Spaces:
Build error

Build error

Merge branch 'main' of https://huggingface.co/spaces/huggingface/data-measurements-tool-2 into main
Browse files- app.py +52 -19
- cache_dir/c4_en.noblocklist_train_text/fig_tok_length.png +3 -0
- cache_dir/c4_en_train_text/fig_tok_length.png +3 -0
- cache_dir/c4_realnewslike_train_text/fig_tok_length.png +3 -0
- cache_dir/c4_realnewslike_train_text/text_dset/dataset.arrow +3 -0
- cache_dir/c4_realnewslike_train_text/text_dset/dataset_info.json +3 -0
- cache_dir/c4_realnewslike_train_text/text_dset/state.json +3 -0
- cache_dir/squad_plain_text_train_context/fig_tok_length.png +2 -2
- cache_dir/squad_plain_text_train_question/fig_tok_length.png +2 -2
- cache_dir/squad_plain_text_train_title/fig_tok_length.png +2 -2
- cache_dir/squad_plain_text_validation_context/fig_tok_length.png +3 -0
- cache_dir/squad_plain_text_validation_question/fig_tok_length.png +3 -0
- cache_dir/squad_plain_text_validation_title/fig_tok_length.png +3 -0
- cache_dir/squad_v2_squad_v2_train_context/fig_tok_length.png +3 -0
- cache_dir/squad_v2_squad_v2_train_question/fig_tok_length.png +3 -0
- cache_dir/squad_v2_squad_v2_train_title/fig_tok_length.png +3 -0
- cache_dir/squad_v2_squad_v2_validation_context/fig_tok_length.png +3 -0
- cache_dir/squad_v2_squad_v2_validation_question/fig_tok_length.png +3 -0
- cache_dir/squad_v2_squad_v2_validation_title/fig_tok_length.png +3 -0
- cache_dir/super_glue_boolq_test_passage/fig_tok_length.png +3 -0
- cache_dir/super_glue_boolq_test_question/fig_tok_length.png +3 -0
- cache_dir/super_glue_cb_test_hypothesis/fig_tok_length.png +3 -0
- cache_dir/super_glue_cb_test_premise/fig_tok_length.png +3 -0
- cache_dir/super_glue_copa_test_choice1/fig_tok_length.png +3 -0
- cache_dir/super_glue_copa_test_choice2/fig_tok_length.png +3 -0
- cache_dir/super_glue_copa_test_premise/fig_tok_length.png +3 -0
- cache_dir/super_glue_copa_test_question/fig_tok_length.png +3 -0
- cache_dir/wikitext_wikitext-103-raw-v1_test_text/fig_tok_length.png +3 -0
- cache_dir/wikitext_wikitext-103-v1_test_text/fig_tok_length.png +3 -0
- cache_dir/wikitext_wikitext-2-raw-v1_test_text/fig_tok_length.png +3 -0
- cache_dir/wikitext_wikitext-2-v1_test_text/fig_tok_length.png +3 -0
- data_measurements/dataset_statistics.py +9 -8
- data_measurements/streamlit_utils.py +79 -67
- requirements.txt +2 -2
app.py
CHANGED
|
@@ -117,7 +117,10 @@ def load_or_prepare(ds_args, show_embeddings, use_cache=False):
|
|
| 117 |
logs.warning("Loading Embeddings")
|
| 118 |
dstats.load_or_prepare_embeddings()
|
| 119 |
logs.warning("Loading nPMI")
|
| 120 |
-
|
|
|
|
|
|
|
|
|
|
| 121 |
logs.warning("Loading Zipf")
|
| 122 |
dstats.load_or_prepare_zipf()
|
| 123 |
return dstats
|
|
@@ -147,25 +150,55 @@ def load_or_prepare_widgets(ds_args, show_embeddings, use_cache=False):
|
|
| 147 |
mkdir(CACHE_DIR)
|
| 148 |
if use_cache:
|
| 149 |
logs.warning("Using cache")
|
| 150 |
-
|
| 151 |
-
|
| 152 |
-
|
| 153 |
-
|
| 154 |
-
|
| 155 |
-
|
| 156 |
-
|
| 157 |
-
|
| 158 |
-
|
| 159 |
-
|
| 160 |
-
|
| 161 |
-
|
| 162 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 163 |
if show_embeddings:
|
| 164 |
-
|
| 165 |
-
|
| 166 |
-
|
| 167 |
-
|
| 168 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 169 |
return dstats
|
| 170 |
|
| 171 |
def show_column(dstats, ds_name_to_dict, show_embeddings, column_id):
|
|
|
|
| 117 |
logs.warning("Loading Embeddings")
|
| 118 |
dstats.load_or_prepare_embeddings()
|
| 119 |
logs.warning("Loading nPMI")
|
| 120 |
+
try:
|
| 121 |
+
dstats.load_or_prepare_npmi()
|
| 122 |
+
except:
|
| 123 |
+
logs.warning("Missing a cache for npmi")
|
| 124 |
logs.warning("Loading Zipf")
|
| 125 |
dstats.load_or_prepare_zipf()
|
| 126 |
return dstats
|
|
|
|
| 150 |
mkdir(CACHE_DIR)
|
| 151 |
if use_cache:
|
| 152 |
logs.warning("Using cache")
|
| 153 |
+
try:
|
| 154 |
+
dstats = dataset_statistics.DatasetStatisticsCacheClass(CACHE_DIR, **ds_args, use_cache=use_cache)
|
| 155 |
+
# Don't recalculate; we're live
|
| 156 |
+
dstats.set_deployment(True)
|
| 157 |
+
except:
|
| 158 |
+
logs.warning("We're screwed")
|
| 159 |
+
try:
|
| 160 |
+
# We need to have the text_dset loaded for further load_or_prepare
|
| 161 |
+
dstats.load_or_prepare_dataset()
|
| 162 |
+
except:
|
| 163 |
+
logs.warning("Missing a cache for load or prepare dataset")
|
| 164 |
+
try:
|
| 165 |
+
# Header widget
|
| 166 |
+
dstats.load_or_prepare_dset_peek()
|
| 167 |
+
except:
|
| 168 |
+
logs.warning("Missing a cache for dset peek")
|
| 169 |
+
try:
|
| 170 |
+
# General stats widget
|
| 171 |
+
dstats.load_or_prepare_general_stats()
|
| 172 |
+
except:
|
| 173 |
+
logs.warning("Missing a cache for general stats")
|
| 174 |
+
try:
|
| 175 |
+
# Labels widget
|
| 176 |
+
dstats.load_or_prepare_labels()
|
| 177 |
+
except:
|
| 178 |
+
logs.warning("Missing a cache for prepare labels")
|
| 179 |
+
try:
|
| 180 |
+
# Text lengths widget
|
| 181 |
+
dstats.load_or_prepare_text_lengths()
|
| 182 |
+
except:
|
| 183 |
+
logs.warning("Missing a cache for text lengths")
|
| 184 |
if show_embeddings:
|
| 185 |
+
try:
|
| 186 |
+
# Embeddings widget
|
| 187 |
+
dstats.load_or_prepare_embeddings()
|
| 188 |
+
except:
|
| 189 |
+
logs.warning("Missing a cache for embeddings")
|
| 190 |
+
try:
|
| 191 |
+
dstats.load_or_prepare_text_duplicates()
|
| 192 |
+
except:
|
| 193 |
+
logs.warning("Missing a cache for text duplicates")
|
| 194 |
+
try:
|
| 195 |
+
dstats.load_or_prepare_npmi()
|
| 196 |
+
except:
|
| 197 |
+
logs.warning("Missing a cache for npmi")
|
| 198 |
+
try:
|
| 199 |
+
dstats.load_or_prepare_zipf()
|
| 200 |
+
except:
|
| 201 |
+
logs.warning("Missing a cache for zipf")
|
| 202 |
return dstats
|
| 203 |
|
| 204 |
def show_column(dstats, ds_name_to_dict, show_embeddings, column_id):
|
cache_dir/c4_en.noblocklist_train_text/fig_tok_length.png
ADDED

