Spaces:
Running

Running
Nathan Habib
commited on
Commit
•
d9cbfab
1
Parent(s):
c84f054
revert dists
Browse files- dist/assets/images/ifeval_score_per_model_type.png +0 -0
- dist/assets/images/math_fn_gsm8k.png +0 -0
- dist/assets/images/math_score_per_model_type.png +0 -0
- dist/assets/images/normalized_vs_raw_scores.png +0 -0
- dist/assets/images/ranking_top10_bottom10.png +0 -0
- dist/assets/images/saturation.png +0 -0
- dist/assets/images/task_vs_mean.png +0 -0
- dist/assets/images/timewise_analysis_full.png +0 -0
- dist/assets/images/timewise_analysis_light.png +0 -0
- dist/assets/images/v2_correlation_heatmap.png +0 -0
- dist/assets/images/v2_fn_of_mmlu.png +0 -0
- dist/assets/scripts/correlation_heatmap.html +0 -0
- dist/assets/scripts/normalized_vs_raw.html +0 -0
- dist/assets/scripts/plot.html +0 -0
- dist/assets/scripts/rankings_change.html +0 -0
- dist/bibliography.bib +334 -0
- dist/distill.bundle.js +0 -0
- dist/distill.bundle.js.map +0 -0
- dist/index.html +451 -0
- dist/main.bundle.js +2 -0
- dist/main.bundle.js.map +1 -0
- dist/style.css +259 -0
dist/assets/images/ifeval_score_per_model_type.png
ADDED

|
dist/assets/images/math_fn_gsm8k.png
ADDED
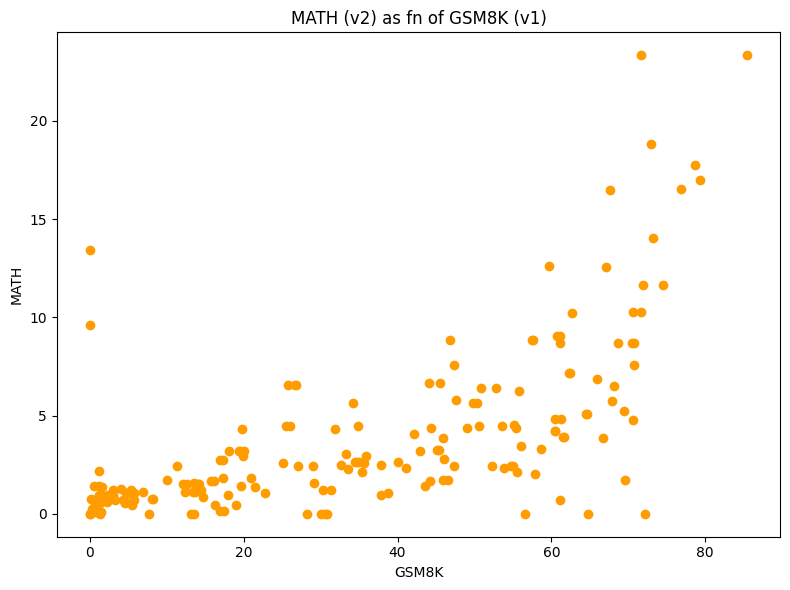
|
dist/assets/images/math_score_per_model_type.png
ADDED

|
dist/assets/images/normalized_vs_raw_scores.png
ADDED

|
dist/assets/images/ranking_top10_bottom10.png
ADDED
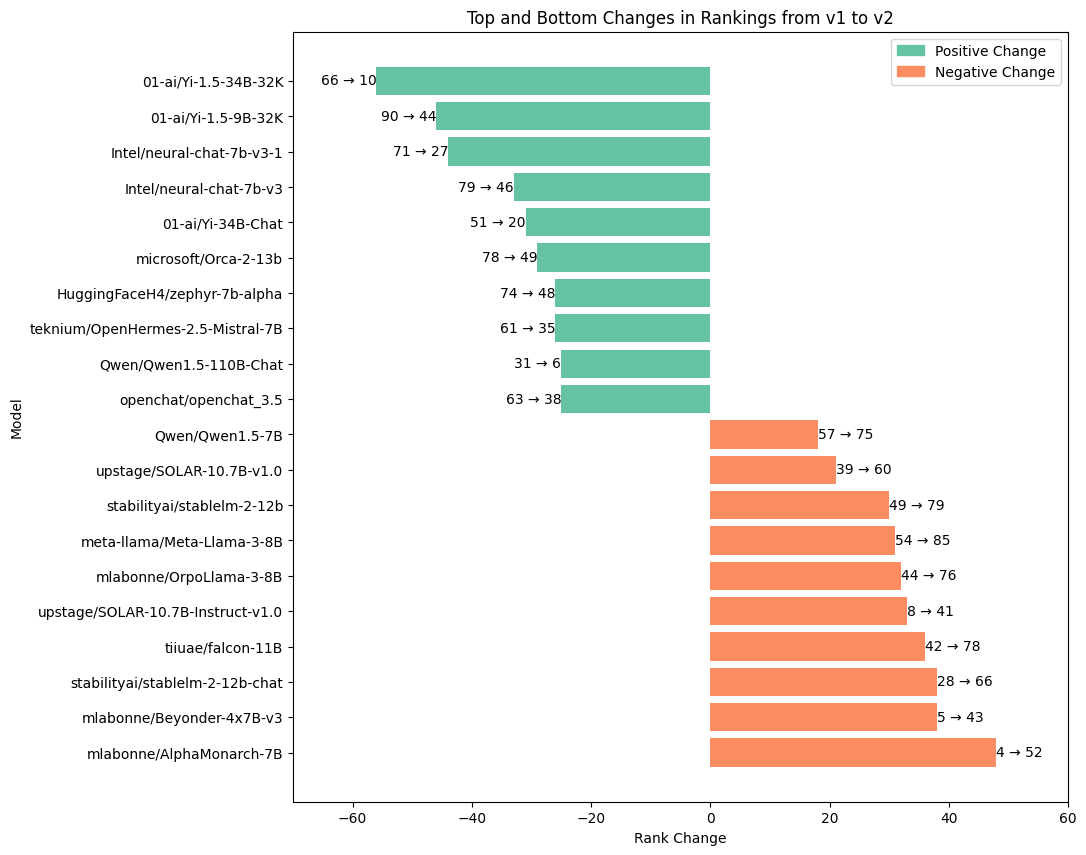
|
dist/assets/images/saturation.png
ADDED
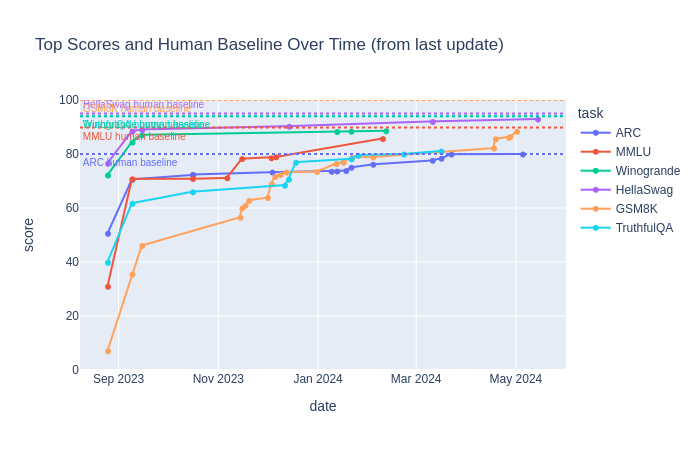
|
dist/assets/images/task_vs_mean.png
ADDED
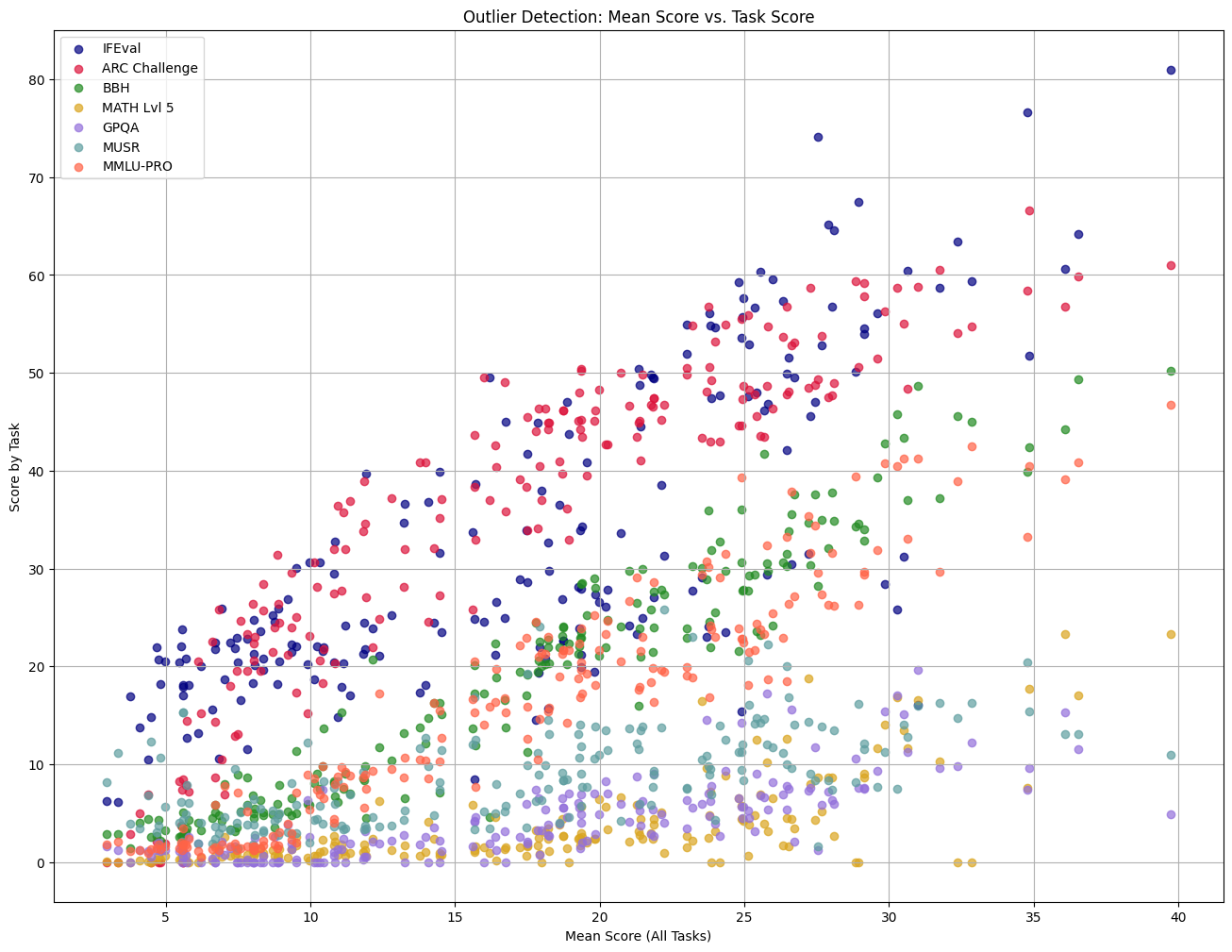
|
dist/assets/images/timewise_analysis_full.png
ADDED
|
dist/assets/images/timewise_analysis_light.png
ADDED
|
dist/assets/images/v2_correlation_heatmap.png
ADDED
|
dist/assets/images/v2_fn_of_mmlu.png
ADDED
|
dist/assets/scripts/correlation_heatmap.html
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
dist/assets/scripts/normalized_vs_raw.html
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
dist/assets/scripts/plot.html
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
dist/assets/scripts/rankings_change.html
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
dist/bibliography.bib
ADDED
|
@@ -0,0 +1,334 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
@article{radford2019language,
|
| 2 |
+
title={Language Models are Unsupervised Multitask Learners},
|
| 3 |
+
author={Radford, Alec and Wu, Jeff and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya},
|
| 4 |
+
year={2019}
|
| 5 |
+
}
|
| 6 |
+
@inproceedings{barbaresi-2021-trafilatura,
|
| 7 |
+
title = {Trafilatura: A Web Scraping Library and Command-Line Tool for Text Discovery and Extraction},
|
| 8 |
+
author = "Barbaresi, Adrien",
|
| 9 |
+
booktitle = "Proceedings of the Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations",
|
| 10 |
+
pages = "122--131",
|
| 11 |
+
publisher = "Association for Computational Linguistics",
|
| 12 |
+
url = "https://aclanthology.org/2021.acl-demo.15",
|
| 13 |
+
year = 2021,
|
| 14 |
+
}
|
| 15 |
+
@misc{penedo2023refinedweb,
|
| 16 |
+
title={The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only},
|
| 17 |
+
author={Guilherme Penedo and Quentin Malartic and Daniel Hesslow and Ruxandra Cojocaru and Alessandro Cappelli and Hamza Alobeidli and Baptiste Pannier and Ebtesam Almazrouei and Julien Launay},
|
| 18 |
+
year={2023},
|
| 19 |
+
eprint={2306.01116},
|
| 20 |
+
archivePrefix={arXiv},
|
| 21 |
+
primaryClass={cs.CL}
|
| 22 |
+
}
|
| 23 |
+
@article{joulin2016fasttext,
|
| 24 |
+
title={FastText.zip: Compressing text classification models},
|
| 25 |
+
author={Joulin, Armand and Grave, Edouard and Bojanowski, Piotr and Douze, Matthijs and J{\'e}gou, H{\'e}rve and Mikolov, Tomas},
|
| 26 |
+
journal={arXiv preprint arXiv:1612.03651},
|
| 27 |
+
year={2016}
|
| 28 |
+
}
|
| 29 |
+
@article{joulin2016bag,
|
| 30 |
+
title={Bag of Tricks for Efficient Text Classification},
|
| 31 |
+
author={Joulin, Armand and Grave, Edouard and Bojanowski, Piotr and Mikolov, Tomas},
|
| 32 |
+
journal={arXiv preprint arXiv:1607.01759},
|
| 33 |
+
year={2016}
|
| 34 |
+
}
|
| 35 |
+
@misc{penedo2024datatrove,
|
| 36 |
+
author = {Penedo, Guilherme and Kydlíček, Hynek and Cappelli, Alessandro and Sasko, Mario and Wolf, Thomas},
|
| 37 |
+
title = {DataTrove: large scale data processing},
|
| 38 |
+
year = {2024},
|
| 39 |
+
publisher = {GitHub},
|
| 40 |
+
journal = {GitHub repository},
|
| 41 |
+
url = {https://github.com/huggingface/datatrove}
|
| 42 |
+
}
|
| 43 |
+
@misc{chiang2024chatbot,
|
| 44 |
+
title={Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference},
|
| 45 |
+
author={Wei-Lin Chiang and Lianmin Zheng and Ying Sheng and Anastasios Nikolas Angelopoulos and Tianle Li and Dacheng Li and Hao Zhang and Banghua Zhu and Michael Jordan and Joseph E. Gonzalez and Ion Stoica},
|
| 46 |
+
year={2024},
|
| 47 |
+
eprint={2403.04132},
|
| 48 |
+
archivePrefix={arXiv},
|
| 49 |
+
primaryClass={cs.AI}
|
| 50 |
+
}
|
| 51 |
+
@misc{rae2022scaling,
|
| 52 |
+
title={Scaling Language Models: Methods, Analysis & Insights from Training Gopher},
|
| 53 |
+
author={Jack W. Rae and Sebastian Borgeaud and Trevor Cai and Katie Millican and Jordan Hoffmann and Francis Song and John Aslanides and Sarah Henderson and Roman Ring and Susannah Young and Eliza Rutherford and Tom Hennigan and Jacob Menick and Albin Cassirer and Richard Powell and George van den Driessche and Lisa Anne Hendricks and Maribeth Rauh and Po-Sen Huang and Amelia Glaese and Johannes Welbl and Sumanth Dathathri and Saffron Huang and Jonathan Uesato and John Mellor and Irina Higgins and Antonia Creswell and Nat McAleese and Amy Wu and Erich Elsen and Siddhant Jayakumar and Elena Buchatskaya and David Budden and Esme Sutherland and Karen Simonyan and Michela Paganini and Laurent Sifre and Lena Martens and Xiang Lorraine Li and Adhiguna Kuncoro and Aida Nematzadeh and Elena Gribovskaya and Domenic Donato and Angeliki Lazaridou and Arthur Mensch and Jean-Baptiste Lespiau and Maria Tsimpoukelli and Nikolai Grigorev and Doug Fritz and Thibault Sottiaux and Mantas Pajarskas and Toby Pohlen and Zhitao Gong and Daniel Toyama and Cyprien de Masson d'Autume and Yujia Li and Tayfun Terzi and Vladimir Mikulik and Igor Babuschkin and Aidan Clark and Diego de Las Casas and Aurelia Guy and Chris Jones and James Bradbury and Matthew Johnson and Blake Hechtman and Laura Weidinger and Iason Gabriel and William Isaac and Ed Lockhart and Simon Osindero and Laura Rimell and Chris Dyer and Oriol Vinyals and Kareem Ayoub and Jeff Stanway and Lorrayne Bennett and Demis Hassabis and Koray Kavukcuoglu and Geoffrey Irving},
|
| 54 |
+
year={2022},
|
| 55 |
+
eprint={2112.11446},
|
| 56 |
+
archivePrefix={arXiv},
|
| 57 |
+
primaryClass={cs.CL}
|
| 58 |
+
}
|
| 59 |
+
@misc{lee2022deduplicating,
|
| 60 |
+
title={Deduplicating Training Data Makes Language Models Better},
|
| 61 |
+
author={Katherine Lee and Daphne Ippolito and Andrew Nystrom and Chiyuan Zhang and Douglas Eck and Chris Callison-Burch and Nicholas Carlini},
|
| 62 |
+
year={2022},
|
| 63 |
+
eprint={2107.06499},
|
| 64 |
+
archivePrefix={arXiv},
|
| 65 |
+
primaryClass={cs.CL}
|
| 66 |
+
}
|
| 67 |
+
@misc{carlini2023quantifying,
|
| 68 |
+
title={Quantifying Memorization Across Neural Language Models},
|
| 69 |
+
author={Nicholas Carlini and Daphne Ippolito and Matthew Jagielski and Katherine Lee and Florian Tramer and Chiyuan Zhang},
|
| 70 |
+
year={2023},
|
| 71 |
+
eprint={2202.07646},
|
| 72 |
+
archivePrefix={arXiv},
|
| 73 |
+
primaryClass={cs.LG}
|
| 74 |
+
}
|
| 75 |
+
@misc{raffel2023exploring,
|
| 76 |
+
title={Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
|
| 77 |
+
author={Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
|
| 78 |
+
year={2023},
|
| 79 |
+
eprint={1910.10683},
|
| 80 |
+
archivePrefix={arXiv},
|
| 81 |
+
primaryClass={cs.LG}
|
| 82 |
+
}
|
| 83 |
+
@misc{touvron2023llama,
|
| 84 |
+
title={LLaMA: Open and Efficient Foundation Language Models},
|
| 85 |
+
author={Hugo Touvron and Thibaut Lavril and Gautier Izacard and Xavier Martinet and Marie-Anne Lachaux and Timothée Lacroix and Baptiste Rozière and Naman Goyal and Eric Hambro and Faisal Azhar and Aurelien Rodriguez and Armand Joulin and Edouard Grave and Guillaume Lample},
|
| 86 |
+
year={2023},
|
