Spaces:
Runtime error

Runtime error
Commit
•
e3a6a57
1
Parent(s):
689d7e7
Upload 194 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +3 -0
- app.py +87 -0
- stylegan3-fun/.github/FUNDING.yml +3 -0
- stylegan3-fun/.github/ISSUE_TEMPLATE/bug_report.md +35 -0
- stylegan3-fun/.github/ISSUE_TEMPLATE/feature_request.md +20 -0
- stylegan3-fun/.gitignore +173 -0
- stylegan3-fun/Dockerfile +19 -0
- stylegan3-fun/LICENSE.txt +97 -0
- stylegan3-fun/README.md +507 -0
- stylegan3-fun/__pycache__/legacy.cpython-311.pyc +0 -0
- stylegan3-fun/__pycache__/legacy.cpython-38.pyc +0 -0
- stylegan3-fun/__pycache__/legacy.cpython-39.pyc +0 -0
- stylegan3-fun/avg_spectra.py +276 -0
- stylegan3-fun/calc_metrics.py +188 -0
- stylegan3-fun/dataset_tool.py +547 -0
- stylegan3-fun/discriminator_synthesis.py +1007 -0
- stylegan3-fun/dnnlib/__init__.py +9 -0
- stylegan3-fun/dnnlib/__pycache__/__init__.cpython-311.pyc +0 -0
- stylegan3-fun/dnnlib/__pycache__/__init__.cpython-38.pyc +0 -0
- stylegan3-fun/dnnlib/__pycache__/__init__.cpython-39.pyc +0 -0
- stylegan3-fun/dnnlib/__pycache__/util.cpython-311.pyc +0 -0
- stylegan3-fun/dnnlib/__pycache__/util.cpython-38.pyc +0 -0
- stylegan3-fun/dnnlib/__pycache__/util.cpython-39.pyc +0 -0
- stylegan3-fun/dnnlib/util.py +491 -0
- stylegan3-fun/docs/avg_spectra_screen0.png +0 -0
- stylegan3-fun/docs/avg_spectra_screen0_half.png +0 -0
- stylegan3-fun/docs/configs.md +201 -0
- stylegan3-fun/docs/dataset-tool-help.txt +70 -0
- stylegan3-fun/docs/stylegan3-teaser-1920x1006.png +3 -0
- stylegan3-fun/docs/train-help.txt +53 -0
- stylegan3-fun/docs/troubleshooting.md +31 -0
- stylegan3-fun/docs/visualizer_screen0.png +3 -0
- stylegan3-fun/docs/visualizer_screen0_half.png +0 -0
- stylegan3-fun/environment.yml +35 -0
- stylegan3-fun/gen_images.py +145 -0
- stylegan3-fun/gen_video.py +281 -0
- stylegan3-fun/generate.py +838 -0
- stylegan3-fun/gui_utils/__init__.py +9 -0
- stylegan3-fun/gui_utils/__pycache__/__init__.cpython-311.pyc +0 -0
- stylegan3-fun/gui_utils/__pycache__/__init__.cpython-38.pyc +0 -0
- stylegan3-fun/gui_utils/__pycache__/__init__.cpython-39.pyc +0 -0
- stylegan3-fun/gui_utils/__pycache__/gl_utils.cpython-311.pyc +0 -0
- stylegan3-fun/gui_utils/__pycache__/gl_utils.cpython-38.pyc +0 -0
- stylegan3-fun/gui_utils/__pycache__/gl_utils.cpython-39.pyc +0 -0
- stylegan3-fun/gui_utils/__pycache__/glfw_window.cpython-311.pyc +0 -0
- stylegan3-fun/gui_utils/__pycache__/glfw_window.cpython-38.pyc +0 -0
- stylegan3-fun/gui_utils/__pycache__/glfw_window.cpython-39.pyc +0 -0
- stylegan3-fun/gui_utils/__pycache__/imgui_utils.cpython-311.pyc +0 -0
- stylegan3-fun/gui_utils/__pycache__/imgui_utils.cpython-38.pyc +0 -0
- stylegan3-fun/gui_utils/__pycache__/imgui_utils.cpython-39.pyc +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
stylegan3-fun/docs/stylegan3-teaser-1920x1006.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
stylegan3-fun/docs/visualizer_screen0.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
stylegan3-fun/out/seed0002.png filter=lfs diff=lfs merge=lfs -text
|
app.py
ADDED
|
@@ -0,0 +1,87 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
import re
|
| 4 |
+
from typing import List, Optional, Tuple, Union
|
| 5 |
+
import random
|
| 6 |
+
|
| 7 |
+
sys.path.append('stylegan3-fun') # change this to the path where dnnlib is located
|
| 8 |
+
|
| 9 |
+
import numpy as np
|
| 10 |
+
import PIL.Image
|
| 11 |
+
import torch
|
| 12 |
+
import streamlit as st
|
| 13 |
+
import dnnlib
|
| 14 |
+
import legacy
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def parse_range(s: Union[str, List]) -> List[int]:
|
| 18 |
+
'''Parse a comma separated list of numbers or ranges and return a list of ints.
|
| 19 |
+
|
| 20 |
+
Example: '1,2,5-10' returns [1, 2, 5, 6, 7]
|
| 21 |
+
'''
|
| 22 |
+
if isinstance(s, list): return s
|
| 23 |
+
ranges = []
|
| 24 |
+
range_re = re.compile(r'^(\d+)-(\d+)$')
|
| 25 |
+
for p in s.split(','):
|
| 26 |
+
m = range_re.match(p)
|
| 27 |
+
if m:
|
| 28 |
+
ranges.extend(range(int(m.group(1)), int(m.group(2))+1))
|
| 29 |
+
else:
|
| 30 |
+
ranges.append(int(p))
|
| 31 |
+
return ranges
|
| 32 |
+
|
| 33 |
+
def make_transform(translate: Tuple[float,float], angle: float):
|
| 34 |
+
m = np.eye(3)
|
| 35 |
+
s = np.sin(angle/360.0*np.pi*2)
|
| 36 |
+
c = np.cos(angle/360.0*np.pi*2)
|
| 37 |
+
m[0][0] = c
|
| 38 |
+
m[0][1] = s
|
| 39 |
+
m[0][2] = translate[0]
|
| 40 |
+
m[1][0] = -s
|
| 41 |
+
m[1][1] = c
|
| 42 |
+
m[1][2] = translate[1]
|
| 43 |
+
return m
|
| 44 |
+
|
| 45 |
+
def generate_image(network_pkl: str, seed: int, truncation_psi: float, noise_mode: str, translate: Tuple[float,float], rotate: float, class_idx: Optional[int]):
|
| 46 |
+
print('Loading networks from "%s"...' % network_pkl)
|
| 47 |
+
device = torch.device('cuda')
|
| 48 |
+
with open(network_pkl, 'rb') as f:
|
| 49 |
+
G = legacy.load_network_pkl(f)['G_ema'].to(device) # type: ignore
|
| 50 |
+
|
| 51 |
+
# Labels.
|
| 52 |
+
label = torch.zeros([1, G.c_dim], device=device)
|
| 53 |
+
if G.c_dim != 0:
|
| 54 |
+
if class_idx is None:
|
| 55 |
+
raise Exception('Must specify class label when using a conditional network')
|
| 56 |
+
label[:, class_idx] = 1
|
| 57 |
+
|
| 58 |
+
z = torch.from_numpy(np.random.RandomState(seed).randn(1, G.z_dim)).to(device)
|
| 59 |
+
|
| 60 |
+
if hasattr(G.synthesis, 'input'):
|
| 61 |
+
m = make_transform(translate, rotate)
|
| 62 |
+
m = np.linalg.inv(m)
|
| 63 |
+
G.synthesis.input.transform.copy_(torch.from_numpy(m))
|
| 64 |
+
|
| 65 |
+
img = G(z, label, truncation_psi=truncation_psi, noise_mode=noise_mode)
|
| 66 |
+
img = (img.permute(0, 2, 3, 1) * 127.5 + 128).clamp(0, 255).to(torch.uint8)
|
| 67 |
+
img = PIL.Image.fromarray(img[0].cpu().numpy(), 'RGB')
|
| 68 |
+
return img
|
| 69 |
+
|
| 70 |
+
def main():
|
| 71 |
+
st.title('Kpop Face Generator')
|
| 72 |
+
|
| 73 |
+
st.write('Press the button below to generate a new image:')
|
| 74 |
+
if st.button('Generate'):
|
| 75 |
+
network_pkl = 'kpopGG.pkl'
|
| 76 |
+
seed = random.randint(0, 99999)
|
| 77 |
+
truncation_psi = 0.45
|
| 78 |
+
noise_mode = 'const'
|
| 79 |
+
translate = (0.0, 0.0)
|
| 80 |
+
rotate = 0.0
|
| 81 |
+
class_idx = None
|
| 82 |
+
|
| 83 |
+
image = generate_image(network_pkl, seed, truncation_psi, noise_mode, translate, rotate, class_idx)
|
| 84 |
+
st.image(image)
|
| 85 |
+
|
| 86 |
+
if __name__ == "__main__":
|
| 87 |
+
main()
|
stylegan3-fun/.github/FUNDING.yml
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# These are supported funding model platforms
|
| 2 |
+
|
| 3 |
+
github: PDillis # Replace with up to 4 GitHub Sponsors-enabled usernames e.g., [user1, user2]
|
stylegan3-fun/.github/ISSUE_TEMPLATE/bug_report.md
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
name: Bug report
|
| 3 |
+
about: Create a report to help us improve
|
| 4 |
+
title: ''
|
| 5 |
+
labels: ''
|
| 6 |
+
assignees: ''
|
| 7 |
+
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
**Describe the bug**
|
| 11 |
+
A clear and concise description of what the bug is.
|
| 12 |
+
|
| 13 |
+
**To Reproduce**
|
| 14 |
+
Steps to reproduce the behavior:
|
| 15 |
+
1. In '...' directory, run command '...'
|
| 16 |
+
2. See error (copy&paste full log, including exceptions and **stacktraces**).
|
| 17 |
+
|
| 18 |
+
Please copy&paste text instead of screenshots for better searchability.
|
| 19 |
+
|
| 20 |
+
**Expected behavior**
|
| 21 |
+
A clear and concise description of what you expected to happen.
|
| 22 |
+
|
| 23 |
+
**Screenshots**
|
| 24 |
+
If applicable, add screenshots to help explain your problem.
|
| 25 |
+
|
| 26 |
+
**Desktop (please complete the following information):**
|
| 27 |
+
- OS: [e.g. Linux Ubuntu 20.04, Windows 10]
|
| 28 |
+
- PyTorch version (e.g., pytorch 1.9.0)
|
| 29 |
+
- CUDA toolkit version (e.g., CUDA 11.4)
|
| 30 |
+
- NVIDIA driver version
|
| 31 |
+
- GPU [e.g., Titan V, RTX 3090]
|
| 32 |
+
- Docker: did you use Docker? If yes, specify docker image URL (e.g., nvcr.io/nvidia/pytorch:21.08-py3)
|
| 33 |
+
|
| 34 |
+
**Additional context**
|
| 35 |
+
Add any other context about the problem here.
|
stylegan3-fun/.github/ISSUE_TEMPLATE/feature_request.md
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
name: Feature request
|
| 3 |
+
about: Suggest an idea for this project
|
| 4 |
+
title: ''
|
| 5 |
+
labels: ''
|
| 6 |
+
assignees: ''
|
| 7 |
+
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
**Is your feature request related to a problem? Please describe.**
|
| 11 |
+
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
|
| 12 |
+
|
| 13 |
+
**Describe the solution you'd like**
|
| 14 |
+
A clear and concise description of what you want to happen.
|
| 15 |
+
|
| 16 |
+
**Describe alternatives you've considered**
|
| 17 |
+
A clear and concise description of any alternative solutions or features you've considered.
|
| 18 |
+
|
| 19 |
+
**Additional context**
|
| 20 |
+
Add any other context or screenshots about the feature request here.
|
stylegan3-fun/.gitignore
ADDED
|
@@ -0,0 +1,173 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
*/**/__pycache__/
|
| 3 |
+
__pycache__/
|
| 4 |
+
*.py[cod]
|
| 5 |
+
*$py.class
|
| 6 |
+
|
| 7 |
+
# C extensions
|
| 8 |
+
*.so
|
| 9 |
+
|
| 10 |
+
# Distribution / packaging
|
| 11 |
+
.Python
|
| 12 |
+
build/
|
| 13 |
+
develop-eggs/
|
| 14 |
+
dist/
|
| 15 |
+
downloads/
|
| 16 |
+
eggs/
|
| 17 |
+
.eggs/
|
| 18 |
+
lib/
|
| 19 |
+
lib64/
|
| 20 |
+
parts/
|
| 21 |
+
sdist/
|
| 22 |
+
var/
|
| 23 |
+
wheels/
|
| 24 |
+
share/python-wheels/
|
| 25 |
+
*.egg-info/
|
| 26 |
+
.installed.cfg
|
| 27 |
+
*.egg
|
| 28 |
+
MANIFEST
|
| 29 |
+
|
| 30 |
+
# PyInstaller
|
| 31 |
+
# Usually these files are written by a python script from a template
|
| 32 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 33 |
+
*.manifest
|
| 34 |
+
*.spec
|
| 35 |
+
|
| 36 |
+
# Installer logs
|
| 37 |
+
pip-log.txt
|
| 38 |
+
pip-delete-this-directory.txt
|
| 39 |
+
|
| 40 |
+
# Unit test / coverage reports
|
| 41 |
+
htmlcov/
|
| 42 |
+
.tox/
|
| 43 |
+
.nox/
|
| 44 |
+
.coverage
|
| 45 |
+
.coverage.*
|
| 46 |
+
.cache
|
| 47 |
+
nosetests.xml
|
| 48 |
+
coverage.xml
|
| 49 |
+
*.cover
|
| 50 |
+
*.py,cover
|
| 51 |
+
.hypothesis/
|
| 52 |
+
.pytest_cache/
|
| 53 |
+
cover/
|
| 54 |
+
|
| 55 |
+
# Translations
|
| 56 |
+
*.mo
|
| 57 |
+
*.pot
|
| 58 |
+
|
| 59 |
+
# Django stuff:
|
| 60 |
+
*.log
|
| 61 |
+
local_settings.py
|
| 62 |
+
db.sqlite3
|
| 63 |
+
db.sqlite3-journal
|
| 64 |
+
|
| 65 |
+
# Flask stuff:
|
| 66 |
+
instance/
|
| 67 |
+
.webassets-cache
|
| 68 |
+
|
| 69 |
+
# Scrapy stuff:
|
| 70 |
+
.scrapy
|
| 71 |
+
|
| 72 |
+
# Sphinx documentation
|
| 73 |
+
docs/_build/
|
| 74 |
+
|
| 75 |
+
# PyBuilder
|
| 76 |
+
.pybuilder/
|
| 77 |
+
target/
|
| 78 |
+
|
| 79 |
+
# Jupyter Notebook
|
| 80 |
+
.ipynb_checkpoints
|
| 81 |
+
|
| 82 |
+
# IPython
|
| 83 |
+
profile_default/
|
| 84 |
+
ipython_config.py
|
| 85 |
+
|
| 86 |
+
# pyenv
|
| 87 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 88 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 89 |
+
# .python-version
|
| 90 |
+
|
| 91 |
+
# pipenv
|
| 92 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 93 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 94 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 95 |
+
# install all needed dependencies.
|
| 96 |
+
#Pipfile.lock
|
| 97 |
+
|
| 98 |
+
# poetry
|
| 99 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 100 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 101 |
+
# commonly ignored for libraries.
|
| 102 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 103 |
+
#poetry.lock
|
| 104 |
+
|
| 105 |
+
# pdm
|
| 106 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 107 |
+
#pdm.lock
|
| 108 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 109 |
+
# in version control.
|
| 110 |
+
# https://pdm.fming.dev/#use-with-ide
|
| 111 |
+
.pdm.toml
|
| 112 |
+
|
| 113 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 114 |
+
__pypackages__/
|
| 115 |
+
|
| 116 |
+
# Celery stuff
|
| 117 |
+
celerybeat-schedule
|
| 118 |
+
celerybeat.pid
|
| 119 |
+
|
| 120 |
+
# SageMath parsed files
|
| 121 |
+
*.sage.py
|
| 122 |
+
|
| 123 |
+
# Environments
|
| 124 |
+
.env
|
| 125 |
+
.venv
|
| 126 |
+
env/
|
| 127 |
+
venv/
|
| 128 |
+
ENV/
|
| 129 |
+
env.bak/
|
| 130 |
+
venv.bak/
|
| 131 |
+
|
| 132 |
+
# Spyder project settings
|
| 133 |
+
.spyderproject
|
| 134 |
+
.spyproject
|
| 135 |
+
|
| 136 |
+
# Rope project settings
|
| 137 |
+
.ropeproject
|
| 138 |
+
|
| 139 |
+
# mkdocs documentation
|
| 140 |
+
/site
|
| 141 |
+
|
| 142 |
+
# mypy
|
| 143 |
+
.mypy_cache/
|
| 144 |
+
.dmypy.json
|
| 145 |
+
dmypy.json
|
| 146 |
+
|
| 147 |
+
# Pyre type checker
|
| 148 |
+
.pyre/
|
| 149 |
+
|
| 150 |
+
# pytype static type analyzer
|
| 151 |
+
.pytype/
|
| 152 |
+
|
| 153 |
+
# Cython debug symbols
|
| 154 |
+
cython_debug/
|
| 155 |
+
|
| 156 |
+
# PyCharm
|
| 157 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 158 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 159 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 160 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 161 |
+
.idea/
|
| 162 |
+
|
| 163 |
+
# Conda temp
|
| 164 |
+
.condatmp/
|
| 165 |
+
|
| 166 |
+
# SGAN specific folders
|
| 167 |
+
datasets/
|
| 168 |
+
dlatents/
|
| 169 |
+
out/
|
| 170 |
+
training-runs/
|
| 171 |
+
pretrained/
|
| 172 |
+
video/
|
| 173 |
+
_screenshots/
|
stylegan3-fun/Dockerfile
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
FROM nvcr.io/nvidia/pytorch:21.08-py3
|
| 10 |
+
|
| 11 |
+
ENV PYTHONDONTWRITEBYTECODE 1
|
| 12 |
+
ENV PYTHONUNBUFFERED 1
|
| 13 |
+
|
| 14 |
+
RUN pip install imageio imageio-ffmpeg==0.4.4 pyspng==0.1.0
|
| 15 |
+
|
| 16 |
+
WORKDIR /workspace
|
| 17 |
+
|
| 18 |
+
RUN (printf '#!/bin/bash\nexec \"$@\"\n' >> /entry.sh) && chmod a+x /entry.sh
|
| 19 |
+
ENTRYPOINT ["/entry.sh"]
|
stylegan3-fun/LICENSE.txt
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Copyright (c) 2021, NVIDIA Corporation & affiliates. All rights reserved.
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
NVIDIA Source Code License for StyleGAN3
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
=======================================================================
|
| 8 |
+
|
| 9 |
+
1. Definitions
|
| 10 |
+
|
| 11 |
+
"Licensor" means any person or entity that distributes its Work.
|
| 12 |
+
|
| 13 |
+
"Software" means the original work of authorship made available under
|
| 14 |
+
this License.
|
| 15 |
+
|
| 16 |
+
"Work" means the Software and any additions to or derivative works of
|
| 17 |
+
the Software that are made available under this License.
|
| 18 |
+
|
| 19 |
+
The terms "reproduce," "reproduction," "derivative works," and
|
| 20 |
+
"distribution" have the meaning as provided under U.S. copyright law;
|
| 21 |
+
provided, however, that for the purposes of this License, derivative
|
| 22 |
+
works shall not include works that remain separable from, or merely
|
| 23 |
+
link (or bind by name) to the interfaces of, the Work.
|
| 24 |
+
|
| 25 |
+
Works, including the Software, are "made available" under this License
|
| 26 |
+
by including in or with the Work either (a) a copyright notice
|
| 27 |
+
referencing the applicability of this License to the Work, or (b) a
|
| 28 |
+
copy of this License.
|
| 29 |
+
|
| 30 |
+
2. License Grants
|
| 31 |
+
|
| 32 |
+
2.1 Copyright Grant. Subject to the terms and conditions of this
|
| 33 |
+
License, each Licensor grants to you a perpetual, worldwide,
|
| 34 |
+
non-exclusive, royalty-free, copyright license to reproduce,
|
| 35 |
+
prepare derivative works of, publicly display, publicly perform,
|
| 36 |
+
sublicense and distribute its Work and any resulting derivative
|
| 37 |
+
works in any form.
|
| 38 |
+
|
| 39 |
+
3. Limitations
|
| 40 |
+
|
| 41 |
+
3.1 Redistribution. You may reproduce or distribute the Work only
|
| 42 |
+
if (a) you do so under this License, (b) you include a complete
|
| 43 |
+
copy of this License with your distribution, and (c) you retain
|
| 44 |
+
without modification any copyright, patent, trademark, or
|
| 45 |
+
attribution notices that are present in the Work.
|
| 46 |
+
|
| 47 |
+
3.2 Derivative Works. You may specify that additional or different
|
| 48 |
+
terms apply to the use, reproduction, and distribution of your
|
| 49 |
+
derivative works of the Work ("Your Terms") only if (a) Your Terms
|
| 50 |
+
provide that the use limitation in Section 3.3 applies to your
|
| 51 |
+
derivative works, and (b) you identify the specific derivative
|
| 52 |
+
works that are subject to Your Terms. Notwithstanding Your Terms,
|
| 53 |
+
this License (including the redistribution requirements in Section
|
| 54 |
+
3.1) will continue to apply to the Work itself.
|
| 55 |
+
|
| 56 |
+
3.3 Use Limitation. The Work and any derivative works thereof only
|
| 57 |
+
may be used or intended for use non-commercially. Notwithstanding
|
| 58 |
+
the foregoing, NVIDIA and its affiliates may use the Work and any
|
| 59 |
+
derivative works commercially. As used herein, "non-commercially"
|
| 60 |
+
means for research or evaluation purposes only.
|
| 61 |
+
|
| 62 |
+
3.4 Patent Claims. If you bring or threaten to bring a patent claim
|
| 63 |
+
against any Licensor (including any claim, cross-claim or
|
| 64 |
+
counterclaim in a lawsuit) to enforce any patents that you allege
|
| 65 |
+
are infringed by any Work, then your rights under this License from
|
| 66 |
+
such Licensor (including the grant in Section 2.1) will terminate
|
| 67 |
+
immediately.
|
| 68 |
+
|
| 69 |
+
3.5 Trademarks. This License does not grant any rights to use any
|
| 70 |
+
Licensor’s or its affiliates’ names, logos, or trademarks, except
|
| 71 |
+
as necessary to reproduce the notices described in this License.
|
| 72 |
+
|
| 73 |
+
3.6 Termination. If you violate any term of this License, then your
|
| 74 |
+
rights under this License (including the grant in Section 2.1) will
|
| 75 |
+
terminate immediately.
|
| 76 |
+
|
| 77 |
+
4. Disclaimer of Warranty.
|
| 78 |
+
|
| 79 |
+
THE WORK IS PROVIDED "AS IS" WITHOUT WARRANTIES OR CONDITIONS OF ANY
|
| 80 |
+
KIND, EITHER EXPRESS OR IMPLIED, INCLUDING WARRANTIES OR CONDITIONS OF
|
| 81 |
+
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, TITLE OR
|
| 82 |
+
NON-INFRINGEMENT. YOU BEAR THE RISK OF UNDERTAKING ANY ACTIVITIES UNDER
|
| 83 |
+
THIS LICENSE.
|
| 84 |
+
|
| 85 |
+
5. Limitation of Liability.
|
| 86 |
+
|
| 87 |
+
EXCEPT AS PROHIBITED BY APPLICABLE LAW, IN NO EVENT AND UNDER NO LEGAL
|
| 88 |
+
THEORY, WHETHER IN TORT (INCLUDING NEGLIGENCE), CONTRACT, OR OTHERWISE
|
| 89 |
+
SHALL ANY LICENSOR BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY DIRECT,
|
| 90 |
+
INDIRECT, SPECIAL, INCIDENTAL, OR CONSEQUENTIAL DAMAGES ARISING OUT OF
|
| 91 |
+
OR RELATED TO THIS LICENSE, THE USE OR INABILITY TO USE THE WORK
|
| 92 |
+
(INCLUDING BUT NOT LIMITED TO LOSS OF GOODWILL, BUSINESS INTERRUPTION,
|
| 93 |
+
LOST PROFITS OR DATA, COMPUTER FAILURE OR MALFUNCTION, OR ANY OTHER
|
| 94 |
+
COMMERCIAL DAMAGES OR LOSSES), EVEN IF THE LICENSOR HAS BEEN ADVISED OF
|
| 95 |
+
THE POSSIBILITY OF SUCH DAMAGES.
|
| 96 |
+
|
| 97 |
+
=======================================================================
|
stylegan3-fun/README.md
ADDED
|
@@ -0,0 +1,507 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# StyleGAN3-Fun<br><sub>Let's have fun with StyleGAN2/ADA/3!</sub>
|
| 2 |
+
|
| 3 |
+
SOTA GANs are hard to train and to explore, and StyleGAN2/ADA/3 are no different. The point of this repository is to allow
|
| 4 |
+
the user to both easily train and explore the trained models without unnecessary headaches.
|
| 5 |
+
|
| 6 |
+
As [before](https://github.com/PDillis/stylegan2-fun), we will build upon the official repository, which has the advantage
|
| 7 |
+
of being backwards-compatible. As such, we can use our previously-trained models from StyleGAN2 and StyleGAN2-ADA. Please
|
| 8 |
+
get acquainted with the official repository and its codebase, as we will be building upon it and as such, increase its
|
| 9 |
+
capabilities (but hopefully not its complexity!).
|
| 10 |
+
|
| 11 |
+
## Additions
|
| 12 |
+
|
| 13 |
+
This repository adds/has the following changes (not yet the complete list):
|
| 14 |
+
|
| 15 |
+
* ***Dataset Setup (`dataset_tool.py`)***
|
| 16 |
+
* **RGBA support**, so revert saving images to `.png` ([Issue #156](https://github.com/NVlabs/stylegan3/issues/156) by @1378dm). Training can use RGBA and images can be generated.
|
| 17 |
+
* ***TODO:*** ~~Check that training code is correct for normalizing the alpha channel~~, as well as making the
|
| 18 |
+
interpolation code work with this new format (look into [`moviepy.editor.VideoClip`](https://zulko.github.io/moviepy/getting_started/videoclips.html?highlight=mask#mask-clips))
|
| 19 |
+
* For now, interpolation videos will only be saved in RGB format, e.g., discarding the alpha channel.
|
| 20 |
+
* **`--center-crop-tall`**: add vertical black bars to the sides of each image in the dataset (rectangular images, with height > width),
|
| 21 |
+
and you wish to train a square model, in the same vein as the horizontal bars added when using `--center-crop-wide` (where width > height).
|
| 22 |
+
* This is useful when you don't want to lose information from the left and right side of the image by only using the center
|
| 23 |
+
crop (ibidem for `--center-crop-wide`, but for the top and bottom of the image)
|
| 24 |
+
* Note that each image doesn't have to be of the same size, and the added bars will only ensure you get a square image, which will then be
|
| 25 |
+
resized to the model's desired resolution (set by `--resolution`).
|
| 26 |
+
* Grayscale images in the dataset are converted to `RGB`
|
| 27 |
+
* If you want to turn this off, remove the respective line in `dataset_tool.py`, e.g., if your dataset is made of images in a folder, then the function to be used is
|
| 28 |
+
`open_image_folder` in `dataset_tool.py`, and the line to be removed is `img = img.convert('RGB')` in the `iterate_images` inner function.
|
| 29 |
+
* The dataset can be forced to be of a specific number of channels, that is, grayscale, RGB or RGBA.
|
| 30 |
+
* To use this, set `--force-channels=1` for grayscale, `--force-channels=3` for RGB, and `--force-channels=4` for RGBA.
|
| 31 |
+
* If the dataset tool encounters an error, print it along the offending image, but continue with the rest of the dataset
|
| 32 |
+
([PR #39](https://github.com/NVlabs/stylegan3/pull/39) from [Andreas Jansson](https://github.com/andreasjansson)).
|
| 33 |
+
* For conditional models, we can use the subdirectories as the classes by adding `--subfolders-as-labels`. This will
|
| 34 |
+
generate the `dataset.json` file automatically as done by @pbaylies [here](https://github.com/pbaylies/stylegan2-ada/blob/a8f0b1c891312631f870c94f996bcd65e0b8aeef/dataset_tool.py#L772)
|
| 35 |
+
* Additionally, in the `--source` folder, we will save a `class_labels.txt` file, to further know which classes correspond to each subdirectory.
|
| 36 |
+
|
| 37 |
+
* ***Training***
|
| 38 |
+
* Add `--cfg=stylegan2-ext`, which uses @aydao's extended modifications for handling large and diverse datasets.
|
| 39 |
+
* A good explanation is found in Gwern's blog [here](https://gwern.net/face#extended-stylegan2-danbooru2019-aydao)
|
| 40 |
+
* If you wish to fine-tune from @aydao's Anime model, use `--cfg=stylegan2-ext --resume=anime512` when running `train.py`
|
| 41 |
+
* Note: ***This is an extremely experimental configuration!*** The `.pkl` files will be ~1.1Gb each and training will slow down
|
| 42 |
+
significantly. Use at your own risk!
|
| 43 |
+
* `--blur-percent`: Blur both real and generated images before passing them to the Discriminator.
|
| 44 |
+
* The blur (`blur_init_sigma=10.0`) will completely fade after the selected percentage of the training is completed (using a linear ramp).
|
| 45 |
+
* Another experimental feature, should help with datasets that have a lot of variation, and you wish the model to slowly
|
| 46 |
+
learn to generate the objects and then its details.
|
| 47 |
+
* `--mirrory`: Added vertical mirroring for doubling the dataset size (quadrupling if `--mirror` is used; make sure your dataset has either or both
|
| 48 |
+
of these symmetries in order for it to make sense to use them)
|
| 49 |
+
* `--gamma`: If no R1 regularization is provided, the heuristic formula from [StyleGAN](https://github.com/NVlabs/stylegan2) will be used.
|
| 50 |
+
* Specifically, we will set `gamma=0.0002 * resolution ** 2 / batch_size`
|
| 51 |
+
* `--aug`: ***TODO:*** add [Deceive-D/APA](https://github.com/EndlessSora/DeceiveD) as an option.
|
| 52 |
+
* `--augpipe`: Now available to use is [StyleGAN2-ADA's](https://github.com/NVlabs/stylegan2-ada-pytorch) full list of augpipe, i.e., individual augmentations (`blit`, `geom`, `color`, `filter`, `noise`, `cutout`) or their combinations (`bg`, `bgc`, `bgcf`, `bgcfn`, `bgcfnc`).
|
| 53 |
+
* `--img-snap`: Set when to save snapshot images, so now it's independent of when the model is saved (e.g., save image snapshots more often to know how the model is training without saving the model itself, to save space).
|
| 54 |
+
* `--snap-res`: The resolution of the snapshots, depending on how many images you wish to see per snapshot. Available resolutions: `1080p`, `4k`, and `8k`.
|
| 55 |
+
* `--resume-kimg`: Starting number of `kimg`, useful when continuing training a previous run
|
| 56 |
+
* `--outdir`: Automatically set as `training-runs`, so no need to set beforehand (in general this is true throughout the repository)
|
| 57 |
+
* `--metrics`: Now set by default to `None`, so there's no need to worry about this one
|
| 58 |
+
* `--freezeD`: Renamed `--freezed` for better readability
|
| 59 |
+
* `--freezeM`: Freeze the first layers of the Mapping Network Gm (`G.mapping`)
|
| 60 |
+
* `--freezeE`: Freeze the embedding layer of the Generator (for class-conditional models)
|
| 61 |
+
* `--freezeG`: ***TODO:*** Freeze the first layers of the Synthesis Network (`G.synthesis`; less cost to transfer learn, focus on high layers?)
|
| 62 |
+
* `--resume`: All available pre-trained models from NVIDIA (and more) can be used with a simple dictionary, depending on the `--cfg` used.
|
| 63 |
+
For example, if you wish to use StyleGAN3's `config-r`, then set `--cfg=stylegan3-r`. In addition, if you wish to transfer learn from FFHQU at 1024 resolution, set `--resume=ffhqu1024`.
|
| 64 |
+
* The full list of currently available models to transfer learn from (or synthesize new images with) is the following (***TODO:*** add small description of each model,
|
| 65 |
+
so the user can better know which to use for their particular use-case; proper citation to original authors as well):
|
| 66 |
+
|
| 67 |
+
<details>
|
| 68 |
+
<summary>StyleGAN2 models</summary>
|
| 69 |
+
|
| 70 |
+
1. Majority, if not all, are `config-f`: set `--cfg=stylegan2`
|
| 71 |
+
* `ffhq256`
|
| 72 |
+
* `ffhqu256`
|
| 73 |
+
* `ffhq512`
|
| 74 |
+
* `ffhq1024`
|
| 75 |
+
* `ffhqu1024`
|
| 76 |
+
* `celebahq256`
|
| 77 |
+
* `lsundog256`
|
| 78 |
+
* `afhqcat512`
|
| 79 |
+
* `afhqdog512`
|
| 80 |
+
* `afhqwild512`
|
| 81 |
+
* `afhq512`
|
| 82 |
+
* `brecahad512`
|
| 83 |
+
* `cifar10` (conditional, 10 classes)
|
| 84 |
+
* `metfaces1024`
|
| 85 |
+
* `metfacesu1024`
|
| 86 |
+
* `lsuncar512` (config-f)
|
| 87 |
+
* `lsuncat256` (config-f)
|
| 88 |
+
* `lsunchurch256` (config-f)
|
| 89 |
+
* `lsunhorse256` (config-f)
|
| 90 |
+
* `minecraft1024` (thanks to @jeffheaton)
|
| 91 |
+
* `imagenet512` (thanks to @shawwn)
|
| 92 |
+
* `wikiart1024-C` (conditional, 167 classes; thanks to @pbaylies)
|
| 93 |
+
* `wikiart1024-U` (thanks to @pbaylies)
|
| 94 |
+
* `maps1024` (thanks to @tjukanov)
|
| 95 |
+
* `fursona512` (thanks to @arfafax)
|
| 96 |
+
* `mlpony512` (thanks to @arfafax)
|
| 97 |
+
* `lhq1024` (thanks to @justinpinkney)
|
| 98 |
+
* `afhqcat256` (Deceive-D/APA models)
|
| 99 |
+
* `anime256` (Deceive-D/APA models)
|
| 100 |
+
* `cub256` (Deceive-D/APA models)
|
| 101 |
+
* `sddogs1024` (Self-Distilled StyleGAN models)
|
| 102 |
+
* `sdelephant512` (Self-Distilled StyleGAN models)
|
| 103 |
+
* `sdhorses512` (Self-Distilled StyleGAN models)
|
| 104 |
+
* `sdbicycles256` (Self-Distilled StyleGAN models)
|
| 105 |
+
* `sdlions512` (Self-Distilled StyleGAN models)
|
| 106 |
+
* `sdgiraffes512` (Self-Distilled StyleGAN models)
|
| 107 |
+
* `sdparrots512` (Self-Distilled StyleGAN models)
|
| 108 |
+
2. Extended StyleGAN2 config from @aydao: set `--cfg=stylegan2-ext`
|
| 109 |
+
* `anime512` (thanks to @aydao; writeup by @gwern: https://gwern.net/Faces#extended-stylegan2-danbooru2019-aydao)
|
| 110 |
+
</details>
|
| 111 |
+
|
| 112 |
+
<details>
|
| 113 |
+
<summary>StyleGAN3 models</summary>
|
| 114 |
+
|
| 115 |
+
1. `config-t`: set `--cfg=stylegan3-t`
|
| 116 |
+
* `afhq512`
|
| 117 |
+
* `ffhqu256`
|
| 118 |
+
* `ffhq1024`
|
| 119 |
+
* `ffhqu1024`
|
| 120 |
+
* `metfaces1024`
|
| 121 |
+
* `metfacesu1024`
|
| 122 |
+
* `landscapes256` (thanks to @justinpinkney)
|
| 123 |
+
* `wikiart1024` (thanks to @justinpinkney)
|
| 124 |
+
* `mechfuture256` (thanks to @edstoica; 29 kimg tick)
|
| 125 |
+
* `vivflowers256` (thanks to @edstoica; 68 kimg tick)
|
| 126 |
+
* `alienglass256` (thanks to @edstoica; 38 kimg tick)
|
| 127 |
+
* `scificity256` (thanks to @edstoica; 210 kimg tick)
|
| 128 |
+
* `scifiship256` (thanks to @edstoica; 168 kimg tick)
|
| 129 |
+
2. `config-r`: set `--cfg=stylegan3-r`
|
| 130 |
+
* `afhq512`
|
| 131 |
+
* `ffhq1024`
|
| 132 |
+
* `ffhqu1024`
|
| 133 |
+
* `ffhqu256`
|
| 134 |
+
* `metfaces1024`
|
| 135 |
+
* `metfacesu1024`
|
| 136 |
+
</details>
|
| 137 |
+
|
| 138 |
+
* The main sources of these pretrained models are both the [official NVIDIA repository](https://catalog.ngc.nvidia.com/orgs/nvidia/teams/research/models/stylegan3),
|
| 139 |
+
as well as other community repositories, such as [Justin Pinkney](https://github.com/justinpinkney) 's [Awesome Pretrained StyleGAN2](https://github.com/justinpinkney/awesome-pretrained-stylegan2)
|
| 140 |
+
and [Awesome Pretrained StyleGAN3](https://github.com/justinpinkney/awesome-pretrained-stylegan3), [Deceive-D/APA](https://github.com/EndlessSora/DeceiveD),
|
| 141 |
+
[Self-Distilled StyleGAN/Internet Photos](https://github.com/self-distilled-stylegan/self-distilled-internet-photos), and [edstoica](https://github.com/edstoica) 's
|
| 142 |
+
[Wombo Dream](https://www.wombo.art/) [-based models](https://github.com/edstoica/lucid_stylegan3_datasets_models). Others can be found around the net and are properly credited in this repository,
|
| 143 |
+
so long as they can be easily downloaded with [`dnnlib.util.open_url`](https://github.com/PDillis/stylegan3-fun/blob/4ce9d6f7601641ba1e2906ed97f2739a63fb96e2/dnnlib/util.py#L396).
|
| 144 |
+
|
| 145 |
+
* ***Interpolation videos***
|
| 146 |
+
* [Random interpolation](https://youtu.be/DNfocO1IOUE)
|
| 147 |
+
* [Generate images/interpolations with the internal representations of the model](https://nvlabs-fi-cdn.nvidia.com/_web/stylegan3/videos/video_8_internal_activations.mp4)
|
| 148 |
+
* Usage: Add `--layer=<layer_name>` to specify which layer to use for interpolation.
|
| 149 |
+
* If you don't know the names of the layers available for your model, add the flag `--available-layers` and the
|
| 150 |
+
layers will be printed to the console, along their names, number of channels, and sizes.
|
| 151 |
+
* Use one of `--grayscale` or `--rgb` to specify whether to save the images as grayscale or RGB during the interpolation.
|
| 152 |
+
* For `--rgb`, three consecutive channels (starting at `--starting-channel=0`) will be used to create the RGB image. For `--grayscale`, only the first channel will be used.
|
| 153 |
+
* Style-mixing
|
| 154 |
+
* [Sightseeding](https://twitter.com/PDillis/status/1270341433401249793?s=20&t=yLueNkagqsidZFqZ2jNPAw) (jumpiness has been fixed)
|
| 155 |
+
* [Circular interpolation](https://youtu.be/4nktYGjSVHg)
|
| 156 |
+
* [Visual-reactive interpolation](https://youtu.be/KoEAkPnE-zA) (Beta)
|
| 157 |
+
* Audiovisual-reactive interpolation (TODO)
|
| 158 |
+
* ***TODO:*** Give support to RGBA models!
|
| 159 |
+
* ***Projection into the latent space***
|
| 160 |
+
* [Project into $\mathcal{W}+$](https://arxiv.org/abs/1904.03189)
|
| 161 |
+
* Additional losses to use for better projection (e.g., using VGG16 or [CLIP](https://github.com/openai/CLIP))
|
| 162 |
+
* ***[Discriminator Synthesis](https://arxiv.org/abs/2111.02175)*** (official code)
|
| 163 |
+
* Generate a static image (`python discriminator_synthesis.py dream --help`) or a [video](https://youtu.be/hEJKWL2VQTE) with a feedback loop (`python discriminator_synthesis.py dream-zoom --help`,
|
| 164 |
+
`python discriminator_synthesis.py channel-zoom --help`, or `python discriminator_synthesis.py interp --help`)
|
| 165 |
+
* Start from a random image (`random` for noise or `perlin` for 2D fractal Perlin noise, using
|
| 166 |
+
[Mathieu Duchesneau's implementation](https://github.com/duchesneaumathieu/pyperlin)) or from an existing one
|
| 167 |
+
* ***Expansion on GUI/`visualizer.py`***
|
| 168 |
+
* Added the rest of the affine transformations
|
| 169 |
+
* Added widget for class-conditional models (***TODO:*** mix classes with continuous values for `cls`!)
|
| 170 |
+
* ***General model and code additions***
|
| 171 |
+
* [Multi-modal truncation trick](https://arxiv.org/abs/2202.12211): find the different clusters in your model and use the closest one to your dlatent, in order to increase the fidelity
|
| 172 |
+
* Usage: Run `python multimodal_truncation.py get-centroids --network=<path_to_model>` to use default values; for extra options, run `python multimodal_truncation.py get-centroids --help`
|
| 173 |
+
* StyleGAN3: anchor the latent space for easier to follow interpolations (thanks to [Rivers Have Wings](https://github.com/crowsonkb) and [nshepperd](https://github.com/nshepperd)).
|
| 174 |
+
* Use CPU instead of GPU if desired (not recommended, but perfectly fine for generating images, whenever the custom CUDA kernels fail to compile).
|
| 175 |
+
* Add missing dependencies and channels so that the [`conda`](https://docs.conda.io/en/latest/) environment is correctly setup in Windows
|
| 176 |
+
(PR's [#111](https://github.com/NVlabs/stylegan3/pull/111)/[#125](https://github.com/NVlabs/stylegan3/pull/125) and [#80](https://github.com/NVlabs/stylegan3/pull/80) /[#143](https://github.com/NVlabs/stylegan3/pull/143) from the base, respectively)
|
| 177 |
+
* Use [StyleGAN-NADA](https://github.com/rinongal/StyleGAN-nada) models with any part of the code (Issue [#9](https://github.com/PDillis/stylegan3-fun/issues/9))
|
| 178 |
+
* The StyleGAN-NADA models must first be converted via [Vadim Epstein](https://github.com/eps696) 's conversion code found [here](https://github.com/eps696/stylegan2ada#tweaking-models).
|
| 179 |
+
* Add PR [#173](https://github.com/NVlabs/stylegan3/pull/173) for adding the last remaining unknown kwarg for using StyleGAN2 models using TF 1.15.
|
| 180 |
+
* ***TODO*** list (this is a long one with more to come, so any help is appreciated):
|
| 181 |
+
* Add `--device={cuda, ref}` option to pass to each of the custom operations in order to (theoretically) be able to use AMD GPUs, as explained in
|
| 182 |
+
@l4rz's post [here](https://github.com/l4rz/practical-aspects-of-stylegan2-training#hardware)
|
| 183 |
+
* Define a [custom Generator](https://github.com/dvschultz/stylegan2-ada-pytorch/blob/59e05bb115c1c7d0de56be0523754076c2b7ee83/legacy.py#L131) in `legacy.py` to modify the output size
|
| 184 |
+
* Related: the [multi-latent](https://github.com/dvschultz/stylegan2-ada-pytorch/blob/main/training/stylegan2_multi.py), i.e., the one from [@eps696](https://github.com/eps696/stylegan2)
|
| 185 |
+
* Add [Top-K training](https://arxiv.org/abs/2002.06224) as done [here](https://github.com/dvschultz/stylegan2-ada/blob/8f4ab24f494483542d31bf10f4fdb0005dc62739/train.py#L272) and [here](https://github.com/dvschultz/stylegan2-ada-pytorch/blob/59e05bb115c1c7d0de56be0523754076c2b7ee83/training/loss.py#L79)
|
| 186 |
+
* Add panorama/SinGAN/feature interpolation from [StyleGAN of All Trades](https://arxiv.org/abs/2111.01619)
|
| 187 |
+
* [PTI](https://github.com/danielroich/PTI) for better inversion
|
| 188 |
+
* [Better sampling](https://arxiv.org/abs/2110.08009)
|
| 189 |
+
* [Add cross-model interpolation](https://twitter.com/arfafax/status/1297681537337446400?s=20&t=xspnTaLFTvd7y4krg8tkxA)
|
| 190 |
+
* Blend different models (average checkpoints, copy weights, create initial network), as in @aydao's [StyleGAN2-Surgery](https://github.com/aydao/stylegan2-surgery)
|
| 191 |
+
* Add multi-crop for the dataset creation, as used in [Earth View](https://github.com/PDillis/earthview#multi-crop---data_augmentpy).
|
| 192 |
+
* Make it easy to download pretrained models from Drive, otherwise a lot of models can't be used with `dnnlib.util.open_url`
|
| 193 |
+
(e.g., [StyleGAN-Human](https://github.com/stylegan-human/StyleGAN-Human) models)
|
| 194 |
+
* Finish documentation for better user experience, add videos/images, code samples, visuals...
|
| 195 |
+
* Add [Ensembling Off-the-shelf Models for GAN Training](https://arxiv.org/abs/2112.09130) and [Any-resolution Training for High-resolution Image Synthesis](https://chail.github.io/anyres-gan/)
|
| 196 |
+
|
| 197 |
+
## Notebooks (Coming soon!)
|
| 198 |
+
|
| 199 |
+
## Sponsors 
|
| 200 |
+
|
| 201 |
+
This repository has been sponsored by:
|
| 202 |
+
|
| 203 |
+
[isosceles](https://www.jasonfletcher.info/vjloops/)
|
| 204 |
+
|
| 205 |
+
Thank you so much!
