Spaces:
Running

Running
small update to include visual definition of ECE
Browse files- ECE_definition.jpg +0 -0
- README.md +40 -11
- app.py +4 -3
- ece.py +1 -4
- local_app.py +31 -20
ECE_definition.jpg
ADDED
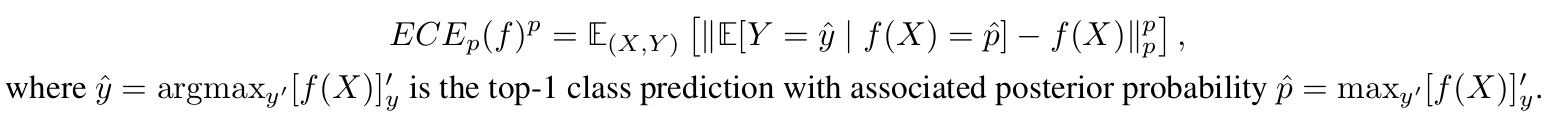
|
README.md
CHANGED
|
@@ -14,30 +14,32 @@ pinned: false
|
|
| 14 |
|
| 15 |
# Metric Card for ECE
|
| 16 |
|
| 17 |
-
***Module Card Instructions:*** *Fill out the following subsections. Feel free to take a look at existing metric cards if you'd like examples.*
|
| 18 |
-
|
| 19 |
## Metric Description
|
| 20 |
<!---
|
| 21 |
*Give a brief overview of this metric, including what task(s) it is usually used for, if any.*
|
| 22 |
-->
|
| 23 |
-
|
|
|
|
| 24 |
It measures the L^p norm difference between a model’s posterior and the true likelihood of being correct.
|
| 25 |
-
```
|
| 26 |
-
$$ ECE_p(f)^p= \mathbb{E}_{(X,Y)} \left[\|\mathbb{E}[Y = \hat{y} \mid f(X) = \hat{p}] - f(X)\|^p_p\right]$$, where $$ \hat{y} = \argmax_{y'}[f(X)]_y'$$ is a class prediction with associated posterior probability $$ \hat{p}= \max_{y'}[f(X)]_y'$$.
|
| 27 |
-
```
|
| 28 |
-
It is generally implemented as a binned estimator that discretizes predicted probabilities into a range of possible values (bins) for which conditional expectation can be estimated.
|
| 29 |
|
| 30 |
-
|
| 31 |
-
|
|
|
|
| 32 |
|
| 33 |
|
| 34 |
## How to Use
|
| 35 |
<!---
|
| 36 |
*Give general statement of how to use the metric*
|
| 37 |
*Provide simplest possible example for using the metric*
|
| 38 |
-
-->
|
| 39 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 40 |
|
|
|
|
| 41 |
|
| 42 |
|
| 43 |
### Inputs
|
|
@@ -55,12 +57,32 @@ For valid model comparisons, ensure to use the same keyword arguments.
|
|
| 55 |
#### Values from Popular Papers
|
| 56 |
*Give examples, preferrably with links to leaderboards or publications, to papers that have reported this metric, along with the values they have reported.*
|
| 57 |
-->
|
|
|
|
|
|
|
| 58 |
|
| 59 |
|
| 60 |
### Examples
|
| 61 |
<!---
|
| 62 |
*Give code examples of the metric being used. Try to include examples that clear up any potential ambiguity left from the metric description above. If possible, provide a range of examples that show both typical and atypical results, as well as examples where a variety of input parameters are passed.*
|
| 63 |
-->
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 64 |
|
| 65 |
|
| 66 |
## Limitations and Bias
|
|
@@ -71,11 +93,18 @@ See [3],[4] and [5].
|
|
| 71 |
|
| 72 |
## Citation
|
| 73 |
[1] Naeini, M.P., Cooper, G. and Hauskrecht, M., 2015, February. Obtaining well calibrated probabilities using bayesian binning. In Twenty-Ninth AAAI Conference on Artificial Intelligence.
|
|
|
|
| 74 |
[2] Guo, C., Pleiss, G., Sun, Y. and Weinberger, K.Q., 2017, July. On calibration of modern neural networks. In International Conference on Machine Learning (pp. 1321-1330). PMLR.
