Spaces:
Sleeping

Sleeping
Upload 24 files
Browse files- .gitattributes +2 -0
- LICENSE +21 -0
- arguments.py +111 -0
- assets/concept.png +3 -0
- assets/example_prompts.txt +30 -0
- assets/examples.png +3 -0
- assets/logo.png +0 -0
- environment.yml +24 -0
- main.py +274 -0
- models/RewardPixart.py +394 -0
- models/RewardStableDiffusion.py +277 -0
- models/RewardStableDiffusionXL.py +320 -0
- models/__init__.py +1 -0
- models/utils.py +109 -0
- rewards/__init__.py +1 -0
- rewards/aesthetic.py +118 -0
- rewards/base_reward.py +46 -0
- rewards/clip.py +54 -0
- rewards/hps.py +57 -0
- rewards/imagereward.py +61 -0
- rewards/pickscore.py +55 -0
- rewards/utils.py +79 -0
- training/__init__.py +2 -0
- training/optim.py +21 -0
- training/trainer.py +125 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
assets/concept.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
assets/examples.png filter=lfs diff=lfs merge=lfs -text
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2024 EML
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
arguments.py
ADDED
|
@@ -0,0 +1,111 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def parse_args():
|
| 5 |
+
parser = argparse.ArgumentParser(description="Process Reward Optimization.")
|
| 6 |
+
|
| 7 |
+
# update paths here!
|
| 8 |
+
parser.add_argument(
|
| 9 |
+
"--cache_dir",
|
| 10 |
+
type=str,
|
| 11 |
+
help="HF cache directory",
|
| 12 |
+
default="/shared-local/aoq951/HF_CACHE/",
|
| 13 |
+
)
|
| 14 |
+
parser.add_argument(
|
| 15 |
+
"--save_dir",
|
| 16 |
+
type=str,
|
| 17 |
+
help="Directory to save images",
|
| 18 |
+
default="/shared-local/aoq951/ReNO/outputs",
|
| 19 |
+
)
|
| 20 |
+
|
| 21 |
+
# model and optim
|
| 22 |
+
parser.add_argument("--model", type=str, help="Model to use", default="sdxl-turbo")
|
| 23 |
+
parser.add_argument("--lr", type=float, help="Learning rate", default=5.0)
|
| 24 |
+
parser.add_argument("--n_iters", type=int, help="Number of iterations", default=50)
|
| 25 |
+
parser.add_argument(
|
| 26 |
+
"--n_inference_steps", type=int, help="Number of iterations", default=1
|
| 27 |
+
)
|
| 28 |
+
parser.add_argument(
|
| 29 |
+
"--optim",
|
| 30 |
+
choices=["sgd", "adam", "lbfgs"],
|
| 31 |
+
default="sgd",
|
| 32 |
+
help="Optimizer to be used",
|
| 33 |
+
)
|
| 34 |
+
parser.add_argument("--nesterov", default=True, action="store_false")
|
| 35 |
+
parser.add_argument(
|
| 36 |
+
"--grad_clip", type=float, help="Gradient clipping", default=0.1
|
| 37 |
+
)
|
| 38 |
+
parser.add_argument("--seed", type=int, help="Seed to use", default=0)
|
| 39 |
+
|
| 40 |
+
# reward losses
|
| 41 |
+
parser.add_argument("--disable_hps", default=True, action="store_false",dest="enable_hps")
|
| 42 |
+
parser.add_argument(
|
| 43 |
+
"--hps_weighting", type=float, help="Weighting for HPS", default=5.0
|
| 44 |
+
)
|
| 45 |
+
parser.add_argument("--disable_imagereward", default=True, action="store_false",dest='enable_imagereward')
|
| 46 |
+
parser.add_argument(
|
| 47 |
+
"--imagereward_weighting",
|
| 48 |
+
type=float,
|
| 49 |
+
help="Weighting for ImageReward",
|
| 50 |
+
default=1.0,
|
| 51 |
+
)
|
| 52 |
+
parser.add_argument("--disable_clip", default=True, action="store_false",dest='enable_clip')
|
| 53 |
+
parser.add_argument(
|
| 54 |
+
"--clip_weighting", type=float, help="Weighting for CLIP", default=0.01
|
| 55 |
+
)
|
| 56 |
+
parser.add_argument("--disable_pickscore", default=True, action="store_false",dest='enable_pickscore')
|
| 57 |
+
parser.add_argument(
|
| 58 |
+
"--pickscore_weighting",
|
| 59 |
+
type=float,
|
| 60 |
+
help="Weighting for PickScore",
|
| 61 |
+
default=0.05,
|
| 62 |
+
)
|
| 63 |
+
parser.add_argument("--disable_aesthetic", default=False, action="store_false",dest='enable_aesthetic')
|
| 64 |
+
parser.add_argument(
|
| 65 |
+
"--aesthetic_weighting",
|
| 66 |
+
type=float,
|
| 67 |
+
help="Weighting for Aesthetic",
|
| 68 |
+
default=0.0,
|
| 69 |
+
)
|
| 70 |
+
parser.add_argument("--disable_reg", default=True, action="store_false",dest='enable_reg')
|
| 71 |
+
parser.add_argument(
|
| 72 |
+
"--reg_weight", type=float, help="Regularization weight", default=0.01
|
| 73 |
+
)
|
| 74 |
+
|
| 75 |
+
# task specific
|
| 76 |
+
parser.add_argument(
|
| 77 |
+
"--task",
|
| 78 |
+
type=str,
|
| 79 |
+
help="Task to run",
|
| 80 |
+
default="single",
|
| 81 |
+
choices=[
|
| 82 |
+
"t2i-compbench",
|
| 83 |
+
"single",
|
| 84 |
+
"parti-prompts",
|
| 85 |
+
"geneval",
|
| 86 |
+
"example-prompts",
|
| 87 |
+
],
|
| 88 |
+
)
|
| 89 |
+
parser.add_argument(
|
| 90 |
+
"--prompt",
|
| 91 |
+
type=str,
|
| 92 |
+
help="Prompt to run",
|
| 93 |
+
default="A red dog and a green cat",
|
| 94 |
+
)
|
| 95 |
+
parser.add_argument(
|
| 96 |
+
"--benchmark_reward",
|
| 97 |
+
help="Reward to benchmark on",
|
| 98 |
+
default="total",
|
| 99 |
+
choices=["ImageReward", "PickScore", "HPS", "CLIP", "total"],
|
| 100 |
+
)
|
| 101 |
+
|
| 102 |
+
# general
|
| 103 |
+
parser.add_argument("--save_all_images", default=False, action="store_true")
|
| 104 |
+
parser.add_argument("--no_optim", default=False, action="store_true")
|
| 105 |
+
parser.add_argument("--imageselect", default=False, action="store_true")
|
| 106 |
+
parser.add_argument("--memsave", default=False, action="store_true")
|
| 107 |
+
parser.add_argument("--device", type=str, help="Device to use", default="cuda")
|
| 108 |
+
parser.add_argument("--device_id", type=int, help="Device ID to use", default=None)
|
| 109 |
+
|
| 110 |
+
args = parser.parse_args()
|
| 111 |
+
return args
|
assets/concept.png
ADDED
|
Git LFS Details
|
assets/example_prompts.txt
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
A minimalist logo design of a reindeer, fully rendered. The reindeer features distinct, complete shapes using bold and flat colors. The design emphasizes simplicity and clarity, suitable for logo use with a sharp outline and white background.
|
| 2 |
+
A red dog and a green cat
|
| 3 |
+
A green dog and a red cat
|
| 4 |
+
A pink elephant and a grey cow
|
| 5 |
+
A grey elephant and a pink cow
|
| 6 |
+
A yellow reindeer and a blue elephant
|
| 7 |
+
A blue reindeer and a yellow elephant
|
| 8 |
+
An orange chair to the right of a black airplane
|
| 9 |
+
Three dogs and two horses
|
| 10 |
+
A cat playing checkers
|
| 11 |
+
High quality photo of a monkey astronaut infront of the Eiffel tower
|
| 12 |
+
A bird with 8 legs
|
| 13 |
+
A brain riding a rocketship towards the moon
|
| 14 |
+
A toaster riding a bike
|
| 15 |
+
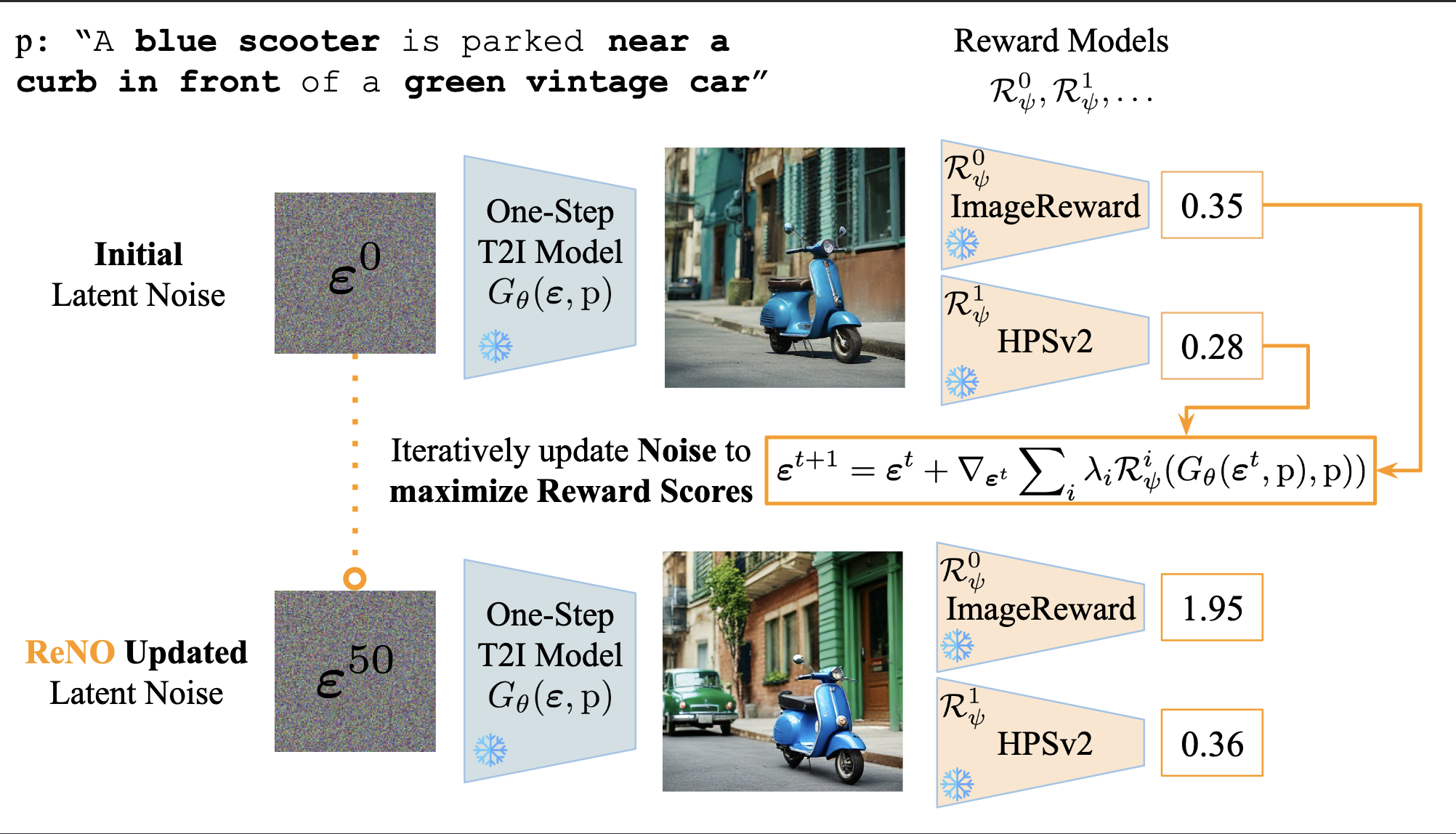
A blue scooter is parked near a curb in front of a green vintage car
|
| 16 |
+
A curious, orange fox and a fluffy, white rabbit, playing together in a lush, green meadow filled with yellow dandelions
|
| 17 |
+
An epic oil painting: a red portal infront of a cityscape, a solitary figure, and a colorful sky over snowy mountains
|
| 18 |
+
A futuristic painting: Red car escapes giant shark's leap, right; ominous mountains, blue sky
|
| 19 |
+
A majestic, resilient sea ship navigates the icy wilderness in the style of Star Wars
|
| 20 |
+
Dwayne Johnson depicted as a philosopher king in an academic painting by Greg Rutkowski
|
| 21 |
+
Taylor Swift depicted as a prime minister in an academic painting by Kandinsky
|
| 22 |
+
A watercolor painting: a floating island, multiple animals under a majestic tree with golden leaves, and a vibrant rainbow stretching across a pastel sky
|
| 23 |
+
A Japanese-style ink painting: a traditional wooden bridge, a pagoda, a lone samurai warrior, and cherry blossom petals over a tranquil river
|
| 24 |
+
A retro-futuristic pixel art scene: a flying car, an imperial senate building, a green park, and a purple sunset
|
| 25 |
+
A impressionistic oil painting: a lone figure walking on a misty beach, a weathered lighthouse on a cliff, seagulls above crashing waves
|
| 26 |
+
A fairytale castle with a golden-haired woman in a floral-patterned metallic frame, and a vase with lilies
|
| 27 |
+
A post-apocalyptic digital artwork: crumbling skyscrapers, an abandoned car overgrown with vines, and a fiery orange sunset casting long shadows
|
| 28 |
+
A stop sign infront of a traffic light
|
| 29 |
+
A sign on a grocery store that has 'ENTRY' written on it
|
| 30 |
+
A colorful poster with the title 'INTERGALACTICAL' written on it
|
assets/examples.png
ADDED

|
Git LFS Details
|
assets/logo.png
ADDED
|
|
environment.yml
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: reno
|
| 2 |
+
channels:
|
| 3 |
+
- pytorch
|
| 4 |
+
- nvidia
|
| 5 |
+
- conda-forge
|
| 6 |
+
dependencies:
|
| 7 |
+
- python=3.11
|
| 8 |
+
- pytorch=2.3
|
| 9 |
+
- torchvision=0.18.0
|
| 10 |
+
- pytorch-cuda
|
| 11 |
+
- pytorch-lightning=2.2
|
| 12 |
+
- pip
|
| 13 |
+
- pip:
|
| 14 |
+
- datasets==2.18
|
| 15 |
+
- transformers==4.38.2
|
| 16 |
+
- diffusers==0.28
|
| 17 |
+
- hpsv2==1.2
|
| 18 |
+
- image-reward==1.5
|
| 19 |
+
- open-clip-torch==2.24
|
| 20 |
+
- blobfile
|
| 21 |
+
- openai-clip
|
| 22 |
+
- setuptools==60.2
|
| 23 |
+
- optimum
|
| 24 |
+
- xformers
|
main.py
ADDED
|
@@ -0,0 +1,274 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import logging
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
import blobfile as bf
|
| 6 |
+
import torch
|
| 7 |
+
from datasets import load_dataset
|
| 8 |
+
from pytorch_lightning import seed_everything
|
| 9 |
+
from tqdm import tqdm
|
| 10 |
+
|
| 11 |
+
from arguments import parse_args
|
| 12 |
+
from models import get_model
|
| 13 |
+
from rewards import get_reward_losses
|
| 14 |
+
from training import LatentNoiseTrainer, get_optimizer
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def main(args):
|
| 18 |
+
seed_everything(args.seed)
|
| 19 |
+
bf.makedirs(f"{args.save_dir}/logs/{args.task}")
|
| 20 |
+
# Set up logging and name settings
|
| 21 |
+
logger = logging.getLogger()
|
| 22 |
+
settings = (
|
| 23 |
+
f"{args.model}{'_' + args.prompt if args.task == 't2i-compbench' else ''}"
|
| 24 |
+
f"{'_no-optim' if args.no_optim else ''}_{args.seed if args.task != 'geneval' else ''}"
|
| 25 |
+
f"_lr{args.lr}_gc{args.grad_clip}_iter{args.n_iters}"
|
| 26 |
+
f"_reg{args.reg_weight if args.enable_reg else '0'}"
|
| 27 |
+
f"{'_pickscore' + str(args.pickscore_weighting) if args.enable_pickscore else ''}"
|
| 28 |
+
f"{'_clip' + str(args.clip_weighting) if args.enable_clip else ''}"
|
| 29 |
+
f"{'_hps' + str(args.hps_weighting) if args.enable_hps else ''}"
|
| 30 |
+
f"{'_imagereward' + str(args.imagereward_weighting) if args.enable_imagereward else ''}"
|
| 31 |
+
f"{'_aesthetic' + str(args.aesthetic_weighting) if args.enable_aesthetic else ''}"
|
| 32 |
+
)
|
| 33 |
+
file_stream = open(f"{args.save_dir}/logs/{args.task}/{settings}.txt", "w")
|
| 34 |
+
handler = logging.StreamHandler(file_stream)