|
Git LFS Details
|
cache_dir/c4_en_train_text/fig_tok_length.png
ADDED

|
Git LFS Details
|
cache_dir/c4_realnewslike_train_text/fig_tok_length.png
ADDED

|
Git LFS Details
|
cache_dir/c4_realnewslike_train_text/text_dset/dataset.arrow
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9813f70c9be641905ca737aa8f16e29d6aa17155a76cd830e7a627aed91431f4
|
| 3 |
+
size 529606944
|
cache_dir/c4_realnewslike_train_text/text_dset/dataset_info.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ff9f59542efc98b40f23b64408e3fbaed544ad8f0d1fb1e7126ead5af52844ac
|
| 3 |
+
size 945
|
cache_dir/c4_realnewslike_train_text/text_dset/state.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c2f6884f5ee381e5df2d267dae699aaf4792ba06c8f16830c9c19c144b4b3003
|
| 3 |
+
size 256
|
cache_dir/squad_plain_text_train_context/fig_tok_length.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|
cache_dir/squad_plain_text_train_question/fig_tok_length.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|
cache_dir/squad_plain_text_train_title/fig_tok_length.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|
cache_dir/squad_plain_text_validation_context/fig_tok_length.png
ADDED

|
Git LFS Details
|
cache_dir/squad_plain_text_validation_question/fig_tok_length.png
ADDED

|
Git LFS Details
|
cache_dir/squad_plain_text_validation_title/fig_tok_length.png
ADDED

|
Git LFS Details
|
cache_dir/squad_v2_squad_v2_train_context/fig_tok_length.png
ADDED

|
Git LFS Details
|
cache_dir/squad_v2_squad_v2_train_question/fig_tok_length.png
ADDED

|
Git LFS Details
|
cache_dir/squad_v2_squad_v2_train_title/fig_tok_length.png
ADDED

