Spaces:
Running

Running
| #import module | |
| import streamlit as st | |
| from PIL import Image | |
| #===config=== | |
| st.set_page_config( | |
| page_title="Coconut", | |
| page_icon="🥥", | |
| layout="wide" | |
| ) | |
| st.title('🥥 Coconut Library Tool') | |
| hide_streamlit_style = """ | |
| <style> | |
| #MainMenu {visibility: hidden;} | |
| footer {visibility: hidden;} | |
| </style> | |
| """ | |
| st.markdown(hide_streamlit_style, unsafe_allow_html=True) | |
| st.sidebar.success('Select page above') | |
| #===page=== | |
| mt1, mt2, mt3 = st.tabs(["About", "How to", "Behind this app"]) | |
| with mt1: | |
| st.header("Hello and welcome to the Coconut Library Tool!") | |
| st.write("The coconut tree is known as one of the most useful trees. Each part of this important tree has an integral function from the leaves producing oxygen through photosynthesis to the shells, oil, wood, flowers, and husks being used in a variety of ways, such as building houses, cooking, and more.") | |
| st.write("Our philosophy aspires to emulate this highly cohesive and functionally unified environment where each part serves a specific function to the greater whole. 🌴 Just like the coconut tree, the Coconut Library Tool is the all-in-one data mining and textual analysis tool for librarians or anyone interested in these applications. Our tool does not require any prior knowledge of coding or programming, making it approachable and great for users who want to test out these data analysis and visualization techniques.") | |
| st.write("We cannot thank everyone enough for who has assisted in the creation of this tool. Due to each individual’s efforts, science will advance, allowing for multiple analysis and visualization techniques to coexist within this one tool. 🧑🏻🤝🧑🏾") | |
| st.text('') | |
| st.divider() | |
| st.text('We support Scopus, Web of Science, Lens, as well as personalized CSV files. Further information can be found in the "How to" section.') | |
| st.text('') | |
| st.divider() | |
| st.write('To cite the Coconut Library Tool, please use the following reference:') | |
| st.info("Santosa, Faizhal Arif, George, Crissandra J., & Lamba, Manika. (2023). Coconut Library Tool (1.0.0). Zenodo. https://doi.org/10.5281/zenodo.8323458", icon="✍️ ") | |
| with mt2: | |
| st.header("Before you start") | |
| option = st.selectbox( | |
| 'Please choose....', | |
| ('Keyword Stem', 'Topic Modeling', 'Bidirected Network', 'Sunburst')) | |
| if option == 'Keyword Stem': | |
| tab1, tab2, tab3, tab4 = st.tabs(["Prologue", "Steps", "Requirements", "Download Result"]) | |
| with tab1: | |
| st.write("This approach is effective for locating basic words and aids in catching the true meaning of the word, which can lead to improved semantic analysis and comprehension of the text. Some people find it difficult to check keywords before performing bibliometrics (using software such as VOSviewer and Bibliometrix). This strategy makes it easy to combine and search for fundamental words from keywords, especially if you have a large number of keywords. To do stemming or lemmatization on other text, change the column name to 'Keyword' in your file.") | |
| st.divider() | |
| st.write('💡 The idea came from this:') | |
| st.write('Santosa, F. A. (2022). Prior steps into knowledge mapping: Text mining application and comparison. Issues in Science and Technology Librarianship, 102. https://doi.org/10.29173/istl2736') | |
| with tab2: | |
| st.text("1. Put your file.") | |
| st.text("2. Choose your preferable method. Picture below may help you to choose wisely.") | |
| st.markdown("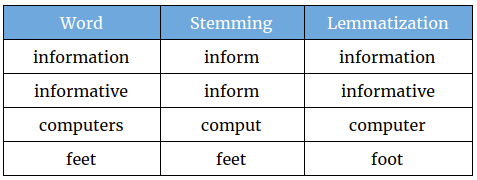") | |
| st.text('Source: https://studymachinelearning.com/stemming-and-lemmatization/') | |
| st.text("3. Now you need to select what kind of keywords you need.") | |
| st.text("4. Finally, you can download and use the file on VOSviewer, Bibliometrix, or put it on OpenRefine to get better result!") | |
| st.error("Please check what has changed. It's possible some keywords failed to find their roots.", icon="🚨") | |
| with tab3: | |
| st.text(""" | |
| +----------------+------------------------+---------------------------------+ | |
| | Source | File Type | Column | | |
| +----------------+------------------------+---------------------------------+ | |
| | Scopus | Comma-separated values | Author Keywords | | |
| | | (.csv) | Index Keywords | | |
| +----------------+------------------------+---------------------------------+ | |
| | Web of Science | Tab delimited file | Author Keywords | | |
| | | (.txt) | Keywords Plus | | |
| +----------------+------------------------+---------------------------------+ | |
| | Lens.org | Comma-separated values | Keywords (Scholarly Works) | | |
| | | (.csv) | | | |
| +----------------+------------------------+---------------------------------+ | |
