Spaces:
Runtime error

Runtime error
Upload folder using huggingface_hub
Browse files- .ipynb_checkpoints/run_deploy-checkpoint.ipynb +112 -975
- _assets/deployment_pipeline.png +0 -0
- run.py +38 -4
- run_deploy.ipynb +154 -6
- steps/__pycache__/data_splitter.cpython-38.pyc +0 -0
- steps/__pycache__/model_trainer.cpython-38.pyc +0 -0
- steps/model_trainer.py +1 -1
.ipynb_checkpoints/run_deploy-checkpoint.ipynb
CHANGED
|
@@ -11,10 +11,6 @@
|
|
| 11 |
"\n",
|
| 12 |
"This repository is a minimalistic MLOps project intended as a starting point to learn how to put ML workflows in production. It features: \n",
|
| 13 |
"\n",
|
| 14 |
-
"- A feature engineering pipeline that loads data and prepares it for training.\n",
|
| 15 |
-
"- A training pipeline that loads the preprocessed dataset and trains a model.\n",
|
| 16 |
-
"- A batch inference pipeline that runs predictions on the trained model with new data.\n",
|
| 17 |
-
"\n",
|
| 18 |
"Follow along this notebook to understand how you can use ZenML to productionalize your ML workflows!\n",
|
| 19 |
"\n",
|
| 20 |
"<img src=\"_assets/pipeline_overview.png\" width=\"50%\" alt=\"Pipelines Overview\">"
|
|
@@ -22,511 +18,66 @@
|
|
| 22 |
},
|
| 23 |
{
|
| 24 |
"cell_type": "markdown",
|
| 25 |
-
"id": "
|
| 26 |
-
"metadata": {},
|
| 27 |
-
"source": [
|
| 28 |
-
"## Run on Colab\n",
|
| 29 |
-
"\n",
|
| 30 |
-
"You can use Google Colab to see ZenML in action, no signup / installation\n",
|
| 31 |
-
"required!\n",
|
| 32 |
-
"\n",
|
| 33 |
-
"[](\n",
|
| 34 |
-
"https://colab.research.google.com/github/zenml-io/zenml/blob/main/examples/quickstart/quickstart.ipynb)"
|
| 35 |
-
]
|
| 36 |
-
},
|
| 37 |
-
{
|
| 38 |
-
"cell_type": "markdown",
|
| 39 |
-
"id": "66b2977c",
|
| 40 |
-
"metadata": {},
|
| 41 |
-
"source": [
|
| 42 |
-
"# 👶 Step 0. Install Requirements\n",
|
| 43 |
-
"\n",
|
| 44 |
-
"Let's install ZenML to get started. First we'll install the latest version of\n",
|
| 45 |
-
"ZenML as well as the `sklearn` integration of ZenML:"
|
| 46 |
-
]
|
| 47 |
-
},
|
| 48 |
-
{
|
| 49 |
-
"cell_type": "code",
|
| 50 |
-
"execution_count": null,
|
| 51 |
-
"id": "ce2f40eb",
|
| 52 |
-
"metadata": {},
|
| 53 |
-
"outputs": [],
|
| 54 |
-
"source": [
|
| 55 |
-
"!pip install \"zenml[server]\""
|
| 56 |
-
]
|
| 57 |
-
},
|
| 58 |
-
{
|
| 59 |
-
"cell_type": "code",
|
| 60 |
-
"execution_count": null,
|
| 61 |
-
"id": "5aad397e",
|
| 62 |
-
"metadata": {},
|
| 63 |
-
"outputs": [],
|
| 64 |
-
"source": [
|
| 65 |
-
"from zenml.environment import Environment\n",
|
| 66 |
-
"\n",
|
| 67 |
-
"if Environment.in_google_colab():\n",
|
| 68 |
-
" # Install Cloudflare Tunnel binary\n",
|
| 69 |
-
" !wget -q https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64.deb && dpkg -i cloudflared-linux-amd64.deb\n",
|
| 70 |
-
"\n",
|
| 71 |
-
" # Pull required modules from this example\n",
|
| 72 |
-
" !git clone -b main https://github.com/zenml-io/zenml\n",
|
| 73 |
-
" !cp -r zenml/examples/quickstart/* .\n",
|
| 74 |
-
" !rm -rf zenml\n"
|
| 75 |
-
]
|
| 76 |
-
},
|
| 77 |
-
{
|
| 78 |
-
"cell_type": "code",
|
| 79 |
-
"execution_count": null,
|
| 80 |
-
"id": "f76f562e",
|
| 81 |
-
"metadata": {},
|
| 82 |
-
"outputs": [],
|
| 83 |
-
"source": [
|
| 84 |
-
"!zenml integration install sklearn -y\n",
|
| 85 |
-
"\n",
|
| 86 |
-
"import IPython\n",
|
| 87 |
-
"IPython.Application.instance().kernel.do_shutdown(restart=True)"
|
| 88 |
-
]
|
| 89 |
-
},
|
| 90 |
-
{
|
| 91 |
-
"cell_type": "markdown",
|
| 92 |
-
"id": "3b044374",
|
| 93 |
-
"metadata": {},
|
| 94 |
-
"source": [
|
| 95 |
-
"Please wait for the installation to complete before running subsequent cells. At\n",
|
| 96 |
-
"the end of the installation, the notebook kernel will automatically restart."
|
| 97 |
-
]
|
| 98 |
-
},
|
| 99 |
-
{
|
| 100 |
-
"cell_type": "markdown",
|
| 101 |
-
"id": "e3955ff1",
|
| 102 |
-
"metadata": {},
|
| 103 |
-
"source": [
|
| 104 |
-
"Optional: If you are using [ZenML Cloud](https://zenml.io/cloud), execute the following cell with your tenant URL. Otherwise ignore."
|
| 105 |
-
]
|
| 106 |
-
},
|
| 107 |
-
{
|
| 108 |
-
"cell_type": "code",
|
| 109 |
-
"execution_count": null,
|
| 110 |
-
"id": "e2587315",
|
| 111 |
-
"metadata": {},
|
| 112 |
-
"outputs": [],
|
| 113 |
-
"source": [
|
| 114 |
-
"zenml_server_url = \"PLEASE_UPDATE_ME\" # in the form \"https://URL_TO_SERVER\"\n",
|
| 115 |
-
"\n",
|
| 116 |
-
"!zenml connect --url $zenml_server_url"
|
| 117 |
-
]
|
| 118 |
-
},
|
| 119 |
-
{
|
| 120 |
-
"cell_type": "code",
|
| 121 |
-
"execution_count": null,
|
| 122 |
-
"id": "081d5616",
|
| 123 |
-
"metadata": {},
|
| 124 |
-
"outputs": [],
|
| 125 |
-
"source": [
|
| 126 |
-
"# Initialize ZenML and set the default stack\n",
|
| 127 |
-
"!zenml init\n",
|
| 128 |
-
"\n",
|
| 129 |
-
"!zenml stack set default"
|
| 130 |
-
]
|
| 131 |
-
},
|
| 132 |
-
{
|
| 133 |
-
"cell_type": "code",
|
| 134 |
-
"execution_count": null,
|
| 135 |
-
"id": "79f775f2",
|
| 136 |
-
"metadata": {},
|
| 137 |
-
"outputs": [],
|
| 138 |
-
"source": [
|
| 139 |
-
"# Do the imports at the top\n",
|
| 140 |
-
"from typing_extensions import Annotated\n",
|
| 141 |
-
"from sklearn.datasets import load_breast_cancer\n",
|
| 142 |
-
"\n",
|
| 143 |
-
"import random\n",
|
| 144 |
-
"import pandas as pd\n",
|
| 145 |
-
"from zenml import step, ExternalArtifact, pipeline, ModelVersion, get_step_context\n",
|
| 146 |
-
"from zenml.client import Client\n",
|
| 147 |
-
"from zenml.logger import get_logger\n",
|
| 148 |
-
"from uuid import UUID\n",
|
| 149 |
-
"\n",
|
| 150 |
-
"from typing import Optional, List\n",
|
| 151 |
-
"\n",
|
| 152 |
-
"from zenml import pipeline\n",
|
| 153 |
-
"\n",
|
| 154 |
-
"from steps import (\n",
|
| 155 |
-
" data_loader,\n",
|
| 156 |
-
" data_preprocessor,\n",
|
| 157 |
-
" data_splitter,\n",
|
| 158 |
-
" model_evaluator,\n",
|
| 159 |
-
" inference_preprocessor\n",
|
| 160 |
-
")\n",
|
| 161 |
-
"\n",
|
| 162 |
-
"from zenml.logger import get_logger\n",
|
| 163 |
-
"\n",
|
| 164 |
-
"logger = get_logger(__name__)\n",
|
| 165 |
-
"\n",
|
| 166 |
-
"# Initialize the ZenML client to fetch objects from the ZenML Server\n",
|
| 167 |
-
"client = Client()"
|
| 168 |
-
]
|
| 169 |
-
},
|
| 170 |
-
{
|
| 171 |
-
"cell_type": "markdown",
|
| 172 |
-
"id": "35e48460",
|
| 173 |
-
"metadata": {},
|
| 174 |
-
"source": [
|
| 175 |
-
"## 🥇 Step 1: Load your data and execute feature engineering\n",
|
| 176 |
-
"\n",
|
| 177 |
-
"We'll start off by importing our data. In this quickstart we'll be working with\n",
|
| 178 |
-
"[the Breast Cancer](https://archive.ics.uci.edu/dataset/17/breast+cancer+wisconsin+diagnostic) dataset\n",
|
| 179 |
-
"which is publicly available on the UCI Machine Learning Repository. The task is a classification\n",
|
| 180 |
-
"problem, to predict whether a patient is diagnosed with breast cancer or not.\n",
|
| 181 |
-
"\n",
|
| 182 |
-
"When you're getting started with a machine learning problem you'll want to do\n",
|
| 183 |
-
"something similar to this: import your data and get it in the right shape for\n",
|
| 184 |
-
"your training. ZenML mostly gets out of your way when you're writing your Python\n",
|
| 185 |
-
"code, as you'll see from the following cell.\n",
|
| 186 |
-
"\n",
|
| 187 |
-
"<img src=\".assets/feature_engineering_pipeline.png\" width=\"50%\" alt=\"Feature engineering pipeline\" />"
|
| 188 |
-
]
|
| 189 |
-
},
|
| 190 |
-
{
|
| 191 |
-
"cell_type": "code",
|
| 192 |
-
"execution_count": null,
|
| 193 |
-
"id": "3cd974d1",
|
| 194 |
-
"metadata": {},
|
| 195 |
-
"outputs": [],
|
| 196 |
-
"source": [
|
| 197 |
-
"@step\n",
|
| 198 |
-
"def data_loader_simplified(\n",
|
| 199 |
-
" random_state: int, is_inference: bool = False, target: str = \"target\"\n",
|
| 200 |
-
") -> Annotated[pd.DataFrame, \"dataset\"]: # We name the dataset \n",
|
| 201 |
-
" \"\"\"Dataset reader step.\"\"\"\n",
|
| 202 |
-
" dataset = load_breast_cancer(as_frame=True)\n",
|
| 203 |
-
" inference_size = int(len(dataset.target) * 0.05)\n",
|
| 204 |
-
" dataset: pd.DataFrame = dataset.frame\n",
|
| 205 |
-
" inference_subset = dataset.sample(inference_size, random_state=random_state)\n",
|
| 206 |
-
" if is_inference:\n",
|
| 207 |
-
" dataset = inference_subset\n",
|
| 208 |
-
" dataset.drop(columns=target, inplace=True)\n",
|
| 209 |
-
" else:\n",
|
| 210 |
-
" dataset.drop(inference_subset.index, inplace=True)\n",
|
| 211 |
-
" dataset.reset_index(drop=True, inplace=True)\n",
|
| 212 |
-
" logger.info(f\"Dataset with {len(dataset)} records loaded!\")\n",
|
| 213 |
-
" return dataset\n"
|
| 214 |
-
]
|
| 215 |
-
},
|
| 216 |
-
{
|
| 217 |
-
"cell_type": "markdown",
|
| 218 |
-
"id": "1e8ba4c6",
|
| 219 |
-
"metadata": {},
|
| 220 |
-
"source": [
|
| 221 |
-
"The whole function is decorated with the `@step` decorator, which\n",
|
| 222 |
-
"tells ZenML to track this function as a step in the pipeline. This means that\n",
|
| 223 |
-
"ZenML will automatically version, track, and cache the data that is produced by\n",
|
| 224 |
-
"this function as an `artifact`. This is a very powerful feature, as it means that you can\n",
|
| 225 |
-
"reproduce your data at any point in the future, even if the original data source\n",
|
| 226 |
-
"changes or disappears. \n",
|
| 227 |
-
"\n",
|
| 228 |
-
"Note the use of the `typing` module's `Annotated` type hint in the output of the\n",
|
| 229 |
-
"step. We're using this to give a name to the output of the step, which will make\n",
|
| 230 |
-
"it possible to access it via a keyword later on.\n",
|
| 231 |
-
"\n",
|
| 232 |
-
"You'll also notice that we have included type hints for the outputs\n",
|
| 233 |
-
"to the function. These are not only useful for anyone reading your code, but\n",
|
| 234 |
-
"help ZenML process your data in a way appropriate to the specific data types."
