Spaces:
Sleeping

Sleeping
Upload 78 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- age_estimator/.DS_Store +0 -0
- age_estimator/__init__.py +0 -0
- age_estimator/__pycache__/__init__.cpython-38.pyc +0 -0
- age_estimator/__pycache__/admin.cpython-38.pyc +0 -0
- age_estimator/__pycache__/apps.cpython-38.pyc +0 -0
- age_estimator/__pycache__/models.cpython-38.pyc +0 -0
- age_estimator/__pycache__/urls.cpython-38.pyc +0 -0
- age_estimator/__pycache__/views.cpython-38.pyc +0 -0
- age_estimator/admin.py +3 -0
- age_estimator/apps.py +6 -0
- age_estimator/migrations/__init__.py +0 -0
- age_estimator/migrations/__pycache__/__init__.cpython-38.pyc +0 -0
- age_estimator/mivolo/.DS_Store +0 -0
- age_estimator/mivolo/.flake8 +5 -0
- age_estimator/mivolo/.gitignore +85 -0
- age_estimator/mivolo/.isort.cfg +5 -0
- age_estimator/mivolo/.pre-commit-config.yaml +31 -0
- age_estimator/mivolo/CHANGELOG.md +16 -0
- age_estimator/mivolo/README.md +417 -0
- age_estimator/mivolo/__pycache__/demo_copy.cpython-38.pyc +0 -0
- age_estimator/mivolo/demo.py +145 -0
- age_estimator/mivolo/demo_copy.py +144 -0
- age_estimator/mivolo/eval_pretrained.py +232 -0
- age_estimator/mivolo/eval_tools.py +149 -0
- age_estimator/mivolo/images/MiVOLO.jpg +0 -0
- age_estimator/mivolo/infer.py +88 -0
- age_estimator/mivolo/license/en_us.pdf +0 -0
- age_estimator/mivolo/license/ru.pdf +0 -0
- age_estimator/mivolo/measure_time.py +77 -0
- age_estimator/mivolo/mivolo/__init__.py +0 -0
- age_estimator/mivolo/mivolo/__pycache__/__init__.cpython-38.pyc +0 -0
- age_estimator/mivolo/mivolo/__pycache__/predictor.cpython-38.pyc +0 -0
- age_estimator/mivolo/mivolo/__pycache__/structures.cpython-38.pyc +0 -0
- age_estimator/mivolo/mivolo/data/__init__.py +0 -0
- age_estimator/mivolo/mivolo/data/__pycache__/__init__.cpython-38.pyc +0 -0
- age_estimator/mivolo/mivolo/data/__pycache__/data_reader.cpython-38.pyc +0 -0
- age_estimator/mivolo/mivolo/data/__pycache__/misc.cpython-38.pyc +0 -0
- age_estimator/mivolo/mivolo/data/data_reader.py +125 -0
- age_estimator/mivolo/mivolo/data/dataset/__init__.py +66 -0
- age_estimator/mivolo/mivolo/data/dataset/age_gender_dataset.py +194 -0
- age_estimator/mivolo/mivolo/data/dataset/age_gender_loader.py +169 -0
- age_estimator/mivolo/mivolo/data/dataset/classification_dataset.py +47 -0
- age_estimator/mivolo/mivolo/data/dataset/reader_age_gender.py +492 -0
- age_estimator/mivolo/mivolo/data/misc.py +246 -0
- age_estimator/mivolo/mivolo/model/__init__.py +0 -0
- age_estimator/mivolo/mivolo/model/__pycache__/__init__.cpython-38.pyc +0 -0
- age_estimator/mivolo/mivolo/model/__pycache__/create_timm_model.cpython-38.pyc +0 -0
- age_estimator/mivolo/mivolo/model/__pycache__/cross_bottleneck_attn.cpython-38.pyc +0 -0
- age_estimator/mivolo/mivolo/model/__pycache__/mi_volo.cpython-38.pyc +0 -0
- age_estimator/mivolo/mivolo/model/__pycache__/mivolo_model.cpython-38.pyc +0 -0
age_estimator/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
age_estimator/__init__.py
ADDED
|
File without changes
|
age_estimator/__pycache__/__init__.cpython-38.pyc
ADDED
|
Binary file (159 Bytes). View file
|
|
|
age_estimator/__pycache__/admin.cpython-38.pyc
ADDED
|
Binary file (200 Bytes). View file
|
|
|
age_estimator/__pycache__/apps.cpython-38.pyc
ADDED
|
Binary file (449 Bytes). View file
|
|
|
age_estimator/__pycache__/models.cpython-38.pyc
ADDED
|
Binary file (197 Bytes). View file
|
|
|
age_estimator/__pycache__/urls.cpython-38.pyc
ADDED
|
Binary file (357 Bytes). View file
|
|
|
age_estimator/__pycache__/views.cpython-38.pyc
ADDED
|
Binary file (1.62 kB). View file
|
|
|
age_estimator/admin.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from django.contrib import admin
|
| 2 |
+
|
| 3 |
+
# Register your models here.
|
age_estimator/apps.py
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from django.apps import AppConfig
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class AgeEstimatorConfig(AppConfig):
|
| 5 |
+
default_auto_field = 'django.db.models.BigAutoField'
|
| 6 |
+
name = 'age_estimator'
|
age_estimator/migrations/__init__.py
ADDED
|
File without changes
|
age_estimator/migrations/__pycache__/__init__.cpython-38.pyc
ADDED
|
Binary file (170 Bytes). View file
|
|
|
age_estimator/mivolo/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
age_estimator/mivolo/.flake8
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[flake8]
|
| 2 |
+
max-line-length = 120
|
| 3 |
+
inline-quotes = "
|
| 4 |
+
multiline-quotes = "
|
| 5 |
+
ignore = E203,W503
|
age_estimator/mivolo/.gitignore
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
*.DS_Store
|
| 7 |
+
|
| 8 |
+
# Distribution / packaging
|
| 9 |
+
.Python
|
| 10 |
+
build/
|
| 11 |
+
develop-eggs/
|
| 12 |
+
dist/
|
| 13 |
+
downloads/
|
| 14 |
+
eggs/
|
| 15 |
+
.eggs/
|
| 16 |
+
lib/
|
| 17 |
+
lib64/
|
| 18 |
+
parts/
|
| 19 |
+
sdist/
|
| 20 |
+
var/
|
| 21 |
+
wheels/
|
| 22 |
+
*.egg-info/
|
| 23 |
+
.installed.cfg
|
| 24 |
+
*.egg
|
| 25 |
+
MANIFEST
|
| 26 |
+
|
| 27 |
+
# Installer logs
|
| 28 |
+
pip-log.txt
|
| 29 |
+
pip-delete-this-directory.txt
|
| 30 |
+
|
| 31 |
+
# Unit test / coverage reports
|
| 32 |
+
htmlcov/
|
| 33 |
+
.tox/
|
| 34 |
+
.coverage
|
| 35 |
+
.coverage.*
|
| 36 |
+
.cache
|
| 37 |
+
nosetests.xml
|
| 38 |
+
coverage.xml
|
| 39 |
+
*.cover
|
| 40 |
+
.hypothesis/
|
| 41 |
+
.pytest_cache/
|
| 42 |
+
|
| 43 |
+
# Sphinx documentation
|
| 44 |
+
docs/_build/
|
| 45 |
+
|
| 46 |
+
# PyBuilder
|
| 47 |
+
target/
|
| 48 |
+
|
| 49 |
+
# Jupyter Notebook
|
| 50 |
+
.ipynb_checkpoints
|
| 51 |
+
|
| 52 |
+
# pyenv
|
| 53 |
+
.python-version
|
| 54 |
+
|
| 55 |
+
# PyTorch weights
|
| 56 |
+
*.tar
|
| 57 |
+
*.pth
|
| 58 |
+
*.pt
|
| 59 |
+
*.torch
|
| 60 |
+
*.gz
|
| 61 |
+
Untitled.ipynb
|
| 62 |
+
Testing notebook.ipynb
|
| 63 |
+
|
| 64 |
+
# Root dir exclusions
|
| 65 |
+
/*.csv
|
| 66 |
+
/*.yaml
|
| 67 |
+
/*.json
|
| 68 |
+
/*.jpg
|
| 69 |
+
/*.png
|
| 70 |
+
/*.zip
|
| 71 |
+
/*.tar.*
|
| 72 |
+
*.jpg
|
| 73 |
+
*.png
|
| 74 |
+
*.avi
|
| 75 |
+
*.mp4
|
| 76 |
+
*.svg
|
| 77 |
+
|
| 78 |
+
.mypy_cache/
|
| 79 |
+
.vscode/
|
| 80 |
+
.idea
|
| 81 |
+
|
| 82 |
+
output/
|
| 83 |
+
input/
|
| 84 |
+
|
| 85 |
+
run.sh
|
age_estimator/mivolo/.isort.cfg
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[settings]
|
| 2 |
+
profile = black
|
| 3 |
+
line_length = 120
|
| 4 |
+
src_paths = ["mivolo", "scripts", "tools"]
|
| 5 |
+
filter_files = true
|
age_estimator/mivolo/.pre-commit-config.yaml
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
repos:
|
| 2 |
+
- repo: https://github.com/pre-commit/pre-commit-hooks
|
| 3 |
+
rev: v4.2.0
|
| 4 |
+
hooks:
|
| 5 |
+
- id: check-yaml
|
| 6 |
+
args: ['--unsafe']
|
| 7 |
+
- id: check-toml
|
| 8 |
+
- id: debug-statements
|
| 9 |
+
- id: end-of-file-fixer
|
| 10 |
+
exclude: poetry.lock
|
| 11 |
+
- id: trailing-whitespace
|
| 12 |
+
- repo: https://github.com/PyCQA/isort
|
| 13 |
+
rev: 5.12.0
|
| 14 |
+
hooks:
|
| 15 |
+
- id: isort
|
| 16 |
+
args: [ "--profile", "black", "--filter-files" ]
|
| 17 |
+
- repo: https://github.com/psf/black
|
| 18 |
+
rev: 22.3.0
|
| 19 |
+
hooks:
|
| 20 |
+
- id: black
|
| 21 |
+
args: ["--line-length", "120"]
|
| 22 |
+
- repo: https://github.com/PyCQA/flake8
|
| 23 |
+
rev: 3.9.2
|
| 24 |
+
hooks:
|
| 25 |
+
- id: flake8
|
| 26 |
+
args: [ "--config", ".flake8" ]
|
| 27 |
+
additional_dependencies: [ "flake8-quotes" ]
|
| 28 |
+
- repo: https://github.com/pre-commit/mirrors-mypy
|
| 29 |
+
rev: v0.942
|
| 30 |
+
hooks:
|
| 31 |
+
- id: mypy
|
age_estimator/mivolo/CHANGELOG.md
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
## 0.4.1dev (15.08.2023)
|
| 3 |
+
|
| 4 |
+
### Added
|
| 5 |
+
- Support for video streams, including YouTube URLs
|
| 6 |
+
- Instructions and explanations for various export types.
|
| 7 |
+
|
| 8 |
+
### Changed
|
| 9 |
+
- Removed CutOff operation. It has been proven to be ineffective for inference time and quite costly at the same time. Now it is only used during training.
|
| 10 |
+
|
| 11 |
+
## 0.4.2dev (22.09.2023)
|
| 12 |
+
|
| 13 |
+
### Added
|
| 14 |
+
|
| 15 |
+
- Script for AgeDB dataset convertation to csv format
|
| 16 |
+
- Additional metrics were added to README
|
age_estimator/mivolo/README.md
ADDED
|
@@ -0,0 +1,417 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
<p>
|
| 3 |
+
<a align="center" target="_blank">
|
| 4 |
+
<img width="900" src="./images/MiVOLO.jpg"></a>
|
| 5 |
+
</p>
|
| 6 |
+
<br>
|
| 7 |
+
</div>
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
## MiVOLO: Multi-input Transformer for Age and Gender Estimation
|
| 12 |
+
|
| 13 |
+
[](https://paperswithcode.com/sota/age-estimation-on-utkface?p=mivolo-multi-input-transformer-for-age-and) [](https://paperswithcode.com/sota/age-estimation-on-imdb-clean?p=beyond-specialization-assessing-the-1) [](https://paperswithcode.com/sota/facial-attribute-classification-on-fairface?p=beyond-specialization-assessing-the-1) [](https://paperswithcode.com/sota/age-and-gender-classification-on-adience?p=beyond-specialization-assessing-the-1) [](https://paperswithcode.com/sota/age-and-gender-classification-on-adience-age?p=beyond-specialization-assessing-the-1) [](https://paperswithcode.com/sota/age-and-gender-estimation-on-lagenda-age?p=beyond-specialization-assessing-the-1) [](https://paperswithcode.com/sota/gender-prediction-on-lagenda?p=beyond-specialization-assessing-the-1) [](https://paperswithcode.com/sota/age-estimation-on-agedb?p=mivolo-multi-input-transformer-for-age-and) [](https://paperswithcode.com/sota/gender-prediction-on-agedb?p=mivolo-multi-input-transformer-for-age-and) [](https://paperswithcode.com/sota/age-estimation-on-cacd?p=beyond-specialization-assessing-the-1)
|
| 14 |
+
|
| 15 |
+
> [**MiVOLO: Multi-input Transformer for Age and Gender Estimation**](https://arxiv.org/abs/2307.04616),
|
| 16 |
+
> Maksim Kuprashevich, Irina Tolstykh,
|
| 17 |
+
> *2023 [arXiv 2307.04616](https://arxiv.org/abs/2307.04616)*
|
| 18 |
+
|
| 19 |
+
> [**Beyond Specialization: Assessing the Capabilities of MLLMs in Age and Gender Estimation**](https://arxiv.org/abs/2403.02302),
|
| 20 |
+
> Maksim Kuprashevich, Grigorii Alekseenko, Irina Tolstykh
|
| 21 |
+
> *2024 [arXiv 2403.02302](https://arxiv.org/abs/2403.02302)*
|
| 22 |
+
|
| 23 |
+
[[`Paper 2023`](https://arxiv.org/abs/2307.04616)] [[`Paper 2024`](https://arxiv.org/abs/2403.02302)] [[`Demo`](https://huggingface.co/spaces/iitolstykh/age_gender_estimation_demo)] [[`Telegram Bot`](https://t.me/AnyAgeBot)] [[`BibTex`](#citing)] [[`Data`](https://wildchlamydia.github.io/lagenda/)]
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
## MiVOLO pretrained models
|
| 27 |
+
|
| 28 |
+
Gender & Age recognition performance.
|
| 29 |
+
|
| 30 |
+
<table style="margin: auto">
|
| 31 |
+
<tr>
|
| 32 |
+
<th align="left">Model</th>
|
| 33 |
+
<th align="left" style="color:LightBlue">Type</th>
|
| 34 |
+
<th align="left">Dataset (train and test)</th>
|
| 35 |
+
<th align="left">Age MAE</th>
|
| 36 |
+
<th align="left">Age CS@5</th>
|
| 37 |
+
<th align="left">Gender Accuracy</th>
|
| 38 |
+
<th align="left">download</th>
|
| 39 |
+
</tr>
|
| 40 |
+
<tr>
|
| 41 |
+
<td>volo_d1</td>
|
| 42 |
+
<td align="left">face_only, age</td>
|
| 43 |
+
<td align="left">IMDB-cleaned</td>
|
| 44 |
+
<td align="left">4.29</td>
|
| 45 |
+
<td align="left">67.71</td>
|
| 46 |
+
<td align="left">-</td>
|
| 47 |
+
<td><a href="https://drive.google.com/file/d/17ysOqgG3FUyEuxrV3Uh49EpmuOiGDxrq/view?usp=drive_link">checkpoint</a></td>
|
| 48 |
+
</tr>
|
| 49 |
+
<tr>
|
| 50 |
+
<td>volo_d1</td>
|
| 51 |
+
<td align="left">face_only, age, gender</td>
|
| 52 |
+
<td align="left">IMDB-cleaned</td>
|
| 53 |
+
<td align="left">4.22</td>
|
| 54 |
+
<td align="left">68.68</td>
|
| 55 |
+
<td align="left">99.38</td>
|
| 56 |
+
<td><a href="https://drive.google.com/file/d/1NlsNEVijX2tjMe8LBb1rI56WB_ADVHeP/view?usp=drive_link">checkpoint</a></td>
|
| 57 |
+
</tr>
|
| 58 |
+
<tr>
|
| 59 |
+
<td>mivolo_d1</td>
|
| 60 |
+
<td align="left">face_body, age, gender</td>
|
| 61 |
+
<td align="left">IMDB-cleaned</td>
|
| 62 |
+
<td align="left">4.24 [face+body]<br>6.87 [body]</td>
|
| 63 |
+
<td align="left">68.32 [face+body]<br>46.32 [body]</td>
|
| 64 |
+
<td align="left">99.46 [face+body]<br>96.48 [body]</td>
|
| 65 |
+
<td><a href="https://drive.google.com/file/d/11i8pKctxz3wVkDBlWKvhYIh7kpVFXSZ4/view?usp=drive_link">model_imdb_cross_person_4.24_99.46.pth.tar</a></td>
|
| 66 |
+
</tr>
|
| 67 |
+
<tr>
|
| 68 |
+
<td>volo_d1</td>
|
| 69 |
+
<td align="left">face_only, age</td>
|
| 70 |
+
<td align="left">UTKFace</td>
|
| 71 |
+
<td align="left">4.23</td>
|
| 72 |
+
<td align="left">69.72</td>
|
| 73 |
+
<td align="left">-</td>
|
| 74 |
+
<td><a href="https://drive.google.com/file/d/1LtDfAJrWrw-QA9U5IuC3_JImbvAQhrJE/view?usp=drive_link">checkpoint</a></td>
|
| 75 |
+
</tr>
|
| 76 |
+
<tr>
|
| 77 |
+
<td>volo_d1</td>
|
| 78 |
+
<td align="left">face_only, age, gender</td>
|
| 79 |
+
<td align="left">UTKFace</td>
|
| 80 |
+
<td align="left">4.23</td>
|
| 81 |
+
<td align="left">69.78</td>
|
| 82 |
+
<td align="left">97.69</td>
|
| 83 |
+
<td><a href="https://drive.google.com/file/d/1hKFmIR6fjHMevm-a9uPEAkDLrTAh-W4D/view?usp=drive_link">checkpoint</a></td>
|
| 84 |
+
</tr>
|
| 85 |
+
<tr>
|
| 86 |
+
<td>mivolo_d1</td>
|
| 87 |
+
<td align="left">face_body, age, gender</td>
|
| 88 |
+
<td align="left">Lagenda</td>
|
| 89 |
+
<td align="left">3.99 [face+body]</td>
|
| 90 |
+
<td align="left">71.27 [face+body]</td>
|
| 91 |
+
<td align="left">97.36 [face+body]</td>
|
| 92 |
+
<td><a href="https://huggingface.co/spaces/iitolstykh/demo">demo</a></td>
|
| 93 |
+
</tr>
|
| 94 |
+
<tr>
|
| 95 |
+
<td>mivolov2_d1_384x384</td>
|
| 96 |
+
<td align="left">face_body, age, gender</td>
|
| 97 |
+
<td align="left">Lagenda</td>
|
| 98 |
+
<td align="left">3.65 [face+body]</td>
|
| 99 |
+
<td align="left">74.48 [face+body]</td>
|
| 100 |
+
<td align="left">97.99 [face+body]</td>
|
| 101 |
+
<td><a href="https://t.me/AnyAgeBot">telegram bot</a></td>
|
| 102 |
+
</tr>
|
| 103 |
+
|
| 104 |
+
</table>
|
| 105 |
+
|
| 106 |
+
## MiVOLO regression benchmarks
|
| 107 |
+
|
| 108 |
+
Gender & Age recognition performance.
|
| 109 |
+
|
| 110 |
+
Use [valid_age_gender.sh](scripts/valid_age_gender.sh) to reproduce results with our checkpoints.
