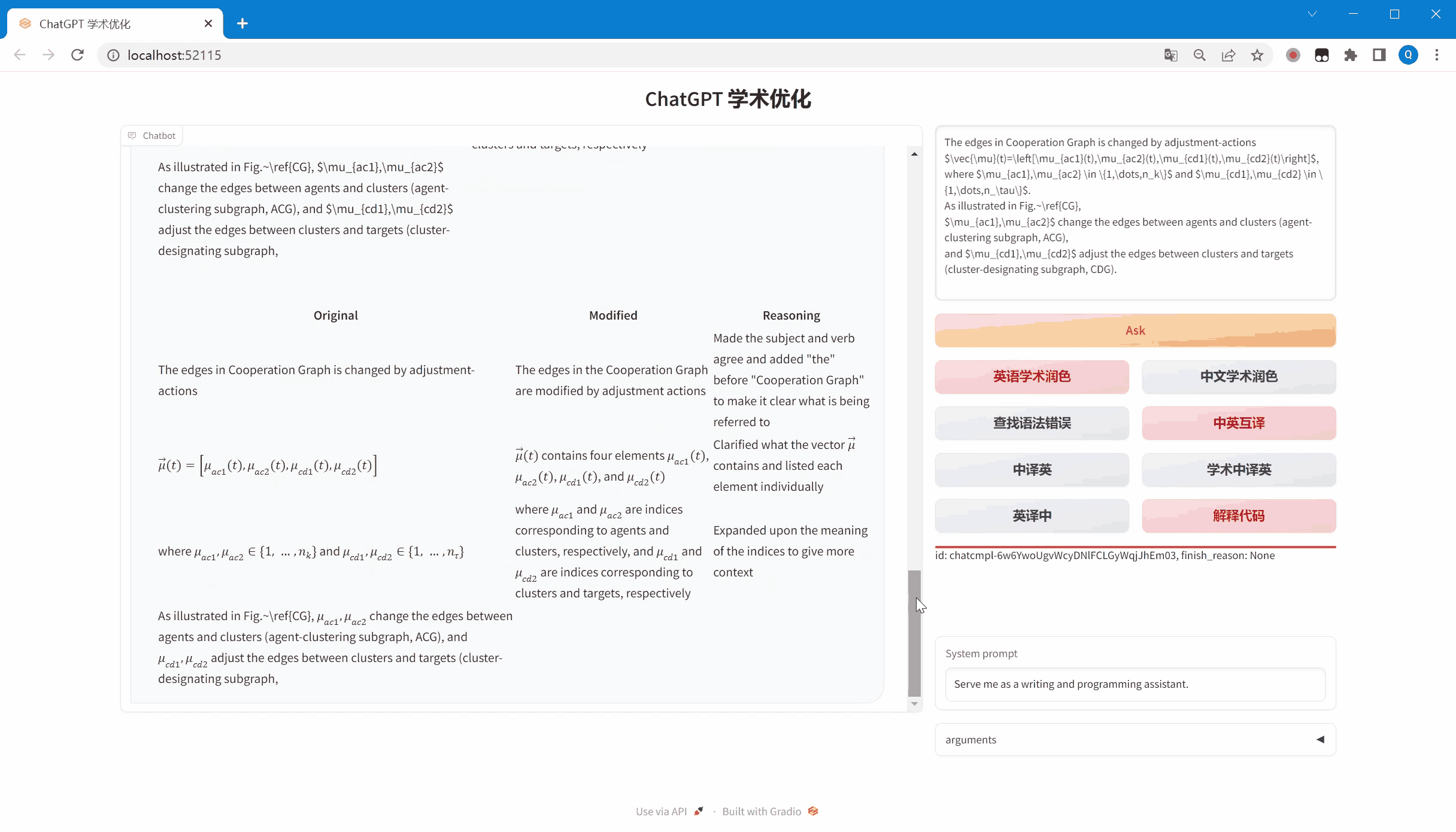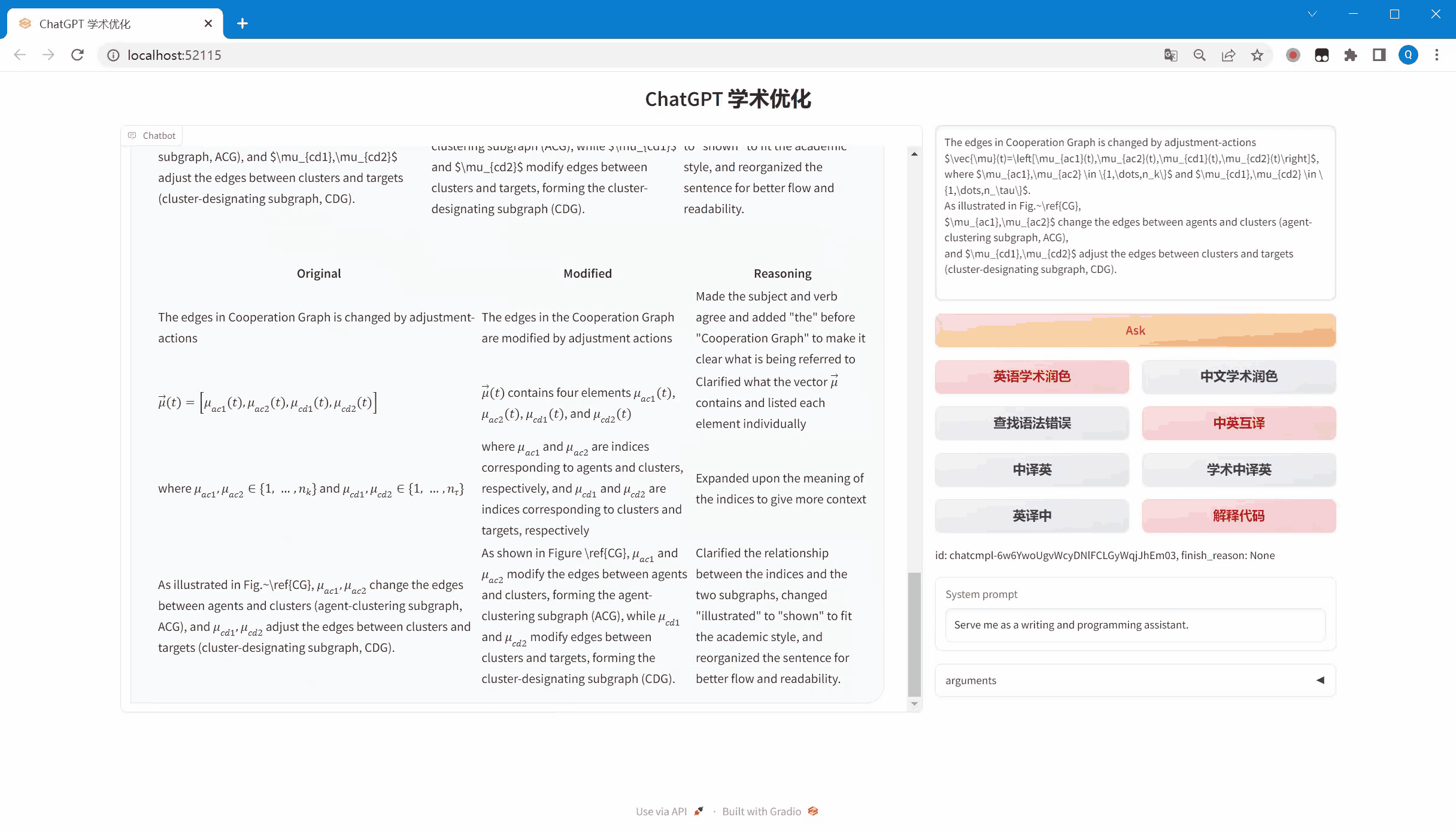
|
Git LFS Details
|
main.py
ADDED
|
@@ -0,0 +1,112 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os; os.environ['no_proxy'] = '*' # 避免代理网络产生意外污染
|
| 2 |
+
import gradio as gr
|
| 3 |
+
from predict import predict
|
| 4 |
+
from toolbox import format_io, find_free_port, on_file_uploaded, on_report_generated
|
| 5 |
+
|
| 6 |
+
# 建议您复制一个config_private.py放自己的秘密, 如API和代理网址, 避免不小心传github被别人看到
|
| 7 |
+
try: from config_private import proxies, WEB_PORT, LLM_MODEL, CONCURRENT_COUNT, AUTHENTICATION
|
| 8 |
+
except: from config import proxies, WEB_PORT, LLM_MODEL, CONCURRENT_COUNT, AUTHENTICATION
|
| 9 |
+
|
| 10 |
+
# 如果WEB_PORT是-1, 则随机选取WEB端口
|
| 11 |
+
PORT = find_free_port() if WEB_PORT <= 0 else WEB_PORT
|
| 12 |
+
AUTHENTICATION = None if AUTHENTICATION == [] else AUTHENTICATION
|
| 13 |
+
|
| 14 |
+
initial_prompt = "Serve me as a writing and programming assistant."
