Spaces:
Running

Running

Upload with huggingface_hub
Browse files- README.md +7 -8
- run.ipynb +1 -0
- run.py +46 -0
- screenshot.gif +0 -0
- screenshot.png +0 -0
README.md
CHANGED
|
@@ -1,12 +1,11 @@
|
|
|
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
sdk: gradio
|
| 7 |
-
sdk_version: 3.
|
| 8 |
-
app_file:
|
| 9 |
pinned: false
|
| 10 |
---
|
| 11 |
-
|
| 12 |
-
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
| 1 |
+
|
| 2 |
---
|
| 3 |
+
title: chatbot_dialogpt
|
| 4 |
+
emoji: 🔥
|
| 5 |
+
colorFrom: indigo
|
| 6 |
+
colorTo: indigo
|
| 7 |
sdk: gradio
|
| 8 |
+
sdk_version: 3.21.0
|
| 9 |
+
app_file: run.py
|
| 10 |
pinned: false
|
| 11 |
---
|
|
|
|
|
|
run.ipynb
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"cells": [{"cell_type": "markdown", "id": 302934307671667531413257853548643485645, "metadata": {}, "source": ["# Gradio Demo: chatbot_dialogpt"]}, {"cell_type": "code", "execution_count": null, "id": 272996653310673477252411125948039410165, "metadata": {}, "outputs": [], "source": ["!pip install -q gradio "]}, {"cell_type": "code", "execution_count": null, "id": 288918539441861185822528903084949547379, "metadata": {}, "outputs": [], "source": ["import gradio as gr\n", "from transformers import AutoModelForCausalLM, AutoTokenizer\n", "import torch\n", "\n", "tokenizer = AutoTokenizer.from_pretrained(\"microsoft/DialoGPT-medium\")\n", "model = AutoModelForCausalLM.from_pretrained(\"microsoft/DialoGPT-medium\")\n", "\n", "def user(message, history):\n", " return \"\", history + [[message, None]]\n", "\n", "\n", "# bot_message = random.choice([\"Yes\", \"No\"])\n", "# history[-1][1] = bot_message\n", "# time.sleep(1)\n", "# return history\n", "\n", "# def