|
| 35 |
+
formatter = logging.Formatter("%(asctime)s - %(message)s")
|
| 36 |
+
handler.setFormatter(formatter)
|
| 37 |
+
logger.addHandler(handler)
|
| 38 |
+
logger.setLevel("INFO")
|
| 39 |
+
consoleHandler = logging.StreamHandler()
|
| 40 |
+
consoleHandler.setFormatter(formatter)
|
| 41 |
+
logger.addHandler(consoleHandler)
|
| 42 |
+
logging.info(args)
|
| 43 |
+
if args.device_id is not None:
|
| 44 |
+
logging.info(f"Using CUDA device {args.device_id}")
|
| 45 |
+
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
|
| 46 |
+
os.environ["CUDA_VISIBLE_DEVICE"] = args.device_id
|
| 47 |
+
if args.device == "cuda":
|
| 48 |
+
device = torch.device("cuda")
|
| 49 |
+
else:
|
| 50 |
+
device = torch.device("cpu")
|
| 51 |
+
# Set dtype to fp16
|
| 52 |
+
dtype = torch.float16
|
| 53 |
+
# Get reward losses
|
| 54 |
+
reward_losses = get_reward_losses(args, dtype, device, args.cache_dir)
|
| 55 |
+
|
| 56 |
+
# Get model and noise trainer
|
| 57 |
+
sd_model = get_model(args.model, dtype, device, args.cache_dir, args.memsave)
|
| 58 |
+
trainer = LatentNoiseTrainer(
|
| 59 |
+
reward_losses=reward_losses,
|
| 60 |
+
model=sd_model,
|
| 61 |
+
n_iters=args.n_iters,
|
| 62 |
+
n_inference_steps=args.n_inference_steps,
|
| 63 |
+
seed=args.seed,
|
| 64 |
+
save_all_images=args.save_all_images,
|
| 65 |
+
device=device,
|
| 66 |
+
no_optim=args.no_optim,
|
| 67 |
+
regularize=args.enable_reg,
|
| 68 |
+
regularization_weight=args.reg_weight,
|
| 69 |
+
grad_clip=args.grad_clip,
|
| 70 |
+
log_metrics=args.task == "single" or not args.no_optim,
|
| 71 |
+
imageselect=args.imageselect,
|
| 72 |
+
)
|
| 73 |
+
|
| 74 |
+
# Create latents
|
| 75 |
+
if args.model != "pixart":
|
| 76 |
+
height = sd_model.unet.config.sample_size * sd_model.vae_scale_factor
|
| 77 |
+
width = sd_model.unet.config.sample_size * sd_model.vae_scale_factor
|
| 78 |
+
shape = (
|
| 79 |
+
1,
|
| 80 |
+
sd_model.unet.in_channels,
|
| 81 |
+
height // sd_model.vae_scale_factor,
|
| 82 |
+
width // sd_model.vae_scale_factor,
|
| 83 |
+
)
|
| 84 |
+
else:
|
| 85 |
+
height = sd_model.transformer.config.sample_size * sd_model.vae_scale_factor
|
| 86 |
+
width = sd_model.transformer.config.sample_size * sd_model.vae_scale_factor
|
| 87 |
+
shape = (
|
| 88 |
+
1,
|
| 89 |
+
sd_model.transformer.config.in_channels,
|
| 90 |
+
height // sd_model.vae_scale_factor,
|
| 91 |
+
width // sd_model.vae_scale_factor,
|
| 92 |
+
)
|
| 93 |
+
enable_grad = not args.no_optim
|
| 94 |
+
|
| 95 |
+
if args.task == "single":
|
| 96 |
+
init_latents = torch.randn(shape, device=device, dtype=dtype)
|
| 97 |
+
latents = torch.nn.Parameter(init_latents, requires_grad=enable_grad)
|
| 98 |
+
optimizer = get_optimizer(args.optim, latents, args.lr, args.nesterov)
|
| 99 |
+
save_dir = f"{args.save_dir}/{args.task}/{settings}/{args.prompt}"
|
| 100 |
+
os.makedirs(f"{save_dir}", exist_ok=True)
|
| 101 |
+
best_image, total_init_rewards, total_best_rewards = trainer.train(
|
| 102 |
+
latents, args.prompt, optimizer, save_dir
|
| 103 |
+
)
|
| 104 |
+
best_image.save(f"{save_dir}/best_image.png")
|
| 105 |
+
elif args.task == "example-prompts":
|
| 106 |
+
fo = open("assets/example_prompts.txt", "r")
|
| 107 |
+
prompts = fo.readlines()
|
| 108 |
+
fo.close()
|
| 109 |
+
for i, prompt in tqdm(enumerate(prompts)):
|
| 110 |
+
# Get new latents and optimizer
|
| 111 |
+
init_latents = torch.randn(shape, device=device, dtype=dtype)
|
| 112 |
+
latents = torch.nn.Parameter(init_latents, requires_grad=enable_grad)
|
| 113 |
+
optimizer = get_optimizer(args.optim, latents, args.lr, args.nesterov)
|
| 114 |
+
|
| 115 |
+
prompt = prompt.strip()
|
| 116 |
+
name = f"{i:03d}_{prompt}.png"
|
| 117 |
+
save_dir = f"{args.save_dir}/{args.task}/{settings}/{name}"
|
| 118 |
+
os.makedirs(save_dir, exist_ok=True)
|
| 119 |
+
best_image, init_rewards, best_rewards = trainer.train(
|
| 120 |
+
latents, prompt, optimizer, save_dir
|
| 121 |
+
)
|
| 122 |
+
if i == 0:
|
| 123 |
+
total_best_rewards = {k: 0.0 for k in best_rewards.keys()}
|
| 124 |
+
total_init_rewards = {k: 0.0 for k in best_rewards.keys()}
|
| 125 |
+
for k in best_rewards.keys():
|
| 126 |
+
total_best_rewards[k] += best_rewards[k]
|
| 127 |
+
total_init_rewards[k] += init_rewards[k]
|
| 128 |
+
best_image.save(f"{save_dir}/best_image.png")
|
| 129 |
+
logging.info(f"Initial rewards: {init_rewards}")
|
| 130 |
+
logging.info(f"Best rewards: {best_rewards}")
|
| 131 |
+
for k in total_best_rewards.keys():
|
| 132 |
+
total_best_rewards[k] /= len(prompts)
|
| 133 |
+
total_init_rewards[k] /= len(prompts)
|
| 134 |
+
|
| 135 |
+
# save results to directory
|
| 136 |
+
with open(f"{args.save_dir}/example-prompts/{settings}/results.txt", "w") as f:
|
| 137 |
+
f.write(
|
| 138 |
+
f"Mean initial all rewards: {total_init_rewards}\n"
|
| 139 |
+
f"Mean best all rewards: {total_best_rewards}\n"
|
| 140 |
+
)
|
| 141 |
+
elif args.task == "t2i-compbench":
|
| 142 |
+
prompt_list_file = f"../T2I-CompBench/examples/dataset/{args.prompt}.txt"
|
| 143 |
+
fo = open(prompt_list_file, "r")
|
| 144 |
+
prompts = fo.readlines()
|
| 145 |
+
fo.close()
|
| 146 |
+
os.makedirs(f"{args.save_dir}/{args.task}/{settings}/samples", exist_ok=True)
|
| 147 |
+
for i, prompt in tqdm(enumerate(prompts)):
|
| 148 |
+
# Get new latents and optimizer
|
| 149 |
+
init_latents = torch.randn(shape, device=device, dtype=dtype)
|
| 150 |
+
latents = torch.nn.Parameter(init_latents, requires_grad=enable_grad)
|
| 151 |
+
optimizer = get_optimizer(args.optim, latents, args.lr, args.nesterov)
|
| 152 |
+
|
| 153 |
+
prompt = prompt.strip()
|
| 154 |
+
best_image, init_rewards, best_rewards = trainer.train(
|
| 155 |
+
latents, prompt, optimizer
|
| 156 |
+
)
|
| 157 |
+
if i == 0:
|
| 158 |
+
total_best_rewards = {k: 0.0 for k in best_rewards.keys()}
|
| 159 |
+
total_init_rewards = {k: 0.0 for k in best_rewards.keys()}
|
| 160 |
+
for k in best_rewards.keys():
|
| 161 |
+
total_best_rewards[k] += best_rewards[k]
|
| 162 |
+
total_init_rewards[k] += init_rewards[k]
|
| 163 |
+
name = f"{prompt}_{i:06d}.png"
|
| 164 |
+
best_image.save(f"{args.save_dir}/{args.task}/{settings}/samples/{name}")
|
| 165 |
+
logging.info(f"Initial rewards: {init_rewards}")
|
| 166 |
+
logging.info(f"Best rewards: {best_rewards}")
|
| 167 |
+
for k in total_best_rewards.keys():
|
| 168 |
+
total_best_rewards[k] /= len(prompts)
|
| 169 |
+
total_init_rewards[k] /= len(prompts)
|
| 170 |
+
elif args.task == "parti-prompts":
|
| 171 |
+
parti_dataset = load_dataset("nateraw/parti-prompts", split="train")
|
| 172 |
+
total_reward_diff = 0.0
|
| 173 |
+
total_best_reward = 0.0
|
| 174 |
+
total_init_reward = 0.0
|
| 175 |
+
total_improved_samples = 0
|
| 176 |
+
for index, sample in enumerate(parti_dataset):
|
| 177 |
+
os.makedirs(
|
| 178 |
+
f"{args.save_dir}/{args.task}/{settings}/{index}", exist_ok=True
|
| 179 |
+
)
|
| 180 |
+
prompt = sample["Prompt"]
|
| 181 |
+
best_image, init_rewards, best_rewards = trainer.train(
|
| 182 |
+
latents, prompt, optimizer
|
| 183 |
+
)
|
| 184 |
+
best_image.save(
|
| 185 |
+
f"{args.save_dir}/{args.task}/{settings}/{index}/best_image.png"
|
| 186 |
+
)
|
| 187 |
+
open(
|
| 188 |
+
f"{args.save_dir}/{args.task}/{settings}/{index}/prompt.txt", "w"
|
| 189 |
+
).write(
|
| 190 |
+
f"{prompt} \n Initial Rewards: {init_rewards} \n Best Rewards: {best_rewards}"
|
| 191 |
+
)
|
| 192 |
+
logging.info(f"Initial rewards: {init_rewards}")
|
| 193 |
+
logging.info(f"Best rewards: {best_rewards}")
|
| 194 |
+
initial_reward = init_rewards[args.benchmark_reward]
|
| 195 |
+
best_reward = best_rewards[args.benchmark_reward]
|
| 196 |
+
total_reward_diff += best_reward - initial_reward
|
| 197 |
+
total_best_reward += best_reward
|
| 198 |
+
total_init_reward += initial_reward
|
| 199 |
+
if best_reward < initial_reward:
|
| 200 |
+
total_improved_samples += 1
|
| 201 |
+
if i == 0:
|
| 202 |
+
total_best_rewards = {k: 0.0 for k in best_rewards.keys()}
|
| 203 |
+
total_init_rewards = {k: 0.0 for k in best_rewards.keys()}
|
| 204 |
+
for k in best_rewards.keys():
|
| 205 |
+
total_best_rewards[k] += best_rewards[k]
|
| 206 |
+
total_init_rewards[k] += init_rewards[k]
|
| 207 |
+
# Get new latents and optimizer
|
| 208 |
+
init_latents = torch.randn(shape, device=device, dtype=dtype)
|
| 209 |
+
latents = torch.nn.Parameter(init_latents, requires_grad=enable_grad)
|
| 210 |
+
optimizer = get_optimizer(args.optim, latents, args.lr, args.nesterov)
|
| 211 |
+
improvement_percentage = total_improved_samples / parti_dataset.num_rows
|
| 212 |
+
mean_best_reward = total_best_reward / parti_dataset.num_rows
|
| 213 |
+
mean_init_reward = total_init_reward / parti_dataset.num_rows
|
| 214 |
+
mean_reward_diff = total_reward_diff / parti_dataset.num_rows
|
| 215 |
+
logging.info(
|
| 216 |
+
f"Improvement percentage: {improvement_percentage:.4f}, "
|
| 217 |
+
f"mean initial reward: {mean_init_reward:.4f}, "
|
| 218 |
+
f"mean best reward: {mean_best_reward:.4f}, "
|
| 219 |
+
f"mean reward diff: {mean_reward_diff:.4f}"
|
| 220 |
+
)
|
| 221 |
+
for k in total_best_rewards.keys():
|
| 222 |
+
total_best_rewards[k] /= len(parti_dataset)
|
| 223 |
+
total_init_rewards[k] /= len(parti_dataset)
|
| 224 |
+
# save results
|
| 225 |
+
os.makedirs(f"{args.save_dir}/parti-prompts/{settings}", exist_ok=True)
|
| 226 |
+
with open(f"{args.save_dir}/parti-prompts/{settings}/results.txt", "w") as f:
|
| 227 |
+
f.write(
|
| 228 |
+
f"Mean improvement: {improvement_percentage:.4f}, "
|
| 229 |
+
f"mean initial reward: {mean_init_reward:.4f}, "
|
| 230 |
+
f"mean best reward: {mean_best_reward:.4f}, "
|
| 231 |
+
f"mean reward diff: {mean_reward_diff:.4f}\n"
|
| 232 |
+
f"Mean initial all rewards: {total_init_rewards}\n"
|
| 233 |
+
f"Mean best all rewards: {total_best_rewards}"
|
| 234 |
+
)
|
| 235 |
+
elif args.task == "geneval":
|
| 236 |
+
prompt_list_file = "../geneval/prompts/evaluation_metadata.jsonl"
|
| 237 |
+
with open(prompt_list_file) as fp:
|
| 238 |
+
metadatas = [json.loads(line) for line in fp]
|
| 239 |
+
outdir = f"{args.save_dir}/{args.task}/{settings}"
|
| 240 |
+
for index, metadata in enumerate(metadatas):
|
| 241 |
+
# Get new latents and optimizer
|
| 242 |
+
init_latents = torch.randn(shape, device=device, dtype=dtype)
|
| 243 |
+
latents = torch.nn.Parameter(init_latents, requires_grad=True)
|
| 244 |
+
optimizer = get_optimizer(args.optim, latents, args.lr, args.nesterov)
|
| 245 |
+
|
| 246 |
+
prompt = metadata["prompt"]
|
| 247 |
+
best_image, init_rewards, best_rewards = trainer.train(
|
| 248 |
+
latents, prompt, optimizer
|
| 249 |
+
)
|
| 250 |
+
logging.info(f"Initial rewards: {init_rewards}")
|
| 251 |
+
logging.info(f"Best rewards: {best_rewards}")
|
| 252 |
+
outpath = f"{outdir}/{index:0>5}"