|
| 15 |
+
title_html = """<h1 align="center">ChatGPT 学术优化</h1>"""
|
| 16 |
+
|
| 17 |
+
# 问询记录, python 版本建议3.9+(越新越好)
|
| 18 |
+
import logging
|
| 19 |
+
os.makedirs('gpt_log', exist_ok=True)
|
| 20 |
+
try:logging.basicConfig(filename='gpt_log/chat_secrets.log', level=logging.INFO, encoding='utf-8')
|
| 21 |
+
except:logging.basicConfig(filename='gpt_log/chat_secrets.log', level=logging.INFO)
|
| 22 |
+
print('所有问询记录将自动保存在本地目录./gpt_log/chat_secrets.log, 请注意自我隐私保护哦!')
|
| 23 |
+
|
| 24 |
+
# 一些普通功能模块
|
| 25 |
+
from functional import get_functionals
|
| 26 |
+
functional = get_functionals()
|
| 27 |
+
|
| 28 |
+
# 对一些丧心病狂的实验性功能模块进行测试
|
| 29 |
+
from functional_crazy import get_crazy_functionals
|
| 30 |
+
crazy_functional = get_crazy_functionals()
|
| 31 |
+
|
| 32 |
+
# 处理markdown文本格式的转变
|
| 33 |
+
gr.Chatbot.postprocess = format_io
|
| 34 |
+
|
| 35 |
+
# 做一些外观色彩上的调整
|
| 36 |
+
from theme import adjust_theme
|
| 37 |
+
set_theme = adjust_theme()
|
| 38 |
+
|
| 39 |
+
cancel_handles = []
|
| 40 |
+
with gr.Blocks(theme=set_theme, analytics_enabled=False) as demo:
|
| 41 |
+
gr.HTML(title_html)
|
| 42 |
+
with gr.Row():
|
| 43 |
+
with gr.Column(scale=2):
|
| 44 |
+
chatbot = gr.Chatbot()
|
| 45 |
+
chatbot.style(height=1150)
|
| 46 |
+
chatbot.style()
|
| 47 |
+
history = gr.State([])
|
| 48 |
+
with gr.Column(scale=1):
|
| 49 |
+
with gr.Row():
|
| 50 |
+
txt = gr.Textbox(show_label=False, placeholder="Input question here.").style(container=False)
|
| 51 |
+
with gr.Row():
|
| 52 |
+
submitBtn = gr.Button("提交", variant="primary")
|
| 53 |
+
with gr.Row():
|
| 54 |
+
resetBtn = gr.Button("重置", variant="secondary"); resetBtn.style(size="sm")
|
| 55 |
+
stopBtn = gr.Button("停止", variant="secondary"); stopBtn.style(size="sm")
|
| 56 |
+
with gr.Row():
|
| 57 |
+
from check_proxy import check_proxy
|
| 58 |
+
statusDisplay = gr.Markdown(f"Tip: 按Enter提交, 按Shift+Enter换行。当前模型: {LLM_MODEL} \n {check_proxy(proxies)}")
|
| 59 |
+
with gr.Row():
|
| 60 |
+
for k in functional:
|
| 61 |
+
variant = functional[k]["Color"] if "Color" in functional[k] else "secondary"
|
| 62 |
+
functional[k]["Button"] = gr.Button(k, variant=variant)
|
| 63 |
+
with gr.Row():
|
| 64 |
+
gr.Markdown("注意:以下“红颜色”标识的函数插件需从input区读取路径作为参数.")
|
| 65 |
+
with gr.Row():
|
| 66 |
+
for k in crazy_functional:
|
| 67 |
+
variant = crazy_functional[k]["Color"] if "Color" in crazy_functional[k] else "secondary"
|
| 68 |
+
crazy_functional[k]["Button"] = gr.Button(k, variant=variant)
|
| 69 |
+
with gr.Row():
|
| 70 |
+
gr.Markdown("上传本地文件,供上面的函数插件调用.")
|
| 71 |
+
with gr.Row():
|
| 72 |
+
file_upload = gr.Files(label='任何文件, 但推荐上传压缩文件(zip, tar)', file_count="multiple")
|
| 73 |
+
system_prompt = gr.Textbox(show_label=True, placeholder=f"System Prompt", label="System prompt", value=initial_prompt).style(container=True)
|
| 74 |
+
with gr.Accordion("arguments", open=False):
|
| 75 |
+
top_p = gr.Slider(minimum=-0, maximum=1.0, value=1.0, step=0.01,interactive=True, label="Top-p (nucleus sampling)",)
|
| 76 |
+
temperature = gr.Slider(minimum=-0, maximum=2.0, value=1.0, step=0.01, interactive=True, label="Temperature",)
|
| 77 |
+
|
| 78 |
+
predict_args = dict(fn=predict, inputs=[txt, top_p, temperature, chatbot, history, system_prompt], outputs=[chatbot, history, statusDisplay], show_progress=True)
|
| 79 |
+
empty_txt_args = dict(fn=lambda: "", inputs=[], outputs=[txt]) # 用于在提交后清空输入栏
|
| 80 |
+
|
| 81 |
+
cancel_handles.append(txt.submit(**predict_args))
|
| 82 |
+
# txt.submit(**empty_txt_args) 在提交后清空输入栏
|
| 83 |
+
cancel_handles.append(submitBtn.click(**predict_args))
|
| 84 |
+
# submitBtn.click(**empty_txt_args) 在提交后清空输入栏
|
| 85 |
+
resetBtn.click(lambda: ([], [], "已重置"), None, [chatbot, history, statusDisplay])
|
| 86 |
+
for k in functional:
|
| 87 |
+
click_handle = functional[k]["Button"].click(predict,
|
| 88 |
+
[txt, top_p, temperature, chatbot, history, system_prompt, gr.State(True), gr.State(k)], [chatbot, history, statusDisplay], show_progress=True)
|
| 89 |
+
cancel_handles.append(click_handle)
|
| 90 |
+
file_upload.upload(on_file_uploaded, [file_upload, chatbot, txt], [chatbot, txt])
|
| 91 |
+
for k in crazy_functional:
|
| 92 |
+
click_handle = crazy_functional[k]["Button"].click(crazy_functional[k]["Function"],
|
| 93 |
+
[txt, top_p, temperature, chatbot, history, system_prompt, gr.State(PORT)], [chatbot, history, statusDisplay]
|
| 94 |
+
)
|
| 95 |
+
try: click_handle.then(on_report_generated, [file_upload, chatbot], [file_upload, chatbot])
|
| 96 |
+
except: pass
|
| 97 |
+
cancel_handles.append(click_handle)
|
| 98 |
+
stopBtn.click(fn=None, inputs=None, outputs=None, cancels=cancel_handles)
|
| 99 |
+
|
| 100 |
+
# gradio的inbrowser触发不太稳定,回滚代码到原始的浏览器打开函数
|
| 101 |
+
def auto_opentab_delay():
|
| 102 |
+
import threading, webbrowser, time
|
| 103 |
+
print(f"URL http://localhost:{PORT}")
|
| 104 |
+
def open():
|
| 105 |
+
time.sleep(2)
|
| 106 |
+
webbrowser.open_new_tab(f'http://localhost:{PORT}')
|
| 107 |
+
t = threading.Thread(target=open)
|
| 108 |
+
t.daemon = True; t.start()
|
| 109 |
+
|
| 110 |
+
auto_opentab_delay()
|
| 111 |
+
demo.title = "ChatGPT 学术优化"
|
| 112 |
+
demo.queue(concurrency_count=CONCURRENT_COUNT).launch(server_name="0.0.0.0", share=True, server_port=PORT, auth=AUTHENTICATION)
|
predict.py
ADDED
|
@@ -0,0 +1,237 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 借鉴了 https://github.com/GaiZhenbiao/ChuanhuChatGPT 项目
|
| 2 |
+
|
| 3 |
+
"""
|
| 4 |
+
该文件中主要包含三个函数
|
| 5 |
+
|
| 6 |
+
不具备多线程能力的函数:
|
| 7 |
+
1. predict: 正常对话时使用,具备完备的交互功能,不可多线程
|
| 8 |
+
|
| 9 |
+
具备多线程调用能力的函数
|
| 10 |
+
2. predict_no_ui:高级实验性功能模块调用,不会实时显示在界面上,参数简单,可以多线程并行,方便实现复杂的功能逻辑
|
| 11 |
+
3. predict_no_ui_long_connection:在实验过程中发现调用predict_no_ui处理长文档时,和openai的连接容易断掉,这个函数用stream的方式解决这个问题,同样支持多线程
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
import json
|
| 15 |
+
import gradio as gr
|
| 16 |
+
import logging
|
| 17 |
+
import traceback
|
| 18 |
+
import requests
|
| 19 |
+
import importlib
|
| 20 |
+
|
| 21 |
+
# config_private.py放自己的秘密如API和代理网址
|
| 22 |
+
# 读取时首先看是否存在私密的config_private配置文件(不受git管控),如果有,则覆盖原config文件
|
| 23 |
+
try: from config_private import proxies, API_URL, API_KEY, TIMEOUT_SECONDS, MAX_RETRY, LLM_MODEL
|
| 24 |
+
except: from config import proxies, API_URL, API_KEY, TIMEOUT_SECONDS, MAX_RETRY, LLM_MODEL
|
| 25 |
+
|
| 26 |
+
timeout_bot_msg = '[local] Request timeout, network error. please check proxy settings in config.py.'
