import gradio as gr
import os
import requests
from text_generation import Client
HF_TOKEN = os.getenv('HF_TOKEN')
ENDPOINT = os.getenv('INFERENCE_ENDPOINT')
system_message = "\nYou are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.\n\nIf a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information."
if ENDPOINT:
client = Client(ENDPOINT, headers={"Authorization": f"Bearer {HF_TOKEN}"})
def predict(message, chatbot):
input_prompt = f"[INST] <>\n{system_message}\n<>\n\n "
for interaction in chatbot:
input_prompt = input_prompt + str(interaction[0]) + " [/INST] " + str(interaction[1]) + " [INST] "
input_prompt = input_prompt + str(message) + " [/INST] "
response = client.generate(input_prompt, max_new_tokens=256).generated_text
return response
interface = gr.ChatInterface(predict).queue()
with gr.Blocks() as demo:
gr.Markdown("""
# Llama-2-13b-chat-hf Discord Bot Powered by Gradio and Hugging Face Endpoints
Make sure you read the 'Inference Endpoints' section below first! 🦙
### First install the `gradio_client`
```bash
pip install gradio_client
```
### Then deploy to discord in one line! ⚡️
```python
secrets = {"HF_TOKEN": "", "INFERENCE_ENDPOINT": ""}
client = grc.Client.duplicate("gradio-discord-bots/Llama-2-13b-chat-hf", private=False, secrets=secrets, sleep_timeout=2880)
client.deploy_discord(api_names=["chat"])
```
""")
with gr.Accordion(label="Inference Endpoints", open=False):
gr.Markdown("""
## Setting Up Inference Endpoints 💪
To deploy this space as a discord bot, you will need to deploy your own Llama model to Hugging Face Endpoints.
Don't worry it's super easy!
1. Go to the [model page](https://huggingface.co/meta-llama/Llama-2-13b-chat-hf) 🦙
2. Click Deploy > Inference Endpoints
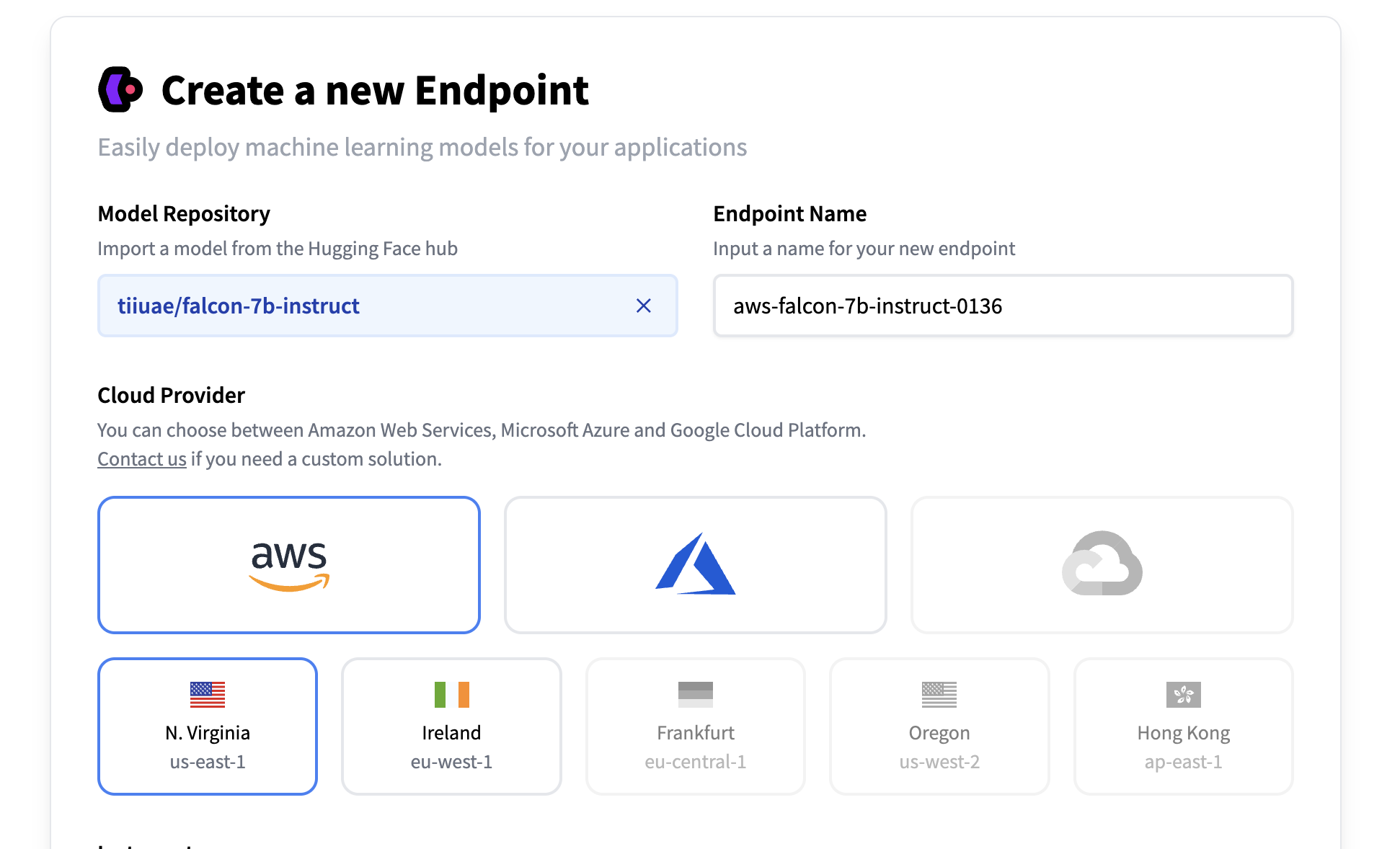
 3. Select your desired cloud provider and region ☁️
3. Select your desired cloud provider and region ☁️
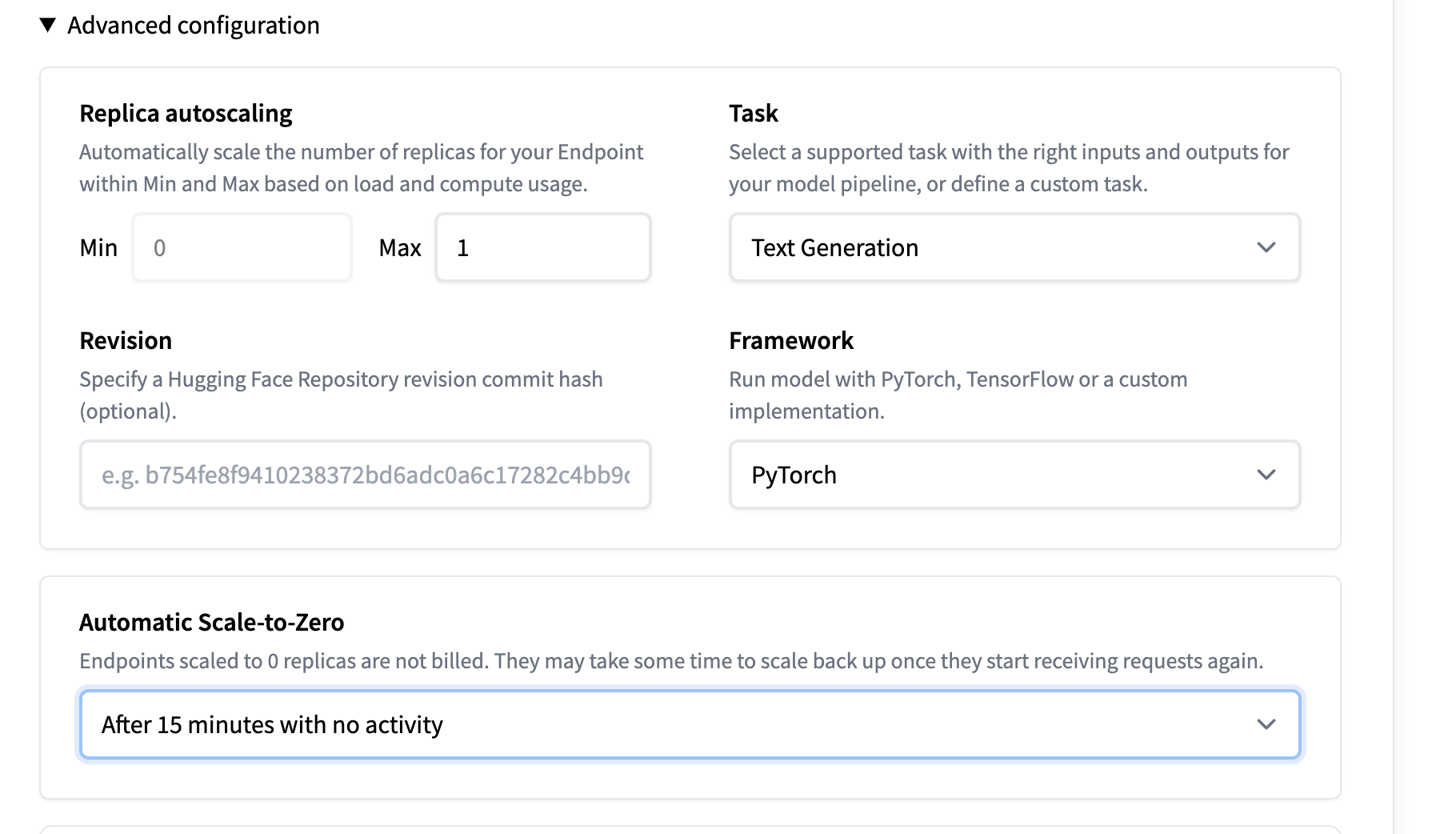
 4. Optional: Set Automatic Scale to Zero. This will pause your endpoint after 15 minutes of inactivity to prevent unwanted billing. 💰
4. Optional: Set Automatic Scale to Zero. This will pause your endpoint after 15 minutes of inactivity to prevent unwanted billing. 💰