|
| 253 |
+
os.makedirs(f"{outpath}/samples", exist_ok=True)
|
| 254 |
+
with open(f"{outpath}/metadata.jsonl", "w") as fp:
|
| 255 |
+
json.dump(metadata, fp)
|
| 256 |
+
best_image.save(f"{outpath}/samples/{args.seed:05}.png")
|
| 257 |
+
if i == 0:
|
| 258 |
+
total_best_rewards = {k: 0.0 for k in best_rewards.keys()}
|
| 259 |
+
total_init_rewards = {k: 0.0 for k in best_rewards.keys()}
|
| 260 |
+
for k in best_rewards.keys():
|
| 261 |
+
total_best_rewards[k] += best_rewards[k]
|
| 262 |
+
total_init_rewards[k] += init_rewards[k]
|
| 263 |
+
for k in total_best_rewards.keys():
|
| 264 |
+
total_best_rewards[k] /= len(parti_dataset)
|
| 265 |
+
total_init_rewards[k] /= len(parti_dataset)
|
| 266 |
+
else:
|
| 267 |
+
raise ValueError(f"Unknown task {args.task}")
|
| 268 |
+
# log total rewards
|
| 269 |
+
logging.info(f"Mean initial rewards: {total_init_rewards}")
|
| 270 |
+
logging.info(f"Mean best rewards: {total_best_rewards}")
|
| 271 |
+
|
| 272 |
+
if __name__ == "__main__":
|
| 273 |
+
args = parse_args()
|
| 274 |
+
main(args)
|
models/RewardPixart.py
ADDED
|
@@ -0,0 +1,394 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List, Optional, Union
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from diffusers import PixArtAlphaPipeline
|
| 5 |
+
from diffusers.pipelines.pixart_alpha.pipeline_pixart_alpha import \
|
| 6 |
+
retrieve_timesteps
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def freeze_params(params):
|
| 10 |
+
for param in params:
|
| 11 |
+
param.requires_grad = False
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class RewardPixartPipeline(PixArtAlphaPipeline):
|
| 15 |
+
def __init__(
|
| 16 |
+
self, tokenizer, text_encoder, transformer, scheduler, vae, memsave=False
|
| 17 |
+
):
|
| 18 |
+
super().__init__(
|
| 19 |
+
tokenizer,
|
| 20 |
+
text_encoder,
|
| 21 |
+
vae,
|
| 22 |
+
transformer,
|
| 23 |
+
scheduler,
|
| 24 |
+
)
|
| 25 |
+
# optionally enable memsave_torch
|
| 26 |
+
if memsave:
|
| 27 |
+
import memsave_torch.nn
|
| 28 |
+
|
| 29 |
+
self.vae = memsave_torch.nn.convert_to_memory_saving(self.vae)
|
| 30 |
+
self.text_encoder = memsave_torch.nn.convert_to_memory_saving(
|
| 31 |
+
self.text_encoder
|
| 32 |
+
)
|
| 33 |
+
self.text_encoder.gradient_checkpointing_enable()
|
| 34 |
+
self.vae.enable_gradient_checkpointing()
|
| 35 |
+
self.text_encoder.eval()
|
| 36 |
+
self.vae.eval()
|
| 37 |
+
freeze_params(self.vae.parameters())
|
| 38 |
+
freeze_params(self.text_encoder.parameters())
|
| 39 |
+
|
| 40 |
+
def apply(
|
| 41 |
+
self,
|
| 42 |
+
latents: torch.Tensor = None,
|
| 43 |
+
prompt: Union[str, List[str]] = None,
|
| 44 |
+
negative_prompt: str = "",
|
| 45 |
+
num_inference_steps: int = 20,
|
| 46 |
+
timesteps: List[int] = [400],
|
| 47 |
+
sigmas: List[float] = None,
|
| 48 |
+
guidance_scale: float = 1.0,
|
| 49 |
+
num_images_per_prompt: Optional[int] = 1,
|
| 50 |
+
height: Optional[int] = 512,
|
| 51 |
+
width: Optional[int] = 512,
|
| 52 |
+
eta: float = 0.0,
|
| 53 |
+
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
| 54 |
+
prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 55 |
+
prompt_attention_mask: Optional[torch.FloatTensor] = None,
|
| 56 |
+
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 57 |
+
negative_prompt_attention_mask: Optional[torch.FloatTensor] = None,
|
| 58 |
+
callback_steps: int = 1,
|
| 59 |
+
clean_caption: bool = False,
|
| 60 |
+
use_resolution_binning: bool = True,
|
| 61 |
+
max_sequence_length: int = 120,
|
| 62 |
+
**kwargs,
|
| 63 |
+
):
|
| 64 |
+
# 1. Check inputs. Raise error if not correct
|
| 65 |
+
height = height or self.transformer.config.sample_size * self.vae_scale_factor
|
| 66 |
+
width = width or self.transformer.config.sample_size * self.vae_scale_factor
|
| 67 |
+
if use_resolution_binning:
|
| 68 |
+
if self.transformer.config.sample_size == 128:
|
| 69 |
+
aspect_ratio_bin = ASPECT_RATIO_1024_BIN
|
| 70 |
+
elif self.transformer.config.sample_size == 64:
|
| 71 |
+
aspect_ratio_bin = ASPECT_RATIO_512_BIN
|
| 72 |
+
elif self.transformer.config.sample_size == 32:
|
| 73 |
+
aspect_ratio_bin = ASPECT_RATIO_256_BIN
|
| 74 |
+
else:
|
| 75 |
+
raise ValueError("Invalid sample size")
|
| 76 |
+
orig_height, orig_width = height, width
|
| 77 |
+
height, width = self.image_processor.classify_height_width_bin(
|
| 78 |
+
height, width, ratios=aspect_ratio_bin
|
| 79 |
+
)
|
| 80 |
+
|
| 81 |
+
self.check_inputs(
|
| 82 |
+
prompt,
|
| 83 |
+
height,
|
| 84 |
+
width,
|
| 85 |
+
negative_prompt,
|
| 86 |
+
callback_steps,
|
| 87 |
+
prompt_embeds,
|
| 88 |
+
negative_prompt_embeds,
|
| 89 |
+
prompt_attention_mask,
|
| 90 |
+
negative_prompt_attention_mask,
|
| 91 |
+
)
|
| 92 |
+
|
| 93 |
+
# 2. Default height and width to transformer
|
| 94 |
+
if prompt is not None and isinstance(prompt, str):
|
| 95 |
+
batch_size = 1
|
| 96 |
+
elif prompt is not None and isinstance(prompt, list):
|
| 97 |
+
batch_size = len(prompt)
|
| 98 |
+
else:
|
| 99 |
+
batch_size = prompt_embeds.shape[0]
|
| 100 |
+
|
| 101 |
+
device = self._execution_device
|
| 102 |
+
|
| 103 |
+
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
|
| 104 |
+
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
|
| 105 |
+
# corresponds to doing no classifier free guidance.
|
| 106 |
+
do_classifier_free_guidance = guidance_scale > 1.0
|
| 107 |
+
|
| 108 |
+
# 3. Encode input prompt
|
| 109 |
+
(
|
| 110 |
+
prompt_embeds,
|
| 111 |
+
prompt_attention_mask,
|
| 112 |
+
negative_prompt_embeds,
|
| 113 |
+
negative_prompt_attention_mask,
|
| 114 |
+
) = self.encode_prompt(
|
| 115 |
+
prompt,
|
| 116 |
+
do_classifier_free_guidance,
|
| 117 |
+
negative_prompt=negative_prompt,
|
| 118 |
+
num_images_per_prompt=num_images_per_prompt,
|
| 119 |
+
device=device,
|
| 120 |
+
prompt_embeds=prompt_embeds,
|
| 121 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 122 |
+
prompt_attention_mask=prompt_attention_mask,
|
| 123 |
+
negative_prompt_attention_mask=negative_prompt_attention_mask,
|
| 124 |
+
clean_caption=clean_caption,
|
| 125 |
+
max_sequence_length=max_sequence_length,
|
| 126 |
+
)
|
| 127 |
+
if do_classifier_free_guidance:
|
| 128 |
+
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
|
| 129 |
+
prompt_attention_mask = torch.cat(
|
| 130 |
+
[negative_prompt_attention_mask, prompt_attention_mask], dim=0
|
| 131 |
+
)
|
| 132 |
+
|
| 133 |
+
# 4. Prepare timesteps
|
| 134 |
+
timesteps, num_inference_steps = retrieve_timesteps(
|
| 135 |
+
self.scheduler, num_inference_steps, device, timesteps, sigmas
|
| 136 |
+
)
|
| 137 |
+
|
| 138 |
+
# 5. Prepare latents.
|
| 139 |
+
latent_channels = self.transformer.config.in_channels
|
| 140 |
+
latents = self.prepare_latents(
|
| 141 |
+
batch_size * num_images_per_prompt,
|
| 142 |
+
latent_channels,
|
| 143 |
+
height,
|
| 144 |
+
width,
|
| 145 |
+
prompt_embeds.dtype,
|
| 146 |
+
device,
|
| 147 |
+
generator,
|
| 148 |
+
latents,
|
| 149 |
+
)
|
| 150 |
+
|
| 151 |
+
# 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
|
| 152 |
+
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
|
| 153 |
+
|
| 154 |
+
# 6.1 Prepare micro-conditions.
|
| 155 |
+
added_cond_kwargs = {"resolution": None, "aspect_ratio": None}
|
| 156 |
+
if self.transformer.config.sample_size == 128:
|
| 157 |
+
resolution = torch.tensor([height, width]).repeat(
|
| 158 |
+
batch_size * num_images_per_prompt, 1
|
| 159 |
+
)
|
| 160 |
+
aspect_ratio = torch.tensor([float(height / width)]).repeat(
|
| 161 |
+
batch_size * num_images_per_prompt, 1
|
| 162 |
+
)
|
| 163 |
+
resolution = resolution.to(dtype=prompt_embeds.dtype, device=device)
|
| 164 |
+
aspect_ratio = aspect_ratio.to(dtype=prompt_embeds.dtype, device=device)
|
| 165 |
+
|
| 166 |
+
if do_classifier_free_guidance:
|
| 167 |
+
resolution = torch.cat([resolution, resolution], dim=0)
|
| 168 |
+
aspect_ratio = torch.cat([aspect_ratio, aspect_ratio], dim=0)
|
| 169 |
+
|
| 170 |
+
added_cond_kwargs = {"resolution": resolution, "aspect_ratio": aspect_ratio}
|
| 171 |
+
|
| 172 |
+
# 7. Denoising loop
|
| 173 |
+
num_warmup_steps = max(
|
| 174 |
+
len(timesteps) - num_inference_steps * self.scheduler.order, 0
|
| 175 |
+
)
|
| 176 |
+
|
| 177 |
+
for i, t in enumerate(timesteps):
|
| 178 |
+
latent_model_input = (
|
| 179 |
+
torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
| 180 |
+
)
|
| 181 |
+
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
| 182 |
+
|
| 183 |
+
current_timestep = t
|
| 184 |
+
if not torch.is_tensor(current_timestep):
|
| 185 |
+
# TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
|
| 186 |
+
# This would be a good case for the `match` statement (Python 3.10+)
|
| 187 |
+
is_mps = latent_model_input.device.type == "mps"
|
| 188 |
+
if isinstance(current_timestep, float):
|
| 189 |
+
dtype = torch.float32 if is_mps else torch.float64
|
| 190 |
+
else:
|
| 191 |
+
dtype = torch.int32 if is_mps else torch.int64
|
| 192 |
+
current_timestep = torch.tensor(
|
| 193 |
+
[current_timestep], dtype=dtype, device=latent_model_input.device
|
| 194 |
+
)
|
| 195 |
+
elif len(current_timestep.shape) == 0:
|
| 196 |
+
current_timestep = current_timestep[None].to(latent_model_input.device)
|
| 197 |
+
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
| 198 |
+
current_timestep = current_timestep.expand(latent_model_input.shape[0])
|
| 199 |
+
|
| 200 |
+
# predict noise model_output
|
| 201 |
+
noise_pred = self.transformer(
|
| 202 |
+
latent_model_input,
|
| 203 |
+
encoder_hidden_states=prompt_embeds,
|
| 204 |
+
encoder_attention_mask=prompt_attention_mask,
|
| 205 |
+
timestep=current_timestep,
|
| 206 |
+
added_cond_kwargs=added_cond_kwargs,
|
| 207 |
+
return_dict=False,
|
| 208 |
+
)[0]
|
| 209 |
+
|
| 210 |
+
# perform guidance
|
| 211 |
+
if do_classifier_free_guidance:
|
| 212 |
+
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
| 213 |
+
noise_pred = noise_pred_uncond + guidance_scale * (
|
| 214 |
+
noise_pred_text - noise_pred_uncond
|
| 215 |
+
)
|
| 216 |
+
|
| 217 |
+
# learned sigma
|
| 218 |
+
if self.transformer.config.out_channels // 2 == latent_channels:
|
| 219 |
+
noise_pred = noise_pred.chunk(2, dim=1)[0]
|
| 220 |
+
else:
|
| 221 |
+
noise_pred = noise_pred
|
| 222 |
+
|
| 223 |
+
# compute previous image: x_t -> x_t-1
|
| 224 |
+
if num_inference_steps == 1:
|
| 225 |
+
# For DMD one step sampling: https://arxiv.org/abs/2311.18828
|
| 226 |
+
latents = self.scheduler.step(
|
| 227 |
+
noise_pred, t, latents, **extra_step_kwargs
|
| 228 |
+
).pred_original_sample
|
| 229 |
+
|
| 230 |
+
image = self.vae.decode(
|
| 231 |
+
latents / self.vae.config.scaling_factor, return_dict=False
|
| 232 |
+
)[0]
|
| 233 |
+
if use_resolution_binning:
|
| 234 |
+
image = self.image_processor.resize_and_crop_tensor(
