Spaces:
Build error

Build error
Merge branch 'main' of https://huggingface.co/spaces/huggingface/data-measurements-tool-2 into main
Browse files- cache_dir/wikitext_wikitext-103-v1_train_text/fig_tok_length.png +3 -0
- cache_dir/wikitext_wikitext-103-v1_validation_text/fig_tok_length.png +3 -0
- cache_dir/wikitext_wikitext-2-v1_train_text/fig_tok_length.png +3 -0
- cache_dir/wikitext_wikitext-2-v1_validation_text/fig_tok_length.png +3 -0
- data_measurements/dataset_statistics.py +1 -1
- run_data_measurements.py +28 -32
cache_dir/wikitext_wikitext-103-v1_train_text/fig_tok_length.png
ADDED
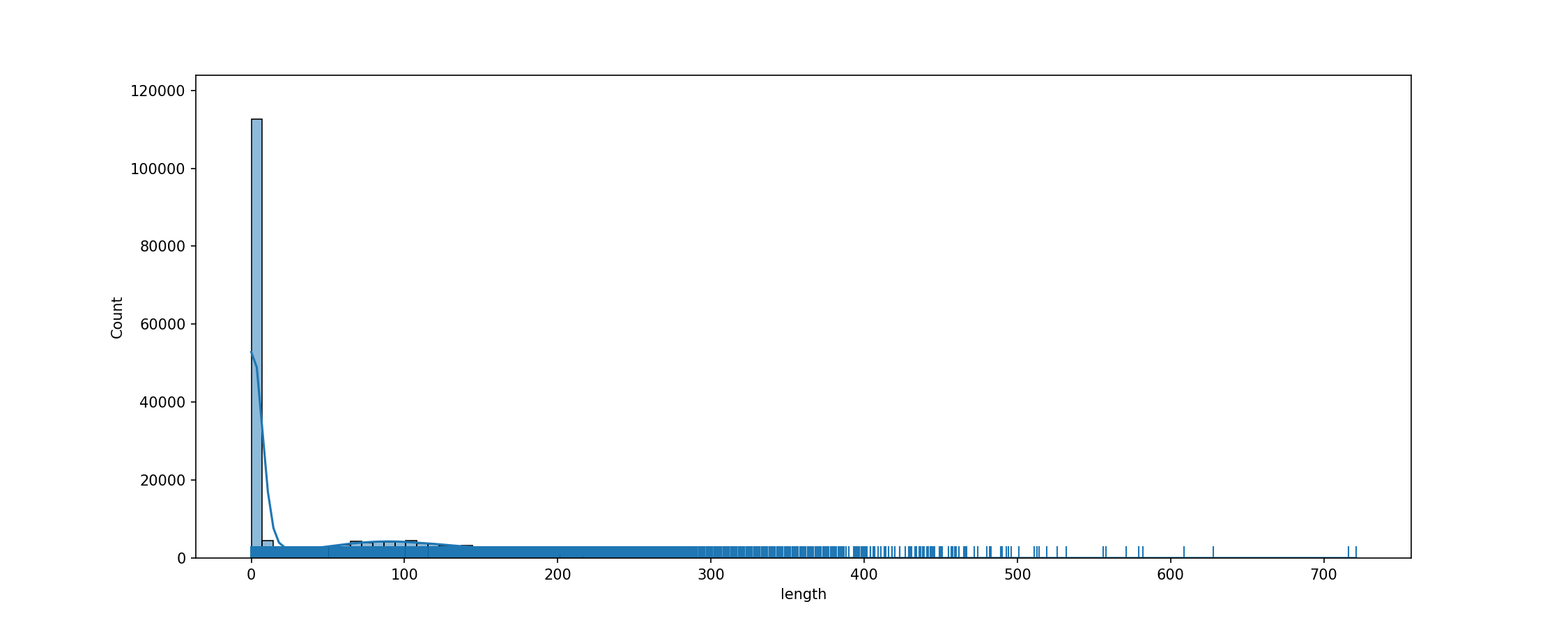
|
Git LFS Details
|
cache_dir/wikitext_wikitext-103-v1_validation_text/fig_tok_length.png
ADDED
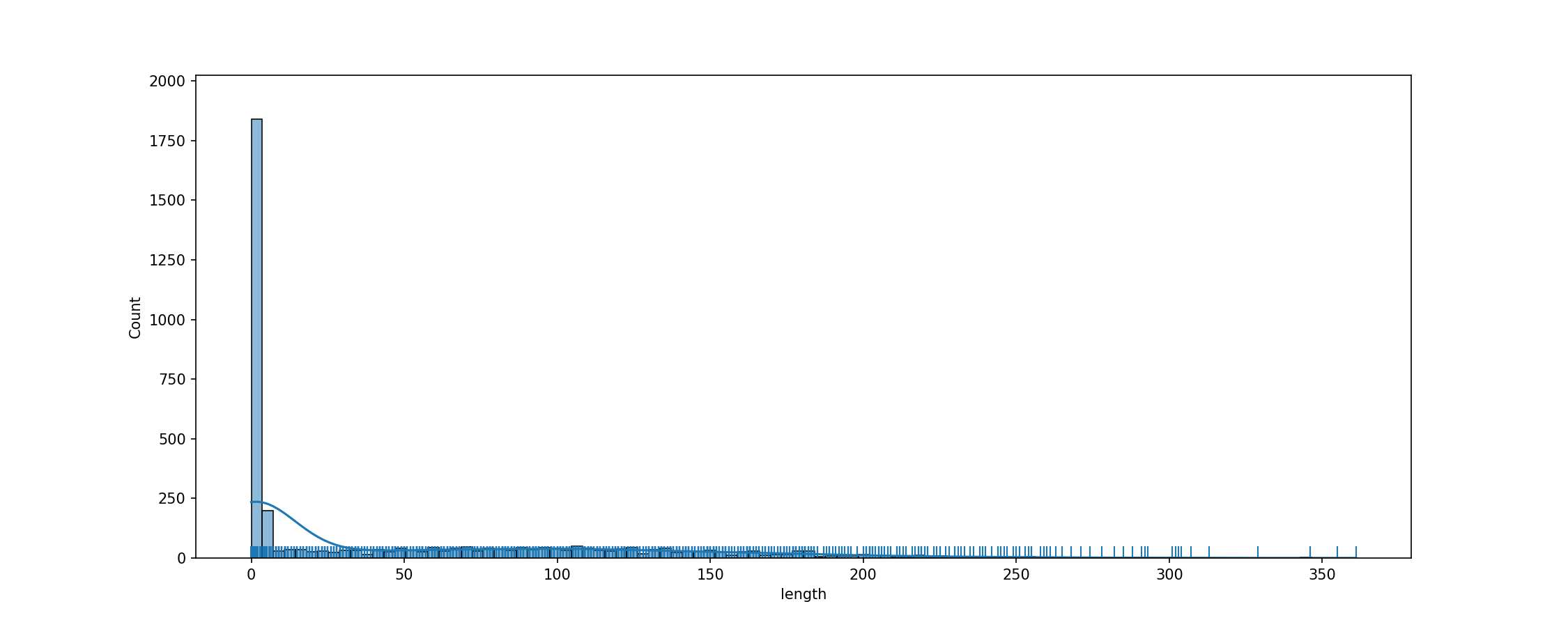
|
Git LFS Details
|
cache_dir/wikitext_wikitext-2-v1_train_text/fig_tok_length.png
