Spaces:
Sleeping

Sleeping
Upload 10 files
Browse files- .gitattributes +3 -0
- README.md +68 -13
- app.py +73 -0
- photos/after.jpg +3 -0
- photos/app.png +0 -0
- photos/before.jpg +3 -0
- photos/example.jpg +3 -0
- photos/icon.png +0 -0
- requirements.txt +7 -0
- src/__init__.py +5 -0
- src/functions.py +271 -0
.gitattributes
CHANGED
|
@@ -36,3 +36,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 36 |
smart-pdf-highlighter-main/photos/after.jpg filter=lfs diff=lfs merge=lfs -text
|
| 37 |
smart-pdf-highlighter-main/photos/before.jpg filter=lfs diff=lfs merge=lfs -text
|
| 38 |
smart-pdf-highlighter-main/photos/example.jpg filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 36 |
smart-pdf-highlighter-main/photos/after.jpg filter=lfs diff=lfs merge=lfs -text
|
| 37 |
smart-pdf-highlighter-main/photos/before.jpg filter=lfs diff=lfs merge=lfs -text
|
| 38 |
smart-pdf-highlighter-main/photos/example.jpg filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
photos/after.jpg filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
photos/before.jpg filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
photos/example.jpg filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,13 +1,68 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Smart PDF Highlighter
|
| 2 |
+
|
| 3 |
+
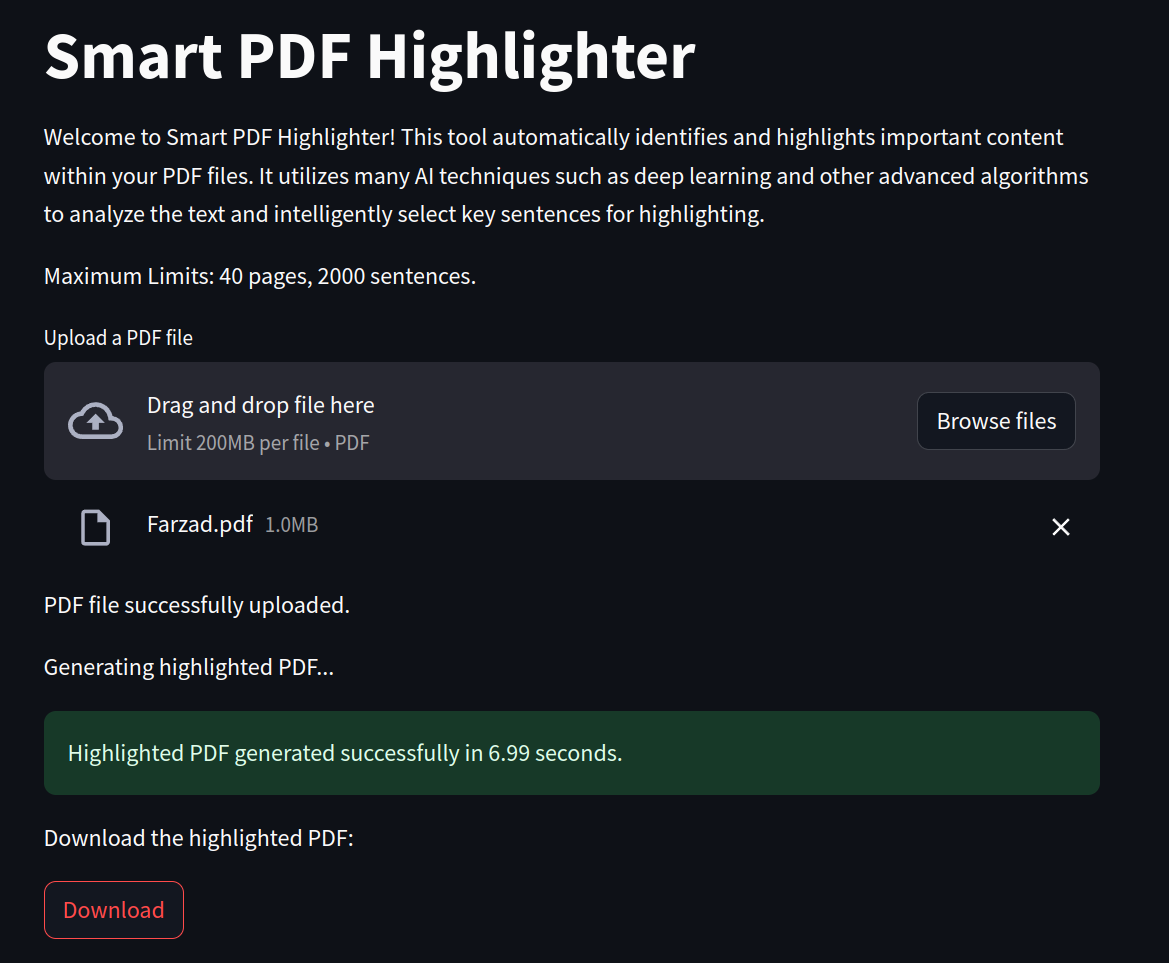
Welcome to Smart PDF Highlighter! This tool finds and highlights important parts in your PDFs all by itself. It uses smart AI methods like deep learning and fancy algorithms to pick out the most important sentences.