|
| 206 |
+
|
| 207 |
+
If you wish to sponsor me, click here: [](https://github.com/sponsors/PDillis)
|
| 208 |
+
|
| 209 |
+
|
| 210 |
+
---
|
| 211 |
+
|
| 212 |
+
## Alias-Free Generative Adversarial Networks (StyleGAN3)<br><sub>Official PyTorch implementation of the NeurIPS 2021 paper</sub>
|
| 213 |
+
|
| 214 |
+

|
| 215 |
+
|
| 216 |
+
**Alias-Free Generative Adversarial Networks**<br>
|
| 217 |
+
Tero Karras, Miika Aittala, Samuli Laine, Erik Härkönen, Janne Hellsten, Jaakko Lehtinen, Timo Aila<br>
|
| 218 |
+
https://nvlabs.github.io/stylegan3<br>
|
| 219 |
+
|
| 220 |
+
Abstract: *We observe that despite their hierarchical convolutional nature, the synthesis process of typical generative adversarial networks depends on absolute pixel coordinates in an unhealthy manner. This manifests itself as, e.g., detail appearing to be glued to image coordinates instead of the surfaces of depicted objects. We trace the root cause to careless signal processing that causes aliasing in the generator network. Interpreting all signals in the network as continuous, we derive generally applicable, small architectural changes that guarantee that unwanted information cannot leak into the hierarchical synthesis process. The resulting networks match the FID of StyleGAN2 but differ dramatically in their internal representations, and they are fully equivariant to translation and rotation even at subpixel scales. Our results pave the way for generative models better suited for video and animation.*
|
| 221 |
+
|
| 222 |
+
For business inquiries, please visit our website and submit the form: [NVIDIA Research Licensing](https://www.nvidia.com/en-us/research/inquiries/)
|
| 223 |
+
|
| 224 |
+
## Release notes
|
| 225 |
+
|
| 226 |
+
This repository is an updated version of [stylegan2-ada-pytorch](https://github.com/NVlabs/stylegan2-ada-pytorch), with several new features:
|
| 227 |
+
- Alias-free generator architecture and training configurations (`stylegan3-t`, `stylegan3-r`).
|
| 228 |
+
- Tools for interactive visualization (`visualizer.py`), spectral analysis (`avg_spectra.py`), and video generation (`gen_video.py`).
|
| 229 |
+
- Equivariance metrics (`eqt50k_int`, `eqt50k_frac`, `eqr50k`).
|
| 230 |
+
- General improvements: reduced memory usage, slightly faster training, bug fixes.
|
| 231 |
+
|
| 232 |
+
Compatibility:
|
| 233 |
+
- Compatible with old network pickles created using [stylegan2-ada](https://github.com/NVlabs/stylegan2-ada) and [stylegan2-ada-pytorch](https://github.com/NVlabs/stylegan2-ada-pytorch). (Note: running old StyleGAN2 models on StyleGAN3 code will produce the same results as running them on stylegan2-ada/stylegan2-ada-pytorch. To benefit from the StyleGAN3 architecture, you need to retrain.)
|
| 234 |
+
- Supports old StyleGAN2 training configurations, including ADA and transfer learning. See [Training configurations](./docs/configs.md) for details.
|
| 235 |
+
- Improved compatibility with Ampere GPUs and newer versions of PyTorch, CuDNN, etc.
|
| 236 |
+
|
| 237 |
+
## Synthetic image detection
|
| 238 |
+
|
| 239 |
+
While new generator approaches enable new media synthesis capabilities, they may also present a new challenge for AI forensics algorithms for detection and attribution of synthetic media. In collaboration with digital forensic researchers participating in DARPA's SemaFor program, we curated a synthetic image dataset that allowed the researchers to test and validate the performance of their image detectors in advance of the public release. Please see [here](https://github.com/NVlabs/stylegan3-detector) for more details.
|
| 240 |
+
|
| 241 |
+
## Additional material
|
| 242 |
+
|
| 243 |
+
- [Result videos](https://nvlabs-fi-cdn.nvidia.com/stylegan3/videos/)
|
| 244 |
+
- [Curated example images](https://nvlabs-fi-cdn.nvidia.com/stylegan3/images/)
|
| 245 |
+
- [StyleGAN3 pre-trained models](https://ngc.nvidia.com/catalog/models/nvidia:research:stylegan3) for config T (translation equiv.) and config R (translation and rotation equiv.)
|
| 246 |
+
> <sub>Access individual networks via `https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/<MODEL>`, where `<MODEL>` is one of:</sub><br>
|
| 247 |
+
> <sub>`stylegan3-t-ffhq-1024x1024.pkl`, `stylegan3-t-ffhqu-1024x1024.pkl`, `stylegan3-t-ffhqu-256x256.pkl`</sub><br>
|
| 248 |
+
> <sub>`stylegan3-r-ffhq-1024x1024.pkl`, `stylegan3-r-ffhqu-1024x1024.pkl`, `stylegan3-r-ffhqu-256x256.pkl`</sub><br>
|
| 249 |
+
> <sub>`stylegan3-t-metfaces-1024x1024.pkl`, `stylegan3-t-metfacesu-1024x1024.pkl`</sub><br>
|
| 250 |
+
> <sub>`stylegan3-r-metfaces-1024x1024.pkl`, `stylegan3-r-metfacesu-1024x1024.pkl`</sub><br>
|
| 251 |
+
> <sub>`stylegan3-t-afhqv2-512x512.pkl`</sub><br>
|
| 252 |
+
> <sub>`stylegan3-r-afhqv2-512x512.pkl`</sub><br>
|
| 253 |
+
- [StyleGAN2 pre-trained models](https://ngc.nvidia.com/catalog/models/nvidia:research:stylegan2) compatible with this codebase
|
| 254 |
+
> <sub>Access individual networks via `https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan2/versions/1/files/<MODEL>`, where `<MODEL>` is one of:</sub><br>
|
| 255 |
+
> <sub>`stylegan2-ffhq-1024x1024.pkl`, `stylegan2-ffhq-512x512.pkl`, `stylegan2-ffhq-256x256.pkl`</sub><br>
|
| 256 |
+
> <sub>`stylegan2-ffhqu-1024x1024.pkl`, `stylegan2-ffhqu-256x256.pkl`</sub><br>
|
| 257 |
+
> <sub>`stylegan2-metfaces-1024x1024.pkl`, `stylegan2-metfacesu-1024x1024.pkl`</sub><br>
|
| 258 |
+
> <sub>`stylegan2-afhqv2-512x512.pkl`</sub><br>
|
| 259 |
+
> <sub>`stylegan2-afhqcat-512x512.pkl`, `stylegan2-afhqdog-512x512.pkl`, `stylegan2-afhqwild-512x512.pkl`</sub><br>
|
| 260 |
+
> <sub>`stylegan2-brecahad-512x512.pkl`, `stylegan2-cifar10-32x32.pkl`</sub><br>
|
| 261 |
+
> <sub>`stylegan2-celebahq-256x256.pkl`, `stylegan2-lsundog-256x256.pkl`</sub><br>
|
| 262 |
+
|
| 263 |
+
## Requirements
|
| 264 |
+
|
| 265 |
+
* Linux and Windows are supported, but we recommend Linux for performance and compatibility reasons.
|
| 266 |
+
* 1–8 high-end NVIDIA GPUs with at least 12 GB of memory. We have done all testing and development using Tesla V100 and A100 GPUs.
|
| 267 |
+
* 64-bit Python 3.8 and PyTorch 1.9.0 (or later). See https://pytorch.org for PyTorch install instructions.
|
| 268 |
+
* CUDA toolkit 11.1 or later. (Why is a separate CUDA toolkit installation required? See [Troubleshooting](./docs/troubleshooting.md#why-is-cuda-toolkit-installation-necessary)).
|
| 269 |
+
* GCC 7 or later (Linux) or Visual Studio (Windows) compilers. Recommended GCC version depends on CUDA version, see for example [CUDA 11.4 system requirements](https://docs.nvidia.com/cuda/archive/11.4.1/cuda-installation-guide-linux/index.html#system-requirements).
|
| 270 |
+
* Python libraries: see [environment.yml](./environment.yml) for exact library dependencies. You can use the following commands with Miniconda3 to create and activate your StyleGAN3 Python environment:
|
| 271 |
+
- `conda env create -f environment.yml`
|
| 272 |
+
- `conda activate stylegan3`
|
| 273 |
+
* Docker users:
|
| 274 |
+
- Ensure you have correctly installed the [NVIDIA container runtime](https://docs.docker.com/config/containers/resource_constraints/#gpu).
|
| 275 |
+
- Use the [provided Dockerfile](./Dockerfile) to build an image with the required library dependencies.
|
| 276 |
+
|
| 277 |
+
The code relies heavily on custom PyTorch extensions that are compiled on the fly using NVCC. On Windows, the compilation requires Microsoft Visual Studio. We recommend installing [Visual Studio Community Edition](https://visualstudio.microsoft.com/vs/) and adding it into `PATH` using `"C:\Program Files (x86)\Microsoft Visual Studio\<VERSION>\Community\VC\Auxiliary\Build\vcvars64.bat"`.
|
| 278 |
+
|
| 279 |
+
See [Troubleshooting](./docs/troubleshooting.md) for help on common installation and run-time problems.
|
| 280 |
+
|
| 281 |
+
## Getting started
|
| 282 |
+
|
| 283 |
+
Pre-trained networks are stored as `*.pkl` files that can be referenced using local filenames or URLs:
|
| 284 |
+
|
| 285 |
+
```bash
|
| 286 |
+
# Generate an image using pre-trained AFHQv2 model ("Ours" in Figure 1, left).
|
| 287 |
+
python gen_images.py --outdir=out --trunc=1 --seeds=2 \
|
| 288 |
+
--network=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-r-afhqv2-512x512.pkl
|
| 289 |
+
|
| 290 |
+
# Render a 4x2 grid of interpolations for seeds 0 through 31.
|
| 291 |
+
python gen_video.py --output=lerp.mp4 --trunc=1 --seeds=0-31 --grid=4x2 \
|
| 292 |
+
--network=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-r-afhqv2-512x512.pkl
|
| 293 |
+
```
|
| 294 |
+
|
| 295 |
+
Outputs from the above commands are placed under `out/*.png`, controlled by `--outdir`. Downloaded network pickles are cached under `$HOME/.cache/dnnlib`, which can be overridden by setting the `DNNLIB_CACHE_DIR` environment variable. The default PyTorch extension build directory is `$HOME/.cache/torch_extensions`, which can be overridden by setting `TORCH_EXTENSIONS_DIR`.
|
| 296 |
+
|
| 297 |
+
**Docker**: You can run the above curated image example using Docker as follows:
|
| 298 |
+
|
| 299 |
+
```bash
|
| 300 |
+
# Build the stylegan3:latest image
|
| 301 |
+
docker build --tag stylegan3 .
|
| 302 |
+
|
| 303 |
+
# Run the gen_images.py script using Docker:
|
| 304 |
+
docker run --gpus all -it --rm --user $(id -u):$(id -g) \
|
| 305 |
+
-v `pwd`:/scratch --workdir /scratch -e HOME=/scratch \
|
| 306 |
+
stylegan3 \
|
| 307 |
+
python gen_images.py --outdir=out --trunc=1 --seeds=2 \
|
| 308 |
+
--network=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-r-afhqv2-512x512.pkl
|
| 309 |
+
```
|
| 310 |
+
|
| 311 |
+
Note: The Docker image requires NVIDIA driver release `r470` or later.
|
| 312 |
+
|
| 313 |
+
The `docker run` invocation may look daunting, so let's unpack its contents here:
|
| 314 |
+
|
| 315 |
+
- `--gpus all -it --rm --user $(id -u):$(id -g)`: with all GPUs enabled, run an interactive session with current user's UID/GID to avoid Docker writing files as root.
|
| 316 |
+
- ``-v `pwd`:/scratch --workdir /scratch``: mount current running dir (e.g., the top of this git repo on your host machine) to `/scratch` in the container and use that as the current working dir.
|
| 317 |
+
- `-e HOME=/scratch`: let PyTorch and StyleGAN3 code know where to cache temporary files such as pre-trained models and custom PyTorch extension build results. Note: if you want more fine-grained control, you can instead set `TORCH_EXTENSIONS_DIR` (for custom extensions build dir) and `DNNLIB_CACHE_DIR` (for pre-trained model download cache). You want these cache dirs to reside on persistent volumes so that their contents are retained across multiple `docker run` invocations.
|
| 318 |
+
|
| 319 |
+
## Interactive visualization
|
| 320 |
+
|
| 321 |
+
This release contains an interactive model visualization tool that can be used to explore various characteristics of a trained model. To start it, run:
|
| 322 |
+
|
| 323 |
+
```bash
|
| 324 |
+
python visualizer.py
|
| 325 |
+
```
|
| 326 |
+
|
| 327 |
+
<a href="./docs/visualizer_screen0.png"><img alt="Visualizer screenshot" src="./docs/visualizer_screen0_half.png"></img></a>
|
| 328 |
+
|
| 329 |
+
## Using networks from Python
|
| 330 |
+
|
| 331 |
+
You can use pre-trained networks in your own Python code as follows:
|
| 332 |
+
|
| 333 |
+
```python
|
| 334 |
+
with open('ffhq.pkl', 'rb') as f:
|
| 335 |
+
G = pickle.load(f)['G_ema'].cuda() # torch.nn.Module
|
| 336 |
+
z = torch.randn([1, G.z_dim]).cuda() # latent codes
|
| 337 |
+
c = None # class labels (not used in this example)
|
| 338 |
+
img = G(z, c) # NCHW, float32, dynamic range [-1, +1], no truncation
|
| 339 |
+
```
|
| 340 |
+
|
| 341 |
+
The above code requires `torch_utils` and `dnnlib` to be accessible via `PYTHONPATH`. It does not need source code for the networks themselves — their class definitions are loaded from the pickle via `torch_utils.persistence`.
|
| 342 |
+
|
| 343 |
+
The pickle contains three networks. `'G'` and `'D'` are instantaneous snapshots taken during training, and `'G_ema'` represents a moving average of the generator weights over several training steps. The networks are regular instances of `torch.nn.Module`, with all of their parameters and buffers placed on the CPU at import and gradient computation disabled by default.
|
| 344 |
+
|
| 345 |
+
The generator consists of two submodules, `G.mapping` and `G.synthesis`, that can be executed separately. They also support various additional options:
|
| 346 |
+
|
| 347 |
+
```python
|
| 348 |
+
w = G.mapping(z, c, truncation_psi=0.5, truncation_cutoff=8)
|
| 349 |
+
img = G.synthesis(w, noise_mode='const', force_fp32=True)
|
| 350 |
+
```
|
| 351 |
+
|
| 352 |
+
Please refer to [`gen_images.py`](./gen_images.py) for complete code example.
|
| 353 |
+
|
| 354 |
+
## Preparing datasets
|
| 355 |
+
|
| 356 |
+
Datasets are stored as uncompressed ZIP archives containing uncompressed PNG files and a metadata file `dataset.json` for labels. Custom datasets can be created from a folder containing images; see [`python dataset_tool.py --help`](./docs/dataset-tool-help.txt) for more information. Alternatively, the folder can also be used directly as a dataset, without running it through `dataset_tool.py` first, but doing so may lead to suboptimal performance.
|
| 357 |
+
|
| 358 |
+
**FFHQ**: Download the [Flickr-Faces-HQ dataset](https://github.com/NVlabs/ffhq-dataset) as 1024x1024 images and create a zip archive using `dataset_tool.py`:
|
| 359 |
+
|
| 360 |
+
```bash
|
| 361 |
+
# Original 1024x1024 resolution.
|
| 362 |
+
python dataset_tool.py --source=/tmp/images1024x1024 --dest=~/datasets/ffhq-1024x1024.zip
|
| 363 |
+
|
| 364 |
+
# Scaled down 256x256 resolution.
|
| 365 |
+
python dataset_tool.py --source=/tmp/images1024x1024 --dest=~/datasets/ffhq-256x256.zip \
|
| 366 |
+
--resolution=256x256
|
| 367 |
+
```
|
| 368 |
+
|
| 369 |
+
See the [FFHQ README](https://github.com/NVlabs/ffhq-dataset) for information on how to obtain the unaligned FFHQ dataset images. Use the same steps as above to create a ZIP archive for training and validation.
|
| 370 |
+
|
| 371 |
+
**MetFaces**: Download the [MetFaces dataset](https://github.com/NVlabs/metfaces-dataset) and create a ZIP archive:
|
| 372 |
+
|
| 373 |
+
```bash
|
| 374 |
+
python dataset_tool.py --source=~/downloads/metfaces/images --dest=~/datasets/metfaces-1024x1024.zip
|
| 375 |
+
```
|
| 376 |
+
|
| 377 |
+
See the [MetFaces README](https://github.com/NVlabs/metfaces-dataset) for information on how to obtain the unaligned MetFaces dataset images. Use the same steps as above to create a ZIP archive for training and validation.
|
| 378 |
+
|
| 379 |
+
**AFHQv2**: Download the [AFHQv2 dataset](https://github.com/clovaai/stargan-v2/blob/master/README.md#animal-faces-hq-dataset-afhq) and create a ZIP archive:
|
| 380 |
+
|
| 381 |
+
```bash
|
| 382 |
+
python dataset_tool.py --source=~/downloads/afhqv2 --dest=~/datasets/afhqv2-512x512.zip
|
| 383 |
+
```
|
| 384 |
+
|
| 385 |
+
Note that the above command creates a single combined dataset using all images of all three classes (cats, dogs, and wild animals), matching the setup used in the StyleGAN3 paper. Alternatively, you can also create a separate dataset for each class:
|
| 386 |
+
|
| 387 |
+
```bash
|
| 388 |
+
python dataset_tool.py --source=~/downloads/afhqv2/train/cat --dest=~/datasets/afhqv2cat-512x512.zip
|
| 389 |
+
python dataset_tool.py --source=~/downloads/afhqv2/train/dog --dest=~/datasets/afhqv2dog-512x512.zip
|
| 390 |
+
python dataset_tool.py --source=~/downloads/afhqv2/train/wild --dest=~/datasets/afhqv2wild-512x512.zip
|
| 391 |
+
```
|
| 392 |
+
|
| 393 |
+
## Training
|
| 394 |
+
|
| 395 |
+
You can train new networks using `train.py`. For example:
|
| 396 |
+
|
| 397 |
+
```bash
|
| 398 |
+
# Train StyleGAN3-T for AFHQv2 using 8 GPUs.
|
| 399 |
+
python train.py --outdir=~/training-runs --cfg=stylegan3-t --data=~/datasets/afhqv2-512x512.zip \
|
| 400 |
+
--gpus=8 --batch=32 --gamma=8.2 --mirror=1
|
| 401 |
+
|
| 402 |
+
# Fine-tune StyleGAN3-R for MetFaces-U using 1 GPU, starting from the pre-trained FFHQ-U pickle.
|
| 403 |
+
python train.py --outdir=~/training-runs --cfg=stylegan3-r --data=~/datasets/metfacesu-1024x1024.zip \
|
| 404 |
+
--gpus=8 --batch=32 --gamma=6.6 --mirror=1 --kimg=5000 --snap=5 \
|
| 405 |
+
--resume=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-r-ffhqu-1024x1024.pkl
|
| 406 |
+
|
| 407 |
+
# Train StyleGAN2 for FFHQ at 1024x1024 resolution using 8 GPUs.
|
| 408 |
+
python train.py --outdir=~/training-runs --cfg=stylegan2 --data=~/datasets/ffhq-1024x1024.zip \
|
| 409 |
+
--gpus=8 --batch=32 --gamma=10 --mirror=1 --aug=noaug
|
| 410 |
+
```
|
| 411 |
+
|
| 412 |
+
Note that the result quality and training time depend heavily on the exact set of options. The most important ones (`--gpus`, `--batch`, and `--gamma`) must be specified explicitly, and they should be selected with care. See [`python train.py --help`](./docs/train-help.txt) for the full list of options and [Training configurations](./docs/configs.md) for general guidelines & recommendations, along with the expected training speed & memory usage in different scenarios.
|
| 413 |
+
|
| 414 |
+
The results of each training run are saved to a newly created directory, for example `~/training-runs/00000-stylegan3-t-afhqv2-512x512-gpus8-batch32-gamma8.2`. The training loop exports network pickles (`network-snapshot-<KIMG>.pkl`) and random image grids (`fakes<KIMG>.png`) at regular intervals (controlled by `--snap`). For each exported pickle, it evaluates FID (controlled by `--metrics`) and logs the result in `metric-fid50k_full.jsonl`. It also records various statistics in `training_stats.jsonl`, as well as `*.tfevents` if TensorBoard is installed.
|
| 415 |
+
|
| 416 |
+
## Quality metrics
|
| 417 |
+
|
| 418 |
+
By default, `train.py` automatically computes FID for each network pickle exported during training. We recommend inspecting `metric-fid50k_full.jsonl` (or TensorBoard) at regular intervals to monitor the training progress. When desired, the automatic computation can be disabled with `--metrics=none` to speed up the training slightly.
|
| 419 |
+
|
| 420 |
+
Additional quality metrics can also be computed after the training:
|
| 421 |
+
|
| 422 |
+
```bash
|
| 423 |
+
# Previous training run: look up options automatically, save result to JSONL file.
|
| 424 |
+
python calc_metrics.py --metrics=eqt50k_int,eqr50k \
|
| 425 |
+
--network=~/training-runs/00000-stylegan3-r-mydataset/network-snapshot-000000.pkl
|
| 426 |
+
|
| 427 |
+
# Pre-trained network pickle: specify dataset explicitly, print result to stdout.
|
| 428 |
+
python calc_metrics.py --metrics=fid50k_full --data=~/datasets/ffhq-1024x1024.zip --mirror=1 \
|
| 429 |
+
--network=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-t-ffhq-1024x1024.pkl
|
| 430 |
+
```
|
| 431 |
+
|
| 432 |
+
The first example looks up the training configuration and performs the same operation as if `--metrics=eqt50k_int,eqr50k` had been specified during training. The second example downloads a pre-trained network pickle, in which case the values of `--data` and `--mirror` must be specified explicitly.
|
| 433 |
+
|
| 434 |
+
Note that the metrics can be quite expensive to compute (up to 1h), and many of them have an additional one-off cost for each new dataset (up to 30min). Also note that the evaluation is done using a different random seed each time, so the results will vary if the same metric is computed multiple times.
|
| 435 |
+
|
| 436 |
+
Recommended metrics:
|
| 437 |
+
* `fid50k_full`: Fréchet inception distance<sup>[1]</sup> against the full dataset.
|
| 438 |
+
* `kid50k_full`: Kernel inception distance<sup>[2]</sup> against the full dataset.
|
| 439 |
+
* `pr50k3_full`: Precision and recall<sup>[3]</sup> againt the full dataset.
|
| 440 |
+
* `ppl2_wend`: Perceptual path length<sup>[4]</sup> in W, endpoints, full image.
|
| 441 |
+
* `eqt50k_int`: Equivariance<sup>[5]</sup> w.r.t. integer translation (EQ-T).
|
| 442 |
+
* `eqt50k_frac`: Equivariance w.r.t. fractional translation (EQ-T<sub>frac</sub>).
|
| 443 |
+
* `eqr50k`: Equivariance w.r.t. rotation (EQ-R).
|
| 444 |
+
|
| 445 |
+
Legacy metrics:
|
| 446 |
+
* `fid50k`: Fréchet inception distance against 50k real images.
|
| 447 |
+
* `kid50k`: Kernel inception distance against 50k real images.
|
| 448 |
+
* `pr50k3`: Precision and recall against 50k real images.
|
| 449 |
+
* `is50k`: Inception score<sup>[6]</sup> for CIFAR-10.
|
| 450 |
+
|
| 451 |
+
References:
|
| 452 |
+
1. [GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium](https://arxiv.org/abs/1706.08500), Heusel et al. 2017
|
| 453 |
+
2. [Demystifying MMD GANs](https://arxiv.org/abs/1801.01401), Bińkowski et al. 2018
|
| 454 |
+
3. [Improved Precision and Recall Metric for Assessing Generative Models](https://arxiv.org/abs/1904.06991), Kynkäänniemi et al. 2019
|
| 455 |
+
4. [A Style-Based Generator Architecture for Generative Adversarial Networks](https://arxiv.org/abs/1812.04948), Karras et al. 2018
|
| 456 |
+
5. [Alias-Free Generative Adversarial Networks](https://nvlabs.github.io/stylegan3), Karras et al. 2021
|
| 457 |
+
6. [Improved Techniques for Training GANs](https://arxiv.org/abs/1606.03498), Salimans et al. 2016
|
| 458 |
+
|
| 459 |
+
## Spectral analysis
|
| 460 |
+
|
| 461 |
+
The easiest way to inspect the spectral properties of a given generator is to use the built-in FFT mode in `visualizer.py`. In addition, you can visualize average 2D power spectra (Appendix A, Figure 15) as follows:
|
| 462 |
+
|
| 463 |
+
```bash
|
| 464 |
+
# Calculate dataset mean and std, needed in subsequent steps.
|
| 465 |
+
python avg_spectra.py stats --source=~/datasets/ffhq-1024x1024.zip
|
| 466 |
+
|
| 467 |
+
# Calculate average spectrum for the training data.
|
| 468 |
+
python avg_spectra.py calc --source=~/datasets/ffhq-1024x1024.zip \
|
| 469 |
+
--dest=tmp/training-data.npz --mean=112.684 --std=69.509
|
| 470 |
+
|
| 471 |
+
# Calculate average spectrum for a pre-trained generator.
|
| 472 |
+
python avg_spectra.py calc \
|
| 473 |
+
--source=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-r-ffhq-1024x1024.pkl \
|
| 474 |
+
--dest=tmp/stylegan3-r.npz --mean=112.684 --std=69.509 --num=70000
|
| 475 |
+
|
| 476 |
+
# Display results.
|
| 477 |
+
python avg_spectra.py heatmap tmp/training-data.npz
|
| 478 |
+
python avg_spectra.py heatmap tmp/stylegan3-r.npz
|
| 479 |
+
python avg_spectra.py slices tmp/training-data.npz tmp/stylegan3-r.npz
|
| 480 |
+
```
|
| 481 |
+
|
| 482 |
+
<a href="./docs/avg_spectra_screen0.png"><img alt="Average spectra screenshot" src="./docs/avg_spectra_screen0_half.png"></img></a>
|
| 483 |
+
|
| 484 |
+
## License
|
| 485 |
+
|
| 486 |
+
Copyright © 2021, NVIDIA Corporation & affiliates. All rights reserved.
|
| 487 |
+
|
| 488 |
+
This work is made available under the [Nvidia Source Code License](https://github.com/NVlabs/stylegan3/blob/main/LICENSE.txt).
|
| 489 |
+
|
| 490 |
+
## Citation
|
| 491 |
+
|
| 492 |
+
```
|
| 493 |
+
@inproceedings{Karras2021,
|
| 494 |
+
author = {Tero Karras and Miika Aittala and Samuli Laine and Erik H\"ark\"onen and Janne Hellsten and Jaakko Lehtinen and Timo Aila},
|
| 495 |
+
title = {Alias-Free Generative Adversarial Networks},
|
| 496 |
+
booktitle = {Proc. NeurIPS},
|
| 497 |
+
year = {2021}
|
| 498 |
+
}
|
| 499 |
+
```
|
| 500 |
+
|
| 501 |
+
## Development
|
| 502 |
+
|
| 503 |
+
This is a research reference implementation and is treated as a one-time code drop. As such, we do not accept outside code contributions in the form of pull requests.
|
| 504 |
+
|
| 505 |
+
## Acknowledgements
|
| 506 |
+
|
| 507 |
+
We thank David Luebke, Ming-Yu Liu, Koki Nagano, Tuomas Kynkäänniemi, and Timo Viitanen for reviewing early drafts and helpful suggestions. Frédo Durand for early discussions. Tero Kuosmanen for maintaining our compute infrastructure. AFHQ authors for an updated version of their dataset. Getty Images for the training images in the Beaches dataset. We did not receive external funding or additional revenues for this project.
|
stylegan3-fun/__pycache__/legacy.cpython-311.pyc
ADDED
|
Binary file (29 kB). View file
|
|
|
stylegan3-fun/__pycache__/legacy.cpython-38.pyc
ADDED
|
Binary file (15.4 kB). View file
|
|
|
stylegan3-fun/__pycache__/legacy.cpython-39.pyc
ADDED
|
Binary file (15.3 kB). View file
|
|
|
stylegan3-fun/avg_spectra.py
ADDED
|
@@ -0,0 +1,276 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Compare average power spectra between real and generated images,
|
| 10 |
+
or between multiple generators."""
|
| 11 |
+
|
| 12 |
+
import os
|
| 13 |
+
import numpy as np
|
| 14 |
+
import torch
|
| 15 |
+
import torch.fft
|
| 16 |
+
import scipy.ndimage
|
| 17 |
+
import matplotlib.pyplot as plt
|
| 18 |
+
import click
|
| 19 |
+
import tqdm
|
| 20 |
+
import dnnlib
|
| 21 |
+
|
| 22 |
+
import legacy
|
| 23 |
+
from training import dataset
|
| 24 |
+
|
| 25 |
+
#----------------------------------------------------------------------------
|
| 26 |
+
# Setup an iterator for streaming images, in uint8 NCHW format, based on the
|
| 27 |
+
# respective command line options.
|
| 28 |
+
|
| 29 |
+
def stream_source_images(source, num, seed, device, data_loader_kwargs=None): # => num_images, image_size, image_iter
|
| 30 |
+
ext = source.split('.')[-1].lower()
|
| 31 |
+
if data_loader_kwargs is None:
|
| 32 |
+
data_loader_kwargs = dict(pin_memory=True, num_workers=3, prefetch_factor=2)
|
| 33 |
+
|
| 34 |
+
if ext == 'pkl':
|
| 35 |
+
if num is None:
|
| 36 |
+
raise click.ClickException('--num is required when --source points to network pickle')
|
| 37 |
+
with dnnlib.util.open_url(source) as f:
|
| 38 |
+
G = legacy.load_network_pkl(f)['G_ema'].to(device)
|
| 39 |
+
def generate_image(seed):
|
| 40 |
+
rnd = np.random.RandomState(seed)
|
| 41 |
+
z = torch.from_numpy(rnd.randn(1, G.z_dim)).to(device)
|
| 42 |
+
c = torch.zeros([1, G.c_dim], device=device)
|
| 43 |
+
if G.c_dim > 0:
|
| 44 |
+
c[:, rnd.randint(G.c_dim)] = 1
|
| 45 |
+
return (G(z=z, c=c) * 127.5 + 128).clamp(0, 255).to(torch.uint8)
|
| 46 |
+
_ = generate_image(seed) # warm up
|
| 47 |
+
image_iter = (generate_image(seed + idx) for idx in range(num))
|
| 48 |
+
return num, G.img_resolution, image_iter
|
| 49 |
+
|
| 50 |
+
elif ext == 'zip' or os.path.isdir(source):
|
| 51 |
+
dataset_obj = dataset.ImageFolderDataset(path=source, max_size=num, random_seed=seed)
|
| 52 |
+
if num is not None and num != len(dataset_obj):
|
| 53 |
+
raise click.ClickException(f'--source contains fewer than {num} images')
|
| 54 |
+
data_loader = torch.utils.data.DataLoader(dataset_obj, batch_size=1, **data_loader_kwargs)
|
| 55 |
+
image_iter = (image.to(device) for image, _label in data_loader)
|
| 56 |
+
return len(dataset_obj), dataset_obj.resolution, image_iter
|
| 57 |
+
|
| 58 |
+
else:
|
| 59 |
+
raise click.ClickException('--source must point to network pickle, dataset zip, or directory')
|
| 60 |
+
|
| 61 |
+
#----------------------------------------------------------------------------
|
| 62 |
+
# Load average power spectrum from the specified .npz file and construct
|
| 63 |
+
# the corresponding heatmap for visualization.
|
| 64 |
+
|
| 65 |
+
def construct_heatmap(npz_file, smooth):
|
| 66 |
+
npz_data = np.load(npz_file)
|
| 67 |
+
spectrum = npz_data['spectrum']
|
| 68 |
+
image_size = npz_data['image_size']
|
| 69 |
+
hmap = np.log10(spectrum) * 10 # dB
|
| 70 |
+
hmap = np.fft.fftshift(hmap)
|
| 71 |
+
hmap = np.concatenate([hmap, hmap[:1, :]], axis=0)
|
| 72 |
+
hmap = np.concatenate([hmap, hmap[:, :1]], axis=1)
|
| 73 |
+
if smooth > 0:
|
| 74 |
+
sigma = spectrum.shape[0] / image_size * smooth
|
| 75 |
+
hmap = scipy.ndimage.gaussian_filter(hmap, sigma=sigma, mode='nearest')
|
| 76 |
+
return hmap, image_size
|
| 77 |
+
|
| 78 |
+
#----------------------------------------------------------------------------
|
| 79 |
+
|
| 80 |
+
@click.group()
|
| 81 |
+
def main():
|
| 82 |
+
"""Compare average power spectra between real and generated images,
|
| 83 |
+
or between multiple generators.
|
| 84 |
+
|
| 85 |
+
Example:
|
| 86 |
+
|
| 87 |
+
\b
|
| 88 |
+
# Calculate dataset mean and std, needed in subsequent steps.
|
| 89 |
+
python avg_spectra.py stats --source=~/datasets/ffhq-1024x1024.zip
|
| 90 |
+
|
| 91 |
+
\b
|
| 92 |
+
# Calculate average spectrum for the training data.
|
| 93 |
+
python avg_spectra.py calc --source=~/datasets/ffhq-1024x1024.zip \\
|
| 94 |
+
--dest=tmp/training-data.npz --mean=112.684 --std=69.509
|
| 95 |
+
|
| 96 |
+
\b
|
| 97 |
+
# Calculate average spectrum for a pre-trained generator.
|
| 98 |
+
python avg_spectra.py calc \\
|
| 99 |
+
--source=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-r-ffhq-1024x1024.pkl \\
|
| 100 |
+
--dest=tmp/stylegan3-r.npz --mean=112.684 --std=69.509 --num=70000
|
| 101 |
+
|
| 102 |
+
\b
|
| 103 |
+
# Display results.
|
| 104 |
+
python avg_spectra.py heatmap tmp/training-data.npz
|
| 105 |
+
python avg_spectra.py heatmap tmp/stylegan3-r.npz
|
| 106 |
+
python avg_spectra.py slices tmp/training-data.npz tmp/stylegan3-r.npz
|
| 107 |
+
|
| 108 |
+
\b
|
| 109 |
+
# Save as PNG.
|
| 110 |
+
python avg_spectra.py heatmap tmp/training-data.npz --save=tmp/training-data.png --dpi=300
|
| 111 |
+
python avg_spectra.py heatmap tmp/stylegan3-r.npz --save=tmp/stylegan3-r.png --dpi=300
|
| 112 |
+
python avg_spectra.py slices tmp/training-data.npz tmp/stylegan3-r.npz --save=tmp/slices.png --dpi=300
|
| 113 |
+
"""
|
| 114 |
+
|
| 115 |
+
#----------------------------------------------------------------------------
|
| 116 |
+
|
| 117 |
+
@main.command()
|
| 118 |
+
@click.option('--source', help='Network pkl, dataset zip, or directory', metavar='[PKL|ZIP|DIR]', required=True)
|
| 119 |
+
@click.option('--num', help='Number of images to process [default: all]', metavar='INT', type=click.IntRange(min=1))
|
| 120 |
+
@click.option('--seed', help='Random seed for selecting the images', metavar='INT', type=click.IntRange(min=0), default=0, show_default=True)
|
| 121 |
+
def stats(source, num, seed, device=torch.device('cuda')):
|
| 122 |
+
"""Calculate dataset mean and standard deviation needed by 'calc'."""
|
| 123 |
+
torch.multiprocessing.set_start_method('spawn')
|
| 124 |
+
num_images, _image_size, image_iter = stream_source_images(source=source, num=num, seed=seed, device=device)
|
| 125 |
+
|
| 126 |
+
# Accumulate moments.
|
| 127 |
+
moments = torch.zeros([3], dtype=torch.float64, device=device)
|
| 128 |
+
for image in tqdm.tqdm(image_iter, total=num_images):
|
| 129 |
+
image = image.to(torch.float64)
|
| 130 |
+
moments += torch.stack([torch.ones_like(image).sum(), image.sum(), image.square().sum()])
|
| 131 |
+
moments = moments / moments[0]
|
| 132 |
+
|
| 133 |
+
# Compute mean and standard deviation.
|
| 134 |
+
mean = moments[1]
|
| 135 |
+
std = (moments[2] - moments[1].square()).sqrt()
|
| 136 |
+
print(f'--mean={mean:g} --std={std:g}')
|
| 137 |
+
|
| 138 |
+
#----------------------------------------------------------------------------
|
| 139 |
+
|
| 140 |
+
@main.command()
|
| 141 |
+
@click.option('--source', help='Network pkl, dataset zip, or directory', metavar='[PKL|ZIP|DIR]', required=True)
|
| 142 |
+
@click.option('--dest', help='Where to store the result', metavar='NPZ', required=True)
|
| 143 |
+
@click.option('--mean', help='Dataset mean for whitening', metavar='FLOAT', type=float, required=True)
|
| 144 |
+
@click.option('--std', help='Dataset standard deviation for whitening', metavar='FLOAT', type=click.FloatRange(min=0), required=True)
|
| 145 |
+
@click.option('--num', help='Number of images to process [default: all]', metavar='INT', type=click.IntRange(min=1))
|
| 146 |
+
@click.option('--seed', help='Random seed for selecting the images', metavar='INT', type=click.IntRange(min=0), default=0, show_default=True)
|
| 147 |
+
@click.option('--beta', help='Shape parameter for the Kaiser window', metavar='FLOAT', type=click.FloatRange(min=0), default=8, show_default=True)
|
| 148 |
+
@click.option('--interp', help='Frequency-domain interpolation factor', metavar='INT', type=click.IntRange(min=1), default=4, show_default=True)
|
| 149 |
+
def calc(source, dest, mean, std, num, seed, beta, interp, device=torch.device('cuda')):
|
| 150 |
+
"""Calculate average power spectrum and store it in .npz file."""
|
| 151 |
+
torch.multiprocessing.set_start_method('spawn')
|
| 152 |
+
num_images, image_size, image_iter = stream_source_images(source=source, num=num, seed=seed, device=device)
|
| 153 |
+
spectrum_size = image_size * interp
|
| 154 |
+
padding = spectrum_size - image_size
|
| 155 |
+
|
| 156 |
+
# Setup window function.
|
| 157 |
+
window = torch.kaiser_window(image_size, periodic=False, beta=beta, device=device)
|
| 158 |
+
window *= window.square().sum().rsqrt()
|
| 159 |
+
window = window.ger(window).unsqueeze(0).unsqueeze(1)
|
| 160 |
+
|
| 161 |
+
# Accumulate power spectrum.
|
| 162 |
+
spectrum = torch.zeros([spectrum_size, spectrum_size], dtype=torch.float64, device=device)
|
| 163 |
+
for image in tqdm.tqdm(image_iter, total=num_images):
|
| 164 |
+
image = (image.to(torch.float64) - mean) / std
|
| 165 |
+
image = torch.nn.functional.pad(image * window, [0, padding, 0, padding])
|
| 166 |
+
spectrum += torch.fft.fftn(image, dim=[2,3]).abs().square().mean(dim=[0,1])
|
| 167 |
+
spectrum /= num_images
|
| 168 |
+
|
| 169 |
+
# Save result.
|
| 170 |
+
if os.path.dirname(dest):
|
| 171 |
+
os.makedirs(os.path.dirname(dest), exist_ok=True)
|
| 172 |
+
np.savez(dest, spectrum=spectrum.cpu().numpy(), image_size=image_size)
|
| 173 |
+
|
| 174 |
+
#----------------------------------------------------------------------------
|
| 175 |
+
|
| 176 |
+
@main.command()
|
| 177 |
+
@click.argument('npz-file', nargs=1)
|
| 178 |
+
@click.option('--save', help='Save the plot and exit', metavar='[PNG|PDF|...]')
|
| 179 |
+
@click.option('--dpi', help='Figure resolution', metavar='FLOAT', type=click.FloatRange(min=1), default=100, show_default=True)
|
| 180 |
+
@click.option('--smooth', help='Amount of smoothing', metavar='FLOAT', type=click.FloatRange(min=0), default=1.25, show_default=True)
|
| 181 |
+
def heatmap(npz_file, save, smooth, dpi):
|
| 182 |
+
"""Visualize 2D heatmap based on the given .npz file."""
|
| 183 |
+
hmap, image_size = construct_heatmap(npz_file=npz_file, smooth=smooth)
|
| 184 |
+
|
| 185 |
+
# Setup plot.
|
| 186 |
+
plt.figure(figsize=[6, 4.8], dpi=dpi, tight_layout=True)
|
| 187 |
+
freqs = np.linspace(-0.5, 0.5, num=hmap.shape[0], endpoint=True) * image_size
|
| 188 |
+
ticks = np.linspace(freqs[0], freqs[-1], num=5, endpoint=True)
|
| 189 |
+
levels = np.linspace(-40, 20, num=13, endpoint=True)
|
| 190 |
+
|
| 191 |
+
# Draw heatmap.
|
| 192 |
+
plt.xlim(ticks[0], ticks[-1])
|
| 193 |
+
plt.ylim(ticks[0], ticks[-1])
|
| 194 |
+
plt.xticks(ticks)
|
| 195 |
+
plt.yticks(ticks)
|
| 196 |
+
plt.contourf(freqs, freqs, hmap, levels=levels, extend='both', cmap='Blues')
|
| 197 |
+
plt.gca().set_aspect('equal')
|
| 198 |
+
plt.colorbar(ticks=levels)
|
| 199 |
+
plt.contour(freqs, freqs, hmap, levels=levels, extend='both', linestyles='solid', linewidths=1, colors='midnightblue', alpha=0.2)
|
| 200 |
+
|
| 201 |
+
# Display or save.
|
| 202 |
+
if save is None:
|
| 203 |
+
plt.show()
|
| 204 |
+
else:
|
| 205 |
+
if os.path.dirname(save):
|
| 206 |
+
os.makedirs(os.path.dirname(save), exist_ok=True)
|
| 207 |
+
plt.savefig(save)
|
| 208 |
+
|
| 209 |
+
#----------------------------------------------------------------------------
|
| 210 |
+
|
| 211 |
+
@main.command()
|
| 212 |
+
@click.argument('npz-files', nargs=-1, required=True)
|
| 213 |
+
@click.option('--save', help='Save the plot and exit', metavar='[PNG|PDF|...]')
|
| 214 |
+
@click.option('--dpi', help='Figure resolution', metavar='FLOAT', type=click.FloatRange(min=1), default=100, show_default=True)
|
| 215 |
+
@click.option('--smooth', help='Amount of smoothing', metavar='FLOAT', type=click.FloatRange(min=0), default=0, show_default=True)
|
| 216 |
+
def slices(npz_files, save, dpi, smooth):
|
| 217 |
+
"""Visualize 1D slices based on the given .npz files."""
|
| 218 |
+
cases = [dnnlib.EasyDict(npz_file=npz_file) for npz_file in npz_files]
|
| 219 |
+
for c in cases:
|
| 220 |
+
c.hmap, c.image_size = construct_heatmap(npz_file=c.npz_file, smooth=smooth)
|
| 221 |
+
c.label = os.path.splitext(os.path.basename(c.npz_file))[0]
|
| 222 |
+
|
| 223 |
+
# Check consistency.
|
| 224 |
+
image_size = cases[0].image_size
|
| 225 |
+
hmap_size = cases[0].hmap.shape[0]
|
| 226 |
+
if any(c.image_size != image_size or c.hmap.shape[0] != hmap_size for c in cases):
|
| 227 |
+
raise click.ClickException('All .npz must have the same resolution')
|
| 228 |
+
|
| 229 |
+
# Setup plot.
|
| 230 |
+
plt.figure(figsize=[12, 4.6], dpi=dpi, tight_layout=True)
|
| 231 |
+
hmap_center = hmap_size // 2
|
| 232 |
+
hmap_range = np.arange(hmap_center, hmap_size)
|
| 233 |
+
freqs0 = np.linspace(0, image_size / 2, num=(hmap_size // 2 + 1), endpoint=True)
|
| 234 |
+
freqs45 = np.linspace(0, image_size / np.sqrt(2), num=(hmap_size // 2 + 1), endpoint=True)
|
| 235 |
+
xticks0 = np.linspace(freqs0[0], freqs0[-1], num=9, endpoint=True)
|
| 236 |
+
xticks45 = np.round(np.linspace(freqs45[0], freqs45[-1], num=9, endpoint=True))
|
| 237 |
+
yticks = np.linspace(-50, 30, num=9, endpoint=True)
|
| 238 |
+
|
| 239 |
+
# Draw 0 degree slice.
|
| 240 |
+
plt.subplot(1, 2, 1)
|
| 241 |
+
plt.title('0\u00b0 slice')
|
| 242 |
+
plt.xlim(xticks0[0], xticks0[-1])
|
| 243 |
+
plt.ylim(yticks[0], yticks[-1])
|
| 244 |
+
plt.xticks(xticks0)
|
| 245 |
+
plt.yticks(yticks)
|
| 246 |
+
for c in cases:
|
| 247 |
+
plt.plot(freqs0, c.hmap[hmap_center, hmap_range], label=c.label)
|
| 248 |
+
plt.grid()
|
| 249 |
+
plt.legend(loc='upper right')
|
| 250 |
+
|
| 251 |
+
# Draw 45 degree slice.
|
| 252 |
+
plt.subplot(1, 2, 2)
|
| 253 |
+
plt.title('45\u00b0 slice')
|
| 254 |
+
plt.xlim(xticks45[0], xticks45[-1])
|
| 255 |
+
plt.ylim(yticks[0], yticks[-1])
|
| 256 |
+
plt.xticks(xticks45)
|
| 257 |
+
plt.yticks(yticks)
|
| 258 |
+
for c in cases:
|
| 259 |
+
plt.plot(freqs45, c.hmap[hmap_range, hmap_range], label=c.label)
|
| 260 |
+
plt.grid()
|
| 261 |
+
plt.legend(loc='upper right')
|
| 262 |
+
|
| 263 |
+
# Display or save.
|
| 264 |
+
if save is None:
|
| 265 |
+
plt.show()
|
| 266 |
+
else:
|
| 267 |
+
if os.path.dirname(save):
|
| 268 |
+
os.makedirs(os.path.dirname(save), exist_ok=True)
|
| 269 |
+
plt.savefig(save)
|
| 270 |
+
|
| 271 |
+
#----------------------------------------------------------------------------
|
| 272 |
+
|
| 273 |
+
if __name__ == "__main__":
|
| 274 |
+
main() # pylint: disable=no-value-for-parameter
|
| 275 |
+
|
| 276 |
+
#----------------------------------------------------------------------------
|
stylegan3-fun/calc_metrics.py
ADDED
|
@@ -0,0 +1,188 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Calculate quality metrics for previous training run or pretrained network pickle."""