| | Other | .csv | Change your column to 'Keyword' | | |
| +----------------+------------------------+---------------------------------+ | |
| """) | |
| with tab4: | |
| st.subheader(':blue[Result]') | |
| st.button('Press to download result 👈') | |
| st.text("Go to Result and click Download button.") | |
| st.divider() | |
| st.subheader(':blue[List of Keywords]') | |
| st.button('Press to download keywords 👈') | |
| st.text("Go to List of Keywords and click Download button.") | |
| elif option == 'Topic Modeling': | |
| tab1, tab2, tab3, tab4 = st.tabs(["Prologue", "Steps", "Requirements", "Download Visualization"]) | |
| with tab1: | |
| st.write("Topic modeling has numerous advantages for librarians in different aspects of their work. A crucial benefit is an ability to quickly organize and categorize a huge volume of textual content found in websites, institutional archives, databases, emails, and reference desk questions. Librarians can use topic modeling approaches to automatically identify the primary themes or topics within these documents, making navigating and retrieving relevant information easier. Librarians can identify and understand the prevailing topics of discussion by analyzing text data with topic modeling tools, allowing them to assess user feedback, tailor their services to meet specific needs and make informed decisions about collection development and resource allocation. Making ontologies, automatic subject classification, recommendation services, bibliometrics, altmetrics, and better resource searching and retrieval are a few examples of topic modeling. To do topic modeling on other text like chats and surveys, change the column name to 'Abstract' in your file.") | |
| st.divider() | |
| st.write('💡 The idea came from this:') | |
| st.write('Lamba, M., & Madhusudhan, M. (2021, July 31). Topic Modeling. Text Mining for Information Professionals, 105–137. https://doi.org/10.1007/978-3-030-85085-2_4') | |
| with tab2: | |
| st.text("1. Put your file. Choose your preferred column.") | |
| st.text("2. Choose your preferred method. LDA is the most widely used, whereas Biterm is appropriate for short text, and BERTopic works well for large text data as well as supports more than 50+ languages.") | |
| st.text("3. Finally, you can visualize your data.") | |
| st.error("This app includes lemmatization and stopwords for the abstract text. Currently, we only offer English words.", icon="💬") | |
| with tab3: | |
| st.text(""" | |
| +----------------+------------------------+----------------------------------+ | |
| | Source | File Type | Column | | |
| +----------------+------------------------+----------------------------------+ | |
| | Scopus | Comma-separated values | Choose your preferred column | | |
| | | (.csv) | that you have | | |
| +----------------+------------------------| | | |
| | Web of Science | Tab delimited file | | | |
| | | (.txt) | | | |
| +----------------+------------------------| | | |
| | Lens.org | Comma-separated values | | | |
| | | (.csv) | | | |
| +----------------+------------------------| | | |
| | Other | .csv | | | |
| +----------------+------------------------+----------------------------------+ | |
| """) | |
| with tab4: | |
| st.subheader(':blue[pyLDA]') | |
| st.button('Download image') | |
| st.text("Click Download Image button.") | |
| st.divider() | |
| st.subheader(':blue[Biterm]') | |
| st.text("Click the three dots at the top right then select the desired format.") | |
| st.markdown("") | |
| st.divider() | |
| st.subheader(':blue[BERTopic]') | |
| st.text("Click the camera icon on the top right menu") | |
| st.markdown("") | |
| elif option == 'Bidirected Network': | |
| tab1, tab2, tab3, tab4 = st.tabs(["Prologue", "Steps", "Requirements", "Download Graph"]) | |
| with tab1: | |
| st.write("The use of network text analysis by librarians can be quite beneficial. Finding hidden correlations and connections in textual material is a significant advantage. Using network text analysis tools, librarians can improve knowledge discovery, obtain deeper insights, and support scholars meaningfully, ultimately enhancing the library's services and resources. This menu provides a two-way relationship instead of the general network of relationships to enhance the co-word analysis. Since it is based on ARM, you may obtain transactional data information using this menu. Please name the column in your file 'Keyword' instead.") | |
| st.divider() | |
| st.write('💡 The idea came from this:') | |
| st.write('Santosa, F. (2023). Adding Perspective to the Bibliometric Mapping Using Bidirected Graph. Open Information Science, 7(1), 20220152. https://doi.org/10.1515/opis-2022-0152') | |
| with tab2: | |
| st.text("1. Put your file.") | |
