Spaces:
Running
on
CPU Upgrade

Running
on
CPU Upgrade
Jack Clark and Alec Radford and Jeff Wu
commited on
Commit
•
cba7812
1
Parent(s):
6f48b7f
detection stuff update
Browse files- README.md +6 -17
- detection.md +50 -0
- images/detection_by_length.png +0 -0
- images/parts_of_speech.png +0 -0
- images/self_detection_k40.png +0 -0
- images/self_detection_t1.png +0 -0
README.md
CHANGED
|
@@ -28,28 +28,17 @@ where split is one of `train`, `test`, and `valid`.
|
|
| 28 |
|
| 29 |
We've provided a script to download all of them, in `download_dataset.py`.
|
| 30 |
|
| 31 |
-
|
| 32 |
-
|
| 33 |
-
We're interested in seeing research in detectability of GPT-2 model family generations.
|
| 34 |
-
|
| 35 |
-
We've provided a starter baseline which trains a logistic regression detector on TF-IDF unigram and bigram features, in `baseline.py`. The baseline achieves the following accuracies:
|
| 36 |
|
| 37 |
-
|
| 38 |
-
| ----- | ------ | ------ |
|
| 39 |
-
| 117M | 88.29% | 96.79% |
|
| 40 |
-
| 345M | 88.94% | 95.22% |
|
| 41 |
-
| 762M | 77.16% | 94.43% |
|
| 42 |
-
| 1542M | 74.31% | 92.69% |
|
| 43 |
|
| 44 |
-
###
|
| 45 |
-
|
| 46 |
-
<img src="https://i.imgur.com/PZ3GOeS.png" width="475" height="335" title="Impact of Document Length">
|
| 47 |
|
| 48 |
-
|
| 49 |
|
| 50 |
-
|
| 51 |
|
| 52 |
-
|
| 53 |
|
| 54 |
### Data removal requests
|
| 55 |
|
|
|
|
| 28 |
|
| 29 |
We've provided a script to download all of them, in `download_dataset.py`.
|
| 30 |
|
| 31 |
+
#### Finetuned model samples
|
|
|
|
|
|
|
|
|
|
|
|
|
| 32 |
|
| 33 |
+
Additionally, we encourage research on detection of finetuned models. We have released data under `gs://gpt-2/output-dataset/v1-amazonfinetune/` with samples from a GPT-2 full model finetuned to output Amazon reviews.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 34 |
|
| 35 |
+
### Detectability baselines
|
|
|
|
|
|
|
| 36 |
|
| 37 |
+
We're interested in seeing research in detectability of GPT-2 model family generations.
|
| 38 |
|
| 39 |
+
We provide some [initial analysis](detection.md) of two baselines, as well as [code](./baseline.py) for the better baseline.
|
| 40 |
|
| 41 |
+
Overall, we are able to achieve accuracies in the mid-90s for Top-K 40 generations, and mid-70s to high-80s (depending on model size) for random generations. We also find some evidence that adversaries can evade detection via finetuning from released models.
|
| 42 |
|
| 43 |
### Data removal requests
|
| 44 |
|
detection.md
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
We encourage you to try improving our baselines. Please let us know if you have questions or find any interesting results!
|
| 2 |
+
|
| 3 |
+
## Simple baseline
|
| 4 |
+
|
| 5 |
+
We've provided a starter baseline which trains a logistic regression detector on TF-IDF unigram and bigram features, in [`baseline.py`](./baseline.py).