|
|
|
|
| 75 |
[3] Nixon, J., Dusenberry, M.W., Zhang, L., Jerfel, G. and Tran, D., 2019, June. Measuring Calibration in Deep Learning. In CVPR Workshops (Vol. 2, No. 7).
|
|
|
|
| 76 |
[4] Kumar, A., Liang, P.S. and Ma, T., 2019. Verified uncertainty calibration. Advances in Neural Information Processing Systems, 32.
|
|
|
|
| 77 |
[5] Vaicenavicius, J., Widmann, D., Andersson, C., Lindsten, F., Roll, J. and Schön, T., 2019, April. Evaluating model calibration in classification. In The 22nd International Conference on Artificial Intelligence and Statistics (pp. 3459-3467). PMLR.
|
|
|
|
| 78 |
[6] Allen-Zhu, Z., Li, Y. and Liang, Y., 2019. Learning and generalization in overparameterized neural networks, going beyond two layers. Advances in neural information processing systems, 32.
|
| 79 |
|
| 80 |
## Further References
|
|
|
|
| 81 |
*Add any useful further references.*
|
|
|
|
|
|
| 14 |
|
| 15 |
# Metric Card for ECE
|
| 16 |
|
|
|
|
|
|
|
| 17 |
## Metric Description
|
| 18 |
<!---
|
| 19 |
*Give a brief overview of this metric, including what task(s) it is usually used for, if any.*
|
| 20 |
-->
|
| 21 |
+
|
| 22 |
+
Expected Calibration Error *ECE* is a popular metric to evaluate top-1 prediction miscalibration.
|
| 23 |
It measures the L^p norm difference between a model’s posterior and the true likelihood of being correct.
|
|
|
|
|
|
|
|
|
|
|
|
|
| 24 |
|
| 25 |
+

|
| 26 |
+
|
| 27 |
+
It is generally implemented as a binned estimator that discretizes predicted probabilities into ranges of possible values (bins) for which conditional expectation can be estimated.
|
| 28 |
|
| 29 |
|
| 30 |
## How to Use
|
| 31 |
<!---
|
| 32 |
*Give general statement of how to use the metric*
|
| 33 |
*Provide simplest possible example for using the metric*
|
| 34 |
+
-->
|
| 35 |
+
```
|
| 36 |
+
>>> metric = evaluate.load("jordyvl/ece")
|
| 37 |
+
>>> results = metric.compute(references=[0, 1, 2], predictions=[[0.6, 0.2, 0.2], [0, 0.95, 0.05], [0.7, 0.1 ,0.2]])
|
| 38 |
+
>>> print(results)
|
| 39 |
+
{'ECE': 0.1333333333333334}
|
| 40 |
+
```
|
| 41 |
|
| 42 |
+
For valid model comparisons, ensure to use the same keyword arguments.
|
| 43 |
|
| 44 |
|
| 45 |
### Inputs
|
|
|
|
| 57 |
#### Values from Popular Papers
|
| 58 |
*Give examples, preferrably with links to leaderboards or publications, to papers that have reported this metric, along with the values they have reported.*
|
| 59 |
-->
|
| 60 |
+
As a metric of calibration *error*, it holds that the lower, the better calibrated a model is. Depending on the L^p norm, ECE will either take value between 0 and 1 (p=2) or between 0 and \infty_+.
|
| 61 |
+
The module returns dictionary with a key value pair, e.g., {"ECE": 0.64}.