|
| 10 |
+
|
| 11 |
+
import os
|
| 12 |
+
import click
|
| 13 |
+
import json
|
| 14 |
+
import tempfile
|
| 15 |
+
import copy
|
| 16 |
+
import torch
|
| 17 |
+
|
| 18 |
+
import dnnlib
|
| 19 |
+
import legacy
|
| 20 |
+
from metrics import metric_main
|
| 21 |
+
from metrics import metric_utils
|
| 22 |
+
from torch_utils import training_stats
|
| 23 |
+
from torch_utils import custom_ops
|
| 24 |
+
from torch_utils import misc
|
| 25 |
+
from torch_utils.ops import conv2d_gradfix
|
| 26 |
+
|
| 27 |
+
#----------------------------------------------------------------------------
|
| 28 |
+
|
| 29 |
+
def subprocess_fn(rank, args, temp_dir):
|
| 30 |
+
dnnlib.util.Logger(should_flush=True)
|
| 31 |
+
|
| 32 |
+
# Init torch.distributed.
|
| 33 |
+
if args.num_gpus > 1:
|
| 34 |
+
init_file = os.path.abspath(os.path.join(temp_dir, '.torch_distributed_init'))
|
| 35 |
+
if os.name == 'nt':
|
| 36 |
+
init_method = 'file:///' + init_file.replace('\\', '/')
|
| 37 |
+
torch.distributed.init_process_group(backend='gloo', init_method=init_method, rank=rank, world_size=args.num_gpus)
|
| 38 |
+
else:
|
| 39 |
+
init_method = f'file://{init_file}'
|
| 40 |
+
torch.distributed.init_process_group(backend='nccl', init_method=init_method, rank=rank, world_size=args.num_gpus)
|
| 41 |
+
|
| 42 |
+
# Init torch_utils.
|
| 43 |
+
sync_device = torch.device('cuda', rank) if args.num_gpus > 1 else None
|
| 44 |
+
training_stats.init_multiprocessing(rank=rank, sync_device=sync_device)
|
| 45 |
+
if rank != 0 or not args.verbose:
|
| 46 |
+
custom_ops.verbosity = 'none'
|
| 47 |
+
|
| 48 |
+
# Configure torch.
|
| 49 |
+
device = torch.device('cuda', rank)
|
| 50 |
+
torch.backends.cuda.matmul.allow_tf32 = False
|
| 51 |
+
torch.backends.cudnn.allow_tf32 = False
|
| 52 |
+
conv2d_gradfix.enabled = True
|
| 53 |
+
|
| 54 |
+
# Print network summary.
|
| 55 |
+
G = copy.deepcopy(args.G).eval().requires_grad_(False).to(device)
|
| 56 |
+
if rank == 0 and args.verbose:
|
| 57 |
+
z = torch.empty([1, G.z_dim], device=device)
|
| 58 |
+
c = torch.empty([1, G.c_dim], device=device)
|
| 59 |
+
misc.print_module_summary(G, [z, c])
|
| 60 |
+
|
| 61 |
+
# Calculate each metric.
|
| 62 |
+
for metric in args.metrics:
|
| 63 |
+
if rank == 0 and args.verbose:
|
| 64 |
+
print(f'Calculating {metric}...')
|
| 65 |
+
progress = metric_utils.ProgressMonitor(verbose=args.verbose)
|
| 66 |
+
result_dict = metric_main.calc_metric(metric=metric, G=G, dataset_kwargs=args.dataset_kwargs,
|
| 67 |
+
num_gpus=args.num_gpus, rank=rank, device=device, progress=progress)
|
| 68 |
+
if rank == 0:
|
| 69 |
+
metric_main.report_metric(result_dict, run_dir=args.run_dir, snapshot_pkl=args.network_pkl)
|
| 70 |
+
if rank == 0 and args.verbose:
|
| 71 |
+
print()
|
| 72 |
+
|
| 73 |
+
# Done.
|
| 74 |
+
if rank == 0 and args.verbose:
|
| 75 |
+
print('Exiting...')
|
| 76 |
+
|
| 77 |
+
#----------------------------------------------------------------------------
|
| 78 |
+
|
| 79 |
+
def parse_comma_separated_list(s):
|
| 80 |
+
if isinstance(s, list):
|
| 81 |
+
return s
|
| 82 |
+
if s is None or s.lower() == 'none' or s == '':
|
| 83 |
+
return []
|
| 84 |
+
return s.split(',')
|
| 85 |
+
|
| 86 |
+
#----------------------------------------------------------------------------
|
| 87 |
+
|
| 88 |
+
@click.command()
|
| 89 |
+
@click.pass_context
|
| 90 |
+
@click.option('network_pkl', '--network', help='Network pickle filename or URL', metavar='PATH', required=True)
|
| 91 |
+
@click.option('--metrics', help='Quality metrics', metavar='[NAME|A,B,C|none]', type=parse_comma_separated_list, default='fid50k_full', show_default=True)
|
| 92 |
+
@click.option('--data', help='Dataset to evaluate against [default: look up]', metavar='[ZIP|DIR]')
|
| 93 |
+
@click.option('--mirror', help='Enable dataset x-flips [default: look up]', type=bool, metavar='BOOL')
|
| 94 |
+
@click.option('--gpus', help='Number of GPUs to use', type=int, default=1, metavar='INT', show_default=True)
|
| 95 |
+
@click.option('--verbose', help='Print optional information', type=bool, default=True, metavar='BOOL', show_default=True)
|
| 96 |
+
|
| 97 |
+
def calc_metrics(ctx, network_pkl, metrics, data, mirror, gpus, verbose):
|
| 98 |
+
"""Calculate quality metrics for previous training run or pretrained network pickle.
|
| 99 |
+
|
| 100 |
+
Examples:
|
| 101 |
+
|
| 102 |
+
\b
|
| 103 |
+
# Previous training run: look up options automatically, save result to JSONL file.
|
| 104 |
+
python calc_metrics.py --metrics=eqt50k_int,eqr50k \\
|
| 105 |
+
--network=~/training-runs/00000-stylegan3-r-mydataset/network-snapshot-000000.pkl
|
| 106 |
+
|
| 107 |
+
\b
|
| 108 |
+
# Pre-trained network pickle: specify dataset explicitly, print result to stdout.
|
| 109 |
+
python calc_metrics.py --metrics=fid50k_full --data=~/datasets/ffhq-1024x1024.zip --mirror=1 \\
|
| 110 |
+
--network=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-t-ffhq-1024x1024.pkl
|
| 111 |
+
|
| 112 |
+
\b
|
| 113 |
+
Recommended metrics:
|
| 114 |
+
fid50k_full Frechet inception distance against the full dataset.
|
| 115 |
+
kid50k_full Kernel inception distance against the full dataset.
|
| 116 |
+
pr50k3_full Precision and recall againt the full dataset.
|
| 117 |
+
ppl2_wend Perceptual path length in W, endpoints, full image.
|
| 118 |
+
eqt50k_int Equivariance w.r.t. integer translation (EQ-T).
|
| 119 |
+
eqt50k_frac Equivariance w.r.t. fractional translation (EQ-T_frac).
|
| 120 |
+
eqr50k Equivariance w.r.t. rotation (EQ-R).
|
| 121 |
+
|
| 122 |
+
\b
|
| 123 |
+
Legacy metrics:
|
| 124 |
+
fid50k Frechet inception distance against 50k real images.
|
| 125 |
+
kid50k Kernel inception distance against 50k real images.
|
| 126 |
+
pr50k3 Precision and recall against 50k real images.
|
| 127 |
+
is50k Inception score for CIFAR-10.
|
| 128 |
+
"""
|
| 129 |
+
dnnlib.util.Logger(should_flush=True)
|
| 130 |
+
|
| 131 |
+
# Validate arguments.
|
| 132 |
+
args = dnnlib.EasyDict(metrics=metrics, num_gpus=gpus, network_pkl=network_pkl, verbose=verbose)
|
| 133 |
+
if not all(metric_main.is_valid_metric(metric) for metric in args.metrics):
|
| 134 |
+
ctx.fail('\n'.join(['--metrics can only contain the following values:'] + metric_main.list_valid_metrics()))
|
| 135 |
+
if not args.num_gpus >= 1:
|
| 136 |
+
ctx.fail('--gpus must be at least 1')
|
| 137 |
+
|
| 138 |
+
# Load network.
|
| 139 |
+
if not dnnlib.util.is_url(network_pkl, allow_file_urls=True) and not os.path.isfile(network_pkl):
|
| 140 |
+
ctx.fail('--network must point to a file or URL')
|
| 141 |
+
if args.verbose:
|
| 142 |
+
print(f'Loading network from "{network_pkl}"...')
|
| 143 |
+
with dnnlib.util.open_url(network_pkl, verbose=args.verbose) as f:
|
| 144 |
+
network_dict = legacy.load_network_pkl(f)
|
| 145 |
+
args.G = network_dict['G_ema'] # subclass of torch.nn.Module
|
| 146 |
+
|
| 147 |
+
# Initialize dataset options.
|
| 148 |
+
if data is not None:
|
| 149 |
+
args.dataset_kwargs = dnnlib.EasyDict(class_name='training.dataset.ImageFolderDataset', path=data)
|
| 150 |
+
elif network_dict['training_set_kwargs'] is not None:
|
| 151 |
+
args.dataset_kwargs = dnnlib.EasyDict(network_dict['training_set_kwargs'])
|
| 152 |
+
else:
|
| 153 |
+
ctx.fail('Could not look up dataset options; please specify --data')
|
| 154 |
+
|
| 155 |
+
# Finalize dataset options.
|
| 156 |
+
args.dataset_kwargs.resolution = args.G.img_resolution
|
| 157 |
+
args.dataset_kwargs.use_labels = (args.G.c_dim != 0)
|
| 158 |
+
if mirror is not None:
|
| 159 |
+
args.dataset_kwargs.xflip = mirror
|
| 160 |
+
|
| 161 |
+
# Print dataset options.
|
| 162 |
+
if args.verbose:
|
| 163 |
+
print('Dataset options:')
|
| 164 |
+
print(json.dumps(args.dataset_kwargs, indent=2))
|
| 165 |
+
|
| 166 |
+
# Locate run dir.
|
| 167 |
+
args.run_dir = None
|
| 168 |
+
if os.path.isfile(network_pkl):
|
| 169 |
+
pkl_dir = os.path.dirname(network_pkl)
|
| 170 |
+
if os.path.isfile(os.path.join(pkl_dir, 'training_options.json')):
|
| 171 |
+
args.run_dir = pkl_dir
|
| 172 |
+
|
| 173 |
+
# Launch processes.
|
| 174 |
+
if args.verbose:
|
| 175 |
+
print('Launching processes...')
|
| 176 |
+
torch.multiprocessing.set_start_method('spawn')
|
| 177 |
+
with tempfile.TemporaryDirectory() as temp_dir:
|
| 178 |
+
if args.num_gpus == 1:
|
| 179 |
+
subprocess_fn(rank=0, args=args, temp_dir=temp_dir)
|
| 180 |
+
else:
|
| 181 |
+
torch.multiprocessing.spawn(fn=subprocess_fn, args=(args, temp_dir), nprocs=args.num_gpus)
|
| 182 |
+
|
| 183 |
+
#----------------------------------------------------------------------------
|
| 184 |
+
|
| 185 |
+
if __name__ == "__main__":
|
| 186 |
+
calc_metrics() # pylint: disable=no-value-for-parameter
|
| 187 |
+
|
| 188 |
+
#----------------------------------------------------------------------------
|
stylegan3-fun/dataset_tool.py
ADDED
|
@@ -0,0 +1,547 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Tool for creating ZIP/PNG based datasets."""
|
| 10 |
+
|
| 11 |
+
import functools
|
| 12 |
+
import gzip
|
| 13 |
+
import io
|
| 14 |
+
import json
|
| 15 |
+
import os
|
| 16 |
+
import pickle
|
| 17 |
+
import re
|
| 18 |
+
import sys
|
| 19 |
+
import tarfile
|
| 20 |
+
import zipfile
|
| 21 |
+
from pathlib import Path
|
| 22 |
+
from typing import Callable, Optional, Tuple, Union
|
| 23 |
+
|
| 24 |
+
import click
|
| 25 |
+
import numpy as np
|
| 26 |
+
import PIL.Image
|
| 27 |
+
from tqdm import tqdm
|
| 28 |
+
from torch_utils import gen_utils
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
# ----------------------------------------------------------------------------
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def error(msg):
|
| 35 |
+
print('Error: ' + msg)
|
| 36 |
+
sys.exit(1)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
# ----------------------------------------------------------------------------
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def parse_tuple(s: str) -> Tuple[int, int]:
|
| 43 |
+
"""Parse a 'M,N' or 'MxN' integer tuple.
|
| 44 |
+
|
| 45 |
+
Example:
|
| 46 |
+
'4x2' returns (4,2)
|
| 47 |
+
'0,1' returns (0,1)
|
| 48 |
+
"""
|
| 49 |
+
m = re.match(r'^(\d+)[x,](\d+)$', s)
|
| 50 |
+
if m:
|
| 51 |
+
return int(m.group(1)), int(m.group(2))
|
| 52 |
+
raise ValueError(f'cannot parse tuple {s}')
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
# ----------------------------------------------------------------------------
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def maybe_min(a: int, b: Optional[int]) -> int:
|
| 59 |
+
if b is not None:
|
| 60 |
+
return min(a, b)
|
| 61 |
+
return a
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
# ----------------------------------------------------------------------------
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def file_ext(name: Union[str, Path]) -> str:
|
| 68 |
+
return str(name).split('.')[-1]
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
# ----------------------------------------------------------------------------
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def is_image_ext(fname: Union[str, Path]) -> bool:
|
| 75 |
+
ext = file_ext(fname).lower()
|
| 76 |
+
return f'.{ext}' in PIL.Image.EXTENSION # type: ignore
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
# ----------------------------------------------------------------------------
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def open_image_folder(source_dir, force_channels: int = None, *, max_images: Optional[int], subfolders_as_labels: Optional[bool] = False):
|
| 83 |
+
input_images = [str(f) for f in sorted(Path(source_dir).rglob('*')) if is_image_ext(f) and os.path.isfile(f)]
|
| 84 |
+
|
| 85 |
+
# Load labels.
|
| 86 |
+
labels = {}
|
| 87 |
+
meta_fname = os.path.join(source_dir, 'dataset.json')
|
| 88 |
+
if os.path.isfile(meta_fname) and not subfolders_as_labels:
|
| 89 |
+
# The `dataset.json` file exists and will be used (whether empty or not)
|
| 90 |
+
with open(meta_fname, 'r') as file:
|
| 91 |
+
labels = json.load(file)['labels']
|
| 92 |
+
if labels is not None:
|
| 93 |
+
labels = {x[0]: x[1] for x in labels}
|
| 94 |
+
else:
|
| 95 |
+
labels = {}
|
| 96 |
+
elif subfolders_as_labels:
|
| 97 |
+
# Use the folders in the directory as the labels themselves
|
| 98 |
+
# Get the subfolder names from the input_images names
|
| 99 |
+
labels = {os.path.relpath(fname, source_dir).replace('\\', '/'): os.path.basename(os.path.dirname(fname)) for fname in input_images}
|
| 100 |
+
# Change folder name (value) to a number (from 0 to n-1)
|
| 101 |
+
label_names = list(set(labels.values()))
|
| 102 |
+
label_names.sort()
|
| 103 |
+
labels = {fname: label_names.index(label) for fname, label in labels.items()}
|
| 104 |
+
print(f'Conditional dataset has {len(label_names)} labels! Saving to `class_labels.txt` in the source directory...')
|
| 105 |
+
with open(os.path.join(source_dir, 'class_labels.txt'), 'w') as f:
|
| 106 |
+
# Write, one per line, the index and the label name
|
| 107 |
+
for i, label in enumerate(label_names):
|
| 108 |
+
f.write(f'{i}: {label}\n')
|
| 109 |
+
|
| 110 |
+
max_idx = maybe_min(len(input_images), max_images)
|
| 111 |
+
|
| 112 |
+
def iterate_images():
|
| 113 |
+
for idx, fname in enumerate(input_images):
|
| 114 |
+
arch_fname = os.path.relpath(fname, source_dir)
|
| 115 |
+
arch_fname = arch_fname.replace('\\', '/')
|
| 116 |
+
# Adding Pull #39 from Andreas Jansson: https://github.com/NVlabs/stylegan3/pull/39
|
| 117 |
+
try:
|
| 118 |
+
img = PIL.Image.open(fname) # Let PIL handle the mode
|
| 119 |
+
# Convert grayscale image to RGB
|
| 120 |
+
if img.mode == 'L':
|
| 121 |
+
img = img.convert('RGB')
|
| 122 |
+
# Force the number of channels if so requested
|
| 123 |
+
if force_channels is not None:
|
| 124 |
+
img = img.convert(gen_utils.channels_dict[int(force_channels)])
|
| 125 |
+
img = np.array(img)
|
| 126 |
+
except Exception as e:
|
| 127 |
+
sys.stderr.write(f'Failed to read {fname}: {e}')
|
| 128 |
+
continue
|
| 129 |
+
yield dict(img=img, label=labels.get(arch_fname))
|
| 130 |
+
if idx >= max_idx-1:
|
| 131 |
+
break
|
| 132 |
+
return max_idx, iterate_images()
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
# ----------------------------------------------------------------------------
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
def open_image_zip(source, force_channels: int = None, *, max_images: Optional[int]):
|
| 139 |
+
with zipfile.ZipFile(source, mode='r') as z:
|
| 140 |
+
input_images = [str(f) for f in sorted(z.namelist()) if is_image_ext(f)]
|
| 141 |
+
|
| 142 |
+
# Load labels.
|
| 143 |
+
labels = {}
|
| 144 |
+
if 'dataset.json' in z.namelist():
|
| 145 |
+
with z.open('dataset.json', 'r') as file:
|
| 146 |
+
labels = json.load(file)['labels']
|
| 147 |
+
if labels is not None:
|
| 148 |
+
labels = {x[0]: x[1] for x in labels}
|
| 149 |
+
else:
|
| 150 |
+
labels = {}
|
| 151 |
+
|
| 152 |
+
max_idx = maybe_min(len(input_images), max_images)
|
| 153 |
+
|
| 154 |
+
def iterate_images():
|
| 155 |
+
with zipfile.ZipFile(source, mode='r') as z:
|
| 156 |
+
for idx, fname in enumerate(input_images):
|
| 157 |
+
with z.open(fname, 'r') as file:
|
| 158 |
+
# Same as above: PR #39 by Andreas Jansson and turn Grayscale to RGB
|
| 159 |
+
try:
|
| 160 |
+
img = PIL.Image.open(file) # type: ignore
|
| 161 |
+
if img.mode == 'L':
|
| 162 |
+
img = img.convert('RGB')
|
| 163 |
+
# Force the number of channels if so requested
|
| 164 |
+
if force_channels is not None:
|
| 165 |
+
img = img.convert(gen_utils.channels_dict[int(force_channels)])
|
| 166 |
+
img = np.array(img)
|
| 167 |
+
except Exception as e:
|
| 168 |
+
sys.stderr.write(f'Failed to read {fname}: {e}')
|
| 169 |
+
continue
|
| 170 |
+
yield dict(img=img, label=labels.get(fname))
|
| 171 |
+
if idx >= max_idx-1:
|
| 172 |
+
break
|
| 173 |
+
return max_idx, iterate_images()
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
# ----------------------------------------------------------------------------
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
def open_lmdb(lmdb_dir: str, *, max_images: Optional[int]):
|
| 180 |
+
import cv2 # pip install opencv-python # pylint: disable=import-error
|
| 181 |
+
import lmdb # pip install lmdb # pylint: disable=import-error
|
| 182 |
+
|
| 183 |
+
with lmdb.open(lmdb_dir, readonly=True, lock=False).begin(write=False) as txn:
|
| 184 |
+
max_idx = maybe_min(txn.stat()['entries'], max_images)
|
| 185 |
+
|
| 186 |
+
def iterate_images():
|
| 187 |
+
with lmdb.open(lmdb_dir, readonly=True, lock=False).begin(write=False) as txn:
|
| 188 |
+
for idx, (_key, value) in enumerate(txn.cursor()):
|
| 189 |
+
try:
|
| 190 |
+
try:
|
| 191 |
+
img = cv2.imdecode(np.frombuffer(value, dtype=np.uint8), 1)
|
| 192 |
+
if img is None:
|
| 193 |
+
raise IOError('cv2.imdecode failed')
|
| 194 |
+
img = img[:, :, ::-1] # BGR => RGB
|
| 195 |
+
except IOError:
|
| 196 |
+
img = np.array(PIL.Image.open(io.BytesIO(value)))
|
| 197 |
+
yield dict(img=img, label=None)
|
| 198 |
+
if idx >= max_idx-1:
|
| 199 |
+
break
|
| 200 |
+
except:
|
| 201 |
+
print(sys.exc_info()[1])
|
| 202 |
+
|
| 203 |
+
return max_idx, iterate_images()
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
# ----------------------------------------------------------------------------
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
def open_cifar10(tarball: str, *, max_images: Optional[int]):
|
| 210 |
+
images = []
|
| 211 |
+
labels = []
|
| 212 |
+
|
| 213 |
+
with tarfile.open(tarball, 'r:gz') as tar:
|
| 214 |
+
for batch in range(1, 6):
|
| 215 |
+
member = tar.getmember(f'cifar-10-batches-py/data_batch_{batch}')
|
| 216 |
+
with tar.extractfile(member) as file:
|
| 217 |
+
data = pickle.load(file, encoding='latin1')
|
| 218 |
+
images.append(data['data'].reshape(-1, 3, 32, 32))
|
| 219 |
+
labels.append(data['labels'])
|
| 220 |
+
|
| 221 |
+
images = np.concatenate(images)
|
| 222 |
+
labels = np.concatenate(labels)
|
| 223 |
+
images = images.transpose([0, 2, 3, 1]) # NCHW -> NHWC
|
| 224 |
+
assert images.shape == (50000, 32, 32, 3) and images.dtype == np.uint8
|
| 225 |
+
assert labels.shape == (50000,) and labels.dtype in [np.int32, np.int64]
|
| 226 |
+
assert np.min(images) == 0 and np.max(images) == 255
|
| 227 |
+
assert np.min(labels) == 0 and np.max(labels) == 9
|
| 228 |
+
|
| 229 |
+
max_idx = maybe_min(len(images), max_images)
|
| 230 |
+
|
| 231 |
+
def iterate_images():
|
| 232 |
+
for idx, img in enumerate(images):
|
| 233 |
+
yield dict(img=img, label=int(labels[idx]))
|
| 234 |
+
if idx >= max_idx-1:
|
| 235 |
+
break
|
| 236 |
+
|
| 237 |
+
return max_idx, iterate_images()
|
| 238 |
+
|
| 239 |
+
|
| 240 |
+
# ----------------------------------------------------------------------------
|
| 241 |
+
|
| 242 |
+
|
| 243 |
+
def open_mnist(images_gz: str, *, max_images: Optional[int]):
|
| 244 |
+
labels_gz = images_gz.replace('-images-idx3-ubyte.gz', '-labels-idx1-ubyte.gz')
|
| 245 |
+
assert labels_gz != images_gz
|
| 246 |
+
images = []
|
| 247 |
+
labels = []
|
| 248 |
+
|
| 249 |
+
with gzip.open(images_gz, 'rb') as f:
|
| 250 |
+
images = np.frombuffer(f.read(), np.uint8, offset=16)
|
| 251 |
+
with gzip.open(labels_gz, 'rb') as f:
|
| 252 |
+
labels = np.frombuffer(f.read(), np.uint8, offset=8)
|
| 253 |
+
|
| 254 |
+
images = images.reshape(-1, 28, 28)
|
| 255 |
+
images = np.pad(images, [(0, 0), (2, 2), (2, 2)], 'constant', constant_values=0)
|
| 256 |
+
assert images.shape == (60000, 32, 32) and images.dtype == np.uint8
|
| 257 |
+
assert labels.shape == (60000,) and labels.dtype == np.uint8
|
| 258 |
+
assert np.min(images) == 0 and np.max(images) == 255
|
| 259 |
+
assert np.min(labels) == 0 and np.max(labels) == 9
|
| 260 |
+
|
| 261 |
+
max_idx = maybe_min(len(images), max_images)
|
| 262 |
+
|
| 263 |
+
def iterate_images():
|
| 264 |
+
for idx, img in enumerate(images):
|
| 265 |
+
yield dict(img=img, label=int(labels[idx]))
|
| 266 |
+
if idx >= max_idx-1:
|
| 267 |
+
break
|
| 268 |
+
|
| 269 |
+
return max_idx, iterate_images()
|
| 270 |
+
|
| 271 |
+
|
| 272 |
+
# ----------------------------------------------------------------------------
|
| 273 |
+
|
| 274 |
+
|
| 275 |
+
def make_transform(
|
| 276 |
+
transform: Optional[str],
|
| 277 |
+
output_width: Optional[int],
|
| 278 |
+
output_height: Optional[int]
|
| 279 |
+
) -> Callable[[np.ndarray], Optional[np.ndarray]]:
|
| 280 |
+
def scale(width, height, img):
|
| 281 |
+
w = img.shape[1]
|
| 282 |
+
h = img.shape[0]
|
| 283 |
+
if width == w and height == h:
|
| 284 |
+
return img
|
| 285 |
+
img = PIL.Image.fromarray(img)
|
| 286 |
+
ww = width if width is not None else w
|
| 287 |
+
hh = height if height is not None else h
|
| 288 |
+
img = img.resize((ww, hh), PIL.Image.LANCZOS)
|
| 289 |
+
return np.array(img)
|
| 290 |
+
|
| 291 |
+
def center_crop(width, height, img):
|
| 292 |
+
crop = np.min(img.shape[:2])
|
| 293 |
+
img = img[(img.shape[0] - crop) // 2: (img.shape[0] + crop) // 2,
|
| 294 |
+
(img.shape[1] - crop) // 2: (img.shape[1] + crop) // 2]
|
| 295 |
+
img = PIL.Image.fromarray(img, gen_utils.channels_dict[img.shape[2]])
|
| 296 |
+
img = img.resize((width, height), PIL.Image.LANCZOS)
|
| 297 |
+
return np.array(img)
|
| 298 |
+
|
| 299 |
+
def center_crop_wide(width, height, img):
|
| 300 |
+
ch = int(np.round(width * img.shape[0] / img.shape[1]))
|
| 301 |
+
if img.shape[1] < width or ch < height:
|
| 302 |
+
return None
|
| 303 |
+
|
| 304 |
+
img = img[(img.shape[0] - ch) // 2: (img.shape[0] + ch) // 2]
|
| 305 |
+
img = PIL.Image.fromarray(img, gen_utils.channels_dict[img.shape[2]])
|
| 306 |
+
img = img.resize((width, height), PIL.Image.LANCZOS)
|
| 307 |
+
img = np.array(img)
|
| 308 |
+
|
| 309 |
+
canvas = np.zeros([width, width, 3], dtype=np.uint8)
|
| 310 |
+
canvas[(width - height) // 2 : (width + height) // 2, :] = img
|
| 311 |
+
return canvas
|
| 312 |
+
|
| 313 |
+
def center_crop_tall(width, height, img):
|
| 314 |
+
ch = int(np.round(height * img.shape[1] / img.shape[0]))
|
| 315 |
+
if img.shape[0] < height or ch < width:
|
| 316 |
+
return None
|
| 317 |
+
|
| 318 |
+
img = img[:, (img.shape[1] - ch) // 2: (img.shape[1] + ch) // 2] # center-crop: [width0, height0, C] -> [width0, height, C]
|
| 319 |
+
img = PIL.Image.fromarray(img, gen_utils.channels_dict[img.shape[2]])
|
| 320 |
+
img = img.resize((width, height), PIL.Image.LANCZOS) # resize: [width0, height, 3] -> [width, height, 3]
|
| 321 |
+
img = np.array(img)
|
| 322 |
+
|
| 323 |
+
canvas = np.zeros([height, height, 3], dtype=np.uint8) # square canvas
|
| 324 |
+
canvas[:, (height - width) // 2: (height + width) // 2] = img # replace the middle with img
|
| 325 |
+
return canvas
|
| 326 |
+
|
| 327 |
+
if transform is None:
|
| 328 |
+
return functools.partial(scale, output_width, output_height)
|
| 329 |
+
if transform == 'center-crop':
|
| 330 |
+
if (output_width is None) or (output_height is None):
|
| 331 |
+
error(f'must specify --resolution=WxH when using {transform} transform')
|
| 332 |
+
return functools.partial(center_crop, output_width, output_height)
|
| 333 |
+
if transform == 'center-crop-wide':
|
| 334 |
+
if (output_width is None) or (output_height is None):
|
| 335 |
+
error(f'must specify --resolution=WxH when using {transform} transform')
|
| 336 |
+
return functools.partial(center_crop_wide, output_width, output_height)
|
| 337 |
+
if transform == 'center-crop-tall':
|
| 338 |
+
if (output_width is None) or (output_height is None):
|
| 339 |
+
error(f'must specify --resolution=WxH when using {transform} transform')
|
| 340 |
+
return functools.partial(center_crop_tall, output_width, output_height)
|
| 341 |
+
assert False, 'unknown transform'
|
| 342 |
+
|
| 343 |
+
|
| 344 |
+
# ----------------------------------------------------------------------------
|
| 345 |
+
|
| 346 |
+
|
| 347 |
+
def open_dataset(source, force_channels, *, max_images: Optional[int], subfolders_as_labels: Optional[bool] = False):
|
| 348 |
+
if os.path.isdir(source):
|
| 349 |
+
if source.rstrip('/').endswith('_lmdb'):
|
| 350 |
+
return open_lmdb(source, max_images=max_images)
|
| 351 |
+
else:
|
| 352 |
+
return open_image_folder(source, force_channels, max_images=max_images, subfolders_as_labels=subfolders_as_labels)
|
| 353 |
+
elif os.path.isfile(source):
|
| 354 |
+
if os.path.basename(source) == 'cifar-10-python.tar.gz':
|
| 355 |
+
return open_cifar10(source, max_images=max_images)
|
| 356 |
+
elif os.path.basename(source) == 'train-images-idx3-ubyte.gz':
|
| 357 |
+
return open_mnist(source, max_images=max_images)
|
| 358 |
+
elif file_ext(source) == 'zip':
|
| 359 |
+
return open_image_zip(source, force_channels, max_images=max_images)
|
| 360 |
+
else:
|
| 361 |
+
assert False, 'unknown archive type'
|
| 362 |
+
else:
|
| 363 |
+
error(f'Missing input file or directory: {source}')
|
| 364 |
+
|
| 365 |
+
|
| 366 |
+
# ----------------------------------------------------------------------------
|
| 367 |
+
|
| 368 |
+
|
| 369 |
+
def open_dest(dest: str) -> Tuple[str, Callable[[str, Union[bytes, str]], None], Callable[[], None]]:
|
| 370 |
+
dest_ext = file_ext(dest)
|
| 371 |
+
|
| 372 |
+
if dest_ext == 'zip':
|
| 373 |
+
if os.path.dirname(dest) != '':
|
| 374 |
+
os.makedirs(os.path.dirname(dest), exist_ok=True)
|
| 375 |
+
zf = zipfile.ZipFile(file=dest, mode='w', compression=zipfile.ZIP_STORED)
|
| 376 |
+
def zip_write_bytes(fname: str, data: Union[bytes, str]):
|
| 377 |
+
zf.writestr(fname, data)
|
| 378 |
+
return '', zip_write_bytes, zf.close
|
| 379 |
+
else:
|
| 380 |
+
# If the output folder already exists, check that it is
|
| 381 |
+
# empty.
|
| 382 |
+
#
|
| 383 |
+
# Note: creating the output directory is not strictly
|
| 384 |
+
# necessary as folder_write_bytes() also mkdirs, but it's better
|
| 385 |
+
# to give an error message earlier in case the dest folder
|
| 386 |
+
# somehow cannot be created.
|
| 387 |
+
if os.path.isdir(dest) and len(os.listdir(dest)) != 0:
|
| 388 |
+
error('--dest folder must be empty')
|
| 389 |
+
os.makedirs(dest, exist_ok=True)
|
| 390 |
+
|
| 391 |
+
def folder_write_bytes(fname: str, data: Union[bytes, str]):
|
| 392 |
+
os.makedirs(os.path.dirname(fname), exist_ok=True)
|
| 393 |
+
with open(fname, 'wb') as fout:
|
| 394 |
+
if isinstance(data, str):
|
| 395 |
+
data = data.encode('utf8')
|
| 396 |
+
fout.write(data)
|
| 397 |
+
return dest, folder_write_bytes, lambda: None
|
| 398 |
+
|
| 399 |
+
|
| 400 |
+
# ----------------------------------------------------------------------------
|
| 401 |
+
|
| 402 |
+
|
| 403 |
+
@click.command()
|
| 404 |
+
@click.pass_context
|
| 405 |
+
@click.option('--source', help='Directory or archive name for input dataset', required=True, metavar='PATH')
|
| 406 |
+
@click.option('--dest', help='Output directory or archive name for output dataset', required=True, metavar='PATH')
|
| 407 |
+
@click.option('--max-images', help='Output only up to `max-images` images', type=int, default=None)
|
| 408 |
+
@click.option('--force-channels', help='Force the number of channels in the image (1: grayscale, 3: RGB, 4: RGBA)', type=click.Choice(['1', '3', '4']), default=None)
|
| 409 |
+
@click.option('--subfolders-as-labels', help='Use the folder names as the labels, to avoid setting up `dataset.json`', is_flag=True)
|
| 410 |
+
@click.option('--transform', help='Input crop/resize mode', type=click.Choice(['center-crop', 'center-crop-wide', 'center-crop-tall']))
|
| 411 |
+
@click.option('--resolution', help='Output resolution (e.g., \'512x512\')', metavar='WxH', type=parse_tuple)
|
| 412 |
+
def convert_dataset(
|
| 413 |
+
ctx: click.Context,
|
| 414 |
+
source: str,
|
| 415 |
+
dest: str,
|
| 416 |
+
max_images: Optional[int],
|
| 417 |
+
force_channels: Optional[int],
|
| 418 |
+
subfolders_as_labels: Optional[bool],
|
| 419 |
+
transform: Optional[str],
|
| 420 |
+
resolution: Optional[Tuple[int, int]]
|
| 421 |
+
):
|
| 422 |
+
"""Convert an image dataset into a dataset archive usable with StyleGAN2 ADA PyTorch.
|
| 423 |
+
|
| 424 |
+
The input dataset format is guessed from the --source argument:
|
| 425 |
+
|
| 426 |
+
\b
|
| 427 |
+
--source *_lmdb/ Load LSUN dataset
|
| 428 |
+
--source cifar-10-python.tar.gz Load CIFAR-10 dataset
|
| 429 |
+
--source train-images-idx3-ubyte.gz Load MNIST dataset
|
| 430 |
+
--source path/ Recursively load all images from path/
|
| 431 |
+
--source dataset.zip Recursively load all images from dataset.zip
|
| 432 |
+
|
| 433 |
+
Specifying the output format and path:
|
| 434 |
+
|
| 435 |
+
\b
|
| 436 |
+
--dest /path/to/dir Save output files under /path/to/dir
|
| 437 |
+
--dest /path/to/dataset.zip Save output files into /path/to/dataset.zip
|
| 438 |
+
|
| 439 |
+
The output dataset format can be either an image folder or an uncompressed zip archive.
|
| 440 |
+
Zip archives makes it easier to move datasets around file servers and clusters, and may
|
| 441 |
+
offer better training performance on network file systems.
|
| 442 |
+
|
| 443 |
+
Images within the dataset archive will be stored as uncompressed PNG.
|
| 444 |
+
Uncompresed PNGs can be efficiently decoded in the training loop.
|
| 445 |
+
|
| 446 |
+
Class labels are stored in a file called 'dataset.json' that is stored at the
|
| 447 |
+
dataset root folder. This file has the following structure:
|
| 448 |
+
|
| 449 |
+
\b
|
| 450 |
+
{
|
| 451 |
+
"labels": [
|
| 452 |
+
["00000/img00000000.png",6],
|
| 453 |
+
["00000/img00000001.png",9],
|
| 454 |
+
... repeated for every image in the dataset
|
| 455 |
+
["00049/img00049999.png",1]
|
| 456 |
+
]
|
| 457 |
+
}
|
| 458 |
+
|
| 459 |
+
If the 'dataset.json' file cannot be found, the dataset is interpreted as
|
| 460 |
+
not containing class labels.
|
| 461 |
+
|
| 462 |
+
Image scale/crop and resolution requirements:
|
| 463 |
+
|
| 464 |
+
Output images must be square-shaped and they must all have the same power-of-two
|
| 465 |
+
dimensions.
|
| 466 |
+
|
| 467 |
+
To scale arbitrary input image size to a specific width and height, use the
|
| 468 |
+
--resolution option. Output resolution will be either the original
|
| 469 |
+
input resolution (if resolution was not specified) or the one specified with
|
| 470 |
+
--resolution option.
|
| 471 |
+
|
| 472 |
+
Use the --transform=center-crop or --transform=center-crop-wide options to apply a
|
| 473 |
+
center crop transform on the input image. These options should be used with the
|
| 474 |
+
--resolution option. For example:
|
| 475 |
+
|
| 476 |
+
\b
|
| 477 |
+
python dataset_tool.py --source LSUN/raw/cat_lmdb --dest /tmp/lsun_cat \\
|
| 478 |
+
--transform=center-crop-wide --resolution=512x384
|
| 479 |
+
"""
|
| 480 |
+
|
| 481 |
+
PIL.Image.init() # type: ignore
|
| 482 |
+
|
| 483 |
+
if dest == '':
|
| 484 |
+
ctx.fail('--dest output filename or directory must not be an empty string')
|
| 485 |
+
|
| 486 |
+
num_files, input_iter = open_dataset(source, force_channels, max_images=max_images, subfolders_as_labels=subfolders_as_labels)
|
| 487 |
+
archive_root_dir, save_bytes, close_dest = open_dest(dest)
|
| 488 |
+
|
| 489 |
+
if resolution is None: resolution = (None, None)
|
| 490 |
+
transform_image = make_transform(transform, *resolution)
|
| 491 |
+
|
| 492 |
+
dataset_attrs = None
|
| 493 |
+
|
| 494 |
+
labels = []
|
| 495 |
+
for idx, image in tqdm(enumerate(input_iter), total=num_files):
|
| 496 |
+
idx_str = f'{idx:08d}'
|
| 497 |
+
archive_fname = f'{idx_str[:5]}/img{idx_str}.png'
|
| 498 |
+
|
| 499 |
+
# Apply crop and resize.
|
| 500 |
+
img = transform_image(image['img'])
|
| 501 |
+
|
| 502 |
+
# Transform may drop images.
|
| 503 |
+
if img is None:
|
| 504 |
+
continue
|
| 505 |
+
|
| 506 |
+
# Error check to require uniform image attributes across
|
| 507 |
+
# the whole dataset.
|
| 508 |
+
channels = img.shape[2] if img.ndim == 3 else 1
|
| 509 |
+
cur_image_attrs = {
|
| 510 |
+
'width': img.shape[1],
|
| 511 |
+
'height': img.shape[0],
|
| 512 |
+
'channels': channels
|
| 513 |
+
}
|
| 514 |
+
if dataset_attrs is None:
|
| 515 |
+
dataset_attrs = cur_image_attrs
|
| 516 |
+
width = dataset_attrs['width']
|
| 517 |
+
height = dataset_attrs['height']
|
| 518 |
+
if width != height:
|
| 519 |
+
error(f'Image dimensions after scale and crop are required to be square. Got {width}x{height}')
|
| 520 |
+
if dataset_attrs['channels'] not in [1, 3, 4]:
|
| 521 |
+
error('Input images must be stored as grayscale, RGB, or RGBA')
|
| 522 |
+
if width != 2 ** int(np.floor(np.log2(width))):
|
| 523 |
+
error('Image width/height after scale and crop are required to be power-of-two')
|
| 524 |
+
elif dataset_attrs != cur_image_attrs:
|
| 525 |
+
err = [f' dataset {k}/cur image {k}: {dataset_attrs[k]}/{cur_image_attrs[k]}' for k in dataset_attrs.keys()] # pylint: disable=unsubscriptable-object
|
| 526 |
+
error(f'Image {archive_fname} attributes must be equal across all images of the dataset. Got:\n' + '\n'.join(err))