|
| 111 |
+
|
| 112 |
+
<table style="margin: auto">
|
| 113 |
+
<tr>
|
| 114 |
+
<th align="left">Model</th>
|
| 115 |
+
<th align="left" style="color:LightBlue">Type</th>
|
| 116 |
+
<th align="left">Train Dataset</th>
|
| 117 |
+
<th align="left">Test Dataset</th>
|
| 118 |
+
<th align="left">Age MAE</th>
|
| 119 |
+
<th align="left">Age CS@5</th>
|
| 120 |
+
<th align="left">Gender Accuracy</th>
|
| 121 |
+
<th align="left">download</th>
|
| 122 |
+
</tr>
|
| 123 |
+
|
| 124 |
+
<tr>
|
| 125 |
+
<td>mivolo_d1</td>
|
| 126 |
+
<td align="left">face_body, age, gender</td>
|
| 127 |
+
<td align="left">Lagenda</td>
|
| 128 |
+
<td align="left">AgeDB</td>
|
| 129 |
+
<td align="left">5.55 [face]</td>
|
| 130 |
+
<td align="left">55.08 [face]</td>
|
| 131 |
+
<td align="left">98.3 [face]</td>
|
| 132 |
+
<td><a href="https://huggingface.co/spaces/iitolstykh/demo">demo</a></td>
|
| 133 |
+
</tr>
|
| 134 |
+
<tr>
|
| 135 |
+
<td>mivolo_d1</td>
|
| 136 |
+
<td align="left">face_body, age, gender</td>
|
| 137 |
+
<td align="left">IMDB-cleaned</td>
|
| 138 |
+
<td align="left">AgeDB</td>
|
| 139 |
+
<td align="left">5.58 [face]</td>
|
| 140 |
+
<td align="left">55.54 [face]</td>
|
| 141 |
+
<td align="left">97.93 [face]</td>
|
| 142 |
+
<td><a href="https://drive.google.com/file/d/11i8pKctxz3wVkDBlWKvhYIh7kpVFXSZ4/view?usp=drive_link">model_imdb_cross_person_4.24_99.46.pth.tar</a></td>
|
| 143 |
+
</tr>
|
| 144 |
+
|
| 145 |
+
</table>
|
| 146 |
+
|
| 147 |
+
## MiVOLO classification benchmarks
|
| 148 |
+
|
| 149 |
+
Gender & Age recognition performance.
|
| 150 |
+
|
| 151 |
+
<table style="margin: auto">
|
| 152 |
+
<tr>
|
| 153 |
+
<th align="left">Model</th>
|
| 154 |
+
<th align="left" style="color:LightBlue">Type</th>
|
| 155 |
+
<th align="left">Train Dataset</th>
|
| 156 |
+
<th align="left">Test Dataset</th>
|
| 157 |
+
<th align="left">Age Accuracy</th>
|
| 158 |
+
<th align="left">Gender Accuracy</th>
|
| 159 |
+
</tr>
|
| 160 |
+
|
| 161 |
+
<tr>
|
| 162 |
+
<td>mivolo_d1</td>
|
| 163 |
+
<td align="left">face_body, age, gender</td>
|
| 164 |
+
<td align="left">Lagenda</td>
|
| 165 |
+
<td align="left">FairFace</td>
|
| 166 |
+
<td align="left">61.07 [face+body]</td>
|
| 167 |
+
<td align="left">95.73 [face+body]</td>
|
| 168 |
+
</tr>
|
| 169 |
+
<tr>
|
| 170 |
+
<td>mivolo_d1</td>
|
| 171 |
+
<td align="left">face_body, age, gender</td>
|
| 172 |
+
<td align="left">Lagenda</td>
|
| 173 |
+
<td align="left">Adience</td>
|
| 174 |
+
<td align="left">68.69 [face]</td>
|
| 175 |
+
<td align="left">96.51[face]</td>
|
| 176 |
+
</tr>
|
| 177 |
+
<tr>
|
| 178 |
+
<td>mivolov2_d1_384</td>
|
| 179 |
+
<td align="left">face_body, age, gender</td>
|
| 180 |
+
<td align="left">Lagenda</td>
|
| 181 |
+
<td align="left">Adience</td>
|
| 182 |
+
<td align="left">69.43 [face]</td>
|
| 183 |
+
<td align="left">97.39[face]</td>
|
| 184 |
+
</tr>
|
| 185 |
+
|
| 186 |
+
</table>
|
| 187 |
+
|
| 188 |
+
## Dataset
|
| 189 |
+
|
| 190 |
+
**Please, [cite our papers](#citing) if you use any this data!**
|
| 191 |
+
|
| 192 |
+
- Lagenda dataset: [images](https://drive.google.com/file/d/1QXO0NlkABPZT6x1_0Uc2i6KAtdcrpTbG/view?usp=sharing) and [annotation](https://drive.google.com/file/d/1mNYjYFb3MuKg-OL1UISoYsKObMUllbJx/view?usp=sharing).
|
| 193 |
+
- IMDB-clean: follow [these instructions](https://github.com/yiminglin-ai/imdb-clean) to get images and [download](https://drive.google.com/file/d/17uEqyU3uQ5trWZ5vRJKzh41yeuDe5hyL/view?usp=sharing) our annotations.
|
| 194 |
+
- UTK dataset: [origin full images](https://susanqq.github.io/UTKFace/) and our annotation: [split from the article](https://drive.google.com/file/d/1Fo1vPWrKtC5bPtnnVWNTdD4ZTKRXL9kv/view?usp=sharing), [random full split](https://drive.google.com/file/d/177AV631C3SIfi5nrmZA8CEihIt29cznJ/view?usp=sharing).
|
| 195 |
+
- Adience dataset: follow [these instructions](https://talhassner.github.io/home/projects/Adience/Adience-data.html) to get images and [download](https://drive.google.com/file/d/1wS1Q4FpksxnCR88A1tGLsLIr91xHwcVv/view?usp=sharing) our annotations.
|
| 196 |
+
<details>
|
| 197 |
+
<summary>Click to expand!</summary>
|
| 198 |
+
|
| 199 |
+
After downloading them, your `data` directory should look something like this:
|
| 200 |
+
|
| 201 |
+
```console
|
| 202 |
+
data
|
| 203 |
+
└── Adience
|
| 204 |
+
├── annotations (folder with our annotations)
|
| 205 |
+
├── aligned (will not be used)
|
| 206 |
+
├── faces
|
| 207 |
+
├── fold_0_data.txt
|
| 208 |
+
├── fold_1_data.txt
|
| 209 |
+
├── fold_2_data.txt
|
| 210 |
+
├── fold_3_data.txt
|
| 211 |
+
└── fold_4_data.txt
|
| 212 |
+
```
|
| 213 |
+
|
| 214 |
+
We use coarse aligned images from `faces/` dir.
|
| 215 |
+
|
| 216 |
+
Using our detector we found a face bbox for each image (see [tools/prepare_adience.py](tools/prepare_adience.py)).
|
| 217 |
+
|
| 218 |
+
This dataset has five folds. The performance metric is accuracy on five-fold cross validation.
|
| 219 |
+
|
| 220 |
+
| images before removal | fold 0 | fold 1 | fold 2 | fold 3 | fold 4 |
|
| 221 |
+
| --------------------- | ------ | ------ | ------ | ------ | ------ |
|
| 222 |
+
| 19,370 | 4,484 | 3,730 | 3,894 | 3,446 | 3,816 |
|
| 223 |
+
|
| 224 |
+
Not complete data
|
| 225 |
+
|
| 226 |
+
| only age not found | only gender not found | SUM |
|
| 227 |
+
| ------------------ | --------------------- | ------------- |
|
| 228 |
+
| 40 | 1170 | 1,210 (6.2 %) |
|
| 229 |
+
|
| 230 |
+
Removed data
|
| 231 |
+
|
| 232 |
+
| failed to process image | age and gender not found | SUM |
|
| 233 |
+
| ----------------------- | ------------------------ | ----------- |
|
| 234 |
+
| 0 | 708 | 708 (3.6 %) |
|
| 235 |
+
|
| 236 |
+
Genders
|
| 237 |
+
|
| 238 |
+
| female | male |
|
| 239 |
+
| ------ | ----- |
|
| 240 |
+
| 9,372 | 8,120 |
|
| 241 |
+
|
| 242 |
+
Ages (8 classes) after mapping to not intersected ages intervals
|
| 243 |
+
|
| 244 |
+
| 0-2 | 4-6 | 8-12 | 15-20 | 25-32 | 38-43 | 48-53 | 60-100 |
|
| 245 |
+
| ----- | ----- | ----- | ----- | ----- | ----- | ----- | ------ |
|
| 246 |
+
| 2,509 | 2,140 | 2,293 | 1,791 | 5,589 | 2,490 | 909 | 901 |
|
| 247 |
+
|
| 248 |
+
</details>
|
| 249 |
+
|
| 250 |
+
- FairFace dataset: follow [these instructions](https://github.com/joojs/fairface) to get images and [download](https://drive.google.com/file/d/1EdY30A1SQmox96Y39VhBxdgALYhbkzdm/view?usp=drive_link) our annotations.
|
| 251 |
+
<details>
|
| 252 |
+
<summary>Click to expand!</summary>
|
| 253 |
+
|
| 254 |
+
After downloading them, your `data` directory should look something like this:
|
| 255 |
+
|
| 256 |
+
```console
|
| 257 |
+
data
|
| 258 |
+
└── FairFace
|
| 259 |
+
├── annotations (folder with our annotations)
|
| 260 |
+
├── fairface-img-margin025-trainval (will not be used)
|
| 261 |
+
├── train
|
| 262 |
+
├── val
|
| 263 |
+
├── fairface-img-margin125-trainval
|
| 264 |
+
├── train
|
| 265 |
+
├── val
|
| 266 |
+
├── fairface_label_train.csv
|
| 267 |
+
├── fairface_label_val.csv
|
| 268 |
+
|
| 269 |
+
```
|
| 270 |
+
|
| 271 |
+
We use aligned images from `fairface-img-margin125-trainval/` dir.
|
| 272 |
+
|
| 273 |
+
Using our detector we found a face bbox for each image and added a person bbox if it was possible (see [tools/prepare_fairface.py](tools/prepare_fairface.py)).
|
| 274 |
+
|
| 275 |
+
This dataset has 2 splits: train and val. The performance metric is accuracy on validation.
|
| 276 |
+
|
| 277 |
+
| images train | images val |
|
| 278 |
+
| ------------ | ---------- |
|
| 279 |
+
| 86,744 | 10,954 |
|
| 280 |
+
|
| 281 |
+
Genders for **validation**
|
| 282 |
+
|
| 283 |
+
| female | male |
|
| 284 |
+
| ------ | ----- |
|
| 285 |
+
| 5,162 | 5,792 |
|
| 286 |
+
|
| 287 |
+
Ages for **validation** (9 classes):
|
| 288 |
+
|
| 289 |
+
| 0-2 | 3-9 | 10-19 | 20-29 | 30-39 | 40-49 | 50-59 | 60-69 | 70+ |
|
| 290 |
+
| --- | ----- | ----- | ----- | ----- | ----- | ----- | ----- | --- |
|
| 291 |
+
| 199 | 1,356 | 1,181 | 3,300 | 2,330 | 1,353 | 796 | 321 | 118 |
|
| 292 |
+
|
| 293 |
+
</details>
|
| 294 |
+
- AgeDB dataset: follow [these instructions](https://ibug.doc.ic.ac.uk/resources/agedb/) to get images and [download](https://drive.google.com/file/d/1Dp72BUlAsyUKeSoyE_DOsFRS1x6ZBJen/view) our annotations.
|
| 295 |
+
<details>
|
| 296 |
+
<summary>Click to expand!</summary>
|
| 297 |
+
|
| 298 |
+
**Ages**: 1 - 101
|
| 299 |
+
|
| 300 |
+
**Genders**: 9788 faces of `M`, 6700 faces of `F`
|
| 301 |
+
|
| 302 |
+
| images 0 | images 1 | images 2 | images 3 | images 4 | images 5 | images 6 | images 7 | images 8 | images 9 |
|
| 303 |
+
|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|
|
| 304 |
+
| 1701 | 1721 | 1615 | 1619 | 1626 | 1643 | 1634 | 1596 | 1676 | 1657 |
|
| 305 |
+
|
| 306 |
+
Data splits were taken from [here](https://github.com/paplhjak/Facial-Age-Estimation-Benchmark-Databases)
|
| 307 |
+
|
| 308 |
+
!! **All splits(all dataset) were used for models evaluation.**
|
| 309 |
+
</details>
|
| 310 |
+
|
| 311 |
+
## Install
|
| 312 |
+
|
| 313 |
+
Install pytorch 1.13+ and other requirements.
|
| 314 |
+
|
| 315 |
+
```
|
| 316 |
+
pip install -r requirements.txt
|
| 317 |
+
pip install .
|
| 318 |
+
```
|
| 319 |
+
|
| 320 |
+
|
| 321 |
+
## Demo
|
| 322 |
+
|
| 323 |
+
1. [Download](https://drive.google.com/file/d/1CGNCkZQNj5WkP3rLpENWAOgrBQkUWRdw/view) body + face detector model to `models/yolov8x_person_face.pt`
|
| 324 |
+
2. [Download](https://drive.google.com/file/d/11i8pKctxz3wVkDBlWKvhYIh7kpVFXSZ4/view) mivolo checkpoint to `models/mivolo_imbd.pth.tar`
|
| 325 |
+
|
| 326 |
+
```bash
|
| 327 |
+
wget https://variety.com/wp-content/uploads/2023/04/MCDNOHA_SP001.jpg -O jennifer_lawrence.jpg
|
| 328 |
+
|
| 329 |
+
python3 demo.py \
|
| 330 |
+
--input "jennifer_lawrence.jpg" \
|
| 331 |
+
--output "output" \
|
| 332 |
+
--detector-weights "models/yolov8x_person_face.pt " \
|
| 333 |
+
--checkpoint "models/mivolo_imbd.pth.tar" \
|
| 334 |
+
--device "cuda:0" \
|
| 335 |
+
--with-persons \
|
| 336 |
+
--draw
|
| 337 |
+
```
|
| 338 |
+
|
| 339 |
+
To run demo for a youtube video:
|
| 340 |
+
```bash
|
| 341 |
+
python3 demo.py \
|
| 342 |
+
--input "https://www.youtube.com/shorts/pVh32k0hGEI" \
|
| 343 |
+
--output "output" \
|
| 344 |
+
--detector-weights "models/yolov8x_person_face.pt" \
|
| 345 |
+
--checkpoint "models/mivolo_imbd.pth.tar" \
|
| 346 |
+
--device "cuda:0" \
|
| 347 |
+
--draw \
|
| 348 |
+
--with-persons
|
| 349 |
+
```
|
| 350 |
+
|
| 351 |
+
|
| 352 |
+
## Validation
|
| 353 |
+
|
| 354 |
+
To reproduce validation metrics:
|
| 355 |
+
|
| 356 |
+
1. Download prepared annotations for imbd-clean / utk / adience / lagenda / fairface.
|
| 357 |
+
2. Download checkpoint
|
| 358 |
+
3. Run validation:
|
| 359 |
+
|
| 360 |
+
```bash
|
| 361 |
+
python3 eval_pretrained.py \
|
| 362 |
+
--dataset_images /path/to/dataset/utk/images \
|
| 363 |
+
--dataset_annotations /path/to/dataset/utk/annotation \
|
| 364 |
+
--dataset_name utk \
|
| 365 |
+
--split valid \
|
| 366 |
+
--batch-size 512 \
|
| 367 |
+
--checkpoint models/mivolo_imbd.pth.tar \
|
| 368 |
+
--half \
|
| 369 |
+
--with-persons \
|
| 370 |
+
--device "cuda:0"
|
| 371 |
+
````
|
| 372 |
+
|
| 373 |
+
Supported dataset names: "utk", "imdb", "lagenda", "fairface", "adience".
|
| 374 |
+
|
| 375 |
+
|
| 376 |
+
## Changelog
|
| 377 |
+
|
| 378 |
+
[CHANGELOG.md](CHANGELOG.md)
|
| 379 |
+
|
| 380 |
+
## ONNX and TensorRT export
|
| 381 |
+
|
| 382 |
+
As of now (11.08.2023), while ONNX export is technically feasible, it is not advisable due to the poor performance of the resulting model with batch processing.
|
| 383 |
+
**TensorRT** and **OpenVINO** export is impossible due to its lack of support for col2im.
|
| 384 |
+
|
| 385 |
+
If you remain absolutely committed to utilizing ONNX export, you can refer to [these instructions](https://github.com/WildChlamydia/MiVOLO/issues/14#issuecomment-1675245889).
|
| 386 |
+
|
| 387 |
+
The most highly recommended export method at present **is using TorchScript**. You can achieve this with a single line of code:
|
| 388 |
+
```python
|
| 389 |
+
torch.jit.trace(model)
|
| 390 |
+
```
|
| 391 |
+
This approach provides you with a model that maintains its original speed and only requires a single file for usage, eliminating the need for additional code.
|
| 392 |
+
|
| 393 |
+
## License
|
| 394 |
+
|
| 395 |
+
Please, see [here](./license)
|
| 396 |
+
|
| 397 |
+
|
| 398 |
+
## Citing
|
| 399 |
+
|
| 400 |
+
If you use our models, code or dataset, we kindly request you to cite the following paper and give repository a :star:
|
| 401 |
+
|
| 402 |
+
```bibtex
|
| 403 |
+
@article{mivolo2023,
|
| 404 |
+
Author = {Maksim Kuprashevich and Irina Tolstykh},
|
| 405 |
+
Title = {MiVOLO: Multi-input Transformer for Age and Gender Estimation},
|
| 406 |
+
Year = {2023},
|
| 407 |
+
Eprint = {arXiv:2307.04616},
|
| 408 |
+
}
|
| 409 |
+
```
|
| 410 |
+
```bibtex
|
| 411 |
+
@article{mivolo2024,
|
| 412 |
+
Author = {Maksim Kuprashevich and Grigorii Alekseenko and Irina Tolstykh},
|
| 413 |
+
Title = {Beyond Specialization: Assessing the Capabilities of MLLMs in Age and Gender Estimation},
|
| 414 |
+
Year = {2024},
|
| 415 |
+
Eprint = {arXiv:2403.02302},
|
| 416 |
+
}
|
| 417 |
+
```
|
age_estimator/mivolo/__pycache__/demo_copy.cpython-38.pyc
ADDED
|
Binary file (4.06 kB). View file
|
|
|
age_estimator/mivolo/demo.py
ADDED
|
@@ -0,0 +1,145 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import logging
|
| 3 |
+
import os
|
| 4 |
+
import random
|
| 5 |
+
|
| 6 |
+
import cv2
|
| 7 |
+
import torch
|
| 8 |
+
import yt_dlp
|
| 9 |
+
from mivolo.data.data_reader import InputType, get_all_files, get_input_type
|
| 10 |
+
from mivolo.predictor import Predictor
|
| 11 |
+
from timm.utils import setup_default_logging
|
| 12 |
+
|
| 13 |
+
_logger = logging.getLogger("inference")
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def get_direct_video_url(video_url):
|
| 17 |
+
ydl_opts = {
|
| 18 |
+
"format": "bestvideo",
|
| 19 |
+
"quiet": True, # Suppress terminal output
|
| 20 |
+
}
|
| 21 |
+
|
| 22 |
+
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
|
| 23 |
+
info_dict = ydl.extract_info(video_url, download=False)
|
| 24 |
+
|
| 25 |
+
if "url" in info_dict:
|
| 26 |
+
direct_url = info_dict["url"]
|
| 27 |
+
resolution = (info_dict["width"], info_dict["height"])
|
| 28 |
+
fps = info_dict["fps"]
|
| 29 |
+
yid = info_dict["id"]
|
| 30 |
+
return direct_url, resolution, fps, yid
|
| 31 |
+
|
| 32 |
+
return None, None, None, None
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def get_local_video_info(vid_uri):
|
| 36 |
+
cap = cv2.VideoCapture(vid_uri)
|
| 37 |
+
if not cap.isOpened():
|
| 38 |
+
raise ValueError(f"Failed to open video source {vid_uri}")
|
| 39 |
+
res = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
|
| 40 |
+
fps = cap.get(cv2.CAP_PROP_FPS)
|
| 41 |
+
return res, fps
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def get_random_frames(cap, num_frames):
|
| 45 |
+
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
|
| 46 |
+
frame_indices = random.sample(range(total_frames), num_frames)
|
| 47 |
+
|
| 48 |
+
frames = []
|
| 49 |
+
for idx in frame_indices:
|
| 50 |
+
cap.set(cv2.CAP_PROP_POS_FRAMES, idx)
|
| 51 |
+
ret, frame = cap.read()
|
| 52 |
+
if ret:
|
| 53 |
+
frames.append(frame)
|
| 54 |
+
return frames
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def get_parser():
|
| 58 |
+
parser = argparse.ArgumentParser(description="PyTorch MiVOLO Inference")
|
| 59 |
+
parser.add_argument("--input", type=str, default=None, required=True, help="image file or folder with images")
|
| 60 |
+
parser.add_argument("--output", type=str, default=None, required=True, help="folder for output results")
|
| 61 |
+
parser.add_argument("--detector-weights", type=str, default=None, required=True, help="Detector weights (YOLOv8).")
