Spaces:
Running

Running
Commit
•
20528a2
1
Parent(s):
1c83ac0
deploy
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .dockerignore +7 -0
- .gitignore +32 -0
- .pre-commit-config.yaml +25 -0
- .project-root +0 -0
- .readthedocs.yaml +19 -0
- API_FLAGS.txt +6 -0
- LICENSE +437 -0
- app.py +14 -57
- checkpoints/fish-speech-1.4/.gitattributes +35 -0
- checkpoints/fish-speech-1.4/README.md +63 -0
- checkpoints/fish-speech-1.4/config.json +21 -0
- checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth +3 -0
- checkpoints/fish-speech-1.4/model.pth +3 -0
- checkpoints/fish-speech-1.4/special_tokens_map.json +23 -0
- checkpoints/fish-speech-1.4/tokenizer.json +0 -0
- checkpoints/fish-speech-1.4/tokenizer_config.json +82 -0
- docker-compose.dev.yml +18 -0
- dockerfile +50 -0
- dockerfile.dev +37 -0
- docs/CNAME +1 -0
- docs/README.ja.md +106 -0
- docs/README.ko.md +111 -0
- docs/README.pt-BR.md +114 -0
- docs/README.zh.md +109 -0
- docs/assets/figs/VS_1.jpg +0 -0
- docs/assets/figs/VS_1_pt-BR.png +0 -0
- docs/assets/figs/agent_gradio.png +0 -0
- docs/assets/figs/diagram.png +0 -0
- docs/assets/figs/diagrama.png +0 -0
- docs/assets/figs/logo-circle.png +0 -0
- docs/en/finetune.md +128 -0
- docs/en/index.md +215 -0
- docs/en/inference.md +135 -0
- docs/en/samples.md +137 -0
- docs/en/start_agent.md +77 -0
- docs/ja/finetune.md +128 -0
- docs/ja/index.md +214 -0
- docs/ja/inference.md +114 -0
- docs/ja/samples.md +225 -0
- docs/ja/start_agent.md +80 -0
- docs/ko/finetune.md +128 -0
- docs/ko/index.md +215 -0
- docs/ko/inference.md +134 -0
- docs/ko/samples.md +137 -0
- docs/ko/start_agent.md +80 -0
- docs/pt/finetune.md +128 -0
- docs/pt/index.md +210 -0
- docs/pt/inference.md +114 -0
- docs/pt/samples.md +225 -0
- docs/pt/start_agent.md +80 -0
.dockerignore
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.git
|
| 2 |
+
.github
|
| 3 |
+
results
|
| 4 |
+
data
|
| 5 |
+
*.filelist
|
| 6 |
+
/data_server/target
|
| 7 |
+
#checkpoints
|
.gitignore
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.DS_Store
|
| 2 |
+
.pgx.*
|
| 3 |
+
.pdm-python
|
| 4 |
+
/fish_speech.egg-info
|
| 5 |
+
__pycache__
|
| 6 |
+
/results
|
| 7 |
+
/data
|
| 8 |
+
/*.test.sh
|
| 9 |
+
*.filelist
|
| 10 |
+
filelists
|
| 11 |
+
/fish_speech/text/cmudict_cache.pickle
|
| 12 |
+
#/checkpoints
|
| 13 |
+
/.vscode
|
| 14 |
+
/data_server/target
|
| 15 |
+
/*.npy
|
| 16 |
+
/*.wav
|
| 17 |
+
/*.mp3
|
| 18 |
+
/*.lab
|
| 19 |
+
/results
|
| 20 |
+
/data
|
| 21 |
+
/.idea
|
| 22 |
+
ffmpeg.exe
|
| 23 |
+
ffprobe.exe
|
| 24 |
+
asr-label*
|
| 25 |
+
/.cache
|
| 26 |
+
/fishenv
|
| 27 |
+
/.locale
|
| 28 |
+
/demo-audios
|
| 29 |
+
/references
|
| 30 |
+
/example
|
| 31 |
+
/faster_whisper
|
| 32 |
+
/.gradio
|
.pre-commit-config.yaml
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ci:
|
| 2 |
+
autoupdate_schedule: monthly
|
| 3 |
+
|
| 4 |
+
repos:
|
| 5 |
+
- repo: https://github.com/pycqa/isort
|
| 6 |
+
rev: 5.13.2
|
| 7 |
+
hooks:
|
| 8 |
+
- id: isort
|
| 9 |
+
args: [--profile=black]
|
| 10 |
+
|
| 11 |
+
- repo: https://github.com/psf/black
|
| 12 |
+
rev: 24.10.0
|
| 13 |
+
hooks:
|
| 14 |
+
- id: black
|
| 15 |
+
|
| 16 |
+
- repo: https://github.com/pre-commit/pre-commit-hooks
|
| 17 |
+
rev: v5.0.0
|
| 18 |
+
hooks:
|
| 19 |
+
- id: end-of-file-fixer
|
| 20 |
+
- id: check-yaml
|
| 21 |
+
- id: check-json
|
| 22 |
+
- id: mixed-line-ending
|
| 23 |
+
args: ['--fix=lf']
|
| 24 |
+
- id: check-added-large-files
|
| 25 |
+
args: ['--maxkb=5000']
|
.project-root
ADDED
|
File without changes
|
.readthedocs.yaml
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Read the Docs configuration file for MkDocs projects
|
| 2 |
+
# See https://docs.readthedocs.io/en/stable/config-file/v2.html for details
|
| 3 |
+
|
| 4 |
+
# Required
|
| 5 |
+
version: 2
|
| 6 |
+
|
| 7 |
+
# Set the version of Python and other tools you might need
|
| 8 |
+
build:
|
| 9 |
+
os: ubuntu-22.04
|
| 10 |
+
tools:
|
| 11 |
+
python: "3.12"
|
| 12 |
+
|
| 13 |
+
mkdocs:
|
| 14 |
+
configuration: mkdocs.yml
|
| 15 |
+
|
| 16 |
+
# Optionally declare the Python requirements required to build your docs
|
| 17 |
+
python:
|
| 18 |
+
install:
|
| 19 |
+
- requirements: docs/requirements.txt
|
API_FLAGS.txt
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --infer
|
| 2 |
+
--api
|
| 3 |
+
--listen 0.0.0.0:8080 \
|
| 4 |
+
--llama-checkpoint-path "checkpoints/fish-speech-1.4" \
|
| 5 |
+
--decoder-checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth" \
|
| 6 |
+
--decoder-config-name firefly_gan_vq
|
LICENSE
ADDED
|
@@ -0,0 +1,437 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Attribution-NonCommercial-ShareAlike 4.0 International
|
| 2 |
+
|
| 3 |
+
=======================================================================
|
| 4 |
+
|
| 5 |
+
Creative Commons Corporation ("Creative Commons") is not a law firm and
|
| 6 |
+
does not provide legal services or legal advice. Distribution of
|
| 7 |
+
Creative Commons public licenses does not create a lawyer-client or
|
| 8 |
+
other relationship. Creative Commons makes its licenses and related
|
| 9 |
+
information available on an "as-is" basis. Creative Commons gives no
|
| 10 |
+
warranties regarding its licenses, any material licensed under their
|
| 11 |
+
terms and conditions, or any related information. Creative Commons
|
| 12 |
+
disclaims all liability for damages resulting from their use to the
|
| 13 |
+
fullest extent possible.
|
| 14 |
+
|
| 15 |
+
Using Creative Commons Public Licenses
|
| 16 |
+
|
| 17 |
+
Creative Commons public licenses provide a standard set of terms and
|
| 18 |
+
conditions that creators and other rights holders may use to share
|
| 19 |
+
original works of authorship and other material subject to copyright
|
| 20 |
+
and certain other rights specified in the public license below. The
|
| 21 |
+
following considerations are for informational purposes only, are not
|
| 22 |
+
exhaustive, and do not form part of our licenses.
|
| 23 |
+
|
| 24 |
+
Considerations for licensors: Our public licenses are
|
| 25 |
+
intended for use by those authorized to give the public
|
| 26 |
+
permission to use material in ways otherwise restricted by
|
| 27 |
+
copyright and certain other rights. Our licenses are
|
| 28 |
+
irrevocable. Licensors should read and understand the terms
|
| 29 |
+
and conditions of the license they choose before applying it.
|
| 30 |
+
Licensors should also secure all rights necessary before
|
| 31 |
+
applying our licenses so that the public can reuse the
|
| 32 |
+
material as expected. Licensors should clearly mark any
|
| 33 |
+
material not subject to the license. This includes other CC-
|
| 34 |
+
licensed material, or material used under an exception or
|
| 35 |
+
limitation to copyright. More considerations for licensors:
|
| 36 |
+
wiki.creativecommons.org/Considerations_for_licensors
|
| 37 |
+
|
| 38 |
+
Considerations for the public: By using one of our public
|
| 39 |
+
licenses, a licensor grants the public permission to use the
|
| 40 |
+
licensed material under specified terms and conditions. If
|
| 41 |
+
the licensor's permission is not necessary for any reason--for
|
| 42 |
+
example, because of any applicable exception or limitation to
|
| 43 |
+
copyright--then that use is not regulated by the license. Our
|
| 44 |
+
licenses grant only permissions under copyright and certain
|
| 45 |
+
other rights that a licensor has authority to grant. Use of
|
| 46 |
+
the licensed material may still be restricted for other
|
| 47 |
+
reasons, including because others have copyright or other
|
| 48 |
+
rights in the material. A licensor may make special requests,
|
| 49 |
+
such as asking that all changes be marked or described.
|
| 50 |
+
Although not required by our licenses, you are encouraged to
|
| 51 |
+
respect those requests where reasonable. More considerations
|
| 52 |
+
for the public:
|
| 53 |
+
wiki.creativecommons.org/Considerations_for_licensees
|
| 54 |
+
|
| 55 |
+
=======================================================================
|
| 56 |
+
|
| 57 |
+
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International
|
| 58 |
+
Public License
|
| 59 |
+
|
| 60 |
+
By exercising the Licensed Rights (defined below), You accept and agree
|
| 61 |
+
to be bound by the terms and conditions of this Creative Commons
|
| 62 |
+
Attribution-NonCommercial-ShareAlike 4.0 International Public License
|
| 63 |
+
("Public License"). To the extent this Public License may be
|
| 64 |
+
interpreted as a contract, You are granted the Licensed Rights in
|
| 65 |
+
consideration of Your acceptance of these terms and conditions, and the
|
| 66 |
+
Licensor grants You such rights in consideration of benefits the
|
| 67 |
+
Licensor receives from making the Licensed Material available under
|
| 68 |
+
these terms and conditions.
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
Section 1 -- Definitions.
|
| 72 |
+
|
| 73 |
+
a. Adapted Material means material subject to Copyright and Similar
|
| 74 |
+
Rights that is derived from or based upon the Licensed Material
|
| 75 |
+
and in which the Licensed Material is translated, altered,
|
| 76 |
+
arranged, transformed, or otherwise modified in a manner requiring
|
| 77 |
+
permission under the Copyright and Similar Rights held by the
|
| 78 |
+
Licensor. For purposes of this Public License, where the Licensed
|
| 79 |
+
Material is a musical work, performance, or sound recording,
|
| 80 |
+
Adapted Material is always produced where the Licensed Material is
|
| 81 |
+
synched in timed relation with a moving image.
|
| 82 |
+
|
| 83 |
+
b. Adapter's License means the license You apply to Your Copyright
|
| 84 |
+
and Similar Rights in Your contributions to Adapted Material in
|
| 85 |
+
accordance with the terms and conditions of this Public License.
|
| 86 |
+
|
| 87 |
+
c. BY-NC-SA Compatible License means a license listed at
|
| 88 |
+
creativecommons.org/compatiblelicenses, approved by Creative
|
| 89 |
+
Commons as essentially the equivalent of this Public License.
|
| 90 |
+
|
| 91 |
+
d. Copyright and Similar Rights means copyright and/or similar rights
|
| 92 |
+
closely related to copyright including, without limitation,
|
| 93 |
+
performance, broadcast, sound recording, and Sui Generis Database
|
| 94 |
+
Rights, without regard to how the rights are labeled or
|
| 95 |
+
categorized. For purposes of this Public License, the rights
|
| 96 |
+
specified in Section 2(b)(1)-(2) are not Copyright and Similar
|
| 97 |
+
Rights.
|
| 98 |
+
|
| 99 |
+
e. Effective Technological Measures means those measures that, in the
|
| 100 |
+
absence of proper authority, may not be circumvented under laws
|
| 101 |
+
fulfilling obligations under Article 11 of the WIPO Copyright
|
| 102 |
+
Treaty adopted on December 20, 1996, and/or similar international
|
| 103 |
+
agreements.
|
| 104 |
+
|
| 105 |
+
f. Exceptions and Limitations means fair use, fair dealing, and/or
|
| 106 |
+
any other exception or limitation to Copyright and Similar Rights
|
| 107 |
+
that applies to Your use of the Licensed Material.
|
| 108 |
+
|
| 109 |
+
g. License Elements means the license attributes listed in the name
|
| 110 |
+
of a Creative Commons Public License. The License Elements of this
|
| 111 |
+
Public License are Attribution, NonCommercial, and ShareAlike.
|
| 112 |
+
|
| 113 |
+
h. Licensed Material means the artistic or literary work, database,
|
| 114 |
+
or other material to which the Licensor applied this Public
|
| 115 |
+
License.
|
| 116 |
+
|
| 117 |
+
i. Licensed Rights means the rights granted to You subject to the
|
| 118 |
+
terms and conditions of this Public License, which are limited to
|
| 119 |
+
all Copyright and Similar Rights that apply to Your use of the
|
| 120 |
+
Licensed Material and that the Licensor has authority to license.
|
| 121 |
+
|
| 122 |
+
j. Licensor means the individual(s) or entity(ies) granting rights
|
| 123 |
+
under this Public License.
|
| 124 |
+
|
| 125 |
+
k. NonCommercial means not primarily intended for or directed towards
|
| 126 |
+
commercial advantage or monetary compensation. For purposes of
|
| 127 |
+
this Public License, the exchange of the Licensed Material for
|
| 128 |
+
other material subject to Copyright and Similar Rights by digital
|
| 129 |
+
file-sharing or similar means is NonCommercial provided there is
|
| 130 |
+
no payment of monetary compensation in connection with the
|
| 131 |
+
exchange.
|
| 132 |
+
|
| 133 |
+
l. Share means to provide material to the public by any means or
|
| 134 |
+
process that requires permission under the Licensed Rights, such
|
| 135 |
+
as reproduction, public display, public performance, distribution,
|
| 136 |
+
dissemination, communication, or importation, and to make material
|
| 137 |
+
available to the public including in ways that members of the
|
| 138 |
+
public may access the material from a place and at a time
|
| 139 |
+
individually chosen by them.
|
| 140 |
+
|
| 141 |
+
m. Sui Generis Database Rights means rights other than copyright
|
| 142 |
+
resulting from Directive 96/9/EC of the European Parliament and of
|
| 143 |
+
the Council of 11 March 1996 on the legal protection of databases,
|
| 144 |
+
as amended and/or succeeded, as well as other essentially
|
| 145 |
+
equivalent rights anywhere in the world.
|
| 146 |
+
|
| 147 |
+
n. You means the individual or entity exercising the Licensed Rights
|
| 148 |
+
under this Public License. Your has a corresponding meaning.
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
Section 2 -- Scope.
|
| 152 |
+
|
| 153 |
+
a. License grant.
|
| 154 |
+
|
| 155 |
+
1. Subject to the terms and conditions of this Public License,
|
| 156 |
+
the Licensor hereby grants You a worldwide, royalty-free,
|
| 157 |
+
non-sublicensable, non-exclusive, irrevocable license to
|
| 158 |
+
exercise the Licensed Rights in the Licensed Material to:
|
| 159 |
+
|
| 160 |
+
a. reproduce and Share the Licensed Material, in whole or
|
| 161 |
+
in part, for NonCommercial purposes only; and
|
| 162 |
+
|
| 163 |
+
b. produce, reproduce, and Share Adapted Material for
|
| 164 |
+
NonCommercial purposes only.
|
| 165 |
+
|
| 166 |
+
2. Exceptions and Limitations. For the avoidance of doubt, where
|
| 167 |
+
Exceptions and Limitations apply to Your use, this Public
|
| 168 |
+
License does not apply, and You do not need to comply with
|
| 169 |
+
its terms and conditions.
|
| 170 |
+
|
| 171 |
+
3. Term. The term of this Public License is specified in Section
|
| 172 |
+
6(a).
|
| 173 |
+
|
| 174 |
+
4. Media and formats; technical modifications allowed. The
|
| 175 |
+
Licensor authorizes You to exercise the Licensed Rights in
|
| 176 |
+
all media and formats whether now known or hereafter created,
|
| 177 |
+
and to make technical modifications necessary to do so. The
|
| 178 |
+
Licensor waives and/or agrees not to assert any right or
|
| 179 |
+
authority to forbid You from making technical modifications
|
| 180 |
+
necessary to exercise the Licensed Rights, including
|
| 181 |
+
technical modifications necessary to circumvent Effective
|
| 182 |
+
Technological Measures. For purposes of this Public License,
|
| 183 |
+
simply making modifications authorized by this Section 2(a)
|
| 184 |
+
(4) never produces Adapted Material.
|
| 185 |
+
|
| 186 |
+
5. Downstream recipients.
|
| 187 |
+
|
| 188 |
+
a. Offer from the Licensor -- Licensed Material. Every
|
| 189 |
+
recipient of the Licensed Material automatically
|
| 190 |
+
receives an offer from the Licensor to exercise the
|
| 191 |
+
Licensed Rights under the terms and conditions of this
|
| 192 |
+
Public License.
|
| 193 |
+
|
| 194 |
+
b. Additional offer from the Licensor -- Adapted Material.
|
| 195 |
+
Every recipient of Adapted Material from You
|
| 196 |
+
automatically receives an offer from the Licensor to
|
| 197 |
+
exercise the Licensed Rights in the Adapted Material
|
| 198 |
+
under the conditions of the Adapter's License You apply.
|
| 199 |
+
|
| 200 |
+
c. No downstream restrictions. You may not offer or impose
|
| 201 |
+
any additional or different terms or conditions on, or
|
| 202 |
+
apply any Effective Technological Measures to, the
|
| 203 |
+
Licensed Material if doing so restricts exercise of the
|
| 204 |
+
Licensed Rights by any recipient of the Licensed
|
| 205 |
+
Material.
|
| 206 |
+
|
| 207 |
+
6. No endorsement. Nothing in this Public License constitutes or
|
| 208 |
+
may be construed as permission to assert or imply that You
|
| 209 |
+
are, or that Your use of the Licensed Material is, connected
|
| 210 |
+
with, or sponsored, endorsed, or granted official status by,
|
| 211 |
+
the Licensor or others designated to receive attribution as
|
| 212 |
+
provided in Section 3(a)(1)(A)(i).
|
| 213 |
+
|
| 214 |
+
b. Other rights.
|
| 215 |
+
|
| 216 |
+
1. Moral rights, such as the right of integrity, are not
|
| 217 |
+
licensed under this Public License, nor are publicity,
|
| 218 |
+
privacy, and/or other similar personality rights; however, to
|
| 219 |
+
the extent possible, the Licensor waives and/or agrees not to
|
| 220 |
+
assert any such rights held by the Licensor to the limited
|
| 221 |
+
extent necessary to allow You to exercise the Licensed
|
| 222 |
+
Rights, but not otherwise.
|
| 223 |
+
|
| 224 |
+
2. Patent and trademark rights are not licensed under this
|
| 225 |
+
Public License.
|
| 226 |
+
|
| 227 |
+
3. To the extent possible, the Licensor waives any right to
|
| 228 |
+
collect royalties from You for the exercise of the Licensed
|
| 229 |
+
Rights, whether directly or through a collecting society
|
| 230 |
+
under any voluntary or waivable statutory or compulsory
|
| 231 |
+
licensing scheme. In all other cases the Licensor expressly
|
| 232 |
+
reserves any right to collect such royalties, including when
|
| 233 |
+
the Licensed Material is used other than for NonCommercial
|
| 234 |
+
purposes.
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
Section 3 -- License Conditions.
|
| 238 |
+
|
| 239 |
+
Your exercise of the Licensed Rights is expressly made subject to the
|
| 240 |
+
following conditions.
|
| 241 |
+
|
| 242 |
+
a. Attribution.
|
| 243 |
+
|
| 244 |
+
1. If You Share the Licensed Material (including in modified
|
| 245 |
+
form), You must:
|
| 246 |
+
|
| 247 |
+
a. retain the following if it is supplied by the Licensor
|
| 248 |
+
with the Licensed Material:
|
| 249 |
+
|
| 250 |
+
i. identification of the creator(s) of the Licensed
|
| 251 |
+
Material and any others designated to receive
|
| 252 |
+
attribution, in any reasonable manner requested by
|
| 253 |
+
the Licensor (including by pseudonym if
|
| 254 |
+
designated);
|
| 255 |
+
|
| 256 |
+
ii. a copyright notice;
|
| 257 |
+
|
| 258 |
+
iii. a notice that refers to this Public License;
|
| 259 |
+
|
| 260 |
+
iv. a notice that refers to the disclaimer of
|
| 261 |
+
warranties;
|
| 262 |
+
|
| 263 |
+
v. a URI or hyperlink to the Licensed Material to the
|
| 264 |
+
extent reasonably practicable;
|
| 265 |
+
|
| 266 |
+
b. indicate if You modified the Licensed Material and
|
| 267 |
+
retain an indication of any previous modifications; and
|
| 268 |
+
|
| 269 |
+
c. indicate the Licensed Material is licensed under this
|
| 270 |
+
Public License, and include the text of, or the URI or
|
| 271 |
+
hyperlink to, this Public License.
|
| 272 |
+
|
| 273 |
+
2. You may satisfy the conditions in Section 3(a)(1) in any
|
| 274 |
+
reasonable manner based on the medium, means, and context in
|
| 275 |
+
which You Share the Licensed Material. For example, it may be
|
| 276 |
+
reasonable to satisfy the conditions by providing a URI or
|
| 277 |
+
hyperlink to a resource that includes the required
|
| 278 |
+
information.
|
| 279 |
+
3. If requested by the Licensor, You must remove any of the
|
| 280 |
+
information required by Section 3(a)(1)(A) to the extent
|
| 281 |
+
reasonably practicable.
|
| 282 |
+
|
| 283 |
+
b. ShareAlike.
|
| 284 |
+
|
| 285 |
+
In addition to the conditions in Section 3(a), if You Share
|
| 286 |
+
Adapted Material You produce, the following conditions also apply.
|
| 287 |
+
|
| 288 |
+
1. The Adapter's License You apply must be a Creative Commons
|
| 289 |
+
license with the same License Elements, this version or
|
| 290 |
+
later, or a BY-NC-SA Compatible License.
|
| 291 |
+
|
| 292 |
+
2. You must include the text of, or the URI or hyperlink to, the
|
| 293 |
+
Adapter's License You apply. You may satisfy this condition
|
| 294 |
+
in any reasonable manner based on the medium, means, and
|
| 295 |
+
context in which You Share Adapted Material.
|
| 296 |
+
|
| 297 |
+
3. You may not offer or impose any additional or different terms
|
| 298 |
+
or conditions on, or apply any Effective Technological
|
| 299 |
+
Measures to, Adapted Material that restrict exercise of the
|
| 300 |
+
rights granted under the Adapter's License You apply.
|
| 301 |
+
|
| 302 |
+
|
| 303 |
+
Section 4 -- Sui Generis Database Rights.
|
| 304 |
+
|
| 305 |
+
Where the Licensed Rights include Sui Generis Database Rights that
|
| 306 |
+
apply to Your use of the Licensed Material:
|
| 307 |
+
|
| 308 |
+
a. for the avoidance of doubt, Section 2(a)(1) grants You the right
|
| 309 |
+
to extract, reuse, reproduce, and Share all or a substantial
|
| 310 |
+
portion of the contents of the database for NonCommercial purposes
|
| 311 |
+
only;
|
| 312 |
+
|
| 313 |
+
b. if You include all or a substantial portion of the database
|
| 314 |
+
contents in a database in which You have Sui Generis Database
|
| 315 |
+
Rights, then the database in which You have Sui Generis Database
|
| 316 |
+
Rights (but not its individual contents) is Adapted Material,
|
| 317 |
+
including for purposes of Section 3(b); and
|
| 318 |
+
|
| 319 |
+
c. You must comply with the conditions in Section 3(a) if You Share
|
| 320 |
+
all or a substantial portion of the contents of the database.
|
| 321 |
+
|
| 322 |
+
For the avoidance of doubt, this Section 4 supplements and does not
|
| 323 |
+
replace Your obligations under this Public License where the Licensed
|
| 324 |
+
Rights include other Copyright and Similar Rights.
|
| 325 |
+
|
| 326 |
+
|
| 327 |
+
Section 5 -- Disclaimer of Warranties and Limitation of Liability.
|
| 328 |
+
|
| 329 |
+
a. UNLESS OTHERWISE SEPARATELY UNDERTAKEN BY THE LICENSOR, TO THE
|
| 330 |
+
EXTENT POSSIBLE, THE LICENSOR OFFERS THE LICENSED MATERIAL AS-IS
|
| 331 |
+
AND AS-AVAILABLE, AND MAKES NO REPRESENTATIONS OR WARRANTIES OF
|
| 332 |
+
ANY KIND CONCERNING THE LICENSED MATERIAL, WHETHER EXPRESS,
|
| 333 |
+
IMPLIED, STATUTORY, OR OTHER. THIS INCLUDES, WITHOUT LIMITATION,
|
| 334 |
+
WARRANTIES OF TITLE, MERCHANTABILITY, FITNESS FOR A PARTICULAR
|
| 335 |
+
PURPOSE, NON-INFRINGEMENT, ABSENCE OF LATENT OR OTHER DEFECTS,
|
| 336 |
+
ACCURACY, OR THE PRESENCE OR ABSENCE OF ERRORS, WHETHER OR NOT
|
| 337 |
+
KNOWN OR DISCOVERABLE. WHERE DISCLAIMERS OF WARRANTIES ARE NOT
|
| 338 |
+
ALLOWED IN FULL OR IN PART, THIS DISCLAIMER MAY NOT APPLY TO YOU.
|
| 339 |
+
|
| 340 |
+
b. TO THE EXTENT POSSIBLE, IN NO EVENT WILL THE LICENSOR BE LIABLE
|
| 341 |
+
TO YOU ON ANY LEGAL THEORY (INCLUDING, WITHOUT LIMITATION,
|
| 342 |
+
NEGLIGENCE) OR OTHERWISE FOR ANY DIRECT, SPECIAL, INDIRECT,
|
| 343 |
+
INCIDENTAL, CONSEQUENTIAL, PUNITIVE, EXEMPLARY, OR OTHER LOSSES,
|
| 344 |
+
COSTS, EXPENSES, OR DAMAGES ARISING OUT OF THIS PUBLIC LICENSE OR
|
| 345 |
+
USE OF THE LICENSED MATERIAL, EVEN IF THE LICENSOR HAS BEEN
|
| 346 |
+
ADVISED OF THE POSSIBILITY OF SUCH LOSSES, COSTS, EXPENSES, OR
|
| 347 |
+
DAMAGES. WHERE A LIMITATION OF LIABILITY IS NOT ALLOWED IN FULL OR
|
| 348 |
+
IN PART, THIS LIMITATION MAY NOT APPLY TO YOU.
|
| 349 |
+
|
| 350 |
+
c. The disclaimer of warranties and limitation of liability provided
|
| 351 |
+
above shall be interpreted in a manner that, to the extent
|
| 352 |
+
possible, most closely approximates an absolute disclaimer and
|
| 353 |
+
waiver of all liability.
|
| 354 |
+
|
| 355 |
+
|
| 356 |
+
Section 6 -- Term and Termination.
|
| 357 |
+
|
| 358 |
+
a. This Public License applies for the term of the Copyright and
|
| 359 |
+
Similar Rights licensed here. However, if You fail to comply with
|
| 360 |
+
this Public License, then Your rights under this Public License
|
| 361 |
+
terminate automatically.
|
| 362 |
+
|
| 363 |
+
b. Where Your right to use the Licensed Material has terminated under
|
| 364 |
+
Section 6(a), it reinstates:
|
| 365 |
+
|
| 366 |
+
1. automatically as of the date the violation is cured, provided
|
| 367 |
+
it is cured within 30 days of Your discovery of the
|
| 368 |
+
violation; or
|
| 369 |
+
|
| 370 |
+
2. upon express reinstatement by the Licensor.
|
| 371 |
+
|
| 372 |
+
For the avoidance of doubt, this Section 6(b) does not affect any
|
| 373 |
+
right the Licensor may have to seek remedies for Your violations
|
| 374 |
+
of this Public License.
|
| 375 |
+
|
| 376 |
+
c. For the avoidance of doubt, the Licensor may also offer the
|
| 377 |
+
Licensed Material under separate terms or conditions or stop
|
| 378 |
+
distributing the Licensed Material at any time; however, doing so
|
| 379 |
+
will not terminate this Public License.
|
| 380 |
+
|
| 381 |
+
d. Sections 1, 5, 6, 7, and 8 survive termination of this Public
|
| 382 |
+
License.
|
| 383 |
+
|
| 384 |
+
|
| 385 |
+
Section 7 -- Other Terms and Conditions.
|
| 386 |
+
|
| 387 |
+
a. The Licensor shall not be bound by any additional or different
|
| 388 |
+
terms or conditions communicated by You unless expressly agreed.
|
| 389 |
+
|
| 390 |
+
b. Any arrangements, understandings, or agreements regarding the
|
| 391 |
+
Licensed Material not stated herein are separate from and
|
| 392 |
+
independent of the terms and conditions of this Public License.
|
| 393 |
+
|
| 394 |
+
|
| 395 |
+
Section 8 -- Interpretation.
|
| 396 |
+
|
| 397 |
+
a. For the avoidance of doubt, this Public License does not, and
|
| 398 |
+
shall not be interpreted to, reduce, limit, restrict, or impose
|
| 399 |
+
conditions on any use of the Licensed Material that could lawfully
|
| 400 |
+
be made without permission under this Public License.
|
| 401 |
+
|
| 402 |
+
b. To the extent possible, if any provision of this Public License is
|
| 403 |
+
deemed unenforceable, it shall be automatically reformed to the
|
| 404 |
+
minimum extent necessary to make it enforceable. If the provision
|
| 405 |
+
cannot be reformed, it shall be severed from this Public License
|
| 406 |
+
without affecting the enforceability of the remaining terms and
|
| 407 |
+
conditions.
|
| 408 |
+
|
| 409 |
+
c. No term or condition of this Public License will be waived and no
|
| 410 |
+
failure to comply consented to unless expressly agreed to by the
|
| 411 |
+
Licensor.
|
| 412 |
+
|
| 413 |
+
d. Nothing in this Public License constitutes or may be interpreted
|
| 414 |
+
as a limitation upon, or waiver of, any privileges and immunities
|
| 415 |
+
that apply to the Licensor or You, including from the legal
|
| 416 |
+
processes of any jurisdiction or authority.
|
| 417 |
+
|
| 418 |
+
=======================================================================
|
| 419 |
+
|
| 420 |
+
Creative Commons is not a party to its public
|
| 421 |
+
licenses. Notwithstanding, Creative Commons may elect to apply one of
|
| 422 |
+
its public licenses to material it publishes and in those instances
|
| 423 |
+
will be considered the “Licensor.” The text of the Creative Commons
|
| 424 |
+
public licenses is dedicated to the public domain under the CC0 Public
|
| 425 |
+
Domain Dedication. Except for the limited purpose of indicating that
|
| 426 |
+
material is shared under a Creative Commons public license or as
|
| 427 |
+
otherwise permitted by the Creative Commons policies published at
|
| 428 |
+
creativecommons.org/policies, Creative Commons does not authorize the
|
| 429 |
+
use of the trademark "Creative Commons" or any other trademark or logo
|
| 430 |
+
of Creative Commons without its prior written consent including,
|
| 431 |
+
without limitation, in connection with any unauthorized modifications
|
| 432 |
+
to any of its public licenses or any other arrangements,
|
| 433 |
+
understandings, or agreements concerning use of licensed material. For
|
| 434 |
+
the avoidance of doubt, this paragraph does not form part of the
|
| 435 |
+
public licenses.
|
| 436 |
+
|
| 437 |
+
Creative Commons may be contacted at creativecommons.org.