|
| 235 |
-
]
|
| 236 |
-
},
|
| 237 |
-
{
|
| 238 |
-
"cell_type": "markdown",
|
| 239 |
-
"id": "b6286b67",
|
| 240 |
-
"metadata": {},
|
| 241 |
-
"source": [
|
| 242 |
-
"ZenML is built in a way that allows you to experiment with your data and build\n",
|
| 243 |
-
"your pipelines as you work, so if you want to call this function to see how it\n",
|
| 244 |
-
"works, you can just call it directly. Here we take a look at the first few rows\n",
|
| 245 |
-
"of your training dataset."
|
| 246 |
-
]
|
| 247 |
-
},
|
| 248 |
-
{
|
| 249 |
-
"cell_type": "code",
|
| 250 |
-
"execution_count": null,
|
| 251 |
-
"id": "d838e2ea",
|
| 252 |
-
"metadata": {},
|
| 253 |
-
"outputs": [],
|
| 254 |
-
"source": [
|
| 255 |
-
"df = data_loader_simplified(random_state=42)\n",
|
| 256 |
-
"df.head()"
|
| 257 |
-
]
|
| 258 |
-
},
|
| 259 |
-
{
|
| 260 |
-
"cell_type": "markdown",
|
| 261 |
-
"id": "28c05291",
|
| 262 |
-
"metadata": {},
|
| 263 |
-
"source": [
|
| 264 |
-
"Everything looks as we'd expect and the values are all in the right format 🥳.\n",
|
| 265 |
-
"\n",
|
| 266 |
-
"We're now at the point where can bring this step (and some others) together into a single\n",
|
| 267 |
-
"pipeline, the top-level organising entity for code in ZenML. Creating such a pipeline is\n",
|
| 268 |
-
"as simple as adding a `@pipeline` decorator to a function. This specific\n",
|
| 269 |
-
"pipeline doesn't return a value, but that option is available to you if you need."
|
| 270 |
-
]
|
| 271 |
-
},
|
| 272 |
-
{
|
| 273 |
-
"cell_type": "code",
|
| 274 |
-
"execution_count": null,
|
| 275 |
-
"id": "b50a9537",
|
| 276 |
-
"metadata": {},
|
| 277 |
-
"outputs": [],
|
| 278 |
-
"source": [
|
| 279 |
-
"@pipeline\n",
|
| 280 |
-
"def feature_engineering(\n",
|
| 281 |
-
" test_size: float = 0.3,\n",
|
| 282 |
-
" drop_na: Optional[bool] = None,\n",
|
| 283 |
-
" normalize: Optional[bool] = None,\n",
|
| 284 |
-
" drop_columns: Optional[List[str]] = None,\n",
|
| 285 |
-
" target: Optional[str] = \"target\",\n",
|
| 286 |
-
" random_state: int = 17\n",
|
| 287 |
-
"):\n",
|
| 288 |
-
" \"\"\"Feature engineering pipeline.\"\"\"\n",
|
| 289 |
-
" # Link all the steps together by calling them and passing the output\n",
|
| 290 |
-
" # of one step as the input of the next step.\n",
|
| 291 |
-
" raw_data = data_loader(random_state=random_state, target=target)\n",
|
| 292 |
-
" dataset_trn, dataset_tst = data_splitter(\n",
|
| 293 |
-
" dataset=raw_data,\n",
|
| 294 |
-
" test_size=test_size,\n",
|
| 295 |
-
" )\n",
|
| 296 |
-
" dataset_trn, dataset_tst, _ = data_preprocessor(\n",
|
| 297 |
-
" dataset_trn=dataset_trn,\n",
|
| 298 |
-
" dataset_tst=dataset_tst,\n",
|
| 299 |
-
" drop_na=drop_na,\n",
|
| 300 |
-
" normalize=normalize,\n",
|
| 301 |
-
" drop_columns=drop_columns,\n",
|
| 302 |
-
" target=target,\n",
|
| 303 |
-
" random_state=random_state,\n",
|
| 304 |
-
" )"
|
| 305 |
-
]
|
| 306 |
-
},
|
| 307 |
-
{
|
| 308 |
-
"cell_type": "markdown",
|
| 309 |
-
"id": "7cd73c23",
|
| 310 |
-
"metadata": {},
|
| 311 |
-
"source": [
|
| 312 |
-
"We're ready to run the pipeline now, which we can do just as with the step - by calling the\n",
|
| 313 |
-
"pipeline function itself:"
|
| 314 |
-
]
|
| 315 |
-
},
|
| 316 |
-
{
|
| 317 |
-
"cell_type": "code",
|
| 318 |
-
"execution_count": null,
|
| 319 |
-
"id": "1e0aa9af",
|
| 320 |
-
"metadata": {},
|
| 321 |
-
"outputs": [],
|
| 322 |
-
"source": [
|
| 323 |
-
"feature_engineering()"
|
| 324 |
-
]
|
| 325 |
-
},
|
| 326 |
-
{
|
| 327 |
-
"cell_type": "markdown",
|
| 328 |
-
"id": "1785c303",
|
| 329 |
-
"metadata": {},
|
| 330 |
-
"source": [
|
| 331 |
-
"Let's run this again with a slightly different test size, to create more datasets:"
|
| 332 |
-
]
|
| 333 |
-
},
|
| 334 |
-
{
|
| 335 |
-
"cell_type": "code",
|
| 336 |
-
"execution_count": null,
|
| 337 |
-
"id": "658c0570-2607-4b97-a72d-d45c92633e48",
|
| 338 |
-
"metadata": {},
|
| 339 |
-
"outputs": [],
|
| 340 |
-
"source": [
|
| 341 |
-
"feature_engineering(test_size=0.25)"
|
| 342 |
-
]
|
| 343 |
-
},
|
| 344 |
-
{
|
| 345 |
-
"cell_type": "markdown",
|
| 346 |
-
"id": "64bb7206",
|
| 347 |
-
"metadata": {},
|
| 348 |
-
"source": [
|
| 349 |
-
"Notice the second time around, the data loader step was **cached**, while the rest of the pipeline was rerun. \n",
|
| 350 |
-
"This is because ZenML automatically determined that nothing had changed in the data loader step, \n",
|
| 351 |
-
"so it didn't need to rerun it."
|
| 352 |
-
]
|
| 353 |
-
},
|
| 354 |
-
{
|
| 355 |
-
"cell_type": "markdown",
|
| 356 |
-
"id": "5bc6849d-31ac-4c08-9ca2-cf7f5f35ccbf",
|
| 357 |
-
"metadata": {},
|
| 358 |
-
"source": [
|
| 359 |
-
"Let's run this again with a slightly different test size and random state, to disable the cache and to create more datasets:"
|
| 360 |
-
]
|
| 361 |
-
},
|
| 362 |
-
{
|
| 363 |
-
"cell_type": "code",
|
| 364 |
-
"execution_count": null,
|
| 365 |
-
"id": "1e1d8546",
|
| 366 |
-
"metadata": {},
|
| 367 |
-
"outputs": [],
|
| 368 |
-
"source": [
|
| 369 |
-
"feature_engineering(test_size=0.25, random_state=104)"
|
| 370 |
-
]
|
| 371 |
-
},
|
| 372 |
-
{
|
| 373 |
-
"cell_type": "markdown",
|
| 374 |
-
"id": "6c42078a",
|
| 375 |
-
"metadata": {},
|
| 376 |
-
"source": [
|
| 377 |
-
"At this point you might be interested to view your pipeline runs in the ZenML\n",
|
| 378 |
-
"Dashboard. In case you are not using a hosted instance of ZenML, you can spin this up by executing the next cell. This will start a\n",
|
| 379 |
-
"server which you can access by clicking on the link that appears in the output\n",
|
| 380 |
-
"of the cell.\n",
|
| 381 |
-
"\n",
|
| 382 |
-
"Log into the Dashboard using default credentials (username 'default' and\n",
|
| 383 |
-
"password left blank). From there you can inspect the pipeline or the specific\n",
|
| 384 |
-
"pipeline run.\n"
|
| 385 |
-
]
|
| 386 |
-
},
|
| 387 |
-
{
|
| 388 |
-
"cell_type": "code",
|
| 389 |
-
"execution_count": null,
|
| 390 |
-
"id": "8cd3cc8c",
|
| 391 |
-
"metadata": {},
|
| 392 |
-
"outputs": [],
|
| 393 |
-
"source": [
|
| 394 |
-
"from zenml.environment import Environment\n",
|
| 395 |
-
"from zenml.zen_stores.rest_zen_store import RestZenStore\n",
|
| 396 |
-
"\n",
|
| 397 |
-
"\n",
|
| 398 |
-
"if not isinstance(client.zen_store, RestZenStore):\n",
|
| 399 |
-
" # Only spin up a local Dashboard in case you aren't already connected to a remote server\n",
|
| 400 |
-
" if Environment.in_google_colab():\n",
|
| 401 |
-
" # run ZenML through a cloudflare tunnel to get a public endpoint\n",
|
| 402 |
-
" !zenml up --port 8237 & cloudflared tunnel --url http://localhost:8237\n",
|
| 403 |
-
" else:\n",
|
| 404 |
-
" !zenml up"
|
| 405 |
-
]
|
| 406 |
-
},
|
| 407 |
-
{
|
| 408 |
-
"cell_type": "markdown",
|
| 409 |
-
"id": "e8471f93",
|
| 410 |
-
"metadata": {},
|
| 411 |
-
"source": [
|
| 412 |
-
"We can also fetch the pipeline from the server and view the results directly in the notebook:"
|
| 413 |
-
]
|
| 414 |
-
},
|
| 415 |
-
{
|
| 416 |
-
"cell_type": "code",
|
| 417 |
-
"execution_count": null,
|
| 418 |
-
"id": "f208b200",
|
| 419 |
-
"metadata": {},
|
| 420 |
-
"outputs": [],
|
| 421 |
-
"source": [
|
| 422 |
-
"client = Client()\n",
|
| 423 |
-
"run = client.get_pipeline(\"feature_engineering\").last_run\n",
|
| 424 |
-
"print(run.name)"
|
| 425 |
-
]
|
| 426 |
-
},
|
| 427 |
-
{
|
| 428 |
-
"cell_type": "markdown",
|
| 429 |
-
"id": "a037f09d",
|
| 430 |
-
"metadata": {},
|
| 431 |
-
"source": [
|
| 432 |
-
"We can also see the data artifacts that were produced by the last step of the pipeline:"
|
| 433 |
-
]
|
| 434 |
-
},
|
| 435 |
-
{
|
| 436 |
-
"cell_type": "code",
|
| 437 |
-
"execution_count": null,
|
| 438 |
-
"id": "34283e89",
|
| 439 |
-
"metadata": {},
|
| 440 |
-
"outputs": [],
|
| 441 |
-
"source": [
|
| 442 |
-
"run.steps[\"data_preprocessor\"].outputs"
|
| 443 |
-
]
|
| 444 |
-
},
|
| 445 |
-
{
|
| 446 |
-
"cell_type": "code",
|
| 447 |
-
"execution_count": null,
|
| 448 |
-
"id": "bceb0312",
|
| 449 |
"metadata": {},
|
| 450 |
-
"outputs": [],
|
| 451 |
"source": [
|
| 452 |
-
"#
|
| 453 |
-
"run.steps[\"data_preprocessor\"].outputs[\"dataset_trn\"].load()"
|
| 454 |
]
|
| 455 |
},
|
| 456 |
{
|
| 457 |
"cell_type": "markdown",
|
| 458 |
-
"id": "
|
| 459 |
"metadata": {},
|
| 460 |
"source": [
|
| 461 |
-
"
|
| 462 |
"\n",
|
| 463 |
-
"
|
| 464 |
-
]
|
| 465 |
-
},
|
| 466 |
-
{
|
| 467 |
-
"cell_type": "code",
|
| 468 |
-
"execution_count": null,
|
| 469 |
-
"id": "c8f90647",
|
| 470 |
-
"metadata": {},
|
| 471 |
-
"outputs": [],
|
| 472 |
-
"source": [
|
| 473 |
-
"# Get artifact version from our run\n",
|
| 474 |
-
"dataset_trn_artifact_version_via_run = run.steps[\"data_preprocessor\"].outputs[\"dataset_trn\"] \n",
|
| 475 |
-
"\n",
|
| 476 |
-
"# Get latest version from client directly\n",
|
| 477 |
-
"dataset_trn_artifact_version = client.get_artifact_version(\"dataset_trn\")\n",
|
| 478 |
-
"\n",
|