|
| 62 |
+
parser.add_argument("--checkpoint", default="", type=str, required=True, help="path to mivolo checkpoint")
|
| 63 |
+
|
| 64 |
+
parser.add_argument(
|
| 65 |
+
"--with-persons", action="store_true", default=False, help="If set model will run with persons, if available"
|
| 66 |
+
)
|
| 67 |
+
parser.add_argument(
|
| 68 |
+
"--disable-faces", action="store_true", default=False, help="If set model will use only persons if available"
|
| 69 |
+
)
|
| 70 |
+
|
| 71 |
+
parser.add_argument("--draw", action="store_true", default=False, help="If set, resulted images will be drawn")
|
| 72 |
+
parser.add_argument("--device", default="cuda", type=str, help="Device (accelerator) to use.")
|
| 73 |
+
|
| 74 |
+
return parser
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def main():
|
| 78 |
+
parser = get_parser()
|
| 79 |
+
setup_default_logging()
|
| 80 |
+
args = parser.parse_args()
|
| 81 |
+
|
| 82 |
+
if torch.cuda.is_available():
|
| 83 |
+
torch.backends.cuda.matmul.allow_tf32 = True
|
| 84 |
+
torch.backends.cudnn.benchmark = True
|
| 85 |
+
os.makedirs(args.output, exist_ok=True)
|
| 86 |
+
|
| 87 |
+
predictor = Predictor(args, verbose=True)
|
| 88 |
+
|
| 89 |
+
input_type = get_input_type(args.input)
|
| 90 |
+
|
| 91 |
+
if input_type == InputType.Video or input_type == InputType.VideoStream:
|
| 92 |
+
if "youtube" in args.input:
|
| 93 |
+
args.input, res, fps, yid = get_direct_video_url(args.input)
|
| 94 |
+
if not args.input:
|
| 95 |
+
raise ValueError(f"Failed to get direct video url {args.input}")
|
| 96 |
+
else:
|
| 97 |
+
cap = cv2.VideoCapture(args.input)
|
| 98 |
+
if not cap.isOpened():
|
| 99 |
+
raise ValueError(f"Failed to open video source {args.input}")
|
| 100 |
+
|
| 101 |
+
# Extract 4-5 random frames from the video
|
| 102 |
+
random_frames = get_random_frames(cap, num_frames=5)
|
| 103 |
+
|
| 104 |
+
age_list = []
|
| 105 |
+
for frame in random_frames:
|
| 106 |
+
detected_objects, out_im, age = predictor.recognize(frame)
|
| 107 |
+
age_list.append(age[0])
|
| 108 |
+
|
| 109 |
+
if args.draw:
|
| 110 |
+
bname = os.path.splitext(os.path.basename(args.input))[0]
|
| 111 |
+
filename = os.path.join(args.output, f"out_{bname}.jpg")
|
| 112 |
+
cv2.imwrite(filename, out_im)
|
| 113 |
+
_logger.info(f"Saved result to {filename}")
|
| 114 |
+
|
| 115 |
+
# Calculate and print average age
|
| 116 |
+
avg_age = sum(age_list) / len(age_list) if age_list else 0
|
| 117 |
+
print(f"Age list: {age_list}")
|
| 118 |
+
print(f"Average age: {avg_age:.2f}")
|
| 119 |
+
absolute_age = round(abs(avg_age))
|
| 120 |
+
# Define the range
|
| 121 |
+
lower_bound = absolute_age - 2
|
| 122 |
+
upper_bound = absolute_age + 2
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
return absolute_age, lower_bound, upper_bound
|
| 126 |
+
|
| 127 |
+
elif input_type == InputType.Image:
|
| 128 |
+
image_files = get_all_files(args.input) if os.path.isdir(args.input) else [args.input]
|
| 129 |
+
|
| 130 |
+
for img_p in image_files:
|
| 131 |
+
img = cv2.imread(img_p)
|
| 132 |
+
detected_objects, out_im, age = predictor.recognize(img)
|
| 133 |
+
|
| 134 |
+
if args.draw:
|
| 135 |
+
bname = os.path.splitext(os.path.basename(img_p))[0]
|
| 136 |
+
filename = os.path.join(args.output, f"out_{bname}.jpg")
|
| 137 |
+
cv2.imwrite(filename, out_im)
|
| 138 |
+
_logger.info(f"Saved result to {filename}")
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
if __name__ == "__main__":
|
| 142 |
+
absolute_age, lower_bound, upper_bound = main()
|
| 143 |
+
# Output the results in the desired format
|
| 144 |
+
print(f"Absolute Age: {absolute_age}")
|
| 145 |
+
print(f"Range: {lower_bound} - {upper_bound}")
|
age_estimator/mivolo/demo_copy.py
ADDED
|
@@ -0,0 +1,144 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import logging
|
| 3 |
+
import os
|
| 4 |
+
import random
|
| 5 |
+
|
| 6 |
+
import cv2
|
| 7 |
+
import torch
|
| 8 |
+
import yt_dlp
|
| 9 |
+
import sys
|
| 10 |
+
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '././')))
|
| 11 |
+
|
| 12 |
+
from mivolo.data.data_reader import InputType, get_all_files, get_input_type
|
| 13 |
+
from mivolo.predictor import Predictor
|
| 14 |
+
from timm.utils import setup_default_logging
|
| 15 |
+
|
| 16 |
+
_logger = logging.getLogger("inference")
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def get_direct_video_url(video_url):
|
| 20 |
+
ydl_opts = {
|
| 21 |
+
"format": "bestvideo",
|
| 22 |
+
"quiet": True, # Suppress terminal output
|
| 23 |
+
}
|
| 24 |
+
|
| 25 |
+
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
|
| 26 |
+
info_dict = ydl.extract_info(video_url, download=False)
|
| 27 |
+
|
| 28 |
+
if "url" in info_dict:
|
| 29 |
+
direct_url = info_dict["url"]
|
| 30 |
+
resolution = (info_dict["width"], info_dict["height"])
|
| 31 |
+
fps = info_dict["fps"]
|
| 32 |
+
yid = info_dict["id"]
|
| 33 |
+
return direct_url, resolution, fps, yid
|
| 34 |
+
|
| 35 |
+
return None, None, None, None
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def get_random_frames(cap, num_frames):
|
| 39 |
+
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
|
| 40 |
+
frame_indices = random.sample(range(total_frames), num_frames)
|
| 41 |
+
|
| 42 |
+
frames = []
|
| 43 |
+
for idx in frame_indices:
|
| 44 |
+
cap.set(cv2.CAP_PROP_POS_FRAMES, idx)
|
| 45 |
+
ret, frame = cap.read()
|
| 46 |
+
if ret:
|
| 47 |
+
frames.append(frame)
|
| 48 |
+
return frames
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def get_parser():
|
| 52 |
+
parser = argparse.ArgumentParser(description="PyTorch MiVOLO Inference")
|
| 53 |
+
parser.add_argument("--input", type=str, default=None, required=True, help="image file or folder with images")
|
| 54 |
+
parser.add_argument("--output", type=str, default=None, required=True, help="folder for output results")
|
| 55 |
+
parser.add_argument("--detector-weights", type=str, default=None, required=True, help="Detector weights (YOLOv8).")
|
| 56 |
+
parser.add_argument("--checkpoint", default="", type=str, required=True, help="path to mivolo checkpoint")
|
| 57 |
+
|
| 58 |
+
parser.add_argument(
|
| 59 |
+
"--with_persons", action="store_true", default=False, help="If set model will run with persons, if available"
|
| 60 |
+
)
|
| 61 |
+
parser.add_argument(
|
| 62 |
+
"--disable_faces", action="store_true", default=False, help="If set model will use only persons if available"
|
| 63 |
+
)
|
| 64 |
+
|
| 65 |
+
parser.add_argument("--draw", action="store_true", default=False, help="If set, resulted images will be drawn")
|
| 66 |
+
parser.add_argument("--device", default="cpu", type=str, help="Device (accelerator) to use.")
|
| 67 |
+
|
| 68 |
+
return parser
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def main(video_path, output_folder, detector_weights, checkpoint, device, with_persons, disable_faces,draw=False):
|
| 72 |
+
setup_default_logging()
|
| 73 |
+
|
| 74 |
+
if torch.cuda.is_available():
|
| 75 |
+
torch.backends.cuda.matmul.allow_tf32 = True
|
| 76 |
+
torch.backends.cudnn.benchmark = True
|
| 77 |
+
|
| 78 |
+
os.makedirs(output_folder, exist_ok=True)
|
| 79 |
+
|
| 80 |
+
# Initialize predictor
|
| 81 |
+
args = argparse.Namespace(
|
| 82 |
+
input=video_path,
|
| 83 |
+
output=output_folder,
|
| 84 |
+
detector_weights=detector_weights,
|
| 85 |
+
checkpoint=checkpoint,
|
| 86 |
+
draw=draw,
|
| 87 |
+
device=device,
|
| 88 |
+
with_persons=with_persons,
|
| 89 |
+
disable_faces=disable_faces
|
| 90 |
+
)
|
| 91 |
+
|
| 92 |
+
predictor = Predictor(args, verbose=True)
|
| 93 |
+
|
| 94 |
+
if "youtube" in video_path:
|
| 95 |
+
video_path, res, fps, yid = get_direct_video_url(video_path)
|
| 96 |
+
if not video_path:
|
| 97 |
+
raise ValueError(f"Failed to get direct video url {video_path}")
|
| 98 |
+
|
| 99 |
+
cap = cv2.VideoCapture(video_path)
|
| 100 |
+
if not cap.isOpened():
|
| 101 |
+
raise ValueError(f"Failed to open video source {video_path}")
|
| 102 |
+
|
| 103 |
+
# Extract 4-5 random frames from the video
|
| 104 |
+
random_frames = get_random_frames(cap, num_frames=10)
|
| 105 |
+
age_list = []
|
| 106 |
+
|
| 107 |
+
for frame in random_frames:
|
| 108 |
+
detected_objects, out_im, age = predictor.recognize(frame)
|
| 109 |
+
try:
|
| 110 |
+
age_list.append(age[0]) # Attempt to access the first element of age
|
| 111 |
+
if draw:
|
| 112 |
+
bname = os.path.splitext(os.path.basename(video_path))[0]
|
| 113 |
+
filename = os.path.join(output_folder, f"out_{bname}.jpg")
|
| 114 |
+
cv2.imwrite(filename, out_im)
|
| 115 |
+
_logger.info(f"Saved result to {filename}")
|
| 116 |
+
except IndexError:
|
| 117 |
+
continue
|
| 118 |
+
|
| 119 |
+
if len(age_list)==0:
|
| 120 |
+
raise ValueError("No person was detected in the frame. Please upload a proper face video.")
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
# Calculate and print average age
|
| 125 |
+
avg_age = sum(age_list) / len(age_list) if age_list else 0
|
| 126 |
+
print(f"Age list: {age_list}")
|
| 127 |
+
print(f"Average age: {avg_age:.2f}")
|
| 128 |
+
absolute_age = round(abs(avg_age))
|
| 129 |
+
|
| 130 |
+
# Define the range
|
| 131 |
+
lower_bound = absolute_age - 2
|
| 132 |
+
upper_bound = absolute_age + 2
|
| 133 |
+
|
| 134 |
+
return absolute_age, lower_bound, upper_bound
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
if __name__ == "__main__":
|
| 138 |
+
parser = get_parser()
|
| 139 |
+
args = parser.parse_args()
|
| 140 |
+
|
| 141 |
+
absolute_age, lower_bound, upper_bound = main(args.input, args.output, args.detector_weights, args.checkpoint, args.device, args.with_persons, args.disable_faces ,args.draw)
|
| 142 |
+
# Output the results in the desired format
|
| 143 |
+
print(f"Absolute Age: {absolute_age}")
|
| 144 |
+
print(f"Range: {lower_bound} - {upper_bound}")
|
age_estimator/mivolo/eval_pretrained.py
ADDED
|
@@ -0,0 +1,232 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import json
|
| 3 |
+
import logging
|
| 4 |
+
from typing import Tuple
|
| 5 |
+
|
| 6 |
+
import matplotlib.pyplot as plt
|
| 7 |
+
import seaborn as sns
|
| 8 |
+
import torch
|
| 9 |
+
from eval_tools import Metrics, time_sync, write_results
|
| 10 |
+
from mivolo.data.dataset import build as build_data
|
| 11 |
+
from mivolo.model.mi_volo import MiVOLO
|
| 12 |
+
from timm.utils import setup_default_logging
|
| 13 |
+
|
| 14 |
+
_logger = logging.getLogger("inference")
|
| 15 |
+
LOG_FREQUENCY = 10
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def get_parser():
|
| 19 |
+
parser = argparse.ArgumentParser(description="PyTorch MiVOLO Validation")
|
| 20 |
+
parser.add_argument("--dataset_images", default="", type=str, required=True, help="path to images")
|
| 21 |
+
parser.add_argument("--dataset_annotations", default="", type=str, required=True, help="path to annotations")
|
| 22 |
+
parser.add_argument(
|
| 23 |
+
"--dataset_name",
|
| 24 |
+
default=None,
|
| 25 |
+
type=str,
|
| 26 |
+
required=True,
|
| 27 |
+
choices=["utk", "imdb", "lagenda", "fairface", "adience", "agedb", "cacd"],
|
| 28 |
+
help="dataset name",
|
| 29 |
+
)
|
| 30 |
+
parser.add_argument("--split", default="validation", help="dataset splits separated by comma (default: validation)")
|
| 31 |
+
parser.add_argument("--checkpoint", default="", type=str, required=True, help="path to mivolo checkpoint")
|
| 32 |
+
|
| 33 |
+
parser.add_argument("--batch-size", default=64, type=int, help="batch size")
|
| 34 |
+
parser.add_argument(
|
| 35 |
+
"--workers", default=4, type=int, metavar="N", help="number of data loading workers (default: 4)"
|
| 36 |
+
)
|
| 37 |
+
parser.add_argument("--device", default="cuda", type=str, help="Device (accelerator) to use.")
|
| 38 |
+
parser.add_argument("--l-for-cs", type=int, default=5, help="L for CS (cumulative score)")
|
| 39 |
+
|
| 40 |
+
parser.add_argument("--half", action="store_true", default=False, help="use half-precision model")
|
| 41 |
+
parser.add_argument(
|
| 42 |
+
"--with-persons", action="store_true", default=False, help="If the model will run with persons, if available"
|
| 43 |
+
)
|
| 44 |
+
parser.add_argument(
|
| 45 |
+
"--disable-faces", action="store_true", default=False, help="If the model will use only persons if available"
|
| 46 |
+
)
|
| 47 |
+
|
| 48 |
+
parser.add_argument("--draw-hist", action="store_true", help="Draws the hist of error by age")
|
| 49 |
+
parser.add_argument(
|
| 50 |
+
"--results-file",
|
| 51 |
+
default="",
|
| 52 |
+
type=str,
|
| 53 |
+
metavar="FILENAME",
|
| 54 |
+
help="Output csv file for validation results (summary)",
|
| 55 |
+
)
|
| 56 |
+
parser.add_argument(
|
| 57 |
+
"--results-format", default="csv", type=str, help="Format for results file one of (csv, json) (default: csv)."
