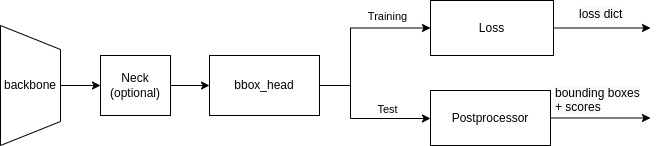
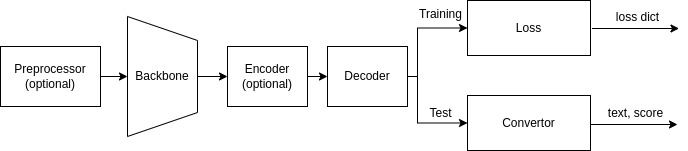
+
+## Results and models
+
+### WildReceipt
+
+| Method | Modality | Macro F1-Score | Download |
+| :--------------------------------------------------------------------: | :--------------: | :------------: | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| [sdmgr_unet16](/configs/kie/sdmgr/sdmgr_unet16_60e_wildreceipt.py) | Visual + Textual | 0.888 | [model](https://download.openmmlab.com/mmocr/kie/sdmgr/sdmgr_unet16_60e_wildreceipt_20210520-7489e6de.pth) \| [log](https://download.openmmlab.com/mmocr/kie/sdmgr/20210520_132236.log.json) |
+| [sdmgr_novisual](/configs/kie/sdmgr/sdmgr_novisual_60e_wildreceipt.py) | Textual | 0.870 | [model](https://download.openmmlab.com/mmocr/kie/sdmgr/sdmgr_novisual_60e_wildreceipt_20210517-a44850da.pth) \| [log](https://download.openmmlab.com/mmocr/kie/sdmgr/20210517_205829.log.json) |
+
+:::{note}
+1. For `sdmgr_novisual`, images are not needed for training and testing. So fake `img_prefix` can be used in configs. As well, fake `file_name` can be used in annotation files.
+:::
+
+### WildReceiptOpenset
+
+| Method | Modality | Edge F1-Score | Node Macro F1-Score | Node Micro F1-Score | Download |
+| :----------------------------------------------------------------------------: | :------: | :-----------: | :-----------------: | :-----------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| [sdmgr_novisual](/configs/kie/sdmgr/sdmgr_novisual_60e_wildreceipt_openset.py) | Textual | 0.786 | 0.926 | 0.935 | [model](https://download.openmmlab.com/mmocr/kie/sdmgr/sdmgr_novisual_60e_wildreceipt_openset_20210917-d236b3ea.pth) \| [log](https://download.openmmlab.com/mmocr/kie/sdmgr/20210917_050824.log.json) |
+
+
+:::{note}
+1. In the case of openset, the number of node categories is unknown or unfixed, and more node category can be added.
+2. To show that our method can handle openset problem, we modify the ground truth of `WildReceipt` to `WildReceiptOpenset`. The `nodes` are just classified into 4 classes: `background, key, value, others`, while adding `edge` labels for each box.
+3. The model is used to predict whether two nodes are a pair connecting by a valid edge.
+4. You can learn more about the key differences between CloseSet and OpenSet annotations in our [tutorial](tutorials/kie_closeset_openset.md).
+:::
+
+## Citation
+
+```bibtex
+@misc{sun2021spatial,
+ title={Spatial Dual-Modality Graph Reasoning for Key Information Extraction},
+ author={Hongbin Sun and Zhanghui Kuang and Xiaoyu Yue and Chenhao Lin and Wayne Zhang},
+ year={2021},
+ eprint={2103.14470},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+}
+```
diff --git a/configs/kie/sdmgr/metafile.yml b/configs/kie/sdmgr/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..f1a9695991156ae658e40f1aa2ab1dba06da2e9c
--- /dev/null
+++ b/configs/kie/sdmgr/metafile.yml
@@ -0,0 +1,39 @@
+Collections:
+- Name: SDMGR
+ Metadata:
+ Training Data: KIEDataset
+ Training Techniques:
+ - Adam
+ Training Resources: 1x GeForce GTX 1080 Ti
+ Architecture:
+ - UNet
+ - SDMGRHead
+ Paper:
+ URL: https://arxiv.org/abs/2103.14470.pdf
+ Title: 'Spatial Dual-Modality Graph Reasoning for Key Information Extraction'
+ README: configs/kie/sdmgr/README.md
+
+Models:
+ - Name: sdmgr_unet16_60e_wildreceipt
+ In Collection: SDMGR
+ Config: configs/kie/sdmgr/sdmgr_unet16_60e_wildreceipt.py
+ Metadata:
+ Training Data: wildreceipt
+ Results:
+ - Task: Key Information Extraction
+ Dataset: wildreceipt
+ Metrics:
+ macro_f1: 0.876
+ Weights: https://download.openmmlab.com/mmocr/kie/sdmgr/sdmgr_unet16_60e_wildreceipt_20210405-16a47642.pth
+
+ - Name: sdmgr_novisual_60e_wildreceipt
+ In Collection: SDMGR
+ Config: configs/kie/sdmgr/sdmgr_novisual_60e_wildreceipt.py
+ Metadata:
+ Training Data: wildreceipt
+ Results:
+ - Task: Key Information Extraction
+ Dataset: wildreceipt
+ Metrics:
+ macro_f1: 0.864
+ Weights: https://download.openmmlab.com/mmocr/kie/sdmgr/sdmgr_novisual_60e_wildreceipt_20210405-07bc26ad.pth
diff --git a/configs/kie/sdmgr/sdmgr_novisual_60e_wildreceipt.py b/configs/kie/sdmgr/sdmgr_novisual_60e_wildreceipt.py
new file mode 100644
index 0000000000000000000000000000000000000000..220135a0b037909599fbaf77c75b06f48f8b1ba7
--- /dev/null
+++ b/configs/kie/sdmgr/sdmgr_novisual_60e_wildreceipt.py
@@ -0,0 +1,98 @@
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+max_scale, min_scale = 1024, 512
+
+train_pipeline = [
+ dict(type='LoadAnnotations'),
+ dict(
+ type='ResizeNoImg', img_scale=(max_scale, min_scale), keep_ratio=True),
+ dict(type='KIEFormatBundle'),
+ dict(
+ type='Collect',
+ keys=['img', 'relations', 'texts', 'gt_bboxes', 'gt_labels'],
+ meta_keys=('filename', 'ori_texts'))
+]
+test_pipeline = [
+ dict(type='LoadAnnotations'),
+ dict(
+ type='ResizeNoImg', img_scale=(max_scale, min_scale), keep_ratio=True),
+ dict(type='KIEFormatBundle'),
+ dict(
+ type='Collect',
+ keys=['img', 'relations', 'texts', 'gt_bboxes'],
+ meta_keys=('filename', 'ori_texts', 'img_norm_cfg', 'ori_filename',
+ 'img_shape'))
+]
+
+dataset_type = 'KIEDataset'
+data_root = 'data/wildreceipt'
+
+loader = dict(
+ type='HardDiskLoader',
+ repeat=1,
+ parser=dict(
+ type='LineJsonParser',
+ keys=['file_name', 'height', 'width', 'annotations']))
+
+train = dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/train.txt',
+ pipeline=train_pipeline,
+ img_prefix=data_root,
+ loader=loader,
+ dict_file=f'{data_root}/dict.txt',
+ test_mode=False)
+test = dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/test.txt',
+ pipeline=test_pipeline,
+ img_prefix=data_root,
+ loader=loader,
+ dict_file=f'{data_root}/dict.txt',
+ test_mode=True)
+
+data = dict(
+ samples_per_gpu=4,
+ workers_per_gpu=1,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=train,
+ val=test,
+ test=test)
+
+evaluation = dict(
+ interval=1,
+ metric='macro_f1',
+ metric_options=dict(
+ macro_f1=dict(
+ ignores=[0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 25])))
+
+model = dict(
+ type='SDMGR',
+ backbone=dict(type='UNet', base_channels=16),
+ bbox_head=dict(
+ type='SDMGRHead', visual_dim=16, num_chars=92, num_classes=26),
+ visual_modality=False,
+ train_cfg=None,
+ test_cfg=None,
+ class_list=f'{data_root}/class_list.txt')
+
+optimizer = dict(type='Adam', weight_decay=0.0001)
+optimizer_config = dict(grad_clip=None)
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=1,
+ warmup_ratio=1,
+ step=[40, 50])
+total_epochs = 60
+
+checkpoint_config = dict(interval=1)
+log_config = dict(interval=50, hooks=[dict(type='TextLoggerHook')])
+dist_params = dict(backend='nccl')
+log_level = 'INFO'
+load_from = None
+resume_from = None
+workflow = [('train', 1)]
+
+find_unused_parameters = True
diff --git a/configs/kie/sdmgr/sdmgr_novisual_60e_wildreceipt_openset.py b/configs/kie/sdmgr/sdmgr_novisual_60e_wildreceipt_openset.py
new file mode 100644
index 0000000000000000000000000000000000000000..8b182fdbd49a36fcf06d2124c6dc32f102a798f7
--- /dev/null
+++ b/configs/kie/sdmgr/sdmgr_novisual_60e_wildreceipt_openset.py
@@ -0,0 +1,84 @@
+_base_ = ['../../_base_/default_runtime.py']
+
+model = dict(
+ type='SDMGR',
+ backbone=dict(type='UNet', base_channels=16),
+ bbox_head=dict(
+ type='SDMGRHead', visual_dim=16, num_chars=92, num_classes=4),
+ visual_modality=False,
+ train_cfg=None,
+ test_cfg=None,
+ class_list=None,
+ openset=True)
+
+optimizer = dict(type='Adam', weight_decay=0.0001)
+optimizer_config = dict(grad_clip=None)
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=1,
+ warmup_ratio=1,
+ step=[40, 50])
+total_epochs = 60
+
+train_pipeline = [
+ dict(type='LoadAnnotations'),
+ dict(type='ResizeNoImg', img_scale=(1024, 512), keep_ratio=True),
+ dict(type='KIEFormatBundle'),
+ dict(
+ type='Collect',
+ keys=['img', 'relations', 'texts', 'gt_bboxes', 'gt_labels'],
+ meta_keys=('filename', 'ori_filename', 'ori_texts'))
+]
+test_pipeline = [
+ dict(type='LoadAnnotations'),
+ dict(type='ResizeNoImg', img_scale=(1024, 512), keep_ratio=True),
+ dict(type='KIEFormatBundle'),
+ dict(
+ type='Collect',
+ keys=['img', 'relations', 'texts', 'gt_bboxes'],
+ meta_keys=('filename', 'ori_filename', 'ori_texts', 'ori_boxes',
+ 'img_norm_cfg', 'ori_filename', 'img_shape'))
+]
+
+dataset_type = 'OpensetKIEDataset'
+data_root = 'data/wildreceipt'
+
+loader = dict(
+ type='HardDiskLoader',
+ repeat=1,
+ parser=dict(
+ type='LineJsonParser',
+ keys=['file_name', 'height', 'width', 'annotations']))
+
+train = dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/openset_train.txt',
+ pipeline=train_pipeline,
+ img_prefix=data_root,
+ link_type='one-to-many',
+ loader=loader,
+ dict_file=f'{data_root}/dict.txt',
+ test_mode=False)
+test = dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/openset_test.txt',
+ pipeline=test_pipeline,
+ img_prefix=data_root,
+ link_type='one-to-many',
+ loader=loader,
+ dict_file=f'{data_root}/dict.txt',
+ test_mode=True)
+
+data = dict(
+ samples_per_gpu=4,
+ workers_per_gpu=1,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=train,
+ val=test,
+ test=test)
+
+evaluation = dict(interval=1, metric='openset_f1', metric_options=None)
+
+find_unused_parameters = True
diff --git a/configs/kie/sdmgr/sdmgr_unet16_60e_wildreceipt.py b/configs/kie/sdmgr/sdmgr_unet16_60e_wildreceipt.py
new file mode 100644
index 0000000000000000000000000000000000000000..f073064affebe05d3830e18d76453c1cceb0f1a1
--- /dev/null
+++ b/configs/kie/sdmgr/sdmgr_unet16_60e_wildreceipt.py
@@ -0,0 +1,105 @@
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+max_scale, min_scale = 1024, 512
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=(max_scale, min_scale), keep_ratio=True),
+ dict(type='RandomFlip', flip_ratio=0.),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='KIEFormatBundle'),
+ dict(
+ type='Collect',
+ keys=['img', 'relations', 'texts', 'gt_bboxes', 'gt_labels'])
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations'),
+ dict(type='Resize', img_scale=(max_scale, min_scale), keep_ratio=True),
+ dict(type='RandomFlip', flip_ratio=0.),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='KIEFormatBundle'),
+ dict(
+ type='Collect',
+ keys=['img', 'relations', 'texts', 'gt_bboxes'],
+ meta_keys=[
+ 'img_norm_cfg', 'img_shape', 'ori_filename', 'filename',
+ 'ori_texts'
+ ])
+]
+
+dataset_type = 'KIEDataset'
+data_root = 'data/wildreceipt'
+
+loader = dict(
+ type='HardDiskLoader',
+ repeat=1,
+ parser=dict(
+ type='LineJsonParser',
+ keys=['file_name', 'height', 'width', 'annotations']))
+
+train = dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/train.txt',
+ pipeline=train_pipeline,
+ img_prefix=data_root,
+ loader=loader,
+ dict_file=f'{data_root}/dict.txt',
+ test_mode=False)
+test = dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/test.txt',
+ pipeline=test_pipeline,
+ img_prefix=data_root,
+ loader=loader,
+ dict_file=f'{data_root}/dict.txt',
+ test_mode=True)
+
+data = dict(
+ samples_per_gpu=4,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=train,
+ val=test,
+ test=test)
+
+evaluation = dict(
+ interval=1,
+ metric='macro_f1',
+ metric_options=dict(
+ macro_f1=dict(
+ ignores=[0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 25])))
+
+model = dict(
+ type='SDMGR',
+ backbone=dict(type='UNet', base_channels=16),
+ bbox_head=dict(
+ type='SDMGRHead', visual_dim=16, num_chars=92, num_classes=26),
+ visual_modality=True,
+ train_cfg=None,
+ test_cfg=None,
+ class_list=f'{data_root}/class_list.txt')
+
+optimizer = dict(type='Adam', weight_decay=0.0001)
+optimizer_config = dict(grad_clip=None)
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=1,
+ warmup_ratio=1,
+ step=[40, 50])
+total_epochs = 60
+
+checkpoint_config = dict(interval=1)
+log_config = dict(interval=50, hooks=[dict(type='TextLoggerHook')])
+dist_params = dict(backend='nccl')
+log_level = 'INFO'
+load_from = None
+resume_from = None
+workflow = [('train', 1)]
+
+find_unused_parameters = True
diff --git a/configs/ner/bert_softmax/README.md b/configs/ner/bert_softmax/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..9da45a3ac294794512cafeb14a8f8c847d651cea
--- /dev/null
+++ b/configs/ner/bert_softmax/README.md
@@ -0,0 +1,50 @@
+# Bert
+
+>[Bert: Pre-training of deep bidirectional transformers for language understanding](https://arxiv.org/abs/1810.04805)
+
+
+
+## Abstract
+
+We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications.
+BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks, including pushing the GLUE score to 80.5% (7.7% point absolute improvement), MultiNLI accuracy to 86.7% (4.6% absolute improvement), SQuAD v1.1 question answering Test F1 to 93.2 (1.5 point absolute improvement) and SQuAD v2.0 Test F1 to 83.1 (5.1 point absolute improvement).
+
+
+
+
+
+
+
+
+## Dataset
+
+### Train Dataset
+
+| trainset | text_num | entity_num |
+| :---------: | :------: | :--------: |
+| CLUENER2020 | 10748 | 23338 |
+
+### Test Dataset
+
+| testset | text_num | entity_num |
+| :---------: | :------: | :--------: |
+| CLUENER2020 | 1343 | 2982 |
+
+
+## Results and models
+
+| Method | Pretrain | Precision | Recall | F1-Score | Download |
+| :-------------------------------------------------------------------: | :---------------------------------------------------------------------------------: | :-------: | :----: | :------: | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| [bert_softmax](/configs/ner/bert_softmax/bert_softmax_cluener_18e.py) | [pretrain](https://download.openmmlab.com/mmocr/ner/bert_softmax/bert_pretrain.pth) | 0.7885 | 0.7998 | 0.7941 | [model](https://download.openmmlab.com/mmocr/ner/bert_softmax/bert_softmax_cluener-eea70ea2.pth) \| [log](https://download.openmmlab.com/mmocr/ner/bert_softmax/20210514_172645.log.json) |
+
+
+## Citation
+
+```bibtex
+@article{devlin2018bert,
+ title={Bert: Pre-training of deep bidirectional transformers for language understanding},
+ author={Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
+ journal={arXiv preprint arXiv:1810.04805},
+ year={2018}
+}
+```
diff --git a/configs/ner/bert_softmax/bert_softmax_cluener_18e.py b/configs/ner/bert_softmax/bert_softmax_cluener_18e.py
new file mode 100755
index 0000000000000000000000000000000000000000..5fd85d9a858236f4feb8903e3f4bf95f9eccaf94
--- /dev/null
+++ b/configs/ner/bert_softmax/bert_softmax_cluener_18e.py
@@ -0,0 +1,70 @@
+_base_ = [
+ '../../_base_/schedules/schedule_adadelta_18e.py',
+ '../../_base_/default_runtime.py'
+]
+
+categories = [
+ 'address', 'book', 'company', 'game', 'government', 'movie', 'name',
+ 'organization', 'position', 'scene'
+]
+
+test_ann_file = 'data/cluener2020/dev.json'
+train_ann_file = 'data/cluener2020/train.json'
+vocab_file = 'data/cluener2020/vocab.txt'
+
+max_len = 128
+loader = dict(
+ type='HardDiskLoader',
+ repeat=1,
+ parser=dict(type='LineJsonParser', keys=['text', 'label']))
+
+ner_convertor = dict(
+ type='NerConvertor',
+ annotation_type='bio',
+ vocab_file=vocab_file,
+ categories=categories,
+ max_len=max_len)
+
+test_pipeline = [
+ dict(type='NerTransform', label_convertor=ner_convertor, max_len=max_len),
+ dict(type='ToTensorNER')
+]
+
+train_pipeline = [
+ dict(type='NerTransform', label_convertor=ner_convertor, max_len=max_len),
+ dict(type='ToTensorNER')
+]
+dataset_type = 'NerDataset'
+
+train = dict(
+ type=dataset_type,
+ ann_file=train_ann_file,
+ loader=loader,
+ pipeline=train_pipeline,
+ test_mode=False)
+
+test = dict(
+ type=dataset_type,
+ ann_file=test_ann_file,
+ loader=loader,
+ pipeline=test_pipeline,
+ test_mode=True)
+data = dict(
+ samples_per_gpu=8, workers_per_gpu=2, train=train, val=test, test=test)
+
+evaluation = dict(interval=1, metric='f1-score')
+
+model = dict(
+ type='NerClassifier',
+ encoder=dict(
+ type='BertEncoder',
+ max_position_embeddings=512,
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='https://download.openmmlab.com/mmocr/ner/'
+ 'bert_softmax/bert_pretrain.pth')),
+ decoder=dict(type='FCDecoder'),
+ loss=dict(type='MaskedCrossEntropyLoss'),
+ label_convertor=ner_convertor)
+
+test_cfg = None
diff --git a/configs/textdet/dbnet/README.md b/configs/textdet/dbnet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..0b451d6635f69645801e4de52786253328e29fd3
--- /dev/null
+++ b/configs/textdet/dbnet/README.md
@@ -0,0 +1,33 @@
+# DBNet
+
+> [Real-time Scene Text Detection with Differentiable Binarization](https://arxiv.org/abs/1911.08947)
+
+
+## Abstract
+
+Recently, segmentation-based methods are quite popular in scene text detection, as the segmentation results can more accurately describe scene text of various shapes such as curve text. However, the post-processing of binarization is essential for segmentation-based detection, which converts probability maps produced by a segmentation method into bounding boxes/regions of text. In this paper, we propose a module named Differentiable Binarization (DB), which can perform the binarization process in a segmentation network. Optimized along with a DB module, a segmentation network can adaptively set the thresholds for binarization, which not only simplifies the post-processing but also enhances the performance of text detection. Based on a simple segmentation network, we validate the performance improvements of DB on five benchmark datasets, which consistently achieves state-of-the-art results, in terms of both detection accuracy and speed. In particular, with a light-weight backbone, the performance improvements by DB are significant so that we can look for an ideal tradeoff between detection accuracy and efficiency. Specifically, with a backbone of ResNet-18, our detector achieves an F-measure of 82.8, running at 62 FPS, on the MSRA-TD500 dataset.
+
+
+
+
+
+## Results and models
+
+### ICDAR2015
+
+| Method | Pretrained Model | Training set | Test set | #epochs | Test size | Recall | Precision | Hmean | Download |
+| :---------------------------------------------------------------------------: | :------------------------------------------------------------------------------------------------------------------------: | :-------------: | :------------: | :-----: | :-------: | :----: | :-------: | :---: | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| [DBNet_r18](/configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py) | ImageNet | ICDAR2015 Train | ICDAR2015 Test | 1200 | 736 | 0.731 | 0.871 | 0.795 | [model](https://download.openmmlab.com/mmocr/textdet/dbnet/dbnet_r18_fpnc_sbn_1200e_icdar2015_20210329-ba3ab597.pth) \| [log](https://download.openmmlab.com/mmocr/textdet/dbnet/dbnet_r18_fpnc_sbn_1200e_icdar2015_20210329-ba3ab597.log.json) |
+| [DBNet_r50dcn](/configs/textdet/dbnet/dbnet_r50dcnv2_fpnc_1200e_icdar2015.py) | [Synthtext](https://download.openmmlab.com/mmocr/textdet/dbnet/dbnet_r50dcnv2_fpnc_sbn_2e_synthtext_20210325-aa96e477.pth) | ICDAR2015 Train | ICDAR2015 Test | 1200 | 1024 | 0.814 | 0.868 | 0.840 | [model](https://download.openmmlab.com/mmocr/textdet/dbnet/dbnet_r50dcnv2_fpnc_sbn_1200e_icdar2015_20211025-9fe3b590.pth) \| [log](https://download.openmmlab.com/mmocr/textdet/dbnet/dbnet_r50dcnv2_fpnc_sbn_1200e_icdar2015_20211025-9fe3b590.log.json) |
+
+
+## Citation
+
+```bibtex
+@article{Liao_Wan_Yao_Chen_Bai_2020,
+ title={Real-Time Scene Text Detection with Differentiable Binarization},
+ journal={Proceedings of the AAAI Conference on Artificial Intelligence},
+ author={Liao, Minghui and Wan, Zhaoyi and Yao, Cong and Chen, Kai and Bai, Xiang},
+ year={2020},
+ pages={11474-11481}}
+```
diff --git a/configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py b/configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py
new file mode 100644
index 0000000000000000000000000000000000000000..997668f2e9e54780b13d433490feb8cfab95e807
--- /dev/null
+++ b/configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py
@@ -0,0 +1,33 @@
+_base_ = [
+ '../../_base_/runtime_10e.py',
+ '../../_base_/schedules/schedule_sgd_1200e.py',
+ '../../_base_/det_models/dbnet_r18_fpnc.py',
+ '../../_base_/det_datasets/icdar2015.py',
+ '../../_base_/det_pipelines/dbnet_pipeline.py'
+]
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline_r18 = {{_base_.train_pipeline_r18}}
+test_pipeline_1333_736 = {{_base_.test_pipeline_1333_736}}
+
+data = dict(
+ samples_per_gpu=16,
+ workers_per_gpu=8,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline_r18),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_1333_736),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_1333_736))
+
+evaluation = dict(interval=100, metric='hmean-iou')
diff --git a/configs/textdet/dbnet/dbnet_r50dcnv2_fpnc_1200e_icdar2015.py b/configs/textdet/dbnet/dbnet_r50dcnv2_fpnc_1200e_icdar2015.py
new file mode 100644
index 0000000000000000000000000000000000000000..bd0b8c847f788a68e97798ea83e8f22a1ec24d2f
--- /dev/null
+++ b/configs/textdet/dbnet/dbnet_r50dcnv2_fpnc_1200e_icdar2015.py
@@ -0,0 +1,35 @@
+_base_ = [
+ '../../_base_/runtime_10e.py',
+ '../../_base_/schedules/schedule_sgd_1200e.py',
+ '../../_base_/det_models/dbnet_r50dcnv2_fpnc.py',
+ '../../_base_/det_datasets/icdar2015.py',
+ '../../_base_/det_pipelines/dbnet_pipeline.py'
+]
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline_r50dcnv2 = {{_base_.train_pipeline_r50dcnv2}}
+test_pipeline_4068_1024 = {{_base_.test_pipeline_4068_1024}}
+
+load_from = 'checkpoints/textdet/dbnet/res50dcnv2_synthtext.pth'
+
+data = dict(
+ samples_per_gpu=8,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline_r50dcnv2),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_4068_1024),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_4068_1024))
+
+evaluation = dict(interval=100, metric='hmean-iou')
diff --git a/configs/textdet/dbnet/metafile.yml b/configs/textdet/dbnet/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..597fe42e42ea4fb75c97136ac751c96d270e4684
--- /dev/null
+++ b/configs/textdet/dbnet/metafile.yml
@@ -0,0 +1,40 @@
+Collections:
+- Name: DBNet
+ Metadata:
+ Training Data: ICDAR2015
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x GeForce GTX 1080 Ti
+ Architecture:
+ - ResNet
+ - FPNC
+ Paper:
+ URL: https://arxiv.org/pdf/1911.08947.pdf
+ Title: 'Real-time Scene Text Detection with Differentiable Binarization'
+ README: configs/textdet/dbnet/README.md
+
+Models:
+ - Name: dbnet_r18_fpnc_1200e_icdar2015
+ In Collection: DBNet
+ Config: configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py
+ Metadata:
+ Training Data: ICDAR2015
+ Results:
+ - Task: Text Detection
+ Dataset: ICDAR2015
+ Metrics:
+ hmean-iou: 0.795
+ Weights: https://download.openmmlab.com/mmocr/textdet/dbnet/dbnet_r18_fpnc_sbn_1200e_icdar2015_20210329-ba3ab597.pth
+
+ - Name: dbnet_r50dcnv2_fpnc_1200e_icdar2015
+ In Collection: DBNet
+ Config: configs/textdet/dbnet/dbnet_r50dcnv2_fpnc_1200e_icdar2015.py
+ Metadata:
+ Training Data: ICDAR2015
+ Results:
+ - Task: Text Detection
+ Dataset: ICDAR2015
+ Metrics:
+ hmean-iou: 0.840
+ Weights: https://download.openmmlab.com/mmocr/textdet/dbnet/dbnet_r50dcnv2_fpnc_sbn_1200e_icdar2015_20211025-9fe3b590.pth
diff --git a/configs/textdet/drrg/README.md b/configs/textdet/drrg/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..b40d53042f63dd4ccaf85bb1043676869144051b
--- /dev/null
+++ b/configs/textdet/drrg/README.md
@@ -0,0 +1,37 @@
+# DRRG
+
+> [Deep relational reasoning graph network for arbitrary shape text detection](https://arxiv.org/abs/2003.07493)
+
+
+
+## Abstract
+Arbitrary shape text detection is a challenging task due to the high variety and complexity of scenes texts. In this paper, we propose a novel unified relational reasoning graph network for arbitrary shape text detection. In our method, an innovative local graph bridges a text proposal model via Convolutional Neural Network (CNN) and a deep relational reasoning network via Graph Convolutional Network (GCN), making our network end-to-end trainable. To be concrete, every text instance will be divided into a series of small rectangular components, and the geometry attributes (e.g., height, width, and orientation) of the small components will be estimated by our text proposal model. Given the geometry attributes, the local graph construction model can roughly establish linkages between different text components. For further reasoning and deducing the likelihood of linkages between the component and its neighbors, we adopt a graph-based network to perform deep relational reasoning on local graphs. Experiments on public available datasets demonstrate the state-of-the-art performance of our method.
+
+
+
+
+
+## Results and models
+
+### CTW1500
+
+| Method | Pretrained Model | Training set | Test set | #epochs | Test size | Recall | Precision | Hmean | Download |
+| :-------------------------------------------------------------: | :--------------: | :-----------: | :----------: | :-----: | :-------: | :-----------: | :-----------: | :-----------: | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| [DRRG](configs/textdet/drrg/drrg_r50_fpn_unet_1200e_ctw1500.py) | ImageNet | CTW1500 Train | CTW1500 Test | 1200 | 640 | 0.822 (0.791) | 0.858 (0.862) | 0.840 (0.825) | [model](https://download.openmmlab.com/mmocr/textdet/drrg/drrg_r50_fpn_unet_1200e_ctw1500_20211022-fb30b001.pth) \ [log](https://download.openmmlab.com/mmocr/textdet/drrg/20210511_234719.log) |
+
+:::{note}
+We've upgraded our IoU backend from `Polygon3` to `shapely`. There are some performance differences for some models due to the backends' different logics to handle invalid polygons (more info [here](https://github.com/open-mmlab/mmocr/issues/465)). **New evaluation result is presented in brackets** and new logs will be uploaded soon.
+:::
+
+
+## Citation
+
+```bibtex
+@article{zhang2020drrg,
+ title={Deep relational reasoning graph network for arbitrary shape text detection},
+ author={Zhang, Shi-Xue and Zhu, Xiaobin and Hou, Jie-Bo and Liu, Chang and Yang, Chun and Wang, Hongfa and Yin, Xu-Cheng},
+ booktitle={CVPR},
+ pages={9699-9708},
+ year={2020}
+}
+```
diff --git a/configs/textdet/drrg/drrg_r50_fpn_unet_1200e_ctw1500.py b/configs/textdet/drrg/drrg_r50_fpn_unet_1200e_ctw1500.py
new file mode 100644
index 0000000000000000000000000000000000000000..e30b1a749d089e9e71722bf6f3bad6d63530a4db
--- /dev/null
+++ b/configs/textdet/drrg/drrg_r50_fpn_unet_1200e_ctw1500.py
@@ -0,0 +1,33 @@
+_base_ = [
+ '../../_base_/schedules/schedule_sgd_1200e.py',
+ '../../_base_/default_runtime.py',
+ '../../_base_/det_models/drrg_r50_fpn_unet.py',
+ '../../_base_/det_datasets/ctw1500.py',
+ '../../_base_/det_pipelines/drrg_pipeline.py'
+]
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline = {{_base_.train_pipeline}}
+test_pipeline = {{_base_.test_pipeline}}
+
+data = dict(
+ samples_per_gpu=4,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline))
+
+evaluation = dict(interval=20, metric='hmean-iou')
diff --git a/configs/textdet/drrg/metafile.yml b/configs/textdet/drrg/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..8e7224eb352d419fc65637d6b0fc17d6cc4230d8
--- /dev/null
+++ b/configs/textdet/drrg/metafile.yml
@@ -0,0 +1,27 @@
+Collections:
+- Name: DRRG
+ Metadata:
+ Training Data: SCUT-CTW1500
+ Training Techniques:
+ - SGD with Momentum
+ Training Resources: 1x GeForce GTX 3090
+ Architecture:
+ - ResNet
+ - FPN_UNet
+ Paper:
+ URL: https://arxiv.org/abs/2003.07493.pdf
+ Title: 'Deep Relational Reasoning Graph Network for Arbitrary Shape Text Detection'
+ README: configs/textdet/drrg/README.md
+
+Models:
+ - Name: drrg_r50_fpn_unet_1200e_ctw1500
+ In Collection: DRRG
+ Config: configs/textdet/drrg/drrg_r50_fpn_unet_1200e_ctw1500.py
+ Metadata:
+ Training Data: CTW1500
+ Results:
+ - Task: Text Detection
+ Dataset: CTW1500
+ Metrics:
+ hmean-iou: 0.840
+ Weights: https://download.openmmlab.com/mmocr/textdet/drrg/drrg_r50_fpn_unet_1200e_ctw1500_20211022-fb30b001.pth
diff --git a/configs/textdet/fcenet/README.md b/configs/textdet/fcenet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..f04cc3f2bea01352a674912581244f3080a16954
--- /dev/null
+++ b/configs/textdet/fcenet/README.md
@@ -0,0 +1,39 @@
+# FCENet
+
+> [Fourier Contour Embedding for Arbitrary-Shaped Text Detection](https://arxiv.org/abs/2104.10442)
+
+
+
+## Abstract
+
+One of the main challenges for arbitrary-shaped text detection is to design a good text instance representation that allows networks to learn diverse text geometry variances. Most of existing methods model text instances in image spatial domain via masks or contour point sequences in the Cartesian or the polar coordinate system. However, the mask representation might lead to expensive post-processing, while the point sequence one may have limited capability to model texts with highly-curved shapes. To tackle these problems, we model text instances in the Fourier domain and propose one novel Fourier Contour Embedding (FCE) method to represent arbitrary shaped text contours as compact signatures. We further construct FCENet with a backbone, feature pyramid networks (FPN) and a simple post-processing with the Inverse Fourier Transformation (IFT) and Non-Maximum Suppression (NMS). Different from previous methods, FCENet first predicts compact Fourier signatures of text instances, and then reconstructs text contours via IFT and NMS during test. Extensive experiments demonstrate that FCE is accurate and robust to fit contours of scene texts even with highly-curved shapes, and also validate the effectiveness and the good generalization of FCENet for arbitrary-shaped text detection. Furthermore, experimental results show that our FCENet is superior to the state-of-the-art (SOTA) methods on CTW1500 and Total-Text, especially on challenging highly-curved text subset.
+
+
+
+
+
+
+## Results and models
+
+### CTW1500
+
+| Method | Backbone | Pretrained Model | Training set | Test set | #epochs | Test size | Recall | Precision | Hmean | Download |
+| :--------------------------------------------------------------------: | :--------------: | :--------------: | :-----------: | :----------: | :-----: | :---------: | :----: | :-------: | :---: | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| [FCENet](/configs/textdet/fcenet/fcenet_r50dcnv2_fpn_1500e_ctw1500.py) | ResNet50 + DCNv2 | ImageNet | CTW1500 Train | CTW1500 Test | 1500 | (736, 1080) | 0.828 | 0.875 | 0.851 | [model](https://download.openmmlab.com/mmocr/textdet/fcenet/fcenet_r50dcnv2_fpn_1500e_ctw1500_20211022-e326d7ec.pth) \| [log](https://download.openmmlab.com/mmocr/textdet/fcenet/20210511_181328.log.json) |
+
+### ICDAR2015
+
+| Method | Backbone | Pretrained Model | Training set | Test set | #epochs | Test size | Recall | Precision | Hmean | Download |
+| :-----------------------------------------------------------------: | :------: | :--------------: | :----------: | :-------: | :-----: | :----------: | :----: | :-------: | :---: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| [FCENet](/configs/textdet/fcenet/fcenet_r50_fpn_1500e_icdar2015.py) | ResNet50 | ImageNet | IC15 Train | IC15 Test | 1500 | (2260, 2260) | 0.819 | 0.880 | 0.849 | [model](https://download.openmmlab.com/mmocr/textdet/fcenet/fcenet_r50_fpn_1500e_icdar2015_20211022-daefb6ed.pth) \| [log](https://download.openmmlab.com/mmocr/textdet/fcenet/20210601_222655.log.json) |
+
+## Citation
+
+```bibtex
+@InProceedings{zhu2021fourier,
+ title={Fourier Contour Embedding for Arbitrary-Shaped Text Detection},
+ author={Yiqin Zhu and Jianyong Chen and Lingyu Liang and Zhanghui Kuang and Lianwen Jin and Wayne Zhang},
+ year={2021},
+ booktitle = {CVPR}
+ }
+```
diff --git a/configs/textdet/fcenet/fcenet_r50_fpn_1500e_icdar2015.py b/configs/textdet/fcenet/fcenet_r50_fpn_1500e_icdar2015.py
new file mode 100644
index 0000000000000000000000000000000000000000..c17f892c7466e6304ab5fcddff5bb27572524370
--- /dev/null
+++ b/configs/textdet/fcenet/fcenet_r50_fpn_1500e_icdar2015.py
@@ -0,0 +1,33 @@
+_base_ = [
+ '../../_base_/runtime_10e.py',
+ '../../_base_/schedules/schedule_sgd_1500e.py',
+ '../../_base_/det_models/fcenet_r50_fpn.py',
+ '../../_base_/det_datasets/icdar2015.py',
+ '../../_base_/det_pipelines/fcenet_pipeline.py'
+]
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline_icdar2015 = {{_base_.train_pipeline_icdar2015}}
+test_pipeline_icdar2015 = {{_base_.test_pipeline_icdar2015}}
+
+data = dict(
+ samples_per_gpu=8,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline_icdar2015),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_icdar2015),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_icdar2015))
+
+evaluation = dict(interval=10, metric='hmean-iou')
diff --git a/configs/textdet/fcenet/fcenet_r50dcnv2_fpn_1500e_ctw1500.py b/configs/textdet/fcenet/fcenet_r50dcnv2_fpn_1500e_ctw1500.py
new file mode 100644
index 0000000000000000000000000000000000000000..56ee49990c45fceb7a7161a498d96a623baee5d9
--- /dev/null
+++ b/configs/textdet/fcenet/fcenet_r50dcnv2_fpn_1500e_ctw1500.py
@@ -0,0 +1,33 @@
+_base_ = [
+ '../../_base_/runtime_10e.py',
+ '../../_base_/schedules/schedule_sgd_1500e.py',
+ '../../_base_/det_models/fcenet_r50dcnv2_fpn.py',
+ '../../_base_/det_datasets/ctw1500.py',
+ '../../_base_/det_pipelines/fcenet_pipeline.py'
+]
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline_ctw1500 = {{_base_.train_pipeline_ctw1500}}
+test_pipeline_ctw1500 = {{_base_.test_pipeline_ctw1500}}
+
+data = dict(
+ samples_per_gpu=6,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline_ctw1500),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_ctw1500),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_ctw1500))
+
+evaluation = dict(interval=10, metric='hmean-iou')
diff --git a/configs/textdet/fcenet/metafile.yml b/configs/textdet/fcenet/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..7b60e518e2b28f281ea799179848cfb53e065d1c
--- /dev/null
+++ b/configs/textdet/fcenet/metafile.yml
@@ -0,0 +1,38 @@
+Collections:
+- Name: FCENet
+ Metadata:
+ Training Data: SCUT-CTW1500
+ Training Techniques:
+ - SGD with Momentum
+ Training Resources: 1x GeForce GTX 2080 Ti
+ Architecture:
+ - ResNet with DCNv2
+ - FPN
+ Paper:
+ URL: https://arxiv.org/abs/2002.02709.pdf
+ Title: 'FourierNet: Compact mask representation for instance segmentation using differentiable shape decoders'
+ README: configs/textdet/fcenet/README.md
+
+Models:
+ - Name: fcenet_r50dcnv2_fpn_1500e_ctw1500
+ In Collection: FCENet
+ Config: configs/textdet/fcenet/fcenet_r50dcnv2_fpn_1500e_ctw1500.py
+ Metadata:
+ Training Data: CTW1500
+ Results:
+ - Task: Text Detection
+ Dataset: CTW1500
+ Metrics:
+ hmean-iou: 0.851
+ Weights: https://download.openmmlab.com/mmocr/textdet/fcenet/fcenet_r50dcnv2_fpn_1500e_ctw1500_20211022-e326d7ec.pth
+ - Name: fcenet_r50_fpn_1500e_icdar2015
+ In Collection: FCENet
+ Config: configs/textdet/fcenet/fcenet_r50_fpn_1500e_icdar2015.py
+ Metadata:
+ Training Data: ICDAR2015
+ Results:
+ - Task: Text Detection
+ Dataset: ICDAR2015
+ Metrics:
+ hmean-iou: 0.849
+ Weights: https://download.openmmlab.com/mmocr/textdet/fcenet/fcenet_r50_fpn_1500e_icdar2015_20211022-daefb6ed.pth
diff --git a/configs/textdet/maskrcnn/README.md b/configs/textdet/maskrcnn/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..100f1718d90ff32111a9199336f328d9158b3db2
--- /dev/null
+++ b/configs/textdet/maskrcnn/README.md
@@ -0,0 +1,47 @@
+# Mask R-CNN
+> [Mask R-CNN](https://arxiv.org/abs/1703.06870)
+
+
+
+## Abstract
+We present a conceptually simple, flexible, and general framework for object instance segmentation. Our approach efficiently detects objects in an image while simultaneously generating a high-quality segmentation mask for each instance. The method, called Mask R-CNN, extends Faster R-CNN by adding a branch for predicting an object mask in parallel with the existing branch for bounding box recognition. Mask R-CNN is simple to train and adds only a small overhead to Faster R-CNN, running at 5 fps. Moreover, Mask R-CNN is easy to generalize to other tasks, e.g., allowing us to estimate human poses in the same framework. We show top results in all three tracks of the COCO suite of challenges, including instance segmentation, bounding-box object detection, and person keypoint detection. Without bells and whistles, Mask R-CNN outperforms all existing, single-model entries on every task, including the COCO 2016 challenge winners. We hope our simple and effective approach will serve as a solid baseline and help ease future research in instance-level recognition.
+
+
+
+
+
+## Results and models
+
+### CTW1500
+
+| Method | Pretrained Model | Training set | Test set | #epochs | Test size | Recall | Precision | Hmean | Download |
+| :---------------------------------------------------------------------: | :--------------: | :-----------: | :----------: | :-----: | :-------: | :----: | :-------: | :---: | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| [MaskRCNN](/configs/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_ctw1500.py) | ImageNet | CTW1500 Train | CTW1500 Test | 160 | 1600 | 0.753 | 0.712 | 0.732 | [model](https://download.openmmlab.com/mmocr/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_ctw1500_20210219-96497a76.pth) \| [log](https://download.openmmlab.com/mmocr/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_ctw1500_20210219-96497a76.log.json) |
+
+### ICDAR2015
+
+| Method | Pretrained Model | Training set | Test set | #epochs | Test size | Recall | Precision | Hmean | Download |
+| :-----------------------------------------------------------------------: | :--------------: | :-------------: | :------------: | :-----: | :-------: | :----: | :-------: | :---: | :-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| [MaskRCNN](/configs/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_icdar2015.py) | ImageNet | ICDAR2015 Train | ICDAR2015 Test | 160 | 1920 | 0.783 | 0.872 | 0.825 | [model](https://download.openmmlab.com/mmocr/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_icdar2015_20210219-8eb340a3.pth) \| [log](https://download.openmmlab.com/mmocr/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_icdar2015_20210219-8eb340a3.log.json) |
+
+### ICDAR2017
+
+| Method | Pretrained Model | Training set | Test set | #epochs | Test size | Recall | Precision | Hmean | Download |
+| :-----------------------------------------------------------------------: | :--------------: | :-------------: | :-----------: | :-----: | :-------: | :----: | :-------: | :---: | :-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| [MaskRCNN](/configs/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_icdar2017.py) | ImageNet | ICDAR2017 Train | ICDAR2017 Val | 160 | 1600 | 0.754 | 0.827 | 0.789 | [model](https://download.openmmlab.com/mmocr/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_icdar2017_20210218-c6ec3ebb.pth) \| [log](https://download.openmmlab.com/mmocr/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_icdar2017_20210218-c6ec3ebb.log.json) |
+
+:::{note}
+We tuned parameters with the techniques in [Pyramid Mask Text Detector](https://arxiv.org/abs/1903.11800)
+:::
+
+## Citation
+
+```bibtex
+@INPROCEEDINGS{8237584,
+ author={K. {He} and G. {Gkioxari} and P. {Dollár} and R. {Girshick}},
+ booktitle={2017 IEEE International Conference on Computer Vision (ICCV)},
+ title={Mask R-CNN},
+ year={2017},
+ pages={2980-2988},
+ doi={10.1109/ICCV.2017.322}}
+```
diff --git a/configs/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_ctw1500.py b/configs/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_ctw1500.py
new file mode 100644
index 0000000000000000000000000000000000000000..42b7e7b80b7f605340ec076fe2d52f2c9f5e6681
--- /dev/null
+++ b/configs/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_ctw1500.py
@@ -0,0 +1,33 @@
+_base_ = [
+ '../../_base_/runtime_10e.py',
+ '../../_base_/det_models/ocr_mask_rcnn_r50_fpn_ohem_poly.py',
+ '../../_base_/schedules/schedule_sgd_160e.py',
+ '../../_base_/det_datasets/ctw1500.py',
+ '../../_base_/det_pipelines/maskrcnn_pipeline.py'
+]
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline = {{_base_.train_pipeline}}
+test_pipeline_ctw1500 = {{_base_.test_pipeline_ctw1500}}
+
+data = dict(
+ samples_per_gpu=8,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_ctw1500),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_ctw1500))
+
+evaluation = dict(interval=10, metric='hmean-iou')
diff --git a/configs/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_icdar2015.py b/configs/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_icdar2015.py
new file mode 100644
index 0000000000000000000000000000000000000000..efffa12b5d8c5823fcaf77ef8fe70ace012e700b
--- /dev/null
+++ b/configs/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_icdar2015.py
@@ -0,0 +1,33 @@
+_base_ = [
+ '../../_base_/runtime_10e.py',
+ '../../_base_/det_models/ocr_mask_rcnn_r50_fpn_ohem.py',
+ '../../_base_/schedules/schedule_sgd_160e.py',
+ '../../_base_/det_datasets/icdar2015.py',
+ '../../_base_/det_pipelines/maskrcnn_pipeline.py'
+]
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline = {{_base_.train_pipeline}}
+test_pipeline_icdar2015 = {{_base_.test_pipeline_icdar2015}}
+
+data = dict(
+ samples_per_gpu=8,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_icdar2015),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_icdar2015))
+
+evaluation = dict(interval=10, metric='hmean-iou')
diff --git a/configs/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_icdar2017.py b/configs/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_icdar2017.py
new file mode 100644
index 0000000000000000000000000000000000000000..b6b46ba4af194b6ffa406d9b0abc97149ac4e1df
--- /dev/null
+++ b/configs/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_icdar2017.py
@@ -0,0 +1,33 @@
+_base_ = [
+ '../../_base_/runtime_10e.py',
+ '../../_base_/det_models/ocr_mask_rcnn_r50_fpn_ohem.py',
+ '../../_base_/schedules/schedule_sgd_160e.py',
+ '../../_base_/det_datasets/icdar2017.py',
+ '../../_base_/det_pipelines/maskrcnn_pipeline.py'
+]
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline = {{_base_.train_pipeline}}
+test_pipeline_icdar2015 = {{_base_.test_pipeline_icdar2015}}
+
+data = dict(
+ samples_per_gpu=8,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_icdar2015),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_icdar2015))
+
+evaluation = dict(interval=10, metric='hmean-iou')
diff --git a/configs/textdet/maskrcnn/metafile.yml b/configs/textdet/maskrcnn/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..90a2e3c3d33888beba652bf02c4cc1ae685eb24c
--- /dev/null
+++ b/configs/textdet/maskrcnn/metafile.yml
@@ -0,0 +1,53 @@
+Collections:
+- Name: Mask R-CNN
+ Metadata:
+ Training Data: ICDAR SCUT-CTW1500
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x GeForce GTX 1080 Ti
+ Architecture:
+ - ResNet
+ - FPN
+ - RPN
+ Paper:
+ URL: https://arxiv.org/pdf/1703.06870.pdf
+ Title: 'Mask R-CNN'
+ README: configs/textdet/maskrcnn/README.md
+
+Models:
+ - Name: mask_rcnn_r50_fpn_160e_ctw1500
+ In Collection: Mask R-CNN
+ Config: configs/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_ctw1500.py
+ Metadata:
+ Training Data: CTW1500
+ Results:
+ - Task: Text Detection
+ Dataset: CTW1500
+ Metrics:
+ hmean: 0.732
+ Weights: https://download.openmmlab.com/mmocr/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_ctw1500_20210219-96497a76.pth
+
+ - Name: mask_rcnn_r50_fpn_160e_icdar2015
+ In Collection: Mask R-CNN
+ Config: configs/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_icdar2015.py
+ Metadata:
+ Training Data: ICDAR2015
+ Results:
+ - Task: Text Detection
+ Dataset: ICDAR2015
+ Metrics:
+ hmean: 0.825
+ Weights: https://download.openmmlab.com/mmocr/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_icdar2015_20210219-8eb340a3.pth
+
+ - Name: mask_rcnn_r50_fpn_160e_icdar2017
+ In Collection: Mask R-CNN
+ Config: configs/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_icdar2017.py
+ Metadata:
+ Training Data: ICDAR2017
+ Results:
+ - Task: Text Detection
+ Dataset: ICDAR2017
+ Metrics:
+ hmean: 0.789
+ Weights: https://download.openmmlab.com/mmocr/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_icdar2017_20210218-c6ec3ebb.pth
diff --git a/configs/textdet/panet/README.md b/configs/textdet/panet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..0c677409028163e5320b49e22d10958486cf8084
--- /dev/null
+++ b/configs/textdet/panet/README.md
@@ -0,0 +1,45 @@
+# PANet
+
+> [Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network](https://arxiv.org/abs/1908.05900)
+
+
+
+## Abstract
+
+Scene text detection, an important step of scene text reading systems, has witnessed rapid development with convolutional neural networks. Nonetheless, two main challenges still exist and hamper its deployment to real-world applications. The first problem is the trade-off between speed and accuracy. The second one is to model the arbitrary-shaped text instance. Recently, some methods have been proposed to tackle arbitrary-shaped text detection, but they rarely take the speed of the entire pipeline into consideration, which may fall short in practical this http URL this paper, we propose an efficient and accurate arbitrary-shaped text detector, termed Pixel Aggregation Network (PAN), which is equipped with a low computational-cost segmentation head and a learnable post-processing. More specifically, the segmentation head is made up of Feature Pyramid Enhancement Module (FPEM) and Feature Fusion Module (FFM). FPEM is a cascadable U-shaped module, which can introduce multi-level information to guide the better segmentation. FFM can gather the features given by the FPEMs of different depths into a final feature for segmentation. The learnable post-processing is implemented by Pixel Aggregation (PA), which can precisely aggregate text pixels by predicted similarity vectors. Experiments on several standard benchmarks validate the superiority of the proposed PAN. It is worth noting that our method can achieve a competitive F-measure of 79.9% at 84.2 FPS on CTW1500.
+
+
+
+
+
+
+
+## Results and models
+
+### CTW1500
+
+| Method | Pretrained Model | Training set | Test set | #epochs | Test size | Recall | Precision | Hmean | Download |
+| :---------------------------------------------------------------: | :--------------: | :-----------: | :----------: | :-----: | :-------: | :-----------: | :-----------: | :-----------: | :-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| [PANet](configs/textdet/panet/panet_r18_fpem_ffm_600e_ctw1500.py) | ImageNet | CTW1500 Train | CTW1500 Test | 600 | 640 | 0.776 (0.717) | 0.838 (0.835) | 0.806 (0.801) | [model](https://download.openmmlab.com/mmocr/textdet/panet/panet_r18_fpem_ffm_sbn_600e_ctw1500_20210219-3b3a9aa3.pth) \| [log](https://download.openmmlab.com/mmocr/textdet/panet/panet_r18_fpem_ffm_sbn_600e_ctw1500_20210219-3b3a9aa3.log.json) |
+
+### ICDAR2015
+
+| Method | Pretrained Model | Training set | Test set | #epochs | Test size | Recall | Precision | Hmean | Download |
+| :-----------------------------------------------------------------: | :--------------: | :-------------: | :------------: | :-----: | :-------: | :----------: | :----------: | :-----------: | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| [PANet](configs/textdet/panet/panet_r18_fpem_ffm_600e_icdar2015.py) | ImageNet | ICDAR2015 Train | ICDAR2015 Test | 600 | 736 | 0.734 (0.74) | 0.856 (0.86) | 0.791 (0.795) | [model](https://download.openmmlab.com/mmocr/textdet/panet/panet_r18_fpem_ffm_sbn_600e_icdar2015_20210219-42dbe46a.pth) \| [log](https://download.openmmlab.com/mmocr/textdet/panet/panet_r18_fpem_ffm_sbn_600e_icdar2015_20210219-42dbe46a.log.json) |
+
+:::{note}
+We've upgraded our IoU backend from `Polygon3` to `shapely`. There are some performance differences for some models due to the backends' different logics to handle invalid polygons (more info [here](https://github.com/open-mmlab/mmocr/issues/465)). **New evaluation result is presented in brackets** and new logs will be uploaded soon.
+:::
+
+## Citation
+
+```bibtex
+@inproceedings{WangXSZWLYS19,
+ author={Wenhai Wang and Enze Xie and Xiaoge Song and Yuhang Zang and Wenjia Wang and Tong Lu and Gang Yu and Chunhua Shen},
+ title={Efficient and Accurate Arbitrary-Shaped Text Detection With Pixel Aggregation Network},
+ booktitle={ICCV},
+ pages={8439--8448},
+ year={2019}
+ }
+```
diff --git a/configs/textdet/panet/metafile.yml b/configs/textdet/panet/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..468c4126c2571ad9899a2a1ed7a9ef9a37f15533
--- /dev/null
+++ b/configs/textdet/panet/metafile.yml
@@ -0,0 +1,39 @@
+Collections:
+- Name: PANet
+ Metadata:
+ Training Data: ICDAR SCUT-CTW1500
+ Training Techniques:
+ - Adam
+ Training Resources: 8x GeForce GTX 1080 Ti
+ Architecture:
+ - ResNet
+ - FPEM_FFM
+ Paper:
+ URL: https://arxiv.org/pdf/1803.01534.pdf
+ Title: 'Path Aggregation Network for Instance Segmentation'
+ README: configs/textdet/panet/README.md
+
+Models:
+ - Name: panet_r18_fpem_ffm_600e_ctw1500
+ In Collection: PANet
+ Config: configs/textdet/panet/panet_r18_fpem_ffm_600e_ctw1500.py
+ Metadata:
+ Training Data: CTW1500
+ Results:
+ - Task: Text Detection
+ Dataset: CTW1500
+ Metrics:
+ hmean-iou: 0.806
+ Weights: https://download.openmmlab.com/mmocr/textdet/panet/panet_r18_fpem_ffm_sbn_600e_ctw1500_20210219-3b3a9aa3.pth
+
+ - Name: panet_r18_fpem_ffm_600e_icdar2015
+ In Collection: PANet
+ Config: configs/textdet/panet/panet_r18_fpem_ffm_600e_icdar2015.py
+ Metadata:
+ Training Data: ICDAR2015
+ Results:
+ - Task: Text Detection
+ Dataset: ICDAR2015
+ Metrics:
+ hmean-iou: 0.791
+ Weights: https://download.openmmlab.com/mmocr/textdet/panet/panet_r18_fpem_ffm_sbn_600e_icdar2015_20210219-42dbe46a.pth
diff --git a/configs/textdet/panet/panet_r18_fpem_ffm_600e_ctw1500.py b/configs/textdet/panet/panet_r18_fpem_ffm_600e_ctw1500.py
new file mode 100644
index 0000000000000000000000000000000000000000..b564a1aaf627d33e4dcf04efa03f43db00791f0d
--- /dev/null
+++ b/configs/textdet/panet/panet_r18_fpem_ffm_600e_ctw1500.py
@@ -0,0 +1,35 @@
+_base_ = [
+ '../../_base_/schedules/schedule_adam_600e.py',
+ '../../_base_/runtime_10e.py',
+ '../../_base_/det_models/panet_r18_fpem_ffm.py',
+ '../../_base_/det_datasets/ctw1500.py',
+ '../../_base_/det_pipelines/panet_pipeline.py'
+]
+
+model = {{_base_.model_poly}}
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline_ctw1500 = {{_base_.train_pipeline_ctw1500}}
+test_pipeline_ctw1500 = {{_base_.test_pipeline_ctw1500}}
+
+data = dict(
+ samples_per_gpu=2,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline_ctw1500),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_ctw1500),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_ctw1500))
+
+evaluation = dict(interval=10, metric='hmean-iou')
diff --git a/configs/textdet/panet/panet_r18_fpem_ffm_600e_icdar2015.py b/configs/textdet/panet/panet_r18_fpem_ffm_600e_icdar2015.py
new file mode 100644
index 0000000000000000000000000000000000000000..e06fcd854e1238e0294d6c6911b810a025ddcfa2
--- /dev/null
+++ b/configs/textdet/panet/panet_r18_fpem_ffm_600e_icdar2015.py
@@ -0,0 +1,35 @@
+_base_ = [
+ '../../_base_/schedules/schedule_adam_600e.py',
+ '../../_base_/runtime_10e.py',
+ '../../_base_/det_models/panet_r18_fpem_ffm.py',
+ '../../_base_/det_datasets/icdar2015.py',
+ '../../_base_/det_pipelines/panet_pipeline.py'
+]
+
+model = {{_base_.model_quad}}
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline_icdar2015 = {{_base_.train_pipeline_icdar2015}}
+test_pipeline_icdar2015 = {{_base_.test_pipeline_icdar2015}}
+
+data = dict(
+ samples_per_gpu=8,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline_icdar2015),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_icdar2015),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_icdar2015))
+
+evaluation = dict(interval=10, metric='hmean-iou')
diff --git a/configs/textdet/panet/panet_r50_fpem_ffm_600e_icdar2017.py b/configs/textdet/panet/panet_r50_fpem_ffm_600e_icdar2017.py
new file mode 100644
index 0000000000000000000000000000000000000000..9cb311436be8cd5803ffd0348b28499c08922223
--- /dev/null
+++ b/configs/textdet/panet/panet_r50_fpem_ffm_600e_icdar2017.py
@@ -0,0 +1,33 @@
+_base_ = [
+ '../../_base_/schedules/schedule_adam_600e.py',
+ '../../_base_/runtime_10e.py',
+ '../../_base_/det_models/panet_r50_fpem_ffm.py',
+ '../../_base_/det_datasets/icdar2017.py',
+ '../../_base_/det_pipelines/panet_pipeline.py'
+]
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline_icdar2017 = {{_base_.train_pipeline_icdar2017}}
+test_pipeline_icdar2017 = {{_base_.test_pipeline_icdar2017}}
+
+data = dict(
+ samples_per_gpu=4,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline_icdar2017),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_icdar2017),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_icdar2017))
+
+evaluation = dict(interval=10, metric='hmean-iou')
diff --git a/configs/textdet/psenet/README.md b/configs/textdet/psenet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..c0053c6b9bb920a0243aa41f3f30ed5afc8cdf4b
--- /dev/null
+++ b/configs/textdet/psenet/README.md
@@ -0,0 +1,46 @@
+# PSENet
+
+>[Shape robust text detection with progressive scale expansion network](https://arxiv.org/abs/1903.12473)
+
+
+
+## Abstract
+
+Scene text detection has witnessed rapid progress especially with the recent development of convolutional neural networks. However, there still exists two challenges which prevent the algorithm into industry applications. On the one hand, most of the state-of-art algorithms require quadrangle bounding box which is in-accurate to locate the texts with arbitrary shape. On the other hand, two text instances which are close to each other may lead to a false detection which covers both instances. Traditionally, the segmentation-based approach can relieve the first problem but usually fail to solve the second challenge. To address these two challenges, in this paper, we propose a novel Progressive Scale Expansion Network (PSENet), which can precisely detect text instances with arbitrary shapes. More specifically, PSENet generates the different scale of kernels for each text instance, and gradually expands the minimal scale kernel to the text instance with the complete shape. Due to the fact that there are large geometrical margins among the minimal scale kernels, our method is effective to split the close text instances, making it easier to use segmentation-based methods to detect arbitrary-shaped text instances. Extensive experiments on CTW1500, Total-Text, ICDAR 2015 and ICDAR 2017 MLT validate the effectiveness of PSENet. Notably, on CTW1500, a dataset full of long curve texts, PSENet achieves a F-measure of 74.3% at 27 FPS, and our best F-measure (82.2%) outperforms state-of-art algorithms by 6.6%. The code will be released in the future.
+
+
+
+
+
+
+## Results and models
+
+### CTW1500
+
+| Method | Backbone | Extra Data | Training set | Test set | #epochs | Test size | Recall | Precision | Hmean | Download |
+| :-----------------------------------------------------------------: | :------: | :--------: | :-----------: | :----------: | :-----: | :-------: | :-----------: | :-----------: | :-----------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| [PSENet-4s](configs/textdet/psenet/psenet_r50_fpnf_600e_ctw1500.py) | ResNet50 | - | CTW1500 Train | CTW1500 Test | 600 | 1280 | 0.728 (0.717) | 0.849 (0.852) | 0.784 (0.779) | [model](https://download.openmmlab.com/mmocr/textdet/psenet/psenet_r50_fpnf_600e_ctw1500_20210401-216fed50.pth) \| [log](https://download.openmmlab.com/mmocr/textdet/psenet/20210401_215421.log.json) |
+
+### ICDAR2015
+
+| Method | Backbone | Extra Data | Training set | Test set | #epochs | Test size | Recall | Precision | Hmean | Download |
+| :-------------------------------------------------------------------: | :------: | :---------------------------------------------------------------------------------------------------------------------------------------: | :----------: | :-------: | :-----: | :-------: | :-----------: | :-----------: | :-----------: | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| [PSENet-4s](configs/textdet/psenet/psenet_r50_fpnf_600e_icdar2015.py) | ResNet50 | - | IC15 Train | IC15 Test | 600 | 2240 | 0.784 (0.753) | 0.831 (0.867) | 0.807 (0.806) | [model](https://download.openmmlab.com/mmocr/textdet/psenet/psenet_r50_fpnf_600e_icdar2015-c6131f0d.pth) \| [log](https://download.openmmlab.com/mmocr/textdet/psenet/20210331_214145.log.json) |
+| [PSENet-4s](configs/textdet/psenet/psenet_r50_fpnf_600e_icdar2015.py) | ResNet50 | pretrain on IC17 MLT [model](https://download.openmmlab.com/mmocr/textdet/psenet/psenet_r50_fpnf_600e_icdar2017_as_pretrain-3bd6056c.pth) | IC15 Train | IC15 Test | 600 | 2240 | 0.834 | 0.861 | 0.847 | [model](https://download.openmmlab.com/mmocr/textdet/psenet/psenet_r50_fpnf_600e_icdar2015_pretrain-eefd8fe6.pth) \| [log]() |
+
+:::{note}
+We've upgraded our IoU backend from `Polygon3` to `shapely`. There are some performance differences for some models due to the backends' different logics to handle invalid polygons (more info [here](https://github.com/open-mmlab/mmocr/issues/465)). **New evaluation result is presented in brackets** and new logs will be uploaded soon.
+:::
+
+
+## Citation
+
+```bibtex
+@inproceedings{wang2019shape,
+ title={Shape robust text detection with progressive scale expansion network},
+ author={Wang, Wenhai and Xie, Enze and Li, Xiang and Hou, Wenbo and Lu, Tong and Yu, Gang and Shao, Shuai},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ pages={9336--9345},
+ year={2019}
+}
+```
diff --git a/configs/textdet/psenet/metafile.yml b/configs/textdet/psenet/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..7e449b4392b218a5535e188526d8faaa089be830
--- /dev/null
+++ b/configs/textdet/psenet/metafile.yml
@@ -0,0 +1,51 @@
+Collections:
+- Name: PSENet
+ Metadata:
+ Training Data: ICDAR SCUT-CTW1500
+ Training Techniques:
+ - Adam
+ Training Resources: 8x GeForce GTX 1080 Ti
+ Architecture:
+ - ResNet
+ - FPNF
+ Paper:
+ URL: https://arxiv.org/abs/1806.02559.pdf
+ Title: 'Shape Robust Text Detection with Progressive Scale Expansion Network'
+ README: configs/textdet/psenet/README.md
+
+Models:
+ - Name: psenet_r50_fpnf_600e_ctw1500
+ In Collection: PSENet
+ Config: configs/textdet/psenet/psenet_r50_fpnf_600e_ctw1500.py
+ Metadata:
+ Training Data: CTW1500
+ Results:
+ - Task: Text Detection
+ Dataset: CTW1500
+ Metrics:
+ hmean-iou: 0.784
+ Weights: https://download.openmmlab.com/mmocr/textdet/psenet/psenet_r50_fpnf_600e_ctw1500_20210401-216fed50.pth
+
+ - Name: psenet_r50_fpnf_600e_icdar2015
+ In Collection: PSENet
+ Config: configs/textdet/psenet/psenet_r50_fpnf_600e_icdar2015.py
+ Metadata:
+ Training Data: ICDAR2015
+ Results:
+ - Task: Text Detection
+ Dataset: ICDAR2015
+ Metrics:
+ hmean-iou: 0.807
+ Weights: https://download.openmmlab.com/mmocr/textdet/psenet/psenet_r50_fpnf_600e_icdar2015-c6131f0d.pth
+
+ - Name: psenet_r50_fpnf_600e_icdar2015_with_pretrain
+ In Collection: PSENet
+ Config: configs/textdet/psenet/psenet_r50_fpnf_600e_icdar2015.py
+ Metadata:
+ Training Data: ICDAR2017 ICDAR2015
+ Results:
+ - Task: Text Detection
+ Dataset: ICDAR2017 ICDAR2015
+ Metrics:
+ hmean-iou: 0.847
+ Weights: https://download.openmmlab.com/mmocr/textdet/psenet/psenet_r50_fpnf_600e_icdar2015_pretrain-eefd8fe6.pth
diff --git a/configs/textdet/psenet/psenet_r50_fpnf_600e_ctw1500.py b/configs/textdet/psenet/psenet_r50_fpnf_600e_ctw1500.py
new file mode 100644
index 0000000000000000000000000000000000000000..483a2b2e1e7e584dfba26c7c5f506ce544953db8
--- /dev/null
+++ b/configs/textdet/psenet/psenet_r50_fpnf_600e_ctw1500.py
@@ -0,0 +1,35 @@
+_base_ = [
+ '../../_base_/default_runtime.py',
+ '../../_base_/schedules/schedule_adam_step_600e.py',
+ '../../_base_/det_models/psenet_r50_fpnf.py',
+ '../../_base_/det_datasets/ctw1500.py',
+ '../../_base_/det_pipelines/psenet_pipeline.py'
+]
+
+model = {{_base_.model_poly}}
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline = {{_base_.train_pipeline}}
+test_pipeline_ctw1500 = {{_base_.test_pipeline_ctw1500}}
+
+data = dict(
+ samples_per_gpu=2,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_ctw1500),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_ctw1500))
+
+evaluation = dict(interval=10, metric='hmean-iou')
diff --git a/configs/textdet/psenet/psenet_r50_fpnf_600e_icdar2015.py b/configs/textdet/psenet/psenet_r50_fpnf_600e_icdar2015.py
new file mode 100644
index 0000000000000000000000000000000000000000..f96d8a5d55e85282b23619f2f11a53e4327fe0c2
--- /dev/null
+++ b/configs/textdet/psenet/psenet_r50_fpnf_600e_icdar2015.py
@@ -0,0 +1,35 @@
+_base_ = [
+ '../../_base_/runtime_10e.py',
+ '../../_base_/schedules/schedule_adam_step_600e.py',
+ '../../_base_/det_models/psenet_r50_fpnf.py',
+ '../../_base_/det_datasets/icdar2015.py',
+ '../../_base_/det_pipelines/psenet_pipeline.py'
+]
+
+model = {{_base_.model_quad}}
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline = {{_base_.train_pipeline}}
+test_pipeline_icdar2015 = {{_base_.test_pipeline_icdar2015}}
+
+data = dict(
+ samples_per_gpu=8,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_icdar2015),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_icdar2015))
+
+evaluation = dict(interval=10, metric='hmean-iou')
diff --git a/configs/textdet/psenet/psenet_r50_fpnf_600e_icdar2017.py b/configs/textdet/psenet/psenet_r50_fpnf_600e_icdar2017.py
new file mode 100644
index 0000000000000000000000000000000000000000..acd406841b6f16d31e30cc5839e4cb95279f6268
--- /dev/null
+++ b/configs/textdet/psenet/psenet_r50_fpnf_600e_icdar2017.py
@@ -0,0 +1,35 @@
+_base_ = [
+ '../../_base_/schedules/schedule_sgd_600e.py',
+ '../../_base_/runtime_10e.py',
+ '../../_base_/det_models/psenet_r50_fpnf.py',
+ '../../_base_/det_datasets/icdar2017.py',
+ '../../_base_/det_pipelines/psenet_pipeline.py'
+]
+
+model = {{_base_.model_quad}}
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline = {{_base_.train_pipeline}}
+test_pipeline_icdar2015 = {{_base_.test_pipeline_icdar2015}}
+
+data = dict(
+ samples_per_gpu=8,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_icdar2015),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline_icdar2015))
+
+evaluation = dict(interval=10, metric='hmean-iou')
diff --git a/configs/textdet/textsnake/README.md b/configs/textdet/textsnake/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..05015b1869eb5db7a09b40b096ddb26065123a08
--- /dev/null
+++ b/configs/textdet/textsnake/README.md
@@ -0,0 +1,33 @@
+# Textsnake
+
+>[TextSnake: A Flexible Representation for Detecting Text of Arbitrary Shapes](https://arxiv.org/abs/1807.01544)
+
+
+
+## Abstract
+
+Driven by deep neural networks and large scale datasets, scene text detection methods have progressed substantially over the past years, continuously refreshing the performance records on various standard benchmarks. However, limited by the representations (axis-aligned rectangles, rotated rectangles or quadrangles) adopted to describe text, existing methods may fall short when dealing with much more free-form text instances, such as curved text, which are actually very common in real-world scenarios. To tackle this problem, we propose a more flexible representation for scene text, termed as TextSnake, which is able to effectively represent text instances in horizontal, oriented and curved forms. In TextSnake, a text instance is described as a sequence of ordered, overlapping disks centered at symmetric axes, each of which is associated with potentially variable radius and orientation. Such geometry attributes are estimated via a Fully Convolutional Network (FCN) model. In experiments, the text detector based on TextSnake achieves state-of-the-art or comparable performance on Total-Text and SCUT-CTW1500, the two newly published benchmarks with special emphasis on curved text in natural images, as well as the widely-used datasets ICDAR 2015 and MSRA-TD500. Specifically, TextSnake outperforms the baseline on Total-Text by more than 40% in F-measure.
+
+
+
+
+
+## Results and models
+
+### CTW1500
+
+| Method | Pretrained Model | Training set | Test set | #epochs | Test size | Recall | Precision | Hmean | Download |
+| :----------------------------------------------------------------------------: | :--------------: | :-----------: | :----------: | :-----: | :-------: | :----: | :-------: | :---: | :--------------------------------------------------------------------------------------------------------------------------: |
+| [TextSnake](/configs/textdet/textsnake/textsnake_r50_fpn_unet_600e_ctw1500.py) | ImageNet | CTW1500 Train | CTW1500 Test | 1200 | 736 | 0.795 | 0.840 | 0.817 | [model](https://download.openmmlab.com/mmocr/textdet/textsnake/textsnake_r50_fpn_unet_1200e_ctw1500-27f65b64.pth) \| [log]() |
+
+## Citation
+
+```bibtex
+@article{long2018textsnake,
+ title={TextSnake: A Flexible Representation for Detecting Text of Arbitrary Shapes},
+ author={Long, Shangbang and Ruan, Jiaqiang and Zhang, Wenjie and He, Xin and Wu, Wenhao and Yao, Cong},
+ booktitle={ECCV},
+ pages={20-36},
+ year={2018}
+}
+```
diff --git a/configs/textdet/textsnake/metafile.yml b/configs/textdet/textsnake/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..9be247b84304df68df199c61592972aaf0b30fc9
--- /dev/null
+++ b/configs/textdet/textsnake/metafile.yml
@@ -0,0 +1,27 @@
+Collections:
+- Name: TextSnake
+ Metadata:
+ Training Data: SCUT-CTW1500
+ Training Techniques:
+ - SGD with Momentum
+ Training Resources: 8x GeForce GTX 1080 Ti
+ Architecture:
+ - ResNet
+ - FPN_UNet
+ Paper:
+ URL: https://arxiv.org/abs/1807.01544.pdf
+ Title: 'TextSnake: A Flexible Representation for Detecting Text of Arbitrary Shapes'
+ README: configs/textdet/textsnake/README.md
+
+Models:
+ - Name: textsnake_r50_fpn_unet_1200e_ctw1500
+ In Collection: TextSnake
+ Config: configs/textdet/textsnake/textsnake_r50_fpn_unet_1200e_ctw1500.py
+ Metadata:
+ Training Data: CTW1500
+ Results:
+ - Task: Text Detection
+ Dataset: CTW1500
+ Metrics:
+ hmean-iou: 0.817
+ Weights: https://download.openmmlab.com/mmocr/textdet/textsnake/textsnake_r50_fpn_unet_1200e_ctw1500-27f65b64.pth
diff --git a/configs/textdet/textsnake/textsnake_r50_fpn_unet_1200e_ctw1500.py b/configs/textdet/textsnake/textsnake_r50_fpn_unet_1200e_ctw1500.py
new file mode 100644
index 0000000000000000000000000000000000000000..0270b05930a32c12d69817847b5419f08012c4cd
--- /dev/null
+++ b/configs/textdet/textsnake/textsnake_r50_fpn_unet_1200e_ctw1500.py
@@ -0,0 +1,33 @@
+_base_ = [
+ '../../_base_/schedules/schedule_sgd_1200e.py',
+ '../../_base_/default_runtime.py',
+ '../../_base_/det_models/textsnake_r50_fpn_unet.py',
+ '../../_base_/det_datasets/ctw1500.py',
+ '../../_base_/det_pipelines/textsnake_pipeline.py'
+]
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline = {{_base_.train_pipeline}}
+test_pipeline = {{_base_.test_pipeline}}
+
+data = dict(
+ samples_per_gpu=4,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline))
+
+evaluation = dict(interval=10, metric='hmean-iou')
diff --git a/configs/textrecog/abinet/README.md b/configs/textrecog/abinet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..ab3e8fcf067042d63849998fc332de2112158c26
--- /dev/null
+++ b/configs/textrecog/abinet/README.md
@@ -0,0 +1,58 @@
+# ABINet
+
+>[Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition](https://arxiv.org/abs/2103.06495)
+
+
+## Abstract
+
+Linguistic knowledge is of great benefit to scene text recognition. However, how to effectively model linguistic rules in end-to-end deep networks remains a research challenge. In this paper, we argue that the limited capacity of language models comes from: 1) implicitly language modeling; 2) unidirectional feature representation; and 3) language model with noise input. Correspondingly, we propose an autonomous, bidirectional and iterative ABINet for scene text recognition. Firstly, the autonomous suggests to block gradient flow between vision and language models to enforce explicitly language modeling. Secondly, a novel bidirectional cloze network (BCN) as the language model is proposed based on bidirectional feature representation. Thirdly, we propose an execution manner of iterative correction for language model which can effectively alleviate the impact of noise input. Additionally, based on the ensemble of iterative predictions, we propose a self-training method which can learn from unlabeled images effectively. Extensive experiments indicate that ABINet has superiority on low-quality images and achieves state-of-the-art results on several mainstream benchmarks. Besides, the ABINet trained with ensemble self-training shows promising improvement in realizing human-level recognition.
+
+
+
+
+
+## Dataset
+
+### Train Dataset
+
+| trainset | instance_num | repeat_num | note |
+| :-------: | :----------: | :--------: | :----------: |
+| Syn90k | 8919273 | 1 | synth |
+| SynthText | 7239272 | 1 | alphanumeric |
+
+### Test Dataset
+
+| testset | instance_num | note |
+| :-----: | :----------: | :-------: |
+| IIIT5K | 3000 | regular |
+| SVT | 647 | regular |
+| IC13 | 1015 | regular |
+| IC15 | 2077 | irregular |
+| SVTP | 645 | irregular |
+| CT80 | 288 | irregular |
+
+## Results and models
+
+| methods | pretrained | | Regular Text | | | Irregular Text | | download |
+| :----------------------------------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------: | :----: | :----------: | :---: | :---: | :------------: | :---: | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| | | IIIT5K | SVT | IC13 | IC15 | SVTP | CT80 | |
+| [ABINet-Vision](https://github.com/open-mmlab/mmocr/tree/master/configs/textrecog/abinet/abinet_vision_only_academic.py) | - | 94.7 | 91.7 | 93.6 | 83.0 | 85.1 | 86.5 | [model](https://download.openmmlab.com/mmocr/textrecog/abinet/abinet_vision_only_academic-e6b9ea89.pth) \| [log](https://download.openmmlab.com/mmocr/textrecog/abinet/20211201_195512.log) |
+| [ABINet](https://github.com/open-mmlab/mmocr/tree/master/configs/textrecog/abinet/abinet_academic.py) | [Pretrained](https://download.openmmlab.com/mmocr/textrecog/abinet/abinet_pretrain-1bed979b.pth) | 95.7 | 94.6 | 95.7 | 85.1 | 90.4 | 90.3 | [model](https://download.openmmlab.com/mmocr/textrecog/abinet/abinet_academic-f718abf6.pth) \| [log1](https://download.openmmlab.com/mmocr/textrecog/abinet/20211210_095832.log) \| [log2](https://download.openmmlab.com/mmocr/textrecog/abinet/20211213_131724.log) |
+
+:::{note}
+1. ABINet allows its encoder to run and be trained without decoder and fuser. Its encoder is designed to recognize texts as a stand-alone model and therefore can work as an independent text recognizer. We release it as ABINet-Vision.
+2. Facts about the pretrained model: MMOCR does not have a systematic pipeline to pretrain the language model (LM) yet, thus the weights of LM are converted from [the official pretrained model](https://github.com/FangShancheng/ABINet). The weights of ABINet-Vision are directly used as the vision model of ABINet.
+3. Due to some technical issues, the training process of ABINet was interrupted at the 13th epoch and we resumed it later. Both logs are released for full reference.
+4. The model architecture in the logs looks slightly different from the final released version, since it was refactored afterward. However, both architectures are essentially equivalent.
+:::
+
+## Citation
+
+```bibtex
+@article{fang2021read,
+ title={Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition},
+ author={Fang, Shancheng and Xie, Hongtao and Wang, Yuxin and Mao, Zhendong and Zhang, Yongdong},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ year={2021}
+}
+```
diff --git a/configs/textrecog/abinet/abinet_academic.py b/configs/textrecog/abinet/abinet_academic.py
new file mode 100644
index 0000000000000000000000000000000000000000..da7231b4ccef80c40f645119115f887f1f19b54f
--- /dev/null
+++ b/configs/textrecog/abinet/abinet_academic.py
@@ -0,0 +1,34 @@
+_base_ = [
+ '../../_base_/default_runtime.py',
+ '../../_base_/schedules/schedule_adam_step_20e.py',
+ '../../_base_/recog_pipelines/abinet_pipeline.py',
+ '../../_base_/recog_models/abinet.py',
+ '../../_base_/recog_datasets/ST_MJ_alphanumeric_train.py',
+ '../../_base_/recog_datasets/academic_test.py'
+]
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline = {{_base_.train_pipeline}}
+test_pipeline = {{_base_.test_pipeline}}
+
+data = dict(
+ samples_per_gpu=192,
+ workers_per_gpu=8,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline))
+
+evaluation = dict(interval=1, metric='acc')
diff --git a/configs/textrecog/abinet/abinet_vision_only_academic.py b/configs/textrecog/abinet/abinet_vision_only_academic.py
new file mode 100644
index 0000000000000000000000000000000000000000..4c0f55083d4735f6c2c2f56338877cbac2b71d9a
--- /dev/null
+++ b/configs/textrecog/abinet/abinet_vision_only_academic.py
@@ -0,0 +1,80 @@
+_base_ = [
+ '../../_base_/default_runtime.py',
+ '../../_base_/schedules/schedule_adam_step_20e.py',
+ '../../_base_/recog_pipelines/abinet_pipeline.py',
+ '../../_base_/recog_datasets/ST_MJ_alphanumeric_train.py',
+ '../../_base_/recog_datasets/academic_test.py'
+]
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline = {{_base_.train_pipeline}}
+test_pipeline = {{_base_.test_pipeline}}
+
+# Model
+num_chars = 37
+max_seq_len = 26
+label_convertor = dict(
+ type='ABIConvertor',
+ dict_type='DICT36',
+ with_unknown=False,
+ with_padding=False,
+ lower=True,
+)
+
+model = dict(
+ type='ABINet',
+ backbone=dict(type='ResNetABI'),
+ encoder=dict(
+ type='ABIVisionModel',
+ encoder=dict(
+ type='TransformerEncoder',
+ n_layers=3,
+ n_head=8,
+ d_model=512,
+ d_inner=2048,
+ dropout=0.1,
+ max_len=8 * 32,
+ ),
+ decoder=dict(
+ type='ABIVisionDecoder',
+ in_channels=512,
+ num_channels=64,
+ attn_height=8,
+ attn_width=32,
+ attn_mode='nearest',
+ use_result='feature',
+ num_chars=num_chars,
+ max_seq_len=max_seq_len,
+ init_cfg=dict(type='Xavier', layer='Conv2d')),
+ ),
+ loss=dict(
+ type='ABILoss',
+ enc_weight=1.0,
+ dec_weight=1.0,
+ fusion_weight=1.0,
+ num_classes=num_chars),
+ label_convertor=label_convertor,
+ max_seq_len=max_seq_len,
+ iter_size=1)
+
+data = dict(
+ samples_per_gpu=192,
+ workers_per_gpu=8,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline))
+
+evaluation = dict(interval=1, metric='acc')
diff --git a/configs/textrecog/abinet/metafile.yml b/configs/textrecog/abinet/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..14b5561019191aac73ad3bf63c5dc331f66972fe
--- /dev/null
+++ b/configs/textrecog/abinet/metafile.yml
@@ -0,0 +1,87 @@
+Collections:
+- Name: ABINet
+ Metadata:
+ Training Data: OCRDataset
+ Training Techniques:
+ - Adam
+ Epochs: 20
+ Batch Size: 1536
+ Training Resources: 8x Tesla V100
+ Architecture:
+ - ResNetABI
+ - ABIVisionModel
+ - ABILanguageDecoder
+ - ABIFuser
+ Paper:
+ URL: https://arxiv.org/pdf/2103.06495.pdf
+ Title: 'Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition'
+ README: configs/textrecog/abinet/README.md
+
+Models:
+ - Name: abinet_vision_only_academic
+ In Collection: ABINet
+ Config: configs/textrecog/abinet/abinet_vision_only_academic.py
+ Metadata:
+ Training Data:
+ - SynthText
+ - Syn90k
+ Results:
+ - Task: Text Recognition
+ Dataset: IIIT5K
+ Metrics:
+ word_acc: 94.7
+ - Task: Text Recognition
+ Dataset: SVT
+ Metrics:
+ word_acc: 91.7
+ - Task: Text Recognition
+ Dataset: ICDAR2013
+ Metrics:
+ word_acc: 93.6
+ - Task: Text Recognition
+ Dataset: ICDAR2015
+ Metrics:
+ word_acc: 83.0
+ - Task: Text Recognition
+ Dataset: SVTP
+ Metrics:
+ word_acc: 85.1
+ - Task: Text Recognition
+ Dataset: CT80
+ Metrics:
+ word_acc: 86.5
+ Weights: https://download.openmmlab.com/mmocr/textrecog/abinet/abinet_vision_only_academic-e6b9ea89.pth
+
+ - Name: abinet_academic
+ In Collection: ABINet
+ Config: configs/textrecog/abinet/abinet_academic.py
+ Metadata:
+ Training Data:
+ - SynthText
+ - Syn90k
+ Results:
+ - Task: Text Recognition
+ Dataset: IIIT5K
+ Metrics:
+ word_acc: 95.7
+ - Task: Text Recognition
+ Dataset: SVT
+ Metrics:
+ word_acc: 94.6
+ - Task: Text Recognition
+ Dataset: ICDAR2013
+ Metrics:
+ word_acc: 95.7
+ - Task: Text Recognition
+ Dataset: ICDAR2015
+ Metrics:
+ word_acc: 85.1
+ - Task: Text Recognition
+ Dataset: SVTP
+ Metrics:
+ word_acc: 90.4
+ - Task: Text Recognition
+ Dataset: CT80
+ Metrics:
+ word_acc: 90.3
+ Weights: https://download.openmmlab.com/mmocr/textrecog/abinet/abinet_academic-f718abf6.pth
diff --git a/configs/textrecog/crnn/README.md b/configs/textrecog/crnn/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..a39b10daaa482625d66c285ba85f551d509776cc
--- /dev/null
+++ b/configs/textrecog/crnn/README.md
@@ -0,0 +1,50 @@
+# CRNN
+
+>[An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition](https://arxiv.org/abs/1507.05717)
+
+
+
+## Abstract
+
+Image-based sequence recognition has been a long-standing research topic in computer vision. In this paper, we investigate the problem of scene text recognition, which is among the most important and challenging tasks in image-based sequence recognition. A novel neural network architecture, which integrates feature extraction, sequence modeling and transcription into a unified framework, is proposed. Compared with previous systems for scene text recognition, the proposed architecture possesses four distinctive properties: (1) It is end-to-end trainable, in contrast to most of the existing algorithms whose components are separately trained and tuned. (2) It naturally handles sequences in arbitrary lengths, involving no character segmentation or horizontal scale normalization. (3) It is not confined to any predefined lexicon and achieves remarkable performances in both lexicon-free and lexicon-based scene text recognition tasks. (4) It generates an effective yet much smaller model, which is more practical for real-world application scenarios. The experiments on standard benchmarks, including the IIIT-5K, Street View Text and ICDAR datasets, demonstrate the superiority of the proposed algorithm over the prior arts. Moreover, the proposed algorithm performs well in the task of image-based music score recognition, which evidently verifies the generality of it.
+
+
+
+
+
+## Dataset
+
+### Train Dataset
+
+| trainset | instance_num | repeat_num | note |
+| :------: | :----------: | :--------: | :---: |
+| Syn90k | 8919273 | 1 | synth |
+
+### Test Dataset
+
+| testset | instance_num | note |
+| :-----: | :----------: | :-------: |
+| IIIT5K | 3000 | regular |
+| SVT | 647 | regular |
+| IC13 | 1015 | regular |
+| IC15 | 2077 | irregular |
+| SVTP | 645 | irregular |
+| CT80 | 288 | irregular |
+
+## Results and models
+
+| methods | | Regular Text | | | | Irregular Text | | download |
+| :------------------------------------------------------: | :----: | :----------: | :---: | :---: | :---: | :------------: | :---: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| methods | IIIT5K | SVT | IC13 | | IC15 | SVTP | CT80 |
+| [CRNN](/configs/textrecog/crnn/crnn_academic_dataset.py) | 80.5 | 81.5 | 86.5 | | 54.1 | 59.1 | 55.6 | [model](https://download.openmmlab.com/mmocr/textrecog/crnn/crnn_academic-a723a1c5.pth) \| [log](https://download.openmmlab.com/mmocr/textrecog/crnn/20210326_111035.log.json) |
+
+## Citation
+
+```bibtex
+@article{shi2016end,
+ title={An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition},
+ author={Shi, Baoguang and Bai, Xiang and Yao, Cong},
+ journal={IEEE transactions on pattern analysis and machine intelligence},
+ year={2016}
+}
+```
diff --git a/configs/textrecog/crnn/crnn_academic_dataset.py b/configs/textrecog/crnn/crnn_academic_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..b8288cb5a1cb48ddc6b32e988b45305e01e76df5
--- /dev/null
+++ b/configs/textrecog/crnn/crnn_academic_dataset.py
@@ -0,0 +1,35 @@
+_base_ = [
+ '../../_base_/default_runtime.py', '../../_base_/recog_models/crnn.py',
+ '../../_base_/recog_pipelines/crnn_pipeline.py',
+ '../../_base_/recog_datasets/MJ_train.py',
+ '../../_base_/recog_datasets/academic_test.py',
+ '../../_base_/schedules/schedule_adadelta_5e.py'
+]
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline = {{_base_.train_pipeline}}
+test_pipeline = {{_base_.test_pipeline}}
+
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline))
+
+evaluation = dict(interval=1, metric='acc')
+
+cudnn_benchmark = True
diff --git a/configs/textrecog/crnn/crnn_toy_dataset.py b/configs/textrecog/crnn/crnn_toy_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..f61c68afe285e4d1943cbcbb8ede1fe965a99a4b
--- /dev/null
+++ b/configs/textrecog/crnn/crnn_toy_dataset.py
@@ -0,0 +1,47 @@
+_base_ = [
+ '../../_base_/default_runtime.py',
+ '../../_base_/recog_pipelines/crnn_pipeline.py',
+ '../../_base_/recog_datasets/toy_data.py',
+ '../../_base_/schedules/schedule_adadelta_5e.py'
+]
+
+label_convertor = dict(
+ type='CTCConvertor', dict_type='DICT36', with_unknown=True, lower=True)
+
+model = dict(
+ type='CRNNNet',
+ preprocessor=None,
+ backbone=dict(type='VeryDeepVgg', leaky_relu=False, input_channels=1),
+ encoder=None,
+ decoder=dict(type='CRNNDecoder', in_channels=512, rnn_flag=True),
+ loss=dict(type='CTCLoss'),
+ label_convertor=label_convertor,
+ pretrained=None)
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline = {{_base_.train_pipeline}}
+test_pipeline = {{_base_.test_pipeline}}
+
+data = dict(
+ samples_per_gpu=32,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline))
+
+evaluation = dict(interval=1, metric='acc')
+
+cudnn_benchmark = True
diff --git a/configs/textrecog/crnn/metafile.yml b/configs/textrecog/crnn/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..c7b058c6a27d8a627788d702bc4ee942713ad7db
--- /dev/null
+++ b/configs/textrecog/crnn/metafile.yml
@@ -0,0 +1,37 @@
+Collections:
+- Name: CRNN
+ Metadata:
+ Training Data: OCRDataset
+ Training Techniques:
+ - Adadelta
+ Epochs: 5
+ Batch Size: 256
+ Training Resources: 4x GeForce GTX 1080 Ti
+ Architecture:
+ - VeryDeepVgg
+ - CRNNDecoder
+ Paper:
+ URL: https://arxiv.org/pdf/1507.05717.pdf
+ Title: 'An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition'
+ README: configs/textrecog/crnn/README.md
+
+Models:
+ - Name: crnn_academic_dataset
+ In Collection: CRNN
+ Config: configs/textrecog/crnn/crnn_academic_dataset.py
+ Metadata:
+ Training Data: Syn90k
+ Results:
+ - Task: Text Recognition
+ Dataset: IIIT5K
+ Metrics:
+ word_acc: 80.5
+ - Task: Text Recognition
+ Dataset: SVT
+ Metrics:
+ word_acc: 81.5
+ - Task: Text Recognition
+ Dataset: ICDAR2013
+ Metrics:
+ word_acc: 86.5
+ Weights: https://download.openmmlab.com/mmocr/textrecog/crnn/crnn_academic-a723a1c5.pth
diff --git a/configs/textrecog/nrtr/README.md b/configs/textrecog/nrtr/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..dab1879afa6d71f5feebf6d31c34a78f89ca5083
--- /dev/null
+++ b/configs/textrecog/nrtr/README.md
@@ -0,0 +1,66 @@
+# NRTR
+
+>[NRTR: A No-Recurrence Sequence-to-Sequence Model For Scene Text Recognition](https://arxiv.org/abs/1806.00926)
+
+
+
+## Abstract
+
+Scene text recognition has attracted a great many researches due to its importance to various applications. Existing methods mainly adopt recurrence or convolution based networks. Though have obtained good performance, these methods still suffer from two limitations: slow training speed due to the internal recurrence of RNNs, and high complexity due to stacked convolutional layers for long-term feature extraction. This paper, for the first time, proposes a no-recurrence sequence-to-sequence text recognizer, named NRTR, that dispenses with recurrences and convolutions entirely. NRTR follows the encoder-decoder paradigm, where the encoder uses stacked self-attention to extract image features, and the decoder applies stacked self-attention to recognize texts based on encoder output. NRTR relies solely on self-attention mechanism thus could be trained with more parallelization and less complexity. Considering scene image has large variation in text and background, we further design a modality-transform block to effectively transform 2D input images to 1D sequences, combined with the encoder to extract more discriminative features. NRTR achieves state-of-the-art or highly competitive performance on both regular and irregular benchmarks, while requires only a small fraction of training time compared to the best model from the literature (at least 8 times faster).
+
+
+
+
+
+## Dataset
+
+### Train Dataset
+
+| trainset | instance_num | repeat_num | source |
+| :-------: | :----------: | :--------: | :----: |
+| SynthText | 7266686 | 1 | synth |
+| Syn90k | 8919273 | 1 | synth |
+
+### Test Dataset
+
+| testset | instance_num | type |
+| :-----: | :----------: | :-------: |
+| IIIT5K | 3000 | regular |
+| SVT | 647 | regular |
+| IC13 | 1015 | regular |
+| IC15 | 2077 | irregular |
+| SVTP | 645 | irregular |
+| CT80 | 288 | irregular |
+
+## Results and Models
+
+| Methods | Backbone | | Regular Text | | | | Irregular Text | | download |
+| :-------------------------------------------------------------: | :----------: | :----: | :----------: | :---: | :---: | :---: | :------------: | :---: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| | | IIIT5K | SVT | IC13 | | IC15 | SVTP | CT80 |
+| [NRTR](/configs/textrecog/nrtr/nrtr_r31_1by16_1by8_academic.py) | R31-1/16-1/8 | 94.7 | 87.3 | 94.3 | | 73.5 | 78.9 | 85.1 | [model](https://download.openmmlab.com/mmocr/textrecog/nrtr/nrtr_r31_1by16_1by8_academic_20211124-f60cebf4.pth) \| [log](https://download.openmmlab.com/mmocr/textrecog/nrtr/20211124_002420.log.json) |
+| [NRTR](/configs/textrecog/nrtr/nrtr_r31_1by8_1by4_academic.py) | R31-1/8-1/4 | 95.2 | 90.0 | 94.0 | | 74.1 | 79.4 | 88.2 | [model](https://download.openmmlab.com/mmocr/textrecog/nrtr/nrtr_r31_1by8_1by4_academic_20211123-e1fdb322.pth) \| [log](https://download.openmmlab.com/mmocr/textrecog/nrtr/20211123_232151.log.json) |
+
+:::{note}
+
+- For backbone `R31-1/16-1/8`:
+ - The output consists of 92 classes, including 26 lowercase letters, 26 uppercase letters, 28 symbols, 10 digital numbers, 1 unknown token and 1 end-of-sequence token.
+ - The encoder-block number is 6.
+ - `1/16-1/8` means the height of feature from backbone is 1/16 of input image, where 1/8 for width.
+- For backbone `R31-1/8-1/4`:
+ - The output consists of 92 classes, including 26 lowercase letters, 26 uppercase letters, 28 symbols, 10 digital numbers, 1 unknown token and 1 end-of-sequence token.
+ - The encoder-block number is 6.
+ - `1/8-1/4` means the height of feature from backbone is 1/8 of input image, where 1/4 for width.
+:::
+
+## Citation
+
+```bibtex
+@inproceedings{sheng2019nrtr,
+ title={NRTR: A no-recurrence sequence-to-sequence model for scene text recognition},
+ author={Sheng, Fenfen and Chen, Zhineng and Xu, Bo},
+ booktitle={2019 International Conference on Document Analysis and Recognition (ICDAR)},
+ pages={781--786},
+ year={2019},
+ organization={IEEE}
+}
+```
diff --git a/configs/textrecog/nrtr/metafile.yml b/configs/textrecog/nrtr/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..7d5ca150109386635eba9f3739891d2b58955634
--- /dev/null
+++ b/configs/textrecog/nrtr/metafile.yml
@@ -0,0 +1,86 @@
+Collections:
+- Name: NRTR
+ Metadata:
+ Training Data: OCRDataset
+ Training Techniques:
+ - Adam
+ Epochs: 6
+ Batch Size: 6144
+ Training Resources: 48x GeForce GTX 1080 Ti
+ Architecture:
+ - CNN
+ - NRTREncoder
+ - NRTRDecoder
+ Paper:
+ URL: https://arxiv.org/pdf/1806.00926.pdf
+ Title: 'NRTR: A No-Recurrence Sequence-to-Sequence Model For Scene Text Recognition'
+ README: configs/textrecog/nrtr/README.md
+
+Models:
+ - Name: nrtr_r31_1by16_1by8_academic
+ In Collection: NRTR
+ Config: configs/textrecog/nrtr/nrtr_r31_1by16_1by8_academic.py
+ Metadata:
+ Training Data:
+ - SynthText
+ - Syn90k
+ Results:
+ - Task: Text Recognition
+ Dataset: IIIT5K
+ Metrics:
+ word_acc: 94.7
+ - Task: Text Recognition
+ Dataset: SVT
+ Metrics:
+ word_acc: 87.3
+ - Task: Text Recognition
+ Dataset: ICDAR2013
+ Metrics:
+ word_acc: 94.3
+ - Task: Text Recognition
+ Dataset: ICDAR2015
+ Metrics:
+ word_acc: 73.5
+ - Task: Text Recognition
+ Dataset: SVTP
+ Metrics:
+ word_acc: 78.9
+ - Task: Text Recognition
+ Dataset: CT80
+ Metrics:
+ word_acc: 85.1
+ Weights: https://download.openmmlab.com/mmocr/textrecog/nrtr/nrtr_r31_1by16_1by8_academic_20211124-f60cebf4.pth
+
+ - Name: nrtr_r31_1by8_1by4_academic
+ In Collection: NRTR
+ Config: configs/textrecog/nrtr/nrtr_r31_1by8_1by4_academic.py
+ Metadata:
+ Training Data:
+ - SynthText
+ - Syn90k
+ Results:
+ - Task: Text Recognition
+ Dataset: IIIT5K
+ Metrics:
+ word_acc: 95.2
+ - Task: Text Recognition
+ Dataset: SVT
+ Metrics:
+ word_acc: 90.0
+ - Task: Text Recognition
+ Dataset: ICDAR2013
+ Metrics:
+ word_acc: 94.0
+ - Task: Text Recognition
+ Dataset: ICDAR2015
+ Metrics:
+ word_acc: 74.1
+ - Task: Text Recognition
+ Dataset: SVTP
+ Metrics:
+ word_acc: 79.4
+ - Task: Text Recognition
+ Dataset: CT80
+ Metrics:
+ word_acc: 88.2
+ Weights: https://download.openmmlab.com/mmocr/textrecog/nrtr/nrtr_r31_1by8_1by4_academic_20211123-e1fdb322.pth
diff --git a/configs/textrecog/nrtr/nrtr_modality_transform_academic.py b/configs/textrecog/nrtr/nrtr_modality_transform_academic.py
new file mode 100644
index 0000000000000000000000000000000000000000..471926ba998640123ff356c146dc8bbdb9b3c261
--- /dev/null
+++ b/configs/textrecog/nrtr/nrtr_modality_transform_academic.py
@@ -0,0 +1,32 @@
+_base_ = [
+ '../../_base_/default_runtime.py',
+ '../../_base_/recog_models/nrtr_modality_transform.py',
+ '../../_base_/schedules/schedule_adam_step_6e.py',
+ '../../_base_/recog_datasets/ST_MJ_train.py',
+ '../../_base_/recog_datasets/academic_test.py',
+ '../../_base_/recog_pipelines/nrtr_pipeline.py'
+]
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline = {{_base_.train_pipeline}}
+test_pipeline = {{_base_.test_pipeline}}
+
+data = dict(
+ samples_per_gpu=128,
+ workers_per_gpu=4,
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline))
+
+evaluation = dict(interval=1, metric='acc')
diff --git a/configs/textrecog/nrtr/nrtr_modality_transform_toy_dataset.py b/configs/textrecog/nrtr/nrtr_modality_transform_toy_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..1bb350fc3f49418f2841df2d65f183c34e08db0e
--- /dev/null
+++ b/configs/textrecog/nrtr/nrtr_modality_transform_toy_dataset.py
@@ -0,0 +1,31 @@
+_base_ = [
+ '../../_base_/default_runtime.py',
+ '../../_base_/recog_models/nrtr_modality_transform.py',
+ '../../_base_/schedules/schedule_adam_step_6e.py',
+ '../../_base_/recog_datasets/toy_data.py',
+ '../../_base_/recog_pipelines/nrtr_pipeline.py'
+]
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline = {{_base_.train_pipeline}}
+test_pipeline = {{_base_.test_pipeline}}
+
+data = dict(
+ samples_per_gpu=16,
+ workers_per_gpu=2,
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline))
+
+evaluation = dict(interval=1, metric='acc')
diff --git a/configs/textrecog/nrtr/nrtr_r31_1by16_1by8_academic.py b/configs/textrecog/nrtr/nrtr_r31_1by16_1by8_academic.py
new file mode 100644
index 0000000000000000000000000000000000000000..b7adc0d30cda5e5556821ff941d6e00dcd3b4ba7
--- /dev/null
+++ b/configs/textrecog/nrtr/nrtr_r31_1by16_1by8_academic.py
@@ -0,0 +1,48 @@
+_base_ = [
+ '../../_base_/default_runtime.py',
+ '../../_base_/schedules/schedule_adam_step_6e.py',
+ '../../_base_/recog_pipelines/nrtr_pipeline.py',
+ '../../_base_/recog_datasets/ST_MJ_train.py',
+ '../../_base_/recog_datasets/academic_test.py'
+]
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline = {{_base_.train_pipeline}}
+test_pipeline = {{_base_.test_pipeline}}
+
+label_convertor = dict(
+ type='AttnConvertor', dict_type='DICT90', with_unknown=True)
+
+model = dict(
+ type='NRTR',
+ backbone=dict(
+ type='ResNet31OCR',
+ layers=[1, 2, 5, 3],
+ channels=[32, 64, 128, 256, 512, 512],
+ stage4_pool_cfg=dict(kernel_size=(2, 1), stride=(2, 1)),
+ last_stage_pool=True),
+ encoder=dict(type='NRTREncoder'),
+ decoder=dict(type='NRTRDecoder'),
+ loss=dict(type='TFLoss'),
+ label_convertor=label_convertor,
+ max_seq_len=40)
+
+data = dict(
+ samples_per_gpu=128,
+ workers_per_gpu=4,
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline))
+
+evaluation = dict(interval=1, metric='acc')
diff --git a/configs/textrecog/nrtr/nrtr_r31_1by8_1by4_academic.py b/configs/textrecog/nrtr/nrtr_r31_1by8_1by4_academic.py
new file mode 100644
index 0000000000000000000000000000000000000000..397122b55ea57df647a6bb5097973e0eebf4979d
--- /dev/null
+++ b/configs/textrecog/nrtr/nrtr_r31_1by8_1by4_academic.py
@@ -0,0 +1,48 @@
+_base_ = [
+ '../../_base_/default_runtime.py',
+ '../../_base_/schedules/schedule_adam_step_6e.py',
+ '../../_base_/recog_pipelines/nrtr_pipeline.py',
+ '../../_base_/recog_datasets/ST_MJ_train.py',
+ '../../_base_/recog_datasets/academic_test.py'
+]
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline = {{_base_.train_pipeline}}
+test_pipeline = {{_base_.test_pipeline}}
+
+label_convertor = dict(
+ type='AttnConvertor', dict_type='DICT90', with_unknown=True)
+
+model = dict(
+ type='NRTR',
+ backbone=dict(
+ type='ResNet31OCR',
+ layers=[1, 2, 5, 3],
+ channels=[32, 64, 128, 256, 512, 512],
+ stage4_pool_cfg=dict(kernel_size=(2, 1), stride=(2, 1)),
+ last_stage_pool=False),
+ encoder=dict(type='NRTREncoder'),
+ decoder=dict(type='NRTRDecoder'),
+ loss=dict(type='TFLoss'),
+ label_convertor=label_convertor,
+ max_seq_len=40)
+
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=4,
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline))
+
+evaluation = dict(interval=1, metric='acc')
diff --git a/configs/textrecog/robust_scanner/README.md b/configs/textrecog/robust_scanner/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..60ea38e546bc8ec2bdb451c3c5c155812927170c
--- /dev/null
+++ b/configs/textrecog/robust_scanner/README.md
@@ -0,0 +1,61 @@
+# RobustScanner
+
+>[RobustScanner: Dynamically Enhancing Positional Clues for Robust Text Recognition](https://arxiv.org/abs/2007.07542)
+
+
+
+## Abstract
+
+The attention-based encoder-decoder framework has recently achieved impressive results for scene text recognition, and many variants have emerged with improvements in recognition quality. However, it performs poorly on contextless texts (e.g., random character sequences) which is unacceptable in most of real application scenarios. In this paper, we first deeply investigate the decoding process of the decoder. We empirically find that a representative character-level sequence decoder utilizes not only context information but also positional information. Contextual information, which the existing approaches heavily rely on, causes the problem of attention drift. To suppress such side-effect, we propose a novel position enhancement branch, and dynamically fuse its outputs with those of the decoder attention module for scene text recognition. Specifically, it contains a position aware module to enable the encoder to output feature vectors encoding their own spatial positions, and an attention module to estimate glimpses using the positional clue (i.e., the current decoding time step) only. The dynamic fusion is conducted for more robust feature via an element-wise gate mechanism. Theoretically, our proposed method, dubbed \emph{RobustScanner}, decodes individual characters with dynamic ratio between context and positional clues, and utilizes more positional ones when the decoding sequences with scarce context, and thus is robust and practical. Empirically, it has achieved new state-of-the-art results on popular regular and irregular text recognition benchmarks while without much performance drop on contextless benchmarks, validating its robustness in both contextual and contextless application scenarios.
+
+
+
+
+
+## Dataset
+
+### Train Dataset
+
+| trainset | instance_num | repeat_num | source |
+| :--------: | :----------: | :--------: | :----------------------: |
+| icdar_2011 | 3567 | 20 | real |
+| icdar_2013 | 848 | 20 | real |
+| icdar2015 | 4468 | 20 | real |
+| coco_text | 42142 | 20 | real |
+| IIIT5K | 2000 | 20 | real |
+| SynthText | 2400000 | 1 | synth |
+| SynthAdd | 1216889 | 1 | synth, 1.6m in [[1]](#1) |
+| Syn90k | 2400000 | 1 | synth |
+
+### Test Dataset
+
+| testset | instance_num | type |
+| :-----: | :----------: | :-------------------------: |
+| IIIT5K | 3000 | regular |
+| SVT | 647 | regular |
+| IC13 | 1015 | regular |
+| IC15 | 2077 | irregular |
+| SVTP | 645 | irregular, 639 in [[1]](#1) |
+| CT80 | 288 | irregular |
+
+## Results and Models
+
+| Methods | GPUs | | Regular Text | | | | Irregular Text | | download |
+| :-----------------------------------------------------------------------------: | :---: | :----: | :----------: | :---: | :---: | :---: | :------------: | :---: | :-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| | | IIIT5K | SVT | IC13 | | IC15 | SVTP | CT80 |
+| [RobustScanner](configs/textrecog/robust_scanner/robustscanner_r31_academic.py) | 16 | 95.1 | 89.2 | 93.1 | | 77.8 | 80.3 | 90.3 | [model](https://download.openmmlab.com/mmocr/textrecog/robustscanner/robustscanner_r31_academic-5f05874f.pth) \| [log](https://download.openmmlab.com/mmocr/textrecog/robustscanner/20210401_170932.log.json) |
+
+## References
+
+[1] Li, Hui and Wang, Peng and Shen, Chunhua and Zhang, Guyu. Show, attend and read: A simple and strong baseline for irregular text recognition. In AAAI 2019.
+
+## Citation
+
+```bibtex
+@inproceedings{yue2020robustscanner,
+ title={RobustScanner: Dynamically Enhancing Positional Clues for Robust Text Recognition},
+ author={Yue, Xiaoyu and Kuang, Zhanghui and Lin, Chenhao and Sun, Hongbin and Zhang, Wayne},
+ booktitle={European Conference on Computer Vision},
+ year={2020}
+}
+```
diff --git a/configs/textrecog/robust_scanner/metafile.yml b/configs/textrecog/robust_scanner/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..95892543d9bc81bf45b08aecdb4e139c90490100
--- /dev/null
+++ b/configs/textrecog/robust_scanner/metafile.yml
@@ -0,0 +1,58 @@
+Collections:
+- Name: RobustScanner
+ Metadata:
+ Training Data: OCRDataset
+ Training Techniques:
+ - Adam
+ Epochs: 5
+ Batch Size: 1024
+ Training Resources: 16x GeForce GTX 1080 Ti
+ Architecture:
+ - ResNet31OCR
+ - ChannelReductionEncoder
+ - RobustScannerDecoder
+ Paper:
+ URL: https://arxiv.org/pdf/2007.07542.pdf
+ Title: 'RobustScanner: Dynamically Enhancing Positional Clues for Robust Text Recognition'
+ README: configs/textrecog/robust_scanner/README.md
+
+Models:
+ - Name: robustscanner_r31_academic
+ In Collection: RobustScanner
+ Config: configs/textrecog/robust_scanner/robustscanner_r31_academic.py
+ Metadata:
+ Training Data:
+ - ICDAR2011
+ - ICDAR2013
+ - ICDAR2015
+ - COCO text
+ - IIIT5K
+ - SynthText
+ - SynthAdd
+ - Syn90k
+ Results:
+ - Task: Text Recognition
+ Dataset: IIIT5K
+ Metrics:
+ word_acc: 95.1
+ - Task: Text Recognition
+ Dataset: SVT
+ Metrics:
+ word_acc: 89.2
+ - Task: Text Recognition
+ Dataset: ICDAR2013
+ Metrics:
+ word_acc: 93.1
+ - Task: Text Recognition
+ Dataset: ICDAR2015
+ Metrics:
+ word_acc: 77.8
+ - Task: Text Recognition
+ Dataset: SVTP
+ Metrics:
+ word_acc: 80.3
+ - Task: Text Recognition
+ Dataset: CT80
+ Metrics:
+ word_acc: 90.3
+ Weights: https://download.openmmlab.com/mmocr/textrecog/robustscanner/robustscanner_r31_academic-5f05874f.pth
diff --git a/configs/textrecog/robust_scanner/robustscanner_r31_academic.py b/configs/textrecog/robust_scanner/robustscanner_r31_academic.py
new file mode 100644
index 0000000000000000000000000000000000000000..65a980b61684dee9929b7800ee82b4461ed2fc40
--- /dev/null
+++ b/configs/textrecog/robust_scanner/robustscanner_r31_academic.py
@@ -0,0 +1,34 @@
+_base_ = [
+ '../../_base_/default_runtime.py',
+ '../../_base_/recog_models/robust_scanner.py',
+ '../../_base_/schedules/schedule_adam_step_5e.py',
+ '../../_base_/recog_pipelines/sar_pipeline.py',
+ '../../_base_/recog_datasets/ST_SA_MJ_real_train.py',
+ '../../_base_/recog_datasets/academic_test.py'
+]
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline = {{_base_.train_pipeline}}
+test_pipeline = {{_base_.test_pipeline}}
+
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline))
+
+evaluation = dict(interval=1, metric='acc')
diff --git a/configs/textrecog/sar/README.md b/configs/textrecog/sar/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..b7211855b2666e1688a683fbf671b59becfc28ab
--- /dev/null
+++ b/configs/textrecog/sar/README.md
@@ -0,0 +1,84 @@
+# SAR
+> [Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition](https://arxiv.org/abs/1811.00751)
+
+
+
+## Abstract
+
+Recognizing irregular text in natural scene images is challenging due to the large variance in text appearance, such as curvature, orientation and distortion. Most existing approaches rely heavily on sophisticated model designs and/or extra fine-grained annotations, which, to some extent, increase the difficulty in algorithm implementation and data collection. In this work, we propose an easy-to-implement strong baseline for irregular scene text recognition, using off-the-shelf neural network components and only word-level annotations. It is composed of a 31-layer ResNet, an LSTM-based encoder-decoder framework and a 2-dimensional attention module. Despite its simplicity, the proposed method is robust and achieves state-of-the-art performance on both regular and irregular scene text recognition benchmarks.
+
+
+
+
+
+
+
+## Dataset
+
+### Train Dataset
+
+| trainset | instance_num | repeat_num | source |
+| :--------: | :----------: | :--------: | :----------------------: |
+| icdar_2011 | 3567 | 20 | real |
+| icdar_2013 | 848 | 20 | real |
+| icdar2015 | 4468 | 20 | real |
+| coco_text | 42142 | 20 | real |
+| IIIT5K | 2000 | 20 | real |
+| SynthText | 2400000 | 1 | synth |
+| SynthAdd | 1216889 | 1 | synth, 1.6m in [[1]](#1) |
+| Syn90k | 2400000 | 1 | synth |
+
+### Test Dataset
+
+| testset | instance_num | type |
+| :-----: | :----------: | :-------------------------: |
+| IIIT5K | 3000 | regular |
+| SVT | 647 | regular |
+| IC13 | 1015 | regular |
+| IC15 | 2077 | irregular |
+| SVTP | 645 | irregular, 639 in [[1]](#1) |
+| CT80 | 288 | irregular |
+
+## Results and Models
+
+| Methods | Backbone | Decoder | | Regular Text | | | | Irregular Text | | download |
+| :-----------------------------------------------------------------: | :---------: | :------------------: | :----: | :----------: | :---: | :---: | :---: | :------------: | :---: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| | | | IIIT5K | SVT | IC13 | | IC15 | SVTP | CT80 |
+| [SAR](/configs/textrecog/sar/sar_r31_parallel_decoder_academic.py) | R31-1/8-1/4 | ParallelSARDecoder | 95.0 | 89.6 | 93.7 | | 79.0 | 82.2 | 88.9 | [model](https://download.openmmlab.com/mmocr/textrecog/sar/sar_r31_parallel_decoder_academic-dba3a4a3.pth) \| [log](https://download.openmmlab.com/mmocr/textrecog/sar/20210327_154129.log.json) |
+| [SAR](configs/textrecog/sar/sar_r31_sequential_decoder_academic.py) | R31-1/8-1/4 | SequentialSARDecoder | 95.2 | 88.7 | 92.4 | | 78.2 | 81.9 | 89.6 | [model](https://download.openmmlab.com/mmocr/textrecog/sar/sar_r31_sequential_decoder_academic-d06c9a8e.pth) \| [log](https://download.openmmlab.com/mmocr/textrecog/sar/20210330_105728.log.json) |
+
+## Chinese Dataset
+
+## Results and Models
+
+| Methods | Backbone | Decoder | | download |
+| :---------------------------------------------------------------: | :---------: | :----------------: | :---: | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| [SAR](/configs/textrecog/sar/sar_r31_parallel_decoder_chinese.py) | R31-1/8-1/4 | ParallelSARDecoder | | [model](https://download.openmmlab.com/mmocr/textrecog/sar/sar_r31_parallel_decoder_chineseocr_20210507-b4be8214.pth) \| [log](https://download.openmmlab.com/mmocr/textrecog/sar/20210506_225557.log.json) \| [dict](https://download.openmmlab.com/mmocr/textrecog/sar/dict_printed_chinese_english_digits.txt) |
+
+:::{note}
+
+- `R31-1/8-1/4` means the height of feature from backbone is 1/8 of input image, where 1/4 for width.
+- We did not use beam search during decoding.
+- We implemented two kinds of decoder. Namely, `ParallelSARDecoder` and `SequentialSARDecoder`.
+ - `ParallelSARDecoder`: Parallel decoding during training with `LSTM` layer. It would be faster.
+ - `SequentialSARDecoder`: Sequential Decoding during training with `LSTMCell`. It would be easier to understand.
+- For train dataset.
+ - We did not construct distinct data groups (20 groups in [[1]](#1)) to train the model group-by-group since it would render model training too complicated.
+ - Instead, we randomly selected `2.4m` patches from `Syn90k`, `2.4m` from `SynthText` and `1.2m` from `SynthAdd`, and grouped all data together. See [config](https://download.openmmlab.com/mmocr/textrecog/sar/sar_r31_academic.py) for details.
+- We used 48 GPUs with `total_batch_size = 64 * 48` in the experiment above to speedup training, while keeping the `initial lr = 1e-3` unchanged.
+:::
+
+
+## Citation
+
+```bibtex
+@inproceedings{li2019show,
+ title={Show, attend and read: A simple and strong baseline for irregular text recognition},
+ author={Li, Hui and Wang, Peng and Shen, Chunhua and Zhang, Guyu},
+ booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
+ volume={33},
+ number={01},
+ pages={8610--8617},
+ year={2019}
+}
+```
diff --git a/configs/textrecog/sar/metafile.yml b/configs/textrecog/sar/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..9f4115817efefb8b5f9c9bbdcebdaf33411febea
--- /dev/null
+++ b/configs/textrecog/sar/metafile.yml
@@ -0,0 +1,98 @@
+Collections:
+- Name: SAR
+ Metadata:
+ Training Data: OCRDataset
+ Training Techniques:
+ - Adam
+ Training Resources: 48x GeForce GTX 1080 Ti
+ Epochs: 5
+ Batch Size: 3072
+ Architecture:
+ - ResNet31OCR
+ - SAREncoder
+ - ParallelSARDecoder
+ Paper:
+ URL: https://arxiv.org/pdf/1811.00751.pdf
+ Title: 'Show, Attend and Read:A Simple and Strong Baseline for Irregular Text Recognition'
+ README: configs/textrecog/sar/README.md
+
+Models:
+ - Name: sar_r31_parallel_decoder_academic
+ In Collection: SAR
+ Config: configs/textrecog/sar/sar_r31_parallel_decoder_academic.py
+ Metadata:
+ Training Data:
+ - ICDAR2011
+ - ICDAR2013
+ - ICDAR2015
+ - COCO text
+ - IIIT5K
+ - SynthText
+ - SynthAdd
+ - Syn90k
+ Results:
+ - Task: Text Recognition
+ Dataset: IIIT5K
+ Metrics:
+ word_acc: 95.0
+ - Task: Text Recognition
+ Dataset: SVT
+ Metrics:
+ word_acc: 89.6
+ - Task: Text Recognition
+ Dataset: ICDAR2013
+ Metrics:
+ word_acc: 93.7
+ - Task: Text Recognition
+ Dataset: ICDAR2015
+ Metrics:
+ word_acc: 79.0
+ - Task: Text Recognition
+ Dataset: SVTP
+ Metrics:
+ word_acc: 82.2
+ - Task: Text Recognition
+ Dataset: CT80
+ Metrics:
+ word_acc: 88.9
+ Weights: https://download.openmmlab.com/mmocr/textrecog/sar/sar_r31_parallel_decoder_academic-dba3a4a3.pth
+
+ - Name: sar_r31_sequential_decoder_academic
+ In Collection: SAR
+ Config: configs/textrecog/sar/sar_r31_sequential_decoder_academic.py
+ Metadata:
+ Training Data:
+ - ICDAR2011
+ - ICDAR2013
+ - ICDAR2015
+ - COCO text
+ - IIIT5K
+ - SynthText
+ - SynthAdd
+ - Syn90k
+ Results:
+ - Task: Text Recognition
+ Dataset: IIIT5K
+ Metrics:
+ word_acc: 95.2
+ - Task: Text Recognition
+ Dataset: SVT
+ Metrics:
+ word_acc: 88.7
+ - Task: Text Recognition
+ Dataset: ICDAR2013
+ Metrics:
+ word_acc: 92.4
+ - Task: Text Recognition
+ Dataset: ICDAR2015
+ Metrics:
+ word_acc: 78.2
+ - Task: Text Recognition
+ Dataset: SVTP
+ Metrics:
+ word_acc: 81.9
+ - Task: Text Recognition
+ Dataset: CT80
+ Metrics:
+ word_acc: 89.6
+ Weights: https://download.openmmlab.com/mmocr/textrecog/sar/sar_r31_sequential_decoder_academic-d06c9a8e.pth
diff --git a/configs/textrecog/sar/sar_r31_parallel_decoder_academic.py b/configs/textrecog/sar/sar_r31_parallel_decoder_academic.py
new file mode 100644
index 0000000000000000000000000000000000000000..983378118b4d589f531a7f401a06d238966a45d4
--- /dev/null
+++ b/configs/textrecog/sar/sar_r31_parallel_decoder_academic.py
@@ -0,0 +1,33 @@
+_base_ = [
+ '../../_base_/default_runtime.py', '../../_base_/recog_models/sar.py',
+ '../../_base_/schedules/schedule_adam_step_5e.py',
+ '../../_base_/recog_pipelines/sar_pipeline.py',
+ '../../_base_/recog_datasets/ST_SA_MJ_real_train.py',
+ '../../_base_/recog_datasets/academic_test.py'
+]
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline = {{_base_.train_pipeline}}
+test_pipeline = {{_base_.test_pipeline}}
+
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline))
+
+evaluation = dict(interval=1, metric='acc')
diff --git a/configs/textrecog/sar/sar_r31_parallel_decoder_chinese.py b/configs/textrecog/sar/sar_r31_parallel_decoder_chinese.py
new file mode 100644
index 0000000000000000000000000000000000000000..58856312705bcc757550ca84f97a097f80f9be24
--- /dev/null
+++ b/configs/textrecog/sar/sar_r31_parallel_decoder_chinese.py
@@ -0,0 +1,128 @@
+_base_ = [
+ '../../_base_/default_runtime.py',
+ '../../_base_/schedules/schedule_adam_step_5e.py'
+]
+
+dict_file = 'data/chineseocr/labels/dict_printed_chinese_english_digits.txt'
+label_convertor = dict(
+ type='AttnConvertor', dict_file=dict_file, with_unknown=True)
+
+model = dict(
+ type='SARNet',
+ backbone=dict(type='ResNet31OCR'),
+ encoder=dict(
+ type='SAREncoder',
+ enc_bi_rnn=False,
+ enc_do_rnn=0.1,
+ enc_gru=False,
+ ),
+ decoder=dict(
+ type='ParallelSARDecoder',
+ enc_bi_rnn=False,
+ dec_bi_rnn=False,
+ dec_do_rnn=0,
+ dec_gru=False,
+ pred_dropout=0.1,
+ d_k=512,
+ pred_concat=True),
+ loss=dict(type='SARLoss'),
+ label_convertor=label_convertor,
+ max_seq_len=30)
+
+img_norm_cfg = dict(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='ResizeOCR',
+ height=48,
+ min_width=48,
+ max_width=256,
+ keep_aspect_ratio=True,
+ width_downsample_ratio=0.25),
+ dict(type='ToTensorOCR'),
+ dict(type='NormalizeOCR', **img_norm_cfg),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'filename', 'ori_shape', 'resize_shape', 'text', 'valid_ratio'
+ ]),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiRotateAugOCR',
+ rotate_degrees=[0, 90, 270],
+ transforms=[
+ dict(
+ type='ResizeOCR',
+ height=48,
+ min_width=48,
+ max_width=256,
+ keep_aspect_ratio=True,
+ width_downsample_ratio=0.25),
+ dict(type='ToTensorOCR'),
+ dict(type='NormalizeOCR', **img_norm_cfg),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'filename', 'ori_shape', 'resize_shape', 'valid_ratio'
+ ]),
+ ])
+]
+
+dataset_type = 'OCRDataset'
+
+train_prefix = 'data/chinese/'
+
+train_ann_file = train_prefix + 'labels/train.txt'
+
+train = dict(
+ type=dataset_type,
+ img_prefix=train_prefix,
+ ann_file=train_ann_file,
+ loader=dict(
+ type='HardDiskLoader',
+ repeat=1,
+ parser=dict(
+ type='LineStrParser',
+ keys=['filename', 'text'],
+ keys_idx=[0, 1],
+ separator=' ')),
+ pipeline=None,
+ test_mode=False)
+
+test_prefix = 'data/chineseocr/'
+
+test_ann_file = test_prefix + 'labels/test.txt'
+
+test = dict(
+ type=dataset_type,
+ img_prefix=test_prefix,
+ ann_file=test_ann_file,
+ loader=dict(
+ type='HardDiskLoader',
+ repeat=1,
+ parser=dict(
+ type='LineStrParser',
+ keys=['filename', 'text'],
+ keys_idx=[0, 1],
+ separator=' ')),
+ pipeline=None,
+ test_mode=False)
+
+data = dict(
+ samples_per_gpu=40,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='UniformConcatDataset', datasets=[train],
+ pipeline=train_pipeline),
+ val=dict(
+ type='UniformConcatDataset', datasets=[test], pipeline=test_pipeline),
+ test=dict(
+ type='UniformConcatDataset', datasets=[test], pipeline=test_pipeline))
+
+evaluation = dict(interval=1, metric='acc')
diff --git a/configs/textrecog/sar/sar_r31_parallel_decoder_toy_dataset.py b/configs/textrecog/sar/sar_r31_parallel_decoder_toy_dataset.py
new file mode 100755
index 0000000000000000000000000000000000000000..40688d1290080c010beccc271214e5b246b45a32
--- /dev/null
+++ b/configs/textrecog/sar/sar_r31_parallel_decoder_toy_dataset.py
@@ -0,0 +1,30 @@
+_base_ = [
+ '../../_base_/default_runtime.py', '../../_base_/recog_models/sar.py',
+ '../../_base_/schedules/schedule_adam_step_5e.py',
+ '../../_base_/recog_pipelines/sar_pipeline.py',
+ '../../_base_/recog_datasets/toy_data.py'
+]
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline = {{_base_.train_pipeline}}
+test_pipeline = {{_base_.test_pipeline}}
+
+data = dict(
+ workers_per_gpu=2,
+ samples_per_gpu=8,
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline))
+
+evaluation = dict(interval=1, metric='acc')
diff --git a/configs/textrecog/sar/sar_r31_sequential_decoder_academic.py b/configs/textrecog/sar/sar_r31_sequential_decoder_academic.py
new file mode 100644
index 0000000000000000000000000000000000000000..46ca259b3abb8863348f8eef71b0126f77e269eb
--- /dev/null
+++ b/configs/textrecog/sar/sar_r31_sequential_decoder_academic.py
@@ -0,0 +1,58 @@
+_base_ = [
+ '../../_base_/default_runtime.py',
+ '../../_base_/schedules/schedule_adam_step_5e.py',
+ '../../_base_/recog_pipelines/sar_pipeline.py',
+ '../../_base_/recog_datasets/ST_SA_MJ_real_train.py',
+ '../../_base_/recog_datasets/academic_test.py'
+]
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline = {{_base_.train_pipeline}}
+test_pipeline = {{_base_.test_pipeline}}
+
+label_convertor = dict(
+ type='AttnConvertor', dict_type='DICT90', with_unknown=True)
+
+model = dict(
+ type='SARNet',
+ backbone=dict(type='ResNet31OCR'),
+ encoder=dict(
+ type='SAREncoder',
+ enc_bi_rnn=False,
+ enc_do_rnn=0.1,
+ enc_gru=False,
+ ),
+ decoder=dict(
+ type='SequentialSARDecoder',
+ enc_bi_rnn=False,
+ dec_bi_rnn=False,
+ dec_do_rnn=0,
+ dec_gru=False,
+ pred_dropout=0.1,
+ d_k=512,
+ pred_concat=True),
+ loss=dict(type='SARLoss'),
+ label_convertor=label_convertor,
+ max_seq_len=30)
+
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=2,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline))
+
+evaluation = dict(interval=1, metric='acc')
diff --git a/configs/textrecog/satrn/README.md b/configs/textrecog/satrn/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..9e26021a69df8076b2a959d5d4e986700c338457
--- /dev/null
+++ b/configs/textrecog/satrn/README.md
@@ -0,0 +1,52 @@
+# SATRN
+
+>[On Recognizing Texts of Arbitrary Shapes with 2D Self-Attention](https://arxiv.org/abs/1910.04396)
+
+
+
+## Abstract
+
+Scene text recognition (STR) is the task of recognizing character sequences in natural scenes. While there have been great advances in STR methods, current methods still fail to recognize texts in arbitrary shapes, such as heavily curved or rotated texts, which are abundant in daily life (e.g. restaurant signs, product labels, company logos, etc). This paper introduces a novel architecture to recognizing texts of arbitrary shapes, named Self-Attention Text Recognition Network (SATRN), which is inspired by the Transformer. SATRN utilizes the self-attention mechanism to describe two-dimensional (2D) spatial dependencies of characters in a scene text image. Exploiting the full-graph propagation of self-attention, SATRN can recognize texts with arbitrary arrangements and large inter-character spacing. As a result, SATRN outperforms existing STR models by a large margin of 5.7 pp on average in "irregular text" benchmarks. We provide empirical analyses that illustrate the inner mechanisms and the extent to which the model is applicable (e.g. rotated and multi-line text). We will open-source the code.
+
+
+
+
+
+
+## Dataset
+
+### Train Dataset
+
+| trainset | instance_num | repeat_num | source |
+| :-------: | :----------: | :--------: | :----: |
+| SynthText | 7266686 | 1 | synth |
+| Syn90k | 8919273 | 1 | synth |
+
+### Test Dataset
+
+| testset | instance_num | type |
+| :-----: | :----------: | :-------: |
+| IIIT5K | 3000 | regular |
+| SVT | 647 | regular |
+| IC13 | 1015 | regular |
+| IC15 | 2077 | irregular |
+| SVTP | 645 | irregular |
+| CT80 | 288 | irregular |
+
+## Results and Models
+
+| Methods | | Regular Text | | | | Irregular Text | | download |
+| :----------------------------------------------------: | :----: | :----------: | :---: | :---: | :---: | :------------: | :---: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| | IIIT5K | SVT | IC13 | | IC15 | SVTP | CT80 |
+| [Satrn](/configs/textrecog/satrn/satrn_academic.py) | 96.1 | 93.5 | 95.7 | | 84.1 | 88.5 | 90.3 | [model](https://download.openmmlab.com/mmocr/textrecog/satrn/satrn_academic_20211009-cb8b1580.pth) \| [log](https://download.openmmlab.com/mmocr/textrecog/satrn/20210809_093244.log.json) |
+| [Satrn_small](/configs/textrecog/satrn/satrn_small.py) | 94.7 | 91.3 | 95.4 | | 81.9 | 85.9 | 86.5 | [model](https://download.openmmlab.com/mmocr/textrecog/satrn/satrn_small_20211009-2cf13355.pth) \| [log](https://download.openmmlab.com/mmocr/textrecog/satrn/20210811_053047.log.json) |
+
+## Citation
+
+```bibtex
+@article{junyeop2019recognizing,
+ title={On Recognizing Texts of Arbitrary Shapes with 2D Self-Attention},
+ author={Junyeop Lee, Sungrae Park, Jeonghun Baek, Seong Joon Oh, Seonghyeon Kim, Hwalsuk Lee},
+ year={2019}
+}
+```
diff --git a/configs/textrecog/satrn/metafile.yml b/configs/textrecog/satrn/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..5dd03fe550617330589c2880d88734a1fb3a4b3a
--- /dev/null
+++ b/configs/textrecog/satrn/metafile.yml
@@ -0,0 +1,86 @@
+Collections:
+- Name: SATRN
+ Metadata:
+ Training Data: OCRDataset
+ Training Techniques:
+ - Adam
+ Training Resources: 8x Tesla V100
+ Epochs: 6
+ Batch Size: 512
+ Architecture:
+ - ShallowCNN
+ - SatrnEncoder
+ - TFDecoder
+ Paper:
+ URL: https://arxiv.org/pdf/1910.04396.pdf
+ Title: 'On Recognizing Texts of Arbitrary Shapes with 2D Self-Attention'
+ README: configs/textrecog/satrn/README.md
+
+Models:
+ - Name: satrn_academic
+ In Collection: SATRN
+ Config: configs/textrecog/satrn/satrn_academic.py
+ Metadata:
+ Training Data:
+ - SynthText
+ - Syn90k
+ Results:
+ - Task: Text Recognition
+ Dataset: IIIT5K
+ Metrics:
+ word_acc: 96.1
+ - Task: Text Recognition
+ Dataset: SVT
+ Metrics:
+ word_acc: 93.5
+ - Task: Text Recognition
+ Dataset: ICDAR2013
+ Metrics:
+ word_acc: 95.7
+ - Task: Text Recognition
+ Dataset: ICDAR2015
+ Metrics:
+ word_acc: 84.1
+ - Task: Text Recognition
+ Dataset: SVTP
+ Metrics:
+ word_acc: 88.5
+ - Task: Text Recognition
+ Dataset: CT80
+ Metrics:
+ word_acc: 90.3
+ Weights: https://download.openmmlab.com/mmocr/textrecog/satrn/satrn_academic_20211009-cb8b1580.pth
+
+ - Name: satrn_small
+ In Collection: SATRN
+ Config: configs/textrecog/satrn/satrn_small.py
+ Metadata:
+ Training Data:
+ - SynthText
+ - Syn90k
+ Results:
+ - Task: Text Recognition
+ Dataset: IIIT5K
+ Metrics:
+ word_acc: 94.7
+ - Task: Text Recognition
+ Dataset: SVT
+ Metrics:
+ word_acc: 91.3
+ - Task: Text Recognition
+ Dataset: ICDAR2013
+ Metrics:
+ word_acc: 95.4
+ - Task: Text Recognition
+ Dataset: ICDAR2015
+ Metrics:
+ word_acc: 81.9
+ - Task: Text Recognition
+ Dataset: SVTP
+ Metrics:
+ word_acc: 85.9
+ - Task: Text Recognition
+ Dataset: CT80
+ Metrics:
+ word_acc: 86.5
+ Weights: https://download.openmmlab.com/mmocr/textrecog/satrn/satrn_small_20211009-2cf13355.pth
diff --git a/configs/textrecog/satrn/satrn_academic.py b/configs/textrecog/satrn/satrn_academic.py
new file mode 100644
index 0000000000000000000000000000000000000000..00a664e2093f4b4c5cbf77708813c66761428814
--- /dev/null
+++ b/configs/textrecog/satrn/satrn_academic.py
@@ -0,0 +1,68 @@
+_base_ = [
+ '../../_base_/default_runtime.py',
+ '../../_base_/recog_pipelines/satrn_pipeline.py',
+ '../../_base_/recog_datasets/ST_MJ_train.py',
+ '../../_base_/recog_datasets/academic_test.py'
+]
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline = {{_base_.train_pipeline}}
+test_pipeline = {{_base_.test_pipeline}}
+
+label_convertor = dict(
+ type='AttnConvertor', dict_type='DICT90', with_unknown=True)
+
+model = dict(
+ type='SATRN',
+ backbone=dict(type='ShallowCNN', input_channels=3, hidden_dim=512),
+ encoder=dict(
+ type='SatrnEncoder',
+ n_layers=12,
+ n_head=8,
+ d_k=512 // 8,
+ d_v=512 // 8,
+ d_model=512,
+ n_position=100,
+ d_inner=512 * 4,
+ dropout=0.1),
+ decoder=dict(
+ type='NRTRDecoder',
+ n_layers=6,
+ d_embedding=512,
+ n_head=8,
+ d_model=512,
+ d_inner=512 * 4,
+ d_k=512 // 8,
+ d_v=512 // 8),
+ loss=dict(type='TFLoss'),
+ label_convertor=label_convertor,
+ max_seq_len=25)
+
+# optimizer
+optimizer = dict(type='Adam', lr=3e-4)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(policy='step', step=[3, 4])
+total_epochs = 6
+
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline))
+
+evaluation = dict(interval=1, metric='acc')
diff --git a/configs/textrecog/satrn/satrn_small.py b/configs/textrecog/satrn/satrn_small.py
new file mode 100644
index 0000000000000000000000000000000000000000..96f86797f4700fd6ab9590fa983323f3e22d15c2
--- /dev/null
+++ b/configs/textrecog/satrn/satrn_small.py
@@ -0,0 +1,68 @@
+_base_ = [
+ '../../_base_/default_runtime.py',
+ '../../_base_/recog_pipelines/satrn_pipeline.py',
+ '../../_base_/recog_datasets/ST_MJ_train.py',
+ '../../_base_/recog_datasets/academic_test.py'
+]
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline = {{_base_.train_pipeline}}
+test_pipeline = {{_base_.test_pipeline}}
+
+label_convertor = dict(
+ type='AttnConvertor', dict_type='DICT90', with_unknown=True)
+
+model = dict(
+ type='SATRN',
+ backbone=dict(type='ShallowCNN', input_channels=3, hidden_dim=256),
+ encoder=dict(
+ type='SatrnEncoder',
+ n_layers=6,
+ n_head=8,
+ d_k=256 // 8,
+ d_v=256 // 8,
+ d_model=256,
+ n_position=100,
+ d_inner=256 * 4,
+ dropout=0.1),
+ decoder=dict(
+ type='NRTRDecoder',
+ n_layers=6,
+ d_embedding=256,
+ n_head=8,
+ d_model=256,
+ d_inner=256 * 4,
+ d_k=256 // 8,
+ d_v=256 // 8),
+ loss=dict(type='TFLoss'),
+ label_convertor=label_convertor,
+ max_seq_len=25)
+
+# optimizer
+optimizer = dict(type='Adam', lr=3e-4)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(policy='step', step=[3, 4])
+total_epochs = 6
+
+data = dict(
+ samples_per_gpu=64,
+ workers_per_gpu=4,
+ val_dataloader=dict(samples_per_gpu=1),
+ test_dataloader=dict(samples_per_gpu=1),
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline))
+
+evaluation = dict(interval=1, metric='acc')
diff --git a/configs/textrecog/seg/README.md b/configs/textrecog/seg/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..fab667c7e796b4c8f186e24a30593d2af7412c60
--- /dev/null
+++ b/configs/textrecog/seg/README.md
@@ -0,0 +1,48 @@
+# SegOCR
+
+
+## Abstract
+
+Just a simple Seg-based baseline for text recognition tasks.
+
+
+## Dataset
+
+### Train Dataset
+
+| trainset | instance_num | repeat_num | source |
+| :-------: | :----------: | :--------: | :----: |
+| SynthText | 7266686 | 1 | synth |
+
+### Test Dataset
+
+| testset | instance_num | type |
+| :-----: | :----------: | :-------: |
+| IIIT5K | 3000 | regular |
+| SVT | 647 | regular |
+| IC13 | 1015 | regular |
+| CT80 | 288 | irregular |
+
+## Results and Models
+
+| Backbone | Neck | Head | | | Regular Text | | | Irregular Text | download |
+| :------: | :----: | :---: | :---: | :----: | :----------: | :---: | :---: | :------------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| | | | | IIIT5K | SVT | IC13 | | CT80 |
+| R31-1/16 | FPNOCR | 1x | | 90.9 | 81.8 | 90.7 | | 80.9 | [model](https://download.openmmlab.com/mmocr/textrecog/seg/seg_r31_1by16_fpnocr_academic-72235b11.pth) \| [log](https://download.openmmlab.com/mmocr/textrecog/seg/20210325_112835.log.json) |
+
+:::{note}
+
+- `R31-1/16` means the size (both height and width ) of feature from backbone is 1/16 of input image.
+- `1x` means the size (both height and width) of feature from head is the same with input image.
+:::
+
+## Citation
+
+```bibtex
+@unpublished{key,
+ title={SegOCR Simple Baseline.},
+ author={},
+ note={Unpublished Manuscript},
+ year={2021}
+}
+```
diff --git a/configs/textrecog/seg/metafile.yml b/configs/textrecog/seg/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..937747f41dcdce01e297ab44d9a9ee9189073fd9
--- /dev/null
+++ b/configs/textrecog/seg/metafile.yml
@@ -0,0 +1,39 @@
+Collections:
+- Name: SegOCR
+ Metadata:
+ Training Data: mixture
+ Training Techniques:
+ - Adam
+ Epochs: 5
+ Batch Size: 64
+ Training Resources: 4x GeForce GTX 1080 Ti
+ Architecture:
+ - ResNet31OCR
+ - FPNOCR
+ Paper:
+ README: configs/textrecog/seg/README.md
+
+Models:
+ - Name: seg_r31_1by16_fpnocr_academic
+ In Collection: SegOCR
+ Config: configs/textrecog/seg/seg_r31_1by16_fpnocr_academic.py
+ Metadata:
+ Training Data: SynthText
+ Results:
+ - Task: Text Recognition
+ Dataset: IIIT5K
+ Metrics:
+ word_acc: 90.9
+ - Task: Text Recognition
+ Dataset: SVT
+ Metrics:
+ word_acc: 81.8
+ - Task: Text Recognition
+ Dataset: ICDAR2013
+ Metrics:
+ word_acc: 90.7
+ - Task: Text Recognition
+ Dataset: CT80
+ Metrics:
+ word_acc: 80.9
+ Weights: https://download.openmmlab.com/mmocr/textrecog/seg/seg_r31_1by16_fpnocr_academic-72235b11.pth
diff --git a/configs/textrecog/seg/seg_r31_1by16_fpnocr_academic.py b/configs/textrecog/seg/seg_r31_1by16_fpnocr_academic.py
new file mode 100644
index 0000000000000000000000000000000000000000..4e37856c06fb43cb0b67a6a1760bd7ef9eeddb66
--- /dev/null
+++ b/configs/textrecog/seg/seg_r31_1by16_fpnocr_academic.py
@@ -0,0 +1,40 @@
+_base_ = [
+ '../../_base_/default_runtime.py',
+ '../../_base_/recog_pipelines/seg_pipeline.py',
+ '../../_base_/recog_models/seg.py',
+ '../../_base_/recog_datasets/ST_charbox_train.py',
+ '../../_base_/recog_datasets/academic_test.py'
+]
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline = {{_base_.train_pipeline}}
+test_pipeline = {{_base_.test_pipeline}}
+
+# optimizer
+optimizer = dict(type='Adam', lr=1e-4)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(policy='step', step=[3, 4])
+total_epochs = 5
+
+find_unused_parameters = True
+
+data = dict(
+ samples_per_gpu=16,
+ workers_per_gpu=2,
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline))
+
+evaluation = dict(interval=1, metric='acc')
diff --git a/configs/textrecog/seg/seg_r31_1by16_fpnocr_toy_dataset.py b/configs/textrecog/seg/seg_r31_1by16_fpnocr_toy_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..893bebba496c04e9364bdcea3caef651e3d426d0
--- /dev/null
+++ b/configs/textrecog/seg/seg_r31_1by16_fpnocr_toy_dataset.py
@@ -0,0 +1,39 @@
+_base_ = [
+ '../../_base_/default_runtime.py',
+ '../../_base_/recog_datasets/seg_toy_data.py',
+ '../../_base_/recog_models/seg.py',
+ '../../_base_/recog_pipelines/seg_pipeline.py',
+]
+
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline = {{_base_.train_pipeline}}
+test_pipeline = {{_base_.test_pipeline}}
+
+# optimizer
+optimizer = dict(type='Adam', lr=1e-4)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(policy='step', step=[3, 4])
+total_epochs = 5
+
+data = dict(
+ samples_per_gpu=8,
+ workers_per_gpu=1,
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=train_list,
+ pipeline=train_pipeline),
+ val=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline),
+ test=dict(
+ type='UniformConcatDataset',
+ datasets=test_list,
+ pipeline=test_pipeline))
+
+evaluation = dict(interval=1, metric='acc')
+
+find_unused_parameters = True
diff --git a/configs/textrecog/tps/README.md b/configs/textrecog/tps/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..8767fb0653c49ee26bb967ba9b3f3ffc3fae32da
--- /dev/null
+++ b/configs/textrecog/tps/README.md
@@ -0,0 +1,52 @@
+# CRNN-STN
+
+
+
+## Abstract
+
+Image-based sequence recognition has been a long-standing research topic in computer vision. In this paper, we investigate the problem of scene text recognition, which is among the most important and challenging tasks in image-based sequence recognition. A novel neural network architecture, which integrates feature extraction, sequence modeling and transcription into a unified framework, is proposed. Compared with previous systems for scene text recognition, the proposed architecture possesses four distinctive properties: (1) It is end-to-end trainable, in contrast to most of the existing algorithms whose components are separately trained and tuned. (2) It naturally handles sequences in arbitrary lengths, involving no character segmentation or horizontal scale normalization. (3) It is not confined to any predefined lexicon and achieves remarkable performances in both lexicon-free and lexicon-based scene text recognition tasks. (4) It generates an effective yet much smaller model, which is more practical for real-world application scenarios. The experiments on standard benchmarks, including the IIIT-5K, Street View Text and ICDAR datasets, demonstrate the superiority of the proposed algorithm over the prior arts. Moreover, the proposed algorithm performs well in the task of image-based music score recognition, which evidently verifies the generality of it.