|
| 4 |
+
|
| 5 |
+
## Overview
|
| 6 |
+
|
| 7 |
+

|
| 8 |
+
|
| 9 |
+
The Smart PDF Highlighter functions with the following workflow:
|
| 10 |
+
|
| 11 |
+
1. **User Interface**: Users interact with the Streamlit-based graphical user interface (GUI) to upload their PDF files.
|
| 12 |
+
2. **PDF Processing**: Upon file upload, the tool processes the PDF content to identify important sentences.
|
| 13 |
+
3. **Highlighting**: Important sentences are highlighted within the PDF, emphasizing key content.
|
| 14 |
+
4. **Download**: Users can download the highlighted PDF for further reference.
|
| 15 |
+
|
| 16 |
+
## Installation
|
| 17 |
+
|
| 18 |
+
To use the Smart PDF Highlighter, follow these simple steps:
|
| 19 |
+
|
| 20 |
+
1. **Clone the Repository:** Clone the repository to your local machine.
|
| 21 |
+
```python
|
| 22 |
+
git clone https://github.com/FzS92/smart-pdf-highlighter.git
|
| 23 |
+
cd smart-pdf-highlighter
|
| 24 |
+
```
|
| 25 |
+
|
| 26 |
+
2. **Create Virtual Environment:** Set up a Python 3.8 virtual environment and activate it.
|
| 27 |
+
```python
|
| 28 |
+
conda create -n smart-pdf-env python=3.8
|
| 29 |
+
conda activate smart-pdf-env
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
3. **Install Requirements:** Install the required dependencies.
|
| 33 |
+
```python
|
| 34 |
+
pip install -r requirements.txt
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
## Usage
|
| 38 |
+
|
| 39 |
+
Follow these steps to run the Smart PDF Highlighter:
|
| 40 |
+
|
| 41 |
+
1. **Run the Application:** Execute the `app.py` script to start the Streamlit application.
|
| 42 |
+
```python
|
| 43 |
+
streamlit run app.py
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
2. **Upload PDF:** Use the provided interface to upload your PDF file.
|
| 47 |
+
|
| 48 |
+
3. **Highlighting:** Once the file is uploaded, the tool will automatically process it and generate a highlighted version.
|
| 49 |
+
|
| 50 |
+
4. **Download:** Download the highlighted PDF using the provided download button.
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
## Online Version
|
| 54 |
+
|
| 55 |
+
Additionally, an online version of Smart PDF Highlighter is available with the following modifications:
|
| 56 |
+
|
| 57 |
+
1. **Langchain Encoding**: Utilizing langchain encoding (powered by OpenAI), employing the "text-embedding-3-small" model. This feature is currently free for users.
|
| 58 |
+
2. **Backend Technology Change**: Instead of PyTorch, the online version operates using NumPy for efficiency, running on CPU on AWS service.
|
| 59 |
+
|
| 60 |
+
You can access the online version here: https://FzS92.github.io
|
| 61 |
+
(You may get warning from your browser since it does not have a domain + SSL).
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
## Example
|
| 65 |
+
|
| 66 |
+
Before Highlighting | After Highlighting
|
| 67 |
+
:-------------------------:|:-------------------------:
|
| 68 |
+
 | 
|
app.py
ADDED
|
@@ -0,0 +1,73 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Smart PDF Highlighter
|
| 3 |
+
This script provides a Streamlit web application for automatically identifying and
|
| 4 |
+
highlighting important content within PDF files. It utilizes AI techniques such as
|
| 5 |
+
deep learning, clustering, and advanced algorithms such as PageRank to analyze text
|
| 6 |
+
and intelligently select key sentences for highlighting.