| 479 |
-
"# This should be true if our run is the latest run and no artifact has been produced\n",
|
| 480 |
-
"# in the intervening time\n",
|
| 481 |
-
"dataset_trn_artifact_version_via_run.id == dataset_trn_artifact_version.id"
|
| 482 |
-
]
|
| 483 |
-
},
|
| 484 |
-
{
|
| 485 |
-
"cell_type": "code",
|
| 486 |
-
"execution_count": null,
|
| 487 |
-
"id": "3f9d3dfd",
|
| 488 |
-
"metadata": {},
|
| 489 |
-
"outputs": [],
|
| 490 |
-
"source": [
|
| 491 |
-
"# Fetch the rest of the artifacts\n",
|
| 492 |
-
"dataset_tst_artifact_version = client.get_artifact_version(\"dataset_tst\")\n",
|
| 493 |
-
"preprocessing_pipeline_artifact_version = client.get_artifact_version(\"preprocess_pipeline\")"
|
| 494 |
-
]
|
| 495 |
-
},
|
| 496 |
-
{
|
| 497 |
-
"cell_type": "markdown",
|
| 498 |
-
"id": "7a7d1b04",
|
| 499 |
-
"metadata": {},
|
| 500 |
-
"source": [
|
| 501 |
-
"If you started with a fresh install, then you would have two versions corresponding\n",
|
| 502 |
-
"to the two pipelines that we ran above. We can even load a artifact version in memory: "
|
| 503 |
]
|
| 504 |
},
|
| 505 |
{
|
| 506 |
"cell_type": "code",
|
| 507 |
-
"execution_count":
|
| 508 |
-
"id": "
|
| 509 |
-
"metadata": {},
|
| 510 |
-
"outputs": [],
|
| 511 |
-
"source": [
|
| 512 |
-
"# Load an artifact to verify you can fetch it\n",
|
| 513 |
-
"dataset_trn_artifact_version.load()"
|
| 514 |
-
]
|
| 515 |
-
},
|
| 516 |
-
{
|
| 517 |
-
"cell_type": "markdown",
|
| 518 |
-
"id": "5963509e",
|
| 519 |
-
"metadata": {},
|
| 520 |
-
"source": [
|
| 521 |
-
"We'll use these artifacts from above in our next pipeline"
|
| 522 |
-
]
|
| 523 |
-
},
|
| 524 |
-
{
|
| 525 |
-
"cell_type": "markdown",
|
| 526 |
-
"id": "8c28b474",
|
| 527 |
"metadata": {},
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 528 |
"source": [
|
| 529 |
-
"
|
| 530 |
]
|
| 531 |
},
|
| 532 |
{
|
|
@@ -534,379 +85,69 @@
|
|
| 534 |
"id": "87909827",
|
| 535 |
"metadata": {},
|
| 536 |
"source": [
|
| 537 |
-
"
|
| 538 |
-
"how difficult the task is. The Breast Cancer dataset is sufficiently large and complex \n",
|
| 539 |
-
"that it's unlikely we'll be able to train a model that behaves perfectly since the problem \n",
|
| 540 |
-
"is inherently complex, but we can get a sense of what a reasonable baseline looks like.\n",
|
| 541 |
"\n",
|
| 542 |
-
"
|
| 543 |
-
"Classifier, both batteries-included from `sklearn`. We'll train them both on the\n",
|
| 544 |
-
"same data and then compare their performance.\n",
|
| 545 |
-
"\n",
|
| 546 |
-
"<img src=\".assets/training_pipeline.png\" width=\"50%\" alt=\"Training pipeline\">"
|
| 547 |
]
|
| 548 |
},
|
| 549 |
{
|
| 550 |
"cell_type": "code",
|
| 551 |
-
"execution_count":
|
| 552 |
"id": "fccf1bd9",
|
| 553 |
-
"metadata": {
|
| 554 |
-
|
| 555 |
-
|
| 556 |
-
|
| 557 |
-
|
| 558 |
-
|
| 559 |
-
|
| 560 |
-
|
| 561 |
-
|
| 562 |
-
|
| 563 |
-
|
| 564 |
-
|
| 565 |
-
|
| 566 |
-
|
| 567 |
-
|
| 568 |
-
|
| 569 |
-
|
| 570 |
-
|
| 571 |
-
|
| 572 |
-
|
| 573 |
-
|
| 574 |
-
|
| 575 |
-
|
| 576 |
-
|
| 577 |
-
|
| 578 |
-
|
| 579 |
-
|
| 580 |
-
|
| 581 |
-
|
| 582 |
-
|
| 583 |
-
|
| 584 |
-
|
| 585 |
-
|
| 586 |
-
|
| 587 |
-
|
| 588 |
-
|
| 589 |
-
|
| 590 |
-
|
| 591 |
-
|
| 592 |
-
|
| 593 |
-
|
| 594 |
-
|
| 595 |
-
|
| 596 |
-
|
| 597 |
-
|
| 598 |
-
|
| 599 |
-
|
| 600 |
-
|
| 601 |
-
|
| 602 |
-
|
| 603 |
-
|
| 604 |
-
|
| 605 |
-
|
| 606 |
-
"
|
| 607 |
-
"into the training pipeline."
|
| 608 |
-
]
|
| 609 |
-
},
|
| 610 |
-
{
|
| 611 |
-
"cell_type": "code",
|
| 612 |
-
"execution_count": null,
|
| 613 |
-
"id": "1aa98f2f",
|
| 614 |
-
"metadata": {},
|
| 615 |
-
"outputs": [],
|
| 616 |
-
"source": [
|
| 617 |
-
"@pipeline\n",
|
| 618 |
-
"def training(\n",
|
| 619 |
-
" train_dataset_id: Optional[UUID] = None,\n",
|
| 620 |
-
" test_dataset_id: Optional[UUID] = None,\n",
|
| 621 |
-
" model_type: str = \"sgd\",\n",
|
| 622 |
-
" min_train_accuracy: float = 0.0,\n",
|
| 623 |
-
" min_test_accuracy: float = 0.0,\n",
|
| 624 |
-
"):\n",
|
| 625 |
-
" \"\"\"Model training pipeline.\"\"\" \n",
|
| 626 |
-
" if train_dataset_id is None or test_dataset_id is None:\n",
|
| 627 |
-
" # If we dont pass the IDs, this will run the feature engineering pipeline \n",
|
| 628 |
-
" dataset_trn, dataset_tst = feature_engineering()\n",
|
| 629 |
-
" else:\n",
|
| 630 |
-
" # Load the datasets from an older pipeline\n",
|
| 631 |
-
" dataset_trn = ExternalArtifact(id=train_dataset_id)\n",
|
| 632 |
-
" dataset_tst = ExternalArtifact(id=test_dataset_id) \n",
|
| 633 |
-
"\n",
|
| 634 |
-
" trained_model = model_trainer(\n",
|
| 635 |
-
" dataset_trn=dataset_trn,\n",
|
| 636 |
-
" model_type=model_type,\n",
|
| 637 |
-
" )\n",
|
| 638 |
-
"\n",
|
| 639 |
-
" model_evaluator(\n",
|
| 640 |
-
" model=trained_model,\n",
|
| 641 |
-
" dataset_trn=dataset_trn,\n",
|
| 642 |
-
" dataset_tst=dataset_tst,\n",
|
| 643 |
-
" min_train_accuracy=min_train_accuracy,\n",
|
| 644 |
-
" min_test_accuracy=min_test_accuracy,\n",
|
| 645 |
-
" )"
|
| 646 |
-
]
|
| 647 |
-
},
|
| 648 |
-
{
|
| 649 |
-
"cell_type": "markdown",
|
| 650 |
-
"id": "88b70fd3",
|
| 651 |
-
"metadata": {},
|
| 652 |
-
"source": [
|
| 653 |
-
"The end goal of this quick baseline evaluation is to understand which of the two\n",
|
| 654 |
-
"models performs better. We'll use the `evaluator` step to compare the two\n",
|
| 655 |
-
"models. This step takes in the model from the trainer step, and computes its score\n",
|
| 656 |
-
"over the testing set."
|
| 657 |
-
]
|
| 658 |
-
},
|
| 659 |
-
{
|
| 660 |
-
"cell_type": "code",
|
| 661 |
-
"execution_count": null,
|
| 662 |
-
"id": "c64885ac",
|
| 663 |
-
"metadata": {},
|
| 664 |
-
"outputs": [],
|
| 665 |
-
"source": [
|
| 666 |
-
"# Use a random forest model with the chosen datasets.\n",
|
| 667 |
-
"# We need to pass the ID's of the datasets into the function\n",
|
| 668 |
-
"training(\n",
|
| 669 |
-
" model_type=\"rf\",\n",
|
| 670 |
-
" train_dataset_id=dataset_trn_artifact_version.id,\n",
|
| 671 |
-
" test_dataset_id=dataset_tst_artifact_version.id\n",
|
| 672 |
-
")\n",
|
| 673 |
-
"\n",
|
| 674 |
-
"rf_run = client.get_pipeline(\"training\").last_run"
|
| 675 |
-
]
|
| 676 |
-
},
|
| 677 |
-
{
|
| 678 |
-
"cell_type": "code",
|
| 679 |
-
"execution_count": null,
|
| 680 |
-
"id": "4300c82f",
|
| 681 |
-
"metadata": {},
|
| 682 |
-
"outputs": [],
|
| 683 |
-
"source": [
|
| 684 |
-
"# Use a SGD classifier\n",
|
| 685 |
-
"sgd_run = training(\n",
|
| 686 |
-
" model_type=\"sgd\",\n",
|
| 687 |
-
" train_dataset_id=dataset_trn_artifact_version.id,\n",
|
| 688 |
-
" test_dataset_id=dataset_tst_artifact_version.id\n",
|
| 689 |
-
")\n",
|
| 690 |
-
"\n",
|
| 691 |
-
"sgd_run = client.get_pipeline(\"training\").last_run"
|
| 692 |
-
]
|
| 693 |
-
},
|
| 694 |
-
{
|
| 695 |
-
"cell_type": "markdown",
|
| 696 |
-
"id": "43f1a68a",
|
| 697 |
-
"metadata": {},
|
| 698 |
-
"source": [
|
| 699 |
-
"You can see from the logs already how our model training went: the\n",
|
| 700 |
-
"`RandomForestClassifier` performed considerably better than the `SGDClassifier`.\n",
|
| 701 |
-
"We can use the ZenML `Client` to verify this:"
|
| 702 |
-
]
|
| 703 |
-
},
|
| 704 |
-
{
|
| 705 |
-
"cell_type": "code",
|
| 706 |
-
"execution_count": null,
|
| 707 |
-
"id": "d95810b1",
|
| 708 |
-
"metadata": {},
|
| 709 |
-
"outputs": [],
|
| 710 |
-
"source": [
|
| 711 |
-
"# The evaluator returns a float value with the accuracy\n",
|
| 712 |
-
"rf_run.steps[\"model_evaluator\"].output.load() > sgd_run.steps[\"model_evaluator\"].output.load()"
|
| 713 |
-
]
|
| 714 |
-
},
|
| 715 |
-
{
|
| 716 |
-
"cell_type": "markdown",
|
| 717 |
-
"id": "e256d145",
|
| 718 |
-
"metadata": {},
|
| 719 |
-
"source": [
|
| 720 |
-
"# 💯 Step 3: Associating a model with your pipeline"
|
| 721 |
-
]
|
| 722 |
-
},
|
| 723 |
-
{
|
| 724 |
-
"cell_type": "markdown",
|
| 725 |
-
"id": "927978f3",
|
| 726 |
-
"metadata": {},
|
| 727 |
-
"source": [
|
| 728 |
-
"You can see it is relatively easy to train ML models using ZenML pipelines. But it can be somewhat clunky to track\n",
|
| 729 |
-
"all the models produced as you develop your experiments and use-cases. Luckily, ZenML offers a *Model Control Plane*,\n",
|
| 730 |
-
"which is a central register of all your ML models.\n",
|
| 731 |
-
"\n",
|
| 732 |
-
"You can easily create a ZenML `Model` and associate it with your pipelines using the `ModelVersion` object:"
|
| 733 |
-
]
|
| 734 |
-
},
|
| 735 |
-
{
|
| 736 |
-
"cell_type": "code",
|
| 737 |
-
"execution_count": null,
|
| 738 |
-
"id": "99ca00c0",
|
| 739 |
-
"metadata": {},
|
| 740 |
-
"outputs": [],
|
| 741 |
-
"source": [
|
| 742 |
-
"pipeline_settings = {}\n",
|
| 743 |
-
"\n",
|
| 744 |
-
"# Lets add some metadata to the model to make it identifiable\n",
|
| 745 |
-
"pipeline_settings[\"model_version\"] = ModelVersion(\n",
|
| 746 |
-
" name=\"breast_cancer_classifier\",\n",
|
| 747 |
-
" license=\"Apache 2.0\",\n",
|
| 748 |
-