|
app.py
CHANGED
|
@@ -1,64 +1,21 @@
|
|
| 1 |
-
import gradio as gr
|
| 2 |
-
from huggingface_hub import InferenceClient
|
| 3 |
-
|
| 4 |
-
"""
|
| 5 |
-
For more information on `huggingface_hub` Inference API support, please check the docs: https://huggingface.co/docs/huggingface_hub/v0.22.2/en/guides/inference
|
| 6 |
"""
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
def respond(
|
| 11 |
-
message,
|
| 12 |
-
history: list[tuple[str, str]],
|
| 13 |
-
system_message,
|
| 14 |
-
max_tokens,
|
| 15 |
-
temperature,
|
| 16 |
-
top_p,
|
| 17 |
-
):
|
| 18 |
-
messages = [{"role": "system", "content": system_message}]
|
| 19 |
-
|
| 20 |
-
for val in history:
|
| 21 |
-
if val[0]:
|
| 22 |
-
messages.append({"role": "user", "content": val[0]})
|
| 23 |
-
if val[1]:
|
| 24 |
-
messages.append({"role": "assistant", "content": val[1]})
|
| 25 |
|
| 26 |
-
|
| 27 |
-
|
| 28 |
-
response = ""
|
| 29 |
-
|
| 30 |
-
for message in client.chat_completion(
|
| 31 |
-
messages,
|
| 32 |
-
max_tokens=max_tokens,
|
| 33 |
-
stream=True,
|
| 34 |
-
temperature=temperature,
|
| 35 |
-
top_p=top_p,
|
| 36 |
-
):
|
| 37 |
-
token = message.choices[0].delta.content
|
| 38 |
-
|
| 39 |
-
response += token
|
| 40 |
-
yield response
|
| 41 |
|
|
|
|
|
|
|
|
|
|
| 42 |
|
|
|
|
| 43 |
"""
|
| 44 |
-
For information on how to customize the ChatInterface, peruse the gradio docs: https://www.gradio.app/docs/chatinterface
|
| 45 |
-
"""
|
| 46 |
-
demo = gr.ChatInterface(
|
| 47 |
-
respond,
|
| 48 |
-
additional_inputs=[
|
| 49 |
-
gr.Textbox(value="You are a friendly Chatbot.", label="System message"),
|
| 50 |
-
gr.Slider(minimum=1, maximum=2048, value=512, step=1, label="Max new tokens"),
|
| 51 |
-
gr.Slider(minimum=0.1, maximum=4.0, value=0.7, step=0.1, label="Temperature"),
|
| 52 |
-
gr.Slider(
|
| 53 |
-
minimum=0.1,
|
| 54 |
-
maximum=1.0,
|
| 55 |
-
value=0.95,
|
| 56 |
-
step=0.05,
|
| 57 |
-
label="Top-p (nucleus sampling)",
|
| 58 |
-
),
|
| 59 |
-
],
|
| 60 |
-
)
|
| 61 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 62 |
|
| 63 |
-
|
| 64 |
-
demo.launch()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
"""
|
| 2 |
+
#!/bin/bash
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
|
| 4 |
+
CUDA_ENABLED=${CUDA_ENABLED:-true}
|
| 5 |
+
DEVICE=""
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
|
| 7 |
+
if [ "${CUDA_ENABLED}" != "true" ]; then
|
| 8 |
+
DEVICE="--device cpu"
|
| 9 |
+
fi
|
| 10 |
|
| 11 |
+
exec python tools/webui.py ${DEVICE}
|
| 12 |
"""
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 13 |
|
| 14 |
+
import os
|
| 15 |
+
|
| 16 |
+
CUDA_ENABLED = os.environ.get("CUDA_ENABLED", "true")
|
| 17 |
+
DEVICE = ""
|
| 18 |
+
if CUDA_ENABLED != "true":
|
| 19 |
+
DEVICE = "--device cpu"
|
| 20 |
|
| 21 |
+
os.system(f"python tools/webui.py {DEVICE}")
|
|
|
checkpoints/fish-speech-1.4/.gitattributes
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
checkpoints/fish-speech-1.4/README.md
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
tags:
|
| 3 |
+
- text-to-speech
|
| 4 |
+
license: cc-by-nc-sa-4.0
|
| 5 |
+
language:
|
| 6 |
+
- zh
|
| 7 |
+
- en
|
| 8 |
+
- de
|
| 9 |
+
- ja
|
| 10 |
+
- fr
|
| 11 |
+
- es
|
| 12 |
+
- ko
|
| 13 |
+
- ar
|
| 14 |
+
pipeline_tag: text-to-speech
|
| 15 |
+
inference: false
|
| 16 |
+
extra_gated_prompt: >-
|
| 17 |
+
You agree to not use the model to generate contents that violate DMCA or local
|
| 18 |
+
laws.
|
| 19 |
+
extra_gated_fields:
|
| 20 |
+
Country: country
|
| 21 |
+
Specific date: date_picker
|
| 22 |
+
I agree to use this model for non-commercial use ONLY: checkbox
|
| 23 |
+
---
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
# Fish Speech V1.4
|
| 27 |
+
|
| 28 |
+
**Fish Speech V1.4** is a leading text-to-speech (TTS) model trained on 700k hours of audio data in multiple languages.
|
| 29 |
+
|
| 30 |
+
Supported languages:
|
| 31 |
+
- English (en) ~300k hours
|
| 32 |
+
- Chinese (zh) ~300k hours
|
| 33 |
+
- German (de) ~20k hours
|
| 34 |
+
- Japanese (ja) ~20k hours
|
| 35 |
+
- French (fr) ~20k hours
|
| 36 |
+
- Spanish (es) ~20k hours
|
| 37 |
+
- Korean (ko) ~20k hours
|
| 38 |
+
- Arabic (ar) ~20k hours
|
| 39 |
+
|
| 40 |
+
Please refer to [Fish Speech Github](https://github.com/fishaudio/fish-speech) for more info.
|
| 41 |
+
Demo available at [Fish Audio](https://fish.audio/).
|
| 42 |
+
|
| 43 |
+
## Citation
|
| 44 |
+
|
| 45 |
+
If you found this repository useful, please consider citing this work:
|
| 46 |
+
|
| 47 |
+
```
|
| 48 |
+
@article{fish-speech-v1.4,
|
| 49 |
+
author = {Shijia Liao, Tianyu Li and others},
|
| 50 |
+
title = {Fish-Speech: Leveraging Large Language Models for Advanced Multilingual Text-to-Speech Synthesis},
|
| 51 |
+
year = {2024},
|
| 52 |
+
journal = {arXiv preprint arXiv:2411.01156},
|
| 53 |
+
eprint = {2411.01156},
|
| 54 |
+
archivePrefix = {arXiv},
|
| 55 |
+
primaryClass = {cs.SD},
|
| 56 |
+
url = {https://arxiv.org/abs/2411.01156}
|
| 57 |
+
}
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
## License
|
| 61 |
+
|
| 62 |
+
This model is permissively licensed under the BY-CC-NC-SA-4.0 license.
|
| 63 |
+
The source code is released under BSD-3-Clause license.
|
checkpoints/fish-speech-1.4/config.json
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"attention_qkv_bias": false,
|
| 3 |
+
"codebook_size": 1024,
|
| 4 |
+
"dim": 1024,
|
| 5 |
+
"dropout": 0.1,
|
| 6 |
+
"head_dim": 64,
|
| 7 |
+
"initializer_range": 0.02,
|
| 8 |
+
"intermediate_size": 4096,
|
| 9 |
+
"max_seq_len": 4096,
|
| 10 |
+
"model_type": "dual_ar",
|
| 11 |
+
"n_fast_layer": 4,
|
| 12 |
+
"n_head": 16,
|
| 13 |
+
"n_layer": 24,
|
| 14 |
+
"n_local_heads": 2,
|
| 15 |
+
"norm_eps": 1e-06,
|
| 16 |
+
"num_codebooks": 8,
|
| 17 |
+
"rope_base": 1000000.0,
|
| 18 |
+
"tie_word_embeddings": false,
|
| 19 |
+
"use_gradient_checkpointing": true,
|
| 20 |
+
"vocab_size": 32000
|
| 21 |
+
}
|
checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:01b81dbf753224a156c3fe139b88bf0b9a0f54b11bee864f95e66511c3ccd754
|
| 3 |
+
size 188518579
|
checkpoints/fish-speech-1.4/model.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5792b78b48d1f92d0b2cef8f07aad6b7ac19db2aff23a2054a5cce1d019ab4fb
|
| 3 |
+
size 988991358
|
checkpoints/fish-speech-1.4/special_tokens_map.json
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<|begin_of_sequence|>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "<|end_of_sequence|>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": {
|
| 17 |
+
"content": "<|pad|>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
}
|
| 23 |
+
}
|
checkpoints/fish-speech-1.4/tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
checkpoints/fish-speech-1.4/tokenizer_config.json
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"added_tokens_decoder": {
|
| 3 |
+
"0": {
|
| 4 |
+
"content": "<|begin_of_sequence|>",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false,
|
| 9 |
+
"special": true
|
| 10 |
+
},
|
| 11 |
+
"1": {
|
| 12 |
+
"content": "<|end_of_sequence|>",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false,
|
| 17 |
+
"special": true
|
| 18 |
+
},
|
| 19 |
+
"2": {
|
| 20 |
+
"content": "<|pad|>",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false,
|
| 25 |
+
"special": true
|
| 26 |
+
},
|
| 27 |
+
"3": {
|
| 28 |
+
"content": "<|im_start|>",
|
| 29 |
+
"lstrip": false,
|
| 30 |
+
"normalized": false,
|
| 31 |
+
"rstrip": false,
|
| 32 |
+
"single_word": false,
|
| 33 |
+
"special": true
|
| 34 |
+
},
|
| 35 |
+
"4": {
|
| 36 |
+
"content": "<|im_end|>",
|
| 37 |
+
"lstrip": false,
|
| 38 |
+
"normalized": false,
|
| 39 |
+
"rstrip": false,
|
| 40 |
+
"single_word": false,
|
| 41 |
+
"special": true
|
| 42 |
+
},
|
| 43 |
+
"5": {
|
| 44 |
+
"content": "<|semantic|>",
|
| 45 |
+
"lstrip": false,
|
| 46 |
+
"normalized": false,
|
| 47 |
+
"rstrip": false,
|
| 48 |
+
"single_word": false,
|
| 49 |
+
"special": true
|
| 50 |
+
},
|
| 51 |
+
"6": {
|
| 52 |
+
"content": "<|mel|>",
|
| 53 |
+
"lstrip": false,
|
| 54 |
+
"normalized": false,
|
| 55 |
+
"rstrip": false,
|
| 56 |
+
"single_word": false,
|
| 57 |
+
"special": true
|
| 58 |
+
},
|
| 59 |
+
"7": {
|
| 60 |
+
"content": "<|reserve_0|>",
|
| 61 |
+
"lstrip": false,
|
| 62 |
+
"normalized": false,
|
| 63 |
+
"rstrip": false,
|
| 64 |
+
"single_word": false,
|
| 65 |
+
"special": true
|
| 66 |
+
},
|
| 67 |
+
"8": {
|
| 68 |
+
"content": "<|reserve_1|>",
|
| 69 |
+
"lstrip": false,
|
| 70 |
+
"normalized": false,
|
| 71 |
+
"rstrip": false,
|
| 72 |
+
"single_word": false,
|
| 73 |
+
"special": true
|
| 74 |
+
}
|
| 75 |
+
},
|
| 76 |
+
"bos_token": "<|begin_of_sequence|>",
|
| 77 |
+
"clean_up_tokenization_spaces": true,
|
| 78 |
+
"eos_token": "<|end_of_sequence|>",
|
| 79 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 80 |
+
"pad_token": "<|pad|>",
|
| 81 |
+
"tokenizer_class": "PreTrainedTokenizerFast"
|
| 82 |
+
}
|
docker-compose.dev.yml
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version: '3.8'
|
| 2 |
+
|
| 3 |
+
services:
|
| 4 |
+
fish-speech:
|
| 5 |
+
build:
|
| 6 |
+
context: .
|
| 7 |
+
dockerfile: dockerfile.dev
|
| 8 |
+
container_name: fish-speech
|
| 9 |
+
volumes:
|
| 10 |
+
- ./:/exp
|
| 11 |
+
deploy:
|
| 12 |
+
resources:
|
| 13 |
+
reservations:
|
| 14 |
+
devices:
|
| 15 |
+
- driver: nvidia
|
| 16 |
+
count: all
|
| 17 |
+
capabilities: [gpu]
|
| 18 |
+
command: tail -f /dev/null
|
dockerfile
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM python:3.12-slim-bookworm AS stage-1
|
| 2 |
+
ARG TARGETARCH
|
| 3 |
+
|
| 4 |
+
ARG HUGGINGFACE_MODEL=fish-speech-1.4
|
| 5 |
+
ARG HF_ENDPOINT=https://huggingface.co
|
| 6 |
+
|
| 7 |
+
WORKDIR /opt/fish-speech
|
| 8 |
+
|
| 9 |
+
RUN set -ex \
|
| 10 |
+
&& pip install huggingface_hub \
|
| 11 |
+
&& HF_ENDPOINT=${HF_ENDPOINT} huggingface-cli download --resume-download fishaudio/${HUGGINGFACE_MODEL} --local-dir checkpoints/${HUGGINGFACE_MODEL}
|
| 12 |
+
|
| 13 |
+
FROM python:3.12-slim-bookworm
|
| 14 |
+
ARG TARGETARCH
|
| 15 |
+
|
| 16 |
+
ARG DEPENDENCIES=" \
|
| 17 |
+
ca-certificates \
|
| 18 |
+
libsox-dev \
|
| 19 |
+
build-essential \
|
| 20 |
+
cmake \
|
| 21 |
+
libasound-dev \
|
| 22 |
+
portaudio19-dev \
|
| 23 |
+
libportaudio2 \
|
| 24 |
+
libportaudiocpp0 \
|
| 25 |
+
ffmpeg"
|
| 26 |
+
|
| 27 |
+
RUN --mount=type=cache,target=/var/cache/apt,sharing=locked \
|
| 28 |
+
--mount=type=cache,target=/var/lib/apt,sharing=locked \
|
| 29 |
+
set -ex \
|
| 30 |
+
&& rm -f /etc/apt/apt.conf.d/docker-clean \
|
| 31 |
+
&& echo 'Binary::apt::APT::Keep-Downloaded-Packages "true";' >/etc/apt/apt.conf.d/keep-cache \
|
| 32 |
+
&& apt-get update \
|
| 33 |
+
&& apt-get -y install --no-install-recommends ${DEPENDENCIES} \
|
| 34 |
+
&& echo "no" | dpkg-reconfigure dash
|
| 35 |
+
|
| 36 |
+
WORKDIR /opt/fish-speech
|
| 37 |
+
|
| 38 |
+
COPY . .
|
| 39 |
+
|
| 40 |
+
RUN --mount=type=cache,target=/root/.cache,sharing=locked \
|
| 41 |
+
set -ex \
|
| 42 |
+
&& pip install -e .[stable]
|
| 43 |
+
|
| 44 |
+
COPY --from=stage-1 /opt/fish-speech/checkpoints /opt/fish-speech/checkpoints
|
| 45 |
+
|
| 46 |
+
ENV GRADIO_SERVER_NAME="0.0.0.0"
|
| 47 |
+
|
| 48 |
+
EXPOSE 7860
|
| 49 |
+
|
| 50 |
+
CMD ["./entrypoint.sh"]
|
dockerfile.dev
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ARG VERSION=dev
|
| 2 |
+
ARG BASE_IMAGE=ghcr.io/fishaudio/fish-speech:${VERSION}
|
| 3 |
+
|
| 4 |
+
FROM ${BASE_IMAGE}
|
| 5 |
+
|
| 6 |
+
ARG TOOLS=" \
|
| 7 |
+
git \
|
| 8 |
+
curl \
|
| 9 |
+
build-essential \
|
| 10 |
+
ffmpeg \
|
| 11 |
+
libsm6 \
|
| 12 |
+
libxext6 \
|
| 13 |
+
libjpeg-dev \
|
| 14 |
+
zlib1g-dev \
|
| 15 |
+
aria2 \
|
| 16 |
+
zsh \
|
| 17 |
+
openssh-server \
|
| 18 |
+
sudo \
|
| 19 |
+
protobuf-compiler \
|
| 20 |
+
libasound-dev \
|
| 21 |
+
portaudio19-dev \
|
| 22 |
+
libportaudio2 \
|
| 23 |
+
libportaudiocpp0 \
|
| 24 |
+
cmake"
|
| 25 |
+
|
| 26 |
+
RUN --mount=type=cache,target=/var/cache/apt,sharing=locked \
|
| 27 |
+
--mount=type=cache,target=/var/lib/apt,sharing=locked \
|
| 28 |
+
set -ex \
|
| 29 |
+
&& apt-get update \
|
| 30 |
+
&& apt-get -y install --no-install-recommends ${TOOLS}
|
| 31 |
+
|
| 32 |
+
# Install oh-my-zsh so your terminal looks nice
|
| 33 |
+
RUN sh -c "$(curl https://raw.githubusercontent.com/robbyrussell/oh-my-zsh/master/tools/install.sh)" "" --unattended
|
| 34 |
+
|
| 35 |
+
# Set zsh as default shell
|
| 36 |
+
RUN chsh -s /usr/bin/zsh
|
| 37 |
+
ENV SHELL=/usr/bin/zsh
|
docs/CNAME
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
speech.fish.audio
|
docs/README.ja.md
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
<h1>Fish Speech</h1>
|
| 3 |
+
|
| 4 |
+
[English](../README.md) | [简体中文](README.zh.md) | [Portuguese](README.pt-BR.md) | **日本語** | [한국어](README.ko.md)<br>
|
| 5 |
+
|
| 6 |
+
<a href="https://www.producthunt.com/posts/fish-speech-1-4?embed=true&utm_source=badge-featured&utm_medium=badge&utm_souce=badge-fish-speech-1-4" target="_blank">
|
| 7 |
+
<img src="https://api.producthunt.com/widgets/embed-image/v1/featured.svg?post_id=488440&theme=light" alt="Fish Speech 1.4 - Open-Source Multilingual Text-to-Speech with Voice Cloning | Product Hunt" style="width: 250px; height: 54px;" width="250" height="54" />
|
| 8 |
+
</a>
|
| 9 |
+
<a href="https://trendshift.io/repositories/7014" target="_blank">
|
| 10 |
+
<img src="https://trendshift.io/api/badge/repositories/7014" alt="fishaudio%2Ffish-speech | Trendshift" style="width: 250px; height: 55px;" width="250" height="55"/>
|
| 11 |
+
</a>
|
| 12 |
+
<br>
|
| 13 |
+
</div>
|
| 14 |
+
<br>
|
| 15 |
+
|
| 16 |
+
<div align="center">
|
| 17 |
+
<img src="https://count.getloli.com/get/@fish-speech?theme=asoul" /><br>
|
| 18 |
+
</div>
|
| 19 |
+
<br>
|
| 20 |
+
|
| 21 |
+
<div align="center">
|
| 22 |
+
<a target="_blank" href="https://discord.gg/Es5qTB9BcN">
|
| 23 |
+
<img alt="Discord" src="https://img.shields.io/discord/1214047546020728892?color=%23738ADB&label=Discord&logo=discord&logoColor=white&style=flat-square"/>
|
| 24 |
+
</a>
|
| 25 |
+
<a target="_blank" href="https://hub.docker.com/r/fishaudio/fish-speech">
|
| 26 |
+
<img alt="Docker" src="https://img.shields.io/docker/pulls/fishaudio/fish-speech?style=flat-square&logo=docker"/>
|
| 27 |
+
</a>
|
| 28 |
+
<a target="_blank" href="https://huggingface.co/spaces/fishaudio/fish-speech-1">
|
| 29 |
+
<img alt="Huggingface" src="https://img.shields.io/badge/🤗%20-space%20demo-yellow"/>
|
| 30 |
+
</a>
|
| 31 |
+
</div>
|
| 32 |
+
|
| 33 |
+
このコードベースとすべてのモデルは、CC-BY-NC-SA-4.0 ライセンスの下でリリースされています。詳細については、[LICENSE](LICENSE)を参照してください。
|
| 34 |
+
|
| 35 |
+
---
|
| 36 |
+
|
| 37 |
+
## 機能
|
| 38 |
+
|
| 39 |
+
1. **ゼロショット & フューショット TTS**:10〜30 秒の音声サンプルを入力して、高品質の TTS 出力を生成します。**詳細は [音声クローンのベストプラクティス](https://docs.fish.audio/text-to-speech/voice-clone-best-practices) を参照してください。**
|
| 40 |
+
2. **多言語 & クロスリンガル対応**:多言語テキストを入力ボックスにコピーペーストするだけで、言語を気にする必要はありません。現在、英語、日本語、韓国語、中国語、フランス語、ドイツ語、アラビア語、スペイン語に対応しています。
|
| 41 |
+
3. **音素依存なし**:このモデルは強力な汎化能力を持ち、TTS に音素を必要としません。あらゆる言語スクリプトに対応可能です。
|
| 42 |
+
4. **高精度**:5 分間の英語テキストに対し、CER(文字誤り率)と WER(単語誤り率)は約 2%の精度を達成します。
|
| 43 |
+
5. **高速**:fish-tech アクセラレーションにより、Nvidia RTX 4060 ラップトップではリアルタイムファクターが約 1:5、Nvidia RTX 4090 では約 1:15 です。
|
| 44 |
+
6. **WebUI 推論**:使いやすい Gradio ベースの Web ユーザーインターフェースを搭載し、Chrome、Firefox、Edge などのブラウザに対応しています。
|
| 45 |
+
7. **GUI 推論**:PyQt6 のグラフィカルインターフェースを提供し、API サーバーとシームレスに連携します。Linux、Windows、macOS に対応しています。[GUI を見る](https://github.com/AnyaCoder/fish-speech-gui)。
|
| 46 |
+
8. **デプロイしやすい**:Linux、Windows、macOS にネイティブ対応した推論サーバーを簡単にセットアップでき、速度の低下を最小限に抑えます。
|
| 47 |
+
|
| 48 |
+
## 免責事項
|
| 49 |
+
|
| 50 |
+
コードベースの違法な使用については一切責任を負いません。DMCA(デジタルミレニアム著作権法)およびその他の関連法については、地域の法律を参照してください。
|
| 51 |
+
|
| 52 |
+
## オンラインデモ
|
| 53 |
+
|
| 54 |
+
[Fish Audio](https://fish.audio)
|
| 55 |
+
|
| 56 |
+
## ローカル推論のクイックスタート
|
| 57 |
+
|
| 58 |
+
[inference.ipynb](/inference.ipynb)
|
| 59 |
+
|
| 60 |
+
## ビデオ
|
| 61 |
+
|
| 62 |
+
#### V1.4 デモビデオ: https://www.bilibili.com/video/BV1pu46eVEk7
|
| 63 |
+
|
| 64 |
+
#### V1.2 デモビデオ: https://www.bilibili.com/video/BV1wz421B71D
|
| 65 |
+
|
| 66 |
+
#### V1.1 デモビデオ: https://www.bilibili.com/video/BV1zJ4m1K7cj
|
| 67 |
+
|
| 68 |
+
## ドキュメント
|
| 69 |
+
|
| 70 |
+
- [英語](https://speech.fish.audio/)
|
| 71 |
+
- [中文](https://speech.fish.audio/zh/)
|
| 72 |
+
- [日本語](https://speech.fish.audio/ja/)
|
| 73 |
+
- [ポルトガル語 (ブラジル)](https://speech.fish.audio/pt/)
|
| 74 |
+
|
| 75 |
+
## サンプル (2024/10/02 V1.4)
|
| 76 |
+
|
| 77 |
+
- [英語](https://speech.fish.audio/samples/)
|
| 78 |
+
- [中文](https://speech.fish.audio/zh/samples/)
|
| 79 |
+
- [日本語](https://speech.fish.audio/ja/samples/)
|
| 80 |
+
- [ポルトガル語 (ブラジル)](https://speech.fish.audio/pt/samples/)
|
| 81 |
+
|
| 82 |
+
## クレジット
|
| 83 |
+
|
| 84 |
+
- [VITS2 (daniilrobnikov)](https://github.com/daniilrobnikov/vits2)
|
| 85 |
+
- [Bert-VITS2](https://github.com/fishaudio/Bert-VITS2)
|
| 86 |
+
- [GPT VITS](https://github.com/innnky/gpt-vits)
|
| 87 |
+
- [MQTTS](https://github.com/b04901014/MQTTS)
|
| 88 |
+
- [GPT Fast](https://github.com/pytorch-labs/gpt-fast)
|
| 89 |
+
- [GPT-SoVITS](https://github.com/RVC-Boss/GPT-SoVITS)
|
| 90 |
+
|
| 91 |
+
## スポンサー
|
| 92 |
+
|
| 93 |
+
<div>
|
| 94 |
+
<a href="https://6block.com/">
|
| 95 |
+
<img src="https://avatars.githubusercontent.com/u/60573493" width="100" height="100" alt="6Block Avatar"/>
|
| 96 |
+
</a>
|
| 97 |
+
<br>
|
| 98 |
+
<a href="https://6block.com/">データ処理スポンサー:6Block</a>
|
| 99 |
+
</div>
|
| 100 |
+
<div>
|
| 101 |
+
<a href="https://www.lepton.ai/">
|
| 102 |
+
<img src="https://www.lepton.ai/favicons/apple-touch-icon.png" width="100" height="100" alt="Lepton Avatar"/>
|
| 103 |
+
</a>
|
| 104 |
+
<br>
|
| 105 |
+
<a href="https://www.lepton.ai/">Fish AudioはLepton.AIで提供されています</a>
|
| 106 |
+
</div>
|
docs/README.ko.md
ADDED
|
@@ -0,0 +1,111 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
<h1>Fish Speech</h1>
|
| 3 |
+
|
| 4 |
+
[English](../README.md) | [简体中文](README.zh.md) | [Portuguese](README.pt-BR.md) | [日本語](README.ja.md) | **한국어** <br>
|
| 5 |
+
|
| 6 |
+
<a href="https://www.producthunt.com/posts/fish-speech-1-4?embed=true&utm_source=badge-featured&utm_medium=badge&utm_souce=badge-fish-speech-1-4" target="_blank">
|
| 7 |
+
<img src="https://api.producthunt.com/widgets/embed-image/v1/featured.svg?post_id=488440&theme=light" alt="Fish Speech 1.4 - Open-Source Multilingual Text-to-Speech with Voice Cloning | Product Hunt" style="width: 250px; height: 54px;" width="250" height="54" />
|
| 8 |
+
</a>
|
| 9 |
+
<a href="https://trendshift.io/repositories/7014" target="_blank">
|
| 10 |
+
<img src="https://trendshift.io/api/badge/repositories/7014" alt="fishaudio%2Ffish-speech | Trendshift" style="width: 250px; height: 55px;" width="250" height="55"/>
|
| 11 |
+
</a>
|
| 12 |
+
<br>
|
| 13 |
+
</div>
|
| 14 |
+
<br>
|
| 15 |
+
|
| 16 |
+
<div align="center">
|
| 17 |
+
<img src="https://count.getloli.com/get/@fish-speech?theme=asoul" /><br>
|
| 18 |
+
</div>
|
| 19 |
+
<br>
|
| 20 |
+
|
| 21 |
+
<div align="center">
|
| 22 |
+
<a target="_blank" href="https://discord.gg/Es5qTB9BcN">
|
| 23 |
+
<img alt="Discord" src="https://img.shields.io/discord/1214047546020728892?color=%23738ADB&label=Discord&logo=discord&logoColor=white&style=flat-square"/>
|
| 24 |
+
</a>
|
| 25 |
+
<a target="_blank" href="https://hub.docker.com/r/fishaudio/fish-speech">
|
| 26 |
+
<img alt="Docker" src="https://img.shields.io/docker/pulls/fishaudio/fish-speech?style=flat-square&logo=docker"/>
|
| 27 |
+
</a>
|
| 28 |
+
<a target="_blank" href="https://huggingface.co/spaces/fishaudio/fish-speech-1">
|
| 29 |
+
<img alt="Huggingface" src="https://img.shields.io/badge/🤗%20-space%20demo-yellow"/>
|
| 30 |
+
</a>
|
| 31 |
+
</div>
|
| 32 |
+
|
| 33 |
+
이 코드베이스와 모든 모델은 CC-BY-NC-SA-4.0 라이선스에 따라 배포됩니다. 자세한 내용은 [LICENSE](LICENSE)를 참조하시길 바랍니다.
|
| 34 |
+
|
| 35 |
+
---
|
| 36 |
+
|
| 37 |
+
## 기능
|
| 38 |
+
|
| 39 |
+
1. **Zero-shot & Few-shot TTS:** 10초에서 30초의 음성 샘플을 입력하여 고품질의 TTS 출력을 생성합니다. **자세한 가이드는 [모범 사례](https://docs.fish.audio/text-to-speech/voice-clone-best-practices)를 참조하시길 바랍니다.**
|
| 40 |
+
|
| 41 |
+
2. **다국어 및 교차 언어 지원:** 다국어 걱정 없이, 텍스트를 입력창에 복사하여 붙여넣기만 하면 됩니다. 현재 영어, 일본어, 한국어, 중국어, 프랑스어, 독일어, 아랍어, 스페인어를 지원합니다.
|
| 42 |
+
|
| 43 |
+
3. **음소 의존성 제거:** 이 모델은 강력한 일반화 능력을 가지고 있으며, TTS가 음소에 의존하지 않습니다. 모든 언어 스크립트 텍스트를 손쉽게 처리할 수 있습니다.
|
| 44 |
+
|
| 45 |
+
4. **높은 정확도:** 영어 텍스트 기준 5분 기준에서 단, 2%의 문자 오류율(CER)과 단어 오류율(WER)을 달성합니다.
|
| 46 |
+
|
| 47 |
+
5. **빠른 속도:** fish-tech 가속을 통해 실시간 인자(RTF)는 Nvidia RTX 4060 노트북에서는 약 1:5, Nvidia RTX 4090에서는 1:15입니다.
|
| 48 |
+
|
| 49 |
+
6. **웹 UI 추론:** Chrome, Firefox, Edge 등 다양한 브라우저에서 호환되는 Gradio 기반의 사용하기 쉬운 웹 UI를 제공합니다.
|
| 50 |
+
|
| 51 |
+
7. **GUI 추론:** PyQt6 그래픽 인터페이스를 제공하여 API 서버와 원활하게 작동합니다. Linux, Windows 및 macOS를 지원합니다. [GUI 참조](https://github.com/AnyaCoder/fish-speech-gui).
|
| 52 |
+
|
| 53 |
+
8. **배포 친화적:** Linux, Windows, macOS에서 네이티브로 지원되는 추론 서버를 쉽게 설정할 수 있어 속도 손실을 최소화합니다.
|
| 54 |
+
|
| 55 |
+
## 면책 조항
|
| 56 |
+
|
| 57 |
+
이 코드베이스의 불법적 사용에 대해 어떠한 책임도 지지 않습니다. DMCA 및 관련 법률에 대한 로컬 법률을 참조하십시오.
|
| 58 |
+
|
| 59 |
+
## 온라인 데모
|
| 60 |
+
|
| 61 |
+
[Fish Audio](https://fish.audio)
|
| 62 |
+
|
| 63 |
+
## 로컬 추론을 위한 빠른 시작
|
| 64 |
+
|
| 65 |
+
[inference.ipynb](/inference.ipynb)
|
| 66 |
+
|
| 67 |
+
## 영상
|
| 68 |
+
|
| 69 |
+
#### V1.4 데모 영상: [Youtube](https://www.youtube.com/watch?v=Ghc8cJdQyKQ)
|
| 70 |
+
|
| 71 |
+
## 문서
|
| 72 |
+
|
| 73 |
+
- [English](https://speech.fish.audio/)
|
| 74 |
+
- [中文](https://speech.fish.audio/zh/)
|
| 75 |
+
- [日本語](https://speech.fish.audio/ja/)
|
| 76 |
+
- [Portuguese (Brazil)](https://speech.fish.audio/pt/)
|
| 77 |
+
- [한국어](https://speech.fish.audio/ko/)
|
| 78 |
+
|
| 79 |
+
## Samples (2024/10/02 V1.4)
|
| 80 |
+
|
| 81 |
+
- [English](https://speech.fish.audio/samples/)
|
| 82 |
+
- [中文](https://speech.fish.audio/zh/samples/)
|
| 83 |
+
- [日本語](https://speech.fish.audio/ja/samples/)
|
| 84 |
+
- [Portuguese (Brazil)](https://speech.fish.audio/pt/samples/)
|
| 85 |
+
- [한국어](https://speech.fish.audio/ko/samples/)
|
| 86 |
+
|
| 87 |
+
## Credits
|
| 88 |
+
|
| 89 |
+
- [VITS2 (daniilrobnikov)](https://github.com/daniilrobnikov/vits2)
|
| 90 |
+
- [Bert-VITS2](https://github.com/fishaudio/Bert-VITS2)
|
| 91 |
+
- [GPT VITS](https://github.com/innnky/gpt-vits)
|
| 92 |
+
- [MQTTS](https://github.com/b04901014/MQTTS)
|
| 93 |
+
- [GPT Fast](https://github.com/pytorch-labs/gpt-fast)
|
| 94 |
+
- [GPT-SoVITS](https://github.com/RVC-Boss/GPT-SoVITS)
|
| 95 |
+
|
| 96 |
+
## Sponsor
|
| 97 |
+
|
| 98 |
+
<div>
|
| 99 |
+
<a href="https://6block.com/">
|
| 100 |
+
<img src="https://avatars.githubusercontent.com/u/60573493" width="100" height="100" alt="6Block Avatar"/>
|
| 101 |
+
</a>
|
| 102 |
+
<br>
|
| 103 |
+
<a href="https://6block.com/">데이터 처리 후원: 6Block</a>
|
| 104 |
+
</div>
|
| 105 |
+
<div>
|
| 106 |
+
<a href="https://www.lepton.ai/">
|
| 107 |
+
<img src="https://www.lepton.ai/favicons/apple-touch-icon.png" width="100" height="100" alt="Lepton Avatar"/>
|
| 108 |
+
</a>
|
| 109 |
+
<br>
|
| 110 |
+
<a href="https://www.lepton.ai/">Fish Audio는 Lepton.AI에서 제공됩니다</a>
|
| 111 |
+
</div>
|
docs/README.pt-BR.md
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
<h1>Fish Speech</h1>
|
| 3 |
+
|
| 4 |
+
[English](../README.md) | [简体中文](README.zh.md) | **Portuguese** | [日本語](README.ja.md) | [한국어](README.ko.md)<br>
|
| 5 |
+
|
| 6 |
+
<a href="https://www.producthunt.com/posts/fish-speech-1-4?embed=true&utm_source=badge-featured&utm_medium=badge&utm_souce=badge-fish-speech-1-4" target="_blank">
|
| 7 |
+
<img src="https://api.producthunt.com/widgets/embed-image/v1/featured.svg?post_id=488440&theme=light" alt="Fish Speech 1.4 - Open-Source Multilingual Text-to-Speech with Voice Cloning | Product Hunt" style="width: 250px; height: 54px;" width="250" height="54" />
|
| 8 |
+
</a>
|
| 9 |
+
<a href="https://trendshift.io/repositories/7014" target="_blank">
|
| 10 |
+
<img src="https://trendshift.io/api/badge/repositories/7014" alt="fishaudio%2Ffish-speech | Trendshift" style="width: 250px; height: 55px;" width="250" height="55"/>
|
| 11 |
+
</a>
|
| 12 |
+
<br>
|
| 13 |
+
</div>
|
| 14 |
+
<br>
|
| 15 |
+
|
| 16 |
+
<div align="center">
|
| 17 |
+
<img src="https://count.getloli.com/get/@fish-speech?theme=asoul" /><br>
|
| 18 |
+
</div>
|
| 19 |
+
|
| 20 |
+
<br>
|
| 21 |
+
|
| 22 |
+
<div align="center">
|
| 23 |
+
<a target="_blank" href="https://discord.gg/Es5qTB9BcN">
|
| 24 |
+
<img alt="Discord" src="https://img.shields.io/discord/1214047546020728892?color=%23738ADB&label=Discord&logo=discord&logoColor=white&style=flat-square"/>
|
| 25 |
+
</a>
|
| 26 |
+
<a target="_blank" href="https://hub.docker.com/r/fishaudio/fish-speech">
|
| 27 |
+
<img alt="Docker" src="https://img.shields.io/docker/pulls/fishaudio/fish-speech?style=flat-square&logo=docker"/>
|
| 28 |
+
</a>
|
| 29 |
+
<a target="_blank" href="https://huggingface.co/spaces/fishaudio/fish-speech-1">
|
| 30 |
+
<img alt="Huggingface" src="https://img.shields.io/badge/🤗%20-space%20demo-yellow"/>
|
| 31 |
+
</a>
|
| 32 |
+
</div>
|
| 33 |
+
|
| 34 |
+
Este código-fonte e os modelos são publicados sob a licença CC-BY-NC-SA-4.0. Consulte [LICENSE](LICENSE) para mais detalhes.