|
| 27 |
+
|
| 28 |
+
def get_full_error(chunk, stream_response):
|
| 29 |
+
"""
|
| 30 |
+
获取完整的从Openai返回的报错
|
| 31 |
+
"""
|
| 32 |
+
while True:
|
| 33 |
+
try:
|
| 34 |
+
chunk += next(stream_response)
|
| 35 |
+
except:
|
| 36 |
+
break
|
| 37 |
+
return chunk
|
| 38 |
+
|
| 39 |
+
def predict_no_ui(inputs, top_p, temperature, history=[], sys_prompt=""):
|
| 40 |
+
"""
|
| 41 |
+
发送至chatGPT,等待回复,一次性完成,不显示中间过程。
|
| 42 |
+
predict函数的简化版。
|
| 43 |
+
用于payload比较大的情况,或者用于实现多线、带嵌套的复杂功能。
|
| 44 |
+
|
| 45 |
+
inputs 是本次问询的输入
|
| 46 |
+
top_p, temperature是chatGPT的内部调优参数
|
| 47 |
+
history 是之前的对话列表
|
| 48 |
+
(注意无论是inputs还是history,内容太长了都会触发token数量溢出的错误,然后raise ConnectionAbortedError)
|
| 49 |
+
"""
|
| 50 |
+
headers, payload = generate_payload(inputs, top_p, temperature, history, system_prompt=sys_prompt, stream=False)
|
| 51 |
+
|
| 52 |
+
retry = 0
|
| 53 |
+
while True:
|
| 54 |
+
try:
|
| 55 |
+
# make a POST request to the API endpoint, stream=False
|
| 56 |
+
response = requests.post(API_URL, headers=headers, proxies=proxies,
|
| 57 |
+
json=payload, stream=False, timeout=TIMEOUT_SECONDS*2); break
|
| 58 |
+
except requests.exceptions.ReadTimeout as e:
|
| 59 |
+
retry += 1
|
| 60 |
+
traceback.print_exc()
|
| 61 |
+
if retry > MAX_RETRY: raise TimeoutError
|
| 62 |
+
if MAX_RETRY!=0: print(f'请求超时,正在重试 ({retry}/{MAX_RETRY}) ……')
|
| 63 |
+
|
| 64 |
+
try:
|
| 65 |
+
result = json.loads(response.text)["choices"][0]["message"]["content"]
|
| 66 |
+
return result
|
| 67 |
+
except Exception as e:
|
| 68 |
+
if "choices" not in response.text: print(response.text)
|
| 69 |
+
raise ConnectionAbortedError("Json解析不合常规,可能是文本过长" + response.text)
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def predict_no_ui_long_connection(inputs, top_p, temperature, history=[], sys_prompt=""):
|
| 73 |
+
"""
|
| 74 |
+
发送至chatGPT,等待回复,一次性完成,不显示中间过程。但内部用stream的方法避免有人中途掐网线。
|
| 75 |
+
"""
|
| 76 |
+
headers, payload = generate_payload(inputs, top_p, temperature, history, system_prompt=sys_prompt, stream=True)
|
| 77 |
+
|
| 78 |
+
retry = 0
|
| 79 |
+
while True:
|
| 80 |
+
try:
|
| 81 |
+
# make a POST request to the API endpoint, stream=False
|
| 82 |
+
response = requests.post(API_URL, headers=headers, proxies=proxies,
|
| 83 |
+
json=payload, stream=True, timeout=TIMEOUT_SECONDS); break
|
| 84 |
+
except requests.exceptions.ReadTimeout as e:
|
| 85 |
+
retry += 1
|
| 86 |
+
traceback.print_exc()
|
| 87 |
+
if retry > MAX_RETRY: raise TimeoutError
|
| 88 |
+
if MAX_RETRY!=0: print(f'请求超时,正在重试 ({retry}/{MAX_RETRY}) ……')
|
| 89 |
+
|
| 90 |
+
stream_response = response.iter_lines()
|
| 91 |
+
result = ''
|
| 92 |
+
while True:
|
| 93 |
+
try: chunk = next(stream_response).decode()
|
| 94 |
+
except StopIteration: break
|
| 95 |
+
if len(chunk)==0: continue
|
| 96 |
+
if not chunk.startswith('data:'):
|
| 97 |
+
chunk = get_full_error(chunk.encode('utf8'), stream_response)
|
| 98 |
+
raise ConnectionAbortedError("OpenAI拒绝了请求:" + chunk.decode())
|
| 99 |
+
delta = json.loads(chunk.lstrip('data:'))['choices'][0]["delta"]
|
| 100 |
+
if len(delta) == 0: break
|
| 101 |
+
if "role" in delta: continue
|
| 102 |
+
if "content" in delta: result += delta["content"]; print(delta["content"], end='')
|
| 103 |
+
else: raise RuntimeError("意外Json结构:"+delta)
|
| 104 |
+
return result
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
def predict(inputs, top_p, temperature, chatbot=[], history=[], system_prompt='',
|
| 108 |
+
stream = True, additional_fn=None):
|
| 109 |
+
"""
|
| 110 |
+
发送至chatGPT,流式获取输出。
|
| 111 |
+
用于基础的对话功能。
|
| 112 |
+
inputs 是本次问询的输入
|
| 113 |
+
top_p, temperature是chatGPT的内部调优参数
|
| 114 |
+
history 是之前的对话列表(注意无论是inputs还是history,内容太长了都会触发token数量溢出的错误)
|
| 115 |
+
chatbot 为WebUI中显示的对话列表,修改它,然后yeild出去,可以直接修改对话界面内容
|
| 116 |
+
additional_fn代表点击的哪个按钮,按钮见functional.py
|
| 117 |
+
"""
|
| 118 |
+
if additional_fn is not None:
|
| 119 |
+
import functional
|
| 120 |
+
importlib.reload(functional)
|
| 121 |
+
functional = functional.get_functionals()
|
| 122 |
+
inputs = functional[additional_fn]["Prefix"] + inputs + functional[additional_fn]["Suffix"]
|
| 123 |
+
|
| 124 |
+
if stream:
|
| 125 |
+
raw_input = inputs
|
| 126 |
+
logging.info(f'[raw_input] {raw_input}')
|
| 127 |
+
chatbot.append((inputs, ""))
|
| 128 |
+
yield chatbot, history, "等待响应"
|
| 129 |
+
|
| 130 |
+
headers, payload = generate_payload(inputs, top_p, temperature, history, system_prompt, stream)
|
| 131 |
+
history.append(inputs); history.append(" ")
|
| 132 |
+
|
| 133 |
+
retry = 0
|
| 134 |
+
while True:
|
| 135 |
+
try:
|
| 136 |
+
# make a POST request to the API endpoint, stream=True
|
| 137 |
+
response = requests.post(API_URL, headers=headers, proxies=proxies,
|
| 138 |
+
json=payload, stream=True, timeout=TIMEOUT_SECONDS);break
|
| 139 |
+
except:
|
| 140 |
+
retry += 1
|
| 141 |
+
chatbot[-1] = ((chatbot[-1][0], timeout_bot_msg))
|
| 142 |
+
retry_msg = f",正在重试 ({retry}/{MAX_RETRY}) ……" if MAX_RETRY > 0 else ""
|
| 143 |
+
yield chatbot, history, "请求超时"+retry_msg
|
| 144 |
+
if retry > MAX_RETRY: raise TimeoutError
|
| 145 |
+
|
| 146 |
+
gpt_replying_buffer = ""
|
| 147 |
+
|
| 148 |
+
is_head_of_the_stream = True
|
| 149 |
+
if stream:
|
| 150 |
+
stream_response = response.iter_lines()
|
| 151 |
+
while True:
|
| 152 |
+
chunk = next(stream_response)
|
| 153 |
+
# print(chunk.decode()[6:])
|
| 154 |
+
if is_head_of_the_stream:
|
| 155 |
+
# 数据流的第一帧不携带content
|
| 156 |
+
is_head_of_the_stream = False; continue
|
| 157 |
+
|
| 158 |
+
if chunk:
|
| 159 |
+
try:
|
| 160 |
+
if len(json.loads(chunk.decode()[6:])['choices'][0]["delta"]) == 0:
|
| 161 |
+
# 判定为数据流的结束,gpt_replying_buffer也写完了
|
| 162 |
+
logging.info(f'[response] {gpt_replying_buffer}')
|
| 163 |
+
break
|
| 164 |
+
# 处理数据流的主体
|
| 165 |
+
chunkjson = json.loads(chunk.decode()[6:])
|
| 166 |
+
status_text = f"finish_reason: {chunkjson['choices'][0]['finish_reason']}"
|
| 167 |
+
# 如果这里抛出异常,一般是文本过长,详情见get_full_error的输出
|
| 168 |
+
gpt_replying_buffer = gpt_replying_buffer + json.loads(chunk.decode()[6:])['choices'][0]["delta"]["content"]
|
| 169 |
+
history[-1] = gpt_replying_buffer
|
| 170 |
+
chatbot[-1] = (history[-2], history[-1])
|
| 171 |
+
yield chatbot, history, status_text
|
| 172 |
+
|
| 173 |
+
except Exception as e:
|
| 174 |
+
traceback.print_exc()
|
| 175 |
+
yield chatbot, history, "Json解析不合常规"
|
| 176 |
+
chunk = get_full_error(chunk, stream_response)
|
| 177 |
+
error_msg = chunk.decode()
|
| 178 |
+
if "reduce the length" in error_msg:
|
| 179 |
+
chatbot[-1] = (chatbot[-1][0], "[Local Message] Input (or history) is too long, please reduce input or clear history by refreshing this page.")