|
| 62 |
|
| 63 |
|
| 64 |
### Examples
|
| 65 |
<!---
|
| 66 |
*Give code examples of the metric being used. Try to include examples that clear up any potential ambiguity left from the metric description above. If possible, provide a range of examples that show both typical and atypical results, as well as examples where a variety of input parameters are passed.*
|
| 67 |
-->
|
| 68 |
+
```
|
| 69 |
+
N = 10 # N evaluation instances {(x_i,y_i)}_{i=1}^N
|
| 70 |
+
K = 5 # K class problem
|
| 71 |
+
|
| 72 |
+
def random_mc_instance(concentration=1, onehot=False):
|
| 73 |
+
reference = np.argmax(
|
| 74 |
+
np.random.dirichlet(([concentration for _ in range(K)])), -1
|
| 75 |
+
) # class targets
|
| 76 |
+
prediction = np.random.dirichlet(([concentration for _ in range(K)])) # probabilities
|
| 77 |
+
if onehot:
|
| 78 |
+
reference = np.eye(K)[np.argmax(reference, -1)]
|
| 79 |
+
return reference, prediction
|
| 80 |
+
|
| 81 |
+
references, predictions = list(zip(*[random_mc_instance() for i in range(N)]))
|
| 82 |
+
references = np.array(references, dtype=np.int64)
|
| 83 |
+
predictions = np.array(predictions, dtype=np.float32)
|
| 84 |
+
res = ECE()._compute(predictions, references) # {'ECE': float}
|
| 85 |
+
```
|
| 86 |
|
| 87 |
|
| 88 |
## Limitations and Bias
|
|
|
|
| 93 |
|
| 94 |
## Citation
|
| 95 |
[1] Naeini, M.P., Cooper, G. and Hauskrecht, M., 2015, February. Obtaining well calibrated probabilities using bayesian binning. In Twenty-Ninth AAAI Conference on Artificial Intelligence.
|
| 96 |
+
|
| 97 |
[2] Guo, C., Pleiss, G., Sun, Y. and Weinberger, K.Q., 2017, July. On calibration of modern neural networks. In International Conference on Machine Learning (pp. 1321-1330). PMLR.
|
| 98 |
+
|
| 99 |
[3] Nixon, J., Dusenberry, M.W., Zhang, L., Jerfel, G. and Tran, D., 2019, June. Measuring Calibration in Deep Learning. In CVPR Workshops (Vol. 2, No. 7).
|
| 100 |
+
|
| 101 |
[4] Kumar, A., Liang, P.S. and Ma, T., 2019. Verified uncertainty calibration. Advances in Neural Information Processing Systems, 32.
|
| 102 |
+
|
| 103 |
[5] Vaicenavicius, J., Widmann, D., Andersson, C., Lindsten, F., Roll, J. and Schön, T., 2019, April. Evaluating model calibration in classification. In The 22nd International Conference on Artificial Intelligence and Statistics (pp. 3459-3467). PMLR.
|
| 104 |
+
|
| 105 |
[6] Allen-Zhu, Z., Li, Y. and Liang, Y., 2019. Learning and generalization in overparameterized neural networks, going beyond two layers. Advances in neural information processing systems, 32.
|
| 106 |
|
| 107 |
## Further References
|
| 108 |
+
<!---
|
| 109 |
*Add any useful further references.*
|
| 110 |
+
-->
|
app.py
CHANGED
|
@@ -1,7 +1,8 @@
|
|
| 1 |
import evaluate
|
| 2 |
-
import numpy as np
|
| 3 |
-
|
| 4 |
|
| 5 |
from evaluate.utils import launch_gradio_widget
|
|
|
|
| 6 |
module = evaluate.load("jordyvl/ece")
|
| 7 |
-
launch_gradio_widget(module)
|
|
|
|
|
|
|
|
|
| 1 |
import evaluate
|
|
|
|
|
|
|
| 2 |
|
| 3 |
from evaluate.utils import launch_gradio_widget
|
| 4 |
+
|
| 5 |
module = evaluate.load("jordyvl/ece")
|
| 6 |
+
launch_gradio_widget(module)
|
| 7 |
+
|
| 8 |
+
|
ece.py
CHANGED
|
@@ -63,13 +63,10 @@ Returns
|
|
| 63 |
Expected calibration error (ECE), float.
|
| 64 |
|
| 65 |
Examples:
|
| 66 |
-
Examples should be written in doctest format, and should illustrate how
|
| 67 |
-
to use the function.
|
| 68 |
-
|
| 69 |
>>> my_new_module = evaluate.load("jordyvl/ece")
|
| 70 |
>>> results = my_new_module.compute(references=[0, 1, 2], predictions=[[0.6, 0.2, 0.2], [0, 0.95, 0.05], [0.7, 0.1 ,0.2]])
|
| 71 |
>>> print(results)
|
| 72 |
-
{'ECE':
|
| 73 |
"""
|
| 74 |
|
| 75 |
# TODO: Define external resources urls if needed
|
|
|
|
| 63 |
Expected calibration error (ECE), float.