| 87 |
+
eprint={2302.13971},
|
| 88 |
+
archivePrefix={arXiv},
|
| 89 |
+
primaryClass={cs.CL}
|
| 90 |
+
}
|
| 91 |
+
@article{dolma,
|
| 92 |
+
title = {Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research},
|
| 93 |
+
author={
|
| 94 |
+
Luca Soldaini and Rodney Kinney and Akshita Bhagia and Dustin Schwenk and David Atkinson and
|
| 95 |
+
Russell Authur and Ben Bogin and Khyathi Chandu and Jennifer Dumas and Yanai Elazar and
|
| 96 |
+
Valentin Hofmann and Ananya Harsh Jha and Sachin Kumar and Li Lucy and Xinxi Lyu and
|
| 97 |
+
Nathan Lambert and Ian Magnusson and Jacob Morrison and Niklas Muennighoff and Aakanksha Naik and
|
| 98 |
+
Crystal Nam and Matthew E. Peters and Abhilasha Ravichander and Kyle Richardson and Zejiang Shen and
|
| 99 |
+
Emma Strubell and Nishant Subramani and Oyvind Tafjord and Pete Walsh and Luke Zettlemoyer and
|
| 100 |
+
Noah A. Smith and Hannaneh Hajishirzi and Iz Beltagy and Dirk Groeneveld and Jesse Dodge and Kyle Lo
|
| 101 |
+
},
|
| 102 |
+
year = {2024},
|
| 103 |
+
journal={arXiv preprint},
|
| 104 |
+
}
|
| 105 |
+
@article{gao2020pile,
|
| 106 |
+
title={The {P}ile: An 800{GB} dataset of diverse text for language modeling},
|
| 107 |
+
author={Gao, Leo and Biderman, Stella and Black, Sid and Golding, Laurence and Hoppe, Travis and Foster, Charles and Phang, Jason and He, Horace and Thite, Anish and Nabeshima, Noa and others},
|
| 108 |
+
journal={arXiv preprint arXiv:2101.00027},
|
| 109 |
+
year={2020}
|
| 110 |
+
}
|
| 111 |
+
@misc{cerebras2023slimpajama,
|
| 112 |
+
author = {Soboleva, Daria and Al-Khateeb, Faisal and Myers, Robert and Steeves, Jacob R and Hestness, Joel and Dey, Nolan},
|
| 113 |
+
title = {SlimPajama: A 627B token cleaned and deduplicated version of RedPajama},
|
| 114 |
+
month = {June},
|
| 115 |
+
year = 2023,
|
| 116 |
+
url = {https://huggingface.co/datasets/cerebras/SlimPajama-627B},
|
| 117 |
+
}
|
| 118 |
+
@software{together2023redpajama,
|
| 119 |
+
author = {Together Computer},
|
| 120 |
+
title = {RedPajama: an Open Dataset for Training Large Language Models},
|
| 121 |
+
month = {October},
|
| 122 |
+
year = 2023,
|
| 123 |
+
url = {https://github.com/togethercomputer/RedPajama-Data}
|
| 124 |
+
}
|
| 125 |
+
@article{jaccard1912distribution,
|
| 126 |
+
title={The distribution of the flora in the alpine zone. 1},
|
| 127 |
+
author={Jaccard, Paul},
|
| 128 |
+
journal={New phytologist},
|
| 129 |
+
volume={11},
|
| 130 |
+
number={2},
|
| 131 |
+
pages={37--50},
|
| 132 |
+
year={1912},
|
| 133 |
+
publisher={Wiley Online Library}
|
| 134 |
+
}
|
| 135 |
+
@misc{albalak2024survey,
|
| 136 |
+
title={A Survey on Data Selection for Language Models},
|
| 137 |
+
author={Alon Albalak and Yanai Elazar and Sang Michael Xie and Shayne Longpre and Nathan Lambert and Xinyi Wang and Niklas Muennighoff and Bairu Hou and Liangming Pan and Haewon Jeong and Colin Raffel and Shiyu Chang and Tatsunori Hashimoto and William Yang Wang},
|
| 138 |
+
year={2024},
|
| 139 |
+
eprint={2402.16827},
|
| 140 |
+
archivePrefix={arXiv},
|
| 141 |
+
primaryClass={cs.CL}
|
| 142 |
+
}
|
| 143 |
+
@misc{longpre2023pretrainers,
|
| 144 |
+
title={A Pretrainer's Guide to Training Data: Measuring the Effects of Data Age, Domain Coverage, Quality, & Toxicity},
|
| 145 |
+
author={Shayne Longpre and Gregory Yauney and Emily Reif and Katherine Lee and Adam Roberts and Barret Zoph and Denny Zhou and Jason Wei and Kevin Robinson and David Mimno and Daphne Ippolito},
|
| 146 |
+
year={2023},
|
| 147 |
+
eprint={2305.13169},
|
| 148 |
+
archivePrefix={arXiv},
|
| 149 |
+
primaryClass={cs.CL}
|
| 150 |
+
}
|
| 151 |
+
@misc{wenzek2019ccnet,
|
| 152 |
+
title={CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data},
|
| 153 |
+
author={Guillaume Wenzek and Marie-Anne Lachaux and Alexis Conneau and Vishrav Chaudhary and Francisco Guzmán and Armand Joulin and Edouard Grave},
|
| 154 |
+
year={2019},
|
| 155 |
+
eprint={1911.00359},
|
| 156 |
+
archivePrefix={arXiv},
|
| 157 |
+
primaryClass={cs.CL}
|
| 158 |
+
}
|
| 159 |
+
@misc{soldaini2024dolma,
|
| 160 |
+
title={Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research},
|
| 161 |
+
author={Luca Soldaini and Rodney Kinney and Akshita Bhagia and Dustin Schwenk and David Atkinson and Russell Authur and Ben Bogin and Khyathi Chandu and Jennifer Dumas and Yanai Elazar and Valentin Hofmann and Ananya Harsh Jha and Sachin Kumar and Li Lucy and Xinxi Lyu and Nathan Lambert and Ian Magnusson and Jacob Morrison and Niklas Muennighoff and Aakanksha Naik and Crystal Nam and Matthew E. Peters and Abhilasha Ravichander and Kyle Richardson and Zejiang Shen and Emma Strubell and Nishant Subramani and Oyvind Tafjord and Pete Walsh and Luke Zettlemoyer and Noah A. Smith and Hannaneh Hajishirzi and Iz Beltagy and Dirk Groeneveld and Jesse Dodge and Kyle Lo},
|
| 162 |
+
year={2024},
|
| 163 |
+
eprint={2402.00159},
|
| 164 |
+
archivePrefix={arXiv},
|
| 165 |
+
primaryClass={cs.CL}
|
| 166 |
+
}
|
| 167 |
+
@misc{ouyang2022training,
|
| 168 |
+
title={Training language models to follow instructions with human feedback},
|
| 169 |
+
author={Long Ouyang and Jeff Wu and Xu Jiang and Diogo Almeida and Carroll L. Wainwright and Pamela Mishkin and Chong Zhang and Sandhini Agarwal and Katarina Slama and Alex Ray and John Schulman and Jacob Hilton and Fraser Kelton and Luke Miller and Maddie Simens and Amanda Askell and Peter Welinder and Paul Christiano and Jan Leike and Ryan Lowe},
|
| 170 |
+
year={2022},
|
| 171 |
+
eprint={2203.02155},
|
| 172 |
+
archivePrefix={arXiv},
|
| 173 |
+
primaryClass={cs.CL}
|
| 174 |
+
}
|
| 175 |
+
@misc{hoffmann2022training,
|
| 176 |
+
title={Training Compute-Optimal Large Language Models},
|
| 177 |
+
author={Jordan Hoffmann and Sebastian Borgeaud and Arthur Mensch and Elena Buchatskaya and Trevor Cai and Eliza Rutherford and Diego de Las Casas and Lisa Anne Hendricks and Johannes Welbl and Aidan Clark and Tom Hennigan and Eric Noland and Katie Millican and George van den Driessche and Bogdan Damoc and Aurelia Guy and Simon Osindero and Karen Simonyan and Erich Elsen and Jack W. Rae and Oriol Vinyals and Laurent Sifre},
|
| 178 |
+
year={2022},
|
| 179 |
+
eprint={2203.15556},
|
| 180 |
+
archivePrefix={arXiv},
|
| 181 |
+
primaryClass={cs.CL}
|
| 182 |
+
}
|
| 183 |
+
@misc{muennighoff2023scaling,
|
| 184 |
+
title={Scaling Data-Constrained Language Models},
|
| 185 |
+
author={Niklas Muennighoff and Alexander M. Rush and Boaz Barak and Teven Le Scao and Aleksandra Piktus and Nouamane Tazi and Sampo Pyysalo and Thomas Wolf and Colin Raffel},
|
| 186 |
+
year={2023},
|
| 187 |
+
eprint={2305.16264},
|
| 188 |
+
archivePrefix={arXiv},
|
| 189 |
+
primaryClass={cs.CL}
|
| 190 |
+
}
|
| 191 |
+
@misc{hernandez2022scaling,
|
| 192 |
+
title={Scaling Laws and Interpretability of Learning from Repeated Data},
|
| 193 |
+
author={Danny Hernandez and Tom Brown and Tom Conerly and Nova DasSarma and Dawn Drain and Sheer El-Showk and Nelson Elhage and Zac Hatfield-Dodds and Tom Henighan and Tristan Hume and Scott Johnston and Ben Mann and Chris Olah and Catherine Olsson and Dario Amodei and Nicholas Joseph and Jared Kaplan and Sam McCandlish},
|
| 194 |
+
year={2022},
|
| 195 |
+
eprint={2205.10487},
|
| 196 |
+
archivePrefix={arXiv},
|
| 197 |
+
primaryClass={cs.LG}
|
| 198 |
+
}
|
| 199 |
+
@article{llama3modelcard,
|
| 200 |
+
|
| 201 |
+
title={Llama 3 Model Card},
|
| 202 |
+
|
| 203 |
+
author={AI@Meta},
|
| 204 |
+
|
| 205 |
+
year={2024},
|
| 206 |
+
|
| 207 |
+
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
|
| 208 |
+
|
| 209 |
+
}
|
| 210 |
+
@misc{jiang2024mixtral,
|
| 211 |
+
title={Mixtral of Experts},
|
| 212 |
+
author={Albert Q. Jiang and Alexandre Sablayrolles and Antoine Roux and Arthur Mensch and Blanche Savary and Chris Bamford and Devendra Singh Chaplot and Diego de las Casas and Emma Bou Hanna and Florian Bressand and Gianna Lengyel and Guillaume Bour and Guillaume Lample and Lélio Renard Lavaud and Lucile Saulnier and Marie-Anne Lachaux and Pierre Stock and Sandeep Subramanian and Sophia Yang and Szymon Antoniak and Teven Le Scao and Théophile Gervet and Thibaut Lavril and Thomas Wang and Timothée Lacroix and William El Sayed},
|
| 213 |
+
year={2024},
|
| 214 |
+
eprint={2401.04088},
|
| 215 |
+
archivePrefix={arXiv},
|
| 216 |