|
| 58 |
+
)
|
| 59 |
+
|
| 60 |
+
return parser
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def process_batch(
|
| 64 |
+
mivolo_model: MiVOLO,
|
| 65 |
+
input: torch.tensor,
|
| 66 |
+
target: torch.tensor,
|
| 67 |
+
num_classes_gender: int = 2,
|
| 68 |
+
):
|
| 69 |
+
|
| 70 |
+
start = time_sync()
|
| 71 |
+
output = mivolo_model.inference(input)
|
| 72 |
+
# target with age == -1 and gender == -1 marks that sample is not valid
|
| 73 |
+
assert not (all(target[:, 0] == -1) and all(target[:, 1] == -1))
|
| 74 |
+
|
| 75 |
+
if not mivolo_model.meta.only_age:
|
| 76 |
+
gender_out = output[:, :num_classes_gender]
|
| 77 |
+
gender_target = target[:, 1]
|
| 78 |
+
age_out = output[:, num_classes_gender:]
|
| 79 |
+
else:
|
| 80 |
+
age_out = output
|
| 81 |
+
gender_out, gender_target = None, None
|
| 82 |
+
|
| 83 |
+
# measure elapsed time
|
| 84 |
+
process_time = time_sync() - start
|
| 85 |
+
|
| 86 |
+
age_target = target[:, 0].unsqueeze(1)
|
| 87 |
+
|
| 88 |
+
return age_out, age_target, gender_out, gender_target, process_time
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def _filter_invalid_target(out: torch.tensor, target: torch.tensor):
|
| 92 |
+
# exclude samples where target gt == -1, that marks sample is not valid
|
| 93 |
+
mask = target != -1
|
| 94 |
+
return out[mask], target[mask]
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
def postprocess_gender(gender_out: torch.tensor, gender_target: torch.tensor) -> Tuple[torch.tensor, torch.tensor]:
|
| 98 |
+
if gender_target is None:
|
| 99 |
+
return gender_out, gender_target
|
| 100 |
+
return _filter_invalid_target(gender_out, gender_target)
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
def postprocess_age(age_out: torch.tensor, age_target: torch.tensor, dataset) -> Tuple[torch.tensor, torch.tensor]:
|
| 104 |
+
# Revert _norm_age() operation. Output is 2 float tensors
|
| 105 |
+
|
| 106 |
+
age_out, age_target = _filter_invalid_target(age_out, age_target)
|
| 107 |
+
|
| 108 |
+
age_out = age_out * (dataset.max_age - dataset.min_age) + dataset.avg_age
|
| 109 |
+
# clamp to 0 because age can be below zero
|
| 110 |
+
age_out = torch.clamp(age_out, min=0)
|
| 111 |
+
|
| 112 |
+
if dataset.age_classes is not None:
|
| 113 |
+
# classification case
|
| 114 |
+
age_out = torch.round(age_out)
|
| 115 |
+
if dataset._intervals.device != age_out.device:
|
| 116 |
+
dataset._intervals = dataset._intervals.to(age_out.device)
|
| 117 |
+
age_inds = torch.searchsorted(dataset._intervals, age_out, side="right") - 1
|
| 118 |
+
age_out = age_inds
|
| 119 |
+
else:
|
| 120 |
+
age_target = age_target * (dataset.max_age - dataset.min_age) + dataset.avg_age
|
| 121 |
+
return age_out, age_target
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
def validate(args):
|
| 125 |
+
|
| 126 |
+
if torch.cuda.is_available():
|
| 127 |
+
torch.backends.cuda.matmul.allow_tf32 = True
|
| 128 |
+
torch.backends.cudnn.benchmark = True
|
| 129 |
+
|
| 130 |
+
mivolo_model = MiVOLO(
|
| 131 |
+
args.checkpoint,
|
| 132 |
+
args.device,
|
| 133 |
+
half=args.half,
|
| 134 |
+
use_persons=args.with_persons,
|
| 135 |
+
disable_faces=args.disable_faces,
|
| 136 |
+
verbose=True,
|
| 137 |
+
)
|
| 138 |
+
|
| 139 |
+
dataset, loader = build_data(
|
| 140 |
+
name=args.dataset_name,
|
| 141 |
+
images_path=args.dataset_images,
|
| 142 |
+
annotations_path=args.dataset_annotations,
|
| 143 |
+
split=args.split,
|
| 144 |
+
mivolo_model=mivolo_model, # to get meta information from model
|
| 145 |
+
workers=args.workers,
|
| 146 |
+
batch_size=args.batch_size,
|
| 147 |
+
)
|
| 148 |
+
|
| 149 |
+
d_stat = Metrics(args.l_for_cs, args.draw_hist, dataset.age_classes)
|
| 150 |
+
|
| 151 |
+
# warmup, reduce variability of first batch time, especially for comparing torchscript vs non
|
| 152 |
+
mivolo_model.warmup(args.batch_size)
|
| 153 |
+
|
| 154 |
+
preproc_end = time_sync()
|
| 155 |
+
for batch_idx, (input, target) in enumerate(loader):
|
| 156 |
+
|
| 157 |
+
preprocess_time = time_sync() - preproc_end
|
| 158 |
+
# get output and calculate loss
|
| 159 |
+
age_out, age_target, gender_out, gender_target, process_time = process_batch(
|
| 160 |
+
mivolo_model, input, target, dataset.num_classes_gender
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
gender_out, gender_target = postprocess_gender(gender_out, gender_target)
|
| 164 |
+
age_out, age_target = postprocess_age(age_out, age_target, dataset)
|
| 165 |
+
|
| 166 |
+
d_stat.update_gender_accuracy(gender_out, gender_target)
|
| 167 |
+
if d_stat.is_regression:
|
| 168 |
+
d_stat.update_regression_age_metrics(age_out, age_target)
|
| 169 |
+
else:
|
| 170 |
+
d_stat.update_age_accuracy(age_out, age_target)
|
| 171 |
+
d_stat.update_time(process_time, preprocess_time, input.shape[0])
|
| 172 |
+
|
| 173 |
+
if batch_idx % LOG_FREQUENCY == 0:
|
| 174 |
+
_logger.info(
|
| 175 |
+
"Test: [{0:>4d}/{1}] " "{2}".format(batch_idx, len(loader), d_stat.get_info_str(input.size(0)))
|
| 176 |
+
)
|
| 177 |
+
|
| 178 |
+
preproc_end = time_sync()
|
| 179 |
+
|
| 180 |
+
# model info
|
| 181 |
+
results = dict(
|
| 182 |
+
model=args.checkpoint,
|
| 183 |
+
dataset_name=args.dataset_name,
|
| 184 |
+
param_count=round(mivolo_model.param_count / 1e6, 2),
|
| 185 |
+
img_size=mivolo_model.input_size,
|
| 186 |
+
use_faces=mivolo_model.meta.use_face_crops,
|
| 187 |
+
use_persons=mivolo_model.meta.use_persons,
|
| 188 |
+
in_chans=mivolo_model.meta.in_chans,
|
| 189 |
+
batch=args.batch_size,
|
| 190 |
+
)
|
| 191 |
+
# metrics info
|
| 192 |
+
results.update(d_stat.get_result())
|
| 193 |
+
return results
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
def main():
|
| 197 |
+
parser = get_parser()
|
| 198 |
+
setup_default_logging()
|
| 199 |
+
args = parser.parse_args()
|
| 200 |
+
|
| 201 |
+
if torch.cuda.is_available():
|
| 202 |
+
torch.backends.cuda.matmul.allow_tf32 = True
|
| 203 |
+
torch.backends.cudnn.benchmark = True
|
| 204 |
+
|
| 205 |
+
results = validate(args)
|
| 206 |
+
|
| 207 |
+
result_str = " * Age Acc@1 {:.3f} ({:.3f})".format(results["agetop1"], results["agetop1_err"])
|
| 208 |
+
if "gendertop1" in results:
|
| 209 |
+
result_str += " Gender Acc@1 1 {:.3f} ({:.3f})".format(results["gendertop1"], results["gendertop1_err"])
|
| 210 |
+
result_str += " Mean inference time {:.3f} ms Mean preprocessing time {:.3f}".format(
|
| 211 |
+
results["mean_inference_time"], results["mean_preprocessing_time"]
|
| 212 |
+
)
|
| 213 |
+
_logger.info(result_str)
|
| 214 |
+
|
| 215 |
+
if args.draw_hist and "per_age_error" in results:
|
| 216 |
+
err = [sum(v) / len(v) for k, v in results["per_age_error"].items()]
|
| 217 |
+
ages = list(results["per_age_error"].keys())
|
| 218 |
+
sns.scatterplot(x=ages, y=err, hue=err)
|
| 219 |
+
plt.legend([], [], frameon=False)
|
| 220 |
+
plt.xlabel("Age")
|
| 221 |
+
plt.ylabel("MAE")
|
| 222 |
+
plt.savefig("age_error.png", dpi=300)
|
| 223 |
+
|
| 224 |
+
if args.results_file:
|
| 225 |
+
write_results(args.results_file, results, format=args.results_format)
|
| 226 |
+
|
| 227 |
+
# output results in JSON to stdout w/ delimiter for runner script
|
| 228 |
+
print(f"--result\n{json.dumps(results, indent=4)}")
|
| 229 |
+
|
| 230 |
+
|
| 231 |
+
if __name__ == "__main__":
|
| 232 |
+
main()
|
age_estimator/mivolo/eval_tools.py
ADDED
|
@@ -0,0 +1,149 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import csv
|
| 2 |
+
import json
|
| 3 |
+
import time
|
| 4 |
+
from collections import OrderedDict, defaultdict
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
from mivolo.data.misc import cumulative_error, cumulative_score
|
| 8 |
+
from timm.utils import AverageMeter, accuracy
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def time_sync():
|
| 12 |
+
# pytorch-accurate time
|
| 13 |
+
if torch.cuda.is_available():
|
| 14 |
+
torch.cuda.synchronize()
|
| 15 |
+
return time.time()
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def write_results(results_file, results, format="csv"):
|
| 19 |
+
with open(results_file, mode="w") as cf:
|
| 20 |
+
if format == "json":
|
| 21 |
+
json.dump(results, cf, indent=4)
|
| 22 |
+
else:
|
| 23 |
+
if not isinstance(results, (list, tuple)):
|
| 24 |
+
results = [results]
|
| 25 |
+
if not results:
|
| 26 |
+
return
|
| 27 |
+
dw = csv.DictWriter(cf, fieldnames=results[0].keys())
|
| 28 |
+
dw.writeheader()
|
| 29 |
+
for r in results:
|
| 30 |
+
dw.writerow(r)
|
| 31 |
+
cf.flush()
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class Metrics:
|
| 35 |
+
def __init__(self, l_for_cs, draw_hist, age_classes=None):
|
| 36 |
+
self.batch_time = AverageMeter()
|
| 37 |
+
self.preproc_batch_time = AverageMeter()
|
| 38 |
+
self.seen = 0
|
| 39 |
+
|
| 40 |
+
self.losses = AverageMeter()
|
| 41 |
+
self.top1_m_gender = AverageMeter()
|
| 42 |
+
self.top1_m_age = AverageMeter()
|
| 43 |
+
|
| 44 |
+
if age_classes is None:
|
| 45 |
+
self.is_regression = True
|
| 46 |
+
self.av_csl_age = AverageMeter()
|
| 47 |
+
self.max_error = AverageMeter()
|
| 48 |
+
self.per_age_error = defaultdict(list)
|
| 49 |
+
self.l_for_cs = l_for_cs
|
| 50 |
+
else:
|
| 51 |
+
self.is_regression = False
|
| 52 |
+
|
| 53 |
+
self.draw_hist = draw_hist
|
| 54 |
+
|
| 55 |
+
def update_regression_age_metrics(self, age_out, age_target):
|
| 56 |
+
batch_size = age_out.size(0)
|
| 57 |
+
|
| 58 |
+
age_abs_err = torch.abs(age_out - age_target)
|
| 59 |
+
age_acc1 = torch.sum(age_abs_err) / age_out.shape[0]
|
| 60 |
+
age_csl = cumulative_score(age_out, age_target, self.l_for_cs)
|
| 61 |
+
me = cumulative_error(age_out, age_target, 20)
|
| 62 |
+
|
| 63 |
+
self.top1_m_age.update(age_acc1.item(), batch_size)
|
| 64 |
+
self.av_csl_age.update(age_csl.item(), batch_size)
|
| 65 |
+
self.max_error.update(me.item(), batch_size)
|
| 66 |
+
|
| 67 |
+
if self.draw_hist:
|
| 68 |
+
for i in range(age_out.shape[0]):
|
| 69 |
+
self.per_age_error[int(age_target[i].item())].append(age_abs_err[i].item())
|
| 70 |
+
|
| 71 |
+
def update_age_accuracy(self, age_out, age_target):
|
| 72 |
+
batch_size = age_out.size(0)
|
| 73 |
+
if batch_size == 0:
|
| 74 |
+
return
|
| 75 |
+
correct = torch.sum(age_out == age_target)
|
| 76 |
+
age_acc1 = correct * 100.0 / batch_size
|
| 77 |
+
self.top1_m_age.update(age_acc1.item(), batch_size)
|
| 78 |
+
|
| 79 |
+
def update_gender_accuracy(self, gender_out, gender_target):
|
| 80 |
+
if gender_out is None or gender_out.size(0) == 0:
|
| 81 |
+
return
|
| 82 |
+
batch_size = gender_out.size(0)
|
| 83 |
+
gender_acc1 = accuracy(gender_out, gender_target, topk=(1,))[0]
|
| 84 |
+
if gender_acc1 is not None:
|
| 85 |
+
self.top1_m_gender.update(gender_acc1.item(), batch_size)
|
| 86 |
+
|
| 87 |
+
def update_loss(self, loss, batch_size):
|
| 88 |
+
self.losses.update(loss.item(), batch_size)
|
| 89 |
+
|
| 90 |
+
def update_time(self, process_time, preprocess_time, batch_size):
|
| 91 |
+
self.seen += batch_size
|
| 92 |
+
self.batch_time.update(process_time)
|
| 93 |
+
self.preproc_batch_time.update(preprocess_time)
|
| 94 |
+
|
| 95 |
+
def get_info_str(self, batch_size):
|
| 96 |
+
avg_time = (self.preproc_batch_time.sum + self.batch_time.sum) / self.batch_time.count
|
| 97 |
+
cur_time = self.batch_time.val + self.preproc_batch_time.val
|
| 98 |
+
middle_info = (
|
| 99 |
+
"Time: {cur_time:.3f}s ({avg_time:.3f}s, {rate_avg:>7.2f}/s) "
|
| 100 |
+
"Loss: {loss.val:>7.4f} ({loss.avg:>6.4f}) "
|
| 101 |
+
"Gender Acc: {top1gender.val:>7.2f} ({top1gender.avg:>7.2f}) ".format(
|
| 102 |
+
cur_time=cur_time,
|
| 103 |
+
avg_time=avg_time,
|
| 104 |
+
rate_avg=batch_size / avg_time,
|
| 105 |
+
loss=self.losses,
|
| 106 |
+
top1gender=self.top1_m_gender,
|
| 107 |
+
)
|
| 108 |
+
)
|
| 109 |
+
|
| 110 |
+
if self.is_regression:
|
| 111 |
+
age_info = (
|
| 112 |
+
"Age CS@{l_for_cs}: {csl.val:>7.4f} ({csl.avg:>7.4f}) "
|
| 113 |
+
"Age CE@20: {max_error.val:>7.4f} ({max_error.avg:>7.4f}) "
|
| 114 |
+
"Age ME: {top1age.val:>7.2f} ({top1age.avg:>7.2f})".format(
|
| 115 |
+
top1age=self.top1_m_age, csl=self.av_csl_age, max_error=self.max_error, l_for_cs=self.l_for_cs
|
| 116 |
+
)
|
| 117 |
+
)
|
| 118 |
+
else:
|
| 119 |
+
age_info = "Age Acc: {top1age.val:>7.2f} ({top1age.avg:>7.2f})".format(top1age=self.top1_m_age)
|
| 120 |
+
|
| 121 |
+
return middle_info + age_info
|
| 122 |
+
|
| 123 |
+
def get_result(self):
|
| 124 |
+
age_top1a = self.top1_m_age.avg
|
| 125 |
+
gender_top1 = self.top1_m_gender.avg if self.top1_m_gender.count > 0 else None
|
| 126 |
+
|
| 127 |
+
mean_per_image_time = self.batch_time.sum / self.seen
|
| 128 |
+
mean_preprocessing_time = self.preproc_batch_time.sum / self.seen
|
| 129 |
+
|
| 130 |
+
results = OrderedDict(
|
| 131 |
+
mean_inference_time=mean_per_image_time * 1e3,
|
| 132 |
+
mean_preprocessing_time=mean_preprocessing_time * 1e3,
|
| 133 |
+
agetop1=round(age_top1a, 4),
|
| 134 |
+
agetop1_err=round(100 - age_top1a, 4),
|
| 135 |
+
)
|
| 136 |
+
|
| 137 |
+
if self.is_regression:
|
| 138 |
+
results.update(
|
| 139 |
+
dict(
|
| 140 |
+
max_error=self.max_error.avg,
|
| 141 |
+
csl=self.av_csl_age.avg,
|
| 142 |
+
per_age_error=self.per_age_error,
|
| 143 |
+
)
|
| 144 |
+
)
|
| 145 |
+
|
| 146 |
+
if gender_top1 is not None:
|
| 147 |
+
results.update(dict(gendertop1=round(gender_top1, 4), gendertop1_err=round(100 - gender_top1, 4)))
|
| 148 |
+
|
| 149 |
+
return results
|
age_estimator/mivolo/images/MiVOLO.jpg
ADDED
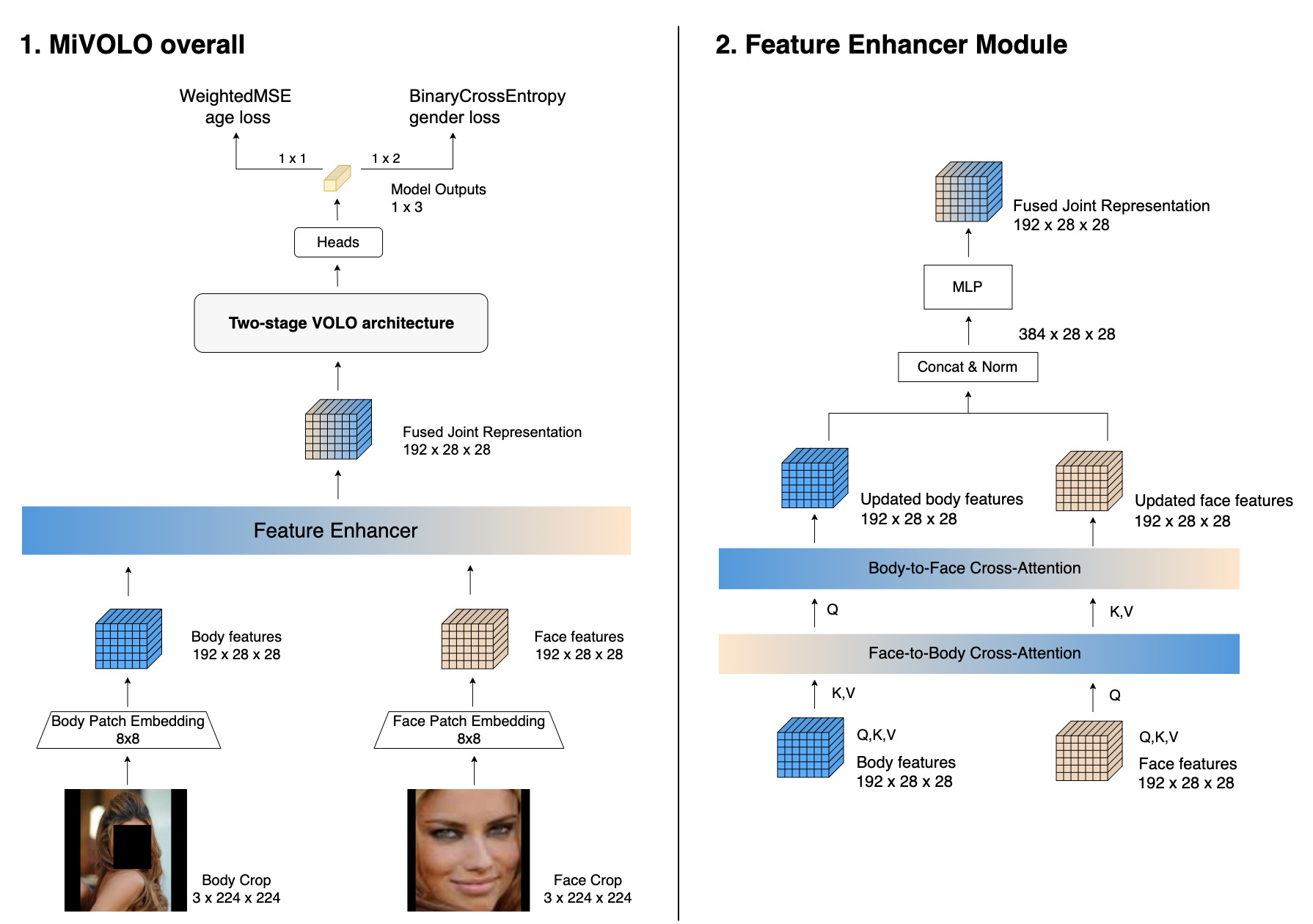
|
age_estimator/mivolo/infer.py
ADDED
|
@@ -0,0 +1,88 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
import pathlib
|
| 3 |
+
import os
|
| 4 |
+
import huggingface_hub
|
| 5 |
+
import numpy as np
|
| 6 |
+
import argparse
|
| 7 |
+
from dataclasses import dataclass
|
| 8 |
+
from mivolo.predictor import Predictor
|
| 9 |
+
from PIL import Image
|
| 10 |
+
|
| 11 |
+
@dataclass
|
| 12 |
+
class Cfg:
|
| 13 |
+
detector_weights: str
|
| 14 |
+
checkpoint: str
|
| 15 |
+
device: str = "cpu"
|
| 16 |
+
with_persons: bool = True
|
| 17 |
+
disable_faces: bool = False
|
| 18 |
+
draw: bool = True
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def load_models():
|
| 22 |
+
detector_path = huggingface_hub.hf_hub_download('iitolstykh/demo_yolov8_detector',
|
| 23 |
+
'yolov8x_person_face.pt')
|
| 24 |
+
|
| 25 |
+
age_gender_path_v1 = 'age_estimator/MiVOLO-main/models/model_imdb_cross_person_4.22_99.46.pth.tar'
|
| 26 |
+
predictor_cfg_v1 = Cfg(detector_path, age_gender_path_v1)
|
| 27 |
+
|
| 28 |
+
predictor_v1 = Predictor(predictor_cfg_v1)
|
| 29 |
+
|
| 30 |
+
return predictor_v1
|
| 31 |
+
|
| 32 |
+
def detect(image: np.ndarray, score_threshold: float, iou_threshold: float, mode: str, predictor: Predictor) -> np.ndarray:
|
| 33 |
+
predictor.detector.detector_kwargs['conf'] = score_threshold
|
| 34 |
+
predictor.detector.detector_kwargs['iou'] = iou_threshold
|
| 35 |
+
|
| 36 |
+
if mode == "Use persons and faces":
|
| 37 |
+
use_persons = True
|
| 38 |
+
disable_faces = False
|
| 39 |
+
elif mode == "Use persons only":
|
| 40 |
+
use_persons = True
|
| 41 |
+
disable_faces = True
|
| 42 |
+
elif mode == "Use faces only":
|
| 43 |
+
use_persons = False
|
| 44 |
+
disable_faces = False
|
| 45 |
+
|
| 46 |
+
predictor.age_gender_model.meta.use_persons = use_persons
|
| 47 |
+
predictor.age_gender_model.meta.disable_faces = disable_faces
|
| 48 |
+
|
| 49 |
+
image = image[:, :, ::-1] # RGB -> BGR for OpenCV
|
| 50 |
+
detected_objects, out_im = predictor.recognize(image)
|
| 51 |
+
return out_im[:, :, ::-1] # BGR -> RGB
|
| 52 |
+
|
| 53 |
+
def load_image(image_path: str):
|
| 54 |
+
image = Image.open(image_path)
|
| 55 |
+
image_np = np.array(image)
|
| 56 |
+
return image_np
|
| 57 |
+
|
| 58 |
+
def main(args):
|
| 59 |
+
# Load models
|
| 60 |
+
predictor_v1 = load_models()
|
| 61 |
+
|
| 62 |
+
# Set parameters from args
|
| 63 |
+
score_threshold = args.score_threshold
|
| 64 |
+
iou_threshold = args.iou_threshold
|
| 65 |
+
mode = args.mode
|
| 66 |
+
|
| 67 |
+
# Load and process image
|
| 68 |
+
image_np = load_image(args.image_path)
|
| 69 |
+
|
| 70 |
+
# Predict with model
|
| 71 |
+
result = detect(image_np, score_threshold, iou_threshold, mode, predictor_v1)
|
| 72 |
+
|
| 73 |
+
output_image = Image.fromarray(result)
|
| 74 |
+
output_image.save(args.output_path)
|
| 75 |
+
output_image.show()
|
| 76 |
+
|
| 77 |
+
if __name__ == "__main__":
|
| 78 |
+
parser = argparse.ArgumentParser(description='Object Detection with YOLOv8 and Age/Gender Prediction')
|
| 79 |
+
parser.add_argument('--image_path', type=str, required=True, help='Path to the input image')
|
| 80 |
+
parser.add_argument('--output_path', type=str, default='output_image.jpg', help='Path to save the output image')
|
| 81 |
+
parser.add_argument('--score_threshold', type=float, default=0.4, help='Score threshold for detection')
|
| 82 |
+
parser.add_argument('--iou_threshold', type=float, default=0.7, help='IoU threshold for detection')
|
| 83 |
+
parser.add_argument('--mode', type=str, choices=["Use persons and faces", "Use persons only", "Use faces only"],
|
| 84 |
+
default="Use persons and faces", help='Detection mode')
|
| 85 |
+
|
| 86 |
+
args = parser.parse_args()
|
| 87 |
+
main(args)
|
| 88 |
+
|
age_estimator/mivolo/license/en_us.pdf
ADDED
|
Binary file (158 kB). View file
|
|
|
age_estimator/mivolo/license/ru.pdf
ADDED
|
Binary file (199 kB). View file
|
|
|
age_estimator/mivolo/measure_time.py
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pandas as pd
|
| 2 |
+
import torch
|
| 3 |
+
import tqdm
|
| 4 |
+
from eval_tools import time_sync
|
| 5 |
+
from mivolo.model.create_timm_model import create_model
|
| 6 |
+
|
| 7 |
+
if __name__ == "__main__":
|
| 8 |
+
|
| 9 |
+
face_person_ckpt_path = "/data/dataset/iikrasnova/age_gender/pretrained/checkpoint-377.pth.tar"
|
| 10 |
+
face_person_input_size = [6, 224, 224]
|
| 11 |
+
|
| 12 |
+
face_age_ckpt_path = "/data/dataset/iikrasnova/age_gender/pretrained/model_only_age_imdb_4.32.pth.tar"
|
| 13 |
+
face_input_size = [3, 224, 224]
|
| 14 |
+
|
| 15 |
+
model_names = ["face_body_model", "face_model"]
|
| 16 |
+
# batch_size = 16
|
| 17 |
+
steps = 1000
|
| 18 |
+
warmup_steps = 10
|
| 19 |
+
device = torch.device("cuda:1")
|
| 20 |
+
|
| 21 |
+
df_data = []
|
| 22 |
+
batch_sizes = [1, 2, 4, 8, 16, 32, 64, 128, 256, 512]
|
| 23 |
+
|
| 24 |
+
for ckpt_path, input_size, model_name, num_classes in zip(
|
| 25 |
+
[face_person_ckpt_path, face_age_ckpt_path], [face_person_input_size, face_input_size], model_names, [3, 1]
|
| 26 |
+
):
|
| 27 |
+
|
| 28 |
+
in_chans = input_size[0]
|
| 29 |
+
print(f"Collecting stat for {ckpt_path} ...")