ADDED
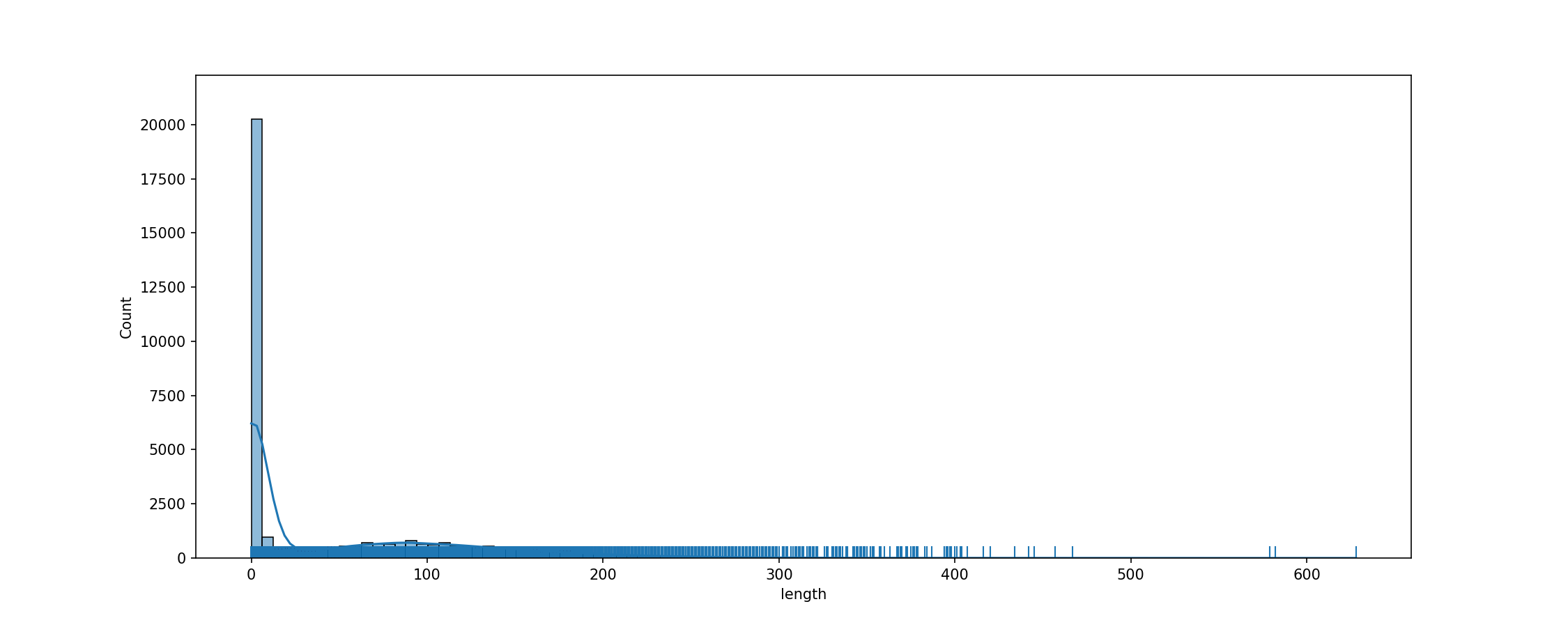
|
Git LFS Details
|
cache_dir/wikitext_wikitext-2-v1_validation_text/fig_tok_length.png
ADDED
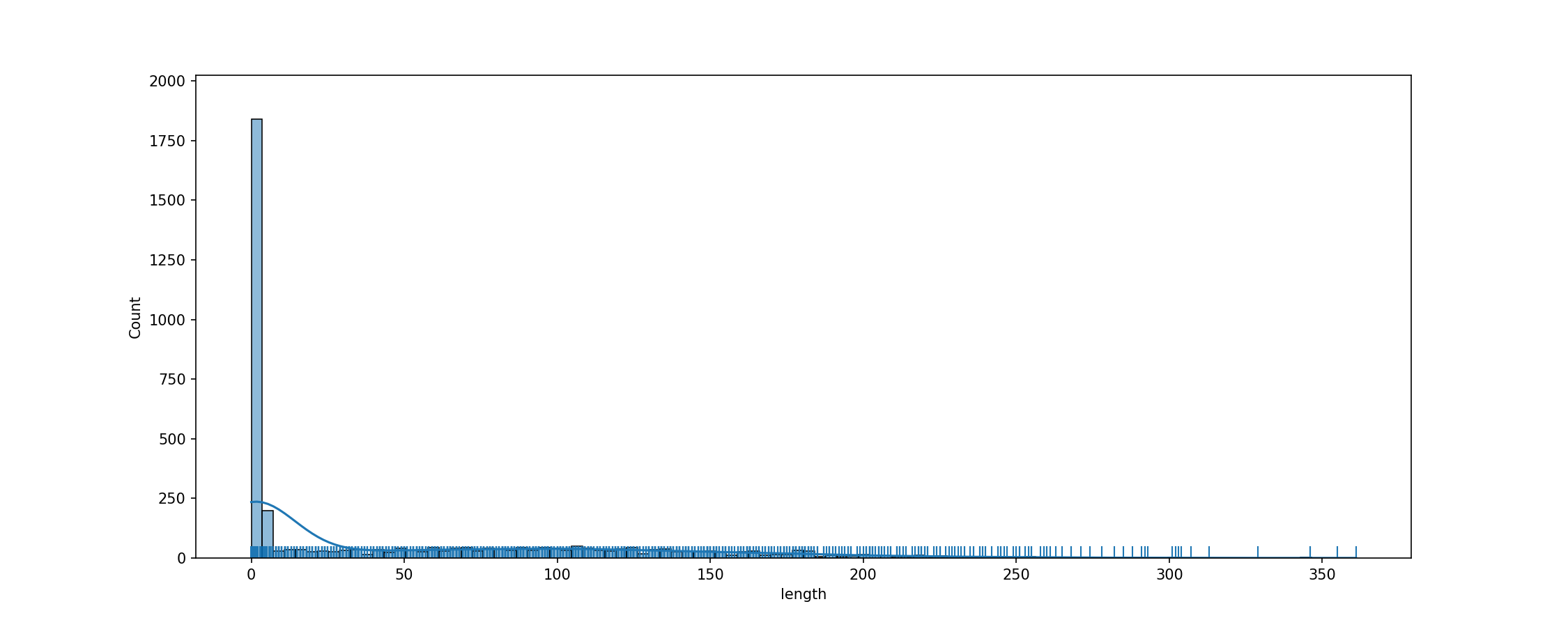
|
Git LFS Details
|
data_measurements/dataset_statistics.py
CHANGED
|
@@ -455,7 +455,7 @@ class DatasetStatisticsCacheClass:
|
|
| 455 |
self.vocab_counts_filtered_df = filter_vocab(self.vocab_counts_df)
|
| 456 |
else:
|
| 457 |
logs.info("Calculating vocab afresh")
|
| 458 |
-
if
|
| 459 |
self.tokenized_df = self.do_tokenization()
|
| 460 |
if save:
|
| 461 |
logs.info("Writing out.")
|
|
|
|
| 455 |
self.vocab_counts_filtered_df = filter_vocab(self.vocab_counts_df)
|
| 456 |
else:
|
| 457 |
logs.info("Calculating vocab afresh")
|
| 458 |
+
if self.tokenized_df is None:
|
| 459 |
self.tokenized_df = self.do_tokenization()