+
primaryClass={cs.LG}
|
| 217 |
+
}
|
| 218 |
+
@article{yuan2024self,
|
| 219 |
+
title={Self-rewarding language models},
|
| 220 |
+
author={Yuan, Weizhe and Pang, Richard Yuanzhe and Cho, Kyunghyun and Sukhbaatar, Sainbayar and Xu, Jing and Weston, Jason},
|
| 221 |
+
journal={arXiv preprint arXiv:2401.10020},
|
| 222 |
+
year={2024}
|
| 223 |
+
}
|
| 224 |
+
@article{verga2024replacing,
|
| 225 |
+
title={Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models},
|
| 226 |
+
author={Verga, Pat and Hofstatter, Sebastian and Althammer, Sophia and Su, Yixuan and Piktus, Aleksandra and Arkhangorodsky, Arkady and Xu, Minjie and White, Naomi and Lewis, Patrick},
|
| 227 |
+
journal={arXiv preprint arXiv:2404.18796},
|
| 228 |
+
year={2024}
|
| 229 |
+
}
|
| 230 |
+
@article{abdin2024phi,
|
| 231 |
+
title={Phi-3 technical report: A highly capable language model locally on your phone},
|
| 232 |
+
author={Abdin, Marah and Jacobs, Sam Ade and Awan, Ammar Ahmad and Aneja, Jyoti and Awadallah, Ahmed and Awadalla, Hany and Bach, Nguyen and Bahree, Amit and Bakhtiari, Arash and Behl, Harkirat and others},
|
| 233 |
+
journal={arXiv preprint arXiv:2404.14219},
|
| 234 |
+
year={2024}
|
| 235 |
+
}
|
| 236 |
+
@misc{meta2024responsible,
|
| 237 |
+
title = {Our responsible approach to Meta AI and Meta Llama 3},
|
| 238 |
+
author = {Meta},
|
| 239 |
+
year = {2024},
|
| 240 |
+
url = {https://ai.meta.com/blog/meta-llama-3-meta-ai-responsibility/},
|
| 241 |
+
note = {Accessed: 2024-05-31}
|
| 242 |
+
}
|
| 243 |
+
@inproceedings{talmor-etal-2019-commonsenseqa,
|
| 244 |
+
title = "CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge",
|
| 245 |
+
author = "Talmor, Alon and
|
| 246 |
+
Herzig, Jonathan and
|
| 247 |
+
Lourie, Nicholas and
|
| 248 |
+
Berant, Jonathan",
|
| 249 |
+
booktitle = "Proceedings of the 2019 Conference of the North {A}merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers)",
|
| 250 |
+
month = jun,
|
| 251 |
+
year = "2019",
|
| 252 |
+
address = "Minneapolis, Minnesota",
|
| 253 |
+
publisher = "Association for Computational Linguistics",
|
| 254 |
+
url = "https://aclanthology.org/N19-1421",
|
| 255 |
+
doi = "10.18653/v1/N19-1421",
|
| 256 |
+
pages = "4149--4158",
|
| 257 |
+
archivePrefix = "arXiv",
|
| 258 |
+
eprint = "1811.00937",
|
| 259 |
+
primaryClass = "cs",
|
| 260 |
+
}
|
| 261 |
+
@inproceedings{zellers-etal-2019-hellaswag,
|
| 262 |
+
title = "HellaSwag: Can a Machine Really Finish Your Sentence?",
|
| 263 |
+
author = "Zellers, Rowan and
|
| 264 |
+
Holtzman, Ari and
|
| 265 |
+
Bisk, Yonatan and
|
| 266 |
+
Farhadi, Ali and
|
| 267 |
+
Choi, Yejin",
|
| 268 |
+
editor = "Korhonen, Anna and
|
| 269 |
+
Traum, David and
|
| 270 |
+
M{\`a}rquez, Llu{\'\i}s",
|
| 271 |
+
booktitle = "Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics",
|
| 272 |
+
month = jul,
|
| 273 |
+
year = "2019",
|
| 274 |
+
address = "Florence, Italy",
|
| 275 |
+
publisher = "Association for Computational Linguistics",
|
| 276 |
+
url = "https://aclanthology.org/P19-1472",
|
| 277 |
+
doi = "10.18653/v1/P19-1472",
|
| 278 |
+
pages = "4791--4800",
|
| 279 |
+
abstract = "Recent work by Zellers et al. (2018) introduced a new task of commonsense natural language inference: given an event description such as {``}A woman sits at a piano,{''} a machine must select the most likely followup: {``}She sets her fingers on the keys.{''} With the introduction of BERT, near human-level performance was reached. Does this mean that machines can perform human level commonsense inference? In this paper, we show that commonsense inference still proves difficult for even state-of-the-art models, by presenting HellaSwag, a new challenge dataset. Though its questions are trivial for humans ({\textgreater}95{\%} accuracy), state-of-the-art models struggle ({\textless}48{\%}). We achieve this via Adversarial Filtering (AF), a data collection paradigm wherein a series of discriminators iteratively select an adversarial set of machine-generated wrong answers. AF proves to be surprisingly robust. The key insight is to scale up the length and complexity of the dataset examples towards a critical {`}Goldilocks{'} zone wherein generated text is ridiculous to humans, yet often misclassified by state-of-the-art models. Our construction of HellaSwag, and its resulting difficulty, sheds light on the inner workings of deep pretrained models. More broadly, it suggests a new path forward for NLP research, in which benchmarks co-evolve with the evolving state-of-the-art in an adversarial way, so as to present ever-harder challenges.",
|
| 280 |
+
}
|
| 281 |
+
@inproceedings{OpenBookQA2018,
|
| 282 |
+
title={Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering},
|
| 283 |
+
author={Todor Mihaylov and Peter Clark and Tushar Khot and Ashish Sabharwal},
|
| 284 |
+
booktitle={EMNLP},
|
| 285 |
+
year={2018}
|
| 286 |
+
}
|
| 287 |
+
@misc{bisk2019piqa,
|
| 288 |
+
title={PIQA: Reasoning about Physical Commonsense in Natural Language},
|
| 289 |
+
author={Yonatan Bisk and Rowan Zellers and Ronan Le Bras and Jianfeng Gao and Yejin Choi},
|
| 290 |
+
year={2019},
|
| 291 |
+
eprint={1911.11641},
|
| 292 |
+
archivePrefix={arXiv},
|
| 293 |
+
primaryClass={cs.CL}
|
| 294 |
+
}
|
| 295 |
+
@misc{sap2019socialiqa,
|
| 296 |
+
title={SocialIQA: Commonsense Reasoning about Social Interactions},
|
| 297 |
+
author={Maarten Sap and Hannah Rashkin and Derek Chen and Ronan LeBras and Yejin Choi},
|
| 298 |
+
year={2019},
|
| 299 |
+
eprint={1904.09728},
|
| 300 |
+
archivePrefix={arXiv},
|
| 301 |
+
primaryClass={cs.CL}
|
| 302 |
+
}
|
| 303 |
+
@misc{sakaguchi2019winogrande,
|
| 304 |
+
title={WinoGrande: An Adversarial Winograd Schema Challenge at Scale},
|
| 305 |
+
author={Keisuke Sakaguchi and Ronan Le Bras and Chandra Bhagavatula and Yejin Choi},
|
| 306 |
+
year={2019},
|
| 307 |
+
eprint={1907.10641},
|
| 308 |
+
archivePrefix={arXiv},
|
| 309 |
+
primaryClass={cs.CL}
|
| 310 |
+
}
|
| 311 |
+
@misc{clark2018think,
|
| 312 |
+
title={Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge},
|
| 313 |
+
author={Peter Clark and Isaac Cowhey and Oren Etzioni and Tushar Khot and Ashish Sabharwal and Carissa Schoenick and Oyvind Tafjord},
|
| 314 |
+
year={2018},
|
| 315 |
+
eprint={1803.05457},
|
| 316 |
+
archivePrefix={arXiv},
|
| 317 |
+
primaryClass={cs.AI}
|
| 318 |
+
}
|
| 319 |
+
@misc{hendrycks2021measuring,
|
| 320 |
+
title={Measuring Massive Multitask Language Understanding},
|
| 321 |
+
author={Dan Hendrycks and Collin Burns and Steven Basart and Andy Zou and Mantas Mazeika and Dawn Song and Jacob Steinhardt},
|
| 322 |
+
year={2021},
|
| 323 |
+
eprint={2009.03300},
|
| 324 |
+
archivePrefix={arXiv},
|
| 325 |
+
primaryClass={cs.CY}
|
| 326 |
+
}
|
| 327 |
+
@misc{mitchell2023measuring,
|
| 328 |
+
title={Measuring Data},
|
| 329 |
+
author={Margaret Mitchell and Alexandra Sasha Luccioni and Nathan Lambert and Marissa Gerchick and Angelina McMillan-Major and Ezinwanne Ozoani and Nazneen Rajani and Tristan Thrush and Yacine Jernite and Douwe Kiela},
|
| 330 |
+
year={2023},
|
| 331 |
+
eprint={2212.05129},
|
| 332 |
+
archivePrefix={arXiv},
|
| 333 |
+
primaryClass={cs.AI}
|
| 334 |
+
}
|
dist/distill.bundle.js
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
dist/distill.bundle.js.map
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
dist/index.html
ADDED
|
@@ -0,0 +1,451 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<!DOCTYPE html>
|
| 2 |
+
<html>
|
| 3 |
+
<head>
|
| 4 |
+
<script src="distill.bundle.js" type="module" fetchpriority="high" blocking></script>
|
| 5 |
+
<script src="main.bundle.js" type="module" fetchpriority="low" defer></script>
|
| 6 |
+
<meta name="viewport" content="width=device-width, initial-scale=1">
|
| 7 |
+
<meta charset="utf8">
|
| 8 |
+
<base target="_blank">
|
| 9 |
+
<title>Open-LLM performances are plateauing, let’s make it steep again </title>
|
| 10 |
+
<link rel="stylesheet" href="style.css">
|
| 11 |
+
</head>
|
| 12 |
+
|
| 13 |
+
<body>
|
| 14 |
+
<d-front-matter>
|
| 15 |
+
<script id='distill-front-matter' type="text/json">{
|
| 16 |
+
"title": "Open-LLM performances are plateauing, let’s make it steep again ",
|
| 17 |
+
"description": "In this blog, we introduce the version 2 of the Open LLM Leaderboard, from the reasons for the change to the new evaluations and rankings.",