" description=\"A breast cancer classifier\",\n",
|
| 749 |
-
" tags=[\"breast_cancer\", \"classifier\"],\n",
|
| 750 |
-
")"
|
| 751 |
-
]
|
| 752 |
-
},
|
| 753 |
-
{
|
| 754 |
-
"cell_type": "code",
|
| 755 |
-
"execution_count": null,
|
| 756 |
-
"id": "0e78a520",
|
| 757 |
-
"metadata": {},
|
| 758 |
-
"outputs": [],
|
| 759 |
-
"source": [
|
| 760 |
-
"# Let's train the SGD model and set the version name to \"sgd\"\n",
|
| 761 |
-
"pipeline_settings[\"model_version\"].version = \"sgd\"\n",
|
| 762 |
-
"\n",
|
| 763 |
-
"# the `with_options` method allows us to pass in pipeline settings\n",
|
| 764 |
-
"# and returns a configured pipeline\n",
|
| 765 |
-
"training_configured = training.with_options(**pipeline_settings)\n",
|
| 766 |
-
"\n",
|
| 767 |
-
"# We can now run this as usual\n",
|
| 768 |
-
"training_configured(\n",
|
| 769 |
-
" model_type=\"sgd\",\n",
|
| 770 |
-
" train_dataset_id=dataset_trn_artifact_version.id,\n",
|
| 771 |
-
" test_dataset_id=dataset_tst_artifact_version.id\n",
|
| 772 |
-
")"
|
| 773 |
-
]
|
| 774 |
-
},
|
| 775 |
-
{
|
| 776 |
-
"cell_type": "code",
|
| 777 |
-
"execution_count": null,
|
| 778 |
-
"id": "9b8e0002",
|
| 779 |
-
"metadata": {},
|
| 780 |
-
"outputs": [],
|
| 781 |
-
"source": [
|
| 782 |
-
"# Let's train the RF model and set the version name to \"rf\"\n",
|
| 783 |
-
"pipeline_settings[\"model_version\"].version = \"rf\"\n",
|
| 784 |
-
"\n",
|
| 785 |
-
"# the `with_options` method allows us to pass in pipeline settings\n",
|
| 786 |
-
"# and returns a configured pipeline\n",
|
| 787 |
-
"training_configured = training.with_options(**pipeline_settings)\n",
|
| 788 |
-
"\n",
|
| 789 |
-
"# Let's run it again to make sure we have two versions\n",
|
| 790 |
-
"training_configured(\n",
|
| 791 |
-
" model_type=\"rf\",\n",
|
| 792 |
-
" train_dataset_id=dataset_trn_artifact_version.id,\n",
|
| 793 |
-
" test_dataset_id=dataset_tst_artifact_version.id\n",
|
| 794 |
-
")"
|
| 795 |
-
]
|
| 796 |
-
},
|
| 797 |
-
{
|
| 798 |
-
"cell_type": "markdown",
|
| 799 |
-
"id": "09597223",
|
| 800 |
-
"metadata": {},
|
| 801 |
-
"source": [
|
| 802 |
-
"This time, running both pipelines has created two associated **model versions**.\n",
|
| 803 |
-
"You can list your ZenML model and their versions as follows:"
|
| 804 |
-
]
|
| 805 |
-
},
|
| 806 |
-
{
|
| 807 |
-
"cell_type": "code",
|
| 808 |
-
"execution_count": null,
|
| 809 |
-
"id": "fbb25913",
|
| 810 |
-
"metadata": {},
|
| 811 |
-
"outputs": [],
|
| 812 |
-
"source": [
|
| 813 |
-
"zenml_model = client.get_model(\"breast_cancer_classifier\")\n",
|
| 814 |
-
"print(zenml_model)\n",
|
| 815 |
-
"\n",
|
| 816 |
-
"print(f\"Model {zenml_model.name} has {len(zenml_model.versions)} versions\")\n",
|
| 817 |
-
"\n",
|
| 818 |
-
"zenml_model.versions[0].version, zenml_model.versions[1].version"
|
| 819 |
-
]
|
| 820 |
-
},
|
| 821 |
-
{
|
| 822 |
-
"cell_type": "markdown",
|
| 823 |
-
"id": "e82cfac2",
|
| 824 |
-
"metadata": {},
|
| 825 |
-
"source": [
|
| 826 |
-
"The interesting part is that ZenML went ahead and linked all artifacts produced by the\n",
|
| 827 |
-
"pipelines to that model version, including the two pickle files that represent our\n",
|
| 828 |
-
"SGD and RandomForest classifier. We can see all artifacts directly from the model\n",
|
| 829 |
-
"version object:"
|
| 830 |
-
]
|
| 831 |
-
},
|
| 832 |
-
{
|
| 833 |
-
"cell_type": "code",
|
| 834 |
-
"execution_count": null,
|
| 835 |
-
"id": "31211413",
|
| 836 |
-
"metadata": {},
|
| 837 |
-
"outputs": [],
|
| 838 |
-
"source": [
|
| 839 |
-
"# Let's load the RF version\n",
|
| 840 |
-
"rf_zenml_model_version = client.get_model_version(\"breast_cancer_classifier\", \"rf\")\n",
|
| 841 |
-
"\n",
|
| 842 |
-
"# We can now load our classifier directly as well\n",
|
| 843 |
-
"random_forest_classifier = rf_zenml_model_version.get_artifact(\"sklearn_classifier\").load()\n",
|
| 844 |
-
"\n",
|
| 845 |
-
"random_forest_classifier"
|
| 846 |
-
]
|
| 847 |
-
},
|
| 848 |
-
{
|
| 849 |
-
"cell_type": "markdown",
|
| 850 |
-
"id": "53517a9a",
|
| 851 |
-
"metadata": {},
|
| 852 |
-
"source": [
|
| 853 |
-
"If you are a [ZenML Cloud](https://zenml.io/cloud) user, you can see all of this visualized in the dashboard:\n",
|
| 854 |
-
"\n",
|
| 855 |
-
"<img src=\".assets/cloud_mcp_screenshot.png\" width=\"70%\" alt=\"Model Control Plane\">"
|
| 856 |
-
]
|
| 857 |
-
},
|
| 858 |
-
{
|
| 859 |
-
"cell_type": "markdown",
|
| 860 |
-
"id": "eb645dde",
|
| 861 |
-
"metadata": {},
|
| 862 |
-
"source": [
|
| 863 |
-
"There is a lot more you can do with ZenML models, including the ability to\n",
|
| 864 |
-
"track metrics by adding metadata to it, or having them persist in a model\n",
|
| 865 |
-
"registry. However, these topics can be explored more in the\n",
|
| 866 |
-
"[ZenML docs](https://docs.zenml.io).\n",
|
| 867 |
-
"\n",
|
| 868 |
-
"For now, we will use the ZenML model control plane to promote our best\n",
|
| 869 |
-
"model to `production`. You can do this by simply setting the `stage` of\n",
|
| 870 |
-
"your chosen model version to the `production` tag."
|
| 871 |
-
]
|
| 872 |
-
},
|
| 873 |
-
{
|
| 874 |
-
"cell_type": "code",
|
| 875 |
-
"execution_count": null,
|
| 876 |
-
"id": "26b718f8",
|
| 877 |
-
"metadata": {},
|
| 878 |
-
"outputs": [],
|
| 879 |
-
"source": [
|
| 880 |
-
"# Set our best classifier to production\n",
|
| 881 |
-
"rf_zenml_model_version.set_stage(\"production\", force=True)"
|
| 882 |
-
]
|
| 883 |
-
},
|
| 884 |
-
{
|
| 885 |
-
"cell_type": "markdown",
|
| 886 |
-
"id": "9fddf3d0",
|
| 887 |
-
"metadata": {},
|
| 888 |
-
"source": [
|
| 889 |
-
"Of course, normally one would only promote the model by comparing to all other model\n",
|
| 890 |
-
"versions and doing some other tests. But that's a bit more advanced use-case. See the\n",
|
| 891 |
-
"[e2e_batch example](https://github.com/zenml-io/zenml/tree/main/examples/e2e) to get\n",
|
| 892 |
-
"more insight into that sort of flow!"
|
| 893 |
-
]
|
| 894 |
-
},
|
| 895 |
-
{
|
| 896 |
-
"cell_type": "markdown",
|
| 897 |
-
"id": "2ecbc8cf",
|
| 898 |
-
"metadata": {},
|
| 899 |
-
"source": [
|
| 900 |
-
"<img src=\".assets/cloud_mcp.png\" width=\"60%\" alt=\"Model Control Plane\">"
|
| 901 |
-
]
|
| 902 |
-
},
|
| 903 |
-
{
|
| 904 |
-
"cell_type": "markdown",
|
| 905 |
-
"id": "8f1146db",
|
| 906 |
-
"metadata": {},
|
| 907 |
-
"source": [
|
| 908 |
-
"Once the model is promoted, we can now consume the right model version in our\n",
|
| 909 |
-
"batch inference pipeline directly. Let's see how that works."
|
| 910 |
]
|
| 911 |
},
|
| 912 |
{
|
|
@@ -914,7 +155,7 @@
|
|
| 914 |
"id": "d6306f14",
|
| 915 |
"metadata": {},
|
| 916 |
"source": [
|
| 917 |
-
"# 🫅 Step
|
| 918 |
]
|
| 919 |
},
|
| 920 |
{
|
|
@@ -926,147 +167,43 @@
|
|
| 926 |
"with `live data`. The critical step here is the `inference_predict` step, where we load the model in memory\n",
|
| 927 |
"and generate predictions:\n",
|
| 928 |
"\n",
|
| 929 |
-
"<img src=\"
|
| 930 |
]
|
| 931 |
},
|
| 932 |
{
|
| 933 |
"cell_type": "code",
|
| 934 |
"execution_count": null,
|
| 935 |
-
"id": "
|
| 936 |
"metadata": {},
|
| 937 |
"outputs": [],
|
| 938 |
"source": [
|
| 939 |
-
"
|
| 940 |
-
"def inference_predict(dataset_inf: pd.DataFrame) -> Annotated[pd.Series, \"predictions\"]:\n",
|
| 941 |
-
" \"\"\"Predictions step\"\"\"\n",
|
| 942 |
-
" # Get the model_version\n",
|
| 943 |
-
" model_version = get_step_context().model_version\n",
|
| 944 |
-
"\n",
|
| 945 |
-
" # run prediction from memory\n",
|
| 946 |
-
" predictor = model_version.load_artifact(\"sklearn_classifier\")\n",
|
| 947 |
-
" predictions = predictor.predict(dataset_inf)\n",
|
| 948 |
-
"\n",
|
| 949 |
-
" predictions = pd.Series(predictions, name=\"predicted\")\n",
|
| 950 |
-
"\n",
|
| 951 |
-
" return predictions\n"
|
| 952 |
]
|
| 953 |
},
|
| 954 |
{
|
| 955 |
"cell_type": "markdown",
|
| 956 |
-
"id": "
|
| 957 |
-
"metadata": {},
|
| 958 |
-
"source": [
|
| 959 |
-
"Apart from the loading the model, we must also load the preprocessing pipeline that we ran in feature engineering,\n",
|
| 960 |
-
"so that we can do the exact steps that we did on training time, in inference time. Let's bring it all together:"
|
| 961 |
-
]
|
| 962 |
-
},
|
| 963 |
-
{
|
| 964 |
-
"cell_type": "code",
|
| 965 |
-
"execution_count": null,
|
| 966 |
-
"id": "37c409bd",
|
| 967 |
"metadata": {},
|
| 968 |
-
"outputs": [],
|
| 969 |
"source": [
|
| 970 |
-
"
|
| 971 |
-
"def inference(preprocess_pipeline_id: UUID):\n",
|
| 972 |
-
" \"\"\"Model batch inference pipeline\"\"\"\n",
|
| 973 |
-
" # random_state = client.get_artifact_version(id=preprocess_pipeline_id).metadata[\"random_state\"].value\n",
|
| 974 |
-
" # target = client.get_artifact_version(id=preprocess_pipeline_id).run_metadata['target'].value\n",
|
| 975 |
-
" random_state = 42\n",
|
| 976 |
-
" target = \"target\"\n",
|
| 977 |
-
"\n",
|
| 978 |
-
" df_inference = data_loader(\n",
