Spaces:
Build error

Build error
Commit
•
910e2ad
1
Parent(s):
43fbfb0
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitignore +119 -0
- .gradio/certificate.pem +31 -0
- LICENSE +21 -0
- README - コピー.md +295 -0
- README.md +295 -12
- annotation/image_text.jsonl +20 -0
- annotation/video_text.jsonl +17 -0
- app.py +356 -0
- app_multigpu.py +143 -0
- assets/motivation.jpg +0 -0
- assets/the_great_wall.jpg +0 -0
- assets/user_study.jpg +0 -0
- assets/vbench.jpg +0 -0
- causal_video_vae_demo.ipynb +221 -0
- dataset/__init__.py +12 -0
- dataset/bucket_loader.py +148 -0
- dataset/dataloaders.py +190 -0
- dataset/dataset_cls.py +377 -0
- diffusion_schedulers/__init__.py +2 -0
- diffusion_schedulers/scheduling_cosine_ddpm.py +137 -0
- diffusion_schedulers/scheduling_flow_matching.py +297 -0
- docs/DiT.md +54 -0
- docs/VAE.md +42 -0
- image_generation_demo.ipynb +123 -0
- inference_multigpu.py +123 -0
- pyramid_dit/__init__.py +3 -0
- pyramid_dit/flux_modules/__init__.py +3 -0
- pyramid_dit/flux_modules/modeling_embedding.py +201 -0
- pyramid_dit/flux_modules/modeling_flux_block.py +1044 -0
- pyramid_dit/flux_modules/modeling_normalization.py +249 -0
- pyramid_dit/flux_modules/modeling_pyramid_flux.py +543 -0
- pyramid_dit/flux_modules/modeling_text_encoder.py +134 -0
- pyramid_dit/mmdit_modules/__init__.py +3 -0
- pyramid_dit/mmdit_modules/modeling_embedding.py +390 -0
- pyramid_dit/mmdit_modules/modeling_mmdit_block.py +671 -0
- pyramid_dit/mmdit_modules/modeling_normalization.py +179 -0
- pyramid_dit/mmdit_modules/modeling_pyramid_mmdit.py +497 -0
- pyramid_dit/mmdit_modules/modeling_text_encoder.py +140 -0
- pyramid_dit/pyramid_dit_for_video_gen_pipeline.py +1279 -0
- pyramid_flow_model.lnk +0 -0
- pyramid_flow_model/.gitattributes +35 -0
- pyramid_flow_model/README.md +191 -0
- pyramid_flow_model/causal_video_vae/config.json +92 -0
- pyramid_flow_model/causal_video_vae/diffusion_pytorch_model.bin +3 -0
- pyramid_flow_model/diffusion_transformer_384p/config.json +21 -0
- pyramid_flow_model/diffusion_transformer_384p/diffusion_pytorch_model.safetensors +3 -0
- pyramid_flow_model/diffusion_transformer_768p/config.json +21 -0
- pyramid_flow_model/diffusion_transformer_768p/diffusion_pytorch_model.safetensors +3 -0
- pyramid_flow_model/diffusion_transformer_image/config.json +21 -0
- pyramid_flow_model/diffusion_transformer_image/diffusion_pytorch_model.safetensors +3 -0
.gitignore
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Xcode
|
| 2 |
+
.DS_Store
|
| 3 |
+
.idea
|
| 4 |
+
|
| 5 |
+
# tyte-compiled / optimized / DLL files
|
| 6 |
+
__pycache__/
|
| 7 |
+
*.py[cod]
|
| 8 |
+
*$py.class
|
| 9 |
+
# C extensions
|
| 10 |
+
*.so
|
| 11 |
+
onnx_model/*.onnx
|
| 12 |
+
onnx_model/antelope/*.onnx
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
logs/
|
| 16 |
+
prompts/
|
| 17 |
+
|
| 18 |
+
# Distribution / packaging
|
| 19 |
+
.Python
|
| 20 |
+
build/
|
| 21 |
+
develop-eggs/
|
| 22 |
+
downloads/
|
| 23 |
+
eggs/
|
| 24 |
+
.eggs/
|
| 25 |
+
lib/
|
| 26 |
+
lib64/
|
| 27 |
+
parts/
|
| 28 |
+
sdist/
|
| 29 |
+
wheels/
|
| 30 |
+
share/python-wheels/
|
| 31 |
+
*.egg-info/
|
| 32 |
+
.installed.cfg
|
| 33 |
+
*.egg
|
| 34 |
+
MANIFEST
|
| 35 |
+
|
| 36 |
+
# PyInstaller
|
| 37 |
+
# Usually these files are written by a python script from a template
|
| 38 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 39 |
+
*.manifest
|
| 40 |
+
*.spec
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
# Unit test / coverage reports
|
| 44 |
+
htmlcov/
|
| 45 |
+
.tox/
|
| 46 |
+
.nox/
|
| 47 |
+
.coverage
|
| 48 |
+
.coverage.*
|
| 49 |
+
.cache
|
| 50 |
+
nosetests.xml
|
| 51 |
+
coverage.xml
|
| 52 |
+
*.cover
|
| 53 |
+
.hypothesis/
|
| 54 |
+
.pytest_cache/
|
| 55 |
+
|
| 56 |
+
# Translations
|
| 57 |
+
*.mo
|
| 58 |
+
*.pot
|
| 59 |
+
|
| 60 |
+
# Django stuff:
|
| 61 |
+
*.log
|
| 62 |
+
local_settings.py
|
| 63 |
+
db.sqlite3
|
| 64 |
+
|
| 65 |
+
# Flask stuff:
|
| 66 |
+
instance/
|
| 67 |
+
.webassets-cache
|
| 68 |
+
|
| 69 |
+
# Scrapy stuff:
|
| 70 |
+
.scrapy
|
| 71 |
+
|
| 72 |
+
# Sphinx documentation
|
| 73 |
+
docs/_build/
|
| 74 |
+
|
| 75 |
+
# PyBuilder
|
| 76 |
+
target/
|
| 77 |
+
|
| 78 |
+
# Jupyter Notebook
|
| 79 |
+
.ipynb_checkpoints
|
| 80 |
+
|
| 81 |
+
# IPython
|
| 82 |
+
profile_default/
|
| 83 |
+
ipython_config.py
|
| 84 |
+
|
| 85 |
+
# pyenv
|
| 86 |
+
.python-version
|
| 87 |
+
|
| 88 |
+
# celery beat schedule file
|
| 89 |
+
celerybeat-schedule
|
| 90 |
+
|
| 91 |
+
# SageMath parsed files
|
| 92 |
+
*.sage.py
|
| 93 |
+
|
| 94 |
+
# Environments
|
| 95 |
+
.env
|
| 96 |
+
.pt2/
|
| 97 |
+
.venv
|
| 98 |
+
env/
|
| 99 |
+
venv/
|
| 100 |
+
ENV/
|
| 101 |
+
env.bak/
|
| 102 |
+
venv.bak/
|
| 103 |
+
|
| 104 |
+
# Spyder project settings
|
| 105 |
+
.spyderproject
|
| 106 |
+
.spyproject
|
| 107 |
+
|
| 108 |
+
# Rope project settings
|
| 109 |
+
.ropeproject
|
| 110 |
+
|
| 111 |
+
# mkdocs documentation
|
| 112 |
+
/site
|
| 113 |
+
|
| 114 |
+
# mypy
|
| 115 |
+
.mypy_cache/
|
| 116 |
+
.dmypy.json
|
| 117 |
+
dmypy.json
|
| 118 |
+
.bak
|
| 119 |
+
|
.gradio/certificate.pem
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
-----BEGIN CERTIFICATE-----
|
| 2 |
+
MIIFazCCA1OgAwIBAgIRAIIQz7DSQONZRGPgu2OCiwAwDQYJKoZIhvcNAQELBQAw
|
| 3 |
+
TzELMAkGA1UEBhMCVVMxKTAnBgNVBAoTIEludGVybmV0IFNlY3VyaXR5IFJlc2Vh
|
| 4 |
+
cmNoIEdyb3VwMRUwEwYDVQQDEwxJU1JHIFJvb3QgWDEwHhcNMTUwNjA0MTEwNDM4
|
| 5 |
+
WhcNMzUwNjA0MTEwNDM4WjBPMQswCQYDVQQGEwJVUzEpMCcGA1UEChMgSW50ZXJu
|
| 6 |
+
ZXQgU2VjdXJpdHkgUmVzZWFyY2ggR3JvdXAxFTATBgNVBAMTDElTUkcgUm9vdCBY
|
| 7 |
+
MTCCAiIwDQYJKoZIhvcNAQEBBQADggIPADCCAgoCggIBAK3oJHP0FDfzm54rVygc
|
| 8 |
+
h77ct984kIxuPOZXoHj3dcKi/vVqbvYATyjb3miGbESTtrFj/RQSa78f0uoxmyF+
|
| 9 |
+
0TM8ukj13Xnfs7j/EvEhmkvBioZxaUpmZmyPfjxwv60pIgbz5MDmgK7iS4+3mX6U
|
| 10 |
+
A5/TR5d8mUgjU+g4rk8Kb4Mu0UlXjIB0ttov0DiNewNwIRt18jA8+o+u3dpjq+sW
|
| 11 |
+
T8KOEUt+zwvo/7V3LvSye0rgTBIlDHCNAymg4VMk7BPZ7hm/ELNKjD+Jo2FR3qyH
|
| 12 |
+
B5T0Y3HsLuJvW5iB4YlcNHlsdu87kGJ55tukmi8mxdAQ4Q7e2RCOFvu396j3x+UC
|
| 13 |
+
B5iPNgiV5+I3lg02dZ77DnKxHZu8A/lJBdiB3QW0KtZB6awBdpUKD9jf1b0SHzUv
|
| 14 |
+
KBds0pjBqAlkd25HN7rOrFleaJ1/ctaJxQZBKT5ZPt0m9STJEadao0xAH0ahmbWn
|
| 15 |
+
OlFuhjuefXKnEgV4We0+UXgVCwOPjdAvBbI+e0ocS3MFEvzG6uBQE3xDk3SzynTn
|
| 16 |
+
jh8BCNAw1FtxNrQHusEwMFxIt4I7mKZ9YIqioymCzLq9gwQbooMDQaHWBfEbwrbw
|
| 17 |
+
qHyGO0aoSCqI3Haadr8faqU9GY/rOPNk3sgrDQoo//fb4hVC1CLQJ13hef4Y53CI
|
| 18 |
+
rU7m2Ys6xt0nUW7/vGT1M0NPAgMBAAGjQjBAMA4GA1UdDwEB/wQEAwIBBjAPBgNV
|
| 19 |
+
HRMBAf8EBTADAQH/MB0GA1UdDgQWBBR5tFnme7bl5AFzgAiIyBpY9umbbjANBgkq
|
| 20 |
+
hkiG9w0BAQsFAAOCAgEAVR9YqbyyqFDQDLHYGmkgJykIrGF1XIpu+ILlaS/V9lZL
|
| 21 |
+
ubhzEFnTIZd+50xx+7LSYK05qAvqFyFWhfFQDlnrzuBZ6brJFe+GnY+EgPbk6ZGQ
|
| 22 |
+
3BebYhtF8GaV0nxvwuo77x/Py9auJ/GpsMiu/X1+mvoiBOv/2X/qkSsisRcOj/KK
|
| 23 |
+
NFtY2PwByVS5uCbMiogziUwthDyC3+6WVwW6LLv3xLfHTjuCvjHIInNzktHCgKQ5
|
| 24 |
+
ORAzI4JMPJ+GslWYHb4phowim57iaztXOoJwTdwJx4nLCgdNbOhdjsnvzqvHu7Ur
|
| 25 |
+
TkXWStAmzOVyyghqpZXjFaH3pO3JLF+l+/+sKAIuvtd7u+Nxe5AW0wdeRlN8NwdC
|
| 26 |
+
jNPElpzVmbUq4JUagEiuTDkHzsxHpFKVK7q4+63SM1N95R1NbdWhscdCb+ZAJzVc
|
| 27 |
+
oyi3B43njTOQ5yOf+1CceWxG1bQVs5ZufpsMljq4Ui0/1lvh+wjChP4kqKOJ2qxq
|
| 28 |
+
4RgqsahDYVvTH9w7jXbyLeiNdd8XM2w9U/t7y0Ff/9yi0GE44Za4rF2LN9d11TPA
|
| 29 |
+
mRGunUHBcnWEvgJBQl9nJEiU0Zsnvgc/ubhPgXRR4Xq37Z0j4r7g1SgEEzwxA57d
|
| 30 |
+
emyPxgcYxn/eR44/KJ4EBs+lVDR3veyJm+kXQ99b21/+jh5Xos1AnX5iItreGCc=
|
| 31 |
+
-----END CERTIFICATE-----
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2024 Yang Jin
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README - コピー.md
ADDED
|
@@ -0,0 +1,295 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: Pyramid-Flow
|
| 3 |
+
app_file: app.py
|
| 4 |
+
sdk: gradio
|
| 5 |
+
sdk_version: 5.6.0
|
| 6 |
+
---
|
| 7 |
+
<div align="center">
|
| 8 |
+
|
| 9 |
+
# ⚡️Pyramid Flow⚡️
|
| 10 |
+
|
| 11 |
+
[[Paper]](https://arxiv.org/abs/2410.05954) [[Project Page ✨]](https://pyramid-flow.github.io) [[miniFLUX Model 🚀]](https://huggingface.co/rain1011/pyramid-flow-miniflux) [[SD3 Model ⚡️]](https://huggingface.co/rain1011/pyramid-flow-sd3) [[demo 🤗](https://huggingface.co/spaces/Pyramid-Flow/pyramid-flow)]
|
| 12 |
+
|
| 13 |
+
</div>
|
| 14 |
+
|
| 15 |
+
This is the official repository for Pyramid Flow, a training-efficient **Autoregressive Video Generation** method based on **Flow Matching**. By training only on **open-source datasets**, it can generate high-quality 10-second videos at 768p resolution and 24 FPS, and naturally supports image-to-video generation.
|
| 16 |
+
|
| 17 |
+
<table class="center" border="0" style="width: 100%; text-align: left;">
|
| 18 |
+
<tr>
|
| 19 |
+
<th>10s, 768p, 24fps</th>
|
| 20 |
+
<th>5s, 768p, 24fps</th>
|
| 21 |
+
<th>Image-to-video</th>
|
| 22 |
+
</tr>
|
| 23 |
+
<tr>
|
| 24 |
+
<td><video src="https://github.com/user-attachments/assets/9935da83-ae56-4672-8747-0f46e90f7b2b" autoplay muted loop playsinline></video></td>
|
| 25 |
+
<td><video src="https://github.com/user-attachments/assets/3412848b-64db-4d9e-8dbf-11403f6d02c5" autoplay muted loop playsinline></video></td>
|
| 26 |
+
<td><video src="https://github.com/user-attachments/assets/3bd7251f-7b2c-4bee-951d-656fdb45f427" autoplay muted loop playsinline></video></td>
|
| 27 |
+
</tr>
|
| 28 |
+
</table>
|
| 29 |
+
|
| 30 |
+
## News
|
| 31 |
+
* `2024.11.13` 🚀🚀🚀 We release the [768p miniFLUX checkpoint](https://huggingface.co/rain1011/pyramid-flow-miniflux) (up to 10s).
|
| 32 |
+
|
| 33 |
+
> We have switched the model structure from SD3 to a mini FLUX to fix human structure issues, please try our 1024p image checkpoint, 384p video checkpoint (up to 5s) and 768p video checkpoint (up to 10s). The new miniflux model shows great improvement on human structure and motion stability
|
| 34 |
+
|
| 35 |
+
* `2024.10.29` ⚡️⚡️⚡️ We release [training code for VAE](#1-training-vae), [finetuning code for DiT](#2-finetuning-dit) and [new model checkpoints](https://huggingface.co/rain1011/pyramid-flow-miniflux) with FLUX structure trained from scratch.
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
* `2024.10.13` ✨✨✨ [Multi-GPU inference](#3-multi-gpu-inference) and [CPU offloading](#cpu-offloading) are supported. Use it with **less than 8GB** of GPU memory, with great speedup on multiple GPUs.
|
| 39 |
+
|
| 40 |
+
* `2024.10.11` 🤗🤗🤗 [Hugging Face demo](https://huggingface.co/spaces/Pyramid-Flow/pyramid-flow) is available. Thanks [@multimodalart](https://huggingface.co/multimodalart) for the commit!
|
| 41 |
+
|
| 42 |
+
* `2024.10.10` 🚀🚀🚀 We release the [technical report](https://arxiv.org/abs/2410.05954), [project page](https://pyramid-flow.github.io) and [model checkpoint](https://huggingface.co/rain1011/pyramid-flow-sd3) of Pyramid Flow.
|
| 43 |
+
|
| 44 |
+
## Table of Contents
|
| 45 |
+
|
| 46 |
+
* [Introduction](#introduction)
|
| 47 |
+
* [Installation](#installation)
|
| 48 |
+
* [Inference](#inference)
|
| 49 |
+
1. [Quick Start with Gradio](#1-quick-start-with-gradio)
|
| 50 |
+
2. [Inference Code](#2-inference-code)
|
| 51 |
+
3. [Multi-GPU Inference](#3-multi-gpu-inference)
|
| 52 |
+
4. [Usage Tips](#4-usage-tips)
|
| 53 |
+
* [Training](#Training)
|
| 54 |
+
1. [Training VAE](#training-vae)
|
| 55 |
+
2. [Finetuning DiT](#finetuning-dit)
|
| 56 |
+
* [Gallery](#gallery)
|
| 57 |
+
* [Comparison](#comparison)
|
| 58 |
+
* [Acknowledgement](#acknowledgement)
|
| 59 |
+
* [Citation](#citation)
|
| 60 |
+
|
| 61 |
+
## Introduction
|
| 62 |
+
|
| 63 |
+

|
| 64 |
+
|
| 65 |
+
Existing video diffusion models operate at full resolution, spending a lot of computation on very noisy latents. By contrast, our method harnesses the flexibility of flow matching ([Lipman et al., 2023](https://openreview.net/forum?id=PqvMRDCJT9t); [Liu et al., 2023](https://openreview.net/forum?id=XVjTT1nw5z); [Albergo & Vanden-Eijnden, 2023](https://openreview.net/forum?id=li7qeBbCR1t)) to interpolate between latents of different resolutions and noise levels, allowing for simultaneous generation and decompression of visual content with better computational efficiency. The entire framework is end-to-end optimized with a single DiT ([Peebles & Xie, 2023](http://openaccess.thecvf.com/content/ICCV2023/html/Peebles_Scalable_Diffusion_Models_with_Transformers_ICCV_2023_paper.html)), generating high-quality 10-second videos at 768p resolution and 24 FPS within 20.7k A100 GPU training hours.
|
| 66 |
+
|
| 67 |
+
## Installation
|
| 68 |
+
|
| 69 |
+
We recommend setting up the environment with conda. The codebase currently uses Python 3.8.10 and PyTorch 2.1.2 ([guide](https://pytorch.org/get-started/previous-versions/#v212)), and we are actively working to support a wider range of versions.
|
| 70 |
+
|
| 71 |
+
```bash
|
| 72 |
+
git clone https://github.com/jy0205/Pyramid-Flow
|
| 73 |
+
cd Pyramid-Flow
|
| 74 |
+
|
| 75 |
+
# create env using conda
|
| 76 |
+
conda create -n pyramid python==3.8.10
|
| 77 |
+
conda activate pyramid
|
| 78 |
+
pip install -r requirements.txt
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
Then, download the model from [Huggingface](https://huggingface.co/rain1011) (there are two variants: [miniFLUX](https://huggingface.co/rain1011/pyramid-flow-miniflux) or [SD3](https://huggingface.co/rain1011/pyramid-flow-sd3)). The miniFLUX models support 1024p image, 384p and 768p video generation, and the SD3-based models support 768p and 384p video generation. The 384p checkpoint generates 5-second video at 24FPS, while the 768p checkpoint generates up to 10-second video at 24FPS.
|
| 82 |
+
|
| 83 |
+
```python
|
| 84 |
+
from huggingface_hub import snapshot_download
|
| 85 |
+
|
| 86 |
+
model_path = 'PATH' # The local directory to save downloaded checkpoint
|
| 87 |
+
snapshot_download("rain1011/pyramid-flow-miniflux", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')
|
| 88 |
+
```
|
| 89 |
+
|
| 90 |
+
## Inference
|
| 91 |
+
|
| 92 |
+
### 1. Quick start with Gradio
|
| 93 |
+
|
| 94 |
+
To get started, first install [Gradio](https://www.gradio.app/guides/quickstart), set your model path at [#L36](https://github.com/jy0205/Pyramid-Flow/blob/3777f8b84bddfa2aa2b497ca919b3f40567712e6/app.py#L36), and then run on your local machine:
|
| 95 |
+
|
| 96 |
+
```bash
|
| 97 |
+
python app.py
|
| 98 |
+
```
|
| 99 |
+
|
| 100 |
+
The Gradio demo will be opened in a browser. Thanks to [@tpc2233](https://github.com/tpc2233) the commit, see [#48](https://github.com/jy0205/Pyramid-Flow/pull/48) for details.
|
| 101 |
+
|
| 102 |
+
Or, try it out effortlessly on [Hugging Face Space 🤗](https://huggingface.co/spaces/Pyramid-Flow/pyramid-flow) created by [@multimodalart](https://huggingface.co/multimodalart). Due to GPU limits, this online demo can only generate 25 frames (export at 8FPS or 24FPS). Duplicate the space to generate longer videos.
|
| 103 |
+
|
| 104 |
+
#### Quick Start on Google Colab
|
| 105 |
+
|
| 106 |
+
To quickly try out Pyramid Flow on Google Colab, run the code below:
|
| 107 |
+
|
| 108 |
+
```
|
| 109 |
+
# Setup
|
| 110 |
+
!git clone https://github.com/jy0205/Pyramid-Flow
|
| 111 |
+
%cd Pyramid-Flow
|
| 112 |
+
!pip install -r requirements.txt
|
| 113 |
+
!pip install gradio
|
| 114 |
+
|
| 115 |
+
# This code downloads miniFLUX
|
| 116 |
+
from huggingface_hub import snapshot_download
|
| 117 |
+
|
| 118 |
+
model_path = '/content/Pyramid-Flow'
|
| 119 |
+
snapshot_download("rain1011/pyramid-flow-miniflux", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')
|
| 120 |
+
|
| 121 |
+
# Start
|
| 122 |
+
!python app.py
|
| 123 |
+
```
|
| 124 |
+
|
| 125 |
+
### 2. Inference Code
|
| 126 |
+
|
| 127 |
+
To use our model, please follow the inference code in `video_generation_demo.ipynb` at [this link](https://github.com/jy0205/Pyramid-Flow/blob/main/video_generation_demo.ipynb). We strongly recommend you to try the latest published pyramid-miniflux, which shows great improvement on human structure and motion stability. Set the param `model_name` to `pyramid_flux` to use. We further simplify it into the following two-step procedure. First, load the downloaded model:
|
| 128 |
+
|
| 129 |
+
```python
|
| 130 |
+
import torch
|
| 131 |
+
from PIL import Image
|
| 132 |
+
from pyramid_dit import PyramidDiTForVideoGeneration
|
| 133 |
+
from diffusers.utils import load_image, export_to_video
|
| 134 |
+
|
| 135 |
+
torch.cuda.set_device(0)
|
| 136 |
+
model_dtype, torch_dtype = 'bf16', torch.bfloat16 # Use bf16 (not support fp16 yet)
|
| 137 |
+
|
| 138 |
+
model = PyramidDiTForVideoGeneration(
|
| 139 |
+
'PATH', # The downloaded checkpoint dir
|
| 140 |
+
model_name="pyramid_flux",
|
| 141 |
+
model_dtype,
|
| 142 |
+
model_variant='diffusion_transformer_768p',
|
| 143 |
+
)
|
| 144 |
+
|
| 145 |
+
model.vae.enable_tiling()
|
| 146 |
+
# model.vae.to("cuda")
|
| 147 |
+
# model.dit.to("cuda")
|
| 148 |
+
# model.text_encoder.to("cuda")
|
| 149 |
+
|
| 150 |
+
# if you're not using sequential offloading bellow uncomment the lines above ^
|
| 151 |
+
model.enable_sequential_cpu_offload()
|
| 152 |
+
```
|
| 153 |
+
|
| 154 |
+
Then, you can try text-to-video generation on your own prompts. Noting that the 384p version only support 5s now (set temp up to 16)!
|
| 155 |
+
|
| 156 |
+
```python
|
| 157 |
+
prompt = "A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors"
|
| 158 |
+
|
| 159 |
+
# used for 384p model variant
|
| 160 |
+
# width = 640
|
| 161 |
+
# height = 384
|
| 162 |
+
|
| 163 |
+
# used for 768p model variant
|
| 164 |
+
width = 1280
|
| 165 |
+
height = 768
|
| 166 |
+
|
| 167 |
+
with torch.no_grad(), torch.cuda.amp.autocast(enabled=True, dtype=torch_dtype):
|
| 168 |
+
frames = model.generate(
|
| 169 |
+
prompt=prompt,
|
| 170 |
+
num_inference_steps=[20, 20, 20],
|
| 171 |
+
video_num_inference_steps=[10, 10, 10],
|
| 172 |
+
height=height,
|
| 173 |
+
width=width,
|
| 174 |
+
temp=16, # temp=16: 5s, temp=31: 10s
|
| 175 |
+
guidance_scale=7.0, # The guidance for the first frame, set it to 7 for 384p variant
|
| 176 |
+
video_guidance_scale=5.0, # The guidance for the other video latent
|
| 177 |
+
output_type="pil",
|
| 178 |
+
save_memory=True, # If you have enough GPU memory, set it to `False` to improve vae decoding speed
|
| 179 |
+
)
|
| 180 |
+
|
| 181 |
+
export_to_video(frames, "./text_to_video_sample.mp4", fps=24)
|
| 182 |
+
```
|
| 183 |
+
|
| 184 |
+
As an autoregressive model, our model also supports (text conditioned) image-to-video generation:
|
| 185 |
+
|
| 186 |
+
```python
|
| 187 |
+
# used for 384p model variant
|
| 188 |
+
# width = 640
|
| 189 |
+
# height = 384
|
| 190 |
+
|
| 191 |
+
# used for 768p model variant
|
| 192 |
+
width = 1280
|
| 193 |
+
height = 768
|
| 194 |
+
|
| 195 |
+
image = Image.open('assets/the_great_wall.jpg').convert("RGB").resize((width, height))
|
| 196 |
+
prompt = "FPV flying over the Great Wall"
|
| 197 |
+
|
| 198 |
+
with torch.no_grad(), torch.cuda.amp.autocast(enabled=True, dtype=torch_dtype):
|
| 199 |
+
frames = model.generate_i2v(
|
| 200 |
+
prompt=prompt,
|
| 201 |
+
input_image=image,
|
| 202 |
+
num_inference_steps=[10, 10, 10],
|
| 203 |
+
temp=16,
|
| 204 |
+
video_guidance_scale=4.0,
|
| 205 |
+
output_type="pil",
|
| 206 |
+
save_memory=True, # If you have enough GPU memory, set it to `False` to improve vae decoding speed
|
| 207 |
+
)
|
| 208 |
+
|
| 209 |
+
export_to_video(frames, "./image_to_video_sample.mp4", fps=24)
|
| 210 |
+
```
|
| 211 |
+
|
| 212 |
+
#### CPU offloading
|
| 213 |
+
|
| 214 |
+
We also support two types of CPU offloading to reduce GPU memory requirements. Note that they may sacrifice efficiency.
|
| 215 |
+
* Adding a `cpu_offloading=True` parameter to the generate function allows inference with **less than 12GB** of GPU memory. This feature was contributed by [@Ednaordinary](https://github.com/Ednaordinary), see [#23](https://github.com/jy0205/Pyramid-Flow/pull/23) for details.
|
| 216 |
+
* Calling `model.enable_sequential_cpu_offload()` before the above procedure allows inference with **less than 8GB** of GPU memory. This feature was contributed by [@rodjjo](https://github.com/rodjjo), see [#75](https://github.com/jy0205/Pyramid-Flow/pull/75) for details.
|
| 217 |
+
|
| 218 |
+
#### MPS backend
|
| 219 |
+
|
| 220 |
+
Thanks to [@niw](https://github.com/niw), Apple Silicon users (e.g. MacBook Pro with M2 24GB) can also try our model using the MPS backend! Please see [#113](https://github.com/jy0205/Pyramid-Flow/pull/113) for the details.
|
| 221 |
+
|
| 222 |
+
### 3. Multi-GPU Inference
|
| 223 |
+
|
| 224 |
+
For users with multiple GPUs, we provide an [inference script](https://github.com/jy0205/Pyramid-Flow/blob/main/scripts/inference_multigpu.sh) that uses sequence parallelism to save memory on each GPU. This also brings a big speedup, taking only 2.5 minutes to generate a 5s, 768p, 24fps video on 4 A100 GPUs (vs. 5.5 minutes on a single A100 GPU). Run it on 2 GPUs with the following command:
|
| 225 |
+
|
| 226 |
+
```bash
|
| 227 |
+
CUDA_VISIBLE_DEVICES=0,1 sh scripts/inference_multigpu.sh
|
| 228 |
+
```
|
| 229 |
+
|
| 230 |
+
It currently supports 2 or 4 GPUs (For SD3 Version), with more configurations available in the original script. You can also launch a [multi-GPU Gradio demo](https://github.com/jy0205/Pyramid-Flow/blob/main/scripts/app_multigpu_engine.sh) created by [@tpc2233](https://github.com/tpc2233), see [#59](https://github.com/jy0205/Pyramid-Flow/pull/59) for details.
|
| 231 |
+
|
| 232 |
+
> Spoiler: We didn't even use sequence parallelism in training, thanks to our efficient pyramid flow designs.
|
| 233 |
+
|
| 234 |
+
### 4. Usage tips
|
| 235 |
+
|
| 236 |
+
* The `guidance_scale` parameter controls the visual quality. We suggest using a guidance within [7, 9] for the 768p checkpoint during text-to-video generation, and 7 for the 384p checkpoint.
|
| 237 |
+
* The `video_guidance_scale` parameter controls the motion. A larger value increases the dynamic degree and mitigates the autoregressive generation degradation, while a smaller value stabilizes the video.
|
| 238 |
+
* For 10-second video generation, we recommend using a guidance scale of 7 and a video guidance scale of 5.
|
| 239 |
+
|
| 240 |
+
## Training
|
| 241 |
+
|
| 242 |
+
### 1. Training VAE
|
| 243 |
+
|
| 244 |
+
The hardware requirements for training VAE are at least 8 A100 GPUs. Please refer to [this document](https://github.com/jy0205/Pyramid-Flow/blob/main/docs/VAE.md). This is a [MAGVIT-v2](https://arxiv.org/abs/2310.05737) like continuous 3D VAE, which should be quite flexible. Feel free to build your own video generative model on this part of VAE training code.
|
| 245 |
+
|
| 246 |
+
### 2. Finetuning DiT
|
| 247 |
+
|
| 248 |
+
The hardware requirements for finetuning DiT are at least 8 A100 GPUs. Please refer to [this document](https://github.com/jy0205/Pyramid-Flow/blob/main/docs/DiT.md). We provide instructions for both autoregressive and non-autoregressive versions of Pyramid Flow. The former is more research oriented and the latter is more stable (but less efficient without temporal pyramid).
|
| 249 |
+
|
| 250 |
+
## Gallery
|
| 251 |
+
|
| 252 |
+
The following video examples are generated at 5s, 768p, 24fps. For more results, please visit our [project page](https://pyramid-flow.github.io).
|
| 253 |
+
|
| 254 |
+
<table class="center" border="0" style="width: 100%; text-align: left;">
|
| 255 |
+
<tr>
|
| 256 |
+
<td><video src="https://github.com/user-attachments/assets/5b44a57e-fa08-4554-84a2-2c7a99f2b343" autoplay muted loop playsinline></video></td>
|
| 257 |
+
<td><video src="https://github.com/user-attachments/assets/5afd5970-de72-40e2-900d-a20d18308e8e" autoplay muted loop playsinline></video></td>
|
| 258 |
+
</tr>
|
| 259 |
+
<tr>
|
| 260 |
+
<td><video src="https://github.com/user-attachments/assets/1d44daf8-017f-40e9-bf18-1e19c0a8983b" autoplay muted loop playsinline></video></td>
|
| 261 |
+
<td><video src="https://github.com/user-attachments/assets/7f5dd901-b7d7-48cc-b67a-3c5f9e1546d2" autoplay muted loop playsinline></video></td>
|
| 262 |
+
</tr>
|
| 263 |
+
</table>
|
| 264 |
+
|
| 265 |
+
## Comparison
|
| 266 |
+
|
| 267 |
+
On VBench ([Huang et al., 2024](https://huggingface.co/spaces/Vchitect/VBench_Leaderboard)), our method surpasses all the compared open-source baselines. Even with only public video data, it achieves comparable performance to commercial models like Kling ([Kuaishou, 2024](https://kling.kuaishou.com/en)) and Gen-3 Alpha ([Runway, 2024](https://runwayml.com/research/introducing-gen-3-alpha)), especially in the quality score (84.74 vs. 84.11 of Gen-3) and motion smoothness.
|
| 268 |
+
|
| 269 |
+

|
| 270 |
+
|
| 271 |
+
We conduct an additional user study with 20+ participants. As can be seen, our method is preferred over open-source models such as [Open-Sora](https://github.com/hpcaitech/Open-Sora) and [CogVideoX-2B](https://github.com/THUDM/CogVideo) especially in terms of motion smoothness.
|
| 272 |
+
|
| 273 |
+

|
| 274 |
+
|
| 275 |
+
## Acknowledgement
|
| 276 |
+
|
| 277 |
+
We are grateful for the following awesome projects when implementing Pyramid Flow:
|
| 278 |
+
|
| 279 |
+
* [SD3 Medium](https://huggingface.co/stabilityai/stable-diffusion-3-medium) and [Flux 1.0](https://huggingface.co/black-forest-labs/FLUX.1-dev): State-of-the-art image generation models based on flow matching.
|
| 280 |
+
* [Diffusion Forcing](https://boyuan.space/diffusion-forcing) and [GameNGen](https://gamengen.github.io): Next-token prediction meets full-sequence diffusion.
|
| 281 |
+
* [WebVid-10M](https://github.com/m-bain/webvid), [OpenVid-1M](https://github.com/NJU-PCALab/OpenVid-1M) and [Open-Sora Plan](https://github.com/PKU-YuanGroup/Open-Sora-Plan): Large-scale datasets for text-to-video generation.
|
| 282 |
+
* [CogVideoX](https://github.com/THUDM/CogVideo): An open-source text-to-video generation model that shares many training details.
|
| 283 |
+
* [Video-LLaMA2](https://github.com/DAMO-NLP-SG/VideoLLaMA2): An open-source video LLM for our video recaptioning.
|
| 284 |
+
|
| 285 |
+
## Citation
|
| 286 |
+
|
| 287 |
+
Consider giving this repository a star and cite Pyramid Flow in your publications if it helps your research.
|
| 288 |
+
```
|
| 289 |
+
@article{jin2024pyramidal,
|
| 290 |
+
title={Pyramidal Flow Matching for Efficient Video Generative Modeling},
|
| 291 |
+
author={Jin, Yang and Sun, Zhicheng and Li, Ningyuan and Xu, Kun and Xu, Kun and Jiang, Hao and Zhuang, Nan and Huang, Quzhe and Song, Yang and Mu, Yadong and Lin, Zhouchen},
|
| 292 |
+
jounal={arXiv preprint arXiv:2410.05954},
|
| 293 |
+
year={2024}
|
| 294 |
+
}
|
| 295 |
+
```
|
README.md
CHANGED
|
@@ -1,12 +1,295 @@
|
|
| 1 |
-
---
|
| 2 |
-
title: Pyramid
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: Pyramid-Flow
|
| 3 |
+
app_file: app.py
|
| 4 |
+
sdk: gradio
|
| 5 |
+
sdk_version: 5.6.0
|
| 6 |
+
---
|
| 7 |
+
<div align="center">
|
| 8 |
+
|
| 9 |
+
# Pyramid Flow
|
| 10 |
+
|
| 11 |
+
[[Paper]](https://arxiv.org/abs/2410.05954) [[Project Page]](https://pyramid-flow.github.io) [[miniFLUX Model]](https://huggingface.co/rain1011/pyramid-flow-miniflux) [[SD3 Model]](https://huggingface.co/rain1011/pyramid-flow-sd3) [[demo](https://huggingface.co/spaces/Pyramid-Flow/pyramid-flow)]
|
| 12 |
+
|
| 13 |
+
</div>
|
| 14 |
+
|
| 15 |
+
This is the official repository for Pyramid Flow, a training-efficient **Autoregressive Video Generation** method based on **Flow Matching**. By training only on **open-source datasets**, it can generate high-quality 10-second videos at 768p resolution and 24 FPS, and naturally supports image-to-video generation.
|
| 16 |
+
|
| 17 |
+
<table class="center" border="0" style="width: 100%; text-align: left;">
|
| 18 |
+
<tr>
|
| 19 |
+
<th>10s, 768p, 24fps</th>
|
| 20 |
+
<th>5s, 768p, 24fps</th>
|
| 21 |
+
<th>Image-to-video</th>
|
| 22 |
+
</tr>
|
| 23 |
+
<tr>
|
| 24 |
+
<td><video src="https://github.com/user-attachments/assets/9935da83-ae56-4672-8747-0f46e90f7b2b" autoplay muted loop playsinline></video></td>
|
| 25 |
+
<td><video src="https://github.com/user-attachments/assets/3412848b-64db-4d9e-8dbf-11403f6d02c5" autoplay muted loop playsinline></video></td>
|
| 26 |
+
<td><video src="https://github.com/user-attachments/assets/3bd7251f-7b2c-4bee-951d-656fdb45f427" autoplay muted loop playsinline></video></td>
|
| 27 |
+
</tr>
|
| 28 |
+
</table>
|
| 29 |
+
|
| 30 |
+
## News
|
| 31 |
+
* `2024.11.13` We release the [768p miniFLUX checkpoint](https://huggingface.co/rain1011/pyramid-flow-miniflux) (up to 10s).
|
| 32 |
+
|
| 33 |
+
> We have switched the model structure from SD3 to a mini FLUX to fix human structure issues, please try our 1024p image checkpoint, 384p video checkpoint (up to 5s) and 768p video checkpoint (up to 10s). The new miniflux model shows great improvement on human structure and motion stability
|
| 34 |
+
|
| 35 |
+
* `2024.10.29` We release [training code for VAE](#1-training-vae), [finetuning code for DiT](#2-finetuning-dit) and [new model checkpoints](https://huggingface.co/rain1011/pyramid-flow-miniflux) with FLUX structure trained from scratch.
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
* `2024.10.13` [Multi-GPU inference](#3-multi-gpu-inference) and [CPU offloading](#cpu-offloading) are supported. Use it with **less than 8GB** of GPU memory, with great speedup on multiple GPUs.
|
| 39 |
+
|
| 40 |
+
* `2024.10.11` [Hugging Face demo](https://huggingface.co/spaces/Pyramid-Flow/pyramid-flow) is available. Thanks [@multimodalart](https://huggingface.co/multimodalart) for the commit!
|
| 41 |
+
|
| 42 |
+
* `2024.10.10` We release the [technical report](https://arxiv.org/abs/2410.05954), [project page](https://pyramid-flow.github.io) and [model checkpoint](https://huggingface.co/rain1011/pyramid-flow-sd3) of Pyramid Flow.
|
| 43 |
+
|
| 44 |
+
## Table of Contents
|
| 45 |
+
|
| 46 |
+
* [Introduction](#introduction)
|
| 47 |
+
* [Installation](#installation)
|
| 48 |
+
* [Inference](#inference)
|
| 49 |
+
1. [Quick Start with Gradio](#1-quick-start-with-gradio)
|
| 50 |
+
2. [Inference Code](#2-inference-code)
|
| 51 |
+
3. [Multi-GPU Inference](#3-multi-gpu-inference)
|
| 52 |
+
4. [Usage Tips](#4-usage-tips)
|
| 53 |
+
* [Training](#Training)
|
| 54 |
+
1. [Training VAE](#training-vae)
|
| 55 |
+
2. [Finetuning DiT](#finetuning-dit)
|
| 56 |
+
* [Gallery](#gallery)
|
| 57 |
+
* [Comparison](#comparison)
|
| 58 |
+
* [Acknowledgement](#acknowledgement)
|
| 59 |
+
* [Citation](#citation)
|
| 60 |
+
|
| 61 |
+
## Introduction
|
| 62 |
+
|
| 63 |
+

|
| 64 |
+
|
| 65 |
+
Existing video diffusion models operate at full resolution, spending a lot of computation on very noisy latents. By contrast, our method harnesses the flexibility of flow matching ([Lipman et al., 2023](https://openreview.net/forum?id=PqvMRDCJT9t); [Liu et al., 2023](https://openreview.net/forum?id=XVjTT1nw5z); [Albergo & Vanden-Eijnden, 2023](https://openreview.net/forum?id=li7qeBbCR1t)) to interpolate between latents of different resolutions and noise levels, allowing for simultaneous generation and decompression of visual content with better computational efficiency. The entire framework is end-to-end optimized with a single DiT ([Peebles & Xie, 2023](http://openaccess.thecvf.com/content/ICCV2023/html/Peebles_Scalable_Diffusion_Models_with_Transformers_ICCV_2023_paper.html)), generating high-quality 10-second videos at 768p resolution and 24 FPS within 20.7k A100 GPU training hours.
|
| 66 |
+
|
| 67 |
+
## Installation
|
| 68 |
+
|
| 69 |
+
We recommend setting up the environment with conda. The codebase currently uses Python 3.8.10 and PyTorch 2.1.2 ([guide](https://pytorch.org/get-started/previous-versions/#v212)), and we are actively working to support a wider range of versions.
|
| 70 |
+
|
| 71 |
+
```bash
|
| 72 |
+
git clone https://github.com/jy0205/Pyramid-Flow
|
| 73 |
+
cd Pyramid-Flow
|
| 74 |
+
|
| 75 |
+
# create env using conda
|
| 76 |
+
conda create -n pyramid python==3.8.10
|
| 77 |
+
conda activate pyramid
|
| 78 |
+
pip install -r requirements.txt
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
Then, download the model from [Huggingface](https://huggingface.co/rain1011) (there are two variants: [miniFLUX](https://huggingface.co/rain1011/pyramid-flow-miniflux) or [SD3](https://huggingface.co/rain1011/pyramid-flow-sd3)). The miniFLUX models support 1024p image, 384p and 768p video generation, and the SD3-based models support 768p and 384p video generation. The 384p checkpoint generates 5-second video at 24FPS, while the 768p checkpoint generates up to 10-second video at 24FPS.
|
| 82 |
+
|
| 83 |
+
```python
|
| 84 |
+
from huggingface_hub import snapshot_download
|
| 85 |
+
|
| 86 |
+
model_path = 'PATH' # The local directory to save downloaded checkpoint
|
| 87 |
+
snapshot_download("rain1011/pyramid-flow-miniflux", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')
|
| 88 |
+
```
|
| 89 |
+
|
| 90 |
+
## Inference
|
| 91 |
+
|
| 92 |
+
### 1. Quick start with Gradio
|
| 93 |
+
|
| 94 |
+
To get started, first install [Gradio](https://www.gradio.app/guides/quickstart), set your model path at [#L36](https://github.com/jy0205/Pyramid-Flow/blob/3777f8b84bddfa2aa2b497ca919b3f40567712e6/app.py#L36), and then run on your local machine:
|
| 95 |
+
|
| 96 |
+
```bash
|
| 97 |
+
python app.py
|
| 98 |
+
```
|
| 99 |
+
|
| 100 |
+
The Gradio demo will be opened in a browser. Thanks to [@tpc2233](https://github.com/tpc2233) the commit, see [#48](https://github.com/jy0205/Pyramid-Flow/pull/48) for details.
|
| 101 |
+
|
| 102 |
+
Or, try it out effortlessly on [Hugging Face Space](https://huggingface.co/spaces/Pyramid-Flow/pyramid-flow) created by [@multimodalart](https://huggingface.co/multimodalart). Due to GPU limits, this online demo can only generate 25 frames (export at 8FPS or 24FPS). Duplicate the space to generate longer videos.
|
| 103 |
+
|
| 104 |
+
#### Quick Start on Google Colab
|
| 105 |
+
|
| 106 |
+
To quickly try out Pyramid Flow on Google Colab, run the code below:
|
| 107 |
+
|
| 108 |
+
```
|
| 109 |
+
# Setup
|
| 110 |
+
!git clone https://github.com/jy0205/Pyramid-Flow
|
| 111 |
+
%cd Pyramid-Flow
|
| 112 |
+
!pip install -r requirements.txt
|
| 113 |
+
!pip install gradio
|
| 114 |
+
|
| 115 |
+
# This code downloads miniFLUX
|
| 116 |
+
from huggingface_hub import snapshot_download
|
| 117 |
+
|
| 118 |
+
model_path = '/content/Pyramid-Flow'
|
| 119 |
+
snapshot_download("rain1011/pyramid-flow-miniflux", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')
|
| 120 |
+
|
| 121 |
+
# Start
|
| 122 |
+
!python app.py
|
| 123 |
+
```
|
| 124 |
+
|
| 125 |
+
### 2. Inference Code
|
| 126 |
+
|
| 127 |
+
To use our model, please follow the inference code in `video_generation_demo.ipynb` at [this link](https://github.com/jy0205/Pyramid-Flow/blob/main/video_generation_demo.ipynb). We strongly recommend you to try the latest published pyramid-miniflux, which shows great improvement on human structure and motion stability. Set the param `model_name` to `pyramid_flux` to use. We further simplify it into the following two-step procedure. First, load the downloaded model:
|
| 128 |
+
|
| 129 |
+
```python
|
| 130 |
+
import torch
|
| 131 |
+
from PIL import Image
|
| 132 |
+
from pyramid_dit import PyramidDiTForVideoGeneration
|
| 133 |
+
from diffusers.utils import load_image, export_to_video
|
| 134 |
+
|
| 135 |
+
torch.cuda.set_device(0)
|
| 136 |
+
model_dtype, torch_dtype = 'bf16', torch.bfloat16 # Use bf16 (not support fp16 yet)
|
| 137 |
+
|
| 138 |
+
model = PyramidDiTForVideoGeneration(
|
| 139 |
+
'PATH', # The downloaded checkpoint dir
|
| 140 |
+
model_name="pyramid_flux",
|
| 141 |
+
model_dtype,
|
| 142 |
+
model_variant='diffusion_transformer_768p',
|
| 143 |
+
)
|
| 144 |
+
|
| 145 |
+
model.vae.enable_tiling()
|
| 146 |
+
# model.vae.to("cuda")
|
| 147 |
+
# model.dit.to("cuda")
|
| 148 |
+
# model.text_encoder.to("cuda")
|
| 149 |
+
|
| 150 |
+
# if you're not using sequential offloading bellow uncomment the lines above ^
|
| 151 |
+
model.enable_sequential_cpu_offload()
|
| 152 |
+
```
|
| 153 |
+
|
| 154 |
+
Then, you can try text-to-video generation on your own prompts. Noting that the 384p version only support 5s now (set temp up to 16)!
|
| 155 |
+
|
| 156 |
+
```python
|
| 157 |
+
prompt = "A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors"
|
| 158 |
+
|
| 159 |
+
# used for 384p model variant
|
| 160 |
+
# width = 640
|
| 161 |
+
# height = 384
|
| 162 |
+
|
| 163 |
+
# used for 768p model variant
|
| 164 |
+
width = 1280
|
| 165 |
+
height = 768
|
| 166 |
+
|
| 167 |
+
with torch.no_grad(), torch.cuda.amp.autocast(enabled=True, dtype=torch_dtype):
|
| 168 |
+
frames = model.generate(
|
| 169 |
+
prompt=prompt,
|
| 170 |
+
num_inference_steps=[20, 20, 20],
|
| 171 |
+
video_num_inference_steps=[10, 10, 10],
|
| 172 |
+
height=height,
|
| 173 |
+
width=width,
|
| 174 |
+
temp=16, # temp=16: 5s, temp=31: 10s
|
| 175 |
+
guidance_scale=7.0, # The guidance for the first frame, set it to 7 for 384p variant
|
| 176 |
+
video_guidance_scale=5.0, # The guidance for the other video latent
|
| 177 |
+
output_type="pil",
|
| 178 |
+
save_memory=True, # If you have enough GPU memory, set it to `False` to improve vae decoding speed
|
| 179 |
+
)
|
| 180 |
+
|
| 181 |
+
export_to_video(frames, "./text_to_video_sample.mp4", fps=24)
|
| 182 |
+
```
|
| 183 |
+
|
| 184 |
+
As an autoregressive model, our model also supports (text conditioned) image-to-video generation:
|
| 185 |
+
|
| 186 |
+
```python
|
| 187 |
+
# used for 384p model variant
|
| 188 |
+
# width = 640
|
| 189 |
+
# height = 384
|
| 190 |
+
|
| 191 |
+
# used for 768p model variant
|
| 192 |
+
width = 1280
|
| 193 |
+
height = 768
|
| 194 |
+
|
| 195 |
+
image = Image.open('assets/the_great_wall.jpg').convert("RGB").resize((width, height))
|
| 196 |
+
prompt = "FPV flying over the Great Wall"
|
| 197 |
+
|
| 198 |
+
with torch.no_grad(), torch.cuda.amp.autocast(enabled=True, dtype=torch_dtype):
|
| 199 |
+
frames = model.generate_i2v(
|
| 200 |
+
prompt=prompt,
|
| 201 |
+
input_image=image,
|
| 202 |
+
num_inference_steps=[10, 10, 10],
|
| 203 |
+
temp=16,
|
| 204 |
+
video_guidance_scale=4.0,
|
| 205 |
+
output_type="pil",
|
| 206 |
+
save_memory=True, # If you have enough GPU memory, set it to `False` to improve vae decoding speed
|
| 207 |
+
)
|
| 208 |
+
|
| 209 |
+
export_to_video(frames, "./image_to_video_sample.mp4", fps=24)
|
| 210 |
+
```
|
| 211 |
+
|
| 212 |
+
#### CPU offloading
|
| 213 |
+
|
| 214 |
+
We also support two types of CPU offloading to reduce GPU memory requirements. Note that they may sacrifice efficiency.
|
| 215 |
+
* Adding a `cpu_offloading=True` parameter to the generate function allows inference with **less than 12GB** of GPU memory. This feature was contributed by [@Ednaordinary](https://github.com/Ednaordinary), see [#23](https://github.com/jy0205/Pyramid-Flow/pull/23) for details.
|
| 216 |
+
* Calling `model.enable_sequential_cpu_offload()` before the above procedure allows inference with **less than 8GB** of GPU memory. This feature was contributed by [@rodjjo](https://github.com/rodjjo), see [#75](https://github.com/jy0205/Pyramid-Flow/pull/75) for details.
|
| 217 |
+
|
| 218 |
+
#### MPS backend
|
| 219 |
+
|
| 220 |
+
Thanks to [@niw](https://github.com/niw), Apple Silicon users (e.g. MacBook Pro with M2 24GB) can also try our model using the MPS backend! Please see [#113](https://github.com/jy0205/Pyramid-Flow/pull/113) for the details.
|
| 221 |
+
|
| 222 |
+
### 3. Multi-GPU Inference
|
| 223 |
+
|
| 224 |
+
For users with multiple GPUs, we provide an [inference script](https://github.com/jy0205/Pyramid-Flow/blob/main/scripts/inference_multigpu.sh) that uses sequence parallelism to save memory on each GPU. This also brings a big speedup, taking only 2.5 minutes to generate a 5s, 768p, 24fps video on 4 A100 GPUs (vs. 5.5 minutes on a single A100 GPU). Run it on 2 GPUs with the following command:
|
| 225 |
+
|
| 226 |
+
```bash
|
| 227 |
+
CUDA_VISIBLE_DEVICES=0,1 sh scripts/inference_multigpu.sh
|
| 228 |
+
```
|
| 229 |
+
|
| 230 |
+
It currently supports 2 or 4 GPUs (For SD3 Version), with more configurations available in the original script. You can also launch a [multi-GPU Gradio demo](https://github.com/jy0205/Pyramid-Flow/blob/main/scripts/app_multigpu_engine.sh) created by [@tpc2233](https://github.com/tpc2233), see [#59](https://github.com/jy0205/Pyramid-Flow/pull/59) for details.
|
| 231 |
+
|
| 232 |
+
> Spoiler: We didn't even use sequence parallelism in training, thanks to our efficient pyramid flow designs.
|
| 233 |
+
|
| 234 |
+
### 4. Usage tips
|
| 235 |
+
|
| 236 |
+
* The `guidance_scale` parameter controls the visual quality. We suggest using a guidance within [7, 9] for the 768p checkpoint during text-to-video generation, and 7 for the 384p checkpoint.
|
| 237 |
+
* The `video_guidance_scale` parameter controls the motion. A larger value increases the dynamic degree and mitigates the autoregressive generation degradation, while a smaller value stabilizes the video.
|
| 238 |
+
* For 10-second video generation, we recommend using a guidance scale of 7 and a video guidance scale of 5.
|
| 239 |
+
|
| 240 |
+
## Training
|
| 241 |
+
|
| 242 |
+
### 1. Training VAE
|
| 243 |
+
|
| 244 |
+
The hardware requirements for training VAE are at least 8 A100 GPUs. Please refer to [this document](https://github.com/jy0205/Pyramid-Flow/blob/main/docs/VAE.md). This is a [MAGVIT-v2](https://arxiv.org/abs/2310.05737) like continuous 3D VAE, which should be quite flexible. Feel free to build your own video generative model on this part of VAE training code.
|
| 245 |
+
|
| 246 |
+
### 2. Finetuning DiT
|
| 247 |
+
|
| 248 |
+
The hardware requirements for finetuning DiT are at least 8 A100 GPUs. Please refer to [this document](https://github.com/jy0205/Pyramid-Flow/blob/main/docs/DiT.md). We provide instructions for both autoregressive and non-autoregressive versions of Pyramid Flow. The former is more research oriented and the latter is more stable (but less efficient without temporal pyramid).
|
| 249 |
+
|
| 250 |
+
## Gallery
|
| 251 |
+
|
| 252 |
+
The following video examples are generated at 5s, 768p, 24fps. For more results, please visit our [project page](https://pyramid-flow.github.io).
|
| 253 |
+
|
| 254 |
+
<table class="center" border="0" style="width: 100%; text-align: left;">
|
| 255 |
+
<tr>
|
| 256 |
+
<td><video src="https://github.com/user-attachments/assets/5b44a57e-fa08-4554-84a2-2c7a99f2b343" autoplay muted loop playsinline></video></td>
|
| 257 |
+
<td><video src="https://github.com/user-attachments/assets/5afd5970-de72-40e2-900d-a20d18308e8e" autoplay muted loop playsinline></video></td>
|
| 258 |
+
</tr>
|
| 259 |
+
<tr>
|
| 260 |
+
<td><video src="https://github.com/user-attachments/assets/1d44daf8-017f-40e9-bf18-1e19c0a8983b" autoplay muted loop playsinline></video></td>
|
| 261 |
+
<td><video src="https://github.com/user-attachments/assets/7f5dd901-b7d7-48cc-b67a-3c5f9e1546d2" autoplay muted loop playsinline></video></td>
|
| 262 |
+
</tr>
|
| 263 |
+
</table>
|
| 264 |
+
|
| 265 |
+
## Comparison
|
| 266 |
+
|
| 267 |
+
On VBench ([Huang et al., 2024](https://huggingface.co/spaces/Vchitect/VBench_Leaderboard)), our method surpasses all the compared open-source baselines. Even with only public video data, it achieves comparable performance to commercial models like Kling ([Kuaishou, 2024](https://kling.kuaishou.com/en)) and Gen-3 Alpha ([Runway, 2024](https://runwayml.com/research/introducing-gen-3-alpha)), especially in the quality score (84.74 vs. 84.11 of Gen-3) and motion smoothness.
|
| 268 |
+
|
| 269 |
+

|
| 270 |
+
|
| 271 |
+
We conduct an additional user study with 20+ participants. As can be seen, our method is preferred over open-source models such as [Open-Sora](https://github.com/hpcaitech/Open-Sora) and [CogVideoX-2B](https://github.com/THUDM/CogVideo) especially in terms of motion smoothness.
|
| 272 |
+
|
| 273 |
+

|
| 274 |
+
|
| 275 |
+
## Acknowledgement
|
| 276 |
+
|
| 277 |
+
We are grateful for the following awesome projects when implementing Pyramid Flow:
|
| 278 |
+
|
| 279 |
+
* [SD3 Medium](https://huggingface.co/stabilityai/stable-diffusion-3-medium) and [Flux 1.0](https://huggingface.co/black-forest-labs/FLUX.1-dev): State-of-the-art image generation models based on flow matching.
|
| 280 |
+
* [Diffusion Forcing](https://boyuan.space/diffusion-forcing) and [GameNGen](https://gamengen.github.io): Next-token prediction meets full-sequence diffusion.
|
| 281 |
+
* [WebVid-10M](https://github.com/m-bain/webvid), [OpenVid-1M](https://github.com/NJU-PCALab/OpenVid-1M) and [Open-Sora Plan](https://github.com/PKU-YuanGroup/Open-Sora-Plan): Large-scale datasets for text-to-video generation.
|
| 282 |
+
* [CogVideoX](https://github.com/THUDM/CogVideo): An open-source text-to-video generation model that shares many training details.
|
| 283 |
+
* [Video-LLaMA2](https://github.com/DAMO-NLP-SG/VideoLLaMA2): An open-source video LLM for our video recaptioning.
|
| 284 |
+
|
| 285 |
+
## Citation
|
| 286 |
+
|
| 287 |
+
Consider giving this repository a star and cite Pyramid Flow in your publications if it helps your research.
|
| 288 |
+
```
|
| 289 |
+
@article{jin2024pyramidal,
|
| 290 |
+
title={Pyramidal Flow Matching for Efficient Video Generative Modeling},
|
| 291 |
+
author={Jin, Yang and Sun, Zhicheng and Li, Ningyuan and Xu, Kun and Xu, Kun and Jiang, Hao and Zhuang, Nan and Huang, Quzhe and Song, Yang and Mu, Yadong and Lin, Zhouchen},
|
| 292 |
+
jounal={arXiv preprint arXiv:2410.05954},
|
| 293 |
+
year={2024}
|
| 294 |
+
}
|
| 295 |
+
```
|
annotation/image_text.jsonl
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"image": "SAM_filter/000424/sa_4749867.jpg", "text": "a cityscape with a large body of water, such as a lake or a river, in the foreground"}
|
| 2 |
+
{"image": "SAM_filter/000311/sa_3490721.jpg", "text": "a large, stately building with a white and blue color scheme, which gives it a grand and elegant appearance"}
|
| 3 |
+
{"image": "SAM_filter/000273/sa_3059407.jpg", "text": "a close-up of a green bag containing a package of Japanese soybeans, along with a bottle of sake, a traditional Japanese alcoholic beverage"}
|
| 4 |
+
{"image": "SAM_filter/000745/sa_8344729.jpg", "text": "a large, old-fashioned building with a red and white color scheme"}
|
| 5 |
+
{"image": "SAM_filter/000832/sa_9310794.jpg", "text": "a cityscape with a large tower, likely the Eiffel Tower, as the main focal point"}
|
| 6 |
+
{"image": "SAM_filter/000427/sa_4779422.jpg", "text": "a large cruise ship, specifically a Royal Caribbean cruise ship, docked at a pier in a harbor"}
|
| 7 |
+
{"image": "SAM_filter/000105/sa_1178255.jpg", "text": "a close-up view of a computer screen with a magnifying glass placed over it"}
|
| 8 |
+
{"image": "SAM_filter/000765/sa_8560467.jpg", "text": "a tree with a sign attached to it, which is located in a lush green field"}
|
| 9 |
+
{"image": "SAM_filter/000216/sa_2417372.jpg", "text": "a large airport terminal with a long blue and white rope-style security line"}
|
| 10 |
+
{"image": "SAM_filter/000385/sa_4308806.jpg", "text": "a close-up of a cell phone screen displaying a blue and white logo, which appears to be a bank logo"}
|
| 11 |
+
{"image": "SAM_filter/000931/sa_10425835.jpg", "text": "a large body of water, possibly a lake, with a lush green landscape surrounding it"}
|
| 12 |
+
{"image": "SAM_filter/000364/sa_4079002.jpg", "text": "a large, empty airport terminal with a long row of gray metal chairs arranged in a straight line"}
|
| 13 |
+
{"image": "SAM_filter/000474/sa_5306222.jpg", "text": "a large, modern building with a tall, glass structure, which is likely a museum"}
|
| 14 |
+
{"image": "SAM_filter/000584/sa_6536849.jpg", "text": "a city street scene with a black car parked in a parking lot, a building with a balcony, and a city skyline in the background"}
|
| 15 |
+
{"image": "SAM_filter/000188/sa_2104485.jpg", "text": "a large jet fighter airplane flying through the sky, captured in a high-quality photograph"}
|
| 16 |
+
{"image": "SAM_filter/000219/sa_2458908.jpg", "text": "a stone structure with a tall tower, which is situated in a lush green garden"}
|
| 17 |
+
{"image": "SAM_filter/000440/sa_4929413.jpg", "text": "a large city street with a mix of architectural styles, including a Gothic-style building and a modern building"}
|
| 18 |
+
{"image": "SAM_filter/000739/sa_8279296.jpg", "text": "a vintage blue and white bus parked on the side of a dirt road, with a building in the background"}
|
| 19 |
+
{"image": "SAM_filter/000809/sa_9052304.jpg", "text": "a large, old stone building with a clock tower, which is situated in a small town"}
|
| 20 |
+
{"image": "SAM_filter/000294/sa_3300200.jpg", "text": "a table with various utensils, including a bowl, spoon, and fork, placed on a wooden surface"}
|
annotation/video_text.jsonl
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"video": "webvid10m/train/010451_010500/23388121.mp4", "text": "the serene beauty of a valley with a river, mountains, and clouds", "latent": "webvid10m/train/010451_010500/23388121-latent-384-2.pt", "text_fea": "text_feature/webvid10m/train/010451_010500/23388121-text.pt"}
|
| 2 |
+
{"video": "pexels/8440980-uhd_3840_2160_25fps.mp4", "text": "A group of people, including two men and two women, are seen sitting at a table, smiling and waving at the camera, and appear to be in a good mood", "latent": "pexels/8440980-uhd_3840_2160_25fps-latent-384-2.pt", "text_fea": "text_feature/pexels/8440980-uhd_3840_2160_25fps-text.pt"}
|
| 3 |
+
{"video": "webvid10m/train/176251_176300/1011015221.mp4", "text": "an aerial view of a large wheat field with a road running through it, and a car driving on the road", "latent": "webvid10m/train/176251_176300/1011015221-latent-384-4.pt", "text_fea": "text_feature/webvid10m/train/176251_176300/1011015221-text.pt"}
|
| 4 |
+
{"video": "webvid10m/train/005801_005850/22143805.mp4", "text": "a close-up of paint mixing in water, creating swirling patterns", "latent": "webvid10m/train/005801_005850/22143805-latent-384-8.pt", "text_fea": "text_feature/webvid10m/train/005801_005850/22143805-text.pt"}
|
| 5 |
+
{"video": "OpenVid-1M/videos/qsXY7FkNFwE_2_0to743.mp4", "text": "A baby girl in a pink shirt and striped pants sits in a high chair, eats a piece of bread, and looks at the camera", "latent": "OpenVid-1M/videos/qsXY7FkNFwE_2_0to743-latent-384-0.pt", "text_fea": "text_feature/OpenVid-1M/videos/qsXY7FkNFwE_2_0to743-text.pt"}
|
| 6 |
+
{"video": "webvid10m/train/134901_134950/1037990273.mp4", "text": "a field of green wheat waving in the wind", "latent": "webvid10m/train/134901_134950/1037990273-latent-384-6.pt", "text_fea": "text_feature/webvid10m/train/134901_134950/1037990273-text.pt"}
|
| 7 |
+
{"video": "pexels/5263258-uhd_2160_4096_30fps.mp4", "text": "A dog sits patiently in front of its bowl, waiting for it to be filled with food", "latent": "pexels/5263258-uhd_2160_4096_30fps-latent-384-6.pt", "text_fea": "text_feature/pexels/5263258-uhd_2160_4096_30fps-text.pt"}
|
| 8 |
+
{"video": "webvid10m/train/117851_117900/6461432.mp4", "text": "A ladybug crawls along a blade of grass in a serene natural setting", "latent": "webvid10m/train/117851_117900/6461432-latent-384-4.pt", "text_fea": "text_feature/webvid10m/train/117851_117900/6461432-text.pt"}
|
| 9 |
+
{"video": "webvid10m/train/053051_053100/1058396656.mp4", "text": "a group of construction workers working on a rooftop, with a supervisor overseeing the work", "latent": "webvid10m/train/053051_053100/1058396656-latent-384-10.pt", "text_fea": "text_feature/webvid10m/train/053051_053100/1058396656-text.pt"}
|
| 10 |
+
{"video": "webvid10m/train/073651_073700/1021916425.mp4", "text": "an aerial view of a beautiful coastline with rocky islands, blue water, and a white cloud in the sky", "latent": "webvid10m/train/073651_073700/1021916425-latent-384-4.pt", "text_fea": "text_feature/webvid10m/train/073651_073700/1021916425-text.pt"}
|
| 11 |
+
{"video": "webvid10m/train/027051_027100/1032549941.mp4", "text": "a young woman waking up in bed, smiling at the camera, and then lying back down on the bed", "latent": "webvid10m/train/027051_027100/1032549941-latent-384-10.pt", "text_fea": "text_feature/webvid10m/train/027051_027100/1032549941-text.pt"}
|
| 12 |
+
{"video": "pexels/5564564-uhd_3840_2160_24fps.mp4", "text": "a person rolling out dough on a table using a rolling pin", "latent": "pexels/5564564-uhd_3840_2160_24fps-latent-384-8.pt", "text_fea": "text_feature/pexels/5564564-uhd_3840_2160_24fps-text.pt"}
|
| 13 |
+
{"video": "webvid10m/train/073701_073750/24008116.mp4", "text": "a cityscape with a moon in the sky, and the camera pans across the city", "latent": "webvid10m/train/073701_073750/24008116-latent-384-2.pt", "text_fea": "text_feature/webvid10m/train/073701_073750/24008116-text.pt"}
|
| 14 |
+
{"video": "webvid10m/train/118351_118400/23370991.mp4", "text": "a group of dolphins swimming in the ocean, with a person on a boat nearby", "latent": "webvid10m/train/118351_118400/23370991-latent-384-2.pt", "text_fea": "text_feature/webvid10m/train/118351_118400/23370991-text.pt"}
|
| 15 |
+
{"video": "webvid10m/train/022001_022050/1023013066.mp4", "text": "a bird's eye view of a beachfront city, highlighting the hotels, pools, and proximity to the ocean", "latent": "webvid10m/train/022001_022050/1023013066-latent-384-10.pt", "text_fea": "text_feature/webvid10m/train/022001_022050/1023013066-text.pt"}
|
| 16 |
+
{"video": "webvid10m/train/004601_004650/1015979020.mp4", "text": "a bridge over a body of water, with a boat passing under it", "latent": "webvid10m/train/004601_004650/1015979020-latent-384-4.pt", "text_fea": "text_feature/webvid10m/train/004601_004650/1015979020-text.pt"}
|
| 17 |
+
{"video": "webvid10m/train/149701_149750/1034525579.mp4", "text": "a group of owls and a moon, with the moon appearing to grow larger as the video progresses", "latent": "webvid10m/train/149701_149750/1034525579-latent-384-2.pt", "text_fea": "text_feature/webvid10m/train/149701_149750/1034525579-text.pt"}
|
app.py
ADDED
|
@@ -0,0 +1,356 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import uuid
|
| 3 |
+
import gradio as gr
|
| 4 |
+
import torch
|
| 5 |
+
import PIL
|
| 6 |
+
from PIL import Image
|
| 7 |
+
from pyramid_dit import PyramidDiTForVideoGeneration
|
| 8 |
+
from diffusers.utils import export_to_video
|
| 9 |
+
from huggingface_hub import snapshot_download
|
| 10 |
+
import threading
|
| 11 |
+
import random
|
| 12 |
+
|
| 13 |
+
# Global model cache
|
| 14 |
+
model_cache = {}
|
| 15 |
+
|
| 16 |
+
# Lock to ensure thread-safe access to the model cache
|
| 17 |
+
model_cache_lock = threading.Lock()
|
| 18 |
+
|
| 19 |
+
# Configuration
|
| 20 |
+
model_name = "pyramid_flux" # or pyramid_mmdit
|
| 21 |
+
model_repo = "rain1011/pyramid-flow-sd3" if model_name == "pyramid_mmdit" else "rain1011/pyramid-flow-miniflux"
|
| 22 |
+
|
| 23 |
+
model_dtype = "bf16" # Support bf16 and fp32
|
| 24 |
+
variants = {
|
| 25 |
+
'high': 'diffusion_transformer_768p', # For high-resolution version
|
| 26 |
+
'low': 'diffusion_transformer_384p' # For low-resolution version
|
| 27 |
+
}
|
| 28 |
+
required_file = 'config.json' # Ensure config.json is present
|
| 29 |
+
width_high = 1280
|
| 30 |
+
height_high = 768
|
| 31 |
+
width_low = 640
|
| 32 |
+
height_low = 384
|
| 33 |
+
cpu_offloading = True # enable cpu_offloading by default
|
| 34 |
+
|
| 35 |
+
# Get the current working directory and create a folder to store the model
|
| 36 |
+
current_directory = os.getcwd()
|
| 37 |
+
model_path = os.path.join(current_directory, "pyramid_flow_model") # Directory to store the model
|
| 38 |
+
|
| 39 |
+
# Download the model if not already present
|
| 40 |
+
def download_model_from_hf(model_repo, model_dir, variants, required_file):
|
| 41 |
+
need_download = False
|
| 42 |
+
if not os.path.exists(model_dir):
|
| 43 |
+
print(f"[INFO] Model directory '{model_dir}' does not exist. Initiating download...")