|
| 64 |
|
| 65 |
Examples:
|
|
|
|
|
|
|
|
|
|
| 66 |
>>> my_new_module = evaluate.load("jordyvl/ece")
|
| 67 |
>>> results = my_new_module.compute(references=[0, 1, 2], predictions=[[0.6, 0.2, 0.2], [0, 0.95, 0.05], [0.7, 0.1 ,0.2]])
|
| 68 |
>>> print(results)
|
| 69 |
+
{'ECE': 0.1333333333333334}
|
| 70 |
"""
|
| 71 |
|
| 72 |
# TODO: Define external resources urls if needed
|
local_app.py
CHANGED
|
@@ -1,23 +1,33 @@
|
|
| 1 |
import evaluate
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
import numpy as np
|
| 3 |
import pandas as pd
|
| 4 |
import ast
|
| 5 |
-
import
|
| 6 |
-
|
| 7 |
-
from evaluate.utils import launch_gradio_widget
|
| 8 |
-
from ece import ECE
|
| 9 |
|
| 10 |
import matplotlib.pyplot as plt
|
|
|
|
|
|
|
| 11 |
import seaborn as sns
|
| 12 |
sns.set_style('white')
|
| 13 |
sns.set_context("paper", font_scale=1) # 2
|
|
|
|
| 14 |
# plt.rcParams['figure.figsize'] = [10, 7]
|
| 15 |
-
plt.rcParams[
|
| 16 |
-
plt.switch_backend(
|
|
|
|
|
|
|
| 17 |
|
| 18 |
sliders = [
|
| 19 |
gr.Slider(0, 100, value=10, label="n_bins"),
|
| 20 |
-
gr.Slider(
|
|
|
|
|
|
|
| 21 |
gr.Dropdown(choices=["equal-range", "equal-mass"], value="equal-range", label="scheme"),
|
| 22 |
gr.Dropdown(choices=["upper-edge", "center"], value="upper-edge", label="proxy"),
|
| 23 |
gr.Dropdown(choices=[1, 2, np.inf], value=1, label="p"),
|
|
@@ -42,6 +52,7 @@ component.value = [
|
|
| 42 |
sample_data = [[component] + slider_defaults] ##json.dumps(df)
|
| 43 |
|
| 44 |
|
|
|
|
| 45 |
metric = ECE()
|
| 46 |
# module = evaluate.load("jordyvl/ece")
|
| 47 |
# launch_gradio_widget(module)
|
|
@@ -50,6 +61,7 @@ metric = ECE()
|
|
| 50 |
Switch inputs and compute_fn
|
| 51 |
"""
|
| 52 |
|
|
|
|
| 53 |
def reliability_plot(results):
|
| 54 |
fig = plt.figure()
|
| 55 |
ax1 = plt.subplot2grid((3, 1), (0, 0), rowspan=2)
|
|
@@ -77,7 +89,7 @@ def reliability_plot(results):
|
|
| 77 |
bin_freqs[anindices] = results["bin_freq"]
|
| 78 |
ax2.hist(results["y_bar"], results["y_bar"], weights=bin_freqs)
|
| 79 |
|
| 80 |
-
#widths = np.diff(results["y_bar"])
|
| 81 |
for j, bin in enumerate(results["y_bar"]):
|
| 82 |
perfect = results["y_bar"][j]
|
| 83 |
empirical = results["p_bar"][j]
|
|
@@ -86,31 +98,30 @@ def reliability_plot(results):
|
|
| 86 |
continue
|
| 87 |
|
| 88 |
ax1.bar([perfect], height=[empirical], width=-ranged[j], align="edge", color="lightblue")
|
| 89 |
-
|
| 90 |
if perfect == empirical:
|
| 91 |
continue
|
| 92 |
-
|
| 93 |
-
acc_plt = ax2.axvline(
|
| 94 |
-
x=results["accuracy"], ls="solid", lw=3, c="black", label="Accuracy"
|
| 95 |
-
)
|
| 96 |
conf_plt = ax2.axvline(
|
| 97 |
x=results["p_bar_cont"], ls="dotted", lw=3, c="#444", label="Avg. confidence"
|
| 98 |
)
|
| 99 |