|
| 180 |
+
history = []
|
| 181 |
+
elif "Incorrect API key" in error_msg:
|
| 182 |
+
chatbot[-1] = (chatbot[-1][0], "[Local Message] Incorrect API key provided.")
|
| 183 |
+
else:
|
| 184 |
+
from toolbox import regular_txt_to_markdown
|
| 185 |
+
tb_str = regular_txt_to_markdown(traceback.format_exc())
|
| 186 |
+
chatbot[-1] = (chatbot[-1][0], f"[Local Message] Json Error \n\n {tb_str} \n\n {regular_txt_to_markdown(chunk.decode()[4:])}")
|
| 187 |
+
yield chatbot, history, "Json解析不合常规" + error_msg
|
| 188 |
+
return
|
| 189 |
+
|
| 190 |
+
def generate_payload(inputs, top_p, temperature, history, system_prompt, stream):
|
| 191 |
+
"""
|
| 192 |
+
整合所有信息,选择LLM模型,生成http请求,为发送请求做准备
|
| 193 |
+
"""
|
| 194 |
+
headers = {
|
| 195 |
+
"Content-Type": "application/json",
|
| 196 |
+
"Authorization": f"Bearer {API_KEY}"
|
| 197 |
+
}
|
| 198 |
+
|
| 199 |
+
conversation_cnt = len(history) // 2
|
| 200 |
+
|
| 201 |
+
messages = [{"role": "system", "content": system_prompt}]
|
| 202 |
+
if conversation_cnt:
|
| 203 |
+
for index in range(0, 2*conversation_cnt, 2):
|
| 204 |
+
what_i_have_asked = {}
|
| 205 |
+
what_i_have_asked["role"] = "user"
|
| 206 |
+
what_i_have_asked["content"] = history[index]
|
| 207 |
+
what_gpt_answer = {}
|
| 208 |
+
what_gpt_answer["role"] = "assistant"
|
| 209 |
+
what_gpt_answer["content"] = history[index+1]
|
| 210 |
+
if what_i_have_asked["content"] != "":
|
| 211 |
+
if what_gpt_answer["content"] == "": continue
|
| 212 |
+
if what_gpt_answer["content"] == timeout_bot_msg: continue
|
| 213 |
+
messages.append(what_i_have_asked)
|
| 214 |
+
messages.append(what_gpt_answer)
|
| 215 |
+
else:
|
| 216 |
+
messages[-1]['content'] = what_gpt_answer['content']
|
| 217 |
+
|
| 218 |
+
what_i_ask_now = {}
|
| 219 |
+
what_i_ask_now["role"] = "user"
|
| 220 |
+
what_i_ask_now["content"] = inputs
|
| 221 |
+
messages.append(what_i_ask_now)
|
| 222 |
+
|
| 223 |
+
payload = {
|
| 224 |
+
"model": LLM_MODEL,
|
| 225 |
+
"messages": messages,
|
| 226 |
+
"temperature": temperature, # 1.0,
|
| 227 |
+
"top_p": top_p, # 1.0,
|
| 228 |
+
"n": 1,
|
| 229 |
+
"stream": stream,
|
| 230 |
+
"presence_penalty": 0,
|
| 231 |
+
"frequency_penalty": 0,
|
| 232 |
+
}
|
| 233 |
+
|
| 234 |
+
print(f" {LLM_MODEL} : {conversation_cnt} : {inputs}")
|
| 235 |
+
return headers,payload
|
| 236 |
+
|
| 237 |
+
|
project_self_analysis.md
ADDED
|
@@ -0,0 +1,122 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# chatgpt-academic项目分析报告
|
| 2 |
+
(Author补充:以下分析均由本项目调用ChatGPT一键生成,如果有不准确的地方全怪GPT)
|
| 3 |
+
|
| 4 |
+
## [0/10] 程序摘要: check_proxy.py
|
| 5 |
+
|
| 6 |
+
这个程序是一个用来检查代理服务器是否有效的 Python 程序代码。程序文件名为 check_proxy.py。其中定义了一个函数 check_proxy,该函数接收一个代理配置信息 proxies,使用 requests 库向一个代理服务器发送请求,获取该代理的所在地信息并返回。如果请求超时或者异常,该函数将返回一个代理无效的结果。
|
| 7 |
+
|
| 8 |
+
程序代码分为两个部分,首先是 check_proxy 函数的定义部分,其次是程序文件的入口部分,在该部分代码中,程序从 config_private.py 文件或者 config.py 文件中加载代理配置信息,然后调用 check_proxy 函数来检测代理服务器是否有效。如果配置文件 config_private.py 存在,则会加载其中的代理配置信息,否则会从 config.py 文件中读取。
|
| 9 |
+
|
| 10 |
+
## [1/10] 程序摘要: config.py
|
| 11 |
+
|
| 12 |
+
本程序文件名为config.py,主要功能是存储应用所需的常量和配置信息。
|
| 13 |
+
|
| 14 |
+
其中,包含了应用所需的OpenAI API密钥、API接口地址、网络代理设置、超时设置、网络端口和OpenAI模型选择等信息,在运行应用前需要进行相应的配置。在未配置网络代理时,程序给出了相应的警告提示。
|
| 15 |
+
|
| 16 |
+
此外,还包含了一个检查函数,用于检查是否忘记修改API密钥。
|
| 17 |
+
|
| 18 |
+
总之,config.py文件是应用中的一个重要配置文件,用来存储应用所需的常量和配置信息,需要在应用运行前进行相应的配置。
|
| 19 |
+
|
| 20 |
+
## [2/10] 程序摘要: config_private.py
|
| 21 |
+
|
| 22 |
+
该文件是一个配置文件,命名为config_private.py。它是一个Python脚本,用于配置OpenAI的API密钥、模型和其它相关设置。该配置文件还可以设置是否使用代理。如果使用代理,需要设置代理协议、地址和端口。在设置代理之后,该文件还包括一些用于测试代理是否正常工作的代码。该文件还包括超时时间、随机端口、重试次数等设置。在文件末尾,还有一个检查代码,如果没有更改API密钥,则抛出异常。
|
| 23 |
+
|
| 24 |
+
## [3/10] 程序摘要: functional.py
|
| 25 |
+
|
| 26 |
+
该程序文件名为 functional.py,其中包含一个名为 get_functionals 的函数,该函数返回一个字典,该字典包含了各种翻译、校对等功能的名称、前缀、后缀以及默认按钮颜色等信息。具体功能包括:英语学术润色、中文学术润色、查找语法错误、中英互译、中译英、学术中译英、英译中、解释代码等。该程序的作用为提供各种翻译、校对等功能的模板,以便后续程序可以直接调用。
|
| 27 |
+
|
| 28 |
+
(Author补充:这个文件汇总了模块化的Prompt调用,如果发现了新的好用Prompt,别藏着哦^_^速速PR)
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
## [4/10] 程序摘要: functional_crazy.py
|
| 32 |
+
|
| 33 |
+
这个程序文件 functional_crazy.py 导入了一些 python 模块,并提供了一个函数 get_crazy_functionals(),该函数返回不同实验功能的描述和函数。其中,使用的的模块包括:
|
| 34 |
+
|
| 35 |
+
- crazy_functions.读文章写摘要 中的 读文章写摘要
|
| 36 |
+
- crazy_functions.生成函数注释 中的 批量生成函数注释
|
| 37 |
+
- crazy_functions.解析项目源代码 中的 解析项目本身、解析一个Python项目、解析一个C项目的头文件、解析一个C项目
|
| 38 |
+
- crazy_functions.高级功能函数模板 中的 高阶功能模板函数
|
| 39 |
+
|
| 40 |
+
返回的实验功能函数包括:
|
| 41 |
+
|
| 42 |
+
- "[实验] 请解析并解构此项目本身",包含函数:解析项目本身
|
| 43 |
+
- "[实验] 解析整个py项目(配合input输入框)",包含函数:解析一个Python项目
|
| 44 |
+
- "[实验] 解析整个C++项目头文件(配合input输入框)",包含函数:解析一个C项目的头文件
|
| 45 |
+
- "[实验] 解析整个C++项目(配合input输入框)",包含函数:解析一个C项目
|
| 46 |
+
- "[实验] 读tex论文写摘要(配合input输入框)",包含函数:读文章写摘要
|
| 47 |
+
- "[实验] 批量生成函数注释(配合input输入框)",包含函数:批量生成函数注释
|
| 48 |
+
- "[实验] 实验功能函数模板",包含函数:高阶功能模板函数
|
| 49 |
+
|
| 50 |
+
这些函数用于系统开发和测试,方便开发者进行特定程序语言后台功能开发的测试和实验,增加系统可靠稳定性和用户友好性。
|
| 51 |
+
|
| 52 |
+
(Author补充:这个文件汇总了模块化的函数,如此设计以方便任何新功能的加入)
|
| 53 |
+
|
| 54 |
+
## [5/10] 程序摘要: main.py
|
| 55 |
+
|
| 56 |
+
该程序是一个基于Gradio框架的聊天机器人应用程序。用户可以通过输入问题来获取答案,并与聊天机器人进行对话。该应用程序还集成了一些实验性功能模块,用户可以通过上传本地文件或点击相关按钮来使用这些模块。程序还可以生成对话日志,并且具有一些外观上的调整。在运行时,它会自动打开一个网页并在本地启动服务器。
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
## [6/10] 程序摘要: predict.py
|
| 60 |
+
|
| 61 |
+
该程序文件名为predict.py,主要是针对一个基于ChatGPT的聊天机器人进行交互和预测。