|
Git LFS Details
|
cache_dir/squad_v2_squad_v2_validation_context/fig_tok_length.png
ADDED

|
Git LFS Details
|
cache_dir/squad_v2_squad_v2_validation_question/fig_tok_length.png
ADDED

|
Git LFS Details
|
cache_dir/squad_v2_squad_v2_validation_title/fig_tok_length.png
ADDED

|
Git LFS Details
|
cache_dir/super_glue_boolq_test_passage/fig_tok_length.png
ADDED

|
Git LFS Details
|
cache_dir/super_glue_boolq_test_question/fig_tok_length.png
ADDED

|
Git LFS Details
|
cache_dir/super_glue_cb_test_hypothesis/fig_tok_length.png
ADDED

|
Git LFS Details
|
cache_dir/super_glue_cb_test_premise/fig_tok_length.png
ADDED

|
Git LFS Details
|
cache_dir/super_glue_copa_test_choice1/fig_tok_length.png
ADDED

|
Git LFS Details
|
cache_dir/super_glue_copa_test_choice2/fig_tok_length.png
ADDED

|
Git LFS Details
|
cache_dir/super_glue_copa_test_premise/fig_tok_length.png
ADDED

|
Git LFS Details
|
cache_dir/super_glue_copa_test_question/fig_tok_length.png
ADDED