ax2.legend(handles=[acc_plt, conf_plt])
|
| 100 |
|
| 101 |
-
#Bin differences
|
| 102 |
ax1.set_ylabel("Conditional Expectation")
|
| 103 |
-
ax1.set_ylim([-0.05, 1.05])
|
| 104 |
ax1.legend(loc="lower right")
|
| 105 |
ax1.set_title("Reliability Diagram")
|
| 106 |
|
| 107 |
-
#Bin frequencies
|
| 108 |
ax2.set_xlabel("Confidence")
|
| 109 |
ax2.set_ylabel("Count")
|
| 110 |
-
ax2.legend(loc="upper left")
|
| 111 |
plt.tight_layout()
|
| 112 |
return fig
|
| 113 |
|
|
|
|
| 114 |
def compute_and_plot(data, n_bins, bin_range, scheme, proxy, p):
|
| 115 |
# DEV: check on invalid datatypes with better warnings
|
| 116 |
|
|
@@ -127,7 +138,6 @@ def compute_and_plot(data, n_bins, bin_range, scheme, proxy, p):
|
|
| 127 |
predictions,
|
| 128 |
references,
|
| 129 |
n_bins=n_bins,
|
| 130 |
-
# bin_range=None,#not needed
|
| 131 |
scheme=scheme,
|
| 132 |
proxy=proxy,
|
| 133 |
p=p,
|
|
@@ -135,7 +145,7 @@ def compute_and_plot(data, n_bins, bin_range, scheme, proxy, p):
|
|
| 135 |
)
|
| 136 |
|
| 137 |
plot = reliability_plot(results)
|
| 138 |
-
return results["ECE"], plot
|
| 139 |
|
| 140 |
|
| 141 |
outputs = [gr.outputs.Textbox(label="ECE"), gr.Plot(label="Reliability diagram")]
|
|
@@ -145,6 +155,7 @@ iface = gr.Interface(
|
|
| 145 |
inputs=[component] + sliders,
|
| 146 |
outputs=outputs,
|
| 147 |
description=metric.info.description,
|
| 148 |
-
article=
|
|
|
|
| 149 |
# examples=sample_data; # ValueError: Examples argument must either be a directory or a nested list, where each sublist represents a set of inputs.
|
| 150 |
).launch()
|
|
|
|
| 1 |
import evaluate
|
| 2 |
+
import json
|
| 3 |
+
import sys
|
| 4 |
+
from pathlib import Path
|
| 5 |
+
import gradio as gr
|
| 6 |
+
|
| 7 |
import numpy as np
|
| 8 |
import pandas as pd
|
| 9 |
import ast
|
| 10 |
+
from ece import ECE # loads local instead
|
| 11 |
+
|
|
|
|
|
|
|
| 12 |
|
| 13 |
import matplotlib.pyplot as plt
|
| 14 |
+
|
| 15 |
+
"""
|
| 16 |
import seaborn as sns
|
| 17 |
sns.set_style('white')
|
| 18 |
sns.set_context("paper", font_scale=1) # 2
|
| 19 |
+
"""
|
| 20 |
# plt.rcParams['figure.figsize'] = [10, 7]
|
| 21 |
+
plt.rcParams["figure.dpi"] = 300
|
| 22 |
+
plt.switch_backend(
|
| 23 |
+
"agg"
|
| 24 |
+
) # ; https://stackoverflow.com/questions/14694408/runtimeerror-main-thread-is-not-in-main-loop
|
| 25 |
|
| 26 |
sliders = [
|
| 27 |
gr.Slider(0, 100, value=10, label="n_bins"),
|
| 28 |
+
gr.Slider(
|
| 29 |
+
0, 100, value=None, label="bin_range", visible=False
|
| 30 |
+
), # DEV: need to have a double slider
|
| 31 |
gr.Dropdown(choices=["equal-range", "equal-mass"], value="equal-range", label="scheme"),
|
| 32 |
gr.Dropdown(choices=["upper-edge", "center"], value="upper-edge", label="proxy"),
|
| 33 |