|
| 62 |
+
|
| 63 |
+
第一部分是导入所需的库和配置文件。
|
| 64 |
+
|
| 65 |
+
第二部分是一个用于获取Openai返回的完整错误信息的函数。
|
| 66 |
+
|
| 67 |
+
第三部分是用于一次性完成向ChatGPT发送请求和等待回复的函数。
|
| 68 |
+
|
| 69 |
+
第四部分是用于基础的对话功能的函数,通过stream参数可以选择是否显示中间的过程。
|
| 70 |
+
|
| 71 |
+
第五部分是用于整合所需信息和选择LLM模型生成的HTTP请求。
|
| 72 |
+
|
| 73 |
+
(Author补充:主要是predict_no_ui和predict两个函数。前者不用stream,方便、高效、易用。后者用stream,展现效果好。)
|
| 74 |
+
|
| 75 |
+
## [7/10] 程序摘要: show_math.py
|
| 76 |
+
|
| 77 |
+
这是一个名为show_math.py的Python程序文件,主要用于将Markdown-LaTeX混合文本转换为HTML格式,并包括MathML数学公式。程序使用latex2mathml.converter库将LaTeX公式转换为MathML格式,并使用正则表达式递归地翻译输入的Markdown-LaTeX混合文本。程序包括转换成双美元符号($$)形式、转换成单美元符号($)形式、转换成\[\]形式以及转换成\(\)形式的LaTeX数学公式。如果转换中出现错误,程序将返回相应的错误消息。
|
| 78 |
+
|
| 79 |
+
## [8/10] 程序摘要: theme.py
|
| 80 |
+
|
| 81 |
+
这是一个名为theme.py的程序文件,用于设置Gradio界面的颜色和字体主题。该文件中定义了一个名为adjust_theme()的函数,其作用是返回一个Gradio theme对象,设置了Gradio界面的颜色和字体主题。在该函数里面,使用了Graido可用的颜色列表,主要参数包括primary_hue、neutral_hue、font和font_mono等,用于设置Gradio界面的主题色调、字体等。另外,该函数还实现了一些参数的自定义,如input_background_fill_dark、button_transition、button_shadow_hover等,用于设置Gradio界面的渐变、阴影等特效。如果Gradio版本过于陈旧,该函数会抛出异常并返回None。
|
| 82 |
+
|
| 83 |
+
## [9/10] 程序摘要: toolbox.py
|
| 84 |
+
|
| 85 |
+
该文件为Python程序文件,文件名为toolbox.py。主要功能包括:
|
| 86 |
+
|
| 87 |
+
1. 导入markdown、mdtex2html、threading、functools等模块。
|
| 88 |
+
2. 定义函数predict_no_ui_but_counting_down,用于生成对话。
|
| 89 |
+
3. 定义函数write_results_to_file,用于将对话记录生成Markdown文件。
|
| 90 |
+
4. 定义函数regular_txt_to_markdown,将普通文本转换为Markdown格式的文本。
|
| 91 |
+
5. 定义装饰器函数CatchException,用于捕获函数执行异常并返回生成器。
|
| 92 |
+
6. 定义函数report_execption,用于向chatbot中添加错误信息。
|
| 93 |
+
7. 定义函数text_divide_paragraph,用于将文本按照段落分隔符分割开,生成带有段落标签的HTML代码。
|
| 94 |
+
8. 定义函数markdown_convertion,用于将Markdown格式的文本转换为HTML格式。
|
| 95 |
+
9. 定义函数format_io,用于将输入和输出解析为HTML格式。
|
| 96 |
+
10. 定义函数find_free_port,用于返回当前系统中可用的未使用端口。
|
| 97 |
+
11. 定义函数extract_archive,用于解压归档文件。
|
| 98 |
+
12. 定义函数find_recent_files,用于查找最近创建的文件。
|
| 99 |
+
13. 定义函数on_file_uploaded,用于处理上传文件的操作。
|
| 100 |
+
14. 定义函数on_report_generated,用于处理生成报告文件的操作。
|
| 101 |
+
|
| 102 |
+
## 程序的整体功能和构架做出概括。然后用一张markdown表格整理每个文件的功能。
|
| 103 |
+
|
| 104 |
+
这是一个基于Gradio框架的聊天机器人应用,支持通过文本聊天来获取答案,并可以使用一系列实验性功能模块,例如生成函数注释、解析项目源代码、读取Latex论文写摘要等。 程序架构分为前端和后端两个部分。前端使用Gradio实现,包括用户输入区域、应答区域、按钮、调用方式等。后端使用Python实现,包括聊天机器人模型、实验性功能模块、模板模块、管理模块、主程序模块等。
|
| 105 |
+
|
| 106 |
+
每个程序文件的功能如下:
|
| 107 |
+
|
| 108 |
+
| 文件名 | 功能描述 |
|
| 109 |
+
|:----:|:----:|
|
| 110 |
+
| check_proxy.py | 检查代理服务器是否有效 |
|
| 111 |
+
| config.py | 存储应用所需的常量和配置信息 |
|
| 112 |
+
| config_private.py | 存储Openai的API密钥、模型和其他相关设置 |
|
| 113 |
+
| functional.py | 提供各种翻译、校对等实用模板 |
|
| 114 |
+
| functional_crazy.py | 提供一些实验性质的高级功能 |
|
| 115 |
+
| main.py | 基于Gradio框架的聊天机器人应用程序的主程序 |
|
| 116 |
+
| predict.py | 用于chatbot预测方案创建,向ChatGPT发送请求和获取回复 |
|
| 117 |
+
| show_math.py | 将Markdown-LaTeX混合文本转换为HTML格式,并包括MathML数学公式 |
|
| 118 |
+
| theme.py | 设置Gradio界面的颜色和字体主题 |
|
| 119 |
+
| toolbox.py | 定义一系列工具函数,用于对输入输出进行格式转换、文件操作、异常捕捉和处理等 |
|
| 120 |
+
|
| 121 |
+
这些程序文件共同组成了一个聊天机器人应用程序的前端和后端实现,使用户可以方便地进行聊天,并可以使用相应的实验功能模块。
|
| 122 |
+
|
requirements.txt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
gradio>=3.23
|
| 2 |
+
requests[socks]
|
| 3 |
+
mdtex2html
|
show_math.py
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This program is written by: https://github.com/polarwinkel/mdtex2html
|
| 2 |
+
|
| 3 |
+
from latex2mathml.converter import convert as tex2mathml
|
| 4 |
+
import re
|
| 5 |
+
|
| 6 |
+
incomplete = '<font style="color:orange;" class="tooltip">⚠<span class="tooltiptext">formula incomplete</span></font>'
|
| 7 |
+
convError = '<font style="color:red" class="tooltip">⚠<span class="tooltiptext">LaTeX-convert-error</span></font>'
|
| 8 |
+
|
| 9 |
+
def convert(mdtex, extensions=[], splitParagraphs=True):
|
| 10 |
+
''' converts recursively the Markdown-LaTeX-mixture to HTML with MathML '''
|
| 11 |
+
found = False
|
| 12 |
+
# handle all paragraphs separately (prevents aftereffects)
|
| 13 |
+
if splitParagraphs:
|
| 14 |
+
parts = re.split("\n\n", mdtex)
|
| 15 |
+
result = ''
|
| 16 |
+
for part in parts:
|
| 17 |
+
result += convert(part, extensions, splitParagraphs=False)
|
| 18 |
+
return result
|
| 19 |
+
# find first $$-formula:
|
| 20 |
+
parts = re.split('\${2}', mdtex, 2)
|
| 21 |
+
if len(parts)>1:
|
| 22 |
+
found = True
|
| 23 |
+
result = convert(parts[0], extensions, splitParagraphs=False)+'\n'
|
| 24 |
+
try:
|
| 25 |
+
result += '<div class="blockformula">'+tex2mathml(parts[1])+'</div>\n'
|
| 26 |
+
except:
|
| 27 |
+
result += '<div class="blockformula">'+convError+'</div>'
|
| 28 |
+
if len(parts)==3:
|
| 29 |
+
result += convert(parts[2], extensions, splitParagraphs=False)
|
| 30 |
+
else:
|
| 31 |
+
result += '<div class="blockformula">'+incomplete+'</div>'
|
| 32 |
+
# else find first $-formulas:
|
| 33 |
+
else:
|
| 34 |
+
parts = re.split('\${1}', mdtex, 2)
|
| 35 |
+
if len(parts)>1 and not found:
|
| 36 |
+
found = True
|
| 37 |
+
try:
|
| 38 |
+
mathml = tex2mathml(parts[1])
|
| 39 |
+
except:
|
| 40 |
+
mathml = convError
|
| 41 |
+
if parts[0].endswith('\n\n') or parts[0]=='': # make sure textblock starts before formula!
|
| 42 |
+
parts[0]=parts[0]+'​'
|
| 43 |
+
if len(parts)==3:
|
| 44 |
+
result = convert(parts[0]+mathml+parts[2], extensions, splitParagraphs=False)
|
| 45 |
+
else:
|
| 46 |
+
result = convert(parts[0]+mathml+incomplete, extensions, splitParagraphs=False)