|
| 35 |
+
|
| 36 |
+
---
|
| 37 |
+
|
| 38 |
+
## Funcionalidades
|
| 39 |
+
|
| 40 |
+
1. **TTS Zero-shot & Few-shot**: Insira uma amostra vocal de 10 a 30 segundos para gerar saída de TTS de alta qualidade. **Para diretrizes detalhadas, veja [Melhores Práticas para Clonagem de Voz](https://docs.fish.audio/text-to-speech/voice-clone-best-practices).**
|
| 41 |
+
|
| 42 |
+
2. **Suporte Multilíngue e Interlingual**: Basta copiar e colar o texto multilíngue na caixa de entrada—não se preocupe com o idioma. Atualmente suporta inglês, japonês, coreano, chinês, francês, alemão, árabe e espanhol.
|
| 43 |
+
|
| 44 |
+
3. **Sem Dependência de Fonemas**: O modelo tem forte capacidade de generalização e não depende de fonemas para TTS. Ele pode lidar com textos em qualquer script de idioma.
|
| 45 |
+
|
| 46 |
+
4. **Alta Precisão**: Alcança uma CER (Taxa de Erro de Caracteres) e WER (Taxa de Erro de Palavras) de cerca de 2% para textos de 5 minutos em inglês.
|
| 47 |
+
|
| 48 |
+
5. **Rápido**: Com a aceleração fish-tech, o fator de tempo real é de aproximadamente 1:5 em um laptop Nvidia RTX 4060 e 1:15 em uma Nvidia RTX 4090.
|
| 49 |
+
|
| 50 |
+
6. **Inferência WebUI**: Apresenta uma interface de usuário web baseada em Gradio, fácil de usar e compatível com navegadores como Chrome, Firefox e Edge.
|
| 51 |
+
|
| 52 |
+
7. **Inferência GUI**: Oferece uma interface gráfica PyQt6 que funciona perfeitamente com o servidor API. Suporta Linux, Windows e macOS. [Veja o GUI](https://github.com/AnyaCoder/fish-speech-gui).
|
| 53 |
+
|
| 54 |
+
8. **Fácil de Implantar**: Configura facilmente um servidor de inferência com suporte nativo para Linux, Windows e macOS, minimizando a perda de velocidade.
|
| 55 |
+
|
| 56 |
+
## Isenção de Responsabilidade
|
| 57 |
+
|
| 58 |
+
Não nos responsabilizamos por qualquer uso ilegal do código-fonte. Consulte as leis locais sobre DMCA (Digital Millennium Copyright Act) e outras leis relevantes em sua região.
|
| 59 |
+
|
| 60 |
+
## Demonstração Online
|
| 61 |
+
|
| 62 |
+
[Fish Audio](https://fish.audio)
|
| 63 |
+
|
| 64 |
+
## Início Rápido de Inferência Local
|
| 65 |
+
|
| 66 |
+
[inference.ipynb](/inference.ipynb)
|
| 67 |
+
|
| 68 |
+
## Vídeos
|
| 69 |
+
|
| 70 |
+
#### 1.4 Introdução: https://www.bilibili.com/video/BV1pu46eVEk7
|
| 71 |
+
|
| 72 |
+
#### 1.2 Introdução: https://www.bilibili.com/video/BV1wz421B71D
|
| 73 |
+
|
| 74 |
+
#### 1.1 Apresentação Técnica: https://www.bilibili.com/video/BV1zJ4m1K7cj
|
| 75 |
+
|
| 76 |
+
## Documentação
|
| 77 |
+
|
| 78 |
+
- [Inglês](https://speech.fish.audio/)
|
| 79 |
+
- [Chinês](https://speech.fish.audio/zh/)
|
| 80 |
+
- [Japonês](https://speech.fish.audio/ja/)
|
| 81 |
+
- [Português (Brasil)](https://speech.fish.audio/pt/)
|
| 82 |
+
|
| 83 |
+
## Exemplos
|
| 84 |
+
|
| 85 |
+
- [Inglês](https://speech.fish.audio/samples/)
|
| 86 |
+
- [Chinês](https://speech.fish.audio/zh/samples/)
|
| 87 |
+
- [Japonês](https://speech.fish.audio/ja/samples/)
|
| 88 |
+
- [Português (Brasil)](https://speech.fish.audio/pt/samples/)
|
| 89 |
+
|
| 90 |
+
## Agradecimentos
|
| 91 |
+
|
| 92 |
+
- [VITS2 (daniilrobnikov)](https://github.com/daniilrobnikov/vits2)
|
| 93 |
+
- [Bert-VITS2](https://github.com/fishaudio/Bert-VITS2)
|
| 94 |
+
- [GPT VITS](https://github.com/innnky/gpt-vits)
|
| 95 |
+
- [MQTTS](https://github.com/b04901014/MQTTS)
|
| 96 |
+
- [GPT Fast](https://github.com/pytorch-labs/gpt-fast)
|
| 97 |
+
- [GPT-SoVITS](https://github.com/RVC-Boss/GPT-SoVITS)
|
| 98 |
+
|
| 99 |
+
## Patrocinadores
|
| 100 |
+
|
| 101 |
+
<div>
|
| 102 |
+
<a href="https://6block.com/">
|
| 103 |
+
<img src="https://avatars.githubusercontent.com/u/60573493" width="100" height="100" alt="6Block Avatar"/>
|
| 104 |
+
</a>
|
| 105 |
+
<br>
|
| 106 |
+
<a href="https://6block.com/">Servidores de processamento de dados fornecidos por 6Block</a>
|
| 107 |
+
</div>
|
| 108 |
+
<div>
|
| 109 |
+
<a href="https://www.lepton.ai/">
|
| 110 |
+
<img src="https://www.lepton.ai/favicons/apple-touch-icon.png" width="100" height="100" alt="Lepton Avatar"/>
|
| 111 |
+
</a>
|
| 112 |
+
<br>
|
| 113 |
+
<a href="https://www.lepton.ai/">Inferência online do Fish Audio em parceria com a Lepton</a>
|
| 114 |
+
</div>
|
docs/README.zh.md
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
<h1>Fish Speech</h1>
|
| 3 |
+
|
| 4 |
+
[English](../README.md) | **简体中文** | [Portuguese](README.pt-BR.md) | [日本語](README.ja.md) | [한국어](README.ko.md)<br>
|
| 5 |
+
|
| 6 |
+
<a href="https://www.producthunt.com/posts/fish-speech-1-4?embed=true&utm_source=badge-featured&utm_medium=badge&utm_souce=badge-fish-speech-1-4" target="_blank">
|
| 7 |
+
<img src="https://api.producthunt.com/widgets/embed-image/v1/featured.svg?post_id=488440&theme=light" alt="Fish Speech 1.4 - Open-Source Multilingual Text-to-Speech with Voice Cloning | Product Hunt" style="width: 250px; height: 54px;" width="250" height="54" />
|
| 8 |
+
</a>
|
| 9 |
+
<a href="https://trendshift.io/repositories/7014" target="_blank">
|
| 10 |
+
<img src="https://trendshift.io/api/badge/repositories/7014" alt="fishaudio%2Ffish-speech | Trendshift" style="width: 250px; height: 55px;" width="250" height="55"/>
|
| 11 |
+
</a>
|
| 12 |
+
<br>
|
| 13 |
+
</div>
|
| 14 |
+
<br>
|
| 15 |
+
|
| 16 |
+
<div align="center">
|
| 17 |
+
<img src="https://count.getloli.com/get/@fish-speech?theme=asoul" /><br>
|
| 18 |
+
</div>
|
| 19 |
+
|
| 20 |
+
<br>
|
| 21 |
+
|
| 22 |
+
<div align="center">
|
| 23 |
+
<a target="_blank" href="https://discord.gg/Es5qTB9BcN">
|
| 24 |
+
<img alt="Discord" src="https://img.shields.io/discord/1214047546020728892?color=%23738ADB&label=Discord&logo=discord&logoColor=white&style=flat-square"/>
|
| 25 |
+
</a>
|
| 26 |
+
<a target="_blank" href="https://hub.docker.com/r/fishaudio/fish-speech">
|
| 27 |
+
<img alt="Docker" src="https://img.shields.io/docker/pulls/fishaudio/fish-speech?style=flat-square&logo=docker"/>
|
| 28 |
+
</a>
|
| 29 |
+
<a target="_blank" href="https://huggingface.co/spaces/fishaudio/fish-speech-1">
|
| 30 |
+
<img alt="Huggingface" src="https://img.shields.io/badge/🤗%20-space%20demo-yellow"/>
|
| 31 |
+
</a>
|
| 32 |
+
<br>
|
| 33 |
+
|
| 34 |
+
</div>
|
| 35 |
+
|
| 36 |
+
此代码库及模型根据 CC-BY-NC-SA-4.0 许可证发布。请参阅 [LICENSE](LICENSE) 了解更多细节.
|
| 37 |
+
|
| 38 |
+
---
|
| 39 |
+
|
| 40 |
+
## 特性
|
| 41 |
+
|
| 42 |
+
1. **零样本 & 小样本 TTS**:输入 10 到 30 秒的声音样本即可生成高质量的 TTS 输出。**详见 [语音克隆最佳实践指南](https://docs.fish.audio/text-to-speech/voice-clone-best-practices)。**
|
| 43 |
+
2. **多语言 & 跨语言支持**:只需复制并粘贴多语言文本到输入框中,无需担心语言问题。目前支持英语、日语、韩语、中文、法语、德语、阿拉伯语和西班牙语。
|
| 44 |
+
3. **无音素依赖**:模型具备强大的泛化能力,不依赖音素进行 TTS,能够处理任何文字表示的语言。
|
| 45 |
+
4. **高准确率**:在 5 分钟的英文文本上,达到了约 2% 的 CER(字符错误率)和 WER(词错误率)。
|
| 46 |
+
5. **快速**:通过 fish-tech 加速,在 Nvidia RTX 4060 笔记本上的实时因子约为 1:5,在 Nvidia RTX 4090 上约为 1:15。
|
| 47 |
+
6. **WebUI 推理**:提供易于使用的基于 Gradio 的网页用户界面,兼容 Chrome、Firefox、Edge 等浏览器。
|
| 48 |
+
7. **GUI 推理**:提供 PyQt6 图形界面,与 API 服务器无缝协作。支持 Linux、Windows 和 macOS。[查看 GUI](https://github.com/AnyaCoder/fish-speech-gui)。
|
| 49 |
+
8. **易于部署**:轻松设置推理服务器,原生支持 Linux、Windows 和 macOS,最大程度减少速度损失。
|
| 50 |
+
|
| 51 |
+
## 免责声明
|
| 52 |
+
|
| 53 |
+
我们不对代码库的任何非法使用承担任何责任. 请参阅您当地关于 DMCA (数字千年法案) 和其他相关法律法规.
|
| 54 |
+
|
| 55 |
+
## 在线 DEMO
|
| 56 |
+
|
| 57 |
+
[Fish Audio](https://fish.audio)
|
| 58 |
+
|
| 59 |
+
## 快速开始本地推理
|
| 60 |
+
|
| 61 |
+
[inference.ipynb](/inference.ipynb)
|
| 62 |
+
|
| 63 |
+
## 视频
|
| 64 |
+
|
| 65 |
+
#### 1.4 介绍: https://www.bilibili.com/video/BV1pu46eVEk7
|
| 66 |
+
|
| 67 |
+
#### 1.2 介绍: https://www.bilibili.com/video/BV1wz421B71D
|
| 68 |
+
|
| 69 |
+
#### 1.1 介绍: https://www.bilibili.com/video/BV1zJ4m1K7cj
|
| 70 |
+
|
| 71 |
+
## 文档
|
| 72 |
+
|
| 73 |
+
- [English](https://speech.fish.audio/)
|
| 74 |
+
- [中文](https://speech.fish.audio/zh/)
|
| 75 |
+
- [日本語](https://speech.fish.audio/ja/)
|
| 76 |
+
- [Portuguese (Brazil)](https://speech.fish.audio/pt/)
|
| 77 |
+
|
| 78 |
+
## 例子 (2024/10/02 V1.4)
|
| 79 |
+
|
| 80 |
+
- [English](https://speech.fish.audio/samples/)
|
| 81 |
+
- [中文](https://speech.fish.audio/zh/samples/)
|
| 82 |
+
- [日本語](https://speech.fish.audio/ja/samples/)
|
| 83 |
+
- [Portuguese (Brazil)](https://speech.fish.audio/pt/samples/)
|
| 84 |
+
|
| 85 |
+
## 鸣谢
|
| 86 |
+
|
| 87 |
+
- [VITS2 (daniilrobnikov)](https://github.com/daniilrobnikov/vits2)
|
| 88 |
+
- [Bert-VITS2](https://github.com/fishaudio/Bert-VITS2)
|
| 89 |
+
- [GPT VITS](https://github.com/innnky/gpt-vits)
|
| 90 |
+
- [MQTTS](https://github.com/b04901014/MQTTS)
|
| 91 |
+
- [GPT Fast](https://github.com/pytorch-labs/gpt-fast)
|
| 92 |
+
- [GPT-SoVITS](https://github.com/RVC-Boss/GPT-SoVITS)
|
| 93 |
+
|
| 94 |
+
## 赞助
|
| 95 |
+
|
| 96 |
+
<div>
|
| 97 |
+
<a href="https://6block.com/">
|
| 98 |
+
<img src="https://avatars.githubusercontent.com/u/60573493" width="100" height="100" alt="6Block Avatar"/>
|
| 99 |
+
</a>
|
| 100 |
+
<br>
|
| 101 |
+
<a href="https://6block.com/">数据处理服务器由 6Block 提供</a>
|
| 102 |
+
</div>
|
| 103 |
+
<div>
|
| 104 |
+
<a href="https://www.lepton.ai/">
|
| 105 |
+
<img src="https://www.lepton.ai/favicons/apple-touch-icon.png" width="100" height="100" alt="Lepton Avatar"/>
|
| 106 |
+
</a>
|
| 107 |
+
<br>
|
| 108 |
+
<a href="https://www.lepton.ai/">Fish Audio 在线推理与 Lepton 合作</a>
|
| 109 |
+
</div>
|
docs/assets/figs/VS_1.jpg
ADDED

|
docs/assets/figs/VS_1_pt-BR.png
ADDED
|
docs/assets/figs/agent_gradio.png
ADDED
|
docs/assets/figs/diagram.png
ADDED
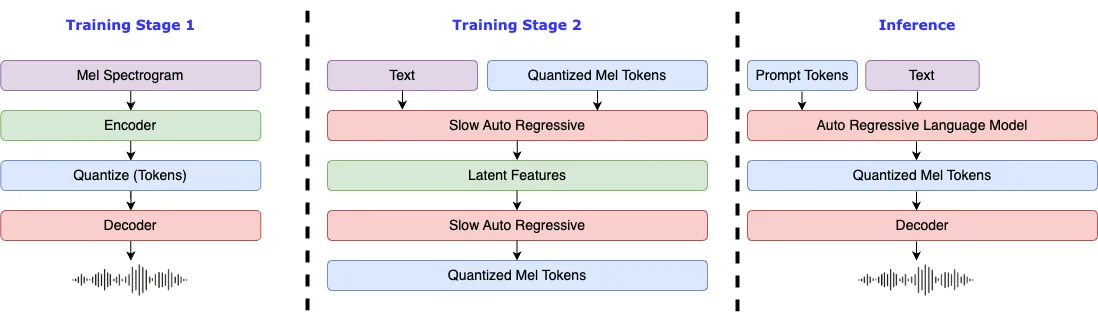
|
docs/assets/figs/diagrama.png
ADDED
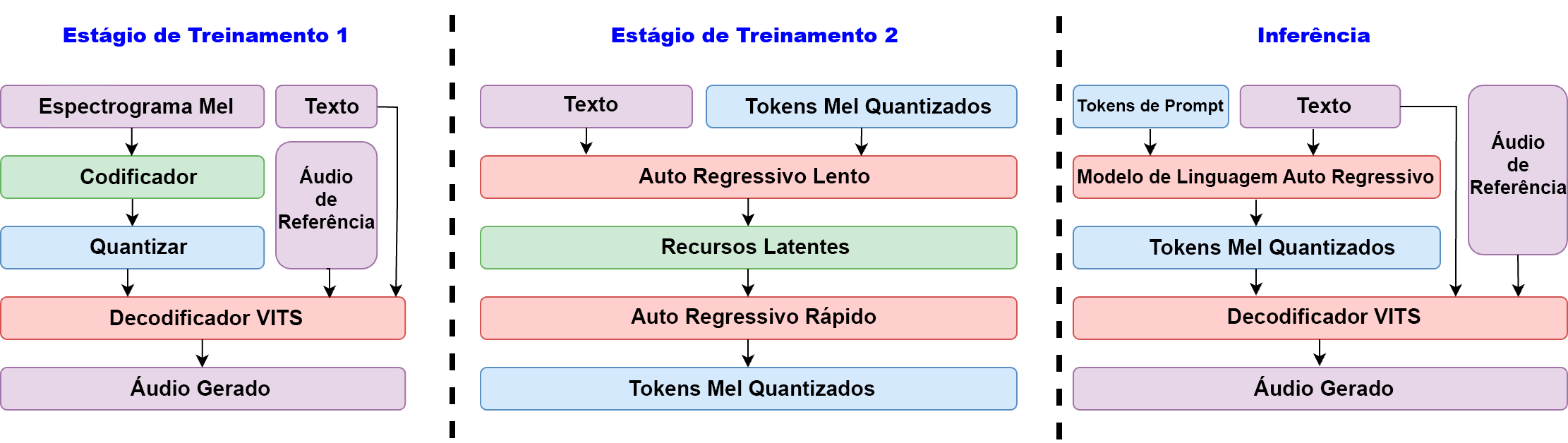
|
docs/assets/figs/logo-circle.png
ADDED
|
|
docs/en/finetune.md
ADDED
|
@@ -0,0 +1,128 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Fine-tuning
|
| 2 |
+
|
| 3 |
+
Obviously, when you opened this page, you were not satisfied with the performance of the few-shot pre-trained model. You want to fine-tune a model to improve its performance on your dataset.
|
| 4 |
+
|
| 5 |
+
In current version, you only need to finetune the 'LLAMA' part.
|
| 6 |
+
|
| 7 |
+
## Fine-tuning LLAMA
|
| 8 |
+
### 1. Prepare the dataset
|
| 9 |
+
|
| 10 |
+
```
|
| 11 |
+
.
|
| 12 |
+
├── SPK1
|
| 13 |
+
│ ├── 21.15-26.44.lab
|
| 14 |
+
│ ├── 21.15-26.44.mp3
|
| 15 |
+
│ ├── 27.51-29.98.lab
|
| 16 |
+
│ ├── 27.51-29.98.mp3
|
| 17 |
+
│ ├── 30.1-32.71.lab
|
| 18 |
+
│ └── 30.1-32.71.mp3
|
| 19 |
+
└── SPK2
|
| 20 |
+
├── 38.79-40.85.lab
|
| 21 |
+
└── 38.79-40.85.mp3
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
You need to convert your dataset into the above format and place it under `data`. The audio file can have the extensions `.mp3`, `.wav`, or `.flac`, and the annotation file should have the extensions `.lab`.
|
| 25 |
+
|
| 26 |
+
!!! info "Dataset Format"
|
| 27 |
+
The `.lab` annotation file only needs to contain the transcription of the audio, with no special formatting required. For example, if `hi.mp3` says "Hello, goodbye," then the `hi.lab` file would contain a single line of text: "Hello, goodbye."
|
| 28 |
+
|
| 29 |
+
!!! warning
|
| 30 |
+
It's recommended to apply loudness normalization to the dataset. You can use [fish-audio-preprocess](https://github.com/fishaudio/audio-preprocess) to do this.
|
| 31 |
+
|
| 32 |
+
```bash
|
| 33 |
+
fap loudness-norm data-raw data --clean
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
### 2. Batch extraction of semantic tokens
|
| 38 |
+
|
| 39 |
+
Make sure you have downloaded the VQGAN weights. If not, run the following command:
|
| 40 |
+
|
| 41 |
+
```bash
|
| 42 |
+
huggingface-cli download fishaudio/fish-speech-1.4 --local-dir checkpoints/fish-speech-1.4
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
You can then run the following command to extract semantic tokens:
|
| 46 |
+
|
| 47 |
+
```bash
|
| 48 |
+
python tools/vqgan/extract_vq.py data \
|
| 49 |
+
--num-workers 1 --batch-size 16 \
|
| 50 |
+
--config-name "firefly_gan_vq" \
|
| 51 |
+
--checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth"
|
| 52 |
+
```
|
| 53 |
+
|
| 54 |
+
!!! note
|
| 55 |
+
You can adjust `--num-workers` and `--batch-size` to increase extraction speed, but please make sure not to exceed your GPU memory limit.
|
| 56 |
+
For the VITS format, you can specify a file list using `--filelist xxx.list`.
|
| 57 |
+
|
| 58 |
+
This command will create `.npy` files in the `data` directory, as shown below:
|
| 59 |
+
|
| 60 |
+
```
|
| 61 |
+
.
|
| 62 |
+
├── SPK1
|
| 63 |
+
│ ├── 21.15-26.44.lab
|
| 64 |
+
│ ├── 21.15-26.44.mp3
|
| 65 |
+
│ ├── 21.15-26.44.npy
|
| 66 |
+
│ ├── 27.51-29.98.lab
|
| 67 |
+
│ ├── 27.51-29.98.mp3
|
| 68 |
+
│ ├── 27.51-29.98.npy
|
| 69 |
+
│ ├── 30.1-32.71.lab
|
| 70 |
+
│ ├── 30.1-32.71.mp3
|
| 71 |
+
│ └── 30.1-32.71.npy
|
| 72 |
+
└── SPK2
|
| 73 |
+
├── 38.79-40.85.lab
|
| 74 |
+
├── 38.79-40.85.mp3
|
| 75 |
+
└── 38.79-40.85.npy
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
### 3. Pack the dataset into protobuf
|
| 79 |
+
|
| 80 |
+
```bash
|
| 81 |
+
python tools/llama/build_dataset.py \
|
| 82 |
+
--input "data" \
|
| 83 |
+
--output "data/protos" \
|
| 84 |
+
--text-extension .lab \
|
| 85 |
+
--num-workers 16
|
| 86 |
+
```
|
| 87 |
+
|
| 88 |
+
After the command finishes executing, you should see the `quantized-dataset-ft.protos` file in the `data` directory.
|
| 89 |
+
|
| 90 |
+
### 4. Finally, fine-tuning with LoRA
|
| 91 |
+
|
| 92 |
+
Similarly, make sure you have downloaded the `LLAMA` weights. If not, run the following command:
|
| 93 |
+
|
| 94 |
+
```bash
|
| 95 |
+
huggingface-cli download fishaudio/fish-speech-1.4 --local-dir checkpoints/fish-speech-1.4
|
| 96 |
+
```
|
| 97 |
+
|
| 98 |
+
Finally, you can start the fine-tuning by running the following command:
|
| 99 |
+
|
| 100 |
+
```bash
|
| 101 |
+
python fish_speech/train.py --config-name text2semantic_finetune \
|
| 102 |
+
project=$project \
|
| 103 |
+
[email protected]_config=r_8_alpha_16
|
| 104 |
+
```
|
| 105 |
+
|
| 106 |
+
!!! note
|
| 107 |
+
You can modify the training parameters such as `batch_size`, `gradient_accumulation_steps`, etc. to fit your GPU memory by modifying `fish_speech/configs/text2semantic_finetune.yaml`.
|
| 108 |
+
|
| 109 |
+
!!! note
|
| 110 |
+
For Windows users, you can use `trainer.strategy.process_group_backend=gloo` to avoid `nccl` issues.
|
| 111 |
+
|
| 112 |
+
After training is complete, you can refer to the [inference](inference.md) section to generate speech.
|
| 113 |
+
|
| 114 |
+
!!! info
|
| 115 |
+
By default, the model will only learn the speaker's speech patterns and not the timbre. You still need to use prompts to ensure timbre stability.
|
| 116 |
+
If you want to learn the timbre, you can increase the number of training steps, but this may lead to overfitting.
|
| 117 |
+
|
| 118 |
+
After training, you need to convert the LoRA weights to regular weights before performing inference.
|
| 119 |
+
|
| 120 |
+
```bash
|
| 121 |
+
python tools/llama/merge_lora.py \
|
| 122 |
+
--lora-config r_8_alpha_16 \
|
| 123 |
+
--base-weight checkpoints/fish-speech-1.4 \
|
| 124 |
+
--lora-weight results/$project/checkpoints/step_000000010.ckpt \
|
| 125 |
+
--output checkpoints/fish-speech-1.4-yth-lora/
|
| 126 |
+
```
|
| 127 |
+
!!! note
|
| 128 |
+
You may also try other checkpoints. We suggest using the earliest checkpoint that meets your requirements, as they often perform better on out-of-distribution (OOD) data.
|
docs/en/index.md
ADDED
|
@@ -0,0 +1,215 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Introduction
|
| 2 |
+
|
| 3 |
+
<div>
|
| 4 |
+
<a target="_blank" href="https://discord.gg/Es5qTB9BcN">
|
| 5 |
+
<img alt="Discord" src="https://img.shields.io/discord/1214047546020728892?color=%23738ADB&label=Discord&logo=discord&logoColor=white&style=flat-square"/>
|
| 6 |
+
</a>
|
| 7 |
+
<a target="_blank" href="http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=jCKlUP7QgSm9kh95UlBoYv6s1I-Apl1M&authKey=xI5ttVAp3do68IpEYEalwXSYZFdfxZSkah%2BctF5FIMyN2NqAa003vFtLqJyAVRfF&noverify=0&group_code=593946093">
|
| 8 |
+
<img alt="QQ" src="https://img.shields.io/badge/QQ Group-%2312B7F5?logo=tencent-qq&logoColor=white&style=flat-square"/>
|
| 9 |
+
</a>
|
| 10 |
+
<a target="_blank" href="https://hub.docker.com/r/fishaudio/fish-speech">
|
| 11 |
+
<img alt="Docker" src="https://img.shields.io/docker/pulls/fishaudio/fish-speech?style=flat-square&logo=docker"/>
|
| 12 |
+
</a>
|
| 13 |
+
</div>
|
| 14 |
+
|
| 15 |
+
!!! warning
|
| 16 |
+
We assume no responsibility for any illegal use of the codebase. Please refer to the local laws regarding DMCA (Digital Millennium Copyright Act) and other relevant laws in your area. <br/>
|
| 17 |
+
This codebase and all models are released under the CC-BY-NC-SA-4.0 license.
|
| 18 |
+
|
| 19 |
+
<p align="center">
|
| 20 |
+
<img src="../assets/figs/diagram.png" width="75%">
|
| 21 |
+
</p>
|
| 22 |
+
|
| 23 |
+
## Requirements
|
| 24 |
+
|
| 25 |
+
- GPU Memory: 4GB (for inference), 8GB (for fine-tuning)
|
| 26 |
+
- System: Linux, Windows
|
| 27 |
+
|
| 28 |
+
## Windows Setup
|
| 29 |
+
|
| 30 |
+
Professional Windows users may consider using WSL2 or Docker to run the codebase.
|
| 31 |
+
|
| 32 |
+
```bash
|
| 33 |
+
# Create a python 3.10 virtual environment, you can also use virtualenv
|
| 34 |
+
conda create -n fish-speech python=3.10
|
| 35 |
+
conda activate fish-speech
|
| 36 |
+
|
| 37 |
+
# Install pytorch
|
| 38 |
+
pip3 install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu121
|
| 39 |
+
|
| 40 |
+
# Install fish-speech
|
| 41 |
+
pip3 install -e .
|
| 42 |
+
|
| 43 |
+
# (Enable acceleration) Install triton-windows
|
| 44 |
+
pip install https://github.com/AnyaCoder/fish-speech/releases/download/v0.1.0/triton_windows-0.1.0-py3-none-any.whl
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
Non-professional Windows users can consider the following basic methods to run the project without a Linux environment (with model compilation capabilities, i.e., `torch.compile`):
|
| 48 |
+
|
| 49 |
+
1. Extract the project package.
|
| 50 |
+
2. Click `install_env.bat` to install the environment.
|
| 51 |
+
3. If you want to enable compilation acceleration, follow this step:
|
| 52 |
+
1. Download the LLVM compiler from the following links:
|
| 53 |
+
- [LLVM-17.0.6 (Official Site Download)](https://huggingface.co/fishaudio/fish-speech-1/resolve/main/LLVM-17.0.6-win64.exe?download=true)
|
| 54 |
+
- [LLVM-17.0.6 (Mirror Site Download)](https://hf-mirror.com/fishaudio/fish-speech-1/resolve/main/LLVM-17.0.6-win64.exe?download=true)
|
| 55 |
+
- After downloading `LLVM-17.0.6-win64.exe`, double-click to install, select an appropriate installation location, and most importantly, check the `Add Path to Current User` option to add the environment variable.
|
| 56 |
+
- Confirm that the installation is complete.
|
| 57 |
+
2. Download and install the Microsoft Visual C++ Redistributable to solve potential .dll missing issues:
|
| 58 |
+
- [MSVC++ 14.40.33810.0 Download](https://aka.ms/vs/17/release/vc_redist.x64.exe)
|
| 59 |
+
3. Download and install Visual Studio Community Edition to get MSVC++ build tools and resolve LLVM's header file dependencies:
|
| 60 |
+
- [Visual Studio Download](https://visualstudio.microsoft.com/zh-hans/downloads/)
|
| 61 |
+
- After installing Visual Studio Installer, download Visual Studio Community 2022.
|
| 62 |
+
- As shown below, click the `Modify` button and find the `Desktop development with C++` option to select and download.
|
| 63 |
+
4. Download and install [CUDA Toolkit 12.x](https://developer.nvidia.com/cuda-12-1-0-download-archive?target_os=Windows&target_arch=x86_64)
|
| 64 |
+
4. Double-click `start.bat` to open the training inference WebUI management interface. If needed, you can modify the `API_FLAGS` as prompted below.
|
| 65 |
+
|
| 66 |
+
!!! info "Optional"
|
| 67 |
+
|
| 68 |
+
Want to start the inference WebUI?
|
| 69 |
+
|
| 70 |
+
Edit the `API_FLAGS.txt` file in the project root directory and modify the first three lines as follows:
|
| 71 |
+
```
|
| 72 |
+
--infer
|
| 73 |
+
# --api
|
| 74 |
+
# --listen ...
|
| 75 |
+
...
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
!!! info "Optional"
|
| 79 |
+
|
| 80 |
+
Want to start the API server?
|
| 81 |
+
|
| 82 |
+
Edit the `API_FLAGS.txt` file in the project root directory and modify the first three lines as follows:
|
| 83 |
+
|
| 84 |
+
```
|
| 85 |
+
# --infer
|
| 86 |
+
--api
|
| 87 |
+
--listen ...
|
| 88 |
+
...