|
| 7 |
+
|
| 8 |
+
Author: Farzad Salajegheh
|
| 9 |
+
Date: 2024
|
| 10 |
+
"""
|
| 11 |
+
|
| 12 |
+
import logging
|
| 13 |
+
import time
|
| 14 |
+
|
| 15 |
+
import streamlit as st
|
| 16 |
+
|
| 17 |
+
from src import generate_highlighted_pdf
|
| 18 |
+
|
| 19 |
+
logging.basicConfig(level=logging.INFO)
|
| 20 |
+
logger = logging.getLogger(__name__)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def main():
|
| 24 |
+
"""Main function to run the PDF Highlighter tool."""
|
| 25 |
+
st.set_page_config(page_title="Smart PDF Highlighter", page_icon="./photos/icon.png")
|
| 26 |
+
st.title("Smart PDF Highlighter")
|
| 27 |
+
show_description()
|
| 28 |
+
|
| 29 |
+
uploaded_file = st.file_uploader("Upload a PDF file", type=["pdf"])
|
| 30 |
+
if uploaded_file is not None:
|
| 31 |
+
st.write("PDF file successfully uploaded.")
|
| 32 |
+
process_pdf(uploaded_file)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def show_description():
|
| 36 |
+
"""Display description of functionality and maximum limits."""
|
| 37 |
+
st.write("""Welcome to Smart PDF Highlighter! This tool automatically identifies
|
| 38 |
+
and highlights important content within your PDF files. It utilizes many
|
| 39 |
+
AI techniques such as deep learning and other advanced algorithms to
|
| 40 |
+
analyze the text and intelligently select key sentences for highlighting.""")
|
| 41 |
+
st.write("Maximum Limits: 40 pages, 2000 sentences.")
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def process_pdf(uploaded_file):
|
| 45 |
+
"""Process the uploaded PDF file and generate highlighted PDF."""
|
| 46 |
+
st.write("Generating highlighted PDF...")
|
| 47 |
+
start_time = time.time()
|
| 48 |
+
|
| 49 |
+
with st.spinner("Processing..."):
|
| 50 |
+
result = generate_highlighted_pdf(uploaded_file)
|
| 51 |
+
if isinstance(result, str):
|
| 52 |
+
st.error(result)
|
| 53 |
+
logger.error("Error generating highlighted PDF: %s", result)
|
| 54 |
+
return
|
| 55 |
+
else:
|
| 56 |
+
file = result
|
| 57 |
+
|
| 58 |
+
end_time = time.time()
|
| 59 |
+
execution_time = end_time - start_time
|
| 60 |
+
st.success(
|
| 61 |
+
f"Highlighted PDF generated successfully in {execution_time:.2f} seconds."
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
st.write("Download the highlighted PDF:")
|
| 65 |
+
st.download_button(
|
| 66 |
+
label="Download",
|
| 67 |
+
data=file,
|
| 68 |
+
file_name="highlighted_pdf.pdf",
|
| 69 |
+
)
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
if __name__ == "__main__":
|
| 73 |
+
main()
|
photos/after.jpg
ADDED

|
Git LFS Details
|
photos/app.png
ADDED
|
photos/before.jpg
ADDED

|
Git LFS Details
|
photos/example.jpg
ADDED

|
Git LFS Details
|
photos/icon.png
ADDED
|
|
requirements.txt
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
PyMuPDF==1.23.25
|
| 2 |
+
networkx==3.1
|
| 3 |
+
numpy==1.24.4
|
| 4 |
+
scikit_learn==1.3.2
|
| 5 |
+
sentence_transformers==2.3.1
|
| 6 |
+
streamlit==1.31.1
|
| 7 |
+
torch==2.2.0
|
src/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Import necessary modules.
|
| 3 |
+
"""
|
| 4 |
+
|
| 5 |
+
from .functions import generate_highlighted_pdf
|
src/functions.py
ADDED
|
@@ -0,0 +1,271 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
This module provides functions for generating a highlighted PDF with important sentences.
|
| 3 |
+
|
| 4 |
+
The main function, `generate_highlighted_pdf`, takes an input PDF file and a pre-trained
|
| 5 |
+
sentence embedding model as input.
|
| 6 |
+
|
| 7 |
+
It splits the text of the PDF into sentences, computes sentence embeddings, and builds a
|
| 8 |
+
graph based on the cosine similarity between embeddings and at the same time split the
|
| 9 |
+
sentences to different clusters using clustering.