|
| 235 |
+
image, orig_width, orig_height
|
| 236 |
+
)
|
| 237 |
+
|
| 238 |
+
image = (image / 2 + 0.5).clamp(0, 1)
|
| 239 |
+
|
| 240 |
+
# Offload all models
|
| 241 |
+
self.maybe_free_model_hooks()
|
| 242 |
+
return image
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
ASPECT_RATIO_2048_BIN = {
|
| 246 |
+
"0.25": [1024.0, 4096.0],
|
| 247 |
+
"0.26": [1024.0, 3968.0],
|
| 248 |
+
"0.27": [1024.0, 3840.0],
|
| 249 |
+
"0.28": [1024.0, 3712.0],
|
| 250 |
+
"0.32": [1152.0, 3584.0],
|
| 251 |
+
"0.33": [1152.0, 3456.0],
|
| 252 |
+
"0.35": [1152.0, 3328.0],
|
| 253 |
+
"0.4": [1280.0, 3200.0],
|
| 254 |
+
"0.42": [1280.0, 3072.0],
|
| 255 |
+
"0.48": [1408.0, 2944.0],
|
| 256 |
+
"0.5": [1408.0, 2816.0],
|
| 257 |
+
"0.52": [1408.0, 2688.0],
|
| 258 |
+
"0.57": [1536.0, 2688.0],
|
| 259 |
+
"0.6": [1536.0, 2560.0],
|
| 260 |
+
"0.68": [1664.0, 2432.0],
|
| 261 |
+
"0.72": [1664.0, 2304.0],
|
| 262 |
+
"0.78": [1792.0, 2304.0],
|
| 263 |
+
"0.82": [1792.0, 2176.0],
|
| 264 |
+
"0.88": [1920.0, 2176.0],
|
| 265 |
+
"0.94": [1920.0, 2048.0],
|
| 266 |
+
"1.0": [2048.0, 2048.0],
|
| 267 |
+
"1.07": [2048.0, 1920.0],
|
| 268 |
+
"1.13": [2176.0, 1920.0],
|
| 269 |
+
"1.21": [2176.0, 1792.0],
|
| 270 |
+
"1.29": [2304.0, 1792.0],
|
| 271 |
+
"1.38": [2304.0, 1664.0],
|
| 272 |
+
"1.46": [2432.0, 1664.0],
|
| 273 |
+
"1.67": [2560.0, 1536.0],
|
| 274 |
+
"1.75": [2688.0, 1536.0],
|
| 275 |
+
"2.0": [2816.0, 1408.0],
|
| 276 |
+
"2.09": [2944.0, 1408.0],
|
| 277 |
+
"2.4": [3072.0, 1280.0],
|
| 278 |
+
"2.5": [3200.0, 1280.0],
|
| 279 |
+
"2.89": [3328.0, 1152.0],
|
| 280 |
+
"3.0": [3456.0, 1152.0],
|
| 281 |
+
"3.11": [3584.0, 1152.0],
|
| 282 |
+
"3.62": [3712.0, 1024.0],
|
| 283 |
+
"3.75": [3840.0, 1024.0],
|
| 284 |
+
"3.88": [3968.0, 1024.0],
|
| 285 |
+
"4.0": [4096.0, 1024.0],
|
| 286 |
+
}
|
| 287 |
+
|
| 288 |
+
ASPECT_RATIO_256_BIN = {
|
| 289 |
+
"0.25": [128.0, 512.0],
|
| 290 |
+
"0.28": [128.0, 464.0],
|
| 291 |
+
"0.32": [144.0, 448.0],
|
| 292 |
+
"0.33": [144.0, 432.0],
|
| 293 |
+
"0.35": [144.0, 416.0],
|
| 294 |
+
"0.4": [160.0, 400.0],
|
| 295 |
+
"0.42": [160.0, 384.0],
|
| 296 |
+
"0.48": [176.0, 368.0],
|
| 297 |
+
"0.5": [176.0, 352.0],
|
| 298 |
+
"0.52": [176.0, 336.0],
|
| 299 |
+
"0.57": [192.0, 336.0],
|
| 300 |
+
"0.6": [192.0, 320.0],
|
| 301 |
+
"0.68": [208.0, 304.0],
|
| 302 |
+
"0.72": [208.0, 288.0],
|
| 303 |
+
"0.78": [224.0, 288.0],
|
| 304 |
+
"0.82": [224.0, 272.0],
|
| 305 |
+
"0.88": [240.0, 272.0],
|
| 306 |
+
"0.94": [240.0, 256.0],
|
| 307 |
+
"1.0": [256.0, 256.0],
|
| 308 |
+
"1.07": [256.0, 240.0],
|
| 309 |
+
"1.13": [272.0, 240.0],
|
| 310 |
+
"1.21": [272.0, 224.0],
|
| 311 |
+
"1.29": [288.0, 224.0],
|
| 312 |
+
"1.38": [288.0, 208.0],
|
| 313 |
+
"1.46": [304.0, 208.0],
|
| 314 |
+
"1.67": [320.0, 192.0],
|
| 315 |
+
"1.75": [336.0, 192.0],
|
| 316 |
+
"2.0": [352.0, 176.0],
|
| 317 |
+
"2.09": [368.0, 176.0],
|
| 318 |
+
"2.4": [384.0, 160.0],
|
| 319 |
+
"2.5": [400.0, 160.0],
|
| 320 |
+
"3.0": [432.0, 144.0],
|
| 321 |
+
"4.0": [512.0, 128.0],
|
| 322 |
+
}
|
| 323 |
+
|
| 324 |
+
ASPECT_RATIO_1024_BIN = {
|
| 325 |
+
"0.25": [512.0, 2048.0],
|
| 326 |
+
"0.28": [512.0, 1856.0],
|
| 327 |
+
"0.32": [576.0, 1792.0],
|
| 328 |
+
"0.33": [576.0, 1728.0],
|
| 329 |
+
"0.35": [576.0, 1664.0],
|
| 330 |
+
"0.4": [640.0, 1600.0],
|
| 331 |
+
"0.42": [640.0, 1536.0],
|
| 332 |
+
"0.48": [704.0, 1472.0],
|
| 333 |
+
"0.5": [704.0, 1408.0],
|
| 334 |
+
"0.52": [704.0, 1344.0],
|
| 335 |
+
"0.57": [768.0, 1344.0],
|
| 336 |
+
"0.6": [768.0, 1280.0],
|
| 337 |
+
"0.68": [832.0, 1216.0],
|
| 338 |
+
"0.72": [832.0, 1152.0],
|
| 339 |
+
"0.78": [896.0, 1152.0],
|
| 340 |
+
"0.82": [896.0, 1088.0],
|
| 341 |
+
"0.88": [960.0, 1088.0],
|
| 342 |
+
"0.94": [960.0, 1024.0],
|
| 343 |
+
"1.0": [1024.0, 1024.0],
|
| 344 |
+
"1.07": [1024.0, 960.0],
|
| 345 |
+
"1.13": [1088.0, 960.0],
|
| 346 |
+
"1.21": [1088.0, 896.0],
|
| 347 |
+
"1.29": [1152.0, 896.0],
|
| 348 |
+
"1.38": [1152.0, 832.0],
|
| 349 |
+
"1.46": [1216.0, 832.0],
|
| 350 |
+
"1.67": [1280.0, 768.0],
|
| 351 |
+
"1.75": [1344.0, 768.0],
|
| 352 |
+
"2.0": [1408.0, 704.0],
|
| 353 |
+
"2.09": [1472.0, 704.0],
|
| 354 |
+
"2.4": [1536.0, 640.0],
|
| 355 |
+
"2.5": [1600.0, 640.0],
|
| 356 |
+
"3.0": [1728.0, 576.0],
|
| 357 |
+
"4.0": [2048.0, 512.0],
|
| 358 |
+
}
|
| 359 |
+
|
| 360 |
+
ASPECT_RATIO_512_BIN = {
|
| 361 |
+
"0.25": [256.0, 1024.0],
|
| 362 |
+
"0.28": [256.0, 928.0],
|
| 363 |
+
"0.32": [288.0, 896.0],
|
| 364 |
+
"0.33": [288.0, 864.0],
|
| 365 |
+
"0.35": [288.0, 832.0],
|
| 366 |
+
"0.4": [320.0, 800.0],
|
| 367 |
+
"0.42": [320.0, 768.0],
|
| 368 |
+
"0.48": [352.0, 736.0],
|
| 369 |
+
"0.5": [352.0, 704.0],
|
| 370 |
+
"0.52": [352.0, 672.0],
|
| 371 |
+
"0.57": [384.0, 672.0],
|
| 372 |
+
"0.6": [384.0, 640.0],
|
| 373 |
+
"0.68": [416.0, 608.0],
|
| 374 |
+
"0.72": [416.0, 576.0],
|
| 375 |
+
"0.78": [448.0, 576.0],
|
| 376 |
+
"0.82": [448.0, 544.0],
|
| 377 |
+
"0.88": [480.0, 544.0],
|
| 378 |
+
"0.94": [480.0, 512.0],
|
| 379 |
+
"1.0": [512.0, 512.0],
|
| 380 |
+
"1.07": [512.0, 480.0],
|
| 381 |
+
"1.13": [544.0, 480.0],
|
| 382 |
+
"1.21": [544.0, 448.0],
|
| 383 |
+
"1.29": [576.0, 448.0],
|
| 384 |
+
"1.38": [576.0, 416.0],
|
| 385 |
+
"1.46": [608.0, 416.0],
|
| 386 |
+
"1.67": [640.0, 384.0],
|
| 387 |
+
"1.75": [672.0, 384.0],
|
| 388 |
+
"2.0": [704.0, 352.0],
|
| 389 |
+
"2.09": [736.0, 352.0],
|
| 390 |
+
"2.4": [768.0, 320.0],
|
| 391 |
+
"2.5": [800.0, 320.0],
|
| 392 |
+
"3.0": [864.0, 288.0],
|
| 393 |
+
"4.0": [1024.0, 256.0],
|
| 394 |
+
}
|
models/RewardStableDiffusion.py
ADDED
|
@@ -0,0 +1,277 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import inspect
|
| 2 |
+
from typing import Callable, List, Optional, Union
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from diffusers import StableDiffusionPipeline
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def freeze_params(params):
|
| 9 |
+
for param in params:
|
| 10 |
+
param.requires_grad = False
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class RewardStableDiffusion(StableDiffusionPipeline):
|
| 14 |
+
def __init__(
|
| 15 |
+
self,
|
| 16 |
+
vae,
|
| 17 |
+
text_encoder,
|
| 18 |
+
tokenizer,
|
| 19 |
+
unet,
|
| 20 |
+
scheduler,
|
| 21 |
+
safety_checker,
|
| 22 |
+
feature_extractor,
|
| 23 |
+
image_encoder=None,
|
| 24 |
+
requires_safety_checker: bool = True,
|
| 25 |
+
memsave=False,
|
| 26 |
+
):
|
| 27 |
+
super().__init__(
|
| 28 |
+
vae,
|
| 29 |
+
text_encoder,
|
| 30 |
+
tokenizer,
|
| 31 |
+
unet,
|
| 32 |
+
scheduler,
|
| 33 |
+
safety_checker,
|
| 34 |
+
feature_extractor,
|
| 35 |
+
image_encoder,
|
| 36 |
+
)
|
| 37 |
+
# optionally enable memsave_torch
|
| 38 |
+
if memsave:
|
| 39 |
+
import memsave_torch.nn
|
| 40 |
+
|
| 41 |
+
self.vae = memsave_torch.nn.convert_to_memory_saving(self.vae)
|
| 42 |
+
self.unet = memsave_torch.nn.convert_to_memory_saving(self.unet)
|
| 43 |
+
self.text_encoder = memsave_torch.nn.convert_to_memory_saving(
|
| 44 |
+
self.text_encoder
|
| 45 |
+
)
|
| 46 |
+
# enable checkpointing
|
| 47 |
+
self.text_encoder.gradient_checkpointing_enable()
|
| 48 |
+
self.unet.enable_gradient_checkpointing()
|
| 49 |
+
self.vae.eval()
|
| 50 |
+
self.text_encoder.eval()
|
| 51 |
+
self.unet.eval()
|
| 52 |
+
|
| 53 |
+
# freeze diffusion parameters
|
| 54 |
+
freeze_params(self.vae.parameters())
|
| 55 |
+
freeze_params(self.unet.parameters())
|
| 56 |
+
freeze_params(self.text_encoder.parameters())
|
| 57 |
+
|
| 58 |
+
def decode_latents_tensors(self, latents):
|
| 59 |
+
latents = 1 / 0.18215 * latents
|
| 60 |
+
image = self.vae.decode(latents).sample
|
| 61 |
+
image = (image / 2 + 0.5).clamp(0, 1)
|
| 62 |
+
return image
|
| 63 |
+
|
| 64 |
+
def apply(
|
| 65 |
+
self,
|
| 66 |
+
latents: torch.Tensor,
|
| 67 |
+
prompt: Union[str, List[str]] = None,
|
| 68 |
+
text_embeddings=None,
|
| 69 |
+
image=None,
|
| 70 |
+
height: Optional[int] = None,
|
| 71 |
+
width: Optional[int] = None,
|
| 72 |
+
timesteps: Optional[List[int]] = None,
|
| 73 |
+
num_inference_steps: int = 1,
|
| 74 |
+
guidance_scale: float = 1.0,
|
| 75 |
+
negative_prompt: Optional[Union[str, List[str]]] = None,
|
| 76 |
+
num_images_per_prompt: Optional[int] = 1,
|
| 77 |
+
eta: float = 0.0,
|
| 78 |
+
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
| 79 |
+
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
|
| 80 |
+
callback_steps: Optional[int] = 1,
|
| 81 |
+
) -> torch.Tensor:
|
| 82 |
+
# 0. Default height and width to unet
|
| 83 |
+
height = height or self.unet.config.sample_size * self.vae_scale_factor
|
| 84 |
+
width = width or self.unet.config.sample_size * self.vae_scale_factor
|
| 85 |
+
# to deal with lora scaling and other possible forward hooks
|
| 86 |
+
|
| 87 |
+
prompt_embeds = None
|
| 88 |
+
negative_prompt_embeds = None
|
| 89 |
+
ip_adapter_image = None
|
| 90 |
+
ip_adapter_image_embeds = None
|
| 91 |
+
callback_on_step_end_tensor_inputs = None
|
| 92 |
+
guidance_rescale = 0.0
|
| 93 |
+
clip_skip = None
|
| 94 |
+
cross_attention_kwargs = None
|
| 95 |
+
# 1. Check inputs. Raise error if not correct
|
| 96 |
+
self.check_inputs(
|
| 97 |
+
prompt,
|
| 98 |
+
height,
|
| 99 |
+
width,
|
| 100 |
+
callback_steps,
|
| 101 |
+
negative_prompt,
|
| 102 |
+
prompt_embeds,
|
| 103 |
+
negative_prompt_embeds,
|
| 104 |
+
ip_adapter_image,
|
| 105 |
+
ip_adapter_image_embeds,
|
| 106 |
+
callback_on_step_end_tensor_inputs,
|
| 107 |
+
)
|
| 108 |
+
|
| 109 |
+
self._guidance_scale = guidance_scale
|
| 110 |
+
self._guidance_rescale = guidance_rescale
|
| 111 |
+
self._clip_skip = clip_skip
|
| 112 |
+
self._cross_attention_kwargs = cross_attention_kwargs
|
| 113 |
+
self._interrupt = False
|
| 114 |
+
|
| 115 |
+
# 2. Define call parameters
|
| 116 |
+
if prompt is not None and isinstance(prompt, str):
|
| 117 |
+
batch_size = 1
|
| 118 |
+
elif prompt is not None and isinstance(prompt, list):
|
| 119 |
+
batch_size = len(prompt)
|
| 120 |
+
else:
|
| 121 |
+
batch_size = prompt_embeds.shape[0]
|
| 122 |
+
|
| 123 |
+
device = self._execution_device
|
| 124 |
+
|
| 125 |
+
# 3. Encode input prompt
|
| 126 |
+
lora_scale = (
|
| 127 |
+
self.cross_attention_kwargs.get("scale", None)
|
| 128 |
+
if self.cross_attention_kwargs is not None
|
| 129 |
+
else None
|
| 130 |
+
)
|
| 131 |
+
|
| 132 |
+
prompt_embeds, negative_prompt_embeds = self.encode_prompt(
|
| 133 |
+
prompt,
|
| 134 |
+
device,
|
| 135 |
+
num_images_per_prompt,
|
| 136 |
+
self.do_classifier_free_guidance,
|
| 137 |
+
negative_prompt,
|
| 138 |
+
prompt_embeds=prompt_embeds,
|
| 139 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 140 |
+
lora_scale=lora_scale,
|
| 141 |
+
clip_skip=self.clip_skip,
|
| 142 |
+
)