|
| 47 |
+
# else find first \[..\]-equation:
|
| 48 |
+
else:
|
| 49 |
+
parts = re.split(r'\\\[', mdtex, 1)
|
| 50 |
+
if len(parts)>1 and not found:
|
| 51 |
+
found = True
|
| 52 |
+
result = convert(parts[0], extensions, splitParagraphs=False)+'\n'
|
| 53 |
+
parts = re.split(r'\\\]', parts[1], 1)
|
| 54 |
+
try:
|
| 55 |
+
result += '<div class="blockformula">'+tex2mathml(parts[0])+'</div>\n'
|
| 56 |
+
except:
|
| 57 |
+
result += '<div class="blockformula">'+convError+'</div>'
|
| 58 |
+
if len(parts)==2:
|
| 59 |
+
result += convert(parts[1], extensions, splitParagraphs=False)
|
| 60 |
+
else:
|
| 61 |
+
result += '<div class="blockformula">'+incomplete+'</div>'
|
| 62 |
+
# else find first \(..\)-equation:
|
| 63 |
+
else:
|
| 64 |
+
parts = re.split(r'\\\(', mdtex, 1)
|
| 65 |
+
if len(parts)>1 and not found:
|
| 66 |
+
found = True
|
| 67 |
+
subp = re.split(r'\\\)', parts[1], 1)
|
| 68 |
+
try:
|
| 69 |
+
mathml = tex2mathml(subp[0])
|
| 70 |
+
except:
|
| 71 |
+
mathml = convError
|
| 72 |
+
if parts[0].endswith('\n\n') or parts[0]=='': # make sure textblock starts before formula!
|
| 73 |
+
parts[0]=parts[0]+'​'
|
| 74 |
+
if len(subp)==2:
|
| 75 |
+
result = convert(parts[0]+mathml+subp[1], extensions, splitParagraphs=False)
|
| 76 |
+
else:
|
| 77 |
+
result = convert(parts[0]+mathml+incomplete, extensions, splitParagraphs=False)
|
| 78 |
+
if not found:
|
| 79 |
+
result = mdtex
|
| 80 |
+
return result
|
theme.py
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
|
| 3 |
+
# gradio可用颜色列表
|
| 4 |
+
# gr.themes.utils.colors.slate (石板色)
|
| 5 |
+
# gr.themes.utils.colors.gray (灰色)
|
| 6 |
+
# gr.themes.utils.colors.zinc (锌色)
|
| 7 |
+
# gr.themes.utils.colors.neutral (中性色)
|
| 8 |
+
# gr.themes.utils.colors.stone (石头色)
|
| 9 |
+
# gr.themes.utils.colors.red (红色)
|
| 10 |
+
# gr.themes.utils.colors.orange (橙色)
|
| 11 |
+
# gr.themes.utils.colors.amber (琥珀色)
|
| 12 |
+
# gr.themes.utils.colors.yellow (黄色)
|
| 13 |
+
# gr.themes.utils.colors.lime (酸橙色)
|
| 14 |
+
# gr.themes.utils.colors.green (绿色)
|
| 15 |
+
# gr.themes.utils.colors.emerald (祖母绿)
|
| 16 |
+
# gr.themes.utils.colors.teal (青蓝色)
|
| 17 |
+
# gr.themes.utils.colors.cyan (青色)
|
| 18 |
+
# gr.themes.utils.colors.sky (天蓝色)
|
| 19 |
+
# gr.themes.utils.colors.blue (蓝色)
|
| 20 |
+
# gr.themes.utils.colors.indigo (靛蓝色)
|
| 21 |
+
# gr.themes.utils.colors.violet (紫罗兰色)
|
| 22 |
+
# gr.themes.utils.colors.purple (紫色)
|
| 23 |
+
# gr.themes.utils.colors.fuchsia (洋红色)
|
| 24 |
+
# gr.themes.utils.colors.pink (粉红色)
|
| 25 |
+
# gr.themes.utils.colors.rose (玫瑰色)
|
| 26 |
+
|
| 27 |
+
def adjust_theme():
|
| 28 |
+
try:
|
| 29 |
+
color_er = gr.themes.utils.colors.pink
|
| 30 |
+
set_theme = gr.themes.Default(
|
| 31 |
+
primary_hue=gr.themes.utils.colors.orange,
|
| 32 |
+
neutral_hue=gr.themes.utils.colors.gray,
|
| 33 |
+
font=["sans-serif", "Microsoft YaHei", "ui-sans-serif", "system-ui", "sans-serif", gr.themes.utils.fonts.GoogleFont("Source Sans Pro")],
|
| 34 |
+
font_mono=["ui-monospace", "Consolas", "monospace", gr.themes.utils.fonts.GoogleFont("IBM Plex Mono")])
|
| 35 |
+
set_theme.set(
|
| 36 |
+
# Colors
|
| 37 |
+
input_background_fill_dark="*neutral_800",
|
| 38 |
+
# Transition
|
| 39 |
+
button_transition="none",
|
| 40 |
+
# Shadows
|
| 41 |
+
button_shadow="*shadow_drop",
|
| 42 |
+
button_shadow_hover="*shadow_drop_lg",
|
| 43 |
+
button_shadow_active="*shadow_inset",
|
| 44 |
+
input_shadow="0 0 0 *shadow_spread transparent, *shadow_inset",
|
| 45 |
+
input_shadow_focus="0 0 0 *shadow_spread *secondary_50, *shadow_inset",
|
| 46 |
+
input_shadow_focus_dark="0 0 0 *shadow_spread *neutral_700, *shadow_inset",
|
| 47 |
+
checkbox_label_shadow="*shadow_drop",
|
| 48 |
+
block_shadow="*shadow_drop",
|
| 49 |
+
form_gap_width="1px",
|
| 50 |
+
# Button borders
|
| 51 |
+
input_border_width="1px",
|
| 52 |
+
input_background_fill="white",
|
| 53 |
+
# Gradients
|
| 54 |
+
stat_background_fill="linear-gradient(to right, *primary_400, *primary_200)",
|
| 55 |
+
stat_background_fill_dark="linear-gradient(to right, *primary_400, *primary_600)",
|
| 56 |
+
error_background_fill=f"linear-gradient(to right, {color_er.c100}, *background_fill_secondary)",
|
| 57 |
+
error_background_fill_dark="*background_fill_primary",
|
| 58 |
+
checkbox_label_background_fill="linear-gradient(to top, *neutral_50, white)",
|
| 59 |
+
checkbox_label_background_fill_dark="linear-gradient(to top, *neutral_900, *neutral_800)",
|
| 60 |
+
checkbox_label_background_fill_hover="linear-gradient(to top, *neutral_100, white)",
|
| 61 |
+
checkbox_label_background_fill_hover_dark="linear-gradient(to top, *neutral_900, *neutral_800)",
|
| 62 |
+
button_primary_background_fill="linear-gradient(to bottom right, *primary_100, *primary_300)",
|
| 63 |
+
button_primary_background_fill_dark="linear-gradient(to bottom right, *primary_500, *primary_600)",
|
| 64 |
+
button_primary_background_fill_hover="linear-gradient(to bottom right, *primary_100, *primary_200)",
|
| 65 |
+
button_primary_background_fill_hover_dark="linear-gradient(to bottom right, *primary_500, *primary_500)",
|
| 66 |
+
button_primary_border_color_dark="*primary_500",
|
| 67 |
+
button_secondary_background_fill="linear-gradient(to bottom right, *neutral_100, *neutral_200)",
|
| 68 |
+