|
| 979 |
-
" random_state=random_state, is_inference=True\n",
|
| 980 |
-
" )\n",
|
| 981 |
-
" df_inference = inference_preprocessor(\n",
|
| 982 |
-
" dataset_inf=df_inference,\n",
|
| 983 |
-
" # We use the preprocess pipeline from the feature engineering pipeline\n",
|
| 984 |
-
" preprocess_pipeline=ExternalArtifact(id=preprocess_pipeline_id),\n",
|
| 985 |
-
" target=target,\n",
|
| 986 |
-
" )\n",
|
| 987 |
-
" inference_predict(\n",
|
| 988 |
-
" dataset_inf=df_inference,\n",
|
| 989 |
-
" )\n"
|
| 990 |
]
|
| 991 |
},
|
| 992 |
{
|
| 993 |
"cell_type": "markdown",
|
| 994 |
-
"id": "
|
| 995 |
"metadata": {},
|
| 996 |
"source": [
|
| 997 |
-
"
|
| 998 |
-
"This will ensure to always load the production model, decoupled from all other pipelines:"
|
| 999 |
]
|
| 1000 |
},
|
| 1001 |
{
|
| 1002 |
"cell_type": "code",
|
| 1003 |
"execution_count": null,
|
| 1004 |
-
"id": "
|
| 1005 |
"metadata": {},
|
| 1006 |
"outputs": [],
|
| 1007 |
"source": [
|
| 1008 |
-
"
|
| 1009 |
-
"\n",
|
| 1010 |
-
"# Lets add some metadata to the model to make it identifiable\n",
|
| 1011 |
-
"pipeline_settings[\"model_version\"] = ModelVersion(\n",
|
| 1012 |
-
" name=\"breast_cancer_classifier\",\n",
|
| 1013 |
-
" version=\"production\", # We can pass in the stage name here!\n",
|
| 1014 |
-
" license=\"Apache 2.0\",\n",
|
| 1015 |
-
" description=\"A breast cancer classifier\",\n",
|
| 1016 |
-
" tags=[\"breast_cancer\", \"classifier\"],\n",
|
| 1017 |
-
")"
|
| 1018 |
-
]
|
| 1019 |
-
},
|
| 1020 |
-
{
|
| 1021 |
-
"cell_type": "code",
|
| 1022 |
-
"execution_count": null,
|
| 1023 |
-
"id": "ff3402f1",
|
| 1024 |
-
"metadata": {},
|
| 1025 |
-
"outputs": [],
|
| 1026 |
-
"source": [
|
| 1027 |
-
"# the `with_options` method allows us to pass in pipeline settings\n",
|
| 1028 |
-
"# and returns a configured pipeline\n",
|
| 1029 |
-
"inference_configured = inference.with_options(**pipeline_settings)\n",
|
| 1030 |
-
"\n",
|
| 1031 |
-
"# Let's run it again to make sure we have two versions\n",
|
| 1032 |
-
"# We need to pass in the ID of the preprocessing done in the feature engineering pipeline\n",
|
| 1033 |
-
"# in order to avoid training-serving skew\n",
|
| 1034 |
-
"inference_configured(\n",
|
| 1035 |
-
" preprocess_pipeline_id=preprocessing_pipeline_artifact_version.id\n",
|
| 1036 |
-
")"
|
| 1037 |
-
]
|
| 1038 |
-
},
|
| 1039 |
-
{
|
| 1040 |
-
"cell_type": "markdown",
|
| 1041 |
-
"id": "2935d1fa",
|
| 1042 |
-
"metadata": {},
|
| 1043 |
-
"source": [
|
| 1044 |
-
"ZenML automatically links all artifacts to the `production` model version as well, including the predictions\n",
|
| 1045 |
-
"that were returned in the pipeline. This completes the MLOps loop of training to inference:"
|
| 1046 |
-
]
|
| 1047 |
-
},
|
| 1048 |
-
{
|
| 1049 |
-
"cell_type": "code",
|
| 1050 |
-
"execution_count": null,
|
| 1051 |
-
"id": "e191d019",
|
| 1052 |
-
"metadata": {},
|
| 1053 |
-
"outputs": [],
|
| 1054 |
-
"source": [
|
| 1055 |
-
"# Fetch production model\n",
|
| 1056 |
-
"production_model_version = client.get_model_version(\"breast_cancer_classifier\", \"production\")\n",
|
| 1057 |
-
"\n",
|
| 1058 |
-
"# Get the predictions artifact\n",
|
| 1059 |
-
"production_model_version.get_artifact(\"predictions\").load()"
|
| 1060 |
-
]
|
| 1061 |
-
},
|
| 1062 |
-
{
|
| 1063 |
-
"cell_type": "markdown",
|
| 1064 |
-
"id": "b0a73cdf",
|
| 1065 |
-
"metadata": {},
|
| 1066 |
-
"source": [
|
| 1067 |
-
"You can also see all predictions ever created as a complete history in the dashboard:\n",
|
| 1068 |
-
"\n",
|
| 1069 |
-
"<img src=\".assets/cloud_mcp_predictions.png\" width=\"70%\" alt=\"Model Control Plane\">"
|
| 1070 |
]
|
| 1071 |
},
|
| 1072 |
{
|
|
|
|
| 11 |
"\n",
|
| 12 |
"This repository is a minimalistic MLOps project intended as a starting point to learn how to put ML workflows in production. It features: \n",
|
| 13 |
"\n",
|
|
|
|
|
|
|
|
|
|
|
|
|
| 14 |
"Follow along this notebook to understand how you can use ZenML to productionalize your ML workflows!\n",
|
| 15 |
"\n",
|
| 16 |
"<img src=\"_assets/pipeline_overview.png\" width=\"50%\" alt=\"Pipelines Overview\">"
|
|
|
|
| 18 |
},
|
| 19 |
{
|
| 20 |
"cell_type": "markdown",
|
| 21 |
+
"id": "8c28b474",
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 22 |
"metadata": {},
|
|
|
|
| 23 |
"source": [
|
| 24 |
+
"# ⌚ Step 1: (Feature engineering) + Training pipeline"
|
|
|
|
| 25 |
]
|
| 26 |
},
|
| 27 |
{
|
| 28 |
"cell_type": "markdown",
|
| 29 |
+
"id": "8e5a76e6-8655-47d5-ab61-015b2d69d720",
|
| 30 |
"metadata": {},
|
| 31 |
"source": [
|
| 32 |
+
"Lets run the feature engineering pipeline\n",
|
| 33 |
"\n",
|
| 34 |
+
"<img src=\"_assets/feature_engineering_pipeline.png\" width=\"50%\" alt=\"Training pipeline\">"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 35 |
]
|
| 36 |
},
|
| 37 |
{
|
| 38 |
"cell_type": "code",
|
| 39 |
+
"execution_count": 1,
|
| 40 |
+
"id": "942a20f9-244b-4761-933e-55989a7377d6",
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 41 |
"metadata": {},
|
| 42 |
+
"outputs": [
|
| 43 |
+
{
|
| 44 |
+
"name": "stdout",
|
| 45 |
+
"output_type": "stream",
|
| 46 |
+
"text": [
|
| 47 |
+
"\u001b[1;35mInitiating a new run for the pipeline: \u001b[0m\u001b[1;36mfeature_engineering\u001b[1;35m.\u001b[0m\n",
|
| 48 |
+
"\u001b[1;35mReusing registered version: \u001b[0m\u001b[1;36m(version: 28)\u001b[1;35m.\u001b[0m\n",
|
| 49 |
+
"\u001b[1;35mNew model version \u001b[0m\u001b[1;36m5\u001b[1;35m was created.\u001b[0m\n",
|
| 50 |
+
"\u001b[1;35mExecuting a new run.\u001b[0m\n",
|
| 51 |
+
"\u001b[1;35mUsing user: \u001b[0m\u001b[1;[email protected]\u001b[1;35m\u001b[0m\n",
|
| 52 |
+
"\u001b[1;35mUsing stack: \u001b[0m\u001b[1;36mlocal-sagemaker-step-operator-stack\u001b[1;35m\u001b[0m\n",
|
| 53 |
+
"\u001b[1;35m model_registry: \u001b[0m\u001b[1;36mmlflow\u001b[1;35m\u001b[0m\n",
|
| 54 |
+
"\u001b[1;35m step_operator: \u001b[0m\u001b[1;36msagemaker-eu\u001b[1;35m\u001b[0m\n",
|
| 55 |
+
"\u001b[1;35m experiment_tracker: \u001b[0m\u001b[1;36mmlflow\u001b[1;35m\u001b[0m\n",
|
| 56 |
+
"\u001b[1;35m container_registry: \u001b[0m\u001b[1;36maws-eu\u001b[1;35m\u001b[0m\n",
|
| 57 |
+
"\u001b[1;35m orchestrator: \u001b[0m\u001b[1;36mdefault\u001b[1;35m\u001b[0m\n",
|
| 58 |
+
"\u001b[1;35m image_builder: \u001b[0m\u001b[1;36mlocal\u001b[1;35m\u001b[0m\n",
|
| 59 |
+
"\u001b[1;35m artifact_store: \u001b[0m\u001b[1;36ms3-zenfiles\u001b[1;35m\u001b[0m\n",
|
| 60 |
+
"\u001b[33mCould not import GCP service connector: No module named 'google.api_core'.\u001b[0m\n",
|
| 61 |
+
"\u001b[33mCould not import Azure service connector: No module named 'azure.identity'.\u001b[0m\n",
|
| 62 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mdata_loader\u001b[1;35m has started.\u001b[0m\n",
|
| 63 |
+
"\u001b[1;35mDataset with 541 records loaded!\u001b[0m\n",
|
| 64 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mdata_loader\u001b[1;35m has finished in \u001b[0m\u001b[1;36m7.553s\u001b[1;35m.\u001b[0m\n",
|
| 65 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mdata_splitter\u001b[1;35m has started.\u001b[0m\n",
|
| 66 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mdata_splitter\u001b[1;35m has finished in \u001b[0m\u001b[1;36m12.965s\u001b[1;35m.\u001b[0m\n",
|
| 67 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mdata_preprocessor\u001b[1;35m has started.\u001b[0m\n",
|
| 68 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mdata_preprocessor\u001b[1;35m has finished in \u001b[0m\u001b[1;36m16.314s\u001b[1;35m.\u001b[0m\n",
|
| 69 |
+
"\u001b[1;35mRun \u001b[0m\u001b[1;36mfeature_engineering-2024_01_04-14_12_15_307718\u001b[1;35m has finished in \u001b[0m\u001b[1;36m56.379s\u001b[1;35m.\u001b[0m\n",
|
| 70 |
+
"\u001b[1;35mDashboard URL: https://1cf18d95-zenml.cloudinfra.zenml.io/workspaces/default/pipelines/c8c78176-d287-4fa1-ab35-a90f35670aa4/runs/411c6ccc-45f3-4db1-9e46-c21c605f7c7a/dag\u001b[0m\n",
|
| 71 |
+
"\u001b[1;35mFeature Engineering pipeline finished successfully!\u001b[0m\n",
|
| 72 |
+
"\u001b[1;35mThe latest feature engineering pipeline produced the following artifacts: \n",
|
| 73 |
+
"\n",
|
| 74 |
+
"1. Train Dataset - Name: dataset_trn, Version Name: 190 \n",
|
| 75 |
+
"2. Test Dataset: Name: dataset_tst, Version Name: 188\u001b[0m\n"
|
| 76 |
+
]
|
| 77 |
+
}
|
| 78 |
+
],
|
| 79 |
"source": [
|
| 80 |
+
"!python run.py --feature-pipeline"
|
| 81 |
]
|
| 82 |
},
|
| 83 |
{
|
|
|
|
| 85 |
"id": "87909827",
|
| 86 |
"metadata": {},
|
| 87 |
"source": [
|
| 88 |
+
"Lets run the training pipeline\n",
|
|
|
|
|
|
|
|
|
|
| 89 |
"\n",
|
| 90 |
+
"<img src=\"_assets/training_pipeline.png\" width=\"50%\" alt=\"Training pipeline\">"
|
|
|
|
|
|
|
|
|
|
|
|
|
| 91 |
]
|
| 92 |
},
|
| 93 |
{
|
| 94 |
"cell_type": "code",
|
| 95 |
+
"execution_count": 3,
|
| 96 |
"id": "fccf1bd9",
|
| 97 |
+
"metadata": {
|
| 98 |
+
"scrolled": true
|
| 99 |
+
},
|
| 100 |
+
"outputs": [