+
+
"
+ ],
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAABBQAAAHhCAYAAADeeO2RAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjIsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+WH4yJAAAgAElEQVR4nOy9ebxlV1Xv+x1zzrX3Pv2pOtWk+lRV+pYmQAwBLkEQAS9X+YiIAgF9iihXbK7Xx71i38v7PHmACn64SitX0Gsgj3dVlEZACCAF6ROSVN+f6s85e68153h/jLnW3qeqiDeQfIzeNT6fpM7eezVzzTWbMX7jN8YQVaWVVlpppZVWWmmllVZaaaWVVlpp5ZGI+5duQCuttNJKK6200korrbTSSiuttPKvT1pAoZVWWmmllVZaaaWVVlpppZVWWnnE0gIKrbTSSiuttNJKK6200korrbTSyiOWFlBopZVWWmmllVZaaaWVVlpppZVWHrG0gEIrrbTSSiuttNJKK6200korrbTyiKUFFFpppZVWWmmllVZaaaWVVlpppZVHLI8JoCAizxeRe0TkfhH5+cfiHq200korrbTSSiuttNJKK6200sq/nIiqProXFPHAvcBzgT3AbcD3q+qdj+qNWmmllVZaaaWVVlpppZVWWmmllX8xeSwYCk8F7lfVB1R1APwZ8OLH4D6ttNJKK6200korrbTSSiuttNLKv5CEx+CaG4DdI5/3AE97uBPGO05XjjtEHDjP2OQUEgpEHIqgqghivwuoJkBABHEeJ87+BkRARQBBUXhYBoadgyo6/IQIJM3nigyvIfa71v8TEEDJ7ct/16KaryiCJh29RHOUjPx9Tlulvq0g+nDHSXOwtWXk+vUNz75oc/TIMfm6itp3OuwVVT2rsSOtl7rf8rsa+ZfcbjvEvq87rmbH1C2q2zHKmtGR/4OiqmhKiAzvVze9fgwZdhzi/DmdbW0btmf0/qP3s/bocLwBmurnG22dNm13+Rr1I5w7/HTYRwgy0oVJEykmEEP66t5XVcRJM+bqJg6H5vAmdZ9oc6yMnDPsiLNHxVkvluFrOvtIpZkt9fVR0OF8Gx1z5zCgmnNGP45OipGHzA/YjFHVYY+P3kdBZKRdjL7L+mEUnCBaj7HUPNvy4+oXApr7V9TWHtXUzHVk2Uy38Ui97pzbr3bVhKiytHSGqlwCTfWKAyqIaP5Xmner+fUJkJLinN0bTYgLzK3bjkjBYy0P7TzK5s1zuNw9J0/1GQwq5uYm2LP7GOs3zOC8MD+/gPee2eke/UHkyNFTbFg/AyocP7YIDmZmxti39yTjE4EVs+P2+E3P2f+PHD7B2HiPifEuS/2S48cWWLd2hmMnFkFgdnaM4/MLzM8vsm37HKdOL9HvV6yem2T3nmOsWzeL98L80TMUXc/UZI+TJxdIMTG7YpIDBxYIQZhbNcbu/GxyFryeFHbvPsamjbPW7yOiwKEDJ5meGmNsvLCxkmD37nk2b1rJrt3H2LR5BS6/06PHFgjeMTPTRVU4fPgUExNdJiY6LF+gWmmllVa+GTn/OtLvVxw9coZ162cQURYWSk6d7LN27RR79x1n9eopOh0P2Hq3bt0swQtHj56h6AQmp7o8+OAxZma6WV92nDixxNbts+ddsWKl7Nt3jI2bVnL02Bk6wdbfXbvn2bx5pe1tCXbtmmfLlpWcXhiwcKbP6tVT7N1znAsumCIUjuPHF0kKK2bHeXDnCaYmu3ixvXz+2BIXblvJnt1HuXDL3Hn6Qdi95xgXrJ2hCK7pklpHOHLoNGPjBZOT3eaMnTuPsnHjHHv3HGXL5rmmK0+cWCTGxMoVE6jA/Lyt5dMzvXbF/lcoChzcf5KZ2TG6Y6Y7nTnZpz8omVs1QUqwd89xNm1aAcCuXUfZtHml6fYJdu46ypYtcxw8eJLpmTF6+RoLZ5aYmOhx6uQS1SCyYm4CBAaDCgGKIjAYRI4cOcX69bMcPHSK6akeY+MF1HolkCLs2TPP5i0rmxk9eo2yjBw6fJING1aAwonjCwDMzI5zYN9xVqyapNu1444ePs2atdN4bzbL7l3H2LhpFtfoOo98BD/00EMcOXLkvCc+FoDC/5KIyI8APwIwM+b4iWfNggQ6s6u55hnPoTe7Foox1Hn6ZaSQDoIjhIBqySAB3Q7dbpdeZwxXdBHx+CIgPuBDlxgj5aAPo4aOKgkz9lE1A0PBu4B31h1VVRJTiaaEc45YJcQJLgiIoyxLVMB5Z8ZbrAjehoMTRxUj4EiVAxWcBFSVUASUmA0vSMkMDFXsPilmg9U+S37rRfDEWBFFSSgSFY9DnSMKOBViWaHOjOPgAyL2G84MFCferqmCc4GUEippaPBJIiX7zzmHQ4hlaYaMJrsGBtw4cVRVRJzDe2fGm2RDB/ucUmqGqjYGmZKSIs6T8tKuKRG8bwCZ4ANJEzHlI0QoY4loIsYBIolYDqiqJYJ32QYUYozWbwjeeTQ5RALd8UkUh5L7FKEqS5JWZgQnxYmjKOzdJyCliIpSFAHnIppKYkwMlkp7n86jqsQYCYUDBxoThQsgQtKE4qgUYgSDB2rwICFURBLJBQrXoQN4FxloyfEzSwyWlui6QOFsoUFAnJBUcYLdPyV7ZgTnhRirxvAUdZQxoiKETge8Y1AOQBMOgQixqvDegyje2diIsWo23KQJJx5QNCkxxcbQLYpAwuaEiBm6qaxBGjKgoXmuqo01VZyz9xCCJ8ZITIngPN57OybRjPn6vBoYCCEQYyKpveeqKgF7R15BiVSxQhB6roMUBQOt8A5cqvvQxmA56CMC3jlcHjvkEejEU1YVZSHcMzPHvrFppkrFp0R0JYrgtQApSShJlSCQdEDwDhFPSs7elQdN0focIQIu9Vk8dYD+6X10GUAEj81XjSXBd2xMO2EQlVB4NEXQaEBa6HCy02Vm/gE27LyHV/zsBym6ax+lVblWuLQBXkCJSfihH30Pb3/rKxnrKFHh439/P7t3H+EJV27ii5/byc0/ej1F1/G+P7uNFdOTvOC5V/DgruP8tz/5B37lV15AlYQXv+jDbNo0A/44E9OnWbtmkQ+853X4AFEUjwG5gnDs8AK/+3u38vNv+h7+9D1/x9Ouu5inXruVH3rd+3jb219O10NZwetf9wHe/taX8+nP3ssDO4/zmlc8lZ/+mQ/zX37xRczOdnn/n3yBzVtmufGZl/B9L/sT5lZNEXzivvv6+CJyyy2v5HWvezdve9ur6Ba2AqhEBOiXgZ96w4d482+/mLHJogEtk0FD/P6b/4bn/buruPoJ64gejh8b8Cu/9Ff81m+9hDe84UP8/lteSrcbqUrH+z/wRTZumOE5N11CVcHb3vFprn/KFp76lM0ZSLJ17FwAuJVWWmnl4cXW7WjqgvpGH0sKDz54lPe963O88U0vwnv4p6/s5e8+cS8/+fqb+IVf/Ete+9rnsGnTFAK84ac+zJt+4btYMd3lPe/9Aps2zfLMGy/h1a9+D9/7g0/EiUNih+lpzzOeuQXRCOJR8zpRiaMsE+/7k09x4ZZ1fOKz+/jx1z6FVSum+InXv5e3vf3lBC9US8JPvO59vO2dL+fzt+3mi198kB/70Wfxpjfewk//zLNZtXaCj3z0dgZLiZe8+An88Ov+kud/59VM9UwX7EwUPO36i/nJ17+bP3rHK3E+G2QKiOlfP/OzH+Jnf/aFrFs9hvhU72ykKPzxH3yGJ167nqc+/UIqEf7yw1+kFwLPee4T+Mk3vId3/MErwcPiUuTNv/tXvPrVz2bThllU4P0f+BIrZqd43ndcgncp60VDp14rjzdRVE3HUxxVUu752kF+/uc+wOatczgCK2c7vOZHb2LT1pUsLpS85MXv4porp/nlX34pb/rVP+WXf/OVjIdAKoWf/rk/4vf+rx/hvrsP8tM/9R62b1uPuAHf871P5JnPegKf+eTtHNl3nO9+2Q3g4Ja/+hLvfveXuWD1HEuLji1be7zxF17AO9/x1zzl2m1c99Tt4BOSHAllMFD+63/5b/zem19t8wrh1o/8Ex/+4Of4g3e+lgrlPe/+JF/9ykFEPYcOHOG9f/7jSAH33bWfd7/r05w6rczPn+CFP30NL//B6xEHS6cjv/B//g9+9bf/PRPjHsHsU4AkqXEgns/dOCrXXXfdN/ztsQAU9gKbRj5vzN8tE1V9B/AOgA2zQWOVFbkUSZiBWlUlEsxDLB7EKVFLgnQIkpXeGEEV7wIRT5UgoCCRIA7NxpeKgQopmYEkzpuCiBlqCsSUspFlRnfUChCc9xmMiAatqpqRkNRQK3GkaEZT8ODwgEecEEslEfG+ABVS1Ma7LiqN8xTyZyBGMxZDEJx3DAYR1Yh6Qb0HgX40wz/FCKJIcOZhy+1Y7sm2hTZVCefMmFNVXBCcM+OxPqFeHGtgAQRJkg0yQ7FVBHXZEBOHc+YVjynhgzNDzYu1jRGGgprBXns5lTye6wVZlUQyoCZfX5wjUIAmVM2oJXhidMRknacqIIL3DpIyGAwQAt47A0OcM6M4xsZ7Xft9ffA47zPIlDLQAj54+rGisAe2dnsbM0v9JZw4nPfE/IBVTIjmPpMMqlQR8FRVtI3YWRtTqkEeEC0heKpYgvMsTc2xb7wkFV060qEsF3EeXBEyuFVRVVUGh8B7TwghG9iJxTNLiAhFpwPiqNQgLMMyEk4cPrN5vPeU5QDQBtBCQMSj5DGeAa9Bf5DbHun2ugZsiWSv+5BJkec2IKQUm/kFig+eVINnMZIymNTtdEhJjAGgUJYl3W7HFINk81KcGHCRbOx6b/2pKdIRCP0+E4tLTJdLRI0UyVOIQipZKiuC7yIJvBdcsPkcYzRgDIZjXcTmtMJ8Z5yDYZyp/ikO7tvF4mIfSR1C6uG8JxQFUQZMTDrmVk8jokRVyOCLGxIjIEHwnhRh6cRpdt7/daQ6TUc8khzBOWIq6XS6Nn69Z1Alio6QYomI4J0w0MCDq7bwbes3sOb+ux/p2vy/IIqZzL75ZpTxkfJ/kskcR46eZHamRxE8gpL3JVLGF2swRR2sXlPwm7/5bKRj7IuOq+83PKHezlbMjnPRxZu55SM72HvwGNc+aYutFy5f1ylSgLgq0z+G62kkkQQqoNIuSQs0wYrZGX7rd15EECElcBkErnSamIZPKzga5TzZA6kmY8glA0iTH7J3anbCW996K697/U2oA4hZxfecOrPEji/fyw9838sh2VmpYfrUPdxKK6208i2I5jXbaASQ931boBxOTYcWGa7RtRcgZZadakQForMrOLH/xidKnvucKwzwV+WLt91PioLEQMp6nSLEYHrFE5+wnU98/OtcunWGVWumiAkSkUFJ42ipdIyUHWI+7y8xdRmUjjML8Jl/mOe6J61FgG7R59ufcyHj4wFx8I+fvx3v4PTJBXbs2MsTnrjB3EYKKi7rJNk54UBxnDkdueOOvTzpKZu49PJV3H3PPNdct5XjZ/rcc9cJfvhVT6FbwPZL1vCVuw5x+aVr+MLn9rNuzQVs3DCbbQgHWtq+MwK6t2v441skOxWFhHfCpVdcwJ/9+evrgUvoCJ0xmz/jvYIP/8UP41B6Xc+v/vqr6BTexpSD3/6dH8I5uPiStXz4Q29AK3AOOpMBJ4kbb7wCMwxsVHzndz6ZZz/7iY1u5HuCeuXm1zyHd//h3zDW63LlEzba8QJFx/Ebv3Vzcz6qPP87nshN/+4aul1PcMrNr76JaiHiRBAPIU/9yy5bxy/94kvQCtQrvusRgbiUeP97PsHLX/Fkur1RRmt2tlErQJ5vRR4LQOE24GIR2YoBCS8DXv6wZyh4POoCU1Mz2RgySnjwZoQYwuQ44zyL3TGCdBAvEAKhO4b3PdQHcAkPiAuE0CH5DimZ8VJVFb5jRmGqDcy8oBo7QQxQCAWaIrEqG3q7akJcYYue7+B8Nq4xCn7+i+DM215VCacBCjNmfX18USyj66dkL1JViT4imeEgtdc8G3+x6tvfnY55oKsK77zxY0iIUxyOca9MliVeHCpG0NaU6da4hjbtnFG4kybzbo+ELdi/jkQcepfFgTNFXBCKTpeqjDYDnCdVFTGBJEMDvffEfC8fcp+LIt5YDgiIGoKu0GxUqWaSmOvbwJ4couBDQawGRBVcKNBUNSEQzmWmRG3UZwq+y0BDmb/XEaNURKhSpPAu/2ZAVkIzvR1cCGg05okQzZgPHu+y9z1vXJLDblShrEozwivFB0eMCQkGOjnnIVkoj/NmdA9y2wa+y74wzj6XqELAR0E7gJNMfRfUB7TQBkzyztoeM3sgSoHk71Qg6pAICWbgOWiMN+2EbDDlEdyETBig4DI4EruVjYsMDERNTchDrb8YEJWVmHxNcl8iwxAJm085jAPy3BAD5QDGxnDZcFQdml31O0sjbAkb4RVFd4zVYZHe8SWC9un5Al+pjbngSNkDbu2w8ei8kKjwCN4HUgbyUoo4p4xXS2xV5fIDO/n7W2/loTseQvo9KAucHyN56HOKJ15/CZc//5mELkSjWRjA5SCVJV68LfwaIS5yZH4Xa+Z3EpeO41JCVAjeEYKjCAWLiwuEECiXBthyZONWEKpOB/WRqZXboWREqXmURWzFqMM7Upk4fOAUncJAvy996T5e9gNPp1d4/vAtf8tDOy+kN15w+uQSK2enmmssLCxw5MhpVs5Nsmp2iaXTC0gHKlU+fOvHedlLns9iv2LEnkdIrJie4HnfcRlvedvf8sqbn0UQYzxNTgqHDp8yhoIqVaqMIeQi4iuS2fwcOnyGI0cXeOc77+BXfv1G1MPUzAJnTi/gM7p5662f4lU3v4gD+4T/96MP8JLv3maMLoz55ADv+0BqxsxDD+zn05++g+9/5XN58YufxHv/5LOsWPcsdj14hKnJDuvWzxCC4xk3bONjH/0nnnr9xbz33R/nla94BsELSKLC2Gmdwo+M4X/OL9BKK620cn4RRsM167BX23eLAFNT5ohSIp0CJids/5yZVDoBfDa3ZmeUIkcITIxDpwcpwPe/4un85H/8U8jOsu95yZP4i4/8A3/3sftJsdeAGMlHfujm63nqky7mlg99nh//iafjRVEv/OArvo2f+sn3UuHQOM2ZRWP69jrK1HjCC4xNwH990y2oTPD52/ZzwzPWg4dX3vxt/Oc3/nfTpXzku154JXh4yUtv4C/++11ccdV6ekUGv9V6YGYafLB2RRXe8c7PMH/0DE9+6mae+azL+OH3fZi/++weqvIUT33iFtaum0E8fPtNV/NzP///sWXdGLsfOsL73vsqC6kUOHFyiXvv28XrnvtCA2cyZN7EJrbyOBQxpyO2qYsKvoCxIjTKcR2w7lDUCWOTPjtBla54atjNeaEbDKgSL4xNhdomz8xGNcejF0TMUdvtCEXhGkY0PuV56Hn2857ILbd8jouvWk8oHI7aPgu1Ag0ovoBeEQyQQPAdhcJnIMDX0x4Ewrhv2N31kx05dIpdDx3hNa+9aegNyicpw5Cgb3UIP+pVHgBE5AXA/42tPu9S1V9/uOPXTwd9/Y1z9IFV2y7iqqffhHQniRIoOgXmJXdEVfZMz/DV6TX4MI4khysK887jTZEnIaIkCdQ5J0XMS5pSJPhgoQU6jFkx6MI86+ZMNW+4hUkYVBvVmABko4lM83fiSVqHMWQ2BRZL73ComucTIMUK581wds43oQRAMwBUjaGgKJKNZBHBpYwcA0JAUjKvpiaSJJwmBpVnu/NcdfwwXY0kEXwwNKoaGNuiKIrGGDOHW6QqK5wLw1AFEUII5imVYT6EbreLeZ5tzNSGOyJUVbXsnXpvFHrvh+ENIkKZj3POW1hGjBZiIa4BBpx3makRG9DFZS9hjAMG5RKpKjEyyRAYCmIMhVil3K7A+NQUPnSMmaL5mjFh7mPr74aan9+BhXCYcVt4T4qlvasUMz2+BoQgJpuQDijE3m1ZVURVUgRxNn77/T4hBPOKRmPchPECrUoqBR+6nBwb58tjPVafOsMFSwt4H+n4ghQjZVWa0Zs0hzskYooUocgeWws/0WTtS6pUKRpA4z1kdNSBMRSyUZV0yCJRMbZHTIkyVrhkRn4N9jgsXAGxsJCUwQUnDo32nmIVM4Bki5VzLo+p2hniqKqKlCJF0UGThdR47/HOU6XMojknZMbGpMZIItk40vxQRcH9U5OUXnjysaNMaIUn4CJUccBiXqALBCWPyZgQbOw4ETreFvBYGaAQg7Bj9WrKosO1+/Zy32d2sPO+PRw7dJKd9+/ngjXbWTE3y4P77mXthTN87w98FxMzXaKLBrbgLBSiqii8RxN4D6Qljuy7j30PfY2TR3dToARvgEMRhJgRoG4o8E5IlYVoxRjp+kC/F/jsmi1sv+gS1nz5K7zmje+n6K16uOX1kYlqBpayB10dLglv/t2Pc/TQAC99JFT8xH96ASvnJpAEH/zgP/KlHftw6hAtedWrns7lV6xnfv4Mv/27t7J61Tg/84YXsm/PCf7o7X9nm3uIvP5nv4PP/f2d3PaP+6m8oKJ5LJ/hB1/xDK68dDN/8eef4rv/w424wubbroMneNtb/5YQO6CR9VumeO2PfTtf//oejh47w9Ouu5T3v/9LfG3HPCKRMhX8Hz90DZdesYr9R8/w+2/+a6gE75b48dc9nw3rZ/nUZ3fzx+/6JG95y0uZmermvAeRmDx//qFP8pL/cCNFx6FReNcff5S169fwohc9jRTh99/yPzlwaAmJnue/4BKe+eyLEVXuvusgf/qnnwUdo9dV/vMbn8fYmIF8e/af4u1v/Ti/9ovfg+9kKEVdBlIfvVfZSiut/O8jNYAv9WaPmUgpQYxKCJljpoGYAf1UJbx3jf82JvvecpdZiKQ4jGEQax6COaQSKbMT1AwpFRJC4RweodJk91RHEnMIpCrDHinryMEhlqgIxNqZMmG2yg6oMTGdJMaEqCO57LgT2L9vgZt/4CP8P3/4PC65dIWxAfPDV1nv8Lk/qoE09yRBLI25nASCE9O3sXYOUswgt9AJxjlOwK0fu51TJxZ52UufgviUQwOlXbsf56Kptvqzg6oxqo1l6xoD2/41rStQW2cwAJzpohiLXZOAG9VTbeCKuMzwlqy7jjbE9OyUHXtVUj7x8dt4wlWXsOqCWURKVC1cuwEJ0MZeMRJOmceaQ6hACzJSAlqB+OZRVA0MueUvP8NNz7mO8enaSW0QpKV4ktwfNfzw8AP5uuuu44tf/OJ5D3pMAIVHKhtmCv2Rp82wpLD1midw6dOeSQpj4EKOu07Zq+vZNTvHHStWs2mhZLoc0B3vMj4xgSNQRUGCN+aCmBLvvFH6BWniwM1DChoNCKg9lDUNWhsvpcuJOBJVTGhmC2gOc2gSRjoz6Pr9fqZjZ+PLFcQIKRrqZNe0QeFDyIZZZZ5xVVxhhm2/P8hhHj4bbJLpw5YoTNQRJOd3iAnvPCXKXQ4misBTjx1nLBqgMCijAQFKw5QQkRyTH3HeUDPL4xAa2r/lCUjUCf4ke/GbwShYboj8DmNVe42tn10GcZw3D7SFR9jGkJLa82eusMse9ZoNUS/OMVP0q7LKdLxETCVlv49qhThFU4VgHvVuURAHkaWFJbwvEOcZn5qiKLpEyEakoDFRVn3AgI1ut8egNDaKC9420BgRB0UoGAz6NsdS1Ww4MUYz/sQRE3jxFM7w6rIq81jxlJUtMlVVNSECDsEXntBzoLZJIoH5sXG+MD7O9pNn2HrmJMiAwtsCF2PC+2B5QaqSQb+knvidEGyjdGKbszMPaBMqgOAzDRAVHMmSPqqCJKPpCxlMcfaOVC3cIIM1ll9AcnK6OqcCTYhArOoQHANi6gXV+dHxkJfRpA36Kli+AQuX8Vk58QZiNAwIaZBkLxaaMSgN7PLeQLs75lYxXziuO3KQmWDAoHeOKpVEtTCnoga3VJtlM+UwGE+dTwMgseQiO+ZWETsTPO3QUcLJJZYGAw7sOcwtH/gYUxMbuGj7NnbccRvTa8b5nu9/AeMrOyRXkVCcePP6VBGfWUveC6lc4OThXey878ucmt9NR7Ax4JTghXJQ0emN2doQB3hVCB1UHEWCM87z+Qsu5pLLLmPmc5/jx3/5gxS91Y/eYpw3Mdv0ao+P2DpGva8phJwZJNk8L21vzeywYbLRmOxadcJDZ4QqkgMNIAk0ClEyCym/Zw1CsK6xcZI3vISxpEhY/pkAXqyNCXAYayhHQ5EchEyKSgpaZfKjDENRTpzu84u/8mFe/Zpnc+VV6wiSQBOJQFIhyHCPTJrZQhn8MEDM7mVheRk+VQPxojkJCd6U7lQ5fuN3/gff97Knc9HW1Yir2W2+WVdbaaWVVh6p1LbHaFpgc8xmI0lithuGe2u93o8muM4ud0Y+QGY7NIw4NSNEgVR7ZutdVeuMbwoSLafDiEc07yTUIRrWxNR8r9TXzoC2YhsFgLplZICk8NBDJ/mjP/wC/+k/P4MVK7vULjzbvxSn2iRqtx2EfJ/GYstPmHOModmhVPPmBEmeU6f7/NKvfpBf+sWXMzWRDbj6btIyzB7XYhTcDCaw3GbWekyaPjpk+tRihrs2LrnRC4wmwY8jv0NNErB0fdGO1QxGoAiW50ySb5QrcTrihK515OZyI/+vORWGHDTARzPfwWALG6Mpz0kb23Y9OWuKGxv1n+/KhwMU/sWSMo5KSspgEJFul+7YJM6Hhm5rBqp5iqOaUeITrFk4wwWDJXrSp5v6BOkSUwBnHnhNlSm23uFDTrRW2ncpmkdUgMFgADlpoC1yNSXemA5G9/ekGC0EQZUqxozkOpzz+OAYlGXjhRaUIgSI2HM5M7q8qweSDUjnPf2yb+PAOTrdLorlACjLATgL+TBKuCVCdLlfXCpzcjyhCD0GwJ5ugfSMRVDFZH0ojiqDDg29VurkipZ0L8bUGI0xKmVZEYIQgjEgnHeNt9s58zCrQvA5jCCDDg7JIRTm9Xbe4XKCSKP3J+u7mPDBEkOmWBFCQUyVIXpAWQ6MHdAwC4zR0el06PctNKSqkgE9VSJkAKIcVMbEEMtjYNcqLabOufzOhUFV5nFn46AcDJqJlGKVaSBquTAy/Z9shPr8vPX30daJZm82EMVTRQslSbS2/4UAACAASURBVInc92Zcg+VWkKTEJQOiOiGgKVL2F4hjPSosUaK4gqRlBjc8EjyF91Qx0un2qHI+hTIlvFjMfqcIKIa8q9NM4VYznHMi0uA9zglVLBkMBiQ1gEfz6FSlAVYcOd9AVdk8wMCx4ArEYX3nLA+FgVXGHvBFyCBCpCgKm7c4yv6g6Y+Uc5B45/BFoIoVKSm9XoE6S57pg4OY2xUTFcbMqOKAIhQ2dulkIEpxJChjDk9SJKYcNpXyPLMXbUlGDURIsbIxWhvCCOo8yQViEgaDEucqwphj9do1XHHl1fzDP+7ggZ33MjbmuepJl9PrjBG80k+JFCMug4w26VIOJXGIOrpFz/o1ScPkEbWwmoCHCKFb0NeKxIBqsEDXT5gFHLyljYmOssr5Qx4LUcFJDjAUS0g7SsuvlVaRHD9IlRNqupF9TfGhVuvy7hVs4/L1hukEXAYiMBZVTcAFMsms3vDtnTnf6KKMKoguf3YuDZXbrKAKBjyQEy/GDO05BzNTXX7z117GS7//d/iNX38ZV1+1xdYQBcmJMDKeP0Ty894rHizdZt2g3Bp7DMTXXg9TNu648yHGxzts27KquYYiFkvcnN1KK6208sikXmVtxamwID/Hcu9jXnNqYJjaV4kZxZodDRkTkJoqTm061ftnfR/NIHBtWI8YYpKZolh+myFQka8zxDMYvagdtjwITLJBpE1rjYnhRLjwwmk2rh/j7jv2c8ONF4Jk/TO3SWUIsUizFtuaC4LLBmUTvtDsdK7RK1Bl56793HzzM5kYD4Ykq6dyBhQPoZFWHn+S9QeRZe+/Ab4EGElQWO/JNUvTKWjDVhiFEFIzTuoxucw9L8tnTjNH6ope9QwS0yNGj7TzRyCEBiSoR+dwpNa60RAZGB5FPldG5uXoU56DKnyL8rgAFABc0aUSn9VDjxCMlSBiLC1niqsiVGp0rAqlUqFIguQEhpqcUW+d0aWqVBGjdW5tVPvgsgdXc04Ah2ZF2JIxmpc8ajSvcAZUzajKceXOEjyiCfGWVK0Ui5sRlUwxNwOOCK7wmWoPVVURisI85upyRQdbzqqY8OJR56lSbGgJiWSfk+JDxyLZklqCGxdR8TjXIUYDTyQb2y4EItBfGtApAkVREFPEi88VGiA5AxWsr2wTqMqKWBmlvYrR4vjVwA4wAKQ/6NMpOrmig2u81eJGYnhU7JqZGeKchaZo9lI756mq0rzbuRJE0ek0YRUARVFYuIATiqKLZLAgVn1LdpkSPlcHiKnMlSTqnBEp4wsOUJx3hMIIbObdtjwSlpSwLkVoFLngBe8CwXuqwQDN3vy6uoJFwBjVD4Uyjw+fKewqZliUZYk4sX8FgkuQEsFbadRqUKJUSNEhSUSzuWMe+A7eKzGpeXsTOF9QliVlWVFVZqj4YElAydezxtWJlvI4VAPT+nFA0SlQHKHoUlWl4ZgShjkUklmKKsYsER+MtRAtPKiKFtrgfZFDd3KoToaAUw7tcr7AeaEqLamj9wEnNcBCs4UnAaK9jyolQlFYyFCyBIwp2hwwoMXjXA+w8BKlotIKxaGSkBLUJSR4gkpmiWTlipgVFs1smWFVE7A1gcwKEGfvJ4lSkTh++AwnD/WZnFnJVddeTv/MGTZuuIArr7qMogjEahEXTL2wRFPeqjVUAwMfUQMavIFbsYr23Aqa1JJRFj2CC6QykaIy0IgbKL6IhG7Hxn5KqArOFTz6Lu08bpoNx/pVNCDLtktTHtMIQFpvlgg5fCgiefE2muAoADKCwolSI+k16l7ffwhg1H8M79ioo8uU1SHAMNSKh4da2yw0Tom52YGi4/i13/gB1q6ebZTgoSKSGQeore/ZkzVUoLV+DFsLEIZeCMthY3WaEhdsmOPm19yEd25kkx/2Q6uUttJKK9+MaLbGz/awitbf1MyB2ggZ+SgsW93rlag2kSTrx82yuEwEycyBUcPHNIWaccDIunzO6blto5DF6DONAALNs+RE69YyXv8fb7QqSCMQRb0CK+RwOsnfDg27kbvYOcvW5JF9xglXXnUhkBCNBnBkXUdlmNS8lcep5PLNJmnEI6EjY3Zoao+a7ue+2zzGJBuGIw6PZXrDiItAyCyEZiIMx+Eo3JeaWWphF3UpbcuTIEN2QX1mXSGqGbbZw6m1vlu31a5u86cG2kxHQ8N5nvGbk8cFoKBYLIl6ZwYiDi9+SG3NcWDOOcvengSRCvUlVQqkqpO9v0qlZY4JYajfmvvPwhHq3ADOSu0lNQYBOf5F1ehOZcwMALHP3jlSmQ1itbJ15tkVBqXF2JvRnGPrVQnOETodq1aRvZWDwRI+FFZuLgRcpqcLdg65PGC/KnPMvVHCrTydlQH0oUt/UJEE83b7SPLkLP2mzIpkhkAIpgAXloOiyL/FHIsOORRAzHuvOabeWBGpSWbpimBJLX2uipAyg4NcdjAjdWmECk+d/wBjKDTldbLNVhRFU6qyzl1QJ6/0Oat/HXYiIpml4HJlA0+/76nKARqN3bC0uAR4vAOw0okusyLQRK/bI6ZI0pg9w7kPxKo0LC318d7R6RQZRCgzyGSTvaoqM7ijVYJQPMF5S1AvQox1skuLQ3RqYS517g2TZGMKRaNlkg/ZMBGrm2eIaDIwyzsrGeqFnKfCEcvE/r0H2Lt3L6mKzM7Osn3bNoIUxDINwQxyboMqUoQuh/Yf4qEHH6Q7VrBxw0ZmZ2dJmti9aw/HTxwHhInJKSYmJ5mdnaWT2S5ObGGqKzMMqkRZDlg4s2BhM+KYnJhgcnKSsqpYXFyiLEucd4yPjzE23sWLgRkpWnWR4AMa7d0v9fssLC1RVhHfKQgpMuEs0WXZH1Dmue+wEq5FCHQ6HQMTnLIUB4irEDpUyRMrhaCZfm73xVl8qJMMGiVtwASpFZkMptisqAgZbPK+4OD+g/zPWz7JQ/fttXKq3pbl3bsf4uCxAzzv3z+L6VVdYqqM9aCOMiVLxuMtiSWa6DhFvFCmaCCNYNU/cpreJI5BaXEBqonx8WmiH1i8aoq4KlpCUBG8U5Yb+Y/CWpx5/LXyp1rQ0E3BAAIiSmGmu9TYVUb4XS7LW3+PNzQ4rweN3V8ridmbJJnyb3/n+WEtGlFEa3BCszJJ9jJIVkqVeuNdtj3W4TVKBmJqIAJqmoAPcMVVGzMhIpMbRTL4ULeRRolsFAcFGdlGtemrEQVZauUBVs5N5UuMVnnIPIo2sVcrrbTyzYrWxjMIOZN7/QWMrC0jYO7o5+ZvO1hRC2dQwTdAwPL9poEAajtKzMGhCEkzQJzDw5q1c2Q/aa6oMDTf631t9NoDa5MUGXf1zR7hqPMtiOVLyAZYE8EhZ7d6uM8MxcJAhrnVhnCKZIDYSlTR7D2S763q2nX7cS7LOSTnGtBng3A2smtQ4DzSOBmgKekw6sBo/kjN1YZsy/pfY+6MtmT4qR579QivzzkLdDtnbp8tCRgglt2dYSBQHVI0OuuGM+OblccFoGBsAItXn5ycxolHMU+cdw4XzKtdaUUqlBSgchEfIURBAkQfSdTl9AKxcpSLfVSEzngPAEdAo6BRWBoMrIxOEk4dO8biYp8qASTmVs3R63VRVQ4dOMjBgweZnZnlwg2b0Yglk4tmlBOFw0cOMTk1iXjH4SNHWFw8w+nTp5mdnuXCLReacejg6JEjHDp0iJmZWdZecAGqES+W4O7Q4SNMz0wzNTWF5kRuKVYcP32CQb+PE8fc3CrLfi+WQKZKNVBSkVIF0kXVaPA9cRSFR52jPyiz0m8MA+9dXuQtFEDBaF9iWeZTNnQtgWQi1WCMd4TgKauSmBKd0GmOMwDIvP5ALvMXczk8oxj7ECDaOxUF6twRzt51UkUKaRb1OnZe0Sa+z8r7GdPCOUfqdEnVABFjYUSNOe+G3S9poixLQhGoYklwmZWhOfGgczkrK4y5niVWEcwwtC5BEgzKPsFZuIIZosFi4lMdLmL5KVxmssSYkzLmPo2xotMJBuakKichHNKoUgQtIUVL/qaVEqlwopmkkuwdaWTxzClOzB8lCIxPTbL7oQdJVZ9rrrrS7CNHLgdqYFVJYvH0Ce6642uUgz5jZY/P797Jtq1buXDrVo7PH2Wpv8SgKjl8+BDzR+d51rOexdya1ThvSZNisjhJNJI08bWv/hP79u6l2+1y5vRpVq1azfVPexpJla9+9XZ27d5F0sjq1at4xjNvZHy8hyMRJTagm+YKIw8+cB/33H8fC0t9fAj0Jsa54dtuIPiCu26/k00bN7Fh3XoWzyywY8cOLr/8clasXGljCUfwPaBDjEKBQ90AdRVSeUQLA3pQq1WdgZ16rHrvqcqyQYYNUIjUXmhVRR0cOHiEnQ/tZu3qtaxfdwGTK2ZwEXbv2sm9d93FNU/ezuzcVst5gNEovVjYRl2qK6ZEP5aIeJzv0OmOkQZ9NNocDN4Tk0M1UnQc3dRh3I2zIImKClD66TQuVDgZkNLSMqP0UVqNTVnT4baS1BsQ03juDS1wI7GyQkJzogTXIPd5Ex+iCM0tGmeXMHLd0eNMrXTLNrehh02yFjrcXu3ooarHyPVyngLxlncBIeFzvoyMSajiGw+AhXDVKchGt8mmFFnT9kgdMmcgo5CIeK1ZDPVWbS0bFmWyHDdOR5+w1Upb+bcgeVUaVZbruVZ/HHEEo8uPGVXs9ew5ocN1Y9kp52nD8it9A1X5rAaNegvPbss5DzFy3qiBPhqFdi6j+DzXe9Rk6LRg1BARoC4eLfXaeS5AsMywyQ/h8cPDmso/dj0LK3U5ZKDeWy1xnUWy5SR1zdLfoA75TwWpwesRjzERPduQywBCpns1160ZCb7p/3yP5n51LgTfHFs/u+X5qZ/I9KVhl+jImLDKX94Zu03JDjsFidH05HbtfhzLyJg4W9eQOgGja75aJqPrQ8rjtmGk1NdZXmJ7+Xc1MFfbNCPOjFF9hjrgWEYWt6x7LGNDjt67vludEN8vu+bw3w7D8I7695QBtLqCxfK58c3K4wJQsFh0pRd6hKJXQ6wgSqURp54gllgOh8WGiy0RTqDUiNOIJjh94gTHj55AXI+qShw/eZLLr7yK8YkJMxJR+oOSI4ePMDM1g6bIqVOnGAxKlpYGHDxwALnkUjZv3sjhQ4c5cWQeFxNf/sJtTNzQY9WqVUSpLNs9wp69e1haWmR6epr+0oCjR+ZZObeCsozcfvudCI5NGzeye9ce5o8eJqE8+JWvcM2117Bx4yYWB3327tvHjh07uOTSS7nsssuMBl8OOHhwP6dPn+T0qdMcOHCIyy69jMuvuJJBWgKGHm1NEd/pGLggghQdqnKAy4tgCN5CDMBo7M6MFpGUk9zl5HSFJfWzMphmaNcOuhQrcJaUrwgBiYlYRlxhC3WMFVXOmO+8IzijCKdkORiMvZHM+5eRYM3Z/S25pLEGLEdDNLTZG5JYZvCHnO2/U3RBoCqtZFyn64mxpFt08EmoNBolX5yV1tRhBQdNglaJMlWkTNiuqopOUVB0O1aBQPPmGyNlaYBBiokyDvfButznsMylG5Y/zHkkLGFmIIRg9PqYk9NpIkbLH6CeXDawQCO2dWkkpmThDclyXqgmQvBUVeTY/DyHDx/i6quvZnx8nJOnTlmC0RQR54hV5PTiGYpOMCZOWXHq5Akuvngrq+dWI4Vnx46vsH//fi677HKuvPIKOp0uSZWv7PgKRw4ftISKopASg1g1CT1dsIocGzdt5OJLLgIRvnjbbew7uI9+LCn7JVVV8vSnPx1Euffeu9m5cyeXXX4pMWpOUGchQkksad3S0iK9Tofrr7+e04NFPvnpT3H33XdyyUVXcNedd3N8/jgrZ1eyc+cu7r7rHrZt22ZVLLRmGBil3hllB/G26MYyJ1wUy32SlxQz7jUh+JwINC+uWAJL5wp8UZDEgQukBN1OgQ9Ct1dw0SXbufyaazl64CDH5o8Q90bSIGbjMIdduJi94ZbHpQ6HEW+5MHxR2O+q4HzD/BEVCAaIVWVkSZaoy3iqizgBSRGnOTfHo74YS96ybK6SldAmsVeunmL9qc0hFnMINepuqL3NX81KYsqZExqSX62AY2Anmtd2W6hotnqlMfSbjfRsQ6AGAzQnO1q24dr8V0m5/GtWmGu6oBhQIDJcJ+y7GrAYmifnUiAlMxCGZojjrKRnUiuv2ahpvh6lRLbSyr8BycblKLs4I7XQzP5aoZbhMY2BmfdAhqBkklzOTbPqrfV8G4VTh8iE5ilshinNulOn4RseYBNRGqOiToiWr6dDg6Ou9mU3qA/RkefK5yQlOfvbnc9IAAsjRJbN/0dDzg+CjPw+ktn+bBDz7M/n/j2ywg3/t8wkqvcJGXmXo0bKsAtqgykNz1320ygNvF55c8hZPuYbt1pQGQLZmv+oV/HhMmzjRYbDpomEHxlKTQvOvq/L+6FzNa28XcH/dcpZ411Gv7VxpGf9Vh9x/jScIzrKsmO/0U4/OvZH9AOt14flx7hRg/+s9tRHLJezWBMjYztrPfnv9KgM4ccFoABmYJZJqZLRgVVLJFjVgZgSTkurSFBaFQaXcqLDjofCysy55Oj4LuPdMSKe+eOH+foDX2f9xg2Mjfdy/oKSw0cOU5Z9Or0CTZ6Vq+cYLPbZtWs3IQQ6RYdjR4+xZ9cutly4hbGxHgtnznDXPXfy9FU3EIoOZVWyuLTAkSMHWblyjhACPgS2bNnC5PQ06xCOHTvJ8ROnmJo+xb59+1izZg2zK2YQcdxxx52sueACC7IXOHX6NFVMVNHi5RPgQ8GFW7YRvOd2fyd33Xkv27dfQjHRsazrCTpFgaZE6QLqAlEdMa+KVVkSY5VL1lk8uMX0WvZ/cQbYJCCIompGKQJRHcRM13eCRHLpzdQkRTUqeULrfBKuDmswH4XzufyfQBUtEaKBJWWux6oQc+6LvDFrLpsnWEUIhRziYMaJlYSM9AcDympg7fVmROcSGCRL1gBkcKRWBnLJRSce72uVBDQpVWmhGd55yFU5nC+IVQ57wBJk1sZdHbohuYKAd86MoTSMu1IyQyCWjG5eqpYLIMVoiesIaJKc2NCQfXsPIbM18qaalCCe6alp5o/O88lPfJLJyWn27d3LjTfeQMJyPlRV5PiJ00xOjTM21rMqByJMzcwQuh1cEYgKvtMlqtCbmKIcDDh9ZoEDBw9x1dXXMLtilhitIsehQwdZWuqzcdMmOt0OKsqGzZtZOHOGL932RfYfOMhTnvJkZmdXMOiXPOlJ1zE9PU1Z9nnoga9z6MBBtm3bZuwXsQoMVRWRYEybotOh2+vRHevhxrusW7eO/lKfctCnv9Tna1+7nbWr1nDP3Xdz6OBBTp8+w2w5AElUEZIzb7CI5UwpSXR8N79/C3cRVbyEptqKz5VFYq7oAgLeI87An1hhc9HwKDasX8tVV1/MV798O+U/9rnwkq08uOd+du57gE0XbmD12jXUnhPL+ZCImih8pwlZEk14B65TUHS7iGAsolw+Nlb2u5VTtRwPlZaglnRTtEJSwCXLLyPu0Yt9GxXB/Does+RdPW4zIqO1MZ43Wc15C+pSSMPwBG0UtFqhq3F6+5SGIE5943pDztO2oaWqkFR4cOc+tm1ZnxVYSFRIzYSoPUtDjT+3w9alXFAVV6uOOqokZ0MoKQ88eIQLt622rOi1h0DqXAqjqqs0hsaoyipnbfpSGy+NVqFNm1s9tJV/e2LOg6ECPfSYD/OOD9eEek2R0XUmSw0+1CxFycZiTSTOvurGgE2acohefb5w4tQig8U+F6yaBTcSLpVna04vlFeOvCbkij+aQ1mT5ioG2UNut8tVDogcObpIxwdmZsfqp8pAaV7IRuWxCm1qLps98MuMoBHw+eHy7nxDG2k5a2P5GncWIKD1d8sNonMvPdovsuz7bwh4yFkAhJ5179HmNOtybaiN9MtoG2QUODiLUbHMwFxuKtYJns81IFt5vImc/SJHPsiyt3vOieeBAM4ObTj3mue58/Jf5exjzzpu5HdZftJ5/vbnfvdww1GWP8PomvGtjuPHBaCgKDHHK6tgCRi9JTSLlRl36iQDy4LHU6inI5YMJkajnXrnGB8bZ6I3QamRo8eOsnHjenq9LpITfy0snOHI0cOsX7+eotcxz3NV8cDOhzh84BAXbb+I2Zlpjs7Pc+z4Ca6YmKDT6zA+OcHpgwdJmkhElgaL7Nm/m9ANrFm3Bl8IIRQUhaOMiVOnz7CwtMDcypWUg5L5Y8fYum0rIRRMzUxx7/330h8sMTE1zdq1a5lbPcfYWK+J7R8bG2PdunV0QmBpaYmJsR5OEjEO6ODxOKIKZeVyrG8uD+iNpBZEKDUZZU0UjSWSEyKCNp666HMCtQpczhtiZfwq1Hucd8QKnM9Z8dXODUVBygZvignnPaEIkMy7jioxl0pMmZWADEMEFKs5bIkEa6DCNvhQN8SRKehm3kg+v6pKyljlPBE+G4TgCvOeu6jEsoRcxUJSgtIeMEKdn4SO71hoglgFAAM3cplOrKJD0tLYAU5yMjzNXvFcBlHJxxsQ5L3FSysWFhFyNYuYwz/sGUDwaGXAgs+lRGu6oKgScrstkWdWoqLifWDF7CybN27iIx/9CMF7tl90EavXrCF0e5bjQSLTK1bR7RVAwneE2dVjeBcoq4rdD3ydQ0cOc+011xoYgzKIkd179zI2Mc7mbduQIpCqEkhMTU1ShEC3W2R6n23ORw8f5atf+RrdXsHK2RVWCcUFXMf66sihQxzYv5/NWzYTxNHrdOgPyswuiFCawjaIFTv37GFsdoaZFTMcO3qMzRs2MtbtsGrlLB3v+NQnP8HaNWuYWzmLakUs+4ROyLV+DdRS73C+g1cLD0gazTMdE0GcsWxyPQE0g1MCzoWcaHXobbZSoI7kHKoVsyum+PbvuImLLr6I/qCkmPRcctV2ZteMM7dylrkLVpCcgWcpl2EF8nqRzKmfHFGjAXreW86TaOFNPnhiv8RwNsuvEYLlAykH0cJyEJoayFiFmvP7or55kTzuxJHnjxn3VjY3g31irAsnSiYdIcYHbfKHWC4Dhh4g9Tmpbm1OZDZAppDGbGh7PCRbq5vgArEcOp/8xJ3s2buHCzett9CimPMsq+Ud8SEDHVLPI4iVhWrk6UWlSijqcEa1sDG1xIkhCBrh4x/7Kk962kVce93mYVhENh8cDFOi1IrzOfv4+ZSX5b38sD+30sq/YlEFpx7F8hdpEiSB9+bEQNQAbWwOVClZFaMapyRT6VEk6wQq9k1NO669/2a055uK7f8NsUo91UB577v+hpuedTVrV802nIGYlOBSBigcwxKG2R8pWCUpDDC0tQXbN1StiFzM+Y984NDhU/z1x3bwY69/Hr3QBArYWkQGJBu6tXtM5/65ntNv8W7faH37Z4//5+57PgPoG59zXo/wP2M4fYOzznvyN2rCw9uN7Sr+r1sewfv7Ft75NxhpD3vw+Y8637ffzBg8e148OuP4cQEooFDFSNHtUvS6+BAQ5yybu6UjoyZHVaLEUKEhIZXQkQ6DvIFUmaLmxXHy2Em8d1x6ycVMTk6YoRAjx44cZeXsCibGJxvPvWUed+x8aBcrZubYunk7g6VBzqhvVR7EeXq9sVxeT5g/fpyj8/Ns37adoghW+rCKLA4GnDhxmv37DzI7M8eaNes4eeI4/bLC+UCn2yOELuKCUfei5uSTgncFDo+XbKhiJeKOHDrCzj17WLdxA0WnQ6VVQ7Ov1HIYqCghG86qJVUaIA5CYRtiWVWZQZA3Yo0wEMsor7bBk8RKcwJJUqZzVRmMcBTBMuzHmKiqQe6/QFGEXNnB3kEVY7OhdrqBGKPlbghWbkdjogiWJMTKgiZTOlTME0smPcaEk2yUVRXiIaWqSaoJw0SPVYwM+n1iLI2Ngcepo3AFMUbKWOF9gSvqqgQW61xrMXWppIQlxCNZTHjK9ZHV1WwHIWpliotAnVxNxRSjlFUW33GkZMCMLwKh43PIBxQEXFLUg2q0MoM4rDSNgq9QVyIpIoWnjAOCD7jgSKni0OGD3H3v3XzbDdczMzPDV7/6Nb72tR3ccMMNdLpdvKvZFGbgFcHyTZw+dYZ77rmHXbse5IrLr2DVqpVm5GkkxZI9e3axbfs2JsbH8N5Z1ZWoTE5PMD45hni1sYc5ai5Yv5YXf/d38dUdO/jorbfyghe+kNVzq0mqfP3Br3PH7V9h7bq1XH7V5YROYFCVpiA6AS8oRrMJHcfh+cNcWC4xnaa49OKL2Lh2A6Eo6PS6XL31WhzC3Mo5brvtC+YfCRaKIAIVanQdIhIVSYIU9i4HKeIloN48EXVi0f+fvTePtuyq630/s1lr7336tvomqVSlTyqpJAQktIL0qHiHgIAgoE9Br+K1xQvXd69DnjwbbBCHeO8VffcBIigI6h22CCKEBGnSkqpUUqm+PadOt/dac87f++M31zqVBJ86RhjGsH9DrJyqfdZee+215lq/7+/bAC041k63os6VrNPzUpIaWur+CpOz4+ydvkZZN2VBZ3SKuc2ThNTXabbX6XSTeJJEzwYFNhLGFUhUWm2n7FGUHUwVNKY26OtiVVOniM8xnv2YGOn2sMaysnyeulTAMaZEHSMtcvHYLcU0iQRRFMg79MBp3vOev2Xh3IDz5y2X7LmYn/npmxgZtfzd393Lwrk1XvSS61laWOPdv/4n/Oef/Y7cbDfGhFmOkBTIycstJns1WAwmH6s2gpncuGdfhMMPneNvP3WAn/7xF2KdYXGxz//87//AHXcdQ+IE3RJ+/TdfpNeIjqZYXal4609+kP6aghmJDoeO1Lzznd/MVVfN8xd/eTd/+OHbSOJ58GDirT9xC89+9i5e87pn8Pb/9hEu3r2JmfFug43wKF3vsIY1rEeXaJzyRz/2Bf73n34FocuBg4Z3vONZ3HjjBpI1vO2tH+Ltb/8OfOn4H7/7aZ508y6uu1qZR811lvLgRsEmTgAAIABJREFUQx/+3MPYxCav/dIaHYHE9X9vkop+/Vf/lOc/70auvGprjgm0nDrW57+8/c/55Xe9iNHR9RZZgQkF/P/6k3fywQ9+liRdHnpggff+1qvYtnOKswur/I/f+ST3HzhLSIHJqQl+4R0v46o9W+g5z7t+4c/4qZ98sbIvzSPI8O3ou9nR4XoyrGEN64lTjwtAoUkEKMoim+cFpZ7n6ZfzHiOGlAySHFEsNVBZckMEXtSFPhphEAYcOfIQk1PTjI+PAdoALy+vkEiMTYxTlGrYJwl6YyNcedWVpBC57557ufzyy6nqCuc1GQGJqgDuaFO3srbC4aOH2bh5I2MTYxSdEmMNK2srPPDggxw/fpJt23cyNTHJyNgI5xbP5KGoNptV0CazXw8oQklMgTrUlJ0ys/MTdUzEuuL0mTPcf/AA2y/awfZtFyGmwBqhrtdwpqDwBd5Z+jEiFqJNrWRCB/EZcc8NvyaXKGvApagMAOMwRqm9NuZmyKC6cCsUYrPPRdTZYpL2pt1IKERkPVoQIcRAWWozLyJZskArgWikEQDe60RRUiJkNoOxlhhDZjBoTF6KQJYbxBDAqJ9DkwKhTWBCskmJMzY3JQZjnMZJRjUXTKKsCuOUtuys1USN1NAz9Rg1LofOe2U90Dx40CY6hBBwXielRd5GFMEZNWNJoVZQIXtZBBGiRLzXSYkg1KkmUBCs1QRpr41pqFM+BrofSSLnFhYwxvCkJ91Mp9OhqmrOnDlDSgnvCwaDmv0H7mfjpg1MzUxinKO/1ue+/fdz5sxZvukpT2ViYlJ9G8QgYimKLnUVcb6D8x1toIyyN/r9PisrK0xNTeOLgkGtngod79m8ZRtl2eVDH/oDBv3AYBC4//6D7N9/H5deupvdl17CyEhPz3nr1+nfeVBtxdDrdNixfTuX7bkM7wvKDVvoWE8tms7Q7Xa5+OKLkSSMT05hnMM6ZX6EOmTvDUOy2W9XlCUQJCGinhixFo2iNNAY4DRPka2nR75mGkc+K2pu6Vw2+7MmT7RMNt1MiEutbCmJtHGQKq0x+hmzz4OGTWjUZqfTAzFUg5rCCSFUrKys0Ss93U6RjTV9BrsADEXZQcoSa10G+74+JVnKY6zl+InzvP8Dn+U//dgLmJke4djxAW/6j3/CmXNX4v0oC2c7nD1tqPqRuoKFZTWWrFYj2ESnZ7FWo3TrCGuVRtCO9CyOPAWMRs9zb/ClMOhHjEDHGYqOIyT4k4/fzgtetJeyowyGA/cdw7qKd7/7u0hJ+F/v+xyf/8x+bn7q7pz4A6MjJb/0rteQRGGN02dWee9v38bmDeNIhA9/6B/5jd94HWLgC7cfY2lhEWMTnRHPc77lev74j7/A619zs04ZWyLCBYyE4XBqWMN6WOWnDT7y0dtwRcG73vM6rMCf/+UR3vu+W7nxxhfTX4qcPDHL8nJibMyycl5IlSFUlqpKuI7gS4NHIMIgJKpa6HQs3quyMdYJCQpsF6U+71S1esyUHY3EfuCB0yRg20WzGJedXPqR33/fJzl8bLWVhj78AyRCDR/4wK38+rtfTxLDP952hI994st83w8+jc998UHmN0/xlh95AYOQ+O33/gN33nGUvddtZsuWaYqix/0HT7F7z0zLTjAteKBPYI/2YRnWsIY1rH//9bgAFESEoijolJ3WhT2GoLRV63SKLwLJqndCshjRmLGUNe0x6eQ01JG6ipw8dZJNmzbTKUuiQL/fZ3VlhYnxCUZGRimKkhgCddQEBF94tm3bwuLZc1hgbGyEGAMrq8sM6oqzZ8+yc+cOkghHjh6hKEpmZmfo9no5YaDPsePHOHniBNu372Bufo7CeayDTqdkefk8K6srdDod1taWmZ6eoixLYtKboKRIjBXOGbwzrPT7PPjAA9RVzaV79jA9N42YAsHpQ3jyiHMQsyrRC8EkgsnU3JbCbbPRoLSNiEE03tFp05WsX6cfSiAmwVCqj0A2c0yiqRbr5mJG4xWt+gqEGJV67AwhSjuhzWOBFjRKUaevzum0OASdthaFp7CulQ+EWiMcL5zyNlGDxtACFMYYNSusM0BhheREu0EnCJr6UHqn26oThXfULQixHmnZgBUmyxBCCKTYMDqyYVOeascUkaSAhwjEOujvDPpKvczJGCaqrMEbS6r184r3RNtEGGZAIa4byTmb4yhDPm5KmMBZEDEURcnS8gpfvferbNy4kZXlFSYnp3S/QsxAj/oUxKDvcX55hfsPPsCGuTlWV/rUVWJqcpqREW1QYwpgPDEq3T/EgC88AiyvLHDyxCkmJ6dJUUh14siRIywtnmfzxk0cP36MuZkNTI5PMViruOeee9m5cycbNm4i1ImV5TW63a7+LoIzjYpDafO9To+JsXGs0VjUjvH4pA27s0JdD+h0CiTp91nVA+pQ4ayj9J5AJEhErMeXJfRXqdvjIJgUQSyuKGiMtFKKLf1e6fv6naruP1NhjX63dR3oGEcIwvHDR1lZGbC0vEaoasZGSmZmR5nfNAOlnoN1StkTIBsUSpY6SNYKi8Xbghgkp5tERBK9TslIr1TZUKjxpdcUipioWmq+wfkS6xwjI6PtevlYVQuo5HPx/PkBqS6YmxnBe2Hr1i7f/rJNHNh/hE/9zVne/4HD9MM4lRzj2771yYTQ4bOf2c8H/9/P8sChPh/4wzfQ6VpMgr/4y9v5o4/dwfGj53nXL38Xuy6e5Z3v+DiTk/Pcdc997L1+A3uvu4Lf+/2/I4XErotmecPrn8X45Bhf+OJRvu/7vxlrtfl43+/9Df/tHa+m7AAk9lw2xYH7zvCkb9qd3cXJBq5CwlInuOuug1xyiWV+tkcdhMVFyyf/5m59zDcdnva03arXtombbtzJxz/2GeS1T8ntQNMqrRt3DVuCYQ3r0SUGbv/HI3zv9z0b56Ew8MxnbuT22ysO3n+aX/u1v+LW22re+jN/xn96y5Nw0bN8vua3fusv+dznTnLjU3bzA2++GYvj3Jllfud3/4pbbz3BDfu28pYfewGr/Yof++H3s337Rs6cOcob3/Bc/v4z+7njzqMgiZe85Dqe9/y9nDi5SmdkjLFJ9dOxGKx3vP6Nz+TAkY9lL4X8fENWFTvhv7/v73n1a59JkaVRN+7bwu++76+p4y184uN38I6f+3Z8F2x0bN48zkOHz3Lt9ZsoRwompyzHTy1w8Z45HKLmfSbfdtq1eohIDmtYw3ri1eMCUDCYVn9r7boOTlB9eowpAwoRUoUVocRTisGLI1r189WpoxDCAJKhLLpY45EorCyu0F9eY2Z+jpHuiG7blSwtnuXg/QeZmZ7m3OkzbNuyjZHeCJ1OBwTuvvNuxiYn2LhhExs2bCTWkVgntm3ZzsTohOpzIyCGc2cWWFpcYmVqGZKaDe7YtpW5mVmmJ6b4/Gdv5aorr+TsqTPs3n0J3aKD955+SIz1Ruj6AmJipDvCmROneeDAA+zatYtep6f69E5B6S0RQzK93HxHkByzEw2l9XhncSkbC5IoCqvNi6R1R2WkfUT2zqs7vgEpsqN/dDqhdpoE4Y1BYtApf3sj1G2mRldtdKsmAySIKh1t9h8gJUpf5ClunYEC1btLzBTHnA6h8Zjo/7OaoND4LDjnHtVIGWP1c1BS2YRYQyJhxWQ5gco8jNO4OI2zjPhC/RBiY8wnOb0hmfzZIt65bGCcm9FYZ513VkManYg7qzKHEAOWxtsiKWMhZAaFJEgRIRJiauOOjDEQE50ApWov9FhIPrMz4JBiYOOGDdx4wz5OHD+Od44N8/Ps2bObbrdDjBFvHTt37qToKPslRb2OxsfGWF5a4tgx6JYdjMDI6AgGofCO7du3MjkxhsTsQZBUcjI1NcHk2CjOGArnoBCmpya57557OHH0KDPTU9x4w/VMTYxz4vhJzi8ucurkCUJYY2pqgvGxcTZv2qTgoNfkA5ePf5BEp1PS63UBTcFohCOFs8zPzNDrFJjGPNRbqqqfVbbKBAneIsZig8Ulg3HgxUIUYnJYSRgiMYbc6CsLxTUmm5neTz5HYkzUtiCkQMi+HVU/cteXv8pf/8Xfs7i4wtpqoLCO0gpzc+M894XPYs81l5A8YA0hxexl4tWLoVafGGvVu8FgkSjUgwpfWjqlspycUblP4RXQCyFQDVSuUxSe6As1QxWjRqiPcWXWb3uNt2yc3EU7K7zqFU/lR9/8+/zqr72WiQ33cuLsGq/5zutYONPn9tuOce010/zyr7yK17zuE3z4I/fy8pdfzsc/fgdLS2u88+dexe/9zt/xZx+9izf90NM5f36CK6/YyJve/BTEJN7ylj/gp3/qOxidKPmjj3yeO+45ypNuvhQxLpuiqXfCSt/TGy0UMDIQxTAwhmhzXJlAMl7lFOhk8qMf/iLv+rVXZGM2qKLh5OlVBMMff+wQt33uDG/7mRsJCL2u56rLN3PbFw5y075dra9a49C+/r9hDWtY65Wn8MngBYpMBJvoFuy9Ygd3fOUwv/Qrr+BNb/4Q7/zFFzHSdRg5xO//ry/wQz94M896+j7e9Ja/4D9857VMjZW857c/yQtfuI9ve1GPn/ypD7GyWGGtZfHMJG/7L89g+0WjHD28wIOHl/j5n38FhXf8xE+8n295/l6i5oJjibpfYrDeMj7Z0XVD8v621DSDYFipazojBTah3lupUUYKcTUyUniUR5o/rYVk9Hnq6c+8nI/+8W3ccPMeSp99IlpPh+zFkt9ruHoMa1jDeiLV4wJQAHDW0+uNIliqugYc1jj1AXAFsQ6o9NqtT9/RibIzHkMBVqhYQ1zEdwoSOqVNAmINkzPTFGVByHR56womp6fo9EpWVpfZvnM7E2NjdDol1hiu23cdJ0+fYnbDPN1el7GxMQywadtWiqLAl2XrFG/Fc8mlu5mencVYNWi01hBSwJWOm558I/v338cgDNh92W6mpqfxZZ6ye8v8pg2UvQ7GG5JJRAn0qzVOnj5BSDXdbsn8zAydGcF3nWbXi9L7A4LEAkK+OTq9ESaJqE+BBauT9SbmxhhDLWAiOBMRJzgrFKJmhAaDWItx2uCDUBRlG5cIOoFPWbhoncdYCJIoi4IYA5BISaNOTGYxFEV2gDeCpKBGTcZm5oFFiNmUURt156zGYYpOcxvKvGB0iu4dQZJKZdYcUFCHAclGolV3/5SS5gcbsN4wgDalwlrBO5uBq6j7a6GOtaYwiBCSGueJUSbMerzVuoRdJ9Nq+JSMbQInMM5Tx6jniM0anRCBSLBKgbeAydSASKRPYk2gzIkEeqwa7bngS8d1+65T80bv6a+u0en1iEmo64D1Bb3eKHWsUQMqGB+f5ClPvUVBgUKBDWscIfNGfeHYfelufOk19lBQ8AO02S3WP2enUzA9Pckzn/V0DBpf2O12EDFMz03zvOc9l7JXMjY2QlGoJKUsSvqDKnsY6PVM0ut0am6Wq6+9hs7IaFYhROqY6JRdrr12r3p8oE3g3uuvVw+EfIzVgE8n4I6cR+0NdTXI60eB9crAMEZjTQUhxrRuNS7rYJjq7xPW6VflnKXwJYPBeb74xa9w/twSe6/eh7ddRrsjSDXgrru/xO2f+yKbtm1kcuOobtdqOkmKauzlbIExCSOJoigpyy6Csk2sUxCKCL7ToSw7GUioWRusMdIbxTmf2Us5ZjU99v4J+bLOMimTP0b2FrFgqBHx3HPnQ1x+1Uacg4JIIQrU2CjcsG+aV333zThveNvbvon3v/9WDh3czP/9zi9z9dVzfO4zfw5xjRe/5CqChVSscMNTNmKsYMVy5e5t/F//519TdBI33HQRF+/amK81FUmLsdTWKIAkgrHSurQnsjwk+QwaRURUe/0H7/8ML/+2G/GihmhJYHo68V2v3IcBXvy8wM/89B9huFHXq9Iwv2GOow8twvXQJj0Q81k2bAeGNaxHl1L81z2GAJMIAzhzeoG9N+7WtdEEnJK3SH7Ad7/uBq7Zu5W6gqd80yRry2v8zrs/z913O44cuQOxFZt3zlCWDqkjO3Zatm4dxaPMrrNnAm992yfYvnWW5z5vXzssaQxbhIDN0YOIyQ++ogOEnGTTMASNOJVYClgnRGsyaxN9BqG9bbQxt1YMDsMlu7ewf/9ZUhDEZ2nfemzAsIY1rGE9YetxASiIqP640xvBeo9xjrLokoIQQ1I3d6NmW7VY6ugI4olOMIVVqjMFdV0TU43vjbFz927olAx0/MvIxAS+ULPHJKll9bqy4NLLL9dprLVKNTeGkBJTG+cZnZ3SSSaAc4SUGBkfVx2/1YhGsRbxMDEzw8jEBNlgYJ1GD0zOzXLN+JiyMJyl7HTazHNTFuzcvYuRkRGSZhUxv2UTz3zOczSf3lic9XhvqNSeHOf0hlYLmOQRfG6OdaLuLaQUqepat2E9KeqUVMEGjahEElYEklPvBbF6g6VSU8igvX3h1RsgNX4IIsQ64l2RwRmTHZ2Tpm6QWh+EKJYUI8Za6nqg3gV58tuwUsg69iRCneUZxqjuXIkKrv3eGv27ySCANUJhHa7bZW25QupApzAU3rXNhsVQx4AYS3QWnxTISEmIqJeGyewIERR8KSxJnOrw1UUOIbbNREr6HTdaeckGf8av7xto+oaxljqqQaKgoIRzhQItddT3N0KwFUEiNUk9JOqYfTWazFg1rXLeUVc1DovvdIlASJFoUYM7ySal1mrznRLG55QGDykGnfE3Eg5rKEY6LVMjpaAU0fxg5b1HUszeBZEkQrfXo3CeFBMpRU1LcI5NWzbjCofJ6Rkpu+krWGMxMctuMKRoCc7ixyeUlREizjqiEUKsKcoC44z6ISRhfGpM5VCofMRaD3YcYzzWR6JTg8vaCJ6ESY46g0peEimCcbZlJ0COeWySQmw+ytbhskFLjIlu2aFTdBgbGWPzhg0cPXKCTTu2s2FmhpMnjxBDTR303NCISn2YlHwtWG8xVtT40Sr1tux0iKkkpQHOef1dq2aTNkdcjo7abGBqsvN4TVUNaL1LHvPFGGzjJ2EMJMdgpSQGUafzYPjwH3yO73/Tc3G+iTSVbCILHU+WGQS6XYc3Nc4Kz3nOJn7yJ59F6XUtCFGTJIwd5AduBate/don4cuStSrxs//142zb0WPT/GRu6LPbuzecPn6a//2xO3n+S6/R72gwoFfq97m6WtHtFhgXMSly6tyAw0dP8JIXXqeeOyYpWCoBJwmcoTviEFMpo0oMy6s1d9z9IN/zumchOb1DF6kc1fkYS02GNawnSolYQhpleS1RS6LAsLZWc+ddJ3j99z2XZNTrCcAmZaSNjHhlAThDp9Q1FB9568/ezGWXzGAc9NcGjJQFqyHmuyoghpmpHr/wi9/KSLdk/1fP8l9/7o948UuuwCawYlUqZ7Xhl2TVGydpMoyIywwnYaVf0euWdOwo/89v38GTf2MLiGGtqun01Iz74MHE333yQZ71nJ2YJKQ60vElxkRScvztX97JM599GbYw6GKa46qAC+ihDBlOwxrWsJ5o9bgAFDAQklB2u2C1yUnZwCxJIMak6QYhsNzpcu/sJs5PzjJtEhT6gOcptGGOFckEZEujhfe0ucF5QJwaLXPTAKLO89Za1bhLysyDPI0XNQXEKvoeohrBaWOt3gJNgyup8XSIuSHRSbg2qqrjM87kJAuTM+81tcFaZRBI1BtP3JLa6b3C5YaYKeMWEBMIKUEqMcBZK0wScd0ROjHofriAc01evclGgpEQVZKADXhvsdIjGVjxntGq4qowwIWAlaTRmpLNGqH1SxBJhBiIKVJQIsa02c2aGZ0nAJicyqBARulLlZxks0dtlvL/ROULSQfFmNwQG2O1ocqT/hj0mKs0QhvOw+Pj3FN4uvUY4yZhSQRniMbiKJBshinOYnO+fGN4p8emibWEJBFjhJhyykjSJtGN5OZTjH4nkLXx+v0kURNFaQ0iLW1UnhhNXDBRmQ62CzFogoVJLHvHkh3lRJlIo4aIw+amMZGPhc5GVJYybnP8HWCFkKKaLGb3/HW+umnNKVNKhFhjOib/03pzrfiXsjKiqNRFolB4r7ncVj1LEgnG9DHJ5ym8yedFY/jpvVfgKiWsdcoUiknlI6LbCuh3vdx1rKbA1EDwIbXJEwo7KGtAjKaZhKipGN4V+X0tuC6rHrpxlRDXcOLwroOp+tiozaMqpgRX5LXAKEBkrSfUNWrOqGBeyjIISaJsH6s+HZPTE9z55Xv4xJ9+FO9Lxkc9R48e5NDRQ9z01OuZnBjXax6LycYXWbGDEFXy4B2hrvBlQac3wvmlk/pw7EwGTYEkeKugXeE8IWTKrhH6TfIEzSzwMV+K9Vw1SukdH+9w6z/cz7vfY9iwaRyTEr3RDqOjJQ1X+LbPH2LX9jGuvHQnxvR1r4xgXcSYVXbsmGJiLPDe9/wVmzZPsdo/x+5LZnn602/AmT7OZF93A2//2d/jqmuvpeiWrK4FnIAXcKwSk8VZ8BZ+8Z2v4qMf/kfOrK0Rg+Ezf/MFfvM33whW+M9v/31e+qKn8IxnX0ayhltvvZc9e7Yxs2mEJpHFO7j6yo28/wOfxzhHFSLXXrc5p8pAVSVOnKrZsnUSY4LePMTx9Y58G9aw/n2XXh3XXD3Pj/zwh3nta6/FiTL+9u7bQU4dpr9W85GP3Mq3POdKvFnDZiNlC3jbx5F4y48+je/53vfyH15yE8Ykjh65nzf/wMtIRrDFajNp4NTJc7zlpz7AS573JBBPSrotbwSfAkbUHLF1SzAGa9Z0kKKUOE4dX+BHf/x3+aVf+l7e+PobeM+v/z0f+uDnCc7w8T//Im9967dSWsMvvPO5/O3f3MWJ0ydZHQRuv/0gv/qLr4QsyTtwYIGrr9tMx4neA9b1FFnqoPuwTo8b1rCGNawnRj0uAAVtxhzdkRGscySbHfmtyQBDUkO3lBgUniNjYxwzUCbJnrnS0tVgBENqG0VjfAYTmuRi2j9NpvXmvdCH+VJ/MrlxI60v+02MkZq20U4HMxku03JVa6/ggZbNjIWGtaBJC+SJt+6PaXT0usEs7VtvGRx6w4o4DDbnMtcYsURKrFRM1hWdMOB4d5SCRFEU1HW+UVvfgh0YnXeTDDhNcrChQ22Fw2Ndxs6fZ/diwElN8ymttS2joJE9WMy6ebFRozuNbLSEUNMg8yLNBNJQFIU27da2IArkRAVriCFrHZ3Tplw3raCFL3JzZTWHPkUMVifkznCwLPji2BgbVwdMVANKD8FChUCtVH/vXZ4Q+5ah0DQJRVEQYp2NMjVWMsSoQAlNikQkhaiNMjY34vlsUZpBpl6rRh/XOPxLNgJNWKmVyWEL9ZpIKgFJ1jCaOtQucLQLYr0a/FmvE1HbdKfaaFaDgcZbS8I5wTs1EqyqoMqXfKwh4qwnhqhGmdmXpPErMaJXhMoBUpbS6DcsomaQRPWCMNlB3zrXpns0KRuSwTXrXN4npefXdY0pTfs9F85inWMgAYmG42Md1grDjqUKX9WEWOOdozCuZa0Yr+uAfucG5xxVVeOswRAYrVaY66/gU8AGpyyHBC5T4k2yJKfHT6JgnEESDOoKSYmidDjnlbkRIUrQq8/olW+d4dJLL6HjunR9lxAiF+/YjrOOuS3zXHrFLnzhaELPYozq9ZHlD21qulH5lbEWnMUWnsIaBtUA7wx1iBTGZ2BT1JCxqvTcjxWmKCnLUs/7JO0a9FiVLpum1fpu3DLGe37npdx9/2kiFkfi5d/0VKamVNpx3fU7SOIYGe8yMtHhe974DDAOA8xvGOeVr7oFZw3f/u37OHjfaWqB7TPTPPXJF2FJfM+rn8HMVK/Byfie734+Dx1dRYzh2198LVdetQXn4FUvfzJ/+IFP8R3f+VTK0rJnzxwvfdle7nvwDAnL9/7A8ylKlYu97ruflwE0RwJ2bJ/l8st26LKamQaFNbzx9c/k05+9X00ynXDLy24AMVRV5A8/9Pd892ueouwjnIKvplmNm6M+bAiGNawLq7kiXvnyq9m6tcvqqkpVfUd42i2XYRSj5Yd/4Js5dfY8rnC89CX7mJ4bxSA4a3jlK57Mpk2TFF3PD37fNzNY0/vj05/+fDojHls6Xv+GZ6qxr0Smp8Z57Xc9u42XfMsPfwvWwu4983z203fw0MEzbN09kyUYCeMcb/w/nk2nV5D5jkyPj/G6Vz2PrnN0epY3fP+T+MynDxCc4VWvvoUdW6fwFq6/fiNFETl0ZJExa3jDvh3YwiLJcPTIOZZWlrni8s0qFRPbrqXKpnAZ5Lc89lDwsIY1rGH925Zpmr1/y9o46uXlN27mGS99KbM7L6LGqQmXKdAmJCFBObX7Z+a5c9suruovswVoPAJSQhfvJBgR6qrWmDjnsb7AeQ+5yYipJqVIkV3sm3hAnSgri8DldIQYQp5E67TdOadNjTH4ssjpB9qAOasGgDFFNfzzjhSybjslkEhdB8qio9PRwiuGLUoNb5tQ0QQESeR0BovLbIam8RZj86RWJRGpjvgYKWKNRb0J1MhQWvM22zrXa9qCMQZf2ExDN9TecefUFIurazzj/BIjscIYqOpAJzNErLWkENtmUTJTQZMbFARQnfy6rKEBSoxpvBB06htJOKfNtjWuPQbWuNwMC9Y5lUigZIcYI2RgJMRI2dGmOQC3dTsc73bZdfgw07GmNOC8IZlIyiaZkiUK1nlAtZImZ1wU3iMmIhJJSdMn6lBjsnZdkkCKpHxOeOdAzwxSStR11PfIYJD+n1pCmcyywBi8Veq6NCBSBpv0WnQ4dLoRUSqmTug1wtT5UpslySCUAKjsAwTnPVVdZ4a4banrep7r1L1wCvhYqzTTlFJmXaifREqa19qAcMSUm+QmxrMdu2taQj5vU1Qmj56vCrxhIIaYqacK7NmcvpEkkbznrukZVnyHK48fYxyNJ/ViKK3Tzx0CxllCfn/JUqEoSTWtkiiNoYtQZnFIXdeQIkVREJOsT3I3AAAgAElEQVSoPMLp+dBM4VU2oD4JkiLG63ExgNgOX57ZQFWWXHvyIbr9yOEHTnDPVw7gKPG+Q+EsEhKudEzPj7P78u10xywxVYRY0elo/KZxCgDWqSamRMcaGJzn3ts+xerpwxQE6rrCGqfGojFlUDESpQaaazkyKEpu33gFV1x9LSP/8Cl+6Oc/SNmbe8zW4vZ+8Ahw88JZmzEPb6UvvIX8k0qAC7aDIZ+v+YeWTaMbS+3fmyZinjQQfuNdf8aznn81V+7dpmCPNIBsnve12zDtph+9E3knL9wf0PllvhT/+hN3cGZpme94xZNxF35WcwHQ/LXfYFjD+sYuWf+jMdZuTQnNw1/XkAPNhdc/+S+blzWPXkavb/Ow16z/ThKz/uK8SBkxVEuRH//x3+NX3vO6vJZkdoCY9fWifS/zsH3M9gqArlc6Ksj3vTzE0vsrUBl+9D/+T37hl19Nd8Q/Yg8vWDUaedcjPuewhjWsYf17qBtvvJHbbrvtay5ejwuGQhJBjMHkhlS1xE6XbGsIlVKqrbF0MEz2B2xbW2GbJBBLDKgG2To11stTeR+0sVK6dEFRdjHOK406BWK9plToPHFXzfu6KaERoeoPCLU2Gb7UfOP2uXSgDVtsaPuC0sSBOtQUhVNjvxjz76wDHcYYjNcG3zndb5omMcf/DapagYfME2yeg2OLeet32ikKQlUjURt740GCIHWtTWWzv06p+yFEQqjxzuKjx3mPw1CJpVcN6CdNBWgeuI1VcAVojRGbY5aSgiwhKIPC5kSGpi4EFRowART40btsnvllswNjMq29+V3A53NCTRLJaQpZmpB9DGII2JQYkcRUCPTWlulYR+EdMa0BDrwjIpRFocaAUZCk0wU1DiwwTqiDMjOMUVNNj0NCjiWtKqX5p4iEqgVVQh2IMScHtPRKwObJt2gMqj59pGyKqPKJGFTG4Z0jhaqVBoQUESCQFAwTwaWIEUOsapwxmZWAJk+IslKqLKHBqNQkZdlEVVUazVqrL4Cx9QXfizbnzlq8y/GTOWnDobGYKcU8cc+Tl4Q27gidbgmSPSmqpMaaJp8jMRGj4G2hrIgEMVXqHyGJsVp9BmZSojfok6KCNd7UChblzyMIRbejqQtVlVMTrAKA3rafWVCAJMaoDKcGiBODzwBkywiy+dvSk0m9D6wQSK30CjwiwtFjx7j1ts9T9yNISaoT3aJATGB20yQzG17KltFZrLUUpkOKgvWulUA1/hQi2bcxpzg4k/BGjf6sMRohGgU1lVDAbmxsjDrUiC9xzufJ+WMPBj8qhjIvM+5rvrr5nX/JhvUP98i/aP+z+Txm/TVG5QkiCVNaXvbym/nIH/8FV17zcmUZrdPLHr7Nf3J/HvGeF3yuBpgIdeTOuw/wylc/G/ewlw9BhGEN65+tCy7B/9914RFA3T91XT18G498zfrPzbXaShhFnyv9iOX5L76ST33yCzzjmddjMnvUZJTjwvXuUUvfIxc9Wd9Ve8GKIAifufVOnv2cK+h0/cO3+ai9Ha4fwxrWsJ6Y9bgAFMhggtLQVX8eYtCfEYyDoiyz3tuv03JjnrxbBRNSprxp8kBSQ0KfDf+cpQ4V3uqCnkSIUaehDW1dH/aFEHLEYVHgnFLFYwhIEHWNzzpxcqNsrOqfYx0JMegkGCEGaafDIdRI0qm68coqIEY6nQ51XeepMDmVoLm5iQICqYlG0+0V2RSxrrXJHUSdKGtTCNSi6QchqM9DbmJiCHmKLOugSPYtiDERnSgrI0orbYjZ6T8kBSusUUPAmJMLmoY0RHVtjjFm/bxpJQ2Nx0BKCZebykauoDLGHIEnasbYTEkVtDDql5B/X4f4yijwRdG+1uaJubWe3kgPO1glpqQpFt6vfyZJWdeP6tSNoU7awItEZcLkSUcD8mT3JgQofEFdV5mNocfFWvVwsNn80HkPRtM/DAqAeKNAQx3UE8Rk2n9MsaXCx5iUOZLPwwaMcV7ZCRq3aLA4NZxDmy39HTVxXF1dVYmA0fdKMTI2Pk5RFPTKjn7PSWUJKSoYJEnyOabfVQxRAR+UgWAyoOW9U4Av6j57X6ivRQgqrRH1HakGNb2uRqLGGFhb69PrjuTPo5/VuwKJiRjyOZvyeRBzdKhkk8lQZ/aPNtyDwaBdM9qo2czqwdCeb0VRrLNoAM12pfWKUCAnKBCBTqaMafU7kINGkgGsxRSOS6+4jE5nhHotYaRDGEQIif7aCq6nhpsPS4/I567kxtdm8MyKptU443BYjCRiUM+VwdoaoQ44WyCSKL0aXQ4GFdbZzKZqzjv7BHw+bXkQkKE5yakwW3bO8OYf/E6+Ht4RZADZecebf+RbcdnzRRuPJirStq8d1rCG9XirvG4IeRilyO3zX/SkbOWkXCYlBer99F9XF17/+kzQSOJufsqVWGm8ooY1rGEN6xuvHh+AgoDzBWW3q/E8zuAL19JjtaHJDVamYhsMIbuqWytUgxpfdEhRzd/qWNPtFkrlttpPOGMQCmUAJMkNXKa6JqE/6FMNKqanpjDeEYOCDmSH/6qusdkhHhGcs9QpQYRkUkOAAySbEypNXF3whbW1NYpOSUxqMtlMX0WEfr9PWZQttTwJ1HVQE0Ln2mQIEaHuD/RYZGlBS6IzGjPYeDyARtfVda3TcZRhkFJaZyBEtQ00mQWgLvcRCSlr5NXvoAEFYjbtWwcrUGPJlDApaZN8AdCwnnag1U6bs5RDcpxj8102Ta1kGYpzrp0GWKufpc4Ueyv2YQ8Fii1YnC/wRQdijXWGmCJr/QFVrLMhm2N+bpNO+rPpYEoJ7zWKM9baaDaeBN456hCQFDDOcd99+5mfn2dmZga03cFZh2Sfj1RnOYE1eGtpECJjDSY1rh+GkHKihNNEi7quMEn9ESRpc6OeIvrwUsdIigFD9i0ASELhHMY6Qqj4/Odv5ezZc4z0eiyvrGCt5alPfSqbN29WCUmWTyjjR5kdIkr7t+iEtihLQqozU8gQ6pDNRJWZYRrWjNHpuYjgMqi3srLEHV+5gysuv4LJyXGWl1e444472bv3OkZ6o+0oOISIN5bCFerjQAMQGqxx6i3BuhypOc+sVylNCFGBNTKTJUaM2GwxIe21ZXPkVwOipSQ4p/u/LsdRn4ZGwGIlAz0mITYSqYlSMzLeY8+lu6lWAyvLNUvnljh9/DSnz5xhqX+O3ZfvYMaMK2CGMpOMVckGRt83RVHDSWMos7GkoGAUQD0YaMIJ4AuP9z6byOrnijEQG0aVNMynJ1CZBtBbpx+0bCwDxqv4wjzGpmYNP8Ia1HuxeV9p+Np64kq7xg9hhWEN6/FVzZSk+U+912JVOnXhFdsMkP4VW33UVW/M+mrg7IWvHq4MwxrWsL7x6nEBKBhjGB0dpwkuVhq7NgFitQEkChh9+Ha50TNGG2ZnPCFULCwscPLkKc6fOwsmseOi7czNz2RzRxCJhKrCOp8bDNsayq0N+jx06Ajnz5/nhn376JRFbp4s1jii0SlVVVWUZZm9FEKexDsaw0XrDRKaqbsSeOu6ZnFxkbvuuovdu3ezYcO8mtdZRzUIHDt2jMXFBS6/4jIiUKfIwsIi++87wFq/T9kpKTsd9l53HVW/z1fvvocUAoNBxejICJdedhmjE+OcXzrP0WPH8E4no5OTE2zavBkEFs4tsrS83E695+fn6Xa7iEngtYE1qHcExJYmHnOig83NvTIhJKdgqA7eZolDHSNlQztvjkc2X2y+5zz4bmMhk0CoAyEE1btHfW8JgaIo298zefrfJGE0Ugvv1UPBN3CO0Zi9Tm+EwdoKMSooc/8DB7njrruU4i7wnGd9C1u3bmuPh0RtVqVhgFxAp46ZneBcQQiBo0eP0el0mJ6exooyIzSxQ2UhC+cWCCGyadMmbYXy1L8oSwprQZLOXlOWgIiATZpu72wGXSwmGZIRTfLI7IQQavW9cAafE0CUvaJAz8rSEps2zHPNNdcAhk6ny+joaAssJax6cIi0DBBrDc4YTp06Racs6ZSlDmCyt4LEhM+eFq25aQaEjDF41yQmKDBw9MhRdl+yGzB47zl79iwrKysUXg0FQ6jAqIFnSjlJI8Uc3ZhUvgHa3eVrNRlLlEQKqfUGaR/cMuvG20Yu1ZiCqqeDJJWUFEWZG/OU/85oc28VsExNZKYo48chSKxwpsYSOX1qkU//1ec4fvQMy+fXWFtaYaTTwxeeDVunW7YIVtcqfX+VbRkMVoSyKCHVeDzGOEId8U7w1tJfW9O+NUler5Txo3GrAakjoezoNWc1qvWJ9+xq9djJhU7o+mfmll3wd49lCRjB5JSWh2/foSyFJxp6M6xhPbHKmJSfHxtUcJ1xqNe0DkkasdOjJF5fsx553a8zpxTYdK2H0b9M/zWsYQ1rWE+8elwACiLgfdE2mWpiqNFzTfNCEs0ONxrpFyWiyQKBmCd3hw8fwgAzs9McO36Uu+66k5uedAO9kS4xCNYZRGqMQLiAWl1VFdYYqoH6JdR1rc2dgESd1AMthbvVkovgCqV9p5gTIPI0UU34hLquiTGxsLDAV796H3Nz82zatElBipA4ceokd997D3Vdc/Elu7TJAYxzbNyymRADh48c4aGDR9i9ZzerS8scfughLr/0MmI3ZPq4ejWcO3eOk8dP0CkcK8vL/OPJU7zwhS+kKAoOHrifhcUFYkqcO3uWiy66iBtuugFwLS2/H9a3VxSewihgUMdIkaMFrbHEVGffhNA2nkBrUmitbZkIzc+NtMRavy5pkKSmls2kWJQp4l2hqYxJ8pRXAQhtCpvkAlotfZMkYLu9LJ/xlJ0uoaoIklhe6nPo8BH2Xncdo2OjfOVLX+Tuu+9my+atCnoYcKVHROMcU0p4a7HOU4Wg8pscVRlD4PziedZW+6ytrNIpy9YTA+fzBNwruyQzSKyzOONYXVkBIIhgnFNavrXq05GS+mCIMDo6miUtFdEIJ0+fYmJ6im63S1EUKg0xhrpWPwcxCgo0x3tubo6ZmRmssXnyreyahYUFik5JyvrSXq9HWZY6+a5q6kFNYQsFjDL9vz8YsLq6isNQlCW+U1CUBYpLKFsnJPU4STFHpQKrqyvADCLC4uIi/f4abnaWlEK2YLBICiSryQgmX9sWWnaPoB4T0np62Cxt0egESZmWnmM6gyRMXeMLt+6Hks9Jl1MpjJh2gqXAVCCmoDGUqeX64MRgo+AEqBM+WgZLA+69Yz9nTy7RLUbZtfNirrrqCmY2TDEx12N8qpPBikRMNTFGylIZGCkGPaeJOTrTURQlxnqqepWQWULKRvJZmqMmr43cpwo1tbVUVQVWctrDE6lansD6X2VJlLRAgjb7X5/PnUXSciGY0AgsHENAYVjDerzXhcaK64OMhqFpsHq/kH/pCtKAEUArics/y4UsqWFuw7CGNaxv7HpcAAogFEWHTqdLE18XkpDqOsfuKR3aWAUB1DQx69dEUelBtcaxY4fZvXs387Mz+NLwla98mX5/Td19rSMOAhiP9RHrOlQ5Mm4wGLC8vMzx48fp9XogwtLSEmsrq5gsR5icmcQVhsXzi9jsbzCo+kzNzDAxMUEdAtZ3cpxglhPkWL2iKNm0aQtjY+PtZDVlGvb01DQbNmzkoYcOEWPCFx3EJsYnJxgZG1OQ4ORJNm7cSFl2WI7nmd+wgYt2XpS9HBK9Xg+xhs2bNjM7PY2EwBe+8AV1xwdGej0u2XUx3hcsnl/ks5/9HFVVtT4VTQpFURTUVU2ItOwD7x11BlEa3aBOiBtJBDjvCFWVkyMsZVlq+kQ21rzQE8H6xhRJ4x5DprZbqzd6ojaPmsphsjnjemRlY7zXaOON0Sl4YcA6qz4PzmrD3u3CQKhyYsb27TspOp5ueTOxjjhn6a8NOPzQEcbGxjT5wMGGDfMYYzh75iwPPHQIsYbx8XG2bNqMiHDyxEnWlldZWlhgbHSUyclJtmzZQsqAyNEjR1ldXWFudo6UHfsXFs5x3337GR8b5/jJU4yOj3PVVVdx/vwiB/bvpywK6qpicXGRKy6/nO3bt6uRX/ZFGBkdwfS62c0eMIIvHM76hx1j6yzHT5xgYmKCqclJnHWMjk2wsLDAn3z84+y6ZBdTM7OcPHmS8fExrrnm2hyXGbnzzrvYuWMHM9PTyrAh8eCDhzh25Chjo6N0u1361YArr7mKkdGePkBJG4pFzGafKyvLHDhwACSRJBHqgTbUKaosh6gUUdNEviZSCup9IgljdUifUg6DdYYYA9DEXaoJq0iiqgLJ6lpQ+lIlKyG0ch2xlsLpOVFXNWSPFOdQ40j0fQJ6jhjj1OxP8pTaeJASaw0zM7NccdXlHBk7ycLpZY4eO865c2fpjZdMzPZ46rNvYsfoRrxTKYjNhpi2mZDl59CYIsRId2QU4zwpEzK8s/nz6uNp6QuEmH02aP/s9rr5c9Zfn+X436wEHgYcmPbvDQ0Q1Nyyvi4uCtC+zyO23yZHDNuGYQ3r8VnrAAJZ/tgsug9LZ5HmjvWvuJZbLPECyUO7zQt8X4aKh2ENa1jfoPW4ABREVNEQk4BkYzanjvzW5ljE3Jgbo/GJ6yljkZSgqtYIcYC1gjEJ5wzeKx396JGjLK+ssnnzNs6eO08Uw86du+hXA9bW1ogxsrq6ypEjR9i3bx+DQcX+r36VuZlZxkZGOHLkCGfOnubi3Rdxz913s7a6whVXXM6gWuPQoQe5+tq9jI+Nrze9zaOpsVjrCCHR7Y4wMz1Lt9vN+m41L+x1e/Q6XTqlRkmGGHHeY4xlYeEMt912G9Zadl9yCUWe/C8uLLC0vEThPc55ihCw3lEWBRIjX/zSlwghcMsttzA2Po6xlrHxMVaWVzh06BATE+NcftllOOuwRo3unDGIVcNFiUoXNyjRtywLUsimdq0ZkcGilPzGxE99CAx1VZGcxfsC5/OEOPswgEZWYoQozfbQZIeUNDQxJcjpDd45vPeEGKnrGtNYu18gp6jrOht46k3dWAU1rIGYky6MdZRlBwNMTU7hTHbfz8yJqhpw/8H9PPDAQV74ghdgrOFLX/4KW7dvZ3Z+ngceOMj87BwjnS6TE5PsvuQSrrhsD6urq3z605/mabc8jdm5eZJJrK2ucurEKYwoayPGyOdvvY2xsTE2btxIf1Dx9//wD2yYn2dlZYW7776LJz/5yezZvZuHHnqIhfOLzA82UJYlnU7JrosuBqvHUCMOlfbf0PtTyF4bVq+T/ffdB6JA0vz8PJfs1oSA1bVVpqanueyyS5mYGOfIkSOAHoOyKJicnKTf7ytYk4S11T5HDx/lyiuuYMuWLdR1zVrVZ3x8PMsE8n4YSx2CniepS4qBM2dOsmXzBmKMhFCRkqaKGGMwzgBBQwzyd2hz/On6c1nEGJ9ZRZJBwfXJkoI/Fl86TG7eQQEVkwRnrEZUYloGjcvSBpXFp+yhoBGXagardhdRErX11DiiKcCX1LFiZGqEF37b8xisBpbPVyycPMeh+w9x6uRJls6f5fTJU2zdOYcvc3JLiJjMhNBGtEl6SCoj8p6y26VfrWJI+DKb0BqN1azqviZOhISIpdvpUBUeSfl6kybM8YlUFz6NP1y9rD+aR7/sMXpfueC/v3aIhrngVcOuYVjDevyVueC6lUf8ydcGC//ZLT7y9Y/8Of0z/z6sYQ1rWE/8elwAChiDy1PSwqhhXR2DRoMZpxxoA6A/K23eUNdBZQtYQl2BCEXhwAiD/lqrjT5+7BghJLZs3sH83AbOnlvAAKdPnyaEwI4dO5ienmZ2dpaUEktL5zl48CC9Tpe11dVsQKiGcstLS2zZtIkN8/MkiXR7PVLU6ao2wgZvfDvJstbjnPoOxGw6Z8TisFhBm4Wc8FA4NWFr0gOKoqDX63Hgq/dxYsdOtm7agveewWDA6dOncc6xsrLCzMwM23Zsx1jL6uoqDx05wtL58+zZs0cTKJxFgnDwwYN86ctf5Nprr2VsfGw9ncEW6ntAVBPGbH4ZGod/YxGbtKHPTbI1hjoFEG2eHEZd7pEsd/CkFLHJ0CR3NCZ41plsNKcTbGvyadgwjpNo82x9a0aX/zkDNaYFb2zbDGon2qYUoJ4HruwwqEM+dyzOWwQFKqqqog6Bs2fPsrh4jnvuvZul84sM+n3EwH1fvZeyLIkxMjE6Rq8sSSFQFgWbNm1iYmKCTkfTDPqDvu43lpFOj5Fuj9IXGJRWf+bMGRYXFzHGcOLkKbZu2cLo6CgLC2eZmppi165dFEXBJXt2t6aVDTvfZelP0aRa5HOrAURCTqNojsfV11zNdXv3YTOwIkYlDmPj48zNzyMizM3NMTs7q1KAnH5R11n6U1V0vIJTayur9DpdnLEUIyOU3W5mBSnLJkZtbp0xOKfMoYmJMa655mouvfRSRBIHDtyHc5ai9Jlp0HwG/YCFbxgt63RVm70ayEykmJNMmhhI6232QAARk00VJYN4Jks5lC3URpeKZH/VHPWZgQYj5ChGm5t5C0aNLsUIySTwQj2ouPfAAZbPrZCiZ7QcZW7DLOOjY9SykanJaQpfama5SmvxzmfZhjJK6pDTOYyyaFxZ4rsdTKpbrUeQgLEgVo1erTV6LjtDtJayKJSl8ejcxH/nZfLDfuNBsS5/WKcoS3sv+HpwFNaHmG3KPK0UwwzBhGEN6/FbcgHc9whgMq8ZoNd28zTxz68ij/x3yXiEtMCEyd4MTYrEsIY1rGF9I9bjA1AARifGEWsY1DUpPyg7W1DXEesMVkw7qbM4RGzbbEpKrPX7gCYvgDAY9Bn01xgMBvT7fbZu3c746BhF2WN0dBzjPCtLS7nx1Cn6zMwMvV5PKdAhMBgMsMDk5CRzs3PaNGGYmZ6m2+lgnKHslMSscbaigEcIAYi5ybW6vToQY6Rwqpv3uYGpwhr9lb5GDolpb3FWYGp8gmfc8jTmp2a45557uOqKK5mZmWHfvn1snN+AiHDHHXewf/9+Nm3ZTLfbZXJykluedgu33347n/v8rWzesQ2JINZw0a6LObtwjrvuvYfpuVkuvvhiClvmGL1EbKQOiH6mGLNnhTbpvijUqE+kbeyVraAP2yJC4S3OmvaYPkzu0EyRrSVUofVkMEYN8VyOwWvv9+RH+fzf3jlNlLggRSKlROE9YlRfbzOrgaheCGVRtOwWMJq4ESOD/oBer8cdX/kKqytrXHbZ5czPz/HJT/4tzjlmZme46aabWFhYZGVxiS9/+Uss7V1k79699Pt9RPT7TYD16p2gPg/uAsNI3xoyDgYDZmdn2bx5M1u2bmN0YoKxsTHcyYKR8TGiJCwJ3ykA/R6st6QYefDQIWbnZvHFBMaY1kdCzzNLuKBJL4qCstPT6b3zObpSm+f2MSq/zrn1+M8UVFoRav1e6lATU2JlZYXTZ04zPjFJGlScX15icnqSwjgkJorCI1b9Sf4/9t487razqvP8rud59j7nHe575zG5mW4mEhJCEmICmBBBUEoGtYGCakXKoS39INXYZXWV1qAWpaVFW9BOpa1Y1X6qWpDuohTUhgIFGQMCgRAykTm5ucnNvbnT+569n+dZ/cdae79von6kPxZywbM+n5vc4T3n7L3Ps4f1W7+hZDM6nE6ntG1DSoGuL8QUfX1lJEQkqHlNpEQRS+FQtT+3OhmvCdXXVN/3tr5k3U3b4lgrzaRBwKMzB5nREANqppXUSiBQRSjqHii4D4MMUZPmmSHBJBCtQEOlCDRkpOvoT/Z8+P0f48F7HyE1i5S1Ga20xrSYZK5f+AYOXHwmNSvVMi0JzsApJZuV18isARVhdW2NFIe0Ewceq30fm5aXWOtmfg4U81QIzbo3ydc1/V43/NoAJlDYkMv5FaxioIYm1r0dhvjIpwbUz2te8zo9amBSxqfIGjZeRzaClV/mdWQAEcbPGIwdBwDBQYV5zWte8/pbWqcFoJAFcjuBtjWztwjiU+vq5mpNM0FiY+aNbmpXi5ndpQBrp2acWD1JV3r6NUt8aNqWWgqrq6fMb6D2oA0pRFLT0MSGhw89wmw2I+fM2topb3ptMri4tMAeb9wXFqb0/RqzWUfTNAhCDMHAD63UrqNpJ9ic36jUEFAsjnBttWc2WyMmi6QrNZA127S+WuMeg2Wh5z5z8tRJQoy0bcu27dvM/K7vWZxO2bJ5CwvTBYsZFKHPZuZ3anWV1CR27t7FpZddyh9/8E+YdWvUpiXEQDNpuepZV1FRHn/8MGedtR8J4kZ5yXwrxCbCA6hRaiFjDSMoMRlFfKAfmyO6eGRfoGZ3oMeaqFwzOP08xkQgmMkeQi49YEkPWipFKxIDVaBiDbaESMmZ6o3fYOA4mO6FQUoh5pMB2IQYsaYxBGgajp9co2SYThvue+BhTh4/zoUXXsSjjx5m88oKO3bsoOvW3AhUWF1dY/PmzZy1/yyeOHKUkjPHT5wAMcbAYCLa99kc+MWa01OnTvHIoUd49LFHeeTRQ+zYsQME2smEO+68k6WlZSaLy0gzZWEJZn2x1JEY0ODRkmIxqiIBiYFNK8ukZEwCpZKLGjCygeqv1SYlq6sdn/nMZ1lbm9G0DUtLS5xz7rm23ictTZPMKNI9KCz1JHLk6BEeeewQ/azjkqdfwq6du1jesok9+/bysU98glINWDp56hSXLj6NxYUVsg7+Fhk0kFIkxkTbNsRosh1UbHLftMQgUAuqQkoNo741qKeoKLXg4MI6YKRA07bj9UI86WNkMbgfSXWGBkDv/iFDHGp1VCqmhObhncyvpZZB3mPRpTkXSoKqGaSh9JWgkUkM1FVleXELV1x1NZ+/+WYW2gkXX3ghn/38TRw7foyaq8kwPFkiO8hi2ywUKoVCkyKkSLuwALOekgt9X/wYNiQN5N5ZTwghwHSaoBX6sopEJaSvQ0BBnvqbp0ocvsL7/KTP2dhwbGQrzGte8zo9a903YR0IfOp5+5Rry//veuq1YficOTthXvOa144azs4AACAASURBVN/eOj0AhaocV5jVatFvqiMjejKxyXJI1jxULZTSGWVeIiBk7dm+cyfp7sTBhx/ixHSZUitn7t8PQdiyeTOTSUOtma6f0bYL5NyzZ88e7vjSl7jrrruZTic07ZSFxSU2r2xm97693HPvvfR9ZnlpiYXlJYSG3fvOYLK4RA2BWqDrDQxIqbVMeVWnYlfb3mrTyFJNHjGZTtAAfeks3k4Lmcpk2trPu6b/yONHePiRg2zZupX777uPAwcOsLiwwOqpU3zg/e/nimc+k4XplKPHnmDz1q2EFLnjjjuZzdbYvXsXt37xNm/kphw79gQPP/wwu3fv5uSJExx9/Cibzz6bKNFE46jpsiXZYG4jrd4nvkgw0zwC6v6MpRSTEQR3oi+YzKFN9F1njdSgmxfTkdeqxg7Eb8kiFFWa2Bh4UAsUaGl8WtwTYhop/SnGsXEcKP8WVwgFRX2daKlEAsTErl27WVvt+OiffoS9+3Zx7MRJLrrwIla2buOyK67gTz/4QbIWjh17goXlZdKkJTSRW2/7IksLC2hVzj73bJ559ZUUUfacsZd2OqUC7XTK/rPPZnllE6FpmOWOOG3ZsWc3XekNCEmR6593A7fdfjtxMiG1LdOFBWJM7N27l82bV5wxMMgADCApNRMksXXbNpto10rVTFajWwYxv4nAoNMPXH7ZZRx+/DDbtm0jtY19TjJQ4pprrmJxcYoEHVNKJtMGFLZs3cL1N1zP2toqyytLaFBSTFz77Ou44PCFTNoJMZpnx/LyMrnvjZY/mEEGa8zbNnHtN3wDC4uL1GLAzuWXXcbypuWRxVNV0erniJhcQmohoHSzQmptrfXZ0jWG71w8urR6FGN2FkoUSxEZWCG5Nz+OIRLWWC3VfSgiMTVuBFnGdSSIr+fokp/qUaBljE9NIbG8tEDTLHDFlZfR6xr92oxLr7yYBw/fwanZCSoV1YiEZN+jSx+EgEQoXaaiRKmEZGkma6dOEWtnXhM6QaSyaXmRbnWNFBMxBE9/gFJ7Z/Rkur77m71Q/43VcHVY/7P8hX//3/9T1ys85S/nzcK85nV6l18nZCOA8OdBA/lL/v7LeX/778Zrw18XnJjXvOY1r6+POi0AhaoQ05SYJkjUdf24a+NLUQJC00SqFpuMhmCSYyxybuu2bVx79bPIuaedLrKyYyttamjblvPOP9/y3wOuibb/b9+xg2+8/nq6vielxK7dezwyccIVz7yKbm1GipFJ25qp32SJpz/jmaQU0JCMih1bUhOp2RqaWqxBHzLtrRkWJpOWZ1xxOdPpxJrAJjHrZoQg7Nm7m9VTq1RvmGMIbN+xnWMnjiPAOeeey66dO0lty3JKnHPeuTzw0APs2b2Hffv2sWfvXmLTsLyyiU9/8NMcf+IYmuHqq66hiQ2TZsojDx/i4QceJqXEts3bOHDOARIBSiU1yae0SqxCVOhLT6OFQCAWIFgCBZibfwyJpkl0s94M4sq6fj0M09iSTRKBkmtvs4Oi5q4/6BhgHCKUwZgxDu77RiEsxdIBcsnGAtmQ+CAbEh+KFsRj90QLtRSaNrJrZRvffOONrJ48wcq2TZzZTti6fQdV4JwD57Frz24ANw/MbFo2RsANz7+RFJInCiipaUgp8axrv4FJ0xqw0USefsVlNnGPwuZt27jhxucB+HEw0GbX3j1s37Xb4wvV/SGU7du2s3PHdmKU8ZipG92LCloySYyZkWse/QDskaZS/ThprbTthHPO3s85Z+9HojWhuWRnPQj7zzzDAICSzdBPjDZfaqFtIueeexal7/39ekKT2LRpkem09Um/vacxWgK59NSajXXTmUliBLZt3TK2gCqwfesW//mMNBNqLgSFyIRCRmokiskTBt+TqmXdH8NlTRt9OCLRLhyAuGdCrXVkNAHj+tjowVVKIUo0k0cRS4Qo1bxa1PxbVJXcm7Qmq9KXGSpK0cK+s3bRzZSmrVz37KvIXceWrcs8/YpL6MuaxV9GSzepGABk4IZSu+KyJkCVFBKiFmkRJZDaCaEZkh0M0EArMSZmszUgEduWnMsYmfr1Zsm4Xn/ZA/rf1IP7Uz9n3jDMa16nf3055+lf91yeXwvmNa95zeupdXoAClWZLK7QF0giNMlc5o2xHl33HYkpWQJCNAPHTMFai0ggsH3bTmb9jNg2lJrHaLXlTYuWM6/Q547YmAlcpWdlZQlYN2obJuHTNrHQNt6omc9Al3sWJg0xmdFaG4123c1mRtGu2aj+XU9K0aMRTec+aRJ7d+90R3nQmolSiSGyb7cZ5U0mxnLIJTNtGp528UXknImxcQ25EpvI05/xdEs28DjFdtISo7B3325e8tKXoGrvuzCdEgIsLi1w3bOvZW11jRCEyWTCtJ1AFLJUGi1oqUgT3T+homUGoZhUAQdyHHgZaOWjMWKM1JJNKhFNghEcEIrRTDWDm62pmg+Gz7WN4l4VghIIBkq4XrGU4hGC5pfRDB4OGwwZU1pfwsG+PrrY0rXWoK5phskCew5ciAZFEta8JfMh0KbQtAvGKlk9RULpI6yVTFrZ6skDBpBUhNVSYGkTPUKNlk1fS2YmcKLrDJyJ1ggGMWCk00pBSZOGLEIkUdX8IizaUOi8STfvwYoWi+RMIZkXR4QqyenzQqlKdkZMpSJByYA0Jg2Q6OyBJo0Gimm6SN91DIz/IHZcJdoxzEBJyRI2QqD3Kb22iaaZjIBPxQ0Y0wQE+lpNYOIAAKl1j4eeEpOlUgRBmpYokBMUzbTSMIsNpxBySBAibROpwcCD6AafA3iUy+CzscHgU3EQzx7zioMuw1oBX1+Yx0VRAwoGs8bhvYoWYogGBLpJo7iGv2hPRmmmU2rIHDp8mI989CPs23smO3fs4OTxVS48/2KmSw2pwRgSFEJklDtEv85JtLUfREmxtetSMWhocXGKBjM7rTW7Kae4tCXY9hVjjmi1NJyvY0RhXvOa17zmNa95zWteXwN1WgAKg9FVkyZA53RurLn3aLfBFCdEMdCBwKSNZC1IFVJfSG2kJ/qE1Q3/QkOUYAZwxeImS58RjUY51uo596YllyBGyY82vdeg9PTWcJsoG3VHX4sw9BQFjIZdi03JVSLO7jfJAEa9HpzcYwgIyVoWgRAb1JulnDOSEqUqIbUo5hYfCJ4G0RJJBphgBnPmJZFYXFywJtD14YgSgOWVJRaXF2zfRUYKfQwJMJBDslIr1BCQZE1ryT2hhnGiq7WODVyQaI2l9dxItGlxyYWmbbyRLYhEalU7Roh7MVtDVHIGMRJhTNGJC7pun6QVIbrXw6AnHyIo3ZRTFYmJ1WbC/ZMFNsWGNhdyrsz6NZoYyJsqBfOsiAgxJXIuo/8CWulma24OabGEqWlGBkRVRdSbz9IPqgTbZqffq0ddWrPrX2ytZK3evNt7oThQYSBL0TJS9meztXVKphvLmwGhAT0pGetBa/Uoz3WNaJMSRYslC7hBlAQzdqylEqPtR5/7cb+G41kdqBmTA6qOkoDgcaUxJvci0PGslWBrIqiMbIKBGQBuRqjG1ui7jmlK5JCZaUdkiqYJ9yyv0M7W6DXQ55OEZGyMIImANf1Pkriomg+Ep42IWPRpiNHXlRm5juyVFNFexzVj/htmFFKyG1qiqJqEJ8REdfALVWOo1J6+FKaLSzx08AvccuuXWF7YxKbFFSaThq3bl9l75naee8M1tAuWdhGDg2hF14+YGhNFsGSXSWuRsa1BHJRcTFrUJAMl1dZL27ZmLK6VIS1yjNmc17zmNa95zWte85rXvL5KdVoACiEEFhcWR1Nv1UJsklGygdg0hJRAzA09JnOop7fGs6oSU2RWC2kyQUuhdE4Nl+iTvGrxcrkSFdSnuk2TCE0gl6HZyvbeagBA4ywFCSZrqLV6ozmkOUBqGmo1ir2ECDJMmpVSzY9Aq1KBbjZjOp3Q537cd3FjQlGLx8sq1ihFo7rXak71llPvHgdVUXcbN2q8mk5bTTIgDlwYLmNGj9bcr+vKY0huqmevbZqGGIQQbZKKp060qbXxP+5lPCQ3aAHxpj9601uqszNkfXquBhHUqubbIAMQYFT9mGyKbZGCkDAAwia8iZiMkdL3PluXDSkS1aa3opWdRTn62BGOd6cQrc6IF1apCIGMxSuKQogGDA0GjykEi/fTSlczaCXPZuuRlIOjvhpAMyRgaGdmgAijXKMO21Tt80WEisU7ykjj97dDRwCi641iISGCmlGgWswGlcFXQUemwGjIqJUUIl22NIRc3enavUhq9f+rAzH+uuLroTgwIRgw4jiHQT+1jPGKuWT7+yBuQ6VQgxsnypiqp8Pn+esMkLHUik6rr6uGXntiqWxbVZbXOuh79wsADQFR8esBzroJY7KBIGgu1CDjkN4AADP81FpHcG5j1GaQwRCyUmqhaRLVvRocsxxBEZPv2LoWEdKk5dpnP5vFhZ28+/fey4GzLiSvFR64/z4euv9hDj/2KJc/4xJ2TFYQqaOZeIqBgDM5JBi4k4KZL6ZEDBHNHbnriG1iurBMV2bmCRHMJLLve7vWuTmnga5zXf+85jWvec1rXvOa17y+unXaAApNtLhBrTaNp1aL4yuF4NPYlKbUIpzKhcdSA+2SNeqN0dtr8CxgTTDBdMhYExHFHNdrNK2/pJYQolPsIzTJGv8JGI29UlPr8XMmCUhTiyBMTQKt9DH7pNoU0yUX04Jj03315k9isuYN0JI5mSLq0X8hRAMABuPCCDkNRnfWWNdaaULgWHWfhlwIjUsLovkaSAhUlFx6JNq0Gn+tSiW0Ht3nU+dalazKpPXZqIK2ibUmoH1PzRBLIGgkKG5al41F4VXdsR9Zn8CmaDT6IdoxBKHve2LbkrxJVK3kbHT6GC3mMefssokw0uWb0CJgTSH2vdiAXCEOsVBYMoMql5bCRXWNFF0OUKs1pWLbOjASmpRoGmMMoO6pUTK57wzYqNnyOVyPrxLWp92qaMljTKEIVAp9yRAs2rLrOpt0SzTwwmJLyIMJYIUuO1MEX6cDS2AwmQymrdc6mDEWY7JIcBDNWSA4myIYUJNSIjvgMLAeBoNCtCIxIgK5FIvXdNbJwFJQHbwFejNLxACJ6saFEm0qHiUYFV/CeJwC68daUY+RDIRoTIhSChqUKC2aoQ8dTSgm1dCGBRECCRU3jczOEsCMsDZO5C3xAlvjgzGkBAy6MTCjaZr1pAiPoLRQiGpJMopdZzas6TGS0Zk7tRoAYuymwpfuvofP3/I5+r7j3nvvZrFZomkSC8tb2bJti0FXMRJiQ6kdSLUUj2omrQyGon5uDkaXeVYQMpor2hUQNdlWMM8SkUCTIqf8OxquMfOa17zmNa95zWte85rXV7NOC0AhBmFh2o6T90LxJlGQEAkYY0CqMtGCSuYLCy1xYYrWlkADtRBTgbKGBKHDJ7M+pbdouWGa6bRxdwMOMY3NYohhNLkzSnRPislp5x4/J6YhRy0z3qam1gyKD0OtiQtu+NhY0yXWdMVo0/BBBw4WEzhOUn07jYIevYGwqaYOdG2nfzOYV7pWu+RszWwwOriWOk6KB2aCRGMeDFR0akFSJVPoY8POvhJozYxRYXVtlcmkXTfJG5rPMbJQvcc32nbOPU2KnjxgE2GtZpqIN/k2DXeGQ82IqGve1c3mzJshNQ1lmDgj41TeO18zzvMJc1s7A58kkFSpfTHZCjBNDYVAXzNNVZredi4lY5R0uUOKTeRjcc0/7gkgxl7Js95ADyA49T82gb5UYlVEPJIw2/Q4RgcFemMgNGJRo7n00PcGdHlqgdbs+6NU96oQ9dhUVzVUlCCWIoIEpBjQNRV1o0qIFGLfj74JAQMTggNq0c0CSylIMQlO9EZcBxCsFmrJtMEYMcWb8KZtKdWm5eZBYQCaa0Y8HcSYDwPdKJhbJrkvTIJ9520QRIXVktEiTEQs9aBUcrDmWauxikZTRrVjqC6tGM4bsDRwVaX03ZOMHLODNgNgtw5yGQuq+nYOMZolF4IzOkpQY7iIx07WQkjK8ZNHOHr0EfafvYv9O/ezdct2tu3cxsrWZZZXFmiXhKwFSkaCkmKgr51LJ9yzQZVSMtN2QttOCDHSTFpma2toCZCVkIJ5RrjngmAgVHW5joT1yNZ5zWte85rXvOY1r3nN66tVpwWgEESYNNEm4BgtPsREUSHGFgnJaOAom2czLj9+gpKsqdLaETQQRQnFaPMhJrqSqdlSBqIEp9RXarFGITYNbTuhAqlJrg+vtJhnQc4dpRS6bkbbNIgnCeBNcqy2PT4yp/jUutbigIF5DXRrM2c0GECQQiSmSM3ZKPBOp2/cpR7W6fAxxtEjIEZBZmrshGDT+a7v3bgwEJpEbBpyZ8ejbRpSiPRdb9IMBzmKVmLTGLjRuGygN4PIXivEGSulMq1rFClUqUiqKGamOKQWlFqpmI9E0TIyC0yHLvZzOLCSkk+4vTf2SXrROtL9QxBnYyix9QbPtxeJYxwnrNPYhwm0fS3BQQgzT4wuG6nBmRBi5nbWMFukpLEL7OdyNdZDTNaomz+B7RfWbpPV9jeKoINcAIx2LxEVnx4LZLU0gSpQxWIsbTuLmfJ5kzvIKYYpv0TT35daSSFZMonLbPDja0oATz5wM8EgNgEvKCpG9zdqSfXIxYSIUjVDFLQUKkITG6raWm1CpFKoaskQxZMWqsc79rkzo9QkVLJbAugYGali54LEARwy9kaQANFkQ0GjGVSKkDRQq/g6VDLmWRD64rIUX5/+HQ/GqRt9GgagwHwRdPzz8BoYPBNwcCE4OLHBY8HBuXVfCV/v2PVCq7IwmQJwySVPY/vm3TRxgW1L26gZTs5O8tjjj3LfQ8c558CZbNu9TAiVIIXe/SvaduKeK8a2UJVxrZw8dQLJp2hjIjZC1xs7Z9xvjL1USk/e4FOxkVkxr3nNa17zmte85jWveX016rQAFGKMtE0yozKJVODkrKdtpkhsUaJp4AssaOactVVryhDS0ACUapPAkIjSksvM6OPYA3zps9Hq3cFeJFiTlgIhhbHBi8Eo4SVn+r6ziD+fYOZaLLEgmP5Z0LHByd3MogVTpKo13KpKyYqsDg2RGQKqmzL2fSbXQmqSbQtDU11Hmv90MvGYwEoaGQhi5olVx/i/MoASpRAxqnp0JkF27wEJQlaj10sQMxTEEhiSVLpcWSuZpokEVYoYkyJ57GB0mYE6ODB4D9hE2JIMmpBILtWYTltyLZRSIQb3UhjMFNeBBGvc3MiQIS3AGumczWDPqOv6pAn00AQO6RzmcxiIRWiy0NeCJAeqSqGoEoJN7UUiTdOY8adbJITBoDCbth6NI92/FgNKUojI8P2OZAmXFqDkrrd9EDPT02qsG9EhRtLiE4EnU+29sa3D9qhFbYqKSwaMpg/xSf4EBPE1YHIDqhJDHJtqC5Mwn4SSs5soOriV3B/EaAVUF++kmAgS3LAQ9+MwhkmURIzRmDnqE3Ixmj86AE+Dp4QBMuKMBMRSGUrNdAJlMJoskYCQa0+KJosZCAiDWaQdOzZIM/483X8dfIsjO6FpmicBDKUYCIMMwIQlhfR9P66tWpXQYLKLCk1MhFooGdZOrnH/fQ/w0IOPMjvWceSxY5zq1kAKk6XIyuYXsHPPMikZsGGeG0LtTZIVU0MlDHYxTBemlvyQocsdk9SYb4uup3CUnAlBkRhpk68zNYB0XvOa17zmNa95zWte8/pq1mkBKKSUCK4Pr0DfZ2I7RSUCNqkW8Sa+MUPGojiVXKgiVAmmddfBtNDN3Ny4TKL5AVhCgzVOSiUIPm2vTNqJTduLN73ewGgpowmcCIQmEaSMrutRzKgw595NCl2r7fn24zTZmzgzcNTRn0GA3GfzTMAo56XahHs2myHAJEVQi7MzA0aAQf4g43uUnAmNUaIrFVXbt+hJFLUWo/UTkb6SYuMNqzVs2hVmtdCGBqrQxJYQjHTdu7Rg1OW79KJJyY6hu+KXkgnBpA8QHMAI5JpBrJkv6o2dWjNdnJ1h25eAYfJtwI7JRipCMikH0HUdbduOgI8Z94kxVgBNkdXa+zdtrpcWZ2kNfu2zxTxqJcVIyfY9RTGTx1otXjAOchIHqIIhIW7WB4ilC5ReiQ5h9X0hanATSwdhFKT6FD4YM2IEZwamhkAtOpoEDlP1XOzYqzsHGn4gowdCxMxHVRVJJlVIMTiLYZjoJ6f/Q6GgZTD3hFogihA8JUWikEJj6ykl8+GQZMBHdY9OtXWh2f0VCB5sYR4UIbR2fhbQImbcWQpBlCKKBgPzpKr9koKKUNRSI8xDU9cNPmsFgnk/wOgVMaRrDPT/qkoVRUQ3mHBGcsnkPpv0wL0tVE1mIrJulllqoet0BGqssS9M2gnHjj3MJz/5KR687zFiTuzYuocD513M/nP2sHXHIrt3bUWqmjSpKtRKLeYtIhHw2EpUyaUQYmIyXaDrT5LixCJp1Qw3U0jk0hNiw6Rt6UtPVSi5jmf/vP7q+ovApyfVRtXIX/qjwzVXNvzIhr8Z6Fd/4Vus/6MiDD8+fK6t0+G1g8Bl2KiN76Y8eWPdnHT8t/XXGuD+5/dhdE4d92j9/ebimXnNa17z+gqV2n90vN7Lhiu6gAwm6sMLZMM1eRjE8ZQLtQ+SdP36byxgv+f45/z5u5KM71pq5dgTJ9i2deVJn/WkH1VZf5cnvd1fMNjxf9+4mV1fOHWyY/OWBcLGVz31vf2FMr8bfU3WaQEoiNiG1GxyhcXJIgUZc9dDSjTNZJwU2wQ0UXDDNDeds2a7UrT3Jt+awpgShUKmWMzi4I6ulaaaT4PUROlnPoVP5AKESK09sQa0swYNgF7BPRCsuS5EAtXTFtqUUJRZKXTdGtPplM5p2cFlEqVaUxkj/iuMVH7NPaLqZnkWEVgASerxf43JGNROvBCDMx/MtyEQaGJjqQlipofmn5BJwej7WrIFCwahulnhrOsRlwVk6+8JVRAN1og7gKK9RwxqgGz+DoPZY0yRFKBqJmtHKC01CFmNJTBNnnyhkeASh4GVoAqxbahayLmzUM3icoXeWAzGlrCGMkaXLdRCxuL9TIJR6dSOT829N4vRwaNix76osReq6fJDiGhU8zAQdRAjmX6+9EAleUOc1RI7ilojL8EiKEOwuMZRYuLAhSVgQF87onhDXwox2ulnvbm4z4fSxGR+BpiJYq7VGm1HycZbQbUEjSa1PrU3YESoNDFaYkjOYxMxUO5LNtBqkNSIYMwLhmSUQCmV4NT8mi11pZRM8huVCGN8KDr8vJJDATEALouxXxrMtyAPHiMqBtQ4yJFrT1EltRNj35Q6Ai2m3oj0OZMArWbsONwsdZTMDOkjgqRIjJWoJk3SUunLzGUo1tCpg1wK4zYZS8bOl9WSR3nUrHS0Wql5xtatKzzj8kvZsflxTjy+ytEjJ7jzrjt4+NF7WV5JXPucZ7Jl2wHsjEyoQExmKFlrsdSTEJAqBEnEMEFJ9BVS26KSyP2MphGTbRWTdtEbENGLRbvG0HjM7ry+nKr+bBXUwmsH+wmLYzUfDg/zRDxhZWjJVSpoMYSZaGiay1Us1BZQN4A1mhAq62vL2FNKRfjc5+9ky6Zlzj5zj18j7FkwMAALxT5joD+ZVY8lGaHjZ4pfjx2fhDCQlJSPfuxmLnraAbavLLMBZ7PyZB7/xK/oMZ/XvOY1r3k9uZQC2DNAFnVPMbsah+HeshEULs6WlOG+4+Hr/nsUbBRrAxd7csP7A79R+SBqBJ39/lIqvOs9NxHqjJe95HrWcQiHtv2eIh5ZjwjZcekwzjPtOT1E3HvKbmpRh48RDh8+ydt+64/5ge9/Ptu3Lo6Ah/Nj/RF1ALzn96Wv1TotAIXBnE4RkwygNKl1KrXH7mklRG8Wu56YKoRIoRoVO1j8mjnpC1IhpWjJDqWMlHB1YrfRqBO12ES7RKWUmdHlw5QYGrSHTjNVBAkVLZm2aQClHxpVTCcuwRIaKpVa3RSPSqGw1s+MJZCGh1NruAnRp1tmHFjFteDi+nP1FIgQIBSqqDWVCJLWaf/VNeHVfSIGBkb1ZjGESJdNkiEh+OC0ENuWvgzsjwShEtQfoqvJMmxKa2aJOWea5OkK4m710bT2RcsYQ5hSQmuhABOyTb17a2yLgqgxAIo7+A9U9VqVIaJvkH2klAghOeXdpvEqGAiEPGl6LVLI2VglsQnUYpNzrZXgqRq1DNNswBkWIur0cXFJgoKIT+NNhiMiiJpRZAD6ku2i7RT5GG3SHYJR6MEYIwPLQPH3lPUJ55DCoFUd9DHZhWDxovaZw9IVl+WYQaFFbBqIpEOKgwyMBIjRmBVDrOIgr1AH2QZfgYGxIKwnc8CAcItPzMsIPIwGn+r7VSsl9wSMbdCEaPtXlViHG5rdyKrf5UxxYMwFasFEKM5ykDAe9yEyNUaQGKnYWpOq6/GRwW9MUtBoppo9kDQgRSiqjvxXohgjQ8QSXezaEwwwUnWAyr4dAwQMnDGwq6CamSw1nH/xuaxs3cnqEx233fIl7n/gIE8cPMrKasvjR54g50pIZvAqtZi/CoKK3z7dL0RC8AQIJaXGm087f0ruUFFmM5Nu9AIpCaFJdH2Hr4i/xlX3b0eZGko48thJHjl4ggJMp4lzD2wb0lN5+KGjnLFnGwCHHj3Kzm2biMmuDUqgOntlZCcoBLErcRHzx4kY6GcMhIEph4EGwdgud9x2mA++71Ze97rnQ4BTq5k77znsobZw4MBWllpDGVQUQqUCx473PHTvE0gV4gTOPX8nMQqPHznBIwePU4tJAgmV88/dxjn7z+Btv/4HvO51L2bb9kUCGXs0DUDaMOYaKBLDFWn+IDevec1rXl+pUhUgUlW4845H+Ll/+/tUnXD0cMsPfP+1vOBb9pNE+M23vZ8bbnwG5561g5tvvpd77jnIy7/jaqrfVMLAuEXQKox8NBGirKehiQ69hQxPWAabYV4OgQAAIABJREFUOw3ig398K6eOZP7uq58LAocfP8Vb3/J+7n/wJGtried/05l83/dcbT2Km5PfftuD/Pyb/4Cmtm62vsLxE5X/8B9eRmyFd77rE7zvj+4g5kCp8Ku/9hr27Frhu77rBn7hF97DT/7zV5IsRGuA8N0g/8+zHeb1tVWnBaCQmoaQkjWlg/N8CoTYgGfY52yTW+t+qtGqAyiBJpqpW9/35GyRfcm11uJT6eqNWQjehA2u8W6MJ+DxfNCVVQIzpAaQQg3BPps4onQGChS0N5ZC7vNI1anVJkladYz5SzGiA6tBxJ337aGuFvXJcwAt1GKNUgomb+hyJiaIuPs9NqU3MEGHp2bAtwkDUvDmPDaNgygFCRBQYhPHKbbp/W0iPCRLVCo1m0lmkkTfd3YM6lMePtWa2emkdfd6IfemYyf5Z3p7Fnwijjq9PriDv+vuB+nDupa9uszCoM52MnE6lZlTDtQuQX36HrxhHrwtrGEeGuWU0pMM+nCUN4y+GIGchehJDqo42BJQ8ujJoaKj38Z6moCliNjUXEcPiCEOcqDu1w2mgsP6NO+NBrDjIgraGIjS9xnzJlBwcE3r+ndlQIKsS33UgKiCSSQGechGv4Yi2UEJJaXgsp46Hg+Atm3pOzP9NK8N8x+wdBNGrwIDqDJJAqTgdH77rODbaaBNNYaBBIoMAFgx88mUaGMao0PxfdNqho5Dk68lI7g5pyrg37U4CFfFJsNZx+hPlR4PjyU5y6PP2eIzg1A9eSSMYImBGJO2pY2BNQ00qUFypuTKyRMn+f3f+33u+dIj0Ae2ruziwovPZ/uOLWzeusCBC84gxkSQSi09Jfc0TWPnY7WZQyk9MSSTYJTMaj9DaiHXQj/rMP5LtmtgsHjYtomk1JBjZNK2jDTJeRP4V9YTx9f4zbf9N7QkqgTe9a47+dc/8xJueN4+tAo//S9+h1/6pX8AwC+8+b/yY//o5WzfsWTPaBvkEioG0iYJBhr4xEcRF58ZABHEgOXBgtNkNJH//a3v5ud/9rtZWEoo8I53fIL7HzqKSOLjH76Vn33zq7jogt0GfIlZg3ad8Lbf/ADdKSXGhne/58/40Te+iJe85Aruvuch3v/eW6hlE48dnnH77XfzG7/xWnbv3c5zvvFK/tPbP8oP/eDzHXTDGRR/Wc0nQ/Oa17zm9ZUrH26ocMvnHuL/ff8tvOXf/X1SEG76+GP87L95P89/4VnkCg/et8yJJyJ9UR4/XnjkaE9XArVAikMvY8+FuRhbIKRAjSZF7itIFlK1OPESLa0LoJFAFFhdK3z2s3fzohddaezbqvyX/+cmnn/jRVxz7fkcPrrKb73tIzxy8BS7dy9BMnLeReefwa/80vfZm1W49YuP8Z4/+BIhCE88fpLPfPJWfukXv4dU4NWvfhcf+uD9PP8FZ3LGvhXOOGMPH7/pSzznuvNssBR9mqWDafv8HvS1XKcFoCAhUAU3LLNFVnWgMVd3oc9uGWBcz1xM1pBSY5PYESSwODUzc7PpnkkLArNZx0DXjjEYfVpAtZAUb2iVWs0QMdFA9ajG2BujyB8bRwd2N5yL4vrxwd9A1OjazjKKWDOFVm+oo78fIN7wqb0mMhjn2WNqAOO2Fsbmv5Y8UrRhmJJHQgC0uk7c0gNqMUQzV8u5hwGsqASFGLAmq1b7BVjCnTWImjNtsEl6k5KZ9Yk15SVnM5VzAMUJGOZZUY1REXyKX2Y9ISaTjkSLAS25oIhH5DWW7uCTe/HRuYhF6M36nujNeNO0Zh4YnP5riBBgIJOBLgPFC3qPUhxc/cGZEcPE3CfW6u9hqR9G3Y+eMlIlU9UmzjLKLeqYUGF+AcWiIZ1dUUoZ92n4/QCYjJGhMTko1aNhA2CQCyFA6c0HQzBjPvWoUoURmFKPkIwpESVQdJ3tYdQ3GRuLEISmSeM2DJp+a37WGRyKjl4eA+AysEkClrYxzG2rGGjSlYxUoXHzynVmEObZ4IwFUQPblGpRsbV3A0tf06UYOyAFNK+bKiYHSUo1sAstSDDb1lLsmtG6L0KN9h4qE6jGfhg8S0ZPETUmTvR1ZOkLBmY494++62myQg4stUuce8a59McCq090iFYefexBjp16lOUjE9rFwradFxGKQhAkGqpvEaImTxqjKbVCsthQKYXQ2LrJJTOdmo+IOnAaUyQ1JttJTbImdW7K+FeWKvybn/8DfuD7n8c5+zdTq3LllRfz4Q/dxzXP2sMdtx/i6JFd3HzzQS66eCc5r5Br5N77j3L46Cr7z9rO9i0Tn/RE7rrrCKsnCheet4XFpYZ+ljlyZMYTJ06S+1UuvOBMDh06weNPnCCKcPGFe4kx8N4//DQ33ngJaRpRgUcPHecLt97PT/3UK2kTHD54HT/3lt/jX73p1YRkzISggX61cPvtx3nrW14JwHe+4momfq+46soLuPqK8zl4cJX/+H9+hB9742vZsX0ZiYVLL93Pu9/zRR597CS7dy+xPv9Zf2Rb50rNJ0Pzmte85vWVLZe0aeSWWw5y/vlnsjA1+d21z97JlVc1HHr4CX791/+YP/rDNW6++RCv/d79LC5vpfSJ9/3R5/i/3/EZtu/czpt++u8gbaDLlXf+7od573vuZO8Zm/mxn/g7LC23/K8//nYu2H8On73pc7zsO55Bs7DMf/q/PooQecGNF/Odr7iatbXC3fcc46JLdiMojx06xb33PsIrX3Utkwns27NA08KDh06yc+8yYB5fJtEWipif02c/dztXXbONdhLZunmJN/7Db6dtBInwilefz213HeLGb95PUOVZV53NRz52G9ded54/O/qdSXB9xBxQ+Fqu0wJQQECaRJc7Qoo0TURSsAg8bNrf50LpZyBCk1pz7lejPvdOtTdzQR0nylHsAR2GqbH9WymWHCDVGhtKT9EMIdmgswyMBtc4a2+T+GhNqgQhiDnJV4qnEfQu21BG4y1RBxCUWq2xCuLGf01DKesT6qrFAQT/HISimRgTpZjjv2bxSXYFCcTkU27bQUo2Xb6Z7HvahCpRAAmEsP51l2KUWkUsjhDbrzRGNDpFng2Rhs4OQap7FWRqzcTUGCgTA1J7UKHPwT0NWpMQOD2fWshkJERniihNk8i5p5SeEJJR6L3xrqrMcme+F1qgiEsK7PsctGRDqVrjHWKiYk3sIIvY2MyDgzgOKNn+Dttp0hupQslOZa7+vQ6zYRGympzGzP2cadAkSi5js74eeegAQrDGdqDs279h4FYt1Gpsg4ElEiL0fedGo4pKdlaGpXiMnyMC0ZJIDFQzQABPdSi1mLJOhnQMlywMTJ0RHzb50cwlF9ENNwMmnen7zo+lAT4BoYoyEyUN7Jkh0cOiLSgIVQN9yeDyiYh/j8r4nRSKGT66YWUphSDRpEQb/ErymNqgxJQQc32kSRHNPaW6J4aIrcsQqGLSqGFKUGomxGg+Gf49gq3FWoUqlkKBBPfYSIQohDZwww03cPmlq8yOdRw/dYxHnjjIQ488yGOHH+a++yOXPP0AsQmjr0r1tSY4iOKgVa7m4zFdXKDvj5H7njqYnPo1KobIwsIEMCCrSGBtddX8FPpu3gt+GfXY4VNs374C7gXzjCt28qk/+zx33v4o733vbdzzYMMH/vguzjl7C1obbrvtIB/92G3cevsJvvXFl/GdL72YEISPf+J+PvD+u7nppmNcfOEi/+qnv4m77zzCP3rjh7jhBTuZTp+grk1497u/SLNojJ9bPvcAr3jFN3D8SM/WHcs0LZQMv/uOT/Hy77iG1BpouW3XMo8fVqSYvCfIwDwTbvvicX7yp38fCcYE+9Ef+SaXXlQ0FH7nHZ/lrjs7Pn/LQ3zT7gsRjSy1EenWKF0GHYy6BkZF8avY4CXk17X5s9y85jWveX2FyuUOATQOYy8fPLTw3a/7Rn7z//gA//Sffztp8j5e/tJncNHTdvKxP72f973nLl7zmgt561tfw7d929v53C2HuPzynbzzHZ9i6+ZF/u3/9mpe/4b/zOc+/TDXXXcOd38x8PIXnckP/k/X0KP8gx/4bX7lF1+HCPyTH38Hz3vRpaTQoLSIs+hyV5nlyGRTCyihQqgVDUoVQDKiikgEDcQKJ471fOqmL/Hmf/ccS+FqA3t2b0ZV+egnbuXx4wd53fc/30zREfbv3czqyRM8fuQkO7ZP/Z4zt2D8eqnTAlBQhVnNhBQhhHHijaolOKja9K4YBbrX3qfx0Rt3Zwa4oVzwB6i+ZPMK8Ei76Ks2Jp9+hwoU+n5GE6b0vdKGRCvW4KdUECkuMXUWBJWg5msQRiZEcWCgjjTuEI1q1DTJpqmqJMv9Q7HYOktPwP0CipsqeuOpFvmXkp3sk5TsgVBsKl2yObW0yYm1g7Y9WKJBiN5EBmdcuFfAenPt2+GMi1rzOiuADQ24Bjo1irzFUGaPcawGsjj7o2KTXk1GvMiqRmdvMpSeGCsSFYJJKLQMTXwm527U8YMlNZTcUUpgMp0yaPC1ZJORJM9SqAbYxKZxLdlgDhkd1DADzpjSqP0Pvr6KgxR1g/ygejMeo6WLhBCoYoDUEAvZ970f5wDZIS95cqxmVzpijCZfSIk+90ZH02qgSWpGaYdWJcTGm0z7fm29Ggrc970zSIpLF9ZZGaWUMR5x0OWrAy1ggIF5fZjoBFUHLfycgHE9mAmirJ97YX1+OUgBhp9NDiaMkalaISVCrjQqEPE1X8xUriihCG0w5kRVW58heiKDZpM2BFsf6ro/SUIVjxTFmCq2Pdb8p5Ts3JfWwMFs5PMmuTIvNIgki4p0GctwvRno6pZIYaDSYGwJ7qEgASGQmkiuHVkrSuCmz93EY48c54KzLmDXvh2ccf5enpWupstrtJNI206otTeWkiQG8kypGe11ZG3EFCkxICkSYmSShL7LVK00KZGaQEgNKi6rwXwiEGdGyfw2/OVUqnapH1b09p1LlriRAj/0Pz+fL9z2Ln74h5+DJOgk84E/uZkfff2LuekTh/mpN32Ub3vhBXz2s4/xa792G69+9blcfulefuO3Pk7G/BEuv3oTr/+R57I4ET78oQc5djzxrdefxVlnrvCu3/sAKBQCg/21GStGkIBbOhqFVavdksy2xUG+yrlnLfG9r7uOLMKvvPXPeNPP/Cn/4qevJ7nXznd9zzN57PCMd7z9w5xz7hYOXLCT0AhveMMLecubf4+f/JnXgFn/+PObO+76+8+RhHnNa17z+psoj0kfhkBifxOycPCBRznzrE3GSAwDAxqEwnOu28vLv/0qahT+3mufxh13PcLDDx/jV3/5Ls49f4G3/+691BzYstwSFbZvU65+9j5yrEbcDRN+8Ifeyb59SzzvhstZWpyy1hVq6EexmyKkKiS1FC7z8LIBV8CkGvbD1SV5gbe+9Q/5kde/eAMDzp51/uxTd3DrF+7lda95ARMZAG3YtW8La6uB40dmZs4YrQfDvSXm9bVdpwWgEFMkJJ+Mp4jEQNO2rHW9T4bNg6B6KsAw5e9z8SbVXeBD8IewODYgQSwZYaDoM5r/DXn0Rh+XqiSpiPs4hAoaMhqyiQ4kUarpUE2GYYkANikfIgSHRsG8Hoz+bo1JycX3RVENbqQSIQilnzmlvBmbNJsuWwNWqtHCmyYaYBISBZs81QpRAik2IyNBxajqZkYn7n7PCHIINm0ewAlECFjDGzYkYCjWuDRtg1b1RjSNZpcxibEsMMo4EuhrIaVEUy19o3QZwdI7hGgGdU47Z8OEPcXgTAOTSTRNcgOb6ix5k3Q0TWOeGWrxk4NUZGBRMHgyiI6yAPAmHbXEBTWd/Kyb0bTtBulBpO+zU+PXGQ1g03J1oEjdUC81jU/jLbkie8xkamzynrMBWharaU28mUwG3zdGd/ZafdtKparQpGS+HAGCRKKDWaqVvh/AGEZgYZ0B4bINETfUtAt9SAGqKWfAP090fb2pGceJe088qbkOYQRbmpRG1gUOQgQVQjFmR1GF2oNmcjFT1RBMClPNhcf2H6XL6xP2Pvd2HgbbtlztRti05qOiqsz6TIyB4ABRl7PJl0JEZEjbAKrJIIQINUFYIyVLpYjOFGCUPJhRosIoURERci0jc6hoIWFRmiiszdb4zGc+zSc/8km2bt7O4qYVtm7dzJZtKxy44GyWlpZopw2IAZKqntiSPPI0F4vGbOwcQAQVyMWuKyFE2snEXr/h2KfQuO/G4AMzpyd8ebXuSSDAwUeOU2tm394VmgCJE8QANUBsle/7wReyuNxy/Tfu5WkXL0BV/v2vfpQrrjzAXXc/hIjy7a+6EInmqb15a6BpBQnKeeevcNZ5C9z6hQf44Ad7zjnnfG/bzSAVVYIKUoXaWYrI4LyqUv0h0x/x/NxdWIazz9kCwP/yxufw5l/4EwqgfaSJwraVxKalBZSGWe8sK4GlLQscPX6cJ/lAKHY/GwGFjb/mNa95zWteX4lSzGxXEKgTcm5GNjMZ/vN//Ahv/eXvRQQbXgRPng6VLdsbUmum5ju2TZjlnuOrHW94w1W8+NsuQNyPLAhoAA1r3gnZ5/3iW14BIfDgg8f40R95O9dcu9+eU2tBMWP2EJSbbrqTu+56nHPP30HNioRMiHZPKTlYSpZYmsRtXzjI5s0tZ+5bwT2MqcDHP3EbX7jlbr7ntd9CY3rtMQHpvgcPs7Ac2LZ90ZnVxpodDCPn9bVdpwWgEEJgYXHRtOm+pgSsqSre2EowEzw3TRMsko/gDvR1Xa8tPglGZNSzj693PwaLngSI5JqppaNtlRMhcWJ5MzOJRvVhRq5KiFOTDCjr4AHYnwVvNoMBHsFOjlwy0Rv36vKGUoziOjSZCuiiE859wm6adTsBqyqztTUHAYTJZEp0ACWESOmzgwJGHKrYxDglM8zTUsklO71fRgmIuCa+bc23oBal6zubtK/TBdwcz0AThqbVj3WKkd73J0QLrinTgrjRo4QEtVJkjRAT09yw48RRUvZGGR2ZAwOLJBczIQySjDJvwgWb+PtkPnvChkXxWRLGKGfA/Cxq8dwA99doYhpRUnBwxfePAZQY9Pu+3uz3LqdJiVoMOFDBARsDZMbjg1o6RkzU0QgyjokZIQYDUZwVMvg5iECIgdybd0fpO98GM9nEG98hJnOQCtRq3gchric4SBD63ox58Pc14Mk8FlJqQJMzMnSUe8QYx7WxnrARR+NMA+MqfW9rumkn5M7kD0lAaqGnWtNWhV4Sjy5vZdYERCzIaDh2eIrDYCoZRgNVl/rUYvuHrWmt/jvB2DFucllLsWMSDKSTwTS1FghKjg1CYt+JQ6zIDDCgwhhEMhp0Khv9LBzYdMBhALmiBNqYKAWuv+a5NGvLfOJDn2Tvtv10VG77wpeo9Nx9z928cvvL2LVnC7Vk83eIQ6hTNSYFQwtnrJYYE5lA32ViSrTTKU3bMOtWoSg5+zUvCRLS6PmQ0pMSnef1l9TqbIHb7zzOJZdsBoHHDq0itWXn9gXMK3OBXEEyhFKNKRNBM5COU0V52mXLPO/GfTztksshwO133mcsAoHoIAEIk6WGF7/kAvbu2MyDD57k53/uJv7eqw3MHhwvArD/zGXe/HP/ld/+ndcTonDfPUc58+wVSoLjT8w4dqzjzP2b7DO00OfgIHklyCmOPHqCN/3UH/Iv/9lL2bJlYkDB8AEVqgq/8Nbf54f/4UuQ5H85rvNhEiSMsod5zWte85rXV7SGu/WuHYv85E/9N1aWCpMUyL2ya992vF0giPCpT93LpmWADMGeX4IGAh0hdHzzCy/hJ/7xO1nZXGjawB133c71N1zB+eftJ8jMo5CtVX/jG3+N/+GV34xWYfPShFShqdBIQd1Ee8euZV73vc/jYx+5kwfvP8Khh48z6zouvHA3VeH1P/zv+fF/8irOPHsrpSh/9qm7uPzys1lYtGGdCnzso3fxa7/+YV71yufyoQ/fSUI566zNnH3OLrQqBw+eZGFhic1bWp58R5yDCV8PdVoACrpOliHnzKSNY+NtBv9hnaDp09TolOvi5ndNMsNDrUqujA2bDIkBbjxn0YqDJ4BSVMiA1A6t8Ei7lQcWl5mlSKGlyMwo5DWtywV8qr++PY5lyDBN3DDV9eZRq00e1RMIbErrO2UjeJdurKccDOBFWVgaGRZCcC25R0D22afv3mT5kVJMY68YQ0OiNeC5ZP9cO4Ebjzi0PsyOS/B9U4+fUU8jsJcNUYay/jpVn9ybyWOluAGlyU9qWGAWIst9w9Vrp1ip2exih81wKr5qpUmRUmUEhEzjb01xkGjJE2pmnMPktui6xn6QLxCigTl2ZKwxH8ECj4fMmbZt7fcuZRhqeJ8h1rH4xL5q8UYflwkM035xgMMkBQOjIgWTLZRaxkm7YrSwyuALUNfBg4onJwysEpuo1xqe1HjHYOkDXdeBKk3bMuuqmWT668C20Xw63YOh6jiJH+I2o//ssC2jjEWrM2Dc+DIYw0LVTFENALTmViXT9wVRi7A7Pm35wuYdlGZCIttEtVRnXIQRSBpOHovnZESpBx+I4dIwgB0hxPFcDsEAo6yFmFpj/WglVPP5eHxhkZIm3Hj3SRZPrRKDBUGWWp/0OQP7hkGSpGZ+GYLlOVsqC8ZiInLk0BFOHjlJzInVY2tGKyyVmIRJ24zyGcTXTLU1SIC+yzTE0fQzhkiTGmZ+6w+ppaCsdTM3bjQJj1DJuYO2McYVSpzfh7+s+pYXXc4bXv9HXPWsFpXCQmz5u694JsN19/6HT/ET/+yd/JMf+1amqXgcrA1PUrNGCfA/ftezee1r3sYVV+xFQ+bKK3Zx8QX70Vhpm45BzPb5Lx7kZ/71n3LxBdvIaw2itm5TLFCy+XFE4SUvvYKuKj/x4/+FmhtuvuUQv/zLLyVG5ZYvHuJn3vQ+fuu3X8PKYssVl57BP/3Hv0sNQpSGl33bFSxPp6zOtvCGN76bXbsNrtq9cwt796zYlmTl+LHC8qbFDZhBBhLrcaO6Yf0MxNd5zWte85rXf/8yz7YqyvOedy61PJf77n0cEDQof/+HX4AGCKq8+AWX8JmbH+TYkVNccN4u9u5aMLYlcNkz96G1smmh4WUvv5z7HjhKqJXLL72YCw+ciaJ892uuM1N7oIhy4wuexd13P06owre+8OksL7UQAhdftIvPfvoerrzyHEIrvPJVz+J9f/h57r7rcZDIt7zwmSy2gV7/P/beO16y66rz/a699zlVdfO9nVtStzqoW62sVrIky7YcsRljYxMsTDAwGBwGPOEzHgx8eDMDMzYGGzPwYMABDA8wMBgcMc7GsrEVrdySLLU6SOocb99bdXZ4f6y9T92WPcAw771PS68WyN19Q9WpqnP22eu3fgFe8MKrOXp8gbUyxcAI6zbNce212yibNEmJhZMDnnvd5Ty+5wRYj0mJ8QnHunOFvg989Ss7eMGNF+YOJQslCuG17QNH96Gna8mZQJvduOHs9Bvv+tk8KI5IMlhTa2wkqoFP6PS+aQakGOl1uwD4plHgwZjWzM5aRzLaOJDp6CEoFT8G3wIDMQR1fzeA9USpuH/Z2SxUhvUnDmmWvVOjuNgYrCvbRpVgNN5DNuLzXpsc65x2i3m6WVIZgGHjFGVIMc9GjmSgQmPzpAUkkGKOGJUOHiLOasSgUqlTnlhHNapEG1JJtDrrViVrDI1vchPplLZvnYIWeaKesg9FKDp1a/MU3CJJJQ6lyU95wqzafpONFoWAR0wGAho149s9PsHh3hRXHX6cmcEChSBSRAnKyNDGvAkKGiDFQNPRqbv6KpJS60UMVdXBOIeIxhpWVZUfS2UF1jmljOXnsM5qBGJS4KppPN1OtwUiUp7Ml4l8AY/aibgfqHmnJJowNEfURj0SCnsmRLLdBaHRxttalbfEoLRmMRYx+tmV2MzgteFIIebz2BBR2UTKQIJhyXElBYtSkiwZipn1kv00sgGgpMyQIctKctqDcwqqDOUT0jb6SU9eipHgUjaBMoJSG4epb0GgSYIxFaQBh7uG21asY81C4qzjx4n0aRhgxeo5l5kClGjJTPvPt5gMsKXS87UAiEZG6s1HPT0UXASnn7vE7HfgeXJuJU9OzHLV3m8ye/JIBk6MsnuqHKcUgoKTIWHNMGLUG8d9K8/mlAiXHdpDd7CAMxWhD7fcfAdf+/LdmKZiamqG3tQYy1bOsmLVHBMzPVasnmF8ssanRb2GnFPvCAI2QZ0NUxV9O8WeB+7gwM4d+IV5Ot2eUt6T17jJDDCSAin06dc1tyzfzLaLL6b+uy/y1l/7GHVvxf/eAvwMrpTA+8jhY4skibgETixTU93sUwBHji2SQmRmusviQkNvrFYKKTB/apGxsQ4S4PiRBQIQbWJmrEdVW5oUaPqesV4NAoNB5PixAWISIUK3Y5mcqOn3Pe9//+e5/rptXHLZOSRJDHzk1LFFUhCCFeamOrgq0R9Ejp8cMDPTw4mhWfTMz/cV3LXC9EwPK3BiMTCYH2CJJIF6rKLXrSHAR/7669ja8bKXXZ7laNkHJbkl3hvxKXu3/7n04R/f6v1zN4NL9x+jjeSoRjWqZ2aVyHSyPECiQryQZ12St2YhZcmqpmm1SQgZB1YnJ90Lx6TMAFOW0RYrFjXyNgCJEMvamgdMViAKiwuet/3Cn/Cff+k1jI/pHl/38AmTkgLlVrLBOXlYGnIosrTJyjqkDJhgddgmEITck2lL9Ou/8Te84MaLuPSSs9thUfaqZzieHA5rR3Vm1pVXXsmtt976bT+iM4KhYDKdOoXSoOmFFZsmx/XRNm/WaFNQYhVNAmNTmwCRop6pQkX0oZ2eF0q3Gh/q1DHli4uYnfytZZ6IeM/E/Ak6ISI24FxNbIpZH2o2mKnRiMF4o1GKcBrzQPLKEWMYsg6iTouVsWBU70Sm0EN2tpdWnpEfSCtT7E1U8KAwCcJiGDaYKVEac7HDiXimAqhO2weNF7QOZ3SDGbzvJXBBAAAgAElEQVQHIxlMUPDCe9WsUya2pcEXk19DbEGLYugXgzIUSiJG8up0f3IscdSWmEZ9rYUd4X3T0q6i6ELpclpFTJEUkk63GbIBIgrwpJAy0T4DBsYQQkOMpm0KVK6hb6E2p/qYzlQKUEQ94TQhIk+oM2ASW3mL+ntoAkjMng963lrraOJgmLiRGSykhHEGkcwCCdqIi9WJtzGG6BW4SVL8DVJ+NVGTKiKENJTYSEltyI18+d8YNLVAHd2lZWPEqNKgFBOdShvmKAo6Fe8E8mt+6p8GacGEGD1kJke5FlNmqogYnHGZPRLyua2yjLHmFHP9E4gJBDzBK1iS4hB0QTGCVoZSgJ0CsokxDJpGb5yiso8CfEmmi6R8zhhJxNQQJXFy/iSu6hKavgIizmZZjGl9CCQlTfKICXFD+UVhBCn+ogyZ4AOurtm4ZQOzc6uY7EwzMT5BZ6xGLJxaOMGT+/YyGNT0oprGRomabiGo/CV4BmFACFnC4kFSReV6BBbwvlFWiqgko9/vU1c1dWUZNOrbUoxErRnR1f+xUomQsGJZF70vlASSfD0BczPd/NOJicmKAnMKMDnRbR9ndvkYxfqEpNdAZQzVWFWejbo2LF9RHm9Yna7h1a++jve8+6Nsu/D7sTXUVaS7rAPoWiLoJrBbC525HmXRqnuWTq+n17ZkcBmY6BlMr5cvxLy2Av0Fz+c/8wDv+s0fwdoSE5n4VnmDDKdDSyJ2h2yF0/cMwxUntUbFBQJMpxk9kr//1IdY+hy6zitLIjIy5BrVqEb1TC5pV2I1j8YKVkdELOlGKO7xNn+dVHoKXT9NWVQlYbIk+Fvka2U91w0wurU6ff0VA92e4xWv2M5HP/p5vv/7XtRuXR3lLhgAo6be7RJtKGPO0ufk7kwlntkTochuJSWefPIIxi+w8dzlKikkgNj2N6XcveT0e86onl51RgAKacmJHnwkek9sNJpQY+sarKvU8VRH19rYpEQIDS6J5sYbg49e6el4vZCcza7wmVKeojaVSS9WyU1yjJGBWJrolcKdN3jRQz8OsOII/QbbmurlaTaSmwM73E6JTk4hU5+TxgFqI15YFGpQWHwPUlRZQokVRFBadNaat5YPztA0TattJxXXe5OlAQXAsMTkW0AlZnq+M5ZghOijNl9kgMEYoo+EnBJByMhj1CY2BnXsjzliUs0bpX0t3nt8o6/HOatmdjHkuEGNHgz5QUszFEODCNRVRUyJwaDJW2V0IktucGNk0B9ks8NECLoBbaRPEtXzW+eyUV0GmqymayBC5QyNV8+AOkshUl4IY1RGiJUcg2iEGJS9UuIRITfmBnTRLlNjCE1QAAWLIZzup5BUJmBE/REAnHVq+Geigl9F2iAGazOI45xS+UNowQSVVCjDwWegyVqr2guSpn6gIEXwkUjM8Zqx9VZQBotGmKYsF4GhqWORAunr1dcYYtCv5ya+AF5iVEKTUMkAGQQh6Gfgm9wwSCTSZLmDejJ4r/FDBn2cEKIaghbWUFIGkI+BAPhBo8doDeKE/kBZSp26oze9bHYamj6+8dSVwVhLMwj4BBiHGKvPU15fK+8x5BSklsUkGRTU61J/xqApGk1o6PW6hGmLjcKiX+DxPU+we9dOduy4n4WFeV76nS9mZnZam7wU9b02Qn4bs3FmIgToiMPZDiGAtRU6s0jtvb92FUYgBJV2OVerFwVgnRndgP8JNZzID/+Upf88reuVpT/xlAfiKb9XHvtbf79UMeJFhGXLx3nhS7by6M49bNlyDpJy/C3lY4zf5lGWbALl9O+Z0w6q8LASn/vCnfz7t748O4QLUpr9VIDVpayAp9S3+1b+nW9/pg2BBD3S9C2wxRCF4ducrzL8/uhUHtWoRvUMrRaDhUxFKHtdWbLKD2EHXeGLuXr+mqTT1tOlUeY85avD5zsdIJYli7wxiefdcAGLC+fptkOW3FeW/K0AE+3ryN9Q6EDZr7RAfXme2P7gylWzvOmNL6fq5j1p/p32PivDVz6qp2+dEYCCiBqxaR5qbtwk5mmMJwSNmYtBL7IYtGEOMWQdsU59y3Q3EvDNIDfmNQUv0zM+6VQdPYG91+jEMh0tYEHTNFQJjBtOem2eXrYmdaAShQS+yVrnqBs740xu0HQSqSCATqJiCFRV3fokSJ4YGzFgpZ3uFDChNOwhRgjKkNCplk5wnatJhRodwbpKm9Y4PM4UaaM2A4066fuAVDmmM3s7xJiwzqo5IpoWoZPg4eS6yAOiD7qdTOik3ejkPQXVjwuqtbcuGxLmZdM5p4hkMplVoX21yYwD1c+XRrX8WiI12ejQqrRCYgITc0oG+CYhVa2TYMmxmdYxaBqsrdqpfGFUxBSynCGzCWToJRCCvvckye+bykWKiWEBAgqToZhE+uTzlFtZKJJTBAo45EPQX02pbeCLEWAIyqiRzHxJxJbN0rJMIpAx7eCDem7kZjc2HldVVFVFSEWaor9nRE1CnXMtY6E9h4tBojHtnyKyxKQxZQALSNnfIb+W1lTTKYBTehc9tkQz8JlFkq8VEidPnFCDyDxhHx8fJ6VE3/fzsUUaEY3XzMBOf9CwsLBAMxhgrGViYgJjFNxo+gMOHTpETImVy1eQEBYX+/SrhhTztNnYbEwZWu+FpmmorFP5QQFoRA0sm0bBBGIievVIUHZRZPeu3Xz60zcTB2BNxfH5eY4dOcKKZcu4+JLtrFq+NrM0Ih2nRo7GGHxcQjFPuloVwI+cphKLjEWUQePzdWatYCuHDwFbVYizuG5ndAv+J9Zpm5X/6Zv2D7yb36YP/serTHD0F6yFG2+8vPT/GZxQ1kH7xXa7VmImyz6uTP6fyjQobbz+XYi89OXb9Z4nCjSXjeqwmU95s5fQsVPM9xzDt8ZIpiX/lePKgCkxb3Bt+7WyeU0luna4tc2Pu5QFUb42YieMalSjeoaXpHa/LCnHBZO7FiEPMYcNv7T/G4f7PyzkKHPBIWmJH87pT6bJCkuZZwW4kKVrsCZDjHXskq8PH6PcP4bciuFRk/dNCg20NzTSaaCI7mWNU1PrVv2N09dSSAnDJxnV07jOCEABaCewhWqtdP9ISgogLC4Osn5H4wQNefJXqblZjAEfUz5/Dc7oBi6EAYmEMw5rVLusGfPSTttVyx2Joo179A2PP/EEq8Yn6PRq3cDHRBRtvqqqGprpJVhcWODggQM0zYBup8PM7DS9sTFtCip9Tuu0GbfGKCgQPEZsSxtXA7wlcYDQ0st9KqiDaqacc62uvwkBV3cIqWjJMwNADElQunW+Ur0PGElZumEI0efjMFg0qSGEQOMbJGvVAWU9BAUMnLWqx09LJCBBp9gmGWxd5QYtAzdZ4jFkb+i0fTBoFKApx2UMIpaqUuNJ7bm1AU5NwmJaP4o48Eg+lpTBKJuUdtv4PgmHrTpZfqLxgzE1mfFSGkWdtltrMoFLF8Sm8fr9kEEo0cdNecWz1iGiTAJ17FeJSAxNbgaVIRFDIOXPMxUTQYVRADApn+NGcgIHhGRUemMyGwHB+5ilB0J/iXGkUvf1JhRiIiT1uwghEJoGcZamGWDzY5U1O0Fr7NjS+6H145AEofH6eRqXJTMRY9wSY8QsGTBqkqhSmCaf3zYDDdoYB58lBSSSCAsLp/ja126hspZTJ+cZLPa5/tnXs2z5clKJYU1DmYePCprcfffd7Hz0Uaqq4tixY2zdej6Xb9+OtZaHv/kI9957L/Pzp9i0aRNXbr+MulNnUEbveymWNI7sB4LGrVLeDwSbmTIhJExVZdZGg28aqqi3zbquqeuaTrdLsob+QkMYRKx0GSxGSAp2Vc7RxH4mHJRozrymFT8Ka7ExUXUqrHP4vse4HKObEgun5hGEutMhpsDi4iLSG6c71iPkyzONbsJneMUW0FaZTf5yGw05hAKyYnXJWlkeYwkK1VZmBAm5mbcIgbLZM+1zLwVT8nMW8EAC4BUQGI7OoH2cAhIU5pI9HQ8QM2TO5ftYu5FsJ1oJaPR3cfnrXo8dx+ngyOhkHtWoRvUMrXR6e66rY57wtzdzyf9ffu7byRpP/1pheA8fVZZ+c9j/52+nlllQpKsBrKO9p2R/hJRBYwPZGD+yFDAo5r5lX0+Osi9gSWsMUe4j4vMQq4DSSw91tPY/E+qMARTIjRFJVHIQYp50Nrkhd8pgCOppEIJO4FXTrv+lpNN7k2yma+up76zGF5bdXPBefzdFmiboBSkwMAMWFk4xf+IkB+65h5nLttPpdghNMR9MucnwbcJAM+iz89FHOH7sGL1el0MHF7j33qNcd/21jI2PEQaaJW+MRVLCh4CzGtWYYklgULp5QnXWMQSsGAaDgZoL1kp7FkkanZg3ivue3MexI0e4YNsFVMaSQsyUcWllDtooasSkuvsrJd1ay4GD+5kYG2NyYgKAo0eOUnVr6k4nszE00UAKoJGbc0Gn/ynF9rUU9//gPT4McJXFoP4XPngGgz4xdrNURKfXOjST7JWQIKrBZQi6CW+jBKXESmbwB90kp1Z+IcTYAA5xLtPqB4qMZvCkeFsUjwlD1qDHRJSgaRRRUxIMJns16DORpAVYSkOg72teYIM2oZKpaTHEtoksDXtMsaXSp5BfV04RKJtvMej5grJGtKnXYwzet2yV8vwmx6j6EPTGEPX1KXNHpTgxZFOcIm9oAQS9cVirjBz9PHIDYgQb9TxH9Nwtz11eT/GVUE+G2KY0hJLKgWhjbizFgSf4wDcfeZQQIpdcdDEWw1e/+hV27HiQq2dmWsDIiBBSzMkacPz4cfY/sY+rr7iKmdlZ9uzezV333MOWLVtomobH9+zhgm3bmJqe5o7bbueb33yYrVvPRzIQcxqgldTHQs/dHN2akhqWNk3bBIXoiWSZRZEhJUX3121Yxyu/ZwU2dYhN4Mjhozz4wEPs2b2bO++6jc54YMWa6zBGYy4FIficDoPRx8UgkSzf0Sm1cVbPW6CbAQ1iJDQeJOIqR8yfvw+BEydPDk/IUZ2hNVSJwnBTJ+0cCpTNlZv6lH9KysYuMwlOa/rLX83wAQFBAWqjhCtECpj8VMbB0lImRJKyhU0gieGwKq97MoxxlSUMB73Dmvba0uMuwocCplhO2wQnS2FvDI9ptKEc1ahG9cytIaxbWGXtuH7JejuEB05nkaGL8FIWQVrCHTtNShYYytui/luGPj+Syj1J/x3FUbgG5L2JSSqVS5IoozAFlu3wiYvUgSztFHV9KICInLaul+MuPl9ATkw7HT1/6v1qVE+nOiMAhQSEqFnvuofWaWblXJ72qkGb9l06IQ9Bm9syCU9RTQGJtOaEppyoMZuZhYiITlDJxnshJt1TtfRzh/cNx48eJzVBte8iOFtjsrwitpu2xGJ/kUcefYTLLr2EZXNz9PuL7Hvyydzcq47dN4Fk1KjOilNmQpYcxEyX1+ZNaLw63/uo0+jSWMaImrhlrXvwkQP79nFq/hSDfh9x2oDUlWPgG6LXBs8YYZCjFo1R08IyLd1x/wNU1nH11VfTDBq+8PnPc8FFF7Jh00aCDyqjaCdo2nRpsx6GtP7c0BQpyP6D+zly5DDnbdmMiTkyr6CRiSXSikhoEsYOm3dnHU0TskljJleJqLt+TisoiRQE6FjTMjFiKGkFmuAQE5qgkU0DidmTw5jMqPB5sq5Ns7VVbkANscgdUDaID8paKBKBpsma/piUVpZ/D4lDaYcYki9gh369vO6SlJBCAiuYpAuzbRkDCuC0wEQYpjwslSaAAgOafKDHUW5SrXllDK3kwFqbXXlT+z6R/22t+jyUdAvJPxMzcEQiezKQJQiD9jyonNNITImERgE/ySCTgjQhv37h2LETWOeYmZmjW9WsWrWagwcPEoK+R8VwqJUIJIg+cvL4CSbHJlg+PUdqAg/c9wDN4oBDhw9TuYpNGzcqe2HDRnY9tpMLLrggg1DD2MdifZTKe5dTJsr7uJS1lITMTNG0GPWPSwx8H6xldvkUBMEZw4pVE2zespaTJ06we88uOmMVTRwAkaq9TvT8I6kvgl7zuQezlsXBABqPJKgqx6nFBSTGvIYlXPaQSTESmgYToXJqIDiqM7VOJ/zrECpfn3krJu3mbDjpb/8+fJglf0lP+UZmpTEkBSh1NmU6bAYy5PTfK7jF6dvczGdIooBA7vmT2AxcZVCdcm0M52LtQ7XTMMlMwtT+TDl2fVfcU1/lqEY1qlE9Y2u4kzbtWq8YgSESM7B8OmNLd26eIaiQ2u9os6PAQUqnL+fylEdp1+1UXMoyNHyae65gcLRmueigTb8XNQoe3RvqvrfI6cqrG3IYWiZGK8kwDG8Q+Z5l4tDf57T7wQhgfrrWGQEokOPmvA8QE1XlSDHgoyDiKMmLxlp0EGp0Q2ZMO9kmgW9UImFE8CkiQUEKn0LeXFm81yY3oeaB1ql2SJyjHxQssLZidmaOTqer7AbR6VBICcmNPSL0FwfMLyySEHq9CXwAV/U4++z1WGvYv+8Qi4uLTE1N0gzUC2LlylW4Cgb9PkeOHKEJnsVmwPTsDNMzMzT9AQvzp2gGDZDodnuM9Xq4ymGtZXFxQL/fp39qkcOHDlPnSWbKE+CBj4QUcJVrUxQcQNbEW5ulHzFy9MhRjh89zuWXbmfv3r3semw3m7ecB2QgNA23gkqx1zSI0lib/G9THNNFOHnyFPfddz/nbjiXqrLEWJYWpcc23tNf7OtELOr7XVgKPmXphJF2YzqUA+hCqA2fygVCpsMba4jeq1+B98Rk1NE/ViQf6HRtBiGyoWCWjxQPgxIjKXmXnVIGOoI29zE3lDFHMrbMhUzxbX0qigmfLPGBSOo/EDI4EHOCRsyNrHEub+510XfWagMbFXBIxBb8kHysIYMLqgEqKSnS+jCYJfGHaiqpTbQvjIcl73mRPpAZD8WzwKlpid4cTInyTDmeUo/VWMFmxo6IzewPaf0jQpHwGGUcGGOYmpri9tse4p6Z+5iemOTue+5hbnYWHyJV9hLIH0r2LwhMjo1TVzV/96Uvs3HDBg4dOsTxo8dx4rBiW0lHjIFut2ZxcYHB4kDTXEwixaDnhwwjMEvChXWuBVGU0QNiBVdZkmQqoBGVsqTSuPk2ajSGgHMGZyIzy2rmVm5tU0d88DQ+4lw+l0KCpAkxxgjiXAahLL3eGIGGwaJ6pUQj1NbRqSuNa/WhzAJIPlFbh5MyoR7VGV0tAh2x0obYctoGatjh61eWbMSGk6oM7EppysvvZFYBJeGobMhMO9WSlFqW0vA5ytqlm9OhJGuJNAMFKJDTt7rl8aWADO1la/S58o98i562HBdL2Rj/S+/mqEY1qlE9/UoKY3i4fis4C6mVBeRhTpa/akM+NOttWQ3tullW2JJQJgw9aXStjckiRJLEHNNoMAGOHDnB1Oy4JjNkgKC9RcjwOdvnTzYDHEWupq9JX4BFJGAKuyEqWHH48Dwzs+MYq0BCu3Uuvwv5NS5Bo0f3g6dtnRmAggg+KT3dVrpJNlWtbIUUiRicM4i1qm03FdLkSMgS92cSkuPmXF1jDQz6A8g+BYZsfJfA1jpB1Sx4skmjRhOKrUhiqasOrupSVV1CBFfVRFGfgxADRIN1NSEaxHWwnR7zCwvs3bMXYmLL1i08se8we/bs4ortV9DtjbF352P0m8j6detBDPOnFkgkdu3Zw5O33sbzX/ACFgcD7rjtNpUxWMt99+5g2fLlbNmymSNHjnHixEl84zl54iQ7HnqEyy+7lIRhz+NPcvjIIcbHxzl+4hjTM7Ocs/6cHDFXDCeBVFz9DafmF1hY6HP3PffyxON7s3u8pgQsLi7Q9Pvqpt+pGZ8Ya80hY1i6TRTE2Mzs8ExMTNL4yMBHTFXlCW+WGkimO2VwqF0aU8oSlYjLAIn3XuPzjFEjOuO0OY556hc9PkaNK1wi5PW+UTYHndzM1QwW+9TdXssQqFxFE337b1lqtplQ6YIo1X3pRji1DWfWGedNekrZ2JBAiF6PfUksY8xARiKnMITUehPY6PSxotLerTH4JuRmHjDZFBKTTUn1egH1cVApjDbxrampKGNnqXmoWItv1OeheAekJV2DnhNDcMRHDR1WBokybVosuwBKRqUkMaT8+lVGEONQWoE1w+hNa9iwYSPz8/OcPHlSvQRcRTJq2lOYSj4GOnVHZUo2IcbyvBtvZOcjO6k7HcbGxzXFoWmyIaXeTNv0lJx40TS+ZWoYGTINWhZGBiKcGHwGivTTzv+bVNoTyWDDUtlTjJiYFeeNzzGiMSdJ5HnAEqlHSUYxGYRQv0/NenZ1ja1q/LymjYTgqeuK8W6XQX+RxVMLysQhknq1roEBkh+hCWd+SRnwtJYCUsBBMptAbN5cZYlCS1ctgFHxMii15O/txm8pe6F090t3ZsPHiLnhN+garMelm7qcQJ5/vcjLMjBR1gsB9WzIkzIJ7XEvVdemlCPVTYk3a7/D6VOo0Q5yVKMa1TO8crNfZK5JRLHmzKZOIsRIy9KMMQ/UUh6ClQGf6OO0u/BUWAhFbrrE6wZBsLRyViAm4dFHD/CRD3+Bn3zjK+mNuzY9L6FDMYMh4XQ4BspaCxDFEDOyrEmUCbLfVyLLKYIea7LCX3/465x3/jquffbmkobJ6ev/U+Rwo3pa1xkBKBhjmZpehjU6tbEmMwdixPtGJ7TGgtUptzNVmx2vGvAwpNGnqC7/KVB1g2bTY0gh0gwajNOJo6s0CcFkIzuSJyQYm5xh3xP7qcTRG5/G1hZJ2XyunPeisXNKwT8Opsv4+DImpwwLC4lvfONOtl5wCf1GmFu+hmUr1zIxOcn07ApSgqquOXl4kX0HDmKs5djxE+w/cJCBDywuNhipWLP6bJx1DAawe/du1p+bePyJ/XS7Pc7dsJnFhUUefuQxZpat5MSpPvfcv4NzzjmLmWXLOXpynq9+7RamZmeZnpnRpcbHLB9Qj4YQPGIcm87bwu69e1k2N0fnwAGqusPC4iKPPvoonbomDAY88cTjbD5vM+ecsw4w7Nr1qDblTUN/0LBx4yY6na5OuJMgVaUU+LwwuqpqWR7GOJyrMC5P4ktjlxkDJfGgNKs+BBLaEGqPptPaEBTNLYZnMSVsUjJZ4xtELOIqlQikzKYo5nvG0GTPgspWOaoRYvStKW6MHhEl7PoSC5qPUc81/Tlry3Q80UT1+jBWvT7UQ8BgjE7sy3Zb54E5ZcN4rAFX2VY+kcprzmkWJae+raxBCyFkQEOlAXXVwWWvCYM254Hy/kKMQjMImNq2k0kRUVmHz+kTRmUkPgMMen00bQpJyEwFQa9PjV/VFJDKanSpEb2+sBo7WcjUKSV64+NcccWVWCOcOjnP4cOH6fa6GvtJBisktYwGEcFaw9zyOWZmZugvDnjooYdYvmI5dV3nRI5E4wO2quk3nrrbyecN+b0DEYu1+l6paag2dgX0SVGZAuTzsT/w+nmUjiuDKwaVVfUXI/NHT3Hi6PGWHeEqw9T0JBPT49jKIC6/N0ZvtD6DRMPzPRJTyAkgGocam0RdV0gMNP0+weu5p++9Xi9VVWen6P/XluRR/T9US2mohSKqW7+k16nYzJ5LpKJlLROcFNvkmeFjPBUsKH4E6alPlk+QIUCgJseW0CQ++YmvcO6GNVx46aYMouaoWLH5IWIGF/L6Q6Qk/cQMeJiUzWXt0MBLMkhhEnz8r77OOetXc+H2dUqXLakzJJBiBjlKeBjVqEb1zK+EcOxYnw/89ufY8cBB+qlm3Tnr+XdvvYLxSWHv48f55Ce+wQ/9yI0YEr/6jr/krT//agTBtMMf0/biESW+FUZaAWuHPlaanKdDPEFwGAS/GPj9936WN7/l5bixmkGIfOKv7uZvPn43Pk4QE7z3fa8EV+41ekvon/L80R/dzNdv3YWtAz/zb76TzZtXAPDozkO8850fpxlYThyted2PXMGLvnMj3/uDN/A7v/W3LF85ydYtKxFTgITCVBvK8kb19K8zAlCw1jIxPZebB9dubKw7neatEWsalWJkSeSIZJ15igy8p6pdNm1UA0RBqHLMpA/quWCsxQc1OgvRE3xDLcLM3CrE7WJieo7p2WUa/wg4WxOT0s9tNjwUhO6ReVKqqHtTjPV6mGo/vYkZJmdWMDY5zYoVK1ix+mxcZZmamSN4z6DfZ88T93PO+g2sXrWK2cd28sT+g0xMTDMYRFavOZuZmeVUruLUqQFHj51kcmqWQfMYK1bOMTk1S90ZML1sBclUSFXz5KHDVL0uUYR9+w+wYeNmqnqMEs1orG0N6qqqw2JzCusqNm7eDMDY2Bh79z2JdY79hw6xe89errxyO92q5sCBAzz22C7WrVuPtZbJqSmawYATJ09yzz330ul02bRpM2Js9llwWFtpMxoToYltI16o9iEENf+zrk2JqKoMAGRQISYFIwaNzykeipyKaJNepuExBazTSbmaKmbQYeCpuj3A4p0yHorBoUhLIG+jQovhJom8kU/qlxCH3gftsRXZQUvTEqytqOoa4wc0qUFimThanM1Go6SMFguurrDOQgo0gyYvqxqdSdKjM9YpMydT8UMIhBRbqYs6MUZsnrp3O11CiqrHN+Xmot+ra5UPOetofNOi376JVFWHkvQQU8yafQVq6q5rYzwTGgnZJp3kGExBMA4Gg0abDWexVYWrK+pet/WqUFKQY9Dvs+PBB6nqmosuvoi609FPIyYWFxu893Q7XarKYZ2jaRoGoWHXnl3s2rOb87dtY2Z2BmMtd997L3d84y7O3bCBXXv2ctbZ5yjzIQkRZRIlr1GpCYOzFhEy8CRZwkRG2vUjq0yFlYrKKQAlRoFOohAauOPrd3PH39/JkYPHMgtKo207Xcd1z7mKZ91wJYRGjRml3DR9ltno88UohQmPiKG/OEBCpNdxkDxNv8FYh7VOpwbWUHe7KFtGmUGjOtMrDf8vWu6663E+89n7iFTMTM7xujvMbocAACAASURBVNddSlUnTIJPfPxOXvSyywH4yufv4apnncf4RAc4nSJ7OhNhuOlrrUeXRoUt+dmYt56f+NidCF22XbyRCMwf7fO+93+ZJjqq1OEHfvhiVq2u8lavIib47Gfv5q5v7NfHSIYYulxy4Rwve+lWmmj5s7+4hcd3H4fg2H7lZp73nLP4jpdfzfve+1n6A88V12xETE41MsVwcjSZGtWoRvX/j2qawAc+8CVe9JJLefNb1nBkPvCm13+aW297nGffsI7545Zdj4wpYTXCozvn1T2hAWKOsLfKZAghQbaAslVe9xPkZG7FanOMfGp0byZWMBG++Jl7ufjidcytmACBY0cX+fLN9/Drv/WDpAR/+sd38vkv7uDG552vgzyTGJD44B9/mYsvWMfrXvdcFprAv3vrR/lvv/HdCPCed32K//pLr2G8W3PnXfv4yte+yYvYwFjPcfVVW/m7Lz7M1i0rOU3a8O3W/xG28LSuMwJQQDJdRixiKlzR22QTQmcMlcDCoE9xlSaZHAOo1MuGAUKiskqNFwcpRqyYVjctxhHjgLruaOxgBZoqoY2pWEdVdamrHlNTc3THJ7G1I6F6JsnTTIR24r967dks9D333P8Amzdt4on9B2mSQ6ouPhlOLCxiOj3EGCRBp9Zm4OTJU4yPTzI2OU2vN8n09DKmZ5YRouXQweOMTUzrhNbVuE6P3sQU3fEpkq1w3TGk6tLpjjO3fCVj45OsWrOWbRdewvT0FJu2bqNyFb1eL5t0xRxxqU24s44klrGJCeZWrGB2Zob5U/PU3R51b5wTJ49x744dTE1PM94bo+6NsWnTRqpOl2NHj7HvyQM5vu8Ex0/Mg7GIreh0exhbUdUdfIj0bE3mdoFYBJONIVUrn2xqjSsxmUFgLGIdZOq4MkMUTIoxYqU444Muovp5BF+M9oq8QjnGoWkQtPHtdLsA2behUI5pEyC8Dyr7SED0Clgk9W+IMWEFKldrE01+aUmp7NY5bJnii8M4jTgFaAZ9QhQ6nS4hemyMpBAoEYYkQ8LjXKXPnWUh1jlwtgVh1FBSp3zWGaqqUjZO/mxTMWLs96k7+tw+/3zKlDaSAjZd61pZhs3pHz4ETGWGxo+AFQXgvPcKRhhDp6fSAmesJqak7FMgka6xCMJ8XVFV+rmK6DUmYhg0Dbt2PsbRo0fxMXLBRRcyO7eMulMp4Ddo2L9vP51Oh+lzptvP+cjRoxw8eBCccMXVV7J2zVqMMcx2ai6/Yjt33nUHx0+dYHJiivXnbqbqdnHdOgPhJkP5ioqHpHpxjM3eHNqchxiREilpKqUKZoq6FZM/X8epxVPcf+/DHD5wivM2XUy306PT6bCweJJdex7l7jvv44KLtjK3YkzBS1HphLVOQSKMag6tfqam7lDXXXpjPcYqix+c0vPNlthOsheGgqDeezBG17HRDfiMrWFLr5unB3Y8yRe/9CAvfP7FkAzv/K930/Rv46fefAXBw4f/YjfPe+F2jIVP/c0DbL1wPZ1eBxNF2XFtJIwpOCK4oQFWjDJ8UpONF6NTgE8AMRw9usDXv/YgP/dzr84AKvzar32MV73yOpKxfPqTD3LvfU+yYtUGjOS4SIHzz1/HimUr27z0bz50jNtvP8BLXno+f/VXt2Gt5YUvuJCD+xZ597tuZuOmF7Nu/STPfu4F/O1H7+GSy9bT6dm87maATUBSNhbLzzOqUY1qVM/EaprAww8d4o1vWoNUkena8v03rebYsaN89jMn+MDv3ccjj3QxfIS3/dzLidTs23uM//bOj7Lz4RP89u/+MMvXjBMSPLpzH7/+zo9zYN8ib3/Xa1h37hwf/h+3sHAcbr75fladZXj9G17Je971cY4fWmTV2ine9JYXMzczwWc++xBvfdt3YG3EB+F3futveNObXkzd1Ub/BS8+l//+u1/mxudsRazuhyPwtdt386Ovex6uo2bvN3/Z8ref3Mt3vOQsfNPjoW/uZ6pbMTlm+dHXXU2de6Zrn7WJD/7Rl/mxH7+OsmEpXF1ZSrMsUcqjG8HTtv5RQEFE3g/8C2B/Sumi/LU54EPAucBO4PtSSkdER7bvAV4GnAJel1K6/Z/wHK0O3PuIyQ1ObdS8zGfqZ1XVDJqBmt+J+isUvxBbVerGX/rXSDaTMm2TKFmz5H0g5Sg4KzohxghS1QjCsslZls2tQuoKW9U0jZqZxBiwxubIR22kJqamuea663n44YeZmVvGuZu2sHztIuJ6zM6toOoaxDqM7agOSSLdMcs552zilttvZZCEffv2s2z5GrqdKcZ7kU53HNdRGnh3cpKF4HG9MdasW8edd9xJb3wym+k5KtdhcmqGEAw7H3ucy7avYBAGzMzMMj01SfCaSBB9aLXvzjpsp0dncorO+CTjM7MkY+iMjTE+McnCwgLL5lZy2farmZyYYDAYMDbWwxnL3iceZnJmOVu3bOXQocMcPnaKyak5ur1xNewTbdi7nR511aHvFMSo6i5GKqytcS77DZjYNvOC5KGVQaKaCYokMODqWj/XkD0OoqdyyhKpKqfTb7TxG0Sf3f0lU/c9gT6kngJMrrjJxsxkN+25ZxGqukMIUSMEs8ylypE71lidskXodNSTwYngsrdEMuqD4DJAhoXoA7bqak9bWVLIkoCk9HVDagGKWBgP1ubnknzuDNMVRCKVNThrCDEbZBqTDRyzKaOr1RwyJapKJT1uyeuunW3PBcmpF9qQJGLSGCFBZRI+DNoYeslTfL0+szwlx2mSY0adMbkhzyCGCEYcIkkTTpxhcmKaqalppmam6PZ6araa5RdVZVm1aq2aFhbAw1pmZqbpdrt0Oh0F2ozNKSmwfv25TM6O41PDxNgsHTuGT14djAWCQJCYre0M1lqaLKNypiIVM1BXKbiZEgGdBCQpcieVTlmj730zaBgfm+bZ1z2XudkZXGVZ6J/kc1/4G3Y98TBC0vUnRpqWJWJIKIsnJYGkchAxhro7ho8NpxZOUFdWJRrG5M/HZ/2k+kUgahpqrWM05T2Dq6gQMEgSfuM3P8M7fuU1TI5ZJMIv/rLjQ3/2FQ7u38p//52vctfdhre//TP81BuupbE1Pgkf+8jt3PuNJ/mu77qciy5dqyyakPjTP7mZh755ktf+yNVs2DDD4UMn+Madu3nogQMcO3KQH3v9d/C12x7h9lsfw1rDz7z5RUyO1Xz+M/fzrOu3MjbuICRuu/1RVp09yYWXrqEycMmlK/mJN/wBz75hE64q4ixh9VkzrFkLNoFP8P73fpFf+uXvJgFHD/bZuGUFF120GrkAnvPCc6kMGALnb17Dnx+/hX37jnPO+hld09uc8qzrXWqnMKpRjWpUz9gSolGhVy3wyldezhvf+Ae86z0/xMbNa/ngH97KL7ztxcSYeGJvw5/+wdd428+/mrf/l5v5yw8/xL/8yUu5f8c+Pvm3t/L2X/lhPvrhW3nPez7Hr/za93LwoGPPzpP81u/+ENYK73zHp/iR1z6PbdtW8bWv7+Sv//J2fvTHnkMwQ8FBjLB3X8PKNbMqVsvyBpVIAJKl0tGw/fIN3HLrTq65dj1NhJPHJzl2LBEEGl/xyU89QKcy3HVLn7VrZ/iVX3sWtookZ7n2uvV86Uv38ZznXaj7F2jB72HQxOhG8HSvfwpD4feB3wQ+uORr/wH4bErp7SLyH/K/3wq8FDgv/3cN8Nv5z3+wytRfN+Ge0OQGxyeC14YLkuqyQ8g0ZlWkxxxdB+qOajP1JyU0mjEOUwk0Jk+bPdW3J0zyVM6QjNAXwAkzK5exZapLdNDERqcyEZoY1N/UCDij5m/WcOElF7HxvE24qmJ8bIzFxT61dVxy0YWk6Klyc4AxRDEkK1xw+aXMrlmFFcO6czZgjWV8bIJed5yq6ihYUNdMz8yy7fxtdDsdNm7cyLGjx9RZ3lo2bdrIxOQEUxNTXHPNs9ix4wF273mchcUFnK3p9cay3t7gKm0SU1KTO1tVzMyppKPu1vTCGMuWL2NiYoyx3tlMTI6z48EH2LrlfACmZ6aprKXT7fLQgzsYGx+HqO9p1anp9LrEVKj8HZJxuKoDWEwyjNfjiKsZWAtVnRtxbfrJkpaUG9ZENigk4WxODQiRaCPWOPrS1+lt9Ih1dDs9ZWGECJKb3ZxGUIlr3c1Lc2pNRUgaxYikNrLQuo7KYyqoXDcDULHV9seoTI+qqnTCnZKeCylR1WouSNYiW6tJGrjU+g4YY5XtElNuirO3gffEUGQeWcuPNvuajrFULJ+TJJBs8KipGLZyJO+VwZA1+zZT8dG3NYMAJmvvlMpfpEQpgRGr31PaRj5mbbi1kdV7QEhodKuN2ecCxHaojCUGNcVM0WKjonsLIiST6FoBHMtXr8Y4k/0mzBI9uT7u5NwypICG2SdC6i7dSn06mhyxGq3SuI2tmO2tIyS9PlMQJFTExmKj4JtAoCKRYxiLx0OOBxUjCjSJtAaM+mfEGEfM11BMBt/0qTsVZ61bwx177+VDf/bHVFWlRp42cvT4AdZtXKMsoLIOgRp8JsE6k+kxhuB9llAJrltTdWtkoFIU4xwmCQH1VQjeU1cV1ho6HWVehCKhGdUZWZkjgKREAxhxauSZWT/rNswyNi7se/wIP3DTFTxw3xd5zU3XMTnZRZoxPvXRe1i23LFq7Wo+8ak9nHfBapIk/uLPv8yqFdOcnE+89S0f4k8/9FMc3t/wi2/7Ou989wtZtWobux47yKP3H+C13/csFpvAO975Mf7jL74Kj6WTDJhEk4S77tzDxRdtxFWaDmGDYJNVn0VnSQRsBheRhAThc5+9n2uvX8/4RJUNd7u8+1038yd/dAsLpyyr1p/D//G2q5iaNIiFs8+eYM/jh1i7bjbHEBe2VHmjlko4RjWqUY3qmVoJE8FaXW8PHzjByuU1tQFLBGnUsy3CihXCv/zJG5ia6/LmtzyL//QfP8EP9i/iZ/7V55lbNskDd/01xD4XXDiHi1Ax4KUvXZ9T0hIr18zwK7/6JXqdyEtecTnPft423R8ZCCaSCCCORMimjLlEmalByFGRgkG4/tmbeMd/+gi//74xGjPG6370HJYva7AJqnrAv/nplzDRqzh82POWf/sRAlGHdAaefdVWPv6RO7jhhgsxLg/H8oBLzatHErhnQv2jgEJK6Usicu5TvvwK4Hn5738AfAEFFF4BfDBpF/P3IjIjImtSSk/8w09Cdj5X+rHJzVjIWnIxog1M8BhRPTpZuw3SxrnFQoUX2kasNIDa5Dli9PjGE0jUVa3Nj1fHa2tEUwSMo9PtISkgLkcSIlhRarnGz4GrdUrq6gpjwDlL5QzVeI/kA92pSY2+i1GN88gTcevoTkxw1tlnQ1RNuiBUrgZg9ZqzqOqa4BtmZ+eYnJjMRpOJq666UhccEXzjs+mfZePGTaxduxZTqZzAWU1eiMFTNNu6ldP4S2MsF110MZOT05As1nXZtHELExPTjPXGeMUrvofH9+7FB6iyqaKtumw6bwun5hc5fvwkdd1l46YtTE7OajykGB544EF2PPRN1p6zjquvupLK1FhsO/3tjk9Smz4SNILQFef7pDGEkcSp0MdLosJgI3gJmI5tTfKM1NmoTo3ynDXE4PGhQZoBNsQWRMIYQoC6qrHGUlc1ShlWtogxgoh6ApSoRWUHJ6wx2ek/MhgMCCHmJAGjYIR+oGpHlgpZS6hcReU09SJmT4IYQk7cMEQCKQmW4m/hcmSjp2kaUozUdQ0iiGUY5egsVgpgpgknJjMDYjkeyvmmPgat0Uhm9JgMRIC+ruIFUTwkOs7ReI041bfPErLUR5JgjRp7UudUgxgx2OwJZ/ApS1VSYLIZcLQ7xomqQ8JQmQQ+QhJiCohVtoDGYJJ9IHQNIKn/Q6kSs2mNUSPIDPCkBMkkDJV6VIgmZMQoHO+ME6wj4Yip0USYoLKWulNncCS1/Y33ISd4iL53mTauEhmXUzUsVcdy7XVXMTjZsOfRJ2kGAzB68zzvvC1ccsUFjE9OggRSUuNXEU3OSKmwRXLihNWYvbrbRZylY3uYlLLxqEY9LTUvtdbSeE9KkcY3pBGecOZWpvQnFJgiBsySz6t2BpfXm42b5piYHLDp3GW64WJA3at5+Su389Ajx/hXP/1RfuINl/HnH7qXP/rgYzzn2WdhJLK46FvZy0teuomrrjobWyUOHtrF5z73GIcO9nn+Sy7gWddvIxiwXjBVBs4QUrS4lFOOihdKFD3OkkChgjAABo3wjdse5xXffSnWxbzuJ97y08/judev58jRhp948yfY+chhLrl0BVh43Y/fyBvf/EGuumozmKQyhwwa632p5aiNalSjGtUzs5KQ/KQmNLmEBz728Tt50Usux1W6+gUSSf1rqTowOdslCczO9aid3j+2bpzgne/+Tuq6mOGSU4g9khllADfddA2v+V6d577jVz/P/if2c965KzDBEDHEIjwYLPLxj9zFq773SsSqTNbIovZdWT1sBbadv4YPfPAnAeHUoudtb/sLXviia0gRrASMTdjKMz3r6IwNKGt6bOBLX7ifG248H2Oy049ASp7T4o/KRmxUT9v653oorFoCEjwJrMp/PwvYveTn9uSvfQugICKvB14PsGrVSo0izG70IpEUffuz0ZfNDiRJhJQIBD2RbaVT0uLWjtKBi9Gf0rnJDZdpG80UE74JGMnJEdZhsYjXQCzBkWKiEY2LMzGpLD8zIWLwGuUWGpIknIHaabMZBh4fPN4YjZvMV6WQoIk5AQEEhziDsXosKdPvU9RkgZj1A3XdJRFo/IDKOSSBtQ4xjhQjg0xZHx+fBKvTYE1yiK1bP9lVHnTynSKsWLVKZSYRjK04b+u2TPcWVq4+i+UrVufYRo9zlgCMTcxw+VXXQILKVYSkjTdWU8xveM5z2HL+NmaXLaOqeziyP0VlwSScUf8LK6JpD0lNOdUBPyngk5kDIpaUsucD2UyTYdqGc2pWl8SQcnOaAKml/dyNsdQdl9MjVH8uYjNo1Z6NOeUgZXRXWo8Fbd7UWM+4bGyZ5QQCGQgxSIyU7i5mAKAZNJm2T5bexPaYlIngMAJNM8AYaeMXRUT9DFIxe1BAwqeIMzb7LhTGzZDho5+tPk5C4xdb4CMDc4gwaBqqymVzS5Ovx8I28BnA0N1+DBEf1fSyqJ9LBGaM6oFhFRUjGn1fTrqKJ+oOi+I4NDbGfNUhRcGEfhtNKsZo6oIeml43PrSpGSklfQ/Kh52GPhDlJhozG8OnASbmSFETMegakQQ6/T77J8bozPdZRtRIyxAUjMvyBtDP1xbdeZGhxEjIz6u+EhZrEr4ZYCRy3XXXMLgk4Rth4BsgUHVhbLIiRjXaE2MQAyF4lWhJpGSTkKVeKaLpHCKcnD9FRY5fSsIgDHBOqDsdTaahJNsU5taozvjKZqQwrlKaPPF/bOdhTp4csGXbWmXjGK+XcQSqAS980XmIgXXnTrP5vBqRxB237uO3/89X0BsXLPD66hoN0DEB7AJGwBC55OKzefevvxoBPvrxHTy48zFe/OJtOeorY4wJRBIP7djHNddtQlr8cYCxehgxClZAxBKT8OBDe6ldw3mblyMo0G6koa49VRdmltXc8KwpBdNQ75eduw+xbt2ydk0dQgflCwowjGpUoxrVM7WsEXY9dpzf/q2/54prVtIkOHnSMzkzBkY9tZ7Yc4w7v7GTSy5cjzELeRaUdIgvp6i7lhe86Cx+772f4aorN+EHizy+7zG+/6aXIqbBmLInEN7/vk+wfHYlK9fMsXrFBCYOqAArWRqOxVn42Z99JR9435dZddZDJLH8X3/4OX75v9xEEnjv732Ss1et5jtftp3773uUj3z0azz3uVfz539+M//6X7+E7I3Phg2TfP2WR+hUFcEnVq/sYEWzggYBbrnjSX78jTfmlAcgpwa1kcS0f+SjH9XTsf63TRlTSklOc9b4J//e7wK/C3D++VuSNUq9KVnuKQMGUiaqCmlld/pIVdWAtPTvwk5IIkhMlFy1lCe2xWiuON474/Ah4I3S3WOy+JQgDZAUSLEhxEBAm5wSNVcac0Ed4cXYPME02jQmGFQ1J8SQnMUbq1T3MKASYJBIUiEGvAxTA4KiFVhjadDHS6lM0BPWVvhMUydps43Rpq4AfDFGXO2IqDxAtOsHEiYftw86/S7NmTawRpufTq0UbDNkdyglXN9r7W0TptvDiNAknbDGqMBFSgm7bAXLZuawVcVx7RQRcSyMdVjEc9JXuDpR2Rrn1LTFWKfSFBKYDv1QQfAsRkdDzVRcoM5TLYzRyNCUdHQMGSTKshen0ThibE6SsO0U31mXm36NCUz5Mcv3QeUPzlWtnCBkJoxtvRaUZq4SAD0PUpSW2bCUIaDnuR6bkWHignUOfNC4Smvy8ys4YJa89yKqwVfTRY2+TCn7JFj9+1DSIDr9swooGGswRiikHe89zjk9zpxykuLwM9bXlY87JWV9RMlgmsogYgqEBN5rMoJONRXMsmJJEnFYTtTTPDy9jGD1mu32F7AkOjHik9D3SY8lSCvxSIOcohHJn01ShoAvzCVa6UmKKtsJXn0SIgGXFBwMMZEaj1irQINN7Fk+zXhcYG7+BCJQu0ojaU9jOqikatCmX6T8fkeM6OsUUTZR8IG//8pXefi+XZg4hjU9FhcXiGlAkoaJmS6veNV3sOas5SAJP/AKyERNlSkmm8aIxtrmrED1BKmQxkOKpBIniEo0bJbCFKZLVVX/q8vuqP4/rBK5CHofm583fPgvH+A1N21DEswveKKtqLrqIRLE0/hAXRkQrwndSbAROhFshFd817ncefeDfPf3bMcCf/U/Ps33fN9LSKiUwiQFvA88cYidj+7nmusu5LU/cBm/8AvfxGY2T5QEyWAQrr1+I7/48x/mVd9/NbY2fPFz9/Kc528BB7v27OfBhx/nBc+9FJsMYZD4wAe+wC/8/KvyzkFwCJVRAH2hiYQAKTVEkzIgAX/4+1/hx378BozL8bFiWq0uLTw4mk6NalSjeuZWp+t492++mC9+9kEeuGcfSGL79nO56JJzgIblc+Ncf+Vmdj96gMsvXs9rb7o6r+mRqjJ832uvJllh+9XrOPTpE9x/3z7GOsJNN70YmxI3XLeR2Zkpiq3VNVddwO23PM6R4/vBVDzr2k2Ig3/xXRfzyU/cxg+89gZqJ6w/d46bfvBqbv7Sg8RUc+ONlzI71wOJXHnVRex6+ABiEqtXLuOsVat58L59XHbpJs46e5ZkE2LhDW9+ER/6k78nDAQk8IaffD7WGvoRPvvle3n287cwhJLLJM8puF7W/ZR3eSMvhadt/XMBhX1FyiAia4D9+et7gXOW/NzZ+Wv/YKXckBsjhNC0zZSrXM5q158J3mMEqiqbzolog9N4nSxKdus3xd9P3bF9aLIEQpuf/5u9N4+37LrqO79r73PufWMNr+ZSlVRSlapKgyVrtK3BsmUhHIPNYBImE+KBQCBTp3EIncRpOvl8mgS6QzCZTAYC6YCBAEmMkY0kyzFGozVZkmVJpaGqJNU8vXrDvefsvfqPtfa5t9z0J/BJf9Iq9DY8l9579517zrnn7LPXb/0GsM5MTq2xElTJZJJEKhJCYhjFNOXRiipNjfsnWBsniJCzFViVL/SbtkUmp9i3ei2PnzpNHQK5sq55jkrE4v0aqYxDpNY1FxW0qw0U+pMOAJg+HtwNVWq0K6JDqY29q+RAgzvaZy0mjLm7NXPOZj6JnNOBDiF0N7U4OpFTyR03hgbFYA/p9FZm3GckKxWj0BcQpywWkwgxB06GmkNVD83CtPboVTVZzAxTs6AaCSgahESPkJXFaoKzGrn99JBtwwYVoR223ULVutyxA4tM2mE0rRjCmAyAkQ9Dm8ysLwTTkCEO2vj50NYKaS/qcap/m1ovBJNLG+z4C103W36lAwKcwzQokZjq3e7BYOimmlAMSY09UyF9jEKPde0lYAaUHdMgd0aKwY9RvINYwAbAmTcGemVnMhijQen1evb3TqEXv9YKuCSiHVMITMozfh2JF9hZkx1DDAZi+fWTKkF0wOUnTjM9GBgQ1bZMVIGmTQwbo/3HujYZSRXIbvKIE/FyTkbK9nNWvuyYnang3g/aGgDS5iEhVmiTaYMybAc0E5O8smEDyzmRydTeJm2796M7bzFGi5d1r4koguQWTUNUXfYUAiqwaeNmFo4naPqcXRhw/NhxlpbPEmsl9tQ60g7OCJaCUcBAVZOJtKncKyZ3qkJN2ypR7TxWVU0kUPWif1+Rm5YqxhHosjLe8MPuC+Xv/2+38ff+7u/w4B8+jgBr5vr8xE++38yxEFbNTPPxH/+/+F8/8R1ctns1/b4ZnNYBLr9ihl4t3HzTDv763/hVvvTF56m05WM/fAtSwdRMZOfOaY/1VpaGmV/65cf497/xdSTV7Nm5jphh86ZJnn/+VdJQCTVcftkW/tHPfA8/+fH/QE41S4stn/gH34IEGCxn/sMvP8D1V+9ibm6arz/3Mu957+VMr50wOQcm5fme776Rf/ILn+fT/+FRkJab37mLPXs2oyhnTg/oxR5T/Z5DK87OkxGEIN2MujJWxspYGX86hwjsumQdF1/ydmNS44lPYtDsqtU1H/vYDRSJ6m3vuspnxUi/Em675UoEZedF67j4Y7d50wOsya/svvJCWy+56eG1113ENdfsIJc1eRAScOOtezl0coG7fu9RPvCt1xJE2LtnM3t2b/Y6CqJp3rj+6u1cf9WFSICNm1fzFz76bmuABGdNAKBMTcAP/oWbjSUqNsurwv79x3n4oWf5yY9/O6FjJzjQXh4EjLazMs7vIX+cRal7KHxmLOXhZ4DjY6aMc6r6N0XkW4C/jKU8vA34eVW98b+1/d27L9V/+alPUtWuy06NF1PBO3mRnMzcToCqroxS7I77bU4WqxYKZxNq9xYoxV3bJiMtOGNAvWl3PwAAIABJREFUigRA1bvEFYtRODi9hpeHS/R6iUoDA7/DIkVnbvsYQ0BzGjOWsrdOdc1Lq9dyNCkbMM26sRkykJAstCF2E0opMnPnBD+iYKtm8wwIARHz27ZoQNfAp+wRdFag2MQkHtVnBWEpEs1wvrAxzHguiBemDgyUL82jDr51vst+qZko4qe5yEdQl0YkVBJGnbCoTSQQsjKIQtaG65cWWdskenVNFtuH3DIGXsCwTUQRDveneAl4z+ljbF0822l625RArAgLYlR+AzeUlE1XXtITjFkREIlUsaLXn0BioC2MlXKu7ORRlrnZtfaFJdM4Rd5Phx27+Nw/NinatdZ2151CJ3UonfARwJC8S+3XEsZGaAbD7nqQIC7XcDK+Kv1+n6GDDqUQRmDYDsDBoux+D3a92N+a3EPo9WpnVLgpZGoZNg0xVJ1fQ+mig5By6+QQA+XMEFU7iYe4BKIlQRJemV3PvukZrjp8kNnhoslFUiZI1clBBCHWdSfXsG1nB/oSOTuYpiaxsPM3YosgwnA4tIjQUJM1oWlAL1SgQktGg3Kqrvna1h1sPnOCXaeOUokQJHTnouw/LpcygCrRIDy7aTsLAd567ADTbdsxRSI9Th9tOfD8EV4/cIL9B1/j1VcP0p+s2XnpRey4ZAuXXraD6VUVsacQMiKZYTs0yp9CoHJSTSKklrPHD/PCVx9g+fRxeg6I1nUfiebVYraQwrzCY1t3s2vvZUx++cv8jX/4m/Qm1/23ptiV8f/LKAaqJrfTFBhTRpk8IWA+KQpFwRLLVORzjWJBK5VATpAc8KwUi0eOYtrbbB2CEJScLBKyeLvEaO+TM3zx3qd57bVTfOjP3+yYl2AELQOCLTwkkTWSWwM0COa5kBSqYPOveHqFKqRGKXi9VDYnt0n5+Z/7DN/yzdey94ot5jQmHsGMuBdjAZ/5hsXlylgZK2Nl/CkaPu9nMiqt1SMmcPTfKUgeUf/V43W7IqN0EAMdxescuUCZS8V/bVVG+bvs6zRVOHjwJL/5q5/jr/ylD9Kf6mEU5SI9K4wBPed7iwwezdcjMDgDLaUrWogGqvDPPvW7vOPGt3DtNRd2TGp7SIzVnYKvv+gefCuOOm/ccf311/PII4/8kR/QHyc28lcxA8b1InIQ+HvATwO/LiIfBV4B/py//LMYmPACFhv54T/uTsYgZNfqW4fYrrnsRnmlyDEWQ+qc8pVsXdvSWQ3FMM8Wc03jBaY4XTiZrKLos2NV0eYGSQ1No8xozYWrp5nvJ7TNxNgDT2lQ15lrznaburYd9QVU2xJiRV1H1rVLXE6mbhqi1mTNJBoQyKFnRXxKFimHddtbTQ6epM4wr46xAxBaBzCCgyKl+NOUrehy8CEEoa7s36y2Si10+4CZupWCKmcr7kJXfDom6jr/rAYstNkAmViKMKxjau8XaBrrwLbN0MkMNSAkBMmZGIVeu8wl8yeZGg6p657py5OCukkdVjAOnZnRm2k4NdGndoqUUopNK9TryhbqwSfdtm07aUpO5fgygkftSTC/Aq3MKA/r3o8KS9xbwb03fC4VCcRKICsxCNHp9hLDGJignpZgTA7TKNuUXsVo3gRtY+esiuTc+HkMtKkhiptAYukFkoNvM7vXg3Ssh6ZpOlZGVVUdiJGyk6yDGYwWuZAxCnLH2tCsJo3x+6gAI0om5TR23sxbwsgbSpPM2DAqLscJHRimCLVEWtQ8MLJ1ImsJBm7EmtRYFnMVLfJTWpP5lGPI3r2nu8ICrXtqBMz7YXFxkYlej7ruEdwcs2kWmZ8/w8KZM6xdNcuaVXMIBtw0UUjB2EYxVKg2tMnmiRAcPHMWQU6t90+VlO18lFjRlJJ99jEyOLvMQw9+hUf/8GnOnh4waFtmZ2fYtHkLdS/w6qHX2LRtLdOr1tnf5gQ+dyCJGCvaxpgvmqESA0Gyg1dRhIm+RaXGKhBjYHFhgSpENNYsLS2R2rTioXCejK5wDhCi+mwmhEL9VJOchcrupchYrGJXpTuXJUZCtMViGK3Auk5VieMKQSHg2SajX4rA9W+/lE/+/G9x+OhJNm2YQ8TYCgrnmEaKtNS1mUnikq66W2yO5j0RAyG0AgkOnqjywnMH0QyXXbEFoknKzlmwmpPr6PuVsTJWxsr4UzqKtMvA1Grs58WYsHTuxzxlSiHEaF1ks+gYxYuEaISuKVb+cdDWtx20yMuE7dtW86N/6Tvp9WtGm/JmYBfrW+bnsW2W12r3H/7b8ShgwVud/OD3fxNTU71xqGM03Z8DKqgf2UrSw/k8/jgpD9/7//Kr9/wRr1Xgx/6kOxEEMzdEaXIi5dQVK03TOJAQSK2iyQqAGK3dkt10MAao6+hd8kI5L9Rtc3c3zXqFiBeNOUG0zra2DSG3rKoic4stcrYl55YcapdjWJGKWvFuTu0KOXeFfc6ZQYyEnFhaWGTXwhlWRaXKNYFAS0PSlkxFTTDHeQkeTye0mjvX+5wTTdMyOTGBZtNXl260nY/ooOaIyo8Y1b+ubVKqe7WfP18shoCiDBvrOOeMGQGqUkXTlcdgE0NVVZ27fAEWTHtiBSmq1HXPzP2ibVcRctsyHNp7VtE/GIWKCnJGdJnUZhKRKirS2jG1Yl3cSoPHdCY3dQk0TWsFtNgx9+q6A0JwOnkQMA8Auz5yO0rA0KQgiWEzoAbqaKBNDNE/wuzSEp+A80hbn1Uh4mAVpr1P1nWMCmSbxNUX/Cq4KagjzVkdALNzG5zZoJmueDeA1orp1FrEZO0JDckfGsa20e5aKx4PYPufKbIAoODSqvYejM4Nai3SnFpyLrIYOvlEyZ0vM3900ESCkpI6iFZQaWfXoMSqIiYxSUMakqShigFZBlpoUkPKUFcV8/OnefyJJzhz5izXXXcdG9avJ9aRWEWapgA8SpOGds+GwKBp+fqzX+fxxx9n7dq13HzzTczOrgKUdnGBZ598giPHjzEYDrjt1ttZu3Yt9YQlNSSfV4p2O2PgjUiRvRj7IYiMzGBdOmRgZIVEmyrb1q6VpaV5mrRM1Q+koDRpiX0vPUd6qWV29QQXXrKZjVvXGmAV7HPr9SoHPM0DQjWTs+1bdvZUVfeZ6EV6ld3zSiY1rbE8fE7UrA7mxT/pVLsy/ocOQYhkDd58L+A3oJWlfBR4weO5orgbondzTMokY8us8Y5+ImsgGD/N1352zagD6GUBqWoeDACrZnt8/59/l12HY2tXKau9pDZvl45SaaB1i9w4+q5swBBUks89iJKD8kM/cocdd7eHBqTZ3/uc2W19BVhYGStjZfwpHaIYjSvSsQzwxhWxmw2NmcA5xfyoCh810Mr6HxLiAopz/6is47T7aUntjRKYmq7N5F4KyCHf8F7j37W+34U9MHqf7tkgdLN5FiUKTE/3bD0v/twKpTlYnmgZ1OLRV6b/83/8d5sy/n8xrPPceHa7rWDalIhAv9+34ja5P7aErvhChLp2OnhWM9bTYuAmXfEFdJ1PW8xlRI0BoI2LErJd4j0yYbBMDEqTBmQSMVTUYaSTB5DWUwlSttusFGYoPSKDNjOVE1GH5GZIv56kEot6I1gW7cljx9n30n727NlLPdlHc+pISi/u20dOma1bt7JmzVpCSULwojEELyy9iD9x7LgxEnJi1cwsk5MT1Em9Q2WgAf7fvWTSAk3FYFDpYRKKXs/o/TG3hJSQUFz1ffHpwEIQIeQh0raQpJNSGAjRWIxmhspZCikPyG2iChBDbSwLCUY/R2gEMxo0h0srxFKmSmWik65bH2NFjG7C6NQukUAVonsljAApcmENGNhSmCuioQMSSjdeRUmMJTi0CffFc/mJ/302A0AU96qAVjMSqo750TQGDIj/7XhHP+WWqgpdoR/EEgu0RJ22LSpm3ljiJsv1O26WiV93ImL7inXiLdrUUgPI2UBnByFCiMSqyAuk26aIdswMCcWA0o/TXwMlRq4UOgYyCBnRliEVjag5FocGYQgRYlWRmgEimcEw88Jzz3P8yFEm+hPc9Znf5Y5vuoMLL7qQqNCk4sYAIFShJrUtr796iBdfeJG9u/Zw4uRx7vn83bznPe9h1ewsh147glJxxTXX8MSTX+XhRx7ljjveRYyl1yudL0ZwllPbth6bN/KmiEFALZ6z3+sBZtLZZqUnBvSp+4Rcff1b2bxhG/160h6etQGPw3ZAbyKyacs6e4iGYPe7mCQrpcbpiHZNq9p9V9U9+hOTNM2yd6oN2Ei5xA6OPntVZ+PkFYbCn2x8w2LrT/z7/+dL9Y94mZzzMuswuf2rMV60lNbZCnApvjQG1IpLesyvpRhX4Qlbck6XR8QZDGrxt55Fii3Z7F27haIqkgQquHD7Zl9cKhrKMzNYp6jKvrT1aEen3lqzy+YpD8vFTRvsCaHJj8V28Iq920li7LiYDXRQX3R2zASxxWfZ4rnnb2WFuTJWxsr40zIEqPBHgsfmjhhb4rJo44GpN6lCt1YYbcMYCyNuWq97B5udE2Z4OPqLDqUuzw9nlepIh0CZy7uhYbSN0rCzTC8EJcjoHTIF9A7lyWHgSYj+fQFJMiPTRUGJ3dGvjPN/vCEABbs4s1kghEA7HNoiuqpAbPEcQjB2AcYOsAW1OgshdLntwePXCMUHwGn8alp1vINd5BOlXJYoRCK5GVp3JwRiqKgkmAFj65RNaycbEykEQhTvctviXlUYDgfe4JTOpKTJTfeznBKnz5zloUce5vnnXmTLlq1snNhAFYSmbTlw8AAHX3mZrJmD+1/mpptvYXpmxjubSlXVDhCYhv7MmTN84b77aNsGsrJ6dob33H47cdWM69tzl/mdciKLF4ixLAbdUK+KRi932r99NrYQLt1rBOvUo7QenRljpG0STTNkeTgkxEgV+2TNDFvrnhOiF7ag4jIEte5xpiGgBurEQGqSsSeyabNEXN6StZO8gJlhinfSugLZC7RiGKlYl71JrYE5UQha0isCUS0qsaayBW9uPSazMmPM7AWuGlgUQrBIQnCqv10LKWdyOyTn3Jn9oaXLbNeKfV4NSa1ADL7vmbFiohT+fh2LlDQFm4QLkDDOUBARM1gMAU1W7JeI0AxoStZwlGJ0aiBFjEUCYRKT4tWQs0Kyf5VMXVUdOBOCGHin2WQ0XoS3jYEv2j0sAo0qLXYfClDFwNETRzh95jQ33HAd69at4+mnnuHw4dfZesFmJDg1TmLHmGialsFgmUOHD7Fz504uueRiFs6e5Z677+bIkUNozhw4cJCLd13C+s0bmZ2a5f7/ej/z8/NMzsxRhYqotWU/Ny1aKTFWnfTDbgPbX0G7901N2xmgopnUGlMqYT4h6y9Yy6atm+xxKJkYK1JWmmQGsZbKEMg0KDZXtSkZACk27eZsq4pizzRoM0kyi8Nli3eKgVazmXImi9INVY9e3xYQsYqcQxt8Uw2laDw7OmXxYbHvOmD53JF8cVOK2tBtz+9qOvpmeR8M5JQxmr/9vxnSZrGuu0UoQjFJ0CKHKkX0+MJQMkEygjEQOnbAmMO1+G6GsugLI42rsU0DIo3ts2VH+kIuOyttbDFqyKs3vwqLoHSwQqd7RdVBEjfg9WdeOdOdHwQFnLft26bC6HgLs0rKJ4GDB+5bJB4Xpth5LZ20DiApC026v10ZK2NlrIzzdugINO2eP4LFw5e5Fh2By+XZPsYSk+4ZpXQAwBj9oGQKFU+F8owULfHlZcouSTsjk+jRc6XM9bYtGAPEFcIYrU39f8qjzp98fgwB0URxb+yeyw4uZ7EtB08dEh09P1bG+TneEIKVc70/tNMNN+2QwXCJtm1pmoa2HTfZE5J7ARRDtZxNV5zb1N2U5VYti5qURnpQzdYtTtoatVzNUyC1LYPBkNxahzm3LU0zNOM3TUgwAKEU3cPhoNO3l2QJivs+ow51F/OXMhOTE1ywfTuNa9Sz/35+/gyHXn+dyy+/jGuvuRYUnn/u65ASQu7c+EdfyuTUFBOTE2zevIVbbrmFo0eO8sILz6NZaduGtm3Q7IyKnEy64edG1Qr35OeumP21ngyQXX5RIhS7c62ZrNaFT23i1IkT3P353+d3//N/4f4/+DIv73uRxcVl2uQTX3Z/C9euG28hk3KLaoPkliqX8yZIFW1BHpS6V1shK8UTwCYw1eKV4QWum3aW/UYx08Ug7pcRaduW4XCZNjUkBw9y6fwW53xVTx0wMKn8nxW4jfkVuISmbZMVimXuV3WJhnpRPzbhYyBCFWPn6aFlQg/WLR83cswuJwhOzx//3DvZj1/T6j4DRTbRNm2X4BFjMSI1JkR20MLAF78WRKhiNICoFCJ+vaaUyG1Gk32Vu6nsS9ta3GRqGzQl0AgaiRosbtKLcUmJk8ePkzWxYcN6pqemWD+3huNHDkPORLFIxyD2/jn54ykrr732Ov1+n15dMzs9w4YNG9zLouHUmRPU/Ui/V7N6aobZ2RlirNAcaIdjxqsuvylzBpgfRpFUFUClaVvaVBgcinUN7AEf64BUgtQQekIKLVkamrxEk5ZAstV24macKmauKNHniIrosaQhRCREJAQynk5Sm0yjVWWYGvPeyJZRHSrrWmeXM9V19eZ99uo3fmNMDu2+T45e6je8NnSvKfBDgRIc2u5WSR58SPf5j32p+LY9UjWSbctlhQV+jek5z5/CWLDvrGgOMvacOseYUM79zwIKiM/eEjA9VuksCepeQvZO/vOiwfW/H+2Tb1rsOUdSByL03MNAPIXZJBxlXws9Y7SXpTs1ykI/t+dVjjN2f3vuKG84Btz44nn8s1oZK2NlrIzzb2g3kxndN41AXEzwYGsnfw4RCjbd1Q8d7iuFB6CoZG/kAN02oDy7FCWP1Vflb8eNcbv5Ve1vsmR/TnkTsZuzFXFzalvB23t223EgIUg0DoU3L7M/Gq2JEkePUrQDpVem9vN/vCEABaNxRm+fRJCqM5irYslTtEWGOb27yV4MnS+AiBWPOWeGzcCp5150anGR9w7kWGe3bVszQXSGQ6GlospwOGR5efkcmnlK1onPOVmxnlrqXq97TRe/54Zv5b1LEQi2n1VVs3ZujlWrZr1gNxf5kydPcurkKdauXcu6uXXs2HExrx18jWbYUjnVvxREVYxIEOq6Zs2aNWzYsIEN6zYwt3Ydy8tDUmq7qLrB8jJn5+dph411h7LSDoakwZCQlTQckhvPPhelrutOQmFf40kFBiaEaAVs2zbEIJw5dZq5tXOsXbuG555/nuPHj3uBbqkVonQGdzklyJkqRIK6wtZlLtYvLp05m2hyVn+vtitykxtspuSTZu6y+lCyG/olj7MshpVO5/f4R/NmwPXsVkTWtV1zOWVnwfhC3/8tPhblGirnpURPqppG38AllyT49SESXP9uSQymifdp2U0WFRykGCV/FMlPXdeuZBglRnRFf2opVLPyuMltS3JwqDNbFIEiwxjT5htiLR3IVFgPIlZ4V27cqV7o96qauqrtQeEgTyWV2fFkRVICTVS9ihAr8+toGpYXFky6k4x9MhwOyKmBnNE0JGCsCdFEHSOaEs3ykjEpsMJ/eWnJj0tomyGxiogK/brPsBmwPBjQDt3mPiRylckB9y4ox0on70Bg2DQoEGtnq4wBUhIKcANoJDXC0kKDNhXLC0oa1rSDCm0rQq4J2ZgwmlPn55FymX/susKv1FhFqhiZnJiwCNuUOjZTahPDgRmdDpaXiTHS70/Y3+qbubwqlPxS8Oey0rLCV83k1UYBFnzx4skEXYE9VqiLBmciFClPQbvLusc6+Nm/DyLmTaDmryNjkIbRUt10V8eL+1EXfrSAxBeZdICpPYtGBb/4a62jX/a96vaPsoCTYH4hFEAj0XkdqNFPpZxBKaDJyJDX9lm9e3aOndY3FPtjn4bKSMoh+g0dMpdwiHXKgjMT/OMawxYCohWFG2EgSLKvlbEyVsbKOM9HSVRTkc4qwaoeF7ZJJIfsPnAyUkR4E1X9L5RAFmd8ibEmrT63CdWeOT53S7bXBkXD2M87cCG6vY85MSCZRCZLMrACGH8GqtHOSkXmz2Db3gg894eYrSgpPm4iVcditWeaAScFrFgBjc/v8YaQPBjrwKifbZvdwCOMGSuWDrctVkpxC3QFfPETiB5LpZrRDDHYIXZeCm6DIGKa+mZoJo5VhdPLQ1e8FiZEtzzMxiYIHX19JAvo6OLqkYFpVAyqR1yWyEm8ox5ipKotTcFiMmEwGBh4ECxOpt/rMTM5Y1F/GLW96lUF2LQCtE1MT02zMH+W119/nSPHjnHp7ktRFc6ePcuxY0dZXFrg+LHj1L0+ey+/gunpaU4cP8r8/FmTioTAxo0bWbNmDYvz8wyaYceoyKpMTEwxOdkniLI8WDQDzHboFjGBif4E/X6fC7ZtZ/uFF7Jv38scP36S9es3mow/2II1esGdQyIFRaQCzbRNS6/qo21CVc6JMDSTSj+vmgn0vMgvUYgKuCFnmYuiSQJS21DXHhOaW+qqsqKtJIRgpnsFaACj+uec/ToynwywhAspxnile++/DyLWwS/XGUpVRwaDgSHQuUCy1v9P2RIpqmAQSsoZUemu58KmwK+tEEaFfpfu4Z4OgrELKBr/DLWbCCaPrTPQypgQlZv5FRBMspTbkBACdWVxrM1wYO8dzTAoJ3XZjUE+qW1NyqFSrByRrEjKBBWUioaGpsnUnkyinpbS5IZKA3W/JlRCm1uGaQAinsASu458qALD1qQiUhmLqOrX9vl44TURJohaMxws0CwsQjJqdt3robQ0qTGJkrMEckldwBg2LlAnaTaZUmWmjDm1LC0vUasb5qkSNfDKK6/x7Ff30ZPafUMEzQHVhlgpV1y1m4sv2UZVVTTt0HwzYqBtWsRlQqWoMolRawavwyG0LUM3m62rmqqq7L/rHurzjIIZR77ph12LpX71yhwkmkSgc8wuYGMxxBrN66UTfq4xlHCu9MFf6cV/8tdV+MPkj+y627Uuqr4AGxX+ebTX5+yDjdi9rvtVV9bbgit0HahxoKK8fNwvu/W/rToQbbRt9cWnZ5uE0c8F7TwbcPDlHBKstL4995XppBoRaLGQSek+F9MD+7GLSSHIzgERX2iPnz/x/+nkEL4b3/iBrIyVsTJWxvkyso5F6YQRmKw2/6oD2ardJNmtrWz4864U4KL+5PLnh8bRo0Bs3YaKW+KOedj4phRladDwxAPPcMstb2Xce8Eatz7ndni9gwXZDkNl/JkZbA0qOCQtiBoz9uTJefa9+CrXXbu3k0fYLhRPoPJ8WJnlz+fxhgAUFMvgjsGkDhZxONLEqyZyVuqqZ8yANHRX/lLYmYlfUum072VIwAtCk0qk3Ho3u/goBEqHS9wICyDntnPWb1u7PYqO3X6fHUTIftOOFnQhiBcJ2bqSYtSltmmBRNBgXX/v3hLUJQeZ5aWhJT20mSoC2Ywpy2JUcP18B6JYYXjyxEn2v/wyp7du49Drhzh67BgXL1/Evn0vMFhe4uKLdzDZn+SLX/wSq1etZeclO5mZmGawuMSwTRw9dJivP/0M3/ze93L0yBH2vfgie3bvJtYVT371KbZfeBG7dl3MsG065kfOLVXVJ7VGex8Oh8zPz7O0uMj8/Dy5Ndr9wYMHWbN6NatXrQIJLC4u0q8r6hBYWFhienqKxcUFenWPqakZNFrMps084+yOUvhml02YZtmAAIumbIatgwE49VzQ4LGjzkKIbuwJeJSisU2KNKC8n4ggzsKQ0vlTK9oL66SkhZjhY3DTTKUdNkgMndGoSuooazkZ06LueYKCWOJHMdsrdVHKmSrGLt2jpJ4UP4nUtl1N5FYeBoxEi580n5HCzhgVSKHQz1pjiUhV2XbFafiYC3COVScjqqLdV1mCd+nteg3+2tRmA4Mk00pLUxk7gTYRq4BIC5WZXi4NGlSELMLZxSUyYhKDEFkukpvkyQYIdWXXxalTZ1hebpmfX+TswpBWA7GeQEJk/4FX2T21mqPHjqEhQNUnxAmi9EF79JmgTssoDU0z9JQWaNuSmmEskhJh2eFSVUW/3ycMSwFlXeUjh07y8AOPo0OL1kwZ+r0JRFti1bB54xwXXrilixm1eSYTo7NPckaiQMKSagDN9nkEoNfrGYMkGmtFglL1Ii3m+QGYPOlNC+aXArwsQ7zT0UVdBbwdA2RfZBX+k/pCbqyz333ZNZwpnfJCM9Wx10AzaFlYWGL9milsiVbUq6O/sB0b82soFtsyMsYa32Znvji+qDoHpCiMg7LP5wIiRp31RIluvoxjC7VwzuUiWrS24te2H6VEcgo88vDXOH3mDLd/043dvph+NkCJPSurYXH3ch0dC4x9RKEsZEfdsRyEe+59kTOnG779A3upYnaAY/xzCWPvsbLcXBkrY2WcxyM4iKtC2ygHXjlhkG+ATZtXMT1tza+TJxeZnp6g34ssLjW0w5bVqyc8Eo/yGPG4yDJ8nSkF6JXu52BsgMI8K7XT4pmWX/qle/gz3/wWCtC9/9XTDBZbQg6sXd9n3fq+J17ZEyol4ejRBRbODMz/IcLGjdPMzvbJWdj/ynFSCmRnya2b6zM91ePhh59jop7kiisvQmKRJ9t+GkgNK7P7+T3eGIBCzqScTW+dpSv4weP8XIusxSiwFLTJNEgxuq4ziEkHABL0+xMjF3fK70amjKZdd627RBBI2fXVomhuvc/iqJ1T3rvOfUqWbjAe51iWS04tN513cvZPWaIW87dkbv9iWfWq0DQNw6GxA5qhOcKXoieGQJOSyz6sW6wi1HVFSi17917GW658C2vn1vHUV5/grVdfxeuvv87rr71KVUUOvX6Y5aWBRW9mOHHsOPv3v8zy0jIHDhzk5KmTvP3tb+P4sWMMlpdYv34dsa6o65qnn36aHTu2G+08ijnTB+96iUkjhsMhTz75BCdOHOfUqZPUdUUI8PJLL7Hjoh2sWbWanDPPP/ccmzasY2piks/J1PeAAAAgAElEQVTd9Xkuu2wva9as5sD+A2zcuIVLL7/Cuq9avBAMlMljmn7T/AePzjMWQ5lpQwxu+KId86AkOaSUqHtOE3amiIE0IzmAyRTM1V+8+6eqtNnkMZo83tMTEQJWFNombdJtcws50e/1OyYAqkgcafbLtdSVK/7zNieatvXtncuIaFsrtAvYViQkEhz4CAVkskOMlYFPQ49fjSHQ+vkUX6GnNjlwl0FG5j1oLjZvlGQVk0e4L4GzE0zeAJIFjQaQZA20mowp0CoSQSWzedMWHnrgER588GF2776UffvMlHRycoqiBT9y5Aj9Xo/Vs6sJsWaiN8EVl13BIw8/TL83xfLSEpqUdXMbmJ1ZzZbt27j7v97L0fnTnDx8iLXrNrBm9RyCMMwtVkgpioMgYoBM2zGOIjEG6uAGpbkdgQBqcZ8xGCNEsxjDoYUofS5/y1U0TeJrT3+NPTv30AyXeO3QC7RNQtQMWAnGbGnbBnDQJ4iblQpt01Bg+zpGglT0e30oxRsmd2gCLGrDYNo8W3q93pv8+StkFe79wj6eePwEyDJRWnpVxUc+fDP9SY+5Ei9ji1ZTctcBL4kEULroVpTfc+/T3PT2vUxPVC4LKEU3oPDq/qP85E/8M/7lP/9x5tat4q7PP8qdd147sjPoxjiB0+coFV+62Y2mvpo6x5RqbL/A7r9O5uAPuHH4oXNF8M7V4dfOcPi1U1x97Q40ZD8qGdumdsdr58hhChVoIw99+Wmefe5Vvu/Dd5KycN99z/DUk68RCOzauYH3futbkDBa30LgyUdf4Uv3vUh2Sm/WSTZs7PM93/tWfuXf3Mf8vOt9qcipxze/bxcb1q3i7/+d32ayl3nv+y4fARYIhSfbwQsraMLKWBkr47wdHXWAnIX/8pmv8PRTr5IIPProEa65Zid/+xO3UUvkX//i53j/+29i954tPPboSzz/7H4+/NE70A521nOeXWBpOZby4DJwf9Z0NAN/5nW+DFm4+/e/yo5tm7nk0m1ogMcfP8Dv/pfHkBQ5eaJh/ebIx//Wt1KJ+twMQSt+9md/l6rqMTHV5/nnT7Bm1Wp+7v98H8O24dd+8wsMh9PQ9rnr3kf5qZ96H3fefiUf/aEP8Nd+5Bf5p//8hyCKsc8L9aGAxyuQ8Xk93hCAgri2vSQXlLVESokoETPEU3Ne75xP1YshQ7qsyMznbLcZDKl7PUQiTdOgavr4lMzAL3unuaorqqqYppXubUvl3dpmOLAFV6zQqFSxct8H7fwYwIvfEn3pxSXQsRWKt4IBF6krYIsuP4jJDp792tc4dOgQ6+bWsX//fiYmJseSA5ScW5djFPq5aZSmpiaZnZ1h89bNvPzSPgctYG5uHb1enzVr1rL1gu1s27aNswtnefiRR1i7ZhXbtm9jfn6ek6dPUtUVqom6rkyKAczOTjN/dp7oVPgiQ6lD5UyNwHDYMGwG7N61k0t27eLUqRO88Pzz7Nq1k15ddYaDOSVOnz7NujWrGAZL55hdNcuFF16IZuXV1w5xSUpG4S8MktKyV+nAAQMrxM9j2zEYxD0jBDwi0Ark4oFQucN/YawUMkv5rFJqOgNDHOgJYZQsIhj7pBuuzRboQCH7LHHwo/Xi366VBP552zlJtASxdOHiVaFqoAh+XxSJQ1VV1q1W62AvLy93IER2Fg85ORVeO2+EAqKNCiLjq8VoaSbF1NEAG7sBO78PP0EFcCkgnyk43LtBDXipq0iTgRQJWjHEgI6+1sYSihVr59Zx44038OCDD3D48Ots2bKFXZfuJFZ2/L1exXCwzHB5iQ1zc2YSGQK7Lr6Y1Ax57vl9XLDtAm65+SY2rNuAivLWt1yNSuTEmTNsvWgbu3fsoXYflKYZkNqWpeEiSdyzQyIqEIvJYS4xnFbIxFCTxzKXLfpRiFRIiOShQI4EIhds2YaEin3PvQhZmZ2dpT7Ro+c+B6h0CR/lvAaPO2ndQ6KubH9EFAL06j4SAoPlgUk/ooGdOWeGDlyFGN7cpoyleM7w+d97hXe+axfrN/UJmhkstvzcP/4CP/GTd1jZnqMTF8SALdf7W2iCeBM8AYGsFW0Ln/lPL3LNWy5laqJ4FJQvuy+2bVnP3/07H2FicpImwa//xku8+93XEfo4OOfAM578IGBO1kB2gYVPbTkpkoVoBjaOBjrY4PFeMsaoSAAa/eGdyQRSKqFddtXu33+Krzy4nyuvvthoqYUdBYC6EaQBMpYMg9kXKbzy/BEevP8FfvivfgtEeOzhV3j26dd556170Sw89dgBvnjf17nt9ktJDngFDWzdso5bbukZ3y8L//aXn2XX5ZtoBG64cQ/DJSUHWFrOfPLnHuP7P3QN69dN8guffD//5Ocf5KZbd7N6lUso/DMeiXrGgIaVsTJWxso4z0bxp0LgrrufYWEAf+vvfAAReO31JT7+8btIGV596TiHX5vlhX3LzK0/S6M1jU6ycHbIwVdPMjk9wfYLVqMhkzUwf2KZQ4cXmVnbZ/PmaVA4+PoZ6lgxf2Ke9Rum6U322f/qCURhy4ZVzK6dZGGh4eFHnufH/+dvA4HlYeL+L3+d9915NddddxFLw4af/6e/x4v7jrJ75wZ/SKgZ2EvFn/vud3DllZs5sP80//Cnv0jTJKZmIj/xtz7IYAC//atf4ebb3s9t79rraxb4zm9/J7/x6Uf5rg9dax5TODOum9bP4dD9D/6EVsZ/73hDAArWVVZCcM13pwV3/VDnJh1ITXuOwWKhnpfCZ7ybqyqEWBGix1r5DRGjFX1No505nxVtyXTyCr3KisZiShiDae9FGRXHmpwmH/y1mVYbAy/cqMH2zwo160qb5r5NiaqumZ6edjo6DIZDNm7cyIaNm7nn3nu56MKLUFWuvvoqqipa11syInFMPq0sLS1w9uwZogROnTnFgYP76U32CXXF1MwMX//aQW648W2s37CJXq/HxNQkw/kznD47z9ZtF7Bm3Xq2bt/Ga4cPkXJmcXGRM/Pz0BXsxQzRCnHzoVCq2nX9yczvqhDZunULG9evY+fFl/DCvn0sLy1x5MhhtmzZbAVcVs7OnybrNkRhbt0cmzdvRmLk4p072XbRDqp+7e9TnGatm26s/SJJyJ4gkYnjxoV+reScrQisahQhZ0itJQkU+UCREhgoIn4N2JWWc0vs1cBIHjPuwF4K/xHbRTuAJ+UGw4p1dG3KCAwp4ARkiOZR0ZkDApotik5zi7j3RPEN6VV156NQXp9S6q7xpk0+SVt3fRSbSmfQiY6YG+PHVZgm5dyU1Ijg/h7BWT1VVSPZIh0RJYZiw2Pc5hhqKwSioNEcfttkVH8B9uzdzZYLNtPv96mqyMz0tMs7KkIM7LhkB7k17wRtLeKy7le85aor2XXppdT9HnWvT9uYk3/sTXPjldcxlAxVZiJE1Iu3KenTDzWTvWlkOCRG6wiPPjeXYxC7cyydrMPYGCkpKSspNUQghppVq2YJItx7zz3dIuHrLzxDjJm166eZXTVr90iMlPhNkeD3eiCloYEFkruoUpxVQxBCFYk9Az9Vzc8jhsiqqSmmpqaMwdQOz3n8vplG11sXIcRFLrtijgu2rSJmOHN8wO/8xiNIFh7/6ssEET7/2SeYWTXJR37sDk4dO8u/+9QXIPd45227ufGWS8wbJcHnPvMETzx+gqeePEtC3M/Hh6hL4oSFxWVOzM9zZnGJf/Nzd/PEkxU/+3/cw4/96DuYXT3FSy8c5jd+40GyVrz/269hz5Vb+NxnHuXO26/mt/7jA7zy8jLf/4PXs//AUb54zytEDfzFH72R9Rumypt170kOfO73HuC291xPNVHTZrjrsw/xre+9Hg2Bhx54gS/e8zKqPTZtqfkLH76JVoQUAxm49/cf5R1vv5JV0z2e/foBQhT27rmAlOCxx17i7rueQan53h98O1suWMXd973AtTddiUxGMsrSQmJ2epprrrkAzXDgpaOcOb0IiAkqFITEhs3TzG2eIWXh6KF5tm9b5Ia3bmQiC1dcvsXAkwx3ffZxvvu7tzE3N4FE5eLdG1lenuThhw7xnju2mSmrg28qJlUTshtNroyVsTJWxvk3Css5AydPLzK7agoNECWzedMk33znJr78hWd4cd9Jnnq2JcmrrJlLNFqx3AR+6V/fx+mTmRdeXuRT/+o7EYFTCw3/4hcf4OSJwMOPvsa/+dfv45Ltq/mxv3wX11x9Mf36GLfedglfefwkZ86cIiZhMsAP/5XbaVrl7IKyZm6SjHLs6AKvHjjOtT9yOxqU3mQFoc/CYnLGg8PVAW697TJ+9Efu4X3v20EV5vlrf/kGetM1eA114uhZfuVXnuX937GTd7/Tm5DA3Pppnt33mpHOgyLFL8ge5nROlbICJpyP4w3zhM6a3N/AOs6mNzaSprZN51ZfOs8CRhWmFDraUctLYZBSYjBYZjgc+O9aVJ3mHAMhehdb3DBOBSMcuB7XbFSte5xyl0xQ4gXNs8Qj7saKka5YA9fcu341M3odwszMDFdffTX9ft/NBe0metvbbuCWW2/l4ksu5oYbrmPdhvVW1GHZ8xKgTQ0SFNWWNjX0JyY4cvQwr772Kk0z5G1vfzv9iUkuv+ItzM2t56tPfY0nnvwqT3/tWXKANXNruPzKy3nymad48umneP3IYVavW8swNUzOzjAxNdkVrm1qPSpzFGEIgbYxcGPkPZFZWlxgOBiwvLREVUV6dU2/3+P06VMMh0NOnTnN2cVFxOUbw6aBGCAKOUDs12RRhu0QUMKYxAHoCncwYMASE8JILtBmUsoGACWxuMO2JWKGlm1qSajvt3fXHKAamTK2Vng6O2E8TSGj7vFhrJIqVt71Dt5N/wZJA4mcGsQ9HgrjIsbKdWm4QZ92jJkQCqOhPSfNIbWpe00ZRfpRALMg4rKMlihQRTFTuJypQkBKusAY8FYAEbsHG1ST7bfa/SiSadsBOTfk3NK2Q1QzdR2Z6NXUdSTUESqhqgJVXqJOS0SZoJWKQYC2F9EqIHWN9KZYu2ELM2vXMzGzhpaIVH2oemSpkHqCamIKjT3o9RkgpFjTSkWcmkKrHo0KOUTaGGkm++TJPpOT04Q4QepVDCLk3gRt7BMj1JWZ8WVG0pICStpnUBMkIuI6cAkOJAWPBC2pAgabXHzJDq697q1s2rSOCy/ayrvedRM3vuMa9ly5i3d/021s37EdYiSpuqdFieKTLro2Rr9uq9Axl3BQddAMRykl6n4t9oFTmA5Dl1C8WYeYTTQ5r+Lpr87z2KOv8djjB3nmuddZv2WGJPDU40f4mX/0e7z/A9dz53uv5siR0/z7X7mLD3zwBi67age//VsvMVxK5Az33v04S0sL7No7x+tHX7P36OQJY4aJGjhxfIn7v/Qia2an+LMfvJaLL275tm+/ismpPq+8fJzPfOZ+vu07b2Tt+nXc/bkD5Eb5nf90kF/594+xfv0aBkPhP/3nr/HVrx3k277rKo6cOs3xUwuMOWpRujWa4emnDvLyS8fIGU4cW+D+P3iFnJXHv3KAJ586yAc+eDWnTizxy7/8BKmQ+MSYa/fe+wJLZxs0Cc888zrPPX+IlIWnnznAAw8/w7d+1/XMDyf4w/uP0GZ44OGXuOFtO4liyz1RJWgmBiVEWLO+z7/4Z7/P4nxj7CRn5CVpUbFnxbPPHmLrlrVsXD/VLSYlZuYXl3nwoRd4952XESsImpmZDNx+53oIy9Y80ICZSbaglm4zDpy9WUG0lbEyVsb5PYr0UlCfVy2FJwTl1lv3cP8f7ONDH7mFt902xQ9+7DKuf9suhMDv/PYjvPubruKv/vid7H818/nPv8TJow2f+Jv3c/nuLbz/AzvZuXOWgwfOkBVWrYKP/NDV/I2feB/XvX0PX/7SMW5/57V84DuuJ08s2bo7A1pTQiOzCkptc7V7OaEVavphk5m7UePll23g3e+a5ru/ay8XXrCFB+8/Bi22hlJh88Zpfv4X3seVl2/iX33qXsDId3uu2szp0/McOXga1fKMcwqfr7NGHjor43wbbwyGgio5DxGpwOnmmkZRVuLUeM1KiEZfjSIQR271JXGhc9n3tuGwSURV6ppOcqBiTu1WLAajnKrdDFDyXu2ijiEiRJrUWrHmzAkJDnZk76ZQdOmlMPXOb+fcjxv8uUkjpkmfnJx0AzYDOdSBhomJCWKs6Pd7ZJSmbezGzxb9Yp1T62bXdcU733kLg6Uh0zPTbL9oG9PTs1SxYvPmLbz/277NkNHcMGwa6l5NjIG3vPWtrFo7x+zMNIOh0ednVs2yY3KCDRs3GoghgbVza5memSbnloQQxb0TQnBwBRYWFlhaWuCZp55Ck0VJXnXVlcQY2Lx5E0899RTLywPm5+c5u3CWpmnoT9bEqjLaPepUfS/Wq9h11o3u7ermIDRN9s/Oius4Jgswqn9FwEz2JOPAgcU0xioaCNSxGtw3wRffwd0Nc85WQnTsgxFoFIKBBzln9x/wJW4wGUx0SUCJBoRRlzNGk6Ek19aDeyCoX7PdtafnmIsWD4eAnHO9m6yjIpNM3+/7F9QYHsEZN5GApmxGjjI6nnK/4PKdrKP7zsALi000qZt29HvFvAjMXFS9Bg9obqmGC9Rpgv2rN1GvSmQ1o8WQDMjJDqLknAx4QbvI1xhGTAGyyTKM2eAgC26k6ZKLrJDrgLSJCXq0KjRxyT7TXNn1mhqmNSGiHRtoXG4UXFYlRV6l7tmCIG7UGd20UZ2ZdPToYWZXTXPbu25lbt1aVq+doeoJWVqIikQlVgaUFqPX0WduRaJokXUpw6ZhcXkZPD62SD3I2RhPnk4ybIdmtunMmTd3deXMj9TylQcPsWbdWYK01HXkr/5P77FlUo585CN3sOeyLUiGf/LP7+Ld77qB3bu3sGr1an7xU09w6NA8z37tFc6eXeaDH7yJVuBLD7zs8VoGBndy1E52ICStmZyouXT3JlavWWbn7g0EhX/xyS8hoeLTv/YYz+9b5A+/tJ+PfeytpAY2b93E7e/Zzty6NfzUP7ibT3/6z1NXwtxcH/Tcwln83Ynw0b/4fn7qE7/J//6z38/nP/cYd9xxBVWMfOpf3sc//uQP0O/Dd3zXHl545XAhPhF8/sm5795EkOn5Mw9+5qfv4cKLt/LpX3uCJx47zec++xwf/M5dBLEUiaiQNXQyXJwlcNOte9nzW4+ire1j6Sz5ExNN8Ou//kV+4ZMfw9UWiEDOgYcf2cfO3ZtZNTtpRyfGJJSQiJLNNjIbCFfOQRklnWllubkyVsbKOP9GiXO0JmXQ4LK7gKpw3xef4V2376WqoA6L1GIx6lXO/Lk/eyOX7t2MAj/8Y1cxv7DEffe9xHC54ZVXDrP/wCGuvHyGHRfNEhSmqiGb1/XoRaVF+TN3buORh15muV1ifmnO2I8DHdsz24ekPXIWQmWeDIh2MrriufPKSyf47d98iP/lb/8ZZmb65BD463/td/mzH9prslCBqg5cunctOcB//YOvdzL2iX5F0pamsTQ3xHyrxs/Pygx//o43BqAgVlyrNhhs5vrS7JFu2U2lvIDNmLldVVUM3BX+G+no3c/UOlk5p64QcuN7YqgsJx67uDWDJiWKFy4SiE5RCqHuukeq2kUIZgcugq+cis48i9GkA5kQnckQxMCLgMUXiiDZUyik0MYtMsbMGk0GYnGV6p4BuZPYdrF/ITA1Pc309Cwi0PfzmUloiMysmXVzSjMh1GDnZnrVLLsv22OFpRvR5ZzpTWQmp6apej2Gg4YLLthu3a5QAVb8Z80MWlu8V1Vgzdxa7nzve5mY6NOr+2zfcSEz0zNI3WP33r2snltLalq2bdnKVVdcwfRkH03C9gu3+3G1hFgRY8UgLRM0MGwHtFpMDUtKQvBkhtzFORZwxrr7dnI0qxnrSSB5oZ5SJqsdpzjTqnSqiyTBjA3NyLAUueoyl+JDoH78xVjPwI9yebgHgjr9R8RN+YSmMco8EqxoTdlN3IJfl0VKo12hDnkEHng3vbttcPmNX/uVRJJasoYGk5cU1zQh0DYNJRM4p9YTBCz2kDzyWjAvg7qTj7TJIi5zzkTMjDEGiwtq2tY6mdH02DnAahKLg2X2Ta3iVK9iKK3JGVIACTTZGCcxBCQW0zzool+raEUFVnCnPIpgLWBdXdWdf0N274qgFUrFUJbQlKilIqbExsE8S2SG/QppUtf7Vc2E7EAIZs6YdUSlF4zxUiRLdjoDKSkvvPACD973CJXUrN+wnk2bNrJ6bpYNm+ZYvX4V6zeu98m1JZhzht3dqsRo79emFslC0hZNZg6Ke6MMhkNElKnpaXraoxkMSLmlHZoJrC1K3rwP3lGaAlRxkR/66I1suWiGKB6nKkKbgZAgJkJokRSRpudMFNiwYYprbpgFEg/ef4CPfuxWJCqVCDEnqtI8ATrkxivagi3koM56sevK5oEpPvjdV7Jm3SQ5C3UQpidrpqYWue22LVS1cs31W9m0Saiwwj369orkatS7MfB5erbPtdfu5jP/+XGeffZlPvidN/ozLFjSTcjccNMO1v67P+x2N/oVEso+C+S2D7UBhBMTa/mB772eWAd+4PsC/VqoAfKkW0YmEzWEREtLq+b18YV7n+Lmmy9heqY2G4s0YvrlDP/u336BD33oncTK39NZPcPlxOc++wh/+xPfg9vKGNgbZETMwIxhRT2Dfewaf/Ne7StjZayM83/Y+jEQ0LbmpX1LNI0gOdIkeOD+/Xz4B28liBKbCaQN7h+sSLA6wnyzGyQ2rF0zwzveOcf3fs81VEE4cuwEM7M9AGuYdv0G5dabt7Njx3rOLLZ8/Me/yNJSoiehc4rKwMRE4OGHnuGhR67guut3sDAwVvj0TCQJvPD8KXZdsp6DBxY4fWoWkZomw0UXr2Xn7j5JlL/7if/Ih77vPey8bA1KICVLWUsIQeHZpw6welWPLdvXdP5v0PpitkQ6r4zzdbwxAAUdAwTUigMJJQ0BL6ysuBJxQyupLDPeC/EYAhIiTdNS13XXeRUphaeZ2qFWfKYshBgYhsjZqiVGQ+baZpleZW76deiZj4NEcgyIZNDCTpAR28Ep6yEKZ3NiqRdZTsrJuk8/ZwKR3LrfQx2pPDpmMGwg1DTN0HTiMSIFaMBjAz12rnSJjN1QnPddb6+2vRhMDpHUPBxiVVFXgaqKCJUX1KNUW4k19AywSGlkCFg6t23dY1g1RmdNLUvOuijpBohp9+sqQq9mZucuUjtkqEK/6rOoClWf1O+xevUskgK5hVXS0BsuEqi4dOZSqsqkAZohh2gL0axeaKqddy/Uc2P/1nVNQKgkYm74lbnoSzamiRpTARFCiKRs+1zXFdb88u67F6ohVJ2kQbP7JqAOKtn2NGvXbktqJmEqRlFHwZwfhKDBPQiqwlA3ACIKw3bZzC0xmn3OSk4QJaKaaJN5IFgRq+TcjD6TEKjq2q8FGTEatIBO5fpIqLfAs5aY0RYVi88r563NLYMm+fkxIKOcL3Xavwid7KNyvwl7Q4utXDp7lioGpqamCHUfiYm6WWTT4lnmwzShmmVBxEL4EqhYdz1KBAcWkprfhYizSLKlQ0SRzqhVgowSW0SQxq/XnImIgVzButXJKdZRodWKPDHJ8ZCZyMrmdpGoI6ZAVrvOqhDs/kDJkmnVHrJtm2jbTOOmjSIGBuzauYeXn3mdV/btJ7UnOXzwJDk3VBMws3qSb/mOb2HHpVvRYNKRKtREiX6ODUiKaikoOmhplweQMnXsUUlL7OFI/rIxEVKiCr5ISFCFSB3rN3GVZeW2iqBxSA6m8vSmt5v3is0NqkA0H4raALrGgSJhiAbljjuv4POff4of+PDbEVViaglA0+LziwMVHs8oSQlq92oSM3jMTSJXgbq3xKZt06zfOAMJPvuZP2D7BTcRaLpUS4tFHpqfR+n+o7TJmELqFXflAKCEyA3vuIhP/9oj3PHu65maqo0yK4nUZpqmgPKtJdwUvwfFPToyZxYbfuu3XuH7v283CMT+PNv+b/beO9qyq77z/OxwbnixXr3KOaiqFCjlLBDRQmATTHZ7bLc9eHW7bZzGpsfumdU2tnva7bHd9MKp25jBBowBY2xAGAMCjEECZalKoVAoSVWqoMrhvXfP2Xv/5o/f3ufekuk1vWb1TEvmbVahqvfuvSfeffbv+/uGDZOYymMQPv2pL7Nmwys5cMjw5a/u43tuWosHztuyjG/c9iBHj8/T61Xce/c+3vqWKzAOTpya56tfuYc3fu/1WBM5enyeg4fO8oY3rsXaPKfklKTPf+YebrzhYqamehnoGJK7kJxfXjpi+edihoZd5VZfpMQujsWxOF5wo8zzYrn0knW86ye+wuP79uMrgZi4/totFCTZuIr3vu/veccP7MBUfYyNLYjtXAOx4SUv2caH/sVHefCBJ3DeMrVE+OEfeRkT42MYXxMd2YvL8K6f/htetHMdQuLxbx9W5oEFlxqt5yuYne3x3vf+IJ/8+N381V/ez7FTFRs39dm4dZbawC/89N/w7l98BZu2Lufuex7gl3/pM4xNJFIULty2kqpyXLLzIn7yX32Gy68fxxqHN4bve/3FJANR1I+nU/XxndIOUfnHCA1ucbyAx/MCUChriraQDYGmUe8Bm4sK7xwua97FaAc5Fop7jtGLMeJ91UYylgg+iZEYQ0uzRlS/vAA8PrmEx6zHIwRriEY7ip2cZiIxgvUkYzE5BaJEGJrMeDAtD1OojWFfNU5yjoGfB+a1yxSVOm0J2d3U5SIld9lHtO2Fln2uad4wblKSGbIUyIxTyaZ+JiHoQtIWSrdVmn+UssAr+v58/iXlAjRTwRlKM8yYGvJp159cyKqu1aifd/YF0JnQSSIlLUYhYsSSbCQZT2N7nHCJy04cZfspxUajsUSrWtoUDSlVJGtJxhCcoq0hBpyzWS6Q/QRizCBAykkK5MJbjyll36wGuG0AACAASURBVAARaWm35TyPegcgaHfYofIHPSG64M3MBJMBADWmHL7XicMZQxMj3jo16Swbk7LAz1KWFLOzugy3kQRvXKbRZ2aOsTQxtPcCDI0drTFIjIhzOU61sBSG/iHD71C+RpZzj9eor0TtNH2E/LtyvwF470lSok01iMiYNPSq8B6DoXIwPb0ERA0VxXskWTrSZUE6LPQ8a86cZvbUabzTgljjXzN7xBlMjviMogWVySwA/a+ySqzNHiY54lNlK9kwNAb1djCGRiwmelyCyIBoE5I8xlUcXjrFsV6PVfUAk4onhp6vyroMTipLIaSo5zaDLx3ncCLE7DOBMazduJarrr+KgweOcN62i5Bg2LPnQebPzoGrqWsBqxIujGQGhHaTxajJkUX9LpzR9BmDwRlH5Q04w/ygoR40OGupnCOFiK88nU6HFBP1YPBdKnkoB50wWLZsHaPfH6YDFLaQMbB6TZelSzuAwXj4oR97Me/7D3/H//V73yC5mhtv2sG6dUtZu3opH/7IV/nWnY8DlkGzQOoZ/uiPP8f99x6G1Gm3boAf+sGr2bx5GhGDFWGsM867f/rP+JV/92Z+7t2v4jd+/ZMsnAbsAm96+9V0Ks/5O6bxBQMSw0UXzRYCE5u2TjLZq/jsJ77J57/wGMF2iEbnz8rO8yM/dj1XXrmDJTNww/XntUy2n//51/Kvf+7DEBUAW7pUPUOWLPGs39jHWti4aZZfec8XEBJnaphZ7rCdxL/+X1/LL/3CRxmIRzjLT/7EK7HAu999NX/+sbu44fqVTE141qydYWZqmv/tFz6Ns4Et25ayebPKO/78g5/Huo4CAOIIIbBh0wQzS8eBWHA7gsCxk8/yute9hGIXkskYnDw5z6OPHORt77gKjZoYAofD652fW4uLzsWxOBbHC3JIntsM2y+Y4S/+8rXMx1qNt8Uws2QMYw2GyE/81NWcPVszNemx3nPlZWtVHiGGm19xEUag8sJv//brGQwCCRjrVyyZ7GOA/+M/vI3KlyBGwwc/9Daa2LYSmZrtYcXwmjdewl98/Ju85W1XYSu4aOca1q5ZwqAJJCyT4xWVUSbdBz7wDsbGKnrjng//+U0MFtTnDGB6sk/fW970lvN58UvXk5wC7x1vmZ2ZwCR47PFDfP32+/mf3/nqkVnc5yKmzPGL8/sLeZihhvp/3Ni+bYv8/u//xjDmTpQhkFLCYrJmvejDHQlDTOqZ6LxTozkRlTJY1zr3W6t+0TEpoACSC2yveiHfZfeK5TzjPOvnG3rG0EiDSZFKlH0Q6gFJwHf6pBizuRutiaJxIwZ8kgjOs6s3yYneBDPWILbJWnZPdjakYx0hCQtNDUYIsejwzYjhnuQECZV2ZGJ/9nFQ6lNMinpYP8SFigZeRE34nPd463MueFmjlWlFR2EnFN180zQtIGGtw1U58SLvo/pGaEGmUgmb5QYOUlD5iBiSBEgK3ljvOWUs+xxccPIU5505o74JvsIT1cnbVEh0NKZGjOHZ3jiHnONVh/azcV5dxWMs19DinEON2fSYQwhIgsp3CI1O3KrvN22KgkFj+goIlbLPgHdOqeRWWQdFftA0Db6qRjwXIilGjQ7N10rBDYtjWHSnJNRBGRxqwldkGaYFgorxp7cOQX0nouh9H1PKCRt6bbrdrl4zY6h8noSz1j5FfV1J5JAWJMh2OxLbnznnWvlGt9dTgEES+hUqIIgyM1QKkP0UYgDRY+11u1S+wgh474ihUXaQ9Wp82SQOd7rcPTvL+hOnOf/0SaxpQIrhTjYYdVaZI87QiBYR3rncZVZZCdkY0RiTvycqXXLWEoKawlXe0YRITJYmJewgYWyALiQc89Lh22vWQwpccvwQndgQZSjdsJTUDv0+NCEwiLBn1XoWnHDpkafpDBZIGIx1SDLce+fD3HP7Lh57eC9dP07X9xkszNHrW2aWT3Hz629iw9ZVmKomNPN4W2lkqUSiBJ03kl5DG2qO7n+CvXvuYbwTcTQ0zQIxDYhR5RZj/T6paTidPPevexHnv+giev/wVX7h//wrOv1l/30m4hfMEO1oI6SkwCSg7KT8dyGRjPqVeEvmdBmCCKZWc9JkQToZfEATCMhBMUrQyS4GOr2cMzJTH5NTTCSoB7YUP99gMDF/sDcqo8vfe+/0w0JUiZYBooDXwyIlaErDJu+/zWzQkgprMpiSkiFF/b6IUdaoccrOycQfUoKgXyWwBu8EZyMpGUxjVark9JgqA88eneNnf/Yv+OVf/l4uvHA5xggh6nZIBirwpgDP+qPyBBKj2/K2PGsUkIT8iBPTAtQAEuBPP/BVtpy/hutv2IazJdWpfVhl9EGvn3o2/Pe5ixbH4lgci+P/r1EcckTy86horzMbNPf6oJVIWhUj5AaXmhjm5l15aBVktrB5BZ2Qbemg2VysB30wJGV9hdKkDPDun/8g73nP25mc7rVsgTbGOu+zSdlHqEiKW2mCNlmRchz6uSk3z5CAEY80ht/893/Nm95xLVu3r1SGntgyo+fjKUwFRsDkxfF8G1deeSV33nnnd7xAzwuGQumMA61e2hSRpR1205XpnXWhTgsKk/J3sKVrm7bgFHInshRFbbykphNgEinVTMaGbXMDJpsBTQhK6Y+JIGqY5ozFuDkiCe81crAJIXdaDFVHO7oGCNYyNtWwb/50G3vpMm1VWQ4lF8K0iQGSfRDKfkoash7aY8mafkDN9zKwAGTuaP5ZNp/T9Zh2vNX0KvsBUMwn8wREoZVr11g78QooVN6r4WEuOHXrGqWXRJ1pkWHygMVmqm2mpUrEGu3sRQLdjufM1DS2DkoltkLTLDBAKejqGO4RabRzNy8sdRW9pGBRVfk2LrMtjiWisZAKIJRJ2znVuhdvhNE/2ik2rYTBZFPHMj+rhEDjPUfNGAsLgMzgIAasc3hrM1NFC3Kw+drly5PTHIwxSByCDvpM0WtvjXpT6D1uWsaKta6NRy2pBOS7Rx13bVvs2NacUr9UytjxWOcQhLquWz+GwlaIKanhqLNtjCZASInQ1HjvFdCyPqPdWt2kPP8b5/GuIuGRVOcoSatVjygQE1LAJsH5DiKJhfl56sEAA3THelSdDrh8wky+v/JR+qpSxlIInD51KjOMEr1eH+/1Zhg0ibmz8xw/eZzxmQmmOuN4WxGbBusT1qnMx1qf7/ssdRCBFDW9JBuqJhGsIUdlmkI8au+dpqkJQXji6ad45tAzjE/3mJmaYtXy1ayYnWX1mhUsXbmEqdlxnE/UoabT7UDMjKYCdIrKapwxkCIx1FTekUJDXc+BqESl8hXOVcQQldVhPSFFnO/QHxsbSsW+y0ZeYrUd8HO7GwWuG5p+FmNFj0Uy2cAVXn0+h86iZgYmy8ISGCvgIm3yTzvSkJVlEsnr80qTWS2usogvyhpdXNm20w4Gh3PFzrcwmwzGCUYiXeMUENCYBUj6vcfFDCZ4/X0u3EXbV1ku4CjsJNACvlN0BKmcJoMzQAd1aTB5zwSWzY7xvt//QX7mpz/Ir/7b17F54wq8DTQOrLos5Pldt+1MXgBnxo+3GejNi+JyTWyhjuR/C3DgmePse+oob//hG7A2UqLJzr2Wxaj2u/NeXxyLY3H8ExhSGnkqRzM2ZUSbdi5V3yvXkrKSyUC1EcSkvM4fsrtaaVhOWZPS9DAmp9Dl1xgHEQVrXcLlRluyll/65e/nls99jbe99XvaGoP8/JP8bMj+4e3TywhgQ2aN2nwAFRmPGME5FPA/dOgEO3asYdPm5RgT8/HKcFvtSVhkKbyQx/MCUCi3T4iRhKiBG5ZGJHdGSzSh0u2jJNX/owVhTKXDb7HWt0WT61RYaAsrY9xIQSV476hcj6pOuHCWUM8TQ2Lf08+wasVK6HqcM7isTBBXcsjBWmmTBg4c2M/Ro0fpdLusWrWSNTSs9hUSLNJEupVDba2EEIRe1VOqfPZOUJkBuZjRwto5LSCdV4aCsjNU561MBqcZ9eQvfSqFsdL/1fQuvzfT8EOOqys+DEkkJ0vQ6tOdtVoUAv1+T1+bUkuhlyxJThIosW1N01D5isqpr0GTooqKQ4N3atbSSOR406fT6bLx7CkunJvXorgyJGmoJWF8FyueFAZIaIjW07gO/Wy8KTIs6tVHwecCWyUuoItZ8rmy1hJiyn4HtLR/yUAVdgiupFamkJkhxuBMLgNkBJASTShQjwTJfghaHNp8zZJE7R86le/oyKCNUTgphnwdc6FjnYJhEpXKL/naKJCQWjBMt6usD13AC0U2U8CSlArbwGCM3jNRIjZLJVoGg1HJQcd1MlPA4ivfSnp88linhUtT11Te4ztKwXPGYjHZe8EizuNJNCSSIoQKImR2SOW71MkQBjV79jzKA/fdz9zcHKtXr+L6l7yYJctmtOOZ2TfOulKjgBgOPnOQO++8kzOnTzN39izbt2/nqquuoNvtcebMGW6/7ZvseewRZlcs4VWv/B4m+1NU1mGaiHUN1tSYpMCaww19WaQwT5TBVBCrJApExgyYlYJGfS8SO7bvYKIzw0S3z8rly5keX0JlLGMTPaoxi3GBlGqcFyQ1lAhW6+wIsAcphCwTiqQQqJv57JvicVWF954QhWLkWXUqqqrT3s/PaZx/l4zyxLDtv1qinc1gg4BKIiKIG0p+GPFmaavrkUWUKZ1wCza/vy1yh0MoYJ6BkhJiE0KT59fWpiM31zV+FSwm+by1vDwrAG8u9I3J0V0WNDZRV3T6iJNh5a8rzRbobRv/grKyMr2W/D6NgM02XGKzTwqI0Xvf4vNC1zI+UfG2H7iSehD0O4LNJo9y7pkwuXNmskao5YiUc1v+PfIuKQtHaCTyIz/+MrqVH3nFyELTCNqxczz3GiyOxbE4FscLauR6WZuk2sAzmW1QrHhNZviKkewpY0lkM3qT2WftezKruzQjczQ2kB+PSVkKGI2ZB60BpEioEytXTvC2H/geZTaY8ppcWZgCg6dMINDnpe5pTu3CZD+cjIpkU3tNAnMYk1i1YZI3rL9C15wUGXfMO7o4t/9TGc8LQEFAgYAQMMZqkecMVSdH3+WbzTlHqGuMH0oaJC/GLaNUyrykyUVySikXgYkQAt5XraxCmogVQag5fvYoRw4f44lH9jI1McHMxCykQDRaYCBJ3futwVstwo8fO8qDux4gxETHd1g4O8fyVctYs2odNBYbvcoAbMoGfgbbaL62DYE4sscFUGj7b9lwzklxpo/4XATW8/McPXyYpbOzOOtzVGAiZdBATfRkSH11Vi+2CNYolb8JibH+GCI5mi5BVVX0i5ygUZMvEFyUXDjnOSOzSiSpWywx0TUKALk8GRlJdENDYw0NhiYYOiHSMfNUZh6iJ9aCJ+EBK6Ja9WjUh0GElAIhCWItTdQ0jmF0YnH/j1jjyViCFtL5NYKacUo5dnQyDxlksFZ/LsQMrgh1VAAjkdoJsI0yNCYnhqjcJIaIzTr8plaTNZXooPRqPQwtMqK2FFOMmcqfl9pG2u7eOSyK7MtQ7uGWrSKZBWIcuZ1OCg2tnMCIGiuSZS7OKb0ejX2U8vnOIjEoKGONZg9nhoICJx1C1MKp0+kNmROiaQ1iBGucglCpJqSGYvnprSBOwXZnhDrVpCQcOHSAXQ8+yLbzz2fpzAz33Hsvd951Nze+/KX4ymvRA6Sg//XOMT+/wAP3P8D01BIu2Xkxx44d47bbb2P9xg2sXr2Kh594CN93vOTGl3L3/Xdw/64HuPrK67Cm0u9eEEL+kqWkc4DLwIHJRbnJ5zjFoOfCe6LJSRsWfdiKGnQaD+O9Cc6ceILdjz3EwtwAkwwOy9hYlyuuexFXXX8RzgWMiWp+5Awx5bSZfB8V5pVSFRXgTNHS63U0HcaWRUPEWUNMRkHQjproSZY8fVeO0qYZYWPJMCpA7/GyUDGlG5L1DC1AkDtBpvBhhgwnJRYYMM99RJZtDD9bd6eUzaodKDGnZVd1WAUqTLuFcw8p/ze1+6FSKdP+TzL7IMvazJAuKgrj6QLTMvy7blYTfwBj258CSm2NxmCJGAImT6LOwatvvlSXvELLDNRnU0TycQItgFLOoWIYQ4ZBkQO2588IZemxfuPy0T1VAMcI0i5NDIsLzsWxOBbHC30YCmg8ZG+pvC5L6woAXtoXhnZetNhcq+vi2yLto0jJzC7jr2ZkLs7ocvtczD5VI6/Vl2b2nC3vLKjHKCcv5n8XGh8YfLulsh9FruHKwrf9rBwJ3L4HfYacUwEVXsPieKGO5wWgAHobOe9bSnlJTogixJSonLrw+6pLlKRFopGhpt4o9zOmXHyL0PG+7VyVIiyl0uGGOtUa2YZgCYz3O5zuVBw/fYLTgzNMpCmq3K1NRrAhKetBCj4nPL13Hx7PlZdfhneeY8ePY2uDDxZrKsQkQnbLlxxz1+l1lGmQTcNd6VWllIs0AzmZgqTU1ZR18MY4JEYG8/M8uHs3O3fuZHbZckUIM3BCPlbN89ZON0JLaTfGsLAw4IFdu7l45076/T4nTp7k0UcfY+fOFzHWH8N532r+1aBRO97lhEqO9at8TirI53Z+YR6LYXysh+CIKIiCheR08kjJEpJti6vKWipjsWKUho7BuEoX1UkRWmsUzU0paoznSPFdrGfyIbf/ck6TQFJGQZwxSIqQDSw1+jF7ChhN6Sixn2UqjSGQEpm1MASwyIhs0wS8ddhsqqf7pd3kpqlxmUmTRHJySWZDGPW7UDxg+JrE0MBPF/FpxONCTf1iTkcwxhCaMJTyGJM74CqV8Mbla4gCIVkeMpRQQKfTVQZLU+t30PrMqii9yNKxRyUExtKpTAtaZdEeYgLBRwUwmoR4fehpiWGRLBGaO3uasYk+F150PuP9Mep6nl27d5Nig+049U6IAZ/9Q2JTE+oBZ06f5EUXns/atWtZOjPNQw/vIoaa4yeOcuz0MS46/0XMTs1iO8JDu3cxP3+K7pKlJGOJoh1Zh1L1iheGzUVpKdasRsq0bJVifJmtDnKn2dAMAvfedR/33fUAjoqq08G7inq+5vDpo9z+jTvYvH0VK9dOo1tFv5NJyiNe2SYpYbLnCTktxpQkDfQ8xBRwzmOcBWdIzpCS/rwJQ1Ok78rRLs7K0O/5sJgtcqCUZ2ubAdv8fSmd9SGklD/Dtdd6OIShC2oGJEpkQ+nYmAJSDDs4w1VkmZXMuZ+n3/bhZzBcRAqapDNUCZi8S+UYR/bPZKBvdH8LsoBkUL5ss+y2QhdOBM1hyZ9rdKmnezVkGpQtj5z8/PvhcZ5z7o20XlstkCKj10va4ykfUY5FIZUCQowuNBeBhcWxOBbHC3MUULbYILg89+kvY57vbQZrh/OuPqHKHNy6cTP6/EBE493P+czcUcySvRG4vAWjy/qjnVmlPAtHnycjQLwMP6M01oZz9OhrRoHgUbBe8rNnCE4sjn8a43kBKJi8CLTW4n2VDfHUjM07TzSaTmCT0si988SR7nOKQgqx7Q5rJ7eYOFoFH0Sp+TGWYkwXOHVsiNayMBgw7iqWLpnJxotaVKTc/SEDF0T1PXBOs7IX5hbodfpMT07jbMWSqVlivYCL0IQFBk0DHQj1Ah1X4ToVdT1gYTBPCA3WeFKIdHtdpeiHgOSIPOd9LugViPBO5QspFvlBykUsWCNDunYsFHibQQVNSpCUkCyGCk3N7gfuo9fpcOGFF/Lk3r3cc9ddXLBjB2YMvDOatJG78Bqx5nCZehtFNHUhxlZSkaLwzdvvYGbJFJdffnH2bVBqvJjcsaaDTX2QrG83WrTFlPLyUQEDk6UMIkmNN41tWSk6huaMMUrrRSA5ycJbR0yh1au3MgKr4FPK1xcRrAMrto3PpD2VOjl7Z9sOpBoYprwAlgzeJOp6oMaPqZhWZpnE6AJa8v8ZLQxSVAAhSWqvcfv5OFIsaJhS7cszxGQDH0EwzlF59TdQsChLHIIaO44aLcYk6iic5/gCKqSUtcuSCCERmojzFSGbVBpjWzq2y/egiOAypzuEBls5OsYysBG8QYq5JSDOISFAEubmzjI/d5amHpA6HRbm5qmshRAxIWSQRZAQsVUHi5L45k6d4szJk6QVyzl7+hSxrjEIp0+dJgyEqcmliBiWTs3QtX5YJ2KI2Oz5kKVQ1uVzXK5LBuDy/VB8TFLQqE9rNKlBv3uJpg4cOniIXrfLK1/6CpaumGG8O8bxI6e4/bbbOHJqP3NzZxGmAcfCwqDVIGLy9zJvV4H8yEK9kP0vhIVBjUigymaCatwnxBSIkmhCA5m1sDhGu/kALi+bht2XstAx5fvXdnfKBRn6kAwFqvm159Syzy3YJVsjSvuiskz6x2NkG+1nDyUJBRtpvQeKELVNCi9vkwx0lD96o7feA60EygxPQd7+EAwYQhYYUYBcbAZEyvbL+1y7Phyev+EiUNptDuflc46x3WoGis8BBEybxjE8z6YFbBbv7sWxOBbHP71hho2EdpRnlivYQB4KRA/BVmiNbkfiy/7xXNm6DKFPKQUICrCsU22edI2uN8sG9BMDwzkbynPoOwHt+gQeggejoLO0z7GhPHH41nLM5zyoFscLeDwvAAVdI2nhYm25cXPUHZbKe6WT59dXVQcJjRozpgbIQEJ+b8wxg0BmLzjElGLUt2syLdDVPd5apyZ8WGanl+BTwsWU3eCzdZbkKMtihCWC7zgq3yEhHDtymLNn51i9bDkpJm6/8w5c5di4aQNHDx6GJGw6fwedbsXZU6c5fPQIYDh96jRr161l5cqVHHr2MJ3Kc/r0KTCGFcuXMzY+DkYYDOY5fepM7rAKJ06cQCQiKVE3kUE9IMZI5Su63R7OqdRBz4XQNIkQapoAdb3AsaNH2P3AfaxdvYpHHnqIo88eIYYGZwwxaLwlSUhBqbBa0KYsIdFueYgKWCBqhDg5McXxUycJBE0gkCxZCQFpKsR0NMbSQsodPjEWrDJOjIPQhOyQrpx5O7JEL4BC+f9heoEfmsGEIWgkSDZChBgSJmUWghU1U0xRt5skF7OmnWiNUQArZTBpKFEY/rekMOTGp5Y2koGbzO4osZ8q0cjTeabae+cy+yTlYtPk74Dey9a6DIS4Ft1O2R3YV25E358jFo12SqNoEgqYTHO2OFGWxfB7V2JIM9MHi0RpddZgiUF1ds5ViFWjyhg07USy074IEC0mJj333oHzpMrRiJo+RgPeW1auWsX9993P1//h66yYXc79993P1PQkDgtR8K5IWhKxDvr9d55VK1dx3733cfDgYY4ePcKpU2eoqi6nj5+gmY+QHKayhBCZn6txpkKUaIH1DrymT4QU6IjStGOMGBGVPEU1XHXZ2JIIVowCTUHBmLZAygZIg4WzPLxnFy/f8BJWrJhm39NPcXruhAJUlQGrbJKYEsZpdzyRcNa2ySMa+anRp4XVEpsFxsd79DqeZjBo7zVfeaJTaZfSHOW79iFsRkCBIROgFKLDa6UvHi3xi/Ff6fwMAQQtmp/bMRnp1IxQRCmAnik/T+cwAoaO199p381wv2W4x8N11WiVzXCBado9RmmvUJCzQmNtJ6H8O0NZcz7X/SB/fvFReO45A6XPZj2sycdYZCUFXNB/2XwcKZ8ipd6ZDIy2+4Ud0nslgzwj+yMtmDLcfkEapIAv5+zh4lgci2NxvDDGED7QtZXOiW74GzFANZya85vKum/4AQU8LmCutDLf4ZbMyLw/6n0jSGFBnLNXufjPG0wF7GUIZxgyqzo/Z899WuTjMhpBbwrwPApSn3P8buTvoz9fnN1fyON5ASgYY1oqPtB2oqMUPbalqipCrfTzpgm5kNECUKzVTr4xSLJtwV/i/NQRv8Qw2tztzi7+1uKNoRKPjYLrGNxYj6pXZVM+XTQ5Tzbe06g8gxaOoRlQZXlA0wzYvfsB5rduY836tTy67wk2rlvHkukpJjt9Hnv8cRYGAzqdirGxCabrhqYJ7HtqH8ePHWfJi6fZ99TT1HXN9h3bSCly9913s27dOtatXcuj336Uuh4wPb2E+fkFjh4+jMREbBr27t3LsWPH6HZ7nDp1ii2bNrN23Toqq5GTNoGJiW5VaZHTBPrdPs1CzROPPsbxI8eonCPWgTCoOXL8GCeOH6eqHFNT00xPz+C8Y35+wNFjR+n3elhnGBsbw4rBYYhNw1iv4sChkzSDhk6vT/I6odEEUligkTmCm0dsjY059SJrjlMKiEQcklkE+gdM9m0Y8TKwmUKci+JitpiSFmwldaMwE0CLd0kqU7BOvTCUyWIwRlMu6qZRiU2l2fUpBGVoONcmIKBYgXoitDN+kVHIOfGaADEKVdXBZEZHkQoUtDehcp8OCh7UjUa6uWyimIrfQmab2EzZLxo8RpuE1kIy2tU2vjXKsS24MaxzyvmMTWyNAsu2VAqk6/4YQVKjTvT5nFZiW3aGsxBCjUiiMiBB8NHhItgorXwnYVi2Yjk33fxq5s6cJTaBsckxOr0uWEPV7RBCTSK13+cYI77rueb6a3nmmQM47+lNjHF6ME8jifl6AecNlRd8x9IQMb5Lp+phTMJYFd74qEBYClGdk3MUbYoaz0kSYsyed6LGSA5lITnrgAbr1EOiP9Zj2/YtHNl3mMce3cO28zczOT7Jrgd3c+bsWS64ZAuzy5aASUQinX4nS3kU0DJGGUNGVLqjaTSBOtQYY+h0OlmKkk1X8/VOKTGQATEGmtBQN/VoK+O7dJTF2XPpmd/pdUrtH44CFozKnFwLGIxUtowWusMx2vUvutLRMcIWwFL0pVJkMOe8etitOWf5lakBpQ9VfDeGxXUGRtriexQQKdu3GeMoQGkp6EcWoOdIJkYZDkILWIjJgEBZJJb9GDlGKfNhOeayjeewGlAvBnAtLHHu+RiVlwCmGC+75wAjGZqR57zfyDnneNS+dJQSfA6QU75LZf+fe73znC3FCLPMve0HPecQFsfiWByLo4yR+VTnFzecco68QQAAIABJREFUNkbnuvaHo8+dc+e2dhSQu0jPZIQpkNOKzk3IkWEyBKBNuXNgXSQDHcOflrm0PMMi4Ed+9txJ77k/S3kNPso8k/Y5MDw1ZnH+fIGP78zO/B8wjNFINGNcWxyCapeV0o52fI2QJOCc6u0d2tFMSYgh05QB0E5jCAGDwRuLAmza8aysy0ZnxZvAYp2jiZE61FhncJWAN9iOx+SIOpOMGlqn3PW1FRIVnFg2u4yZmaUshIYmBmYmJ9myaRO+UzG+bJrzL76IftWlHizw5JNPsu/pfex/Zj979+7lxIkT1HVDCIGJsXGmJqZYPruc8bExTpw4wfz8PCdOnGDFitWsW7eBdevW0x8bI0ni6LEjHD16lI0bN7Fu3TpiE7jtm7frV9ZlDwho/y5iqGzF6tWrOW/bNg4cOMBll13C1OQE3ariyKHDPPLQQzRNzcmTp/jsZ29hz7f3MKgXmF84y/79T/PEE49z/333cffdd7cAj/eWXqdLv6Ph7o1ENaITg/EdvK8wxOx4r2BAsjkHPWWTMZPp6iZpVyrl16ViRGjo+CpH6NkWJNJJS00znXP4ymvsnymxm5HQDEgpYEyislaJvynpnzzpWqPGezbTw4woI0U9JGILuIpoeBvGEZPWzEEU2SXr/zXhUD0EjBiccTjfwbqKqurR641RVRW+qlojQKzDVh1cpa9zvkvV6WF9hThPwmG8x/qKmMBbj8UhySBJZSrqEeHxvtMyK2JKmhrhnHpqmBxlmoEERMnizli88fk+13u9fMfa6LukcpsYsyQmKgBUeYP3KgsJsSbGeUSaLCcwOGuprGPlsuVsWL+O5ctm6fd7bFi/FmcFSSEj6QpUlILbGsv4+DibN29m9erV9Pt9ZmdmGe+Pq8dBikSBpo4sDGqs8ySbCNIQJVLMKq1XplLK9HgxmSVjDdZr8kOMEUkR53SuidlTwVsg1ZhU0/Nw7ZVX8ppX38Q1V13F6uUr6Xf77Ni+netuuJqrr7mcbrfC2hILWe5dS8hzEkAst58IC4N5FhYWEGPodnuEQSAENcl03uKswQqYELGi4FhvrPdfa4J/lw3T/jEjfx/93ej/DyvIIVA5QvsYedtziuL2red+vnnO9osxIfluTu010m1omZ9Bi+LonRdXKQOMKcfpiN6tuWTPQIBE/ZPUj0bE6s2c2VolT1gxLI0lFoFjR06rqWoif2I2fBXyt27Iniq7l8oCtDyPxRAFokntklCZCGnYESv/zovTktRCUnBMzW6l3WZZY5dnUxlCIpmUmWyunAHdl6QJLEXORYKTpxb4gz/4FHVTfq6MwjaZCJWzpRh1v0SPNxV/k6TmvFI8gdB5TmKRjumz69d/9VaOHauJFLnaSPdwePoWx+JYHIujHUV9J6jBO6L2turRNCINK5hDAS7bTF/yHNUuQlvBW2nuZCvx/EkZWJBSwuv8K/m5hKj5+d6nj/GhD3++fQ4YsXk+Ltsd8tfK/KY/09opwnDejgB6XLmHgmB4+pmTfOjDX2dQx7wfJu//EN0obGNZnD1fsON5wVAACCFQVWpOpzTvhPeaeZ2akA0FLd4pUKCJEJzToSZpjF9o1JhxqJ9Prb68gIQlOtCKZrHiLRZHGjScOnpcTQeNwWfat3YlHAmhDiHHoRjqGDm7MI8YWBgMODt3Bt/t4mJkqttjamKKutFOZb8/TrANTz3zFA/veYSdL9rJ1NQ482fPsG//fjVhaxr8+DjdqsJaQzNQrXjXV5w+eQZvPf1On2ahobKeZn7AYLDA7vt3sXB2nqmpaY4dO8amjZtUTx/CaEuaJidpqIbcsGXLVjZt3ISzlt0P7AYRDh86xLGjx9h63tbcUU8cPXyEbZvPo191WbNiJWfPnKWem2fPgw+xZeMmli9fhrUwPzfH3OkzWJEcLelzlKXqrByCE+2iq1GhYKTR3xu0oLaO0ARNIUhgnGnlA4jGi/oRICFlGUaJUYwxEEKT5S7ZfDHHhEr2TNBFubR1gZROXxI1z2xRXjKrOBvpMAS7MAqEkO8FMoPBG6WbOUuWXehrndO4xeLl0OlUhNBQVY4mBJz3BBPxUQvd9rjydpKkDAaY9umkPgvFMFP3L+Viv4AtRcph8vlSVoRS/a2xiMkLcEzrs+Gs00IYfa+zBsnsiqryrYyj7KPzgCSaQU2Kjto2hAhYg6+sAi5hgNWnFvVgnvsfuJc6LLBi9XJ81yGi3+mFwQDnHM5lhboIdRgQQuTJJ5/iqX1PsmnzJsbGeiyZnuTRRx/myScfZ8XylRw7cIjls8tIxhDy0y8CKRvQVZ0K0zSE2OCsa01MrUATGowIlbdEqyaatKl9yk5wRr+TDz6wm7MnFpjoTrJ/70EO7TvG3Ol56lSz76n9zK46j4pKC8j8hA9ZmmMyMGacwyQFdarKMzE+TscLViKhUfZSkICpRVlQSeUk3rpzJDjfnWNY/JuRH/0/veU7/+Mfa/v/2zZ/7g78o3cZGNL6ixmi5dSZAR/6wP2IBIR5sMIVV23lmqs2arKHlM9OeemXAYvMNioLz/YTJXHi+ByP7HmGq67ehjHFstEg2f8jRPiV9/wpN73yUl73uut5+KGD9HpdNm5a1t5HhYsw2kPSecK2XS2b/VvazpbAObQnyY0mGap1Td714XGpQSZC6xmRgC9+4T5eduPFdLr5edve36b93PKXtrtGwiTL/FzgA3/yeV5981VYazlxYsCHP3IbJjgwiTe//UqWr+i30rLRNatBSNHw5S89xo0v30Kno9/Zv/6b29j/VIOkPuLP8rZ3XMGymUnm5xI/+a8+zvv+6M0sme6MNv/KQf6330eLY3Esju+uIYYkhvmzNe//068iyUPq8/1v3MnadX2cgdu/tYet561ldmaCA/uOcez4KXZevB4pwUR59i/MsSHw3c66udZJecocAdGhoAs8+u1DfOrT3+KnfvK1GCAGw6c+dQ8HDp4ihT5XX72aa69dP2KRY5Fk+OJXHuXhB59Rj7nU46ZXnc+285fwd5+5hyeePEWwCR87pNTnsquWc/V1G1i2YoZPfOKbvOOt1+tS2T4nV6n1O1qcN1+o43kDKHjvW2AghJB15Jp4MKhVs6/65tT+TlMCslZeskwiRmJSwzJjLUbSsNPisnlgKqaF2jUOYqibGh8j0gTGqj7OdrXzEzKx1RhwDDsSVhdt45Pj3H77LqanZ0gxcur0aZYsmSGFhkE9j6u0exRCIvpESA29sT6DwTxHnj2It6uYHBtnemKSjvM4DCnEVubhrZrlSUw0CzWnT5xifmqJeh0A3ljqKHSsY/XylUxOTzE5OcGGDeupXNZO5SJWstbf5nVgf6zP1PQU/W6PkydOMDY2RgiBuqm5f9cDuMoyMTHB9OQUmzZsIDSBJ/c+wcEDBzAWjjx7hGcPHoQUIKcn9Po9Kldh6kTlhIEMsEmZ+Gr8ZyFFnCRdnKYAJPVhMNr9stZik8MZD77SDl9Z0Rqy4aBgY/5cIzhviBFSyJGOZGd+FHDKl54YAzEWYCDfS9n40mbpDMnmDHntqkuWMZQEklLkW6vGOLb8nVLoaUygtQ5jhrQ2m5MiYkxUlZqPdrs9mkbNOUkGi0dMQutcaYv69vo5Q4qRGEPuYEr7OxGofIemaQBDCA3O62eCAislQcAV/X4GYlLU2MyhG3yhvokCNaLsBoymhsQYVC5iwGUzypQt6bxzyiAxXZVdpEb9EQSaUPPkk09y4uQJ5hbOcv0N17Ji5TIFgkiEpuGRbz/CsmXLWL16te5FSiwM5nl6334OHjrIqtUr2bRlA9YY1qxdxfqDq7nnrm+yYcNG5s+c4fwLLqbX6xNshMJ6ED1OSflq5PPaAkT5GVZYL/rvHEuaUjZM1E7CmZNz3PXNezmy/wRpAZzvAMIgBPCJ1Ztm2Hbherpjvo3WhGz2mJ/mCnRptzQ2Dd469aVIAwb1gK53xNjovGgMqcnxrW1yjSGE2HYhFsf/m/H/0blrAYZhh8eQF3UCp07W3H3ns7zznZdiK5UWffELu1mzaopNG2badMuEVeJEIptpK9vBZEBJDLn7bzl4aI4vfulxLrtquwJOulmSyUW3gZ/+mbdiJdEkw7fuOsLSmQnWbVyOy4V9ub+T0/lSp90Ceql3BwImanKPseCsAqoRNVPVY3bDLpYaPWh0cTG6TZYUi2eC/jwaw6c+eT8vuW4n4vPGs59FiceMkrBYJELAYJw+/5LAe//T53jTm65my/ZViMDv/PYtvPZ7r8CIgsj/6T9+kd/49TeopskMO2RGIAS45XOP8+v/7ut84YZNVB1dte/YsYlVayJPPTXg1i8dod/rgjH80r+5kV/8xb/lkQePc/21K1E23SgDZnFRvDgWx+J47shgsXGcPDXg/e//CtdeuwPnPF/8u0P8Lz/3JT78sdchAl/8u330x2aZnp5gz97jfPvb+7ng4o2a4GUU2LV5fRaj0YQ0axArmgQmYKLB5jm0hDNmCELnvSjcccdjXL7zPHodDwKf/vS9xEa45oqtHDg44Eu3Ps7Oy9Yw1nPtmjgm+OwtT3DTq7Yws6TL3Xef5F3v+hKf/Mwb2LZjHctX1kQjuOC4b9cx7rrzWa67fi3f88oLefcvfpybXjXP8mVjKuG1QpF2PAfnXRwvwPE8ARSGUXYwTGqQHO1mrUXQTPgQIt77zDjIiwOTO8xGX1co5CG79o9+NlmzXAoJaz0uCpXzYBLdqT5XXns1k5NTJGtU6pCG3eqUzeuI2infsmkrRKWET01OsPry1YxPjNMb77B+xyZ8z+NwhJSIqcaYyOTkBBdcdCEHnt7P3Ok5nHVsWLsBksb2TfQnsOJIQZgcm2RhYV6NFnsVt93+Dep6AAaOnThBIlH1KgbNAo/vfZzLLruM2ZkZXC6iddFU0gvUIDGGGu8MIUs7IgHrVTfvO46z82dYumyGiy+5GOscla+YmJhkYbDAQ48+zPbt29RA8tAhDhw9RCCSbCLGGgBfdSFZTCM4koINDpAuIl5BmqTu9VESyTRK+83GMkks+IqBCN62lmUtIwXIlNaYO/faOU9R/Q5GTRM1pQCN6USBqyH3TGmsiAYcppQpsmTAwlqM0Qm6yIPBYHO0nzEO3xnKL3RBnqM7rTr5mlxEiAwXnOrrYTDGEULCUPxDlCehiRXgjMZARtFzKAgmAwCkLL8wCowkSTjrGdTzeq/nLrjupyZyFEDpHP5aSqSYFIAzqEyEnKhhBO80aSVlCrFVzgDJqAlnkkhsJNOZwXifARM1AzUZHPHR4JLHmEQMgaVLZrjw/AvUg8Oql0FVVRgxTE8tofJVCy42TYPznumpKVavWkW/329jZPu9HhfvvITKVYyNj3PB9u0smZlVICXvU2UcHeOos7xJsqllSqE1qVSmR/GRyPRv1VmppCIlNXdNFkfF2lUbmHLLOLzvKMeOndI0CFexft1a1m9eRr87gUQwXk1iBVGgLc94MUYwQkpBARsSTd1gpEFSYCFGYmpwSefCsW6XbqfiWC3td6BNi1gcz9vRdoPM0OXaibBslXD5VWtUItTAVz+/m2YQCAE+f8vdVD3PfXc/zatv3slFL9rI5z57Jw8+dJj+WJ9/8eM30ukpoHDq5Dzv/6OvcuRZw+SScdzQMqFlN5gsN3h0z1O87OWX8OnPfIvP3HKEbn8c6+a5+dU7iQIf+dBXObh/npmVk/zzf34Dzx48wdNPHWX58hk+/pd3s2HTLK///kv4o9+7lflBl4t2zvD6731Rq4wd6Ytx+NmTPP7401x97UVg4Ol9z3Li+AkuuWQzTQN/8Hu3cma+i7GJN33/hWzdvpKU9BydODnHffft5SU3XoSI8LlbbuN1r70OaxU8/+P//EVOn4ZNW5bzljdfxp6HD+KrPhs3r8AaIUTDoYNnuOLytThniI3lT97/FZ2f5FyPCgFu+dtdnDwjXHr5mLI7BIwVzj9/JUEsD+2+k7e+fgdTvS5ihYlJzxvfcCn/8Xfu5LqPfR8lBk3rhef6eSyOxbE4Fge0aGzy/O0tu9i6fQNXXbUJB1y+cx3v+pk9mAR/+sGv841/GHD82MO88a2rSOII4nn8sSN88mP3cN6OVbzxdTuxlcay3/fAXr70t49w6WXredmrd2Ax/PUtd7F0bJa7bnuQF9+4lZXrV/KRj96OwXLzqy7k0kvXM3em5lt3PM7v/O4PYo1w+lTNo99+ije/+Xo2bVxGMsLux/fw8KOHufyi1fkIknrWyTwHDhzhVa+4hqmJDnNzR/AOztuxDJJBRBtWf/z+W3nf+/4nvKj5+Tvefh0f+eg3eNdPvQqEbLieGzqt3G0RjH2hjucFoKCMSYs1Lhe+Jsc76j3mvLq3G2OpKpVDhBAypT0XcqWb6op7N+cAFAVYyFtUTTLZf8EmohMqI3S7np6bQqwjWEC0e2hxiDFUlZ4yTVPw0Otx8cU7SSGo6t5YfK+P9YkLxi8gxIrK9jASSCZgugYnkW3bt7N25Ro6zhNDpNPt0O12uWjnRVqgeouvKjZu3sRgsECn1+Pqa67l4MHDGNRk75prr2F8cpKJiQmuue56ntn/DIcOH8Z7r0yBpoPz2ZMA7f673KofNDVN05BCg3UObz0dX2ExzM4shSjsemAXK1asoNfv0ev2tRgH7rjjTq64/HKOHj1C6bZ656ibmuMnDzFfn2QuzuHsGEkctvJawDXqhWA9JGmQZDUiU6JGFLquFuSSFDQScBJoohaA1tph/B7F1yAhOUbTorra0MTWE8NkXZaRsu0R1oAVQn6vMeCMzdGT5TaxWG9wlW4wivbgFZywOOfzjWbAKHChqQ2atpCSZKmOw3nVADun0aAFBNEYSIPPhbixbe2hsYCSM+Gt+nWoxEPBBp2ENa2iiSl3tLUj5ytPSjEDHVmtnKIajWbgw2S9NpLwXpkWReeNsXhnsg8F7b0tKRFTQEQY1I1KKvTJgE1JIxm9IxIxpia6wIINuMrgOxZDh+07L8rHGzMrRdkqtTGIc6zZtAkRoTEg3pNEqKqK5f1+BgISKUtjksDYzDIuvuZahEDPVzjnGTTq3eCcJxpPzBRtkeJ5LEMAyGRDUPQeiVb1jYX4ba3SzyUZEEu/N8YVl13Gt3c9xuF9hxkb65KMplkIkW3bttHtdjGmxjtHI4I16vFiAJOTHYxRj45Q1zSDBVTZYxCjLAlJ6n3hjCclyR4LnZb5Epq4COk/n0cL3IEQMknVEo3h4FHL/bsO400kCQwsVB1PCPBb7/17fuydV/Ca113GylXTfPbzd9CkwM2vu5R//xvf4OabznDetmmOHD/DBz/4OV792hv41fd8jsuXnIcRo/Ni9gswSeedkAy3fP4hrr7+Iq68ciuP7glMTU1wyc711IPAxz7+96xZt4xLrljGr/3b27j55gX275/nU5/cx8zyx3jZK3fyu7/9NQ7uf5aX3ngB8wuWT3z8Nt7wmhdlKoPOEySVD509Pcc/fO0hdl6yg17Xs+u+fTTNgM1bNvAnH/gKL75xB4Om4i1v+XMuvGgN521bCagfzYlTC3zpy3u47saLSAk+85n7+b7XXMfcmZoP/dkXuOby8/GdPr/5m3fwipddyEN7DrDlvJW4ymJNxESHSYU5BslCvVDzZ3/yTX74R6/JTAkFFo6dXuD223fzcz/9/XzrH/YUZQrFG/0rX7yPT3zsDpybZM3GaXZcMIvF8LKXrefjf/WtoX2ZZLPIDNiaRYOxxbE4Fsdzh9gcoa61h7e6vhBv+NF3XsN/+aMv8apXX8J9u+7ipS9fzXlbV/DIwyc4sHfAp//qDm666WJ+8ze/yctesp2Z2R6P7DnI1792H9ddv5N/879/gpkV01xy8Vr++A8f5A2v3cn3vv4yZlaM81u/9Xl+5IdeDBg++tHbWLd5VpuW0m89686cGvDssQXWbVlGyXEoU5iV7LXjLFh417tewj97x6f4xtcOsWJlwzv/5SvpVdm00TpSgI9/7Ju89S2XUFUgVpnaE31HDAvM14Gx7ncCEBYnzRfyeF4AClrwaHxjXQ/odLpq/pY70sWMzxpLXQftlDrVhqsu3GJs1uSjxVnxVghBix8zwlJQh/zMivAG04AzHpO0CBGrHWtB6FQOJxrjF7OfgNK8M5iR1DCt0+22Gv+YVIPf6VaYptJt5SQDi6cyHi8dujN9XBv7pZ3o6ZmZofadxOzyWT2GBDMzS5mZmVXjSQNJYus7sWP7drZu3oqxBucdvV4Pycfa6XYJUT0JYtJu9sTkBFdceQXWe6xzdHtdLr30Unzl2bFjB9PT0xw6fEi749mHwLuKSy+7jHvvvYdnjx7h1MkTrFu3jqpTIahz/dzcGebmz7Lv6ac4f8d2ZY/kTjnRUdxoTfYwMK5SlFJAcBjjIRhk0GAqiIX/K4ARJIpKLBAkOpW9pIi0Bbpe91To/MYSQySW+8hqOWmda7W9GjcKJneQnUZ66P2RARhBqKzP8YHKTnDOZ+DLtlIHIEcqCiVDuE2TyK8p1F9rLbjMfNAanpRilmLoz2TED0TyC733iNd7O6aofgyV3vNF3qIYh20NyLB5Ca27nz1HtKitqqEzMFlCUczqiixEz1VqIy6Lh0KhXqckVE71ylYER4doYP/YBAuuokOV5Ugaz1iYG0WipGBRBgdjxFiIsck/032KKfte5Eg+a61KPEICE/FWr3EdIiEYvHHaofTwbL/LkrMDDOrXkrInS+u/gqZqlH1MWcOdckKFyekZzhmOnT7Ol7/yBZ585Cmcq9hy4VaqbsXjj+/lwOG9fO3rNW/Z9H1MjHeJKWRGU8jp0QpUOOtyx3QI9hhJSFLmgi0glXVUtkJioGkCdKoMgpGlX4vjeT3axAj1UjFGMCaxb/9Jbr31UbyZQ4zhZa88nw3rl9IsCFs3b+Ltb78R52DudMPn//YBfve9P4oz8OrXXMjv/cE3eM97Xs4H3v9l/tkPvJJ162b4jV97PZ/4y/sQKxhKlKwhWd2yyiM6OAPr1y1l3ZouM0u6rFq1hKefOsFHPrSHa25IGHuA++49wsc+ci8vfulGHn3sJH/4S69hbNyzevUYy5eu5JJLNnDy+DxOzFD2WrS9WfawacsqmtRl7xNH2b51Bbd85k7e974f59av7WFyeimXX7qJwSDy+u/brH4xBZSwuRiXXmtyHugTLdy/6wB/98WDPPusRyJ85Wv7ufWrj1L5wgBD32AAowW+GAEHP/sLN3PrF3breTFKs4218IH/cidvfsONjHW7LDRLaYJRdlqmerzqFZfw8pdewm+/914+/BeP8p5fmaXNU7MDZWqh11fHIsK3OBbH4vhOI8/JJmkTppXxCiYZls1OcvToCTZvXc7KlZYtm6dYvnySRx88xt7HDvJ7f/hmOj3P7IoJvvSVx7ng/GX8xL/8LC9/xWa+eOuTzM4upz7b4IHVyyb54R+9lKqnxtK7dx/jk3/5IJs2TXP9DRdQdT11XeJ4dd9EDA6Pa7UHFiMOVxjajmxEa9i1+2l+5uev4k2v38mnb3mQX/21r/Cff//19Dq6ljx1Zp4n9p7ixhsvyGtPhSfOv2AtH//47Rx65iSbNs9kD52UT8XieuaFPp4XgAJoEa4O9Oq2XgAEYwSc0q2bplFgwHhaJ1Brsc4Tm4YQtBvchIArn1OKqpQjJkX558YqndxYNbszwVBFTzSGaBwOp53YGIYu3WKyo37KnWnVMiHqrWBzXmVrm+U9HddFUmoLxcp0cQaMEzWNo8mUcoFsepeMFjciiSL+V0p6IiXVvxsDIQgieqz9fo/UzXr6XH9jlLkRUmgj7wzaRbdujPXj4xp9aKHqeract1kTMKqKdevXsXL1CnXABirvaZrAqtUreenMSyHr8SVFJqcmiEm71RdccBEbN2xmenIy77fKCKwoVV6kVgp41tQ2TcCiZnXglW4eEslGglWopcJrUZYSEhVQIh+nzSyWJKIyg0wR164yOQbRUrLqtaRziNG4MuNtNgFVLXx5b2gaBY68ghalqLfOUFXa5Rcp92iWCDhyAa6dfmsLeED2+yjAQCnI1R9A78mo10gkX+fU3qdGNAEhFcmCUaZDBLy3LUDmsxRDJCLRKDsFNRNVo8qg91pmMxR/CC1yTFu4K26hVP2UwQWKdwgjjJ9sVGhRHwUxSZ3XE/SSsPzMPHMdx5wbYyE5cBGpysM0FwA5chV0mykmyL4BgoJlQPu9pbAMrMdaw4JAqgRvEklQP5QK9W4QaGwkmcR4GLC0XtAJL3+fqmyimVI85/rEGIn/N3tvHm/ZVd13ftfe59z73qt5nlWaVZpnIQkkEJYAG4MBM9gxNk5iEpw0wY6HdkjS3Z+4kw5OPICduJ2k48YBDB4xNpMASQwGgSQ0z3NprHqlKtX87j1779V/rLXPvSWIneSTfFoKb/NBVfXeHc64z16/9RtCoORqjGksFtVMlzJHFg5y4OhzrFw/x8WXXMSOc8+gaRueeuIUvvHNb5FlzGh8hNkcHQezEi8ES4YRdUWjAz9aEuOFo6SFBZbMNRQyXTdmZjBAisk+Bk1DEwMaGlKyua7aQSyOF+moYIIAnvQSKESUi84d8rM/czlt1IlEoailqujYYl+dIRvKkCbYtX/NNcdzx+33c+jwmOf3JbZsXkUTMgNRu0fti+3ykhoCVkCjm+HWZa19b1azfjz51K284x0XICg/8pZLWLd2hkd27ubyV65gxcqGEAqved3JzD9zuAY2UHMeJLgfiVrSjLW3lL/5U9/HB/7FZzlh2xzv/juvcdmYOugIczOR1119ApHkWz3lCOLPHc2gZQkJSKXh3AtO4offdg6i8Oa/cSmbN89y/RcfADW2UgXslLEzRMzY96MfuY5ffP9bKO6hUAqkotzx7ad58K5djHTAN28d8zM/8wf83M+9nE2bVzEctKxcPosIvPZ12/jd37vL0d8CEo0B8R0Civrvnua+cu6IAAAgAElEQVT2P/IKWxyLY3G8RIZWMBNQWkppeqq/dPAff+fz/OzPvwkneuHTNRoyr7pqG8tWNCQVrr5mK+PUcc99z/HOv3ExV756m83bP3IOW7csB0DiYS/kre75zQ+9g9FYefzxffzbD13PxZduR2JE6VDMmwZRnps/wOHnF1i+YgYrDQrRG1lq/Tlu+fbTPPLYUf7uuy9hMIBXvupk/vjPdzLqCjNtAwUevP9pVqwUNmxZTt0hCXDw6JjQRIZt48Ax0MdbLo6X+niRAArWcSylFgqBruswprxR9Us2Y7wQ1OnjgXHqvJtghncNtmCp8obiXebohUPwTrn2DukWypUa4XAzBI3kkNFgWuncZDSPzF9BI4Xo6QgOHmhhVEZECQzcZA+8KGkjXRwgg1naICzkMR2FAQ1gJos5VYf8SCk61Xk0/XlxnXysRahCLsW69LUQDJPFi3pyApi0IbujddNYhGItGAWjUjs4aAkACDqcJYoZEwYJFLFjWYpR6FOydA2dnSFEf00pHFCLjCxFybNzhBDYJzBfMsM2QDL9+XPDAfuHDYcHQw7PzKHBDMJCsKhHobEZq20pjbV+YoZ2nJFSKMkLezuZZkwIRIGSCxIbM++M0eQzRc2cBqFRN/6Mwcw5KwukFNp2YNeep4DEJhDbljzuPC3CDD21MhqoAEFwjwax9AaSHwc3/QxYvJkDRdOMGQMWkgFdocZ5VrYOzkDRemtQsoFqOReaGFhI4z6hQHOZ+D0EPGLTut7Vk6Hk3G93KUruigHCzpDxj3Jg2lAaETXwC+1BPoCaMBBDdGBB/RwICaPFDUvhlEOH6UKhBFAJlNyB2nUeG3uYGnBgo3jEnfj1XtwDpV7hFnlnD7fK4qmmjQ1Ko5FcTHqjLTStyTBKCTQ5M5dGxJIJsaFGwMUYJ8abNVXD56SqCQ/BnuyxMbPGmaUDzr7wTLZv3MJxJ2yjDAw0O+nMbazetIK9z88znG2cdm6IvbneO6jnAA0VZCtmstlEYzulLpPSmCyBEAaWPpMyIShdtvQSYwTl/x6T7+L4HzhUqrFp9OLT0IMoJouyW8piFAlAEyAeBui7/xIyXbJUFi2FEDuWLBuyes2Qxx6f58TtxloLFCiQOgNZc/UD6GN589SHGtsoi5JjYcWaMSeduJIisOfpfdx97/0Ml62EWDyyshhVN6jdzwFokkU6JvVox0r1L2iA1SvnOOesDezafZjtp6yHqDQhEzUxKoW22HO9LRAKPbBg80EhpcINX3ySPU83Dlp2bFgrnHTiKjLw0P07efKxPQQGfPKTD/L9bzjNwPYgXHPNqXz+87dyzWvO58s33M+555zC6lVz5ACf++w3uOzSc1i5agm/+5/eikhgIcHP/twn+Nf/11tZuqThP334a2zbsp4rrjyVEoQvfekW3vXOs4wlp5A9BSpOKAq+IPbj5ILKxbE4FsfiqKMoJsfVhj/95AO85uqTGEbIY+X5vZk1q5aCy7S6YileGgolJCATNRJLIUjm9HPW8ek/uZ3jjzuDdhD45s130cyOOX7pJlQ6mzOxKf+Wm+7kjW9+Bccfv5LrPnsHISmN/95cvGD58iGpZG65/Qkuv/wk9uw+iKYFNm5cDih/9IkbeNPbXsXC0cKXvvAkP/6j59Msb5mZa1ix/GDvadcl+I//8Xo+9Ft/E3H2WRCBLNx/37OsWLWETVuWIZYPD73vzCKk8FIfLw5AQaAi++pdhRib3lCvaVpGozHjlBgMWtPRmw7CHdnlGCChbdu+m1pBhTpqrj0AWQkLcGi4lLvWLgECSUdewAVKNGp+ExuM+exeAGWiuy+eUT1o2/77cu44PLuMp2aWMj8bSSL+3sbo55rtZtJiLtRMmNzVNW9SZpk3QA0CMwVCoC5CKxVd1T0jVMxEsuei4g0r9W0OvYSkSjQqoOCxCPQ56oIzHtxR3AEJY2Jg9Gz6l9r7VLwjGygivp+KhEIXEwvS8rzM8lw7RKVDs0C04pWsqAys2JdA0cicBs49tJdV3YJT+Y2aZRvqXhsIIZp0IzatsTsQBtEBCvUjKG4fFoKb5WVPW8AkCb4PJVtcW2wiIZjpo0yBUHjRX4+dlkKhkEsHfSxk8IVncraJHfOca0EJNebSACoDu5LHelawo17fFcCqp7QJsY82bePAGDDVeDLECXjk7AbRakRqVPmm8f2C3rzRWByBGCIp2z4GmUzy1Q8ihNB/l/afKyQpNEBQYb9E7lu+ksMDk0tkLcamUYtnrcdyYjAoJJ2krxT3zZBskpt6vUrVqfRzhzE4RBwcLIGoAY2KYgkPUeG4555lbUqUYtvSxEjJ2cSB/p0mITCZR71fYr2nVNwLM7Nm3Rouv/JSYilo6MiSkcYSRlauXcqKNUvIZUQqjvx7SkTQ2j0txOipG57oMjc7SwmZ0egIqomg1atDCQTG4w7Vji62zlCaur8Xx4tyOJ/HuveegAJKOxM48aQ5m5qkvlbIFDQKp56+zKj6Iswtj7zlzRfxD97zESREBjPKP/onb2JmyZDTd2zkl3/5U8x4Uswrr9rBE0/u4Vc+8Cd0aQkSii3VSjSfgpPnDPAE1q5fykc+/C2ef24Xb337Kzn3rG38vb/3MRBh86bIz//8G3nm6b0cv3nG+WGR9atbWloaYNgKJ50yy4HDC7z/Fz5Kl4YEIkEDKomNW+B//6c/xhWvOImb73iMJStmEOCyS0/hnnuv573/y0eRHBl3R3n3T7+SBjj55CXEVhjONDz0wD5+9qf/mAMHhOOPn6FBueD8rdx39+O89z0fRYJw2mkrec97ruGE7YE/+9Nbuf/eZznrnM3EtvDyV57J+/7h7/PJT93P4UMH+eX/84eJKjz68DP84e/fwEUXnAmYdFGxxN9TTxn0TYwffvOlfOg3v8DHP/FtUhCuePk2zt6x3p9L8Nu//SX+/nteZRQS+yQ/keJI8uLieHEsjsUxPXy9TuEHfuAUbr/tYd773o/ZnELmp/7uq9DGDMtP2LSKD/3qtbz97aezedM6tm6asxoCWLexJWU4/ZS1fDIf5n0/+zGCZi69bCsXX3g6QeD0U5db2gOFTOCGrz7Ktdc9g+RAPpgYRJODrl4ReW7+MBvWLWNu+YBf+/V38m9+67N89KNfo3QzXPXK41m/bgkKfOWrO1m+5m5eceUOXnH5Kv7hz/8BTYQoibe+/RKWzNj2fePGO3jnu15BiAKSEWfnJVWeemo/WzatIVS5B+4ivDj+pxii+v//onTH6afqv/sPHyQEoylrkUl3PgbQzGi0QMqda9Gro746fd8KqGrUWErpfRTAWUW1c+8xf6rWvZ6fmeW5wcAKeGnIZYSRsi1DvsEKsIRCmZi3mT5fe7CiUrJDiEgIPLV0FY+2S1kdMwPNiNrqUWNGtEE1mcu8CqUA0Trd2Tuk1n03930thRgbZ3A4TVudpi1e9DjNFf+8xhkOhZpWMOksZwdBEKwb7P+OVD050NPShVK7wLGCH9axVnfNb2KDuHdBco+JUhTLgkzWrREhhEzMwoaDh1mVFkAs/1ujEtVkKakZ0DZDZuIszyLsHQoX73uOzV3nBbJtW5+droVBE/sOdmxblyAoM7NzxNg6KmwxfdVHITZe0GU1M0Q3HLQCzq87lC6N3GRRet0/WG1v11/r12Im4xGYIr3pYM5lqmqw99duv2B5cBO/AjVZTwUUqpcBFXOz/a9eEer+FmDfb6wWB3DcJFJdl18cLCqqRroumVKSxz8aeyMXo0yH2NB12eKJeu+HKjVwT4NsrJOUEhKclaNC494Me9oh39q4kUHq2DAeE1Q97cAYNylVoEV7BkL2Il61kJOlujTi13vOzuJQT48IvbGkZkUap9skyAihsUJ+1A7ZtWI5x+9+irMOH0KLGutETaY0GEz8Vrpk0pFUEmMKD246nqPScM6uJxiMxwYs5kTb2H5TMkZecuZEiZTsXhdiUimR6L4fZkBpTWjFIiwLmo5ydN+T7HrsHsrCIUpeQCS7rMfi9XCjPZHEwmDILZt3cMY557H0mzfyvn/+CQYza/87zMKL47/30P7/SvDoVcTDWIunqjgymR24leK+BNEBCFU0GZiVAWnsPUEEkj3DDIwWNELEjF5xApJif9cItJMOQi6CZoM7grOTUjEsOgYjSog/iw2VqHOPg2IOgBcUDxDCrWHMSDm4qSzKOBjpqcGOQVcg29Rn82oDzuex7RXIY5d64dvTgIqSipjvl5E+PMlI+ItP384XvnQfH/jVtzHTFLRExlmIxVhb4l6z1OMYIZAx+VuxZKH+PrP9yQVSMePaNkAbOyDy6KPP8wd/dCPvec+rWbHcUoNELQ9+YlQ+MXWdjO8OMujUf+U7XvfXv39xLI7F8eIftYGnoqja/JsmhEgk2jxDtt/n4n7fIn33HyYluCCkAlmtaRL8M1RAsjcVo63pUueNRPVnQAsU4ZFHdvGHf/pNfuZnfoDh0HyicKapqM2dsbF1Y072LJCIRRsnYzeEqMQq7/XnUVEhBiVLsYZPjnz62js4fGjE295yMdX+qUyvb6tcrJ87F8eLcVx00UXcfPPN3/UUvTgYCtREhknHPETTfde4Qxv1stM+BlC1asi9g9o0VDO5UrSXO9TP7YEGVRqUdekIa9NhggZCCWAhiJZOIKFflGUgldRr5LvUEdA++aA66gexBVMbAtJ2XPj8PlamozQhEBCjfYqlGRTtKF1xKYd1/VONdqwxfSKUlGhb81moNHN1QCHGatanxGD6eDOnDKhmM68s2qdTFNVeqmDJCgHxiU6w2Er1WSF4YZuyfZcBCtqzKIpT0E1LagvkjmKTWjHKKpIRGRCD6eJzB3RjQiioNHZOg0JKtu1NZBCHLJlZRjsccHAwpGkjTa/jKp6GEDwOVGiaSpEvtuANtu9Hjx6lbTMxtv11wZREBPWUCNfUl9r97m8VTwKo+n2/jgTpi+Gi2aj4gpHk/WUpGX03SLRrxaMiQ4gOTkDyJIIQ6K9h26yJt0LGWAYxRJMveAE+oeZrfz2LMxlSlxDJE/NDjHVQSqGkhOaCRCFK9KJGSV7s13snhupDUcsiX+pKIKfOCnzc3DKYB4pItAeliSSQ0rHx8EFOPbjfzl8RijM+xh4FWQECrZppTJ6Rk5lxRgfaSlFySuCMJXpQz6xOx6lDVBlKZCyeCoKwdzDHvmUrkDikS/uR6r/BseyLrkvO0hAzf2xApbikKKBFGKdMIw2jcTLvFjUJEmJFXBMbtLPCMIS2R+HFDpyzk+x+mbBe3CjWk2sGsWE0NjlLFKvEcpdJJTMzExkOh8zMzCJBSKlbJCm8ZEbo5xWh9Eaw/W9l2rSRnqGmEhAz/vAc8ClCXwOBhMEIQhFjsxFl8hoqzlycKVHTZhSiLRpx/lvbBP+7AZ8iQNQJw00qx8ILdGzqjm1NRXHWkXelUHtR6wCwmSwqMQoxVuPIfo8Qki8uI3EIXvpTZSIiQhNxsCX7Vpu04Pt/4Bzm9xziw//hi/ydd19NCMJMU/feqbUSIChNhTBVwb8zWlbkZFuCgRWh55mAuE/Dbbc+zGmnbmb58mH/+QaEyGSq1AqO1PkzTE5Gfdj6s8SOGQ7de8wnVnhM5t8wdaQWx+JYHC+1IS/4WwgQGhCf50wmZeZiImoSNq3PiTpnCFFszpdi82EztaTtnzGNvVaKpUoMGqga5+LfFYNy4onrWTLTcN99j3HuuScRgn3/AGtGmYsCiGTadmJWL1GcYVfnblt7VzZpdKWfSADJHD5ylDtve5if+ImrCM1U09I3WXTSd1scL93x4gAUFCtyJKB5QjGP3v0vDiiY6ZzltjdxUlhXGiK4Q3w0mingNPlalJhxW84TdkETGjPgC5A1+cInGDNhml5dCqmzWL4mWofXiP3GFggUpLgWvZhUQqUQ6Qia0ARKIORA5qjlZR85Ss7K3JzlX5ecCJj5pLqnwmAwoAkBTaa3T3SAgQ6SE43Tx0spaBpZnGDKRHfmj4jpXd1vIKi6cWVHgyIJp6xXu0KcCTDpsDT4YjRPKOkiXkQa0dU7rtCKsSgUcZaE+RJoTiYTTrZgDqEhA2RLKchi5poNQhOEplVmhi1Ns4S2yTR5RIyNTVpqcGxFbqtxYteNJ6bqfi2M8wjCmMFghtA2SIzO0BDriYlNjJXJkVJxwCCgyRIOtHhHWZWccm+KaZdG7teI1Si0ng87fKWPhCxqGb5R6OUKIcTeELAWmL1cQcSZH55CIYFcOr9XKkPDwAdRpaTsRmm2qk3FJBWCMV60GocSyLnze6QyHehBiZw6RCISbHqoHclSgJIpWYnNwI+fklJ2dghojaoUW4BHFSQlL+AjUZW0MGb/3r3kUtiwaSOhWIJDDME12A3FJSjVFFFKYc+zuzhy+DCbNm1iODOgaRpKKYxGiWd37aJLHVs3b6QZDg1IIyOSCVrMk0ATwxAJzh5JKZFz9ZjQvjsaJfjDzSQqu3fvZd+jT6AZIg0lZxZGHeREE0GCMYjMi8PMMAeDhqYNDGcbNm/egIhpIdU9SdrWFgTQsNA0SGho2hnII2YHcyyMR2QSbTNgMGzJHTTtAGmG4OyKLo1ZRBRevGNSLssxlaD0btYvLKgnBSbOzJGp/0zhnMe+tbLv6idU3wbcFNSXkIYg1G8xyZ19TwXm7LP6mb//Dnu/aDimA1//mN56qJKuCYASnGkhviAO/tNetuMgpEHuldNRr2ud/uipY+RQv1TfosgrrziZu+98mFJAok5tV02xqcdFfF/EAO9+pwrHOI1LlR6Ksw/smzdsWMLLXnZG/7uiDsxWKZx/r/ZgRsZaglPnvALkFThym0vRqe/vwYfFe3xxLI7/KYZH1/SsA5gCmqHOP9IjulMT3/S87/NCFepOqwaOqcvFgV6jlxkI615haCE08J73XMMdtz1EyZhMwQFYCQaQ1vl68hyabFMFru1XBZXoc71tbPBtKKXwxtefz6ZNK2121xpH7nyL+vxZBBVe0uNFASgYLdtcQKd1+lVD3rYt2enZYDrwSu+uFOwYGmjswg2YYV/AaOxZC413eNVp0tWksKRqDGJyA9OqY51ML7RjjDQhMGxb1Kn5reuta6UVRMgpk3JBYuteCma2JrUT7jd3Lonn9z/PTTd+k7m5pVx66SUMZEBOiS6NefiRR3jooYdompbzzjufDRs3Mu5M7hFd7mH0pkjuEgcPHmTnzictDq9kTj99B0uWLLEYvGTFatM0pJSc+WHdZHKytIsgnoYA1XCyePe3ooyl1I6QL4OKdWXtJ8UbPooGgaSE2CBYlGAfEZgybROswBY1oEWKtbkEAi3mXRD6qEXrGk04q6oQYtubVqoDGajFPWpR80TwxWIpBc1ix0+VduAdIZ14KsQAKZsPRZXGpJTMdV1qxyigJfn1pL0MAKS/Duv/weMQnXUQQ9ObW4ZQKC67QcyYUxwgMxlO6e8BwCMb7TrLJdmfU14GIsaWKCXZ+XJkzWQJVZJTP9MKUaFGIvpDwRkmhWLRhFh6RE3ysH2NhqiLbVMIQkrGzKkPHirTBrW4TRFPRCl9Ckc3HnPvvfdy1913c+TIEc444wzOv/ACY5D0oIz2shFVZTwasXvXbm78xo08/fTTbNiwnmuuuZrly1eQc+GRBx/itjtuZ9ee3ZyxYwev/r7vo5DNmC51LmUxEEdxB2U/vhX4adpISgYwxdigAo3MkMfKffc+wi1fuIE0smtt2A4pBNoYEBISlZwmMpysyszsECSzdt0qfuD1r2HV6mWIuiQmmKQrFKjmkFmNmRFSYdCG/ng20abomdkh3WjEwmhElzo7L2Hx6ftiH995hr77OZNj/vLXndfpAtNAgmNrTu1fIxUlkwmIof2fLtfroQj6Ob+PmECmumRgxfFfFe8loI1/hwOaWpcZ6gX8VNet3x6ofIB+W/pXTdpv06wGn8ltLg/KiSdt4MSTNkxWuVPk4H7bjl29/xX7UhkUvlKXmqAUeNnLT7ctda8imf4+EQNTjvkO7+r18UtQWX79nquBi8eO+v1T4MriintxLI6X7jAq0gvaALHSmV5wh0/PEVPUp++Yw/4z4zt+b2tBC6Q3gEAUBoOGCy7egfqyI1TgeGojq4eb1L+/gBFRAWQlOxgyZRBEYPnKJZyxYkn/tomHwhRQLi/80MXxUhsvCkABDKFPrje3giVYRxc1bpAXkykX2qZ1OYPR2K1wSwhCEDxi0TqJJhuI/tCXSZdWXU/uBVMpxYuxQpDQexmUqlVX8yVQ1KjIFFJWum5sTIdoi7Kcs0VRFuvqqHsNgBUPtWu8d888Tz7xJJs2baLkwng8Qins2bOHxx97jE0bN/L0089w++23cuWKVzIcDp227nr4UM36GrpRxy033cSKFSs4cuQIz83Pc/XVV9sU4MfHDCtt4goSLUrSFzXamwuIRW46PT6EKh9QJDS93l1cjBriJOFg//P7eXzn4yxbupwYG7Zs3UITW9rBwKlTYhFpVfcuikhjHaYIQkSI5JRoqtFmRUQlemEdJ6iun5vqCVG3l2pYSTCGK4EuJTRDtdprB21vmghm0hmDUer7hA1fpEbfVq2ULsWSLrIxD0xK4UadXqhW6UGVLShVpzwBbRQ8tcCK2JyzUe2dKcEUMKHVRNDMIKZkNlMmhn7tVnCjT2TAHgCKkJIZWJYyIsQwkXtE71Kqa5oty5BunGlaO1Y5JQNcenRdaBqTOORckBgpYseg3lM1ecJwN6WUzP79+3l8505OOeUUcs7ceeedbNm6la1btxqgUrIV0g6A5ZwZjzue3bWb7du3c9ZZZ3HnnXdy9933cOEFF3LwwAF2797N+eefz6gb8a0bb+Txxx5j+/Hbia35qxhoFIlNQ06WFGORn7EHMYEeEMq5Q4MgmhCB7ds3MXz5Rcy0S5idmaNxv4gggTZCJhsY0V+TVr9JKCCJ2SURxFyaxaNBFZBgaSRN6wa0VV6Ux2gpzM7N0rYtKSW6rmPUjdF24OBaYDicpXaKF8f3yqhdeWcc1MzJHkQQX8h5oV6jfI4p02vx6x14bXpGmjLlA+DMAvsYcaNI76Cp9p90bFFeF7s6+Yx+hGNfp1PFOrYGEK3bOQGvJwyCyTdO/hm8XLf5ur6vsq8mHIAXQhS+6IWJtKD/7goOHruAF7GYZjsGkxX3dAGgtZOn7jnh50im9qcCHsfyGaZtmKeHv6YyRxZv98WxOF6Sw+ZjX5v6TV4xxkBt3kFlvcoL5s4+Mei7jL9+WqizewU37TPBp/igVONgk10xmZelzlaKajh2JnWm1UTaJRNQVdQlEfatIrnuKZPn12Tjp2fTxWnupTlePICCFi9kJwVJ0zYU1xYD1okRMz1MnenStZg8Qqv5krhMHnEzPnuI9wZuZRKBF4L0Rm9W+BeKWqcWtSVJDMG00V4QiS8WrIBQZzNgtO++Qzu12BClFCvSpdjiKJfMhnXr2bZli4EmJaMhMB6PePTRR9m4cSMnn3wyxx13HF/96leZn9/N1i3b+o58ZWVU/fXs7Bzr12/ggvMvIKWOz3zmMxw8cJBVq1fTdR0xRlKXiNEK4BACJJydYIWlFeXZggSKJVtU34EQzemlVF2Jd0bFaUsxBJ4/cICvf/1G1q5ex/4DB9hx+ulcfvllky6PmPmWZjs6TYyk3JFqxKdmmjCZYEyeUuURwQIoHJio4FDt3hvIkv1nE2cYkWBGN2Lsk5KyszaSd8lMYpBcYmPXocc3Fu1TN4zVYudds3euVN0DQf06tYm55NrRn8Zz6//pQSbAjQ0xSQuVQVAvdenPsfo9EKeiUGvXvW5zPY8VTLAawwtXl1JU34cKJIUoPfVMfdEePDZUtd4vpfdt6D/bgbjk0ZUhRD9mFjE3kRO41MFvzJwKzz7zDCtXrmTHjh3Mzs4yGo3YvWsXGzds8LhPAxJTzj2L6ODBQzy3Zw/nn38+K1asZMmSpXzzxhsZLYx46smnWb50GTtOO41UMoeef5498/OccMLxBIQ2RGf1+L0agkt1cO+GaS+KCoQAZJCMBNiydT2nbVxLlAZRpUtjk4MUu5iDp3jYPZK9WDH/ECSDZiSOKbkjBoue1Mr4UQOXsieLDIYDYqWjq4Fcg8GA0XgBFRh1Y5+zhFG36KHwvTmmllvHgAn173Lsrx3ElB58mMxN8Fc1hqa9GKY/f/oNUyCFMNWV+i7brC8siOs2lP7vdW6f7MA0CKKTt5ENCOn3uP6+2pXR//3YzShTr3vBPvXg3AsAjOpp4J9s5pP1vZP0jh7EoVL37Psr10F6MIgeTLCAyelvtTk7O8R+7LFeHItjcbxkx/RU1v9oIjGr5LDeUECn3qTfbX46dq7/L96AXprl4IIUrEWoPhU605iJd913V1195/eH/pkwmcVslH7+rO+dNNgW57j/WcaLAlCwolTcK8EuxuJhidm1/z093Tu1vdu8ugl1cEdsNQ+G0DaWL++MgKZpj6GSqypk9Xz34AVG7LvKUYJTpC17W7V4zN70Re8Fuf2V7FVljGZYWDQ7W6LeYNVB2rrbM7OzHDp8wPZWIuNxx+7duznzzDOZm5vzbmnm4IED6Ba1orWPwaxdFmgGMwyGs4TQMDc3YDgcMh5bsdGEhoWjC0ZlD8LM7Ayzs3Pmo9CNydQCMDM7O0s7HABGa89FCU0kBtN/xuogW8+NHzsE1q3fwLp167n8slcwHnfccMP1nHHG6axbv55qGil1TanqWnLrqFeJRC6p7wzVJAMr+icT6XRBe+w1NJEgiEg/+VbGgOnz6dMDyHYcY9OSc2E4HE6YKv6+2o2PwdkniKdtZC/Cte9E2WcXsp/zfutq88sBrxAMfCrZFpIhTnwKUPoEkpLd30HogZw+keUF+//CY1KK5ZRUQ1JjF9i/c0nu3j79/tA/q+wQet8xhv7P1FkqROwlM5MYxwnQY2wVY2HXBb722ygi7D9wwAwHY3r1iu0AACAASURBVGQ8HjMcDtm/fz/j8ZjBYNCfgxADqVikYsqJI0ePGhgmkbYZEMS6+0eOHGXQNl4PCHNzc3TZpCmiEw8Wi7mUvniPUfrzW0+UyIRxhARKD7YUVDJJkznOD5RUFgjRQaDatQ3i5pQ6MQrVZEWE1ihQM1JFgoEIxZhV0RNS2hBoYwM5oRRi0zLuOr8nAzMzs8SmMVBv0cXoe3C88LzXe6x4N7wWs+J4t3WLzPgrA82k41/jk+vn1PWhAwj2nmn6fgXRfdE4tcrsATtH2EWDb1kFYJ35oJP39HuhttB0B5+pMnoabOjh2KnPmN5gnXrd5Bu+Yx2sL3idGCtCqYaUFQL24v8YeYZiSyadHOO6KD9mTRz6w4kbLdZfTfaL/vhMf66SKaKg7eQ71bwd/mvLh8WxOBbHi2goTEuo+nnI51tjwsoxPir9ms+lt/3M8d/iq9Jjo3We8/nVWROBxjdp+rOLvylOfcZknqw/1H5ftN8XAyLqFlco1uu7YkzRagBct2FxhntpjxcFoNAviYppys0J37PbayyjKJKF1CWn3mvfba3a996cUG1ppe5jYEXPxPiu5OKxe7YQKCn3NHKti5upIq1+Rv/5TG70GK3YrpKCnu3g3eWxd7FTyrShtYJaBGmia6kxOQHWhc9JaZshWoQYWkrGorvEivikZjkQphypx7lj957nuP2uu4lBOHjwMDMzc0Bg165nmZ+fZ9WqVRw4eIh9zz/PJZdcwrJlyzh08AjPPPM0XZd57rnnOPPMM9m6dRvz8/McPnqUo0eOIiIsW7aMjRs3EltP0MBN96IV5iV3aIGF0ZjYNmxcu4Zm0NA5s2ScxjRtQxtbFrojkza8ThILVDKp62hjC8HOaxTpz6EVYgDHHmMr0hRxGmqVCIif6+lrKLgPQ8mFXCfN1PVFMlPn1S8WFJOVoNnPtW2TusQBUdK4s9QJsUnTJCL1esk9KAZiPhYh+KL72CXvhHniVl7T0gGOBQ6mafp1u6vMojqq12OU/XhUYKcmYvRMCnEvBFVP6xA/RWrXnZqvRWXphGgFQnSZj6hQhB7gsnQI6SUEld1hBoojZmZmpuQFuWfRTLNEcsrExveteln47ytwkkohlcxsO0SZHJeSkiVFhGD3tgRiCOSc7EHm50JLFcFUpJz++Jbo96QqoWkQl9V0JVsqhxQqRFFp1TllhsMZUk72bMy1seCdSt8PLWpGdWKgVi6FEBvzSIkGjOacaQaRKkuRILTDAcVTW0KIfXLL4vheHnX+qBG9eLfJvGcmkIEv+Ioj8Bh930DeiBnzmj9CfQYqVT5WkWBLz5nuOlUjQ+1rbCuAtQctKqgwJc2Q5L+I1KSGyeepASOqECoYV19jc3zpn391P5iSKPghkTBZqKpYTKctCuj9JLwTYNtaUBIw8O2eFPL9kS4VeBU7lIBMU4D7bttUB1GVqOILZtsPA+W1B1F6yKQIKpGOQlMfkT6nyl/rXbE4FsfieDEPmx6Kr5WEoEzAYf9ZlmJG1hQvyqe82mTKw+C/Yag4UzsoMPaawub22nzRY4xobY1SPB3I/BGqcWzAaM5ijZdp9ttUs0P7/0yeVGaIX8HiY+Vji+OlPcJf/5L/8cOy4ZNr4E3HX6qrvuv/1UEAoE9/QI1hUCnhyTuxlard68inCpEqG6j/ngYiSinEWhiq0rgZY+o6N+PDbiC01+NXgAFPmii+SImxsUWPVgmH3TIhBkLTmjcBoCJkNfaBxIYuZYazcxAjC10iNC3NYIjEhqYd0LRDJDTEdoCGhmYwtCxygRWrVrJ8+QqGgxn2zD8HBB5/4knWrF3Plm3HsXrNOh566GEOHjxM2w5ZtmwFK1euYe3adeSs3HjjTXTjzEMPPcoD9z7I8uWrGAxm+Na3bmLnzidsLVa9G6R6GgTadkiMDePxmF27d/HEU0+w9/l9ZC0sjBa47dZbOXzwkMUNpswDDzzAaDRi//P7ufeee3j6qad54P4H2LVrN9WkrgdywKP+rEOunvKhZRKdOVnYTgwlVTzukRrhWHwxbJGItrRzI82ug5JQzS6bUU8QKx6n6DGDsTrYCjUZwy7D2jWz66vkTEnZDAH12GJ40hHnGBPS+jnTRTVM4iSnfRFUzWOgbVsHwvSY94QQesO++t31HqtgWdNGK9jFumJ4TClemNcYuJzNL6KU4velocsG3KibYLr5ZTFmRXEAaJpFUe9Nr3OITaRpIiFaod9144mJpRtO1jEajyZATDA/i3Eaec2g5FIYp44udSyMjhqIJP5Q9nkkiHkeNCHQtpHBoD0GGLT7uBD6OKTsBU1CJZG1s+tNCxItkURC9OSRQin++5I8xSPbLKEWcVvZNlUbozjgWSyFxlIzLP2kZJtdum7MwuioRZP214AdkyAmxVoE9L8Hh3znP7QvSyO5mGyoPqcKZiQLTPxgAJEWy0c1Ay2dAhP6It7lU8Vz0Y/lFziorZBHcHD/UYoKStP/Xouz6cQ8G47p7PfP5fqZFTRQNNTIyAakQWWS/2CsoeBAQO1yTQB2Fbv3KpiBJCRawlPdRwMiusnBVHFQuh7LCStAETRF7rvzCT73F1/3VxigWOp+TY+6iq4dSX88TBbvQvHtN+VyfZvwrW88yZ/90QOUHoMOJI0sggmLY3G89MekX59BChqUEsqkx+/1AxKNpf1C0pU3MMTnke/49V/53cbCrKtf1UjRSMqB/XuPULJ7bVVilM/llvOGAczSoDUFawqEUMm9dAL1hlid97SQuuzPB/r1tKpMkc2qbOw/7xOxOF7848XR4hLTw+fsBVE0x/XiNHF/iTnLd4XkjugC7qEw2Y3a5a1/r3pw0+DXwoseVGib2nX3X2C086pJR4Kxi+uSrf4OMZ23Wq5109Q4QrWio3Z/gxnDWSceQtOimigCs0uXMi6ePd00tMMhw7k55vfuY+2GjcS2ZW7ZMpauWIFItAjJppBLpm3bvpO5ZMlSZmdnOe3UU1mzeg1HDh/mscef4ORTd/DYYzt58slnOOmkk3j22WfZvHkby1esRFV56KGHeeihh8g589CDDzEczjIedzy/bz/Lli1n08bNgPLAAw+wd+9zbD/+eFKXwT0Pcs40wTr+xRkfd991F+vWr2e0YIDBimXL2Pn44xy/fTtLl8xRcuGRhx9hy6bN7Jmf54brb+DCiy5g9fr13H7bbRzcfzynn3nGpGgtBc0JUkZDoQSPCfNiapqpUM9pCJ7yEQJNE0nJO+fS96atwNYxEmwxPR6PCI35AYQYJ9KDUmjb1lgiWkghoN0kyrFno3jXql5jvSFnBRQcEJiAXt65ngIUKgMheyJI7eCnlFA3/gwh0KVMnpIIqE5UuvXpIgq4B4GZa8be5DDGSjvzyduMM5wFgQMDzsSxV5pJYZU5OPCnqqQy8Z9AKgBSC40K1Lk0KQRCjBw6fMgAAYWDBw8wMztj+xImn2Pn3YCHwcC6hkePHmU4HHLk6GGGwyFFM0uWzrF//36yL/IPHznCsqXLLIZSw1RkrD3d6nnNKblZqk7AF0yyUBsCygRksTrICvqSIRVoqPIOh6dkYlqq7pfSeOKLyVZMdhKDQBFUA2hGNSASGAwGxp7JBvA0jRU0WZXxeESMwqiIzU/15CwiCt9joz/xPup9bwVsUeWmbzzFrbfMQzyKSqIJkb/xY5cyXBqJUucnf5+6TZdM3AD6jpIa4F0EvvGX93LBuScxu7QxEFKqWaLNqXvm9/K+9/0Gv/Fvf471G1dy3Zdu49WvOq+PbzzWv7wug53iG32R6dezyIQeO+lwTV/nExlhjREWZ/BBNWGsf9rP984fZudj85x/wQkQLY09hOgyRgdrNfoUWrPapZ8e77j1QW755n387Xe/nspqyBm++fXHueiiLSyZa79jG1OGT3/mLp55ch9FCueeu5XLX3YyorB7/iB/8slbESxy+sd+9BUsWTpk6bJZPvTBzzHbFl7/A2cibekbEz2auDgWx+J4yY3aeBSthbPQdTbvNgJNoJdQm0LT1huh+IIkTHsO/NfPBYLjxFQ5mqBZ+OJnb2U0OsQb3nSlzfklMM6O/0ax9aIcyyNIBbSrsRAgDRO2q5g4DqVv0O3bd4Df+/AXeNff/EFWrZkzlkJlmak/v+qHLY6X7HhxAArAuKu6dKEaJqoWOv+5GQt2lOJO/OKdj6l4yTqm6d8V9pPApEvoN0eonVBnI5RS6NzsESp1226SLo2hHfQLMfE0ATOxs88J4t1KzBOg9PtirIeskHKiHQ5IkhjnTGhaBrPm5l4QTj51B7fcfAuzs0s4eOggM3NzrF6zlsFwhiBCM2jN7d1BjInTv2+HRJYsWc7hw0ewDpGwZG4pJ55wEhs3bmb58uUsXbqM+T17uefee7noootYtnQZQuTZZ3chEmka63znlDwRQRiPRrbPITDqkheVnqfgRVrbNFx00UWsWbOGPfPzPLFzJxvWrWO0MKIki9zLXWZ0dMSRw0dpJLBx3XrOOeccmuGQ5ctXkrvuOzv6Hj0YNNjyUAA3UpzgmQKYuaS9r4JRZj5YrxGtlHexwr1vJCFotp9ZFm+YOvedpwQEYhMpuZkCtIode4mk0jkTRY2BUibktOKvM5NLo7l3OSPFwIBqmAi2iK8pI1WOcaxHQvbJWJ1VUU0avVvo7IBA8JQDTx/pEQP6eyOIoHliMFqy9vcgDgIUl0hMd/Ql2PEqnqISfJulQIziHiIGvFS2SdsEtm3byhe+eC1Lls6xYe06UOWE44/vH5RdGnPgwAFmZ2eZHc5QUmbliuWActNNN7Fjxw7uufceNm3ZxOzcLOs3beD2u+5geMcc69et4ejCUU47bQeDQds/sCy6Uo19FEwGMxotIOLxmC6JijFaYZUzuRhwYAWLgWZS/1efmC4NKd7htVZrcDBE3YOiAks4qDNGRYjS2rHJnbMROvJoRJcy0YGMNppMqBEYeKTqQufnKWVylxbB/O/JoZOueN+ZDxSxeeLazz7OOadtZP32dRAKeaT8xq99iV/4p68FDIyqvi80tla169hmq9h/ByQ15t2nP/UAJ2/bxuzS1rdhYtgFsGr1Cn7hF3+CmdkZRkn4+O8/wJWvOM8Zf9CvocEkFlPrRls8y2RdmUA0EBpqWU/1LqpFvskefDNd9oiDIlpiL/0tEogBnn3mINdf+wjnnXciGhSj+05uH6P6BjSbTaIifYzas0/t5XOfv433vu8N0BrI8dyeg3zgX1zH17+yh0/+xTuYm3PPg/5+FD73+bvYt2/E2edsp0Tlq395D2tWLeW0UzbwwQ9ex+tefx5tUEiZ3/iNz/GP/vEPcdpZ6/jgb7+B3/jAX/KqK09l2QqL6zWppFY+xuJYHIvjpTZqRe5ssIcf3cOvfuCzpASHD414z9+9iiuuPAlt4aMfuY4rrziXzcet5f47HuPxnc/yg2+8ZMLw0h5unfrwv3rYq2tEpf3rKzfcy3O7j/C2d74ConLw+QV+84Of5/EnDlBGcNVVJ/Dj77rCGRVWZxSE3bsO8Cv/8s85cgCOHj3Mm99yAW/64QuNQVqE++57hq9/+S7e/XeugSisXr+Kt77jav7Nh/6Cf/y/vZ3QxgkucgzI/V+2L4vjxTleHICCVvDdzfiqw3zvwI4v+MVoOSm55tppgzqhYLcec1dHjI1pp9VjBZ2pMF0QThgJU51iJhd4OxgQgY5J8Swi9l2KObfbbpj2e2DdCgmBth0QqR4NhVQKEYhNy6bNWzl8+BChbSA0DGdbTjv9DEIz4MlnnmbJkiWcddbZLF2+grYZ9J1oAzAsrm/QDti3sI+jR45y++13sP2449i7bx/HbTuOGCMrVq7kmV272X/wECtXrmQwnEEVRqMR8/PzHDp0kGXLlrFi5Urm5+etYyNV6w9oYWYwRBXG4xHtYOhxgZMyXrBIzfF4zPJlK1i+dAVbNm1h3I1oJJBGHaOjC2gq5HGipEwbLe5r9erVDAdDNATWr19vGn4FSkJwc0KneU1WwZDS2Gnndo6KM0OI0oOdqqWPvQwCwV+jDqWWrKCZdtAYA0ULFCvuoh9jDVOL1aJWoIvLKYpAUb8uEyrWAU+5IHHiuVElOtnZCLXADn6tlaJI9UWocgyRXrLxQhlEjLGPRK0Aiha1zre/XqR+jlHuS852zaTsVDTj3Ng5NlAiNIGcanSjOCjirBuxYznxeaggSJUOGWCCqEsaQr+vxQG+lDPr1q/nrLPO4v7772fX089w8oknsWXzJppo5p5dl9m7dy/r1q1jdmYWMFDiggsv4JZbbuGBB+9n7dq1nHLaKcRBZMPG9Zx1ztncfc89oCdx8imnsHbtWlSdSqzOuKgGoAVyHjtYaMcz586vqYQGB0YkEmnQ0oGDZanrCCIMBg0xGzhm0sZIE4RE58CO08rNRZXo8UtIQIOzX4q4q7JLrlK2yFY3ka2S8EJG3Iiy5I4Y5Rj5xuKz93txTPSqNuq17LG6zQI7zl/D9h2rAegOJv7gj74FCA/e+zTdKPHV6+9mMGj58fe8miOHRvze/3MdWgZcdNEJXPGKk5HG8LEv33A3t317F7ffut/nwsqGqBTVDqVhNE4cXFigK4V//+tf5N675vjQr3+Nv/VT57NyzVKe2bmXP/nETaANV71uBzvO3sIN193Kyy89m2s/fwePPHKQN7z1bPbvO8BXr30YoeFHf/J8NmxaBr1/gM1pJcNXbriZl112FrNzQ7TAF669iVd93wWENnDHrTv58rUPU2TAynWBd77rMpNMhEAR+NrX7uLcc05ixfI5Hnt4FwvjETvO2EYpcN9dT3Hd5+6maMMb3nYBW09cxVdueIiLLjmTmWUDBDNYvePOB/mFX7qaX4vXO0DhN6LhMGSUPXsPs2XDKi6/dBspCt/61qMcPJhIwO7njnDxRduZGcC4K/zuf7qFlJW2KZx88jqyLOGGL+/kDW84ATRTJEyFTy6OxbE4XnqjRxS4555dfPoLd/Brv/ljtDHwl19/mn/xz2/g01echObCUzsLRw7aumH/84lnd43IqkQ3uw2+yDW2tUwV595a8zWwyPS3Sk9wkyAsLGTuuOMhrrnmAuLA1rR//Eff5FVXnsElV57C8/MH+fDvXsuu+QOs27AMIZu8oRN+61e/wC/+0htZvX4p99/1LJ/981vpusxgJnDnbY/ziY99G2HWJXS2Ttm4dRUb1m3g1pt3cuFlx02xLQo6Zci4OMe9dMeLA1DwhXXfeiB4pKFRElVNaywYBTpVKjzHShya2uVVJZdE07RQhNwZfbgaj1jX2mP0smkrqz9CMxiAMySmGw7DtiViNJ3sOnHUqaI9PT4T24bQCKGBEIUYW0IpNKGBJtsXFUWahi3HbWc8Ooq0zm4YC207y6k7Tmb79q1EhNmZIVoKKXfmtq+5X7vkkgkxMJwZcs655xAckDl1x+ls27aNdmaGV131am655RYOHz7MoYMHWL16NUvmtrJ+3RrOO/9c7r3vHvbtf57DC4dYsXqFddkb6PKY2BjjYjAc0gyiUV010YTGqO5UGUHh4MED7N69i8cfe5Q0GvHsM0+xadMmmiYwNzvkrjtvZ3bY8sTOJ9g7v5ugynjcsTAa2TwYcHfrAUET4p4HYMtIVSYd8Vj9J8y4EDEDx6zZ2ALuqO88e0ILoSTKeAShIYsvioP24FKMsV8UduMFMsJwOEMzGJJyIRUlihCaAdIYKCKh5vTWWdpTQShWWBadAjcsbaCoGR/GGNGUPHJw4uWRs+1fYApACAG09JQyReyABeuYj8edmQ7W2EOp0ZHlmOQH9QcJMDHh0QLRJvOUsmncgut8USRESi4EtdhT9Y67RIFoXgzjbkSMgViGdDoi6YhSQi+7KKKI+4TMzMxw7nnncuKJJ9KGyNzsLM2gpeazD4YNG7dsYDiYIbTBgL8orN+4gSuvehVaCrNzs8wMh2Z+qMrpZ57JtuOOYzZG85aILblEmraB4gafQRBRS9dwgKcUA1miNKRs/hIlK1Ls2qgnr4JmZphoKR1dVrRkYggOKGZCUPf0sAd9l/NE7qQFSZ2BBTH210jTNP1jVAg00T63K4lhGBojpsB4NCanMSHOOGMnM1o4ClOg6+L4XhhTTt94bS9ue1hs7sk6w0OPHGaUEoFCNy6sWjsHCnfdPc8nPnYD//T9P8TMbMv+54/wsQ9/hmtefSk7nzrMH/zxg1x00fHMzkRuvPE+nnziWbZtX81DO29CZRLJXEEz47jCvgMLfOlL93LZpafzumtO5+ZvfIurrzmFuSVD5p/dzx984jpe85pL+dZNz/K5zz7OaWds4lN/9jjPPAlLlwkLC/CZzzyAyH5e/dqz+fjv38yzzxxg46ZloAHzebF0FBW49fYHWb9pA6ft2MaB/Ue57voHeOUV5/HAg/N87cb7uOr7z+bjH7+Lj/3x/fzYOy8DIAdbtl73xfvYtn0Lc0vnePCBefYdPMippx/H44/s5rrrbuHVr7mQT37qYb7+9Wd42/Er+epX7udDH3onjU6aDK++6gK6JGjMnkRZWxBa4W9jMqmgTlVetWItv/qvb+EjH91CVuMUhwBR4MknI5/97CO88U3bmBlEfvD7t0FM/Ry/6H++OBbHS3xYVwGCcsddT3PqqccxjJEQlcsu38w5FwzZNX+A3/md67n2Mx233nwL7/qpLcwtXcY4D7ju2nv4w4/fzLqNG/nlf/Y6YqOMM/zpn9zFZ/7sEY47YSU/90svZ26u5Z/8k89z4ra1fPvmb/NDbzmX2bk1fOQjX0WIvPbq03nLmy9g4Wjm0Uf3s2PHZhTYM3+YJ3c+x4+87TIGAdZvWIa0szy9+yBr1y/rGdsFWMizPPjgc6yZP4wgvOunX007jAiZ7cet4Sf/1sv53Q/fbGxX8NpJuPjik/j6TQ9ywWXHUQTCVIJEzXmYoCOL46U2XjyAAtYVDNEKoqrJ11IoWmhaK27VXfs1F9ci1Wg/kxVU8zYJBjy0Ehm0Q2rqgoJ1k2th1Hd7pAcoYtO4/GJqC0WIYvTtpmlJCil1XhDaC0N0/X3TENqhOW2XiGpDh1C8sEGseJwbzjJsG4hWfFoBZ8BIjHOm0UbNMyJ1NBpdD29+ASGaxnr5yhWcf9GFlJSJoaEUY08gwrLly3jZpZfSNJEmRuuYNpEYWy65+CJOPfVkcJCkbQbMzc2xY8dp7mFgnfrjjtuGivtNYN1U3CFfIr0h5rZt29gzP0/OiS1btnDiCScwNzvL+Reczy233Mz9991HLpmtW7faMQ7Cuk0bMa2YFWahCORiDTD3HZAqQXGpQMoZgphMpRbqHhMoWQhFaFTRGMyMrJg6uBnMmLQmSH8d1U5+ZarkUvy4235mSahi4JRr75umJbWZ1I3ss7zwLDnbOXS5QB996eaBYD8zgACKO/y3jdG/SvE0hppqgFiur078QMbjSYRg6oyp0zRNz5yZNoGspmX19RMT0sq0sWtbJFCysWckhF6uUYoVKWZ6VtFwNzsrpXryUD1KGlXEIxqlmN2YZmcAtY39LAjDwQzD1UOT8LjUqJREThmJkSWzc+RSTGYQgu1fUVavXGXH2wGYJjS+gM+sXraUgW9PcuPHoNAgqCRTRYu5FuOMJJEayelyBpfXhGCpEEjFmCapLXXfESE21aTT3ZPFgJbKiKjX7XhsUhiLLp0k0TRBegNKA4Lsgdy0BjKY2WxHSm4sWRRpvKRxo9fFB+/36LALBHD+lqpd26pA5rqvPMm6tUcIkogh8PO/+FqfkwI/8RPfx7kXbEeBf/f/fpmLLz6Xs8/exqYtC/zb//s2HnpsL8/NP8cTj+/mx9/5fRTg5pufciPi6tfiQ405YAvHITPDhnPO3szK1Uc48+wNxCj8zr/5CqPRHJ/6i/t4ZOdR/vzTD/Cud59P17U0g2W8/o0nccKJz/BL7/8cf/LHP8lsG7huw1Imvgq2b24TQQjCT7/nrfzCL3yEf/XrP8kXvnwnL3v56QwGLR/6zev5lV99O0tmI0ePjrnjjqeNlQiUPkxiBi0G2pbSIHmAJPiVD3yJTZvW8qnP3Mudd+3nox+/k7e+YwdF6lwnWDctEwWyNHWG9mOAMd98PVMtJg1oEH7kHWfxtRseAYXoIIEZwQbe+94L2bP7gIHNIkhI7gZfG48yxeRcHItjcbzURg/D+k0tZQIPhyj81Ltfyb//d9fxj97/JkK8iTe98VROP2MFX/nmTq677k7WvOks/tWv/Thvesufc+c9eznjjNX84R/ez8xwwL/8wOv5B+/7C26/7Rkuv/Q4HrhvP6+96jz+9k9ewFjg7//0Z/ngr72LEOH/+Ge/x1VXnwZhQJbW0toUulFhNIalywe2cSUArXk84UaS2ph0W5QvffEeli+J3H3fc0gzx2//1g8ybIXVa5ZwZCGDuJS2at0ksOm4ZRz56iH27T3KmtWzQCVNTIdQLjKxXqrjRQIo4PR2i5MqvlgSdzLPmjGdecPYYyMDVsBLsLx6wLrR3hG0Z7t3fAXrtBY1V/Y+Wlr614trPUM0fwQJMpGpSl3IxEkQlxiyaF3jGgln67mUQEtw91Mv9ARCI8RsN2NWpVUIGsldQSXZ9uNaVlVKb3ZnRVk1hoxeSIjT4gPibAIlNg1Bbb8VaAet5daDdbkp/fuaQcuq1atc7z5x11+/Yb2xPYqSNLFm7Rq61DEejT3azgCXlFJP2d6wYT1vfstbrHiMBvi00dy5t2zdwspVKxkOBszOzLIwGjE7HDAzu42jKXmEpgLJ6KIlExiARDLZAQEoeUoLLw3FzRZjiChmEKgZW5D5cekp6BJBhhA6wCy04zSgkF3nrjUhJKAUujyiGQzMwK9oH2/YpUDqAFE37i9Osa+SFGfOTBXuTWxQtaSLEAwEq8wBatypeyZUg0/1otMSAXz/a8Six0mGKc+J6djLalw2nWZirymeAheoTzeJJt+gZ9uYfK2ROAAAIABJREFUjAiJvQZaZGJAqSXjFhTEaEZtqYxc9tEy0MhcLhxphjyzbDXZ2UelFJoYydllSw6kxGjeBlW6Mom1nJhfFvc6sVvdtzMli7xEjVRAoWsjRYUmw0gaQsm0pbrG1/u1TH2O32+l9Mwn9e2tJklFK7Ay8eiwtYCdqxgDyQ0VB22Nki3E2FiaRb0e1I57FEVzx2icem+NtmnJo6Mm3Zqx+3k0HlmXMxfzD2lnSdkScQaDwSKe8L06+rixKRNUBzNjs8Dffvc5nHzKSpuP/RXJQT570GVKieTcUkKDBli1coYrXr4eDYWvfuMR3v6WS4gRoiiNPwyLTCy9fAMmlNv6G1EyHdk3q+gsV7/mJDZuXEom8A9+9nJWLh8yM3OU1752G00L55y/iROPX0LISmiso2XkBzVzWYQYYu+dMGwbrrjiPP70z+7g5tsf4v3/61vQCMWf2xHlkpdtZ9vmWbtFxKm1djM7swO0tFAGUKAJS/nBN57N3EzkDW8INK3QBiExS1IYAjjQW1EKceZkP786dU7d40Z0wrD7+Cf+kh995+k1jc0BksAoF750/Td5/y/+EPWG7r2BpH6XLN7ri2NxvNRHPx8oQdTmUy9Ydj/7PJs2rkTa/4+9N4+39CrrfL/PWu+795nq1Kl5TlWlqlKZKoRAJIEQRiMkTNrdtCCttn1FxBYc6VbbVq9eFT8ootiKtq0gDQqKjBpigCRABjIQSEKSqlQqSaVS83SqzrD3u9Z67h/PWu/eFQPq/XzuvYmcBZWqs8+733G9a63n9/ye30+QzjFcp4+vhEqU5zxrI//me55H9I5/+/ot3P/gYR5/4gR/8N772L4dPv3pr6DMMTnu8QrLlzRcccVKqq4tWTT2ePtPfIL1G7u85Krn050YpTcfW0AD7LxicgSlHe9dkmxTr0iyucaJ4KvAW3/sZaxYOc7RYw0//RPX0jRKt1usgPM4adkPE/dFWbVmivm5wPSJOZYtGbH1ZrbItHKOhXHumdyeFoCCZWUjMUSceKra04omlRKGEPCdTs7Apyx4lhf6bV23BRtNMH9tU8E3nQURn7OKpocQip1cDlBSitRV1Yo7/uMATYmxWOopVVUjUtM0OfuYhf9CrtP2KeGccqoyX1mfgYtKHXMuEXF0pGSWK/pOaOqaoInKkWvPTW8asaCjzWQ6lxX8acGVKgeibS2AYsKVMiBiaq5173TrLLIXSRrp9fqIy0EqQuUzE6EEWPmaQ4h0cxBTdBYEyewRhanFxBxUjYyYYn0IDc6No8uW0viaUzmLPh0iMTY0RE5XFpBa9tkTY5e6GuVoZ4wZgWMJRqouMSn4DCThTKfAOxusohKkAad0pSb67FCoCTqWLwqNo+rUdLVPF8uYaw4aC3hjNPaqffbihND0cbGizmwUE/Pz9L2Y2GTWCNCgbRaa8gdzWVDE6Pu5nKawaUStTt47b+eaSqBKy3KIsVidDjQYSh9tbVKH2AnldznEGPQZMphQ+o3zbR2/Fjpe9ilyTihVu1Z6oi2QZM/fxAxjjOASEBFfZ0FJ8CpM9gL7xifZuXgpCcVLjcjATlE0Zx3zPS2k4ZAiSgnmB8yhYe2TlpFBfobikFxmkZwYRdpF6qZhw8w8E/NzhNDLLIACNkZiSPm5GvBYABWnxZ6JnIU05lTTNAY2em8gaFKSBpyv83UoIZqwqKtM0DKEYKKrGSRJOVjSIfZDXdUk5+iOjNA0PUhKJFIV8Mg7Uoi5NMMAjxCbM2lUC+3boD2VC/kgj61JkNTDk6gQRM1CFRSDw2Nm4xgY6X1EYyTkocfT4FLixS88jy/euJMtW5ebtVmMOAWNJQOPHVPUNFlQEoHiiSLOWxkhilYzbNwyycYNS9EIn/2HWzlnwyUYby8DlADakMlbeW7SPG4qis+WzNblvYNnP2c9H/qrr3DF8y9g0aLawHLXtNa2CSGqzc+iauMrGCNPYb6JfOwTe3jpSzeQHPh6mq1blzA+1gGFT336i5y95QqOHxvj89fv5dVXn5XdbjyqBtR4FzLjMKHq6c83XPfZO3nFqy7nWRdv4PPXf4PLXr6F4ydmOXjoEFe9cgfq4bLLNvHlLz/E86/cyvXXfZXLn3cWS5d085hvp+nKnLSQsVtoC+1fR9Mye0NQAxRUIfThA392I+/9wx9CnOIyM0AjSEqsXD5B3XH4BGvXOGKYY+50j5/52fO45urzshODDRyWIBWSB5VIxzv+7E9fR+OE3Y9M87YfvZ5LL15PVTmqJLgoRJMG4667HuOhPUfZunkZqLnheCzRFlLHBMsdNo+oCTCOT3SYXNznTMvHPJApmPKvffTEY8cZG/FMLR1rxzXJ90UzZ2thrHvmtqcFoABWn6w5GC4Lb1W1IFITSSA0Te58zhYbkoNLEVy2WHMidOs6Wzd6y86rBXniPOJsO0LI1H+fqeYCOJrG6um9L7FV7vTiWpZDm1WGViAxpWT6Caqgno44+hXcOzlGRyu8VCgOrxWNmP6CF4d4zzxwtBphf9XhZJWIztEqTatmUTcB8Zleb0PSQBgxB65ictA5Tmmp7yk7AIgmc7soVNnsf1tKP1pat5brzs/CDbIkki0ZLVuUhlDIJwsJGoDROhDkCKqcjxN73kkjVbsDj0RjqIhTJEYWB8VF4aHY5PKBTOcvmasc4dp4NWKHCQn1drwqU4FVao5PdFg+f4qX9btIP7T3wfsaiIN75Qq4YLoJTdMgXom2REWxftMd6dLvQwzmDOLwAxHDNsM+0CePKZqgZbJ/Cwzq+VvbRgMbUAwsKYvgdjGtlq3O97W4RjQxGrMjlwi0Qolu8L0iTOgyfTeE2P5OMCvOlPVJShlRAUGMIWBKv+WcY7TJRjMLyFdksUkH2qCuT3LJyn2ckmECc8SIDb6qrTzCulu2iXVoAcfEZdQ8QbR3LZRrHronxcElJtPdqL3HeyWoJXCXTZ9icQh47zCfkDR45zMQE2JogaFhZxY0ZUeFSHIpjw2Ofi7zqbyV6qSgoC6/A6l1qREndEY6WdBT2uCuMIzE+WwlaQyHud4c3oNzNdqWJ5mORcgAVxlvmqb55w+wC+1fURsK6NtskGW7RWDDWSOMjzpcysAfAA5JsGpFTdXNDkXO8/rXX8r73nM9H37/nUTX8IIXbGbrOSvxzvOh//0lbv2RR0CU+dkZOl3H+99/Hbfdsg/VEcjjoajje7//eZy1acwYYwoT9Sg/+ZY/55d+7XX85594Ge/69U9w6kSi0Tmued3FVKM1m7aM0u0IHltYb9s+Bl7QClZvHGV0ccWnP30Hn/nEfSTxBoQoIDO86U2Xc+UVF7FisXLVC86lkywB8VM/+Qp++mc+iAsdUKUzkhAPE+OeDRu6iIO165fyf/3yF6iqhv1PJFYs20hVKT/5c6/k5/7bR2jmwMkcP/D9L6R2wjt++jn82ftv5coXrWJyUbe9687Bhk1d6jpzQBJ84M+vZXp6nle96nIuOH8tH/nIzfznt36AJniuvPIs1qycBOCFV2zlV37lY/zvD9/J7KnT/N57v5cy9c7ON9x1xyP80n+7ugWFM83i/5PetdAW2kL7f6eVMsVly5bza792F4vGxqgqW18tW7UCRPEImrrcffcBJhcZ+KnZLh0HFaah9J0vv4Bf+MVrmVzcoa4cD+7czZUvPp9tW9ah9AwQEGiS8hNv+yRveP1zaKKyfMmoSYglcEVLS2D56nHe9P3fwe03P8KRx06z79AcM/2KreetICXhx9/+SX72517K2nWTbD5rMXd/9XEmRkZIqiyeqLIdeaIsOgcyulBAlIMHpxkdGWNyctRiGclMLxxJdME08hneZJgi/f9X2759i/6PP/gNQjBPaJdZCCUrb3Ryy2NU3pNCEagTfF1Z4C2GypVM4oDSXGUquzP6dl6MFzE/511WwHetU4FzMmTVJGUUQKiIwRwbYoz5WGYFqaQsIGmCj9MjYzxRVTTSkKIQo+JchSRH5UBJxNSAQFNV7JlaxgFXszKBJFN2j9GcDuqc9Y2Y/3dVZdtCP6BRlwWHUVxdDsgGWQ7LNKd2U/s7DS1RrGI/ZkvC4V6hmj30MmhR6spLmYdkoaw2IFQTlhMnLW3cvpGDLmce3oqiHnyKVM4TRTCChwWMYzEyFRqmYo8ORvVPOesFgss6EU5MkDCliBdBm0DyZk0mMRjQUk/w0OJJ4rEjvGp2ltGmZ/cjKVXdaftbSlkLQZWUgmWvk21XNDLUWYmA80K/16fp91CNSDNgBxTNgrpjdmIhhNznaAGDYVeRFGOr06CKlTiEaI4J3pNSzIJ/Z+7f+rjLNpPWF5w39oBpfNg5hRCGnmh6UhmEtm4RpkWRyxDEdCTqum7ZAK70ubytc2ap6JzD1ULTa0Ads+Nj3LN0OS7BeL+fGQjmgIFYDXFMBt5ZmU/KjhjemBveLBkLni+FQkwpSSHDExBTsHfb16TY4KIxlI6OjTE7MsrFjz7Csrm5zEayfmKsAEfoN/YuxtCWulRVRV9g19rNnAzKhQf2Mhb69oa4DKqlzPgxb0kM1MolHbVrJ9eY32VjSsUWxPBi3tMa+8TZafY88HVk7iQSZqhqRxP7hNSn6nZyNtlEjeLIBLct28KWc7bT/dIN/NQ7P05ndMW/eMxdaM/gdsacbQu1JM7AbPRJ9o9lK2mzRCYSaH02Yqrd2bwA78BlsdkYbTy2EgIQL0RRc0dNJbuUbXwdOJ/L8WK2XAWkMlFCgn2uzhAHP1hnWkmVmLd5+Tw7SaIBiBlAJo8HAloLdT6W4d82WCSEELF5J29bVXmMw44Vk5AC+KR2zZWtgSMQ+4JTE0t0DiQJJ07N8dYf/3N+6qev4eJnbzA6sEYSFTGJWT/ma0kqA/FKzU6yKQuOeXDO6L+SsHWB2pXVla0lUoQPf/RWli2b4KqXXWDgr0CSlNUaSsnFQltoC+0Z1fIaCoQmwvXXPswTew+DJnDK1a/ZwerVkwjwlTv2ctfd+7j8O1azbNkUJ0+e4oIL1gGw5+GjaIqcvXkV1133DR59/BignHf+ai67/BxE4IYb7+FFV16IdyY6/1cfvo+Z6QZIUFe88Y0XUonjT//k87zgiu2cf/EGc46Iwt9/+l72HzhFkC7Pec4qnvvs9YgqH/7o1zj/glXs2LGa2Ch//Ze3MT8bSaJc+dJz2bZleZscOjXT4+tf28vll23LSUxzs/mT//FZXvjiC9hx8TrA4XIMogwcq2Tovwvt6dee+9zncscddzzlA3qaMBQki685BDdE7zeBOLEoLAfwgquxLHldZYq1Zip3oU5ilETnbEHUEiutY8csmGYZ2/yKi9CEIiJCS30uugRNEzDifPlerskWl23mdEBPl8DEfOQc9QhWumBlAwkvFaJZJd8Z7XseqEa7LG2U556cYzTO54WVErTBhVwjn4Mon1X5tc16G2jinInrCaWuPpcmxNj+O8ZkAWIy4bwiKZViagGBcv3kunXVhNMSiKW2JjyEpj223UOX9QSy44UDR34OOehKmbXQPgtvQX+V/W0tiy1UUiOaSBJwUkFZTolQxDVd1oYQZzTcImooUUnOmVZGinSlYj7NczrCiV5j1Fcx9ktKCaI9S42W/Y5ZFJEMTLl8OwQrjUFtm1oqyM9Do5KKOF9evBetg5iz/HVVZaBiwEZIuaQHZwG2uYcYO8B7A0pK5ryo7JrGQswCoRVFvBQyeyADAgNxxmH9BG2/XzQzYgbUUhZCLHoCVv9fDRgh7bNNbSYfjNmgWDlASgKizMbEKd9lw9xxtpw4TC0VSTxN6Nu9GXJnsWsKZ5xryBoLpS+V/u5yH7L+GYf6t8eLhxTQJhjbZfky9nU8MA8aCU0uT3BkYHFYwNL0V5p+YxO8DJgjxZJWEGJTLB0rYhbFRJWmCTy0+2EOHTrARc86n6XLFmdLTovibHyyd6yqKsR7c23AxqN+0yfNz7Oo65mdOU1ntGPuEZqV+/M73PT7LWulqqoW7Fxo305NhkBkC6QLBGxzZEYObJSkjJ06RIktNfkehbpQVXNkLwNHJaO7JtOWEQt6vS963JK1CDJQVmYTJzifypGsVQkqGfos7yPPaYJQuXLOAzFDvAwhI4OSheJtor5AKtqeQacq+0x5T/b7kjETB3TIbIdyI4UKqGo7ThJtz29qcoQ/fO8P8dPveD8//wuvYfPGlbY2UXC+HLuw5QbskVypZONd+6vsA+EEL2ZnnND2a0ePTvPg/Xt5x8+9xjSatLDvyl1aaAttoT0jW076KVB55ZXXbIJ0dh5bMRXpPLJ9x6XrufTSDe0Qv379YiylCJvOXp53qFz1yvPbf7e6OsBLXrwDIeWAXXjjG3bYVlKOEHEkvv+HXsR/+8WP8qvnvJ7xsQrnlFe9egfqrNzBYQ5dCLzhe3e0I5CvlTe+6Xnt+K0M9GIAJsY7XPb8rbQaDQne9wfX8qIrzmfHRRuAgX6DFkZuLnFTWRjnnqntaQEoKJDygt45R1WE2HLG2LXK8zlo8kJIZiUZU0K8ibC5LDJXpnTnPDFqzhBaMO2ryjK4OdBtlfi9ZeJLxlbEk6JlL0UxCr5k0cQsigYOEaXCEWOg9hXeO/OOR5HYQ1LWgU6aszmBkOlGYyNdE2dEqZOnDoGOBDq+D2FQOuCrrgkT5qAElLo2/QaaYOrvOTAiBDp1h9Dv4asMymR7yZQSTqFW12bnY4hWehFtcemhtRYsA0UbdJJIkkhNoO5mJdjYGHjh7H65/BxCSlTZ7pBoYIpZOhp93WeAyDJXyajjKjSpj3ihqoSIp69ChdW9xxhzLXpePMZiHeotu+WMYVEAI0VIKggG4ngiXhoS82Vth+RsvqhrGSaQA3JHpu+X7L2xLkSsL5rbhSIp1/RLdlBwJa9uIFcJ7guw0Gop+LzYlQGrxlVVzl5Z6k2cMGARxDO0EoYtU+VJgaWmhPMD8cHSP2KMLXDSBu+ZIVKcD8xxww3AJk0tO6EtRSpuK2pTZC0QkyP5NhlJTNkBQwOS7Jl7qeg3fULo2z68o9Ppmm5FLmOyso/8XgK1qy3gjpGYFF9Zf3DOE0OAEBFNdCoH6omqprGey2VSiEQNOFdnm6JSslR0O+yehVDKOwxga0M0MT0SLzaeNE0yoVj1pH4ihMjM7By77t/Dzp33s2bVaqamJjH3h5gDi6o9jqoxVjRGOhncGB0d5dT0UUIT8yJC6fd71HRwlVlghn6PGAMpO20UF4mF9u3WdPB3G8S2CEO7qNMyJpSOJ9mZR2UIh7Lyh1QAAnIlbF78FtaDLTBLfi1RhLc0Lyid5KBaXWYKZMHYvBgFlwGNLDDYBvrDVyS0PrsFRRDy+JvLCkx0pUAkFIhCWoAi5cDbjjEI7112hcrnNHSNLbpNAe0dSWzOqpyCVoyPd3n1a5/N9PFZ5KzhsTbmcyraSzEfa2gTyT4yQl4PYN8p7EHVzCRMzDY93vSDVzA+WrdPM9NK8vYLS+2FttCeiU3P+EcWbXcGBisGzDotsKEbvOkCSsp6C97ExrHRz7W6BVnvKm/v2gPlsbSAyQWfzbSy0RHh6mt2cO2nb+Tf/ruXtSB1SXhZiB+zzXhJtEhmfNt5SXbgGZxwHmfFaG+CcuDQCZp+YOPZKzM7zpdZ6h/fn4X2jG1PC0DBidAdGWvri3xeTChGR/S5JjwlC2aaEK2uKFidtVmo+VzXb4uNmLLdny8L+RIImXZCG4g5aSd2U7PPGViNeeFkL6VzWXgxWqCmFnXYS+0cIlXO4ANkur3ErFvgSJWJ0YVkdCezPLRFkAIBq9EHo32rGJshqRKCBZi93jwHDx1g5tQptm/fzsjICJU3dO/o0aPsfmg3lfecs20rk4sWIVERZ0wE1ZSt8ITUBPr9QL/fMDo6RlIlamJ2do4lU1NZDAvITgcFonHeo9GAlRQTla/Mdk8dqZ9y8OoIavT92IQWhbRbnNrMdKn3l+hoSCRtqNUhlaPvlEYTlY5A8KRK8d5s9cCekTiXF7NWyoJEY3yIItHhg9IpiZ/Ug64n1YEUhKQVaDT3jzZDTatL4MUWtlqOxZDgYcogSw7oUaU3P5/7oNmCxmRuJSWAP0NPoWTnrUsCRnsl7z+XlOXtIaTYAgow0C8orQSnQKsHQv7+QOsgDt4154yhgrlpFGCg6Ef47O5hrAyX7TSLQOqALVH2VYQlI2qq7l5ITQ9PZe9QVFQ9ISiVs/KEPXse5o477ySEyAuvvIJ169eZ/oQUXRCBzCBAlSb0mZ6e5qHdu9m7dy9bt2zh3HO3W2lGiOzft5+HHtiJF8clz3kOk0uMNmhWrID3KA0hRpvkyOUatd3j1GRHDS19OpG8XbN3QlV70nyDw3H69Cw33fhl9j1x1GxKs0NEv2k4dOgQna4zQaVopSd272wMqfJ9K6AMzhFjgzhHp+4wOjqCi3Pm9BHigBGSdS1GRkZQ3wGMldHv9xdm4W/X1lpyVbRB5xCocGazRWcaQIR5uzLPluVnWcrqQAARExxs62IV0CLgW/Ze7FutZpd8Jr7tm5EBzSAN/btsmb+UgYczO3U518Fnw1db2BSZjkbLxsjXowSbo7UUDGge28v55oxb1pgwQFNNe2do7vI1XP2q52btFsvG2Q8uX1/JPQ6up0CSbvik3dCV5M9c+VAcG9atyHsYMlJTKbI+C22hLbRndCsFvQXDtPGtKEyZgKEMDeOp/bt1mKOMNZQBq3wILegrZO91EFvFI2UP5tYgauvVl794B/O9Xg70NQ9YMY+kBdhVhMoSmlLKZ30+jufJ846dimt/Wr5qMW9+2yuYGK2z4U7RQXMGBkvI33pahKQL7f9he3qkuMThfIW4Cud8Vu63z7yvzfZEBe9ry2Q6b7X2yTLjmsX+YijiikM/yyCoGlCoS9BFm/FNKbTBo3f2wrbU/FS2iTnwI/8ZWPiVYC7FANEo6JGE+orkamL+I77GqanghxiIqbHyh6zSWuFIwY5ZFOGDb9AKjp04xh133smDD+0yq0wBFaXf9Nm9ezeHjxxm566d3PLlLxOafluiUAYKqxO3IP/o0cPcdusthKYHmjh96iS7HnyApt9DSDix++CGxjZNabBUsgdgeSNRKifs37ePr3/1br56x508umePARoKtfdUeTBzZCCm2BVivtvmSFERqdFo24j26XgFHVC+Y4y55MLsZpLGHMBn9CBZ0O5U0RDMPSRnxlxKSBCIWXU2JnNpiGZNOZRCxhQlhBRDXusNsvOakukshABJCU0gNI1l/xnoEqQUWlYCbT8a7MsOpRnpzaKJGcwR59pF/LBWQiviOPRZld1JSj8svy/bDJc5FO2E8ixjLl+w90Hac3PiWtCkfCejZG15CWSrUe9JIsZeUWMmkDxOKwMWnEO97e/UyZPs3vUQU4sXU3vP1+7+Gr1evw2cSzmIKyU3ITI7M8vuh3bT9HqMdke46867OHn8BCSYm5lh/6ED1OMj7Du0nzvvubtlkhgeYbZ29k7ZS1+YGDpUzgC5hKDcu2jITkpKCA2tlWZIHDt6kv2PH2LPQ3s5sO8I08dnOH1yjtiHFARRbwBJBjddfne8l6Gxg/b5tYNRBrYkl4/UdYfKe6rKrCdDsP40LJS5gCh8k6aDP6Uka/CrEk5+ky886ecz7/KZ2+lT7K3doj3+8FbKk/56itMY2r7daOh8BFQcKr7dRlQGC1UyOKD2xxaVWZhYS7ncsPljCXw1L3AjroUZ8qJS25mVgdBjxLJW2O+LxZgqPlsUa2YMDC6hnU3y3od+1qFtctAuRWT4jLtl2Xzbpwzt07XPO+MGiLrWscX+X0oT7M10Ss7yGdNAWj0Ub9eNJ2XNowFAMvx8hxfUkkHGvIVkeCPfE2lPivw82jszeAY5g9iyRCRl1sPwvVhoC22hPf3ak+eQM5u0I6G245OtTxSntl4a7EUylFDGSd+O3YOWnsRaiuTUjs0LefywvbkB+SuDtiaKaMnSsTFLVGibADHXrIxODM2EDkkexfyCktjezxzXh2eWbPnrHd3ROu/DRCWlgMFlFtD2QE85856xf33Kfw5Nl0MTwVOd2VNM9d/66S20f0572sBBppyfazLVRNdCE3KQIzm7mLMkVQX9XhsUFCX9mBK+9tZfc/1/SAGn0gZ7FrgkEBOUK5lg269HU16s5F5VWA117dGykE9QXuIQsoijeNsmiQWOJEKy/IimaHaQlS24anGk0CeIw1c1YBoFtcN0A3IJQFKr5SzZiRUrV7B16xbuueceQmjMGcA5Dh4+BALPvfS51L7ivrvv5uCBg6zfsC7Xn9vgYjGzgSTzs/Pcf9/9rFu9lu3bz2F+bp6DBw5QShxUCriSKfveLMk0K9nHEIwxkCxDfvDAAe697z5GRsaYnZnljrvu5BXf9V1s3ryptfUk2TNJaoGzUzVx7Fzzrs5DEhyeygmaGnCJqq6Ngp5M5K5SswDVzLyIYdg6VKi8QzTRxJAFChVpEi6CJCXFQEzGGLERxNvglsETV5lQJ2SBQzIrI6nVd3mfn1O5Ry6Lf1Xt4FvcLirvB+KVmV4f05kBoctuHykm8yenLFhTPn7OamODrAgtyybG4laRHUGK7anL20crv6mG2QvOZ3DBLOVSiMZeKcG8t2xdjBEpIIYIQRNNaGxbitCjmHZBjjE0KS7ZO+hyuY8l44UYGx7b+xhr1qzlnHPOYW5+nhtvupF9jz/B1q1baLK9YrkeUUeKgcMHDzFz6jQX7biIkW6X2++4nUcfeZTx8yc4fmKa1avWsHLlCtaftZ6bb76Z6VMnmVg0lWu+K2IwKKtT16ia1aJgbKMztCUySwGBuluDdzRNv6Ujh9TQHe3w/OdfztazpyE5xsdGGBkfARVuuvEmnjj4uH2/rjMx3LeAXuu8IUb39pWnwhH6QkqRkBqSBkKYJ2mk42pEhJGREZomkJKxEpKmVmz127UNB8LDtaPDywFpf60lOsNMfe9cAAAgAElEQVQWUumM71j9uy10RN1g35mymXtj2RibH0omvWSE2rVXHgOkDWJp5yny92iDTh2cxOBaxAJY0VxSJHltRETa7L4MXengDEq96yC7XS51ODB3DJZyeUzI9yNJbAUF273oAFoYnHEun0CGFqpnLndzXowzZQSFQf59+M4OgwXD1yT5Zg10G4YfxbcKssvvkaJFMtj/YCFb2HjlIoYX6PZbpYgbDyjF5TTc8Af53pbvuvYYQBseuKG9l/44dOxsK3dGf9MFK7WFttCetk0Hwa+lW0rgr+2oMGhlDMtrvxzsoyBic5OcUQ5mtvd5IG7Xl1BGGB2MD3kMHywNEioRtMolCcXVa7jcQPPpDM8JGZhuS+aGz3/wWRJL4A7zzQZfGMAB5dTbhCIKLov5Fo839QwKNbRN7raKjmfse7DPor9gs83QXKMGljx55DSgXQcVbjrYq+a50ulTX7LksX54zl4Yl89sTwtAwZ5TqXfUNoNqcYy0C2gLwqwsoKp9S1OGgcBay0AQoapcrjlWxHtcbQEwSRFvVBuzpYSqrm0/aBblw6ie2IseQkPlazth0RZUkGwP14Qs3FbqNMXhZbDPjhQ3eyWI4iqfz9uETzRENFrpQe1smacpGu0736Tae5ZOTTHe7VIo8jFFDh8+jKbE8qXLcMBYd4yHH9rNurVr8B3fCv8JkIIJQcZ+ZO7UDHff+VXWr11PinB6Zo4mRDpdjHKdX37f6hHYS5cyuyBmUUdfVew/eJDOyAiXXfYdqArXXvtZ9h88yMZNG03sUiJN09Aplp45o65EZmdnQYRFk4sJTYOrHE0UvLfBppmfp6prC95zuYnL9xORIaFDAyyIVjrgfQWa8CnTfROIU/BDLgfkxbvkQSYpKh5xav7nKbXaAcVVI2H3oXJCaMx7XdxArwBog9WoccAaKLW77d/kOvuAd3UGm7WtjU/YgtiOmSn5lS2OS22+uPysMg05hMy0kaz5IQZMaSp2kKUWV/FZN8EOlmhi3j9C1IErRCzHc2aRWN5ZzbogSWKrS6JZK8F5gSrlvmcIdQoNx0+cYMmS5VR1h0WdLlNTS5mfmyeEiPdV1j2JmYFiDKTZ2XlWr1jF1ORiYoysWL6Cx/ftY77XY98T+zl74ybG6hGWL17K1OQE8705xicmTZxOBZLLWVUjfcdofbGUf0gp3XBCJOG9owk9EjE/I6GqvI0VUVmydIqlU6sY7Y5Sd8DVnhigFy7lkUeXMLF4PFtsWoCQYjCFdy22qvYipZCIYvv3tbc/lWdsfIK5udksmmlOImY76UCCaado0er4Nm2FyZPv5fDs3obXObgmL/JKnaeVxSmaCjukfKuEjy2BnyLoWxY1A73O3LcyndQlnx93yuNDppfmx51cbBkDdh4D54LWgQEM1HNleWT1p+XyynWUDD6ZheMEytLJjp+zQmXqyO4idg9KYK4kSVZemON1FQh4eqd7LBov4OiTpQCHwAsGmgkFzNUMapj410AQsdU4UNt2erZh0Vhl72hhDBQ0BhgOzO2//oyfSzj+VLiaPNVPOenQ/qdd6Q+YHWW78muhQA6DPQ0v3PP085RHPvNjuz7brzxpe6E4bgxf2xn7kX+8ZF9oC22hPT1aG++WUiotY16eT0SGgvVh8DHl+csig0QikoOylPWdsIA6qSKuaBlkrasWDC0A95nlYgpZG6yUTJUJYWgMknYWHUTX+QyTaAsEnAGby+D62q3bwXX4+DkBl9fZZ4xiYjwsLbvM/yswRFJzbMu0UkAIydjQrkzHhdHgtFWSSIBP5VoHc7lQIHCbl1tAvz3lRIF4IkPzoihR+UegSTslL0AKZ7SnB6CQjHYjaC5NcIPgC3uxzF3BHmMrQJgXW5aFN3/7lGwhH9RE+7xAVKO9i7hcmhBABZEK1Zyt7mf6UM4EW8BmgWupHVdvrhEt1pYD9brqoCm0opGtg4JYttWLBeFWb23+35awVzQoUgvqK5qQaJJS9ROuzshkymJWMSApMlJVuKT2J5ogXOo3dH1F7T0+LzZDv7HgOFrAWqBNUROYI0bWrFzJSKfDE48/zsjoGNMnT6IhcerkNPsef5yqrpibOU1Vec7ecrYFfGKYjJSMtuSykBAZ7XSoqwrvK1YsXw4pEZvA6dOnaMI8p2dOsWRqirGxcbpVbbXhMTF7+jRjY+N4EaQALVGZm5+l8h7VaBIuqlRVTWoa5no9YlK6IyP4usZ7x3x/nlOnTkEjdMQzNjGC63rUBDBIVKZboYG6MmCplLzYCrjYJxb9gaGafqBoQKSkWf/Ct/R1LQHOk1a45eeic2D2mql1B1CUGIKJIoq0ThGomniis0BY8wAYU7DJZ6icwbQfch+TQclFOX7ROshv2xnnVsogal+ZBkksrgq5vCQvxEspRNXqmRjDR9UAmJSsT4kH6Vb0VJnTQMxibiFGQt8yrFVl19rr9SBGRuraQLSkSLCKbKdCJJoAa2+ekOxdrusKDY2xeWLD7OlpxCeiBJxTOhm8qTuVvYdqugmVV3RI26I8l6Zpsp3bQNSVlAhxYGPpnENDomkCs7OBz372c8ycbFg8sZipqQnGJ8YYG5tkaukSLr/sciYmK0Q0s2AC4uw5p5Sn4WjaL2KRICEmYsKYI40SJdHpdmn6fZurXdaHya4e5bkPa2N8O7V2AZcGoJyK5sWYI5VcRQZcDOqKIBUkwePAJdSVbJBtpTnjYWusHLhj5VSKQ6Nw8y33cdnzL8D7lHG5XK4FoBBJBFE6uUZ1cMKZ6YSBf4ZFyGBhkhd86ktef5huqnnRVeUxxr4gFPeADIuKsRqMsZdrdVMWLyUSULploYQas4h8zc7m0vvueYzbvvhV3vKW1xE9NLRyiGaniIG1KYOZiJFsPWIWjw7URwrVVbTcR1qSSG8u8B/f9FF+453XsPWcxflchgNqvsW/v9kn36R9qw3lSf+QJ338zXbxL1lDPvkY/9Tv/tE5LCxYF9pCe1q3rP0UKGziwbjuNUEqrIQCVpbYxgDXVmdsWCWhrCNTSVAqZGau/abM/aU0CwqTSzBAW8XmQieFNVHleSQ3TagUBmzRgcmuesQBmNmWDhQg1sZq356HDoGsbVhPy14bapqyZgKKiG+z/mVZWubUaig0FS3i61aIV1h7+UKx5Koljr10KO5pDp91JJvBPSKS7DeAJbyEChVjTGsSooiBCK6sLwbr/+H189NFMeDp1P5JQEFENgAfAFZhd/OPVfU9IrIU+CtgE/AI8HpVPS52998DXA3MAj+oqnd962NgC3/nc0AF4DLTwASTch6Hqq6G0DIGASFq+F5KVFVNjbNA2htl24kg0Wju4hwxJlJbkx4JoQGETqeDirZ0dgPJsr1TiIjLL4pzbTmBpsZeQycWyOcyDUVpQpOzo2rlBi6jZlnF3+WI1OrWhbry+CaYjR5C7SpiiKQUMmNDqTtVHoTMaDGmhsp3rKbBuVaTQcVs8iQHqTGZAnXlHVEbJhaPs/2cczh4+CCr167F14JK5MEHHyTGwDlbt9KbGOGWm29mdGKETZs3WxCTygsuWVxRmJk5TaeuLeADEKtPP3X6JF/60hfZtPksuiM1u3bvQlW55JLnUHUrYkzsfvRhVq5cxeSyKVJmf+x+eDfHjx9nxYoVHD50iCWTizn33HN59LFHeGLfPiYnJ5mZnWdmbpbnXXY54xMT7N+/jyf2PcHkoinmZ+dYtmwJ6zeus4GrILSpmKQXLYE8mDsBZ/W2heVS7EtVUwZRcoCSHT6SRhvEfGUOFxmwCiG0Qas93oFAYhNDjh2GCWZCYZz40jez/kXp262IJZKZBqVkAgOe8nmZ3aXmcVZpmgafzd2L3WPLzhjaR+s8MSTkOHi37CUtOiR2LKs/jtHuZZKIq41NlEKgqmucKrU4KjwaA6kJnDh5nKllU6hLuAr6sUeIDYiaK0l2xVCNqEAMiV6/x9jIqAGKDvr9Pt3uCCnB/Nw8TsXq/ajozQa869DvR3TckZygXgnzPQTFicdnzQnrEYWN5O05xyKM6nCYaGKIkRiTabx4qOsuB/Y/zmOze628xjlqP8roxCijiype/LLLOPf8zbgKQjAwyA9ZQml+/pAtbHO/Ee9JjTDf9HPJk9LtdokxEYKVPMRuhyo71XTqTjsOfru1h3Yd45d+8UYWLRaUORTlVa+5mGu+6zxcJSX3k981W32kXL/uVNDk20he89hwz72P88S+E1x11bMMmFNBtMJJBEkE8bz/g3/PgUOH+Z7vfgkf+9itXHzxFjafvbxdWjh11Km4DyR7F43HRdSsSyBqYoB6puqB/atkkbLOx9DiS7VoBNk+iplqW5Cgnvf8zqd529tehauLHkdpDm/Ly6xPUkqo7E5F9Ty0az9fvOFr/MAPvIJ+hHu/tpf3ve8GFEddef7LO17Jhg1TLcgFiaZR/u66+7j2k/fgwiJ85fmVd76UJZMjnJ7u8eu/+RlOHeshSXnlay7gu67eQd3xvPilm/mZn/xLPvyh/8T4ZN0ygRfaQltoC+0Z18TI/5LM8UAlO+DIsIDtUJIUW0MCubzYmmvXW3lWcIKjyb+tcgkXDAQP88ZDGfmid2PJTFtb9ucjMUVGR7sYVTcRc1QugKhHJA3NRK4FvFWGuQh2rAEoUZzKUp5TBJWsuVPK0YQsN18sjaVlsdmvz2Q1pAzqGzs336YoPPTgXh58+DGuvvr5Q0UltLI0lRgQgrg8X5b538opioaFXXYpkPD5rpng5N13HOCxR0/xyu/ebmvSUlJRWGZlUSHfnsmcf6r9cxgKAfhpVb1LRBYBd4rIPwA/CHxOVX9TRP4r8F+B/wK8EtiW/zwP+MP89zdtgpJCA5UFMM5bpjRXF9k2Qhaqs97pvVm4FaROdRAApmh0GckBr6jRhVUjOOvMhY6aMIooWYTOe49iQU1IyQL8bJuIlvoazfvQDDzmWvYYM6XcPtdcOgGpzXiXl7EEj6pKL1volc4rzujoMZl1lVfLiKu6XI5hJQjiHM7X9PsNMdj5xqjM9ftEoB+jiSE6QRx4qVowpOp0cL5m3YYNPPjQbqZPn2bRokmqqubgoUOsXrWKycVTdvy6w+zsfAEDsbpiywO67FgglaczMmo6Fr7CiacX+8zMzHLq1GnWr9/A5OQE+/fv5/Nf+AI7Ln4WLlW4qkJxnDhx0hw0nOfk6VM88sgjnHvuuWxYv4GOr7n11ls466yNHD9+nOlTp7hgx0XElPjyl29m9+6HOWf7ORw6eIgVK1awbt0GenM9Ku+oqw6FGmUimgnvotlylqC+gA0ZjRxk4AcB9WBOyINuZgZEbdpAvfKV6Q5YhzTUWsNQ6YxQ+SqzXoqeh5UuFJeIlAUfSw2Z81bGUKwoyQKkKWWhSky/w0rNCuVucDwgsy5M4yGEDHgJQ4BF7pkt64EMhrisn+FaIKJca2FklHdPk6HgLgcs3unAijXleuvatCbmej2iKiFDzSFGYkj4yianpNaPi/uFIszOzVnGXx3z8z0rhxETm2tiRLwznQFVQi/k2D0LMkYhNkpdScsQKfe/LflQ09Mw69EsPpoUXzQsnMepMDo6xkte8nImR1Zwx613cNaGjWgS9ux5jLn5aTjR48jhI6S0Gdpn46k8aOrn9zuzrVKeoPM4NTc/T53rWJyvWrDLe0/TbyhTfafTIYY0KIf6NmynTgV2PGsdP/pjlyKVkgL8n//947zwsk0sXjLWuhS4iGVhPAQbTvEKLuvoKRBzkuXwocjevU1eiAyiccGCeQTe/Z6fonLCfAO7dnk2niWs3wyV2LNMIdP6HbgqB+4KIRrw12AlQaEBElQenB+ATTZ2ZMcBBXWuZQ+k5LIzjRKTECMkFbxAZWQE7rt3miZYORbQ0kMliY0hAhqFEGxBJ97hnRIjvPt3/47f+90fwleOkJQ/et/1vPu3f8De2fnIL/33v+YPfv+NheCAiHDy5Aw33rCTd77r3+NVePfvfJnfe88X+MWffyXv+8MbeMO/fwHnbFsOCX711z7Oxc/ZzOq1i3jzj17Ovfec4As3Ps41r97UgqsLbaEttIX2zGm2Rjl2rMdf/c038BqpaUjAJc/bxLMuWjuUTFCSGOjc8hLajH8Z/VKuaHMcOnya/fuOseOis3AutuXU5K2Hw/CBla/LgIa2wtaqwj1f28X//F+f4F2/83bGx6oMYjjKmTnRQflaZrcNCoJtqyGfHDuDM1gJirEABmB+1plHEY4fP83uPYd49sWb8BKQtowrtd8twL79ce36PCXH17+2h1u/fB//8c3XQBJuv2M3X7tnPyCsWb2YV77yAnwV7V5KQvGEJFx37b3s33fS9iPwqlc/i9Urx1omSYzCzbc9ysUXrWbReIfRkS6/89t/j3QDV19zQcZt8nWeITy5wE54qvZP3hVV3V8YBqp6CrgfWAe8Fnh/3uz9wOvyv18LfECt3QpMiciab3mMpMTQkIq3fa45ct7Qo5gDmVbMz7lcNqCt5V2pJ7YgKhEJraOWy4v05My2TjTgnQWW5VX2VY2vOnkh6jA6exYKcR5xRuUnI185MhgAHYD4nPXK2gICVK68hnYeLovu2YsSs7Bi0YOwoE8qY2E4J9QjNVXl8VLlXJSjn+vNRSqqusOyZSvZ98RBDh48wrHjJzg5fZply1eQ1GpcNTlQT1GKjSHSm+/TqTuMTyxi27Zt7Nq5m5MnpgFHbBSSlZCEoEajxbfJfdShSSzRrw6So+knYjTELwYLfOuqQ6czSl2PUPkO3nfo1CMGEyVn+4mCRIEAsW+1S9okjh06zqKRRfjkGO2MIupBHZXvsGhiipHOKBPjk0xOTnHi+DQaoDfX55abb+X+++7n8Uf2oiGhwUQPVYWouQ/FxtwbkuGmFMCGMwPxtoyhAExNMGFGtRqvUgKQV9etPaT3nsobrd8JLduguITEGImlBCIlvBh6WrZzApV3OZg1QcWybcpuDU3T5H6YdR1SJGlx9ZCWEm+0eGldIJzzeO/OEHsEK0tIWsqCKpyr8JWBWk0IQ6wLO14IgailJENQNX50fz7QBLs/KsYaau+sc6xcsYoH7nuAQ08cYu+ex9AIy5auICWIUWmayPx8nzKIi3MsWrSIBx58kP0HDnDkyBGOHTvO1OIpunUHUXh072OcnD7J43sfo+5UdDtWyhRCz2rGg+KpOcOXvlx3slKGEExjAjXdDI3mdFKAv5TsHqQY2f/EE8ycngGEffv2cfDgQURgZLTDqtUrmJycACJoMGaU0i4G2rp5sYlWfLEQtTENMYZK1ISva/pNQ7/Xo4jMtqKbXjLA+q1G1n/FTSKuCnQ6jm7HM9Lx+Oy5OjPT8Fu/9Sne8+5P8mNv/Z/c/8A+pqfneedv/DU/9tY/521v+wghWWCeVLnz9l382I/8Gb/y3z9rjAQ0g8JWSqEZcFaF9/7+J3AC7/rtT/DxTz7Mr//mrfz9tXeRVDh8/DTv+PkP8tYf/SC//Kt/RxOFm2/Zyee/8ADX/v3X+dE3f4j3vvdL7Hz4MD/+Y+/nR/6Pj/KB999SkkrYSJNlpRS+eudDfO66O63sTYUbbvw6t932ACkJex4+wo+/9YO8+Yc/xmte8z527Txkc4pzRBHuf3AvH//kzUSE/nzk9373b7LIo/D4vqO8/e1/zlve/CH+6A++SIqOj3/yq1z1ikup61xvm2whV407umOOTtcxO9fn1EyvMHcBxangkzAy4hlZJHzvfzifmCAa6kqnFrpjjtEJEMY5cqSPkqh94j/98KV8+rpdJEnf/DkvtIW20Bba07lJ4uixWW6/9QBbt61i6/a1bDtnDZ/427s5dOS0JSzVo6kiRY/m8TwlSEGIWoJwzclMT0zC449Oc9PnHkE1u/JImxszQELFfHYUYnLElHXOhHb/mgSNjrO3n8X3/cdXWUmxeHM6axzEwnW2+S4qhOQIqWgOMHTQzOwdAg3sVw5Vn/eTsqaZxQrR8nQc3H+Kz1/7oF2LVCQ14D2pQzOYoOSfk5WWl+t9Yv8JPv13d/DG7/9OfO3YvesgN920k3POWcu2bWs4fGSOz/7D/bQ2mdlp5/rrH2T/gTnO3raWbdvWcv83TrLn0elMWDRtidvu2M9P/uQNHD/ZRwS2X7CM3/2ja/ibjzzA7OmQS4hTZnUMsUAWKHVP2f5FGgoisgl4NnAbsEpV9+dfHcBKIsDAhr1DX3s8f7Z/6DNE5M3AmwFWrVyOWbgFOr4yxMy77Jbg8B5iDPgcKFlZhAVKIG0tuGDoVGGnJI1459FG6aU+deWQEFFJ9D04X+FSrqfRROVMbT2mhMZcOxvAd0yM0VTxLcNUMlaGQFhW2DnLNkr+o0ktw+8GgWESSCHgRAkxW1+FYIGXy9JZTogh4sWh0UIynGVPR0dGWLViRQ5yTC9i06aN7HzgAW74/OeYGJ9AUdatWWMsCjUgI6XQChk6Z+JcGiPEyKaNG1m5chlNPi/v4LHHHmHL5k30e/NMnzjBSLdjDAxVBlaUhknGGIhNj97sjDkoxMTRI0dYv2EDGiMpBqrKU4YuJ1A7ByHhndD1nrmZGbre41XR0EBoCPNzSEr05+eYn5kh9vs0vR6Ti8apciDWrSrm5o2NcN72c1mxfDmLJid58IEHeOiRB/muq19Bt+NovDeKlwpevbEUcn8KoRnUpouxEYqK/rBeQVJDab0z0ESHMt0hBHyr0THI/KPD4jUWxFhtvyIaqVwu1FJphR3LPkWE2DRt2URhFaRkgWWKBpBYkCmtRWUpXRgua1AtP5P7ckKc+RBbtju1ooROQJ2VB6Smb7aYIVBVdS6fiTRNv7VhNSqCsypt5wihz9xcwPchNaZHQISKmq0bz+YbX7+H22++hbneHBs3bWRy0Xh23lBOnjzJvv1PsOXsLXQ7Rulft3YNd6bE56+/nqVLllDXNcuXLaVTV2w7+2xuuOlGHt/9OB1fsW7TWrrjIwQCTeoTtEGwAL3Xa3CVIesFhBzITWjWiYBKKpri8qGamUdQ147pmVnuuvN2Hn5gH7XvMj4xyoqVK5hcPMWatStYsXqSpSvGSKmHiN1TAWNcidWzh2SlUy3ALyZ26V2NSwG8lQIhQ6UoGQSKVYV43wJEQ13r26pFKm66ZRrHrdQyj6pj+fIpuiM1cz3l89c/wu++53t4+9vXcXq2x5/86bW84Q1Xsn7jSv79v/0YX7n1AM9//mpuuXkXOx98lHe/5wf5hf/6tziN7fvYSjJKdggKFY88MINX5Rfe8WpGqpt46cvO5aKLV3HwwEn+4i8+x8/97Hcz1h3htd/7Ee594DCHj8An/3YPV129il/5pdfxwz/ytwRtePfvfz+PPnyMj370jsyIKGVxGPXUCYsWj3PTl+7j8hdchNSOr3/1AFe9Ygf33neA66+7h9/9/Tfy6GOnuOLyP+DkdHFUMCvfU9OR/fsaJEIIsGv3HEmFXbv288nP3Mo73/Umpo/2+aEfvpZXveYUBw5Oc8klZ6OarR8DmP0p1MCId4x2az75yXt4wxuea+V3CpIUSSnbReaHI4YXN6JEh5U3pcSlz93Ku37rTj7wF1fhk7Jt8yTdatrm34W12UJbaAvtmdgEEGXDxhFe8IKN1B5iA/9w3X3M9yO9oNx0/b1IcDz44H6+65oLOXvrGv7+U3fy2MMn6C4e5T/8wOV0alspHj44w0c+dDtPPN6wYs1UXjUXzQIb5VUVjfAP19/DqpVT3HTjAyAVr/03l7Bh/RSHj51m984D7Nm5n2PHe7zoO89nbGyMkW5NUnhkz0E+/amvkah4xTU72LZtOQnlnrsf48bP7SbR4fXf9yxWrZkw5mYuYwDT67rpS1/jOZeey8RYFyJ8/nNf44UvuRBXOb5xz+PceN1uREdZtCzxfT9wGUWfKAG3fekBLjxvE4umxnjs0UPMzs1x/gUbiOrY9cA+PvvZe0A6vPq1z2bj+iV84cbdXPLc85mY7KIo06cbOlWXK67YTATme4ED+4+jucwCMR7F8YN97rz9BOvPWsILr9zK1+/ea5oWGHDy5Vt2c+89x3jZS1aYALcJzLH1vJUkHeVz1+/hdf/m7Bbgz4IMZF7pQnuK9s8GFERkAvgb4CdUdXpYfE5VVUqE+c9sqvrHwB8DbN++VUNMOA0E34B4o/w6W2xbRqQaUHRSajNGMS/2vbgMLBgQUIkzYQ8dBF8umJhhcmo18f1gmgj5zENvzlTf1SjPIUa8F1zO+kaxkgPI/vFqgX7KmgIh5mPl7HAWPTCAQjU7JxiTQVMWXgzJ6rPVRBqzHrmJ9GF0916uxXWpYWzRGOdfcB64bInpPXW34ooXXcETe/fhnWfdurUsmVqc77SdY4XR8ZOYbeGiyQmWLl+C88LY2Ag7LrqAg4cO42vPuedv54YbbuSWr9xCXdWsXruGycWLwCteBqKEMZpYooqybsM6br/tdnzlqDsdmtiwctVKNGs+OC92r0hUdWX2j5Xn5MmTHDpykLm5OY4eO8LSqSWMdCtEEnfeeTs7LrqIXQ89RKmxn+vNMjtv4oTOe1SUzkiHftNn5/0PsHhyMf3RPrO9GXzHNCGSJpyvENdBCUStMq2LNvhOZAHO7KwxLNxXqP7FRSFlBxLnhKYJrbaAZIpZ7t+t+KJ3Vg9fWAPmmpHFF3M5jIhpdJgOxlBJRNJsSwoFDXDZftJE/TIIkaljRo0utni5rg/JZQ+577b6DgPKWgl8Y4qZxWcuBPndz+9aoog+VlWdj5fxapcI3hBslwRfj6BSGb1fGySZONGiiVFe8uIXcXpmhtHRESanFufSEdNQ6Yx0mFi8CKky4h0To2PjvOilL+XQoUPUVcWqFSsZHRsjxMTGTZt4Yb/h6LHjrFm3jpVrV9q1JMWjiDexOlxmqmRKYQzBWCBZd8K7ipZ2nlkJRWfDZCnM7nG022X9+nVMji5n/ZqzmJycYGJyAl/ViFMic9Z7Sh0AACAASURBVG2AKKqZuh7Bu7bcQvKk5LN+SwGMVJW67hAIZpmalNA0dDpdnHN0OjW9XH4Vk2lLfLsiCiKBs7dUvOglG6mdiW2uW7+E0bGa+fk+F164nvPPW5eD6x6Hj/bZvHkVovDDb76Ym754P2tWOG778kO85ce/k27X8d3f8yx27T5iIoVkvkCmj1pGKJNLXcJVDueVGqhUeGLvKa77zAEevv8z4BwnTszx2J4jqCrnXbiE177uElQTl1+xmot2bKTrHN6BkzhYsOTUvwkRK1u2raHXEx7dc4LOKJw+fZpztq/lgx++lfN2nEWncmzcMMEP/aeLSJmY6sWkvipMEDE4sCqMDih846tH+fx1J7j/6x9Dk+PIsRMcOTzdltcM8l8DVyLUgMeXvmwbvuuIedhwCJNTY+y4ZB1v/dE/B/VMn06cc+76zKWz++fVYI7nXLqCr9z1MEXdwsDuZJmlkvhZaAttoS20Z1JTjybP4SPCgzuPUrloy25vDOXYS7zz167lLW+5gue/dDtTyxbxqU/dAipc/uJzeOdv3MZVL59l7YZxjp2Y4S/+4rO85Mrv4Bd+/lNcte4SGxq1zA0BsphjSo6//NDXOf+CJbzs5Rfytx/fyVduO8i6NYs5enCGd/yXv+SXf/m7Of+iRRw+dJqdu/Zx8YWb2b/vOH/78S/ykpdeyhe+8Bg3fP5RNm9ezkO7jnLTjTt54ZXn8pG/vpe77nyMV1x9vpVip0Lzt0H69tsfZPmKZZx73npmpvv8w3W7uOyK83n84WPc8IV7ueLFO/jERx7kf33wHr73+wxQiJlV8bnrd7Fu1WrGJ8fY+dBhDh8+zvbzN/LII4e59trbeNGLLuEzn9nDTTfu541vnOLGG3by3t97Aw4lqBBFCT7ivAHaE4sqPvCbN/KaV13EkmVdJLMkXv6KLVAJv/euL/HBDzzAlrM7XHjBSlxyzM0HvnjDPfy7f/ci/tefHqZWEzVPLlHXjle/7mxD1ZO3uslWa0Ep+gsLE9Y/bv8sQEFEagxM+N+q+rH88UERWaOq+3NJw6H8+T5gw9DX1+fPvmmzpYw9nNA0OGfq6prtH1PC7OoK5TplOen8PbNPtCxzoX9DwiuIVIiDWp11hKpGNVEnl4MtSCnXwYsQmn7WJrB6cJyj6Td0RkYpVo7FyrIwFIp+Q0oRx6BG23kL+IoooFnnhUz1yY7UTnAOfLDzDVl13zJkRkEXZ3XULiUqX+Gxz1Iyu76qqli2dClLFy+hU1ug58XRNH1bBJuiIJWvsv2csHLVapYtXQ4CvvacvWULW7Ztw1eOTWdv4rVTi3FiGeix0VFGR7uWHS+U+giVt5oS5z3nnXse46PjWQNAWbZ0BWtWr2Z2boYLL7ywLQEYHxvnvPPOs+Au15DXVYfGB+bn/2/23jve0rO67/0+5d3l9DJzpvcqIQkV1BAIhEwvLjg4sWMH4twQt09ssB23xEkcx1xySQik2DfXn+uA4yRcgm1sYyTAFNtIAoGQNOplNDOaGU2vp+z9PuX+sdbz7n1GOIbcT25kOA8cnTn77PPutz7PWr/1W79fD4yh0+ly/fXXc//99/Pss4fIOXPTzTcxMjbC6OioCP6phePaNWvJxtDutOmOjHDk2DHG4hJTM9Ps2rUN54T+FGKgjjXJijdv1glE9CWcAiSpqVwXQGCgSWiaeytnq/aKA3Cp6BfIDZ2XgRBG9QcaVX7nSPpvowrBJplmW1hDvw7aSWEIQVqBnFozin5I0Q6RzywCoSLcWAALfbIU5zD6Q3FQCSEsYzUMQA9J0Eo7UdEryQrODZwv9HhT0sdRUhBvLN54TI7aImJwDu3/dqxbt16fnyIcqs4nQNVqM7d6NQaoez0qLw4eGzasY+1aIUE1GhRJrtnO3dvZUAdsu0Or5an7fby32GyxQaqk/VxaGsQpIWuLh8PqOa6x1uC8MIukfckBEZMyqQ64yhGD1K0XF5c4ePAg/X6fOgRp1wh9Iotcf/MVXHvtFXJ8yIkXbREBRJ2viOV+kJVW3JGU45di0XBIypCJ0vaSoV/3Ra9FTsR/b1r9lh6WxOb1jmuuWYNzEmQVVwO51xPWJsQpx2CRedGYzJYt4zz0QGBpMWBNi6pdyaV2mWgzwUhVvnHzwwp10wLWqkq0MIuysiBzhO/+nqv4ez9yCzlBNKKPcOcf72PL5hFa2qKyaeMoLouhonZVoDm7ClcNCJW4xI/8xBv4+Z/9KN7W/NN/9rYh7QcJMLttx6aN48IYUyCwabHR5z8HQ0pjBCBg+Dt/5ybe+Ka9kHU/PXzx7kNCg1XgMjtIZkHeYKAfIn/y2Qd5/wf/tjz5EcBgveX7vu8m3vbXbsIk2L//FB/56JfktCnbAVXO/ve/cQc/8WOvlQto5HymLADfSs1nZayMlfFXbyiT1WSeePIUv//7D1C5BciG173xRaxdM87SYmLX5Vt469+4mWzh7JlFPv+nj/Hef/G3MNbwslec5Nd//S7e/TM385v/52f4oR+6nTVrJ/ln7/lOvvCFp8kKvBYZ3dKImzJ0u6P86I++lpFRT69f8U//6Wd461t2Y5PlDW+4mVe86nKqDH/+ZwcxpkWd4f0f/CQ/+zNvZtXqUdqtNnd+8lFySvzar97F7p3r+PSnn+KJx07zuc/fzete/48xVhi1QrGUo/6xH3sr7/7J3+L9H/xhPvv5h7nxxh202xUfeP9nec9730pn1FH3I1/ed6gRNDcKIqfsRHjRQMielFsQ4X3v/RTr51bzmU8+ySP7LvI7v/Mkb/u+vc2aJrnUEPacRWD5+uu28ZLrthJDadKQgvPRI6c4+dwxPvbffohz833+r9/8MqdP9xnpVnzoww9w441XsW7dDDHOEHqenCzW6jpqpDAtDFZL0cJsRhNP//9zl/1VGd+Iy4MBfhN4JOf8L4d+9XHgbwHv0e+/P/T6jxtj/gsixnhuqDXiLxzZSDIttm+ZFMV1oekVSnIFjUkN1bwkt0aTrKRiapXzWg0UwauYA5ZEPwf6MVFlj7NtTnXbzJsAVEJNN1Yql156maWy7RobL+MdtHQC0TYGYzMx1lLdjRlnvVhOloQum4Y+b62FKjaVcWOhToFejByzHZas55kcmYiich9Twvu2JICaXMS6hpa2WDiHcao3oV+S7AnjgVYbkKqzMZJYi/sEmC5Nwmq9pd9u45zjuG7DbBpvROPOZ+knjzHh/cAlIKloShGXzHsvF9p/NuRkOAD4iSnaq+d4NiecN8TWCKMzczzXass5G51g2xveLL3snTYH1cbGXznJlXtfhNWfq6ricFXRueZaMJYDVUuC+V17iDnzbLvN+M03002ROou95qK1LFpDto6etZxseUzq0U81nVSmZos1VqvGNEwSUf83CjLItRPLRHEEiZGm1aaAUeJ2MGAXmKHE99LXMKUVZeC4UEYIqVH/N9Ak8XUdtL1hyKXBpIYu3bAOctkH2V5xbLBO7kUR+EzNPTm8D+VnowDs88QLKS0gBUgzZCtZnK07WCsWsC4FuqHHQtXhyMQqTKoFbIsCMMj+iICqJNm6H8qAyEmek5xysxiB2DyW4wwxNFX+kA0hWVreK/BVc64zhjUdsnUikgeQ7aCFJSWiAoFOWSJ1LW4KqdWW+UfPYctXksRlOHbsOI8++jTetnHG0VvqMzI6RkyRXrjA0kIt1HHnSQRyFjDRqGBsDmrjCkPtLIZ+rwd1IIWadsthjKWqKpxzdDodYgrUdS2aMlncbDDfniua1LxrqaEbgyAJaillM5ge8pBl2h1Lu8o89OARkoHDR86xanWXHbvmWPj9+/jC5x9l9epxnn76OMbAhfOLHD50EpuEZBrUaXFydBRjFtWVRYK8J/cfZ25jl864IXCRhx4/gk1w8OCzrJodAWqcSdgEmIynxhtxMMk2k02PpaWaR588RrKirG1zJpvE2FiLjZvmuOXWHdRLgZHRFs5kVk11OXP6PA/uO4IzhueOnMKa7QBEs0B2AjgcOz7Pww88x4d/63HOnU0kB+OzlueOnuGRx45Azux7+BGuu24Ps9MT/Mv33c2NH/lurPY5vPX7buID//qT3H77i/nIR77EO//uG6iM4cK5ed77nt/mF37x7fTqwPve9/t87/e+EoPhP/7HO/nZn5VtvOPtt/Cef/4HvP3vvIInnjrKps2TrFo9JgKyEY4cO8fc2kl9ElYoCitjZayMv2pDi0pEbrlpjJ/7B6+k8gpkmzKzZUwlLEmXjYC0dDFOWirf8OZt/N+/eZCzZxdZ6llm5yaxLmN8JmsLqtECzLCAozFgXA/vBCi/9rp1bNrsRF86ZzBBhREzzmSsxj0htynW4i+6fA2X7VkLDqqW47Wv3063nXj9G15Eq/uapn1A1ehV69pQtSy333Ytv/+7X+OrX9vHz/2D75W4Tc+INZnrb9rMug0tZfZpHAlgkzguATF7yJVYDudxXve6y+l2Pa95vaOqLG1nILWXOTZ6o24YKr3z1a8+xa5ds0xNd8UZIokI8759R9m7dwOdjqEz2mbrplne/a5P89v/5Tv50lcOc9c9h/jwh/fxwAOWZ5/9A975I1fxildcNsjZBgcjRpiFyr5MnHFlzRoe3whD4RbgB4EHjTFf09d+AQESPmKM+WHgAPA2/d0nEMvIJxHbyHf85R8hNRnnHSGGxm1Bkht5R7FaSSk1tnmp2DnmoeqMIl/Oeq3yy+adszjr8f2AzY7zxvDARMUZ26aVnCSueWCHMowF4hw5SdU/K1tCWMuqqJ+jMiekOmadJCkpqTJqSSJBe+ZTYwMYcqSf4eTIDPNYznct3YxUX7N4hfssFZ5sNCHRPiBjLbaSZDjFiLde1fY10UsCREgCSZMUGhAwApqqNFZUUIudGBmqqkWMUS0z66bKWqjuTV1pKOEsLcjO+qGENJJzxNhBclsq4GgFtqoqTc4FFfROxC+FUq/XxtpGvKU4esSYtKUlS5VRy31VEoAlGghWdCEOj3SZS4Zk50lhSdtWpCUF0EnWNMKLzqnFmiZ9l7Y+OO1lF0tOdRmBZVX/AiiUfzst1Tvj5NooGFEAYLTqTgF29BwZI4n68L002CdBU4tQqdwjDLErrLQq6Lku169sx9oBK6Ouha1TVS2xS20ABxBhTnnWTGm7MIa+dSxYi01tMAHjA4sm0u7XHBmf4onJabxzInyYhRVSQImysGW9R7O2G2VoGBLDoEaKUcUjTdOOkEkQDA6vvsuRxBLJVoyEivM4JpyjSoFkhAlRxA1jijhTno3cfM+anMopshgr7B6DoeVbjI2NccNLbmb+/Dz77n+Ia66+BuMsX7zns/R6PWIWq1dfiWtEJgsNXZkgzjlSHcRqNojYZwgRawLeOfr9QKdd4ZWdFEIQABWZx8Td49tXaXjdugle9tJteh8MWUJZ6HQ9b3rD5Q0ItXpulDe/6Tru/ONHyN4wMdvhHW9/GZUx3PrK3XzpngMyp7jI7bdfzpnj5/n0J+7H0CUbqJ3Ma9dcuZHvfMsVeAXbXvrSHfz5nz7Nuk0drrt+NydPX+TOTz6MN5ktWye5/qYreWr/YWKQ1ptsItdcs5GJ8TGSg8nVI9x62x4uXuzxmTseJNLCRYvLmWj7bN05yeYta7juhk3U/YjzQjV64+uv4qMf+wp3fuphbLDMrBpj3cZJrIW3vPVqsoO1m6YZnRjj03c8zvo1LV7+8u04k3n1q/byhx+/n0998hGsi1x11Rou276Z3VvgYx+7i89+7hFuv+1yjM1c9qLNPHDfSe6841FWzY2ybfssNsOJo2fYuGENruXw1jAzs4477ngMLOy9cger147jDMzNjXLVtZv49J2PAJnbvmMPviPXKpP5jf9wJ//ol793CFC4dPxFgVt+3uu5mTWW/60pi5lh2e/zsu1dWn36OkGiKTHI8D6UAD8PEbbMsr9ZGStjZXyrjyjxWZmFDJIfaBIsqUIcVPkzYJJoxCWNN4lMTY3SantOHD/P+nXjkBLWKqs1ecHMgVSKLkpCS0np+tmQcx88JJsRa8Nio5hxOeKzgB8xZ1ISWtwnPvnnvOa1N+K7F9h12STjXdF3+oM//Bxbd7ySmKUBLpObdkCL4errNvFf/8u93HjDlUxMdIQlZ0UsPAUR7LVEina0M7npbstJRNj/6OMHeOmNa4SF3Vpg22WzjE20MRHu+IMvsGf3yzl/puKznzvI6163BQtsWDfB0tI8J07PMzkxwp/ffYDbX7UH37L0+zWfuvNLvO6NtxBtpLaJSMYl2Lq5zXd8xzqcg//wG2/GkKij5R//8h/zI3/vDWzeNI5ovDlMipiGphjBqMJ/M/K3bTHnvzf+UkAh5/xn/MVL4+1f5/0Z+LFvdkdCzmo6IvTgEAOVBswpSABurCZRRqq0rVZbEqAYyCk2bRGpSQycoHskQorEOgmCZTLZZ4LxrO3XbFkSoa0USsUTQGzrsgHfbku4mjSJVotJqdAKglfo8KWNoalEU/zskyZLGdRmz3lJLhZi5lQvcbhVMd+2zFsPzjfCotZo/3UDS2olDoNNVpMtTy3cKFK2OGOIJgqDIUFWupA1A4lAaYdAZr+UG+tBjFDX65AUKIlgHdkaagV2YtZENReHDQV1bNJnTenaquGQs1KElbNbaPiZDNbRS+p2oZ68PUyjEWCs7GzKhaXiFAxAGtWWHYMjAbWR/t9oMhERDltK6jYQEYq7E2X9pC0hoDT6kPBWRGisdaQ88JwtE/kgyROPeoyg0iFLRT2koAmf1SQSjHXElHVqlkUA6wmqtSBtAFbPV260Dor2gtz2sbne4nQole/CgilsiKYtwoigX2m1sQ0wFfSIkib4Bcyx2jbhRCg0i6ChMQ7TwMRqEGksKSaOTq3iwfXbmKgXcblHtGCjpZc9S5Wnrgwhg/cVkUQw8lyg6LmE975pxdDHrwFE0AU0Adm7cqvJgmwMySDWgRmMaatNpQcXqSs4sX4H1aEn2FD3IUdxEtGNCEsk0uvLebDOYKxv7rmcEiEnlkLAeS9aBp2KxaUFDjzzJM606Meahx5+SNgiBjqdjuw2CJiWEq7ypJAIMeN1O8k6Yo74Vgucw3ZaxFhTtSt1dUlUtk2KAraEmME4HBU2GuJi/+vnYd8GY82aKebmpnRNl2dXyyl0u57vePU1EuDoXHPttZu55uotjXK00yDn5bfu5mUv363g2CBG+KmffnNz/2k3kgSGtrwnc+ONW7nhhm3CfjFw2617eOXL98h7Jepi984NDSPJ4Ljyym2yMZNZPT3C3MsuxyTDu971erl/Ud2G8jkWdu9Yp7RXBYMtfO9br5NpLynDxQq49ubX3wBkNm6Y4Kd/+uWU4lKDPVl4y1uuJpXTZZBg2MMv/tKr+dQf7uOlN+ykO1GxYd0k73r3bU3rR3E+3rlnIzv2bAQL7Tb85E/e1tyGRs8tgHOGd7z9FpmvspHWXxIpG77wmUe48bqtTEy0NFFP6BsG17L599DPzQep16eqNQxGEWt2LB+X+oYP/03Z/l8cIAoGXsoaEQiIv3ml71jpq10ZK+Pbc1g6HcuWDV5aaMvcYmQ+r6xhx9Z2U+ycnG1z2217+PH/7UOQWoxOen72F17P+EyXzZum+Yc//1FaladX93nNG67i8SeP8IH3fZwcxpvoK5nA1ddt48IFx0/86H/F+0TKkbf/8MvBweiIZdO6DujMOj7uWLO2hfGZn3r3a/jVX/ldli46jO3zPd93DbZyvPunbufnfvp3BKUwNW//kVv5xB1f5Q8/to9yQFKYWuBv/MBLedkrXszYZOC22/bq1Jd597tey8/99G8Ta3E/M1ZYEt2uZeP6FsnAuvXT/Oo/+QyVyzx7OPKdb9oAVebdP/Nq/tHP/z/0a3As8UPffxPGGH7qXTfwWx/+Mje9fC2T4y3Wrp1gdmaGn33Xx2lViem5DpdfuZEE/PaHPsmpExd57Rtv4U1vvoZ//8E7+IOPfAUynL9wkV/6J98lxn16RD7Bto2WrpwqEo75XuDLdz3OL/zyWwgkPE4FhyXOlyLYpevLygAwOf+vj0h379mVP/jr/xJyxntLjhHvKypfIaqiUoXPmqyhFUVrYWlxiaXekgigQVP9q7zDukoqmkks70K/h3UO5yvO+or7plcxt3CBvRfOYpK4KjitmMYYiIrIuarSaEqi0RgHSRiIIGTx+LYYtW2RPnpvnIAJqrXgnBOdBmNwlYOcqUNioao44S0X2i2S89KDnkTMzzqH944cA3Wvp327EqRKciKCgN4LcJEwVN6p40Igx6QOFU4EEaM4BUS1ySsaANZpVccIjbjyLXWcENZITFIlhdKfbwTNyxmvxxKCJFVF2JA8cEEoFfVS2Y8xEkKg2DN6fU3AI6sTsKOqJNnuKd29qlp4VwHSb55CaQ/I+JantgYTkwjpZQEUgjM8NTlJ6+J5Xn3yBK3eEimDc5UmspJIhzoIiKOaBYJTCOOgtB4U4U+gabtJMWLVwjFnFY0sirCaheRybhUUyIhQYNKWlEuZECDtO/I5kawMD3JuGDGyX6IdIkBVblgUSdsKnHPEUMu1NhBSoOhheK+CkPqZOQsA5X1FSLERoSy+wa5kJvp5IQSeWbWWr67dzNozxxgPPWK2VNEQ6z7GZ3o50qra+AiYTF0cVApjIyWcrwjKjiitRyQR4iwLmSIGWOuoQ6COAYuc+2yVsWMcOWYgEXNgqVXRW7WJNc8+zo5zx/BZeu2H2zyytoA4r9fcQK4qHlu7jVOLfa49/SydupZz1zM8tm8/n/zEnxAWa2yyTE2votfvU4clVq+b5vbX3sqmrXMkllCuu96vYsGJFd2RGBI2J2zscfzw05x67mksi1gi3ltcCthkqPu1tjfARSoe2HA5l+29HP+5T/Puf/V7tLqr/6fNzSvj/9vIzX+j+nbbMnNo9cOCMiwkF/1GE9JLq/FaSdH6EeUzSJr4XlrBL/V2o4lyJgbLv3vfH3Nh8Rw//w//OtigQKWVsDRDU4P4RnaziS0GolaQ6deRf//+P+T1b76ZnXvXNGn4Ml3nPNi3wfEOMwKWAwq5YRXEARLTnCahBA8Of8gDXs+TsCYagQr5G/3Mhpeg25D3JgZgRpZAMxfRMv2glQrWylgZ3/KjMGlJQ+wEE5WNUOI0wEgck0mEZMlBZzUjdTFjxWoxD+o2GI3JpZqSyzeyFR2zd//93+U9730znY4UXK1KP5mCn6q+ELEIe2eigRgMRQbOWLBePjdFmeYMkCt9rS5uWLkB3a01GFemyqwsBGE9xDhoUbdWAGYHwsbwEFNGSbU4wHnAyXoU+wLg2wyVATycOtfjx3/8w/z0338t1123CWMyIRnqiLR0GNS9CwjIefe5aXvnEuzZuoJ/CEPEJMDL+hmz52MfvZvRkQ6vfcPVDbNXycEMIdrftvP7S17yEu69996ve/DflG3k/6xhDLRbLVIQLQKjdHyjyQOlikxJVEVIEIqgm20YjSYlnPNigVeS5iT09RKUp5ybhK2ug1o0inDfmfPnGR8bFQq4AgMh1DoZaEtBlop71oRrcWFRkmRv6Xa7tFotrXRH6tAXCrl+dkkGS9KdgbbxVCHSrnvE3gI51EIX8hXWt+QJyElYFHXQ5FH+tqoqeVZMUe03MilYxBYyF8ZASVYHYn0xBqy1VJXXRDg110SoTUYEELWfKIQ+jTd7zqQIXmn2zqsFYy3nJ6UsWhRSim9EBI0V9kMBJUoffpNIpij2ltpKYK3DerHay3ruqqqiqlqQhS5ujRM1/MqBhWAN5ISJEULC+hYL1rJkHQuhL+q7VSX98mrDWCj/so/CjpBkX2jpDUU+RpzzKs6YxOjDCfARCziS0QS8UPvFwaCOQUGJomFgwCZp5ci5AZ3QezkjTAoQEKAADkWoUWxJIXvUZjUJwKKAAjqhltaBUNdEsjIOGOiOmKIVIAl10uvrrCM7aaWAwpRIeu8N7kEf+0wvXWDLuTOsrwMuyr3Ti30SNUmPv5UtmEy/7jVsImuMgiSFlWEHLUwxUFVewY6sVpVeAS95f92vaVdtYQeooOJCvYQ3FhPgRNXmmdk1KoLqcENzSSOkqhasBqURpoSp5B406qqQcyIbEePctn07r3hFzfzpi3RaHbZv3w7GcPLMCSamRlg1O4VFGBNFJDBR5iBPiJFQi7aCV30Imb8yKURC7pMCtK1RzQnV80jKtAqSNHW6XZZXWlfGC27k4X8MV8ILT6nMhgrmfjMbHc6Km/5OO/RaqZQNV85lPwap+yBAMsbw9r/7KpYWekN7MxCfVQpb8/6/dB8bxclSzZG/cc7zg3/71UxOjw69ahqQfFmlP4NEfOX18vl22fEP9kZeb/CFZjPL2QPLYsPh35VougFo7OCc6kZzAW2WnQKrvx5c52/PcHNlrIxvtyFzXbZDWljDmKJTFbZsBUc24G0itqCYEwuR10mo7/S1PDRrWzC2AJmi6xZ70LJnca2E61isAqNGxeSXgbHONJpojqQJdG6mOqs0u2R1psyGTJIpv22ff0w5qwOSZP8ZAVCsZuvSeiqaCU4PwFiRTsYmTCspd7vMlDqPtzIRae0UZ4vM5FTFv/u3P8gv/cyHWDP7XWzauhrjEpUz2mZiMQU1UPFqoe5pXOwKMFzg4QG4bAsmrMvPuZMXeOSBg/zkz30XGGUJD/au2U4ZK3P88vGCABQA0ERSKqfaGz3EnhBUzKFqeNLbby2tVrthA1hbkmq1z8siZNfykkQ4in0f2MpJsmotzlp6CwscPXqERx9+mCuuuILNmzc2lXNn1F1CE+VBn3rm8LOHeeyxxyTJIXHdddexZvWc3Ig588zT+3nqqaeYm5vjsssug3a7OZYTJ07gnGdmapqYEzaLcEoIUonPUczAnK9IMbHY69NfXMQ7T7vVltDFpYYqXwQqc86KyiWcQc5pFBHHynnqWEvCqG0BFmV+igHGLQAAIABJREFUYJuKNFgBExo3AUnw5MGLTXXZqKUY2vteeUsMEWsz3iIMETLWDERZQggiNue1/9kYYpQJzmnyCwlfWQ0hIw6x1HQWcQ8INc5aWt7Q6y0J6JGEiu+SBs2pluMJkezbEMDQps4VPkW1PjTUOWjiLvaBwk7QtopkMc402g8ppeYciVWkFQcEdTOoa2FitFotnHPUdc3S0pKABqgLg1pvFpCl3a4aUCXEoL1zwpiwCmTYbIhJ9QO0Em+8J9aSnJo4aA0p2/WVPN4hBErfsiTuRnUTpAXDKMOmsE4ajQ7QRWJIyFABvNK/b8hk7wlO2CK+H/FY6hRJqcY7AU9sRu6HFLEpyj1nZLu2PL+FjaK2pFiwOZJTxOaMSQL++corMAUt76l7fWEXZEMyWbcfhaoWEwmHsRUmu0YvQ559R85OWDwKlths8ZWjHwLCKslYb2TBRUCNZw8d5dTpk9gaUl3z8EMPsdhbIhKp4wJbd2zguuuvxHqH855eX5wZpFVJEAZXtDHIqqsymFfalYcc6ff72GxotzsN6FNVnla7I9v6NtZQ+Ks3SlMtDMIQub9Ka8Y3NvLQ16XX/xIafy7vMUPB5SXJennVZKxNTEy1GZ9sy5/g9c80gdZK/DcKYmWGglYKHCDtGRMzw2BC2ZkCGORlfzH4HUMgxRBw0pTzhv706+EeZmjbefgcKDtMr0/RY8hD+1LCyGEM53kvLEcpVsbKWBnf8qPMR1Fak3Nhc5bEVrV9YDB3qpCAdYGBNXEBECQuWg7IWsWGM+LTI5wxnOVtf/162i2xmDfZMqAmFLqExICFjYAWQ61Num9m2RxWojo0NxD2lha/jFavlCU2AFANpoDGWdYSr1uyCszqSgdkXZG0HViPX7aXG/5e05toJAYcH2/z+tdfxdmTF9i0dTVFNckWoFdzBmOinssMxgk+XNjBemzyPSI9xAocpwpjPAtLPb7/B1/G6GhLTbQKAK/n43mshBVIYXi8IACFclNJL6jQ3nNKWsUzeE3cSnXWWquV5dRUjlNKwmwoiZEm0sMq9s5rhVLv2RCLArunqioWFxd55sABduzYrolbEdXLhBywxjfVQu89J0+e5ODBg2zfvp3JyQkefexRHnroIWZumabbavPcsePMz19kbnYVTz3+BJ2qxeUvuoyMJKhPP/00nZEu41MTJAsGByFTuTb9EMjGUnmPyZ6Fi+f52n33cf7MGUbaHUbHxphZNcuOHTvIGGo9liKw51yxMhQmgkGqv6QoE4Q1qn8gSKDRyTCFzLPPHubs2XOsW7uW3lKP1XNzdDrtZvvGiPhdTpY6Rrx3DUNBKvqoer8hxloSNQPzF+cZHRnBWSvopXCwhN6ulXmD3AfOyiRqrKGOEZOTuHfkRAoR48HYShNRCHUfvKeyngpD7C/J9UVFKlPE1H1hP9QRM0RPK9c0JXHtUK8zAZ8M1P1+AzI45+j3+7K71khrQAgCsmiwLiBDqaoPWj2sNhdnBvMlaWAxmZO2aDRJr6XoJyR1+TDG4J3HGEuoh4AdtR9NJGGtZBVp1EWhAALlWfFVJeCYrnGyCIamtcNlSVhLu5BQ7XLjdgHC1ghRroeL0MJAjvRin6UYePrAM8xMjDIzOYbvdOVeSIlHHnyY544dY82aNezds0dcNqwVClqQlo4Uo9Kt5UQdO3qMx594Au88ey/by/T0DJlMnSOPP/UEzx0+zNbNm9i4dSsuC8cueoupPMaIYV6MfQGcnLQhhRCHWBq2uRet9aLV0JwvvS+ynLuDhw7w1a/eB/1Mt+pgMIQkDAlsYHyqSwiRysv5d87gfQtx5zDKKzQ4/Yq1WFm2Wy3q5Mgp4I0RbQV1xOj1ejhf0W53RIhJ92VlvNDHcIZrISsjwSBteiY3AZqRrPYb3KYGnMsy3OEqvASfgx7/8lrJuoeCW92HEjg+j9q5bHwzWgFF22L4c+VfzhTQcjggNAzMM4dDk2HA5dLv5ceyX4UdMBAXpjmvlx4/8rlDqt1aQkBCYcvwbwy1/u4v0npoduYbODcrY2WsjG+VYYwbzO3lOwXHVY49Q/0EBJ1rWpdsSL4tY1Q1c5sFfInoMN5y061XSLGuaTF2NOJrGIoYj9HWS5mlEplApsJmbfEsbRmUmUzWq6K9lgkYVLvNoFpnMlerIaS832RMTtokV45BQQ0FuTOmEXcUIGEY1DDPg6sNGW/gjW+5STS3zAAWEEB+6JyZsm5o34hpVpkB9qNQxGC9KafasGHjasraalFxbozEkGYYxP7GgfVvp/GCABQADZzlrjbGYp3WVPMQ5VcrryFIpdx51+gYNGr6trg8WHIyWJuwiKVjIlM5R47SFoG1WCcq7O1Oh61bt/Hw6ockCU+RyreIWo2WfUlNa4GzlqXFRY4eOcJVV1zBxOQk17/kBk6dPkmhhV48f56lxUWuvurFrF69Cl+SFwVBlhYXaflKaORO7MKsQSuVQcKqLI/D6OgYV1xxJYcPPsuxo88xN7eWqelpQlD7PeGAS6tB5RswJObCELAqpAhWE85iNpkAUiaGQIiZL9/7VZaWlpifX+DY0WOMjY1z8y0vZWS0o3oDijZmEdA0yWBzpVR+o5V1aQPAisDhmTNnOHToEHt276ZyfqhWZ0TwUdtThEGV8V7AAmeKnaEjp8SBg4c4duwYM9OzxJSYmppi/br19Po9Dj+zn+3bdjLSGSVmSMaKBob1krQCmUjMYRk1raC9zgmYYc2gIt9qyXEV4CqEwKBqjyT1Se4vTGEgmObvCwhmlMZPTljrwViiajNISwFEpfwPAI7nJ4xZafHOGRXslOsu7JnBe6y16hQi4p9FGBJEN6Kg4MVmcuDkkBVgMmqXCjFEcUNQDYlLj80ZiwlSeU9WPOuPnjjGg/v2sW3zBmanryRGuU/PnTvHE08+RahrDh48xNjoBDt37RSgKCVZorL6CRtLHSILiws8/cwznD59ltOnT3PqzFle/ZrvwHrH8RMnePqZJ1m8eIEDB/dzYwjs3rYdrBUkvlDzQlQwxunjqaKhMUpLlFW02mjrTgyEGHSx1ePNmZFuRwVBM5u3bGHX9u3SMkTGekvMNXPrZnT+SsIAUcFNg+hvZGR+Mno/5JQ0yTJk50j9PtYJcFQAKWstLV9xoQ7Mz88rg+MbTUBXxv+yMZyc5wIo6lxgVA8F11RjvomNIjQ0X7bIACRQBxZbkmBPThrcLdsf/U82YAbuKuXnBgRZ9pmOb2xHh98zBKo0ZbISEg4C50xqgOUBMDC0rQbjKIHgIKhsNBcIQ+9v0FJdk0uQXKp/YLIEwfJpVtrIFGPIuvbK/4rHeZnHzWBXGATweSXIXBkr49toFH2BAS5Z0vYyIw2gRonzskiVU3RlhJUwmGubWr6h0d1pNliS7hwRQW2JW4zJ+l4jn1PAZjMMIgy5Neg8Xn5n7KDYNQwaW1PAbtlfabso856wIgbJeaniyzxpxdeqYSAYqxbPBUAvQMlgg7JEZbEPLy17VkX4S96UGxBD/p2zClCYht8wOJ7m5JfcUs9Rs96KAHk5dtssNXlwbcu1GnL/Gd7llTEYLwhAoVx0Ue+XixibXnC0N0mV7m2hiQ4udqmoiIuCukGglH5to/Deiv1hUuoxRYxQtpFywlee0fFxnPeEmKiUiSA3mtV+aH3kQmBmapqlhQXuuusubr75ZsbGx1m9arWIC9Y1Fy5c4PixYxgDmzZubGjzS4uLnD59moMHDjI+MsrWndtpj45Ib5VzRDJWxRP7i4tUHRGZHB8fZXx8hGcP9Vi7Zo7R8TGsug3kFJWdIYlhv9+n8p4UIdQB771Wn61S3aMed2wSUOstuRZ69rXXXsOe3Xs4evQ5PvGJP2Lv5XvojqwHM0QIVRtJSX5Dk2zmrL3/FQ09fmFhkePHT7Bzxy6cy1SVBqYFQSwJlpG+J4zBOAnjqspT15FQR06fPk2sRUDz0LOHuOeuu3nNa15Dt9th/1NPsnnjRmrvSNaRyrxhvfSnWUnsQwxk4xqXgqS6GyHUWr1WscCcG9FIabGRvwl5AGIJ6CoJacyhsbIsGgULCwsAVJXTlhQGSWS5l2JUa8+sTAgzdB5j0ybhnFDlnE6KWVkmIAKMIUlybAxNz71V/YeQaij3vN7vIJN1zkMChUkS52yHq29ilWqNIeo+F+ZPSoW+n+VeMglfORwGb71S4SxkR+pH9j/1NJs2bWLXrl3s37+fJ558nNVrVjM+PiYtHSlgncXYTB17GCwHDx0gG7j5lptZWFjgvq99jWMnjjMxOc7jjz/C1s3r2bVzO/sefox9j+xjw/q1jFSjkDPO+AY9b7c6xLpubD3lHh5YVwrgUKmQUGn5EPeWOtR4a1FME2sdmzdv5uaX3oh1kmyIo0nGtgBbg40KysjiaHUVKu0sRNHBKDa5KaYG3Egp0Ov19Po7vPNAYvHiRRYrARSCOnesjBfyKNUXrWo3NFajALilsVyA4UfuL9mehqpGRbdypun5L2/TEpnMMyW0HQpQ9d6UqtNQ4GgkWG0m5GWf+T8SRZmh74WJYRpQYUCdLWBCqYQVnu4gYB28r5yvvOwZKEB3gRrIIgjZVKsaYEHn0GV7WGpZ5eSVjSoSTzX0UWmAzRQBtgYAueSwV8bKWBnfwsPo/4fnsPLwD+aUkpAaiUaH/lzB2zKH6Bphls0nA9RCfuOGPmV4omlmvuV/12zNYIfTPjO0z1n1zZr9capjMLxdBQ1U30AovpesC81aUt5XfpEUgBgeoglRcorle52Hzu1wntic2mYGz0nc+6wpc/UwEMLQ8Q8OJ+s6VHD1skYIiWRwfaSYPACQcy4idZec+pXxwoDTJdFtYa3XyqkEEEkT+JJcWe07Hqa5QMZZUTAV+0it9lkDWlVwjSWgUMcxubHEGxbcwxiqqhKHiaqNMV5BDt9oJxTNBWssM9PT3P6q2yFlvvD5z/PE44+TY8JkuHjxIgcOHOCJxx7noX0PUdc1rVarqTz3+j0WluY5fuIo8wsXRcPAOpL1ULXAe5z3OGuIuSalPs4kDNIf7myGGEihT91f4ujhQxx65hkeffhhDj1zgNAL5DqyuLDAoQOHOHr4KE898TTHnjtGv9drqs4YEVS0CtrknIihz/jYKFXlWLtmNXNzq3BW3AkuXjjHqZMnuHD2HP2lRVJd461haXGBnCILF+ZZWlik7tXkIJoGJLkGda/Wh1WCyRSi9naJYm1OWeNYQwxR57osiVbO2AxLF+cZ7XbZuX0HL7v5pcxOTXHx3Dl6C4vEpUUIS6RY0+/3qOtAr64JOROTfJbNDofVz0PuJ52pikWjMBIEdIpp4PBQgurSipC1PSEPJdnOueb4is7HgFZfKM5SiSsWoilGsiaTKWaKk0hKaMVr8HlekdeSlCaVyxVGAiowaRuXipxRa1URCRWnlPIsDYAFMs21Am0hyihgAeixlvYLadFQE7WUyY2Yo4iHrplZxaa1G2i5FjFI0N9fqjl/5ixbNm1iYmyMrZs3M3/xIouLC9R1j5RquQ9R9J0IuebkiWOsnVvF6EiHVatmabcrzp87w+LiPGfOnGZuzRq6nS4bN25kobfIxf4i0UaSqQnUSs9zpCACqynJPJHTAPjJKmjkFNC0xioDBLyzVE71D4CZmRlmZ1czNjaO85aUA1mdGcr25dyqLoK2tcQofZbD9w8GvHfNwmitJjM677U7baqqIsbIwsIC3jtGRrqNaOwKovBCHiV5Hf45gUlkk0SaGid3nkGqMt/QMJd8HyTi5XMEcG8BTq3PI7k4I+QB2CA2WMXBobQoKKDwvGgp8/xj+u+N4XR9+Gv5sQz6eIuElx1U/pvjKoGp9qo9LyBPSkLwZJyGs47izpSzk4DZDALSXM57s7syHxvVfBEfdWgcIrK0QSQ9d7mhLQ/t4zd1flbGylgZ37qjgMcoeDrQU5DKffly8lVSfnWHoFjco0ktA2bwIIkfmmPljxmArsPz0LD8ofk6n28HM3S2zZ9mdQDKxgxtrUygg8+XeXTgHGSyHbhFmKxrT1p+DsrnD23VFLFyCuugAL9Nps9ygBnZrtFOZV3cTJbWC0NsjnnZ7ktwO7hGy34e2rYJFMvhBlIxMLCOWJnrh8cLgqEgwJBTpf1ETDXF9z6nRERs9TJCm85RknJfetJzEjEPI/GDM0hbg1XlfYqNXsJbT4g1pmpJMGVFQb/SZDKmJP09qu5eQAyrbgZlpJRYWlpi66bNrF+7jqf2P819993H6VOneOWtt9LtdvHes2bNGmZmZgDpOffe0+l0WL9+PevWrWXN3DRza2eJOYImlbgimicV9GCSJCJYnHFUrhL9A2NpVS1MNoyNjBFC5MK5i3z+T77ArS+/lW1bN/PkY09Sec9odwyTa55+cj+dVpfx8QkFXkRXIqtloMmGixfmOXLoMJ2qw+lTpyEa2q0OJsPpE6c5d/4cvV6fM6fP8OKrrmL9+vXc/+X7NfkW68WZ2Rl27dpFy1WcPHmKp594mvu/+jVmp2e54oor6La77H9mP6OjY6yanYUERw8/R7tVMbdmjnan0vA2I+4Dnl6ouXh+nsq2IGZCr2Zpfoluq03bV8Q6kZPh7KlznD9/gbl1a+l2O5hsCNkQraNOCVyLFAXccN5SBwGjJD/LjRCigFOaqDMQoRlOCJNqbDjnqFQEMXkRwQz9mhwj1llxlrAiJZOSAgMpyf7AstYe4ywOtYJsBMO0gt2AAbnZF2F7qUMDA+2FrCBYg7yqMKSAq4li0zawTxz6rverMZaWbxGTAFAhiv6CMCAEMEoRQs4ko4sA0k5T1zWjIyOiSYCjV/eZn1+k0+pisqVVtal7NZX1eFuRUmyAQAykbMQWdqGHM56Wb1HXAW89/aWapYUeS4s1+DbRtHCmRdu2cDHTKmh2zrgMHkMKNTH0MdaRchwwK6KwbTCGgcuGarkbBRB1Pqh8xdzqNaxft4H5+SW++pUHcTbRq/vEnFjqzTO7dpq9l+/Atxwx1ZrMFTJ0FpcG67BDoFRKiRRD0/bU8i2ZE4xooNR1H4Ohjj1yCtrqtbKYvfBHCeyUYmogZ0PMjd60AlhZ6zTfzCiJtc4TiguYAa5Axg1kAjKEmMWmC2VEGcvz2hty9fWDq+Z4vtk6xLDugrnktYLTCqgMBuPKZ9tLKlxD+3jJKIH2l7/0ENdcdzmmkqXUZFESt1/nz7IW0BTXE+0Vm4BITsJMbNgbSWL8kOHeLz7OjTfuFks3I9e2YTY0z+RK+WplrIxvrzEMdOZLftYf8xBQO2xF07RxldfNYDoxIK1cwwK78gtJtEvsWhJxeP7cU7Zf5tXyWvnsS+f7S+ddM7T/w1oCZvCeYbbDsvfoz8agkzyDg3ND77l0fh8GpKEk9kXMseQGDBVWROS9pvhLDGAQ1eYxQ8e37HO+3lydGDj9oPuPLrDx67x/ZbwwAAVQNkK54eXiVpUISokoBoD2bDup4EbtcS4Jk3MWZ2j6fjJKxx5K1srDlrJ4dhc6e1VVTdU2xtjQop2T9gfrLFl73tHbubck9lpVq8WunTux1nL33Xczf+11tNstJiYmqZxn3dq1tKqq6css3J2q1aFVjZGCVIYNEV8pcSoGLI6cPTFbAVhc4uLCPBcW5gk5kkgka+iFPs8ePUIIgcMHD3PgwDMsvuRaev0lzp07y9VXv5iR0VGssazbsB7nnbSRWHG9cFYmprofCClSx8CxkyeYnp0l5sT1N9zA9OwszhmmZmboh4B1nkcffZx9Dz3C7Oo5Dj17mG63ww033ECvt8STTz7J2nVr6XQ7jE2MMTY5zqq5VezYtYOqXRFJPHv0Wdav38jqNatJOXLqzCnGxkaZjtPYCK221+sgSVVUIZpHH38UV3nqfo/OSIfp2RmWlhbBGJ577jjnLi6yZm4N3ltMrkXGxlV4I4q1OUrLROmFd056zpqE3ohjgUFAqBT1XvIeZ13TUpBSKq1bTcA66LvNA2YDSV0j5D0iRilIZ5k+C0smKz3ZWkeIUe9j9anPxbbSNXoGOYuOBTno80HTclFag9B9dQo0QKHVJ+3t15EHrQw5Sc9dDIEcsq4HKrwZxUGBLHvmrcVHqKRHQ6ufojeytHBRRAidoR/69EOQZMo4Mg7f7oigoXMCiKRajtggjAejopzek40l5kyvX5OM2jo6Ef7ECEPAyERCTlEsMmNf2Eg24lqWCi9sJ1POdxHAlPVCxDPljIh+QqkwyDkL/ZojR47wwIMPkupMx3eIfbX+tJGQemzftYltW7c2FkqljauI7kkip+cyJ6y6emSEldBSzYW6riVpUYcPkxK23RKQzIL39uuvgyvjBTNMLgl/kiAnO2LInDy2KLonZHAwMlYxOdam2I4vg4qyhI6aMzcvSuVcQbGQ6M3XdMbaQNRVVKxZE4kcDL/565/jO7/nWmbXTdDvRUyytLum6VFtkvwSkA6JFQ6sGy/JzId39JJ70TQVrMAg1MhNjUqYEYPK/vyFJUZHumBVvCx73WYRFJP9GO4rzlmYCCnA5+58kNPnz3DtDcg5PrGAEeyOqZkurbbFZtU50H3tL0ROn1siZ0NlYHZuRKzbDJw5vUTdVxadhclVXayzvO/X7uFt35v57u/fjWtZaagYCmrL/pqvd1JWxspYGd9iYzgZL2MwkZcm4UEbVSnymOWAaZPYw/LEXLc91MM/cIwwNLa8Q70AYvuo/26SdwWPG8sHu3ydWQaIDi82Q3FGAQ3yICZdLiZgGQZKhtcroLGjJw/9riTqlyT5pVWvYSeoknkphDXtH8o47/czOWbaI57B1gbbbLSKlgEnz1/ABmfAkrPkoMZCToneYsBbh217Be5X5vfh8YIAFLIB4+Rmt433ehGJUzu9WoKMlKx+lweu8o7KV8R+rap0luLw7b304Ye+WNeZqk1SlXrvvHxWHqifGg32S+WmEfZIiToFFXTLynRwzC/Mc//997Np4ybWrJnj4oWLjHS6av8XiSS1zjNqnyjq1jEEsoEQEsa0IVoqh1rrCYXaJq1oGoPDURlHNCLq5rzDVZ5SUT1+7DgpRrZt2cL0xCT7HrifUPep+z3qfq06BgZXOUZbI6ScG8eBOgRxtCiV7Azdbpedu3axc9dOvBdF/DrUXLg4z5e/dA9V1cJaS29pkX5vEWKk3W6zc8dOZmdnyTmxavUqqlYL5x0+J8bHxplbM8fY+FiDKDrnOXf2DHW9gfmLF3jmmafZuXMnkLQqK4kXVhw6QggsLs4zPjnB+vXrSDGwZ+8upibHOXD2FM/s38+zh49ww0tvYXp2GkxR5+8JIJFrTNGf1eRRJtgCSA1YKEmb5QU/ksUgpSCsGCPMhqyTXhHgC0HuyZRi0zpREvsyTUW17wTUmcFqO4QZfBW0NwVJmgt9yw7aLUIYODKE0CemGuu9ghYFJDEkZRXIpZXjHG5XMGpfWQCWpKBeKklQVsqbtkII0ydThyCCZojar3dyXq3NhJjBG7KpaXVGsV4S6mK1GmMgxsji0iLWGpZ6Pfr9Pt5bPY+1sj1E7yLlTL/fJ6Yk+iYh6Lm1pBioTCL0etiUmRofxbcs0TkByPqBbGqiqcl63SUZEwtOSfAZ2GBmSCHhdMHIOcq5S1lAPevp9/uEEJieXMX0+AzPHnyObrfL7KpVPLX/SWLtKFOrsw6sAGIpQdWqxGkE7S5RxLuAHDFEQhbQK5FJtQg4GeOk/WFkRAAlY0grGgov8DEcbET92XL8+Hn+1t/8ba67egvW90kkplZ1eec7b2N6agSQZ1Wuu6bOWQCJbFLDdmkqNBj2P/0cv/vRL/JT/+Ct2OJOoHGYMRAtjE92+JPP3Mv3/cDt/MHv3cOqqUlue81VFIZCHmIfSGxbKjOlrWv4eErSXKo2g3h5EKYNB6cFQJBAzTSVntxs7Rd/6bf4P977TqSOMLSFktEXMMKAyVECaWOIGf7kMw9y7tQ8b/3rt5Ix/NEf3cs9X3wKm9rE1OPqG7bwtrfdqKJbchwpZD784T/jiSdPgGlxz92P8Uu/+GZe9R17eeTx5/jIf72b/mIN2bFv30H+2a+9jSuuXM+/eO938s53fpzrX7aerdvHi9H6IJBuqmArY2WsjG/50eS3+ZIXoMx9KUOIxflAm7u0I2tIGrHMqE3RPTfiiqViVZgChqSC6n6YJdB82WafTB7SA8gGtA2grCIRePLx43S7LTZsnKYhXg21OWQFtQf2luVF+ayiOVAaM8pRZRi0Oet+XbqSFDH3nIy0cjcx96XnuIDINMZAJkMN1MHy4Q99khuu28HVV++mzhCjtMJbB96U8wGNDWayhAwhq8A5But1u8i1y8k2p99Yw3/80BeZP+/5+++6pTk/ZmWqb8YLAlAwRvzji9qo9HoXQEHU9CU5bMIdoXqTVRRO1ESjcBxJSDWxWE62Ox36MRBtpS6uqquQoapatFptnJUkbPuO7czMzCpNWwAG5ww2G+2PpxG8m5yeYmp6mvsffICtZzczv7DAVVdeyfjoGFjDyMgILZs1GDT4qo1JNZUXf1RfeQ4fPcSevTtwVTWYB5IyJxD7zMpbiIEcaml90ETSOvGffe7oUU4cO862TZtpec/szAwxBJYWlzh6+AhnTp9lYmyCfj+wuLTI5NSkVKtRjfA0CA5TikxNTjI9NYn3RttQwDs4dfIEp06e4HWvfZ0kP70+/V4f7x113afdbuvTaGm1OsIwyeCsV6tBizUCAFnr2bN7D0cOH+bxxx6n3W5x/vx5CbmNxVllA6BCgSoYmDLs3b2HLVu26J2QyCHhrGfV7CrGxid4+KEHmZicYNOWjahbDv0c6edEVGFKkiisC5W9ppBjnBfxRJxp9ASckyleyCVRE/8MxAFTwYg7iVGwIaWEy6U1xyuAIYwCWWcMWIPVe6EM55zGownb9soQG7QiXNqeIH9jQZN51F4VcsP4KUmtNVaEE1HhxiHEu0wFC+HvAAAgAElEQVT/OUlbRcwRkqriamuHMYN2ChrwQ5gCSUGQOkaldMNCb57uaLtZHTudNtZkDh04wMieDkcOP4slM9rtKGiSBYiLUZwTUqJVeaanJznwzDNMT02xtNhjfHSUqfEJRtptbM48/eRTXL73Co4eOcr4+Ki6qRiMqXC2anR8Ywg4K4CKWHMq8KK0cGel1STEWhlTYLyR+7UWZkUiU7Uczma2bNnA7p17OXP202zYMMeVV17D8VPHyVhiEjFF5x11EhEf6wxZNUEKQ8g4dVop7BgVxYx1YqnXA+/IxtDutMCKKKZVi80UVtoeXvBDwciG8qnh1jU3beRX/smbqHymDvC/v/cOThy/yOR4lzNnF8kO5hd6TE+NMN5pceb0IvNLAaxh7dpxrLYt9erEiWPzHD5c0wuTQsQ0RjQAoAFIs4Hb33QVsxMjnDt9kVPHKkLfcvbMAjMzXXJ2nDh5kX4tTJ/Vc+OEOtBfCjhfcfLUIu22Y2a2y/Fj50nJMNLxzEx3MSbRCC0i+X8/JHpLfcbGW4Cn1wvEOjAy1iGmzMnnzhOS6K7MznRpdT39epyYgGCYX6iZGJfq0Nkzi8xMj5AMhGQ5cew8xEynVTG9apSL830+cecj/PNf+W6sgxDgE5/Yx7/7Nz9I5Sy9Gn7kxz/MX/trN+q5kEUhhsRX7zvCBz7w/VgHX/nKM/zOh77Cq15xGV+6Zz97X7SD17xyD9NTbT74gU9ho6yX23ZP8Oo37uVff+DLvP9fvUqv7yBkHirn/c+/v1bGylgZL4AxXNHXKj4oKJu5996DvP/9d9EdAUzAmMAP/I2bufUVu6VFm9Qk5WQjOYBRkFf1nJptJ8BYvvCn+/Ctiltu3DPU5qZrTYJkCxBQmGCDXS0/JwzJwL59h7jjj+/m3/zbH8VVhbkwaMEoOKwUmAxiiG0ZtFGUgmRBl2n0HyiAgtHCjB0IIWbVFLv7rifoLQZue+UVA43hAtIOB8gKppRil8mWhX7gP/32n/OSay7j6hdvY2m+z7/9jTt59LHzmJy5+vq1/PAP3Uq744UnmDOYxLlzfX7tPX/EsVMLeGeZv3iRD37gh5ieHSElOH/6Ip/77ENs2DjL9TftBAOvef21/MSP38HU7Fd4+ztegh3u2FgZLwxAAYAchfKsQXJhCRR/1KxiTOV1qSgmTToFeLDGibBhqShqAoFzSvdOeKNIlEWFBlNzw/pWxc6dOwWkqKRnPeUslGXrNZFDlNoyGOe48sVXsWXbVtqtFjll2q02VatDjold23YRU41rj5CMJTqpWKY60akqrn7RFZy9cF625zRJIIMVNkFO0O8HWqYFZEJITE5MMT0zi7EOjCMZw7btO3ji8Sd58KGHOX/uHJPTU4xNjDO7ehUbNm/krnvu4sLCRRYXF2l32lw5/WJcZVX0bzCssbQ6bap2C+ud2Dg6i6scMUe6I11OnDrFPV/6MmvXrOWp/fvZunUr1knSk53BVoqXGkmWY4ySCJE5f/ECS/0e7W4H5x2zq1fR6XaFdeEc0zMzwsioJHmyavGXohreuApftcA5MUyzTnABI72t3ZFRbr/9dv783nv4k89/lle+8pXs3r4Nk6FdVVRVizrUkHuAuF0YI04eKSWwg0TdYpqCk7WuSaQbO8csn1+S+ku/p5QEJApBE/4CTihzQFstsm6vsZvMUpG3RtkImrhbIwBHEUQsnzNIGATIGba3HN4nZ0Rzo19HjKXRzRBwTp0eyMScyFFaIVq+LeKdMei5KKCJggpZeAwxCPiQo8VGbdkJgRYOlzLOJHIKjHQdW7du5vOf/zzPHT/K4tISO3buZHR8nKSfffjIERYXF9i+fTveC2C2fcd2PvnHdzC/MM/U1BTjk+OsXjOHs7Bjxw7uu+8rnDh+goxhx44djLS62BQIBmyrDbGC6CGbxhWltFAJgKOWQMYQcyQbRdyzCMPWIdAiNkJ27U6mOwJjk45Vc6Ns3DzD2nWTjE86RscsY+MtWpU4n8RelGfB+ub6N+0NqtdhkPf06xqTM71+n8o6mYNAwCAnYFaIgaXeEiFETCy0yJXxgh+l9UHvu0RFzFrc1vUtmUy/D+94+3/mups20L+4wHd9z4uZmh7nP/+nL7G0BPfec5Tf+2/vwI85snf87u99ma/ee57f+9hhfvBv7lZJQ9V+yYZsM5lICp5f/ZWP849/+bu445P386lPn6Q1dp7OWI+3fNd1PHDfEX7vY/fTS4EHHzrHf/voD/DgA4f54p8+hW9P8PT+eY4dW+AHfmALf/aFp1i8+P+y995RlxzV2e9vV3Wf8+YJb5qkyZqRQBJKA0JCCAVEFPDhQDDJJlwbPhuwDQaMjT+8jDEm2BgwTh8fNmCDQTY2JhgkkiRAWUI5zShPzm84p7tq3z92VZ/zDqy71r1rXVu23mIhjc6c011d3V1V+9nPfp42dd3hTz76fAoX0uxW2LUJ3HX7Tr7xzet46288H1S5+rod3HvHg7zqNRfwre/cyvcuv4uZuRE++/e38Td/+Wye95ytOG2hCg8/dJBPf/r7vPPdL0Jr5d3v+BKf+MSrEQdXfP8+vvX12whd4aG9kb/+6xfwzW/dxtlPO4FiwIFTogoSW8bTSDjHoX1z3Hj1drY9eYOVG2HMNxdMNsGVsGnzCgNTBbaesJLPfPZuPvs3O3jms6aZrWqWTg2jYmvir/zqGbzlrV/ozYt2k1nAyljw78W22Bbbf/9mLLSeToGCqzlwaJZnXbyJV7zkDGIJVQVvf8s/cM5Zm/AtW+Bj0pv1TUwuZgePCcQ2bFc1x4i9u7q0Wjn4zuf2vdg+2r7Q2KgQkvCg07TfScG6Kjz/hWfyghecQeETkKHaWA3bFQV6TgdpjhV6IEhuidWmQrK2NOYBGURwYiLVJNv6aCV3Bw52ODJTUSsU2ttHGwvYyvZExAyIRJBoTOEIXP397QyUbc48Yx0SlK987Wa2bl3NW3/tOVAJf/W33+fa6+/nnHM2pavxoIE///PLec0rns6GTRN4B+/+nX+imo24JXDPvQ/z+S9cxc03HuEXX3OuJXocrF07ygc+dBG/9bbLee4lT2DF9ND/T8/Rf8322AAU1Ow+LKOS1OZT9lOcPdQxWeBZxtzE4kCo62iBR9kiapeYQAc8tApHdBCcEPHUVUBjSBJKbUQsYGmXBdQ1ZWFCac4VaFSCI9XSJ6YEwbKKzl5SVwiuKBifGsel7GIdrF47oiybXJ5EnYyCGjXiKHDeLOamJieZmJjEF84oOaJGdVajJBXeEQVcNETNO2HliimWLBmj9A4vRjdfuWKKiy++yF44taBlZGiYwXabZzz9PB5+5GFa7TYiwsjYKK2iQFRsHARI9plRI4PtQU7ceiJDg4N2H2oFL7RbLVauWMUFz7iAgwcPMjI8zBOf8ASWLVuGE8dxq9ewbMlS2mWZSglSUI4FxMuXLmN6csosLH1JqALzs/Mc2n+AoaFhZo/OcPTwUZYtXU7pvY1xMM0AAEQpnDDYLimcNNfuHUQRWqVnZGyE9mCbp539VDyOXQ8/ypaN6ykKRwcggEQPsQANRCpEnNkUJvqS9j1nIVigHxNZ4RhTsEZzIwv45ax9fwmDK4o+SlRW/Y+EjPQ6Y2PEGJq9qE/lKPmZt7IF0yvwvkgZeAM1nDirs++rwW9cS3IfExsDSC4GSaw06SqICN1uhahLZR+CqrEZjNGQzA8V8whOzzRiGgsh1kQN1KGy0gsig86zZuUq2qOD1Brx4mi3Rzh+6wnMd2vm5mZZt3EDa9asMbtIjYgraLcHUMBLQaztGieWj3PuOeewb98+li1bxvj4OO3SU3jPiVtOoPSembmjjC5dytSKlbgSXIi0xeNijbpIN3SNdVFly0+hKJJ1aRpz1VQGgyRyijSfibN3tKoDGzau5bnPexZjY0tZNj7Ks559IWWroKpgcnIZY6NDtMqCwtcm5qlgDJLCWFT5WYhQE5BQN6yn0nlaAwOm/VKbdoIrCxN31IAWLTqdecS55EG9GLA8plufpZb90zZm3/3WYX7l4X+l5Q+iLvKkM9dy3OrlEGF0uMXrXnsOU8tH6MwF/vADX+LNb3key8aG+c1fv4KPffIm3vzrp/Hlz1/DsmWD/MHvb+OCc7dz7XUPpLkoWUmmzaVL/65igSL8/MvOphtvYcn4MM+6aCM7Hz3KZz5zLS976TYGBtu8/nV38fnP7uCJTxzgS1/ayR9/4ERe9cppfvbnPsX99y7jt3/7+Rw91OWP3v8NnAhRC7LTgku5q3WbJ5j/WmD7jgOsW72cr3/lVn71TRdw3fXbufvu3fzOb7+A+bnAdy+7Ew0W+AeJjWhlNxTNxrRS6/ePb9rJZf9+Nz/7c0+GUPCyV9/CZZc/2rACsvCyvbeRmEghUsCrX3MWV3znbs48YwMiqdxLhMHRNnfctxcpYOZolxjb4GDLCStZt/ZBXvHyU9i37yA33LiL5ctGILOJHCBVuqkxleYmPYgkprr4bi62xfbfvdne3HLxPScwNAXDJGAAUCdQChQ2x8VE63909yyf+tsfMDPTZefOnbz73S9kaGiQD/zR1zl4YJ4lywb54/f9D5xXuiJ867I7+cJn7+DHNx/id99zDllZVpPOjYpZitcB3vvef2P9qnGuvvo+Dhya588+/lKmJ4e56qrt3H3Pbn509T34ouSCCzexduUStj15I52u8o//eD2Xf/dODhya433vezFbNy1nbrbm7/72Sq750V4OHAj85f9+ARPLB9M19/R3Qg1//MFLedvbX4hzQlULH/7gpbz9nS9mdr7mc5+7kh/8YC/79pScsKXNH/7hswnqqNUTnfChD/4rb3zjcygHC778z9fwhC0rOOHEFczX8PnPXc8V37+Tgwc7/MmfvISp6REuv+xO3vTmC5rEcIie6AtoWdwmtNize5YYwPls3e4YHR3mnb97JRddeDznX7AKX0TKlgEmE5NjvP5Nz+Yb37ibVHyaEnPK2uNG2bBpiF27Dy8CCse0xwagIIpqbRlx8cnrXXDeRPlUQ0/XQBLokIK57MVeFAWhDsTk6S3Jxq4oCqtbCor3jppIHW1TJ0l5W8Qh3ryqy7K0l52IU48rnWV40jkVq4cWNepyq9UiJTsssCMxGkgK2nizTdRA0GD6ECnL4bxRU004MhC1tg2h9DIe3gmhO0+rPUirLOhWNePjyzCSuhKj6S5MT0/b2KQM9kCyqBwaGWDj5g0ASTNC7VwxDWSiPpm1obFDNm3aQFF6JFoJQEjjVbY8p552Ct1uhXeOzVs2UxYmcrftyWcmHYxM97ISFF/YJLtk6RjnX/AMBgYGKQpjX8S65o477iCEwKpVK5mYWM7k5DhRAy4m94I0VTtxKMLpp5/BwMBAqn83Gn5UZfnkJKc/ZRt+oMWIG+Tcc59OiMEYIVarQJLjMlGVRHsXSQJ5KeoPGhoQIwsamipHJMZcbmDlKmbzGBL41bMJzNoGDbDi7Lmt68qQ34TWVnWNFlaWYzcoyS+qNvdCNZUWONImGDRkL/f0/jTFyy7V/WvzuSSamjEw1DQCEt1f0jVmO1RpXFPSs96XAc92rNpslJWQ7Hh9yxGdlZ3Y417j6sBxa1bjWgVRDKXWIAwPDbFt2xl0Op1kb+nJdXjOOSYmJqiqugfKYDV5q9esZNWaFWYzJFmkVSlbBcdv3kyr9Kj3tmjHbroHprEgMdIqHd4Z2p1tGDPbApKuRFPa4azMKQFNxpRy1HVE8QwOjjI13ULUc+jADAOtNlVHOTozx6OP7OLIkUFmjs6ydGCQuuo29z+mMTT9kiSagrGgglq5SsT0V2I0xpYrDfByqngpCM5ZiUlU5jvd/y+z7WL7D2y9fHWeF23eOu/8Sd7zuxfQsqQ+UkAhQnc+MjLqWDk9hCjMq3LwUGD5xDAuRn7zHWfyoY9cwe79R7nm+kd43/teROmVTZuHueaGTnqrExU1e2Xn/7tomi8u4t08hSvxHrrzgZt+vJMly27Ax5LnXTzB5rVtRCP/42c2ceYZKyk8/Mavncue3TOULYcrFOc6Nr+IAfY+UV69KCNDBWed+QS+e/mDrF+/iy1bxplaMcatdz5iDkilZ2nb8a53nQsSGivGNDy9qQ3Shg5mjtTcdusuWu1rER3gJT+7jJXTJdu3G57hg7kzSQZaScdR2LP3ENuesgFxBnsIJmr6+v/rXL7wjz8CVebmldC1PvzrP1/HmWes4MlPmUZ1mrvv2sXH/+wq3vb2c5MGitoa1YQL/Zm6Y7J2i22xLbb/xk1+4r961aSJDaUl//6N3ezecwX4iqiBjVuXQ+GYmw9cftm9/OUnX8qqVUvYf+Aon/rfl/HWX7+YZaPD/MzP/BM33LCb006f4pvf+jGHDs7y0T+9hF/9tW/0MYyTDk7WPVDLI91w/W6eecET+YVXn8W7330VX/7ydl73Sydx4GDFd75zHx/76M9TlAWf//y1HB6siUH44pd+yPKJMf7so7/ARz7yPb78Tzfzll9/Bv/nb2/khM0beOnPnce7f+cG/uXL9/KqV51E3r7mvXr0worVk3z3u3dy7nlP4Nrr7mfp0kmI8PefvYItW9bwipedx7vecTl33rWfOlVKCDaP37d9lm4wpsYjO+dZtaqm0oLP/f21rFqxnA99+JX8wR/cxZe+tJdf/pURDuyZYXL5MEqkdhbSZHhbCjjttBW89399kec9x/pq4+N43evPo5Zr2bnvCB/8k8s458krWbp8mOhh2dIRgoC4iLqss2dHHWh5Vq8Y+AlJy8X2GAEUbNG3jXXO5WQl+7qukyq+ZR8kWvAbmlrrMmWGjWYUU21NEU0FW0NE1eGiUTG9GIhQq5FDcY5ak41fCihUFRWfkMRICGpe8SKJguMJ0cQRY7Bia+cLVAUnBQ6hW3jmioKj3hNrgy4igRAcQWtjKWhEUv220dtjI+QXY41TiAMmoNduDxGxIBTxyZXCKNGFL0zwDkWDCdb1VOTLJihCNNWOWyBpv+sF7A1NXkjHUYqk1RDV+obSBNV2nJ5zQGMZmMYp2yna98aslMSbhkJd13Tag6w8/3yqqmJk6RK2nPYkDg0Ps6fbbfrhUlDvxSPiiKNjdFQ5RAZ4bAPIyBhhfJKHVClKRxwyivoBLJCLrRYHRkaQ2RnAbPckBfsZUMiBeFO2EEITxBtTIZcaCCHUWfoMJ2LAV2IlZHtQc1HQxkDHgAFLm2mMiR0WCdHAHl846m7HguHCpzEVYh37XBpi0nLo9TUDF9kHWHMJRQJQQhqr5pkIIVn89pdN9KHqzqXxSb9zjkJjKpEgsYZoHH86GpkZHGLv2FKqdjSB0a4gsUALITpFa2OciLfsXrfqIjicE3vHfbICSgCIRns/SJoV3apr5QmagZA+cUpNG/xCCAIQqLs1rXKA2YEBQtmi5T3tVongkjtMr9QkAzg+aV1IyjrGGIwu6AtiVaOY2OL99z/Ald+7mrqjxK4yMjBMiBWdbsX+fUcYGh6hKAdRHM6XRtfDADS7BppxLFxBVSeAVOx6fBJxLMqSVrtFt+rgnZW9GHOpRJynKMo8ey62x2oTmuxRzowIEVccxQ+C8zHND0k1GwiKPTuSqutiTR2wANYrzh2h5R1Fu+Do0YqRkZJKHUEKQhQkJMtZtXnaWVSOC9l/xgAtrXzSY1SeevYqfuu3n0sZoZqvmJ2b474HDiJFx4SqXKTwEZGAS1hmVFs76piqbYOYZo2z5/T8c7bwjq9+le0PKW94w7k4n+bCKGkTKQY20vNHt5VEIJbEALt3VXTmlprrt6u46OL1vOH15+EUjszOoaLsuLdg98NzDYbiPExNDrL74RmmV4yyZ88sd961n1e95lyCwq6dh1k2PkKrcAwNDvCutz0PVbj7vr18+dJrrWxE1fR6ayuPfOb5J/FXf3WDzb8iRtXVtDuVDF3Igtu++G4utsX2371J7985ks+uNNrnTofnCSdOcsH5a/EmlMTa9cuTmLVy9lNWsXHdGCrK3l0zOBlg1YphpBZe+YqTue6GR+nGOR667xC/9LqzaRWOF16yGkdFPqtpHbhm7imisnpFyTlPX48I/PIbn8Tv//73eO3rTiJqxfOfu4XRUUvgGlNZCEH49rfv5hOfeCUtH3n9q8/g4OF5iPDFz+9g3ZpDfObvruORnVC0BkBPIp0ayTsdJ1z8rNP4yz/7DiefvJErf3Abz3/uGajA1Vffz6te9QxKB2996+n83h98IwksCoVKcsyJRMkXJQRntu9f+uKtrJgo+McvXMMjj0yyb/8wKutx4pFgo2zrScRpbBjYx2+a4uSTViVBXiWmBN2nPn0lp562hrPPXs/M0Q4ffP9XufX23Zx08hQAXi3hq82e0NYmRfCqC6QdFpu1xwSgAOk1jIrvscgby8CcrdRUd56ziU39eKKPF0XaSAmE0Ek7KYe4gqAWoPgotGjRVU/tYNY7jvqWPSDe+mC2ez4F4gYEdLGHKtQhZZRaxLpOQIambGcKxlEODQ1yj3fsbpXUDCCZN68eTwAfrKaJMm2k+qz+MKeAwjlCVRlt1TurP1IDFYrCgBTnPUVicpACMVQTHZom052D55DV5jBtgJiFB1Ogm2n2pl2QNo/OAuHGASNbC2pmDtBk6vutN/M5m4w5vTIWE9EMxGXGrPCplCQEC+JCCOZqkF5mycF1PyYbAuK80W6zh7mA+oBDkSjEKKgUVEQeGhxiLYGuU4oYKMpW8yxJA171BapgTJQUTFu9vSRxReuPlcCYXaE9w7EBFYDmmQhE8OaJjhPqGPFeGutGn7LmeawKl+5pnsjy837MHjWEYNfgTQhQk4K69x4njlB103VAXVXN3reuQ1PPX1VVc99yoK3ZKpVIWZbEKMTa+hHqgCukAfac83TKNvdPTjAYB4niiQxC9ARXE5xZb3pXNmBTCDU0ZQcpE1kbayCq4sVoy5ocMyRr2sVI5i245I5gNX01OEeMVprkouLEU4tQpqJEA2J6Y5wBFXsXXAMkWJlDEsFEe2VLIogUdDod9uzZQ+hGXCiYc7OoBDp1aBgqEaGqIzVKUZZJJ8T13h16qLwCnW6Hubk5BoF2y4TsnDdQtPCeGALdqoO2HN1OByfSOGEstsdm0/zPRrE6SworhcwnvQO1uUpdj1bpalIVAK22Y+vmST70h18jJNz2omdsYXz5CKtXTfBbv/UlVq9eyr6DHZZMjLFr1wH+7tOXE+IAoiXRKT4qm9dPUmiFuEiUQHAFX7z0FvBHOOusExkdgg+87ytJrCNywYWbKVstxFVWUyuK+hp8RaHJW8JVHJnp8vGP/TvzdYkPQqmeQJfplcLrXvtsXvbKk7j8ijuYmh5DBDaum+BHV97HB/7oa7gId9yxn5972bbkCNYlOqi98IOrd/H+P/o2V30/MjMzSHSwYt0S9l1xkPf94Vdpq6d2FS968ZM4/viVfOLj3+JVrzmVwTFTbn7dGy7gF3/xnzj3aSu5+tp7+F/vezFRhEcf3ssb3/BJPv7JNzG5YozX/dKlPPWcjSiRK6+8jy9e+gp8oZx2yjr+9d9u5QdX7iBKzXVXP8p7f+/5JmyLcuUVt/P0czdhdymn6NJ9XsQRFttie/y0xt1FzX0m7VUlQcUGl3Y57jjHqU+a6gVdTnss0pj0BoDamQ9DVMELrF5bcufds8zODjIw1Db2daLhm4UjxCCJ6WkRcCI/ItGSqSLKqukhBloHbc/hEitXxHRjXCQ6Sxj5WOADgGNqepiJ6WFQ2Ly+5s8+fiG+BVGgkKT3ELG+Jytup8L08lEmJ8f55tfvYHa2YvMJ00jUhhGNh6lVY/iyJ/yYrSSVwvQfokJd4oKnDLBmquATn/wFciW2ePtOZfJnOJXGGcliEkUCXPrF67nkhWfhSrMdrxMrefe+Qzx9/ATKGkaH2py57WQ+9MFr+D+ffm4OOnq7q5jiILX7ohLoWSkvttweI4CCoXku1fLn4Mkyhzk47oEK0AtYe4r3ENQyuWVZkDkBTrNTgD2qjgKkoBKoYocH221m2gMmo5ID6WgAQQy2GfTexPJUWJDhz/oKlg2m6Q8q7Bkc4gEnLCNS1mq13CHifUmH0iCEaGJWOZjT5A/rvUNjZLaqkFaJhpgU4QtCiNAqkFSaAVA7B65A1bLYMdS9PkZp/mwj3avprxtRPkeVAuF0eXYtTQlDwiAkBUEC6rObQLrm0jVUebsnxuWt0gGNIUFzPrvRRSMyWDvTEyBl9q3MIiaQqQfa5M4rivpUHiIOLYBkY6ixY9Y3zsZGxROlIJZt4myJp4WTsOAJrOvemOVnLGeEjSFjbBTLoBsIUYU6jXd6FqFX6pBa7Hte+i0YXWYWqAmACtrQh1XNJtG5JFrj03jFZNvDwtIKxDL7Li1ezgmi0dgz+dxZzNF8ivDeNywK51xiA1WNIKRVrmgCIuqUXbXgJxDRaJN3DIGVRw5ywYP3EOoOGmt2ji7nrtEBKALOYWKpgjmsJBRfnQEH84kJ4xI4E9PCGkJt768ka8r0zIYEeAkWjOGhjl2qUDEgg+nehUavoAiR5YcPMxLmkexhr6BJOyPPI81MlO9LtiiK9p5WoSKK4ERZuXqCCy96Gq2ijQsFrcI87vcfPMh3vnsFVZyjW8/Rpm3PrHN4Ka2/mjYPqcxD0/PtvaPdbjPkCwqPlWoQTZRWHTF0TUNDPGXhjdkSahYBhf8qrZfBnpoe4y1vfQ42vTqyP4CitFqO33/vi2glhW3Xcrz2tRewa/chAoJ4YcO6cbwoL3/JqTzngk3JolsYHh9iyVCLl77sHIIKoo7gTHRwdKDFBRdvZnRoAFHhkudt4axtq1k2VjC+dIBfef357N4/QxBhqPCsWb2MTl1z/MapxKQSznnqFqraXGBGl7f5rXdcwkir5KU/8xTLTCm24fKRsg0UsPXEVaxZP453Bsyt3zDOa1//NA7NzNQ6EZMAACAASURBVOPSuzi1YoyWKO99zwsZbDvWrhrlE594HhF46cs8A+2CFrB+9XLe8NoLOHxwjiIKAyMl09NLkAhnPWWYD3z4G7zz3c+jLJQVq0b4+CeeDy7wkleewpo14xTA5OQYf/qx17Jy1SjOOf7iL15EHWxz/upXnczgcEF0cMppa5iYGmW2UwHKy14Ox61ZhgjMH6n40Q9v4xdfe9Ex4EEfQogsAguLbbE9nppmcDG7LwnZIaGgppAkBu0y9pgK4cRkvWISkRsZ9NRVl6uveQgXhUceOcj08kGeesYG3vu1y/jO9+9jeLjF3fce5sSt0+zcc5iHH9hPjJ4U9uBUWDY5xoG5kquvfcASoxUct3IUSGwCMVjCgIVkbu5genqY6659EPGOWuCHP/oxv/bG5zA9NchNNz5M7ZUggZtvuJFnXfQ09u+bBTstToWCmo3Hr+DnX3Eav/+er/Cudz0Hb6ENExOjXHfDQzinVLUSqjKVuNn6FwSq7jA3XreLznzkwx/az2c/uwHvYOXKQa67/kFETTjymmt/zBte/xx27Wnx5a/cy4tfvAkv8NyLn8jvvecylg1NUHXnuPv+OV7yirU4he999zZuue1h3vDLF7Nyein33b2HuQOzVAjf/f52fuNtZzfuZ1EsWVVk3av0edWtCKq0B1v/Mc/Vf6H2mAAULKgu8T4FOIkpkDPBmjLuvvApS6tWsZlrwyEFRUYJBxrngeBMRdRecgswRRxDUTlhtmZ/qEBT4JMABU2ImwUXASUHtzGJofWJ5mHfzfsHBZy0mHFtBlGOnzvCcHce1S4iEQ0FlXcUWtDGEaTuZfNThj0HmhZ8xiZ4dN5ADnHSOA9Y8BVSXbZ1INfh54y2Zc1ds7/JwWH+n/fekNGUVc/2mBpjooC7JvCEnlZA06/MXuhLz8SUSc5OCjFagOucb+jtaFyQyTf2goEHc3NzjTihuF7ZAYlmmwGGzE4BowqLcxQOYwyomgOPQi2OoTjOcHeOwgvOC1XVBbFnhRScq0arvdfMwEi0Y4NMe2Oe+qDpWavrKgEfLGDR+MI1G8vGSSGxHbwzVoTWAfX5Owk4oT8rbg9XJPQcHoTkSpFfogjJ8lFI2fa+QBkBXxQGHMTemNu71Zepl1Qek0c52j/EpzINMnsANEQK7xnpzjEyPwOq1FGo22Ps9o6JmSMMdTugtfVfFU9yrEjPl9JjGomk4rfETsi1ecZcyLam6ZlEQAx4ChJACkRmgZoiWSMEEbrO0W0PAwVeoapNiBNVQp3G0hQ3+8AEmmfbQDWzDlWN4GqWjY8yMrSZgXIAose7kqAdlhwa5KGdx1EOtChaQhQTtfR4Y1GESAy1XX9iXWSKpHOWjQh1Rbc29koINSFoj4ETlU7skEPQxipqsT0mm60HCUgQGmZY4T1TE2P2jPXNyuZSJExNj2EvgjnkDC9psWlsMmVvUvJElaXLB1i+dMCe3yQ+7IFNG6dsZkqaHA0zDDusqLBsrM3yJe0EFCtLlrcZGx+w/qriFAaLgsHBIpUiOoaG0gZKIh6YnBrDRdi4eSK93wn0B8ugSWBowDM0MJSKfqyfUytGmZIhSPZm4ozZMzU9CkQKJ2zdtCQBpWLfSVc/PTnCislhoCd2KuL47Xc+m4/+xRXcd9detp44QdkSNm9dZudMQAeqFAOezZsmSXAkGzYuSTNdZghmVzZlzXGjdh5cUiW3vtx92yMsXTrC9KolvZudxtEwhSzOyCKosNgW2+Og5XI1m26sXNXmavv8+C2TrFw11iRrsqWiCixd1ubii7dg+wBl88YJLnzGCVxz9T0IjpUrR7nkktNxDi545npuveUBA4mH4AknjbNv/35+dPWdRG0bZSAoXj2nnLqB7sw8V//wHrwHr45ff8vFOFGecOJkU+IsCtvOWMPocBvvlLf+5rP4zGevIqgl8F760vMQgTf96vl86dIbqYj4UnnNK5/LD35wJ3fesQewUoIiCo55plaOsGbNBJdcsoXJiWFcApTf+OYLufTS65Bg8cElzz+ewisnnjjFfDBNsxdespGbb3oYJ5E3v2UdazcMo6Xyprc+m3/43I9QHCKRV7ziAnwp/M9fPZm/+evv86xnrmVktMWSkTYXXbCRm256CNwsF128nqGhAkTZtWcfp526EVF47avP5rOf+SH3b3+EiGPzxhYbN4wkZrtN3ac/aSXtsmWguoBE4dGHDtCtZti4cfI//kF7jDfp0dH/89oJJ2zVv/rUX5A973OgU3W7qJoVY64/l1RfTOx9L9fpV1VFVVUWEHuHOCWqo1W0oa6JJrWIw1GIgCuotCZq1wQSJTMZTOHfQAVNNOkISfW/qUVP1OXMUAjRAixXtLhn6XLujMrZRw+yZH6OSI1KIEaIzqOdSKlCLMw6rhBnIn+JNo0YRd15SSUOxgAIMdIqWgk8SU4CLtv5mbe205TtxcoTctAeQ6D0VhbinbOsawwULdsohuTRKViwKKLJRt3GxGwcE5gAiaqQtmPp86IsILE3SMGj6TPYGGYgxLn8HU1jTaObIQKHDx82kMgZGKQam3tEE1BaDJ0zzjFliLwa3d0M00xAs/Ztbl4+yWwIPPXwftrdrj0rhUdSKUMu58glD957vPjUB2N05PGsY1hQg2/PQGxQzCYwJfauN9H3rUwg1e736VLYkEoDptn1WyY/e3z2MyCcM92LRsMCQ0BE+xgRqs2eNn9ex969yEBZf58lBRUxRisDEcEXqRxGkjiN5pxqTMF5TVm2icD2pZNsXzrFSbsfZunsDFpXuMIQ31AFvBi9WzWzYmLzPhW+sEuNFU7sbbWynMzi0dR3K3wwh4kIRYll/DsUiYIcJLKvXbJjwymMP7CdE4/uJWpoxF9RaLWs7KUKVgIS0n0NRYvt67eyZ3aOJ+1+kNFQJdsloxPWnZqWK5pgo2gJdR3odoxV0x4s8d7udx0D7VabmAIjJ8awKsqC0jlC9yhH9z3KI/fegnSO0J2fwXvP0GCbuo5U3ZpCHHPzM9TtIa5ZcTynbdtGeeV3efuH/oXW4OLC9pht2vuD5qJLdc2mEhKe1QdIQw53AxHBYDiQND/n2tykqw0hgFMChbnfJNRB0zHMEtU18a3rYwpBtsdNOh/pU6dk2Cr3vplzacJrl0BMsfWN5ChBlinUPvA6g5R2JJejd1GgBopeYJ/pcLmUQO0Y+NwLC/tVC5Ta+hUKvnHZrXztX7/Hhz78BlwrgbKJ2dUA6mlja5Suft0cyPQ8TZpNEkNKMjZXAhH++s+/xs+//HzGlg5gxU0JNBabC7PYsx34/8WzstgW22L7r9eauTQmlqxNLybhnLRYxCWdASDNtCo1qCdq1kfKx7D5R8lMV7Oxzsd0RCsfSMxP1QDJGS/mRIhCmIc3vvFzfPKvXo74bCWcANwMesZUQCoVgpVQRtGUY7HUhYEgOf2Y50zBSRYr7IHizWohanOv5KSXAdx1+vvSLoboM9YekmWmT/v5LCgupqmADarXpLMlIa0ojrnZwJ9+5LtceOEJbDtzDc5HFFMMVyW5BtreMaZ9tstxb8PcVrJYghJtBUvWlCohLUGmh/eud3yOt7/rRUwsHyZXjTye2plnnsm11177U6/6McFQsLviCRopiiLRrSO+KBDMKg9SAKPgXGE10/RE45rMLRbcglCqUKip1cdYm/BiNIGsyoHErmVubN+FuLRNEt+r/c97rxQY51G0PVsO6Hvn9yKgXTR2iOLxXvAKhXoCSpCIVBWzR2e454EHOG79WsbGxnDOArrO/Bz379iBiNVIr1q90mwUSc4BOeEdaNwBQlVz8OB+VJWB9gCtsqTVSqBDDIhaUGJZTY/E5HiQAmecw5VFk1FxCOoFE/VKZR0ixBBMVyEH0b4HVrg0FhKVvH30SSsBNQVz50sLCGNyBCDpZmDMAlPPtozTQKuk0+mmras2QJP4XkkHYg4MDdlfHHVdIRoovKPSGu8NPNGUXYpRqWOkTMFrs09Mm8m6rinLsgGpTJSzF/Db8xUbVkkGCACjMLuF5RNCBp96+gr5WI0lJr3seO95NtHRQpwBpon6f6x2SK/1wKPMgDj2fBksymFLFifMwXwu25D0307MgcKYIWb9GLLoZyqd0GiZdlcWhMSiUA24qouvjlJoFzRQBKuxqxWcg6qqTVeg8Pi08FShxmUGBEkHIwVOIVQGNGTwxLtER4sQKzqdOZyUDBQtotQQAu2WY048IqbjEESMFRJCeje0uVdePDExFoyxk/LLLmmP1LaUqyoOR6schDqV5ngI0XQ4WgNFYnwY68k2B+mZlcSqSiCoS0FfqG1hLoqCQttU83PNPXHiktZJpFW2CK6gKEqccwwODj7+VrOm6U/5Y5MnWhjHNRoGOYhPAWNaJzR9pwnoNW3uLBqmyVfoMceltzaw4MzanHZhb3Igno9ZJ1VubxtFMYFRoWg2fEK0DaNkN5RUjofNlSoJlMaSU5I2l4ok6qYgmf4kBiSaeCw0FF2Ffn0H13Re8h45bW7VNp3JHtH2X44MRlgGP2m49LNnxNmc0oAqfRl8sPcigRAG4kvTn/RJyvRlRkfaGEOjau688qxnPpFnPfOJzSsRiSDB3JfUHHPIdm0uWDlk48WujeZSpinjPFFqJKbe2M957RufY3NpsyntfyIer+/jYltsj+eWwICG3dlXXy9ZJyomUCEJ82oAygYAzgE+ksBj5xJg2luzmnO5bDPuEQpbUzSLmNv3owc/MGdBey7LVtPsyvpTTTZe8+8SfBH7TicWMyExuasVJnioLgX+KRhPALESiBIQ8SYTkZSCvMYEQqR0f98a7oXmvzOgCxmuyHC09NipeX1UYWjA8T9/7Rm8+Gc+wvv/6MWcdtqGBrCWvPar/R6xuEcICZpJYD1pjV0wzjQgQ/YMuuIHd3DiKetYvmwIcbrwu4vtsQEoiHP4sm1K5inDiiq+rixATLLSgkvZRbOULJynqirLYEbBS0HLZ+ql1YVbLKqI86am75PZh0XXiU6dgYSsmp5BgoSnaXKdEBOky+rZuWVnBiC5NdhGzTZ4NkfYF4VCPfv2HeT22+/koQcfYnzZBMtGlqHimO92uOOuOzl88ACtsmTH9h2smF7B2WefQ9FyCJ7CCVVVURQuBZAVe/fu5pprruXAgYOICJs3bmTbtm2oFtR1zfbt23nowYeIIfCkU05hxYoVgEKM3H7bbYxPTrJ2/Tqr4cqIWzAGQSEeV5ql5KMPPcx999xr2hGFZ2hkkNVrVrFqzSrqysYqRrPuLIoSXxTEKjZig5b1L42dnzLbSZfGXmtVsudLWbSougk08g7VQB0qDu7ZTdXpEkNgZHSU8fFxo4+pgTlHDx/i4MEDLFs2zsjosIFJDijBeYHEinDiTLRQA06tICb303uPR+h2awNaRJtyhajJAUFJrguKF4cXB2KWpLhEnQ/xGMDJNwG+qlIULQippCXX9tc2IXtndOUMXGTWgjE4XKNv4MQRteq9S7mcIDMTUgDrkuhl7ldW1s3sgJ7QZk+9VlSSK4oFzMYSMdQkJjFGgLru4oui+U1EiU7sfdOYkHWh6tZ064qHH3qY2ZkjrFixgonJcUOEVSmcoGrPT87kxwTYPProbu67bztRYePGTaxaOU0dIp1Ohzvvup2djzxCuzXAySefzMTEhLkrqKDB5gArszE5eittCQYslIWxFVKQF4KZytV0jP2AJrFLYy958YRuINSBwrWQKGhVI0XbvieB2lW40oz0nCvQ9ExL4RJyLgQidVXR9iWFb+MorcQLR6tsUxRCWVqgVceIL1vUlYITyrKFuIKYSzUfjy1lPXrh/sL6jxxw0rdRsYjQymMWTOALDtq/mVCQLJYlfedIUfaxCEPeu0hmGPS0OKz5vGUiC3eaQwlETDMkM2f6DyqSFhL1zbX09noRhzd9D0hgRL52BXwf4OF7pVCa/37hJWQ9h+bTBLKL+rRZrBHpEwPNhyKBE8fsxySNQhQSN7CX0EuQHSGBIz5tPIPhi7g+tkWvPjkdN9X7uGyNmdat/m2qbSrTJjFfN5o2h+m+uP7rdr3v5mOk8WtKU0R7vZC+A3Dsn48Z2MW22Bbbf9OW50Kf1hVB8HipoW8+laRA1WOyFlhZW29eM4ec2AAMNqvXWJjvU+AtoEViTvVmHclrnUbAUxbw/ve/3FhruR+S10pZmIuQHArauiXexBiaFSKBBh5PQ7XI822fKKV926WiD/un6wPxmytNyZYMGNiZpX80AWNLOLJTXOpL0zI7TBgZ8vzDZ36Z0dG2fTuD3mDubGntoRnbIo2vpLU6rRPNviHbemuv1yKceeZGznrq8TTycotz/IL22AAUEMp22wJkjRasockCRHu2IkWBJCFBkwHV3uYIUla/pKprC8DcwhrVOtZN1jPTN8VZFrah8TTCkD1BOyu3EIiBorCA2DLxtl3KmeXG017NktGFSAjRSlzTBOEUhoeGGR0ZZd++/UYB90VKbwujS8ZYd9xxDA8OMjQwxHXXXseZZ27DeUeRgracsdSUKb/n3ruZnJzkjDPO5PChI9x5x+3MzMwyNraEffv2cc8997D+uLU88MAD3HzzzYyPj6csrLJ7924GR4bJteQhBPCeIvndhxCTJWXE+4KybHHLHbfgS8+GTestI56dLxC8MyaDKNTdKulRWGv6n+rRXZM1tN84b9ktK3G32v7Q2Cva+N17zz3ce/c9HLdmDfv27efsc57GmnVriUE5sH8/t9xyKw89/CAjI6OcfNJJrDluVSPyaJvUvI21cEQSTQwBX5hrQQyhebSMdpXV180+00oXpCldyMBCrO2/Y6qNDn3WlBmEUlET+wTy7toCaAPW8jlDjL1pVhze27PWuDF4y2CH0BP2zAKX/WUVRXJiaEROVa0cKAVU+XiZd219tfGvq8RgSD3Jrg9WAlH0lYn4NBG7ZOsoJHsQK2dRm5/rumbXzp1s334f+/ft5cc/vokLzj+ficlxvHPGKgl1E//EEME7Dh8+xI4dO5ibm2Nufp5bb/kxE+PL8N5x5PARDhw4xOjYEnbu3MkPrvkRz7rwmZStFjiPk9LozkKji2GjirFdcs0MJPaTAZGxSioZmmtq1EqSEA4fOsp9dz1IDELhSoiRbtcyEJXOMTDqOPWMJyLOowGbM0Iu69DEXIiIs/ITl+7j/Pw8MVaIatKTUbpVRYjRnB0cSCHmSBIic3Pzj0tAYWEYrEkolQWf0lsWGpElazlg7/2+2YdJ77N8ENXeZqI5XxN0ZtDARDJ7WZP+I+cNU8p8S29Ncn2Zeic+MQl6KxYYq6ehY/ZdYUM60sxk6F/pEjyW6ZyqTV/s+rUHNjSXG/sCZOl9rrmLSdA0C3dIj5rbAyD6AZZIJujaZi5vF+WY3+dtX968WbZKo5izi8F8feMvfX/O/82CJgv+7tgdX/9xfspnP9EWHl845tw/5euLbbEttsdR6w90Jc//ac6W3iSaIQKzDoZGnRHozaHpWGrfzc4J9psGKu0ZS5BLa/vmbTLYKiwdG6LZ3yBNEJ+bmqgOPbC2xxXru7h0/v7JLV1Xxhr6rsHO4Jv5XqBX7te/tkheG/v+rpluE7CR1lnR/l7n76bSBsxOeXxqOJ0tfdbf1wSIiDY7/6bvPVhDMeHudHZJ3GftjfHwcKu32Vic7H+iPSYABSU7HiQhE5fUz8si0eqtTlq8b+qPcwBWliVob7NSVzXaBwx4bxhUDrBywOZdqh3VXpbWF3090t7/y2T7FgOpNKGHQsZUi+59qvVO+gWq0jhUWF14jfcFWlW0Wy02btzIXffcQ1Ga/aPGyODAAJvWb7SMVYgsWbrM2A3JtrGqLBPtUrmAiDECDh06xLq1G1i9ejXTU4HjVq+m3R6g8J5upwOqHL9lC8dv2cKRI4fTZhNmZ+bodLt05jvMz83RGmjbi5/qpUQcUtg1KrBi1Uomlo9z6NBhRsdGOPPJZ4LTZN+Y3R1IWhTGEum3/GzugXPEOjSlLKGuKcoUoEarG3bOwCGqqnk2JFrANzU1xRmnn8GPrr6aHTt2sGr1KlSFBx94kKNHjnDhRReyZ+deqm7XAlonTUAPGJvAJcFLkR5bS9K9A3umxBwOkFRak54NlKYkIjMCvIgxEJwk/QkhZoApaHIOyc9lovUmZxMnPaHGplzCJWf6UKfS3gxeBaIqRWE06ZAADgmBVqtsyh5y+UIGGfoBB3Hp/vT1P6rmwpGksWAU5bKxdUxCoZrgBaW5r9JkQI3p4Bqdh/wcCXVVMT8/x85HH2Xj+vWcfuop3PLjm7nj9ts4e/nZhmInpkC2owSh2+mw/b7tDA60OPmkk1FVLrv8Mu65+y42rl/P9nvvY8P69ayYnmZ2dpZvXf5Ndu3aydr16xIYpKbiroJ3hXkRi9g4a7Yndc27qhqJleJ9CycFQoUoFM5YFyjs2r2b73//KubnIrECR0GoHa7wBJ1ncvUoGzdvZumEWYGa9amxI/KyH1UpxJv7RhWQCEMDA+h8QNXRrUw3paqtDMzug6Jl0Rcj5cDw8dfyO+s00enTvJW3bfmVaXQvsQ9yCVZv7PoD4oxM9IRem1IAtQ2OQtJryZuN3uZv4QbD/tvWGAuu8yZnQWBtB++dh967tKBfze/TKrkAJFEahYT88+a6+5+PYwGT9Fk+f5ogU7UteVMcJDZZJlH3EzG6NITUmMatb6Ocxk3SZtb+lcADydvq9Bt6380OQqQeqWQO7rEb28W22BbbYvtPbgtA6tx8mvszGKDGVmzAhwU/7h1jAYBpx2kC3j7WW6O5INDIw2v+vH8d6dc5oO/P+bz9/90HLjRzcP91JStzzcy3/qWoH7jIvc9RnWKsAXfMMGXQN/QBzL2+9DMreutzD+TorclJB4yiWZc1j0cqF1547T95t3JPjQUSkQXJB2WhTeTiGvTT2mMCUGg29qqm8q89QTrxivfORPBUm8ytpDqborCMqktBgdkrWmmE83kDmYQb1TIdFvQkinvs0WbrOiBiG/hGJK6PFaDp4WpqNGPoC5rzBsn1smUiIBZAewqro1bThDDGRUmn6hJSTXchjjq9JHOzs9x3370MDQ1RlEXaRObz2wZTUZwXRkdHufHGG1i+fJyJ5RMMDw7RarWYm5vj8MFDHD18hPluh3a7xZJlSyiKgtnZWW657Tbu276DBx54CAROPvlkvNg4RsnK9j23DZGIK4uUmHIUvkAlEmJNZ3aOQwcPm86ECGOjYwwMDqEx0q1rqqpK1+kZGRmh8J4YAjMzM4RomfCh4WEb+3wfUz27SwGpLwoGB4eZn5ml3R6gVbQIVW1siDpw9MgRBloDjA6PsmTTEhsfsUCvCpG6CskMITaBceNYISk4SWBITOUYqAk8Zk2Cuq6bQFw0BTE5E+iEGNQYLGJaHD0byt737B6aNWhIz18j8qlJl12Sq4Aa5dkcSNKxnAlohlROkIG2fs2EfH3asGdkgaNGvr7spBHzu5cAFlL/VQSTUJCEKKfQRXsOKwu0JLz0iHKJKuwcdLs1Bw8eYM/uXTzhhC0MDw6yZfMmrr/hekJVUfq29VUMvKhD1ZSSHDp4kNWr1zA2MgwqrJyaYv/evaxbs4Y9u3ezcvVKBtqDlEXB4MAAMzNHE4skpppxc0dRtbcmxkgdeqKaOEnPXBrfPLZNOYtZmhbi6XYDS5csYf36DRw5UrF31wE6s13Wrd1Ia6DNjgfuQrSg8G2EAiSgEhFn5RJInjeywKhDEnAqAlVd05mbBSLtgRZVlb7b8rTKkrmgzM7PGsDzuF3TeqwCsCDcabLQ1NL+XmiomNl9ptk2NQFt6AXADTaTN18ZpMiFDgZw9QimmrgJCViMaWPUB/BYPJ9/kzNBOejP30vvZB+d3z7I+iq9oLq3Scwbm1RCIblvvgGLe7+V3ng1QyZ95++DLZLtbkyiQg5Ql/VEpNnw2S9TBmgB3bU3PtpHU5WsX5AgB6P95utNwEvMeEPObKWyErHrQmOivy62xbbYFttjp+lP+VMPGvZ9a0JMjLJ+xFd7Wix9LAFtANw090rv+0DDulN6Yo+9KT0Fz5LXimPK6LR/jWgKJo7pQ7qGPjB+Icjdd6z+6z2WiQDHBOL9fexflfJcL02c1azLkvtiY9c7gwM1LS2lVzyhiQ/nUn8EISYhY2mObWtgBl9ENe09e9fagDeaAPKMUCzo9+N2E/ZT22MCUFA1BwJBm9oU54oUXJpqundC0EDhS1M47XtBRI2xbUCDA/FkJremoC99M2ULeyr6MXdAaQLYsiwbUbrexl+ImoUa7YFzzmo+RWoLSuyM9D9kFktKE+gVZdnYJ2rKSksq2xCEsih45MEHuX/H/RCFc84+h7LVokgWgzkw9Eloqt1us23bNsZGlnLXHXdxj7uX9cetZePGjXS7Xe648y5uvuXHTK6Y5swzz2B0dASAgYEB1m/cyPU33sjWrVvZuH4TpW9RhZrCmX1ZiElVHKuhd2KAa6fTpdPpJG0KR+FazNVzzBw+QlVV7N27lzoEznrqOcQYuf3226mqmqGhIeoQWLlyJatXrmTXIw9zx+23U7ZbKNDpdHj6eedRDrTTfbcAOaQylxgjc3Nz7Hx0Fw89+BD379jB1q1b0RA5fPAAd91xB1WoWbVmFWvXrkvAUExCZwYUgDbZ76AWRHpfJDp8CvrT/Y2aBAJjbNxD2u0BqqwXkb7fBPC1NiUVqG1+j/2OgQYpcE2sBe/72ANizg8ZlPDeNvnZfYDE3sl2nJn14DCmSA7ygebv+pkEmXVTFAWxMqDHJTZDrvPw3qc4wa7Dzl33MorOWRmKqgnoqDZAUpTMRMmgRqSuY6PfEEJN6RyFt/KYmSNH6M7PMzTYJtR1Km8yVo8Tz3y3QwhKt1OBWrmIlwIvAa2DlV9I0pVQZWBgAOddEkaUxr40AFUMCQ7plYiIzy4dNIBX0SqpQx9QnRJteAAAIABJREFUJEKoAhBx4pmamOQFL3oBc7OBq773A66/5gYGBj0rV02xa892hofbQDTLyFSLaMBjwKf71vIlGkN6TlIIFSKzs7MUThDXc/Oo69qELwWcb9FqtxGBsuxTk38ctfR2ps1ApoQWzXbH9SU0er/oP4AFzAuPuPA7DZjQLB0u1WJqKsmz7UbIsk7ST8nMZTS+b0OWNRdSKU2msuL6vnNs9qU/WE9LdePY0F/OVzSMjAVX0yyTeYPUn51xzXol/WCJmFSVbaAcGuDaa+9g2xkn4ouFK1xzxOYCHJmnYACN9IZVchGEAbdkkEFgrltx200PctIZGygceI0gdRqzornmY0ZosS22xbbYHhut4f0fO0NJkqzNeiw5E29JwbxO9FlANIB2AwY0hz12ncqBsSUXemy8lLgQ077pi0Z6P2sA6mOD43xet/A3TesJ/Da6Awv6kxwnFnye17r8dxzz98eCEP3aSDkxkPZifUG9LviJRwgmbNz0S8mlda5h4GnfWOfzpDX4GAbdgjHK5StJpPGnazAttscI4K9orNFQIamGXQAXbbNdFgXeeYqiBHH4VqsRvuuhWRYMiff4sgCXhBSdN/X0orBsbF+W2CU2BEqjrp8p42VRNDaG+fOss5B/r5pcCnyB92USqUsPXH75RUyYDaOCk7K2rVaLwaGh5vgxKlW34tCBg9x2622ICE/eto3j1qzpWT320eyNym1B3vDQMKedejpnnfVUiqLg29/+NoeOHGF4bIz1G9azfsNGTjnlFAaHhhLgAuIdY2NjLF26jHVr1zEyMmLncL7ZjAoG9CC9mnmBZkzzWFh22oLubrfL4cOHufeee5k9cpQ9u3Zz+NBhTjjhBLZu3cLGDRsYGRmmOz/PTTfdyMqVKzn11NM4/vjjefTRR6mqqgmEe9ebA0azxUTFgnpx3L/jATRYQDs7O8vsrCnkCy6VhjhjJqgdx4JM7Y2nQB3qJtC2eaQXfPcYJ0KMxoTITIXm6W1AA1sYVKWPpZCQW9W+76kJfooF3FnUMyuwI6Yz4bwzEURoavkdkjQbbHsuSTAyak9fYYFmQmMJGegXDzUBQXCFN+vMxE6oYyCkQFc1EmIFog0wkt8DTeiuaCodSXVmToTCCVGTYmA6TkxlIKHbpa67DWBXV12qqtNcg7E1QmILQFG0UilIAhPF3h3nPBGhDiEJs5orzOjIaG+cnc0H2X40hj6L0sJAs3wt2a40j00eyxiNcRICaLR7672jVToGBjyrVk1SeOHuu27niiu+w9z8EaZWjNNqO1TtuQpRqauQ7EfzmFhfNCatCFU63Q6t5DDixcq5BgcH8WXZzB2+KGiVVtrSarUet9FVFu4FCAjz3ciu3XPs3jXHnl1z7Nk5y/yclbVEskdB2kBEwey6ACWVFNl36uxmoErVqenM1+mXCahLTgFEIdbCn37kG8wcralVODrboVtbVWdTwCe9jEreb2ZAsVbT2+llVvrUBPqFf7V3/kwnXaCYEBWXtIdEndFqUynG0cMdTLIls7JCb87RgOT3lIhqnbI2AuqoOvCFz13F3GwXk0kxAcXZTmR+3uZhG1u71qj2/9mZiv0759j76AwH9s+leTSgtXJozxz7dnbYubvD3Lyde+5oxdve/O/86KpHqC0rgG2KfTN2i22xLbbF9lhrmtehZuLOIVXAVoI67ZGAmHS0SHO+uibGzfFEToBGzQlMmv1q2jqkY6Q9WEygQWJW9jdJluQzR7tW9tkEyTmQDjRst771NOfmbb1ISTBACUSy71ruW0ZBNF2LJ2guG04roZqOnLU6fd6X6I1pf6sBsvi5ybbbHq8LX/nnK3lwx64E4vfW9HSlSARRj4u+h9OgoMFc2TJEkWsl0++iCjVQu8inPn0tDzx4lFqTr4SCEJJtpPYBQbauP173Xv9P7THBULDcSApOU6ARqxpNYnbipKfI73xSnE8ifwoaYhPEK4J4KzEQBVfkWnLzJXWASyrvVk9u2tO53jrbGkIvcLfSCOurc3mjl8CF9F7Udd0IM7qGqmOBjHjTXNRgwZIrPHOH55nvdAASgFGy/9AhbrnpZsqi5IStJzA0MkzZLs05APqo6zE5Jjjm5uaoOl1a5SAjI8Mcv3kLt9x8C92qS1RleHSU6elpxscnKMqCqq7IApdO6qR4r412gKYae1JQlss/MnU+15rnEhBNQMIN11/P7NGjLFm6lNnZWQ4fPoQI1FXF+Phyli1dQlmUFM5TlCWd2VmOHD3K9MoVjC0ZQ5wwMDi4ICucg1er61d86el0uqxYtYr16zcg4rj+uuvpditGRkY57rjjGB4dZdOmTRS+bWNWtBJgABozeORp8olqoIkvih67ABo6egwW6Aqmn9EfUMfEMHHOUde1CYmJPatWbmHBaYRmnBsnBZEF85EF71k/ITFuYp3KJkywsGFsaOz9Vk1sMHUa6NN3gGRx2bOFtHvZAzcQoUYbMMN53xfYx+YaTcST5t2IIds6GtJugXePiWBsCVs4VCNF4SkKR7fqUFUVdSqBaZU27hnMimLMnzpk1kNkeGSEAwcO0Ol2qaua2dkZnPe0BwYoypK9+/eydt06js4c5dCRw6yYnrIg3SVbxhioqi6q9v6GEAjHiq5KnxsHAkVEJC2+IhS+pA6xAds6c7N0u5FVq1Zx+qlnsPPRvSiB1eunOPFJG0EM7AzpeBojwdc43xPxFCG5jZgDStWtGCxL2q0BIOJLx+xsB5eeMSurcs070s9GeVy2PoX/q35wLx/5yPfZvHk5BRGNgeNPmOS1v/Q0fAlRrXxHYp63BZxP2iHaN51nEdLI1//9Bpw6nnfJGT29BDux/VPNsveHV93Cec88nQ/9yT/z6ldcxOq1S6y8RbO1oqEW/U4CgmVC8lIS07kzSJeTINKXTSH9xsCUVJubMjbaKB9kQABiFXnXOz/Nh//0DbjC5jZN388aLlk/IWDzm6TrDAG++MUfMjG1lKedd6L1NQhXXfUA//LPt3Du01fxgheeZn3Mc6lEDh/u8td/8R327JwhBBgaE17ys2fxxCeu5rqrt3PppdcTIgTv2LxxjF/6xfMZWzLIu9/7PH7vPd/ky195FeWAgbNKf8YjMSd+aoZrsS22xbbY/nPaLbft4bprd1PQJWJJvudfcgpLl5SoxPRZztq7BMTa3Ct92XyNmlj+gZtvfoi1x02zdGzQSk5z2YDaLGh2jeDVgmlN37FlLFshGpDxsY/+I2s3TvOSl1xE1jkLidGwoAovxUCZRSfJpcHKgBV12aw4qUJo7i8GaCRtIWNlaEqmKbfe8jDT08uZnBgms38zGzb/2wAWKyG3ed+b1brC1/7tR0DB9JopugG+/tWbOHyoi+I5/bS1nPjEqT5HIMMT5udqLv3yDdTBQWjzzIvXs3LFcBNLfPWrN3LwQIcIPOmM9Zx44hS+1eZ1r/s8H/v4i9i0aZzCZdClBmmlK8sI0OL689PaYwJQ4P9m773D7brqO+/Pb629T7ld96pLlosk25Jc5I47GBwIgQA2LdQJCS2QAfIMkEJm3mSSDJOXZBIIaZO8CRBCQgkQSGIMBEwxbrhhW3JTtXrXbeecvcr88VtrnyOT+et93iee13c9j+wr3XvP2Xufvddav+/vW0S13DEmgz9Uw9wJnrJsAKbukGqh1Tf8s8aAKAXbpJx3Ec19j0bjJfMGzTlH5RwF6l9g6HcK+5F86aGCupgVo53ikMzqsnmbOuCb+rmoowEzEAJpIvFqom9srZ+WwqqJW5IVOO84duwYWx7dytozzuTg4UPEwwcZHhtm6bJlAwyJDGrkwjawY9dOjh05yTnrz2XfvgO4ECjKspZHGJuOCQUjrDV15F9hC2rihVAbQOYJBrQoKoqC6BSVK4qCZlNZIs55ut0O+/bu5TmXX8Ga09ewfccO9u/fT4iebrfL3MwsvnIK/MRIcA4fAp1ul4hKHeY7nVM667VMgKjxlUWBqyqqqqK0pRpcosdbNMqaXq6gRHGKUaTq+IsBdkrqGBc2dcoT7V1UTpB9NUyaGG2SgEimNScmDNmLoT5mU983WuxphGgcKPzqlAb9QYC6aK8nqchA0Rjr31Fk2teIeEa0rem/b+62q9mgMAjQqHzE18cpRlLChhbfOZ84Qx1+gPYPap5pbWKwBI8L6g2gSLmi6kZy0gMpq1j9fiMwOjJCUZbc/8D9bNq0id1PPcXU1BRDw0N6jiIcP3GcTrfD+PgipfQbYdny5dxy378wNDTEimXL6XTnWbtuLc1Wg9PPOJ0777lL7w9X0el2mJhanMoqqZ/hSP+a5jSZGrAaOMdaIhUTpV7QZycDj1iCixzYf5CHfrSFk8fm6M5EOvMVphSmp2eJHppliyp069+vP8PgCWSTIKlBHQUKDM73aCQX6G4CHLPBrHOBShy9nsZR9bsbz64RB76KqMQherjpZefz+jdfRmEivUp47/v+lp6LFGKYm+3iq4DvVUxMjlCWliMH56iqQKthmJgcTqmMQmfec+REh4OHDVMjbcSrBCWamFiRCYAw8HNvez6To0PsPzTNiSPDHNrXY/GkZ3hEEz4OHZkhxECrWTIx3mZuvqfgeBU5PttjeKRkuFlw5OgsPhjGJkqGh4t+KkL+T7TMz1dEA+2WygBmZns0C0ujYem5yJHD08Sga+Hk1BANBFcNEQJ0O57goTVU4kJk/mSH8bE2Eahc5ODhWZDIyFCD8eEW08c63HXXbj7yP15FNDp/bXn4KR5/eDdjQ5N411YQI+MdOsty5PAsMzOO3/rvr8RauO++vdz6jW1s2LCaL/7jA7zjPT/B6lXDCIZfet8XmJ11jE+WXPm81Zz+d8v41F89yDvfsVlZXHVKRAZ/Y38HvDAWxsJYGM+A8a/f2IVQcs7ZE2CUDfuxj36LX/31F0E0ZKcevGBsZqVBCFo72LSmiJHULLX881e28oqXDTMx1k69+L4sTURdaHKasCrUhGAVaCCAiZpQFCPcfNPzOT4zXbPeYoyEJLkzqQAvgODAi651RrSplOXCGWz3SUIRJSImCQejpMhf8L7vgRAMFGL55te2cv11G1kyOUKUvqlvbsyGqGuHJGZvRP0OTBT+6at340LkJS97DsEKn/vMnbQLy4qli/DB8LnP/ZB3rriOxVMNTQdCcBg+/ie3seHcVdhmyfe+tY9vfO1L/PVfvx5v4LOfvxNjLMuWL2LnziPcfft2zj9nGa95zfkcPXSCb92ynTPfOZUaUpltnlCbU8bCOvT08cwAFKICCjnFoAoeSYaKla+IXijKprqxJ2ND3evnNIUUzWhC3Wk0hSW4TN3OxoIkeULRpx4lJoEIqbgc6I4H7WabhBioN4fe7NYW+OApbUkIrj4Ok6QWOmHo+/oUE2gKo8ibD7SHh7j08ssYGW4TUzE3tXwpG87bpGyNwhK8o+equqFGLgqdI4oyOYxYJicneXTrExANVeW45rprGR4epSgatNvDTE4uVtlFjBTJEDJ49V9YvXo109PThKjJF4Pbdcld/QCVr7AJsMnABlENM4uiZGh4mAceeIBOr8vu3bvpdruICJOTk2zdupWHH3qI8fFx5ubmWLRogqmpKSanprj7nns455xzeOLJJzVVoKXMgjDg3xAyDSwEjh8/QdXt8dgTT7BlyyOMjI0SjU5ItiwobJGec1OzEtTYMUlOvE+fSyA6vaYxdfyC0Z+XVBirIa2iviHp6zOokBMrAhCTuaex/QnGDBT5WUaTvw5BwYuabRalBsTE6r2gZpE6Ueu5KHhR9zcT+6EGJhJ4lJkICrYpiJI776TftWJSOkQAazBloV/7mPTPAwwGEiiVAQ7viV5p4NbkyEs1jcTngl3fIyPboMkaI+0hLr7kYr79rW9x9NgxxkZGOH/TBtqtdrrhYH5+ngOHDjK+aAofPY2iZOXK5Vx2+aU8+fjjzM1Ns+aM01ixagVF03LmujM5evIoWx/dwsTEBGvXrqfVaut8EA0hrcNlUWCsJNPRQB9Fi6dcG4NKTUJG5aMm0Pjg1VchwvTRab759e+wd/cBDJbCNCEWVL7iqX076LhpXvyyF2CbhqJQILI2iCVT4SW9LhqFK5pqYpx+pr1eFx89tmjgnNckFCN409f+hz6P8Fk4MgCGsqkAnGBCHzcMEvFROLh/nve8+/NcfP4SOr0Z3vofb+TQvmn+6R9+RNcFtm0/ySf/9g2UBqgCn/x/bueRx7p85u+38Wcfe4F6Shn95DyBAgsGXAW//Mt/x8c//hb+5q++xz13OeZmf8Qb33wmF1+xntv+9TG+/Y0tzPYcHTfER//gJ/n7f7iHiYlxHn/4GNuenGXpqlHWry/Yct8BDu8TzrtsMe967+XkzJXU/iEE4Zav3EtrrMELfvIiQoRPfeZ2Np+/mssuW8/nPv9DHrj3IMcONPniPz3Cd+58M2euGcelGeM7397KiaPzvOLVV3D8+Dwf+fCX+d3ffS0VkS996WHuvXsnx453WbF6Kb/2K9fyJ392G2996/MAyPk2G847jbPPWc0Xv/wI0VbUWtuBjZYetU0bZQ+h4I67pnnLyR6YrFhVZkWvN8Z3vrObl71sLaWBD33oav7iz24D2QwoJ0HNR5NrtzwztisLY2EsjIWRh6Xiks0ruezKVQQB14l86XM/RIKwd+8xDh6b5v77diEdz2vfdBUxCp/59HdxleWcDSu55vp16vkW4MH7dnPXD/Zw792z/PTLC3LsZEy7E3BEYL4j3Hvn43Snu+zYeYL2cIufed3lFBYevG8nrZEm3/72I0yOT7BqzSgbNq5ONQ5877ZH2bLlIGXZ5LVvuJTGkOAC3PpPP2LXzi7D4yWvfcNmxJzquwMF0cNtt93Pc2+4AIPQ6wXuuuNhrr/mPLxEbr3lIZ7a1iEgbNy8iGuuWo+nwBtDFSPfv+1Brr32QsTAHT94hAsvPoNmu0HwBd/5xkNsf/wE5VDJa193Ga6qeGTLEW5+1SWYQggOdm8/zstv2sy6c5ZRefjWbVvodX2KXFaPKxuFp544wtvffB2tRQU3XH8W7/qF7fR8ZH66w87Hp3nTmy9n2YpxSEa/Fk1qe8FzN/GL7/4GN7/uAqYmG5jaayjvK/rMZv3H/+/vr/+TxjNihdbiOyi6lqg4WuwUdcZ4duMvbKnbOp/o+iEbn8VawmBTEeVCRS9WFKlDb4uC6CMiSiFWs79BvbTeH0XSrVfeaVGR2jA+egpTqATDDHY99edNYgFot1vqzqS1ykTQKL7U3LKWJcuWKa1GwPnA0Ngolz7nCu2Me4c1om73ZY6JNAompK5rlkAsXryEG2+8EWtKQoBmu0XRKMEIK1auZGrJ4roAzvn2oHKGCzdfWB+b867uFJOo8YJq9gnaCY8hcN55m2g0S+2AY2k2G1xzzTVse+JJgg+sWbOGqakp2u02Q23LqlWr6PV6FEWB947h4SEazQabL76YXbt3gTGsWLWSs889p5ZYZCNGUsGQGQDnbtiA6/VoNBts3LSJ5cuWJz+HyIYNGykbzRTJl7rwVogSa1+ATMcnZllDMkuMkkJAcvGdivWks+/1epjkxTHoTWCt0qZzFROj0tezbCAzOtSQUOUuRC3SJcTEFjHJG8JgpCDiMMnErx9rGk6Zu2rJREzSigTyZFmDGob2mTb534wxBOf0mJO0xSdDyEGiClnmkpI+fDK01GsX8q+SvRNIqLJzFdEH+skWCpR0e10MljWnreHGF/4E3jnGR0eZGBtP4Ij6CUxNTTE8Nqqmo6hkw5aWjedtZM3pq7HG0h5qg0Q8ntZQi4su3sy555xLq9miaBYpTcHgvINGE5H+PeyiMoQUVExAZGKx1FpFFOQBfc59dPRcD6TAAseOnuTQgeMsGlvGBedvoNUsaTSGOHb8JLff/T2OHjnG3GyXIdtATFDKYpaFxICrgqY6oEBHSMfUbDbp9uaYnZsnRqexqemzsNbiXaUMI7HEkCJNn4UjRzWaqOChF4+XBp/49FN8985dlHTw4rjhxRtplnqtJhcN8d73voD2WJPtu4/xra8/zAc++EJMu+SVN32Zr37pcV78k2fyqU9+lyuuWssb33oaK08fIZguwZI+QwZiw7W141wTI/DeX3oRx098mzf97CWsOXOMH961m3vu2MUb33A1M/PC69+0hXvvOAK9ET71ie38tw9fjcHw5jf/DZdf8nx+47cu59679/GDH24n1CV8RD1ZFNy86nmb+PjHvsZ111/AzHyXvbtnee3Np/Hlz9/F+Eib//w7L2HbI0f4+m0PQ0iGkjm6NhR4n2J6g+BiSYjCV7/yEPv3n+RNb76KnTsr3v2+B/mZn5nGRwX1bUwCkCRFohDEqHdLPfIeqzYmS20va1i3bpKh0Q5Hp+cA3eyZCMHAz/78Zv76L27n5T+9DgOUkgLSfIAi0s9MjwtgwsJYGAvjGTkcJbsOdpnccUy1/Q6GxhqECDseP8pv/rcv8MFfeSmjQ006HcenP/0NzrvwbGbnIn//qce45NIzaI8UPLplN9///oMsW7mGux94jCDPUxlqlksoJZcYI925ig/96pd4z7ufy/kXncZHfv8ubnjB+axYNsS/fmcbP3rkCd7+H25gqN3ms1+9k6UrFzE+2ub227fw5FMHOH/z6Xz8j+7l2uvP4cwzx/jKLT/CVT02bV7BH/7hbbzwhetZvHRY3zbmHq4nBMOt/3wPl120gdHxFgf2H+Ob39zCtVeez7/8y4+Yme+wcfMK/vOv3sqlTy3nquesByu41Ij7u7+5m2uvupAIfPUrD3DW+lWUzTa3fet+Dh8+zsaLz+Cjf3APz71hE7bpOXSiw6rTFwOaSiZBKIBCPNEaJhYV/PHvfZ3f/vDNUPb9iBCPGJWaI5m9DocOdzh0qMEffexujhzfy4rVbd7ziy9haryNGFi/cZJNF7XA5v221ncDAZbIoFnmwjhlPCNWaW2EGqxJrvxWMMZShYCJYGxB5RwSLcoM14crMwBI2qMQNawqFzFZb1zfCir4BHLnWGqdagiJ2ZAprcFT2EK1TgZEIjZnr0qk59V13qQ0hOADJplAuqiIIlHAGqRCKUExAjY5ckeaDYv3FVFEQQOBslninVPphDWUpSUaW6dgRBHKRqmabOcprEFMpN0eSh30AsQgaHd2ZGQ00VL7habuMQXwtNptxT8ldcGh7lKHEJQtkTt+yUdh+YoVhJhj9/S6L5qa4oKRkWR0qLKQwhYEH3jOc66or/eKlcsAofKeyalFjE2MYYxhRbFSO8MxasRkjJRFQaPRoCgLnPNgAudsOIdet4e1BWWZCvwEdEwtW4r3uh03ApXziZkBPjhCVGaHJ+JioLSNOpEgJJ8BIxbvYq19NmK1by39DHlJngnee7x3RCKNUr0aVFZTKYPGSh032Wd1qGQnBmiUjVpyAyl5IBXjxkZMVCq87qkjJkkZikL/n838iNIHgmqpSHozSWAcsQaOfIwUSZdfRWUciCRmQvLLUU8Er/4LvqqBhRg8NlHBQkx+GyFq997GpAvXez8baOZUCi/6nKxYviIV+X1zUR98Mh40jAwNpzjNPgsjEhkdG60BH2NtulaB9lCLdrOtgJtEilhSpc/aWu2ZBhdqgETEKO08RGyUFCkLEZfiaJNfidHoTu89Nl3b4HJSiCMER7PdYP25Z1JVgROzRxkeaajXQYy0G01c7EGIfTaUsZio/WcjkoA6ZQcZKZJfR6QsC0Sg1W7Sc47gPGWrQSwKKtclxqfHCj7LRtaZAUnRyRtedxavfeMFZO9dU0CBYGJk9fI244ua9AS6cw6JJSOjBZVE3v+fLuPRh/dx7907aNg25124Bmxg/dohjPOENBeov4BJ94rOxUIqukuPacxgrccYOHm0y0M/2kflO4TY5lU3T7F4wvBEiLz9rRew9qxFmAivfMV5rFgxQVEItgxQd/4TnzXatJ7B5JIRzj7nDL7zrzuZmTvMlZeuZmKsxb5901x55QoapXDO+VO86ec2YmLABLAJ+PQGfA2Co/NCgEP753ngwac4dOQEMQ7x6ldOMDpskgQKBdPxmORVLtFiYlCabd5UJUmEJG1wViXECHOdedae1WZsrJHNyAlGI4gP7D3I9defXu+VJVF3sULEqyv6oGP4vxVJtjAWxsJYGP+ew0T++ZYdPPSjx4nSxYjh/R98IdGAj8JrXnUdz73+XESEL335hyxftZyrrj6bzqzjr/9kC/feu5eh0cAd39/C2975EhB45LEDaMykNqvq4jbLgSNcfNHZvOJVKgW47voTfPSjt/M7v/0CfLS8/Z0v5rILV0MA/5USMPR6gU/97Q/4g4+/hYYR9u6Z4f4HdjG1+Gz+9I8f5cYb17B7106efPwIf/Sxf+b/+s1Xkyl/qb1CUQovful1fOFzd/H6n72OP/zYP/GrH7yJmZku3/jaE3z492+isMJNr1zPU3tm6mZwNjEMMqwyCYGKFi4KnTnHH/7+7dz4gvPZd2Qn23bO8nu//x0+8CtXU3tN4RAKNWSUFKUOvPtdL+SD7/sbBrbXRCJXXnsmf/nX30ILRsPuPR2i0drmoUcO8Rd//lMsW9Hih/dv528/czvvescNaV0UpOgqKxCV6+YK8sdHbsEtjDyeIYCCFsAxFUeSJAO2KOpurjEFMXiNqSPdpCjYgElWWjGBC76/8ShtgRH1T3CpSy8pXyWb7XVbDY7bNl60QCnQ1xDTIAhgPAaP2KKO9wOUqYBQOYdL8XtZbnF8aJhjHcd+icwXRQItkoNpKsxi8LmBRKo0kxwh9L0W8u4vyRGiD1oARv0da4x6M2SwQAqI/dxZY2oFeSoATfqbAOrin43jctxelohYyakBLpmKGUxKnHDOEaPDZBaFWOLQqG4EU/c199lAO9k5BaPX66VufZG+l1kbRfLSoC7AjTVYYjKirNKxaUc7RI0/tLmYHmoTfaCwTUw/P7MrAAAgAElEQVQMNFxFO4DpdQkS8L5S4KpoQejR6TmEQJkiByXJC5SwktguidEh2X0mavGXWQeRoNdJEghhhYbVZIIs4cnyAWuLGsTSiHW9lzPDIqIuNEVuhwLB+UR+yHBG4vCHBBKl62utRTJgkBkNqSiGOIClJf+QRLnHO4pCUlZ8YstEn6QugegCEpPnriokcN6lsDxBYqAQS8QQQlfPTwJVYTg8PIxvNCCokaQvAjFECmPxLnk8kFIvYjaLzDGPiZViEiCQChqD1ACNPgJqXmii0c6rBErfoDIV3dAhlEOYnqPwFWJiLZ+JyQHZGAteXyuGiCl0HqpcT5MwUPDFJoBDTGRycozR8SbTxw9z2+3/SnvRT9AoGzz0+AN03CxrTz+X0dFhsi9HNuTMUYeFVRmVGv1FonME56gqpywglLlibRNXdWuDS+9TwJ9Vs9miLBmUKD1rRmItJSqNUhZjj6bp0GwKxmYfakksK2WXZeNCnf4DPuj1NLYCM8/Q0BJ6VaBXKcMpOoMEo+ZQIb+d1MWy89QsIA+E0CB6k+SWFS9+6Tm89mcuJwJzs3OUhSHc1cGaSt04BMQEfMqmzHnkEYP3sQa7FeTVaf2FL9rER373W1TVLP/9wzcRi6DaWcD0MmigmzDyOgcECnwoCA4O7HF4N57SGHu84XWXcPW164jAzNFpRsYaEJrsPzjPOedqR8bGNB/UEWfZ1RuIhkP7TzK1fAzbsIixzM97Wi3LIw/tZ83KUcbGh1g6NcyRQ3MsXjnC/Izn9u9t5Zd/5aVE6SuEIYd1CX0ItyaALYyFsTAWxjNqGOZ521vWccUVpyGmXpZwEqlMAKNNmBAgeAulpTCB0ZblhS9eDrHHXXc8xeZLNui6LlBKRDx1V1x7Q9o4JSqgYKxD1ICBm356Hf/zT/cAIHjKIiLW47zun0QVrURp0TCRQiKvuvkCosDBEx0WTw1z9VVnYG3g2qvXsnR5ayA0USsGE5Xte+FFp/PNW7fxta89wIYNKxifaDE/0wMjGIHC9Lj55gv44z/6LqlGr2Fhj9P104MPLcAQvLBoYhlXX72WYCJXXnkOyxa3FLwPLd3rplIiFp5KwEWLBPjEX32Dt7z9urqSlaDShVe8/HIefngPzmt85g/u2FM3i6+7ZjGrVrWwjcC6tUv5xte3cOzYHJOLh3R/nxpwUUK/lsrrTwSSWeUCmPDj4xkBKAD64SUdeaaVZ8q0OulLHT0iqWWje5ysLVdWg26khGbZqGMhg9NO62AMZHZzL4oG20zBvUOpqPQFBWWi1VqQgKHSjr+kqDkTU4GsBX8wBcGWdObmwHtGWk32EtnbHqIXAu1WSzekAQyJ0h8VUDBCcrkPqHO31NuouqstUks/1LnVnxJtaJIHhIhJzuX6OjHE5AmRmnmmv0EDCF6RvrwpHpQ7pOa2FnAxKC0bg0hOKxiIIczHLWjhN0DHz3p/HYl+69V009gcPVnjr/3jQAtXQUERBLzz9c9n8zw9rWwkqf4ImBITe0xWjlVzHZaVFh8cXVMSgsXQxpiAd12sFarg6wJdhHT/5XCaJLWp0y5IVmEkwKeo7yfnM53+x+lQCvaka5fMzDRxQEEJkZQuImBtqZIIhByOo8BQPy0iioISudAJRL03k6kkGVnNm/4Q6zjE3OUPzml3HI1f9F673v1rG/CopMjYZC4ZI4glBsFGS5Amc2IIhScGSywMMzEyXTZ4dOVKiijgizRB6+SuBY9+2jEkcx/fp+8bkleI7xsnpseglhP1J44IUuGlwAWDJWCloJIeXYkMh5JVRw/T7s4kcyTTZwyEiHM9yrJMUaCewug94FO3NSZ2SpXAKGMLFi0d5/kvei6Pbn2cSKA12qBRNlm5ZgWjo+s559yzKZsNfOil1AtJmGB+Tmu1SXpGkwRGhGarqfOV61GU4H2g0bA4F+l2ejgxZBChKJ7ltLvsSEVExGFMVU9xksEaEwk2EssuGN0KLF7axscev/vhW3BWAZyfuOFcNl+8hk9+5n5+57dvod0ueGzrIV7205t54KHtfP2W+8G3lUXiPSKRi644E8w8QYSAJYSCv/jzH3Dza85hzVlTPHDfE/yPD/8LiEGk4hWvvoRgK4JxpFuCaByI+rcYCRRU7Nl9lL/71D1JdKU3ijU9Nm5YzE+99Ao2nLeI5cvPQkpDIHLxpWdy69ce5rZbH8VF4Z4fPMXrf+ZyvIk421H/HWe55R93smf7Mb7wxR4XXzqMGLjwotV885aHuPP7O1UmIXP87M9fy3OeczZ/9If3cu21q9QzPCalqYlQ6PH7tOH60X3b+I0P/QN/+8VfYtnqcZpDLX7j1/6RRVPLuee+XXzhC68hmMgvvON5vPJlf8Fznr+OR56Y4yU/eS4jo/3o0+9+byvXXbdeDb/SVrr/pC9s3hbGwlgYz7xhcFjRvXbNACMVtzFiJNR7VTX0jcRgknmix0jg4ovO4O57d3LFFacrkyvmGiBHTeqeU5szER9Qc+e8Vw8xc58RU5Fj6YzR95BUS5nQwwZdU3rzFd/+3g+56MoLWLpkns0XLcM04eSJOR744aOsXD1B8AoSiPZ6icDwSJMrrl7Ng/ft4cUvPY+yhLkYEal0fxxKvBdtkAImVtjMmIsREyJ7nprlobs6iNeG4cSiHudfsgIszM31uOv2Bzlv40buv3eGPXtmOOv0ETBwzZXruOv7j3L2Wcs4sOc4sycja89eQQS2PbaP3nzFOZvO4FvfuJvnPe8SpGG4//5tXH/NEhpGsMFwx+0HOXB0jiXL22zbeZiJiTaTE20kpuZg9MqNy6709Yca+n9dWI/+zfHMABQEGo1GKmjqtodSjW1JWdo+SyH9Sq1Ld9qt9+lBLZLOPXsXVL2evoUk+jgM6MktMVrmg0Gk5DxvGK8qou+ACL3oMWLUrCsEQnQ1YyAE12cQRC1MKucoixKZcywCPF3K4RZVLyj/tlkgWGxwBHp4sVD1jU+UdZ4mglxw1VyC/oSkNbwCC1qgaMyWkRT7F3JMoCEaM1BI5o5wkovEUP+JyVAyswv02dFZRDvXRWKJpGOUEu8qIEtHUmc5pthPr9cuvy96CfU8jNLuJbnXG7F1ekBI56TqEFsXB8YafKEyixioO5Qa06hFalRECiMFPRfY22zy+NAop893ETxPjTSYmungjyXWQComfKXnn00G9ZgBCWida2rQQP/oPajFfRi4v6T2Smg0GjXgk+pzjMmxf8kUUkQjIkPKuk/XLobk4CvJ1C/dryGG2o9DkhGlSUW2d3UL9WnpBQOpGQgxdbsFiN7V3gWRCNEr9uC9glgkrb8YfKzU2yTZRBYBqsKwbXyII0uWIsFql1Ei80ULMUM44wkSiI2IFzQvmQSekeP5EiBSNFJkLHrPek8sTX0NSYtaTXuOyqBRaKCJj9pJjuJwRghSMle26cYmZ+16kmFX4SMUaR6IGYjMqRuSJQg6l0RRMCFEcCFQpvsciVS+xxnrV7HqjGV0ux0arSbNRovrFl2JtSrT8VR48TUTwftAke7XECJYUWaHKHCl/iKacGOMwST2gXMVRdmi2WwqoNNoUBb6vZwC8ewcebHXOeKyK9ayebNPyalZ/6jdmZVLR3jfu1+kBbOBJUtGedvbbuDY4Rm8EZrtkjWrJzECH/jA8zgx3YGoG8QVy8cJ0TP2iiuIIcWxpntwbHKY88+7GYnQIPKe/3gFR4/MsXzpMKOLhph807XMTneICGOjLZatGGdqyRhlUWAjGIm86Y1X0hpuYU1k4/krOOPsSVqtJq98xWaldiLJHDgwOqZO1i//6QuUzYXOK1dfcSanLRunmld5xstefT5nrBmjKYbf+vWbadvI9devYt3acYoYuenmkpHxEiuRSy4+nZWLR5mb8wQDU4uGmFoyzLVTY/zlX36Tz376Xl7z+ktqLSoSef6NGzBRKNSlmLPOWsrvf+yNNBq66fzZt1zKscMzxFDw+jduVAkKEds2fPRPb6LnIx7L6hUjWBTYPn50hocffpL//F9eU7NAfnzPtrCJWxgLY2E8s8biJQUjo6ZGATJDTDCMjlqmpkoQZYze8BPn8md//nV+7q0PY4xhw/mLufnS0xlqNPn0Z77LO9/2SQTh4LETvOJ1l/L5f7iNr39tK8E3NYVMBOeFm199BXfceZh3/tzfYaTLcFt4/wdfjhhYtrTFcLsgm82vWN6k1RKaTeFVr7qct/38JwjG0Gx0+U8feCmjoy2uuuYMfvFdn8JHGJ8Qfvn9L+F3f+eL7Nw+j48QxBNswJTT/M5v/Qeed+NGHnxgKxdsWoVEx+hoybXXrePd7/gE4rXpcf7mlYiB5UsbjLSVGRjE8vO/8FnmO4a52KVoQnvU8uIXb+Ldb/80PeMZbgd+5QMvZfHiNldevZQ779zGmtMuwBi45tr1fOaT3+PO7+5hfn6Wl7x8M0MjLVzl+L2PfJZX3Pxc1l5wBt+7czuf/dw2KIQTJ07y67/2QgorrDl9jOc9fxm//P7P0WwWrFjR5hff+yKwarl81w+2c8GmNYy026lZmiM/+8lcfc7Gwnj6kLoL/u84Np63MX7qs3+TfALUCC2EhKgZmzb7ir+51LXMsYfqOh/qYq/RKGmUBWXRIBKouj1C6r6GoIBFLnKttQSEh5pNnhwe5obuPOPzc0r3x2pslajxICF1kFPfWFLBlVkAVdUjhKC+ARI50R5mZ4jMVV2MaeCIBAkIDTUUoYcnICF3TJXyGpI22qbCx7lQx1bGBJqQHP8lexhkJ31jFVBAIHWhRQSxqs0X+gCIXtxYd4ajV3q3SYyD/LMZgFBTQzUNRFCWhMQaVKg7x7WkAsUjUjHrk/+CZLM8UWqsd05pRiZ3W6OmTaTjDJmBkYrk6EMCgrLngf5OLRFJcoFeITzeHqYyTc49cYJCKuYbBeMdx9kz8zT8vEYeeo/LngdRdDObPl9jEyRLTvDoR3XmNI8MgkW08MwRkIPJCvr7fRAreGUzNJulFvHBkdFPna60G5h9fYPSJ5J3gBASQ8SlGFP9DZNAqDo6QpkKQs0myTIHKwbnenrNEjsgMyBM/fmIeh4EkCBE8cl3QChsQcMFZo1w79QiTixdxqJDR5Aq4LzTjmZQbw9sxKESijKqPEUEqqoikEwJUwJGNswsCqvKpXQ/xHy/pvM2oEarKe7ThUio1IsA6wBDlMCe1jh++RquePxeFs8fJThPEYtUpIXEuOgzYuqEDIHKluxcu4EDc3NcuH8nw66rtDsxyY9BUxn0+Qn1omPE4JMnhZF+8oskZ/uyURCjPnMSdZmi6jJzbD+Hdz9OrE5QGI+IMiYCvvZxKGxBGBrlnqXrWL9hE8N33MH7Pvx5Gu3F/+8m4P8DR5aoCPkR7bNylG4UUlddagYVkP490xhTSkEeucNUg3Cm/2ZkgFc/G/05m7pJalSoDQ2D0g/6QF6+ffU9EkMnP6fk+TJDxkYprZl9UR9romAOeArkeNa6j1/vcBJrw6t0EBP0PsIoHCixPu8AybwxsctiihSLsHfXNJ/4xD38wjuvZNGiNqEIeAkKhgSr+2fj1Ywxp+pITLiDHTgWk4gWfQAxz7NIgGD49Ce+x8rTprju+RtJATvpci1s2xbGwlgYz8yRm0UK+up8lptrIDivEloxOepZCM5SBWVsWiuUqVnifVTfGjT1S4w2bnLDJ8+eIcL0yS7/9Te/xkf+75cmFjeI1aXHByhFEvsYXARr1NcpeoN34CR5DCWJRvQQq8RCKKBIy2byMgdJkZJFpDBpzYhpNZJAEEMVSAeg18YUyRQxXSgBeqrqVTmFgdJGrATwFlcpg9WYSJGWvXvu381//Y0v89m/fxetlq4zvpeOCUFsROzAOQhgITohJi+0KNBQey4iakrs00FYA4UFJOC68Md//DWef+OFbNi0MrG7Q1qri7T+CrpG51jnZ9/6dOmll3LPPff8myf+zGAoAM75RP2nlico7Vkd79VXIccUFpnRgy1LbMPQ6/XodOZxVaUPmFHTPmlEup0w4Eeg94AkGr01EZNdpCRwYuYkIZaMtUcpjFAFnQisMRS2xDmPmroJVeU4ceKkThiQ8sZbNFuWyWqeSWkQRTuPnoqAR1In3JB8FEzAJ0BEW98KFqguX8+rLEvtHKeCJ0Y15MuvEZzHGkOz2cCWJVriJlDGGoy39Z46O/6XRYEE6Hbn6yKZGLBG3eSVlp1Mx6wlEPEuddgB1fsHer2+QZwkQMGkjFtiVCDDDnbMoeecks9NkYz1NDZUEgBRlhZrlAYeAWOKBOBEvPOqgk5dfkETMZyrsFgaRYkUhvkC7TaXhgump2mbHojB9Ty2MEhpwHlsUVKUBVW3SvKAiHMe5zw2KnBhbU528DXQFWLEhETMjZC39TlyNJsxakGZDUL1D6LdyZBkK7lwkbr2scREt/K1eDtPhqnkEZsWrwRUpM+lNkHUNyEDaD4E/VyJuNBL82DAOy14IRkxku6ttBKYCIUx9KImYzSs3s8d31VpSTBMdANnHz9MY24eiNhSNWYxRCqvoFwhFhtSVGJ0NQ9J0mIqRhkCVbdXT9QDJJl+sZSkUDaZiIoYKhfBR8pCcDYgwWIRhkYCh8enKLs9pHIK3KVn3QcFWMqiqL0u8v1pRDRyNuRoVi3yvA+IhGSiaak9MUNMrJOUkkLQlIro04Kk6LwaM8b6fsnFawiOXq+L847SWMDX91Gr1aTTna+Bqiga02oTMPWsHqfU0TUaUG/mskFov3weWAMlqj8OCRBId2RNtc8PtqRuecLda5AhAQAiakLbhzaibgbpz3d6aF6PogYXXJ4xkGiS+aHeFX0Llf4b545XVLdYYvRpw5h2TAO/LwlQiAPSKyWWmoHXra9S3VXT7PE+mXPF6lEmlxr+8n/+I+//4KuTp4Gto5UV5MivovOa3u+xvl5I3yFb5JS7HkTB5Pm5ivn5LldcuV4TJABin9lGOrMf++AXxsJYGAvj33NImuuzrD4183Qkc+3EaItIYhGDTQFO2QtNACliWksGIoOT0ix7dJE8dUobKc0RylYkSJ6ztSFbZJYxAAEjyU8Ig7HZrLjegQHqO5S1DUGc7liswRZ58xkzEkxtaiCCqMkcIpHCCsECZVoR8q8gYLTuaNjs+xUSiK6yZ7Ge0qaFT1Jzk4JLNq/mv/z6y/nN3/h7PvShlzM03MQ29LcFBUkkAe2xSIA/hV6zIqb3sTVor5+V1fNFY8DVaNmwY8d+ZjsVG85bkfwWqK+PXoP+OruwBP3b4xkBKMQIhRSpw5xMAb1uiiCZDiYDPGMNBAeh79aevRGKQjve3gm+cLRMA1s28M4TghswOjSpiNIHzUaDDSXHjk1zaOs2hoYWMbR2VI/FmERbRl37jaGwBVW3y1xnjh/c+X1mZ2Yoy5J2u8Vpq0/j/I3nA5aQosVs8LgYiEaIzoMxNGyBqq8C3jusqGkfxKQd10LGpNg7EQNWZSAYo8WLKBBz7OhxglNTyKGhIUbGhmkNDenGMyUXGKsPRghBJ44Q8EBhipRxX+JcD/EB40NiSGhxZfN1sDHJDUICUCIFQoiJzRD1WhZiU3QgCkIE/booCnyMGG8IIujMWhB9SHvxFIcZUnRnitMjosdoC6wUCioY1TjFGJGoDJZYQfQeokNiwDSHcCEiLlJYgykhGq8ASFQNegY0tOiPypgQZYqEXlTTG+PTwqFASggRg8Fntoe+AKRJrm9aObgJTlGT0RBDBrZETSgDyZAwb7jT94zR+yZ1S/NzEJJcxJoGIr7/Dkm6IiHWhjqgZpQ+MTHUHTfU/VFJ230jBk8fGDJo8xBd47DGYAKUQSfhyoALPUWpnUAVaOEJ0RNDRZRIb7aLNQ2MlECKoTMwPzvH7Owso2OjlGVJ9twwGBqlFt+ul5gOKGtiZnaWkzPTiAhTE4sUgBLBVxV0uxw/cYLW6DCN9hCl5NInYmJaULr6Ohp/p6yXGAJSZL8GPXdjjKZrENWnJCRQDHQxj0J0wvxsh0OH9tDtdAjeUzmVraxevZIlSyeJTr0hJOrzI1GgMLXcQ59Fn+7xSIweHxxWlKVhDDSbjQQsWIoyFajJIyP48KyNjRwsskHTf5SNkDdJee2w6adtKucjgj7nAZXhEFFzxPoBT2sOpAdIi+xTNxAmGTYl4IG80QjpGVaGhHbp+54X9X4TXXmiREy9UVPw1pD3bkLQ3Y6yFaJ2SQySOkaGgEN9bVIHqz5Gq/cbUPtMxATYiieKwWSAhNRVU97PgNpAN8lve8dz0X1uTBu4wddN1wLqzS6xf+36W9b+PU/6dPR6WYwYhkaEt/zCjQpGiMsHxinskTyXPgs7QgtjYSyMZ+boz0YZXDX1/Am6tmTAWRJjLhs3RskAAmlPrR5hMTEvcxMi0QCAejWi2S542U0Xg9Twg+4+EzMvQ9GCmv8quzi9gkQkWgXb83Se9u+g4LOyypKZQ2Kf1e+RjXlBgYJ0JfS3BrwijKcfr5jZg/k1dP7XtUIXC12D87VK+85oWHvWFKefPs7cdI+hoVbaK2pzB8nrSn5tk9bM/Ok8rZWQzkPlgn3gJUpg35EjvPs9L6p953SJC6e+dswvEgdfdWGk8YwAFIjZLyFpVNECJlPGY/IrMAKh6uFSDF1RlIQY8AQapSU4S3A9QtXDW0uHeYaHh2o6txDVMT2jigKYUmlGBo7OHGXPnu0sm+pSnn0GkgzjgghBjNJjxEDwFIVhcnIRV135HPbv28/WrVs544wzmJiYoPIVhcqmMClG0tiCSMBZCIXQM1BElVI0ywYAPhUIRfIWKKzFitW0C5S6XpoinbM+hD3f4Xu3fYeq12VseIRu1WXVmtVcfe21GFsqxT6ov3lZFFirIITOOCG9vhbv6jwuBLHMzk6zfdt2Nm7cqDr6aCiMasqDV823C4HCGCrviN5hTAkpRtNaQ3SePXv3sG37dtqtNmWjyapVqxgbG6NstkAsvW4PEaWPxyyLMBG8TmzBe2yhFKUTJ4+xd+9e1p61lqKhZl4+eKVyidCVLrEwCY1N6QHGEYsK66HqBWKipMWgxaGkCccHD6Q4whjThJPkHunelMQtyyVCnfaRFgDvY/JPKGtJRLq965/T+LnkeUCi7UtQM80QB9gC6m0QUmuv9oepWTYKDkkYQI5T917ZJqnzmOjypELae0eRjiukDmw2NpWB19Z6eoBFEYWApxN6tQGkyc+kUYS3m30zvGF25jj333cvy5au4Oy152ITjDE9M8ejjz7K1kcfpd1uc9111zGxaEJBvxgokpwlqkcrPiqAs3v3bh5+ZAsnp6fZsOFcLr7oIgUevOeRxx7j4UceATFc+ZyrWbNqpfogGElNYQXhfCqMsnQEI1RJ8pNlD1l6oQBO/ty0gPdBl82ZY7Pc8f172PbEdpxXAFATIQKTU2M87/nXsW79GQjqB+KcJ/oKKQxlWdaMEWWrJE8QE2v2xnC7hTHQ7Xbx0SvQJ3pPz7sO8/NdvIv4TnVq4/ZZNTJwkEbeQaUCWYfXqOH65+utDoJQxv/9hiC5F/RfL6qkJb9v9gNhcF9Rb7oMfVpNokam+Mf+v1kkR38G6o5//52zkCFvxHKhHmujVcn55CgroZYZDMYrapQDGcnQo/L9f8ugHREykCanbB3717f+36A8I81p+drnE6o31gncicrkqN9RI3HSyacrK3mrN8i8yfPaALiwMBbGwlgYz7AxOGufUmzWa8HAQlH/jK/XI6LuaUPUgrlfLOef9vknabQtV19/wdPf6Wl/668gp4wo9XclO0BmeSCQ3h2TQfraJBeyniGITfvsfD661tQMtbQ2RsmgQlqgY/+Yagw6ex5F+oW69Iv3iUVtfu7tL0qsQfX3qtfUdFz1EebfS+DJj1+TmM4h08qBBLJfdfUm0na7Pu/6V35spNdg8LotjGfMKq2bdqedukRhD97pDRSymCf/Cfiqojs/T6/Toep2CK6i1Shp2EKLKFclXwOPtdJPZAjKVqiqLs5VOF8RgiP6LsuXLGbJ4ik63RmiVHg83vfwsYuLlXa2g8boafceli1dyprTTmN4aIjVK1exbPFSikaphWJQYZKXHgFlIRArNWcLgk0JAY1Gg6KwNFvNOrYx9ZwoCpvMEgXbKDGNgqKh0oYQAy54Ot0OF23ezNXXXMUF55/Hg/c/wLHDRymMpbCFMhRIpnVB6gdEjNHC0FqKstS/p/edm5tn+47tVCmq0aPmjWLVk8EHjf2LqWjVoSBNLmJ98OzatYtdO3fSmZ9nfm6WO35wO3v3PKVbZAONZpHO0dBoNhCbzPpE8pOtXURjmZ/v8OST27QLnjaqPiTjPwKNZpGkLAZjmkRTJgqWpZKIS+kYRYBCrBaCLqpzrneEoAW3LQzDIyOUjTIV3EpttkWp0Y8pncKHqAmlxgyAN+GUAj2SAIx0z0hiflg7KMHRiUl/XiPuXHS4WOFFAbMo+idEBQdi9CqdSWyTGDzBV/r/oGyEXq+Lq3p6f0en2mRr+p9zkr/kKNFcTOsxST2naipJ1AzgGIheEz9s0QCrXfcQXUKaDaEn7HxyN1sefYyZmWmEgIuOrgvs2bufmZk5zjvvfObm5rn3vvupKk/wKnUiHYemYeixnZyZZu/+A6w6bQ2rT1vDY48/ydHj01QBjhw/ycnZec674CLa7WEeuPd+qqqn7v6pa6u6RBUZ5rSOqqcyB+e9PgOmbyCafSkE0fsrqmzDGEPwkad27eWxh5+gjC2WTKxg2eLTWL38TKYWLePQwWPs2L4L50JKsI2qm4wkXw1Pr1clf4SYnhVHr9cjoqBCVVVUVUW326PX66nkB33vznyPqlthpMDakmfrYiZROz6i+avpHwc2blG06E/3cF3LD+zRpG6tQw04SPrGjxXlg10JU29klG6ZGRH5Xwc8G3KxX/9L3qQYJJfrRmmbpxzPYPFNKswHNjb9Yn1A1/LaSnUAACAASURBVIlualXCMSBpGNAMCbn7E/unnK6jpOuagckMKiCBkP70jakGvRxqNCe9p4MkvCMBqPVlHTwBFHypgRJ0Y6uf29PlPE/flC+MhbEwFsa//8g6/QxX62yoKVlpF9Of51AvnMjAfB8NIRkuxij1TK7/y4AsZOaBoJJZGVyj0C67EOp/zzN+v5qAlIeXXvbU30/hx/TTDJ4OaOS5P3n85An96QV4ugr95Sp/1Wfx1hLDyCnrWh+cUIBZl/dAIaG/PuVjFkn74sF3VWNriXHg+lJfPzL7IgMaqWGs7Gplteb1UY9SZaY/3ntYABL+rfHMYCgQ6XbmiBFarZZq6lM6QbejhbwxojFpUY1LiCZ1dC3RG4JzDA21KcuCKhnOES3zc7OqaTfaSfEJtChKm4z+HEKFDT0aEhkdGmbb/h3gPaYocV5NqCSCc9otCU6p+I2irJ+n4ANZZx2iw2DZt2c/3vcoWiqHWLZ4CVECc3MzTB+dZajVZrYzQ6vdZvHUJMYIvRCZPnFSi56qYsnSpbSazWRWYlJ3NXVPEx2+KAsmpxaxePEUxgilFQiO4Hv0el16TlHQRqNJs9nCWi2UEKPd0xAorTA8NER3fo65bhdXVRw5eoROt0N7ZAifuudWSLKTZBJo8v/VScsYjTLTBxJAOP3007nyOVfiveeOO+7g2NGjnLk2puumSJ+meGhEZaZy59QJn5xhKlfRq3raG0tFcVHY1NkN4NOGWdR7IHeavUR60SECpSkwUfCoFMR5T6Ns0Chb+FDhg0MQnHcqLRBDqzVUF5vGGqqqR1V5bEoacT5SlqlTJwbnXDonCNGroWiSNKixYy5AQj2nG2NxPi0GNZaiAE7wAUyBqyo1DDUGCRFjtUD1rqcSDa9eGsqQTt1PSQVBuleyiSXpGvqoRYKxJskuItmQ04rgkhmcNVq8hqjdfmMa6iHgVEJB1OSJWAXa5RCr15zF0h07aJTDeA9YYWa+x4FDRznrzLNYunwZk5NTfP/22zl27BhTiyaBJD1IBp+Cmjfu27uP0dFR1q1bDyLcdtt32b5jJ+vXrefAgUOsW7eeyckpli9dxpaHHmR2bpbx1gQEj4SUKCKCBE8M+hxFMuiT4kkjtYdLjmKNCSzSJVZp4SHAzMlZCim5cOOFjIyOUxE4c+0Z7Nqzg1tu/SpRAj5WkGJZ8z3qXECjQ0GMzmUK4ji9T4xgovqmNJsNrC3wLqQEFEGMpSmRwjYobIP28Fi/mH5WjT7Q2PcO6P+37n/Uxn9P23ghWozX1y4XvgPU/HqTk71J+pupfhcq1i9b2zvG/t8zGykmHYH+lk+buoHjkfT60v83GdzByNNkFwNf9rd59Y524DzTlwNsicFNotRfD27+/jdDYi3FyBiF+i7Ub0rSVEBNfk3+EPTPrT6yxProv69P383drPwZp69l8Aifjff8wlgYC+OZOgZmwf6/ie5tJRe19c/qPGwiKr/mVE7W4NpQV9xpHszrgtRzanrFzCKIeT4/tZzPiV/ZgyGD5zH7+qTjSl/0O80i9fdOWTsy6DzAZns6PBHTuWeuX/5erFEEU6+59VqFNuGyBDEDIRJN7Z2mp5GgmlOA97zWB4gFsT6LJKMgw/Cnfie7LORj1Rcb7LU/fe2Rge8vrEWD45kBKEQSM8HT7WihpzRq7cRKVFpw1cuu9n33UWsLqggqm3A0mw1i8DgfaZQNqqpSjbTrQQwUqaPa63bwzvb3jmWJVI6GMRQRYq/CmKbqiZxqoUJ0CmYQIECnm4zSEDrdLi4EMAYJgcIUjA6PcWLmOL2uZ9eObcR1MLVykn17dnP88DHOOuNMoqvY8cQebFzL0iVL2Lf7KU6ePEmz1WLnjh00m02uvf56imYzs0OJMdJsNOl1ulhrcc5z+PARxkdGOXhgH/OdWUJU5sWunTuZnp1lvtulbDQ588wzmZyaZMeOHZw4McPk5BSHDh5gZHiIs9evo9losvPwDp584nEO7T/Ij+5/kM0XX8zI2ChHjxxhuD3MyMgIiHD8+AmKwmqMXVTzuezIHyIUZZESBmKtlc+MDAEOHzzI3HwHawu6nS7Lli2j1W7hep4DB/fjXUWj0aBhCyYmJigwKjnx0Ot0OXbiKKOjI9iiwIih5xwmCu3SUEWHxIrCKjhlvU4dQSyVj8TolLmR4hiLsiC6AFJm77Q6TUKMxZj8s5FGo4VIlqGEVJeoVKMsSwWUjCXiwaeNt1G3XyBFPkZAzR9NSueIJOp88guJMWBQ4Mt5TdOQqCwLAYILBFcRvUvfyx4NKnmwVs9NmREpdjL5eMRUjFlbaBfe6+cmxqZoyZi5d6o1d8oOijYVS5V2/8XrBG9EzTijOHqhR2t4mMlFS4EWmAaFjbjuLNMnT9JqrcMYy8jIiD6rVU/BJK8glxEhGUsgMTB9/Dgj42O0GiUYy9joKFWni+/22Lt7N1PjExiEkZFhjECvW2HFYIJmHms31kHw+JgZGumzEGrLxHo1BVzwyYhU/TZCVH8NEWXBxODZ+sgWgoBtFzTblgcfvA9jYWpqUr0qSo3I9FSaKBJR46JUYPqgxqo+pdt45zAxUFqbnpkGYlLkZP4sTYlJn1m313kauv9sGnnzkAvpp2/JpL+5yKkGMT+Asf8a2TTglB1fDROnn0nURm2R0Ke2Dm4m+vdOjrIc3Ajq33zqTpFkUgpuqLTK6Pdjlmzl+9HX59PflOlrEIuBY9dzzMCDdvuDHsvgsdVFe7/zFWXg+5JfLXXKsjFl7pwNbEhVOgGxTtPIr5Kli/mzSdc4ZgVwvsZ5hP6lquERe+p7xXTOA54U9U643kg/HRqJDAJAp8JApz44ks5o8Cee/tf+ZcxfxIHfHywAnn5vLIyFsTD+/zueNrPkZSmDAAPfk4iyEaCPd0vAnDIfpqSqeg5Mc22eF4kggwBsSPLdNNfn9bBe9wbhjlRcm9qhoT6HgDY7DHkai/VvDJxBvRpFNPmtb0KZzztfk3Ss6e+SjCXz+iLpPPprVDZbTGzolKwgNSOwP9+qHZlg6zShbFBc0N/LZUBi0Jgxgwm+3rfGXFgNnBm1bDHtIWoDyXwl6hVyYQyMZwSgEImURlMH8IFAQFIkX4xBZTERYogUtqAsSqTsU8ZDSEkJ3lH1qM3LXK+LLZLDvffgHc1CAYD5To+qq4VM11q6ZZPu/By9+RO43gxVrwe2Uoo/6qUQfYVzLpnr6fvELsx15gjR46sewVXpeLrs37eTfUcP060q9u3Zw9z0UW6YvJ5DB/YzObGIsZEhxsdGmBgbodVsMn3iOHufeopNmzbRGmpTFJZbb72Viy69mIkyp15UmELzYdrNkpMx0O122LlzF77qcfjIIS6+7DLGJydBYGJslMIaRv0Q99x9D9u3buHFP/VTbNuyhcOHj3DV1deyeGKMO+6+i6mpCZYsWcLI2DArVi5n0fgYK5cspiGCcY7tW7cyNjbOpk2bCDGye9cuJhYtYsmSxbn2xAePNYWqi6JQ2oJHH9/K6pWrqKqK/Qf2seb0NRhraJQN5mfn8K7LloceZNf2Ya5/7vXMzhxn145tnLZ6NcOtJseOHVNgSaA7P8vJY0fYsWsnS5YuYXJykQIYeKLxhBipghB8KvijdiLLwuKj4KN2gyWzA6y6wXsfEQrV2uMpjFUKVFHQcxUueIokD/HO9f0RQiB67fDbhmAKQ4gWQdMiJAW4qya/wDmn+Gb2oyClfcRQG65JCPioPhQE3UwXIaqhZ9BjBzWqzMQsIUUOOa9Gb0QkOqyJBElShiTRsKSOvaiE4X+x997Rll1Xme9vrrX3OTffyulKqlKpokIplLIsS7JsWQY3YGNsbHjgQHDGpv3ofk2DoRsYTTMePBqDaYIDNjY2zzbZsixLsnLOpVilSlLldOumc/Ze4f0x19rnliQM3aP7ucB3jXFVuvecs8+Oa835zW9+n0mOCVnLJKZzZuIJU7iCcQa6tSd6R2gsQlW80EZDsIW6IITAzNQk3aFh6hARb7BRK/BGEioRBF8HRZ/FIFZwrtbkOYEw3RiogqNvYBBjCqL3mKAWigWCcYH+dh9WIl3n6UxW+OAw4lNfOGothNV2nyJCjBSSqv5pXhFRO86ssemCSwi4LmWlFJgi4CpP0Wex/YbJaoIILF+6DOdqDJbN513A6lWraBD9NEcZ0Z+I13soJtoj6kgjSLMfZVkwMzOtx5tYDDOdroqfDrbAqHp0q2U4sXL7PTS01PGSP7zS6IFFwqxQ44Rey/y+V/oSeYVNv/y7Zld0er/33qdAqz63GjwmDZXYC2FEVKSq5+CgW4o5sImSLB5N04XRY1bk0zFL+yHZWkbJlRz9TmVTJOedRuAlfSZGdZBp6LCRZHLaaFHk50bDhwTsxJCwhxQAN8hjjst0+1m8sffskRyc0prauGEki95UpTK5ajQ7uSfgI6jvj6jFmknAUhRE/KwgMGEjiUqi569HlyXqtoPJLSoK9Gg1K8G/QQsLJqRzZUJ+yumJj3lOkrBqbsyNufH/y3gpZJlTTpuAXZ/mMZuo+NJgrMkTUmNYAZOFBps5f9a8nvSyvCTouMEuY9I7kFkBm+ATWG6JmTLXw9klB3cBxChckRisWY9AV6DEsmhYdb3t61qSZj/JPM4ize3pnMwC/WP6PSfsugr2dPMyJB5FW10lJtnGCJnBp6uL6TkhNccAITHepAEhSHN5dp3Lu66FK42/QpKGjL3TFyWdYzABhSBMrxnExKxxAXOtDyeOk2fli4nKnXqYVQHfosJ1YIpEHUoQmDEm+cD75jPGSFKyN9R1Fx9q2rSUyuxrut0ObVr09bUZGhygqrt064oc2scIrnZ0uh1mujP4CEECpTVIWSarRr3pnffJRk7wVYdSIlVnithXYgvD0fFDHDu8l/nDQ0Ta7Nk+zYEXdzJ59AjTE+P0lZbpziS2sPgQmJqpOH58guOTRynahrJlGZk3xOBwPxOT4wz0t7DWULka64UYavr7+hkYbDNv3jAXX7KZkaEBJiaXItbg6grXrXj6yaeYmJig3WpxeP8BrDXUMx1mJidYd8Zqli9bjA+eq668gna7hREYGBig3W4xNDTAosULsCYy053i4KEDvPDiblacshznHHv2vkjZLlleakKV+/FdyBRyk1rEhKJVEK1w/oWbWTq2HBc8znfZu/dFujMdDh86wN69Fa++6gq2b99Kf1+LU8eW02r3MTw8RIiBfXv3sWPnDrrdDitXrWTBogXYwlK7GrHachCDI2AQKTRhjxbvkzevMYS6JjpP0dLJpygMhUSqqiaIQQoVwozRIdZC01OvSYFWqZMeh0tCokma3TvVN7DGYowm/D7UxEgCCDRhD8E3Pft631swRhOJrL8QVQHe+1TRVDVMDfhD2p+g4Bv09BCUfaDtQTFGZRtIaNxToleWQkMVD7qgNOBcDNpGgQqQGhQICDHifMAEkNpr/G3Bi8dIJFo1AZZYILFGoiP4mjJqFb4KjqqaotOdSpNz0Kp9qiCHkDQYEpXNhZqiKAhEJmem8cGhahKO2nUpC0vtOsToiDiELiFMMNk5SllavBiCNWDBm4g3IYGQkJ0WYrJhJahGQkhtIiEGTKtUUCBqX2HwPunYRcZOWU7/1a8Cr8h6u7+PBfMWs3DhIoZG+mi1IYSaGJPFrVdnkRC8ip5GjyQ3CRLQU1cVrVYb8b5p+3C1PlNZ46SuHWIEW+i98r29jp2Y6H/nnF+af+Q7/f6yz77SCX7pJ2ZJXskrbS1BS9HgKYhEbFM1SoBXA46kzyexQs3xTSo0JYAhBZw55PMpEbdR2+Ci+BQVadbsZjzeBso+aQimoIwbk5L/kOLXDFY0ex4iYrPZZF5/40sOMKP96Pybq2GzBBM0BPQQsghtYlNh1Ds9V7AyayLLRWjE3QR6gV4rlM6Rlujh7nueYGSon/POPaN3VVIADxCkB7qSdGoSnJOEadPUIwGHApEFRRJV1s/9zV89w6rViznz7EVN25iyv1IIFfLNZL7Hn8u5MTe+t0YP048n/CHGPNfr/OpIotXNO7MbQe9jUcxLdAVULF0TatsTlI9ZMSBSzNIB6rG80u+xgYB7fwsOsWVG1vExsTqN0GqJgquoVl3DeiDod0oGhXWdyKy17NjQsNoSUNFT0ImzpvOe1pCckJDH3vfEVFzLwLfJZ8w0IMaslYroLQ/c/zRi4IKLN5CbHGKUZAGZ9N0y2B6F7Hdm0grX4A2SRYoVvMntKRH4xg1bWb54hPPPXwy2OYVzI42TA1BIldFMie8prUvTuy4k5fvYc4DodDpktXtN1EICszTYVvHFFDiFgHM1dd2l05mkKG1yFlDhxxg8PkScQLCGru8iNXS60xQWClvQbg+o/3tUYCEE7ctvmUB0HerOcY6PV7QG+piYOMrO55/liiuuwMfIvIEWx48eY3riGIf276eqOqxevYoYIt7VGIxW3rc/x6azNyLzFzA1fhQTPC2J+G4HJxHnHdEaOlNThP4OVBV9ZUEpkeC69JWWuqroHB/n2NFxdj+/jU2bNjE6OsrU+DjT09NU01NMT0xQz8xgvSbISxcsBCO4ThcLdKamcd2K6AJ1t8JFz9jypdx8y83cc1c/RGHP3r0sGB3Fd7sU1hJQMUzN0bRC5nzNqtNXcsqpK5Q2nq7jsfGj3H///RTGsnjhItrtkomJY9RVl5mpKQYHBgje00kaGCaCiZGRwSEKa9nzwousPmO1WusZIbgaX6nbhLRKfHCo3kXAVxXOO2236CspnFpPijGqS9CI8um9ZDBEk+/FRDcPKgQaUYFIdSJQt4us8+CdCpGFGCiKVAFPk2mIKpyYhRkBvHfgA1IokurrirIsMEVBXVcJPNBkNiY3i9zrr4+NQmFA87zYUgPh7FqRGj0SM0AXD5BkoZoBcq/ihNCzX/Ve+9SSIwaQUHbBFpYgERcrRYol4FF9guBVXBUJ2NJgrdoV+ZjU3CXpJATVCGkVLcW/k6tCDLoAZAZIqywpbUFddyEGnHM45+lPeikhRnzl9BrEirJPhXxU0kTwktpBUqLVLGXR0ypKZW2gYoiqU6CJnSdQiDquGIkUhSgoZGDXzh0c3HNEwRMpqJ0H/6w6OBSeCy45iwVLR/Qau5jaQVAP6NQ2o9dPQdRohG6lFpzBe6Y6M4hA1XH0DfRrW1UMtNstpr3DWtGfYo5y9y9iRIEAt922gxf3ziBUiAQGh1q88fvOxmrJQ2HtVFUKiApvNZm1Bluhh4UQRbjn7m1cetG6HkYSfS++iYb77n+Kr/3tt/nPv/7TlNZy30PbuOTCM3rfl8OypkeXJvCS5DhjwmxKa54LNMLKr2St3x6TIAvJmqbqMwvHIQepO3YcxljDqacsTG0fUUUqo84rpFpTZFbYmcFTL9x71xZ2bd/Pj779GgUegsE5uP/+XVx+6WmI1cobyV43GkvlhH/4+8eoJiuiRC6++HRWrV5EEOH5HePcf99OCi8Mtg1v/DfnIgW0ixYf+eDf8Du/931sOntZsnWe3acL6az1TtX/6H0yN+bG3PgXOHR+jhlIzcxDSEULy94XjvOtW3cjpsLgETFc/qo1nHrKSBJRVKZmICIhp9uAsQrGpvk1J8pEw+4dR4iFZeWp87UQI/R0ABIwqpbJQpI407212l4XcsIf4W+/dju7d+3hoz//DkyR58zsYkDv+HK7XQZo05qhk51VUDi19anulE0CkrPPFRqLRSFr6by4+zB1HVm1eiH5SNVCTBpiWk+nIZIZdD4KUSwP3PsMT2/ZyY/9xOsULIjga7j/vj1ccvkYRTEL7E4bDEH4u79/ks5kDTFwwUWnsXrtUiDywvZx7r5nG55A2W/5oTeeT1EIpSn46M/9A7/zu9dx/gUrwLzMQ+N7epwkEWnvkswGEoAGKPAuNIJp+W/5/XWq5Km1ZAYhtJJb17Uq91vTiKNVdZe6rqiqDt7V4FW8TQUOW6w4ZUXyqVd6ecDTdV06M1NU3WmCr/WzdYfgK7rVNM538L5DpzvF9PQErdJQdae59647eOqpx5iaHmfRkgUYEzn1lBXs3P48D9x3D0888jC7t2+nMzVBuzC4zgx3fPsWtj61hUfuv5fQnaE7OUE1PUk1o2DAzOQEE0cPM37kEEcPHQBf46uKAqFlDC2BWHVpGTh26ADjRw4Rqi6xrqimpygMxLqiNOC6M5CsNjsTE3SnJsFppVxixBqhXZYM9bVZs2olr7/2WtasXMna1afTZ4RYdfGdjm6/qsBV+KqD785QzUwivkZ8Tai7uKpDKWAlMjN5nN07t7Ni+RJOPWU5p4wtR2LAV12EwP59e+hMT+KrLlMTE3hXUxjDvJERrrz8chYvWsi9d93N/j176ExNUnc6el8AM90u3c4Mwdd0p8eppo5Rd6aY6c4wMTNBp+okkULoVDUT09NUviaYgHddQt1BnCNUFa7TIboakntCDI5ud4a67qKaB1ox98l+MFtIOudwtcNIsus0miBYk2jLQe11rNHKnOog6L+u7hKDw1VdDIHCCKW1lLZQNoMAom04xuh9XZZlY21pjEmAmjJGyrJFUZQIBmstpigwxjZCPYIufNZaFdyEhvWT23tMsomMiT1njVBIOo5oKLDEWsG5ojBYK9SxpuO6gNK8h4bm0dfu55ktT3Fo/0G2Pv0cI4NDjAyN6ALmI65b0ZmaoTRWW2ZMwbLFi3ni0cc5uG8/Rw8dxoqwfPESRoaGGR4cYtu25zk+PsX+/UcZHZ3P4OCgtn24xAqIgVaEIoM6iTUhKEBQllaPp1RQwxqhMCDJGzq/10jE+5rjx8fZ9vxWtm7bxjPPPMv253eybdt2tj63jZ07dnL82LgufpkBIclJpSiaa5MXRCMGayx9rXYz94mItnQUBSLKohkYGKCvr626GL6nJfPPkNObG9+1kWs2epU+/9kt9Pf1MTp/kHmjQ0xPer745/eTO2QzSy4bHAQEH1SPJib7x4ghRMF7/fnMpx+mquhhDtikOq4A3tqzVvL6N1wGwTA14fnCZ7YQKkh+tKmYpIFb9OnfXMRx4NNreGmYXllStik5EfCorKJP4AnREMWm5gENr0MQ6gB1EKLXtoYHHtjJIw+9mATGhRhVRHeWGZHuS9oHfKpeIdz/0PNsefpF3vb2aygKjeX37T7KRz74N/zi/3V7ArW1DmXSDkeEz3/+PqoOjI4OMX9kiD//7B1MHa+Ymqr5s0/dw7zhIUZGB6l95HOfv4MYhOvesIb3vu9CvvKlLdR1Ckxj0wyRmCPQqLLPjbkxN74Hxgl0AnoJa4JNRYtMjz96hCceOsz8kSEWjA4xOjTEn/zRHVR1UOJ91GJPHbJFuJL1nYcYlKmdhw/gveH++1/ksQf3ZSfHhuSvC4BNbjmSChWgxEch6IzYrCPOCZddcS4XXXRO2n/BU1J7q/N9cqJAtK3Ae0MdM2yi4LKehcwDs8SkiyDJFlPDFS1/hZiOIQo+qJbQo4+8yAMP7MJ7IQbdP5fPbqS3/Ugy/tPvEoFHHt3Fgw9t5+0//lqKluZ+B/eN87EPf53/8H/eTe0iMZqmIJYtMr/8hfuZnnDMHxli/vAQX/rzuxk/MkM14/nUn97F6PAQC0aHsdHyqU9/mxiE1157Oh/5t5fwxS8/Tbeam+dfOk4OhgIxtSyYXvUhB9eJGh5Tc3MOuPP7NKGaLZCnrRLWlGC0oinRpN7kMtkD6k3qfcDFQFVrxTR2a05dvITu/Pm0gLYtkNDCRaciJhFV8HdJ6NGruF271ccVl7+KsrR0uxUkEbXXXHs1vnbQtkx2ZiiLAo9j9apTmTc8iAvaiz8yMkyMNf39JVdffQX79uzDuw5jK5Zw1pnr6WtbOtU0MSWQIuBizdRMjS0MY6cux7aFaFTgzscaUxoGi342nLWeg4f3MzUzRdd1WLR0IT7W9A+3Kdow1RnHtkoUn9HJxBjD4EgfRZ9h78EXWWYUtet2Krzr0ioHmZqa5Pj4YYysYnp6HJtt9xKdvucY4OhrF9TdDghUwRFFGBpsMzrazy233MCa1Wdw4MBBRkcH6HQnWL50AY8/+iBD/W3mzZvHxPQU69avZ6aexLYjZb/hvM3ncMedd7Dt+WfYdP4miKI6B2VJIQbva2LoQCtSGIdFMHXQtpjoCXSwrTb9AyXTk9PU0zN0fEHlvdpKYihiKx1PZBbEquJ+IRKC1STcqLVkSO1vAqkqr9l3klFI7ITYsISttcQQ8L7W8xcjwan4YgYcsiggs56PvCtq7ehTgB2TrSGE4LXlQfR6hNgD4FS8stb+NNMTtBno76P2Pj0foQHnJKAsGjxFFIqoFXUNokXp2cEisSCKtlcYBBMMoyMjDAz24aWGUuiXgjNWncadd97Jof17GBoa5LxNZzHQV2BEmRjdmUmOHx+n/5RT9J6MkTNOX8n40cM8+MC9zBsZ5ZQVy1i2dBHWGs46ay33PfwADz10L/Pnz2f16tPpHyjIYnYt6aOUEpEuYoS+MjmKkACDJE7UamW9AkCEYE0DAhmgMBasIFJw/vnnc8qyVUhsQVBthlBHqm6Xyk2xYN58WrYk2JAQ7AwcxRM05WxiXhlBxSmdo90qEEoAhkaGUguXUBRCVTmsLRIzIyQNjblxMo+ceIuJtAY6XP3alQwOKYto+3OH+er/ex8R4aEHtzM61M+dtz7DsiWjvOEHzmP7i0f45o2PY0PBVVeuY9WGxcoAcPDNGx7mhT01L+z1eAtB1E0mJvgrd7x2uxVjpyxi74Fj/N3fPsNTT7X48y/cz4/9+GaMWJ54+gXuuWsbUPLGN57D0sVD3HbrFq647Cz++msPcGwq8CM/ch5PPLqLLU8eoWwJP/aOC+jrmyXsmOiu3gt33vYor77yXIwVfB257Y7Hec1VZ+MR7rr7ObY8eQQoOOO0Qa59zUaEAkcBUbjj1ie49MozEVvwxKM7WDG2kEWLPhcrEAAAIABJREFUhwgB7n1gK489vh+D4a1v3Ux/f8kDD77IhRetV5pu6pO4+66H+fX/8n189N/9Fd7kLuaezScRdmw7wE++60pWrhpFItxw81NM1oESYWaiy+tfs46iFXlhz3E++fvfpkY1Sy591Rn84Se3sH3XMdatnd+UQU7UMJ/rqZ0bc+N7a+RGshOV/yWp1USEUNSs3zTCa69bp+2wNfzd3z2I9ZGp4xVbntjNwf3H2X9ogh960wXMnz/EV75yH8ePVSxfMo/ve+M5kKRtdu84yE3fepqHHzrK9ddtmE3+msVOE2KAW7/9JANDbbY8shcxlje/7UKGRkp2bD/MzGSXh+7fjlBw3oVjrFwzBoWa/j7++E7uvW8nkZI3v+lcli7ogyjce882Hn1cWWXveMe5DAyUDXss6wb5ALff9hhXvOocykLwDm67/XGuvuocosA99z3P448cRCgZO7XF668/B2egQqO2e25/kosv24hpGZ7aspPFS4ZZvGSYGAoeengnDz68G7C89S0XMDzU5t77drLpgrWUfbZhzd1950P88q+/ll/4D189AeTNbW9E2L77MD/w5otYt24hEuBbdzxNt+Npty37jk1x9XXraZWR/Yen+C+/9U26EfotXH7p6fzuJx7jmWcPc+6mxf8b76t/eeMkYSgodhWSGJU15oRqa/D+RBZCannITAVrbWqHiLPABgCjYniiD5eIVmutbRGDEIOkwkLER08UT9kSBgcLjNQYagqb+oEIgFPRlOx1mqqW1gijIyO0yzbtso2YEooWrcFhhhYuoD04zND8+ZSDg0RrsUXB/IULWLRkCYuWLmXeggVIUSCFZcGiRWw460yWj41x6qqVDI0M4yPqINFMVIbBgUFiBFMUrF+/kYFBfR8CXhyV7+JxrNt4BudfdB5rz1zDBRefz8ZNGzAt4ezzzmJkwTAu1DhXUbuKqu7iYk2UyPDIMBddehHtgX7q4FQzIgSe37GD+x94gMeeeIKRefMYHhnBOUddO4L3hFATfBdChcVx6ooljC1fhHPTxNAlhoroKwyBKy67lEsvuoRTlq3g4vM3c82rX01f2WbFsuV8//VvYNXKlSycv4CxsRX09bdZsHA+m849h6K0FIXhoosuZN36dUrGSnR6a1SAsbAFFpNsy1KPVFQqvjfqfODqWpkpweHdNH6mQ6w9LtTUoUvtO9TdGYKrcVUX72v9cbVuKzhlNHh1WgjO4apae+ZDzw/Xu1qBA+fwzuFcRfC1Vpq9hxD09+DwvtaWAZQNEbxLrTW5dKkaB2pDWCkbwjvqWgVDsyWl9+oWUbs66X34pmVI+3yTKOSsqjippaJpyVDSQGIteBwOZwPeRIKPeC8EsQQTceKpJVAT6XqPLy0bN5zF2NipRGOp076PnXYKr/u+67nwsks5/+KLmL90CRRWnSRKy8DoMIvHlkOrQNoFsbSUg/2cf8lFXPKqKzjzvE2csnoV0tciWMPiU5Zz1dVXcc55F7Bm/VmMrTgVa1tIXx/0DYBpKcAnJdaUlKagtBZrlDHw0vaqolDR13arhRFDYVuURYkVgxVLWbRYvHgJa9euZ+XK01m6ZBkDff1MH59i34t72LVjB9OTk7TKgtIKVtRaL4TMYFHGSlHYxvlDrW5rnHfMdDtqH2okWeUWtFqWED1V3Un3cGp3SW0qc+PkHBlMiGjRqHZ97Hlhihd3HWPPrmMcOjzJwHAbH+DGrz/LJ37vBtafuZxTVy/k4JFJ/vLLN7Nu43IOj3u+9a1dBBcJdeDGr9/H5MQ0+/YdZu++QwBJdyH3p5pE+xSeffYg99yzg+GRPtZvWMzChV3Wrl8CRti98yA3feNezly/nKefHOeRhw4RgT/97GN8/gv30T/Qx1137eKGbzzJM1tfZO36Jdx089PMzNRKWQ0ZONbqmI3w9X+4j6PHVH/o+PEO//A3j0AU7rtvO08+9wJrNy7hxm9s4zOfeSzNRYq0BgN/8eUHqOuIC8JNtz7Drj1HCUF4/NEdPPrQs2xYv4zb79jHtm0T1FVgy6P72HzOyqYoF0zkTW+9lv7BEmu6iTuR2QT6I1GQIJigTDkr0FfO4w//4EFIrU9WwBh1kLr51uM888wRTBSWLxvkqmuXN+yPzO7S+TTpwTRh9RzUNzfmxr/+kVPpWWBCo/VWoI32AaTg6OHIrt3j7Nx1jN17jtEaMHgDh4/O8LGPfYngPRs3LseK4S++eDPDgyXr1y3l8194iqPHKsTDoQPjfPVr32blykXcdvuTRBMJolaLWe8JqbW4GOA3/+sNPPTINtacuYzbbt/L9q3jeC88tWU/v/jvv8Rppy5gzfolPPTwTrY+t48QYevWvdx226Ns3LicJx47xBOPHcRH4d4Hd/L4Ezs5c/0Svn3rc+zcdTTpHOT8KDUmROGGG+5n/Mg00RuOj3f5u796hOjhoYd28eij29mwYSm3fnsHf/THDxM9ugaIAuFf/MsHmak8IcAddz7L9u2HCbHgiade4P57nuTM9ct44N6DbH36GMEHHnpoFxdedIZCuYm9+6YfvoaBkRKxLsHJBgk94coAuBAxBgoTKUykv28hn/jEIw1AYtFiTyGWe+4a54knDhCJLFrUx+teP9a00c2N3jg5GAppAY8xNAmMMXpjEnOle9bbc1tD+j2G0IAMuYprxCJWK8fGKk1c6eLaw6yVZYNN2gjRWFx6NLLNnIuRaLXC7FyFWAFJ9HUjqccoQNTe+6IoNXmtnQY4KnuN2EgRLHVdaQhSKFuClDAEBLEFxqbqcqn97iGALfRhMCJYa1J1OmCMpa/dT2FLCqO96jF4opSUtKmqSi3typJ2UZKF9zLoMjQyjIlKWtJ+e/0OiRCco7CGRQsX4pzXoFGg1d/PeRdcgBEVxIypgzTG7K6eFFBFAzkhsnjJYrwP1EET2rLsUb6HBgc4/fTTKcSo0KCA846ybLFs+TIkUZw8IVkeGk4dG0sMiMDw0FBqcwiaFPqIcRFbRjAF1vYTggXpQ6Sjvf7RE1HqbVFYXF1TGiEYiw0KRHjxSeyvxhiLtSV4j3cqHNgqS3zS5LBFoX8n9faG5CThSToKgeBDA3hZa9LEJwoYOJe0A5SRICYSnGsYOGKVBRESG0bvfRUfbSwrE2shJsVgI8lqMqjgqEgWYcvnXqd+Ywy2sA3zJiYWQwyqfu699nSHoJReYyzR6LbKqJS5IIHxPsvTowvViSIaJDqEGkbnK/XNtiBEDLXqT4xJAj9ialHqEUBCVKDQpOezxxqAsFzvRdIcoedMaC08FUxBt64Q6xAMNYa9I4up2/2sNgXBdzDG4JNmSEysqKIoVNMhnY8eG0qfO2sLSltind7jvnZs27qTrU/vYvzoNJPjU0xPTlGEEmuF0YUD6TkNCRxNuglOxSezu0cWkY0hNI4n7VaLvrLASsBYiD5Slir66Z0jRo/zjomJ4wQfmOl0mKNXn9wjxqRyEoWqU/O5Tz9Bu30UCwwvGOCDP3cNACEWvO8D38+G9YvxEX7pl7/EB9//epatmMeC4QX83Af/nh/9iXO445YtuAre9JbLccD2F8axgdQ7m/3I85cLIRREWiycP8hll63kb7/2OJsvWUUU+JVfvYFzzl3Now/tZ98LNR//pVu47nXv4uhhGBsb45prxnBG+IvPPcpn/+wdYIS//quHUztCIrxKcqIRKAz89M/8EJ/85I187N//EH/0x9/gp37qdXgPn/6T+/jdP3gbRQn7XzjON77+XBJj1HXCCzhaxAA2gg8tAhYX4D/9pxu5+tXn8Pgj+9i/3/HxX/kmX/zijzRAMlFSUB2xNmIdFNlVhtSCkS1E0fnXzAooPvaxK/mlj38znzKy5sXixYP8yFs3MjXZTTovgOmSdWukOQ9zQoxzY258746EGjdzTP6bUgeSAhy3376Hw4cPIrZCJPKe91yltu9RuPKq8/iBH7wQMcKWLXvY9+IM73jba4gCX/rKdv7yq49z/etW8aW/uJP3vfeNDA61+eX/WJGFbE8QXYxpCvNw2thpvPPd11Fa4dBB4Td/6zY+87kfJkbLO95xDVddsxEn8Oy2Q8RYEDz89m//Pf/t/3kX7dISusITW3bz6lefxq/+2t289poNPProPg7u7/Drv/wl/vwLH0KK2ZNfxIrwvve9mU/87j/wi7/0Vj772Vv4P37iGqLAJ//7Lfz+7/0kbSscPjjFl7+6BZda+kxM+Udsa7E3Qje08RTUXvjVX7mBqy4/i8cf2c/+vRUf//hNfO2v3w5IEnJEBcKJYFS7IoZZYv66e2QIhMTAlaBr50d//nL+3S98Q3XKEkhOhHmj/bzzx89l8tg0kvQvjOkiJ1hVzw04SQCFGCMhqt1g7uuGRAmPkRhTG0NiLfT6h5WObaxRoZGULHuvwbuIqChUFnwDxCiAQFKzj1GFo7AtjOmjMI5Cxf3xqGVlaVNVw6pQVRZvM9jk9KAZUUT3c1AMLgZcEvbDq7GVLVVczYC6EljtIw3OY0yh/dHBIQi2KDSRR631bEr2rTFk9dJ22caaQhPAEBExhCAY29ZKvAuUZYvgBTIIggIvElPy5PWzxmQ2SCBIpN1uE0PEGrUB9DFQ2IKhkRHKVkutE42lqioFgpynjoEigjGF0rqCSy0rBYXPCvppojVJ7bvQYwwS8EF7272vm8SutIW6vKCCdbUPvftCtLdfovrdWltgIriqIlp1zwhi8FXA1w7TtoChCFF7fdM2gwcfCkoMJZYoBTURF/TYciIfsuOCSMOICF6tKjOgRdItEEUJ1DHB9doIYm4IM3qfi1FSnA8KQum19E07jz4fswAJY9PvPr2erH4iGmAbQ/BO74WoVTOT7CdjjPgEFggK3oQQFNBJ2iSgCbCLqjJfiFEhUKMLhb5H+9yMwPyqS3SOuHAZTtTr1+AgJJFBKREpMdFQUWHS/Z/Po09CnUhsQA8ffGpF6LElMnii4vFq65NuKLqi4oguOoLtYr26Uwy2+onGaYJewmxrO+/VocMnPYIsAukSOBRSjbHRkaCXMxwbH2fLlifoTEfaRZtVp65i5SmrWThvlHmL+hld0lZNirbFR91eURaq65AAoAx+GiNEF1TQ0VrKlkVirU4VtVcQzDsw0Gq1iGUfISSXmbrmROvEuXEyDkn/GR2u+I+/dAmDQxYrWcYg4h0IDmsjIoHoBO/aWDEUwXPm+oWcs2kIiZEbv/EMv/EbP4wphSJCIS7pA+Q+1p74aEyV86xnbYPOBxFlHkUZYfOFp9GycMHmNQz0GwpgxVLh6qvHKMrI9W84k6//9ZO65knP1ksFF1N1zsb8QLN8bD6tcohbbn4SY+C0VQsbVfAiQCmBH/zBM7nzjmeaW9fojuNRkWMbQUJL18YI7b4FbL50JWIi5164mtFRVSj3saUFiBTYFUkRXINRk7RqSGuzzkzKFpnV8yvwqc/czM/87ObGVSOIVqeOHJhkYnwvG9Zv6hUe08ygdnC5qEDqGX6lCz835sbc+Nc+YgYTouotaUxrVVA2aInjTW9eyo+9YzPW6lykybNOE1IEpFBKqA8GpI2xCle+5a3reOaZPWzdfpAly5cwNNSnDCoTUmssNH20BHW/IcntRocakUWue/1qbvjmA6kI6PU7bUg2xpEskBVdS3MgAtdcfQavvmYNIUb6+wc4/4IVtArH5otXsnjYpoSc5LrbE7ZeumSE+fMXcfPNTzI1M83p65bgBUSKVPmP/Js3buSGmx4j17mKLEUTo7oqeAUXQrIZL+x8LrxkJUjgvM15HRDE99HrZMjuDiEBAzZRBHuvhVSgarR10tr1qc/ewrt/5lw9m01cJRw/Ps3uF3fwo287k6y/YJI2xdw4cZwUgIKknnsfXSMW10uoepZ4PSvJVE1EMwxrLXVKsHKPueb4kSJtoyhKnNMeZKWMgxihNBFTGlzLUvcPMB0CxopWBQ0ECbSkQApHN1QURYFzmni1+koVF3Ge2qi4iBiDLQ11YZg0kTpGSimIPhJFkJxoW8Eag6qbhIYSHYNWmLJmQ8ye3USC9w07IqQWjpCr0kaTUmV6RPyAo9PpNolmYQtNxIlq6yiifeGpAmxRUMSIwUetENMnSZU/4ILH2oKslKp6AKah2dd1rYGrSVQha5KTgD6Ymshpj38MKroViBTWauUc1MIzTbK5ctwuS2yM+OTSkBVcQ7ovsiq/2g7q/aRWaC2OFUKHimkbiRSYWGqNqtDkvDDaEjFNmxlrmEeHgdDBxDYWgxf1Wc92glrRL9LcHTW7jZEYPIh26/rokeQnE31mDUSy/kc+jpBeE4kEQ7qOSeegsGRrQwjUtW+0M4xRscVcTc96ALomKIvDJ5RWbTulB6BrpqHPE714VxlA0mwPFCwxpZ4fE/SBEgwmRKKBioDpelYdOMLKY5OEIovt1HREmLYlxlcUptSJ3URCMDjfTXT+nl6KGNUj9j5QWNuADZlFIFGBHxGlITPrNe88RSGEWBCwiITkjuxYDjgx9BtHVQi2Vs/hIrEfchtIb96QBlzwCWCJCnurm4RXUGPJwkUsmL+AyaKLr4Vjx47TndnKQLvF4LyCc84/gzMWnYaLteYz2dlBsuVnT3Q2A6DtdpuiVQK1WnQGdfCoqy4QsFbZErVztNttWq02fcPDPWrH3DgpxyzcCx8rooVoQwq+isQokGRTpYBCIaqMrUFQToJ1fbj8inV8+85nue4NZ6WCWAJqIYFsGvBIzHOCJr+5gFaa2FhgtduTXHDhCvralujgphvvZtOmJYjpKuUzJfdePCG744rXVgcKktqLrj/pp90uueSyVdx5x3NcfsVG2gNWAWvpKsAY1P87pv0mRmzMa5727x4e73L77Ue46tp1mADDAzNccPGYzrsucMtN97N65YVs3x7Y8vQRNp03P4mPpYM2EG2FNw6MMgAPHRxnx9YXufjis7j8irXcc/c2Tlu5mee37cfQZc0ZCzECY8uH2LrzAGtWL+HWWx/j8ktPZXS41TBNUkNJqnHZpuJ1Ingw90zOjbnxvTUS7T8W6fGvUbeDUueMGPSn0YDTTDxEjRtFKp1GrMYJThye1KodPQWOlacu5MGHdjHZrRkaKIGIMQoC5Iq7Ok1owTGE2ENroyAhIlHn9tweEBP0YIhNIm9xDUvLRfj6N+/mdddfysjwOJdcvBRjtdh62033snrDklTQUgAlW2gWLctFl53G7bc+x8UXn8nAUEulDEKtZ0uxEyQEbExKEybFpxKoJVLN1Nx26xEuvOA0osDQaJfzL1mBQY/tmzfdzRlrFvLiTs+Wxw9ywQWLUzzkGy2zwuj35Sn56OEJtjy5k0suP4fLLlnNvfc8w+o1V/DiC4eou1OsW7cY27KsOn0+z23dx7q1y7jlW49xyeUrGRpt69riE6thrpjzsnFSAAqa4Gj1NVP6ISerkO+Gnt1eos/bovHSziNXcrWfKFOYOaFCnHvGRQTxJc4OcLB/iKdbLVqdAU3Wo6gVnWhSLC6ekMhICiKstQTn036rhcnBvgF2CEwUQlfAUKRefgETm2qrHnwiK0nQBBMS2iaaDEYU4UziehA0UYxNipjOThbrS9WXMOvcztKeiDFoBVgyY2E20qa/985RbLahCR4JGZglPBVDQ6nXfZCGOg9J9C5mJ1wt84QEckQiVpI2rZCq58kbPNPBjcl5u4JNaX/SaUpU/7Qr9JJCglCKsGBqnNK2KULA0KfhuZ0hBKGkJMTIRFEwYVucu/95Th8/SiSopm6+H2uHLQoFL4zS9Y0xDW1fJP9N21Ksyc62khLhnKzXBOebpBhRsELPQK5aJ9DJJ10IYzGzqfnSew5iVEAmBl2sFFgJjTVhRBenunZpcempD/eueE/gNJ/bEIJaKQqYoP38QQzdOrkjRKEwhmAcJkzRDh1wFh8MdV2xf/Fynj19HSOdKfprAakIpgthIN0/s6hiMS+AsRG3bEq6udWpucY91kZINpSadDmQAmLRUJkl3Y/RwgHXZcULu1jRPQYSqeq6OX8q1KqCiGVZNvePS64d3geqqmLQGMRYoousWrWSH/iBeRwfn+HI4QmOHDzG+JFJxieOse/wEQbnF5yydjmmT63lfAgE72gZgy0MLjGS1DlEAYz+wUH6+/rBRwKOulLb0JmZGQYG+yjKMjGvoGy1EsB00kjg/PPHS1H9l63J8RVemP23V3r9n/cVvU/GV3j1n9rSK+xPfpbkpe9Nf87VD1RHY/lYC2vz51JbTNS9WbLM0Oo32jJk4QPvv5r/+lt/y8RkIETHG75/E+2hkmuv38hPveeP+MpXHqCIMFN3CQZ+7de+yI5dXWIs0bhMg9e3/PAmFs5PHIXSsOuFcT72kc/wm//3j/OhD13Nv/3w54hYgp/kne98NbGAFWNW95NIgbDyVGVUFMBpy0vaBv7kD77JvQ/uTywFBURExvmFX3gTV7xqDbfe+iBXXLFOnVEEfuRHL+R97/8MwZQEHMuXDGMsDM+HVqnAxVDfIB/6wFcJzrPvwAztPqEs4d3vvIwP/exnFIIxFR/+4HX0tQw//JbVfPvWpznrzMsoWulci4fCsmzMYFHr3uAjv/PbX2bjhpVceMlZXHntOt79rj/mpm89w+RUh59454UMDBYQYNM5Y3z8l7/CwPA8utOT/Nmn39Os1S/sOETLCqeNLYTESNDXHD0xxtxyIv/EvTU35sbc+NcwYgZyo0kJtQEpyVEvAoNDhgULMrsYZUVHwYow1IJTlqrQssWyZs0iRu9v856f+RxFMIytGOTDH3wd8xcOUVXTfPhDn0dswcTxSd7/3mu5/Y4tfO7zd+DjoMbNPmDEcv1157J95xTv/ZnPI07n0g986LUYAyOjQtknkFilo/MtQ8MWU8LPfvBa3ve+z+BDgbE1737PlbSAd739Ej70/k8RpEWrqPm5n7uWT332Vu6+60UlqYm2E4uZ5qMf/X4uvmwNN954H1ddfb0ys8Xwkz9+Oe99/58SRFPPBaNtjIGhEUPRMlDAyLxBPvqRvyL6ihd2Vwz2Q1lG3vOeS/nwez9F8C0oOrzvA6/BlsJb376BG2/cwtlnv5qyLQg2tQvD8jGDsYFAgFDw3373q6wYW8pll5/DVVdt4Kff8yfc9u3tTE873vK2sxkZbgHCuReM8Su/+jUGB+YxMT3Jpz//bgrR4uHufRPMVB1Wn7Hou3XLnbRDcnL23RwbNqyNf/rpT2iAnKuvYlNyYZLVmmmqGJmqTGIxSELmfErwQlShxNkJiAGMLYgxawZofoWP7G718XSrpN9X4J0GJjkhNymBC2p10mvD6CVhJiu4x0htC54dXcB+EZYaIQaPFauV91wdTg+XoPsqs5LLGFWZOlPWIQlfoSCJ5ACuocPnRDozEayCFJISl0TvjiGktgcSPSs2PeghARkx5r4Q1FovsTtyVqfV1QSiRJSer3tB7z4KaV9V96BMrAZjTNJtEbUAlUjAY43FgLZaJEp4CJmNYhSQCLGpxEZITAUFMfR6aysIuV0mqmNCe7rDgs40Q91JbdGQNq2WRWxN8BHxGswfbrXYNW8+F+7byYYjhymLNkSHg2RZWmOsbQLFGHRfvVOmRwjZcYRkT1po20F6b+5vCyHgatcADLYwSGqriVGp7WJSRXuW5WDT6hDCrOup+gOktovCqAaGphKpeq/Uk1ktQKo7QGY/hJ6pm6+96hJEtBUH0gKn26x8rSBMAqX0fgkINYVVxkw0BVYMTy1byT0Ll3LqgT2MdrtgAtE4JLZT60VoXEBiuocRescTYnMpvffKWMluGg3Yla9/bv+wlGVbt00mj0RmyoKZpStYuXMbZxzaq5oRqULgawdIA9CUZUr+Q6Ajhp1nnMmhbpfzDuxgoPLKPpGS7mRkarzGSB+dmRpXBaqZiomJcY5PHmTeogHO2bweSo8YPffWGEQ5fIgtyAdeGJC6w+SxA+zb8SzRTVFIsi8NXt0B2i2MCFVdEfqGuG/RWtZvOIv2nXfw87/1FVr9J/fC1gN8FbzMVYwT8vH0zgZsyhTynJXnVqkGjDLfsdvjH4MltGXGpzkwBYHN+/POzYYg9H0nghIxHUOqCDWfy6wi0/v/mFh2REJIIHRCSAXR/Yjgo0ltdPp3H8C52ICmYnWdIYJ3MVFD9TSJFUguM5FUlErDWtHKT5pGY51S3UL3xdc6f+rcJQ37SitYAaLFp5Y4gaTSKkQfcaFZJvWKSNL8MaQWPAWllZFgCS63N+kZKoqGO6Gtaj4mZxcIFsoimaV5UesvUT0ja3QtfXbbQT7y/k/zxb/4MMML+7FJkDakdSy762RXJwGwas8WQkT08ccWYIzOhdELdaqe6T4mFxYHn/3Uraw7c4zLL1egpMHiJV936d2yGQmdG3NjbvwrHrFZJXQZyHNeXisSuzjqPFQYnXez/0NmApDcv0ifqdP8agMUAkZdGDUmdekjhuTEFXO3QmJe65dHBx/8wJf5/f/+1pSn6HZySI2oP0+MmfUKIhEfDa5OTWKiNtpJlxsXIz4kscJC8CHifVpzROdlZZJKkpjT2F0kJj0u9DPpSIs0n+dCohXBueSYpqeCwgrGBGIUfJXiRQOm0Neff/4IH/ngn/HpT/80C5cOYiUX6HK+oGtziLbRURTbW0ujyuBhSl0HNGiORJ9aAw2UpRbXQjR8+s9u5YzVy3j1lRt0Xfwem+YvvPBCHnjggVc86pOCoaAZrFHqu+k9hsbkgC0/limJolelruuaIlUWxVhNLElMhZD92iPG2OYpMpIo6UQwgTFfsbzrkBBST33AB6d9/qlyXNhSq0euJiRAIERFGUzuhwfqoqTlK06fnuESV9OutQ0hkPrXCfgAEiKu6mi1UUyizevxSIxUVUVZtihSQh4SE0AnrgyqKBW6qmutZls9h4Up9XWnGhHOZ5qRPqXGpnMYFIDRFo6ITahhDKoYa42Z9bDMqmSPRE/FAAAgAElEQVSLbc5/TvBCmgFsoZV4H1TkT3UhVPcAD9ErddxYi4s1iDQ9/JnC3ul0aLVaSURT2zEkJer5ekhUwEXPac+lQFsBLK52RJ+up3MJBPEKSBWCRXUXIHCwb4Cq1cJWjuC1rywkHlkMHrGG2mu/elEWmMIizp9QWY/J89wlB4gQkn1iauHRBByyxaNkEEZSNT327nQFC/T4Cmv0GBvBxNhca2tsuh9iAncEayzO+1T4F6LXdChGmntImSKxYfMUVpkYMaQWkgwOefWXj6BMEquVeyuCsbrtGCwhkK6/w3mwU5Os6Btkw+G9LOxO6XkKCuQVxjZ4Rgb/jEm07hCwhW3aLlQvIrOOQMTq/RR1HtBzrUwKK4aisATxukCk83u8f5Btixert701zXMqKVNr5pkQk289qQ1Dt+FDwMeowp+oYOa+/Ye5+Rt3MDOdEq7aJ1DM4+mydsNKNp69lnZpicFjrBCcUw0FtD3HGptANtWICT5SVQ7jA9bmey9StlpIulcLY5muXcLMkkXrv4Tx0uxeevP37JdzAn8ClTCjACmxf/lGZ/+aEYr0LOW/ZaZVA+3p8xYkd9X/Y7uceuXzexoERNCQKDF+MiIhL91C74BFBGt628rEeSEQxacgSBrg1BiSHeJLhoAtX+Hv3/Fe0NesAK2XfOwVvyOvZwraWJtnJjS6Td9XfqdvNLM+g2oYmZa8LOBoxMQkBduvNAooi3SSYxJWFFh7xiL+8A9+il/7z3/Jf/iVNzNv3iCGiCUB0KLHYl5C5DGSTsYJsgd6LTCW1qz7RVdsYf++Y+x4/gDv+qmr022Yjk9m35cvQ8jmxtyYG//qR9ZYUjGAKNKA5vqCxmxWevNDnv2BNA9JM2/EqLpthdUZKEVwpMZdaPUW1EhKjnOKHi2qRxXw0dCyxylVk723Gom606kbEKl4B9oqoNGGfcm6IEAsoODEObwwQvGdsshmTpeUe2j+UTIbgM/22freZq5/2RoaKdqS1txIloJfdfoCPvnJd/Ebv/4VfvFX38ziBUMIYM0s7roYPc3NvuoakZlteWmPSbQ3K8wbUT8/BUws+/cd4/nnDvCun7zqBDHxuaHjJAEUaNoe8k2FURE8oEHKMrW8LEutAs+yvIvpwQB6/ckmfzr2Kik5yIykUEGVoCUp8bdMQSRQhwApgamqCgmq5pzRPWVA2CYJ0a1o5boQwcZAywf6ABMjPlXsg3e4IEwdP87O57exfsNG2n19GGOoqi7HDx/myJHDHDp0iLIsWbt2LfNG5+vng2ohIBCcp88WdKZn6BwfZ/fu3UxPT7Fw4SI2bNio9nfpnNRBCNGRK7NWLGLUNiWGSIvUq5UmlJzcGkiJrAZNSocHkZ6mgA9KCZcYabXbxLqiJTRVIKKK35mkNZFbNQyROulF2NQGkhPc6clJZlLC0d/fD6ZkcGgQqaumxSCnB9om0VP8xzuMCdgkltmpHYZImfaJGJMquupWiIkU6JRdWEtRlmrJGDzZGSMncyLKgrFl2Wh0hPS9hTVgULE85xF6y0xeK3r7nv9flwTVaOgdV0gQrFpN6nSbP4/0wBPvavJkbE2vf02vi16j/GyEfB0T66SxWU2PhUmOKJrw6nPlvKcoihSX66RqZkfnpncs6hIRKW1Lj8t7bAiY5CCi91dAXMRVNd2qS9lq0d8/kIAWBRacd5iozJVCoKqrhKILVdVFyrIRMyxSX8/0dJfxyUmGBgfoG+qjVZTUziHWJB96laLLuh65gtu0PRlDiJ68/Ojv+rySbDqdryGd1xADh44cRGIfA32jHBs/TrvVYmhoiMnjExw6dIROp0trsB9lkOj5KWzam4i6jSQQLXNf1FUjUpYtpFXgXKXnN0Scr4nBU0FjA1q7+h+bTk+qkWmevTQ9goSePvUJiX2POj57xFySz1lgDKmtZVbA0rz5hE9C1Faq3jt0dpNX+J7cgiB5BpTQK4kwCxic9Vw3qXM0TZtaL1udBW5IKoU0gEn+plktZHk/vuuBymxA4B979Z+3nf+Vh5LvIGXhCUvHRtm4cQlHDxxn/uhgqg46RCzZSvOftwN6/fS8ayGBSGqpDOzZf5APfuR6eFlF6rt+oebG3Jgb38XRFCgA0vrek31NSXuTHL8Eef7H8Vx96YS3Sm+5SuvMCYB3BjTSqmQKeNNbzm/AhBzHkXKVlybsWRNGmoN5OajwPz9mAQQN0G9fuvw27zxx3XjJm5rkX+dmYyxLlw9zzqYVHDkwzuIFQ4mBOOvYcksv0AMycsCcdM+QxGA88fglCRkThX37D/O+D153EqzPJ+c4KQAFEShSdT3rA2g/tWCt0pDzzZidHoAksJhAhzirvzqEWYmP3nZK/0+xocREpRdcqvJbsZikp+J9xBS9PuXC9mj4GsjQU4hPPUtlYfE+VZrT/mUht2BSy0LQnu1D+w7y8AMPcOzIEVafvob+dj8ShamJKbZte56R4WEGB4d45JGH6XQ6XHnllU3bhVhVcCVoX3/tPE9ueZqq26EsSx595DGmp7ts3rwZ22gtkIIrtdPMTI3StqijIym/kKu1IajzgUmVmBh7/1qjwo1NRdkYtj77HGINZ599Nj5A9NrmUViL8w5JVF9NbjMSm10yPN7VxEgjNrl161b279/PxMQErVaLU05ZycYzz2LhgvnJwSBVndI2iaQWmHS/+IiJqRXAqvBk8D7Rk3paAS5pXwQfUgVRUzvnPaYsGpaH8y7ZhhllroQAwSMxYHOrilgsBitG3UESeyF4TySDJWmCEjmhoJhZNCEJgvaeAZP6obNIX6QoeqKkkq5B8qUjouchOzkoSJC0OUT1GOq6xooCJC765vszC4bURhBFcNFptTgk0ndqJVI2g6LNLkR8EkT1aOKc9TasLWiEOCNYW1JVMzy37Tm2b99Bf/8AmzdfxPDIaEKvDeKTLY9VK1HVjgjs2bOX557birWWRYsWsXbtGqwt6HZn2LFjB88+8yxIZN2GdWzYsAHE4FMi7yPU3lM7p5amks+XChH5RrchhwGxWfd8dNS+ZsCoerG2V+i9Mrb8FM47dzN33HknVgwXXbiZm2+9CecrnKvpdoWyTGrLWmhQdpNRBxcXPGXSGLHW0tduE51XYAGnoFRQVoh3Ne2+FqVpNRFHXTtecUU+CUeTVKMOAVoLSMtPw0KAHok+Q5q8/PdI+v/ZQVr+XAYdzKy/5ypPem80CQzocRaawCz2QDi90WftQ9r/XtKZ/9iraM86oJcERLMCGOnBjbMhibnxT410D6TTKTj6+i3v/unX66USIZLjg/+Z52LWtWgCa/0574I1sxpf5sbcmBtzI4/Zc3ik4dUn4LlnWxj/B5Di+JKf2Z+TWf/k7zInvho1X7/2+s0n5CS98UpsvzxvvvT7/leMvBbn9Vle8to/9plk8ZbZgCe8t7fGFi3DO9/zWm3vS6/1NjP7eCI9dkMGaXIyEXsFBMmpsW/AIBHDueetVjHJuaXgFcdJASiAJjvW2tQLmizyEnhgbdH0/GhVUWn02fot92o21n1p+KQMr9QUtY/MmgtNpTcnf6AtFxFV8ieLP2p/tvaFhgZUCOq7pZoKIrO+W/cvNThpv2nSQMitAYMDA5yxejUPHjpCt1Nh5mmyPzAwyNo1axkeHiLEQKfT4cCB/XrcxqaeU9I+lsQIM50Oe/bs5dprrmF0ZIQX9+7liSe3sGnTJqRsKe6YnC2y44AkJC5GVN81IS0hBIIPWGMVBImabPqUcOdj07/reQ4+4JyjO9VVGrdYAq7RUNA0u8cgEQlk4T/1c00WLyJNj/CZG89i1crTuf3221m5ciVr1m1gcHBIqeFRmqnQOaf3gBhKazVhj8qEyNe3UBU0ulWPoREDhKDaEYXR1pF0Wvn/2HvvOMmO8t77+1TV6e7JMzubc1RE2hVKSEIgMgKEwIAD2MYGG8frADhnX7++9nu5fm2ubcAmmGAytowIJoMCICEk7SKtwmqlVdw4uzOzOzPdfU5VvX88Vad7ZdmIe1/7la6n9FlNz0xP9+mTqp7f8wsAhXOE7LKedF16P0war7KbZAxaXOQCPkoklFWSePTMJGNCrfO5p+eqIp8++DrBwFiT9kHyCsi0cNFEEJ/jI/WHye02IEElPSE5+1rj8LFKMZeq3w8xJKBHekAE1KyfWraSfhZiBkWStjiGJBU2ad+XSNSOfYxRdXwCmsKR5Cupkx41Hw/vPYePHOGR/Y+wYcMG7rvvAe648y7OeepTKQo9R/W4keIsHWVZ0ul0OXDgAKOjo1RVxa5duxgbG2P58uUcPnyEo0ePcvqppzE9O8Ptt+9m5cpVTE4uhaixqTEqSFQFr07GtVEo9XGBWAM+kECHukjR+1PM+ybde4wxLFs+wZJlQ0gQxieHGB1rganwsYtQ1FGjiXCn7ATvEfR+EdDzR8TSbDUJnRKqNqBATbvTTeksaUKNoj4cxqRz+8k0Qiq6k9wo5kZL/4T/KH66PPqb/Nw+a8UsF8iLlngyECHkLGrSoiQDC71FRnbHDgISsyxG6vdXTDX5w6D3TUkLnBpIqNld/cBC/3aHdA/KC5i0fU8OTOgJMiQlY0Be/GZPFf1tlu2a+vz6bqNmJvX9JHs/5PPHJgAqH7PFsTgWx+KA3v2jByxk7zGdr2O+d+RkmMczpP9BX6Hff/+JKRo4/VxycQBIWlerZUNfIf5Yc03tW5SZcv8e97d+cF5O+vHJG9a3gbEPQH70fujbzsS5TTJVfY28XyTqPpeTmgX9DYd6oZderd8VKO+7rBfR+GV9bE9qGSwOHd8VUBCRFnAN0EzP/3iM8fdEZBPwYWAS+DbwIzHGrog0gfcB5wJTwA/EGPd9lzchO5brot3URbn3AecaWGvwZZUW5KHu4NaO/7FHm7cpFi4E0+tkJ1DBGFsXOwo29E6sCHXRnYu/EDSpwFpD1U008ZRy4L3HOu0oG2MoioJgHTGJaxQkEXU/jaohN0CrNcDq1WvYaW/R20wyvRoYGKSRHNw7nQUahT621lLFSJm8AAiCNQWV93Q7JTFAq9GiWTRZv3YdY2NjNBtNZmZmENSXwfuKoaFBhgYHCN5z4vgJWoNKya6qik6nTavZIvHjKasu7XabZrNBo9FCMJRlyXxnnm6njbWG4eHhOsbzkUce4cjhKYpC42xazSbGSCrWTTKzDMkbokigUAYZUjJDhBgiExNLFEAAVqxYwcjIaHr/ShkCEQge5yzWOWJiJ8QAnbbSwKuqYnBwoO5WxUzxt0qTCj69pyPFiGpurYJUTv0DxBP9yV4cyi7I8Y9ZbqAu7npeaTqAEVcXSlneQDrDQ1/EKTF7cGQWALUUoee9EMmE/Hw+VsHj6msmJomD6S2uY2YSxDotQ0EeNeiUdI3EBCIhYKyti2WMplXodqRbssQ6tUJrpx74Z6IycpyxJzOEkkGoiKXTmeeBBx5gw4aNbNywmWXLV/PNG27k6NFjLFu+LEWrBtQMjgQ2RR5++GHa7QW2bz+HRtHAV549e/YwPj7Ogw8+xJLxcTZv2kS3LDl4+AD333c/42MTyU1N5SCFa6RzruqBCeRyMKozss3O7WmSqemBBp88FoqiyfDQCGtXr2XN6jVYZ7n44gshBkZHRrngwnPxscPIyCDOSj0HWrH4UKZ9Y8kxoEis69pOuwO+wsZQg1UiQrM5gBApqy5RIt1umUC6J0clWq8H6uleepNxH5YQM9AJ1DrJOj41ydjSM2P9akL2/OilXkjfV+l7du409PZb/x48iap60kInv2tIkEimasaTtj1/e/JRkTypIfWCjfR5euyJxSL18Q/dxxWCqxft0PO7UP+Z77WLlP+gb2Hbt5CVk86JxbE4Fsfi6I1+SDwb8fYXwbEP3Xw8t5FY33v6wYr+/+ef5/fqL7RzOlZ/kZ7NgTOokVl7cNI973Fv4fc2Yg3kn/TT3rv1ywBruUKPZd6bU6VvZ0u9yT2mYR943weixJNkHP3gRP82AlkmV79H9klK+zdGTPaao795sDjg8TEUOsCzY4wnRKQArhORzwJvBP6fGOOHReTtwOuBt6Wvx2KMW0XkB4E/BX7g33qDDBKIpAWCUVdULWbSQjLR2WPUAqY/4k1fI3e9heyiXxQFVaVp2SYVOrno6uXAk6jvPVCj163tAQs5kz6DFbEPdDCpuKpp7lopqxGkD8lsUrRg8xUhprhBYzTdwPcZG6Jf9+/fz/0P3M/KlSsUcLAGUlc0a/tj0AvKWKu6frE0Go7JyUliCNy/bx+7d+9my5YtiAjHjk1x0dOeRgyBr3/96zzt4ototlosLCywc+etnHfOUzlw4ABTU1MMDDaZmprCWsuO7efQaLR46KGHOXBgP74q6XTaTE5Ocuqpp1KWJQ888AA333wzrVaLhbl5tp99FqOjI/r+27YyPDJCt9Nhz549bNiwgaHBEaXNG11Ye+8ToKOAjWr3hVZrAGcdIShT4oF99zM9PQ3JNHLLli2MjY0xd2KO+fkFpqePMzIywqFDh9i6dQuNRsH09DSHjxxkeHgY55xSxxsDQKTsdqms08IlRiwGX3k8yZzT+yTHkfp8yYVHvuUFIPgK45yaFSZQoKo0Tiyfr5C9DAK9dIiUTZyK9+BDcusNSVZDSsRILBcryRQ0xZr6qndrTKyRMnlNGGvrRXAGVGJikMUq+2WgEZD5Qkxgm4W6wCZmk1P9fSRinUkyIJNQ8CRT8noOx6jnp03MEe+VcTM7c5wN6zeBCOMTE1RVxdzcHEvDZLob9SbFnHoyNzdPt1vSaimwNTm5lEceeYQYYG5ujiXjEwrm+cD4yLhKbFJajK98agxrEduLT80SpnT/kDRtxXxkHUSTQEFH1e4mQELPw7n5ee6//0E63S5Ll00wMT5Gx1WsXbMeW3iMAe9LbDaxw9Rxt1p4KmtEjFD6Ch8DnbKL8SWuIUSvXg3ZKyYEXxc4zUaTqgrIk8RDIc/7ATVc1PK5t4jRpJlcDkZy7kI+HiI9uqN2p3PXIYN1sQdCYOvn1u9dr+X0QQTKUsFZMRn0Sed1vQjRRVj2SshLH0suYNHrTUTBvhQBpkNhh3YZcFYjFw2kzojU29Vb9DyKlbE4/vWR0jT6kyxOksuInkHmcVf/PWiqPm8EcvrHSYvsPsbK4lgci2Nx9HfedZ7JxazJ9aeu9dKsJjz+e4jObf2SBklTTwINpJ+N96gXFV1jQI8Bp+uaDGLrYwXxLSot6K29HvM1/7fGo4r3AGJz1kNmbeT5O92T6+5C/9/3NyJ6LFPJDxCtj/DpVp6YoTWzoB967gkX6+mij90Y0uIhRwPorrcJoFCPtZO2aXF895VM1HEifVukfxF4NvDx9PP3Ai9Lj69M35N+/xz5lwKekzdCDGIKQhTEOIwtMK5ArENsMssQUed/61KHzybGgRbXudDP/zLCJ6kAD8RU8OXYOC2AELCFQSTifYn2gjWuzVhR53jvkQjOFTWdG8A5p54E6cLN3VpIcYN1ZxuyLjcXzBm88EFlG5lu7n3g3nvv5ZZbbmH9+vWcddZZdaFZuAKCvk+3262vv/mFE5RVl27VqaUI3nsOHTrE3Nwc69ev5ylPOYPBwUEOHjpIGUqOHTtGp9MlVJ6y3WHv3XuYm5vj4Ycf5tChQ6xds56zz9rBoUNHuO2222m32+zcuZOx0TEuuOACzj//fJYsWYK1lk6nw5q1azj3/Kdy2umnMjN7jDvvvIMQAnv37mVmehpfVgQfuXP3XSzMt/EpAjEkdkGjaOCcS4yHFHmZPTFS7KURWLJkCSuWTTIxPs7u3bu5/vrrCZXnjt27ObB/P0snJxgaGkQkcuzYUebmj7Nz1y0MDg4yPDzEzMwx7th9B912myIt9vHKTqjKkk67Tae9QNntahQjynYoyzLR7zt0Oh0FoTJ4hLJMfFkhEYrk22BS8eqc6wMYSMdHZSE1sBX7okijErYMqvTKAIL6aGg3vaoqut2y/pvKV5TB6/NrAFa9JAihfs3C2hpsrVLMqkmJARmQK5w7yaMhF/aSQDFJ51dm85AmTUQoioKiUODP+yo9j3ofhQDG6HUjosyVTrejJoV5X+ZiMl33ncSIqRJDJ8ZIu91OEp3e9dhstZTJlFgiOi9JzfQAakZNbUopSV6SJEvWuVr6FENEoqkXBXk4VxCD8OADD3HDN27ms5/6Cld94nN87COf5J8/80Vuufk7dDsVUVIBKZEqlslMtgFiKYOv56EMDrUGlFFTliU+eDqdDj4ELX7T/U6BIsFaYaA1wJNiMstNh+gIUQ06o4cYE4gY8vkPIBqxRVozJNlNcksCsvNBTv7IpX4CHUIuCjV1BKpUZKrUIAKz0x3e/j8/yaFHjimYHQMhVkmilDxqoqklMLmvE6MhekMMCmkEQ+IsgCUgXv1MfBR8jHzso9fxjW/uodKMn77CNw/LE0h1+CQa6fieRE/9l12t7+0l83WUAaO+7/vf53t82cWxOBbH//lD7xi5i52NfKnTonQ59r3O1brAjwlID3XYYh4epOwDAvr/nbxlGRWPmHoejP1dfIwW04rMf4/b+fg+itZWlc6FptdYUR+I/m3J230ymJsbDllenL2uMCWkAr+WH0ZDDVQkUCZms13SKiJqo1qli0lOLIEoJZFAiCmmMwMb0fTNE7k58CRYf/0Hjse1mhF19Ps2sBX4K2AvMB1jzBXSQ8Ca9HgN8CBAjLESkRlUFnHkX319Y3BFk263Q9EoauahtU7N9KSHe+SCINPIc2Z9Zg+cVMDrg5oMA9opzR3K3mv0tOPa8c9mYT3te+/5Cgb42hxQ5Q0hZFNDU1PXSd3MuutWMyrS83KHzECVioapqSnuuusutm7dyvr16xkeGUrUdDURjAm4MOLqz+iDT3ToAY1rjIo8FoVl1eqVjI6NYKxlx44dGCO0OwuU3kMy6yvLbl3YWmsZHh5maGiIqvIsmVjCzMws7XabqqqYXDqJdY6R0REGhgZqVtDg0BCDQ0OEsmTd2jW0F9qAyi0evP8BhoeGOTZ9jIMHD9JpdxL7RI9M9lPIkhVjtHisKk+no+72MUQ6nQ4H9z/CQw89iPcVR6eO0Cgc3ldMTR3R/TU8hFjDKadspVuWTM9MM3N8hpGRYZrNBitXrqTd7tJuL2CN0GwWFM6RpR4xqM+AD56qTAV7UKp/7pqKoZZzSAKcTS2tiIh1atxnNVIRoKxSlGQ6lX02L4xG39fY1KmlPl/L0vcK2aiGiL7yvXi1xNapM99NBgACNhVitdo4F+vp/FNPD9u3/6W2raOW+theYFE+/0m3/pxNXzM39P2Dz8dQoyWlknStqNdJVXl8lY532cU5m2QXasZok8whp7GJERqNJnNzC32soh5jqCxLfAIEvPeU3lOEQOWDAjvp8/l0/LLcodloaLxmgrcl3VMUvIrKKEoyEciSD6EsK4aHh7nk4ov5+vU3Mzs7z4plK5g+eoypQ8c4eOARpo4eZNupG5gYGKEKyZOEbPaj22pStzMfoRA1ntQUKV41gC0UaLTGYqxNoJqp4z1d8eTwUBAC0UeqKHzykzdzzZfvxsSCpSvW8ku/cgEDAxA6FR/4wDX8yI89B4nwvnd/kVf/2GUUjZPBHNU62hSLCj3JAMnssT5DyW79/cwIHyPv+psv8fznX8jyVZOEGLnz9sO8623XEOMQHR/5o7c8j/HhZkrzSlG/3vG1L9/B1VftBAM//TOXcdppKxGBhYWKv/jvn+bo4Q7tKvCyV53Hsy/byg+96hn83d99lQLHBRdtUvAyJ+nUHI2eK0Nvnloc/9qQzELRCSStOev2Ej0tbP6D7/qKj/GUx1pQ53NrcRG5OBbH4ugbEZQd5XU9Jy4B2Dr3KfhpHvNO828NXVKaBIgHbYyKvqa+Ur/nQX8Hv/99+u5bEglB6C6UNFoOk13o6w8hfX/z7yXD60k0YpYOiuljGIQEMmSmR/JbSgByjA5fRT79yWu45NJzmFw+mmbQiM6tBlsnMvXm1h7Q0Ftf93gKiYkgecuUifj+d97IS16+nbGlatr/L/fH4jzw6PG4AIUYowd2iMg48I/Aaf+7bywibwDeALBq9SoazZbqtp2rqcgmdWR7rIOe5CCboqm/Wk+Xnruu1mZpg60LqywpMKSUB1Ih1Ge6Qd8X75WSnjvMOSIyfYL679VkjZoxYa1V87tcqKCFXNZRaUQmWGfTdaufa+rIFLvv2M2aNWvYsGEjjWahKRFZdw1UPmjqgIHKV8QQ6HQ7tDttBsoWCwsV++69j22nnELZTUCB6HNdoYVue6bNseljLCwsMDw0pGwHdB+22+3688YYca5gbm6BRqNBWZZ0u0qnzxrVsqqwziJGUU/nLK5wNEKDRqPgnB072Lt3L7t27sQ6R9XppnQIWwNBvZQDLfC0+NPibW5uTn0MYmBm+ih7997D9rPPplE4QlUxMzOD95VG+1UV3W4H1yjqwr9bdlloL9Rskbm5eY4ePcqypUvxvqLTDrTRNIcQkq9GAoi6nQ6uKPpuG5IMDlM0pLP1sW84R8TjY8RXFZWPWGeJIdnxJAmNpn3occuyHVKR6LNkJ53v0rdviBEnyQhG26W9E9VosE2M+hoxRqIk8nZ+zdiLk/Q+YJxN3hF6rahUIYENiXUQfWZfaEEuCUDIHiJaEadbcGE1jSX2Yi37pQUiClYVrmB6epalS5cxNzenUZ1O/9kiA3cgKXGDCM1mk9nZWaqqwoito2NDiAyPjDC3MI8n0u52iCIMJP8NldHoiRpEgTeX9q/vAxFj0LjXGCFU2dNCJ7SYIiqstVQhUBSOTqdK15NRNkt7ASMBl/Kkm80GJNM+wSmdP+kqK9/FGGU5eO/x0ePSvsleJjaWOBtTNGSk1SiYPX6cWFWEwWEFWdOxfdIMgav/6RbEOP7gD19BrOCNb7qeD37kO/zYa7fTmYcbb6z4gdeAjfDtmw7w/dltGzAAACAASURBVD8KtrJ1WqQx2bATpEr3oMLWQEL0omCMMb11i9e/zZj0njsOUEXPKU9ZowwDD2//q8/zR7//Q0QDH/vH2/j2jft49mWnqu5SIjEavvblOznwyCy/91+/D4Df/I2reetbX0Fhhbf91dVc+dLzWbd+OdfdsJ9PfHwvl1ywiaEhy7nnbOOb37yPHedtoNUL6DiZrVDPPYsLlO8+UrcoU1nrhaj+TmqGAd/D7ux/Yi+FJNOMJQvb5HswVVsci2Nx/OcYQuqgCxWW23cd4o7dU2A7CBFn4PIXnkVrQLAm/8F3HwpI6HO/c+uDbNu2htZQUTMSYrS9V5JHywfy6rDfg0j/7o//6L0887IdPOd55yUylt7vepYL30vc7vcytLDfvet+Nm9aSWvIadOolprl+27fJxBlAMboidERPVx91fUMDA0yPjFC1YV//vydLLT1859/7kY2bproUe8FQhRmZ0s+97nbkGAxvsmzn7eJsckCxPCdmx9mzz2HiBJZuXqEiy/eRoxw4njgDT/5Uf7iL1/K+tUjaT3Q+zTyGI/+s4/vSbwZY5wGvgJcBIyL1Nkaa4GH0+OHgXUA6fdjqDnjo1/rb2KM58UYz5uYWIJzBY1GS2nRPmlT/aMcNx+lnOj3Megv8HNxG1PkXUwXe5RsqBf6zoHkdYDUFOwMNqgPQ6NmJWR/hv5tefRXJSLkNIZIpoRH0Cz0RC8XEVoDLaJEqlDhfcWJuePceded3Hffvdxzzx52376bgwcOaOGdtNdZJ++DdrxbA00GBlpcd+213HvvXvbu3cOxY0fxvqJoFDRbDTW3I+KjarUbzSYAd919N/v37+e2225jZnYaMdDpthPAkApQn3X5FcePH2fnzls5fnyWo0ePcuDAIcoq0OmWCchR0z/vS6qqi/clGzau58ILL+Ccc3aw7ZStTC6dpGgUqZj1KFYV0t8mEMNq4sdAs0mr0aAonMYVgkoVnMU5R7vdTsCSGks+8oia9y0szHPixCxV1cVaqDpdpqYOU5Ylx2dm6CR2QuFcutVqUWwS+uurUqUxscdMSIx+YgxUZYWvchQktdFnCBoLGEMvqjSDHaDJDifpw9HXU4ApYJ0gJsU2xnxzDXrsvSZICCSqFom1oudOZgZIeoKaNJJSUABizaqxtk+nBj35je/FSNZf0/mcvTt8AsZCzCaovmYuKNCk2n+kz68g/TfQbNFqDXDrrbfw0EMP8vDDD9HpdBgbH6sLrG63w8z0LMSo8Z3GsGTJBEePHmXnzp3s27ePhx56iFWrVjMwMMiy5cu54+67uHPP3dz/4IN0y5LJZUvVsyIdr/q20XcNhzqBItRGkyZFQ2Y/k8wIqOPiohpcHjt2jG/e8A0OHjqAmMDsiSmaA4YNm9Zyznlnc85TtzM8PKSUuaCFb0igWGZZ5H2s5w5UpVemkPSiW0VQ3wir+vyicEhivsSgJq2P3U19Yo2IUInhs5+5jcsv387IeIOJJU1++qc2ELpH2b3rYX7lTZ/kum+c4Nd/4x/ptkugoL1Q8tb/8Vl+9if+nj13HsZHxQfm5zv84R9+gp96/fu4994pPMKu7zzAVZ/4Nr/xq5/g13/1XUxPL/BX//NL/NIvfIjf/vWPcHymg6+EL3z2Tp71/HMQFyFEPv7R63nxlTsYWlYwstTxmh85m6s//C1MiXaFMEQMV33iZl7+svMYHXeMjDXY9+AIH/ro/QSBl730QjZvXcbokiZnb1/G7PQJ5ua6RIGnnLOW3Xc9QLesyFKKHqU+L/R6srnF8W+N1LWqmSh5Idr3j/yrPsD18Yz6xgo9nXF/1y+L0BbH4lgciyONfNuJQu7PXvUPdzM7VTLQbDLYbNKg4J3v+JqC4YAP4L3+i7rEI3iovILltQE46JwXhI996FZmj7R7DL1UnNf/YpIyJDlhjuomGkJiS1RBjdB/4Pufx5KJsbz5+CAEb9N7Sw2OBA++yq8V6f8vs7dD+hfjyT/rJX3pa3hPvR1XfeIWjhyYV+lC3S8TQjBJcphqNu/SNgtCgQThqk/cwEBrgOe94AKiNXzwA9dRHvcM2xZDtsn73vUNFua71DK1qPLEt73jqxSNBq1mk2u++jC/8/ufposwXwY+/oldLLQjrVaLO2/fz3VfvRsQXv8z53Pamcu54bqHtVmRweooui5/Eqy9/qPH40l5WAaUMcZpERkAnocaLX4FeCWa9PBa4J/Sn3wyff+N9Psvx+9qR6668MJYjEm0FzGqXRGh8h7bJ2noj4fsBxXq5AfAS6QwTuvv6KmMqMwmgQ9KVe9tVu6mhpio3Nao038qwnLcX+64anqE1AVLFC2mqiCU3hOD0ppNLInG0fYBYsCGihig0SjYsnUrjWaDIJ5oIkuXLeGiiy5EiIyNjWo8HJGy28FYS+l7RXe+CFsNxzMvfTp77rqLqtNhZHSUNWtXIxbWrltNp+ziY4U4pZsTAo3BBpc++xnsueMuHjmwn9WrVzE6MgQhsmR8TAGWWFF2u4yNDVE0DM2m4/wLzmHXrbdwy803UTQHWTKxlPHx5Qw1B5GhqpZbDA4NUHW7iEQOHzrA4cOHWbtuHVPHjlL6DsZC5UusZJYCJ92oQroLDQ20aDUcvlRviKHBFoODA+zauZPBwQGOHD7EsuXLqcqSLVs2c+ONN/Dtm2FycpKy7LJp0yZGhgbZvGkD9+3dg+92ePihh5gYG6UoAuApjMHZiEiFiEd8lxgD3cpirFCWbS3okjlfvwRGE0i0Mx+NqJ461QTGOu2WJkcAokeiwZkkg0ngi0gvPaGoaVXKcnC58M+ggzj9XQJRIvma0NkjR+PZBHBE0t+lIl/See9TqkVtTEgy/YNadiKSrjUy6yYm0ESL3egrYmbjGKszX952AliLSmoC4iLOGqDJWWc+hdnZaXbuuoXh4WFOP/M0xsfHkkcEdDptDh18hJGhARquwPuSsbExzjjjDHbffgeHJg6zZOky1m3ciGs2WL9pIw8cfJibb7mF4cFh1m/awPjoGBI91ubECK/dbFsQYlWzm2y6f/RSYXw6JomemJgfRiyVr1DDIINrNBgZG2VkdJIVK1ezauVKxkZGaA04xHg8JbbVQGwAEzSZhKDGTEnSEdAkDRL7I3j1uWgUjoYxGGkQ8Cy0S6rS02q1lDJvG2SvgUajxZOhCI2ip4cEQyOAE4gOznvaZq7+9E285PJz+b/e8mJ+89c+yx//wRU0C0tnocm7/+YaXvKis2k0D3LVJ+/njacvY3Zqgfe8+wv8yOufxU037OO3fuOf+MAHXs/Rg4EPfOBe3v3OKxgcK/jUp3exfv0yfvL1l3Hg4Cx/9pbP8Du//310VaGGC0Ko4K67p/nh156GMwkENJGQUgJsokK6AE/dsZFbb72fp126mYrI3Ikx9t7dQUzklFNXE4JQ+ciXv3gDP/WG01m2dEDBOAvnnreGm2/cyzOeebpqR6XfBVzHE/8oPkFGLxss/6Dv8aPYA//LO1Xvs49NcV08UotjcSyOPLIcQbX4LgrGtrn4WWew7ZRJjMDCiYrP/fptSBTu2XeYbqfi5m/txRnL97/qQjoLJR+76kbKULD9jNWcd/46vc154ds372XXbUe47c4OKdspvavo/JJqgbnjJbfvfpCpwyc4fGCe4YlBXnrldqwx3HzzfYyNDXLt9XeybMUyJscMT92xWdnVAb785dt4ZN8srcEBXvmKHThniAKf+uROjhzyTC5p8JLvO6P2nKvvjRHaXc9NN9/B0y86A7wwv9Bl5x33csH5p0ApfObTuzh0pCQaOHvHcs7bvg5PQccIZQzcdP0dXHLRmUQD13/jDi48fxuNhiF4w5c+v4v7D51gdHCQV7xsB8dn2ty5Z5of//GLsDbiK7hzzxS/+LNns3LlGF0Pn/vKLsoyomboeoQMkb17D/ELP/dcBgrD5S84hZ/8+Q8SPBw+MMVlz17DMy87G4vwxS/czsMPzxCItFqGF11+Nr/921/jipeeSquulvv8GRbng5PG45E8rALem3wUDPDRGOOnRGQ38GER+SPgFuBd6fnvAt4vIvcAR4Ef/K7vEFEYTJR+nQ+Scbp5dbGf6Nv9oEJ+nPXO3idTuxCJoUSsInlBIsb10D+fnfJr/Yzq00P0mKLQTnPUrjVoYVXFSg3cSEBCSMEhWT8fvXYafZcYK/AVkVLlGBhsjPiqgxgtQtesWUsgEKqAFUOr0eK0U0/VWD9JCQK+Ui+GWNbbQaK3x6AO/atWrGDJ6Ciu9mRQNsLE5Bjee7plO1F/ItY5rLNs2bKJjevX1EaCMSh1f+Pm9TjnKH0HJLBp87oEZGjRvmbVKn0PIg3ToKBk66a1lFUbQhukYO269cTVIXWqDbffcQePHDiAD4HNW7bQGhhQwz408tI6m/a/Mh1cits897ynMjI0TOVLQowUzQbnX3AeJ07MMTw8xKYtm3GFJZrI+g3raA02qUpPs6UMjKLRQEQ47fTT6HY7BO8ZHDyFwcEmrZZLyHCgKksqIt0YKFPTS9MTDBIDMYAnJHNEQ9HQm8nCwgIxhkRX1/PXWY0YVD2WJwfk6bkakIZV00OvMoTgS2XC2KTXj9TnJFGNQjU+EaqqrM//fgPQXtpJz+ug/3pRwE19PzK13ySPgCzFyNdZfi2lmFEf636PCxFNUKkNSJPGT2LEGoelIAZDxCE4RDzd4AneMDQxzqXPejZTR6doDQwyNjaKaTiqqAaSQ6NjrBKLFE3de05wVnjK9h2sWrsB1ygYHBxmcHCQYAxFa5BLnvZ0ZmdnME2nSR6NJhUKblUEvCkTiyKxJvp9WNItKASf2Esx6fNPVjxqCoemV4yPj/OMSy8lBocxBVVZcfToMY4cOcjU0YMULeFpl5zHxNKRHphTy1ckMUEM5AjPFPHpq4qu72ILIYin023jPRRFk1azSfAVrihw1lGTIZ8E85kutJL5bl6ThEhVepyDwhkGG5ZG0aE5oKBdbJS88EUXctoZK2kOjfGrv/5ppDqP3/3Nr3LPPR323HUtQbq0Rp36MBJ56RXbmBhvQQG2KHjf393K5z5zF9/3fedwxUvP140xqYMiUQGjUCTqkRaLIQZNbTAQjXZqrMBLXr6d1/7I29m0fiWVGJ7z3FMYGT5Bvua6nchHPvoVNm1ezSWXbEvrLv2wV7zsafy33/kHnvH005VOn0Htk3T59d76jzswT7ohJ33Rh/KYT/lf249y8v/lX/5ucSyOxbE46pFuC75P7+9jk8MHO4wNHkeILHQDreEWPsLOWx7m7z/wFX7mZ5/HYKvgxEKX97/nc5x21lb2H+ry0Q/fzVlPWUuzJezatY9bv3U30Y1xy637ehKGqCbypPVEBI5Od3jjmz7CL/7Cc1i7eZK3/vW3efqzz2B8tME/fWo30zNHuPLK8xkfHeXDf/9VTt26hqJR8OVrbmX//qNs3LSGv/rLW7jsstMYX97in666iSjCmo1Leec7ruEZz9/K6GgL07dmQiCUnqv/6RvsOPsURpoN9j8yy5c+v5tzd5zCp6+6BU9g/YYlvPnNn+EHfvAszj1rnRqHA76KfPADN3DR+WcSDHz0Y99m+1mbMcbyhc/dzPHpBTZtWMrb3norz33mGRyZmiUiLF8+WoPKVWYPmworlkbL8I63fY03v/n5GNsDPkxm2zo1tRYCNsKmdZNsXLMMjErc2+UCrSGDGH3dc89bybZTmrq/T5qrQ9/jxbkhj+8KKMQYdwHnPMbP7wUueIyft4FXfW+bEfFVia96RWB6rZpKYxLnvL9v0F8wafFVaREbQbzBOksVPUFC4hLpwlFEMDEmWrmlKiv9GxGsuNr4jNCjfldo3KNGQqbiC9FCCsFXqetMAgEMBBuJojQjSSkA1li6VRcRNVrTotLrDSnR2PW1E/0/RV/6Sk/ggE/eCUAEZyzRJ08CtJMeYoUE9XxoNhqEKkfPoJ1bMQiGwjlNBqg8VSgRYxhsNdRMMFH1Q4y1JKCqAo1GE+cMtnZObdNsFTSkARHKspM8KoSy02F8dJjnPftZyvgwgnMFhbOEJNnwVUXwyXTOe7VRC6pbHh0eJpv9aYvZMDY6SqPRoHCOwYEBut02ofI455gYGyPEkHwOAjGU2KKgcII1jZqybgRi1cVYoRuDurJXFRISy6JKNDajevpoqb0yfPTY2O8NIImtoGySTqkFdxVLiKIgj2gzWqSXWBG9V78QY9T80Vqs0bizbAIpJLPHGGtj0pjo8/qa6vWQdWbEnDoh9bZlsC2EgLEOTTPpS5cQZRw4l2UbPe+DfO2F2JMe5fQHMTmhI9OMHeIDUSLdRsGBoWHs+BLGuwMaA4shxiZGIlVVEtduwhjD4VRhGit0y1JZPEtWJ9NLjXx0rqEeDms2Acm3w7oU+SdpXg2EUOo5hgVRYGDBOtq2wYQIxqvbfpY+Sd89Ro9Pz/ckx87pteDVUkkgGliYP8Geu+9i6sgsM9NzLJxYoCxLqm6H5mDB6vXLKFIUqTGCLZyuA1JcqCDp+PaiBquywvuAL7uJR1jifcnwyDjWNpifn8caYaEKFCsaRBE63ZKe6/ATeURMhOBHqILegwyWm751L2vWL2Ny+TB+rqoXCRGwjcDWU5YSTWTl2mFGxyI2QtkJfOzjr6RoUjMQlS1WgS2ToiDwgsufwrOfdSaNCG9/5w0cuPYAO85dh/EZPwggFisdvvbF3Wz68UuVgRYEayolt8cUfwpMLhniH/7xjUhUyuovvfFD/OVf/hA2qnfDxz70RTZuXsVFl5yRFh9ppgrCjd/YwwUXb0mYRQ6afbQW/7E64otjcSyOxbE4ntjDJJcVLUKtwIf+/k5WLF1QhmTD8hu/eXlq3Fle85rn8NxnnwlRePd7r+PMHady6TNO5ciRNh949yfZc88U8+3j3HLzXn7y9S+ksnDP3qN1UZt4kwqmRmX/VUG49Onn8PKXXwhW+NJ1U/zt33yLN//yJYRo+fmffzFbt0ziu/DhOEzAcHyuy6eu3slb3vJarAj37jvB9TfuZftT1/Pe997P81+4kYPhIN+5/SB/+84v88u//CLMo6RkA62Ciy48h89//ju87MXn8md//mn+5E9ezdTB49x480P8wR9cgTHCS6/cWsfcYzTqWSKUDFChL1n6JhFhamqBv3rbt3jhC7ZzZHaKPffO8da//jo/8Koz9IlC2hepMtEFGxLg137tSv7r71+ljMh6fwnnn7ee9777Gl0zY5k+JlgPYiNiPGWwXHf9bRybPsarX/1chWm050BhFpLYTU0x66jJ/7gT7EkznjCZVanvDqHSojzkEyfTy/v8EmpRtB70UFXJrKvCGEPbFRwYHEZiwPguIXpsjiAMaEGXehtRIFqHTUkKIdGhEUu0GVRIuvHH0FBms7voVHM9j3BIDDMDA9zYaGDjQKKDKwDiRAsLHxRciF411jZFXeYowmzeJSZFDIYcfabaaUnbYkWNKHMahnO2zrCPJJDEaoc6xxbW3eXoKatO0ner6V4MsS6mKu8x1qoBZCipvGAwjDlHozOP685TWMFXQsCBFURKBRRC1M8XAjKk8XZRoPI9/4AQAj7F9FmXaOdeP79BO7ZFUQBa9BITJX9Akx2MMZTkzqdAawBj845TT4AQoyZiIDhjKKsuhEDTGYJ1hJZhyg0w5wrEgAslVQWGAk9FkICJNvlsJAAkCM662j/AWgVzjGg6RNJwaJGaHHnz74JP4BWikhYT6yJWu5p6vlmnCQtZ2qM+EwloC+nYolr6zKax1iig1Mfc6TEOYopFtMnAVE7S86tmX1LsYgbq6rO8Tt8wqSAWUdPLEAKh9NjCYE1BGTqYaoHRliGsXslCpUQ9gk2U/8SGEdKeyYBESncQ8CJUMZmRiiFZntbyGIh4kVqDF6yF6DHBY8Sqv4PonrcxMr7QZayqKASqzH7KrA4RnHNAIKSoUmstXhJwEpR1IpWmNAiG9vw8u2+/jeljc4TKMNQaYcXylaxYvpLxpSMsXTnMQKuFtYJxdcghYHS/O0kGk7m41L2gfi0tJLSx1uFcNpbVWMmyLOkG3wckxEfRv5+oQ2OvZudK/uZd3+LFL9mMIBw7tsDw6JDedwTm5ksefnCKlauXYKSNRM3aNmL1e4Hvf/UpvO+DX+PFLz4biZHPff4a3vAT3wdURFvik7/u17++i9kjXc7ZvpULn7aOf7z6ACFCQdBuRVSg77U/fglv+dNPc9llZyDG8LEPX8vrXv9MxAnXX3M7R4/Oc8UV5zE7O8c73/UZXvHK5/LFL+ziZVeeQcMJ3bbnnW//KhPLRlm9bg0PPHAMR2D92nGVvJSOz199G3/4p6/AuHyVZ6Da/MtG+OJYHItjcSyOJ8eIyjQlgBGVzbmwwJt++Vy2nboEYwW1GAfr1ZvFWjDiicHiK0c0DjEwOdniOS9YTpCKL375Lq684lwoItaAscpQzqy3PPXr2jJiJWIocU7DGV/1yq185qqdFBEMJU0bMVLiRQ3LoyRvhDCAsfoaP/q684gx8tCDx1k+McaOM1dhTeRv//aHWLN+OM1TEfDJ9FsQK1xyyWn82Z9/hSLCJU/fTGvAMTur8eUiIDbwqh/cwac++Z0032UmLgTjCdkTPzT01b1hYslKzjp7DcZG/vwvN7J2zRBluyT6Rr0NBqGQtH4SQwDe954v8RM/cSnGKp87H59X/9Al7Nr5IKHSn1/7tQfT8bN4D9/8xh08uO8gr/r+Z2Ft4r1FNYgm9MTxpl5vmcRO//c7tZ6M44kBKMSIpKw0BQd0MV9VSjNXLbmh8iURaBQNYvCY1AHUAksLZBHHYeP4mIsMuwYTnYD1BiMo1caoO6rBYmLACwSjwEF2De+lTNjUxSRJBnR3aQe9106LUSP2og8E69jvGuwrmlzfaOApcFE021SUJREyUTOE2osrY169i1ZUG5/r45qdoR1ZI0blF7FXHNUxjDFLQzj5hE/fZ0qnT5T2mGjvGVDInx9JIIfkhAK9EQ51SyZmZ1gze4ih0AVviDTwAjFUWMlgh9QFIGISfR5K72vX9ZMbc6KeWyJKEU/0eiNKRa5S1KKeMjkGUaUraYmuRVrWqecYShEFHVKsoomq467Szb7jGswPDDF/OKghpY8Y1/NEiF5d/UOIGMnnhRYmMVSUZVeLcaMFeU4aiUEIojwWlxgIoSpTsoIaQsagEp1ehrECKcYYwqOOa46q7GcQ6OMUEVn7e2QGhan3bT5/okBROEIydMwxrPURSOivAhQubaslVD4xS/RcyKCFcw5MIIpn3jaoZIDJE9PsuOMmCHocJRoMlkCZQELpGVqm988xkI2i0ONKTpYw+NLTTMwl79X/gWROWHm95sVUicam12E3elxDjXyMDwwboXQNimgUZc/Rm/V+N/VsocCJ3oOKwtJsNCikwhAJXpicGGfL5k0cOnCM+fkK34Xp6ROU1X6OTB9mrjPOqrXb1fTTeAVmjF73IajvhjGGWHmscTgrSDWAdY4YLOKFRkM9FLrdkhh78pRma0hBHSO0Wq0nTTUqBv7sL57HO95xLe9910GsiazbMM4Pv1aZAdIQTj11BR/50Nf5uV+8nOc/f5uCahGaAi+5fBtYOOuslVx33e28/93XY0zgp3/p+WADGzdMMDrexCXwd+nEEq75wnfY9e2jBOO45OItWAtPPX81O2++h+1nrcM4WL9hCW/61Rfz/vdcT/ANbGHYduYqxAbGJ8a59usP8IKXBGzh6C5YPvDurxMwXH75dsTCsdk59h/t8NBRw3f2fAtnPIW0+aU3vpDB4Qb33neQ9esnaTRyaomA5Lisfvrkv2dU1+JYHItjcSyO/+9H1K6iTav3KOrFhTZckCSdhcSMBBtQ9ptErARsakDFAMZXiATOv2ATN920l9NOX0pEn2fyUsULIa2fTSSt/wRMkgsiIBHrupqiIOBJTT8DIm0sERVOqvyAAPMn2tz67TvZsmUDa9Z0uOjCtTgHR45Mc9++R9iwdiKxxJ02dNDZamJymB1nr+KO3Ue48hXbcYU29Gz0ui4PCXTJDA4CJkT1tFMSLPfdM8O9d3qNd7aB5csqLr1kPUSYmj3BHXfey+TEOm648QRHj3RZvqKBMXDpxZu47vrbufIVF3PfvYeJXcepW1YgIty+ex/DrRYbN67kmutv5ZmXnYs1wk3fvJtnPnMZUkAVheuu3c2++/fzmh9+DmJViFjHwEcAqxJJklR1cY7+V8cTAlCIMVB1FmpKcJK74FNFHKKFqB3eCJS+xFhDqKr6ORJD6kpX+Fgx3jBs8wXru22cDyARL4HSa/SiFbVaFSFBZboQrSpfFzyFUzQvsxa0E6xFqZA64GppqsVeWSHWcNoMzIqhY5qUqDld7rPGoABGqDrYxHrwKRZS0wBjAlhIzIL8PhUhGToCKrFQNCMZ80FZlVpQq4A/yT+UKZA79gbBOaveATGoNjztt9zRLssydeCVOWFihTWRthiiN5yYmOQEgVUH9jFRdtT/Olrw6I0usUoyPJL3W13UJnAiEuuEhEwDJ0YKVyRfgrIupnsgR5a6gK98QjwzaiuEGGk2m1TeU6a/FxGcsbVOPrMATMMQgxqrlabJ6PETBKPgUzDKJtHjrqkJppYLaISns2p0GYNHUlSoIVJYm3zXstOt3oh6hbqmWIQQMDEb/wlWNBGhZxIY6u3XfaDFvrIl0h6Mep7EkG6A6ZqyNsVGCjXw4IzRM85YxGhmcvAhJUFI/X4ueZfoBOmxRjDO1K9DOk+zSSrRcLzVYtfW7bSNMF62scFQib5fZquU0sFgazN2PSd60gvvA8aamjkQ85OgZkaAGqdmHbo+1H0hMeLEUcVuAi4KQjTEWGKtY+iRh9h6/BiN1FLIvCOf5QdG40MLUxCNslBcYg+J6DYUtsCONrnwwvM5cniGqSMnOHjwGPfes4+5w3PYIrJQTnPm9i2MLVmazk+dUsXncgAAIABJREFUtBUwUDaItRYf1T9AAjSbA9iiABqU5Tw+pNjRSqVBnU4HZy1Dg4P1sTc9CskTeuSF1pqVo/zu775I1Yeik0/+BKZp+ZVfe56yQgReduXFmbKDWHjpyy9BgJUrR/m933u5djhihEJB1c2bV7FRlNEg0XD2mWt5yu+tVakFAgYskaddcjpVZXnP+67lx173dAzCho1L+K3fvYKEmOK0LcGZZ63mtKesxhlouSa/+duvUIabAayePctXjvI7f/AiDQgICfA1us1z8xXvff+1vOlNL6LRVBASyd4XoQaRlXmU01gWx+JYHItjcTwphqA+SUSiFBhgYjk0BnvrXV22aJTxyCgUkpp1Bq542Vn8zVv/mQ/93fV4POc+dSObtyzj1NNX8xOv+1uuvW4vgcDhw1NIw/Cev/sCN3z9QTwFUbV7RCKveOVFfPFLD3Lo4AfxJjAxUfDmX3oRYmHFCkuz0PhbA6xe7nAOhoYLnvWMLfzsT7wHEw0Dg4E3veklLFs+wpYtY/zMf3kPRMuKScsv/uLl/O5vfZiDh7tkF4UogdbAPH/6317Hiy5/Cm/7689wyrYVSIRlS4c59dSl/Nwb3o2hwUKn5OnP2goCy5Y6BlqCWJg50uYXfuqjHJ+GsruAtTA22eSp56/mp97wXqIRRkc8b37TFYyNj7BpS4vbdj/MZUu3YG3kec/bwWtf8w6+8JkHOD43zY/+6MW0Wo4TJ9r833/8fn7+Z1/Jxg0rufrTt/Ohj+7BiOfogWn+x5+9CuPgnnsP8Sd/9gUmJpdy7TUfweFxrQX++1t+mIGhgi9/5U6e8YwtuCKtU2M+pj0vpEWAoTfkuwYw/AeM00/bFt//rrcCqfiRlDdOUsAYpXL7GNRMEZMKQwUjgvda9FvtED9kLDeMDrO9U7FhegZC8igwGs+GWHzoEqoKJ3UoXCqig0oK8upOhKosa1p0jFoExkhNRzcI3bKLMfq1aBh89OC1qJOYkguikp8rEyEE7XhGD2JUW59O0OwBHnMBTCSEiqrqajEIGOPUQKwsa0BBN1kIPtZFYfC+7uZnLb6pmQIVVVD/gV6BGOouuBGDFYMh4pywEC0hCvtWrOXBRsG5B+5ltLOg/nJBkK5SoPpl3b5SI0BrHZJYFVEiZbek8hphKdk3oMrRarqdzUaDJPRAjPQBDJmB4LW4N320/vQ5SBKDKvlHNFPnOx+/4AONVoErAoaS0geqqHE8Gl0KTeNUAoD6MlS+wlc+FfwW74MCSmi33FlTbxeAcyZ13unzXDBJWuDSrUiZApKAnip14B9dLPb7NfT/LCY2ClHTG/qjVXVCS4Bb6u6LgLHJJDLkgr4Xldg77aVmUGSmRwZCMvujH/Q4OjDEV0/dQXdmhs3HZylCpBSwNhJCR/e9aIGcj4VJBbwCHJrmkifggDIysmRPvSV0f0fUayUE9dvwif7mpAAMgQorChxGa4lOmJlczsixGXYceoCWr9AlgMp8cupD8KE2Says5Z6Np3Ks2+Wcg/cz4AMSAtYUdNvC1754HbftuosTCxXeG0aHxli3bh2j44OMjLXYvG0NE0uHcC5gjV6HIQFtmRGksgdoWBC/wIP33s787BTV3AxVZ47BwSadbkmz2SKGQFFYyuYQ142u58zt2xn4xnX88p9+nMbA0u9yh/3/efTIN0TRFBAN4TN1BnWsTY/Sk2vqVkQztjPyS72gEdWIaREPSVkKvUk+I1e91/XAocNz/N37PsPrfuwFrJgcg5qBpRGRpn41CBgsvW1LXC4i6oKgYFHymVExZ7r/Ra7+5LfolpaXv+Lcuq/Ruzo9UXJyyJPLZHNxLI7FsTgWB2iDI/mfJV+DEHWN4kxMM46l3+/AgK5xUodRugYftBnnDIgjeWVBmaYwK0qqlPTzQAK20eCgR/af4K/f9nX+6A+fr75CFpzRBlcNghudSo2HUJBYwEJZpfcwGs6FgTJAlUDyQupAKnyaxyUT6tI2W9Hf14r02IvHTPZniIUiqTwjpHqMukkqAq4RiVIRqwIpwefGQwGlwDXX7uEv3/p5PvrBn8MVyhmQFG1Jeg9je68Jut86QbfHRmV1FA7ERU3lq3TfW5/YIxZw0F2oePtff4ErrjyPbduW1fWVrqorZV3/J2QsnHfeedx0002P+aGfEAwFYqQqO7hkrhhC0IV+0A50yJqDVCCZFOtmRFRm4L2a6qWOctVoElst4vwJ/NwM0QS8BDUarODwoSmq0ME6R6vZYnRwBBCCUbp6WZUcP36CkZERxGoB6LsBYok1lipClQr59nyboiiwxtCtKjrdktBsKbPVdCFWSAhIUD1PtJFQdohilbMQPVWp7u29Lr70mArG4KuKGD2xqjBOnegxkaIoMMbVunljNTJQCqP6fBGkcLpvEkXcpsIyxkjhsmZJTe6UFVARUsGbReohQlmBU6IIDREGjGPAGgoLlRh19xdDiJWCAIl6X5G9HEg+CAEnFtMscEG9G4wYxOpdMKYc3sK6pOHXu5O1isaGoBIYZTYkX4xMGYu9cwQDzjmsSayI6CmcA1y6GTo1xEtUsaKoMJWnW5XKTDGGUHqlqBn1X4gh3dWj+jk0nCNE1HMAlTVodGY2TPTJm8DULAARnVxSzZFiSlOhlH0KUqpDBg+ysSLktIhedKnS4aWmuqXcEf291eukm4AoY4RGo1AQizQxiO5LBQh6LOzMEkA4CXDKv8vARVEUhBBoICzvdBmZO84Z04ewVUVlVCLiUbNE451KYmx6jWRMZ63BWKslfkjRm70NUfaQDwkESZO1VRaLTt4+ySoKulWFSKRwyvzBWLrOcvfAMBUQq6BMpz55QwajRATrHGXp06mfpE0CJEDShwpXtBgbG6XVahKio/KRKixw+MjDHJsxDA43GR5rMj45mlRNKY4yH+d0fagRZqgnqlZriOPHjoCISiFcQczmrVaPd1WVxHQdVWXSVT7Bh4JakCfeXrqOAgw1ApkvCmINJJ38+fLZnZ4uvZ8rENsHROSRXzMhVSKwbPkIr//xFzLaGqxXNhnIkt4f6Rxz0mIhJvmXw8S+7eh7Tg3sRrjg/FNYsnSsd72fNNST5T/bYmRxLI7FsTj+zxmS1jGxbhDpg5B+mxo2aQqyAiEzTtH1UWjoHGhNTHMOEEleC4oiGMXOFWN3gSjZGjBggqFwgaIxTdFQfytdNuubGiLBpFnSKlvPi6ZqGRuxRhnW2Xw9ogxX3XKfvhot1vNcG3W7MtQPKk/W5CRdJlunRUNM+8bl/ZFAB48CCLktaxIkozFNgFFvCILKUY0ELn3GFnz1XN76F1fzX37hckzLYYsKU2SI31JKxNmQVxsIkaYkc/V81LQowAk4JwQTEJuOigQ8ln33HSJ42Lw1gQm13Dp9jti3YF4cwBMFUCBqYd0ttYOMFmRVt41YS0gGbRij5amqG7Bi1fsgaGcxJAq8H4JYRToL83TaJ8BlFNFzaP8RDh04jA8dji8s0Gy2OOspZ9FstOiWFXNzc8zMznDg4EE2b9nC0PAQ9WI1BIKpkmY/cOzYNN+68VtsP/tslk5OMj8/x3337mPbttMZaLXwvqR0bQormK7RTpQTmiYQQgXRUfrAIw89yMqVqxgeHdXiKSqV3WnOJY2iYM+e+5mZmcFZR6fTZdmypWzatJlGobqpTMF11uGjRiyG5IfgQ6BoNBI1PqTsWr3pGGuIEjHW4GNg5vgMjUaT4WaTWGkHlwilDxSipCmHAg7RGUwoKCqDMwUSK3w06ZYkGNFIx5qyb6Wv2y0YozGf1mZwSM1ijGgCRe2/gPpJNAtXs0JEqAu0nGygbASNX7SpUI42EYujSgoUrDKUQfuPDVOkv9FivCgcYBUAKnrvL2iihhWh8mXyUtDEBSvgCkuIPh27QPZSzJGNWrCrOaRP3h91ooBRunMMyibJf9PPgtHPLKm49/U+iGTwIuBMZkQELUIladaM+juY9B6SDBmNU9AogxcKhCg/JrMhxGSKV+oCe9/3uRIzRKdGGkFohC5N6WIIEFRWMT01TavVYGJ0lE7Z5aEHHqEsS4xYhoaHGBoaYmx8TMGfqDIiY3swc4yBhfl5HnjgAU6cmMOZghUrV7Fs2fIkb+kiUSi7bfbvf5CBgYLVq1fhbKFtgNAzxfTJSFNrzFiDa+q1YXUyTP4VQCrmDd35LoWzONug6lSccebpTE6uQGiwcHye6dljtDsLzByf4fjccY4cPsL6TesYHi7+X/bePM6yq6z7/T5r7X2mGrurunruTqe7k04nnTkhgYSEhDCFkBdkHhQH4FUUvSAgKipe9UVFVMSo74twFQRlkCEQ5ikCIaEzdDpDk6nnqXqqrvGcs/da6/7xrLVPdcB778fP5/omWItPk+rqc/bZZ09rPb/nN+AiyEbwEb9StoVzJVlMq8jyOrV6Q49xgEazAWKo12tqyur0+acTd6j+PCnG44v6kLr9ThcqsVsjgISUtS2RtaB4Q1ojxSk9blilbAos6v2cXtXDGtSAlyilI6h/ytjiXvTU/C2aeXIaCOqTUi0azCmLrvSmFBusP/d+v2xsKHp1JK7d4w5KyCrQLplz9kQgC2NhLIyFsTCe6EPXYZGNEDKoYO/es1xBdW3rpwJbAQKdx9VvrCfrVEp9wEYeHPPneikxZLGgtXiB/qE6z3rWWQQSq9kTQjQONCDRXw4imICuvwlOG7k+7pBoIa4QiY0/aQNDRJm/aS7WV/TmRpHY7DJxn4Ng8OSSXhH9ukxqipkoBbeRmZ4aTaLLtihzFTtvnwQ2n72cHdt3MDfTZaAej7ekoxwqAETnbvWtqzAWkxIyvB7jICCZrjskaAMYBUX2HxjnTb/2LDKTkJzeOUifsgAnnDqeEICC956y29aOfNTbO5TmjytIum9NO4gUcucpvYIKVbxdLL40PhI6ZUnXF9ANZHhKr9F+K5cvo9nMOTk7w9333EN7dhqDZ9/+/czNzTG6ZAlnbVJTsFqmiJorvHZS0SjArusydfIkjz38MCPDwwy0+nhoxw+ZnZnB0CbPM6wXxBl1984teKu0paxOt9PRwtZ1OHj4AEuWLUUyLaolCOKD0paynKLdYXJqgpnZGdav38D+/fu5Y+sdLF+5jL6+/ghwaHSho1TTvaB8I+89M7MnsdkANq8pIyCHms3odEuCc+A9IQIH9967nTPPOJPhwSFMPVMaOF7lJBhKEcoMSquoTk0s3lgwekMaH3lQ9Arg+TT8EKQqhJ0LsaAQ8qyGZFQgCCgIICIxwjKaMPpekZ66yyYmZIAny/XzQpR15Ebp9WVZxpQFTwgFYiKI4jxGapAZLJayjCixgMu0c54FG5MJQtVdTnGWNhNlVfiAyfQx7L0+2qxR+YRS6q16YRAimGCo1WqE+N2ci2yI6J8Q4n3RM1hM6Kj+7GNn24gyFFLBn4mtpAshTgJpG0D0grCYZAwXz1PydFBJRuzYJ6hcX5WwlSrCspJJoMyi0nRwaKoKxlC2S45PTXD3tu0MDwzz1EsvZm5ujvHD48oWCYFHH3qIkbElnHf+eWSNmiZtGBNlOjGS1ZXs3r2TA/sPMDqyBFcW3H7b97jgggtZe9o6TBC6nYJDh49x97Z7qdUtz16yjCwDxOFNNL2Lx6ACpSJTIqnZjdFJMEkgtLhXAKxey1WmZIQ8txydPs4dd9xBf2OA4YFhhgb7WTo6TKN1Os4ItWaDWq2OWEMIXVUvGomGm1KlSSRgCTE0Wi2MyQii3WvvA1mm4FdRdMnzht7jroAQsE/C2UzjmPRaMlWxrVOzBBNfMe95oauA9M7eNtKC7RRMpTedpVeEyuzQx0s4dkwkgLhIiMhQ/x4g+pgEQbswj9t7bXOE6q8JXEidKR90MWRBUx7mLSwT9DbPOWLe3p4q2Ejf6xTyRgIyTuFR/LgRgZjHsytOeVcP4PmRDz3lg8O838q8s/D/vAfzHxsLY2EsjIXxkzpC9RxNEocfAwpLD2ZIz9BTGgJ+3ruMq7r2NuLM3ji8BHSOy3UWS6blRhgaaHD1FVuqHQqRLSCxyMZH7yrxKswIzAPZjTZvxBKC1bmPiH+EAMbiJM1k1aIRMFVNrrOX8gt8muVChBvSGjHSLOJqC8HHdWnoSdjj8ZMAmQRcsAQxPdaGwLKxQd74q/9NDenj/um6WAGLLL42Ul3nYQEeKPVbhJ5gseJ6pKZFEDKBZz7zgvjenpRYHc96rY2Fcep4QgAKEOh2ZrHGkMWOujFaLGlHOyJk9Aitzke3d+t7iJnRBZwPXZwUhFBq19Y7XFB39dGRRVgsHsfRyeOMLhnBGMOJE8fpdNosHRtjYHAAJDmru17X1mghVzjtEk6enGBmZoaHH/ohVoT7tm9n3enryGqWufY0IUB3ro3JDbVGk3pNTR477S4zs3OUZWDfwQN0y0Ct0VSzPWP0ynYxwhE1i5udnWVwaJA1a1bR39/iyJHDQGBmZoosy6L2XvX9tq8VfQQCs3MzBOfIrSUzgosFU7foMDvTjt07qJsGszNtpianaTZauNLjQkme5TgvSLBgs3gCBPx8TwBD6R0mi4giZh6TwFS+Byp70LQEwZCFHNBoQO34RUPIXP0bCKJeEeLIcnX5xztN/Yi7oakUWtBmtazScAla8BZFGQ0JLcZmOKOd4UC3epj5UGCC0vozWyPFMwrEn5X9YI3BimDz6E8RIvoZny1VAgFq6Kf76KnVon+EVyNJZQjow16MiVGN0vO6IFLdjPphWGtiwZ8mIDUgVDCll/oBagin+JpONtZkCL4nlcBWjVw14lTAgYgQQ48hkz5NQSEFe0Kg8h0gEK8B1a05qwwZ8YaiKNm7ey8TU5P0t/rptDsU3YJFw8Ns2XIO3nsOHTzEocOHaTSaZFlefXcf7+08GmRKZpk4cYL+vn7O3XKuFv1lYO/e/axavQZXdtm35yCTJ2dYs3ole/fvY2a2S39fHWOhIFAGp2CaAesFJ6FKi9D4H6F0EXSQQOELfHB4r74rEkCyjDJ4jAT6+lsMDQ7ywPZHaE93WTQ0ABLIajn1/hYDo4M87arLGGn0q6kjykwRExM5kOhRot4wAag3+8lqDejMQigiO8JSupJuUVAvM5xDmVxlwJfpKn1yjCTI0Z8lMgs8QYJGfAIJAgB1wxAfn/ii0isjbl5RHf/ML15D8nBJRXp89oB2g3CVsVKIYKaIqlxV3hI7GFFOFaS3naqcDmnxQ8VekMRCEF0o+ejrkbSziYFB2jWJ93BV0PdYM0AlSNX9TDTYAPOaSf/+cVbDUY+NhM9IzYB5xyrEVZZJa2FIqUKxP0VahIlXY+R4TnQVmc7WfKBCF2hyyv6ZJ9MlujAWxsJYGP/BEY11ExgbesZ9aa7QRC/Q56s+f0W0gq9kfrGRVhXE4ZTZjihiiBT9BJ6H3gaqOGLV+utaI5V68yciQUyuE0rVnQjVdCCSIIQQ13rxvym6EmXv6fbR+aOac6pPA2MqtqF+hzTnaI1S+YJJiMwLnYfxcbequUT3TWPsY+NViOyC+H2quU4LASFUUnJtTGT6GiN6vmIzLHENEigBKmXGCMbYuDZRB6Ue+P5fzz/h/208IfiVaqZXErx237wvK+p2iEkF+EgLciVFp4MQyIyALwmhIFACLoIKJRKcZrOGUFGSbLDkkoMP7Nqzm90H9rFsxTKMFe6//34euO8+Dh88yGMPP8zRw4erSEoBjJXK8EOLYs/xY0e5+OILWbxoETMzMwwODjC8aBgw7Nm9lyOHx+l2C3Y+uou77riTotth/NAhHnnkUdqzc3TabR647wFqeU6jVlM6uXeEssCVhf7sSrqdNu32HMuXLcVaBT8GBwcQEbZt28a2bfdw/Pgxxg8f5s6tW5memqHslvjSc3T8KDse3IF3AVdq8f7IQw+z7Z5tTEyc4NCBA3zrW7dy8sQURbsbkVJhz+697Nq5i6LbUXOXuG53QVMNbGRROLwaXkqoHjQeB0YBGDHEnPl4c2YGY4U8y2g2GtQy7YiXMUYwsznJAZdIt5eYTiBG9falKyldl9IVEfF0EdkMFaBQFl2KbjdGjkYElJQQIRiTo1QrKF1J0e3gXVBDRu8pvK/o8o6U7hHnCKKcw0NKJSmKgqIoAAVRQB9EeV6rDBwl/s47BTXUMNPN09ET398ruqxVMGu+d0JCxE1k5yQjzfSatA9GTO+1xmJtRmbVc0NEImgT1GOjKtN6/hfpPQHoFgUuOE1XEWUv2HmyB0VyLSbk+G5g98497N65l0X9Q6wYXUp3rkNRBjCGZl+LdqfDAw/uoNt1jI6MaTkZoiGmV5mPMeoFEjysWrWGiYmTPPLIoxweP8LRY8c5dOgwIobde/fy4I4HsBkMDw/Sac9x6OABjAQyNLLSGp1QjdH4UCP6s4JTgkiGzfIoFVG6fTK7TEamOr8KQRwDgy0uu/xSNm8+B7E1Wn2LWDQ8xskT0+x8bBfbtm1j/8EDlN5RuJKAqRJksixTmYorK5M/B9TqTRYNj2KzGu1Om7m5OYqyBNEYyU5H40mbjSaaiuJ7i5cn8JC01qmKZyoPC4IhYFGsTBdZyicJ0X0qdtvjfU1ygsL0pCvBAT7O9z7KcHRb0dJVOzZoXLAmQBlC9LWhKtvTokOfJel/CuBVL1P5CWleiVKgCAbGBLEKWE3nR8HCGENVoXXxmRRSgZ4WovF+En26hvmvT2BGCKSpsUe3jT8HvRcLBzse3K34ND5Kb3ofk3S+Cpn0wBEfOTvzO2/VC9Nxjcei0/Xs2HEcxeIUVElHbUFfujAWxsL4SR+CmkMnF4LSQ7cLZSF0CyiS8WD1/EwQdw9wlriGrgrVWBNrG14BXe+zKBeEtNBNvlm6DvanPHN9UJi+SkEDnBceemicTju6H1TgQHJHCCqPSLsbG1RGKlgkWatVc4lUkYrpS4bq+yT/pMQ3DXFNHX0sqdiCac7w6dgYEBOlD2kBIXgfmDzZ4e9u+hQTx0+S2IRlEFyc/ys2ooQKyFDCtlB2DZ2yt94IQSi8UBRCWQhlafDB4Hzgd3/7U2y7a7xnRJkObNB5/cmiOP3PHE8MhoLExYj09NyJBg5EM7hQ0bytler1pqJq62WoJncWS+z0x8LHlBbf9cxMzTIxeZK5ToflK1ayeNEInelpjh0dZ+WKlfT3NTl+/DgPPHAf1z372TSaLTULsTFZIBaGRdGl025z9uZzaLVaOOeYnZ1h6ZIlTE9Ocu8921m//nSajSaHDx1hoL8fXzgee/QxloyOsnRsKc57xpaMsmr5cgiqi6qSJ4JKPpwEZmdn8N4zMDSEJzDbnmNoeJggMH7kMGdt3sySsSVYa2g0GmRWC1nnHN1Ol/bcnD66glB0Cvbu3svq1WtYtXIV3gXuuedeTp44QZ7lHD1yhIcffoTMWs48YyN9rRadbhtD7D4LYALOBCRYxBdRiyWIC5BpwdQtCsrgsFnsZHkofYHHY3KjMYTO423ABR/pRoYMq1IEE2JfUAGdVIz1UgZ6RnppJKp6umaS3CAZB4YILlmbYYwmbJSlWtyGoBKI9NjQIl27mUl6IZH6EIKaB5alJ8t7tHUxvSQGTVSQyCLQdASCKIW97HkgpM+ePxK7o2e+2PNTmB/d6Lwjy0zFXJgf6ZhkIeqREKrf630TMJJV+1clSER2BUI0k9SfJbKF0t997ORLNA1yJeANWcjITA0xlpnZGWbmZjh69Ci+hJ0P7+LMs8+h3jeGFaGv1c+ZZ2xi7579bL/3Pmq1OiNjI/jk6RDlTEY8BMOqlatp1JvMTM0CwvDwYqan9+NKR71WQ0zg5PQE026ak8dOcOzQPsLpq8myJrnPMM6QW/3OxloFMINXCU7QZI4kvwkhYMVW8g9jLSYoy8H7kowcT2DX3sfYu38nQQqOHj/I0OAAI0uGWZwP07d4gGajhnOBvFED0TQVH9kI1gh5nivbI6QedKBWb+I81JstCCXddhtBr1kXC73SB8Ra6vX6kwQgTzKGuGhK9tSiQJ0vhW7p9dh4wRvB5mqEqoSakGps5v9/L3IUKutoo8yA0hl8EIxN96zM2xtDcPBP//QlXvmq68hyq2CrjWwbHDFJnKySTNA71iZ2UCIHwROwKS0FIAg2ZkPo+0JSjxJEM8FFIvZN7IqkJk2Mo/JBj0ktMwo3iVEQBKrOlEhaAkZIQPTwem/wAT7/ue/RyA0bN67BI5QOfHDkQL2m6HgQ3wNdgsEXnm6I4GzQpJrc5JgAna7DmwDOUMuUsHbyZJfXve5z/PVf38A554wgotyM1PBawBQWxsJYGD/JI/kjeNRY+uZbtvPNb+zD0iXYgpp1vP2tN7B4pKXzhth50t8Iisd1LiZT0+XoF6cmwJ7PfnorV191PosWtZjHa4sAQABxFashwRJIr/D1McnIe8sH/+c3Wb9+gNe97nrS1BOCsjZtEEzIqm2rtFLXn0H8PKaBqbr6ii7HNasoIG1wMG+NaUQ5fF6EL33+di5+ytkML+mnHtc9IQEpsWwjEFuV2kzM0ESoohT+4YO3cs0zLmPJ6JCuhxxMznT54he+z6te/jSSB0NAJfQGy6Gjk/zpn32R4DKc6fJrv/Is1q1ZROngXz93J7fdtpPgLZvOXMxrf+7p1Ixw1eUX8pZf/hJ/8XfP5vxzl1bLlh4qvzC5PX48MQCFENQboaL5xF8TTQNjNKSxSqnEhAiRhVg0+iqNoYclGTA2LkY9wTjGTxxh4vgJWq0Wa9auIq81qGV1jhw8zNDwYs4+ewvNZhPEMn7kKARDluUaZ1eGSFVXZ/ZuUdBoNRkcHqK/f4DJkycpvafZ18fBgwfBWGxex9bqrF67lhUrltMpS44eO8HylaswWcbU5BRz7Q7Nvn7VukuGD6pxR6AolXY9NTuLrTWo1Zu0u44Dh8ZZs2YtUzNz2FqdZStWYfMaICxdsUKlGpFKPDkzTbN/QB1VTcZMe5q5dpeRJUuGevtAAAAgAElEQVSxWY3CdcAa6s0mM9PTLBoZodNp8+j+/Zy2bi3tbkGIJorBdbXzjWBsTm4b2NLhJHowxI6uK7yayYjEQAQt0Krz4Twl6o0hoiQkBYU8YtWvwCRPAWMofDIqjMVejLcsy7JKQJgfq5iK+VSI96QIve6/MVrgWyt4X9LtdgFDntViYR6jG0VlConhkOQczmsSQEogMcYqdTvGK/aKe6lYD67sbZO4NX1N7KrOL+5DOOWPfkYPMJAIOqV/r9UUQJoPZIQoyehtQ28bK+oE7H1J8AGb5T3ABLApdSPC6t4pEGNEogmlweQmNitVnpSJJw+OInQJDcO6TRsZXbmclq0zPTnND3c+qo7CVnBFQa1WY8OGDSwZHePOO+/i+PHjDI8MA1rAF92CIOqt4X0gz4Sx0SX4xTA726av1WLVihVIEFatWMPYkmV4CXgLE0cmCF5NOEtfUlqDC12SL4FzTgEtr9eGtXl1nHyUiqRzk8DMQDoGRjWBRhgc6mN4pI+1p61kZNFiFg8votXfT8gMpdEMooDT7q14yqKM7foUHZo8QLSb7cqSvNbE5jWML/CliwWZnr8szxEMNsvwIdAtnxwpD6fOuz02QIi6ym9/exfv+dM7WLcqx0iB83D5FRt41SsvUGaUJMEBRHgB7ahE2pRYXVQBBC3kb7nlHrKsxvOedc6PMBMDAibw4A/38vVv3M01113Cn7z7K7z2NVewfOUAJrNRDaqFtpegyTdx972oA7YJvnqdj12cnueBf9y3TUTQkEgGlcTIh56zQupAFV3PO97xCd7zx6/AZNpJEaN7pJnnXiGLoAayQTQuVaLB7Gc/dzu1POc5z74YXOCTH7+df/veoxifYWvwmp95GhddtBojPjbGhOmpgg/8r+/zwMMH8MYzNdnh2qefxet+7jK23bufv//H25jrCOP7DZdfPsKb33IFo8NN3vJ/XMrb3vopPvPp11NvqGu4npeFBdfCWBgL4yd9aL0hQBYMD969j1e/9FzWnb4YMYH2rOPdf3Qzf/xnL1XQNr3LS0xxcLGxEeUFBggOIxklhjIIt99xkMsuPAeGlCVdgcjaniB4qzPDvE6+kXngAqaKk3zn77wILz6CCT7mOEDUBuh7xEWMukdiF4lygeo7B3w0iTaRaZie+4l5oXsZQQUACWzdeohNZ53BojEIQeduSSwGKWNPy4LPIiAgmhbm4H1/8w2uvmYzZ527Sr99CHz6o3fxta9P0i6neeXLTJRBpP1QEP5//NGnedvbf4pGTT/o9//gX/mz97ya7dv3cnDvJL/x688js4Hvfu9hPvvpu3jRT13Mtdefzp5DM3z5lt2cu3kMXSbq916wY/zx44kBKBDXe6HXlSUWk5WmVNTkjljQeYj68bhI87GLQywggwe0KBVjmZya4v4Ht6ur/HCLufYs3gm1vhzX7bJv9242nbGRuZlpDh3Yz+LhYRp1Nc2zom3aAPhSC6rJk5O4MkYRek+73aZeq1HLM1xRcnJiEsHQ3+rDGENfc4Bu0aEz12HHAzvIbM7JyQlc6ehvNtRcpCypGYsEj3OF1ufeM37oMOOHDjI+Po5zJc1Gg0XDQ8xMT9Fo1Gk1G9EA0KsPhc3Aw9xsm2NHjwNQFiV9jT7mZjp4B32tfoKH9lwbXzpazSZHx48yPDjMpjPPot1uc/tt3+eyyy5ndHQxIuCM4MWA5IjklEDXaSSntaLoZuzUO6cRfxKNCX1MLzDEB2pQT4HgPLVanUxUd28ydCFqFK0sglDOkwQkFkLyb0gsFkHi9aKd+jIWY3me/0ixrmaCqQDRpbyIShG6vkuW5dpNjukhISZDpGsxMQUSmyZpsH4c4yDJEQhoYkZ8TY9tQFXk9qIle8wBSLGNRD+REEGQUAEfCURJN5LzPvoe6HdCNOFAAvOAFn2/C05Burh/IR6XVMxmVo1EnfcaCuwjEyMk48RojmmsYuxaadHX16Jeb5DZjLxVZ3DJIN1ylhBKxo+MMz5+hBXLVjAzPaeRiFn03bBqTDo7O0ezFuUvgeiVAZNTJ2Psa8H6jaeT13MMhma9SeG7eOtZOraUkycm8SGaBBmPy4Sio7Ib8T10uZKXGMGXeizmg0HxoOnkaiSyBZS9sGbtakYWjSFe1GukDMzMttm7dx97DuylXba59rqns3z5YopiVie5CCKUEYgJqLQEBLE5rYFB8lqTmYkJJJTkuTJyMmvJa4YuGY1WE2/UuPZJAShUQ0ja+x7wK7hu4CUvOotXveo8rAFXwq+9+eO89CXnk4mhUygg6DuBvsEcMYaZ2QJfBExmqPXlmmQSoFM45uYcx09YhvpzZSmgyTZpMYAIzsDb3/mzNBsZ0zNdjh0bZuJkYGSJp24UsJmeKQgB8pqhVhf1P0Fo+0DZceQNS5YF2pMqJWi0LPVGWmr0Oi/eQ1l6rIHM6sJqruuQTLCi/z49pdsQA/2tHALMTqnbtC+FMgRqNWVWuK6jXlf9adE1zMx1cQj1hqVVM3Tajm989UHe91evxVhoTzu+893HeO9fvZrMwbGJNv/jTz/PRRetpjK8FDh4eIbxI/Du//OnaAzl3LltH3d8fzdO4GOf+AG//ubnMLa0nwP7pnjL2z7OzNxlDA/lXH/D2fzzpx7jE596kNe88iwIPs4T1VlfGAtjYSyMn7wReiBwDEjHG0P/UIPFo01EArN1z8xcwAfDnVv3Mnmyzde+fC+NRsk73vlijh2b48/+5Kvg4Yor1nPji8/VArob+NfP3M+3bj3KnXfM8qY32HkfGz0EggLIE0fbfOGL93Pw6En27j/CcH+L333nDQQRPvmZe1g6OsCnP3MX6zcsZXg4cMONlxJEpRkf+tB3+eEDh8nrlj/4/ReQ1wxzhXDT+77O/p2eJWMN3v7Oq6J4IsoZIrTQnvV86hPf5TWvuQoInDjZ4UtfuYtXvPRptDuOm276Krt2OjqdjOdfv4brb9hEQBkaoQh86MPf5md++hkQ4J8+9i1e+rLLqNWFsmP4n3/7bR7aeZTBVoPf/93nc/jISeamCzasGcUmBgLCaesH+ePnnM87fueLCUnQlUXQnxwwN2cYWdSiUdd13dTEIJ22x5WQhRqji1tkWUktH+Dw4WnwAZN5rrp2LW/99S9Qlhdj41oMWZjT/r3xhAAUBCpdd0X3TkUMkFvVQHvvKsf/EIJyLmFe91iLMWsA43FBF4A4NRXMsgbtuYLxQ0dYNDyMmA59zSbLlo6xbt1p7Nuzh4HBQRYtXsTY2Bj1Wo4LUY8TTQiNQFl2qdVrrN+wHokZptjAyjUryBs5GzedwfGJCU5OTmAsDA0NEcTTaNa56OILOTx+iNn2DMYazj//XPr6+iK1PGj0ZeT8iICxlsGhQVatWkWnPYvzntPXrWVk8TAhOM7adCYigeDLCpTxXhenJ04eZ3jRINMzMxRlQbfsUG/krFm3lryucXbGCmtPW8PgUD/Diwdp9tVZNDLM1Vc/ne333svE5AkWjy7WIt2XlBIoPTgfKH2H4D15JppoF6UAEoQ8z3DRk8BIiLTuWJs5h3PqtmpDTiAHCWrC5x2lDXSLMhZ0Np7fXpfdGKMJESJ477TLbiw2s8ociOaBWSzegveK1sYaJjFZjGghjPfkWa6eBij4YkyIenpTpQBoB1tBEhPZMYl23evW69/Lsoxyi7qaZpalAkRBNWOmYhH0CtsEJMxnXiT5TwIYkqeCtUYTCJwmoPhoURuQSrrhvXZzjTGYkIwXTQVMGGtijGJkhgRlXogx2MxGDwaJpqi6L9Zk+royMT6ih6iPhXe810Q8zUzdgU0z47T162J6A4yMjnLw4GF27tpNs9Hi7LPPYXRsFDGZ0riN0J7r4gvHcK0R7wVDt+jSbhcMDA2yfOUK+vsHtTgMjlBqBKkYYfXaNfQNTkCWxX62QDA4jwJDJgJfokkjxhCNOkNMHkjACxFgUY8Pg1HfiGBwpafdaXPnXXcyN9XGYJmbKzhw8CjHJycZHB7mtA2rkWBxhcOg3iE+RUcag/M+GnIq28UCttGi3jfA3PRRcPr8ymxGuzNLkBxp1OmUBTbLaLaaT4ou8I+FPKKUJcRiNojgVTaJ4j0OBxw9OMnv/Pa/sHLVIDOTJb/2lucyOT3NRz9yKzPThsNHPR/6yGuwAq70fPSfvsn37zjELZ/fy/vf9+JYL0u1E+rQoP4nv/mOD/Lev3w9f/EXN/O929scnzjGL/zCGVx+2ZnccfsOPvnJrczMWVqNPv7kPTfyLx//PmMji7j/of3cfdcxNp69jDM39fOdrz7MkWNw5TNW8YbXX6EiBK+fq5eT8IWbv8fQcItrnnEB4oWP/OM3uOTC07ngvPV86Qt38ZWv/ZCjxzK+872HuPVbv8yqZQPRt0b45rfuZXq2yw0veArHj89w019+lnf9/itxQfj6N+/iC1+8n4kpw+YzV/OWt1zF+9//Nd74i89DTMBJoAggklPLwGSab75/73EOHpxk5bLBePwDrYGM8aPTvPzlH+IX3nAVJ2ZOcsYZgwpSBoexgXoOp60fYMWqvsS3QKzwW799JR/98F2EsLknQ0uY0cJYGAtjYfzED4l6/gZf/toB7n/gAFZKOqXjrHPGEAd79szwyX/Zyl+970XkNcvuPce4+TNbecdvPo/de6Z475/ezlXXnsnwcJ3PfvYHtBp1fvaVW7jr+/twuoyZ91hNDDqYnnX8r7+7k798/42sWDPM69/wJe5/4BibN49yz71Hyf1hfu83X0Cwwrv+4Gae/RxPp+b5yIdv5Zyz1/CSF17Cr775s9x9917OPnsFf/OBH3D1NeexYnQRb/yl73D/Dt1Wz9rRk7wE9uw9wd69x1m1ajFb79xLp5MxM9vlAx+4lWuv2cLKZaPccMO/snbNEM99nr5bYk11++2HeNWrdIq+4/aDvPCFgveWD33gNi66aCM3vvSp/Oov3c092ybpG+xggMH+BhJU5h4kcMlT1zE5FcBO6TQfklxD589ggiZnBZSZi9A30M8H/v4unvrUpVXPKAgsXTbIH/zhbbzkJZtYNJyxdu0gY8tPTTdKdVbvLwsjjScEoACpV5UMy3Sx3S261Go1BRmCgglihHpeo3Rl1IhTndQqgiRGGBIXp9456rUGF1/0FIpuSauek4lQxouu2dfPZZc/VbvEWUYgkGU5XjQVQdDVvo8UcMkMA4sGGVo8VBV+i0dHGBgeQDJDnlsuufwSdapP0XBWvb9XrFnB4qWjsescncvzHB+UepTMtcRmINrpWbl2LatOW1tFD4rov4+NLUWM5r/6VHiKapG9BEaWjTKweBAw1Gs1vAnUmg1O33i6doLx1Fp1tpy/BVuzrF63mqLbRXKwWDafe7bKJ8SDD2TRjM9YjwsdjCnI8NiQ4UoXqbhKCy9dqQyqyCrJkiOtj7Qs8eRZRuYtkhnKoksIBQToeq86cmrgBW+1yBRrUOcVKh8FI9EVNtGfPRix5NbgSgf0GA3WmhhRWlTMBYMyHfI8o5RSmRWJruV8dc4xQhFBgqyWx2uux3gQVDtWlkU0YjTxHPfYBgkgSL4KCVCokhagAtUqs0N6XfQkp3A+RgYZQYxSvCvAK4EQ8XPm+y4k9kGyFPYhVNd7UrHZPKv+DZ+8G4igRYlzvX2aH2Xpgmc2yzD1FicaAzjvsCEQTKDtcxZvuZAmGRM1i8ez8tIrInBiyfIak8ZQOKe0bgG/fA2lEY5FFpJgcbUS278YEaEjhk6QSN3TNAyCwYsjrGzQGBvjcLOJFUtXLKXJsUjlYeCjCWi6f/U7qXeEfqnI3EjOOxGACU6U+RE8xmRMTU1zYPc+RHKKAqZnSrwz1PImA60BurMdQtlEjHqvZMZS+IKApreEyBpRhkQgM5ZmXz+HOiV1q+kiGAW5bKasnqIsKctCTUmfFASF0PtvLO414UHNBD0Z//Sxg9z+g91YMwMh8JSnno6tGVwplO0Gb37TDQyN9rFv73Fu+fxWfuMdL6bZavCc5/8zX/vKYzz7mrX888duZcOGFbzsZc9g6ehXcJQVq6hS0iWjUgflbIM8eH7rt19Et/MFXv8LV7J67RB337Wb2257lLe97YXMzDpe8tLPcc+9h5nrtvjQP+7krW+7gOc8t8nP/8LHOWPjZbznz1/B7T/Yy513P6afEZPDlKGlXIVLLj6Lf/jIN3na5ecxN9Pm4KFZVq9Zzhdu3k5Zwp//5Su4+55DfPP5jxBtXSBJ37qWop0pBuOE2XYDF4Qvf+Ne9u89we/81kt4dOckv/xLX+PlL5+i2y3JaxleolWtgHiP9Wpw1ddXY8PpS9i+7QArlw2i6RcwtqSP6587xvTsUowxfOeb+/mbv70BC7RaMDXbZmIiIxg1HCMkEB9aDcGY6UhAMRVRVhZAhYWxMBbGT+oQqjmGijVQx5JhRJOz6n2Wn37B06OkreAVrziXkWU5RbB8+9MP85RLNzAylmMbwzRbGfv3TfH1r99PrV7j2ddvwSJcfc0gXjxF3KaN5MQQoJSAF88VVy7jvPPGcAg3vPAsPnvLw2w6exRMm9f+zOUML67jSvWmkgDt6ZL77j3Ea3/uaizwS790KVkz48iJNp/8l4PseOgkeM8jjx7nW1+ps3nTqMYuVGYCQqOVseXCddz6/cd44fVD3HLzVv7gj17KiYlpxg/NsGXzCgR44y9vYu++iXSUekEYEirDZWM1xWp6puDDH7uX+x44RBkMOx7u4wtf2cWLf2oZAYM3AVv5B6G+S1G2F/OeK0NKIK7BXZQaakzSK159BnfeuVObseIi60DYdOYIl1w6pEKJiN705JYhCii0KbGAmP/oeOIAChLj1IIu2ENQ9K10jmQOEgJkXk2wNN6vt1StaOg+XmCS0c1qTDKDzS02A9uq47uBAoPzJUEcTgVJuFYMBokaoo5AO6SLXYtOH3zUlgd8nkV9dfx88Zh6k27S8YsCBlWsWOyKF95gWg2688CPOSOUrsQaQWp1ym6hJl8GxNrYhVTGQhG71y7LYg6taKyjoLGNRlQb7rUYtn1NNTMxhm4IhEaObQ7QlkjzDo6Q15mOHW5fM5TWYo3FmZzgA0WmDxATDM4YOniMdVrgWAsY1TqFqBw2JprrpeITejR+S55ZHAXGRodXXxJ8QTCOkGWYkJEh1G1OERxlKrBRgMjMK7Qza6siXYuznuZrPrU/yQLSa4uiiMVk7/xYmxNCWRX6ZVEqiAGVRCLLLGVZYjMFQoqywIrFmhiKF+HL+UXqfOBB90uvnYR6auHvquI27W91bcVrOwEK3iuTwmJ7x5jocZDkHZGlINJj7vjgqgJW903lJ847iPun6QMuMh4MKXlBpRWngiPOlfq9MkNRy9jf16LdajA+PIxxhoKSYF3s7uc0fEagxOFOBVTEKFvCOXwVXRdTXZKcBKOmkXoxKZU8nlsh4AIIBuNjYF4ueGfwwWKMp2jUWdaeQaxFQhmlM3r9lJVJZk9C5SOzxTtPqHT70Q/DKEulVs+5+pormT55EjE1vDccPnyCvXsOcmj8ENvv3Uq7fYhly6/Cisc7yGp5FfFJMFijkh4i+BYkMDC0CCSnKApcd5Z6bmk1m5S+VFNYUT1kp9PhyYEoxAo+zIuuQhdilkAmbV7x0hFe/orz9JmAUKsZsCpNWLNxEUNLmjgJnJjq4k0f/YMNxME73noZj+48zPduK3CuxhWXn4VI4Pxzl2ONnzfdR9ZX7KoYH7Belxya/9CTVR041OUbt06wa/fXyYLhKReM0jABpMurf24T52xZDiZw/fPXs/G0pdgAOUEL/uDAahdEbC+iddWqEZaMLuEHW/cwNTXBmZuXMjzSx0M7j3D1lZvIvHD+ucv4+Z87FwkhemZHEm0wGBczyb3Eowa7Hu7yb/92nAe3fwUfLBdcNERulVqrsKvR7xdcjPWKz3xxLFmZs2x1fy+pBti76yj333+Yt779uUguLFnZ4k1v+jp//t5rePOvv4A/fvfNtCcVL3nw/hNxWvKYoPumj1K15LI+LsKeEDlSC2NhLIyF8f/HiJU9rtcUDZNc94yNbNi0WOW/JvpWlTrPWAEj0Qo3FsEShL5WxplnNUBKHnn0MDfceDHBRJ8uS5Wu4HV2ifHHqQjSdZiPTcgLLljM+N69WId67AApdEhwMT0B8Go4LR4uu/Q0vIF9+yZ4xtObvP2d12EsZAHyXMgE8BE+iYiAEbj22nN5y1s/R3ey5DnP3EJfw3IyAC5Gmmdw4UXL2HvwqH6uKRRICOCwMVMJCmf1+xrPUy4b5Q/fdaN6EWPIasLOR44iwZIMhHVd6PHGgKREC12veTLFFpC45rV4qJimH/6Hb/Le976K++/fhxPRJAcvfOffHuLC85YxMNDQMxvUK6kX6dDjhiyACT86niCAgnbriCfflZ7Su3jhaFQgQVGo5Puf4vfScF5PsIjQMRkHm/3Mesd4Y4ASQ+a7gGCkRnBg8BgTYjZ8NJiLF4mLDvc+ut6ngtjPN7wjadyNmgTGjrGLkWJVbFmi+ivXHh8NBhPtPMkaAikikyq6MaCFCxXYMs8LIHZbq2i7VIgScL5U6UNQqriNEYDJyT9EXb21hm5ZKCXfqTu686rlN/FmSSZ/IkIwmtw61+pDyi6uqOnC10Y5glq8Il6p53pDhqq7a8RUvXBrcgKBwgh4TymCmJzM1sm8QA2c9eBKfLfEkldMAxcLwCzTCMRut1sV1C4eo14aRM+McX5Rnob3STqh517lCW4eEKGvy/Jcj13wGgtXUc0TYpmkCDYWq0Q5Q4if04t01Lcp0izSu76Ixyt1xkMgSn1OlVI8fqSiWyPjQlrZV3vnUnEcjXqqtApQSY8x6u8QojzAWIwEBfPS9oyo/0WMc02pGya+Ly9L+qYKOs2ME5kgkoHUMJnDGyidMOeEIDa66Zvq/iKdJ2MQ0eQDiCyMeN9ULJT0IJf51xeQWQIB49Lx8NhajTIYkA4SSi32IuiU51l17CD5IihME4JHoq8GkemkUp1SYwdR92WTCYtGB1m0uIX3IKbG8tXL2HTOek5OTnLk8EGKYhrnuhFAoroXxFiNXhWUTRN8BFMMeb3JwOAw3ZlATQK+bONKF5+JeggMQr1W48kwqanGNHYLqv3VZ6dKEBx53dPo1+vOxKefD8TFjoLKNi6iEgExSKCegfEqASmDxeHJYwqDT/ZX1dyvvwlilD4a47mUMRV3y+ti4WUv38JLXnIewUOn3aVWE75/9y5quV7zxkKeA7FjpN9QQdUEeAmolEMCYjwvfOHFvPc9X2auPce73/MKxISqqYJo8kctCxVgOu8IAgrWTk0WeN+KhlQlb3jjU3jaU9YSHEzNtenryyEMMnnSK1EiLujyVoeZuYJWX43j49OcONJm8+bV+ADTkzO0BloavOwNuRXEeNavX0RRzjAz1abVn/HO3/pv6mkxW/B7v/tJ9X8xBuvAxzQOkXQQVc7yxL86F8bCWBgL4z8+JKYVBZTtaUzAClj1hY+Yaok3htKgFHx0Ld3XMExNttm3fxYXwPmCLBNe/KJL+PCHt/G6X7yMEGBqWieKmRNzzM5q5KMuzdTUt932TJ7MOLivjbOB6ROztOraeMB4nAFvAj42voheXHkeOHxgBg9MzrbZds9DXPG0c7C1wNTkHEbgyPhxDhw+zEUXnE1ZahSjib0dawLDIwO89tUX8vlP38f1z98CseFirGXvkWlEAkeOtSmkFhnMVAmZc+0+Dh2c4f5tM3zv1j7EGzIrNHLLyRMdEJiYnOLBR3azefOZfOHmw7z6NdOctrZfj32cwyXVHXFd4Uv44ufvZtWqEbZcuJaXvPhSPvjBH3DjjWfz5S8+zPOffxH1uuH008e4+XOP8cCOYwy0Gtz6b/v57//94iiBCHQLR6OmnyQh4ShpbluY3R4/nhCAgpAo1bGAt4Yss+DKmBevRafJep3bIuqLq6IixuSJCH3OcfrkCbIQmG4MMN6KtM7gVN8dF6yOsqKCJ4CgqgHn14vEwi8kmk2Ptu4jQnhKASqKkqW4Qf6dBaLEG8vFyC91TBVMqlFJ76dyBudxyzQtMHpdeGLXaH4nOtVhggITRlRP39tmb6TiVXobjwvjQCkZuQfjA/X2DI8tWkbNl4jxMXYv07I65pH39lKL7Yq6H7X8ISgF1+ApQokYS+5V5uBMl/5ikqWTU4gLFcMgz7L49Ojd0OqbkTryPWZEKuITM6FWq1WgBEhl6vn4ZAWRCNCIsgG89xRFUQFEJhP1SCg8tTyPYJDCSArAqClkkjLMZxgk4Mc5h9hEt+/tLwTmkSyq7zL//TJvm+nfnY+O8/MK7cQkUPDKVefV+aDskiiNAHXpRZI3vZ4jTUhR/b+akabjTcV48NEHoB5gqXcsnm2zuDMJXgGIgKcQlQfkZVCEOoTqHOi1QnXcE9hBQNM+JCHMVO8hIfURMDNBKFBAIt3deg94nBicFQ43mjQbzeqzEhMh3Z8qM+kdczG2ep6I2Cjd0Q60i9IirIkyH6UcIh2cCTQHarQGRxgbGyL4UhcWAkiBGPVEcLGKDJFRUTr1MwkCNs/pGxymO3sSEJV9lQX1eo1ZlwBKldc8ORgK84YQn4fxuRIsIg5juqpljEaY6TmcicfYuaiUCCwerYPv8n/9/W14AnNTc5x/8Vouvex0Pv2prdz0N21azZxt23Zy7XVbePiH+/nubQ8TQq6gUNyNc85ZjbMzeNQV2gfPxz9xO9c/7yzWrO7joa89wkf+YYogjhPTR7jhOZeQh1lq0kVMjFRkDjHa7cGWIG0OHZrkli/ep9uN80igZOOGYa582rlsOnMJq9cuQT0VA+eeu4LvfG8H99yzCw/ct303Yp6qsYtmmrhe4tu37uLEdJt//IdHOP+CxWTAuVuGuXvbDh7ZsQ/jHUenD/GqVz2TLecv591/8l0+9s83YjNo1C3XPPM83vaOT3D+eRbuVA0AACAASURBVKdzy81b+dA/vh4D7HhoN+/6nQ/wkY++i4GBBnk98KEPfZcgwt79R7jkokGWL+vnHe/8MEuWrmGor87923fz9KdvoK8/r1iCd969h/MvXIeKyEpClIFVN9XCWBgLY2H8JI4oAdD5TDj/ojGGRmoxEtrHAloboaetG8LagAkZJggve9ml/P0Hv823v/cYXoSnX7GeM85YingY7A+8/31fx4dAq08Y7Mv41ldv5867xnHkMdEhAIbrnnke27fv46/ffyuFaTO2eIBfe9O1iIHLL13G0GBNyxoDV1yximYro6+R88pXXcb7bvoKRRD6+5q8/S3X0ahZrrl2I+9//5cxCEuX9vOLb7yOv/qLL3P8WCeudQA8jVqH33jbSzhvyzL2PbafxWN9IIGlSwe45rqN3HTT1zTFIQSe/ozNZAKXXriC4cEamRU2ntbP377/O4hv8tznjlLLDQMDTW58wQXcdNPX8AGGhuv86pufhTGG5z1vNV+8ZTuve/3lykAUsBgauXD1Vat0XYrQ6XTZuvUBNm68FgEuPH8FX//avbz/r47ifI3rr38K1noWDTe44IIRPvqR2wi+xcaNg6xcOaRscC984ZatPPvZZ5PlPTPpqlbkydDO+c8dckrX9H/T2LTxtPD3f/nOqAM3lLGDniIf82hEh+/pwpWibmOn1FSFt3NO3eZrGW3neWTRMh4dGiUr22S+S6JPl64gGNX7G3radjExLzV2ttNnpeQxazIgmg+KFmXVEUz0bJOMHH1V6Bmj3V0i3dmHlP6NdumMmsup8aMmNXinbAKJ3R5EtyepGCYCGWJiskFBAioSyBFXdcp6MLpt50rtfKNAROkcBNXTx0pOb8x4bJFYQKHaMFd2sTZgKWI3V8AJRuoEtBPcK9KlMp8TtBC31mJtpqkOBkQcRSgJGOo+x9uMdssyOD3BufsO0ejOoiRgqOc1XFlGEMooK8H5yHDpeQckpoAW90WVDgGpoBRqtZi3O0+OkK4DZS4oC8aHBJhoEW1iIankXmVG2GjeqCkMFiNRH29MpKlLdT5EhLIoyDMb0ySU9JUMG5UtkHCtU70VjDGYKLtQbxGq/bbWYqyh9C5eXzGRQYTgPJmx0UNAPUY8qjXz6H5m8zweiCaLzsf3OV+xlyvWjSgIEDxM1VtsW3cWfccOcfbkMaSMBpfB4UTIbUZWOsRaus6TZZbgg3qhoGwbaySyE9BzmZIrglSskh5rSA15CJFEYNVtrvQO63X/ylAQjKGoNbl3ZAXNPGPjrh00Q6mfH4G4slugUY5xuvCOrmQ8vPoMJnzJhUf20Cq61TFUNlKg8AGCQcgrAkVIQIFTFkFmUxSsx7s5xEBWrytp0aMHz6iTgLUWgsN0C04c2MvBXQ/iZk6QW0+n2yGrZ8zlde5atpFNZ5+N+eZX+e33f4Vac8l//OH7nzLUy4SQ6+UqAUI6txknjs/Q7pYsXzoUL/rIinHQbpccHD/O2nWj+vIg7Nk5wb5dE3gbGBqqs/m8VQiwc8dh9o/P4EIgt4HNZyyjLEseenRcpS/zWIsr1iyi251j88aViMAjjxxl/8EJ1m8YYfmyRTyy4xBHDs0QjGfRij42r1/B0UMnqDVrDC1WGdm+fccYHO5noK/Byak5ZqZnaTWbbL/3ACH0Ug6COJYtbXHmGSsZH5+gVstZNNwCHCWWe+7Zy8yk+moYE7j4wjU0mhk/fOwAGzes5MSxGe6/75gyWEzO8qUNzjpjhABsu3cfU8e7iARWrBtm9ZpRijLwshffxM//9GXc+MILEeM4erTD9gfG8UAjD1x6yWnYzHDowDEO7jvOBRdsAKsGWzt3HVfGhHjWrRtl1cpFPPToOPv2z+g8KIFNm5cwtqQFQZie7PJ77/pX/vCPXk6jAZJMJDDVc3VhLIyFsTB+Ise8tbbWUz42dgSPw2IQb6pmjxCnQOIPyu2K3W8fm57aSFH2XGSrxnV8YrVpQ9ARguXQnin+7u++zrv+8Ea86GcaH+eg4MBotLCEACHgYuNSgjIXAg5x0QA9dhNDXM9UrbtUK4oy73rfJS1CowFihJUD2sAlxiJLBEBCbArpNj2JGRskNoPS6yKbVAWE4INh984J/ujdX+Xd734BI4tq8UDO89ITnX2EntyxmoF8j9lo0vsAn/Yznhg9N8LEVJc//7PP8Cu/fD1LRvtic0DX6kIWm5r/9cbFF1/M1q1bf+xXf0IwFAC6MZIrz2IXlEAmgphITUYXZmotML/LnJF880IAVwTEBPJugfMOExxDxSybju6nr5yLxobR+T/qxQXBuTLS2iMpPyQZBVWhZ2NxnrLrJQID+vd5oESUUyT9bDXiA0Ip6CFKOSoKRHTlN1XEYghBNbCiOvbUycyzvPJPAHpSAKcdYyKNvrprI9uBeYU2aBpAlmUU3RJDBBpyGyUTul9ZYiuQthdN/3CRuh5N+8TiXUov8ArEJCNAEYxYRKjAC0yUQPhAUXaBENMJAqXJ2LN8NdOFEHyJLzWb1ojBFbpvEvdLP78EAtZmVREaBLJaDee8Glx6jWfT8+SwViqQYT7tvSeVKAhB40fFWOr1/BS2gwma3x7iw1CLcov3hRbGouAWzleARzpPwWvxDLrvUnXhYwc+6tPUwLKMdPl5po5OteAVUAxgYtqJD9ignxEvOKWfGU10wEi8Bn2F5urll0CuWLT7QJZlcSJSVkZiOtgsThI+1sMihMj2yH0gK0qMd/q8Lgt8UWLrjXi9e+oCOEcoAxT6/bLMRkmR3ihlWWKCx1qlEYr3GMnwgQogAqjXa1p7duZwUdJhrTIqjIDNBVe0seIBT5YZKEJk6kQ0JOoZjSjo5UmsFZRG5wFvyKyJviNU15lgKDslB/cf4cjh4wpEGTWJbDSaDA0NsHLVEvI6hMiDdCS+oJ4vI6JRlkEdjsUIeb1FLa/TzVBD0jwnGNH9j/dhntf/Pz5d/3cP4VQxvYBYiJPzopH+akEgkY4SUFCh0cpYt24MRY70vevWLWbd2sXEXCjVYyKsP2sp6zdRAbXxUmLZiqFItkpd85jbIoujNDKwYcMI6zeMVJ31MzYv5Yyz4vNfdJtjKxfF/dfPXbV6lMTiGh5qMDzUgABXXrkhfs0Qu0gRtCSwdOkQFQVHhIzARResJrHP9IrSe3LTxhUIgSUjLa66sq/3aBBdghrg/HNXVccuLVBNHvjzv3gZn/yXH3DVbJehgZzR0QZXX7kGh17DMV+DFctHWLF8JK6tAmtPG2LN2uFqHyV+9zM2jrFxg74nhCTJgxL4+Ce28sIXXERTb+zqHP9XXGwtjIWxMP4LDgFI65dkVuCjEWOUKMs8+TM98lbiHOs60FRroB4YK4nkC1YBW/0XSxCLC2AJGAoQNSyUyDiV+XK+al+jXWGcSzRFzSZVYtq7uA+ht8eP2470NkfV2ap+Hxta8vj39QwOwfU86k6ZL7Ro6WHRar4dgNVrh3nDzz+VX3njB/jrv/lZBeal9xEB7UXokr63TSGQMP7efofI7zDz9jGQKMLfufUBtmxZz+iIsi58PLem91UXxuPGEwRQEExWU4pyQLvesXBN7vxl8LHLbqOjp14KhNC7Mb3XYieiCzYax2XBM1B0aHXmsFnsJoaALwKd9hztdls15lY7xo1GI3bmtaOu3V+DNclpP+Po+EHmZtsYY2k2m/QP9Pfo68FVhZkWgfp94lfVSEzn8YWnljrp6C3oqo6xdmVD4XQpLhrfV7qCuu9p/EnygfhZhVeGhnNOoxSt0aJaNCoPV1Tgg3EGukJwgcMHD3Po8EG8d3S6bfoG+jhz40Ya9Ub1EEzFM0YfVCZGCXqniKQPaEd2ntRAC/R4jiPVX1kkqHzBQRmiuZ/XQreLkBcFgiXEwk1ZGPqk6LFUbEwdUA+ELJv/5JJ510/0NdCrpPqdpPNL1LRlFrEGV5ZKPRfBB5n3YKMCFOIVF6MhtfOaQB7vPZnVCMRU+EJEr72eW1+xbXqSi/myC4i6fqOTUzqGIBrZGK9v4nUmcfvpurCRPVOBGJV0ghgNGY9P0HhMAGsM3W5XQQlRZkUyAMKCsRKdeB0S1PekYi2gRfo8vg7OKS3/oR/+kP6BYdaevpZcuf94H+i0O+zZvRsjhg0bNmBzE8Eh5kkcescu4Dl5cpJdu3YxOzsLwMBAP+vWnUaj0WD3rt3MtufwvqQ916V0nnXr19G/YkzZPjGpJclOKvBEr5Yo1wnVn0pSISbevz6mgMThlemyZ9cBbv3mbRwZP4bBkmcZxmSUzpPVhKddeREXXHQOtlkn/N/svXmcHUd57/2tqu4+y+wz0oyk0b5alnfLxgazmMVhvaw2W4KvgwNJgIQ94YZA4OaFhCz3JoEE4oQAN7kBkkBYciEGbAyE1ca7LFmyZO3bSLMv53RX1fvHU9V9RuSPe98/7ivI1Acsjeac093Vfaqe5/f8nt9POfmOO4tRGhVEjrz3qCQpE8M0q4VnMkEpR80kFC4X1xHly+/jT8cIAUs5QpmFpNrHI31TdRg0KXmtMEcqZWmUR5mOa4+tOBGUCABRlI+OAYwPUZEiMK58QqRzxSCqI4QLXzdXsk4WnRau40WxkSIEcVGCu4Q2zvnM8qewX+ggzhWuLe5tEfwALwKP4Qx9GcAJsOo7P98LTrV2zRAmsXzsw5/jne98RTi1gkTpUC0CJWhgGdDGD/gJIMAHOEhB1BmS+fbMzSwwM3eWSy/fSem/hYnoxrmftDSWxtJYGj9DQxgGAheb8p9iL79XHfpsEcj2mpKZoCpxbkL7nfwY24ZDu3C5yHfse96jnCS4y0e6eP2vPENcyzq0u8Kb5P/egxK5XyV+yiX07lEoFdkCEuvIsXR5yMXRRthjy/3PQXktcW/UHW/8d2IVn5SAhYwQi/kwlyqevcQLOkzdBRcu5+3veC71ehYm24XdMAg1+vAeBWI75MvrrGyHgs6R79zxQi6BQ+G55JLVrFw1hBN9aBFnjKhOx+uXRjXOD0BBKXSS4mwhSZkR6o18CYMICFINca7qeVVolA5VHa1RymKtWNFp70hMSMoBlEbpRL4GvqpAnjlzluPHj5HnBTPT0wDsvOoq+vv6y0A/SZKQ3Iiw3djYKfbseZS8XZDnYuF2zTVPoL+/H/AkSYYPbAEdevttSLKlwhno6cFhwqhKxEtrgxjWhUTdmJC4OLQ21IwB70nTNFDefRm8OeeDboNUU6WiDEmSYm0hX3Vr0cZI77yXpL6dtzmwfz/tvM3WrVuYmBrn4UceppHV2Lxpc5l4nT17lt7ePmr1utD9g+OFqO+LFU2e56UlZrRmdB2JNuGzIp2+ZtJAcwqWfRpSI/3rPrQPpD6VxDxU8TuZGQLwpBRFwfz8AkBwQvBi19nRKgAebwPYEYQXbdAWINwXOgCDdp6H4NvjcvkM+ezYwlABDBG08KEFJgIGwoIw5HmOMYYsE5qWD+yGTpeJTkCgBAFCrhI/x/vACOh4TwQUZM/oRLYrEcpyzpQSq0lVJc8xEXHWkSjZ7OLc6ggglYm2i3mfMAqMMAusDa09qnLUcDhOnz7Nnj2PMjC0nNG1q1FGKrDWeg4dOsS9P76X3t5e1qxZTSNpVLaXDgEDkyA26sR149DBg5w4fpyRFStwznH//Q8wOTnJzit3lgCWNop8coYHH96FSQ07RleE+ywgiPIuiHDK85AmKd660iWjspIMqWMAwZQJIJPSpQWpLxLGz0xx4tgpVq1cy9bN2wJLImVqaor7H7iHu39wHxs3rqcv7UKlCEhk5Z6aDmBAQZhnR3dPN739A0ycnsD7nFZrgbm5GVRfL1Fv4qdvLwuBTrTijUHGTwRLMWmODj8x+Kk+BSgBgsVVj3Bfy88LdMYOsMDHBrZFp6AWvabymZQgpfrZl8FgxboIa0uZ6Fcv7bxJZc9r7I8Jx6tiRFUBcjHrj9fhq+Op8r++vOLOT8B7UqN4y1uet2i+UGnQr1Ed5+arPzpAy594uMofddir5Kg9XQ3e8MYXiAhtBB/j/P3UPZ9LY2ksjaXxfzhi/0L0P6x+0fFHrIZXybNU3U0pQtz5caWQ1rm4gA9AdNg0PCIKrGuG0TWD4T2mBNbPHS5U2MskWrnAd9Ad/0WuYxGQ7ivEuiwIqDK3qk528VVWF0THvveTYIeK+6evcokIqkSgINowd/VkXHbFhnKX8l6VsYB0nlT7U2QvxtNQXlVbX3m+SoB737EnA2vXDOJK1nAHSAQBmOkociwN4DwBFGKFWGnpAZd4zQXqig3t3KIcH3t6pAea0unBOhcqtsGOTiPUzjQRhXqdkJgE76HwLvSWe/r6+6k3GigPDz+8i7Nnz5afKUm/FgG+IAjonGff3n30dPeyfv1GlFKcOHEcrROUinQlqdZrk+Biu0FoZagSxNgeIIuR1oZWuy3Xn4TKvA8idlFrAEizjLzdxtp2DHXLYbRBKxGriwBGXABi0lJWo41U953zuMKyML/Ahg3rWbVqJUPLBzk9dkrcE2KFz4uoodGiVh91ANrttugxeCuVvBhPek+73Q7zV7VnlG0GzuGdY97m6MQERkawgdTys7dCfffhWcD70jZTnDVk8RJGhLRdoCgdQM4VNCxV/glJonMkaSLJc/hFHu51Fa6rnwAxosVp6ZwR51aLGGOSqkXH1qpD7NAFG8IS1Ko++1wtB5mvCMIEfYUgZlldU/gcHdtPXCXYGL5dRZizeO5ai2aBtS6wJZxsMk7AIaN0mWD7ABw4FS0ahUUjIEpSzlJ0rPBhHlz4c2R4hAu2bePgkaNh8xOATAOjo6NMjk9w+vRpeQ6dK78TSimSJCU6cMRncH5unmZXF5s2bcIYQ563GRs7jfeejRs3YtIEpxxHDx1j7Mw4K1asKF1LFJ3zGx0kqnjA2gjQdWzuStqCUhTe5eG7ZQMQJABEX28vRmvydk69Vg/sFE0ra2N0ysJci4X5BfpVj8xW2NG0lp7GksUTgAJtNHluyeqN0A/ocd5iXY5rtwTI0XJePx2jSsCrTdlXvyuBAb3oHWUlpdQjkKCjSnw7AxWkwhICGt/x+6qOEIMlXVVNyoqFD9WZjoCqClk6QIS44pqKVbDoGqmuIwYt8Xy9p+pTihxWVV7GuXPmiNUWvWhuOqetDKTwoV1EAiOlIEniESqQIoRmVCfYcQ3eV5ezKNhadLAQbEpAJThtIefX+d7yni6NpbE0lsbP8uhc7+lAiMtmhmrND1tJ1DPw5boqb3aKTpMuYjtmTJPLA8UYRUUtok4GYAC4y3OJ+5sSFyKfdCT5tswiVOce4ztBDtnbQtpfLe+d54MpXxcLAOUeojo5AKrM93Sn+jgKvC7tJJUq5Np8hrAkvFgW4Ut2RbV16o7zCUcoAZlOEXtXzuFPxAQd+2AsIHTu7nQ4VVHGGUvj3HHeRKTKSEJstIEQ2CulaLdbdPreuyhK4kPiESr23jlsoG87W5QsBnnuOhX8pQ1ARA0dfX2DzM7McPDQQdCanVddRV/fgFBJI308HENQMpicnKbddmRZjSzL2LRpCyAJtLUF9XoTYzJarQVarRaNRpOzZ88yNzeLMjoko4pVK1ZgrefE8eM0m03aeU5hC3r7++np7WF+YZ6pyUmmxicwWlo/VqxYgdaa06dPMzs9Q7vVotnsDmqsI2SNOuMTk8zOzWKtZXZ2hpGREZYtE1EzcS0Qmn6SSDJeWMvk1CTOeWZmZrGuoLvZRU9PDyCg4djYGMeOHeOiiy5BIVoIC/NzjJ0ZIzEpRWE5dWqMZcPL2bBhA6dOnWJychJjEmZmZpmYmGDdunUMDw8zOzvLiRMnKPKC+Zk5+gf62bxlM3leyHqU1fCIYKAN5xtF9GK13VkfEisV+viDyJ7Spbd6YoTZUNh2qXMRF1KtNTosEEVRYNIkqPcHoFlrsboMm8C59HLvHUmSBlHFAGoFFkEnCBHFBGPyZ4MAYwSyz2UQdDIM4u+ikCWLls2qpUYHnYO4yMXvS/w8ETftYIqU+4Qvc6DYxRaXX2etiOQkpupJC5+RBJ2JMkmMFc/wPVQ6HN9IJX94ZJjHDhxkYX6eWk+vfPeco6enh9HRUcbHx9EmgEQEFwU8WSLXnOeFABHAwMAAD+16mMOHD7Ns2RAzM9PMzM1hnaNez/Da024JyDAyPEx/Xx9RfyLOqYisxueIkokR2yFsEYROlUb6IuP9iA4gQQDUCpC1avUIWy7YxN7dB/j6N24nTTLw0k7jfJu161eQZanMbbjvAiYE/D2sNUkirjG+EJ2VtFFHpzV8IaJKaZpSGI0JlpdGL9ryzvPhK1S/FEMSISaQ9bxKmwOoo0z5L/KzDxt7cK72BihQJdXUI7TTzjlJiAl3BUCoc/4eXx+CM2VKwCPc+UUgk18UwITzpaNt4SdAiLLZCtAlKC4BThECGNNxfTEI80RbrEXJeoUPlMGdirRTPNJRG/+9AzxQBOvYTrpq5TLTeYV0/l1FwMAEUAI5RnyW4xzHNWEJTFgaS2Np/IcYEWT1pQtcuWZ6UD7h3LVQ1m0pkIowYtCuUjFec6GvX/Y6eX1M2M/5HCUtfIv2BBXhdBUq8r7cH1TZAlAB5Nov3rNKHFx1ruW+AyiIhwsAu6djP4li8eF9yktrXbnXyL4fLYZVKHrGRN+GfcqE7dNFmENVkL3u2L7LPa8EVMLO7XVI/Dtny1HtW4H9UAlZlPfTh001Xn60+Sy1zdCIufU5W/PSOD8ABaUVKpEnJroYGG2whUWpFBMqq8ZoEQIkJltBQb8z5tKqDMJEZE7kSpRkAoAuPy8v2qDg2PETPPTgLlauXEF//xBZvYZCzqXssS6D/pQ1a9bx43vuJU3qIUlehkkMZ8+OMz09zfr1G0jSGmfOTvD444+zY8dFPH7wCN3dTZYPL2Nhfp4HH3qAVKd0NRr86Ef3MDo6ysaNG5menuXoid1cuONCJsbHGT87zrKhQXCWhx56kMnJKbZtvYAD+x8nS1P27d3HqpWjTE9P41EMDg3x8MOPsHnLRrq6ujhx4gQnT57kuuuuI01TYYFojVNit6IMFM4yNT3LYwf2M7swy9z8LF09TZYvX44xCcpIsjx2+kxYPBRZkqKbTVZmK5mfX+Cxffs5duwYIytX4T0MDAxRqzWYmJjg0KFDFHnB1s1bSLQhNYmQvJxjYmKCxx8/wOo1q0lrKa6w+MSV9w+t0VQuCZJw6zI4jgCtWDQK5cm5KKaoyzaEJEkEUCBYO8YFzFpMmpAkibgjhCQ+AgHeCpPCWwtKGC+SsEtbR1FIz3+SJFVrTAS7OhJ7EQANziClRWEFIsQ/zwUuxKmiYh+UyYlCNhwtbAkRv2TR50QAJvZNEw4Z+BhhPkTttyiE4aPC+40SD2Nv4/MfQQMqbQwXtqbYNoGAGT7oQrhQcY+gS95ul5+fJAbnCrTRLCzM024tkNVSTBLBGGE5OGtDcq9QJmH16tVMTU1x8sQJFhYWOH32DGfPTtDOC7q1orAF09PTnD51iq1btlGv1Re1olRzIzOptIYAJGmjKfICrYL7h5fWmMj60OE+eKWwRSFzZxR9/U2e9ORrWLVyNbMzC/hCCfDpHF3ddVatHqSnp0tag5wKcyltKmUrkJd2IRXcUIxJyZrdJI0mC1NzeGdpNOsU9Ybs1j6yV85/pFyejqQj8JDVWiFz7OP27KutWanYuxkQZBUALw+Uz3OoGkT/28BQivWcaleoknCU+HbrmOyXiXx4rbLhOYkBShDA8tFpRwxQTAj+IsulAg46wgsPFZhQiaR2tgNUoZTv2MRCkKZsOKege1BKfBOqNeqc42g5f0X4hitRBseGICg8e4tCoGq25J+j4Fdnm4nMVVVvk7UhqJ2QhpeocK7OV4oXS2NpLI2l8bM/OtZiSUSI9HhXbkMuwN8VSyz2/MdkPq63VX+/w6tE2qQ7wQOlsd6DEqvsstNCxTbBpGP7k9fF0ysDOV/tkhW8HNsMostecF/wgZkcDuM9OCXAh/I2HCcwH3x5oPCOpNpfnAoMjM4WxOqVyruQ5Mv8xdMPvwTvq7iAoHzlPIePnGRkxXKyTMcdP+yVopdUFcwswr5QYUcWIEj0I3S510bgIoIeDjh04BRr1g6HXDWwJZfghEXjvNj3lRKvdRvEC7VJ0NpgTBoSN41zFcIV6aiFFXs8lBbLQ63DzwqlRKNAgkBJAI2WB9s6EVxL0hRjEnr7+unq7uHosWOcPn0a76SKG5PX6EmfJHI+F1xwAc945jNJkoRvf/vbPLp3H97D7Ow8QOn8MDc3x8zMLN7DwsICtVqDnu5elDIsLLRYaLVot0VzYPXq1QwMDjK6ZjUbNm4kSVIOHTrC7t17mJmeZWzsLHleUKvVsNYyNTXD4NAyPIrR1Wvo7u1DJymnxsZ4ZNfDHDp4iKNHjnL27Fl6enqFPh4sB+P82ZCI5u2cLMvYvn07W7Zs5eJLLmHr1m00Gs2qHz/Q2U0i+gsC1mjydsHjBw4yOzvP5VdcycjIsCRroXK+e/du8HDlFVewbNky8jxnz549nDh5krEzZzh27Bhnz46XyW+WZSV4kKYpWRDRdG7RshM+X9BEOZ+KzRC1KqwVYMEEsU2Iyay0OSitUUaeKRtaTJQPy5iXOqRGdAciWOCslWQwLDY6qKN7XwlROi8V1OhGEIGHvBCbzbiELgYKKNkwkbGglEIbE+w8AyjhpIIfV+0ohBhZAaUTxDlMB++i9aWctzHSduIKW1pdqnhRxHNS5YboQ7KnozuHlYQ2JlXx7kS9gXgONtptFpZiQawXNRU4lKUpeZ4zOzsb3h+EELUWpoJzaKWDS4ai2WxyySWXcOWVO1m/fj3r1m2gr78fAGMStDHk7TYzM9P09ffRaNSA4KQQzrHUIJAfKtZLsArlHIZHvG5UEO4MIIlsPI7CFRw9eoSz4+O0W7noZzho55azZyfYvXsvjzzyKEVRBNsmV7Ke/ziqNAAAIABJREFUIjgAwu6IFqNKJ5isgfW6dIVJtKZRq8vaphSJOSeBPV9HTKIBSZbj/yHWK6JXdXxJpM54HL5DVjkGI5LgUwVFyuNVVJ/x4d1iQ1LGNz5awHpcgTzYHcm3sCcMykv1oWw38CJSpUKwVFJSFx2zM/mu1irvdfjuREDBV39HI1aaumOK4u+hBCi8nLu0rrlQeTm3+iJ/OK9xTnPw8VP84PsPy78hkIKsSpUVa3msCAaU5x6PG1oufIJyRqzPnAYne9z99x7jkQdOhbXCd6wCHZ+9NJbG0lgaP8Mjcskk1/DE+n9kw9rcU8xCMatoz0Or7bFxP3S2jAmVlyKfDntQuaw7RMA57HsAvgAtlIbAjAtn4iNYANGmMQLxzoMLNpQlS9BpPv+PP2Z+oYi8P6INow72lfE8VNhPJSAkaD/IvtkJTBD2RHRI2eMW1nmdIbD0TmGtFGDEocxhHGWro3ABKiFJ1VEDl7wA9u8+xRf+6TvkVoo8YlUPtojz5cP/NMF3A1soijmws2DnFd4lsg87sG0o5jytBU/eBuUUyine8+4v87++tA9XdEqPL43OcV4wFORp02iVBDtGCVqUCkFcgMa0r5KvJBG1+ahY76I9oTaAARer0Cq0RwioECtM2iDVcGD58AjXPeUpPPjAfZw4eZJ169eTaIMyQoMGMEZEELOshnee0dFRlg0txxjD7kd2s27tWmZnZ6nXMxFMtJaZmRmp8GvN+MQEhS1oteaZnp5mdNVqlg8vZ2p8kt7+PlasWoVS0Eib9PT3kec5rVYb57w4QljH+nUbWL9uIwsL8xRFQZpmDC1bTr3ZZH6hRZJmzM3PA55mcJ7YsWNHYBqYMobUSpI1pSTka+c5SZoyODhIs6tLbCOVCNZZ6yjyNlNT07RzsdZ0zuGsZ3p6il27dmGtY8dFF9HV3UOWZXjvOXnyJKdOnaKvr4/NmzYzODCA1ppjx45x5MgRrrn2WprNJv09fex5dE9pA4lCGAFIIm90UE5XUXjTdyR/Cm0iACtVYx0F8wg9+QFmjIyW6LbhvAutJ1XiqMokTZ6NqDxf6g6EBFd1JO0dDzAgwIOct7TW5HmBtY4kMQGUgEgzrjQUfAmiRI0JCNX+CD4EhoCncvdQqjp2BfxQgi3i5iHXKZV4j3WFXLcxJMaEZCq2LYjGgcfitYhmUu57wgSKmhqxBcI7H+ZysUBcbFHSWlFLM1KTyNyFuY7Mi1otwxhNq90i6jI4nDA/FNhA96e0+UxEqDNJGDszxsmTJ1mzejW1ep2iyPE4ajVR/20tRJHOYA3qqzkHVWpNhKa9oDsiz59KU7SpNDKUouO+RzBJU1iHs5Y8Lzh86DC4FJvD1OQcc7NzOJ9Tb8L45Eq27tiIz4RB5VxRgvkgjh0q3I9IF1Q6RSUZeeFIdYK1BcpKldp7hTk/8OD/jREjkrCxl99BxWOPTnLi+CzKtFFOtF2uuHodaQqSQGupWCiPCjVx72Udj2mrPKISxDgM+/aeYP26YdKUYIkVDh8ERx8/cIK/+asv8Fvvvpmsadi77xhbt4yGxolOHYfw3cOhlJWfVQCp5QrkPKJQVgglVXhX+GU4Z13KMlTChTEYjf2qAs1NTS0wPdli1eiAxHa+am8p3YJwJSwRK0fCFtI8vv8kX/zi9/jFW5+N7H8GZ+Gxx86waXM/mfEBIK5AeufgvvuOMDsn92HdukFG14rI1+SZFo88fCwAxbDzqg3ommb8TIsPvu8rfPijz2f79pHwUeHL4eMcLI2lsTSWxn+kERzqAlj7Bx/8Kvv3LpDVWjhdoBP45V99OjsuXklSdvSFVdyCyEyFmEOaMwMbFGKQ/P/817/lzW+5ka7+DPmXuNYaAdFD7BqBDhVAeskBAsPXy/66d88xJmfGuPmWG0rwIX5cLKpV7WyyZwjBT3dsPh1rvlKgc8SpQaFCm4EHtA+Fu7Cfeaf54Ac/za+8/j+xfLBBySYvTyE6h1UW515Jgu+BvftOc8dX7uW1t76AZr2Gt3Dq1Az33HuKH/3oAd77nheWcyNMEYVycNc3HuGzn/0Rxmu0znnFa5/M1U/YwuTZGf7qY3dy8MAEDsemTf289tZn0j/UxW/91ov55dd9jtHV3Vy2c0VZnFsa1Tg/AAUU1kKa1EswgaDI7hFKfgzMFlWadYKyEvBLdVf0CYSSnQrAYFI0UvF0ucc6T5pleG+Zb81hC2g2uwKCpujq7kYbg06MBIG+Er/TWjM7O8v01AwDA4PU63WGh4eZmJgIAnF5cD4QXYK5uTm6u7uxzjK/MM/o6lF6enroH+ijp7uLnu4eTp44KRXIkLBEqr1co6Neq7F61SjeC5LZaDSYnZ3FWk+93mT1mnUonZAXlqxWx7oJarUa9Xqd/j5xZKjVatI9pE1FxY+JopPqWpIJgyFegwgnyqI2MzfHoaNHGTt7ltNnzjK8fDm2yNm37zEOHz3C0NAyxifGmZyaZsWKFeR5zt13382pU6fYtGkTJ0+eYG52luHhYer1OnNzcxw6eJDhkRHGxsbo7esrnSEIX3oTEmDvRRdDEa0WoapeUgERYTHrTMa1rsTfPFI9V8qTaOmRPlcAcdET6avFwnuLc4o0lWdCPi+6SFQJiFKQpplQ270knGmaADlJYspjRQcF51xwMYgVclcmvFHzgAAMRDFKbYLLSQDQVBm/u/LzVWBuyMYg99D7CLy5oCWhgqhldf0lW80HUc/QOqQDkBDn2If5FdaAKc/F+2rS4rUQRB6b9Tq2nYsFY4ezhVKKRqOBLawIcOrIhDAURc7x48cZ6Bukr7ePJMkoioK5uTlOnT7FyVOnGBkZYdPmzdRqKSoAELVaje7uLubmZinyHNJa+VzgBChzHSyOQCwnSNWLfWbp0hKBnoLEiC6CCtes0Bihe3DBBdvoqg8ydmqKk8fGWJg9gU09fX3LGF7Ry4ZNKwOrwFSOLwj7QsQgKd07rPcoB9pk9Pb2c+boATIt97rIc/keF4652fn44J/fo2QcSA8jSKUkBz76l/exclkPPUMFvvBg4cDjY9z4qisxKIrIOPNRHcHgAishNLMB4FWC9R7r4KN/dhfvec+L6RuS/tUIYsXkvW+gh01b1jI/X6Drdf7wQ9/gI39+MyrzpQK28178vRVBQ0Q+K15FDPawIVwJIr+VXw8CuBGXNBPfWaIALlhSOqfK77JWml0PH+fBHx/mta9/GlZHMFHhiLobMqlOCSgjz6w8B0cPneVz//Rdbn39z9Hd08ADrYWCP/jAnXzz66f43FdvJO0zQcARIhBy5527uf/+o3R11/EOvvWd3bzm1qcyuLybv/r4t+nv6Q7XYtm7/xiv+oWncP31G5kcn+K2v7ybD/3B80gzQMV7shRpLY2lsTT+gw2vSmcB0fZxzMwu8L4P3MDw6i7wMHFmgQ988Ev8wR/fSF5onIGi8CR4aommcJ5WKBzUtBLQQUmEl1tPYT1jZzKKQgoLEprFOEASfuvAOYV1gS+hoJaAcZo8F9F654X4/7Z3Pg+TCHDgrIioO+XRXpElETRQtHIV9kRPmqjQdRdgbRWFpRXOKlRgcOKECa2NxM62iG5zTnSzFExMZDgrrPDCSZFQa7C5wySi+WCBVssTnSvqqSFvez75ye/y62+4nmZvBt6Ttws+9Yk7Melqzo51i55a2R7oMGicg09/9m7+9COvIUk9rnC84c2f5oort3DP3QdZtWaYt/7GCzAGPvv3P+J7PzjIDc+9kC0XDnDjK67gU598iMsuXwHJ0h537jhPAAXQShwRjIpK9BCibExIwLyTh1CHxNf7qj+7TA5DldgWVsI3rUFrTJKibLu0v0PBxMQEe3bvZXR0DTMzM3ilGF29miRJAUgSsQJ0rsBEuzs3x67dj9Dd3cPA4CDHjx9j/cYNNLu7WTk6yr59j3Li5MnSNnBgYAClFD09PWzevJne7m48Vq5PeawvaDabQstPU2JPepKkbNt2Iff84IccOPA4hc3p7+ulp6cXrTWrRkfp6e1jYNlyZmZnGRhaRpLVWbd+PcePHeLEiRNk9RpdzpHVaj+RNKsI2ChPT08327dvp95okmYJRZELyJilKA9JljKycgW1WgNrLe08BzwrR0dpFwX1ZoMkq4UKoCSI27Zto9ls0tPTI4liOP7Q0BDXXHMNc/NzaKMZWbmCnp5uCZrPoaUThBa9lOg6iQDQkQw7JwtWmkkVvHymjCy4aIW1UvH23lO4Ao0uRQ1NEBksK9aumis5D0nOY1U9zl9lR0nJmoj2lr502YjVeruoDSGOyLg51/Uh/uyVJLOdbhIlABCABKmcBxXeDuZEfE91jsLw8CW9PAIXQRgQgq1kBNJ80KbQWJuX11IKG0YbS61KbbvyGlD4IITZqNe5aMcOslpKYQtMEEQ0StNsNrn00kvp6uoiyzJcB9CVphmDA8tKppErLEYl1Ot1uru76RvoJ6vXaTabeCctJuCp1WpceOGFNJvdKO3FjjYAcrFKbLQmfiXiHFnrSqBHJVk5h1rrQC8MYHxg0FhnS2me1vw8+/bu4fHHjjI33ca2ob9/kA3r1jI80kdPl7CWpOUjvDdJgjNNNW/CFxE7XOct9WYPXd29JPkUyjkW5hdotXJhj1j7E+vo+TsWsym0JwRQbV7x8gtZNtqNUTB5doHf/b0vceOrdnLs4DhOa3btOkqznvCk67YyO9Pi+9/bi/MJW7cOs27DEMoIkPDIw8c5cmiOo4cTrFNBlzqKoCrwoV0lTXjiUy5Hpwl3fGUPxw6N8LWvPcrTrt9Ao5EydnKK++85jMdw0eWjjIx0s2fXEbZuWs299x9kfLzNldesYXJshsd3j+OV4pqnrqPZawJkUck1eafY9cjjbNqyhlqmUQU88vAhLrh4LV57Djw2xr7d43iV0NuvufqaDTinKXyCdbBn9xE2bFyJSRNOHDtLkmqGl/XjneLwkTF2P3IcMFx1zQZ6e+vcd89RNm5cS29fA+08aPjil+7iFa++kmMn7ojUohAIxnviefSRE1z7hC1cds1aAP7od/8Xc2MLLBvoYv8jZ/mTD9+AqsPcbM5/+Y1/5pWvhDSFpz99Ox/58KN8/0fHeNKTRkrAYynUWhpLY2n8xxoRpPWUbQXK49DyV+Ux+EDpl73hn/7nvRw8Mc6BgycYHsp4z3tfxjdu383nvvgAU1MtnnHdBdz6uidA4hkbm+W2237Ij74/w4P3TfHu93a22anAOpCY97E9Y/z5R+4iyWBqus3cguMTH381AP/1/f/K4KouHnzwIFdfup4jB47wW+99CWkz5eDhs/zlbd/k9NlZJk4UfPrTt6ASxd49Y3zsL+9kcrKGUwUfu+3F1AyUNpY4UJrxE7N89Lav8s7ffgkexdH9Z/j8F3/AG9/yPB579DQf/+hdjE/U+c4PTvL2d17JL/zC5USgfnquzQd//4u89/03YXL47d/4DL/7ey+HTLN//zh//dHvMDk+y+SU55N/+yruf+gwIyODDC3rCfGnI61rbn3jM5mZgT/60NeiUBY+NDtEAl2OECyMVnilOXmqztEjU4DCay36CYDzXex6aJYbbvDoFF75mov5tV//7P/Vp+qnaZwXgIJCkgtfFhFdQJZUxRTQHh+sDks1+lA19c5j8dLfrBPppVeQe0vuxWfVoVE6kc/R4J1lZMUwU1OztIqCNKtxwfYLWbZsmdgWemEzmETU2Z1zOA99fYPsuPhiJsYnSLOMDZs2MTg4iEkTRtesJUlTsY5LEvoHhzA6ZW5ujv6+ARr1JiZJcU6qzF55Vq5cQ3//MryKolnCcbW5ZdWqVTSf9tQgluep1VIwmp6+Xrbv2I5ODSY1NLsaXHLZxfT09KK85UlPfjLeOZI0LXv/fUdyWVlVKpzy1Jt1NmzagEmFcu28F1cwJf3l3T29XLhjR3lPPNI/P7R8mN6+fkySkKZZ5VgArN+wgTVr1qC8KinqPrSPbFi7jrYtUEYzMjyMxUopMNCrhJzgQ3c10mcWiU8xWcVDaD/QCrT3ohGgFDpB+pw8oMX1QxtwWvrNtHNSOddG+ta9LavthRVHBVsUlTBhWKwjKGCMkaQTSgq82IZWib7pcH8Qi05b/hw5ZaXIXwQPvLQPqNCTFq0JtVGVOKhSpQ0kgZ4W2vJFP0RQE0n8OzUOvDxbogXgghaD9PrLuSv4CcBCEg8friFS8RelC6FnEB/E4LyItXnlUKmgzkm9xqo1o9i8HSwlBZxzAflePjwsz70K2iXIeYGj0WwCYL0g9lp7TJaxbHiEItx/Ee60WOuxWpG6lFWjayEJpG6XgMtRSqxbnS4wKkMVirJV0YU+wE5xYO+qK/WhHcKHjvmg1K+0ADSFbXP02EFm52fwSpPUU3I3y+GjBzh4ZIGkZrk23cn2iy4Qxo02OA95YcP9Cr35TmiILjjd1LKMrN5A0SbB0ECRJKKtUe/qWnwvztfRoZ/gO87XeEXhEmYWHD2zOdpDe74gSTQ5itvveJRv33E/z37OxeTdGa2243986usMDg5w8NA8991/hje//UkYBbseOsQ373yI48fhnnsOkKioBCBVogjW4D3HDo/zhS9/n9f90rOYGJ+mbScYH5/Fe8fcXJu/+7vbWTGymh/fc4aJKcdLXradP/vw93nh8y7m8MGT/ODu08wt5Dz22AFWDa/iX778ABu39rOhZyigfNU1eg+f/MS/8pu/+fPUB7rIW46P/sUd/PGf3Mzx09P88+d/yKqRFXz5Xx7n6MmTfP1rb6B0BNeKT3z8Tt7+jpdSG0r4znf30tuV8XM/dzmnx6b4x3/4JqtXrOTrXz9Md08vV18zyhf/5QE+/OevKtuoAG668Rm0ckibrvTAKEUiUeA1hQefQKpDj6vu5W8/tZt3v/9JFNrjDaRaQNoHH8q5796TXHXVML29GTe9YjOFzSlXcF9NwU/B07k0lsbSWBr/n4bv+K/8tSpAgcU7KIpu3vfeu+ntncD4Nlo7XvrSK/EeZhckrvnT//YqFPCvtz/E7OQ8f/anr+C+B8b4rbfdxYtfcimNnoRPfuouXvKyq3jlTU3e/tZ/CWL0XtwYMEH/y4e4wnNmfIH//icvoatZ50Uv/Dx33XmQpz51HVMzlivWDvHLr7sOX8A73vZp8Iqpswv83f/8Nr/6pmcyNNTHzS//JLffvouLLl3Dpz/9EL/2pudSyzJuevlX+PZdB7n+aeswZfFLYqVmb41mb5Pdu0+wddsqvvClB3jKUy7lxLEJPvdPd/PO//J8mo061z3pr1iYVWVMFTWSp6YllrUexqcl9hw7PsfffurH/OKtT6O/t8FNN/6Yr371BEPDFp3InkQoxGoUvT115ubnUdqWdynwXuUnDV7HlmFha1991UruvHMPa1d3S6zspehx1c5VfPoz/8KvvfkKwNBopGQ1j9NehJlRS3tcxzgvAAWPx9ocbZKyPxklitRKJdJvHHpxbFC+VtpglMZZi0lSqQmp2B6hMGlG6gnCjA4XgQTrEFFSjTEZm7dsidgVWQftXoX+aa01ynpxmEAqzSPDKxkYGMQkSanybx1onbJq1VqsK5BWfEnksixjy5Yt1Go1cVlAhWRdiyBkV28ovktwV/ZsK8Xg0HLwQvVxXhTv0QVdaSaBmxeafZbVA/1f0+jurjp6YxXWSf9TKRmjYp+WJqvVJdEKIIpXAniIfoEGDWmWhgq+VI91IkKVQgkOVPwA63mlMEElXXlVUrlLMMOoUiATLboFWiXoQqFcgddCBVeuUrIFJc4A1pWtD7EXuxTODCwHSxtcgdJpmazhLd6pQFUOyXcUQ1QdQobE5F1EP5XyaFNVkRc9t0HUrdOBAkI7QkdBNoIJEdBJgkF8nuei3ms6BACVOBUoFehqXqjU1hZlO4wxRqrdgT7trDAlJB8VYdN4eUoZcRzwIuCotAobEB3X1HHt0Tkgvj5cs7QRJSUrAeR59JH25g3eGMZ7hziQ1ki1w9u27LUmWCfZXACeAORrrSCIRZaSbvLgR3IS0UGiEhZywakkioMGjQjv0IkmB2o2QSmHNQXOWXBdzDZ6qbt5AR+9R2FJdApGAKY4N8YZNGLmF8U0fbCxdDbI94XFRgWdCW+hr7+XnU+4gtnpGYxOMDojTRqidZKB120GhvoFJDUqsEUAFyyenI3ceNGrkBkjSRIazW4Kn2NcC+NFY0MlumRznO+jZB0J7EswQ0R5T+EV7/+9HzDYPQE4amnCu377uSig8IYbX/4UnvOcC7BK8Rcf/RpXX72dq67ayIEDk9z8mn/mZa+6hMmJSb73nV3ceuvPgVaMj89L40E0cUAYPOJDFSpHrkF/fzevePVOvvGt3dx00+UkBt7zns+xft0aGl09pPUFfuc93+T5z9vC1FSNo0c9t9x8HavW7eHDH/k+n/3sz1NvZux9/ESg+lPuJeW1G89b3/oK/vBDX+T9738l//C5H/L8Fz4BoxW//8Gv8LsfeCk93RlJPeVvPjUtpBMPgRADro638l3OXYolxXr47d/5Z578pIvp6kox6RTv+s07+MYdv4ANk60jFVZJG4dWAs6KKKjCq4SS8hVcJxwSRCkFv/KGa3jbm29He7BGem+Vh0bN8NpbL+fwkUmuunpYwNxkAaVygQmDuqRYjgnfZglWWBpLY2n8bA5ZQ0t7w3LnFqBABWD4TW++jJHhGlqBMdDXX8crsCrn2ieuJcsc1ike2nWK596wnTSFHTuGuOzKZUzP5Pz5X9zBy199LRs2D6KdY/06U9pNlvo8RMheYXFsv2SIwWUZroC3vOVK9u4b4ylPW4c2bZ547VpqxtFGU4R4cX62YHYaVq3oRXnPbR9/BVmiOfDYOHd87SQnT34Tr2HdBodv57LOlym1xG21roSLL9rIPd87RaINMwszXHTpKPv2ngSV0DvYQOP5/Q9dz2P7z4R4XNonVDj/+He0iCvOTeTccft+xs6MQ6FZvXYlzrVk6wr3QK7blAwEGVKsEZeHaCcvMaTBSNE0ATSMrkpYvbIHb52YLofiYJp5rriiv2TM61iQ7ASRlva3cpwfgILz2KIIFe6kqvIEhU5nnThioYI3vPSzq5gsB6q8MhqKHOvFGiRRSvxMBbJAaYey4sVqkrokxCZSYintBGNOI4ki4L1UsENlOk2zUnQuS1PSJBGLSRsqzY5gixcV62uMrBgOooKU3qfGJFjrBBAJiV3sydeJCEvGFpCiEIV8G4K0SE334Rg+BIbKyLzpUPH1vkM5PraFBCcEwTWCk4WSBE0rBSZU9JzDuigZ1mEtpqsvUBSuLILYioj3ydzEqr93LsSV4lIAoUc+aDR4ZYP9jAKtSLUhAbzLRSnWKJJExB5tqOArE3q+wjkWrsDUagJE2Sj6Ip+vlUY0/sJ1hHnxQW0/6hdEhoVzrmxpUFC1yRCSeR9dfGXOdWANxN8rhfTahzmPrRGRiVBEK0ijUVStET48g0DZUiDCijaABJ2LWNi2QmtNXN/iMYuiKFs5pIUh1CVtQeEL0jQJ4o6qfM4j0BIBPa10SKardovKwcHh8AHIUCTOk8xMc6rey6laFxbIDHhvsdqATrC+HXSBI4gB+CCeqoWd4FyFHKuwY+iQfMfnt7CVtkYo60vC5MECiXPgCpyOkpN1HHWy6bNM1XtJraVp21jXQltH3WhazoMyAkygRGzRi+iec6EXvmSTdCZJ8v2s1Q0XXbwdkLVCqQSQtUxrh04sJqLpWuFcUc650QnOB3CCiqWkk4SaaVLv6mFiZoJ2K2c2b5H3SgvR4qfhp2GIvVSsYoMnNbN84ANPZ/UqYVvoci2WZ6zWnYBROAsLLUW9UUMbWLeuj2c8YzneFXz2sz/kV1/3LJqNBAukDSjCOhv3CEGBgsioU2ivMUqYMMrrskIyN9Ug0TXytuOyy0Z4wtUryDJDX88cr3zlFrKG5jnP384XvvggqShH0lmnKkU7Q1CiUAwMdLFq9Wq+9d3H2HfoEE971rPxStEqHGk9RWnHS196CV/92oPCztK+BP1sENKSSo7BoXEeZqZrpDphIXc8/VnrefFLtwjJy9cCGiElFuWV6CzQGfZ4ImQV20sVlH93Cr76tft54YvXh3+v1qcitzy2fx+vveWpQAApyu90+KAOAc1zW12WxtJYGkvjZ2t07DNeUeoKBL0gZaboG0oYWN5AB00rjccXBHg9rK/BztiLHQNGKbL6HCqxIiQf9eW8xttEgGarAlMh7J2EOEopcYhykks1ugGzEM9WzlWHgKkzlrAKb8WFoasrxRYW7Qte8IJBfu2tz8IlobjkPNpRiS1igr6Q4inXXcDb3/Jlzoyf5YZnXYpJZU8DG0QnFfVmUnbfEQqcHgU2wzvIW46i1UT2FMcNz1zNu97zXIyHBSsFpPvvPUZrXq7XEBF4iCpGOoAVeNHiW2jZ4PimqWlD3rakacLCbM6P797Hq//oVXzrrj3CdLWeAvi37zzKk6/ZhElUWYjVXtiV+Ch2uTTiOC8ABfAUrQVMklKWL0NiH6uy8mCEwD4klbawi/rFjQ6V6sILZSAxOK2xJmXWi+2aaqRoEhSiC+6tIQkJuUMs+ySRKiNRrAqUcOVxKqOlAZMiMmEelyTkuSB2GkVuFLnRFR1de1SgX3e2HrRDVcg5qYIXHcm2AAyJ0PpRYDIKRaC6O4pC+tNVKpZ6LiTzwkKQAE+H9gNhdcQCqBIquFK08pYgpon43FIqr4pInCtySWwgUNLTkBDLSuKcwwWqU6F0iCfF/k4lmThJoITtEem1OiutB4vC4nBobci1IdeeDI1LDXMmZ0F55hJIvVSeUQqrjSTIERwJlHPrHYlNSL1B5fMUBpIsgcKS+HD9RgXgWGFSQ0SXrS8CCwTAYYwSccoAyqBVqE77smouZAJTPnsROIgJt6YCcHQ4307AIuoxCGIqAo/44BxQFEF81JeUMHEvkbvorSTJmkWFAAAgAElEQVQbpYZDZFcEbZEIkhRFgUmEoRP3EGU0qUrCZ8oimeehhSIkXdGiU8TgfLDBDOBUqZ+gy3YN7zxN1+aCY/vp7R7g6LIRxms1tE1xKsA43pXEMxU2D+U9PrR3SAsBJEYFcUS5TnVOPiLPcFRAdkF4OCT43pN6j9diQ5gFq9ncOIzKGW/W2VXbAt6x8fTjjE7PCvCgamiX4ZXGqZaIAjlp1VFWztsFq6ToCiFz5FHKUFhh7tRqCSaJ1QJTiq1G8U6xI3V4Z9FGdD20iuBCyOS0fF8KmweTEU1a60KZOtZNM7/QYm52Thxu8oLFSPn5PqQcEPvsvdOk5CQeknJzDtUdBQkFRlUWrT6wqMLyhKLA4Ll0xzp2PXSY1aM7goq1LZ93F1BQ0Q3VqBBAhb+EIC4yhKCWtXne87cwsKwL7+Geex7BGo9JC3kWjVT9HS1p8XHyPAZDrOp2RB9IBWlquPTKlfzg+4+xfv0owyM94HwJrlovlQ/lIhuH0EpDyTayuePHP5zk+utXg4PeLs9/etGFqJpUZe79wUMoD5PjNR7Zc4ZLLx0URW0VnGUsaCXOEATwemEh59GHD3LJpVvZvHmY/XuPc9XONUxMzrN//2H+883Xo7Ri0/oRDhwYY/Om5dzzwwOsXd3N6Oq+yurSe1TUtInrvIogw9JYGktjafxsjsicDNGoFMCkTADKoTykypJ4T6J8qMWFVkqvSMrOM402sG37Mu7+3j4eue8YhVbUmpqsO+NNb3sWr7/lM7zkJdvBew4ensBp+Pa/7eLEkZkyaRbWgGZk3TIefPAsn/m7+wDLmZl5tm5dDoDx7bICbzwYbfHKU28m9HYb/unvfoRHM9tqsWJVnYsv2UjuHf/42XtwGqZmx7lw2womT+XM5RbrPYnTOOWoNS3Pf8HVvOGd1/Lxv/42l16yBgP0djewXvEPn74H7R37DkwyONyP9eBNQaElBjh4yPH3n3mIH32/xXe/08BpaA6kmHqbz3zmh+ANc7PzbNrQy7o1a/nSPx7i1a+8ghUrm7FmKQVgD9rZ8i7NTrd4x7s+yS2vfTZXXrqOW295Km/59c/ztKdv4/Yv7eW3f+852MRxzVO38s63fYki/xHO1Xno4VP8wR/uBCXYy95HT7F1wyq0VaW4+NI2V43zAlCIliS2aCNBXocCu5GEw2gd3L5FFT/RQQMgOgFojcditMZkCcp7WhimTI1DjR6S/mFSIXWSBVtJEUWkos5TJW8+KNfjQvypI0IVqOA+qOkHy7ySDm8hthYEzmoIhsO1hn9XOiT9dFRAy2hUlZX1kkofKLXWWRQ+9MsH1obWdLy1/JyyfUQOXL6+PJlgyaK0xjoPusreNB5nLVqpssbUeX5lTz+U4Es8VJkAxAC5THglAi2dDrBY50hUAloI0QphEIzVm7S15mDaJHPlmeOsD9oDQmOOleN4/ObkJGvPLFD3ohqvFJKcGYPyBWihimvkHletDgKaOHxo0fBltT6yF4Cy7aNkr5TPjA7OGK5MUBazDfQii8ryuIFjHMUORZAzKSv1MYGPdpKqPHZ47pVUtqOlYRSZhKBDEQQEOx0klPaLPsMECr4N/fyV+0V8D3inymuJ8+GQ1yYaUqBuLYVJ6NeKVaePUvNWWl5IEXeMPHyHY8W089kKj2hgljgX7nN8vlR1/FKIs7TGFBVgbQzaOyLVzXiF8hpvFD4z4C1TGI4NLcfVU9S0AWVYsJ40gmEENxCTUdZeQ3IUNUBii48Lppsm0djC4Z0nbwnjQiw3S2EEnC9QDrJaSqMrpXAtjGERGKS1CUwn2eCdB60MadpgYT6nNZ+LtoRXJCo4TPxUDbN471XQ1ZWTJdKeEAo6RAut7oalnlrwDqM1L3zhZXzitjv4m48qcpdzwcUrGBru4UUvupyX3/jf+dKX78cC+/cfxyi47S+/wv33jQlQrCXx9rbgRS+7nKy7jVMep+Hk2CRveesneN/7X8bLf/4Kfv+Dn2e+rYGCJz1xNVfv3EZvoyWbZXiu+ntbsgcZaHbn6MTz+c99n298fR9SsQpAmVrgF295Ck+8ZjNf+vy3eMPrXyNiiShuunEnb/u1v8UElsv8/DxKQZpaGs0CraGe1Pidd91OguXr3z7FDc9ehUo9N736Ct7xjr8n9wbNAs9/znYU8KLnb+SLX3iIbTueTD01peWX1tDVs4BJCM+x5rY//xLTE3NceulWnvHMC7nlP3+M7377MSZnc65+0iqWr+xFAU9+6mbe+c6/Z3RkhIMHjvL3//ArGOMpvGdyps2xI+O85IWXUobVSliAJWNhaSyNpbE0fmZHFU+XxdD4zwp+/uZrGBishzY/G4JjKVZd/6xtdPXXwl4Bz37Opdz93X3MTrZxCq554k5GBruwzvOGN15N3hKXhDe86Vp6exMGeusUQ7KeC5NNrBibRtHbMCxf1sBjWbdtiKt2bkDjufmXrqW3twZolIHXvv7JZI2EeiPlVTdfw55HjuMxrGz2cd11mwF48Usv5+CBMbyCzVsHuPLyDfzbXXtoFDaQ4aRwlDQsiYbVK3t4zc9fRWIUysGaVX3c+LIrOfzYaXCeweVdbN2+ksx4fvGWaxnoy0hQvPFNl1E4z/Oe38NLXrIKbRTLhnt4+SueyL5HTwGang0DXHPtBryDZz5zOR/7yDd59/ueizdOGCBOMdCb8drXPlHyIQXGKF78wqvZtGE5Gs+WbYPc9PIdWBJ+4ebLWLOih5qSouPrXruT40encCrl6mt3UgtaYNbCnd+8j+tv2IZsb0sKCucO9e9Z5v3fHtu2rPd/9afvI7oEVEm0ItL2Y1VaeqYViUnIsgxbuEqkLjgXoBAve5Py3d4RHu3qZfP0GA0NSiXUdQZFQeEtLogMFrYg0YayuzxQwZ0neMAGWo63ZRVJG43rqDQZpUsWRVTmF8Ag+qd3AA8+VC3DNVlb9dhLFiV5v9YR+wx93M5VdOlQIU5NIlVUawMGEmxaQiU8KbUGpOrqbaiQI+InKgjlqaB0772TurGLNi1y7da5IBAZquNelk6bF1I1V3KeaSoV8jzPRUXVubIlIFbctPC+BKt1CkVBkhqUrlFYx0KrTWo0mRHybEyqsVX7QJhGnPckacpkbzdJkXPV4WP0tRZwyoJ2qKIl1jxQUpYSlS5ybeh0awDK5L6TARP/lNdWAEBM1k0Adkprzg57yMhM0FqLVoW1uFCpjiBA9XkVcNPZKhF760VPIbhThHtMvLfhfLXW5NLncQ6gERkHlNcjoJQhb7eDSKMun7kKkNLl9URww4Vn2gSCwIzJuG9gFc2+XjYf2k3Dtkh9ivYJhbN41ZbKpXD00MoEwCDYOEYNDl/NWQk+hPtMAFTa7RaJCWwVnUhqH8EjG2iDaBKVCLU9lerAWNbgx2u3sOXMcTaOn8ErQ+4LMpWKngMFynlaOuHRNZuY8XDR4ceoWzkeAYDTTtMu2iXo6ArPzNQ8D9z3CK25Alv44BYjoFFhc5xzXHTJdtZsXEmSeZySFhCtkvC9E3YSKrCWvEJTMDc1zq4f/4CZs0cg0zy85kIuv3In9e9+i7f+8efJGsv+d5fa/39GBN7KHrVQ2XEiSqmMDtZYICCnlsAod2JZamQfKIDWnIXcgwZT16SJOJK05y3BfRNtoJYZ8tyV4qwhtpPaUV2jjCcxwoyZn5fveVY3YKCYsSULol7X6FRj25bUSADmvScvPImRPaddWBKjsW1HkVdWkYFwQj3VJImmyK0wWLSQMgsH+YLF2aA4bRSNmgHvyb0nNZp2y2JbAvAWiaJWVyRG1u35WYd2coxa3WC04tChcW75pdv46Md+kc3rh6L8DIWH3DrqWqO0wztN3pLvd5JJdau9YPGFp1CQ1jVZKmtlXijabStUWA2NpsZri3UJ//rVB5ienuemG5+ADs2vHi9tJEuAwtJYGkvjZ32U3P3QIhmaD3T4ZxuWQVkeXdnyLLVFVbIFRPvAh0JLqGSWNV8bXhet38MHxIy53Dslnn7kodN8+cv38s533QAQmMQ6pBZBh85rvJJjGi+xfhQ/D2eMLvfuMi0J5s/yU9RQ8AFQQNnyvURD7rIvQgUdg5hTxNeE4ieVLtSiRL2sJ1XnFs+jPef48B99h+e/eAebdwxhlA/tD0L9iHMdP8/jUFH9P4A/smHHfFPmER/PJbR8ezh4aIK//vg3ePd7Xoo2jkQR5vQ/1ia3c+dO7r777n/3os8LhoJUTVVZbS1BjhgJetFYMElSPlLttiRkUskN9MoguOa8laoknq58ltXzigsnx+j1FrwiVRneWYpgJ1jParRaLal+RtKmMuhgW2hLCrh8ERQh8Pfy6jwvUEAS+us14oKglVQ7xX0gJHYhwnOB2WCiz31I1kus00XKtySBKog4in2mHNfaPFSQAxAQ7TNVZRVIqJhHHQWP9Hg7a8P0SpittCaPLQqEam0QH7EU4pzghJmhlabdajE3PYtRCtsuaGQ10jRFJ1EmX6wJjaksE+MtjfR958EbOXeNI9UKdEbbOWzeFqV2rfBaql3O2iDEGarTsaqPx2rNXr2KM1ldKsda6GYm6DLk1uKMErseC053WI12AAedjgtxxIq/TGdsCaiYKeVc+wqI6LR+hIqt4BCmhohVSoLqA8AQGQTG6BJgWmwVGW0ck58AOCIbISbiEOaOqjWiU+zTWitgU0ja4702JoB6wUrSufCcRKeNDkvNeB8jqGISWVASIPGO1KYYZ3Aup5XPM5/P0tXVLe0cTqETOadWa4G8yKk3Gpg0CY4tugQWtJEkOwqLOudAe6ZnppiZmaW7q5dGIyPJDK1Wi5nxGQymbOVIFAwO9YsuidEYm2Ew4F0QqoPc5vK8lopAlNeWJAnKtYNtrSqZO9HW03lLkqTYwvPorv2cOTlNo9aDLywLC3P09HZR2Da5z+np6WXdxjUobMWEKlPduL4ojFaBaKHIsjq1WoP5JCFrZGIzGwGsn6KhAtMqTrDSkGS6AnGJv5e/myzOifyscdSbUYUj9p5KoFXv0oGqFO+fFy1QbxYFcDGGkPVJQJxmM3afSuNb2tWhkaHEeNKE1gKvJGhKMx1adsQ7HBSmZshq1ffDx+MAeE+SBRqssuATjAHTFdvtxGwy3tFaCA5rdQM1X4Lk8cy0AtNtQsDnQiiqGV3Xz4c/eguf+uRdvOttz6PZW5e5UKCSqDukUNqRNVR5ndpDoy42wlaw3vDZljQxJEls74q3SdOaaXPn7Q/z/g/dCDoGvOEqKvGK/7OHZGksjaWxNH6qRlzjJEFWBDVgQtt23NeVtCPIW4qwhyXltgUqJOquen25XaqYVYfYL7RWlGACiD2ivCytQXcfRMsqhQrs1nCeSgUBXUjCNtApK4nKiZaQirB3h1/KlVWFRsqf5ZzKtm4q3TUVEnUVHOuqNlxTHTPuwkpyBwkVKupiBbvE/R/SmuaJT17N77z3b7jtb97I/8vee4dJdlVnv7+99zkVuqtz9+QgjTQajcKMIkEgggkiiPABJhtfMMEmXISNbQw2vjgBn/09vg48BAM2wQgjok0wQRiMjECARlmjMBppZjSxp6fDdHdVnbP3vn+stU/VCP9x732+ez8J934eabqrq06qc/Ze613vet/WcKPvGkX9vKlig2h62xBrT5WItknJIlTnZav9SU74ja/fwCtf/gSsTcLldmV5e8h4WAAKsbrBet9Of1KXkqZME6WyLCEGYum1KiwaDKDJnxEkzEao1SHLAqYoyfFk0eLoEBA/2OADdEvqSIJU3XAWoCQEqcxnmYNQ0i26ZNZVCaBzGQ0regCuepBEUVSYC3rDRtVCSAl+7PWW++A1We9T+0+4V+oDygwhFFLN1f7t3CSQI0j7gLpAWGMpum1qtZo89mUpCaJzOGuraU+CVGFY2JBhi0KYA3q9fZSEzLgMHKI1YCD6wH337OHmG3fRag5gItSznIsuuoixiRFSm0d7eYm8Xq/EEzN10bBA4YWWXrMZBZ6ascSuJ7iSAWvAGQUiSmJhCQHqTkpzFoMJYjUatO2h4wtq2o4STJcydnHBUMYALor2grGIhr9MMgnsSAyB5MbQE1ujSvKLotBJqheEOyOAhtNkPYEG1XmqHkK6V6IRgCO1T6RWH9PHIEm6DPDQ91E9H+J6WfZAKmvBy7PQ/9wklkI/O6IfzKrleQWCVPuxPVAvsz1tAvQz1jmtqHtt90kgjIVCKpNEiykhFIF2LFjuLrJ//1727z/AZY95HGPDoxhjCWVkYWGBBw8c4Nj0NDt27qA1PCQLkLYEBdt3zWMPDV9cWOLWm29mZvo4BssFO3ewcfNGaJfsufteuu2SotNl+eQi84sLXPrYx3DWttMFQTfa2mB1IYye0npiiGTRkZkeMyIJdLpevi+tVt6LYKVFxGAxNJtNGrUBBnLLznMvZnF+gTvvvJXTN5xBVnPcfvdtzJ9YoOiUuFyEBo0VDQb10KzuJ2sswQigmmUZo2OjUIwS80iWCRBRFgW9hPthPno4gizySVPDiNhUVF8amS9FhFSca0MvzDFSSUkjhRVyndQ5wpie00GfdkgKbNIvMs1LQBChcjFIsVug1LDDUcGJaX0yGWKTKhWjn/NINMnNIt1fAci04tFzwMEIVZRocKlKpdtKTjvVdTNi+VgdLJXkTe/yRrA2ctqWSZojll233cfjHnsORoOq1HBiSEyC9OHYi7lSEBb1GEhaM16Amehke9Fyzz0HePWvPZ5G3puzemMl0loZK2Nl/FcZab4T7au+qRmqZBuo1gWjYvIPqW/rRF4xBao1Rf7YI9n3FxOSEIMm/8Zz+lkTvH7rU0mMv37r5pQ6C2W/l6jLsiAJPbG/8p6A/th3rCnNNlUIEozHxkz3Farj6Z1YGrbaXjruVGjoXbe+xbjaiOl9zAJ4jIPHPPE0HnP5W0XEPBqwUdsmne5WxSr7AY7qeHpXQLSRDDY6PY6o66Ac1+tf9zQpJCU2w89/e//lx8MCUCAKTUjEB/WFKFVSCZI0UVIAIPiogoNyg5VlSaq8+9JLYBkCHijKNrF0hM4yRSzA1fGq6n3g4EHmTy6Q5zViDIxPTDIyNqrBpakSKOO0LaJbsOvGXSy329QbDWZnZ9l+9rmctnmziKzFSOYy0uRhVGivp7MgLAI1MK363iWARZOVPsFBrQZbY0U7wVoBBZzBlwVloW0C2DRtYCPkzkCwRF9ijCXLJSHPVDxSUExDNJKYOCv980cOHWZycopmU2wkM5djs4yiLMhcLoF0CJS+YGG+zejYKi44fwc1l3PrzTdz+MgMYxNTuAy6nTazcycZHAi0Wi1x74iqC+E1kNaEKeApfKBGjo2BwhdgcqzLCL5ECQEqMOh7rhVodRwBEmxE1GejJ/oCQyZJn4PcZsJIi2CdCh6GqKyWXo00sQ0SOJAq0QnJNJpki3OFqRL4fkZDStArgUZ7KpKpR16F91nl5hAwThggAm5Zut1utQ85fwTwyTKdb1XHwGTKMpDvtteGIW4jwlpQIUBnevtLj2BqqwheheYsRekledZ72WhLR1mW+n61sbS5PKtZhslFaR8DmdwuTB8/yp133cnyQpdupwBrpfWlDMzPLXDvvfdxbPoYW8/axuDQEMnR4hRQEYO1mbAwfGRmeoay8Gzffi7Tx45y82130BweZXBgkC1bthCR+eL40Wmu/+GPWJidJ5SBYMTxhRgwPqoOBGQxVqrAwVDdE74sKbodalG1NYLcRGJqEsShAQG5sswxNjbG0QP7OHbsKM4YrINj00cZGmpBjHTbbaL3WFMTumGQ+0qej4gPXbkvnTpoOEPpu9QHmuT1GoUpaLeXKX1J7HYfIXhCCkioqh4VcBv7QghjFZCiWvQT2FYJWVUhVV9oE02VDPeHXFRP2EOPRVyAoMf+ihpwWE2gbcUFAFBAMCbQQ2irkdS6k6KclKBbAUV0Gyb1txoBSyRWchBL3ZOjospU9NdTD7lX8Q9Eo/oEPbRBftY4p2bgd972fFwqzvQHdgaq2kvsnV8/oO+IqiuUwi75nkzUOlSU7e28YIu2r0UN1nqVo5WxMlbGyvivNVJSHh/yqiS3VQpbzcEqVR7NKZuoWF4p4U4WRCTstw/ArtZVAQ1MEls0SQS7x5Q4dZQpY3jI2pD+UVaASauM+khoMUBSxz40HmFbVGuFEQ0icD1HoR5UUG2fvldOWc8SOwNd+U1Qfaxes4VsxUkMrPFtDBD7rkNi5FXfQqzgA1IMHqvrq6peJp34qd+LhGjCBCTYnxMMXxkPF0DBGKFjquicD0Wlqt5PHZcqsFR0Y6BPfR6xKDRWKvopOaJ3T2TGYAOURZcsb7C4uMihQ4coypLW0BAHDx7k0KEjXHzJxdQHmtrXDcaq4GMMdDttDh04yGCrxfjYOCfnFrnuB9cxMjzK1NSk9PI7R1kW0g8egRiE2h6NeJzWasIgKErKwpNlmVR9tScfjNpBGiJC8QepRoXgwYruAtFJf7EGwJmt6Q2e0EqhtMvxSyLe6XTF0cEHsbqMBmMEysHAcGuYulatxb5TFMidy7CIEF0kEHWbk5NTrF2/gVAG1m7cRNEVIZngA0UI1OoN6s0mpZfzLL2nvbwodplJVC8GaBiCkcSJrqfwJcYFMuvI1FKzDF3a7Ta+KMldJv31zlSVRaGPG1yeV3TwAASlh1kV9gu+0GQi3XqKOOq9hukl1/oOiJC5vE/pX9tyFEQty1KEERV8SMl8GrYPONItaiBuSa0T6T4OPqjzRS+p7m/NCDGJSJoqASiD2G6S/mZ6E3IMUYEreXuMPQDEQJ9eA6o/YnFO3udDIBppfcmU+ZOumRxPEPAhoe+hAJUqLKMk5ZnLWLd6Le1t53HzT2+h2+niQ8DHQPSB8clJzjzrLI7PnqBbdOUzVpJrue9Ndc+WoYQgwN7x6eOctvk0Nm/azPr1a/nBf1zP/fc/yAUX7GRq9Sqi8fgSFhZOsmb1GjZu2EDmMozJxWbJKAgUIEYrYIguMLbSDqGqEos9adDvtyQzNWKILLc7ot1Sz6k1amw/dxuH9k9z3/13U6vljE+NYmzk6PQRhocG2LB+DVDSLYKu9RIIBI0brKpDo+1RPpTYzNIYqGMyYcoUoQRj6Ha7/8/n2v8lQ+YjTF81P/ZVtbUVIgFtipSJjkv1rKb6er9dZgoKEoURCaqqyC2J1fbAu94/fQGFsht61FN5U6+WI8FF9UQrKNJL6gMYL0KE0en2+wMm+aSIcplelGa1cUPPV96W5m/XC0772kSEJfDQq9sLwoiityBrQURosL2zT4DkqfGloYqOYu/cK4eWVBJSJ45gkohtX8Wod3H0v35AZmWsjJWxMn5BR1pPquRV1jtxgbN9E6+OhzLa5EXiqRNp7+e+l2VXCv4qyzn2M2cjss/QcwYLgFWB7Vgly7ZaS2TTmihz6lQeTawKrL1jP5WRljZZAf3VBiyJBXHqOfWtYSkY7r+O/Z/Qlo5TlpkKdLd911zBmb61vdKUSIUD/X9/N15QNp5BrdUfumQZqlha6p+RaGIlrPxzX9l/8fGwARR80hnoe3Jc5rAYpY33HB6sTX35kmyJGrwl+pQ8B8qYqk4Wj8XaDBcDRVEK/b6Ws2HTRupZztzsHJ3lZQaaTXxZYnxQlXbw3UB00kqADxgC27edxdTqNWxct5HvfOc7dJaX8YVY/YWihBCkOmkzyrIQsTt9oMuyK9aUNquSxhAiZaGihc7RLTyZzSiLkk4hLIO8kYuGRJ91n/fS/mCtpZ7nGKDdbjN/co52p4OzlvHxCUIwzM0vkTnH4tIcwUcGGg1GxkZBE7+lpSWOHzvG6PCwJJx6jVJ7gDU90UfrBGApy5LFpUWp3BqwuSOr1QihpL3QYdctN3PxxRczMtQihkCn2+HIkaOUvmRh4SSLCws44LwLzyfWHPPzC7Tnl/BlyeLiEo1GnTPP3Iqr5Rw/cYLlxUWWTi7ijGVycpKpVat6dpsuw0coYySUgLF4DdattZRKUS99Qa76GHLryf2WOSeJcOn73BjAmKgVfrnnkiWjtLMo2GNT71pvZklaCuJEogIxKNPgFGgzAWb9P5vqv1OYDwlYQ6dL/VvwIhAjoJN0Y9sksEmas2M1b8cg7Ix07+ir+juamyRtBmlrCFH62iyqfeCpWjlCEEu9DIfVamcZwBtBpRu1QdasWs+9g/fJ8dhegtZwGWvWrqHZaNBut7V9RNH4PsFJuc6JIQCzJ2YZHx3HZY56o87I8Ajzs7OEEMlrwl7yocvM8eNs2LiOsYlRnM1wMSN6mR+CNdjg5KiDJ9go/YQx9KWt2iIShDkSEYaEN2VPONIJWJZZy+TqMS55zIVMH5qlVsvZuHEDExMjTE8fo97MmFg9RKNZJ9gSjxedFCCvWCoqWAr4KG0l1liyrEZeq9NdOkFZlrJUZu4Rspilar6gf1W1W4MJIU+KrkDqn6Si2ssdnPo9o9Vagr5PSYqJ7CQj7Sf92vcMVdFPFcD1tVpUoJ+hCkYUJIhVEGOq46neqvsU4d7wkOS8b9cROa/qeFxPhCqtffHUD8ZENU2BYgVy9DM1hGnj0j50jqgUtVCLzL5AsHdNNODqv0anHEeq3vTNWUYFwyqWR3UR9DhVWPM/ic9WxspYGSvjF2qkuCpl5xEMXqfRNMGn9UTZuf0fTJ8l6QUEXcL62g6Sa5BuSzfKKcl5BX/3adhEbY2r3pLWPNmPMUGZd0Yj1LTd3m8xsSOq5Pwhp2+isu8MJAZetBWgbwh6/gBZDyhPh5P2E/uhASrgJTVX9C6urrFRzzN9sKoI6LVU3bEEtAd661ECF2JMSg+22md15uk6R2WNR4nNAr7StltZ4U4dDw9AIUbyPCczqnCtTgNBg75+loLL3CkWeCkpjwb5krX64tRKLyVMZQgUZUk0hlB6CJ6psTHm5+Y5fPAAqybGOW3L6WTOiHbyudEAACAASURBVMUbUarFIRC9BWtZWjpJCCV5LraV0ZfUMgu+oOgsM3diicWFeZwTEavxiXFCDMzNznD06FFtOShpNpusX7+Bsiy5/777yPIcjGGw1aLVatEcbLHUXmTfAw/QXlqm2xW/+bO3n83A4AD79++n3W7TbDZYWjxJCIGtW7firGXfvn20222KouDIkcNMTa3i/PPP59CBgxRFweDgIN1ul5/ccw+XPvpRbNiwgaIj1f8f33ADU6umGJ+coCgLEbeMwggJRhVo9dldXl7m8MFDtBqDNOp12ktLnLV1GxGHdRab1ZmZWWB5uUtrUHrCBxot1q/L8aXnwXiAe+++m8mJCRyOZj5AbTijaLY4Nj3Nvt272bB+g+gRAAMDAxTdLi7PmJ05zpFjh3nS6icJMOONuFUYVETQUZaSpBjr8F4sRb2P+MKQZUYYJCDnFgJlmSaPRLVyAhoYmURiDOqqKZOZcUY0JQCsqbQrYuw5fOgGVZRTJyRr+8Q0RTMhMRTS+wVk6jkxyIFSiVCmJCQmgU6N7aMxYFW5Nz0/EWxMAosq9Ogj3gtIklwdErOiKAswRoETQaaNlWthEcZHDEpisxGSLWU0+Ojw3Q71gQFqWUZm5BnBQC3PyRs57W4bi6mAjxhFi6JRb1AUhYiTGqcev6KkH4qkYyCsk55tY7JPzWg0GszOL1CWHbKsTiTj2PQR5uZmuXDnThq1OtJSUJJ5yLCUMYmQGkwIhFBQaFuRtTI1hijV3hgi3SC2tjY6DR4U7faQNXKMyZg5eYLd9+7G+joTw1PMzS6S1XIGRoZoDOSYzInFpbGI0KpcYxEcdYjKRxBg00hF2OJo1ocgZJjgKMoCV3M0hlo8Yha0aImm1EXe6e/pbwBG6ZSJjg/RuKrGAFRsESF/qWln7LeijLodTcKrQKEP6JN3VEFLgo5cTG0Np0RfuuPe7wpvcGppPgkRBg2+Kjmqh4wq2gQVWEzSVT1qZt/eoyqCR9NHmJW9+hjJooZBRrvo+gSoDJGghylsG3Uaqqo66YjSL9riE41Yb6Eq5aYHNArGoIJhuISC9AEc6RxSWLEScK2MlbEyfpHHqUBsb/Z3wgbt+xsK+3qjCjtqLZ3A6qjAOMqu1jKpfLpiNegaaQJET0ytB0ZAjJjA+xR/mjT/awIstmgERx9IrWl4X8GqYvyBAvwJ2KcC9k+5BtETTab5Qaj0hWQdt33v610zcZuQWKqMEZfiKVO9u7pyNmnQmVPX8oi2JWtMilVmXWJv0I+t9AEUxkN02npt9Fhs33qmoUpi44agWgrCJo/qmrGyvJ06Hh6AAlJlLWPAqb+6seKYEDGoqh+SbKnQoTGiFq9V2aA90D6UJAu/aCUow0hVPRQRp7oB1hi63YIH9u5l9+7dbD9nO4ODA1KJLopK4V5E0qQi3Vk+yfTRI9xx221s3LiJ6WPTtJoDwnI4fpx9+x5gZGSEeqPOzTfdzuo1q9m2bSv7993PQLNBs57jQ8kPf3gdl1/+BBqNJvseeIBzzj2XgdYgMzMnuOuuu3jc4y9n+tgxFhZOsmHdemKE66//IfV6na1nncXtt9/BmjVrOOOMM5ibm+PO22+n2OyZW5xj//4DXHLJJeR5jSyrsXv3nZx99jkcOXKM1atXc/rpZ9Dtdjh48BDHpqdZt24dWZbRarWoNeqUmiBa5wg+ql2niE7meQ4hUpQdDIZ16zewfuMGGo0GmctoDbTwJlTUepfXyPM6xjgJcGNJrVbjwSMHuPfue1i/bh07dpzP4OAgxkA9y5idneHA/v1s3rSJbdvOJs8ypk+c4NbbbsWXBcF79t3/AGvWrKEsRd0cFTq0xqr2BdoSE8QvLRqik+RbAARhDiR3ghgjZVlKEmsStVex0hjVHlSWiqAMA2t6CbpBqthGwYBKNwGNuTVZT0k90CfqKe9LLAaj4EVZCjPFWqd2O7ESS0yTv2xfgQmbBHlM9bq1hrIUHYeiKKjVamrfmSwm03ZC3/GqXocxst+o+gseMKECH4x+NpqgjiRIwmgBa8iswXcLrJHn1bqAzSy+LPFlQWZV2BHIaxm1WsbJkwuAtBq5aMQi1FhiUIZQchkhUsscSycXRM4vcwwNtdi/fx8mlmTZICF4ik4bl1mGhluSGBkoopdWKV9C6BKsxcYaNkJ0jhKP80b1MawCK8LUCN6LZkkwuqAnRNxTlh2s9TQHalhneGDvPva299NsDtAYqOFqhsFWg0YrZ8eFZ3PameshU2ZKjMQo/tJGrTPRhS5EEWs1xok+q7U0moPEaCqGysN/pGaGvkTbisaN0WdJNHMC1qqNVCr/K4h0akIdlbHQo5MKV6HEkmvAoAChib0kX7VzeqyEqnihugQyJFToYz30OU+IYJXMZ9WH+6pI9P2a7o5TgjEDYq0F4Og3FZE/JwEtL/NmteveRpMyg7HKOjIqjmrEMcIqymBTdGQskEulpdqXPJfyNwVigtVqVqmITk6Mam0cAsZIS1Qk4pMUUAwq3igBc7WtKixdibhWxspYGb/Ioz/1TRVuU60TMar9ohHR915V3pLYZNFEfITMeAwOF3tblhk0KNCgYr0IA+BUmr6h90tIOAPph6rt1iWJQk2WE7hhpQ3a0b/cqHZY6i1O616ysYwqhGgcxMTa7aWVSZ9AzsNRtcdWe5ZtOtMPYuirutYIG9H2gSqqXYRcyyJGjj44w9pV49iagjrKngtG7LcNRrWOvF5HBT+UfBc1/rUK7icgP7UkOgx7759m08ZJMqPr2gpJ4efGw0ZWwgRV749JWKOXNAEQJUFMFaUQffWQGCuCaFYZCcnpIdm6SW6Y7P0kQcQYjDVMrVpFo9Hghp/cwKFDh0Bp1sJMCAJ0lGVVDV5eWsLESGd5mUZe47xzz2Gg2eDo4UMcOXSI3Fq6nTZzc7PMnpihvbzM/OwJrDWMjg4zOtzCEJk9MU2nvcTJhXkGBhoMtVqEEFg8eZKi02Hx5Emmjx7l2NFjzJ44gbMZIyOiju/LwOpVq2kNtpicmOSyyx7PyPCwCFJaR6M+QL02wPDwCM3GIGAofaDeaJDXatTqDZoDg1rJEkE45zI6nUIS24gmU5kkU1564ROV3hiDdRnr169nzZo1jI+P0xpqYZxTO03I8jrWZRgr2wCD95FDhw5z9OgxVq1ezfk7djA8PFx9xYcOHuT2225jZGSYbWdvY2BgAF+WzJ6YwRcFO3bs4JKLL2bt2rWAJuVWhBKdy/Se6d0y1jp9PUIQ0c5cE8QKNIlQek+IkdKHHhgg8yAhRLpFQVF6EcKLVPaM0JfQp6m7qu4bbXEpq/s4bds5V1k7JvHHBAQIwyJtW3OWELT1QPQVKiaG1Ojld++1NUhrsHot+vUXvLZ9CHPHVcdilFnRf+2q+0ATIfneHcFL9TwBJzHKdSQTMcNohNLmY0GI0uvvPWSuRi1v0C1LSi8aC0ER57zWoDEwyFKnI7oetp9KLefiS/2O9PjrjSbHpo+xuLRE6QPtdkfRfouxoqDcDZ7Z+XkxcrIWrxVkbyLW5mRG2oSiFbFGrIpyekPZLapzFFeZPsHOUEqirwKPxkgSF0LJ+PgoT3zS5ZxzznaszRgdnWB8fIrj03PcvXsvt950J7vv3IMvAW/wZagWTU9B4TuUIVUaejowNstotoYwLiev1QlRAKZHxghAKfUWFTZUeA6rSahPhf5KkErT5igMG0376dUZpPIiuIO43CTXBkixT0rOLdEbQplucgUOTdp+/7GmJ1m1B0yoCJ9yPKmiY/vYDCmRTndsOGVbKcys4AVjCSadX6+nM4AI0PZVgqj2nbbfuwYJoJB7xBFK+MqXrsMnMJVITIrXSexSj0cYMqkyk6yS+0NiKiYUoKyFQLcd+Oo1d+NLqYf1aK1pH6ln6j+7D1bGylgZK+MXa8SKmYZW6GXNkZzUUPpIpwNFG7ptKAqpz2Cl3djouiKwbNIxkAC0ByZEnWeRXCgYfBDtpR5ojSb7un8F2kU3S183QarzijUXwfDlL+6iaKtOQK8+T/9aG/V/Efn8qTIQ/eLKpkIjkqtRxZqoth3o5wqGYImlgv0hVu9PrRSxOkPTO5b0U4C99x7jnz7/AzpB4rSiA90l8G3A9wEhUQTYI4YyQKeAbheKrjBsZXuGWBo6bVjsGrppaY/wrnd9jX/56h5pqX6k1HL+fx4PC4aCNRYblVWgSZy1FpfXALQqqzWQ4CUAtwbrDEVZSoWrv988cWONJDvGStW3SuzUwtAQmFq9iqc+9Slc+93vcvTIEdatW1fZ7IHGuBGIkbIsWLtmDdu3b6fZHIAQqdcbBC9J794999Js1AnRMz42yplnbKEsukxPH2N2boaDBw+wsLDAxPgIE+OjdDrLTE8f4e67djO1ahX7HtjHunVrMQaWlxfptNtYE4nec8GO81m7dg0Gw9joCIMDA5hoyLOMzDry3FEURVVJB0OnXVCvN7HG9TE+UlHNVEACmkxnLqtoWjFEbCYVrTyvEUq55iEErMtoNJsVupq2GxT1NC6j3e5w8uQSy+0OY6Mirnj40BGuvfa71Ot1LrjgfJbbyxAjrdYg09PH+NmNP2NoeJhWq8XS0hLOWpqNJvNzcxzYv4/Vq6YYGx2j2+1Sq9XUnQNJJKMhhCiOEUUB9Nph8izHI44F6QIEzaATCyYa6SMOQVgLoRDrOrlu6jARe8yGlFwmloJzshwkgABQFkBf5VPvqZ6+gtXjTLXMqCCCrZJZ78tKB0KACzk+l/VEG9H3VskSvWNM1yCxI4y1VfXQaotQ9XmTrIpC5WaR7v+gIEfpAzF4oovSjhKQViInuvYhCIpemBJnoQhR2zrkupRdL0CTAnpEEbV0WUbpS31sHUW3I6i1NbTbbRYXTzI2NqbfeWTTpk1879++x49/dAMbNmzkwQMPMjk5VVl2GmNoNBp0y4J20aFlhjBGWxmMo/QGXxhsLaNU5Np6S+4ysJEu8dTvyej3FhTEjBZDECZOJgmq1QBhZmaa+YU5YvTMzEzT7jaxFgYaNXAeS6Tb6TBYz3vff4Sks2JUrC8oYFOGkgyoNwfAObweU7LRfaQM0ZIyzM95br3jKE7FUqOFDWdMsHqiVVXXK7FV4+n18Pfwb9FPiCR66ImFLp12ybqp4R7FU6s3BgGpf+93P8Sb3vLf2HD6avYfnGFspMVgo4a18uzpU0F6GsVuMRAUJEuAd9BpxJJcJfSY5CzpBUsKGpgoJ6802KDHXHk16Hq1Z88htpwuop2ur2Wq30u76rU1GnRFCMayuNTl6k9+i8see54cizF4b5idbdMtSlavHtT7rOfFHaLj0KEl9j8wAwbqDceO8zdgjcNHwy23HKTb6WJDZNPpE0ytGcYHz8c+chOHji7wmjdcSk1bdvqvQO/nFVRhZayMlfGLPpJmgbau6XwYFYx+359/k3vvOkkta2OJ5HV401uezvZtUziN/QzJ4M4oA8HrOpSR5ATRNTFg+OM/+TRXvfVFDA/Vq3WnanmDqsqe4v0EU1SuDqkdI8Adtz/I/Inj/Mprnla1WMRqrz2EPkpfubYa2gp47tHo0PNOP/QaN0xMW+1rf9CWiPf+2TX8xq9fyfhEU16PvViX1MZheuty9f9guG/vMb721Rt5zWufRa1eZ/cdD/K3H/g2RccBXZ515U6e+/wLdZ1VBnAwfO/7d3H1Z67H+BoHD03z++96FpdddiYzM0t87KPf4957j7McLI1m5H3veSFjY03e8XvP4Y2/8c+ctn6QHReuqZgcK6tcbzwsAAXla5Lc+4xWgV0SIjFGhACDVGMlORJ1U5fnVSXYGOmND6ouX3plFmil1lkVCsEytzCPiZZGLSfEyMDAACPDI32JGxKsGiOCfSHQ7nQYGh6m0aiT5w6T+uxjZHbmBEOtQTZtXI/Nc6FaDw0yPz/H0tIiW7acztjYKGtWr6LVajE0NMi+E8cZGW0xNjrEUKvJ2dvOpF5vYGMgFF1quWVycoxaVqc50MQS6Ha7hLJL7gyd9iLOKSMjBgYHmxw9eoSZmRkGB1scPz4jwIkx5HkmgpUxUqvVqgp6jJHgPSdmTzA7P8f9DzzAxOQEWU1ujVThdlbCX2sd3geGhoao1WvS0Gx69oRR2w+OTk/jfeTw4SNs2rARY8DlOXmtwcLCAvfuuY+JyXFGh4c5o7WFbreg0+nQmZ4my0WQkhCp1+qsX7eOgw8+yOFDh1laXGJ4eJhVU6uwJrVlOHwQNolxmThnFF5aVry4BjjnRNAvmqoNpr9tAGN6YnheP5cJSJBleV9S3s8gMBq4a/91n01kZTup+gPys6Usyz4HB0Wxo7BikrhjSt6TfohUEiM+/LymiPdejtG4vgS4d1797Ih+tkICkvuBttSaIXoUVoEGEUMsikLYDBiMzcBYSp8ADUHXnYIVypsQPQcvwELmAqPDLXJnyEzERNVeCIJHj40Os3jyJCaURC+9g2JnWtBeXmJhYZ7x8TGcFabL+NgoO84/jzvvvIPlpUVarRZnbN5IbsEEaatoDTZZs3oSa6XdxtoMjxN6u7FVlTpQ4H0gw0pLhYuVaGeMPStCAZg0VdLqgzM5Yk+KiqTCPffcw969e3CxRr3eotHMGZ/ayMTYIMOjA6zeMEmeG2IsEUKPLs020fS0zh2Dgk0CbOWNuoIhwtZ45KxkUu0XLQq4+67j/PVf3sDll68nM9L28q3v7ua33vpLZAM1okG7KyEFQUQr1Xsj1MUkECW2sZZdP9vPgftP8KpXPRaneo5yV2tybwyPu/xCDh6cYe2mNXz6Uz/jWc/cwY5zV1fVhlSFKTXmEY1uQQ+8hloOWa4Sc8QRBDRMpaNUqU/bI5JUteV0on5etpsgoRjhf7zv6/zNB16DrdkUi8l1i4ktke4VWz2zDgMlfOoT1/KoS7Zx/vmngS2J3vG1L9/G5z+3nyddsZZXvWaHAOwkCcyShYWST3zsR4wPtyCDZb/MgYMnuPKKHXznG3ey+95pslzaTb75/dv49Tc/nbFWg7/4wNP5rau+wktecgG1iZpoqZh0nnqaDx/y48pYGStjZfx/NBI7tVdJl1ch4rHRsjjX4U/+5FmsWd8kJzIzXfDeP/sKf/E/XipW1hZ8CGQgLdchSnsjRkhfzuIwuAi+jHRi5Nh0RukN2B5LUTneAPgIPogmDhoT5s5igoi5S1edtI/+9juupOYMaa0sy4g3ovGTW2F7RxPphqixoaHuUvChDEud733Ugq0VIN0rHu6UFdzRbVgMmQNnDCdOGLqlqPzYJAwOhDIVNYU9UfqACcK6c5nFe/jYx3/Am978VEaGGvgSPvSRf+O973spzaEaZWm46i3/yDOfeSH1mnwjqXb32X/8CR/8wP9G7gzX/cc9fPgDP+RRl27lhhv3snb9JG9/27NplyW//Ttf4Cc/2scVz9zGeeeM85KXXMjHP7Wbv7hodd/VXhlpPDwABSOonLOaxDgnyv2xl1T5VJGyWoG1KeDu9aVX9nyoRrfVkFBBhBhlHyEaDh06zLGj02xYt44jhw4zPDLGqtVrKypoVdHto63Pn1wgb+RktQybiU2lQZLEiVUT7Ll/D/fctwfnLBs2bmB4eIhuUZBlGRs3blSNBqeV68Di4knq9ZxVqyfI8xpNDM7mBN9ldLTFnXfcxg0/vp5NmzbjnGP79u0U3TaZA2sCvuwSg4GYURCZnBxnamqSPXvuYWxsnOGRFtu3n4V1MDUxzuBgE+skbxkeaTE40CBzhuVuQQglp23ZTHOg0WMiWH2Yg1cbSange18yMTFOq9WqqPtJ8T4EAYa2nXU2a9asYbA5QK3ZxAJr1q7n2c99rpx3I6fZrGNNxNmMtevW8dSnXUHhuzQaTZqNplyrzDE6PsYTnvTEChwRpooKcWo1P/iADx7vA74MlL7EOrEcjF5aAgSRjdKTr4yDhOCGoNTm2HNh6E/Ak95COkdhAfRaH7z3mMgp7JZeMt+bdqzNSDoJ6bqBMGmiVsX77+nUXmHVJtPo/SntC5HcZafc//37TeBFAgr6R8+hoQeOYIw8dyRSTqwEFI1Jfsa9YwerDhgZPnicMdRiJPeR3FvyYAlBQBhjLWeevZXgRYDHGmljEB0Uw4ZNGyq71UDAOIuPgHW0RkapDwyKm4ICiVm9zpatW5las4bgSxr1Oq3hIVzmMFY0U0bGRrj40kuoNxqqQuwxsQAbKCnBOvCG3Bq87cq2Y6TmA9EJ2OOjl/si9Z8YAVjk+0LYF0HTW2txtYzTTz+N2HU07BCjo+OsWjNFfSCnNZDRGMiot2oEW4AptRqhwqfIfOesE2qeQaAZK1T4rFYjq9cwLgNrKMuCRwL3rkdZlLaEaAOXPnY1r3v9Y3AWSg+/847Ps1yWmNKxZ88ROp2C2WOL7LxoE2Ojg+y68X5OnOgy2Gpw6aM3YV2A6Fg4vsyun+3jlltOMDw+qHvS74oUZImg0mlb13H29o3c+OP72HvXADeMzDLWzNm8ZZzSG66//h7abRifanH+znUcmT6JKcUN9Y7dR9mwYYTNm8f4wY/2Qplz+hlDnLl1rAoqKtGnYJmZnmfZl6xZO4qLhkMH58jrjrHJQZbbgRv+/T4oa8Ss5KJHb2S4VSfGTNgWs20WZ5fZsGmSsgjs2fMgZ29fj8dQdjzXX3cP3jvWbRxj29Yp9j8ww/ThLhddvFVxDcve+w/h4wJXvuA0Ti4valCWeBESBrc7XWbm5/nN330a1sF9e47x2c/+lGc+bQc/u2k/z3vBRZx11gQ2wu/9wRdZWigYbdXZvHWCRz3mHN733h/yvr+4nFPcKSrK7cpYGStjZfxXGLrqaM99ktYxml7FmFVViBIoLHStoYhwzWdu4eDRWe6+ez+rVuW8+49ewne/vZsvf34Xc/Ndnvjk83j16y7FWsP0sZP83d/9iOt/Os+tt5zgPe82ECxYrz3/wogLEe6++zgf+dB1ZCawML/MYhH56MdfgQPe855vMbV2iFtueoALLtjEAwf28+53v5B63XJw3xwf/eB1HDt+kpnjbT7zmVfjMsPde2b42498hxPzDUwM/MNH/psCDapzEMFEy8yxRf7uI9/kne96AeB4YO9x/vnLP+Kqt1zJffdN87cf/j6zc01uuOEov/3bF/GKV+wkKOtvfqnDX773X/jDP/xlCPD7v/9p/vjPXoFzhgfum+XDH/o+0yeWWGxbPvEPL+WWWx9gau0Yq6aGsFHk0rzJsTGSm4g3hm5hufueI5xz3lqs9SSxYouIDlsDj37sGXzy0zcSAB8thbF4B3me8ejHnUWhILwj8KqXn8ub3/ZFHJVZMyvrXW88PACFGKue7lPp4L0qcJaSVVT0TpP+1DOe+v0jQau2USp9RqrqzjryrKa1xsiades4dmya6ePHmVw1xdDQkCYkeUUBT8BCqvSOT0wxOjYulB8rFP/MCN3pzG1bqQ/U1Y5PBAyTYN9Ac4Bara7nKP31ReFZXm7TaDQ0Kdcky3cxxjA1NcFjHvsorGoZWOfodpew1rP1zNMxJuDLNsE6vC8koXMZF198IWUZaTaaYKBWqwGRTZs20Gw2tIWiZPu2bVhjKYqCLHOsW7eWyckJcmVX9Cei1lp8KCvKv3OW1atXk+f5z2kJxCitBbVazuTkJHmWk+x0snqdiVWrGCnH6BYdnIOi2xHF8lqNialJYQegFn3aJ+6co95skixCQQCFMnhRH1cLwzzPT0GJK9tG1IMXSRAtvep9phTy9H4hFPdV9fvAlZSoJwaCtb0kXg4qnvKeBEjJ/el+TntB3mqxrndf94sqVqKPiZFQUZ4VPKNnIZpsDXuWqvGUY+4HD6rPxJ6AZGJGpONMjIkk2iYilylP04WrbzvWOMpg8EbKrpZMrFRdDk5o+81mDbF+lWtiMotH9Auag01CqFeaGERVOrYysZNZgkutTfqd1GuM1CYwQRJzcd7waCkWh2WwNah6AwpQmmT747HWixBddJiYEWMhLBNMz39ZNUQUpahaUrK8RiDgi6SlYPAhkFsBD5fnPQfvP8rCwgEe2P8ANovkmWF8cpQtZ53G2o2rVC/Gg037Ekph8pWOIeCjiPMFDHm9SV5vYmwmGkom6Uw8/EdIpk1G3ECKbk57qcQ56KozqImG9smCN77x73nhL1/E2GCLrdvXctPNt3Hv3YdpNFp8+cv38el/fBn1AUu34/nUJ77DyNA4H/rwd3n7O5+rdMs+WqWRICFE+Ou/+QYf+ODrOHp8joWlaY5M5ywsDVGU8M9fu57Z2TYmNPnUp27ngx9+Hj/8j30snCg4dvgYjcYAX/vqbs7e3qAxOMyRwwU//uksv//7z1YGnIA/wqaI3HrzHh48doJfftmTIcL3rr2LybWDXP7Ec/nMJ/+deq3JicPwp+//Ft+49vVcsGOttAxh2H3HIW6/aT+vfu2TabdLPvjBb/KXf/VaiiJw9dXfxVBnfsHw1a/dx/vffwVf/ZebufJZl6jwl5z5aVvWsmHzOr73vXtZPFD2KK8a+MmyZVTwUxhEmc34t2tnePWrTlaaIs7q1QxDfO4zu3nbb16CtYHX/fpFvP9PvwvBgetRbeWqpzn4kXFvroyVsTJWxv+7kUR/oWonANLc52OgUw7wnj/6GaPDcxBLooPnPv8CQoSlJU/R9nzgr18JxvCdb97Cidkl/upvX84tN03zu+/4Ps97wXkMDeZ88pPf5/kvupgXvXSQt1/11T5HBNdnOiT6Bh0fePDIPB/8qxcxNNDg2S/4At/7/j6eePkmZuc8F14yxutfexmlN/zW268mesPciYJ/vPrfed2bn8yqyRF+9WWf4lvfvoPzdm7k6s/cxtveciV5vcbLX/wd/uP793P5E07DJMqeNii0Bus0Bxrcufsw27at5atfu5XHXb6DBw/P8rnP/4h3/N6zGRhocPllf8fJBWHDWqfXrYTZWWEwRODEvKMEZo4stf5sCwAAIABJREFU8elP/ozXvf6XaI0O8JIX/ZRv/+thxlZJoQ2ntNEAYq8pFyO38Kwrt/MPn/4hf/beF5LjlD8LmTUsL3k6TtghkToAuTVEH1lYklbjbsdhyCp3sWbTMJB7FVPuW3BXBvAwARSkuBEVCNBkLLkzJBFApO1BKqjKQlCKvXMiDBVClBsMsWHr73OvkmPncDZjeGSESy65lLIsqeU5zgprQNwirFq6pCAfjLWsW7ceYiTPs8pNooyeQCCv55x51lZRKtckLPjA2Ng4O3dewODAINY5qcIqpXzdunXkeVZV+ftFKJ21oplgpIc8yxyYQK2WkblBMmfwviCWBXleoywLgi+xBk3cJAkuymWctdTrjjy3BAUsDKpYL5eeWr1WPdjiMtCzOkx0cWNQAKevp7+vih+Ufo81OCNMDOtcpQVA5jDRyvWzEHxBNPKQB4zY2aSkQ90mnLXYzGGSvoHuB2NU10Ds5oyVnvOqkh+sVvRRG0tV6g/SxZVlWXXvxRDwVfKv5xgixhtqWa6FN3MKwCIsE39Kwt6zikzMA9F1SOCB1baQEGTCs7a3TWP72hH08/2tE5EoLRv97BFjhTJfuVb02BRpW/3gXAIneueZQAPVM/BeAB0FUlKbSIgRo24UqcWC0Lc9BReCddSLgtIa9k9NYUPo0cJixMcSa9P1VOp4VFtGfV6sHouIFSqhUL9bjHxvwYt2gZxHFPcHZQ5U96K+31lpEQChYS/UG8RaHWciMZTEaEU9KAqwEGKgVLeP6vs0VhP+TMA2hDHlfdCuCQGtXCaKxzMzM9x0080cPXiCwWaLrObAidrw3ffezz17H+Bpz3gS6zetSkLP+FD2einQ70BurIo2aLMaEYexOQ5HZvP/u1Ps/+IhzBpPqNoIvvbV/ezb8yAmO0l0Gc9/7kWMtBrMn+hw7vaz+LXXPI3BPOPAgTm+/727eee7nk+eOX7y0wU+9tGf8qpXncfHP/5vvPB5l7Fx0wTDa0Y5dnzpP9m3yj8Gg4ktIPDsK8/n9t1HefoVmzn73DX87KcPcO21+3jG03cSfeC6627jW9+4F6jzpX/Zx0c/9EsYAy9/5Se44sqn8JSnnsndd0/zhS/cQKjcDkToyiDY02Mffz5/8O6redoVyzhn2XXTPv6PF72QL37+RjatX8cvPeNsjh08yT996UZ6OitJoNHhY46x0klbhAEI8K/fuIX797R51KXrybKC919zGy952SFlVvWFNkZVvDXQslFFs/rmJ8ULMGTybwxsXD/Kky/fzML8srCKiFgFxX/7qifw++++Vt9rFERb1mcbtdTS5xFpLZP793/qjbQyVsbKWBkPwxFTn0MFp8YIFkuWGd78xp2sm6xJh3AOI+NNqXvHgsdfvpm8Him94Y7bj/GUK7aT1Qzn7ZjgwgsnWFrs8ncfvpaXveQxnLF1lBgip58uhczelJ4y6hIQT8gdF6xibCqHMnLVVZdy9z3HuPwJm8jygic8dhP1PJEuJR5tLxbMz3nWrR8GIh/+6C+T1S337J3l2985wuGD3wGTsXG9p9PpUE3+JpkOR5qDGeedv4UbfnqYLMuYm5vl/As3cs+9h/E2Z3isSWYi73/fk7lvz4wcdfS4CFmQFj6LhGTBSOvj3GzBd67dy6FjM8RoWbN2NR3fVp0lUzWbCOvA4JMlPDA52WTbOVNqEy8ubdFE3nLVU/ndd31OLOFLmJuRb+2Jl5/F3//DdbzjHf+EsYb79yzz5jc+Udw2gWh7DN2k67cyeuNhASgAVQBdVU5BnRW0j7jP1gvkYTVKZw0+Vr3OYqWm/e59Lgapehu1xwcDtUadLNSk6h0i0aeKdBTWhNKQjT44BtSj3uI1oSq1GuyjaDXUsj7tASMJ25q163CaAGYu1751mJpajXNSsU3VY2eljQInyZuAAXWSxJcvC7leKsGdZZLYGhMpfan9UULbL8tAljlKtcnsdASwkd70krLoYowjyzJRm+1LNsuypJblktAapa0ngIWevWFKDJ1zRC9OBNbaqspfpqTVOawihBCxIZfjjJFYllXC7IOABVUCj7QrVNcUqGJjC/iIccJc6GkOUAWyZQhiCdiHJxrbC35LdYrI8kzbFtR/Halq++CqxDwl51W1X6nu6d6zfe0OwhLoCUN6L1akvgyE6CtAQ66v+r7re4Pen9EabLS9Noi0LwVVrEl93YnNQHWd0nb6tTL6wQZQUMhKsuzLUn5OjAhEbDFtNCSfX0DU9XqtF957sZYzkaHlNgcWu9w1MkLX5mClby8jk6Y+85BEw/T0IhIrJelLEHtMj2RhmT4YFWCyNtnaiZaJc6ZCKyJyX5ZlakExRGfJY2DWZzRsk1pmaJWFgBnWEkOkNFGdFqBU5o+JJb70lCHgEHDKp2sikUMlere4vMzs7Cwjw0Ps3LmT4bEhbCYKz3fuvpMHjxxg7959rF43hc2sKAyYBJpErMlQH06EqQDgcK5GljUougFjM7xaoj4iRjDaRxmxdHnhCyb539/0RMgjHr0GSD9pvRYZqDuMjxgPscy0B9Lzhjfs5F+/fgv37z0Ots76zRO4LNIazDk+HU5xbDDoPE7sVRSixZiIDT39gqLM8J1Blk+WBAJ/9CeP44KdU9xyyz5e+cpNjE80sM7z4pfuIMst3prKkUG+c50HsSo8GXH1yHOfdxnXfHYXLl/keS+8gHrd0e16XC3HGli7ocULX3IuAZ84UST1haC+YaLi3QAP7cUc322wPN+ljuW//8WTOW3LCD++PickYTAVpIzRVo4UVFvvAXnJRUTxcsAyc2KBRn2BDetbWNtH6Yxw7bdv5pdfdJa8U50pTMXOUikvk2bZ5CixUsFZGStjZfwiD9M3z6KuBFQsahMiNbvA1ETG6tVNjIFgA8YGfGmIecDbQDCBYCyl8VIoDRL7NJttMitMSGszgk/uPDLn+tCDccUeMScgwoPBO0IQ17XBITBmWaSNjVo+EkVE26T2SoMNkjkbC4PDNY1xPM95zgRvv+op4KBLEJ23CCYYyihFxKQJ+cQnbeetb/tnZo7O8swrLiLLtHBnI3iwzjA4kItzUFSFJd2WjzmxRNqWuw1Zo1zgl56ynnf+wbMAKKK4nt2y60G6XUUdXMQ4qDUCJ7uBgWgplyNf+Owu/vwvX0xmkLXXGGxu2LBlgr/8wMsxATpLBe98xzWVIPSv/urj+bVc4v7PfvYG8lqhktAi1l1Y0dazvRVyZeh4eAAKUdXtra281VOykxgJwRfayywAgVR5pfJVJeOuV42M1tKxjsJJt0vH5uR5XexBjDklDvfKjgil0OFLX6oFoiQOIkgoxmcmJTZOgQNNuoOT5K0whlqea6VJxURiFDp+CJi8hg+e0gpboZsSKUUbK1GVsoQsl4Qhy4ihFOAhQp7ldL0ksU4p0sFYuj7i6rmIimlV2Tm1otGKKkSMVvijoprGlwKkiOKKJvABV6JOAVoVN7bX+6/MDo0kcVhMZul0O6LcLogQwSBq9Jrwh2hEe2JggLKsURYlZXsZ32mL4CPJwkwr5FppNtYSvNgQCv3IkLlMYtdgKIL0SRNKAaeM6V3Xh1TunVLXk01kDOFU5oWT4DyUpSbM8m86Hl+WBN+zg3xoC0HUa+196Kuo9yr61okuh9yzAsz40ldMFaPCPCZ4TNJ+iEKLL4NYPwr7wxB9oAS873NyMFJBTJoPRVH2P2pAOk4IJdo6Yk8BRILSCCqH+dR+odeI4E89/wjdWo1ywFCagFEae/Sy4IYYBIhQO6UEmshiqCAKyn4wySowsQ2C2Pmg20T+8zEgyhOZ6KXEQDDSKpCEFEOpbSZRWSIx4rPAvvE1HBhZzXCxxPZD99IMbRzK2sgyCi9MlbLwlN7T7RaE6Mldhg8BH1PlW8CPUHryzGFdzsDAIC53FGWXk8tzbDl7PVOrJtm394jgoiZwcvEkCVtP7QBVshfV+caKOKWAMhB8l8w1KNuB9nLB0olZ+lt8Hq7DoOVwvILA0o+YGBkWyCTi0Gc9Vp8JatYg84kRCShbMjI6QLvrWVruMtLK5T5VgC1hZiJoKOwm0Q3UeSkpa6ZLZwp2XDzCC156PiHA4cPHMaGrab4KWBkRg3QmknvIDFgrIpwOo+uKhhfBYE3Gzos28+3v7sbEyCtfebqIpUaPMUFBbYMlSGBlqMSoolH7yAC33DRNt92Uw7QFj758Pc98xrkQ4Z69D+JMCbHBT342zYWPWksOAnRKDwnJbDtqW46JcNONd3PujjPIahn1QcP08ZOMTw3xoxv3cNa2CUaGm2zfto7ddx1i65lTHJ2e5579B3j6c3ZgTBDQlQgxsWqkKhYxjxyAa2WsjJWxMv4njJ7Pj/xW2QhHRzQGb9qELBIy0T7rFbcMDqnOWxzOwFnbVnHTDfdx351HKQ1ktUizmXPVW5/Br7/hS7zgRdsIJrJv/zIR+OGP7uDwg0uEKMCBjeL6s2btBHfeOcs119yMiTAzt8TWM6YEcI8lpU7VmYFaiDgPg01HY9DyhS/sImJYXG6zarLGjnO2QBn40pdvorCRuYV5tp8xwcKsZ7ETZH0NFmsi+WDJFc+6mN/8rcfx9x+7jp3nbyQLMDrQIJaWr3xxF8bAXfdOMzExLOuestFLa9j7YMnnvnQHP7m+zfU/GMAGaA3nZLnni1+8EW8MJ5eWOH1di9PXb+TL1+zl5S++iLVrB7AZ/M7vPptff/PXecHzzuHmn+7jmVdcQsNalufavPNdV/Mrr34KF+7cyJt+7Ys848rzwHq+9s+7+eP3XEGeRa69dg//+vW9POqStSy2DbtumebP//slUrCMkfv3HmXrlikBE1aWup8bDw9AwRiMcdWDFiJVi4NVtoGPBUajLBO1vmItRhMmo24DhICzlq6tsWtkjPtbQ9RKz83Do9R8xIgih6CEQS0PTY9qbo3qBSiNWgJJyWJiYi3EQLJ4q+gvUYTVovahm5TA9NkMxpCqTqKDX6n5B6WfGlBfGElUnK2o3TFKO0OqJlV9S5pwRzSxc332maiTQN+dn5LR6EOVmGF6E1xKekMMOEzV8uFTMpx0LkD1DGT7xqT2CQV0YgKIdMcuRctqLWkjy8Yynw0x2D5JrT2vlURNChFV+CDdI9p+0VeB1Eq3NVYZJRCyyMTccbkXupGatZQOusGDD5gQIEiCUMZIUVHhe+yHJMDpnIAbNgYFL5wmNRFfemy6pFEUbEOMYn+oopvCKChEs8FZPU5JyiVZVzWPimqRkkrVQ0CYGcGn1hNlYBCrFgdrLEUoKYMn04QalKlgrbRH6PkJy8Hh1JJQWikixIBTtkHaVwIO8iwX/QCA6OVaWKtPqXzXyQFDdC8MC/UaIwMDrJk+jEVsFoO6QdScaAEEregnxotoS4jIpNNkT54h5JmRL1raXRQMIeqC7JLRkT5vCigEZRZYY7VNQ5NNEyETAOZwawwzMgpHHJlLThUO6yweg3OiBeJU9ySzubB7gmwvIAI/zlosFpflhAhjE2Ns2LSOPffez65bd1Fr5YxOjrP/8H72H3qALDeMjAyKGj8CmATVSiBG8KIDYVRbxRgr3tFY8lqD8uRSBQg9EkZVH1f7xFruGWx0cbb/b/Kvs5GBZhtUw2JiaoB1awe56k1XEwk0B+u85rVPYONpE4RQ8LarPkOrUefo8QWe/fwL2XXbHj7x0W8T/QjEDEyJJXLZZVtptjpgpaBRr2X8n3/+r7z4FTu48NFncd1/3MpvvuVqIDC12vHqX3sK9UYJMem2GBq1gkYmrQ15FmgMdDlw6Dh//mdfwSf9j2gwsWT7eSO89jeew6WPWo/vBhoNEbV90pO38fGPfo+vfOGnEC333vcgT3nq2Rig1WhjHLjc8o1/uYvdu45yy62LbD93mJhFHvP4zfzDx77PN79+G1jP5s01XvOap/PMZ5zBO9/1XV7xq2czNJgjLqcCogxkgVrdk2ihu3bdwx+++6Ncfc2fMjzcZMuWUd7+1s8wMjrFwWOHuOZzbwQTef5zLuDFL/kbvvuN3UzPLvKs55zF6FgDYzzewDWfu4GXvfhSPOqOgrZVxL51bGWsjJWxMn7Rh3noj4npKzHqq37lsUyMNZTprHoBxmAcPOWpZzPUagAGZ+A5z7qAH/3gLubnuwQLL3/FpUxOtQg+8trXX0CnECHmN7zhEoaGMpq1jKFmRsChpGVCtPxf7L1ZrG3ZdZ73jTnn2nufc257bt9U3apiFasjWcVGpHpZtmQbspIYdgQJcgzJMMLELzGcxAksB4Ifkgc/BImBJBaEKLATGBCQAEGcBkkQKzIQU4EshaQos6u+ilW375tz9l5zzpGHMeZa69y6VawSSbNI7XFx7z1nN6tfc83xj3/8fxeUjVlha5+1tJ05e4If/pHHEOCXfvmHOHRgAyEQE3z2sz/GYpHY3Jrxb/zlH+ErXz6PIhw/vs2P//iHiSr8+b/wMV5++TJZlHMPP8SnP/kI//S3v4IkA0+i2kQ9bQgxwNnT+/lLv/hJ0sz0es6ePczP/cWP8+KLFxGB5z9+kmeeOU0M8Mu//MMcODQjROGv/dvPUfvKT/30YX72XznJvBNOnNjPz//Cp/nq1y+iCGdPH+dHf+gJqPCnfuoY//Wv/d/87V/9c0hXOXRowV/95eepfeVP/OTDfOpTJ5EIIQl/9mc+xqOPHkUCfPbf/DQ3by/RAL/4i89x5oyBGx/96Cnu7UAis7Uv8Vd+6RPMZsGZ0sI/+b8+z5/56af2nvR1DCH6AZiVPv3kh/Qf/P2/6xoIE0usFMybHvGeTkC9+hisKhmaZaDaTKaUQkTYSQv+92OnWC4WPHrnNrFWKAYK9NoTuoD0pl4v0ZKOZj1ZcgZa+4QlVF1q1XgLsw80emtxsT2tla6zvn68Eh+j0/eHtgYFCZRiyUTf56Esaa4BjfJUicns+dCA1t7Aidoo73lI8FvpVoFSetPRaxe8mN1mlzqrSNdqjAFVo7Q7DdkYCM6OcIp98pJZDI3i7WVn2wtiNLu84IBQCAmVQu57UkzmsOCq/HjVLYVAFyI1KDfnC76x/ySnd25x8NYV7ty8YWhlCA4wVbJYH370hFU82bT2AZvcl75SSmZf2WX/nZscy8qBCjEIO9qzqplFnCGlknNPnM0c/GjtBQZe1Vrp+37QLoghkmK0NpTqAFZrqdBKyXloOyjuZNAuEgMLRqCiTgQbzc7XgSYHqpqoZLtGxEEuO29miWnF1XEgG2wea3Xf+lG0UV2fAR1dK7SaTkH16zfG6MvwNgNP2ksuhBjpuhmrVU8M4oKhPapqrIvBNcJYMyrQh8QXjp1m6/A2j774ZRZ1x6w9+0LsOoK3gBR1Rw1pIB5omTgUO2AQQ6DP2bQycNZEcKFUNZeI5rhQLVe1ew9jT0QJjiwb+0aioLEO/XBf3j7F7onTPP3ilziYd60C7mDErgivP/4s15aZ58+/wSKvBnZGpVKzaT+EFCnFxytJBBJ5Cdcv3+BLX/gyFy5e5NFHH+Vjz32Mt85f4MUXXuDAgU0ef+JhTp4+gsae0ImPJUKtQgzJQKBigGdMASiEWnjrylv8o7eu8YMf/yjz3/4/+JX/8n9mtnnkvQ2036Vo4IeIAXg1B7RX4sJp+ohV7dWsoHIudDOGlrPlLqx27V4PSdjYSEiA5bJQlnVwLIwLZ5KtylA8b0yE1AVISpo7ULWs5GVF5oG4EPKuUnZdi6MTZhvRrskKIQXzFM+2rcQAxdrcCIHlvTy2QGB/UyfMFsna2yqkZAyHWoXVbmHVOxMrwGKR6CLkZSHMExll904ZKk5pJsw3DQjcvVfI2b47nwVms4hW+Du/+j+y78CCv/E3/yxdNHqmVqFmJaOkmbV5lZWS+0K3MKeQPlfKTjGNiQib+6xSVjPs7hb6YsDOfCOy6Ox0vfLaVX7zH/0z/p2/8bMsNp0B0ibQ2lgRfqyGv+tYxzrW8cchhqrX20D/xrDc8zH2Eube/7q8uIixJarCi1+6yD/+X/4//r1f+dPeTtgEnP/lj8V/9H1791CFu/cy/9V/+v/w5//iR3n0yW1iZCz2DWyRyHvf79EmfDyNSlHhrddv8N/8xv/J3/7Vn/O8bpzf/3GKT33qU/ze7/3eA3f8g8FQaBXuoJ4YW1KV3dc9uoUbVGuDyJnSr1CE2XxBLtkq+sGV9EUotWdzucOR3V0+fO0K87I0MCIGdsvKqs5ZjGrUJZbLpaVjatT+VqmuWqi10qWEoqRok8RSJkKPIdD3K8DcKqqLS6aUSLFzJoKankExixfrP+/Nu75UEPUbX+h7AxuC6ym09gGrLuNuAtX7xhlmzmYFaD6uIQbruarOplBjNYwsA4gpsez7IUkvtZBios89glXlLXc2JXsRE0uMtgI7V62AXSGlDpwhUV2bALVBzlbvSR6CBuXq5iZaKx+6c4dHd+5y585NclmhKuavXio1VG/b8IzRd1eCaWLUYgKSBgZFAkIXAppgSaEUCGKJM85oyW4zKCGwWq1G5sDEfrE5QDSniS4lp10YeBCCELvOgCFVYvLj0VoevEWkiSq2GAQDnRrctD3ae02jYnCWcIjgfiZx+07w44AnbUNrh1OwG3Ol7ZM6vQyUnHsHSOLwfkCQmIgOsBgrxhNCXLxRp9vKkGgX16YQhOQrD/6eqBIJ9MuVCaNGMc2G6kyhel/bh193wUERCa39wmjbtRQ7z4Bmu9ZWyxUxdkRvKVnmpZ9XvzazkmYm2tmlzoAW1UHMsQlpGj43nsvWQhKkaYDYmMTkwWV2nu2Rrdy9c5etrX2ce2iTLi546YXXUJRDB7cRem5cv8WpU8dcpNIZS3U80TY5GM6+X/vKYr5gsWEU+N3d5XfkQf3tj8aRsnMbIg4yKtIaL9v9EIRulghioFKQymwhyNzu7SCNXK9szkFTNCZUBYl+rXbJAYyByIVSXCzXMdG5MJtHqpiAYZwLOo9+4WWiACkMok9BwPREbZJi17jRbGb7k7UUKGgVYtBRuFAEjSCGZhNCYraRCBvVl6skX17n6xeBcIDhWg8iwxHc2IxUV6iJagy+mip/81d+hl/7e/+Er/+Lb/DsR8/aMReI3eiMI1j/aOrM6QSBbmYiuXYhCUGM5RSSsNgXmGEOHe2YaxV+/3Mv8dwnHmW2aQCqkQN18iyqw3W5lq1axzrW8ccrpkWfd3lX3uH19xOqYFxab/lzdmkH+/aB+LPFnybfNWz3273aVjibb0R++Mce5lf/o3/Ir/+Dv8b+AwuaDXfToNrLlnvnLbkf6LFzVzwrE/63//V3+flf+AmsA3542K1jEh8QQMEo6E14jlbt8IlUqQMxlhgDSWZozvS50OeeUqtrJ+ShgrqUBCp0pdL1Szq1hL+UyqJa1ajTznqa+8KsZqpWUjA2QKQaUOGq9l2rWjvAkQel/kC/6pnFhoIpkrqhrzzqmKxGL9NLFNMlkGBKpj4hCw7ldTFZ0o5VXKMnXs25orpafq4OHMRAzoUqPql2G6+ATdyVwM2btyjZ9kWB7e1tZkGYz9wCUQpFCgFlJiY2J06HL5otQY6RTpQUrQVDW9KqXkmt3vZRqyW4vY4sklKdKm7aCFKVrsxYhUztd0k7uxyKiZ2yMlp7LtBnoCDzZBQxGSv3tc9Gt6+mRJ4QYq50YoltT6WoidtogVwVpbUPWLtD0DpYOTaWAKrklQtfSh2q44VRpExFvL+66VREah7bE5r+wxSgaNGS+jZ4lWoT9RDePjhNxRWbI8P0tT3soqoDeyE6TNu0JNAm0AgxRXPDmDhITIUbQ5igudUeRiYiaoyN4CyggJiQYbQk24qS0VThncEeMW2BGBJaKpeuXOPSpYs88ugjbGxuolURMfDp4oWLvPH662xvb3P0yDEOHDxIlab14cBLezpX9V5A17/Qyt2793j11dc4eeo0R7YPc+P6db72ta/5cbL++o2NOU89/WH2Hzo4gl4DQ8PHHW2CoGEAaEQa8IOLsRZE7b4rakI/RY1ZhAirZc8ffPFLfP3LL2G0+0SfCykZMymIaQAcO7bN0ZOH7OE4XNvZAKuY3HVFTJAy2/Z23ZzFfGH6Dqv+OwP9fydCGihlkwGJ0w23KkK7Aww8BGtOMFCqc9A0gLW+tWeE31rBukMs1KsUUp0VEYHWsmQis23gCoDWQIyTQylN0LBtUfaFG1fKVqjeKuvTtYYmxerbHRk0IcB+btsGA6PIeWW+nOhraXBSsM/pyLYINHHUxkyzSeP+rY5PfPI0//S3fo+PPHsWot2zhk/6dqttgEhrVGuMnrar1UFT24r2mYi34mCsMJGen/6pz7jjAyB53L/hjK0nW+tYxzrW8Z0NASvf0FpihcCjTx7n3/rwn7YRfM8Y/30UokhQPvMT5/j0j/51ujQVITaNKxdZG55p73HB/rcxyu3Vv/LZnyYmGea363h7fCAAhYHOjAvKtWoqGDW8jBXAks1SrVXYxan5LWkrpdDFwCwqUTNRlNgFou+q9JVQC9fv3mI+3zIaNkoXk9HLq004uySkkEz9HtyCsef2jevOBAhsbx8GlNu3brGxWLB///4hASkODlg13lsTEFLX+uvdQ1WtKtf60pt4GFh1NIZEFFtGU5ONzhyYdcmwswASAzVAUUt1RZ2SLcKVy1f5rd/6bRaLBUECu/d2+eQPfIpzj5wz9kc0a8paCouNhVX08Tm7swoaPT+XStZi5wUMCQQMKykkrH2A3NojxCwjxSbREtya0gURJVqFMZdClxKLxSa7uafXbJ+veFXYE2TUE/ZgrwdcF6FSvGdfNVLVVOVjSCyXu+jMdSBUiWJChBSj/oOQZOyVbqNFcxUQcbE+CX5c97IISrEe5Sba2IQRbRnWjuMFQHOY8F5jwNgmKKqjw0J7s7mHWLIyVtFb8o8n1fjimtCbqjuWtHW2z/t+NTeFdk1WB+yigwlWaa0m+uigTFtXVbOpiTXwAAAgAElEQVRKbMwUnNUwtu1YNV38GjTGTuXWndt85Stf4fXXXufIkSNsbG4AQs6V69eu841vvEm/yrzy8mtcOH+Jj3/yE2zt23S9kZFlEWO060kZ2CH37t3jtVdf48tf/gqByKEDBywRCoEumjvChfMXePONW5w+fYL9Bw8ganoZtbjOgysrG4Mn2j3gY0otharFkT8D8SgOADg4GQZmlTmrHDmyzaHD11jtKLdu32O5KuzcWTGbJY6fOM7xYwcp2e9ptSqwHzQspTQAqFSQoman5IDSfD5H0QFo/eCHHRdpSb34A18aeFUZqIligrBam9PHyCpQbZMEnyT5k101M+iRNAsYUQfU9ia3EhqlyhlF4q0w7X1goEg2wM4GIax9jKGlrIaRrWB3bXG2SXAAFGPXDFUiq+irmBZMHaxPEwMfpYGNkqZbPVRk7IlSMBCi6dYYcPEn/8xz/Kmfft5AujoCmaMjTxOkMbDYljzApH5OlClF1MCQthnG8PkLP/+jjQA1YYHIZFmsCzjrWMc61vEdjzbImiZWyxHatNyKFWFox/t+GpKbuLO6g57Ndx80J3pvQIKXg+87RuNzMMXxSY9rWk0/s44PCKCAQOzGCtUgYuiJmNH3ndYqlhSibvGH9VCLF2CymMVHjJAibMQZm/MFUlbUYkJtl69c4g+//CWWfSaGyGq54qkPP8Uj5x62Sa7YRDQluxEFWK6WvPDii5x/601iTOzuLHnk0Ud44vEnuHDpEjEEnnnmGVSNEt+E/YYLsiXTwdoGKjYRC3HsbxcX6uvc1rG4JWVfMl1KnsS7VaGL7Bm93mxgWu+PWWXa8BEkstxdUUvlY89+jBQTr732Gn/whT/g+PGTbG5tEmPk3r0lq9WK+WIL0MGuU4uBGkksMQwKQaMNXD4/NXVvM3+rxRLKAF4pFGv7wHuOxZTaJQRCTOYOQUTSjCJKIDHbnFHjirJcEasQgyUZ5ubpDgcOwTQmSBKhF6UfquVeHZfEvJuTfQBQ7X05Vgec2pXGGAfBRQNznFKs0O2ZnFuibFaXbicpXrH2c9YwgBBGLYXBQaEOl/0wIW9AgV3nLroYmvgmQ79WAzBqdY2HFL2lRgbti8ZeCK19QFpCYhezCS2O4p1NOFTdOSVGo4IbI8aTnhi9DcL2r1IHVsXQusCEnl3tmKAyCEgGCezs7rLq7Ry0Fpo33zqPKjz51NMsl7t8/vOf59LlS5xdnB10HgwoYXDjaCyC5c4O589f4OLFSyx3d9nZ2SGIcOjgQZ5/7jlSirjEK/0bK2bdbM8zZ2p/GmIaXGYMtGxWobY/gyWtcetd78Q1PmKkVnMAkdjxzEeeYd7t483XLyLnL7O6fI3YmcDjgX0HOHP2IebzDZozQSk9WtVsZ5vArNpDEx8HYzDBz9l8QepmbBw69D3Sw+dVeKJjjH4vgVdPGpBQhuRVQpv+tDFtBNWGB7gAFGchWIWfCSAX/KGgLSsWd/fRyaIG7lHTP/GEWqarSbQXzM3UUQWVweYR30aVQHCmgTFr2oJG4NVYAjoAt43lYLiAA4c0pkL7TtsYX7I9POylNpnCcBJV4xcMRRr8udmeHj4O24Go9iXEPx/bEwaR4uCnv9bw1kEfoS17Oo3YC82sYx3rWMc6vjMxtsLuTYTVK1g2Vnu73/fEXOG9hT2hPMfxZ5NqZWIOP/nke437wQifmww5QvuUAr0/9z4YKfQHJT4QR2OYAooQPfFqCbmI0PerIVk2wbKKJKvKKCBNqFCVJJHUJfoQCRoJNVBKJQLVaakqldOnTrC1tcX16zf5wh/8IdduXOXcIw+DV5prNc2CEC2pu3vvHhcuX+KRDz3Oke0jvPziS7zxxjd47LHHWS57NjYW5OJJaLBpcKkKtRjtv1W3fGKsuaBiVfOq6gKIrmRfvMIUO0suU6SvliDmPiPqApCxY9nv0qVkopUxWX95LS7uZpPe3XsrNmebnDpxmsVigyCJGzdug9o25pKJsWM2D0Z5V6UiLFc9y91dqErpe2KILDY30KrkuqRWpe9X7C6XLBZzDh06TK6Zu3fvcOfWbaJE5vM5h7aPmKp/MO0EJBCTiR0mCeYyECJBrNqtEpilGaUq2jQrS3XbzADV9SJCGKwhq/ryTXHQWR5e92vif1FAE6j16psAodGZS9O9iGEAFGziXp0W7aKMnngIMhYuEdfR6PeAYbXmQRPAinjOghAdnCmGPMEBDfuwDmDJYDXprSSjFCKolrEdSEftB7Cfm+uEfV4HAMRAhRGoMLbF6H3chAlbhTU4CFaahevgcpJAXJBSxNkEExMlB5Qqwv79B/jwk09y/uIF7t7bsfOlsLtacf3GdR46c4aDhw5RSubY8RNcuHCRU6dPk1KHhEAZwBhvw6mF1XLFm2+9xY0bNzl37hyqynK5BEy/pJtZb/i9e7us+iUPPfQQ+/fvd2FIdVaB22dWjFnhVVzTijC2ydA64kBYrdUAkxhcW6MBQqZoXHLm0uXzfPXrX+bK5euULJw5e4z5fM7tmzd58/yrXL/9FrOtyqEjz0IIpG6O+3+Q+x6kEiU5Td+FX5ONh5tbmwNY9L0QMk2Ihwu+JfBt9A8MBth7JgHTSYKOzIS9a5j8xZeDsxsEhrsGfCAagQvAfWXHFyYV+YE5oeObtj/tWsGr/ZaUT6d1LfHe2z4xndfZ/rTfW8JvkLD69xVrWRhZFGNm3zZVh/ebJoWMaxiOlw4PzGifblUWwY5rSOM6pqKKgi9fh9fNNnI4gv4dpzJp6z+5f3K3jnWsYx3r+PZHe3AZiiwDkG2MuL1j8PfDeNxaD8b9NvZhYzA2JF33fOebxxRkH9bEdK4yMobfawvFH5/4YAAKE+RMYiTd1yseQiQF69Vu/c6tYguGTKmLBYoINRdkNgPMVm+Zd4nRLN4kCAePbnPoyEF27+5w4fxFjh3Z5sypk6hmZt3MEw3xyq9R95erXfZtbHL21Bk2NzeZPdVx69YtQFnu3uPWzRscO3qE2WxG6iKzWcesm7PKK+7cvE0pldVqxfETx5nPO0C4ffsOt2/fou97Zl3H9va2gQBVuXn9Bju7u9y7d49jx6ynvOkoXL50yUCWWtm3fz9Hjx4m50rqktHuJ/3mWk0voKLc291BRbh2/ZoJRqZADEIumVdffZmtrS2ObB/CVPErV69e5e7du+R+xYW3zpP7zEc/9lGOHjvG3Tv3uH7jBrlkLlw4T62FH/7hH6abd+zu3GNn5y5llXn55Vd46Nw5Pvrx58jujBG8eFY1G7MhQMScCgrWGtGFSAmJZSzUGiga3WWhDATpoEps1VwZAaiqdcg9snu/l1rNGcPzCYGhqi4OWMQgQ/Iz0IUN+rR8oyoEr9+VOrxnSaeBF6P7AQOjJsamUzFaMwZ8O7wSjQpaivfrTwCTaMKTrd0giolFFkbRQBNv9IRfx20ft8MYLI0lEWO0dobaQAXfb+u3wZpHqrlxODg12FHCAFo05oX4Mjz3ba3lXuW3QT7EyGKxwebGFqvVylpcooFsy+XK2y6EGDv27d/PhQsXWO4ujZljJ2LY3yqWel++eoUv/Ys/5OjRY2zu2yJ2HTdv36Ivmdhai6py5doVKpVzj5xjNp+TS6Z4oiMuZrQ34Y3GzAhiYpttn9VargiQQvJrTb2nH2u58THsxq2rXLz8BovFPp567DGeevJpDm8f4srly3zxC1/gzTff4Nat66xWS+azmY03pXethjhpjRHrDGBiv9nNQIyZ9b0xN3Ckf4iWbE7eVyZgwnSnGktHh+/qsMymOzB9+DNW2Id1TZan97/W9AHkvqR9+oU8br8MC6FZvU5hkb0gyTTZnmIWDp4MApy+f2LaHNqsxdQ+Ny7FAE6HG0wI0rgIvrzpQdBx9e34ifeUDhHftpl7j+G4z8M2Dka00+VMhTXFlzeFPtexjnWsYx3fkVAY2tXa2D+ZzzQdLJpX9/dNtAmpTJ5tet/77e/70E/QyPj8Cg6U91aMpBUIZ+xp8VsH8D4ABRGJwO8Bb6rqz4rIo8BvAkeA3wf+sqquRGQO/LfAJ4GrwM+r6qvfZOnMZguvjJoavFHRbWKVGlMh9yZiFxLBk4tRdb0bWgZacpNRNFgy04VKKZBIiHTsLu/xxmsXuHz+Gk8/8xTHjxxn0S0A75luNn/VWArLnSW793aMgSCwb2uTrc1NqJV+d5dLFy9y+egRYkpcu3aFZ599GjYKb37jPLUqu7tLrl69ymuvvMTzzz+PauXVl16i6zoWiwW///kvcvToUZ5/7mNcvXqNt958k2PHjzGbJd568xvMuhnz+YIXvvo1VCsnT57k3r17fPELX+Djzz/H4cOHxyqStx6XXBBVdnbv8dbF83zhDz7PYmODGzdu8ORTT7JYLEwwryq3bt4hhhm1BrOVTIFjx09ycLni3r27vPjSK2hRFlv7Cd2cA4e2mW/u4/z58+zs9mwfPkxMMwKJWqDfyXSxI9Jx9fJ1VruZ2WJOplCyklJAY6SK/S+xs+Q0ut0ZFdLMGSsrWv0O3ImjVWhDoDlzRLXvZS30WiharAkdSwibdWcAslsgtjTCLCmF+ynkVpUD/Jpqcorq2gvFq/KhJYAwgAoGiJU9gouWhJo4pSFcDipMEv5SCqkzNxGqkvPKmS+2nNZW0doRanUlWhFnjfSDuGKZMA3AwA2j7Psx9m0KAXMX0QkgoqNoI2r3gTjYUWsdWBciQtY82IO2Q1i1EkOiVmWVeypK13UIgRSnlX0H8GolJdMFuXvn7tA20aw9G6jQ2AoahBu3b7HMPTdu3+by5SuUnLl+8yYn5scQP5ZvvPEN5vM5h7cP+zU0tnuAASvmaJFME0EgZwMQWptB0IjWYiKgnviWaoyPMEm3QrTfDm7v58NPP8rDD53jkUceZWvfJl0XOLh9ipNnDvL666+zubkB0YQ5KwrS2XJqQTCmkgSzL8y9qfKTvE0qCNJ9r7AUpgyCaTJ+/0N+T12dPUnqnhgnTnrfd61o3iBHS6Jlz7Knx0zu+78xFaa9kWnvR4ZlKNbGYYm3rVf2bPqYfMu4zW27GNkMQ0uGL9dgVQcdJp2v47++MU3IYDgkAVXbJh2awh6AFkwnYntChzNk9o8V3QO2TSdrbd/9fZkszxbw9nWvYx3rWMc6vn0xDMkOvMsDnqtqbkVDZeb7Je4HzscXJ7+/vUTwbgscSwphz+v2bA5eqLR5yfTxuw6L98NQ+OvAV4AD/vvfBf4zVf1NEfk14K8Cf9//v66qj4vIL/jnfv7dFqwKQRKE6slKE2E0qmeQRCl1EK6rtQlu4TRjsxMLXmHW6paLQUjJhNk6Eev/r5EihUKl73tu3brF+fMXOHfuUZBovcxq/dSIUFhRtXL73l2yYtaUKsQ0o9ZKn1fEbs4zH/kIH37yKVarnhdfepE33jzPuYcf5qtf/zofeuwJTp9+iNJXXnn1VZa7PTdvXufS5as8++yzHDx4kJdefJmLFy5RPqJcu3adl19+hVOnzzCbz9jePspiY5Pl7opXXnmNU6dOEkKi6+Ysd3t2d3rSsZn184P52hcTz4tRyKVy4vhJHnnkMTa3NhCEI0ePDkmySHRKu1nXZVFEIjEJSQNvfP0FNjf388QTT7C17wDiJdO7d+5x6eJljh87wRNPPM5ivsH1Gzd47bU32bl9l32bW1y9eoONVQ9E+qxoDF5dTSRPeisCIVqlOFgSX1QgWItAqhEkWcm/9kPCBdWB2UYJNps2iZFAtdqd2jR5lTMiQhIDhHKtnjAGRKGL0Wn8PsnXcSCaggwtARbvX9aiEzZDALcZbRoIIgyih4NOgifh2twFsIGpJc6p8+TVE5zgdHsTDyzMFvPBoWFoiwiNIdCsQY1dMEmz2t4MOgTA0N4jIoQoo76Dj8u1FlKKiFuQDktx+0jbZt+OoEO6pE4jqqqeMFsbQoiRnXv3qLkQOtcEmM1Z7S7dIhK6rrPzAt5qggl31ib0CSFGjhw5wnMf//iwjMXGJq+//lqDnYYa9e7uLpubW4gEEw51cGJsG/Bz5SJ5KuMSBvCkgZ3RqsMlF0KKw0MtxujijXasHz53ltOnT9ClxHwxR6WnqDKbzdjaP+eZjzxpY1i0bTLF4gSlurhnNlBIZAJQ2fURkrl4zOdzvnceadMH/zTRbu+1JNuuIH1gRWFv5WUvnXHy854Wg/vvgLaMNvEYt2X8t1XkJ1WKNtloufgwydDJdkyAE0MY7pvDtS/fz8SYbJ1/wcDJwOAtI5MPqG/L0BIxWadEn+i0z02Xvwft8MnndL1ud6njfuzBHHTUarB2ienOjUCJbX9jz3yvXJ/rWMc61vG9FTK06/l4PULCk5H3+3gMlr1PuPF5bq/aM9s1gt7LYdB3+sV1lOT+5/06pvGeAAUROQv8OeA/Af5dsQzrTwK/6B/5h8DfwQCFf81/BvgfgP9CRET3eNy9PSyXinTJnBVqKcQUXIjNJnImQmjJS4pgVmQ2obLqrIEKeHIVUJ9z2eQ0BKWq2SPOt+Y8/sSjhBj43Od+hxMnT/LEk08SYrI+aBe+ExEkRVarFV3qXLVeybm3aq2CxMD2kaN0iwV9KaTZjD4Xcq689srrXL9ykyeffIq33nqL06dP083n7KxWvPzKy4QY2b9/P7lWnn72GTa3tjhx6hRf+OIX+X9/93c5cOAgIvCZT/8guc9cunKZO3fvcPvOHTY3NnjkkUc4cvQYEIkpULAec43VKuGu0XD0+HHOPvQQs66j1MxsZtTvakbnSAh0s47UxaHdJK96Xn/9NXZ3d3j2mWc4euwYqesIIXDz5k1efvllDhw4wCPnHmaxmKFqbRI3bt7kE89/gs2NTe7u7nL95o09lcQQIxRFs2uqBnOxMGHJ6r28At7TH9zJQ0umFhNbs32r5GxidjGYNWRztkjRlPprMVvBrrP+4KhKEjFld1VzNjBUhUHfwivW4mKC06RjcHEIOGgVwIUSRRhABGRsSQBcJNP2H3UKmgshSgieE3i7RsEFDe16DcHaHoyZEZxF0Hr/jQWRXKcjdJGcjWnQdR1oJdfeLExDHPr/m6ih+LEy29XmVOCOD4P4ZKXkUUmy1kpFCcEq+k0ssrXtVZojhz3cJAZrEaiBmDp6B0tEhI3Fgo3FnIsXz/PQmTPM5wtWyyWz2YxmsSlESinkkgnRQIhSK6FLPP7E43aNiNmTXrx0kVnXDf3tOZteRs49QiW5SGYAktj1oGQQJZee4Or60sQoGzyh1VpWGsAhMgiXlloHJxofL5ktEotFRy0Zpbe2lGrCpJVi9Wd1FxhVcinm5EDLE2W4DwWsTapmMsVYHpINYHlfCPwHJabJdAu97xM+SWpVCOB+jYX7ZKjYCxY86GE/qeAMc4Lp5GAEMWRY3gOWwdTRQBlFDttypv9P9+m9TECm7IhxEjRMEfeAE3WyHeM+P3gtDQAYxS7Hv2HvzwPT4t20EO6v4AiDhgLRgY933Jh1rGMd61jHtxz+TGtJM2EEmuG+59z322D8LnOIP/KuTp6Ng/bE/cWNB7Er1wHvnaHwnwP/AbDffz8C3FDV7L9/AzjjP58B3gBQ1SwiN/3zV6YLFJHPAp8FOHnyOJasMfSjB4kTpVJPfgYxOFyArymvCyGYQntRJaWZJQ0+YUctiRbpB3q8ouw7cIAPPfY4L3z9JXZ3dz35ruY8EIxWvFqVoQi1MZ/ReV/75SvXWC1XHD12jNu3btGvVkN/fAyRrc1NA0VEOPfQQxzZ3mbf/i1Onj7BYnMGQZkvZpw5fYqtzU3OnD3N0aNHibPIvgP7+LGf/AmCCP1yxef+2ee4du0a+w/sp+sijz32CI88co6tzS3m8wWz2Xw4RgFBVN2dIaJaCFGIXSDNzCKyk86OQzDAZrlcUvrMvTtWOTa3g8wLX/saL77wAo8++hibGxt2zLVy585dXnjhBS6cP89HP/IsOzt3qdojEfrVigvnL/D6kdc4dGibazeuQzCBSHPj8MS8KuqVsFoqNVirQimFGgJRTLRRw1iZRcXsP0OlZk/yUnAtAKOet7aAIJEqFaL3pKs7V6glaV3CE1ascu1aHbmMIFITZhSaECHOTjCnCpt7N8qvHesYI7mv1JoRdUBEGCze7eIPrYw/CPoTzPKztEqjmkOHXf/4AGlV3uKWm6NgY7Leaz8OaWBPWBIR1KrnpVYHNqpV3aVSvSJeao9WSDENiayKWfFpcPcOR8NV8HVVJLSEWwnRQT8MsKEISqFKRTNQTFR1lTNFlU6EFANnz57hdz73Kv/89/85x48f58qlKxzZPkw3nzWJIXZ2drh24xrHjh03kUatppPQbVhmXpX5fMa8myEEpNo9HmNnrQVUSu5NqFECEgqad4i1N7H8XJ3Nk5nFOaq9AYpBKFpsmYIhnxkDO1G3jTTB1ECzEHVGg5/voIFEoqCUAiEkhOSCoAEJiU46ailo8HtXZNAJMRHPQuwCJa+InTGpVn3/Hofv73bcn4zKfT9OH9oP+NwA7DSB0QfNFibreMDb40tNF0D2/v7AZd7fUiKT702XPNn29zKRkft/fcD+v8OuTKtOMt2Xhr+8w2F+4L7sAVAevEJ5x+Ma7vtd9q7j+23uuo51rGMdH7jwcXcYou971srbfvi+jBFKf0CrwvvZ9WE+Am+bG/h7sgYT3jG+KaAgIj8LXFLV3xeRP/HtWrGq/jrw6wDPPP2ktgTX3rMEUpsSu1bTUQiRqhnTqKve4y0uSmcUZsFU54mJKoKGiKZAKEYHUoWrV64SRFgs5rx18QL7Dh7k8JFjEIIlnGLJVN+vkBQHKvqNm7e5c2+Hrut44YWXzdlg+wi5gqQOYkJipRLoZpuoBnKB1aowm28QZjOQjtgtWGztZ2e54uLlqxw6mOnmM44cP4mGxEuvvMatW7fYt7WPzY0NTp5+iH0HDpFmMw5tH+frL71CN1+wtbnJiRMn2dg64M4LSuxmFM12rNxqMXYbzCVBnEF01wtXRtRauXb9BhcvX+GNN97i7NmHOXPmDLUWrl67QZ8rFy9dRiVw5Ogxjhw9wrKvXLtxk1yUN9+6yM1btzl2/Bhb+w5y9uw5PvT4VS5dvkaf4cChbba3tzFl8Yg7HFJroVDQUukKkAs5gkhk5o4GBesb16IIyZP5CrUQRCEKSKBmT/xblT8bziUhILWOIC1Gu9dizA0V0xgw94LRJaHW4oyYMLG/NPBBW/U4jGwFS/qNOWDtOs4w8DXb8Qawz8QQUQIxeoXaWSJoHJbRALYGsgFOhbcEM4j1bbd2hcl9NWl72Ov6UFXp+2w0OYzdkILQl+xUf4ZlVXeUME0AO5Y4Y2B6rzbdB5Fg9xtu61qVjIlIhloNPBLh+PHjrPolwS1fq8Kxo8d47mPP8+qrr3H16nUOHDzEw488yqxbIBIo2RgS/TLbclTogmlurHJPxICKzcUmD50+S3JdEBO/jBw5cozVammQk3aULNSgrKj0AQILQsmEWEGXprvhDiK15uE8NG0WmoCktwrNYseNa7e4c+eeXQdFBw0Y01wwReKqBuCIRFLqCKFz3QpjR1TNnDlzkm5rhiQHb1wnRrWa8Goy55coYXQF+b6Ib/bU/3ZMiN4JiPhW1/ed2rZ3eFfe9so3+fofYR/f9y59f09Y17GOdazjgxfrcXdvvCOi/i0s5/2898c73gtD4UeAf1VEfgZYYBoKfw84JCLJWQpngTf9828CDwHfEDPqPIiJM75LWGW5CcKlZL2aNWcUIXXJkg+q9XnrmECWYpXF4MnWSEUGiBCsb5uaiWrgwM0bt/nqV7/KqZPHuX37DqdPn+Do0cM0ldRcChJlqMgjwskzp7hy9TovvfIKEoRuMePMuYeRFDl28gTzjYUJBAbh0JFtNvdtceDgIZ7/5Cd44esvIF1itpjTbc7Z1C2OnzjGk089zY2bN1n2PYePbIMIuSonTp+iL4WCstuvePLZpzm4fZgQAh//gU/ywte+yr4D+1ksFqT5nFwzMXRWyaTCoAcQCQFOnz3rrA6zOEizONjvARw6dIhPf/rTlFI4vH0YBBYbCz723MfY2dkhhMDGxgYSI7Hr2D+f8ckf+BTLeztsbW6ymM8JKdB1c1Ka8enPfIblauXtFZZQpa7z82yJrbE+XD1SlVIqhcaeUKtq0yzQojOTjbUSgBjVW2EUiZ3l4zWDVtNRcOaBMVmcZeK+9JbcqSn4N/oA1uYSolkSGjBgjBfTo/C2moEt4UJ82lgRTvc1+wq3h7Ree1TJtZLSbJKAi/eJW3JanG3TZOZUsJYHZxXYKh0IKMYOCCEMzhbB2y6MaWEgQB2AOZAYkKrGomnMCq3Nl8A/b4KHo0OICRTW2nx4rTWmtUw0oKNigAWlmr5FECBRy4oYDagoYmySsw+dIJdC6gSRAhRElIfPPcQRFzUNEtnYWBjLQSshwsbGnNOnTpK6SAwmGFmygUsVISbh4OH9PPHU48w3Zl7Nz9RaOHXqOKvV0lueVtQcKQGURHXtDkFJhhzRS3FND2OIxJgg6+DUgRirJqRo128JvPCVl/jKV76GVtOoyLkiGlxM0506XKDTrE4D1OBAlFJqZj5P/MRP/jhbj52i1t7Ef6qzspKYS0lMxpYg7NHCWMc61rGOdaxjHetYxzq+G/FNAQVV/VvA3wJwhsK/r6p/SUT+e+Bfx5wefgn4n/wr/9h//x1//7e+mX6CAn1eetUukHNBSyFFq1T3/RLpOlfAz5SShwQ5JKsyUyOd911LCKwauKCWXIYIWiCFyLkzZxEJRKmcOnGSQ4cPsbm5Se7z0EoRolm3Ra9Knjx5hoMHDtP3vYnLBWE2nxNT5LnnP0qXOpDKfNHx7EeeIYbEYjHnU5/6JM8++wxdNyN0EQ3mcBDTBj/4Q58hL3tmiwXdrEO84njk6BEOHDrIrOvo+95E5zpLRh8+9xDHjm0TPTGJMVl1mDoIyrUEJaMtm7wAACAASURBVEYhxsDJ06coJQ8JsKp53Yc0A2D//n3s3/841cUso7MYto9sm/VfMaZAdB2CIIGjx46guVBydm2J4AJzlY1ug43NjT0aAnirCmqshIBgWZ31vkexc6Mah/57LUb7jmL9/KX2dCEhKP0yez+7VZJFdOjLj9FBg6GPzGhg0anBEiJJmiViHXvVgyffLghoWby1QlQXA5UYKa72L5MqvcVe3YSmAdCljlKsnWM262je8yai6UCCt9uUWoh+PFXdFcHbHdqydWINaaKMoC4GCc4qUMjOPADM/RQHdqSSSxnanJtrRIwmPNPcFoILPk4dHZDWujE9t+YQEdKMEJUqmarCnESgosG2s4tC2ugQmVG1aS8oNZrGxOEjB6neGtJEEFWbHajSddFaLDQTRDw5F3IpVIXURQ4dPuBgTYFgwOK86wzACEoIleACO0E7Qg1oXRI6Yz4IadBgsZaG8bg3Rwt1C03TzTB9hq2tLWIIFFW2NvcBLvbpApNBghFqxICbxWLBzm7PfLYg50zfL1lszOi66EKYDpKik22BXCqzbkZZlUGzYR3rWMc61rGOdaxjHev4bsX7cXm4P/5D4DdF5D8GPg/8hr/+G8B/JyIvAteAX/imS1IlJaumGx27WuHY6edeFByovzEGpwLjtF/znM+eGFXNkBLVEzGpxZKQYL3dmxtzzp07h2pvYnEakCpEMap0lACZQWtBVUlhxtYmllhHqyyaz30lzBfEFI1CXwqbm5u4mgHz+YyNjcVQfdYg1JqptbK5uUHY2KTP2Zdplequ6zy5U1JKI9Vd7bhsLhaD4nwTjwwhGstDsP7yELytoRKcsh1aoqxm08k0mRYxe7whSQYkEINYJV+Vgpp1IDIKJqZuXIY2aQB1cMCTMVfJd0kM16oQ+jJSuqNaBbfUSBKhC5FeIU/EEoO4+CEO+ERjZUitCG6xV10hXkb7zwaUKJZBl5xJXRiS7ZYYF6fut+MBQlXrmBr0Fpq2QWi6AaZPYAtowmcMx6Ql6ADB9SCMCi9D63MtxiQQEaI7mwzb7OfWEviypyWhCVaK6zcMLRuTNodm82jLhyra5Cj8fOxlN8RBjBBndYx2ms1ZwpZriX4pxa6zUlhppWjPKgm3NhfsINZGkIQ+ZxYSIEQKjWEUBjDFdBnqAJaomvFdY7SoV+pTigQRCtVaU1I7h/hxamBERdLMr3dFOyXGdh0l+ly5HWYkiYhms4AkmPBiyZCCH/Pq2ig2Lln7B976YQcpdsKjjz3E4e0DCOY4gd//vnWDcKQJCzaHCb/GqpJzJjoTI0TnqbjziumgGBulSsD0PIXlrreArGMd61jHOtaxjnWsYx3fpXhfgIKq/jbw2/7zy8CnH/CZXeDn3u+GtOSn/QyFUizRrtV+btVzdW0AtPWVB3ToGa/ULJTaUVRYxcROmLFZQWOgxEofCjoLxDqjYBP07AmTWAP8mJSJqbiv6tISFAkGTAQhxUTOhRo6E9iLwQTcUqCA05qVVbEUqglsl2KV/Nwyu+RMA7fmqyjF1dxrrGQw2j6KpEiYzam50KtC7Gj99g14aBT0XAtVM9IlNM2ouVC1miNACGTNSCee7Ku5BLhQo8TOaqNeCZZWSffzVSWixdoB7NyFoYWg1EzfhP0amOCV9JqtqltD5V5YUcOSIj29ZBKBFI2Kv6KnRrF+drWyuKBowNoPivXfN+FEqiW2VU03L8WmUO6fF9cicEp/7gsxWpJXm6igU/qbu0cDAko160MwZCYEGduofP21FAKeCIfgQEar5jtt3sUQjVkfvPLfmg5cQHRgRxjrwBYwaijAqJvQlm2V/oQI5vDg2xZidDeGETgRTL9iaNvw6zylRCkOvgB9349ilxIgjsl9RZHCwOhQzQiVVDtmvXBzscXNh84hedSIEJSYe6oE2xvxZNvv+1zHBD2l5NoDDRDJA1gV2rHB9StEXRtFiSmNNpp+/aXQAJjiLT9mhdpr5a2N/WxvzOkJ1NKjKZJx0UQ/PjFaO4vq2GYSQgPhACp9X4jzwOFjh5xR4iegQsk9IVrLQwiJlOw6KGpjmIgxsjbiwtq01NhAJjJr16MW1/lwdoO1oATenfe1jnWsYx3rWMc61rGOdXzn41thKHz7QlrC1SrBxZU0m5r99MNGDW8q09ayrmgtwyQ/iNAJRCqva+bOvi26ug+w6mhdWK/9XE1wrVXBSy2WPAUZEq1xE2WkfuPtFmLVxaqtAu1K+55vmiSDuHOFJ3HCoBUx2Orhven+WfV1NavBgUavdVgv6paDvi22Xt9uiZ445qH3HTyhVjX3BEy8Uib7OmyPOKgQZHjVFCwY6NfGUlCCtxOoMxp0+BTe5mAtJAyVeVdlDMq9LlC6LbTco2okl94sHQFNAZVmP+btEgJUdSV99WTT2Amt7z+ENFw/s9mc5WoFxar3SDD2iuAOGNXaK4Kd/+AV91aRD8EsGAniIoitiUIm59DOc5gc5/F42r+lVGeUGIuk6XwQfB2lN6aFXy9aCjLgITpsUwOMWgW/5a12bEwQEW8DYLIeVTXdg8m2dTGSHTAZ6fw4yGDLjROQT2m4juldaK103m5jWgGClsrp23c49NrrRJGBKWOgRyB4Up+d6TAqRjThRwPy2n1kx1aHSn8ThmwH3ZgdI9NivL8mzBgXdEXtqkUCHRWNcGJ1h3Qlk8qugZTZzvAszl2zQ++zj7TXDDBqzI9gwq9qx75Qh/tTAmiqEBXvOSHXYq4S3vISU4fJa/YGuNUCEqnZAUkthGjXiPpmVIQUO7a29k/abdaxjnWsYx3rWMc61rGOf/nxwQAUsKoyNEs8S4pEAqVYe0CNSnQxuSAmyFcxWnuMHYFojIYUiCkwk8LjolysGRYzQjdHsqA5o5LMhq0GKkonDk7UZDZxxdwjYgxW8W2JcYkuZsdQoQ4u3Nd1ndlYBktSu5TGBFEVpVBVzTteXKxNPBGvSgjJ6OMxWWIRWhIl1uvvvf1pUPq3vvXidodDwRy8fSSQnVYvIqQYBz2EIOJuC5V+ZZoQRr23nvs+r1CF2cw0FmJsYobq7IxILrkVzn3/BLBkXcTBChzsyMUSaKk0L70QYNH37LvZs3VvacyKUFHxCjhGNbDtDUiIni/KwE5pooS15AHYEYQYO2NC4NdLYBCCxPvOiwMwfc50825gMFhybYyR1WrlII23JDSIwCkEjVpvIoWj7Vut1UGYYPsMNOHEpp0gIn74TBxSBDTXgXXTWCbW8uDCfaW1/8Sh3caAjTjs417HBya0+5EFpP5KinHQUBjOc6XRKsytwbddUbvOQvB7yKwzRe0+JSZCyBxf3oG37hICZO1tH8MMkUiquDBi7y0YYRCCbE4qIQQHePAKf6ZLye0odXKdq2upyMCiKWrn1Cxi7fWae7rUDcCEFiP1ZK2sfOxIwmATWrOSc6GItcgMgOHk/E8BGPXDFSQaE6Ha2FFRtGaiMyRiimhuOh/RT46Sc28isqaUaW0RAhLt+pAqfjxMu8N0SK11q7V4rGMd61jHOtaxjnWsYx3frfhgAApqyvUpJVOV9wl7kEhRr2ZWSwhN08CSbPEKaYuY3CYvgJYVZ273nJaEeuIeRKD0lvqqLVNLMW2C0FgC1s8cgiUIfb+yOmoFqdEo3J7Qtwl9E2psiZkG118olVlKqFYTyIsmnthsCXEtAJzCLN4fXRrbwqn1lpx7EuP7KhjwoUWHhK8VUYXo7AK1RLNU0z5wmr0lw5bQlJK9H9zF79QSa+vp7ry6a9XqQrWWic72tebqx9+S1NAcFQSUUZ9BS6uSV6iWcIdoTI1IIkmlSE/sOnI19wMphUghiAkVVq0E3LrQ/wRPrNGI4FXyaqCCUQaaoN+Y5BOjo1d2rlJKVDVqegrjtZTzaKXYmB/t2PRqWgNUdRtA+9mo/cGTbEtAldZdUP26Cv66OSi0a24CAwB2rVb2alxYC4oOSSswYbKMTBNt4AnGTIgSCN1oyRoIDmi4c4GDW0HiwFgpDcgRcZHMSZsBjNvVjhemlRBcRLQSSCGQFWtzqOaQYTIGwQApb6lpAIv6/gjGoKhYG5GxZuzKrnVkNwysFRQTVDSVg8YYai4mNL0Dd+DIWSnq7+eMSDKzEd+ZLMZksP13zQK/X0TDwFWw4xBIIZqAZGtxUbOrrFRETQB1Npu5aKm1P1VM1LOWioRo1zZirhhaEXEWULR2kBADUdTYVNG0XfqSB47HOtaxjnWsYx3rWMc61vHdiA8GoIBNxHMuxBjpOnEhtNbjDstV7/3bjWYcXKTPkq7oVdwmbohWNpJP2IuVEkuypIBSSQSK96CrKlJbT3lFqiJaSEFIE8G6pGN1spZKUN/eoFD7IZGpxZMBVVLxFg4tBI1DIoeouUpU6+XXajT9UioRS6ySJE/QlVILKcUBNMirgnhFfao/YYuuQz+/ZqfwEwgxkb2ab5oBMBe8QpxJxvOm71d0CPSFmK3vWzRTxZJC6QuxGkXcrASt0q21UdQ9sZWWgBqYoKUSxbbBsmlIZCRFOxfeGgEmtFlcJ0CpiE4t8lpCVZwFEtCaqe0acpq9Je+RUntLQIP39NNYFa0f3cCsWisl58Hqz4An63dvwESsWEtC0wJo9Hpt7gsjS0C10e/delHGfbBrqFAQYqPt10pQQaW6zoAdutRFqosDRrewUGUAM9T78Yu3UVStBHUGTNMCaQCUVjsObi0aQhiZCIzXd/D2Aq2+7zGgAlGVvu9pIo1NelAq3toDEgOlt3tyJlC0EERBXERQBaonziEOVXl18JBqy6AUUkwGBNZm/ymNZGJAgBqcpdX7TlRJ0Rxhal9s/MiuvRACJDG3kG5OXplGRR+t6p8wgcso0YEtY/JIiATfP4IMdo1tnBGFKOIiqTLqihD8fghmcSmYFaQ3zyhQZTzuDRMUMeaVBr+pFKq2BhoDTmITJZ1AUetYxzrefzRITiY/ffNPv1Ps/e47L/ud1rUHrnwP2zBtx7oflsZbt95lUe/67XfazG+2D/dv4/0hb/vEg4/9ezkf61jH+w2d/Cdvu7ymIL28h2tPJ//Ku4wiD77eWzlJJ3fyg9b6Xu+F93HPfIu319vHtvsX9uDX37bad92OdxpH1mPCBzE+MIBCuzxG+nUylX7tCSENjgsuiE9MCQjEaMkytOpgGNqsWw5qFX5LSmLsyPT2uhYHIsSevGoV0eqJVq0KnlRoNUZCS5AHN4TWhlCV0PrPax566hWrhurgGz+hTYfOqpRilna5Lw6k2PZUtSpuA0qMsW/Zp8RRHI46iuuFECzRb/R3ieRiYoRRdE+iWrRStFlFzqzu75aBfc6UUgldJNdCl6LTvMdKN9ISUxfGQ4FCc8YwxwLbrqq2baUWU2OoLiIZ3OVBAhRFWlXe1xEkDOe3JbqlFNqONOYAQYbzZd0MYm0xgz2hixLI0HVh5zHa8F21orUYy0FHt4FOAuq0dGLEmPl2zTQ6Pl7RV2XQOwgu7qitTcQv8NVqae0wDnw1K8ZarLzdevdbZimqJn6J0epLaVV7s4e0wztqDmg1d4TSZ0LX+V5Wr4yXcf9L8XYEo9/XXAZWSTv+Zrcah5uzATF2nypR4vDos4TYK/PF9TZyRaLbcza2gbprg9i1gIMkqtVbOMoE6DHNDfH7qrU81Gr3QdPREIWSC7kWJEBKHQjEkKjVwLgowZejxpbwVoZait3b0YQazRpUqSTTR5SIENGSMVEE19Pw9gprharDOR/BJRuoqprVqLFL7LVS7T6SIMQg9KviziF2vsXbJES8lUYNGG2MI9VMDYnZYrZ+rK5jHd+GcHgPNCDYfbo3KZ8kwdLcfBpFytlvGoelNbHYcbrdkpiWNnhxQ8OwbNqnpYHqJkise943oN4egGF4jaYr1QBz8XUge7Z/3BJ7f2jfmx4LteewoogmjM2nDcr0XfBtaC2gk/0ZEqPhODVBoOr7O26HeesIkFFTXLZtFdsGexTGB+V961jH+4527bshOc2U2RiO471ZpTFiAWS4n2S4H/1fmVzHqrR7UidInn0Hm9ODFY3afa7GxLRikzuU+femN6WICXijZnk9Qg9MxhqwcUHGZTCOA+31RuocJnn34yv3O0d5bjQuQ0eXsGEdFdFx28cxqo1B/l3190Rpdu7DnBebU+3d9zYe+nd9bLZxZj0ofNDiAwEo+GVF3xuFNziFGK9gWuIQQEzEzK61ONrm4WJ1GoY+aFN+pxX4kCBWnW4gwdBT70KOQ0/6KPCHjnaKVoE1AEE86TQqvk4o295r3kT3wFgLaor1zTmiJbiqQEsK1QqooVV+3bGitVcMDdvtmLV2gkF8Tgc6fRP+gxEIyd7rH2K0ZNJBk1KLUfWb64D3c4cQKGL97UGUqmFyn7uFYgiWkGGtAY3aj+AaGDIcVz+ce1T4ay1oiOBifVGDAwDN0aB918Qep0KZVsWdJN7+GXGaPoKLIRrFPKVW2a+WzOOPlVwHSn8IkdyvzHHD1ffFgYpazYKSWgdRS0XIudB1iQAmroh9XsIIvDRrvwY2VAeBQgq2j6XaeZJo06vWYqBjwkw1y1FLSCfHoVqirrUiQcjOHpgNYMIUCW7CjQb74AyfBmQ0dk+7TnMpdCImYIlvg9twigM9fZ/dRaJZgOLWooW+VK/st6m1Ca1Wv2/abVYcpGssD9VKJiMa3BWh3Y62bgO+RjtLrU20U1yDxYA4cdZArc5samymGFkul+RcfPkG5rU2IymVXLOtr9jEIqWOvjjI5i0Rdn/VYf3t+7nPKJUY4gikFWsFMRvIOLCSQhCzy233VWiuHAEC1Dy6Xahmb7MphDhjsbXFcBDXsY51/JFDGojrzxOzshUsmQ6MD19h6I1qE2yxcQ0aEDB+fEzs6+R77QMGpjfZ472vT7brvi3d+/M4oZ8mDXu//05VUwG1/bPJefaEpn3K5ijS7G5H2GUczyfJQHvW7Nni6bGSvfupfmy1tuOoe75sJMb1+LaOb0/o8L89X6cpeJh+SMST47330tujMU7DCEYMN4E0JHJcQivyDRVPe9kS/HEMkeE+md7PeyA/WssuxPvGFSbJ+oPv+gEcGZAFpkdgWMd4R9vvjXVN+74zhQ143DPTnETYOwYM2z+OleOh8gRDxuO6F1y4fznr+KDFBwNQEBNhjEHQlhDi11Gwi7i2pMHvxJak2u/W7x2iqfJXrx4OmEEIe6qHLUyl3hKnpiGA4loBOrg4IEKIiaitqgwqkUBHEGHVrwbGAjh7wfv2UzQbuVxMB6GtQ1WpWgi1TpJ5ZwsEU3vPxdohBGuxUDV3AkvUx956aVaPnlSZTZ2JL4YYKE5brzgSGwIiVo21ZAUHJKIn2WWo0DcUss0bFKvsjsfRkssGYhT17Ypjr/ngehAiyfe1jZnNspGq1nPuln21NjvKEQSS4LT6apoXIYbR9aFU19lQr1473utWi+2YWf5c9og0huD7TIEQybniRBDXFghD1biqC4cGNQ0Pl5Cszm4prlehqFlcShhAIUWtaq7VWlvEH0Mq1qLimpXR2y2qr6fP2e0fR2bDarUyoU0BdRHCGCLz+Zzlcmnghd8rQaJP2gIpCgVjJ0y1GKY2mX5BDICdXasTIA53rtDmXOFAgV+E1VsXJFhbSHMwaRoM6seqgUJ2Lvwc+4VhixrXF5rjSEOr7SYaroeY4tttNX16XGsdHCJaC03Jtpxam8DiKGBqGh/OfOgLJdfBSlSRgQkRHHwJvs25GPumqH221ErOPfP5zCw81axEYzSthNzYESJEaRP/6sCLjxnawLF2P0cTx5QHTCTWsY51vO+QyZyg5QRIY9y1yfPwafaABm3evgfYk5YNe6te9mHWNIo8g0C1pcvF3mvrm1T6xnXr3uXfPzn3Vip14EK8WIIDx8NmDTlGSzrGxKpZ4woR0yUSNDSgZVzGdFv2pC17khgwxsZ0O6d74K2R2th7JmCsYExP2vYJIg3UWY936/jWQsHvu2mi7O/o24G3lue2a1GH67+NCzL54JiU+2wR3MOpAXuircLuQOQwHjiIIXVM2v19nwFNltzu67ffw7jO2AN3vI07uEC675y28WwYIBrSUVGC7+V4/wt1wmJoGUJ853Fw+JRtswzH0+b/gQbetqh+PNoKzWHNYipE/U4gxjq+W/GBABQAVv2SmNJAG7fKnVWsSy32OAnBHzRO96/jNayeDBhF27zrbfDQITGp7ogQcLp1ANQs2No9bNewuyZ4FV2wfvDoN3jF1pU8mSqlUZwZAID8/7P35mGXVdWd/2ftfc5935oHiiqggGJS5kFFLRHBxDhE2wnBtBrSUeOEaWNM7MQ2SSf6M+l0hs6gdqIm2jEdIyImGpQgCkbRGAEDMoMyF1DUQM3vvWfvvfqPtfY5t0j693sS8vy6/rj7eQqq3vcOZ9xnr+/6Dl1npoauzZdcCJgRXC6m3Y7i9Hp38o+hRYt1R4ME2lAz7WuX22/LqX1StZQAVSu8Uy60scbr2c0WQpgCLK0wtWKXnmpeSqFpBzSwSgusGRtwooCb3qlJDFLuQRkbdbsA93AQNa8AvPTup1wJdr5Tsm6tF/iiGEvCf5ZSNiM8Nbq3AReV+p4HxokECAoeBdmDGFPHqae6F6e2C9bpxlMfEMygzya4KuUIoemP0VSeI2asaP4PKpGmCah2/bUw0Px9cSkNSqRkyKrul2FgmtZIzVLsdaouzRArUP0clpzJauaYyUHqxtk7pSTv8NcCHfeFGMCBXJRUARVPN8HlCk2IfcedKdCqRiLWQt/AL7FrORVKMICnODVOXJ4UgpKsRT/1OfTXQn1YBo9dFHVpj39H4xKjaTAwNBbtqX1aSLBtC0JoGoiB0nXGeqjXk6dT9IaSKNJE92bQAYDQwcQzOJBV542u6yBGJIr7WDhrw8+jRGXUBEqyeNiCMQlyScQSe2CkduRy9sJBvL8hODhZyCnTtCOC4pIfBx1CIKktPIKYz8jsgTobs/FEhxfliJmz9j8XhGa/Gnq/rl7f4Jgu8P0T/Xk79ECMcTd0LYcCuWdH0FOVHgdg1LljaKJMlTL+hVUqMPV+rZTj+tTNU38fJBLDaPvN80wce6X4o9VfG1AvSKTflv5IKCAT+2xtDFiXqf0k27EQ7+qqHfPioDo6/fq67xX4ns11s/HERr1igf62Er8Xao2sZIpkM6/+Pz5ja7vicb+Tese6RIGIiIOH+4EOdYJI/Xf4isY/XlEpAxjYv6f+remLf/X7Qx5/j/St/+zr1qmf1/3dD7ys++XsAX9/ZSAHrWyqwcttf4nC4wDFqWPlxlgM81EFS+ucVee4eq+Hx32cSSXEY+RtdT1IbmfjwBgHBKCgWAERdOhgFjdtqw9RK0alLz6sNqhReoHoD6Hapczq0Wyuw7caa2qp4J3nWlzWuEAwtG3Qcbu0QgI5JX9NcFwtQojEdkSXxrYvvogIEl3zXsx8MVhUpKEcdgNacgH2mepd2BgtvlKqCZ3ad4Th7srJu/BFfEIYUEnBfSik6uDVNet4xGQAzb3Gv3hh1jS2cCp94SO07cj0X97ZjaFOHm6MV7s46jsepKf390W8dxtqfGYqg06/lNIbXtaCt6YrIBhjQ4KZXPbeBgbemIemgSa1uKyslJxzD4ZEraCK7Hd8UrbOsmCyDvU0hJwzuVRNvPQJFXW7grMfihY0Z0KwIrp23EMT6VKi9rdSSkiI/YQ7yQlHF+hyJpVCGyNN9Xio21PxIJG+aM7qVn4i/WUEZhwpyYv6XHoAJKdaKENKlgYRorEGUikQtL9GIsFMIWuyA+7d4CBO9Q4R90kwPocSmobUTaAoo7mW8WTSA1jFu071nq73Xb9PPZPIJRFi8YgWkzj8rqj2Ep3Hm0basTemQEqpBwfq9VS/s0+umPp5ngISBiNN85Mo6mi9X97FJil7fAVb3EufDIN7nBRPb3BmU4Aoje8/xmhxkESzm136AzF1xaQP9QFfjKkSvEMQQwSyg3N2LTWx6ilnYzZm418zhnWwMwdFTD+tQijY/OWpONZwqP4C9Y0y/Un9+reIdeCjCqjJNIuIFQk+gtY1c+gX5i4OpHoYIIHQdwMr4GDlSuwZDvsXKUPfrlKxKxMuDov03u9hABam/Y7c7ZiihUcefox1a1YRG5PKVdChblWWziRz2vgTrOm/015XGyGxP94GPoh/B2zatJXD1h1EiIUsEKuwQgNou/8XzsZs/KuH0t+rgq/TxO8/Z/dQU5cGYM08DPyuVxlaY5VlKoVCIfT3VbB5w/8ltZCWeofaGn1g8Wi/nqtAmuznr1Jv3Glpkzhg52DodHld72EKQ5FuIIH4pvRSZfU99ZtTKz3XpV7irMlplsQ0OdJAUx2Oj5RhXqrbYAtCkGCNJym9oTqlHsO66AUkO2nVwQ+kr61EAyrBgM6pIzQb//fHgQEoqDptf7rocP8BtC80U86M3ARw2k3V3hMY6PyKiKUYqETrsv8zwFnVZMNA+ze6czQAwU31VMWtBo2YWDX3UaKBGbH1QtyKTNNZhyFNweMlrf5x+UEpaCq9qWHdnscfk77gnQJAekDFX17lECBD8ZQSTWMJDUHVYivFjm3O2aj1MfYdlzJV6IuDNjlnSi5ezBTIJgfJORGioDlTUnaJB2bIV6o/gm1cSsliNftj4HKVrgPvuj7eD6IuubIzGwINJau785sXQmUaRKeAV5ZILvZH6zFUoYmhZ0HkrD2zpZ5b66hD534CfYEpgZKTAy/1+AzMDUvSmCpYy3D9Vq1+jek0+wVjkAAeCVqvc48qxRgsRb0oVWMkVKmH+R/Y5FuZL6UU73BXRkV/RxCbxq8N9WLcj2l0pkkubm5aF9bDNomdUAPWKqBfWQ39NUp/vyjZU1oaJIiZffrDoZ6navZoDIMKDtl3VWPTUqZNLO04mEeESZP66FQ1hklOlo5iBoeh/76mafZjNhRnXUzLnxo31KQZ6apx8AAAIABJREFUAIc69yQHrXK9plR749Vqymj3qB0y8+oIwzwmRhO05Af3zshKiPaekm3B0AQ7/iE46KIGjg7yy+rxIobwZ+uMmHSi/aeT2mzMxmz8i0b2JWl0ECAUS63RDEkDWUCC0ohbHlXw0c0Y1UF2SjVh9d+J/65gKUb+/PU62j8DwL+vuEyuLvYN4egBAvse+1lRIUzVGkPX1SGPTG/eC272WkF4asEwFCP9l0gyOZV//523PszfXvFN3vbWV9g6BygJKPb9bTPVaMCOTSbYaxLkAPOtzfEGaigL5vHIKECM9qz96levZcPhh/Gcc05FvOLpn2W9LGI2ZuOJj+LP19q0gNqPG8A3Aw+Hu1R7g0HzuZquqG0tac/n4V6lb64NAtzBMFH9nrP1ZwYpqNaiXenlDPUm6OVLZuS4n6eCR1lLD484F1j9c3oAQvttG/5T96O2bJWB2WRmitPQIFpQqWsQnZqDKiOjMnKHBpROS8QeX7l56ldvYqkVyHE/lxKoVi3B57/qPKPTmz8bB8Q4IAAFEaMrDwaDpe9Ip5QG88VaDGdDzOokUHT4d04WXRckDh1FHR6ktQCsGucqg+g73X1xy9SfofApWNJEkELybmEFOCQYI0FxczigccZESrkvDCpuEGtCQMluxjhotcE7qD51aMpoqB4OoT9GJQ909uotIGLf23Udk8nEu+eOaHrXtS+eMNp41yXbpt5MsK9o+g6rxXY6nd8jFoOYpjy61EQk7sc+yF7QTlJnhXBsXEue7bjXboeYuV7qOsNUnblgE25hNBrtt49VU187+bVgHo8TKaWBqeLXkxJ78AJsMVSTFUIYzF8qENJLSQTyOPUFZAjB9sGlAYoyGrWEIHTdmKI1tWDw+ShaKAVSrp2tAbSo/hMU2+fYRO9w116Vna+aViFT4EHdTvMyCP0DyIry2HfVarqB3wrgoE/rEiOg75bXa31AiiuAJv3PtJ4vvz+MtTGka+DyG1NUDAah+Gtj29q9VLIBPB7/aaaU6kaf9WFoQI0ZadqxiDEMUiLpepZAznZPTLMQ6n7HaB4LVQ5Tr9EeRGNgNxm1JaBR0ChkKS55dMPU5D4Xwa7Z+jAsORt7oT8/ZqDZP3hFKdrRBKMC56Imd/KDE0MYDENVjR0jCmoylxBqCQMWnSuzB+pszMYTGVpLiMqGtDl266N7+OAHr+C+TTuQENi8ZTsXXfR8XvD8kxhyDOxeN7Kk8I2v3czCvsTzfvQ08OU5pYAGfvXXPsmvvPdC2sapu+IGhzKUMQt7Er/1+5/hvb/yGqIKKpZ+03ssOcPxgXsf5W/+5jre9pYXIS21+hl2qcBv//bFvO2il7Js2fxQFikGIKhY8eLysx4e0Wq2a8+RfXszn/iTq/nFXzqPdq6lm2Q+c8m3ufKq21BdzGTvTj75iTcRRrGvWZIqu3ZP+OSfXs0NNzxCnFfecdGPcMqJ6wG4/daH+N0PXUFKwqknr+GNb3gey5fN8erzf4Q//OAXOWz9Op583FqXV9oYoIXZZDcbT3Do0Ge3kalJKkVNRi3Fi1cBieqXnd+L1X3cn/la/D2h9mKK3dR+rYrUDv8ARMJw1+XiMl5w0G+QEtE3vKg6axw9pN7wtT4JfdoKfY1jt7ECrX+nv0/EQFRPNat3WIUcKkOiAqXin2mLPQMTUlIu/9u/5+BVS9n4rFOs5qnvrvKl/QALt3XNJm8iRCS4aNOnU80yWE0Gk1J/+uK/Y37xCl7y4tOJwT8kVM+Y/c/kbPzfHwcMoCBeVLVtS1Er4FJSKt28aZqpQsoe6bV4AY8SJHixWnrwwSIRzfCoyiUqUGGdbPEkBAME6udaV7XpO5dmcmc6oFqkhFKgHfXFrS1OBhM7dYRwKAJNHw9W9HXdBNAeNEHcfBHrHFfKO17k1YJaJDDxY1IXHEOagiUPNEH645pKsnSMYmkC/WTWR3S25kDv5pQVBDFTycYBDNsWk28YW8JPnklBooMcWYdz6gUzSF/0E6wbE/xzi5oSaigQ3a8iDqwOb+r3xW8pShMaYjAGRNK0X5rENH1dFYoUjwC0YrNpGlJKNv3VwtO/u21b63z3XfQyeDwwfL+ZQRYzEi0DbS5I48WsXYfmd0B/XfYPCAcVDCDLDuiqy2LEjpMIWqo0xfYtKsTWkgnUt6Oo0qnjyzosvkKISIhu8lksztHZAhXYidG8QUruUP9MBSQO9FplimVTWRgOgFewqQJUVRZSF6YStH9PE4KnLtTzFIgNaAjklAlRGI1GpJRJ2XwQRqMGQnDmUb0OlOwASzsa9fdrHcmPbfVEqABPzpkoQ7zj9H0XxCQEqUsgQtM27lthcose5A8C0e71MAWyFHzhESDl5HMHHuPZ+Bxg8owQcD8Wix/VftGhfdqH1AemgnrHIJeMEm3f24a5RfNTj+vZmI3Z+JcOweZURUgOLAfgC1+6gXPOPZVn/dCTiAGu+8693HHHQyDutyPOEFBIaszFPbuUXbuVlCCKUCQQAqQMmx6KdJ3SBpAGUCWp+QU03rPrgAceCUxKYVEt+EsgKx50be/vkrJ9m1pAQ1uLAB8qaBYe3pRJzozo91GE4mskAyxtTq4FgwQvNLwR+rdfup7nPOd4li5bRBbYvmMfN15/Hx/+ozegAS799De48is38vwXnuaNSfvc//mxb3DOuSfyH9/xfBb2Fn72Zy/lDz54AbfeuomvXX0Lv/d7FzI3Ej7+sW9x/XUPcu5zjmF+ruGsZ5/Kl6+8kycfu9aemSF7kTXzipmNJz767nw/alfdmAIPPriDj/3xVYQSCQWOOnoVP/GGs9GoFBHilNeBYp5Pl156DS976XNoo3sZaAZpePD+x7jn3kc569nHG3ioEa3eUiRb45WG6//hDtasW8bRx6xFCIM1CQ5AOJhwxeXXcdazTmbpqvmpvcmIeGOwDBJSi3q1rRSJfSffPL+UUiK33P4AjCecfvoGa5r5Gj0qaPH7rcqefPnTM1YzfOlvriWjPGPjKXY0ijGTLvvcd3jxS85kbj4Ms5I4C1fhQx+6kkcenSCx8IIXncSznnkMUZTbbnmQSz71HbooLF004l3veCGjuciTn3Q0P/PT32Ckq/nRFx/pyd2R6mDxeNBiNv7vjgMC4lEUiZHQNIQm9t3oEAJta8VukEgMLcELci2GYtVObEnKZDyhm3QsLIxJqVBSJneJnDI5mcFfLlbgaY/e7a/lny4cc85WsCbr3qc8aOnBaM7F/Qjado5GWswsJdi2SeOa/GzGdOIdSy/Sstbua7SiqYlmKgeDzCF6Pn0w3VBsR6jA3NwcYABMry1n8BOovfDa0c+563XwyqAZzzlbXKfq1H4Nx6EmOgSEyXjBixtAmTpPbhCnj2OS+OfEGPvtHFIpXBtfUi8tCS4TaLwItM8WYmNQZtFixWYq7qFRDfIKXRqTcjcASFJ9GnLPFuhy7qnsIQZaL8wNbAr7FcRNU2P9cAqmdbCsxnZASYyyrkmh4IkedkulNDAsqjxjutgvWclpAHhqUse46+hckpKqBKPYJG6WGkruMprUvjfjPhdCVm+I6RRYMVVoi4MUk27Sg0cK7j1gyLEGe/DZvwFCf4/ZOSso9rk1cpQg1llv7JyV7NeSszhGTUsbohfX0DbuCaKF0iWkFKvRS0Zzpo2BtjHPgBAs+jEECI2Y1IYqYfDnshr7p22jna+iPUBkp0v7uWSavTAajfpYynoP4j4T6nGvMUQDB2pHAgcYfJ/VP980hDWJZpDraPEHsgbTGHcByZHIHJs3befuO+9n92N7aCR6XKhJWDTrkFoCDkSYjEWi0QBj2wxMktmYjdn4Vw114N4s2ExzvGbdSu59cAff/ubd7N65wNPP3MCPv24jqvDLv/BptANQuq7wa//5YqQDLfPcfPMC77ro85z/yo+zeyGz5bG9vP2iP+eb34pc9I6/4p4HtpIKfOWKO3j7mz7FT7zmE3zyz66nK8KfX3wbX78Gfvadf8G+fR2K8MjmXbz/V7/M+S/7PC974Z+TxtZJTYA0igcAoyTsYeBAry6iqNAl5dOfupKbvvd9FNi3UPjTP/kmb7jw0/znn/s2u3dk/ujDV3DP97dCDux4bB8f/sNL2bF1L9d8/W6efdZJSFC6pPzu713Oz/zcixkFGAXlmRtP4Jvf+gEZesO0qMJtNz/AySceYXTpLFx19Qou+9LD3HHXZo448hDmYySWQkmH8t73PECxzebMpx7F9dff4wy44vOhga6zMRv/VqOu5syUUKjeAr//25fzE//hXH7yzWfzH970bL7+9du55u9u69kLfTKBQIexfL7y5XusLgCUBrShAA9t3s211z/sXnB2f3TY+1L1BChw002Pct8Du81vqt82ZVKsAE8oOcDf/d1d7N41sfWgv7D3WKhGCEZzcHMW+1M80SsDY9S2G7j7+9u5444ttv7T6sFgr+4JEmL/zgKdFJIoWYTrr/sBjzywkxe/eKPVUSrc8r37edfbPsUf/Na1lEld5zrrS0FT4I8/dBVPe/rRvPVNZ/HWC5/NVX99I9u37GHv3sQn/ufVvP7N5/DmN5zDi190Br/zu5dDgFOfciS/9Ts/zF994Tvs2rvQEzRsz6tYbTYOlHFAAApAH7sXZDBJq4Vo24yohb96F7cWiSXbHy3V/K140gKAuCli58BA58aKQoy2GM+1i4zS+etijPtpsPFivXoSNE1kNGq96LQIwGp+FJy27JEEIMGKw+TGKGLFX1Hbhti0hNgSmtbavjEijcUBZrQ3bx5o5tp34wfau2my6Wno6h34IRIPGGj0qv3r6mdVtgL+Pb3mvc5TWDe7ibGf1PrfexpHoSZphL5rrN5JrsezfnaM0YrQWA3y7PvbtiVUp/1gxZ14ERlipGlHgEk0kscc9GAAtanuRVjV1GftzRbL9IQM5CnAqBp0DlGC3sH3P8GL4BjMJK8R8wG2uXuIuqySg9rVL2UwJlStzAK7PqtsYDAONH+MLplcJGer7AWmkkYG8AdwtohfW1gHLWXtJT2VeVG9LkBM4uIMEvEufT2ntWs/gG1lv33IxeQ+6gexxkVWw8X62lIKJRXyJFksZ0qUnIkIuevoJmNKNjCrbVtiiORkKRl2jzV9oZ77784OQLohEZVdMlzPlUKIgyoppSnfC0ipwyIztQcsbNPVvQr8gaUW9Rqk3tcG8EkIZJzZ6G3K6hchIi6BqecpoMXOa+4C3d7CZK8y3qP84I4HuOZr/8B9dz+EJjFdslaDNAMHY7A5kcocEjUWhGZCMx2hNBuzMRv/4tE/NKw7F5yu+6IXncRBq+e47fYH+e+//0V+6b2fY9MDj6EFtm3LPn8be2Dr1mRgb0hs2bWH3/idl/Ef3ngOf/P5W1ixaDEf+oMLefrTl/EHH3wlh65fw1euvJnNW3bwoQ9fyE+//SX85V/ey86dY15zwYmc9YzV/PffuZD5RSN27ljgz/78a/z465/G+/6fc5kbNVSfZmuITJnD4SkSKEUUJZIm8NmLv8a6dQdz4snH0XXKJ/7ke2w4cj3v//XzuOvuCXffs4tdO4TxXnsu3Xjj/SxdehDLly2hlAYiSMigsH1Hx6rV8wQpxpQTodAY8Kzq9G7hGRuP5+vX3MvufYU9Y2VhYcTC7o7TTzmcW27Zzs5dHQv7hEk3YuuO5I/CQtvCc597DFd+9RY0uxmen6RBzz4bs/EEhiiId/ZVQK0BWIBduxNrD17B2kNWsv7og/jgn/4UG885gdtvfZDvfucHvs5Rrrv2Tu647UFyEXJ3EFd/5V7e+4tf5G8vu4WsDVd++WY++KHv8jdf3M3H/uRrqLbkHPj0xdfx3vdeyvt+5TLGe5Wdezv++gvb+ehHb+JvLrvOoUF44P5d/PJ7vsov/txXueqrPyCpUGTeGj5UB4Ja9TcUIp/5y7+nG3uTEuXTn7qGlCKpRL502c388i9+gf/889fy0Q/dbjINGkppKanhkou/Te7Mw+vv//5O7rrrEWcGB7565W380nu+yHt/4Sts3rqPbhK45u/u5OxzTqBtTY5cgK07d/Kbv/taTjp1vdc3GM3JE9lU4bHtHQevXc6RG5Zx5OGr0PGIyd5CmcC+fYEjN6ziyCNWsW7dSrY+lkhFiUE5/qSV7B5v4fbvbyY7zcRSL2dzwoE2DghAwbQ6ZkiiEoDocgeIsaFtR7Rt2xezxbv+inWaFaMZV26P6dyts1gLDcC1iOrd2epmPHWTelHXdd1UgS39z3sjN3spTdMwmhvRNKYhzBS6om5MpGjE9OIx+kNz/xugFDe8cwFWNbjz6saL6YjEhqZt68EyiYOnSGgxY7qUEqlLTCYd3SQBoS9WqcaDXjDXHagykgo01MKpRkbiIIKK0hXr/rehoQkCJDKZbIIzRD2+MJiZpTEbin+mFUSVgSAiPe0yl0KXu54lYd3y3Bd8iklUSsmkkujSZPCZqMCJ71LWTCH3Ji6gNG07Vdjn3uizyhimKfHBqe+D8z9mOqmBpjGmzGjU0DaRUWzMrNJR61zSYJIog9cFWDHftq0f7wrsiElNQtO/vm1bj05VP6+lZxJIPT9TAJExDIYYz+AgDZXG7/tVWTY1blGw62cAWgYwqQILJo/w41ipbziyjzMAHEYr2QCZPnkB+nusB+WwYrvkTOoSUYQ5lwv1x8SPufZ/N7aDFtue1CVSHlIc7HyaeamlW9g13bax1xQOXg8u5yhVDuTfhXs3WJ1upMZSXHYQh3Pp80eM5sXRBJwykmmisTiim7lWM1YKbH10GzfdeAs333A7N11/J3fech+33/gDbrvhB2y6ZysP37+NLY/soJtYlVB06nwGoUsdqVgEblcqKGYOyeb98v85vc7GbMzG/9vQqf97e64J8NKXnczrf+rZvPWiF9C0B/P1rz3iDbdKszWDxWqkiEx41tmrGC0NnH3OkXzi43/Ltf9wO02E0WgbMdr8ct13HuQpZx5NnFfOeNrBHHvsMiZ7OxpgrtlK21jh8l9//Yu87jXP5ahjDuKUp6zmkPWDWVrU2BfbNkxCVZHyVAqXXHINj+0oPOvZp4LAJZ+5li/+9ff47MXf4wO/8QUWLd3KsuXCW97yXD72sauZJOWSS6/l/AvOMmPJprpKuCwiQ9bBq8cRaANqRUGtWfPMjUfxZ5+8mp9516f5xV/+Am964yIOOyRw7LEHE8MC7/6Fi3nnuy7mkc3f59+9dGRpcg6UnnrakfzjDff13yrTuzgbs/EER+1uB+9u99eXwNve8UP83H/6X3zg/Zfwtatu44Zb7kcD3HvvY9x551ZqksEdd2zlvnt2IMDWx8Y88GDmgledyXev3cLuHWOecebxnP+qp3LWWet55cufTkrKZy/9NiuWtlz01h/hvrtbbrpxG/NzDWc/ewMvf9npnH32yYBw9z1b+czF3+SiN2/k4QcW+N53t1Z/wwFIUOlvP7x2uvfu3dx156NkhLvv284ddz5KznDlFd9jYfdeLnrLD7HnsVV88fM7Cf5mjUJX4O++dh+5M2bkrTc/yqYHd1MKXHXl3Wy6fx9vfsM5dPtW8q1rHiFNlFtv3c7xJx9KkGxci6Cc/ZxTaBdHaPb2IAL0K3hbJ7pkQlCIcMSxy/j191+KZpdzq/luzS0KfO/G2/n7a+5CCixfOeJpZx5HUY+67NMgwgxUOMDGAeGhgEIMI2MpBKGUCUggRLt5Alb4KUM3NGA0oqSZIkrW7EW2PewkmhY/FzeIoz6iqr46U/0YwAoPaSKigyv90MFXUs40Teh/V4oSPa6umsdpEL9pQl9kSdUo5mIGLG1LmCriraAxPWYcjUilc+8H7x57SkVJZghTtdlgEo6uq6aVlVGQMbdYozCpghTvwrZDB1vETQBjtO/S0k+wVrDhBaFPXhKYSIRmjgmZiXSoHwey0khDIJA0UbX44lIJA3ncBC8GSix0IdoaqLRoLrQhstC25Jx68zz8GBBwAzslTzqkQDtqiT0zAjomaBNdRlGLZiu+u0lHLpmmjUYdFyEq5KhoawBSSblnyOBadxE1TZmqIaNlwpKUWZwrOmpeEhmlhDScZz+Q07GFQQKhEVKZoBIIwRgbQUsfOSlRKF1HyZg3QvESvm4Xg7miMVBwGU3GLUh6AEZRNNtTKPg2AD1LIZeCB59arCWDR0dNKehXjVrIKrbdEaKYRKE/zu5xUKaAuyrBAfNRKA5QiUoPYBigUz1F3LhIDawI0hBDQ5cMBLHzatsYQ4O6xKSUQhNaM09CQXN/f5hxprMLqPdcvSLFUznsGs3FzrnJMRrGIRrSntXvUQPkYgyEUogUl8RUyzCXnbidu80fsG3Ldr71je+QxwJdg5CdQTVivA8ktYwXHBQLkRAbA2+KLXiKG7iVnK1gCL7QdpnLfvlNszEbs/EvGtNu6dO3UkqmC9ZGWLVmKS97+Yn85vu/xfk/9mTAUhQkw2RSKMVozqoNsQgxwUjgh37oGNYfs5YSQUtDzH2vwFN/oGkCy5Z2IIUS1fx+ilGU94wL83MjQra0BEMubPukGOBrUduVwmiv8cYgG445hLad45LPfIdXX/AMxpMF3v3up3POuSegQcjJ1jQUeMqZx/KOd36VH33xqSxdPDIQt5dw2TNTJ5nPXPIdfvw1GwlANym0je1Hp5Z+EwKccMI6PvbRn0AksHv3mPf90mc5+5yNEOCd73webWvNjv/5p9dw4omHEYN7OxS46srv8vznnz6ci3p6ZtPcbPwbjNq8tBWAuykSiKKcdtohfPiPXseWzXu44gs388WP3MDHP34BRYQczOWoEcW8j2xtt2rNmH//E8cw1wauvup2fusDn+f9v3E+a9cJK1fu5qDVSxiPE1/92p384QdfR1Hhla86iU9+8iZ+56k/zKrl+1izdgnLl8+z/dHd/MVffJs3vfW5rFq9mJ9592l84+t3ETtjTtm2W0Ol50RrQTTw2h/fyB//0d/ynl96FZ+79AZe8opnIMDnPnMdH/nIT6LAv79wDR/9yP1Wb6kxP4uTW33y8GNk88cf/sE/csSG1fzD9Vdz442Zm+64jeedexQluDdWfUdRogOZ1hDCGr8qFF9Dg/ayKIhIhNf95EZuvOVenwu9/hBYvnyO177mLLSrHhelEksGepavd4dcjdk4EMYBASg42NTr/4mCqBWLuJa5jhrFF0Ls/QyapnHdtnUTU0rIxDrqVvDlocPbNkZ5VmiCRcBI7/6PO58G75DXIi57R7MyFUpf7ImM/DXGLojFDR+TOovBUgH6fcOKOUIgtu1gIFnMnC9E61T3xWNxbwQxmv0gJQArYgYDul6mIVBSR60La0dcxGjzKXXE2BCa4B1Yi4XUvqgrPUtBVSEGJs2Ih+aXsnXJYna1DZlIKZVVktBgbjJSC2Ed/GKHrn9B3cSweBwfavm3bTQpSeo6RnNzTrlyyr/TyosL+2tMoqGa2QtZ+1PUXHaltp+pFPxkhXuoEgnrtJRS6LrkRbnLGih9BxuKmYR6rN9xW3dw9PbHCJqhAllNY8WtdpRigAp9AW+ymuDGljXGcpBViB/v2B93dZ+P4GBU0eG1vXFljIwnY3Tq57jkok7yqRjYpBXYQOhyhwYctGqpJqGVmVPlRhaJaNwyDZEk8+QgoMnYJLEhBdfb0dBOUf5LNL+Dzo0aQ2igMb+KJGpSIQcOUjJgrWmMgVO9D7rgdN4mMsmJXITSRt8L28YASAxM/JqIjcVXFolkKSQpDp4Jo9ggXuRrSaAjA68k0VCQ4oq8YPdDlergYIRJe6RnNWS1hJOmtez1QiBSAbtCGwMpF1YsX86a1Wt4bPse5pbNExulbSOike1b9zDescC+hZ0o2RktYbgOPNazlEzbNh7FGXwegFHbzh6lszEbT3AUKb6I7nuWXPKXN/LwfQscfcJSSmMeNqc9fREaYf1Rq/ni5TchAjfe9iA7do9tTtWWf7zuURaPbiVNxqw++CDWHr6KTgt797ZcftnNnHPuMRx1/EFcd+3d3HXroyiBuflAs6iBucDBa5dx+edv4pDDF/GOd76Ad73rr3j1K04iNbBlW6ITSNHm0e279vGtb96C5kUONhhQe/DqZczLhGc981iWr5jjU/9rJ3/4oW/wljdt5F0/exmP7miIbcfdd9/PBeefyRHrV3P8Ccfw0z/9dd7z7uOQYEbI0ec9c2WHX/3Ay/jo//g6n7/sZrI2/NVnbuQjH34FowC/93t/z6GHruCV//40vnP9fVxy8XU891kn8/nP3sSv/saLoVHI8Eu/cCkbzzmeXXuFO+/ZyYWvf5Yfu4KmwG03b+U//swR/sgX7wrPSobZ+LccMvzxZXmgD01k3ZplvPa1G7nyip381SW3s3KNzQ212WjmiS6rVrcsCPC8FxzD5V/YbM0kwdYpzhKWYu+Pomw8ax1XX/XdntkjLhfatXuBbgIrViyxLn8NnQrWDFVnKfT/r20tgTWHLuWQw1dx2edvZOd24UknHEYO1nCq73nq01axeMkOglhKXcDMyjXbZ5cS0NKgREqAgw7ueM+vbKRplZiFthGaBiQUSgkQPda9T5io6347xmYBZSwCARo1FKCoIAl+/zcv450//6PEFkQjpdj6avuj+7jzjof58dc8i6CBpJaoZce7JrtZU0cOjBJ2NnwcMGcj547YRIpHpPX4V9V2+41fzeYqc0BRmibSjkZuQqdIiN6597SGqdSAkq24K5rdWR6qpCFGW9BLwB3+zdSvRj3mnNzID6zAtW0UGej00/GCtr3WeW5Ho94fwuIKi5nyUT/DH97OgIgh9H4P9Xe5FGLVqbsXQIhNLyMITWNFWk5uOENP3U+p8wQDuzFTmtA2I7pihZHgLvjBDemmGQwIkxh5dMU8813Hhr0L5GCdDU0ZyOZ8H1rQ6J4EBoZo5c2L7avURAyxmD8tJjVoPbYQEcqe3Z5A0Hp8qJsBljKE0agZ1VVueRhPAAAgAElEQVTH//5g62CIF1x2UHLu4xxjNKCqan261DG8XTGjb+9cixn+IYVx0/DIyoPRxZm8dQsarHtMKAY4ddHibLAOPVINMYMb19CDCMN1Y+emBhkNxpj2+5oyUiUrxnYZwJO28WLWYkoQCYzHY0Zta0kfTdNb/QSxSJ4a81mv0zIVH1qyJ4dUloMj1zt0jntWHcrCKIImUpdBoi3E1eJApQQHDzwFpV57FZSr2xEsrrLGtqYu9fe5eGc/eNpKrrIXgRAjk8nEoyEDUWIPNNoVVXqwqHqWpFz6NIsQhHY05zKjMZrgoB07OHLfDqI96UmaSdlQ9BLx7TKQRP3/KWdCybQx0jYNTdsw6UxOEppIyZnGWTBN07B27Rqec+7ZLOxNzC1eRNNC0wilU+69ZxPfuuabjNMexpN9LNKG4LFUghJiQ9YOfM4DMaOkbOCX+DGdjdmYjX/tMN+SKZ4CIDxj4xHc0G4mlQW0s+7aRW9/Fk2At731uXz96tsRgQte9RR+5Pl7aKJy5lPXMRlnNCfmFgV+8lXneBEBb/ypM9ixdRcE5bzznsbVX76ZPbs6VAOvfe2ZrFm5iBLgLW88h+u+9X3ILYcdsphXnXcC3aSjqPJTb3wai1rh8HXLeNWrTiNSSJMJ6jpwxExyiyQu/IkzWb60YSTKc88+mptu2sTSJQ0XXngGmzcvQNfxvOedymHrV9vzKU4474JlHHzwyI5FhPNf/VQ+d8l3eN1Pnk07J6w7ZBkX/uQz+e5376eo8trXnc6ipS0S4IUvfDKbNu2kRTnu6DU8+1lHk3LHy847kYPXLcXT6bjg1U/jgYd3smTRiFdfcDqjNrj3knD5l67jJS85lRisYKhnowovZrDCbDzRId4t7/8rtjopKnz0Q9dwwQXPQBslK/zYjx/H1h17kHaOrlMe22am7xd/+kbe/LZz6ICSlrN7e0c7B5df8Y+8+PyzyA1kbVjYO2L33gm0gdAoO7Z2ILBn94RmHlKEsDgznozZ8diEZSuWMppfyh23beGww5axZ1chM08XYRw6UlB2781049LPVwFIARYva3juD5/OX3z827zqgqcxP7Jox1EjPLZ9QgLG+xTyHFkgixu7RlDm2LG9Y+tDEz79F/fznv9yBCgsnleThwZbj3z+r6/m/B97Pnff9zBXXnUHP/y8J3kcdjWDdZFSxWo08OAPdvLd6+/nFa86hVe8/FQ+d+ltvPHNK7nn7q2Mlq1h7aErGMXIGaceydeuup/TTj+E//WXN/Kylz6dtvF1dIJcFmhad4wJ6lPBAaHYn42pcUAACgYSJKD0hVgtsqv0oAIKtZCumfc1ptEM7KzLF/uIydJr48GKjUAg5WwxeVrNBa1zX4s8e62QVem6cd8Nr11708LHXlNtaFxxpkM1JoxO/xkyn1U94aGi7nGIv6xd6hD6g0J0Z3ywgkqlWLEhZhwlavF/laKuGKgQfD+KQDcZ934BldExGrVG8/cCth2NDFDYt4+uyi2mwBxUycDupmHNzl0cs3MnnRZCMSfmGLB0AEYUpI8QTGlCN57QxEjTDrnXFTRKyYhbjSc75JQN/fWiW/z7LaUio8XMoXrjPZ+4xt3Yiy6nRgUxj4BUejaJarG0CDDNu9j5MN+JCTE2DubUzy0Gfqht4444x6NhmV1nZJcseHRYKeR6DkqVHDhAAQ5yVN+EiMUIebKIqCcaDEyTEAO5JLquQ4IV+gkhl0gThRiFKMH2xymv5tMhzM3NuWRAQC0ZuF6LxgZRGjf6CzBlUmpyoUrjj03DJCeESFmylN1HHEkz2c3yydhduRtKo1ASkovLJqS/n1Rl6tquSjo3l4zRj61JiXzTHNkfmA4UHX7uMph6jwcZDEPrX4JUzw36PyE0ZLXrsW0aSi7sZZ6ti5ayaulS5K6dqCiTYvNPg3mYJK0dALVuga9lq4yjplyQzOck4N4OYmZltl3m67CwsJdMYNHSxYzmInOjhigtixYtp+TM3LzQtiObU7BrN2smBjPnDB4LG2MklRo7mvdjbs3GbMzGv3zULmNfqvoz55jjDuKoY1b6M6vC2OaXfvDBizjv/DP6DygcDAqHrl/O+RcsM1AwDMA3KvzwDx3nqQX2ZS984UnDFjhGHCgcfvgSDj//DNCAhsJLX3EKgiUZqRaEworFc5x2ynrIynnnPdOB3wod29opaPBkGmHDhlVs2LAKgnLuuUdRuw0asvkiZPjB97/PeT+2mkVLG0QMTH/mM49h86YdfPlLN/CSlz8FkcLRx6zg2KMPsnWJx0wKcOJJ6zjp5LVA5pCDFnPBeWf4OqcCAQUks/HZG5z4Kd5sKKgE7v3+o9x6y/28+90vR3rJndHS1aP4ZmM2/u2GyR9rp18RNm/ew/ve92VKsw+VjmOPXseb33ouEoU//8S3+cD7/5q5UeStb9nIusMWESOccMJyfv0DXyU2uznr3GM5/vhDQQprVs9x732b+bM/u4q3vP0FvOH15/KB9/01EBjNN7znvS8iRHj1jz2Tj/yPy7niS9/k7W9/KSeffBAf+eMv00Zhkgov+HdPIUbzWplf0vCFz3+da7+9maK2jqQIGie85W3P5cnHrufoo+c5/fRDULHm2Lve+WJ+7X1/BRIoeRknnrCCILD+8GWMx3M0EU45dSW/+V8vR9MiNhw9x9p1cwSBX/z5F/Jf3/95UiiIJv7Tz76IthHe+c5X8LlLv8/ZG49lyVIvWNTWbk99xiGEubqGg0s/ewNHHbUaRDn5lEP5y0/fyvt/9QqUXbzy5U9j8XxDoPDUM4/kTz72j1z2he9C2/HWtzzd5lBVHrhvG7t27OWUk9fjJYRJqiX2TODZODCG6AGwKD3xxCfrJz7+YacsO9Xf9fcxRqOAe2cSEcbjMYAXn4GuM6pf8rSFpmnMFb4USkomPfDkBnGdeJcSWQuhdRd/L1ob/746FhYWepq5YCBC2zZerFgKRZUfFHBH/KHTXJkPxl7IvUldLyfAiqecE02M1afZW9pWkOZczNHdu/q1C7ywbwxUdkV0Kr8ZBGpK5Nw5qFGcyj8UeF3X9UkE8/PzhAjjhTELCwu2HU6LR5UmNmybX8R3Dz6Mo3Zs5dhdj9F1meDFNsEK6CBzFB06y103IU0mbpYXCd5ULmhfHJpRY0PbmJdCNbSr3X1ffTiVygtQkT7yUUUZjxf8/FSRhbMEanHv9PVq7lh9I0zukOm6zgwWBQeIijNT3HMgKztCy3ePeDLr0x6OeegHZoqVEsHlKybvsuNVnFFRz3WXUh/BqDoASJYiUSMUPdqys8TxktWkAg7MRAdQQoC5Gs9YMrkkK0KbljzFtBDnucUQaNq2B+RyzmQdTBSrZKi+rw4JFiFZusS2Rcu49Uknsu7+H3Dknu2kSUFKw6TO7s70ibExtkRdIzu4U4cZJ0LbND14YCacLlVRZTRqB3RBzSsiNJGmaSkoOWUcnQNctuSeIBIs+SGn5J4bmKmpm0q2wQr2bQo3rD2M9fMjjrz9ZkZNMPYP2cyaNLAQGu570sk8ujDhjEfuY3E3duaAAWltaIiNsT2a0cglNkI3mZikA0VKZPeuBb502Vd49NHtLF9xMCtXrOSg1atYsXwVSxcvIwRhNAcrVs0zmjOvk6aNlGKeHOM0NuaGBIiwrwSuP/hQlqxcwfH3P8Arf+xtNKMl/5ppdzZmYzbqesOeYFRoYehhGqhaf16keFybNz08aLJGxhpoYGzIyg7sP88lFda0SM6FeHyhXP1lHKCVAdiswrW+PSnYdoj2n+3cN39qutQRo1szvS3+6ofv386vf+Cz/OjLn8mPvOhUex738G/g4Qd38OlPXc5Fbz+P0aKIEDzeRs3byD829B9qDC9bEnkSjwCaMfghgNace2M3Zm34H394Oc9/3tM4/qRD+n1Tsq2ZMGbljKAwG09sVKakM0l16HD3UwC1WVn6RoIi1VHQlh5Td5l15enXI30HSYUs2qeAqRRvTtm6FWd/+mZNbaGNylPNIjS+zjXPAKAUigS/r6dubH+PBGtUSQlQAiVU6ASXA0ORbPVM8TnGdBlTQJ5PK17XeNAlKsojmyf8p5//Ku//L2ez4ejlfvOLm9EXn6tC7+klmHwKxdnAxdbnPuVWNnU9LAZgWARtUeF3f/tL/OiLz+CkUw7pG511n2d4wv//48wzz+Taa6/9Z4/8AQP7BhRy6R38gxu75WLFT5RIyhnCwFqIoSHnoQAF79A71bvrOnI3scJFzUgOwanJnZkaYfKB6OBFEyPV8z6EQNM0TCYT355g3gPBWQFuJGTFrxVTo9EcCwtW6NfoQeu2GluhsnSqAR4McY6gbvYYew+HGvEIViT3wABmxJhz7v/UFIGe+l0MnqhUf5OEFC/iiptCuWygWGe8ba2gq+wOiroWXSCb8WKDFTcTzTS+L6lYuq6qGcYFCWho0aik1BHqpOPFtgShCY15RJSAZiuiU2cFv2iw44W4/MRMMGNo/PpoSLmz/ZPGqOhB+iJZ1TooQiBo9QwIfq1BSXb+AtDGodutGWOaGPJhwIP7JViS8ATRRCPR/Qsa0EjQQleSJV4EsUjwuh2YdKZep1bAO2OhsejJGm1aWQqI/U4RQjGJTmVn5GzbUzT3JopRhXpxVWlNjUPEE1Hq9Vg/B+h9N3rQTNxzIhe0JL+eCjHDKBea1CElIV1nJpJiD7mYheC+GNqnQog9oxisEDUpknLPHGpjcPaGgQXBZUBz7cgK6i5RuoQ02Tr/NX7TfRPm5+b6GMjgMoXoAJ8i4IBiSh2hsa2Y15YmeX57UEIqtGoJDUnVum5t7KVMIIM3hZrExG5lS9LAWRFdN3F5lDoQF5mbG3HQQavZ9OAW7rr5XmJ4iPn5eWJsmZ9fxOLFI1YdtJiNzz6ddYessO9UoxBakoMYEq8muSI2buLpC+zZA3U2ZuOJDV+gqrOSagcdmAITbNUbtBeR+ZyqQzHt846vxIeC2lPmVfw9/v5+Fd3fxLVikX+yUJ72BEIyRlgOQOxX5OrFS21myJSJo/0/4Tk29dWsW7+a//Z7r6cZNcRas6v07MDD1q/gP77zVcb69I8qbhMfUKIX/sXLhtBvn5UVduSswVAj+nrJtUddBhHe/LYXOlNv6lBiCTwyM56djX+zMQ0eFr8P/Z71rkuF46oE1whA9lrzA6zxV8ZIlh6oqI2QoXnnHzhVCNfWo7/OpxbnXft8M/x9UF6K1S9qQJ7NQg4m8nj5Y/WZUphq4ov6Yg3wEt/TaWrOXf1jIKn0YKYMWAOwdu08v/+hF/D6Cy/mt/7bC3nS8av672xqsa/VOL/OKYAUpBZhU8OwleR/sRpDxBLw7rjtPoKMOeH4Q/z7e1hlNg7AcWAACoqbyFl3NjRuiuYFaABzFZ3SZgN98SVi8gQAqcW5YA90sdsXZyU0bYNhDxERK5yaEIixNeSvZxfQSx3qJk5/59DVsC/LOaNi2m0DE0LfUa4eCLVgEym9LKBGDYIxLFA1ozovSNSTHWD47LZpB0nA1LEw1kGgiZXa31By8t95cTj1nirjqIZ+tVudc7LubqXgo6gmhExw53sk0MYW7UovQ0mSEVrToBdLGWiCZ1krxGCGmKKuW9VafBlAUIohkyXZhJ1yRtXML5umsVhEZyJotoK/fo9mJTR44e6LNpehmDTBNfo9k8Est0tOpJzNzwGMSaHi6RaFLhWf/oIvECOZOcZdMKd/wZgaubMiv2gPbIBPqKHuL77PheApJMEBE9t3M6cMIfZTOwXatqF4AG/dp5pYEnw1W801q2mpCFPAlHWrih+YaUZCZYKklHovDrsWEyGYWaKGBkJEpCUU8wmosYiWIhZIk4yS7Xg31fTSGCAxBIhuouhVeeo6SkX6RXpWUFADtbImYx6EQBMCXU4QhJSLmRV6FOvuPbupZqzioFj1/rB7zCUWnp6QcwdxzthPYvrAVPz6DoI2zXD9+jXUAzeOB8amcSMi7QGEwf/C5x1VJt2E+blFnHHGU1ixdC1fu+I6GlnE+vWHs+2xHTzyyENsLmM2bxE2HH0I6w5dRdaOWEEoX9AULS57cKmIWFdhJiGcjdl4okP6x7hQrDOJo/J990+mFty11Kg/63tl/Seqyn4/tyJhSFEaagv/ydT6Wvpix19I9t+7tBJAAoEaIz18i0xvQ79rw/NrKPCtIQFm/Da/qPWixQoZe1/wVytNa9RCW4+JS8v8uPgxkil2BwTryJJ9u61IkgrcgDm+gwEMKKN2OEaVi+Haub7Qm6Gns/HERr1+qtthzWP8Zwrc/k5x4E+Gkl10qqAVB8v6UsrrFgm9B1XNZOiva39//dr+vpWp+76fk6boC1SQInpzw+cgr9rV793+fnTkLux3+wgVOFA3PTWwox6LAfTEjRtrLm6y7hSBxJIlgXf+/FksWTbyexiq99j08ZRKP5Aq0WwY5gB7TXBWl2Iyba0sigDLVszzhjf8CLGx/fNNHhgXsznhgBoHBqCA3yjemU0ehVi7p8n1/jV33VJJtMcFwYo2dbZAyhlFPYIw0DQR9eKiLg6imMawFDNHLI11GtSLrvrgb2JDDNGp+Nm7nbUgNx29FWJG8ZlMUt+NRqxz3Lat6Z+TmRBanWCFbskdIH1hUlRRN11TqleAG6NEl0qAsQlGrXX7y2AaqVosYQLT5ocYneqvPfXfutxlqgga4gj3A2uK9o7yTSPkUEharBAUjDmAsHvXLjZt3sRkkoil4cgjNjC/eBFz83Ps27fH9iFYDJWqRe9tfmQz+/aN2XDUUS7LSEgEycpDDz/MQ5seZu/evSAwHu/liCOP4PjjTzDDwS5bGkCgp3LGaE6wOWUeeOB+VGH94Ycx15j2PHemSQ+hMSNCtfSBEqzzv2fXHu76/vd58pOfxNKlS7zAVZ/joxXxzqaYJCvu2pIMdQ2NU1SVkl2C4OdNnRMqwZZcITQGJsTgzAs7D02MEJqphab9r4gbHcZITgmQvvAXKcaxEE/bcIBgSGrwiCHN/d9jbKgmkPW1QzzqlPmVGhtEJVJCIAXoxCh4GTufqNKlzFiVxx7awmQy4YgNRxKITLpEbA3g2L5tG5PxmHVr11rHCWVhPOa+++/3azP1LIW1a9eydt1aokaiNH49O3o9Revds2cv44Ux27ZspW1b1q1bx+Il84zHE7Zs2ULTRMYLHXPzI2KMLF22lHZ+hEhrx6rUB5yh9gWF4IBIMmCopqlUH5MK/I2aiObiz1nx+9nOkz/2/PVKwIwnF/YtEAjs3b2HnTt2Ml5YAAohKrGJ7FvYR5cSocnE1toKmuu1oMa2qfOAg12zZ+lszMYTH7Lf32pB/8+wB3oJAd7YkJ7irP5eofQFh3r30OqR/RsTfaKEWIe/Agb78X9RpjPd618qjDEIGv7ZnZn6Z9/vt230f2r/l+k3VoBg+J4BbKhHaDg2WgET/wyt+IzGKSCgfnf9GmNt1C7mAGIMazrpudDDNs3GbDzxUa/s1P+r/7k+7nXuyTRV+f8fPs/vMq3goTdK+uvW/7/f9Vyf326Cvt9nVUjD31fBgn/ymqn7QgGvQepMVO/j0N9Vw7zSy6dwPEKnuxMDY6HOHxUcMe+2QhvgnOdssPXn9HHT0m+XTB+bqb87KkOFZqdnF2NYVVcLZf361UyDOuqs4io56+fN2TggxoEBKNR7WcTovI+7QEI0RM6SFPzS825/20br4KfOvBQU66B6kWnzghXAFkVkDzLUEwjEFv45WTFhTPmqixKa2BJDR04TEO9guzYesDjC0JjcAKFpChLafgFR0w1sm6vxo28XgjZAMuQPTIcuHjFY31N8W43Cbv8WP16xaRDvSEuy/ZMixCDuE2CpF+bT4LGAIRAqrXFKNz/991E7aPLJCkkpFLLWaSATUPbs28ddd9zJtse2IAg7HtvN3n17OOOMM1xGYUVXKZkYImFkneNHt2xm+9ZtbDjqCEKIxCiQldLAovkRixaNeOSRTezavZOjjj2KdmSmlFkzhUTRQtRA7cAYHmUGkTt2PEbOicMOW0dOwwKtlAQq5OxxPjkTCESMYv/Y1m08/OAmnvTk43pAoGhdJkKDENULyiBoV6hboNKad4RrTlQ8HpRabNqhjLWbDsNE7CwNddCsPw8qzjJIVlMGoQmtn9fKhKnnduiQV5NSdaaFgVXhnz3Xdl9Z5KklLkgPPKCBlIqlrkhHIdNpITdKzOaJkHLHpk0Pc/8dP2Dp0qUcfuThfhwULZndu3Zzx+23s3PHDjZu3MjKlavI2UC/vXv3IiJ03YS9e/eyadODPOlJY1auXsVcIyC5Z1zknGlHI0paIHWZhx/eTOo6tm3Zxu7du9i5cwfHHncMOSfuuvNOQqysi4YVK5Zz3HHHMmLOrt+ixk4qHTkXoi+yNZnMI2AMBEsJcZAyOSAZHJQRQTV7MkrjgF6peVHuXdFQOti2ZTvX/sO17NlXaNtF7Ni9jfnFI9ZvWMPK1UtZffByDj1iHSoFicHAA89wVlX7GeLXvklKipZ+LpyN2ZiNf/3QfjL2hXC/8B/KZ/unLc/NEHVKf10XyzLIE/0BbfpjXzyr1GdRoXok9A+BWpADxp4rqHf3pZ+ra/p8/Vbp/18p07b9U2soGfalCh2soan7fb/UIt+ZeI4KUIuX/WcadU24R+pO7/L03/rCoa5vpl6h01BIpZ57d1Sn96v6MczKhtl44mNIeTDqvMpwPw0vsv8MazTt37v/NejzgU5BbPuBD25ZWr1T+vcNgIMiIHWhXRkMflf5PTZsSwUY3ItEamPB6gpFHNTw+cY3o96rxjKqc4l9ror2Xgn9fSfVxyXsd9dGxWun6JGWXtRPYTHTUOQAhtAfg+kDWS0xq8zLfqX9awZhFlTpSWVbaP+a2TiQxoEBKPgTI8ZmSEAQodRHtXdzi5pEoUoAcsm9tCB6xnwpFssoMugQm6albazAECxWjmDpAlo7ufWB7venFWm5Z0qklIyGTSZ4vKT5yFmHtesUiSYXCNGYFYjJE7QMUZf2XbbwKNm0ldG1+DX3PlbK9GRij1rfx+LOphVMgUwItfNsxoclZ2IR1+MzRf0WYmzJWmyZEmt8ZTWILINOc8oYsZpUihtEinicJJmmFMa79vDIgw/xlDNOY/Xq1Wzeso1Ht25lvGcfi5csJqi4JMHlB2IleCSwd+ce0r4J7eLF9h0Ic3HEQatWs2bVahbNjbjppu9xxqmnMTdnNPXSJaIY4b+k4ppNM7UUUVJXyONEygmy+oRZnKFSzWasSE6SQCJZE6P5ltVrVrNrzy7G3Zi5YEZ75rjv16kEENOJSkomA6CYRINRf21NJhPaUcOQXqKY3k58jlV/j3silGFirKyB4KkjxmAB1HOSFaqvxiCrMc2ZXf/FwQs3oVR63W8IQpc6JJi8BAeXwM5Pv+BVi/cs2ZHposwXmCMQiz80RUih0EpD2ynduGOv7CV13ZSBaLaox5TYs2s3431jwqoAQVm6ZAnHHHO0s5CEzY9uZsv2LUjj6RVijKAuZZcoGSDWhMBCmqAls3rlStYfeijbt23n1ltvZvGiedYdspb5+TmWLl3KmjUHO8hnEY9Bbe7YK9mkIgISI+qmmUECpQgTEUoI/TwUQmQ08jnJ/ShQAwbFzSTrkrz3oei7b4Fly1ewevVBrDlonrUHH8LS5ctYtXoFc4sb5he1LF4+x9yiCMGYVSlnokscUsHSXpxynIsBovXcz8ZszMYTHP38XthvMdyXCf5vX/QWEUQSItGfZMPnVA+GvtDu79H9O3U1TcqddPZbGKtMSQimPmT4BIEpPyZq8UEGbdgfrR4i5oZ9+qfdvdq3rP8qDi6EqXfVAqEQDLTwiiU7U64nJHiXcT8wxrfDntwytW9g1UnxEqs+o+vvlFKZeLPyYTb+TYYAo/3/qaDSW4xOQXXYL8kO8JmEYVixTd+b9bX4u80E+p9etRWIqPKqKqGozU5hMBqpc9Dj9I39jeU0XU/VqmLZ/cAQ6bD16XDfGdAw7Fs/F4h/Zg9LYIW7g4OGORQHBJmaMyvYOh3BO4UnUudOv8sroCjDHipq4KsqfZS6DJ9u+5UQbVEJzGaFA28cGICCVDq8UeyHnwtEo2IX1Bb/xbrUQaoZmrEWgghNMH0zSN/Fr2Zz2XX/htB7V7sRNxBsXWNver6SoWnMiyCEaCCDDEaRqcvuPxCnuvwKms3YSEsfeVfUTQSp3U6/UV27XrexJjUAfTHfezj0eu5sCKSImzNOd6XptZtKoYnBi2zTXReseBTvZJecicG166XS3sULe3qDwKLeEaVSJYsjpwqxocsdj+3Yjgq0oznWH7aetWvX0bYtC/sW2Luwj8VLFiEC3dg60StWrEQQNm9+lM2bN7N69Wr27NvLQatXm+llFGdSWKRlcCAgBiGlzJat29izZw8AixcvYdWKlVjax4QdO3awdfs2du7cwYqVyznyiCNo5hdRFHbt2sWeXbvZt7BAbBvWHnIIbdvStCPG44kDPjhjwv0HxA21sgE0Nq8Wo8w7Baug5LyAhGzSBpfIFEenKmpbu+1dqZ0mMUthpy/YNSZoGbwNpFLd3egPLWg1E80FdZNOC5sIhFCveSU2TX+d9X4JIqSS/HpSIoHi7IgY/CE2df3VazWXaMkoLh3KOVmRPgeHHb6efeMxmzdvphSlDR57OGpZfdAqNhy9gb179tr+aKERCG1g5YrltiDlf7P35tGWXVd572+utfc599x7q+9LVaVSV2psJKuxbMt2wHKDaQ0YYpsIbDrzQvPAiTNIAiQEJyTjQUJaCCEEbDBxyAt5YOSGBBtssJ9t2eos2+qbUklVpWpuNbc5Z++15vtjzrX3uZIfY4AZ70nRmQzhW/ees8/e+6y19prf/Ob3GcVt69at7NmzlxgrqiqarkrKDuDhbSORhdECF+4/0ImoxhgI90fOriyzp66p5oaMFhdY2HHUxzIAACAASURBVLSBQayoggEKKScSLWFQoyG6vWwiYJ8hPteLNgIi1MOhuboUsVB8niSb33U9JJFomgkJJWQDenJK1DEQKxgtjNixexdBh2zYsMhgbkjTZibn1jh95hx6dMLChgEXXrSHudGQNk2YtC2VGCCmmqeeqsHWMo00zfq64SxmMYu/eHRJg4JS9V0H3QsS1vds4GvQ6S1uMaDDgb7qmcelT61lWvxE7N/TyXP5wzRLDekroNMJQfc36c+9y44KpVgB64S2Ty2J/jPaCUoy4W/vwIXs9tKxLzB6QoAD0KEkMA6W97nW1Fa/MDanNB/WZwJTQIMhEt29mKZOz2IWX3l8mbEkdEks0I3T/u9hin0gvZMJ/Qw37YTSPlw0WKbmmkyvAX5MbG0xdlDqgAFUpor6akXIKXCzsHeM/2wKBIIaE1XKHFOEZNb1It0aMN1Wa/O4ckClByMKv6FnZdi7y4yn+4SyMpn7TXY3ChEhaNm79LCk9L4wjncUdka/pnUwjkytjd0Zl3VIng6xzOJZEM8OQMGrrtNhDzFo3UavUy72CmBVVV2SBAYoNG0DUbtEozu8azPQVXCDWxYWZoMlr23bdgr5pRKctaWqB9SpoU2Nv16cUs66cxE1Zf22TQ5EZNNqLVaUpXrpvQSmW9cnmtMijTnnrld+uge+ABgm0NgDJuV8LWmza0vOoCjMg6xqwoZ2gwkCrYs7VqGy6qu3T5RjK9mYD34fO80FbMKPFuaZmx/x6c/extVXXcPeCy4wpwhgaWmJw48f5sqrDhGCaWPcd999XHHFleSUOX78GA89+BAryyvc98D97Nmzmxe/+Aa/luxU/b7PX1VZW1vjwQcfZDgcAvD44cfZsmULhy67zBLG3HL+/DmWl893lp8+CMgpM55MOHvmDA8fPsxlhw5x2WWHuvsqEtbZeabUdp1roZ7vFupiEaYFzZaMYO0kZSwUhkjwJF2zVX2ya1NkdescT/ZFhNodKuzYDkhg4oFlnlDgCXUKrZXR1491DBSxNgpIrfeoKhCsTahtDaQzsc4yRgzQC+IPINFOuDNhD6qq9r+THGVW5hdGbNy0iRNPnSCoWkuIBH9/ZOOGBdMxyWYTWlWmETCWhoTSrK1xemmJXbt2sXv3bgb1AMhIhEFVUxDz4G4HojAcDgyYV6VpJwZJ5ExtVALOnT/PaH6eSgJzgyGLCwvEukZJDOrabDaBuoqMQnBR1+h6H0Ibg98LWzvC1LgH17XQRJszKTv7iOxghOmzpGT2lctrqxw9eowTR5dsvMRIVQ1oWmsjyTph5+7NbNv2OupBRVU7EBQj2bcaVbRNR25cQV2LSO1soz2LWfzlY7qK3m+Uu7qZ6DPe0ff9GtNAfHEtBb++tWF9pd1y7f5vfQV0/fn050AHJpjYm9vRSprq14Z1lOp1AoZC341M/9rpRH8KWOgkFXy/ZJ2i/pyaOrenn7Vo7PZX03dp6iqmfv3l1qvp5g16pmQ5r1nqMIu/qng6TjD1k079/MxhGtZV2g2AmIYMfQ9eRvEUrmbTyVqKhOIU4YfSQvz3Ody1OpUjr0M2KYBi+Xs3V0qRjw7aoFvbHOScPlu/Svvc8j5JDpT4XoaCGZbmAyuiPeO6s3Qi1fb7suf2NtsCiuA5ROFRFGDAi1jFYlylhxGfsYBI0aSZqrHM4lkTz4qV2gQULUGO0TQK8AqhUfX7yn0RamyaxujUqbfjC/7eAjJYMro+Ebdk3T5LwG0qlbadgJhNZc6Z8Xjs4mcwaRvM3ih4q0KyFojOqcF61nNX6TeqU6f07+BIsfKLVSRE6c7TzrWvSsfo1dOiIO8CLl/Oi7l8Rvk5htg5IsTg1KXsiaEnRiXJTtn1HHyhsop4L9hnybC1XtgNM+aHitCmlqZpmJ+f52U33cTC4iKf+cxn+PiffpwTJ0443T9x6tQJ+3yniz9x5Ahrq2uMRiMu3H+ASy+5hIMXXsgLrriSJw4fYeX8edPAyN7b5e0iMVo7x8mTJ2mbhosuuojLDx1i8+ZNPPjgA5w/f44owsYNGzhwYD9btmzhwgMHqGKkbRpU4ezZc5w7e462TUzGDYcPP+7jzpgPbduytraGIEwmE1TNaSJ1VoWFNdIn+Kq9/I0QXMyvsAVixzKxtoRADBVVNSC4/WXHcOnGZv9dF6aCaQiYJaOt8Kbt0GHQ2cCitm07xkrbpu57VqfRdXRTjQ6e95WfwmJIyS1FtczJMlZa2tyScn/cEHBXkchobgiaXfASqhAhW0tKDIF2MmZ1ZQVQkjuulHNdWlpibW2NPXv2MBgM/F7avRnUNYOqMvcLvy/m2mG34uyZJZ54/AgL8/Ps2L6dQYg0q2s8eN/9PHX0GCdPnODOu+7izrvuMmZTtIelLTHSiapaa5OxHcxm1YBGawuCjiCiymQ87oVXFWJlrw2+fvlNt7UrRIaDGhGYjBsWFxapYs3pU0uICpsWNtGutZw/s8zy8hqare0iVjUpZ9omdWMNTNukqsziclDVXzbhmcUsZvEXCHFNACnJtgMJUmp6Bqb2+/jQVd1ChzmU1/c/y7ot73SVPfWvLXZ1T3cycHqxWfCm/tdlGx/o3iPT/xXKtPa/FcpGr2c9SPfRDpRKMcsuWgq9TlMHnpRT7Y48/eybOv70pfY3+cv9ct3f173C/1Fcnb4c9DKLWfxVxv/7SJueYfDnjeWiu1SKPwWcKEsEhYlAWvcaW2Oq3h1CLGfoP8m1UboKfsYEYAs7qkzMacaQgFTlX93/t5yinNDU/qFjEoAW5mouC4+tjarZ10pb49S8re29pdgrpYnLW7OlJbuWnIli96BIVmsPFRVIz8xvvuz3INPXM4tnUzwrAAVjzLjzgvYWbOV/S+V+OkEvifc0s8HcGLKLqLmKq4+/Alj0/efF9aAk9BlVR+BcGC2rdq0WsfYEkNAh9tOq+sW2sW2zJ8SZ3CaayZg2NaScUDKtOzH4RXcJUjkfvDocqmAiiCSkimalGcwes4AspU0ieGVbXT8i+T3oEtnQUyh1OnHFHtgpuS2eMy+KoB9ASkoMVUe9L0CBSI+sbt22lRtvvJEbX/oSzp8/x8f/9GOsrq7Stq1bFCp1XSPA2uoaa6srVDGwbds2dm7fThUC27dupYoGFJVqT+WU/ZwSzWRCzpmlpSVUldHcHMPhkMXFBVIzIae2SzSrKAzqSF1bxTmlxPHjx7n33vs4d36Zc+eXOXXqJMvLy0wmE5qm6b7Hcm/KOAlPa8HprAHBXBoc/ChdL2hP3VS1VgQDm+xe5mysADt2NQUiSMeGKBWijIEEk6Zh3DRM2pY2mz+v9dDbo6NpWprJhLZtu/+Cg0ltm2malvG4YTxumEySu2QI5hZqDzPxTbJOVbxLC4gl4MVxxCZsAZvIpglSR+slzsmcTIruBmrzOkpgvLpmgpL09L2cM8vLy7Rty+LioolWguukGGuoaRpMqySTUmOPXwmcPXu2E3y87JJLObBvP4OqYu+u3ezbs5cD+/Zz8MKD7Ny1kyNPPsGZM2cAmzNa5jze3jF97zWZ9kUBjIQpZw3x82gdMHBaXrbrjmJ9fdHbmUQzg6pifn7EYFhz6NDlXPuia1mcX2D3jl286KuuZuumLeQms7YyISVFJXQgUYzW+lHGiYg5mdCNllnMYhZfUXRrt6OGHf049Mn59L57XYJQfnDhW8HfX7QLtPt3154gARNblHWf2yX4Kt26q94KaueCealRAw4KWzlmakUtCUefLHi6YqcqZR8Qpl4BReQNCQSJKAkkUYTZns4gnbppdB+Hgx88/bWzmMX/6mFjPmVj/SbwVtJpVMDnPX37VP/eAj76ZFIrBK1jFxUU8Mu81rZl2cHH1vc300CIt02qkIO1fatMAZsUrS3xc4eTx8/ysT+53Zi14GtBRQ+VBsyKKvVqiVnRHAyIUHwfa/+XsjlXWZpjrnoPPnCUO25/yHTKgpZlchbP0XhWtDyUjXqbWgLOQhBITg8XlEhROICCsk1Xfw11M3V5S6Zc5EezJ1iRImSmmlzosKjlu2FRLok9nc+9WUNGEibuaMBDqQK3XeXZ0DjXe0iZQV1350e2akOogin2d9fdt1aUfvXWRfg0PxNM6cQY/ZgdOyH3D/eqHqC5ITcJnVqvStdHyqn7fOuNtwWlS1ayi7+l5LYYdp2rq6sGPGimaRvisLY1SpWV1VXqumbbjh1cd921/PEf/zHnl88RQmBlZZnJZMzc3ICcWyTAeLyGqNlNtm3LYDhkPBmjGCgTYjSF/qoy2r8vhJOx3ZvxeEzTTFBP/AooknKLijIYDolVRcqZSTOhCjVLZ88yaRtedPkh5kfz5CAcPXqUlBJzcwHV2AlYppQYDudRTWQSIUbw+99mYyyIqiV/asKVhggHP5fsApq2mKeUvGJtY71tS4LeV7DKGEhe6S5fXi7jPFpSTvDeORceBdxS0AQirVfOxCMLSFSYEiJu2NHmztHEDtEDTiKuAh7tgSDiLJYO+AqktjXhRLOyMAaLX28uSXoydlBQqIIxDYpbQ6grY7pomddeB1ScVWMRQ20gD0XY0tp0EOX8uTM89MD9nDt3jksuu5S9e3Yb4wDYf8EFbN20mQ2bNlIPh+zevZuHH32Us+fPsXnrxq7NaJr5ZD+rAxdWQygRQiA3fj0ihBipQtWvBaLm6JAzuTXdEnvI25O+qiKLGxaYNGMeefQhNixupG3WePLxx8nNhNXzy4RBL/Nk7Vj+cO2aHqX7d4xeVdTps5zFLGbxFw+vdmnA1M2jA432N8lT1NtOy8DFoMtGXVxgTZREtKS8SwWcH1DIAeW4Dsyur7VN19x6gcQCNatjEYqSMhx+8EkuungvGu2Z0Gu9e3QbgOKiYEkO4IUU6T9fO9jDG8wiKWUeefQo+w/spq4KeDB1TV1MJzgzmbRZPM9CICfhyOOnOHL4DEkHZAKVNGzcFLj0qn2EwJT06vp5160vOr1mTIfNyuk8u5dMjH4Yc4Qpm/2V5ZYzp86y94JtSNDu/SK4V4x9hmlTrwdMBTh65Az/5bc/wtu+97W+7ilK5PHHTrJ9x2bmR/a5QaOBEgpJhfu+dIwzp8aIwM5dixy4aCshDFg933D3XY/YOhszL7hmH3PzFWdPrfGOv/0/+ef/8tu44fpthGDuG1/+Pszi2R7PCoaCQOemEGMkTVmilUpssVMsSXpJrkvlsDvWFCW9tDtYstBXlwsAIai1PHSV116M0BI3NZaCqlsvGrJYQIzphMS0FGq7hiBOHS/aBwU88FYLKQ901jEMSmW+tID0av+sO/fK3xMkmDq/etdUtvaENiltNpqk2QY66IJ2bgoloSrVeEt0W6f62+eXe2HMC3NOEL/urCaOee78Ob7wpS9y7KnjtKlldTxmw8aNtKmlHlacP3+OEydOcPbsWZ566inOnTtrgn51zdKZMzz82COcXz7HqaXT5uYB3XdCgCa13feumtm4YQNHjhzh8ccfZ2lpiaWlJTZv3mwuEG6fMzca0rQTJo21ahgtSzi5dIonjh7l1NJplpeXu/aZch/OnFni+PFjnDmzRIiWxJdkswA+TH0PMcbuGMFdRnSKPZBdoA9KVbtnhvQMAm+poGePpJQ6xoLdD2dNiI9PFAIu+mjHqusaLQ4m0I2fMl9snLmuR3Z8OfTzabpdqDBcjN5WLjl3mhqGLyg52bkEgVgFbydwDXEHT1QzdV2zsDCikD2MEli0Omzsto2NvcIsKuNyMpmwfP48k8nYwQ07l2PHjnLs2FH27t3Ntm1bba6ItVesLi+zdPoUa6urNJMJUaydoeixqN/jaTZKzslcV4KJsbp0whQzgG4e9SyFZICkKurODILR99xEgpwSg0HFpZddwvziHEeePMwjjz7A3LBifn7IieNP0jZr7Nq1nQ2LCwhKcpZJ7r4ryK2LGU09+Lv2ilnMYhZfQdjanjTQtMJ4JbKyElleVSYrmXbsAssUqbKybfIVugP0pQNGp0UcCzypWWjbIrBcivrSPTd6XRQ/fEchMFFeCS7dluFjf3QPn/rUFzusIiO0yRhxWqqRRQHeD5aAZqw0y8pkBSYttLgddAtpOdMsZ5pVRZOQVPjghz7N5+9+BLL3VmuYOlc7tx4sKf3Xs0RgFs+XMBexAJw4foo77nyIf/4LH+WP/vB+7rjzER588HFi6P0PCjvT2M9piufjc6Y4zmk5tv0j4/s+gO4oxY1Bu99lXz8ef+QEv/2bH+uKcQW4KEUe8dep5w24xgOqnDm1wnvf/Sd85y2vZtPWRVQr8iTwb/75h3j7297LyWPnrXgFvpkzXbnPfe5hPvDh2/nc3Y/x2Tsf4Xf+6yc5fPgkuRV+8zc+zu13PcQddz7CZ257mN/6z59AgeuvP8jf/Ymv55f+3WdpWgclJc+whOdoPCsYCiVpCupVQvDkuq/eTse0eGFH91d9RoJsCVKx1QtmORmMBt9MJsQYGFQVrQv/lX56/3iyuiChJqvGT7UJWMtBJlbRQcFiDWngxGQy6UASq2TSP3hdcLBUr8vrSnW8c3joriFP3QtzZSiLQzmXIuJYEs5O76F78BcmSOgXliK451oQpQd/MpmYToQqA9djCG6jV9TvbR0RBqM5EOG2z32Wg/su4vTJE2zavJmqrhmNRmzbvp2jR491TIV9+y5gOBwymp9j+64dfOGLX2B1bZU2tRw8eJDRwrwZ9MTAcG6OAwcOdD3qiLBx40b27NnDQw8/zIH9+1ldXWP//v0M54Z2P4KYkv5wwJmzZ5nbOSJUgb0X7GXfsf088NADbNywiTa17Nu3z46Nsrq6wurqCuPJmKeeeoodO7ebOJ7SJ494FT4rUQoooN33Zvc9dqBCLO4EGAosQToAomhtxBhJTdtdXwGQcvedha5to4yN2ttvNNtDwDZ3sW8J6pi0vQtIGWdFILQwFqCAa2Xv6hogARMDzaUFpmfMlNaP0vYQYiRWkbn5EURBfM6UvWyMgbm5kW/KM6TWRCl9Mzo/P0/tDIZyrjbnhaZpOHbsGFu3bWXzpk3Onmk5evQJnnrqOKPRHNVgQAiBDQsL7Nqxg7ZteeTRR3j08cc4cOFBls6dY3V1jboeuMCl0YtNvLUCb0OyOWPChzHWBpQEAwkC0umXxRiM5efAZRDTtBAM0HAsz1qfNFAPKvbv38crXnkTjz/2BIKwfes2dm7bzrkzZxg3q2zduZnNGxepq0AKJrhmhQWF5PM5Z4iYI4WUlXMWs5jFVxzOFvzUZ+/lPf/pkxx+vGYwP8eeTavs2pn5qXd9t9fopve61tcMRgf28l9HKKIwGDxygp/6qXfzT/7ZWxHRp5lFliqk6RkE/6Ty7C5rjwIPPXyCT33iAf7WT3yjUZcJpEZ532/exmjU8h1vutGFc8v6YO0YR55Y4j/++z/i2BNj1sZjvuraPfz4O15PIvA//8dd3Pq7d9DmmkcPH+XX3/12duxZ5Lve9nX8k3/4X7jsor1s2DT063KnJ54OaK6voc5iFs+bCJlrb7iUa66/hJMnP8y3v/EFXHLFdqLYHvz0yRW+dOdRmjigCsqNL93Pg48e4dDF+60NNMED9x3hisv39mQf6IDBBx96in0XbGM4iKjA/fcf5+ILd1FVcOToWR68/zg5z1PP1bzkxh20uSKxQAYeeegp9u7ZzNyo4szpVVZWJ+zduxlVOH7iLF/44nGUmqtfuJ2tW+a5+/OH2bF7Izt2bSQEJWXhg7d+gtfc/EIefRhyKmKLCZXo4thw771PceUL9vO6172QlOA//NuP8eST59m7azufveMo/+5X38IAYW0NfuTH3sf3vQ0kws2v2sOv/If38+EP3c03f8MLIc72Nc/VeFYACtCj8+I9R4VSqJotKU/ZmAudMF5Y1/c+/bvpkABtsp7nKsROjXRY15gNI5DVRORCD1RUlPqD9hVyP74l3mq0b6yia9oKSgjGsqi95QGctu5JoYEfCVyLYfr8wcGP5Eru7iRRuQ1dl/j5DC42lt3nOKjQpBbFqPehs7Gxqnbw6mvObddWMX0fQwi0rlqfUqJNqUMjxSsSxbJSVali5LJDl7F121YWRxvYtWsHw+GQubk5RqMR191wPWeWlhhUlqQeOLCfKtQMhkNedtNLWRuPiVVFEGFubo7BnG1akiqLGzdwyaHLqAe1gSaSGcocL7r2WsbjMcPhkH379lNVvfZGTonFxUWuvfZaY7W4sGY9HHDt9deyurJKDBVN01DXkVgFsibmF0dcc+01NM2ETZs2WdtFasiayNnp/v5dGiCQaZJR8c25oDJWCL2gZac3QdEfKCwZ6UCoAhyJz4EO/Mo2llJqiNGo/4ogIdDkTBVCVzUvQo7BWzayZtMjmZpb02MRSqXfn1ulMlZsg6ZacfoyWe+00Z+roK0da25ujn379zGaH5FyojiKB0wP5ODBC0kdvc7/JgFiZtPGDRzYv79z7ujXBNPRWFhcZDAwAcKUjMGwe/culs+dB6BpxgjCWgyMmwnbdmzj4ksv4dFHH+XcsrXVHDiwn23btnXtG6X6X/RQjL2hoC4iWUBKH+spJUJVRDbNdrVjWDgTyNgKODOlr0TaPFI2b9lMXc+hOTOIFbEOzC/OM9IBKTWcOXuaen4LVGrW1Do1Ltw+tzi6iAOGs5jFLL6C8GqdicAqL33JIW688RC//u5Ps//Adl771ZfYXkCMGdB4K6FibjmaMjGamLFm0Db5vgBfT0P37NSknDphSXhSs2iuJHibmpDaTMoKFcwF/PkdurW7bTM5CB/64Gd43ddfTVVHcGG2D7//du65/RxXXr3d1gYKfdrOISf40K1f4FWvfRGveOWlLC2t8qu/8jGefPwMW7dt5L//3l380r+/BSTwiY8/zO+//y6+9+0vYTSqeN1rXsz7f/8u3vJd5sAkFIZlQrvWj6kbOgMTZvE8CUWg6Im55gHS0lEUBVbGiV/7jT9h5/w27rhzjd9//73cdtf38sBDx7jz9id4w7e8hE/86T08efgEhy6/gFCsFxFnMAnv/rVP8Pbvv5l9BzeSWviVX/4wP/2Tb0Fkwm+952Ns3bqDj/3xErd97iy333UzTYBxDKyJ8Ou/9Qne9t0v5+KLtnDnXY/zyP2neOv3vIyV5Qm/8WufYnHLBj5z2zne+O2Z19x8kHf/1if5pV96K14vI4TMN33ry8kZ5rfcjXoLBWp7MZVItsSkE3kVINbwvvd9nKtfeKGtQr5fqkR48tET/OnH7uOrv/oQw/nI97/9layutCZIHQpT4f+HL3QWX1E8KwAFEairqkPUS/VVvBqeczYBvKkq6TpxPO0T437TXUq8ga53vWmsR1uVWFn3dlZFsvWk59QSPLktSZqBAHmdg4LpMjQouWMqFAKSarTNf5u8z93bE3R9QlCIip2a/FRSj1rVU7Pa50wlhEDXPz/NTijXm3OmqgbktumqJKFzi7CNU1GoL0WUULltpYMedVWTU2MAiVh/vn0GnnThzgemU7Fx40bmFxaQ5MQrd7Bpc2ZhcYODK4qm1hKkbH3oo8UBGzZvQkpS7NRx8QQ9oWxa3OB6FoqEQDWMbBzUBGC8Nu4q/bncw5yJoWJuMIQgpLYheWI6Gs6xML9A9mo/4NV/E/3bsnUT4FRyyevus0LvgKHWK98L5mg3PgtLoG3brq1Epsa1MUEaivZ2cYPonCymtDPsXGpSUkp/XKHHFiHBAlxkzGmk3L8yBzRn1MEhcJAsFC91B8zAPje4lkcHNhiAESrrC/bJZmMzJaJUZnuZlbqq2L59G7EeGLAVCpXOznH79u2u3SDrBQ0RRsM59u7d6wKePbBiWhORbVu3OnNCTCBUhIMHD7Br5w7QSBwMOv0LCQFiYO/+fWzftdOOKdHnijNDJLjYZl/2a5qWuhpQgBPotUSeoYeRMnWorO1Ds68Rdg/x8YiTf2Md0QwnnnqKj3zkY6wsT8hunynZ6JJoSxwoF122n1d+zctY2DTfgY1BhKSZ1LYg3hLTGpAlcfbEncUsvtLQqZ8C7v6CgfEiRjjOGvjDP7yHW3/3Hk4tLXL7HU9w64fewqc/+1ku2Lubl9x0JSeOn+F9v/kn/PCPvJ7RqHdPKsyvLIHs6unnzq3y3v/0e/yN7/w6Nu/czLETK7z7V/+E2z51lmuuu4y/+xPX8o/+wfv4+z/51xkt1jz66Al+/79/hB/8we/gzjuO8kN/8/WmwaMQRHnVa69itHCExw6fRKUYxxUGhXB6aYX7HzzJd37XS4mS2bRhjhACS6eW+T//2+18/w+8umNcXXf9hbz3tz/J96m99vrrDvKud72fN33X9XTOFxq9dS31zwZglgXM4vkXvXCioC5wXdwX4Bf+j/fz5re8kosPbOeS//sxPnHbl9AIr371i3nPr97Gv/qFP2PvfuE73vxKUmBKH62sHfCOH/s6/uk//T1+7hfezEc+fA833HgVc4tDfubv/Q7v/HvfwOatC+zceYxHHr6dOkPMSpTWcI1cE9UEITOBpIEW+Nmf/ThXXLGfzTsCGzbAT/3dj/KKP34rMMRcJrRrlbAEX+nsKVWQUPdC4uIaWIaHohH+xne/lB//0XuNvRkyEdOSiwPhb73jZh649xivesUhtPKiTHom52kWz614VgAKxm5e/yBKnvRGT4ZMkLF/9Jf+/qJB8PRKf+cAoYamiWBuDW5n17YtdQzePuAijziQEcMzkni6RK7/VWFFVFW0pE+sFzulpmMLmJJ+z6Doj7veNcF+H/qqpH9QFHN9QLWzL+zo5iJMOkV/Z3n4eeH0bX/qW6U0l15O7/3sBN/8El1NXl13wWj2JjpYhdgtcnTn79JTYmiiBq+8i1e3YyBNWqrhgMl4DVW7noxSxYpQm3CilIp+MrFACYE2Z7c+TDRtC3FKu0K8QhytQpQpibq1tKRk97K4USDm2BEDznipDfRRc90wvQlvOYh2LYmMZyAB4gAAIABJREFUeFU4Y8liScoRu5exGlJ0AnJuu7aCMJXA++3vQB+j2RcQyQRBRUprQ9FhMAaLAQmltSEgWDUsiPQsgNYBN9/UVfWAIOaCEBxQEH0aSDGMlHaDpml9/CdyUiT07RGqGdRaPIyKa991cqZCQZKzbypjVfu48yqVBP+fQMqKdpC36zUotKoQI4PabBKzg3kCECsQc06waph9f5oVqSrmFhatxUQCdT1we1fIDrQtzM3Z+JLeylFpXePBwMRJ01BJ7MEGXws626YOUPLNexA0GYCDZoIUcVZXdKbvIC6gRXZ4/uy5FZZOn2NxcYHRaI4QLIFpJzb/l5dXGK9NGC3Oec+lr0c+N1WK84idu7k9zGIWs/hLh5SautA59ChEVYo7GiHwoQ/ezdlza/yLf/Nm7rzzGN/0Te8hqfKGb/1q3vfrn2Bl6X7uvOdL/PU33cRwWMO6FMP/v4AyYLKaeM9vfJivfe3L2bp1M+fPN/zyv/4c3/gN1/L6r13kJ37yk6ysJdbGA9bGiWq+4sP/425e8tLr3X3K2rE6o0VVFhYGSK2oNICSxf3dfd+UyLS5ZVAFgiaixg5sWF0ZMxrV5XYAELQXwR5uqLn00Bbu/uzjvPD6fZZoSHfjpqK/5lnM4vkQnnPTe6b0lqwlGR8vCwujOaoKXnbTAW586U4iygAhMOA///YdfPzP3sZgICSv4BtFQcku3L1x85CrvmoXH/3oF/nMp0/wlrddDUE4t5JZWLQ2ite/fhe3/v7ECptiMz8kENc9Ed/D5AitwPLamKTK8toqL37JJm5+5UuZi6EXwcplmq8vggLdnsQY3x3GYOHX/ok/u5dXv+YqQoSQIaRAjjDJcNtdD/Kt33KjybxQ8gc7r6p8wCyec/GsABRKVbBTntdAHYOJ2KlYQ3l0CmDX1lCcIZJXHMM6NC21qaOBC0oI2gnOCVaxFiwxKxNAxBKfkjRb1dbYEyllklOZYzUArMc8e/IUohP/cus0ylwya7dibKhcHBKnuKNFUzk7UpG7vkq7H3Z3LDmdkjryxB9nMaTg1+RiiZoaoihJU0e7NoAxWBIrthi0bo1HbslNi2hmWAdUi3OCJZtCJFrNhiNzI9Y2b0NyIucJORtzw6z4it6AqeHbN2Hf7+rqMs14zNxggKLU9cCSugK22Dfq5+uqsTkRQ6RpTZQmRjr7yUlSSIK2DgaQye0iqWlccyE7wwXHTgxYqGJl33F0V5EQrIXE72mQXoivrmtKO8D5OOD4aJGtK0sOstSgQpMtsY4BqmHVjUsJAx+nXu0uLS0iVPWgF55EaRx8ChJJ/mXZ12StEqGqSLkFAjEKmnsWgiXsPa7bgVReBS86HIX1EwJ+z8yRgZyJde0VdvuucvLXiaJJISl5EDm9fSfV4kafZ0rl7UNrEliqhyxVFW01Z0CCNp1dZHF/MOBDuuq72afiIJKzYGwiuvZHoApCaT4SAc0tmi1ZD9I/xs0Nwx9sZS74OpFzsV80Ucl2UHF4w052TVaYbDnJQmqZH4/ZNBmzQVtibZZuOTtAmCdkTZb8Z4XUEmLVt6iE4gKCATCuo1zAK4gM52rqYWR+w4jrbriW/fsuIIaM5sbAHG0ZjQaM5ucdDDMgxFpK+taHtp3QTFqGRGKs/+JL7SxmMYt14ZC7A/rld2buVp4f9993klf8tcuJA+Ga63byPd93JYRMqAMX7NvPD3//B/mTT9zC3gvnMVy96OcUmUJBMqycHfMr//5W9u/bx+WHDqACv/DzH+KhBxPvec8ZUsgcvDQQa3jHO7+Wn//FD/DDP/paHn3kJN/71q82pQWpbEmM/mAvojkyRRbQ4gwRHHMQSHP2PBZnjmmFEEg6IuVIMn8gVL0dLRl7sZ4Ttu9Y5NiRU1x93X5E3FZTivAk0PH1nhU637OYxf9nUfa41qhgewfbCthvyEpoQcf4dl/QDJNxw/mVk/z8L76K//ArH+Vt3/UKNuwakZJV67NA41bosQpcd8Pl/I8P3seW7QMOHNjitdJE0wr1RNBWaLUhB0vO1XG/REXbCpNl4fbPnGJha00OEAcrfPM3X8SGrXMg8IW7HkCiMpmc5/OfP8K1V+9zxgX93NaSu9hec7KauecLT3L19RdwwcHNPPClk6yuwXjS8vk7TvHN33oV1Zxw6eXb+eI9J7jo8h3cfc9x6nqRiw/ttKUrCyG3BCms6lk8V+NZAih4ApEsCTdVfTqqfUqZSqIlHV2feekXt42A9rkbVQzkGEnadgJ0KoqGjAvj02Z76Md6QNs0ZE90gjMDNGdySpbMpeST031hswkhGb1/uloLqJ1rq0A2YboqumOEV6SNXeCtEprQNpVnvIMY4gm1JYZ49RSvoHpnOkKgzUZ/VrBkjWxghpHg6Ssk0e9n6iriZG/zQIkka0twa7yUe+FIxEQS2xh5fMsiR9hMlQOqY1SFqJbQZud4iYgn6BCDQSS5NT2C4m4Rot8/r4R0K4laAtnbGAbIwly7yrw2BgyQaaRCciC0iUZaqqBIdjVuNYDFyQldr3kBR0DQACm3HcW/a7OZus+mUZHIAcZSMxxuIZ5fItjIsb2nOuskJzQEQrREsjhElHETCgCQMoQpkT3UxraWarQQpCJEY3JkbWlTg2MHiFfJHYLudD66douSpGOigNEZHyEEkua+UqYJyUodBXLrCbol0cEUGYlREamo2oyePcXpasi50cjHsBJFCCqcGI54cvde1hY3kGREEgEZE3IwdFwAyURVcjDKrxQWi/ZjpkhDyjTLwTfj/YNmSsvBBnI/8ctqIrFvefJ7Vu4JZHKApHOMTj/FuQsuZJImTBpFnjjMhrWz5pqsxR0jUFU+6nJrYEVdgRg4l1TIXtnM6s4xRfA0RiYpQ26p6sBoFGhaZc/ebVx4yW5CbO0+xkjbJkSV6G0n4uBOKaHm3KKSqUIkSjQV9iZPlQVmMYtZ/KXCWwQoLMWyYPRLEFJYUxmiBIZ1ZdXJrKzlNb7tTRfzgQ98llu+9xXMDabrlR4qkIWI8LrXv5j7v3ScW2+9g9e9/hokJH7mXa/k4IXbUGBtMmF+UBG2zrNz925+8qf/jB//oRupq0DT+roZBMSe7yLB26cEfIcg3oW9stIymKuAwG2fPM4X7jnBlddso02239IA9WCeX/9Pd/PPfv6VVArjtYZqEC1/yLC2MuG++x7l+9/2um6fUvYWnc2EIRXTVzyLWfyvH9P7GEfz5uaUKnr7rwjf/tdv4F/8wgdpGvvdAw88hQT47ff9Ia/8miu5+rqLeOzRU7zrZz7C679lLx+49S40DW0fg4KMeeObr+MVN72Q//rbn+R7fuDrCFEhwVvefCN//yd/B9oBqR1x9NiywRoBRnMGJo7mlX/6c7cyN9zO//zIYX7yH74UAd70phv4uX/8ASY5obLGTTddyAteeDHf9m0v5r3vvZMrr7qA4cCLfZoQKubnIcR+2/Fb7/0st9/5BL94/V5eedOlvO899/Cpz/wBTTrDRXt3cslF25GofP0bbuCHf+hWLrtsMw/de4T/+Gu3IODOMy133/4At9zy6qcJ1c7iuRbPEkChMAlCZ5Nm7QUJFXHqMEBfbbUKvSvp5zRFyfG+cacENm1j74mRnGziR6c7qydGbel/n0pQOttGEVLbemIYu6RNxGjlubQR+ElbD79Ru3NysKGu/Zp6nYSSFE3TrEvFWbPbZor1sCt4lbKAGYpoQrM5CxTByorKtResgl1XNY33+hd3Au2q9a7enw1AkCA0jVlDDofDrpUkpQRBkFpoQyY3DbFVNNZWlc1mGaOaPaHvmROdZbVXafCKr5LILRg93hL64PaK6hZcJR3MmiAm9p46yYUnz1KpQq1motNYtbgJiRqQrCR1hoH36QdnvdSVtVeAC19GAxQ6W1B3UzCHST+PbKJYSZWkgSCLzDfnqKQh5QZECFWNaEWII6tke5tCCA5I+JWkZPaCBiiYhgQpdwDLdMtLYeugBuSUTgt1tot4u4tdi/1v27Y+btx9YmpdLowL8FYIwTaU2dkBItbuIELw9oCcM1kqlMDieI0XPPIoSCRrCyERNBOkopIBD80tMqgqLrjjTjasnCOFMYRElWqSRFQiaEvUxu6Gs4lCFJ9fJiQpIRjzA/dE93YSca2FzmPdr73obghCFZ3dVMC4tu3mpF2z1yHF+vhCgjlNzOXEpBpwdM9lnJERuyZnSJLRWPQTvHWlW4F8LiVrvaByydIy12MgFkHOpjX0PQTm5oYcvHAfR48+RYzqdBDTSAkDICVSagm1ECsjQ9roMQqiAalC42sI6j2OnS3cLGYxi79MFGac/cNpvZLW9RBfecVuPvOph/j8PUeIKnzxnuOQhbs+fS9PPvkYP/PPXsMffuCLvOun/4hbvu+ruPO2hyHVpADJGQtXXrKbhQ2Zy6/Yw6VX7uYfv+ujnDl/N+/88W/gu7/3/+KbvukKqrjGk08+wY/9yNcxPzdg06Z9fPSPv8gv/dt9Tg+GKC1thjoYcFA4EEHVCyIGzrYaeOffuZVv/7av4pWvOshP/+zL+diffYHPfX6e0ydXGK8lrrxiFxdftoN/+68+wn97z21E4A/+4Ev83M+/gWy1BJq1zKkTmV17N3cLoVBZGdT+4QD3bC2axfMziiedCvzwj38toTKRdkW45rp9XH7VGwAheLFrOKx56y2vo64rIPE9b72O9i3GePprf+2FxhhVQZx9XNcVMcA/+Nk3UNUgtBAiL3/FZbzoxQeRbG0JIUJVKVce2s6hi15LFeCd77iZ1FqRRAUGg0BN5mU3XsiLvuoCy5pCZljVRAm88iVX8sv/+gG+eNcJrr12JxIUlQy0/O13vt4YwEEJKnznd1/LW/Ra25dn4V/+y29k4nnYMEQq14S48tLt/O77/4YXL2HkbWE5K5/7zCNs37mT3Qe3kJ/hfjOL51I8OwAFKZVkV6sPRrsTCl2vf1DZXlpdBT90LQv1VN86wZLqnNWOoUJurRoeQyCICwp5QmXtDamr+oYQqES6JDCK0eKb1FoS7NR4ZCrJga4ibWJ42lG4JWdSTh1IUawDC93f+uEhhsoo5iKdhgK4/Rx0wEr2VoQQot07hKhO4RdxG5dpXQaraFj1O3rPf0nUSm9+tHYQde0A6OwpEWHcTtggypaTJ9m91hI1EwaKJuuFN39bc4MIMdI27ZRmRPlOM81kjZTb7h4E+mpysa4smhAAKzHw+JYtbKFm+ziRdGLckJyhNRHHiX82zk5QV4VUtEvuZCIuWFlZoi8GwihFsNJZCskdFApjIFQ+1pQQlZQbEpFMpibYNRv3DJGqu++A2y32IqECiFtJqot+4kyRIsiYtN/ETjt/GMjgvWz+e9NWMBaH+HdAuR6fMklNgLE4jABoaUlxMGJa0DTGaCADlqCPU0uMwrbVZEAEDS1mJ1lpRYxDFsKQjRn2nj/NruWTJNZIqkiqSDEQqwEhZ5QGTaUi3zIY1JYol8/XRF0ZmNWqtUeU+1cEF4uoYrGB7dwmKN+9M5iwpB9VYh1slGcDVCQrEhI5CDkLqzGRQ2BSVcZqKeMROgATFyONVTRryMw654Vex8VYSDlnyA7Q5EwdK/buvoDcBFbOjjn6+AmMNuwck5wJEXbs2MxiZYuTtSeJi7pGJEyDTz2YNItZzOIriel5ZGv5za+9isHcgOKJ9prXX8UnPvMwy2fGRBV+8O03csGueWhGfM8tX8OgFl7+sgNsWpxj48KAnbvMv72wyNDA5i01P/xjX02M9sy+5Tuv5typVRYWKn7kf38xk3FLkMirb/4ahkNrq6zDWX70b+5hLrrMYgXf8abr+N3f+TRvfOMN1EMrXiQRXnjNbi69fItdkZrt7Nt/4EZihBiVV736UjZvrjl1epU9uxa4ZP92Yg1zdeDtP/gKbvv0w2SBt/1vL2bn7gUEYXmt4b/+t49zy3fdhITs7A1xMEHW37pZIjCL512oM5wABxWqutg6u4OUwOJ8r6vS6bSEkn4JVaVUVQBRc7RS6CtyAc02/6M7u9jbbO+xYVR5vlTCkv8wsH3ccBBhEF1rzFuTvKV6fsEZu6i1M6iybfscv/TLr+O33nM7hy7ezIbNtbFGgeEgdCoKCgyGwcUnrSg5NxcZiCJizndOoSWKsnHetLukaDQAk7WWP7j1k7zz77zRN72tO8cUUdtZPJfi2QEoUDbnVsXuVerpfi4U6SK0Z2KHqUsmkrsjAB0rIQSjbmenAsYYycn6lYu/PDlR1VVHGxeESdOsY0IUgce+MOyWczF6rzoER+vFBdNK9RSh6x/vhfHUEzgXDcQWmVTeA57YSe9eIKYpULsSfk6Z4FVUxRJVzQ1JhZBLcmnnau0hLalNXYWVbFZ0EjCwxc+9GtS0OaFZie5CYLTKipgS286e58Jz56hQCA1KZZXk3EJqGVSDzhEiRrO7NAZ9ES5s/LoN3CkWiaXVok3JUVtLmJeqmqODeUIWkiaSZGgTETVAIATqFEhiCalmvMdeXBfA0NIYTDRQ1dBWq/QEUgcI2XlECc48cSHL1pkORJq86gtiRRVg4O4MrWRvT1BPxDO9LaH03ycOhk0lrIQ+GU05QYh+3pmqCv24wK6lruM6yr9mJVMETHstBQMoXB9ExFDlbkz2DIfi1GG2Z9lEEh34itGOV8QQ28LkQNAg1Or3iUSbxuTQkHRCjJU9AGsHq7Bx3mRx9kfu7jGqBHd4icHOsc0GarUOJlCuV6FygKeAZTEGE+90MMVO2BlPzloq64ATdCElWpSEoezkTKMNxEwCBkTG/kAv30XbmgiosWhcaLXIONMLWZqwZqaKYqyoVjvW0OlTZ7n3iw/x+bsepIo1WRMxit+LhqoSXv6KG3nBiy4j1K6rErz1KPRgpwFLibZtuvViFrOYxVcafaPCBRdsceFVTxhCy8teepGJNVqPHIpy2ZUXeEKR2LlrxM27D4IG9u3baht+iiuCJf4qmUwmErjy0q0UNt6rvuYgkLEVqCI3MF5pOH3qMb7u66+hmNLEqNx88wv4xZ//IA/ee4wrXrAHjbbP2L59hDBHQaSjCi+6ZhcEa38MIfDiGy7skgmLlkhk86YRr/naK2kwAezobMGPfuRutmzbyDXXHUCl9Y1+sSTO/ZZfeg7XLGbxvIqp1lZr2Sytow7+26bDXoqpqkjXIgQd9Uh7++5SYBWiTWfpH/VF68V0X+yY3aGytZWKGjihJCuOlX9rP1VNws3bpbEihrgW1MWXbWLz9sAnP/Uwr33dIWMkkUGD6zJA8Pmf8aKLn18Q05Mo4telHTx0lhDqhWLh8OEnecO3XMfmLSMrkjjYMltGnpvxrAEU1EED8QSrbVtKi0MZ8JakVsRYgfeWl4p2CELySUmpCIspr4cQESJNtmkQYnAbtkxV9QhdqSxPO0dAz5AQUVJqTCQlWK9ljAUkMOcBTbmf4IVpkPse924ydwk/XQJugkuWkIYQzaHFF6gqBlLOJkIZgvVRe3tByi2S7TO12Dv6wqRqzgpWYfV2hK4tIXvPvwE1xZoxpZZQ1F7BE2rTfYhRQFNXqUhZWV5dpR2vkVPDoIqQleFwyGg070ksxOhCeQHa5JR0vz67v9nbWxTVNOXYUZE10eSWREtuG+oAIVS02ZJszQZMRAwUSWrMkioGWm99EKLraTiFXFpjaKi1flDaUbzaLz5OyK1VhrIQtUHciUEwBw/VQNZEmt5s+dir67qjzcfYu4J3jABnD2RKG0ZxGAD8vihqCboaAJU7cMEBqsKgcVZHOXYRZSwAhjuwAmqPgZwJMaJunZrVtodF6BCn28dQGbAShaxChX2B5gQSydog0lKFBGLgVpsyWWpzBmkT2ja0BCZNSwxQV9FFE81icTwed7aZMYg9jHJCo+kQ9Gi+dGKF4veyaZKBPn4PY2V2jtq1Kyg6MT2UKkZiLaQISBFrBQ2KhMwkrZkDCYHJ1Pws9qyIO5HE6ECmY/XTtmmKgy7qIpilTStDhpXlVVIbGM3VnDu/gmpmcWGRtmlIeY1TT50htxBqcfaU9V1mF23NQUANzJh2vpzFLGbxlURZnQ0AEAzDCzgYKaaaJL4RptvIR5SWoIq5yUjHGtTOqwVKRU8o3gzGhCgMhmgZAkhFBj53+3289zf+lB/4oa/liit32/pR9BECvPHNN/LB3/sYV1z1rXZ0ySYGVzRrwJ//ppujEjqxOEf4zeetKBiJljOyT1GhnSQeuPcI33nL1xCCds83vMUxhIxI8neVxagAnLOFaRbPhyhlijLuPceYKhSad0OZ76Grzltha5pXYJs0a2PydseynkhhM3qxrVtFym6tEBp6zTTVBKHoZlWUtlFVF+mmqFaVnKW0V9t696PvuMntJu0KbF0oqEb5QHf/UvE9ZhFnNdt3DbbARaR7PaGsS4FLDu3nEoRQ2ss0+tLxdPbTLJ4L8SwBFPoebkGnbOvUq3Re6RZTwkfFXBrE1OPFETHRWAqyBDD7wBCdGRCovdprFf1oNcrCgIgRiZDbPpntKOCOAohXj4vQYxGILIlfieTJi05NvmLDt5514fT31FsKlslUjlcSyJ610WstJAcEogtUWpU5eSUjeAKa3Ac2QKGIR+u3zDkRiCSvqBtjIRLVFoYQsJaBnFyCMhFCQnXNe/wjbUo8+KX7OXPqNCdPPsXc3JCdO3dw4cEDxMGcXV+2vihzHajAKz9a1pdo32kniJVBk9VrtIYUlVwlAi1RrE1DWyWq3cNWtBsHhkqZVZ8J5tktTa21eBT3ibI506y2KRTf6hlJxp8PShAlYtXwCqEl0QhUUtG0rY05UQgZy197hk1pwZm29SzjqnMrCc5awBgjuXVByODfvRSGDF797gGXTujR3SC6VhYfW2qX6SwdB0mC/TKn1IFTbU6diCDBHVL8waMERBO4KJkGtdch5OCqvzmgORLbmqARKrNnTK410mri1JnTLC0tsWfXbgaDjZjURGCtaUhZOX16CRHYtm2bnYuYJWiJnJUqxj55V2jalvPnzvHk0Sdp25Y9e/awffs2QrDWmfPnlzl16hQpJUbDIZs3bUHnFwiDoa0XApqNYYIIVV2b6wLRW1NsPAQfu2VYtK1RkzsRzGy2meW7rWME1Nt+DMiq68j8QkUVEtt3bOXqq6/lrrvu5MSJk7zgystZWT3Pffd/geWV8zavnSbo+4Y+SQjBbFpxVekZQ2EWs/grjAi4iw59UoCChGSVvtBNS39OTCN7/uwW1xDqkge6vwcV/wxLDGKH3Ad7TiLceMNlvPi6S8FtjDt5Aicr7T+4jR/80W/xcxECPUNL1J6j2X0v3WOiL2Zgz/dyDmjPWIsSO6Z1PYz82Du+0d1/e/BBC2FKUn9S3fXPyouzeH7FM9gGqCf/3rItEVsjLDWnW1dy93skT4mT+37RD+kriL1enCWw7gwKaFCgBFuPjFWQgOTz1wGMks+IFSlCOf9uK2Gvj9Knh85T7kCB6J8EZrGbKWxcZ8V2e6bcWUt2gAKlCCPrVg7xa5utH8/deJYACp4spey9QOq/s9YGEQMQbJCWXuViN2hK/IiYuKIna8nFHUsaoJp6jQU1hkHOvT6B5kxd1Wgdeor1NNMhpyksEHDKfvZKcts0RBFiVZEkecu10ao7VA+1hB9BYuioS0UzorAtqqrqPymYFWRhLkz3uyOFdBAIlVV8bb2QklebqKEqgYoQ1cUGDSyoBjWpbbrdSkBM2DBn32NYn7pIRKQiSI2EQKxNLEaBKgQOXnQBp+dHHH3iMDt3bOXAgX1s2rSRKkpXzXCOllWRQySL2SYabdtaXvAEDxFCJTRtS2obYk5UqYW0Zsir1CT1xE1NQAtp7LunJgYgZWsLEWsV6SzBHJ21sVGSfLM3zO6yUIAsYzN420eomKButWhAVojSMTBCwZVVO0tDh1wJIXZMiZLEm22kgU91XdG2rYE4Mdo5t/adlLFQqPQSxdgo3uaQE8SKzhoxY8CXdm4hhgjn1jaPqTUKnjjAldSYCojj6C7waeOvte9EkyHIIjR48kxk3CaiCkEjIQeyRlKoibTUKIqN3XNnlnnwSw9w7NhRNt20gYWFRW8HCaw1LSdOPsXDjzzMlk2b2Lx1swFbogxDZW06we53lApKOxHCeHmFhx54gIceeZjJZMKx409yww3Xs7i4QM6Jxx57lCNHjpDcHnXn1p1ccfmVbNy2hTZkRJVaApVEc6wAqsrGRi5sjgK2ibjNqc9jH8/GcjBxUfF1RR0piwNrebC2o8DcqGY4iswv1Fx4cA8nTh5hbXyWPRdsR/NWHn3sAdbWVkxfggGIg5+Y2KNOtX+oTm8AZjGLWXwlIet+9k3+1I5exKi92auKvR6qo30d6KeoFJvnuH6fbg8cB85jX8vP5jpkoLYdV0QgCllKaUH6vYwXTELsk/hQzsUOiMPH5c8embKJL8fr3uY/iJYKo51PLCKVDsDbq8oBC+jai2bPhBln8bwL7aA8OjAAtX0pCkRrC1BbE/q1pjAbpv/rGdNSQEnwOY07ufA0ItBUNb+nJ9lc1J5V1L2+m6IFSExPK0zEsl0vEISvSeqHKS4yHXzagZWibgEh4qLSikjrRwn+DunOuYAllqMBQafu5Syea/EsARSEQT3HJK8heKI+pYlQEHNLyIogYU/xTglP2Ew8EQmEiPvIWw9yzm1XGe7bDlzgLVo3kBa3h6mKchGz6xT2BXDgQmI0inRlbRhBxO2bslffbREp7Q2dMJ/g9oSWaMQQLXEP0fujS1+TEmNNbpJ/tnTOCyLSaSyUqkAQQWKNJOuvTrmxo2g2dX765L4AMyn3CVMU8apqd0hjYThlQLOSMrRZSU0mSiAG2LplM6PhiIV7F9m5ewd79u7uNBPalMitfWdt2zI3HFoClpWmbdx9oaVpJkhQ6tpaHFLb9uwQFRKZcWoYCESpycA4je1aqtpFazDLzOzFdB/OAAAgAElEQVTn7PoPVe3aCYpXuV17IllSmVNDLtX/jDMZgifShimLZoK6yF4IaFKk6p0RkjMkQnSUx8kSiIluWs+9U1xzsu8eAxbaBNCPVVUx28isNJOWqopl2falPJtZhOs1WH+/2YyqOgvHRDccdMOtI22MZ3Qde6KMc2RqkRehOFCIBOpo1pZNzh2bQzQjVSRXkGIiS2sPpuRJOWbTuroy5vz5Vc6cPsN4dewgEw5WwMrqGseOHmdtbcwVl19BcXtJmGuFZFwcE2cqGaj21IkTPPHEk1x88GKqKnDv/ffy6MOPcOVVV7G2toYAB/YdYOOmTawur3D/vfeyuLjAC3dsMYAgmZJ7yILkRCVCzNYCItEf78Hbn1pbp6oqojkZ4yV2C4k/kAtYpR3omVWJnlQsLIzYsm0zc3M1oc4cuvxiNmycZ+vWjYRQsXvPburBHEiFhIiJLmEP2XI8b5/SrKQ0qwbOYhZ/VaHSz6V+o0tf0aOkC/43mf65r7WJqv/T1mH15y2u5VQ25U/7ME8WetCgrPcFmC6fJZae2OadAhH4mXnV0SXc+tP0XX+XhyggxqRyiKRLAFSynauWamZw3YippEOgNEisu4hZzOJ5F/Ln/mwcIeVpq4q/pGX9PAL3uPL3xPXze90BSolz+jPLOjD9aVNtUE8/RQqA2sGI/QscRMABgGnwUda1eZRPckesdevoFMDhb+4xjaeBKYWx/cxTnMVzJJ4lgALm0RwG5M6i0QZX2YyXBBt6n/peOM4ehyH0FeeSEClFE8GSrR5UMJ2GlBKDGKnq2qz3pnQTpvvV8xSoITHa71IiVPZQt357r1x6UpFT3z5hjIHgrlRGVzZHBnuoay6CKNJZWhbxI4WuxzwXQbjo1zh9C60R3ia7mlKqBPX3Gk0qlZ7KlE0xNhiQkF30ro4VBHsdDlooCQltwRsRqcwJIUPMSqOZVqBwOHJO3f07f/4cRw4/jio0axM2bdrIxRdfzNrKmCNPPM7uPbsZzc0hqpx66iSLGxaYH42ovMpuGWVFJpKlLM6+vIVodP0s5BYqCWhqKQYKQazn3pJly/lavF/LEeDixNFti4JYRdtZC0nNkjRqpCKQgokgTiPCihBc18P0EqqOdVKSv9KzZsKgZmmYs30H1obiYodqooRVqCjaHOrfrQTp3DOqaFM3xsr1KJQ2ucaDOIbs2hRWOXfAGtNUSLkX1DJXhHJvrV0iePuROQ1EyO5oUMSGSFRijJKkiUQLMiboBIgkAklaqijs2LmDS1rlzNJpH6OZKhibYjQasW/vPk6dOMmZM0tMJo0rnFu7SnYwr46W6BNNt6NJLSdOn2TTlk1ceumlDAemonz48GEuPHCA+fl5du/cw3A4x/zcPO2WluPHj3Hm3BLjtVViNUBD7FpgrODvDz0t64gBlQWEK6Ai2osXBfX5QwEVbP737Sc2T2MV2b1nD6+6+VU0TWJuNGDL5v3s27cHkZrV1YbtO3aiWOuMqjNqgnaOL0XLwf5zLZlZzGIWf4Xh210FS+ztOWw5vXSbb9P8cUZll1wXCm/oC34ydcx1IIK/wK3cpowrUTLqLWtB8UQ/u/1ucJaD9ofvfvLq39MAi6L10lUI/e9aSNZaPl+nrr2AwuW67Zp7IGH6M/6cbGUWs/hfOqabne3fNhMFNPZgwjowrts80ifaU3OpsBGmE/mOBcTTptsz1xVFfK9nnyWFIdyBniW/KIzcnn3UHcPf12u9iAOS/w97bx5t2VXX+35+c861T1PnVN+lq4T0DYQmIbQBhKggiALSqYC+60V9IqjoheG7Y7x7r17BZ8NDBwp4r17fQCOgIBAJ0oMBQhqIEFLpSFuVpCpdtafZa835e3/8fnOtfQquvYiMPcc4VXXq7LP32muvOdf8fX/f5psxCKyJpmtirCs7ahIoGWq4wVsm+x568IuYriH/fse3zY40d2XYMAt9R7dU3TmDDGHSV6A4q6BSzSUF2naVGBpCDC5VMEpPTTqIKfWU64CbKU7IHOooxTuwQk8jN1aD+xn440xTXZGPyY3BAPJrKcRgposdrUst3LxFsO61vyfFCpcYjY0Q/LxMSjCOPQ9CRDzpoOscrKBGXEaiF6i5y+blYNWamQZ22YqiLrsu3M5JEPudDiVHc/a3bkexwseZGEWE0o0JnUUuBjFC1KhpmGlmWL+4ntwVDo8Pce1V1zITR2zfsY2cC3fcfgfHH38cbbdC27b22th5rPGgUoSkwkiqw6wxH2abGUq2jrhoIuvYukJezFuihAEqzWhk654UikgfPTgaNXTenTdZgIBEu+6cqYBTzFsshlGDuW13nWlOg7hPgqdLQPHusX2mKaW+W91/xjp81gb2GOIx6b8gMrAmcja33po+UgET2wwKuFFn8c/b2DA11lAtKtX1tjgY1sdI1uPybpYxegoqHa12iBpAUkTR5B13Nw7VrjDqAqPckAioif/7JIQ2F5o0w9ZNW1i/Yb0lUriuziELZmZHzK2bZ//++2zj7GBbcEOfooWuXSWGSEzJsfGOcbvCwsI6ZmYbRqOG7Tu2cfsdt3L48CHWrZtj8+ZN/Xtrc4tqoOsEukgzOzKjT1VWtJhcoyhdNNpv0YxFgBba8djmY4q0XUsSM0arUZ4lOzHQ750xBEoMQI1ODX0qy+L6BXI2FtTq6ooD84Gjy0vs3XsPbbfKeY8+h8VNsz6PSs9cqSBijQuNQ+zMdEzHdPwTR5Uv9aNv0FVwYXLjP/EgtQybPshNlKgM8LQMa+rQlQOq98BkkbAGUrCVsUoqzAQyTkASkaHNUjfpgb4XqmlNv1N9nXXLNWNHigsZqlGjVlZE1XeDujlb9ZDQ4cQc02WsR0xfI4l66THJrNCJM9Gfyun6NR3fwjHZ3beL3L7tL2i/qtcAgWuHTM4FAbNN9r1VNSpcU0jL0Gzo/11/OQ5TQPz1dfBQGIr37H/7PJdh3g0HbGDE8DvSH74Qjnnrdc0YvMNqA5YeQLT3X2EE2+sX+y0NBnz4+bO9ZE3Wyv41rG/D2mfny95npJagk6dfjgVJpuPfzfi2ABR6HM5voJWCJxhDwbqpTi+PDUWU8eqqx7jRAxHVW8AcTq0Ln7wgLLkjlGI6dDXTEVUlIyRS719QGQz1ebXL7obv5iWKe7Bi7ASBdnVMDNE7wcEp92L/5wtIwRzpU7LkAYsRNOq/Fa/2mtm9GsS7nFI3ACVTZdMxRrrSDeCCT+IgkFIkK1ZoF6PNR5dJgGOTqjQxIU4AUHEvgGCSkZJN3iB+HKEESjYFQaKg7ZgsSgoNqvY+TXpu3erBUFLpxh0HHjrIg/c/wMEDB7h/334OHjjAiSedwMm7dnHTzTfzpS9dy0m7TmDncTsZjWYx7an2lPtcjB2BmFmfCDRNom2dYkWHSukLtQr2mF8FNE1EKMRotPmcCxoKIQ5Ff2UxVJlCPa+5qMcm5kFJqkY6DcFZBajHe5qsIsa1i6FAn7wgbt5HBZL8PlMZKJby4OCNswRCtN1fz8rx99i1rV1zKZJV/UaR7JrK6rGE/thiKQMxGLhVSmE0GtlzCmac6VGrIrg8IjAKMyjQ5RakRlz6MbsXg0QQKbbpVRzZDjQyIou/Z48jK50FdVomcjC2RoH52TmT86gBVeId+iiDA5pKoPXYWA2B2IxYWl2hzZkRI2ZnZ5mdnSfnQgjJAMlcWFlaYe+evTz40EPsOO54B2rc0FK6gdWRQTolic9jDURJNGlEEpv1KUUisU/GEIkorXlRaKDNhVAq2AmokGI0yc7qCtd/9QYeevAgQUa0bWbUzBBjZHVllQMPPUzRzNLSkgEyIoQmEVQo2Tw21JNbYIgfnY7pmI5//hg250MXba3IoXYOXb7g9yIFT1gYOnRDH2+ikK6b6b6wZuK56586sVGP/Z5IqU4GlZ0wFB6D2ZnvfY4phGpU3VD2Fy8RTM89dDP95au8QQYWWzWNsMDLOnyvwmBArQ4mrH1/mZplMRQZ06JhOv6txkRxP/lf/VhbDFfvkeHxwxw3TEIm1gAr6s3/yFlAulbQMIzJ51uLaA68B2c1HyNb6P1bpAKegSqVKHVe843A3xqPBf++x1S0An11XZEB9OzRjQmpg+/RbA0slhKGeWop5kP1jSvdpOnisfvk6X7m3/v4tgAUjFrvyJubKcbGkguyswdiElScjo4jYl6I145uUevQ16JHi/U7oxhtuHQdzagBEe/QGvU7F5t25sU3sBTEu4GhL+4HLLJoobQ12tCZA4pHRPp2RIQQPYEB+3dvrJgtejF5BJ6Z9IXew6HrMiEm0+57oZdLNgf4MEg+UJAYvFhWSmvnR/H34np0EQMitAjFi+UKGlDjKKOBA0Uz0aM7a5deWkVzRrMyCskJS5FWIbf+Gc3NWFcjKKjQti233Hozhw8dYcPGDSDKzbfcxLhdBWBudo4tmzZx001fY9PG9YxO2mULYLGiF1FCI+4rgJ9nyO6X0eWadGCfWUwJ1Y6S/dwg9r0XeMEjH9HKgBFLuggupygOChTtmRYqYjKR4JE7DhAJ5lnRebpGUE8/KIXofgxD9CVuGDnBbFEstlIqKDZx7alaNz4m9xJR95oYJDiqSpczURzS8PuKiHoxXGpKaE/fBzWzUtfvdF3umRgp1E2hnQO7UbiqtjJh/LgVTD6k7sEQAzkILepmo0rbjZGY0FDItISoNI15haiDE3b9B0tZULUoV/eXqMAKAikIbS4UOhAhpQrKKF079vdl5o0alHFuzdCMQlcy9z94PzfdeguLiwuccMJOQhPQbDGXEs2Y0Sh7xgQICcimew7ippzZvEgk2HyPIVC6zHjc0iRjp7R5SOQA8WhXoWuzsUxK4d777uPWW+8kd0JuIaUZu0VroV0dk5rE0tEVuq5jZhToupbgspkimeDpNv0iMx3TMR3/zLG2UFjzfzrRpVvTxbQNfOiLj6Ej2FOcdfKpapkf1r7OmscN9Oa+y9gXDO6F47FsQ3QlDAWAghZq1KX9vqcfHQs0aLVsHPwazKndXOjVgfP6voobxE1YztWby5pzJ73vAj24MhQR37yQmI7p+NaNCdCuv5oZvl8DhtW5eSwcsBZgsKah7/Mc6Buu8Gp+6kADE74o5L4on0DuqJIHdIJVUDdfDmNMWKcOQCjia4c/xzHHXtPoQu+PYu9Fod+XTkIZ/VIBVGmF1HckeWKdGkCVYY9cl4cCMmnoOvz5jcvAdF349z6+LQAFL+dNNiDmR1Awarl12cvgWIy6w77JISxi0qeBx9RJEDPNc5d7iYGQrfBBjEKdkjnbV3dk89HT/pquQEaTEjFE2rbrpUS5mC5fYqAaLdZbphk74vIIL1AkoGKgQu4sL9qAAddGevGZaje2PqdYwWsd9dRP/No9Np8DXKvvwIYEYvLJXKwzoAgxmfzB8RozCtTiE97jIdV7IN4Fr8W1iGn9hUgIiSaOCMBKzv7ckTJWiNKbSoKQu47bb7+d43Yex6mnn8rqyip79u6hmRmRmsShw4dZXl7ilJNPZt/+/SwsLHDyrpOJ0brU0VMUuq4la0cuHSE4/X5C1178vICbTQZ1P4ziEgRb6rrcWmxl/xnbYlqZHNUQFMHjKY0hU/N5q32VlkLJrTWQVF3yIOS2mJ+Bg0KThp6VQVMjUcMkdT0GYgi0XWcpAe7r0OZxz1roi0hnTwRn51RjTS149KMYVR/1iEg7T/U4SilWTGNeBEXNr6GCaapDFGGM1W24gjF+U6keAVl7ZoiqoB5p2ObOPxMlhGLRpaFFUmC1HfuxBQdI6uxXui73QIJ5W5h8I3c13swYAqr2Hkap4cDqmC53hDSHinl/rIxXyCUzblv23Xc/d++5m/Ub13P66aeyfftWCM7ACeChkOYLIYoGj7uMTb9W9CklE4BS6+awqTHvBhylzxPMHpNCmbQmhMBodsQjzjiFMGpoWxANiBposbq8yp2330XJhYMHD7g0xLYOuRSTLGFUShEzke1ydZGejumYjn/qWLuNrXN9KArU2UmTEoWBKX2MhrrfqNd4OAcQKkC65nWr65ADEt/wmLp2GyBQgewqJeiV1hXE8L+Nddb3TyftGlBxrkLdL1AmgAzf9ktd56w72ptVau3IGvV5SLnAKdjGkKhr+nB2J7/WnKxv+glMx3T8q42+MLcxdP0nQLJaNvdeJZOAo+/2Za2XgD2tToBoQ1FddzhFPYi2JqesYRjKN7+Vqz1eRVGygwGDTKLO8gFeCAx8JukfoWvf9fB6wcAV1TSsLcccgPrSFKj4p/uO9TiKN9ioayU9Y2tgHaxBTabjO3R8WwAKlUrtW/KB9o2iUdzx3IoFraYjgrn0BwMQrF9gk6SUDog9lb+UgKRIOgZoLN7CLar9TTNUSrqP2hW27rdtAGIQLzbstXE/hmpiZ91b9ZQJpQl2Y5Yg/aRNMaFayLlzjBBq/GUp2QGT7JGRA7MBKmFRnZqeegq3bSiCFWLRXP2LGgCRix8b0HXu56DFQIdiyQgywXywLrT/O0YzyPPidTVXrwI7V+24RbQlLx1hvDymGxv7I4WGdXML3HD9bgKR1dVVxstjtMDRpWXu3ruHOEo88tGP4t577+H22+9gYf0i27dvJ0ok5840+YKbb5oPRr9MVvNAYShQHTHpqfnUzrKdXw0Wr2lgjfaFskz4F+DvHXX81qn9leypYiwPiwM0xoT5UlTDz2O9PUJPCY29nMYYICklAi6DkWjgVW6pHgv2WDuulJIbdlraQfZ0DnzmmLFmdDaK3fhUy8Rn6oW8729DCD09NWdH40X6Y6znbkg+kf59VLlHLgXNhVCU4IBFp0IIjQPyLkOKkVEa2TWkQlaQaKwLCYFmZoYwasgIEhJaMiIJ3DByaXnZPQQiIQZSM2J2bh1Hl+7i8OGjzM+tY2VlbJ03SXRd4d579nHDDbvZuHEjp51+Ghs2rIfoSmILUjeJjghSTAoVKeTckiX4umCnpRqlas5+zWRKsc8zRCGk6FKPCXujYNdYcgComY2cee6p7Dr1JPc5SaAwiiOWj65w5ecCt992JyvjI4QIEtwk0+UZIgEJyRD/fs2cjumYjn/qONZSDS/WIZvsqrYKJjb/6pt826M03+T5ysSz6ZqfTBYn9WnWfE/tBOZ+XyC9sI7hOXqQQIcaSYKDDfbbwYR5xkrMSmzon2HyT8dDqUZyHpCJVjPKCl5UfQeZ4AKMymtWhDZDI0KoipDJwkaPXavcR2INtXw6puNfeVQDwDrNe/Brgq1AtUP3ilms8TfM3fr/w9MOwGK2x6vtVWqzxGZIlQ8Uf/HB4LW+at2DDQBB/bsgLhvS2nTs38Pw+8N7Cn3h30MkQ7+UDtvH1J/psCxN/MMj7uvcrb8vVVxh71tqTK0bwddZnzulSX5OtKbrTUGF7+Tx7bEjVSUEITaR0CTbiKN0pZgJnggluOtxCN75tEJZ+rtppfYV91LIPeKftfRdUysQskUT5tY6kKgXCGYWB1bEBWo3OqNu2Nfj7GpFnXo0H16QVkBi8guBECyftaZXaDGzPYmBlBKjUYNq7mUTUYQYTIIAQ2IE/WsX76oPxxNCJCY3bKoUfC9xzBTQKPyxSb1uPOfcryHqtHMt1mmviCS5ENQMp0TVDR4jiWiLiNhrHLfzeBbnF2wDpJaD/ahHPooTjj+eleVlBOWMM85gw4aNqATSaIat23fSzMxx/Im7OPGkk2k7pcsg0iCSvCMr7o1h51nVOrO1R1O96Qxc9i2ZF+AxuoVfzg7ydCCFXIzx0OXWIzUzRTvabpVei1a6AVzyDWVf2NXPHDdH7H82FN197CVMpH3YDcyO2X+W1RZcBk8QYyUoUirYNEQ9VsZCCLU4XguCVZ+InKsLuV93Wp83MhrNAsEBKfMjiGlEDIPPROnpfy4pKpMSHzOoLKp0oowTjEuLapV8CGiilEAKI1JIhBBo2zGxcZaISH/ss7OzjEYN47EzGKJlvnfZ2Cn77r+P/Q/sI2vrW21ly5bNzM3OcOONu7nrjjvYc/ceRk3DhvXrLVby/v3cc89exuMxS0tLPHz4EA8fOtgfswJNEUInRGkQGZG1ocvRQRcDFDpPLalrjWCRqaNRY4wQGT57M5KtaTIJEHsvxTYac/MzbNy0yKYtC6zfPMvGbXMsbG7YevwCj73obB530Tkcd8IWQnCGiRi7RYGuVCkI0/vydEzHv9AoZDrpyG7Yq0TWZMQXQE3KZHuIup3+JsW5WJJQWdOpz97Bn4QXhN5TwDXX/W4dQAOFhJL6cmTNpFdrLkZVhA6kMiKs2EkaDagG9t5zkN99y2WM20J2qdrQNJgAJ7xiEKdEK4USCr2c0w9PCRS1tQ2Xq2knvONtf8ntd97fMycsqaaeg2PHWn+K6ZiOb+0YZJyighRLLQtaLBVhICX65Ss+77P/tjVFSm1a9dU2oAF1E9W6U62vRf+vtbapEy/EcIOvEiS1fbY2QHRwD/OC04GjYBV/fQ57f4MUwUCMUoQbrr+bP/7Dy8nFwynVGKdZqyljBR8cxCggxWUWau8vkozcoD7PnXChxfbF9+w/zM+85sPsf9DM5+txTMd39vj2YCiAdx8NMGizbb4tUg/PXC+u5a4Fm224u64a3VnXt0ogesxQnAJulZ9Rtb04qJ3pGAIahCDRUhictl7TG6yrmj3Kz7u7tWPsGnf6IlDWeC702iRnS1hhaMVi8OKyuN7d2Ald3zVXj52rZnVaioErTomvlPFkImwvtt1U0k3iKmU+hGjU85wZNYnSmcM9gpv4uelg7z/hpn05k/MYpKHTMZ0WSrD4SjpjKTSxQeOIs899JEHM6yHFhFLYsXM7T9t0sUk6UurPUYzC9h3bSVF6M8uTd5mHQowRivsDqEEivb5fs59X22IV7QjqbAYcPhGXlOCgUzBpS31dVXETw2rAWRkflRHgDAZfXe11hm1jfWw1N0xN08sa6mfcU96dndCDBCE444TeBBQ1SQGYl4YdA4hE82hA+nM3mRRRf39gENAbkxrgltxzpAIZFdCSb5Bj5Jzteoupb8YJ0htJ2nyz16jzqwcYiiDZXqMlIxSCNuY/4TGTEZidG/lnUQw8K2ZYpigzTWLj4iIJJZSaUlJ60As6xqurlNISsXm+bt0MZ551Grtv2M0tX7+F2bkZtmzdzOz8rH2GKUBQ9uy9m6PLR5lfN8/mjRuZPzUxv7iINMkSL8h02hLFXrcTT1Vx9tFwcw8eOYpfV/ajUopH09rcic6WEUx2lX2NCJhsKGs9py5JkkxqItuO28zmbRuJMZGS0SqrGWe9JmwDb8+dmlq0TMd0TMc/aSiEyc5ebTyKbaev+OwNfOgDX2E83oJIQ5h5mJNOEl73mhdY516c+eXPsbzS8u4PfJGXv/RiZvD7hfTBj1ZKFOGOux7g67fs5ZJLzmd4UTugKm269F1X8MIXPYm5+UlNtt+HauHfS8EnAIVa5Gtg+UjHu/74s7ziR59KioGc4dOfvImPXr6bEmDzpnne+IbvJUYnGzgwkcfwnndfy3Vf3sNolHjjG7+XxQ0jOuD+/Uf5rd/8CKEoT3vSmTz3+ecTovDylz2bP/iDT/ITP/lMtm1dZ2u7BEQ7+rKqfyNrVdXTMR3/6qPuaybYPVXz/8mPXsvHPnozy+PNxqaMD3Hmmev4jz/xXCvEHUCI2L7y0OExH/3r63jBC5/o004cE4y9cXJBuPmme3no/gM89Sln9y+u3vCz4YV/lQdUUNGBuIE5YGtAO+649D2f44d/+GmkXnNQqQrqC441qDR4EpvvPEoRbth9J1d8+jpe8ePfhxa45qo7ed97riVrYN1i4g1veA7z8w1FABLiMs7LPvg1Pv25W6DMsevEDfyfP/sEZlLg0JExb3rz5YxXhLab51U/eh6PvWAnC4uzZCn8yn+5jLf89gsJo2F/PR3fuePbA1Dwwsac020S1A5upWrb32sp6eZz4EYnMhRu/qR0nXWeK+TWOl2evnA0F3j1oiHE2IMa4MWdFxdBAjUqT8SdUb3Ab5KlRFR0b2084LCRGN6ubyCCdQGqNt1098UiHIsZzUWTTlrhKWIsw2KShhijyS96hoYtOjl3vQFgcE8A8zgsDroYOCEhWLJDcXql2dbX02N0drWiqO1yTxcnG4obU6BTpW0NBJldN4Pk4v4MBtSkEUiYNU+EEM3BX6zIb1y7DgXyQJ2CWpQb+wBfbEul+Pv5LQ6iZFWjgtctineLixY0dwM7wJ+jZPeNcANBu3aGz6eUDvXOcr8++2fUSwAYIhyrP0J9nE48maqlSwzn06Q2goNnbYuqFYcll77Qr9dvCNH9LAwI6920XV4AuGdIZWuEHmiox2TPFybmTdXm2jXUdZY6Up9fQnDvDHEgagBJJv9dO/IxRFJJhGzMF4Ki2llyRKT3PDnllF39/BK/xkXs5+sXFznn7LOZXzdn8zGY3KRGWG7buZ3x6tg9OjISIMXIjh3bGTUNKytj5uZmmZmdZd26BUIMnHrqacyvW6DkzNzcPKIwSomUGgSlLS1GE0pIgJLHlPGqgU4yGJcmCQ5EdX690INWxmTR/tznLtOVQooeuVoGaYoUMxItRU0iIYInQVJKx8zcjAMsznBQu34otvkOsQKQGZOSdEzSq6djOqbjHzeqoZp5BQz8ASPmCY+98CzOOPtU3v623Vz8lBM49/z1NCPXGhfIGbIITTC/nfGy8sW/OcJLXgAl4ca+0GXzaXKCIvffv8LXvvYglzxrLZjQt/EKXPWFe3je9yujOStWYqjHZhHGoQNTX6a+SCrRIAnBAPGvXncPmzdt5riT1qNSuGfvET7zmRv5pV96DgV4xzuv4qab7+ecc7YSMNZZ28FfvPdKdmzdyBt+8TkcPDzm137tY/zarz6Xu/Y+yHv/4kp+/vXPIRTh0j++mpNv2Me55+9k09ZFTj5lO1+65g4u+e5H2tqmtSgazjbngxQAACAASURBVG1P7bYPYDqm41s3JqaYfWvz6clPPZ/zH3suv/6bX+UFLzyN0x4xz+yMsw+zkAu0MUKw5JWjhwpXf/4IP/g8KDN2EUeBrjWZsUmx4b57jnL37Q/x1KdIVU9QAURF0GKPVbwhlqn0AGOB5kjncz8FkxFc+fm9vOSlLs/uzSDt+aI/vWYh52iihWiOMO248M53fopff9OPMJprOHJolT9/91X8pzd8P6UIDz5whN/8jY/wf/3fz8OexuQhN928nxtuvI/X/9KzocB/+sUP8ifvjrzqhy/iTW/+MD/2Y09ncXGWa665l1/65ffzwQ+8moW5Eb/1W8/l1a98Pzfufojzzt+EP+l0fAePbwvOWWUDoGaqV2P3RIYCCQludDjIBkIIPa28p8VLIMbG/6/WnkN3uQASjbJfu8I6QSuvndiUEqlpvAvpoEAPfHhBDm4kOUFmioEQY69tt+cdCs1SUcdKAfLfr4+pyRLeT6aaJFZNfwUKTBYRetNCoYBmum5MnGBLVGpjk4zabh0TU2NJiBa9WRfKMJzHSnE3wEMo0qDSEFUIXSFRaMuYUlr78k51UUgxEcS74O4hkdxJP8ig0Y/JqO+5FEIU0qghxGC0cXGviFoQO2vCrofhe9SMI+tdYgBo6qeNxXf2uIsbyIQ4dP1LZvgYbTGX6LKbnOm6jq7r3AiSnmDWMwSyHUcp6g1t8WuoehgMxps1QcFYN9k728J4vEzRTNOkPkLUCt9Azmo2F2UoHkuNQA0mAVGqSWV9//ZeKihgjII6f5xnoRn1VJScXQJSWvxCc3BJ+jlmAF0FygpZM51mizBFCIxIZYQUoUiBYGyFgkBMzM2tY3FxI1kZpEwISEBCZP2GjYxGM6gEpxMqRYxN0szMMDM/R0gNRe13zIB0xObN29ix/Tg2b97G/NwCNksiiwvrOfWUUzntEadz4nEnsOvEXRx//Ak06+aQpjGlsCQ0R0f6LS2liQ10w/wWoLRdH6daXAIRZFiD6voRYnCAYAB7JFRgyvxKSlsoq4quCowjZTWgbUByREqkGytBG8y1I9rxqDpbqPXPzlhF0zEd0/HPGB6HWL16ipgZKgoxKLNzwqZtc8xvPMSGLcqWbfNs3DRHQbn+hr38wi/8Ga99zQf4zN/cRinwvvdcydWfO8x/+88ftBQdYHU587u/fTmv+6kP8V9/+eOePiUur6hjqLBVLSKuBCUL5AKf+cSXuP3We6AIuVM+9KFr+bnXvZv3vf86xmP48/dcwcMPHUELtG3hT/7kEyytjPnT91zFi19+kcVBA3/+vqv5gRdcwJYdM2zfNsvzf+BMLvvwlxHpELWGSzdWrvjcrTzje85h045ZFrbM8vHP3so1X76bT3/8Rh5/4els3bGOjdvnyWnE773zs3SqEDI/9NKLeP97r0U7f0dS6eMyvM2eqjCtLqbjWzz6vXdNMjG79/n5hq3b5lhcf5iNGwPbts6xbsMsncKXrrmdX3rdn/HzP/0BvnT13WgR/vzPvshnPn2QX/uVj6B+G15Zyfz6my7jNa++nDf/ymfr0uIBCbaX7hkI2J7/ik9/hRt3303BEtg+8ldXcfeeByjAzbfcxy/83KX83Gs/yE/91Lt46MCSiXEDFBGuvOYmrr3uVlA48PBR3vveTxlIocJddz3AL/78n/ALr3sPH77sBjvm936J5zznImbmEirmAbWalQ07Zti0c5b1G2c4ePgoba1trFiwJmeAHVtnOX7nLK/+yQtYWWnpBFaWOzYszrJjxwzPee4jOPOMTWiGoMriXOT7X/go3vv+3ce0VKfjO3V8WwAKuAwg56EDKzGaRrtYh24UG5pmxg0aA6bjA/VCoDrNh5Bo247qzG6beyuqKzhhHVLT/QQsJ756FdTObErJHOWxRITgzIBcMl3rBaazBsoxZnxmVDL55YaGtezzgt400Xb8ISTDF3XoskMtHCtpSbxjGr1AKYiYgVIpHaW0oEqXO+vG50yKsWdNhCBe/DgbQhVCtHjKGJEQnSViXequtHQl0xbriEoptKOGQ6PA0RhpRzOMQ2K1mWFlNCKPZhmnxBKw2iTyzIhupmHcRJY0s4zSNZFxDCypsCyJZWn878QSiXEzy0poWA0zrKYZVuMIJDnQlNBcGMVECGZsKX5eOo+uVCx5wCIZXc5QCpFICsllFOKfn3Xpa/FnHhQJieair44yVICpAhvVZ0M707YVL/jtUtZBmhDMrC87u6AyX8Th6xgDaRQIyVBkQmbcrVKjdrpc3BRS6DwutUooalpEFDNHNJps1wM81TCyeoqAx4ZqoYmBUQrEYGyWnFtKycRoBoNFTGpQSvG5BE0z6o8/O8hi8h4gdLTpCMsps6KRTmZYTSOOzkSWY6BNDUdiols3z1KKrI4ajsbAyiix3ARWm2Rfo8Rq07CcEkdjZLlJrKQRq80MS8GujXGaoR3NsppGLIXESmwYj2bIszOsNoludoZ2NGI1RbrRiDw7C/PzdDMzjJvEykzkSAOHY+AoDUuMWEozdJpoRVkOmVxs/hil2NXOITijBTeyHIr6SUDTUFA7h5lCEaVKsqUR2m7M3Xfv4fZb7uKOW+7htt33cOdN+7jjpv3cesNebrlhD3vuuJ/DB5YpORClAYQmNibNytVdXXsgYzqmYzr+GUPs/jZs9itzwTZIJoXqCBRGQCjwt1/ey6c+cyP/5U0v5DnPO4sPfOg6VsYdP/CDF/L4JyTe+J+fTZgJHF0e84dv/zjf+5xHc8n3ncsXr3kQlbpZ55gdWKUvY3G7WiUKX+H+Bw9zwinHkTVw+WV/C23Hq3/6Gfzu2z7B1297iOu+sp8jqx0IfO4zN6I6R5odkf0pA0LSwC1f28+5Z53ojYnq3K5ObUiEkmgi7DpxHXfdfn9f9u/Z27HnvmVOOW0ze267D2nd5R3lmmv3GwMSZYRw6mnbueX2/bbb0YgRYWXiawolTMe/wZi46IaWnXiXvyBkYEwUJVCItHzp6ru49st38StveiEXP+UU/upDX6HNhR940eN48tNmeN0vPQsJcPjgCm972+W8+GUX8YxnncXV1xygKMTqPVCff4IeYaTXyDVfvI3cCUcOj9l9/QOUErj+q/fy15d/hf/6phfxgh88nw994