Spaces:
Sleeping

Sleeping
Upload 21 files
Browse files- .gitattributes +5 -0
- app.py +255 -0
- data/catmus/images/Les_glorieuses_conquestes_de_Louis_[...]Beaulieu_S/303/251bastien_bpt6k1090945b_13.jpeg +0 -0
- data/catmus/images/Rhodiorum_historia_Caoursin_Guillaume_bpt6k10953875_13.jpeg +0 -0
- data/catmus/images/Rhodiorum_historia_Caoursin_Guillaume_bpt6k10953875_35.jpeg +0 -0
- data/catmus/models/catmus-tiny.mlmodel +3 -0
- data/default/blla.mlmodel +3 -0
- data/endp/images/FRAN_0393_00571.jpg +3 -0
- data/endp/images/FRAN_0393_13559.jpg +3 -0
- data/endp/images/FRAN_0393_14537.jpg +3 -0
- data/endp/models/e-NDP-seg_V3.mlmodel +3 -0
- data/endp/models/e-NDP_V7.mlmodel +3 -0
- data/lectaurep/images/DAFANCH96_048MIC07692_L-1.jpg +0 -0
- data/lectaurep/images/FRAN_0025_0080_L-0.jpg +3 -0
- data/lectaurep/images/FRAN_0187_16406_L-0.jpg +3 -0
- data/lectaurep/models/lectaurep_base.mlmodel +3 -0
- lib/__init__.py +0 -0
- lib/constants.py +52 -0
- lib/display_utils.py +61 -0
- lib/kraken_utils.py +30 -0
- requirements.txt +4 -0
- tmp/.keepfile +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,8 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
data/endp/images/FRAN_0393_00571.jpg filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
data/endp/images/FRAN_0393_13559.jpg filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
data/endp/images/FRAN_0393_14537.jpg filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
data/lectaurep/images/FRAN_0025_0080_L-0.jpg filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
data/lectaurep/images/FRAN_0187_16406_L-0.jpg filter=lfs diff=lfs merge=lfs -text
|
app.py
ADDED
|
@@ -0,0 +1,255 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
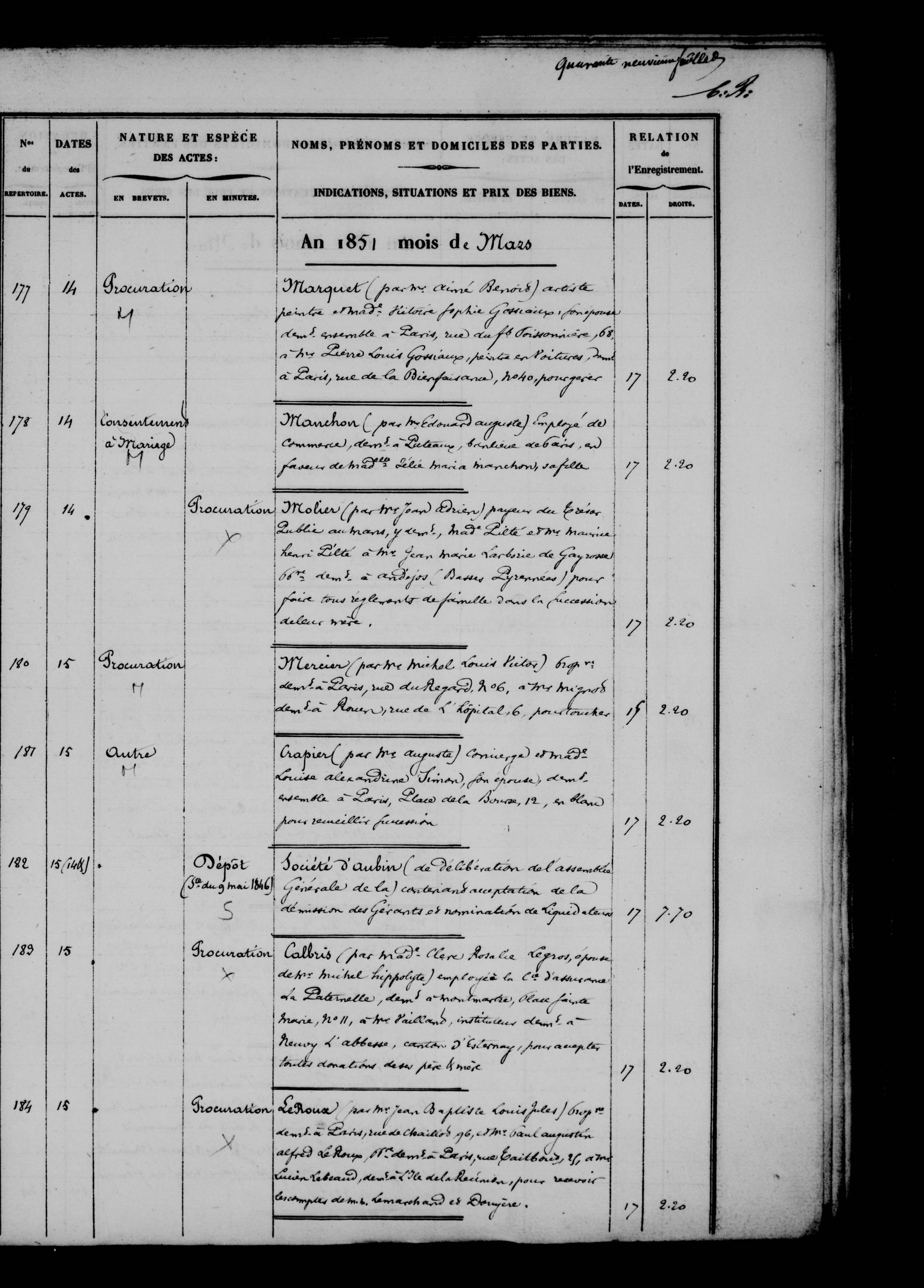
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#! /usr/bin/env python3
|
| 2 |
+
# -*- coding: utf-8 -*-
|
| 3 |
+
"""Streamlit interface for OCR/HTR with Kraken"""
|
| 4 |
+
import os
|
| 5 |
+
import datetime
|
| 6 |
+
import random
|
| 7 |
+
|
| 8 |
+
import streamlit as st
|
| 9 |
+
|
| 10 |
+
from lib.constants import CONFIG_METADATA