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
!!! info "Optional"
|
| 92 |
+
|
| 93 |
+
Double-click `run_cmd.bat` to enter the conda/python command line environment of this project.
|
| 94 |
+
|
| 95 |
+
## Linux Setup
|
| 96 |
+
|
| 97 |
+
See [pyproject.toml](../../pyproject.toml) for details.
|
| 98 |
+
```bash
|
| 99 |
+
# Create a python 3.10 virtual environment, you can also use virtualenv
|
| 100 |
+
conda create -n fish-speech python=3.10
|
| 101 |
+
conda activate fish-speech
|
| 102 |
+
|
| 103 |
+
# Install pytorch
|
| 104 |
+
pip3 install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1
|
| 105 |
+
|
| 106 |
+
# (Ubuntu / Debian User) Install sox + ffmpeg
|
| 107 |
+
apt install libsox-dev ffmpeg
|
| 108 |
+
|
| 109 |
+
# (Ubuntu / Debian User) Install pyaudio
|
| 110 |
+
apt install build-essential \
|
| 111 |
+
cmake \
|
| 112 |
+
libasound-dev \
|
| 113 |
+
portaudio19-dev \
|
| 114 |
+
libportaudio2 \
|
| 115 |
+
libportaudiocpp0
|
| 116 |
+
|
| 117 |
+
# Install fish-speech
|
| 118 |
+
pip3 install -e .[stable]
|
| 119 |
+
```
|
| 120 |
+
|
| 121 |
+
## macos setup
|
| 122 |
+
|
| 123 |
+
If you want to perform inference on MPS, please add the `--device mps` flag.
|
| 124 |
+
Please refer to [this PR](https://github.com/fishaudio/fish-speech/pull/461#issuecomment-2284277772) for a comparison of inference speeds.
|
| 125 |
+
|
| 126 |
+
!!! warning
|
| 127 |
+
The `compile` option is not officially supported on Apple Silicon devices, so there is no guarantee that inference speed will improve.
|
| 128 |
+
|
| 129 |
+
```bash
|
| 130 |
+
# create a python 3.10 virtual environment, you can also use virtualenv
|
| 131 |
+
conda create -n fish-speech python=3.10
|
| 132 |
+
conda activate fish-speech
|
| 133 |
+
# install pytorch
|
| 134 |
+
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1
|
| 135 |
+
# install fish-speech
|
| 136 |
+
pip install -e .[stable]
|
| 137 |
+
```
|
| 138 |
+
|
| 139 |
+
## Docker Setup
|
| 140 |
+
|
| 141 |
+
1. Install NVIDIA Container Toolkit:
|
| 142 |
+
|
| 143 |
+
To use GPU for model training and inference in Docker, you need to install NVIDIA Container Toolkit:
|
| 144 |
+
|
| 145 |
+
For Ubuntu users:
|
| 146 |
+
|
| 147 |
+
```bash
|
| 148 |
+
# Add repository
|
| 149 |
+
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
|
| 150 |
+
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
|
| 151 |
+
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
|
| 152 |
+
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
|
| 153 |
+
# Install nvidia-container-toolkit
|
| 154 |
+
sudo apt-get update
|
| 155 |
+
sudo apt-get install -y nvidia-container-toolkit
|
| 156 |
+
# Restart Docker service
|
| 157 |
+
sudo systemctl restart docker
|
| 158 |
+
```
|
| 159 |
+
|
| 160 |
+
For users of other Linux distributions, please refer to: [NVIDIA Container Toolkit Install-guide](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html).
|
| 161 |
+
|
| 162 |
+
2. Pull and run the fish-speech image
|
| 163 |
+
|
| 164 |
+
```shell
|
| 165 |
+
# Pull the image
|
| 166 |
+
docker pull fishaudio/fish-speech:latest-dev
|
| 167 |
+
# Run the image
|
| 168 |
+
docker run -it \
|
| 169 |
+
--name fish-speech \
|
| 170 |
+
--gpus all \
|
| 171 |
+
-p 7860:7860 \
|
| 172 |
+
fishaudio/fish-speech:latest-dev \
|
| 173 |
+
zsh
|
| 174 |
+
# If you need to use a different port, please modify the -p parameter to YourPort:7860
|
| 175 |
+
```
|
| 176 |
+
|
| 177 |
+
3. Download model dependencies
|
| 178 |
+
|
| 179 |
+
Make sure you are in the terminal inside the docker container, then download the required `vqgan` and `llama` models from our huggingface repository.
|
| 180 |
+
|
| 181 |
+
```bash
|
| 182 |
+
huggingface-cli download fishaudio/fish-speech-1.4 --local-dir checkpoints/fish-speech-1.4
|
| 183 |
+
```
|
| 184 |
+
|
| 185 |
+
4. Configure environment variables and access WebUI
|
| 186 |
+
|
| 187 |
+
In the terminal inside the docker container, enter `export GRADIO_SERVER_NAME="0.0.0.0"` to allow external access to the gradio service inside docker.
|
| 188 |
+
Then in the terminal inside the docker container, enter `python tools/webui.py` to start the WebUI service.
|
| 189 |
+
|
| 190 |
+
If you're using WSL or MacOS, visit [http://localhost:7860](http://localhost:7860) to open the WebUI interface.
|
| 191 |
+
|
| 192 |
+
If it's deployed on a server, replace localhost with your server's IP.
|
| 193 |
+
|
| 194 |
+
## Changelog
|
| 195 |
+
|
| 196 |
+
- 2024/09/10: Updated Fish-Speech to 1.4 version, with an increase in dataset size and a change in the quantizer's n_groups from 4 to 8.
|
| 197 |
+
- 2024/07/02: Updated Fish-Speech to 1.2 version, remove VITS Decoder, and greatly enhanced zero-shot ability.
|
| 198 |
+
- 2024/05/10: Updated Fish-Speech to 1.1 version, implement VITS decoder to reduce WER and improve timbre similarity.
|
| 199 |
+
- 2024/04/22: Finished Fish-Speech 1.0 version, significantly modified VQGAN and LLAMA models.
|
| 200 |
+
- 2023/12/28: Added `lora` fine-tuning support.
|
| 201 |
+
- 2023/12/27: Add `gradient checkpointing`, `causual sampling`, and `flash-attn` support.
|
| 202 |
+
- 2023/12/19: Updated webui and HTTP API.
|
| 203 |
+
- 2023/12/18: Updated fine-tuning documentation and related examples.
|
| 204 |
+
- 2023/12/17: Updated `text2semantic` model, supporting phoneme-free mode.
|
| 205 |
+
- 2023/12/13: Beta version released, includes VQGAN model and a language model based on LLAMA (phoneme support only).
|
| 206 |
+
|
| 207 |
+
## Acknowledgements
|
| 208 |
+
|
| 209 |
+
- [VITS2 (daniilrobnikov)](https://github.com/daniilrobnikov/vits2)
|
| 210 |
+
- [Bert-VITS2](https://github.com/fishaudio/Bert-VITS2)
|
| 211 |
+
- [GPT VITS](https://github.com/innnky/gpt-vits)
|
| 212 |
+
- [MQTTS](https://github.com/b04901014/MQTTS)
|
| 213 |
+
- [GPT Fast](https://github.com/pytorch-labs/gpt-fast)
|
| 214 |
+
- [Transformers](https://github.com/huggingface/transformers)
|
| 215 |
+
- [GPT-SoVITS](https://github.com/RVC-Boss/GPT-SoVITS)
|
docs/en/inference.md
ADDED
|
@@ -0,0 +1,135 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Inference
|
| 2 |
+
|
| 3 |
+
Inference support command line, HTTP API and web UI.
|
| 4 |
+
|
| 5 |
+
!!! note
|
| 6 |
+
Overall, reasoning consists of several parts:
|
| 7 |
+
|
| 8 |
+
1. Encode a given ~10 seconds of voice using VQGAN.
|
| 9 |
+
2. Input the encoded semantic tokens and the corresponding text into the language model as an example.
|
| 10 |
+
3. Given a new piece of text, let the model generate the corresponding semantic tokens.
|
| 11 |
+
4. Input the generated semantic tokens into VITS / VQGAN to decode and generate the corresponding voice.
|
| 12 |
+
|
| 13 |
+
## Command Line Inference
|
| 14 |
+
|
| 15 |
+
Download the required `vqgan` and `llama` models from our Hugging Face repository.
|
| 16 |
+
|
| 17 |
+
```bash
|
| 18 |
+
huggingface-cli download fishaudio/fish-speech-1.4 --local-dir checkpoints/fish-speech-1.4
|
| 19 |
+
```
|
| 20 |
+
|
| 21 |
+
### 1. Generate prompt from voice:
|
| 22 |
+
|
| 23 |
+
!!! note
|
| 24 |
+
If you plan to let the model randomly choose a voice timbre, you can skip this step.
|
| 25 |
+
|
| 26 |
+
```bash
|
| 27 |
+
python tools/vqgan/inference.py \
|
| 28 |
+
-i "paimon.wav" \
|
| 29 |
+
--checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth"
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
You should get a `fake.npy` file.
|
| 33 |
+
|
| 34 |
+
### 2. Generate semantic tokens from text:
|
| 35 |
+
|
| 36 |
+
```bash
|
| 37 |
+
python tools/llama/generate.py \
|
| 38 |
+
--text "The text you want to convert" \
|
| 39 |
+
--prompt-text "Your reference text" \
|
| 40 |
+
--prompt-tokens "fake.npy" \
|
| 41 |
+
--checkpoint-path "checkpoints/fish-speech-1.4" \
|
| 42 |
+
--num-samples 2 \
|
| 43 |
+
--compile
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
This command will create a `codes_N` file in the working directory, where N is an integer starting from 0.
|
| 47 |
+
|
| 48 |
+
!!! note
|
| 49 |
+
You may want to use `--compile` to fuse CUDA kernels for faster inference (~30 tokens/second -> ~500 tokens/second).
|
| 50 |
+
Correspondingly, if you do not plan to use acceleration, you can comment out the `--compile` parameter.
|
| 51 |
+
|
| 52 |
+
!!! info
|
| 53 |
+
For GPUs that do not support bf16, you may need to use the `--half` parameter.
|
| 54 |
+
|
| 55 |
+
### 3. Generate vocals from semantic tokens:
|
| 56 |
+
|
| 57 |
+
#### VQGAN Decoder
|
| 58 |
+
|
| 59 |
+
```bash
|
| 60 |
+
python tools/vqgan/inference.py \
|
| 61 |
+
-i "codes_0.npy" \
|
| 62 |
+
--checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth"
|
| 63 |
+
```
|
| 64 |
+
|
| 65 |
+
## HTTP API Inference
|
| 66 |
+
|
| 67 |
+
We provide a HTTP API for inference. You can use the following command to start the server:
|
| 68 |
+
|
| 69 |
+
```bash
|
| 70 |
+
python -m tools.api \
|
| 71 |
+
--listen 0.0.0.0:8080 \
|
| 72 |
+
--llama-checkpoint-path "checkpoints/fish-speech-1.4" \
|
| 73 |
+
--decoder-checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth" \
|
| 74 |
+
--decoder-config-name firefly_gan_vq
|
| 75 |
+
```
|
| 76 |
+
|
| 77 |
+
> If you want to speed up inference, you can add the `--compile` parameter.
|
| 78 |
+
|
| 79 |
+
After that, you can view and test the API at http://127.0.0.1:8080/.
|
| 80 |
+
|
| 81 |
+
Below is an example of sending a request using `tools/post_api.py`.
|
| 82 |
+
|
| 83 |
+
```bash
|
| 84 |
+
python -m tools.post_api \
|
| 85 |
+
--text "Text to be input" \
|
| 86 |
+
--reference_audio "Path to reference audio" \
|
| 87 |
+
--reference_text "Text content of the reference audio" \
|
| 88 |
+
--streaming True
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
The above command indicates synthesizing the desired audio according to the reference audio information and returning it in a streaming manner.
|
| 92 |
+
|
| 93 |
+
The following example demonstrates that you can use **multiple** reference audio paths and reference audio texts at once. Separate them with spaces in the command.
|
| 94 |
+
|
| 95 |
+
```bash
|
| 96 |
+
python -m tools.post_api \
|
| 97 |
+
--text "Text to input" \
|
| 98 |
+
--reference_audio "reference audio path1" "reference audio path2" \
|
| 99 |
+
--reference_text "reference audio text1" "reference audio text2"\
|
| 100 |
+
--streaming False \
|
| 101 |
+
--output "generated" \
|
| 102 |
+
--format "mp3"
|
| 103 |
+
```
|
| 104 |
+
|
| 105 |
+
The above command synthesizes the desired `MP3` format audio based on the information from multiple reference audios and saves it as `generated.mp3` in the current directory.
|
| 106 |
+
|
| 107 |
+
You can also use `--reference_id` (only one can be used) instead of `--reference-audio` and `--reference_text`, provided that you create a `references/<your reference_id>` folder in the project root directory, which contains any audio and annotation text.
|
| 108 |
+
The currently supported reference audio has a maximum total duration of 90 seconds.
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
!!! info
|
| 112 |
+
To learn more about available parameters, you can use the command `python -m tools.post_api -h`
|
| 113 |
+
|
| 114 |
+
## GUI Inference
|
| 115 |
+
[Download client](https://github.com/AnyaCoder/fish-speech-gui/releases)
|
| 116 |
+
|
| 117 |
+
## WebUI Inference
|
| 118 |
+
|
| 119 |
+
You can start the WebUI using the following command:
|
| 120 |
+
|
| 121 |
+
```bash
|
| 122 |
+
python -m tools.webui \
|
| 123 |
+
--llama-checkpoint-path "checkpoints/fish-speech-1.4" \
|
| 124 |
+
--decoder-checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth" \
|
| 125 |
+
--decoder-config-name firefly_gan_vq
|
| 126 |
+
```
|
| 127 |
+
> If you want to speed up inference, you can add the `--compile` parameter.
|
| 128 |
+
|
| 129 |
+
!!! note
|
| 130 |
+
You can save the label file and reference audio file in advance to the `references` folder in the main directory (which you need to create yourself), so that you can directly call them in the WebUI.
|
| 131 |
+
|
| 132 |
+
!!! note
|
| 133 |
+
You can use Gradio environment variables, such as `GRADIO_SHARE`, `GRADIO_SERVER_PORT`, `GRADIO_SERVER_NAME` to configure WebUI.
|
| 134 |
+
|
| 135 |
+
Enjoy!
|
docs/en/samples.md
ADDED
|
@@ -0,0 +1,137 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Samples
|
| 2 |
+
|
| 3 |
+
ver 1.4
|
| 4 |
+
|
| 5 |
+
## Credits
|
| 6 |
+
Special thanks to [Seed-TTS (2024)](https://bytedancespeech.github.io/seedtts_tech_report/) for providing the evaluation data for demonstration.
|
| 7 |
+
|
| 8 |
+
All prompt audio is from the Seed-TTS effect demo page, and all generated audio is from the first generation of fish-speech version 1.4.
|
| 9 |
+
|
| 10 |
+
## Zero-shot In-context Learning
|
| 11 |
+
<table>
|
| 12 |
+
<thead>
|
| 13 |
+
<tr>
|
| 14 |
+
<th style="vertical-align : middle;text-align: center">Language </th>
|
| 15 |
+
<th style="vertical-align : middle;text-align: center">Prompt </th>
|
| 16 |
+
<th style="vertical-align : middle;text-align: center">Same Language Generation</th>
|
| 17 |
+
<th style="vertical-align : middle;text-align: center">Cross-linugal Generation</th>
|
| 18 |
+
</tr>
|
| 19 |
+
</thead>
|
| 20 |
+
<tbody>
|
| 21 |
+
<tr>
|
| 22 |
+
<td style="vertical-align : middle;text-align:center;" rowspan="3">EN</td>
|
| 23 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/prompts/4245145269330795065.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 24 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/4245145269330795065/same-lang-fish.wav" autoplay="">Your browser does not support the audio element.</audio><br>I don't really care what you call me. I've been a silent spectator, watching species evolve, empires rise and fall. But always remember, I am mighty and enduring. Respect me and I'll nurture you; ignore me and you shall face the consequences.</td>
|
| 25 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/4245145269330795065/cross-lang-fish.wav" autoplay="">Your browser does not support the audio element.</audio><br>顿时,气氛变得沉郁起来。乍看之下,一切的困扰仿佛都围绕在我身边。我皱着眉头,感受着那份压力,但我知道我不能放弃,不能认输。于是,我深吸一口气,心底的声音告诉我:“无论如何,都要冷静下来,重新开始。”</td>
|
| 26 |
+
</tr>
|
| 27 |
+
<tr>
|
| 28 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/prompts/2486365921931244890.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 29 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/2486365921931244890/same-lang-fish.wav" autoplay="">Your browser does not support the audio element.</audio><br>Dealing with family secrets is never easy. Yet, sometimes, omission is a form of protection, intending to safeguard some from the harsh truths. One day, I hope you understand the reasons behind my actions. Until then, Anna, please, bear with me.</td>
|
| 30 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/2486365921931244890/cross-lang-fish.wav" autoplay="">Your browser does not support the audio element.</audio><br>处理家庭秘密从来都不是一件容易的事。然而,有时候,隐瞒是一种保护形式,旨在保护一些人免受残酷的真相伤害。有一天,我希望你能理解我行为背后的原因。在那之前,安娜,请容忍我。</td>
|
| 31 |
+
</tr>
|
| 32 |
+
<tr>
|
| 33 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/prompts/-9102975986427238220.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 34 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/-9102975986427238220/same-lang-fish.wav" autoplay="">Your browser does not support the audio element.</audio><br>The combinations of different textures and flavors create a perfect harmony. The succulence of the steak, the tartness of the cranberries, the crunch of pine nuts, and creaminess of blue cheese make it a truly delectable delight. Enjoy your culinary adventure!</td>
|
| 35 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/-9102975986427238220/cross-lang-fish.wav" autoplay="">Your browser does not support the audio element.</audio><br>听着你的话,我心里五味杂陈。虽然我愿意一直在你身边,承担一切不幸,但我知道只有让你自己面对,才能真正让你变得更强大。所以,你要记得,无论面对何种困难,都请你坚强,我会在心里一直支持你的。</td>
|
| 36 |
+
</tr>
|
| 37 |
+
<tr>
|
| 38 |
+
<td style="vertical-align : middle;text-align:center;" rowspan="3">ZH</td>
|
| 39 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/prompts/2648200402409733590.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 40 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/2648200402409733590/same-lang-fish.wav" autoplay="">Your browser does not support the audio element.</audio><br>突然,身边一阵笑声。我看着他们,意气风发地挺直了胸膛,甩了甩那稍显肉感的双臂,轻笑道:"我身上的肉,是为了掩饰我爆棚的魅力,否则,岂不吓坏了你们呢?"</td>
|
| 41 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/2648200402409733590/cross-lang-fish.wav" autoplay="">Your browser does not support the audio element.</audio><br>Suddenly, there was a burst of laughter beside me. I looked at them, stood up straight with high spirit, shook the slightly fleshy arms, and smiled lightly, saying, "The flesh on my body is to hide my bursting charm. Otherwise, wouldn't it scare you?"</td>
|
| 42 |
+
</tr>
|
| 43 |
+
<tr>
|
| 44 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/prompts/8913957783621352198.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 45 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/8913957783621352198/same-lang-fish.wav" autoplay="">Your browser does not support the audio element.</audio><br>他闭上眼睛,期望这一切都能过去。然而,当他再次睁开眼睛,眼前的景象让他不禁倒吸一口气。雾气中出现的禁闭岛,陌生又熟悉,充满未知的危险。他握紧拳头,心知他的生活即将发生翻天覆地的改变。</td>
|
| 46 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/8913957783621352198/cross-lang-fish.wav" autoplay="">Your browser does not support the audio element.</audio><br>He closed his eyes, expecting that all of this could pass. However, when he opened his eyes again, the sight in front of him made him couldn't help but take a deep breath. The closed island that appeared in the fog, strange and familiar, was full of unknown dangers. He tightened his fist, knowing that his life was about to undergo earth-shaking changes. </td>
|
| 47 |
+
</tr>
|
| 48 |
+
<tr>
|
| 49 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/prompts/2631296891109983590.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 50 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/2631296891109983590/same-lang-fish.wav" autoplay="">Your browser does not support the audio element.</audio><br>顿时,气氛变得沉郁起来。乍看之下,一切的困扰仿佛都围绕在我身边。我皱着眉头,感受着那份压力,但我知道我不能放弃,不能认输。于是,我深吸一口气,心底的声音告诉我:“无论如何,都要冷静下来,重新开始。”</td>
|
| 51 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/2631296891109983590/cross-lang-fish.wav" autoplay="">Your browser does not support the audio element.</audio><br>Suddenly, the atmosphere became gloomy. At first glance, all the troubles seemed to surround me. I frowned, feeling that pressure, but I know I can't give up, can't admit defeat. So, I took a deep breath, and the voice in my heart told me, "Anyway, must calm down and start again."</td>
|
| 52 |
+
</tr>
|
| 53 |
+
</tbody>
|
| 54 |
+
</table>
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
## Speaker Fine-tune
|
| 59 |
+
|
| 60 |
+
<table>
|
| 61 |
+
<thead>
|
| 62 |
+
<tr>
|
| 63 |
+
<th style="text-align: center"> </th>
|
| 64 |
+
<th style="text-align: center">Text </th>
|
| 65 |
+
<th style="text-align: center">Generated</th>
|
| 66 |
+
</tr>
|
| 67 |
+
</thead>
|
| 68 |
+
<tbody>
|
| 69 |
+
<tr>
|
| 70 |
+
<td style="vertical-align : middle;text-align:center;" rowspan="3">Speaker1</td>
|
| 71 |
+
<td style="vertical-align : middle;text-align:center;">好呀,哈哈哈哈哈,喜欢笑的人运气都不会差哦,希望你每天笑口常开~</td>
|
| 72 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/fine-tune/prompts/4781135337205789117.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 73 |
+
</tr>
|
| 74 |
+
<tr>
|
| 75 |
+
<td style="vertical-align : middle;text-align:center;">哇!恭喜你中了大乐透,八百万可真不少呢!有什么特别的计划或想法吗?</td>
|
| 76 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/fine-tune/4781135337205789117/fish_1_to_2.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 77 |
+
</tr>
|
| 78 |
+
<tr>
|
| 79 |
+
<td style="vertical-align : middle;text-align:center;">哼,你这么问是想请本小姐吃饭吗?如果对象是你的话,那也不是不可以。</td>
|
| 80 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/fine-tune/4781135337205789117/fish_1_to_3.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 81 |
+
</tr>
|
| 82 |
+
<tr>
|
| 83 |
+
<td style="vertical-align : middle;text-align:center;" rowspan="3">Speaker2</td>
|
| 84 |
+
<td style="vertical-align : middle;text-align:center;">是呀,他还想换个地球仪哈哈哈,看来给你积累了一些快乐值了,你还想不想再听一个其他的笑话呀?</td>
|
| 85 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/fine-tune/prompts/-1325430967143158944.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 86 |
+
</tr>
|
| 87 |
+
<tr>
|
| 88 |
+
<td style="vertical-align : middle;text-align:center;">嘿嘿,你是不是也想拥有甜甜的恋爱呢?《微微一笑很倾城》是你的不二选择,男女主是校花校草类型,他们通过游戏结识,再到两人见面,全程没有一点误会,真的齁甜,想想都忍不住“姨妈笑”~</td>
|
| 89 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/fine-tune/-1325430967143158944/fish_1_to_2.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 90 |
+
</tr>
|
| 91 |
+
<tr>
|
| 92 |
+
<td style="vertical-align : middle;text-align:center;">小傻瓜,嗯……算是个很可爱很亲切的名字,有点“独特”哦,不过我有些好奇,你为什么会给我选这个昵称呢?</td>
|
| 93 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/fine-tune/-1325430967143158944/fish_1_to_3.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 94 |
+
</tr>
|
| 95 |
+
</tbody>
|
| 96 |
+
</table>
|
| 97 |
+
<br>
|
| 98 |
+
|
| 99 |
+
## Content Editing
|
| 100 |
+
|
| 101 |
+
<table>
|
| 102 |
+
<thead>
|
| 103 |
+
<tr><th style="text-align: center">Language</th>
|
| 104 |
+
<th style="text-align: center">Original Text</th>
|
| 105 |
+
<th style="text-align: center">Original Audio</th>
|
| 106 |
+
<th style="text-align: center">Target Text</th>
|
| 107 |
+
<th style="text-align: center">Edited Audio</th>
|
| 108 |
+
</tr></thead>
|
| 109 |
+
<tbody>
|
| 110 |
+
<tr>
|
| 111 |
+
<td style="vertical-align : middle;text-align:center;" rowspan="2">EN</td>
|
| 112 |
+
<td style="vertical-align : middle;text-align:center;">They can't order me to stop dreaming. If you dream a thing more than once, it's sure to come true. Have faith in your dreams, and someday your rainbow will come shining through.</td>
|
| 113 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/content-edit/prompts/2372076002032794455.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 114 |
+
<td style="vertical-align : middle;text-align:center;">They can't <b>require</b> me to stop <b>imagining.</b> If you envision a thing more than once, it's <b>bound</b> to come <b>about</b>. Have <b>trust</b> in your <b>visions</b>, and someday your <b>radiance</b> will come <b>beaming</b> through.</td>
|
| 115 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/content-edit/2372076002032794455/edit-fish.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 116 |
+
</tr>
|
| 117 |
+
<tr>
|
| 118 |
+
<td style="vertical-align : middle;text-align:center;">Are you familiar with it? Slice the steak and place the strips on top, then garnish with the dried cranberries, pine nuts, and blue cheese. I wonder how people rationalise the decision?</td>
|
| 119 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/content-edit/prompts/3347127306902202498.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 120 |
+
<td style="vertical-align : middle;text-align:center;">Are you <b>acquainted</b> with it? <b>Cut the pork</b> and place the strips on top, then garnish with the dried <b>cherries, almonds,</b> and <b>feta</b> cheese. I <b>query</b> how people <b>justify</b> the <b>choice?</b></td>
|
| 121 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/content-edit/3347127306902202498/edit-fish.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 122 |
+
</tr>
|
| 123 |
+
<tr>
|
| 124 |
+
<td style="vertical-align : middle;text-align:center;" rowspan="2">ZH</td>
|
| 125 |
+
<td style="vertical-align : middle;text-align:center;">自古以来,庸君最怕党政了,可圣君他就不怕,不但不怕,反能利用。要我说,你就让明珠索额图互相争宠,只要你心里明白,左右逢源,你就能立于不败之地。</td>
|
| 126 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/content-edit/prompts/1297014176484007082.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 127 |
+
<td style="vertical-align : middle;text-align:center;"><b>从古至今</b>,庸君最怕<b>朝纲了</b>,可<b>明</b>君他就不怕,不但不怕,反能<b>借助</b>。要我说,你就让<b>李四张三</b>互相争宠,只要你心里<b>清楚</b>,左右<b>周旋</b>,你就能<b>处</b>于不败之<b>境</b>。</td>
|
| 128 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/content-edit/1297014176484007082/edit-fish.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 129 |
+
</tr>
|
| 130 |
+
<tr>
|
| 131 |
+
<td style="vertical-align : middle;text-align:center;">对,这就是我,万人敬仰的太乙真人,虽然有点婴儿肥,但也掩不住我逼人的帅气。</td>
|
| 132 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/content-edit/prompts/-40165564411515767.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 133 |
+
<td style="vertical-align : middle;text-align:center;">对,这就是我,<b>众人尊崇</b>的太<b>白金星</b>,虽然有点<b>娃娃脸</b>,但也<b>遮</b>不住我<b>迷人</b>的<b>魅力。</b></td>
|
| 134 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/content-edit/-40165564411515767/edit-fish.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 135 |
+
</tr>
|
| 136 |
+
</tbody>
|
| 137 |
+
</table>
|
docs/en/start_agent.md
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Start Agent
|
| 2 |
+
|
| 3 |
+
## Requirements
|
| 4 |
+
|
| 5 |
+
- GPU memory: At least 8GB(under quanization), 16GB or more is recommanded.
|
| 6 |
+
- Disk usage: 10GB
|
| 7 |
+
|
| 8 |
+
## Download Model
|
| 9 |
+
|
| 10 |
+
You can get the model by:
|
| 11 |
+
|
| 12 |
+
```bash
|
| 13 |
+
huggingface-cli download fishaudio/fish-agent-v0.1-3b --local-dir checkpoints/fish-agent-v0.1-3b
|
| 14 |
+
```
|
| 15 |
+
|
| 16 |
+
Put them in the 'checkpoints' folder.
|
| 17 |
+
|
| 18 |
+
You also need the fish-speech model which you can download instructed by [inference](inference.md).
|
| 19 |
+
|
| 20 |
+
So there will be 2 folder in the checkpoints.
|
| 21 |
+
|
| 22 |
+
The `checkpoints/fish-speech-1.4` and `checkpoints/fish-agent-v0.1-3b`
|
| 23 |
+
|
| 24 |
+
## Environment Prepare
|
| 25 |
+
|
| 26 |
+
If you already have Fish-speech, you can directly use by adding the follow instruction:
|
| 27 |
+
```bash
|
| 28 |
+
pip install cachetools
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
!!! note
|
| 32 |
+
Please use the Python version below 3.12 for compile.
|
| 33 |
+
|
| 34 |
+
If you don't have, please use the below commands to build yout environment:
|
| 35 |
+
|
| 36 |
+
```bash
|
| 37 |
+
sudo apt-get install portaudio19-dev
|
| 38 |
+
|
| 39 |
+
pip install -e .[stable]
|
| 40 |
+
```
|
| 41 |
+
|
| 42 |
+
## Launch The Agent Demo.
|
| 43 |
+
|
| 44 |
+
To build fish-agent, please use the command below under the main folder:
|
| 45 |
+
|
| 46 |
+
```bash
|
| 47 |
+
python -m tools.api --llama-checkpoint-path checkpoints/fish-agent-v0.1-3b/ --mode agent --compile
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
The `--compile` args only support Python < 3.12 , which will greatly speed up the token generation.
|
| 51 |
+
|
| 52 |
+
It won't compile at once (remember).
|
| 53 |
+
|
| 54 |
+
Then open another terminal and use the command:
|
| 55 |
+
|
| 56 |
+
```bash
|
| 57 |
+
python -m tools.e2e_webui
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
This will create a Gradio WebUI on the device.
|
| 61 |
+
|
| 62 |
+
When you first use the model, it will come to compile (if the `--compile` is True) for a short time, so please wait with patience.
|
| 63 |
+
|
| 64 |
+
## Gradio Webui
|
| 65 |
+
<p align="center">
|
| 66 |
+
<img src="../assets/figs/agent_gradio.png" width="75%">
|
| 67 |
+
</p>
|
| 68 |
+
|
| 69 |
+
Have a good time!
|
| 70 |
+
|
| 71 |
+
## Performance
|
| 72 |
+
|
| 73 |
+
Under our test, a 4060 laptop just barely runs, but is very stretched, which is only about 8 tokens/s. The 4090 is around 95 tokens/s under compile, which is what we recommend.
|
| 74 |
+
|
| 75 |
+
# About Agent
|
| 76 |
+
|
| 77 |
+
The demo is an early alpha test version, the inference speed needs to be optimised, and there are a lot of bugs waiting to be fixed. If you've found a bug or want to fix it, we'd be very happy to receive an issue or a pull request.
|
docs/ja/finetune.md
ADDED
|
@@ -0,0 +1,128 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 微調整
|
| 2 |
+
|
| 3 |
+
明らかに、このページを開いたとき、few-shot 事前トレーニングモデルのパフォーマンスに満足していなかったことでしょう。データセット上でのパフォーマンスを向上させるためにモデルを微調整したいと考えています。
|
| 4 |
+
|
| 5 |
+
現在のバージョンでは、「LLAMA」部分のみを微調整する必要があります。
|
| 6 |
+
|
| 7 |
+
## LLAMAの微調整
|
| 8 |
+
### 1. データセットの準備
|
| 9 |
+
|
| 10 |
+
```
|
| 11 |
+
.
|
| 12 |
+
├── SPK1
|
| 13 |
+
│ ├── 21.15-26.44.lab
|
| 14 |
+
│ ├── 21.15-26.44.mp3
|
| 15 |
+
│ ├── 27.51-29.98.lab
|
| 16 |
+
│ ├── 27.51-29.98.mp3
|
| 17 |
+
│ ├── 30.1-32.71.lab
|
| 18 |
+
│ └── 30.1-32.71.mp3
|
| 19 |
+
└── SPK2
|
| 20 |
+
├── 38.79-40.85.lab
|
| 21 |
+
└── 38.79-40.85.mp3
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
データセットを上記の形式に変換し、「data」ディレクトリに配置する必要があります。音声ファイルの拡張子は「.mp3」、「.wav」、または「.flac」にすることができ、注釈ファイルの拡張子は「.lab」にする必要があります。
|
| 25 |
+
|
| 26 |
+
!!! info
|
| 27 |
+
標準ファイル `.lab` には、音声の転写テキストのみを含め、特別なフォーマットは必要ありません。例えば、`hi.mp3` で「こんにちは、さようなら」と言っている場合、`hi.lab` ファイルには「こんにちは、さようなら」という一行のテキストを含めるだけです。
|
| 28 |
+
|
| 29 |
+
!!! warning
|
| 30 |
+
データセットにラウドネス正規化を適用することをお勧めします。これを行うには、[fish-audio-preprocess](https://github.com/fishaudio/audio-preprocess) を使用できます。
|
| 31 |
+
|
| 32 |
+
```bash
|
| 33 |
+
fap loudness-norm data-raw data --clean
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
### 2. セマンティックトークンのバッチ抽出
|
| 38 |
+
|
| 39 |
+
VQGANの重みをダウンロードしたことを確認してください。まだダウンロードしていない場合は、次のコマンドを実行してください。
|
| 40 |
+
|
| 41 |
+
```bash
|
| 42 |
+
huggingface-cli download fishaudio/fish-speech-1.4 --local-dir checkpoints/fish-speech-1.4
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
次に、次のコマンドを実行してセマンティックトークンを抽出できます。
|
| 46 |
+
|
| 47 |
+
```bash
|
| 48 |
+
python tools/vqgan/extract_vq.py data \
|
| 49 |
+
--num-workers 1 --batch-size 16 \
|
| 50 |
+
--config-name "firefly_gan_vq" \
|
| 51 |
+
--checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth"
|
| 52 |
+
```
|
| 53 |
+
|
| 54 |
+
!!! note
|
| 55 |
+
`--num-workers` と `--batch-size` を調整して抽出速度を上げることができますが、GPUメモリの制限を超えないようにしてください。
|
| 56 |
+
VITS形式の場合、`--filelist xxx.list` を使用してファイルリストを指定できます。
|
| 57 |
+
|
| 58 |
+
このコマンドは、`data`ディレクトリに`.npy`ファイルを作成します。以下のように表示されます。
|
| 59 |
+
|
| 60 |
+
```
|
| 61 |
+
.