|
| 143 |
+
|
| 144 |
+
# For classifier free guidance, we need to do two forward passes.
|
| 145 |
+
# Here we concatenate the unconditional and text embeddings into a single batch
|
| 146 |
+
# to avoid doing two forward passes
|
| 147 |
+
if self.do_classifier_free_guidance:
|
| 148 |
+
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
|
| 149 |
+
|
| 150 |
+
if ip_adapter_image is not None or ip_adapter_image_embeds is not None:
|
| 151 |
+
image_embeds = self.prepare_ip_adapter_image_embeds(
|
| 152 |
+
ip_adapter_image,
|
| 153 |
+
ip_adapter_image_embeds,
|
| 154 |
+
device,
|
| 155 |
+
batch_size * num_images_per_prompt,
|
| 156 |
+
self.do_classifier_free_guidance,
|
| 157 |
+
)
|
| 158 |
+
|
| 159 |
+
# 4. Prepare timesteps
|
| 160 |
+
timesteps, num_inference_steps = retrieve_timesteps(
|
| 161 |
+
self.scheduler, num_inference_steps, device, timesteps
|
| 162 |
+
)
|
| 163 |
+
|
| 164 |
+
# 5. Prepare latent variables
|
| 165 |
+
num_channels_latents = self.unet.config.in_channels
|
| 166 |
+
latents = self.prepare_latents(
|
| 167 |
+
batch_size * num_images_per_prompt,
|
| 168 |
+
num_channels_latents,
|
| 169 |
+
height,
|
| 170 |
+
width,
|
| 171 |
+
prompt_embeds.dtype,
|
| 172 |
+
device,
|
| 173 |
+
generator,
|
| 174 |
+
latents,
|
| 175 |
+
)
|
| 176 |
+
|
| 177 |
+
# 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
|
| 178 |
+
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
|
| 179 |
+
|
| 180 |
+
# 6.1 Add image embeds for IP-Adapter
|
| 181 |
+
added_cond_kwargs = (
|
| 182 |
+
{"image_embeds": image_embeds}
|
| 183 |
+
if (ip_adapter_image is not None or ip_adapter_image_embeds is not None)
|
| 184 |
+
else None
|
| 185 |
+
)
|
| 186 |
+
|
| 187 |
+
# 6.2 Optionally get Guidance Scale Embedding
|
| 188 |
+
timestep_cond = None
|
| 189 |
+
if self.unet.config.time_cond_proj_dim is not None:
|
| 190 |
+
guidance_scale_tensor = torch.tensor(self.guidance_scale - 1).repeat(
|
| 191 |
+
batch_size * num_images_per_prompt
|
| 192 |
+
)
|
| 193 |
+
timestep_cond = self.get_guidance_scale_embedding(
|
| 194 |
+
guidance_scale_tensor, embedding_dim=self.unet.config.time_cond_proj_dim
|
| 195 |
+
).to(device=device, dtype=latents.dtype)
|
| 196 |
+
|
| 197 |
+
# 7. Denoising loop
|
| 198 |
+
self._num_timesteps = len(timesteps)
|
| 199 |
+
for i, t in enumerate(timesteps):
|
| 200 |
+
# expand the latents if we are doing classifier free guidance
|
| 201 |
+
latent_model_input = (
|
| 202 |
+
torch.cat([latents] * 2)
|
| 203 |
+
if self.do_classifier_free_guidance
|
| 204 |
+
else latents
|
| 205 |
+
)
|
| 206 |
+
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
| 207 |
+
|
| 208 |
+
# predict the noise residual
|
| 209 |
+
noise_pred = self.unet(
|
| 210 |
+
latent_model_input,
|
| 211 |
+
t,
|
| 212 |
+
encoder_hidden_states=prompt_embeds,
|
| 213 |
+
timestep_cond=timestep_cond,
|
| 214 |
+
added_cond_kwargs=added_cond_kwargs,
|
| 215 |
+
return_dict=False,
|
| 216 |
+
)[0]
|
| 217 |
+
|
| 218 |
+
# perform guidance
|
| 219 |
+
if self.do_classifier_free_guidance:
|
| 220 |
+
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
| 221 |
+
noise_pred = noise_pred_uncond + guidance_scale * (
|
| 222 |
+
noise_pred_text - noise_pred_uncond
|
| 223 |
+
)
|
| 224 |
+
|
| 225 |
+
# compute the previous noisy sample x_t -> x_t-1
|
| 226 |
+
latents = self.scheduler.step(
|
| 227 |
+
noise_pred, t, latents, **extra_step_kwargs, return_dict=False
|
| 228 |
+
)[0]
|
| 229 |
+
|
| 230 |
+
image = self.decode_latents_tensors(latents)
|
| 231 |
+
return image
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
def retrieve_timesteps(
|
| 235 |
+
scheduler,
|
| 236 |
+
num_inference_steps: Optional[int] = None,
|
| 237 |
+
device: Optional[Union[str, torch.device]] = None,
|
| 238 |
+
timesteps: Optional[List[int]] = None,
|
| 239 |
+
**kwargs,
|
| 240 |
+
):
|
| 241 |
+
"""
|
| 242 |
+
Calls the scheduler's `set_timesteps` method and retrieves timesteps from the scheduler after the call. Handles
|
| 243 |
+
custom timesteps. Any kwargs will be supplied to `scheduler.set_timesteps`.
|
| 244 |
+
|
| 245 |
+
Args:
|
| 246 |
+
scheduler (`SchedulerMixin`):
|
| 247 |
+
The scheduler to get timesteps from.
|
| 248 |
+
num_inference_steps (`int`):
|
| 249 |
+
The number of diffusion steps used when generating samples with a pre-trained model. If used, `timesteps`
|
| 250 |
+
must be `None`.
|
| 251 |
+
device (`str` or `torch.device`, *optional*):
|
| 252 |
+
The device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
|
| 253 |
+
timesteps (`List[int]`, *optional*):
|
| 254 |
+
Custom timesteps used to support arbitrary spacing between timesteps. If `None`, then the default
|
| 255 |
+
timestep spacing strategy of the scheduler is used. If `timesteps` is passed, `num_inference_steps`
|
| 256 |
+
must be `None`.
|
| 257 |
+
|
| 258 |
+
Returns:
|
| 259 |
+
`Tuple[torch.Tensor, int]`: A tuple where the first element is the timestep schedule from the scheduler and the
|
| 260 |
+
second element is the number of inference steps.
|
| 261 |
+
"""
|
| 262 |
+
if timesteps is not None:
|
| 263 |
+
accepts_timesteps = "timesteps" in set(
|
| 264 |
+
inspect.signature(scheduler.set_timesteps).parameters.keys()
|
| 265 |
+
)
|
| 266 |
+
if not accepts_timesteps:
|
| 267 |
+
raise ValueError(
|
| 268 |
+
f"The current scheduler class {scheduler.__class__}'s `set_timesteps` does not support custom"
|
| 269 |
+
f" timestep schedules. Please check whether you are using the correct scheduler."
|
| 270 |
+
)
|
| 271 |
+
scheduler.set_timesteps(timesteps=timesteps, device=device, **kwargs)
|
| 272 |
+
timesteps = scheduler.timesteps
|
| 273 |
+
num_inference_steps = len(timesteps)
|
| 274 |
+
else:
|
| 275 |
+
scheduler.set_timesteps(num_inference_steps, device=device, **kwargs)
|
| 276 |
+
timesteps = scheduler.timesteps
|
| 277 |
+
return timesteps, num_inference_steps
|
models/RewardStableDiffusionXL.py
ADDED
|
@@ -0,0 +1,320 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List, Optional, Union
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from diffusers import (AutoencoderKL, StableDiffusionXLPipeline,
|
| 5 |
+
UNet2DConditionModel)
|
| 6 |
+
from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl import \
|
| 7 |
+
retrieve_timesteps
|
| 8 |
+
from diffusers.schedulers import KarrasDiffusionSchedulers
|
| 9 |
+
from transformers import (CLIPImageProcessor, CLIPTextModel,
|
| 10 |
+
CLIPTextModelWithProjection, CLIPTokenizer,
|
| 11 |
+
CLIPVisionModelWithProjection)
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def freeze_params(params):
|
| 15 |
+
for param in params:
|
| 16 |
+
param.requires_grad = False
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class RewardStableDiffusionXL(StableDiffusionXLPipeline):
|
| 20 |
+
def __init__(
|
| 21 |
+
self,
|
| 22 |
+
vae: AutoencoderKL,
|
| 23 |
+
text_encoder: CLIPTextModel,
|
| 24 |
+
text_encoder_2: CLIPTextModelWithProjection,
|
| 25 |
+
tokenizer: CLIPTokenizer,
|
| 26 |
+
tokenizer_2: CLIPTokenizer,
|
| 27 |
+
unet: UNet2DConditionModel,
|
| 28 |
+
scheduler: KarrasDiffusionSchedulers,
|
| 29 |
+
image_encoder: CLIPVisionModelWithProjection = None,
|
| 30 |
+
feature_extractor: CLIPImageProcessor = None,
|
| 31 |
+
force_zeros_for_empty_prompt: bool = True,
|
| 32 |
+
add_watermarker: bool = False,
|
| 33 |
+
is_hyper: bool = False,
|
| 34 |
+
memsave: bool = False,
|
| 35 |
+
):
|
| 36 |
+
super().__init__(
|
| 37 |
+
vae,
|
| 38 |
+
text_encoder,
|
| 39 |
+
text_encoder_2,
|
| 40 |
+
tokenizer,
|
| 41 |
+
tokenizer_2,
|
| 42 |
+
unet,
|
| 43 |
+
scheduler,
|
| 44 |
+
image_encoder,
|
| 45 |
+
feature_extractor,
|
| 46 |
+
force_zeros_for_empty_prompt,
|
| 47 |
+
add_watermarker,
|
| 48 |
+
)
|
| 49 |
+
# optionally enable memsave_torch
|
| 50 |
+
if memsave:
|
| 51 |
+
import memsave_torch.nn
|
| 52 |
+
|
| 53 |
+
self.vae = memsave_torch.nn.convert_to_memory_saving(self.vae)
|
| 54 |
+
self.unet = memsave_torch.nn.convert_to_memory_saving(self.unet)
|
| 55 |
+
self.text_encoder = memsave_torch.nn.convert_to_memory_saving(
|
| 56 |
+
self.text_encoder
|
| 57 |
+
)
|
| 58 |
+
self.text_encoder_2 = memsave_torch.nn.convert_to_memory_saving(
|
| 59 |
+
self.text_encoder_2
|
| 60 |
+
)
|
| 61 |
+
# enable checkpointing
|
| 62 |
+
self.unet.enable_gradient_checkpointing()
|
| 63 |
+
self.vae.enable_gradient_checkpointing()
|
| 64 |
+
self.text_encoder.eval()
|
| 65 |
+
self.text_encoder_2.eval()
|
| 66 |
+
self.unet.eval()
|
| 67 |
+
self.vae.eval()
|
| 68 |
+
self.is_hyper = is_hyper
|
| 69 |
+
|
| 70 |
+
# freeze diffusion parameters
|
| 71 |
+
freeze_params(self.vae.parameters())
|
| 72 |
+
freeze_params(self.unet.parameters())
|
| 73 |
+
freeze_params(self.text_encoder.parameters())
|
| 74 |
+
freeze_params(self.text_encoder_2.parameters())
|
| 75 |
+
|
| 76 |
+
def decode_latents_tensors(self, latents):
|
| 77 |
+
latents = latents / self.vae.config.scaling_factor
|
| 78 |
+
image = self.vae.decode(latents).sample
|
| 79 |
+
image = (image / 2 + 0.5).clamp(0, 1)
|
| 80 |
+
return image
|
| 81 |
+
|
| 82 |
+
def apply(
|
| 83 |
+
self,
|
| 84 |
+
latents: torch.Tensor,
|
| 85 |
+
prompt: Union[str, List[str]] = None,
|
| 86 |
+
prompt_2: Optional[Union[str, List[str]]] = None,
|
| 87 |
+
height: Optional[int] = None,
|
| 88 |
+
width: Optional[int] = None,
|
| 89 |
+
num_inference_steps: int = 1,
|
| 90 |
+
guidance_scale: float = 0.0,
|
| 91 |
+
timesteps: List[int] = None,
|
| 92 |
+
denoising_end: Optional[float] = None,
|
| 93 |
+
negative_prompt: Optional[Union[str, List[str]]] = None,
|
| 94 |
+
negative_prompt_2: Optional[Union[str, List[str]]] = None,
|
| 95 |
+
num_images_per_prompt: Optional[int] = 1,
|
| 96 |
+
eta: float = 0.0,
|
| 97 |
+
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
| 98 |
+
) -> torch.Tensor:
|
| 99 |
+
if self.is_hyper:
|
| 100 |
+
timesteps = [800]
|
| 101 |
+
# 0. Default height and width to unet
|
| 102 |
+
height = height or self.default_sample_size * self.vae_scale_factor
|
| 103 |
+
width = width or self.default_sample_size * self.vae_scale_factor
|
| 104 |
+
|
| 105 |
+
original_size = (height, width)
|
| 106 |
+
target_size = (height, width)
|
| 107 |
+
|
| 108 |
+
# 1. Check inputs. Raise error if not correct
|
| 109 |
+
self.check_inputs(
|
| 110 |
+
prompt,
|
| 111 |
+
prompt_2,
|
| 112 |
+
height,
|
| 113 |
+
width,
|
| 114 |
+
callback_steps=1,
|
| 115 |
+
)
|
| 116 |
+
|
| 117 |
+
# 2. Define call parameters
|
| 118 |
+
|
| 119 |
+
self._guidance_scale = guidance_scale
|
| 120 |
+
self._clip_skip = 0
|
| 121 |
+
self._cross_attention_kwargs = None
|
| 122 |
+
self._denoising_end = denoising_end
|
| 123 |
+
self._interrupt = False
|
| 124 |
+
|
| 125 |
+
# 2. Define call parameters
|
| 126 |
+
batch_size = 1
|
| 127 |
+
device = self._execution_device
|
| 128 |
+
|
| 129 |
+
# 3. Encode input prompt
|
| 130 |
+
lora_scale = (
|
| 131 |
+
self.cross_attention_kwargs.get("scale", None)
|
| 132 |
+
if self.cross_attention_kwargs is not None
|
| 133 |
+
else None
|
| 134 |
+
)
|
| 135 |
+
prompt_embeds = None
|
| 136 |
+
negative_prompt_embeds = None
|
| 137 |
+
pooled_prompt_embeds = None
|
| 138 |
+
negative_pooled_prompt_embeds = None
|
| 139 |
+
(
|
| 140 |
+
prompt_embeds,
|
| 141 |
+
negative_prompt_embeds,
|
| 142 |
+
pooled_prompt_embeds,
|
| 143 |
+
negative_pooled_prompt_embeds,
|
| 144 |
+
) = self.encode_prompt(
|
| 145 |
+
prompt=prompt,
|
| 146 |
+
prompt_2=prompt_2,
|
| 147 |
+
device=device,