|
| 11 |
+
from lib.display_utils import (display_baselines,
|
| 12 |
+
display_baselines_with_text,
|
| 13 |
+
prepare_segments,
|
| 14 |
+
open_image)
|
| 15 |
+
from lib.kraken_utils import (load_model_seg,
|
| 16 |
+
load_model_rec,
|
| 17 |
+
segment_image,
|
| 18 |
+
recognize_text)
|
| 19 |
+
|
| 20 |
+
# === PAGE CONFIGURATION ===
|
| 21 |
+
st.set_page_config(layout="wide")
|
| 22 |
+
|
| 23 |
+
# === I/O UTILS ===
|
| 24 |
+
def get_real_path(path: str) -> str:
|
| 25 |
+
"""Get absolute path of a file."""
|
| 26 |
+
return os.path.join(os.path.dirname(__file__), path)
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def load_random_example_image(folder_path: str):
|
| 30 |
+
"""Load a random image from a folder."""
|
| 31 |
+
images = [os.path.join(folder_path, img) for img in os.listdir(folder_path) if img.endswith(('jpg', 'jpeg'))]
|
| 32 |
+
return random.choice(images) if images else None
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def write_temporary_model(file_path, custom_model_loaded):
|
| 36 |
+
"""Write a temporary model to disk."""
|
| 37 |
+
with open(get_real_path(file_path), "wb") as file:
|
| 38 |
+
file.write(custom_model_loaded.getbuffer())
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def load_model_seg_cache(model_path):
|
| 42 |
+
return load_model_seg(model_path)
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def load_model_rec_cache(model_path):
|
| 46 |
+
return load_model_rec(model_path)
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
MODEL_SEG_BLLA = load_model_seg_cache(get_real_path("data/default/blla.mlmodel"))
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def load_models(model_rec_in, model_seg_in=None):
|
| 53 |
+
"""Generic bridge to load models.
|
| 54 |
+
"""
|
| 55 |
+
if model_rec_in is not None:
|
| 56 |
+
try:
|
| 57 |
+
model_rec_out = load_model_rec_cache(model_rec_in)
|
| 58 |
+
except Exception as e:
|
| 59 |
+
st.error(f" ❌ Modèle de reconnaissance non chargé. Erreur : {e}")
|
| 60 |
+
return None, None
|
| 61 |
+
else:
|
| 62 |
+
st.error(" ❌ Modèle de reconnaissance non trouvé.")