|
| 527 |
+
|
| 528 |
+
# Save the image as an uncompressed PNG.
|
| 529 |
+
img = PIL.Image.fromarray(img, gen_utils.channels_dict[channels])
|
| 530 |
+
image_bits = io.BytesIO()
|
| 531 |
+
img.save(image_bits, format='png', compress_level=0, optimize=False)
|
| 532 |
+
save_bytes(os.path.join(archive_root_dir, archive_fname), image_bits.getbuffer())
|
| 533 |
+
labels.append([archive_fname, image['label']] if image['label'] is not None else None)
|
| 534 |
+
|
| 535 |
+
metadata = {
|
| 536 |
+
'labels': labels if all(x is not None for x in labels) else None
|
| 537 |
+
}
|
| 538 |
+
save_bytes(os.path.join(archive_root_dir, 'dataset.json'), json.dumps(metadata))
|
| 539 |
+
close_dest()
|
| 540 |
+
|
| 541 |
+
# ----------------------------------------------------------------------------
|
| 542 |
+
|
| 543 |
+
|
| 544 |
+
if __name__ == "__main__":
|
| 545 |
+
convert_dataset() # pylint: disable=no-value-for-parameter
|
| 546 |
+
|
| 547 |
+
# ----------------------------------------------------------------------------
|
stylegan3-fun/discriminator_synthesis.py
ADDED
|
@@ -0,0 +1,1007 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
from torch.autograd import Variable
|
| 5 |
+
from torchvision import transforms
|
| 6 |
+
|
| 7 |
+
import PIL
|
| 8 |
+
from PIL import Image
|
| 9 |
+
|
| 10 |
+
try:
|
| 11 |
+
import ffmpeg
|
| 12 |
+
except ImportError:
|
| 13 |
+
raise ImportError('ffmpeg-python not found! Install it via "pip install ffmpeg-python"')
|
| 14 |
+
|
| 15 |
+
import scipy.ndimage as nd
|
| 16 |
+
import numpy as np
|
| 17 |
+
|
| 18 |
+
import os
|
| 19 |
+
import click
|
| 20 |
+
from typing import Union, Tuple, Optional, List, Type
|
| 21 |
+
from tqdm import tqdm
|
| 22 |
+
import re
|
| 23 |
+
|
| 24 |
+
from torch_utils import gen_utils
|
| 25 |
+
from network_features import DiscriminatorFeatures
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
# ----------------------------------------------------------------------------
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
@click.group()
|
| 32 |
+
def main():
|
| 33 |
+
pass
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
# ----------------------------------------------------------------------------
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def get_available_layers(max_resolution: int) -> List[str]:
|
| 40 |
+
"""Helper function to get the available layers given a max resolution (first block in the Discriminator)"""
|
| 41 |
+
max_res_log2 = int(np.log2(max_resolution))
|
| 42 |
+
block_resolutions = [2**i for i in range(max_res_log2, 2, -1)]
|
| 43 |
+
|
| 44 |
+
available_layers = ['from_rgb']
|
| 45 |
+
for block_res in block_resolutions:
|
| 46 |
+
# We don't add the skip layer, as it's the same as conv1 (due to in-place addition; could be changed)
|
| 47 |
+
available_layers.extend([f'b{block_res}_conv0', f'b{block_res}_conv1'])
|
| 48 |
+
# We also skip 'b4_mbstd', as it doesn't add any new information compared to b8_conv1
|
| 49 |
+
available_layers.extend(['b4_conv', 'fc', 'out'])
|
| 50 |
+
return available_layers
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
# ----------------------------------------------------------------------------
|
| 54 |
+
# DeepDream code; modified from Erik Linder-Norén's repository: https://github.com/eriklindernoren/PyTorch-Deep-Dream
|
| 55 |
+
|
| 56 |
+
def get_image(seed: int = 0,
|
| 57 |
+
image_noise: str = 'random',
|
| 58 |
+
starting_image: Union[str, os.PathLike] = None,
|
| 59 |
+
image_size: int = 1024,
|
| 60 |
+
convert_to_grayscale: bool = False,
|
| 61 |
+
device: torch.device = torch.device('cpu')) -> Tuple[PIL.Image.Image, str]:
|
| 62 |
+
"""Set the random seed (NumPy + PyTorch), as well as get an image from a path or generate a random one with the seed"""
|
| 63 |
+
torch.manual_seed(seed)
|
| 64 |
+
rnd = np.random.RandomState(seed)
|
| 65 |
+
|
| 66 |
+
# Load image or generate a random one if none is provided
|
| 67 |
+
if starting_image is not None:
|
| 68 |
+
image = Image.open(starting_image).convert('RGB').resize((image_size, image_size), Image.LANCZOS)
|
| 69 |
+
else:
|
| 70 |
+
if image_noise == 'random':
|
| 71 |
+
starting_image = f'random_image-seed_{seed:08d}.jpg'
|
| 72 |
+
image = Image.fromarray(rnd.randint(0, 255, (image_size, image_size, 3), dtype='uint8'))
|
| 73 |
+
elif image_noise == 'perlin':
|
| 74 |
+
try:
|
| 75 |
+
# Graciously using Mathieu Duchesneau's implementation: https://github.com/duchesneaumathieu/pyperlin
|
| 76 |
+
from pyperlin import FractalPerlin2D
|
| 77 |
+
starting_image = f'perlin_image-seed_{seed:08d}.jpg'
|
| 78 |
+
shape = (3, image_size, image_size)
|
| 79 |
+
resolutions = [(2**i, 2**i) for i in range(1, 6+1)] # for lacunarity = 2.0 # TODO: set as cli variable
|
| 80 |
+
factors = [0.5**i for i in range(6)] # for persistence = 0.5 TODO: set as cli variables
|
| 81 |
+
g_cuda = torch.Generator(device=device).manual_seed(seed)
|
| 82 |
+
rgb = FractalPerlin2D(shape, resolutions, factors, generator=g_cuda)().cpu().numpy()
|
| 83 |
+
rgb = (255 * (rgb + 1) / 2).astype(np.uint8) # [-1.0, 1.0] => [0, 255]
|
| 84 |
+
image = Image.fromarray(rgb.transpose(1, 2, 0), 'RGB') # Reshape leads us to weird tiling
|
| 85 |
+
|
| 86 |
+
except ImportError:
|
| 87 |
+
raise ImportError('pyperlin not found! Install it via "pip install pyperlin"')
|
| 88 |
+
|
| 89 |
+
if convert_to_grayscale:
|
| 90 |
+
image = image.convert('L').convert('RGB') # We do a little trolling to Pillow (so we have a 3-channel image)
|
| 91 |
+
|
| 92 |
+
return image, starting_image
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def crop_resize_rotate(img: PIL.Image.Image,
|
| 96 |
+
crop_size: int = None,
|
| 97 |
+
new_size: int = None,
|
| 98 |
+
rotation_deg: float = None,
|
| 99 |
+
translate_x: float = 0.0,
|
| 100 |
+
translate_y: float = 0.0) -> PIL.Image.Image:
|
| 101 |
+
"""Center-crop the input image into a square of sides crop_size; can be resized to new_size; rotated rotation_deg counter-clockwise"""
|
| 102 |
+
# Center-crop the input image
|
| 103 |
+
if crop_size is not None:
|
| 104 |
+
w, h = img.size # Input image width and height
|
| 105 |
+
img = img.crop(box=((w - crop_size) // 2, # Left pixel coordinate
|
| 106 |
+
(h - crop_size) // 2, # Upper pixel coordinate
|
| 107 |
+
(w + crop_size) // 2, # Right pixel coordinate
|
| 108 |
+
(h + crop_size) // 2)) # Lower pixel coordinate
|
| 109 |
+
# Resize
|
| 110 |
+
if new_size is not None:
|
| 111 |
+
img = img.resize(size=(new_size, new_size), # Requested size of the image in pixels; (width, height)
|
| 112 |
+
resample=Image.LANCZOS) # Resampling filter
|
| 113 |
+
# Rotation and translation
|
| 114 |
+
if rotation_deg is not None:
|
| 115 |
+
img = img.rotate(angle=rotation_deg, # Angle to rotate image, counter-clockwise
|
| 116 |
+
resample=Image.BICUBIC, # Resampling filter; options: Image.Resampling.{NEAREST, BILINEAR, BICUBIC}
|
| 117 |
+
expand=False, # If True, the whole rotated image will be shown
|
| 118 |
+
translate=(translate_x, translate_y), # Translate the image, from top-left corner (post-rotation)
|
| 119 |
+
fillcolor=(0, 0, 0)) # Black background
|
| 120 |
+
# TODO: tile the background
|
| 121 |
+
return img
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
mean = np.array([0.485, 0.456, 0.406])
|
| 125 |
+
std = np.array([0.229, 0.224, 0.225])
|
| 126 |
+
|
| 127 |
+
preprocess = transforms.Compose([transforms.ToTensor(), transforms.Normalize(mean, std)])
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
def deprocess(image_np: torch.Tensor) -> np.ndarray:
|
| 131 |
+
image_np = image_np.squeeze().transpose(1, 2, 0)
|
| 132 |
+
image_np = image_np * std.reshape((1, 1, 3)) + mean.reshape((1, 1, 3))
|
| 133 |
+
# image_np = (image_np + 1.0) / 2.0
|
| 134 |
+
image_np = np.clip(image_np, 0.0, 1.0)
|
| 135 |
+
image_np = (255 * image_np).astype('uint8')
|
| 136 |
+
return image_np
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
def clip(image_tensor: torch.Tensor) -> torch.Tensor:
|
| 140 |
+
"""Clamp per channel"""
|
| 141 |
+
for c in range(3):
|
| 142 |
+
m, s = mean[c], std[c]
|
| 143 |
+
image_tensor[0, c] = torch.clamp(image_tensor[0, c], -m / s, (1 - m) / s)
|
| 144 |
+
return image_tensor
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
def dream(image: PIL.Image.Image,
|
| 148 |
+
model: torch.nn.Module,
|
| 149 |
+
layers: List[str],
|
| 150 |
+
channels: List[int] = None,
|
| 151 |
+
normed: bool = False,
|
| 152 |
+
sqrt_normed: bool = False,
|
| 153 |
+
iterations: int = 20,
|
| 154 |
+
lr: float = 1e-2) -> np.ndarray:
|
| 155 |
+
""" Updates the image to maximize outputs for n iterations """
|
| 156 |
+
Tensor = torch.cuda.FloatTensor if torch.cuda.is_available() else torch.FloatTensor
|
| 157 |
+
image = Variable(Tensor(image), requires_grad=True)
|
| 158 |
+
for i in range(iterations):
|
| 159 |
+
model.zero_grad()
|
| 160 |
+
out = model.get_layers_features(image, layers=layers, channels=channels, normed=normed, sqrt_normed=sqrt_normed)
|
| 161 |
+
loss = sum(layer.norm() for layer in out) # More than one layer may be used
|
| 162 |
+
loss.backward()
|
| 163 |
+
avg_grad = np.abs(image.grad.data.cpu().numpy()).mean()
|
| 164 |
+
norm_lr = lr / avg_grad
|
| 165 |
+
image.data += norm_lr * image.grad.data
|
| 166 |
+
image.data = clip(image.data)
|
| 167 |
+
# image.data = torch.clamp(image.data, -1.0, 1.0)
|
| 168 |
+
image.grad.data.zero_()
|
| 169 |
+
return image.cpu().data.numpy()
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
def deep_dream(image: PIL.Image.Image,
|
| 173 |
+
model: torch.nn.Module,
|
| 174 |
+
model_resolution: int,
|
| 175 |
+
layers: List[str],
|
| 176 |
+
channels: List[int],
|
| 177 |
+
seed: Union[int, Type[None]],
|
| 178 |
+
normed: bool,
|
| 179 |
+
sqrt_normed: bool,
|
| 180 |
+
iterations: int,
|
| 181 |
+
lr: float,
|
| 182 |
+
octave_scale: float,
|
| 183 |
+
num_octaves: int,
|
| 184 |
+
unzoom_octave: bool = False,
|
| 185 |
+
disable_inner_tqdm: bool = False,
|
| 186 |
+
ignore_initial_transform: bool = False) -> np.ndarray:
|
| 187 |
+
""" Main deep dream method """
|
| 188 |
+
# Center-crop and resize
|
| 189 |
+
if not ignore_initial_transform:
|
| 190 |
+
image = crop_resize_rotate(img=image, crop_size=min(image.size), new_size=model_resolution)
|
| 191 |
+
# Preprocess image
|
| 192 |
+
image = preprocess(image)
|
| 193 |
+
# image = torch.from_numpy(np.array(image)).permute(-1, 0, 1) / 127.5 - 1.0 # alternative
|
| 194 |
+
image = image.unsqueeze(0).cpu().data.numpy()
|
| 195 |
+
# Extract image representations for each octave
|
| 196 |
+
octaves = [image]
|
| 197 |
+
for _ in range(num_octaves - 1):
|
| 198 |
+
# Alternatively, see if we get better results with: https://www.tensorflow.org/tutorials/generative/deepdream#taking_it_up_an_octave
|
| 199 |
+
octave = nd.zoom(octaves[-1], (1, 1, 1 / octave_scale, 1 / octave_scale), order=1)
|
| 200 |
+
# Necessary for StyleGAN's Discriminator, as it cannot handle any image size
|
| 201 |
+
if unzoom_octave:
|
| 202 |
+
octave = nd.zoom(octave, np.array(octaves[-1].shape) / np.array(octave.shape), order=1)
|
| 203 |
+
octaves.append(octave)
|
| 204 |
+
|
| 205 |
+
detail = np.zeros_like(octaves[-1])
|
| 206 |
+
tqdm_desc = f'Dreaming w/layers {"|".join(x for x in layers)}'
|
| 207 |
+
tqdm_desc = f'Seed: {seed} - {tqdm_desc}' if seed is not None else tqdm_desc
|
| 208 |
+
for octave, octave_base in enumerate(tqdm(octaves[::-1], desc=tqdm_desc, disable=disable_inner_tqdm)):
|
| 209 |
+
if octave > 0:
|
| 210 |
+
# Upsample detail to new octave dimension
|
| 211 |
+
detail = nd.zoom(detail, np.array(octave_base.shape) / np.array(detail.shape), order=1)
|
| 212 |
+
# Add deep dream detail from previous octave to new base
|
| 213 |
+
input_image = octave_base + detail
|
| 214 |
+
# Get new deep dream image
|
| 215 |
+
dreamed_image = dream(input_image, model, layers, channels, normed, sqrt_normed, iterations, lr)
|
| 216 |
+
# Extract deep dream details
|
| 217 |
+
detail = dreamed_image - octave_base
|
| 218 |
+
|
| 219 |
+
return deprocess(dreamed_image)
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
# ----------------------------------------------------------------------------
|
| 223 |
+
|
| 224 |
+
# Helper functions (all base code taken from: https://pytorch.org/tutorials/advanced/neural_style_tutorial.html)
|
| 225 |
+
|
| 226 |
+
|
| 227 |
+
class ContentLoss(nn.Module):
|
| 228 |
+
|
| 229 |
+
def __init__(self, target,):
|
| 230 |
+
super(ContentLoss, self).__init__()
|
| 231 |
+
# we 'detach' the target content from the tree used
|
| 232 |
+
# to dynamically compute the gradient: this is a stated value,
|
| 233 |
+
# not a variable. Otherwise the forward method of the criterion
|
| 234 |
+
# will throw an error.
|
| 235 |
+
self.target = target.detach()
|
| 236 |
+
|
| 237 |
+
def forward(self, input):
|
| 238 |
+
self.loss = F.mse_loss(input, self.target)
|
| 239 |
+
return input
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
def gram_matrix(input):
|
| 243 |
+
a, b, c, d = input.size() # (batch_size, no. feature maps, dims of a f. map (N=c*d))
|
| 244 |
+
|
| 245 |
+
features = input.view(a * b, c * d) # resize F_XL into \hat F_XL
|
| 246 |
+
|
| 247 |
+
G = torch.mm(features, features.t()) # compute the gram product
|
| 248 |
+
|
| 249 |
+
# 'Normalize' the values of the gram matrix by dividing by the number of element in each feature maps.
|
| 250 |
+
return G.div(a * b * c * d) # can also do torch.numel(input) to get the number of elements
|
| 251 |
+
|
| 252 |
+
|
| 253 |
+
class StyleLoss(nn.Module):
|
| 254 |
+
def __init__(self, target_feature):
|
| 255 |
+
super(StyleLoss, self).__init__()
|
| 256 |
+
self.target = gram_matrix(target_feature).detach()
|
| 257 |
+
|
| 258 |
+
def forward(self, input):
|
| 259 |
+
G = gram_matrix(input)
|
| 260 |
+
self.loss = F.mse_loss(G, self.target)
|
| 261 |
+
return input
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
@main.command(name='style-transfer', help='Use the StyleGAN2/3 Discriminator to perform style transfer')
|
| 265 |
+
@click.option('--network', 'network_pkl', help='Network pickle filename', required=True)
|
| 266 |
+
@click.option('--cfg', type=click.Choice(['stylegan3-t', 'stylegan3-r', 'stylegan2']), help='Model base configuration', default=None)
|
| 267 |
+
@click.option('--content', type=str, help='Content image filename (url or local path)', required=True)
|
| 268 |
+
@click.option('--style', type=str, help='Style image filename (url or local path)', required=True)
|
| 269 |
+
def style_transfer_discriminator(
|
| 270 |
+
ctx: click.Context,
|
| 271 |
+
network_pkl: str,
|
| 272 |
+
cfg: str,
|
| 273 |
+
content: str,
|
| 274 |
+
style: str,
|
| 275 |
+
):
|
| 276 |
+
print('Coming soon!')
|
| 277 |
+
# Reference: https://pytorch.org/tutorials/advanced/neural_style_tutorial.html
|
| 278 |
+
|
| 279 |
+
# Set up device
|
| 280 |
+
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
|
| 281 |
+
|
| 282 |
+
imsize = 512 if torch.cuda.is_available() else 128 # use small size if no gpu
|
| 283 |
+
|
| 284 |
+
loader = transforms.Compose([transforms.Resize(imsize), # scale imported image
|
| 285 |
+
transforms.ToTensor()]) # transform it into a torch tensor
|
| 286 |
+
|
| 287 |
+
# Helper function
|
| 288 |
+
def image_loader(image_name):
|
| 289 |
+
image = Image.open(image_name)
|
| 290 |
+
# fake batch dimension required to fit network's input dimensions
|
| 291 |
+
image = loader(image).unsqueeze(0)
|
| 292 |
+
return image.to(device, torch.float)
|
| 293 |
+
|
| 294 |
+
style_img = image_loader(style)
|
| 295 |
+
content_img = image_loader(content)
|
| 296 |
+
|
| 297 |
+
# This shouldn't really happen, but just in case
|
| 298 |
+
assert style_img.size() == content_img.size(), 'Style and content images must be the same size'
|
| 299 |
+
|
| 300 |
+
unloader = transforms.ToPILImage() # reconvert into PIL image
|
| 301 |
+
|
| 302 |
+
# Load Discriminator
|
| 303 |
+
D = gen_utils.load_network('D', network_pkl, cfg, device)
|
| 304 |
+
# TODO: finish this!
|
| 305 |
+
|
| 306 |
+
|
| 307 |
+
# ----------------------------------------------------------------------------
|
| 308 |
+
|
| 309 |
+
|
| 310 |
+
@main.command(name='dream', help='Discriminator Dreaming with the StyleGAN2/3 Discriminator and the chosen layers')
|
| 311 |
+
@click.pass_context
|
| 312 |
+
@click.option('--network', 'network_pkl', help='Network pickle filename', required=True)
|
| 313 |
+
@click.option('--cfg', type=click.Choice(['stylegan3-t', 'stylegan3-r', 'stylegan2']), help='Model base configuration', default=None)
|
| 314 |
+
# Synthesis options
|
| 315 |
+
@click.option('--seeds', type=gen_utils.num_range, help='Random seeds to use. Accepted comma-separated values, ranges, or combinations: "a,b,c", "a-c", "a,b-d,e".', default='0')
|
| 316 |
+
@click.option('--random-image-noise', '-noise', 'image_noise', type=click.Choice(['random', 'perlin']), default='perlin', show_default=True)
|
| 317 |
+
@click.option('--starting-image', type=str, help='Path to image to start from', default=None)
|
| 318 |
+
@click.option('--convert-to-grayscale', '-grayscale', is_flag=True, help='Add flag to grayscale the initial image')
|
| 319 |
+
@click.option('--class', 'class_idx', type=int, help='Class label (unconditional if not specified)', default=None)
|
| 320 |
+
@click.option('--lr', 'learning_rate', type=float, help='Learning rate', default=1e-2, show_default=True)
|
| 321 |
+
@click.option('--iterations', '-it', type=int, help='Number of gradient ascent steps per octave', default=20, show_default=True)
|
| 322 |
+
# Layer options
|
| 323 |
+
@click.option('--layers', type=str, help='Layers of the Discriminator to use as the features. If "all", will generate a dream image per available layer in the loaded model. If "use_all", will use all available layers.', default='b16_conv1', show_default=True)
|
| 324 |
+
@click.option('--channels', type=gen_utils.num_range, help='Comma-separated list and/or range of the channels of the Discriminator to use as the features. If "None", will use all channels in each specified layer.', default=None, show_default=True)
|
| 325 |
+
@click.option('--normed', 'norm_model_layers', is_flag=True, help='Add flag to divide the features of each layer of D by its number of elements')
|
| 326 |
+
@click.option('--sqrt-normed', 'sqrt_norm_model_layers', is_flag=True, help='Add flag to divide the features of each layer of D by the square root of its number of elements')
|
| 327 |
+
# Octaves options
|
| 328 |
+
@click.option('--num-octaves', type=int, help='Number of octaves', default=5, show_default=True)
|
| 329 |
+
@click.option('--octave-scale', type=float, help='Image scale between octaves', default=1.4, show_default=True)
|
| 330 |
+
@click.option('--unzoom-octave', type=bool, help='Set to True for the octaves to be unzoomed (this will be slower)', default=True, show_default=True)
|
| 331 |
+
# Extra parameters for saving the results
|
| 332 |
+
@click.option('--outdir', type=click.Path(file_okay=False), help='Directory path to save the results', default=os.path.join(os.getcwd(), 'out', 'discriminator_synthesis'), show_default=True, metavar='DIR')
|
| 333 |
+
@click.option('--description', '-desc', type=str, help='Additional description name for the directory path to save results', default='', show_default=True)
|
| 334 |
+
def discriminator_dream(
|
| 335 |
+
ctx: click.Context,
|
| 336 |
+
network_pkl: Union[str, os.PathLike],
|
| 337 |
+
cfg: Optional[str],
|
| 338 |
+
seeds: List[int],
|
| 339 |
+
image_noise: str,
|
| 340 |
+
starting_image: Union[str, os.PathLike],
|
| 341 |
+
convert_to_grayscale: bool,
|
| 342 |
+
class_idx: Optional[int], # TODO: conditional model
|
| 343 |
+
learning_rate: float,
|
| 344 |
+
iterations: int,
|
| 345 |
+
layers: str,
|
| 346 |
+
channels: Optional[List[int]],
|
| 347 |
+
norm_model_layers: bool,
|
| 348 |
+
sqrt_norm_model_layers: bool,
|
| 349 |
+
num_octaves: int,
|
| 350 |
+
octave_scale: float,
|
| 351 |
+
unzoom_octave: bool,
|
| 352 |
+
outdir: Union[str, os.PathLike],
|
| 353 |
+
description: str,
|
| 354 |
+
):
|
| 355 |
+
# Set up device
|
| 356 |
+
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
|
| 357 |
+
|
| 358 |
+
# Load Discriminator
|
| 359 |
+
D = gen_utils.load_network('D', network_pkl, cfg, device)
|
| 360 |
+
|
| 361 |
+
# Get the model resolution (image resizing and getting available layers)
|
| 362 |
+
model_resolution = D.img_resolution
|
| 363 |
+
|
| 364 |
+
# TODO: do this better, as we can combine these conditions later
|
| 365 |
+
layers = layers.split(',')
|
| 366 |
+
|
| 367 |
+
# We will use the features of the Discriminator, on the layer specified by the user
|
| 368 |
+
model = DiscriminatorFeatures(D).requires_grad_(False).to(device)
|
| 369 |
+
|
| 370 |
+
if 'all' in layers:
|
| 371 |
+
# Get all the available layers in a list
|
| 372 |
+
layers = get_available_layers(max_resolution=model_resolution)
|
| 373 |
+
|
| 374 |
+
for seed in seeds:
|
| 375 |
+
# Get the image and image name
|
| 376 |
+
image, starting_image = get_image(seed=seed, image_noise=image_noise,
|
| 377 |
+
starting_image=starting_image,
|
| 378 |
+
image_size=model_resolution,
|
| 379 |
+
convert_to_grayscale=convert_to_grayscale)
|
| 380 |
+
|
| 381 |
+
# Make the run dir in the specified output directory
|
| 382 |
+
desc = f'discriminator-dream-all_layers-seed_{seed}'
|
| 383 |
+
desc = f'{desc}-{description}' if len(description) != 0 else desc
|
| 384 |
+
run_dir = gen_utils.make_run_dir(outdir, desc)
|
| 385 |
+
|
| 386 |
+
# Save starting image
|
| 387 |
+
image.save(os.path.join(run_dir, f'{os.path.basename(starting_image).split(".")[0]}.jpg'))
|
| 388 |
+
|
| 389 |
+
# Save the configuration used
|
| 390 |
+
ctx.obj = {
|
| 391 |
+
'network_pkl': network_pkl,
|
| 392 |
+
'synthesis_options': {
|
| 393 |
+
'seed': seed,
|
| 394 |
+
'random_image_noise': image_noise,
|
| 395 |
+
'starting_image': starting_image,
|
| 396 |
+
'class_idx': class_idx,
|
| 397 |
+
'learning_rate': learning_rate,
|
| 398 |
+
'iterations': iterations},
|
| 399 |
+
'layer_options': {
|
| 400 |
+
'layer': layers,
|
| 401 |
+
'channels': channels,
|
| 402 |
+
'norm_model_layers': norm_model_layers,
|
| 403 |
+
'sqrt_norm_model_layers': sqrt_norm_model_layers},
|
| 404 |
+
'octaves_options': {
|
| 405 |
+
'num_octaves': num_octaves,
|
| 406 |
+
'octave_scale': octave_scale,
|
| 407 |
+
'unzoom_octave': unzoom_octave},
|
| 408 |
+
'extra_parameters': {
|
| 409 |
+
'outdir': run_dir,
|
| 410 |
+
'description': description}
|
| 411 |
+
}
|
| 412 |
+
# Save the run configuration
|
| 413 |
+
gen_utils.save_config(ctx=ctx, run_dir=run_dir)
|
| 414 |
+
|
| 415 |
+
# For each layer:
|
| 416 |
+
for layer in layers:
|
| 417 |
+
# Extract deep dream image
|
| 418 |
+
dreamed_image = deep_dream(image, model, model_resolution, layers=[layer], channels=channels, seed=seed, normed=norm_model_layers,
|
| 419 |
+
sqrt_normed=sqrt_norm_model_layers, iterations=iterations, lr=learning_rate,
|
| 420 |
+
octave_scale=octave_scale, num_octaves=num_octaves, unzoom_octave=unzoom_octave)
|
| 421 |
+
|
| 422 |
+
# Save the resulting dreamed image
|
| 423 |
+
filename = f'layer-{layer}_dreamed_{os.path.basename(starting_image).split(".")[0]}.jpg'
|
| 424 |
+
Image.fromarray(dreamed_image, 'RGB').save(os.path.join(run_dir, filename))
|
| 425 |
+
|
| 426 |
+
else:
|
| 427 |
+
if 'use_all' in layers:
|
| 428 |
+
# Get all available layers
|
| 429 |
+
layers = get_available_layers(max_resolution=model_resolution)
|
| 430 |
+
else:
|
| 431 |
+
# Parse the layers given by the user and leave only those available by the model
|
| 432 |
+
available_layers = get_available_layers(max_resolution=model_resolution)
|
| 433 |
+
layers = [layer for layer in layers if layer in available_layers]
|
| 434 |
+
|
| 435 |
+
# Make the run dir in the specified output directory
|
| 436 |
+
desc = f'discriminator-dream-layers_{"-".join(x for x in layers)}'
|
| 437 |
+
desc = f'{desc}-{description}' if len(description) != 0 else desc
|
| 438 |
+
run_dir = gen_utils.make_run_dir(outdir, desc)
|
| 439 |
+
|
| 440 |
+
starting_images, used_seeds = [], []
|
| 441 |
+
for seed in seeds:
|
| 442 |
+
# Get the image and image name
|
| 443 |
+
image, starting_image = get_image(seed=seed, image_noise=image_noise,
|
| 444 |
+
starting_image=starting_image,
|
| 445 |
+
image_size=model_resolution,
|
| 446 |
+
convert_to_grayscale=convert_to_grayscale)
|
| 447 |
+
|
| 448 |
+
# Extract deep dream image
|
| 449 |
+
dreamed_image = deep_dream(image, model, model_resolution, layers=layers, channels=channels, seed=seed, normed=norm_model_layers,
|
| 450 |
+
sqrt_normed=sqrt_norm_model_layers, iterations=iterations, lr=learning_rate,
|
| 451 |
+
octave_scale=octave_scale, num_octaves=num_octaves, unzoom_octave=unzoom_octave)
|
| 452 |
+
|
| 453 |
+
# For logging later
|
| 454 |
+
starting_images.append(starting_image)
|
| 455 |
+
used_seeds.append(seed)
|
| 456 |
+
|
| 457 |
+
# Save the resulting image and initial image
|
| 458 |
+
filename = f'dreamed_{os.path.basename(starting_image)}'
|
| 459 |
+
Image.fromarray(dreamed_image, 'RGB').save(os.path.join(run_dir, filename))
|
| 460 |
+
image.save(os.path.join(run_dir, os.path.basename(starting_image)))
|
| 461 |
+
starting_image = None
|
| 462 |
+
|
| 463 |
+
# Save the configuration used
|
| 464 |
+
ctx.obj = {
|
| 465 |
+
'network_pkl': network_pkl,
|
| 466 |
+
'synthesis_options': {
|
| 467 |
+
'seeds': used_seeds,
|
| 468 |
+
'starting_image': starting_images,
|
| 469 |
+
'class_idx': class_idx,
|
| 470 |
+
'learning_rate': learning_rate,
|
| 471 |
+
'iterations': iterations},
|
| 472 |
+
'layer_options': {
|
| 473 |
+
'layer': layers,
|
| 474 |
+
'channels': channels,
|
| 475 |
+
'norm_model_layers': norm_model_layers,
|
| 476 |
+
'sqrt_norm_model_layers': sqrt_norm_model_layers},
|
| 477 |
+
'octaves_options': {
|
| 478 |
+
'octave_scale': octave_scale,
|
| 479 |
+
'num_octaves': num_octaves,
|
| 480 |
+
'unzoom_octave': unzoom_octave},
|
| 481 |
+
'extra_parameters': {
|
| 482 |
+
'outdir': run_dir,
|
| 483 |
+
'description': description}
|
| 484 |
+
}
|
| 485 |
+
# Save the run configuration
|
| 486 |
+
gen_utils.save_config(ctx=ctx, run_dir=run_dir)
|
| 487 |
+
|
| 488 |
+
|
| 489 |
+
# ----------------------------------------------------------------------------
|
| 490 |
+
|
| 491 |
+
|
| 492 |
+
@main.command(name='dream-zoom',
|
| 493 |
+
help='Zoom/rotate/translate after each Discriminator Dreaming iteration. A video will be saved.')
|
| 494 |
+
@click.pass_context
|
| 495 |
+
@click.option('--network', 'network_pkl', help='Network pickle filename', required=True)
|
| 496 |
+
@click.option('--cfg', type=click.Choice(['stylegan3-t', 'stylegan3-r', 'stylegan2']), help='Model base configuration', default=None)
|
| 497 |
+
# Synthesis options
|
| 498 |
+
@click.option('--seed', type=int, help='Random seed to use', default=0, show_default=True)
|
| 499 |
+
@click.option('--random-image-noise', '-noise', 'image_noise', type=click.Choice(['random', 'perlin']), default='random', show_default=True)
|
| 500 |
+
@click.option('--starting-image', type=str, help='Path to image to start from', default=None)
|
| 501 |
+
@click.option('--convert-to-grayscale', '-grayscale', is_flag=True, help='Add flag to grayscale the initial image')
|
| 502 |
+
@click.option('--class', 'class_idx', type=int, help='Class label (unconditional if not specified)', default=None)
|
| 503 |
+
@click.option('--lr', 'learning_rate', type=float, help='Learning rate', default=5e-3, show_default=True)
|
| 504 |
+
@click.option('--iterations', '-it', type=click.IntRange(min=1), help='Number of gradient ascent steps per octave', default=10, show_default=True)
|
| 505 |
+
# Layer options
|
| 506 |
+
@click.option('--layers', type=str, help='Comma-separated list of the layers of the Discriminator to use as the features. If "use_all", will use all available layers.', default='b16_conv0', show_default=True)
|
| 507 |
+
@click.option('--channels', type=gen_utils.num_range, help='Comma-separated list and/or range of the channels of the Discriminator to use as the features. If "None", will use all channels in each specified layer.', default=None, show_default=True)
|
| 508 |
+
@click.option('--normed', 'norm_model_layers', is_flag=True, help='Add flag to divide the features of each layer of D by its number of elements')
|
| 509 |
+
@click.option('--sqrt-normed', 'sqrt_norm_model_layers', is_flag=True, help='Add flag to divide the features of each layer of D by the square root of its number of elements')
|
| 510 |
+
# Octaves options
|
| 511 |
+
@click.option('--num-octaves', type=click.IntRange(min=1), help='Number of octaves', default=5, show_default=True)
|
| 512 |
+
@click.option('--octave-scale', type=float, help='Image scale between octaves', default=1.4, show_default=True)
|
| 513 |
+
@click.option('--unzoom-octave', type=bool, help='Set to True for the octaves to be unzoomed (this will be slower)', default=False, show_default=True)
|
| 514 |
+
# Individual frame manipulation options
|
| 515 |
+
@click.option('--pixel-zoom', '-zoom', type=int, help='How many pixels to zoom per step (positive for zoom in, negative for zoom out, padded with black)', default=2, show_default=True)
|
| 516 |
+
@click.option('--rotation-deg', '-rot', type=float, help='Rotate image counter-clockwise per frame (padded with black)', default=0.0, show_default=True)
|
| 517 |
+
@click.option('--translate-x', '-tx', type=float, help='Translate the image in the horizontal axis per frame (from left to right, padded with black)', default=0.0, show_default=True)
|
| 518 |
+
@click.option('--translate-y', '-ty', type=float, help='Translate the image in the vertical axis per frame (from top to bottom, padded with black)', default=0.0, show_default=True)
|
| 519 |
+
# Video options
|
| 520 |
+
@click.option('--fps', type=gen_utils.parse_fps, help='FPS for the mp4 video of optimization progress (if saved)', default=25, show_default=True)
|
| 521 |
+
@click.option('--duration-sec', type=float, help='Duration length of the video', default=15.0, show_default=True)
|
| 522 |
+
@click.option('--reverse-video', is_flag=True, help='Add flag to reverse the generated video')
|
| 523 |
+
@click.option('--include-starting-image', type=bool, help='Include the starting image in the final video', default=True, show_default=True)
|
| 524 |
+
# Extra parameters for saving the results
|
| 525 |
+
@click.option('--outdir', type=click.Path(file_okay=False), help='Directory path to save the results', default=os.path.join(os.getcwd(), 'out', 'discriminator_synthesis'), show_default=True, metavar='DIR')
|
| 526 |
+
@click.option('--description', '-desc', type=str, help='Additional description name for the directory path to save results', default='', show_default=True)
|
| 527 |
+
def discriminator_dream_zoom(
|
| 528 |
+
ctx: click.Context,
|
| 529 |
+
network_pkl: Union[str, os.PathLike],
|
| 530 |
+
cfg: Optional[str],
|
| 531 |
+
seed: int,
|
| 532 |
+
image_noise: Optional[str],
|
| 533 |
+
starting_image: Optional[Union[str, os.PathLike]],
|
| 534 |
+
convert_to_grayscale: bool,
|
| 535 |
+
class_idx: Optional[int], # TODO: conditional model
|
| 536 |
+
learning_rate: float,
|
| 537 |
+
iterations: int,
|
| 538 |
+
layers: str,
|
| 539 |
+
channels: List[int],
|
| 540 |
+
norm_model_layers: Optional[bool],
|
| 541 |
+
sqrt_norm_model_layers: Optional[bool],
|
| 542 |
+
num_octaves: int,
|
| 543 |
+
octave_scale: float,
|
| 544 |
+
unzoom_octave: Optional[bool],
|
| 545 |
+
pixel_zoom: int,
|
| 546 |
+
rotation_deg: float,
|
| 547 |
+
translate_x: int,
|
| 548 |
+
translate_y: int,
|
| 549 |
+
fps: int,
|
| 550 |
+
duration_sec: float,
|
| 551 |
+
reverse_video: bool,
|
| 552 |
+
include_starting_image: bool,
|
| 553 |
+
outdir: Union[str, os.PathLike],
|
| 554 |
+
description: str,
|
| 555 |
+
):
|
| 556 |
+
# Set up device
|
| 557 |
+
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
|
| 558 |
+
|
| 559 |
+
# Load Discriminator
|
| 560 |
+
D = gen_utils.load_network('D', network_pkl, cfg, device)
|
| 561 |
+
|
| 562 |
+
# Get the model resolution (for resizing the starting image if needed)
|
| 563 |
+
model_resolution = D.img_resolution
|
| 564 |
+
zoom_size = model_resolution - 2 * pixel_zoom
|
| 565 |
+
|
| 566 |
+
layers = layers.split(',')
|
| 567 |
+
if 'use_all' in layers:
|
| 568 |
+
# Get all available layers
|
| 569 |
+
layers = get_available_layers(max_resolution=model_resolution)
|
| 570 |
+
else:
|
| 571 |
+
# Parse the layers given by the user and leave only those available by the model
|
| 572 |
+
available_layers = get_available_layers(max_resolution=model_resolution)
|
| 573 |
+
layers = [layer for layer in layers if layer in available_layers]
|
| 574 |
+
|
| 575 |
+
# We will use the features of the Discriminator, on the layer specified by the user
|
| 576 |
+
model = DiscriminatorFeatures(D).requires_grad_(False).to(device)
|
| 577 |
+
|
| 578 |
+
# Get the image and image name
|
| 579 |
+
image, starting_image = get_image(seed=seed, image_noise=image_noise,
|
| 580 |
+
starting_image=starting_image,
|
| 581 |
+
image_size=model_resolution,
|
| 582 |
+
convert_to_grayscale=convert_to_grayscale)
|
| 583 |
+
|
| 584 |
+
# Make the run dir in the specified output directory
|
| 585 |
+
desc = 'discriminator-dream-zoom'
|
| 586 |
+
desc = f'{desc}-{description}' if len(description) != 0 else desc
|
| 587 |
+
run_dir = gen_utils.make_run_dir(outdir, desc)
|
| 588 |
+
|
| 589 |
+
# Save the configuration used
|
| 590 |
+
ctx.obj = {
|
| 591 |
+
'network_pkl': network_pkl,
|
| 592 |
+
'synthesis_options': {
|
| 593 |
+
'seed': seed,
|
| 594 |
+
'random_image_noise': image_noise,
|
| 595 |
+
'starting_image': starting_image,
|
| 596 |
+
'class_idx': class_idx,
|
| 597 |
+
'learning_rate': learning_rate,
|
| 598 |
+
'iterations': iterations
|
| 599 |
+
},
|
| 600 |
+
'layer_options': {
|
| 601 |
+
'layers': layers,
|
| 602 |
+
'channels': channels,
|
| 603 |
+
'norm_model_layers': norm_model_layers,
|
| 604 |
+
'sqrt_norm_model_layers': sqrt_norm_model_layers
|
| 605 |
+
},
|
| 606 |
+
'octaves_options': {
|
| 607 |
+
'num_octaves': num_octaves,
|
| 608 |
+
'octave_scale': octave_scale,
|
| 609 |
+
'unzoom_octave': unzoom_octave
|
| 610 |
+
},
|
| 611 |
+
'frame_manipulation_options': {
|
| 612 |
+
'pixel_zoom': pixel_zoom,
|
| 613 |
+
'rotation_deg': rotation_deg,
|
| 614 |
+
'translate_x': translate_x,
|
| 615 |
+
'translate_y': translate_y,
|
| 616 |
+
},
|
| 617 |
+
'video_options': {
|
| 618 |
+
'fps': fps,
|
| 619 |
+
'duration_sec': duration_sec,
|
| 620 |
+
'reverse_video': reverse_video,
|
| 621 |
+
'include_starting_image': include_starting_image,
|
| 622 |
+
},
|
| 623 |
+
'extra_parameters': {
|
| 624 |
+
'outdir': run_dir,
|
| 625 |
+
'description': description
|
| 626 |
+
}
|
| 627 |
+
}
|
| 628 |
+
# Save the run configuration
|
| 629 |
+
gen_utils.save_config(ctx=ctx, run_dir=run_dir)
|
| 630 |
+
|
| 631 |
+
num_frames = int(np.rint(duration_sec * fps)) # Number of frames for the video
|
| 632 |
+
n_digits = int(np.log10(num_frames)) + 1 # Number of digits for naming each frame
|
| 633 |
+
|
| 634 |
+
# Save the starting image
|
| 635 |
+
starting_image_name = f'dreamed_{0:0{n_digits}d}.jpg' if include_starting_image else 'starting_image.jpg'
|
| 636 |
+
image.save(os.path.join(run_dir, starting_image_name))
|
| 637 |
+
|
| 638 |
+
for idx, frame in enumerate(tqdm(range(num_frames), desc='Dreaming...', unit='frame')):
|
| 639 |
+
# Zoom in after the first frame
|
| 640 |
+
if idx > 0:
|
| 641 |
+
image = crop_resize_rotate(image, crop_size=zoom_size, new_size=model_resolution,
|
| 642 |
+
rotation_deg=rotation_deg, translate_x=translate_x, translate_y=translate_y)
|
| 643 |
+
# Extract deep dream image
|
| 644 |
+
dreamed_image = deep_dream(image, model, model_resolution, layers=layers, seed=seed, normed=norm_model_layers,
|
| 645 |
+
sqrt_normed=sqrt_norm_model_layers, iterations=iterations, channels=channels,
|
| 646 |
+
lr=learning_rate, octave_scale=octave_scale, num_octaves=num_octaves,
|
| 647 |
+
unzoom_octave=unzoom_octave, disable_inner_tqdm=True)
|
| 648 |
+
|
| 649 |
+
# Save the resulting image and initial image
|
| 650 |
+
filename = f'dreamed_{idx + 1:0{n_digits}d}.jpg'
|
| 651 |
+
Image.fromarray(dreamed_image, 'RGB').save(os.path.join(run_dir, filename))
|
| 652 |
+
|
| 653 |
+
# Now, the dreamed image is the starting image
|
| 654 |
+
image = Image.fromarray(dreamed_image, 'RGB')
|
| 655 |
+
|
| 656 |
+
# Save the final video
|
| 657 |
+
gen_utils.save_video_from_images(run_dir=run_dir, image_names=f'dreamed_%0{n_digits}d.jpg',
|
| 658 |
+
video_name='dream-zoom', fps=fps, reverse_video=reverse_video)
|
| 659 |
+
|
| 660 |
+
|
| 661 |
+
# ----------------------------------------------------------------------------
|
| 662 |
+
|
| 663 |
+
@main.command(name='channel-zoom', help='Dream zoom using only the specified channels in the selected layer')
|
| 664 |
+
@click.pass_context
|
| 665 |
+
@click.option('--network', 'network_pkl', help='Network pickle filename', required=True)
|
| 666 |
+
@click.option('--cfg', type=click.Choice(['stylegan3-t', 'stylegan3-r', 'stylegan2']), help='Model base configuration', default=None)
|
| 667 |
+
# Synthesis options
|
| 668 |
+
@click.option('--seed', type=int, help='Random seed to use', default=0, show_default=True)
|
| 669 |
+
@click.option('--random-image-noise', '-noise', 'image_noise', type=click.Choice(['random', 'perlin']), default='random', show_default=True)
|
| 670 |
+
@click.option('--starting-image', type=str, help='Path to image to start from', default=None)
|
| 671 |
+
@click.option('--convert-to-grayscale', '-grayscale', is_flag=True, help='Add flag to grayscale the initial image')
|
| 672 |
+
@click.option('--class', 'class_idx', type=int, help='Class label (unconditional if not specified)', default=None)
|
| 673 |
+
@click.option('--lr', 'learning_rate', type=float, help='Learning rate', default=5e-3, show_default=True)
|
| 674 |
+
@click.option('--iterations', '-it', type=click.IntRange(min=1), help='Number of gradient ascent steps per octave', default=10, show_default=True)
|
| 675 |
+
# Layer options
|
| 676 |
+
@click.option('--layer', type=str, help='Layers of the Discriminator to use as the features.', default='b8_conv0', show_default=True)
|
| 677 |
+
@click.option('--normed', 'norm_model_layers', is_flag=True, help='Add flag to divide the features of each layer of D by its number of elements')
|
| 678 |
+
@click.option('--sqrt-normed', 'sqrt_norm_model_layers', is_flag=True, help='Add flag to divide the features of each layer of D by the square root of its number of elements')
|
| 679 |
+
# Octaves options
|
| 680 |
+
@click.option('--num-octaves', type=click.IntRange(min=1), help='Number of octaves', default=5, show_default=True)
|
| 681 |
+
@click.option('--octave-scale', type=float, help='Image scale between octaves', default=1.4, show_default=True)
|
| 682 |
+
@click.option('--unzoom-octave', type=bool, help='Set to True for the octaves to be unzoomed (this will be slower)', default=False, show_default=True)
|
| 683 |
+
# Individual frame manipulation options
|
| 684 |
+
@click.option('--pixel-zoom', '-zoom', type=int, help='How many pixels to zoom per step (positive for zoom in, negative for zoom out, padded with black)', default=2, show_default=True)
|
| 685 |
+
@click.option('--rotation-deg', '-rot', type=float, help='Rotate image counter-clockwise per frame (padded with black)', default=0.0, show_default=True)
|
| 686 |
+
@click.option('--translate-x', '-tx', type=float, help='Translate the image in the horizontal axis per frame (from left to right, padded with black)', default=0.0, show_default=True)
|
| 687 |
+
@click.option('--translate-y', '-ty', type=float, help='Translate the image in the vertical axis per frame (from top to bottom, padded with black)', default=0.0, show_default=True)
|
| 688 |
+
# Video options
|
| 689 |
+
@click.option('--frames-per-channel', type=click.IntRange(min=1), help='Number of frames per channel', default=1, show_default=True)
|
| 690 |
+
@click.option('--fps', type=gen_utils.parse_fps, help='FPS for the mp4 video of optimization progress (if saved)', default=25, show_default=True)
|
| 691 |
+
@click.option('--reverse-video', is_flag=True, help='Add flag to reverse the generated video')
|
| 692 |
+
@click.option('--include-starting-image', type=bool, help='Include the starting image in the final video', default=True, show_default=True)
|
| 693 |
+
# Extra parameters for saving the results
|
| 694 |
+
@click.option('--outdir', type=click.Path(file_okay=False), help='Directory path to save the results', default=os.path.join(os.getcwd(), 'out', 'discriminator_synthesis'), show_default=True, metavar='DIR')
|
| 695 |
+
@click.option('--description', '-desc', type=str, help='Additional description name for the directory path to save results', default='', show_default=True)
|
| 696 |
+
def channel_zoom(
|
| 697 |
+
ctx: click.Context,
|
| 698 |
+
network_pkl: Union[str, os.PathLike],
|
| 699 |
+
cfg: Optional[str],
|
| 700 |
+
seed: int,
|
| 701 |
+
image_noise: Optional[str],
|
| 702 |
+
starting_image: Optional[Union[str, os.PathLike]],
|
| 703 |
+
convert_to_grayscale: bool,
|
| 704 |
+
class_idx: Optional[int], # TODO: conditional model
|
| 705 |
+
learning_rate: float,
|
| 706 |
+
iterations: int,
|
| 707 |
+
layer: str,
|
| 708 |
+
norm_model_layers: Optional[bool],
|
| 709 |
+
sqrt_norm_model_layers: Optional[bool],
|
| 710 |
+
num_octaves: int,
|
| 711 |
+
octave_scale: float,
|
| 712 |
+
unzoom_octave: Optional[bool],
|
| 713 |
+
pixel_zoom: int,
|
| 714 |
+
rotation_deg: float,
|
| 715 |
+
translate_x: int,
|
| 716 |
+
translate_y: int,
|
| 717 |
+
frames_per_channel: int,
|
| 718 |
+
fps: int,
|
| 719 |
+
reverse_video: bool,
|
| 720 |
+
include_starting_image: bool,
|
| 721 |
+
outdir: Union[str, os.PathLike],
|
| 722 |
+
description: str,
|
| 723 |
+
):
|
| 724 |
+
"""Zoom in using all the channels of a network (or a specified layer)"""
|
| 725 |
+
# Set up device
|
| 726 |
+
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
|
| 727 |
+
|
| 728 |
+
# Load Discriminator
|
| 729 |
+
D = gen_utils.load_network('D', network_pkl, cfg, device)
|
| 730 |
+
|
| 731 |
+
# Get the model resolution (for resizing the starting image if needed)
|
| 732 |
+
model_resolution = D.img_resolution
|
| 733 |
+
zoom_size = model_resolution - 2 * pixel_zoom
|
| 734 |
+
|
| 735 |
+
if 'use_all' in layer:
|
| 736 |
+
ctx.fail('Cannot use "use_all" with this command. Please specify the layers you want to use.')