|
| 10 |
+
|
| 11 |
+
The sentences are then ranked using PageRank scores and a the middle of the cluster,
|
| 12 |
+
and important sentences are selected based on a threshold and clustering.
|
| 13 |
+
|
| 14 |
+
Finally, the selected sentences are highlighted in the PDF and the highlighted PDF content
|
| 15 |
+
is returned.
|
| 16 |
+
|
| 17 |
+
Other utility functions in this module include functions for loading a sentence embedding
|
| 18 |
+
model, encoding sentences, computing similarity matrices,building graphs, ranking sentences,
|
| 19 |
+
clustering sentence embeddings, and splitting text into sentences.
|
| 20 |
+
|
| 21 |
+
Note: This module requires the PyMuPDF, networkx, numpy, torch, sentence_transformers, and
|
| 22 |
+
sklearn libraries to be installed.
|
| 23 |
+
"""
|
| 24 |
+
|
| 25 |
+
import logging
|
| 26 |
+
from typing import BinaryIO, List, Tuple
|
| 27 |
+
|
| 28 |
+
import fitz # PyMuPDF
|
| 29 |
+
import networkx as nx
|
| 30 |
+
import numpy as np
|
| 31 |
+
import torch
|
| 32 |
+
import torch.nn.functional as F
|
| 33 |
+
from sentence_transformers import SentenceTransformer
|
| 34 |
+
from sklearn.cluster import KMeans
|
| 35 |
+
|
| 36 |
+
# Constants
|
| 37 |
+
MAX_PAGE = 40
|
| 38 |
+
MAX_SENTENCES = 2000
|
| 39 |
+
PAGERANK_THRESHOLD_RATIO = 0.15
|
| 40 |
+
NUM_CLUSTERS_RATIO = 0.05
|
| 41 |
+
MIN_WORDS = 10
|
| 42 |
+
|
| 43 |
+
# Logger configuration
|
| 44 |
+
logging.basicConfig(level=logging.ERROR)
|
| 45 |
+
logger = logging.getLogger(__name__)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def load_sentence_model(revision: str = None) -> SentenceTransformer:
|
| 49 |
+
"""
|
| 50 |
+
Load a pre-trained sentence embedding model.
|
| 51 |
+
|
| 52 |
+
Args:
|
| 53 |
+
revision (str): Optional parameter to specify the model revision.
|
| 54 |
+
|
| 55 |
+
Returns:
|
| 56 |
+
SentenceTransformer: A pre-trained sentence embedding model.
|
| 57 |
+
"""
|
| 58 |
+
return SentenceTransformer("avsolatorio/GIST-Embedding-v0", revision=revision)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def encode_sentence(model: SentenceTransformer, sentence: str) -> torch.Tensor:
|
| 62 |
+
"""
|
| 63 |
+
Encode a sentence into a fixed-dimensional vector representation.
|
| 64 |
+
|
| 65 |
+
Args:
|
| 66 |
+
model (SentenceTransformer): A pre-trained sentence embedding model.
|
| 67 |
+
sentence (str): Input sentence.
|
| 68 |
+
|
| 69 |
+
Returns:
|
| 70 |
+
torch.Tensor: Encoded sentence vector.
|
| 71 |
+
"""
|
| 72 |
+
|
| 73 |
+
model.eval() # Set the model to evaluation mode
|
| 74 |
+
|
| 75 |
+
# Check if GPU is available
|
| 76 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 77 |
+
|
| 78 |
+
with torch.no_grad(): # Disable gradient tracking
|
| 79 |
+
return model.encode(sentence, convert_to_tensor=True).to(device)
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def compute_similarity_matrix(embeddings: torch.Tensor) -> np.ndarray:
|
| 83 |
+
"""
|
| 84 |
+
Compute the cosine similarity matrix between sentence embeddings.
|
| 85 |
+
|
| 86 |
+
Args:
|
| 87 |
+
embeddings (torch.Tensor): Sentence embeddings.
|
| 88 |
+
|
| 89 |
+
Returns:
|
| 90 |
+
np.ndarray: Cosine similarity matrix.
|
| 91 |
+
"""
|
| 92 |
+
scores = F.cosine_similarity(
|
| 93 |
+
embeddings.unsqueeze(1), embeddings.unsqueeze(0), dim=-1
|
| 94 |
+
)
|
| 95 |
+
similarity_matrix = scores.cpu().numpy()
|
| 96 |
+
normalized_adjacency_matrix = similarity_matrix / similarity_matrix.sum(
|
| 97 |
+
axis=1, keepdims=True
|
| 98 |
+
)
|
| 99 |
+
return normalized_adjacency_matrix
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def build_graph(normalized_adjacency_matrix: np.ndarray) -> nx.DiGraph:
|
| 103 |
+
"""
|
| 104 |
+
Build a directed graph from a normalized adjacency matrix.