|
| 30 |
+
model = create_model(
|
| 31 |
+
"mivolo_d1_224",
|
| 32 |
+
num_classes=num_classes,
|
| 33 |
+
in_chans=in_chans,
|
| 34 |
+
pretrained=False,
|
| 35 |
+
checkpoint_path=ckpt_path,
|
| 36 |
+
filter_keys=["fds."],
|
| 37 |
+
)
|
| 38 |
+
model = model.to(device)
|
| 39 |
+
model.eval()
|
| 40 |
+
model = model.half()
|
| 41 |
+
|
| 42 |
+
time_per_batch = {}
|
| 43 |
+
for batch_size in batch_sizes:
|
| 44 |
+
create_t0 = time_sync()
|
| 45 |
+
for _ in range(steps):
|
| 46 |
+
inputs = torch.randn((batch_size,) + tuple(input_size)).to(device).half()
|
| 47 |
+
create_t1 = time_sync()
|
| 48 |
+
create_taken = create_t1 - create_t0
|
| 49 |
+
|
| 50 |
+
with torch.no_grad():
|
| 51 |
+
inputs = torch.randn((batch_size,) + tuple(input_size)).to(device).half()
|
| 52 |
+
for _ in range(warmup_steps):
|
| 53 |
+
out = model(inputs)
|
| 54 |
+
|
| 55 |
+
all_time = 0
|
| 56 |
+
for _ in tqdm.tqdm(range(steps), desc=f"{model_name} batch {batch_size}"):
|
| 57 |
+
start = time_sync()
|
| 58 |
+
inputs = torch.randn((batch_size,) + tuple(input_size)).to(device).half()
|
| 59 |
+
out = model(inputs)
|
| 60 |
+
out += 1
|
| 61 |
+
end = time_sync()
|
| 62 |
+
all_time += end - start
|
| 63 |
+
|
| 64 |
+
time_taken = (all_time - create_taken) * 1000 / steps / batch_size
|
| 65 |
+
print(f"Inference {inputs.shape}, steps: {steps}. Mean time taken {time_taken} ms / image")
|
| 66 |
+
|
| 67 |
+
time_per_batch[str(batch_size)] = f"{time_taken:.2f}"
|
| 68 |
+
df_data.append(time_per_batch)
|
| 69 |
+
|
| 70 |
+
headers = list(map(str, batch_sizes))
|
| 71 |
+
output_df = pd.DataFrame(df_data, columns=headers)
|
| 72 |
+
output_df.index = model_names
|
| 73 |
+
|
| 74 |
+
df2_transposed = output_df.T
|
| 75 |
+
out_file = "batch_sizes.csv"
|
| 76 |
+
df2_transposed.to_csv(out_file, sep=",")
|
| 77 |
+
print(f"Saved time stat for {len(df2_transposed)} batches to {out_file}")
|
age_estimator/mivolo/mivolo/__init__.py
ADDED
|
File without changes
|
age_estimator/mivolo/mivolo/__pycache__/__init__.cpython-38.pyc
ADDED
|
Binary file (156 Bytes). View file
|
|
|
age_estimator/mivolo/mivolo/__pycache__/predictor.cpython-38.pyc
ADDED
|
Binary file (2.52 kB). View file
|
|
|
age_estimator/mivolo/mivolo/__pycache__/structures.cpython-38.pyc
ADDED
|
Binary file (17 kB). View file
|
|
|
age_estimator/mivolo/mivolo/data/__init__.py
ADDED
|
File without changes
|
age_estimator/mivolo/mivolo/data/__pycache__/__init__.cpython-38.pyc
ADDED
|
Binary file (161 Bytes). View file
|
|
|
age_estimator/mivolo/mivolo/data/__pycache__/data_reader.cpython-38.pyc
ADDED
|
Binary file (5.23 kB). View file
|
|
|
age_estimator/mivolo/mivolo/data/__pycache__/misc.cpython-38.pyc
ADDED
|
Binary file (7.47 kB). View file
|
|
|
age_estimator/mivolo/mivolo/data/data_reader.py
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from collections import defaultdict
|
| 3 |
+
from dataclasses import dataclass, field
|
| 4 |
+
from enum import Enum
|
| 5 |
+
from typing import Dict, List, Optional, Tuple
|
| 6 |
+
|
| 7 |
+
import pandas as pd
|
| 8 |
+
|
| 9 |
+
IMAGES_EXT: Tuple = (".jpeg", ".jpg", ".png", ".webp", ".bmp", ".gif")
|
| 10 |
+
VIDEO_EXT: Tuple = (".mp4", ".avi", ".mov", ".mkv", ".webm")
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
@dataclass
|
| 14 |
+
class PictureInfo:
|
| 15 |
+
image_path: str
|
| 16 |
+
age: Optional[str] # age or age range(start;end format) or "-1"
|
| 17 |
+
gender: Optional[str] # "M" of "F" or "-1"
|
| 18 |
+
bbox: List[int] = field(default_factory=lambda: [-1, -1, -1, -1]) # face bbox: xyxy
|
| 19 |
+
person_bbox: List[int] = field(default_factory=lambda: [-1, -1, -1, -1]) # person bbox: xyxy
|
| 20 |
+
|
| 21 |
+
@property
|
| 22 |
+
def has_person_bbox(self) -> bool:
|
| 23 |
+
return any(coord != -1 for coord in self.person_bbox)
|
| 24 |
+
|
| 25 |
+
@property
|
| 26 |
+
def has_face_bbox(self) -> bool:
|
| 27 |
+
return any(coord != -1 for coord in self.bbox)
|
| 28 |
+
|
| 29 |
+
def has_gt(self, only_age: bool = False) -> bool:
|
| 30 |
+
if only_age:
|
| 31 |
+
return self.age != "-1"
|
| 32 |
+
else:
|
| 33 |
+
return not (self.age == "-1" and self.gender == "-1")
|
| 34 |
+
|
| 35 |
+
def clear_person_bbox(self):
|
| 36 |
+
self.person_bbox = [-1, -1, -1, -1]
|
| 37 |
+
|
| 38 |
+
def clear_face_bbox(self):
|
| 39 |
+
self.bbox = [-1, -1, -1, -1]
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
class AnnotType(Enum):
|
| 43 |
+
ORIGINAL = "original"
|
| 44 |
+
PERSONS = "persons"
|
| 45 |
+
NONE = "none"
|
| 46 |
+
|
| 47 |
+
@classmethod
|
| 48 |
+
def _missing_(cls, value):
|
| 49 |
+
print(f"WARN: Unknown annotation type {value}.")
|
| 50 |
+
return AnnotType.NONE
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def get_all_files(path: str, extensions: Tuple = IMAGES_EXT):
|
| 54 |
+
files_all = []
|
| 55 |
+
for root, subFolders, files in os.walk(path):
|
| 56 |
+
for name in files:
|
| 57 |
+
# linux tricks with .directory that still is file
|
| 58 |
+
if "directory" not in name and sum([ext.lower() in name.lower() for ext in extensions]) > 0:
|
| 59 |
+
files_all.append(os.path.join(root, name))
|
| 60 |
+
return files_all
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
class InputType(Enum):
|
| 64 |
+
Image = 0
|
| 65 |
+
Video = 1
|
| 66 |
+
VideoStream = 2
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def get_input_type(input_path: str) -> InputType:
|
| 70 |
+
if os.path.isdir(input_path):
|
| 71 |
+
print("Input is a folder, only images will be processed")
|
| 72 |
+
return InputType.Image
|
| 73 |
+
elif os.path.isfile(input_path):
|
| 74 |
+
if input_path.endswith(VIDEO_EXT):
|
| 75 |
+
return InputType.Video
|
| 76 |
+
if input_path.endswith(IMAGES_EXT):
|
| 77 |
+
return InputType.Image
|
| 78 |
+
else:
|
| 79 |
+
raise ValueError(
|
| 80 |
+
f"Unknown or unsupported input file format {input_path}, \
|
| 81 |
+
supported video formats: {VIDEO_EXT}, \
|
| 82 |
+
supported image formats: {IMAGES_EXT}"
|
| 83 |
+
)
|
| 84 |
+
elif input_path.startswith("http") and not input_path.endswith(IMAGES_EXT):
|
| 85 |
+
return InputType.VideoStream
|
| 86 |
+
else:
|
| 87 |
+
raise ValueError(f"Unknown input {input_path}")
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
def read_csv_annotation_file(annotation_file: str, images_dir: str, ignore_without_gt=False):
|
| 91 |
+
bboxes_per_image: Dict[str, List[PictureInfo]] = defaultdict(list)
|
| 92 |
+
|
| 93 |
+
df = pd.read_csv(annotation_file, sep=",")
|
| 94 |
+
|
| 95 |
+
annot_type = AnnotType("persons") if "person_x0" in df.columns else AnnotType("original")
|
| 96 |
+
print(f"Reading {annotation_file} (type: {annot_type})...")
|
| 97 |
+
|
| 98 |
+
missing_images = 0
|
| 99 |
+
for index, row in df.iterrows():
|
| 100 |
+
img_path = os.path.join(images_dir, row["img_name"])
|
| 101 |
+
if not os.path.exists(img_path):
|
| 102 |
+
missing_images += 1
|
| 103 |
+
continue
|
| 104 |
+
|
| 105 |
+
face_x1, face_y1, face_x2, face_y2 = row["face_x0"], row["face_y0"], row["face_x1"], row["face_y1"]
|
| 106 |
+
age, gender = str(row["age"]), str(row["gender"])
|
| 107 |
+
|
| 108 |
+
if ignore_without_gt and (age == "-1" or gender == "-1"):
|
| 109 |
+
continue
|
| 110 |
+
|
| 111 |
+
if annot_type == AnnotType.PERSONS:
|
| 112 |
+
p_x1, p_y1, p_x2, p_y2 = row["person_x0"], row["person_y0"], row["person_x1"], row["person_y1"]
|
| 113 |
+
person_bbox = list(map(int, [p_x1, p_y1, p_x2, p_y2]))
|
| 114 |
+
else:
|
| 115 |
+
person_bbox = [-1, -1, -1, -1]
|
| 116 |
+
|
| 117 |
+
bbox = list(map(int, [face_x1, face_y1, face_x2, face_y2]))
|
| 118 |
+
pic_info = PictureInfo(img_path, age, gender, bbox, person_bbox)
|
| 119 |
+
assert isinstance(pic_info.person_bbox, list)
|
| 120 |
+
|
| 121 |
+
bboxes_per_image[img_path].append(pic_info)
|
| 122 |
+
|
| 123 |
+
if missing_images > 0:
|
| 124 |
+
print(f"WARNING: Missing images: {missing_images}/{len(df)}")
|
| 125 |
+
return bboxes_per_image, annot_type
|
age_estimator/mivolo/mivolo/data/dataset/__init__.py
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Tuple
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from mivolo.model.mi_volo import MiVOLO
|
| 5 |
+
|
| 6 |
+
from .age_gender_dataset import AgeGenderDataset
|
| 7 |
+
from .age_gender_loader import create_loader
|
| 8 |
+
from .classification_dataset import AdienceDataset, FairFaceDataset
|
| 9 |
+
|
| 10 |
+
DATASET_CLASS_MAP = {
|
| 11 |
+
"utk": AgeGenderDataset,
|
| 12 |
+
"lagenda": AgeGenderDataset,
|
| 13 |
+
"imdb": AgeGenderDataset,
|
| 14 |
+
"agedb": AgeGenderDataset,
|
| 15 |
+
"cacd": AgeGenderDataset,
|
| 16 |
+
"adience": AdienceDataset,
|
| 17 |
+
"fairface": FairFaceDataset,
|
| 18 |
+
}
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def build(
|
| 22 |
+
name: str,
|
| 23 |
+
images_path: str,
|
| 24 |
+
annotations_path: str,
|
| 25 |
+
split: str,
|
| 26 |
+
mivolo_model: MiVOLO,
|
| 27 |
+
workers: int,
|
| 28 |
+
batch_size: int,
|
| 29 |
+
) -> Tuple[torch.utils.data.Dataset, torch.utils.data.DataLoader]:
|
| 30 |
+
|
| 31 |
+
dataset_class = DATASET_CLASS_MAP[name]
|
| 32 |
+
|
| 33 |
+
dataset: torch.utils.data.Dataset = dataset_class(
|
| 34 |
+
images_path=images_path,
|
| 35 |
+
annotations_path=annotations_path,
|
| 36 |
+
name=name,
|
| 37 |
+
split=split,
|
| 38 |
+
target_size=mivolo_model.input_size,
|
| 39 |
+
max_age=mivolo_model.meta.max_age,
|
| 40 |
+
min_age=mivolo_model.meta.min_age,
|
| 41 |
+
model_with_persons=mivolo_model.meta.with_persons_model,
|
| 42 |
+
use_persons=mivolo_model.meta.use_persons,
|
| 43 |
+
disable_faces=mivolo_model.meta.disable_faces,
|
| 44 |
+
only_age=mivolo_model.meta.only_age,
|
| 45 |
+
)
|
| 46 |
+
|
| 47 |
+
data_config = mivolo_model.data_config
|
| 48 |
+
|
| 49 |
+
in_chans = 3 if not mivolo_model.meta.with_persons_model else 6
|
| 50 |
+
input_size = (in_chans, mivolo_model.input_size, mivolo_model.input_size)
|
| 51 |
+
|
| 52 |
+
dataset_loader: torch.utils.data.DataLoader = create_loader(
|
| 53 |
+
dataset,
|
| 54 |
+
input_size=input_size,
|
| 55 |
+
batch_size=batch_size,
|
| 56 |
+
mean=data_config["mean"],
|
| 57 |
+
std=data_config["std"],
|
| 58 |
+
num_workers=workers,
|
| 59 |
+
crop_pct=data_config["crop_pct"],
|
| 60 |
+
crop_mode=data_config["crop_mode"],
|
| 61 |
+
pin_memory=False,
|
| 62 |
+
device=mivolo_model.device,
|
| 63 |
+
target_type=dataset.target_dtype,
|
| 64 |
+
)
|
| 65 |
+
|
| 66 |
+
return dataset, dataset_loader
|
age_estimator/mivolo/mivolo/data/dataset/age_gender_dataset.py
ADDED
|
@@ -0,0 +1,194 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
from typing import Any, List, Optional, Set
|
| 3 |
+
|
| 4 |
+
import cv2
|
| 5 |
+
import numpy as np
|
| 6 |
+
import torch
|
| 7 |
+
from mivolo.data.dataset.reader_age_gender import ReaderAgeGender
|
| 8 |
+
from PIL import Image
|
| 9 |
+
from torchvision import transforms
|
| 10 |
+
|
| 11 |
+
_logger = logging.getLogger("AgeGenderDataset")
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class AgeGenderDataset(torch.utils.data.Dataset):
|
| 15 |
+
def __init__(
|
| 16 |
+
self,
|
| 17 |
+
images_path,
|
| 18 |
+
annotations_path,
|
| 19 |
+
name=None,
|
| 20 |
+
split="train",
|
| 21 |
+
load_bytes=False,
|
| 22 |
+
img_mode="RGB",
|
| 23 |
+
transform=None,
|
| 24 |
+
is_training=False,
|
| 25 |
+
seed=1234,
|
| 26 |
+
target_size=224,
|
| 27 |
+
min_age=None,
|
| 28 |
+
max_age=None,
|
| 29 |
+
model_with_persons=False,
|
| 30 |
+
use_persons=False,
|
| 31 |
+
disable_faces=False,
|
| 32 |
+
only_age=False,
|
| 33 |
+
):
|
| 34 |
+
reader = ReaderAgeGender(
|
| 35 |
+
images_path,
|
| 36 |
+
annotations_path,
|
| 37 |
+
split=split,
|
| 38 |
+
seed=seed,
|
| 39 |
+
target_size=target_size,
|
| 40 |
+
with_persons=use_persons,
|
| 41 |
+
disable_faces=disable_faces,
|
| 42 |
+
only_age=only_age,
|
| 43 |
+
)
