---
title: CogVideo
app_file: gradio_demo.py
sdk: gradio
sdk_version: 4.41.0
---
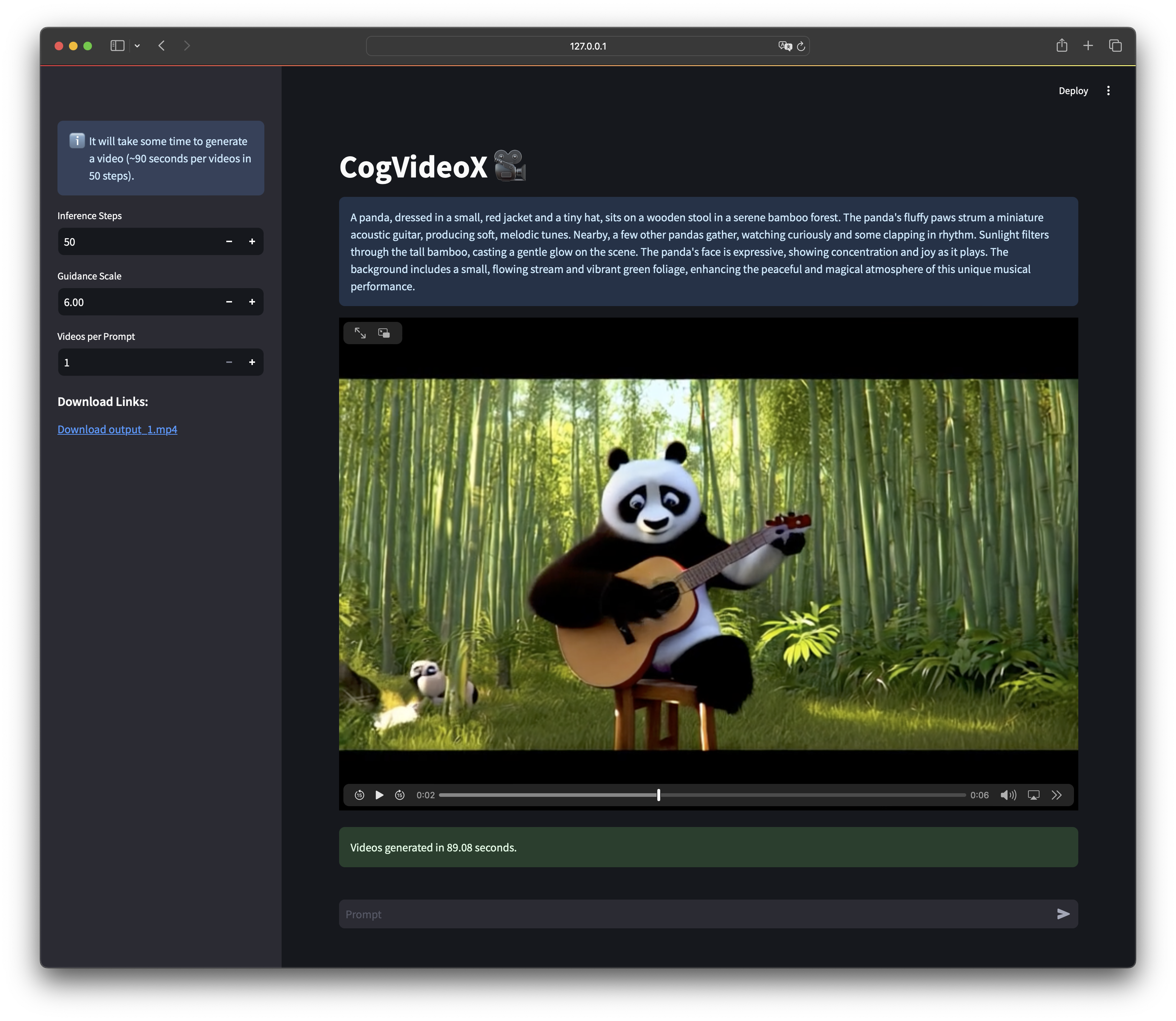
# CogVideo && CogVideoX
[中文阅读](./README_zh.md)
🤗 Experience on CogVideoX Huggingface Space
📚 Check here to view Paper
👋 Join our WeChat and Discord
📍 Visit 清影 and API Platform to experience larger-scale commercial video generation models.
## Update and News
- 🔥 **News**: ``2024/8/6``: We have also open-sourced **3D Causal VAE** used in **CogVideoX-2B**, which can reconstruct
the video almost losslessly.
- 🔥 **News**: ``2024/8/6``: We have open-sourced **CogVideoX-2B**,the first model in the CogVideoX series of video
generation models.
- 🌱 **Source**: ```2022/5/19```: We have open-sourced CogVideo (now you can see in `CogVideo` branch),the **first** open-sourced pretrained text-to-video model, and you can check [ICLR'23 CogVideo Paper](https://arxiv.org/abs/2205.15868) for technical details.
**More powerful models with larger parameter sizes are on the way~ Stay tuned!**
## CogVideoX-2B Gallery
A detailed wooden toy ship with intricately carved masts and sails is seen gliding smoothly over a plush, blue carpet that mimics the waves of the sea. The ship's hull is painted a rich brown, with tiny windows. The carpet, soft and textured, provides a perfect backdrop, resembling an oceanic expanse. Surrounding the ship are various other toys and children's items, hinting at a playful environment. The scene captures the innocence and imagination of childhood, with the toy ship's journey symbolizing endless adventures in a whimsical, indoor setting.