|
| 62 |
+
├── SPK1
|
| 63 |
+
│ ├── 21.15-26.44.lab
|
| 64 |
+
│ ├── 21.15-26.44.mp3
|
| 65 |
+
│ ├── 21.15-26.44.npy
|
| 66 |
+
│ ├── 27.51-29.98.lab
|
| 67 |
+
│ ├── 27.51-29.98.mp3
|
| 68 |
+
│ ├── 27.51-29.98.npy
|
| 69 |
+
│ ├── 30.1-32.71.lab
|
| 70 |
+
│ ├── 30.1-32.71.mp3
|
| 71 |
+
│ └── 30.1-32.71.npy
|
| 72 |
+
└── SPK2
|
| 73 |
+
├── 38.79-40.85.lab
|
| 74 |
+
├── 38.79-40.85.mp3
|
| 75 |
+
└── 38.79-40.85.npy
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
### 3. データセットをprotobufにパックする
|
| 79 |
+
|
| 80 |
+
```bash
|
| 81 |
+
python tools/llama/build_dataset.py \
|
| 82 |
+
--input "data" \
|
| 83 |
+
--output "data/protos" \
|
| 84 |
+
--text-extension .lab \
|
| 85 |
+
--num-workers 16
|
| 86 |
+
```
|
| 87 |
+
|
| 88 |
+
コマンドの実行が完了すると、`data`ディレクトリに`quantized-dataset-ft.protos`ファイルが表示されます。
|
| 89 |
+
|
| 90 |
+
### 4. 最後に、LoRAを使用して微調整する
|
| 91 |
+
|
| 92 |
+
同様に、`LLAMA`の重みをダウンロードしたことを確認してください。まだダウンロードしていない場合は、次のコマンドを実行してください。
|
| 93 |
+
|
| 94 |
+
```bash
|
| 95 |
+
huggingface-cli download fishaudio/fish-speech-1.4 --local-dir checkpoints/fish-speech-1.4
|
| 96 |
+
```
|
| 97 |
+
|
| 98 |
+
最後に、次のコマンドを実行して微調整を開始できます。
|
| 99 |
+
|
| 100 |
+
```bash
|
| 101 |
+
python fish_speech/train.py --config-name text2semantic_finetune \
|
| 102 |
+
project=$project \
|
| 103 |
+
[email protected]_config=r_8_alpha_16
|
| 104 |
+
```
|
| 105 |
+
|
| 106 |
+
!!! note
|
| 107 |
+
`fish_speech/configs/text2semantic_finetune.yaml` を変更して、`batch_size`、`gradient_accumulation_steps` などのトレーニングパラメータを変更し、GPUメモリに適合させることができます。
|
| 108 |
+
|
| 109 |
+
!!! note
|
| 110 |
+
Windowsユーザーの場合、`trainer.strategy.process_group_backend=gloo` を使用して `nccl` の問題を回避できます。
|
| 111 |
+
|
| 112 |
+
トレーニングが完了したら、[推論](inference.md)セクションを参照し、音声を生成します。
|
| 113 |
+
|
| 114 |
+
!!! info
|
| 115 |
+
デフォルトでは、モデルは話者の発話パターンのみを学習し、音色は学習しません。音色の安定性を確保するためにプロンプトを使用する必要があります。
|
| 116 |
+
音色を学習したい場合は、トレーニングステップ数を増やすことができますが、これにより過学習が発生する可能性があります。
|
| 117 |
+
|
| 118 |
+
トレーニングが完了したら、推論を行う前にLoRAの重みを通常の重みに変換する必要があります。
|
| 119 |
+
|
| 120 |
+
```bash
|
| 121 |
+
python tools/llama/merge_lora.py \
|
| 122 |
+
--lora-config r_8_alpha_16 \
|
| 123 |
+
--base-weight checkpoints/fish-speech-1.4 \
|
| 124 |
+
--lora-weight results/$project/checkpoints/step_000000010.ckpt \
|
| 125 |
+
--output checkpoints/fish-speech-1.4-yth-lora/
|
| 126 |
+
```
|
| 127 |
+
!!! note
|
| 128 |
+
他のチェックポイントを試すこともできます。要件を満たす最も早いチェックポイントを使用することをお勧めします。これらは通常、分布外(OOD)データでより良いパフォーマンスを発揮します。
|
docs/ja/index.md
ADDED
|
@@ -0,0 +1,214 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Fish Speech の紹介
|
| 2 |
+
|
| 3 |
+
<div>
|
| 4 |
+
<a target="_blank" href="https://discord.gg/Es5qTB9BcN">
|
| 5 |
+
<img alt="Discord" src="https://img.shields.io/discord/1214047546020728892?color=%23738ADB&label=Discord&logo=discord&logoColor=white&style=flat-square"/>
|
| 6 |
+
</a>
|
| 7 |
+
<a target="_blank" href="http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=jCKlUP7QgSm9kh95UlBoYv6s1I-Apl1M&authKey=xI5ttVAp3do68IpEYEalwXSYZFdfxZSkah%2BctF5FIMyN2NqAa003vFtLqJyAVRfF&noverify=0&group_code=593946093">
|
| 8 |
+
<img alt="QQ" src="https://img.shields.io/badge/QQ Group-%2312B7F5?logo=tencent-qq&logoColor=white&style=flat-square"/>
|
| 9 |
+
</a>
|
| 10 |
+
<a target="_blank" href="https://hub.docker.com/r/fishaudio/fish-speech">
|
| 11 |
+
<img alt="Docker" src="https://img.shields.io/docker/pulls/fishaudio/fish-speech?style=flat-square&logo=docker"/>
|
| 12 |
+
</a>
|
| 13 |
+
</div>
|
| 14 |
+
|
| 15 |
+
!!! warning
|
| 16 |
+
私たちは、コードベースの違法な使用について一切の責任を負いません。お住まいの地域の DMCA(デジタルミレニアム著作権法)およびその他の関連法を参照してください。 <br/>
|
| 17 |
+
このコードベースとモデルは、CC-BY-NC-SA-4.0 ライセンス下でリリースされています。
|
| 18 |
+
|
| 19 |
+
<p align="center">
|
| 20 |
+
<img src="../assets/figs/diagram.png" width="75%">
|
| 21 |
+
</p>
|
| 22 |
+
|
| 23 |
+
## 要件
|
| 24 |
+
|
| 25 |
+
- GPU メモリ: 4GB(推論用)、8GB(ファインチューニング用)
|
| 26 |
+
- システム: Linux、Windows
|
| 27 |
+
|
| 28 |
+
## Windowsセットアップ
|
| 29 |
+
|
| 30 |
+
プロフェッショナルなWindowsユーザーは、WSL2またはDockerを使用してコードベースを実行することを検討してください。
|
| 31 |
+
|
| 32 |
+
```bash
|
| 33 |
+
# Python 3.10の仮想環境を作成(virtualenvも使用可能)
|
| 34 |
+
conda create -n fish-speech python=3.10
|
| 35 |
+
conda activate fish-speech
|
| 36 |
+
|
| 37 |
+
# PyTorchをインストール
|
| 38 |
+
pip3 install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu121
|
| 39 |
+
|
| 40 |
+
# fish-speechをインストール
|
| 41 |
+
pip3 install -e .
|
| 42 |
+
|
| 43 |
+
# (アクセラレーションを有効にする) triton-windowsをインストール
|
| 44 |
+
pip install https://github.com/AnyaCoder/fish-speech/releases/download/v0.1.0/triton_windows-0.1.0-py3-none-any.whl
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
非プロフェッショナルなWindowsユーザーは、Linux環境なしでプロジェクトを実行するための以下の基本的な方法を検討できます(モデルコンパイル機能、つまり`torch.compile`を使用可能):
|
| 48 |
+
|
| 49 |
+
1. プロジェクトパッケージを解凍する。
|
| 50 |
+
2. `install_env.bat`をクリックして環境をインストールする。
|
| 51 |
+
3. コンパイルアクセラレーションを有効にしたい場合は、次のステップに従ってください:
|
| 52 |
+
1. 以下のリンクからLLVMコンパイラをダウンロード:
|
| 53 |
+
- [LLVM-17.0.6(公式サイトのダウンロード)](https://huggingface.co/fishaudio/fish-speech-1/resolve/main/LLVM-17.0.6-win64.exe?download=true)
|
| 54 |
+
- [LLVM-17.0.6(ミラーサイトのダウンロード)](https://hf-mirror.com/fishaudio/fish-speech-1/resolve/main/LLVM-17.0.6-win64.exe?download=true)
|
| 55 |
+
- `LLVM-17.0.6-win64.exe`をダウンロードした後、ダブルクリックしてインストールし、適切なインストール場所を選択し、最も重要なのは`Add Path to Current User`オプションを選択して環境変数を追加することです。
|
| 56 |
+
- インストールが完了したことを確認する。
|
| 57 |
+
2. 欠落している .dll の問題を解決するため、Microsoft Visual C++ Redistributable をダウンロードしてインストールする:
|
| 58 |
+
- [MSVC++ 14.40.33810.0 ダウンロード](https://aka.ms/vs/17/release/vc_redist.x64.exe)
|
| 59 |
+
3. Visual Studio Community Editionをダウンロードして、MSVC++ビルドツールを取得し、LLVMのヘッダーファイルの依存関係を解決する:
|
| 60 |
+
- [Visual Studio ダウンロード](https://visualstudio.microsoft.com/ja/downloads/)
|
| 61 |
+
- Visual Studio Installerをインストールした後、Visual Studio Community 2022をダウンロード。
|
| 62 |
+
- 下記のように、`Modify`ボタンをクリックし、`C++によるデスクトップ開発`オプションを選択してダウンロード。
|
| 63 |
+
- <img src="../assets/figs/VS_1.jpg"/>
|
| 64 |
+
4. [CUDA Toolkit 12.x](https://developer.nvidia.com/cuda-12-1-0-download-archive?target_os=Windows&target_arch=x86_64)をダウンロードしてインストールする。
|
| 65 |
+
4. `start.bat`をダブルクリックして、トレーニング推論WebUI管理インターフェースを開きます。必要に応じて、以下に示すように`API_FLAGS`を修正できます。
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
!!! info "オプション"
|
| 69 |
+
推論WebUIを起動しますか?
|
| 70 |
+
プロジェクトのルートディレクトリにある `API_FLAGS.txt` ファイルを編集し、最初の3行を次のように変更します:
|
| 71 |
+
```
|
| 72 |
+
--infer
|
| 73 |
+
# --api
|
| 74 |
+
# --listen ...
|
| 75 |
+
...
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
!!! info "オプション"
|
| 79 |
+
APIサーバーを起動しますか?
|
| 80 |
+
プロジェクトのルートディレクトリにある `API_FLAGS.txt` ファイルを編集し、最初の3行を次のように変更します:
|
| 81 |
+
```
|
| 82 |
+
# --infer
|
| 83 |
+
--api
|
| 84 |
+
--listen ...
|
| 85 |
+
...
|
| 86 |
+
```
|
| 87 |
+
|
| 88 |
+
!!! info "オプション"
|
| 89 |
+
`run_cmd.bat` をダブルクリックして、このプロジェクトの conda/python コマンドライン環境に入ります。
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
## Linux セットアップ
|
| 94 |
+
|
| 95 |
+
詳細については、[pyproject.toml](../../pyproject.toml) を参照してください。
|
| 96 |
+
```bash
|
| 97 |
+
# python 3.10の仮想環境を作成します。virtualenvも使用できます。
|
| 98 |
+
conda create -n fish-speech python=3.10
|
| 99 |
+
conda activate fish-speech
|
| 100 |
+
|
| 101 |
+
# pytorchをインストールします。
|
| 102 |
+
pip3 install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1
|
| 103 |
+
|
| 104 |
+
# (Ubuntu / Debianユーザー) sox + ffmpegをインストールします。
|
| 105 |
+
apt install libsox-dev ffmpeg
|
| 106 |
+
|
| 107 |
+
# (Ubuntu / Debianユーザー) pyaudio をインストールします。
|
| 108 |
+
apt install build-essential \
|
| 109 |
+
cmake \
|
| 110 |
+
libasound-dev \
|
| 111 |
+
portaudio19-dev \
|
| 112 |
+
libportaudio2 \
|
| 113 |
+
libportaudiocpp0
|
| 114 |
+
|
| 115 |
+
# fish-speechをインストールします。
|
| 116 |
+
pip3 install -e .[stable]
|
| 117 |
+
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
## macos setup
|
| 121 |
+
|
| 122 |
+
推論をMPS上で行う場合は、`--device mps`フラグを追加してください。
|
| 123 |
+
推論速度の比較は[こちらのPR](https://github.com/fishaudio/fish-speech/pull/461#issuecomment-2284277772)を参考にしてください。
|
| 124 |
+
|
| 125 |
+
!!! warning
|
| 126 |
+
AppleSiliconのデバイスでは、compileオプションに正式に対応していませんので、推論速度が向上する保証はありません。
|
| 127 |
+
|
| 128 |
+
```bash
|
| 129 |
+
# create a python 3.10 virtual environment, you can also use virtualenv
|
| 130 |
+
conda create -n fish-speech python=3.10
|
| 131 |
+
conda activate fish-speech
|
| 132 |
+
# install pytorch
|
| 133 |
+
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1
|
| 134 |
+
# install fish-speech
|
| 135 |
+
pip install -e .[stable]
|
| 136 |
+
```
|
| 137 |
+
|
| 138 |
+
## Docker セットアップ
|
| 139 |
+
|
| 140 |
+
1. NVIDIA Container Toolkit のインストール:
|
| 141 |
+
|
| 142 |
+
Docker で GPU を使用してモデルのトレーニングと推論を行うには、NVIDIA Container Toolkit をインストールする必要があります:
|
| 143 |
+
|
| 144 |
+
Ubuntu ユーザーの場合:
|
| 145 |
+
|
| 146 |
+
```bash
|
| 147 |
+
# リポジトリの追加
|
| 148 |
+
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
|
| 149 |
+
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
|
| 150 |
+
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
|
| 151 |
+
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
|
| 152 |
+
# nvidia-container-toolkit のインストール
|
| 153 |
+
sudo apt-get update
|
| 154 |
+
sudo apt-get install -y nvidia-container-toolkit
|
| 155 |
+
# Docker サービスの再起動
|
| 156 |
+
sudo systemctl restart docker
|
| 157 |
+
```
|
| 158 |
+
|
| 159 |
+
他の Linux ディストリビューションを使用している場合は、以下のインストールガイドを参照してください:[NVIDIA Container Toolkit Install-guide](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html)。
|
| 160 |
+
|
| 161 |
+
2. fish-speech イメージのプルと実行
|
| 162 |
+
|
| 163 |
+
```shell
|
| 164 |
+
# イメージのプル
|
| 165 |
+
docker pull fishaudio/fish-speech:latest-dev
|
| 166 |
+
# イメージの実行
|
| 167 |
+
docker run -it \
|
| 168 |
+
--name fish-speech \
|
| 169 |
+
--gpus all \
|
| 170 |
+
-p 7860:7860 \
|
| 171 |
+
fishaudio/fish-speech:latest-dev \
|
| 172 |
+
zsh
|
| 173 |
+
# 他のポートを使用する場合は、-p パラメータを YourPort:7860 に変更してください
|
| 174 |
+
```
|
| 175 |
+
|
| 176 |
+
3. モデルの依存関係のダウンロード
|
| 177 |
+
|
| 178 |
+
Docker コンテナ内のターミナルにいることを確認し、huggingface リポジトリから必要な `vqgan` と `llama` モデルをダウンロードします。
|
| 179 |
+
|
| 180 |
+
```bash
|
| 181 |
+
huggingface-cli download fishaudio/fish-speech-1.4 --local-dir checkpoints/fish-speech-1.4
|
| 182 |
+
```
|
| 183 |
+
|
| 184 |
+
4. 環境変数の設定と WebUI へのアクセス
|
| 185 |
+
|
| 186 |
+
Docker コンテナ内のターミナルで、`export GRADIO_SERVER_NAME="0.0.0.0"` と入力して、外部から Docker 内の gradio サービスにアクセスできるようにします。
|
| 187 |
+
次に、Docker コンテナ内のターミナルで `python tools/webui.py` と入力して WebUI サービスを起動します。
|
| 188 |
+
|
| 189 |
+
WSL または MacOS の場合は、[http://localhost:7860](http://localhost:7860) にアクセスして WebUI インターフェースを開くことができます。
|
| 190 |
+
|
| 191 |
+
サーバーにデプロイしている場合は、localhost をサーバーの IP に置き換えてください。
|
| 192 |
+
|
| 193 |
+
## 変更履歴
|
| 194 |
+
|
| 195 |
+
- 2024/09/10: Fish-Speech を Ver.1.4 に更新し、データセットのサイズを増加させ、quantizer n_groups を 4 から 8 に変更しました。
|
| 196 |
+
- 2024/07/02: Fish-Speech を Ver.1.2 に更新し、VITS デコーダーを削除し、ゼロショット能力を大幅に強化しました。
|
| 197 |
+
- 2024/05/10: Fish-Speech を Ver.1.1 に更新し、VITS デコーダーを実装して WER を減��させ、音色の類似性を向上させました。
|
| 198 |
+
- 2024/04/22: Fish-Speech Ver.1.0 を完成させ、VQGAN および LLAMA モデルを大幅に修正しました。
|
| 199 |
+
- 2023/12/28: `lora`微調整サポートを追加しました。
|
| 200 |
+
- 2023/12/27: `gradient checkpointing`、`causual sampling`、および`flash-attn`サポートを追加しました。
|
| 201 |
+
- 2023/12/19: webui および HTTP API を更新しました。
|
| 202 |
+
- 2023/12/18: 微調整ドキュメントおよび関連例を更新しました。
|
| 203 |
+
- 2023/12/17: `text2semantic`モデルを更新し、自由音素モードをサポートしました。
|
| 204 |
+
- 2023/12/13: ベータ版をリリースし、VQGAN モデルおよび LLAMA に基づく言語モデル(音素のみサポート)を含みます。
|
| 205 |
+
|
| 206 |
+
## 謝辞
|
| 207 |
+
|
| 208 |
+
- [VITS2 (daniilrobnikov)](https://github.com/daniilrobnikov/vits2)
|
| 209 |
+
- [Bert-VITS2](https://github.com/fishaudio/Bert-VITS2)
|
| 210 |
+
- [GPT VITS](https://github.com/innnky/gpt-vits)
|
| 211 |
+
- [MQTTS](https://github.com/b04901014/MQTTS)
|
| 212 |
+
- [GPT Fast](https://github.com/pytorch-labs/gpt-fast)
|
| 213 |
+
- [Transformers](https://github.com/huggingface/transformers)
|
| 214 |
+
- [GPT-SoVITS](https://github.com/RVC-Boss/GPT-SoVITS)
|
docs/ja/inference.md
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 推論
|
| 2 |
+
|
| 3 |
+
推論は、コマンドライン、HTTP API、および Web UI をサポートしています。
|
| 4 |
+
|
| 5 |
+
!!! note
|
| 6 |
+
全体として、推論は次のいくつかの部分で構成されています:
|
| 7 |
+
|
| 8 |
+
1. VQGANを使用して、与えられた約10秒の音声をエンコードします。
|
| 9 |
+
2. エンコードされたセマンティックトークンと対応するテキストを例として言語モデルに入力します。
|
| 10 |
+
3. 新しいテキストが与えられた場合、モデルに対応するセマンティックトークンを生成させます。
|
| 11 |
+
4. 生成されたセマンティックトークンをVITS / VQGANに入力してデコードし、対応する音声を生成します。
|
| 12 |
+
|
| 13 |
+
## コマンドライン推論
|
| 14 |
+
|
| 15 |
+
必要な`vqgan`および`llama`モデルを Hugging Face リポジトリからダウンロードします。
|
| 16 |
+
|
| 17 |
+
```bash
|
| 18 |
+
huggingface-cli download fishaudio/fish-speech-1.4 --local-dir checkpoints/fish-speech-1.4
|
| 19 |
+
```
|
| 20 |
+
|
| 21 |
+
### 1. 音声からプロンプトを生成する:
|
| 22 |
+
|
| 23 |
+
!!! note
|
| 24 |
+
モデルにランダムに音声の音色を選ばせる場合、このステップをスキップできます。
|
| 25 |
+
|
| 26 |
+
```bash
|
| 27 |
+
python tools/vqgan/inference.py \
|
| 28 |
+
-i "paimon.wav" \
|
| 29 |
+
--checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth"
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
`fake.npy`ファイルが生成されるはずです。
|
| 33 |
+
|
| 34 |
+
### 2. テキストからセマンティックトークンを生成する:
|
| 35 |
+
|
| 36 |
+
```bash
|
| 37 |
+
python tools/llama/generate.py \
|
| 38 |
+
--text "変換したいテキスト" \
|
| 39 |
+
--prompt-text "参照テキスト" \
|
| 40 |
+
--prompt-tokens "fake.npy" \
|
| 41 |
+
--checkpoint-path "checkpoints/fish-speech-1.4" \
|
| 42 |
+
--num-samples 2 \
|
| 43 |
+
--compile
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
このコマンドは、作業ディレクトリに`codes_N`ファイルを作成します。ここで、N は 0 から始まる整数です。
|
| 47 |
+
|
| 48 |
+
!!! note
|
| 49 |
+
`--compile`を使用して CUDA カーネルを融合し、より高速な推論を実現することができます(約 30 トークン/秒 -> 約 500 トークン/秒)。
|
| 50 |
+
それに対応して、加速を使用しない場合は、`--compile`パラメータをコメントアウトできます。
|
| 51 |
+
|
| 52 |
+
!!! info
|
| 53 |
+
bf16 をサポートしていない GPU の場合、`--half`パラメータを使用する必要があるかもしれません。
|
| 54 |
+
|
| 55 |
+
### 3. セマンティックトークンから音声を生成する:
|
| 56 |
+
|
| 57 |
+
#### VQGAN デコーダー
|
| 58 |
+
|
| 59 |
+
```bash
|
| 60 |
+
python tools/vqgan/inference.py \
|
| 61 |
+
-i "codes_0.npy" \
|
| 62 |
+
--checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth"
|
| 63 |
+
```
|
| 64 |
+
|
| 65 |
+
## HTTP API 推論
|
| 66 |
+
|
| 67 |
+
推論のための HTTP API を提供しています。次のコマンドを使用してサーバーを起動できます:
|
| 68 |
+
|
| 69 |
+
```bash
|
| 70 |
+
python -m tools.api \
|
| 71 |
+
--listen 0.0.0.0:8080 \
|
| 72 |
+
--llama-checkpoint-path "checkpoints/fish-speech-1.4" \
|
| 73 |
+
--decoder-checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth" \
|
| 74 |
+
--decoder-config-name firefly_gan_vq
|
| 75 |
+
```
|
| 76 |
+
|
| 77 |
+
> 推論を高速化したい場合は、`--compile` パラメータを追加できます。
|
| 78 |
+
|
| 79 |
+
その後、`http://127.0.0.1:8080/`で API を表示およびテストできます。
|
| 80 |
+
|
| 81 |
+
以下は、`tools/post_api.py` を使用してリクエストを送信する例です。
|
| 82 |
+
|
| 83 |
+
```bash
|
| 84 |
+
python -m tools.post_api \
|
| 85 |
+
--text "入力するテキスト" \
|
| 86 |
+
--reference_audio "参照音声へのパス" \
|
| 87 |
+
--reference_text "参照音声テキスト" \
|
| 88 |
+
--streaming True
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
上記のコマンドは、参照音声の情報に基づいて必要な音声を合成し、ストリーミング方式で返すことを示しています。
|
| 92 |
+
|
| 93 |
+
!!! info
|
| 94 |
+
使用可能なパラメータの詳細については、コマンド` python -m tools.post_api -h `を使用してください
|
| 95 |
+
|
| 96 |
+
## WebUI 推論
|
| 97 |
+
|
| 98 |
+
次のコマンドを使用して WebUI を起動できます:
|
| 99 |
+
|
| 100 |
+
```bash
|
| 101 |
+
python -m tools.webui \
|
| 102 |
+
--llama-checkpoint-path "checkpoints/fish-speech-1.4" \
|
| 103 |
+
--decoder-checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth" \
|
| 104 |
+
--decoder-config-name firefly_gan_vq
|
| 105 |
+
```
|
| 106 |
+
> 推論を高速化したい場合は、`--compile` パラメータを追加できます。
|
| 107 |
+
|
| 108 |
+
!!! note
|
| 109 |
+
ラベルファイルと参照音声ファイルをメインディレクトリの `references` フォルダ(自分で作成する必要があります)に事前に保存しておくことで、WebUI で直接呼び出すことができます。
|
| 110 |
+
|
| 111 |
+
!!! note
|
| 112 |
+
Gradio 環境変数(`GRADIO_SHARE`、`GRADIO_SERVER_PORT`、`GRADIO_SERVER_NAME`など)を使用して WebUI を構成できます。
|
| 113 |
+
|
| 114 |
+
お楽しみください!
|
docs/ja/samples.md
ADDED
|
@@ -0,0 +1,225 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# サンプル
|
| 2 |
+
|
| 3 |
+
v1.4デモは[こちら](https://speech.fish.audio/samples/)に更新されています
|
| 4 |
+
|
| 5 |
+
v1.2のサンプルは[Bilibili](https://www.bilibili.com/video/BV1wz421B71D/)で利用可能です。
|
| 6 |
+
|
| 7 |
+
以下のサンプルはv1.1モデルからのものです。
|
| 8 |
+
|
| 9 |
+
## 中国語の文1
|
| 10 |
+
```
|
| 11 |
+
人間灯火倒映湖中,她的渴望让静水泛起涟漪。若代价只是孤独,那就让这份愿望肆意流淌。
|
| 12 |
+
流入她所注视的世间,也流入她如湖水般澄澈的目光。
|
| 13 |
+
```
|
| 14 |
+
|
| 15 |
+
<table>
|
| 16 |
+
<thead>
|
| 17 |
+
<tr>
|
| 18 |
+
<th>話者</th>
|
| 19 |
+
<th>入力音声</th>
|
| 20 |
+
<th>合成音声</th>
|
| 21 |
+
</tr>
|
| 22 |
+
</thead>
|
| 23 |
+
<tbody>
|
| 24 |
+
<tr>
|
| 25 |
+
<td>ナヒーダ (原神)</td>
|
| 26 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/zh/0_input.wav" /></td>
|
| 27 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/zh/0_output.wav" /></td>
|
| 28 |
+
</tr>
|
| 29 |
+
<tr>
|
| 30 |
+
<td>鍾離 (原神)</td>
|
| 31 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/zh/1_input.wav" /></td>
|
| 32 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/zh/1_output.wav" /></td>
|
| 33 |
+
</tr>
|
| 34 |
+
<tr>
|
| 35 |
+
<td>フリナ (原神)</td>
|
| 36 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/zh/2_input.wav" /></td>
|
| 37 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/zh/2_output.wav" /></td>
|
| 38 |
+
</tr>
|
| 39 |
+
<tr>
|
| 40 |
+
<td>ランダム話者1</td>
|
| 41 |
+
<td> - </td>
|
| 42 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/zh/4_output.wav" /></td>
|
| 43 |
+
</tr>
|
| 44 |
+
<tr>
|
| 45 |
+
<td>ランダム話者2</td>
|
| 46 |
+
<td> - </td>
|
| 47 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/zh/5_output.wav" /></td>
|
| 48 |
+
</tr>
|
| 49 |
+
</tbody>
|
| 50 |
+
</table>
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
## 中国語の文2
|
| 54 |
+
```
|
| 55 |
+
你们这个是什么群啊,你们这是害人不浅啊你们这个群!谁是群主,出来!真的太过分了。你们搞这个群干什么?
|
| 56 |
+
我儿子每一科的成绩都不过那个平均分呐,他现在初二,你叫我儿子怎么办啊?他现在还不到高中啊?
|
| 57 |
+
你们害死我儿子了!快点出来你这个群主!再这样我去报警了啊!我跟你们说你们这一帮人啊,一天到晚啊,
|
| 58 |
+
搞这些什么游戏啊,动漫啊,会害死你们的,你们没有前途我跟你说。你们这九百多个人,好好学习不好吗?
|
| 59 |
+
一天到晚在上网。有什么意思啊?麻烦你重视一下你们的生活的目标啊?有一点学习目标行不行?一天到晚上网是不是人啊?
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
<table>
|
| 63 |
+
<thead>
|
| 64 |
+
<tr>
|
| 65 |
+
<th>話者</th>
|
| 66 |
+
<th>入力音声</th>
|
| 67 |
+
<th>合成音声</th>
|
| 68 |
+
</tr>
|
| 69 |
+
</thead>
|
| 70 |
+
<tbody>
|
| 71 |
+
<tr>
|
| 72 |
+
<td>ナヒーダ (原神)</td>
|
| 73 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/zh/0_input.wav" /></td>
|
| 74 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/zh/6_output.wav" /></td>
|
| 75 |
+
</tr>
|
| 76 |
+
<tr>
|
| 77 |
+
<td>ランダム話者</td>
|
| 78 |
+
<td> - </td>
|
| 79 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/zh/7_output.wav" /></td>
|
| 80 |
+
</tr>
|
| 81 |
+
</tbody>
|
| 82 |
+
</table>
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
## 中国語の文3
|
| 86 |
+
```
|
| 87 |
+
大家好,我是 Fish Audio 开发的开源文本转语音模型。经过十五万小时的数据训练,
|
| 88 |
+
我已经能够熟练掌握中文、日语和英语,我的语言处理能力接近人类水平,声音表现形式丰富多变。
|
| 89 |
+
作为一个仅有亿级参数的模型,我相信社区成员能够在个人设备上轻松运行和微调,让我成为您的私人语音助手。
|
| 90 |
+
```
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
<table>
|
| 94 |
+
<thead>
|
| 95 |
+
<tr>
|
| 96 |
+
<th>話者</th>
|
| 97 |
+
<th>入力音声</th>
|
| 98 |
+
<th>合成音声</th>
|
| 99 |
+
</tr>
|
| 100 |
+
</thead>
|
| 101 |
+
<tbody>
|
| 102 |
+
<tr>
|
| 103 |
+
<td>ランダム話者</td>
|
| 104 |
+
<td> - </td>
|
| 105 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/zh/8_output.wav" /></td>
|
| 106 |
+
</tr>
|
| 107 |
+
</tbody>
|
| 108 |
+
</table>
|
| 109 |
+
|
| 110 |
+
## 英語の文1
|
| 111 |
+
|
| 112 |
+
```
|
| 113 |
+
In the realm of advanced technology, the evolution of artificial intelligence stands as a
|
| 114 |
+
monumental achievement. This dynamic field, constantly pushing the boundaries of what
|
| 115 |
+
machines can do, has seen rapid growth and innovation. From deciphering complex data
|
| 116 |
+
patterns to driving cars autonomously, AI's applications are vast and diverse.
|
| 117 |
+
```
|
| 118 |
+
|
| 119 |
+
<table>
|
| 120 |
+
<thead>
|
| 121 |
+
<tr>
|
| 122 |
+
<th>話者</th>
|
| 123 |
+
<th>入力音声</th>
|
| 124 |
+
<th>合成音声</th>
|
| 125 |
+
</tr>
|
| 126 |
+
</thead>
|
| 127 |
+
<tbody>
|
| 128 |
+
<tr>
|
| 129 |
+
<td>ランダム話者1</td>
|
| 130 |
+
<td> - </td>
|
| 131 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/en/0_output.wav" /></td>
|
| 132 |
+
</tr>
|
| 133 |
+
<tr>
|
| 134 |
+
<td>ランダム話者2</td>
|
| 135 |
+
<td> - </td>
|
| 136 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/en/1_output.wav" /></td>
|
| 137 |
+
</tr>
|
| 138 |
+
</tbody>
|
| 139 |
+
</table>
|
| 140 |
+
|
| 141 |
+
## 英語の文2
|
| 142 |
+
```
|
| 143 |
+
Hello everyone, I am an open-source text-to-speech model developed by
|
| 144 |
+
Fish Audio. After training with 150,000 hours of data, I have become proficient
|
| 145 |
+
in Chinese, Japanese, and English, and my language processing abilities
|
| 146 |
+
are close to human level. My voice is capable of a wide range of expressions.
|
| 147 |
+
As a model with only hundreds of millions of parameters, I believe community
|
| 148 |
+
members can easily run and fine-tune me on their personal devices, allowing
|
| 149 |
+
me to serve as your personal voice assistant.