|
| 460 |
if save:
|
| 461 |
logs.info("Writing out.")
|
run_data_measurements.py
CHANGED
|
@@ -12,13 +12,14 @@ from data_measurements import dataset_utils
|
|
| 12 |
def load_or_prepare_widgets(ds_args, show_embeddings=False, use_cache=False):
|
| 13 |
"""
|
| 14 |
Loader specifically for the widgets used in the app.
|
|
|
|
| 15 |
Args:
|
| 16 |
-
ds_args:
|
| 17 |
-
show_embeddings:
|
| 18 |
-
use_cache:
|
| 19 |
|
| 20 |
Returns:
|
| 21 |
-
|
| 22 |
"""
|
| 23 |
|
| 24 |
if not isdir(ds_args["cache_dir"]):
|
|
@@ -30,13 +31,15 @@ def load_or_prepare_widgets(ds_args, show_embeddings=False, use_cache=False):
|
|
| 30 |
|
| 31 |
dstats = dataset_statistics.DatasetStatisticsCacheClass(**ds_args,
|
| 32 |
use_cache=use_cache)
|
|
|
|
|
|
|
| 33 |
# Header widget
|
| 34 |
dstats.load_or_prepare_dset_peek()
|
| 35 |
# General stats widget
|
| 36 |
dstats.load_or_prepare_general_stats()
|
| 37 |
# Labels widget
|
| 38 |
try:
|
| 39 |
-
dstats.set_label_field(
|
| 40 |
dstats.load_or_prepare_labels()
|
| 41 |
except:
|
| 42 |
pass
|
|
@@ -56,7 +59,16 @@ def load_or_prepare_widgets(ds_args, show_embeddings=False, use_cache=False):
|
|
| 56 |
dstats.load_or_prepare_zipf()
|
| 57 |
|
| 58 |
|
| 59 |
-
def load_or_prepare(dataset_args,
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 60 |
all = False
|
| 61 |
dstats = dataset_statistics.DatasetStatisticsCacheClass(**dataset_args, use_cache=use_cache)
|
| 62 |
print("Loading dataset.")
|
|
@@ -79,22 +91,15 @@ def load_or_prepare(dataset_args, do_html=False, use_cache=False):
|
|
| 79 |
|
| 80 |
if all or dataset_args["calculation"] == "lengths":
|
| 81 |
print("\n* Calculating text lengths.")