|
| 18 |
+
"published": "Jun 26, 2024",
|
| 19 |
+
"affiliation": {"name": "HuggingFace"},
|
| 20 |
+
"authors": [
|
| 21 |
+
{
|
| 22 |
+
"author":"Clementine Fourrier",
|
| 23 |
+
"authorURL":"https://huggingface.co/clefourrier"
|
| 24 |
+
},
|
| 25 |
+
{
|
| 26 |
+
"author":"Nathan Habib",
|
| 27 |
+
"authorURL":"https://huggingface.co/saylortwift"
|
| 28 |
+
},
|
| 29 |
+
{
|
| 30 |
+
"author":"Alina Lozovskaya",
|
| 31 |
+
"authorURL":"https://huggingface.co/alozowski"
|
| 32 |
+
},
|
| 33 |
+
{
|
| 34 |
+
"author":"Konrad Szafer",
|
| 35 |
+
"authorURL":"https://huggingface.co/KonradSzafer"
|
| 36 |
+
},
|
| 37 |
+
{
|
| 38 |
+
"author":"Thomas Wolf",
|
| 39 |
+
"authorURL":"https://huggingface.co/thomwolf"
|
| 40 |
+
}
|
| 41 |
+
],
|
| 42 |
+
"katex": {
|
| 43 |
+
"delimiters": [
|
| 44 |
+
{"left": "$$", "right": "$$", "display": false}
|
| 45 |
+
]
|
| 46 |
+
}
|
| 47 |
+
}
|
| 48 |
+
</script>
|
| 49 |
+
</d-front-matter>
|
| 50 |
+
<d-title>
|
| 51 |
+
<h1 class="l-page" style="text-align: center;">Open-LLM performances are plateauing, let’s make it steep again </h1>
|
| 52 |
+
<div id="title-plot" class="l-body l-screen">
|
| 53 |
+
<figure>
|
| 54 |
+
<img src="assets/images/banner.png" alt="Banner">
|
| 55 |
+
</figure>
|
| 56 |
+
</div>
|
| 57 |
+
</d-title>
|
| 58 |
+
<d-byline></d-byline>
|
| 59 |
+
<d-article>
|
| 60 |
+
<d-contents>
|
| 61 |
+
</d-contents>
|
| 62 |
+
|
| 63 |
+
<p>Evaluating and comparing LLMs is hard. Our RLHF team realized this a year ago, when they wanted to reproduce and compare results from several published models.
|
| 64 |
+
It was a nearly impossible task: scores in papers or marketing releases were given without any reproducible code, sometimes doubtful but most of the case,
|
| 65 |
+
just using optimized prompts or evaluation setup to give best chances to the models. They therefore decided to create a place where reference models would be
|
| 66 |
+
evaluated in the exact same setup (same questions, asked in the same order, …), to gather completely reproducible and comparable results; and that’s how the
|
| 67 |
+
Open LLM Leaderboard was born!</p>
|
| 68 |
+
|
| 69 |
+
<p> Following a series of highly-visible model releases, it became a widely used resource in the ML community and beyond, visited by more than 2 million unique people over the last 10 months.</p>
|
| 70 |
+
|
| 71 |
+
<p> We estimate that around 300 000 community members use and collaborate on it monthly through submissions and discussions; usually to: </p>
|
| 72 |
+
<ul>
|
| 73 |
+
<li> Find state-of-the-art open source releases as the leaderboardit provides reproducible scores separating marketing fluff from actual progress in the field.</li>
|
| 74 |
+
<li> Evaluate their own work, be it pretraining or finetuning, comparing methods in the open and to the best existing models, and earning public recognition for their work.</li>
|
| 75 |
+
</ul>
|
| 76 |
+
|
| 77 |
+
<p> However, with success, both in the leaderboard and the increasing performances of the models came challenges and after one intense year and a lot of community feedback, we thought it was time for an upgrade! Therefore, we’re introducing the Open LLM Leaderboard v2!</p>
|
| 78 |
+
|
| 79 |
+
<p>Here is why we think a new leaderboard was needed 👇</p>
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
<h2>Harder, better, faster, stronger: Introducing the Leaderboard v2</h2>
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
<h3>The need for a more challenging leaderboard</h3>
|
| 87 |
+
|
| 88 |
+
<p>
|
| 89 |
+
Over the past year, the benchmarks we were using got overused/saturated:
|
| 90 |
+
</p>
|
| 91 |
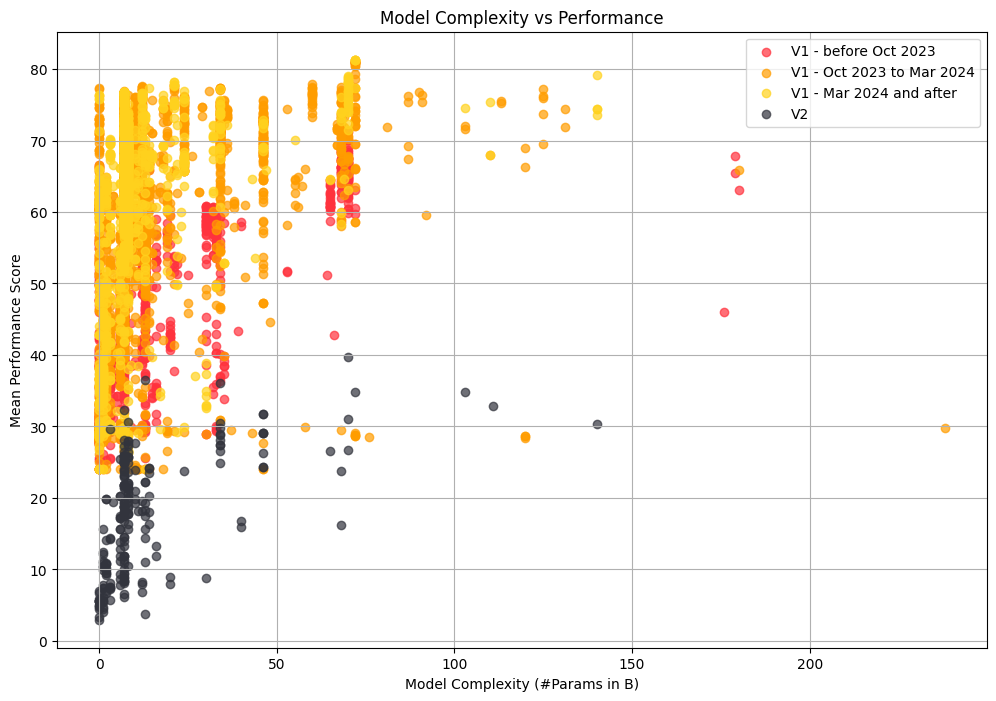
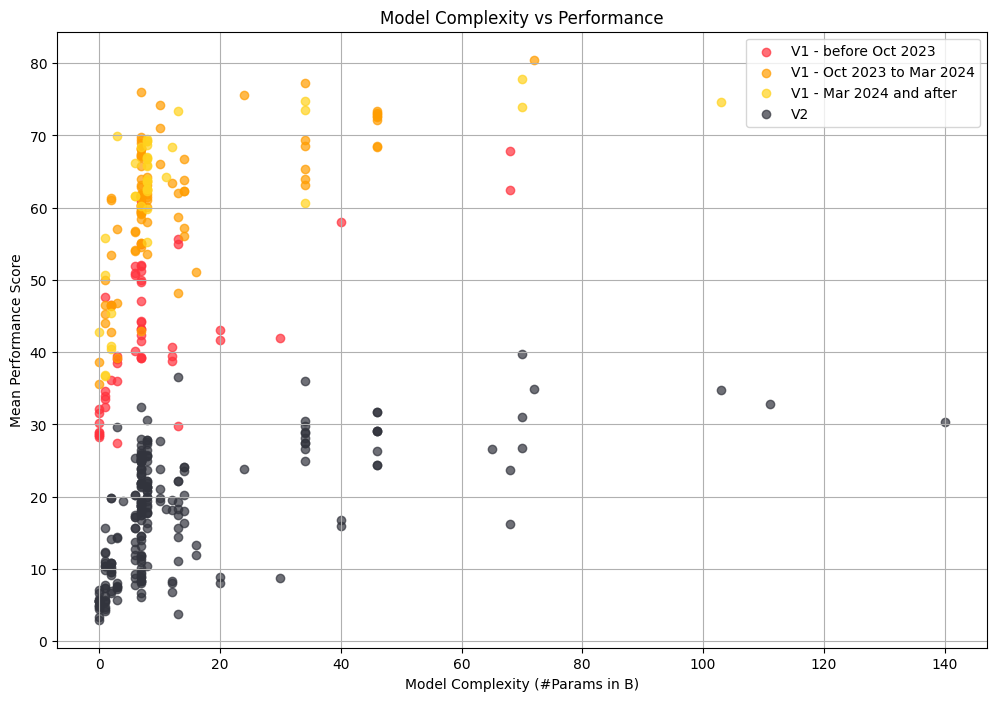
+
|
| 92 |
+
<div class="main-plot-container">
|
| 93 |
+
<div id="saturation">
|
| 94 |
+
<iframe src="assets/scripts/plot.html" title="description", height="500" width="90%", style="border:none;"></iframe></p>
|
| 95 |
+
</div>
|
| 96 |
+
</div>
|
| 97 |
+
|
| 98 |
+
<ol>
|
| 99 |
+
<li>They became too easy for models. For instance on HellaSwag, MMLU and ARC, models are now reaching baseline human performance, a phenomenon called saturation.</li>
|
| 100 |
+
<li>Some newer models also showed signs of contamination. By this we mean that models were possibly trained on benchmark data or on data very similar to benchmark data. As such, some scores stopped reflecting general performances of model and started to over-fit on some evaluation dataset instead of being reflective of the more general performances of the task being tested. This was in particular the case for GSM8K and TruthfulQA which were included in some instruction fine-tuning sets.</li>
|
| 101 |
+
<li>Some benchmarks contained errors: MMLU was recently investigated in depth by several groups who surfaced mistakes in its responses and proposed new versions. Another example was the fact that GSM8K used some specific end of generation token (<code>:</code>) which unfairly pushed down performance of many verbose models.</li>
|
| 102 |
+
</ol>
|
| 103 |
+
|
| 104 |
+
<p>We thus chose to completely change the evaluations we are running for the Open LLM Leaderboard v2!</p>
|
| 105 |
+
|
| 106 |
+
<h3>Rebooting our evaluation selection</h3>
|
| 107 |
+
<p>We started looking for new benchmarks with uncontaminated, high quality datasets, making use of reliable metrics, and measuring model capabilities of interest.</p>
|
| 108 |
+
<p>We decided to cover the following general tasks: knowledge testing (📚), reasoning on short and long contexts (💭), complex mathematical abilities, and tasks well correlated with human preference (🤝), like instruction following.</p>
|
| 109 |
+
<p>We cover these tasks with 6 benchmarks. Let us present them briefly:</p>
|
| 110 |
+
|
| 111 |
+
<p>📚 <strong>MMLU-Pro</strong> (Massive Multitask Language Understanding - Pro version, <a href="https://arxiv.org/abs/2406.01574">paper</a>). MMLU-Pro is a refined version of the MMLU dataset. MMLU has been the reference multichoice knowledge dataset. However, recent research showed that it is both noisy (some questions are unanswerable) and now too easy (through the evolution of model capabilities as well as the increase of contamination). MMLU-Pro presents the models with 10 choices instead of 4, requires reasoning on more questions, and has been expertly reviewed to reduce the amount of noise. It is higher quality than the original, and (for the moment) harder.</p>
|
| 112 |
+
<p>📚 <strong>GPQA</strong> (Google-Proof Q&A Benchmark, <a href="https://arxiv.org/abs/2311.12022">paper</a>). GPQA is an extremely hard knowledge dataset, where questions were designed by domain experts in their field (PhD-level in biology, physics, chemistry, …) to be hard to answer by laypersons, but (relatively) easy for experts. Questions have gone through several rounds of validation to ensure both difficulty and factuality. The dataset is also only accessible through gating mechanisms, which should reduce the risks of contamination. (This is also why we don’t provide a plain text example from this dataset, as requested by the authors in the paper).</p>
|
| 113 |
+
<p><strong>MuSR</strong> (Multistep Soft Reasoning, <a href="https://arxiv.org/abs/2310.16049">paper</a>). MuSR is a very fun new dataset, made of algorithmically generated complex problems of around 1K words in length. Problems are either murder mysteries, object placement questions, or team allocation optimizations. To solve these, the models must combine reasoning and very long range context parsing. Few models score better than random performance.</p>
|
| 114 |
+
<p>🧮 <strong>MATH</strong> (Mathematics Aptitude Test of Heuristics, Level 5 subset, <a href="https://arxiv.org/abs/2103.03874">paper</a>). MATH is a compilation of high-school level competition problems gathered from several sources, formatted consistently using Latex for equations and Asymptote for figures. Generations must fit a very specific output format. We keep only the hardest questions.</p>
|
| 115 |
+