|
| 150 |
+
```
|
| 151 |
+
|
| 152 |
+
<table>
|
| 153 |
+
<thead>
|
| 154 |
+
<tr>
|
| 155 |
+
<th>話者</th>
|
| 156 |
+
<th>入力音声</th>
|
| 157 |
+
<th>合成音声</th>
|
| 158 |
+
</tr>
|
| 159 |
+
</thead>
|
| 160 |
+
<tbody>
|
| 161 |
+
<tr>
|
| 162 |
+
<td>ランダム話者</td>
|
| 163 |
+
<td> - </td>
|
| 164 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/en/2_output.wav" /></td>
|
| 165 |
+
</tr>
|
| 166 |
+
</tbody>
|
| 167 |
+
</table>
|
| 168 |
+
|
| 169 |
+
## 日本語の文1
|
| 170 |
+
|
| 171 |
+
```
|
| 172 |
+
先進技術の領域において、人工知能の進化は画期的な成果として立っています。常に機械ができることの限界を
|
| 173 |
+
押し広げているこのダイナミックな分野は、急速な成長と革新を見せています。複雑なデータパターンの解読か
|
| 174 |
+
ら自動運転車の操縦まで、AIの応用は広範囲に及びます。
|
| 175 |
+
```
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
<table>
|
| 179 |
+
<thead>
|
| 180 |
+
<tr>
|
| 181 |
+
<th>話者</th>
|
| 182 |
+
<th>入力音声</th>
|
| 183 |
+
<th>合成音声</th>
|
| 184 |
+
</tr>
|
| 185 |
+
</thead>
|
| 186 |
+
<tbody>
|
| 187 |
+
<tr>
|
| 188 |
+
<td>ランダム話者1</td>
|
| 189 |
+
<td> - </td>
|
| 190 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/ja/0_output.wav" /></td>
|
| 191 |
+
</tr>
|
| 192 |
+
<tr>
|
| 193 |
+
<td>ランダム話者2</td>
|
| 194 |
+
<td> - </td>
|
| 195 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/ja/1_output.wav" /></td>
|
| 196 |
+
</tr>
|
| 197 |
+
</tbody>
|
| 198 |
+
</table>
|
| 199 |
+
|
| 200 |
+
## 日本語の文2
|
| 201 |
+
```
|
| 202 |
+
皆さん、こんにちは。私はフィッシュオーディオによって開発されたオープンソースのテ
|
| 203 |
+
キストから音声への変換モデルです。15万時間のデータトレーニングを経て、
|
| 204 |
+
中国語、日本語、英語を熟知しており、言語処理能力は人間に近いレベルです。
|
| 205 |
+
声の表現も多彩で豊かです。数億のパラメータを持つこのモデルは、コミュニティ
|
| 206 |
+
のメンバーが個人のデバイスで簡単に実行し、微調整することができると
|
| 207 |
+
信じています。これにより、私を個人の音声アシスタントとして活用できます。
|
| 208 |
+
```
|
| 209 |
+
|
| 210 |
+
<table>
|
| 211 |
+
<thead>
|
| 212 |
+
<tr>
|
| 213 |
+
<th>話者</th>
|
| 214 |
+
<th>入力音声</th>
|
| 215 |
+
<th>合成音声</th>
|
| 216 |
+
</tr>
|
| 217 |
+
</thead>
|
| 218 |
+
<tbody>
|
| 219 |
+
<tr>
|
| 220 |
+
<td>ランダム話者</td>
|
| 221 |
+
<td> - </td>
|
| 222 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/ja/2_output.wav" /></td>
|
| 223 |
+
</tr>
|
| 224 |
+
</tbody>
|
| 225 |
+
</table>
|
docs/ja/start_agent.md
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# エージェントの開始
|
| 2 |
+
|
| 3 |
+
!!! note
|
| 4 |
+
もしあなたがネイティブ・スピーカーで、翻訳に問題があるとお感じでしたら、issueかpull requestをお送りください!
|
| 5 |
+
|
| 6 |
+
## 要件
|
| 7 |
+
|
| 8 |
+
- GPUメモリ: 最低8GB(量子化使用時)、16GB以上推奨
|
| 9 |
+
- ディスク使用量: 10GB
|
| 10 |
+
|
| 11 |
+
## モデルのダウンロード
|
| 12 |
+
|
| 13 |
+
以下のコマンドでモデルを取得できます:
|
| 14 |
+
|
| 15 |
+
```bash
|
| 16 |
+
huggingface-cli download fishaudio/fish-agent-v0.1-3b --local-dir checkpoints/fish-agent-v0.1-3b
|
| 17 |
+
```
|
| 18 |
+
|
| 19 |
+
これらを'checkpoints'フォルダに配置してください。
|
| 20 |
+
|
| 21 |
+
また、[inference](inference.md)の手順に従ってfish-speechモデルもダウンロードする必要があります。
|
| 22 |
+
|
| 23 |
+
checkpointsには2つのフォルダが必要です。
|
| 24 |
+
|
| 25 |
+
`checkpoints/fish-speech-1.4`と`checkpoints/fish-agent-v0.1-3b`です。
|
| 26 |
+
|
| 27 |
+
## 環境準備
|
| 28 |
+
|
| 29 |
+
すでにFish-speechをお持ちの場合は、以下の指示を追加するだけで直接使用できます:
|
| 30 |
+
```bash
|
| 31 |
+
pip install cachetools
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
!!! note
|
| 35 |
+
コンパイルにはPythonバージョン3.12未満を使用してください。
|
| 36 |
+
|
| 37 |
+
お持ちでない場合は、以下のコマンドで環境を構築してください:
|
| 38 |
+
|
| 39 |
+
```bash
|
| 40 |
+
sudo apt-get install portaudio19-dev
|
| 41 |
+
|
| 42 |
+
pip install -e .[stable]
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
## エージェントデモの起動
|
| 46 |
+
|
| 47 |
+
fish-agentを構築するには、メインフォルダで以下のコマンドを使用してください:
|
| 48 |
+
|
| 49 |
+
```bash
|
| 50 |
+
python -m tools.api --llama-checkpoint-path checkpoints/fish-agent-v0.1-3b/ --mode agent --compile
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
`--compile`引数はPython < 3.12でのみサポートされており、トークン生成を大幅に高速化します。
|
| 54 |
+
|
| 55 |
+
一度にコンパイルは行われません(覚えておいてください)。
|
| 56 |
+
|
| 57 |
+
次に、別のターミナルを開いて以下のコマンドを使用します:
|
| 58 |
+
|
| 59 |
+
```bash
|
| 60 |
+
python -m tools.e2e_webui
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
これにより、デバイス上にGradio WebUIが作成されます。
|
| 64 |
+
|
| 65 |
+
モデルを初めて使用する際は、(`--compile`がTrueの場合)しばらくコンパイルが行われますので、お待ちください。
|
| 66 |
+
|
| 67 |
+
## Gradio Webui
|
| 68 |
+
<p align="center">
|
| 69 |
+
<img src="../../assets/figs/agent_gradio.png" width="75%">
|
| 70 |
+
</p>
|
| 71 |
+
|
| 72 |
+
お楽しみください!
|
| 73 |
+
|
| 74 |
+
## パフォーマンス
|
| 75 |
+
|
| 76 |
+
テストでは、4060搭載のラップトップではかろうじて動作しますが、非常に厳しい状態で、約8トークン/秒程度です。4090ではコンパイル時に約95トークン/秒で、これが推奨環境です。
|
| 77 |
+
|
| 78 |
+
# エージェントについて
|
| 79 |
+
|
| 80 |
+
このデモは初期アルファテストバージョンで、推論速度の最適化が必要で、修正を待つバグが多数あります。バグを発見した場合や修正したい場合は、issueやプルリクエストをいただけると大変嬉しく思います。
|
docs/ko/finetune.md
ADDED
|
@@ -0,0 +1,128 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 파인튜닝
|
| 2 |
+
|
| 3 |
+
이 페이지를 열었다는 것은, 사전 학습된 퓨샷(Few-shot) 모델의 성능에 만족하지 못했다는 의미일 것입니다. 데이터셋의 성능을 향상시키기 위해 모델을 파인튜닝하고 싶으시겠죠.
|
| 4 |
+
|
| 5 |
+
현재 버전에서는 'LLAMA' 부분만 파인튜닝하시면 됩니다.
|
| 6 |
+
|
| 7 |
+
## LLAMA 파인튜닝
|
| 8 |
+
### 1. 데이터셋 준비
|
| 9 |
+
|
| 10 |
+
```
|
| 11 |
+
.
|
| 12 |
+
├── SPK1
|
| 13 |
+
│ ├── 21.15-26.44.lab
|
| 14 |
+
│ ├── 21.15-26.44.mp3
|
| 15 |
+
│ ├── 27.51-29.98.lab
|
| 16 |
+
│ ├── 27.51-29.98.mp3
|
| 17 |
+
│ ├── 30.1-32.71.lab
|
| 18 |
+
│ └── 30.1-32.71.mp3
|
| 19 |
+
└── SPK2
|
| 20 |
+
├── 38.79-40.85.lab
|
| 21 |
+
└── 38.79-40.85.mp3
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
위와 같은 형식으로 데이터셋을 변환하여 `data` 디렉토리 안에 배치하세요. 오디오 파일의 확장자는 `.mp3`, `.wav`, `.flac` 중 하나여야 하며, 주석 파일은 `.lab` 확장자를 사용해야 합니다.
|
| 25 |
+
|
| 26 |
+
!!! info "데이터셋 형식"
|
| 27 |
+
`.lab` 주석 파일은 오디오의 전사 내용만 포함하면 되며, 특별한 형식이 필요하지 않습니다. 예를 들어, `hi.mp3`에서 "Hello, goodbye"라는 대사를 말한다면, `hi.lab` 파일에는 "Hello, goodbye"라는 한 줄의 텍스트만 있어야 합니다.
|
| 28 |
+
|
| 29 |
+
!!! warning
|
| 30 |
+
데이터셋에 대한 음량 정규화(loudness normalization)를 적용하는 것이 좋습니다. 이를 위해 [fish-audio-preprocess](https://github.com/fishaudio/audio-preprocess)를 사용할 수 있습니다.
|
| 31 |
+
|
| 32 |
+
```bash
|
| 33 |
+
fap loudness-norm data-raw data --clean
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
### 2. 시맨틱 토큰 배치 추출
|
| 37 |
+
|
| 38 |
+
VQGAN 가중치를 다운로드했는지 확인하세요. 다운로드하지 않았다면 아래 명령어를 실행하세요:
|
| 39 |
+
|
| 40 |
+
```bash
|
| 41 |
+
huggingface-cli download fishaudio/fish-speech-1.4 --local-dir checkpoints/fish-speech-1.4
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
이후 시맨틱 토큰을 추출하기 위해 아래 명령어를 실행하세요:
|
| 45 |
+
|
| 46 |
+
```bash
|
| 47 |
+
python tools/vqgan/extract_vq.py data \
|
| 48 |
+
--num-workers 1 --batch-size 16 \
|
| 49 |
+
--config-name "firefly_gan_vq" \
|
| 50 |
+
--checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth"
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
!!! note
|
| 54 |
+
추출 속도를 높이기 위해 `--num-workers`와 `--batch-size` 값을 조정할 수 있지만, GPU 메모리 한도를 초과하지 않도록 주의하세요.
|
| 55 |
+
VITS 형식의 경우, `--filelist xxx.list`를 사용하여 파일 목록을 지정할 수 있습니다.
|
| 56 |
+
|
| 57 |
+
이 명령을 실행하면 `data` 디렉토리 안에 `.npy` 파일이 생성됩니다. 다음과 같이 표시됩니다:
|
| 58 |
+
|
| 59 |
+
```
|
| 60 |
+
.
|
| 61 |
+
├── SPK1
|
| 62 |
+
│ ├── 21.15-26.44.lab
|
| 63 |
+
│ ├── 21.15-26.44.mp3
|
| 64 |
+
│ ├── 21.15-26.44.npy
|
| 65 |
+
│ ├── 27.51-29.98.lab
|
| 66 |
+
│ ├── 27.51-29.98.mp3
|
| 67 |
+
│ ├── 27.51-29.98.npy
|
| 68 |
+
│ ├── 30.1-32.71.lab
|
| 69 |
+
│ ├── 30.1-32.71.mp3
|
| 70 |
+
│ └── 30.1-32.71.npy
|
| 71 |
+
└── SPK2
|
| 72 |
+
├── 38.79-40.85.lab
|
| 73 |
+
├── 38.79-40.85.mp3
|
| 74 |
+
└── 38.79-40.85.npy
|
| 75 |
+
```
|
| 76 |
+
|
| 77 |
+
### 3. 데이터셋을 protobuf로 패킹
|
| 78 |
+
|
| 79 |
+
```bash
|
| 80 |
+
python tools/llama/build_dataset.py \
|
| 81 |
+
--input "data" \
|
| 82 |
+
--output "data/protos" \
|
| 83 |
+
--text-extension .lab \
|
| 84 |
+
--num-workers 16
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
명령이 완료되면 `data` 디렉토리 안에 `quantized-dataset-ft.protos` 파일이 생성됩니다.
|
| 88 |
+
|
| 89 |
+
### 4. 마지막으로, LoRA를 이용한 파인튜닝
|
| 90 |
+
|
| 91 |
+
마찬가지로, `LLAMA` 가중치를 다운로드했는지 확인하세요. 다운로드하지 않았다면 아래 명령어를 실행하세요:
|
| 92 |
+
|
| 93 |
+
```bash
|
| 94 |
+
huggingface-cli download fishaudio/fish-speech-1.4 --local-dir checkpoints/fish-speech-1.4
|
| 95 |
+
```
|
| 96 |
+
|
| 97 |
+
마지막으로, 아래 명령어를 실행하여 파인튜닝을 시작할 수 있습니다:
|
| 98 |
+
|
| 99 |
+
```bash
|
| 100 |
+
python fish_speech/train.py --config-name text2semantic_finetune \
|
| 101 |
+
project=$project \
|
| 102 |
+
[email protected]_config=r_8_alpha_16
|
| 103 |
+
```
|
| 104 |
+
|
| 105 |
+
!!! note
|
| 106 |
+
`batch_size`, `gradient_accumulation_steps` 등의 학습 매개변수를 GPU 메모리에 맞게 조정하려면 `fish_speech/configs/text2semantic_finetune.yaml` 파일을 수정할 수 있습니다.
|
| 107 |
+
|
| 108 |
+
!!! note
|
| 109 |
+
Windows 사용자의 경우, `nccl` 문제를 피하려면 `trainer.strategy.process_group_backend=gloo`를 사용할 수 있습니다.
|
| 110 |
+
|
| 111 |
+
훈련이 완료되면 [추론](inference.md) 섹션을 참고하여 음성을 생성할 수 있습니다.
|
| 112 |
+
|
| 113 |
+
!!! info
|
| 114 |
+
기본적으로 모델은 화자의 말하는 패턴만 학습하고 음색은 학습하지 않습니다. 음색의 안정성을 위해 프롬프트를 사용해야 합니다.
|
| 115 |
+
음색을 학습하려면 훈련 단계를 늘릴 수 있지만, 이는 과적합의 위험을 초래할 수 있습니다.
|
| 116 |
+
|
| 117 |
+
훈련이 끝나면 LoRA 가중치를 일반 가중치로 변환한 후에 추론을 수행해야 합니다.
|
| 118 |
+
|
| 119 |
+
```bash
|
| 120 |
+
python tools/llama/merge_lora.py \
|
| 121 |
+
--lora-config r_8_alpha_16 \
|
| 122 |
+
--base-weight checkpoints/fish-speech-1.4 \
|
| 123 |
+
--lora-weight results/$project/checkpoints/step_000000010.ckpt \
|
| 124 |
+
--output checkpoints/fish-speech-1.4-yth-lora/
|
| 125 |
+
```
|
| 126 |
+
|
| 127 |
+
!!! note
|
| 128 |
+
다른 체크포인트도 시도해 볼 수 있습니다. 요구 사항에 맞는 가장 초기 체크포인트를 사용하는 것이 좋습니다. 이들은 종종 분포 밖(OOD) 데이터에서 더 좋은 성능을 발휘합니다.
|
docs/ko/index.md
ADDED
|
@@ -0,0 +1,215 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 소개
|
| 2 |
+
|
| 3 |
+
<div>
|
| 4 |
+
<a target="_blank" href="https://discord.gg/Es5qTB9BcN">
|
| 5 |
+
<img alt="Discord" src="https://img.shields.io/discord/1214047546020728892?color=%23738ADB&label=Discord&logo=discord&logoColor=white&style=flat-square"/>
|
| 6 |
+
</a>
|
| 7 |
+
<a target="_blank" href="http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=jCKlUP7QgSm9kh95UlBoYv6s1I-Apl1M&authKey=xI5ttVAp3do68IpEYEalwXSYZFdfxZSkah%2BctF5FIMyN2NqAa003vFtLqJyAVRfF&noverify=0&group_code=593946093">
|
| 8 |
+
<img alt="QQ" src="https://img.shields.io/badge/QQ Group-%2312B7F5?logo=tencent-qq&logoColor=white&style=flat-square"/>
|
| 9 |
+
</a>
|
| 10 |
+
<a target="_blank" href="https://hub.docker.com/r/fishaudio/fish-speech">
|
| 11 |
+
<img alt="Docker" src="https://img.shields.io/docker/pulls/fishaudio/fish-speech?style=flat-square&logo=docker"/>
|
| 12 |
+
</a>
|
| 13 |
+
</div>
|
| 14 |
+
|
| 15 |
+
!!! warning
|
| 16 |
+
이 코드베이스의 불법적인 사용에 대해서는 책임을 지지 않습니다. DMCA(Digital Millennium Copyright Act) 및 해당 지역의 관련 법률을 참조하십시오. <br/>
|
| 17 |
+
이 코드베이스와 모든 모델은 CC-BY-NC-SA-4.0 라이선스에 따라 배포됩니다.
|
| 18 |
+
|
| 19 |
+
<p align="center">
|
| 20 |
+
<img src="../assets/figs/diagram.png" width="75%">
|
| 21 |
+
</p>
|
| 22 |
+
|
| 23 |
+
## 요구 사항
|
| 24 |
+
|
| 25 |
+
- GPU 메모리: 4GB (추론용), 8GB (파인튜닝용)
|
| 26 |
+
- 시스템: Linux, Windows
|
| 27 |
+
|
| 28 |
+
## Windows 설정
|
| 29 |
+
|
| 30 |
+
고급 Windows 사용자는 WSL2 또는 Docker를 사용하여 코드베이스를 실행하는 것을 고려할 수 있습니다.
|
| 31 |
+
|
| 32 |
+
```bash
|
| 33 |
+
# 파이썬 3.10 가상 환경 생성, virtualenv도 사용할 수 있습니다.
|
| 34 |
+
conda create -n fish-speech python=3.10
|
| 35 |
+
conda activate fish-speech
|
| 36 |
+
|
| 37 |
+
# pytorch 설치
|
| 38 |
+
pip3 install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu121
|
| 39 |
+
|
| 40 |
+
# fish-speech 설치
|
| 41 |
+
pip3 install -e .
|
| 42 |
+
|
| 43 |
+
# (가속 활성화) triton-windows 설치
|
| 44 |
+
pip install https://github.com/AnyaCoder/fish-speech/releases/download/v0.1.0/triton_windows-0.1.0-py3-none-any.whl
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
비전문 Windows 사용자는 Linux 환경 없이 프로젝트를 실행할 수 있는 다음 기본 방법을 고려할 수 있습니다 (모델 컴파일 기능 포함, 즉 `torch.compile`):
|
| 48 |
+
|
| 49 |
+
1. 프로젝트 패키지 추출.
|
| 50 |
+
2. `install_env.bat`을 클릭하여 환경 설치.
|
| 51 |
+
3. 컴파일 가속을 활성화하려면 아래 단계를 따르세요:
|
| 52 |
+
1. LLVM 컴파일러 다운로드:
|
| 53 |
+
- [LLVM-17.0.6 (공식 사이트)](https://huggingface.co/fishaudio/fish-speech-1/resolve/main/LLVM-17.0.6-win64.exe?download=true)
|
| 54 |
+
- [LLVM-17.0.6 (미러 사이트)](https://hf-mirror.com/fishaudio/fish-speech-1/resolve/main/LLVM-17.0.6-win64.exe?download=true)
|
| 55 |
+
- `LLVM-17.0.6-win64.exe`를 다운로드 후 더블클릭하여 설치하고, 설치 경로 선택 시 `Add Path to Current User` 옵션을 체크하여 환경 변수를 추가합니다.
|
| 56 |
+
- 설치가 완료되었는지 확인합니다.
|
| 57 |
+
2. Microsoft Visual C++ 재배포 가능 패키지를 다운로드하여 .dll 누락 문제 해결:
|
| 58 |
+
- [MSVC++ 14.40.33810.0 다운로드](https://aka.ms/vs/17/release/vc_redist.x64.exe)
|
| 59 |
+
3. Visual Studio Community Edition을 다운로드하여 LLVM의 헤더 파일 의존성을 해결:
|
| 60 |
+
- [Visual Studio 다운로드](https://visualstudio.microsoft.com/zh-hans/downloads/)
|
| 61 |
+
- Visual Studio Installer를 설치한 후 Visual Studio Community 2022를 다운로드.
|
| 62 |
+
- `Desktop development with C++` 옵션을 선택하여 설치.
|
| 63 |
+
4. [CUDA Toolkit 12.x](https://developer.nvidia.com/cuda-12-1-0-download-archive?target_os=Windows&target_arch=x86_64) 다운로드 및 설치.
|
| 64 |
+
4. `start.bat`을 더블 클릭하여 훈련 추론 WebUI 관리 인터페이스를 엽니다. 필요한 경우 아래 지침에 따라 `API_FLAGS`를 수정할 수 있습니다.
|
| 65 |
+
|
| 66 |
+
!!! info "Optional"
|
| 67 |
+
|
| 68 |
+
추론을 위해 WebUI를 사용하고자 하시나요?
|
| 69 |
+
|
| 70 |
+
프로젝트 루트 디렉토리의 `API_FLAGS.txt` 파일을 편집하고 첫 세 줄을 아래와 같이 수정하세요:
|
| 71 |
+
```
|
| 72 |
+
--infer
|
| 73 |
+
# --api
|
| 74 |
+
# --listen ...
|
| 75 |
+
...
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
!!! info "Optional"
|
| 79 |
+
|
| 80 |
+
API 서버를 시작하고 싶으신가요?
|
| 81 |
+
|
| 82 |
+
프로젝트 루트 디렉토리의 `API_FLAGS.txt` 파일을 편집하고 첫 세 줄을 아래와 같이 수정하세요:
|
| 83 |
+
|
| 84 |
+
```
|
| 85 |
+
# --infer
|
| 86 |
+
--api
|
| 87 |
+
--listen ...
|
| 88 |
+
...
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
!!! info "Optional"
|
| 92 |
+
|
| 93 |
+
`run_cmd.bat`을 더블 클릭하여 이 프로젝트의 conda/python 명령줄 환경에 진입할 수 있습니다.
|
| 94 |
+
|
| 95 |
+
## Linux 설정
|
| 96 |
+
|
| 97 |
+
[pyproject.toml](../../pyproject.toml)에서 자세한 내용을 확인하세요.
|
| 98 |
+
```bash
|
| 99 |
+
# 파이썬 3.10 가상 환경 생성, virtualenv도 사용할 수 있습니다.
|
| 100 |
+
conda create -n fish-speech python=3.10
|
| 101 |
+
conda activate fish-speech
|
| 102 |
+
|
| 103 |
+
# (Ubuntu / Debian 사용자) sox + ffmpeg 설치
|
| 104 |
+
apt install libsox-dev ffmpeg
|
| 105 |
+
|
| 106 |
+
# (Ubuntu / Debian 사용자) pyaudio 설치
|
| 107 |
+
apt install build-essential \
|
| 108 |
+
cmake \
|
| 109 |
+
libasound-dev \
|
| 110 |
+
portaudio19-dev \
|
| 111 |
+
libportaudio2 \
|
| 112 |
+
libportaudiocpp0
|
| 113 |
+
|
| 114 |
+
# pytorch 설치
|
| 115 |
+
pip3 install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1
|
| 116 |
+
|
| 117 |
+
# fish-speech 설치
|
| 118 |
+
pip3 install -e .[stable]
|
| 119 |
+
```
|
| 120 |
+
|
| 121 |
+
## macos 설정
|
| 122 |
+
|
| 123 |
+
MPS에서 추론을 수행하려면 `--device mps` 플래그를 추가하세요.
|
| 124 |
+
추론 속도 비교는 [이 PR](https://github.com/fishaudio/fish-speech/pull/461#issuecomment-2284277772)을 참조하십시오.
|
| 125 |
+
|
| 126 |
+
!!! warning
|
| 127 |
+
Apple Silicon 장치에서는 `compile` 옵션이 공식적으로 지원되지 않으므로 추론 속도가 향상된다는 보장은 없습니다.
|
| 128 |
+
|
| 129 |
+
```bash
|
| 130 |
+
# 파이썬 3.10 가상 환경 생성, virtualenv도 사용할 수 있습니다.
|
| 131 |
+
conda create -n fish-speech python=3.10
|
| 132 |
+
conda activate fish-speech
|
| 133 |
+
# pytorch 설치
|
| 134 |
+
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1
|
| 135 |
+
# fish-speech 설치
|
| 136 |
+
pip install -e .[stable]
|
| 137 |
+
```
|
| 138 |
+
|
| 139 |
+
## Docker 설정
|
| 140 |
+
|
| 141 |
+
1. NVIDIA Container Toolkit 설치:
|
| 142 |
+
|
| 143 |
+
Docker에서 모델 훈련 및 추론에 GPU를 사용하려면 NVIDIA Container Toolkit을 설치해야 합니다:
|
| 144 |
+
|
| 145 |
+
Ubuntu 사용자:
|
| 146 |
+
|
| 147 |
+
```bash
|
| 148 |
+
# 저장소 추가
|
| 149 |
+
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
|
| 150 |
+
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
|
| 151 |
+
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
|
| 152 |
+
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
|
| 153 |
+
# nvidia-container-toolkit 설치
|
| 154 |
+
sudo apt-get update
|
| 155 |
+
sudo apt-get install -y nvidia-container-toolkit
|
| 156 |
+
# Docker 서비스 재시작
|
| 157 |
+
sudo systemctl restart docker
|
| 158 |
+
```
|
| 159 |
+
|
| 160 |
+
다른 Linux 배포판 사용자는: [NVIDIA Container Toolkit 설치 가이드](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html)를 참조하십시오.
|
| 161 |
+
|
| 162 |
+
2. fish-speech 이미지 가져오기 및 실행
|
| 163 |
+
|
| 164 |
+
```bash
|
| 165 |
+
# 이미지 가져오기
|
| 166 |
+
docker pull fishaudio/fish-speech:latest-dev
|
| 167 |
+
# 이미지 실행
|
| 168 |
+
docker run -it \
|
| 169 |
+
--name fish-speech \
|
| 170 |
+
--gpus all \
|
| 171 |
+
-p 7860:7860 \
|
| 172 |
+
fishaudio/fish-speech:latest-dev \
|
| 173 |
+
zsh
|
| 174 |
+
# 다른 포트를 사용하려면 -p 매개변수를 YourPort:7860으로 수정하세요
|
| 175 |
+
```
|
| 176 |
+
|
| 177 |
+
3. 모델 종속성 다운로드
|
| 178 |
+
|
| 179 |
+
Docker 컨테이너 내부의 터미널에서 아래 명령어를 사용하여 필요한 `vqgan` 및 `llama` 모델을 Huggingface 리포지토리에서 다운로드합니다.
|
| 180 |
+
|
| 181 |
+
```bash
|
| 182 |
+
huggingface-cli download fishaudio/fish-speech-1.4 --local-dir checkpoints/fish-speech-1.4
|
| 183 |
+
```
|
| 184 |
+
|
| 185 |
+
4. 환경 변수 설정 및 WebUI 접근
|
| 186 |
+
|
| 187 |
+
Docker 컨테이너 내부의 터미널에서 `export GRADIO_SERVER_NAME="0.0.0.0"`를 입력하여 Docker 내부에서 Gradio 서비스에 외부 접근을 허용합니다.
|
| 188 |
+
이후, 터미널에서 `python tools/webui.py` 명령어를 입력하여 WebUI 서비스를 시작합니다.
|
| 189 |
+
|
| 190 |
+
WSL 또는 macOS를 사용하는 경우 [http://localhost:7860](http://localhost:7860)에서 WebUI 인터페이스를 열 수 있습니다.
|
| 191 |
+
|
| 192 |
+
서버에 배포된 경우, localhost를 서버의 IP로 교체하세요.
|
| 193 |
+
|
| 194 |
+
## 변경 사항
|
| 195 |
+
|
| 196 |
+
- 2024/09/10: Fish-Speech 1.4 버전으로 업데이트, 데이터셋 크기 증가 및 양자화기의 n_groups를 4에서 8로 변경.
|
| 197 |
+
- 2024/07/02: Fish-Speech 1.2 버전으로 업데이트, VITS 디코더 제거 및 제로샷 능력 크게 향상.
|
| 198 |
+
- 2024/05/10: Fish-Speech 1.1 버전으로 업데이트, WER 감소 및 음색 유사성을 개선하기 위해 VITS 디코더 구현.
|
| 199 |
+
- 2024/04/22: Fish-Speech 1.0 버전 완료, VQGAN 및 LLAMA 모델 대폭 수정.
|
| 200 |
+
- 2023/12/28: `lora` 파인튜닝 지원 추가.
|
| 201 |
+
- 2023/12/27: `gradient checkpointing`, `causual sampling`, 및 `flash-attn` 지원 추가.
|
| 202 |
+
- 2023/12/19: WebUI 및 HTTP API 업데이트.
|
| 203 |
+
- 2023/12/18: 파인튜닝 문서 및 관련 예시 업데이트.
|
| 204 |
+
- 2023/12/17: `text2semantic` 모델 업데이트, 음소 없는 모드 지원.
|
| 205 |
+
- 2023/12/13: 베타 버전 출시, VQGAN 모델 및 LLAMA 기반 언어 모델(음소 지원만 포함).
|
| 206 |
+
|
| 207 |
+
## 감사의 말
|
| 208 |
+
|
| 209 |
+
- [VITS2 (daniilrobnikov)](https://github.com/daniilrobnikov/vits2)
|
| 210 |
+
- [Bert-VITS2](https://github.com/fishaudio/Bert-VITS2)
|
| 211 |
+
- [GPT VITS](https://github.com/innnky/gpt-vits)
|
| 212 |
+
- [MQTTS](https://github.com/b04901014/MQTTS)
|
| 213 |
+
- [GPT Fast](https://github.com/pytorch-labs/gpt-fast)
|
| 214 |
+
- [Transformers](https://github.com/huggingface/transformers)
|
| 215 |
+
- [GPT-SoVITS](https://github.com/RVC-Boss/GPT-SoVITS)
|
docs/ko/inference.md
ADDED
|
@@ -0,0 +1,134 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 추론
|
| 2 |
+
|
| 3 |
+
추론은 명령줄, HTTP API, 그리고 웹 UI에서 지원됩니다.
|
| 4 |
+
|
| 5 |
+
!!! note
|
| 6 |
+
전체 추론 과정은 다음의 여러 단계로 구성됩니다:
|
| 7 |
+
|
| 8 |
+
1. VQGAN을 사용하여 약 10초 분량의 음성을 인코딩합니다.
|
| 9 |
+
2. 인코딩된 시맨틱 토큰과 해당 텍스트를 예시로 언어 모델에 입력합니다.
|
| 10 |
+
3. 새로운 텍스트를 입력하면, 모델이 해당하는 시맨틱 토큰을 생성합니다.
|
| 11 |
+
4. 생성된 시맨틱 토큰을 VITS / VQGAN에 입력하여 음성을 디코딩하고 생성합니다.
|
| 12 |
+
|
| 13 |
+
## 명령줄 추론
|
| 14 |
+
|
| 15 |
+
필요한 `vqgan` 및 `llama` 모델을 Hugging Face 리포지토리에서 다운로드하세요.
|
| 16 |
+
|
| 17 |
+
```bash
|
| 18 |
+
huggingface-cli download fishaudio/fish-speech-1.4 --local-dir checkpoints/fish-speech-1.4
|
| 19 |
+
```
|
| 20 |
+
|
| 21 |
+
### 1. 음성에서 프롬프트 생성:
|
| 22 |
+
|
| 23 |
+
!!! note
|
| 24 |
+
모델이 음색을 무작위로 선택하도록 하려면 이 단계를 건너뛸 수 있습니다.
|
| 25 |
+
|
| 26 |
+
```bash
|
| 27 |
+
python tools/vqgan/inference.py \
|
| 28 |
+
-i "paimon.wav" \
|
| 29 |
+
--checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth"
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
이 명령을 실행하면 `fake.npy` 파일을 얻게 됩니다.
|
| 33 |
+
|
| 34 |
+
### 2. 텍스트에서 시맨틱 토큰 생성:
|
| 35 |
+
|
| 36 |
+
```bash
|
| 37 |
+
python tools/llama/generate.py \
|
| 38 |
+
--text "변환할 텍스트" \
|
| 39 |
+
--prompt-text "참고할 텍스트" \
|
| 40 |
+
--prompt-tokens "fake.npy" \
|
| 41 |
+
--checkpoint-path "checkpoints/fish-speech-1.4" \
|
| 42 |
+
--num-samples 2 \
|
| 43 |
+
--compile
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
이 명령을 실행하면 작업 디렉토리에 `codes_N` 파일이 생성되며, N은 0부터 시작하는 정수입니다.
|
| 47 |
+
|
| 48 |
+
!!! note
|
| 49 |
+
빠른 추론을 위해 `--compile` 옵션을 사용하여 CUDA 커널을 결합할 수 있습니다 (~초당 30 토큰 -> ~초당 500 토큰).
|
| 50 |
+
`--compile` 매개변수를 주석 처리하여 가속화 옵션을 사용하지 않을 수도 있습니다.
|
| 51 |
+
|
| 52 |
+
!!! info
|
| 53 |
+
bf16을 지원하지 않는 GPU의 경우 `--half` 매개변수를 사용해야 할 수 있습니다.
|
| 54 |
+
|
| 55 |
+
### 3. 시맨틱 토큰에서 음성 생성:
|
| 56 |
+
|
| 57 |
+
#### VQGAN 디코더
|
| 58 |
+
|
| 59 |
+
```bash
|
| 60 |
+
python tools/vqgan/inference.py \
|
| 61 |
+
-i "codes_0.npy" \
|
| 62 |
+
--checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth"
|
| 63 |
+
```
|
| 64 |
+
|
| 65 |
+
## HTTP API 추론
|
| 66 |
+
|
| 67 |
+
추론을 위한 HTTP API를 제공하고 있습니다. 아래의 명령어로 서버를 시작할 수 있습니다:
|
| 68 |
+
|
| 69 |
+
```bash
|
| 70 |
+
python -m tools.api \
|
| 71 |
+
--listen 0.0.0.0:8080 \
|
| 72 |
+
--llama-checkpoint-path "checkpoints/fish-speech-1.4" \
|
| 73 |
+
--decoder-checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth" \
|
| 74 |
+
--decoder-config-name firefly_gan_vq
|
| 75 |
+
```
|
| 76 |
+
|
| 77 |
+
추론 속도를 높이고 싶다면 `--compile` 매개변수를 추가할 수 있습니다.