|
| 44 |
+
need_download = True
|
| 45 |
+
else:
|
| 46 |
+
# Check if all required files exist for each variant
|
| 47 |
+
for variant_key, variant_dir in variants.items():
|
| 48 |
+
variant_path = os.path.join(model_dir, variant_dir)
|
| 49 |
+
file_path = os.path.join(variant_path, required_file)
|
| 50 |
+
if not os.path.exists(file_path):
|
| 51 |
+
print(f"[WARNING] Required file '{required_file}' missing in '{variant_path}'.")
|
| 52 |
+
need_download = True
|
| 53 |
+
break
|
| 54 |
+
|
| 55 |
+
if need_download:
|
| 56 |
+
print(f"[INFO] Downloading model from '{model_repo}' to '{model_dir}'...")
|
| 57 |
+
try:
|
| 58 |
+
snapshot_download(
|
| 59 |
+
repo_id=model_repo,
|
| 60 |
+
local_dir=model_dir,
|
| 61 |
+
local_dir_use_symlinks=False,
|
| 62 |
+
repo_type='model'
|
| 63 |
+
)
|
| 64 |
+
print("[INFO] Model download complete.")
|
| 65 |
+
except Exception as e:
|
| 66 |
+
print(f"[ERROR] Failed to download the model: {e}")
|
| 67 |
+
raise
|
| 68 |
+
else:
|
| 69 |
+
print(f"[INFO] All required model files are present in '{model_dir}'. Skipping download.")
|
| 70 |
+
|
| 71 |
+
# Download model from Hugging Face if not present
|
| 72 |
+
download_model_from_hf(model_repo, model_path, variants, required_file)
|
| 73 |
+
|
| 74 |
+
# Function to initialize the model based on user options
|
| 75 |
+
def initialize_model(variant):
|
| 76 |
+
print(f"[INFO] Initializing model with variant='{variant}', using bf16 precision...")
|
| 77 |
+
|
| 78 |
+
# Determine the correct variant directory
|
| 79 |
+
variant_dir = variants['high'] if variant == '768p' else variants['low']
|
| 80 |
+
base_path = model_path # Pass the base model path
|
| 81 |
+
|
| 82 |
+
print(f"[DEBUG] Model base path: {base_path}")
|
| 83 |
+
|
| 84 |
+
# Verify that config.json exists in the variant directory
|
| 85 |
+
config_path = os.path.join(model_path, variant_dir, 'config.json')
|
| 86 |
+
if not os.path.exists(config_path):
|
| 87 |
+
print(f"[ERROR] config.json not found in '{os.path.join(model_path, variant_dir)}'.")
|
| 88 |
+
raise FileNotFoundError(f"config.json not found in '{os.path.join(model_path, variant_dir)}'.")
|
| 89 |
+
|
| 90 |
+
if model_dtype == "bf16":
|
| 91 |
+
torch_dtype_selected = torch.bfloat16
|
| 92 |
+
else:
|
| 93 |
+
torch_dtype_selected = torch.float32
|
| 94 |
+
|
| 95 |
+
# Initialize the model
|
| 96 |
+
try:
|
| 97 |
+
|
| 98 |
+
model = PyramidDiTForVideoGeneration(
|
| 99 |
+
base_path, # Pass the base model path
|
| 100 |
+
model_name=model_name, # set to pyramid_flux or pyramid_mmdit
|
| 101 |
+
model_dtype=model_dtype, # Use bf16
|
| 102 |
+
model_variant=variant_dir, # Pass the variant directory name
|
| 103 |
+
cpu_offloading=cpu_offloading, # Pass the CPU offloading flag
|
| 104 |
+
)
|
| 105 |
+
|
| 106 |
+
# Always enable tiling for the VAE
|
| 107 |
+
model.vae.enable_tiling()
|
| 108 |
+
|
| 109 |
+
# Remove manual device placement when using CPU offloading
|
| 110 |
+
# The components will be moved to the appropriate devices automatically
|
| 111 |
+
if torch.cuda.is_available():
|
| 112 |
+
torch.cuda.set_device(0)
|
| 113 |
+
# Manual device replacement when not using CPU offloading
|
| 114 |
+
if not cpu_offloading:
|
| 115 |
+
model.vae.to("cuda")
|
| 116 |
+
model.dit.to("cuda")
|
| 117 |
+
model.text_encoder.to("cuda")
|
| 118 |
+
else:
|
| 119 |
+
print("[WARNING] CUDA is not available. Proceeding without GPU.")
|
| 120 |
+
|
| 121 |
+
print("[INFO] Model initialized successfully.")
|
| 122 |
+
return model, torch_dtype_selected
|
| 123 |
+
except Exception as e:
|
| 124 |
+
print(f"[ERROR] Error initializing model: {e}")
|
| 125 |
+
raise
|
| 126 |
+
|
| 127 |
+
# Function to get the model from cache or initialize it
|
| 128 |
+
def initialize_model_cached(variant, seed):
|
| 129 |
+
key = variant
|
| 130 |
+
|
| 131 |
+
if seed == 0:
|
| 132 |
+
seed = random.randint(0, 2**8 - 1)
|
| 133 |
+
torch.manual_seed(seed)
|
| 134 |
+
if torch.cuda.is_available():
|
| 135 |
+
torch.cuda.manual_seed(seed)
|
| 136 |
+
torch.cuda.manual_seed_all(seed)
|
| 137 |
+
|
| 138 |
+
# Check if the model is already in the cache
|
| 139 |
+
if key not in model_cache:
|
| 140 |
+
with model_cache_lock:
|
| 141 |
+
# Double-checked locking to prevent race conditions
|
| 142 |
+
if key not in model_cache:
|
| 143 |
+
model, dtype = initialize_model(variant)
|
| 144 |
+
model_cache[key] = (model, dtype)
|
| 145 |
+
|
| 146 |
+
return model_cache[key]
|
| 147 |
+
|
| 148 |
+
def resize_crop_image(img: PIL.Image.Image, tgt_width, tgt_height):
|
| 149 |
+
ori_width, ori_height = img.width, img.height
|
| 150 |
+
scale = max(tgt_width / ori_width, tgt_height / ori_height)
|
| 151 |
+
resized_width = round(ori_width * scale)
|
| 152 |
+
resized_height = round(ori_height * scale)
|
| 153 |
+
img = img.resize((resized_width, resized_height), resample=PIL.Image.LANCZOS)
|
| 154 |
+
|
| 155 |
+
left = (resized_width - tgt_width) / 2
|
| 156 |
+
top = (resized_height - tgt_height) / 2
|
| 157 |
+
right = (resized_width + tgt_width) / 2
|
| 158 |
+
bottom = (resized_height + tgt_height) / 2
|
| 159 |
+
|
| 160 |
+
# Crop the center of the image
|
| 161 |
+
img = img.crop((left, top, right, bottom))
|
| 162 |
+
|
| 163 |
+
return img
|
| 164 |
+
|
| 165 |
+
# Function to generate text-to-video
|
| 166 |
+
def generate_text_to_video(prompt, temp, guidance_scale, video_guidance_scale, resolution, seed, progress=gr.Progress()):
|
| 167 |
+
progress(0, desc="Loading model")
|
| 168 |
+
print("[DEBUG] generate_text_to_video called.")
|
| 169 |
+
variant = '768p' if resolution == "768p" else '384p'
|
| 170 |
+
height = height_high if resolution == "768p" else height_low
|
| 171 |
+
width = width_high if resolution == "768p" else width_low
|
| 172 |
+
|
| 173 |
+
def progress_callback(i, m):
|
| 174 |
+
progress(i/m)
|
| 175 |
+
|
| 176 |
+
# Initialize model based on user options using cached function
|
| 177 |
+
try:
|
| 178 |
+
model, torch_dtype_selected = initialize_model_cached(variant, seed)
|
| 179 |
+
except Exception as e:
|
| 180 |
+
print(f"[ERROR] Model initialization failed: {e}")
|
| 181 |
+
return f"Model initialization failed: {e}"
|
| 182 |
+
|
| 183 |
+
try:
|
| 184 |
+
print("[INFO] Starting text-to-video generation...")
|
| 185 |
+
with torch.no_grad(), torch.autocast('cuda', dtype=torch_dtype_selected):
|
| 186 |
+
frames = model.generate(
|
| 187 |
+
prompt=prompt,
|
| 188 |
+
num_inference_steps=[20, 20, 20],
|
| 189 |
+
video_num_inference_steps=[10, 10, 10],
|
| 190 |
+
height=height,
|
| 191 |
+
width=width,
|
| 192 |
+
temp=temp,
|
| 193 |
+
guidance_scale=guidance_scale,
|
| 194 |
+
video_guidance_scale=video_guidance_scale,
|
| 195 |
+
output_type="pil",
|
| 196 |
+
cpu_offloading=cpu_offloading,
|
| 197 |
+
save_memory=True,
|
| 198 |
+
callback=progress_callback,
|
| 199 |
+
)
|
| 200 |
+
print("[INFO] Text-to-video generation completed.")
|
| 201 |
+
except Exception as e:
|
| 202 |
+
print(f"[ERROR] Error during text-to-video generation: {e}")
|
| 203 |
+
return f"Error during video generation: {e}"
|
| 204 |
+
|
| 205 |
+
video_path = f"{str(uuid.uuid4())}_text_to_video_sample.mp4"
|
| 206 |
+
try:
|
| 207 |
+
export_to_video(frames, video_path, fps=24)
|
| 208 |
+
print(f"[INFO] Video exported to {video_path}.")
|
| 209 |
+
except Exception as e:
|
| 210 |
+
print(f"[ERROR] Error exporting video: {e}")
|
| 211 |
+
return f"Error exporting video: {e}"
|
| 212 |
+
return video_path
|
| 213 |
+
|
| 214 |
+
# Function to generate image-to-video
|
| 215 |
+
def generate_image_to_video(image, prompt, temp, video_guidance_scale, resolution, seed, progress=gr.Progress()):
|
| 216 |
+
progress(0, desc="Loading model")
|
| 217 |
+
print("[DEBUG] generate_image_to_video called.")
|
| 218 |
+
variant = '768p' if resolution == "768p" else '384p'
|
| 219 |
+
height = height_high if resolution == "768p" else height_low
|
| 220 |
+
width = width_high if resolution == "768p" else width_low
|
| 221 |
+
|
| 222 |
+
try:
|
| 223 |
+
image = resize_crop_image(image, width, height)
|
| 224 |
+
print("[INFO] Image resized and cropped successfully.")
|
| 225 |
+
except Exception as e:
|
| 226 |
+
print(f"[ERROR] Error processing image: {e}")
|
| 227 |
+
return f"Error processing image: {e}"
|
| 228 |
+
|
| 229 |
+
def progress_callback(i, m):
|
| 230 |
+
progress(i/m)
|
| 231 |
+
|
| 232 |
+
# Initialize model based on user options using cached function
|
| 233 |
+
try:
|
| 234 |
+
model, torch_dtype_selected = initialize_model_cached(variant, seed)
|
| 235 |
+
except Exception as e:
|
| 236 |
+
print(f"[ERROR] Model initialization failed: {e}")
|
| 237 |
+
return f"Model initialization failed: {e}"
|
| 238 |
+
|
| 239 |
+
try:
|
| 240 |
+
print("[INFO] Starting image-to-video generation...")
|
| 241 |
+
with torch.no_grad(), torch.autocast('cuda', dtype=torch_dtype_selected):
|
| 242 |
+
frames = model.generate_i2v(
|
| 243 |
+
prompt=prompt,
|
| 244 |
+
input_image=image,
|
| 245 |
+
num_inference_steps=[10, 10, 10],
|
| 246 |
+
temp=temp,
|
| 247 |
+
video_guidance_scale=video_guidance_scale,
|
| 248 |
+
output_type="pil",
|
| 249 |
+
cpu_offloading=cpu_offloading,
|
| 250 |
+
save_memory=True,
|
| 251 |
+
callback=progress_callback,
|
| 252 |
+
)
|
| 253 |
+
print("[INFO] Image-to-video generation completed.")
|
| 254 |
+
except Exception as e:
|
| 255 |
+
print(f"[ERROR] Error during image-to-video generation: {e}")
|
| 256 |
+
return f"Error during video generation: {e}"
|
| 257 |
+
|
| 258 |
+
video_path = f"{str(uuid.uuid4())}_image_to_video_sample.mp4"
|
| 259 |
+
try:
|
| 260 |
+
export_to_video(frames, video_path, fps=24)
|
| 261 |
+
print(f"[INFO] Video exported to {video_path}.")
|
| 262 |
+
except Exception as e:
|
| 263 |
+
print(f"[ERROR] Error exporting video: {e}")
|
| 264 |
+
return f"Error exporting video: {e}"
|
| 265 |
+
return video_path
|
| 266 |
+
|
| 267 |
+
def update_slider(resolution):
|
| 268 |
+
if resolution == "768p":
|
| 269 |
+
return [gr.update(maximum=31), gr.update(maximum=31)]
|
| 270 |
+
else:
|
| 271 |
+
return [gr.update(maximum=16), gr.update(maximum=16)]
|
| 272 |
+
|
| 273 |
+
# Gradio interface
|
| 274 |
+
with gr.Blocks() as demo:
|
| 275 |
+
gr.Markdown(
|
| 276 |
+
"""
|
| 277 |
+
# Pyramid Flow Video Generation Demo
|
| 278 |
+
|
| 279 |
+
Pyramid Flow is a training-efficient **Autoregressive Video Generation** model based on **Flow Matching**. It is trained only on open-source datasets within 20.7k A100 GPU hours.
|
| 280 |
+
|
| 281 |
+
[[Paper]](https://arxiv.org/abs/2410.05954) [[Project Page]](https://pyramid-flow.github.io) [[Code]](https://github.com/jy0205/Pyramid-Flow) [[Model]](https://huggingface.co/rain1011/pyramid-flow-sd3)
|
| 282 |
+
"""
|
| 283 |
+
)
|
| 284 |
+
|
| 285 |
+
# Shared settings
|
| 286 |
+
with gr.Row():
|
| 287 |
+
resolution_dropdown = gr.Dropdown(
|
| 288 |
+
choices=["768p", "384p"],
|
| 289 |
+
value="384p",
|
| 290 |
+
label="Model Resolution"
|
| 291 |
+
)
|
| 292 |
+
|
| 293 |
+
with gr.Tab("Text-to-Video"):
|
| 294 |
+
with gr.Row():
|
| 295 |
+
with gr.Column():
|
| 296 |
+
text_prompt = gr.Textbox(label="Prompt (Less than 128 words)", placeholder="Enter a text prompt for the video", lines=2)
|
| 297 |
+
temp_slider = gr.Slider(1, 16, value=16, step=1, label="Duration")
|
| 298 |
+
guidance_scale_slider = gr.Slider(1.0, 15.0, value=9.0, step=0.1, label="Guidance Scale")
|
| 299 |
+
video_guidance_scale_slider = gr.Slider(1.0, 10.0, value=5.0, step=0.1, label="Video Guidance Scale")
|
| 300 |
+
text_seed = gr.Number(label="Inference Seed (Enter a positive number, 0 for random)", value=0)
|
| 301 |
+
txt_generate = gr.Button("Generate Video")
|
| 302 |
+
with gr.Column():
|
| 303 |
+
txt_output = gr.Video(label="Generated Video")
|
| 304 |
+
gr.Examples(
|
| 305 |
+
examples=[
|
| 306 |
+
["A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors", 16, 7.0, 5.0, "384p"],
|
| 307 |
+
["Beautiful, snowy Tokyo city is bustling. The camera moves through the bustling city street, following several people enjoying the beautiful snowy weather and shopping at nearby stalls. Gorgeous sakura petals are flying through the wind along with snowflakes", 16, 7.0, 5.0, "384p"],
|
| 308 |
+
# ["Extreme close-up of chicken and green pepper kebabs grilling on a barbeque with flames. Shallow focus and light smoke. vivid colours", 31, 9.0, 5.0, "768p"],
|
| 309 |
+
],
|
| 310 |
+
inputs=[text_prompt, temp_slider, guidance_scale_slider, video_guidance_scale_slider, resolution_dropdown, text_seed],
|
| 311 |
+
outputs=[txt_output],
|
| 312 |
+
fn=generate_text_to_video,
|
| 313 |
+
cache_examples='lazy',
|
| 314 |
+
)
|
| 315 |
+
|
| 316 |
+
with gr.Tab("Image-to-Video"):
|
| 317 |
+
with gr.Row():
|
| 318 |
+
with gr.Column():
|
| 319 |
+
image_input = gr.Image(type="pil", label="Input Image")
|
| 320 |
+
image_prompt = gr.Textbox(label="Prompt (Less than 128 words)", placeholder="Enter a text prompt for the video", lines=2)
|
| 321 |
+
image_temp_slider = gr.Slider(2, 16, value=16, step=1, label="Duration")
|
| 322 |
+
image_video_guidance_scale_slider = gr.Slider(1.0, 7.0, value=4.0, step=0.1, label="Video Guidance Scale")
|
| 323 |
+
image_seed = gr.Number(label="Inference Seed (Enter a positive number, 0 for random)", value=0)
|
| 324 |
+
img_generate = gr.Button("Generate Video")
|
| 325 |
+
with gr.Column():
|
| 326 |
+
img_output = gr.Video(label="Generated Video")
|
| 327 |
+
gr.Examples(
|
| 328 |
+
examples=[
|
| 329 |
+
['assets/the_great_wall.jpg', 'FPV flying over the Great Wall', 16, 4.0, "384p"]
|
| 330 |
+
],
|
| 331 |
+
inputs=[image_input, image_prompt, image_temp_slider, image_video_guidance_scale_slider, resolution_dropdown, image_seed],
|
| 332 |
+
outputs=[img_output],
|
| 333 |
+
fn=generate_image_to_video,
|
| 334 |
+
cache_examples='lazy',
|
| 335 |
+
)
|
| 336 |
+
|
| 337 |
+
# Update generate functions to include resolution options
|
| 338 |
+
txt_generate.click(
|
| 339 |
+
generate_text_to_video,
|
| 340 |
+
inputs=[text_prompt, temp_slider, guidance_scale_slider, video_guidance_scale_slider, resolution_dropdown, text_seed],
|
| 341 |
+
outputs=txt_output
|
| 342 |
+
)
|
| 343 |
+
|
| 344 |
+
img_generate.click(
|
| 345 |
+
generate_image_to_video,
|
| 346 |
+
inputs=[image_input, image_prompt, image_temp_slider, image_video_guidance_scale_slider, resolution_dropdown, image_seed],
|
| 347 |
+
outputs=img_output
|
| 348 |
+
)
|
| 349 |
+
resolution_dropdown.change(
|
| 350 |
+
fn=update_slider,
|
| 351 |
+
inputs=resolution_dropdown,
|
| 352 |
+
outputs=[temp_slider, image_temp_slider]
|
| 353 |
+
)
|
| 354 |
+
|
| 355 |
+
# Launch Gradio app
|
| 356 |
+
demo.launch(share=True)
|
app_multigpu.py
ADDED
|
@@ -0,0 +1,143 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import uuid
|
| 3 |
+
import gradio as gr
|
| 4 |
+
import subprocess
|
| 5 |
+
import tempfile
|
| 6 |
+
import shutil
|
| 7 |
+
|
| 8 |
+
def run_inference_multigpu(gpus, variant, model_path, temp, guidance_scale, video_guidance_scale, resolution, prompt):
|
| 9 |
+
"""
|
| 10 |
+
Runs the external multi-GPU inference script and returns the path to the generated video.
|
| 11 |
+
"""
|
| 12 |
+
# Create a temporary directory to store inputs and outputs
|
| 13 |
+
with tempfile.TemporaryDirectory() as tmpdir:
|
| 14 |
+
output_video = os.path.join(tmpdir, f"{uuid.uuid4()}_output.mp4")
|
| 15 |
+
|
| 16 |
+
# Path to the external shell script
|
| 17 |
+
script_path = "./scripts/app_multigpu_engine.sh" # Updated script path
|
| 18 |
+
|
| 19 |
+
# Prepare the command
|
| 20 |
+
cmd = [
|
| 21 |
+
script_path,
|
| 22 |
+
str(gpus),
|
| 23 |
+
variant,
|
| 24 |
+
model_path,
|
| 25 |
+
't2v', # Task is always 't2v' since 'i2v' is removed
|
| 26 |
+
str(temp),
|
| 27 |
+
str(guidance_scale),
|
| 28 |
+
str(video_guidance_scale),
|
| 29 |
+
resolution,
|
| 30 |
+
output_video,
|
| 31 |
+
prompt # Pass the prompt directly as an argument
|
| 32 |
+
]
|
| 33 |
+
|
| 34 |
+
try:
|
| 35 |
+
# Run the external script
|
| 36 |
+
subprocess.run(cmd, check=True)
|
| 37 |
+
except subprocess.CalledProcessError as e:
|
| 38 |
+
raise RuntimeError(f"Error during video generation: {e}")
|
| 39 |
+
|
| 40 |
+
# After generation, move the video to a permanent location
|
| 41 |
+
final_output = os.path.join("generated_videos", f"{uuid.uuid4()}_output.mp4")
|
| 42 |
+
os.makedirs("generated_videos", exist_ok=True)
|
| 43 |
+
shutil.move(output_video, final_output)
|
| 44 |
+
|
| 45 |
+
return final_output
|
| 46 |
+
|
| 47 |
+
def generate_text_to_video(prompt, temp, guidance_scale, video_guidance_scale, resolution, gpus):
|
| 48 |
+
model_path = "./pyramid_flow_model" # Use the model path as specified
|
| 49 |
+
# Determine variant based on resolution
|
| 50 |
+
if resolution == "768p":
|
| 51 |
+
variant = "diffusion_transformer_768p"
|
| 52 |
+
else:
|
| 53 |
+
variant = "diffusion_transformer_384p"
|
| 54 |
+
return run_inference_multigpu(gpus, variant, model_path, temp, guidance_scale, video_guidance_scale, resolution, prompt)
|
| 55 |
+
|
| 56 |
+
# Gradio interface
|
| 57 |
+
with gr.Blocks() as demo:
|
| 58 |
+
gr.Markdown(
|
| 59 |
+
"""
|
| 60 |
+
# Pyramid Flow Video Generation Demo
|
| 61 |
+
|
| 62 |
+
Pyramid Flow is a training-efficient **Autoregressive Video Generation** model based on **Flow Matching**. It is trained only on open-source datasets within 20.7k A100 GPU hours.
|
| 63 |
+
|
| 64 |
+
[[Paper]](https://arxiv.org/abs/2410.05954) [[Project Page]](https://pyramid-flow.github.io) [[Code]](https://github.com/jy0205/Pyramid-Flow) [[Model]](https://huggingface.co/rain1011/pyramid-flow-sd3)
|
| 65 |
+
"""
|
| 66 |
+
)
|
| 67 |
+
|
| 68 |
+
# Shared settings
|
| 69 |
+
with gr.Row():
|
| 70 |
+
gpus_dropdown = gr.Dropdown(
|
| 71 |
+
choices=[2, 4],
|
| 72 |
+
value=4,
|
| 73 |
+
label="Number of GPUs"
|
| 74 |
+
)
|
| 75 |
+
resolution_dropdown = gr.Dropdown(
|
| 76 |
+
choices=["768p", "384p"],
|
| 77 |
+
value="768p",
|
| 78 |
+
label="Model Resolution"
|
| 79 |
+
)
|
| 80 |
+
|
| 81 |
+
with gr.Tab("Text-to-Video"):
|
| 82 |
+
with gr.Row():
|
| 83 |
+
with gr.Column():
|
| 84 |
+
text_prompt = gr.Textbox(
|
| 85 |
+
label="Prompt (Less than 128 words)",
|
| 86 |
+
placeholder="Enter a text prompt for the video",
|
| 87 |
+
lines=2
|
| 88 |
+
)
|
| 89 |
+
temp_slider = gr.Slider(1, 31, value=16, step=1, label="Duration")
|
| 90 |
+
guidance_scale_slider = gr.Slider(1.0, 15.0, value=9.0, step=0.1, label="Guidance Scale")
|
| 91 |
+
video_guidance_scale_slider = gr.Slider(1.0, 10.0, value=5.0, step=0.1, label="Video Guidance Scale")
|
| 92 |
+
txt_generate = gr.Button("Generate Video")
|
| 93 |
+
with gr.Column():
|
| 94 |
+
txt_output = gr.Video(label="Generated Video")
|
| 95 |
+
gr.Examples(
|
| 96 |
+
examples=[
|
| 97 |
+
[
|
| 98 |
+
"A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors",
|
| 99 |
+
16,
|
| 100 |
+
9.0,
|
| 101 |
+
5.0,
|
| 102 |
+
"768p",
|
| 103 |
+
4
|
| 104 |
+
],
|
| 105 |
+
[
|
| 106 |
+
"Beautiful, snowy Tokyo city is bustling. The camera moves through the bustling city street, following several people enjoying the beautiful snowy weather and shopping at nearby stalls. Gorgeous sakura petals are flying through the wind along with snowflakes",
|
| 107 |
+
16,
|
| 108 |
+
9.0,
|
| 109 |
+
5.0,
|
| 110 |
+
"768p",
|
| 111 |
+
4
|
| 112 |
+
],
|
| 113 |
+
[
|
| 114 |
+
"Extreme close-up of chicken and green pepper kebabs grilling on a barbeque with flames. Shallow focus and light smoke. vivid colours",
|
| 115 |
+
31,
|
| 116 |
+
9.0,
|
| 117 |
+
5.0,
|
| 118 |
+
"768p",
|
| 119 |
+
4
|
| 120 |
+
],
|
| 121 |
+
],
|
| 122 |
+
inputs=[text_prompt, temp_slider, guidance_scale_slider, video_guidance_scale_slider, resolution_dropdown, gpus_dropdown],
|
| 123 |
+
outputs=[txt_output],
|
| 124 |
+
fn=generate_text_to_video,
|
| 125 |
+
cache_examples='lazy',
|
| 126 |
+
)
|
| 127 |
+
|
| 128 |
+
# Update generate function for Text-to-Video
|
| 129 |
+
txt_generate.click(
|
| 130 |
+
generate_text_to_video,
|
| 131 |
+
inputs=[
|
| 132 |
+
text_prompt,
|
| 133 |
+
temp_slider,
|
| 134 |
+
guidance_scale_slider,
|
| 135 |
+
video_guidance_scale_slider,
|
| 136 |
+
resolution_dropdown,
|
| 137 |
+
gpus_dropdown
|
| 138 |
+
],
|
| 139 |
+
outputs=txt_output
|
| 140 |
+
)
|
| 141 |
+
|
| 142 |
+
# Launch Gradio app
|
| 143 |
+
demo.launch(share=True)
|
assets/motivation.jpg
ADDED

|
assets/the_great_wall.jpg
ADDED

|
assets/user_study.jpg
ADDED
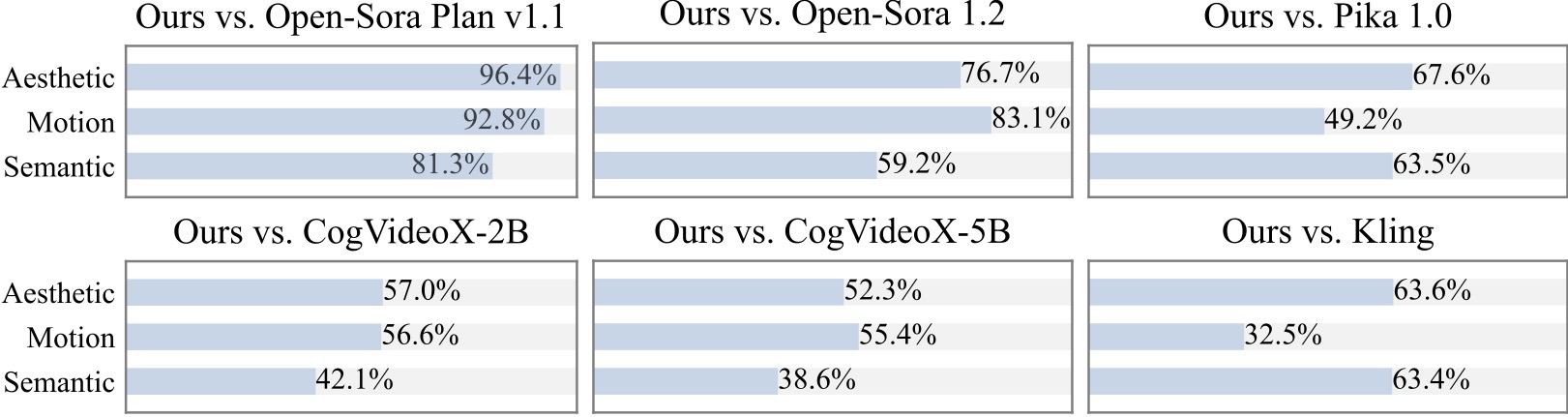
|
assets/vbench.jpg
ADDED
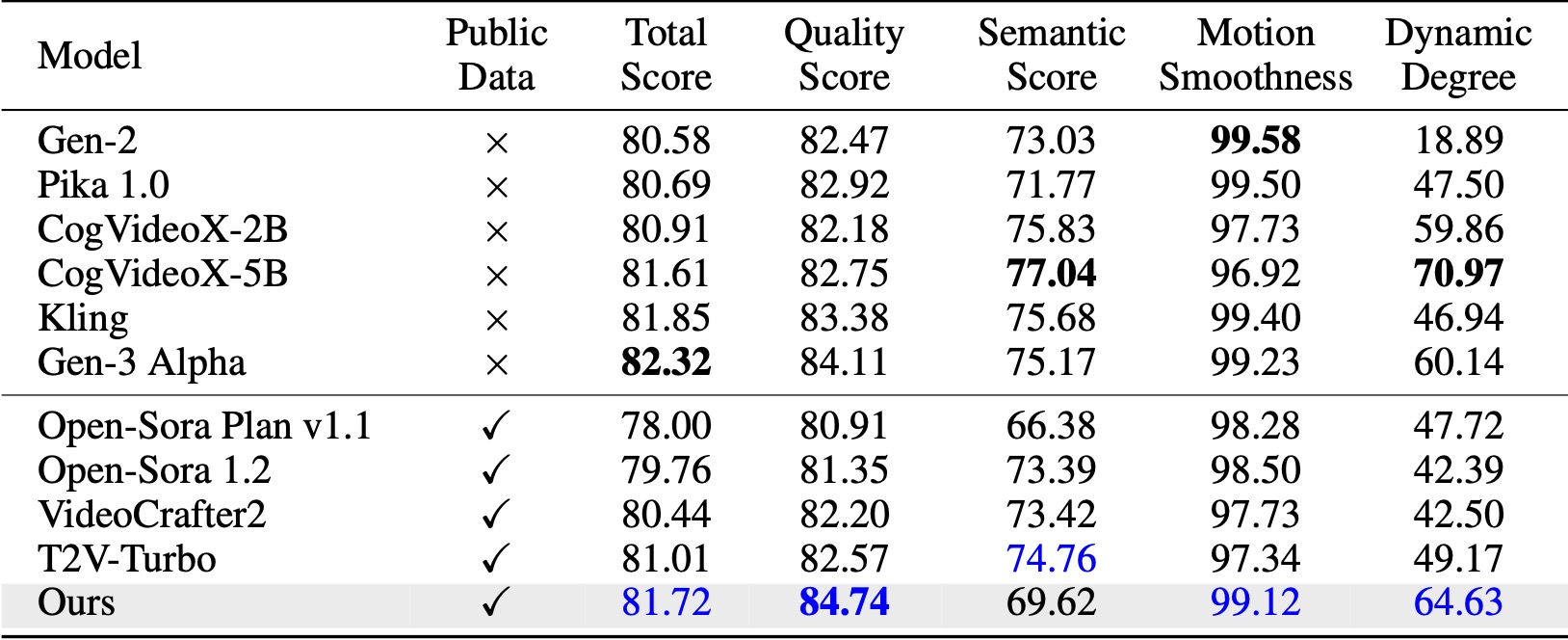
|
causal_video_vae_demo.ipynb
ADDED
|
@@ -0,0 +1,221 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": null,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [],
|
| 8 |
+
"source": [
|
| 9 |
+
"import os\n",
|
| 10 |
+
"import json\n",
|
| 11 |
+
"import cv2\n",
|
| 12 |
+
"import torch\n",
|
| 13 |
+
"import numpy as np\n",
|
| 14 |
+
"import PIL\n",
|
| 15 |
+
"from PIL import Image\n",
|
| 16 |
+
"from einops import rearrange\n",
|
| 17 |
+
"from video_vae import CausalVideoVAELossWrapper\n",
|
| 18 |
+
"from torchvision import transforms as pth_transforms\n",
|
| 19 |
+
"from torchvision.transforms.functional import InterpolationMode\n",
|
| 20 |
+
"from IPython.display import Image as ipython_image\n",
|
| 21 |
+
"from diffusers.utils import load_image, export_to_video, export_to_gif\n",
|
| 22 |
+
"from IPython.display import HTML"
|
| 23 |
+
]
|
| 24 |
+
},
|
| 25 |
+
{
|
| 26 |
+
"cell_type": "code",
|
| 27 |
+
"execution_count": null,
|
| 28 |
+
"metadata": {},
|
| 29 |
+
"outputs": [],
|
| 30 |
+
"source": [
|
| 31 |
+
"model_path = \"pyramid-flow-miniflux/causal_video_vae\" # The video-vae checkpoint dir\n",
|
| 32 |
+
"model_dtype = 'bf16'\n",
|
| 33 |
+
"\n",
|
| 34 |
+
"device_id = 3\n",
|
| 35 |
+
"torch.cuda.set_device(device_id)\n",
|
| 36 |
+
"\n",
|
| 37 |
+
"model = CausalVideoVAELossWrapper(\n",
|
| 38 |
+
" model_path,\n",
|
| 39 |
+
" model_dtype,\n",
|
| 40 |
+
" interpolate=False, \n",
|
| 41 |
+
" add_discriminator=False,\n",
|
| 42 |
+
")\n",
|
| 43 |
+
"model = model.to(\"cuda\")\n",
|
| 44 |
+
"\n",
|
| 45 |
+
"if model_dtype == \"bf16\":\n",
|
| 46 |
+
" torch_dtype = torch.bfloat16 \n",
|
| 47 |
+
"elif model_dtype == \"fp16\":\n",
|
| 48 |
+
" torch_dtype = torch.float16\n",
|
| 49 |
+
"else:\n",
|
| 50 |
+
" torch_dtype = torch.float32\n",
|
| 51 |
+
"\n",
|
| 52 |
+
"def image_transform(images, resize_width, resize_height):\n",
|
| 53 |
+
" transform_list = pth_transforms.Compose([\n",
|
| 54 |
+
" pth_transforms.Resize((resize_height, resize_width), InterpolationMode.BICUBIC, antialias=True),\n",
|
| 55 |
+
" pth_transforms.ToTensor(),\n",
|
| 56 |
+
" pth_transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))\n",
|
| 57 |
+
" ])\n",
|
| 58 |
+
" return torch.stack([transform_list(image) for image in images])\n",
|
| 59 |
+
"\n",
|
| 60 |
+
"\n",
|
| 61 |
+
"def get_transform(width, height, new_width=None, new_height=None, resize=False,):\n",
|
| 62 |
+
" transform_list = []\n",
|
| 63 |
+
"\n",
|
| 64 |
+
" if resize:\n",
|
| 65 |
+
" if new_width is None:\n",
|
| 66 |
+
" new_width = width // 8 * 8\n",
|
| 67 |
+
" if new_height is None:\n",
|
| 68 |
+
" new_height = height // 8 * 8\n",
|
| 69 |
+
" transform_list.append(pth_transforms.Resize((new_height, new_width), InterpolationMode.BICUBIC, antialias=True))\n",
|
| 70 |
+
" \n",
|
| 71 |
+
" transform_list.extend([\n",
|
| 72 |
+
" pth_transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),\n",
|
| 73 |
+
" ])\n",
|
| 74 |
+
" transform_list = pth_transforms.Compose(transform_list)\n",
|
| 75 |
+
"\n",
|
| 76 |
+
" return transform_list\n",
|
| 77 |
+
"\n",
|
| 78 |
+
"\n",
|
| 79 |
+
"def load_video_and_transform(video_path, frame_number, new_width=None, new_height=None, max_frames=600, sample_fps=24, resize=False):\n",
|
| 80 |
+
" try:\n",
|
| 81 |
+
" video_capture = cv2.VideoCapture(video_path)\n",
|
| 82 |
+
" fps = video_capture.get(cv2.CAP_PROP_FPS)\n",
|
| 83 |
+
" frames = []\n",
|
| 84 |
+
" pil_frames = []\n",
|
| 85 |
+
" while True:\n",
|
| 86 |
+
" flag, frame = video_capture.read()\n",
|
| 87 |
+
" if not flag:\n",
|
| 88 |
+
" break\n",
|
| 89 |
+
" \n",
|
| 90 |
+
" pil_frames.append(np.ascontiguousarray(frame[:, :, ::-1]))\n",
|
| 91 |
+
" frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)\n",
|
| 92 |
+
" frame = torch.from_numpy(frame)\n",
|
| 93 |
+
" frame = frame.permute(2, 0, 1)\n",
|
| 94 |
+
" frames.append(frame)\n",
|
| 95 |
+
" if len(frames) >= max_frames:\n",
|
| 96 |
+
" break\n",
|
| 97 |
+
"\n",
|
| 98 |
+
" video_capture.release()\n",
|
| 99 |
+
" interval = max(int(fps / sample_fps), 1)\n",
|
| 100 |
+
" pil_frames = pil_frames[::interval][:frame_number]\n",
|
| 101 |
+
" frames = frames[::interval][:frame_number]\n",
|
| 102 |
+
" frames = torch.stack(frames).float() / 255\n",
|
| 103 |
+
" width = frames.shape[-1]\n",
|
| 104 |
+
" height = frames.shape[-2]\n",
|
| 105 |
+
" video_transform = get_transform(width, height, new_width, new_height, resize=resize)\n",
|
| 106 |
+
" frames = video_transform(frames)\n",
|
| 107 |
+
" pil_frames = [Image.fromarray(frame).convert(\"RGB\") for frame in pil_frames]\n",
|
| 108 |
+
"\n",
|
| 109 |
+
" if resize:\n",
|
| 110 |
+
" if new_width is None:\n",
|
| 111 |
+
" new_width = width // 32 * 32\n",
|
| 112 |
+
" if new_height is None:\n",
|
| 113 |
+
" new_height = height // 32 * 32\n",
|
| 114 |
+
" pil_frames = [frame.resize((new_width or width, new_height or height), PIL.Image.BICUBIC) for frame in pil_frames]\n",
|
| 115 |
+
" return frames, pil_frames\n",
|
| 116 |
+
" except Exception:\n",
|
| 117 |
+
" return None\n",
|
| 118 |
+
"\n",
|
| 119 |
+
"\n",
|
| 120 |
+
"def show_video(ori_path, rec_path, width=\"100%\"):\n",
|
| 121 |
+
" html = ''\n",
|
| 122 |
+
" if ori_path is not None:\n",
|
| 123 |
+
" html += f\"\"\"<video controls=\"\" name=\"media\" data-fullscreen-container=\"true\" width=\"{width}\">\n",
|
| 124 |
+
" <source src=\"{ori_path}\" type=\"video/mp4\">\n",
|
| 125 |
+
" </video>\n",
|
| 126 |
+
" \"\"\"\n",
|
| 127 |
+
" \n",
|
| 128 |
+
" html += f\"\"\"<video controls=\"\" name=\"media\" data-fullscreen-container=\"true\" width=\"{width}\">\n",
|
| 129 |
+
" <source src=\"{rec_path}\" type=\"video/mp4\">\n",
|
| 130 |
+
" </video>\n",
|
| 131 |
+
" \"\"\"\n",
|
| 132 |
+
" return HTML(html)"
|
| 133 |
+
]
|
| 134 |
+
},
|
| 135 |
+
{
|
| 136 |
+
"attachments": {},
|
| 137 |
+
"cell_type": "markdown",
|
| 138 |
+
"metadata": {},
|
| 139 |
+
"source": [
|
| 140 |
+
"### Image Reconstruction"
|
| 141 |
+
]
|
| 142 |
+
},
|
| 143 |
+
{
|
| 144 |
+
"cell_type": "code",
|
| 145 |
+
"execution_count": null,
|
| 146 |
+
"metadata": {},
|
| 147 |
+
"outputs": [],
|
| 148 |
+
"source": [
|
| 149 |
+
"image_path = 'image_path'\n",
|
| 150 |
+
"\n",
|
| 151 |
+
"image = Image.open(image_path).convert(\"RGB\")\n",
|
| 152 |
+
"resize_width = image.width // 8 * 8\n",
|
| 153 |
+
"resize_height = image.height // 8 * 8\n",
|
| 154 |
+
"input_image_tensor = image_transform([image], resize_width, resize_height)\n",
|
| 155 |
+
"input_image_tensor = input_image_tensor.permute(1, 0, 2, 3).unsqueeze(0)\n",
|
| 156 |
+
"\n",
|
| 157 |
+
"with torch.no_grad(), torch.cuda.amp.autocast(enabled=True, dtype=torch.bfloat16):\n",
|
| 158 |
+
" latent = model.encode_latent(input_image_tensor.to(\"cuda\"), sample=True)\n",
|
| 159 |
+
" rec_images = model.decode_latent(latent)\n",
|
| 160 |
+
"\n",
|
| 161 |
+
"display(image)\n",
|
| 162 |
+
"display(rec_images[0])"
|
| 163 |
+
]
|
| 164 |
+
},
|
| 165 |
+
{
|
| 166 |
+
"attachments": {},
|
| 167 |
+
"cell_type": "markdown",
|
| 168 |
+
"metadata": {},
|
| 169 |
+
"source": [
|
| 170 |
+
"### Video Reconstruction"
|
| 171 |
+
]
|
| 172 |
+
},
|
| 173 |
+
{
|
| 174 |
+
"cell_type": "code",
|
| 175 |
+
"execution_count": null,
|
| 176 |
+
"metadata": {},
|
| 177 |
+
"outputs": [],
|
| 178 |
+
"source": [
|
| 179 |
+
"video_path = 'video_path'\n",
|
| 180 |
+
"\n",
|
| 181 |
+
"frame_number = 57 # x*8 + 1\n",
|
| 182 |
+
"width = 640\n",
|
| 183 |
+
"height = 384\n",
|
| 184 |
+
"\n",
|
| 185 |
+
"video_frames_tensor, pil_video_frames = load_video_and_transform(video_path, frame_number, new_width=width, new_height=height, resize=True)\n",
|
| 186 |
+
"video_frames_tensor = video_frames_tensor.permute(1, 0, 2, 3).unsqueeze(0)\n",
|
| 187 |
+
"print(video_frames_tensor.shape)\n",
|
| 188 |
+
"\n",
|
| 189 |
+
"with torch.no_grad(), torch.cuda.amp.autocast(enabled=True, dtype=torch.bfloat16):\n",
|
| 190 |
+
" latent = model.encode_latent(video_frames_tensor.to(\"cuda\"), sample=False, window_size=8, temporal_chunk=True)\n",
|
| 191 |
+
" rec_frames = model.decode_latent(latent.float(), window_size=2, temporal_chunk=True)\n",
|
| 192 |
+
"\n",
|
| 193 |
+
"export_to_video(pil_video_frames, './ori_video.mp4', fps=24)\n",
|
| 194 |
+
"export_to_video(rec_frames, \"./rec_video.mp4\", fps=24)\n",
|
| 195 |
+
"show_video('./ori_video.mp4', \"./rec_video.mp4\", \"60%\")"
|
| 196 |
+
]
|
| 197 |
+
}
|
| 198 |
+
],
|
| 199 |
+
"metadata": {
|
| 200 |
+
"kernelspec": {
|
| 201 |
+
"display_name": "Python 3",
|
| 202 |
+
"language": "python",
|
| 203 |
+
"name": "python3"
|
| 204 |
+
},
|
| 205 |
+
"language_info": {
|
| 206 |
+
"codemirror_mode": {
|
| 207 |
+
"name": "ipython",
|
| 208 |
+
"version": 3
|
| 209 |
+
},
|
| 210 |
+
"file_extension": ".py",
|
| 211 |
+
"mimetype": "text/x-python",
|
| 212 |
+
"name": "python",
|
| 213 |
+
"nbconvert_exporter": "python",
|
| 214 |
+
"pygments_lexer": "ipython3",
|
| 215 |
+
"version": "3.8.10"
|
| 216 |
+
},
|
| 217 |
+
"orig_nbformat": 4
|
| 218 |
+
},
|
| 219 |
+
"nbformat": 4,
|
| 220 |
+
"nbformat_minor": 2
|
| 221 |
+
}
|
dataset/__init__.py
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .dataset_cls import (
|
| 2 |
+
ImageTextDataset,
|
| 3 |
+
LengthGroupedVideoTextDataset,
|
| 4 |
+
ImageDataset,
|
| 5 |
+
VideoDataset,
|
| 6 |
+
)
|
| 7 |
+
|
| 8 |
+
from .dataloaders import (
|
| 9 |
+
create_image_text_dataloaders,
|
| 10 |
+
create_length_grouped_video_text_dataloader,
|
| 11 |
+
create_mixed_dataloaders,
|
| 12 |
+
)
|
dataset/bucket_loader.py
ADDED
|
@@ -0,0 +1,148 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torchvision
|
| 3 |
+
import numpy as np
|
| 4 |
+
import math
|
| 5 |
+
import random
|
| 6 |
+
import time
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class Bucketeer:
|
| 10 |
+
def __init__(
|
| 11 |
+
self, dataloader,
|
| 12 |
+
sizes=[(256, 256), (192, 384), (192, 320), (384, 192), (320, 192)],
|
| 13 |
+
is_infinite=True, epoch=0,
|
| 14 |
+
):
|
| 15 |
+
# Ratios and Sizes : (w h)
|
| 16 |
+
self.sizes = sizes
|
| 17 |
+
self.batch_size = dataloader.batch_size
|
| 18 |
+
self._dataloader = dataloader
|
| 19 |
+
self.iterator = iter(dataloader)
|
| 20 |
+
self.sampler = dataloader.sampler
|
| 21 |
+
self.buckets = {s: [] for s in self.sizes}
|
| 22 |
+
self.is_infinite = is_infinite
|
| 23 |
+
self._epoch = epoch
|
| 24 |
+
|
| 25 |
+
def get_available_batch(self):
|
| 26 |
+
available_size = []
|
| 27 |
+
for b in self.buckets:
|
| 28 |
+
if len(self.buckets[b]) >= self.batch_size:
|
| 29 |
+
available_size.append(b)
|
| 30 |
+
|
| 31 |
+
if len(available_size) == 0:
|
| 32 |
+
return None
|
| 33 |
+
else:
|
| 34 |
+
b = random.choice(available_size)
|
| 35 |
+
batch = self.buckets[b][:self.batch_size]
|
| 36 |
+
self.buckets[b] = self.buckets[b][self.batch_size:]
|
| 37 |
+
return batch
|
| 38 |
+
|
| 39 |
+
def __next__(self):
|
| 40 |
+
batch = self.get_available_batch()
|
| 41 |
+
while batch is None:
|
| 42 |
+
try:
|
| 43 |
+
elements = next(self.iterator)
|
| 44 |
+
except StopIteration:
|
| 45 |
+
# To make it infinity
|
| 46 |
+
if self.is_infinite:
|
| 47 |
+
self._epoch += 1
|
| 48 |
+
if hasattr(self._dataloader.sampler, "set_epoch"):
|
| 49 |
+
self._dataloader.sampler.set_epoch(self._epoch)
|
| 50 |
+
time.sleep(2) # Prevent possible deadlock during epoch transition
|
| 51 |
+
self.iterator = iter(self._dataloader)
|
| 52 |
+
elements = next(self.iterator)
|
| 53 |
+
else:
|
| 54 |
+
raise StopIteration
|
| 55 |
+
|
| 56 |
+
for dct in elements:
|
| 57 |
+
try:
|
| 58 |
+
img = dct['video']
|
| 59 |
+
size = (img.shape[-1], img.shape[-2])
|
| 60 |
+
self.buckets[size].append({**{'video': img}, **{k:dct[k] for k in dct if k != 'video'}})
|
| 61 |
+
except Exception as e:
|
| 62 |
+
continue
|
| 63 |
+
|
| 64 |
+
batch = self.get_available_batch()
|
| 65 |
+
|
| 66 |
+
out = {k:[batch[i][k] for i in range(len(batch))] for k in batch[0]}
|
| 67 |
+
return {k: torch.stack(o, dim=0) if isinstance(o[0], torch.Tensor) else o for k, o in out.items()}
|
| 68 |
+
|
| 69 |
+
def __iter__(self):
|
| 70 |
+
return self
|
| 71 |
+
|
| 72 |
+
def __len__(self):
|
| 73 |
+
return len(self.iterator)
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
class TemporalLengthBucketeer:
|
| 77 |
+
def __init__(
|
| 78 |
+
self, dataloader, max_frames=16, epoch=0,
|
| 79 |
+
):
|
| 80 |
+
self.batch_size = dataloader.batch_size
|
| 81 |
+
self._dataloader = dataloader
|
| 82 |
+
self.iterator = iter(dataloader)
|
| 83 |
+
self.buckets = {temp: [] for temp in range(1, max_frames + 1)}
|
| 84 |
+
self._epoch = epoch
|
| 85 |
+
|
| 86 |
+
def get_available_batch(self):
|
| 87 |
+
available_size = []
|
| 88 |
+
for b in self.buckets:
|
| 89 |
+
if len(self.buckets[b]) >= self.batch_size:
|
| 90 |
+
available_size.append(b)
|
| 91 |
+
|
| 92 |
+
if len(available_size) == 0:
|
| 93 |
+
return None
|
| 94 |
+
else:
|
| 95 |
+
b = random.choice(available_size)
|
| 96 |
+
batch = self.buckets[b][:self.batch_size]
|
| 97 |
+
self.buckets[b] = self.buckets[b][self.batch_size:]
|
| 98 |
+
return batch
|
| 99 |
+
|
| 100 |
+
def __next__(self):
|
| 101 |
+
batch = self.get_available_batch()
|
| 102 |
+
while batch is None:
|
| 103 |
+
try:
|
| 104 |
+
elements = next(self.iterator)
|
| 105 |
+
except StopIteration:
|
| 106 |
+
# To make it infinity
|
| 107 |
+
self._epoch += 1
|
| 108 |
+
if hasattr(self._dataloader.sampler, "set_epoch"):
|
| 109 |
+
self._dataloader.sampler.set_epoch(self._epoch)
|
| 110 |
+
time.sleep(2) # Prevent possible deadlock during epoch transition
|
| 111 |
+
self.iterator = iter(self._dataloader)
|
| 112 |
+
elements = next(self.iterator)
|
| 113 |
+
|
| 114 |
+
for dct in elements:
|
| 115 |
+
try:
|
| 116 |
+
video_latent = dct['video']
|
| 117 |
+
temp = video_latent.shape[2]
|
| 118 |
+
self.buckets[temp].append({**{'video': video_latent}, **{k:dct[k] for k in dct if k != 'video'}})
|
| 119 |
+
except Exception as e:
|
| 120 |
+
continue
|
| 121 |
+
|
| 122 |
+
batch = self.get_available_batch()
|
| 123 |
+
|
| 124 |
+
out = {k:[batch[i][k] for i in range(len(batch))] for k in batch[0]}
|
| 125 |
+
out = {k: torch.cat(o, dim=0) if isinstance(o[0], torch.Tensor) else o for k, o in out.items()}
|
| 126 |
+
|
| 127 |
+
if 'prompt_embed' in out:
|
| 128 |
+
# Loading the pre-extrcted textual features
|
| 129 |
+
prompt_embeds = out['prompt_embed'].clone()
|
| 130 |
+
del out['prompt_embed']
|
| 131 |
+
prompt_attention_mask = out['prompt_attention_mask'].clone()
|
| 132 |
+
del out['prompt_attention_mask']
|
| 133 |
+
pooled_prompt_embeds = out['pooled_prompt_embed'].clone()
|
| 134 |
+
del out['pooled_prompt_embed']
|
| 135 |
+
|
| 136 |
+
out['text'] = {
|
| 137 |
+
'prompt_embeds' : prompt_embeds,
|
| 138 |
+
'prompt_attention_mask': prompt_attention_mask,
|
| 139 |
+
'pooled_prompt_embeds': pooled_prompt_embeds,
|
| 140 |
+
}
|
| 141 |
+
|
| 142 |
+
return out
|
| 143 |
+
|
| 144 |
+
def __iter__(self):
|
| 145 |
+
return self
|
| 146 |
+
|
| 147 |
+
def __len__(self):
|
| 148 |
+
return len(self.iterator)
|
dataset/dataloaders.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import json
|
| 3 |
+
import torch
|
| 4 |
+
import time
|
| 5 |
+
import random
|
| 6 |
+
from typing import Iterable
|
| 7 |
+
|
| 8 |
+
from collections import OrderedDict
|
| 9 |
+
from PIL import Image
|
| 10 |
+
from torch.utils.data import Dataset, DataLoader, ConcatDataset, IterableDataset, DistributedSampler, RandomSampler
|
| 11 |
+
from torch.utils.data.dataloader import default_collate
|
| 12 |
+
from torchvision import transforms
|
| 13 |
+
from torchvision.transforms.functional import InterpolationMode
|
| 14 |
+
from torchvision.transforms import functional as F
|
| 15 |
+
from .bucket_loader import Bucketeer, TemporalLengthBucketeer
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class IterLoader:
|
| 19 |
+
"""
|
| 20 |
+
A wrapper to convert DataLoader as an infinite iterator.