|
| 737 |
+
else:
|
| 738 |
+
# Parse the layers given by the user and leave only those available by the model
|
| 739 |
+
available_layers = get_available_layers(max_resolution=model_resolution)
|
| 740 |
+
assert layer in available_layers, f'Layer {layer} not available. Available layers: {available_layers}'
|
| 741 |
+
layers = [layer]
|
| 742 |
+
|
| 743 |
+
# We will use the features of the Discriminator, on the layer specified by the user
|
| 744 |
+
model = DiscriminatorFeatures(D).requires_grad_(False).to(device)
|
| 745 |
+
|
| 746 |
+
# Get the image and image name
|
| 747 |
+
image, starting_image = get_image(seed=seed, image_noise=image_noise,
|
| 748 |
+
starting_image=starting_image,
|
| 749 |
+
image_size=model_resolution,
|
| 750 |
+
convert_to_grayscale=convert_to_grayscale)
|
| 751 |
+
|
| 752 |
+
# Make the run dir in the specified output directory
|
| 753 |
+
desc = 'discriminator-channel-zoom'
|
| 754 |
+
desc = f'{desc}-{description}' if len(description) != 0 else desc
|
| 755 |
+
run_dir = gen_utils.make_run_dir(outdir, desc)
|
| 756 |
+
|
| 757 |
+
# Finally, let's get the number of channels in the selected layer
|
| 758 |
+
channels_dict = {res: D.get_submodule(f'b{res}.conv0').out_channels for res in D.block_resolutions}
|
| 759 |
+
channels_dict[4] = D.get_submodule('b4.conv').out_channels # Last block has a different name
|
| 760 |
+
# Get the dimension of the block from the selected layer (e.g., from 'b128_conv0' get '128')
|
| 761 |
+
block_resolution = re.search(r'b(\d+)_', layer).group(1)
|
| 762 |
+
total_channels = channels_dict[int(block_resolution)]
|
| 763 |
+
# Make a list of all the channels, each repeated frames_per_channel
|
| 764 |
+
channels = np.repeat(np.arange(total_channels), frames_per_channel)
|
| 765 |
+
|
| 766 |
+
num_frames = int(np.rint(total_channels * frames_per_channel)) # Number of frames for the video
|
| 767 |
+
n_digits = int(np.log10(num_frames)) + 1 # Number of digits for naming each frame
|
| 768 |
+
|
| 769 |
+
# Save the starting image
|
| 770 |
+
starting_image_name = f'dreamed_{0:0{n_digits}d}.jpg' if include_starting_image else 'starting_image.jpg'
|
| 771 |
+
image.save(os.path.join(run_dir, starting_image_name))
|
| 772 |
+
|
| 773 |
+
for idx, frame in enumerate(tqdm(range(num_frames), desc='Dreaming...', unit='frame')):
|
| 774 |
+
# Zoom in after the first frame
|
| 775 |
+
if idx > 0:
|
| 776 |
+
image = crop_resize_rotate(image, crop_size=zoom_size, new_size=model_resolution,
|
| 777 |
+
rotation_deg=rotation_deg, translate_x=translate_x, translate_y=translate_y)
|
| 778 |
+
# Extract deep dream image
|
| 779 |
+
dreamed_image = deep_dream(image, model, model_resolution, layers=layers, seed=seed, normed=norm_model_layers,
|
| 780 |
+
sqrt_normed=sqrt_norm_model_layers, iterations=iterations, channels=channels[idx:idx + 1],
|
| 781 |
+
lr=learning_rate, octave_scale=octave_scale, num_octaves=num_octaves,
|
| 782 |
+
unzoom_octave=unzoom_octave, disable_inner_tqdm=True)
|
| 783 |
+
|
| 784 |
+
# Save the resulting image and initial image
|
| 785 |
+
filename = f'dreamed_{idx + 1:0{n_digits}d}.jpg'
|
| 786 |
+
Image.fromarray(dreamed_image, 'RGB').save(os.path.join(run_dir, filename))
|
| 787 |
+
|
| 788 |
+
# Now, the dreamed image is the starting image
|
| 789 |
+
image = Image.fromarray(dreamed_image, 'RGB')
|
| 790 |
+
|
| 791 |
+
# Save the final video
|
| 792 |
+
gen_utils.save_video_from_images(run_dir=run_dir, image_names=f'dreamed_%0{n_digits}d.jpg', video_name='channel-zoom',
|
| 793 |
+
fps=fps, reverse_video=reverse_video)
|
| 794 |
+
|
| 795 |
+
# Save the configuration used
|
| 796 |
+
ctx.obj = {
|
| 797 |
+
'network_pkl': network_pkl,
|
| 798 |
+
'synthesis_options': {
|
| 799 |
+
'seed': seed,
|
| 800 |
+
'random_image_noise': image_noise,
|
| 801 |
+
'starting_image': starting_image,
|
| 802 |
+
'class_idx': class_idx,
|
| 803 |
+
'learning_rate': learning_rate,
|
| 804 |
+
'iterations': iterations
|
| 805 |
+
},
|
| 806 |
+
'layer_options': {
|
| 807 |
+
'layer': layer,
|
| 808 |
+
'channels': 'all',
|
| 809 |
+
'total_channels': total_channels,
|
| 810 |
+
'norm_model_layers': norm_model_layers,
|
| 811 |
+
'sqrt_norm_model_layers': sqrt_norm_model_layers
|
| 812 |
+
},
|
| 813 |
+
'octaves_options': {
|
| 814 |
+
'num_octaves': num_octaves,
|
| 815 |
+
'octave_scale': octave_scale,
|
| 816 |
+
'unzoom_octave': unzoom_octave
|
| 817 |
+
},
|
| 818 |
+
'frame_manipulation_options': {
|
| 819 |
+
'pixel_zoom': pixel_zoom,
|
| 820 |
+
'rotation_deg': rotation_deg,
|
| 821 |
+
'translate_x': translate_x,
|
| 822 |
+
'translate_y': translate_y,
|
| 823 |
+
},
|
| 824 |
+
'video_options': {
|
| 825 |
+
'fps': fps,
|
| 826 |
+
'frames_per_channel': frames_per_channel,
|
| 827 |
+
'reverse_video': reverse_video,
|
| 828 |
+
'include_starting_image': include_starting_image,
|
| 829 |
+
},
|
| 830 |
+
'extra_parameters': {
|
| 831 |
+
'outdir': run_dir,
|
| 832 |
+
'description': description
|
| 833 |
+
}
|
| 834 |
+
}
|
| 835 |
+
# Save the run configuration
|
| 836 |
+
gen_utils.save_config(ctx=ctx, run_dir=run_dir)
|
| 837 |
+
|
| 838 |
+
|
| 839 |
+
# ----------------------------------------------------------------------------
|
| 840 |
+
|
| 841 |
+
|
| 842 |
+
@main.command(name='interp', help='Interpolate between two or more seeds')
|
| 843 |
+
@click.pass_context
|
| 844 |
+
@click.option('--network', 'network_pkl', help='Network pickle filename', required=True)
|
| 845 |
+
@click.option('--cfg', type=click.Choice(['stylegan3-t', 'stylegan3-r', 'stylegan2']), help='Model base configuration', default=None)
|
| 846 |
+
# Synthesis options
|
| 847 |
+
@click.option('--seeds', type=gen_utils.num_range, help='Random seeds to generate the Perlin noise from', required=True)
|
| 848 |
+
@click.option('--interp-type', '-interp', type=click.Choice(['linear', 'spherical']), help='Type of interpolation in Z or W', default='spherical', show_default=True)
|
| 849 |
+
@click.option('--smooth', is_flag=True, help='Add flag to smooth the interpolation between the seeds')
|
| 850 |
+
@click.option('--random-image-noise', '-noise', 'image_noise', type=click.Choice(['random', 'perlin']), default='random', show_default=True)
|
| 851 |
+
@click.option('--starting-image', type=str, help='Path to image to start from', default=None)
|
| 852 |
+
@click.option('--convert-to-grayscale', '-grayscale', is_flag=True, help='Add flag to grayscale the initial image')
|
| 853 |
+
@click.option('--class', 'class_idx', type=int, help='Class label (unconditional if not specified)', default=None)
|
| 854 |
+
@click.option('--lr', 'learning_rate', type=float, help='Learning rate', default=5e-3, show_default=True)
|
| 855 |
+
@click.option('--iterations', '-it', type=click.IntRange(min=1), help='Number of gradient ascent steps per octave', default=10, show_default=True)
|
| 856 |
+
# Layer options
|
| 857 |
+
@click.option('--layers', type=str, help='Comma-separated list of the layers of the Discriminator to use as the features. If "use_all", will use all available layers.', default='b16_conv0', show_default=True)
|
| 858 |
+
@click.option('--channels', type=gen_utils.num_range, help='Comma-separated list and/or range of the channels of the Discriminator to use as the features. If "None", will use all channels in each specified layer.', default=None, show_default=True)
|
| 859 |
+
@click.option('--normed', 'norm_model_layers', is_flag=True, help='Add flag to divide the features of each layer of D by its number of elements')
|
| 860 |
+
@click.option('--sqrt-normed', 'sqrt_norm_model_layers', is_flag=True, help='Add flag to divide the features of each layer of D by the square root of its number of elements')
|
| 861 |
+
# Octaves options
|
| 862 |
+
@click.option('--num-octaves', type=click.IntRange(min=1), help='Number of octaves', default=5, show_default=True)
|
| 863 |
+
@click.option('--octave-scale', type=float, help='Image scale between octaves', default=1.4, show_default=True)
|
| 864 |
+
@click.option('--unzoom-octave', type=bool, help='Set to True for the octaves to be unzoomed (this will be slower)', default=False, show_default=True)
|
| 865 |
+
# TODO: Individual frame manipulation options
|
| 866 |
+
# Video options
|
| 867 |
+
@click.option('--seed-sec', '-sec', type=float, help='Number of seconds between each seed transition', default=5.0, show_default=True)
|
| 868 |
+
@click.option('--fps', type=gen_utils.parse_fps, help='FPS for the mp4 video of optimization progress (if saved)', default=25, show_default=True)
|
| 869 |
+
# Extra parameters for saving the results
|
| 870 |
+
@click.option('--outdir', type=click.Path(file_okay=False), help='Directory path to save the results', default=os.path.join(os.getcwd(), 'out', 'discriminator_synthesis'), show_default=True, metavar='DIR')
|
| 871 |
+
@click.option('--description', '-desc', type=str, help='Additional description name for the directory path to save results', default='', show_default=True)
|
| 872 |
+
def random_interpolation(
|
| 873 |
+
ctx: click.Context,
|
| 874 |
+
network_pkl: Union[str, os.PathLike],
|
| 875 |
+
cfg: Optional[str],
|
| 876 |
+
seeds: List[int],
|
| 877 |
+
interp_type: Optional[str],
|
| 878 |
+
smooth: Optional[bool],
|
| 879 |
+
image_noise: Optional[str],
|
| 880 |
+
starting_image: Optional[Union[str, os.PathLike]],
|
| 881 |
+
convert_to_grayscale: bool,
|
| 882 |
+
class_idx: Optional[int], # TODO: conditional model
|
| 883 |
+
learning_rate: float,
|
| 884 |
+
iterations: int,
|
| 885 |
+
layers: str,
|
| 886 |
+
channels: List[int],
|
| 887 |
+
norm_model_layers: Optional[bool],
|
| 888 |
+
sqrt_norm_model_layers: Optional[bool],
|
| 889 |
+
num_octaves: int,
|
| 890 |
+
octave_scale: float,
|
| 891 |
+
unzoom_octave: Optional[bool],
|
| 892 |
+
seed_sec: float,
|
| 893 |
+
fps: int,
|
| 894 |
+
outdir: Union[str, os.PathLike],
|
| 895 |
+
description: str,
|
| 896 |
+
):
|
| 897 |
+
"""Do a latent walk between random Perlin images (given the seeds) and generate a video with these frames."""
|
| 898 |
+
# TODO: To make this better and more stable, we generate Perlin noise animations, not interpolations
|
| 899 |
+
# Set up device
|
| 900 |
+
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
|
| 901 |
+
|
| 902 |
+
# Load Discriminator
|
| 903 |
+
D = gen_utils.load_network('D', network_pkl, cfg, device)
|
| 904 |
+
|
| 905 |
+
# Get model resolution
|
| 906 |
+
model_resolution = D.img_resolution
|
| 907 |
+
model = DiscriminatorFeatures(D).requires_grad_(False).to(device)
|
| 908 |
+
|
| 909 |
+
layers = layers.split(',')
|
| 910 |
+
# Get all available layers
|
| 911 |
+
if 'use_all' in layers:
|
| 912 |
+
layers = get_available_layers(max_resolution=model_resolution)
|
| 913 |
+
else:
|
| 914 |
+
# Parse the layers given by the user and leave only those available by the model
|
| 915 |
+
available_layers = get_available_layers(max_resolution=model_resolution)
|
| 916 |
+
layers = [layer for layer in layers if layer in available_layers]
|
| 917 |
+
|
| 918 |
+
# Make the run dir in the specified output directory
|
| 919 |
+
desc = f'random-interp-layers_{"-".join(x for x in layers)}'
|
| 920 |
+
desc = f'{desc}-{description}' if len(description) != 0 else desc
|
| 921 |
+
run_dir = gen_utils.make_run_dir(outdir, desc)
|
| 922 |
+
|
| 923 |
+
# Number of steps to take between each random image
|
| 924 |
+
n_steps = int(np.rint(seed_sec * fps))
|
| 925 |
+
# Total number of frames
|
| 926 |
+
num_frames = int(n_steps * (len(seeds) - 1))
|
| 927 |
+
# Total video length in seconds
|
| 928 |
+
duration_sec = num_frames / fps
|
| 929 |
+
|
| 930 |
+
# Number of digits for naming purposes
|
| 931 |
+
n_digits = int(np.log10(num_frames)) + 1
|
| 932 |
+
|
| 933 |
+
# Create interpolation of noises
|
| 934 |
+
random_images = []
|
| 935 |
+
for seed in seeds:
|
| 936 |
+
# Get the starting seed and image
|
| 937 |
+
image, _ = get_image(seed=seed, image_noise=image_noise, starting_image=starting_image,
|
| 938 |
+
image_size=model_resolution, convert_to_grayscale=convert_to_grayscale)
|
| 939 |
+
image = np.array(image) / 255.0
|
| 940 |
+
random_images.append(image)
|
| 941 |
+
random_images = np.stack(random_images)
|
| 942 |
+
|
| 943 |
+
all_images = np.empty([0] + list(random_images.shape[1:]), dtype=np.float32)
|
| 944 |
+
# Do interpolation
|
| 945 |
+
for i in range(len(random_images) - 1):
|
| 946 |
+
# Interpolate between each pair of images
|
| 947 |
+
interp = gen_utils.interpolate(random_images[i], random_images[i + 1], n_steps, interp_type, smooth)
|
| 948 |
+
# Append it to the list of all images
|
| 949 |
+
all_images = np.append(all_images, interp, axis=0)
|
| 950 |
+
|
| 951 |
+
# DeepDream expects a list of PIL.Image objects
|
| 952 |
+
pil_images = []
|
| 953 |
+
for idx in range(len(all_images)):
|
| 954 |
+
im = (255 * all_images[idx]).astype(dtype=np.uint8)
|
| 955 |
+
pil_images.append(Image.fromarray(im))
|
| 956 |
+
|
| 957 |
+
for idx, image in enumerate(tqdm(pil_images, desc='Interpolating...', unit='frame', total=num_frames)):
|
| 958 |
+
# Extract deep dream image
|
| 959 |
+
dreamed_image = deep_dream(image, model, model_resolution, layers=layers, channels=channels, seed=None,
|
| 960 |
+
normed=norm_model_layers, disable_inner_tqdm=True, ignore_initial_transform=True,
|
| 961 |
+
sqrt_normed=sqrt_norm_model_layers, iterations=iterations, lr=learning_rate,
|
| 962 |
+
octave_scale=octave_scale, num_octaves=num_octaves, unzoom_octave=unzoom_octave)
|
| 963 |
+
|
| 964 |
+
# Save the resulting image and initial image
|
| 965 |
+
filename = f'{image_noise}-interpolation_frame_{idx:0{n_digits}d}.jpg'
|
| 966 |
+
Image.fromarray(dreamed_image, 'RGB').save(os.path.join(run_dir, filename))
|
| 967 |
+
|
| 968 |
+
# Save the configuration used
|
| 969 |
+
ctx.obj = {
|
| 970 |
+
'network_pkl': network_pkl,
|
| 971 |
+
'synthesis_options': {
|
| 972 |
+
'seeds': seeds,
|
| 973 |
+
'starting_image': starting_image,
|
| 974 |
+
'class_idx': class_idx,
|
| 975 |
+
'learning_rate': learning_rate,
|
| 976 |
+
'iterations': iterations},
|
| 977 |
+
'layer_options': {
|
| 978 |
+
'layer': layers,
|
| 979 |
+
'channels': channels,
|
| 980 |
+
'norm_model_layers': norm_model_layers,
|
| 981 |
+
'sqrt_norm_model_layers': sqrt_norm_model_layers},
|
| 982 |
+
'octaves_options': {
|
| 983 |
+
'octave_scale': octave_scale,
|
| 984 |
+
'num_octaves': num_octaves,
|
| 985 |
+
'unzoom_octave': unzoom_octave},
|
| 986 |
+
'extra_parameters': {
|
| 987 |
+
'outdir': run_dir,
|
| 988 |
+
'description': description}
|
| 989 |
+
}
|
| 990 |
+
# Save the run configuration
|
| 991 |
+
gen_utils.save_config(ctx=ctx, run_dir=run_dir)
|
| 992 |
+
|
| 993 |
+
# Generate video
|
| 994 |
+
print('Saving video...')
|
| 995 |
+
ffmpeg_command = r'/usr/bin/ffmpeg' if os.name != 'nt' else r'C:\\Ffmpeg\\bin\\ffmpeg.exe'
|
| 996 |
+
stream = ffmpeg.input(os.path.join(run_dir, f'{image_noise}-interpolation_frame_%0{n_digits}d.jpg'), framerate=fps)
|
| 997 |
+
stream = ffmpeg.output(stream, os.path.join(run_dir, f'{image_noise}-interpolation.mp4'), crf=20, pix_fmt='yuv420p')
|
| 998 |
+
ffmpeg.run(stream, capture_stdout=True, capture_stderr=True, cmd=ffmpeg_command)
|
| 999 |
+
|
| 1000 |
+
# ----------------------------------------------------------------------------
|
| 1001 |
+
|
| 1002 |
+
|
| 1003 |
+
if __name__ == '__main__':
|
| 1004 |
+
main()
|
| 1005 |
+
|
| 1006 |
+
|
| 1007 |
+
# ----------------------------------------------------------------------------
|
stylegan3-fun/dnnlib/__init__.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
from .util import EasyDict, make_cache_dir_path
|
stylegan3-fun/dnnlib/__pycache__/__init__.cpython-311.pyc
ADDED
|
Binary file (285 Bytes). View file
|
|
|
stylegan3-fun/dnnlib/__pycache__/__init__.cpython-38.pyc
ADDED
|
Binary file (245 Bytes). View file
|
|
|
stylegan3-fun/dnnlib/__pycache__/__init__.cpython-39.pyc
ADDED
|
Binary file (245 Bytes). View file
|
|
|
stylegan3-fun/dnnlib/__pycache__/util.cpython-311.pyc
ADDED
|
Binary file (26.1 kB). View file
|
|
|
stylegan3-fun/dnnlib/__pycache__/util.cpython-38.pyc
ADDED
|
Binary file (14.1 kB). View file
|
|
|
stylegan3-fun/dnnlib/__pycache__/util.cpython-39.pyc
ADDED
|
Binary file (14.1 kB). View file
|
|
|
stylegan3-fun/dnnlib/util.py
ADDED
|
@@ -0,0 +1,491 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Miscellaneous utility classes and functions."""
|
| 10 |
+
|
| 11 |
+
import ctypes
|
| 12 |
+
import fnmatch
|
| 13 |
+
import importlib
|
| 14 |
+
import inspect
|
| 15 |
+
import numpy as np
|
| 16 |
+
import os
|
| 17 |
+
import shutil
|
| 18 |
+
import sys
|
| 19 |
+
import types
|
| 20 |
+
import io
|
| 21 |
+
import pickle
|
| 22 |
+
import re
|
| 23 |
+
import requests
|
| 24 |
+
import html
|
| 25 |
+
import hashlib
|
| 26 |
+
import glob
|
| 27 |
+
import tempfile
|
| 28 |
+
import urllib
|
| 29 |
+
import urllib.request
|
| 30 |
+
import uuid
|
| 31 |
+
|
| 32 |
+
from distutils.util import strtobool
|
| 33 |
+
from typing import Any, List, Tuple, Union
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
# Util classes
|
| 37 |
+
# ------------------------------------------------------------------------------------------
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
class EasyDict(dict):
|
| 41 |
+
"""Convenience class that behaves like a dict but allows access with the attribute syntax."""
|
| 42 |
+
|
| 43 |
+
def __getattr__(self, name: str) -> Any:
|
| 44 |
+
try:
|
| 45 |
+
return self[name]
|
| 46 |
+
except KeyError:
|
| 47 |
+
raise AttributeError(name)
|
| 48 |
+
|
| 49 |
+
def __setattr__(self, name: str, value: Any) -> None:
|
| 50 |
+
self[name] = value
|
| 51 |
+
|
| 52 |
+
def __delattr__(self, name: str) -> None:
|
| 53 |
+
del self[name]
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
class Logger(object):
|
| 57 |
+
"""Redirect stderr to stdout, optionally print stdout to a file, and optionally force flushing on both stdout and the file."""
|
| 58 |
+
|
| 59 |
+
def __init__(self, file_name: str = None, file_mode: str = "w", should_flush: bool = True):
|
| 60 |
+
self.file = None
|
| 61 |
+
|
| 62 |
+
if file_name is not None:
|
| 63 |
+
self.file = open(file_name, file_mode)
|
| 64 |
+
|
| 65 |
+
self.should_flush = should_flush
|
| 66 |
+
self.stdout = sys.stdout
|
| 67 |
+
self.stderr = sys.stderr
|
| 68 |
+
|
| 69 |
+
sys.stdout = self
|
| 70 |
+
sys.stderr = self
|
| 71 |
+
|
| 72 |
+
def __enter__(self) -> "Logger":
|
| 73 |
+
return self
|
| 74 |
+
|
| 75 |
+
def __exit__(self, exc_type: Any, exc_value: Any, traceback: Any) -> None:
|
| 76 |
+
self.close()
|
| 77 |
+
|
| 78 |
+
def write(self, text: Union[str, bytes]) -> None:
|
| 79 |
+
"""Write text to stdout (and a file) and optionally flush."""
|
| 80 |
+
if isinstance(text, bytes):
|
| 81 |
+
text = text.decode()
|
| 82 |
+
if len(text) == 0: # workaround for a bug in VSCode debugger: sys.stdout.write(''); sys.stdout.flush() => crash
|
| 83 |
+
return
|
| 84 |
+
|
| 85 |
+
if self.file is not None:
|
| 86 |
+
self.file.write(text)
|
| 87 |
+
|
| 88 |
+
self.stdout.write(text)
|
| 89 |
+
|
| 90 |
+
if self.should_flush:
|
| 91 |
+
self.flush()
|
| 92 |
+
|
| 93 |
+
def flush(self) -> None:
|
| 94 |
+
"""Flush written text to both stdout and a file, if open."""
|
| 95 |
+
if self.file is not None:
|
| 96 |
+
self.file.flush()
|
| 97 |
+
|
| 98 |
+
self.stdout.flush()
|
| 99 |
+
|
| 100 |
+
def close(self) -> None:
|
| 101 |
+
"""Flush, close possible files, and remove stdout/stderr mirroring."""
|
| 102 |
+
self.flush()
|
| 103 |
+
|
| 104 |
+
# if using multiple loggers, prevent closing in wrong order
|
| 105 |
+
if sys.stdout is self:
|
| 106 |
+
sys.stdout = self.stdout
|
| 107 |
+
if sys.stderr is self:
|
| 108 |
+
sys.stderr = self.stderr
|
| 109 |
+
|
| 110 |
+
if self.file is not None:
|
| 111 |
+
self.file.close()
|
| 112 |
+
self.file = None
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
# Cache directories
|
| 116 |
+
# ------------------------------------------------------------------------------------------
|
| 117 |
+
|
| 118 |
+
_dnnlib_cache_dir = None
|
| 119 |
+
|
| 120 |
+
def set_cache_dir(path: str) -> None:
|
| 121 |
+
global _dnnlib_cache_dir
|
| 122 |
+
_dnnlib_cache_dir = path
|
| 123 |
+
|
| 124 |
+
def make_cache_dir_path(*paths: str) -> str:
|
| 125 |
+
if _dnnlib_cache_dir is not None:
|
| 126 |
+
return os.path.join(_dnnlib_cache_dir, *paths)
|
| 127 |
+
if 'DNNLIB_CACHE_DIR' in os.environ:
|
| 128 |
+
return os.path.join(os.environ['DNNLIB_CACHE_DIR'], *paths)
|
| 129 |
+
if 'HOME' in os.environ:
|
| 130 |
+
return os.path.join(os.environ['HOME'], '.cache', 'dnnlib', *paths)
|
| 131 |
+
if 'USERPROFILE' in os.environ:
|
| 132 |
+
return os.path.join(os.environ['USERPROFILE'], '.cache', 'dnnlib', *paths)
|
| 133 |
+
return os.path.join(tempfile.gettempdir(), '.cache', 'dnnlib', *paths)
|
| 134 |
+
|
| 135 |
+
# Small util functions
|
| 136 |
+
# ------------------------------------------------------------------------------------------
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
def format_time(seconds: Union[int, float]) -> str:
|
| 140 |
+
"""Convert the seconds to human readable string with days, hours, minutes and seconds."""
|
| 141 |
+
s = int(np.rint(seconds))
|
| 142 |
+
|
| 143 |
+
if s < 60:
|
| 144 |
+
return "{0}s".format(s)
|
| 145 |
+
elif s < 60 * 60:
|
| 146 |
+
return "{0}m {1:02}s".format(s // 60, s % 60)
|
| 147 |
+
elif s < 24 * 60 * 60:
|
| 148 |
+
return "{0}h {1:02}m {2:02}s".format(s // (60 * 60), (s // 60) % 60, s % 60)
|
| 149 |
+
else:
|
| 150 |
+
return "{0}d {1:02}h {2:02}m".format(s // (24 * 60 * 60), (s // (60 * 60)) % 24, (s // 60) % 60)
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
def format_time_brief(seconds: Union[int, float]) -> str:
|
| 154 |
+
"""Convert the seconds to human readable string with days, hours, minutes and seconds."""
|
| 155 |
+
s = int(np.rint(seconds))
|
| 156 |
+
|
| 157 |
+
if s < 60:
|
| 158 |
+
return "{0}s".format(s)
|
| 159 |
+
elif s < 60 * 60:
|
| 160 |
+
return "{0}m {1:02}s".format(s // 60, s % 60)
|
| 161 |
+
elif s < 24 * 60 * 60:
|
| 162 |
+
return "{0}h {1:02}m".format(s // (60 * 60), (s // 60) % 60)
|
| 163 |
+
else:
|
| 164 |
+
return "{0}d {1:02}h".format(s // (24 * 60 * 60), (s // (60 * 60)) % 24)
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
def ask_yes_no(question: str) -> bool:
|
| 168 |
+
"""Ask the user the question until the user inputs a valid answer."""
|
| 169 |
+
while True:
|
| 170 |
+
try:
|
| 171 |
+
print("{0} [y/n]".format(question))
|
| 172 |
+
return strtobool(input().lower())
|
| 173 |
+
except ValueError:
|
| 174 |
+
pass
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
def tuple_product(t: Tuple) -> Any:
|
| 178 |
+
"""Calculate the product of the tuple elements."""
|
| 179 |
+
result = 1
|
| 180 |
+
|
| 181 |
+
for v in t:
|
| 182 |
+
result *= v
|
| 183 |
+
|
| 184 |
+
return result
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
_str_to_ctype = {
|
| 188 |
+
"uint8": ctypes.c_ubyte,
|
| 189 |
+
"uint16": ctypes.c_uint16,
|
| 190 |
+
"uint32": ctypes.c_uint32,
|
| 191 |
+
"uint64": ctypes.c_uint64,
|
| 192 |
+
"int8": ctypes.c_byte,
|
| 193 |
+
"int16": ctypes.c_int16,
|
| 194 |
+
"int32": ctypes.c_int32,
|
| 195 |
+
"int64": ctypes.c_int64,
|
| 196 |
+
"float32": ctypes.c_float,
|
| 197 |
+
"float64": ctypes.c_double
|
| 198 |
+
}
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
def get_dtype_and_ctype(type_obj: Any) -> Tuple[np.dtype, Any]:
|
| 202 |
+
"""Given a type name string (or an object having a __name__ attribute), return matching Numpy and ctypes types that have the same size in bytes."""
|
| 203 |
+
type_str = None
|
| 204 |
+
|
| 205 |
+
if isinstance(type_obj, str):
|
| 206 |
+
type_str = type_obj
|
| 207 |
+
elif hasattr(type_obj, "__name__"):
|
| 208 |
+
type_str = type_obj.__name__
|
| 209 |
+
elif hasattr(type_obj, "name"):
|
| 210 |
+
type_str = type_obj.name
|
| 211 |
+
else:
|
| 212 |
+
raise RuntimeError("Cannot infer type name from input")
|
| 213 |
+
|
| 214 |
+
assert type_str in _str_to_ctype.keys()
|
| 215 |
+
|
| 216 |
+
my_dtype = np.dtype(type_str)
|
| 217 |
+
my_ctype = _str_to_ctype[type_str]
|
| 218 |
+
|
| 219 |
+
assert my_dtype.itemsize == ctypes.sizeof(my_ctype)
|
| 220 |
+
|
| 221 |
+
return my_dtype, my_ctype
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
def is_pickleable(obj: Any) -> bool:
|
| 225 |
+
try:
|
| 226 |
+
with io.BytesIO() as stream:
|
| 227 |
+
pickle.dump(obj, stream)
|
| 228 |
+
return True
|
| 229 |
+
except:
|
| 230 |
+
return False
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
# Functionality to import modules/objects by name, and call functions by name
|
| 234 |
+
# ------------------------------------------------------------------------------------------
|
| 235 |
+
|
| 236 |
+
def get_module_from_obj_name(obj_name: str) -> Tuple[types.ModuleType, str]:
|
| 237 |
+
"""Searches for the underlying module behind the name to some python object.
|
| 238 |
+
Returns the module and the object name (original name with module part removed)."""
|
| 239 |
+
|
| 240 |
+
# allow convenience shorthands, substitute them by full names
|
| 241 |
+
obj_name = re.sub("^np.", "numpy.", obj_name)
|
| 242 |
+
obj_name = re.sub("^tf.", "tensorflow.", obj_name)
|
| 243 |
+
|
| 244 |
+
# list alternatives for (module_name, local_obj_name)
|
| 245 |
+
parts = obj_name.split(".")
|
| 246 |
+
name_pairs = [(".".join(parts[:i]), ".".join(parts[i:])) for i in range(len(parts), 0, -1)]
|
| 247 |
+
|
| 248 |
+
# try each alternative in turn
|
| 249 |
+
for module_name, local_obj_name in name_pairs:
|
| 250 |
+
try:
|
| 251 |
+
module = importlib.import_module(module_name) # may raise ImportError
|
| 252 |
+
get_obj_from_module(module, local_obj_name) # may raise AttributeError
|
| 253 |
+
return module, local_obj_name
|
| 254 |
+
except:
|
| 255 |
+
pass
|
| 256 |
+
|
| 257 |
+
# maybe some of the modules themselves contain errors?
|
| 258 |
+
for module_name, _local_obj_name in name_pairs:
|
| 259 |
+
try:
|
| 260 |
+
importlib.import_module(module_name) # may raise ImportError
|
| 261 |
+
except ImportError:
|
| 262 |
+
if not str(sys.exc_info()[1]).startswith("No module named '" + module_name + "'"):
|
| 263 |
+
raise
|
| 264 |
+
|
| 265 |
+
# maybe the requested attribute is missing?
|
| 266 |
+
for module_name, local_obj_name in name_pairs:
|
| 267 |
+
try:
|
| 268 |
+
module = importlib.import_module(module_name) # may raise ImportError
|
| 269 |
+
get_obj_from_module(module, local_obj_name) # may raise AttributeError
|
| 270 |
+
except ImportError:
|
| 271 |
+
pass
|
| 272 |
+
|
| 273 |
+
# we are out of luck, but we have no idea why
|
| 274 |
+
raise ImportError(obj_name)
|
| 275 |
+
|
| 276 |
+
|
| 277 |
+
def get_obj_from_module(module: types.ModuleType, obj_name: str) -> Any:
|
| 278 |
+
"""Traverses the object name and returns the last (rightmost) python object."""
|
| 279 |
+
if obj_name == '':
|
| 280 |
+
return module
|
| 281 |
+
obj = module
|
| 282 |
+
for part in obj_name.split("."):
|
| 283 |
+
obj = getattr(obj, part)
|
| 284 |
+
return obj
|
| 285 |
+
|
| 286 |
+
|
| 287 |
+
def get_obj_by_name(name: str) -> Any:
|
| 288 |
+
"""Finds the python object with the given name."""
|
| 289 |
+
module, obj_name = get_module_from_obj_name(name)
|
| 290 |
+
return get_obj_from_module(module, obj_name)
|
| 291 |
+
|
| 292 |
+
|
| 293 |
+
def call_func_by_name(*args, func_name: str = None, **kwargs) -> Any:
|
| 294 |
+
"""Finds the python object with the given name and calls it as a function."""
|
| 295 |
+
assert func_name is not None
|
| 296 |
+
func_obj = get_obj_by_name(func_name)
|
| 297 |
+
assert callable(func_obj)
|
| 298 |
+
return func_obj(*args, **kwargs)
|
| 299 |
+
|
| 300 |
+
|
| 301 |
+
def construct_class_by_name(*args, class_name: str = None, **kwargs) -> Any:
|
| 302 |
+
"""Finds the python class with the given name and constructs it with the given arguments."""
|
| 303 |
+
return call_func_by_name(*args, func_name=class_name, **kwargs)
|
| 304 |
+
|
| 305 |
+
|
| 306 |
+
def get_module_dir_by_obj_name(obj_name: str) -> str:
|
| 307 |
+
"""Get the directory path of the module containing the given object name."""
|
| 308 |
+
module, _ = get_module_from_obj_name(obj_name)
|
| 309 |
+
return os.path.dirname(inspect.getfile(module))
|
| 310 |
+
|
| 311 |
+
|
| 312 |
+
def is_top_level_function(obj: Any) -> bool:
|
| 313 |
+
"""Determine whether the given object is a top-level function, i.e., defined at module scope using 'def'."""
|
| 314 |
+
return callable(obj) and obj.__name__ in sys.modules[obj.__module__].__dict__
|
| 315 |
+
|
| 316 |
+
|
| 317 |
+
def get_top_level_function_name(obj: Any) -> str:
|
| 318 |
+
"""Return the fully-qualified name of a top-level function."""
|
| 319 |
+
assert is_top_level_function(obj)
|
| 320 |
+
module = obj.__module__
|
| 321 |
+
if module == '__main__':
|
| 322 |
+
module = os.path.splitext(os.path.basename(sys.modules[module].__file__))[0]
|
| 323 |
+
return module + "." + obj.__name__
|
| 324 |
+
|
| 325 |
+
|
| 326 |
+
# File system helpers
|
| 327 |
+
# ------------------------------------------------------------------------------------------
|
| 328 |
+
|
| 329 |
+
def list_dir_recursively_with_ignore(dir_path: str, ignores: List[str] = None, add_base_to_relative: bool = False) -> List[Tuple[str, str]]:
|
| 330 |
+
"""List all files recursively in a given directory while ignoring given file and directory names.
|
| 331 |
+
Returns list of tuples containing both absolute and relative paths."""
|
| 332 |
+
assert os.path.isdir(dir_path)
|
| 333 |
+
base_name = os.path.basename(os.path.normpath(dir_path))
|
| 334 |
+
|
| 335 |
+
if ignores is None:
|
| 336 |
+
ignores = []
|
| 337 |
+
|
| 338 |
+
result = []
|
| 339 |
+
|
| 340 |
+
for root, dirs, files in os.walk(dir_path, topdown=True):
|
| 341 |
+
for ignore_ in ignores:
|
| 342 |
+
dirs_to_remove = [d for d in dirs if fnmatch.fnmatch(d, ignore_)]
|
| 343 |
+
|
| 344 |
+
# dirs need to be edited in-place
|
| 345 |
+
for d in dirs_to_remove:
|
| 346 |
+
dirs.remove(d)
|
| 347 |
+
|
| 348 |
+
files = [f for f in files if not fnmatch.fnmatch(f, ignore_)]
|
| 349 |
+
|
| 350 |
+
absolute_paths = [os.path.join(root, f) for f in files]
|
| 351 |
+
relative_paths = [os.path.relpath(p, dir_path) for p in absolute_paths]
|
| 352 |
+
|
| 353 |
+
if add_base_to_relative:
|
| 354 |
+
relative_paths = [os.path.join(base_name, p) for p in relative_paths]
|
| 355 |
+
|
| 356 |
+
assert len(absolute_paths) == len(relative_paths)
|
| 357 |
+
result += zip(absolute_paths, relative_paths)
|
| 358 |
+
|
| 359 |
+
return result
|
| 360 |
+
|
| 361 |
+
|
| 362 |
+
def copy_files_and_create_dirs(files: List[Tuple[str, str]]) -> None:
|
| 363 |
+
"""Takes in a list of tuples of (src, dst) paths and copies files.
|
| 364 |
+
Will create all necessary directories."""
|
| 365 |
+
for file in files:
|
| 366 |
+
target_dir_name = os.path.dirname(file[1])
|
| 367 |
+
|
| 368 |
+
# will create all intermediate-level directories
|
| 369 |
+
if not os.path.exists(target_dir_name):
|
| 370 |
+
os.makedirs(target_dir_name)
|
| 371 |
+
|
| 372 |
+
shutil.copyfile(file[0], file[1])
|
| 373 |
+
|
| 374 |
+
|
| 375 |
+
# URL helpers
|
| 376 |
+
# ------------------------------------------------------------------------------------------
|
| 377 |
+
|
| 378 |
+
def is_url(obj: Any, allow_file_urls: bool = False) -> bool:
|
| 379 |
+
"""Determine whether the given object is a valid URL string."""
|
| 380 |
+
if not isinstance(obj, str) or not "://" in obj:
|
| 381 |
+
return False
|
| 382 |
+
if allow_file_urls and obj.startswith('file://'):
|
| 383 |
+
return True
|
| 384 |
+
try:
|
| 385 |
+
res = requests.compat.urlparse(obj)
|
| 386 |
+
if not res.scheme or not res.netloc or not "." in res.netloc:
|
| 387 |
+
return False
|
| 388 |
+
res = requests.compat.urlparse(requests.compat.urljoin(obj, "/"))
|
| 389 |
+
if not res.scheme or not res.netloc or not "." in res.netloc:
|
| 390 |
+
return False
|
| 391 |
+
except:
|
| 392 |
+
return False
|
| 393 |
+
return True
|
| 394 |
+
|
| 395 |
+
|
| 396 |
+
def open_url(url: str, cache_dir: str = None, num_attempts: int = 10, verbose: bool = True, return_filename: bool = False, cache: bool = True) -> Any:
|
| 397 |
+
"""Download the given URL and return a binary-mode file object to access the data."""
|
| 398 |
+
assert num_attempts >= 1
|
| 399 |
+
assert not (return_filename and (not cache))
|
| 400 |
+
|
| 401 |
+
# Doesn't look like an URL scheme so interpret it as a local filename.
|
| 402 |
+
if not re.match('^[a-z]+://', url):
|
| 403 |
+
return url if return_filename else open(url, "rb")
|
| 404 |
+
|
| 405 |
+
# Handle file URLs. This code handles unusual file:// patterns that
|
| 406 |
+
# arise on Windows:
|
| 407 |
+
#
|
| 408 |
+
# file:///c:/foo.txt
|
| 409 |
+
#
|
| 410 |
+
# which would translate to a local '/c:/foo.txt' filename that's
|
| 411 |
+
# invalid. Drop the forward slash for such pathnames.
|
| 412 |
+
#
|
| 413 |
+
# If you touch this code path, you should test it on both Linux and
|
| 414 |
+
# Windows.
|
| 415 |
+
#
|
| 416 |
+
# Some internet resources suggest using urllib.request.url2pathname() but
|
| 417 |
+
# but that converts forward slashes to backslashes and this causes
|
| 418 |
+
# its own set of problems.
|
| 419 |
+
if url.startswith('file://'):
|
| 420 |
+
filename = urllib.parse.urlparse(url).path
|
| 421 |
+
if re.match(r'^/[a-zA-Z]:', filename):
|
| 422 |
+
filename = filename[1:]
|
| 423 |
+
return filename if return_filename else open(filename, "rb")
|
| 424 |
+
|
| 425 |
+
assert is_url(url)
|
| 426 |
+
|
| 427 |
+
# Lookup from cache.
|
| 428 |
+
if cache_dir is None:
|
| 429 |
+
cache_dir = make_cache_dir_path('downloads')
|
| 430 |
+
|
| 431 |
+
url_md5 = hashlib.md5(url.encode("utf-8")).hexdigest()
|
| 432 |
+
if cache:
|
| 433 |
+
cache_files = glob.glob(os.path.join(cache_dir, url_md5 + "_*"))
|
| 434 |
+
if len(cache_files) == 1:
|
| 435 |
+
filename = cache_files[0]
|
| 436 |
+
return filename if return_filename else open(filename, "rb")
|
| 437 |
+
|
| 438 |
+
# Download.
|
| 439 |
+
url_name = None
|
| 440 |
+
url_data = None
|
| 441 |
+
with requests.Session() as session:
|
| 442 |
+
if verbose:
|
| 443 |
+
print("Downloading %s ..." % url, end="", flush=True)
|
| 444 |
+
for attempts_left in reversed(range(num_attempts)):
|
| 445 |
+
try:
|
| 446 |
+
with session.get(url) as res:
|
| 447 |
+
res.raise_for_status()
|
| 448 |
+
if len(res.content) == 0:
|
| 449 |
+
raise IOError("No data received")
|
| 450 |
+
|
| 451 |
+
if len(res.content) < 8192:
|
| 452 |
+
content_str = res.content.decode("utf-8")
|
| 453 |
+
if "download_warning" in res.headers.get("Set-Cookie", ""):
|
| 454 |
+
links = [html.unescape(link) for link in content_str.split('"') if "export=download" in link]
|
| 455 |
+
if len(links) == 1:
|
| 456 |
+
url = requests.compat.urljoin(url, links[0])
|
| 457 |
+
raise IOError("Google Drive virus checker nag")
|
| 458 |
+
if "Google Drive - Quota exceeded" in content_str:
|
| 459 |
+
raise IOError("Google Drive download quota exceeded -- please try again later")
|
| 460 |
+
|
| 461 |
+
match = re.search(r'filename="([^"]*)"', res.headers.get("Content-Disposition", ""))
|
| 462 |
+
url_name = match[1] if match else url
|
| 463 |
+
url_data = res.content
|
| 464 |
+
if verbose:
|
| 465 |
+
print(" done")
|
| 466 |
+
break
|
| 467 |
+
except KeyboardInterrupt:
|
| 468 |
+
raise
|
| 469 |
+
except:
|
| 470 |
+
if not attempts_left:
|
| 471 |
+
if verbose:
|
| 472 |
+
print(" failed")
|
| 473 |
+
raise
|
| 474 |
+
if verbose:
|
| 475 |
+
print(".", end="", flush=True)
|
| 476 |
+
|
| 477 |
+
# Save to cache.
|
| 478 |
+
if cache:
|
| 479 |
+
safe_name = re.sub(r"[^0-9a-zA-Z-._]", "_", url_name)
|
| 480 |
+
cache_file = os.path.join(cache_dir, url_md5 + "_" + safe_name)
|
| 481 |
+
temp_file = os.path.join(cache_dir, "tmp_" + uuid.uuid4().hex + "_" + url_md5 + "_" + safe_name)
|
| 482 |
+
os.makedirs(cache_dir, exist_ok=True)
|
| 483 |
+
with open(temp_file, "wb") as f:
|
| 484 |
+
f.write(url_data)
|
| 485 |
+
os.replace(temp_file, cache_file) # atomic
|
| 486 |
+
if return_filename:
|
| 487 |
+
return cache_file
|
| 488 |
+
|
| 489 |
+
# Return data as file object.
|
| 490 |
+
assert not return_filename
|
| 491 |
+
return io.BytesIO(url_data)
|
stylegan3-fun/docs/avg_spectra_screen0.png
ADDED
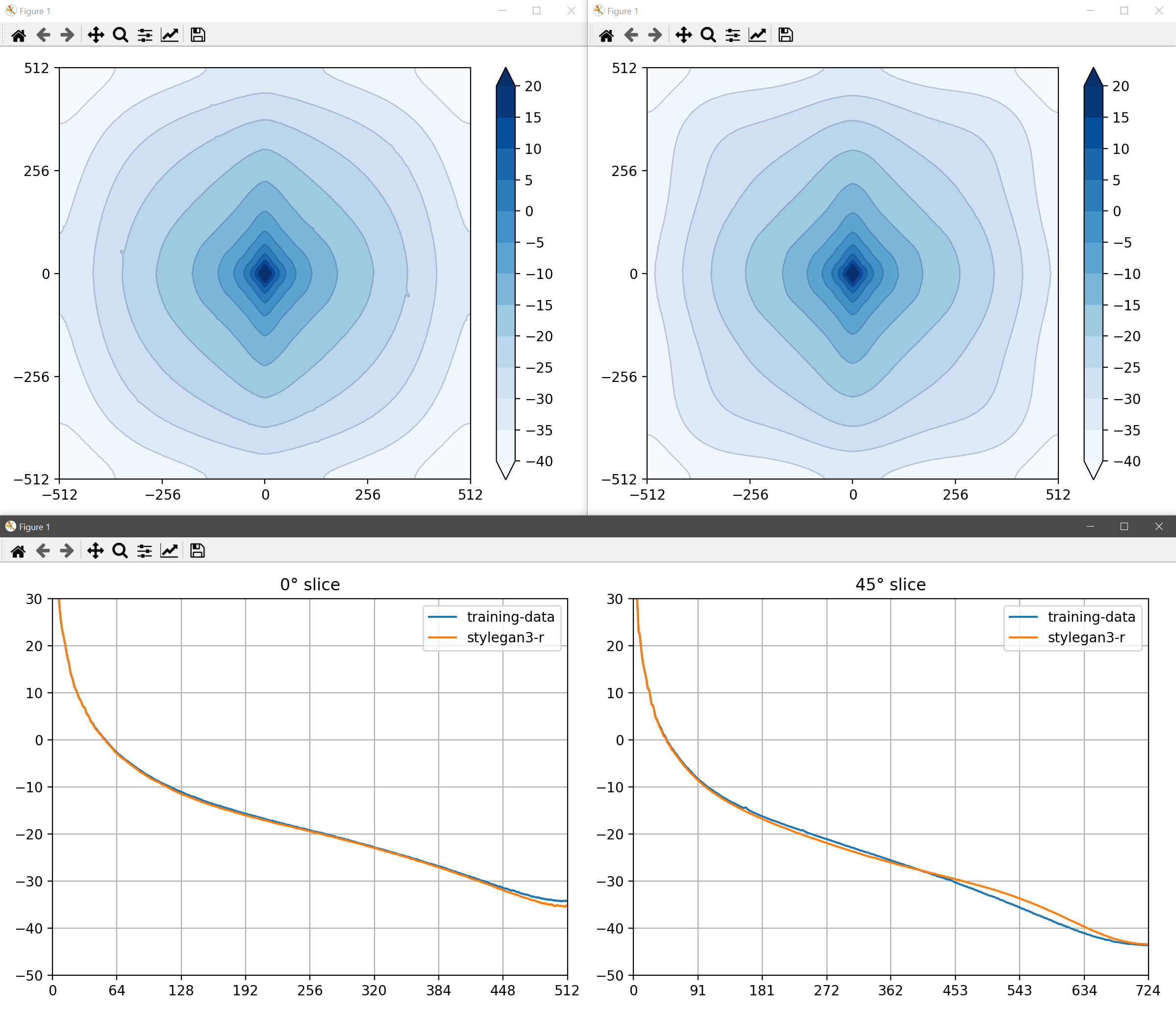
|
stylegan3-fun/docs/avg_spectra_screen0_half.png
ADDED

|
stylegan3-fun/docs/configs.md
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Training configurations
|
| 2 |
+
|
| 3 |
+
This document provides guidelines for selecting appropriate training options for various scenarios, as well as an extensive list of recommended configurations.