The camera follows behind a white vintage SUV with a black roof rack as it speeds up a steep dirt road surrounded by pine trees on a steep mountain slope, dust kicks up from its tires, the sunlight shines on the SUV as it speeds along the dirt road, casting a warm glow over the scene. The dirt road curves gently into the distance, with no other cars or vehicles in sight. The trees on either side of the road are redwoods, with patches of greenery scattered throughout. The car is seen from the rear following the curve with ease, making it seem as if it is on a rugged drive through the rugged terrain. The dirt road itself is surrounded by steep hills and mountains, with a clear blue sky above with wispy clouds.
A street artist, clad in a worn-out denim jacket and a colorful bandana, stands before a vast concrete wall in the heart, holding a can of spray paint, spray-painting a colorful bird on a mottled wall.
In the haunting backdrop of a war-torn city, where ruins and crumbled walls tell a story of devastation, a poignant close-up frames a young girl. Her face is smudged with ash, a silent testament to the chaos around her. Her eyes glistening with a mix of sorrow and resilience, capturing the raw emotion of a world that has lost its innocence to the ravages of conflict.
## Model Introduction
CogVideoX is an open-source version of the video generation model, which is homologous
to [清影](https://chatglm.cn/video?fr=osm_cogvideox).
The table below shows the list of video generation models we currently provide,
along with related basic information:
| Model Name | CogVideoX-2B |
|-------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Prompt Language | English |
| GPU Memory Required for Inference (FP16) | 18GB if using [SAT](https://github.com/THUDM/SwissArmyTransformer); 36GB if using diffusers (will be optimized before the PR is merged) |
| GPU Memory Required for Fine-tuning(bs=1) | 40GB |
| Prompt Max Length | 226 Tokens |
| Video Length | 6 seconds |
| Frames Per Second | 8 frames |
| Resolution | 720 * 480 |
| Quantized Inference | Not Supported |
| Multi-card Inference | Not Supported |
| Download Link (HF diffusers Model) | 🤗 [Huggingface](https://huggingface.co/THUDM/CogVideoX-2B) [🤖 ModelScope](https://modelscope.cn/models/ZhipuAI/CogVideoX-2b) [💫 WiseModel](https://wisemodel.cn/models/ZhipuAI/CogVideoX-2b) |
| Download Link (SAT Model) | [SAT](./sat/README.md) |
## Project Structure
This open-source repository will guide developers to quickly get started with the basic usage and fine-tuning examples
of the **CogVideoX** open-source model.
### Inference
+ [cli_demo](inference/cli_demo.py): A more detailed explanation of the inference code, mentioning the significance of common parameters.
+ [cli_vae_demo](inference/cli_vae_demo.py): Executing the VAE inference code alone currently requires 71GB of memory, but it will be optimized in the future.
+ [convert_demo](inference/convert_demo.py): How to convert user input into a format suitable for CogVideoX. Because CogVideoX is trained on long caption, we need to convert the input text to be consistent with the training distribution using a LLM. By default, the script uses GLM4, but it can also be replaced with any other LLM such as GPT, Gemini, etc.
+ [web_demo](inference/web_demo.py): A simple streamlit web application demonstrating how to use the CogVideoX-2B model to generate videos.
### sat
+ [sat_demo](sat/README.md): Contains the inference code and fine-tuning code of SAT weights. It is
recommended to improve based on the CogVideoX model structure. Innovative researchers use this code to better perform
rapid stacking and development.
### Tools
This folder contains some tools for model conversion / caption generation, etc.
+ [convert_weight_sat2hf](tools/convert_weight_sat2hf.py): Convert SAT model weights to Huggingface model weights.
+ [caption_demo](tools/caption): Caption tool, a model that understands videos and outputs them in text.
## Project Plan
- [x] Open source CogVideoX model
- [x] Open source 3D Causal VAE used in CogVideoX.
- [x] CogVideoX model inference example (CLI / Web Demo)
- [x] CogVideoX online experience demo (Huggingface Space)
- [x] CogVideoX open source model API interface example (Huggingface)
- [x] CogVideoX model fine-tuning example (SAT)
- [ ] CogVideoX model fine-tuning example (Huggingface / SAT)
- [ ] Open source CogVideoX-Pro (adapted for CogVideoX-2B suite)
- [x] Release CogVideoX technical report
We welcome your contributions. You can click [here](resources/contribute.md) for more information.
## Model License
The code in this repository is released under the [Apache 2.0 License](LICENSE).
The model weights and implementation code are released under the [CogVideoX LICENSE](MODEL_LICENSE).
## CogVideo(ICLR'23)
The official repo for the paper: [CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers](https://arxiv.org/abs/2205.15868) is on the [CogVideo branch](https://github.com/THUDM/CogVideo/tree/CogVideo)
**CogVideo is able to generate relatively high-frame-rate videos.**
A 4-second clip of 32 frames is shown below.


The demo for CogVideo is at [https://models.aminer.cn/cogvideo](https://models.aminer.cn/cogvideo/), where you can get hands-on practice on text-to-video generation. *The original input is in Chinese.*
## Citation
🌟 If you find our work helpful, please leave us a star and cite our paper.
```
@article{yang2024cogvideox,
title={CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer},
author={Zhuoyi Yang and Jiayan Teng and Wendi Zheng and Ming Ding and Shiyu Huang and JiaZheng Xu and Yuanming Yang and Xiaohan Zhang and Xiaotao Gu and Guanyu Feng and Da Yin and Wenyi Hong and Weihan Wang and Yean Cheng and Yuxuan Zhang and Ting Liu and Bin Xu and Yuxiao Dong and Jie Tang},
year={2024},
}
@article{hong2022cogvideo,
title={CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers},
author={Hong, Wenyi and Ding, Ming and Zheng, Wendi and Liu, Xinghan and Tang, Jie},
journal={arXiv preprint arXiv:2205.15868},
year={2022}
}
```