|
| 63 |
+
return None, None
|
| 64 |
+
if model_seg_in is not None:
|
| 65 |
+
try:
|
| 66 |
+
model_seg_out = load_model_seg_cache(model_seg_in)
|
| 67 |
+
except Exception as e:
|
| 68 |
+
st.error(f" ❌ Modèle de segmentation non chargé. Erreur : {e}")
|
| 69 |
+
return None, None
|
| 70 |
+
else:
|
| 71 |
+
model_seg_out = MODEL_SEG_BLLA
|
| 72 |
+
return model_rec_out, model_seg_out
|
| 73 |
+
|
| 74 |
+
# === MODELS EXAMPLES ===
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
endp_model_rec, endp_model_seg = load_models(model_rec_in=get_real_path("data/endp/models/e-NDP_V7.mlmodel"),
|
| 78 |
+
model_seg_in=get_real_path("data/endp/models/e-NDP-seg_V3.mlmodel"))
|
| 79 |
+
lectaurep_model_rec = load_model_rec(get_real_path("data/lectaurep/models/lectaurep_base.mlmodel"))
|
| 80 |
+
catmus_model_rec = load_model_rec(get_real_path("data/catmus/models/catmus-tiny.mlmodel"))
|
| 81 |
+
|
| 82 |
+
# === MODELS EXAMPLES CONFIGURATION ===
|
| 83 |
+
DEFAULT_CONFIG = {
|
| 84 |
+
'endp': {
|
| 85 |
+
'model_rec': endp_model_rec,
|
| 86 |
+
'model_seg': endp_model_seg,
|
| 87 |
+
'example_images': get_real_path("data/endp/images")
|
| 88 |
+
},
|
| 89 |
+
'lectaurep': {
|
| 90 |
+
'model_rec': lectaurep_model_rec,
|
| 91 |
+
'model_seg': None,
|
| 92 |
+
'example_images': get_real_path("data/lectaurep/images")
|
| 93 |
+
},
|
| 94 |
+
'catmus':{
|
| 95 |
+
'model_rec': catmus_model_rec,
|
| 96 |
+
'model_seg': None,
|
| 97 |
+
'example_images': get_real_path("data/catmus/images")
|
| 98 |
+
}
|
| 99 |
+
}
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
# === USER INTERFACE ===
|
| 103 |
+
st.title("📜🦑 Reconnaissance de Texte (OCR/HTR) avec Kraken")
|
| 104 |
+
st.markdown("[](https://github.com/mittagessen/kraken)")
|
| 105 |
+
st.markdown(
|
| 106 |
+
"""
|
| 107 |
+
*⚠️ Cette application est à visée pédagogique ou à des fins de tests uniquement.
|
| 108 |
+
L'auteur se dégage de toutes responsabilités quant à son usage pour la production.*
|
| 109 |
+
"""
|
| 110 |
+
)
|
| 111 |
+
st.markdown(
|
| 112 |
+
"""
|
| 113 |
+
##### 🔗 Ressources :
|
| 114 |
+
- 📂 Données de tests ou d'entraînement dans l'organisation [HTR United](https://htr-united.github.io/index.html)
|
| 115 |
+
- 📦 Modèles (mlmodel) à tester sur le groupe [OCR/HTR Zenodo](https://zenodo.org/communities/ocr_models/records?q=&l=list&p=1&s=10&sort=newest)
|
| 116 |
+
- 🛠 Évaluer vos prédictions avec l'application [KaMI (Kraken as Model Inspector)](https://huggingface.co/spaces/lterriel/kami-app)
|
| 117 |
+
""",
|
| 118 |
+
unsafe_allow_html=True
|
| 119 |
+
)
|
| 120 |
+
|
| 121 |
+
# Configuration choices
|
| 122 |
+
st.sidebar.header("📁 Configuration HTR")
|
| 123 |
+
|
| 124 |
+
st.sidebar.markdown('---')
|
| 125 |
+
button_placeholder = st.sidebar.empty()
|
| 126 |
+
success_loaded_models_msg_container = st.sidebar.empty()
|
| 127 |
+
download_predictions_placeholder = st.sidebar.empty()
|
| 128 |
+
st.sidebar.markdown('---')
|
| 129 |
+
|
| 130 |
+
config_choice = st.sidebar.radio(
|
| 131 |
+
"Choisissez une configuration :", options=["Custom", "endp (exemple)", "lectaurep (exemple)", "catmus (exemple)"]
|
| 132 |
+
)
|
| 133 |
+
|
| 134 |
+
config_choice_placeholder = st.sidebar.empty()