predict(input, history=[]):\n", "# # tokenize the new input sentence\n", "\n", "def bot(history):\n", " user_message = history[-1][0]\n", " new_user_input_ids = tokenizer.encode(user_message + tokenizer.eos_token, return_tensors='pt')\n", "\n", " # append the new user input tokens to the chat history\n", " bot_input_ids = torch.cat([torch.LongTensor(history), new_user_input_ids], dim=-1)\n", "\n", " # generate a response \n", " history = model.generate(bot_input_ids, max_length=1000, pad_token_id=tokenizer.eos_token_id).tolist()\n", "\n", " # convert the tokens to text, and then split the responses into lines\n", " response = tokenizer.decode(history[0]).split(\"<|endoftext|>\")\n", " response = [(response[i], response[i+1]) for i in range(0, len(response)-1, 2)] # convert to tuples of list\n", " return history\n", "\n", "with gr.Blocks() as demo:\n", " chatbot = gr.Chatbot()\n", " msg = gr.Textbox()\n", " clear = gr.Button(\"Clear\")\n", "\n", " msg.submit(user, [msg, chatbot], [msg, chatbot], queue=False).then(\n", " bot, chatbot, chatbot\n", " )\n", " clear.click(lambda: None, None, chatbot, queue=False)\n", "\n", "if __name__ == \"__main__\":\n", " demo.launch()\n"]}], "metadata": {}, "nbformat": 4, "nbformat_minor": 5}
|
run.py
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 3 |
+
import torch
|
| 4 |
+
|
| 5 |
+
tokenizer = AutoTokenizer.from_pretrained("microsoft/DialoGPT-medium")
|
| 6 |
+
model = AutoModelForCausalLM.from_pretrained("microsoft/DialoGPT-medium")
|
| 7 |
+
|
| 8 |
+
def user(message, history):
|
| 9 |
+
return "", history + [[message, None]]
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
# bot_message = random.choice(["Yes", "No"])
|