|
| 21 |
+
|
| 22 |
+
Modified from:
|
| 23 |
+
https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/iter_based_runner.py
|
| 24 |
+
"""
|
| 25 |
+
|
| 26 |
+
def __init__(self, dataloader: DataLoader, use_distributed: bool = False, epoch: int = 0):
|
| 27 |
+
self._dataloader = dataloader
|
| 28 |
+
self.iter_loader = iter(self._dataloader)
|
| 29 |
+
self._use_distributed = use_distributed
|
| 30 |
+
self._epoch = epoch
|
| 31 |
+
|
| 32 |
+
@property
|
| 33 |
+
def epoch(self) -> int:
|
| 34 |
+
return self._epoch
|
| 35 |
+
|
| 36 |
+
def __next__(self):
|
| 37 |
+
try:
|
| 38 |
+
data = next(self.iter_loader)
|
| 39 |
+
except StopIteration:
|
| 40 |
+
self._epoch += 1
|
| 41 |
+
if hasattr(self._dataloader.sampler, "set_epoch") and self._use_distributed:
|
| 42 |
+
self._dataloader.sampler.set_epoch(self._epoch)
|
| 43 |
+
time.sleep(2) # Prevent possible deadlock during epoch transition
|
| 44 |
+
self.iter_loader = iter(self._dataloader)
|
| 45 |
+
data = next(self.iter_loader)
|
| 46 |
+
|
| 47 |
+
return data
|
| 48 |
+
|
| 49 |
+
def __iter__(self):
|
| 50 |
+
return self
|
| 51 |
+
|
| 52 |
+
def __len__(self):
|
| 53 |
+
return len(self._dataloader)
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def identity(x):
|
| 57 |
+
return x
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def create_image_text_dataloaders(dataset, batch_size, num_workers,
|
| 61 |
+
multi_aspect_ratio=True, epoch=0, sizes=[(512, 512), (384, 640), (640, 384)],
|
| 62 |
+
use_distributed=True, world_size=None, rank=None,
|
| 63 |
+
):
|
| 64 |
+
"""
|
| 65 |
+
The dataset has already been splited by different rank
|
| 66 |
+
"""
|
| 67 |
+
if use_distributed:
|
| 68 |
+
assert world_size is not None
|
| 69 |
+
assert rank is not None
|
| 70 |
+
sampler = DistributedSampler(
|
| 71 |
+
dataset,
|
| 72 |
+
shuffle=True,
|
| 73 |
+
num_replicas=world_size,
|
| 74 |
+
rank=rank,
|
| 75 |
+
seed=epoch,
|
| 76 |
+
)
|
| 77 |
+
else:
|
| 78 |
+
sampler = RandomSampler(dataset)
|
| 79 |
+
|
| 80 |
+
dataloader = DataLoader(
|
| 81 |
+
dataset,
|
| 82 |
+
batch_size=batch_size,
|
| 83 |
+
num_workers=num_workers,
|
| 84 |
+
pin_memory=True,
|
| 85 |
+
sampler=sampler,
|
| 86 |
+
collate_fn=identity if multi_aspect_ratio else default_collate,
|
| 87 |
+
drop_last=True,
|
| 88 |
+
)
|
| 89 |
+
|
| 90 |
+
if multi_aspect_ratio:
|
| 91 |
+
dataloader_iterator = Bucketeer(
|
| 92 |
+
dataloader,
|
| 93 |
+
sizes=sizes,
|
| 94 |
+
is_infinite=True, epoch=epoch,
|
| 95 |
+
)
|
| 96 |
+
else:
|
| 97 |
+
dataloader_iterator = iter(dataloader)
|
| 98 |
+
|
| 99 |
+
# To make it infinite
|
| 100 |
+
loader = IterLoader(dataloader_iterator, use_distributed=False, epoch=epoch)
|
| 101 |
+
|
| 102 |
+
return loader
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
def create_length_grouped_video_text_dataloader(dataset, batch_size, num_workers, max_frames,
|
| 106 |
+
world_size=None, rank=None, epoch=0, use_distributed=False):
|
| 107 |
+
if use_distributed:
|
| 108 |
+
assert world_size is not None
|
| 109 |
+
assert rank is not None
|
| 110 |
+
sampler = DistributedSampler(
|
| 111 |
+
dataset,
|
| 112 |
+
shuffle=True,
|
| 113 |
+
num_replicas=world_size,
|
| 114 |
+
rank=rank,
|
| 115 |
+
seed=epoch,
|
| 116 |
+
)
|
| 117 |
+
else:
|
| 118 |
+
sampler = RandomSampler(dataset)
|
| 119 |
+
|
| 120 |
+
dataloader = DataLoader(
|
| 121 |
+
dataset,
|
| 122 |
+
batch_size=batch_size,
|
| 123 |
+
num_workers=num_workers,
|
| 124 |
+
pin_memory=True,
|
| 125 |
+
sampler=sampler,
|
| 126 |
+
collate_fn=identity,
|
| 127 |
+
drop_last=True,
|
| 128 |
+
)
|
| 129 |
+
|
| 130 |
+
# make it infinite
|
| 131 |
+
dataloader_iterator = TemporalLengthBucketeer(
|
| 132 |
+
dataloader,
|
| 133 |
+
max_frames=max_frames,
|
| 134 |
+
epoch=epoch,
|
| 135 |
+
)
|
| 136 |
+
|
| 137 |
+
return dataloader_iterator
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
def create_mixed_dataloaders(
|
| 141 |
+
dataset, batch_size, num_workers, world_size=None, rank=None, epoch=0,
|
| 142 |
+
image_mix_ratio=0.1, use_image_video_mixed_training=True,
|
| 143 |
+
):
|
| 144 |
+
"""
|
| 145 |
+
The video & image mixed training dataloader builder
|
| 146 |
+
"""
|
| 147 |
+
|
| 148 |
+
assert world_size is not None
|
| 149 |
+
assert rank is not None
|
| 150 |
+
|
| 151 |
+
image_gpus = max(1, int(world_size * image_mix_ratio))
|
| 152 |
+
if use_image_video_mixed_training:
|
| 153 |
+
video_gpus = world_size - image_gpus
|
| 154 |
+
else:
|
| 155 |
+
# only use video data
|
| 156 |
+
video_gpus = world_size
|
| 157 |
+
image_gpus = 0
|
| 158 |
+
|
| 159 |
+
print(f"{image_gpus} gpus for image, {video_gpus} gpus for video")
|
| 160 |
+
|
| 161 |
+
if rank < video_gpus:
|
| 162 |
+
sampler = DistributedSampler(
|
| 163 |
+
dataset,
|
| 164 |
+
shuffle=True,
|
| 165 |
+
num_replicas=video_gpus,
|
| 166 |
+
rank=rank,
|
| 167 |
+
seed=epoch,
|
| 168 |
+
)
|
| 169 |
+
else:
|
| 170 |
+
sampler = DistributedSampler(
|
| 171 |
+
dataset,
|
| 172 |
+
shuffle=True,
|
| 173 |
+
num_replicas=image_gpus,
|
| 174 |
+
rank=rank - video_gpus,
|
| 175 |
+
seed=epoch,
|
| 176 |
+
)
|
| 177 |
+
|
| 178 |
+
loader = DataLoader(
|
| 179 |
+
dataset,
|
| 180 |
+
batch_size=batch_size,
|
| 181 |
+
num_workers=num_workers,
|
| 182 |
+
pin_memory=True,
|
| 183 |
+
sampler=sampler,
|
| 184 |
+
collate_fn=default_collate,
|
| 185 |
+
drop_last=True,
|
| 186 |
+
)
|
| 187 |
+
|
| 188 |
+
# To make it infinite
|
| 189 |
+
loader = IterLoader(loader, use_distributed=True, epoch=epoch)
|
| 190 |
+
return loader
|
dataset/dataset_cls.py
ADDED
|
@@ -0,0 +1,377 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import json
|
| 3 |
+
import jsonlines
|
| 4 |
+
import torch
|
| 5 |
+
import math
|
| 6 |
+
import random
|
| 7 |
+
import cv2
|
| 8 |
+
|
| 9 |
+
from tqdm import tqdm
|
| 10 |
+
from collections import OrderedDict
|
| 11 |
+
|
| 12 |
+
from PIL import Image
|
| 13 |
+
from PIL import ImageFile
|
| 14 |
+
ImageFile.LOAD_TRUNCATED_IMAGES = True
|
| 15 |
+
|
| 16 |
+
import numpy as np
|
| 17 |
+
import subprocess
|
| 18 |
+
from torch.utils.data import Dataset, DataLoader
|
| 19 |
+
from torchvision import transforms
|
| 20 |
+
from torchvision.transforms.functional import InterpolationMode
|
| 21 |
+
from torchvision.transforms import functional as F
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class ImageTextDataset(Dataset):
|
| 25 |
+
"""
|
| 26 |
+
Usage:
|
| 27 |
+
The dataset class for image-text pairs, used for image generation training
|
| 28 |
+
It supports multi-aspect ratio training
|
| 29 |
+
params:
|
| 30 |
+
anno_file: The annotation file list
|
| 31 |
+
add_normalize: whether to normalize the input image pixel to [-1, 1], default: True
|
| 32 |
+
ratios: The aspect ratios during training, format: width / height
|
| 33 |
+
sizes: The resoultion of training images, format: (width, height)
|
| 34 |
+
"""
|
| 35 |
+
def __init__(
|
| 36 |
+
self, anno_file, add_normalize=True,
|
| 37 |
+
ratios=[1/1, 3/5, 5/3],
|
| 38 |
+
sizes=[(1024, 1024), (768, 1280), (1280, 768)],
|
| 39 |
+
crop_mode='random', p_random_ratio=0.0,
|
| 40 |
+
):
|
| 41 |
+
# Ratios and Sizes : (w h)
|
| 42 |
+
super().__init__()
|
| 43 |
+
|
| 44 |
+
self.image_annos = []
|
| 45 |
+
if not isinstance(anno_file, list):
|
| 46 |
+
anno_file = [anno_file]
|
| 47 |
+
|
| 48 |
+
for anno_file_ in anno_file:
|
| 49 |
+
print(f"Load image annotation files from {anno_file_}")
|
| 50 |
+
with jsonlines.open(anno_file_, 'r') as reader:
|
| 51 |
+
for item in reader:
|
| 52 |
+
self.image_annos.append(item)
|
| 53 |
+
|
| 54 |
+
print(f"Totally Remained {len(self.image_annos)} images")
|
| 55 |
+
|
| 56 |
+
transform_list = [
|
| 57 |
+
transforms.ToTensor(),
|
| 58 |
+
]
|
| 59 |
+
|
| 60 |
+
if add_normalize:
|
| 61 |
+
transform_list.append(transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)))
|
| 62 |
+
|
| 63 |
+
self.transform = transforms.Compose(transform_list)
|
| 64 |
+
|
| 65 |
+
print(f"Transform List is {transform_list}")
|
| 66 |
+
|
| 67 |
+
assert crop_mode in ['center', 'random']
|
| 68 |
+
self.crop_mode = crop_mode
|
| 69 |
+
self.ratios = ratios
|
| 70 |
+
self.sizes = sizes
|
| 71 |
+
self.p_random_ratio = p_random_ratio
|
| 72 |
+
|
| 73 |
+
def get_closest_size(self, x):
|
| 74 |
+
if self.p_random_ratio > 0 and np.random.rand() < self.p_random_ratio:
|
| 75 |
+
best_size_idx = np.random.randint(len(self.ratios))
|
| 76 |
+
else:
|
| 77 |
+
w, h = x.width, x.height
|
| 78 |
+
best_size_idx = np.argmin([abs(w/h-r) for r in self.ratios])
|
| 79 |
+
return self.sizes[best_size_idx]
|
| 80 |
+
|
| 81 |
+
def get_resize_size(self, orig_size, tgt_size):
|
| 82 |
+
if (tgt_size[1]/tgt_size[0] - 1) * (orig_size[1]/orig_size[0] - 1) >= 0:
|
| 83 |
+
alt_min = int(math.ceil(max(tgt_size)*min(orig_size)/max(orig_size)))
|
| 84 |
+
resize_size = max(alt_min, min(tgt_size))
|
| 85 |
+
else:
|
| 86 |
+
alt_max = int(math.ceil(min(tgt_size)*max(orig_size)/min(orig_size)))
|
| 87 |
+
resize_size = max(alt_max, max(tgt_size))
|
| 88 |
+
return resize_size
|
| 89 |
+
|
| 90 |
+
def __len__(self):
|
| 91 |
+
return len(self.image_annos)
|
| 92 |
+
|
| 93 |
+
def __getitem__(self, index):
|
| 94 |
+
image_anno = self.image_annos[index]
|
| 95 |
+
|
| 96 |
+
try:
|
| 97 |
+
img = Image.open(image_anno['image']).convert("RGB")
|
| 98 |
+
text = image_anno['text']
|
| 99 |
+
|
| 100 |
+
assert isinstance(text, str), "Text should be str"
|
| 101 |
+
|
| 102 |
+
size = self.get_closest_size(img)
|
| 103 |
+
resize_size = self.get_resize_size((img.width, img.height), size)
|
| 104 |
+
|
| 105 |
+
img = transforms.functional.resize(img, resize_size, interpolation=transforms.InterpolationMode.BICUBIC, antialias=True)
|
| 106 |
+
|
| 107 |
+
if self.crop_mode == 'center':
|
| 108 |
+
img = transforms.functional.center_crop(img, (size[1], size[0]))
|
| 109 |
+
elif self.crop_mode == 'random':
|
| 110 |
+
img = transforms.RandomCrop((size[1], size[0]))(img)
|
| 111 |
+
else:
|
| 112 |
+
img = transforms.functional.center_crop(img, (size[1], size[0]))
|
| 113 |
+
|
| 114 |
+
image_tensor = self.transform(img)
|
| 115 |
+
|
| 116 |
+
return {
|
| 117 |
+
"video": image_tensor, # using keyname `video`, to be compatible with video
|
| 118 |
+
"text" : text,
|
| 119 |
+
"identifier": 'image',
|
| 120 |
+
}
|
| 121 |
+
|
| 122 |
+
except Exception as e:
|
| 123 |
+
print(f'Load Image Error with {e}')
|
| 124 |
+
return self.__getitem__(random.randint(0, self.__len__() - 1))
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
class LengthGroupedVideoTextDataset(Dataset):
|
| 128 |
+
"""
|
| 129 |
+
Usage:
|
| 130 |
+
The dataset class for video-text pairs, used for video generation training
|
| 131 |
+
It groups the video with the same frames together
|
| 132 |
+
Now only supporting fixed resolution during training
|
| 133 |
+
params:
|
| 134 |
+
anno_file: The annotation file list
|
| 135 |
+
max_frames: The maximum temporal lengths (This is the vae latent temporal length) 16 => (16 - 1) * 8 + 1 = 121 frames
|
| 136 |
+
load_vae_latent: Loading the pre-extracted vae latents during training, we recommend to extract the latents in advance
|
| 137 |
+
to reduce the time cost per batch
|
| 138 |
+
load_text_fea: Loading the pre-extracted text features during training, we recommend to extract the prompt textual features
|
| 139 |
+
in advance, since the T5 encoder will cost many GPU memories
|
| 140 |
+
"""
|
| 141 |
+
|
| 142 |
+
def __init__(self, anno_file, max_frames=16, resolution='384p', load_vae_latent=True, load_text_fea=True):
|
| 143 |
+
super().__init__()
|
| 144 |
+
|
| 145 |
+
self.video_annos = []
|
| 146 |
+
self.max_frames = max_frames
|
| 147 |
+
self.load_vae_latent = load_vae_latent
|
| 148 |
+
self.load_text_fea = load_text_fea
|
| 149 |
+
self.resolution = resolution
|
| 150 |
+
|
| 151 |
+
assert load_vae_latent, "Now only support loading vae latents, we will support to directly load video frames in the future"
|
| 152 |
+
|
| 153 |
+
if not isinstance(anno_file, list):
|
| 154 |
+
anno_file = [anno_file]
|
| 155 |
+
|
| 156 |
+
for anno_file_ in anno_file:
|
| 157 |
+
with jsonlines.open(anno_file_, 'r') as reader:
|
| 158 |
+
for item in tqdm(reader):
|
| 159 |
+
self.video_annos.append(item)
|
| 160 |
+
|
| 161 |
+
print(f"Totally Remained {len(self.video_annos)} videos")
|
| 162 |
+
|
| 163 |
+
def __len__(self):
|
| 164 |
+
return len(self.video_annos)
|
| 165 |
+
|
| 166 |
+
def __getitem__(self, index):
|
| 167 |
+
try:
|
| 168 |
+
video_anno = self.video_annos[index]
|
| 169 |
+
text = video_anno['text']
|
| 170 |
+
latent_path = video_anno['latent']
|
| 171 |
+
latent = torch.load(latent_path, map_location='cpu') # loading the pre-extracted video latents
|
| 172 |
+
|
| 173 |
+
# TODO: remove the hard code latent shape checking
|
| 174 |
+
if self.resolution == '384p':
|
| 175 |
+
assert latent.shape[-1] == 640 // 8
|
| 176 |
+
assert latent.shape[-2] == 384 // 8
|
| 177 |
+
else:
|
| 178 |
+
assert self.resolution == '768p'
|
| 179 |
+
assert latent.shape[-1] == 1280 // 8
|
| 180 |
+
assert latent.shape[-2] == 768 // 8
|
| 181 |
+
|
| 182 |
+
cur_temp = latent.shape[2]
|
| 183 |
+
cur_temp = min(cur_temp, self.max_frames)
|
| 184 |
+
|
| 185 |
+
video_latent = latent[:,:,:cur_temp].float()
|
| 186 |
+
assert video_latent.shape[1] == 16
|
| 187 |
+
|
| 188 |
+
if self.load_text_fea:
|
| 189 |
+
text_fea_path = video_anno['text_fea']
|
| 190 |
+
text_fea = torch.load(text_fea_path, map_location='cpu')
|
| 191 |
+
return {
|
| 192 |
+
'video': video_latent,
|
| 193 |
+
'prompt_embed': text_fea['prompt_embed'],
|
| 194 |
+
'prompt_attention_mask': text_fea['prompt_attention_mask'],
|
| 195 |
+
'pooled_prompt_embed': text_fea['pooled_prompt_embed'],
|
| 196 |
+
"identifier": 'video',
|
| 197 |
+
}
|
| 198 |
+
|
| 199 |
+
else:
|
| 200 |
+
return {
|
| 201 |
+
'video': video_latent,
|
| 202 |
+
'text': text,
|
| 203 |
+
"identifier": 'video',
|
| 204 |
+
}
|
| 205 |
+
|
| 206 |
+
except Exception as e:
|
| 207 |
+
print(f'Load Video Error with {e}')
|
| 208 |
+
return self.__getitem__(random.randint(0, self.__len__() - 1))
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
class VideoFrameProcessor:
|
| 212 |
+
# load a video and transform
|
| 213 |
+
def __init__(self, resolution=256, num_frames=24, add_normalize=True, sample_fps=24):
|
| 214 |
+
|
| 215 |
+
image_size = resolution
|
| 216 |
+
|
| 217 |
+
transform_list = [
|
| 218 |
+
transforms.Resize(image_size, interpolation=InterpolationMode.BICUBIC, antialias=True),
|
| 219 |
+
transforms.CenterCrop(image_size),
|
| 220 |
+
]
|
| 221 |
+
|
| 222 |
+
if add_normalize:
|
| 223 |
+
transform_list.append(transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)))
|
| 224 |
+
|
| 225 |
+
print(f"Transform List is {transform_list}")
|
| 226 |
+
self.num_frames = num_frames
|
| 227 |
+
self.transform = transforms.Compose(transform_list)
|
| 228 |
+
self.sample_fps = sample_fps
|
| 229 |
+
|
| 230 |
+
def __call__(self, video_path):
|
| 231 |
+
try:
|
| 232 |
+
video_capture = cv2.VideoCapture(video_path)
|
| 233 |
+
fps = video_capture.get(cv2.CAP_PROP_FPS)
|
| 234 |
+
frames = []
|
| 235 |
+
|
| 236 |
+
while True:
|
| 237 |
+
flag, frame = video_capture.read()
|
| 238 |
+
if not flag:
|
| 239 |
+
break
|
| 240 |
+
|
| 241 |
+
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
|
| 242 |
+
frame = torch.from_numpy(frame)
|
| 243 |
+
frame = frame.permute(2, 0, 1)
|
| 244 |
+
frames.append(frame)
|
| 245 |
+
|
| 246 |
+
video_capture.release()
|
| 247 |
+
sample_fps = self.sample_fps
|
| 248 |
+
interval = max(int(fps / sample_fps), 1)
|
| 249 |
+
frames = frames[::interval]
|
| 250 |
+
|
| 251 |
+
if len(frames) < self.num_frames:
|
| 252 |
+
num_frame_to_pack = self.num_frames - len(frames)
|
| 253 |
+
recurrent_num = num_frame_to_pack // len(frames)
|
| 254 |
+
frames = frames + recurrent_num * frames + frames[:(num_frame_to_pack % len(frames))]
|
| 255 |
+
assert len(frames) >= self.num_frames, f'{len(frames)}'
|
| 256 |
+
|
| 257 |
+
start_indexs = list(range(0, max(0, len(frames) - self.num_frames + 1)))
|
| 258 |
+
start_index = random.choice(start_indexs)
|
| 259 |
+
|
| 260 |
+
filtered_frames = frames[start_index : start_index+self.num_frames]
|
| 261 |
+
assert len(filtered_frames) == self.num_frames, f"The sampled frames should equals to {self.num_frames}"
|
| 262 |
+
|
| 263 |
+
filtered_frames = torch.stack(filtered_frames).float() / 255
|
| 264 |
+
filtered_frames = self.transform(filtered_frames)
|
| 265 |
+
filtered_frames = filtered_frames.permute(1, 0, 2, 3)
|
| 266 |
+
|
| 267 |
+
return filtered_frames, None
|
| 268 |
+
|
| 269 |
+
except Exception as e:
|
| 270 |
+
print(f"Load video: {video_path} Error, Exception {e}")
|
| 271 |
+
return None, None
|
| 272 |
+
|
| 273 |
+
|
| 274 |
+
class VideoDataset(Dataset):
|
| 275 |
+
def __init__(self, anno_file, resolution=256, max_frames=6, add_normalize=True):
|
| 276 |
+
super().__init__()
|
| 277 |
+
|
| 278 |
+
self.video_annos = []
|
| 279 |
+
self.max_frames = max_frames
|
| 280 |
+
|
| 281 |
+
if not isinstance(anno_file, list):
|
| 282 |
+
anno_file = [anno_file]
|
| 283 |
+
|
| 284 |
+
print(f"The training video clip frame number is {max_frames} ")
|
| 285 |
+
|
| 286 |
+
for anno_file_ in anno_file:
|
| 287 |
+
print(f"Load annotation file from {anno_file_}")
|
| 288 |
+
|
| 289 |
+
with jsonlines.open(anno_file_, 'r') as reader:
|
| 290 |
+
for item in tqdm(reader):
|
| 291 |
+
self.video_annos.append(item)
|
| 292 |
+
|
| 293 |
+
print(f"Totally Remained {len(self.video_annos)} videos")
|
| 294 |
+
|
| 295 |
+
self.video_processor = VideoFrameProcessor(resolution, max_frames, add_normalize)
|
| 296 |
+
|
| 297 |
+
def __len__(self):
|
| 298 |
+
return len(self.video_annos)
|
| 299 |
+
|
| 300 |
+
def __getitem__(self, index):
|
| 301 |
+
video_anno = self.video_annos[index]
|
| 302 |
+
video_path = video_anno['video']
|
| 303 |
+
|
| 304 |
+
try:
|
| 305 |
+
video_tensors, video_frames = self.video_processor(video_path)
|
| 306 |
+
|
| 307 |
+
assert video_tensors.shape[1] == self.max_frames
|
| 308 |
+
|
| 309 |
+
return {
|
| 310 |
+
"video": video_tensors,
|
| 311 |
+
"identifier": 'video',
|
| 312 |
+
}
|
| 313 |
+
|
| 314 |
+
except Exception as e:
|
| 315 |
+
print('Loading Video Error with {e}')
|
| 316 |
+
return self.__getitem__(random.randint(0, self.__len__() - 1))
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
class ImageDataset(Dataset):
|
| 320 |
+
def __init__(self, anno_file, resolution=256, max_frames=8, add_normalize=True):
|
| 321 |
+
super().__init__()
|
| 322 |
+
|
| 323 |
+
self.image_annos = []
|
| 324 |
+
self.max_frames = max_frames
|
| 325 |
+
image_paths = []
|
| 326 |
+
|
| 327 |
+
if not isinstance(anno_file, list):
|
| 328 |
+
anno_file = [anno_file]
|
| 329 |
+
|
| 330 |
+
for anno_file_ in anno_file:
|
| 331 |
+
print(f"Load annotation file from {anno_file_}")
|
| 332 |
+
with jsonlines.open(anno_file_, 'r') as reader:
|
| 333 |
+
for item in tqdm(reader):
|
| 334 |
+
image_paths.append(item['image'])
|
| 335 |
+
|
| 336 |
+
print(f"Totally Remained {len(image_paths)} images")
|
| 337 |
+
|
| 338 |
+
# pack multiple frames
|
| 339 |
+
for idx in range(0, len(image_paths), self.max_frames):
|
| 340 |
+
image_path_shard = image_paths[idx : idx + self.max_frames]
|
| 341 |
+
if len(image_path_shard) < self.max_frames:
|
| 342 |
+
image_path_shard = image_path_shard + image_paths[:self.max_frames - len(image_path_shard)]
|
| 343 |
+
assert len(image_path_shard) == self.max_frames
|
| 344 |
+
self.image_annos.append(image_path_shard)
|
| 345 |
+
|
| 346 |
+
image_size = resolution
|
| 347 |
+
transform_list = [
|
| 348 |
+
transforms.Resize(image_size, interpolation=InterpolationMode.BICUBIC, antialias=True),
|
| 349 |
+
transforms.CenterCrop(image_size),
|
| 350 |
+
transforms.ToTensor(),
|
| 351 |
+
]
|
| 352 |
+
if add_normalize:
|
| 353 |
+
transform_list.append(transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)))
|
| 354 |
+
|
| 355 |
+
print(f"Transform List is {transform_list}")
|
| 356 |
+
self.transform = transforms.Compose(transform_list)
|
| 357 |
+
|
| 358 |
+
def __len__(self):
|
| 359 |
+
return len(self.image_annos)
|
| 360 |
+
|
| 361 |
+
def __getitem__(self, index):
|
| 362 |
+
image_paths = self.image_annos[index]
|
| 363 |
+
|
| 364 |
+
try:
|
| 365 |
+
packed_pil_frames = [Image.open(image_path).convert("RGB") for image_path in image_paths]
|
| 366 |
+
filtered_frames = [self.transform(frame) for frame in packed_pil_frames]
|
| 367 |
+
filtered_frames = torch.stack(filtered_frames) # [t, c, h, w]
|
| 368 |
+
filtered_frames = filtered_frames.permute(1, 0, 2, 3) # [c, t, h, w]
|
| 369 |
+
|
| 370 |
+
return {
|
| 371 |
+
"video": filtered_frames,
|
| 372 |
+
"identifier": 'image',
|
| 373 |
+
}
|
| 374 |
+
|
| 375 |
+
except Exception as e:
|
| 376 |
+
print(f'Load Images Error with {e}')
|
| 377 |
+
return self.__getitem__(random.randint(0, self.__len__() - 1))
|
diffusion_schedulers/__init__.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .scheduling_cosine_ddpm import DDPMCosineScheduler
|
| 2 |
+
from .scheduling_flow_matching import PyramidFlowMatchEulerDiscreteScheduler
|
diffusion_schedulers/scheduling_cosine_ddpm.py
ADDED
|
@@ -0,0 +1,137 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
from dataclasses import dataclass
|
| 3 |
+
from typing import List, Optional, Tuple, Union
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
|
| 7 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 8 |
+
from diffusers.utils import BaseOutput
|
| 9 |
+
from diffusers.utils.torch_utils import randn_tensor
|
| 10 |
+
from diffusers.schedulers.scheduling_utils import SchedulerMixin
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
@dataclass
|
| 14 |
+
class DDPMSchedulerOutput(BaseOutput):
|
| 15 |
+
"""
|
| 16 |
+
Output class for the scheduler's step function output.
|
| 17 |
+
|
| 18 |
+
Args:
|
| 19 |
+
prev_sample (`torch.Tensor` of shape `(batch_size, num_channels, height, width)` for images):
|
| 20 |
+
Computed sample (x_{t-1}) of previous timestep. `prev_sample` should be used as next model input in the
|
| 21 |
+
denoising loop.
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
prev_sample: torch.Tensor
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class DDPMCosineScheduler(SchedulerMixin, ConfigMixin):
|
| 28 |
+
|
| 29 |
+
@register_to_config
|
| 30 |
+
def __init__(
|
| 31 |
+
self,
|
| 32 |
+
scaler: float = 1.0,
|
| 33 |
+
s: float = 0.008,
|
| 34 |
+
):
|
| 35 |
+
self.scaler = scaler
|
| 36 |
+
self.s = torch.tensor([s])
|
| 37 |
+
self._init_alpha_cumprod = torch.cos(self.s / (1 + self.s) * torch.pi * 0.5) ** 2
|
| 38 |
+
|
| 39 |
+
# standard deviation of the initial noise distribution
|
| 40 |
+
self.init_noise_sigma = 1.0
|
| 41 |
+
|
| 42 |
+
def _alpha_cumprod(self, t, device):
|
| 43 |
+
if self.scaler > 1:
|
| 44 |
+
t = 1 - (1 - t) ** self.scaler
|
| 45 |
+
elif self.scaler < 1:
|
| 46 |
+
t = t**self.scaler
|
| 47 |
+
alpha_cumprod = torch.cos(
|
| 48 |
+
(t + self.s.to(device)) / (1 + self.s.to(device)) * torch.pi * 0.5
|
| 49 |
+
) ** 2 / self._init_alpha_cumprod.to(device)
|
| 50 |
+
return alpha_cumprod.clamp(0.0001, 0.9999)
|
| 51 |
+
|
| 52 |
+
def scale_model_input(self, sample: torch.Tensor, timestep: Optional[int] = None) -> torch.Tensor:
|
| 53 |
+
"""
|
| 54 |
+
Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
|
| 55 |
+
current timestep.
|
| 56 |
+
|
| 57 |
+
Args:
|
| 58 |
+
sample (`torch.Tensor`): input sample
|
| 59 |
+
timestep (`int`, optional): current timestep
|
| 60 |
+
|
| 61 |
+
Returns:
|
| 62 |
+
`torch.Tensor`: scaled input sample
|
| 63 |
+
"""
|
| 64 |
+
return sample
|
| 65 |
+
|
| 66 |
+
def set_timesteps(
|
| 67 |
+
self,
|
| 68 |
+
num_inference_steps: int = None,
|
| 69 |
+
timesteps: Optional[List[int]] = None,
|
| 70 |
+
device: Union[str, torch.device] = None,
|
| 71 |
+
):
|
| 72 |
+
"""
|
| 73 |
+
Sets the discrete timesteps used for the diffusion chain. Supporting function to be run before inference.
|
| 74 |
+
|
| 75 |
+
Args:
|
| 76 |
+
num_inference_steps (`Dict[float, int]`):
|
| 77 |
+
the number of diffusion steps used when generating samples with a pre-trained model. If passed, then
|
| 78 |
+
`timesteps` must be `None`.
|
| 79 |
+
device (`str` or `torch.device`, optional):
|
| 80 |
+
the device to which the timesteps are moved to. {2 / 3: 20, 0.0: 10}
|
| 81 |
+
"""
|
| 82 |
+
if timesteps is None:
|
| 83 |
+
timesteps = torch.linspace(1.0, 0.0, num_inference_steps + 1, device=device)
|
| 84 |
+
if not isinstance(timesteps, torch.Tensor):
|
| 85 |
+
timesteps = torch.Tensor(timesteps).to(device)
|
| 86 |
+
self.timesteps = timesteps
|
| 87 |
+
|
| 88 |
+
def step(
|
| 89 |
+
self,
|
| 90 |
+
model_output: torch.Tensor,
|
| 91 |
+
timestep: int,
|
| 92 |
+
sample: torch.Tensor,
|
| 93 |
+
generator=None,
|
| 94 |
+
return_dict: bool = True,
|
| 95 |
+
) -> Union[DDPMSchedulerOutput, Tuple]:
|
| 96 |
+
dtype = model_output.dtype
|
| 97 |
+
device = model_output.device
|
| 98 |
+
t = timestep
|
| 99 |
+
|
| 100 |
+
prev_t = self.previous_timestep(t)
|
| 101 |
+
|
| 102 |
+
alpha_cumprod = self._alpha_cumprod(t, device).view(t.size(0), *[1 for _ in sample.shape[1:]])
|
| 103 |
+
alpha_cumprod_prev = self._alpha_cumprod(prev_t, device).view(prev_t.size(0), *[1 for _ in sample.shape[1:]])
|
| 104 |
+
alpha = alpha_cumprod / alpha_cumprod_prev
|
| 105 |
+
|
| 106 |
+
mu = (1.0 / alpha).sqrt() * (sample - (1 - alpha) * model_output / (1 - alpha_cumprod).sqrt())
|
| 107 |
+
|
| 108 |
+
std_noise = randn_tensor(mu.shape, generator=generator, device=model_output.device, dtype=model_output.dtype)
|
| 109 |
+
std = ((1 - alpha) * (1.0 - alpha_cumprod_prev) / (1.0 - alpha_cumprod)).sqrt() * std_noise
|
| 110 |
+
pred = mu + std * (prev_t != 0).float().view(prev_t.size(0), *[1 for _ in sample.shape[1:]])
|
| 111 |
+
|
| 112 |
+
if not return_dict:
|
| 113 |
+
return (pred.to(dtype),)
|
| 114 |
+
|
| 115 |
+
return DDPMSchedulerOutput(prev_sample=pred.to(dtype))
|
| 116 |
+
|
| 117 |
+
def add_noise(
|
| 118 |
+
self,
|
| 119 |
+
original_samples: torch.Tensor,
|
| 120 |
+
noise: torch.Tensor,
|
| 121 |
+
timesteps: torch.Tensor,
|
| 122 |
+
) -> torch.Tensor:
|
| 123 |
+
device = original_samples.device
|
| 124 |
+
dtype = original_samples.dtype
|
| 125 |
+
alpha_cumprod = self._alpha_cumprod(timesteps, device=device).view(
|
| 126 |
+
timesteps.size(0), *[1 for _ in original_samples.shape[1:]]
|
| 127 |
+
)
|
| 128 |
+
noisy_samples = alpha_cumprod.sqrt() * original_samples + (1 - alpha_cumprod).sqrt() * noise
|
| 129 |
+
return noisy_samples.to(dtype=dtype)
|
| 130 |
+
|
| 131 |
+
def __len__(self):
|
| 132 |
+
return self.config.num_train_timesteps
|
| 133 |
+
|
| 134 |
+
def previous_timestep(self, timestep):
|
| 135 |
+
index = (self.timesteps - timestep[0]).abs().argmin().item()
|
| 136 |
+
prev_t = self.timesteps[index + 1][None].expand(timestep.shape[0])
|
| 137 |
+
return prev_t
|
diffusion_schedulers/scheduling_flow_matching.py
ADDED
|
@@ -0,0 +1,297 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dataclasses import dataclass
|
| 2 |
+
from typing import Optional, Tuple, Union, List
|
| 3 |
+
import math
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
|
| 7 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 8 |
+
from diffusers.utils import BaseOutput, logging
|
| 9 |
+
from diffusers.utils.torch_utils import randn_tensor
|
| 10 |
+
from diffusers.schedulers.scheduling_utils import SchedulerMixin
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
@dataclass
|
| 14 |
+
class FlowMatchEulerDiscreteSchedulerOutput(BaseOutput):
|
| 15 |
+
"""
|
| 16 |
+
Output class for the scheduler's `step` function output.
|
| 17 |
+
|
| 18 |
+
Args:
|
| 19 |
+
prev_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
|
| 20 |
+
Computed sample `(x_{t-1})` of previous timestep. `prev_sample` should be used as next model input in the
|
| 21 |
+
denoising loop.
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
prev_sample: torch.FloatTensor
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class PyramidFlowMatchEulerDiscreteScheduler(SchedulerMixin, ConfigMixin):
|
| 28 |
+
"""
|
| 29 |
+
Euler scheduler.
|
| 30 |
+
|
| 31 |
+
This model inherits from [`SchedulerMixin`] and [`ConfigMixin`]. Check the superclass documentation for the generic
|
| 32 |
+
methods the library implements for all schedulers such as loading and saving.
|
| 33 |
+
|
| 34 |
+
Args:
|
| 35 |
+
num_train_timesteps (`int`, defaults to 1000):
|
| 36 |
+
The number of diffusion steps to train the model.
|
| 37 |
+
timestep_spacing (`str`, defaults to `"linspace"`):
|
| 38 |
+
The way the timesteps should be scaled. Refer to Table 2 of the [Common Diffusion Noise Schedules and
|
| 39 |
+
Sample Steps are Flawed](https://huggingface.co/papers/2305.08891) for more information.
|
| 40 |
+
shift (`float`, defaults to 1.0):
|
| 41 |
+
The shift value for the timestep schedule.
|
| 42 |
+
"""
|
| 43 |
+
|
| 44 |
+
_compatibles = []
|
| 45 |
+
order = 1
|
| 46 |
+
|
| 47 |
+
@register_to_config
|
| 48 |
+
def __init__(
|
| 49 |
+
self,
|
| 50 |
+
num_train_timesteps: int = 1000,
|
| 51 |
+
shift: float = 1.0, # Following Stable diffusion 3,
|
| 52 |
+
stages: int = 3,
|
| 53 |
+
stage_range: List = [0, 1/3, 2/3, 1],
|
| 54 |
+
gamma: float = 1/3,
|
| 55 |
+
):
|
| 56 |
+
|
| 57 |
+
self.timestep_ratios = {} # The timestep ratio for each stage
|
| 58 |
+
self.timesteps_per_stage = {} # The detailed timesteps per stage
|
| 59 |
+
self.sigmas_per_stage = {}
|
| 60 |
+
self.start_sigmas = {}
|
| 61 |
+
self.end_sigmas = {}
|
| 62 |
+
self.ori_start_sigmas = {}
|
| 63 |
+
|
| 64 |
+
# self.init_sigmas()
|
| 65 |
+
self.init_sigmas_for_each_stage()
|
| 66 |
+
self.sigma_min = self.sigmas[-1].item()
|
| 67 |
+
self.sigma_max = self.sigmas[0].item()
|
| 68 |
+
self.gamma = gamma
|
| 69 |
+
|
| 70 |
+
def init_sigmas(self):
|
| 71 |
+
"""
|
| 72 |
+
initialize the global timesteps and sigmas
|
| 73 |
+
"""
|
| 74 |
+
num_train_timesteps = self.config.num_train_timesteps
|
| 75 |
+
shift = self.config.shift
|
| 76 |
+
|
| 77 |
+
timesteps = np.linspace(1, num_train_timesteps, num_train_timesteps, dtype=np.float32)[::-1].copy()
|
| 78 |
+
timesteps = torch.from_numpy(timesteps).to(dtype=torch.float32)
|
| 79 |
+
|
| 80 |
+
sigmas = timesteps / num_train_timesteps
|
| 81 |
+
sigmas = shift * sigmas / (1 + (shift - 1) * sigmas)
|
| 82 |
+
|
| 83 |
+
self.timesteps = sigmas * num_train_timesteps
|
| 84 |
+
|
| 85 |
+
self._step_index = None
|
| 86 |
+
self._begin_index = None
|
| 87 |
+
|
| 88 |
+
self.sigmas = sigmas.to("cpu") # to avoid too much CPU/GPU communication
|
| 89 |
+
|
| 90 |
+
def init_sigmas_for_each_stage(self):
|
| 91 |
+
"""
|
| 92 |
+
Init the timesteps for each stage
|
| 93 |
+
"""
|
| 94 |
+
self.init_sigmas()
|
| 95 |
+
|
| 96 |
+
stage_distance = []
|
| 97 |
+
stages = self.config.stages
|
| 98 |
+
training_steps = self.config.num_train_timesteps
|
| 99 |
+
stage_range = self.config.stage_range
|
| 100 |
+
|
| 101 |
+
# Init the start and end point of each stage
|
| 102 |
+
for i_s in range(stages):
|
| 103 |
+
# To decide the start and ends point
|
| 104 |
+
start_indice = int(stage_range[i_s] * training_steps)
|
| 105 |
+
start_indice = max(start_indice, 0)
|
| 106 |
+
end_indice = int(stage_range[i_s+1] * training_steps)
|
| 107 |
+
end_indice = min(end_indice, training_steps)
|
| 108 |
+
start_sigma = self.sigmas[start_indice].item()
|
| 109 |
+
end_sigma = self.sigmas[end_indice].item() if end_indice < training_steps else 0.0
|
| 110 |
+
self.ori_start_sigmas[i_s] = start_sigma
|
| 111 |
+
|
| 112 |
+
if i_s != 0:
|
| 113 |
+
ori_sigma = 1 - start_sigma
|
| 114 |
+
gamma = self.config.gamma
|
| 115 |
+
corrected_sigma = (1 / (math.sqrt(1 + (1 / gamma)) * (1 - ori_sigma) + ori_sigma)) * ori_sigma
|
| 116 |
+
# corrected_sigma = 1 / (2 - ori_sigma) * ori_sigma
|
| 117 |
+
start_sigma = 1 - corrected_sigma
|
| 118 |
+
|
| 119 |
+
stage_distance.append(start_sigma - end_sigma)
|
| 120 |
+
self.start_sigmas[i_s] = start_sigma
|
| 121 |
+
self.end_sigmas[i_s] = end_sigma
|
| 122 |
+
|
| 123 |
+
# Determine the ratio of each stage according to flow length
|
| 124 |
+
tot_distance = sum(stage_distance)
|
| 125 |
+
for i_s in range(stages):
|
| 126 |
+
if i_s == 0:
|
| 127 |
+
start_ratio = 0.0
|
| 128 |
+
else:
|
| 129 |
+
start_ratio = sum(stage_distance[:i_s]) / tot_distance
|
| 130 |
+
if i_s == stages - 1:
|
| 131 |
+
end_ratio = 1.0
|
| 132 |
+
else:
|
| 133 |
+
end_ratio = sum(stage_distance[:i_s+1]) / tot_distance
|
| 134 |
+
|
| 135 |
+
self.timestep_ratios[i_s] = (start_ratio, end_ratio)
|
| 136 |
+
|
| 137 |
+
# Determine the timesteps and sigmas for each stage
|
| 138 |
+
for i_s in range(stages):
|
| 139 |
+
timestep_ratio = self.timestep_ratios[i_s]
|
| 140 |
+
timestep_max = self.timesteps[int(timestep_ratio[0] * training_steps)]
|
| 141 |
+
timestep_min = self.timesteps[min(int(timestep_ratio[1] * training_steps), training_steps - 1)]
|
| 142 |
+
timesteps = np.linspace(
|
| 143 |
+
timestep_max, timestep_min, training_steps + 1,
|
| 144 |
+
)
|
| 145 |
+
self.timesteps_per_stage[i_s] = timesteps[:-1] if isinstance(timesteps, torch.Tensor) else torch.from_numpy(timesteps[:-1])
|
| 146 |
+
stage_sigmas = np.linspace(
|
| 147 |
+
1, 0, training_steps + 1,
|
| 148 |
+
)
|
| 149 |
+
self.sigmas_per_stage[i_s] = torch.from_numpy(stage_sigmas[:-1])
|
| 150 |
+
|
| 151 |
+
@property
|
| 152 |
+
def step_index(self):
|
| 153 |
+
"""
|
| 154 |
+
The index counter for current timestep. It will increase 1 after each scheduler step.
|
| 155 |
+
"""
|
| 156 |
+
return self._step_index
|
| 157 |
+
|
| 158 |
+
@property
|
| 159 |
+
def begin_index(self):
|
| 160 |
+
"""
|
| 161 |
+
The index for the first timestep. It should be set from pipeline with `set_begin_index` method.
|
| 162 |
+
"""
|
| 163 |
+
return self._begin_index
|
| 164 |
+
|
| 165 |
+
# Copied from diffusers.schedulers.scheduling_dpmsolver_multistep.DPMSolverMultistepScheduler.set_begin_index
|
| 166 |
+
def set_begin_index(self, begin_index: int = 0):
|
| 167 |
+
"""
|
| 168 |
+
Sets the begin index for the scheduler. This function should be run from pipeline before the inference.
|
| 169 |
+
|
| 170 |
+
Args:
|
| 171 |
+
begin_index (`int`):
|
| 172 |
+
The begin index for the scheduler.
|
| 173 |
+
"""
|
| 174 |
+
self._begin_index = begin_index
|
| 175 |
+
|
| 176 |
+
def _sigma_to_t(self, sigma):
|
| 177 |
+
return sigma * self.config.num_train_timesteps
|
| 178 |
+
|
| 179 |
+
def set_timesteps(self, num_inference_steps: int, stage_index: int, device: Union[str, torch.device] = None):
|
| 180 |
+
"""
|
| 181 |
+
Setting the timesteps and sigmas for each stage
|
| 182 |
+
"""
|
| 183 |
+
self.num_inference_steps = num_inference_steps
|
| 184 |
+
training_steps = self.config.num_train_timesteps
|
| 185 |
+
self.init_sigmas()
|
| 186 |
+
|
| 187 |
+
stage_timesteps = self.timesteps_per_stage[stage_index]
|
| 188 |
+
timestep_max = stage_timesteps[0].item()
|
| 189 |
+
timestep_min = stage_timesteps[-1].item()
|
| 190 |
+
|
| 191 |
+
timesteps = np.linspace(
|
| 192 |
+
timestep_max, timestep_min, num_inference_steps,
|
| 193 |
+
)
|
| 194 |
+
self.timesteps = torch.from_numpy(timesteps).to(device=device)
|
| 195 |
+
|
| 196 |
+
stage_sigmas = self.sigmas_per_stage[stage_index]
|
| 197 |
+
sigma_max = stage_sigmas[0].item()
|
| 198 |
+
sigma_min = stage_sigmas[-1].item()
|
| 199 |
+
|
| 200 |
+
ratios = np.linspace(
|
| 201 |
+
sigma_max, sigma_min, num_inference_steps
|
| 202 |
+
)
|
| 203 |
+
sigmas = torch.from_numpy(ratios).to(device=device)
|
| 204 |
+
self.sigmas = torch.cat([sigmas, torch.zeros(1, device=sigmas.device)])
|
| 205 |
+
|
| 206 |
+
self._step_index = None
|
| 207 |
+
|
| 208 |
+
def index_for_timestep(self, timestep, schedule_timesteps=None):
|
| 209 |
+
if schedule_timesteps is None:
|
| 210 |
+
schedule_timesteps = self.timesteps
|
| 211 |
+
|
| 212 |
+
indices = (schedule_timesteps == timestep).nonzero()
|
| 213 |
+
|
| 214 |
+
# The sigma index that is taken for the **very** first `step`
|
| 215 |
+
# is always the second index (or the last index if there is only 1)
|
| 216 |
+
# This way we can ensure we don't accidentally skip a sigma in
|
| 217 |
+
# case we start in the middle of the denoising schedule (e.g. for image-to-image)
|
| 218 |
+
pos = 1 if len(indices) > 1 else 0
|
| 219 |
+
|
| 220 |
+
return indices[pos].item()
|
| 221 |
+
|
| 222 |
+
def _init_step_index(self, timestep):
|
| 223 |
+
if self.begin_index is None:
|
| 224 |
+
if isinstance(timestep, torch.Tensor):
|
| 225 |
+
timestep = timestep.to(self.timesteps.device)
|
| 226 |
+
self._step_index = self.index_for_timestep(timestep)
|
| 227 |
+
else:
|
| 228 |
+
self._step_index = self._begin_index
|
| 229 |
+
|
| 230 |
+
def step(
|
| 231 |
+
self,
|
| 232 |
+
model_output: torch.FloatTensor,
|
| 233 |
+
timestep: Union[float, torch.FloatTensor],
|
| 234 |
+
sample: torch.FloatTensor,
|
| 235 |
+
generator: Optional[torch.Generator] = None,
|
| 236 |
+
return_dict: bool = True,
|
| 237 |
+
) -> Union[FlowMatchEulerDiscreteSchedulerOutput, Tuple]:
|
| 238 |
+
"""
|
| 239 |
+
Predict the sample from the previous timestep by reversing the SDE. This function propagates the diffusion
|
| 240 |
+
process from the learned model outputs (most often the predicted noise).
|
| 241 |
+
|
| 242 |
+
Args:
|
| 243 |
+
model_output (`torch.FloatTensor`):
|
| 244 |
+
The direct output from learned diffusion model.
|
| 245 |
+
timestep (`float`):
|
| 246 |
+
The current discrete timestep in the diffusion chain.
|
| 247 |
+
sample (`torch.FloatTensor`):
|
| 248 |
+
A current instance of a sample created by the diffusion process.
|
| 249 |
+
generator (`torch.Generator`, *optional*):
|
| 250 |
+
A random number generator.
|
| 251 |
+
return_dict (`bool`):
|
| 252 |
+
Whether or not to return a [`~schedulers.scheduling_euler_discrete.EulerDiscreteSchedulerOutput`] or
|
| 253 |
+
tuple.
|
| 254 |
+
|
| 255 |
+
Returns:
|
| 256 |
+
[`~schedulers.scheduling_euler_discrete.EulerDiscreteSchedulerOutput`] or `tuple`:
|
| 257 |
+
If return_dict is `True`, [`~schedulers.scheduling_euler_discrete.EulerDiscreteSchedulerOutput`] is
|
| 258 |
+
returned, otherwise a tuple is returned where the first element is the sample tensor.
|
| 259 |
+
"""
|
| 260 |
+
|
| 261 |
+
if (
|
| 262 |
+
isinstance(timestep, int)
|
| 263 |
+
or isinstance(timestep, torch.IntTensor)
|
| 264 |
+
or isinstance(timestep, torch.LongTensor)
|
| 265 |
+
):
|
| 266 |
+
raise ValueError(
|
| 267 |
+
(
|
| 268 |
+
"Passing integer indices (e.g. from `enumerate(timesteps)`) as timesteps to"
|
| 269 |
+
" `EulerDiscreteScheduler.step()` is not supported. Make sure to pass"
|
| 270 |
+
" one of the `scheduler.timesteps` as a timestep."
|
| 271 |
+
),
|
| 272 |
+
)
|
| 273 |
+
|
| 274 |
+
if self.step_index is None:
|
| 275 |
+
self._step_index = 0
|
| 276 |
+
|
| 277 |
+
# Upcast to avoid precision issues when computing prev_sample
|
| 278 |
+
sample = sample.to(torch.float32)
|
| 279 |
+
|
| 280 |
+
sigma = self.sigmas[self.step_index]
|
| 281 |
+
sigma_next = self.sigmas[self.step_index + 1]
|
| 282 |
+
|
| 283 |
+
prev_sample = sample + (sigma_next - sigma) * model_output
|
| 284 |
+
|
| 285 |
+
# Cast sample back to model compatible dtype
|
| 286 |
+
prev_sample = prev_sample.to(model_output.dtype)
|
| 287 |
+
|
| 288 |
+
# upon completion increase step index by one
|
| 289 |
+
self._step_index += 1
|
| 290 |
+
|
| 291 |
+
if not return_dict:
|
| 292 |
+
return (prev_sample,)
|
| 293 |
+
|
| 294 |
+
return FlowMatchEulerDiscreteSchedulerOutput(prev_sample=prev_sample)
|
| 295 |
+
|
| 296 |
+
def __len__(self):
|
| 297 |
+
return self.config.num_train_timesteps
|
docs/DiT.md
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Pyramid Flow's DiT Finetuning Guide
|
| 2 |
+
|
| 3 |
+
This is the finetuning guide for the DiT in Pyramid Flow. We provide instructions for both autoregressive and non-autoregressive versions. The former is more research oriented and the latter is more stable (but less efficient without temporal pyramid). Please refer to [another document](https://github.com/jy0205/Pyramid-Flow/blob/main/docs/VAE) for VAE finetuning.
|
| 4 |
+
|
| 5 |
+
## Hardware Requirements
|
| 6 |
+
|
| 7 |
+
+ DiT finetuning: At least 8 A100 GPUs.
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
## Prepare the Dataset
|
| 11 |
+
|
| 12 |
+
The training dataset should be arranged into a json file, with `video`, `text` fields. Since the video vae latent extraction is very slow, we strongly recommend you to pre-extract the video vae latents to save the training time. We provide a video vae latent extraction script in folder `tools`. You can run it with the following command:
|
| 13 |
+
|
| 14 |
+
```bash
|
| 15 |
+
sh scripts/extract_vae_latent.sh
|
| 16 |
+
```
|
| 17 |
+
|
| 18 |
+
(optional) Since the T5 text encoder will cost a lot of GPU memory, pre-extract the text features will save the training memory. We also provide a text feature extraction script in folder `tools`. You can run it with the following command:
|
| 19 |
+
|
| 20 |
+
```bash
|
| 21 |
+
sh scripts/extract_text_feature.sh
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
The final training annotation json file should look like the following format:
|
| 25 |
+
|
| 26 |
+
```
|
| 27 |
+
{"video": video_path, "text": text prompt, "latent": extracted video vae latent, "text_fea": extracted text feature}
|
| 28 |
+
```
|
| 29 |
+
|
| 30 |
+
We provide the example json annotation files for [video](https://github.com/jy0205/Pyramid-Flow/blob/main/annotation/video_text.jsonl) and [image](https://github.com/jy0205/Pyramid-Flow/blob/main/annotation/image_text.jsonl)) training in the `annotation` folder. You can refer them to prepare your training dataset.
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
## Run Training
|
| 34 |
+
We provide two types of training scripts: (1) autoregressive video generation training with temporal pyramid. (2) Full-sequence diffusion training with pyramid-flow for both text-to-image and text-to-video training. This corresponds to the following two script files. Running these training scripts using at least 8 GPUs:
|
| 35 |
+
|
| 36 |
+
+ `scripts/train_pyramid_flow.sh`: The autoregressive video generation training with temporal pyramid.
|
| 37 |
+
|
| 38 |
+
```bash
|
| 39 |
+
sh scripts/train_pyramid_flow.sh
|
| 40 |
+
```
|
| 41 |
+
|
| 42 |
+
+ `scripts/train_pyramid_flow_without_ar.sh`: Using pyramid-flow for full-sequence diffusion training.
|
| 43 |
+
|
| 44 |
+
```bash
|
| 45 |
+
sh scripts/train_pyramid_flow_without_ar.sh
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
## Tips
|
| 50 |
+
|
| 51 |
+
+ For the 768p version, make sure to add the args: `--gradient_checkpointing`
|
| 52 |
+
+ Param `NUM_FRAMES` should be set to a multiple of 8
|
| 53 |
+
+ For the param `video_sync_group`, it indicates the number of process that accepts the same input video, used for temporal pyramid AR training. We recommend to set this value to 4, 8 or 16. (16 is better if you have more GPUs)
|
| 54 |
+
+ Make sure to set `NUM_FRAMES % VIDEO_SYNC_GROUP == 0`, `GPUS % VIDEO_SYNC_GROUP == 0`, and `BATCH_SIZE % 4 == 0`
|
docs/VAE.md
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Pyramid Flow's VAE Training Guide
|
| 2 |
+
|
| 3 |
+
This is the training guide for a [MAGVIT-v2](https://arxiv.org/abs/2310.05737) like continuous 3D VAE, which should be quite flexible. Feel free to build your own video generative model on this part of VAE training code. Please refer to [another document](https://github.com/jy0205/Pyramid-Flow/blob/main/docs/DiT) for DiT finetuning.
|
| 4 |
+
|
| 5 |
+
## Hardware Requirements
|
| 6 |
+
|
| 7 |
+
+ VAE training: At least 8 A100 GPUs.
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
## Prepare the Dataset
|
| 11 |
+
|
| 12 |
+
The training of our causal video vae uses both image and video data. Both of them should be arranged into a json file, with `video` or `image` field. The final training annotation json file should look like the following format:
|
| 13 |
+
|
| 14 |
+
```
|
| 15 |
+
# For Video
|
| 16 |
+
{"video": video_path}
|
| 17 |
+
|
| 18 |
+
# For Image
|
| 19 |
+
{"image": image_path}
|
| 20 |
+
```
|
| 21 |
+
|
| 22 |
+
## Run Training
|
| 23 |
+
|
| 24 |
+
The causal video vae undergoes a two-stage training.
|
| 25 |
+
+ Stage-1: image and video mixed training
|
| 26 |
+
+ Stage-2: pure video training, using context parallel to load video with more video frames
|
| 27 |
+
|
| 28 |
+
The VAE training script is `scripts/train_causal_video_vae.sh`, run it as follows:
|
| 29 |
+
|
| 30 |
+
```bash
|
| 31 |
+
sh scripts/train_causal_video_vae.sh
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
We also provide a VAE demo `causal_video_vae_demo.ipynb` for image and video reconstruction.
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
## Tips
|
| 38 |
+
|
| 39 |
+
+ For stage-1, we use a mixed image and video training. Add the param `--use_image_video_mixed_training` to support the mixed training. We set the image ratio to 0.1 by default.
|
| 40 |
+
+ Set the `resolution` to 256 is enough for VAE training.
|
| 41 |
+
+ For stage-1, the `max_frames` is set to 17. It means we use 17 sampled video frames for training.
|
| 42 |
+
+ For stage-2, we open the param `use_context_parallel` to distribute long video frames to multiple GPUs. Make sure to set `GPUS % CONTEXT_SIZE == 0` and `NUM_FRAMES=17 * CONTEXT_SIZE + 1`
|
image_generation_demo.ipynb
ADDED
|
@@ -0,0 +1,123 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": null,
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"outputs": [],
|
| 8 |
+
"source": [
|
| 9 |
+
"import os\n",
|
| 10 |
+
"import json\n",
|
| 11 |
+
"import torch\n",
|
| 12 |
+
"import numpy as np\n",
|
| 13 |
+
"import PIL\n",
|
| 14 |
+
"from PIL import Image\n",
|
| 15 |
+
"from IPython.display import HTML\n",
|
| 16 |
+
"from pyramid_dit import PyramidDiTForVideoGeneration\n",
|
| 17 |
+
"from IPython.display import Image as ipython_image\n",
|
| 18 |
+
"from diffusers.utils import load_image, export_to_video, export_to_gif"
|
| 19 |
+
]
|
| 20 |
+
},
|
| 21 |
+
{
|
| 22 |
+
"cell_type": "code",
|
| 23 |
+
"execution_count": null,
|
| 24 |
+
"metadata": {},
|
| 25 |
+
"outputs": [],
|
| 26 |
+
"source": [
|
| 27 |
+
"variant='diffusion_transformer_image' # For low resolution\n",
|
| 28 |
+
"model_name = \"pyramid_flux\"\n",
|
| 29 |
+
"\n",
|
| 30 |
+
"model_path = \"/home/jinyang06/models/pyramid-flow-miniflux\" # The downloaded checkpoint dir\n",
|
| 31 |
+
"model_dtype = 'bf16'\n",
|
| 32 |
+
"\n",
|
| 33 |
+
"device_id = 0\n",
|
| 34 |
+
"torch.cuda.set_device(device_id)\n",
|
| 35 |
+
"\n",
|
| 36 |
+
"model = PyramidDiTForVideoGeneration(\n",
|
| 37 |
+
" model_path,\n",
|
| 38 |
+
" model_dtype,\n",
|
| 39 |
+
" model_name=model_name,\n",
|
| 40 |
+
" model_variant=variant,\n",
|
| 41 |
+
")\n",
|
| 42 |
+
"\n",
|
| 43 |
+
"model.vae.to(\"cuda\")\n",
|
| 44 |
+
"model.dit.to(\"cuda\")\n",
|
| 45 |
+
"model.text_encoder.to(\"cuda\")\n",
|
| 46 |
+
"\n",
|
| 47 |
+
"model.vae.enable_tiling()\n",
|
| 48 |
+
"\n",
|
| 49 |
+
"if model_dtype == \"bf16\":\n",
|
| 50 |
+
" torch_dtype = torch.bfloat16 \n",
|
| 51 |
+
"elif model_dtype == \"fp16\":\n",
|
| 52 |
+
" torch_dtype = torch.float16\n",
|
| 53 |
+
"else:\n",
|
| 54 |
+
" torch_dtype = torch.float32"
|
| 55 |
+
]
|
| 56 |
+
},
|
| 57 |
+
{
|
| 58 |
+
"attachments": {},
|
| 59 |
+
"cell_type": "markdown",
|
| 60 |
+
"metadata": {},
|
| 61 |
+
"source": [
|
| 62 |
+
"### Text-to-Image"
|
| 63 |
+
]
|
| 64 |
+
},
|
| 65 |
+
{
|
| 66 |
+
"cell_type": "code",
|
| 67 |
+
"execution_count": null,
|
| 68 |
+
"metadata": {},
|
| 69 |
+
"outputs": [],
|
| 70 |
+
"source": [
|
| 71 |
+
"prompt = \"shoulder and full head portrait of a beautiful 19 year old girl, brunette, smiling, stunning, highly detailed, glamour lighting, HDR, photorealistic, hyperrealism, octane render, unreal engine\"\n",
|
| 72 |
+
"\n",
|
| 73 |
+
"# now support 3 aspect ratios\n",
|
| 74 |
+
"resolution_dict = {\n",
|
| 75 |
+
" '1:1' : (1024, 1024),\n",
|
| 76 |
+
" '5:3' : (1280, 768),\n",
|
| 77 |
+
" '3:5' : (768, 1280),\n",
|
| 78 |
+
"}\n",
|
| 79 |
+
"\n",
|
| 80 |
+
"ratio = '1:1' # 1:1, 5:3, 3:5\n",
|
| 81 |
+
"\n",
|
| 82 |
+
"width, height = resolution_dict[ratio]\n",
|
| 83 |
+
"\n",
|
| 84 |
+
"\n",
|
| 85 |
+
"with torch.no_grad(), torch.cuda.amp.autocast(enabled=True if model_dtype != 'fp32' else False, dtype=torch_dtype):\n",
|
| 86 |
+
" images = model.generate(\n",
|
| 87 |
+
" prompt=prompt,\n",
|
| 88 |
+
" num_inference_steps=[20, 20, 20],\n",
|
| 89 |
+
" height=height,\n",
|
| 90 |
+
" width=width,\n",
|
| 91 |
+
" temp=1,\n",
|
| 92 |
+
" guidance_scale=9.0, \n",
|
| 93 |
+
" output_type=\"pil\",\n",
|
| 94 |
+
" save_memory=False, \n",
|
| 95 |
+
" )\n",
|
| 96 |
+
"\n",
|
| 97 |
+
"display(images[0])"
|
| 98 |
+
]
|
| 99 |
+
}
|
| 100 |
+
],
|
| 101 |
+
"metadata": {
|
| 102 |
+
"kernelspec": {
|
| 103 |
+
"display_name": "Python 3",
|
| 104 |
+
"language": "python",
|
| 105 |
+
"name": "python3"
|
| 106 |
+
},
|
| 107 |
+
"language_info": {
|
| 108 |
+
"codemirror_mode": {
|
| 109 |
+
"name": "ipython",
|
| 110 |
+
"version": 3
|
| 111 |
+
},
|
| 112 |
+
"file_extension": ".py",
|
| 113 |
+
"mimetype": "text/x-python",
|
| 114 |
+
"name": "python",
|
| 115 |
+
"nbconvert_exporter": "python",
|
| 116 |
+
"pygments_lexer": "ipython3",
|
| 117 |
+
"version": "3.8.10"
|
| 118 |
+
},
|
| 119 |
+
"orig_nbformat": 4
|
| 120 |
+
},
|
| 121 |
+
"nbformat": 4,
|
| 122 |
+
"nbformat_minor": 2
|
| 123 |
+
}
|
inference_multigpu.py
ADDED
|
@@ -0,0 +1,123 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import torch
|
| 3 |
+
import sys
|
| 4 |
+
import argparse
|
| 5 |
+
import random
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
import torch.nn.functional as F
|
| 8 |
+
import numpy as np
|
| 9 |
+
from diffusers.utils import export_to_video
|
| 10 |
+
from pyramid_dit import PyramidDiTForVideoGeneration
|
| 11 |
+
from trainer_misc import init_distributed_mode, init_sequence_parallel_group
|
| 12 |
+
import PIL
|
| 13 |
+
from PIL import Image
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def get_args():
|
| 17 |
+
parser = argparse.ArgumentParser('Pytorch Multi-process Script', add_help=False)
|
| 18 |
+
parser.add_argument('--model_name', default='pyramid_flux', type=str, help="The model name", choices=["pyramid_flux", "pyramid_mmdit"])
|
| 19 |
+
parser.add_argument('--model_dtype', default='bf16', type=str, help="The Model Dtype: bf16")
|
| 20 |
+
parser.add_argument('--model_path', default='/home/jinyang06/models/pyramid-flow', type=str, help='Set it to the downloaded checkpoint dir')
|
| 21 |
+
parser.add_argument('--variant', default='diffusion_transformer_768p', type=str,)
|
| 22 |
+
parser.add_argument('--task', default='t2v', type=str, choices=['i2v', 't2v'])
|
| 23 |
+
parser.add_argument('--temp', default=16, type=int, help='The generated latent num, num_frames = temp * 8 + 1')
|
| 24 |
+
parser.add_argument('--sp_group_size', default=2, type=int, help="The number of gpus used for inference, should be 2 or 4")
|
| 25 |
+
parser.add_argument('--sp_proc_num', default=-1, type=int, help="The number of process used for video training, default=-1 means using all process.")
|
| 26 |
+
|
| 27 |
+
return parser.parse_args()
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def main():
|
| 31 |
+
args = get_args()
|
| 32 |
+
|
| 33 |
+
# setup DDP
|
| 34 |
+
init_distributed_mode(args)
|
| 35 |
+
|
| 36 |
+
assert args.world_size == args.sp_group_size, "The sequence parallel size should be DDP world size"
|
| 37 |
+
|
| 38 |
+
# Enable sequence parallel
|
| 39 |
+
init_sequence_parallel_group(args)
|
| 40 |
+
|
| 41 |
+
device = torch.device('cuda')
|
| 42 |
+
rank = args.rank
|
| 43 |
+
model_dtype = args.model_dtype
|
| 44 |
+
|
| 45 |
+
model = PyramidDiTForVideoGeneration(
|
| 46 |
+
args.model_path,
|
| 47 |
+
model_dtype,
|
| 48 |
+
model_name=args.model_name,
|
| 49 |
+
model_variant=args.variant,
|
| 50 |
+
)
|
| 51 |
+
|
| 52 |
+
model.vae.to(device)
|
| 53 |
+
model.dit.to(device)
|
| 54 |
+
model.text_encoder.to(device)
|
| 55 |
+
model.vae.enable_tiling()
|
| 56 |
+
|
| 57 |
+
if model_dtype == "bf16":
|
| 58 |
+
torch_dtype = torch.bfloat16
|
| 59 |
+
elif model_dtype == "fp16":
|
| 60 |
+
torch_dtype = torch.float16
|
| 61 |
+
else:
|
| 62 |
+
torch_dtype = torch.float32
|
| 63 |
+
|
| 64 |
+
# The video generation config
|
| 65 |
+
if args.variant == 'diffusion_transformer_768p':
|
| 66 |
+
width = 1280
|
| 67 |
+
height = 768
|
| 68 |
+
else:
|
| 69 |
+
assert args.variant == 'diffusion_transformer_384p'
|
| 70 |
+
width = 640
|
| 71 |
+
height = 384
|
| 72 |
+
|
| 73 |
+
if args.task == 't2v':
|
| 74 |
+
prompt = "A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors"
|
| 75 |
+
|
| 76 |
+
with torch.no_grad(), torch.cuda.amp.autocast(enabled=True if model_dtype != 'fp32' else False, dtype=torch_dtype):
|
| 77 |
+
frames = model.generate(
|
| 78 |
+
prompt=prompt,
|
| 79 |
+
num_inference_steps=[20, 20, 20],
|
| 80 |
+
video_num_inference_steps=[10, 10, 10],
|
| 81 |
+
height=height,
|
| 82 |
+
width=width,
|
| 83 |
+
temp=args.temp,
|
| 84 |
+
guidance_scale=7.0, # The guidance for the first frame, set it to 7 for 384p variant
|
| 85 |
+
video_guidance_scale=5.0, # The guidance for the other video latent
|
| 86 |
+
output_type="pil",
|
| 87 |
+
save_memory=True, # If you have enough GPU memory, set it to `False` to improve vae decoding speed
|
| 88 |
+
cpu_offloading=False, # If OOM, set it to True to reduce memory usage
|
| 89 |
+
inference_multigpu=True,
|
| 90 |
+
)
|
| 91 |
+
if rank == 0:
|
| 92 |
+
export_to_video(frames, "./text_to_video_sample.mp4", fps=24)
|
| 93 |
+
|
| 94 |
+
else:
|
| 95 |
+
assert args.task == 'i2v'
|
| 96 |
+
|
| 97 |
+
image_path = 'assets/the_great_wall.jpg'
|
| 98 |
+
image = Image.open(image_path).convert("RGB")
|
| 99 |
+
image = image.resize((width, height))
|
| 100 |
+
|
| 101 |
+
prompt = "FPV flying over the Great Wall"
|
| 102 |
+
|
| 103 |
+
with torch.no_grad(), torch.cuda.amp.autocast(enabled=True if model_dtype != 'fp32' else False, dtype=torch_dtype):
|
| 104 |
+
frames = model.generate_i2v(
|
| 105 |
+
prompt=prompt,
|
| 106 |
+
input_image=image,
|
| 107 |
+
num_inference_steps=[10, 10, 10],
|
| 108 |
+
temp=args.temp,
|
| 109 |
+
video_guidance_scale=4.0,
|
| 110 |
+
output_type="pil",
|
| 111 |
+
save_memory=True, # If you have enough GPU memory, set it to `False` to improve vae decoding speed
|
| 112 |
+
cpu_offloading=False, # If OOM, set it to True to reduce memory usage
|
| 113 |
+
inference_multigpu=True,
|
| 114 |
+
)
|
| 115 |
+
|
| 116 |
+
if rank == 0:
|
| 117 |
+
export_to_video(frames, "./image_to_video_sample.mp4", fps=24)
|
| 118 |
+
|
| 119 |
+
torch.distributed.barrier()
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
if __name__ == "__main__":
|
| 123 |
+
main()
|
pyramid_dit/__init__.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .pyramid_dit_for_video_gen_pipeline import PyramidDiTForVideoGeneration
|
| 2 |
+
from .flux_modules import FluxSingleTransformerBlock, FluxTransformerBlock, FluxTextEncoderWithMask
|
| 3 |
+
from .mmdit_modules import JointTransformerBlock, SD3TextEncoderWithMask
|
pyramid_dit/flux_modules/__init__.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .modeling_pyramid_flux import PyramidFluxTransformer
|
| 2 |
+
from .modeling_text_encoder import FluxTextEncoderWithMask
|
| 3 |
+
from .modeling_flux_block import FluxSingleTransformerBlock, FluxTransformerBlock
|
pyramid_dit/flux_modules/modeling_embedding.py
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
from typing import List, Optional, Tuple, Union
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
from torch import nn
|
| 8 |
+
|
| 9 |
+
from diffusers.models.activations import get_activation, FP32SiLU
|
| 10 |
+
|
| 11 |
+
def get_timestep_embedding(
|
| 12 |
+
timesteps: torch.Tensor,
|
| 13 |
+
embedding_dim: int,
|
| 14 |
+
flip_sin_to_cos: bool = False,
|
| 15 |
+
downscale_freq_shift: float = 1,
|
| 16 |
+
scale: float = 1,
|
| 17 |
+
max_period: int = 10000,
|
| 18 |
+
):
|
| 19 |
+
"""
|
| 20 |
+
This matches the implementation in Denoising Diffusion Probabilistic Models: Create sinusoidal timestep embeddings.
|
| 21 |
+
|
| 22 |
+
Args
|
| 23 |
+
timesteps (torch.Tensor):
|
| 24 |
+
a 1-D Tensor of N indices, one per batch element. These may be fractional.
|
| 25 |
+
embedding_dim (int):
|
| 26 |
+
the dimension of the output.
|
| 27 |
+
flip_sin_to_cos (bool):
|
| 28 |
+
Whether the embedding order should be `cos, sin` (if True) or `sin, cos` (if False)
|
| 29 |
+
downscale_freq_shift (float):
|
| 30 |
+
Controls the delta between frequencies between dimensions
|
| 31 |
+
scale (float):
|
| 32 |
+
Scaling factor applied to the embeddings.
|
| 33 |
+
max_period (int):
|
| 34 |
+
Controls the maximum frequency of the embeddings
|
| 35 |
+
Returns
|
| 36 |
+
torch.Tensor: an [N x dim] Tensor of positional embeddings.
|
| 37 |
+
"""
|
| 38 |
+
assert len(timesteps.shape) == 1, "Timesteps should be a 1d-array"
|
| 39 |
+
|
| 40 |
+
half_dim = embedding_dim // 2
|
| 41 |
+
exponent = -math.log(max_period) * torch.arange(
|
| 42 |
+
start=0, end=half_dim, dtype=torch.float32, device=timesteps.device
|
| 43 |
+
)
|
| 44 |
+
exponent = exponent / (half_dim - downscale_freq_shift)
|
| 45 |
+
|
| 46 |
+
emb = torch.exp(exponent)
|
| 47 |
+
emb = timesteps[:, None].float() * emb[None, :]
|
| 48 |
+
|
| 49 |
+
# scale embeddings
|
| 50 |
+
emb = scale * emb
|
| 51 |
+
|
| 52 |
+
# concat sine and cosine embeddings
|
| 53 |
+
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=-1)
|
| 54 |
+
|
| 55 |
+
# flip sine and cosine embeddings
|
| 56 |
+
if flip_sin_to_cos:
|
| 57 |
+
emb = torch.cat([emb[:, half_dim:], emb[:, :half_dim]], dim=-1)
|
| 58 |
+
|
| 59 |
+
# zero pad
|
| 60 |
+
if embedding_dim % 2 == 1:
|
| 61 |
+
emb = torch.nn.functional.pad(emb, (0, 1, 0, 0))
|
| 62 |
+
return emb
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
class Timesteps(nn.Module):
|
| 66 |
+
def __init__(self, num_channels: int, flip_sin_to_cos: bool, downscale_freq_shift: float, scale: int = 1):
|
| 67 |
+
super().__init__()
|
| 68 |
+
self.num_channels = num_channels
|
| 69 |
+
self.flip_sin_to_cos = flip_sin_to_cos
|
| 70 |
+
self.downscale_freq_shift = downscale_freq_shift
|
| 71 |
+
self.scale = scale
|
| 72 |
+
|
| 73 |
+
def forward(self, timesteps):
|
| 74 |
+
t_emb = get_timestep_embedding(
|
| 75 |
+
timesteps,
|
| 76 |
+
self.num_channels,
|
| 77 |
+
flip_sin_to_cos=self.flip_sin_to_cos,
|
| 78 |
+
downscale_freq_shift=self.downscale_freq_shift,
|
| 79 |
+
scale=self.scale,
|
| 80 |
+
)
|
| 81 |
+
return t_emb
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
class TimestepEmbedding(nn.Module):
|
| 85 |
+
def __init__(
|
| 86 |
+
self,
|
| 87 |
+
in_channels: int,
|
| 88 |
+
time_embed_dim: int,
|
| 89 |
+
act_fn: str = "silu",
|
| 90 |
+
out_dim: int = None,
|
| 91 |
+
post_act_fn: Optional[str] = None,
|
| 92 |
+
cond_proj_dim=None,
|
| 93 |
+
sample_proj_bias=True,
|
| 94 |
+
):
|
| 95 |
+
super().__init__()
|
| 96 |
+
|
| 97 |
+
self.linear_1 = nn.Linear(in_channels, time_embed_dim, sample_proj_bias)
|
| 98 |
+
|
| 99 |
+
if cond_proj_dim is not None:
|
| 100 |
+
self.cond_proj = nn.Linear(cond_proj_dim, in_channels, bias=False)
|
| 101 |
+
else:
|
| 102 |
+
self.cond_proj = None
|
| 103 |
+
|
| 104 |
+
self.act = get_activation(act_fn)
|
| 105 |
+
|
| 106 |
+
if out_dim is not None:
|
| 107 |
+
time_embed_dim_out = out_dim
|
| 108 |
+
else:
|
| 109 |
+
time_embed_dim_out = time_embed_dim
|
| 110 |
+
self.linear_2 = nn.Linear(time_embed_dim, time_embed_dim_out, sample_proj_bias)
|
| 111 |
+
|
| 112 |
+
if post_act_fn is None:
|
| 113 |
+
self.post_act = None
|
| 114 |
+
else:
|
| 115 |
+
self.post_act = get_activation(post_act_fn)
|
| 116 |
+
|
| 117 |
+
def forward(self, sample, condition=None):
|
| 118 |
+
if condition is not None:
|
| 119 |
+
sample = sample + self.cond_proj(condition)
|
| 120 |
+
sample = self.linear_1(sample)
|
| 121 |
+
|
| 122 |
+
if self.act is not None:
|
| 123 |
+
sample = self.act(sample)
|
| 124 |
+
|
| 125 |
+
sample = self.linear_2(sample)
|
| 126 |
+
|
| 127 |
+
if self.post_act is not None:
|
| 128 |
+
sample = self.post_act(sample)
|
| 129 |
+
return sample
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
class PixArtAlphaTextProjection(nn.Module):
|
| 133 |
+
"""
|
| 134 |
+
Projects caption embeddings. Also handles dropout for classifier-free guidance.