| st.text("2. Choose your preferable method. Picture below may help you to choose wisely.") | |
| st.markdown("") | |
| st.text('Source: https://studymachinelearning.com/stemming-and-lemmatization/') | |
| st.text("3. Choose the value of Support and Confidence. If you're not sure how to use it please read the article above or just try it!") | |
| st.text("4. You can see the table and a simple visualization before making a network visualization.") | |
| st.text('5. Click "Generate network visualization" to see the network') | |
| st.error("The more data on your table, the more you'll see on network.", icon="🚨") | |
| st.error("If the table contains many rows, the network will take more time to process. Please use it efficiently.", icon="⌛") | |
| with tab3: | |
| st.text(""" | |
| +----------------+------------------------+---------------------------------+ | |
| | Source | File Type | Column | | |
| +----------------+------------------------+---------------------------------+ | |
| | Scopus | Comma-separated values | Author Keywords | | |
| | | (.csv) | Index Keywords | | |
| +----------------+------------------------+---------------------------------+ | |
| | Web of Science | Tab delimited file | Author Keywords | | |
| | | (.txt) | Keywords Plus | | |
| +----------------+------------------------+---------------------------------+ | |
| | Lens.org | Comma-separated values | Keywords (Scholarly Works) | | |
| | | (.csv) | | | |
| +----------------+------------------------+---------------------------------+ | |
| | Other | .csv | Change your column to 'Keyword' | | |
| | | | and separate the words with ';' | | |
| +----------------+------------------------+---------------------------------+ | |
| """) | |
| with tab4: | |
| st.subheader(':blue[Bidirected Network]') | |
| st.text("Zoom in, zoom out, or shift the nodes as desired, then right-click and select Save image as ...") | |
| st.markdown("") | |
| elif option == 'Sunburst': | |
| tab1, tab2, tab3, tab4 = st.tabs(["Prologue", "Steps", "Requirements", "Download Visualization"]) | |
| with tab1: | |
| st.write("Sunburst's ability to present a thorough and intuitive picture of complex hierarchical data is an essential benefit. Librarians can easily browse and grasp the relationships between different levels of the hierarchy by employing sunburst visualizations. Sunburst visualizations can also be interactive, letting librarians and users drill down into certain categories or subcategories for further information. This interactive and visually appealing depiction improves the librarian's understanding of the collection and provides users with an engaging and user-friendly experience, resulting in improved information retrieval and decision-making.") | |
| with tab2: | |
| st.text("1. Put your Scopus CSV file.") | |
| st.text("2. You can set the range of years to see how it changed.") | |
| st.text("3. The sunburst has 3 levels. The inner circle is the type of data, meanwhile, the middle is the source title and the outer is the year the article was published.") | |
| st.text("4. The size of the slice depends on total documents. The average of inner and middle levels is calculated by formula below:") | |
| st.code('avg = sum(a * weights) / sum(weights)', language='python') | |
| with tab3: | |
| st.text(""" | |
| +----------------+------------------------+--------------------+ | |
| | Source | File Type | Column | | |
| +----------------+------------------------+--------------------+ | |
| | Scopus | Comma-separated values | Source title, | | |
| | | (.csv) | Document Type, | | |
| +----------------+------------------------| Cited by, Year | | |
| | Web of Science | Tab delimited file | | | |
| | | (.txt) | | | |
| +----------------+------------------------+--------------------+ | |
| | Lens.org | Comma-separated values | Publication Year, | | |
| | | (.csv) | Publication Type, | | |
| | | | Source Title, | | |
| | | | Citing Works Count | | |
| +----------------+------------------------+--------------------+ | |
| """) | |
| with tab4: | |
| st.subheader(':blue[Sunburst]') | |
| st.text("Click the camera icon on the top right menu") | |
| st.markdown("") | |
| with mt3: | |
| st.header('Behind this app') | |
| st.subheader('Faizhal Arif Santosa') | |
| st.text('Academic Librarian. Polytechnic Institute of Nuclear Technology, National Research and Innovation Agency.') | |
| st.text('') | |
| st.subheader('Crissandra George') | |
| st.text('Digital Collections Manager Librarian. Case Western Reserve University.') | |
| st.text('') | |
| st.divider() | |
| st.header('Advisor') | |
| st.subheader('Dr. Manika Lamba') | |
| st.text('Postdoctoral Research Associate. University of Illinois Urbana-Champaign.') | |
| st.text('') | |
| st.text('') | |
| st.divider() | |
| st.text('If you want to take a part, please let us know!') |