|
Git LFS Details
|
cache_dir/wikitext_wikitext-103-raw-v1_test_text/fig_tok_length.png
ADDED
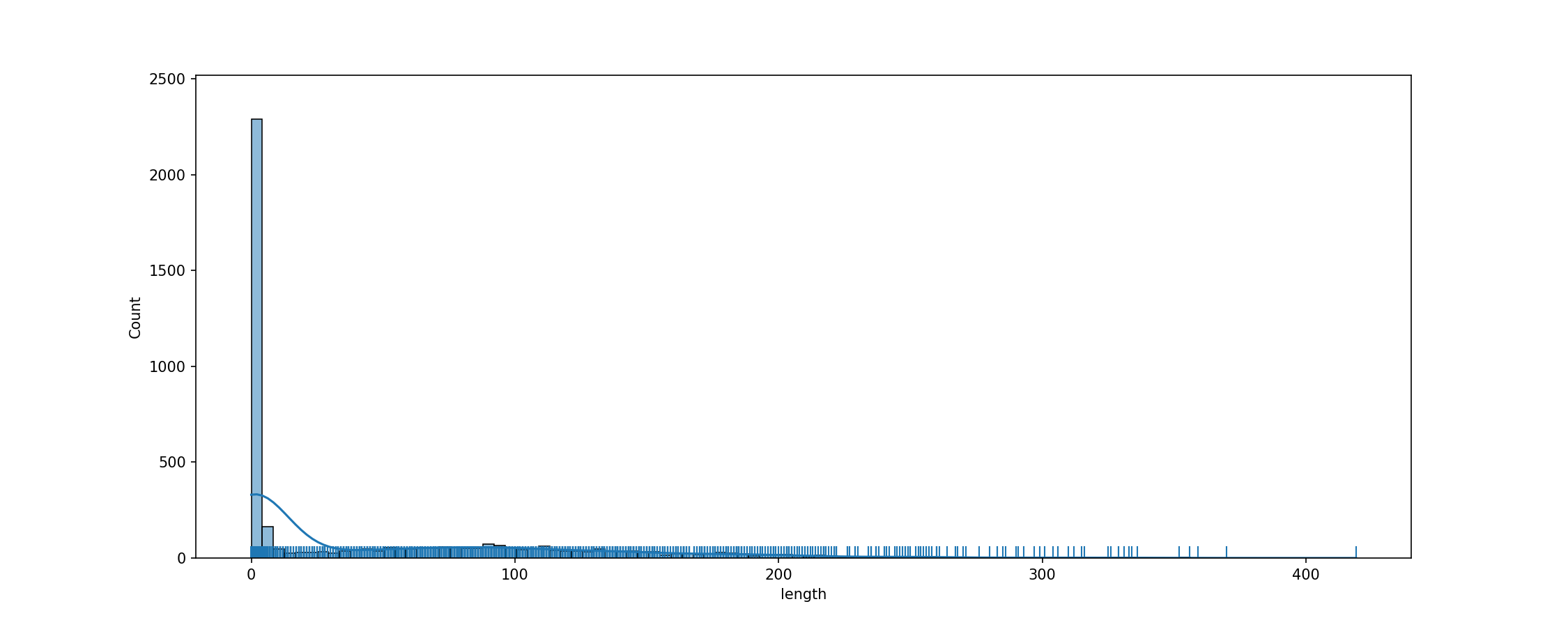
|
Git LFS Details
|
cache_dir/wikitext_wikitext-103-v1_test_text/fig_tok_length.png
ADDED