|
| 135 |
+
|
| 136 |
+
Adapted from https://github.com/PixArt-alpha/PixArt-alpha/blob/master/diffusion/model/nets/PixArt_blocks.py
|
| 137 |
+
"""
|
| 138 |
+
|
| 139 |
+
def __init__(self, in_features, hidden_size, out_features=None, act_fn="gelu_tanh"):
|
| 140 |
+
super().__init__()
|
| 141 |
+
if out_features is None:
|
| 142 |
+
out_features = hidden_size
|
| 143 |
+
self.linear_1 = nn.Linear(in_features=in_features, out_features=hidden_size, bias=True)
|
| 144 |
+
if act_fn == "gelu_tanh":
|
| 145 |
+
self.act_1 = nn.GELU(approximate="tanh")
|
| 146 |
+
elif act_fn == "silu":
|
| 147 |
+
self.act_1 = nn.SiLU()
|
| 148 |
+
elif act_fn == "silu_fp32":
|
| 149 |
+
self.act_1 = FP32SiLU()
|
| 150 |
+
else:
|
| 151 |
+
raise ValueError(f"Unknown activation function: {act_fn}")
|
| 152 |
+
self.linear_2 = nn.Linear(in_features=hidden_size, out_features=out_features, bias=True)
|
| 153 |
+
|
| 154 |
+
def forward(self, caption):
|
| 155 |
+
hidden_states = self.linear_1(caption)
|
| 156 |
+
hidden_states = self.act_1(hidden_states)
|
| 157 |
+
hidden_states = self.linear_2(hidden_states)
|
| 158 |
+
return hidden_states
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
class CombinedTimestepGuidanceTextProjEmbeddings(nn.Module):
|
| 162 |
+
def __init__(self, embedding_dim, pooled_projection_dim):
|
| 163 |
+
super().__init__()
|
| 164 |
+
|
| 165 |
+
self.time_proj = Timesteps(num_channels=256, flip_sin_to_cos=True, downscale_freq_shift=0)
|
| 166 |
+
self.timestep_embedder = TimestepEmbedding(in_channels=256, time_embed_dim=embedding_dim)
|
| 167 |
+
self.guidance_embedder = TimestepEmbedding(in_channels=256, time_embed_dim=embedding_dim)
|
| 168 |
+
self.text_embedder = PixArtAlphaTextProjection(pooled_projection_dim, embedding_dim, act_fn="silu")
|
| 169 |
+
|
| 170 |
+
def forward(self, timestep, guidance, pooled_projection):
|
| 171 |
+
timesteps_proj = self.time_proj(timestep)
|
| 172 |
+
timesteps_emb = self.timestep_embedder(timesteps_proj.to(dtype=pooled_projection.dtype)) # (N, D)
|
| 173 |
+
|
| 174 |
+
guidance_proj = self.time_proj(guidance)
|
| 175 |
+
guidance_emb = self.guidance_embedder(guidance_proj.to(dtype=pooled_projection.dtype)) # (N, D)
|
| 176 |
+
|
| 177 |
+
time_guidance_emb = timesteps_emb + guidance_emb
|
| 178 |
+
|
| 179 |
+
pooled_projections = self.text_embedder(pooled_projection)
|
| 180 |
+
conditioning = time_guidance_emb + pooled_projections
|
| 181 |
+
|
| 182 |
+
return conditioning
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
class CombinedTimestepTextProjEmbeddings(nn.Module):
|
| 186 |
+
def __init__(self, embedding_dim, pooled_projection_dim):
|
| 187 |
+
super().__init__()
|
| 188 |
+
|
| 189 |
+
self.time_proj = Timesteps(num_channels=256, flip_sin_to_cos=True, downscale_freq_shift=0)
|
| 190 |
+
self.timestep_embedder = TimestepEmbedding(in_channels=256, time_embed_dim=embedding_dim)
|
| 191 |
+
self.text_embedder = PixArtAlphaTextProjection(pooled_projection_dim, embedding_dim, act_fn="silu")
|
| 192 |
+
|
| 193 |
+
def forward(self, timestep, pooled_projection):
|
| 194 |
+
timesteps_proj = self.time_proj(timestep)
|
| 195 |
+
timesteps_emb = self.timestep_embedder(timesteps_proj.to(dtype=pooled_projection.dtype)) # (N, D)
|
| 196 |
+
|
| 197 |
+
pooled_projections = self.text_embedder(pooled_projection)
|
| 198 |
+
|
| 199 |
+
conditioning = timesteps_emb + pooled_projections
|
| 200 |
+
|
| 201 |
+
return conditioning
|
pyramid_dit/flux_modules/modeling_flux_block.py
ADDED
|
@@ -0,0 +1,1044 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Any, Dict, List, Optional, Union
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
import torch.nn.functional as F
|
| 6 |
+
import inspect
|
| 7 |
+
from einops import rearrange
|
| 8 |
+
|
| 9 |
+
from diffusers.utils import deprecate
|
| 10 |
+
from diffusers.models.activations import GEGLU, GELU, ApproximateGELU, SwiGLU
|
| 11 |
+
|
| 12 |
+
from .modeling_normalization import (
|
| 13 |
+
AdaLayerNormContinuous, AdaLayerNormZero,
|
| 14 |
+
AdaLayerNormZeroSingle, FP32LayerNorm, RMSNorm
|
| 15 |
+
)
|
| 16 |
+
|
| 17 |
+
from trainer_misc import (
|
| 18 |
+
is_sequence_parallel_initialized,
|
| 19 |
+
get_sequence_parallel_group,
|
| 20 |
+
get_sequence_parallel_world_size,
|
| 21 |
+
all_to_all,
|
| 22 |
+
)
|
| 23 |
+
|
| 24 |
+
try:
|
| 25 |
+
from flash_attn import flash_attn_qkvpacked_func, flash_attn_func
|
| 26 |
+
from flash_attn.bert_padding import pad_input, unpad_input, index_first_axis
|
| 27 |
+
from flash_attn.flash_attn_interface import flash_attn_varlen_func
|
| 28 |
+
except:
|
| 29 |
+
flash_attn_func = None
|
| 30 |
+
flash_attn_qkvpacked_func = None
|
| 31 |
+
flash_attn_varlen_func = None
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def apply_rope(xq, xk, freqs_cis):
|
| 35 |
+
xq_ = xq.float().reshape(*xq.shape[:-1], -1, 1, 2)
|
| 36 |
+
xk_ = xk.float().reshape(*xk.shape[:-1], -1, 1, 2)
|
| 37 |
+
xq_out = freqs_cis[..., 0] * xq_[..., 0] + freqs_cis[..., 1] * xq_[..., 1]
|
| 38 |
+
xk_out = freqs_cis[..., 0] * xk_[..., 0] + freqs_cis[..., 1] * xk_[..., 1]
|
| 39 |
+
return xq_out.reshape(*xq.shape).type_as(xq), xk_out.reshape(*xk.shape).type_as(xk)
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
class FeedForward(nn.Module):
|
| 43 |
+
r"""
|
| 44 |
+
A feed-forward layer.
|
| 45 |
+
|
| 46 |
+
Parameters:
|
| 47 |
+
dim (`int`): The number of channels in the input.
|
| 48 |
+
dim_out (`int`, *optional*): The number of channels in the output. If not given, defaults to `dim`.
|
| 49 |
+
mult (`int`, *optional*, defaults to 4): The multiplier to use for the hidden dimension.
|
| 50 |
+
dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
|
| 51 |
+
activation_fn (`str`, *optional*, defaults to `"geglu"`): Activation function to be used in feed-forward.
|
| 52 |
+
final_dropout (`bool` *optional*, defaults to False): Apply a final dropout.
|
| 53 |
+
bias (`bool`, defaults to True): Whether to use a bias in the linear layer.
|
| 54 |
+
"""
|
| 55 |
+
|
| 56 |
+
def __init__(
|
| 57 |
+
self,
|
| 58 |
+
dim: int,
|
| 59 |
+
dim_out: Optional[int] = None,
|
| 60 |
+
mult: int = 4,
|
| 61 |
+
dropout: float = 0.0,
|
| 62 |
+
activation_fn: str = "geglu",
|
| 63 |
+
final_dropout: bool = False,
|
| 64 |
+
inner_dim=None,
|
| 65 |
+
bias: bool = True,
|
| 66 |
+
):
|
| 67 |
+
super().__init__()
|
| 68 |
+
if inner_dim is None:
|
| 69 |
+
inner_dim = int(dim * mult)
|
| 70 |
+
dim_out = dim_out if dim_out is not None else dim
|
| 71 |
+
|
| 72 |
+
if activation_fn == "gelu":
|
| 73 |
+
act_fn = GELU(dim, inner_dim, bias=bias)
|
| 74 |
+
if activation_fn == "gelu-approximate":
|
| 75 |
+
act_fn = GELU(dim, inner_dim, approximate="tanh", bias=bias)
|
| 76 |
+
elif activation_fn == "geglu":
|
| 77 |
+
act_fn = GEGLU(dim, inner_dim, bias=bias)
|
| 78 |
+
elif activation_fn == "geglu-approximate":
|
| 79 |
+
act_fn = ApproximateGELU(dim, inner_dim, bias=bias)
|
| 80 |
+
elif activation_fn == "swiglu":
|
| 81 |
+
act_fn = SwiGLU(dim, inner_dim, bias=bias)
|
| 82 |
+
|
| 83 |
+
self.net = nn.ModuleList([])
|
| 84 |
+
# project in
|
| 85 |
+
self.net.append(act_fn)
|
| 86 |
+
# project dropout
|
| 87 |
+
self.net.append(nn.Dropout(dropout))
|
| 88 |
+
# project out
|
| 89 |
+
self.net.append(nn.Linear(inner_dim, dim_out, bias=bias))
|
| 90 |
+
# FF as used in Vision Transformer, MLP-Mixer, etc. have a final dropout
|
| 91 |
+
if final_dropout:
|
| 92 |
+
self.net.append(nn.Dropout(dropout))
|
| 93 |
+
|
| 94 |
+
def forward(self, hidden_states: torch.Tensor, *args, **kwargs) -> torch.Tensor:
|
| 95 |
+
if len(args) > 0 or kwargs.get("scale", None) is not None:
|
| 96 |
+
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
|
| 97 |
+
deprecate("scale", "1.0.0", deprecation_message)
|
| 98 |
+
for module in self.net:
|
| 99 |
+
hidden_states = module(hidden_states)
|
| 100 |
+
return hidden_states
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
class SequenceParallelVarlenFlashSelfAttentionWithT5Mask:
|
| 104 |
+
|
| 105 |
+
def __init__(self):
|
| 106 |
+
pass
|
| 107 |
+
|
| 108 |
+
def __call__(
|
| 109 |
+
self, query, key, value, encoder_query, encoder_key, encoder_value,
|
| 110 |
+
heads, scale, hidden_length=None, image_rotary_emb=None, encoder_attention_mask=None,
|
| 111 |
+
):
|
| 112 |
+
assert encoder_attention_mask is not None, "The encoder-hidden mask needed to be set"
|
| 113 |
+
|
| 114 |
+
batch_size = query.shape[0]
|
| 115 |
+
qkv_list = []
|
| 116 |
+
num_stages = len(hidden_length)
|
| 117 |
+
|
| 118 |
+
encoder_qkv = torch.stack([encoder_query, encoder_key, encoder_value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 119 |
+
qkv = torch.stack([query, key, value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 120 |
+
|
| 121 |
+
# To sync the encoder query, key and values
|
| 122 |
+
sp_group = get_sequence_parallel_group()
|
| 123 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 124 |
+
encoder_qkv = all_to_all(encoder_qkv, sp_group, sp_group_size, scatter_dim=3, gather_dim=1) # [bs, seq, 3, sub_head, head_dim]
|
| 125 |
+
|
| 126 |
+
output_hidden = torch.zeros_like(qkv[:,:,0])
|
| 127 |
+
output_encoder_hidden = torch.zeros_like(encoder_qkv[:,:,0])
|
| 128 |
+
encoder_length = encoder_qkv.shape[1]
|
| 129 |
+
|
| 130 |
+
i_sum = 0
|
| 131 |
+
for i_p, length in enumerate(hidden_length):
|
| 132 |
+
# get the query, key, value from padding sequence
|
| 133 |
+
encoder_qkv_tokens = encoder_qkv[i_p::num_stages]
|
| 134 |
+
qkv_tokens = qkv[:, i_sum:i_sum+length]
|
| 135 |
+
qkv_tokens = all_to_all(qkv_tokens, sp_group, sp_group_size, scatter_dim=3, gather_dim=1) # [bs, seq, 3, sub_head, head_dim]
|
| 136 |
+
concat_qkv_tokens = torch.cat([encoder_qkv_tokens, qkv_tokens], dim=1) # [bs, pad_seq, 3, nhead, dim]
|
| 137 |
+
|
| 138 |
+
if image_rotary_emb is not None:
|
| 139 |
+
concat_qkv_tokens[:,:,0], concat_qkv_tokens[:,:,1] = apply_rope(concat_qkv_tokens[:,:,0], concat_qkv_tokens[:,:,1], image_rotary_emb[i_p])
|
| 140 |
+
|
| 141 |
+
indices = encoder_attention_mask[i_p]['indices']
|
| 142 |
+
qkv_list.append(index_first_axis(rearrange(concat_qkv_tokens, "b s ... -> (b s) ..."), indices))
|
| 143 |
+
i_sum += length
|
| 144 |
+
|
| 145 |
+
token_lengths = [x_.shape[0] for x_ in qkv_list]
|
| 146 |
+
qkv = torch.cat(qkv_list, dim=0)
|
| 147 |
+
query, key, value = qkv.unbind(1)
|
| 148 |
+
|
| 149 |
+
cu_seqlens = torch.cat([x_['seqlens_in_batch'] for x_ in encoder_attention_mask], dim=0)
|
| 150 |
+
max_seqlen_q = cu_seqlens.max().item()
|
| 151 |
+
max_seqlen_k = max_seqlen_q
|
| 152 |
+
cu_seqlens_q = F.pad(torch.cumsum(cu_seqlens, dim=0, dtype=torch.int32), (1, 0))
|
| 153 |
+
cu_seqlens_k = cu_seqlens_q.clone()
|
| 154 |
+
|
| 155 |
+
output = flash_attn_varlen_func(
|
| 156 |
+
query,
|
| 157 |
+
key,
|
| 158 |
+
value,
|
| 159 |
+
cu_seqlens_q=cu_seqlens_q,
|
| 160 |
+
cu_seqlens_k=cu_seqlens_k,
|
| 161 |
+
max_seqlen_q=max_seqlen_q,
|
| 162 |
+
max_seqlen_k=max_seqlen_k,
|
| 163 |
+
dropout_p=0.0,
|
| 164 |
+
causal=False,
|
| 165 |
+
softmax_scale=scale,
|
| 166 |
+
)
|
| 167 |
+
|
| 168 |
+
# To merge the tokens
|
| 169 |
+
i_sum = 0;token_sum = 0
|
| 170 |
+
for i_p, length in enumerate(hidden_length):
|
| 171 |
+
tot_token_num = token_lengths[i_p]
|
| 172 |
+
stage_output = output[token_sum : token_sum + tot_token_num]
|
| 173 |
+
stage_output = pad_input(stage_output, encoder_attention_mask[i_p]['indices'], batch_size, encoder_length + length * sp_group_size)
|
| 174 |
+
stage_encoder_hidden_output = stage_output[:, :encoder_length]
|
| 175 |
+
stage_hidden_output = stage_output[:, encoder_length:]
|
| 176 |
+
stage_hidden_output = all_to_all(stage_hidden_output, sp_group, sp_group_size, scatter_dim=1, gather_dim=2)
|
| 177 |
+
output_hidden[:, i_sum:i_sum+length] = stage_hidden_output
|
| 178 |
+
output_encoder_hidden[i_p::num_stages] = stage_encoder_hidden_output
|
| 179 |
+
token_sum += tot_token_num
|
| 180 |
+
i_sum += length
|
| 181 |
+
|
| 182 |
+
output_encoder_hidden = all_to_all(output_encoder_hidden, sp_group, sp_group_size, scatter_dim=1, gather_dim=2)
|
| 183 |
+
output_hidden = output_hidden.flatten(2, 3)
|
| 184 |
+
output_encoder_hidden = output_encoder_hidden.flatten(2, 3)
|
| 185 |
+
|
| 186 |
+
return output_hidden, output_encoder_hidden
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
class VarlenFlashSelfAttentionWithT5Mask:
|
| 190 |
+
|
| 191 |
+
def __init__(self):
|
| 192 |
+
pass
|
| 193 |
+
|
| 194 |
+
def __call__(
|
| 195 |
+
self, query, key, value, encoder_query, encoder_key, encoder_value,
|
| 196 |
+
heads, scale, hidden_length=None, image_rotary_emb=None, encoder_attention_mask=None,
|
| 197 |
+
):
|
| 198 |
+
assert encoder_attention_mask is not None, "The encoder-hidden mask needed to be set"
|
| 199 |
+
|
| 200 |
+
batch_size = query.shape[0]
|
| 201 |
+
output_hidden = torch.zeros_like(query)
|
| 202 |
+
output_encoder_hidden = torch.zeros_like(encoder_query)
|
| 203 |
+
encoder_length = encoder_query.shape[1]
|
| 204 |
+
|
| 205 |
+
qkv_list = []
|
| 206 |
+
num_stages = len(hidden_length)
|
| 207 |
+
|
| 208 |
+
encoder_qkv = torch.stack([encoder_query, encoder_key, encoder_value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 209 |
+
qkv = torch.stack([query, key, value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 210 |
+
|
| 211 |
+
i_sum = 0
|
| 212 |
+
for i_p, length in enumerate(hidden_length):
|
| 213 |
+
encoder_qkv_tokens = encoder_qkv[i_p::num_stages]
|
| 214 |
+
qkv_tokens = qkv[:, i_sum:i_sum+length]
|
| 215 |
+
concat_qkv_tokens = torch.cat([encoder_qkv_tokens, qkv_tokens], dim=1) # [bs, tot_seq, 3, nhead, dim]
|
| 216 |
+
|
| 217 |
+
if image_rotary_emb is not None:
|
| 218 |
+
concat_qkv_tokens[:,:,0], concat_qkv_tokens[:,:,1] = apply_rope(concat_qkv_tokens[:,:,0], concat_qkv_tokens[:,:,1], image_rotary_emb[i_p])
|
| 219 |
+
|
| 220 |
+
indices = encoder_attention_mask[i_p]['indices']
|
| 221 |
+
qkv_list.append(index_first_axis(rearrange(concat_qkv_tokens, "b s ... -> (b s) ..."), indices))
|
| 222 |
+
i_sum += length
|
| 223 |
+
|
| 224 |
+
token_lengths = [x_.shape[0] for x_ in qkv_list]
|
| 225 |
+
qkv = torch.cat(qkv_list, dim=0)
|
| 226 |
+
query, key, value = qkv.unbind(1)
|
| 227 |
+
|
| 228 |
+
cu_seqlens = torch.cat([x_['seqlens_in_batch'] for x_ in encoder_attention_mask], dim=0)
|
| 229 |
+
max_seqlen_q = cu_seqlens.max().item()
|
| 230 |
+
max_seqlen_k = max_seqlen_q
|
| 231 |
+
cu_seqlens_q = F.pad(torch.cumsum(cu_seqlens, dim=0, dtype=torch.int32), (1, 0))
|
| 232 |
+
cu_seqlens_k = cu_seqlens_q.clone()
|
| 233 |
+
|
| 234 |
+
output = flash_attn_varlen_func(
|
| 235 |
+
query,
|
| 236 |
+
key,
|
| 237 |
+
value,
|
| 238 |
+
cu_seqlens_q=cu_seqlens_q,
|
| 239 |
+
cu_seqlens_k=cu_seqlens_k,
|
| 240 |
+
max_seqlen_q=max_seqlen_q,
|
| 241 |
+
max_seqlen_k=max_seqlen_k,
|
| 242 |
+
dropout_p=0.0,
|
| 243 |
+
causal=False,
|
| 244 |
+
softmax_scale=scale,
|
| 245 |
+
)
|
| 246 |
+
|
| 247 |
+
# To merge the tokens
|
| 248 |
+
i_sum = 0;token_sum = 0
|
| 249 |
+
for i_p, length in enumerate(hidden_length):
|
| 250 |
+
tot_token_num = token_lengths[i_p]
|
| 251 |
+
stage_output = output[token_sum : token_sum + tot_token_num]
|
| 252 |
+
stage_output = pad_input(stage_output, encoder_attention_mask[i_p]['indices'], batch_size, encoder_length + length)
|
| 253 |
+
stage_encoder_hidden_output = stage_output[:, :encoder_length]
|
| 254 |
+
stage_hidden_output = stage_output[:, encoder_length:]
|
| 255 |
+
output_hidden[:, i_sum:i_sum+length] = stage_hidden_output
|
| 256 |
+
output_encoder_hidden[i_p::num_stages] = stage_encoder_hidden_output
|
| 257 |
+
token_sum += tot_token_num
|
| 258 |
+
i_sum += length
|
| 259 |
+
|
| 260 |
+
output_hidden = output_hidden.flatten(2, 3)
|
| 261 |
+
output_encoder_hidden = output_encoder_hidden.flatten(2, 3)
|
| 262 |
+
|
| 263 |
+
return output_hidden, output_encoder_hidden
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
class SequenceParallelVarlenSelfAttentionWithT5Mask:
|
| 267 |
+
|
| 268 |
+
def __init__(self):
|
| 269 |
+
pass
|
| 270 |
+
|
| 271 |
+
def __call__(
|
| 272 |
+
self, query, key, value, encoder_query, encoder_key, encoder_value,
|
| 273 |
+
heads, scale, hidden_length=None, image_rotary_emb=None, attention_mask=None,
|
| 274 |
+
):
|
| 275 |
+
assert attention_mask is not None, "The attention mask needed to be set"
|
| 276 |
+
|
| 277 |
+
num_stages = len(hidden_length)
|
| 278 |
+
|
| 279 |
+
encoder_qkv = torch.stack([encoder_query, encoder_key, encoder_value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 280 |
+
qkv = torch.stack([query, key, value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 281 |
+
|
| 282 |
+
# To sync the encoder query, key and values
|
| 283 |
+
sp_group = get_sequence_parallel_group()
|
| 284 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 285 |
+
encoder_qkv = all_to_all(encoder_qkv, sp_group, sp_group_size, scatter_dim=3, gather_dim=1) # [bs, seq, 3, sub_head, head_dim]
|
| 286 |
+
encoder_length = encoder_qkv.shape[1]
|
| 287 |
+
|
| 288 |
+
i_sum = 0
|
| 289 |
+
output_encoder_hidden_list = []
|
| 290 |
+
output_hidden_list = []
|
| 291 |
+
|
| 292 |
+
for i_p, length in enumerate(hidden_length):
|
| 293 |
+
encoder_qkv_tokens = encoder_qkv[i_p::num_stages]
|
| 294 |
+
qkv_tokens = qkv[:, i_sum:i_sum+length]
|
| 295 |
+
qkv_tokens = all_to_all(qkv_tokens, sp_group, sp_group_size, scatter_dim=3, gather_dim=1) # [bs, seq, 3, sub_head, head_dim]
|
| 296 |
+
concat_qkv_tokens = torch.cat([encoder_qkv_tokens, qkv_tokens], dim=1) # [bs, tot_seq, 3, nhead, dim]
|
| 297 |
+
|
| 298 |
+
if image_rotary_emb is not None:
|
| 299 |
+
concat_qkv_tokens[:,:,0], concat_qkv_tokens[:,:,1] = apply_rope(concat_qkv_tokens[:,:,0], concat_qkv_tokens[:,:,1], image_rotary_emb[i_p])
|
| 300 |
+
|
| 301 |
+
query, key, value = concat_qkv_tokens.unbind(2) # [bs, tot_seq, nhead, dim]
|
| 302 |
+
query = query.transpose(1, 2)
|
| 303 |
+
key = key.transpose(1, 2)
|
| 304 |
+
value = value.transpose(1, 2)
|
| 305 |
+
|
| 306 |
+
stage_hidden_states = F.scaled_dot_product_attention(
|
| 307 |
+
query, key, value, dropout_p=0.0, is_causal=False, attn_mask=attention_mask[i_p],
|
| 308 |
+
)
|
| 309 |
+
stage_hidden_states = stage_hidden_states.transpose(1, 2) # [bs, tot_seq, nhead, dim]
|
| 310 |
+
|
| 311 |
+
output_encoder_hidden_list.append(stage_hidden_states[:, :encoder_length])
|
| 312 |
+
|
| 313 |
+
output_hidden = stage_hidden_states[:, encoder_length:]
|
| 314 |
+
output_hidden = all_to_all(output_hidden, sp_group, sp_group_size, scatter_dim=1, gather_dim=2)
|
| 315 |
+
output_hidden_list.append(output_hidden)
|
| 316 |
+
|
| 317 |
+
i_sum += length
|
| 318 |
+
|
| 319 |
+
output_encoder_hidden = torch.stack(output_encoder_hidden_list, dim=1) # [b n s nhead d]
|
| 320 |
+
output_encoder_hidden = rearrange(output_encoder_hidden, 'b n s h d -> (b n) s h d')
|
| 321 |
+
output_encoder_hidden = all_to_all(output_encoder_hidden, sp_group, sp_group_size, scatter_dim=1, gather_dim=2)
|
| 322 |
+
output_encoder_hidden = output_encoder_hidden.flatten(2, 3)
|
| 323 |
+
output_hidden = torch.cat(output_hidden_list, dim=1).flatten(2, 3)
|
| 324 |
+
|
| 325 |
+
return output_hidden, output_encoder_hidden
|
| 326 |
+
|
| 327 |
+
|
| 328 |
+
class VarlenSelfAttentionWithT5Mask:
|
| 329 |
+
|
| 330 |
+
def __init__(self):
|
| 331 |
+
pass
|
| 332 |
+
|
| 333 |
+
def __call__(
|
| 334 |
+
self, query, key, value, encoder_query, encoder_key, encoder_value,
|
| 335 |
+
heads, scale, hidden_length=None, image_rotary_emb=None, attention_mask=None,
|
| 336 |
+
):
|
| 337 |
+
assert attention_mask is not None, "The attention mask needed to be set"
|
| 338 |
+
|
| 339 |
+
encoder_length = encoder_query.shape[1]
|
| 340 |
+
num_stages = len(hidden_length)
|
| 341 |
+
|
| 342 |
+
encoder_qkv = torch.stack([encoder_query, encoder_key, encoder_value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 343 |
+
qkv = torch.stack([query, key, value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 344 |
+
|
| 345 |
+
i_sum = 0
|
| 346 |
+
output_encoder_hidden_list = []
|
| 347 |
+
output_hidden_list = []
|
| 348 |
+
|
| 349 |
+
for i_p, length in enumerate(hidden_length):
|
| 350 |
+
encoder_qkv_tokens = encoder_qkv[i_p::num_stages]
|
| 351 |
+
qkv_tokens = qkv[:, i_sum:i_sum+length]
|
| 352 |
+
concat_qkv_tokens = torch.cat([encoder_qkv_tokens, qkv_tokens], dim=1) # [bs, tot_seq, 3, nhead, dim]
|
| 353 |
+
|
| 354 |
+
if image_rotary_emb is not None:
|
| 355 |
+
concat_qkv_tokens[:,:,0], concat_qkv_tokens[:,:,1] = apply_rope(concat_qkv_tokens[:,:,0], concat_qkv_tokens[:,:,1], image_rotary_emb[i_p])
|
| 356 |
+
|
| 357 |
+
query, key, value = concat_qkv_tokens.unbind(2) # [bs, tot_seq, nhead, dim]
|
| 358 |
+
query = query.transpose(1, 2)
|
| 359 |
+
key = key.transpose(1, 2)
|
| 360 |
+
value = value.transpose(1, 2)
|
| 361 |
+
|
| 362 |
+
# with torch.backends.cuda.sdp_kernel(enable_math=False, enable_flash=False, enable_mem_efficient=True):
|
| 363 |
+
stage_hidden_states = F.scaled_dot_product_attention(
|
| 364 |
+
query, key, value, dropout_p=0.0, is_causal=False, attn_mask=attention_mask[i_p],
|
| 365 |
+
)
|
| 366 |
+
stage_hidden_states = stage_hidden_states.transpose(1, 2).flatten(2, 3) # [bs, tot_seq, dim]
|
| 367 |
+
|
| 368 |
+
output_encoder_hidden_list.append(stage_hidden_states[:, :encoder_length])
|
| 369 |
+
output_hidden_list.append(stage_hidden_states[:, encoder_length:])
|
| 370 |
+
i_sum += length
|
| 371 |
+
|
| 372 |
+
output_encoder_hidden = torch.stack(output_encoder_hidden_list, dim=1) # [b n s d]
|
| 373 |
+
output_encoder_hidden = rearrange(output_encoder_hidden, 'b n s d -> (b n) s d')
|
| 374 |
+
output_hidden = torch.cat(output_hidden_list, dim=1)
|
| 375 |
+
|
| 376 |
+
return output_hidden, output_encoder_hidden
|
| 377 |
+
|
| 378 |
+
|
| 379 |
+
class SequenceParallelVarlenFlashAttnSingle:
|
| 380 |
+
|
| 381 |
+
def __init__(self):
|
| 382 |
+
pass
|
| 383 |
+
|
| 384 |
+
def __call__(
|
| 385 |
+
self, query, key, value, heads, scale,
|
| 386 |
+
hidden_length=None, image_rotary_emb=None, encoder_attention_mask=None,
|
| 387 |
+
):
|
| 388 |
+
assert encoder_attention_mask is not None, "The encoder-hidden mask needed to be set"
|
| 389 |
+
|
| 390 |
+
batch_size = query.shape[0]
|
| 391 |
+
qkv_list = []
|
| 392 |
+
num_stages = len(hidden_length)
|
| 393 |
+
|
| 394 |
+
qkv = torch.stack([query, key, value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 395 |
+
output_hidden = torch.zeros_like(qkv[:,:,0])
|
| 396 |
+
|
| 397 |
+
sp_group = get_sequence_parallel_group()
|
| 398 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 399 |
+
|
| 400 |
+
i_sum = 0
|
| 401 |
+
for i_p, length in enumerate(hidden_length):
|
| 402 |
+
# get the query, key, value from padding sequence
|
| 403 |
+
qkv_tokens = qkv[:, i_sum:i_sum+length]
|
| 404 |
+
qkv_tokens = all_to_all(qkv_tokens, sp_group, sp_group_size, scatter_dim=3, gather_dim=1) # [bs, seq, 3, sub_head, head_dim]
|
| 405 |
+
|
| 406 |
+
if image_rotary_emb is not None:
|
| 407 |
+
qkv_tokens[:,:,0], qkv_tokens[:,:,1] = apply_rope(qkv_tokens[:,:,0], qkv_tokens[:,:,1], image_rotary_emb[i_p])
|
| 408 |
+
|
| 409 |
+
indices = encoder_attention_mask[i_p]['indices']
|
| 410 |
+
qkv_list.append(index_first_axis(rearrange(qkv_tokens, "b s ... -> (b s) ..."), indices))
|
| 411 |
+
i_sum += length
|
| 412 |
+
|
| 413 |
+
token_lengths = [x_.shape[0] for x_ in qkv_list]
|
| 414 |
+
qkv = torch.cat(qkv_list, dim=0)
|
| 415 |
+
query, key, value = qkv.unbind(1)
|
| 416 |
+
|
| 417 |
+
cu_seqlens = torch.cat([x_['seqlens_in_batch'] for x_ in encoder_attention_mask], dim=0)
|
| 418 |
+
max_seqlen_q = cu_seqlens.max().item()
|
| 419 |
+
max_seqlen_k = max_seqlen_q
|
| 420 |
+
cu_seqlens_q = F.pad(torch.cumsum(cu_seqlens, dim=0, dtype=torch.int32), (1, 0))
|
| 421 |
+
cu_seqlens_k = cu_seqlens_q.clone()
|
| 422 |
+
|
| 423 |
+
output = flash_attn_varlen_func(
|
| 424 |
+
query,
|
| 425 |
+
key,
|
| 426 |
+
value,
|
| 427 |
+
cu_seqlens_q=cu_seqlens_q,
|
| 428 |
+
cu_seqlens_k=cu_seqlens_k,
|
| 429 |
+
max_seqlen_q=max_seqlen_q,
|
| 430 |
+
max_seqlen_k=max_seqlen_k,
|
| 431 |
+
dropout_p=0.0,
|
| 432 |
+
causal=False,
|
| 433 |
+
softmax_scale=scale,
|
| 434 |
+
)
|
| 435 |
+
|
| 436 |
+
# To merge the tokens
|
| 437 |
+
i_sum = 0;token_sum = 0
|
| 438 |
+
for i_p, length in enumerate(hidden_length):
|
| 439 |
+
tot_token_num = token_lengths[i_p]
|
| 440 |
+
stage_output = output[token_sum : token_sum + tot_token_num]
|
| 441 |
+
stage_output = pad_input(stage_output, encoder_attention_mask[i_p]['indices'], batch_size, length * sp_group_size)
|
| 442 |
+
stage_hidden_output = all_to_all(stage_output, sp_group, sp_group_size, scatter_dim=1, gather_dim=2)
|
| 443 |
+
output_hidden[:, i_sum:i_sum+length] = stage_hidden_output
|
| 444 |
+
token_sum += tot_token_num
|
| 445 |
+
i_sum += length
|
| 446 |
+
|
| 447 |
+
output_hidden = output_hidden.flatten(2, 3)
|
| 448 |
+
|
| 449 |
+
return output_hidden
|
| 450 |
+
|
| 451 |
+
|
| 452 |
+
class VarlenFlashSelfAttnSingle:
|
| 453 |
+
|
| 454 |
+
def __init__(self):
|
| 455 |
+
pass
|
| 456 |
+
|
| 457 |
+
def __call__(
|
| 458 |
+
self, query, key, value, heads, scale,
|
| 459 |
+
hidden_length=None, image_rotary_emb=None, encoder_attention_mask=None,
|
| 460 |
+
):
|
| 461 |
+
assert encoder_attention_mask is not None, "The encoder-hidden mask needed to be set"
|
| 462 |
+
|
| 463 |
+
batch_size = query.shape[0]
|
| 464 |
+
output_hidden = torch.zeros_like(query)
|
| 465 |
+
|
| 466 |
+
qkv_list = []
|
| 467 |
+
num_stages = len(hidden_length)
|
| 468 |
+
qkv = torch.stack([query, key, value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 469 |
+
|
| 470 |
+
i_sum = 0
|
| 471 |
+
for i_p, length in enumerate(hidden_length):
|
| 472 |
+
qkv_tokens = qkv[:, i_sum:i_sum+length]
|
| 473 |
+
|
| 474 |
+
if image_rotary_emb is not None:
|
| 475 |
+
qkv_tokens[:,:,0], qkv_tokens[:,:,1] = apply_rope(qkv_tokens[:,:,0], qkv_tokens[:,:,1], image_rotary_emb[i_p])
|
| 476 |
+
|
| 477 |
+
indices = encoder_attention_mask[i_p]['indices']
|
| 478 |
+
qkv_list.append(index_first_axis(rearrange(qkv_tokens, "b s ... -> (b s) ..."), indices))
|
| 479 |
+
i_sum += length
|
| 480 |
+
|
| 481 |
+
token_lengths = [x_.shape[0] for x_ in qkv_list]
|
| 482 |
+
qkv = torch.cat(qkv_list, dim=0)
|
| 483 |
+
query, key, value = qkv.unbind(1)
|
| 484 |
+
|
| 485 |
+
cu_seqlens = torch.cat([x_['seqlens_in_batch'] for x_ in encoder_attention_mask], dim=0)
|
| 486 |
+
max_seqlen_q = cu_seqlens.max().item()
|
| 487 |
+
max_seqlen_k = max_seqlen_q
|
| 488 |
+
cu_seqlens_q = F.pad(torch.cumsum(cu_seqlens, dim=0, dtype=torch.int32), (1, 0))
|
| 489 |
+
cu_seqlens_k = cu_seqlens_q.clone()
|
| 490 |
+
|
| 491 |
+
output = flash_attn_varlen_func(
|
| 492 |
+
query,
|
| 493 |
+
key,
|
| 494 |
+
value,
|
| 495 |
+
cu_seqlens_q=cu_seqlens_q,
|
| 496 |
+
cu_seqlens_k=cu_seqlens_k,
|
| 497 |
+
max_seqlen_q=max_seqlen_q,
|
| 498 |
+
max_seqlen_k=max_seqlen_k,
|
| 499 |
+
dropout_p=0.0,
|
| 500 |
+
causal=False,
|
| 501 |
+
softmax_scale=scale,
|
| 502 |
+
)
|
| 503 |
+
|
| 504 |
+
# To merge the tokens
|
| 505 |
+
i_sum = 0;token_sum = 0
|
| 506 |
+
for i_p, length in enumerate(hidden_length):
|
| 507 |
+
tot_token_num = token_lengths[i_p]
|
| 508 |
+
stage_output = output[token_sum : token_sum + tot_token_num]
|
| 509 |
+
stage_output = pad_input(stage_output, encoder_attention_mask[i_p]['indices'], batch_size, length)
|
| 510 |
+
output_hidden[:, i_sum:i_sum+length] = stage_output
|
| 511 |
+
token_sum += tot_token_num
|
| 512 |
+
i_sum += length
|
| 513 |
+
|
| 514 |
+
output_hidden = output_hidden.flatten(2, 3)
|
| 515 |
+
|
| 516 |
+
return output_hidden
|
| 517 |
+
|
| 518 |
+
|
| 519 |
+
class SequenceParallelVarlenAttnSingle:
|
| 520 |
+
|
| 521 |
+
def __init__(self):
|
| 522 |
+
pass
|
| 523 |
+
|
| 524 |
+
def __call__(
|
| 525 |
+
self, query, key, value, heads, scale,
|
| 526 |
+
hidden_length=None, image_rotary_emb=None, attention_mask=None,
|
| 527 |
+
):
|
| 528 |
+
assert attention_mask is not None, "The attention mask needed to be set"
|
| 529 |
+
|
| 530 |
+
num_stages = len(hidden_length)
|
| 531 |
+
qkv = torch.stack([query, key, value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 532 |
+
|
| 533 |
+
# To sync the encoder query, key and values
|
| 534 |
+
sp_group = get_sequence_parallel_group()
|
| 535 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 536 |
+
|
| 537 |
+
i_sum = 0
|
| 538 |
+
output_hidden_list = []
|
| 539 |
+
|
| 540 |
+
for i_p, length in enumerate(hidden_length):
|
| 541 |
+
qkv_tokens = qkv[:, i_sum:i_sum+length]
|
| 542 |
+
qkv_tokens = all_to_all(qkv_tokens, sp_group, sp_group_size, scatter_dim=3, gather_dim=1) # [bs, seq, 3, sub_head, head_dim]
|
| 543 |
+
|
| 544 |
+
if image_rotary_emb is not None:
|
| 545 |
+
qkv_tokens[:,:,0], qkv_tokens[:,:,1] = apply_rope(qkv_tokens[:,:,0], qkv_tokens[:,:,1], image_rotary_emb[i_p])
|
| 546 |
+
|
| 547 |
+
query, key, value = qkv_tokens.unbind(2) # [bs, tot_seq, nhead, dim]
|
| 548 |
+
query = query.transpose(1, 2).contiguous()
|
| 549 |
+
key = key.transpose(1, 2).contiguous()
|
| 550 |
+
value = value.transpose(1, 2).contiguous()
|
| 551 |
+
|
| 552 |
+
stage_hidden_states = F.scaled_dot_product_attention(
|
| 553 |
+
query, key, value, dropout_p=0.0, is_causal=False, attn_mask=attention_mask[i_p],
|
| 554 |
+
)
|
| 555 |
+
stage_hidden_states = stage_hidden_states.transpose(1, 2) # [bs, tot_seq, nhead, dim]
|
| 556 |
+
|
| 557 |
+
output_hidden = stage_hidden_states
|
| 558 |
+
output_hidden = all_to_all(output_hidden, sp_group, sp_group_size, scatter_dim=1, gather_dim=2)
|
| 559 |
+
output_hidden_list.append(output_hidden)
|
| 560 |
+
|
| 561 |
+
i_sum += length
|
| 562 |
+
|
| 563 |
+
output_hidden = torch.cat(output_hidden_list, dim=1).flatten(2, 3)
|
| 564 |
+
|
| 565 |
+
return output_hidden
|
| 566 |
+
|
| 567 |
+
|
| 568 |
+
class VarlenSelfAttnSingle:
|
| 569 |
+
|
| 570 |
+
def __init__(self):
|
| 571 |
+
pass
|
| 572 |
+
|
| 573 |
+
def __call__(
|
| 574 |
+
self, query, key, value, heads, scale,
|
| 575 |
+
hidden_length=None, image_rotary_emb=None, attention_mask=None,
|
| 576 |
+
):
|
| 577 |
+
assert attention_mask is not None, "The attention mask needed to be set"
|
| 578 |
+
|
| 579 |
+
num_stages = len(hidden_length)
|
| 580 |
+
qkv = torch.stack([query, key, value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 581 |
+
|
| 582 |
+
i_sum = 0
|
| 583 |
+
output_hidden_list = []
|
| 584 |
+
|
| 585 |
+
for i_p, length in enumerate(hidden_length):
|
| 586 |
+
qkv_tokens = qkv[:, i_sum:i_sum+length]
|
| 587 |
+
|
| 588 |
+
if image_rotary_emb is not None:
|
| 589 |
+
qkv_tokens[:,:,0], qkv_tokens[:,:,1] = apply_rope(qkv_tokens[:,:,0], qkv_tokens[:,:,1], image_rotary_emb[i_p])
|
| 590 |
+
|
| 591 |
+
query, key, value = qkv_tokens.unbind(2)
|
| 592 |
+
query = query.transpose(1, 2).contiguous()
|
| 593 |
+
key = key.transpose(1, 2).contiguous()
|
| 594 |
+
value = value.transpose(1, 2).contiguous()
|
| 595 |
+
|
| 596 |
+
stage_hidden_states = F.scaled_dot_product_attention(
|
| 597 |
+
query, key, value, dropout_p=0.0, is_causal=False, attn_mask=attention_mask[i_p],
|
| 598 |
+
)
|
| 599 |
+
stage_hidden_states = stage_hidden_states.transpose(1, 2).flatten(2, 3) # [bs, tot_seq, dim]
|
| 600 |
+
|
| 601 |
+
output_hidden_list.append(stage_hidden_states)
|
| 602 |
+
i_sum += length
|
| 603 |
+
|
| 604 |
+
output_hidden = torch.cat(output_hidden_list, dim=1)
|
| 605 |
+
|
| 606 |
+
return output_hidden
|
| 607 |
+
|
| 608 |
+
|
| 609 |
+
class Attention(nn.Module):
|
| 610 |
+
|
| 611 |
+
def __init__(
|
| 612 |
+
self,
|
| 613 |
+
query_dim: int,
|
| 614 |
+
cross_attention_dim: Optional[int] = None,
|
| 615 |
+
heads: int = 8,
|
| 616 |
+
dim_head: int = 64,
|
| 617 |
+
dropout: float = 0.0,
|
| 618 |
+
bias: bool = False,
|
| 619 |
+
qk_norm: Optional[str] = None,
|
| 620 |
+
added_kv_proj_dim: Optional[int] = None,
|
| 621 |
+
added_proj_bias: Optional[bool] = True,
|
| 622 |
+
out_bias: bool = True,
|
| 623 |
+
only_cross_attention: bool = False,
|
| 624 |
+
eps: float = 1e-5,
|
| 625 |
+
processor: Optional["AttnProcessor"] = None,
|
| 626 |
+
out_dim: int = None,
|
| 627 |
+
context_pre_only=None,
|
| 628 |
+
pre_only=False,
|
| 629 |
+
):
|
| 630 |
+
super().__init__()
|
| 631 |
+
|
| 632 |
+
self.inner_dim = out_dim if out_dim is not None else dim_head * heads
|
| 633 |
+
self.inner_kv_dim = self.inner_dim
|
| 634 |
+
self.query_dim = query_dim
|
| 635 |
+
self.use_bias = bias
|
| 636 |
+
self.cross_attention_dim = cross_attention_dim if cross_attention_dim is not None else query_dim
|
| 637 |
+
|
| 638 |
+
self.dropout = dropout
|
| 639 |
+
self.out_dim = out_dim if out_dim is not None else query_dim
|
| 640 |
+
self.context_pre_only = context_pre_only
|
| 641 |
+
self.pre_only = pre_only
|
| 642 |
+
|
| 643 |
+
self.scale = dim_head**-0.5
|
| 644 |
+
self.heads = out_dim // dim_head if out_dim is not None else heads
|
| 645 |
+
|
| 646 |
+
|
| 647 |
+
self.added_kv_proj_dim = added_kv_proj_dim
|
| 648 |
+
self.only_cross_attention = only_cross_attention
|
| 649 |
+
|
| 650 |
+
if self.added_kv_proj_dim is None and self.only_cross_attention:
|
| 651 |
+
raise ValueError(
|
| 652 |
+
"`only_cross_attention` can only be set to True if `added_kv_proj_dim` is not None. Make sure to set either `only_cross_attention=False` or define `added_kv_proj_dim`."
|
| 653 |
+
)
|
| 654 |
+
|
| 655 |
+
if qk_norm is None:
|
| 656 |
+
self.norm_q = None
|
| 657 |
+
self.norm_k = None
|
| 658 |
+
elif qk_norm == "rms_norm":
|
| 659 |
+
self.norm_q = RMSNorm(dim_head, eps=eps)
|
| 660 |
+
self.norm_k = RMSNorm(dim_head, eps=eps)
|
| 661 |
+
else:
|
| 662 |
+
raise ValueError(f"unknown qk_norm: {qk_norm}. Should be None or 'layer_norm'")
|
| 663 |
+
|
| 664 |
+
self.to_q = nn.Linear(query_dim, self.inner_dim, bias=bias)
|
| 665 |
+
|
| 666 |
+
if not self.only_cross_attention:
|
| 667 |
+
# only relevant for the `AddedKVProcessor` classes
|
| 668 |
+
self.to_k = nn.Linear(self.cross_attention_dim, self.inner_kv_dim, bias=bias)
|
| 669 |
+
self.to_v = nn.Linear(self.cross_attention_dim, self.inner_kv_dim, bias=bias)
|
| 670 |
+
else:
|
| 671 |
+
self.to_k = None
|
| 672 |
+
self.to_v = None
|
| 673 |
+
|
| 674 |
+
self.added_proj_bias = added_proj_bias
|
| 675 |
+
if self.added_kv_proj_dim is not None:
|
| 676 |
+
self.add_k_proj = nn.Linear(added_kv_proj_dim, self.inner_kv_dim, bias=added_proj_bias)
|
| 677 |
+
self.add_v_proj = nn.Linear(added_kv_proj_dim, self.inner_kv_dim, bias=added_proj_bias)
|
| 678 |
+
if self.context_pre_only is not None:
|
| 679 |
+
self.add_q_proj = nn.Linear(added_kv_proj_dim, self.inner_dim, bias=added_proj_bias)
|
| 680 |
+
|
| 681 |
+
if not self.pre_only:
|
| 682 |
+
self.to_out = nn.ModuleList([])
|
| 683 |
+
self.to_out.append(nn.Linear(self.inner_dim, self.out_dim, bias=out_bias))
|
| 684 |
+
self.to_out.append(nn.Dropout(dropout))
|
| 685 |
+
|
| 686 |
+
if self.context_pre_only is not None and not self.context_pre_only:
|
| 687 |
+
self.to_add_out = nn.Linear(self.inner_dim, self.out_dim, bias=out_bias)
|
| 688 |
+
|
| 689 |
+
if qk_norm is not None and added_kv_proj_dim is not None:
|
| 690 |
+
if qk_norm == "fp32_layer_norm":
|
| 691 |
+
self.norm_added_q = FP32LayerNorm(dim_head, elementwise_affine=False, bias=False, eps=eps)
|
| 692 |
+
self.norm_added_k = FP32LayerNorm(dim_head, elementwise_affine=False, bias=False, eps=eps)
|
| 693 |
+
elif qk_norm == "rms_norm":
|
| 694 |
+
self.norm_added_q = RMSNorm(dim_head, eps=eps)
|
| 695 |
+
self.norm_added_k = RMSNorm(dim_head, eps=eps)
|
| 696 |
+
else:
|
| 697 |
+
self.norm_added_q = None
|
| 698 |
+
self.norm_added_k = None
|
| 699 |
+
|
| 700 |
+
# set attention processor
|
| 701 |
+
self.set_processor(processor)
|
| 702 |
+
|
| 703 |
+
def set_processor(self, processor: "AttnProcessor") -> None:
|
| 704 |
+
self.processor = processor
|
| 705 |
+
|
| 706 |
+
def forward(
|
| 707 |
+
self,
|
| 708 |
+
hidden_states: torch.Tensor,
|
| 709 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 710 |
+
encoder_attention_mask: Optional[torch.Tensor] = None,
|
| 711 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 712 |
+
hidden_length: List = None,
|
| 713 |
+
image_rotary_emb: Optional[torch.Tensor] = None,
|
| 714 |
+
) -> torch.Tensor:
|
| 715 |
+
|
| 716 |
+
return self.processor(
|
| 717 |
+
self,
|
| 718 |
+
hidden_states,
|
| 719 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 720 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 721 |
+
attention_mask=attention_mask,
|
| 722 |
+
hidden_length=hidden_length,
|
| 723 |
+
image_rotary_emb=image_rotary_emb,
|
| 724 |
+
)
|
| 725 |
+
|
| 726 |
+
|
| 727 |
+
class FluxSingleAttnProcessor2_0:
|
| 728 |
+
r"""
|
| 729 |
+
Processor for implementing scaled dot-product attention (enabled by default if you're using PyTorch 2.0).
|
| 730 |
+
"""
|
| 731 |
+
def __init__(self, use_flash_attn=False):
|
| 732 |
+
self.use_flash_attn = use_flash_attn
|
| 733 |
+
|
| 734 |
+
if self.use_flash_attn:
|
| 735 |
+
if is_sequence_parallel_initialized():
|
| 736 |
+
self.varlen_flash_attn = SequenceParallelVarlenFlashAttnSingle()
|
| 737 |
+
else:
|
| 738 |
+
self.varlen_flash_attn = VarlenFlashSelfAttnSingle()
|
| 739 |
+
else:
|
| 740 |
+
if is_sequence_parallel_initialized():
|
| 741 |
+
self.varlen_attn = SequenceParallelVarlenAttnSingle()
|
| 742 |
+
else:
|
| 743 |
+
self.varlen_attn = VarlenSelfAttnSingle()
|
| 744 |
+
|
| 745 |
+
def __call__(
|
| 746 |
+
self,
|
| 747 |
+
attn: Attention,
|
| 748 |
+
hidden_states: torch.Tensor,
|
| 749 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 750 |
+
encoder_attention_mask: Optional[torch.Tensor] = None,
|
| 751 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 752 |
+
hidden_length: List = None,
|
| 753 |
+
image_rotary_emb: Optional[torch.Tensor] = None,
|
| 754 |
+
) -> torch.Tensor:
|
| 755 |
+
|
| 756 |
+
query = attn.to_q(hidden_states)
|
| 757 |
+
key = attn.to_k(hidden_states)
|
| 758 |
+
value = attn.to_v(hidden_states)
|
| 759 |
+
|
| 760 |
+
inner_dim = key.shape[-1]
|
| 761 |
+
head_dim = inner_dim // attn.heads
|
| 762 |
+
|
| 763 |
+
query = query.view(query.shape[0], -1, attn.heads, head_dim)
|
| 764 |
+
key = key.view(key.shape[0], -1, attn.heads, head_dim)
|
| 765 |
+
value = value.view(value.shape[0], -1, attn.heads, head_dim)
|
| 766 |
+
|
| 767 |
+
if attn.norm_q is not None:
|
| 768 |
+
query = attn.norm_q(query)
|
| 769 |
+
if attn.norm_k is not None:
|
| 770 |
+
key = attn.norm_k(key)
|
| 771 |
+
|
| 772 |
+
if self.use_flash_attn:
|
| 773 |
+
hidden_states = self.varlen_flash_attn(
|
| 774 |
+
query, key, value,
|
| 775 |
+
attn.heads, attn.scale, hidden_length,
|
| 776 |
+
image_rotary_emb, encoder_attention_mask,
|
| 777 |
+
)
|
| 778 |
+
else:
|
| 779 |
+
hidden_states = self.varlen_attn(
|
| 780 |
+
query, key, value,
|
| 781 |
+
attn.heads, attn.scale, hidden_length,
|
| 782 |
+
image_rotary_emb, attention_mask,
|
| 783 |
+
)
|
| 784 |
+
|
| 785 |
+
return hidden_states
|
| 786 |
+
|
| 787 |
+
|
| 788 |
+
class FluxAttnProcessor2_0:
|
| 789 |
+
"""Attention processor used typically in processing the SD3-like self-attention projections."""
|
| 790 |
+
|
| 791 |
+
def __init__(self, use_flash_attn=False):
|
| 792 |
+
self.use_flash_attn = use_flash_attn
|
| 793 |
+
|
| 794 |
+
if self.use_flash_attn:
|
| 795 |
+
if is_sequence_parallel_initialized():
|
| 796 |
+
self.varlen_flash_attn = SequenceParallelVarlenFlashSelfAttentionWithT5Mask()
|
| 797 |
+
else:
|
| 798 |
+
self.varlen_flash_attn = VarlenFlashSelfAttentionWithT5Mask()
|
| 799 |
+
else:
|
| 800 |
+
if is_sequence_parallel_initialized():
|
| 801 |
+
self.varlen_attn = SequenceParallelVarlenSelfAttentionWithT5Mask()
|
| 802 |
+
else:
|
| 803 |
+
self.varlen_attn = VarlenSelfAttentionWithT5Mask()
|
| 804 |
+
|
| 805 |
+
def __call__(
|
| 806 |
+
self,
|
| 807 |
+
attn: Attention,
|
| 808 |
+
hidden_states: torch.FloatTensor,
|
| 809 |
+
encoder_hidden_states: torch.FloatTensor = None,
|
| 810 |
+
encoder_attention_mask: Optional[torch.Tensor] = None,
|
| 811 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 812 |
+
hidden_length: List = None,
|
| 813 |
+
image_rotary_emb: Optional[torch.Tensor] = None,
|
| 814 |
+
) -> torch.FloatTensor:
|
| 815 |
+
# `sample` projections.
|
| 816 |
+
query = attn.to_q(hidden_states)
|
| 817 |
+
key = attn.to_k(hidden_states)
|
| 818 |
+
value = attn.to_v(hidden_states)
|
| 819 |
+
|
| 820 |
+
inner_dim = key.shape[-1]
|
| 821 |
+
head_dim = inner_dim // attn.heads
|
| 822 |
+
|
| 823 |
+
query = query.view(query.shape[0], -1, attn.heads, head_dim)
|
| 824 |
+
key = key.view(key.shape[0], -1, attn.heads, head_dim)
|
| 825 |
+
value = value.view(value.shape[0], -1, attn.heads, head_dim)
|
| 826 |
+
|
| 827 |
+
if attn.norm_q is not None:
|
| 828 |
+
query = attn.norm_q(query)
|
| 829 |
+
if attn.norm_k is not None:
|
| 830 |
+
key = attn.norm_k(key)
|
| 831 |
+
|
| 832 |
+
# `context` projections.
|
| 833 |
+
encoder_hidden_states_query_proj = attn.add_q_proj(encoder_hidden_states)
|
| 834 |
+
encoder_hidden_states_key_proj = attn.add_k_proj(encoder_hidden_states)
|
| 835 |
+
encoder_hidden_states_value_proj = attn.add_v_proj(encoder_hidden_states)
|
| 836 |
+
|
| 837 |
+
encoder_hidden_states_query_proj = encoder_hidden_states_query_proj.view(
|
| 838 |
+
encoder_hidden_states_query_proj.shape[0], -1, attn.heads, head_dim
|
| 839 |
+
)
|
| 840 |
+
encoder_hidden_states_key_proj = encoder_hidden_states_key_proj.view(
|
| 841 |
+
encoder_hidden_states_key_proj.shape[0], -1, attn.heads, head_dim
|
| 842 |
+
)
|
| 843 |
+
encoder_hidden_states_value_proj = encoder_hidden_states_value_proj.view(
|
| 844 |
+
encoder_hidden_states_value_proj.shape[0], -1, attn.heads, head_dim
|
| 845 |
+
)
|
| 846 |
+
|
| 847 |
+
if attn.norm_added_q is not None:
|
| 848 |
+
encoder_hidden_states_query_proj = attn.norm_added_q(encoder_hidden_states_query_proj)
|
| 849 |
+
if attn.norm_added_k is not None:
|
| 850 |
+
encoder_hidden_states_key_proj = attn.norm_added_k(encoder_hidden_states_key_proj)
|
| 851 |
+
|
| 852 |
+
if self.use_flash_attn:
|
| 853 |
+
hidden_states, encoder_hidden_states = self.varlen_flash_attn(
|
| 854 |
+
query, key, value,
|
| 855 |
+
encoder_hidden_states_query_proj, encoder_hidden_states_key_proj,
|
| 856 |
+
encoder_hidden_states_value_proj, attn.heads, attn.scale, hidden_length,
|
| 857 |
+
image_rotary_emb, encoder_attention_mask,
|
| 858 |
+
)
|
| 859 |
+
else:
|
| 860 |
+
hidden_states, encoder_hidden_states = self.varlen_attn(
|
| 861 |
+
query, key, value,
|
| 862 |
+
encoder_hidden_states_query_proj, encoder_hidden_states_key_proj,
|
| 863 |
+
encoder_hidden_states_value_proj, attn.heads, attn.scale, hidden_length,
|
| 864 |
+
image_rotary_emb, attention_mask,
|
| 865 |
+
)
|
| 866 |
+
|
| 867 |
+
# linear proj
|
| 868 |
+
hidden_states = attn.to_out[0](hidden_states)
|
| 869 |
+
# dropout
|
| 870 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 871 |
+
|
| 872 |
+
encoder_hidden_states = attn.to_add_out(encoder_hidden_states)
|
| 873 |
+
|
| 874 |
+
return hidden_states, encoder_hidden_states
|
| 875 |
+
|
| 876 |
+
|
| 877 |
+
class FluxSingleTransformerBlock(nn.Module):
|
| 878 |
+
r"""
|
| 879 |
+
A Transformer block following the MMDiT architecture, introduced in Stable Diffusion 3.
|
| 880 |
+
|
| 881 |
+
Reference: https://arxiv.org/abs/2403.03206
|
| 882 |
+
|
| 883 |
+
Parameters:
|
| 884 |
+
dim (`int`): The number of channels in the input and output.
|
| 885 |
+
num_attention_heads (`int`): The number of heads to use for multi-head attention.
|
| 886 |
+
attention_head_dim (`int`): The number of channels in each head.
|
| 887 |
+
context_pre_only (`bool`): Boolean to determine if we should add some blocks associated with the
|
| 888 |
+
processing of `context` conditions.
|
| 889 |
+
"""
|
| 890 |
+
|
| 891 |
+
def __init__(self, dim, num_attention_heads, attention_head_dim, mlp_ratio=4.0, use_flash_attn=False):
|
| 892 |
+
super().__init__()
|
| 893 |
+
self.mlp_hidden_dim = int(dim * mlp_ratio)
|
| 894 |
+
|
| 895 |
+
self.norm = AdaLayerNormZeroSingle(dim)
|
| 896 |
+
self.proj_mlp = nn.Linear(dim, self.mlp_hidden_dim)
|
| 897 |
+
self.act_mlp = nn.GELU(approximate="tanh")
|
| 898 |
+
self.proj_out = nn.Linear(dim + self.mlp_hidden_dim, dim)
|
| 899 |
+
|
| 900 |
+
processor = FluxSingleAttnProcessor2_0(use_flash_attn)
|
| 901 |
+
self.attn = Attention(
|
| 902 |
+
query_dim=dim,
|
| 903 |
+
cross_attention_dim=None,
|
| 904 |
+
dim_head=attention_head_dim,
|
| 905 |
+
heads=num_attention_heads,
|
| 906 |
+
out_dim=dim,
|
| 907 |
+
bias=True,
|
| 908 |
+
processor=processor,
|
| 909 |
+
qk_norm="rms_norm",
|
| 910 |
+
eps=1e-6,
|
| 911 |
+
pre_only=True,
|
| 912 |
+
)
|
| 913 |
+
|
| 914 |
+
def forward(
|
| 915 |
+
self,
|
| 916 |
+
hidden_states: torch.FloatTensor,
|
| 917 |
+
temb: torch.FloatTensor,
|
| 918 |
+
encoder_attention_mask=None,
|
| 919 |
+
attention_mask=None,
|
| 920 |
+
hidden_length=None,
|
| 921 |
+
image_rotary_emb=None,
|
| 922 |
+
):
|
| 923 |
+
residual = hidden_states
|
| 924 |
+
norm_hidden_states, gate = self.norm(hidden_states, emb=temb, hidden_length=hidden_length)
|
| 925 |
+
mlp_hidden_states = self.act_mlp(self.proj_mlp(norm_hidden_states))
|
| 926 |
+
|
| 927 |
+
attn_output = self.attn(
|
| 928 |
+
hidden_states=norm_hidden_states,
|
| 929 |
+
encoder_hidden_states=None,
|
| 930 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 931 |
+
attention_mask=attention_mask,
|
| 932 |
+
hidden_length=hidden_length,
|
| 933 |
+
image_rotary_emb=image_rotary_emb,
|
| 934 |
+
)
|
| 935 |
+
|
| 936 |
+
hidden_states = torch.cat([attn_output, mlp_hidden_states], dim=2)
|
| 937 |
+
hidden_states = gate * self.proj_out(hidden_states)
|
| 938 |
+
hidden_states = residual + hidden_states
|
| 939 |
+
if hidden_states.dtype == torch.float16:
|
| 940 |
+
hidden_states = hidden_states.clip(-65504, 65504)
|
| 941 |
+
|
| 942 |
+
return hidden_states
|
| 943 |
+
|
| 944 |
+
|
| 945 |
+
class FluxTransformerBlock(nn.Module):
|
| 946 |
+
r"""
|
| 947 |
+
A Transformer block following the MMDiT architecture, introduced in Stable Diffusion 3.
|
| 948 |
+
|
| 949 |
+
Reference: https://arxiv.org/abs/2403.03206
|
| 950 |
+
|
| 951 |
+
Parameters:
|
| 952 |
+
dim (`int`): The number of channels in the input and output.
|
| 953 |
+
num_attention_heads (`int`): The number of heads to use for multi-head attention.
|
| 954 |
+
attention_head_dim (`int`): The number of channels in each head.
|
| 955 |
+
context_pre_only (`bool`): Boolean to determine if we should add some blocks associated with the
|
| 956 |
+
processing of `context` conditions.
|
| 957 |
+
"""
|
| 958 |
+
|
| 959 |
+
def __init__(self, dim, num_attention_heads, attention_head_dim, qk_norm="rms_norm", eps=1e-6, use_flash_attn=False):
|
| 960 |
+
super().__init__()
|
| 961 |
+
|
| 962 |
+
self.norm1 = AdaLayerNormZero(dim)
|
| 963 |
+
|
| 964 |
+
self.norm1_context = AdaLayerNormZero(dim)
|
| 965 |
+
|
| 966 |
+
if hasattr(F, "scaled_dot_product_attention"):
|
| 967 |
+
processor = FluxAttnProcessor2_0(use_flash_attn)
|
| 968 |
+
else:
|
| 969 |
+
raise ValueError(
|
| 970 |
+
"The current PyTorch version does not support the `scaled_dot_product_attention` function."
|
| 971 |
+
)
|
| 972 |
+
self.attn = Attention(
|
| 973 |
+
query_dim=dim,
|
| 974 |
+
cross_attention_dim=None,
|
| 975 |
+
added_kv_proj_dim=dim,
|
| 976 |
+
dim_head=attention_head_dim,
|
| 977 |
+
heads=num_attention_heads,
|
| 978 |
+
out_dim=dim,
|
| 979 |
+
context_pre_only=False,
|
| 980 |
+
bias=True,
|
| 981 |
+
processor=processor,
|
| 982 |
+
qk_norm=qk_norm,
|
| 983 |
+
eps=eps,
|
| 984 |
+
)
|
| 985 |
+
|
| 986 |
+
self.norm2 = nn.LayerNorm(dim, elementwise_affine=False, eps=1e-6)
|
| 987 |
+
self.ff = FeedForward(dim=dim, dim_out=dim, activation_fn="gelu-approximate")
|
| 988 |
+
|
| 989 |
+
self.norm2_context = nn.LayerNorm(dim, elementwise_affine=False, eps=1e-6)
|
| 990 |
+
self.ff_context = FeedForward(dim=dim, dim_out=dim, activation_fn="gelu-approximate")
|
| 991 |
+
|
| 992 |
+
def forward(
|
| 993 |
+
self,
|
| 994 |
+
hidden_states: torch.FloatTensor,
|
| 995 |
+
encoder_hidden_states: torch.FloatTensor,
|
| 996 |
+
encoder_attention_mask: torch.FloatTensor,
|
| 997 |
+
temb: torch.FloatTensor,
|
| 998 |
+
attention_mask: torch.FloatTensor = None,
|
| 999 |
+
hidden_length: List = None,
|
| 1000 |
+
image_rotary_emb=None,
|
| 1001 |
+
):
|
| 1002 |
+
norm_hidden_states, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.norm1(hidden_states, emb=temb, hidden_length=hidden_length)
|
| 1003 |
+
|
| 1004 |
+
norm_encoder_hidden_states, c_gate_msa, c_shift_mlp, c_scale_mlp, c_gate_mlp = self.norm1_context(
|
| 1005 |
+
encoder_hidden_states, emb=temb
|
| 1006 |
+
)
|
| 1007 |
+
|
| 1008 |
+
# Attention.
|
| 1009 |
+
attn_output, context_attn_output = self.attn(
|
| 1010 |
+
hidden_states=norm_hidden_states,
|
| 1011 |
+
encoder_hidden_states=norm_encoder_hidden_states,
|
| 1012 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1013 |
+
attention_mask=attention_mask,
|
| 1014 |
+
hidden_length=hidden_length,
|
| 1015 |
+
image_rotary_emb=image_rotary_emb,
|
| 1016 |
+
)
|
| 1017 |
+
|
| 1018 |
+
# Process attention outputs for the `hidden_states`.
|
| 1019 |
+
attn_output = gate_msa * attn_output
|
| 1020 |
+
hidden_states = hidden_states + attn_output
|
| 1021 |
+
|
| 1022 |
+
norm_hidden_states = self.norm2(hidden_states)
|
| 1023 |
+
norm_hidden_states = norm_hidden_states * (1 + scale_mlp) + shift_mlp
|
| 1024 |
+
|
| 1025 |
+
ff_output = self.ff(norm_hidden_states)
|
| 1026 |
+
ff_output = gate_mlp * ff_output
|
| 1027 |
+
|
| 1028 |
+
hidden_states = hidden_states + ff_output
|
| 1029 |
+
|
| 1030 |
+
# Process attention outputs for the `encoder_hidden_states`.
|
| 1031 |
+
|
| 1032 |
+
context_attn_output = c_gate_msa.unsqueeze(1) * context_attn_output
|
| 1033 |
+
encoder_hidden_states = encoder_hidden_states + context_attn_output
|
| 1034 |
+
|
| 1035 |
+
norm_encoder_hidden_states = self.norm2_context(encoder_hidden_states)
|
| 1036 |
+
norm_encoder_hidden_states = norm_encoder_hidden_states * (1 + c_scale_mlp[:, None]) + c_shift_mlp[:, None]
|
| 1037 |
+
|
| 1038 |
+
context_ff_output = self.ff_context(norm_encoder_hidden_states)
|
| 1039 |
+
encoder_hidden_states = encoder_hidden_states + c_gate_mlp.unsqueeze(1) * context_ff_output
|
| 1040 |
+
|
| 1041 |
+
if encoder_hidden_states.dtype == torch.float16:
|
| 1042 |
+
encoder_hidden_states = encoder_hidden_states.clip(-65504, 65504)
|
| 1043 |
+
|
| 1044 |
+
return encoder_hidden_states, hidden_states
|
pyramid_dit/flux_modules/modeling_normalization.py
ADDED
|
@@ -0,0 +1,249 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numbers
|
| 2 |
+
from typing import Dict, Optional, Tuple
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
from einops import rearrange
|
| 8 |
+
from diffusers.utils import is_torch_version
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
if is_torch_version(">=", "2.1.0"):
|
| 12 |
+
LayerNorm = nn.LayerNorm
|
| 13 |
+
else:
|
| 14 |
+
# Has optional bias parameter compared to torch layer norm
|
| 15 |
+
# TODO: replace with torch layernorm once min required torch version >= 2.1
|
| 16 |
+
class LayerNorm(nn.Module):
|
| 17 |
+
def __init__(self, dim, eps: float = 1e-5, elementwise_affine: bool = True, bias: bool = True):
|
| 18 |
+
super().__init__()
|
| 19 |
+
|
| 20 |
+
self.eps = eps
|
| 21 |
+
|
| 22 |
+
if isinstance(dim, numbers.Integral):
|
| 23 |
+
dim = (dim,)
|
| 24 |
+
|
| 25 |
+
self.dim = torch.Size(dim)
|
| 26 |
+
|
| 27 |
+
if elementwise_affine:
|
| 28 |
+
self.weight = nn.Parameter(torch.ones(dim))
|
| 29 |
+
self.bias = nn.Parameter(torch.zeros(dim)) if bias else None
|
| 30 |
+
else:
|
| 31 |
+
self.weight = None
|
| 32 |
+
self.bias = None
|
| 33 |
+
|
| 34 |
+
def forward(self, input):
|
| 35 |
+
return F.layer_norm(input, self.dim, self.weight, self.bias, self.eps)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
class FP32LayerNorm(nn.LayerNorm):
|
| 39 |
+
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
|
| 40 |
+
origin_dtype = inputs.dtype
|
| 41 |
+
return F.layer_norm(
|
| 42 |
+
inputs.float(),
|
| 43 |
+
self.normalized_shape,
|
| 44 |
+
self.weight.float() if self.weight is not None else None,
|
| 45 |
+
self.bias.float() if self.bias is not None else None,
|
| 46 |
+
self.eps,
|
| 47 |
+
).to(origin_dtype)
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
class RMSNorm(nn.Module):
|
| 51 |
+
def __init__(self, dim, eps: float, elementwise_affine: bool = True):
|
| 52 |
+
super().__init__()
|
| 53 |
+
|
| 54 |
+
self.eps = eps
|
| 55 |
+
|
| 56 |
+
if isinstance(dim, numbers.Integral):
|
| 57 |
+
dim = (dim,)
|
| 58 |
+
|
| 59 |
+
self.dim = torch.Size(dim)
|
| 60 |
+
|
| 61 |
+
if elementwise_affine:
|
| 62 |
+
self.weight = nn.Parameter(torch.ones(dim))
|
| 63 |
+
else:
|
| 64 |
+
self.weight = None
|
| 65 |
+
|
| 66 |
+
def forward(self, hidden_states):
|
| 67 |
+
input_dtype = hidden_states.dtype
|
| 68 |
+
variance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True)
|
| 69 |
+
hidden_states = hidden_states * torch.rsqrt(variance + self.eps)
|
| 70 |
+
|
| 71 |
+
if self.weight is not None:
|
| 72 |
+
# convert into half-precision if necessary
|
| 73 |
+
if self.weight.dtype in [torch.float16, torch.bfloat16]:
|
| 74 |
+
hidden_states = hidden_states.to(self.weight.dtype)
|
| 75 |
+
hidden_states = hidden_states * self.weight
|
| 76 |
+
else:
|
| 77 |
+
hidden_states = hidden_states.to(input_dtype)
|
| 78 |
+
|
| 79 |
+
return hidden_states
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
class AdaLayerNormContinuous(nn.Module):
|
| 83 |
+
def __init__(
|
| 84 |
+
self,
|
| 85 |
+
embedding_dim: int,
|
| 86 |
+
conditioning_embedding_dim: int,
|
| 87 |
+
# NOTE: It is a bit weird that the norm layer can be configured to have scale and shift parameters
|
| 88 |
+
# because the output is immediately scaled and shifted by the projected conditioning embeddings.
|
| 89 |
+
# Note that AdaLayerNorm does not let the norm layer have scale and shift parameters.
|
| 90 |
+
# However, this is how it was implemented in the original code, and it's rather likely you should
|
| 91 |
+
# set `elementwise_affine` to False.
|
| 92 |
+
elementwise_affine=True,
|
| 93 |
+
eps=1e-5,
|
| 94 |
+
bias=True,
|
| 95 |
+
norm_type="layer_norm",
|
| 96 |
+
):
|
| 97 |
+
super().__init__()
|
| 98 |
+
self.silu = nn.SiLU()
|
| 99 |
+
self.linear = nn.Linear(conditioning_embedding_dim, embedding_dim * 2, bias=bias)
|
| 100 |
+
if norm_type == "layer_norm":
|
| 101 |
+
self.norm = LayerNorm(embedding_dim, eps, elementwise_affine, bias)
|
| 102 |
+
elif norm_type == "rms_norm":
|
| 103 |
+
self.norm = RMSNorm(embedding_dim, eps, elementwise_affine)
|
| 104 |
+
else:
|
| 105 |
+
raise ValueError(f"unknown norm_type {norm_type}")
|
| 106 |
+
|
| 107 |
+
def forward_with_pad(self, x: torch.Tensor, conditioning_embedding: torch.Tensor, hidden_length=None) -> torch.Tensor:
|
| 108 |
+
assert hidden_length is not None
|
| 109 |
+
|
| 110 |
+
emb = self.linear(self.silu(conditioning_embedding).to(x.dtype))
|
| 111 |
+
batch_emb = torch.zeros_like(x).repeat(1, 1, 2)
|
| 112 |
+
|
| 113 |
+
i_sum = 0
|
| 114 |
+
num_stages = len(hidden_length)
|
| 115 |
+
for i_p, length in enumerate(hidden_length):
|
| 116 |
+
batch_emb[:, i_sum:i_sum+length] = emb[i_p::num_stages][:,None]
|
| 117 |
+
i_sum += length
|
| 118 |
+
|
| 119 |
+
batch_scale, batch_shift = torch.chunk(batch_emb, 2, dim=2)
|
| 120 |
+
x = self.norm(x) * (1 + batch_scale) + batch_shift
|
| 121 |
+
return x
|
| 122 |
+
|
| 123 |
+
def forward(self, x: torch.Tensor, conditioning_embedding: torch.Tensor, hidden_length=None) -> torch.Tensor:
|
| 124 |
+
# convert back to the original dtype in case `conditioning_embedding`` is upcasted to float32 (needed for hunyuanDiT)
|
| 125 |
+
if hidden_length is not None:
|
| 126 |
+
return self.forward_with_pad(x, conditioning_embedding, hidden_length)
|
| 127 |
+
emb = self.linear(self.silu(conditioning_embedding).to(x.dtype))
|
| 128 |
+
scale, shift = torch.chunk(emb, 2, dim=1)
|
| 129 |
+
x = self.norm(x) * (1 + scale)[:, None, :] + shift[:, None, :]
|
| 130 |
+
return x
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
class AdaLayerNormZero(nn.Module):
|
| 134 |
+
r"""
|
| 135 |
+
Norm layer adaptive layer norm zero (adaLN-Zero).