|
| 135 |
+
info_title_desc = st.sidebar.empty()
|
| 136 |
+
place_metadata = st.sidebar.empty()
|
| 137 |
+
map_config_choice = {
|
| 138 |
+
"Custom": "Custom",
|
| 139 |
+
"endp (exemple)": "endp",
|
| 140 |
+
"lectaurep (exemple)": "lectaurep",
|
| 141 |
+
"catmus (exemple)": "catmus"
|
| 142 |
+
}
|
| 143 |
+
config_choice = map_config_choice[config_choice]
|
| 144 |
+
flag_rec_model = False
|
| 145 |
+
flag_seg_model = False
|
| 146 |
+
if config_choice != "Custom":
|
| 147 |
+
config = DEFAULT_CONFIG[config_choice]
|
| 148 |
+
config_choice_placeholder.success(f"Configuration sélectionnée : {CONFIG_METADATA[config_choice]['title']}")
|
| 149 |
+
place_metadata.markdown(CONFIG_METADATA[config_choice]['description'], unsafe_allow_html=True)
|
| 150 |
+
flag_rec_model = True
|
| 151 |
+
else:
|
| 152 |
+
st.sidebar.warning("Configuration personnalisée")
|
| 153 |
+
custom_model_seg = st.sidebar.file_uploader(
|
| 154 |
+
"Modèle de segmentation (optionnel)", type=["mlmodel"]
|
| 155 |
+
)
|
| 156 |
+
custom_model_rec = st.sidebar.file_uploader(
|
| 157 |
+
"Modèle de reconnaissance", type=["mlmodel"]
|
| 158 |
+
)
|
| 159 |
+
if custom_model_rec:
|
| 160 |
+
write_temporary_model('tmp/model_rec_temp.mlmodel', custom_model_rec)
|
| 161 |
+
flag_rec_model = True
|
| 162 |
+
if custom_model_seg:
|
| 163 |
+
write_temporary_model('tmp/model_seg_temp.mlmodel', custom_model_seg)
|
| 164 |
+
flag_seg_model = True
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
# Image choice
|
| 168 |
+
flag_image = False
|
| 169 |
+
image_source = st.radio("Source de l'image :", options=["Exemple", "Personnalisée"])
|
| 170 |
+
info_example_image = st.empty()
|
| 171 |
+
info_example_image_description = st.empty()
|
| 172 |
+
upload_image_placeholder = st.empty()
|
| 173 |
+
col1, col2, col3 = st.columns([1, 1, 1])
|
| 174 |
+
image = None
|
| 175 |
+
with col1:
|
| 176 |
+
st.markdown("## 🖼 Image Originale")
|
| 177 |
+
st.markdown("---")
|
| 178 |
+
if image_source == "Exemple":
|
| 179 |
+
if config_choice != "Custom":
|
| 180 |
+
example_image_path = load_random_example_image(config["example_images"])
|
| 181 |
+
if example_image_path:
|
| 182 |
+
image = open_image(example_image_path)
|
| 183 |
+
flag_image = True
|
| 184 |
+
info_example_image.info(f"Image d'exemple chargée : {os.path.basename(example_image_path)}")
|
| 185 |
+
info_title_desc.markdown(
|
| 186 |
+
"<h4>Métadonnées de la configuration</h3>", unsafe_allow_html=True)
|
| 187 |
+
info_example_image_description.markdown(
|
| 188 |
+
f"Source : {CONFIG_METADATA[config_choice]['examples_info'][os.path.basename(example_image_path)]}",
|
| 189 |
+
unsafe_allow_html=True)
|
| 190 |
+
else:
|
| 191 |
+
info_example_image.error("Aucune image d'exemple trouvée.")
|
| 192 |
+
else:
|
| 193 |
+
info_example_image.error("Les images d'exemple ne sont pas disponibles pour la configuration personnalisée.")
|
| 194 |
+
else:
|
| 195 |
+
image_file = upload_image_placeholder.file_uploader("Téléchargez votre image :", type=["jpg", "jpeg"])
|
| 196 |
+
if image_file:
|
| 197 |
+
image = open_image(image_file)
|
| 198 |
+
flag_image = True
|
| 199 |
+
else:
|
| 200 |
+
info_example_image.warning("Veuillez télécharger une image.")