|
| 6 |
+
|
| 7 |
+
### Initial Analysis
|
| 8 |
+
|
| 9 |
+
The baseline achieves the following accuracies:
|
| 10 |
+
|
| 11 |
+
| Model | Temperature 1 | Top-K 40 |
|
| 12 |
+
| ----- | ------ | ------ |
|
| 13 |
+
| 117M | 88.29% | 96.79% |
|
| 14 |
+
| 345M | 88.94% | 95.22% |
|
| 15 |
+
| 762M | 77.16% | 94.43% |
|
| 16 |
+
| 1542M | 74.31% | 92.69% |
|
| 17 |
+
|
| 18 |
+
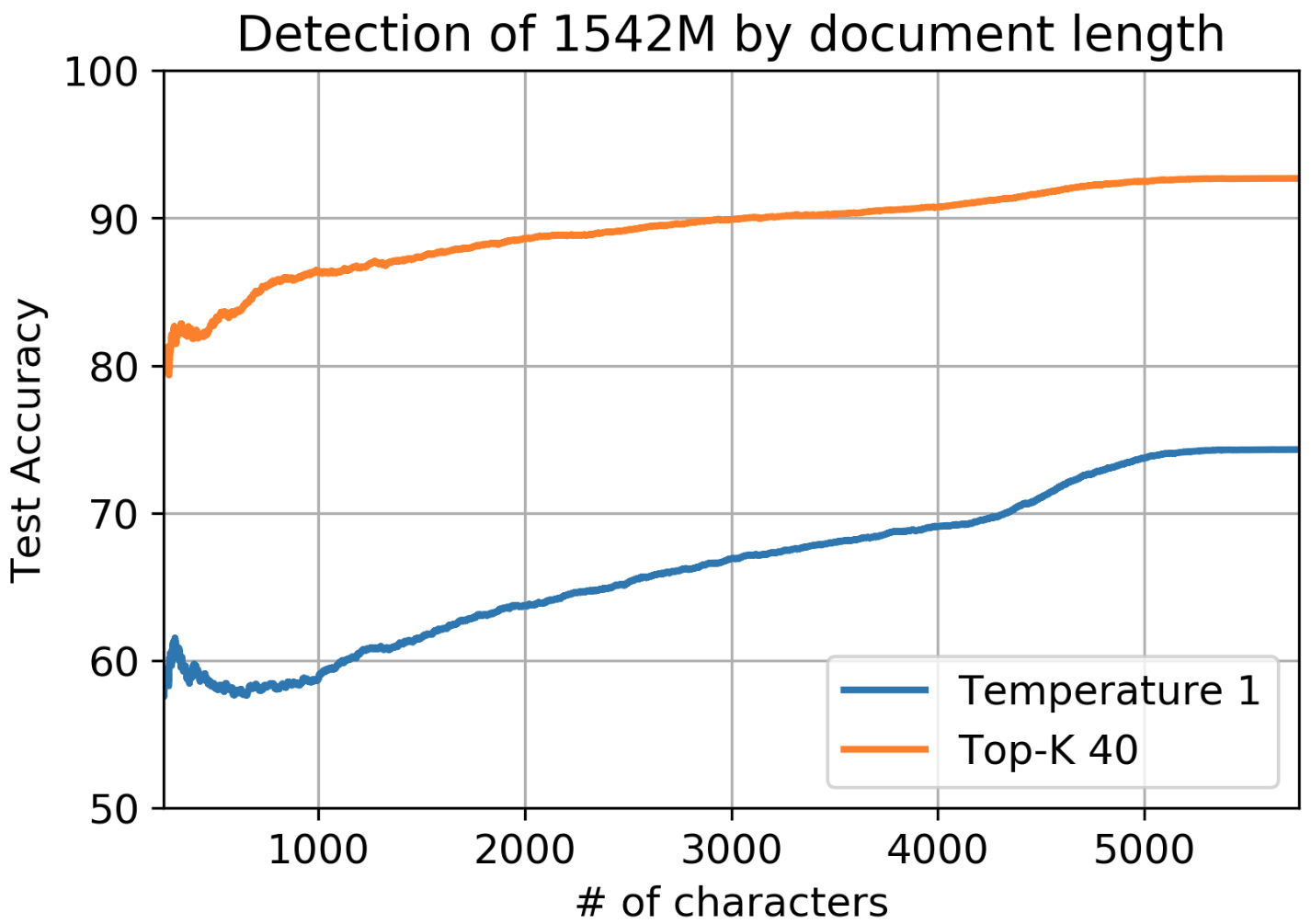
<img src="images/detection_by_length.png" width="475" height="335" title="Impact of Document Length">
|
| 19 |
+
|
| 20 |
+
Unsurprisingly, shorter documents are harder to detect and performance improves gradually with length. Accuracy of detection of short documents of 500 characters (a long paragraph) is about 15% lower.