|
| 136 |
+
|
| 137 |
+
Parameters:
|
| 138 |
+
embedding_dim (`int`): The size of each embedding vector.
|
| 139 |
+
num_embeddings (`int`): The size of the embeddings dictionary.
|
| 140 |
+
"""
|
| 141 |
+
|
| 142 |
+
def __init__(self, embedding_dim: int, num_embeddings: Optional[int] = None):
|
| 143 |
+
super().__init__()
|
| 144 |
+
self.emb = None
|
| 145 |
+
|
| 146 |
+
self.silu = nn.SiLU()
|
| 147 |
+
self.linear = nn.Linear(embedding_dim, 6 * embedding_dim, bias=True)
|
| 148 |
+
self.norm = nn.LayerNorm(embedding_dim, elementwise_affine=False, eps=1e-6)
|
| 149 |
+
|
| 150 |
+
def forward_with_pad(
|
| 151 |
+
self,
|
| 152 |
+
x: torch.Tensor,
|
| 153 |
+
timestep: Optional[torch.Tensor] = None,
|
| 154 |
+
class_labels: Optional[torch.LongTensor] = None,
|
| 155 |
+
hidden_dtype: Optional[torch.dtype] = None,
|
| 156 |
+
emb: Optional[torch.Tensor] = None,
|
| 157 |
+
hidden_length: Optional[torch.Tensor] = None,
|
| 158 |
+
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
|
| 159 |
+
# hidden_length: [[20, 30], [30, 40], [50, 60]]
|
| 160 |
+
# x: [bs, seq_len, dim]
|
| 161 |
+
if self.emb is not None:
|
| 162 |
+
emb = self.emb(timestep, class_labels, hidden_dtype=hidden_dtype)
|
| 163 |
+
|
| 164 |
+
emb = self.linear(self.silu(emb))
|
| 165 |
+
batch_emb = torch.zeros_like(x).repeat(1, 1, 6)
|
| 166 |
+
|
| 167 |
+
i_sum = 0
|
| 168 |
+
num_stages = len(hidden_length)
|
| 169 |
+
for i_p, length in enumerate(hidden_length):
|
| 170 |
+
batch_emb[:, i_sum:i_sum+length] = emb[i_p::num_stages][:,None]
|
| 171 |
+
i_sum += length
|
| 172 |
+
|
| 173 |
+
batch_shift_msa, batch_scale_msa, batch_gate_msa, batch_shift_mlp, batch_scale_mlp, batch_gate_mlp = batch_emb.chunk(6, dim=2)
|
| 174 |
+
x = self.norm(x) * (1 + batch_scale_msa) + batch_shift_msa
|
| 175 |
+
return x, batch_gate_msa, batch_shift_mlp, batch_scale_mlp, batch_gate_mlp
|
| 176 |
+
|
| 177 |
+
def forward(
|
| 178 |
+
self,
|
| 179 |
+
x: torch.Tensor,
|
| 180 |
+
timestep: Optional[torch.Tensor] = None,
|
| 181 |
+
class_labels: Optional[torch.LongTensor] = None,
|
| 182 |
+
hidden_dtype: Optional[torch.dtype] = None,
|
| 183 |
+
emb: Optional[torch.Tensor] = None,
|
| 184 |
+
hidden_length: Optional[torch.Tensor] = None,
|
| 185 |
+
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
|
| 186 |
+
if hidden_length is not None:
|
| 187 |
+
return self.forward_with_pad(x, timestep, class_labels, hidden_dtype, emb, hidden_length)
|
| 188 |
+
if self.emb is not None:
|
| 189 |
+
emb = self.emb(timestep, class_labels, hidden_dtype=hidden_dtype)
|
| 190 |
+
emb = self.linear(self.silu(emb))
|
| 191 |
+
shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = emb.chunk(6, dim=1)
|
| 192 |
+
x = self.norm(x) * (1 + scale_msa[:, None]) + shift_msa[:, None]
|
| 193 |
+
return x, gate_msa, shift_mlp, scale_mlp, gate_mlp
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
class AdaLayerNormZeroSingle(nn.Module):
|
| 197 |
+
r"""
|
| 198 |
+
Norm layer adaptive layer norm zero (adaLN-Zero).
|
| 199 |
+
|
| 200 |
+
Parameters:
|
| 201 |
+
embedding_dim (`int`): The size of each embedding vector.
|
| 202 |
+
num_embeddings (`int`): The size of the embeddings dictionary.
|
| 203 |
+
"""
|
| 204 |
+
|
| 205 |
+
def __init__(self, embedding_dim: int, norm_type="layer_norm", bias=True):
|
| 206 |
+
super().__init__()
|
| 207 |
+
|
| 208 |
+
self.silu = nn.SiLU()
|
| 209 |
+
self.linear = nn.Linear(embedding_dim, 3 * embedding_dim, bias=bias)
|
| 210 |
+
if norm_type == "layer_norm":
|
| 211 |
+
self.norm = nn.LayerNorm(embedding_dim, elementwise_affine=False, eps=1e-6)
|
| 212 |
+
else:
|
| 213 |
+
raise ValueError(
|
| 214 |
+
f"Unsupported `norm_type` ({norm_type}) provided. Supported ones are: 'layer_norm', 'fp32_layer_norm'."
|
| 215 |
+
)
|
| 216 |
+
|
| 217 |
+
def forward_with_pad(
|
| 218 |
+
self,
|
| 219 |
+
x: torch.Tensor,
|
| 220 |
+
emb: Optional[torch.Tensor] = None,
|
| 221 |
+
hidden_length: Optional[torch.Tensor] = None,
|
| 222 |
+
):
|
| 223 |
+
emb = self.linear(self.silu(emb))
|
| 224 |
+
batch_emb = torch.zeros_like(x).repeat(1, 1, 3)
|
| 225 |
+
|
| 226 |
+
i_sum = 0
|
| 227 |
+
num_stages = len(hidden_length)
|
| 228 |
+
for i_p, length in enumerate(hidden_length):
|
| 229 |
+
batch_emb[:, i_sum:i_sum+length] = emb[i_p::num_stages][:,None]
|
| 230 |
+
i_sum += length
|
| 231 |
+
|
| 232 |
+
batch_shift_msa, batch_scale_msa, batch_gate_msa = batch_emb.chunk(3, dim=2)
|
| 233 |
+
|
| 234 |
+
x = self.norm(x) * (1 + batch_scale_msa) + batch_shift_msa
|
| 235 |
+
|
| 236 |
+
return x, batch_gate_msa
|
| 237 |
+
|
| 238 |
+
def forward(
|
| 239 |
+
self,
|
| 240 |
+
x: torch.Tensor,
|
| 241 |
+
emb: Optional[torch.Tensor] = None,
|
| 242 |
+
hidden_length: Optional[torch.Tensor] = None,
|
| 243 |
+
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
|
| 244 |
+
if hidden_length is not None:
|
| 245 |
+
return self.forward_with_pad(x, emb, hidden_length)
|
| 246 |
+
emb = self.linear(self.silu(emb))
|
| 247 |
+
shift_msa, scale_msa, gate_msa = emb.chunk(3, dim=1)
|
| 248 |
+
x = self.norm(x) * (1 + scale_msa[:, None]) + shift_msa[:, None]
|
| 249 |
+
return x, gate_msa
|
pyramid_dit/flux_modules/modeling_pyramid_flux.py
ADDED
|
@@ -0,0 +1,543 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Any, Dict, List, Optional, Union
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import os
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
from einops import rearrange
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
|
| 10 |
+
from diffusers.utils.torch_utils import randn_tensor
|
| 11 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 12 |
+
from diffusers.models.modeling_utils import ModelMixin
|
| 13 |
+
from diffusers.utils import is_torch_version
|
| 14 |
+
|
| 15 |
+
from .modeling_normalization import AdaLayerNormContinuous
|
| 16 |
+
from .modeling_embedding import CombinedTimestepGuidanceTextProjEmbeddings, CombinedTimestepTextProjEmbeddings
|
| 17 |
+
from .modeling_flux_block import FluxTransformerBlock, FluxSingleTransformerBlock
|
| 18 |
+
|
| 19 |
+
from trainer_misc import (
|
| 20 |
+
is_sequence_parallel_initialized,
|
| 21 |
+
get_sequence_parallel_group,
|
| 22 |
+
get_sequence_parallel_world_size,
|
| 23 |
+
get_sequence_parallel_rank,
|
| 24 |
+
all_to_all,
|
| 25 |
+
)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def rope(pos: torch.Tensor, dim: int, theta: int) -> torch.Tensor:
|
| 29 |
+
assert dim % 2 == 0, "The dimension must be even."
|
| 30 |
+
|
| 31 |
+
scale = torch.arange(0, dim, 2, dtype=torch.float64, device=pos.device) / dim
|
| 32 |
+
omega = 1.0 / (theta**scale)
|
| 33 |
+
|
| 34 |
+
batch_size, seq_length = pos.shape
|
| 35 |
+
out = torch.einsum("...n,d->...nd", pos, omega)
|
| 36 |
+
cos_out = torch.cos(out)
|
| 37 |
+
sin_out = torch.sin(out)
|
| 38 |
+
|
| 39 |
+
stacked_out = torch.stack([cos_out, -sin_out, sin_out, cos_out], dim=-1)
|
| 40 |
+
out = stacked_out.view(batch_size, -1, dim // 2, 2, 2)
|
| 41 |
+
return out.float()
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
class EmbedND(nn.Module):
|
| 45 |
+
def __init__(self, dim: int, theta: int, axes_dim: List[int]):
|
| 46 |
+
super().__init__()
|
| 47 |
+
self.dim = dim
|
| 48 |
+
self.theta = theta
|
| 49 |
+
self.axes_dim = axes_dim
|
| 50 |
+
|
| 51 |
+
def forward(self, ids: torch.Tensor) -> torch.Tensor:
|
| 52 |
+
n_axes = ids.shape[-1]
|
| 53 |
+
emb = torch.cat(
|
| 54 |
+
[rope(ids[..., i], self.axes_dim[i], self.theta) for i in range(n_axes)],
|
| 55 |
+
dim=-3,
|
| 56 |
+
)
|
| 57 |
+
return emb.unsqueeze(2)
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
class PyramidFluxTransformer(ModelMixin, ConfigMixin):
|
| 61 |
+
"""
|
| 62 |
+
The Transformer model introduced in Flux.
|
| 63 |
+
|
| 64 |
+
Reference: https://blackforestlabs.ai/announcing-black-forest-labs/
|
| 65 |
+
|
| 66 |
+
Parameters:
|
| 67 |
+
patch_size (`int`): Patch size to turn the input data into small patches.
|
| 68 |
+
in_channels (`int`, *optional*, defaults to 16): The number of channels in the input.
|
| 69 |
+
num_layers (`int`, *optional*, defaults to 18): The number of layers of MMDiT blocks to use.
|
| 70 |
+
num_single_layers (`int`, *optional*, defaults to 18): The number of layers of single DiT blocks to use.
|
| 71 |
+
attention_head_dim (`int`, *optional*, defaults to 64): The number of channels in each head.
|
| 72 |
+
num_attention_heads (`int`, *optional*, defaults to 18): The number of heads to use for multi-head attention.
|
| 73 |
+
joint_attention_dim (`int`, *optional*): The number of `encoder_hidden_states` dimensions to use.
|
| 74 |
+
pooled_projection_dim (`int`): Number of dimensions to use when projecting the `pooled_projections`.
|
| 75 |
+
"""
|
| 76 |
+
|
| 77 |
+
_supports_gradient_checkpointing = True
|
| 78 |
+
|
| 79 |
+
@register_to_config
|
| 80 |
+
def __init__(
|
| 81 |
+
self,
|
| 82 |
+
patch_size: int = 1,
|
| 83 |
+
in_channels: int = 64,
|
| 84 |
+
num_layers: int = 19,
|
| 85 |
+
num_single_layers: int = 38,
|
| 86 |
+
attention_head_dim: int = 64,
|
| 87 |
+
num_attention_heads: int = 24,
|
| 88 |
+
joint_attention_dim: int = 4096,
|
| 89 |
+
pooled_projection_dim: int = 768,
|
| 90 |
+
axes_dims_rope: List[int] = [16, 24, 24],
|
| 91 |
+
use_flash_attn: bool = False,
|
| 92 |
+
use_temporal_causal: bool = True,
|
| 93 |
+
interp_condition_pos: bool = True,
|
| 94 |
+
use_gradient_checkpointing: bool = False,
|
| 95 |
+
gradient_checkpointing_ratio: float = 0.6,
|
| 96 |
+
):
|
| 97 |
+
super().__init__()
|
| 98 |
+
self.out_channels = in_channels
|
| 99 |
+
self.inner_dim = self.config.num_attention_heads * self.config.attention_head_dim
|
| 100 |
+
|
| 101 |
+
self.pos_embed = EmbedND(dim=self.inner_dim, theta=10000, axes_dim=axes_dims_rope)
|
| 102 |
+
self.time_text_embed = CombinedTimestepTextProjEmbeddings(
|
| 103 |
+
embedding_dim=self.inner_dim, pooled_projection_dim=self.config.pooled_projection_dim
|
| 104 |
+
)
|
| 105 |
+
|
| 106 |
+
self.context_embedder = nn.Linear(self.config.joint_attention_dim, self.inner_dim)
|
| 107 |
+
self.x_embedder = torch.nn.Linear(self.config.in_channels, self.inner_dim)
|
| 108 |
+
|
| 109 |
+
self.transformer_blocks = nn.ModuleList(
|
| 110 |
+
[
|
| 111 |
+
FluxTransformerBlock(
|
| 112 |
+
dim=self.inner_dim,
|
| 113 |
+
num_attention_heads=self.config.num_attention_heads,
|
| 114 |
+
attention_head_dim=self.config.attention_head_dim,
|
| 115 |
+
use_flash_attn=use_flash_attn,
|
| 116 |
+
)
|
| 117 |
+
for i in range(self.config.num_layers)
|
| 118 |
+
]
|
| 119 |
+
)
|
| 120 |
+
|
| 121 |
+
self.single_transformer_blocks = nn.ModuleList(
|
| 122 |
+
[
|
| 123 |
+
FluxSingleTransformerBlock(
|
| 124 |
+
dim=self.inner_dim,
|
| 125 |
+
num_attention_heads=self.config.num_attention_heads,
|
| 126 |
+
attention_head_dim=self.config.attention_head_dim,
|
| 127 |
+
use_flash_attn=use_flash_attn,
|
| 128 |
+
)
|
| 129 |
+
for i in range(self.config.num_single_layers)
|
| 130 |
+
]
|
| 131 |
+
)
|
| 132 |
+
|
| 133 |
+
self.norm_out = AdaLayerNormContinuous(self.inner_dim, self.inner_dim, elementwise_affine=False, eps=1e-6)
|
| 134 |
+
self.proj_out = nn.Linear(self.inner_dim, patch_size * patch_size * self.out_channels, bias=True)
|
| 135 |
+
|
| 136 |
+
self.gradient_checkpointing = use_gradient_checkpointing
|
| 137 |
+
self.gradient_checkpointing_ratio = gradient_checkpointing_ratio
|
| 138 |
+
|
| 139 |
+
self.use_temporal_causal = use_temporal_causal
|
| 140 |
+
if self.use_temporal_causal:
|
| 141 |
+
print("Using temporal causal attention")
|
| 142 |
+
|
| 143 |
+
self.use_flash_attn = use_flash_attn
|
| 144 |
+
if self.use_flash_attn:
|
| 145 |
+
print("Using Flash attention")
|
| 146 |
+
|
| 147 |
+
self.patch_size = 2 # hard-code for now
|
| 148 |
+
|
| 149 |
+
# init weights
|
| 150 |
+
self.initialize_weights()
|
| 151 |
+
|
| 152 |
+
def initialize_weights(self):
|
| 153 |
+
# Initialize transformer layers:
|
| 154 |
+
def _basic_init(module):
|
| 155 |
+
if isinstance(module, (nn.Linear, nn.Conv2d, nn.Conv3d)):
|
| 156 |
+
torch.nn.init.xavier_uniform_(module.weight)
|
| 157 |
+
if module.bias is not None:
|
| 158 |
+
nn.init.constant_(module.bias, 0)
|
| 159 |
+
self.apply(_basic_init)
|
| 160 |
+
|
| 161 |
+
# Initialize all the conditioning to normal init
|
| 162 |
+
nn.init.normal_(self.time_text_embed.timestep_embedder.linear_1.weight, std=0.02)
|
| 163 |
+
nn.init.normal_(self.time_text_embed.timestep_embedder.linear_2.weight, std=0.02)
|
| 164 |
+
nn.init.normal_(self.time_text_embed.text_embedder.linear_1.weight, std=0.02)
|
| 165 |
+
nn.init.normal_(self.time_text_embed.text_embedder.linear_2.weight, std=0.02)
|
| 166 |
+
nn.init.normal_(self.context_embedder.weight, std=0.02)
|
| 167 |
+
|
| 168 |
+
# Zero-out adaLN modulation layers in DiT blocks:
|
| 169 |
+
for block in self.transformer_blocks:
|
| 170 |
+
nn.init.constant_(block.norm1.linear.weight, 0)
|
| 171 |
+
nn.init.constant_(block.norm1.linear.bias, 0)
|
| 172 |
+
nn.init.constant_(block.norm1_context.linear.weight, 0)
|
| 173 |
+
nn.init.constant_(block.norm1_context.linear.bias, 0)
|
| 174 |
+
|
| 175 |
+
for block in self.single_transformer_blocks:
|
| 176 |
+
nn.init.constant_(block.norm.linear.weight, 0)
|
| 177 |
+
nn.init.constant_(block.norm.linear.bias, 0)
|
| 178 |
+
|
| 179 |
+
# Zero-out output layers:
|
| 180 |
+
nn.init.constant_(self.norm_out.linear.weight, 0)
|
| 181 |
+
nn.init.constant_(self.norm_out.linear.bias, 0)
|
| 182 |
+
nn.init.constant_(self.proj_out.weight, 0)
|
| 183 |
+
nn.init.constant_(self.proj_out.bias, 0)
|
| 184 |
+
|
| 185 |
+
@torch.no_grad()
|
| 186 |
+
def _prepare_image_ids(self, batch_size, temp, height, width, train_height, train_width, device, start_time_stamp=0):
|
| 187 |
+
latent_image_ids = torch.zeros(temp, height, width, 3)
|
| 188 |
+
|
| 189 |
+
# Temporal Rope
|
| 190 |
+
latent_image_ids[..., 0] = latent_image_ids[..., 0] + torch.arange(start_time_stamp, start_time_stamp + temp)[:, None, None]
|
| 191 |
+
|
| 192 |
+
# height Rope
|
| 193 |
+
if height != train_height:
|
| 194 |
+
height_pos = F.interpolate(torch.arange(train_height)[None, None, :].float(), height, mode='linear').squeeze(0, 1)
|
| 195 |
+
else:
|
| 196 |
+
height_pos = torch.arange(train_height).float()
|
| 197 |
+
|
| 198 |
+
latent_image_ids[..., 1] = latent_image_ids[..., 1] + height_pos[None, :, None]
|
| 199 |
+
|
| 200 |
+
# width rope
|
| 201 |
+
if width != train_width:
|
| 202 |
+
width_pos = F.interpolate(torch.arange(train_width)[None, None, :].float(), width, mode='linear').squeeze(0, 1)
|
| 203 |
+
else:
|
| 204 |
+
width_pos = torch.arange(train_width).float()
|
| 205 |
+
|
| 206 |
+
latent_image_ids[..., 2] = latent_image_ids[..., 2] + width_pos[None, None, :]
|
| 207 |
+
|
| 208 |
+
latent_image_ids = latent_image_ids[None, :].repeat(batch_size, 1, 1, 1, 1)
|
| 209 |
+
latent_image_ids = rearrange(latent_image_ids, 'b t h w c -> b (t h w) c')
|
| 210 |
+
|
| 211 |
+
return latent_image_ids.to(device=device)
|
| 212 |
+
|
| 213 |
+
@torch.no_grad()
|
| 214 |
+
def _prepare_pyramid_image_ids(self, sample, batch_size, device):
|
| 215 |
+
image_ids_list = []
|
| 216 |
+
|
| 217 |
+
for i_b, sample_ in enumerate(sample):
|
| 218 |
+
if not isinstance(sample_, list):
|
| 219 |
+
sample_ = [sample_]
|
| 220 |
+
|
| 221 |
+
cur_image_ids = []
|
| 222 |
+
start_time_stamp = 0
|
| 223 |
+
|
| 224 |
+
train_height = sample_[-1].shape[-2] // self.patch_size
|
| 225 |
+
train_width = sample_[-1].shape[-1] // self.patch_size
|
| 226 |
+
|
| 227 |
+
for clip_ in sample_:
|
| 228 |
+
_, _, temp, height, width = clip_.shape
|
| 229 |
+
height = height // self.patch_size
|
| 230 |
+
width = width // self.patch_size
|
| 231 |
+
cur_image_ids.append(self._prepare_image_ids(batch_size, temp, height, width, train_height, train_width, device, start_time_stamp=start_time_stamp))
|
| 232 |
+
start_time_stamp += temp
|
| 233 |
+
|
| 234 |
+
cur_image_ids = torch.cat(cur_image_ids, dim=1)
|
| 235 |
+
image_ids_list.append(cur_image_ids)
|
| 236 |
+
|
| 237 |
+
return image_ids_list
|
| 238 |
+
|
| 239 |
+
def merge_input(self, sample, encoder_hidden_length, encoder_attention_mask):
|
| 240 |
+
"""
|
| 241 |
+
Merge the input video with different resolutions into one sequence
|
| 242 |
+
Sample: From low resolution to high resolution
|
| 243 |
+
"""
|
| 244 |
+
if isinstance(sample[0], list):
|
| 245 |
+
device = sample[0][-1].device
|
| 246 |
+
pad_batch_size = sample[0][-1].shape[0]
|
| 247 |
+
else:
|
| 248 |
+
device = sample[0].device
|
| 249 |
+
pad_batch_size = sample[0].shape[0]
|
| 250 |
+
|
| 251 |
+
num_stages = len(sample)
|
| 252 |
+
height_list = [];width_list = [];temp_list = []
|
| 253 |
+
trainable_token_list = []
|
| 254 |
+
|
| 255 |
+
for i_b, sample_ in enumerate(sample):
|
| 256 |
+
if isinstance(sample_, list):
|
| 257 |
+
sample_ = sample_[-1]
|
| 258 |
+
_, _, temp, height, width = sample_.shape
|
| 259 |
+
height = height // self.patch_size
|
| 260 |
+
width = width // self.patch_size
|
| 261 |
+
temp_list.append(temp)
|
| 262 |
+
height_list.append(height)
|
| 263 |
+
width_list.append(width)
|
| 264 |
+
trainable_token_list.append(height * width * temp)
|
| 265 |
+
|
| 266 |
+
# prepare the RoPE IDs,
|
| 267 |
+
image_ids_list = self._prepare_pyramid_image_ids(sample, pad_batch_size, device)
|
| 268 |
+
text_ids = torch.zeros(pad_batch_size, encoder_attention_mask.shape[1], 3).to(device=device)
|
| 269 |
+
input_ids_list = [torch.cat([text_ids, image_ids], dim=1) for image_ids in image_ids_list]
|
| 270 |
+
image_rotary_emb = [self.pos_embed(input_ids) for input_ids in input_ids_list] # [bs, seq_len, 1, head_dim // 2, 2, 2]
|
| 271 |
+
|
| 272 |
+
if is_sequence_parallel_initialized():
|
| 273 |
+
sp_group = get_sequence_parallel_group()
|
| 274 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 275 |
+
concat_output = True if self.training else False
|
| 276 |
+
image_rotary_emb = [all_to_all(x_.repeat(1, 1, sp_group_size, 1, 1, 1), sp_group, sp_group_size, scatter_dim=2, gather_dim=0, concat_output=concat_output) for x_ in image_rotary_emb]
|
| 277 |
+
input_ids_list = [all_to_all(input_ids.repeat(1, 1, sp_group_size), sp_group, sp_group_size, scatter_dim=2, gather_dim=0, concat_output=concat_output) for input_ids in input_ids_list]
|
| 278 |
+
|
| 279 |
+
hidden_states, hidden_length = [], []
|
| 280 |
+
|
| 281 |
+
for sample_ in sample:
|
| 282 |
+
video_tokens = []
|
| 283 |
+
|
| 284 |
+
for each_latent in sample_:
|
| 285 |
+
each_latent = rearrange(each_latent, 'b c t h w -> b t h w c')
|
| 286 |
+
each_latent = rearrange(each_latent, 'b t (h p1) (w p2) c -> b (t h w) (p1 p2 c)', p1=self.patch_size, p2=self.patch_size)
|
| 287 |
+
video_tokens.append(each_latent)
|
| 288 |
+
|
| 289 |
+
video_tokens = torch.cat(video_tokens, dim=1)
|
| 290 |
+
video_tokens = self.x_embedder(video_tokens)
|
| 291 |
+
hidden_states.append(video_tokens)
|
| 292 |
+
hidden_length.append(video_tokens.shape[1])
|
| 293 |
+
|
| 294 |
+
# prepare the attention mask
|
| 295 |
+
if self.use_flash_attn:
|
| 296 |
+
attention_mask = None
|
| 297 |
+
indices_list = []
|
| 298 |
+
for i_p, length in enumerate(hidden_length):
|
| 299 |
+
pad_attention_mask = torch.ones((pad_batch_size, length), dtype=encoder_attention_mask.dtype).to(device)
|
| 300 |
+
pad_attention_mask = torch.cat([encoder_attention_mask[i_p::num_stages], pad_attention_mask], dim=1)
|
| 301 |
+
|
| 302 |
+
if is_sequence_parallel_initialized():
|
| 303 |
+
sp_group = get_sequence_parallel_group()
|
| 304 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 305 |
+
pad_attention_mask = all_to_all(pad_attention_mask.unsqueeze(2).repeat(1, 1, sp_group_size), sp_group, sp_group_size, scatter_dim=2, gather_dim=0)
|
| 306 |
+
pad_attention_mask = pad_attention_mask.squeeze(2)
|
| 307 |
+
|
| 308 |
+
seqlens_in_batch = pad_attention_mask.sum(dim=-1, dtype=torch.int32)
|
| 309 |
+
indices = torch.nonzero(pad_attention_mask.flatten(), as_tuple=False).flatten()
|
| 310 |
+
|
| 311 |
+
indices_list.append(
|
| 312 |
+
{
|
| 313 |
+
'indices': indices,
|
| 314 |
+
'seqlens_in_batch': seqlens_in_batch,
|
| 315 |
+
}
|
| 316 |
+
)
|
| 317 |
+
encoder_attention_mask = indices_list
|
| 318 |
+
else:
|
| 319 |
+
assert encoder_attention_mask.shape[1] == encoder_hidden_length
|
| 320 |
+
real_batch_size = encoder_attention_mask.shape[0]
|
| 321 |
+
|
| 322 |
+
# prepare text ids
|
| 323 |
+
text_ids = torch.arange(1, real_batch_size + 1, dtype=encoder_attention_mask.dtype).unsqueeze(1).repeat(1, encoder_hidden_length)
|
| 324 |
+
text_ids = text_ids.to(device)
|
| 325 |
+
text_ids[encoder_attention_mask == 0] = 0
|
| 326 |
+
|
| 327 |
+
# prepare image ids
|
| 328 |
+
image_ids = torch.arange(1, real_batch_size + 1, dtype=encoder_attention_mask.dtype).unsqueeze(1).repeat(1, max(hidden_length))
|
| 329 |
+
image_ids = image_ids.to(device)
|
| 330 |
+
image_ids_list = []
|
| 331 |
+
for i_p, length in enumerate(hidden_length):
|
| 332 |
+
image_ids_list.append(image_ids[i_p::num_stages][:, :length])
|
| 333 |
+
|
| 334 |
+
if is_sequence_parallel_initialized():
|
| 335 |
+
sp_group = get_sequence_parallel_group()
|
| 336 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 337 |
+
concat_output = True if self.training else False
|
| 338 |
+
text_ids = all_to_all(text_ids.unsqueeze(2).repeat(1, 1, sp_group_size), sp_group, sp_group_size, scatter_dim=2, gather_dim=0, concat_output=concat_output).squeeze(2)
|
| 339 |
+
image_ids_list = [all_to_all(image_ids_.unsqueeze(2).repeat(1, 1, sp_group_size), sp_group, sp_group_size, scatter_dim=2, gather_dim=0, concat_output=concat_output).squeeze(2) for image_ids_ in image_ids_list]
|
| 340 |
+
|
| 341 |
+
attention_mask = []
|
| 342 |
+
for i_p in range(len(hidden_length)):
|
| 343 |
+
image_ids = image_ids_list[i_p]
|
| 344 |
+
token_ids = torch.cat([text_ids[i_p::num_stages], image_ids], dim=1)
|
| 345 |
+
stage_attention_mask = rearrange(token_ids, 'b i -> b 1 i 1') == rearrange(token_ids, 'b j -> b 1 1 j') # [bs, 1, q_len, k_len]
|
| 346 |
+
if self.use_temporal_causal:
|
| 347 |
+
input_order_ids = input_ids_list[i_p][:,:,0]
|
| 348 |
+
temporal_causal_mask = rearrange(input_order_ids, 'b i -> b 1 i 1') >= rearrange(input_order_ids, 'b j -> b 1 1 j')
|
| 349 |
+
stage_attention_mask = stage_attention_mask & temporal_causal_mask
|
| 350 |
+
attention_mask.append(stage_attention_mask)
|
| 351 |
+
|
| 352 |
+
return hidden_states, hidden_length, temp_list, height_list, width_list, trainable_token_list, encoder_attention_mask, attention_mask, image_rotary_emb
|
| 353 |
+
|
| 354 |
+
def split_output(self, batch_hidden_states, hidden_length, temps, heights, widths, trainable_token_list):
|
| 355 |
+
# To split the hidden states
|
| 356 |
+
batch_size = batch_hidden_states.shape[0]
|
| 357 |
+
output_hidden_list = []
|
| 358 |
+
batch_hidden_states = torch.split(batch_hidden_states, hidden_length, dim=1)
|
| 359 |
+
|
| 360 |
+
if is_sequence_parallel_initialized():
|
| 361 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 362 |
+
if self.training:
|
| 363 |
+
batch_size = batch_size // sp_group_size
|
| 364 |
+
|
| 365 |
+
for i_p, length in enumerate(hidden_length):
|
| 366 |
+
width, height, temp = widths[i_p], heights[i_p], temps[i_p]
|
| 367 |
+
trainable_token_num = trainable_token_list[i_p]
|
| 368 |
+
hidden_states = batch_hidden_states[i_p]
|
| 369 |
+
|
| 370 |
+
if is_sequence_parallel_initialized():
|
| 371 |
+
sp_group = get_sequence_parallel_group()
|
| 372 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 373 |
+
|
| 374 |
+
if not self.training:
|
| 375 |
+
hidden_states = hidden_states.repeat(sp_group_size, 1, 1)
|
| 376 |
+
|
| 377 |
+
hidden_states = all_to_all(hidden_states, sp_group, sp_group_size, scatter_dim=0, gather_dim=1)
|
| 378 |
+
|
| 379 |
+
# only the trainable token are taking part in loss computation
|
| 380 |
+
hidden_states = hidden_states[:, -trainable_token_num:]
|
| 381 |
+
|
| 382 |
+
# unpatchify
|
| 383 |
+
hidden_states = hidden_states.reshape(
|
| 384 |
+
shape=(batch_size, temp, height, width, self.patch_size, self.patch_size, self.out_channels // 4)
|
| 385 |
+
)
|
| 386 |
+
hidden_states = rearrange(hidden_states, "b t h w p1 p2 c -> b t (h p1) (w p2) c")
|
| 387 |
+
hidden_states = rearrange(hidden_states, "b t h w c -> b c t h w")
|
| 388 |
+
output_hidden_list.append(hidden_states)
|
| 389 |
+
|
| 390 |
+
return output_hidden_list
|
| 391 |
+
|
| 392 |
+
def forward(
|
| 393 |
+
self,
|
| 394 |
+
sample: torch.FloatTensor, # [num_stages]
|
| 395 |
+
encoder_hidden_states: torch.Tensor = None,
|
| 396 |
+
encoder_attention_mask: torch.FloatTensor = None,
|
| 397 |
+
pooled_projections: torch.Tensor = None,
|
| 398 |
+
timestep_ratio: torch.LongTensor = None,
|
| 399 |
+
):
|
| 400 |
+
temb = self.time_text_embed(timestep_ratio, pooled_projections)
|
| 401 |
+
encoder_hidden_states = self.context_embedder(encoder_hidden_states)
|
| 402 |
+
encoder_hidden_length = encoder_hidden_states.shape[1]
|
| 403 |
+
|
| 404 |
+
# Get the input sequence
|
| 405 |
+
hidden_states, hidden_length, temps, heights, widths, trainable_token_list, encoder_attention_mask, attention_mask, \
|
| 406 |
+
image_rotary_emb = self.merge_input(sample, encoder_hidden_length, encoder_attention_mask)
|
| 407 |
+
|
| 408 |
+
# split the long latents if necessary
|
| 409 |
+
if is_sequence_parallel_initialized():
|
| 410 |
+
sp_group = get_sequence_parallel_group()
|
| 411 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 412 |
+
concat_output = True if self.training else False
|
| 413 |
+
|
| 414 |
+
# sync the input hidden states
|
| 415 |
+
batch_hidden_states = []
|
| 416 |
+
for i_p, hidden_states_ in enumerate(hidden_states):
|
| 417 |
+
assert hidden_states_.shape[1] % sp_group_size == 0, "The sequence length should be divided by sequence parallel size"
|
| 418 |
+
hidden_states_ = all_to_all(hidden_states_, sp_group, sp_group_size, scatter_dim=1, gather_dim=0, concat_output=concat_output)
|
| 419 |
+
hidden_length[i_p] = hidden_length[i_p] // sp_group_size
|
| 420 |
+
batch_hidden_states.append(hidden_states_)
|
| 421 |
+
|
| 422 |
+
# sync the encoder hidden states
|
| 423 |
+
hidden_states = torch.cat(batch_hidden_states, dim=1)
|
| 424 |
+
encoder_hidden_states = all_to_all(encoder_hidden_states, sp_group, sp_group_size, scatter_dim=1, gather_dim=0, concat_output=concat_output)
|
| 425 |
+
temb = all_to_all(temb.unsqueeze(1).repeat(1, sp_group_size, 1), sp_group, sp_group_size, scatter_dim=1, gather_dim=0, concat_output=concat_output)
|
| 426 |
+
temb = temb.squeeze(1)
|
| 427 |
+
else:
|
| 428 |
+
hidden_states = torch.cat(hidden_states, dim=1)
|
| 429 |
+
|
| 430 |
+
for index_block, block in enumerate(self.transformer_blocks):
|
| 431 |
+
if self.training and self.gradient_checkpointing and (index_block <= int(len(self.transformer_blocks) * self.gradient_checkpointing_ratio)):
|
| 432 |
+
|
| 433 |
+
def create_custom_forward(module):
|
| 434 |
+
def custom_forward(*inputs):
|
| 435 |
+
return module(*inputs)
|
| 436 |
+
|
| 437 |
+
return custom_forward
|
| 438 |
+
|
| 439 |
+
ckpt_kwargs: Dict[str, Any] = {"use_reentrant": False} if is_torch_version(">=", "1.11.0") else {}
|
| 440 |
+
encoder_hidden_states, hidden_states = torch.utils.checkpoint.checkpoint(
|
| 441 |
+
create_custom_forward(block),
|
| 442 |
+
hidden_states,
|
| 443 |
+
encoder_hidden_states,
|
| 444 |
+
encoder_attention_mask,
|
| 445 |
+
temb,
|
| 446 |
+
attention_mask,
|
| 447 |
+
hidden_length,
|
| 448 |
+
image_rotary_emb,
|
| 449 |
+
**ckpt_kwargs,
|
| 450 |
+
)
|
| 451 |
+
|
| 452 |
+
else:
|
| 453 |
+
encoder_hidden_states, hidden_states = block(
|
| 454 |
+
hidden_states=hidden_states,
|
| 455 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 456 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 457 |
+
temb=temb,
|
| 458 |
+
attention_mask=attention_mask,
|
| 459 |
+
hidden_length=hidden_length,
|
| 460 |
+
image_rotary_emb=image_rotary_emb,
|
| 461 |
+
)
|
| 462 |
+
|
| 463 |
+
# remerge for single attention block
|
| 464 |
+
num_stages = len(hidden_length)
|
| 465 |
+
batch_hidden_states = list(torch.split(hidden_states, hidden_length, dim=1))
|
| 466 |
+
concat_hidden_length = []
|
| 467 |
+
|
| 468 |
+
if is_sequence_parallel_initialized():
|
| 469 |
+
sp_group = get_sequence_parallel_group()
|
| 470 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 471 |
+
encoder_hidden_states = all_to_all(encoder_hidden_states, sp_group, sp_group_size, scatter_dim=0, gather_dim=1)
|
| 472 |
+
|
| 473 |
+
for i_p in range(len(hidden_length)):
|
| 474 |
+
|
| 475 |
+
if is_sequence_parallel_initialized():
|
| 476 |
+
sp_group = get_sequence_parallel_group()
|
| 477 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 478 |
+
batch_hidden_states[i_p] = all_to_all(batch_hidden_states[i_p], sp_group, sp_group_size, scatter_dim=0, gather_dim=1)
|
| 479 |
+
|
| 480 |
+
batch_hidden_states[i_p] = torch.cat([encoder_hidden_states[i_p::num_stages], batch_hidden_states[i_p]], dim=1)
|
| 481 |
+
|
| 482 |
+
if is_sequence_parallel_initialized():
|
| 483 |
+
sp_group = get_sequence_parallel_group()
|
| 484 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 485 |
+
batch_hidden_states[i_p] = all_to_all(batch_hidden_states[i_p], sp_group, sp_group_size, scatter_dim=1, gather_dim=0)
|
| 486 |
+
|
| 487 |
+
concat_hidden_length.append(batch_hidden_states[i_p].shape[1])
|
| 488 |
+
|
| 489 |
+
hidden_states = torch.cat(batch_hidden_states, dim=1)
|
| 490 |
+
|
| 491 |
+
for index_block, block in enumerate(self.single_transformer_blocks):
|
| 492 |
+
if self.training and self.gradient_checkpointing and (index_block <= int(len(self.single_transformer_blocks) * self.gradient_checkpointing_ratio)):
|
| 493 |
+
|
| 494 |
+
def create_custom_forward(module):
|
| 495 |
+
def custom_forward(*inputs):
|
| 496 |
+
return module(*inputs)
|
| 497 |
+
|
| 498 |
+
return custom_forward
|
| 499 |
+
|
| 500 |
+
ckpt_kwargs: Dict[str, Any] = {"use_reentrant": False} if is_torch_version(">=", "1.11.0") else {}
|
| 501 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 502 |
+
create_custom_forward(block),
|
| 503 |
+
hidden_states,
|
| 504 |
+
temb,
|
| 505 |
+
encoder_attention_mask,
|
| 506 |
+
attention_mask,
|
| 507 |
+
concat_hidden_length,
|
| 508 |
+
image_rotary_emb,
|
| 509 |
+
**ckpt_kwargs,
|
| 510 |
+
)
|
| 511 |
+
|
| 512 |
+
else:
|
| 513 |
+
hidden_states = block(
|
| 514 |
+
hidden_states=hidden_states,
|
| 515 |
+
temb=temb,
|
| 516 |
+
encoder_attention_mask=encoder_attention_mask, # used for
|
| 517 |
+
attention_mask=attention_mask,
|
| 518 |
+
hidden_length=concat_hidden_length,
|
| 519 |
+
image_rotary_emb=image_rotary_emb,
|
| 520 |
+
)
|
| 521 |
+
|
| 522 |
+
batch_hidden_states = list(torch.split(hidden_states, concat_hidden_length, dim=1))
|
| 523 |
+
|
| 524 |
+
for i_p in range(len(concat_hidden_length)):
|
| 525 |
+
if is_sequence_parallel_initialized():
|
| 526 |
+
sp_group = get_sequence_parallel_group()
|
| 527 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 528 |
+
batch_hidden_states[i_p] = all_to_all(batch_hidden_states[i_p], sp_group, sp_group_size, scatter_dim=0, gather_dim=1)
|
| 529 |
+
|
| 530 |
+
batch_hidden_states[i_p] = batch_hidden_states[i_p][:, encoder_hidden_length :, ...]
|
| 531 |
+
|
| 532 |
+
if is_sequence_parallel_initialized():
|
| 533 |
+
sp_group = get_sequence_parallel_group()
|
| 534 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 535 |
+
batch_hidden_states[i_p] = all_to_all(batch_hidden_states[i_p], sp_group, sp_group_size, scatter_dim=1, gather_dim=0)
|
| 536 |
+
|
| 537 |
+
hidden_states = torch.cat(batch_hidden_states, dim=1)
|
| 538 |
+
hidden_states = self.norm_out(hidden_states, temb, hidden_length=hidden_length)
|
| 539 |
+
hidden_states = self.proj_out(hidden_states)
|
| 540 |
+
|
| 541 |
+
output = self.split_output(hidden_states, hidden_length, temps, heights, widths, trainable_token_list)
|
| 542 |
+
|
| 543 |
+
return output
|
pyramid_dit/flux_modules/modeling_text_encoder.py
ADDED
|
@@ -0,0 +1,134 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
from transformers import (
|
| 6 |
+
CLIPTextModel,
|
| 7 |
+
CLIPTokenizer,
|
| 8 |
+
T5EncoderModel,
|
| 9 |
+
T5TokenizerFast,
|
| 10 |
+
)
|
| 11 |
+
|
| 12 |
+
from typing import Any, Callable, Dict, List, Optional, Union
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class FluxTextEncoderWithMask(nn.Module):
|
| 16 |
+
def __init__(self, model_path, torch_dtype):
|
| 17 |
+
super().__init__()
|
| 18 |
+
# CLIP-G
|
| 19 |
+
self.tokenizer = CLIPTokenizer.from_pretrained(os.path.join(model_path, 'tokenizer'), torch_dtype=torch_dtype)
|
| 20 |
+
self.tokenizer_max_length = (
|
| 21 |
+
self.tokenizer.model_max_length if hasattr(self, "tokenizer") and self.tokenizer is not None else 77
|
| 22 |
+
)
|
| 23 |
+
self.text_encoder = CLIPTextModel.from_pretrained(os.path.join(model_path, 'text_encoder'), torch_dtype=torch_dtype)
|
| 24 |
+
|
| 25 |
+
# T5
|
| 26 |
+
self.tokenizer_2 = T5TokenizerFast.from_pretrained(os.path.join(model_path, 'tokenizer_2'))
|
| 27 |
+
self.text_encoder_2 = T5EncoderModel.from_pretrained(os.path.join(model_path, 'text_encoder_2'), torch_dtype=torch_dtype)
|
| 28 |
+
|
| 29 |
+
self._freeze()
|
| 30 |
+
|
| 31 |
+
def _freeze(self):
|
| 32 |
+
for param in self.parameters():
|
| 33 |
+
param.requires_grad = False
|
| 34 |
+
|
| 35 |
+
def _get_t5_prompt_embeds(
|
| 36 |
+
self,
|
| 37 |
+
prompt: Union[str, List[str]] = None,
|
| 38 |
+
num_images_per_prompt: int = 1,
|
| 39 |
+
max_sequence_length: int = 128,
|
| 40 |
+
device: Optional[torch.device] = None,
|
| 41 |
+
):
|
| 42 |
+
|
| 43 |
+
prompt = [prompt] if isinstance(prompt, str) else prompt
|
| 44 |
+
batch_size = len(prompt)
|
| 45 |
+
|
| 46 |
+
text_inputs = self.tokenizer_2(
|
| 47 |
+
prompt,
|
| 48 |
+
padding="max_length",
|
| 49 |
+
max_length=max_sequence_length,
|
| 50 |
+
truncation=True,
|
| 51 |
+
return_length=False,
|
| 52 |
+
return_overflowing_tokens=False,
|
| 53 |
+
return_tensors="pt",
|
| 54 |
+
)
|
| 55 |
+
text_input_ids = text_inputs.input_ids
|
| 56 |
+
prompt_attention_mask = text_inputs.attention_mask
|
| 57 |
+
prompt_attention_mask = prompt_attention_mask.to(device)
|
| 58 |
+
|
| 59 |
+
prompt_embeds = self.text_encoder_2(text_input_ids.to(device), attention_mask=prompt_attention_mask, output_hidden_states=False)[0]
|
| 60 |
+
|
| 61 |
+
dtype = self.text_encoder_2.dtype
|
| 62 |
+
prompt_embeds = prompt_embeds.to(dtype=dtype, device=device)
|
| 63 |
+
|
| 64 |
+
_, seq_len, _ = prompt_embeds.shape
|
| 65 |
+
|
| 66 |
+
# duplicate text embeddings and attention mask for each generation per prompt, using mps friendly method
|
| 67 |
+
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
|
| 68 |
+
prompt_embeds = prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
|
| 69 |
+
prompt_attention_mask = prompt_attention_mask.view(batch_size, -1)
|
| 70 |
+
prompt_attention_mask = prompt_attention_mask.repeat(num_images_per_prompt, 1)
|
| 71 |
+
|
| 72 |
+
return prompt_embeds, prompt_attention_mask
|
| 73 |
+
|
| 74 |
+
def _get_clip_prompt_embeds(
|
| 75 |
+
self,
|
| 76 |
+
prompt: Union[str, List[str]],
|
| 77 |
+
num_images_per_prompt: int = 1,
|
| 78 |
+
device: Optional[torch.device] = None,
|
| 79 |
+
):
|
| 80 |
+
|
| 81 |
+
prompt = [prompt] if isinstance(prompt, str) else prompt
|
| 82 |
+
batch_size = len(prompt)
|
| 83 |
+
|
| 84 |
+
text_inputs = self.tokenizer(
|
| 85 |
+
prompt,
|
| 86 |
+
padding="max_length",
|
| 87 |
+
max_length=self.tokenizer_max_length,
|
| 88 |
+
truncation=True,
|
| 89 |
+
return_overflowing_tokens=False,
|
| 90 |
+
return_length=False,
|
| 91 |
+
return_tensors="pt",
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
text_input_ids = text_inputs.input_ids
|
| 95 |
+
prompt_embeds = self.text_encoder(text_input_ids.to(device), output_hidden_states=False)
|
| 96 |
+
|
| 97 |
+
# Use pooled output of CLIPTextModel
|
| 98 |
+
prompt_embeds = prompt_embeds.pooler_output
|
| 99 |
+
prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
|
| 100 |
+
|
| 101 |
+
# duplicate text embeddings for each generation per prompt, using mps friendly method
|
| 102 |
+
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt)
|
| 103 |
+
prompt_embeds = prompt_embeds.view(batch_size * num_images_per_prompt, -1)
|
| 104 |
+
|
| 105 |
+
return prompt_embeds
|
| 106 |
+
|
| 107 |
+
def encode_prompt(self,
|
| 108 |
+
prompt,
|
| 109 |
+
num_images_per_prompt=1,
|
| 110 |
+
device=None,
|
| 111 |
+
):
|
| 112 |
+
prompt = [prompt] if isinstance(prompt, str) else prompt
|
| 113 |
+
|
| 114 |
+
batch_size = len(prompt)
|
| 115 |
+
|
| 116 |
+
pooled_prompt_embeds = self._get_clip_prompt_embeds(
|
| 117 |
+
prompt=prompt,
|
| 118 |
+
device=device,
|
| 119 |
+
num_images_per_prompt=num_images_per_prompt,
|
| 120 |
+
)
|
| 121 |
+
|
| 122 |
+
prompt_embeds, prompt_attention_mask = self._get_t5_prompt_embeds(
|
| 123 |
+
prompt=prompt,
|
| 124 |
+
num_images_per_prompt=num_images_per_prompt,
|
| 125 |
+
device=device,
|
| 126 |
+
)
|
| 127 |
+
|
| 128 |
+
return prompt_embeds, prompt_attention_mask, pooled_prompt_embeds
|
| 129 |
+
|
| 130 |
+
def forward(self, input_prompts, device):
|
| 131 |
+
with torch.no_grad():
|
| 132 |
+
prompt_embeds, prompt_attention_mask, pooled_prompt_embeds = self.encode_prompt(input_prompts, 1, device=device)
|
| 133 |
+
|
| 134 |
+
return prompt_embeds, prompt_attention_mask, pooled_prompt_embeds
|
pyramid_dit/mmdit_modules/__init__.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .modeling_text_encoder import SD3TextEncoderWithMask
|
| 2 |
+
from .modeling_pyramid_mmdit import PyramidDiffusionMMDiT
|
| 3 |
+
from .modeling_mmdit_block import JointTransformerBlock
|
pyramid_dit/mmdit_modules/modeling_embedding.py
ADDED
|
@@ -0,0 +1,390 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Any, Dict, Optional, Union
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
import numpy as np
|
| 6 |
+
import math
|
| 7 |
+
|
| 8 |
+
from diffusers.models.activations import get_activation
|
| 9 |
+
from einops import rearrange
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def get_1d_sincos_pos_embed(
|
| 13 |
+
embed_dim, num_frames, cls_token=False, extra_tokens=0,
|
| 14 |
+
):
|
| 15 |
+
t = np.arange(num_frames, dtype=np.float32)
|
| 16 |
+
pos_embed = get_1d_sincos_pos_embed_from_grid(embed_dim, t) # (T, D)
|
| 17 |
+
if cls_token and extra_tokens > 0:
|
| 18 |
+
pos_embed = np.concatenate([np.zeros([extra_tokens, embed_dim]), pos_embed], axis=0)
|
| 19 |
+
return pos_embed
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def get_2d_sincos_pos_embed(
|
| 23 |
+
embed_dim, grid_size, cls_token=False, extra_tokens=0, interpolation_scale=1.0, base_size=16
|
| 24 |
+
):
|
| 25 |
+
"""
|
| 26 |
+
grid_size: int of the grid height and width return: pos_embed: [grid_size*grid_size, embed_dim] or
|
| 27 |
+
[1+grid_size*grid_size, embed_dim] (w/ or w/o cls_token)
|
| 28 |
+
"""
|
| 29 |
+
if isinstance(grid_size, int):
|
| 30 |
+
grid_size = (grid_size, grid_size)
|
| 31 |
+
|
| 32 |
+
grid_h = np.arange(grid_size[0], dtype=np.float32) / (grid_size[0] / base_size) / interpolation_scale
|
| 33 |
+
grid_w = np.arange(grid_size[1], dtype=np.float32) / (grid_size[1] / base_size) / interpolation_scale
|
| 34 |
+
grid = np.meshgrid(grid_w, grid_h) # here w goes first
|
| 35 |
+
grid = np.stack(grid, axis=0)
|
| 36 |
+
|
| 37 |
+
grid = grid.reshape([2, 1, grid_size[1], grid_size[0]])
|
| 38 |
+
pos_embed = get_2d_sincos_pos_embed_from_grid(embed_dim, grid)
|
| 39 |
+
if cls_token and extra_tokens > 0:
|
| 40 |
+
pos_embed = np.concatenate([np.zeros([extra_tokens, embed_dim]), pos_embed], axis=0)
|
| 41 |
+
return pos_embed
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def get_2d_sincos_pos_embed_from_grid(embed_dim, grid):
|
| 45 |
+
if embed_dim % 2 != 0:
|
| 46 |
+
raise ValueError("embed_dim must be divisible by 2")
|
| 47 |
+
|
| 48 |
+
# use half of dimensions to encode grid_h
|
| 49 |
+
emb_h = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[0]) # (H*W, D/2)
|
| 50 |
+
emb_w = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[1]) # (H*W, D/2)
|
| 51 |
+
|
| 52 |
+
emb = np.concatenate([emb_h, emb_w], axis=1) # (H*W, D)
|
| 53 |
+
return emb
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def get_1d_sincos_pos_embed_from_grid(embed_dim, pos):
|
| 57 |
+
"""
|
| 58 |
+
embed_dim: output dimension for each position pos: a list of positions to be encoded: size (M,) out: (M, D)
|
| 59 |
+
"""
|
| 60 |
+
if embed_dim % 2 != 0:
|
| 61 |
+
raise ValueError("embed_dim must be divisible by 2")
|
| 62 |
+
|
| 63 |
+
omega = np.arange(embed_dim // 2, dtype=np.float64)
|
| 64 |
+
omega /= embed_dim / 2.0
|
| 65 |
+
omega = 1.0 / 10000**omega # (D/2,)
|
| 66 |
+
|
| 67 |
+
pos = pos.reshape(-1) # (M,)
|
| 68 |
+
out = np.einsum("m,d->md", pos, omega) # (M, D/2), outer product
|
| 69 |
+
|
| 70 |
+
emb_sin = np.sin(out) # (M, D/2)
|
| 71 |
+
emb_cos = np.cos(out) # (M, D/2)
|
| 72 |
+
|
| 73 |
+
emb = np.concatenate([emb_sin, emb_cos], axis=1) # (M, D)
|
| 74 |
+
return emb
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def get_timestep_embedding(
|
| 78 |
+
timesteps: torch.Tensor,
|
| 79 |
+
embedding_dim: int,
|
| 80 |
+
flip_sin_to_cos: bool = False,
|
| 81 |
+
downscale_freq_shift: float = 1,
|
| 82 |
+
scale: float = 1,
|
| 83 |
+
max_period: int = 10000,
|
| 84 |
+
):
|
| 85 |
+
"""
|
| 86 |
+
This matches the implementation in Denoising Diffusion Probabilistic Models: Create sinusoidal timestep embeddings.
|
| 87 |
+
:param timesteps: a 1-D Tensor of N indices, one per batch element. These may be fractional.
|
| 88 |
+
:param embedding_dim: the dimension of the output. :param max_period: controls the minimum frequency of the
|
| 89 |
+
embeddings. :return: an [N x dim] Tensor of positional embeddings.
|
| 90 |
+
"""
|
| 91 |
+
assert len(timesteps.shape) == 1, "Timesteps should be a 1d-array"
|
| 92 |
+
|
| 93 |
+
half_dim = embedding_dim // 2
|
| 94 |
+
exponent = -math.log(max_period) * torch.arange(
|
| 95 |
+
start=0, end=half_dim, dtype=torch.float32, device=timesteps.device
|
| 96 |
+
)
|
| 97 |
+
exponent = exponent / (half_dim - downscale_freq_shift)
|
| 98 |
+
|
| 99 |
+
emb = torch.exp(exponent)
|
| 100 |
+
emb = timesteps[:, None].float() * emb[None, :]
|
| 101 |
+
|
| 102 |
+
# scale embeddings
|
| 103 |
+
emb = scale * emb
|
| 104 |
+
|
| 105 |
+
# concat sine and cosine embeddings
|
| 106 |
+
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=-1)
|
| 107 |
+
|
| 108 |
+
# flip sine and cosine embeddings
|
| 109 |
+
if flip_sin_to_cos:
|
| 110 |
+
emb = torch.cat([emb[:, half_dim:], emb[:, :half_dim]], dim=-1)
|
| 111 |
+
|
| 112 |
+
# zero pad
|
| 113 |
+
if embedding_dim % 2 == 1:
|
| 114 |
+
emb = torch.nn.functional.pad(emb, (0, 1, 0, 0))
|
| 115 |
+
return emb
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
class Timesteps(nn.Module):
|
| 119 |
+
def __init__(self, num_channels: int, flip_sin_to_cos: bool, downscale_freq_shift: float):
|
| 120 |
+
super().__init__()
|
| 121 |
+
self.num_channels = num_channels
|
| 122 |
+
self.flip_sin_to_cos = flip_sin_to_cos
|
| 123 |
+
self.downscale_freq_shift = downscale_freq_shift
|
| 124 |
+
|
| 125 |
+
def forward(self, timesteps):
|
| 126 |
+
t_emb = get_timestep_embedding(
|
| 127 |
+
timesteps,
|
| 128 |
+
self.num_channels,
|
| 129 |
+
flip_sin_to_cos=self.flip_sin_to_cos,
|
| 130 |
+
downscale_freq_shift=self.downscale_freq_shift,
|
| 131 |
+
)
|
| 132 |
+
return t_emb
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
class TimestepEmbedding(nn.Module):
|
| 136 |
+
def __init__(
|
| 137 |
+
self,
|
| 138 |
+
in_channels: int,
|
| 139 |
+
time_embed_dim: int,
|
| 140 |
+
act_fn: str = "silu",
|
| 141 |
+
out_dim: int = None,
|
| 142 |
+
post_act_fn: Optional[str] = None,
|
| 143 |
+
sample_proj_bias=True,
|
| 144 |
+
):
|
| 145 |
+
super().__init__()
|
| 146 |
+
self.linear_1 = nn.Linear(in_channels, time_embed_dim, sample_proj_bias)
|
| 147 |
+
self.act = get_activation(act_fn)
|
| 148 |
+
self.linear_2 = nn.Linear(time_embed_dim, time_embed_dim, sample_proj_bias)
|
| 149 |
+
|
| 150 |
+
def forward(self, sample):
|
| 151 |
+
sample = self.linear_1(sample)
|
| 152 |
+
sample = self.act(sample)
|
| 153 |
+
sample = self.linear_2(sample)
|
| 154 |
+
return sample
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
class TextProjection(nn.Module):
|
| 158 |
+
def __init__(self, in_features, hidden_size, act_fn="silu"):
|
| 159 |
+
super().__init__()
|
| 160 |
+
self.linear_1 = nn.Linear(in_features=in_features, out_features=hidden_size, bias=True)
|
| 161 |
+
self.act_1 = get_activation(act_fn)
|
| 162 |
+
self.linear_2 = nn.Linear(in_features=hidden_size, out_features=hidden_size, bias=True)
|
| 163 |
+
|
| 164 |
+
def forward(self, caption):
|
| 165 |
+
hidden_states = self.linear_1(caption)
|
| 166 |
+
hidden_states = self.act_1(hidden_states)
|
| 167 |
+
hidden_states = self.linear_2(hidden_states)
|
| 168 |
+
return hidden_states
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
class CombinedTimestepConditionEmbeddings(nn.Module):
|
| 172 |
+
def __init__(self, embedding_dim, pooled_projection_dim):
|
| 173 |
+
super().__init__()
|
| 174 |
+
|
| 175 |
+
self.time_proj = Timesteps(num_channels=256, flip_sin_to_cos=True, downscale_freq_shift=0)
|
| 176 |
+
self.timestep_embedder = TimestepEmbedding(in_channels=256, time_embed_dim=embedding_dim)
|
| 177 |
+
self.text_embedder = TextProjection(pooled_projection_dim, embedding_dim, act_fn="silu")
|
| 178 |
+
|
| 179 |
+
def forward(self, timestep, pooled_projection):
|
| 180 |
+
timesteps_proj = self.time_proj(timestep)
|
| 181 |
+
timesteps_emb = self.timestep_embedder(timesteps_proj.to(dtype=pooled_projection.dtype)) # (N, D)
|
| 182 |
+
pooled_projections = self.text_embedder(pooled_projection)
|
| 183 |
+
conditioning = timesteps_emb + pooled_projections
|
| 184 |
+
return conditioning
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
class CombinedTimestepEmbeddings(nn.Module):
|
| 188 |
+
def __init__(self, embedding_dim):
|
| 189 |
+
super().__init__()
|
| 190 |
+
self.time_proj = Timesteps(num_channels=256, flip_sin_to_cos=True, downscale_freq_shift=0)
|
| 191 |
+
self.timestep_embedder = TimestepEmbedding(in_channels=256, time_embed_dim=embedding_dim)
|
| 192 |
+
|
| 193 |
+
def forward(self, timestep):
|
| 194 |
+
timesteps_proj = self.time_proj(timestep)
|
| 195 |
+
timesteps_emb = self.timestep_embedder(timesteps_proj) # (N, D)
|
| 196 |
+
return timesteps_emb
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
class PatchEmbed3D(nn.Module):
|
| 200 |
+
"""Support the 3D Tensor input"""
|
| 201 |
+
|
| 202 |
+
def __init__(
|
| 203 |
+
self,
|
| 204 |
+
height=128,
|
| 205 |
+
width=128,
|
| 206 |
+
patch_size=2,
|
| 207 |
+
in_channels=16,
|
| 208 |
+
embed_dim=1536,
|
| 209 |
+
layer_norm=False,
|
| 210 |
+
bias=True,
|
| 211 |
+
interpolation_scale=1,
|
| 212 |
+
pos_embed_type="sincos",
|
| 213 |
+
temp_pos_embed_type='rope',
|
| 214 |
+
pos_embed_max_size=192, # For SD3 cropping
|
| 215 |
+
max_num_frames=64,
|
| 216 |
+
add_temp_pos_embed=False,
|
| 217 |
+
interp_condition_pos=False,
|
| 218 |
+
):
|
| 219 |
+
super().__init__()
|
| 220 |
+
|
| 221 |
+
num_patches = (height // patch_size) * (width // patch_size)
|
| 222 |
+
self.layer_norm = layer_norm
|
| 223 |
+
self.pos_embed_max_size = pos_embed_max_size
|
| 224 |
+
|
| 225 |
+
self.proj = nn.Conv2d(
|
| 226 |
+
in_channels, embed_dim, kernel_size=(patch_size, patch_size), stride=patch_size, bias=bias
|
| 227 |
+
)
|
| 228 |
+
if layer_norm:
|
| 229 |
+
self.norm = nn.LayerNorm(embed_dim, elementwise_affine=False, eps=1e-6)
|
| 230 |
+
else:
|
| 231 |
+
self.norm = None
|
| 232 |
+
|
| 233 |
+
self.patch_size = patch_size
|
| 234 |
+
self.height, self.width = height // patch_size, width // patch_size
|
| 235 |
+
self.base_size = height // patch_size
|
| 236 |
+
self.interpolation_scale = interpolation_scale
|
| 237 |
+
self.add_temp_pos_embed = add_temp_pos_embed
|
| 238 |
+
|
| 239 |
+
# Calculate positional embeddings based on max size or default
|
| 240 |
+
if pos_embed_max_size:
|
| 241 |
+
grid_size = pos_embed_max_size
|
| 242 |
+
else:
|
| 243 |
+
grid_size = int(num_patches**0.5)
|
| 244 |
+
|
| 245 |
+
if pos_embed_type is None:
|
| 246 |
+
self.pos_embed = None
|
| 247 |
+
|
| 248 |
+
elif pos_embed_type == "sincos":
|
| 249 |
+
pos_embed = get_2d_sincos_pos_embed(
|
| 250 |
+
embed_dim, grid_size, base_size=self.base_size, interpolation_scale=self.interpolation_scale
|
| 251 |
+
)
|
| 252 |
+
persistent = True if pos_embed_max_size else False
|
| 253 |
+
self.register_buffer("pos_embed", torch.from_numpy(pos_embed).float().unsqueeze(0), persistent=persistent)
|
| 254 |
+
|
| 255 |
+
if add_temp_pos_embed and temp_pos_embed_type == 'sincos':
|
| 256 |
+
time_pos_embed = get_1d_sincos_pos_embed(embed_dim, max_num_frames)
|
| 257 |
+
self.register_buffer("temp_pos_embed", torch.from_numpy(time_pos_embed).float().unsqueeze(0), persistent=True)
|
| 258 |
+
|
| 259 |
+
elif pos_embed_type == "rope":
|
| 260 |
+
print("Using the rotary position embedding")
|
| 261 |
+
|
| 262 |
+
else:
|
| 263 |
+
raise ValueError(f"Unsupported pos_embed_type: {pos_embed_type}")
|
| 264 |
+
|
| 265 |
+
self.pos_embed_type = pos_embed_type
|
| 266 |
+
self.temp_pos_embed_type = temp_pos_embed_type
|
| 267 |
+
self.interp_condition_pos = interp_condition_pos
|
| 268 |
+
|
| 269 |
+
def cropped_pos_embed(self, height, width, ori_height, ori_width):
|
| 270 |
+
"""Crops positional embeddings for SD3 compatibility."""