button_secondary_background_fill_dark="linear-gradient(to bottom right, *neutral_600, *neutral_700)",
|
| 69 |
+
button_secondary_background_fill_hover="linear-gradient(to bottom right, *neutral_100, *neutral_100)",
|
| 70 |
+
button_secondary_background_fill_hover_dark="linear-gradient(to bottom right, *neutral_600, *neutral_600)",
|
| 71 |
+
button_cancel_background_fill=f"linear-gradient(to bottom right, {color_er.c100}, {color_er.c200})",
|
| 72 |
+
button_cancel_background_fill_dark=f"linear-gradient(to bottom right, {color_er.c600}, {color_er.c700})",
|
| 73 |
+
button_cancel_background_fill_hover=f"linear-gradient(to bottom right, {color_er.c100}, {color_er.c100})",
|
| 74 |
+
button_cancel_background_fill_hover_dark=f"linear-gradient(to bottom right, {color_er.c600}, {color_er.c600})",
|
| 75 |
+
button_cancel_border_color=color_er.c200,
|
| 76 |
+
button_cancel_border_color_dark=color_er.c600,
|
| 77 |
+
button_cancel_text_color=color_er.c600,
|
| 78 |
+
button_cancel_text_color_dark="white",
|
| 79 |
+
)
|
| 80 |
+
except:
|
| 81 |
+
set_theme = None; print('gradio版本较旧, 不能自定义字体和颜色')
|
| 82 |
+
return set_theme
|
toolbox.py
ADDED
|
@@ -0,0 +1,220 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import markdown, mdtex2html, threading
|
| 2 |
+
from show_math import convert as convert_math
|
| 3 |
+
from functools import wraps
|
| 4 |
+
|
| 5 |
+
def predict_no_ui_but_counting_down(i_say, i_say_show_user, chatbot, top_p, temperature, history=[], sys_prompt=''):
|
| 6 |
+
"""
|
| 7 |
+
调用简单的predict_no_ui接口,但是依然保留了些许界面心跳功能,当对话太长时,会自动采用二分法截断
|
| 8 |
+
"""
|
| 9 |
+
import time
|
| 10 |
+
try: from config_private import TIMEOUT_SECONDS, MAX_RETRY
|
| 11 |
+
except: from config import TIMEOUT_SECONDS, MAX_RETRY
|
| 12 |
+
from predict import predict_no_ui
|
| 13 |
+
# 多线程的时候,需要一个mutable结构在不同线程之间传递信息
|
| 14 |
+
# list就是最简单的mutable结构,我们第一个位置放gpt输出,第二个位置传递报错信息
|
| 15 |
+
mutable = [None, '']
|
| 16 |
+
# multi-threading worker
|
| 17 |
+
def mt(i_say, history):
|
| 18 |
+
while True:
|
| 19 |
+
try:
|
| 20 |
+
mutable[0] = predict_no_ui(inputs=i_say, top_p=top_p, temperature=temperature, history=history, sys_prompt=sys_prompt)
|
| 21 |
+
break
|
| 22 |
+
except ConnectionAbortedError as e:
|
| 23 |
+
if len(history) > 0:
|
| 24 |
+
history = [his[len(his)//2:] for his in history if his is not None]
|
| 25 |
+
mutable[1] = 'Warning! History conversation is too long, cut into half. '
|
| 26 |
+
else:
|
| 27 |
+
i_say = i_say[:len(i_say)//2]
|
| 28 |
+
mutable[1] = 'Warning! Input file is too long, cut into half. '
|
| 29 |
+
except TimeoutError as e:
|
| 30 |
+
mutable[0] = '[Local Message] Failed with timeout.'
|
| 31 |
+
raise TimeoutError
|
| 32 |
+
# 创建新线程发出http请求
|
| 33 |
+
thread_name = threading.Thread(target=mt, args=(i_say, history)); thread_name.start()
|
| 34 |
+
# 原来的线程则负责持续更新UI,实现一个超时倒计时,并等待新线程的任务完成
|
| 35 |
+
cnt = 0
|
| 36 |
+
while thread_name.is_alive():
|
| 37 |
+
cnt += 1
|
| 38 |
+
chatbot[-1] = (i_say_show_user, f"[Local Message] {mutable[1]}waiting gpt response {cnt}/{TIMEOUT_SECONDS*2*(MAX_RETRY+1)}"+''.join(['.']*(cnt%4)))
|
| 39 |
+
yield chatbot, history, '正常'
|
| 40 |
+
time.sleep(1)
|
| 41 |
+
# 把gpt的输出从mutable中取出来
|
| 42 |
+
gpt_say = mutable[0]
|
| 43 |
+
if gpt_say=='[Local Message] Failed with timeout.': raise TimeoutError
|
| 44 |
+
return gpt_say
|
| 45 |
+
|
| 46 |
+
def write_results_to_file(history, file_name=None):
|
| 47 |
+
"""
|
| 48 |
+
将对话记录history以Markdown格式写入文件中。如果没有指定文件名,则使用当前时间生成文件名。
|
| 49 |
+
"""
|
| 50 |
+
import os, time
|
| 51 |
+
if file_name is None:
|
| 52 |
+
# file_name = time.strftime("chatGPT分析报告%Y-%m-%d-%H-%M-%S", time.localtime()) + '.md'
|
| 53 |
+
file_name = 'chatGPT分析报告' + time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime()) + '.md'
|
| 54 |
+
os.makedirs('./gpt_log/', exist_ok=True)
|
| 55 |
+
with open(f'./gpt_log/{file_name}', 'w', encoding = 'utf8') as f:
|
| 56 |
+
f.write('# chatGPT 分析报告\n')
|
| 57 |
+
for i, content in enumerate(history):
|
| 58 |
+
if i%2==0: f.write('## ')
|
| 59 |
+
f.write(content)
|
| 60 |
+
f.write('\n\n')
|
| 61 |
+
res = '以上材料已经被写入' + os.path.abspath(f'./gpt_log/{file_name}')
|
| 62 |
+
print(res)
|
| 63 |
+
return res
|
| 64 |
+
|
| 65 |
+
def regular_txt_to_markdown(text):
|
| 66 |
+
"""
|
| 67 |
+
将普通文本转换为Markdown格式的文本。
|
| 68 |
+
"""
|
| 69 |
+
text = text.replace('\n', '\n\n')
|
| 70 |
+
text = text.replace('\n\n\n', '\n\n')
|
| 71 |
+
text = text.replace('\n\n\n', '\n\n')
|
| 72 |
+
return text
|
| 73 |
+
|
| 74 |
+
def CatchException(f):
|
| 75 |
+
"""
|
| 76 |
+
装饰器函数,捕捉函数f中的异常并封装到一个生成器中返回,并显示到聊天当中。
|
| 77 |
+
"""
|
| 78 |
+
@wraps(f)
|
| 79 |
+
def decorated(txt, top_p, temperature, chatbot, history, systemPromptTxt, WEB_PORT):
|
| 80 |
+
try:
|
| 81 |
+
yield from f(txt, top_p, temperature, chatbot, history, systemPromptTxt, WEB_PORT)
|
| 82 |
+
except Exception as e:
|
| 83 |
+
import traceback
|
| 84 |
+
from check_proxy import check_proxy
|
| 85 |
+
try: from config_private import proxies
|
| 86 |
+
except: from config import proxies
|
| 87 |
+
tb_str = regular_txt_to_markdown(traceback.format_exc())
|
| 88 |
+
chatbot[-1] = (chatbot[-1][0], f"[Local Message] 实验性函数调用出错: \n\n {tb_str} \n\n 当前代理可用性: \n\n {check_proxy(proxies)}")
|
| 89 |
+
yield chatbot, history, f'异常 {e}'
|
| 90 |
+
return decorated
|
| 91 |
+
|
| 92 |
+
def report_execption(chatbot, history, a, b):
|
| 93 |