|
| 82 |
-
fig_tok_length_fid = pjoin(dstats.cache_path, "lengths_fig.html")
|
| 83 |
-
tok_length_json_fid = pjoin(dstats.cache_path, "lengths.json")
|
| 84 |
dstats.load_or_prepare_text_lengths()
|
| 85 |
-
with open(tok_length_json_fid, "w+") as f:
|
| 86 |
-
json.dump(dstats.fig_tok_length.to_json(), f)
|
| 87 |
-
print("Token lengths now available at %s." % tok_length_json_fid)
|
| 88 |
-
if do_html:
|
| 89 |
-
dstats.fig_tok_length.write_html(fig_tok_length_fid)
|
| 90 |
-
print("Figure saved to %s." % fig_tok_length_fid)
|
| 91 |
print("Done!")
|
| 92 |
|
| 93 |
if all or dataset_args["calculation"] == "labels":
|
| 94 |
if not dstats.label_field:
|
| 95 |
-
print("Warning: You asked for label calculation, but didn't
|
| 96 |
-
"the labels field name. Assuming it is 'label'...")
|
| 97 |
dstats.set_label_field("label")
|
|
|
|
| 98 |
print("\n* Calculating label distribution.")
|
| 99 |
dstats.load_or_prepare_labels()
|
| 100 |
fig_label_html = pjoin(dstats.cache_path, "labels_fig.html")
|
|
@@ -111,7 +116,7 @@ def load_or_prepare(dataset_args, do_html=False, use_cache=False):
|
|
| 111 |
npmi_stats = dataset_statistics.nPMIStatisticsCacheClass(
|
| 112 |
dstats, use_cache=use_cache
|
| 113 |
)
|
| 114 |
-
do_npmi(npmi_stats
|
| 115 |
print("Done!")
|
| 116 |
print(
|
| 117 |
"nPMI results now available in %s for all identity terms that "
|
|
@@ -142,7 +147,7 @@ def load_or_prepare(dataset_args, do_html=False, use_cache=False):
|
|
| 142 |
dstats.load_or_prepare_embeddings()
|
| 143 |
|
| 144 |
|
| 145 |
-
def do_npmi(npmi_stats
|
| 146 |
available_terms = npmi_stats.load_or_prepare_npmi_terms()
|
| 147 |
completed_pairs = {}
|
| 148 |
print("Iterating through terms for joint npmi.")
|
|
@@ -165,7 +170,6 @@ def get_text_label_df(
|
|
| 165 |
label_field,
|
| 166 |
calculation,
|
| 167 |
out_dir,
|
| 168 |
-
do_html=False,
|
| 169 |
use_cache=True,
|
| 170 |
):
|
| 171 |
if not use_cache:
|
|
@@ -190,7 +194,7 @@ def get_text_label_df(
|
|
| 190 |
"calculation": calculation,
|
| 191 |
"cache_dir": out_dir,
|
| 192 |
}
|
| 193 |
-
|
| 194 |
|
| 195 |
|
| 196 |
def main():
|
|
@@ -272,18 +276,10 @@ def main():
|
|
| 272 |
args = parser.parse_args()
|
| 273 |
print("Proceeding with the following arguments:")
|
| 274 |
print(args)
|
| 275 |
-
# run_data_measurements.py -
|
| 276 |
-
get_text_label_df(
|
| 277 |
-
|
| 278 |
-
|
| 279 |
-
args.split,
|
| 280 |
-
args.feature,
|
| 281 |
-
args.label_field,
|
| 282 |
-
args.calculation,
|
| 283 |
-
args.out_dir,
|
| 284 |
-
do_html=args.do_html,
|
| 285 |
-
use_cache=args.cached,
|
| 286 |
-
)
|
| 287 |
print()
|
| 288 |
|
| 289 |
|
|
|
|
| 12 |
def load_or_prepare_widgets(ds_args, show_embeddings=False, use_cache=False):
|
| 13 |
"""
|
| 14 |
Loader specifically for the widgets used in the app.
|
| 15 |
+
Does not take specifications from user.
|
| 16 |
Args:
|
| 17 |
+
ds_args: Dataset configuration settings (config name, split, etc)
|
| 18 |
+
show_embeddings: Whether to compute embeddings (slow)
|
| 19 |
+
use_cache: Whether to grab files that have already been computed
|
| 20 |
|
| 21 |
Returns:
|
| 22 |
+
Saves files to disk in cache_dir, if user has not specified another dir.