|
| 271 |
+
if self.pos_embed_max_size is None:
|
| 272 |
+
raise ValueError("`pos_embed_max_size` must be set for cropping.")
|
| 273 |
+
|
| 274 |
+
height = height // self.patch_size
|
| 275 |
+
width = width // self.patch_size
|
| 276 |
+
ori_height = ori_height // self.patch_size
|
| 277 |
+
ori_width = ori_width // self.patch_size
|
| 278 |
+
|
| 279 |
+
assert ori_height >= height, "The ori_height needs >= height"
|
| 280 |
+
assert ori_width >= width, "The ori_width needs >= width"
|
| 281 |
+
|
| 282 |
+
if height > self.pos_embed_max_size:
|
| 283 |
+
raise ValueError(
|
| 284 |
+
f"Height ({height}) cannot be greater than `pos_embed_max_size`: {self.pos_embed_max_size}."
|
| 285 |
+
)
|
| 286 |
+
if width > self.pos_embed_max_size:
|
| 287 |
+
raise ValueError(
|
| 288 |
+
f"Width ({width}) cannot be greater than `pos_embed_max_size`: {self.pos_embed_max_size}."
|
| 289 |
+
)
|
| 290 |
+
|
| 291 |
+
if self.interp_condition_pos:
|
| 292 |
+
top = (self.pos_embed_max_size - ori_height) // 2
|
| 293 |
+
left = (self.pos_embed_max_size - ori_width) // 2
|
| 294 |
+
spatial_pos_embed = self.pos_embed.reshape(1, self.pos_embed_max_size, self.pos_embed_max_size, -1)
|
| 295 |
+
spatial_pos_embed = spatial_pos_embed[:, top : top + ori_height, left : left + ori_width, :] # [b h w c]
|
| 296 |
+
if ori_height != height or ori_width != width:
|
| 297 |
+
spatial_pos_embed = spatial_pos_embed.permute(0, 3, 1, 2)
|
| 298 |
+
spatial_pos_embed = torch.nn.functional.interpolate(spatial_pos_embed, size=(height, width), mode='bilinear')
|
| 299 |
+
spatial_pos_embed = spatial_pos_embed.permute(0, 2, 3, 1)
|
| 300 |
+
else:
|
| 301 |
+
top = (self.pos_embed_max_size - height) // 2
|
| 302 |
+
left = (self.pos_embed_max_size - width) // 2
|
| 303 |
+
spatial_pos_embed = self.pos_embed.reshape(1, self.pos_embed_max_size, self.pos_embed_max_size, -1)
|
| 304 |
+
spatial_pos_embed = spatial_pos_embed[:, top : top + height, left : left + width, :]
|
| 305 |
+
|
| 306 |
+
spatial_pos_embed = spatial_pos_embed.reshape(1, -1, spatial_pos_embed.shape[-1])
|
| 307 |
+
|
| 308 |
+
return spatial_pos_embed
|
| 309 |
+
|
| 310 |
+
def forward_func(self, latent, time_index=0, ori_height=None, ori_width=None):
|
| 311 |
+
if self.pos_embed_max_size is not None:
|
| 312 |
+
height, width = latent.shape[-2:]
|
| 313 |
+
else:
|
| 314 |
+
height, width = latent.shape[-2] // self.patch_size, latent.shape[-1] // self.patch_size
|
| 315 |
+
|
| 316 |
+
bs = latent.shape[0]
|
| 317 |
+
temp = latent.shape[2]
|
| 318 |
+
|
| 319 |
+
latent = rearrange(latent, 'b c t h w -> (b t) c h w')
|
| 320 |
+
latent = self.proj(latent)
|
| 321 |
+
latent = latent.flatten(2).transpose(1, 2) # (BT)CHW -> (BT)NC
|
| 322 |
+
|
| 323 |
+
if self.layer_norm:
|
| 324 |
+
latent = self.norm(latent)
|
| 325 |
+
|
| 326 |
+
if self.pos_embed_type == 'sincos':
|
| 327 |
+
# Spatial position embedding, Interpolate or crop positional embeddings as needed
|
| 328 |
+
if self.pos_embed_max_size:
|
| 329 |
+
pos_embed = self.cropped_pos_embed(height, width, ori_height, ori_width)
|
| 330 |
+
else:
|
| 331 |
+
raise NotImplementedError("Not implemented sincos pos embed without sd3 max pos crop")
|
| 332 |
+
if self.height != height or self.width != width:
|
| 333 |
+
pos_embed = get_2d_sincos_pos_embed(
|
| 334 |
+
embed_dim=self.pos_embed.shape[-1],
|
| 335 |
+
grid_size=(height, width),
|
| 336 |
+
base_size=self.base_size,
|
| 337 |
+
interpolation_scale=self.interpolation_scale,
|
| 338 |
+
)
|
| 339 |
+
pos_embed = torch.from_numpy(pos_embed).float().unsqueeze(0).to(latent.device)
|
| 340 |
+
else:
|
| 341 |
+
pos_embed = self.pos_embed
|
| 342 |
+
|
| 343 |
+
if self.add_temp_pos_embed and self.temp_pos_embed_type == 'sincos':
|
| 344 |
+
latent_dtype = latent.dtype
|
| 345 |
+
latent = latent + pos_embed
|
| 346 |
+
latent = rearrange(latent, '(b t) n c -> (b n) t c', t=temp)
|
| 347 |
+
latent = latent + self.temp_pos_embed[:, time_index:time_index + temp, :]
|
| 348 |
+
latent = latent.to(latent_dtype)
|
| 349 |
+
latent = rearrange(latent, '(b n) t c -> b t n c', b=bs)
|
| 350 |
+
else:
|
| 351 |
+
latent = (latent + pos_embed).to(latent.dtype)
|
| 352 |
+
latent = rearrange(latent, '(b t) n c -> b t n c', b=bs, t=temp)
|
| 353 |
+
|
| 354 |
+
else:
|
| 355 |
+
assert self.pos_embed_type == "rope", "Only supporting the sincos and rope embedding"
|
| 356 |
+
latent = rearrange(latent, '(b t) n c -> b t n c', b=bs, t=temp)
|
| 357 |
+
|
| 358 |
+
return latent
|
| 359 |
+
|
| 360 |
+
def forward(self, latent):
|
| 361 |
+
"""
|
| 362 |
+
Arguments:
|
| 363 |
+
past_condition_latents (Torch.FloatTensor): The past latent during the generation
|
| 364 |
+
flatten_input (bool): True indicate flatten the latent into 1D sequence
|
| 365 |
+
"""
|
| 366 |
+
|
| 367 |
+
if isinstance(latent, list):
|
| 368 |
+
output_list = []
|
| 369 |
+
|
| 370 |
+
for latent_ in latent:
|
| 371 |
+
if not isinstance(latent_, list):
|
| 372 |
+
latent_ = [latent_]
|
| 373 |
+
|
| 374 |
+
output_latent = []
|
| 375 |
+
time_index = 0
|
| 376 |
+
ori_height, ori_width = latent_[-1].shape[-2:]
|
| 377 |
+
for each_latent in latent_:
|
| 378 |
+
hidden_state = self.forward_func(each_latent, time_index=time_index, ori_height=ori_height, ori_width=ori_width)
|
| 379 |
+
time_index += each_latent.shape[2]
|
| 380 |
+
hidden_state = rearrange(hidden_state, "b t n c -> b (t n) c")
|
| 381 |
+
output_latent.append(hidden_state)
|
| 382 |
+
|
| 383 |
+
output_latent = torch.cat(output_latent, dim=1)
|
| 384 |
+
output_list.append(output_latent)
|
| 385 |
+
|
| 386 |
+
return output_list
|
| 387 |
+
else:
|
| 388 |
+
hidden_states = self.forward_func(latent)
|
| 389 |
+
hidden_states = rearrange(hidden_states, "b t n c -> b (t n) c")
|
| 390 |
+
return hidden_states
|
pyramid_dit/mmdit_modules/modeling_mmdit_block.py
ADDED
|
@@ -0,0 +1,671 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Dict, Optional, Tuple, List
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
from einops import rearrange
|
| 6 |
+
from diffusers.models.activations import GEGLU, GELU, ApproximateGELU
|
| 7 |
+
|
| 8 |
+
try:
|
| 9 |
+
from flash_attn import flash_attn_qkvpacked_func, flash_attn_func
|
| 10 |
+
from flash_attn.bert_padding import pad_input, unpad_input, index_first_axis
|
| 11 |
+
from flash_attn.flash_attn_interface import flash_attn_varlen_func
|
| 12 |
+
except:
|
| 13 |
+
flash_attn_func = None
|
| 14 |
+
flash_attn_qkvpacked_func = None
|
| 15 |
+
flash_attn_varlen_func = None
|
| 16 |
+
|
| 17 |
+
from trainer_misc import (
|
| 18 |
+
is_sequence_parallel_initialized,
|
| 19 |
+
get_sequence_parallel_group,
|
| 20 |
+
get_sequence_parallel_world_size,
|
| 21 |
+
all_to_all,
|
| 22 |
+
)
|
| 23 |
+
|
| 24 |
+
from .modeling_normalization import AdaLayerNormZero, AdaLayerNormContinuous, RMSNorm
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class FeedForward(nn.Module):
|
| 28 |
+
r"""
|
| 29 |
+
A feed-forward layer.
|
| 30 |
+
|
| 31 |
+
Parameters:
|
| 32 |
+
dim (`int`): The number of channels in the input.
|
| 33 |
+
dim_out (`int`, *optional*): The number of channels in the output. If not given, defaults to `dim`.
|
| 34 |
+
mult (`int`, *optional*, defaults to 4): The multiplier to use for the hidden dimension.
|
| 35 |
+
dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
|
| 36 |
+
activation_fn (`str`, *optional*, defaults to `"geglu"`): Activation function to be used in feed-forward.
|
| 37 |
+
final_dropout (`bool` *optional*, defaults to False): Apply a final dropout.
|
| 38 |
+
bias (`bool`, defaults to True): Whether to use a bias in the linear layer.
|
| 39 |
+
"""
|
| 40 |
+
def __init__(
|
| 41 |
+
self,
|
| 42 |
+
dim: int,
|
| 43 |
+
dim_out: Optional[int] = None,
|
| 44 |
+
mult: int = 4,
|
| 45 |
+
dropout: float = 0.0,
|
| 46 |
+
activation_fn: str = "geglu",
|
| 47 |
+
final_dropout: bool = False,
|
| 48 |
+
inner_dim=None,
|
| 49 |
+
bias: bool = True,
|
| 50 |
+
):
|
| 51 |
+
super().__init__()
|
| 52 |
+
if inner_dim is None:
|
| 53 |
+
inner_dim = int(dim * mult)
|
| 54 |
+
dim_out = dim_out if dim_out is not None else dim
|
| 55 |
+
|
| 56 |
+
if activation_fn == "gelu":
|
| 57 |
+
act_fn = GELU(dim, inner_dim, bias=bias)
|
| 58 |
+
if activation_fn == "gelu-approximate":
|
| 59 |
+
act_fn = GELU(dim, inner_dim, approximate="tanh", bias=bias)
|
| 60 |
+
elif activation_fn == "geglu":
|
| 61 |
+
act_fn = GEGLU(dim, inner_dim, bias=bias)
|
| 62 |
+
elif activation_fn == "geglu-approximate":
|
| 63 |
+
act_fn = ApproximateGELU(dim, inner_dim, bias=bias)
|
| 64 |
+
|
| 65 |
+
self.net = nn.ModuleList([])
|
| 66 |
+
# project in
|
| 67 |
+
self.net.append(act_fn)
|
| 68 |
+
# project dropout
|
| 69 |
+
self.net.append(nn.Dropout(dropout))
|
| 70 |
+
# project out
|
| 71 |
+
self.net.append(nn.Linear(inner_dim, dim_out, bias=bias))
|
| 72 |
+
# FF as used in Vision Transformer, MLP-Mixer, etc. have a final dropout
|
| 73 |
+
if final_dropout:
|
| 74 |
+
self.net.append(nn.Dropout(dropout))
|
| 75 |
+
|
| 76 |
+
def forward(self, hidden_states: torch.Tensor, *args, **kwargs) -> torch.Tensor:
|
| 77 |
+
if len(args) > 0 or kwargs.get("scale", None) is not None:
|
| 78 |
+
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
|
| 79 |
+
deprecate("scale", "1.0.0", deprecation_message)
|
| 80 |
+
for module in self.net:
|
| 81 |
+
hidden_states = module(hidden_states)
|
| 82 |
+
return hidden_states
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
class VarlenFlashSelfAttentionWithT5Mask:
|
| 86 |
+
|
| 87 |
+
def __init__(self):
|
| 88 |
+
pass
|
| 89 |
+
|
| 90 |
+
def apply_rope(self, xq, xk, freqs_cis):
|
| 91 |
+
xq_ = xq.float().reshape(*xq.shape[:-1], -1, 1, 2)
|
| 92 |
+
xk_ = xk.float().reshape(*xk.shape[:-1], -1, 1, 2)
|
| 93 |
+
xq_out = freqs_cis[..., 0] * xq_[..., 0] + freqs_cis[..., 1] * xq_[..., 1]
|
| 94 |
+
xk_out = freqs_cis[..., 0] * xk_[..., 0] + freqs_cis[..., 1] * xk_[..., 1]
|
| 95 |
+
return xq_out.reshape(*xq.shape).type_as(xq), xk_out.reshape(*xk.shape).type_as(xk)
|
| 96 |
+
|
| 97 |
+
def __call__(
|
| 98 |
+
self, query, key, value, encoder_query, encoder_key, encoder_value,
|
| 99 |
+
heads, scale, hidden_length=None, image_rotary_emb=None, encoder_attention_mask=None,
|
| 100 |
+
):
|
| 101 |
+
assert encoder_attention_mask is not None, "The encoder-hidden mask needed to be set"
|
| 102 |
+
|
| 103 |
+
batch_size = query.shape[0]
|
| 104 |
+
output_hidden = torch.zeros_like(query)
|
| 105 |
+
output_encoder_hidden = torch.zeros_like(encoder_query)
|
| 106 |
+
encoder_length = encoder_query.shape[1]
|
| 107 |
+
|
| 108 |
+
qkv_list = []
|
| 109 |
+
num_stages = len(hidden_length)
|
| 110 |
+
|
| 111 |
+
encoder_qkv = torch.stack([encoder_query, encoder_key, encoder_value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 112 |
+
qkv = torch.stack([query, key, value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 113 |
+
|
| 114 |
+
i_sum = 0
|
| 115 |
+
for i_p, length in enumerate(hidden_length):
|
| 116 |
+
encoder_qkv_tokens = encoder_qkv[i_p::num_stages]
|
| 117 |
+
qkv_tokens = qkv[:, i_sum:i_sum+length]
|
| 118 |
+
concat_qkv_tokens = torch.cat([encoder_qkv_tokens, qkv_tokens], dim=1) # [bs, tot_seq, 3, nhead, dim]
|
| 119 |
+
|
| 120 |
+
if image_rotary_emb is not None:
|
| 121 |
+
concat_qkv_tokens[:,:,0], concat_qkv_tokens[:,:,1] = self.apply_rope(concat_qkv_tokens[:,:,0], concat_qkv_tokens[:,:,1], image_rotary_emb[i_p])
|
| 122 |
+
|
| 123 |
+
indices = encoder_attention_mask[i_p]['indices']
|
| 124 |
+
qkv_list.append(index_first_axis(rearrange(concat_qkv_tokens, "b s ... -> (b s) ..."), indices))
|
| 125 |
+
i_sum += length
|
| 126 |
+
|
| 127 |
+
token_lengths = [x_.shape[0] for x_ in qkv_list]
|
| 128 |
+
qkv = torch.cat(qkv_list, dim=0)
|
| 129 |
+
query, key, value = qkv.unbind(1)
|
| 130 |
+
|
| 131 |
+
cu_seqlens = torch.cat([x_['seqlens_in_batch'] for x_ in encoder_attention_mask], dim=0)
|
| 132 |
+
max_seqlen_q = cu_seqlens.max().item()
|
| 133 |
+
max_seqlen_k = max_seqlen_q
|
| 134 |
+
cu_seqlens_q = F.pad(torch.cumsum(cu_seqlens, dim=0, dtype=torch.int32), (1, 0))
|
| 135 |
+
cu_seqlens_k = cu_seqlens_q.clone()
|
| 136 |
+
|
| 137 |
+
output = flash_attn_varlen_func(
|
| 138 |
+
query,
|
| 139 |
+
key,
|
| 140 |
+
value,
|
| 141 |
+
cu_seqlens_q=cu_seqlens_q,
|
| 142 |
+
cu_seqlens_k=cu_seqlens_k,
|
| 143 |
+
max_seqlen_q=max_seqlen_q,
|
| 144 |
+
max_seqlen_k=max_seqlen_k,
|
| 145 |
+
dropout_p=0.0,
|
| 146 |
+
causal=False,
|
| 147 |
+
softmax_scale=scale,
|
| 148 |
+
)
|
| 149 |
+
|
| 150 |
+
# To merge the tokens
|
| 151 |
+
i_sum = 0;token_sum = 0
|
| 152 |
+
for i_p, length in enumerate(hidden_length):
|
| 153 |
+
tot_token_num = token_lengths[i_p]
|
| 154 |
+
stage_output = output[token_sum : token_sum + tot_token_num]
|
| 155 |
+
stage_output = pad_input(stage_output, encoder_attention_mask[i_p]['indices'], batch_size, encoder_length + length)
|
| 156 |
+
stage_encoder_hidden_output = stage_output[:, :encoder_length]
|
| 157 |
+
stage_hidden_output = stage_output[:, encoder_length:]
|
| 158 |
+
output_hidden[:, i_sum:i_sum+length] = stage_hidden_output
|
| 159 |
+
output_encoder_hidden[i_p::num_stages] = stage_encoder_hidden_output
|
| 160 |
+
token_sum += tot_token_num
|
| 161 |
+
i_sum += length
|
| 162 |
+
|
| 163 |
+
output_hidden = output_hidden.flatten(2, 3)
|
| 164 |
+
output_encoder_hidden = output_encoder_hidden.flatten(2, 3)
|
| 165 |
+
|
| 166 |
+
return output_hidden, output_encoder_hidden
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
class SequenceParallelVarlenFlashSelfAttentionWithT5Mask:
|
| 170 |
+
|
| 171 |
+
def __init__(self):
|
| 172 |
+
pass
|
| 173 |
+
|
| 174 |
+
def apply_rope(self, xq, xk, freqs_cis):
|
| 175 |
+
xq_ = xq.float().reshape(*xq.shape[:-1], -1, 1, 2)
|
| 176 |
+
xk_ = xk.float().reshape(*xk.shape[:-1], -1, 1, 2)
|
| 177 |
+
xq_out = freqs_cis[..., 0] * xq_[..., 0] + freqs_cis[..., 1] * xq_[..., 1]
|
| 178 |
+
xk_out = freqs_cis[..., 0] * xk_[..., 0] + freqs_cis[..., 1] * xk_[..., 1]
|
| 179 |
+
return xq_out.reshape(*xq.shape).type_as(xq), xk_out.reshape(*xk.shape).type_as(xk)
|
| 180 |
+
|
| 181 |
+
def __call__(
|
| 182 |
+
self, query, key, value, encoder_query, encoder_key, encoder_value,
|
| 183 |
+
heads, scale, hidden_length=None, image_rotary_emb=None, encoder_attention_mask=None,
|
| 184 |
+
):
|
| 185 |
+
assert encoder_attention_mask is not None, "The encoder-hidden mask needed to be set"
|
| 186 |
+
|
| 187 |
+
batch_size = query.shape[0]
|
| 188 |
+
qkv_list = []
|
| 189 |
+
num_stages = len(hidden_length)
|
| 190 |
+
|
| 191 |
+
encoder_qkv = torch.stack([encoder_query, encoder_key, encoder_value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 192 |
+
qkv = torch.stack([query, key, value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 193 |
+
|
| 194 |
+
# To sync the encoder query, key and values
|
| 195 |
+
sp_group = get_sequence_parallel_group()
|
| 196 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 197 |
+
encoder_qkv = all_to_all(encoder_qkv, sp_group, sp_group_size, scatter_dim=3, gather_dim=1) # [bs, seq, 3, sub_head, head_dim]
|
| 198 |
+
|
| 199 |
+
output_hidden = torch.zeros_like(qkv[:,:,0])
|
| 200 |
+
output_encoder_hidden = torch.zeros_like(encoder_qkv[:,:,0])
|
| 201 |
+
encoder_length = encoder_qkv.shape[1]
|
| 202 |
+
|
| 203 |
+
i_sum = 0
|
| 204 |
+
for i_p, length in enumerate(hidden_length):
|
| 205 |
+
# get the query, key, value from padding sequence
|
| 206 |
+
encoder_qkv_tokens = encoder_qkv[i_p::num_stages]
|
| 207 |
+
qkv_tokens = qkv[:, i_sum:i_sum+length]
|
| 208 |
+
qkv_tokens = all_to_all(qkv_tokens, sp_group, sp_group_size, scatter_dim=3, gather_dim=1) # [bs, seq, 3, sub_head, head_dim]
|
| 209 |
+
concat_qkv_tokens = torch.cat([encoder_qkv_tokens, qkv_tokens], dim=1) # [bs, pad_seq, 3, nhead, dim]
|
| 210 |
+
|
| 211 |
+
if image_rotary_emb is not None:
|
| 212 |
+
concat_qkv_tokens[:,:,0], concat_qkv_tokens[:,:,1] = self.apply_rope(concat_qkv_tokens[:,:,0], concat_qkv_tokens[:,:,1], image_rotary_emb[i_p])
|
| 213 |
+
|
| 214 |
+
indices = encoder_attention_mask[i_p]['indices']
|
| 215 |
+
qkv_list.append(index_first_axis(rearrange(concat_qkv_tokens, "b s ... -> (b s) ..."), indices))
|
| 216 |
+
i_sum += length
|
| 217 |
+
|
| 218 |
+
token_lengths = [x_.shape[0] for x_ in qkv_list]
|
| 219 |
+
qkv = torch.cat(qkv_list, dim=0)
|
| 220 |
+
query, key, value = qkv.unbind(1)
|
| 221 |
+
|
| 222 |
+
cu_seqlens = torch.cat([x_['seqlens_in_batch'] for x_ in encoder_attention_mask], dim=0)
|
| 223 |
+
max_seqlen_q = cu_seqlens.max().item()
|
| 224 |
+
max_seqlen_k = max_seqlen_q
|
| 225 |
+
cu_seqlens_q = F.pad(torch.cumsum(cu_seqlens, dim=0, dtype=torch.int32), (1, 0))
|
| 226 |
+
cu_seqlens_k = cu_seqlens_q.clone()
|
| 227 |
+
|
| 228 |
+
output = flash_attn_varlen_func(
|
| 229 |
+
query,
|
| 230 |
+
key,
|
| 231 |
+
value,
|
| 232 |
+
cu_seqlens_q=cu_seqlens_q,
|
| 233 |
+
cu_seqlens_k=cu_seqlens_k,
|
| 234 |
+
max_seqlen_q=max_seqlen_q,
|
| 235 |
+
max_seqlen_k=max_seqlen_k,
|
| 236 |
+
dropout_p=0.0,
|
| 237 |
+
causal=False,
|
| 238 |
+
softmax_scale=scale,
|
| 239 |
+
)
|
| 240 |
+
|
| 241 |
+
# To merge the tokens
|
| 242 |
+
i_sum = 0;token_sum = 0
|
| 243 |
+
for i_p, length in enumerate(hidden_length):
|
| 244 |
+
tot_token_num = token_lengths[i_p]
|
| 245 |
+
stage_output = output[token_sum : token_sum + tot_token_num]
|
| 246 |
+
stage_output = pad_input(stage_output, encoder_attention_mask[i_p]['indices'], batch_size, encoder_length + length * sp_group_size)
|
| 247 |
+
stage_encoder_hidden_output = stage_output[:, :encoder_length]
|
| 248 |
+
stage_hidden_output = stage_output[:, encoder_length:]
|
| 249 |
+
stage_hidden_output = all_to_all(stage_hidden_output, sp_group, sp_group_size, scatter_dim=1, gather_dim=2)
|
| 250 |
+
output_hidden[:, i_sum:i_sum+length] = stage_hidden_output
|
| 251 |
+
output_encoder_hidden[i_p::num_stages] = stage_encoder_hidden_output
|
| 252 |
+
token_sum += tot_token_num
|
| 253 |
+
i_sum += length
|
| 254 |
+
|
| 255 |
+
output_encoder_hidden = all_to_all(output_encoder_hidden, sp_group, sp_group_size, scatter_dim=1, gather_dim=2)
|
| 256 |
+
output_hidden = output_hidden.flatten(2, 3)
|
| 257 |
+
output_encoder_hidden = output_encoder_hidden.flatten(2, 3)
|
| 258 |
+
|
| 259 |
+
return output_hidden, output_encoder_hidden
|
| 260 |
+
|
| 261 |
+
|
| 262 |
+
class VarlenSelfAttentionWithT5Mask:
|
| 263 |
+
|
| 264 |
+
"""
|
| 265 |
+
For chunk stage attention without using flash attention
|
| 266 |
+
"""
|
| 267 |
+
|
| 268 |
+
def __init__(self):
|
| 269 |
+
pass
|
| 270 |
+
|
| 271 |
+
def apply_rope(self, xq, xk, freqs_cis):
|
| 272 |
+
xq_ = xq.float().reshape(*xq.shape[:-1], -1, 1, 2)
|
| 273 |
+
xk_ = xk.float().reshape(*xk.shape[:-1], -1, 1, 2)
|
| 274 |
+
xq_out = freqs_cis[..., 0] * xq_[..., 0] + freqs_cis[..., 1] * xq_[..., 1]
|
| 275 |
+
xk_out = freqs_cis[..., 0] * xk_[..., 0] + freqs_cis[..., 1] * xk_[..., 1]
|
| 276 |
+
return xq_out.reshape(*xq.shape).type_as(xq), xk_out.reshape(*xk.shape).type_as(xk)
|
| 277 |
+
|
| 278 |
+
def __call__(
|
| 279 |
+
self, query, key, value, encoder_query, encoder_key, encoder_value,
|
| 280 |
+
heads, scale, hidden_length=None, image_rotary_emb=None, attention_mask=None,
|
| 281 |
+
):
|
| 282 |
+
assert attention_mask is not None, "The attention mask needed to be set"
|
| 283 |
+
|
| 284 |
+
encoder_length = encoder_query.shape[1]
|
| 285 |
+
num_stages = len(hidden_length)
|
| 286 |
+
|
| 287 |
+
encoder_qkv = torch.stack([encoder_query, encoder_key, encoder_value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 288 |
+
qkv = torch.stack([query, key, value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 289 |
+
|
| 290 |
+
i_sum = 0
|
| 291 |
+
output_encoder_hidden_list = []
|
| 292 |
+
output_hidden_list = []
|
| 293 |
+
|
| 294 |
+
for i_p, length in enumerate(hidden_length):
|
| 295 |
+
encoder_qkv_tokens = encoder_qkv[i_p::num_stages]
|
| 296 |
+
qkv_tokens = qkv[:, i_sum:i_sum+length]
|
| 297 |
+
concat_qkv_tokens = torch.cat([encoder_qkv_tokens, qkv_tokens], dim=1) # [bs, tot_seq, 3, nhead, dim]
|
| 298 |
+
|
| 299 |
+
if image_rotary_emb is not None:
|
| 300 |
+
concat_qkv_tokens[:,:,0], concat_qkv_tokens[:,:,1] = self.apply_rope(concat_qkv_tokens[:,:,0], concat_qkv_tokens[:,:,1], image_rotary_emb[i_p])
|
| 301 |
+
|
| 302 |
+
query, key, value = concat_qkv_tokens.unbind(2) # [bs, tot_seq, nhead, dim]
|
| 303 |
+
query = query.transpose(1, 2)
|
| 304 |
+
key = key.transpose(1, 2)
|
| 305 |
+
value = value.transpose(1, 2)
|
| 306 |
+
|
| 307 |
+
# with torch.backends.cuda.sdp_kernel(enable_math=False, enable_flash=False, enable_mem_efficient=True):
|
| 308 |
+
stage_hidden_states = F.scaled_dot_product_attention(
|
| 309 |
+
query, key, value, dropout_p=0.0, is_causal=False, attn_mask=attention_mask[i_p],
|
| 310 |
+
)
|
| 311 |
+
stage_hidden_states = stage_hidden_states.transpose(1, 2).flatten(2, 3) # [bs, tot_seq, dim]
|
| 312 |
+
|
| 313 |
+
output_encoder_hidden_list.append(stage_hidden_states[:, :encoder_length])
|
| 314 |
+
output_hidden_list.append(stage_hidden_states[:, encoder_length:])
|
| 315 |
+
i_sum += length
|
| 316 |
+
|
| 317 |
+
output_encoder_hidden = torch.stack(output_encoder_hidden_list, dim=1) # [b n s d]
|
| 318 |
+
output_encoder_hidden = rearrange(output_encoder_hidden, 'b n s d -> (b n) s d')
|
| 319 |
+
output_hidden = torch.cat(output_hidden_list, dim=1)
|
| 320 |
+
|
| 321 |
+
return output_hidden, output_encoder_hidden
|
| 322 |
+
|
| 323 |
+
|
| 324 |
+
class SequenceParallelVarlenSelfAttentionWithT5Mask:
|
| 325 |
+
"""
|
| 326 |
+
For chunk stage attention without using flash attention
|
| 327 |
+
"""
|
| 328 |
+
|
| 329 |
+
def __init__(self):
|
| 330 |
+
pass
|
| 331 |
+
|
| 332 |
+
def apply_rope(self, xq, xk, freqs_cis):
|
| 333 |
+
xq_ = xq.float().reshape(*xq.shape[:-1], -1, 1, 2)
|
| 334 |
+
xk_ = xk.float().reshape(*xk.shape[:-1], -1, 1, 2)
|
| 335 |
+
xq_out = freqs_cis[..., 0] * xq_[..., 0] + freqs_cis[..., 1] * xq_[..., 1]
|
| 336 |
+
xk_out = freqs_cis[..., 0] * xk_[..., 0] + freqs_cis[..., 1] * xk_[..., 1]
|
| 337 |
+
return xq_out.reshape(*xq.shape).type_as(xq), xk_out.reshape(*xk.shape).type_as(xk)
|
| 338 |
+
|
| 339 |
+
def __call__(
|
| 340 |
+
self, query, key, value, encoder_query, encoder_key, encoder_value,
|
| 341 |
+
heads, scale, hidden_length=None, image_rotary_emb=None, attention_mask=None,
|
| 342 |
+
):
|
| 343 |
+
assert attention_mask is not None, "The attention mask needed to be set"
|
| 344 |
+
|
| 345 |
+
num_stages = len(hidden_length)
|
| 346 |
+
|
| 347 |
+
encoder_qkv = torch.stack([encoder_query, encoder_key, encoder_value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 348 |
+
qkv = torch.stack([query, key, value], dim=2) # [bs, sub_seq, 3, head, head_dim]
|
| 349 |
+
|
| 350 |
+
# To sync the encoder query, key and values
|
| 351 |
+
sp_group = get_sequence_parallel_group()
|
| 352 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 353 |
+
encoder_qkv = all_to_all(encoder_qkv, sp_group, sp_group_size, scatter_dim=3, gather_dim=1) # [bs, seq, 3, sub_head, head_dim]
|
| 354 |
+
encoder_length = encoder_qkv.shape[1]
|
| 355 |
+
|
| 356 |
+
i_sum = 0
|
| 357 |
+
output_encoder_hidden_list = []
|
| 358 |
+
output_hidden_list = []
|
| 359 |
+
|
| 360 |
+
for i_p, length in enumerate(hidden_length):
|
| 361 |
+
encoder_qkv_tokens = encoder_qkv[i_p::num_stages]
|
| 362 |
+
qkv_tokens = qkv[:, i_sum:i_sum+length]
|
| 363 |
+
qkv_tokens = all_to_all(qkv_tokens, sp_group, sp_group_size, scatter_dim=3, gather_dim=1) # [bs, seq, 3, sub_head, head_dim]
|
| 364 |
+
concat_qkv_tokens = torch.cat([encoder_qkv_tokens, qkv_tokens], dim=1) # [bs, tot_seq, 3, nhead, dim]
|
| 365 |
+
|
| 366 |
+
if image_rotary_emb is not None:
|
| 367 |
+
concat_qkv_tokens[:,:,0], concat_qkv_tokens[:,:,1] = self.apply_rope(concat_qkv_tokens[:,:,0], concat_qkv_tokens[:,:,1], image_rotary_emb[i_p])
|
| 368 |
+
|
| 369 |
+
query, key, value = concat_qkv_tokens.unbind(2) # [bs, tot_seq, nhead, dim]
|
| 370 |
+
query = query.transpose(1, 2)
|
| 371 |
+
key = key.transpose(1, 2)
|
| 372 |
+
value = value.transpose(1, 2)
|
| 373 |
+
|
| 374 |
+
stage_hidden_states = F.scaled_dot_product_attention(
|
| 375 |
+
query, key, value, dropout_p=0.0, is_causal=False, attn_mask=attention_mask[i_p],
|
| 376 |
+
)
|
| 377 |
+
stage_hidden_states = stage_hidden_states.transpose(1, 2) # [bs, tot_seq, nhead, dim]
|
| 378 |
+
|
| 379 |
+
output_encoder_hidden_list.append(stage_hidden_states[:, :encoder_length])
|
| 380 |
+
|
| 381 |
+
output_hidden = stage_hidden_states[:, encoder_length:]
|
| 382 |
+
output_hidden = all_to_all(output_hidden, sp_group, sp_group_size, scatter_dim=1, gather_dim=2)
|
| 383 |
+
output_hidden_list.append(output_hidden)
|
| 384 |
+
|
| 385 |
+
i_sum += length
|
| 386 |
+
|
| 387 |
+
output_encoder_hidden = torch.stack(output_encoder_hidden_list, dim=1) # [b n s nhead d]
|
| 388 |
+
output_encoder_hidden = rearrange(output_encoder_hidden, 'b n s h d -> (b n) s h d')
|
| 389 |
+
output_encoder_hidden = all_to_all(output_encoder_hidden, sp_group, sp_group_size, scatter_dim=1, gather_dim=2)
|
| 390 |
+
output_encoder_hidden = output_encoder_hidden.flatten(2, 3)
|
| 391 |
+
output_hidden = torch.cat(output_hidden_list, dim=1).flatten(2, 3)
|
| 392 |
+
|
| 393 |
+
return output_hidden, output_encoder_hidden
|
| 394 |
+
|
| 395 |
+
|
| 396 |
+
class JointAttention(nn.Module):
|
| 397 |
+
|
| 398 |
+
def __init__(
|
| 399 |
+
self,
|
| 400 |
+
query_dim: int,
|
| 401 |
+
cross_attention_dim: Optional[int] = None,
|
| 402 |
+
heads: int = 8,
|
| 403 |
+
dim_head: int = 64,
|
| 404 |
+
dropout: float = 0.0,
|
| 405 |
+
bias: bool = False,
|
| 406 |
+
qk_norm: Optional[str] = None,
|
| 407 |
+
added_kv_proj_dim: Optional[int] = None,
|
| 408 |
+
out_bias: bool = True,
|
| 409 |
+
eps: float = 1e-5,
|
| 410 |
+
out_dim: int = None,
|
| 411 |
+
context_pre_only=None,
|
| 412 |
+
use_flash_attn=True,
|
| 413 |
+
):
|
| 414 |
+
"""
|
| 415 |
+
Fixing the QKNorm, following the flux, norm the head dimension
|
| 416 |
+
"""
|
| 417 |
+
super().__init__()
|
| 418 |
+
self.inner_dim = out_dim if out_dim is not None else dim_head * heads
|
| 419 |
+
self.query_dim = query_dim
|
| 420 |
+
self.cross_attention_dim = cross_attention_dim if cross_attention_dim is not None else query_dim
|
| 421 |
+
self.use_bias = bias
|
| 422 |
+
self.dropout = dropout
|
| 423 |
+
|
| 424 |
+
self.out_dim = out_dim if out_dim is not None else query_dim
|
| 425 |
+
self.context_pre_only = context_pre_only
|
| 426 |
+
|
| 427 |
+
self.scale = dim_head**-0.5
|
| 428 |
+
self.heads = out_dim // dim_head if out_dim is not None else heads
|
| 429 |
+
self.added_kv_proj_dim = added_kv_proj_dim
|
| 430 |
+
|
| 431 |
+
if qk_norm is None:
|
| 432 |
+
self.norm_q = None
|
| 433 |
+
self.norm_k = None
|
| 434 |
+
elif qk_norm == "layer_norm":
|
| 435 |
+
self.norm_q = nn.LayerNorm(dim_head, eps=eps)
|
| 436 |
+
self.norm_k = nn.LayerNorm(dim_head, eps=eps)
|
| 437 |
+
elif qk_norm == 'rms_norm':
|
| 438 |
+
self.norm_q = RMSNorm(dim_head, eps=eps)
|
| 439 |
+
self.norm_k = RMSNorm(dim_head, eps=eps)
|
| 440 |
+
else:
|
| 441 |
+
raise ValueError(f"unknown qk_norm: {qk_norm}. Should be None or 'layer_norm'")
|
| 442 |
+
|
| 443 |
+
self.to_q = nn.Linear(query_dim, self.inner_dim, bias=bias)
|
| 444 |
+
self.to_k = nn.Linear(self.cross_attention_dim, self.inner_dim, bias=bias)
|
| 445 |
+
self.to_v = nn.Linear(self.cross_attention_dim, self.inner_dim, bias=bias)
|
| 446 |
+
|
| 447 |
+
if self.added_kv_proj_dim is not None:
|
| 448 |
+
self.add_k_proj = nn.Linear(added_kv_proj_dim, self.inner_dim)
|
| 449 |
+
self.add_v_proj = nn.Linear(added_kv_proj_dim, self.inner_dim)
|
| 450 |
+
self.add_q_proj = nn.Linear(added_kv_proj_dim, self.inner_dim)
|
| 451 |
+
|
| 452 |
+
if qk_norm is None:
|
| 453 |
+
self.norm_add_q = None
|
| 454 |
+
self.norm_add_k = None
|
| 455 |
+
elif qk_norm == "layer_norm":
|
| 456 |
+
self.norm_add_q = nn.LayerNorm(dim_head, eps=eps)
|
| 457 |
+
self.norm_add_k = nn.LayerNorm(dim_head, eps=eps)
|
| 458 |
+
elif qk_norm == 'rms_norm':
|
| 459 |
+
self.norm_add_q = RMSNorm(dim_head, eps=eps)
|
| 460 |
+
self.norm_add_k = RMSNorm(dim_head, eps=eps)
|
| 461 |
+
else:
|
| 462 |
+
raise ValueError(f"unknown qk_norm: {qk_norm}. Should be None or 'layer_norm'")
|
| 463 |
+
|
| 464 |
+
self.to_out = nn.ModuleList([])
|
| 465 |
+
self.to_out.append(nn.Linear(self.inner_dim, self.out_dim, bias=out_bias))
|
| 466 |
+
self.to_out.append(nn.Dropout(dropout))
|
| 467 |
+
|
| 468 |
+
if not self.context_pre_only:
|
| 469 |
+
self.to_add_out = nn.Linear(self.inner_dim, self.out_dim, bias=out_bias)
|
| 470 |
+
|
| 471 |
+
self.use_flash_attn = use_flash_attn
|
| 472 |
+
|
| 473 |
+
if flash_attn_func is None:
|
| 474 |
+
self.use_flash_attn = False
|
| 475 |
+
|
| 476 |
+
# print(f"Using flash-attention: {self.use_flash_attn}")
|
| 477 |
+
if self.use_flash_attn:
|
| 478 |
+
if is_sequence_parallel_initialized():
|
| 479 |
+
self.var_flash_attn = SequenceParallelVarlenFlashSelfAttentionWithT5Mask()
|
| 480 |
+
else:
|
| 481 |
+
self.var_flash_attn = VarlenFlashSelfAttentionWithT5Mask()
|
| 482 |
+
else:
|
| 483 |
+
if is_sequence_parallel_initialized():
|
| 484 |
+
self.var_len_attn = SequenceParallelVarlenSelfAttentionWithT5Mask()
|
| 485 |
+
else:
|
| 486 |
+
self.var_len_attn = VarlenSelfAttentionWithT5Mask()
|
| 487 |
+
|
| 488 |
+
|
| 489 |
+
def forward(
|
| 490 |
+
self,
|
| 491 |
+
hidden_states: torch.FloatTensor,
|
| 492 |
+
encoder_hidden_states: torch.FloatTensor = None,
|
| 493 |
+
encoder_attention_mask: torch.FloatTensor = None,
|
| 494 |
+
attention_mask: torch.FloatTensor = None, # [B, L, S]
|
| 495 |
+
hidden_length: torch.Tensor = None,
|
| 496 |
+
image_rotary_emb: torch.Tensor = None,
|
| 497 |
+
**kwargs,
|
| 498 |
+
) -> torch.FloatTensor:
|
| 499 |
+
# This function is only used during training
|
| 500 |
+
# `sample` projections.
|
| 501 |
+
query = self.to_q(hidden_states)
|
| 502 |
+
key = self.to_k(hidden_states)
|
| 503 |
+
value = self.to_v(hidden_states)
|
| 504 |
+
|
| 505 |
+
inner_dim = key.shape[-1]
|
| 506 |
+
head_dim = inner_dim // self.heads
|
| 507 |
+
|
| 508 |
+
query = query.view(query.shape[0], -1, self.heads, head_dim)
|
| 509 |
+
key = key.view(key.shape[0], -1, self.heads, head_dim)
|
| 510 |
+
value = value.view(value.shape[0], -1, self.heads, head_dim)
|
| 511 |
+
|
| 512 |
+
if self.norm_q is not None:
|
| 513 |
+
query = self.norm_q(query)
|
| 514 |
+
|
| 515 |
+
if self.norm_k is not None:
|
| 516 |
+
key = self.norm_k(key)
|
| 517 |
+
|
| 518 |
+
# `context` projections.
|
| 519 |
+
encoder_hidden_states_query_proj = self.add_q_proj(encoder_hidden_states)
|
| 520 |
+
encoder_hidden_states_key_proj = self.add_k_proj(encoder_hidden_states)
|
| 521 |
+
encoder_hidden_states_value_proj = self.add_v_proj(encoder_hidden_states)
|
| 522 |
+
|
| 523 |
+
encoder_hidden_states_query_proj = encoder_hidden_states_query_proj.view(
|
| 524 |
+
encoder_hidden_states_query_proj.shape[0], -1, self.heads, head_dim
|
| 525 |
+
)
|
| 526 |
+
encoder_hidden_states_key_proj = encoder_hidden_states_key_proj.view(
|
| 527 |
+
encoder_hidden_states_key_proj.shape[0], -1, self.heads, head_dim
|
| 528 |
+
)
|
| 529 |
+
encoder_hidden_states_value_proj = encoder_hidden_states_value_proj.view(
|
| 530 |
+
encoder_hidden_states_value_proj.shape[0], -1, self.heads, head_dim
|
| 531 |
+
)
|
| 532 |
+
|
| 533 |
+
if self.norm_add_q is not None:
|
| 534 |
+
encoder_hidden_states_query_proj = self.norm_add_q(encoder_hidden_states_query_proj)
|
| 535 |
+
|
| 536 |
+
if self.norm_add_k is not None:
|
| 537 |
+
encoder_hidden_states_key_proj = self.norm_add_k(encoder_hidden_states_key_proj)
|
| 538 |
+
|
| 539 |
+
# To cat the hidden and encoder hidden, perform attention compuataion, and then split
|
| 540 |
+
if self.use_flash_attn:
|
| 541 |
+
hidden_states, encoder_hidden_states = self.var_flash_attn(
|
| 542 |
+
query, key, value,
|
| 543 |
+
encoder_hidden_states_query_proj, encoder_hidden_states_key_proj,
|
| 544 |
+
encoder_hidden_states_value_proj, self.heads, self.scale, hidden_length,
|
| 545 |
+
image_rotary_emb, encoder_attention_mask,
|
| 546 |
+
)
|
| 547 |
+
else:
|
| 548 |
+
hidden_states, encoder_hidden_states = self.var_len_attn(
|
| 549 |
+
query, key, value,
|
| 550 |
+
encoder_hidden_states_query_proj, encoder_hidden_states_key_proj,
|
| 551 |
+
encoder_hidden_states_value_proj, self.heads, self.scale, hidden_length,
|
| 552 |
+
image_rotary_emb, attention_mask,
|
| 553 |
+
)
|
| 554 |
+
|
| 555 |
+
# linear proj
|
| 556 |
+
hidden_states = self.to_out[0](hidden_states)
|
| 557 |
+
# dropout
|
| 558 |
+
hidden_states = self.to_out[1](hidden_states)
|
| 559 |
+
if not self.context_pre_only:
|
| 560 |
+
encoder_hidden_states = self.to_add_out(encoder_hidden_states)
|
| 561 |
+
|
| 562 |
+
return hidden_states, encoder_hidden_states
|
| 563 |
+
|
| 564 |
+
|
| 565 |
+
class JointTransformerBlock(nn.Module):
|
| 566 |
+
r"""
|
| 567 |
+
A Transformer block following the MMDiT architecture, introduced in Stable Diffusion 3.
|
| 568 |
+
|
| 569 |
+
Reference: https://arxiv.org/abs/2403.03206
|
| 570 |
+
|
| 571 |
+
Parameters:
|
| 572 |
+
dim (`int`): The number of channels in the input and output.
|
| 573 |
+
num_attention_heads (`int`): The number of heads to use for multi-head attention.
|
| 574 |
+
attention_head_dim (`int`): The number of channels in each head.
|
| 575 |
+
context_pre_only (`bool`): Boolean to determine if we should add some blocks associated with the
|
| 576 |
+
processing of `context` conditions.
|
| 577 |
+
"""
|
| 578 |
+
|
| 579 |
+
def __init__(
|
| 580 |
+
self, dim, num_attention_heads, attention_head_dim, qk_norm=None,
|
| 581 |
+
context_pre_only=False, use_flash_attn=True,
|
| 582 |
+
):
|
| 583 |
+
super().__init__()
|
| 584 |
+
|
| 585 |
+
self.context_pre_only = context_pre_only
|
| 586 |
+
context_norm_type = "ada_norm_continous" if context_pre_only else "ada_norm_zero"
|
| 587 |
+
|
| 588 |
+
self.norm1 = AdaLayerNormZero(dim)
|
| 589 |
+
|
| 590 |
+
if context_norm_type == "ada_norm_continous":
|
| 591 |
+
self.norm1_context = AdaLayerNormContinuous(
|
| 592 |
+
dim, dim, elementwise_affine=False, eps=1e-6, bias=True, norm_type="layer_norm"
|
| 593 |
+
)
|
| 594 |
+
elif context_norm_type == "ada_norm_zero":
|
| 595 |
+
self.norm1_context = AdaLayerNormZero(dim)
|
| 596 |
+
else:
|
| 597 |
+
raise ValueError(
|
| 598 |
+
f"Unknown context_norm_type: {context_norm_type}, currently only support `ada_norm_continous`, `ada_norm_zero`"
|
| 599 |
+
)
|
| 600 |
+
|
| 601 |
+
self.attn = JointAttention(
|
| 602 |
+
query_dim=dim,
|
| 603 |
+
cross_attention_dim=None,
|
| 604 |
+
added_kv_proj_dim=dim,
|
| 605 |
+
dim_head=attention_head_dim // num_attention_heads,
|
| 606 |
+
heads=num_attention_heads,
|
| 607 |
+
out_dim=attention_head_dim,
|
| 608 |
+
qk_norm=qk_norm,
|
| 609 |
+
context_pre_only=context_pre_only,
|
| 610 |
+
bias=True,
|
| 611 |
+
use_flash_attn=use_flash_attn,
|
| 612 |
+
)
|
| 613 |
+
|
| 614 |
+
self.norm2 = nn.LayerNorm(dim, elementwise_affine=False, eps=1e-6)
|
| 615 |
+
self.ff = FeedForward(dim=dim, dim_out=dim, activation_fn="gelu-approximate")
|
| 616 |
+
|
| 617 |
+
if not context_pre_only:
|
| 618 |
+
self.norm2_context = nn.LayerNorm(dim, elementwise_affine=False, eps=1e-6)
|
| 619 |
+
self.ff_context = FeedForward(dim=dim, dim_out=dim, activation_fn="gelu-approximate")
|
| 620 |
+
else:
|
| 621 |
+
self.norm2_context = None
|
| 622 |
+
self.ff_context = None
|
| 623 |
+
|
| 624 |
+
def forward(
|
| 625 |
+
self, hidden_states: torch.FloatTensor, encoder_hidden_states: torch.FloatTensor,
|
| 626 |
+
encoder_attention_mask: torch.FloatTensor, temb: torch.FloatTensor,
|
| 627 |
+
attention_mask: torch.FloatTensor = None, hidden_length: List = None,
|
| 628 |
+
image_rotary_emb: torch.FloatTensor = None,
|
| 629 |
+
):
|
| 630 |
+
norm_hidden_states, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.norm1(hidden_states, emb=temb, hidden_length=hidden_length)
|
| 631 |
+
|
| 632 |
+
if self.context_pre_only:
|
| 633 |
+
norm_encoder_hidden_states = self.norm1_context(encoder_hidden_states, temb)
|
| 634 |
+
else:
|
| 635 |
+
norm_encoder_hidden_states, c_gate_msa, c_shift_mlp, c_scale_mlp, c_gate_mlp = self.norm1_context(
|
| 636 |
+
encoder_hidden_states, emb=temb,
|
| 637 |
+
)
|
| 638 |
+
|
| 639 |
+
# Attention
|
| 640 |
+
attn_output, context_attn_output = self.attn(
|
| 641 |
+
hidden_states=norm_hidden_states, encoder_hidden_states=norm_encoder_hidden_states,
|
| 642 |
+
encoder_attention_mask=encoder_attention_mask, attention_mask=attention_mask,
|
| 643 |
+
hidden_length=hidden_length, image_rotary_emb=image_rotary_emb,
|
| 644 |
+
)
|
| 645 |
+
|
| 646 |
+
# Process attention outputs for the `hidden_states`.
|
| 647 |
+
attn_output = gate_msa * attn_output
|
| 648 |
+
hidden_states = hidden_states + attn_output
|
| 649 |
+
|
| 650 |
+
norm_hidden_states = self.norm2(hidden_states)
|
| 651 |
+
norm_hidden_states = norm_hidden_states * (1 + scale_mlp) + shift_mlp
|
| 652 |
+
|
| 653 |
+
ff_output = self.ff(norm_hidden_states)
|
| 654 |
+
ff_output = gate_mlp * ff_output
|
| 655 |
+
|
| 656 |
+
hidden_states = hidden_states + ff_output
|
| 657 |
+
|
| 658 |
+
# Process attention outputs for the `encoder_hidden_states`.
|
| 659 |
+
if self.context_pre_only:
|
| 660 |
+
encoder_hidden_states = None
|
| 661 |
+
else:
|
| 662 |
+
context_attn_output = c_gate_msa.unsqueeze(1) * context_attn_output
|
| 663 |
+
encoder_hidden_states = encoder_hidden_states + context_attn_output
|
| 664 |
+
|
| 665 |
+
norm_encoder_hidden_states = self.norm2_context(encoder_hidden_states)
|
| 666 |
+
norm_encoder_hidden_states = norm_encoder_hidden_states * (1 + c_scale_mlp[:, None]) + c_shift_mlp[:, None]
|
| 667 |
+
|
| 668 |
+
context_ff_output = self.ff_context(norm_encoder_hidden_states)
|
| 669 |
+
encoder_hidden_states = encoder_hidden_states + c_gate_mlp.unsqueeze(1) * context_ff_output
|
| 670 |
+
|
| 671 |
+
return encoder_hidden_states, hidden_states
|
pyramid_dit/mmdit_modules/modeling_normalization.py
ADDED
|
@@ -0,0 +1,179 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numbers
|
| 2 |
+
from typing import Dict, Optional, Tuple
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
from einops import rearrange
|
| 8 |
+
from diffusers.utils import is_torch_version
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
if is_torch_version(">=", "2.1.0"):
|
| 12 |
+
LayerNorm = nn.LayerNorm
|
| 13 |
+
else:
|
| 14 |
+
# Has optional bias parameter compared to torch layer norm
|
| 15 |
+
# TODO: replace with torch layernorm once min required torch version >= 2.1
|
| 16 |
+
class LayerNorm(nn.Module):
|
| 17 |
+
def __init__(self, dim, eps: float = 1e-5, elementwise_affine: bool = True, bias: bool = True):
|
| 18 |
+
super().__init__()
|
| 19 |
+
|
| 20 |
+
self.eps = eps
|
| 21 |
+
|
| 22 |
+
if isinstance(dim, numbers.Integral):
|
| 23 |
+
dim = (dim,)
|
| 24 |
+
|
| 25 |
+
self.dim = torch.Size(dim)
|
| 26 |
+
|
| 27 |
+
if elementwise_affine:
|
| 28 |
+
self.weight = nn.Parameter(torch.ones(dim))
|
| 29 |
+
self.bias = nn.Parameter(torch.zeros(dim)) if bias else None
|
| 30 |
+
else:
|
| 31 |
+
self.weight = None
|
| 32 |
+
self.bias = None
|
| 33 |
+
|
| 34 |
+
def forward(self, input):
|
| 35 |
+
return F.layer_norm(input, self.dim, self.weight, self.bias, self.eps)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
class RMSNorm(nn.Module):
|
| 39 |
+
def __init__(self, dim, eps: float, elementwise_affine: bool = True):
|
| 40 |
+
super().__init__()
|
| 41 |
+
|
| 42 |
+
self.eps = eps
|
| 43 |
+
|
| 44 |
+
if isinstance(dim, numbers.Integral):
|
| 45 |
+
dim = (dim,)
|
| 46 |
+
|
| 47 |
+
self.dim = torch.Size(dim)
|
| 48 |
+
|
| 49 |
+
if elementwise_affine:
|
| 50 |
+
self.weight = nn.Parameter(torch.ones(dim))
|
| 51 |
+
else:
|
| 52 |
+
self.weight = None
|
| 53 |
+
|
| 54 |
+
def forward(self, hidden_states):
|
| 55 |
+
input_dtype = hidden_states.dtype
|
| 56 |
+
variance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True)
|
| 57 |
+
hidden_states = hidden_states * torch.rsqrt(variance + self.eps)
|
| 58 |
+
|
| 59 |
+
if self.weight is not None:
|
| 60 |
+
# convert into half-precision if necessary
|
| 61 |
+
if self.weight.dtype in [torch.float16, torch.bfloat16]:
|
| 62 |
+
hidden_states = hidden_states.to(self.weight.dtype)
|
| 63 |
+
hidden_states = hidden_states * self.weight
|
| 64 |
+
|
| 65 |
+
hidden_states = hidden_states.to(input_dtype)
|
| 66 |
+
|
| 67 |
+
return hidden_states
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
class AdaLayerNormContinuous(nn.Module):
|
| 71 |
+
def __init__(
|
| 72 |
+
self,
|
| 73 |
+
embedding_dim: int,
|
| 74 |
+
conditioning_embedding_dim: int,
|
| 75 |
+
# NOTE: It is a bit weird that the norm layer can be configured to have scale and shift parameters
|
| 76 |
+
# because the output is immediately scaled and shifted by the projected conditioning embeddings.
|
| 77 |
+
# Note that AdaLayerNorm does not let the norm layer have scale and shift parameters.
|
| 78 |
+
# However, this is how it was implemented in the original code, and it's rather likely you should
|
| 79 |
+
# set `elementwise_affine` to False.
|
| 80 |
+
elementwise_affine=True,
|
| 81 |
+
eps=1e-5,
|
| 82 |
+
bias=True,
|
| 83 |
+
norm_type="layer_norm",
|
| 84 |
+
):
|
| 85 |
+
super().__init__()
|
| 86 |
+
self.silu = nn.SiLU()
|
| 87 |
+
self.linear = nn.Linear(conditioning_embedding_dim, embedding_dim * 2, bias=bias)
|
| 88 |
+
if norm_type == "layer_norm":
|
| 89 |
+
self.norm = LayerNorm(embedding_dim, eps, elementwise_affine, bias)
|
| 90 |
+
elif norm_type == "rms_norm":
|
| 91 |
+
self.norm = RMSNorm(embedding_dim, eps, elementwise_affine)
|
| 92 |
+
else:
|
| 93 |
+
raise ValueError(f"unknown norm_type {norm_type}")
|
| 94 |
+
|
| 95 |
+
def forward_with_pad(self, x: torch.Tensor, conditioning_embedding: torch.Tensor, hidden_length=None) -> torch.Tensor:
|
| 96 |
+
assert hidden_length is not None
|
| 97 |
+
|
| 98 |
+
emb = self.linear(self.silu(conditioning_embedding).to(x.dtype))
|
| 99 |
+
batch_emb = torch.zeros_like(x).repeat(1, 1, 2)
|
| 100 |
+
|
| 101 |
+
i_sum = 0
|
| 102 |
+
num_stages = len(hidden_length)
|
| 103 |
+
for i_p, length in enumerate(hidden_length):
|
| 104 |
+
batch_emb[:, i_sum:i_sum+length] = emb[i_p::num_stages][:,None]
|
| 105 |
+
i_sum += length
|
| 106 |
+
|
| 107 |
+
batch_scale, batch_shift = torch.chunk(batch_emb, 2, dim=2)
|
| 108 |
+
x = self.norm(x) * (1 + batch_scale) + batch_shift
|
| 109 |
+
return x
|
| 110 |
+
|
| 111 |
+
def forward(self, x: torch.Tensor, conditioning_embedding: torch.Tensor, hidden_length=None) -> torch.Tensor:
|
| 112 |
+
# convert back to the original dtype in case `conditioning_embedding`` is upcasted to float32 (needed for hunyuanDiT)
|
| 113 |
+
if hidden_length is not None:
|
| 114 |
+
return self.forward_with_pad(x, conditioning_embedding, hidden_length)
|
| 115 |
+
emb = self.linear(self.silu(conditioning_embedding).to(x.dtype))
|
| 116 |
+
scale, shift = torch.chunk(emb, 2, dim=1)
|
| 117 |
+
x = self.norm(x) * (1 + scale)[:, None, :] + shift[:, None, :]
|
| 118 |
+
return x
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
class AdaLayerNormZero(nn.Module):
|
| 122 |
+
r"""
|
| 123 |
+
Norm layer adaptive layer norm zero (adaLN-Zero).
|
| 124 |
+
|
| 125 |
+
Parameters:
|
| 126 |
+
embedding_dim (`int`): The size of each embedding vector.
|
| 127 |
+
num_embeddings (`int`): The size of the embeddings dictionary.
|
| 128 |
+
"""
|
| 129 |
+
|
| 130 |
+
def __init__(self, embedding_dim: int, num_embeddings: Optional[int] = None):
|
| 131 |
+
super().__init__()
|
| 132 |
+
self.emb = None
|
| 133 |
+
self.silu = nn.SiLU()
|
| 134 |
+
self.linear = nn.Linear(embedding_dim, 6 * embedding_dim, bias=True)
|
| 135 |
+
self.norm = nn.LayerNorm(embedding_dim, elementwise_affine=False, eps=1e-6)
|
| 136 |
+
|
| 137 |
+
def forward_with_pad(
|
| 138 |
+
self,
|
| 139 |
+
x: torch.Tensor,
|
| 140 |
+
timestep: Optional[torch.Tensor] = None,
|
| 141 |
+
class_labels: Optional[torch.LongTensor] = None,
|
| 142 |
+
hidden_dtype: Optional[torch.dtype] = None,
|
| 143 |
+
emb: Optional[torch.Tensor] = None,
|
| 144 |
+
hidden_length: Optional[torch.Tensor] = None,
|
| 145 |
+
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
|
| 146 |
+
# x: [bs, seq_len, dim]
|
| 147 |
+
if self.emb is not None:
|
| 148 |
+
emb = self.emb(timestep, class_labels, hidden_dtype=hidden_dtype)
|
| 149 |
+
|
| 150 |
+
emb = self.linear(self.silu(emb))
|
| 151 |
+
batch_emb = torch.zeros_like(x).repeat(1, 1, 6)
|
| 152 |
+
|
| 153 |
+
i_sum = 0
|
| 154 |
+
num_stages = len(hidden_length)
|
| 155 |
+
for i_p, length in enumerate(hidden_length):
|
| 156 |
+
batch_emb[:, i_sum:i_sum+length] = emb[i_p::num_stages][:,None]
|
| 157 |
+
i_sum += length
|
| 158 |
+
|
| 159 |
+
batch_shift_msa, batch_scale_msa, batch_gate_msa, batch_shift_mlp, batch_scale_mlp, batch_gate_mlp = batch_emb.chunk(6, dim=2)
|
| 160 |
+
x = self.norm(x) * (1 + batch_scale_msa) + batch_shift_msa
|
| 161 |
+
return x, batch_gate_msa, batch_shift_mlp, batch_scale_mlp, batch_gate_mlp
|
| 162 |
+
|
| 163 |
+
def forward(
|
| 164 |
+
self,
|
| 165 |
+
x: torch.Tensor,
|
| 166 |
+
timestep: Optional[torch.Tensor] = None,
|
| 167 |
+
class_labels: Optional[torch.LongTensor] = None,
|
| 168 |
+
hidden_dtype: Optional[torch.dtype] = None,
|
| 169 |
+
emb: Optional[torch.Tensor] = None,
|
| 170 |
+
hidden_length: Optional[torch.Tensor] = None,
|
| 171 |
+
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
|
| 172 |
+
if hidden_length is not None:
|
| 173 |
+
return self.forward_with_pad(x, timestep, class_labels, hidden_dtype, emb, hidden_length)
|
| 174 |
+
if self.emb is not None:
|
| 175 |
+
emb = self.emb(timestep, class_labels, hidden_dtype=hidden_dtype)
|
| 176 |
+
emb = self.linear(self.silu(emb))
|
| 177 |
+
shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = emb.chunk(6, dim=1)
|
| 178 |
+
x = self.norm(x) * (1 + scale_msa[:, None]) + shift_msa[:, None]
|
| 179 |
+
return x, gate_msa, shift_mlp, scale_mlp, gate_mlp
|
pyramid_dit/mmdit_modules/modeling_pyramid_mmdit.py
ADDED
|
@@ -0,0 +1,497 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import os
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
|
| 6 |
+
from einops import rearrange
|
| 7 |
+
from diffusers.utils.torch_utils import randn_tensor
|
| 8 |
+
from diffusers.models.modeling_utils import ModelMixin
|
| 9 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 10 |
+
from diffusers.utils import is_torch_version
|
| 11 |
+
from typing import Any, Callable, Dict, List, Optional, Union
|
| 12 |
+
|
| 13 |
+
from .modeling_embedding import PatchEmbed3D, CombinedTimestepConditionEmbeddings
|
| 14 |
+
from .modeling_normalization import AdaLayerNormContinuous
|
| 15 |
+
from .modeling_mmdit_block import JointTransformerBlock
|
| 16 |
+
|
| 17 |
+
from trainer_misc import (
|
| 18 |
+
is_sequence_parallel_initialized,
|
| 19 |
+
get_sequence_parallel_group,
|
| 20 |
+
get_sequence_parallel_world_size,
|
| 21 |
+
get_sequence_parallel_rank,
|
| 22 |
+
all_to_all,
|
| 23 |
+
)
|
| 24 |
+
|
| 25 |
+
from IPython import embed
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def rope(pos: torch.Tensor, dim: int, theta: int) -> torch.Tensor:
|
| 29 |
+
assert dim % 2 == 0, "The dimension must be even."
|
| 30 |
+
|
| 31 |
+
scale = torch.arange(0, dim, 2, dtype=torch.float64, device=pos.device) / dim
|
| 32 |
+
omega = 1.0 / (theta**scale)
|
| 33 |
+
|
| 34 |
+
batch_size, seq_length = pos.shape
|
| 35 |
+
out = torch.einsum("...n,d->...nd", pos, omega)
|
| 36 |
+
cos_out = torch.cos(out)
|
| 37 |
+
sin_out = torch.sin(out)
|
| 38 |
+
|
| 39 |
+
stacked_out = torch.stack([cos_out, -sin_out, sin_out, cos_out], dim=-1)
|
| 40 |
+
out = stacked_out.view(batch_size, -1, dim // 2, 2, 2)
|
| 41 |
+
return out.float()
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
class EmbedNDRoPE(nn.Module):
|
| 45 |
+
def __init__(self, dim: int, theta: int, axes_dim: List[int]):
|
| 46 |
+
super().__init__()
|
| 47 |
+
self.dim = dim
|
| 48 |
+
self.theta = theta
|
| 49 |
+
self.axes_dim = axes_dim
|
| 50 |
+
|
| 51 |
+
def forward(self, ids: torch.Tensor) -> torch.Tensor:
|
| 52 |
+
n_axes = ids.shape[-1]
|
| 53 |
+
emb = torch.cat(
|
| 54 |
+
[rope(ids[..., i], self.axes_dim[i], self.theta) for i in range(n_axes)],
|
| 55 |
+
dim=-3,
|
| 56 |
+
)
|
| 57 |
+
return emb.unsqueeze(2)
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
class PyramidDiffusionMMDiT(ModelMixin, ConfigMixin):
|
| 61 |
+
_supports_gradient_checkpointing = True
|
| 62 |
+
|
| 63 |
+
@register_to_config
|
| 64 |
+
def __init__(
|
| 65 |
+
self,
|
| 66 |
+
sample_size: int = 128,
|
| 67 |
+
patch_size: int = 2,
|
| 68 |
+
in_channels: int = 16,
|
| 69 |
+
num_layers: int = 24,
|
| 70 |
+
attention_head_dim: int = 64,
|
| 71 |
+
num_attention_heads: int = 24,
|
| 72 |
+
caption_projection_dim: int = 1152,
|
| 73 |
+
pooled_projection_dim: int = 2048,
|
| 74 |
+
pos_embed_max_size: int = 192,
|
| 75 |
+
max_num_frames: int = 200,
|
| 76 |
+
qk_norm: str = 'rms_norm',
|
| 77 |
+
pos_embed_type: str = 'rope',
|
| 78 |
+
temp_pos_embed_type: str = 'sincos',
|
| 79 |
+
joint_attention_dim: int = 4096,
|
| 80 |
+
use_gradient_checkpointing: bool = False,
|
| 81 |
+
use_flash_attn: bool = True,
|
| 82 |
+
use_temporal_causal: bool = False,
|
| 83 |
+
use_t5_mask: bool = False,
|
| 84 |
+
add_temp_pos_embed: bool = False,
|
| 85 |
+
interp_condition_pos: bool = False,
|
| 86 |
+
gradient_checkpointing_ratio: float = 0.6,
|
| 87 |
+
):
|
| 88 |
+
super().__init__()
|
| 89 |
+
|
| 90 |
+
self.out_channels = in_channels
|
| 91 |
+
self.inner_dim = num_attention_heads * attention_head_dim
|
| 92 |
+
assert temp_pos_embed_type in ['rope', 'sincos']
|
| 93 |
+
|
| 94 |
+
# The input latent embeder, using the name pos_embed to remain the same with SD#
|
| 95 |
+
self.pos_embed = PatchEmbed3D(
|
| 96 |
+
height=sample_size,
|
| 97 |
+
width=sample_size,
|
| 98 |
+
patch_size=patch_size,
|
| 99 |
+
in_channels=in_channels,
|
| 100 |
+
embed_dim=self.inner_dim,
|
| 101 |
+
pos_embed_max_size=pos_embed_max_size, # hard-code for now.