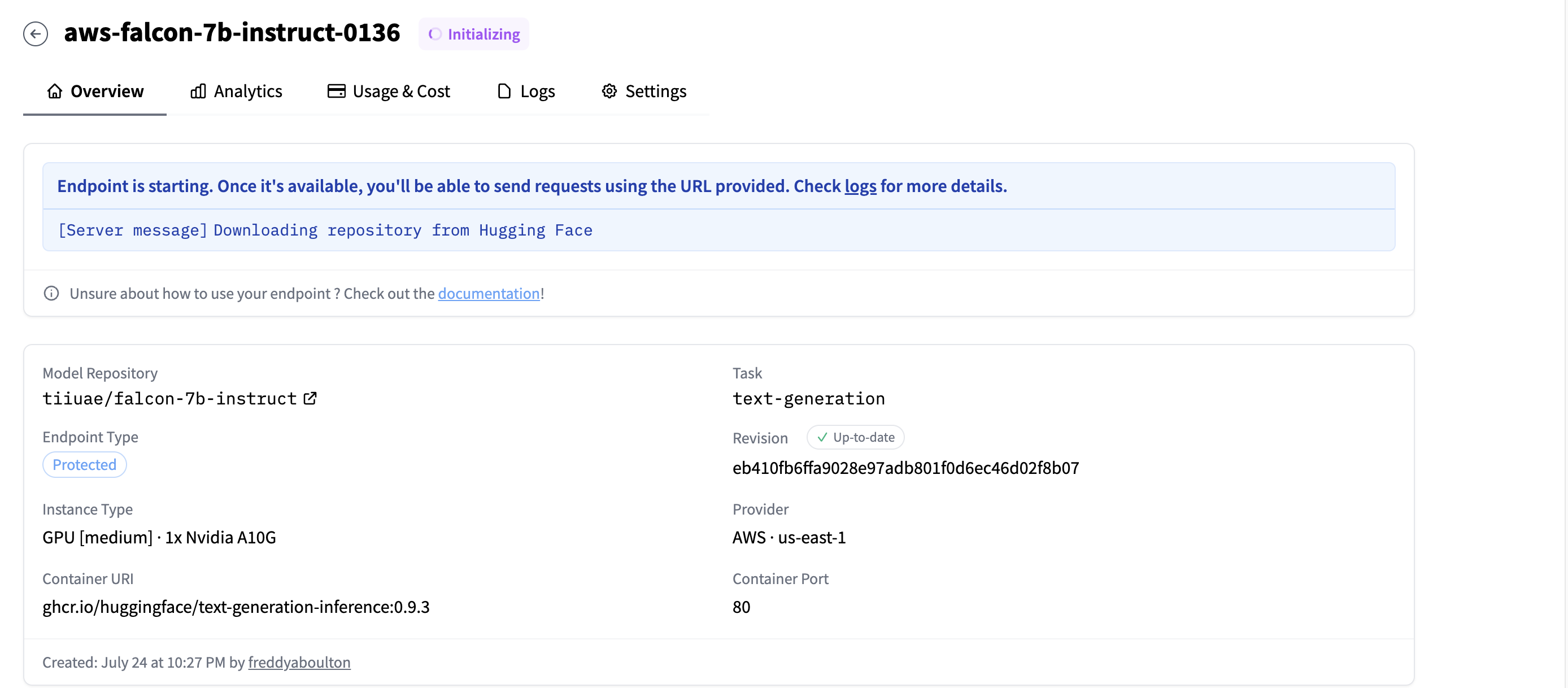
 5. Create the endpoint! Copy the endpoint URL after it's complete.
5. Create the endpoint! Copy the endpoint URL after it's complete.
 """
)
gr.Markdown("""
Note: As a derivate work of [Llama-2-13b-chat-hf](https://huggingface.co/meta-llama/Llama-2-13b-chat-hf) by Meta, this demo is governed by the original [license](https://huggingface.co/spaces/ysharma/Explore_llamav2_with_TGI/blob/main/LICENSE.txt) and [acceptable use policy](https://huggingface.co/spaces/ysharma/Explore_llamav2_with_TGI/blob/main/USE_POLICY.md)
""")
with gr.Row(visible=False):
interface.render()
demo.queue().launch()
"""
)
gr.Markdown("""
Note: As a derivate work of [Llama-2-13b-chat-hf](https://huggingface.co/meta-llama/Llama-2-13b-chat-hf) by Meta, this demo is governed by the original [license](https://huggingface.co/spaces/ysharma/Explore_llamav2_with_TGI/blob/main/LICENSE.txt) and [acceptable use policy](https://huggingface.co/spaces/ysharma/Explore_llamav2_with_TGI/blob/main/USE_POLICY.md)
""")
with gr.Row(visible=False):
interface.render()
demo.queue().launch()