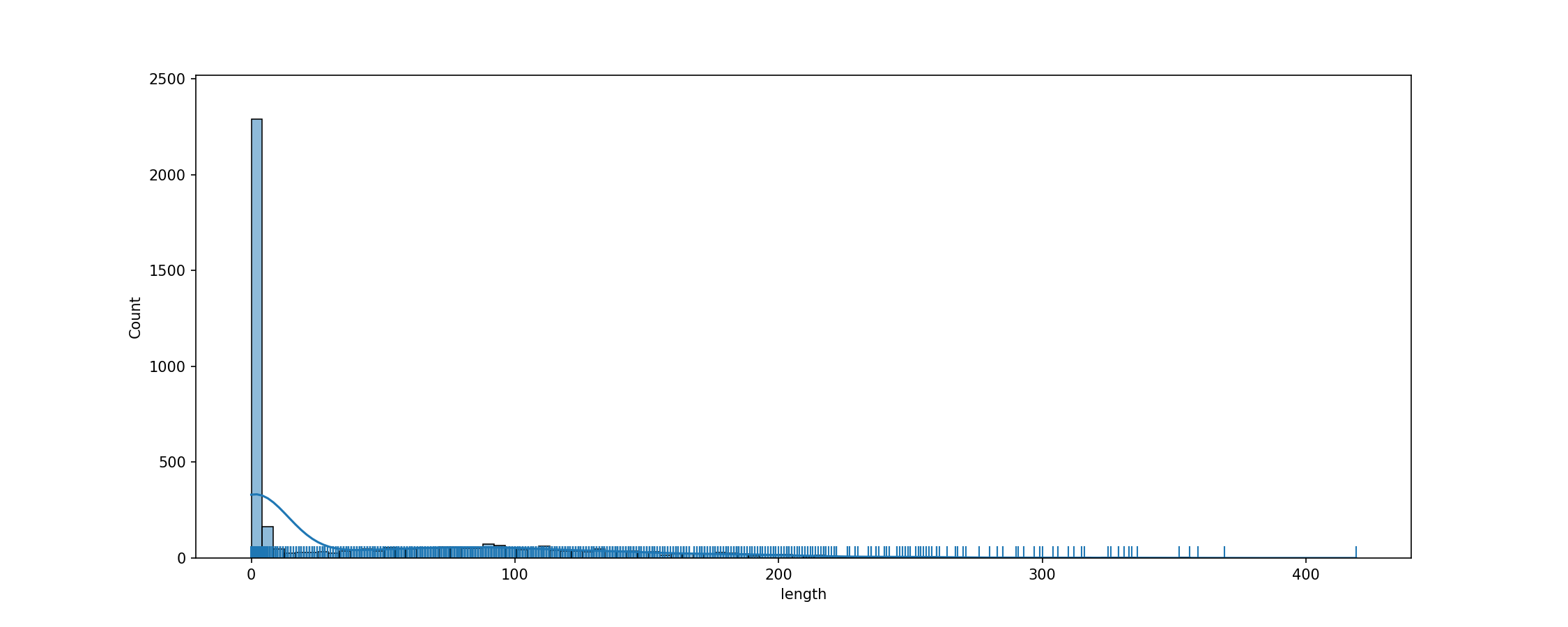
|
Git LFS Details
|
cache_dir/wikitext_wikitext-2-raw-v1_test_text/fig_tok_length.png
ADDED
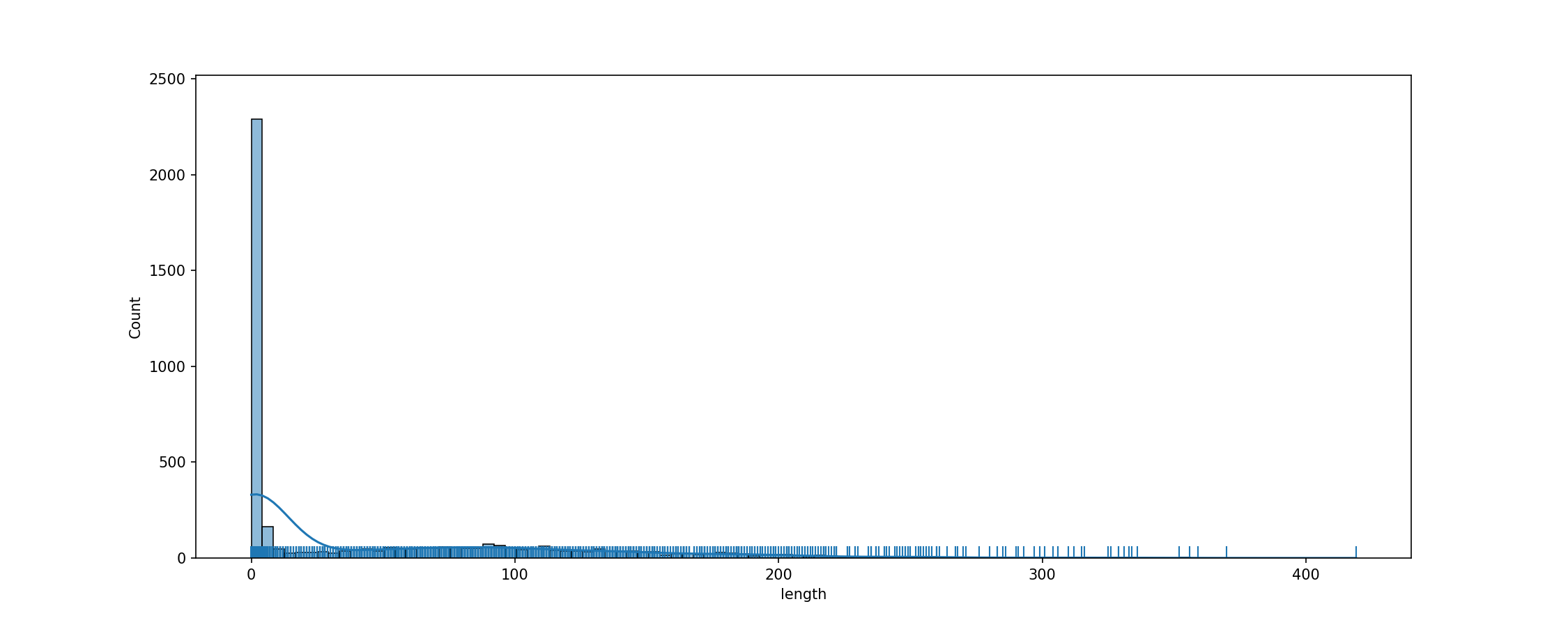
|
Git LFS Details
|
cache_dir/wikitext_wikitext-2-v1_test_text/fig_tok_length.png
ADDED