|
| 102 |
+
max_num_frames=max_num_frames,
|
| 103 |
+
pos_embed_type=pos_embed_type,
|
| 104 |
+
temp_pos_embed_type=temp_pos_embed_type,
|
| 105 |
+
add_temp_pos_embed=add_temp_pos_embed,
|
| 106 |
+
interp_condition_pos=interp_condition_pos,
|
| 107 |
+
)
|
| 108 |
+
|
| 109 |
+
# The RoPE EMbedding
|
| 110 |
+
if pos_embed_type == 'rope':
|
| 111 |
+
self.rope_embed = EmbedNDRoPE(self.inner_dim, 10000, axes_dim=[16, 24, 24])
|
| 112 |
+
else:
|
| 113 |
+
self.rope_embed = None
|
| 114 |
+
|
| 115 |
+
if temp_pos_embed_type == 'rope':
|
| 116 |
+
self.temp_rope_embed = EmbedNDRoPE(self.inner_dim, 10000, axes_dim=[attention_head_dim])
|
| 117 |
+
else:
|
| 118 |
+
self.temp_rope_embed = None
|
| 119 |
+
|
| 120 |
+
self.time_text_embed = CombinedTimestepConditionEmbeddings(
|
| 121 |
+
embedding_dim=self.inner_dim, pooled_projection_dim=self.config.pooled_projection_dim,
|
| 122 |
+
)
|
| 123 |
+
self.context_embedder = nn.Linear(self.config.joint_attention_dim, self.config.caption_projection_dim)
|
| 124 |
+
|
| 125 |
+
self.transformer_blocks = nn.ModuleList(
|
| 126 |
+
[
|
| 127 |
+
JointTransformerBlock(
|
| 128 |
+
dim=self.inner_dim,
|
| 129 |
+
num_attention_heads=num_attention_heads,
|
| 130 |
+
attention_head_dim=self.inner_dim,
|
| 131 |
+
qk_norm=qk_norm,
|
| 132 |
+
context_pre_only=i == num_layers - 1,
|
| 133 |
+
use_flash_attn=use_flash_attn,
|
| 134 |
+
)
|
| 135 |
+
for i in range(num_layers)
|
| 136 |
+
]
|
| 137 |
+
)
|
| 138 |
+
|
| 139 |
+
self.norm_out = AdaLayerNormContinuous(self.inner_dim, self.inner_dim, elementwise_affine=False, eps=1e-6)
|
| 140 |
+
self.proj_out = nn.Linear(self.inner_dim, patch_size * patch_size * self.out_channels, bias=True)
|
| 141 |
+
self.gradient_checkpointing = use_gradient_checkpointing
|
| 142 |
+
self.gradient_checkpointing_ratio = gradient_checkpointing_ratio
|
| 143 |
+
|
| 144 |
+
self.patch_size = patch_size
|
| 145 |
+
self.use_flash_attn = use_flash_attn
|
| 146 |
+
self.use_temporal_causal = use_temporal_causal
|
| 147 |
+
self.pos_embed_type = pos_embed_type
|
| 148 |
+
self.temp_pos_embed_type = temp_pos_embed_type
|
| 149 |
+
self.add_temp_pos_embed = add_temp_pos_embed
|
| 150 |
+
|
| 151 |
+
if self.use_temporal_causal:
|
| 152 |
+
print("Using temporal causal attention")
|
| 153 |
+
assert self.use_flash_attn is False, "The flash attention does not support temporal causal"
|
| 154 |
+
|
| 155 |
+
if interp_condition_pos:
|
| 156 |
+
print("We interp the position embedding of condition latents")
|
| 157 |
+
|
| 158 |
+
# init weights
|
| 159 |
+
self.initialize_weights()
|
| 160 |
+
|
| 161 |
+
def initialize_weights(self):
|
| 162 |
+
# Initialize transformer layers:
|
| 163 |
+
def _basic_init(module):
|
| 164 |
+
if isinstance(module, (nn.Linear, nn.Conv2d, nn.Conv3d)):
|
| 165 |
+
torch.nn.init.xavier_uniform_(module.weight)
|
| 166 |
+
if module.bias is not None:
|
| 167 |
+
nn.init.constant_(module.bias, 0)
|
| 168 |
+
self.apply(_basic_init)
|
| 169 |
+
|
| 170 |
+
# Initialize patch_embed like nn.Linear (instead of nn.Conv2d):
|
| 171 |
+
w = self.pos_embed.proj.weight.data
|
| 172 |
+
nn.init.xavier_uniform_(w.view([w.shape[0], -1]))
|
| 173 |
+
nn.init.constant_(self.pos_embed.proj.bias, 0)
|
| 174 |
+
|
| 175 |
+
# Initialize all the conditioning to normal init
|
| 176 |
+
nn.init.normal_(self.time_text_embed.timestep_embedder.linear_1.weight, std=0.02)
|
| 177 |
+
nn.init.normal_(self.time_text_embed.timestep_embedder.linear_2.weight, std=0.02)
|
| 178 |
+
nn.init.normal_(self.time_text_embed.text_embedder.linear_1.weight, std=0.02)
|
| 179 |
+
nn.init.normal_(self.time_text_embed.text_embedder.linear_2.weight, std=0.02)
|
| 180 |
+
nn.init.normal_(self.context_embedder.weight, std=0.02)
|
| 181 |
+
|
| 182 |
+
# Zero-out adaLN modulation layers in DiT blocks:
|
| 183 |
+
for block in self.transformer_blocks:
|
| 184 |
+
nn.init.constant_(block.norm1.linear.weight, 0)
|
| 185 |
+
nn.init.constant_(block.norm1.linear.bias, 0)
|
| 186 |
+
nn.init.constant_(block.norm1_context.linear.weight, 0)
|
| 187 |
+
nn.init.constant_(block.norm1_context.linear.bias, 0)
|
| 188 |
+
|
| 189 |
+
# Zero-out output layers:
|
| 190 |
+
nn.init.constant_(self.norm_out.linear.weight, 0)
|
| 191 |
+
nn.init.constant_(self.norm_out.linear.bias, 0)
|
| 192 |
+
nn.init.constant_(self.proj_out.weight, 0)
|
| 193 |
+
nn.init.constant_(self.proj_out.bias, 0)
|
| 194 |
+
|
| 195 |
+
@torch.no_grad()
|
| 196 |
+
def _prepare_latent_image_ids(self, batch_size, temp, height, width, device):
|
| 197 |
+
latent_image_ids = torch.zeros(temp, height, width, 3)
|
| 198 |
+
latent_image_ids[..., 0] = latent_image_ids[..., 0] + torch.arange(temp)[:, None, None]
|
| 199 |
+
latent_image_ids[..., 1] = latent_image_ids[..., 1] + torch.arange(height)[None, :, None]
|
| 200 |
+
latent_image_ids[..., 2] = latent_image_ids[..., 2] + torch.arange(width)[None, None, :]
|
| 201 |
+
|
| 202 |
+
latent_image_ids = latent_image_ids[None, :].repeat(batch_size, 1, 1, 1, 1)
|
| 203 |
+
latent_image_ids = rearrange(latent_image_ids, 'b t h w c -> b (t h w) c')
|
| 204 |
+
return latent_image_ids.to(device=device)
|
| 205 |
+
|
| 206 |
+
@torch.no_grad()
|
| 207 |
+
def _prepare_pyramid_latent_image_ids(self, batch_size, temp_list, height_list, width_list, device):
|
| 208 |
+
base_width = width_list[-1]; base_height = height_list[-1]
|
| 209 |
+
assert base_width == max(width_list)
|
| 210 |
+
assert base_height == max(height_list)
|
| 211 |
+
|
| 212 |
+
image_ids_list = []
|
| 213 |
+
for temp, height, width in zip(temp_list, height_list, width_list):
|
| 214 |
+
latent_image_ids = torch.zeros(temp, height, width, 3)
|
| 215 |
+
|
| 216 |
+
if height != base_height:
|
| 217 |
+
height_pos = F.interpolate(torch.arange(base_height)[None, None, :].float(), height, mode='linear').squeeze(0, 1)
|
| 218 |
+
else:
|
| 219 |
+
height_pos = torch.arange(base_height).float()
|
| 220 |
+
if width != base_width:
|
| 221 |
+
width_pos = F.interpolate(torch.arange(base_width)[None, None, :].float(), width, mode='linear').squeeze(0, 1)
|
| 222 |
+
else:
|
| 223 |
+
width_pos = torch.arange(base_width).float()
|
| 224 |
+
|
| 225 |
+
latent_image_ids[..., 0] = latent_image_ids[..., 0] + torch.arange(temp)[:, None, None]
|
| 226 |
+
latent_image_ids[..., 1] = latent_image_ids[..., 1] + height_pos[None, :, None]
|
| 227 |
+
latent_image_ids[..., 2] = latent_image_ids[..., 2] + width_pos[None, None, :]
|
| 228 |
+
latent_image_ids = latent_image_ids[None, :].repeat(batch_size, 1, 1, 1, 1)
|
| 229 |
+
latent_image_ids = rearrange(latent_image_ids, 'b t h w c -> b (t h w) c').to(device)
|
| 230 |
+
image_ids_list.append(latent_image_ids)
|
| 231 |
+
|
| 232 |
+
return image_ids_list
|
| 233 |
+
|
| 234 |
+
@torch.no_grad()
|
| 235 |
+
def _prepare_temporal_rope_ids(self, batch_size, temp, height, width, device, start_time_stamp=0):
|
| 236 |
+
latent_image_ids = torch.zeros(temp, height, width, 1)
|
| 237 |
+
latent_image_ids[..., 0] = latent_image_ids[..., 0] + torch.arange(start_time_stamp, start_time_stamp + temp)[:, None, None]
|
| 238 |
+
latent_image_ids = latent_image_ids[None, :].repeat(batch_size, 1, 1, 1, 1)
|
| 239 |
+
latent_image_ids = rearrange(latent_image_ids, 'b t h w c -> b (t h w) c')
|
| 240 |
+
return latent_image_ids.to(device=device)
|
| 241 |
+
|
| 242 |
+
@torch.no_grad()
|
| 243 |
+
def _prepare_pyramid_temporal_rope_ids(self, sample, batch_size, device):
|
| 244 |
+
image_ids_list = []
|
| 245 |
+
|
| 246 |
+
for i_b, sample_ in enumerate(sample):
|
| 247 |
+
if not isinstance(sample_, list):
|
| 248 |
+
sample_ = [sample_]
|
| 249 |
+
|
| 250 |
+
cur_image_ids = []
|
| 251 |
+
start_time_stamp = 0
|
| 252 |
+
|
| 253 |
+
for clip_ in sample_:
|
| 254 |
+
_, _, temp, height, width = clip_.shape
|
| 255 |
+
height = height // self.patch_size
|
| 256 |
+
width = width // self.patch_size
|
| 257 |
+
cur_image_ids.append(self._prepare_temporal_rope_ids(batch_size, temp, height, width, device, start_time_stamp=start_time_stamp))
|
| 258 |
+
start_time_stamp += temp
|
| 259 |
+
|
| 260 |
+
cur_image_ids = torch.cat(cur_image_ids, dim=1)
|
| 261 |
+
image_ids_list.append(cur_image_ids)
|
| 262 |
+
|
| 263 |
+
return image_ids_list
|
| 264 |
+
|
| 265 |
+
def merge_input(self, sample, encoder_hidden_length, encoder_attention_mask):
|
| 266 |
+
"""
|
| 267 |
+
Merge the input video with different resolutions into one sequence
|
| 268 |
+
Sample: From low resolution to high resolution
|
| 269 |
+
"""
|
| 270 |
+
if isinstance(sample[0], list):
|
| 271 |
+
device = sample[0][-1].device
|
| 272 |
+
pad_batch_size = sample[0][-1].shape[0]
|
| 273 |
+
else:
|
| 274 |
+
device = sample[0].device
|
| 275 |
+
pad_batch_size = sample[0].shape[0]
|
| 276 |
+
|
| 277 |
+
num_stages = len(sample)
|
| 278 |
+
height_list = [];width_list = [];temp_list = []
|
| 279 |
+
trainable_token_list = []
|
| 280 |
+
|
| 281 |
+
for i_b, sample_ in enumerate(sample):
|
| 282 |
+
if isinstance(sample_, list):
|
| 283 |
+
sample_ = sample_[-1]
|
| 284 |
+
_, _, temp, height, width = sample_.shape
|
| 285 |
+
height = height // self.patch_size
|
| 286 |
+
width = width // self.patch_size
|
| 287 |
+
temp_list.append(temp)
|
| 288 |
+
height_list.append(height)
|
| 289 |
+
width_list.append(width)
|
| 290 |
+
trainable_token_list.append(height * width * temp)
|
| 291 |
+
|
| 292 |
+
# prepare the RoPE embedding if needed
|
| 293 |
+
if self.pos_embed_type == 'rope':
|
| 294 |
+
# TODO: support the 3D Rope for video
|
| 295 |
+
raise NotImplementedError("Not compatible with video generation now")
|
| 296 |
+
text_ids = torch.zeros(pad_batch_size, encoder_hidden_length, 3).to(device=device)
|
| 297 |
+
image_ids_list = self._prepare_pyramid_latent_image_ids(pad_batch_size, temp_list, height_list, width_list, device)
|
| 298 |
+
input_ids_list = [torch.cat([text_ids, image_ids], dim=1) for image_ids in image_ids_list]
|
| 299 |
+
image_rotary_emb = [self.rope_embed(input_ids) for input_ids in input_ids_list] # [bs, seq_len, 1, head_dim // 2, 2, 2]
|
| 300 |
+
else:
|
| 301 |
+
if self.temp_pos_embed_type == 'rope' and self.add_temp_pos_embed:
|
| 302 |
+
image_ids_list = self._prepare_pyramid_temporal_rope_ids(sample, pad_batch_size, device)
|
| 303 |
+
text_ids = torch.zeros(pad_batch_size, encoder_attention_mask.shape[1], 1).to(device=device)
|
| 304 |
+
input_ids_list = [torch.cat([text_ids, image_ids], dim=1) for image_ids in image_ids_list]
|
| 305 |
+
image_rotary_emb = [self.temp_rope_embed(input_ids) for input_ids in input_ids_list] # [bs, seq_len, 1, head_dim // 2, 2, 2]
|
| 306 |
+
|
| 307 |
+
if is_sequence_parallel_initialized():
|
| 308 |
+
sp_group = get_sequence_parallel_group()
|
| 309 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 310 |
+
concat_output = True if self.training else False
|
| 311 |
+
image_rotary_emb = [all_to_all(x_.repeat(1, 1, sp_group_size, 1, 1, 1), sp_group, sp_group_size, scatter_dim=2, gather_dim=0, concat_output=concat_output) for x_ in image_rotary_emb]
|
| 312 |
+
input_ids_list = [all_to_all(input_ids.repeat(1, 1, sp_group_size), sp_group, sp_group_size, scatter_dim=2, gather_dim=0, concat_output=concat_output) for input_ids in input_ids_list]
|
| 313 |
+
|
| 314 |
+
else:
|
| 315 |
+
image_rotary_emb = None
|
| 316 |
+
|
| 317 |
+
hidden_states = self.pos_embed(sample) # hidden states is a list of [b c t h w] b = real_b // num_stages
|
| 318 |
+
hidden_length = []
|
| 319 |
+
|
| 320 |
+
for i_b in range(num_stages):
|
| 321 |
+
hidden_length.append(hidden_states[i_b].shape[1])
|
| 322 |
+
|
| 323 |
+
# prepare the attention mask
|
| 324 |
+
if self.use_flash_attn:
|
| 325 |
+
attention_mask = None
|
| 326 |
+
indices_list = []
|
| 327 |
+
for i_p, length in enumerate(hidden_length):
|
| 328 |
+
pad_attention_mask = torch.ones((pad_batch_size, length), dtype=encoder_attention_mask.dtype).to(device)
|
| 329 |
+
pad_attention_mask = torch.cat([encoder_attention_mask[i_p::num_stages], pad_attention_mask], dim=1)
|
| 330 |
+
|
| 331 |
+
if is_sequence_parallel_initialized():
|
| 332 |
+
sp_group = get_sequence_parallel_group()
|
| 333 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 334 |
+
pad_attention_mask = all_to_all(pad_attention_mask.unsqueeze(2).repeat(1, 1, sp_group_size), sp_group, sp_group_size, scatter_dim=2, gather_dim=0)
|
| 335 |
+
pad_attention_mask = pad_attention_mask.squeeze(2)
|
| 336 |
+
|
| 337 |
+
seqlens_in_batch = pad_attention_mask.sum(dim=-1, dtype=torch.int32)
|
| 338 |
+
indices = torch.nonzero(pad_attention_mask.flatten(), as_tuple=False).flatten()
|
| 339 |
+
|
| 340 |
+
indices_list.append(
|
| 341 |
+
{
|
| 342 |
+
'indices': indices,
|
| 343 |
+
'seqlens_in_batch': seqlens_in_batch,
|
| 344 |
+
}
|
| 345 |
+
)
|
| 346 |
+
encoder_attention_mask = indices_list
|
| 347 |
+
else:
|
| 348 |
+
assert encoder_attention_mask.shape[1] == encoder_hidden_length
|
| 349 |
+
real_batch_size = encoder_attention_mask.shape[0]
|
| 350 |
+
# prepare text ids
|
| 351 |
+
text_ids = torch.arange(1, real_batch_size + 1, dtype=encoder_attention_mask.dtype).unsqueeze(1).repeat(1, encoder_hidden_length)
|
| 352 |
+
text_ids = text_ids.to(device)
|
| 353 |
+
text_ids[encoder_attention_mask == 0] = 0
|
| 354 |
+
|
| 355 |
+
# prepare image ids
|
| 356 |
+
image_ids = torch.arange(1, real_batch_size + 1, dtype=encoder_attention_mask.dtype).unsqueeze(1).repeat(1, max(hidden_length))
|
| 357 |
+
image_ids = image_ids.to(device)
|
| 358 |
+
image_ids_list = []
|
| 359 |
+
for i_p, length in enumerate(hidden_length):
|
| 360 |
+
image_ids_list.append(image_ids[i_p::num_stages][:, :length])
|
| 361 |
+
|
| 362 |
+
if is_sequence_parallel_initialized():
|
| 363 |
+
sp_group = get_sequence_parallel_group()
|
| 364 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 365 |
+
concat_output = True if self.training else False
|
| 366 |
+
text_ids = all_to_all(text_ids.unsqueeze(2).repeat(1, 1, sp_group_size), sp_group, sp_group_size, scatter_dim=2, gather_dim=0, concat_output=concat_output).squeeze(2)
|
| 367 |
+
image_ids_list = [all_to_all(image_ids_.unsqueeze(2).repeat(1, 1, sp_group_size), sp_group, sp_group_size, scatter_dim=2, gather_dim=0, concat_output=concat_output).squeeze(2) for image_ids_ in image_ids_list]
|
| 368 |
+
|
| 369 |
+
attention_mask = []
|
| 370 |
+
for i_p in range(len(hidden_length)):
|
| 371 |
+
image_ids = image_ids_list[i_p]
|
| 372 |
+
token_ids = torch.cat([text_ids[i_p::num_stages], image_ids], dim=1)
|
| 373 |
+
stage_attention_mask = rearrange(token_ids, 'b i -> b 1 i 1') == rearrange(token_ids, 'b j -> b 1 1 j') # [bs, 1, q_len, k_len]
|
| 374 |
+
if self.use_temporal_causal:
|
| 375 |
+
input_order_ids = input_ids_list[i_p].squeeze(2)
|
| 376 |
+
temporal_causal_mask = rearrange(input_order_ids, 'b i -> b 1 i 1') >= rearrange(input_order_ids, 'b j -> b 1 1 j')
|
| 377 |
+
stage_attention_mask = stage_attention_mask & temporal_causal_mask
|
| 378 |
+
attention_mask.append(stage_attention_mask)
|
| 379 |
+
|
| 380 |
+
return hidden_states, hidden_length, temp_list, height_list, width_list, trainable_token_list, encoder_attention_mask, attention_mask, image_rotary_emb
|
| 381 |
+
|
| 382 |
+
def split_output(self, batch_hidden_states, hidden_length, temps, heights, widths, trainable_token_list):
|
| 383 |
+
# To split the hidden states
|
| 384 |
+
batch_size = batch_hidden_states.shape[0]
|
| 385 |
+
output_hidden_list = []
|
| 386 |
+
batch_hidden_states = torch.split(batch_hidden_states, hidden_length, dim=1)
|
| 387 |
+
|
| 388 |
+
if is_sequence_parallel_initialized():
|
| 389 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 390 |
+
if self.training:
|
| 391 |
+
batch_size = batch_size // sp_group_size
|
| 392 |
+
|
| 393 |
+
for i_p, length in enumerate(hidden_length):
|
| 394 |
+
width, height, temp = widths[i_p], heights[i_p], temps[i_p]
|
| 395 |
+
trainable_token_num = trainable_token_list[i_p]
|
| 396 |
+
hidden_states = batch_hidden_states[i_p]
|
| 397 |
+
|
| 398 |
+
if is_sequence_parallel_initialized():
|
| 399 |
+
sp_group = get_sequence_parallel_group()
|
| 400 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 401 |
+
|
| 402 |
+
if not self.training:
|
| 403 |
+
hidden_states = hidden_states.repeat(sp_group_size, 1, 1)
|
| 404 |
+
|
| 405 |
+
hidden_states = all_to_all(hidden_states, sp_group, sp_group_size, scatter_dim=0, gather_dim=1)
|
| 406 |
+
|
| 407 |
+
# only the trainable token are taking part in loss computation
|
| 408 |
+
hidden_states = hidden_states[:, -trainable_token_num:]
|
| 409 |
+
|
| 410 |
+
# unpatchify
|
| 411 |
+
hidden_states = hidden_states.reshape(
|
| 412 |
+
shape=(batch_size, temp, height, width, self.patch_size, self.patch_size, self.out_channels)
|
| 413 |
+
)
|
| 414 |
+
hidden_states = rearrange(hidden_states, "b t h w p1 p2 c -> b t (h p1) (w p2) c")
|
| 415 |
+
hidden_states = rearrange(hidden_states, "b t h w c -> b c t h w")
|
| 416 |
+
output_hidden_list.append(hidden_states)
|
| 417 |
+
|
| 418 |
+
return output_hidden_list
|
| 419 |
+
|
| 420 |
+
def forward(
|
| 421 |
+
self,
|
| 422 |
+
sample: torch.FloatTensor, # [num_stages]
|
| 423 |
+
encoder_hidden_states: torch.FloatTensor = None,
|
| 424 |
+
encoder_attention_mask: torch.FloatTensor = None,
|
| 425 |
+
pooled_projections: torch.FloatTensor = None,
|
| 426 |
+
timestep_ratio: torch.FloatTensor = None,
|
| 427 |
+
):
|
| 428 |
+
# Get the timestep embedding
|
| 429 |
+
temb = self.time_text_embed(timestep_ratio, pooled_projections)
|
| 430 |
+
encoder_hidden_states = self.context_embedder(encoder_hidden_states)
|
| 431 |
+
encoder_hidden_length = encoder_hidden_states.shape[1]
|
| 432 |
+
|
| 433 |
+
# Get the input sequence
|
| 434 |
+
hidden_states, hidden_length, temps, heights, widths, trainable_token_list, encoder_attention_mask, \
|
| 435 |
+
attention_mask, image_rotary_emb = self.merge_input(sample, encoder_hidden_length, encoder_attention_mask)
|
| 436 |
+
|
| 437 |
+
# split the long latents if necessary
|
| 438 |
+
if is_sequence_parallel_initialized():
|
| 439 |
+
sp_group = get_sequence_parallel_group()
|
| 440 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 441 |
+
concat_output = True if self.training else False
|
| 442 |
+
|
| 443 |
+
# sync the input hidden states
|
| 444 |
+
batch_hidden_states = []
|
| 445 |
+
for i_p, hidden_states_ in enumerate(hidden_states):
|
| 446 |
+
assert hidden_states_.shape[1] % sp_group_size == 0, "The sequence length should be divided by sequence parallel size"
|
| 447 |
+
hidden_states_ = all_to_all(hidden_states_, sp_group, sp_group_size, scatter_dim=1, gather_dim=0, concat_output=concat_output)
|
| 448 |
+
hidden_length[i_p] = hidden_length[i_p] // sp_group_size
|
| 449 |
+
batch_hidden_states.append(hidden_states_)
|
| 450 |
+
|
| 451 |
+
# sync the encoder hidden states
|
| 452 |
+
hidden_states = torch.cat(batch_hidden_states, dim=1)
|
| 453 |
+
encoder_hidden_states = all_to_all(encoder_hidden_states, sp_group, sp_group_size, scatter_dim=1, gather_dim=0, concat_output=concat_output)
|
| 454 |
+
temb = all_to_all(temb.unsqueeze(1).repeat(1, sp_group_size, 1), sp_group, sp_group_size, scatter_dim=1, gather_dim=0, concat_output=concat_output)
|
| 455 |
+
temb = temb.squeeze(1)
|
| 456 |
+
else:
|
| 457 |
+
hidden_states = torch.cat(hidden_states, dim=1)
|
| 458 |
+
|
| 459 |
+
# print(hidden_length)
|
| 460 |
+
for i_b, block in enumerate(self.transformer_blocks):
|
| 461 |
+
if self.training and self.gradient_checkpointing and (i_b >= int(len(self.transformer_blocks) * self.gradient_checkpointing_ratio)):
|
| 462 |
+
def create_custom_forward(module):
|
| 463 |
+
def custom_forward(*inputs):
|
| 464 |
+
return module(*inputs)
|
| 465 |
+
|
| 466 |
+
return custom_forward
|
| 467 |
+
|
| 468 |
+
ckpt_kwargs: Dict[str, Any] = {"use_reentrant": False} if is_torch_version(">=", "1.11.0") else {}
|
| 469 |
+
encoder_hidden_states, hidden_states = torch.utils.checkpoint.checkpoint(
|
| 470 |
+
create_custom_forward(block),
|
| 471 |
+
hidden_states,
|
| 472 |
+
encoder_hidden_states,
|
| 473 |
+
encoder_attention_mask,
|
| 474 |
+
temb,
|
| 475 |
+
attention_mask,
|
| 476 |
+
hidden_length,
|
| 477 |
+
image_rotary_emb,
|
| 478 |
+
**ckpt_kwargs,
|
| 479 |
+
)
|
| 480 |
+
|
| 481 |
+
else:
|
| 482 |
+
encoder_hidden_states, hidden_states = block(
|
| 483 |
+
hidden_states=hidden_states,
|
| 484 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 485 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 486 |
+
temb=temb,
|
| 487 |
+
attention_mask=attention_mask,
|
| 488 |
+
hidden_length=hidden_length,
|
| 489 |
+
image_rotary_emb=image_rotary_emb,
|
| 490 |
+
)
|
| 491 |
+
|
| 492 |
+
hidden_states = self.norm_out(hidden_states, temb, hidden_length=hidden_length)
|
| 493 |
+
hidden_states = self.proj_out(hidden_states)
|
| 494 |
+
|
| 495 |
+
output = self.split_output(hidden_states, hidden_length, temps, heights, widths, trainable_token_list)
|
| 496 |
+
|
| 497 |
+
return output
|
pyramid_dit/mmdit_modules/modeling_text_encoder.py
ADDED
|
@@ -0,0 +1,140 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
from transformers import (
|
| 6 |
+
CLIPTextModelWithProjection,
|
| 7 |
+
CLIPTokenizer,
|
| 8 |
+
T5EncoderModel,
|
| 9 |
+
T5TokenizerFast,
|
| 10 |
+
)
|
| 11 |
+
|
| 12 |
+
from typing import Any, Callable, Dict, List, Optional, Union
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class SD3TextEncoderWithMask(nn.Module):
|
| 16 |
+
def __init__(self, model_path, torch_dtype):
|
| 17 |
+
super().__init__()
|
| 18 |
+
# CLIP-L
|
| 19 |
+
self.tokenizer = CLIPTokenizer.from_pretrained(os.path.join(model_path, 'tokenizer'))
|
| 20 |
+
self.tokenizer_max_length = self.tokenizer.model_max_length
|
| 21 |
+
self.text_encoder = CLIPTextModelWithProjection.from_pretrained(os.path.join(model_path, 'text_encoder'), torch_dtype=torch_dtype)
|
| 22 |
+
|
| 23 |
+
# CLIP-G
|
| 24 |
+
self.tokenizer_2 = CLIPTokenizer.from_pretrained(os.path.join(model_path, 'tokenizer_2'))
|
| 25 |
+
self.text_encoder_2 = CLIPTextModelWithProjection.from_pretrained(os.path.join(model_path, 'text_encoder_2'), torch_dtype=torch_dtype)
|
| 26 |
+
|
| 27 |
+
# T5
|
| 28 |
+
self.tokenizer_3 = T5TokenizerFast.from_pretrained(os.path.join(model_path, 'tokenizer_3'))
|
| 29 |
+
self.text_encoder_3 = T5EncoderModel.from_pretrained(os.path.join(model_path, 'text_encoder_3'), torch_dtype=torch_dtype)
|
| 30 |
+
|
| 31 |
+
self._freeze()
|
| 32 |
+
|
| 33 |
+
def _freeze(self):
|
| 34 |
+
for param in self.parameters():
|
| 35 |
+
param.requires_grad = False
|
| 36 |
+
|
| 37 |
+
def _get_t5_prompt_embeds(
|
| 38 |
+
self,
|
| 39 |
+
prompt: Union[str, List[str]] = None,
|
| 40 |
+
num_images_per_prompt: int = 1,
|
| 41 |
+
device: Optional[torch.device] = None,
|
| 42 |
+
max_sequence_length: int = 128,
|
| 43 |
+
):
|
| 44 |
+
prompt = [prompt] if isinstance(prompt, str) else prompt
|
| 45 |
+
batch_size = len(prompt)
|
| 46 |
+
|
| 47 |
+
text_inputs = self.tokenizer_3(
|
| 48 |
+
prompt,
|
| 49 |
+
padding="max_length",
|
| 50 |
+
max_length=max_sequence_length,
|
| 51 |
+
truncation=True,
|
| 52 |
+
add_special_tokens=True,
|
| 53 |
+
return_tensors="pt",
|
| 54 |
+
)
|
| 55 |
+
text_input_ids = text_inputs.input_ids
|
| 56 |
+
prompt_attention_mask = text_inputs.attention_mask
|
| 57 |
+
prompt_attention_mask = prompt_attention_mask.to(device)
|
| 58 |
+
prompt_embeds = self.text_encoder_3(text_input_ids.to(device), attention_mask=prompt_attention_mask)[0]
|
| 59 |
+
dtype = self.text_encoder_3.dtype
|
| 60 |
+
prompt_embeds = prompt_embeds.to(dtype=dtype, device=device)
|
| 61 |
+
|
| 62 |
+
_, seq_len, _ = prompt_embeds.shape
|
| 63 |
+
|
| 64 |
+
# duplicate text embeddings and attention mask for each generation per prompt, using mps friendly method
|
| 65 |
+
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
|
| 66 |
+
prompt_embeds = prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
|
| 67 |
+
prompt_attention_mask = prompt_attention_mask.view(batch_size, -1)
|
| 68 |
+
prompt_attention_mask = prompt_attention_mask.repeat(num_images_per_prompt, 1)
|
| 69 |
+
|
| 70 |
+
return prompt_embeds, prompt_attention_mask
|
| 71 |
+
|
| 72 |
+
def _get_clip_prompt_embeds(
|
| 73 |
+
self,
|
| 74 |
+
prompt: Union[str, List[str]],
|
| 75 |
+
num_images_per_prompt: int = 1,
|
| 76 |
+
device: Optional[torch.device] = None,
|
| 77 |
+
clip_skip: Optional[int] = None,
|
| 78 |
+
clip_model_index: int = 0,
|
| 79 |
+
):
|
| 80 |
+
|
| 81 |
+
clip_tokenizers = [self.tokenizer, self.tokenizer_2]
|
| 82 |
+
clip_text_encoders = [self.text_encoder, self.text_encoder_2]
|
| 83 |
+
|
| 84 |
+
tokenizer = clip_tokenizers[clip_model_index]
|
| 85 |
+
text_encoder = clip_text_encoders[clip_model_index]
|
| 86 |
+
|
| 87 |
+
batch_size = len(prompt)
|
| 88 |
+
|
| 89 |
+
text_inputs = tokenizer(
|
| 90 |
+
prompt,
|
| 91 |
+
padding="max_length",
|
| 92 |
+
max_length=self.tokenizer_max_length,
|
| 93 |
+
truncation=True,
|
| 94 |
+
return_tensors="pt",
|
| 95 |
+
)
|
| 96 |
+
|
| 97 |
+
text_input_ids = text_inputs.input_ids
|
| 98 |
+
prompt_embeds = text_encoder(text_input_ids.to(device), output_hidden_states=True)
|
| 99 |
+
pooled_prompt_embeds = prompt_embeds[0]
|
| 100 |
+
pooled_prompt_embeds = pooled_prompt_embeds.repeat(1, num_images_per_prompt, 1)
|
| 101 |
+
pooled_prompt_embeds = pooled_prompt_embeds.view(batch_size * num_images_per_prompt, -1)
|
| 102 |
+
|
| 103 |
+
return pooled_prompt_embeds
|
| 104 |
+
|
| 105 |
+
def encode_prompt(self,
|
| 106 |
+
prompt,
|
| 107 |
+
num_images_per_prompt=1,
|
| 108 |
+
clip_skip: Optional[int] = None,
|
| 109 |
+
device=None,
|
| 110 |
+
):
|
| 111 |
+
prompt = [prompt] if isinstance(prompt, str) else prompt
|
| 112 |
+
|
| 113 |
+
pooled_prompt_embed = self._get_clip_prompt_embeds(
|
| 114 |
+
prompt=prompt,
|
| 115 |
+
device=device,
|
| 116 |
+
num_images_per_prompt=num_images_per_prompt,
|
| 117 |
+
clip_skip=clip_skip,
|
| 118 |
+
clip_model_index=0,
|
| 119 |
+
)
|
| 120 |
+
pooled_prompt_2_embed = self._get_clip_prompt_embeds(
|
| 121 |
+
prompt=prompt,
|
| 122 |
+
device=device,
|
| 123 |
+
num_images_per_prompt=num_images_per_prompt,
|
| 124 |
+
clip_skip=clip_skip,
|
| 125 |
+
clip_model_index=1,
|
| 126 |
+
)
|
| 127 |
+
pooled_prompt_embeds = torch.cat([pooled_prompt_embed, pooled_prompt_2_embed], dim=-1)
|
| 128 |
+
|
| 129 |
+
prompt_embeds, prompt_attention_mask = self._get_t5_prompt_embeds(
|
| 130 |
+
prompt=prompt,
|
| 131 |
+
num_images_per_prompt=num_images_per_prompt,
|
| 132 |
+
device=device,
|
| 133 |
+
)
|
| 134 |
+
return prompt_embeds, prompt_attention_mask, pooled_prompt_embeds
|
| 135 |
+
|
| 136 |
+
def forward(self, input_prompts, device):
|
| 137 |
+
with torch.no_grad():
|
| 138 |
+
prompt_embeds, prompt_attention_mask, pooled_prompt_embeds = self.encode_prompt(input_prompts, 1, clip_skip=None, device=device)
|
| 139 |
+
|
| 140 |
+
return prompt_embeds, prompt_attention_mask, pooled_prompt_embeds
|
pyramid_dit/pyramid_dit_for_video_gen_pipeline.py
ADDED
|
@@ -0,0 +1,1279 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import os
|
| 3 |
+
import gc
|
| 4 |
+
import sys
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
|
| 8 |
+
from collections import OrderedDict
|
| 9 |
+
from einops import rearrange
|
| 10 |
+
from diffusers.utils.torch_utils import randn_tensor
|
| 11 |
+
import numpy as np
|
| 12 |
+
import math
|
| 13 |
+
import random
|
| 14 |
+
import PIL
|
| 15 |
+
from PIL import Image
|
| 16 |
+
from tqdm import tqdm
|
| 17 |
+
from torchvision import transforms
|
| 18 |
+
from copy import deepcopy
|
| 19 |
+
from typing import Any, Callable, Dict, List, Optional, Union
|
| 20 |
+
from accelerate import Accelerator, cpu_offload
|
| 21 |
+
from diffusion_schedulers import PyramidFlowMatchEulerDiscreteScheduler
|
| 22 |
+
from video_vae.modeling_causal_vae import CausalVideoVAE
|
| 23 |
+
|
| 24 |
+
from trainer_misc import (
|
| 25 |
+
all_to_all,
|
| 26 |
+
is_sequence_parallel_initialized,
|
| 27 |
+
get_sequence_parallel_group,
|
| 28 |
+
get_sequence_parallel_group_rank,
|
| 29 |
+
get_sequence_parallel_rank,
|
| 30 |
+
get_sequence_parallel_world_size,
|
| 31 |
+
get_rank,
|
| 32 |
+
)
|
| 33 |
+
|
| 34 |
+
from .mmdit_modules import (
|
| 35 |
+
PyramidDiffusionMMDiT,
|
| 36 |
+
SD3TextEncoderWithMask,
|
| 37 |
+
)
|
| 38 |
+
|
| 39 |
+
from .flux_modules import (
|
| 40 |
+
PyramidFluxTransformer,
|
| 41 |
+
FluxTextEncoderWithMask,
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def compute_density_for_timestep_sampling(
|
| 46 |
+
weighting_scheme: str, batch_size: int, logit_mean: float = None, logit_std: float = None, mode_scale: float = None
|
| 47 |
+
):
|
| 48 |
+
if weighting_scheme == "logit_normal":
|
| 49 |
+
# See 3.1 in the SD3 paper ($rf/lognorm(0.00,1.00)$).
|
| 50 |
+
u = torch.normal(mean=logit_mean, std=logit_std, size=(batch_size,), device="cpu")
|
| 51 |
+
u = torch.nn.functional.sigmoid(u)
|
| 52 |
+
elif weighting_scheme == "mode":
|
| 53 |
+
u = torch.rand(size=(batch_size,), device="cpu")
|
| 54 |
+
u = 1 - u - mode_scale * (torch.cos(math.pi * u / 2) ** 2 - 1 + u)
|
| 55 |
+
else:
|
| 56 |
+
u = torch.rand(size=(batch_size,), device="cpu")
|
| 57 |
+
return u
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def build_pyramid_dit(
|
| 61 |
+
model_name : str,
|
| 62 |
+
model_path : str,
|
| 63 |
+
torch_dtype,
|
| 64 |
+
use_flash_attn : bool,
|
| 65 |
+
use_mixed_training: bool,
|
| 66 |
+
interp_condition_pos: bool = True,
|
| 67 |
+
use_gradient_checkpointing: bool = False,
|
| 68 |
+
use_temporal_causal: bool = True,
|
| 69 |
+
gradient_checkpointing_ratio: float = 0.6,
|
| 70 |
+
):
|
| 71 |
+
model_dtype = torch.float32 if use_mixed_training else torch_dtype
|
| 72 |
+
if model_name == "pyramid_flux":
|
| 73 |
+
dit = PyramidFluxTransformer.from_pretrained(
|
| 74 |
+
model_path, torch_dtype=model_dtype,
|
| 75 |
+
use_gradient_checkpointing=use_gradient_checkpointing,
|
| 76 |
+
gradient_checkpointing_ratio=gradient_checkpointing_ratio,
|
| 77 |
+
use_flash_attn=use_flash_attn, use_temporal_causal=use_temporal_causal,
|
| 78 |
+
interp_condition_pos=interp_condition_pos, axes_dims_rope=[16, 24, 24],
|
| 79 |
+
)
|
| 80 |
+
elif model_name == "pyramid_mmdit":
|
| 81 |
+
dit = PyramidDiffusionMMDiT.from_pretrained(
|
| 82 |
+
model_path, torch_dtype=model_dtype, use_gradient_checkpointing=use_gradient_checkpointing,
|
| 83 |
+
gradient_checkpointing_ratio=gradient_checkpointing_ratio,
|
| 84 |
+
use_flash_attn=use_flash_attn, use_t5_mask=True,
|
| 85 |
+
add_temp_pos_embed=True, temp_pos_embed_type='rope',
|
| 86 |
+
use_temporal_causal=use_temporal_causal, interp_condition_pos=interp_condition_pos,
|
| 87 |
+
)
|
| 88 |
+
else:
|
| 89 |
+
raise NotImplementedError(f"Unsupported DiT architecture, please set the model_name to `pyramid_flux` or `pyramid_mmdit`")
|
| 90 |
+
|
| 91 |
+
return dit
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def build_text_encoder(
|
| 95 |
+
model_name : str,
|
| 96 |
+
model_path : str,
|
| 97 |
+
torch_dtype,
|
| 98 |
+
load_text_encoder: bool = True,
|
| 99 |
+
):
|
| 100 |
+
# The text encoder
|
| 101 |
+
if load_text_encoder:
|
| 102 |
+
if model_name == "pyramid_flux":
|
| 103 |
+
text_encoder = FluxTextEncoderWithMask(model_path, torch_dtype=torch_dtype)
|
| 104 |
+
elif model_name == "pyramid_mmdit":
|
| 105 |
+
text_encoder = SD3TextEncoderWithMask(model_path, torch_dtype=torch_dtype)
|
| 106 |
+
else:
|
| 107 |
+
raise NotImplementedError(f"Unsupported Text Encoder architecture, please set the model_name to `pyramid_flux` or `pyramid_mmdit`")
|
| 108 |
+
else:
|
| 109 |
+
text_encoder = None
|
| 110 |
+
|
| 111 |
+
return text_encoder
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
class PyramidDiTForVideoGeneration:
|
| 115 |
+
"""
|
| 116 |
+
The pyramid dit for both image and video generation, The running class wrapper
|
| 117 |
+
This class is mainly for fixed unit implementation: 1 + n + n + n
|
| 118 |
+
"""
|
| 119 |
+
def __init__(self, model_path, model_dtype='bf16', model_name='pyramid_mmdit', use_gradient_checkpointing=False,
|
| 120 |
+
return_log=True, model_variant="diffusion_transformer_768p", timestep_shift=1.0, stage_range=[0, 1/3, 2/3, 1],
|
| 121 |
+
sample_ratios=[1, 1, 1], scheduler_gamma=1/3, use_mixed_training=False, use_flash_attn=False,
|
| 122 |
+
load_text_encoder=True, load_vae=True, max_temporal_length=31, frame_per_unit=1, use_temporal_causal=True,
|
| 123 |
+
corrupt_ratio=1/3, interp_condition_pos=True, stages=[1, 2, 4], video_sync_group=8, gradient_checkpointing_ratio=0.6, **kwargs,
|
| 124 |
+
):
|
| 125 |
+
super().__init__()
|
| 126 |
+
|
| 127 |
+
if model_dtype == 'bf16':
|
| 128 |
+
torch_dtype = torch.bfloat16
|
| 129 |
+
elif model_dtype == 'fp16':
|
| 130 |
+
torch_dtype = torch.float16
|
| 131 |
+
else:
|
| 132 |
+
torch_dtype = torch.float32
|
| 133 |
+
|
| 134 |
+
self.stages = stages
|
| 135 |
+
self.sample_ratios = sample_ratios
|
| 136 |
+
self.corrupt_ratio = corrupt_ratio
|
| 137 |
+
|
| 138 |
+
dit_path = os.path.join(model_path, model_variant)
|
| 139 |
+
|
| 140 |
+
# The dit
|
| 141 |
+
self.dit = build_pyramid_dit(
|
| 142 |
+
model_name, dit_path, torch_dtype,
|
| 143 |
+
use_flash_attn=use_flash_attn, use_mixed_training=use_mixed_training,
|
| 144 |
+
interp_condition_pos=interp_condition_pos, use_gradient_checkpointing=use_gradient_checkpointing,
|
| 145 |
+
use_temporal_causal=use_temporal_causal, gradient_checkpointing_ratio=gradient_checkpointing_ratio,
|
| 146 |
+
)
|
| 147 |
+
|
| 148 |
+
# The text encoder
|
| 149 |
+
self.text_encoder = build_text_encoder(
|
| 150 |
+
model_name, model_path, torch_dtype, load_text_encoder=load_text_encoder,
|
| 151 |
+
)
|
| 152 |
+
self.load_text_encoder = load_text_encoder
|
| 153 |
+
|
| 154 |
+
# The base video vae decoder
|
| 155 |
+
if load_vae:
|
| 156 |
+
self.vae = CausalVideoVAE.from_pretrained(os.path.join(model_path, 'causal_video_vae'), torch_dtype=torch_dtype, interpolate=False)
|
| 157 |
+
# Freeze vae
|
| 158 |
+
for parameter in self.vae.parameters():
|
| 159 |
+
parameter.requires_grad = False
|
| 160 |
+
else:
|
| 161 |
+
self.vae = None
|
| 162 |
+
self.load_vae = load_vae
|
| 163 |
+
|
| 164 |
+
# For the image latent
|
| 165 |
+
if model_name == "pyramid_flux":
|
| 166 |
+
self.vae_shift_factor = -0.04
|
| 167 |
+
self.vae_scale_factor = 1 / 1.8726
|
| 168 |
+
elif model_name == "pyramid_mmdit":
|
| 169 |
+
self.vae_shift_factor = 0.1490
|
| 170 |
+
self.vae_scale_factor = 1 / 1.8415
|
| 171 |
+
else:
|
| 172 |
+
raise NotImplementedError(f"Unsupported model name : {model_name}")
|
| 173 |
+
|
| 174 |
+
# For the video latent
|
| 175 |
+
self.vae_video_shift_factor = -0.2343
|
| 176 |
+
self.vae_video_scale_factor = 1 / 3.0986
|
| 177 |
+
|
| 178 |
+
self.downsample = 8
|
| 179 |
+
|
| 180 |
+
# Configure the video training hyper-parameters
|
| 181 |
+
# The video sequence: one frame + N * unit
|
| 182 |
+
self.frame_per_unit = frame_per_unit
|
| 183 |
+
self.max_temporal_length = max_temporal_length
|
| 184 |
+
assert (max_temporal_length - 1) % frame_per_unit == 0, "The frame number should be divided by the frame number per unit"
|
| 185 |
+
self.num_units_per_video = 1 + ((max_temporal_length - 1) // frame_per_unit) + int(sum(sample_ratios))
|
| 186 |
+
|
| 187 |
+
self.scheduler = PyramidFlowMatchEulerDiscreteScheduler(
|
| 188 |
+
shift=timestep_shift, stages=len(self.stages),
|
| 189 |
+
stage_range=stage_range, gamma=scheduler_gamma,
|
| 190 |
+
)
|
| 191 |
+
print(f"The start sigmas and end sigmas of each stage is Start: {self.scheduler.start_sigmas}, End: {self.scheduler.end_sigmas}, Ori_start: {self.scheduler.ori_start_sigmas}")
|
| 192 |
+
|
| 193 |
+
self.cfg_rate = 0.1
|
| 194 |
+
self.return_log = return_log
|
| 195 |
+
self.use_flash_attn = use_flash_attn
|
| 196 |
+
self.model_name = model_name
|
| 197 |
+
self.sequential_offload_enabled = False
|
| 198 |
+
self.accumulate_steps = 0
|
| 199 |
+
self.video_sync_group = video_sync_group
|
| 200 |
+
|
| 201 |
+
def _enable_sequential_cpu_offload(self, model):
|
| 202 |
+
self.sequential_offload_enabled = True
|
| 203 |
+
torch_device = torch.device("cuda")
|
| 204 |
+
device_type = torch_device.type
|
| 205 |
+
device = torch.device(f"{device_type}:0")
|
| 206 |
+
offload_buffers = len(model._parameters) > 0
|
| 207 |
+
cpu_offload(model, device, offload_buffers=offload_buffers)
|
| 208 |
+
|
| 209 |
+
def enable_sequential_cpu_offload(self):
|
| 210 |
+
self._enable_sequential_cpu_offload(self.text_encoder)
|
| 211 |
+
self._enable_sequential_cpu_offload(self.dit)
|
| 212 |
+
|
| 213 |
+
def load_checkpoint(self, checkpoint_path, model_key='model', **kwargs):
|
| 214 |
+
checkpoint = torch.load(checkpoint_path, map_location='cpu')
|
| 215 |
+
dit_checkpoint = OrderedDict()
|
| 216 |
+
for key in checkpoint:
|
| 217 |
+
if key.startswith('vae') or key.startswith('text_encoder'):
|
| 218 |
+
continue
|
| 219 |
+
if key.startswith('dit'):
|
| 220 |
+
new_key = key.split('.')
|
| 221 |
+
new_key = '.'.join(new_key[1:])
|
| 222 |
+
dit_checkpoint[new_key] = checkpoint[key]
|
| 223 |
+
else:
|
| 224 |
+
dit_checkpoint[key] = checkpoint[key]
|
| 225 |
+
|
| 226 |
+
load_result = self.dit.load_state_dict(dit_checkpoint, strict=True)
|
| 227 |
+
print(f"Load checkpoint from {checkpoint_path}, load result: {load_result}")
|
| 228 |
+
|
| 229 |
+
def load_vae_checkpoint(self, vae_checkpoint_path, model_key='model'):
|
| 230 |
+
checkpoint = torch.load(vae_checkpoint_path, map_location='cpu')
|
| 231 |
+
checkpoint = checkpoint[model_key]
|
| 232 |
+
loaded_checkpoint = OrderedDict()
|
| 233 |
+
|
| 234 |
+
for key in checkpoint.keys():
|
| 235 |
+
if key.startswith('vae.'):
|
| 236 |
+
new_key = key.split('.')
|
| 237 |
+
new_key = '.'.join(new_key[1:])
|
| 238 |
+
loaded_checkpoint[new_key] = checkpoint[key]
|
| 239 |
+
|
| 240 |
+
load_result = self.vae.load_state_dict(loaded_checkpoint)
|
| 241 |
+
print(f"Load the VAE from {vae_checkpoint_path}, load result: {load_result}")
|
| 242 |
+
|
| 243 |
+
@torch.no_grad()
|
| 244 |
+
def add_pyramid_noise(
|
| 245 |
+
self,
|
| 246 |
+
latents_list,
|
| 247 |
+
sample_ratios=[1, 1, 1],
|
| 248 |
+
):
|
| 249 |
+
"""
|
| 250 |
+
add the noise for each pyramidal stage
|
| 251 |
+
noting that, this method is a general strategy for pyramid-flow, it
|
| 252 |
+
can be used for both image and video training.
|
| 253 |
+
You can also use this method to train pyramid-flow with full-sequence
|
| 254 |
+
diffusion in video generation (without using temporal pyramid and autoregressive modeling)
|
| 255 |
+
|
| 256 |
+
Params:
|
| 257 |
+
latent_list: [low_res, mid_res, high_res] The vae latents of all stages
|
| 258 |
+
sample_ratios: The proportion of each stage in the training batch
|
| 259 |
+
"""
|
| 260 |
+
noise = torch.randn_like(latents_list[-1])
|
| 261 |
+
device = noise.device
|
| 262 |
+
dtype = latents_list[-1].dtype
|
| 263 |
+
t = noise.shape[2]
|
| 264 |
+
|
| 265 |
+
stages = len(self.stages)
|
| 266 |
+
tot_samples = noise.shape[0]
|
| 267 |
+
assert tot_samples % (int(sum(sample_ratios))) == 0
|
| 268 |
+
assert stages == len(sample_ratios)
|
| 269 |
+
|
| 270 |
+
height, width = noise.shape[-2], noise.shape[-1]
|
| 271 |
+
noise_list = [noise]
|
| 272 |
+
cur_noise = noise
|
| 273 |
+
for i_s in range(stages-1):
|
| 274 |
+
height //= 2;width //= 2
|
| 275 |
+
cur_noise = rearrange(cur_noise, 'b c t h w -> (b t) c h w')
|
| 276 |
+
cur_noise = F.interpolate(cur_noise, size=(height, width), mode='bilinear') * 2
|
| 277 |
+
cur_noise = rearrange(cur_noise, '(b t) c h w -> b c t h w', t=t)
|
| 278 |
+
noise_list.append(cur_noise)
|
| 279 |
+
|
| 280 |
+
noise_list = list(reversed(noise_list)) # make sure from low res to high res
|
| 281 |
+
|
| 282 |
+
# To calculate the padding batchsize and column size
|
| 283 |
+
batch_size = tot_samples // int(sum(sample_ratios))
|
| 284 |
+
column_size = int(sum(sample_ratios))
|
| 285 |
+
|
| 286 |
+
column_to_stage = {}
|
| 287 |
+
i_sum = 0
|
| 288 |
+
for i_s, column_num in enumerate(sample_ratios):
|
| 289 |
+
for index in range(i_sum, i_sum + column_num):
|
| 290 |
+
column_to_stage[index] = i_s
|
| 291 |
+
i_sum += column_num
|
| 292 |
+
|
| 293 |
+
noisy_latents_list = []
|
| 294 |
+
ratios_list = []
|
| 295 |
+
targets_list = []
|
| 296 |
+
timesteps_list = []
|
| 297 |
+
training_steps = self.scheduler.config.num_train_timesteps
|
| 298 |
+
|
| 299 |
+
# from low resolution to high resolution
|
| 300 |
+
for index in range(column_size):
|
| 301 |
+
i_s = column_to_stage[index]
|
| 302 |
+
clean_latent = latents_list[i_s][index::column_size] # [bs, c, t, h, w]
|
| 303 |
+
last_clean_latent = None if i_s == 0 else latents_list[i_s-1][index::column_size]
|
| 304 |
+
start_sigma = self.scheduler.start_sigmas[i_s]
|
| 305 |
+
end_sigma = self.scheduler.end_sigmas[i_s]
|
| 306 |
+
|
| 307 |
+
if i_s == 0:
|
| 308 |
+
start_point = noise_list[i_s][index::column_size]
|
| 309 |
+
else:
|
| 310 |
+
# Get the upsampled latent
|
| 311 |
+
last_clean_latent = rearrange(last_clean_latent, 'b c t h w -> (b t) c h w')
|
| 312 |
+
last_clean_latent = F.interpolate(last_clean_latent, size=(last_clean_latent.shape[-2] * 2, last_clean_latent.shape[-1] * 2), mode='nearest')
|
| 313 |
+
last_clean_latent = rearrange(last_clean_latent, '(b t) c h w -> b c t h w', t=t)
|
| 314 |
+
start_point = start_sigma * noise_list[i_s][index::column_size] + (1 - start_sigma) * last_clean_latent
|
| 315 |
+
|
| 316 |
+
if i_s == stages - 1:
|
| 317 |
+
end_point = clean_latent
|
| 318 |
+
else:
|
| 319 |
+
end_point = end_sigma * noise_list[i_s][index::column_size] + (1 - end_sigma) * clean_latent
|
| 320 |
+
|
| 321 |
+
# To sample a timestep
|
| 322 |
+
u = compute_density_for_timestep_sampling(
|
| 323 |
+
weighting_scheme='random',
|
| 324 |
+
batch_size=batch_size,
|
| 325 |
+
logit_mean=0.0,
|
| 326 |
+
logit_std=1.0,
|
| 327 |
+
mode_scale=1.29,
|
| 328 |
+
)
|
| 329 |
+
|
| 330 |
+
indices = (u * training_steps).long() # Totally 1000 training steps per stage
|
| 331 |
+
indices = indices.clamp(0, training_steps-1)
|
| 332 |
+
timesteps = self.scheduler.timesteps_per_stage[i_s][indices].to(device=device)
|
| 333 |
+
ratios = self.scheduler.sigmas_per_stage[i_s][indices].to(device=device)
|
| 334 |
+
|
| 335 |
+
while len(ratios.shape) < start_point.ndim:
|
| 336 |
+
ratios = ratios.unsqueeze(-1)
|
| 337 |
+
|
| 338 |
+
# interpolate the latent
|
| 339 |
+
noisy_latents = ratios * start_point + (1 - ratios) * end_point
|
| 340 |
+
|
| 341 |
+
last_cond_noisy_sigma = torch.rand(size=(batch_size,), device=device) * self.corrupt_ratio
|
| 342 |
+
|
| 343 |
+
# [stage1_latent, stage2_latent, ..., stagen_latent], which will be concat after patching
|
| 344 |
+
noisy_latents_list.append([noisy_latents.to(dtype)])
|
| 345 |
+
ratios_list.append(ratios.to(dtype))
|
| 346 |
+
timesteps_list.append(timesteps.to(dtype))
|
| 347 |
+
targets_list.append(start_point - end_point) # The standard rectified flow matching objective
|
| 348 |
+
|
| 349 |
+
return noisy_latents_list, ratios_list, timesteps_list, targets_list
|
| 350 |
+
|
| 351 |
+
def sample_stage_length(self, num_stages, max_units=None):
|
| 352 |
+
max_units_in_training = 1 + ((self.max_temporal_length - 1) // self.frame_per_unit)
|
| 353 |
+
cur_rank = get_rank()
|
| 354 |
+
|
| 355 |
+
self.accumulate_steps = self.accumulate_steps + 1
|
| 356 |
+
total_turns = max_units_in_training // self.video_sync_group
|
| 357 |
+
update_turn = self.accumulate_steps % total_turns
|
| 358 |
+
|
| 359 |
+
# # uniformly sampling each position
|
| 360 |
+
cur_highres_unit = max(int((cur_rank % self.video_sync_group + 1) + update_turn * self.video_sync_group), 1)
|
| 361 |
+
cur_mid_res_unit = max(1 + max_units_in_training - cur_highres_unit, 1)
|
| 362 |
+
cur_low_res_unit = cur_mid_res_unit
|
| 363 |
+
|
| 364 |
+
if max_units is not None:
|
| 365 |
+
cur_highres_unit = min(cur_highres_unit, max_units)
|
| 366 |
+
cur_mid_res_unit = min(cur_mid_res_unit, max_units)
|
| 367 |
+
cur_low_res_unit = min(cur_low_res_unit, max_units)
|
| 368 |
+
|
| 369 |
+
length_list = [cur_low_res_unit, cur_mid_res_unit, cur_highres_unit]
|
| 370 |
+
|
| 371 |
+
assert len(length_list) == num_stages
|
| 372 |
+
|
| 373 |
+
return length_list
|
| 374 |
+
|
| 375 |
+
@torch.no_grad()
|
| 376 |
+
def add_pyramid_noise_with_temporal_pyramid(
|
| 377 |
+
self,
|
| 378 |
+
latents_list,
|
| 379 |
+
sample_ratios=[1, 1, 1],
|
| 380 |
+
):
|
| 381 |
+
"""
|
| 382 |
+
add the noise for each pyramidal stage, used for AR video training with temporal pyramid
|
| 383 |
+
Params:
|
| 384 |
+
latent_list: [low_res, mid_res, high_res] The vae latents of all stages
|
| 385 |
+
sample_ratios: The proportion of each stage in the training batch
|
| 386 |
+
"""
|
| 387 |
+
stages = len(self.stages)
|
| 388 |
+
tot_samples = latents_list[0].shape[0]
|
| 389 |
+
device = latents_list[0].device
|
| 390 |
+
dtype = latents_list[0].dtype
|
| 391 |
+
|
| 392 |
+
assert tot_samples % (int(sum(sample_ratios))) == 0
|
| 393 |
+
assert stages == len(sample_ratios)
|
| 394 |
+
|
| 395 |
+
noise = torch.randn_like(latents_list[-1])
|
| 396 |
+
t = noise.shape[2]
|
| 397 |
+
|
| 398 |
+
# To allocate the temporal length of each stage, ensuring the sum == constant
|
| 399 |
+
max_units = 1 + (t - 1) // self.frame_per_unit
|
| 400 |
+
|
| 401 |
+
if is_sequence_parallel_initialized():
|
| 402 |
+
max_units_per_sample = torch.LongTensor([max_units]).to(device)
|
| 403 |
+
sp_group = get_sequence_parallel_group()
|
| 404 |
+
sp_group_size = get_sequence_parallel_world_size()
|
| 405 |
+
max_units_per_sample = all_to_all(max_units_per_sample.unsqueeze(1).repeat(1, sp_group_size), sp_group, sp_group_size, scatter_dim=1, gather_dim=0).squeeze(1)
|
| 406 |
+
max_units = min(max_units_per_sample.cpu().tolist())
|
| 407 |
+
|
| 408 |
+
num_units_per_stage = self.sample_stage_length(stages, max_units=max_units) # [The unit number of each stage]
|
| 409 |
+
|
| 410 |
+
# we needs to sync the length alloc of each sequence parallel group
|
| 411 |
+
if is_sequence_parallel_initialized():
|
| 412 |
+
num_units_per_stage = torch.LongTensor(num_units_per_stage).to(device)
|
| 413 |
+
sp_group_rank = get_sequence_parallel_group_rank()
|
| 414 |
+
global_src_rank = sp_group_rank * get_sequence_parallel_world_size()
|
| 415 |
+
torch.distributed.broadcast(num_units_per_stage, global_src_rank, group=get_sequence_parallel_group())
|
| 416 |
+
num_units_per_stage = num_units_per_stage.tolist()
|
| 417 |
+
|
| 418 |
+
height, width = noise.shape[-2], noise.shape[-1]
|
| 419 |
+
noise_list = [noise]
|
| 420 |
+
cur_noise = noise
|
| 421 |
+
for i_s in range(stages-1):
|
| 422 |
+
height //= 2;width //= 2
|
| 423 |
+
cur_noise = rearrange(cur_noise, 'b c t h w -> (b t) c h w')
|
| 424 |
+
cur_noise = F.interpolate(cur_noise, size=(height, width), mode='bilinear') * 2
|
| 425 |
+
cur_noise = rearrange(cur_noise, '(b t) c h w -> b c t h w', t=t)
|
| 426 |
+
noise_list.append(cur_noise)
|
| 427 |
+
|
| 428 |
+
noise_list = list(reversed(noise_list)) # make sure from low res to high res
|
| 429 |
+
|
| 430 |
+
# To calculate the batchsize and column size
|
| 431 |
+
batch_size = tot_samples // int(sum(sample_ratios))
|
| 432 |
+
column_size = int(sum(sample_ratios))
|
| 433 |
+
|
| 434 |
+
column_to_stage = {}
|
| 435 |
+
i_sum = 0
|
| 436 |
+
for i_s, column_num in enumerate(sample_ratios):
|
| 437 |
+
for index in range(i_sum, i_sum + column_num):
|
| 438 |
+
column_to_stage[index] = i_s
|
| 439 |
+
i_sum += column_num
|
| 440 |
+
|
| 441 |
+
noisy_latents_list = []
|
| 442 |
+
ratios_list = []
|
| 443 |
+
targets_list = []
|
| 444 |
+
timesteps_list = []
|
| 445 |
+
training_steps = self.scheduler.config.num_train_timesteps
|
| 446 |
+
|
| 447 |
+
# from low resolution to high resolution
|
| 448 |
+
for index in range(column_size):
|
| 449 |
+
# First prepare the trainable latent construction
|
| 450 |
+
i_s = column_to_stage[index]
|
| 451 |
+
clean_latent = latents_list[i_s][index::column_size] # [bs, c, t, h, w]
|
| 452 |
+
last_clean_latent = None if i_s == 0 else latents_list[i_s-1][index::column_size]
|
| 453 |
+
start_sigma = self.scheduler.start_sigmas[i_s]
|
| 454 |
+
end_sigma = self.scheduler.end_sigmas[i_s]
|
| 455 |
+
|
| 456 |
+
if i_s == 0:
|
| 457 |
+
start_point = noise_list[i_s][index::column_size]
|
| 458 |
+
else:
|
| 459 |
+
# Get the upsampled latent
|
| 460 |
+
last_clean_latent = rearrange(last_clean_latent, 'b c t h w -> (b t) c h w')
|
| 461 |
+
last_clean_latent = F.interpolate(last_clean_latent, size=(last_clean_latent.shape[-2] * 2, last_clean_latent.shape[-1] * 2), mode='nearest')
|
| 462 |
+
last_clean_latent = rearrange(last_clean_latent, '(b t) c h w -> b c t h w', t=t)
|
| 463 |
+
start_point = start_sigma * noise_list[i_s][index::column_size] + (1 - start_sigma) * last_clean_latent
|
| 464 |
+
|
| 465 |
+
if i_s == stages - 1:
|
| 466 |
+
end_point = clean_latent
|
| 467 |
+
else:
|
| 468 |
+
end_point = end_sigma * noise_list[i_s][index::column_size] + (1 - end_sigma) * clean_latent
|
| 469 |
+
|
| 470 |
+
# To sample a timestep
|
| 471 |
+
u = compute_density_for_timestep_sampling(
|
| 472 |
+
weighting_scheme='random',
|
| 473 |
+
batch_size=batch_size,
|
| 474 |
+
logit_mean=0.0,
|
| 475 |
+
logit_std=1.0,
|
| 476 |
+
mode_scale=1.29,
|
| 477 |
+
)
|
| 478 |
+
|
| 479 |
+
indices = (u * training_steps).long() # Totally 1000 training steps per stage
|
| 480 |
+
indices = indices.clamp(0, training_steps-1)
|
| 481 |
+
timesteps = self.scheduler.timesteps_per_stage[i_s][indices].to(device=device)
|
| 482 |
+
ratios = self.scheduler.sigmas_per_stage[i_s][indices].to(device=device)
|
| 483 |
+
noise_ratios = ratios * start_sigma + (1 - ratios) * end_sigma
|
| 484 |
+
|
| 485 |
+
while len(ratios.shape) < start_point.ndim:
|
| 486 |
+
ratios = ratios.unsqueeze(-1)
|
| 487 |
+
|
| 488 |
+
# interpolate the latent
|
| 489 |
+
noisy_latents = ratios * start_point + (1 - ratios) * end_point
|
| 490 |
+
|
| 491 |
+
# The flow matching object
|
| 492 |
+
target_latents = start_point - end_point
|
| 493 |
+
|
| 494 |
+
# pad the noisy previous
|
| 495 |
+
num_units = num_units_per_stage[i_s]
|
| 496 |
+
num_units = min(num_units, 1 + (t - 1) // self.frame_per_unit)
|
| 497 |
+
actual_frames = 1 + (num_units - 1) * self.frame_per_unit
|
| 498 |
+
|
| 499 |
+
noisy_latents = noisy_latents[:, :, :actual_frames]
|
| 500 |
+
target_latents = target_latents[:, :, :actual_frames]
|
| 501 |
+
|
| 502 |
+
clean_latent = clean_latent[:, :, :actual_frames]
|
| 503 |
+
stage_noise = noise_list[i_s][index::column_size][:, :, :actual_frames]
|
| 504 |
+
|
| 505 |
+
# only the last latent takes part in training
|
| 506 |
+
noisy_latents = noisy_latents[:, :, -self.frame_per_unit:]
|
| 507 |
+
target_latents = target_latents[:, :, -self.frame_per_unit:]
|
| 508 |
+
|
| 509 |
+
last_cond_noisy_sigma = torch.rand(size=(batch_size,), device=device) * self.corrupt_ratio
|
| 510 |
+
|
| 511 |
+
if num_units == 1:
|
| 512 |
+
stage_input = [noisy_latents.to(dtype)]
|
| 513 |
+
else:
|
| 514 |
+
# add the random noise for the last cond clip
|
| 515 |
+
last_cond_latent = clean_latent[:, :, -(2*self.frame_per_unit):-self.frame_per_unit]
|
| 516 |
+
|
| 517 |
+
while len(last_cond_noisy_sigma.shape) < last_cond_latent.ndim:
|
| 518 |
+
last_cond_noisy_sigma = last_cond_noisy_sigma.unsqueeze(-1)
|
| 519 |
+
|
| 520 |
+
# We adding some noise to corrupt the clean condition
|
| 521 |
+
last_cond_latent = last_cond_noisy_sigma * torch.randn_like(last_cond_latent) + (1 - last_cond_noisy_sigma) * last_cond_latent
|
| 522 |
+
|
| 523 |
+
# concat the corrupted condition and the input noisy latents
|
| 524 |
+
stage_input = [noisy_latents.to(dtype), last_cond_latent.to(dtype)]
|
| 525 |
+
|
| 526 |
+
cur_unit_num = 2
|
| 527 |
+
cur_stage = i_s
|
| 528 |
+
|
| 529 |
+
while cur_unit_num < num_units:
|
| 530 |
+
cur_stage = max(cur_stage - 1, 0)
|
| 531 |
+
if cur_stage == 0:
|
| 532 |
+
break
|
| 533 |
+
cur_unit_num += 1
|
| 534 |
+
cond_latents = latents_list[cur_stage][index::column_size][:, :, :actual_frames]
|
| 535 |
+
cond_latents = cond_latents[:, :, -(cur_unit_num * self.frame_per_unit) : -((cur_unit_num - 1) * self.frame_per_unit)]
|
| 536 |
+
cond_latents = last_cond_noisy_sigma * torch.randn_like(cond_latents) + (1 - last_cond_noisy_sigma) * cond_latents
|
| 537 |
+
stage_input.append(cond_latents.to(dtype))
|
| 538 |
+
|
| 539 |
+
if cur_stage == 0 and cur_unit_num < num_units:
|
| 540 |
+
cond_latents = latents_list[0][index::column_size][:, :, :actual_frames]
|
| 541 |
+
cond_latents = cond_latents[:, :, :-(cur_unit_num * self.frame_per_unit)]
|
| 542 |
+
|
| 543 |
+
cond_latents = last_cond_noisy_sigma * torch.randn_like(cond_latents) + (1 - last_cond_noisy_sigma) * cond_latents
|
| 544 |
+
stage_input.append(cond_latents.to(dtype))
|
| 545 |
+
|
| 546 |
+
stage_input = list(reversed(stage_input))
|
| 547 |
+
noisy_latents_list.append(stage_input)
|
| 548 |
+
ratios_list.append(ratios.to(dtype))
|
| 549 |
+
timesteps_list.append(timesteps.to(dtype))
|
| 550 |
+
targets_list.append(target_latents) # The standard rectified flow matching objective
|
| 551 |
+
|
| 552 |
+
return noisy_latents_list, ratios_list, timesteps_list, targets_list
|
| 553 |
+
|
| 554 |
+
@torch.no_grad()
|
| 555 |
+
def get_pyramid_latent(self, x, stage_num):
|
| 556 |
+
# x is the origin vae latent
|
| 557 |
+
vae_latent_list = []
|
| 558 |
+
vae_latent_list.append(x)
|
| 559 |
+
|
| 560 |
+
temp, height, width = x.shape[-3], x.shape[-2], x.shape[-1]
|
| 561 |
+
for _ in range(stage_num):
|
| 562 |
+
height //= 2
|
| 563 |
+
width //= 2
|
| 564 |
+
x = rearrange(x, 'b c t h w -> (b t) c h w')
|
| 565 |
+
x = torch.nn.functional.interpolate(x, size=(height, width), mode='bilinear')
|
| 566 |
+
x = rearrange(x, '(b t) c h w -> b c t h w', t=temp)
|
| 567 |
+
vae_latent_list.append(x)
|
| 568 |
+
|
| 569 |
+
vae_latent_list = list(reversed(vae_latent_list))
|
| 570 |
+
return vae_latent_list
|
| 571 |
+
|
| 572 |
+
@torch.no_grad()
|
| 573 |
+
def get_vae_latent(self, video, use_temporal_pyramid=True):
|
| 574 |
+
if self.load_vae:
|
| 575 |
+
assert video.shape[1] == 3, "The vae is loaded, the input should be raw pixels"
|
| 576 |
+
video = self.vae.encode(video).latent_dist.sample() # [b c t h w]
|
| 577 |
+
|
| 578 |
+
if video.shape[2] == 1:
|
| 579 |
+
# is image
|
| 580 |
+
video = (video - self.vae_shift_factor) * self.vae_scale_factor
|
| 581 |
+
else:
|
| 582 |
+
# is video
|
| 583 |
+
video[:, :, :1] = (video[:, :, :1] - self.vae_shift_factor) * self.vae_scale_factor
|
| 584 |
+
video[:, :, 1:] = (video[:, :, 1:] - self.vae_video_shift_factor) * self.vae_video_scale_factor
|
| 585 |
+
|
| 586 |
+
# Get the pyramidal stages
|
| 587 |
+
vae_latent_list = self.get_pyramid_latent(video, len(self.stages) - 1)
|
| 588 |
+
|
| 589 |
+
if use_temporal_pyramid:
|
| 590 |
+
noisy_latents_list, ratios_list, timesteps_list, targets_list = self.add_pyramid_noise_with_temporal_pyramid(vae_latent_list, self.sample_ratios)
|
| 591 |
+
else:
|
| 592 |
+
# Only use the spatial pyramidal (without temporal ar)
|
| 593 |
+
noisy_latents_list, ratios_list, timesteps_list, targets_list = self.add_pyramid_noise(vae_latent_list, self.sample_ratios)
|
| 594 |
+
|
| 595 |
+
return noisy_latents_list, ratios_list, timesteps_list, targets_list
|
| 596 |
+
|
| 597 |
+
@torch.no_grad()
|
| 598 |
+
def get_text_embeddings(self, text, rand_idx, device):
|
| 599 |
+
if self.load_text_encoder:
|
| 600 |
+
batch_size = len(text) # Text is a str list
|
| 601 |
+
for idx in range(batch_size):
|
| 602 |
+
if rand_idx[idx].item():
|
| 603 |
+
text[idx] = ''
|
| 604 |
+
return self.text_encoder(text, device) # [b s c]
|
| 605 |
+
else:
|
| 606 |
+
batch_size = len(text['prompt_embeds'])
|
| 607 |
+
|
| 608 |
+
for idx in range(batch_size):
|
| 609 |
+
if rand_idx[idx].item():
|
| 610 |
+
text['prompt_embeds'][idx] = self.null_text_embeds['prompt_embed'].to(device)
|
| 611 |
+
text['prompt_attention_mask'][idx] = self.null_text_embeds['prompt_attention_mask'].to(device)
|
| 612 |
+
text['pooled_prompt_embeds'][idx] = self.null_text_embeds['pooled_prompt_embed'].to(device)
|
| 613 |
+
|
| 614 |
+
return text['prompt_embeds'], text['prompt_attention_mask'], text['pooled_prompt_embeds']
|
| 615 |
+
|
| 616 |
+
def calculate_loss(self, model_preds_list, targets_list):
|
| 617 |
+
loss_list = []
|
| 618 |
+
|
| 619 |
+
for model_pred, target in zip(model_preds_list, targets_list):