|
| 4 |
+
|
| 5 |
+
#### Example
|
| 6 |
+
|
| 7 |
+
In the remainder of this document, we summarize each configuration as follows:
|
| 8 |
+
|
| 9 |
+
| <sub>Config</sub><br><br> | <sub>s/kimg</sub><br><sup>(V100)</sup> | <sub>s/kimg</sub><br><sup>(A100)</sup> | <sub>GPU</sub><br><sup>mem</sup> | <sub>Options</sub><br><br>
|
| 10 |
+
| :--------------------------- | :--------------: | :--------------: | :------------: | :--
|
| 11 |
+
| <sub>StyleGAN3‑T</sub> | <sub>18.47</sub> | <sub>12.29</sub> | <sub>4.3</sub> | <sub>`--cfg=stylegan3-t --gpus=8 --batch=32 --gamma=8.2 --mirror=1`</sub>
|
| 12 |
+
|
| 13 |
+
This corresponds to the following command line:
|
| 14 |
+
|
| 15 |
+
```.bash
|
| 16 |
+
# Train StyleGAN3-T for AFHQv2 using 8 GPUs.
|
| 17 |
+
python train.py --outdir=~/training-runs --cfg=stylegan3-t --data=~/datasets/afhqv2-512x512.zip \
|
| 18 |
+
--gpus=8 --batch=32 --gamma=8.2 --mirror=1
|
| 19 |
+
```
|
| 20 |
+
|
| 21 |
+
Explanation of the columns:
|
| 22 |
+
- **Config**: StyleGAN3-T (translation equiv.), StyleGAN3-R (translation and rotation equiv.), or StyleGAN2. Reflects the value of `--cfg`.
|
| 23 |
+
- **s/kimg**: Raw training speed, measured separately on Tesla V100 and A100 using our recommended Docker image. The number indicates how many seconds, on average, it takes to process 1000 images from the training set. The number tends to vary slightly over the course of training; typically by no more than ±20%.
|
| 24 |
+
- **GPU mem**: Maximum GPU memory usage observed during training, reported in gigabytes per GPU. The above example uses 8 GPUs, which means that the total GPU memory usage is around 34.4 GB.
|
| 25 |
+
- **Options**: Command line options for `train.py`, excluding `--outdir` and `--data`.
|
| 26 |
+
|
| 27 |
+
#### Total training time
|
| 28 |
+
|
| 29 |
+
In addition the raw s/kimg number, the training time also depends on the `--kimg` and `--metric` options. `--kimg` controls the total number of training iterations and is set to 25000 by default. This is long enough to reach convergence in typical cases, but in practice the results should already look quite reasonable around 5000 kimg. `--metrics` determines which quality metrics are computed periodically during training. The default is `fid50k_full`, which increases the training time slightly; typically by no more than 5%. The automatic computation can be disabled by specifying `--metrics=none`.
|
| 30 |
+
|
| 31 |
+
In the above example, the total training time on V100 is approximately 18.47 s/kimg * 25000 kimg * 1.05 ≈ 485,000 seconds ≈ 5 days and 14 hours. Disabling metric computation (`--metrics=none`) reduces this to approximately 5 days and 8 hours.
|
| 32 |
+
|
| 33 |
+
## General guidelines
|
| 34 |
+
|
| 35 |
+
The most important hyperparameter that needs to be tuned on a per-dataset basis is the R<sub>1</sub> regularization weight, `--gamma`, that must be specified explicitly for `train.py`. As a rule of thumb, the value of `--gamma` scales quadratically with respect to the training set resolution: doubling the resolution (e.g., 256x256 → 512x512) means that `--gamma` should be multiplied by 4 (e.g., 2 → 8). The optimal value is usually the same for `--cfg=stylegan3-t` and `--cfg=stylegan3-r`, but considerably lower for `--cfg=stylegan2`.
|
| 36 |
+
|
| 37 |
+
In practice, we recommend selecting the value of `--gamma` as follows:
|
| 38 |
+
- Find the closest match for your specific case in this document (config, resolution, and GPU count).
|
| 39 |
+
- Try training with the same `--gamma` first.
|
| 40 |
+
- Then, try increasing the value by 2x and 4x, and also decreasing it by 2x and 4x.
|
| 41 |
+
- Pick the value that yields the lowest FID.
|
| 42 |
+
|
| 43 |
+
The results may also be improved by adjusting `--mirror` and `--aug`, depending on the training data. Specifying `--mirror=1` augments the dataset with random *x*-flips, which effectively doubles the number of images. This is generally beneficial with datasets that are horizontally symmetric (e.g., FFHQ), but it can be harmful if the images contain noticeable asymmetric features (e.g., text or letters). Specifying `--aug=noaug` disables adaptive discriminator augmentation (ADA), which may improve the results slightly if the training set is large enough (at least 100k images when accounting for *x*-flips). With small datasets (less than 30k images), it is generally a good idea to leave the augmentations enabled.
|
| 44 |
+
|
| 45 |
+
It is possible to speed up the training by decreasing network capacity, i.e., `--cbase=16384`. This typically leads to lower quality results, but the difference is less pronounced with low-resolution datasets (e.g., 256x256).
|
| 46 |
+
|
| 47 |
+
#### Scaling to different number of GPUs
|
| 48 |
+
|
| 49 |
+
You can select the number of GPUs by changing the value of `--gpu`; this does not affect the convergence curves or training dynamics in any way. By default, the total batch size (`--batch`) is divided evenly among the GPUs, which means that decreasing the number of GPUs yields higher per-GPU memory usage. To avoid running out of memory, you can decrease the per-GPU batch size by specifying `--batch-gpu`, which performs the same computation in multiple passes using gradient accumulation.
|
| 50 |
+
|
| 51 |
+
By default, `train.py` exports network snapshots once every 200 kimg, i.e., the product of `--snap=50` and `--tick=4`. When using few GPUs (e.g., 1–2), this means that it may take a very long time for the first snapshot to appear. We recommend increasing the snapshot frequency in such cases by specifying `--snap=20`, `--snap=10`, or `--snap=5`.
|
| 52 |
+
|
| 53 |
+
Note that the configurations listed in this document have been specifically tuned for 8 GPUs. The safest way to scale them to different GPU counts is to adjust `--gpu`, `--batch-gpu`, and `--snap` as described above, but it may be possible to reach faster convergence by adjusting some of the other hyperparameters as well. Note, however, that adjusting the total batch size (`--batch`) requires some experimentation; decreasing `--batch` usually necessitates increasing regularization (`--gamma`) and/or decreasing the learning rates (most importantly `--dlr`).
|
| 54 |
+
|
| 55 |
+
#### Transfer learning
|
| 56 |
+
|
| 57 |
+
Transfer learning makes it possible to reach very good results very quickly, especially when the training set is small and/or the images resemble the ones produced by a pre-trained model. To enable transfer learning, you can point `--resume` to one of the pre-trained models that we provide for [StyleGAN3](https://ngc.nvidia.com/catalog/models/nvidia:research:stylegan3) and [StyleGAN2](https://ngc.nvidia.com/catalog/models/nvidia:research:stylegan2). For example:
|
| 58 |
+
|
| 59 |
+
```.bash
|
| 60 |
+
# Fine-tune StyleGAN3-R for MetFaces-U using 1 GPU, starting from the pre-trained FFHQ-U pickle.
|
| 61 |
+
python train.py --outdir=~/training-runs --cfg=stylegan3-r --data=~/datasets/metfacesu-1024x1024.zip \
|
| 62 |
+
--gpus=8 --batch=32 --gamma=6.6 --mirror=1 --kimg=5000 --snap=5 \
|
| 63 |
+
--resume=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-r-ffhqu-1024x1024.pkl
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
The pre-trained model should be selected to match the specified config, resolution, and architecture-related hyperparameters (e.g., `--cbase`, `--map-depth`, and `--mbstd-group`). You check this by looking at the `fakes_init.png` exported by `train.py` at the beginning; if the configuration is correct, the images should look reasonable.
|
| 67 |
+
|
| 68 |
+
With transfer learning, the results may be improved slightly by adjusting `--freezed`, in addition to the above guidelines for `--gamma`, `--mirror`, and `--aug`. In our experience, `--freezed=10` and `--freezed=13` tend to work reasonably well.
|
| 69 |
+
|
| 70 |
+
## Recommended configurations
|
| 71 |
+
|
| 72 |
+
This section lists recommended settings for StyleGAN3-T and StyleGAN3-R for different resolutions and GPU counts, selected according to the above guidelines. These are intended to provide a good starting point when experimenting with a new dataset. Please note that many of the options (e.g., `--gamma`, `--mirror`, and `--aug`) are still worth adjusting on a case-by-case basis.
|
| 73 |
+
|
| 74 |
+
#### 128x128 resolution
|
| 75 |
+
|
| 76 |
+
| <sub>Config</sub><br><br> | <sub>GPUs</sub><br><br> | <sub>s/kimg</sub><br><sup>(V100)</sup> | <sub>s/kimg</sub><br><sup>(A100)</sup> | <sub>GPU</sub><br><sup>mem</sup> | <sub>Options</sub><br><br>
|
| 77 |
+
| :--------------------------- | :----------: | :--------------: | :--------------: | :------------: | :--
|
| 78 |
+
| <sub>StyleGAN3‑T</sub> | <sub>1</sub> | <sub>73.68</sub> | <sub>27.20</sub> | <sub>7.2</sub> | <sub>`--cfg=stylegan3-t --gpus=1 --batch=32 --gamma=0.5 --batch-gpu=16 --snap=10`</sub>
|
| 79 |
+
| <sub>StyleGAN3‑T</sub> | <sub>2</sub> | <sub>37.30</sub> | <sub>13.74</sub> | <sub>7.1</sub> | <sub>`--cfg=stylegan3-t --gpus=2 --batch=32 --gamma=0.5 --snap=20`</sub>
|
| 80 |
+
| <sub>StyleGAN3‑T</sub> | <sub>4</sub> | <sub>20.66</sub> | <sub>7.52</sub> | <sub>4.1</sub> | <sub>`--cfg=stylegan3-t --gpus=4 --batch=32 --gamma=0.5`</sub>
|
| 81 |
+
| <sub>StyleGAN3‑T</sub> | <sub>8</sub> | <sub>11.31</sub> | <sub>4.40</sub> | <sub>2.6</sub> | <sub>`--cfg=stylegan3-t --gpus=8 --batch=32 --gamma=0.5`</sub>
|
| 82 |
+
| <sub>StyleGAN3‑R</sub> | <sub>1</sub> | <sub>58.44</sub> | <sub>34.23</sub> | <sub>8.3</sub> | <sub>`--cfg=stylegan3-r --gpus=1 --batch=32 --gamma=0.5 --batch-gpu=16 --snap=10`</sub>
|
| 83 |
+
| <sub>StyleGAN3‑R</sub> | <sub>2</sub> | <sub>29.92</sub> | <sub>17.29</sub> | <sub>8.2</sub> | <sub>`--cfg=stylegan3-r --gpus=2 --batch=32 --gamma=0.5 --snap=20`</sub>
|
| 84 |
+
| <sub>StyleGAN3‑R</sub> | <sub>4</sub> | <sub>15.49</sub> | <sub>9.53</sub> | <sub>4.5</sub> | <sub>`--cfg=stylegan3-r --gpus=4 --batch=32 --gamma=0.5`</sub>
|
| 85 |
+
| <sub>StyleGAN3‑R</sub> | <sub>8</sub> | <sub>8.43</sub> | <sub>5.69</sub> | <sub>2.7</sub> | <sub>`--cfg=stylegan3-r --gpus=8 --batch=32 --gamma=0.5`</sub>
|
| 86 |
+
|
| 87 |
+
#### 256x256 resolution
|
| 88 |
+
|
| 89 |
+
| <sub>Config</sub><br><br> | <sub>GPUs</sub><br><br> | <sub>s/kimg</sub><br><sup>(V100)</sup> | <sub>s/kimg</sub><br><sup>(A100)</sup> | <sub>GPU</sub><br><sup>mem</sup> | <sub>Options</sub><br><br>
|
| 90 |
+
| :--------------------------- | :----------: | :--------------: | :--------------: | :------------: | :--
|
| 91 |
+
| <sub>StyleGAN3‑T</sub> | <sub>1</sub> | <sub>89.15</sub> | <sub>49.81</sub> | <sub>9.5</sub> | <sub>`--cfg=stylegan3-t --gpus=1 --batch=32 --gamma=2 --batch-gpu=16 --snap=10`</sub>
|
| 92 |
+
| <sub>StyleGAN3‑T</sub> | <sub>2</sub> | <sub>45.45</sub> | <sub>25.05</sub> | <sub>9.3</sub> | <sub>`--cfg=stylegan3-t --gpus=2 --batch=32 --gamma=2 --snap=20`</sub>
|
| 93 |
+
| <sub>StyleGAN3‑T</sub> | <sub>4</sub> | <sub>23.94</sub> | <sub>13.26</sub> | <sub>5.2</sub> | <sub>`--cfg=stylegan3-t --gpus=4 --batch=32 --gamma=2`</sub>
|
| 94 |
+
| <sub>StyleGAN3‑T</sub> | <sub>8</sub> | <sub>13.04</sub> | <sub>7.32</sub> | <sub>3.1</sub> | <sub>`--cfg=stylegan3-t --gpus=8 --batch=32 --gamma=2`</sub>
|
| 95 |
+
| <sub>StyleGAN3‑R</sub> | <sub>1</sub> | <sub>87.37</sub> | <sub>56.73</sub> | <sub>6.7</sub> | <sub>`--cfg=stylegan3-r --gpus=1 --batch=32 --gamma=2 --batch-gpu=8 --snap=10`</sub>
|
| 96 |
+
| <sub>StyleGAN3‑R</sub> | <sub>2</sub> | <sub>44.12</sub> | <sub>28.60</sub> | <sub>6.7</sub> | <sub>`--cfg=stylegan3-r --gpus=2 --batch=32 --gamma=2 --batch-gpu=8 --snap=20`</sub>
|
| 97 |
+
| <sub>StyleGAN3‑R</sub> | <sub>4</sub> | <sub>22.42</sub> | <sub>14.39</sub> | <sub>6.6</sub> | <sub>`--cfg=stylegan3-r --gpus=4 --batch=32 --gamma=2`</sub>
|
| 98 |
+
| <sub>StyleGAN3‑R</sub> | <sub>8</sub> | <sub>11.88</sub> | <sub>8.03</sub> | <sub>3.7</sub> | <sub>`--cfg=stylegan3-r --gpus=8 --batch=32 --gamma=2`</sub>
|
| 99 |
+
|
| 100 |
+
#### 512x512 resolution
|
| 101 |
+
|
| 102 |
+
| <sub>Config</sub><br><br> | <sub>GPUs</sub><br><br> | <sub>s/kimg</sub><br><sup>(V100)</sup> | <sub>s/kimg</sub><br><sup>(A100)</sup> | <sub>GPU</sub><br><sup>mem</sup> | <sub>Options</sub><br><br>
|
| 103 |
+
| :--------------------------- | :----------: | :---------------: | :---------------: | :------------: | :--
|
| 104 |
+
| <sub>StyleGAN3‑T</sub> | <sub>1</sub> | <sub>137.33</sub> | <sub>90.25</sub> | <sub>7.8</sub> | <sub>`--cfg=stylegan3-t --gpus=1 --batch=32 --gamma=8 --batch-gpu=8 --snap=10`</sub>
|
| 105 |
+
| <sub>StyleGAN3‑T</sub> | <sub>2</sub> | <sub>69.65</sub> | <sub>45.42</sub> | <sub>7.7</sub> | <sub>`--cfg=stylegan3-t --gpus=2 --batch=32 --gamma=8 --batch-gpu=8 --snap=20`</sub>
|
| 106 |
+
| <sub>StyleGAN3‑T</sub> | <sub>4</sub> | <sub>34.88</sub> | <sub>22.81</sub> | <sub>7.6</sub> | <sub>`--cfg=stylegan3-t --gpus=4 --batch=32 --gamma=8`</sub>
|
| 107 |
+
| <sub>StyleGAN3‑T</sub> | <sub>8</sub> | <sub>18.47</sub> | <sub>12.29</sub> | <sub>4.3</sub> | <sub>`--cfg=stylegan3-t --gpus=8 --batch=32 --gamma=8`</sub>
|
| 108 |
+
| <sub>StyleGAN3‑R</sub> | <sub>1</sub> | <sub>158.91</sub> | <sub>110.13</sub> | <sub>6.0</sub> | <sub>`--cfg=stylegan3-r --gpus=1 --batch=32 --gamma=8 --batch-gpu=4 --snap=10`</sub>
|
| 109 |
+
| <sub>StyleGAN3‑R</sub> | <sub>2</sub> | <sub>79.96</sub> | <sub>55.18</sub> | <sub>6.0</sub> | <sub>`--cfg=stylegan3-r --gpus=2 --batch=32 --gamma=8 --batch-gpu=4 --snap=20`</sub>
|
| 110 |
+
| <sub>StyleGAN3‑R</sub> | <sub>4</sub> | <sub>40.86</sub> | <sub>27.99</sub> | <sub>5.9</sub> | <sub>`--cfg=stylegan3-r --gpus=4 --batch=32 --gamma=8 --batch-gpu=4`</sub>
|
| 111 |
+
| <sub>StyleGAN3‑R</sub> | <sub>8</sub> | <sub>20.44</sub> | <sub>14.04</sub> | <sub>5.9</sub> | <sub>`--cfg=stylegan3-r --gpus=8 --batch=32 --gamma=8`</sub>
|
| 112 |
+
|
| 113 |
+
#### 1024x1024 resolution
|
| 114 |
+
|
| 115 |
+
| <sub>Config</sub><br><br> | <sub>GPUs</sub><br><br> | <sub>s/kimg</sub><br><sup>(V100)</sup> | <sub>s/kimg</sub><br><sup>(A100)</sup> | <sub>GPU</sub><br><sup>mem</sup> | <sub>Options</sub><br><br>
|
| 116 |
+
| :--------------------------- | :----------: | :---------------: | :---------------: | :-------------: | :--
|
| 117 |
+
| <sub>StyleGAN3‑T</sub> | <sub>1</sub> | <sub>221.85</sub> | <sub>156.91</sub> | <sub>7.0</sub> | <sub>`--cfg=stylegan3-t --gpus=1 --batch=32 --gamma=32 --batch-gpu=4 --snap=5`</sub>
|
| 118 |
+
| <sub>StyleGAN3‑T</sub> | <sub>2</sub> | <sub>113.44</sub> | <sub>79.16</sub> | <sub>6.8</sub> | <sub>`--cfg=stylegan3-t --gpus=2 --batch=32 --gamma=32 --batch-gpu=4 --snap=10`</sub>
|
| 119 |
+
| <sub>StyleGAN3‑T</sub> | <sub>4</sub> | <sub>57.04</sub> | <sub>39.62</sub> | <sub>6.7</sub> | <sub>`--cfg=stylegan3-t --gpus=4 --batch=32 --gamma=32 --batch-gpu=4 --snap=20`</sub>
|
| 120 |
+
| <sub>StyleGAN3‑T</sub> | <sub>8</sub> | <sub>28.71</sub> | <sub>20.01</sub> | <sub>6.6</sub> | <sub>`--cfg=stylegan3-t --gpus=8 --batch=32 --gamma=32`</sub>
|
| 121 |
+
| <sub>StyleGAN3‑R</sub> | <sub>1</sub> | <sub>263.44</sub> | <sub>184.81</sub> | <sub>10.2</sub> | <sub>`--cfg=stylegan3-r --gpus=1 --batch=32 --gamma=32 --batch-gpu=4 --snap=5`</sub>
|
| 122 |
+
| <sub>StyleGAN3‑R</sub> | <sub>2</sub> | <sub>134.22</sub> | <sub>92.58</sub> | <sub>10.1</sub> | <sub>`--cfg=stylegan3-r --gpus=2 --batch=32 --gamma=32 --batch-gpu=4 --snap=10`</sub>
|
| 123 |
+
| <sub>StyleGAN3‑R</sub> | <sub>4</sub> | <sub>67.33</sub> | <sub>46.53</sub> | <sub>10.0</sub> | <sub>`--cfg=stylegan3-r --gpus=4 --batch=32 --gamma=32 --batch-gpu=4 --snap=20`</sub>
|
| 124 |
+
| <sub>StyleGAN3‑R</sub> | <sub>8</sub> | <sub>34.12</sub> | <sub>23.42</sub> | <sub>9.9</sub> | <sub>`--cfg=stylegan3-r --gpus=8 --batch=32 --gamma=32`</sub>
|
| 125 |
+
|
| 126 |
+
## Configurations used in StyleGAN3 paper
|
| 127 |
+
|
| 128 |
+
This section lists the exact settings that we used in the "Alias-Free Generative Adversarial Networks" paper.
|
| 129 |
+
|
| 130 |
+
#### FFHQ-U and FFHQ at 1024x1024 resolution
|
| 131 |
+
|
| 132 |
+
| <sub>Config</sub><br><br> | <sub>s/kimg</sub><br><sup>(V100)</sup> | <sub>s/kimg</sub><br><sup>(A100)</sup> | <sub>GPU</sub><br><sup>mem</sup> | <sub>Options</sub><br><br>
|
| 133 |
+
| :--------------------------- | :--------------: | :--------------: | :------------: | :--
|
| 134 |
+
| <sub>StyleGAN2</sub> | <sub>17.55</sub> | <sub>14.57</sub> | <sub>6.2</sub> | <sub>`--cfg=stylegan2 --gpus=8 --batch=32 --gamma=10 --mirror=1 --aug=noaug`</sub>
|
| 135 |
+
| <sub>StyleGAN3‑T</sub> | <sub>28.71</sub> | <sub>20.01</sub> | <sub>6.6</sub> | <sub>`--cfg=stylegan3-t --gpus=8 --batch=32 --gamma=32.8 --mirror=1 --aug=noaug`</sub>
|
| 136 |
+
| <sub>StyleGAN3‑R</sub> | <sub>34.12</sub> | <sub>23.42</sub> | <sub>9.9</sub> | <sub>`--cfg=stylegan3-r --gpus=8 --batch=32 --gamma=32.8 --mirror=1 --aug=noaug`</sub>
|
| 137 |
+
|
| 138 |
+
#### MetFaces-U at 1024x1024 resolution
|
| 139 |
+
|
| 140 |
+
| <sub>Config</sub><br><br> | <sub>s/kimg</sub><br><sup>(V100)</sup> | <sub>s/kimg</sub><br><sup>(A100)</sup> | <sub>GPU</sub><br><sup>mem</sup> | <sub>Options</sub><br><br>
|
| 141 |
+
| :--------------------------- | :--------------: | :--------------: | :-------------: | :--
|
| 142 |
+
| <sub>StyleGAN2</sub> | <sub>18.74</sub> | <sub>11.80</sub> | <sub>7.4</sub> | <sub>`--cfg=stylegan2 --gpus=8 --batch=32 --gamma=10 --mirror=1 --kimg=5000 --snap=10 --resume=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan2/versions/1/files/stylegan2-ffhqu-1024x1024.pkl`</sub>
|
| 143 |
+
| <sub>StyleGAN3‑T</sub> | <sub>29.84</sub> | <sub>21.06</sub> | <sub>7.7</sub> | <sub>`--cfg=stylegan3-t --gpus=8 --batch=32 --gamma=16.4 --mirror=1 --kimg=5000 --snap=10 --resume=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-t-ffhqu-1024x1024.pkl`</sub>
|
| 144 |
+
| <sub>StyleGAN3‑R</sub> | <sub>35.10</sub> | <sub>24.32</sub> | <sub>10.9</sub> | <sub>`--cfg=stylegan3-r --gpus=8 --batch=32 --gamma=6.6 --mirror=1 --kimg=5000 --snap=10 --resume=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-r-ffhqu-1024x1024.pkl`</sub>
|
| 145 |
+
|
| 146 |
+
#### MetFaces at 1024x1024 resolution
|
| 147 |
+
|
| 148 |
+
| <sub>Config</sub><br><br> | <sub>s/kimg</sub><br><sup>(V100)</sup> | <sub>s/kimg</sub><br><sup>(A100)</sup> | <sub>GPU</sub><br><sup>mem</sup> | <sub>Options</sub><br><br>
|
| 149 |
+
| :--------------------------- | :--------------: | :--------------: | :-------------: | :--
|
| 150 |
+
| <sub>StyleGAN2</sub> | <sub>18.74</sub> | <sub>11.80</sub> | <sub>7.4</sub> | <sub>`--cfg=stylegan2 --gpus=8 --batch=32 --gamma=5 --mirror=1 --kimg=5000 --snap=10 --resume=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan2/versions/1/files/stylegan2-ffhq-1024x1024.pkl`</sub>
|
| 151 |
+
| <sub>StyleGAN3‑T</sub> | <sub>29.84</sub> | <sub>21.06</sub> | <sub>7.7</sub> | <sub>`--cfg=stylegan3-t --gpus=8 --batch=32 --gamma=6.6 --mirror=1 --kimg=5000 --snap=10 --resume=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-t-ffhq-1024x1024.pkl`</sub>
|
| 152 |
+
| <sub>StyleGAN3‑R</sub> | <sub>35.10</sub> | <sub>24.32</sub> | <sub>10.9</sub> | <sub>`--cfg=stylegan3-r --gpus=8 --batch=32 --gamma=3.3 --mirror=1 --kimg=5000 --snap=10 --resume=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-r-ffhq-1024x1024.pkl`</sub>
|
| 153 |
+
|
| 154 |
+
#### AFHQv2 at 512x512 resolution
|
| 155 |
+
|
| 156 |
+
| <sub>Config</sub><br><br> | <sub>s/kimg</sub><br><sup>(V100)</sup> | <sub>s/kimg</sub><br><sup>(A100)</sup> | <sub>GPU</sub><br><sup>mem</sup> | <sub>Options</sub><br><br>
|
| 157 |
+
| :--------------------------- | :--------------: | :--------------: | :------------: | :--
|
| 158 |
+
| <sub>StyleGAN2</sub> | <sub>10.90</sub> | <sub>6.60</sub> | <sub>3.9</sub> | <sub>`--cfg=stylegan2 --gpus=8 --batch=32 --gamma=5 --mirror=1`</sub>
|
| 159 |
+
| <sub>StyleGAN3‑T</sub> | <sub>18.47</sub> | <sub>12.29</sub> | <sub>4.3</sub> | <sub>`--cfg=stylegan3-t --gpus=8 --batch=32 --gamma=8.2 --mirror=1`</sub>
|
| 160 |
+
| <sub>StyleGAN3‑R</sub> | <sub>20.44</sub> | <sub>14.04</sub> | <sub>5.9</sub> | <sub>`--cfg=stylegan3-r --gpus=8 --batch=32 --gamma=16.4 --mirror=1`</sub>
|
| 161 |
+
|
| 162 |
+
#### FFHQ-U ablations at 256x256 resolution
|
| 163 |
+
|
| 164 |
+
| <sub>Config</sub><br><br> | <sub>s/kimg</sub><br><sup>(V100)</sup> | <sub>s/kimg</sub><br><sup>(A100)</sup> | <sub>GPU</sub><br><sup>mem</sup> | <sub>Options</sub><br><br>
|
| 165 |
+
| :--------------------------- | :-------------: | :-------------: | :------------: | :--
|
| 166 |
+
| <sub>StyleGAN2</sub> | <sub>3.61</sub> | <sub>2.19</sub> | <sub>2.7</sub> | <sub>`--cfg=stylegan2 --gpus=8 --batch=64 --gamma=1 --mirror=1 --aug=noaug --cbase=16384 --glr=0.0025 --dlr=0.0025 --mbstd-group=8`</sub>
|
| 167 |
+
| <sub>StyleGAN3‑T</sub> | <sub>7.40</sub> | <sub>3.74</sub> | <sub>3.5</sub> | <sub>`--cfg=stylegan3-t --gpus=8 --batch=64 --gamma=1 --mirror=1 --aug=noaug --cbase=16384 --dlr=0.0025`</sub>
|
| 168 |
+
| <sub>StyleGAN3‑R</sub> | <sub>6.71</sub> | <sub>4.81</sub> | <sub>4.2</sub> | <sub>`--cfg=stylegan3-r --gpus=8 --batch=64 --gamma=1 --mirror=1 --aug=noaug --cbase=16384 --dlr=0.0025`</sub>
|
| 169 |
+
|
| 170 |
+
## Old StyleGAN2-ADA configurations
|
| 171 |
+
|
| 172 |
+
This section lists command lines that can be used to match the configurations provided by our previous [StyleGAN2-ADA](https://github.com/NVlabs/stylegan2-ada-pytorch) codebase. The first table corresponds to `--cfg=auto` (default) for different resolutions and GPU counts, while the second table lists the remaining alternatives.
|
| 173 |
+
|
| 174 |
+
#### Default configuration
|
| 175 |
+
|
| 176 |
+
| <sub>Res.</sub><br><br> | <sub>GPUs</sub><br><br> | <sub>s/kimg</sub><br><sup>(V100)</sup> | <sub>s/kimg</sub><br><sup>(A100)</sup> | <sub>GPU</sub><br><sup>mem</sup> | <sub>Options</sub><br><br>
|
| 177 |
+
| :---------------------- | :----------: | :---------------: | :--------------: | :------------: | :--
|
| 178 |
+
| <sub>128²</sub> | <sub>1</sub> | <sub>12.51</sub> | <sub>6.79</sub> | <sub>6.2</sub> | <sub>`--cfg=stylegan2 --gpus=1 --batch=32 --gamma=0.1024 --map-depth=2 --glr=0.0025 --dlr=0.0025 --cbase=16384`</sub>
|
| 179 |
+
| <sub>128²</sub> | <sub>2</sub> | <sub>6.43</sub> | <sub>3.45</sub> | <sub>6.2</sub> | <sub>`--cfg=stylegan2 --gpus=2 --batch=64 --gamma=0.0512 --map-depth=2 --glr=0.0025 --dlr=0.0025 --cbase=16384`</sub>
|
| 180 |
+
| <sub>128²</sub> | <sub>4</sub> | <sub>3.82</sub> | <sub>2.23</sub> | <sub>3.5</sub> | <sub>`--cfg=stylegan2 --gpus=4 --batch=64 --gamma=0.0512 --map-depth=2 --glr=0.0025 --dlr=0.0025 --cbase=16384`</sub>
|
| 181 |
+
| <sub>256²</sub> | <sub>1</sub> | <sub>20.84</sub> | <sub>12.53</sub> | <sub>4.5</sub> | <sub>`--cfg=stylegan2 --gpus=1 --batch=16 --gamma=0.8192 --map-depth=2 --glr=0.0025 --dlr=0.0025 --cbase=16384`</sub>
|
| 182 |
+
| <sub>256²</sub> | <sub>2</sub> | <sub>10.93</sub> | <sub>6.36</sub> | <sub>4.5</sub> | <sub>`--cfg=stylegan2 --gpus=2 --batch=32 --gamma=0.4096 --map-depth=2 --glr=0.0025 --dlr=0.0025 --cbase=16384`</sub>
|
| 183 |
+
| <sub>256²</sub> | <sub>4</sub> | <sub>5.39</sub> | <sub>3.20</sub> | <sub>4.5</sub> | <sub>`--cfg=stylegan2 --gpus=4 --batch=64 --gamma=0.2048 --map-depth=2 --glr=0.0025 --dlr=0.0025 --cbase=16384`</sub>
|
| 184 |
+
| <sub>256²</sub> | <sub>8</sub> | <sub>3.89</sub> | <sub>2.38</sub> | <sub>2.6</sub> | <sub>`--cfg=stylegan2 --gpus=8 --batch=64 --gamma=0.2048 --map-depth=2 --glr=0.0025 --dlr=0.0025 --cbase=16384`</sub>
|
| 185 |
+
| <sub>512²</sub> | <sub>1</sub> | <sub>71.59</sub> | <sub>41.06</sub> | <sub>6.8</sub> | <sub>`--cfg=stylegan2 --gpus=1 --batch=8 --gamma=6.5536 --map-depth=2 --glr=0.0025 --dlr=0.0025`</sub>
|
| 186 |
+
| <sub>512²</sub> | <sub>2</sub> | <sub>36.79</sub> | <sub>20.83</sub> | <sub>6.8</sub> | <sub>`--cfg=stylegan2 --gpus=2 --batch=16 --gamma=3.2768 --map-depth=2 --glr=0.0025 --dlr=0.0025`</sub>
|
| 187 |
+
| <sub>512²</sub> | <sub>4</sub> | <sub>18.12</sub> | <sub>10.45</sub> | <sub>6.7</sub> | <sub>`--cfg=stylegan2 --gpus=4 --batch=32 --gamma=1.6384 --map-depth=2 --glr=0.0025 --dlr=0.0025`</sub>
|
| 188 |
+
| <sub>512²</sub> | <sub>8</sub> | <sub>9.09</sub> | <sub>5.24</sub> | <sub>6.8</sub> | <sub>`--cfg=stylegan2 --gpus=8 --batch=64 --gamma=0.8192 --map-depth=2 --glr=0.0025 --dlr=0.0025`</sub>
|
| 189 |
+
| <sub>1024²</sub> | <sub>1</sub> | <sub>141.83</sub> | <sub>90.39</sub> | <sub>7.2</sub> | <sub>`--cfg=stylegan2 --gpus=1 --batch=4 --gamma=52.4288 --map-depth=2`</sub>
|
| 190 |
+
| <sub>1024²</sub> | <sub>2</sub> | <sub>73.13</sub> | <sub>46.04</sub> | <sub>7.2</sub> | <sub>`--cfg=stylegan2 --gpus=2 --batch=8 --gamma=26.2144 --map-depth=2`</sub>
|
| 191 |
+
| <sub>1024²</sub> | <sub>4</sub> | <sub>36.95</sub> | <sub>23.15</sub> | <sub>7.0</sub> | <sub>`--cfg=stylegan2 --gpus=4 --batch=16 --gamma=13.1072 --map-depth=2`</sub>
|
| 192 |
+
| <sub>1024²</sub> | <sub>8</sub> | <sub>18.47</sub> | <sub>11.66</sub> | <sub>7.3</sub> | <sub>`--cfg=stylegan2 --gpus=8 --batch=32 --gamma=6.5536 --map-depth=2`</sub>
|
| 193 |
+
|
| 194 |
+
#### Repro configurations
|
| 195 |
+
|
| 196 |
+
| <sub>Name</sub><br><br> | <sub>s/kimg</sub><br><sup>(V100)</sup> | <sub>s/kimg</sub><br><sup>(A100)</sup> | <sub>GPU</sub><br><sup>mem</sup> | <sub>Options</sub><br><br>
|
| 197 |
+
| :---------------------- | :--------------: | :--------------: | :------------: | :--
|
| 198 |
+
| <sub>`stylegan2`</sub> | <sub>17.55</sub> | <sub>14.57</sub> | <sub>6.2</sub> | <sub>`--cfg=stylegan2 --gpus=8 --batch=32 --gamma=10`</sub>
|
| 199 |
+
| <sub>`paper256`</sub> | <sub>4.01</sub> | <sub>2.47</sub> | <sub>2.7</sub> | <sub>`--cfg=stylegan2 --gpus=8 --batch=64 --gamma=1 --cbase=16384 --glr=0.0025 --dlr=0.0025 --mbstd-group=8`</sub>
|
| 200 |
+
| <sub>`paper512`</sub> | <sub>9.11</sub> | <sub>5.28</sub> | <sub>6.7</sub> | <sub>`--cfg=stylegan2 --gpus=8 --batch=64 --gamma=0.5 --glr=0.0025 --dlr=0.0025 --mbstd-group=8`</sub>
|
| 201 |
+
| <sub>`paper1024`</sub> | <sub>18.56</sub> | <sub>11.75</sub> | <sub>6.9</sub> | <sub>`--cfg=stylegan2 --gpus=8 --batch=32 --gamma=2`</sub>
|
stylegan3-fun/docs/dataset-tool-help.txt
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Usage: dataset_tool.py [OPTIONS]
|
| 2 |
+
|
| 3 |
+
Convert an image dataset into a dataset archive usable with StyleGAN2 ADA
|
| 4 |
+
PyTorch.
|
| 5 |
+
|
| 6 |
+
The input dataset format is guessed from the --source argument:
|
| 7 |
+
|
| 8 |
+
--source *_lmdb/ Load LSUN dataset
|
| 9 |
+
--source cifar-10-python.tar.gz Load CIFAR-10 dataset
|
| 10 |
+
--source train-images-idx3-ubyte.gz Load MNIST dataset
|
| 11 |
+
--source path/ Recursively load all images from path/
|
| 12 |
+
--source dataset.zip Recursively load all images from dataset.zip
|
| 13 |
+
|
| 14 |
+
Specifying the output format and path:
|
| 15 |
+
|
| 16 |
+
--dest /path/to/dir Save output files under /path/to/dir
|
| 17 |
+
--dest /path/to/dataset.zip Save output files into /path/to/dataset.zip
|
| 18 |
+
|
| 19 |
+
The output dataset format can be either an image folder or an uncompressed
|
| 20 |
+
zip archive. Zip archives makes it easier to move datasets around file
|
| 21 |
+
servers and clusters, and may offer better training performance on network
|
| 22 |
+
file systems.
|
| 23 |
+
|
| 24 |
+
Images within the dataset archive will be stored as uncompressed PNG.
|
| 25 |
+
Uncompresed PNGs can be efficiently decoded in the training loop.
|
| 26 |
+
|
| 27 |
+
Class labels are stored in a file called 'dataset.json' that is stored at
|
| 28 |
+
the dataset root folder. This file has the following structure:
|
| 29 |
+
|
| 30 |
+
{
|
| 31 |
+
"labels": [
|
| 32 |
+
["00000/img00000000.png",6],
|
| 33 |
+
["00000/img00000001.png",9],
|
| 34 |
+
... repeated for every image in the datase
|
| 35 |
+
["00049/img00049999.png",1]
|
| 36 |
+
]
|
| 37 |
+
}
|
| 38 |
+
|
| 39 |
+
If the 'dataset.json' file cannot be found, the dataset is interpreted as
|
| 40 |
+
not containing class labels.
|
| 41 |
+
|
| 42 |
+
Image scale/crop and resolution requirements:
|
| 43 |
+
|
| 44 |
+
Output images must be square-shaped and they must all have the same power-
|
| 45 |
+
of-two dimensions.
|
| 46 |
+
|
| 47 |
+
To scale arbitrary input image size to a specific width and height, use
|
| 48 |
+
the --resolution option. Output resolution will be either the original
|
| 49 |
+
input resolution (if resolution was not specified) or the one specified
|
| 50 |
+
with --resolution option.
|
| 51 |
+
|
| 52 |
+
Use the --transform=center-crop or --transform=center-crop-wide options to
|
| 53 |
+
apply a center crop transform on the input image. These options should be
|
| 54 |
+
used with the --resolution option. For example:
|
| 55 |
+
|
| 56 |
+
python dataset_tool.py --source LSUN/raw/cat_lmdb --dest /tmp/lsun_cat \
|
| 57 |
+
--transform=center-crop-wide --resolution=512x384
|
| 58 |
+
|
| 59 |
+
Options:
|
| 60 |
+
--source PATH Directory or archive name for input dataset
|
| 61 |
+
[required]
|
| 62 |
+
|
| 63 |
+
--dest PATH Output directory or archive name for output
|
| 64 |
+
dataset [required]
|
| 65 |
+
|
| 66 |
+
--max-images INTEGER Output only up to `max-images` images
|
| 67 |
+
--transform [center-crop|center-crop-wide]
|
| 68 |
+
Input crop/resize mode
|
| 69 |
+
--resolution WxH Output resolution (e.g., '512x512')
|
| 70 |
+
--help Show this message and exit.
|
stylegan3-fun/docs/stylegan3-teaser-1920x1006.png
ADDED

|
Git LFS Details
|
stylegan3-fun/docs/train-help.txt
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Usage: train.py [OPTIONS]
|
| 2 |
+
|
| 3 |
+
Train a GAN using the techniques described in the paper "Alias-Free
|
| 4 |
+
Generative Adversarial Networks".
|
| 5 |
+
|
| 6 |
+
Examples:
|
| 7 |
+
|
| 8 |
+
# Train StyleGAN3-T for AFHQv2 using 8 GPUs.
|
| 9 |
+
python train.py --outdir=~/training-runs --cfg=stylegan3-t --data=~/datasets/afhqv2-512x512.zip \
|
| 10 |
+
--gpus=8 --batch=32 --gamma=8.2 --mirror=1
|
| 11 |
+
|
| 12 |
+
# Fine-tune StyleGAN3-R for MetFaces-U using 1 GPU, starting from the pre-trained FFHQ-U pickle.
|
| 13 |
+
python train.py --outdir=~/training-runs --cfg=stylegan3-r --data=~/datasets/metfacesu-1024x1024.zip \
|
| 14 |
+
--gpus=8 --batch=32 --gamma=6.6 --mirror=1 --kimg=5000 --snap=5 \
|
| 15 |
+
--resume=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-r-ffhqu-1024x1024.pkl
|
| 16 |
+
|
| 17 |
+
# Train StyleGAN2 for FFHQ at 1024x1024 resolution using 8 GPUs.
|
| 18 |
+
python train.py --outdir=~/training-runs --cfg=stylegan2 --data=~/datasets/ffhq-1024x1024.zip \
|
| 19 |
+
--gpus=8 --batch=32 --gamma=10 --mirror=1 --aug=noaug
|
| 20 |
+
|
| 21 |
+
Options:
|
| 22 |
+
--outdir DIR Where to save the results [required]
|
| 23 |
+
--cfg [stylegan3-t|stylegan3-r|stylegan2]
|
| 24 |
+
Base configuration [required]
|
| 25 |
+
--data [ZIP|DIR] Training data [required]
|
| 26 |
+
--gpus INT Number of GPUs to use [required]
|
| 27 |
+
--batch INT Total batch size [required]
|
| 28 |
+
--gamma FLOAT R1 regularization weight [required]
|
| 29 |
+
--cond BOOL Train conditional model [default: False]
|
| 30 |
+
--mirror BOOL Enable dataset x-flips [default: False]
|
| 31 |
+
--aug [noaug|ada|fixed] Augmentation mode [default: ada]
|
| 32 |
+
--resume [PATH|URL] Resume from given network pickle
|
| 33 |
+
--freezed INT Freeze first layers of D [default: 0]
|
| 34 |
+
--p FLOAT Probability for --aug=fixed [default: 0.2]
|
| 35 |
+
--target FLOAT Target value for --aug=ada [default: 0.6]
|
| 36 |
+
--batch-gpu INT Limit batch size per GPU
|
| 37 |
+
--cbase INT Capacity multiplier [default: 32768]
|
| 38 |
+
--cmax INT Max. feature maps [default: 512]
|
| 39 |
+
--glr FLOAT G learning rate [default: varies]
|
| 40 |
+
--dlr FLOAT D learning rate [default: 0.002]
|
| 41 |
+
--map-depth INT Mapping network depth [default: varies]
|
| 42 |
+
--mbstd-group INT Minibatch std group size [default: 4]
|
| 43 |
+
--desc STR String to include in result dir name
|
| 44 |
+
--metrics [NAME|A,B,C|none] Quality metrics [default: fid50k_full]
|
| 45 |
+
--kimg KIMG Total training duration [default: 25000]
|
| 46 |
+
--tick KIMG How often to print progress [default: 4]
|
| 47 |
+
--snap TICKS How often to save snapshots [default: 50]
|
| 48 |
+
--seed INT Random seed [default: 0]
|
| 49 |
+
--fp32 BOOL Disable mixed-precision [default: False]
|
| 50 |
+
--nobench BOOL Disable cuDNN benchmarking [default: False]
|
| 51 |
+
--workers INT DataLoader worker processes [default: 3]
|
| 52 |
+
-n, --dry-run Print training options and exit
|
| 53 |
+
--help Show this message and exit.
|
stylegan3-fun/docs/troubleshooting.md
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Troubleshooting
|
| 2 |
+
|
| 3 |
+
Our PyTorch code uses custom [CUDA extensions](https://pytorch.org/tutorials/advanced/cpp_extension.html) to speed up some of the network layers. Getting these to run can sometimes be a hassle.
|
| 4 |
+
|
| 5 |
+
This page aims to give guidance on how to diagnose and fix run-time problems related to these extensions.
|
| 6 |
+
|
| 7 |
+
## Before you start
|
| 8 |
+
|
| 9 |
+
1. Try Docker first! Ensure you can successfully run our models using the recommended Docker image. Follow the instructions in [README.md](/README.md) to get it running.
|
| 10 |
+
2. Can't use Docker? Read on..
|
| 11 |
+
|
| 12 |
+
## Installing dependencies
|
| 13 |
+
|
| 14 |
+
Make sure you've installed everything listed on the requirements section in the [README.md](/README.md). The key components w.r.t. custom extensions are:
|
| 15 |
+
|
| 16 |
+
- **[CUDA toolkit 11.1](https://developer.nvidia.com/cuda-toolkit)** or later (this is not the same as `cudatoolkit` from Conda).
|
| 17 |
+
- PyTorch invokes `nvcc` to compile our CUDA kernels.
|
| 18 |
+
- **ninja**
|
| 19 |
+
- PyTorch uses [Ninja](https://ninja-build.org/) as its build system.