|
| 78 |
+
|
| 79 |
+
이후, http://127.0.0.1:8080/ 에서 API를 확인하고 테스트할 수 있습니다.
|
| 80 |
+
|
| 81 |
+
아래는 `tools/post_api.py`를 사용하여 요청을 보내는 예시입니다.
|
| 82 |
+
|
| 83 |
+
```bash
|
| 84 |
+
python -m tools.post_api \
|
| 85 |
+
--text "입력할 텍스트" \
|
| 86 |
+
--reference_audio "참고 음성 경로" \
|
| 87 |
+
--reference_text "참고 음성의 텍스트 내용" \
|
| 88 |
+
--streaming True
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
위 명령은 참고 음성 정보를 바탕으로 원하는 음성을 합성하고, 스트리밍 방식으로 반환합니다.
|
| 92 |
+
|
| 93 |
+
다음 예시는 여러 개의 참고 음성 경로와 텍스트를 한꺼번에 사용할 수 있음을 보여줍니다. 명령에서 공백으로 구분하여 입력합니다.
|
| 94 |
+
|
| 95 |
+
```bash
|
| 96 |
+
python -m tools.post_api \
|
| 97 |
+
--text "입력할 텍스트" \
|
| 98 |
+
--reference_audio "참고 음성 경로1" "참고 음성 경로2" \
|
| 99 |
+
--reference_text "참고 음성 텍스트1" "참고 음성 텍스트2"\
|
| 100 |
+
--streaming False \
|
| 101 |
+
--output "generated" \
|
| 102 |
+
--format "mp3"
|
| 103 |
+
```
|
| 104 |
+
|
| 105 |
+
위 명령어는 여러 참고 음성 정보를 바탕으로 `MP3` 형식의 음성을 합성하여, 현재 디렉토리에 `generated.mp3`로 저장합니다.
|
| 106 |
+
|
| 107 |
+
`--reference_audio`와 `--reference_text` 대신에 `--reference_id`(하나만 사용 가능)를 사용할 수 있습니다. 프로젝트 루트 디렉토리에 `references/<your reference_id>` 폴더를 만들어 해당 음성과 주석 텍스트를 넣어야 합니다. 참고 음성은 최대 90초까지 지원됩니다.
|
| 108 |
+
|
| 109 |
+
!!! info
|
| 110 |
+
제공되는 파라미터는 `python -m tools.post_api -h`를 사용하여 확인할 수 있습니다.
|
| 111 |
+
|
| 112 |
+
## GUI 추론
|
| 113 |
+
[클라이언트 다운로드](https://github.com/AnyaCoder/fish-speech-gui/releases)
|
| 114 |
+
|
| 115 |
+
## WebUI 추론
|
| 116 |
+
|
| 117 |
+
다음 명령으로 WebUI를 시작할 수 있습니다:
|
| 118 |
+
|
| 119 |
+
```bash
|
| 120 |
+
python -m tools.webui \
|
| 121 |
+
--llama-checkpoint-path "checkpoints/fish-speech-1.4" \
|
| 122 |
+
--decoder-checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth" \
|
| 123 |
+
--decoder-config-name firefly_gan_vq
|
| 124 |
+
```
|
| 125 |
+
|
| 126 |
+
> 추론 속도를 높이고 싶다면 `--compile` 매개변수를 추가할 수 있습니다.
|
| 127 |
+
|
| 128 |
+
!!! note
|
| 129 |
+
라벨 파일과 참고 음성 파일을 미리 메인 디렉토리의 `references` 폴더에 저장해 두면, WebUI에서 바로 호출할 수 있습니다. (해당 폴더는 직접 생성해야 합니다.)
|
| 130 |
+
|
| 131 |
+
!!! note
|
| 132 |
+
WebUI를 구성하기 위해 `GRADIO_SHARE`, `GRADIO_SERVER_PORT`, `GRADIO_SERVER_NAME`과 같은 Gradio 환경 변수를 사용할 수 있습니다.
|
| 133 |
+
|
| 134 |
+
즐기세요!
|
docs/ko/samples.md
ADDED
|
@@ -0,0 +1,137 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 샘플
|
| 2 |
+
|
| 3 |
+
ver 1.4
|
| 4 |
+
|
| 5 |
+
## Credits
|
| 6 |
+
[Seed-TTS (2024)](https://bytedancespeech.github.io/seedtts_tech_report/)에 감사드리며, 평가 데이터를 제공해 주셔서 이 데모를 완성할 수 있었습니다.
|
| 7 |
+
|
| 8 |
+
모든 프롬프트 음성은 Seed-TTS 효과 데모 페이지에서 가져왔으며, 모든 생성된 음성은 fish-speech 버전 1.4에서 첫 번째로 생성된 것입니다.
|
| 9 |
+
|
| 10 |
+
## 제로샷 인컨텍스트 학습
|
| 11 |
+
- TODO: 한국어 제로샷 인컨텍스트 학습 샘플 추가. (현재는 영어와 중국어 데모만 제공됩니다.)
|
| 12 |
+
|
| 13 |
+
<table>
|
| 14 |
+
<thead>
|
| 15 |
+
<tr>
|
| 16 |
+
<th style="vertical-align : middle;text-align: center">언어</th>
|
| 17 |
+
<th style="vertical-align : middle;text-align: center">프롬프트</th>
|
| 18 |
+
<th style="vertical-align : middle;text-align: center">동일 언어 생성</th>
|
| 19 |
+
<th style="vertical-align : middle;text-align: center">교차 언어 생성</th>
|
| 20 |
+
</tr>
|
| 21 |
+
</thead>
|
| 22 |
+
<tbody>
|
| 23 |
+
<tr>
|
| 24 |
+
<td style="vertical-align : middle;text-align:center;" rowspan="3">EN</td>
|
| 25 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/prompts/4245145269330795065.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 26 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/4245145269330795065/same-lang-fish.wav" autoplay="">Your browser does not support the audio element.</audio><br>I don't really care what you call me. I've been a silent spectator, watching species evolve, empires rise and fall. But always remember, I am mighty and enduring. Respect me and I'll nurture you; ignore me and you shall face the consequences.</td>
|
| 27 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/4245145269330795065/cross-lang-fish.wav" autoplay="">Your browser does not support the audio element.</audio><br>顿时,气氛变得沉郁起来。乍看之下,一切的困扰仿佛都围绕在我身边。我皱着眉头,感受着那份压力,但我知道我不能放弃,不能认输。于是,我深吸一口气,心底的声音告诉我:“无论如何,都要冷静下来,重新开始。”</td>
|
| 28 |
+
</tr>
|
| 29 |
+
<tr>
|
| 30 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/prompts/2486365921931244890.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 31 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/2486365921931244890/same-lang-fish.wav" autoplay="">Your browser does not support the audio element.</audio><br>Dealing with family secrets is never easy. Yet, sometimes, omission is a form of protection, intending to safeguard some from the harsh truths. One day, I hope you understand the reasons behind my actions. Until then, Anna, please, bear with me.</td>
|
| 32 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/2486365921931244890/cross-lang-fish.wav" autoplay="">Your browser does not support the audio element.</audio><br>处理家庭秘密从来都不是一件容易的事。然而,有时候,隐瞒是一种保护形式,旨在保护一些人免受残酷的真相伤害。有一天,我希望你能理解我行为背后的原因。在那之前,安娜,请容忍我。</td>
|
| 33 |
+
</tr>
|
| 34 |
+
<tr>
|
| 35 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/prompts/-9102975986427238220.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 36 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/-9102975986427238220/same-lang-fish.wav" autoplay="">Your browser does not support the audio element.</audio><br>The combinations of different textures and flavors create a perfect harmony. The succulence of the steak, the tartness of the cranberries, the crunch of pine nuts, and creaminess of blue cheese make it a truly delectable delight. Enjoy your culinary adventure!</td>
|
| 37 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/-9102975986427238220/cross-lang-fish.wav" autoplay="">Your browser does not support the audio element.</audio><br>听着你的话,我心里五味杂陈。虽然我愿意一直在你身边,承担一切不幸,但我知道只有让你自己面对,才能真正让你变得更强大。所以,你要记得,无论面对何种困难,都请你坚强,我会在心里一直支持你的。</td>
|
| 38 |
+
</tr>
|
| 39 |
+
<tr>
|
| 40 |
+
<td style="vertical-align : middle;text-align:center;" rowspan="3">ZH</td>
|
| 41 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/prompts/2648200402409733590.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 42 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/2648200402409733590/same-lang-fish.wav" autoplay="">Your browser does not support the audio element.</audio><br>突然,身边一阵笑声。我看着他们,意气风发地挺直了胸膛,甩了甩那稍显肉感的双臂,轻笑道:"我身上的肉,是为了掩饰我爆棚的魅力,否则,岂不吓坏了你们呢?"</td>
|
| 43 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/2648200402409733590/cross-lang-fish.wav" autoplay="">Your browser does not support the audio element.</audio><br>Suddenly, there was a burst of laughter beside me. I looked at them, stood up straight with high spirit, shook the slightly fleshy arms, and smiled lightly, saying, "The flesh on my body is to hide my bursting charm. Otherwise, wouldn't it scare you?"</td>
|
| 44 |
+
</tr>
|
| 45 |
+
<tr>
|
| 46 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/prompts/8913957783621352198.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 47 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/8913957783621352198/same-lang-fish.wav" autoplay="">Your browser does not support the audio element.</audio><br>他闭上眼睛,期望这一切都能过去。然而,当他再次睁开眼睛,眼前的景象让他不禁倒吸一口气。雾气中出现的禁闭岛,陌生又熟悉,充满未知的危险。他握紧拳头,心知他的生活即将发生翻天覆地的改变。</td>
|
| 48 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/8913957783621352198/cross-lang-fish.wav" autoplay="">Your browser does not support the audio element.</audio><br>He closed his eyes, expecting that all of this could pass. However, when he opened his eyes again, the sight in front of him made him couldn't help but take a deep breath. The closed island that appeared in the fog, strange and familiar, was full of unknown dangers. He tightened his fist, knowing that his life was about to undergo earth-shaking changes.</td>
|
| 49 |
+
</tr>
|
| 50 |
+
<tr>
|
| 51 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/prompts/2631296891109983590.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 52 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/2631296891109983590/same-lang-fish.wav" autoplay="">Your browser does not support the audio element.</audio><br>顿时,气氛变得沉郁起来。乍看之下,一切的困扰仿佛都围绕在我身边。我皱着眉头,感受着那份压力,但我知道我不能放弃,不能认输。于是,我深吸一口气,心底的声音告诉我:“无论如何,都要冷静下来,重新开始。”</td>
|
| 53 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/zero-shot/2631296891109983590/cross-lang-fish.wav" autoplay="">Your browser does not support the audio element.</audio><br>Suddenly, the atmosphere became gloomy. At first glance, all the troubles seemed to surround me. I frowned, feeling that pressure, but I know I can't give up, can't admit defeat. So, I took a deep breath, and the voice in my heart told me, "Anyway, must calm down and start again."</td>
|
| 54 |
+
</tr>
|
| 55 |
+
</tbody>
|
| 56 |
+
</table>
|
| 57 |
+
|
| 58 |
+
## 화자 파인튜닝
|
| 59 |
+
|
| 60 |
+
<table>
|
| 61 |
+
<thead>
|
| 62 |
+
<tr>
|
| 63 |
+
<th style="text-align: center"> </th>
|
| 64 |
+
<th style="text-align: center">텍스트</th>
|
| 65 |
+
<th style="text-align: center">생성된 음성</th>
|
| 66 |
+
</tr>
|
| 67 |
+
</thead>
|
| 68 |
+
<tbody>
|
| 69 |
+
<tr>
|
| 70 |
+
<td style="vertical-align : middle;text-align:center;" rowspan="3">화자1</td>
|
| 71 |
+
<td style="vertical-align : middle;text-align:center;">好呀,哈哈哈哈哈,喜欢笑的人运气都不会差哦,希望你每天笑口常开~</td>
|
| 72 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/fine-tune/prompts/4781135337205789117.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 73 |
+
</tr>
|
| 74 |
+
<tr>
|
| 75 |
+
<td style="vertical-align : middle;text-align:center;">哇!恭喜你中了大乐透,八百万可真不少呢!有什么特别的计划或想法吗?</td>
|
| 76 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/fine-tune/4781135337205789117/fish_1_to_2.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 77 |
+
</tr>
|
| 78 |
+
<tr>
|
| 79 |
+
<td style="vertical-align : middle;text-align:center;">哼,你这么问是想请本小姐吃饭吗?如果对象是你的话,那也不是不可以。</td>
|
| 80 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/fine-tune/4781135337205789117/fish_1_to_3.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 81 |
+
</tr>
|
| 82 |
+
<tr>
|
| 83 |
+
<td style="vertical-align : middle;text-align:center;" rowspan="3">화자2</td>
|
| 84 |
+
<td style="vertical-align : middle;text-align:center;">是呀,他还想换个地球仪哈哈哈,看来给你积累了一些快乐值了,你还想不想再听一个其他的笑话呀?</td>
|
| 85 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/fine-tune/prompts/-1325430967143158944.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 86 |
+
</tr>
|
| 87 |
+
<tr>
|
| 88 |
+
<td style="vertical-align : middle;text-align:center;">嘿嘿,你是不是也想拥有甜甜的恋爱呢?《微微一笑很倾城》是你的不二选择,男女主是校花校草类型,他们通过游戏结识,再到两人见面,全程没有一点误会,真的齁甜,想想都忍不住“姨妈笑”~</td>
|
| 89 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/fine-tune/-1325430967143158944/fish_1_to_2.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 90 |
+
</tr>
|
| 91 |
+
<tr>
|
| 92 |
+
<td style="vertical-align : middle;text-align:center;">小傻瓜,嗯……算是个很可爱很亲切的名字,有点“独特”哦,不过我有些好奇,你为什么会给我选这个昵称呢?</td>
|
| 93 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/fine-tune/-1325430967143158944/fish_1_to_3.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 94 |
+
</tr>
|
| 95 |
+
</tbody>
|
| 96 |
+
</table>
|
| 97 |
+
<br>
|
| 98 |
+
|
| 99 |
+
## 콘텐츠 편집
|
| 100 |
+
|
| 101 |
+
<table>
|
| 102 |
+
<thead>
|
| 103 |
+
<tr><th style="text-align: center">언어</th>
|
| 104 |
+
<th style="text-align: center">원본 텍스트</th>
|
| 105 |
+
<th style="text-align: center">원본 음성</th>
|
| 106 |
+
<th style="text-align: center">목표 텍스트</th>
|
| 107 |
+
<th style="text-align: center">편집된 음성</th>
|
| 108 |
+
</tr></thead>
|
| 109 |
+
<tbody>
|
| 110 |
+
<tr>
|
| 111 |
+
<td style="vertical-align : middle;text-align:center;" rowspan="2">EN</td>
|
| 112 |
+
<td style="vertical-align : middle;text-align:center;">They can't order me to stop dreaming. If you dream a thing more than once, it's sure to come true. Have faith in your dreams, and someday your rainbow will come shining through.</td>
|
| 113 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/content-edit/prompts/2372076002032794455.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 114 |
+
<td style="vertical-align : middle;text-align:center;">They can't <b>require</b> me to stop <b>imagining.</b> If you envision a thing more than once, it's <b>bound</b> to come <b>about</b>. Have <b>trust</b> in your <b>visions</b>, and someday your <b>radiance</b> will come <b>beaming</b> through.</td>
|
| 115 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/content-edit/2372076002032794455/edit-fish.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 116 |
+
</tr>
|
| 117 |
+
<tr>
|
| 118 |
+
<td style="vertical-align : middle;text-align:center;">Are you familiar with it? Slice the steak and place the strips on top, then garnish with the dried cranberries, pine nuts, and blue cheese. I wonder how people rationalise the decision?</td>
|
| 119 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/content-edit/prompts/3347127306902202498.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 120 |
+
<td style="vertical-align : middle;text-align:center;">Are you <b>acquainted</b> with it? <b>Cut the pork</b> and place the strips on top, then garnish with the dried <b>cherries, almonds,</b> and <b>feta</b> cheese. I <b>query</b> how people <b>justify</b> the <b>choice?</b></td>
|
| 121 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/content-edit/3347127306902202498/edit-fish.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 122 |
+
</tr>
|
| 123 |
+
<tr>
|
| 124 |
+
<td style="vertical-align : middle;text-align:center;" rowspan="2">ZH</td>
|
| 125 |
+
<td style="vertical-align : middle;text-align:center;">自古以来,庸君最怕党政了,可圣君他就不怕,不但不怕,反能利用。要我说,你就让明珠索额图互相争宠,只要你心里明白,左右逢源,你就能立于不败之地。</td>
|
| 126 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/content-edit/prompts/1297014176484007082.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 127 |
+
<td style="vertical-align : middle;text-align:center;"><b>从古至今</b>,庸君最怕<b>朝纲了</b>,可<b>明</b>君他就不怕,不但不怕,反能<b>借助</b>。要我说,你就让<b>李四张三</b>互相争宠,只要你心里<b>清楚</b>,左右<b>周旋</b>,你就能<b>处</b>于不败之<b>境</b>。</td>
|
| 128 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/content-edit/1297014176484007082/edit-fish.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 129 |
+
</tr>
|
| 130 |
+
<tr>
|
| 131 |
+
<td style="vertical-align : middle;text-align:center;">对,这就是我,万人敬仰的太乙真人,虽然有点婴儿肥,但也掩不住我逼人的帅气。</td>
|
| 132 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/content-edit/prompts/-40165564411515767.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 133 |
+
<td style="vertical-align : middle;text-align:center;">对,这就是我,<b>众人尊崇</b>的太<b>白金星</b>,虽然有点<b>娃娃脸</b>,但也<b>遮</b>不住我<b>迷人</b>的<b>魅力。</b></td>
|
| 134 |
+
<td style="vertical-align : middle;text-align:center;"><audio controls="controls" style="width: 190px;"><source src="https://anyacoder.github.io/fishaudio.github.io/samples/content-edit/-40165564411515767/edit-fish.wav" autoplay="">Your browser does not support the audio element.</audio></td>
|
| 135 |
+
</tr>
|
| 136 |
+
</tbody>
|
| 137 |
+
</table>
|
docs/ko/start_agent.md
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 에이전트 시작하기
|
| 2 |
+
|
| 3 |
+
!!! note
|
| 4 |
+
전체 문서는 claude3.5 Sonnet에 의해 번역되었으며, 원어민인 경우 번역에 문제가 있다고 생각되면 이슈나 풀 리퀘스트를 보내주셔서 대단히 감사합니다!
|
| 5 |
+
|
| 6 |
+
## 요구사항
|
| 7 |
+
|
| 8 |
+
- GPU 메모리: 최소 8GB(양자화 사용 시), 16GB 이상 권장
|
| 9 |
+
- 디스크 사용량: 10GB
|
| 10 |
+
|
| 11 |
+
## 모델 다운로드
|
| 12 |
+
|
| 13 |
+
다음 명령어로 모델을 받을 수 있습니다:
|
| 14 |
+
|
| 15 |
+
```bash
|
| 16 |
+
huggingface-cli download fishaudio/fish-agent-v0.1-3b --local-dir checkpoints/fish-agent-v0.1-3b
|
| 17 |
+
```
|
| 18 |
+
|
| 19 |
+
'checkpoints' 폴더에 파일들을 넣으세요.
|
| 20 |
+
|
| 21 |
+
또한 [inference](inference.md)에 설명된 대로 fish-speech 모델도 다운로드해야 합니다.
|
| 22 |
+
|
| 23 |
+
checkpoints에는 2개의 폴더가 있어야 합니다.
|
| 24 |
+
|
| 25 |
+
`checkpoints/fish-speech-1.4`와 `checkpoints/fish-agent-v0.1-3b`입니다.
|
| 26 |
+
|
| 27 |
+
## 환경 준비
|
| 28 |
+
|
| 29 |
+
이미 Fish-speech가 있다면 다음 명령어를 추가하여 바로 사용할 수 있습니다:
|
| 30 |
+
```bash
|
| 31 |
+
pip install cachetools
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
!!! 참고
|
| 35 |
+
컴파일을 위해 Python 3.12 미만 버전을 사용해 주세요.
|
| 36 |
+
|
| 37 |
+
없다면 아래 명령어를 사용하여 환경을 구축하세요:
|
| 38 |
+
|
| 39 |
+
```bash
|
| 40 |
+
sudo apt-get install portaudio19-dev
|
| 41 |
+
|
| 42 |
+
pip install -e .[stable]
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
## 에이전트 데모 실행
|
| 46 |
+
|
| 47 |
+
fish-agent를 구축하려면 메인 폴더에서 아래 명령어를 사용하세요:
|
| 48 |
+
|
| 49 |
+
```bash
|
| 50 |
+
python -m tools.api --llama-checkpoint-path checkpoints/fish-agent-v0.1-3b/ --mode agent --compile
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
`--compile` 인자는 Python < 3.12에서만 지원되며, 토큰 생성 속도를 크게 향상시킵니다.
|
| 54 |
+
|
| 55 |
+
한 번에 컴파일되지 않습니다(기억해 두세요).
|
| 56 |
+
|
| 57 |
+
그런 다음 다른 터미널을 열고 다음 명령어를 사용하세요:
|
| 58 |
+
|
| 59 |
+
```bash
|
| 60 |
+
python -m tools.e2e_webui
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
이렇게 하면 기기에 Gradio WebUI가 생성됩니다.
|
| 64 |
+
|
| 65 |
+
모델을 처음 사용할 때는 (`--compile`이 True인 경우) 잠시 컴파일이 진행되므로 기다려 주세요.
|
| 66 |
+
|
| 67 |
+
## Gradio Webui
|
| 68 |
+
<p align="center">
|
| 69 |
+
<img src="../../assets/figs/agent_gradio.png" width="75%">
|
| 70 |
+
</p>
|
| 71 |
+
|
| 72 |
+
즐거운 시간 되세요!
|
| 73 |
+
|
| 74 |
+
## 성능
|
| 75 |
+
|
| 76 |
+
테스트 결과, 4060 노트북은 겨우 실행되며 매우 부하가 큰 상태로, 초당 약 8토큰 정도만 처리합니다. 4090은 컴파일 상태에서 초당 약 95토큰을 처리하며, 이것이 저희가 권장하는 사양입니다.
|
| 77 |
+
|
| 78 |
+
# 에이전트 소개
|
| 79 |
+
|
| 80 |
+
이 데모는 초기 알파 테스트 버전으로, 추론 속도 최적화가 필요하며 수정해야 할 버그가 많이 있습니다. 버그를 발견하거나 수정하고 싶으시다면 이슈나 풀 리퀘스트를 보내주시면 매우 감사하겠습니다.
|
docs/pt/finetune.md
ADDED
|
@@ -0,0 +1,128 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Ajuste Fino
|
| 2 |
+
|
| 3 |
+
É óbvio que ao abrir esta página, você não deve estar muito satisfeito com o desempenho do modelo pré-treinado com poucos exemplos. Você pode querer ajustar o modelo para melhorar seu desempenho em seu conjunto de dados.
|
| 4 |
+
|
| 5 |
+
Na atual versão, a única coisa que você precisa ajustar é a parte do 'LLAMA'.
|
| 6 |
+
|
| 7 |
+
## Ajuste Fino do LLAMA
|
| 8 |
+
### 1. Preparando o conjunto de dados
|
| 9 |
+
|
| 10 |
+
```
|
| 11 |
+
.
|
| 12 |
+
├── SPK1
|
| 13 |
+
│ ├── 21.15-26.44.lab
|
| 14 |
+
│ ├── 21.15-26.44.mp3
|
| 15 |
+
│ ├── 27.51-29.98.lab
|
| 16 |
+
│ ├── 27.51-29.98.mp3
|
| 17 |
+
│ ├── 30.1-32.71.lab
|
| 18 |
+
│ └── 30.1-32.71.mp3
|
| 19 |
+
└── SPK2
|
| 20 |
+
├── 38.79-40.85.lab
|
| 21 |
+
└── 38.79-40.85.mp3
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
Você precisa converter seu conjunto de dados para o formato acima e colocá-lo em `data`. O arquivo de áudio pode ter as extensões `.mp3`, `.wav` ou `.flac`, e o arquivo de anotação deve ter a extensão `.lab`.
|
| 25 |
+
|
| 26 |
+
!!! info
|
| 27 |
+
O arquivo de anotação `.lab` deve conter apenas a transcrição do áudio, sem a necessidade de formatação especial. Por exemplo, se o arquivo `hi.mp3` disser "Olá, tchau", o arquivo `hi.lab` conterá uma única linha de texto: "Olá, tchau".
|
| 28 |
+
|
| 29 |
+
!!! warning
|
| 30 |
+
É recomendado aplicar normalização de volume ao conjunto de dados. Você pode usar o [fish-audio-preprocess](https://github.com/fishaudio/audio-preprocess) para fazer isso.
|
| 31 |
+
|
| 32 |
+
```bash
|
| 33 |
+
fap loudness-norm data-raw data --clean
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
### 2. Extração em lote de tokens semânticos
|
| 38 |
+
|
| 39 |
+
Certifique-se de ter baixado os pesos do VQGAN. Se não, execute o seguinte comando:
|
| 40 |
+
|
| 41 |
+
```bash
|
| 42 |
+
huggingface-cli download fishaudio/fish-speech-1.4 --local-dir checkpoints/fish-speech-1.4
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
Em seguida, você pode executar o seguinte comando para extrair os tokens semânticos:
|
| 46 |
+
|
| 47 |
+
```bash
|
| 48 |
+
python tools/vqgan/extract_vq.py data \
|
| 49 |
+
--num-workers 1 --batch-size 16 \
|
| 50 |
+
--config-name "firefly_gan_vq" \
|
| 51 |
+
--checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth"
|
| 52 |
+
```
|
| 53 |
+
|
| 54 |
+
!!! note
|
| 55 |
+
Você pode ajustar `--num-workers` e `--batch-size` para aumentar a velocidade de extração, mas certifique-se de não exceder o limite de memória da sua GPU.
|
| 56 |
+
Para o formato VITS, você pode especificar uma lista de arquivos usando `--filelist xxx.list`.
|
| 57 |
+
|
| 58 |
+
Este comando criará arquivos `.npy` no diretório `data`, como mostrado abaixo:
|
| 59 |
+
|
| 60 |
+
```
|
| 61 |
+
.
|
| 62 |
+
├── SPK1
|
| 63 |
+
│ ├── 21.15-26.44.lab
|
| 64 |
+
│ ├── 21.15-26.44.mp3
|
| 65 |
+
│ ├── 21.15-26.44.npy
|
| 66 |
+
│ ├── 27.51-29.98.lab
|
| 67 |
+
│ ├── 27.51-29.98.mp3
|
| 68 |
+
│ ├── 27.51-29.98.npy
|
| 69 |
+
│ ├── 30.1-32.71.lab
|
| 70 |
+
│ ├── 30.1-32.71.mp3
|
| 71 |
+
│ └── 30.1-32.71.npy
|
| 72 |
+
└── SPK2
|
| 73 |
+
├── 38.79-40.85.lab
|
| 74 |
+
├── 38.79-40.85.mp3
|
| 75 |
+
└── 38.79-40.85.npy
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
### 3. Empacotar o conjunto de dados em protobuf
|
| 79 |
+
|
| 80 |
+
```bash
|
| 81 |
+
python tools/llama/build_dataset.py \
|
| 82 |
+
--input "data" \
|
| 83 |
+
--output "data/protos" \
|
| 84 |
+
--text-extension .lab \
|
| 85 |
+
--num-workers 16
|
| 86 |
+
```
|
| 87 |
+
|
| 88 |
+
Após executar o comando, você deverá ver o arquivo `quantized-dataset-ft.protos` no diretório `data`.
|
| 89 |
+
|
| 90 |
+
### 4. E finalmente, chegamos ao ajuste fino com LoRA
|
| 91 |
+
|
| 92 |
+
Da mesma forma, certifique-se de ter baixado os pesos do `LLAMA`. Se não, execute o seguinte comando:
|
| 93 |
+
|
| 94 |
+
```bash
|
| 95 |
+
huggingface-cli download fishaudio/fish-speech-1.4 --local-dir checkpoints/fish-speech-1.4
|
| 96 |
+
```
|
| 97 |
+
|
| 98 |
+
E então, execute o seguinte comando para iniciar o ajuste fino:
|
| 99 |
+
|
| 100 |
+
```bash
|
| 101 |
+
python fish_speech/train.py --config-name text2semantic_finetune \
|
| 102 |
+
project=$project \
|
| 103 |
+
[email protected]_config=r_8_alpha_16
|
| 104 |
+
```
|
| 105 |
+
|
| 106 |
+
!!! note
|
| 107 |
+
Se quiser, você pode modificar os parâmetros de treinamento, como `batch_size`, `gradient_accumulation_steps`, etc., para se ajustar à memória da sua GPU, modificando `fish_speech/configs/text2semantic_finetune.yaml`.
|
| 108 |
+
|
| 109 |
+
!!! note
|
| 110 |
+
Para usuários do Windows, é recomendado usar `trainer.strategy.process_group_backend=gloo` para evitar problemas com `nccl`.
|
| 111 |
+
|
| 112 |
+
Após concluir o treinamento, consulte a seção [inferência](inference.md).
|
| 113 |
+
|
| 114 |
+
!!! info
|
| 115 |
+
Por padrão, o modelo aprenderá apenas os padrões de fala do orador e não o timbre. Ainda pode ser preciso usar prompts para garantir a estabilidade do timbre.
|
| 116 |
+
Se quiser que ele aprenda o timbre, aumente o número de etapas de treinamento, mas isso pode levar ao overfitting (sobreajuste).
|
| 117 |
+
|
| 118 |
+
Após o treinamento, é preciso converter os pesos do LoRA em pesos regulares antes de realizar a inferência.
|
| 119 |
+
|
| 120 |
+
```bash
|
| 121 |
+
python tools/llama/merge_lora.py \
|
| 122 |
+
--lora-config r_8_alpha_16 \
|
| 123 |
+
--base-weight checkpoints/fish-speech-1.4 \
|
| 124 |
+
--lora-weight results/$project/checkpoints/step_000000010.ckpt \
|
| 125 |
+
--output checkpoints/fish-speech-1.4-yth-lora/
|
| 126 |
+
```
|
| 127 |
+
!!! note
|
| 128 |
+
É possível também tentar outros checkpoints. Sugerimos usar o checkpoint que melhor atenda aos seus requisitos, pois eles geralmente têm um desempenho melhor em dados fora da distribuição (OOD).
|
docs/pt/index.md
ADDED
|
@@ -0,0 +1,210 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Introdução
|
| 2 |
+
|
| 3 |
+
<div>
|
| 4 |
+
<a target="_blank" href="https://discord.gg/Es5qTB9BcN">
|
| 5 |
+
<img alt="Discord" src="https://img.shields.io/discord/1214047546020728892?color=%23738ADB&label=Discord&logo=discord&logoColor=white&style=flat-square"/>
|
| 6 |
+
</a>
|
| 7 |
+
<a target="_blank" href="http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=jCKlUP7QgSm9kh95UlBoYv6s1I-Apl1M&authKey=xI5ttVAp3do68IpEYEalwXSYZFdfxZSkah%2BctF5FIMyN2NqAa003vFtLqJyAVRfF&noverify=0&group_code=593946093">
|
| 8 |
+
<img alt="QQ" src="https://img.shields.io/badge/QQ Group-%2312B7F5?logo=tencent-qq&logoColor=white&style=flat-square"/>
|
| 9 |
+
</a>
|
| 10 |
+
<a target="_blank" href="https://hub.docker.com/r/fishaudio/fish-speech">
|
| 11 |
+
<img alt="Docker" src="https://img.shields.io/docker/pulls/fishaudio/fish-speech?style=flat-square&logo=docker"/>
|
| 12 |
+
</a>
|
| 13 |
+
</div>
|
| 14 |
+
|
| 15 |
+
!!! warning
|
| 16 |
+
Não nos responsabilizamos por qualquer uso ilegal do código-fonte. Consulte as leis locais sobre DMCA (Digital Millennium Copyright Act) e outras leis relevantes em sua região. <br/>
|
| 17 |
+
Este repositório de código e os modelos são distribuídos sob a licença CC-BY-NC-SA-4.0.
|
| 18 |
+
|
| 19 |
+
<p align="center">
|
| 20 |
+
<img src="../assets/figs/diagram.png" width="75%">
|
| 21 |
+
</p>
|
| 22 |
+
|
| 23 |
+
## Requisitos
|
| 24 |
+
|
| 25 |
+
- Memória da GPU: 4GB (para inferência), 8GB (para ajuste fino)
|
| 26 |
+
- Sistema: Linux, Windows
|
| 27 |
+
|
| 28 |
+
## Configuração do Windows
|
| 29 |
+
|
| 30 |
+
Usuários profissionais do Windows podem considerar o uso do WSL2 ou Docker para executar a base de código.
|
| 31 |
+
|
| 32 |
+
```bash
|
| 33 |
+
# Crie um ambiente virtual Python 3.10, também é possível usar o virtualenv
|
| 34 |
+
conda create -n fish-speech python=3.10
|
| 35 |
+
conda activate fish-speech
|
| 36 |
+
|
| 37 |
+
# Instale o pytorch
|
| 38 |
+
pip3 install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu121
|
| 39 |
+
|
| 40 |
+
# Instale o fish-speech
|
| 41 |
+
pip3 install -e .
|
| 42 |
+
|
| 43 |
+
# (Ativar aceleração) Instalar triton-windows
|
| 44 |
+
pip install https://github.com/AnyaCoder/fish-speech/releases/download/v0.1.0/triton_windows-0.1.0-py3-none-any.whl
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
Usuários não profissionais do Windows podem considerar os seguintes métodos básicos para executar o projeto sem um ambiente Linux (com capacidades de compilação de modelo, ou seja, `torch.compile`):
|
| 48 |
+
|
| 49 |
+
1. Extraia o pacote do projeto.
|
| 50 |
+
2. Clique em `install_env.bat` para instalar o ambiente.
|
| 51 |
+
3. Se você quiser ativar a aceleração de compilação, siga estas etapas:
|
| 52 |
+
1. Baixe o compilador LLVM nos seguintes links:
|
| 53 |
+
- [LLVM-17.0.6 (Download do site oficial)](https://huggingface.co/fishaudio/fish-speech-1/resolve/main/LLVM-17.0.6-win64.exe?download=true)
|
| 54 |
+
- [LLVM-17.0.6 (Download do site espelho)](https://hf-mirror.com/fishaudio/fish-speech-1/resolve/main/LLVM-17.0.6-win64.exe?download=true)
|
| 55 |
+
- Após baixar o `LLVM-17.0.6-win64.exe`, clique duas vezes para instalar, selecione um local de instalação apropriado e, o mais importante, marque a opção `Add Path to Current User` para adicionar a variável de ambiente.
|
| 56 |
+
- Confirme que a instalação foi concluída.
|
| 57 |
+
2. Baixe e instale o Microsoft Visual C++ Redistributable para resolver possíveis problemas de arquivos .dll ausentes:
|
| 58 |
+
- [Download do MSVC++ 14.40.33810.0](https://aka.ms/vs/17/release/vc_redist.x64.exe)
|
| 59 |
+
3. Baixe e instale o Visual Studio Community Edition para obter as ferramentas de compilação do MSVC++ e resolver as dependências dos arquivos de cabeçalho do LLVM:
|
| 60 |
+
- [Download do Visual Studio](https://visualstudio.microsoft.com/pt-br/downloads/)
|
| 61 |
+
- Após instalar o Visual Studio Installer, baixe o Visual Studio Community 2022.
|
| 62 |
+
- Conforme mostrado abaixo, clique no botão `Modificar`, encontre a opção `Desenvolvimento de área de trabalho com C++` e selecione para fazer o download.
|
| 63 |
+
4. Baixe e instale o [CUDA Toolkit 12.x](https://developer.nvidia.com/cuda-12-1-0-download-archive?target_os=Windows&target_arch=x86_64)
|
| 64 |
+
4. Clique duas vezes em `start.bat` para abrir a interface de gerenciamento WebUI de inferência de treinamento. Se necessário, você pode modificar as `API_FLAGS` conforme mostrado abaixo.
|
| 65 |
+
|
| 66 |
+
!!! info "Opcional"
|
| 67 |
+
Você quer iniciar o WebUI de inferência?
|
| 68 |
+
Edite o arquivo `API_FLAGS.txt` no diretório raiz do projeto e modifique as três primeiras linhas como segue:
|
| 69 |
+
```
|
| 70 |
+
--infer
|
| 71 |
+
# --api
|
| 72 |
+
# --listen ...
|
| 73 |
+
...
|
| 74 |
+
```
|
| 75 |
+
|
| 76 |
+
!!! info "Opcional"
|
| 77 |
+
Você quer iniciar o servidor de API?
|
| 78 |
+
Edite o arquivo `API_FLAGS.txt` no diretório raiz do projeto e modifique as três primeiras linhas como segue:
|
| 79 |
+
|
| 80 |
+
```
|
| 81 |
+
# --infer
|
| 82 |
+
--api
|
| 83 |
+
--listen ...
|
| 84 |
+
...