|
| 201 |
+
if flag_image:
|
| 202 |
+
st.image(image, use_container_width=True)
|
| 203 |
+
|
| 204 |
+
# Display the results
|
| 205 |
+
col4, col5, col6 = st.columns([1, 1, 1])
|
| 206 |
+
if "image" in locals() and flag_rec_model and flag_image:
|
| 207 |
+
button_pred = button_placeholder.button('🚀Lancer la prédiction', key='but_pred')
|
| 208 |
+
if button_pred:
|
| 209 |
+
with st.spinner("⚙️ Chargement des nouveaux modèles..."):
|
| 210 |
+
if config_choice != "Custom":
|
| 211 |
+
model_rec, model_seg = DEFAULT_CONFIG[config_choice]['model_rec'], DEFAULT_CONFIG[config_choice]['model_seg']
|
| 212 |
+
else:
|
| 213 |
+
model_rec = load_model_rec_cache(get_real_path('tmp/model_rec_temp.mlmodel')) if flag_rec_model else None
|
| 214 |
+
model_seg = load_model_seg_cache(get_real_path('tmp/model_seg_temp.mlmodel')) if flag_seg_model else None
|
| 215 |
+
success_loaded_models_msg_container.success("✅️ Configuration OK!")
|
| 216 |
+
|
| 217 |
+
with col2:
|
| 218 |
+
st.markdown("## ✂️Segmentation")
|
| 219 |
+
st.markdown("---")
|
| 220 |
+
with st.spinner("⚙️ Segmentation en cours..."):
|
| 221 |
+
baseline_seg = segment_image(image, model_seg)
|
| 222 |
+
baselines, boundaries = prepare_segments(baseline_seg)
|
| 223 |
+
fig1, fig2 = display_baselines(image, baselines, boundaries)
|
| 224 |
+
st.pyplot(fig1)
|
| 225 |
+
|
| 226 |
+
with col3:
|
| 227 |
+
st.markdown("## ✍️ Texte")
|
| 228 |
+
st.markdown("---")
|
| 229 |
+
with st.spinner("⚙️ Reconnaissance en cours..."):
|
| 230 |
+
pred = recognize_text(model_rec, image, baseline_seg)
|
| 231 |
+
lines = [record.prediction.strip() for record in pred]
|
| 232 |
+
lines_with_idx = [f"{idx}: {line}" for idx, line in enumerate(lines)]
|
| 233 |
+
st.text_area(label='', value="\n".join(lines), height=570, label_visibility="collapsed")
|
| 234 |
+
date = datetime.datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
|
| 235 |
+
|
| 236 |
+
with col4:
|
| 237 |
+
st.markdown("## ✂ Segmentation (Index)")
|
| 238 |
+
st.markdown("---")
|
| 239 |
+
st.pyplot(fig2)
|
| 240 |
+
|
| 241 |
+
with col5:
|
| 242 |
+
st.markdown("## ✏ Texte (Index)")
|
| 243 |
+
st.markdown("---")
|
| 244 |
+
st.text_area(label='', value="\n".join(lines_with_idx), height=570, label_visibility="collapsed")
|
| 245 |
+
|
| 246 |
+
with col6:
|
| 247 |
+
st.markdown("## 🔎 Texte (Image)")
|
| 248 |
+
st.markdown("---")
|
| 249 |
+
st.pyplot(display_baselines_with_text(image, baselines, lines))
|
| 250 |
+
|
| 251 |
+
download_predictions_placeholder.download_button(
|
| 252 |
+
"💾 Télécharger votre prédiction (txt)",
|
| 253 |
+
"\n".join(lines),
|
| 254 |
+
file_name=f"prediction_{date}.txt",
|
| 255 |
+
)
|
data/catmus/images/Les_glorieuses_conquestes_de_Louis_[...]Beaulieu_S/303/251bastien_bpt6k1090945b_13.jpeg
ADDED

|
data/catmus/images/Rhodiorum_historia_Caoursin_Guillaume_bpt6k10953875_13.jpeg
ADDED

|
data/catmus/images/Rhodiorum_historia_Caoursin_Guillaume_bpt6k10953875_35.jpeg
ADDED

|
data/catmus/models/catmus-tiny.mlmodel
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ef14f71c787543f46ded86fbb55b9739b314c04847820fef1a454b9665309002
|
| 3 |
+
size 1183001
|
data/default/blla.mlmodel