|
| 44 |
+
|
| 45 |
+
self.name = name
|
| 46 |
+
self.model_with_persons = model_with_persons
|
| 47 |
+
self.reader = reader
|
| 48 |
+
self.load_bytes = load_bytes
|
| 49 |
+
self.img_mode = img_mode
|
| 50 |
+
self.transform = transform
|
| 51 |
+
self._consecutive_errors = 0
|
| 52 |
+
self.is_training = is_training
|
| 53 |
+
self.random_flip = 0.0
|
| 54 |
+
|
| 55 |
+
# Setting up classes.
|
| 56 |
+
# If min and max classes are passed - use them to have the same preprocessing for validation
|
| 57 |
+
self.max_age: float = None
|
| 58 |
+
self.min_age: float = None
|
| 59 |
+
self.avg_age: float = None
|
| 60 |
+
self.set_ages_min_max(min_age, max_age)
|
| 61 |
+
|
| 62 |
+
self.genders = ["M", "F"]
|
| 63 |
+
self.num_classes_gender = len(self.genders)
|
| 64 |
+
|
| 65 |
+
self.age_classes: Optional[List[str]] = self.set_age_classes()
|
| 66 |
+
|
| 67 |
+
self.num_classes_age = 1 if self.age_classes is None else len(self.age_classes)
|
| 68 |
+
self.num_classes: int = self.num_classes_age + self.num_classes_gender
|
| 69 |
+
self.target_dtype = torch.float32
|
| 70 |
+
|
| 71 |
+
def set_age_classes(self) -> Optional[List[str]]:
|
| 72 |
+
return None # for regression dataset
|
| 73 |
+
|
| 74 |
+
def set_ages_min_max(self, min_age: Optional[float], max_age: Optional[float]):
|
| 75 |
+
|
| 76 |
+
assert all(age is None for age in [min_age, max_age]) or all(
|
| 77 |
+
age is not None for age in [min_age, max_age]
|
| 78 |
+
), "Both min and max age must be passed or none of them"
|
| 79 |
+
|
| 80 |
+
if max_age is not None and min_age is not None:
|
| 81 |
+
_logger.info(f"Received predefined min_age {min_age} and max_age {max_age}")
|
| 82 |
+
self.max_age = max_age
|
| 83 |
+
self.min_age = min_age
|
| 84 |
+
else:
|
| 85 |
+
# collect statistics from loaded dataset
|
| 86 |
+
all_ages_set: Set[int] = set()
|
| 87 |
+
for img_path, image_samples in self.reader._ann.items():
|
| 88 |
+
for image_sample_info in image_samples:
|
| 89 |
+
if image_sample_info.age == "-1":
|
| 90 |
+
continue
|
| 91 |
+
age = round(float(image_sample_info.age))
|
| 92 |
+
all_ages_set.add(age)
|
| 93 |
+
|
| 94 |
+
self.max_age = max(all_ages_set)
|
| 95 |
+
self.min_age = min(all_ages_set)
|
| 96 |
+
|
| 97 |
+
self.avg_age = (self.max_age + self.min_age) / 2.0
|
| 98 |
+
|
| 99 |
+
def _norm_age(self, age):
|
| 100 |
+
return (age - self.avg_age) / (self.max_age - self.min_age)
|
| 101 |
+
|
| 102 |
+
def parse_gender(self, _gender: str) -> float:
|
| 103 |
+
if _gender != "-1":
|
| 104 |
+
gender = float(0 if _gender == "M" or _gender == "0" else 1)
|
| 105 |
+
else:
|
| 106 |
+
gender = -1
|
| 107 |
+
return gender
|
| 108 |
+
|
| 109 |
+
def parse_target(self, _age: str, gender: str) -> List[Any]:
|
| 110 |
+
if _age != "-1":
|
| 111 |
+
age = round(float(_age))
|
| 112 |
+
age = self._norm_age(float(age))
|
| 113 |
+
else:
|
| 114 |
+
age = -1
|
| 115 |
+
|
| 116 |
+
target: List[float] = [age, self.parse_gender(gender)]
|
| 117 |
+
return target
|
| 118 |
+
|
| 119 |
+
@property
|
| 120 |
+
def transform(self):
|
| 121 |
+
return self._transform
|
| 122 |
+
|
| 123 |
+
@transform.setter
|
| 124 |
+
def transform(self, transform):
|
| 125 |
+
# Disable pretrained monkey-patched transforms
|
| 126 |
+
if not transform:
|
| 127 |
+
return
|
| 128 |
+
|
| 129 |
+
_trans = []
|
| 130 |
+
for trans in transform.transforms:
|
| 131 |
+
if "Resize" in str(trans):
|
| 132 |
+
continue
|
| 133 |
+
if "Crop" in str(trans):
|
| 134 |
+
continue
|
| 135 |
+
_trans.append(trans)
|
| 136 |
+
self._transform = transforms.Compose(_trans)
|
| 137 |
+
|
| 138 |
+
def apply_tranforms(self, image: Optional[np.ndarray]) -> np.ndarray:
|
| 139 |
+
if image is None:
|
| 140 |
+
return None
|
| 141 |
+
|
| 142 |
+
if self.transform is None:
|
| 143 |
+
return image
|
| 144 |
+
|
| 145 |
+
image = convert_to_pil(image, self.img_mode)
|
| 146 |
+
for trans in self.transform.transforms:
|
| 147 |
+
image = trans(image)
|
| 148 |
+
return image
|
| 149 |
+
|
| 150 |
+
def __getitem__(self, index):
|
| 151 |
+
# get preprocessed face and person crops (np.ndarray)
|
| 152 |
+
# resize + pad, for person crops: cut off other bboxes
|
| 153 |
+
images, target = self.reader[index]
|
| 154 |
+
|
| 155 |
+
target = self.parse_target(*target)
|
| 156 |
+
|
| 157 |
+
if self.model_with_persons:
|
| 158 |
+
face_image, person_image = images
|
| 159 |
+
person_image: np.ndarray = self.apply_tranforms(person_image)
|
| 160 |
+
else:
|
| 161 |
+
face_image = images[0]
|
| 162 |
+
person_image = None
|
| 163 |
+
|
| 164 |
+
face_image: np.ndarray = self.apply_tranforms(face_image)
|
| 165 |
+
|
| 166 |
+
if person_image is not None:
|
| 167 |
+
img = np.concatenate([face_image, person_image], axis=0)
|
| 168 |
+
else:
|
| 169 |
+
img = face_image
|
| 170 |
+
|
| 171 |
+
return img, target
|
| 172 |
+
|
| 173 |
+
def __len__(self):
|
| 174 |
+
return len(self.reader)
|
| 175 |
+
|
| 176 |
+
def filename(self, index, basename=False, absolute=False):
|
| 177 |
+
return self.reader.filename(index, basename, absolute)
|
| 178 |
+
|
| 179 |
+
def filenames(self, basename=False, absolute=False):
|
| 180 |
+
return self.reader.filenames(basename, absolute)
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
def convert_to_pil(cv_im: Optional[np.ndarray], img_mode: str = "RGB") -> "Image":
|
| 184 |
+
if cv_im is None:
|
| 185 |
+
return None
|
| 186 |
+
|
| 187 |
+
if img_mode == "RGB":
|
| 188 |
+
cv_im = cv2.cvtColor(cv_im, cv2.COLOR_BGR2RGB)
|
| 189 |
+
else:
|
| 190 |
+
raise Exception("Incorrect image mode has been passed!")
|
| 191 |
+
|
| 192 |
+
cv_im = np.ascontiguousarray(cv_im)
|
| 193 |
+
pil_image = Image.fromarray(cv_im)
|
| 194 |
+
return pil_image
|
age_estimator/mivolo/mivolo/data/dataset/age_gender_loader.py
ADDED
|
@@ -0,0 +1,169 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Code adapted from timm https://github.com/huggingface/pytorch-image-models
|
| 3 |
+
|
| 4 |
+
Modifications and additions for mivolo by / Copyright 2023, Irina Tolstykh, Maxim Kuprashevich
|
| 5 |
+
"""
|
| 6 |
+
|
| 7 |
+
import logging
|
| 8 |
+
from contextlib import suppress
|
| 9 |
+
from functools import partial
|
| 10 |
+
from itertools import repeat
|
| 11 |
+
|
| 12 |
+
import numpy as np
|
| 13 |
+
import torch
|
| 14 |
+
import torch.utils.data
|
| 15 |
+
from timm.data.constants import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
|
| 16 |
+
from timm.data.dataset import IterableImageDataset
|
| 17 |
+
from timm.data.loader import PrefetchLoader, _worker_init
|
| 18 |
+
from timm.data.transforms_factory import create_transform
|
| 19 |
+
|
| 20 |
+
_logger = logging.getLogger(__name__)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def fast_collate(batch, target_dtype=torch.uint8):
|
| 24 |
+
"""A fast collation function optimized for uint8 images (np array or torch) and target_dtype targets (labels)"""
|
| 25 |
+
assert isinstance(batch[0], tuple)
|
| 26 |
+
batch_size = len(batch)
|
| 27 |
+
if isinstance(batch[0][0], np.ndarray):
|
| 28 |
+
targets = torch.tensor([b[1] for b in batch], dtype=target_dtype)
|
| 29 |
+
assert len(targets) == batch_size
|
| 30 |
+
tensor = torch.zeros((batch_size, *batch[0][0].shape), dtype=torch.uint8)
|
| 31 |
+
for i in range(batch_size):
|
| 32 |
+
tensor[i] += torch.from_numpy(batch[i][0])
|
| 33 |
+
return tensor, targets
|
| 34 |
+
else:
|
| 35 |
+
raise ValueError(f"Incorrect batch type: {type(batch[0][0])}")
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def adapt_to_chs(x, n):
|
| 39 |
+
if not isinstance(x, (tuple, list)):
|
| 40 |
+
x = tuple(repeat(x, n))
|
| 41 |
+
elif len(x) != n:
|
| 42 |
+
# doubled channels
|
| 43 |
+
if len(x) * 2 == n:
|
| 44 |
+
x = np.concatenate((x, x))
|
| 45 |
+
_logger.warning(f"Pretrained mean/std different shape than model (doubled channes), using concat: {x}.")
|
| 46 |
+
else:
|
| 47 |
+
x_mean = np.mean(x).item()
|
| 48 |
+
x = (x_mean,) * n
|
| 49 |
+
_logger.warning(f"Pretrained mean/std different shape than model, using avg value {x}.")
|
| 50 |
+
else:
|
| 51 |
+
assert len(x) == n, "normalization stats must match image channels"
|
| 52 |
+
return x
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
class PrefetchLoaderForMultiInput(PrefetchLoader):
|
| 56 |
+
def __init__(
|
| 57 |
+
self,
|
| 58 |
+
loader,
|
| 59 |
+
mean=IMAGENET_DEFAULT_MEAN,
|
| 60 |
+
std=IMAGENET_DEFAULT_STD,
|
| 61 |
+
channels=3,
|
| 62 |
+
device=torch.device("cuda"),
|
| 63 |
+
img_dtype=torch.float32,
|
| 64 |
+
):
|
| 65 |
+
|
| 66 |
+
mean = adapt_to_chs(mean, channels)
|
| 67 |
+
std = adapt_to_chs(std, channels)
|
| 68 |
+
normalization_shape = (1, channels, 1, 1)
|
| 69 |
+
|
| 70 |
+
self.loader = loader
|
| 71 |
+
self.device = device
|
| 72 |
+
self.img_dtype = img_dtype
|
| 73 |
+
self.mean = torch.tensor([x * 255 for x in mean], device=device, dtype=img_dtype).view(normalization_shape)
|
| 74 |
+
self.std = torch.tensor([x * 255 for x in std], device=device, dtype=img_dtype).view(normalization_shape)
|
| 75 |
+
|
| 76 |
+
self.is_cuda = torch.cuda.is_available() and device.type == "cuda"
|
| 77 |
+
|
| 78 |
+
def __iter__(self):
|
| 79 |
+
first = True
|
| 80 |
+
if self.is_cuda:
|
| 81 |
+
stream = torch.cuda.Stream()
|
| 82 |
+
stream_context = partial(torch.cuda.stream, stream=stream)
|
| 83 |
+
else:
|
| 84 |
+
stream = None
|
| 85 |
+
stream_context = suppress
|
| 86 |
+
|
| 87 |
+
for next_input, next_target in self.loader:
|
| 88 |
+
|
| 89 |
+
with stream_context():
|
| 90 |
+
next_input = next_input.to(device=self.device, non_blocking=True)
|
| 91 |
+
next_target = next_target.to(device=self.device, non_blocking=True)
|
| 92 |
+
next_input = next_input.to(self.img_dtype).sub_(self.mean).div_(self.std)
|
| 93 |
+
|
| 94 |
+
if not first:
|
| 95 |
+
yield input, target # noqa: F823, F821
|
| 96 |
+
else:
|
| 97 |
+
first = False
|
| 98 |
+
|
| 99 |
+
if stream is not None:
|
| 100 |
+
torch.cuda.current_stream().wait_stream(stream)
|
| 101 |
+
|
| 102 |
+
input = next_input
|
| 103 |
+
target = next_target
|
| 104 |
+
|
| 105 |
+
yield input, target
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
def create_loader(
|
| 109 |
+
dataset,
|
| 110 |
+
input_size,
|
| 111 |
+
batch_size,
|
| 112 |
+
mean=IMAGENET_DEFAULT_MEAN,
|
| 113 |
+
std=IMAGENET_DEFAULT_STD,
|
| 114 |
+
num_workers=1,
|
| 115 |
+
crop_pct=None,
|
| 116 |
+
crop_mode=None,
|
| 117 |
+
pin_memory=False,
|
| 118 |
+
img_dtype=torch.float32,
|
| 119 |
+
device=torch.device("cuda"),
|
| 120 |
+
persistent_workers=True,
|
| 121 |
+
worker_seeding="all",
|
| 122 |
+
target_type=torch.int64,
|
| 123 |
+
):
|
| 124 |
+
|
| 125 |
+
transform = create_transform(
|
| 126 |
+
input_size,
|
| 127 |
+
is_training=False,
|
| 128 |
+
use_prefetcher=True,
|
| 129 |
+
mean=mean,
|
| 130 |
+
std=std,
|
| 131 |
+
crop_pct=crop_pct,
|
| 132 |
+
crop_mode=crop_mode,
|
| 133 |
+
)
|
| 134 |
+
dataset.transform = transform
|
| 135 |
+
|
| 136 |
+
if isinstance(dataset, IterableImageDataset):
|
| 137 |
+
# give Iterable datasets early knowledge of num_workers so that sample estimates
|
| 138 |
+
# are correct before worker processes are launched
|
| 139 |
+
dataset.set_loader_cfg(num_workers=num_workers)
|
| 140 |
+
raise ValueError("Incorrect dataset type: IterableImageDataset")
|
| 141 |
+
|
| 142 |
+
loader_class = torch.utils.data.DataLoader
|
| 143 |
+
loader_args = dict(
|
| 144 |
+
batch_size=batch_size,
|
| 145 |
+
shuffle=False,
|
| 146 |
+
num_workers=num_workers,
|
| 147 |
+
sampler=None,
|
| 148 |
+
collate_fn=lambda batch: fast_collate(batch, target_dtype=target_type),
|
| 149 |
+
pin_memory=pin_memory,
|
| 150 |
+
drop_last=False,
|
| 151 |
+
worker_init_fn=partial(_worker_init, worker_seeding=worker_seeding),
|
| 152 |
+
persistent_workers=persistent_workers,
|
| 153 |
+
)
|
| 154 |
+
try:
|
| 155 |
+
loader = loader_class(dataset, **loader_args)
|
| 156 |
+
except TypeError:
|
| 157 |
+
loader_args.pop("persistent_workers") # only in Pytorch 1.7+
|
| 158 |
+
loader = loader_class(dataset, **loader_args)
|
| 159 |
+
|
| 160 |
+
loader = PrefetchLoaderForMultiInput(
|
| 161 |
+
loader,
|
| 162 |
+
mean=mean,
|
| 163 |
+
std=std,
|
| 164 |
+
channels=input_size[0],
|
| 165 |
+
device=device,
|
| 166 |
+
img_dtype=img_dtype,
|
| 167 |
+
)
|
| 168 |
+
|
| 169 |
+
return loader
|
age_estimator/mivolo/mivolo/data/dataset/classification_dataset.py
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Any, List, Optional
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
|
| 5 |
+
from .age_gender_dataset import AgeGenderDataset
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class ClassificationDataset(AgeGenderDataset):
|
| 9 |
+
def __init__(self, *args, **kwargs):
|
| 10 |
+
super().__init__(*args, **kwargs)
|
| 11 |
+
|
| 12 |
+
self.target_dtype = torch.int32
|
| 13 |
+
|
| 14 |
+
def set_age_classes(self) -> Optional[List[str]]:
|
| 15 |
+
raise NotImplementedError
|
| 16 |
+
|
| 17 |
+
def parse_target(self, age: str, gender: str) -> List[Any]:
|
| 18 |
+
assert self.age_classes is not None
|
| 19 |
+
if age != "-1":
|
| 20 |
+
assert age in self.age_classes, f"Unknown category in {self.name} dataset: {age}"
|
| 21 |
+
age_ind = self.age_classes.index(age)
|
| 22 |
+
else:
|
| 23 |
+
age_ind = -1
|
| 24 |
+
|
| 25 |
+
target: List[int] = [age_ind, int(self.parse_gender(gender))]
|
| 26 |
+
return target
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
class FairFaceDataset(ClassificationDataset):
|
| 30 |
+
def set_age_classes(self) -> Optional[List[str]]:
|
| 31 |
+
age_classes = ["0;2", "3;9", "10;19", "20;29", "30;39", "40;49", "50;59", "60;69", "70;120"]
|
| 32 |
+
# a[i-1] <= v < a[i] => age_classes[i-1]
|
| 33 |
+
self._intervals = torch.tensor([0, 3, 10, 20, 30, 40, 50, 60, 70])
|
| 34 |
+
return age_classes
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
class AdienceDataset(ClassificationDataset):
|
| 38 |
+
def __init__(self, *args, **kwargs):
|
| 39 |
+
super().__init__(*args, **kwargs)
|
| 40 |
+
|
| 41 |
+
self.target_dtype = torch.int32
|
| 42 |
+
|
| 43 |
+
def set_age_classes(self) -> Optional[List[str]]:
|
| 44 |
+
age_classes = ["0;2", "4;6", "8;12", "15;20", "25;32", "38;43", "48;53", "60;100"]
|
| 45 |
+
# a[i-1] <= v < a[i] => age_classes[i-1]
|
| 46 |
+
self._intervals = torch.tensor([0, 4, 7, 14, 24, 36, 46, 57])
|
| 47 |
+
return age_classes
|
age_estimator/mivolo/mivolo/data/dataset/reader_age_gender.py
ADDED
|
@@ -0,0 +1,492 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import os
|
| 3 |
+
from functools import partial
|
| 4 |
+
from multiprocessing.pool import ThreadPool
|
| 5 |
+
from typing import Dict, List, Optional, Tuple
|
| 6 |
+
|
| 7 |
+
import cv2
|
| 8 |
+
import numpy as np
|
| 9 |
+
from mivolo.data.data_reader import AnnotType, PictureInfo, get_all_files, read_csv_annotation_file
|
| 10 |
+
from mivolo.data.misc import IOU, class_letterbox
|
| 11 |
+
from timm.data.readers.reader import Reader
|
| 12 |
+
from tqdm import tqdm
|
| 13 |
+
|
| 14 |
+
CROP_ROUND_TOL = 0.3
|
| 15 |
+
MIN_PERSON_SIZE = 100
|
| 16 |
+
MIN_PERSON_CROP_AFTERCUT_RATIO = 0.4
|
| 17 |
+
|
| 18 |
+
_logger = logging.getLogger("ReaderAgeGender")
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class ReaderAgeGender(Reader):
|
| 22 |
+
"""
|
| 23 |
+
Reader for almost original imdb-wiki cleaned dataset.