|
| 101 |
+
{
|
| 102 |
+
"name": "stdout",
|
| 103 |
+
"output_type": "stream",
|
| 104 |
+
"text": [
|
| 105 |
+
"\u001b[1;35mInitiating a new run for the pipeline: \u001b[0m\u001b[1;36mbreast_cancer_training\u001b[1;35m.\u001b[0m\n",
|
| 106 |
+
"\u001b[1;35mRegistered new version: \u001b[0m\u001b[1;36m(version 7)\u001b[1;35m.\u001b[0m\n",
|
| 107 |
+
"\u001b[1;35mNew model version \u001b[0m\u001b[1;36m6\u001b[1;35m was created.\u001b[0m\n",
|
| 108 |
+
"\u001b[1;35mExecuting a new run.\u001b[0m\n",
|
| 109 |
+
"\u001b[1;35mUsing user: \u001b[0m\u001b[1;[email protected]\u001b[1;35m\u001b[0m\n",
|
| 110 |
+
"\u001b[1;35mUsing stack: \u001b[0m\u001b[1;36mlocal-sagemaker-step-operator-stack\u001b[1;35m\u001b[0m\n",
|
| 111 |
+
"\u001b[1;35m model_registry: \u001b[0m\u001b[1;36mmlflow\u001b[1;35m\u001b[0m\n",
|
| 112 |
+
"\u001b[1;35m step_operator: \u001b[0m\u001b[1;36msagemaker-eu\u001b[1;35m\u001b[0m\n",
|
| 113 |
+
"\u001b[1;35m experiment_tracker: \u001b[0m\u001b[1;36mmlflow\u001b[1;35m\u001b[0m\n",
|
| 114 |
+
"\u001b[1;35m container_registry: \u001b[0m\u001b[1;36maws-eu\u001b[1;35m\u001b[0m\n",
|
| 115 |
+
"\u001b[1;35m orchestrator: \u001b[0m\u001b[1;36mdefault\u001b[1;35m\u001b[0m\n",
|
| 116 |
+
"\u001b[1;35m image_builder: \u001b[0m\u001b[1;36mlocal\u001b[1;35m\u001b[0m\n",
|
| 117 |
+
"\u001b[1;35m artifact_store: \u001b[0m\u001b[1;36ms3-zenfiles\u001b[1;35m\u001b[0m\n",
|
| 118 |
+
"\u001b[33mCould not import GCP service connector: No module named 'google.api_core'.\u001b[0m\n",
|
| 119 |
+
"\u001b[33mCould not import Azure service connector: No module named 'azure.identity'.\u001b[0m\n",
|
| 120 |
+
"\u001b[1;35mCaching \u001b[0m\u001b[1;36mdisabled\u001b[1;35m explicitly for \u001b[0m\u001b[1;36mmodel_trainer\u001b[1;35m.\u001b[0m\n",
|
| 121 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mmodel_trainer\u001b[1;35m has started.\u001b[0m\n",
|
| 122 |
+
"\u001b[1;35mTraining model DecisionTreeClassifier()...\u001b[0m\n",
|
| 123 |
+
"/home/htahir1/.virtualenvs/demo_stack_showcase/lib/python3.8/site-packages/_distutils_hack/__init__.py:33: UserWarning: Setuptools is replacing distutils.\n",
|
| 124 |
+
" warnings.warn(\"Setuptools is replacing distutils.\")\n",
|
| 125 |
+
"/home/htahir1/.virtualenvs/demo_stack_showcase/lib/python3.8/site-packages/zenml/integrations/mlflow/experiment_trackers/mlflow_experiment_tracker.py:245: FutureWarning: ``mlflow.gluon.autolog`` is deprecated since 2.5.0. This method will be removed in a future release.\n",
|
| 126 |
+
" module.autolog(disable=True)\n",
|
| 127 |
+
"\u001b[33mFailed to disable MLflow autologging for the following frameworks: ['tensorflow'].\u001b[0m\n",
|
| 128 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mmodel_trainer\u001b[1;35m has finished in \u001b[0m\u001b[1;36m16.003s\u001b[1;35m.\u001b[0m\n",
|
| 129 |
+
"\u001b[1;35mCaching \u001b[0m\u001b[1;36mdisabled\u001b[1;35m explicitly for \u001b[0m\u001b[1;36mmodel_evaluator\u001b[1;35m.\u001b[0m\n",
|
| 130 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mmodel_evaluator\u001b[1;35m has started.\u001b[0m\n",
|
| 131 |
+
"\u001b[33mYour artifact was materialized under Python version 'unknown' but you are currently using '3.8.10'. This might cause unexpected behavior since pickle is not reproducible across Python versions. Attempting to load anyway...\u001b[0m\n",
|
| 132 |
+
"\u001b[1;35mTrain accuracy=100.00%\u001b[0m\n",
|
| 133 |
+
"\u001b[1;35mTest accuracy=93.58%\u001b[0m\n",
|
| 134 |
+
"/home/htahir1/.virtualenvs/demo_stack_showcase/lib/python3.8/site-packages/zenml/integrations/mlflow/experiment_trackers/mlflow_experiment_tracker.py:245: FutureWarning: ``mlflow.gluon.autolog`` is deprecated since 2.5.0. This method will be removed in a future release.\n",
|
| 135 |
+
" module.autolog(disable=True)\n",
|
| 136 |
+
"\u001b[33mFailed to disable MLflow autologging for the following frameworks: ['tensorflow'].\u001b[0m\n",
|
| 137 |
+
"\u001b[1;35mImplicitly linking artifact \u001b[0m\u001b[1;36moutput\u001b[1;35m to model \u001b[0m\u001b[1;36mbreast_cancer_classifier\u001b[1;35m version \u001b[0m\u001b[1;36m6\u001b[1;35m.\u001b[0m\n",
|
| 138 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mmodel_evaluator\u001b[1;35m has finished in \u001b[0m\u001b[1;36m17.027s\u001b[1;35m.\u001b[0m\n",
|
| 139 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mmodel_promoter\u001b[1;35m has started.\u001b[0m\n",
|
| 140 |
+
"\u001b[1;35mModel promoted to production!\u001b[0m\n",
|
| 141 |
+
"\u001b[1;35mImplicitly linking artifact \u001b[0m\u001b[1;36moutput\u001b[1;35m to model \u001b[0m\u001b[1;36mbreast_cancer_classifier\u001b[1;35m version \u001b[0m\u001b[1;36m6\u001b[1;35m.\u001b[0m\n",
|
| 142 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mmodel_promoter\u001b[1;35m has finished in \u001b[0m\u001b[1;36m7.718s\u001b[1;35m.\u001b[0m\n",
|
| 143 |
+
"\u001b[1;35mRun \u001b[0m\u001b[1;36mbreast_cancer_training-2024_01_04-14_14_32_094692\u001b[1;35m has finished in \u001b[0m\u001b[1;36m1m2s\u001b[1;35m.\u001b[0m\n",
|
| 144 |
+
"\u001b[1;35mDashboard URL: https://1cf18d95-zenml.cloudinfra.zenml.io/workspaces/default/pipelines/a01a3156-fd0e-42db-aeab-0991acd22f51/runs/b4d53364-a2be-45d5-a464-23bb6c46ee11/dag\u001b[0m\n",
|
| 145 |
+
"\u001b[1;35mTraining pipeline finished successfully!\u001b[0m\n"
|
| 146 |
+
]
|
| 147 |
+
}
|
| 148 |
+
],
|
| 149 |
+
"source": [
|
| 150 |
+
"!python run.py --training-pipeline --train-dataset-version-name 190 --test-dataset-version-name 188"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 151 |
]
|
| 152 |
},
|
| 153 |
{
|
|
|
|
| 155 |
"id": "d6306f14",
|
| 156 |
"metadata": {},
|
| 157 |
"source": [
|
| 158 |
+
"# 🫅 Step 2: The inference pipeline"
|
| 159 |
]
|
| 160 |
},
|
| 161 |
{
|
|
|
|
| 167 |
"with `live data`. The critical step here is the `inference_predict` step, where we load the model in memory\n",
|
| 168 |
"and generate predictions:\n",
|
| 169 |
"\n",
|
| 170 |
+
"<img src=\"_assets/inference_pipeline.png\" width=\"45%\" alt=\"Inference pipeline\">"
|
| 171 |
]
|
| 172 |
},
|
| 173 |
{
|
| 174 |
"cell_type": "code",
|
| 175 |
"execution_count": null,
|
| 176 |
+
"id": "9918a8a1-c569-494f-aa40-cb7bd3aaea07",
|
| 177 |
"metadata": {},
|
| 178 |
"outputs": [],
|
| 179 |
"source": [
|
| 180 |
+
"!python run.py --inference-pipeline"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 181 |
]
|
| 182 |
},
|
| 183 |
{
|
| 184 |
"cell_type": "markdown",
|
| 185 |
+
"id": "36140d24-a280-48eb-bb03-5e03280e128c",
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 186 |
"metadata": {},
|
|
|
|
| 187 |
"source": [
|
| 188 |
+
"## Step 3: Deploying the pipeline to Huggingface"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 189 |
]
|
| 190 |
},
|
| 191 |
{
|
| 192 |
"cell_type": "markdown",
|
| 193 |
+
"id": "13bd8087-2ab0-4f9d-8bff-6266a05eb6e7",
|
| 194 |
"metadata": {},
|
| 195 |
"source": [
|
| 196 |
+
"<img src=\"_assets/deployment_pipeline.png\" width=\"45%\" alt=\"Deployment pipeline\">"
|
|
|
|
| 197 |
]
|
| 198 |
},
|
| 199 |
{
|
| 200 |
"cell_type": "code",
|
| 201 |
"execution_count": null,
|
| 202 |
+
"id": "8000849c-1ce8-4900-846e-3ef1873561f8",
|
| 203 |
"metadata": {},
|
| 204 |
"outputs": [],
|
| 205 |
"source": [
|
| 206 |
+
"!python run.py --deployment-pipeline"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 207 |
]
|
| 208 |
},
|
| 209 |
{
|
_assets/deployment_pipeline.png
ADDED
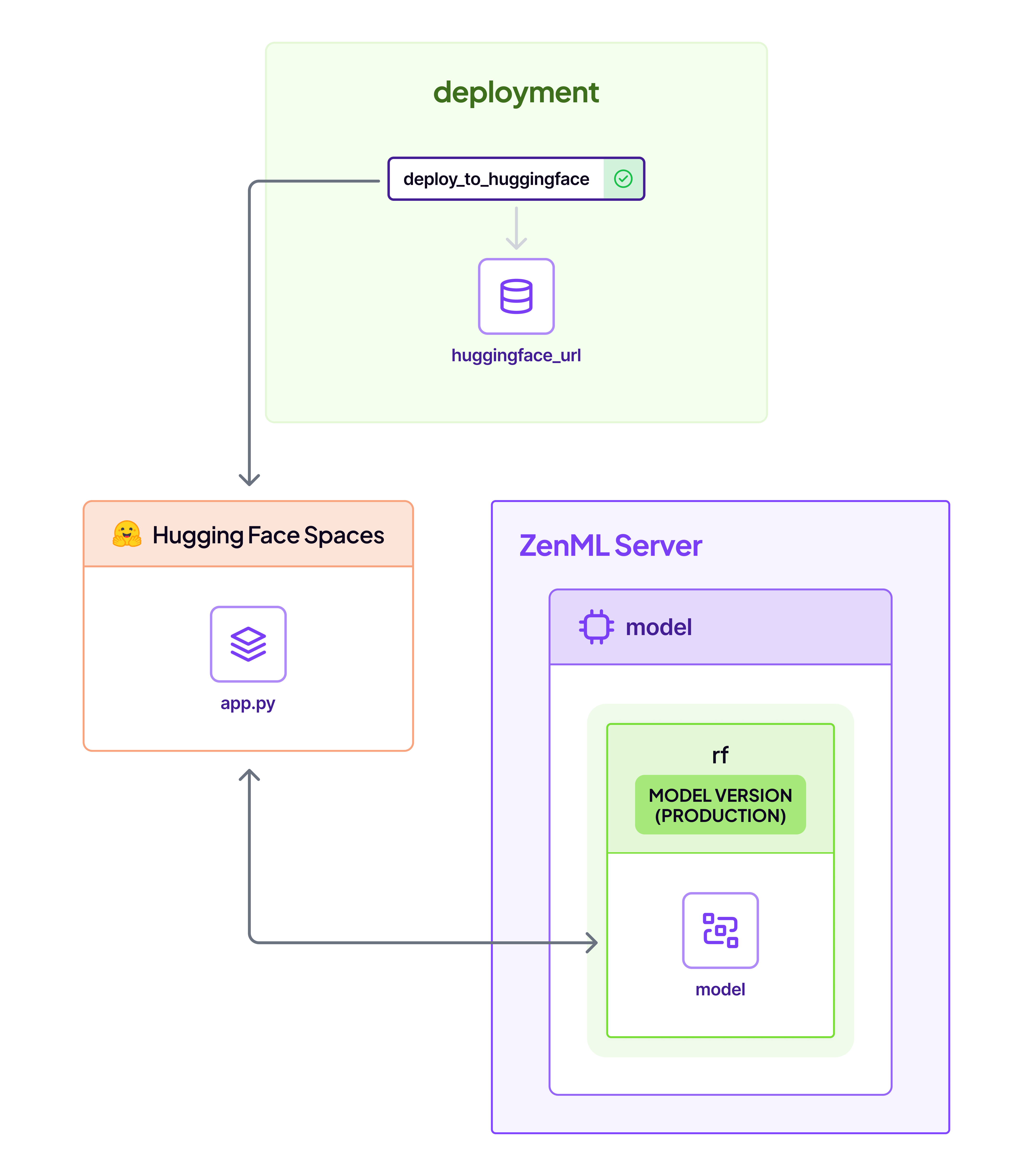
|
run.py
CHANGED
|
@@ -122,6 +122,7 @@ def main(
|
|
| 122 |
os.path.dirname(os.path.realpath(__file__)),
|
| 123 |
"configs",
|
| 124 |
)
|
|
|
|
| 125 |
|
| 126 |
# Execute Feature Engineering Pipeline
|
| 127 |
if feature_pipeline:
|
|
@@ -132,7 +133,17 @@ def main(
|
|
| 132 |
run_args_feature = {}
|
| 133 |
feature_engineering.with_options(**pipeline_args)(**run_args_feature)
|
| 134 |
logger.info("Feature Engineering pipeline finished successfully!")
|
| 135 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 136 |
# Execute Training Pipeline
|
| 137 |
if training_pipeline:
|
| 138 |
pipeline_args = {}
|
|
@@ -149,18 +160,41 @@ def main(
|
|
| 149 |
train_dataset_version_name is not None
|
| 150 |
and test_dataset_version_name is not None
|
| 151 |
)
|
| 152 |
-
|
| 153 |
-
train_dataset_artifact = client.get_artifact(
|
| 154 |
train_dataset_name, train_dataset_version_name
|
| 155 |
)
|
| 156 |
# If train dataset is specified, test dataset must be specified
|
| 157 |
-
test_dataset_artifact = client.
|
| 158 |
test_dataset_name, test_dataset_version_name
|
| 159 |
)
|
| 160 |
# Use versioned artifacts
|
| 161 |
run_args_train["train_dataset_id"] = train_dataset_artifact.id
|
| 162 |
run_args_train["test_dataset_id"] = test_dataset_artifact.id
|
| 163 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 164 |
breast_cancer_training.with_options(**pipeline_args)(**run_args_train)
|
| 165 |
logger.info("Training pipeline finished successfully!")