|
| 21 |
+
|
| 22 |
+
<img src="images/parts_of_speech.png" width="482" height="300" title="Part of Speech Analysis">
|
| 23 |
+
|
| 24 |
+
Truncated sampling, which is commonly used for high-quality generations from the GPT-2 model family, results in a shift in the part of speech distribution of the generated text compared to real text. A clear example is the underuse of proper nouns and overuse of pronouns which are more generic. This shift contributes to the 8% to 18% higher detection rate of Top-K samples compared to random samples across models.
|
| 25 |
+
|
| 26 |
+
### Finetuning
|
| 27 |
+
|
| 28 |
+
When run on samples from the finetuned GPT-2 full model, detection rate falls from 92.7% to 70.2% for Top-K 40 generations. Note that about half of this drop is accounted for by length, since Amazon reviews are shorter than WebText documents.
|
| 29 |
+
|
| 30 |
+
## "Zero-shot" baseline
|
| 31 |
+
|
| 32 |
+
We attempt a second baseline which uses a language model to evaluate total log probability, and thresholds based on this probability. This baseline underperforms relative to the simple baselinie. However, we are interested in further variants, such as binning per-token log probabilities.
|
| 33 |
+
|
| 34 |
+
### Initial analysis
|
| 35 |
+
|
| 36 |
+
Here, we show results of log-prob based detection for both standard (t=1) and Top-K 40 generations.
|
| 37 |
+
<img src="images/self_detection_t1.png" width="300" height="300" title="Accuracy with standard (t=1) generations">
|
| 38 |
+
<img src="images/self_detection_k40.png" width="300" height="300" title="Accuracy with Top-K 40 generations">
|
| 39 |
+
|
| 40 |
+
The main result is that GPT-2 detects itself 81.8% of the time in the easy case of Top-K 40 generations. This is pretty constant across model sizes. All underperform relative to the simple baseline.
|
| 41 |
+
|
| 42 |
+
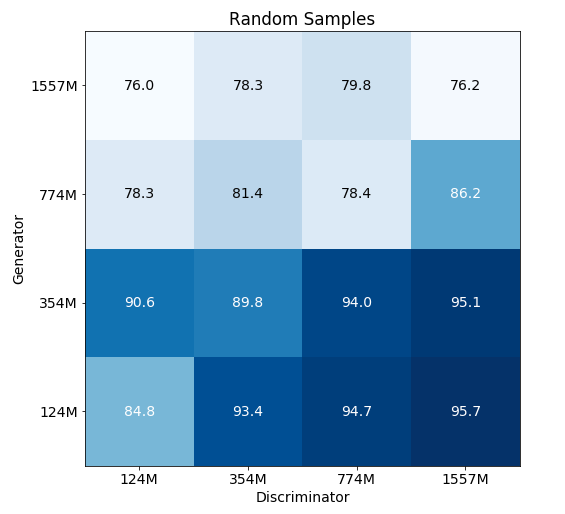
For random samples, results are unsurprising. Bigger models are better able to realize that generated text is still kind of weird and "random". Detection rates also go down as generators get better.
|
| 43 |
+
|
| 44 |
+
For Top-K 40, results are perhaps more surprising. Using a bigger model as a discriminator does not really improve detection rates across the board (the smallest GPT-2 model does as well at detecting full GPT-2 as full GPT-2), and a bigger model does not "detect down well" - that is, full GPT-2 is actually kind of bad at detecting an adversary using small GPT-2.
|
| 45 |
+
|
| 46 |
+
An important difference is that while in the random samples case, generations are less likely than real data, in the Top-K 40 case, they are more likely.
|
| 47 |
+
|
| 48 |
+
### Finetuning
|
| 49 |
+
|
| 50 |
+
When detecting samples from our finetuned GPT-2 full model using GPT-2 full, we observe a 63.2% detection rate on random samples (drop of 13%) and 76.2% detection rate with Top-K 40 samples (drop of 5.6%)
|
images/detection_by_length.png
ADDED
|
images/parts_of_speech.png
ADDED

|
images/self_detection_k40.png
ADDED

|
images/self_detection_t1.png
ADDED
|