|
| 24 |
+
Two changes:
|
| 25 |
+
1. Your annotation must be in ./annotation subdir of dataset root
|
| 26 |
+
2. Images must be in images subdir
|
| 27 |
+
|
| 28 |
+
"""
|
| 29 |
+
|
| 30 |
+
def __init__(
|
| 31 |
+
self,
|
| 32 |
+
images_path,
|
| 33 |
+
annotations_path,
|
| 34 |
+
split="validation",
|
| 35 |
+
target_size=224,
|
| 36 |
+
min_size=5,
|
| 37 |
+
seed=1234,
|
| 38 |
+
with_persons=False,
|
| 39 |
+
min_person_size=MIN_PERSON_SIZE,
|
| 40 |
+
disable_faces=False,
|
| 41 |
+
only_age=False,
|
| 42 |
+
min_person_aftercut_ratio=MIN_PERSON_CROP_AFTERCUT_RATIO,
|
| 43 |
+
crop_round_tol=CROP_ROUND_TOL,
|
| 44 |
+
):
|
| 45 |
+
super().__init__()
|
| 46 |
+
|
| 47 |
+
self.with_persons = with_persons
|
| 48 |
+
self.disable_faces = disable_faces
|
| 49 |
+
self.only_age = only_age
|
| 50 |
+
|
| 51 |
+
# can be only black for now, even though it's not very good with further normalization
|
| 52 |
+
self.crop_out_color = (0, 0, 0)
|
| 53 |
+
|
| 54 |
+
self.empty_crop = np.ones((target_size, target_size, 3)) * self.crop_out_color
|
| 55 |
+
self.empty_crop = self.empty_crop.astype(np.uint8)
|
| 56 |
+
|
| 57 |
+
self.min_person_size = min_person_size
|
| 58 |
+
self.min_person_aftercut_ratio = min_person_aftercut_ratio
|
| 59 |
+
self.crop_round_tol = crop_round_tol
|
| 60 |
+
|
| 61 |
+
splits = split.split(",")
|
| 62 |
+
self.splits = [split.strip() for split in splits if len(split.strip())]
|
| 63 |
+
assert len(self.splits), "Incorrect split arg"
|
| 64 |
+
|
| 65 |
+
self.min_size = min_size
|
| 66 |
+
self.seed = seed
|
| 67 |
+
self.target_size = target_size
|
| 68 |
+
|
| 69 |
+
# Reading annotations. Can be multiple files if annotations_path dir
|
| 70 |
+
self._ann: Dict[str, List[PictureInfo]] = {} # list of samples for each image
|
| 71 |
+
self._associated_objects: Dict[str, Dict[int, List[List[int]]]] = {}
|
| 72 |
+
self._faces_list: List[Tuple[str, int]] = [] # samples from this list will be loaded in __getitem__
|
| 73 |
+
|
| 74 |
+
self._read_annotations(images_path, annotations_path)
|
| 75 |
+
_logger.info(f"Dataset length: {len(self._faces_list)} crops")
|
| 76 |
+
|
| 77 |
+
def __getitem__(self, index):
|
| 78 |
+
return self._read_img_and_label(index)
|
| 79 |
+
|
| 80 |
+
def __len__(self):
|
| 81 |
+
return len(self._faces_list)
|
| 82 |
+
|
| 83 |
+
def _filename(self, index, basename=False, absolute=False):
|
| 84 |
+
img_p = self._faces_list[index][0]
|
| 85 |
+
return os.path.basename(img_p) if basename else img_p
|
| 86 |
+
|
| 87 |
+
def _read_annotations(self, images_path, csvs_path):
|
| 88 |
+
self._ann = {}
|
| 89 |
+
self._faces_list = []
|
| 90 |
+
self._associated_objects = {}
|
| 91 |
+
|
| 92 |
+
csvs = get_all_files(csvs_path, [".csv"])
|
| 93 |
+
csvs = [c for c in csvs if any(split_name in os.path.basename(c) for split_name in self.splits)]
|
| 94 |
+
|
| 95 |
+
# load annotations per image
|
| 96 |
+
for csv in csvs:
|
| 97 |
+
db, ann_type = read_csv_annotation_file(csv, images_path)
|
| 98 |
+
if self.with_persons and ann_type != AnnotType.PERSONS:
|
| 99 |
+
raise ValueError(
|
| 100 |
+
f"Annotation type in file {csv} contains no persons, "
|
| 101 |
+
f"but annotations with persons are requested."
|
| 102 |
+
)
|
| 103 |
+
self._ann.update(db)
|
| 104 |
+
|
| 105 |
+
if len(self._ann) == 0:
|
| 106 |
+
raise ValueError("Annotations are empty!")
|
| 107 |
+
|
| 108 |
+
self._ann, self._associated_objects = self.prepare_annotations()
|
| 109 |
+
images_list = list(self._ann.keys())
|
| 110 |
+
|
| 111 |
+
for img_path in images_list:
|
| 112 |
+
for index, image_sample_info in enumerate(self._ann[img_path]):
|
| 113 |
+
assert image_sample_info.has_gt(
|
| 114 |
+
self.only_age
|
| 115 |
+
), "Annotations must be checked with self.prepare_annotations() func"
|
| 116 |
+
self._faces_list.append((img_path, index))
|
| 117 |
+
|
| 118 |
+
def _read_img_and_label(self, index):
|
| 119 |
+
if not isinstance(index, int):
|
| 120 |
+
raise TypeError("ReaderAgeGender expected index to be integer")
|
| 121 |
+
|
| 122 |
+
img_p, face_index = self._faces_list[index]
|
| 123 |
+
ann: PictureInfo = self._ann[img_p][face_index]
|
| 124 |
+
img = cv2.imread(img_p)
|
| 125 |
+
|
| 126 |
+
face_empty = True
|
| 127 |
+
if ann.has_face_bbox and not (self.with_persons and self.disable_faces):
|
| 128 |
+
face_crop, face_empty = self._get_crop(ann.bbox, img)
|
| 129 |
+
|
| 130 |
+
if not self.with_persons and face_empty:
|
| 131 |
+
# model without persons
|
| 132 |
+
raise ValueError("Annotations must be checked with self.prepare_annotations() func")
|
| 133 |
+
|
| 134 |
+
if face_empty:
|
| 135 |
+
face_crop = self.empty_crop
|
| 136 |
+
|
| 137 |
+
person_empty = True
|
| 138 |
+
if self.with_persons or self.disable_faces:
|
| 139 |
+
if ann.has_person_bbox:
|
| 140 |
+
# cut off all associated objects from person crop
|
| 141 |
+
objects = self._associated_objects[img_p][face_index]
|
| 142 |
+
person_crop, person_empty = self._get_crop(
|
| 143 |
+
ann.person_bbox,
|
| 144 |
+
img,
|
| 145 |
+
crop_out_color=self.crop_out_color,
|
| 146 |
+
asced_objects=objects,
|
| 147 |
+
)
|
| 148 |
+
|
| 149 |
+
if face_empty and person_empty:
|
| 150 |
+
raise ValueError("Annotations must be checked with self.prepare_annotations() func")
|
| 151 |
+
|
| 152 |
+
if person_empty:
|
| 153 |
+
person_crop = self.empty_crop
|
| 154 |
+
|
| 155 |
+
return (face_crop, person_crop), [ann.age, ann.gender]
|
| 156 |
+
|
| 157 |
+
def _get_crop(
|
| 158 |
+
self,
|
| 159 |
+
bbox,
|
| 160 |
+
img,
|
| 161 |
+
asced_objects=None,
|
| 162 |
+
crop_out_color=(0, 0, 0),
|
| 163 |
+
) -> Tuple[np.ndarray, bool]:
|
| 164 |
+
|
| 165 |
+
empty_bbox = False
|
| 166 |
+
|
| 167 |
+
xmin, ymin, xmax, ymax = bbox
|
| 168 |
+
assert not (
|
| 169 |
+
ymax - ymin < self.min_size or xmax - xmin < self.min_size
|
| 170 |
+
), "Annotations must be checked with self.prepare_annotations() func"
|
| 171 |
+
|
| 172 |
+
crop = img[ymin:ymax, xmin:xmax]
|
| 173 |
+
|
| 174 |
+
if asced_objects:
|
| 175 |
+
# cut off other objects for person crop
|
| 176 |
+
crop, empty_bbox = _cropout_asced_objs(
|
| 177 |
+
asced_objects,
|
| 178 |
+
bbox,
|
| 179 |
+
crop.copy(),
|
| 180 |
+
crop_out_color=crop_out_color,
|
| 181 |
+
min_person_size=self.min_person_size,
|
| 182 |
+
crop_round_tol=self.crop_round_tol,
|
| 183 |
+
min_person_aftercut_ratio=self.min_person_aftercut_ratio,
|
| 184 |
+
)
|
| 185 |
+
if empty_bbox:
|
| 186 |
+
crop = self.empty_crop
|
| 187 |
+
|
| 188 |
+
crop = class_letterbox(crop, new_shape=(self.target_size, self.target_size), color=crop_out_color)
|
| 189 |
+
return crop, empty_bbox
|
| 190 |
+
|
| 191 |
+
def prepare_annotations(self):
|
| 192 |
+
|
| 193 |
+
good_anns: Dict[str, List[PictureInfo]] = {}
|
| 194 |
+
all_associated_objects: Dict[str, Dict[int, List[List[int]]]] = {}
|
| 195 |
+
|
| 196 |
+
if not self.with_persons:
|
| 197 |
+
# remove all persons
|
| 198 |
+
for img_path, bboxes in self._ann.items():
|
| 199 |
+
for sample in bboxes:
|
| 200 |
+
sample.clear_person_bbox()
|
| 201 |
+
|
| 202 |
+
# check dataset and collect associated_objects
|
| 203 |
+
verify_images_func = partial(
|
| 204 |
+
verify_images,
|
| 205 |
+
min_size=self.min_size,
|
| 206 |
+
min_person_size=self.min_person_size,
|
| 207 |
+
with_persons=self.with_persons,
|
| 208 |
+
disable_faces=self.disable_faces,
|
| 209 |
+
crop_round_tol=self.crop_round_tol,
|
| 210 |
+
min_person_aftercut_ratio=self.min_person_aftercut_ratio,
|
| 211 |
+
only_age=self.only_age,
|
| 212 |
+
)
|
| 213 |
+
num_threads = min(8, os.cpu_count())
|
| 214 |
+
|
| 215 |
+
all_msgs = []
|
| 216 |
+
broken = 0
|
| 217 |
+
skipped = 0
|
| 218 |
+
all_skipped_crops = 0
|
| 219 |
+
desc = "Check annotations..."
|
| 220 |
+
with ThreadPool(num_threads) as pool:
|
| 221 |
+
pbar = tqdm(
|
| 222 |
+
pool.imap_unordered(verify_images_func, list(self._ann.items())),
|
| 223 |
+
desc=desc,
|
| 224 |
+
total=len(self._ann),
|
| 225 |
+
)
|
| 226 |
+
|
| 227 |
+
for (img_info, associated_objects, msgs, is_corrupted, is_empty_annotations, skipped_crops) in pbar:
|
| 228 |
+
broken += 1 if is_corrupted else 0
|
| 229 |
+
all_msgs.extend(msgs)
|
| 230 |
+
all_skipped_crops += skipped_crops
|
| 231 |
+
skipped += 1 if is_empty_annotations else 0
|
| 232 |
+
if img_info is not None:
|
| 233 |
+
img_path, img_samples = img_info
|
| 234 |
+
good_anns[img_path] = img_samples
|
| 235 |
+
all_associated_objects.update({img_path: associated_objects})
|
| 236 |
+
|
| 237 |
+
pbar.desc = (
|
| 238 |
+
f"{desc} {skipped} images skipped ({all_skipped_crops} crops are incorrect); "
|
| 239 |
+
f"{broken} images corrupted"
|
| 240 |
+
)
|
| 241 |
+
|
| 242 |
+
pbar.close()
|
| 243 |
+
|
| 244 |
+
for msg in all_msgs:
|
| 245 |
+
print(msg)
|
| 246 |
+
print(f"\nLeft images: {len(good_anns)}")
|
| 247 |
+
|
| 248 |
+
return good_anns, all_associated_objects
|
| 249 |
+
|
| 250 |
+
|
| 251 |
+
def verify_images(
|
| 252 |
+
img_info,
|
| 253 |
+
min_size: int,
|
| 254 |
+
min_person_size: int,
|
| 255 |
+
with_persons: bool,
|
| 256 |
+
disable_faces: bool,
|
| 257 |
+
crop_round_tol: float,
|
| 258 |
+
min_person_aftercut_ratio: float,
|
| 259 |
+
only_age: bool,
|
| 260 |
+
):
|
| 261 |
+
# If crop is too small, if image can not be read or if image does not exist
|
| 262 |
+
# then filter out this sample
|
| 263 |
+
|
| 264 |
+
disable_faces = disable_faces and with_persons
|
| 265 |
+
kwargs = dict(
|
| 266 |
+
min_person_size=min_person_size,
|
| 267 |
+
disable_faces=disable_faces,
|
| 268 |
+
with_persons=with_persons,
|
| 269 |
+
crop_round_tol=crop_round_tol,
|
| 270 |
+
min_person_aftercut_ratio=min_person_aftercut_ratio,
|
| 271 |
+
only_age=only_age,
|
| 272 |
+
)
|
| 273 |
+
|
| 274 |
+
def bbox_correct(bbox, min_size, im_h, im_w) -> Tuple[bool, List[int]]:
|
| 275 |
+
ymin, ymax, xmin, xmax = _correct_bbox(bbox, im_h, im_w)
|
| 276 |
+
crop_h, crop_w = ymax - ymin, xmax - xmin
|
| 277 |
+
if crop_h < min_size or crop_w < min_size:
|
| 278 |
+
return False, [-1, -1, -1, -1]
|
| 279 |
+
bbox = [xmin, ymin, xmax, ymax]
|
| 280 |
+
return True, bbox
|
| 281 |
+
|
| 282 |
+
msgs = []
|
| 283 |
+
skipped_crops = 0
|
| 284 |
+
is_corrupted = False
|
| 285 |
+
is_empty_annotations = False
|
| 286 |
+
|
| 287 |
+
img_path: str = img_info[0]
|
| 288 |
+
img_samples: List[PictureInfo] = img_info[1]
|
| 289 |
+
try:
|
| 290 |
+
im_cv = cv2.imread(img_path)
|
| 291 |
+
im_h, im_w = im_cv.shape[:2]
|
| 292 |
+
except Exception:
|
| 293 |
+
msgs.append(f"Can not load image {img_path}")
|
| 294 |
+
is_corrupted = True
|
| 295 |
+
return None, {}, msgs, is_corrupted, is_empty_annotations, skipped_crops
|
| 296 |
+
|
| 297 |
+
out_samples: List[PictureInfo] = []
|
| 298 |
+
for sample in img_samples:
|
| 299 |
+
# correct face bbox
|
| 300 |
+
if sample.has_face_bbox:
|
| 301 |
+
is_correct, sample.bbox = bbox_correct(sample.bbox, min_size, im_h, im_w)
|
| 302 |
+
if not is_correct and sample.has_gt(only_age):
|
| 303 |
+
msgs.append("Small face. Passing..")
|
| 304 |
+
skipped_crops += 1
|
| 305 |
+
|
| 306 |
+
# correct person bbox
|
| 307 |
+
if sample.has_person_bbox:
|
| 308 |
+
is_correct, sample.person_bbox = bbox_correct(
|
| 309 |
+
sample.person_bbox, max(min_person_size, min_size), im_h, im_w
|
| 310 |
+
)
|
| 311 |
+
if not is_correct and sample.has_gt(only_age):
|
| 312 |
+
msgs.append(f"Small person {img_path}. Passing..")
|
| 313 |
+
skipped_crops += 1
|
| 314 |
+
|
| 315 |
+
if sample.has_face_bbox or sample.has_person_bbox:
|
| 316 |
+
out_samples.append(sample)
|
| 317 |
+
elif sample.has_gt(only_age):
|
| 318 |
+
msgs.append("Sample has no face and no body. Passing..")
|
| 319 |
+
skipped_crops += 1
|
| 320 |
+
|
| 321 |
+
# sort that samples with undefined age and gender be the last
|
| 322 |
+
out_samples = sorted(out_samples, key=lambda sample: 1 if not sample.has_gt(only_age) else 0)
|
| 323 |
+
|
| 324 |
+
# for each person find other faces and persons bboxes, intersected with it
|
| 325 |
+
associated_objects: Dict[int, List[List[int]]] = find_associated_objects(out_samples, only_age=only_age)
|
| 326 |
+
|
| 327 |
+
out_samples, associated_objects, skipped_crops = filter_bad_samples(
|
| 328 |
+
out_samples, associated_objects, im_cv, msgs, skipped_crops, **kwargs
|
| 329 |
+
)
|
| 330 |
+
|
| 331 |
+
out_img_info: Optional[Tuple[str, List]] = (img_path, out_samples)
|
| 332 |
+
if len(out_samples) == 0:
|
| 333 |
+
out_img_info = None
|
| 334 |
+
is_empty_annotations = True
|
| 335 |
+
|
| 336 |
+
return out_img_info, associated_objects, msgs, is_corrupted, is_empty_annotations, skipped_crops
|
| 337 |
+
|
| 338 |
+
|
| 339 |
+
def filter_bad_samples(
|
| 340 |
+
out_samples: List[PictureInfo],
|
| 341 |
+
associated_objects: dict,
|
| 342 |
+
im_cv: np.ndarray,
|
| 343 |
+
msgs: List[str],
|
| 344 |
+
skipped_crops: int,
|
| 345 |
+
**kwargs,
|
| 346 |
+
):
|
| 347 |
+
with_persons, disable_faces, min_person_size, crop_round_tol, min_person_aftercut_ratio, only_age = (
|
| 348 |
+
kwargs["with_persons"],
|
| 349 |
+
kwargs["disable_faces"],
|
| 350 |
+
kwargs["min_person_size"],
|
| 351 |
+
kwargs["crop_round_tol"],
|
| 352 |
+
kwargs["min_person_aftercut_ratio"],
|
| 353 |
+
kwargs["only_age"],
|
| 354 |
+
)
|
| 355 |
+
|
| 356 |
+
# left only samples with annotations
|
| 357 |
+
inds = [sample_ind for sample_ind, sample in enumerate(out_samples) if sample.has_gt(only_age)]
|
| 358 |
+
out_samples, associated_objects = _filter_by_ind(out_samples, associated_objects, inds)
|
| 359 |
+
|
| 360 |
+
if kwargs["disable_faces"]:
|
| 361 |
+
# clear all faces
|
| 362 |
+
for ind, sample in enumerate(out_samples):
|
| 363 |
+
sample.clear_face_bbox()
|
| 364 |
+
|
| 365 |
+
# left only samples with person_bbox
|
| 366 |
+
inds = [sample_ind for sample_ind, sample in enumerate(out_samples) if sample.has_person_bbox]
|
| 367 |
+
out_samples, associated_objects = _filter_by_ind(out_samples, associated_objects, inds)
|
| 368 |
+
|
| 369 |
+
if with_persons or disable_faces:
|
| 370 |
+
# check that preprocessing func
|
| 371 |
+
# _cropout_asced_objs() return not empty person_image for each out sample
|
| 372 |
+
|
| 373 |
+
inds = []
|
| 374 |
+
for ind, sample in enumerate(out_samples):
|
| 375 |
+
person_empty = True
|
| 376 |
+
if sample.has_person_bbox:
|
| 377 |
+
xmin, ymin, xmax, ymax = sample.person_bbox
|
| 378 |
+
crop = im_cv[ymin:ymax, xmin:xmax]
|
| 379 |
+
# cut off all associated objects from person crop
|
| 380 |
+
_, person_empty = _cropout_asced_objs(
|
| 381 |
+
associated_objects[ind],
|
| 382 |
+
sample.person_bbox,
|
| 383 |
+
crop.copy(),
|
| 384 |
+
min_person_size=min_person_size,
|
| 385 |
+
crop_round_tol=crop_round_tol,
|
| 386 |
+
min_person_aftercut_ratio=min_person_aftercut_ratio,
|
| 387 |
+
)
|
| 388 |
+
|
| 389 |
+
if person_empty and not sample.has_face_bbox:
|
| 390 |
+
msgs.append("Small person after preprocessing. Passing..")