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:77a638a83c9e535620827a09e410ed36391e9e8e8126d5796a0f15b978186056
|
| 3 |
+
size 5047020
|
data/endp/images/FRAN_0393_00571.jpg
ADDED

|
Git LFS Details
|
data/endp/images/FRAN_0393_13559.jpg
ADDED

|
Git LFS Details
|
data/endp/images/FRAN_0393_14537.jpg
ADDED

|
Git LFS Details
|
data/endp/models/e-NDP-seg_V3.mlmodel
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:35c942713fc252cc8851541ad870e3611335a222df45b97f42a8b65cf7081405
|
| 3 |
+
size 5049049
|
data/endp/models/e-NDP_V7.mlmodel
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3ade5ee65254d1366e34efd25d9cf159b4e15c6938a8ce3f193403b7081f4cd1
|
| 3 |
+
size 23658117
|
data/lectaurep/images/DAFANCH96_048MIC07692_L-1.jpg
ADDED
|
data/lectaurep/images/FRAN_0025_0080_L-0.jpg
ADDED

|
Git LFS Details
|
data/lectaurep/images/FRAN_0187_16406_L-0.jpg
ADDED

|
Git LFS Details
|
data/lectaurep/models/lectaurep_base.mlmodel
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7d7f4217482fbaef8eb6faab18644bdb708d3a5d18391699dec4f9e559086f88
|
| 3 |
+
size 16120811
|
lib/__init__.py
ADDED
|
File without changes
|
lib/constants.py
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
CONFIG_METADATA = {
|
| 2 |
+
"endp": {
|
| 3 |
+
"title": "e-NDP project [exemple configuration]",
|
| 4 |
+
"description": """
|
| 5 |
+
<div style="text-align: justify;">
|
| 6 |
+
<p>The e-NDP project: collaborative digital edition of the Chapter registers of Notre-Dame of Paris (1326-1504) </p>
|
| 7 |
+
<p>Project information: <a href='https://endp.hypotheses.org/' target='blank'>here</a>.</p>
|
| 8 |
+
<p>Model & Dataset description:</p>
|
| 9 |
+
<ul>
|
| 10 |
+
<li><pre>Claustre, J., Smith, D., Torres Aguilar, S., Bretthauer, I., Brochard, P., Canteaut, O., Cottereau, E., Delivré, F., Denglos, M., Jolivet, V., Julerot, V., Kouamé, T., Lusset, E., Massoni, A., Nadiras, S., Perreaux, N., Regazzi, H., & Treglia, M. (2023). The e-NDP project : collaborative digital edition of the Chapter registers of Notre-Dame of Paris (1326-1504). Ground-truth for handwriting text recognition (HTR) on late medieval manuscripts. (1.0, p. https://zenodo.org/record/7575693) [Data set]. Zenodo. <a href='https://doi.org/10.5281/zenodo.7575693' target='blank'>https://doi.org/10.5281/zenodo.7575693</a><pre></li>
|
| 11 |
+
<li>Models: <a href="https://github.com/chartes/e-NDP_HTR/releases/tag/V7.1">https://github.com/chartes/e-NDP_HTR/releases/tag/V7.1</a></li>
|
| 12 |
+
</ul>
|
| 13 |
+
|
| 14 |
+
</div>
|
| 15 |
+
""",
|
| 16 |
+
"examples_info": {
|
| 17 |
+
"FRAN_0393_00571.jpg":"Archives nationales, LL109A , p. 43, février 1400. <a href='https://nakala.fr/10.34847/nkl.bced06qw#7ad1dde915d5ed70d2dd3fb3f8dffebf551b313c'>Nakala</a>",
|
| 18 |
+
"FRAN_0393_13559.jpg":"Archives nationales, LL120, p. 555, décembre 1463. <a href='https://nakala.fr/10.34847/nkl.205cj7td#2e5831e14350511c42b938c0274246aa858c8fec'>Nakala</a>",
|
| 19 |
+
"FRAN_0393_14537.jpg":"Archives nationales, LL127, p. 625, février 1504. <a href='https://nakala.fr/10.34847/nkl.7a9e99jb#fbadd2c18fa17df2ea56c98c8af0a4452aef2fa8'>Nakala</a>"
|
| 20 |
+
}
|
| 21 |
+
},
|
| 22 |
+
"lectaurep": {
|
| 23 |
+