|
Git LFS Details
|
data_measurements/dataset_statistics.py
CHANGED
|
@@ -498,7 +498,7 @@ class DatasetStatisticsCacheClass:
|
|
| 498 |
if not self.live:
|
| 499 |
if self.tokenized_df is None:
|
| 500 |
logs.warning("Tokenized dataset not yet loaded; doing so.")
|
| 501 |
-
self.
|
| 502 |
if self.vocab_counts_df is None:
|
| 503 |
logs.warning("Vocab not yet loaded; doing so.")
|
| 504 |
self.load_or_prepare_vocab()
|
|
@@ -544,8 +544,8 @@ class DatasetStatisticsCacheClass:
|
|
| 544 |
"""
|
| 545 |
logs.info("Doing text dset.")
|
| 546 |
self.load_or_prepare_text_dset(save)
|
| 547 |
-
logs.info("Doing tokenized dataframe")
|
| 548 |
-
self.load_or_prepare_tokenized_df(save)
|
| 549 |
logs.info("Doing dataset peek")
|
| 550 |
self.load_or_prepare_dset_peek(save)
|
| 551 |
|
|
@@ -554,11 +554,12 @@ class DatasetStatisticsCacheClass:
|
|
| 554 |
with open(self.dset_peek_json_fid, "r") as f:
|
| 555 |
self.dset_peek = json.load(f)["dset peek"]
|
| 556 |
else:
|
| 557 |
-
if self.
|
| 558 |
-
self.
|
| 559 |
-
|
| 560 |
-
|
| 561 |
-
|
|
|
|
| 562 |
|
| 563 |
def load_or_prepare_tokenized_df(self, save=True):
|
| 564 |
if self.use_cache and exists(self.tokenized_df_fid):
|
|
|
|
| 498 |
if not self.live:
|
| 499 |
if self.tokenized_df is None:
|
| 500 |
logs.warning("Tokenized dataset not yet loaded; doing so.")
|
| 501 |
+
self.load_or_prepare_tokenized_df()
|
| 502 |
if self.vocab_counts_df is None:
|
| 503 |
logs.warning("Vocab not yet loaded; doing so.")
|
| 504 |
self.load_or_prepare_vocab()
|
|
|
|
| 544 |
"""
|
| 545 |
logs.info("Doing text dset.")
|
| 546 |
self.load_or_prepare_text_dset(save)
|
| 547 |
+
#logs.info("Doing tokenized dataframe")
|
| 548 |
+
#self.load_or_prepare_tokenized_df(save)
|
| 549 |
logs.info("Doing dataset peek")
|
| 550 |
self.load_or_prepare_dset_peek(save)
|
| 551 |
|
|
|
|
| 554 |
with open(self.dset_peek_json_fid, "r") as f:
|
| 555 |
self.dset_peek = json.load(f)["dset peek"]
|
| 556 |
else:
|
| 557 |
+
if not self.live:
|
| 558 |
+
if self.dset is None:
|
| 559 |
+
self.get_base_dataset()
|
| 560 |
+
self.dset_peek = self.dset[:100]
|
| 561 |
+
if save:
|
| 562 |
+
write_json({"dset peek": self.dset_peek}, self.dset_peek_json_fid)
|
| 563 |
|
| 564 |
def load_or_prepare_tokenized_df(self, save=True):
|
| 565 |
if self.use_cache and exists(self.tokenized_df_fid):
|
data_measurements/streamlit_utils.py
CHANGED
|
@@ -20,7 +20,7 @@ import streamlit as st
|
|
| 20 |
from st_aggrid import AgGrid, GridOptionsBuilder
|
| 21 |
|
| 22 |
from .dataset_utils import HF_DESC_FIELD, HF_FEATURE_FIELD, HF_LABEL_FIELD
|
| 23 |
-
|
| 24 |
|
| 25 |
def sidebar_header():
|
| 26 |
st.sidebar.markdown(
|
|
@@ -48,7 +48,10 @@ def sidebar_selection(ds_name_to_dict, column_id):
|
|
| 48 |
)
|
| 49 |
# choose a config to analyze
|
| 50 |
ds_configs = ds_name_to_dict[ds_name]
|
| 51 |
-
|
|
|
|
|
|
|
|
|
|
| 52 |
config_name = st.selectbox(
|
| 53 |
f"Choose configuration{column_id}:",
|
| 54 |
config_names,
|
|
@@ -319,72 +322,75 @@ def expander_npmi_description(min_vocab):
|
|
| 319 |
|
| 320 |
### Finally, show Zipf stuff
|
| 321 |
def expander_zipf(z, zipf_fig, column_id):
|
| 322 |
-
_ZIPF_CAPTION = """This shows how close the observed language is to an ideal
|
| 323 |
-
natural language distribution following [Zipf's law](https://en.wikipedia.org/wiki/Zipf%27s_law),
|
| 324 |
-
calculated by minimizing the [Kolmogorov-Smirnov (KS) statistic](https://en.wikipedia.org/wiki/Kolmogorov%E2%80%93Smirnov_test)."""
|
| 325 |
-
|
| 326 |
-
powerlaw_eq = r"""p(x) \propto x^{- \alpha}"""
|
| 327 |
-
zipf_summary = (
|
| 328 |
-
"The optimal alpha based on this dataset is: **"
|
| 329 |
-
+ str(round(z.alpha, 2))
|
| 330 |
-
+ "**, with a KS distance of: **"
|
| 331 |
-
+ str(round(z.distance, 2))
|
| 332 |
-
)
|
| 333 |
-
zipf_summary += (
|
| 334 |
-
"**. This was fit with a minimum rank value of: **"
|
| 335 |
-
+ str(int(z.xmin))
|
| 336 |
-
+ "**, which is the optimal rank *beyond which* the scaling regime of the power law fits best."
|
| 337 |
-
)
|
| 338 |
-
|
| 339 |
-
alpha_warning = "Your alpha value is a bit on the high side, which means that the distribution over words in this dataset is a bit unnatural. This could be due to non-language items throughout the dataset."
|
| 340 |
-
xmin_warning = "The minimum rank for this fit is a bit on the high side, which means that the frequencies of your most common words aren't distributed as would be expected by Zipf's law."