|
| 391 |
+
skipped_crops += 1
|
| 392 |
+
else:
|
| 393 |
+
inds.append(ind)
|
| 394 |
+
out_samples, associated_objects = _filter_by_ind(out_samples, associated_objects, inds)
|
| 395 |
+
|
| 396 |
+
assert len(associated_objects) == len(out_samples)
|
| 397 |
+
return out_samples, associated_objects, skipped_crops
|
| 398 |
+
|
| 399 |
+
|
| 400 |
+
def _filter_by_ind(out_samples, associated_objects, inds):
|
| 401 |
+
_associated_objects = {}
|
| 402 |
+
_out_samples = []
|
| 403 |
+
for ind, sample in enumerate(out_samples):
|
| 404 |
+
if ind in inds:
|
| 405 |
+
_associated_objects[len(_out_samples)] = associated_objects[ind]
|
| 406 |
+
_out_samples.append(sample)
|
| 407 |
+
|
| 408 |
+
return _out_samples, _associated_objects
|
| 409 |
+
|
| 410 |
+
|
| 411 |
+
def find_associated_objects(
|
| 412 |
+
image_samples: List[PictureInfo], iou_thresh=0.0001, only_age=False
|
| 413 |
+
) -> Dict[int, List[List[int]]]:
|
| 414 |
+
"""
|
| 415 |
+
For each person (which has gt age and gt gender) find other faces and persons bboxes, intersected with it
|
| 416 |
+
"""
|
| 417 |
+
associated_objects: Dict[int, List[List[int]]] = {}
|
| 418 |
+
|
| 419 |
+
for iindex, image_sample_info in enumerate(image_samples):
|
| 420 |
+
# add own face
|
| 421 |
+
associated_objects[iindex] = [image_sample_info.bbox] if image_sample_info.has_face_bbox else []
|
| 422 |
+
|
| 423 |
+
if not image_sample_info.has_person_bbox or not image_sample_info.has_gt(only_age):
|
| 424 |
+
# if sample has not gt => not be used
|
| 425 |
+
continue
|
| 426 |
+
|
| 427 |
+
iperson_box = image_sample_info.person_bbox
|
| 428 |
+
for jindex, other_image_sample in enumerate(image_samples):
|
| 429 |
+
if iindex == jindex:
|
| 430 |
+
continue
|
| 431 |
+
if other_image_sample.has_face_bbox:
|
| 432 |
+
jface_bbox = other_image_sample.bbox
|
| 433 |
+
iou = _get_iou(jface_bbox, iperson_box)
|
| 434 |
+
if iou >= iou_thresh:
|
| 435 |
+
associated_objects[iindex].append(jface_bbox)
|
| 436 |
+
if other_image_sample.has_person_bbox:
|
| 437 |
+
jperson_bbox = other_image_sample.person_bbox
|
| 438 |
+
iou = _get_iou(jperson_bbox, iperson_box)
|
| 439 |
+
if iou >= iou_thresh:
|
| 440 |
+
associated_objects[iindex].append(jperson_bbox)
|
| 441 |
+
|
| 442 |
+
return associated_objects
|
| 443 |
+
|
| 444 |
+
|
| 445 |
+
def _cropout_asced_objs(
|
| 446 |
+
asced_objects,
|
| 447 |
+
person_bbox,
|
| 448 |
+
crop,
|
| 449 |
+
min_person_size,
|
| 450 |
+
crop_round_tol,
|
| 451 |
+
min_person_aftercut_ratio,
|
| 452 |
+
crop_out_color=(0, 0, 0),
|
| 453 |
+
):
|
| 454 |
+
empty = False
|
| 455 |
+
xmin, ymin, xmax, ymax = person_bbox
|
| 456 |
+
|
| 457 |
+
for a_obj in asced_objects:
|
| 458 |
+
aobj_xmin, aobj_ymin, aobj_xmax, aobj_ymax = a_obj
|
| 459 |
+
|
| 460 |
+
aobj_ymin = int(max(aobj_ymin - ymin, 0))
|
| 461 |
+
aobj_xmin = int(max(aobj_xmin - xmin, 0))
|
| 462 |
+
aobj_ymax = int(min(aobj_ymax - ymin, ymax - ymin))
|
| 463 |
+
aobj_xmax = int(min(aobj_xmax - xmin, xmax - xmin))
|
| 464 |
+
|
| 465 |
+
crop[aobj_ymin:aobj_ymax, aobj_xmin:aobj_xmax] = crop_out_color
|
| 466 |
+
|
| 467 |
+
# calc useful non-black area
|
| 468 |
+
remain_ratio = np.count_nonzero(crop) / (crop.shape[0] * crop.shape[1] * crop.shape[2])
|
| 469 |
+
if (crop.shape[0] < min_person_size or crop.shape[1] < min_person_size) or remain_ratio < min_person_aftercut_ratio:
|
| 470 |
+
crop = None
|
| 471 |
+
empty = True
|
| 472 |
+
|
| 473 |
+
return crop, empty
|
| 474 |
+
|
| 475 |
+
|
| 476 |
+
def _correct_bbox(bbox, h, w):
|
| 477 |
+
xmin, ymin, xmax, ymax = bbox
|
| 478 |
+
ymin = min(max(ymin, 0), h)
|
| 479 |
+
ymax = min(max(ymax, 0), h)
|
| 480 |
+
xmin = min(max(xmin, 0), w)
|
| 481 |
+
xmax = min(max(xmax, 0), w)
|
| 482 |
+
return ymin, ymax, xmin, xmax
|
| 483 |
+
|
| 484 |
+
|
| 485 |
+
def _get_iou(bbox1, bbox2):
|
| 486 |
+
xmin1, ymin1, xmax1, ymax1 = bbox1
|
| 487 |
+
xmin2, ymin2, xmax2, ymax2 = bbox2
|
| 488 |
+
iou = IOU(
|
| 489 |
+
[ymin1, xmin1, ymax1, xmax1],
|
| 490 |
+
[ymin2, xmin2, ymax2, xmax2],
|
| 491 |
+
)
|
| 492 |
+
return iou
|
age_estimator/mivolo/mivolo/data/misc.py
ADDED
|
@@ -0,0 +1,246 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import ast
|
| 3 |
+
import re
|
| 4 |
+
from typing import List, Optional, Tuple, Union
|
| 5 |
+
|
| 6 |
+
import cv2
|
| 7 |
+
import numpy as np
|
| 8 |
+
import torch
|
| 9 |
+
import torchvision.transforms.functional as F
|
| 10 |
+
from scipy.optimize import linear_sum_assignment
|
| 11 |
+
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
|
| 12 |
+
|
| 13 |
+
CROP_ROUND_RATE = 0.1
|
| 14 |
+
MIN_PERSON_CROP_NONZERO = 0.5
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def aggregate_votes_winsorized(ages, max_age_dist=6):
|
| 18 |
+
# Replace any annotation that is more than a max_age_dist away from the median
|
| 19 |
+
# with the median + max_age_dist if higher or max_age_dist - max_age_dist if below
|
| 20 |
+
median = np.median(ages)
|
| 21 |
+
ages = np.clip(ages, median - max_age_dist, median + max_age_dist)
|
| 22 |
+
return np.mean(ages)
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def natural_key(string_):
|
| 26 |
+
"""See http://www.codinghorror.com/blog/archives/001018.html"""
|
| 27 |
+
return [int(s) if s.isdigit() else s for s in re.split(r"(\d+)", string_.lower())]
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def add_bool_arg(parser, name, default=False, help=""):
|
| 31 |
+
dest_name = name.replace("-", "_")
|
| 32 |
+
group = parser.add_mutually_exclusive_group(required=False)
|
| 33 |
+
group.add_argument("--" + name, dest=dest_name, action="store_true", help=help)
|
| 34 |
+
group.add_argument("--no-" + name, dest=dest_name, action="store_false", help=help)
|
| 35 |
+
parser.set_defaults(**{dest_name: default})
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def cumulative_score(pred_ages, gt_ages, L, tol=1e-6):
|
| 39 |
+
n = pred_ages.shape[0]
|
| 40 |
+
num_correct = torch.sum(torch.abs(pred_ages - gt_ages) <= L + tol)
|
| 41 |
+
cs_score = num_correct / n
|
| 42 |
+
return cs_score
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def cumulative_error(pred_ages, gt_ages, L, tol=1e-6):
|
| 46 |
+
n = pred_ages.shape[0]
|
| 47 |
+
num_correct = torch.sum(torch.abs(pred_ages - gt_ages) >= L + tol)
|
| 48 |
+
cs_score = num_correct / n
|
| 49 |
+
return cs_score
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
class ParseKwargs(argparse.Action):
|
| 53 |
+
def __call__(self, parser, namespace, values, option_string=None):
|
| 54 |
+
kw = {}
|
| 55 |
+
for value in values:
|
| 56 |
+
key, value = value.split("=")
|
| 57 |
+
try:
|
| 58 |
+
kw[key] = ast.literal_eval(value)
|
| 59 |
+
except ValueError:
|
| 60 |
+
kw[key] = str(value) # fallback to string (avoid need to escape on command line)
|
| 61 |
+
setattr(namespace, self.dest, kw)
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def box_iou(box1, box2, over_second=False):
|
| 65 |
+
"""
|
| 66 |
+
Return intersection-over-union (Jaccard index) of boxes.
|
| 67 |
+
If over_second == True, return mean(intersection-over-union, (inter / area2))
|
| 68 |
+
|
| 69 |
+
Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
|
| 70 |
+
|
| 71 |
+
Arguments:
|
| 72 |
+
box1 (Tensor[N, 4])
|
| 73 |
+
box2 (Tensor[M, 4])
|
| 74 |
+
Returns:
|
| 75 |
+
iou (Tensor[N, M]): the NxM matrix containing the pairwise
|
| 76 |
+
IoU values for every element in boxes1 and boxes2
|
| 77 |
+
"""
|
| 78 |
+
|
| 79 |
+
def box_area(box):
|
| 80 |
+
# box = 4xn
|
| 81 |
+
return (box[2] - box[0]) * (box[3] - box[1])
|
| 82 |
+
|
| 83 |
+
area1 = box_area(box1.T)
|
| 84 |
+
area2 = box_area(box2.T)
|
| 85 |
+
|
| 86 |
+
# inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
|
| 87 |
+
inter = (torch.min(box1[:, None, 2:], box2[:, 2:]) - torch.max(box1[:, None, :2], box2[:, :2])).clamp(0).prod(2)
|
| 88 |
+
|
| 89 |
+
iou = inter / (area1[:, None] + area2 - inter) # iou = inter / (area1 + area2 - inter)
|
| 90 |
+
if over_second:
|
| 91 |
+
return (inter / area2 + iou) / 2 # mean(inter / area2, iou)
|
| 92 |
+
else:
|
| 93 |
+
return iou
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def split_batch(bs: int, dev: int) -> Tuple[int, int]:
|
| 97 |
+
full_bs = (bs // dev) * dev
|
| 98 |
+
part_bs = bs - full_bs
|
| 99 |
+
return full_bs, part_bs
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def assign_faces(
|
| 103 |
+
persons_bboxes: List[torch.tensor], faces_bboxes: List[torch.tensor], iou_thresh: float = 0.0001
|
| 104 |
+
) -> Tuple[List[Optional[int]], List[int]]:
|
| 105 |
+
"""
|
| 106 |
+
Assign person to each face if it is possible.
|
| 107 |
+
Return:
|
| 108 |
+
- assigned_faces List[Optional[int]]: mapping of face_ind to person_ind
|
| 109 |
+
( assigned_faces[face_ind] = person_ind ). person_ind can be None
|
| 110 |
+
- unassigned_persons_inds List[int]: persons indexes without any assigned face
|
| 111 |
+
"""
|
| 112 |
+
|
| 113 |
+
assigned_faces: List[Optional[int]] = [None for _ in range(len(faces_bboxes))]
|
| 114 |
+
unassigned_persons_inds: List[int] = [p_ind for p_ind in range(len(persons_bboxes))]
|
| 115 |
+
|
| 116 |
+
if len(persons_bboxes) == 0 or len(faces_bboxes) == 0:
|
| 117 |
+
return assigned_faces, unassigned_persons_inds
|
| 118 |
+
|
| 119 |
+
cost_matrix = box_iou(torch.stack(persons_bboxes), torch.stack(faces_bboxes), over_second=True).cpu().numpy()
|
| 120 |
+
persons_indexes, face_indexes = [], []
|
| 121 |
+
|
| 122 |
+
if len(cost_matrix) > 0:
|
| 123 |
+
persons_indexes, face_indexes = linear_sum_assignment(cost_matrix, maximize=True)
|
| 124 |
+
|
| 125 |
+
matched_persons = set()
|
| 126 |
+
for person_idx, face_idx in zip(persons_indexes, face_indexes):
|
| 127 |
+
ciou = cost_matrix[person_idx][face_idx]
|
| 128 |
+
if ciou > iou_thresh:
|
| 129 |
+
if person_idx in matched_persons:
|
| 130 |
+
# Person can not be assigned twice, in reality this should not happen
|
| 131 |
+
continue
|
| 132 |
+
assigned_faces[face_idx] = person_idx
|
| 133 |
+
matched_persons.add(person_idx)
|
| 134 |
+
|
| 135 |
+
unassigned_persons_inds = [p_ind for p_ind in range(len(persons_bboxes)) if p_ind not in matched_persons]
|
| 136 |
+
|
| 137 |
+
return assigned_faces, unassigned_persons_inds
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
def class_letterbox(im, new_shape=(640, 640), color=(0, 0, 0), scaleup=True):
|
| 141 |
+
# Resize and pad image while meeting stride-multiple constraints
|
| 142 |
+
shape = im.shape[:2] # current shape [height, width]
|
| 143 |
+
if isinstance(new_shape, int):
|
| 144 |
+
new_shape = (new_shape, new_shape)
|
| 145 |
+
|
| 146 |
+
if im.shape[0] == new_shape[0] and im.shape[1] == new_shape[1]:
|
| 147 |
+
return im
|
| 148 |
+
|
| 149 |
+
# Scale ratio (new / old)
|
| 150 |
+
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
|
| 151 |
+
if not scaleup: # only scale down, do not scale up (for better val mAP)
|
| 152 |
+
r = min(r, 1.0)
|
| 153 |
+
|
| 154 |
+
# Compute padding
|
| 155 |
+
# ratio = r, r # width, height ratios
|
| 156 |
+
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
|
| 157 |
+
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
|
| 158 |
+
|
| 159 |
+
dw /= 2 # divide padding into 2 sides
|
| 160 |
+
dh /= 2
|
| 161 |
+
|
| 162 |
+
if shape[::-1] != new_unpad: # resize
|
| 163 |
+
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
|
| 164 |
+
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
|
| 165 |
+
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
|
| 166 |
+
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
|
| 167 |
+
return im
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
def prepare_classification_images(
|
| 171 |
+
img_list: List[Optional[np.ndarray]],
|
| 172 |
+
target_size: int = 224,
|
| 173 |
+
mean=IMAGENET_DEFAULT_MEAN,
|
| 174 |
+
std=IMAGENET_DEFAULT_STD,
|
| 175 |
+
device=None,
|
| 176 |
+
) -> torch.tensor:
|
| 177 |
+
|
| 178 |
+
prepared_images: List[torch.tensor] = []
|
| 179 |
+
|
| 180 |
+
for img in img_list:
|
| 181 |
+
if img is None:
|
| 182 |
+
img = torch.zeros((3, target_size, target_size), dtype=torch.float32)
|
| 183 |
+
img = F.normalize(img, mean=mean, std=std)
|
| 184 |
+
img = img.unsqueeze(0)
|
| 185 |
+
prepared_images.append(img)
|
| 186 |
+
continue
|
| 187 |
+
img = class_letterbox(img, new_shape=(target_size, target_size))
|
| 188 |
+
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
|
| 189 |
+
|
| 190 |
+
img = img / 255.0
|
| 191 |
+
img = (img - mean) / std
|
| 192 |
+
img = img.astype(dtype=np.float32)
|
| 193 |
+
|
| 194 |
+
img = img.transpose((2, 0, 1))
|
| 195 |
+
img = np.ascontiguousarray(img)
|
| 196 |
+
img = torch.from_numpy(img)
|
| 197 |
+
img = img.unsqueeze(0)
|
| 198 |
+
|
| 199 |
+
prepared_images.append(img)
|
| 200 |
+
|
| 201 |
+
if len(prepared_images) == 0:
|
| 202 |
+
return None
|
| 203 |
+
|
| 204 |
+
prepared_input = torch.concat(prepared_images)
|
| 205 |
+
|
| 206 |
+
if device:
|
| 207 |
+
prepared_input = prepared_input.to(device)
|
| 208 |
+
|
| 209 |
+
return prepared_input
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
def IOU(bb1: Union[tuple, list], bb2: Union[tuple, list], norm_second_bbox: bool = False) -> float:
|
| 213 |
+
# expects [ymin, xmin, ymax, xmax], doesnt matter absolute or relative
|
| 214 |
+
assert bb1[1] < bb1[3]
|
| 215 |
+
assert bb1[0] < bb1[2]
|
| 216 |
+
assert bb2[1] < bb2[3]
|
| 217 |
+
assert bb2[0] < bb2[2]
|
| 218 |
+
|
| 219 |
+
# determine the coordinates of the intersection rectangle
|
| 220 |
+
x_left = max(bb1[1], bb2[1])
|
| 221 |
+
y_top = max(bb1[0], bb2[0])
|
| 222 |
+
x_right = min(bb1[3], bb2[3])
|
| 223 |
+
y_bottom = min(bb1[2], bb2[2])
|
| 224 |
+
|
| 225 |
+
if x_right < x_left or y_bottom < y_top:
|
| 226 |
+
return 0.0
|
| 227 |
+
|
| 228 |
+
# The intersection of two axis-aligned bounding boxes is always an
|
| 229 |
+
# axis-aligned bounding box
|
| 230 |
+
intersection_area = (x_right - x_left) * (y_bottom - y_top)
|
| 231 |
+
# compute the area of both AABBs
|
| 232 |
+
bb1_area = (bb1[3] - bb1[1]) * (bb1[2] - bb1[0])
|
| 233 |
+
bb2_area = (bb2[3] - bb2[1]) * (bb2[2] - bb2[0])
|
| 234 |
+
if not norm_second_bbox:
|
| 235 |
+
# compute the intersection over union by taking the intersection
|
| 236 |
+
# area and dividing it by the sum of prediction + ground-truth
|
| 237 |
+
# areas - the interesection area
|
| 238 |
+
iou = intersection_area / float(bb1_area + bb2_area - intersection_area)
|
| 239 |
+
else:
|
| 240 |
+
# for cases when we search if second bbox is inside first one
|
| 241 |
+
iou = intersection_area / float(bb2_area)
|
| 242 |
+
|
| 243 |
+
assert iou >= 0.0
|
| 244 |
+
assert iou <= 1.01
|
| 245 |
+
|
| 246 |
+
return iou
|
age_estimator/mivolo/mivolo/model/__init__.py
ADDED
|
File without changes
|
age_estimator/mivolo/mivolo/model/__pycache__/__init__.cpython-38.pyc
ADDED
|
Binary file (162 Bytes). View file
|
|
|
age_estimator/mivolo/mivolo/model/__pycache__/create_timm_model.cpython-38.pyc
ADDED
|
Binary file (2.96 kB). View file
|
|
|
age_estimator/mivolo/mivolo/model/__pycache__/cross_bottleneck_attn.cpython-38.pyc
ADDED
|
Binary file (3.66 kB). View file
|
|
|
age_estimator/mivolo/mivolo/model/__pycache__/mi_volo.cpython-38.pyc
ADDED
|
Binary file (7.18 kB). View file
|
|
|
age_estimator/mivolo/mivolo/model/__pycache__/mivolo_model.cpython-38.pyc
ADDED
|
Binary file (10.2 kB). View file
|
|
|