|
| 148 |
+
num_images_per_prompt=num_images_per_prompt,
|
| 149 |
+
do_classifier_free_guidance=self.do_classifier_free_guidance,
|
| 150 |
+
negative_prompt=negative_prompt,
|
| 151 |
+
negative_prompt_2=negative_prompt_2,
|
| 152 |
+
prompt_embeds=prompt_embeds,
|
| 153 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 154 |
+
pooled_prompt_embeds=pooled_prompt_embeds,
|
| 155 |
+
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
|
| 156 |
+
lora_scale=lora_scale,
|
| 157 |
+
clip_skip=self.clip_skip,
|
| 158 |
+
)
|
| 159 |
+
|
| 160 |
+
# 4. Prepare timesteps
|
| 161 |
+
timesteps, num_inference_steps = retrieve_timesteps(
|
| 162 |
+
self.scheduler, num_inference_steps, device, timesteps
|
| 163 |
+
)
|
| 164 |
+
|
| 165 |
+
num_channels_latents = self.unet.config.in_channels
|
| 166 |
+
latents = self.prepare_latents(
|
| 167 |
+
batch_size * num_images_per_prompt,
|
| 168 |
+
num_channels_latents,
|
| 169 |
+
height,
|
| 170 |
+
width,
|
| 171 |
+
prompt_embeds.dtype,
|
| 172 |
+
device,
|
| 173 |
+
generator,
|
| 174 |
+
latents,
|
| 175 |
+
)
|
| 176 |
+
|
| 177 |
+
# 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
|
| 178 |
+
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
|
| 179 |
+
|
| 180 |
+
# 7. Prepare added time ids & embeddings
|
| 181 |
+
add_text_embeds = pooled_prompt_embeds
|
| 182 |
+
if self.text_encoder_2 is None:
|
| 183 |
+
text_encoder_projection_dim = int(pooled_prompt_embeds.shape[-1])
|
| 184 |
+
else:
|
| 185 |
+
text_encoder_projection_dim = self.text_encoder_2.config.projection_dim
|
| 186 |
+
|
| 187 |
+
add_time_ids = self._get_add_time_ids(
|
| 188 |
+
original_size,
|
| 189 |
+
(0, 0),
|
| 190 |
+
target_size,
|
| 191 |
+
dtype=prompt_embeds.dtype,
|
| 192 |
+
text_encoder_projection_dim=text_encoder_projection_dim,
|
| 193 |
+
)
|
| 194 |
+
negative_add_time_ids = add_time_ids
|
| 195 |
+
|
| 196 |
+
if self.do_classifier_free_guidance:
|
| 197 |
+
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
|
| 198 |
+
add_text_embeds = torch.cat(
|
| 199 |
+
[negative_pooled_prompt_embeds, add_text_embeds], dim=0
|
| 200 |
+
)
|
| 201 |
+
add_time_ids = torch.cat([negative_add_time_ids, add_time_ids], dim=0)
|
| 202 |
+
|
| 203 |
+
prompt_embeds = prompt_embeds.to(device)
|
| 204 |
+
add_text_embeds = add_text_embeds.to(device)
|
| 205 |
+
add_time_ids = add_time_ids.to(device).repeat(
|
| 206 |
+
batch_size * num_images_per_prompt, 1
|
| 207 |
+
)
|
| 208 |
+
|
| 209 |
+
# 8. Denoising loop
|
| 210 |
+
num_warmup_steps = max(
|
| 211 |
+
len(timesteps) - num_inference_steps * self.scheduler.order, 0
|
| 212 |
+
)
|
| 213 |
+
|
| 214 |
+
# 8.1 Apply denoising_end
|
| 215 |
+
if (
|
| 216 |
+
self.denoising_end is not None
|
| 217 |
+
and isinstance(self.denoising_end, float)
|
| 218 |
+
and self.denoising_end > 0
|
| 219 |
+
and self.denoising_end < 1
|
| 220 |
+
):
|
| 221 |
+
discrete_timestep_cutoff = int(
|
| 222 |
+
round(
|
| 223 |
+
self.scheduler.config.num_train_timesteps
|
| 224 |
+
- (self.denoising_end * self.scheduler.config.num_train_timesteps)
|
| 225 |
+
)
|
| 226 |
+
)
|
| 227 |
+
num_inference_steps = len(
|
| 228 |
+
list(filter(lambda ts: ts >= discrete_timestep_cutoff, timesteps))
|
| 229 |
+
)
|
| 230 |
+
timesteps = timesteps[:num_inference_steps]
|
| 231 |
+
|
| 232 |
+
# 9. Optionally get Guidance Scale Embedding
|
| 233 |
+
timestep_cond = None
|
| 234 |
+
if self.unet.config.time_cond_proj_dim is not None:
|
| 235 |
+
guidance_scale_tensor = torch.tensor(self.guidance_scale - 1).repeat(
|
| 236 |
+
batch_size * num_images_per_prompt
|
| 237 |
+
)
|
| 238 |
+
timestep_cond = self.get_guidance_scale_embedding(
|
| 239 |
+
guidance_scale_tensor, embedding_dim=self.unet.config.time_cond_proj_dim
|
| 240 |
+
).to(device=device, dtype=latents.dtype)
|
| 241 |
+
|
| 242 |
+
self._num_timesteps = len(timesteps)
|
| 243 |
+
|
| 244 |
+
# 8. Denoising loop
|
| 245 |
+
# 8.1 Apply denoising_end
|
| 246 |
+
if (
|
| 247 |
+
self.denoising_end is not None
|
| 248 |
+
and isinstance(self.denoising_end, float)
|
| 249 |
+
and self.denoising_end > 0
|
| 250 |
+
and self.denoising_end < 1
|
| 251 |
+
):
|
| 252 |
+
discrete_timestep_cutoff = int(
|
| 253 |
+
round(
|
| 254 |
+
self.scheduler.config.num_train_timesteps
|
| 255 |
+
- (self.denoising_end * self.scheduler.config.num_train_timesteps)
|
| 256 |
+
)
|
| 257 |
+
)
|
| 258 |
+
num_inference_steps = len(
|
| 259 |
+
list(filter(lambda ts: ts >= discrete_timestep_cutoff, timesteps))
|
| 260 |
+
)
|
| 261 |
+
timesteps = timesteps[:num_inference_steps]
|
| 262 |
+
|
| 263 |
+
# 9. Optionally get Guidance Scale Embedding
|
| 264 |
+
timestep_cond = None
|
| 265 |
+
|
| 266 |
+
self._num_timesteps = len(timesteps)
|
| 267 |
+
for i, t in enumerate(timesteps):
|
| 268 |
+
if self._interrupt:
|
| 269 |
+
continue
|
| 270 |
+
# expand the latents if we are doing classifier free guidance
|
| 271 |
+
latent_model_input = (
|
| 272 |
+
torch.cat([latents] * 2)
|
| 273 |
+
if self.do_classifier_free_guidance
|
| 274 |
+
else latents
|
| 275 |
+
)
|
| 276 |
+
|
| 277 |
+
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
| 278 |
+
|
| 279 |
+
# predict the noise residual
|
| 280 |
+
added_cond_kwargs = {
|
| 281 |
+
"text_embeds": add_text_embeds,
|
| 282 |
+
"time_ids": add_time_ids,
|
| 283 |
+
}
|
| 284 |
+
noise_pred = self.unet(
|
| 285 |
+
latent_model_input,
|
| 286 |
+
t,
|
| 287 |
+
encoder_hidden_states=prompt_embeds,
|
| 288 |
+
timestep_cond=timestep_cond,
|
| 289 |
+
cross_attention_kwargs=self.cross_attention_kwargs,
|
| 290 |
+
added_cond_kwargs=added_cond_kwargs,
|
| 291 |
+
return_dict=False,
|
| 292 |
+
)[0]
|
| 293 |
+
|
| 294 |
+
# perform guidance
|
| 295 |
+
if self.do_classifier_free_guidance:
|
| 296 |
+
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
| 297 |
+
noise_pred = noise_pred_uncond + self.guidance_scale * (
|
| 298 |
+
noise_pred_text - noise_pred_uncond
|
| 299 |
+
)
|
| 300 |
+
|
| 301 |
+
# compute the previous noisy sample x_t -> x_t-1
|
| 302 |
+
latents = self.scheduler.step(
|
| 303 |
+
noise_pred, t, latents, **extra_step_kwargs, return_dict=False
|
| 304 |
+
)[0]
|
| 305 |
+
|
| 306 |
+
if self.is_hyper:
|
| 307 |
+
latents = latents.to(torch.float32)
|
| 308 |
+
image = self.decode_latents_tensors(latents)
|
| 309 |
+
image = image.to(torch.float16)
|
| 310 |
+
else:
|
| 311 |
+
image = self.decode_latents_tensors(latents)
|
| 312 |
+
|
| 313 |
+
# apply watermark if available
|
| 314 |
+
if self.watermark is not None:
|
| 315 |
+
image = self.watermark.apply_watermark(image)
|
| 316 |
+
|
| 317 |
+
# Offload all models
|
| 318 |
+
self.maybe_free_model_hooks()
|
| 319 |
+
|
| 320 |
+
return image
|
models/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .utils import get_model
|
models/utils.py
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from diffusers import (AutoencoderKL, DDPMScheduler,
|
| 5 |
+
EulerAncestralDiscreteScheduler, LCMScheduler,
|
| 6 |
+
Transformer2DModel, UNet2DConditionModel)
|
| 7 |
+
from huggingface_hub import hf_hub_download
|
| 8 |
+
from safetensors.torch import load_file
|
| 9 |
+
|
| 10 |
+
from models.RewardPixart import RewardPixartPipeline, freeze_params
|
| 11 |
+
from models.RewardStableDiffusion import RewardStableDiffusion
|
| 12 |
+
from models.RewardStableDiffusionXL import RewardStableDiffusionXL
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def get_model(
|
| 16 |
+
model_name: str,
|
| 17 |
+
dtype: torch.dtype,
|
| 18 |
+
device: torch.device,
|
| 19 |
+
cache_dir: str,
|
| 20 |
+
memsave: bool = False,
|
| 21 |
+
):
|
| 22 |
+
logging.info(f"Loading model: {model_name}")
|
| 23 |
+
if model_name == "sd-turbo":
|
| 24 |
+
pipe = RewardStableDiffusion.from_pretrained(
|
| 25 |
+
"stabilityai/sd-turbo",
|
| 26 |
+
torch_dtype=dtype,
|
| 27 |
+
variant="fp16",
|
| 28 |
+
cache_dir=cache_dir,
|
| 29 |
+
memsave=memsave,
|
| 30 |
+
)
|
| 31 |
+
pipe = pipe.to(device, dtype)
|
| 32 |
+
elif model_name == "sdxl-turbo":
|
| 33 |
+
vae = AutoencoderKL.from_pretrained(
|
| 34 |
+
"madebyollin/sdxl-vae-fp16-fix",
|
| 35 |
+
torch_dtype=torch.float16,
|
| 36 |
+
cache_dir=cache_dir,
|
| 37 |
+
)
|
| 38 |
+
pipe = RewardStableDiffusionXL.from_pretrained(
|
| 39 |
+
"stabilityai/sdxl-turbo",
|
| 40 |
+
vae=vae,
|
| 41 |
+
torch_dtype=dtype,
|
| 42 |
+
variant="fp16",
|
| 43 |
+
use_safetensors=True,
|
| 44 |
+
cache_dir=cache_dir,
|
| 45 |
+
memsave=memsave,
|
| 46 |
+
)
|
| 47 |
+
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(
|
| 48 |
+
pipe.scheduler.config, timestep_spacing="trailing"
|
| 49 |
+
)
|
| 50 |
+
pipe = pipe.to(device, dtype)
|
| 51 |
+
elif model_name == "pixart":
|
| 52 |
+
pipe = RewardPixartPipeline.from_pretrained(
|
| 53 |
+
"PixArt-alpha/PixArt-XL-2-1024-MS",
|
| 54 |
+
torch_dtype=dtype,
|
| 55 |
+
cache_dir=cache_dir,
|
| 56 |
+
memsave=memsave,
|
| 57 |
+
)
|
| 58 |
+
pipe.transformer = Transformer2DModel.from_pretrained(
|
| 59 |
+
"PixArt-alpha/PixArt-Alpha-DMD-XL-2-512x512",
|
| 60 |
+
subfolder="transformer",
|
| 61 |
+
torch_dtype=dtype,
|
| 62 |
+
cache_dir=cache_dir,
|
| 63 |
+
)
|
| 64 |
+
pipe.scheduler = DDPMScheduler.from_pretrained(
|
| 65 |
+
"PixArt-alpha/PixArt-Alpha-DMD-XL-2-512x512",
|
| 66 |
+
subfolder="scheduler",
|
| 67 |
+
cache_dir=cache_dir,
|
| 68 |
+
)
|
| 69 |
+
|
| 70 |
+
# speed-up T5
|
| 71 |
+
pipe.text_encoder.to_bettertransformer()
|
| 72 |
+
pipe.transformer.eval()
|
| 73 |
+
freeze_params(pipe.transformer.parameters())
|
| 74 |
+
pipe.transformer.enable_gradient_checkpointing()
|
| 75 |
+
pipe = pipe.to(device)
|
| 76 |
+
elif model_name == "hyper-sd":
|
| 77 |
+
base_model_id = "stabilityai/stable-diffusion-xl-base-1.0"
|
| 78 |
+
repo_name = "ByteDance/Hyper-SD"
|
| 79 |
+
ckpt_name = "Hyper-SDXL-1step-Unet.safetensors"
|
| 80 |
+
# Load model.
|
| 81 |
+
unet = UNet2DConditionModel.from_config(
|
| 82 |
+
base_model_id, subfolder="unet", cache_dir=cache_dir
|
| 83 |
+
).to(device, dtype)
|
| 84 |
+
unet.load_state_dict(
|
| 85 |
+
load_file(
|
| 86 |
+
hf_hub_download(repo_name, ckpt_name, cache_dir=cache_dir),
|
| 87 |
+
device="cuda",
|
| 88 |
+
)
|
| 89 |
+
)
|
| 90 |
+
pipe = RewardStableDiffusionXL.from_pretrained(
|
| 91 |
+
base_model_id,
|
| 92 |
+
unet=unet,
|
| 93 |
+
torch_dtype=dtype,
|
| 94 |
+
variant="fp16",
|
| 95 |
+
cache_dir=cache_dir,
|
| 96 |
+
is_hyper=True,
|
| 97 |
+
memsave=memsave,
|
| 98 |
+
)
|
| 99 |
+
# Use LCM scheduler instead of ddim scheduler to support specific timestep number inputs
|
| 100 |
+
pipe.scheduler = LCMScheduler.from_config(
|
| 101 |
+
pipe.scheduler.config, cache_dir=cache_dir
|
| 102 |
+
)
|
| 103 |
+
pipe = pipe.to(device, dtype)
|
| 104 |
+
# upcast vae
|
| 105 |
+
pipe.vae = pipe.vae.to(dtype=torch.float32)
|
| 106 |
+
# pipe.enable_sequential_cpu_offload()
|
| 107 |
+
else:
|
| 108 |
+
raise ValueError(f"Unknown model name: {model_name}")
|
| 109 |
+
return pipe
|
rewards/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .utils import clip_img_transform, get_reward_losses
|
rewards/aesthetic.py
ADDED
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
import clip
|
| 4 |
+
import pytorch_lightning as pl
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
import torch.nn.functional as F
|
| 8 |
+
|
| 9 |
+
from rewards.base_reward import BaseRewardLoss
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class AestheticLoss(BaseRewardLoss):
|
| 13 |
+
"""CLIP reward loss function for optimization."""