|
| 620 |
+
# Compute the loss.
|
| 621 |
+
loss_weight = torch.ones_like(target)
|
| 622 |
+
|
| 623 |
+
loss = torch.mean(
|
| 624 |
+
(loss_weight.float() * (model_pred.float() - target.float()) ** 2).reshape(target.shape[0], -1),
|
| 625 |
+
1,
|
| 626 |
+
)
|
| 627 |
+
loss_list.append(loss)
|
| 628 |
+
|
| 629 |
+
diffusion_loss = torch.cat(loss_list, dim=0).mean()
|
| 630 |
+
|
| 631 |
+
if self.return_log:
|
| 632 |
+
log = {}
|
| 633 |
+
split="train"
|
| 634 |
+
log[f'{split}/loss'] = diffusion_loss.detach()
|
| 635 |
+
return diffusion_loss, log
|
| 636 |
+
else:
|
| 637 |
+
return diffusion_loss, {}
|
| 638 |
+
|
| 639 |
+
def __call__(self, video, text, identifier=['video'], use_temporal_pyramid=True, accelerator: Accelerator=None):
|
| 640 |
+
xdim = video.ndim
|
| 641 |
+
device = video.device
|
| 642 |
+
|
| 643 |
+
if 'video' in identifier:
|
| 644 |
+
assert 'image' not in identifier
|
| 645 |
+
is_image = False
|
| 646 |
+
else:
|
| 647 |
+
assert 'video' not in identifier
|
| 648 |
+
video = video.unsqueeze(2) # 'b c h w -> b c 1 h w'
|
| 649 |
+
is_image = True
|
| 650 |
+
|
| 651 |
+
# TODO: now have 3 stages, firstly get the vae latents
|
| 652 |
+
with torch.no_grad(), accelerator.autocast():
|
| 653 |
+
# 10% prob drop the text
|
| 654 |
+
batch_size = len(video)
|
| 655 |
+
rand_idx = torch.rand((batch_size,)) <= self.cfg_rate
|
| 656 |
+
prompt_embeds, prompt_attention_mask, pooled_prompt_embeds = self.get_text_embeddings(text, rand_idx, device)
|
| 657 |
+
noisy_latents_list, ratios_list, timesteps_list, targets_list = self.get_vae_latent(video, use_temporal_pyramid=use_temporal_pyramid)
|
| 658 |
+
|
| 659 |
+
timesteps = torch.cat([timestep.unsqueeze(-1) for timestep in timesteps_list], dim=-1)
|
| 660 |
+
timesteps = timesteps.reshape(-1)
|
| 661 |
+
|
| 662 |
+
assert timesteps.shape[0] == prompt_embeds.shape[0]
|
| 663 |
+
|
| 664 |
+
# DiT forward
|
| 665 |
+
model_preds_list = self.dit(
|
| 666 |
+
sample=noisy_latents_list,
|
| 667 |
+
timestep_ratio=timesteps,
|
| 668 |
+
encoder_hidden_states=prompt_embeds,
|
| 669 |
+
encoder_attention_mask=prompt_attention_mask,
|
| 670 |
+
pooled_projections=pooled_prompt_embeds,
|
| 671 |
+
)
|
| 672 |
+
|
| 673 |
+
# calculate the loss
|
| 674 |
+
return self.calculate_loss(model_preds_list, targets_list)
|
| 675 |
+
|
| 676 |
+
def prepare_latents(
|
| 677 |
+
self,
|
| 678 |
+
batch_size,
|
| 679 |
+
num_channels_latents,
|
| 680 |
+
temp,
|
| 681 |
+
height,
|
| 682 |
+
width,
|
| 683 |
+
dtype,
|
| 684 |
+
device,
|
| 685 |
+
generator,
|
| 686 |
+
):
|
| 687 |
+
shape = (
|
| 688 |
+
batch_size,
|
| 689 |
+
num_channels_latents,
|
| 690 |
+
int(temp),
|
| 691 |
+
int(height) // self.downsample,
|
| 692 |
+
int(width) // self.downsample,
|
| 693 |
+
)
|
| 694 |
+
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
| 695 |
+
return latents
|
| 696 |
+
|
| 697 |
+
def sample_block_noise(self, bs, ch, temp, height, width):
|
| 698 |
+
gamma = self.scheduler.config.gamma
|
| 699 |
+
dist = torch.distributions.multivariate_normal.MultivariateNormal(torch.zeros(4), torch.eye(4) * (1 + gamma) - torch.ones(4, 4) * gamma)
|
| 700 |
+
block_number = bs * ch * temp * (height // 2) * (width // 2)
|
| 701 |
+
noise = torch.stack([dist.sample() for _ in range(block_number)]) # [block number, 4]
|
| 702 |
+
noise = rearrange(noise, '(b c t h w) (p q) -> b c t (h p) (w q)',b=bs,c=ch,t=temp,h=height//2,w=width//2,p=2,q=2)
|
| 703 |
+
return noise
|
| 704 |
+
|
| 705 |
+
@torch.no_grad()
|
| 706 |
+
def generate_one_unit(
|
| 707 |
+
self,
|
| 708 |
+
latents,
|
| 709 |
+
past_conditions, # List of past conditions, contains the conditions of each stage
|
| 710 |
+
prompt_embeds,
|
| 711 |
+
prompt_attention_mask,
|
| 712 |
+
pooled_prompt_embeds,
|
| 713 |
+
num_inference_steps,
|
| 714 |
+
height,
|
| 715 |
+
width,
|
| 716 |
+
temp,
|
| 717 |
+
device,
|
| 718 |
+
dtype,
|
| 719 |
+
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
| 720 |
+
is_first_frame: bool = False,
|
| 721 |
+
):
|
| 722 |
+
stages = self.stages
|
| 723 |
+
intermed_latents = []
|
| 724 |
+
|
| 725 |
+
for i_s in range(len(stages)):
|
| 726 |
+
self.scheduler.set_timesteps(num_inference_steps[i_s], i_s, device=device)
|
| 727 |
+
timesteps = self.scheduler.timesteps
|
| 728 |
+
|
| 729 |
+
if i_s > 0:
|
| 730 |
+
height *= 2; width *= 2
|
| 731 |
+
latents = rearrange(latents, 'b c t h w -> (b t) c h w')
|
| 732 |
+
latents = F.interpolate(latents, size=(height, width), mode='nearest')
|
| 733 |
+
latents = rearrange(latents, '(b t) c h w -> b c t h w', t=temp)
|
| 734 |
+
# Fix the stage
|
| 735 |
+
ori_sigma = 1 - self.scheduler.ori_start_sigmas[i_s] # the original coeff of signal
|
| 736 |
+
gamma = self.scheduler.config.gamma
|
| 737 |
+
alpha = 1 / (math.sqrt(1 + (1 / gamma)) * (1 - ori_sigma) + ori_sigma)
|
| 738 |
+
beta = alpha * (1 - ori_sigma) / math.sqrt(gamma)
|
| 739 |
+
|
| 740 |
+
bs, ch, temp, height, width = latents.shape
|
| 741 |
+
noise = self.sample_block_noise(bs, ch, temp, height, width)
|
| 742 |
+
noise = noise.to(device=device, dtype=dtype)
|
| 743 |
+
latents = alpha * latents + beta * noise # To fix the block artifact
|
| 744 |
+
|
| 745 |
+
for idx, t in enumerate(timesteps):
|
| 746 |
+
# expand the latents if we are doing classifier free guidance
|
| 747 |
+
latent_model_input = torch.cat([latents] * 2) if self.do_classifier_free_guidance else latents
|
| 748 |
+
|
| 749 |
+
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
| 750 |
+
timestep = t.expand(latent_model_input.shape[0]).to(latent_model_input.dtype)
|
| 751 |
+
|
| 752 |
+
if is_sequence_parallel_initialized():
|
| 753 |
+
# sync the input latent
|
| 754 |
+
sp_group_rank = get_sequence_parallel_group_rank()
|
| 755 |
+
global_src_rank = sp_group_rank * get_sequence_parallel_world_size()
|
| 756 |
+
torch.distributed.broadcast(latent_model_input, global_src_rank, group=get_sequence_parallel_group())
|
| 757 |
+
|
| 758 |
+
latent_model_input = past_conditions[i_s] + [latent_model_input]
|
| 759 |
+
|
| 760 |
+
noise_pred = self.dit(
|
| 761 |
+
sample=[latent_model_input],
|
| 762 |
+
timestep_ratio=timestep,
|
| 763 |
+
encoder_hidden_states=prompt_embeds,
|
| 764 |
+
encoder_attention_mask=prompt_attention_mask,
|
| 765 |
+
pooled_projections=pooled_prompt_embeds,
|
| 766 |
+
)
|
| 767 |
+
|
| 768 |
+
noise_pred = noise_pred[0]
|
| 769 |
+
|
| 770 |
+
# perform guidance
|
| 771 |
+
if self.do_classifier_free_guidance:
|
| 772 |
+
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
| 773 |
+
if is_first_frame:
|
| 774 |
+
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
|
| 775 |
+
else:
|
| 776 |
+
noise_pred = noise_pred_uncond + self.video_guidance_scale * (noise_pred_text - noise_pred_uncond)
|
| 777 |
+
|
| 778 |
+
# compute the previous noisy sample x_t -> x_t-1
|
| 779 |
+
latents = self.scheduler.step(
|
| 780 |
+
model_output=noise_pred,
|
| 781 |
+
timestep=timestep,
|
| 782 |
+
sample=latents,
|
| 783 |
+
generator=generator,
|
| 784 |
+
).prev_sample
|
| 785 |
+
|
| 786 |
+
intermed_latents.append(latents)
|
| 787 |
+
|
| 788 |
+
return intermed_latents
|
| 789 |
+
|
| 790 |
+
@torch.no_grad()
|
| 791 |
+
def generate_i2v(
|
| 792 |
+
self,
|
| 793 |
+
prompt: Union[str, List[str]] = '',
|
| 794 |
+
input_image: PIL.Image = None,
|
| 795 |
+
temp: int = 1,
|
| 796 |
+
num_inference_steps: Optional[Union[int, List[int]]] = 28,
|
| 797 |
+
guidance_scale: float = 7.0,
|
| 798 |
+
video_guidance_scale: float = 4.0,
|
| 799 |
+
min_guidance_scale: float = 2.0,
|
| 800 |
+
use_linear_guidance: bool = False,
|
| 801 |
+
alpha: float = 0.5,
|
| 802 |
+
negative_prompt: Optional[Union[str, List[str]]]="cartoon style, worst quality, low quality, blurry, absolute black, absolute white, low res, extra limbs, extra digits, misplaced objects, mutated anatomy, monochrome, horror",
|
| 803 |
+
num_images_per_prompt: Optional[int] = 1,
|
| 804 |
+
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
| 805 |
+
output_type: Optional[str] = "pil",
|
| 806 |
+
save_memory: bool = True,
|
| 807 |
+
cpu_offloading: bool = False, # If true, reload device will be cuda.
|
| 808 |
+
inference_multigpu: bool = False,
|
| 809 |
+
callback: Optional[Callable[[int, int, Dict], None]] = None,
|
| 810 |
+
):
|
| 811 |
+
if self.sequential_offload_enabled and not cpu_offloading:
|
| 812 |
+
print("Warning: overriding cpu_offloading set to false, as it's needed for sequential cpu offload")
|
| 813 |
+
cpu_offloading=True
|
| 814 |
+
device = self.device if not cpu_offloading else torch.device("cuda")
|
| 815 |
+
dtype = self.dtype
|
| 816 |
+
if cpu_offloading:
|
| 817 |
+
# skip caring about the text encoder here as its about to be used anyways.
|
| 818 |
+
if not self.sequential_offload_enabled:
|
| 819 |
+
if str(self.dit.device) != "cpu":
|
| 820 |
+
print("(dit) Warning: Do not preload pipeline components (i.e. to cuda) with cpu offloading enabled! Otherwise, a second transfer will occur needlessly taking up time.")
|
| 821 |
+
self.dit.to("cpu")
|
| 822 |
+
torch.cuda.empty_cache()
|
| 823 |
+
if str(self.vae.device) != "cpu":
|
| 824 |
+
print("(vae) Warning: Do not preload pipeline components (i.e. to cuda) with cpu offloading enabled! Otherwise, a second transfer will occur needlessly taking up time.")
|
| 825 |
+
self.vae.to("cpu")
|
| 826 |
+
torch.cuda.empty_cache()
|
| 827 |
+
|
| 828 |
+
width = input_image.width
|
| 829 |
+
height = input_image.height
|
| 830 |
+
|
| 831 |
+
assert temp % self.frame_per_unit == 0, "The frames should be divided by frame_per unit"
|
| 832 |
+
|
| 833 |
+
if isinstance(prompt, str):
|
| 834 |
+
batch_size = 1
|
| 835 |
+
prompt = prompt + ", hyper quality, Ultra HD, 8K" # adding this prompt to improve aesthetics
|
| 836 |
+
else:
|
| 837 |
+
assert isinstance(prompt, list)
|
| 838 |
+
batch_size = len(prompt)
|
| 839 |
+
prompt = [_ + ", hyper quality, Ultra HD, 8K" for _ in prompt]
|
| 840 |
+
|
| 841 |
+
if isinstance(num_inference_steps, int):
|
| 842 |
+
num_inference_steps = [num_inference_steps] * len(self.stages)
|
| 843 |
+
|
| 844 |
+
negative_prompt = negative_prompt or ""
|
| 845 |
+
|
| 846 |
+
# Get the text embeddings
|
| 847 |
+
if cpu_offloading and not self.sequential_offload_enabled:
|
| 848 |
+
self.text_encoder.to("cuda")
|
| 849 |
+
prompt_embeds, prompt_attention_mask, pooled_prompt_embeds = self.text_encoder(prompt, device)
|
| 850 |
+
negative_prompt_embeds, negative_prompt_attention_mask, negative_pooled_prompt_embeds = self.text_encoder(negative_prompt, device)
|
| 851 |
+
|
| 852 |
+
if cpu_offloading:
|
| 853 |
+
if not self.sequential_offload_enabled:
|
| 854 |
+
self.text_encoder.to("cpu")
|
| 855 |
+
self.vae.to("cuda")
|
| 856 |
+
torch.cuda.empty_cache()
|
| 857 |
+
|
| 858 |
+
if use_linear_guidance:
|
| 859 |
+
max_guidance_scale = guidance_scale
|
| 860 |
+
guidance_scale_list = [max(max_guidance_scale - alpha * t_, min_guidance_scale) for t_ in range(temp+1)]
|
| 861 |
+
print(guidance_scale_list)
|
| 862 |
+
|
| 863 |
+
self._guidance_scale = guidance_scale
|
| 864 |
+
self._video_guidance_scale = video_guidance_scale
|
| 865 |
+
|
| 866 |
+
if self.do_classifier_free_guidance:
|
| 867 |
+
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
|
| 868 |
+
pooled_prompt_embeds = torch.cat([negative_pooled_prompt_embeds, pooled_prompt_embeds], dim=0)
|
| 869 |
+
prompt_attention_mask = torch.cat([negative_prompt_attention_mask, prompt_attention_mask], dim=0)
|
| 870 |
+
|
| 871 |
+
if is_sequence_parallel_initialized():
|
| 872 |
+
# sync the prompt embedding across multiple GPUs
|
| 873 |
+
sp_group_rank = get_sequence_parallel_group_rank()
|
| 874 |
+
global_src_rank = sp_group_rank * get_sequence_parallel_world_size()
|
| 875 |
+
torch.distributed.broadcast(prompt_embeds, global_src_rank, group=get_sequence_parallel_group())
|
| 876 |
+
torch.distributed.broadcast(pooled_prompt_embeds, global_src_rank, group=get_sequence_parallel_group())
|
| 877 |
+
torch.distributed.broadcast(prompt_attention_mask, global_src_rank, group=get_sequence_parallel_group())
|
| 878 |
+
|
| 879 |
+
# Create the initial random noise
|
| 880 |
+
num_channels_latents = (self.dit.config.in_channels // 4) if self.model_name == "pyramid_flux" else self.dit.config.in_channels
|
| 881 |
+
latents = self.prepare_latents(
|
| 882 |
+
batch_size * num_images_per_prompt,
|
| 883 |
+
num_channels_latents,
|
| 884 |
+
temp,
|
| 885 |
+
height,
|
| 886 |
+
width,
|
| 887 |
+
prompt_embeds.dtype,
|
| 888 |
+
device,
|
| 889 |
+
generator,
|
| 890 |
+
)
|
| 891 |
+
|
| 892 |
+
temp, height, width = latents.shape[-3], latents.shape[-2], latents.shape[-1]
|
| 893 |
+
|
| 894 |
+
latents = rearrange(latents, 'b c t h w -> (b t) c h w')
|
| 895 |
+
# by defalut, we needs to start from the block noise
|
| 896 |
+
for _ in range(len(self.stages)-1):
|
| 897 |
+
height //= 2;width //= 2
|
| 898 |
+
latents = F.interpolate(latents, size=(height, width), mode='bilinear') * 2
|
| 899 |
+
|
| 900 |
+
latents = rearrange(latents, '(b t) c h w -> b c t h w', t=temp)
|
| 901 |
+
|
| 902 |
+
num_units = temp // self.frame_per_unit
|
| 903 |
+
stages = self.stages
|
| 904 |
+
|
| 905 |
+
# encode the image latents
|
| 906 |
+
image_transform = transforms.Compose([
|
| 907 |
+
transforms.ToTensor(),
|
| 908 |
+
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)),
|
| 909 |
+
])
|
| 910 |
+
input_image_tensor = image_transform(input_image).unsqueeze(0).unsqueeze(2) # [b c 1 h w]
|
| 911 |
+
input_image_latent = (self.vae.encode(input_image_tensor.to(self.vae.device, dtype=self.vae.dtype)).latent_dist.sample() - self.vae_shift_factor) * self.vae_scale_factor # [b c 1 h w]
|
| 912 |
+
|
| 913 |
+
if is_sequence_parallel_initialized():
|
| 914 |
+
# sync the image latent across multiple GPUs
|
| 915 |
+
sp_group_rank = get_sequence_parallel_group_rank()
|
| 916 |
+
global_src_rank = sp_group_rank * get_sequence_parallel_world_size()
|
| 917 |
+
torch.distributed.broadcast(input_image_latent, global_src_rank, group=get_sequence_parallel_group())
|
| 918 |
+
|
| 919 |
+
generated_latents_list = [input_image_latent] # The generated results
|
| 920 |
+
last_generated_latents = input_image_latent
|
| 921 |
+
|
| 922 |
+
if cpu_offloading:
|
| 923 |
+
self.vae.to("cpu")
|
| 924 |
+
if not self.sequential_offload_enabled:
|
| 925 |
+
self.dit.to("cuda")
|
| 926 |
+
torch.cuda.empty_cache()
|
| 927 |
+
|
| 928 |
+
for unit_index in tqdm(range(1, num_units)):
|
| 929 |
+
gc.collect()
|
| 930 |
+
torch.cuda.empty_cache()
|
| 931 |
+
|
| 932 |
+
if callback:
|
| 933 |
+
callback(unit_index, num_units)
|
| 934 |
+
|
| 935 |
+
if use_linear_guidance:
|
| 936 |
+
self._guidance_scale = guidance_scale_list[unit_index]
|
| 937 |
+
self._video_guidance_scale = guidance_scale_list[unit_index]
|
| 938 |
+
|
| 939 |
+
# prepare the condition latents
|
| 940 |
+
past_condition_latents = []
|
| 941 |
+
clean_latents_list = self.get_pyramid_latent(torch.cat(generated_latents_list, dim=2), len(stages) - 1)
|
| 942 |
+
|
| 943 |
+
for i_s in range(len(stages)):
|
| 944 |
+
last_cond_latent = clean_latents_list[i_s][:,:,-self.frame_per_unit:]
|
| 945 |
+
|
| 946 |
+
stage_input = [torch.cat([last_cond_latent] * 2) if self.do_classifier_free_guidance else last_cond_latent]
|
| 947 |
+
|
| 948 |
+
# pad the past clean latents
|
| 949 |
+
cur_unit_num = unit_index
|
| 950 |
+
cur_stage = i_s
|
| 951 |
+
cur_unit_ptx = 1
|
| 952 |
+
|
| 953 |
+
while cur_unit_ptx < cur_unit_num:
|
| 954 |
+
cur_stage = max(cur_stage - 1, 0)
|
| 955 |
+
if cur_stage == 0:
|
| 956 |
+
break
|
| 957 |
+
cur_unit_ptx += 1
|
| 958 |
+
cond_latents = clean_latents_list[cur_stage][:, :, -(cur_unit_ptx * self.frame_per_unit) : -((cur_unit_ptx - 1) * self.frame_per_unit)]
|
| 959 |
+
stage_input.append(torch.cat([cond_latents] * 2) if self.do_classifier_free_guidance else cond_latents)
|
| 960 |
+
|
| 961 |
+
if cur_stage == 0 and cur_unit_ptx < cur_unit_num:
|
| 962 |
+
cond_latents = clean_latents_list[0][:, :, :-(cur_unit_ptx * self.frame_per_unit)]
|
| 963 |
+
stage_input.append(torch.cat([cond_latents] * 2) if self.do_classifier_free_guidance else cond_latents)
|
| 964 |
+
|
| 965 |
+
stage_input = list(reversed(stage_input))
|
| 966 |
+
past_condition_latents.append(stage_input)
|
| 967 |
+
|
| 968 |
+
intermed_latents = self.generate_one_unit(
|
| 969 |
+
latents[:,:,(unit_index - 1) * self.frame_per_unit:unit_index * self.frame_per_unit],
|
| 970 |
+
past_condition_latents,
|
| 971 |
+
prompt_embeds,
|
| 972 |
+
prompt_attention_mask,
|
| 973 |
+
pooled_prompt_embeds,
|
| 974 |
+
num_inference_steps,
|
| 975 |
+
height,
|
| 976 |
+
width,
|
| 977 |
+
self.frame_per_unit,
|
| 978 |
+
device,
|
| 979 |
+
dtype,
|
| 980 |
+
generator,
|
| 981 |
+
is_first_frame=False,
|
| 982 |
+
)
|
| 983 |
+
|
| 984 |
+
generated_latents_list.append(intermed_latents[-1])
|
| 985 |
+
last_generated_latents = intermed_latents
|
| 986 |
+
|
| 987 |
+
generated_latents = torch.cat(generated_latents_list, dim=2)
|
| 988 |
+
|
| 989 |
+
if output_type == "latent":
|
| 990 |
+
image = generated_latents
|
| 991 |
+
else:
|
| 992 |
+
if cpu_offloading:
|
| 993 |
+
if not self.sequential_offload_enabled:
|
| 994 |
+
self.dit.to("cpu")
|
| 995 |
+
self.vae.to("cuda")
|
| 996 |
+
torch.cuda.empty_cache()
|
| 997 |
+
image = self.decode_latent(generated_latents, save_memory=save_memory, inference_multigpu=inference_multigpu)
|
| 998 |
+
if cpu_offloading:
|
| 999 |
+
self.vae.to("cpu")
|
| 1000 |
+
torch.cuda.empty_cache()
|
| 1001 |
+
# not technically necessary, but returns the pipeline to its original state
|
| 1002 |
+
|
| 1003 |
+
return image
|
| 1004 |
+
|
| 1005 |
+
@torch.no_grad()
|
| 1006 |
+
def generate(
|
| 1007 |
+
self,
|
| 1008 |
+
prompt: Union[str, List[str]] = None,
|
| 1009 |
+
height: Optional[int] = None,
|
| 1010 |
+
width: Optional[int] = None,
|
| 1011 |
+
temp: int = 1,
|
| 1012 |
+
num_inference_steps: Optional[Union[int, List[int]]] = 28,
|
| 1013 |
+
video_num_inference_steps: Optional[Union[int, List[int]]] = 28,
|
| 1014 |
+
guidance_scale: float = 7.0,
|
| 1015 |
+
video_guidance_scale: float = 7.0,
|
| 1016 |
+
min_guidance_scale: float = 2.0,
|
| 1017 |
+
use_linear_guidance: bool = False,
|
| 1018 |
+
alpha: float = 0.5,
|
| 1019 |
+
negative_prompt: Optional[Union[str, List[str]]]="cartoon style, worst quality, low quality, blurry, absolute black, absolute white, low res, extra limbs, extra digits, misplaced objects, mutated anatomy, monochrome, horror",
|
| 1020 |
+
num_images_per_prompt: Optional[int] = 1,
|
| 1021 |
+
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
| 1022 |
+
output_type: Optional[str] = "pil",
|
| 1023 |
+
save_memory: bool = True,
|
| 1024 |
+
cpu_offloading: bool = False, # If true, reload device will be cuda.
|
| 1025 |
+
inference_multigpu: bool = False,
|
| 1026 |
+
callback: Optional[Callable[[int, int, Dict], None]] = None,
|
| 1027 |
+
):
|
| 1028 |
+
if self.sequential_offload_enabled and not cpu_offloading:
|
| 1029 |
+
print("Warning: overriding cpu_offloading set to false, as it's needed for sequential cpu offload")
|
| 1030 |
+
cpu_offloading=True
|
| 1031 |
+
device = self.device if not cpu_offloading else torch.device("cuda")
|
| 1032 |
+
dtype = self.dtype
|
| 1033 |
+
if cpu_offloading:
|
| 1034 |
+
# skip caring about the text encoder here as its about to be used anyways.
|
| 1035 |
+
if not self.sequential_offload_enabled:
|
| 1036 |
+
if str(self.dit.device) != "cpu":
|
| 1037 |
+
print("(dit) Warning: Do not preload pipeline components (i.e. to cuda) with cpu offloading enabled! Otherwise, a second transfer will occur needlessly taking up time.")
|
| 1038 |
+
self.dit.to("cpu")
|
| 1039 |
+
torch.cuda.empty_cache()
|
| 1040 |
+
if str(self.vae.device) != "cpu":
|
| 1041 |
+
print("(vae) Warning: Do not preload pipeline components (i.e. to cuda) with cpu offloading enabled! Otherwise, a second transfer will occur needlessly taking up time.")
|
| 1042 |
+
self.vae.to("cpu")
|
| 1043 |
+
torch.cuda.empty_cache()
|
| 1044 |
+
|
| 1045 |
+
|
| 1046 |
+
assert (temp - 1) % self.frame_per_unit == 0, "The frames should be divided by frame_per unit"
|
| 1047 |
+
|
| 1048 |
+
if isinstance(prompt, str):
|
| 1049 |
+
batch_size = 1
|
| 1050 |
+
prompt = prompt + ", hyper quality, Ultra HD, 8K" # adding this prompt to improve aesthetics
|
| 1051 |
+
else:
|
| 1052 |
+
assert isinstance(prompt, list)
|
| 1053 |
+
batch_size = len(prompt)
|
| 1054 |
+
prompt = [_ + ", hyper quality, Ultra HD, 8K" for _ in prompt]
|
| 1055 |
+
|
| 1056 |
+
if isinstance(num_inference_steps, int):
|
| 1057 |
+
num_inference_steps = [num_inference_steps] * len(self.stages)
|
| 1058 |
+
|
| 1059 |
+
if isinstance(video_num_inference_steps, int):
|
| 1060 |
+
video_num_inference_steps = [video_num_inference_steps] * len(self.stages)
|
| 1061 |
+
|
| 1062 |
+
negative_prompt = negative_prompt or ""
|
| 1063 |
+
|
| 1064 |
+
# Get the text embeddings
|
| 1065 |
+
if cpu_offloading and not self.sequential_offload_enabled:
|
| 1066 |
+
self.text_encoder.to("cuda")
|
| 1067 |
+
prompt_embeds, prompt_attention_mask, pooled_prompt_embeds = self.text_encoder(prompt, device)
|
| 1068 |
+
negative_prompt_embeds, negative_prompt_attention_mask, negative_pooled_prompt_embeds = self.text_encoder(negative_prompt, device)
|
| 1069 |
+
if cpu_offloading:
|
| 1070 |
+
if not self.sequential_offload_enabled:
|
| 1071 |
+
self.text_encoder.to("cpu")
|
| 1072 |
+
self.dit.to("cuda")
|
| 1073 |
+
torch.cuda.empty_cache()
|
| 1074 |
+
|
| 1075 |
+
if use_linear_guidance:
|
| 1076 |
+
max_guidance_scale = guidance_scale
|
| 1077 |
+
# guidance_scale_list = torch.linspace(max_guidance_scale, min_guidance_scale, temp).tolist()
|
| 1078 |
+
guidance_scale_list = [max(max_guidance_scale - alpha * t_, min_guidance_scale) for t_ in range(temp)]
|
| 1079 |
+
print(guidance_scale_list)
|
| 1080 |
+
|
| 1081 |
+
self._guidance_scale = guidance_scale
|
| 1082 |
+
self._video_guidance_scale = video_guidance_scale
|
| 1083 |
+
|
| 1084 |
+
if self.do_classifier_free_guidance:
|
| 1085 |
+
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
|
| 1086 |
+
pooled_prompt_embeds = torch.cat([negative_pooled_prompt_embeds, pooled_prompt_embeds], dim=0)
|
| 1087 |
+
prompt_attention_mask = torch.cat([negative_prompt_attention_mask, prompt_attention_mask], dim=0)
|
| 1088 |
+
|
| 1089 |
+
if is_sequence_parallel_initialized():
|
| 1090 |
+
# sync the prompt embedding across multiple GPUs
|
| 1091 |
+
sp_group_rank = get_sequence_parallel_group_rank()
|
| 1092 |
+
global_src_rank = sp_group_rank * get_sequence_parallel_world_size()
|
| 1093 |
+
torch.distributed.broadcast(prompt_embeds, global_src_rank, group=get_sequence_parallel_group())
|
| 1094 |
+
torch.distributed.broadcast(pooled_prompt_embeds, global_src_rank, group=get_sequence_parallel_group())
|
| 1095 |
+
torch.distributed.broadcast(prompt_attention_mask, global_src_rank, group=get_sequence_parallel_group())
|
| 1096 |
+
|
| 1097 |
+
# Create the initial random noise
|
| 1098 |
+
num_channels_latents = (self.dit.config.in_channels // 4) if self.model_name == "pyramid_flux" else self.dit.config.in_channels
|
| 1099 |
+
latents = self.prepare_latents(
|
| 1100 |
+
batch_size * num_images_per_prompt,
|
| 1101 |
+
num_channels_latents,
|
| 1102 |
+
temp,
|
| 1103 |
+
height,
|
| 1104 |
+
width,
|
| 1105 |
+
prompt_embeds.dtype,
|
| 1106 |
+
device,
|
| 1107 |
+
generator,
|
| 1108 |
+
)
|
| 1109 |
+
|
| 1110 |
+
temp, height, width = latents.shape[-3], latents.shape[-2], latents.shape[-1]
|
| 1111 |
+
|
| 1112 |
+
latents = rearrange(latents, 'b c t h w -> (b t) c h w')
|
| 1113 |
+
# by default, we needs to start from the block noise
|
| 1114 |
+
for _ in range(len(self.stages)-1):
|
| 1115 |
+
height //= 2;width //= 2
|
| 1116 |
+
latents = F.interpolate(latents, size=(height, width), mode='bilinear') * 2
|
| 1117 |
+
|
| 1118 |
+
latents = rearrange(latents, '(b t) c h w -> b c t h w', t=temp)
|
| 1119 |
+
|
| 1120 |
+
num_units = 1 + (temp - 1) // self.frame_per_unit
|
| 1121 |
+
stages = self.stages
|
| 1122 |
+
|
| 1123 |
+
generated_latents_list = [] # The generated results
|
| 1124 |
+
last_generated_latents = None
|
| 1125 |
+
|
| 1126 |
+
for unit_index in tqdm(range(num_units)):
|
| 1127 |
+
gc.collect()
|
| 1128 |
+
torch.cuda.empty_cache()
|
| 1129 |
+
|
| 1130 |
+
if callback:
|
| 1131 |
+
callback(unit_index, num_units)
|
| 1132 |
+
|
| 1133 |
+
if use_linear_guidance:
|
| 1134 |
+
self._guidance_scale = guidance_scale_list[unit_index]
|
| 1135 |
+
self._video_guidance_scale = guidance_scale_list[unit_index]
|
| 1136 |
+
|
| 1137 |
+
if unit_index == 0:
|
| 1138 |
+
past_condition_latents = [[] for _ in range(len(stages))]
|
| 1139 |
+
intermed_latents = self.generate_one_unit(
|
| 1140 |
+
latents[:,:,:1],
|
| 1141 |
+
past_condition_latents,
|
| 1142 |
+
prompt_embeds,
|
| 1143 |
+
prompt_attention_mask,
|
| 1144 |
+
pooled_prompt_embeds,
|
| 1145 |
+
num_inference_steps,
|
| 1146 |
+
height,
|
| 1147 |
+
width,
|
| 1148 |
+
1,
|
| 1149 |
+
device,
|
| 1150 |
+
dtype,
|
| 1151 |
+
generator,
|
| 1152 |
+
is_first_frame=True,
|
| 1153 |
+
)
|
| 1154 |
+
else:
|
| 1155 |
+
# prepare the condition latents
|
| 1156 |
+
past_condition_latents = []
|
| 1157 |
+
clean_latents_list = self.get_pyramid_latent(torch.cat(generated_latents_list, dim=2), len(stages) - 1)
|
| 1158 |
+
|
| 1159 |
+
for i_s in range(len(stages)):
|
| 1160 |
+
last_cond_latent = clean_latents_list[i_s][:,:,-(self.frame_per_unit):]
|
| 1161 |
+
|
| 1162 |
+
stage_input = [torch.cat([last_cond_latent] * 2) if self.do_classifier_free_guidance else last_cond_latent]
|
| 1163 |
+
|
| 1164 |
+
# pad the past clean latents
|
| 1165 |
+
cur_unit_num = unit_index
|
| 1166 |
+
cur_stage = i_s
|
| 1167 |
+
cur_unit_ptx = 1
|
| 1168 |
+
|
| 1169 |
+
while cur_unit_ptx < cur_unit_num:
|
| 1170 |
+
cur_stage = max(cur_stage - 1, 0)
|
| 1171 |
+
if cur_stage == 0:
|
| 1172 |
+
break
|
| 1173 |
+
cur_unit_ptx += 1
|
| 1174 |
+
cond_latents = clean_latents_list[cur_stage][:, :, -(cur_unit_ptx * self.frame_per_unit) : -((cur_unit_ptx - 1) * self.frame_per_unit)]
|
| 1175 |
+
stage_input.append(torch.cat([cond_latents] * 2) if self.do_classifier_free_guidance else cond_latents)
|
| 1176 |
+
|
| 1177 |
+
if cur_stage == 0 and cur_unit_ptx < cur_unit_num:
|
| 1178 |
+
cond_latents = clean_latents_list[0][:, :, :-(cur_unit_ptx * self.frame_per_unit)]
|
| 1179 |
+
stage_input.append(torch.cat([cond_latents] * 2) if self.do_classifier_free_guidance else cond_latents)
|
| 1180 |
+
|
| 1181 |
+
stage_input = list(reversed(stage_input))
|
| 1182 |
+
past_condition_latents.append(stage_input)
|
| 1183 |
+
|
| 1184 |
+
intermed_latents = self.generate_one_unit(
|
| 1185 |
+
latents[:,:, 1 + (unit_index - 1) * self.frame_per_unit:1 + unit_index * self.frame_per_unit],
|
| 1186 |
+
past_condition_latents,
|
| 1187 |
+
prompt_embeds,
|
| 1188 |
+
prompt_attention_mask,
|
| 1189 |
+
pooled_prompt_embeds,
|
| 1190 |
+
video_num_inference_steps,
|
| 1191 |
+
height,
|
| 1192 |
+
width,
|
| 1193 |
+
self.frame_per_unit,
|
| 1194 |
+
device,
|
| 1195 |
+
dtype,
|
| 1196 |
+
generator,
|
| 1197 |
+
is_first_frame=False,
|
| 1198 |
+
)
|
| 1199 |
+
|
| 1200 |
+
generated_latents_list.append(intermed_latents[-1])
|
| 1201 |
+
last_generated_latents = intermed_latents
|
| 1202 |
+
|
| 1203 |
+
generated_latents = torch.cat(generated_latents_list, dim=2)
|
| 1204 |
+
|
| 1205 |
+
if output_type == "latent":
|
| 1206 |
+
image = generated_latents
|
| 1207 |
+
else:
|
| 1208 |
+
if cpu_offloading:
|
| 1209 |
+
if not self.sequential_offload_enabled:
|
| 1210 |
+
self.dit.to("cpu")
|
| 1211 |
+
self.vae.to("cuda")
|
| 1212 |
+
torch.cuda.empty_cache()
|
| 1213 |
+
image = self.decode_latent(generated_latents, save_memory=save_memory, inference_multigpu=inference_multigpu)
|
| 1214 |
+
if cpu_offloading:
|
| 1215 |
+
self.vae.to("cpu")
|
| 1216 |
+
torch.cuda.empty_cache()
|
| 1217 |
+
# not technically necessary, but returns the pipeline to its original state
|
| 1218 |
+
|
| 1219 |
+
return image
|
| 1220 |
+
|
| 1221 |
+
def decode_latent(self, latents, save_memory=True, inference_multigpu=False):
|
| 1222 |
+
# only the main process needs vae decoding
|
| 1223 |
+
if inference_multigpu and get_rank() != 0:
|
| 1224 |
+
return None
|
| 1225 |
+
|
| 1226 |
+
if latents.shape[2] == 1:
|
| 1227 |
+
latents = (latents / self.vae_scale_factor) + self.vae_shift_factor
|
| 1228 |
+
else:
|
| 1229 |
+
latents[:, :, :1] = (latents[:, :, :1] / self.vae_scale_factor) + self.vae_shift_factor
|
| 1230 |
+
latents[:, :, 1:] = (latents[:, :, 1:] / self.vae_video_scale_factor) + self.vae_video_shift_factor
|
| 1231 |
+
|
| 1232 |
+
if save_memory:
|
| 1233 |
+
# reducing the tile size and temporal chunk window size
|
| 1234 |
+
image = self.vae.decode(latents, temporal_chunk=True, window_size=1, tile_sample_min_size=256).sample
|
| 1235 |
+
else:
|
| 1236 |
+
image = self.vae.decode(latents, temporal_chunk=True, window_size=2, tile_sample_min_size=512).sample
|
| 1237 |
+
|
| 1238 |
+
image = image.mul(127.5).add(127.5).clamp(0, 255).byte()
|
| 1239 |
+
image = rearrange(image, "B C T H W -> (B T) H W C")
|
| 1240 |
+
image = image.cpu().numpy()
|
| 1241 |
+
image = self.numpy_to_pil(image)
|
| 1242 |
+
|
| 1243 |
+
return image
|
| 1244 |
+
|
| 1245 |
+
@staticmethod
|
| 1246 |
+
def numpy_to_pil(images):
|
| 1247 |
+
"""
|
| 1248 |
+
Convert a numpy image or a batch of images to a PIL image.
|
| 1249 |
+
"""
|
| 1250 |
+
if images.ndim == 3:
|
| 1251 |
+
images = images[None, ...]
|
| 1252 |
+
|
| 1253 |
+
if images.shape[-1] == 1:
|
| 1254 |
+
# special case for grayscale (single channel) images
|
| 1255 |
+
pil_images = [Image.fromarray(image.squeeze(), mode="L") for image in images]
|
| 1256 |
+
else:
|
| 1257 |
+
pil_images = [Image.fromarray(image) for image in images]
|
| 1258 |
+
|
| 1259 |
+
return pil_images
|
| 1260 |
+
|
| 1261 |
+
@property
|
| 1262 |
+
def device(self):
|
| 1263 |
+
return next(self.dit.parameters()).device
|
| 1264 |
+
|
| 1265 |
+
@property
|
| 1266 |
+
def dtype(self):
|
| 1267 |
+
return next(self.dit.parameters()).dtype
|
| 1268 |
+
|
| 1269 |
+
@property
|
| 1270 |
+
def guidance_scale(self):
|
| 1271 |
+
return self._guidance_scale
|
| 1272 |
+
|
| 1273 |
+
@property
|
| 1274 |
+
def video_guidance_scale(self):
|
| 1275 |
+
return self._video_guidance_scale
|
| 1276 |
+
|
| 1277 |
+
@property
|
| 1278 |
+
def do_classifier_free_guidance(self):
|
| 1279 |
+
return self._guidance_scale > 0
|
pyramid_flow_model.lnk
ADDED
|
Binary file (982 Bytes). View file
|
|
|
pyramid_flow_model/.gitattributes
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
pyramid_flow_model/README.md
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
pipeline_tag: text-to-video
|
| 4 |
+
tags:
|
| 5 |
+
- text-to-image
|
| 6 |
+
- image-to-video
|
| 7 |
+
- flux
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
# ⚡️Pyramid Flow miniFLUX⚡️
|
| 11 |
+
|
| 12 |
+
[[Paper]](https://arxiv.org/abs/2410.05954) [[Project Page ✨]](https://pyramid-flow.github.io) [[Code 🚀]](https://github.com/jy0205/Pyramid-Flow) [[SD3 Model ⚡️]](https://huggingface.co/rain1011/pyramid-flow-sd3) [[demo 🤗](https://huggingface.co/spaces/Pyramid-Flow/pyramid-flow)]
|
| 13 |
+
|
| 14 |
+
This is the model repository for Pyramid Flow, a training-efficient **Autoregressive Video Generation** method based on **Flow Matching**. By training only on open-source datasets, it generates high-quality 10-second videos at 768p resolution and 24 FPS, and naturally supports image-to-video generation.
|
| 15 |
+
|
| 16 |
+
<table class="center" border="0" style="width: 100%; text-align: left;">
|
| 17 |
+
<tr>
|
| 18 |
+
<th>10s, 768p, 24fps</th>
|
| 19 |
+
<th>5s, 768p, 24fps</th>
|
| 20 |
+
<th>Image-to-video</th>
|
| 21 |
+
</tr>
|
| 22 |
+
<tr>
|
| 23 |
+
<td><video src="https://pyramid-flow.github.io/static/videos/t2v_10s/fireworks.mp4" autoplay muted loop playsinline></video></td>
|
| 24 |
+
<td><video src="https://pyramid-flow.github.io/static/videos/t2v/trailer.mp4" autoplay muted loop playsinline></video></td>
|
| 25 |
+
<td><video src="https://pyramid-flow.github.io/static/videos/i2v/sunday.mp4" autoplay muted loop playsinline></video></td>
|
| 26 |
+
</tr>
|
| 27 |
+
</table>
|
| 28 |
+
|
| 29 |
+
## News
|
| 30 |
+
|
| 31 |
+
* `2024.11.13` 🚀🚀🚀 We release the [768p miniFLUX checkpoint](https://huggingface.co/rain1011/pyramid-flow-miniflux) (up to 10s).
|
| 32 |
+
|
| 33 |
+
> We have switched the model structure from SD3 to a mini FLUX to fix human structure issues, please try our 1024p image checkpoint, 384p video checkpoint (up to 5s) and 768p video checkpoint (up to 10s). The new miniflux model shows great improvement on human structure and motion stability
|
| 34 |
+
* `2024.10.29` ⚡️⚡️⚡️ We release [training code](https://github.com/jy0205/Pyramid-Flow?tab=readme-ov-file#training) and [new model checkpoints](https://huggingface.co/rain1011/pyramid-flow-miniflux) with FLUX structure trained from scratch.
|
| 35 |
+
* `2024.10.11` 🤗🤗🤗 [Hugging Face demo](https://huggingface.co/spaces/Pyramid-Flow/pyramid-flow) is available. Thanks [@multimodalart](https://huggingface.co/multimodalart) for the commit!
|
| 36 |
+
* `2024.10.10` 🚀🚀🚀 We release the [technical report](https://arxiv.org/abs/2410.05954), [project page](https://pyramid-flow.github.io) and [model checkpoint](https://huggingface.co/rain1011/pyramid-flow-sd3) of Pyramid Flow.
|
| 37 |
+
|
| 38 |
+
## Installation
|
| 39 |
+
|
| 40 |
+
We recommend setting up the environment with conda. The codebase currently uses Python 3.8.10 and PyTorch 2.1.2 ([guide](https://pytorch.org/get-started/previous-versions/#v212)), and we are actively working to support a wider range of versions.
|
| 41 |
+
|
| 42 |
+
```bash
|
| 43 |
+
git clone https://github.com/jy0205/Pyramid-Flow
|
| 44 |
+
cd Pyramid-Flow
|
| 45 |
+
|
| 46 |
+
# create env using conda
|
| 47 |
+
conda create -n pyramid python==3.8.10
|
| 48 |
+
conda activate pyramid
|
| 49 |
+
pip install -r requirements.txt
|
| 50 |
+
```
|
| 51 |
+
|
| 52 |
+
Then, download the model from [Huggingface](https://huggingface.co/rain1011) (there are two variants: [miniFLUX](https://huggingface.co/rain1011/pyramid-flow-miniflux) or [SD3](https://huggingface.co/rain1011/pyramid-flow-sd3)). The miniFLUX models support 1024p image, 384p and 768p video generation, and the SD3-based models support 768p and 384p video generation. The 384p checkpoint generates 5-second video at 24FPS, while the 768p checkpoint generates up to 10-second video at 24FPS.
|
| 53 |
+
|
| 54 |
+
```python
|
| 55 |
+
from huggingface_hub import snapshot_download
|
| 56 |
+
|
| 57 |
+
model_path = 'PATH' # The local directory to save downloaded checkpoint
|
| 58 |
+
snapshot_download("rain1011/pyramid-flow-miniflux", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
## Usage
|
| 62 |
+
|
| 63 |
+
For inference, we provide Gradio demo, single-GPU, multi-GPU, and Apple Silicon inference code, as well as VRAM-efficient features such as CPU offloading. Please check our [code repository](https://github.com/jy0205/Pyramid-Flow?tab=readme-ov-file#inference) for usage.
|
| 64 |
+
|
| 65 |
+
Below is a simplified two-step usage procedure. First, load the downloaded model:
|
| 66 |
+
|
| 67 |
+
```python
|
| 68 |
+
import torch
|
| 69 |
+
from PIL import Image
|
| 70 |
+
from pyramid_dit import PyramidDiTForVideoGeneration
|
| 71 |
+
from diffusers.utils import load_image, export_to_video
|
| 72 |
+
|
| 73 |
+
torch.cuda.set_device(0)
|
| 74 |
+
model_dtype, torch_dtype = 'bf16', torch.bfloat16 # Use bf16 (not support fp16 yet)
|
| 75 |
+
|
| 76 |
+
model = PyramidDiTForVideoGeneration(
|
| 77 |
+
'PATH', # The downloaded checkpoint dir
|
| 78 |
+
model_name="pyramid_flux",
|
| 79 |
+
model_dtype,
|
| 80 |
+
model_variant='diffusion_transformer_768p',
|
| 81 |
+
)
|
| 82 |
+
|
| 83 |
+
model.vae.enable_tiling()
|
| 84 |
+
# model.vae.to("cuda")
|
| 85 |
+
# model.dit.to("cuda")
|
| 86 |
+
# model.text_encoder.to("cuda")
|
| 87 |
+
|
| 88 |
+
# if you're not using sequential offloading bellow uncomment the lines above ^
|
| 89 |
+
model.enable_sequential_cpu_offload()
|
| 90 |
+
```
|
| 91 |
+
|
| 92 |
+
Then, you can try text-to-video generation on your own prompts:
|
| 93 |
+
|
| 94 |
+
```python
|
| 95 |
+
prompt = "A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors"
|
| 96 |
+
|
| 97 |
+
# used for 384p model variant
|
| 98 |
+
# width = 640
|
| 99 |
+
# height = 384
|
| 100 |
+
|
| 101 |
+
# used for 768p model variant
|
| 102 |
+
width = 1280
|
| 103 |
+
height = 768
|
| 104 |
+
|
| 105 |
+
with torch.no_grad(), torch.cuda.amp.autocast(enabled=True, dtype=torch_dtype):
|
| 106 |
+
frames = model.generate(
|
| 107 |
+
prompt=prompt,
|
| 108 |
+
num_inference_steps=[20, 20, 20],
|
| 109 |
+
video_num_inference_steps=[10, 10, 10],
|
| 110 |
+
height=height,
|
| 111 |
+
width=width,
|
| 112 |
+
temp=16, # temp=16: 5s, temp=31: 10s
|
| 113 |
+
guidance_scale=7.0, # The guidance for the first frame, set it to 7 for 384p variant
|
| 114 |
+
video_guidance_scale=5.0, # The guidance for the other video latent
|
| 115 |
+
output_type="pil",
|
| 116 |
+
save_memory=True, # If you have enough GPU memory, set it to `False` to improve vae decoding speed
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
export_to_video(frames, "./text_to_video_sample.mp4", fps=24)
|
| 120 |
+
```
|
| 121 |
+
|
| 122 |
+
As an autoregressive model, our model also supports (text conditioned) image-to-video generation:
|
| 123 |
+
|
| 124 |
+
```python
|
| 125 |
+
# used for 384p model variant
|
| 126 |
+
# width = 640
|
| 127 |
+
# height = 384
|
| 128 |
+
|
| 129 |
+
# used for 768p model variant
|
| 130 |
+
width = 1280
|
| 131 |
+
height = 768
|
| 132 |
+
|
| 133 |
+
image = Image.open('assets/the_great_wall.jpg').convert("RGB").resize((width, height))
|
| 134 |
+
prompt = "FPV flying over the Great Wall"
|
| 135 |
+
|
| 136 |
+
with torch.no_grad(), torch.cuda.amp.autocast(enabled=True, dtype=torch_dtype):
|
| 137 |
+
frames = model.generate_i2v(
|
| 138 |
+
prompt=prompt,
|
| 139 |
+
input_image=image,
|
| 140 |
+
num_inference_steps=[10, 10, 10],
|
| 141 |
+
temp=16,
|
| 142 |
+
video_guidance_scale=4.0,
|
| 143 |
+
output_type="pil",
|
| 144 |
+
save_memory=True, # If you have enough GPU memory, set it to `False` to improve vae decoding speed
|
| 145 |
+
)
|
| 146 |
+
|
| 147 |
+
export_to_video(frames, "./image_to_video_sample.mp4", fps=24)
|
| 148 |
+
```
|
| 149 |
+
|
| 150 |
+
## Usage tips
|
| 151 |
+
|
| 152 |
+
* The `guidance_scale` parameter controls the visual quality. We suggest using a guidance within [7, 9] for the 768p checkpoint during text-to-video generation, and 7 for the 384p checkpoint.
|
| 153 |
+
* The `video_guidance_scale` parameter controls the motion. A larger value increases the dynamic degree and mitigates the autoregressive generation degradation, while a smaller value stabilizes the video.
|
| 154 |
+
* For 10-second video generation, we recommend using a guidance scale of 7 and a video guidance scale of 5.
|
| 155 |
+
|
| 156 |
+
## Gallery
|
| 157 |
+
|
| 158 |
+
The following video examples are generated at 5s, 768p, 24fps. For more results, please visit our [project page](https://pyramid-flow.github.io).
|
| 159 |
+
|
| 160 |
+
<table class="center" border="0" style="width: 100%; text-align: left;">
|
| 161 |
+
<tr>
|
| 162 |
+
<td><video src="https://pyramid-flow.github.io/static/videos/t2v/tokyo.mp4" autoplay muted loop playsinline></video></td>
|
| 163 |
+
<td><video src="https://pyramid-flow.github.io/static/videos/t2v/eiffel.mp4" autoplay muted loop playsinline></video></td>
|
| 164 |
+
</tr>
|
| 165 |
+
<tr>
|
| 166 |
+
<td><video src="https://pyramid-flow.github.io/static/videos/t2v/waves.mp4" autoplay muted loop playsinline></video></td>
|
| 167 |
+
<td><video src="https://pyramid-flow.github.io/static/videos/t2v/rail.mp4" autoplay muted loop playsinline></video></td>
|
| 168 |
+
</tr>
|
| 169 |
+
</table>
|
| 170 |
+
|
| 171 |
+
## Acknowledgement
|
| 172 |
+
|
| 173 |
+
We are grateful for the following awesome projects when implementing Pyramid Flow:
|
| 174 |
+
|
| 175 |
+
* [SD3 Medium](https://huggingface.co/stabilityai/stable-diffusion-3-medium) and [Flux 1.0](https://huggingface.co/black-forest-labs/FLUX.1-dev): State-of-the-art image generation models based on flow matching.
|
| 176 |
+
* [Diffusion Forcing](https://boyuan.space/diffusion-forcing) and [GameNGen](https://gamengen.github.io): Next-token prediction meets full-sequence diffusion.
|
| 177 |
+
* [WebVid-10M](https://github.com/m-bain/webvid), [OpenVid-1M](https://github.com/NJU-PCALab/OpenVid-1M) and [Open-Sora Plan](https://github.com/PKU-YuanGroup/Open-Sora-Plan): Large-scale datasets for text-to-video generation.
|
| 178 |
+
* [CogVideoX](https://github.com/THUDM/CogVideo): An open-source text-to-video generation model that shares many training details.
|
| 179 |
+
* [Video-LLaMA2](https://github.com/DAMO-NLP-SG/VideoLLaMA2): An open-source video LLM for our video recaptioning.
|
| 180 |
+
|
| 181 |
+
## Citation
|
| 182 |
+
|
| 183 |
+
Consider giving this repository a star and cite Pyramid Flow in your publications if it helps your research.
|
| 184 |
+
```
|
| 185 |
+
@article{jin2024pyramidal,
|
| 186 |
+
title={Pyramidal Flow Matching for Efficient Video Generative Modeling},
|
| 187 |
+
author={Jin, Yang and Sun, Zhicheng and Li, Ningyuan and Xu, Kun and Xu, Kun and Jiang, Hao and Zhuang, Nan and Huang, Quzhe and Song, Yang and Mu, Yadong and Lin, Zhouchen},
|
| 188 |
+
jounal={arXiv preprint arXiv:2410.05954},
|
| 189 |
+
year={2024}
|
| 190 |
+
}
|
| 191 |
+
```
|
pyramid_flow_model/causal_video_vae/config.json
ADDED
|
@@ -0,0 +1,92 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "CausalVideoVAE",
|
| 3 |
+
"_diffusers_version": "0.29.2",
|
| 4 |
+
"add_post_quant_conv": true,
|
| 5 |
+
"decoder_act_fn": "silu",
|
| 6 |
+
"decoder_block_dropout": [
|
| 7 |
+
0.0,
|
| 8 |
+
0.0,
|
| 9 |
+
0.0,
|
| 10 |
+
0.0
|
| 11 |
+
],
|
| 12 |
+
"decoder_block_out_channels": [
|
| 13 |
+
128,
|
| 14 |
+
256,
|
| 15 |
+
512,
|
| 16 |
+
512
|
| 17 |
+
],
|
| 18 |
+
"decoder_in_channels": 16,
|
| 19 |
+
"decoder_layers_per_block": [
|
| 20 |
+
3,
|
| 21 |
+
3,
|
| 22 |
+
3,
|
| 23 |
+
3
|
| 24 |
+
],
|
| 25 |
+
"decoder_norm_num_groups": 32,
|
| 26 |
+
"decoder_out_channels": 3,
|
| 27 |
+
"decoder_spatial_up_sample": [
|
| 28 |
+
true,
|
| 29 |
+
true,
|
| 30 |
+
true,
|
| 31 |
+
false
|
| 32 |
+
],
|
| 33 |
+
"decoder_temporal_up_sample": [
|
| 34 |
+
true,
|
| 35 |
+
true,
|
| 36 |
+
true,
|
| 37 |
+
false
|
| 38 |
+
],
|
| 39 |
+
"decoder_type": "causal_vae_conv",
|
| 40 |
+
"decoder_up_block_types": [
|
| 41 |
+
"UpDecoderBlockCausal3D",
|
| 42 |
+
"UpDecoderBlockCausal3D",
|
| 43 |
+
"UpDecoderBlockCausal3D",
|
| 44 |
+
"UpDecoderBlockCausal3D"
|
| 45 |
+
],
|
| 46 |
+
"downsample_scale": 8,
|
| 47 |
+
"encoder_act_fn": "silu",
|
| 48 |
+
"encoder_block_dropout": [
|
| 49 |
+
0.0,
|
| 50 |
+
0.0,
|
| 51 |
+
0.0,
|
| 52 |
+
0.0
|
| 53 |
+
],
|
| 54 |
+
"encoder_block_out_channels": [
|
| 55 |
+
128,
|
| 56 |
+
256,
|
| 57 |
+
512,
|
| 58 |
+
512
|
| 59 |
+
],
|
| 60 |
+
"encoder_double_z": true,
|
| 61 |
+
"encoder_down_block_types": [
|
| 62 |
+
"DownEncoderBlockCausal3D",
|
| 63 |
+
"DownEncoderBlockCausal3D",
|
| 64 |
+
"DownEncoderBlockCausal3D",
|
| 65 |
+
"DownEncoderBlockCausal3D"
|
| 66 |
+
],
|
| 67 |
+
"encoder_in_channels": 3,
|
| 68 |
+
"encoder_layers_per_block": [
|
| 69 |
+
2,
|
| 70 |
+
2,
|
| 71 |
+
2,
|
| 72 |
+
2
|
| 73 |
+
],
|
| 74 |
+
"encoder_norm_num_groups": 32,
|
| 75 |
+
"encoder_out_channels": 16,
|
| 76 |
+
"encoder_spatial_down_sample": [
|
| 77 |
+
true,
|
| 78 |
+
true,
|
| 79 |
+
true,
|
| 80 |
+
false
|
| 81 |
+
],
|
| 82 |
+
"encoder_temporal_down_sample": [
|
| 83 |
+
true,
|
| 84 |
+
true,
|
| 85 |
+
true,
|
| 86 |
+
false
|
| 87 |
+
],
|
| 88 |
+
"encoder_type": "causal_vae_conv",
|
| 89 |
+
"interpolate": false,
|
| 90 |
+
"sample_size": 256,
|
| 91 |
+
"scaling_factor": 0.13025
|
| 92 |
+
}
|
pyramid_flow_model/causal_video_vae/diffusion_pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8385177ef6dc62f9e0665213c1509f750a59b496ddf573b4524d7a641b21d260
|
| 3 |
+
size 1341696682
|
pyramid_flow_model/diffusion_transformer_384p/config.json
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "PyramidFluxTransformer",
|
| 3 |
+
"_diffusers_version": "0.30.3",
|
| 4 |
+
"attention_head_dim": 64,
|
| 5 |
+
"axes_dims_rope": [
|
| 6 |
+
16,
|
| 7 |
+
24,
|
| 8 |
+
24
|
| 9 |
+
],
|
| 10 |
+
"in_channels": 64,
|
| 11 |
+
"interp_condition_pos": true,
|
| 12 |
+
"joint_attention_dim": 4096,
|
| 13 |
+
"num_attention_heads": 30,
|
| 14 |
+
"num_layers": 8,
|
| 15 |
+
"num_single_layers": 16,
|
| 16 |
+
"patch_size": 1,
|
| 17 |
+
"pooled_projection_dim": 768,
|
| 18 |
+
"use_flash_attn": false,
|
| 19 |
+
"use_gradient_checkpointing": false,
|
| 20 |
+
"use_temporal_causal": true
|
| 21 |
+
}
|
pyramid_flow_model/diffusion_transformer_384p/diffusion_pytorch_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:76ab1a5f81f5c69285ad8040e8282a6260dae5ca601d7f614bd9de38a46316b5
|
| 3 |
+
size 7888294568
|
pyramid_flow_model/diffusion_transformer_768p/config.json
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "PyramidFluxTransformer",
|
| 3 |
+
"_diffusers_version": "0.30.3",
|
| 4 |
+
"attention_head_dim": 64,
|
| 5 |
+
"axes_dims_rope": [
|
| 6 |
+
16,
|
| 7 |
+
24,
|
| 8 |
+
24
|
| 9 |
+
],
|
| 10 |
+
"in_channels": 64,
|
| 11 |
+
"interp_condition_pos": true,
|
| 12 |
+
"joint_attention_dim": 4096,
|
| 13 |
+
"num_attention_heads": 30,
|
| 14 |
+
"num_layers": 8,
|
| 15 |
+
"num_single_layers": 16,
|
| 16 |
+
"patch_size": 1,
|
| 17 |
+
"pooled_projection_dim": 768,
|
| 18 |
+
"use_flash_attn": false,
|
| 19 |
+
"use_gradient_checkpointing": false,
|
| 20 |
+
"use_temporal_causal": true
|
| 21 |
+
}
|
pyramid_flow_model/diffusion_transformer_768p/diffusion_pytorch_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:864de0e1afd9dd2c373d957ac2c54346f5006036dc7aa8ec7605db80eea2272c
|
| 3 |
+
size 7888294568
|
pyramid_flow_model/diffusion_transformer_image/config.json
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "PyramidFluxTransformer",
|
| 3 |
+
"_diffusers_version": "0.30.3",
|
| 4 |
+
"attention_head_dim": 64,
|
| 5 |
+
"axes_dims_rope": [
|
| 6 |
+
16,
|
| 7 |
+
24,
|
| 8 |
+
24
|
| 9 |
+
],
|
| 10 |
+
"in_channels": 64,
|
| 11 |
+
"interp_condition_pos": true,
|
| 12 |
+
"joint_attention_dim": 4096,
|
| 13 |
+
"num_attention_heads": 30,
|
| 14 |
+
"num_layers": 8,
|
| 15 |
+
"num_single_layers": 16,
|
| 16 |
+
"patch_size": 1,
|
| 17 |
+
"pooled_projection_dim": 768,
|
| 18 |
+
"use_flash_attn": false,
|
| 19 |
+
"use_gradient_checkpointing": false,
|
| 20 |
+
"use_temporal_causal": true
|
| 21 |
+
}
|
pyramid_flow_model/diffusion_transformer_image/diffusion_pytorch_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2a16bcc2f50fe52de93d6a7aa13a31dde384dda13a98007e3a5b17e02257697e
|
| 3 |
+
size 7888294568
|