|
| 105 |
+
|
| 106 |
+
Args:
|
| 107 |
+
normalized_adjacency_matrix (np.ndarray): Normalized adjacency matrix.
|
| 108 |
+
|
| 109 |
+
Returns:
|
| 110 |
+
nx.DiGraph: Directed graph.
|
| 111 |
+
"""
|
| 112 |
+
return nx.DiGraph(normalized_adjacency_matrix)
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
def rank_sentences(graph: nx.DiGraph, sentences: List[str]) -> List[Tuple[str, float]]:
|
| 116 |
+
"""
|
| 117 |
+
Rank sentences based on PageRank scores.
|
| 118 |
+
|
| 119 |
+
Args:
|
| 120 |
+
graph (nx.DiGraph): Directed graph.
|
| 121 |
+
sentences (List[str]): List of sentences.
|
| 122 |
+
|
| 123 |
+
Returns:
|
| 124 |
+
List[Tuple[str, float]]: Ranked sentences with their PageRank scores.
|
| 125 |
+
"""
|
| 126 |
+
pagerank_scores = nx.pagerank(graph)
|
| 127 |
+
ranked_sentences = sorted(
|
| 128 |
+
zip(sentences, pagerank_scores.values()),
|
| 129 |
+
key=lambda x: x[1],
|
| 130 |
+
reverse=True,
|
| 131 |
+
)
|
| 132 |
+
return ranked_sentences
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
def cluster_sentences(
|
| 136 |
+
embeddings: torch.Tensor, num_clusters: int
|
| 137 |
+
) -> Tuple[np.ndarray, np.ndarray]:
|
| 138 |
+
"""
|
| 139 |
+
Cluster sentence embeddings using K-means clustering.
|
| 140 |
+
|
| 141 |
+
Args:
|
| 142 |
+
embeddings (torch.Tensor): Sentence embeddings.
|
| 143 |
+
num_clusters (int): Number of clusters.
|
| 144 |
+
|
| 145 |
+
Returns:
|
| 146 |
+
Tuple[np.ndarray, np.ndarray]: Cluster assignments and cluster centers.
|
| 147 |
+
"""
|
| 148 |
+
kmeans = KMeans(n_clusters=num_clusters, random_state=42)
|
| 149 |
+
cluster_assignments = kmeans.fit_predict(embeddings.cpu())
|
| 150 |
+
cluster_centers = kmeans.cluster_centers_
|
| 151 |
+
return cluster_assignments, cluster_centers
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
def get_middle_sentence(cluster_indices: np.ndarray, sentences: List[str]) -> List[str]:
|
| 155 |
+
"""
|
| 156 |
+
Get the middle sentence from each cluster.
|
| 157 |
+
|
| 158 |
+
Args:
|
| 159 |
+
cluster_indices (np.ndarray): Cluster assignments.
|
| 160 |
+
sentences (List[str]): List of sentences.
|
| 161 |
+
|
| 162 |
+
Returns:
|
| 163 |
+
List[str]: Middle sentences from each cluster.
|
| 164 |
+
"""
|
| 165 |
+
middle_indices = [
|
| 166 |
+
int(np.median(np.where(cluster_indices == i)[0]))
|
| 167 |
+
for i in range(max(cluster_indices) + 1)
|
| 168 |
+
]
|
| 169 |
+
middle_sentences = [sentences[i] for i in middle_indices]
|
| 170 |
+
return middle_sentences
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
def split_text_into_sentences(text: str, min_words: int = MIN_WORDS) -> List[str]:
|
| 174 |
+
"""
|
| 175 |
+
Split text into sentences.
|
| 176 |
+
|
| 177 |
+
Args:
|
| 178 |
+
text (str): Input text.
|
| 179 |
+
min_words (int): Minimum number of words for a valid sentence.
|
| 180 |
+
|
| 181 |
+
Returns:
|
| 182 |
+
List[str]: List of sentences.