|
| 166 |
|
|
|
|
| 122 |
os.path.dirname(os.path.realpath(__file__)),
|
| 123 |
"configs",
|
| 124 |
)
|
| 125 |
+
client = Client()
|
| 126 |
|
| 127 |
# Execute Feature Engineering Pipeline
|
| 128 |
if feature_pipeline:
|
|
|
|
| 133 |
run_args_feature = {}
|
| 134 |
feature_engineering.with_options(**pipeline_args)(**run_args_feature)
|
| 135 |
logger.info("Feature Engineering pipeline finished successfully!")
|
| 136 |
+
train_dataset_artifact = client.get_artifact_version(
|
| 137 |
+
train_dataset_name
|
| 138 |
+
)
|
| 139 |
+
test_dataset_artifact = client.get_artifact_version(test_dataset_name)
|
| 140 |
+
logger.info(
|
| 141 |
+
"The latest feature engineering pipeline produced the following "
|
| 142 |
+
f"artifacts: \n\n1. Train Dataset - Name: {train_dataset_name}, "
|
| 143 |
+
f"Version Name: {train_dataset_artifact.version} \n2. Test Dataset: "
|
| 144 |
+
f"Name: {test_dataset_name}, Version Name: {test_dataset_artifact.version}"
|
| 145 |
+
)
|
| 146 |
+
|
| 147 |
# Execute Training Pipeline
|
| 148 |
if training_pipeline:
|
| 149 |
pipeline_args = {}
|
|
|
|
| 160 |
train_dataset_version_name is not None
|
| 161 |
and test_dataset_version_name is not None
|
| 162 |
)
|
| 163 |
+
train_dataset_artifact = client.get_artifact_version(
|
|
|
|
| 164 |
train_dataset_name, train_dataset_version_name
|
| 165 |
)
|
| 166 |
# If train dataset is specified, test dataset must be specified
|
| 167 |
+
test_dataset_artifact = client.get_artifact_version(
|
| 168 |
test_dataset_name, test_dataset_version_name
|
| 169 |
)
|
| 170 |
# Use versioned artifacts
|
| 171 |
run_args_train["train_dataset_id"] = train_dataset_artifact.id
|
| 172 |
run_args_train["test_dataset_id"] = test_dataset_artifact.id
|
| 173 |
|
| 174 |
+
from zenml.config import DockerSettings
|
| 175 |
+
|
| 176 |
+
# The actual code will stay the same, all that needs to be done is some configuration
|
| 177 |
+
step_args = {}
|
| 178 |
+
|
| 179 |
+
# We configure which step operator should be used
|
| 180 |
+
# M5 Large is what we need for this big data!
|
| 181 |
+
step_args["settings"] = {"step_operator.sagemaker": {"estimator_args": {"instance_type" : "ml.m5.large"}}}
|
| 182 |
+
|
| 183 |
+
# Update the step. We could also do this in YAML
|
| 184 |
+
model_trainer = model_trainer.with_options(**step_args)
|
| 185 |
+
|
| 186 |
+
docker_settings = DockerSettings(
|
| 187 |
+
requirements=[
|
| 188 |
+
"pyarrow",
|
| 189 |
+
"scikit-learn==1.1.1"
|
| 190 |
+
],
|
| 191 |
+
)
|
| 192 |
+
|
| 193 |
+
pipeline_args = {
|
| 194 |
+
"enable_cache": True,
|
| 195 |
+
"settings": {"docker": docker_settings}
|
| 196 |
+
}
|
| 197 |
+
|
| 198 |
breast_cancer_training.with_options(**pipeline_args)(**run_args_train)
|
| 199 |
logger.info("Training pipeline finished successfully!")
|
| 200 |
|
run_deploy.ipynb
CHANGED
|
@@ -21,7 +21,63 @@
|
|
| 21 |
"id": "8c28b474",
|
| 22 |
"metadata": {},
|
| 23 |
"source": [
|
| 24 |
-
"# ⌚ Step
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 25 |
]
|
| 26 |
},
|
| 27 |
{
|
|
@@ -36,10 +92,67 @@
|
|
| 36 |
},
|
| 37 |
{
|
| 38 |
"cell_type": "code",
|
| 39 |
-
"execution_count":
|
| 40 |
"id": "fccf1bd9",
|
| 41 |
-
"metadata": {
|
| 42 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 43 |
"source": [
|
| 44 |
"!python run.py --training-pipeline"
|
| 45 |
]
|
|
@@ -66,10 +179,45 @@
|
|
| 66 |
},
|
| 67 |
{
|
| 68 |
"cell_type": "code",
|
| 69 |
-
"execution_count":
|
| 70 |
"id": "9918a8a1-c569-494f-aa40-cb7bd3aaea07",
|
| 71 |
"metadata": {},
|
| 72 |
-
"outputs": [
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 73 |
"source": [
|
| 74 |
"!python run.py --inference-pipeline"
|
| 75 |
]
|
|
|
|
| 21 |
"id": "8c28b474",
|
| 22 |
"metadata": {},
|
| 23 |
"source": [
|
| 24 |
+
"# ⌚ Step 1: (Feature engineering) + Training pipeline"
|
| 25 |
+
]
|
| 26 |
+
},
|
| 27 |
+
{
|
| 28 |
+
"cell_type": "markdown",
|
| 29 |
+
"id": "8e5a76e6-8655-47d5-ab61-015b2d69d720",
|
| 30 |
+
"metadata": {},
|
| 31 |
+
"source": [
|
| 32 |
+
"Lets run the feature engineering pipeline\n",
|
| 33 |
+
"\n",
|
| 34 |
+
"<img src=\"_assets/feature_engineering_pipeline.png\" width=\"50%\" alt=\"Training pipeline\">"
|
| 35 |
+
]
|
| 36 |
+
},
|
| 37 |
+
{
|
| 38 |
+
"cell_type": "code",
|
| 39 |
+
"execution_count": 4,
|
| 40 |
+
"id": "942a20f9-244b-4761-933e-55989a7377d6",
|
| 41 |
+
"metadata": {},
|
| 42 |
+
"outputs": [
|
| 43 |
+
{
|
| 44 |
+
"name": "stdout",
|
| 45 |
+
"output_type": "stream",
|
| 46 |
+
"text": [
|
| 47 |
+
"\u001b[1;35mInitiating a new run for the pipeline: \u001b[0m\u001b[1;36mfeature_engineering\u001b[1;35m.\u001b[0m\n",
|
| 48 |
+
"\u001b[1;35mReusing registered version: \u001b[0m\u001b[1;36m(version: 28)\u001b[1;35m.\u001b[0m\n",
|
| 49 |
+
"\u001b[1;35mNew model version \u001b[0m\u001b[1;36m7\u001b[1;35m was created.\u001b[0m\n",
|
| 50 |
+
"\u001b[1;35mExecuting a new run.\u001b[0m\n",
|
| 51 |
+
"\u001b[1;35mUsing user: \u001b[0m\u001b[1;[email protected]\u001b[1;35m\u001b[0m\n",
|
| 52 |
+
"\u001b[1;35mUsing stack: \u001b[0m\u001b[1;36mlocal-sagemaker-step-operator-stack\u001b[1;35m\u001b[0m\n",
|
| 53 |
+
"\u001b[1;35m model_registry: \u001b[0m\u001b[1;36mmlflow\u001b[1;35m\u001b[0m\n",
|
| 54 |
+
"\u001b[1;35m step_operator: \u001b[0m\u001b[1;36msagemaker-eu\u001b[1;35m\u001b[0m\n",
|
| 55 |
+
"\u001b[1;35m experiment_tracker: \u001b[0m\u001b[1;36mmlflow\u001b[1;35m\u001b[0m\n",
|
| 56 |
+
"\u001b[1;35m container_registry: \u001b[0m\u001b[1;36maws-eu\u001b[1;35m\u001b[0m\n",
|
| 57 |
+
"\u001b[1;35m orchestrator: \u001b[0m\u001b[1;36mdefault\u001b[1;35m\u001b[0m\n",
|
| 58 |
+
"\u001b[1;35m image_builder: \u001b[0m\u001b[1;36mlocal\u001b[1;35m\u001b[0m\n",
|
| 59 |
+
"\u001b[1;35m artifact_store: \u001b[0m\u001b[1;36ms3-zenfiles\u001b[1;35m\u001b[0m\n",
|
| 60 |
+
"\u001b[33mCould not import GCP service connector: No module named 'google.api_core'.\u001b[0m\n",
|
| 61 |
+
"\u001b[33mCould not import Azure service connector: No module named 'azure.identity'.\u001b[0m\n",
|
| 62 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mdata_loader\u001b[1;35m has started.\u001b[0m\n",
|
| 63 |
+
"\u001b[1;35mDataset with 541 records loaded!\u001b[0m\n",
|
| 64 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mdata_loader\u001b[1;35m has finished in \u001b[0m\u001b[1;36m7.510s\u001b[1;35m.\u001b[0m\n",
|
| 65 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mdata_splitter\u001b[1;35m has started.\u001b[0m\n",
|
| 66 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mdata_splitter\u001b[1;35m has finished in \u001b[0m\u001b[1;36m11.852s\u001b[1;35m.\u001b[0m\n",
|
| 67 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mdata_preprocessor\u001b[1;35m has started.\u001b[0m\n",
|
| 68 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mdata_preprocessor\u001b[1;35m has finished in \u001b[0m\u001b[1;36m16.644s\u001b[1;35m.\u001b[0m\n",
|
| 69 |
+
"\u001b[1;35mRun \u001b[0m\u001b[1;36mfeature_engineering-2024_01_04-14_23_46_664507\u001b[1;35m has finished in \u001b[0m\u001b[1;36m55.055s\u001b[1;35m.\u001b[0m\n",
|
| 70 |
+
"\u001b[1;35mDashboard URL: https://1cf18d95-zenml.cloudinfra.zenml.io/workspaces/default/pipelines/c8c78176-d287-4fa1-ab35-a90f35670aa4/runs/29cb4996-65a5-449a-a53a-f140e971d97c/dag\u001b[0m\n",
|
| 71 |
+
"\u001b[1;35mFeature Engineering pipeline finished successfully!\u001b[0m\n",
|
| 72 |
+
"\u001b[1;35mThe latest feature engineering pipeline produced the following artifacts: \n",
|
| 73 |
+
"\n",
|
| 74 |
+
"1. Train Dataset - Name: dataset_trn, Version Name: 191 \n",
|
| 75 |
+
"2. Test Dataset: Name: dataset_tst, Version Name: 189\u001b[0m\n"
|
| 76 |
+
]
|
| 77 |
+
}
|
| 78 |
+
],
|
| 79 |
+
"source": [
|
| 80 |
+
"!python run.py --feature-pipeline"
|
| 81 |
]
|
| 82 |
},
|
| 83 |
{
|
|
|
|
| 92 |
},
|
| 93 |
{
|
| 94 |
"cell_type": "code",
|
| 95 |
+
"execution_count": 7,
|
| 96 |
"id": "fccf1bd9",
|
| 97 |
+
"metadata": {
|
| 98 |
+
"scrolled": true
|
| 99 |
+
},
|
| 100 |
+
"outputs": [
|
| 101 |
+
{
|
| 102 |
+
"name": "stdout",
|
| 103 |
+
"output_type": "stream",
|
| 104 |
+
"text": [
|
| 105 |
+
"\u001b[1;35mInitiating a new run for the pipeline: \u001b[0m\u001b[1;36mbreast_cancer_training\u001b[1;35m.\u001b[0m\n",
|
| 106 |
+
"\u001b[1;35mReusing registered version: \u001b[0m\u001b[1;36m(version: 6)\u001b[1;35m.\u001b[0m\n",
|
| 107 |
+
"\u001b[1;35mNew model version \u001b[0m\u001b[1;36m8\u001b[1;35m was created.\u001b[0m\n",
|
| 108 |
+
"\u001b[1;35mExecuting a new run.\u001b[0m\n",
|
| 109 |
+
"\u001b[1;35mUsing user: \u001b[0m\u001b[1;[email protected]\u001b[1;35m\u001b[0m\n",
|
| 110 |
+
"\u001b[1;35mUsing stack: \u001b[0m\u001b[1;36mlocal-sagemaker-step-operator-stack\u001b[1;35m\u001b[0m\n",
|
| 111 |
+
"\u001b[1;35m model_registry: \u001b[0m\u001b[1;36mmlflow\u001b[1;35m\u001b[0m\n",
|
| 112 |
+
"\u001b[1;35m step_operator: \u001b[0m\u001b[1;36msagemaker-eu\u001b[1;35m\u001b[0m\n",
|
| 113 |
+
"\u001b[1;35m experiment_tracker: \u001b[0m\u001b[1;36mmlflow\u001b[1;35m\u001b[0m\n",
|
| 114 |
+
"\u001b[1;35m container_registry: \u001b[0m\u001b[1;36maws-eu\u001b[1;35m\u001b[0m\n",
|
| 115 |
+
"\u001b[1;35m orchestrator: \u001b[0m\u001b[1;36mdefault\u001b[1;35m\u001b[0m\n",
|
| 116 |
+
"\u001b[1;35m image_builder: \u001b[0m\u001b[1;36mlocal\u001b[1;35m\u001b[0m\n",
|
| 117 |
+
"\u001b[1;35m artifact_store: \u001b[0m\u001b[1;36ms3-zenfiles\u001b[1;35m\u001b[0m\n",
|
| 118 |
+
"\u001b[33mCould not import GCP service connector: No module named 'google.api_core'.\u001b[0m\n",
|
| 119 |
+
"\u001b[33mCould not import Azure service connector: No module named 'azure.identity'.\u001b[0m\n",
|
| 120 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mdata_loader\u001b[1;35m has started.\u001b[0m\n",
|
| 121 |
+
"\u001b[1;35mDataset with 541 records loaded!\u001b[0m\n",
|