|
| 20 |
+
- **GCC** (Linux) or **Visual Studio** (Windows)
|
| 21 |
+
- GCC 7.x or later is required. Earlier versions such as GCC 6.3 [are known not to work](https://github.com/NVlabs/stylegan3/issues/2).
|
| 22 |
+
|
| 23 |
+
#### Why is CUDA toolkit installation necessary?
|
| 24 |
+
|
| 25 |
+
The PyTorch package contains the required CUDA toolkit libraries needed to run PyTorch, so why is a separate CUDA toolkit installation required? Our models use custom CUDA kernels to implement operations such as efficient resampling of 2D images. PyTorch code invokes the CUDA compiler at run-time to compile these kernels on first-use. The tools and libraries required for this compilation are not bundled in PyTorch and thus a host CUDA toolkit installation is required.
|
| 26 |
+
|
| 27 |
+
## Things to try
|
| 28 |
+
|
| 29 |
+
- Completely remove: `$HOME/.cache/torch_extensions` (Linux) or `C:\Users\<username>\AppData\Local\torch_extensions\torch_extensions\Cache` (Windows) and re-run StyleGAN3 python code.
|
| 30 |
+
- Run ninja in `$HOME/.cache/torch_extensions` to see that it builds.
|
| 31 |
+
- Inspect the `build.ninja` in the build directories under `$HOME/.cache/torch_extensions` and check CUDA tools and versions are consistent with what you intended to use.
|
stylegan3-fun/docs/visualizer_screen0.png
ADDED
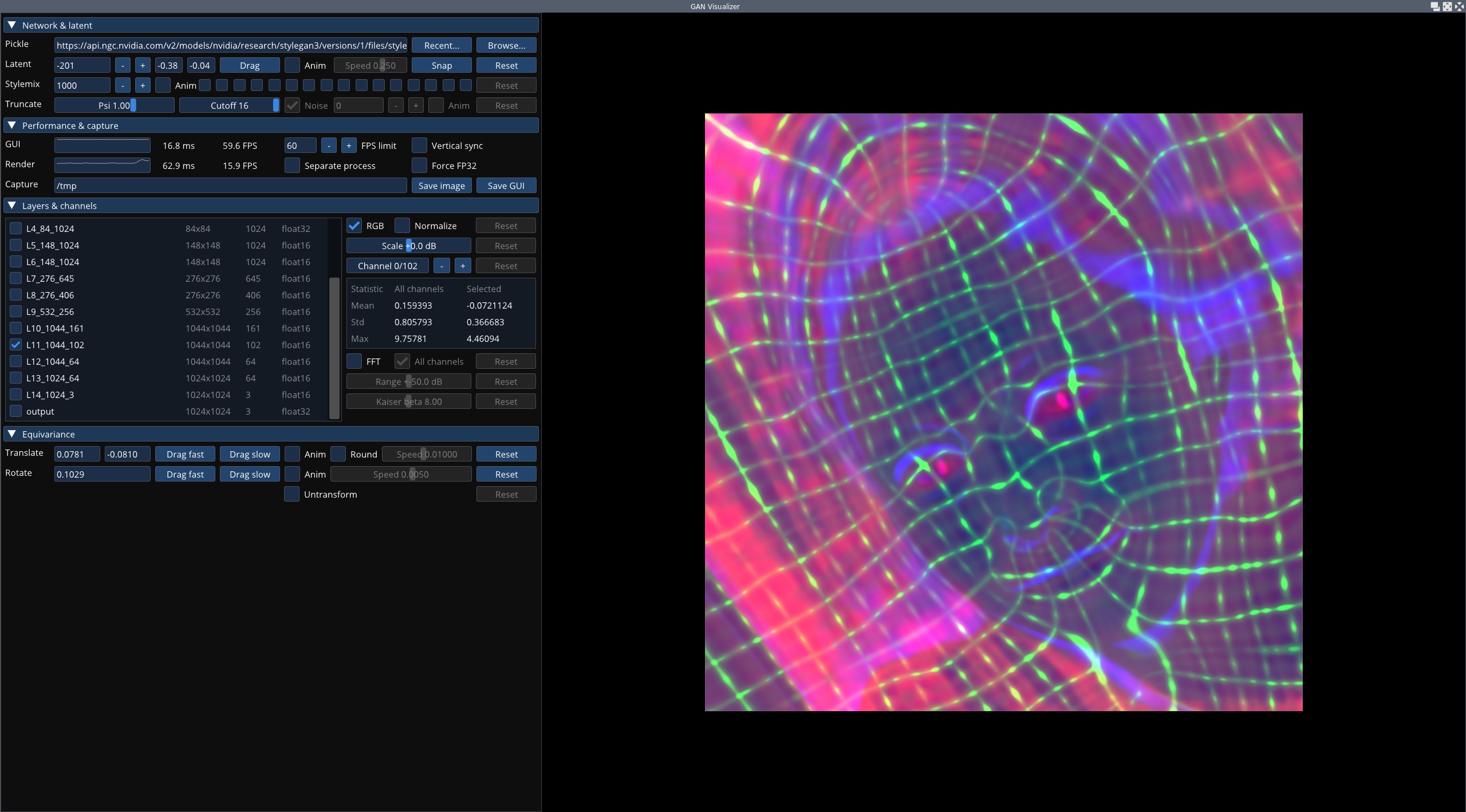
|
Git LFS Details
|
stylegan3-fun/docs/visualizer_screen0_half.png
ADDED

|
stylegan3-fun/environment.yml
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: stylegan3
|
| 2 |
+
channels:
|
| 3 |
+
- pytorch
|
| 4 |
+
- nvidia
|
| 5 |
+
- conda-forge # PR #80 by @SetZero / #143 by @coldwaterq
|
| 6 |
+
dependencies:
|
| 7 |
+
- python >= 3.8
|
| 8 |
+
- pip
|
| 9 |
+
- numpy>=1.20
|
| 10 |
+
- click>=8.0
|
| 11 |
+
- pillow=8.3.1
|
| 12 |
+
- scipy=1.7.1
|
| 13 |
+
- pytorch::pytorch=1.11 # We can now use Pytorch 1.11!
|
| 14 |
+
- nvidia::cudatoolkit=11.3 # Necessary to remove previous PR by @edstoica
|
| 15 |
+
- requests=2.26.0
|
| 16 |
+
- tqdm=4.62.2
|
| 17 |
+
- ninja=1.10.2
|
| 18 |
+
- matplotlib=3.4.2
|
| 19 |
+
- imageio=2.9.0
|
| 20 |
+
- pip:
|
| 21 |
+
- imgui==1.3.0
|
| 22 |
+
- glfw==2.2.0
|
| 23 |
+
- pyopengl==3.1.5
|
| 24 |
+
- imageio-ffmpeg==0.4.3
|
| 25 |
+
- pyspng
|
| 26 |
+
- pyperlin # for Discriminator Synthesis
|
| 27 |
+
- psutil # PR #125 by @fastflair / #111 by @siddharthksah
|
| 28 |
+
- tensorboard # PR #125 by @fastflair
|
| 29 |
+
- torchvision==0.12.0 # For "Discriminator Synthesis" / discriminator_synthesis.py
|
| 30 |
+
- pyperlin # For "Discriminator Synthesis" / discriminator_synthesis.py
|
| 31 |
+
- scikit-learn # For "Self-Distilled StyleGAN" / multimodal_truncation.py
|
| 32 |
+
- moviepy==1.0.3
|
| 33 |
+
- ffmpeg-python==0.2.0
|
| 34 |
+
- scikit-video==1.1.11
|
| 35 |
+
- setuptools==59.5.0 # PR #8 by @ZibbeZabbe
|
stylegan3-fun/gen_images.py
ADDED
|
@@ -0,0 +1,145 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Generate images using pretrained network pickle."""
|
| 10 |
+
|
| 11 |
+
import os
|
| 12 |
+
import re
|
| 13 |
+
from typing import List, Optional, Tuple, Union
|
| 14 |
+
|
| 15 |
+
import click
|
| 16 |
+
import dnnlib
|
| 17 |
+
import numpy as np
|
| 18 |
+
import PIL.Image
|
| 19 |
+
import torch
|
| 20 |
+
|
| 21 |
+
import legacy
|
| 22 |
+
|
| 23 |
+
#----------------------------------------------------------------------------
|
| 24 |
+
|
| 25 |
+
def parse_range(s: Union[str, List]) -> List[int]:
|
| 26 |
+
'''Parse a comma separated list of numbers or ranges and return a list of ints.
|
| 27 |
+
|
| 28 |
+
Example: '1,2,5-10' returns [1, 2, 5, 6, 7]
|
| 29 |
+
'''
|
| 30 |
+
if isinstance(s, list): return s
|
| 31 |
+
ranges = []
|
| 32 |
+
range_re = re.compile(r'^(\d+)-(\d+)$')
|
| 33 |
+
for p in s.split(','):
|
| 34 |
+
m = range_re.match(p)
|
| 35 |
+
if m:
|
| 36 |
+
ranges.extend(range(int(m.group(1)), int(m.group(2))+1))
|
| 37 |
+
else:
|
| 38 |
+
ranges.append(int(p))
|
| 39 |
+
return ranges
|
| 40 |
+
|
| 41 |
+
#----------------------------------------------------------------------------
|
| 42 |
+
|
| 43 |
+
def parse_vec2(s: Union[str, Tuple[float, float]]) -> Tuple[float, float]:
|
| 44 |
+
'''Parse a floating point 2-vector of syntax 'a,b'.
|
| 45 |
+
|
| 46 |
+
Example:
|
| 47 |
+
'0,1' returns (0,1)
|
| 48 |
+
'''
|
| 49 |
+
if isinstance(s, tuple): return s
|
| 50 |
+
parts = s.split(',')
|
| 51 |
+
if len(parts) == 2:
|
| 52 |
+
return (float(parts[0]), float(parts[1]))
|
| 53 |
+
raise ValueError(f'cannot parse 2-vector {s}')
|
| 54 |
+
|
| 55 |
+
#----------------------------------------------------------------------------
|
| 56 |
+
|
| 57 |
+
def make_transform(translate: Tuple[float,float], angle: float):
|
| 58 |
+
m = np.eye(3)
|
| 59 |
+
s = np.sin(angle/360.0*np.pi*2)
|
| 60 |
+
c = np.cos(angle/360.0*np.pi*2)
|
| 61 |
+
m[0][0] = c
|
| 62 |
+
m[0][1] = s
|
| 63 |
+
m[0][2] = translate[0]
|
| 64 |
+
m[1][0] = -s
|
| 65 |
+
m[1][1] = c
|
| 66 |
+
m[1][2] = translate[1]
|
| 67 |
+
return m
|
| 68 |
+
|
| 69 |
+
#----------------------------------------------------------------------------
|
| 70 |
+
|
| 71 |
+
@click.command()
|
| 72 |
+
@click.option('--network', 'network_pkl', help='Network pickle filename', required=True)
|
| 73 |
+
@click.option('--seeds', type=parse_range, help='List of random seeds (e.g., \'0,1,4-6\')', required=True)
|
| 74 |
+
@click.option('--trunc', 'truncation_psi', type=float, help='Truncation psi', default=1, show_default=True)
|
| 75 |
+
@click.option('--class', 'class_idx', type=int, help='Class label (unconditional if not specified)')
|
| 76 |
+
@click.option('--noise-mode', help='Noise mode', type=click.Choice(['const', 'random', 'none']), default='const', show_default=True)
|
| 77 |
+
@click.option('--translate', help='Translate XY-coordinate (e.g. \'0.3,1\')', type=parse_vec2, default='0,0', show_default=True, metavar='VEC2')
|
| 78 |
+
@click.option('--rotate', help='Rotation angle in degrees', type=float, default=0, show_default=True, metavar='ANGLE')
|
| 79 |
+
@click.option('--outdir', help='Where to save the output images', type=str, required=True, metavar='DIR')
|
| 80 |
+
def generate_images(
|
| 81 |
+
network_pkl: str,
|
| 82 |
+
seeds: List[int],
|
| 83 |
+
truncation_psi: float,
|
| 84 |
+
noise_mode: str,
|
| 85 |
+
outdir: str,
|
| 86 |
+
translate: Tuple[float,float],
|
| 87 |
+
rotate: float,
|
| 88 |
+
class_idx: Optional[int]
|
| 89 |
+
):
|
| 90 |
+
"""Generate images using pretrained network pickle.
|
| 91 |
+
|
| 92 |
+
Examples:
|
| 93 |
+
|
| 94 |
+
\b
|
| 95 |
+
# Generate an image using pre-trained AFHQv2 model ("Ours" in Figure 1, left).
|
| 96 |
+
python gen_images.py --outdir=out --trunc=1 --seeds=2 \\
|
| 97 |
+
--network=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-r-afhqv2-512x512.pkl
|
| 98 |
+
|
| 99 |
+
\b
|
| 100 |
+
# Generate uncurated images with truncation using the MetFaces-U dataset
|
| 101 |
+
python gen_images.py --outdir=out --trunc=0.7 --seeds=600-605 \\
|
| 102 |
+
--network=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-t-metfacesu-1024x1024.pkl
|
| 103 |
+
"""
|
| 104 |
+
|
| 105 |
+
print('Loading networks from "%s"...' % network_pkl)
|
| 106 |
+
device = torch.device('cuda')
|
| 107 |
+
with dnnlib.util.open_url(network_pkl) as f:
|
| 108 |
+
G = legacy.load_network_pkl(f)['G_ema'].to(device) # type: ignore
|
| 109 |
+
|
| 110 |
+
os.makedirs(outdir, exist_ok=True)
|
| 111 |
+
|
| 112 |
+
# Labels.
|
| 113 |
+
label = torch.zeros([1, G.c_dim], device=device)
|
| 114 |
+
if G.c_dim != 0:
|
| 115 |
+
if class_idx is None:
|
| 116 |
+
raise click.ClickException('Must specify class label with --class when using a conditional network')
|
| 117 |
+
label[:, class_idx] = 1
|
| 118 |
+
else:
|
| 119 |
+
if class_idx is not None:
|
| 120 |
+
print ('warn: --class=lbl ignored when running on an unconditional network')
|
| 121 |
+
|
| 122 |
+
# Generate images.
|
| 123 |
+
for seed_idx, seed in enumerate(seeds):
|
| 124 |
+
print('Generating image for seed %d (%d/%d) ...' % (seed, seed_idx, len(seeds)))
|
| 125 |
+
z = torch.from_numpy(np.random.RandomState(seed).randn(1, G.z_dim)).to(device)
|
| 126 |
+
|
| 127 |
+
# Construct an inverse rotation/translation matrix and pass to the generator. The
|
| 128 |
+
# generator expects this matrix as an inverse to avoid potentially failing numerical
|
| 129 |
+
# operations in the network.
|
| 130 |
+
if hasattr(G.synthesis, 'input'):
|
| 131 |
+
m = make_transform(translate, rotate)
|
| 132 |
+
m = np.linalg.inv(m)
|
| 133 |
+
G.synthesis.input.transform.copy_(torch.from_numpy(m))
|
| 134 |
+
|
| 135 |
+
img = G(z, label, truncation_psi=truncation_psi, noise_mode=noise_mode)
|
| 136 |
+
img = (img.permute(0, 2, 3, 1) * 127.5 + 128).clamp(0, 255).to(torch.uint8)
|
| 137 |
+
PIL.Image.fromarray(img[0].cpu().numpy(), 'RGB').save(f'{outdir}/seed{seed:04d}.png')
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
#----------------------------------------------------------------------------
|
| 141 |
+
|
| 142 |
+
if __name__ == "__main__":
|
| 143 |
+
generate_images() # pylint: disable=no-value-for-parameter
|
| 144 |
+
|
| 145 |
+
#----------------------------------------------------------------------------
|
stylegan3-fun/gen_video.py
ADDED
|
@@ -0,0 +1,281 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Generate lerp videos using pretrained network pickle."""
|
| 10 |
+
|
| 11 |
+
import copy
|
| 12 |
+
import os
|
| 13 |
+
import re
|
| 14 |
+
from typing import List, Optional, Tuple, Union
|
| 15 |
+
|
| 16 |
+
import click
|
| 17 |
+
import dnnlib
|
| 18 |
+
import imageio
|
| 19 |
+
import numpy as np
|
| 20 |
+
import scipy.interpolate
|
| 21 |
+
import torch
|
| 22 |
+
from tqdm import tqdm
|
| 23 |
+
|
| 24 |
+
import legacy
|
| 25 |
+
from torch_utils import gen_utils
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
# ----------------------------------------------------------------------------
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def layout_grid(img, grid_w=None, grid_h=1, float_to_uint8=True, chw_to_hwc=True, to_numpy=True):
|
| 32 |
+
batch_size, channels, img_h, img_w = img.shape
|
| 33 |
+
if grid_w is None:
|
| 34 |
+
grid_w = batch_size // grid_h
|
| 35 |
+
assert batch_size == grid_w * grid_h
|
| 36 |
+
if float_to_uint8:
|
| 37 |
+
img = (img * 127.5 + 128).clamp(0, 255).to(torch.uint8)
|
| 38 |
+
img = img.reshape(grid_h, grid_w, channels, img_h, img_w)
|
| 39 |
+
img = img.permute(2, 0, 3, 1, 4)
|
| 40 |
+
img = img.reshape(channels, grid_h * img_h, grid_w * img_w)
|
| 41 |
+
if chw_to_hwc:
|
| 42 |
+
img = img.permute(1, 2, 0)
|
| 43 |
+
if to_numpy:
|
| 44 |
+
img = img.cpu().numpy()
|
| 45 |
+
return img
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
# ----------------------------------------------------------------------------
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def parse_vec2(s: Union[str, Tuple[float, float]]) -> Tuple[float, float]:
|
| 52 |
+
"""Parse a floating point 2-vector of syntax 'a,b'.
|
| 53 |
+
|
| 54 |
+
Example:
|
| 55 |
+
'0,1' returns (0,1)
|
| 56 |
+
"""
|
| 57 |
+
if isinstance(s, tuple): return s
|
| 58 |
+
parts = s.split(',')
|
| 59 |
+
if len(parts) == 2:
|
| 60 |
+
return (float(parts[0]), float(parts[1]))
|
| 61 |
+
raise ValueError(f'cannot parse 2-vector {s}')
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
# ----------------------------------------------------------------------------
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def make_transform(translate: Tuple[float,float], angle: float):
|
| 68 |
+
m = np.eye(3)
|
| 69 |
+
s = np.sin(angle/360.0*np.pi*2)
|
| 70 |
+
c = np.cos(angle/360.0*np.pi*2)
|
| 71 |
+
m[0][0] = c
|
| 72 |
+
m[0][1] = s
|
| 73 |
+
m[0][2] = translate[0]
|
| 74 |
+
m[1][0] = -s
|
| 75 |
+
m[1][1] = c
|
| 76 |
+
m[1][2] = translate[1]
|
| 77 |
+
return m
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
# ----------------------------------------------------------------------------
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def gen_interp_video(G,
|
| 84 |
+
mp4: str,
|
| 85 |
+
seeds: List[int],
|
| 86 |
+
shuffle_seed: int = None,
|
| 87 |
+
w_frames: int = 60*4,
|
| 88 |
+
kind: str = 'cubic',
|
| 89 |
+
grid_dims: Tuple[int] = (1,1),
|
| 90 |
+
num_keyframes: int = None,
|
| 91 |
+
wraps: int = 2,
|
| 92 |
+
psi: float = 1.0,
|
| 93 |
+
device: torch.device = torch.device('cuda'),
|
| 94 |
+
stabilize_video: bool = True,
|
| 95 |
+
**video_kwargs):
|
| 96 |
+
grid_w = grid_dims[0]
|
| 97 |
+
grid_h = grid_dims[1]
|
| 98 |
+
|
| 99 |
+
if stabilize_video:
|
| 100 |
+
# Thanks to @RiversHaveWings and @nshepperd1
|
| 101 |
+
if hasattr(G.synthesis, 'input'):
|
| 102 |
+
shift = G.synthesis.input.affine(G.mapping.w_avg.unsqueeze(0))
|
| 103 |
+
G.synthesis.input.affine.bias.data.add_(shift.squeeze(0))
|
| 104 |
+
G.synthesis.input.affine.weight.data.zero_()
|
| 105 |
+
|
| 106 |
+
# Get the Generator's transform
|
| 107 |
+
m = G.synthesis.input.transform if hasattr(G.synthesis, 'input') else None
|
| 108 |
+
|
| 109 |
+
if num_keyframes is None:
|
| 110 |
+
if len(seeds) % (grid_w*grid_h) != 0:
|
| 111 |
+
raise ValueError('Number of input seeds must be divisible by grid W*H')
|
| 112 |
+
num_keyframes = len(seeds) // (grid_w*grid_h)
|
| 113 |
+
|
| 114 |
+
all_seeds = np.zeros(num_keyframes*grid_h*grid_w, dtype=np.int64)
|
| 115 |
+
for idx in range(num_keyframes*grid_h*grid_w):
|
| 116 |
+
all_seeds[idx] = seeds[idx % len(seeds)]
|
| 117 |
+
|
| 118 |
+
if shuffle_seed is not None:
|
| 119 |
+
rng = np.random.RandomState(seed=shuffle_seed)
|
| 120 |
+
rng.shuffle(all_seeds)
|
| 121 |
+
|
| 122 |
+
zs = torch.from_numpy(np.stack([np.random.RandomState(seed).randn(G.z_dim) for seed in all_seeds])).to(device)
|
| 123 |
+
ws = G.mapping(z=zs, c=None, truncation_psi=psi)
|
| 124 |
+
_ = G.synthesis(ws[:1]) # warm up
|
| 125 |
+
ws = ws.reshape(grid_h, grid_w, num_keyframes, *ws.shape[1:])
|
| 126 |
+
|
| 127 |
+
# Interpolation.
|
| 128 |
+
grid = []
|
| 129 |
+
for yi in range(grid_h):
|
| 130 |
+
row = []
|
| 131 |
+
for xi in range(grid_w):
|
| 132 |
+
x = np.arange(-num_keyframes * wraps, num_keyframes * (wraps + 1))
|
| 133 |
+
y = np.tile(ws[yi][xi].cpu().numpy(), [wraps * 2 + 1, 1, 1])
|
| 134 |
+
interp = scipy.interpolate.interp1d(x, y, kind=kind, axis=0)
|
| 135 |
+
row.append(interp)
|
| 136 |
+
grid.append(row)
|
| 137 |
+
|
| 138 |
+
# Render video.
|
| 139 |
+
video_out = imageio.get_writer(mp4, mode='I', fps=60, codec='libx264', **video_kwargs)
|
| 140 |
+
for frame_idx in tqdm(range(num_keyframes * w_frames)):
|
| 141 |
+
imgs = []
|
| 142 |
+
# Construct an inverse affine matrix and pass to the generator. The generator expects
|
| 143 |
+
# this matrix as an inverse to avoid potentially failing numerical operations in the network.
|
| 144 |
+
if hasattr(G.synthesis, 'input'):
|
| 145 |
+
# Set default values for each affine transformation
|
| 146 |
+
total_rotation = 0.0 # If >= 0.0, will rotate the pixels counter-clockwise w.r.t. the center; in radians
|
| 147 |
+
total_translation_x = 0.0 # If >= 0.0, will translate all pixels to the right; if <= 0.0, to the left
|
| 148 |
+
total_translation_y = 0.0 # If >= 0.0, will translate all pixels upwards; if <= 0.0, downwards
|
| 149 |
+
total_scale_x = 1.0 # If <= 1.0, will zoom in; else, will zoom out (x-axis)
|
| 150 |
+
total_scale_y = 1.0 # If <= 1.0, will zoom in; else, will zoom out (y-axis)
|
| 151 |
+
total_shear_x = 0.0 # If >= 0.0, will shear pixels to the right, keeping y fixed; if <= 0.0, to the left
|
| 152 |
+
total_shear_y = 0.0 # If >= 0.0, will shear pixels upwards, keeping x fixed; if <= 0.0, downwards
|
| 153 |
+
mirror_x = False # Mirror along the x-axis; if True, will flip the image horizontally (can't be a function of frame_idx)
|
| 154 |
+
mirror_y = False # Mirror along the y-axis; if True, will flip the image vertically (can't be a function of frame_idx)
|
| 155 |
+
|
| 156 |
+
# Go nuts with these. They can be constants as above to fix centering/rotation in your video,
|
| 157 |
+
# or you can make them functions of frame_idx to animate them, such as (uncomment as many as you want to try):
|
| 158 |
+
# total_scale_x = 1 + np.sin(np.pi*frame_idx/(num_keyframes * w_frames))/2 # will oscillate between 0.5 and 1.5
|
| 159 |
+
# total_rotation = 4*np.pi*frame_idx/(num_keyframes * w_frames) # 4 will dictate the number of rotations, so 1 full rotation
|
| 160 |
+
# total_shear_y = 2*np.sin(2*np.pi*frame_idx/(num_keyframes * w_frames)) # will oscillate between -2 and 2
|
| 161 |
+
|
| 162 |
+
# We then use these values to construct the affine matrix
|
| 163 |
+
m = gen_utils.make_affine_transform(m, angle=total_rotation, translate_x=total_translation_x,
|
| 164 |
+
translate_y=total_translation_y, scale_x=total_scale_x,
|
| 165 |
+
scale_y=total_scale_y, shear_x=total_shear_x, shear_y=total_shear_y,
|
| 166 |
+
mirror_x=mirror_x, mirror_y=mirror_y)
|
| 167 |
+
m = np.linalg.inv(m)
|
| 168 |
+
# Finally, we pass the matrix to the generator
|
| 169 |
+
G.synthesis.input.transform.copy_(torch.from_numpy(m))
|
| 170 |
+
|
| 171 |
+
# The rest stays the same, for all you gen_video.py lovers out there
|
| 172 |
+
for yi in range(grid_h):
|
| 173 |
+
for xi in range(grid_w):
|
| 174 |
+
interp = grid[yi][xi]
|
| 175 |
+
w = torch.from_numpy(interp(frame_idx / w_frames)).to(device)
|
| 176 |
+
img = G.synthesis(ws=w.unsqueeze(0), noise_mode='const')[0]
|
| 177 |
+
imgs.append(img)
|
| 178 |
+
video_out.append_data(layout_grid(torch.stack(imgs), grid_w=grid_w, grid_h=grid_h))
|
| 179 |
+
video_out.close()
|
| 180 |
+
|
| 181 |
+
|
| 182 |
+
# ----------------------------------------------------------------------------
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
def parse_range(s: Union[str, List[int]]) -> List[int]:
|
| 186 |
+
"""Parse a comma separated list of numbers or ranges and return a list of ints.
|
| 187 |
+
|
| 188 |
+
Example: '1,2,5-10' returns [1, 2, 5, 6, 7]
|
| 189 |
+
"""
|
| 190 |
+
if isinstance(s, list): return s
|
| 191 |
+
ranges = []
|
| 192 |
+
range_re = re.compile(r'^(\d+)-(\d+)$')
|
| 193 |
+
for p in s.split(','):
|
| 194 |
+
m = range_re.match(p)
|
| 195 |
+
if m:
|
| 196 |
+
ranges.extend(range(int(m.group(1)), int(m.group(2))+1))
|
| 197 |
+
else:
|
| 198 |
+
ranges.append(int(p))
|
| 199 |
+
return ranges
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
# ----------------------------------------------------------------------------
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
def parse_tuple(s: Union[str, Tuple[int,int]]) -> Tuple[int, int]:
|
| 206 |
+
"""Parse a 'M,N' or 'MxN' integer tuple.
|
| 207 |
+
|
| 208 |
+
Example:
|
| 209 |
+
'4x2' returns (4,2)
|
| 210 |
+
'0,1' returns (0,1)
|
| 211 |
+
"""
|
| 212 |
+
if isinstance(s, tuple): return s
|
| 213 |
+
m = re.match(r'^(\d+)[x,](\d+)$', s)
|
| 214 |
+
if m:
|
| 215 |
+
return (int(m.group(1)), int(m.group(2)))
|
| 216 |
+
raise ValueError(f'cannot parse tuple {s}')
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
# ----------------------------------------------------------------------------
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
@click.command()
|
| 223 |
+
@click.option('--network', 'network_pkl', help='Network pickle filename', required=True)
|
| 224 |
+
@click.option('--seeds', type=parse_range, help='List of random seeds', required=True)
|
| 225 |
+
@click.option('--shuffle-seed', type=int, help='Random seed to use for shuffling seed order', default=None)
|
| 226 |
+
@click.option('--grid', type=parse_tuple, help='Grid width/height, e.g. \'4x3\' (default: 1x1)', default=(1,1))
|
| 227 |
+
@click.option('--num-keyframes', type=int, help='Number of seeds to interpolate through. If not specified, determine based on the length of the seeds array given by --seeds.', default=None)
|
| 228 |
+
@click.option('--w-frames', type=int, help='Number of frames to interpolate between latents', default=120)
|
| 229 |
+
@click.option('--trunc', 'truncation_psi', type=float, help='Truncation psi', default=1, show_default=True)
|
| 230 |
+
@click.option('--stabilize-video', is_flag=True, help='Stabilize the video by anchoring the mapping to w_avg')
|
| 231 |
+
@click.option('--output', help='Output .mp4 filename', type=str, required=True, metavar='FILE')
|
| 232 |
+
def generate_images(
|
| 233 |
+
network_pkl: str,
|
| 234 |
+
seeds: List[int],
|
| 235 |
+
shuffle_seed: Optional[int],
|
| 236 |
+
truncation_psi: float,
|
| 237 |
+
grid: Tuple[int,int],
|
| 238 |
+
num_keyframes: Optional[int],
|
| 239 |
+
stabilize_video: bool,
|
| 240 |
+
w_frames: int,
|
| 241 |
+
output: str
|
| 242 |
+
):
|
| 243 |
+
"""Render a latent vector interpolation video.
|
| 244 |
+
|
| 245 |
+
Examples:
|
| 246 |
+
|
| 247 |
+
\b
|
| 248 |
+
# Render a 4x2 grid of interpolations for seeds 0 through 31.
|
| 249 |
+
python gen_video.py --output=lerp.mp4 --trunc=1 --seeds=0-31 --grid=4x2 \\
|
| 250 |
+
--network=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-r-afhqv2-512x512.pkl
|
| 251 |
+
|
| 252 |
+
Animation length and seed keyframes:
|
| 253 |
+
|
| 254 |
+
The animation length is either determined based on the --seeds value or explicitly
|
| 255 |
+
specified using the --num-keyframes option.
|
| 256 |
+
|
| 257 |
+
When num keyframes is specified with --num-keyframes, the output video length
|
| 258 |
+
will be 'num_keyframes*w_frames' frames.
|
| 259 |
+
|
| 260 |
+
If --num-keyframes is not specified, the number of seeds given with
|
| 261 |
+
--seeds must be divisible by grid size W*H (--grid). In this case the
|
| 262 |
+
output video length will be '# seeds/(w*h)*w_frames' frames.
|
| 263 |
+
"""
|
| 264 |
+
|
| 265 |
+
print('Loading networks from "%s"...' % network_pkl)
|
| 266 |
+
device = torch.device('cuda')
|
| 267 |
+
with dnnlib.util.open_url(network_pkl) as f:
|
| 268 |
+
G = legacy.load_network_pkl(f)['G_ema'].to(device) # type: ignore
|
| 269 |
+
|
| 270 |
+
gen_interp_video(G=G, mp4=output, bitrate='12M', grid_dims=grid, num_keyframes=num_keyframes, w_frames=w_frames,
|
| 271 |
+
seeds=seeds, shuffle_seed=shuffle_seed, psi=truncation_psi, stabilize_video=stabilize_video)
|
| 272 |
+
|
| 273 |
+
|
| 274 |
+
# ----------------------------------------------------------------------------
|
| 275 |
+
|
| 276 |
+
|
| 277 |
+
if __name__ == "__main__":
|
| 278 |
+
generate_images() # pylint: disable=no-value-for-parameter
|
| 279 |
+
|
| 280 |
+
|
| 281 |
+
# ----------------------------------------------------------------------------
|
stylegan3-fun/generate.py
ADDED
|
@@ -0,0 +1,838 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
from typing import List, Optional, Union, Tuple
|
| 4 |
+
import click
|
| 5 |
+
|
| 6 |
+
import dnnlib
|
| 7 |
+
from torch_utils import gen_utils
|
| 8 |
+
import copy
|
| 9 |
+
|
| 10 |
+
import scipy
|
| 11 |
+
import numpy as np
|
| 12 |
+
import PIL.Image
|
| 13 |
+
import torch
|
| 14 |
+
|
| 15 |
+
import legacy
|
| 16 |
+
from viz.renderer import Renderer
|
| 17 |
+
|
| 18 |
+
os.environ['PYGAME_HIDE_SUPPORT_PROMPT'] = 'hide'
|
| 19 |
+
import moviepy.editor
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
# ----------------------------------------------------------------------------
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
# We group the different types of generation (images, grid, video, wacky stuff) into a main function
|
| 26 |
+
@click.group()
|
| 27 |
+
def main():
|
| 28 |
+
pass
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
# ----------------------------------------------------------------------------
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
@main.command(name='images')
|
| 35 |
+
@click.pass_context
|
| 36 |
+
@click.option('--network', 'network_pkl', help='Network pickle filename: can be URL, local file, or the name of the model in torch_utils.gen_utils.resume_specs', required=True)
|
| 37 |
+
@click.option('--device', help='Device to use for image generation; using the CPU is slower than the GPU', type=click.Choice(['cpu', 'cuda']), default='cuda', show_default=True)
|
| 38 |
+
@click.option('--cfg', type=click.Choice(gen_utils.available_cfgs), help='Config of the network, used only if you want to use the pretrained models in torch_utils.gen_utils.resume_specs')
|
| 39 |
+
# Synthesis options (feed a list of seeds or give the projected w to synthesize)
|
| 40 |
+
@click.option('--seeds', type=gen_utils.num_range, help='List of random seeds')
|
| 41 |
+
@click.option('--trunc', 'truncation_psi', type=float, help='Truncation psi', default=1, show_default=True)
|
| 42 |
+
@click.option('--class', 'class_idx', type=int, help='Class label (unconditional if not specified)', default=None, show_default=True)
|
| 43 |
+
@click.option('--noise-mode', help='Noise mode', type=click.Choice(['const', 'random', 'none']), default='const', show_default=True)
|
| 44 |
+
@click.option('--anchor-latent-space', '-anchor', is_flag=True, help='Anchor the latent space to w_avg to stabilize the video')
|
| 45 |
+
@click.option('--projected-w', help='Projection result file; can be either .npy or .npz files', type=click.Path(exists=True, dir_okay=False), metavar='FILE')
|
| 46 |
+
@click.option('--new-center', type=gen_utils.parse_new_center, help='New center for the W latent space; a seed (int) or a path to a projected dlatent (.npy/.npz)', default=None)
|
| 47 |
+
# Save the output of the intermediate layers
|
| 48 |
+
@click.option('--layer', 'layer_name', type=str, help='Layer name to extract; if unsure, use `--available-layers`', default=None, show_default=True)
|
| 49 |
+
@click.option('--available-layers', is_flag=True, help='List the available layers in the trained model and exit')
|
| 50 |
+
@click.option('--starting-channel', 'starting_channel', type=int, help='Starting channel for the layer extraction', default=0, show_default=True)
|
| 51 |
+
@click.option('--grayscale', 'save_grayscale', type=bool, help='Use the first channel starting from `--starting-channel` to generate a grayscale image.', default=False, show_default=True)
|
| 52 |
+
@click.option('--rgb', 'save_rgb', type=bool, help='Use 3 consecutive channels (if they exist) to generate a RGB image, starting from `--starting-channel`.', default=False, show_default=True)
|
| 53 |
+
@click.option('--rgba', 'save_rgba', type=bool, help='Use 4 consecutive channels (if they exist) to generate a RGBA image, starting from `--starting-channel`.', default=False, show_default=True)
|
| 54 |
+
@click.option('--img-scale-db', 'img_scale_db', type=click.FloatRange(min=-40, max=40), help='Scale the image pixel values, akin to "exposure" (lower, the image is grayer/, higher the more white/burnt regions)', default=0, show_default=True)
|
| 55 |
+
@click.option('--img-normalize', 'img_normalize', type=bool, help='Normalize images of the selected layer and channel', default=False, show_default=True)
|
| 56 |
+
# Grid options
|
| 57 |
+
@click.option('--save-grid', is_flag=True, help='Use flag to save image grid')
|
| 58 |
+
@click.option('--grid-width', '-gw', type=click.IntRange(min=1), help='Grid width (number of columns)', default=None)
|
| 59 |
+
@click.option('--grid-height', '-gh', type=click.IntRange(min=1), help='Grid height (number of rows)', default=None)
|
| 60 |
+
# Extra parameters for saving the results
|
| 61 |
+
@click.option('--save-dlatents', is_flag=True, help='Use flag to save individual dlatents (W) for each individual resulting image')
|
| 62 |
+
@click.option('--outdir', type=click.Path(file_okay=False), help='Directory path to save the results', default=os.path.join(os.getcwd(), 'out', 'images'), show_default=True, metavar='DIR')
|
| 63 |
+
@click.option('--description', '-desc', type=str, help='Description name for the directory path to save results', default='generate-images', show_default=True)
|
| 64 |
+
def generate_images(
|
| 65 |
+
ctx: click.Context,
|
| 66 |
+
network_pkl: str,
|
| 67 |
+
device: Optional[str],
|
| 68 |
+
cfg: Optional[str],
|
| 69 |
+
seeds: Optional[List[int]],
|
| 70 |
+
truncation_psi: Optional[float],
|
| 71 |
+
class_idx: Optional[int],
|
| 72 |
+
noise_mode: Optional[str],
|
| 73 |
+
anchor_latent_space: Optional[bool],
|
| 74 |
+
projected_w: Optional[Union[str, os.PathLike]],
|
| 75 |
+
new_center: Tuple[str, Union[int, np.ndarray]],
|
| 76 |
+
layer_name: Optional[str],
|
| 77 |
+
available_layers: Optional[bool],
|
| 78 |
+
starting_channel: Optional[int],
|
| 79 |
+
save_grayscale: Optional[bool],
|
| 80 |
+
save_rgb: Optional[bool],
|
| 81 |
+
save_rgba: Optional[bool],
|
| 82 |
+
img_scale_db: Optional[float],
|
| 83 |
+
img_normalize: Optional[bool],
|
| 84 |
+
save_grid: Optional[bool],
|
| 85 |
+
grid_width: int,
|
| 86 |
+
grid_height: int,
|
| 87 |
+
save_dlatents: Optional[bool],
|
| 88 |
+
outdir: Union[str, os.PathLike],
|
| 89 |
+
description: str,
|
| 90 |
+
):
|
| 91 |
+
"""Generate images using pretrained network pickle.
|
| 92 |
+
|
| 93 |
+
Examples:
|
| 94 |
+
|
| 95 |
+
\b
|
| 96 |
+
# Generate curated MetFaces images without truncation (Fig.10 left)
|
| 97 |
+
python generate.py images --trunc=1 --seeds=85,265,297,849 \\
|
| 98 |
+
--network=https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/metfaces.pkl
|
| 99 |
+
|
| 100 |
+
\b
|
| 101 |
+
# Generate uncurated MetFaces images with truncation (Fig.12 upper left)
|
| 102 |
+
python generate.py images --trunc=0.7 --seeds=600-605 \\
|
| 103 |
+
--network=https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/metfaces.pkl
|
| 104 |
+
|
| 105 |
+
\b
|
| 106 |
+
# Generate class conditional CIFAR-10 images (Fig.17 left, Car)
|
| 107 |
+
python generate.py images --seeds=0-35 --class=1 \\
|
| 108 |
+
--network=https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/cifar10.pkl
|
| 109 |
+
|
| 110 |
+
\b
|
| 111 |
+
# Render an image from projected W
|
| 112 |
+
python generate.py images --projected_w=projected_w.npz \\
|
| 113 |
+
--network=https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/metfaces.pkl
|
| 114 |
+
|
| 115 |
+
\b
|
| 116 |
+
Generate class conditional StyleGAN2 WikiArt images, save each individually, and save all of them as a grid
|
| 117 |
+
python generate.py images --cfg=stylegan2 --network=wikiart1024-C --class=155 \\
|
| 118 |
+
--trunc=0.7 --seeds=10-50 --save-grid
|
| 119 |
+
"""
|
| 120 |
+
# Sanity check
|
| 121 |
+
if len(seeds) < 1:
|
| 122 |
+
ctx.fail('Use `--seeds` to specify at least one seed.')
|
| 123 |
+
|
| 124 |
+
device = torch.device('cuda') if torch.cuda.is_available() and device == 'cuda' else torch.device('cpu')
|
| 125 |
+
|
| 126 |
+
# Load the network
|
| 127 |
+
G = gen_utils.load_network('G_ema', network_pkl, cfg, device)
|
| 128 |
+
|
| 129 |
+
if available_layers:
|
| 130 |
+
click.secho(f'Printing available layers (name, channels and size) for "{network_pkl}"...', fg='blue')
|
| 131 |
+
_ = Renderer().render(G=G, available_layers=available_layers)
|
| 132 |
+
sys.exit(1)
|
| 133 |
+
|
| 134 |
+
# Setup for using CPU
|
| 135 |
+
if device.type == 'cpu':
|
| 136 |
+
gen_utils.use_cpu(G)
|
| 137 |
+
|
| 138 |
+
# Stabilize/anchor the latent space
|
| 139 |
+
if anchor_latent_space:
|
| 140 |
+
gen_utils.anchor_latent_space(G)
|
| 141 |
+
|
| 142 |
+
description = 'generate-images' if len(description) == 0 else description
|
| 143 |
+
description = f'{description}-{layer_name}_layer' if layer_name is not None else description
|
| 144 |
+
# Create the run dir with the given name description
|
| 145 |
+
run_dir = gen_utils.make_run_dir(outdir, description)
|
| 146 |
+
|
| 147 |
+
# Synthesize the result of a W projection.
|
| 148 |
+
if projected_w is not None:
|
| 149 |
+
if seeds is not None:
|
| 150 |
+
print('warn: --seeds is ignored when using --projected-w')
|
| 151 |
+
print(f'Generating images from projected W "{projected_w}"')
|
| 152 |
+
ws, ext = gen_utils.get_latent_from_file(projected_w, return_ext=True)
|
| 153 |
+
ws = torch.tensor(ws, device=device)
|
| 154 |
+
assert ws.shape[1:] == (G.num_ws, G.w_dim)
|
| 155 |
+
n_digits = int(np.log10(len(ws))) + 1 # number of digits for naming the images
|
| 156 |
+
if ext == '.npy':
|
| 157 |
+
img = gen_utils.w_to_img(G, ws, noise_mode)[0]
|
| 158 |
+
PIL.Image.fromarray(img, gen_utils.channels_dict[G.synthesis.img_channels]).save(f'{run_dir}/proj.png')
|
| 159 |
+
else:
|
| 160 |
+
for idx, w in enumerate(ws):
|
| 161 |
+
img = gen_utils.w_to_img(G, w, noise_mode)[0]
|
| 162 |
+
PIL.Image.fromarray(img,
|
| 163 |
+
gen_utils.channels_dict[G.synthesis.img_channels]).save(f'{run_dir}/proj{idx:0{n_digits}d}.png')
|
| 164 |
+
return
|
| 165 |
+
|
| 166 |
+
# Labels.
|
| 167 |
+
class_idx = gen_utils.parse_class(G, class_idx, ctx)
|
| 168 |
+
label = torch.zeros([1, G.c_dim], device=device)
|
| 169 |
+
if G.c_dim != 0:
|
| 170 |
+
label[:, class_idx] = 1
|
| 171 |
+
else:
|
| 172 |
+
if class_idx is not None:
|
| 173 |
+
print('warn: --class=lbl ignored when running on an unconditional network')
|
| 174 |
+
|
| 175 |
+
if seeds is None:
|
| 176 |
+
ctx.fail('--seeds option is required when not using --projected-w')
|
| 177 |
+
|
| 178 |
+
# Recenter the latent space, if specified
|
| 179 |
+
if new_center is None:
|
| 180 |
+
w_avg = G.mapping.w_avg
|
| 181 |
+
else:
|
| 182 |
+
new_center, new_center_value = new_center
|
| 183 |
+
# We get the new center using the int (a seed) or recovered dlatent (an np.ndarray)
|
| 184 |
+
if isinstance(new_center_value, int):
|
| 185 |
+
w_avg = gen_utils.get_w_from_seed(G, device, new_center_value,
|
| 186 |
+
truncation_psi=1.0) # We want the pure dlatent
|
| 187 |
+
elif isinstance(new_center_value, np.ndarray):
|
| 188 |
+
w_avg = torch.from_numpy(new_center_value).to(device)
|
| 189 |
+
else:
|
| 190 |
+
ctx.fail('Error: New center has strange format! Only an int (seed) or a file (.npy/.npz) are accepted!')