|
| 183 |
+
"""
|
| 184 |
+
sentences = []
|
| 185 |
+
for s in text.split("."):
|
| 186 |
+
s = s.strip()
|
| 187 |
+
# filtering out short sentences and sentences that contain more than 40% digits
|
| 188 |
+
if (
|
| 189 |
+
s
|
| 190 |
+
and len(s.split()) >= min_words
|
| 191 |
+
and (sum(c.isdigit() for c in s) / len(s)) < 0.4
|
| 192 |
+
):
|
| 193 |
+
sentences.append(s)
|
| 194 |
+
return sentences
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
def extract_text_from_pages(doc):
|
| 198 |
+
"""Generator to yield text per page from the PDF, for memory efficiency for large PDFs."""
|
| 199 |
+
for page_num in range(len(doc)):
|
| 200 |
+
yield doc[page_num].get_text()
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
def generate_highlighted_pdf(
|
| 204 |
+
input_pdf_file: BinaryIO, model=load_sentence_model()
|
| 205 |
+
) -> bytes:
|
| 206 |
+
"""
|
| 207 |
+
Generate a highlighted PDF with important sentences.
|
| 208 |
+
|
| 209 |
+
Args:
|
| 210 |
+
input_pdf_file: Input PDF file object.
|
| 211 |
+
model (SentenceTransformer): Pre-trained sentence embedding model.
|
| 212 |
+
|
| 213 |
+
Returns:
|
| 214 |
+
bytes: Highlighted PDF content.
|
| 215 |
+
"""
|
| 216 |
+
with fitz.open(stream=input_pdf_file.read(), filetype="pdf") as doc:
|
| 217 |
+
num_pages = doc.page_count
|
| 218 |
+
|
| 219 |
+
if num_pages > MAX_PAGE:
|
| 220 |
+
# It will show the error message for the user.
|
| 221 |
+
return f"The PDF file exceeds the maximum limit of {MAX_PAGE} pages."
|
| 222 |
+
|
| 223 |
+
sentences = []
|
| 224 |
+
for page_text in extract_text_from_pages(doc): # Memory efficient
|
| 225 |
+
sentences.extend(split_text_into_sentences(page_text))
|
| 226 |
+
|
| 227 |
+
len_sentences = len(sentences)
|
| 228 |
+
|
| 229 |
+
print(len_sentences)
|
| 230 |
+
|
| 231 |
+
if len_sentences > MAX_SENTENCES:
|
| 232 |
+
# It will show the error message for the user.
|
| 233 |
+
return (
|
| 234 |
+
f"The PDF file exceeds the maximum limit of {MAX_SENTENCES} sentences."
|
| 235 |
+
)
|
| 236 |
+
|
| 237 |
+
embeddings = encode_sentence(model, sentences)
|
| 238 |
+
similarity_matrix = compute_similarity_matrix(embeddings)
|
| 239 |
+
graph = build_graph(similarity_matrix)
|
| 240 |
+
ranked_sentences = rank_sentences(graph, sentences)
|
| 241 |
+
|
| 242 |
+
pagerank_threshold = int(len(ranked_sentences) * PAGERANK_THRESHOLD_RATIO) + 1
|
| 243 |
+
top_pagerank_sentences = [
|
| 244 |
+
sentence[0] for sentence in ranked_sentences[:pagerank_threshold]
|
| 245 |
+
]
|
| 246 |
+
|
| 247 |
+
num_clusters = int(len_sentences * NUM_CLUSTERS_RATIO) + 1
|
| 248 |
+
cluster_assignments, _ = cluster_sentences(embeddings, num_clusters)
|
| 249 |
+
|
| 250 |
+
center_sentences = get_middle_sentence(cluster_assignments, sentences)
|
| 251 |
+
important_sentences = list(set(top_pagerank_sentences + center_sentences))
|
| 252 |
+
|
| 253 |
+
for i in range(num_pages):
|
| 254 |
+
try:
|
| 255 |
+
page = doc[i]
|
| 256 |
+
|
| 257 |
+
for sentence in important_sentences:
|
| 258 |
+
rects = page.search_for(sentence)
|
| 259 |
+
colors = (fitz.pdfcolor["yellow"], fitz.pdfcolor["green"])
|
| 260 |
+
|
| 261 |
+
for i, rect in enumerate(rects):
|
| 262 |
+
color = colors[i % 2]
|
| 263 |
+
annot = page.add_highlight_annot(rect)
|
| 264 |
+
annot.set_colors(stroke=color)
|
| 265 |
+
annot.update()
|
| 266 |
+
except Exception as e:
|
| 267 |
+
logger.error(f"Error processing page {i}: {e}")
|
| 268 |
+
|
| 269 |
+
output_pdf = doc.write()
|
| 270 |
+
|
| 271 |
+
return output_pdf
|