|
| 23 |
"""
|
| 24 |
|
| 25 |
if not isdir(ds_args["cache_dir"]):
|
|
|
|
| 31 |
|
| 32 |
dstats = dataset_statistics.DatasetStatisticsCacheClass(**ds_args,
|
| 33 |
use_cache=use_cache)
|
| 34 |
+
# Embeddings widget
|
| 35 |
+
dstats.load_or_prepare_dataset()
|
| 36 |
# Header widget
|
| 37 |
dstats.load_or_prepare_dset_peek()
|
| 38 |
# General stats widget
|
| 39 |
dstats.load_or_prepare_general_stats()
|
| 40 |
# Labels widget
|
| 41 |
try:
|
| 42 |
+
dstats.set_label_field(ds_args['label_field'])
|
| 43 |
dstats.load_or_prepare_labels()
|
| 44 |
except:
|
| 45 |
pass
|
|
|
|
| 59 |
dstats.load_or_prepare_zipf()
|
| 60 |
|
| 61 |
|
| 62 |
+
def load_or_prepare(dataset_args, use_cache=False):
|
| 63 |
+
"""
|
| 64 |
+
Users can specify which aspects of the dataset they would like to compute.
|
| 65 |
+
Args:
|
| 66 |
+
dataset_args: Dataset configuration settings (config name, split, etc)
|
| 67 |
+
use_cache: Whether to grab files that have already been computed
|
| 68 |
+
|
| 69 |
+
Returns:
|
| 70 |
+
Saves files to disk in cache_dir, if user has not specified another dir.
|
| 71 |
+
"""
|
| 72 |
all = False
|
| 73 |
dstats = dataset_statistics.DatasetStatisticsCacheClass(**dataset_args, use_cache=use_cache)
|
| 74 |
print("Loading dataset.")
|
|
|
|
| 91 |
|
| 92 |
if all or dataset_args["calculation"] == "lengths":
|
| 93 |
print("\n* Calculating text lengths.")
|
|
|
|
|
|
|
| 94 |
dstats.load_or_prepare_text_lengths()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 95 |
print("Done!")
|
| 96 |
|
| 97 |
if all or dataset_args["calculation"] == "labels":
|
| 98 |
if not dstats.label_field:
|
| 99 |
+
print("Warning: You asked for label calculation, but didn't "
|
| 100 |
+
"provide the labels field name. Assuming it is 'label'...")
|
| 101 |
dstats.set_label_field("label")
|
| 102 |
+
else:
|
| 103 |
print("\n* Calculating label distribution.")
|
| 104 |
dstats.load_or_prepare_labels()
|
| 105 |
fig_label_html = pjoin(dstats.cache_path, "labels_fig.html")
|
|
|
|
| 116 |
npmi_stats = dataset_statistics.nPMIStatisticsCacheClass(
|
| 117 |
dstats, use_cache=use_cache
|
| 118 |
)
|
| 119 |
+
do_npmi(npmi_stats)
|
| 120 |
print("Done!")
|
| 121 |
print(
|
| 122 |
"nPMI results now available in %s for all identity terms that "
|
|
|
|
| 147 |
dstats.load_or_prepare_embeddings()
|
| 148 |
|
| 149 |
|
| 150 |
+
def do_npmi(npmi_stats):
|
| 151 |
available_terms = npmi_stats.load_or_prepare_npmi_terms()
|
| 152 |
completed_pairs = {}
|
| 153 |
print("Iterating through terms for joint npmi.")
|
|
|
|
| 170 |
label_field,
|
| 171 |
calculation,
|
| 172 |
out_dir,
|
|
|
|
| 173 |
use_cache=True,
|
| 174 |
):
|
| 175 |
if not use_cache:
|
|
|
|
| 194 |
"calculation": calculation,
|
| 195 |
"cache_dir": out_dir,
|
| 196 |
}
|
| 197 |
+
load_or_prepare(dataset_args, use_cache=use_cache)
|
| 198 |
|
| 199 |
|
| 200 |
def main():
|
|
|
|
| 276 |
args = parser.parse_args()
|
| 277 |
print("Proceeding with the following arguments:")
|
| 278 |
print(args)
|
| 279 |
+
# run_data_measurements.py -d hate_speech18 -c default -s train -f text -w npmi
|
| 280 |
+
get_text_label_df(args.dataset, args.config, args.split, args.feature,
|
| 281 |
+
args.label_field, args.calculation, args.out_dir,
|
| 282 |
+
use_cache=args.cached)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 283 |
print()
|
| 284 |
|
| 285 |
|