"title": "LECTAUREP project [exemple configuration]",
|
| 24 |
+
"description": """
|
| 25 |
+
<div style="text-align: justify;">
|
| 26 |
+
<p>LECTAUREP Contemporary French Model (Administration)</p>
|
| 27 |
+
<p>Project information: <a href='https://lectaurep.hypotheses.org/'>here</a>.</p>
|
| 28 |
+
<p>Model & Dataset description: <pre>Chagué, A. (2022). LECTAUREP Contemporary French Model (Administration) (1.0.0). Zenodo. <a href='https://zenodo.org/records/6542744'>https://zenodo.org/records/6542744</a></pre></p>
|
| 29 |
+
</div>
|
| 30 |
+
""",
|
| 31 |
+
"examples_info": {
|
| 32 |
+
"DAFANCH96_048MIC07692_L-1.jpg": "Archives nationales, Répertoire de notaires (19e-20e)",
|
| 33 |
+
"FRAN_0025_0080_L-0.jpg": "Archives nationales, Répertoire de notaires (19e-20e)",
|
| 34 |
+
"FRAN_0187_16406_L-0.jpg": "Archives nationales, Répertoire de notaires (19e-20e)"
|
| 35 |
+
}
|
| 36 |
+
},
|
| 37 |
+
"catmus": {
|
| 38 |
+
"title": "CATMuS-Print [exemple configuration]",
|
| 39 |
+
"description": """
|
| 40 |
+
<div style="text-align: justify;">
|
| 41 |
+
<p>CATMuS-Print (Tiny) - Diachronic model for French prints and other West European languages</p>
|
| 42 |
+
<p>CATMuS (Consistent Approach to Transcribing ManuScript) Print is a Kraken HTR model trained on data produced by several projects, dealing with different languages (French, Spanish, German, English, Corsican, Catalan, Latin, Italian…) and different centuries (from the first prints of the 16th c. to digital documents of the 21st century).</p>
|
| 43 |
+
<p>Model & Dataset description: <pre>Gabay, S., & Clérice, T. (2024). CATMuS-Print [Tiny] (31-01-2024). Zenodo. <a href='https://doi.org/10.5281/zenodo.10602357' target='blank'>https://doi.org/10.5281/zenodo.10602357</a></pre></p>
|
| 44 |
+
</div>
|
| 45 |
+
""",
|
| 46 |
+
"examples_info": {
|
| 47 |
+
"Rhodiorum_historia_Caoursin_Guillaume_bpt6k10953875_35.jpeg": "Caoursin, Guillaume, Rhodiorum historia (1496), BnF, <a href='https://gallica.bnf.fr/ark:/12148/bpt6k10953875' target='blank'>Gallica</a>",
|
| 48 |
+
"Rhodiorum_historia_Caoursin_Guillaume_bpt6k10953875_13.jpeg": "Caoursin, Guillaume, Rhodiorum historia (1496), BnF, <a href='https://gallica.bnf.fr/ark:/12148/bpt6k10953875/f13.item' target='blank'>Gallica</a>",
|
| 49 |
+
"Les_glorieuses_conquestes_de_Louis_[...]Beaulieu_Sébastien_bpt6k1090945b_13.jpeg":"Beaulieu, Sébastien de, Les glorieuses conquestes de Louis le Grand, roy de France et de Navarre [Grand Beaulieu]. Tome 2 (16.), BnF, <a href='https://gallica.bnf.fr/ark:/12148/bpt6k10953875' target='blank'>Gallica</a>"
|
| 50 |
+
}
|
| 51 |
+
}
|
| 52 |
+
}
|
lib/display_utils.py
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
"""Utils for display input and output"""
|
| 3 |
+
|
| 4 |
+
import matplotlib.pyplot as plt
|
| 5 |
+
from PIL import Image
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def open_image(image_path: str) -> Image.Image:
|
| 9 |
+
"""Open an image from a path."""
|
| 10 |
+
return Image.open(image_path)
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def display_baselines(image, baselines, boundaries=None):
|
| 14 |
+
"""Display baselines and boundaries on an image."""