| 122 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mdata_loader\u001b[1;35m has finished in \u001b[0m\u001b[1;36m7.566s\u001b[1;35m.\u001b[0m\n",
|
| 123 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mdata_splitter\u001b[1;35m has started.\u001b[0m\n",
|
| 124 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mdata_splitter\u001b[1;35m has finished in \u001b[0m\u001b[1;36m12.308s\u001b[1;35m.\u001b[0m\n",
|
| 125 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mdata_preprocessor\u001b[1;35m has started.\u001b[0m\n",
|
| 126 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mdata_preprocessor\u001b[1;35m has finished in \u001b[0m\u001b[1;36m18.092s\u001b[1;35m.\u001b[0m\n",
|
| 127 |
+
"\u001b[1;35mCaching \u001b[0m\u001b[1;36mdisabled\u001b[1;35m explicitly for \u001b[0m\u001b[1;36mmodel_trainer\u001b[1;35m.\u001b[0m\n",
|
| 128 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mmodel_trainer\u001b[1;35m has started.\u001b[0m\n",
|
| 129 |
+
"\u001b[1;35mTraining model DecisionTreeClassifier()...\u001b[0m\n",
|
| 130 |
+
"/home/htahir1/.virtualenvs/demo_stack_showcase/lib/python3.8/site-packages/_distutils_hack/__init__.py:33: UserWarning: Setuptools is replacing distutils.\n",
|
| 131 |
+
" warnings.warn(\"Setuptools is replacing distutils.\")\n",
|
| 132 |
+
"/home/htahir1/.virtualenvs/demo_stack_showcase/lib/python3.8/site-packages/zenml/integrations/mlflow/experiment_trackers/mlflow_experiment_tracker.py:245: FutureWarning: ``mlflow.gluon.autolog`` is deprecated since 2.5.0. This method will be removed in a future release.\n",
|
| 133 |
+
" module.autolog(disable=True)\n",
|
| 134 |
+
"\u001b[33mFailed to disable MLflow autologging for the following frameworks: ['tensorflow'].\u001b[0m\n",
|
| 135 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mmodel_trainer\u001b[1;35m has finished in \u001b[0m\u001b[1;36m15.244s\u001b[1;35m.\u001b[0m\n",
|
| 136 |
+
"\u001b[1;35mCaching \u001b[0m\u001b[1;36mdisabled\u001b[1;35m explicitly for \u001b[0m\u001b[1;36mmodel_evaluator\u001b[1;35m.\u001b[0m\n",
|
| 137 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mmodel_evaluator\u001b[1;35m has started.\u001b[0m\n",
|
| 138 |
+
"\u001b[33mYour artifact was materialized under Python version 'unknown' but you are currently using '3.8.10'. This might cause unexpected behavior since pickle is not reproducible across Python versions. Attempting to load anyway...\u001b[0m\n",
|
| 139 |
+
"\u001b[1;35mTrain accuracy=100.00%\u001b[0m\n",
|
| 140 |
+
"\u001b[1;35mTest accuracy=92.66%\u001b[0m\n",
|
| 141 |
+
"/home/htahir1/.virtualenvs/demo_stack_showcase/lib/python3.8/site-packages/zenml/integrations/mlflow/experiment_trackers/mlflow_experiment_tracker.py:245: FutureWarning: ``mlflow.gluon.autolog`` is deprecated since 2.5.0. This method will be removed in a future release.\n",
|
| 142 |
+
" module.autolog(disable=True)\n",
|
| 143 |
+
"\u001b[33mFailed to disable MLflow autologging for the following frameworks: ['tensorflow'].\u001b[0m\n",
|
| 144 |
+
"\u001b[1;35mImplicitly linking artifact \u001b[0m\u001b[1;36moutput\u001b[1;35m to model \u001b[0m\u001b[1;36mbreast_cancer_classifier\u001b[1;35m version \u001b[0m\u001b[1;36m8\u001b[1;35m.\u001b[0m\n",
|
| 145 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mmodel_evaluator\u001b[1;35m has finished in \u001b[0m\u001b[1;36m15.865s\u001b[1;35m.\u001b[0m\n",
|
| 146 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mmodel_promoter\u001b[1;35m has started.\u001b[0m\n",
|
| 147 |
+
"\u001b[1;35mModel promoted to production!\u001b[0m\n",
|
| 148 |
+
"\u001b[1;35mImplicitly linking artifact \u001b[0m\u001b[1;36moutput\u001b[1;35m to model \u001b[0m\u001b[1;36mbreast_cancer_classifier\u001b[1;35m version \u001b[0m\u001b[1;36m8\u001b[1;35m.\u001b[0m\n",
|
| 149 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mmodel_promoter\u001b[1;35m has finished in \u001b[0m\u001b[1;36m8.292s\u001b[1;35m.\u001b[0m\n",
|
| 150 |
+
"\u001b[1;35mRun \u001b[0m\u001b[1;36mbreast_cancer_training-2024_01_04-14_30_21_437288\u001b[1;35m has finished in \u001b[0m\u001b[1;36m1m51s\u001b[1;35m.\u001b[0m\n",
|
| 151 |
+
"\u001b[1;35mDashboard URL: https://1cf18d95-zenml.cloudinfra.zenml.io/workspaces/default/pipelines/bb529fac-e51f-44c0-a2c5-c1a8930f6d44/runs/23510d3a-dbb8-4ebd-904a-6a4ddf8105c5/dag\u001b[0m\n",
|
| 152 |
+
"\u001b[1;35mTraining pipeline finished successfully!\u001b[0m\n"
|
| 153 |
+
]
|
| 154 |
+
}
|
| 155 |
+
],
|
| 156 |
"source": [
|
| 157 |
"!python run.py --training-pipeline"
|
| 158 |
]
|
|
|
|
| 179 |
},
|
| 180 |
{
|
| 181 |
"cell_type": "code",
|
| 182 |
+
"execution_count": 8,
|
| 183 |
"id": "9918a8a1-c569-494f-aa40-cb7bd3aaea07",
|
| 184 |
"metadata": {},
|
| 185 |
+
"outputs": [
|
| 186 |
+
{
|
| 187 |
+
"name": "stdout",
|
| 188 |
+
"output_type": "stream",
|
| 189 |
+
"text": [
|
| 190 |
+
"\u001b[1;35m\u001b[0m\u001b[1;36mversion\u001b[1;35m \u001b[0m\u001b[1;36mproduction\u001b[1;35m matches one of the possible \u001b[0m\u001b[1;36mModelStages\u001b[1;35m and will be fetched using stage.\u001b[0m\n",
|
| 191 |
+
"\u001b[33mUsing an external artifact as step input currently invalidates caching for the step and all downstream steps. Future releases will introduce hashing of artifacts which will improve this behavior.\u001b[0m\n",
|
| 192 |
+
"\u001b[1;35mInitiating a new run for the pipeline: \u001b[0m\u001b[1;36minference\u001b[1;35m.\u001b[0m\n",
|
| 193 |
+
"\u001b[1;35mReusing registered version: \u001b[0m\u001b[1;36m(version: 9)\u001b[1;35m.\u001b[0m\n",
|
| 194 |
+
"\u001b[1;35mExecuting a new run.\u001b[0m\n",
|
| 195 |
+
"\u001b[1;35mUsing user: \u001b[0m\u001b[1;[email protected]\u001b[1;35m\u001b[0m\n",
|
| 196 |
+
"\u001b[1;35mUsing stack: \u001b[0m\u001b[1;36mlocal-sagemaker-step-operator-stack\u001b[1;35m\u001b[0m\n",
|
| 197 |
+
"\u001b[1;35m model_registry: \u001b[0m\u001b[1;36mmlflow\u001b[1;35m\u001b[0m\n",
|
| 198 |
+
"\u001b[1;35m step_operator: \u001b[0m\u001b[1;36msagemaker-eu\u001b[1;35m\u001b[0m\n",
|
| 199 |
+
"\u001b[1;35m experiment_tracker: \u001b[0m\u001b[1;36mmlflow\u001b[1;35m\u001b[0m\n",
|
| 200 |
+
"\u001b[1;35m container_registry: \u001b[0m\u001b[1;36maws-eu\u001b[1;35m\u001b[0m\n",
|
| 201 |
+
"\u001b[1;35m orchestrator: \u001b[0m\u001b[1;36mdefault\u001b[1;35m\u001b[0m\n",
|
| 202 |
+
"\u001b[1;35m image_builder: \u001b[0m\u001b[1;36mlocal\u001b[1;35m\u001b[0m\n",
|
| 203 |
+
"\u001b[1;35m artifact_store: \u001b[0m\u001b[1;36ms3-zenfiles\u001b[1;35m\u001b[0m\n",
|
| 204 |
+
"\u001b[33mCould not import GCP service connector: No module named 'google.api_core'.\u001b[0m\n",
|
| 205 |
+
"\u001b[33mCould not import Azure service connector: No module named 'azure.identity'.\u001b[0m\n",
|
| 206 |
+
"\u001b[1;35mUsing cached version of \u001b[0m\u001b[1;36mdata_loader\u001b[1;35m.\u001b[0m\n",
|
| 207 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36mdata_loader\u001b[1;35m has started.\u001b[0m\n",
|
| 208 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36minference_preprocessor\u001b[1;35m has started.\u001b[0m\n",
|
| 209 |
+
"\u001b[33mYour artifact was materialized under Python version 'unknown' but you are currently using '3.8.10'. This might cause unexpected behavior since pickle is not reproducible across Python versions. Attempting to load anyway...\u001b[0m\n",
|
| 210 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36minference_preprocessor\u001b[1;35m has finished in \u001b[0m\u001b[1;36m8.990s\u001b[1;35m.\u001b[0m\n",
|
| 211 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36minference_predict\u001b[1;35m has started.\u001b[0m\n",
|
| 212 |
+
"\u001b[33mYou specified both an ID as well as a version of the artifact_versions. Ignoring the version and fetching the artifact_versions by ID.\u001b[0m\n",
|
| 213 |
+
"\u001b[33mYour artifact was materialized under Python version 'unknown' but you are currently using '3.8.10'. This might cause unexpected behavior since pickle is not reproducible across Python versions. Attempting to load anyway...\u001b[0m\n",
|
| 214 |
+
"\u001b[1;35mStep \u001b[0m\u001b[1;36minference_predict\u001b[1;35m has finished in \u001b[0m\u001b[1;36m16.236s\u001b[1;35m.\u001b[0m\n",
|
| 215 |
+
"\u001b[1;35mRun \u001b[0m\u001b[1;36minference-2024_01_04-14_44_48_944106\u001b[1;35m has finished in \u001b[0m\u001b[1;36m42.637s\u001b[1;35m.\u001b[0m\n",
|
| 216 |
+
"\u001b[1;35mDashboard URL: https://1cf18d95-zenml.cloudinfra.zenml.io/workspaces/default/pipelines/4ac825a0-d89c-4109-91ef-f077327cfe4f/runs/3fab91f4-7c52-497b-9aa4-a491d1f0a60b/dag\u001b[0m\n",
|
| 217 |
+
"\u001b[1;35mInference pipeline finished successfully!\u001b[0m\n"
|
| 218 |
+
]
|
| 219 |
+
}
|
| 220 |
+
],
|
| 221 |
"source": [
|
| 222 |
"!python run.py --inference-pipeline"
|
| 223 |
]
|
steps/__pycache__/data_splitter.cpython-38.pyc
CHANGED
|
Binary files a/steps/__pycache__/data_splitter.cpython-38.pyc and b/steps/__pycache__/data_splitter.cpython-38.pyc differ
|
|
|
steps/__pycache__/model_trainer.cpython-38.pyc
CHANGED
|
Binary files a/steps/__pycache__/model_trainer.cpython-38.pyc and b/steps/__pycache__/model_trainer.cpython-38.pyc differ
|
|
|
steps/model_trainer.py
CHANGED
|
@@ -13,7 +13,7 @@ logger = get_logger(__name__)
|
|
| 13 |
|
| 14 |
experiment_tracker = Client().active_stack.experiment_tracker
|
| 15 |
|
| 16 |
-
@step(enable_cache=False, experiment_tracker="mlflow")
|
| 17 |
def model_trainer(
|
| 18 |
dataset_trn: pd.DataFrame,
|
| 19 |
) -> Annotated[ClassifierMixin, ArtifactConfig(name="model", is_model_artifact=True)]:
|
|
|
|
| 13 |
|
| 14 |
experiment_tracker = Client().active_stack.experiment_tracker
|
| 15 |
|
| 16 |
+
@step(enable_cache=False, experiment_tracker="mlflow", step_operator="sagemaker-eu")
|
| 17 |
def model_trainer(
|
| 18 |
dataset_trn: pd.DataFrame,
|
| 19 |
) -> Annotated[ClassifierMixin, ArtifactConfig(name="model", is_model_artifact=True)]:
|