| 13 |
+
# history[-1][1] = bot_message
|
| 14 |
+
# time.sleep(1)
|
| 15 |
+
# return history
|
| 16 |
+
|
| 17 |
+
# def predict(input, history=[]):
|
| 18 |
+
# # tokenize the new input sentence
|
| 19 |
+
|
| 20 |
+
def bot(history):
|
| 21 |
+
user_message = history[-1][0]
|
| 22 |
+
new_user_input_ids = tokenizer.encode(user_message + tokenizer.eos_token, return_tensors='pt')
|
| 23 |
+
|
| 24 |
+
# append the new user input tokens to the chat history
|
| 25 |
+
bot_input_ids = torch.cat([torch.LongTensor(history), new_user_input_ids], dim=-1)
|
| 26 |
+
|
| 27 |
+
# generate a response
|
| 28 |
+
history = model.generate(bot_input_ids, max_length=1000, pad_token_id=tokenizer.eos_token_id).tolist()
|
| 29 |
+
|
| 30 |
+
# convert the tokens to text, and then split the responses into lines
|
| 31 |
+
response = tokenizer.decode(history[0]).split("<|endoftext|>")
|
| 32 |
+
response = [(response[i], response[i+1]) for i in range(0, len(response)-1, 2)] # convert to tuples of list
|
| 33 |
+
return history
|
| 34 |
+
|
| 35 |
+
with gr.Blocks() as demo:
|
| 36 |
+
chatbot = gr.Chatbot()
|
| 37 |
+
msg = gr.Textbox()
|
| 38 |
+
clear = gr.Button("Clear")
|
| 39 |
+
|
| 40 |
+
msg.submit(user, [msg, chatbot], [msg, chatbot], queue=False).then(
|
| 41 |
+
bot, chatbot, chatbot
|
| 42 |
+
)
|
| 43 |
+
clear.click(lambda: None, None, chatbot, queue=False)
|
| 44 |
+
|
| 45 |
+
if __name__ == "__main__":
|
| 46 |
+
demo.launch()
|
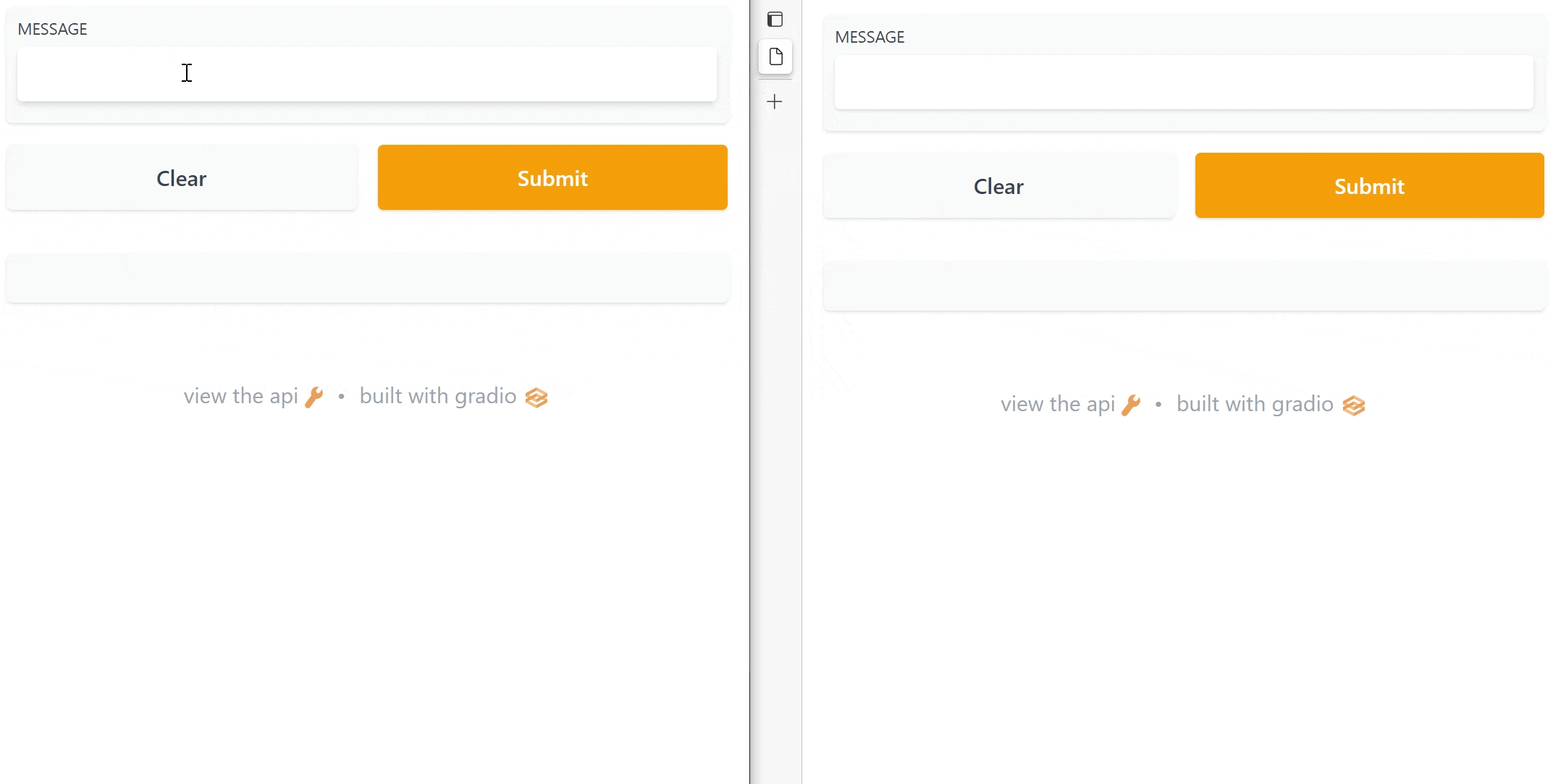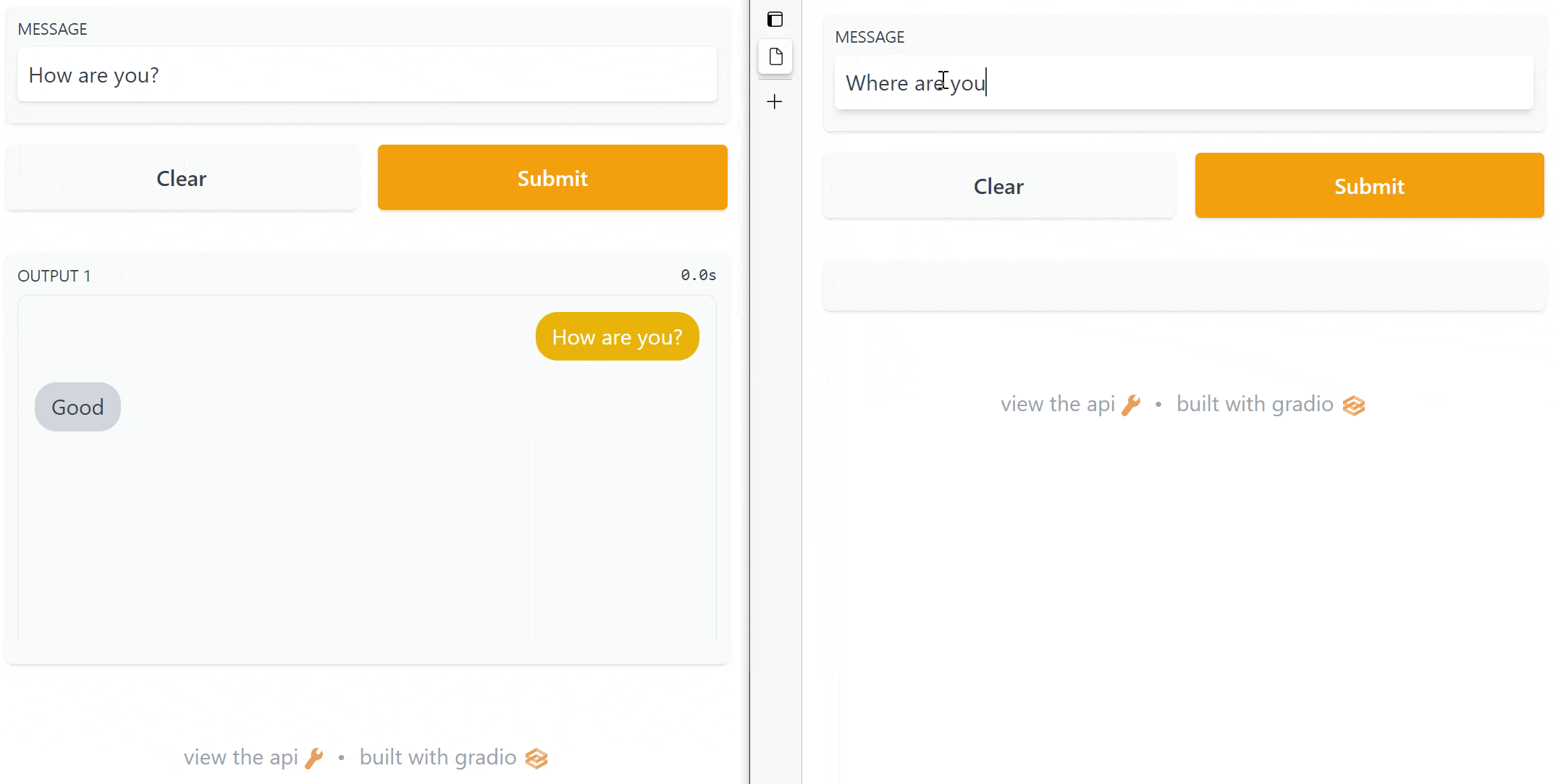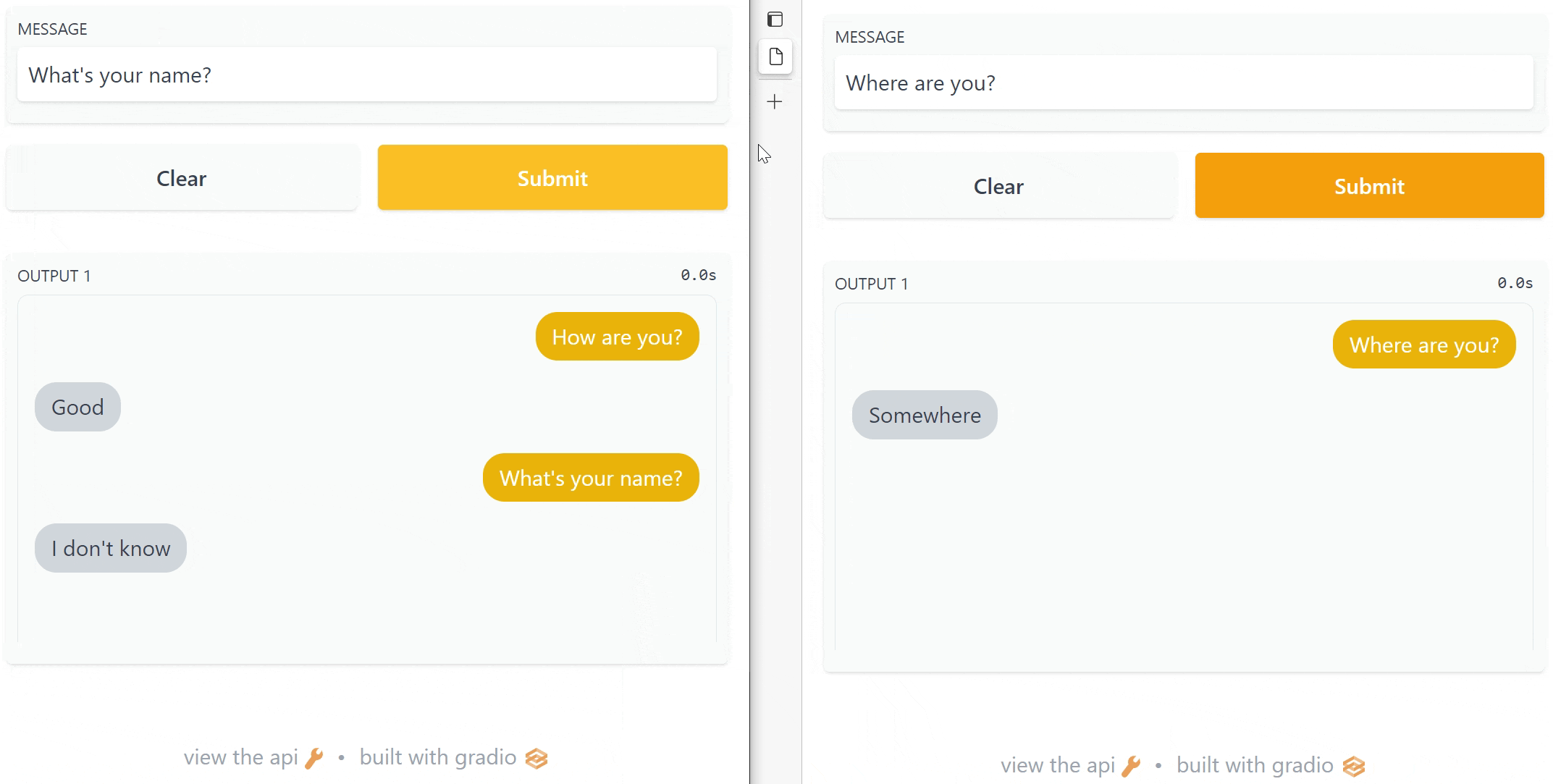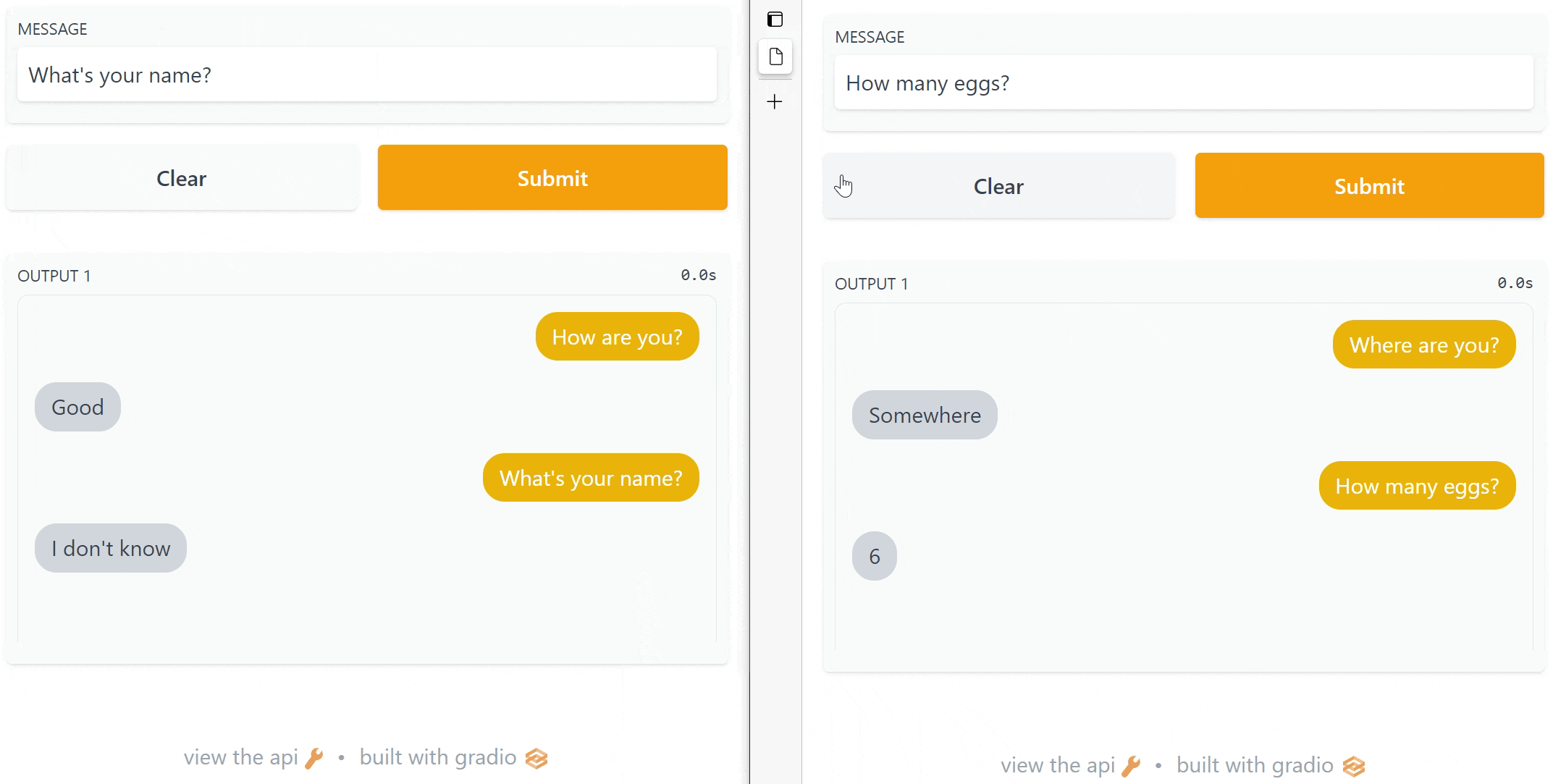
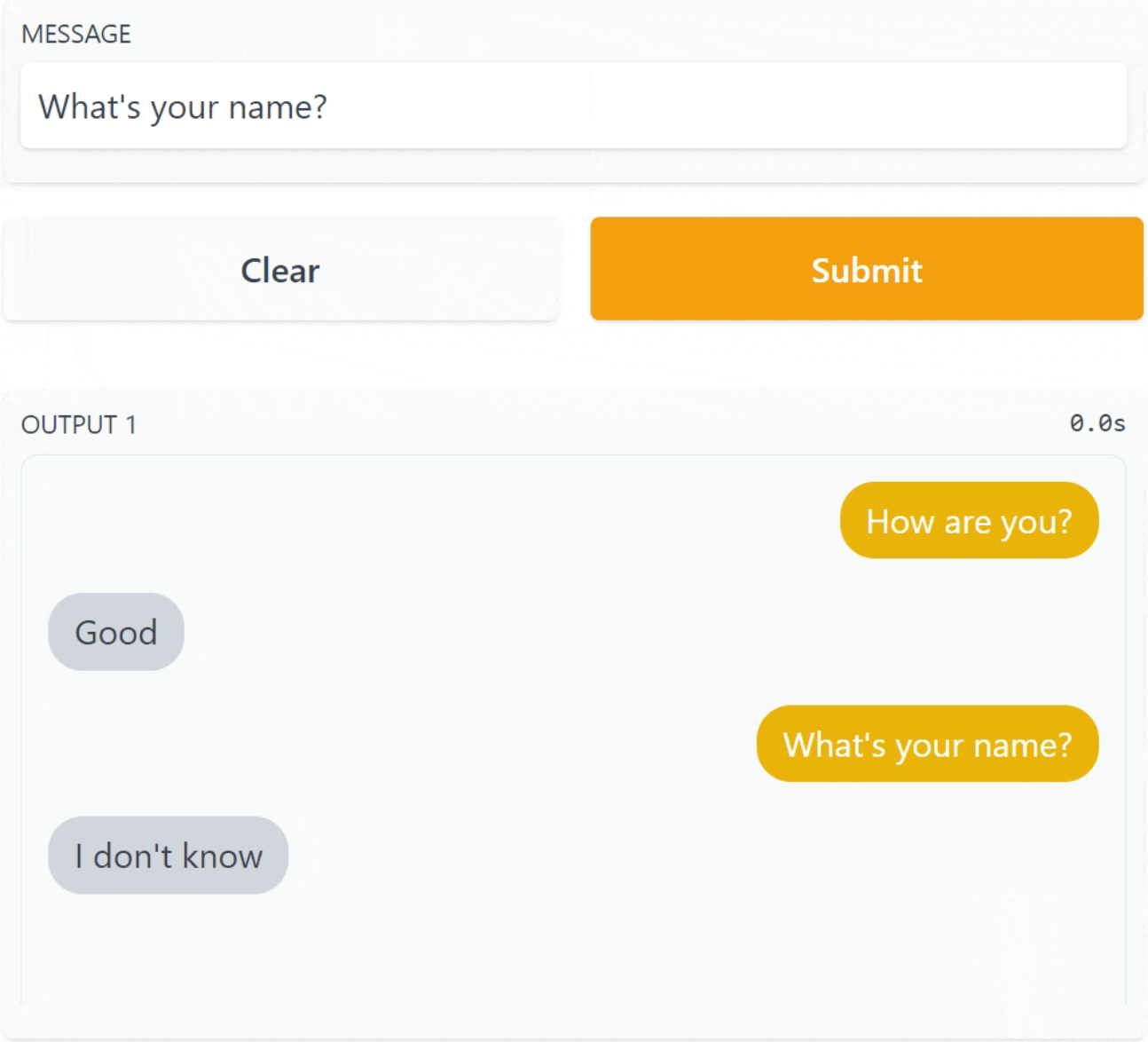
screenshot.gif
ADDED
|
screenshot.png
ADDED
|