|
| 341 |
-
fit_results_table = pd.DataFrame.from_dict(
|
| 342 |
-
{
|
| 343 |
-
r"Alpha:": [str("%.2f" % z.alpha)],
|
| 344 |
-
"KS distance:": [str("%.2f" % z.distance)],
|
| 345 |
-
"Min rank:": [str("%s" % int(z.xmin))],
|
| 346 |
-
},
|
| 347 |
-
columns=["Results"],
|
| 348 |
-
orient="index",
|
| 349 |
-
)
|
| 350 |
-
fit_results_table.index.name = column_id
|
| 351 |
with st.expander(
|
| 352 |
f"Vocabulary Distribution{column_id}: Zipf's Law Fit", expanded=False
|
| 353 |
):
|
| 354 |
-
|
| 355 |
-
|
| 356 |
-
|
| 357 |
-
|
| 358 |
-
|
| 359 |
-
"""
|
| 360 |
-
|
| 361 |
-
|
| 362 |
-
|
| 363 |
-
|
| 364 |
-
|
| 365 |
-
|
| 366 |
-
|
| 367 |
-
|
| 368 |
-
|
| 369 |
-
|
| 370 |
-
|
| 371 |
-
|
| 372 |
-
|
| 373 |
-
|
| 374 |
-
|
| 375 |
-
|
| 376 |
-
|
| 377 |
-
|
| 378 |
-
|
| 379 |
-
|
| 380 |
-
|
| 381 |
-
|
| 382 |
-
|
| 383 |
-
|
| 384 |
-
|
| 385 |
-
|
| 386 |
-
|
| 387 |
-
st.markdown(
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 388 |
|
| 389 |
|
| 390 |
### Finally finally finally, show nPMI stuff.
|
|
@@ -427,17 +433,23 @@ def npmi_widget(npmi_stats, min_vocab, column_id):
|
|
| 427 |
|
| 428 |
def npmi_show(paired_results):
|
| 429 |
if paired_results.empty:
|
| 430 |
-
st.markdown("No words that co-occur enough times for results! Or there's a 🐛.")
|
| 431 |
else:
|
| 432 |
s = pd.DataFrame(paired_results.sort_values(by="npmi-bias", ascending=True))
|
| 433 |
# s.columns=pd.MultiIndex.from_arrays([['npmi','npmi','npmi','count', 'count'],['bias','man','straight','man','straight']])
|
| 434 |
s.index.name = "word"
|
| 435 |
npmi_cols = s.filter(like="npmi").columns
|
| 436 |
count_cols = s.filter(like="count").columns
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 437 |
# TODO: This is very different look than the duplicates table above. Should probably standardize.
|
| 438 |
cm = sns.palplot(sns.diverging_palette(270, 36, s=99, l=48, n=16))
|
| 439 |
out_df = (
|
| 440 |
-
|
| 441 |
.format(subset=npmi_cols, formatter="{:,.3f}")
|
| 442 |
.format(subset=count_cols, formatter=int)
|
| 443 |
.set_properties(
|
|
|
|
| 20 |
from st_aggrid import AgGrid, GridOptionsBuilder
|
| 21 |
|
| 22 |
from .dataset_utils import HF_DESC_FIELD, HF_FEATURE_FIELD, HF_LABEL_FIELD
|
| 23 |
+
st.set_option('deprecation.showPyplotGlobalUse', False)
|
| 24 |
|
| 25 |
def sidebar_header():
|
| 26 |
st.sidebar.markdown(
|
|
|
|
| 48 |
)
|
| 49 |
# choose a config to analyze
|
| 50 |
ds_configs = ds_name_to_dict[ds_name]
|
| 51 |
+
if ds_name == "c4":
|
| 52 |
+
config_names = ['en','en.noblocklist','realnewslike']
|
| 53 |
+
else:
|
| 54 |
+
config_names = list(ds_configs.keys())
|
| 55 |
config_name = st.selectbox(
|
| 56 |
f"Choose configuration{column_id}:",
|
| 57 |
config_names,
|
|
|
|
| 322 |
|
| 323 |
### Finally, show Zipf stuff
|
| 324 |
def expander_zipf(z, zipf_fig, column_id):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 325 |
with st.expander(
|
| 326 |
f"Vocabulary Distribution{column_id}: Zipf's Law Fit", expanded=False
|
| 327 |
):
|
| 328 |
+
try:
|
| 329 |
+
_ZIPF_CAPTION = """This shows how close the observed language is to an ideal
|
| 330 |
+
natural language distribution following [Zipf's law](https://en.wikipedia.org/wiki/Zipf%27s_law),
|
| 331 |
+
calculated by minimizing the [Kolmogorov-Smirnov (KS) statistic](https://en.wikipedia.org/wiki/Kolmogorov%E2%80%93Smirnov_test)."""
|
| 332 |
+
|
| 333 |
+
powerlaw_eq = r"""p(x) \propto x^{- \alpha}"""
|
| 334 |
+
zipf_summary = (
|
| 335 |
+
"The optimal alpha based on this dataset is: **"
|
| 336 |
+
+ str(round(z.alpha, 2))
|
| 337 |
+
+ "**, with a KS distance of: **"
|
| 338 |
+
+ str(round(z.distance, 2))
|
| 339 |
+
)
|
| 340 |
+
zipf_summary += (
|
| 341 |
+
"**. This was fit with a minimum rank value of: **"
|
| 342 |
+
+ str(int(z.xmin))
|
| 343 |
+
+ "**, which is the optimal rank *beyond which* the scaling regime of the power law fits best."
|
| 344 |
+
)
|
| 345 |
+
|
| 346 |
+
alpha_warning = "Your alpha value is a bit on the high side, which means that the distribution over words in this dataset is a bit unnatural. This could be due to non-language items throughout the dataset."
|
| 347 |
+
xmin_warning = "The minimum rank for this fit is a bit on the high side, which means that the frequencies of your most common words aren't distributed as would be expected by Zipf's law."