|
| 14 |
+
|
| 15 |
+
def __init__(
|
| 16 |
+
self,
|
| 17 |
+
weigthing: float,
|
| 18 |
+
dtype: torch.dtype,
|
| 19 |
+
device: torch.device,
|
| 20 |
+
cache_dir: str,
|
| 21 |
+
memsave: bool = False,
|
| 22 |
+
):
|
| 23 |
+
self.clip_model, self.preprocess_fn = clip.load(
|
| 24 |
+
"ViT-L/14", device=device, download_root=cache_dir
|
| 25 |
+
)
|
| 26 |
+
self.clip_model = self.clip_model.to(device, dtype=dtype)
|
| 27 |
+
self.mlp = MLP(768).to(device, dtype=dtype)
|
| 28 |
+
s = torch.load(
|
| 29 |
+
f"{os.getcwd()}/ckpts/aesthetic-model.pth"
|
| 30 |
+
) # load the model you trained previously or the model available in this repo
|
| 31 |
+
self.mlp.load_state_dict(s)
|
| 32 |
+
self.clip_model.eval()
|
| 33 |
+
if memsave:
|
| 34 |
+
import memsave_torch.nn
|
| 35 |
+
|
| 36 |
+
self.mlp = memsave_torch.nn.convert_to_memory_saving(self.mlp)
|
| 37 |
+
self.clip_model = memsave_torch.nn.convert_to_memory_saving(
|
| 38 |
+
self.clip_model
|
| 39 |
+
).to(device, dtype=dtype)
|
| 40 |
+
|
| 41 |
+
self.freeze_parameters(self.clip_model.parameters())
|
| 42 |
+
self.freeze_parameters(self.mlp.parameters())
|
| 43 |
+
super().__init__("Aesthetic", weigthing)
|
| 44 |
+
|
| 45 |
+
def get_image_features(self, image: torch.Tensor) -> torch.Tensor:
|
| 46 |
+
with torch.autocast("cuda"):
|
| 47 |
+
clip_img_features = self.clip_model.encode_image(image)
|
| 48 |
+
l2 = torch.norm(clip_img_features, p=2, dim=-1, keepdim=True)
|
| 49 |
+
l2 = torch.where(
|
| 50 |
+
l2 == 0,
|
| 51 |
+
torch.tensor(
|
| 52 |
+
1.0, device=clip_img_features.device, dtype=clip_img_features.dtype
|
| 53 |
+
),
|
| 54 |
+
l2,
|
| 55 |
+
)
|
| 56 |
+
clip_img_features = clip_img_features / l2
|
| 57 |
+
return clip_img_features
|
| 58 |
+
|
| 59 |
+
def get_text_features(self, prompt: str) -> torch.Tensor:
|
| 60 |
+
return None
|
| 61 |
+
|
| 62 |
+
def compute_loss(
|
| 63 |
+
self, image_features: torch.Tensor, text_features: torch.Tensor
|
| 64 |
+
) -> torch.Tensor:
|
| 65 |
+
return None
|
| 66 |
+
|
| 67 |
+
def __call__(self, image: torch.Tensor, prompt: torch.Tensor) -> torch.Tensor:
|
| 68 |
+
if self.memsave:
|
| 69 |
+
image = image.to(torch.float32)
|
| 70 |
+
image_features = self.get_image_features(image)
|
| 71 |
+
|
| 72 |
+
image_features_normed = self.process_features(image_features.to(torch.float16))
|
| 73 |
+
|
| 74 |
+
aesthetic_loss = 10.0 - self.mlp(image_features_normed).mean()
|
| 75 |
+
return aesthetic_loss
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
class MLP(pl.LightningModule):
|
| 79 |
+
def __init__(self, input_size, xcol="emb", ycol="avg_rating"):
|
| 80 |
+
super().__init__()
|
| 81 |
+
self.input_size = input_size
|
| 82 |
+
self.xcol = xcol
|
| 83 |
+
self.ycol = ycol
|
| 84 |
+
self.layers = nn.Sequential(
|
| 85 |
+
nn.Linear(self.input_size, 1024),
|
| 86 |
+
# nn.ReLU(),
|
| 87 |
+
nn.Dropout(0.2),
|
| 88 |
+
nn.Linear(1024, 128),
|
| 89 |
+
# nn.ReLU(),
|
| 90 |
+
nn.Dropout(0.2),
|
| 91 |
+
nn.Linear(128, 64),
|
| 92 |
+
# nn.ReLU(),
|
| 93 |
+
nn.Dropout(0.1),
|
| 94 |
+
nn.Linear(64, 16),
|
| 95 |
+
# nn.ReLU(),
|
| 96 |
+
nn.Linear(16, 1),
|
| 97 |
+
)
|
| 98 |
+
|
| 99 |
+
def forward(self, x):
|
| 100 |
+
return self.layers(x)
|
| 101 |
+
|
| 102 |
+
def training_step(self, batch, batch_idx):
|
| 103 |
+
x = batch[self.xcol]
|
| 104 |
+
y = batch[self.ycol].reshape(-1, 1)
|
| 105 |
+
x_hat = self.layers(x)
|
| 106 |
+
loss = F.mse_loss(x_hat, y)
|
| 107 |
+
return loss
|
| 108 |
+
|
| 109 |
+
def validation_step(self, batch, batch_idx):
|
| 110 |
+
x = batch[self.xcol]
|
| 111 |
+
y = batch[self.ycol].reshape(-1, 1)
|
| 112 |
+
x_hat = self.layers(x)
|
| 113 |
+
loss = F.mse_loss(x_hat, y)
|
| 114 |
+
return loss
|
| 115 |
+
|
| 116 |
+
def configure_optimizers(self):
|
| 117 |
+
optimizer = torch.optim.Adam(self.parameters(), lr=1e-3)
|
| 118 |
+
return optimizer
|
rewards/base_reward.py
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import ABC, abstractmethod
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class BaseRewardLoss(ABC):
|
| 7 |
+
"""
|
| 8 |
+
Base class for reward functions implementing a differentiable reward function for optimization.
|
| 9 |
+
"""
|
| 10 |
+
|
| 11 |
+
def __init__(self, name: str, weighting: float):
|
| 12 |
+
self.name = name
|
| 13 |
+
self.weighting = weighting
|
| 14 |
+
|
| 15 |
+
@staticmethod
|
| 16 |
+
def freeze_parameters(params: torch.nn.ParameterList):
|
| 17 |
+
for param in params:
|
| 18 |
+
param.requires_grad = False
|
| 19 |
+
|
| 20 |
+
@abstractmethod
|
| 21 |
+
def get_image_features(self, image: torch.Tensor) -> torch.Tensor:
|
| 22 |
+
pass
|
| 23 |
+
|
| 24 |
+
@abstractmethod
|
| 25 |
+
def get_text_features(self, prompt: str) -> torch.Tensor:
|
| 26 |
+
pass
|
| 27 |
+
|
| 28 |
+
@abstractmethod
|
| 29 |
+
def compute_loss(
|
| 30 |
+
self, image_features: torch.Tensor, text_features: torch.Tensor
|
| 31 |
+
) -> torch.Tensor:
|
| 32 |
+
pass
|
| 33 |
+
|
| 34 |
+
def process_features(self, features: torch.Tensor) -> torch.Tensor:
|
| 35 |
+
features_normed = features / features.norm(dim=-1, keepdim=True)
|
| 36 |
+
return features_normed
|
| 37 |
+
|
| 38 |
+
def __call__(self, image: torch.Tensor, prompt: str) -> torch.Tensor:
|
| 39 |
+
image_features = self.get_image_features(image)
|
| 40 |
+
text_features = self.get_text_features(prompt)
|
| 41 |
+
|
| 42 |
+
image_features_normed = self.process_features(image_features)
|
| 43 |
+
text_features_normed = self.process_features(text_features)
|
| 44 |
+
|
| 45 |
+
loss = self.compute_loss(image_features_normed, text_features_normed)
|
| 46 |
+
return loss
|
rewards/clip.py
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from transformers import CLIPModel
|
| 3 |
+
|
| 4 |
+
from rewards.base_reward import BaseRewardLoss
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class CLIPLoss(BaseRewardLoss):
|
| 8 |
+
"""CLIP reward loss function for optimization."""
|
| 9 |
+
|
| 10 |
+
def __init__(
|
| 11 |
+
self,
|
| 12 |
+
weigthing: float,
|
| 13 |
+
dtype: torch.dtype,
|
| 14 |
+
device: torch.device,
|
| 15 |
+
cache_dir: str,
|
| 16 |
+
tokenizer,
|
| 17 |
+
memsave: bool = False,
|
| 18 |
+
):
|
| 19 |
+
self.tokenizer = tokenizer
|
| 20 |
+
self.clip_model = CLIPModel.from_pretrained(
|
| 21 |
+
"laion/CLIP-ViT-H-14-laion2B-s32B-b79K",
|
| 22 |
+
cache_dir=cache_dir,
|
| 23 |
+
)
|
| 24 |
+
# freeze all models parameters
|
| 25 |
+
if memsave:
|
| 26 |
+
import memsave_torch.nn
|
| 27 |
+
|
| 28 |
+
self.clip_model = memsave_torch.nn.convert_to_memory_saving(self.clip_model)
|
| 29 |
+
self.clip_model = self.clip_model.to(device, dtype=dtype)
|
| 30 |
+
self.clip_model.eval()
|
| 31 |
+
self.freeze_parameters(self.clip_model.parameters())
|
| 32 |
+
super().__init__("CLIP", weigthing)
|
| 33 |
+
self.clip_model.gradient_checkpointing_enable()
|
| 34 |
+
|
| 35 |
+
def get_image_features(self, image: torch.Tensor) -> torch.Tensor:
|
| 36 |
+
clip_img_features = self.clip_model.get_image_features(image)
|
| 37 |
+
return clip_img_features
|
| 38 |
+
|
| 39 |
+
def get_text_features(self, prompt: str) -> torch.Tensor:
|
| 40 |
+
prompt_token = self.tokenizer(
|
| 41 |
+
prompt, return_tensors="pt", padding=True, max_length=77, truncation=True
|
| 42 |
+
).to("cuda")
|
| 43 |
+
clip_text_features = self.clip_model.get_text_features(**prompt_token)
|
| 44 |
+
return clip_text_features
|
| 45 |
+
|
| 46 |
+
def compute_loss(
|
| 47 |
+
self, image_features: torch.Tensor, text_features: torch.Tensor
|
| 48 |
+
) -> torch.Tensor:
|
| 49 |
+
clip_loss = (
|
| 50 |
+
100
|
| 51 |
+
- (image_features @ text_features.T).mean()
|
| 52 |
+
* self.clip_model.logit_scale.exp()
|
| 53 |
+
)
|
| 54 |
+
return clip_loss
|
rewards/hps.py
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import huggingface_hub
|
| 2 |
+
import torch
|
| 3 |
+
from hpsv2.src.open_clip import create_model, get_tokenizer
|
| 4 |
+
|
| 5 |
+
from rewards.base_reward import BaseRewardLoss
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class HPSLoss(BaseRewardLoss):
|
| 9 |
+
"""HPS reward loss function for optimization."""
|
| 10 |
+
|
| 11 |
+
def __init__(
|
| 12 |
+
self,
|
| 13 |
+
weighting: float,
|
| 14 |
+
dtype: torch.dtype,
|
| 15 |
+
device: torch.device,
|
| 16 |
+
cache_dir: str,
|
| 17 |
+
memsave: bool = False,
|
| 18 |
+
):
|
| 19 |
+
self.hps_model = create_model(
|
| 20 |
+
"ViT-H-14",
|
| 21 |
+
"laion2B-s32B-b79K",
|
| 22 |
+
precision=dtype,
|
| 23 |
+
device=device,
|
| 24 |
+
cache_dir=cache_dir,
|
| 25 |
+
)
|
| 26 |
+
checkpoint_path = huggingface_hub.hf_hub_download(
|
| 27 |
+
"xswu/HPSv2", "HPS_v2.1_compressed.pt", cache_dir=cache_dir
|
| 28 |
+
)
|
| 29 |
+
self.hps_model.load_state_dict(
|
| 30 |
+
torch.load(checkpoint_path, map_location=device)["state_dict"]
|
| 31 |
+
)
|
| 32 |
+
self.hps_tokenizer = get_tokenizer("ViT-H-14")
|
| 33 |
+
if memsave:
|
| 34 |
+
import memsave_torch.nn
|
| 35 |
+
|
| 36 |
+
self.hps_model = memsave_torch.nn.convert_to_memory_saving(self.hps_model)
|
| 37 |
+
self.hps_model = self.hps_model.to(device, dtype=dtype)
|
| 38 |
+
self.hps_model.eval()
|
| 39 |
+
self.freeze_parameters(self.hps_model.parameters())
|
| 40 |
+
super().__init__("HPS", weighting)
|
| 41 |
+
self.hps_model.set_grad_checkpointing(True)
|
| 42 |
+
|
| 43 |
+
def get_image_features(self, image: torch.Tensor) -> torch.Tensor:
|
| 44 |
+
hps_image_features = self.hps_model.encode_image(image)
|
| 45 |
+
return hps_image_features
|
| 46 |
+
|
| 47 |
+
def get_text_features(self, prompt: str) -> torch.Tensor:
|
| 48 |
+
hps_text = self.hps_tokenizer(prompt).to("cuda")
|
| 49 |
+
hps_text_features = self.hps_model.encode_text(hps_text)
|
| 50 |
+
return hps_text_features
|
| 51 |
+
|
| 52 |
+
def compute_loss(
|
| 53 |
+
self, image_features: torch.Tensor, text_features: torch.Tensor
|
| 54 |
+
) -> torch.Tensor:
|
| 55 |
+
logits_per_image = image_features @ text_features.T
|
| 56 |
+
hps_loss = 1 - torch.diagonal(logits_per_image)[0]
|
| 57 |
+
return hps_loss
|
rewards/imagereward.py
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import ImageReward as RM
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
from rewards.base_reward import BaseRewardLoss
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class ImageRewardLoss:
|
| 8 |
+
"""Image reward loss for optimization."""
|
| 9 |
+
|
| 10 |
+
def __init__(
|
| 11 |
+
self,
|
| 12 |
+
weighting: float,
|
| 13 |
+
dtype: torch.dtype,
|
| 14 |
+
device: torch.device,
|
| 15 |
+
cache_dir: str,
|
| 16 |
+
memsave: bool = False,
|
| 17 |
+
):
|
| 18 |
+
self.name = "ImageReward"
|
| 19 |
+
self.weighting = weighting
|
| 20 |
+
self.dtype = dtype
|
| 21 |
+
self.imagereward_model = RM.load("ImageReward-v1.0", download_root=cache_dir)
|
| 22 |
+
self.imagereward_model = self.imagereward_model.to(
|
| 23 |
+
device=device, dtype=self.dtype
|
| 24 |
+
)
|
| 25 |
+
self.imagereward_model.eval()
|
| 26 |
+
BaseRewardLoss.freeze_parameters(self.imagereward_model.parameters())
|
| 27 |
+
|
| 28 |
+
def __call__(self, image: torch.Tensor, prompt: str) -> torch.Tensor:
|
| 29 |
+
imagereward_score = self.score_diff(prompt, image)
|
| 30 |
+
return (2 - imagereward_score).mean()
|
| 31 |
+
|
| 32 |
+
def score_diff(self, prompt, image):
|
| 33 |
+
# text encode
|
| 34 |
+
text_input = self.imagereward_model.blip.tokenizer(
|
| 35 |
+
prompt,
|
| 36 |
+
padding="max_length",
|
| 37 |
+
truncation=True,
|
| 38 |
+
max_length=35,
|
| 39 |
+
return_tensors="pt",
|
| 40 |
+
).to(self.imagereward_model.device)
|
| 41 |
+
image_embeds = self.imagereward_model.blip.visual_encoder(image)
|
| 42 |
+
|
| 43 |
+
# text encode cross attention with image
|
| 44 |
+
image_atts = torch.ones(image_embeds.size()[:-1], dtype=torch.long).to(
|
| 45 |
+
self.imagereward_model.device
|
| 46 |
+
)
|
| 47 |
+
text_output = self.imagereward_model.blip.text_encoder(
|
| 48 |
+
text_input.input_ids,
|
| 49 |
+
attention_mask=text_input.attention_mask,
|
| 50 |
+
encoder_hidden_states=image_embeds,
|
| 51 |
+
encoder_attention_mask=image_atts,
|
| 52 |
+
return_dict=True,
|
| 53 |
+
)
|
| 54 |
+
|
| 55 |
+
txt_features = text_output.last_hidden_state[:, 0, :].to(
|
| 56 |
+
self.imagereward_model.device, dtype=self.dtype
|
| 57 |
+
)
|
| 58 |
+
rewards = self.imagereward_model.mlp(txt_features)
|
| 59 |
+
rewards = (rewards - self.imagereward_model.mean) / self.imagereward_model.std
|
| 60 |
+
|
| 61 |
+
return rewards
|
rewards/pickscore.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from transformers import AutoModel
|
| 3 |
+
|
| 4 |
+
from rewards.base_reward import BaseRewardLoss
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class PickScoreLoss(BaseRewardLoss):
|
| 8 |
+
"""PickScore reward loss function for optimization."""