<p>🤝 <strong>IFEval</strong> (Instruction Following Evaluation, <a href="https://arxiv.org/abs/2311.07911">paper</a>). IFEval is a fairly interesting dataset, which tests the capability of models to clearly follow explicit instructions, such as “include keyword x” or “use format y”. The models are tested on their ability to strictly follow formatting instructions, rather than the actual contents generated, which allows the use of strict and rigorous metrics.</p>
|
| 116 |
+
<p>🧮 🤝 <strong>BBH</strong> (Big Bench Hard, <a href="https://arxiv.org/abs/2210.09261">paper</a>). BBH is a subset of 23 challenging tasks from the BigBench dataset, which 1) use objective metrics, 2) are hard, measured as language models not originally outperforming human baselines, 3) contain enough samples to be statistically significant. They contain multistep arithmetic and algorithmic reasoning (understanding boolean expressions, svg for geometric shapes, etc), language understanding (sarcasm detection, name disambiguation, etc), and some world knowledge. Performance on BBH has been on average very well correlated with human preference. We expect this dataset to provide interesting insights on specific capabilities which could interest people.</p>
|
| 117 |
+
|
| 118 |
+
<!-- TODO: Interactive prompts exploration -->
|
| 119 |
+
|
| 120 |
+
<h3>Why did we choose these subsets?</h3>
|
| 121 |
+
<p>In summary, our criterion were: </p>
|
| 122 |
+
<ol>
|
| 123 |
+
<li>Evaluation quality:</li>
|
| 124 |
+
<ul>
|
| 125 |
+
<li>Human review of dataset: MMLU-Pro and GPQA</li>
|
| 126 |
+
<li>Widespread use in the academic and/or open source community: ARC, BBH, IFeval, MATH</li>
|
| 127 |
+
</ul>
|
| 128 |
+
<li>Reliability and fairness of metrics:</li>
|
| 129 |
+
<ul>
|
| 130 |
+
<li>Multichoice evaluations are in general fair across models.</li>
|
| 131 |
+
<li>Generative evaluations should either constrain the format very much (like MATH), or use very unambiguous metrics (like IFEval) or post processing (like BBH) to extract the correct answers.</li>
|
| 132 |
+
</ul>
|
| 133 |
+
<li>General absence of contamination in models as of today:</li>
|
| 134 |
+
<ul>
|
| 135 |
+
<li>Gating: GPQA </li>
|
| 136 |
+
<li>“Youth”: MuSR, MMLU-Pro</li>
|
| 137 |
+
</ul>
|
| 138 |
+
<li>Measuring model skills that are interesting for the community: </li>
|
| 139 |
+
<ul>
|
| 140 |
+
<li>Correlation with human preferences: BBH, IFEval, ARC</li>
|
| 141 |
+
<li>Evaluation of a specific capability we are interested in: MATH, MuSR</li>
|
| 142 |
+
</ul>
|
| 143 |
+
</ol>
|
| 144 |
+
|
| 145 |
+
<aside>
|
| 146 |
+
<p><em>Should we have included more evaluations?</em></p>
|
| 147 |
+
|
| 148 |
+
<p>We chose to focus on a limited number of evaluations to keep the computation time realistic. There are many other evaluations which we wanted to include (MTBench, AGIEval, DROP, etc), but we are, in the end, still compute constrained - so to keep the evaluation budgets under control we ranked evals according to our above criterion and kept the top ranking benchmarks. This is also why we didn’t select any benchmark requiring the use of another model as a judge.</p>
|
| 149 |
+
</aside>
|
| 150 |
+
|
| 151 |
+
<p>Selecting new benchmarks is not the whole story, and we also pushed several other interesting improvements to the leaderboard that we’ll now briefly cover.</p>
|
| 152 |
+
|
| 153 |
+
<h3>Reporting a fairer average for ranking: using normalized scores</h3>
|
| 154 |
+
<p>We decided to change the final grade for the model. Instead of summing each benchmark output score, we normalized these scores between the random baseline (0 points) and the maximal possible score (100 points). We then average all normalized scores to get the final average score and compute final rankings. As a matter of example, in a benchmark containing two-choices for each questions, a random baseline will get 50 points (out of 100 points). If you use a random number generator, you will thus likely get around 50 on this evaluation. This means that scores are actually always between 50 (the lowest score you reasonably get if the benchmark is not adversarial) and 100. We therefore change the range so that a 50 on the raw score is a 0 on the normalized score. Note that for generative evaluations (like IFEval or MATH), it doesn’t change anything.</p>
|
| 155 |
+
|
| 156 |
+
<div class="main-plot-container">
|
| 157 |
+
<!--todo: if you use an interactive visualisation instead of a plot,
|
| 158 |
+
replace the class `l-body` by `main-plot-container` and import your interactive plot in the
|
| 159 |
+
below div id, while leaving the image as such. -->
|
| 160 |
+
<div id="normalisation">
|
| 161 |
+
<iframe src="assets/scripts/normalized_vs_raw.html" title="description", height="500" width="90%", style="border:none;"></iframe>
|
| 162 |
+
</div>
|
| 163 |
+
</div>
|
| 164 |
+
|
| 165 |
+
<p>This change is more significant than it may seem as it can be seen as changing the weight assigned to each benchmark in the final average score.</p>
|
| 166 |
+
<p>On the above figure, we plot the mean scores for our evaluations, with normalized scores on the left, and raw scores on the right. If you take a look at the right hand side, you would conclude that the hardest benchmarks are MATH Level 5 and MMLU-Pro (lowest raw averages). However, our 2 hardest evaluations are actually MATH Level 5 and GPQA, which is considerably harder (PhD level questions!) - most models of today get close to random performance on it, and there is thus a huge difference between unnormalized score and normalized score where the random number baseline is assigned zero points!</p>
|
| 167 |
+
<p>This change thus also affects model ranking in general. Say we have two very hard evaluations, one generative and one multichoice with 2 option samples. Model A gets 0 on the generative evaluation, and 52 on the multichoice, and model B gets 10 on the generative and 40 on the multichoice. If you look at the raw averages, you could conclude that model A is better, with an average score of 26, while model B’s average is 25. However, for the multichoice benchmark, they are in fact both similarly bad (!): 52 is almost a random score on the multichoice evaluation, and 40 is an unlucky random score. This becomes obvious when taking the normalized scores, where A gets 0 and B gets around 1. However, on the generative evaluation, model B is 10 points better! If we take the normalized averages, we would get 5 for model B and almost 0 for model A, hence a very different ranking.</p>
|
| 168 |
+
|
| 169 |
+
<h3>Easier reproducibility: updating the evaluation suite</h3>
|
| 170 |
+
<p>A year ago, we made the choice to use the Harness (lm-eval) from EleutherAI to power our evaluations. It provides a standard and stable implementation for a number of tasks. To ensure fairness and reproducibility, we pinned the version we were using, which allowed us to compare all models in an apples to apples setup, as all evaluations were run in exactly the same way, on the same hardware, using the same evaluation suite commit and parameters.</p>
|
| 171 |
+
<p>However, <code>lm-eval</code> evolved, and the implementation of some tasks or metrics changed, which led to discrepancies between 1) evaluation results people would get on more recent versions of the harness and 2) our results using our pinned version.</p>
|
| 172 |
+
<p>For the new version of the Open LLM Leaderboard, we have therefore worked together with the amazing EleutherAI team (notably Hailey Schoelkopf, so many, huge kudos!) to update the harness.</p>
|
| 173 |
+
<p>Features side, we added in the harness support for delta weights (LoRA finetuning/adaptation of models), a logging system compatible with the leaderboard, and the highly requested use of chat templates for evaluation.</p>
|
| 174 |
+
<p>On the task side, we took a couple of weeks to manually check all implementations and generations thoroughly, and fix the problems we observed with inconsistent few shot samples, too restrictive end of sentence tokens, etc. We created specific configuration files for the leaderboard task implementations, and are now working on adding a test suite to make sure that evaluation results stay unchanging through time for the leaderboard tasks.</p>
|
| 175 |
+
<p>This should allow us to keep our version up to date with new features added in the future!</p>
|
| 176 |
+
<p>Enough said on the leaderboard backend and metrics, now let’s turn to the models and model selection/submission.