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
!!! info "Opcional"
|
| 88 |
+
Clique duas vezes em `run_cmd.bat` para entrar no ambiente de linha de comando conda/python deste projeto.
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
## Configuração para Linux
|
| 92 |
+
|
| 93 |
+
Para mais detalhes, consulte [pyproject.toml](../../pyproject.toml).
|
| 94 |
+
```bash
|
| 95 |
+
# Crie um ambiente virtual python 3.10, você também pode usar virtualenv
|
| 96 |
+
conda create -n fish-speech python=3.10
|
| 97 |
+
conda activate fish-speech
|
| 98 |
+
|
| 99 |
+
# Instale o pytorch
|
| 100 |
+
pip3 install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1
|
| 101 |
+
|
| 102 |
+
# Para os Usuário do Ubuntu / Debian: Instale o sox + ffmpeg
|
| 103 |
+
apt install libsox-dev ffmpeg
|
| 104 |
+
|
| 105 |
+
# Para os Usuário do Ubuntu / Debian: Instale o pyaudio
|
| 106 |
+
apt install build-essential \
|
| 107 |
+
cmake \
|
| 108 |
+
libasound-dev \
|
| 109 |
+
portaudio19-dev \
|
| 110 |
+
libportaudio2 \
|
| 111 |
+
libportaudiocpp0
|
| 112 |
+
|
| 113 |
+
# Instale o fish-speech
|
| 114 |
+
pip3 install -e .[stable]
|
| 115 |
+
```
|
| 116 |
+
|
| 117 |
+
## Configuração para macos
|
| 118 |
+
|
| 119 |
+
Se você quiser realizar inferências no MPS, adicione a flag `--device mps`.
|
| 120 |
+
Para uma comparação das velocidades de inferência, consulte [este PR](https://github.com/fishaudio/fish-speech/pull/461#issuecomment-2284277772).
|
| 121 |
+
|
| 122 |
+
!!! aviso
|
| 123 |
+
A opção `compile` não é oficialmente suportada em dispositivos Apple Silicon, então não há garantia de que a velocidade de inferência irá melhorar.
|
| 124 |
+
|
| 125 |
+
```bash
|
| 126 |
+
# create a python 3.10 virtual environment, you can also use virtualenv
|
| 127 |
+
conda create -n fish-speech python=3.10
|
| 128 |
+
conda activate fish-speech
|
| 129 |
+
# install pytorch
|
| 130 |
+
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1
|
| 131 |
+
# install fish-speech
|
| 132 |
+
pip install -e .[stable]
|
| 133 |
+
```
|
| 134 |
+
|
| 135 |
+
## Configuração do Docker
|
| 136 |
+
|
| 137 |
+
1. Instale o NVIDIA Container Toolkit:
|
| 138 |
+
|
| 139 |
+
Para usar a GPU com Docker para treinamento e inferência de modelos, você precisa instalar o NVIDIA Container Toolkit:
|
| 140 |
+
|
| 141 |
+
Para usuários Ubuntu:
|
| 142 |
+
|
| 143 |
+
```bash
|
| 144 |
+
# Adicione o repositório remoto
|
| 145 |
+
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
|
| 146 |
+
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
|
| 147 |
+
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
|
| 148 |
+
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
|
| 149 |
+
# Instale o nvidia-container-toolkit
|
| 150 |
+
sudo apt-get update
|
| 151 |
+
sudo apt-get install -y nvidia-container-toolkit
|
| 152 |
+
# Reinicie o serviço Docker
|
| 153 |
+
sudo systemctl restart docker
|
| 154 |
+
```
|
| 155 |
+
|
| 156 |
+
Para usuários de outras distribuições Linux, consulte o guia de instalação: [NVIDIA Container Toolkit Install-guide](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html).
|
| 157 |
+
|
| 158 |
+
2. Baixe e execute a imagem fish-speech
|
| 159 |
+
|
| 160 |
+
```shell
|
| 161 |
+
# Baixe a imagem
|
| 162 |
+
docker pull fishaudio/fish-speech:latest-dev
|
| 163 |
+
# Execute a imagem
|
| 164 |
+
docker run -it \
|
| 165 |
+
--name fish-speech \
|
| 166 |
+
--gpus all \
|
| 167 |
+
-p 7860:7860 \
|
| 168 |
+
fishaudio/fish-speech:latest-dev \
|
| 169 |
+
zsh
|
| 170 |
+
# Se precisar usar outra porta, modifique o parâmetro -p para YourPort:7860
|
| 171 |
+
```
|
| 172 |
+
|
| 173 |
+
3. Baixe as dependências do modelo
|
| 174 |
+
|
| 175 |
+
Certifique-se de estar no terminal do contêiner Docker e, em seguida, baixe os modelos necessários `vqgan` e `llama` do nosso repositório HuggingFace.
|
| 176 |
+
|
| 177 |
+
```bash
|
| 178 |
+
huggingface-cli download fishaudio/fish-speech-1.4 --local-dir checkpoints/fish-speech-1.4
|
| 179 |
+
```
|
| 180 |
+
|
| 181 |
+
4. Configure as variáveis de ambiente e acesse a WebUI
|
| 182 |
+
|
| 183 |
+
No terminal do contêiner Docker, digite `export GRADIO_SERVER_NAME="0.0.0.0"` para permitir o acesso externo ao serviço gradio dentro do Docker.
|
| 184 |
+
Em seguida, no terminal do contêiner Docker, digite `python tools/webui.py` para iniciar o serviço WebUI.
|
| 185 |
+
|
| 186 |
+
Se estiver usando WSL ou MacOS, acesse [http://localhost:7860](http://localhost:7860) para abrir a interface WebUI.
|
| 187 |
+
|
| 188 |
+
Se estiver implantando em um servidor, substitua localhost pelo IP do seu servidor.
|
| 189 |
+
|
| 190 |
+
## Histórico de Alterações
|
| 191 |
+
- 10/09/2024: Fish-Speech atualizado para a versão 1.4, aumentado o tamanho do conjunto de dados, quantizer n_groups 4 -> 8.
|
| 192 |
+
- 02/07/2024: Fish-Speech atualizado para a versão 1.2, removido o Decodificador VITS e aprimorado consideravelmente a capacidade de zero-shot.
|
| 193 |
+
- 10/05/2024: Fish-Speech atualizado para a versão 1.1, implementado o decodificador VITS para reduzir a WER e melhorar a similaridade de timbre.
|
| 194 |
+
- 22/04/2024: Finalizada a versão 1.0 do Fish-Speech, modificados significativamente os modelos VQGAN e LLAMA.
|
| 195 |
+
- 28/12/2023: Adicionado suporte para ajuste fino `lora`.
|
| 196 |
+
- 27/12/2023: Adicionado suporte para `gradient checkpointing`, `causual sampling` e `flash-attn`.
|
| 197 |
+
- 19/12/2023: Atualizada a interface web e a API HTTP.
|
| 198 |
+
- 18/12/2023: Atualizada a documentação de ajuste fino e exemplos relacionados.
|
| 199 |
+
- 17/12/2023: Atualizado o modelo `text2semantic`, suportando o modo sem fonemas.
|
| 200 |
+
- 13/12/2023: Versão beta lançada, incluindo o modelo VQGAN e um modelo de linguagem baseado em LLAMA (suporte apenas a fonemas).
|
| 201 |
+
|
| 202 |
+
## Agradecimentos
|
| 203 |
+
|
| 204 |
+
- [VITS2 (daniilrobnikov)](https://github.com/daniilrobnikov/vits2)
|
| 205 |
+
- [Bert-VITS2](https://github.com/fishaudio/Bert-VITS2)
|
| 206 |
+
- [GPT VITS](https://github.com/innnky/gpt-vits)
|
| 207 |
+
- [MQTTS](https://github.com/b04901014/MQTTS)
|
| 208 |
+
- [GPT Fast](https://github.com/pytorch-labs/gpt-fast)
|
| 209 |
+
- [Transformers](https://github.com/huggingface/transformers)
|
| 210 |
+
- [GPT-SoVITS](https://github.com/RVC-Boss/GPT-SoVITS)
|
docs/pt/inference.md
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Inferência
|
| 2 |
+
|
| 3 |
+
Suporte para inferência por linha de comando, API HTTP e interface web (WebUI).
|
| 4 |
+
|
| 5 |
+
!!! note
|
| 6 |
+
O processo de raciocínio, em geral, consiste em várias partes:
|
| 7 |
+
|
| 8 |
+
1. Codificar cerca de 10 segundos de voz usando VQGAN.
|
| 9 |
+
2. Inserir os tokens semânticos codificados e o texto correspondente no modelo de linguagem como um exemplo.
|
| 10 |
+
3. Dado um novo trecho de texto, fazer com que o modelo gere os tokens semânticos correspondentes.
|
| 11 |
+
4. Inserir os tokens semânticos gerados no VITS / VQGAN para decodificar e gerar a voz correspondente.
|
| 12 |
+
|
| 13 |
+
## Inferência por Linha de Comando
|
| 14 |
+
|
| 15 |
+
Baixe os modelos `vqgan` e `llama` necessários do nosso repositório Hugging Face.
|
| 16 |
+
|
| 17 |
+
```bash
|
| 18 |
+
huggingface-cli download fishaudio/fish-speech-1.4 --local-dir checkpoints/fish-speech-1.4
|
| 19 |
+
```
|
| 20 |
+
|
| 21 |
+
### 1. Gerar prompt a partir da voz:
|
| 22 |
+
|
| 23 |
+
!!! note
|
| 24 |
+
Se quiser permitir que o modelo escolha aleatoriamente um timbre de voz, pule esta etapa.
|
| 25 |
+
|
| 26 |
+
```bash
|
| 27 |
+
python tools/vqgan/inference.py \
|
| 28 |
+
-i "paimon.wav" \
|
| 29 |
+
--checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth"
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
Você deverá obter um arquivo `fake.npy`.
|
| 33 |
+
|
| 34 |
+
### 2. Gerar tokens semânticos a partir do texto:
|
| 35 |
+
|
| 36 |
+
```bash
|
| 37 |
+
python tools/llama/generate.py \
|
| 38 |
+
--text "O texto que você deseja converter" \
|
| 39 |
+
--prompt-text "Seu texto de referência" \
|
| 40 |
+
--prompt-tokens "fake.npy" \
|
| 41 |
+
--checkpoint-path "checkpoints/fish-speech-1.4" \
|
| 42 |
+
--num-samples 2 \
|
| 43 |
+
--compile
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
Este comando criará um arquivo `codes_N` no diretório de trabalho, onde N é um número inteiro começando de 0.
|
| 47 |
+
|
| 48 |
+
!!! note
|
| 49 |
+
Use `--compile` para fundir kernels CUDA para ter uma inferência mais rápida (~30 tokens/segundo -> ~500 tokens/segundo).
|
| 50 |
+
Mas, se não planeja usar a aceleração CUDA, comente o parâmetro `--compile`.
|
| 51 |
+
|
| 52 |
+
!!! info
|
| 53 |
+
Para GPUs que não suportam bf16, pode ser necessário usar o parâmetro `--half`.
|
| 54 |
+
|
| 55 |
+
### 3. Gerar vocais a partir de tokens semânticos:
|
| 56 |
+
|
| 57 |
+
#### Decodificador VQGAN
|
| 58 |
+
|
| 59 |
+
```bash
|
| 60 |
+
python tools/vqgan/inference.py \
|
| 61 |
+
-i "codes_0.npy" \
|
| 62 |
+
--checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth"
|
| 63 |
+
```
|
| 64 |
+
|
| 65 |
+
## Inferência por API HTTP
|
| 66 |
+
|
| 67 |
+
Fornecemos uma API HTTP para inferência. O seguinte comando pode ser usado para iniciar o servidor:
|
| 68 |
+
|
| 69 |
+
```bash
|
| 70 |
+
python -m tools.api \
|
| 71 |
+
--listen 0.0.0.0:8080 \
|
| 72 |
+
--llama-checkpoint-path "checkpoints/fish-speech-1.4" \
|
| 73 |
+
--decoder-checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth" \
|
| 74 |
+
--decoder-config-name firefly_gan_vq
|
| 75 |
+
```
|
| 76 |
+
|
| 77 |
+
> Para acelerar a inferência, adicione o parâmetro `--compile`.
|
| 78 |
+
|
| 79 |
+
Depois disso, é possível visualizar e testar a API em http://127.0.0.1:8080/.
|
| 80 |
+
|
| 81 |
+
Abaixo está um exemplo de envio de uma solicitação usando `tools/post_api.py`.
|
| 82 |
+
|
| 83 |
+
```bash
|
| 84 |
+
python -m tools.post_api \
|
| 85 |
+
--text "Texto a ser inserido" \
|
| 86 |
+
--reference_audio "Caminho para o áudio de referência" \
|
| 87 |
+
--reference_text "Conteúdo de texto do áudio de referência" \
|
| 88 |
+
--streaming True
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
O comando acima indica a síntese do áudio desejada de acordo com as informações do áudio de referência e a retorna em modo de streaming.
|
| 92 |
+
|
| 93 |
+
!!! info
|
| 94 |
+
Para aprender mais sobre parâmetros disponíveis, você pode usar o comando `python -m tools.post_api -h`
|
| 95 |
+
|
| 96 |
+
## Inferência por WebUI
|
| 97 |
+
|
| 98 |
+
Para iniciar a WebUI de Inferência execute o seguinte comando:
|
| 99 |
+
|
| 100 |
+
```bash
|
| 101 |
+
python -m tools.webui \
|
| 102 |
+
--llama-checkpoint-path "checkpoints/fish-speech-1.4" \
|
| 103 |
+
--decoder-checkpoint-path "checkpoints/fish-speech-1.4/firefly-gan-vq-fsq-8x1024-21hz-generator.pth" \
|
| 104 |
+
--decoder-config-name firefly_gan_vq
|
| 105 |
+
```
|
| 106 |
+
> Para acelerar a inferência, adicione o parâmetro `--compile`.
|
| 107 |
+
|
| 108 |
+
!!! note
|
| 109 |
+
Você pode salvar antecipadamente o arquivo de rótulos e o arquivo de áudio de referência na pasta `references` do diretório principal (que você precisa criar), para que possa chamá-los diretamente na WebUI.
|
| 110 |
+
|
| 111 |
+
!!! note
|
| 112 |
+
É possível usar variáveis de ambiente do Gradio, como `GRADIO_SHARE`, `GRADIO_SERVER_PORT`, `GRADIO_SERVER_NAME`, para configurar a WebUI.
|
| 113 |
+
|
| 114 |
+
Divirta-se!
|
docs/pt/samples.md
ADDED
|
@@ -0,0 +1,225 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Amostras
|
| 2 |
+
|
| 3 |
+
A demonstração da versão 1.4 foi atualizada [aqui](https://speech.fish.audio/samples/)
|
| 4 |
+
|
| 5 |
+
As amostras da v1.2 estão disponíveis em [Bilibili](https://www.bilibili.com/video/BV1wz421B71D/).
|
| 6 |
+
|
| 7 |
+
As seguintes amostras são do modelo v1.1.
|
| 8 |
+
|
| 9 |
+
## Frase em Chinês 1
|
| 10 |
+
```
|
| 11 |
+
人间灯火倒映湖中,她的渴望让静水泛起涟漪。若代价只是孤独,那就让这份愿望肆意流淌。
|
| 12 |
+
流入她所注视的世间,也流入她如湖水般澄澈的目光。
|
| 13 |
+
```
|
| 14 |
+
|
| 15 |
+
<table>
|
| 16 |
+
<thead>
|
| 17 |
+
<tr>
|
| 18 |
+
<th>Orador</th>
|
| 19 |
+
<th>Áudio de Entrada</th>
|
| 20 |
+
<th>Áudio Sintetizado</th>
|
| 21 |
+
</tr>
|
| 22 |
+
</thead>
|
| 23 |
+
<tbody>
|
| 24 |
+
<tr>
|
| 25 |
+
<td>Nahida (Genshin Impact)</td>
|
| 26 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/zh/0_input.wav" /></td>
|
| 27 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/zh/0_output.wav" /></td>
|
| 28 |
+
</tr>
|
| 29 |
+
<tr>
|
| 30 |
+
<td>Zhongli (Genshin Impact)</td>
|
| 31 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/zh/1_input.wav" /></td>
|
| 32 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/zh/1_output.wav" /></td>
|
| 33 |
+
</tr>
|
| 34 |
+
<tr>
|
| 35 |
+
<td>Furina (Genshin Impact)</td>
|
| 36 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/zh/2_input.wav" /></td>
|
| 37 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/zh/2_output.wav" /></td>
|
| 38 |
+
</tr>
|
| 39 |
+
<tr>
|
| 40 |
+
<td>Orador Aleatório 1</td>
|
| 41 |
+
<td> - </td>
|
| 42 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/zh/4_output.wav" /></td>
|
| 43 |
+
</tr>
|
| 44 |
+
<tr>
|
| 45 |
+
<td>Orador Aleatório 2</td>
|
| 46 |
+
<td> - </td>
|
| 47 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/zh/5_output.wav" /></td>
|
| 48 |
+
</tr>
|
| 49 |
+
</tbody>
|
| 50 |
+
</table>
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
## Frase em Chinês 2
|
| 54 |
+
```
|
| 55 |
+
你们这个是什么群啊,你们这是害人不浅啊你们这个群!谁是群主,出来!真的太过分了。你们搞这个群干什么?
|
| 56 |
+
我儿子每一科的成绩都不过那个平均分呐,他现在初二,你叫我儿子怎么办啊?他现在还不到高中啊?
|
| 57 |
+
你们害死我儿子了!快点出来你这个群主!再这样我去报警了啊!我跟你们说你们这一帮人啊,一天到晚啊,
|
| 58 |
+
搞这些什么游戏啊,动漫啊,会害死你们的,你们没有前途我跟你说。你们这九百多个人,好好学习不好吗?
|
| 59 |
+
一天到晚在上网。有什么意思啊?麻烦你重视一下你们的生活的目标啊?有一点学习目标行不行?一天到晚上网是不是人啊?
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
<table>
|
| 63 |
+
<thead>
|
| 64 |
+
<tr>
|
| 65 |
+
<th>Orador</th>
|
| 66 |
+
<th>Áudio de Entrada</th>
|
| 67 |
+
<th>Áudio Sintetizado</th>
|
| 68 |
+
</tr>
|
| 69 |
+
</thead>
|
| 70 |
+
<tbody>
|
| 71 |
+
<tr>
|
| 72 |
+
<td>Nahida (Genshin Impact)</td>
|
| 73 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/zh/0_input.wav" /></td>
|
| 74 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/zh/6_output.wav" /></td>
|
| 75 |
+
</tr>
|
| 76 |
+
<tr>
|
| 77 |
+
<td>Orador Aleatório</td>
|
| 78 |
+
<td> - </td>
|
| 79 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/zh/7_output.wav" /></td>
|
| 80 |
+
</tr>
|
| 81 |
+
</tbody>
|
| 82 |
+
</table>
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
## Frase em Chinês 3
|
| 86 |
+
```
|
| 87 |
+
大家好,我是 Fish Audio 开发的开源文本转语音模型。经过十五万小时的数据训练,
|
| 88 |
+
我已经能够熟练掌握中文、日语和英语,我的语言处理能力接近人类水平,声音表现形式丰富多变。
|
| 89 |
+
作为一个仅有亿级参数的模型,我相信社区成员能够在个人设备上轻松运行和微调,让我成为您的私人语音助手。
|
| 90 |
+
```
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
<table>
|
| 94 |
+
<thead>
|
| 95 |
+
<tr>
|
| 96 |
+
<th>Orador</th>
|
| 97 |
+
<th>Áudio de Entrada</th>
|
| 98 |
+
<th>Áudio Sintetizado</th>
|
| 99 |
+
</tr>
|
| 100 |
+
</thead>
|
| 101 |
+
<tbody>
|
| 102 |
+
<tr>
|
| 103 |
+
<td>Orador Aleatório</td>
|
| 104 |
+
<td> - </td>
|
| 105 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/zh/8_output.wav" /></td>
|
| 106 |
+
</tr>
|
| 107 |
+
</tbody>
|
| 108 |
+
</table>
|
| 109 |
+
|
| 110 |
+
## Frase em Inglês 1
|
| 111 |
+
|
| 112 |
+
```
|
| 113 |
+
In the realm of advanced technology, the evolution of artificial intelligence stands as a
|
| 114 |
+
monumental achievement. This dynamic field, constantly pushing the boundaries of what
|
| 115 |
+
machines can do, has seen rapid growth and innovation. From deciphering complex data
|
| 116 |
+
patterns to driving cars autonomously, AI's applications are vast and diverse.
|
| 117 |
+
```
|
| 118 |
+
|
| 119 |
+
<table>
|
| 120 |
+
<thead>
|
| 121 |
+
<tr>
|
| 122 |
+
<th>Orador</th>
|
| 123 |
+
<th>Áudio de Entrada</th>
|
| 124 |
+
<th>Áudio Sintetizado</th>
|
| 125 |
+
</tr>
|
| 126 |
+
</thead>
|
| 127 |
+
<tbody>
|
| 128 |
+
<tr>
|
| 129 |
+
<td>Orador Aleatório 1</td>
|
| 130 |
+
<td> - </td>
|
| 131 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/en/0_output.wav" /></td>
|
| 132 |
+
</tr>
|
| 133 |
+
<tr>
|
| 134 |
+
<td>Orador Aleatório 2</td>
|
| 135 |
+
<td> - </td>
|
| 136 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/en/1_output.wav" /></td>
|
| 137 |
+
</tr>
|
| 138 |
+
</tbody>
|
| 139 |
+
</table>
|
| 140 |
+
|
| 141 |
+
## Frase em Inglês 2
|
| 142 |
+
```
|
| 143 |
+
Hello everyone, I am an open-source text-to-speech model developed by
|
| 144 |
+
Fish Audio. After training with 150,000 hours of data, I have become proficient
|
| 145 |
+
in Chinese, Japanese, and English, and my language processing abilities
|
| 146 |
+
are close to human level. My voice is capable of a wide range of expressions.
|
| 147 |
+
As a model with only hundreds of millions of parameters, I believe community
|
| 148 |
+
members can easily run and fine-tune me on their personal devices, allowing
|
| 149 |
+
me to serve as your personal voice assistant.
|
| 150 |
+
```
|
| 151 |
+
|
| 152 |
+
<table>
|
| 153 |
+
<thead>
|
| 154 |
+
<tr>
|
| 155 |
+
<th>Orador</th>
|
| 156 |
+
<th>Áudio de Entrada</th>
|
| 157 |
+
<th>Áudio Sintetizado</th>
|
| 158 |
+
</tr>
|
| 159 |
+
</thead>
|
| 160 |
+
<tbody>
|
| 161 |
+
<tr>
|
| 162 |
+
<td>Orador Aleatório</td>
|
| 163 |
+
<td> - </td>
|
| 164 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/en/2_output.wav" /></td>
|
| 165 |
+
</tr>
|
| 166 |
+
</tbody>
|
| 167 |
+
</table>
|
| 168 |
+
|
| 169 |
+
## Frase em Japonês 1
|
| 170 |
+
|
| 171 |
+
```
|
| 172 |
+
先進技術の領域において、人工知能の進化は画期的な成果として立っています。常に機械ができることの限界を
|
| 173 |
+
押し広げているこのダイナミックな分野は、急速な成長と革新を見せています。複雑なデータパターンの解読か
|
| 174 |
+
ら自動運転車の操縦まで、AIの応用は広範囲に及びます。
|
| 175 |
+
```
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
<table>
|
| 179 |
+
<thead>
|
| 180 |
+
<tr>
|
| 181 |
+
<th>Orador</th>
|
| 182 |
+
<th>Áudio de Entrada</th>
|
| 183 |
+
<th>Áudio Sintetizado</th>
|
| 184 |
+
</tr>
|
| 185 |
+
</thead>
|
| 186 |
+
<tbody>
|
| 187 |
+
<tr>
|
| 188 |
+
<td>Orador Aleatório 1</td>
|
| 189 |
+
<td> - </td>
|
| 190 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/ja/0_output.wav" /></td>
|
| 191 |
+
</tr>
|
| 192 |
+
<tr>
|
| 193 |
+
<td>Orador Aleatório 2</td>
|
| 194 |
+
<td> - </td>
|
| 195 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/ja/1_output.wav" /></td>
|
| 196 |
+
</tr>
|
| 197 |
+
</tbody>
|
| 198 |
+
</table>
|
| 199 |
+
|
| 200 |
+
## Frase em Japonês 2
|
| 201 |
+
```
|
| 202 |
+
皆さん、こんにちは。私はフィッシュオーディオによって開発されたオープンソースのテ
|
| 203 |
+
キストから音声への変換モデルです。15万時間のデータトレーニングを経て、
|
| 204 |
+
中国語、日本語、英語を熟知しており、言語処理能力は人間に近いレベルです。
|
| 205 |
+
声の表現も多彩で豊かです。数億のパラメータを持つこのモデルは、コミュニティ
|
| 206 |
+
のメンバーが個人のデバイスで簡単に実行し、微調整することができると
|
| 207 |
+
信じています。これにより、私を個人の音声アシスタントとして活用できます。
|
| 208 |
+
```
|
| 209 |
+
|
| 210 |
+
<table>
|
| 211 |
+
<thead>
|
| 212 |
+
<tr>
|
| 213 |
+
<th>Orador</th>
|
| 214 |
+
<th>Áudio de Entrada</th>
|
| 215 |
+
<th>Áudio Sintetizado</th>
|
| 216 |
+
</tr>
|
| 217 |
+
</thead>
|
| 218 |
+
<tbody>
|
| 219 |
+
<tr>
|
| 220 |
+
<td>Orador Aleatório</td>
|
| 221 |
+
<td> - </td>
|
| 222 |
+
<td><audio controls preload="auto" src="https://demo-r2.speech.fish.audio/v1.1-sft-large/ja/2_output.wav" /></td>
|
| 223 |
+
</tr>
|
| 224 |
+
</tbody>
|
| 225 |
+
</table>
|
docs/pt/start_agent.md
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Iniciar Agente
|
| 2 |
+
|
| 3 |
+
!!! note
|
| 4 |
+
Todo o documento foi traduzido por claude3.5 Sonnet, se você for um falante nativo e achar a tradução problemática, muito obrigado por nos enviar um problema ou uma solicitação pull!
|
| 5 |
+
|
| 6 |
+
## Requisitos
|
| 7 |
+
|
| 8 |
+
- Memória GPU: No mínimo 8GB (com quantização), 16GB ou mais é recomendado.
|
| 9 |
+
- Uso de disco: 10GB
|
| 10 |
+
|
| 11 |
+
## Download do Modelo
|
| 12 |
+
|
| 13 |
+
Você pode obter o modelo através de:
|
| 14 |
+
|
| 15 |
+
```bash
|
| 16 |
+
huggingface-cli download fishaudio/fish-agent-v0.1-3b --local-dir checkpoints/fish-agent-v0.1-3b
|
| 17 |
+
```
|
| 18 |
+
|
| 19 |
+
Coloque-os na pasta 'checkpoints'.
|
| 20 |
+
|
| 21 |
+
Você também precisará do modelo fish-speech que pode ser baixado seguindo as instruções em [inference](inference.md).
|
| 22 |
+
|
| 23 |
+
Então haverá 2 pastas em checkpoints.
|
| 24 |
+
|
| 25 |
+
O `checkpoints/fish-speech-1.4` e `checkpoints/fish-agent-v0.1-3b`
|
| 26 |
+
|
| 27 |
+
## Preparação do Ambiente
|
| 28 |
+
|
| 29 |
+
Se você já tem o Fish-speech, pode usar diretamente adicionando a seguinte instrução:
|
| 30 |
+
```bash
|
| 31 |
+
pip install cachetools
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
!!! nota
|
| 35 |
+
Por favor, use a versão Python abaixo de 3.12 para compilação.
|
| 36 |
+
|
| 37 |
+
Se você não tem, use os comandos abaixo para construir seu ambiente:
|
| 38 |
+
|
| 39 |
+
```bash
|
| 40 |
+
sudo apt-get install portaudio19-dev
|
| 41 |
+
|
| 42 |
+
pip install -e .[stable]
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
## Iniciar a Demo do Agente
|
| 46 |
+
|
| 47 |
+
Para construir o fish-agent, use o comando abaixo na pasta principal:
|
| 48 |
+
|
| 49 |
+
```bash
|
| 50 |
+
python -m tools.api --llama-checkpoint-path checkpoints/fish-agent-v0.1-3b/ --mode agent --compile
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
O argumento `--compile` só suporta Python < 3.12, o que aumentará muito a velocidade de geração de tokens.
|
| 54 |
+
|
| 55 |
+
Não será compilado de uma vez (lembre-se).
|
| 56 |
+
|
| 57 |
+
Então abra outro terminal e use o comando:
|
| 58 |
+
|
| 59 |
+
```bash
|
| 60 |
+
python -m tools.e2e_webui
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
Isso criará uma WebUI Gradio no dispositivo.
|
| 64 |
+
|
| 65 |
+
Quando você usar o modelo pela primeira vez, ele irá compilar (se `--compile` estiver True) por um curto período, então aguarde com paciência.
|
| 66 |
+
|
| 67 |
+
## Gradio Webui
|
| 68 |
+
<p align="center">
|
| 69 |
+
<img src="../../assets/figs/agent_gradio.png" width="75%">
|
| 70 |
+
</p>
|
| 71 |
+
|
| 72 |
+
Divirta-se!
|
| 73 |
+
|
| 74 |
+
## Desempenho
|
| 75 |
+
|
| 76 |
+
Em nossos testes, um laptop com 4060 mal consegue rodar, ficando muito sobrecarregado, gerando apenas cerca de 8 tokens/s. A 4090 gera cerca de 95 tokens/s com compilação, que é o que recomendamos.
|
| 77 |
+
|
| 78 |
+
# Sobre o Agente
|
| 79 |
+
|
| 80 |
+
A demo é uma versão alpha inicial de teste, a velocidade de inferência precisa ser otimizada, e há muitos bugs aguardando correção. Se você encontrou um bug ou quer corrigi-lo, ficaremos muito felizes em receber uma issue ou um pull request.
|