|
| 9 |
+
|
| 10 |
+
def __init__(
|
| 11 |
+
self,
|
| 12 |
+
weighting: float,
|
| 13 |
+
dtype: torch.dtype,
|
| 14 |
+
device: torch.device,
|
| 15 |
+
cache_dir: str,
|
| 16 |
+
tokenizer,
|
| 17 |
+
memsave: bool = False,
|
| 18 |
+
):
|
| 19 |
+
self.tokenizer = tokenizer
|
| 20 |
+
self.pickscore_model = AutoModel.from_pretrained(
|
| 21 |
+
"yuvalkirstain/PickScore_v1", cache_dir=cache_dir
|
| 22 |
+
).eval()
|
| 23 |
+
if memsave:
|
| 24 |
+
import memsave_torch.nn
|
| 25 |
+
|
| 26 |
+
self.pickscore_model = memsave_torch.nn.convert_to_memory_saving(
|
| 27 |
+
self.pickscore_model
|
| 28 |
+
)
|
| 29 |
+
self.pickscore_model = self.pickscore_model.to(device, dtype=dtype)
|
| 30 |
+
self.freeze_parameters(self.pickscore_model.parameters())
|
| 31 |
+
super().__init__("PickScore", weighting)
|
| 32 |
+
self.pickscore_model._set_gradient_checkpointing(True)
|
| 33 |
+
|
| 34 |
+
def get_image_features(self, image) -> torch.Tensor:
|
| 35 |
+
reward_img_features = self.pickscore_model.get_image_features(image)
|
| 36 |
+
return reward_img_features
|
| 37 |
+
|
| 38 |
+
def get_text_features(self, prompt: str) -> torch.Tensor:
|
| 39 |
+
prompt_token = self.tokenizer(
|
| 40 |
+
prompt, return_tensors="pt", padding=True, max_length=77, truncation=True
|
| 41 |
+
).to("cuda")
|
| 42 |
+
reward_text_features = self.pickscore_model.get_text_features(**prompt_token)
|
| 43 |
+
return reward_text_features
|
| 44 |
+
|
| 45 |
+
def compute_loss(
|
| 46 |
+
self, image_features: torch.Tensor, text_features: torch.Tensor
|
| 47 |
+
) -> torch.Tensor:
|
| 48 |
+
pickscore_loss = (
|
| 49 |
+
30
|
| 50 |
+
- (
|
| 51 |
+
self.pickscore_model.logit_scale.exp()
|
| 52 |
+
* (image_features @ text_features.T)
|
| 53 |
+
).mean()
|
| 54 |
+
)
|
| 55 |
+
return pickscore_loss
|
rewards/utils.py
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Any, List
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from torchvision.transforms import (CenterCrop, Compose, InterpolationMode,
|
| 5 |
+
Normalize, Resize)
|
| 6 |
+
from transformers import AutoProcessor
|
| 7 |
+
|
| 8 |
+
from rewards.aesthetic import AestheticLoss
|
| 9 |
+
from rewards.base_reward import BaseRewardLoss
|
| 10 |
+
from rewards.clip import CLIPLoss
|
| 11 |
+
from rewards.hps import HPSLoss
|
| 12 |
+
from rewards.imagereward import ImageRewardLoss
|
| 13 |
+
from rewards.pickscore import PickScoreLoss
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def get_reward_losses(
|
| 17 |
+
args: Any, dtype: torch.dtype, device: torch.device, cache_dir: str
|
| 18 |
+
) -> List[BaseRewardLoss]:
|
| 19 |
+
if args.enable_clip or args.enable_pickscore:
|
| 20 |
+
tokenizer = AutoProcessor.from_pretrained(
|
| 21 |
+
"laion/CLIP-ViT-H-14-laion2B-s32B-b79K", cache_dir=cache_dir
|
| 22 |
+
)
|
| 23 |
+
reward_losses = []
|
| 24 |
+
if args.enable_hps:
|
| 25 |
+
reward_losses.append(
|
| 26 |
+
HPSLoss(args.hps_weighting, dtype, device, cache_dir, memsave=args.memsave)
|
| 27 |
+
)
|
| 28 |
+
if args.enable_imagereward:
|
| 29 |
+
reward_losses.append(
|
| 30 |
+
ImageRewardLoss(
|
| 31 |
+
args.imagereward_weighting,
|
| 32 |
+
dtype,
|
| 33 |
+
device,
|
| 34 |
+
cache_dir,
|
| 35 |
+
memsave=args.memsave,
|
| 36 |
+
)
|
| 37 |
+
)
|
| 38 |
+
if args.enable_clip:
|
| 39 |
+
reward_losses.append(
|
| 40 |
+
CLIPLoss(
|
| 41 |
+
args.clip_weighting,
|
| 42 |
+
dtype,
|
| 43 |
+
device,
|
| 44 |
+
cache_dir,
|
| 45 |
+
tokenizer,
|
| 46 |
+
memsave=args.memsave,
|
| 47 |
+
)
|
| 48 |
+
)
|
| 49 |
+
if args.enable_pickscore:
|
| 50 |
+
reward_losses.append(
|
| 51 |
+
PickScoreLoss(
|
| 52 |
+
args.pickscore_weighting,
|
| 53 |
+
dtype,
|
| 54 |
+
device,
|
| 55 |
+
cache_dir,
|
| 56 |
+
tokenizer,
|
| 57 |
+
memsave=args.memsave,
|
| 58 |
+
)
|
| 59 |
+
)
|
| 60 |
+
if args.enable_aesthetic:
|
| 61 |
+
reward_losses.append(
|
| 62 |
+
AestheticLoss(
|
| 63 |
+
args.aesthetic_weighting, dtype, device, cache_dir, memsave=args.memsave
|
| 64 |
+
)
|
| 65 |
+
)
|
| 66 |
+
return reward_losses
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def clip_img_transform(size: int = 224):
|
| 70 |
+
return Compose(
|
| 71 |
+
[
|
| 72 |
+
Resize(size, interpolation=InterpolationMode.BICUBIC),
|
| 73 |
+
CenterCrop(size),
|
| 74 |
+
Normalize(
|
| 75 |
+
(0.48145466, 0.4578275, 0.40821073),
|
| 76 |
+
(0.26862954, 0.26130258, 0.27577711),
|
| 77 |
+
),
|
| 78 |
+
]
|
| 79 |
+
)
|
training/__init__.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .optim import get_optimizer
|
| 2 |
+
from .trainer import LatentNoiseTrainer
|
training/optim.py
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def get_optimizer(
|
| 5 |
+
optimizer_name: str, latents: torch.Tensor, lr: float, nesterov: bool
|
| 6 |
+
):
|
| 7 |
+
if optimizer_name == "adam":
|
| 8 |
+
optimizer = torch.optim.Adam([latents], lr=lr, eps=1e-2)
|
| 9 |
+
elif optimizer_name == "sgd":
|
| 10 |
+
optimizer = torch.optim.SGD([latents], lr=lr, nesterov=nesterov, momentum=0.9)
|
| 11 |
+
elif optimizer_name == "lbfgs":
|
| 12 |
+
optimizer = torch.optim.LBFGS(
|
| 13 |
+
[latents],
|
| 14 |
+
lr=lr,
|
| 15 |
+
max_iter=10,
|
| 16 |
+
history_size=3,
|
| 17 |
+
line_search_fn="strong_wolfe",
|
| 18 |
+
)
|
| 19 |
+
else:
|
| 20 |
+
raise ValueError(f"Unknown optimizer {optimizer_name}")
|
| 21 |
+
return optimizer
|
training/trainer.py
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import math
|
| 3 |
+
from typing import Dict, List, Optional, Tuple
|
| 4 |
+
|
| 5 |
+
import PIL
|
| 6 |
+
import PIL.Image
|
| 7 |
+
import torch
|
| 8 |
+
from diffusers import DiffusionPipeline
|
| 9 |
+
|
| 10 |
+
from rewards import clip_img_transform
|
| 11 |
+
from rewards.base_reward import BaseRewardLoss
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class LatentNoiseTrainer:
|
| 15 |
+
"""Trainer for optimizing latents with reward losses."""
|
| 16 |
+
|
| 17 |
+
def __init__(
|
| 18 |
+
self,
|
| 19 |
+
reward_losses: List[BaseRewardLoss],
|
| 20 |
+
model: DiffusionPipeline,
|
| 21 |
+
n_iters: int,
|
| 22 |
+
n_inference_steps: int,
|
| 23 |
+
seed: int,
|
| 24 |
+
no_optim: bool = False,
|
| 25 |
+
regularize: bool = True,
|
| 26 |
+
regularization_weight: float = 0.01,
|
| 27 |
+
grad_clip: float = 0.1,
|
| 28 |
+
log_metrics: bool = True,
|
| 29 |
+
save_all_images: bool = False,
|
| 30 |
+
imageselect: bool = False,
|
| 31 |
+
device: torch.device = torch.device("cuda"),
|
| 32 |
+
):
|
| 33 |
+
self.reward_losses = reward_losses
|
| 34 |
+
self.model = model
|
| 35 |
+
self.n_iters = n_iters
|
| 36 |
+
self.n_inference_steps = n_inference_steps
|
| 37 |
+
self.seed = seed
|
| 38 |
+
self.no_optim = no_optim
|
| 39 |
+
self.regularize = regularize
|
| 40 |
+
self.regularization_weight = regularization_weight
|
| 41 |
+
self.grad_clip = grad_clip
|
| 42 |
+
self.log_metrics = log_metrics
|
| 43 |
+
self.save_all_images = save_all_images
|
| 44 |
+
self.imageselect = imageselect
|
| 45 |
+
self.device = device
|
| 46 |
+
self.preprocess_fn = clip_img_transform(224)
|
| 47 |
+
|
| 48 |
+
def train(
|
| 49 |
+
self,
|
| 50 |
+
latents: torch.Tensor,
|
| 51 |
+
prompt: str,
|
| 52 |
+
optimizer: torch.optim.Optimizer,
|
| 53 |
+
save_dir: Optional[str] = None,
|
| 54 |
+
) -> Tuple[PIL.Image.Image, Dict[str, float], Dict[str, float]]:
|
| 55 |
+
logging.info(f"Optimizing latents for prompt '{prompt}'.")
|
| 56 |
+
best_loss = torch.inf
|
| 57 |
+
best_image = None
|
| 58 |
+
initial_rewards = None
|
| 59 |
+
best_rewards = None
|
| 60 |
+
latent_dim = math.prod(latents.shape[1:])
|
| 61 |
+
for iteration in range(self.n_iters):
|
| 62 |
+
to_log = ""
|
| 63 |
+
rewards = {}
|
| 64 |
+
optimizer.zero_grad()
|
| 65 |
+
generator = torch.Generator("cuda").manual_seed(self.seed)
|
| 66 |
+
if self.imageselect:
|
| 67 |
+
new_latents = torch.randn_like(
|
| 68 |
+
latents, device=self.device, dtype=latents.dtype
|
| 69 |
+
)
|
| 70 |
+
image = self.model.apply(
|
| 71 |
+
new_latents,
|
| 72 |
+
prompt,
|
| 73 |
+
generator=generator,
|
| 74 |
+
num_inference_steps=self.n_inference_steps,
|
| 75 |
+
)
|
| 76 |
+
else:
|
| 77 |
+
image = self.model.apply(
|
| 78 |
+
latents,
|
| 79 |
+
prompt,
|
| 80 |
+
generator=generator,
|
| 81 |
+
num_inference_steps=self.n_inference_steps,
|
| 82 |
+
)
|
| 83 |
+
if self.no_optim:
|
| 84 |
+
best_image = image
|
| 85 |
+
break
|
| 86 |
+
|
| 87 |
+
total_loss = 0
|
| 88 |
+
preprocessed_image = self.preprocess_fn(image)
|
| 89 |
+
for reward_loss in self.reward_losses:
|
| 90 |
+
loss = reward_loss(preprocessed_image, prompt)
|
| 91 |
+
to_log += f"{reward_loss.name}: {loss.item():.4f}, "
|
| 92 |
+
total_loss += loss * reward_loss.weighting
|
| 93 |
+
rewards[reward_loss.name] = loss.item()
|
| 94 |
+
rewards["total"] = total_loss.item()
|
| 95 |
+
to_log += f"Total: {total_loss.item():.4f}"
|
| 96 |
+
total_reward_loss = total_loss.item()
|
| 97 |
+
if self.regularize:
|
| 98 |
+
# compute in fp32 to avoid overflow
|
| 99 |
+
latent_norm = torch.linalg.vector_norm(latents).to(torch.float32)
|
| 100 |
+
log_norm = torch.log(latent_norm)
|
| 101 |
+
regularization = self.regularization_weight * (
|
| 102 |
+
0.5 * latent_norm**2 - (latent_dim - 1) * log_norm
|
| 103 |
+
)
|
| 104 |
+
to_log += f", Latent norm: {latent_norm.item()}"
|
| 105 |
+
rewards["norm"] = latent_norm.item()
|
| 106 |
+
total_loss += regularization.to(total_loss.dtype)
|
| 107 |
+
if self.log_metrics:
|
| 108 |
+
logging.info(f"Iteration {iteration}: {to_log}")
|
| 109 |
+
if initial_rewards is None:
|
| 110 |
+
initial_rewards = rewards
|
| 111 |
+
if total_reward_loss < best_loss:
|
| 112 |
+
best_loss = total_reward_loss
|
| 113 |
+
best_image = image
|
| 114 |
+
best_rewards = rewards
|
| 115 |
+
if iteration != self.n_iters - 1 and not self.imageselect:
|
| 116 |
+
total_loss.backward()
|
| 117 |
+
torch.nn.utils.clip_grad_norm_(latents, self.grad_clip)
|
| 118 |
+
optimizer.step()
|
| 119 |
+
if self.save_all_images:
|
| 120 |
+
image_numpy = image.detach().cpu().permute(0, 2, 3, 1).float().numpy()
|
| 121 |
+
image_pil = DiffusionPipeline.numpy_to_pil(image_numpy)[0]
|
| 122 |
+
image_pil.save(f"{save_dir}/{iteration}.png")
|
| 123 |
+
image_numpy = best_image.detach().cpu().permute(0, 2, 3, 1).float().numpy()
|
| 124 |
+
image_pil = DiffusionPipeline.numpy_to_pil(image_numpy)[0]
|
| 125 |
+
return image_pil, initial_rewards, best_rewards
|