|
| 177 |
+
|
| 178 |
+
<h2>Focusing on the models most relevant to the community</h2>
|
| 179 |
+
<h3>Introducing the <em>maintainer’s choice</em></h3>
|
| 180 |
+
<p>Throughout the year, we’ve evaluated more than 7.5K models, and observed that not all of them were used as much by the community.</p>
|
| 181 |
+
<p>The most used ones are usually new base pretrained models, often built by using a lot of compute and which can later be fine-tuned by the community for their own use cases (such as Meta’s Llama3 or Alibaba’s Qwen2). Some high quality chat or instruction models also find a large user community, for instance Cohere’s Command + R, and become also strong starting points for community experiments. ♥️</p>
|
| 182 |
+
<p>However, the story can be different for other models, even when ranking on top of the leaderboard. A number of models are experimental, fascinating and impressive concatenations of more than 20 steps of fine-tuning or merging. </p>
|
| 183 |
+
<p>However these models present some challenges as:</p>
|
| 184 |
+
<ul>
|
| 185 |
+
<li> When stacking so many steps, it can be easy to lose the precise model recipe and history, as some parent models can get deleted, fine-tuning information of a prior step can disappear, etc. </li>
|
| 186 |
+
<li>Models can then become accidentally contaminated 😓
|
| 187 |
+
</br>This happened several times last year, with models derived from parent models fine-tuned on instruction datasets containing information from TruthfulQA or GSM8K.
|
| 188 |
+
</li>
|
| 189 |
+
<li>Models can also performance on benchmarks which become unrelated to their real-life performance 🙃
|
| 190 |
+
</br> This can happen if you select models to merge based on their high performance on the same benchmarks - it seems to improve performance selectively on said benchmarks, without actually correlating with quality in real life situations. (More research is likely needed on this).
|
| 191 |
+
</li>
|
| 192 |
+
</ul>
|
| 193 |
+
<p>To highlight high quality models in the leaderboard, as well as prioritize the most useful models for evaluation, we’ve therefore decided to introduce a category called “maintainer’s choice” ⭐.</p>
|
| 194 |
+
<p>In this list, you’ll find LLMs from model creators with access to a lot of compute power such as Meta,Google, Cohere or Mistral, as well as well known collectives, like EleutherAI or NousResearch, and power users of the Hugging Face hub, among others.</p>
|
| 195 |
+
<p>We plan to make this list evolutive based on community suggestions and our own observations, and will aim to include as much as possible SOTA LLMs as they come out and keep evaluating these models in priority.</p>
|
| 196 |
+
<p>We hope it will also make it easier for non ML users to orient themselves among the many, many models we’ll rank on the leaderboard.</p>
|
| 197 |
+
|
| 198 |
+
<h3>Voting on model relevance</h3>
|
| 199 |
+
<p>For the previous version of the Open LLM Leaderboard, evaluations were usually run in a “first submitted, first evaluated” manner. With users sometimes submitting many LLMs variants at once and the Open LLM Leaderboard running on the limited compute of the spare cycles on the Hugging Face science cluster, we’ve decided to introduce a voting system for submitted models. The community will be able to vote for models and we will prioritize running models with the most votes first, hopefully surfacing the most awaited models on the top of the priority stack. If a model gets an extremely high number of votes when the cluster is full, we could even consider running it manually in place of other internal jobs at Hugging Face.</p>
|
| 200 |
+
<p>To avoid spamming the vote system, users will need to be connected to their Hugging Face account to vote, and we will save the votes. We hope this system will help us prioritize models that the community is enthusiastic about.</p>
|
| 201 |
+
<p>Finally, we’ve been hard at work on improving and simplifying the leaderboard interface itself.</p>
|
| 202 |
+
|
| 203 |
+
<h3>Better and simpler interface</h3>
|
| 204 |
+
<p>If you’re among our regular users, you may have noticed in the last month that our front end became much faster.</p>
|
| 205 |
+
<p>This is thanks to the work of the Gradio team, notably Freddy Boulton, who developed a Leaderboard <code>gradio</code> component! It notably loads data client side, which makes any column selection or search virtually instantaneous! It’s also a component that you can re-use yourself in your own leaderboard!</p>
|
| 206 |
+
<p>We’ve also decided to move the FAQ and About tabs to their own dedicated documentation page!</p>
|
| 207 |
+
|
| 208 |
+
<h2>New leaderboard, new results!</h2>
|
| 209 |
+
<p>We’ve started with adding and evaluating the models in the “maintainer’s highlights” section (cf. above) and are looking forward to the community submitting their new models to this new version of the leaderboard!!</p>
|
| 210 |
+
|
| 211 |
+
<h3>What do the rankings look like?</h3>
|
| 212 |
+
|
| 213 |
+
<p>Taking a look at the top 10 models on the previous version of the Open LLM Leaderboard, and comparing with this updated version, 5 models appear to have a relatively stable ranking: Meta’s Llama3-70B, both instruct and base version, 01-ai’s Yi-1.5-34B, chat version, Cohere’s Command R + model, and lastly Smaug-72B, from AbacusAI.</p>
|
| 214 |
+
<p>We’ve been particularly impressed by Llama-70B-instruct, ranking top across many evaluations (even though this instruct version loses 15 points to its pretrained version counterpart on GPQA which begs the question whether the particularly extensive instruction fine-tuning done by the Meta team on this model affected some expert/graduate level knowledge?).</p>
|
| 215 |
+
<p>Also very interesting is the fact that a new challenger climbed the ranks to reach 2nd place despite its smaller size. With only 13B parameters, Microsoft’s Phi-3-medium-4K-instruct model shows a performance equivalent to models 2 to 4 times its size. It would be very interesting to have more information on the training procedure for Phi or an independant reproduction from an external team with open training recipes/datasets.</p>
|
| 216 |
+
<p>Here is a detail of the changes in rankings:</p>
|
| 217 |
+
|
| 218 |
+
<table>
|
| 219 |
+
<tr>
|
| 220 |
+
<th>Rank</th>
|
| 221 |
+
<th>Leaderboard v1</th>
|
| 222 |
+
<th>Leaderboard v2</th>
|
| 223 |
+
</tr>
|
| 224 |
+
<tr>
|
| 225 |
+
<td>⭐</td>
|
| 226 |
+
<td><b>abacusai/Smaug-72B-v0.1</b></td>
|
| 227 |
+
<td><b>meta-llama/Meta-Llama-3-70B-Instruct</b></td>
|
| 228 |
+
</tr>
|
| 229 |
+
<tr>
|
| 230 |
+
<td>2</td>
|
| 231 |
+
<td><b>meta-llama/Meta-Llama-3-70B-Instruct</b></td>
|
| 232 |
+
<td><em>microsoft/Phi-3-medium-4k-instruct</em></td>
|
| 233 |
+
</tr>
|
| 234 |
+
<tr>
|
| 235 |
+
<td>3</td>
|
| 236 |
+
<td><b>abacusai/Smaug-34B-v0.1</b></td>
|
| 237 |
+
<td>01-ai/Yi-1.5-34B-Chat</td>
|
| 238 |
+
</tr>
|
| 239 |
+
<tr>
|
| 240 |
+
<td>4</td>
|
| 241 |
+
<td>mlabonne/AlphaMonarch-7B</td>
|
| 242 |
+
<td><b>abacusai/Smaug-72B-v0.1</b></td>
|
| 243 |
+
</tr>
|
| 244 |
+
<tr>
|
| 245 |
+
<td>5</td>
|
| 246 |
+
<td>mlabonne/Beyonder-4x7B-v3</td>
|
| 247 |
+
<td><b>CohereForAI/c4ai-command-r-plus<b></td>
|
| 248 |
+
</tr>
|
| 249 |
+
<tr>
|
| 250 |
+
<td>6</td>
|
| 251 |
+
<td><b>01-ai/Yi-1.5-34B-Chat</b></td>
|
| 252 |
+
<td>Qwen/Qwen1.5-110B-Chat</td>
|
| 253 |
+
</tr>
|
| 254 |
+
<tr>
|
| 255 |
+
<td>7</td>
|
| 256 |
+
<td><b>CohereForAI/c4ai-command-r-plus</b></td>
|
| 257 |
+
<td>NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO</td>
|
| 258 |
+
</tr>
|
| 259 |
+
<tr>
|
| 260 |
+
<td>8</td>
|
| 261 |
+
<td>upstage/SOLAR-10.7B-Instruct-v1.0</td>
|
| 262 |
+
<td><b>meta-llama/Meta-Llama-3-70B</b></td>
|
| 263 |
+
</tr>
|
| 264 |
+
<tr>
|
| 265 |
+
<td>9</td>
|
| 266 |
+
<td><b>meta-llama/Meta-Llama-3-70B</b></td>
|
| 267 |
+
<td>01-ai/Yi-1.5-9B-Chat</td>
|
| 268 |
+
</tr>
|
| 269 |
+
<tr>
|
| 270 |
+
<td>10</td>
|
| 271 |
+
<td>01-ai/Yi-1.5-34B</td>
|
| 272 |
+
<td>01-ai/Yi-1.5-34B-32K</td>
|
| 273 |
+
</tr>
|
| 274 |
+
</table>
|
| 275 |
+
<p>We’ve been particularly impressed by Llama-70B-instruct, who is the best model across many evaluations (though it has 15 points less than it’s base counterpart on GPQA - does instruct tuning remove knowledge?).</p>
|
| 276 |
+
|
| 277 |
+
<p>Interestingly, a new challenger climbed the ranks to arrive in 2nd place despite its smaller size: Phi-3-medium-4K-instruct, only 13B parameters but a performance equivalent to models 2 to 4 times its size.</p>
|
| 278 |
+
|
| 279 |
+
<p>We also provide the most important top and bottom ranking changes.</p>
|
| 280 |
+
|
| 281 |
+
<div class="main-plot-container">
|
| 282 |
+
<figure><img src="assets/images/ranking_top10_bottom10.png"/></figure>
|
| 283 |
+
<div id="ranking">
|
| 284 |
+
<iframe src="assets/scripts/rankings_change.html" title="description", height="800" width="100%", style="border:none;"></iframe>
|
| 285 |
+
</div>
|
| 286 |
+
</div>
|
| 287 |
+
|
| 288 |
+