+
"""
|
| 94 |
+
向chatbot中添加错误信息
|
| 95 |
+
"""
|
| 96 |
+
chatbot.append((a, b))
|
| 97 |
+
history.append(a); history.append(b)
|
| 98 |
+
|
| 99 |
+
def text_divide_paragraph(text):
|
| 100 |
+
"""
|
| 101 |
+
将文本按照段落分隔符分割开,生成带有段落标签的HTML代码。
|
| 102 |
+
"""
|
| 103 |
+
if '```' in text:
|
| 104 |
+
# careful input
|
| 105 |
+
return text
|
| 106 |
+
else:
|
| 107 |
+
# wtf input
|
| 108 |
+
lines = text.split("\n")
|
| 109 |
+
for i, line in enumerate(lines):
|
| 110 |
+
lines[i] = "<p>"+lines[i].replace(" ", " ")+"</p>"
|
| 111 |
+
text = "\n".join(lines)
|
| 112 |
+
return text
|
| 113 |
+
|
| 114 |
+
def markdown_convertion(txt):
|
| 115 |
+
"""
|
| 116 |
+
将Markdown格式的文本转换为HTML格式。如果包含数学公式,则先将公式转换为HTML格式。
|
| 117 |
+
"""
|
| 118 |
+
if ('$' in txt) and ('```' not in txt):
|
| 119 |
+
return markdown.markdown(txt,extensions=['fenced_code','tables']) + '<br><br>' + \
|
| 120 |
+
markdown.markdown(convert_math(txt, splitParagraphs=False),extensions=['fenced_code','tables'])
|
| 121 |
+
else:
|
| 122 |
+
return markdown.markdown(txt,extensions=['fenced_code','tables'])
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
def format_io(self, y):
|
| 126 |
+
"""
|
| 127 |
+
将输入和输出解析为HTML格式。将y中最后一项的输入部分段落化,并将输出部分的Markdown和数学公式转换为HTML格式。
|
| 128 |
+
"""
|
| 129 |
+
if y is None or y == []: return []
|
| 130 |
+
i_ask, gpt_reply = y[-1]
|
| 131 |
+
i_ask = text_divide_paragraph(i_ask) # 输入部分太自由,预处理一波
|
| 132 |
+
y[-1] = (
|
| 133 |
+
None if i_ask is None else markdown.markdown(i_ask, extensions=['fenced_code','tables']),
|
| 134 |
+
None if gpt_reply is None else markdown_convertion(gpt_reply)
|
| 135 |
+
)
|
| 136 |
+
return y
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
def find_free_port():
|
| 140 |
+
"""
|
| 141 |
+
返回当前系统中可用的未使用端口。
|
| 142 |
+
"""
|
| 143 |
+
import socket
|
| 144 |
+
from contextlib import closing
|
| 145 |
+
with closing(socket.socket(socket.AF_INET, socket.SOCK_STREAM)) as s:
|
| 146 |
+
s.bind(('', 0))
|
| 147 |
+
s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
| 148 |
+
return s.getsockname()[1]
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
def extract_archive(file_path, dest_dir):
|
| 152 |
+
import zipfile
|
| 153 |
+
import tarfile
|
| 154 |
+
import os
|
| 155 |
+
# Get the file extension of the input file
|
| 156 |
+
file_extension = os.path.splitext(file_path)[1]
|
| 157 |
+
|
| 158 |
+
# Extract the archive based on its extension
|
| 159 |
+
if file_extension == '.zip':
|
| 160 |
+
with zipfile.ZipFile(file_path, 'r') as zipobj:
|
| 161 |
+
zipobj.extractall(path=dest_dir)
|
| 162 |
+
print("Successfully extracted zip archive to {}".format(dest_dir))
|
| 163 |
+
|
| 164 |
+
elif file_extension in ['.tar', '.gz', '.bz2']:
|
| 165 |
+
with tarfile.open(file_path, 'r:*') as tarobj:
|
| 166 |
+
tarobj.extractall(path=dest_dir)
|
| 167 |
+
print("Successfully extracted tar archive to {}".format(dest_dir))
|
| 168 |
+
else:
|
| 169 |
+
return
|
| 170 |
+
|
| 171 |
+
def find_recent_files(directory):
|
| 172 |
+
"""
|
| 173 |
+
me: find files that is created with in one minutes under a directory with python, write a function
|
| 174 |
+
gpt: here it is!
|
| 175 |
+
"""
|
| 176 |
+
import os
|
| 177 |
+
import time
|
| 178 |
+
current_time = time.time()
|
| 179 |
+
one_minute_ago = current_time - 60
|
| 180 |
+
recent_files = []
|
| 181 |
+
|
| 182 |
+
for filename in os.listdir(directory):
|
| 183 |
+
file_path = os.path.join(directory, filename)
|
| 184 |
+
if file_path.endswith('.log'): continue
|
| 185 |
+
created_time = os.path.getctime(file_path)
|
| 186 |
+
if created_time >= one_minute_ago:
|
| 187 |
+
if os.path.isdir(file_path): continue
|
| 188 |
+
recent_files.append(file_path)
|
| 189 |
+
|
| 190 |
+
return recent_files
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
def on_file_uploaded(files, chatbot, txt):
|
| 194 |
+
if len(files) == 0: return chatbot, txt
|
| 195 |
+
import shutil, os, time, glob
|
| 196 |
+
from toolbox import extract_archive
|
| 197 |
+
try: shutil.rmtree('./private_upload/')
|
| 198 |
+
except: pass
|
| 199 |
+
time_tag = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime())
|
| 200 |
+
os.makedirs(f'private_upload/{time_tag}', exist_ok=True)
|
| 201 |
+
for file in files:
|
| 202 |
+
file_origin_name = os.path.basename(file.orig_name)
|
| 203 |
+
shutil.copy(file.name, f'private_upload/{time_tag}/{file_origin_name}')
|
| 204 |
+
extract_archive(f'private_upload/{time_tag}/{file_origin_name}',
|
| 205 |
+
dest_dir=f'private_upload/{time_tag}/{file_origin_name}.extract')
|
| 206 |
+
moved_files = [fp for fp in glob.glob('private_upload/**/*', recursive=True)]
|
| 207 |
+
txt = f'private_upload/{time_tag}'
|
| 208 |
+
moved_files_str = '\t\n\n'.join(moved_files)
|
| 209 |
+
chatbot.append(['我上传了文件,请查收',
|
| 210 |
+
f'[Local Message] 收到以下文件: \n\n{moved_files_str}\n\n调用路径参数已自动修正到: \n\n{txt}\n\n现在您点击任意实验功能时,以上文件将被作为输入参数'])
|
| 211 |
+
return chatbot, txt
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
def on_report_generated(files, chatbot):
|
| 215 |
+
from toolbox import find_recent_files
|
| 216 |
+
report_files = find_recent_files('gpt_log')
|
| 217 |
+
if len(report_files) == 0: return report_files, chatbot
|
| 218 |
+
# files.extend(report_files)
|
| 219 |
+
chatbot.append(['汇总报告如何远程获取?', '汇总报告已经添加到右侧文件上传区,请查收。'])
|
| 220 |
+
return report_files, chatbot
|