gr.Dropdown(choices=[1, 2, np.inf], value=1, label="p"),
|
|
|
|
| 52 |
sample_data = [[component] + slider_defaults] ##json.dumps(df)
|
| 53 |
|
| 54 |
|
| 55 |
+
local_path = Path(sys.path[0])
|
| 56 |
metric = ECE()
|
| 57 |
# module = evaluate.load("jordyvl/ece")
|
| 58 |
# launch_gradio_widget(module)
|
|
|
|
| 61 |
Switch inputs and compute_fn
|
| 62 |
"""
|
| 63 |
|
| 64 |
+
|
| 65 |
def reliability_plot(results):
|
| 66 |
fig = plt.figure()
|
| 67 |
ax1 = plt.subplot2grid((3, 1), (0, 0), rowspan=2)
|
|
|
|
| 89 |
bin_freqs[anindices] = results["bin_freq"]
|
| 90 |
ax2.hist(results["y_bar"], results["y_bar"], weights=bin_freqs)
|
| 91 |
|
| 92 |
+
# widths = np.diff(results["y_bar"])
|
| 93 |
for j, bin in enumerate(results["y_bar"]):
|
| 94 |
perfect = results["y_bar"][j]
|
| 95 |
empirical = results["p_bar"][j]
|
|
|
|
| 98 |
continue
|
| 99 |
|
| 100 |
ax1.bar([perfect], height=[empirical], width=-ranged[j], align="edge", color="lightblue")
|
| 101 |
+
"""
|
| 102 |
if perfect == empirical:
|
| 103 |
continue
|
| 104 |
+
"""
|
| 105 |
+
acc_plt = ax2.axvline(x=results["accuracy"], ls="solid", lw=3, c="black", label="Accuracy")
|
|
|
|
|
|
|
| 106 |
conf_plt = ax2.axvline(
|
| 107 |
x=results["p_bar_cont"], ls="dotted", lw=3, c="#444", label="Avg. confidence"
|
| 108 |
)
|
| 109 |
ax2.legend(handles=[acc_plt, conf_plt])
|
| 110 |
|
| 111 |
+
# Bin differences
|
| 112 |
ax1.set_ylabel("Conditional Expectation")
|
| 113 |
+
ax1.set_ylim([-0.05, 1.05]) # respective to bin range
|
| 114 |
ax1.legend(loc="lower right")
|
| 115 |
ax1.set_title("Reliability Diagram")
|
| 116 |
|
| 117 |
+
# Bin frequencies
|
| 118 |
ax2.set_xlabel("Confidence")
|
| 119 |
ax2.set_ylabel("Count")
|
| 120 |
+
ax2.legend(loc="upper left") # , ncol=2
|
| 121 |
plt.tight_layout()
|
| 122 |
return fig
|
| 123 |
|
| 124 |
+
|
| 125 |
def compute_and_plot(data, n_bins, bin_range, scheme, proxy, p):
|
| 126 |
# DEV: check on invalid datatypes with better warnings
|
| 127 |
|
|
|
|
| 138 |
predictions,
|
| 139 |
references,
|
| 140 |
n_bins=n_bins,
|
|
|
|
| 141 |
scheme=scheme,
|
| 142 |
proxy=proxy,
|
| 143 |
p=p,
|
|
|
|
| 145 |
)
|
| 146 |
|
| 147 |
plot = reliability_plot(results)
|
| 148 |
+
return results["ECE"], plot # plt.gcf()
|
| 149 |
|
| 150 |
|
| 151 |
outputs = [gr.outputs.Textbox(label="ECE"), gr.Plot(label="Reliability diagram")]
|
|
|
|
| 155 |
inputs=[component] + sliders,
|
| 156 |
outputs=outputs,
|
| 157 |
description=metric.info.description,
|
| 158 |
+
article=evaluate.utils.parse_readme(local_path / "README.md"),
|
| 159 |
+
title=f"Metric: {metric.name}",
|
| 160 |
# examples=sample_data; # ValueError: Examples argument must either be a directory or a nested list, where each sublist represents a set of inputs.
|
| 161 |
).launch()
|