<p>Let’s finish with some food for thoughts and advices from the maintainer’s team.</p>
|
| 289 |
+
|
| 290 |
+
<h3>Which evaluations should you pay most attention to?</h3>
|
| 291 |
+
<p>Depending on your practical use case, you should probably focus on various aspects of the leaderboard. The overall ranking will tell you which model is better on average, but you might be more interested in specific capabilities.</p>
|
| 292 |
+
|
| 293 |
+
<p>In particular, we observed that our different evaluations results are not always correlated with one another as illustrated on this correlation matrice:</p>
|
| 294 |
+
|
| 295 |
+
<div class="main-plot-container">
|
| 296 |
+
<figure><img src="assets/images/v2_correlation_heatmap.png"/></figure>
|
| 297 |
+
<div id="heatmap">
|
| 298 |
+
<iframe src="assets/scripts/correlation_heatmap.html" title="description", height="500" width="100%", style="border:none;"></iframe>
|
| 299 |
+
</div>
|
| 300 |
+
</div>
|
| 301 |
+
|
| 302 |
+
<p>As you can see, MMLU-Pro, BBH and ARC-challenge are rather well correlated. As it’s been also noted by other teams, these 3 benchmarks are also quite correlated with human preference (for instance they tend to align with human judgment on LMSys’s chatbot arena).</p>
|
| 303 |
+
<p>Another of our benchmarks, IFEval, is targeting chat capabilities. It investigates whether models can follow precise instructions or not. However, the format used in this benchmark tends to favor chat and instruction tuned models, with pretrained models having a harder time reaching high performances.</p>
|
| 304 |
+
|
| 305 |
+
<div class="l-body">
|
| 306 |
+
<figure><img src="assets/images/ifeval_score_per_model_type.png"/></figure>
|
| 307 |
+
<div id="ifeval"></div>
|
| 308 |
+
</div>
|
| 309 |
+
|
| 310 |
+
|
| 311 |
+
<p>If you are especially interested in model knowledge rather than alignment or chat capabilities, the most relevant evaluations for you will likely be MMLU-Pro and GPQA.</p>
|
| 312 |
+
<p>Let’s see how performances on these updated benchmarks compare to our evaluation on the previous version of the leaderboard.</p>
|
| 313 |
+
|
| 314 |
+
<div class="l-body">
|
| 315 |
+
<figure><img src="assets/images/v2_fn_of_mmlu.png"/></figure>
|
| 316 |
+
<div id="mmlu"></div>
|
| 317 |
+
</div>
|
| 318 |
+
|
| 319 |
+
|
| 320 |
+
<p>As we can see, both MMLU-PRO scores (in orange) and GPQA scores (in yellow) are reasonably correlated with MMLU scores from the Open LLM Leaderboard v1. However, we note that the scores are overall much lower since GPQA is much harder. There is thus quite some room for model to improve – which is great news :)</p>
|
| 321 |
+
<p>MATH-Lvl5 is, obviously, interesting for people focusing on math capabilities. The results on this benchmark are generally correlated with performance on GSM8K, except for some outliers as we can see on the following figure.</p>
|
| 322 |
+
|
| 323 |
+
<div class="l-body">
|
| 324 |
+
<figure><img src="assets/images/math_fn_gsm8k.png"/></figure>
|
| 325 |
+
<div id="math"></div>
|
| 326 |
+
</div>
|
| 327 |
+
|
| 328 |
+
<p>In the green box, we highlight models which previously scored 0 on GSM8K due to evaluation limitations mentioned above, but now have very decent scores on the new benchmark MATH-Level5. These models (mostly from 01-ai) were quite strongly penalized by the previous format. In the red box we show models which scored high on GSM8K but are now almost at 0 on MATH-Lvl5. From our current dive in the outputs and behaviors of these models, these would appear to be mostly chat versions of base models (where the base models score higher on MATH!).</p>
|
| 329 |
+
<p>This observation seems to imply that some chat finetuning procedures can impair math capabilities (from our observations, by making models exceedingly verbose).</p>
|
| 330 |
+
<p>MuSR, our last evaluation, is particularly interesting for long context models. We’ve observed that the best performers are models with 10K and plus of context size, and it seems discriminative enough to target long context reasoning specifically.</p>
|
| 331 |
+
<p>Let’s conclude with a look at the future of Open LLM leaderboard!</p>
|
| 332 |
+
|
| 333 |
+
<h2>What’s next?</h2>
|
| 334 |
+
<p>Much like the first version of the Open LLM Leaderboard pushed a community approach to model development during the past year, we hope that the new version 2 will be a milestone of open and reproducible model evaluations.</p>
|
| 335 |
+
<p>Because backward compatibility and open knowledge is important, you’ll still be able to find all the previous results archived in the <a href="https://huggingface.co/open-llm-leaderboard-old">Open LLM Leaderboard Archive</a>!</p>
|
| 336 |
+
<p>Taking a step back to look at the evolution of all the 7400 evaluated models on the Open LLM Leaderboard through time, we can note some much wider trends in the field! For instance we see a strong trend going from larger (red dots) models to smaller (yellow dots) models, while at the same time improving performance.</p>
|
| 337 |
+
|
| 338 |
+
<div class="l-body">
|
| 339 |
+
<figure><img src="assets/images/timewise_analysis_full.png"/></figure>
|
| 340 |
+
<div id="timewise"></div>
|
| 341 |
+
</div>
|
| 342 |
+
|
| 343 |
+
<p>This is great news for the field as smaller models are much easier to embedded as well as much more energy/memory/compute efficient and we hope to observe a similar pattern of progress in the new version of the leaderboard Given our harder benchmarks, our starting point is for now much lower (black dots) so let’s see where the field take us in a few months from now :)</p>
|
| 344 |
+
<p>If you’ve read to this point, thanks a lot, we hope you’ll enjoy this new version of the Open LLM Leaderboard. May the open-source winds push our LLMs boats to sail far away on the sea of deep learning.</p>
|
| 345 |
+
|
| 346 |
+
|
| 347 |
+
</d-article>
|
| 348 |
+
|
| 349 |
+
<d-appendix>
|
| 350 |
+
<d-bibliography src="bibliography.bib"></d-bibliography>
|
| 351 |
+
</d-appendix>
|
| 352 |
+
|
| 353 |
+
<script>
|
| 354 |
+
const article = document.querySelector('d-article');
|
| 355 |
+
const toc = document.querySelector('d-contents');
|
| 356 |
+
if (toc) {
|
| 357 |
+
const headings = article.querySelectorAll('h2, h3, h4');
|
| 358 |
+
let ToC = `<nav role="navigation" class="l-text figcaption"><h3>Table of contents</h3>`;
|
| 359 |
+
let prevLevel = 0;
|
| 360 |
+
|
| 361 |
+
for (const el of headings) {
|
| 362 |
+
// should element be included in TOC?
|
| 363 |
+
const isInTitle = el.parentElement.tagName == 'D-TITLE';
|
| 364 |
+
const isException = el.getAttribute('no-toc');
|
| 365 |
+
if (isInTitle || isException) continue;
|
| 366 |
+
el.setAttribute('id', el.textContent.toLowerCase().replaceAll(" ", "_"))
|
| 367 |
+
const link = '<a target="_self" href="' + '#' + el.getAttribute('id') + '">' + el.textContent + '</a>';
|
| 368 |
+
|
| 369 |
+
const level = el.tagName === 'H2' ? 0 : (el.tagName === 'H3' ? 1 : 2);
|
| 370 |
+
while (prevLevel < level) {
|
| 371 |
+
ToC += '<ul>'
|
| 372 |
+
prevLevel++;
|
| 373 |
+
}
|
| 374 |
+
while (prevLevel > level) {
|
| 375 |
+
ToC += '</ul>'
|
| 376 |
+
prevLevel--;
|
| 377 |
+
}
|
| 378 |
+
if (level === 0)
|
| 379 |
+
ToC += '<div>' + link + '</div>';
|
| 380 |
+
else
|
| 381 |
+
ToC += '<li>' + link + '</li>';
|
| 382 |
+
}
|
| 383 |
+
|
| 384 |
+
while (prevLevel > 0) {
|
| 385 |
+
ToC += '</ul>'
|
| 386 |
+
prevLevel--;
|
| 387 |
+
}
|
| 388 |
+
ToC += '</nav>';
|
| 389 |
+
toc.innerHTML = ToC;
|
| 390 |
+
toc.setAttribute('prerendered', 'true');
|
| 391 |
+
const toc_links = document.querySelectorAll('d-contents > nav a');
|
| 392 |
+
|
| 393 |
+
window.addEventListener('scroll', (_event) => {
|
| 394 |
+
if (typeof (headings) != 'undefined' && headings != null && typeof (toc_links) != 'undefined' && toc_links != null) {
|
| 395 |
+
// Then iterate forwards, on the first match highlight it and break
|
| 396 |
+
find_active: {
|
| 397 |
+
for (let i = headings.length - 1; i >= 0; i--) {
|
| 398 |
+
if (headings[i].getBoundingClientRect().top - 50 <= 0) {
|
| 399 |
+
if (!toc_links[i].classList.contains("active")) {
|
| 400 |
+
toc_links.forEach((link, _index) => {
|
| 401 |
+
link.classList.remove("active");
|
| 402 |
+
});
|
| 403 |
+
toc_links[i].classList.add('active');
|
| 404 |
+
}
|
| 405 |
+
break find_active;
|
| 406 |
+
}
|
| 407 |
+
}
|
| 408 |
+
toc_links.forEach((link, _index) => {
|
| 409 |
+
link.classList.remove("active");
|
| 410 |
+
});
|
| 411 |
+
}
|
| 412 |
+
}
|
| 413 |
+
});
|
| 414 |
+
}
|
| 415 |
+
function includeHTML() {
|
| 416 |
+
var z, i, elmnt, file, xhttp;
|
| 417 |
+
/* Loop through a collection of all HTML elements: */
|
| 418 |
+
z = document.getElementsByTagName("*");
|
| 419 |
+
for (i = 0; i < z.length; i++) {
|
| 420 |
+
elmnt = z[i];
|
| 421 |
+
/*search for elements with a certain atrribute:*/
|
| 422 |
+
file = elmnt.getAttribute("w3-include-html");
|
| 423 |
+
/* print the file on the console */
|
| 424 |
+
console.log("HELP");
|
| 425 |
+
console.log(file);