|
| 191 |
+
|
| 192 |
+
# Generate images.
|
| 193 |
+
images = []
|
| 194 |
+
for seed_idx, seed in enumerate(seeds):
|
| 195 |
+
print('Generating image for seed %d (%d/%d) ...' % (seed, seed_idx, len(seeds)))
|
| 196 |
+
dlatent = gen_utils.get_w_from_seed(G, device, seed, truncation_psi=1.0)
|
| 197 |
+
# Do truncation trick with center (new or global)
|
| 198 |
+
w = w_avg + (dlatent - w_avg) * truncation_psi
|
| 199 |
+
|
| 200 |
+
# TODO: this is starting to look like an auxiliary function!
|
| 201 |
+
# Save the intermediate layer output.
|
| 202 |
+
if layer_name is not None:
|
| 203 |
+
# Sanity check (meh, could be done better)
|
| 204 |
+
submodule_names = {name: mod for name, mod in G.synthesis.named_modules()}
|
| 205 |
+
assert layer_name in submodule_names, f'Layer "{layer_name}" not found in the network! Available layers: {", ".join(submodule_names)}'
|
| 206 |
+
assert True in (save_grayscale, save_rgb, save_rgba), 'You must select to save the image in at least one of the three possible formats! (L, RGB, RGBA)'
|
| 207 |
+
|
| 208 |
+
sel_channels = 3 if save_rgb else (1 if save_grayscale else 4)
|
| 209 |
+
res = Renderer().render(G=G, layer_name=layer_name, dlatent=w, sel_channels=sel_channels,
|
| 210 |
+
base_channel=starting_channel, img_scale_db=img_scale_db, img_normalize=img_normalize)
|
| 211 |
+
img = res.image
|
| 212 |
+
else:
|
| 213 |
+
img = gen_utils.w_to_img(G, w, noise_mode)[0]
|
| 214 |
+
|
| 215 |
+
if save_grid:
|
| 216 |
+
images.append(img)
|
| 217 |
+
|
| 218 |
+
# Get the image format, whether user-specified or the one from the model
|
| 219 |
+
try:
|
| 220 |
+
img_format = gen_utils.channels_dict[sel_channels]
|
| 221 |
+
except NameError:
|
| 222 |
+
img_format = gen_utils.channels_dict[G.synthesis.img_channels]
|
| 223 |
+
|
| 224 |
+
# Save image, avoiding grayscale errors in PIL
|
| 225 |
+
PIL.Image.fromarray(img[:, :, 0] if img.shape[-1] == 1 else img,
|
| 226 |
+
img_format).save(os.path.join(run_dir, f'seed{seed}.png'))
|
| 227 |
+
if save_dlatents:
|
| 228 |
+
np.save(os.path.join(run_dir, f'seed{seed}.npy'), w.unsqueeze(0).cpu().numpy())
|
| 229 |
+
|
| 230 |
+
if save_grid:
|
| 231 |
+
print('Saving image grid...')
|
| 232 |
+
images = np.array(images)
|
| 233 |
+
|
| 234 |
+
# We let the function infer the shape of the grid
|
| 235 |
+
if (grid_width, grid_height) == (None, None):
|
| 236 |
+
grid = gen_utils.create_image_grid(images)
|
| 237 |
+
# The user tells the specific shape of the grid, but one value may be None
|
| 238 |
+
else:
|
| 239 |
+
grid = gen_utils.create_image_grid(images, (grid_width, grid_height))
|
| 240 |
+
|
| 241 |
+
grid = grid[:, :, 0] if grid.shape[-1] == 1 else grid
|
| 242 |
+
PIL.Image.fromarray(grid, img_format).save(os.path.join(run_dir, 'grid.png'))
|
| 243 |
+
|
| 244 |
+
# Save the configuration used
|
| 245 |
+
ctx.obj = {
|
| 246 |
+
'network_pkl': network_pkl,
|
| 247 |
+
'device': device.type,
|
| 248 |
+
'config': cfg,
|
| 249 |
+
'synthesis': {
|
| 250 |
+
'seeds': seeds,
|
| 251 |
+
'truncation_psi': truncation_psi,
|
| 252 |
+
'class_idx': class_idx,
|
| 253 |
+
'noise_mode': noise_mode,
|
| 254 |
+
'anchor_latent_space': anchor_latent_space,
|
| 255 |
+
'projected_w': projected_w,
|
| 256 |
+
'new_center': new_center
|
| 257 |
+
},
|
| 258 |
+
'intermediate_representations': {
|
| 259 |
+
'layer': layer_name,
|
| 260 |
+
'starting_channel': starting_channel,
|
| 261 |
+
'grayscale': save_grayscale,
|
| 262 |
+
'rgb': save_rgb,
|
| 263 |
+
'rgba': save_rgba,
|
| 264 |
+
'img_scale_db': img_scale_db,
|
| 265 |
+
'img_normalize': img_normalize
|
| 266 |
+
},
|
| 267 |
+
'grid_options': {
|
| 268 |
+
'save_grid': save_grid,
|
| 269 |
+
'grid_width': grid_width,
|
| 270 |
+
'grid_height': grid_height,
|
| 271 |
+
},
|
| 272 |
+
'extra_parameters': {
|
| 273 |
+
'save_dlatents': save_dlatents,
|
| 274 |
+
'run_dir': run_dir,
|
| 275 |
+
'description': description,
|
| 276 |
+
}
|
| 277 |
+
}
|
| 278 |
+
gen_utils.save_config(ctx=ctx, run_dir=run_dir)
|
| 279 |
+
|
| 280 |
+
|
| 281 |
+
# ----------------------------------------------------------------------------
|
| 282 |
+
|
| 283 |
+
|
| 284 |
+
@main.command(name='random-video')
|
| 285 |
+
@click.pass_context
|
| 286 |
+
@click.option('--network', 'network_pkl', help='Network pickle filename', required=True)
|
| 287 |
+
@click.option('--cfg', type=click.Choice(gen_utils.available_cfgs), help='Config of the network, used only if you want to use the pretrained models in torch_utils.gen_utils.resume_specs')
|
| 288 |
+
# Synthesis options
|
| 289 |
+
@click.option('--seeds', type=gen_utils.num_range, help='List of random seeds', required=True)
|
| 290 |
+
@click.option('--trunc', 'truncation_psi', type=float, help='Truncation psi', default=1, show_default=True)
|
| 291 |
+
@click.option('--new-center', type=gen_utils.parse_new_center, help='New center for the W latent space; a seed (int) or a path to a projected dlatent (.npy/.npz)', default=None)
|
| 292 |
+
@click.option('--class', 'class_idx', type=int, help='Class label (unconditional if not specified)')
|
| 293 |
+
@click.option('--noise-mode', help='Noise mode', type=click.Choice(['const', 'random', 'none']), default='const', show_default=True)
|
| 294 |
+
@click.option('--anchor-latent-space', '-anchor', is_flag=True, help='Anchor the latent space to w_avg to stabilize the video')
|
| 295 |
+
# Save the output of the intermediate layers
|
| 296 |
+
@click.option('--layer', 'layer_name', type=str, help='Layer name to extract; if unsure, use `--available-layers`', default=None, show_default=True)
|
| 297 |
+
@click.option('--available-layers', is_flag=True, help='List the available layers in the trained model and exit')
|
| 298 |
+
@click.option('--starting-channel', 'starting_channel', type=int, help='Starting channel for the layer extraction', default=0, show_default=True)
|
| 299 |
+
@click.option('--grayscale', 'save_grayscale', type=bool, help='Use the first channel starting from `--starting-channel` to generate a grayscale image.', default=False, show_default=True)
|
| 300 |
+
@click.option('--rgb', 'save_rgb', type=bool, help='Use 3 consecutive channels (if they exist) to generate a RGB image, starting from `--starting-channel`.', default=False, show_default=True)
|
| 301 |
+
@click.option('--img-scale-db', 'img_scale_db', type=click.FloatRange(min=-40, max=40), help='Scale the image pixel values, akin to "exposure" (lower, the image is grayer/, higher the more white/burnt regions)', default=0, show_default=True)
|
| 302 |
+
@click.option('--img-normalize', 'img_normalize', type=bool, help='Normalize images of the selected layer and channel', default=False, show_default=True)
|
| 303 |
+
# Video options
|
| 304 |
+
@click.option('--grid-width', '-gw', type=click.IntRange(min=1), help='Video grid width / number of columns', default=None, show_default=True)
|
| 305 |
+
@click.option('--grid-height', '-gh', type=click.IntRange(min=1), help='Video grid height / number of rows', default=None, show_default=True)
|
| 306 |
+
@click.option('--slowdown', type=gen_utils.parse_slowdown, help='Slow down the video by this amount; will be approximated to the nearest power of 2', default='1', show_default=True)
|
| 307 |
+
@click.option('--duration-sec', '-sec', type=float, help='Duration length of the video', default=30.0, show_default=True)
|
| 308 |
+
@click.option('--fps', type=click.IntRange(min=1), help='Video FPS.', default=30, show_default=True)
|
| 309 |
+
@click.option('--compress', is_flag=True, help='Add flag to compress the final mp4 file with ffmpeg-python (same resolution, lower file size)')
|
| 310 |
+
# Extra parameters for saving the results
|
| 311 |
+
@click.option('--outdir', type=click.Path(file_okay=False), help='Directory path to save the results', default=os.path.join(os.getcwd(), 'out', 'video'), show_default=True, metavar='DIR')
|
| 312 |
+
@click.option('--description', '-desc', type=str, help='Description name for the directory path to save results')
|
| 313 |
+
def random_interpolation_video(
|
| 314 |
+
ctx: click.Context,
|
| 315 |
+
network_pkl: Union[str, os.PathLike],
|
| 316 |
+
cfg: Optional[str],
|
| 317 |
+
seeds: List[int],
|
| 318 |
+
truncation_psi: Optional[float],
|
| 319 |
+
new_center: Tuple[str, Union[int, np.ndarray]],
|
| 320 |
+
class_idx: Optional[int],
|
| 321 |
+
noise_mode: Optional[str],
|
| 322 |
+
anchor_latent_space: Optional[bool],
|
| 323 |
+
layer_name: Optional[str],
|
| 324 |
+
available_layers: Optional[bool],
|
| 325 |
+
starting_channel: Optional[int],
|
| 326 |
+
save_grayscale: Optional[bool],
|
| 327 |
+
save_rgb: Optional[bool],
|
| 328 |
+
img_scale_db: Optional[float],
|
| 329 |
+
img_normalize: Optional[bool],
|
| 330 |
+
grid_width: int,
|
| 331 |
+
grid_height: int,
|
| 332 |
+
slowdown: Optional[int],
|
| 333 |
+
duration_sec: Optional[float],
|
| 334 |
+
fps: int,
|
| 335 |
+
outdir: Union[str, os.PathLike],
|
| 336 |
+
description: str,
|
| 337 |
+
compress: bool,
|
| 338 |
+
smoothing_sec: Optional[float] = 3.0 # for Gaussian blur; won't be a command-line parameter, change at own risk
|
| 339 |
+
):
|
| 340 |
+
"""
|
| 341 |
+
Generate a random interpolation video using a pretrained network.
|
| 342 |
+
|
| 343 |
+
Examples:
|
| 344 |
+
|
| 345 |
+
\b
|
| 346 |
+
# Generate a 30-second long, untruncated MetFaces video at 30 FPS (3 rows and 2 columns; horizontal):
|
| 347 |
+
python generate.py random-video --seeds=0-5 \\
|
| 348 |
+
--network=https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/metfaces.pkl
|
| 349 |
+
|
| 350 |
+
\b
|
| 351 |
+
# Generate a 60-second long, truncated 1x2 MetFaces video at 60 FPS (2 rows and 1 column; vertical):
|
| 352 |
+
python generate.py random-video --trunc=0.7 --seeds=10,20 --grid-width=1 --grid-height=2 \\
|
| 353 |
+
--fps=60 -sec=60 --network=https://nvlabs-fi-cdn.nvidia.com/stylegan2-ada-pytorch/pretrained/metfaces.pkl
|
| 354 |
+
|
| 355 |
+
"""
|
| 356 |
+
# Sanity check
|
| 357 |
+
if len(seeds) < 1:
|
| 358 |
+
ctx.fail('Use `--seeds` to specify at least one seed.')
|
| 359 |
+
|
| 360 |
+
device = torch.device('cuda')
|
| 361 |
+
|
| 362 |
+
# Load the network
|
| 363 |
+
G = gen_utils.load_network('G_ema', network_pkl, cfg, device)
|
| 364 |
+
|
| 365 |
+
# Print the available layers in the model
|
| 366 |
+
if available_layers:
|
| 367 |
+
click.secho(f'Printing available layers (name, channels and size) for "{network_pkl}"...', fg='blue')
|
| 368 |
+
_ = Renderer().render(G=G, available_layers=available_layers)
|
| 369 |
+
sys.exit(1)
|
| 370 |
+
|
| 371 |
+
# Sadly, render can only generate one image at a time, so for now we'll just use the first seed
|
| 372 |
+
if layer_name is not None and len(seeds) > 1:
|
| 373 |
+
print(f'Note: Only one seed is supported for layer extraction, using seed "{seeds[0]}"...')
|
| 374 |
+
seeds = seeds[:1]
|
| 375 |
+
|
| 376 |
+
# Stabilize/anchor the latent space
|
| 377 |
+
if anchor_latent_space:
|
| 378 |
+
gen_utils.anchor_latent_space(G)
|
| 379 |
+
|
| 380 |
+
# Create the run dir with the given name description; add slowdown if different from the default (1)
|
| 381 |
+
desc = 'random-video'
|
| 382 |
+
desc = f'random-video-{description}' if description is not None else desc
|
| 383 |
+
desc = f'{desc}-{slowdown}xslowdown' if slowdown != 1 else desc
|
| 384 |
+
desc = f'{desc}-{layer_name}_layer' if layer_name is not None else desc
|
| 385 |
+
run_dir = gen_utils.make_run_dir(outdir, desc)
|
| 386 |
+
|
| 387 |
+
# Number of frames in the video and its total duration in seconds
|
| 388 |
+
num_frames = int(np.rint(duration_sec * fps))
|
| 389 |
+
total_duration = duration_sec * slowdown
|
| 390 |
+
|
| 391 |
+
print('Generating latent vectors...')
|
| 392 |
+
# TODO: let another helper function handle each case, we will use it for the grid
|
| 393 |
+
# If there's more than one seed provided and the shape isn't specified by the user
|
| 394 |
+
if (grid_width is None and grid_height is None) and len(seeds) >= 1:
|
| 395 |
+
# TODO: this can be done by another function
|
| 396 |
+
# Number of images in the grid video according to the seeds provided
|
| 397 |
+
num_seeds = len(seeds)
|
| 398 |
+
# Get the grid width and height according to num, giving priority to the number of columns
|
| 399 |
+
grid_width = max(int(np.ceil(np.sqrt(num_seeds))), 1)
|
| 400 |
+
grid_height = max((num_seeds - 1) // grid_width + 1, 1)
|
| 401 |
+
grid_size = (grid_width, grid_height)
|
| 402 |
+
shape = [num_frames, G.z_dim] # This is per seed
|
| 403 |
+
# Get the z latents
|
| 404 |
+
all_latents = np.stack([np.random.RandomState(seed).randn(*shape).astype(np.float32) for seed in seeds], axis=1)
|
| 405 |
+
|
| 406 |
+
# If only one seed is provided, but the user specifies the grid shape:
|
| 407 |
+
elif None not in (grid_width, grid_height) and len(seeds) == 1:
|
| 408 |
+
grid_size = (grid_width, grid_height)
|
| 409 |
+
shape = [num_frames, np.prod(grid_size), G.z_dim]
|
| 410 |
+
# Since we have one seed, we use it to generate all latents
|
| 411 |
+
all_latents = np.random.RandomState(*seeds).randn(*shape).astype(np.float32)
|
| 412 |
+
|
| 413 |
+
# If one or more seeds are provided, and the user also specifies the grid shape:
|
| 414 |
+
elif None not in (grid_width, grid_height) and len(seeds) >= 1:
|
| 415 |
+
# Case is similar to the first one
|
| 416 |
+
num_seeds = len(seeds)
|
| 417 |
+
grid_size = (grid_width, grid_height)
|
| 418 |
+
available_slots = np.prod(grid_size)
|
| 419 |
+
if available_slots < num_seeds:
|
| 420 |
+
diff = num_seeds - available_slots
|
| 421 |
+
click.secho(f'More seeds were provided ({num_seeds}) than available spaces in the grid ({available_slots})',
|
| 422 |
+
fg='red')
|
| 423 |
+
click.secho(f'Removing the last {diff} seeds: {seeds[-diff:]}', fg='blue')
|
| 424 |
+
seeds = seeds[:available_slots]
|
| 425 |
+
shape = [num_frames, G.z_dim]
|
| 426 |
+
all_latents = np.stack([np.random.RandomState(seed).randn(*shape).astype(np.float32) for seed in seeds], axis=1)
|
| 427 |
+
|
| 428 |
+
else:
|
| 429 |
+
ctx.fail('Error: wrong combination of arguments! Please provide either a list of seeds, one seed and the grid '
|
| 430 |
+
'width and height, or more than one seed and the grid width and height')
|
| 431 |
+
|
| 432 |
+
# Let's smooth out the random latents so that now they form a loop (and are correctly generated in a 512-dim space)
|
| 433 |
+
all_latents = scipy.ndimage.gaussian_filter(all_latents, sigma=[smoothing_sec * fps, 0, 0], mode='wrap')
|
| 434 |
+
all_latents /= np.sqrt(np.mean(np.square(all_latents)))
|
| 435 |
+
|
| 436 |
+
# Name of the video
|
| 437 |
+
mp4_name = f'{grid_width}x{grid_height}-slerp-{slowdown}xslowdown'
|
| 438 |
+
|
| 439 |
+
# Labels.
|
| 440 |
+
class_idx = gen_utils.parse_class(G, class_idx, ctx)
|
| 441 |
+
label = torch.zeros([1, G.c_dim], device=device)
|
| 442 |
+
if G.c_dim != 0:
|
| 443 |
+
label[:, class_idx] = 1
|
| 444 |
+
else:
|
| 445 |
+
if class_idx is not None:
|
| 446 |
+
print('warn: --class=lbl ignored when running on an unconditional network')
|
| 447 |
+
|
| 448 |
+
# Let's slowdown the video, if so desired
|
| 449 |
+
while slowdown > 1:
|
| 450 |
+
all_latents, duration_sec, num_frames = gen_utils.double_slowdown(latents=all_latents,
|
| 451 |
+
duration=duration_sec,
|
| 452 |
+
frames=num_frames)
|
| 453 |
+
slowdown //= 2
|
| 454 |
+
|
| 455 |
+
if new_center is None:
|
| 456 |
+
w_avg = G.mapping.w_avg
|
| 457 |
+
else:
|
| 458 |
+
new_center, new_center_value = new_center
|
| 459 |
+
# We get the new center using the int (a seed) or recovered dlatent (an np.ndarray)
|
| 460 |
+
if isinstance(new_center_value, int):
|
| 461 |
+
w_avg = gen_utils.get_w_from_seed(G, device, new_center_value,
|
| 462 |
+
truncation_psi=1.0) # We want the pure dlatent
|
| 463 |
+
elif isinstance(new_center_value, np.ndarray):
|
| 464 |
+
w_avg = torch.from_numpy(new_center_value).to(device)
|
| 465 |
+
else:
|
| 466 |
+
ctx.fail('Error: New center has strange format! Only an int (seed) or a file (.npy/.npz) are accepted!')
|
| 467 |
+
|
| 468 |
+
# Auxiliary function for moviepy
|
| 469 |
+
def make_frame(t):
|
| 470 |
+
frame_idx = int(np.clip(np.round(t * fps), 0, num_frames - 1))
|
| 471 |
+
latents = torch.from_numpy(all_latents[frame_idx]).to(device)
|
| 472 |
+
# Do the truncation trick (with the global centroid or the new center provided by the user)
|
| 473 |
+
w = G.mapping(latents, None)
|
| 474 |
+
w = w_avg + (w - w_avg) * truncation_psi
|
| 475 |
+
|
| 476 |
+
# Get the images
|
| 477 |
+
|
| 478 |
+
# Save the intermediate layer output.
|
| 479 |
+
if layer_name is not None:
|
| 480 |
+
# Sanity check (again, could be done better)
|
| 481 |
+
submodule_names = {name: mod for name, mod in G.synthesis.named_modules()}
|
| 482 |
+
assert layer_name in submodule_names, f'Layer "{layer_name}" not found in the network! Available layers: {", ".join(submodule_names)}'
|
| 483 |
+
assert True in (save_grayscale, save_rgb), 'You must select to save the video in at least one of the two possible formats! (L, RGB)'
|
| 484 |
+
|
| 485 |
+
sel_channels = 3 if save_rgb else 1
|
| 486 |
+
res = Renderer().render(G=G, layer_name=layer_name, dlatent=w, sel_channels=sel_channels,
|
| 487 |
+
base_channel=starting_channel, img_scale_db=img_scale_db, img_normalize=img_normalize)
|
| 488 |
+
images = res.image
|
| 489 |
+
images = np.expand_dims(np.array(images), axis=0)
|
| 490 |
+
else:
|
| 491 |
+
images = gen_utils.w_to_img(G, w, noise_mode) # Remember, it can only be a single image
|
| 492 |
+
# RGBA -> RGB, if necessary
|
| 493 |
+
images = images[:, :, :, :3]
|
| 494 |
+
|
| 495 |
+
# Generate the grid for this timestamp
|
| 496 |
+
grid = gen_utils.create_image_grid(images, grid_size)
|
| 497 |
+
# moviepy.editor.VideoClip expects 3 channels
|
| 498 |
+
if grid.shape[2] == 1:
|
| 499 |
+
grid = grid.repeat(3, 2)
|
| 500 |
+
return grid
|
| 501 |
+
|
| 502 |
+
# Generate video using the respective make_frame function
|
| 503 |
+
videoclip = moviepy.editor.VideoClip(make_frame, duration=duration_sec)
|
| 504 |
+
videoclip.set_duration(total_duration)
|
| 505 |
+
|
| 506 |
+
mp4_name = f'{mp4_name}_{layer_name}' if layer_name is not None else mp4_name
|
| 507 |
+
|
| 508 |
+
# Change the video parameters (codec, bitrate) if you so desire
|
| 509 |
+
final_video = os.path.join(run_dir, f'{mp4_name}.mp4')
|
| 510 |
+
videoclip.write_videofile(final_video, fps=fps, codec='libx264', bitrate='16M')
|
| 511 |
+
|
| 512 |
+
# Save the configuration used
|
| 513 |
+
new_center = 'w_avg' if new_center is None else new_center
|
| 514 |
+
ctx.obj = {
|
| 515 |
+
'network_pkl': network_pkl,
|
| 516 |
+
'config': cfg,
|
| 517 |
+
'synthesis_options': {
|
| 518 |
+
'seeds': seeds,
|
| 519 |
+
'truncation_psi': truncation_psi,
|
| 520 |
+
'new_center': new_center,
|
| 521 |
+
'class_idx': class_idx,
|
| 522 |
+
'noise_mode': noise_mode,
|
| 523 |
+
'anchor_latent_space': anchor_latent_space
|
| 524 |
+
},
|
| 525 |
+
'intermediate_representations': {
|
| 526 |
+
'layer': layer_name,
|
| 527 |
+
'starting_channel': starting_channel,
|
| 528 |
+
'grayscale': save_grayscale,
|
| 529 |
+
'rgb': save_rgb,
|
| 530 |
+
'img_scale_db': img_scale_db,
|
| 531 |
+
'img_normalize': img_normalize
|
| 532 |
+
},
|
| 533 |
+
'video_options': {
|
| 534 |
+
'grid_width': grid_width,
|
| 535 |
+
'grid_height': grid_height,
|
| 536 |
+
'slowdown': slowdown,
|
| 537 |
+
'duration_sec': duration_sec,
|
| 538 |
+
'video_fps': fps,
|
| 539 |
+
'compress': compress,
|
| 540 |
+
'smoothing_sec': smoothing_sec
|
| 541 |
+
},
|
| 542 |
+
'extra_parameters': {
|
| 543 |
+
'run_dir': run_dir,
|
| 544 |
+
'description': desc
|
| 545 |
+
}
|
| 546 |
+
}
|
| 547 |
+
gen_utils.save_config(ctx=ctx, run_dir=run_dir)
|
| 548 |
+
|
| 549 |
+
# Compress the video (lower file size, same resolution)
|
| 550 |
+
if compress:
|
| 551 |
+
gen_utils.compress_video(original_video=final_video, original_video_name=mp4_name, outdir=run_dir, ctx=ctx)
|
| 552 |
+
|
| 553 |
+
|
| 554 |
+
# ----------------------------------------------------------------------------
|
| 555 |
+
|
| 556 |
+
|
| 557 |
+
@main.command('circular-video')
|
| 558 |
+
@click.pass_context
|
| 559 |
+
@click.option('--network', 'network_pkl', help='Network pickle filename', required=True)
|
| 560 |
+
@click.option('--cfg', type=click.Choice(gen_utils.available_cfgs), help='Config of the network, used only if you want to use the pretrained models in torch_utils.gen_utils.resume_specs')
|
| 561 |
+
# Synthesis options
|
| 562 |
+
@click.option('--seed', type=int, help='Random seed', required=True)
|
| 563 |
+
@click.option('--trunc', 'truncation_psi', type=float, help='Truncation psi', default=1, show_default=True)
|
| 564 |
+
@click.option('--trunc-start', 'truncation_psi_start', type=float, help='Initial value of pulsating truncation psi', default=None, show_default=True)
|
| 565 |
+
@click.option('--trunc-end', 'truncation_psi_end', type=float, help='Maximum/minimum value of pulsating truncation psi', default=None, show_default=True)
|
| 566 |
+
@click.option('--global-pulse', 'global_pulsation_trick', is_flag=True, help='If set, the truncation psi will pulsate globally (on all grid cells)')
|
| 567 |
+
@click.option('--wave-pulse', 'wave_pulsation_trick', is_flag=True, help='If set, the truncation psi will pulsate in a wave-like fashion from the upper left to the lower right in the grid')
|
| 568 |
+
@click.option('--frequency', 'pulsation_frequency', type=int, help='Frequency of the pulsation', default=1, show_default=True)
|
| 569 |
+
@click.option('--new-center', type=str, help='New center for the W latent space; a seed (int) or a path to a projected dlatent (.npy/.npz)', default=None)
|
| 570 |
+
@click.option('--new-w-avg', 'new_w_avg', type=gen_utils.parse_new_center, help='Path to a new "global" w_avg (seed or .npy/.npz file) to be used in the truncation trick', default=None)
|
| 571 |
+
@click.option('--class', 'class_idx', type=int, help='Class label (unconditional if not specified)')
|
| 572 |
+
@click.option('--noise-mode', help='Noise mode', type=click.Choice(['const', 'random', 'none']), default='const', show_default=True)
|
| 573 |
+
@click.option('--anchor-latent-space', '-anchor', is_flag=True, help='Anchor the latent space to w_avg to stabilize the video')
|
| 574 |
+
@click.option('--flesh', 'aydao_flesh_digression', is_flag=True, help='If set, we will slowly modify the constant input to the network (based on @aydao\'s work')
|
| 575 |
+
# Video options
|
| 576 |
+
@click.option('--grid-width', '-gw', type=click.IntRange(min=1), help='Video grid width / number of columns', required=True)
|
| 577 |
+
@click.option('--grid-height', '-gh', type=click.IntRange(min=1), help='Video grid height / number of rows', required=True)
|
| 578 |
+
@click.option('--duration-sec', '-sec', type=float, help='Duration length of the video', default=10.0, show_default=True)
|
| 579 |
+
@click.option('--fps', type=click.IntRange(min=1), help='Video FPS.', default=30, show_default=True)
|
| 580 |
+
@click.option('--compress', is_flag=True, help='Add flag to compress the final mp4 file with ffmpeg-python (same resolution, lower file size)')
|
| 581 |
+
# Extra parameters for saving the results
|
| 582 |
+
@click.option('--outdir', type=click.Path(file_okay=False), help='Directory path to save the results', default=os.path.join(os.getcwd(), 'out', 'video'), show_default=True, metavar='DIR')
|
| 583 |
+
@click.option('--description', '-desc', type=str, help='Description name for the directory path to save results')
|
| 584 |
+
def circular_video(
|
| 585 |
+
ctx: click.Context,
|
| 586 |
+
network_pkl: Union[str, os.PathLike],
|
| 587 |
+
cfg: Optional[str],
|
| 588 |
+
seed: int,
|
| 589 |
+
truncation_psi: Optional[float],
|
| 590 |
+
truncation_psi_start: Optional[float],
|
| 591 |
+
truncation_psi_end: Optional[float],
|
| 592 |
+
global_pulsation_trick: Optional[bool],
|
| 593 |
+
wave_pulsation_trick: Optional[bool],
|
| 594 |
+
pulsation_frequency: Optional[int],
|
| 595 |
+
new_center: Tuple[str, Union[int, np.ndarray]],
|
| 596 |
+
new_w_avg: Optional[Union[str, os.PathLike]],
|
| 597 |
+
class_idx: Optional[int],
|
| 598 |
+
noise_mode: Optional[str],
|
| 599 |
+
anchor_latent_space: Optional[bool],
|
| 600 |
+
aydao_flesh_digression: Optional[bool],
|
| 601 |
+
grid_width: int,
|
| 602 |
+
grid_height: int,
|
| 603 |
+
duration_sec: float,
|
| 604 |
+
fps: int,
|
| 605 |
+
compress: Optional[bool],
|
| 606 |
+
outdir: Union[str, os.PathLike],
|
| 607 |
+
description: str
|
| 608 |
+
):
|
| 609 |
+
"""
|
| 610 |
+
Generate a circular interpolation video in two random axes of Z, given a seed
|
| 611 |
+
"""
|
| 612 |
+
|
| 613 |
+
device = torch.device('cuda')
|
| 614 |
+
|
| 615 |
+
# Load the network
|
| 616 |
+
G = gen_utils.load_network('G_ema', network_pkl, cfg, device)
|
| 617 |
+
|
| 618 |
+
# Get the constant input
|
| 619 |
+
if aydao_flesh_digression:
|
| 620 |
+
if hasattr(G.synthesis, 'b4'):
|
| 621 |
+
model_type = 'stylegan2'
|
| 622 |
+
const_input = copy.deepcopy(G.synthesis.b4.const).cpu().numpy()
|
| 623 |
+
elif hasattr(G.synthesis, 'input'):
|
| 624 |
+
model_type = 'stylegan3'
|
| 625 |
+
input_frequencies = copy.deepcopy(G.synthesis.input.freqs).cpu().numpy()
|
| 626 |
+
input_phases = copy.deepcopy(G.synthesis.input.phases).cpu().numpy()
|
| 627 |
+
else:
|
| 628 |
+
ctx.fail('Error: This option is only available for StyleGAN2 and StyleGAN3 models!')
|
| 629 |
+
|
| 630 |
+
# Get the labels, if the model is conditional
|
| 631 |
+
class_idx = gen_utils.parse_class(G, class_idx, ctx)
|
| 632 |
+
label = torch.zeros([1, G.c_dim], device=device)
|
| 633 |
+
if G.c_dim != 0:
|
| 634 |
+
label[:, class_idx] = 1
|
| 635 |
+
else:
|
| 636 |
+
if class_idx is not None:
|
| 637 |
+
print('warn: --class=lbl ignored when running on an unconditional network')
|
| 638 |
+
|
| 639 |
+
# Get center of the latent space (global or user-indicated)
|
| 640 |
+
if new_center is None:
|
| 641 |
+
w_avg = G.mapping.w_avg
|
| 642 |
+
w_avg = w_avg.view(1, 1, -1) # [w_dim] => [1, 1, w_dim]
|
| 643 |
+
else:
|
| 644 |
+
# It's an int, so use as a seed
|
| 645 |
+
if new_center.isdigit():
|
| 646 |
+
w_avg = gen_utils.get_w_from_seed(G, device, int(new_center), truncation_psi=1.0).to(device)
|
| 647 |
+
# It's a file, so load it
|
| 648 |
+
elif os.path.isfile(new_center):
|
| 649 |
+
w_avg = gen_utils.get_latent_from_file(new_center, return_ext=False)
|
| 650 |
+
w_avg = torch.from_numpy(w_avg).to(device)
|
| 651 |
+
# It's a directory, so get all latents inside it (including subdirectories, so be careful)
|
| 652 |
+
elif os.path.isdir(new_center):
|
| 653 |
+
w_avg = gen_utils.parse_all_projected_dlatents(new_center)
|
| 654 |
+
w_avg = torch.tensor(w_avg).squeeze(1).to(device)
|
| 655 |
+
else:
|
| 656 |
+
message = 'Only seeds (int) or paths to latent files (.npy/.npz) or directories containing these are allowed for "--new-center"'
|
| 657 |
+
raise ctx.fail(message)
|
| 658 |
+
|
| 659 |
+
# Some sanity checks
|
| 660 |
+
num_centers = len(w_avg)
|
| 661 |
+
if num_centers == 0:
|
| 662 |
+
raise ctx.fail('No centers were found! If files, makes sure they are .npy or .npz files.')
|
| 663 |
+
# Just one is provided, so this will be a sort of 'global' center
|
| 664 |
+
elif num_centers == 1:
|
| 665 |
+
print(f'Using only one center (if more than one is desired, provide a directory with all of them)')
|
| 666 |
+
elif num_centers != grid_height * grid_width:
|
| 667 |
+
message = f"Number of centers ({num_centers}) doesn't match the grid size ({grid_height}x{grid_width})"
|
| 668 |
+
raise ctx.fail(message)
|
| 669 |
+
|
| 670 |
+
print('Using wave pulsation trick' if wave_pulsation_trick else 'Using global pulsation trick' if global_pulsation_trick else 'Using standard truncation trick...')
|
| 671 |
+
# Stabilize/anchor the latent space
|
| 672 |
+
if anchor_latent_space:
|
| 673 |
+
gen_utils.anchor_latent_space(G)
|
| 674 |
+
|
| 675 |
+
# Create the run dir with the given name description; add slowdown if different from the default (1)
|
| 676 |
+
desc = 'circular-video'
|
| 677 |
+
desc = f'circular-video-{description}' if description is not None else desc
|
| 678 |
+
desc = f'{desc}-aydao-flesh-digression' if aydao_flesh_digression else desc
|
| 679 |
+
run_dir = gen_utils.make_run_dir(outdir, desc)
|
| 680 |
+
|
| 681 |
+
# Calculate the total number of frames in the video
|
| 682 |
+
num_frames = int(np.rint(duration_sec * fps))
|
| 683 |
+
|
| 684 |
+
grid_size = (grid_width, grid_height)
|
| 685 |
+
# Get the latents with the random state
|
| 686 |
+
random_state = np.random.RandomState(seed)
|
| 687 |
+
# Choose two random dims on which to plot the circles (from 0 to G.z_dim-1),
|
| 688 |
+
# one pair for each element of the grid (2*grid_width*grid_height in total)
|
| 689 |
+
try:
|
| 690 |
+
z1, z2 = np.split(random_state.choice(G.z_dim, 2 * np.prod(grid_size), replace=False), 2)
|
| 691 |
+
except ValueError:
|
| 692 |
+
# Extreme case: G.z_dim < 2 * grid_width * grid_height (low G.z_dim most likely)
|
| 693 |
+
z1, z2 = np.split(random_state.choice(G.z_dim, 2 * np.prod(grid_size), replace=True), 2)
|
| 694 |
+
|
| 695 |
+
# We partition the circle in equal strides w.r.t. num_frames
|
| 696 |
+
get_angles = lambda num_frames: np.linspace(0, 2*np.pi, num_frames)
|
| 697 |
+
angles = get_angles(num_frames=num_frames)
|
| 698 |
+
|
| 699 |
+
# Basic Polar to Cartesian transformation
|
| 700 |
+
polar_to_cartesian = lambda radius, theta: (radius * np.cos(theta), radius * np.sin(theta))
|
| 701 |
+
# Using a fixed radius (this value is irrelevant), we generate the circles in each chosen grid
|
| 702 |
+
Z1, Z2 = polar_to_cartesian(radius=5.0, theta=angles)
|
| 703 |
+
|
| 704 |
+
# Our latents will be comprising mostly of zeros
|
| 705 |
+
all_latents = np.zeros([num_frames, np.prod(grid_size), G.z_dim]).astype(np.float32)
|
| 706 |
+
# Obtain all the frames belonging to the specific box in the grid,
|
| 707 |
+
# replacing the zero values with the circle perimeter values
|
| 708 |
+
for box in range(np.prod(grid_size)):
|
| 709 |
+
box_frames = all_latents[:, box]
|
| 710 |
+
box_frames[:, [z1[box], z2[box]]] = np.vstack((Z1, Z2)).T
|
| 711 |
+
|
| 712 |
+
if aydao_flesh_digression:
|
| 713 |
+
# We will modify the constant input to the network (for --cfg=stylegan2)
|
| 714 |
+
if model_type == 'stylegan2':
|
| 715 |
+
const_input_interpolation = np.random.randn(num_frames, *const_input.shape).astype(np.float32) / 4 # [num_frames, G.w_dim, 4, 4] ; "/ 4" is arbitrary
|
| 716 |
+
const_input_interpolation = scipy.ndimage.gaussian_filter(const_input_interpolation, sigma=[fps, 0, 0, 0], mode='wrap')
|
| 717 |
+
const_input_interpolation /= np.sqrt(np.mean(np.square(const_input_interpolation)))
|
| 718 |
+
elif model_type == 'stylegan3':
|
| 719 |
+
const_freq_interpolation = np.random.randn(num_frames, *input_frequencies.shape).astype(np.float32) / 32 # [num_frames, G.w_dim, 2]
|
| 720 |
+
const_freq_interpolation = scipy.ndimage.gaussian_filter(const_freq_interpolation, sigma=[5.0*fps, 0, 0], mode='wrap')
|
| 721 |
+
const_freq_interpolation /= np.sqrt(np.mean(np.square(const_freq_interpolation)))
|
| 722 |
+
|
| 723 |
+
const_phase_interpolation = np.random.randn(num_frames, *input_phases.shape).astype(np.float32) / 8 # [num_frames, G.w_dim, 2]
|
| 724 |
+
const_phase_interpolation = scipy.ndimage.gaussian_filter(const_phase_interpolation, sigma=[5.0*fps, 0], mode='wrap')
|
| 725 |
+
const_phase_interpolation /= np.sqrt(np.mean(np.square(const_phase_interpolation)))
|
| 726 |
+
|
| 727 |
+
# Convert to torch tensor
|
| 728 |
+
if new_w_avg is not None:
|
| 729 |
+
print("Moving all the latent space towards the new center...")
|
| 730 |
+
_, new_w_avg = new_w_avg
|
| 731 |
+
# We get the new center using the int (a seed) or recovered dlatent (an np.ndarray)
|
| 732 |
+
if isinstance(new_w_avg, int):
|
| 733 |
+
new_w_avg = gen_utils.get_w_from_seed(G, device, new_w_avg,
|
| 734 |
+
truncation_psi=1.0) # We want the pure dlatent
|
| 735 |
+
elif isinstance(new_w_avg, np.ndarray):
|
| 736 |
+
new_w_avg = torch.from_numpy(new_w_avg).to(device) # [1, num_ws, w_dim]
|
| 737 |
+
else:
|
| 738 |
+
ctx.fail('Error: New center has strange format! Only an int (seed) or a file (.npy/.npz) are accepted!')
|
| 739 |
+
|
| 740 |
+
# Auxiliary function for moviepy
|
| 741 |
+
def make_frame(t):
|
| 742 |
+
frame_idx = int(np.clip(np.round(t * fps), 0, num_frames - 1))
|
| 743 |
+
latents = torch.from_numpy(all_latents[frame_idx]).to(device)
|
| 744 |
+
# Get the images with the respective label
|
| 745 |
+
dlatents = gen_utils.z_to_dlatent(G, latents, label, truncation_psi=1.0) # Get the pure dlatent
|
| 746 |
+
# Do truncation trick
|
| 747 |
+
# For the truncation trick (supersedes any value chosen for truncation_psi)
|
| 748 |
+
if None not in (truncation_psi_start, truncation_psi_end):
|
| 749 |
+
# For both, truncation psi will have the general form of a sinusoid: psi = (cos(t) + alpha) / beta
|
| 750 |
+
if global_pulsation_trick:
|
| 751 |
+
tr = gen_utils.global_pulsate_psi(psi_start=truncation_psi_start,
|
| 752 |
+
psi_end=truncation_psi_end,
|
| 753 |
+
n_steps=num_frames)
|
| 754 |
+
elif wave_pulsation_trick:
|
| 755 |
+
tr = gen_utils.wave_pulse_truncation_psi(psi_start=truncation_psi_start,
|
| 756 |
+
psi_end=truncation_psi_end,
|
| 757 |
+
n_steps=num_frames,
|
| 758 |
+
grid_shape=grid_size,
|
| 759 |
+
frequency=pulsation_frequency,
|
| 760 |
+
time=frame_idx)
|
| 761 |
+
# Define how to use the truncation psi
|
| 762 |
+
if global_pulsation_trick:
|
| 763 |
+
tr = tr[frame_idx].to(device)
|
| 764 |
+
elif wave_pulsation_trick:
|
| 765 |
+
tr = tr.to(device)
|
| 766 |
+
else:
|
| 767 |
+
# It's a float, so we can just use it
|
| 768 |
+
tr = truncation_psi
|
| 769 |
+
|
| 770 |
+
w = w_avg + (dlatents - w_avg) * tr
|
| 771 |
+
# Modify the constant input
|
| 772 |
+
if aydao_flesh_digression:
|
| 773 |
+
if model_type == 'stylegan2':
|
| 774 |
+
G.synthesis.b4.const.copy_(torch.from_numpy(const_input_interpolation[frame_idx]))
|
| 775 |
+
elif model_type == 'stylegan3':
|
| 776 |
+
pass
|
| 777 |
+
# G.synthesis.input.freqs.copy_(torch.from_numpy(const_freq_interpolation[frame_idx]))
|
| 778 |
+
# G.synthesis.input.phases.copy_(torch.from_numpy(const_phase_interpolation[frame_idx]))
|
| 779 |
+
# G.synthesis.input.phases.copy_(torch.from_numpy(
|
| 780 |
+
# input_phases * np.cos(np.pi * frame_idx / num_frames) ** 2
|
| 781 |
+
# ))
|
| 782 |
+
# Get the images
|
| 783 |
+
images = gen_utils.w_to_img(G, w, noise_mode, new_w_avg, tr)
|
| 784 |
+
# RGBA -> RGB
|
| 785 |
+
images = images[:, :, :, :3]
|
| 786 |
+
# Generate the grid for this timestep
|
| 787 |
+
grid = gen_utils.create_image_grid(images, grid_size)
|
| 788 |
+
# Grayscale => RGB
|
| 789 |
+
if grid.shape[2] == 1:
|
| 790 |
+
grid = grid.repeat(3, 2)
|
| 791 |
+
return grid
|
| 792 |
+
|
| 793 |
+
# Generate video using the respective make_frame function
|
| 794 |
+
videoclip = moviepy.editor.VideoClip(make_frame, duration=duration_sec)
|
| 795 |
+
videoclip.set_duration(duration_sec)
|
| 796 |
+
|
| 797 |
+
# Name of the video
|
| 798 |
+
mp4_name = f'{grid_width}x{grid_height}-circular'
|
| 799 |
+
|
| 800 |
+
# Change the video parameters (codec, bitrate) if you so desire
|
| 801 |
+
final_video = os.path.join(run_dir, f'{mp4_name}.mp4')
|
| 802 |
+
videoclip.write_videofile(final_video, fps=fps, codec='libx264', bitrate='16M')
|
| 803 |
+
|
| 804 |
+
# Save the configuration used
|
| 805 |
+
new_center = 'w_avg' if new_center is None else new_center
|
| 806 |
+
ctx.obj = {
|
| 807 |
+
'network_pkl': network_pkl,
|
| 808 |
+
'config': cfg,
|
| 809 |
+
'seed': seed,
|
| 810 |
+
'z1, z2': [[int(i), int(j)] for i, j in zip(z1, z2)],
|
| 811 |
+
'truncation_psi': truncation_psi if isinstance(truncation_psi, float) else 'pulsating',
|
| 812 |
+
'truncation_psi_start': truncation_psi_start,
|
| 813 |
+
'truncation_psi_end': truncation_psi_end,
|
| 814 |
+
'new_center': new_center,
|
| 815 |
+
'class_idx': class_idx,
|
| 816 |
+
'noise_mode': noise_mode,
|
| 817 |
+
'grid_width': grid_width,
|
| 818 |
+
'grid_height': grid_height,
|
| 819 |
+
'duration_sec': duration_sec,
|
| 820 |
+
'video_fps': fps,
|
| 821 |
+
'run_dir': run_dir,
|
| 822 |
+
'description': desc,
|
| 823 |
+
'compress': compress
|
| 824 |
+
}
|
| 825 |
+
gen_utils.save_config(ctx=ctx, run_dir=run_dir)
|
| 826 |
+
|
| 827 |
+
# Compress the video (lower file size, same resolution)
|
| 828 |
+
if compress:
|
| 829 |
+
gen_utils.compress_video(original_video=final_video, original_video_name=mp4_name, outdir=run_dir, ctx=ctx)
|
| 830 |
+
|
| 831 |
+
# ----------------------------------------------------------------------------
|
| 832 |
+
|
| 833 |
+
|
| 834 |
+
if __name__ == "__main__":
|
| 835 |
+
main() # pylint: disable=no-value-for-parameter
|
| 836 |
+
|
| 837 |
+
|
| 838 |
+
# ----------------------------------------------------------------------------
|
stylegan3-fun/gui_utils/__init__.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
# empty
|
stylegan3-fun/gui_utils/__pycache__/__init__.cpython-311.pyc
ADDED
|
Binary file (199 Bytes). View file
|
|
|
stylegan3-fun/gui_utils/__pycache__/__init__.cpython-38.pyc
ADDED
|
Binary file (181 Bytes). View file
|
|
|
stylegan3-fun/gui_utils/__pycache__/__init__.cpython-39.pyc
ADDED
|
Binary file (181 Bytes). View file
|
|
|
stylegan3-fun/gui_utils/__pycache__/gl_utils.cpython-311.pyc
ADDED
|
Binary file (26.9 kB). View file
|
|
|
stylegan3-fun/gui_utils/__pycache__/gl_utils.cpython-38.pyc
ADDED
|
Binary file (12.1 kB). View file
|
|
|
stylegan3-fun/gui_utils/__pycache__/gl_utils.cpython-39.pyc
ADDED
|
Binary file (12.1 kB). View file
|
|
|
stylegan3-fun/gui_utils/__pycache__/glfw_window.cpython-311.pyc
ADDED
|
Binary file (13.2 kB). View file
|
|
|
stylegan3-fun/gui_utils/__pycache__/glfw_window.cpython-38.pyc
ADDED
|
Binary file (7.8 kB). View file
|
|
|
stylegan3-fun/gui_utils/__pycache__/glfw_window.cpython-39.pyc
ADDED
|
Binary file (7.78 kB). View file
|
|
|
stylegan3-fun/gui_utils/__pycache__/imgui_utils.cpython-311.pyc
ADDED
|
Binary file (9.73 kB). View file
|
|
|
stylegan3-fun/gui_utils/__pycache__/imgui_utils.cpython-38.pyc
ADDED
|
Binary file (5.1 kB). View file
|
|
|
stylegan3-fun/gui_utils/__pycache__/imgui_utils.cpython-39.pyc
ADDED
|
Binary file (5.19 kB). View file
|
|
|