|
| 15 |
+
fig, ax = plt.subplots(figsize=(10, 10))
|
| 16 |
+
ax.imshow(image, cmap='gray')
|
| 17 |
+
ax.axis('off')
|
| 18 |
+
for idx, baseline in enumerate(baselines):
|
| 19 |
+
baseline_x = [point[0] for point in baseline]
|
| 20 |
+
baseline_y = [point[1] for point in baseline]
|
| 21 |
+
ax.plot(baseline_x, baseline_y, color='blue', linewidth=0.7)
|
| 22 |
+
if boundaries:
|
| 23 |
+
for boundary in boundaries:
|
| 24 |
+
boundary_x = [point[0] for point in boundary]
|
| 25 |
+
boundary_y = [point[1] for point in boundary]
|
| 26 |
+
ax.plot(boundary_x, boundary_y, color='red', linestyle='--', linewidth=1)
|
| 27 |
+
|
| 28 |
+
fig_special, ax_special = plt.subplots(figsize=(10, 10))
|
| 29 |
+
ax_special.set_xlim(0, image.size[0])
|
| 30 |
+
ax_special.set_ylim(0, image.size[1])
|
| 31 |
+
ax_special.invert_yaxis()
|
| 32 |
+
for idx, baseline in enumerate(baselines):
|
| 33 |
+
baseline_x = [point[0] for point in baseline]
|
| 34 |
+
baseline_y = [point[1] for point in baseline]
|
| 35 |
+
ax_special.plot(baseline_x, baseline_y, color='blue', linewidth=0.7)
|
| 36 |
+
ax_special.text(baseline_x[0], baseline_y[0], str(idx), fontsize=10, color='red')
|
| 37 |
+
return fig, fig_special
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def display_baselines_with_text(image, baselines, lines):
|
| 41 |
+
"""Display baselines with text on an image."""
|
| 42 |
+
fig_special, ax_special = plt.subplots(figsize=(10, 10))
|
| 43 |
+
ax_special.set_xlim(0, image.size[0])
|
| 44 |
+
ax_special.set_ylim(0, image.size[1])
|
| 45 |
+
ax_special.invert_yaxis()
|
| 46 |
+
for idx, group in enumerate(zip(lines, baselines)):
|
| 47 |
+
baseline_x = [point[0] for point in group[1]]
|
| 48 |
+
baseline_y = [point[1] for point in group[1]]
|
| 49 |
+
ax_special.text(baseline_x[0], baseline_y[0], f"{str(idx)}: {group[0]}", fontsize=5.5, color='black')
|
| 50 |
+
ax_special.axis('off')
|
| 51 |
+
return fig_special
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def prepare_segments(seg_obj):
|
| 55 |
+
"""Prepare baselines and boundaries for display."""
|
| 56 |
+
baselines = []
|
| 57 |
+
boundaries = []
|
| 58 |
+
for line in seg_obj.lines:
|
| 59 |
+
baselines.append(line.baseline)
|
| 60 |
+
boundaries.append(line.boundary)
|
| 61 |
+
return baselines, boundaries
|
lib/kraken_utils.py
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
"""Kraken utils for OCR/HTR engine"""
|
| 3 |
+
|
| 4 |
+
import streamlit as st
|
| 5 |
+
|
| 6 |
+
from kraken.lib import (vgsl,
|
| 7 |
+
models)
|
| 8 |
+
from kraken import (blla,
|
| 9 |
+
rpred)
|
| 10 |
+
from PIL import Image
|
| 11 |
+
|
| 12 |
+
@st.cache_data(show_spinner=False)
|
| 13 |
+
def load_model_seg(model_path: str) -> vgsl.TorchVGSLModel:
|
| 14 |
+
"""Load a segmentation model"""
|
| 15 |
+
return vgsl.TorchVGSLModel.load_model(model_path)
|
| 16 |
+
|
| 17 |
+
@st.cache_data(show_spinner=False)
|
| 18 |
+
def load_model_rec(model_path: str):
|
| 19 |
+
"""Load a recognition model"""
|
| 20 |
+
return models.load_any(model_path)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def segment_image(image: Image, model_seg: vgsl.TorchVGSLModel):
|
| 24 |
+
"""Segment an image"""
|
| 25 |
+
return blla.segment(image, model=model_seg)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def recognize_text(model, image: Image, baseline_seg):
|
| 29 |
+
"""Recognize text in an image"""
|
| 30 |
+
return rpred.rpred(network=model, im=image, bounds=baseline_seg, pad=16, bidi_reordering=True)
|
requirements.txt
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
kraken==5.2.9
|
| 2 |
+
matplotlib==3.9.2
|
| 3 |
+
Pillow==11.0.0
|
| 4 |
+
streamlit==1.40.1
|
tmp/.keepfile
ADDED
|
File without changes
|