|
| 426 |
+
|
| 427 |
+
if (file) {
|
| 428 |
+
/* Make an HTTP request using the attribute value as the file name: */
|
| 429 |
+
xhttp = new XMLHttpRequest();
|
| 430 |
+
xhttp.onreadystatechange = function() {
|
| 431 |
+
if (this.readyState == 4) {
|
| 432 |
+
if (this.status == 200) {elmnt.innerHTML = this.responseText;}
|
| 433 |
+
if (this.status == 404) {elmnt.innerHTML = "Page not found.";}
|
| 434 |
+
/* Remove the attribute, and call this function once more: */
|
| 435 |
+
elmnt.removeAttribute("w3-include-html");
|
| 436 |
+
includeHTML();
|
| 437 |
+
}
|
| 438 |
+
}
|
| 439 |
+
xhttp.open("GET", file, true);
|
| 440 |
+
xhttp.send();
|
| 441 |
+
/* Exit the function: */
|
| 442 |
+
return;
|
| 443 |
+
}
|
| 444 |
+
}
|
| 445 |
+
}
|
| 446 |
+
</script>
|
| 447 |
+
<script>
|
| 448 |
+
includeHTML();
|
| 449 |
+
</script>
|
| 450 |
+
</body>
|
| 451 |
+
</html>
|
dist/main.bundle.js
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
document.addEventListener("DOMContentLoaded",(function(){console.log("DOMContentLoaded")}),{once:!0});
|
| 2 |
+
//# sourceMappingURL=main.bundle.js.map
|
dist/main.bundle.js.map
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"version":3,"file":"main.bundle.js","mappings":"AAAAA,SAASC,iBAAiB,oBAAoB,WAC1CC,QAAQC,IAAI,mBAChB,GAAG,CAAEC,MAAM","sources":["webpack://blogpost/./src/index.js"],"sourcesContent":["document.addEventListener(\"DOMContentLoaded\", () => {\n console.log(\"DOMContentLoaded\");\n}, { once: true });"],"names":["document","addEventListener","console","log","once"],"sourceRoot":""}
|
dist/style.css
ADDED
|
@@ -0,0 +1,259 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/* style.css */
|
| 2 |
+
/* Define colors */
|
| 3 |
+
:root {
|
| 4 |
+
--distill-gray: rgb(107, 114, 128);
|
| 5 |
+
--distill-gray-light: rgb(185, 185, 185);
|
| 6 |
+
--distill-gray-lighter: rgb(228, 228, 228);
|
| 7 |
+
--distill-gray-lightest: rgb(245, 245, 245);
|
| 8 |
+
--distill-blue: #007BFF;
|
| 9 |
+
}
|
| 10 |
+
|
| 11 |
+
/* Container for the controls */
|
| 12 |
+
[id^="plot-"] {
|
| 13 |
+
display: flex;
|
| 14 |
+
flex-direction: column;
|
| 15 |
+
align-items: center;
|
| 16 |
+
gap: 15px; /* Adjust the gap between controls as needed */
|
| 17 |
+
}
|
| 18 |
+
[id^="plot-"] figure {
|
| 19 |
+
margin-bottom: 0px;
|
| 20 |
+
margin-top: 0px;
|
| 21 |
+
padding: 0px;
|
| 22 |
+
}
|
| 23 |
+
|
| 24 |
+
.plotly_caption {
|
| 25 |
+
font-style: italic;
|
| 26 |
+
margin-top: 10px;
|
| 27 |
+
}
|
| 28 |
+
|
| 29 |
+
.plotly_controls {
|
| 30 |
+
display: flex;
|
| 31 |
+
flex-wrap: wrap;
|
| 32 |
+
flex-direction: row;
|
| 33 |
+
justify-content: center;
|
| 34 |
+
align-items: flex-start;
|
| 35 |
+
gap: 30px;
|
| 36 |
+
}
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
.plotly_input_container {
|
| 40 |
+
display: flex;
|
| 41 |
+
align-items: center;
|
| 42 |
+
flex-direction: column;
|
| 43 |
+
gap: 10px;
|
| 44 |
+
}
|
| 45 |
+
|
| 46 |
+
/* Style for the select dropdown */
|
| 47 |
+
.plotly_input_container > select {
|
| 48 |
+
padding: 2px 4px;
|
| 49 |
+
/* border: 1px solid #ccc; */
|
| 50 |
+
line-height: 1.5em;
|
| 51 |
+
text-align: center;
|
| 52 |
+
border-radius: 4px;
|
| 53 |
+
font-size: 12px;
|
| 54 |
+
background-color: var(--distill-gray-lightest);
|
| 55 |
+
outline: none;
|
| 56 |
+
}
|
| 57 |
+
|
| 58 |
+
/* Style for the range input */
|
| 59 |
+
|
| 60 |
+
.plotly_slider {
|
| 61 |
+
display: flex;
|
| 62 |
+
align-items: center;
|
| 63 |
+
gap: 10px;
|
| 64 |
+
}
|
| 65 |
+
|
| 66 |
+
.plotly_slider > input[type="range"] {
|
| 67 |
+
-webkit-appearance: none;
|
| 68 |
+
height: 2px;
|
| 69 |
+
background: var(--distill-gray-light);
|
| 70 |
+
border-radius: 5px;
|
| 71 |
+
outline: none;
|
| 72 |
+
}
|
| 73 |
+
|
| 74 |
+
.plotly_slider > span {
|
| 75 |
+
font-size: 14px;
|
| 76 |
+
line-height: 1.6em;
|
| 77 |
+
min-width: 16px;
|
| 78 |
+
}
|
| 79 |
+
|
| 80 |
+
.plotly_slider > input[type="range"]::-webkit-slider-thumb {
|
| 81 |
+
-webkit-appearance: none;
|
| 82 |
+
appearance: none;
|
| 83 |
+
width: 18px;
|
| 84 |
+
height: 18px;
|
| 85 |
+
border-radius: 50%;
|
| 86 |
+
background: var(--distill-blue);
|
| 87 |
+
cursor: pointer;
|
| 88 |
+
}
|
| 89 |
+
|
| 90 |
+
.plotly_slider > input[type="range"]::-moz-range-thumb {
|
| 91 |
+
width: 18px;
|
| 92 |
+
height: 18px;
|
| 93 |
+
border-radius: 50%;
|
| 94 |
+
background: var(--distill-blue);
|
| 95 |
+
cursor: pointer;
|
| 96 |
+
}
|
| 97 |
+
|
| 98 |
+
/* Style for the labels */
|
| 99 |
+
.plotly_input_container > label {
|
| 100 |
+
font-size: 14px;
|
| 101 |
+
font-weight: bold;
|
| 102 |
+
}
|
| 103 |
+
|
| 104 |
+
.main-plot-container {
|
| 105 |
+
margin-top: 21px;
|
| 106 |
+
margin-bottom: 35px;
|
| 107 |
+
}
|
| 108 |
+
|
| 109 |
+
.main-plot-container > figure {
|
| 110 |
+
display: block !important;
|
| 111 |
+
/* Let this be handled by graph-container */
|
| 112 |
+
margin-bottom: 0px;
|
| 113 |
+
margin-top: 0px;
|
| 114 |
+
}
|
| 115 |
+
.main-plot-container > div {
|
| 116 |
+
display: none !important;
|
| 117 |
+
}
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
@media (min-width: 768px) {
|
| 121 |
+
.main-plot-container > figure {
|
| 122 |
+
display: none !important;
|
| 123 |
+
}
|
| 124 |
+
.main-plot-container > div {
|
| 125 |
+
display: flex !important;
|
| 126 |
+
}
|
| 127 |
+
}
|
| 128 |
+
|
| 129 |
+
d-byline .byline {
|
| 130 |
+
grid-template-columns: 1fr;
|
| 131 |
+
grid-column: text;
|
| 132 |
+
font-size: 0.9rem;
|
| 133 |
+
line-height: 1.8em;
|
| 134 |
+
}
|
| 135 |
+
|
| 136 |
+
@media (min-width: 768px) {
|
| 137 |
+
d-byline .byline {
|
| 138 |
+
grid-template-columns: 5fr 1fr 1fr;
|
| 139 |
+
}
|
| 140 |
+
}
|
| 141 |
+
|
| 142 |
+
#title-plot {
|
| 143 |
+
margin-top: 0px;
|
| 144 |
+
margin-bottom: 0px;
|
| 145 |
+
}
|
| 146 |
+
|
| 147 |
+
d-contents > nav a.active {
|
| 148 |
+
text-decoration: underline;
|
| 149 |
+
}
|
| 150 |
+
|
| 151 |
+
@media (max-width: 1199px) {
|
| 152 |
+
d-contents {
|
| 153 |
+
display: none;
|
| 154 |
+
justify-self: start;
|
| 155 |
+
align-self: start;
|
| 156 |
+
padding-bottom: 0.5em;
|
| 157 |
+
margin-bottom: 1em;
|
| 158 |
+
padding-left: 0.25em;
|
| 159 |
+
border-bottom: 1px solid rgba(0, 0, 0, 0.1);
|
| 160 |
+
border-bottom-width: 1px;
|
| 161 |
+
border-bottom-style: solid;
|
| 162 |
+
border-bottom-color: rgba(0, 0, 0, 0.1);
|
| 163 |
+
}
|
| 164 |
+
}
|
| 165 |
+
|
| 166 |
+
d-contents a:hover {
|
| 167 |
+
border-bottom: none;
|
| 168 |
+
}
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
@media (min-width: 1200px) {
|
| 172 |
+
d-article {
|
| 173 |
+
/* Ensure d-article does not prevent sticky positioning */
|
| 174 |
+
overflow: visible;
|
| 175 |
+
}
|
| 176 |
+
|
| 177 |
+
d-contents {
|
| 178 |
+
align-self: start;
|
| 179 |
+
grid-column-start: 1 !important;
|
| 180 |
+
grid-column-end: 4 !important;
|
| 181 |
+
grid-row: auto / span 6;
|
| 182 |
+
justify-self: end;
|
| 183 |
+
margin-top: 0em;
|
| 184 |
+
padding-right: 3em;
|
| 185 |
+
padding-left: 2em;
|
| 186 |
+
border-right: 1px solid rgba(0, 0, 0, 0.1);
|
| 187 |
+
border-right-width: 1px;
|
| 188 |
+
border-right-style: solid;
|
| 189 |
+
border-right-color: rgba(0, 0, 0, 0.1);
|
| 190 |
+
position: -webkit-sticky; /* For Safari */
|
| 191 |
+
position: sticky;
|
| 192 |
+
top: 10px; /* Adjust this value if needed */
|
| 193 |
+
}
|
| 194 |
+
}
|
| 195 |
+
|
| 196 |
+
d-contents nav h3 {
|
| 197 |
+
margin-top: 0;
|
| 198 |
+
margin-bottom: 1em;
|
| 199 |
+
}
|
| 200 |
+
|
| 201 |
+
d-contents nav div {
|
| 202 |
+
color: rgba(0, 0, 0, 0.8);
|
| 203 |
+
font-weight: bold;
|
| 204 |
+
}
|
| 205 |
+
|
| 206 |
+
d-contents nav a {
|
| 207 |
+
color: rgba(0, 0, 0, 0.8);
|
| 208 |
+
border-bottom: none;
|
| 209 |
+
text-decoration: none;
|
| 210 |
+
}
|
| 211 |
+
|
| 212 |
+
d-contents li {
|
| 213 |
+
list-style-type: none;
|
| 214 |
+
}
|
| 215 |
+
|
| 216 |
+
d-contents ul, d-article d-contents ul {
|
| 217 |
+
padding-left: 1em;
|
| 218 |
+
}
|
| 219 |
+
|
| 220 |
+
d-contents nav ul li {
|
| 221 |
+
margin-bottom: .25em;
|
| 222 |
+
}
|
| 223 |
+
|
| 224 |
+
d-contents nav a:hover {
|
| 225 |
+
text-decoration: underline solid rgba(0, 0, 0, 0.6);
|
| 226 |
+
}
|
| 227 |
+
|
| 228 |
+
d-contents nav ul {
|
| 229 |
+
margin-top: 0;
|
| 230 |
+
margin-bottom: 6px;
|
| 231 |
+
}
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
d-contents nav > div {
|
| 235 |
+
display: block;
|
| 236 |
+
outline: none;
|
| 237 |
+
margin-bottom: 0.5em;
|
| 238 |
+
}
|
| 239 |
+
|
| 240 |
+
d-contents nav > div > a {
|
| 241 |
+
font-size: 13px;
|
| 242 |
+
font-weight: 600;
|
| 243 |
+
}
|
| 244 |
+
|
| 245 |
+
d-article aside {
|
| 246 |
+
margin-bottom: 1em;
|
| 247 |
+
}
|
| 248 |
+
|
| 249 |
+
@media (min-width: 768px) {
|
| 250 |
+
d-article aside {
|
| 251 |
+
margin-bottom: 0;
|
| 252 |
+
}
|
| 253 |
+
}
|
| 254 |
+
|
| 255 |
+
d-contents nav > div > a:hover,
|
| 256 |
+
d-contents nav > ul > li > a:hover {
|
| 257 |
+
text-decoration: none;
|
| 258 |
+
}
|
| 259 |
+
|