|
| 348 |
+
fit_results_table = pd.DataFrame.from_dict(
|
| 349 |
+
{
|
| 350 |
+
r"Alpha:": [str("%.2f" % z.alpha)],
|
| 351 |
+
"KS distance:": [str("%.2f" % z.distance)],
|
| 352 |
+
"Min rank:": [str("%s" % int(z.xmin))],
|
| 353 |
+
},
|
| 354 |
+
columns=["Results"],
|
| 355 |
+
orient="index",
|
| 356 |
+
)
|
| 357 |
+
fit_results_table.index.name = column_id
|
| 358 |
+
st.caption(
|
| 359 |
+
"Use this widget for the counts of different words in your dataset, measuring the difference between the observed count and the expected count under Zipf's law."
|
| 360 |
+
)
|
| 361 |
+
st.markdown(_ZIPF_CAPTION)
|
| 362 |
+
st.write(
|
| 363 |
+
"""
|
| 364 |
+
A Zipfian distribution follows the power law: $p(x) \propto x^{-α}$
|
| 365 |
+
with an ideal α value of 1."""
|
| 366 |
+
)
|
| 367 |
+
st.markdown(
|
| 368 |
+
"In general, an alpha greater than 2 or a minimum rank greater than 10 (take with a grain of salt) means that your distribution is relativaly _unnatural_ for natural language. This can be a sign of mixed artefacts in the dataset, such as HTML markup."
|
| 369 |
+
)
|
| 370 |
+
st.markdown(
|
| 371 |
+
"Below, you can see the counts of each word in your dataset vs. the expected number of counts following a Zipfian distribution."
|
| 372 |
+
)
|
| 373 |
+
st.markdown("-----")
|
| 374 |
+
st.write("### Here is your dataset's Zipf results:")
|
| 375 |
+
st.dataframe(fit_results_table)
|
| 376 |
+
st.write(zipf_summary)
|
| 377 |
+
# TODO: Nice UI version of the content in the comments.
|
| 378 |
+
# st.markdown("\nThe KS test p-value is < %.2f" % z.ks_test.pvalue)
|
| 379 |
+
# if z.ks_test.pvalue < 0.01:
|
| 380 |
+
# st.markdown(
|
| 381 |
+
# "\n Great news! Your data fits a powerlaw with a minimum KS " "distance of %.4f" % z.distance)
|
| 382 |
+
# else:
|
| 383 |
+
# st.markdown("\n Sadly, your data does not fit a powerlaw. =(")
|
| 384 |
+
# st.markdown("Checking the goodness of fit of our observed distribution")
|
| 385 |
+
# st.markdown("to the hypothesized power law distribution")
|
| 386 |
+
# st.markdown("using a Kolmogorov–Smirnov (KS) test.")
|
| 387 |
+
st.plotly_chart(zipf_fig, use_container_width=True)
|
| 388 |
+
if z.alpha > 2:
|
| 389 |
+
st.markdown(alpha_warning)
|
| 390 |
+
if z.xmin > 5:
|
| 391 |
+
st.markdown(xmin_warning)
|
| 392 |
+
except:
|
| 393 |
+
st.write("Under construction!")
|
| 394 |
|
| 395 |
|
| 396 |
### Finally finally finally, show nPMI stuff.
|
|
|
|
| 433 |
|
| 434 |
def npmi_show(paired_results):
|
| 435 |
if paired_results.empty:
|
| 436 |
+
st.markdown("No words that co-occur enough times for results! Or there's a 🐛. Or we're still computing this one. 🤷")
|
| 437 |
else:
|
| 438 |
s = pd.DataFrame(paired_results.sort_values(by="npmi-bias", ascending=True))
|
| 439 |
# s.columns=pd.MultiIndex.from_arrays([['npmi','npmi','npmi','count', 'count'],['bias','man','straight','man','straight']])
|
| 440 |
s.index.name = "word"
|
| 441 |
npmi_cols = s.filter(like="npmi").columns
|
| 442 |
count_cols = s.filter(like="count").columns
|
| 443 |
+
if s.shape[0] > 10000:
|
| 444 |
+
bias_thres = max(abs(s["npmi-bias"][5000]), abs(s["npmi-bias"][-5000]))
|
| 445 |
+
print(f"filtering with bias threshold: {bias_thres}")
|
| 446 |
+
s_filtered = s[s["npmi-bias"].abs() > bias_thres]
|
| 447 |
+
else:
|
| 448 |
+
s_filtered = s
|
| 449 |
# TODO: This is very different look than the duplicates table above. Should probably standardize.
|
| 450 |
cm = sns.palplot(sns.diverging_palette(270, 36, s=99, l=48, n=16))
|
| 451 |
out_df = (
|
| 452 |
+
s_filtered.style.background_gradient(subset=npmi_cols, cmap=cm)
|
| 453 |
.format(subset=npmi_cols, formatter="{:,.3f}")
|
| 454 |
.format(subset=count_cols, formatter=int)
|
| 455 |
.set_properties(
|
requirements.txt
CHANGED
|
@@ -10,7 +10,7 @@ iso_639==0.4.5
|
|
| 10 |
datasets==1.15.1
|
| 11 |
powerlaw==1.5
|
| 12 |
numpy==1.19.5
|
| 13 |
-
pandas==1.
|
| 14 |
dataclasses==0.6
|
| 15 |
iso639==0.1.4
|
| 16 |
python_igraph==0.9.6
|
|
@@ -23,4 +23,4 @@ numexpr==2.7.3
|
|
| 23 |
scikit-learn~=0.24.2
|
| 24 |
scipy~=1.7.3
|
| 25 |
tqdm~=4.62.3
|
| 26 |
-
pyarrow~=6.0.1
|
|
|
|
| 10 |
datasets==1.15.1
|
| 11 |
powerlaw==1.5
|
| 12 |
numpy==1.19.5
|
| 13 |
+
pandas==1.0.0
|
| 14 |
dataclasses==0.6
|
| 15 |
iso639==0.1.4
|
| 16 |
python_igraph==0.9.6
|
|
|
|
| 23 |
scikit-learn~=0.24.2
|
| 24 |
scipy~=1.7.3
|
| 25 |
tqdm~=4.62.3
|
| 26 |
+
pyarrow~=6.0.1
|