DaOHsnWsNJABO6+6zB79h6lKCwdyXzlugcpCrt338tffODz/Of//mJe8qMX8/4/v9ue+8a9nH3OCc5qkh7nCwQaYH6uYfcN93D1lXdaHSY+xxWTkBZbtwKCikWtSxiTIpRisuJYzCDfidFccME2ghwl6Bq76un4Dh3fNpKH3glfzMugL9TF/ANyKRSKNZDrdTnR+Q9B6FrtmQPWzTPtXkHtBh6CGw7mniIYJDgV3zrMGpS2bXvqedM0rI6XTQvuG3gJg+Fi8WO2At+p+P671b/gWEO+2hWvusoYLDqueiagDoLU99o3nG12hyYg2fwQYrRCp2SL8atU8nE7JsZkdHtxA8naxVclRYvjU5cN4CAHWpwZYDr8lJIlEBCIMsu+bds5umGeVCJBo3VbQqaEQiD17ze5O3/w4qcWoFUuopjcIucO1Lwq+h5Nn8mljENAZuaR+w57okNwMADTpjo5QYIBDp22lK6rihKTgYhCUTfVMeNML+2dBWOeBnaMHsun9PKKNWyPUhAxeUJyhkvuOkKT/HOm/3ypv+fgTozRfTwq1Q4HwoyhIZVF4Bd3UdPmDjII/QbPhMoksQ3xhORHK1hlwFMFT5LLPLouk12O0UtqfFQPBmMA2BJRYzirvKOUbIBcisTYsBJG3LJtC3fOLdCEERo6xqElZkhhRIcQK7PHmR1hoiDOpVCynf8QBop/kEjbtQYiqvsYeKRpBXf64xExUCTE/pyFIESJdF1rxX1QkkAgkovPxybRNvMs6gjNSlRLNolB/DOWfq0xlVA01m6xOZdza94QE2kelS0F0GWTfzQpMe4yN+6+lT237yOWEVJCj97HJKy0Y9ZtmOXxT3wM5z3yNFJUuq6liQZuNU0ytpEnyUzHdEzHP3OoQ7Iy1PfSRyS68a0Gz1owVtgHPvRlXvGKp7JpfoYnXXQSl176GQ4fHTM/GwmjzNzcCG3hf7zjkzzru87jnHNO4JTT4UOXf9VxBAclffarrn19Ays38OmP383DDx/hx/7D0wgxcNlf3sKbfvWrnH/hBj7ysT00o4bUwItf/gTe/Wef56d+8tl84fO38KpXPZ1GhYh5DqGxN3w2wMJfQzBGBC7/A5om8qQnncvrf+E9HH/8diSs46UvOpvZETzlaefymj+5ks9duR+ScPz2HZx11noHWg2sf+pTzuZTn9nNmWdfPFFATW5koE9/mBYZ0/EtG9p/qUz4kgg2LxTwGHVrRQl/8Rdf5ude992sW5jhaZc8gg9e/gVWVzpmZyOjZpX5dSNKhnf83sd43gsu5JTTd3Diidv55Ce/YlIn7xGKBtuj9bs7kxI/6Wnn8Zc/fynPfe6Yvfc9gAbl+F1beNevf5gffP6FLK6b4YILdvA9l5xqhwkmNy4QSwPZkqKM8dRQMnz08lv44lWHuenmD3LwUMcXrryfhw88Ea16q6JEUVJdD7A6Y2Fxlu9//mMIwU1Y3Uj25F2bKCnzmp+/lJBh3/6WZz77UTQFfvTlT+K//ur7WO0SEWX31x7CoEV7l0GUIpksSrWIn47v3PEPAhRE5A7gMGZI0KnqhSKyGXg3cApwB/ASVX1YrKJ5K/B9wBLwY6r6pb/r+bUUutxZTCLmYyBOmVeJfSFhBZejfFK7+GZE1HWZLnc0yeQOuRsmb/AipbhRXzVxLJUe7lWpVFjNO/oxBlITKHR9Idd3e0ONbxG6XBMmDHTIuSVK7CnxlRVRqfhd1/av07YdGpN1hV17PckKjDH0EoTQsyhK78EiivkpiDnJ51yMHq+K9OwGJ/9npR2PGTXJkVkvorVuaqxQHU1IAWxRiDSrmQ379rDUwErXMQozNGLHuprHbgDjKbiqtMGjb0r1wDA9P965twyI4EkbVgxmlxak2Pj5MXPE2a6lOfIw6kV5ZbJUOUSVtYzbVQg4IOXZ4WXIwlUHCUyVIA6oFI/XrBKGiQszDvm9VQ3Rd5WC0uXWitgUKKUjF/Uutstt0P6cdsVAEETcqkJcItH2S2yI0T9v6cG1IVlhADX6eePHHPzgSil0nT0+xeTafumNGUOIhAnWTJAK4lWQrD6v9p9lcbobUdBVv7YChCYSg93MFlaWOf7+B0mLs8hojlAsVlGT3fxEheKxqgF6dkWprz2Bmg2OxWbcGMSvxXp9xohocMlBfaxJU/r5Fod5Z9evy6X88xxlB9JCQMmEUMgHH2R2aYmgipZMltgzksyrxdYdpQIYfg4dNMz+el3X9YjnkJTh8ZJEZkazjEYj2jym7TLLh1vGK8r6xY3Mzc6weuQoRw8f5Oihw7QrK+6hIe6nYp9RLh1Zs5tVTm/Q0zEd//Rx7PwZ1qJa5IMZKUrBWWuF4QYM27YvcOIJW8xAVWpH0sD0m3fv46d+5rtB8Njqw0QxlkOEvrFhxfzQKdFQWF0Zc/BhIHZcddVtPPEJp3PHnQd4029cwmMu2G6sNmBuJhKBv75sN5f+6VfZvn0rJ5240QBU6F3hUTiyNMuXrtvPE5+yo2dkSAh0vmZFgSDKk59yFo973BkocOjgmN/+zY9zybPOQAP89ltfRZvtvf/R73+e1/3sM90LxmRsX7/lfs4580TweL6aWORvlAFMmI7p+BYP3ytJD+PXCe4yarXklBIEJFDCUHDvOGEDW3Ys9I25Cb9mbrttP6edcZzJIAVCXO4BAO1fJw4TXhWkQ2LkZ1/7HH7ntz7BAw/v4/956ystYdXnowps2jrPrpMXCDqkg9lLa59Fk7sAus6bdZHXve4ZnP/InRSFNsDCXKSUebS42bMoBIjSQoFOYP8Dh7n77gf5iZ94hr1GNn+HhfVz/MzPfDdtp0iGqz53O3fveYiocP6jT+FXfu0kOl8Of/n170Es/sHASgGp66VM5/x3+vjHMBS+S1UfmPj+jcAnVPXNIvJG//4NwHOAM/zrCcDv+9//+2HwtpUSUmUPRp3Jrtuu+n51U78gFVVnoICL+A2sOtHHNbr3lBLteNAgi0Qv/Gqd6OZ8nlFf/HGpGdF2Y9NRO5IpaqyC4A75BCyy0elEk+7+fXfbj12pUZP0iQ8Fdfq4GewNRXghd61NzpKdbl9jCi2WqXTZIwQd1AiRISrSQIUUAhIjY7Xf1qIuGwjmd9BWSn30YrejlEzbKUESs9px6qH9HA7CapwlxA7RTJBoyQ9iJpYxCOpmmTEGN/pzfX+pfXmL5AwEOjdwDEHoshVtoWvtHLjnAhRiSjzUbLBFWjzdI5jRVfQucquWJBGykGMHWszzIY9ZXFlhxqM/7RgKKQZUXf/u59LOa80LDlZIUi9B1716jrCKF60eVzqppa/d6QoIVGDIGDbRfRvsGjQKGnStnQshElNjzAEt/XPoN1mTS92bqQMpweaCpIENY0wZ+vSPnDsvzP1MOAsDj2Otx52BUWxYJvPQ4jpGs4lGA10saFRCMZAgU5h/cB/pgDN4cPZAFP/O0Pg6D3OXe5YCQm/WaS+s7iFh59hSV4qDQCY9Qe3zj5UV4CkwMUUznJRqLmlzL4VofgNim4SEktWYEkEViQXVERLh4OJGjrYdczm7aapfCn5DzKW4l0ciRJuLJXsxoMY2Kg58FB3qDi1QNDPTRB79mHPZsX0rqysdN994J3vueJAt27dx9umn8fVbrmfPfbeRx8ukUFknnvSSW1SC+zRMGQrTMR3/IsPvMaIFK/PrBngw5Q0ydpIwiEbWr0s8dOAoc/sSQZWZZAbKBJgfwf79B1mYb/jRVzyJ33/Hx3jpi55MzmIxwArEgmpLO848/NBRgL7EKUFpZgKL6w7z4pedRJjZxR+9/VOkrDzv+WfwP//ws5xx1tORAJ/69FU867su5Litm3j8RWfysh+5lC9/+bX9Bl5liIlE4BU/9ng+fPmNnPqIORB4359/kVf+HxeTFf7sXR/lqU9+JKedfjzXX38bt932ABc98Vze9a7P8cofu4CYzNfone/8IC/6oWdy4MBRVpYPc+YZ25BQqosPV37hRt76ylcOHdV6foE+RrIHg6djOr5Vo15vEfc3nYAP7V+Jjqh2nUNgYSHw0MOHEcm0UZmbMaPpGCA2yr59B1lYN+JFL3kCf/SHn+AHv+8i2lYYZ0900YzSsbLa8dBDSz2DVAENmbm5hu07F9m8ZY7HPu5xNKOAUFicTxw6cJR99x1CRFleXh2aWjKmeKDLoUPL3LvvEG/57S8xM2uNuPn1HSvdUQ4dsQbJX3/qar73ey5kfmYdb/+9L/PmX78YDZnZhYbzH3UiH//wVznvglP4o/91BT/y8otJQVhaWuXtb3sfP/f6l3PH3fv47Cev55LvfTyalSuuuJb/+JPfSwH+4H9czrMuuYjZ+Rm+eNXNPPVpJzEa2d6yIBw5ssqG+Rlizzr+Fn3U0/FvMv45kocfAJ7h//5j4NMYoPADwP+nhgpcKSIbReQ4Vb3373oy25tHd3F36j5Gk8G7lma+J54CEYy6EwJt1zGTmt5ET73jXgq0nXX2qqxCXHtvcZPWRazeAUilKQ9FVf02xoR21qnUYt1RiYEYcYp85/FxgZgGZ/zqom8FpMkgGhrrJpN7bb6WTExNX2QxAUrEZDGPpYa9+mLXpETuMpncu/p7yQYIuXS0rZn7VVr4aNQANYrPilBLFxiiEDsdzP1y2xGTgQqRGfZu2MzDO49D20xTrIvdaQdSXekD2rvcWodb1zjRu7+A0qcXUD9z6D97KdrH9hWPnUL8Goh1VTIDmh5tdoZB7BRtIKjZYEuX2XXzTexcPQq5JTSmm2vbjhgTWdVoXi43GZIUci9jqNdDNceMMVjHW6uWvvTXWC9H6JSYgkNjgoSaVGHgj4E31hE3gMlNEEPsk0eGFAljixi7ZpgjiDM/GOZFKVVKYZdLjGkClBBEhkSM4MyEMpFYYNnCBvLlohzasJWvPfbRxCOF9eNMkY4ibc8sCBJs7rokxwAkS/WoJqbDvK4fpQNuE4kq0WU4IQSym0PGmJyV5zGeVfbggJwILkMR3wT4lTFxjkouzsxwarMaYJf8edpQKDQEdaPTpTEn772FmqxB9UXwWsDWkcC4bU224deyltwDJyVDFSCKVv8F+/w3b9vExo0bEB0Rwxz377+ahw89xAMPb6AjowGTefh5UYEYEkGMdWLMk0hKM0zv0NMxHf8SQxgEB7WzDrbmFh71mJ1s2THnrDvhZ1/7bN7ylss5fP+YWAo/+EMXsnHLDKKBl7788fz+736MCx+/i6c/61H85Ydv4G3/76coRM465wRKhM075znvsTu4676Heec7PoWWBinWCAiyynnnb+GpF5/CTCOMmsRFj93FF664jte87oc4fus8v/fWj1EEvvu7z+a4bRvxw+KiJ+5gdi6aSTLwxItO5bqrb+aSZ55HScp3XXISo9EKb3vLJ4DA5u2znLxrE0Fg28ZNfOZj13L6KSewMLvIdV+4keuu/BRxtnDWWTus4SHK4vwm3vE7VyB0XHzxI1hcGFnCbYGrrvw6j73geCSCWe5WqeekWcSwx5qO6fhWj6G1YY2gWl+AcMGFJ7B+0whBiAXe8Prn8uu/8WFWjhYKHa96+XexONuwONvw/Oc8hrf9zke5+OLTuPDxZ/Dxj9/CW37nk2RmOf9xFoF+0omLzM5mbr9jP3/0x58nu6eISbBXuOiJx/H877+Yxz5xO7uO30bj0+Knf+pZ/O5b/5rL/3KM0rFuVli32JCScPHTTyZEeMQjtvHuS7/CdbvvJc2MeMqTTyAJvPLHL+btb/8El//V1wgh88zvOYetWzbw+tdfxEte+j/Zvft0zjv3OEKECy44g0v/9G/51GdvZXExcuaZ20HgmqtvpoQRnUAzmuHm3Ye4+cZPohp4xOnHsX3XRhRl0/rN/PHbrzTPLen4kVddREzibE74g3d+nLf+9iv8PH97WPZNx7/ekEkK9f/2QSK3Aw9j18g7VPWdInJAVTf6zwV4WFU3ishlwJtV9Qr/2SeAN6jqNcc856uBVwPs3Lnjgssue28fKWhyg8Y16wYioEwURYUmNZTSecpBt8asDqxg1mDyghiNGNSMrLDW3p/AqMQ4i0CosYa1sCw9hT0IdOMx4/GYOlua1DAajbCUitY6nqEWLcp4PO5d4FUHc7yinf9OdslEi2phZjQy0zUvhnLXuVzDvAaKFlAvWh3psALMIi8tlcG7/Z15JjRNY0Vz15lZo0tJTDpghnxd20LJ1rHWGguofcGoRdGsrDSz/O327ejCBrbvu59ZNcp/27WUXIx34GwTnPZfj7tGWBY100hja1S+gq2iMbpfAHhBbd4DxQtAM1AcrtfobIrsxZcmi6NMHQSPkXx4YZGHN23ljJt3s6tboeSxsdtCYqUdmwmjmFa/FPXrqHpYqH9uuTfdtBdSjxEc/BXs3Fe5wxDZaUBA9dMQuq7tpSum+7eq30AFc/e28zh4J9ixGPsixogyHFO95us5Syn2RadMRJ1WAkCVYuA0fSrjwlYDS+BQyLk1vwWEfRs285VzH8ns7XdywtJhiq4S3DgyaySExkNCxJBpv85TBVZq4kGF2Cttr8aUIhPgkwEUuZiFqcVSJjr3ihDMI8F8FjwatGtN4uHARf0c7RgiJZtZmYgY2Ndlp+LZee6wVIWimUOb1vPwhvWcfsdtrO44kf1LSzzugb2sa1ftlhgTZuscyGRGjfkuiJ+zmBIxRVa7zgEQ6Y1fs7ZoERpGtvvPDfvuPcBff+Qz7L17v0mPpGVxwwwXP/0JPPrRZ8DIYJImJopmVkLky9tOZLSwjtPvvoOX/cjPkpp1f+8aPh3TMR1/1/AdMLWDWIF7KBRKcVtkvwVkLH0hZI9qi+a/JM4I6A3dg0VLhmL3xeLxb2UiQrIrDo56x1T8H4PPj+Lpsfa4IuRglOIoHieX4a/+ajdHl8a8+MWP8QYNtOPMu/7XZznvvF1c8ORTUTJSIhSnTcfKDDWmVTQSF6qQXb2lzqtOEU/ooT/eJCARlMKtNz/IZe//Mq/+mWcyt5BAOgPTVSbkaX6uhYnvp2M6vtWjzu/akDGp6WBWWIjYvOz8K2HzTaQ2MoROnVnsy4c6sCcBGn+FqvLJxR8jE1e+CNEoEQYy+NwvCNUay/uHmGWXkitDWa1xUfz5ou9xEKXL1b9MIFqmRVHh0kuvYunoKj/+40+lSfZexz6XG8f9VATJ3twL9hyl0+GgA4RYTHqafa3A1okYICGUFj7wl9cgs5HnPfcxpFj3f9M5/+99XHjhhVxzzTXf9IP8hzIUnqqqe0VkO/AxEblx8oeqqtKL5P5hQ1XfCbwT4JxzztIKCoBdcqXL3omsxntWeqJQcqHTKl2wQqsCCZOdSYG+0LCiPDuLIJq2f0I/b53UjpzNZ6HWrcEp2yGaZjwEYxtYkWsxjVW7TSloSKZZ9/tn1XPXyD3VQlGTBJRcHDgpvW7daPy+yInrG7PlzQen+PddXwcucrZOrkiga8eUCdmICIxGibHTzqs5Yu2qBwJRosk7ypAkAG42J0KSQEdhJa8y1sLW8SonH9jPLGOyCktHV1hdaVld6chlhaaJrFtYYGFhHVoK49ZM62Kyz6LrOjNIdKBgZWWFGAKzc7PECvIUL0ydlm+FpwEKucu0Xcfy0aMsLC4waiymswShw5gnUUZohtQ0HMzWZWppKQGiBpd4SE+fF6nSgBq1aAt6KRNGh359iftxUK9JpAc7KitlMDmsn5FHRhL63825EKPJdzLVjNG9Pdwzo4JoNeK061piGjw5eqaC/3KX7fUtRtRUdjkPBoE5F4IbcvW/S2VBdFTjyRQjoUCWQi5jNowLW5eOcPLhbBxiuwAAIABJREFUB8wUCECFLAlCIJD9nGnvyTHMn8mtpFqQpEzKNSqkVFNI/PqO9OaN/XtQer+CJiXatkVUHTSEyurov1By15p3ShMRlEQih0KbCyGOIEZSp7S5Y8+McGTT+r62CEZBMhZTyTYPRVxa4XIHdd1kssjP3HUu/fHUh35e23pAto1AHnfMjGZ45CPPY9TMceToUZomcNJJOznhxJORkCh0qAybkeE6NJO4XuQ9HdMxHf+kUeeVfMP/uolvBRKkMiRBgpIippBQkzyJey5EKRDVdE5EJAYvus2kTEpwkp3dI0a1+p98dc1USSMCEur9Svpo2loS7dl3gL949xVs2biRl/3wU0nRWFsFYZQiF1xwGp/9wvWc/4STmU0goaChgtfqzDg1UIQWsHUsjByo7tcZIQRzq1eUQOqbAZoDX/j81Vz4hNOYnU9elvnaJ14RTbzHb37Op2M6/nXHmnsowx4NqtzTim9qcU+mCXgQtfS/lRFSgEa8AafW6OmL5r75ZPtRQvRiSyty4I/zfaSzICt64IRt2wP19YzN+FTZFf4yyTdT6hJaFJqow96g1iIKL3vpRbzxDX/K+973WV7ykmfYOkY2sFSr50M0kEO1P2EeNuVHNzy3JDWAUYRAR1STHy8vL/P1W+/mh370aUi09zvpEjMd35njHwQoqOpe/3u/iLwfuAjYV6UMInIcsN8fvhc4aeLXT/T/+7tfwyn/dg9Sd9l3x32ndXudS5PSQD9noKJb138AJoIbOqqzG4LTxS0yMffd+grJG7vA6OZBlWocCE45TsaaWFldrueFLrdEmr5gG49bcrHuuxUP2ejwWhcsm7jKYOhmRecAKmjX+v/ZuSlaUwKc7l7svcUYETHmQ9u23mk3ODREK3q6tqWNwQva4Zypb4LqmmE0c9Ou99R0jOlgsXeB1CRiHNlxBUVDoFvuuP76r3Hfvn2Ml8c8+OB+NmxczwUXXMDpp59mxX0y40rtxj1zAYSsGS2wf/9+ZmdG7BztpATbmMVosZYF2xwp4kkDVhQvL61w3XV/y8kn7+K0Ux+BBKHRCCUwTi2FMTEFNHZoULIUujIGiYbeurSgGhdOpiYAfRGfHamt/2fHgn8fejCpMl7q4+o5NnPA6M9ln2t//sXOf+lfL/SssFK0T+3oUx3EAKnsoMHw2s64cYlB52Bc7zXiLIaUUn99AEgY5BNdNs+JFA3AMlfz2MeJajG2gxShCTMg0LUtKiYDijGg2VgXQYaEEyckoKgxYUTIahIBCQZmEWBlecXAsy6TovsTqG1Kc5cdRHBAR1xiYB8OiqXACFb0p5R87phu1yQgHdEBxK4Ym6Vudlu/LoMoTQnQNuTOpTkOaBaXWlTQz9oUfjzqNmwKuW2JTWMOz9r5+x4kGVoylMjBBw9xz90PcPDgMocOLvfzfDQzx+zcIjHOoiS6UuU+pY9iMoNHu/74x+G40zEd0/ENo7bc64Ye+psvgHs1VZqXVMNh/xMx5lS/YdZqfFZt0wbGw9Ck83bghG3bcCz2c7unVKA52TNJMTYbkUAhi7CwMM/TLn4U551zAjHaminiG38Rzn/MLtZvm7P9Q32rASzGbqAhB1Gsr9rDuwgZoXjaha2ZdhxuGNG3YJWnfdcF7DplO6Gnkdt5UDLVtPobz/u0xJiOf8tR5yE25wXwppS7b9septKJ6t6pVtdYswrBkhwmrmdrnFiDpO86qFN+KkCJsR217h2ZaFMpdt+vwCL1P6HShsScYqk5tFmKOUQ4uDnRCgOBGITXvvbZZiju61Gqx+17G/H9RvV6M/lrMB8pFFVfD33tCjUJhxoNqYzmGn74lU9n5/GbCHiN1b/D6fhOHX8voCAi64Cgqof9398D/Dfgg8CrgDf73x/wX/kg8BoR+TPMjPHg3+efYKigGDU5mAZf6zwJwwXYswxydk+Cql0egIQeTPC/Y0rmvlyNAb24qkVgKUoMThFHbTKKoK5/zm3HaDRyZrrQh8pTnNlgVOcmjcyHAI/mC5UFUDcTwx5FJBpNui88XQrh7IkcbfOgZaL4r2ZvaoWEohNsA5zm7Qiqv5eSCyma4WJR1pgG2jlQ91YAzXnNfqoer7g+vhRhpA3SJiTNkEPDuFVKSYzbwsHDh7nv3r2EEFiUDYxzR1frrpCIwYxubF9mEYG5WLG4b98DbNu6hS7bYtg0I0rJ5uUAqARSGqHedUcyadSxtLrKgUOHIAYKSu5sAZ+hoYSWQiFrBs0EgegL4tCtzz2TQER6P4vKCug6W3SbpunPG/7zWNk0/hmWYsaRvUHoxHVYgYXorl1VClKlJfZzR5yLm3iW3CcV1NeIISBiJqBVTtMnG8jw2ZZSSMmQ4rWpEO5vIOYNou4RUBk8weUPwbtXndrxpDw4A6sWk+VEY5wEzXSloysG+Bw6eIimSWzcsIGapoIq43HLQw8+xOHDR1CB7Tt2sLi4aABDl3nwwEGWlpYpOTM3N8eOndtoZhsHBFz6oSbJEKRn4UgMrBxZ5tChQ3RtYTQasWnTJlLTkLuO5aUlxqurLnXKpBSJYYaFTQvMzo5oCCQJjGkN4FIlakMI1qWr7JhSr0W/dZr3hiUtBMV8WlBfj0rPOIkhIo3N1xgSEFg9Oubmm27j2iu/wspyR9bAatuSHbTYt+9+Dh85xJOf8ijmNiQDMIKgkn2DXo/k2GJkOqZjOv5xY6LQdd8YHBrQtdvxPnZtgnTsj3ATX3EDX/G1twIOdjcGMX8a39v7awyFysDlsj2I7w4Qyaim4WhC/xNEYGHdiEc95hQSQ0GEZISmP5xHnLTNapKifdGi1Qjbn62udfW0WEET6Q0VKxJB7JsiPfgQ4eRTdvRQxOQQ4tDxPbYwmhYY0/FvNbQ6tPnV3RfgxvDUCaaB9o8LPURohEmPlQYzQIV+Tg3ltXMhxHROa7LDJGCxtRVnVMQlld8wNdz8m4njgkAWiBj7skauq2Syry9N/XUBorLr5C3+3EOjzH7HWM/RgRQxlIRqY15BiuFsTDJRi0OqdnzNKHD8iZsmDr4a3k7Hd/L4hzAUdgDv94suAX+qqh8RkauB94jIfwDuBF7ij/8wFhl5KxYb+eN//0t4p1ytiK5GdJMd2JSqE7zTxHs6eKBI7inOtQCb7MaHMOjKexaPG8iZDsnN7DpDGkNv3mYTNGggd4WQ7DWaNGJ1nPuCu2r8czGKYDWc64cO3gKWvtDRNE2vkY+x6YumKo3oF7IJCn0phc6jJat5XQVJ6mNVC13/s8DKytgAkRB6FkN9DQnGwTD65GDKVzyWsp7jeq4ymRI6ckpoBBkLKc1w9jnnseO4HfzNFZ9h587tnP+oR7Jhw/o+7q54zGNxNLMaDI5iw/K4Y7yySjtuvcNdaPPY9i2+P8pZaUvrBn2FINA0iW1bt9KurtKNW++ACJSOJLaBKwrSAVkpbelBKmJCu7ExBlxKYewHXRvxGYSSM63LWnIu7lOQrGPu15kdp0keOve0qEh2BXEG6cLAmAFjW1TpTdd1fWd/8jO1x5lMpje4Uiwi0k+SBDwekp51UEdlXVTmSYh1ftj8MaaLTYziTJZmZJ4CigMyXYZOycXkGSkIIaT/n703j7Yrv+o7P/v3+51733t6eu/pPc1SSSWp5sE2dmEzhNHgNiE2IZ2kGcJMA2bopAkNK1npTiBeIQxhyFp0gF4xmchgCGMnZMDGMYPxiLFddg1SlUpVmmfpTfee39B/7P075z6VDHYHiJbr7loqSU/3nnvuueec+9vf/R1MNuNJuXDz2g0++vjj7D+wn4X5BZzX45Vi5OSzz/LkE09w4+YqOcN999/Py1/xcuZmh6xvrvP0U09z9uw5gvfMzc4yO/vprAyWySbD8U6Jtm7iy6xIYbw54uy5czxz4hk2NjaZnZvjgQceZP+BA8ScOf7ss5w6ebKTGs0MZ1leWObRVzxCM/BdEoSKAU2GU5JO8IyRUJf5vVt6IZr8ocZNVZ1wTMnAeDVu7X00MCRfWF/d4PSpM6ze2GBpcZkdu3bSphZxnvX1EVcuX+WJjz3B3Ud2c+/SYcQVSknGxEATK1CzzankYVrT+hOoerssfYvdL/z7dqJQQCw1h2LSvbpQNkCiyg27VqVCFAoUTGKAdauTTAE1hy79vhRvzQa27UKVEIh9H+omaztjTU4HDpRu13r5XkFKqO+I2gIVEpWb2b2nbiI5eZhK15Oo0W/91ypbnWiauu1MHu+KWExrWv8j6sXfm73wErD4+o7av+VZt563vVTb1fjXsvXKt8B3e76lyBRPl3oCet2Xgumo+sfYxo1PMPG6CjA4AyV0DWJPFWUwqRlCZSAYqHnbxj5PACuZjgFRCgU13Jbu/lNfvt83XUPZPaOawUyAkuVFx2xan4r1xwIKpZRngJff5ueXgdfe5ucF+I5Pai8KXQRaNRtsY1SNIhNpCxRCoxFwal4IMbVdcxZj1Fg5uzCcE22ivWxpsjpzx9SbM3rxiOsd5HPu3dzrFFflTln10UUd8LtYPkFfx/6LSVH9YFNrNferiZRuS9NI0Si9kgs5RY2/m7i9VQZCMuCjbaOxD0JnIli17zlHKMUwgNxJBIK4LtKumjJWkKOCLBq/l0gp6s2xM5ikn4y6RC6JcUoEA0S2z29jpnEszM2xvLSDnTt34b3S17v0iaL7X6tpdN9nmhlyWxhvjikJYo7KIHB1cm7AEUJqx3pTFukkIKPWZsFFj39MEbIjJU1ZKC1IUZp9ysZ4STpZTrnqVPv9qp+XOEWNW2u8Pb6uE/vPzbT0bRu7RAM9B6uUoj7WvqI6I8zUSR5qZGNOStsfOvNiyBWQcN12K9ihRp+B3EaSJYtUn44Kxm15jZzwvqEamtbzsXSLU7rY1VzUrFFiwnn9ecyJWBKjlLvzcpQj5IJLquHb3Bhx8uQLnDhxkrlt2xm3iYEoNn7t+k2On3iGm2sbzMxu4+qV65w48Sz79x9kz57A5UtXOHf2PBvrGzgRzpw+w/aF7bzyVa9gdnZGPRSyGS9a6oag129qC2eeP83F8xeIbeL8uQvkVNixtIIIXLl0mXPnzhO8J6YxORVuLK5y+OghFhe3G+ifbTmtDX/RuBKVt+Ss9xv9MPVREmwNYYaWpf9zlRJVMDTGSNvqfck501qLo00qnVleWeaVj72C7QvzlCJcOH+Fd/y332Y0XuXSxUscTQc1473eC7Im2dzamExrWtP6/1O30/WWLf/eyxKke3zXGHRf4dbIl/5ZTCyjJ1+le24346uj0dI/tmtI+sYkG3Ks6/Viz3cT+7sVwLCblq0FSgc8bIU6+lfVBmJiMioT09Dua6x01Gdztu2A/zLx6hVQZ8vP+r9PHsVpTevPqm4PCLz4HO2v3B5M7B9er3vf/7xMgGzAVsZRnoAV7PW667u/fqWCCx2ouQWBg4ktAr0HCkDpAb6te51RP61JJsWk1GnyvbkJYFLXQ/XaruBffYe3YoFVnqH3vFs8Yep9Ylqf8vXfExv5J1cCoQkUzOzMfhdjHmjpl1g1xSP2LvxSvzCtudbFfJ3W6kTPhZ46PmmGVwnEcSJdIdemQMeUtMlM+0QHkiofcLS1aavao4Jp7B259F+d3ZvEkh3om7nYRjUhRGjHLU4KcVxomoA4T9vGjkZf+1h9nJBdocStvgjFXOVz0oa8uv07c+9vowIwKSWCC5SSGY/HBkSoyWTumBOe4Bujwmsj5AuIgRtJMo6Ic5mYRnjvCKHpEhY0drEQx8qYqE23UvptIpJsgZMNYXUBpZgnk5hoA5fMJ6JpzOHfFcbtiJTNihohlUy0Bs/lgBdBvIArOLOvjm1i4ALBOxDXnTOgvgqt6fzFWAoa7WjnjroZ9owWA2LEzhNQ9kLbjjU+1Fg2/edTkz6qPEWXiZhsxTmvC0bJ3TS8pm3U60KTR0IP1EDHeKgsnUmgoH7W+j58Bz7Vc7KUgneeVDJt0vNQY1TBZU+KkTYnIgo06HS8EFOmCQ7nAqONERcuXOHDH3mCC5eucvPmBm0sOF9IKbK2sclo1HLk6FEO7L+La9dv8IH3f4CzZ88xO7eNF06fYTAc8uCDDzEzM+TDH/kwp06d4uixI8zOzdlxqF9S1VtEz8nV1VWuXb3KoQN3sbS8zIWLlzh99ixnz5zjwMH97Nmzl6WlJQaDATm2nD93jnMXrzDaHENS3wUFkLzdW0z3a0CPN7aSfkwKPpWiDsc4mzpiHhV+gt2CMhYyxlKpAF8uzM4N2b4wTyqZ85fO8+RTH+WVr3o5MzNzXLl6gZTGFnOp+uMqk6lpJE4CQkCJCtMv6mlN67+vJq+hyYa5Th7N68BYcN3CX2H3iU2U24B89XH1y6KYXnqiwe7+WL8n3G22UbdUHWm6L5+JxX1dzN/uPVXGpf3kReyASm2efH8VGHCd3KOfZPatmdiwQYGQQr9Drt/z7tjVfZvet6b1P7KyXXquA97UanGyGZ5s3+tPyuRfOmZOT0iQvn8uhQ4wqMak3fm/FbDQP0003qUXTNwOAOlBwMoSKBPbmgQpbRtS7ysFTanqY2h0nb2VkUR3RQvV66FU1ka3R1XU1XtQlMqs6gCGCkBIt/lpferWnQEooBe2LsazmtE5MXNDNUtr24L3WJqBNctpUtZQDeZ0ax1mLsoKmGy4qiN/TrEznauT5X570jd63lkvmbobhfeeaNNrROUOzgt4x3gcrTGUrvET6WnuqnEP2shbwoATwTdNt58dpbE2iZgTf0y6P6LNe4xtBwCIU2O8gtD4QJsimbRFRhGjGsWVXMDRNb3OBdqYKCK4ENSO0uk+qBu/I2WhxIxvdIKbvN5AcpvJPlB8lVaMGAwG9qnqcdOmtlEvAzvepcDm5iYlZ9Y31jtwKNlEPpfc0a9KKQyGgULCBcFlGAyDAQ/JmuBi8hMIRSiin5t9LErzR0hkmoEnj6NJEnrpQgWUvCgLQH0bTBtLP8GvQIQaICrI5URlJZrI0MdK9nIH8/XwPeXMGXOliwpNfcJFBcBqiklndAgd4NP7M+iXSz3nJqu6gotT1FyMgRNjJMbEsBka8BTIWQ0QlakhCkKI4BwMxCExkUUlR0qhVTaH84HZ2VkGgwEbo03aGBkM1ZzQB8+e/Xs5ePAgSwtLzM7Osri8yKgdkcmM2hHLO5fZf9d+ZmaGxDTmQx/6Q0ajUe9wLGLnECq1yHrdxThmfvs2Dh89xI7lXSzv2smV61c5c+EMB+8+yP67DjAYNPjgIUaGwwHnr12ljSOVGTWBVHTBLWC6hqTfx3URjuvYKYjFUgpdXKcruhRPSeUdElynhBADS9X8Vd/LcHbI4bvv4vnnznHlylWOn3iSg3fvZt/e/Zw5+xxr69dYWVlix/IiQrHzRZkoDo/zQdmLMtUkTmtafyI1Od7DFtyo50kPHFRKcn2Cp1L7uyW/TEzm66TRvBMmHQtqI7B1fW2GvzIJKPQNRdVuU40aBaSoDKyQDSSwfbUdEokIGUeD4GpfPxGNx9bHTxyQUry9H9e9DwUFdE+y2OuSO0O6yWln3zgVIOrPJHC7Rm1a0/qzrYlGvRonknrmgAj5FnhBnyXdr97ezQADYwH0WF0vPZItj9Prooj6CkzymFRq0fEAJl690MkXDEjsX8sAg/qeip94pt4PCkYUoBdg1F9FKifBqUcb1Z/Jd7uwlX1UX79iMcWOlL8F+kh2C6hxONP6VK87BlDwiLnGa0Rj7YmqA71zqqVXbX3BORiPxzo1dxbIYjeDXKn/nQkfSK5T5QwZPA4X9HlO9H9iVHNxnpxgTB9J2XiPYJrqoqhekADeK0MiZopXmrzLCkSkGK35cjjnNbkgtd0UU+z9KUXaLriguipv0o4QGpUPpIQ4xygn/CCQY6SQ8EGqRBLtjR0pRcap7VgNvkbfSQ2/sfC+rCaGCsa4ruHJ2UwvVShKNTRwFCIZvMObZMQFhw8BGQrD2jhZg+4cxAznL17kwoWLlJw5euwYSwuLZApra6t85COPc+bMOXKKLC4scPCuA7ggbGyu8+STT7C2usZgMMuunbu5595jBhxoAsTc/DxhMKCI0FaTQ4vmK1LsfSgAUGLRz9dYAiU1DAZNZ3yIKBMhmTZCEwp0uRhTNdRKeOfxwaLAxKtfgyHRuUC2RWQFt4p5LSCQDRkuVOaINx8Ek59U3Nlu1tpI3+qRUWUpFeTQEjwhqF4/GyAj3jEYhA5Fz7nVbVC6960+FxDCAJ2ER0TUQLJQ8OIZ+AHeN/imwQ+CgiAFKInsC24grOxa5rFXv4oPvF8jN4MXvNdElp3LSzgK8/PbaYKH4YCVxR20my2S9XjnUhgM9DPZtn07zXCWNhWcawxArGwgU/cW7f23Lyxw7N5jLK+sMBzM4MOAPbv3GkCUmJufYzgcqoQkKGDSOM/s7CyIm/j8XXdfKagJqSp1em+WmBM4PdccheD1izunVmd53b0rki2sXdNTkhodpWSDysSxew8DmRPHn6FtxzRemJ1ruOvwHmbnG/Yf2M/+u/YThkNiiQgqq9HzJyqIIz2NcVrTmtafVNUF8K3X1q3MgVpymz/Li/7/x9cnsn1b07yoYQfplnPd6BQ1V5vYrpv8bdK3obIrJpp9qY+ZfP2tVOmerTD5nNsdt4ZpTevOqdpUT16vDZPn7se/GqvZdL3+esOvHky43T1h8s89K0Bu+7itr1j3SBkDt26xNvf1PU3W7aQNcsvvt77XCmzcfjsv+l3Y+rMOnLX70VSe+ZKpOwNQKNDGaAZp0Mcfopp4epAg5cjMYGA6ct81zKVg8gAsXpEOQEhG09YmX70KvG+6Bk0bK0eMeUujX/XqmiyhjVi3bfG44DpKecqZUAQkm36+p7zX/YfqS1C37/E+k4pprJzrEiwQCMET29bi66By89VTwoFTzwmX7XlFLAnAzPLE0FGpyQVYLIwladTmutQmVpkPmUSNHKy6+7puEed0f3PG2aij6v07DNMo9zkXrl+/ztNPH+fs2bNcu3qd1bU1HnvsMebm5ri5tsrJkye5eOkS2+ZmuXTpEvv27zWgp3Du3HmeP/U8QmD37t0s7Vhi955djEeb5KxSjc3Nzc7cMueeqp6ymTBORE6mGPFN6AxyivkWKDnB6P/eU4qZgbrSSQ2qBCalbF4WoTtH6zvPyXx1zdMACikLIfiOJZDIXcJDlX9ooIh+Ph0LZSKxpPP8qHIRAwyapunBBtRBOIRg7I6CTBqaTqRZIGq9pRITZz4VTMiEKo1Oz58UNfpUmWy6/xkhOJWf4Byzfsj+/Xs5d3Yvq6s39WQxT4HBYMDOlWUDIRRk8M6TqKaQgRdOP8/Rq8fYvXs3167d4Pr1G4xGY5MjSHfuUyC2sWMtzM7OEnbtZjiYsf32zM9vZ219lZwzg0HTvZdx2zIaj9m3dy/z2+a7Y+uct+ulQM7mV9JHb3aSGOc1bhYxELMQnCNPpKfoS9ly3StrRoqCSfV+VDI0A899Dxzh4F172djYYHZ2ltm5AY++/AFiTsxtn6cJAQlKQS7JJCcGTqkUYvotPa1p/clVbf8nF8Zb/+3Fa/5bIQO59Z+6P39cWKH7B3ebx9wKJtw6tZwEGG5XE03Lll2b2EbpH6f/WCYeU+jNHrceg34bH//NbXnMtKZ1R1R/Tm69buXFl/ktp61w6/X9R90zPu5GXrytWx9wm/uM3O7nsvUdfLwG/4+6r7z4Nnfrnn28Pf3jtvpx7oXT+pStOwJQqBntFQtXEz6dmpdc8EGnh6obKGxubDI7O6e0+5jxLneMhkkTu2YQOkq4lk1ePZ2mZzIRQkEIpe1UWnofzVhMtqCNsveBlNpOaqAebX3kYL2CooEZFbRo2xbBmiQBjZGBVDK5TV1TokCFPr+6+8vEzaOnzfc3jVKy0rRMqlDMsb/N2VhS0rEV1Nyw95VQWUQFFyz5IVcgREzzX2yK30caVg1+zFUq4juNey6ZU6dOce7cWY7cfYQLcxc5deoUe/bs4f7772dhYYFHH32Ex/kIczMz7N+3T5tkCjPDWR568CGO3H2MjfVNTpw4wYkTJ1he2aGPafWYBB+2TPS726rUpIcqS6lu/noeFQMSUk740KiEJVUZDVDUUyH4oBP9pLKKCgSlmPCNAjAp5w746pkG/YQaUS+ByhQQofPSEKfv13ml1NYEjKbxypaw9+O9787FGnGpcaP6ejkn2tYiLrvPuXQygXr+doCdnSMp1uhQ9feo0ZnjcUsw6n6NFm3HOnkXcZ0LeIqJUlrAE6N6XGjSSEvOweI1C6EJCrQVYTxqGQwaRiNlGC0sLLL6xBMcP36cEAZcvHgZ5zyDgUp6Ghc6MGXyeqyAncZ6SucXovs/7q6l+pzRaMSNmzdZ2bmL2bnZ7vOa9GnRxA29j1QrpRrhmW0K4QzgUFNN/cxkgqaciy7SczSDUQPsqnFqQeMuB8HTDLaxfXFWEyE8LC7N0+YWCSCS7f6h11NBWVoq3UlUE6RpTWtaL6HaEr1o3xET8opPcmO8GLSovz4eSDGtaU1rWtOa1ta6IwCFbM2BWFOsBoL6JacTVNUKiUW/Oe8Zj8fKDIiJ5DwUndIXl81jQEhtVPp7t30zXQPIssV8sE7qK/05TzQBHS2a2oBXACKoiSFFKfdmFNn4gJBIuZCsqQlAb8oHjffKMAhCjtHo1r2pXvWEUINJOhM/0ObSe5VEZCrYALWB1Wm6JhTkrAwI8XpMRUzm4bc2UlWiUIcSpQhhIvIQfde6zLCUAUElFSnrMfdeGz8fGsQ70jhy9vw5lpeXeeDBBzh69Bjv/O3/xvXr10FgZnbAsWPHuHDuHNu3zbN33z5t5KQQQsPddx/Fiacdj4lty2hzU3cva/ykF0exfdRjpYsq771Okb2391CgFLxTtWlNvaAUBSRclRwoIORdQIK34yjdlNyJ0wm1qOFkL0FoO7Cp+oAoByLpeVSqLMJYIUVTS0q23N7ehoVJAAAgAElEQVQt6K2CH7UJjrF04FEFq2ojnVK0ZnbS+K8/150Tcom2X9LtN6UHwbIUY9TIlteoXiOgnhdqGCmWfqHmX96JMRbMGDVXJpCxL0zyIaE3gxS02b958yabm2OaENizZw/z8/M8+eTTCA1nz5xnaXEH27cvUMESJen0+9iZJvqa+V6Pr57L6+vrFsnZH4+UM22KDGdmEAMMcimUpNIYXP3cSufRkIuakEkBcZMpGdW8jf7cSIkiKrlJ2cAfFKAzBQ0F9VqpqTUk9U8RZyCf12u+TS2D4bCmYdt1ZoCJM8+OCkpOa1rT+hSvSaYA+vuElnrrjWDC9+CTfo2CekjY9m/DTJjWtKY1rWlN69a6IwAFsOQEJ1SHY+eUneCco0TNYK9EPJgE4pWN4L3vFulCH9Gn8gZPTKnTiSejpgNmaOepWcq9uqA3g+uMC8EmyApypJQQ7/HiFTxI2txl9L04m4SDej+0MdIYeNG2Sllv46aZNDba1Ih5SueoTIng1fDIJAttbI3RUQ9CIaPabmV2FLz9PDSOdpy08a5NotOJrTdjynqsNcZRaGNNzugp9vU44UPfTJXcTWtTUoO6jdGmsTv6qexwOGR57wpzc9uYnYP9Bw70bAEcPjgWFxcJzqmnQVFJyjiOuXb1Gtev36SYZ4A3kEXtHmSLl4BDOsCjAkB1/eO9J4RA3tApc1NBCCwelEwbq7lhMAaAI8dkzbhXKUgpeC+0bTQAIVoD2+KdowlmDGlT6AqGYedNlTB0TAGLFgwTYJcgtONoDbh0wFJOSRV0xS4WKeb9ob4JqURtuA3gaduWJjQ2+VZpQrY0kcoyECeExlGy615LzTJNiuG8nUcNznndnvMUa/ALBjZYgorD41xgc3PUmW72kgo7f8ctV69e5ezZsyzv3EUuhe3bt3Ps2L28452/zQc/+CHm57fzyKOPsLCgsoTxaGzyn2imjL3UKOdioJEyFNbW1rh48SIAMbaUMgPo+Xnj5k2cc8zMzGiMo+8ncMXOu17GUhv51N91cmUYGoCRoZjDeRtbUsk4FOiqr9mnsGkqRc4KAoTgiKPE+vpI5SapZwJlB37gESmEYYMyWfr7km4LRuNRJ8eY1rSm9aleteG/nVa6PsSy5z9pdkHddpx4jSmCMK1pTWta0/rE6o4AFPq4O/17NZ4Ti2xz1SMhtp2kIaXYLcK3sAhKZTlUAN98TYMn5axmguaTIKKL9kojrhT+MjFlrc3VZETfpHO/UN3nJyPjFPxw3nUMibr9MGjIMfU6/2p46Lzuc9Kmt23VkV5lHy01CrN6OtTj5CYo26VoY9PMzNKONP6xUF34nVHXDfSw3+v70fIqX2ijTc57cKc2yXWSX4r6W+gwXgGOmdlZnbTadLwmE0jVfRu4k7NO6Wt0TWg8lOosW9TULmdOnDjB8ePPkMYt43bMvffdq7r4plG9v7EOpKh0QSUJqsvPORPHLTHptlKuC6WM9wretOMWcZ5kkptSVEoAmgDStlElOCkZq1TIOSJSaJoBOUdiUhPDZtCQk+5PsgQRcITgTTogE+e1auL1+GsjTM44px4dlSkht9BXJ6UdufpfoE2uyiZ8R8WvjwHBlWL+En3KSAU6nHNdPGkIej3oRD0bo0ZTQlKq3iC9CSVF1ItEjHlThMFghuFwVq+tCUZB/X20ucnp06fZGG2yc+cyg0GgALv37mZ5eYlz5y4yGAyZn5tjEIKeFzmTYu93oP4f0qU9JLJ5oLRcunSJK1cvc/jwIWZmZrrPPOfExsYGKWUGMzMG5vSyiYKHrN4TOSnjJk9cV0lpQuQMwYFkky1VGYRXMFTTKKKeDznb9asshZRVEqQyCsf1G6s89+wLXL+2ymhz3HmjZAd79uxi/8F9LO9ewAVlUUBGBrNMOk1Pa1rTeqlUldMlqmv6Fof4on/Xtc0nsU1jN1r2QydZ7NHKYg+7lQkxrWlNa1rTmpbWHQEoQNXt9yaJNcpRsIEsQvANqWgjWRt9H1w3Vc5JJ/WV/qyNazFTQ/NksNGqflfWqXRvnlgNBfv96j0GvEkQKgU9paTGhV7YHG121PNkjXuVb0xOEWNKFANLYkzGKuxTH2LsG+UYW1xWI7hY2QfB29RUrAGUrnHulhtFm6xio/BSMiWrvj7nrNT0js5I54nQG0d64jiSJTM7M0MuBecCwQU9VmLmj0UoohKC8WjEeNxqM10yJamUZTQaEZrGpv7KFLhx4wYpxY6Gf3NtjcYrhR+nBnaXLl/m7PlzLCwssLm2ztWr19jY2KBmXScDZXLK3eeh7ARLmJDeKC/ZNNt7T8mVgaFGibUh95byIIKxJMAHR0nZpj5eExFEQYuUW9XaAzW3t/OZsD87MxnNWb0ZEAhOjR29a9QMMhfalLo0Eed6T4/6fGUzqCeGdw5KpgmBlNVoEDEgomRiVMBExHVGirqN/ryukZCdiWVuqd4PFUSoDBK9riq4oMyH6vOgcpTWDEH1794Fciq0YzUJdThKFlJOjMeRK1evcvrMC+zcucLevXv0eImwvrFGyirPuHr1KpcvX+bAgV00TWA4GOrrd94PdF4POWew97G5ucmpU6dIKbK8vIOZmQG+CbSt+imMRpvMzc0xnBluYfPGnMzTxOnxchWkTAZGGePEAMRirAhvn3c2jw6H62JLK+BYPTm2GMhmGI8STz71LO9/9x+yenNUc5vIRX0TmpkBR4/dxed+0Wewe/cSGHtlnDWlpiZAT2ta03oplHTfM8pAMBaCDTAodf3CFj+XT2i73Z2kyiR64KCQETEJxJ2zXJzWtKY1rWndYXXHfEN0NHXR6aM4YyakuphXczuSNcgi1CDYXBLBB6PZaxMZU1JnfedNHqENVDW6U1C+ggula6Cq277+cw9cTE6Hezf37oH42txIMYlBNUwr3fYm/RHql3dKKoOg0DEPBKWt+6BGfV4c+Grqhmrgpf9VjD4vJrFocyKZzEKK4J2fiNcVfAiUZGAHPdti8r12E/g24oLrGtOeDi9I1s9JfMGHwGAwsGmsx3vBJ5NI5Bq/mRkOh2YcaJ4MWVMIhkNN7sCDL46r164wHA74tJe/ksYF3vve96jsIEZkqCkBwQc2xhudvCFmNf+TUsix9wII3jMYDCBudA2pNvxOJ8JFWRwqm5EuNtI5nQJ7CdqgS8ZJsAYz44zp4c28MEYFatSA03fns3ceyUlZFCJdJrlzjsaYOaHx5BJxHmM7ZJOPqO+BE0GCym5SMraFEwOwej+BEBQ4CyGQooJQFGUrhODtfKyGnn30ZEqxSzCxk7oDNuokPlo6hTJW9BxWWYj6dCQ7NzY3R8Sk/hE5l44lEmPm4qWLrK6tcuTIUZaWFpUBkSOXL18EMocO7eP8+Sucev45jhzZx86dO7vX7O8PZeu1ZJFnV69e5fz5sywtLrJr1069pxRlY4xGI27cuMHMYEbPwdAQ25F5nPSGiRbq2Xmc5dKDbHYFKeBi16OyVzLOa5QrIspuMP8IHe5Vo1JMCiKMR5HTL5zl+rVVFuZX2LG4QkqRlBQcvHz1CqeeeZ4zpw6xe2XR/BJKx/ZRGcQUUpjWtF46NeGf0EkUJj0OSgekf3JMAtvG5O2kqKxObk14mNa0pjWtaU3rNnVHAAo95b5q+q1ZEIfaB6jZWcqlmyKqhr9AF31YzDchqYeBMQWKyQliNA8G8ygg63Q7m8ShN/Wz/bFpaE2MCCEQXK+N1sY0E7yQIgTnKcY0UCO30vEOJ5MmggRCUFf6mvxQYy0FlOYNNAQqVTsb+1Abwu6obZFe6NRZj1+bE4OmwRfIUWPuMkq3DxbZlyWBU4JkoIFS3f4zdA2cRiOWidfTQ1hjFLUBL7lG4umxrE2TdmUKnITQIKLN53DQ6LGVQsqJ4YyCCVkKwcz/RqNNDh0+xO49uxi4hsOHDnPp8qVuKp2z+iesrq5SUsKHQPWn0iZPj0nwyqrw5gEQc6tT5lIjQNXAU8+UrDKRDgRRRgVZ9L0V1NxS1FwwGwPFm9RAvTJEvQ4q66Rg8oSCxxvTRs9NF5pOAoEruM68UTXzmGTB23nkzfivplXUbTknJGoUZZX8OCRMTrCkA8jqOLxr0F3pzEpdsZQCoGmUNYEoMyY0AZzQhEDbFvMc8J0ZJiYZqaaYGrlp779Ebq7d5Pz5c6ysLHPwrv0Mhrr99dVVrl2/yp69u3jg/od4+ukTPH/qOS5evMiOHTtMhsIt0qP+mvLiWN/Y4OTJk6SUuPe+e1lYWCAEneh5M+ZMSaNpvfckYxXoWlmBOgVFepZTLqWb9gnO5BAJX4G8XNkxJu8x4K7eTxREScZk6eNbVbKhfhJOPPccu5ddK7u5ce0qe/fuZDAz5IMf+iDPPPskN69fox2NCEE6gDHnCJLQwJYpqDCtab20ypgKBWUmFChSOUv2vftJ9f8TsgnowARzg4I8sb0prjCtaU1rWtO6Td0RgEJ15K/07kq1ThaZWEy20PkOWOOrD3WktsVVijHYl6EyHFpzy0ek9xuwqaroixvVvRrmqTlenND/qzdD6fYpmpdDSolghnM5JzN0U2+AjtUwMVGt3gHVfb7+PJiMoNA3ilW2UWtyOlsd/S0YsTfuM513EDPCiwnxSpWWXOMsteFJuYIYrpdLVu09lbJtikwxzTwT4E9PuwDRhruNrcVP9sfRiUZldu+BHrhx4vBmttcWPd656H6NxyOGwxmVdWDRgJUdYcOZlBLteNxNrxsnJMlmQKkLLQU5sPhIbbhTSoRGGQS5Tnq6BrWPVIyxBadmg3rcqtmkxXIW0FhFBSDq82Ti+CijRFkrgpprYnKIkmJn3BhT7ExFq4GjRkW2gBqUYukaxfZTxJGKRpg6kY5BkFLEu4CTQC7RWCleExdsuuUsAnMSlFLfi4j39RhYqoqlOVSTzc7uMmczyiykEokx0TSNSX8codFrmlyIMXP58mVW11Z54P4HWFxc6B63ubnBaLTO3Xcf5cCBfQwGA65dvcylSxc5cuRIdyx6QKSeer1k59o1lUns2LGDlZUV9VqpLgNSTV4z45HKHzRRwZPMWFOcN2ZB6f5dPw39f8rZ7hXSgYCOCh4qCJdJndFmKdlkGeq7kJIay9YEm6bxbJudJcfEmdOnWbuxyrUrF9k255mXedbWrtGO1sntGMkZJw1kTeXQe2Ii5TGlaiWmNa1p/RmU3RnKrZ11MeLA7TvuSeZX/9sf1fjfChTWNUG2yGu9v928vsbscBY/o/doZS+qya69Alt29zb4YwUlS32dkhEx4DYL16+ssrg4D430pIjSiyK6m+yWF5giD9N6idTkNSWfwM8/4Q18Is+RF/2k++lWe5UXb33LWr501//Wx9j/uh9K/+NbX2eybr3fTe8HL4m6M4KGpSBo41K10U40iq025rUJF2MnVF15pa0n0zrXx6aSjRqulVPS6XNtDJwgvjfN817d8rNN5+vEf1LukFIk5UQumTZGUsl9lKI1PLpGEHJU34Ico07sbXqtho+xew/VsA9rTHKKChSkSGzHup8GtFRfhhA85Kw+Akkn20E8jQt4FDAp9l4rw6KyKqLtjw9BtfYVLIH+dzFJphNwovIJEQIBwSkMIdIZzGlKhGdubpbGjPS08dYdP/X8aTZHkbXVTU6fPkMbNbGAgsoTzPivpl0E3xD8gHOnz7F+c53R+ibXr9/oYvO8Cwje9sWREsRYQDyCV5YDon93ClJkB+OcLK1g0Mk9EFFfgJJNR29rpi4+tGi0on1uMbaUnMgpkpOaFaZUw/2cARYmTUENBHNR6CaXQkZI9nsRMUZHSy6pO1/VmLHgQOMtveAaTTFJJZFF9PlFKFmBidQmyI7gB3hvE32nsgjxDucbnA8qdyk25UYb01ISKbWMxyNjbfRshhppiLE26jkVvBC84KQQnNB4xzA4BkHwTn0ZgnfGoHCMxpEzZ88xnJll566dDIaD7rx2IgxcYO/OXcwOhxzct5fDdx1gNNpkPB53IEIy9ghg9wiPFKEdRZ4/9Tzj8ZhDhw+xbds2Pd65KLukLXgcwTV6/rctKSbaFFX0YewaxBJVbDgnosBidpDJJAoumCzGAd7iHp3KiJyX7h7j7J5DJ52p8aDS3cOWlhYYDD1nTz/P8ac+xqWL57l54zqXL57j6uXzzG+bYceORQMMIeXYeXN4gTBhfDmtaU3rT7lKJaIVYoLRGMZjSLGuu1XilDOkgkm+9Ik9ewzUA2kifraTXvbbZ+Lful8US5URSoYL59f42Z/5dW7cXAWElD0xOjbHsBnZsg397gHI5FQYjyGOMU8hfckOXMdRSqA2F29727t529vfT04qksv1YdZsvPi/aU3rJVJbyNUTF8YtPy822CoTT5y89qshanc91Z/3N4XJrW+51vQl7J5RX3vi9cvkry07nif+3IOKZeItFOq9KG99/TKx7S3HYXK/9DWm94WXTt0RgII2VaPOBE0bFzU+a0LTUcqVil5N9dgysawTzGqUmIvRjUX17D0FOVqDJRRROre63xdrcISYUteEdzIAgfF4RCbjjfotzpEoFEEbiqbRSSeOgEPMdE/syjObBpvCK4AQ05jKaoBiGnil4/vgDUjooyfFoZNtEYLT15Ai3SYUXHAQ1azu1oajHq9u0psLDttWPZZOjSbxjiy20CgZyeoVUSgqwzD/Bud1Uh9EkKJJGsZzYHnnTp49eYr3vucDPPHE01y6dIW52TmVs7SZII5BaDh//gKrq2ukCN4NOLDvLq5cusbHPvIETz3xFM+fekGn9Pq2WF9b58L5i5w+fZZTL5wmFhiNI3EU1QOBgviAOG8UdgMJUEkCWRdZKelUOYSw9WZtDAuxSbdOnwXnCjm1lJIsdtD8EHyDSMC5BnBkk3wUhDYm2pyR4MkOYqnMD8sCNGZCqs2o6KeWU4KUNRKzFAUipIITMI6ZpHQSPShFeiDHFp+uUSlJmyJtLowNPMlZE0B6mU8/6a4mlzUyVdCmP5isRETZKzrFSpQScRQDEMCRyGkMWYGzGDNXrlxjfWPEnn0HWNyxTDGZQA+GNQQJ+CIMfWBh+/ZuH3rfC9exXIKBWUEa1tbWuXTxEouLiyzvXKY4UbDPZE2uODweipBiREzukG0RXU0o2zaa+alYN4B5NKDXAyiAZFKqNrW0OZJFX69jG/UfqV19WUEiUaBL02Vgz+5dHD16mHvuOcyRu+/i2NHDrCwvsf/APo4dO8ojjz7K/n0HCE2j52NQCZgqNTwl3xG372lN6yVRBQWK1zcSb3nL2/mON/0Lvu3b/hXf/b//EteujinA2vqIH/+Jf0/JkBP88D/8d7QxWxNuTEuSpQD1S+w8seovJVG0dWdrd6BIfzGf4J/8yf/KX/3qL2HHrnlyzvzOO5/i29/0L3nTm97KV33Vz3DzRm/2qi9fGG8W3vrWd/Gm7/jnfOu3vYX3vf9ZclRgWtD72AtnN3jzm3+Dkj0imTd++Rfy/Olr/N7vPUmqDUOZbBOmLKlpvYSrTDT4ZfLvt7TqXRPeS0+79WYFHCYu934bdWw5scFbfk2CDB1YkYutXcuWrW0BIyrQObmft+y5LmJuBR/y1m2mfjvdfavAx2NsTetTs+4YyYNzQUl9Fj9X++BOGuCEnHp6dtVPd8aIdVs2XUU0tlEfmzqpQAUVPEzETPaURCeoTGJLDCRd5GGhN0Ps4iIrpboUSqn+Ao6MAh+umHtyEaQUvKsASTb6eA8n5jzBiig6PRfT+qeUqKIK7z0pxi1SiHosRRzF9cBBCGEiwaFvQlJMpoOvhpJiDA5duFQ6ODadHdEiLoE4ohMktbhS1OCxQBMao6cLzguSC/v27WXb3Czve+97aJqG7dtn2LVrRVkgTUNJmeWVXTz59HFiKiDqL7BjZRczs9v4yEc/CkWn9jtWdpCKuubfWF3l+dNnuHzpCs+cOMmB/XcxHAwUbEKN8jJjZScUh0ueUDyOhCMTxW9ZqhX6WEL7JPTz8noMc1QTRnE6GVd9vaeInkAx6k1UvSGkO/bV38I518tv7DzN1dzRZAPOGchhn6ue984kOlCcx4UGl1oFu4KCGOT6+SUqVwJnqSepTxxQiQcdC8M5R4rRzrvcMRvixOtXPwllrxRcd8E4SknajDcNscZhispwVH4hJifyXL5ylWYwZP++g8zMzJnkSJM1vHhyguvXbrBrZbf5phRiq0aRev72Hh+NDyajEfAN12/eYHVjnXvuu5eFxR047xUIMs+Vem0PmsC4HaGSJLvOgJRbZSeIGmiS7XN06q9RkgKcYhGveh1WthSdBKtpGjSEw4w+6/2pGKAldeGuAOTy8g5e9rJHieOMwyMlMTs3w2BmyIOPvFxBq2ZILBbY5tTsMdYv7wn5x7SmNa0//SrAv/wX7+aRh+7im7/x82gjfPd3/ya//mtP8NVf+zI2UuG5ZzIYXvD8s61GzYqNELxC2nj0+yUqzw5vILZ9v03K60pR1aEqD5WZ9u7ffZK7Dy+we98iSaCkzC/8/Dv5Jz/1zRQP/++vv4+3/eYf8sYve7UCnAUkwy/+4h+wtLydn/npryUD3/Jt/5qf/qkjDM3bNhfhh37kKU4+s03TtZwQGscrP+1+3vH2J3n1a+7BDYAay02GMuHtJNMGYlovnSqgQ0lroqV4+1mmYMl12Lq8YgJdg26G6qWurKSXk0pB+UD67F63MAEu2h7IlkdlOo8VScZoCjb26qZXVjos0WdIvx3peNf9a295FZN5MiHODqEDMHTgoVstHeV3el94KdQdASiAnbql9w7oGnwngCemakhXOiZCBQhEpNPu15/VSDy9fqRrukWEQdMgJdPGEdU8sBo71m04o2q3basNJZgswqQME8kIbUrWyG+9aJw4kk2CpZscQ5UWOBFi9YMoE7cIkymISLegUIM7pTvnlDr6d5Uc9GZ12XTw+iVf97NLhCj98WPi9Yo1RLkUYk7qGmBxh76ZsYZZIGk8ngChOAJjUoEogeXdu3Us08kzCgvb5nnsVa/kxPGTeO/Zs3uF5eUVa4iUDbK8ssKRY8cYzAyRILjiaYYNDzz8AMeffppBM2Bh+3b27N1rVHNYXFrknnuOsWfPHvbu3QtAbFu8A5wnmD9CASRrxKXYZF9pm/qZijgK9XyBnPrzzzuvSQnibLqt5oQ1VUDTErIxThR00nNUt5vsJq6fUZ1OiwFYDucKMZVOyuG8AVHGUsiuNo4WEZY9OWpqAmiyiTigdUCiiCYalKwTdmcsi2pAWgyYEa9pJrcz9Zy8DiavGUomx9a+mPTzFadRrvVYOgEXgkoIUJNDXzRxZfXmKilmnGtYXxvRBDWbjKWQsrC2usH5sxc4dPAIKUeuXLlq5p567jvzLbh+/Rrz8/M0jUpjSklsjkYMZudY2bmL0CiolZMBAPX7WTQxI8Zxd25WdkYTghm3Rjumdj3VaYJds5rsoRSBHvTrTUz1mFQvlt6TxTlHbGP3PIoCJpevXOX4k8+xuRYJMiA0Gklaghp+jkbrLO7azmOvfgULi3MaRxsUoDGMh/6uMa1pTetPvwq//76TfM03fDbFF4IIX/lV9/L448/z7nef5Kf+79/nw3/g+evf8wv84D/4S7RlhkuXVvnZn/pNPvT4Zb7/H/xFHnpwF0ky58+u8mP/8J0cf2aVH/iBz+XRT9vHO3/neT7yh1d5/CNPMze8wd/8vq/gZ//pO3nh5EWW5ub4nu/7YvbuW+K/vetp/sJf+DS8h5TgZ3767Xzzt34x0gBO+KIvfjl/+3vfyhve8GoI1voLvP0dx/nJH/+reFEOxJPH9/KWf3aKb/umQ5Dh7b91nIcf8dy8ed1aCH3eAw/fxc/+7DtJqdAU10k7KQrY9m1NbTqmNa2XQNUlvQ1a6hI/d4BAouCheHtoP92nAxkmQ6Anrp9JoK57uXqNVWCgRrrWoaXvmAHZiXqsGVTR63kn5QfdG5j4m/pn9Q2JKLuye5Lrfy+aiJVR9jKi8k6DNKiOcNO0mJdG3SGAgqFnRRsfH7T5qk1LwZp858lZm4ycCyFsZSpU53V17bdmsWvynDX0OvX3XqnHOeWaPqmGd6VvpKrsoWu2Sm/MmMzhvUyaHdq/1yx79XRw1c6QKttIpdLa+8Yk54yviGEuOmUVIafY32qMKq9ARTVnopvc5qxggl7QbguYoP+WOlZFZ/DovKYOtK1Ox+14Yseq/uc9SE7kom2yy56mONTbUT0V9h86qN4NugEKheHsDA8+9BCHDh1VfwWSRjiKI5UWvDC7bY6XvfxRcKCBl0Ao3H3PYQ7ctU+nxKUwaAYMhw3iCtsXtvGZn/Ua9Th0jsYSE6okwBWPYMdZCt4Z2GLggXdqrhdTBXzs/CuR4BuLSkyqwy/JzsGA90LbqulerCaO5jMwSTcTMbaDAVspq9C2Snb03KBDsItR9MXrfoGixpoGESipIFm1s86rxKKUjDfTRJfpmBEYawLEjBi1XJVCWCOau5SCGlnan8cpqcFiPXUdYsdMSDnhnF4TsQJmE/GbNZWhoFGaFbA688JpZoYzLCxsZ8fSdmYHDTtXVlhcXGTQDHjqqRMMB7OExnP+7Dn27N/dnd9V+nPm7Bl279rJ7t17OiBodWOd1dVVLl66RBgEQlD50+LCAvOzM10k6NzcLDdWm+5YFFsUl5hpU2umoAYQYIaXzpm8InbXUsrZAMaeGVSZP7lo5GsXRWrmoM45Ys4Mm0BqEyULG5ubHD/xDOs3Wp1sWLxncZkkESmJPasr3P/AMRYX5zWytIjOMcRpRNyUUjitaf2ZVSli4LTeYoODz3zNUX7pl9/Fl77hMX7sx/5n/t7/+bv88A9/Pk6EtdWWf/5zv8U3fNPn8wu/eJK3/pun+bvfv4vTL4z4+X/+Ef7m93wh7/7AJX70R36Hf/Yv/gobNxN/8L5r/MQ//stsGwr/+t9+lFe+4iG++68f5sK5yyOAsE4AACAASURBVPw///Q3+Nt/5yvJ0oAInkIqwtlzm+zau6QMqVLQFVSw+4M2N0WEP/cF9/G2dzzLF732KFlgvDbD5Uvr5CK8420f5vLFG3zFX/4M/vC9H8J1ErqCBPjC193Hb/7XD/Olf+EVyMTAstRmQWSiMZrel6b1qV/1PqDG3bmjOysrOaFUpNqAqwx1kk8g3VaUvdzxlSe+120lZyvqrU25dQDdz+u9KUsmFeHcuRu8cPIMn/mah+1lSjfQrKyDGi1er159aen2QVm4wsTO9bsgjqc+doY2wsMP7weTw6oJmz5XSr8end4WPrXrzgAUtKNCvHSxgerKn5FSp/wQQiDGjLLye1ZBt5jPWRvLGG0arc2c5RxAgZijJjhkZ+Z3+vq52ITeGuqUqwmk6xsNstHiHd6mud45Suo1hM45NWxqx5YS4czhveC8dAwKBRVUVuFFTK+tzZ3zdGBGTEmN4GqDL+a+n/S9OjF0FKNAi8pH1FzSk7Maw6WkZpLOUh8qQ0HbZjO8S4o2uuBtceDUFDInZoNjXLKCknZPlAIuzJCjNj9h4JDYu9wL6l+BLyxsn9eG2WkzXyjWnOrNctA0Fl+oU1/fBGTQUIZDYmqpoFPKkYIwHA5oo2j0Z4acowJIIkSTkkjOCgZIMQNEAAcuE+24iOgEXJtFDKxKONDzxBpnRZ1Kb0xIpf4r46CkTEmJ0IQO2KJOqZ2CDjhIrbIING4zT3gYKGuibVuGg4He3G3/lFKv6QsUTc5Qqhy4pNR/54x0V/qkilKUzeKcsnK6dAM7v0MIvVGpXQhi52Sl8es5otN8713HUCjZ5BVOTA6g72M4HLBt2zYzNtWGdzxSj4e11TWOP/00s7MzBC+s7FjksVe9it27dnP02FHOX7jA4x/9iEaJzjbs3buvuyZiUubL6voaS3FBvUQo5KLyg/PnL3Ljxg12LC8xMzMkBM8jDz/M0cOHOy+KubltNI2+55ha1NjTPp9qqBn1c6uJLPXagQkGVdEvyUnZgYKUHjHJi+s8GkCynXkCo/EmDpVOLS8vcu99R9lYjaSosplSCmHgwUFsR8wvzeJESDEhLuO8pj1Icd2xmda0pvVnUwKELPiiMgZK4ebqJvNzDXNDB64QwhWC1+nj7Ezga7/uC9i7b5G/9jXzfM/3/AYlw//xN36T2DqeOfkrFBKHDiwQEgzSiNe/don5bUJwsHdnw1v+5Qf4tV9+F6//8y/jjV/2uXb/Nai/WOpRdpQkW5iOSQpJwBep8wG+4LX38V3f8W/45V/+fUD4S2+8h/17M2trI9767x/nL77x5Xz0Q5e4cqHhDz7wHEsrA+4+upcg8Dmf8yA/+oO/zpd86Svo7zympSiClGqGPO0apvXSqDo8q2tBKSpJurk25vjTZyF7Cg0PPbKbmaFehM+dusKB/TsJXrh04SbDWZUC17WkbrH0mIIxIbWXdySpnIQKUNSEuDrG00b+7Okb/MK/fhdf9/WfCwgpFz76+FnSuCDZc9fRRXbsnKWTJxjh8qmnLrK6OrK1UcsDDxxgZnbIzZsjTjx5AYDsMouLDfcc28eB/Sv83Ft+m8HAc899e4ydIN370Jr6Pb0U6s4AFCq6LaLufh2qLh1lWBvifhGvcWzmQ2AT92CJBcPBTNeQK5Xcq5N/zvgQQKT/exeb2DflbYzkemGL0vJrA9gxAbpmi26CXvfL+YDPGaT000qv+ufavGmKgN4ZUkyqeQel6lfauYimLKSkKKhTqrOjejZkxAVDHPtIOjV5yWrK51TrjmRK1gYZBC/ODOl0Ap9SAvEUJ+Q26c0lRYL35HEhJ0FCQykOUmaUWsbB6cS08aqndwqaVEMY6N8b9r5C4+2ml8kiYJGHpSjFyjmlyotN0IvL+kOgjdq0OXG6cApDsmTV2rugzT/CJuo70bgh68NZ1l3DNRniZQ5CwjsFkOrEuW1bXLAYyVy0YS/gh9408qVLE6FAcvaZUsEireIToYv0lAlvCpVPIJDEHLWkgEOPrzEbUlSWwGYIRmjJxDjGATMIXtTLIjgobWHoPaEkRiSi7XeKEfGhA9nEzAtrugnFjjV0nhx6nWH+HRWsK+CKMYP6ayTZ+e9CgxONTcyKwkAuDELDsSNHFFQoGSee2eGAI3cfYjQaKbMnOFJqmdk2SyaRSmTvgT3cc98xbt64wY0bN1jZtcLOXTsZDoeEEBRUFBgMGkbjscpyvF4HM4MBM4MB4/GYK5ev0jQB72DtrkOkmBk2XqPURaNkc6l+CE59MSuAjkmsOqaOLgCcLZCdsY76ZJlkEobSbVucJ2UjJTox3xXIbauMAikmDRH27l1hYf4x4ljUP6TA5miD0SiysTHi5vWrjPM6w9DoAt4iZ+uQo8SeuDitaU3rT7e6WX9RmYHe8oTfe++z3HvvAZYXhtxYbdHMKvvaazLLe+ZxvrC0PGBmdhUHLO9Y5cf/8VfSzAiuFLx9rxcpFF/UA6nAF73uXj7/dfciSXjLP/0wv/SBUzz60AG9nwEKAiuo8Eu/9F6+4ztfCw42ciE32pRkSxxyDvbs2sZb/+03q9yyFN70pn/D93zvV3Llyk0efOggHzt+mbw55tyFOd7x+yc4ds88hw/vQzL8l//wAb749Y+Y9DrZDiidewudeap6mNZLqJQVq2bUSKBtCz/3z95JSY6cB/yn/3iZN/zFI3zrt7+MkuFHfuS3ePMPfDnbtw341V/7Q+65fzef8zn36TpENLWtSHVT1QGlDh4VLIgUYw+J+jyhw6NiUz5XIBXHz//87/DGP/8qlle2k4H/8B8/xNNPXWEggRMfW+MzvnA/X/6Vj+IxxjJj2jzg7/xfb+fVr9mHBxq/xv6DO3EzQz74+CV+6sd/m9e8+iA5RO65extHj+xjfmHA13z9n+Pv/71f4Yd+5CvwAxRkxHcs6ukN4aVRdwSgYL5lvZ2I6AS+NkWdjtu+tNTsTU/QlDSmL7VjMwUsjOJoy/Zj25JajW4MgwbJpmtO+rPiCt43xghQ+pD3jtbSFFLWibcawUFMbUerrhn23mt8YSn6JR6ahlwyqUQzVdTJt75fBQmkRlM6ZQNU9gWAeA+mSyoldQBCyXRgRpVlbGFqlESqDatJKzqmhkUlSlGAolCb5wIuqIbchY4hkjOMYot3niyJJIJ4QfyAG7NLPLt3hZtkXIKA1+ZJCm0a450ntmmLV4OmBtTpr0pIvNEknYEnlZlSKg2i6Mglmemfr1p1cZZsUEjJDPa8I5P03MHhHKwvLHFtfifjA2O2jTcRr9P8uhArBZKxFVTaQve5Ohe6WC2Vw1TTzHoDrlGGZmSZE97XyXEx/X+VmIDGEMZO0lDP/WwMnBqTSn3rgqYIZOHw9ascvnaBUEaUHCkijAts5kRb1ABzprH4U+Ot1Ql29f3wlnKRS7/iE6esg5Ri976D8+C9HldFryhFzUpH7VgBoKzNca5ifmPsOOfYtWuXWl04b7IauOvgAVZWVhQrFChFXcsWtm9HHCzsWODRVzxCipHxeIzzjh07doBUnxH9fA4dOqxJKKCRowX2H9jPZ3/2azpjRNCkkt27dikbI6mHyY6lHaRSaJqBRp56r1KUlI3Z099jxK4bZfgAxh7BGEWdc7J5LIgI4zYq9mVSq4JQohlz+gGU1AFNhdJJokbjMRtrI26urnH9+lVWV9e4euUKG+trZBmzf99ulha34QNI9bLIhZL7WNxpTWtaf/olFEbjHfz9H3gPr3vdbrKD0y/c5NC+JfDKErt0AT747md57NMOE8oIj60D3ACcArtf/dWfyQ+++T/z2tfdBySOf+xjfMu3vJHsisry0HvMr/3K45w9u8mDD+9kfmmGfGbV2MeJRDZmI3zX930+P/HD/4nffeezpBL4d7/wQb73b72eEAq/+msf5dL5db7x6x/jwvlVfvRH/ytf9mWv5D/95+N8wzd8Fk0Q9u7ezv/2nZ9FFlhfLzz17HHe9O1fqlLHAqWFd//es/zQP/osvNDFLAv09GYUSJ/WtF5K5epAoghI4mf+yTv4rM+4n0deeQgE/tJf2eDNb/41YnqU973nOc4+v4t3/e5ZXvHpO2lzQ8bz/AvXOPXMFQ4eXOLQkWVltyZ4/plLnDpzg2PHVti/fxsJxzNPX6Bseq5dvs59D+5ls808+8xFAB555ACLO2Z45vhFSk4cu28XWeDm9XX+4INP8U3/6+vZtXOedj3y5u//VV7/uvtZWB7aUMQjGWbCPK949CBe4O7DS+xcXlCmZYEDe5d4xcsOkAeFz3j13TYLFrbPz/CyR47ye797nM/7gqOU3l5yek94CdUdAShoBrxF8FXq0ARzrlKwsaa4JjeMRiNibDtZQ4yJECptSBfyo9FIm9sYlc4ftRmrkoCaMNEZG9oYQpxGzVVmhPTyKFJMJpfQCWHOOm1PKVNSnV6rsiklM2NDv4QLxcAHbbSbzo2+Ni+6zdp46+MmfCKckKJOiQfNQOnbZuCYsxmk5EyRjDivXADzVhAxL9dSKFnMc0C6ZrmLV7Rj4L1HPQoVXCjJs30UGW8bcuruu3l+zz6akpnLrRoTZihOKCK0pU5u6WjihaKshEqLrJRw6mP0nlzZCkrrUtTWd1TOgphcRLEGJa7r1LngUZmMQ8jSskRm4coNdrLOLCNCdkjKFIsf1CZa6e2SxspQqAkfdsxyLpBGen5ackDnP2DyBjGWhUT9nOrJW7Iu+rRxVzBIrEetpn6F3O0LggJeIiQKG+I4t7gDP3Bw9RwuZ7L35Ky+DK5x+KTHT9MZwgR7J3XMmxBU/hJT1NfoDB8Lcdxu8SBJE+ycUgoxZWLJOhUzw0VnAEnOSWU/dcJfYxOtac4GtszMDmiGDW1SwCgEpQYE72jHLc4HllZ2dPKAmFpCo1GeNfUihIbl5eXOVFENMz0Liwvcc999UAo+BGLbErzHi3oNFH0zbF9YwA+HeC9mvlllKQoP1GjOZPTCPrKyv86rXwbG7gmNHWujHcqkZAsUaIlJp5WiZkUq6xFGm2Me/8gJzr5whatX11hf32Q0GpFzi3OZuWHD3OIMwQeCV/8Rin6uIgnnpdu3aU1rWn/apff0H/rRz+M3/sMTnHj2PFkK+/ct8tovfpAkiZltni/5krs5+ex5Pv2xw/wvf+1VmlRjaTNf81WfjgMeengXz5w4w3MnzlN84iu/5n+iSOHhh/eyOYoEQKTw8KN7uXzteU6cPE8uM7zhDQdxvvDnX/cgv/X2D3H/PfsIA1jZMct3ftcX8V9+43GkDPns19zFgb3bcZJ46IE9vP/680Bh+8KAR1+2jxPPXOTIvTu4/4HdHUvLe123zM4KX/PVDzD0ai6XMrz/D57hkZffxXBojYLYMETUf6hMai2mDcS0XiIlxmCVUgxQLFy7OWb7/BwDW7Tu3jfk0161k/e96wQnTl7m+toljp9c4t6H5hEaLl7c5L3v/h0kzbJ60/G3/u4X4AOceu4iv/wrv8eVG8Lj/+gE/+rn3kSYDbzpm3+FL3vDy1heiSzumuVXfvWD7NqzBAXe8+6n+Rvf/XrG44LIkEGja/qPfewMu/cssWfPPE6g2e6JUU3INbFKEyUaAdxZTj63A0fhPe99lr/yFZ/OoUOLDGXM6s2znHxugSiZE09e5Ru/7jFkUHAO5rYX1jbWSdkZqdgiuDv5hkzBhU/xuiMABV24+87oEGvyxHLbu6bIB2JqiVETHrwPTGa/p6SU4BgjIQRTDGj0W2PRdjklm/5DPcG9GSCKczijeqtJXt/Ix9TqRBx18Y9RWQopJXCeXMyd3wlNNUREQLxN3WvqQ6RNYxAYNA05KWXfuUCMSVkFrsa11Km+fkwpxe7nnQFjjbiz6XmR3Om6Uk74piG3mf+PvTePtuy+7jo/+/f7nXPvfe/Ve6/eq3lQlcolWZIlS5aV2CZ2bKAhgwNOwHYmJ8SJCSTEQMIydEMW3Z2mG7I6kHZoBtMEWNB0JkiHEFZoJ7YJThsTy4kjW540l0qqeXjzu/f8hv5j79+5rxTTvVboqNXW3WvZqjfdc+65Z/jt7/4OMXZmKhjMqDLfwh7I1vTqtH4qNYm569kCoQiH1te5ECM35vcRlw4wuvgcc1s3wGUkFcSH3jAudpGUOrKZOYooBd85pfknm/565ygxkWLSY2qpCUGmVHwMiBGgixNAJSBSROMYC5rwYHR2cYJIYpg6ljfWOTRZp5l0NKISkVzom+jKMugjI4tFexrY1HUVQBK6SUfTtn16h56flkLQpf5c2suu0X11PWiliR2FpmlIKRroVHo2SaWJlZxZc55Lt51BFubwwZHHELtMNl1s7sa0viWibIicwYemT63QcwgQBZcKZnwqNclAZQ1d11kEqrJYNCkhmUwHa5ILsTdI1IdIBXaMVGHMG0+XOjv/9XNKpZAlK/NnEokx07RBGTO+fl6VeVQjOe08FEdOGcm6Xe+90f4NPBShbVtqWsVEVPoUmoCza10JJInhcEjKqc+F36vse2G6BZgfs/27aRpwZp4kGvWUs6GM4ijJjo+BLjGqoWrJmeAdOUZa85UQHJPdjqeffIann7pM7DS+ZN++RY6eOMihg8sszA1YWp3n4MFVlQAZACJOg1xTvjXLflazmtXvbTkHh4+0vPs9D+CZap7tLs+gSXznn3iNgsel8Ma33GP3KmVqvfnNdyFSOHRwxLu/+w090zLbOvu221YNWFf52x13rXLHXav6w1x6ZcH9959iZ5z4h//ow/yp7/2DNE44dmyR7/qe16N3H48i18Kdd65yx9lVxGUWGs93f89XKkOquKlRL5ZE5RyNh69+0z26ZsFxc2OXn/uFj/Mj/807kWBxlti+FNnjH7f3XjRrHGb1MilrlimQRchOgThNdssE77n99BHOPXmNb/+O1/OJh5/m27/tXhYXWqQ8w7/+xUf48fd/E7sbmW975y/wjm+9RtM6fvgvf5Bv/rYHuX0Q+MLnLrG91bGvbTh75hTv/pOvY2nZce36Do985irf+dBdHD+2yK9+8BGVZNVhbBFNYYsecktA15e5FKJEkoMuZ1oPZEE8vP/vvIulxSGuwE//zOf5ob/wf/DzP/sOXvPASd7/t9/FcN4zngjf+s5f4OD+Rf7Y28+SPbz1jzzIX/3hn+Ytb34Vo3nrsUzGofeGmefTl3u9JACFXArRNO11Kt+YidzUPFAX7c43uD3a4RiN/k6N47NmrBRDDzPJmA2h6plz3ZZOzFNRijxSHew1Wg+jq+v8USgkfHBI1sYpxqiRfLlSyAslq7lJTmnPlHrPqiNbXq3upBr8lUKMHU3TErvUf60rkWlcJKCpD3uSGPYyGXp/CV8p26mPNFRQojIldHLsve+BCDvI2kiaB0IqsarISTkSpGNlHJnb2WRuPOHp+WUOXzrP0c1r4AOSxWjoBS/eogshlcju7rYdV6/TayckNIGg8YESjWnhxD6fguTp56+TYf18NQJR6eb1PShLQ29ewcCAVGqabsecS9qoZz1G6v2o03PJetOvDWnXdZScjAKWCdrB4b3Dt21/7tWWM+XU6+w99EkjIlN5SooR37ZI1veVc7Lc8WKmWjos96VOvzPegS9JEwCyJyEE73Amkykx4aVRVkhWDb/STx25ZGK060hyPzHvoyKTARK2LTB5RuN6FpCeu3q9RAqbzYCbw3k7f+1zRCNKM64HRVLXIU2DuNx7FSSTXeRUkOEI5536XEqh+D2gHspQqR4GzkBDJ0JKHXj14HDOqycBKsUQ5whNozITP7Bz3tEEb8qZTEyxj3fMApgUyaHMhJwS284TMgSEhBC7jlwFDhbFGes9yVk0bYEuTXDO41HfjVxK/3vKPCk0RSBLf76kkvGNI5doqouGlCfGNlEBWGdeMF3scMEkKCa3iXv8O2Y1q1n9XpfeqH2lThZ0MukKUsz7Sbw12PZMKJpFXyl3lcukD1v9l9OXMLCg2qp5phFxtTtIUDQETrxw9s4jfOxjv8m1q+scPLio906vvg4O+wKdE+r0NBHKlHEVSt0nMxk2jyDpGwD1KvqlX/w4b33rQwxGjiKlT5h3JSmQakfHVijMGodZvVyqTt6VXGrpVuYpomzbQjdJ/NYnv8i3/vGvIgAhFUIBL+Bkwru/+yvZtzxg37zwjW87Riod/+pnnuQrX/Mq1tciKXS87Ztew/z+IdkVmuEmo3lPITM3N+Dr3/oAVy5s8ugjF1hb27YBkiBZV+/qrSCkLivSYGsIXFI/FOfN1kt7gbn5AaAGr3/sG+/iVz70STUpR2hHLZmID8KffM+9bK5tk20bTQh0E98zxHv0EzEW7qy+3OslASgUIEomSICkyQnee53YQ+8z4LwjTpJq5U1XLeYxMMlqVqaNYSHnCM4j2uEZzXtPzKQTnNPGv8sQfGMgACCQugg51xBDvBMNY3Q6vaxRkpM4xkmBDtrQ6LYt9cHJ1NCtT4fwqqMHlVFUl2YbAtsNqhCCGuxNdsc0TcA1YQoAFE1LyLmCFjXfPpvLvLq/agKCxtY4UQZE6hvIAuZV4UOjM4qSdGGUTF7idartvVLHxRckFdqUaeMuoXS0RMLuDu1gCNUpP2WC10Y5x8goeEqMhOBVA14yLng1XxTBZ02YGIo37bnSxEuu+5ppGotO3BMRGbuO3I1pgiMm1d2nmBEXNcXAOTPRg+ztszMWiTD1F1Bvi2Tmn/EWVkTKmZJUx29EEQUdUodQCN7TmHFh57IaeKL00VI1+KhHRxdrTGM2rEkXqLpfkKP6HGiMTyGIV8OcnBASKU5wJsuRAj54JuOub3L13EykSUKcnjMxJ23085QeL1IIwa6vUhkJgWLgUxFjw5RMIy0+OiQUdl55D88nlbIUKZTUqREqhSSO3dDoe022LbeN0EJubbiW6PfCni4Z1eKWoiaG1eA0pmzSAHpQTz0ItLFXJpO+SCrJpA1ix7Jes0HZIyblUNmNgYlVQCM6VYgu05bMMMLg+jYUz7gIEyms0dEWT1MKKU966YczICrlyqoITEw+Ut+icwpSOXGkyYSuaKIJeIaLI+6695XgGm7e3GR7c4fxeIunzz3Gc8952uBwg8JXvv4BHnjgbkLriA6L1Q0IDTP35FnN6sWpKp3aS9utKev9ja1PVDCm2Z5VtNjUUkGG3L9Ckem9WX9vz+tNNwTcan54YHWeH/j+t9E2QUGNfl/E1vN2H+xfpLE/NTNeV1/JTf9ENPK41Nx6gW96xxsYDlu8vIAPJQZOWORQIVLvR7PmYVYvl5peyXUYNOJTn7rK2btWSeKY5My5c+ucOntQ1+UuaLIaIJIQnwl12Cca+37HHftoW8cfepuaoD726FMUVVMSSocv9XqFe+9d5r57TrO9E/lzP/jPcRlCAigknYVxYHXEz/yLj/NHv+m1nDiyyPNX1lhdbhg2jthFPvP5Z7n/ntv5qX/+m9zcyvypP/0Q/d0hRzLwp9/zL/gv/8of5sxdi3SinMki6m0mWfjXv/Cb/KE/fC/DeYeusHSNprdFN7snvAzqJQEo9AZoJanWsEg/9RdzXa+Naj8Xtui+wtQkT7VAOu3sUtR4wlz6yWyoDu9OelACVxuW3MdAOnEWj2hJCj3rIZOz9A25iAIY5knXT80rDTvZD+pUuIIkUn8vKXLoQmOsKWUc6HZqI+qsydRou+BUEpKNpp8sNMA5h28autj1BoYOZ5F+zmIva6OseKMeX1BtNnjfVHxC1wgOit721NfAOsF+ZiLGEqhGdUVxyC52XLt6lf1LSyrryIXr164zvzDH/MKCTrwnidA2OOeYdF3fSPvgbDqLRlx69TJISSUCMSaur91gYX5BGR1Mep1+CDpXTmbq6J2+CTWtFAM6qssUU9+ASiApma5LChZZU712fZ2rV29QgMNHjrK0vEwsatxZQxSrnMG7YlPzCnRlnCu98SE2dRepiSB63nSdygOc+N6PwFWnH9HtVDaLA4o18XoNiGn7p/4YNWnCCXRmFJliwov0RokpWmwm9NdPXcVWtgcOYpownOyw8OlHyc1IHxClo+ROtwF4HHF+gQt3v5rEgMVxJPtIcgUYIGWAFE0ZCeLMFFI3l/eAfWLXezYGh7OHkBg7pTJzqmeFc97OOU2TSLlGyBYzobRYSDsuiURWHiKl6AxQ1/WO6DLiMnM+srzfc3PpLq6tHmHr8FGutMLys5cZTsYkKTgKvnhSckQDhpQtI5Si8hE19RRCaAzA0vtQ9WkQyTSDhpOnj7N64CDbW2PWrq9z8+YaW5s7bK1vs7Wxzna3YSwdBbcmcXo99sdxVrOa1YtQ03tk/VJJb8Z0oz4dARzSg3092oA9eOzn+rU6uk9ZD9j9avqNOmnQIUDdkhQYjRr7G/NN2gME1C1PUYBCjyTscV+vqUv08of6E/3Xwqid/m4fMWMPiNJvilL0abB3+7Oa1Zd7mcUyeu5n3vaNd/EX/9zP8/GPPgK+kGSHt7/zddNLvAg//F/9S77v+76Kpu3wIVnv4mhHY7xPfNMfv493vP39fPjDj4Bk7rpnmbNnjyOlMDfaUQ8rYHt7zF9830/zqjvvIJeGK5d3yAJNk3HsUiaF0Ah33XmI9//4u/iJv/VvSLueZy/f5Nu/9TUszDWsre/wvvf9r/z4j38Pr/+qM/zZ9/4cX/zsYzg8qUS+7hteTXLw0JtO84M/9FOcvWOFSObgyhzf9V1vMtN3YWcrs7w6wImujuutS8TuL7Phx5d9SXkJLEpfeded5X/5x3+Pxnm8qFGi1Ez3Uki5NtDmRp/VJ6HrxlSanehYuadrp6JGKd773tRNRBMbEMEHr5ThrBpvBRXUzE9k2rB1KWozTQFSb5ynzvnayIFOQIPzSie35hVUdy2i1OleGFG0mVOPAqUxVxlCTbRQYztIk6gPbZM8iBNi7OjMeA6AMqWMj8djM2R0BhL4fl+1WVTAgTJNnAgh9K+TS10w0bSfPQAAIABJREFUKANEbQmU1u+DI0ggZ7i0MM8XT57h+LknOXHzGmoqKeTiWFtf59c+8hEeeu1rOXP6djY21vnkJx/m2PGjnDhxXI8fmrhRm0Tf0y21scwlK2MESF1HKXosuy7yyU98grNnz3Lo0CFKSZSczKhOGSdF9Hh6A5A0ItLZ+WFa/VIjHc1MUYqxEwzEEsf62iafe/TzdGNN6ghNy4nbTnL4yBFEnPnYKjCgQJSYsWY2Bkm2tWEx7woMXKpgBkwmHRcuXGA4GLCyvKLTJpQWm0tmux3ymZNnOdQ6jj/+KG2OxFK9EPQhJk5wEnopiHOexvw5ck79klFZOY7d8U4PBFX/DXpwzk4FA2kyQs6O4FoohUiiSKdSkBBIMeNcYH1hH7/50O9j/fxVTqzdIMmYiUsgDb44mIxxjadxnhQz2L7kosBBzJoy0TatSlWSglzOrkWdytdUhHEPBuWkXgkgTKL5QHjfL+ebplG5ifckCpPcUZcAJWZch0a2NZ7SOnKZ4FKm8w3rt9/FRec5u73GA5/+NCvjbYP+EylmOvS6cyibx/tAStkALE3vCMH14FKOub/eQmjIEdbXttndScSJMnrG4w5Hw8b6NutrN1nfus5tp49w1z230wyFHck8eux2FpZWOPvMs7zz27+P0M79v31LntWsZvXCMoy3z201htneab70NsNiBIG9FIVsC2tB4xb1RaVfbO8VD1Tg/wU70K8ipP+OPjhf+DOZghs9eJBv+fmtf5/3/N50v2XP/HWKUiizTR9ue399zz7PAIVZvUxqmkim5qQpC9ubHUxsJtQU5hbbKQiwpSzS0SiQBKQRWi+QhN0YCUHZtNubHXmsQ592IdAOBbLQ7UaaQUB8JmfH+lo3NfpuYGGxocTCv/3Xn0RwfP03PghO1+c7Gx0lQnSwMOdpGwUCb25OGI4amuDY2erIk6zGLqEw3NfgvKOLmclmp/NHB651zM8HXIaP/foXePKpy7zzW9/IcCDT24FgYGWGnocxq/8/10MPPcTDDz/8JT/IlwZDAfAUStYoJDV6yzgf7HGrqH62ybs4RwiBnBMpdcYSUFFSoehk2yjTqagburrRe3V4z1mjJmOl6GkT67z+d2+EXi11hseYC9rwKX19OpfQJsebr0F3S5xj07bEyURBhJh67wJ1hS+AUsx12gk4pxp+pwZ0zpzlU1IvgMY31ijTgwnKgnBGLxdrNLVhdN5PfRasWZVKJy/Tya4TTbEIzlNKxPzttLEralZZpQhizXIFO/rUvVLY2triiSee4Mihw5w/f54rV65w/PhxSyJwOO/M/V6n5jmZDMDWVpJROYb3NMETY6akQuoiN2+uMR5PjPGhi7pchBJtau6cLs8MkPB2bCpbA6OLlVLp8QUXVGajgJUOa27evEHbtrzyzrtpBy1Pn3uGJ554nP0rK4xGc8qGEZWmpJQRr29AZS/KICkl40OAnPSzZMqKyDZFX7+5TpybY2X/inpnoKkMNW4yl9RPu4rdpCsjQcTbdEzfV01EcUVlP8Gm9DhLFimFQTMwnwy91pS9kjUKFWVmOKeeIrEUYkkMclLgK0XwENoB0kGMQBtwk8yBnTEHbl7i7OXzOFeIWcgh0JRE03VMRCMbS5Ur+coAwiQbjrYdqCSolD7xQURoB43FuDomkzG5FDVYjFWUJMQY8SEoEJmUaTIajUiTsS79k0p+CpDreR3BxYILnuKFSMdkMsYPFrh08AA7g31I9qRQ9PqvbKVGkFRwYowQAzurH4kattb4Ufu8jTWiA8LC7njC4489xVNPnEdo1NRTfC9PmozHJNllYXHApDtB8QKDoN4oZIu9ndWsZvViVZWjQe2/BSmuDvcplaFG3jO697e8gjntUJvvHpAAW3jrM62yAHovBWHayO9lSdj6ZS9bQH9Wt7HnwdqXMTfFWHb46d8a0IHYgqfuD3u2LZlSjR9vAVB6/uKsZvXyqSIqhUTwUti3GNT4ua7cKqkHGM57ZEHXDB5LtDMvluGgAnXC/L4GFuz1JSMkcI7BKKDsYDUiX172NgzELsWC8/B1b32Iv/AX/jFv+Zp7aedbxBUWlhqkZLVSKDbEc7C41OKMBTW/4HCEfqik7yLRBMdoqe0HVMo+gPFO5Bf/5Sf4q3/9nTSDYt5gMAVbZ/VyqZcMoOBKpvG6kC5SKE6d3jNmXEgBp9n22VIemsZ03+r8p27yKRoNWnX4wavDfPUyqAwAbwaBYrr/kpIt+H0vccjZDPfcHt1ktgVFwbwQVIZQUiFJ6eUbYk1tv03oXf6V5KA3jpwTLhgIYA1WsKZX/ximppPpFpBC1zY69ciJW1IpnFHnU1QQJkX1h/DeW4PjSbFTH6aSKHGa+EBOeitwatRXgZOqP7/lWKANU0o1yaIgJbG9tcEXvvAFjh89xrPPPsPly5fVxLLofnWTTm+o3qmhYy8/yIy3x72h3WAw0MbaGsbxeMz6+jo3btzg0KFDluahhoC5wGR3h1wyo8GQJjS914aCRLAz2aYJgeFozkwFFVjIMdlNuxBjwjkY746ZG41Y3LcPFzxnzpxhNDdHH6cYo7r6GvBRsslbippk6nRav48TJOvnJ66xv0+kTt9TTXpQ1kmhGhOWtu3nUvbhKrAD/WesMgm9u+ecaUOgpEjjK/1fI1V1uKYwuRedPVWDUud8P32r7Ansuhw0gZSrvCVoykERXI40ojGeLUIggYsMRRiUlnHOxDjBxQllZ8wwNARFQ/R6Tpnd8a7GRjqHH7Q0zuHNh6KkRE6aZpInDc7O35FzTLpd/AQa5wxUgoFzOAolRmVbdBNlD2Asm5RoTEYzTpFxjIiE/l5BygQRRmFAcYKkBBJIWWU0zkC4IqL57wiND/2gTnKGPb4mfYIHut9FMMADum6Mc4HNzR0FFHJL4wfs7u6q9MurCayEyNL+OVJKtK7pfWDsDve7vufOalaz+l1W7zFw6zS+pv7os9JXCwP7nVtG+dS/uJXBYGjjrXf8HjCVOgnt2QXZuGx7fAv6zbyQ4dCjG7dsU8oek8jKabAX2vv9W/e5TP+Jn+EHs3pZl6BgwdTFRK8PZ4CcFD9dI1Ds+3UQBBCN9eM1acF5KhFK7L5R7MKUatpqfQyAiJqjemM9JcxftS38+fd9PZ/42Gf46v/iwT4BTvDqwSCWBlHAGxhYB6MVNFSg0sxW9si/+9tZgccef5ZvedcbmBs11J299S5Th7az+nKvlwSgAEV18uhJmHLU6XFjsgfTU7PHcK3S9CuTQEI240N1n0/W+CeTSngzUaysg64zrwEcIbT9a1V6vPd7pgpC3/DWi1pZhhat2KX+fdRmUwTwL3DM728A0m8rloIv0n+v7odjyhzIyabwlSLBNPkA08THHPupf8k2gu8v4elUXKUYuQcmiqGSIq6fjivlfw+kijIkulSgWKwke6leNkex8av3nuFgiOB4+OGHWVnZT9sOeh+J7e0t1tdvasKBqKHgyeMnyAI3b9zg8uXLhEbBgNHcHEePHkVE2Nzc5PLly2xv7/Dkk0+xunqAgwcPENqG3Z0d1m/coNvdYXt7i9FgyKGDB/E+cPnyZXa2tpnbt8DNGzfpUuTMmVcwNzcyFoe+x5xM5+809pKUVaZgn+vcaMTJkyfJpTCZ7LKxtknsuh60WVleZG5uxNbWNhvr6wyHLV2KbG1tsbS0xOrqCjjPZDLh2rXrdF1ie3Ob8+ef58iRg3aO2PLReSRb4kadJmG3/L3eD8aySCWTgeDVk4Jc2R/OPDYLEjSmMXWdGYbWyMfKlpH+vBDnNKUjOxUCZQcWwUrR5IFCoglCYUfP89JBzDS5xRWP95HYZa5evsH1y9c5fuIIy60aFHqT51x87nmuX79O06jXwNFjx1hZXcGLY3c84caNG6yvr4NzzM/NsbK6wvz8HM1wREENF31QrxCEip2rXKnr2N3aNLlRZm5ujsHcSL1NciJubdNlS0DxAe8VWfc4Op9tshDBJRxR35/TRsKLHsuSwfnpOVLjQnNKCoA0TS/dqjIPNZe0lqSoIefCaIFXvOJOHn/8MdbWr3Py5AlimvDcxWeYTMZMuglzorKTKQg0e0TPalYvVtnttv4LrIHQ0WRlEFSRQNZnYhZNg8kWg90/b/V31JGlbkBfV4cNKuPauzIv1LXFnqdBqe1LMe6APR/6Z3+msgsqMFF6X/aaJGGyuKKTz0zR2Moit7QCNRabUvdNbN+S7Y9nbxsxq1m9LKr239T/7fVOkR5wqDGuYqChXqvOYsK9Ghfa8LAOdPrruCbF9D+TPZsOTJ1VahW8wOnbDnP78SP2Pd1uNY+s9yH9Otm9oA4PUbaVbTZbuk2p27X7F8Cr7r9dk2Uq+HHLgam7P5NCvRzqJQEoFNBIOEsp0HhIx+7uNjhHOxjgSqEbR7xvoUocgBBaum5iZonGEMiawhCjTgdFHOI8sdOGWU30zIHUzn6Ris7rQ3tv46bgnBnCGedc1w/azGkTIexlNtTtiHO9/wOo5rrU1yuYPEIfyHVpsDfSUZxALkY/YnqB29fZjCq9UeRzSvjejNGiq6Vu25GLV+ZHieRYzQH7u1cPbGi0on4OLvgeAJneEKeTk6k0xJY0pTA3P8eZ02e4cuUqt99+e89y8N4zGs2RY4ScWF9f54tf+AIBYf/yfp58/AnmFxY4dPAQ169fZ2d7h5gibTtgbm7EysoKS0vLHDp0mKWlZZzzTLqOq1evMdnZ5eDKMk1o+e3f+i22T25x5x13cOn5C1y5coVX338/hw8d5tnz57l8+RInjh+nbRti7AiNo8ZQYu4IjW9IsSOEhqZpmMTOZA5CEwJpNCI2Dbs7u1x8/gLPPvMMr371/ezuTPjt336E/fv3c+jwIa5dv865c89y/wMPsLCwwKXLl7l48RJzo3k217e4efMmBw7sVwlPziqDKap3TSmpr4VgQFejCSSCyRVg0qlEoYsRgjEI9hhx4tQXxJwXeo+QZB4PVT6k566dEw77PUutwJgoJVEceHEIHnJUxouTPjqtuKSvlxJb65ucO3+Bp59+hnYusLR/n54zCBubWzz15JPs7u6ysLDA9s4212/c4NWvfjVLi0tcvXqVJ598mvHumOJgZ3uHU6dP8cpX3sFobg7nVULinDBJk6n/igEjV69e49wzzzAe7xJjZGVlhdvPnmVh/yIba+s8+fnHlGHsPNk52rbh4P4VhocPgRP1VsiokzEO8QFwBDyxQJasUWzZUiiYApw1ptZuLiphMjBBJT8KRszNtbSNcODgEg8+eC9dt8njT2xy9o4zOCesbV3VuEuZGqKJ6P0jW1rMrGY1qxehKvCMNgGOus7XUYjU5t4W6ZXxVZ+x/bPWQNypP0H1D9rDKqjShj46WvEGMRAYEUr2fPLhz3HHHbexuDxPkWQ9/h75ArYP6AS0Pqqz7Rdipr91caFUK/V8KbpW+di/+xyve/2dhKHovvSyixccmFnN6mVXpX/291dBfU5bvkoFIRXSm147uq7AgL29HKL69zAFAWzYdMvj3u43pQ7FlFXg91zPIgVCBT+NP9HPGTVhDttOqUYMllSzd1UvvPCan+6DyJRJ8TuPg25ntkx5edRLAlAQaoOCNc5mxOZ1ES7VuC/4Xr9fKdpdF/EukIrRl1Nn8YHGcjBafUyZySRqVmpKNCGYRCLZNjWBwQdrlnOmmMEaVQeN0E1UAqAeA6rIdqZjn04OXc9oiCn2Ro85F42htAaDnPqbUTVNnGr8jUkRNQFAvGZCq/u9UqhSjqSSzFxPm0/nVIKRYnWBL71PQjHTR6w5LM6RY9TwgTJ10K8TagURqopT9e+k0sc3qsmf3TSpVCk1nRsMBqyurnDbqVM0oeHatWu07cC2UdhY3+DGtWtsb29x6cJFTp04yerKCt2k4+LFi6wcOMDc/DyLbavxlQKD0Yh9BRYXFzlw4ACDwQBEmIwnXLp8meXFRZrBkN3dMT4Euk4n6ePxmGPHjrFv3yJzCwuEpgEybaMUcjXRTL2HBuLISXX965tbdDHhvOtBHuccuzu7bG5u0E3089ne3ubSpUucPr1OSomd3Y7Ty/s5fPgoq6sHePKpJ5lMOsbjCVeuXGVldZVDB46wu7PLtWvX6KL6dqSsPhYivge4FNhSoC3FDie+n44H1+hUrGiqietTEnQ/k8lSEPT99WtWMxGwT6/sOedgygTSwb+em45CLtH8GDKhgJNAEUfsPKWof0H0HbEkfHYMhyPm9+2juMKkm1hM4/R8O3z0KPuXlpjft8DVq1f53Oc+z+UrVxkMR1y4dIW1jU3uvvsu5ucXeOKpp3ji6adZXF7mtlO3EZxN/et00DnVBOfMznjMlWvX2BmPaQdD2pHj/PnnmcTE/V/xGvVgGI1onWe3i6xtrHPuyUvsHj/GwQMrUEK/0NYYt4Zix6GI4INQiP0EoeTSX/MV2HMh4J0n5YRKqlWaU8zbAi8szA8ZDjw+ZNq2cOz4KjvjmyyvLJBiYjhqaVuNwi1mONqnXMiXesDPalaz+r0oMaljwXPjxhZba7tIEdphy6Ej8zhRJsK1G1usHFiAAtevbbB6wITQtujXpn8KDIg18T0jQX/NwIi0B0hUk2HNtxc+85vn+PQnn+FVd51FW/1CToGb17Y5eGiun2HWuWGhUIpjY33CjZvbyiwcBI4dWcTb8OHy+ZvEWOhcYWl1nqX5wOrKIj/5kx/m29/91eybV+nZ9NlR31gVSOyhVMxqVi+LUtPBCiBgUqR++levlXJruyWYtOEWXoH9/x5vEqi+KiY96Lnc05SVUu8hZn44fbVscKRTzwToG/0pBmDMgzJlPehf1HuSMXZ7dlS2+5fvX8TV75vvi96xTNoxAxNeNvWSABT0uer76X2iKDVfhOAdXpxNtGsTqxeGE48X8ycQZ7p7T06a95ysEawxijhhkqLSwGu0onOqVRcQUS1/1ymzofGBEDyTsaVJOEdwQRcV2fTkIr3ZXaomgJVdsEfqkHMh5WSZ9Eo7R+qlJ2TUXyEXpXF3k6gRklKIKRJciziYdDXnXqfIRUrPcNC4P5uAmI7JmxmjgjB6vFNK5qKvjaqayaWeQq1Rm9mSCVR7rgkISgdXrwebsRT9rHSaDTkqgBK7jkxhZXVFj6cIW1tb5AwXLl4ip8zi0rLKPnJie7xLOxzyyrvv4hMPP8xjjz0GzhFz5jUP3k9TGtpmgATPYDDo35MXZWZcvnKF559/HooaBx49foKTx48Rs+rGhnNztMMBuWTmFhZwHgVNUHAkl0JnevfgG2IuxKzmkiklUm76iXBKia3tLT7/uc8yaAaMhiOuXr7MtavXGe92NG3Ae8/y8greN7SDAXff8ypEhPXNNdbW1zh69JiZBs6zuLjEeLJN100YhtbOAUfNN68Gjvq5irEyJjhE98kZml0SOSmFP2FgkHPkrJ9v4wI5R6RM5TTVtwKyShwsMjXnghSPF2U8OAxYy4VkFFoRIVJwCG1otOmNEaK13s7TDAPHTh7jyuUL+KKgWEkd3gf2Ly8yNxoyHDS4EBgNBzx77hk21m9COU4umZ3dbUIILC0tsrp/mcuXLiioYgCH5IR4IXil7dVnb+Mdq/uXOXRglYWFfXjv+ULzeZ6/8DxbGxss7Vtg7uwp2qYl5syli5fZ2VwntEInkeAd4gXnCyQhiAIX0Re6NKGVAURRA1hxFFKP1Huv+unKTFZ5hDYRSjE0r4UiLO7bx+FDBzlwYAUfhLN3nGH/6hL79+8nxch9993N3ELLYNDgnRDF5BR2f5kpE2c1qxer9B558dIW/+SffJTJTqakwIf/3Tb/099/C/e/epXdjTH//Y/8G370b34LkuG//ss/x9/6O99FaIySLNMGQHAVV+1ZDYi2I5rfXoyRIL0PU5Fs7imeD/y9D/F3/ud3IwNAlFHwq798jn/xM5/iH/7TP4LI1GPF7pasr+3yk3//I2xvKMDwyU9d5Od+/nsgCB/99S/wsQ9/gRIbnjq/xhv/wJ1853e8hntefYTPffF5fv1DX+RrvuFeY68lbg3KtJvdLXTvWc3q5VDW3L/A9PSWH1OM2VN/Vq+fL2VauJfJUOXUX4oVpK+jOKT6wVFqR1H/hj3rhLLn9fbut+z5ml52WwER2fPrhYjeoQa2wNHULKkyqKlznPZUZbZGeTnVSwJQUNTfpt0ilJxM+qDNbUwdxQAGUiYmTWwA10sbui73YICIms5VM7zqIA82PcyFIoXgFITIRRv50Lj+equme40PNgkUm0KqaZ42ffq7NX7QGVAxsTSHtm17kCFb1GUFGnIvScik2KksA538xqxgglhCg75tAw1SMvpzXZgUJilplEvJtKEh5ah/m9Uzoevi1HMiV09ooUumnczFIgaVOpVzxokn5UwXI8H2N5dIkYbgnZkwFjMi1JtWTkUBhpyJMVmigycEECfs7u6ytb3NuXPnWF1d4RVnbmd5ZYnzz50npkQXO0LT8Or778eFwM54zMc+/nFWn1vl1G23IaLJGV3s2Nzc0P0MoQd0QtOwsLTI/GgOLzA/HLC9tclu7FTm6j1ZaiIHTFJHJhO86yc/agLY4X3LYDhia2uHnZ1dxDnG4x0uXrrIsWPH2NxY5/rVazz4mgc5dOAQy4tL/If/+DAxRgaDlrYd4H0wJofDiy7gJpMJGxsb7OzusLoa1LMhBDa3OlJOPdOjVGCoyngMuAmiBotOxD6zQhBlqIjzBuw4k08oEFDjLUvW4yReyF3sQaAqWRFjQxRjsIixGlKM5Ip0BwW+cGoE6itoYcZCwUMr6hCQyGQRfAAJhZQn7HZjBoOBGhQ2DQOn8pzYJTY3t23hq/KCQ0eP88RT5/jUI5/hrrvu5rkLlxiOFhjNL5JxyhoQZeKkUoERRe1DO+DQkWOUUmhCIOfM0v4Vrl6/gWQYuoaFuYbsHTvdBHLh4IGDHDl6mNA0OGeRow66rHIDR8GTcR71qKjpJDX5pThKUiShXuM5Rbw4EE8mIykCne6jaxAcTho2N3Z54vGnWV5eYmlpkdB4miDceecdtAOhbdR12Tn1n3BowsgM/p/VrF6cKjiyFH7iJz7In3nv13L00AJEOH36t/nMI0/zitMLPPHoDS5dO8wXvniFs6cOACNygWefvMF4O3LyzAqD+UY1yKnwzONX6CaF03cdQJrE9mZHt5O5dnkLfOL0K47w/HM32V2fMGwcp+44QHHwv/3jX+ed73oDMqj9iuMLn3+e8xefww8n6OLJ37L/OcPTj1/Bt46/9CNfSy7wa7/2BP/0p/8D3/yOr+AjH/ki3/ueN3Pk6CI31if8zR/7IFsb97Cw1PDm3/8q/scf/WV+/9fezbAVNZoroJxpm6TO+oZZvdyqoM99sPP/hddCNimUggN9mOstmgJLdOlZBrIHfJhew/ry5ZbvUUcrogxkZ8BhhfoKMvUvsNdTc9dbwQ+pbAJQ6cNesOEWd9lmOikBu8eYibzsAUwkU9SCG2VH2RBqdpP4sq6XBqAg9E1TZf3p9FRp2ckmpwVlEzQuWBOUmXQdPgSaNpBiZDQcqndC1njF2EWVC4hApe1YGoQXcD4QvKfrNAUgZV2010mnc0LwGtWWUiLHSGN+BXsbsWwRK8YUt8ZcvRNSUhRPvRtc/7e1gSyWfEAp1mBYs+hUHlGMdp7NS8HsnvBoAymSLQJTowKLJV7kVPqJdmVklGIT72QExSJ419DF3F/qKWdKBN+oZj53GkfpncdlT4p6+ylik2ycsT4s7k9gNDfqYw9LUUPJ6By+Cfi24TOf+yzjOGbQBHa7ic03hAsXL3Lh4iVWDx5kbXOTlMH7lrYdKUulFIJ3XLz4PPfeew8ld4TgOXT4EJ/97Ge5dvUasgptCAyHQ/AN+MY074IPnq7r9Bh5weOMpRL7tAZnbJm50ZCdnS2eeOIxbrvtNq5cu8L6+jrHjx1jcXGZXOD5i5do2yE74zFN62naQJFclQpTeqjRyYaDObxznH/2WVaXV4kxsTveUe8E8ZQsOBeQ4tQci6LU+hLUINIVMh05mpeFy0xiR9uo+ZdKdJIdc6Os2TOukPHBGCv2meSsxpjOWBoqc1EPEkTBm5yiPoTMEyCnjMOTEaXul0JGo4gQoSu2D1IIEvA1npJCcF7TN5JGHzrRh+G1a1d59rnz5JxYXFqiAKurqxw6fJTPffZzXLlyAyg88MD9LC4u6bHIhdB4BU9iwvugCStmbNQ0jTb8OOJ4zMbNdbxTYqKXKg/JTHZ32NzaYHFpH0vLSwTvcc4jzsCnko3xoQwIb8dKBCY5qmmlMZSqxrlkBdsar7fYnBMxZbw34KZoysd4ssPNm9e5eeN5nnzsHPsW9rFycJmFxTkW9s0zvzRkeXUe3y4waJxFQ+l1nmPHDFCY1axenCpARLh2ZczhAwv4AC4Ib/kDx/j5f/UbPPX4YX75V77IM89c40O/8ih3fM+byGnAJz/xJB//6Of5jY9f431/5Wt44CuOIqXw0X//CA//x2f4yIee5Jve8Vre/T1v5P/86Of5qX/2CPffu8pwYcJXvP4+PvwrnyUYePnQ60/xpjffw+VLO7zu9UuIs1D44rj7zmOcOHGYT/7Wz9IzB3qTKPACH/jAR/jxn3gXISgh+eDhOX7rUxt8/vMXOLC8wNHji4iHfYsDxjvjnn24tDzH5vaarRsq1fmFE9NZzerlVtL33GXv914w9e+xhlvYB3DLdSMv+P3fcU3tveYq42CPbartxC1X5R7govyObdb/lunL3bJ1W8ROX+BL7JPUDf2O/Zy+h/wCUGJWX6710gAUjKKPTcdzKdNIQnFKpc6QcrHGS//Mh4APuvCnQNM26nsQEzXipPGeZJFxYtPQkpM26UF9E3Tb00QG7e0zTWhISRuvSmcOvsotdCeqKz6gMYLZgpycarmd8+Q8nQJPQQhHNUsMZnqYLA4zxoj3Te/bUEgCl4W8AAAgAElEQVSqm0Z0n4zGrywEbYLFGA/q6t9pk5WK6e2zpTkA1kArcqk+EU6cauFzRIJHUO+BMGjx3mvyBcpAoBhTwcADZ/KH2owjQjsYcPr0aRYXl/Rz8o6TJ0+SCowWFnjVffeBF3a6MYPRgGMnT7J6+BDiPftXDnDtxjrbO2Oca7j/gddw/PhtBN+CeGIZc/q2Uzx/4Tkm4zFzZph49z13k1Li+rVrlJwZDIcM5udwbcuBo0eZX1ggZmWlVMlMyRnxohGftmDLuSg4lRKLSwu86r572NnZYXN7A+eEU6dP4duGUWg5c/YsTz/1FCllxuNd5vfNIx7mFkYcO3FUz1uyBWPouTwajjh27DiPP/ZFPi3CYDBgfWONhYV5wNEORnTdhFKiRgxKzSzXzy5aMom3z9B5oXRJ5Q0WHZminh++JoxIsQYZQmjIedw/3JS+Sg/8xCol8Yo6py7qOdAzHYSUOkoB5xs60ejTcexIBeK4I6ZC0wSEDCnSBk/btpp64p0BZ3r8cymsra3x1FNPsra2xonbTnLkyGHF82PUGMx2gIhjd2ebnZ0dYpwQIwQPOXmcqDyp2DXoQ4P3TiVPArs721x87nnWb17n4Ooyo9FQ7wmWDLG9tUXJieWVZcQLk8mE0Gj8rBRBjKkzSRGymMxGyCX1x827PQ92VIIFWUGJAj4Izge6bmzHRqd8+/fv59Spk0x2zrF2Y5e4K2xujBmnXQW8hnD4+ApvesvrODjcR8yQzI9B5IUP91nNala/Z1XvpaUQigKTWeDU7Ye49PwaJ4+v8N4ffCNXr/4S3/99b4ECaxuJ3/7U83z/e7+Gw8ce50d/7Df4qZ/+o/zqBx/nV3/laf74O17Lq+67k5/52d/gu/7Em5A84qHX3skPfP+DuKHwz3/qE6ysrvAVD93GcK7lw7/2Wd70Fno6cU2NAI159kLvh6NreGPeoV4NxddIOkuXytUjprKsbDZpkq2e/izw/T/wtfz99/9bfvB930Dx6js1JTTXZqcfu76IH8ysZvX/UdVTvvbe9s0vffa7W3+65/f7f8kL//HCjb3g61uIQbqYkxf+/i3/+U9dlzX+dWq6/ju2K1/iNb7kywn1XUr/mv5L/eKsvszqJQEoCKiEoXLRjUoP2aII6ZtoF6oUAGKVRlCmTaL9fwiBUuMcc8H5yhhQECC40PsGSHU7tRtDNJ+CmhJRUqZtg2nPo0k0TMNcdCocGm1o6gRSnDENrOHPqYILmW5SpQ+2TxSC9/hGXeTTpNMs+mDU6yTTx7RoFGC2WMBUMDDBHutFWRcOj5Osx6lLOvW25k8PSYaiM3CHTnq7LqmdjPM0tq/ZJA04jwTbi66jocUnZW0U58gCydyhnQu84hV3EEIw4AQOHzlCyiojmV+Y5/4HHiAVNadr7lBApKTCgcOHWT5wEBAkBG1Aq1GhJWIcOnqYAwcP0g5afAjEnBgN57jn7nuhqHlkTJHR3AIxRk6dvh2h0LQt1WpGQRwFdXJRZom4AALjiUpQ2sGI28+c1uSMRmnzzcBMIjO84pVnOHHbMfXSwJFRs8/BYMDJUydVVedrCoZJCTycOn2KwUCn6cPBgKXlJYbDET4oeOO80KVsOvmG1HloPXhHyA3kjoiyCxrXmCQl0WUQCT0rRc+d1EehptgxobMkCWeeIOYibDo7ycrKiSn2PgvKZNFrs3qbiGiqREcCEXZj1vMwZ4JzTHYj4tTLwHmBkpmMd+jMBFQopC6yu7vL448/wcbGJkePHuPYsePMz83TxcTNm2vESccrzpzhxPGTPPPUEzz95BOs7l/kjjvPAHo+VUAuY9Ki8Vh9TFKmG4+5dOEily9eYjAYcOTQUQbtENMpMBlPuPDcRboYmZ/fZwkMgT7tJOdeduKdV/2yyZf2xkQiRY1g81S33PigHiel2GRP/z2JicarF/P8wj4eePA1xInnM488xtxoxNLyMhcuXWJzbR12MrjC9sYucmBZzyFpKL1mc7Zwn9WsXoySUggZhLYfDLgEjz9+kWPHF5mbayEmRCLidSYyv1J4z/e+kTY43v4td/ORj34an+ADf/szvOGrTvPxXz9Hch1f97Z7dTVWJhw6HPCNrjFedd8JfvWDT/HvP/IYNzc7HnpDjYBTlmA/1bTGpnozZIpF/E6nmJUFqMFQQtbbMiXr4CLa7/ShdoZliz23VlcXuXppS9mbviZPOduTvfrw2T1pVi+j+n863b8EcPC7+p3/203851xz/wnWwX/G68kLvp7Vy6NeEoBCQY0CvfOkmPqGz5kmPKVkkYdF/QWalmJT2JpIUJ3VxQmD4RApiZzFOOe68O+KmS22ASdBJ7g91VtwFm2YXSKmRGO6ZfF6QXgc3R5akBMhG6ggqKY5lYz46UI/Vw2EKKtBH9jVgFEBDedVCaVsh9THTaauQxwMQkPMiS5G9XVoGm0EC31EYKmTBYsHzKXofmQIQZujVKLq53OijiKc02PvRCzlADOazDold7o4EWM5OgTxAd8MiDg6cSTzMXBAFE2PCPNz+jpeGx/feEpOKlHxjrAwosTOjBHV2DIMA0k0DzsVlWD4xlNSIjhHihkGLS4EpKg+P+YCIVAE3PwQ7zw+BFyB7BzZCU3YR9dNiMHT5UQOnpjVzLJtGrwXUrY3KEIRnb5kcbjBCEFlMDpzLuB0ytPOzRMGc1N5jnkXdCkig5F6A/igjWvXKYPDe8JonuO332ENuzb/MWaygwmCuEZNOkOgc4UoHTmM6EgESQYme1IpdLngcwEvZO/08896XKRk1dZJwTVBjUFLIRVH0zQkhGQamFIKIbQggZTiLakhMWnzLN6ryWUIuBBUToQjhCFOhoQSiAHGoiCTsmoyUgqt8+xsb9FNOpq5AeTM9s6Yc888zY0bNzh48CDHjx9nbjhH8C0pTVhbW0dEOH3bKY4eOcrcaMD161e4eeM6qTul/iZePVEmXaSIJnOIOHLK7GxtcfnSJa5eucr8aMSJY8dYXloiRwUUU1YTy9hlui5RsoDzeN8Q9xikSqGXiWicqse56mmg3g05ZktRyT1YGDO4qBPClLIt3DONayjGCoqx48rVq2xubdLFHbZ3Cq4RkEzbtPgBzA/mGIYhHt87LxdR89oZkXBWs3oxq7C+MeT8pS1O3DbASeDpp2+wemiV4XzD7lqi4Pq0R8FSGlzWeyIdAtxz3xxv/7YznDixhFB48snncAWN3HWR7PQ5dOjIPN/5HQ9wYGmeT37qPL/0y5/ga/7Qvf3epKKSRyFTijfoQKWU9f517co6eM/+5QXmBwf5uz/xCX7oL30lWQqXLt3k+NElFobz/O8/fZ53vGOTYyfmubm+y9xwSOMNVYjC333/v+W97/s6ij1/6E0f/xMU7lnNalazmtXLpl4SgAJos52SPqBq/GAfwyZK7RPBqNg1rtH1+e6qWjCU3BcCkHMgWeySOGjEk5KaKQoqiShZQQYxX4KcM20TFMCwKEGK9NS/pmmJnbEUkn7Pe983ZbGb4KXFm3a6voeSypQaXarsUUh0OgkVM8tLWZlLDv0lUSPGIuorEUIwung1QwBxSsMOIVDIxNTZhNqacJOSVGo7SdMRdAKbSKX0HhAC+jql0Jm5I1mbIaFo1nUQtp1wc2WVFBzs7uBM6lHjBqU2lL0+35rbbO6vXnoQqVg0pyBGkXIk+1oZKxlvPhUOk5KATaULzntyVrAp+MBU9+WpMZk5R5vW2HErapIRvEpC2COlUQmM0jkxRkt14MylKBvFXiqZP4LsMdLR8yghxc5XCl3sVGoit5LGsjE6apWcenNEKOz6wNb+VS6EQHGOtmTDghwpQ6fQA85Z1jlCSXoM67ErFLzXxjdlNQCqgFR1D1dWjbIolLlT5beiAINXQ51kn3EIwcAyAXFc2dwhNYFhyUQiLnhcJ2AmoI1vmRSNWRNjm3TdhAsXLhCjSmzW19c1oSIlXFDJz/VrV9k+cozdnR2Cc8yPRpA18rNtGrquo8uJ3W5C06pEByPiXr16lfPnz7N/adliQ/epXAGnBqJmBqmggrKd9l63+nnRS2Kcc+yOxzgybTMEMdlGigo4FehMtlTNSYv5ltQ1d0koQONbyImNrQ0+/ZlHOPfsBZBMKhN2xxssLM6xdPQg+/bPc/DQfvbND6FEBSVLIpdITDMPhVnN6sUrfTY/+LoD/Jkf+Cnuv+8AjkI7cPyxb34d4gpJ4NFHn+dH/8Yv8Od/6I8QwqYauhZogGG7iTh4+zvv4c++9x9x/6tP4STy2tcd5Y47juNdR2i6fs7/7z78CB/8pce47dhh1jcK+w9ogowPXc82nEbU6YDA+0293dig4dc+9Cgf/sjn+Ft/+9388I+8mX/0Dz7Gf/tXfpHi4NFHn+Fnf/a9OA9/48fewgc+8CFiEZ47f42v+YOvYmFhqA+CCOvXOvavzONNxjWNuNZ1SuVAVMrzrGY1q1nN6uVTLwlAwRloUCfrVfmQUiJ4NX7rUqSUpEkM1v7HlLWpzxpxiHkvlJxJYvrlmElZmQtqUqcPPG0QMA8FEKdu8DHRN1ZVIiDmWl8TFrzRlTVeceqfQKVAF4169F516yRtMkou5Bi1IfNB/QpKIZVOm2oxSYezRAmnk1bfKBVfUiR45VJO4gQvapSYcwVHSk9nz+ZBUSg9UOO9MxZEVmDFV0d/M1e0plkTNKCb2LEpnpKELIUkeqyd88RU2NidMNztFHRwBSmlB1pqM69ABwp2RDXr6xvYXEy7qf/Vqb2nFP25HjebBJsXRck6edH3qh+p944uRbzTzyHFAvZ+MbZDbfRzygYo2ISlFJvw2H7bsQy9oV6dRBeKU7q/+kqo7ixb4+1su00w9ogTSJlJnCAi/XEQga6LFtNpr2vrsFJyHzsanGMbuDGaRxpHXrtJyBDEa/KJE1xoiGVCjskMJtVkM0U9F7TxT4ACJrmadBW97iqY0I0nBlrp9Ds49fIoueDNhDTGSJZingDB6P1CWVrmxsFV5puGOe8VzEsFL6i0KBUOrB6mcS1U0KgUQuNo2oZJN2FtbY2UEhsb66ysrLK8ssLqyn4W9+3j2XPn2N3eZjLZwTvYv3+/AmFJ/U92d3e5eOUy+/fvZ2HfPgUKYuTy5ctcunSJxYV9jCdjbtzQtJO5uTnm5ucNPGwIwdNtdXRRgRBMkiFFDSjrvQDMLLYoWKbXnTorB6cmldlVeYSazFZWSAihj3gV58nFvFtcwTeO5f2L7DuxzNK+RVZWV5ibn2NlaT++dThJzI9ahGReJWhUqGIns5rVrF6EqoD3e9/7er7lm++jZHCuMBwGVlbmEArziy3/7J9+NyKFtnX8tb/27XgXgELj4K//D98BDu655xgf+LvfrRiFg9XjC4hk3vzV9xJLIZhc8W1vfR1vfv39SFaQeX4x4HzhPd/7B/gn/+BX2bcw4uSZFdReGNqB50f+u3fdwhf4+rc+xBu/6l58EBaWA+/5029g+9pYk3ZGDt+Ak8zve+MJzrximYndu1eWhuBgMsn83M98jLd/84MMWq/AgRixWejXQFOxw+ymNKtZzWpWL7d6SQAKpRRiVvRfdfdVo91pA+SCggZOcNaAlixGEYTqu6CMdem13uIcTdPqw09s0ipqzJiJPW3Ze2+T5KxZ81Hd8HuXfDBTR493QopKKdSGzNGlDrAprxnmSTAJBqL7WFL//dRFck6E2pg6IVcJhU3wU6kO+GpG6R3UKDqHNnxiHg21EU5JmRvTSb8dX2NjaISl/q5O3RW8EJtYl5z7Y1hK6RtbZU9AKbY/sRBiYnVrm5Xraxze2qDLHa5x/VQ7JpOX2OdZTOY56Toyycw2mTbxewEFi9B0BtwAfQqBiB7/vsHzjhg7A4eMmt/HJ9ZmXU0lC0mzs4A43sW7igboMcyW8FFQsMg7TyGRql4+6DHHCV3X4V2DeAWaKBCMgl8p8t55coo9/bQeV7HzsTPDw1KU5aISA3vHJkfZLBDnHSd94MiFZ2lLVoAtjskFfDMksUVJ4GVggEzQc9w8EHJKhCZggg1SNADD2Alt0Ka+2LkoXtk6JZXesCtYOkS0ZIjQtv02bpTCztwygjNJj8dnRxN0miYOlldXWFheIgx0mlZKYjQacOcr72Bra5P5/4u9d/mVJM/u+z7n9/tFZObN+751b72ruqu6e2bYwyGHEkwCMgzbghfyRgsbMmADtuCFVhYMeGET/gu05cqAYMCwVzZgGJBXtgUDhiGIHFkcqUmR3TPdmq6qruqu533VfWRG/B5enPOLvD0cUiRguhuYOI3GraqbGRkZ+YvION/zfczmrK3N8d4zmUxomsD29hbf+5XvcvjqECewu7PDtb1t9g+u6TluDIAaDZuGJl/Xf2gCIXiOj4+IsWfSNLRNy+3bt5hvzJXhECOz2Yxl16nExjs1dGR1LdHPw4BOY2woIKPrxHmPmmfa2SX1qrGSH/VJWR8KViqY5ZxjfXPOh9//Hv0S1mfqpTGdToixo1/2vH79nPPzt9y9d4ODG9u4xg2f6y82bhprrLH+ckqv7bMWbt/ZIFmUbChuYLM5V7h5e13Pf4G9nTWqu7r4zPb2DIDp1HP7jpoWiwGLUmA2a8iml5Di2Jh71udN/fbS7w4Sm5st/85f/yH/4H/5EX/3v/gbeilwCS+One01hDywOmcbgcn6OnapZGOzYWOjAUQlhgDF44FbN9cpV6CB7DJHpwt+/C+e8B/8x/86zpiaK5V0ZIiyK9XXZXj6WGONNdZYvyT1rQAUdExazDDRouxcspv3TElRGQExke2LKhdttIvqIAiNV9+BlBScEG0wndPOLCfNja9Te7AmlkwRBQU8xfwLGBpMjX1MiCjoEKvJnVMNu6YkqAt+rZwL0hsY4bSVFfOAgIwLOjmPOa301bZXKSedzntrzmxfYsxXGnAZAIJSlLafrJHKOZNiUsDBKUgxyArqZMEaWGcSC+89se+N3aHyEO89ruh+eqe6fGwbyXsuQsPr3R0ug6dbXOLwRNIqipZizA9tIHNWgCINOnSdxg/HzIwDa3qGEz+wLGwMYs2YSlCyeU3U5rQY/VPMRNCJNx8GGVIqKhNBzfFMClOZHAZW1GM4SFUGoMN8FJwaJ+ZSBgd/LD0EKqikwJL6WpTBB8R5Z5Pplbwi55Uh4iDjqc7auVBKYG0SCF99yTRCS4+kBQ26TlwvOAKZRCpLex+9/XTKFinqGYBo2kcfNTXFOwW/XOoJxuKhFErfGUtEb1ALhdL31CjKUsD1uuJFhPMSNcLYCaGZ4MMUh2jMp62f6bQluYSUhJNCFphOJ9y9d5uUNLI1uIarEayh8dy6eYP93T1lxXgQKXjvcEE/39A2rIU1bt2+SRNaZQd4jxPh/v377G5vM5lMLK5S13nTtgZy6c30zt4u84112ra1cyyRs2VL2+eci0qPxNX4V711zjlTqAamcThH1bPETMsMYPAidpUoFBLZsqc3t7Y4fnPG6elbnj79iuVyyfn5OW9PTzl9ewxEJPw6+zf2bF05cnY4aa7c2I811lh/2VWBAjf8rDq5K49xMOROFz9czmuq0/AES6capvqi/y5ik5Iqj7MXdXU7RYGN7/zqTT759Cccvjxm/8amvU4dglT2gG7TObtvMFlednZNMskeGB5QQIoOAPSfM//H//67/PZ/+TcHIPzrKisPdPaaP+8OP9ZYY4011i9LfSsAhVJ16gIUb0Z1zvTdKmlQA0Tsy0yN0RKaQoArpJxMdgAuaKpCTDpxd0b1jn1n0YbKACgZmy5WE8KM9/qFqU0jVHlEyUIqCiaANv7kYpNoN2wH06anmCwijwGUyOYV4F0YGg2GCDjdbgiBHLNS4kVMul+bV2tHVMCIiNCYIWLKEXGNTiGQVYIFGiWVKBap5/UYZI3XFFFQod701OjMqw21CEhOOhkV087HnvD2mMnzZ6xdnJNSJgiahmHHx4kbmvNoE3usYVcafrEmVT8/HwLBWXxNqVMQi7m0NRKTNvZd39E03o5PJsUeRD0uqtG+KK2CnDXqEmvw1TejQEm6H8liFr0BBjkRYxqMQbuuJ6dM0zYE08fHlHSSbwBGztnSHzIOM/dMZVjHvgIQ9YYRbc7VrE8/dz3+ppHPOtfyCBMR5hcXuNST6enJNK7FFdPql6JeH6zet0hloiTzTuiHibve8JoIJRsUJsotcF5jJ4dkiJKH5AKRMpg15orseQUenGQgqRdBghbHEjXq9EbrTVKGlDPnBB+8yoh8wGhEBh95xHlIGWkgePMHKRUUK8ai0Di0XArz+Zxo55wz/4hr+3tsbMyZtK0apqZkMatBd0g0jWVraxsctG1LLleBKUzCtIpWEyeEGv9UMCBTzCOEKzIiZ82GIyPKesg9khUQ0c0Vuq7nk08+4cnnz3l7smS5iMq+8p752hpIy+bmFpsbO4jzhKbFhxYnHsENzcBYY431l1tl1f0bMC/2VZUNRVgx8ep5KfWZUscYWc/boduv21QgQGcrGfCrvr0+7goY4ShI4/j3/ta/Ban63TB8X6thorf9cPb0bFGQAiQFu41FhRQyDjfcY63AiP/oP/y3h31bfS9fLU2nuvqskaIw1lhjjfXLVd8KQAEYvn9KbWSsAffikCxD4+CD3UiLwxUxCnaiFGt+UlYKujXAfqDgCdPZTIGGGO11hJxNziA21Y5ZG1GpdH1tKGumfOz6AYt3iJnAKWOibpMsFIP4FQOwTHqE4nRK2ceIJu6p7j3GBE4lDV6umDyWTNtockFntOxs0oRssZnFNNqY1tsJxD6Sk9HLa3PqtMUpuZCTJllo5B6rCb55BaSU9H2a4SRe9LgkICUmJbHXX3D38pQ7pyf0OWlTVqMKjd3hfSB4T4yJlJPKN3xAxAwhcwEHfd/TNI3JGoCiPhlijATnPMuut/QNbfzEQU493kHwlVng7Zg6de4HgneDb4KyATIl93Zsov7OmBvVc8KZHGS4QyyFcl70hkoU3HE+kFl5RGR0fTS+tQl/ZVro9hT4STgPfb9UHw2FzAamSL0hS6nXxtmBd4HUJRzJ4kkdkhtIheItogzIdb0NtFRMwmHrAEjm9TEARrZvFCHGnhJXTIyCGggG740Nkk36U49vHCZWpagUpxGhQUhpQQk9jgbJkMkKXFXpgIEbuXpmoGsf0WMRjCnkvTPvgUhoNIFCnIo3st0O51LwToGSEDyp1/PZi2NtbWagotA0QQ08U705F3xoyKh0ph61qzIccXr9ETNEpeg697Iyca0snGCeHSnV89AMSbMxXMRZULz+OSV9v2dvL3j54g3nZxFyoGlnrK+vc23vBvPtKXt7c3YP9klSGUzZwLU4sK3GGmusv+Sy7wGd9NcGuzBEOlxFG+p3F2Jggg0BigyPW4VB63WglKvP//k/XQEZpFATFoo4XJABULi6DysI4gpKYC/3tX5fb1koZuAr9n3g6nedpEHS9Se2hWCxD18DRkZAYayxxhrrl6u+FYCCft0qkFClBkO6AzqtcyKQdJqdc8YHnXCWLtL3vbrWy6pZb7zT2ETR5sN7bVpSjuaNUFkRMjARSl4ZNDoRok1EB9O8kofUhxgjjfd4UbO6KlkIobHH6r4PuvxSv7B1yumC+hOkmNTvwZgC+n6d6vuBnLVJrI2Ecx5cTY3QSTkUmqZVwKHSJJFhsgxcMTvMQ/qCIMQ+qs9EzqQIWZK5269uLgqFvu8pOIIowd6ZdCFl9W2o1PicEsvLBY8ePWK56Hj/vfeZz9d0JzI4NYigjx1izAkvnrZtBxBJRKn4KWrkoBT1njh89Ybnz1/wwfe+qxNucYjzuJKRLDjTsuaUiGRevXyF95693V1EhOXlEkphMmm4uLxASsEH83LIhcuLCybTKV3fkXNmvjYnBM+yW3BxfsFsbYYTx9n5GWtrM1rRNfTVy+fMpjMmszVevXzFwf4B0+kaKSa6WAYa/nK5RLyjEY+j0HcLci60bTuss6uNfl27YiBEyboevFMWCGKeCCmBRRlmO4+GOMNcTPLB4FshNXJUFCRAPJVcE2NHNnDFBzUgTAYOOWNY6Dmbjf5v5oPF4RG60HK8PqdLnugDTQ5I8pTqUVJUgqEeCAn8FPEOV8GVgkWjBnKKelteKktImRNYQkqfsplD6rRNjVb186/ynWCAmKaOGIA3ceZZUVkY1S09GVupo7RTTiczsg/4yzNIClw6UWBKzS89nemfi4FSes4oUyHlVZQkiEawFks5MZAxhIb9/QOebx8zaRKpd1wuOi4uLnn+/AWzi4ZFt87m7oSNnRuICxZfqe95oBaNNdZYf8l1FQgwqYB+oYMYs6myD+Rqk8/XwITKCKgh0hr5dPUlrHkvV3t/fc0yJAoJK32hRuVW8Ft9lPzXNynVhLiCHRUgWL20s+98wz7sF354RqkUhYHC8PMAyHgtGmusscb6Za1vBaAA2lg6LPddnMXLGY3QIvLEB3JK9CmSABe0wQ/FUWKvVGMRGq8T61KUdu59Q4oas5SMFYAUlUykTNO0pJi57BdMWjVNUhM1/cKujW4IAS/eov7MsNBlimh6ATZNFxQ0iDZNrakA+mVdwYyoj3dikYx16iGQwNsNQUEodjxUbpAoZniYjDbvnafvemKf1FxSNE6xshk01tJZAwVdF032IKrHTnpjo8SIQiqYXlw/k2xeDTpd7imuEJO+9rLvdfpclD55uej44ounPPr8MbGPnB6f8Bs//CGztbUhFSDmrjJEEVCzTDxd3xO8Jl+4UpR1kFR+EuOSPi558foFD+JDJpOJaWVU1y4iGs1o4FPfdRy9ec3J8TFbP/wrtG3L2dszXrx4wYMH7/DFsy+J/ZKH776LE+Hs7VseP37M3bt3WSwWPP3iKb/y3e/STiZ0XcfH/+IT7t6/y/bONo8ePeHW7Vvs7jbknHn29Dnr6+vcvHmDxz97BAnu3r1Ljpknj59QgP39A3jPccQAACAASURBVB4/fsz169fZu7aLc57T07e8ePGCO3duc3J8TPANBwcHII7LiyXHJyfs7u7ydnFBKZn19TnOZ2BB33e0TYsUT0wKBJS8pGkalYKEMABnUtxqeJQdTqp8QCdQOfbgvCZNVlPCkihRG+Wm0ffZp4QYkd8UK8NwzmWh68/pHtznSdTYzz5kmgKkQvIBjPVSJQGIAVGl2M2z3j5XH4liZplS7Oa8YAAXZNE1pzfqeg3RSNZVAghFQRQYyMR2tRGVb5ivSfW0KOZw4JwjCjzfvYP0HTtf/Yy1nFXuknpa73GoNERclWtosksFbFJJeh6WMrAiYlGGiveeLiVIQtO0PHz4Dptr2xwfXvD25JJnX37Ji9evOTp+y5vTyFdfZdbmwq07+0znHu8agjQEFwZN9FhjjfX/V8nqh1QBQG3gf9Fk/hc5nfxFp/gqo9M5g2MVrW2/qyDAlX1wqz/CFaDj51/1KmdChrjh4ccv2M0/a7/H69FYY4011i9jfWsABdAb+eCCNuApDxNEzLGYVCeU6nnc9dGi2dIgh/A+6FTfYtlKKZauoJn1OfeEoKZq2Yz2BBmmw4C57bsh5SBGbeBzSQPzwDmh75ZKW0ab7bq/YtPIKlsoRSURWY0AzENAUyhwmGFkGBIoaupFCEGZF0Ds+8GgUWnUWRsiDDww34m+j4TGDUCCiLBcLpm2s4GlMMRMDvR6m2A7d8V4Lw+JA845vAv0ndLO+5SGKbhTFzplOFB4/eoVXz59xgff+Q5r0xl/8M//OT/+8Y/5a3/tr9GEQB/j4FHQTBqWyyW+CTo7sWhPlQBoCoZzjpITMWVi7OmXC6W/hzVEitL8izaPJavBZsxqJri5vs5Xz55xcXGBiHB4eEjfdzYBbzg6fEPf9UwnE46OjlksOkJoEdezWCw5efuWa+2E5aLDO0/TNLTthL7v+erLr9je3mGxUEOqENRfoWkanj59yrVr14gxc3x8zHQ2wzlH27a8fPmS7e1NXKuN9NHREfv71+i6ni9ffcXm5jbOORaLJV8++4q2mbBcLjk8fMPDhw+YTBpi6vj8859xsH+dzc1tjo5O+PzzR0ynU5omcOPGddbX5zopdyujSYDlcsnabN0YD5kUI4vFAhfUf6NpwiDNwIUhglENTMuV6NGauBEREtN0xvqnj1k/X5AjTJtA9iC5R5yjL4JPZnBo21G4zCmg5JyaFma+1uCLTfbUuNRue53KIGJOV84zbL3rWqz7V7LFvJqMprKRRIrKI7KxINzq/Bfn6JzjWmk4PDpk//AVk9iRXaE4TxQHUYE8ZRkVY5Toa+WswItzTuNjLe2Duo+1wXDKynh7ds7r12+4eNtzedGx7CIFoW1bXGhoJhY5WiwqMydlr1yJrR1rrLH+cksn/b8YMPiFoIH83F/kF/7ia/jEL37+L9q+/InN/8Jt/Nw+/onHXd2tqyDHL9ie/Py//InHjDKHscYaa6xf1vrWAAolZfVJoNKEMW20H1IWoJrMFTOjM5qhqEY6xUjse2ukzO3frcCCEFSDrfGJtdHSyaGII+fEslsiuGEqW5vvpmlIucc5x+XlQn0ATFdOlVSUBGRyEc2NRhH+lJPqnUtWXwAx80Pn1DEyVb8Br9IJAw1ijAOogQhdp0aEOen7RlT7rdpzQbxQDIhZyQd037uuG7bbNI1GLDptgEqungmFZM2jVMdnbOLaa6NfKoAAw9RYQRBlGrx5/QYQDvYPmLQTHjx4wMcff8yy62iahrdv33J0dMSiXxLaQNM07F7bIzjH0eERi8tLuq6DUlhfm3Owdw0p8Ob1G548eszjx4+4+bPbvPfeQ+Zra2rQuFxyebHk8uKS7Z1dPTAUdnd32dzc5NGjz7l79y5nZ2+5fv2AyWTC1tY2n336U5588ZR7d+7w5s0h1/b38U3D+vom12/e4snTL9nc2ObVq9fs7O6xtbVD0zTcvnWLn376KRcXF5ydnbO3t8f29hbtZMK9+/f5/X/6+7x48RIQzs/PuH7jBm3bsru7w0cffcT16/usb8w4OTnh4OCA6XRG8IFHnz/i+fPn3Lp1i7Ozc0SEmYERKWXOzy/x3rwL0PXT9z2Hh4eUUuj7yNnZGc+ePeMHP/hVdna3oej6Cz7w5s0bPvvsM+7cucedu7dJMfHi+Qu+/PJLQtPivOf27Vvs7GyzXFxyePjSYlzL0JRvb28PgJb3dvlwMKFw5+Qt187PWMQe8Y62CaS0UCkTfpA0uSHy1OQ1Bo5hyRSYdEYZS96ABDFZkQxeHynngcWgAKAxgcwTJfgKjuh550NL30WcdzSN7bsoIFlQBgKisZBL55gcXMd3C3YuFwTzRvAhaCSsWFJHTFjEBZjERIwV0ff9cB0y0vDgzyBY1GWBJ198wR989DGXZ5HYCX2G9Y1Nbt64zvbOGuubE27d2aNpGgaBWE6D8eZYY4011lhjjTXWWGN9U/WtARTc4JmgtOdc1LAvo1NLNRSsbACVCkgy13fQ7rZoioITp9PwPg/Nz5CyoLP4IUJSJA2vqdNF3WaMkRijNVRiCRAeSye06b0MzY7zjjA0RH5Ijchm2uSDPTdndJip0X1OHKFpSDEPSQZ1P5IBB84pWAJFQQWbEscU1bDOKOMYcBJjbxrxZJPNlTa/si9yzpqoYEkaNR3CmQzDN95YHMrK0GbKD0aKK/aIrJgZRk0/OTnl7dk5eVboY2TZdaSUOD454dGjR2xsbDDfXCeTeXt+xub2FovlgmfPnrKxvsHabI3Y97x8+Yr1tTnrsxnz+RqztSmTSUtK/crx38Cc2MFysaQkZXY4cdC2HBwc8Id/+IccHx8xnU7Z2NjAe8/6+gZ3bt/hs08/Nc8IYWt7G/GeJjTcun2Xw8NjPvnJZ8R+yTvvvms6ftjd2aUJDT/55BOadsLe3jVmsxk5Z7a3ttje3uZf/st/yfr6BvP5nN2dHbwXNjc3WN9Y59Hjz7l16wYnJyfcunVLmSg+sLu7y7NnT5nN5hweHrKzs8NkMkEMTHr27Bmz2QPevDmkFJhOp8Q+8vTpU/Z2r3H/nXfplgv+6T/9f3j69At2d3fUdDQnTk9O+ezTz3jyxVN2dvbIOXF8fMTjx4/o+8RkAm8ODzk+PuFXf/VDUop89tlnCjyJGKvH8eGHH7K9vWXeIHYu5gCxoXENvhG8h5wiqc/WsEeTOKDmqalGo6HNvlNQStc+5u9RzCSzni8qo6gNuTPGUo2FLblQRD039M8qi0gxGm3XDedQncMVCiUlnKCpEmBgnRi0qYwAH6GgkaaSIfeW0JGLkoSdMh1yKeSYaMLKwMw5b3Ioe81czNRSz69uqcahmUIXe0pR082UEt1yycWlIL7n/GJCijuUVGM1nRqQjlPBscYaa6yxxhprrLG+wfpWAArq9WPZ7TmTbNJXCjQmyStShuZGqczJBuVCznFolNu2paRESRlXtCHOljYADKkMHp2oF/zAaCglomBDGLTXzjma4EmxV+p1KTRNs2rSEWtGdL+cpTiUXBT0MJPJGDWyrm0aNRzM0ZzxZZAYpGIu92gsXuNa/Z2UYRpZfR00lk6NJwetPOrhkOIq/rEzZsBVPwURCGZG6CwKUKe+BR9MEWppEc55cgHfNHqMYqYJLd43w/F0pmPPpdCEhmfPnvHpTz8leM/p6Sln55fEVDg7u+Dt27d8+P0Pma7NiCQWiwUiwsnpKV3XcffuXSZtC7lw+8ZNmqbBF7h2bcbl8g7PX7zgO2b0WEpCnMZgzmYz1mYzNSasCRPi2NrYxCF8+tOf8pu/9VvMZjN17BfPrdu3+eijj/i9H/2IDz/8kLX1DU1uKAXfTphM1/jkj/+Y9997yO7uLrPpjJQTa2vrbG5u86Mf/Yhbt2/z4MFDM+PMZCncvXuXf/gP/yGz2Zzf+q3fGuItmzZw//5d/vE//ke8evWCO3fuMJ/PDSwTbt++w+/+7u/xk5/8hPX1Dfb3D/DeM51OuXv3Hp98/DFffPEFy8Ul+/vXmE5mLMqCnBNvDg+5d+8dUqwyAD2nUkocHR3y6aefcX5+MTBQckxM2gl7e3vs7l4jhIbXr4/4+JOPefniFTu721xeXnJwcMDe3i5NE66kiYg1xM6SLASPo5dMkoQriVCCun87T8wJSkBKQMxboF92eK/mmzkaK4mMENSQUVRGULKyEvrUU0TML6SzBBBlMInJJ3LWa0FlAJVUkKLGjN45uj4OxmVkzJzU2DbmX6pAlaOUlpKnpNSTU6F4IcVEYxzhDCwX5vnR6LninSdnS1jJGiNZZVer6NNq1ArONbSt5+GDd1leJN68PCF2wuVyyWLRc3J6yKvjC0q55Hx5h5t3tpmv79p1T31lRo7CWGONNdZYY4011ljfZH0rAAXQG+/KT6hMAvVz03i+SvtPxkrQWDhvxmsqZxCnSQm1uRMRJBezkWPQSAPD5DDFHm/NUkGTIwCjY6tjfCIPsXleTAdexGIeberpNFbRi7rON60zWreYHEAnkSn1ZsJYXffLlX2ToRkefBIcNuHU49OGZtCcq9u7DCBDiUmPhQ92IAtt09rv1WthSK1yYp4NGrN5FagoVcuAGmPGGFHihmrerx5L55yazhmAEhqdtL/z7jvMZjNevXrFy9evVMoi5nBvEXyV+g6wuLzk9ORUDfYKNKGh8WFIqogxMZm0eC+koqkaTdOow79FFMQ+4ksafDEUyInM53M2Nze5uLgY/BOKRSy2zYSz83POLi5UAx88sevJMXFxeUkphTdv3rBYdDRNS0HXxWQyYTabcXlxwXKxJG9os+1aPT7z+VyNDPulSXj0fc4mLdN2whdPHnP94BptG9SLwjlmsxlt2/Lxxx/zV//KX2U6meq5UODa3jW2trb49CefcnB9n+3tHSiFSdvy7rsP+PHv/zM++eRj2qYhhMDe3i7OCWdn57x48YLJZMrtW3f49NPPBlBuc3OT6XRiUgRl1rRNy+Xlgu2sn/3GhgIbTePxBiKInZc5qVQh5kzvIkkSUhI+Q0qFiW8pFGLp1FQ1Z2UkBI2B9RLAOfpugXPgvcZvdrHHK8qnVq1Zkx1yVj8UnMp0vA8gQkwWoUYxNoMCHOoxouaJbRMoooBlTkktWZKZmDpjSFX5EJD6CCkRY8ciXSIkvBm9ejGD01QG49IYIy54Uu7tvNBI22LmspowEaDUlBkF75wXJtOGdx7e5913G3IPi64j9pF+ueDw5DVn54dsbW2QzIxVJSR/UVO3scYaa6yxxhprrLHG+v++vjWAgq/u7ZYo4JwbTAiLTfgpTlPunKh5I6jpmU3dY4z0NoW0FMnBREl16GlgFdQ4R+eDNjKlEK7kOYuXFS1aMx/N9FFIGZa9NfVZgQbVTpsMopo9ikobpMo1XI1yrD4EqhUfYgCRYQrc9/1gjBhC0LSDGMkpGRMB85VQJkd9vhOPCzIYSVKBGsEi/hJePCF4janUnTT3ZwM3nL7zXNDHFDWZdM6Rk1LIrxpY1nLeE5qG+fo6O7s7tG1LzJF22loCg+Ps/JzLxSUSnJripYgPgSY0LC4XXJydE7Y8y5jUmNF7XIHQNnS9NmsVAMllZS656DqOD484uLavn3VM9LHn5PSUdjLhX/vN3+TRo0ecnZ0xnWpCxOnJKWtra9y7f5e3F+c8f/mcO3fv4r3j8PUhb9++5Xvf+x6vXr7k8ePHvP/+Q7wTLrolF+fn/Mr3vsey63jy5AnrGxsqx+gjr1+/5saNG4gIT5484ebNm8zWplDg+PiI2dqE999/j9PTU/quo1nTWM2+79Q0cW3Gm8ND+r5n1kwHBgsIy2XH2dszBdIMdJqvrVGAP/rjP2JzY53333+P/X09Do8ePeLZs2c8fPge6xsb5Fw4PjqilHcAaNuWvu+JseP87C3eK9jjvYIHXd9zfn4OJTOdTFhfX9cEEBGKK+ZR0ONKpgUCjp5Ulf6QM14gEe0cCTgJCJkY9fNT+r6uJ2XRaBSlc0EZFQLiAiX3LCs7wTtcCENkJij4l/MKrNK/QykVdKjgm3mOmEFkSZksGomqPB8hl4hIwgcorlByVFaO+baorKGyD4Sm8Wo4mhJN2ww+JjLIuJTp5L0jpYWxGXT/jk+O+eSTz2j9Gns7+2xubTPf26L1gXv5JoWepilsbs1JFdiTEVAYa6yxxhprrLHGGuubr28NoFCBA5UzWJRbzZ7P+jvvHGWYrBeySSOgeg14vC9DlGLNnUe0Ua+RgqXqrK159z4McooKBthOgWjCQhaHuEaboprIUDAKuDZWNfLSuYCYaVux9AHs/eWYcGJ6bKnyiEzJEEJDtnjHmg6hDXt1R9REBi+OWIy14GqkXoGscomKigxSCBGKyytH52rmVl/DHOqd6HOrzEFEGR9FyQr6EimTKaTBHDPb/0o/D03DZDZVBkRwhLahaRv6HJlvzDlfXPB7/+RHfPDB+7RtO9DqN9bXccA/+/GPuX37NrPplK7ruH3rFuvzdUDNJRfdkqOjI3b2ds1lP6tBX9JEhf29ayRL0FgslxweHbK7t8v+/j5v3rzm9PSEvb1dLi8vef3mNbt7Ozx47wFfPHvK4y8ecXD9AIpw+PoVG/M5Dx88YDad8uTJE+7eucX6+pzjw0Ni3/Pg4UO6ruOjP/gDXrx4zu3btzk6PuL169fcv3+f7e1tPvqDj3jx8iveffddlssFh0ev2Nra5Nat23z00T/n6dMvePDgISC8ePGC2WzGBx98l08//Ywvv/yS9z94jxACzw9fEPueW7ducXT0hrdnb1mbz+j7ntevXuFEePjwXRaLSz5/9DNu3NynadRH4/j4mM8/f8SLF694/fo14gqXl5eEUH1EhNPTU168fM7a2oytra0hheHFixfkGDk5OWbStrzzzjvs7+/bunKknPHiKTGSewUJikl/+rxUOY3XNPMKEEpJODGgK2e8iCUYFDtntPFX/4SE9wosUP1FUh7Wd5UUKBamfhp1XVSgLZiZYd93miTjnYaoeWegoVOgzhp15zyt92a6qsCdyw6JgkNlGolMysmMFvX1VDeh+xZCY6oTXZtONMJWr0VCjHkAbs7Oznjy+Asu3nZM2znz+TrbuztszTdY35iysbHG9s4cKZ5KMVLJ1wrMG2usscYaa6yxxhprrG+ivh2hwbW/vZKqIFcm5qA7qk2Imrzp/4mUerquGxIZUkrW+ELKhRjT0FgDg6lbzNUoTaf5V6Mi67ZAadjOqc+CTjzLlcmjNlUijhAaRLxqys2VP0aLrys297QJqDOGQTafB7Iawy2Xy0GjXhMqRJRVkOv+1kluTORUkCK4otF6TjzBNYOb/tckHuYJodNbnQiL9xY3KSCZmBOxKC09RnW1d84eXxiYIzpVNpm+qyZx6vswm0/Zv34N33hSyUymE27duYUPjq2dLX7t13/A2nyNk5MTTk5OCCGwNp2xvbHJ93/lQ9bnc1KMnJ+d4RGC08ZOnLCxscHtO3cUrDBpRsqZWDKhDdy+e0f3xybHb9++5fz8nIODA0IIHBxc56uvvuL4+JjT01Nev3rJ7Tu3ma/P2dvb4fzijJPTY/puydHRG+7fu8t8PufOnTtsb29zfnaOAM+fP2djvs7a2hrb29tsbW/x8uVLYoycnJyyublp3gN73L93l2fPnnJ5ec5icUmMkdu3b7K3t8P9+/d48uQxFxfnLJdL3rx5w/Xr17lz5zZ3797l+YvnLDr1SDg9PaVpW7773e+yv7/P61evSSkRY+T58xfcunWDX/u1H/DD3/h1nIfHjz5HpPDeew/44Q9/yL1799je2l75CxRNCoip5/TtCU+fPkGkcO/+HXb3tmnawHx9jkhhZ3eb+/fusVgsePLkCV3XDfGI3ns1QPSeRYYuO5CA94JvHKVxNlV3KlEiA4kQNKrRewYPCT1P1Fw1pUiMvUaG9kvIieCgdYInk2NEKGqoSCF4wUuBHCm5J/YdOXbE2EFJqLJBLwxiBq4O9VDIsQNUXkRRgEPPVUdKEPuC0OAISBKIRQ0hixqZlpSJfacXMsMUmtDgfZXW6PZyKYPkRj0oAjkJ1/au8+Cd93AlcHJ8zuHhGc+evOajH3/CP/ndj/hH//c/4Q//4BPOTxeQVZ6BJApxdfEca6yxxhprrLHGGmusb6C+FQyFmqbuvVcn96Gh1+m75GINuxCN9q7mimImZyvzs6uAgBi9OSU1ZgTTTVtTnGL8mr9CzjbFd2r+Vg3sEJ2GOm+u7SnjQ6DkcoXZoMBBGxpyQenaKUEWjV2M0RgTGk2HeTsUM21EhL6vfg5XzdwUgEg5oRtWjwfnNE6vTkBLUhaE1w5riMZsW42IRMoVEEQj+/o+ruQSxeQX3uuEvyZe5LyaihpTQkGFSlNXXwQnOlHe2tpiasaHMUdC6/n+r36IOUDy3nsPuX//nkkpIFgiRymFd995h5s3bqjJn/PqVdBOKE6IMeFD4Ac/+MEAGMTq0C9CaFvadmISEk+KibX5Gjdu3GB9fZ0QPHt7u5yenph5Z8Pe3h57e7vmJ7DBnTu3mc0mTNuGmzeus7mxjnPC+sa6SQgU4NnZ2WFtPqdtW0LTcHBwwOHREQCz6ZRmf5/5fA3vPfvXrnF09GaQsEwmLZubm0wmEwUNnj/n4uLCojx77t69w9raGvfv3+NHP/oRZ2dnpEnizZvX7O8fsLm5yfvvv88ff/xHnJycMJlMNPKw8cxmU2ZrE/b2dsloCsjW1hZra+s4F+i7xOHhEWvzKW3bWvLGMY8fP0YQ7ty5xfbODqFpyTnx3nsPSSly/eC6+gbEyKc//SmLiwsmkwnOV4ZDwUmmcY5Q2QaSEcmUCK4EnGtwttayFAXfskoZUlb/Ae+roWbSc7eAb9QnxTtl9ZSUKDjEQ3FOgbIhvUVBijKsc8ixpzfPBNc0xL5n0fW6/+KIMSE+kFNi2UfFBEokO0eRggsOJ4VUImbXSBYhiif5gsuZqfMQnV4TioKGfZ+InaafqCRLJVDeu8G8NaWEuJad7Wt854Nf4fj1gi+fveJg/zbBT3j1/CVvT484O4uExnF2dsnawTbqKDkCCmONNdZYY4011lhjffP1LQEUsFQHpdDrlB763qZ5XiMdY0rgC2QNdQOxRIgMllRQija4XYpIkeF+O6VEE7Sp0YhKR3QWzWg8DSmqn04xWvydJ/YdKfd4p81HNYeTK4wB5z0OBQGS2g+CTfXFBUrJGhsZk9Kiq/Z/AE20YXa++jw4i9BEQYTi8Hg0s84aeK+eE5pln5QlkMoQb1eKG5zlSymUVPDBto8j9okUM07Ui8Bl0cg7HwxhSGY/YYBIKSQiBTXJxIEXRxCjqePUAFOESdtq86Qcd4LzOK8Rd0nUKLI06oavfg3WDjrP2trcABDlp3Q29S2IySpaGu8gOxqngIw2ZibdyJBQE8T19U3WZnOTuMCknfDg3XcNGJrywfvv03j1cWh94DsPNa3BiePu3dtM2plaWZbM3Xt3FJRxjtv37mrDK6rbv3XzFnt7ezTBc/PWDQOztNFe35jz/V/9Po2ZJc5ma0wmU0QcTdvw3e99l83tTQAevPcus7UpzgtNG7h9+5aycFBZydbOJr5xrG/MEec4PDzm7r27zNbW+Pzx5zQTz/r6nK7r2NzctPQRr6kJMTGbtszX1wjB45xnuex49vRLumXPO++8w9bWlnluZLwT1udzXVd2Ek2nM5xv6Gyt5mKSGwRcS+M9DUIsQhZBRJM28I7sCimrb4FaChZc4wnegXhKiVfYPWmQOtUUkRqFKgI+OAXDciYW9WuYNC3BQLyC4NtALhlPHpgs+lxNJxHvQNSnJcdeASxxuKDARPLGoAjQtB4fez2vvZktSsD7huCV2SDeIc7hg66LlIuydAyUE28eJFmZIY1vKTniKCwuL3n18iWXlxcsFpe8ev2SaTsl5Q7xhcm0pZ00aoAZq7eKI/gaTznWWGONNdZYY4011ljfTH0rAAVRWoAZA2rcW87qFZD6SKkpBqVoI+3KkFufctKmVPRGP6UVDRtW/gXq3q8RiiVl+qymiuLKMOMTFGhoG41rzKWayxW6GLXRR6MZo7EXxHnzhBMzziuI1xSIUooyoIekCX1uTsokGJImzFnemVShFPVjcOhUc7Hshql9yhHnVU7Q9R3ivXpVpmKu9tp8Ox+gZPq+N8/F6s2QcebS2EjQBidl/KShmJGd6ucx6YlObMXZdDglxTiGOMxIHyPB27aM5eGsqRL73HKKgyEmohGTrglIUQeMkrLS0sXjfUOXehCh67shotB2CocMAE9B10IytkLJiWzmnbZq7DjrcQjBmd69mDmjAh/BeXIy0MjD2nyNnKHvtIFrhrQMoZ1OhvVX0Pe6vjYno8dOvQsiMXWIE+bz+SC1mUwmlpyhwNH2zi7TyYQMXNsPBO/JOTKdNLz74D4+NIj3fOe7H2gig4eJn/C9730PEY1Jff87H9BF9Ys4eXtCO5ly48YtmmZqnh7GJrH33McIznF5ueDlyzdMJhPevj03mn9mc2uTyXTC69cv+fLLL3nw7gPW5xscHR+baWJQXwAnKzlREVLqKCXR+oYs0KdLwA3sFQWqVBOgvgcKPJQUiSmquWGrzJQUkwJypSaoqGllY34I3gsV9FIvhkTwDR5PMqBx8E8oBV9ZRs5SF9BtOydDlCwlI1nAO010oFiShafJQUE1J5CKynFMmlVQL5ZSWTy4lQGqd7hWFDC1Y+CD03PK5FuHb17yR3/0EYdHb3E+08UTmqZjZ2+Dze17bG9vcv36Lpuba7Z2hZyg60YPhbHGGmusscYaa6yxvtn6VgAKGvemhmshBMTo/9VPoZj2uEYOriITrRF3zijEZSVdQBvipm3IMZFiWk2zZZXy4H2wKezKxLC651eDthA8l5eL4XcxJnJMaqrmzNDNJu2lZEoSM290KtEoGtkoaNKCE28JFWmg79dYipVPhm0vbgAAIABJREFUgU73Y9RUBaTYRFhjHNVVTuUZJRZSiogP2mxk1Z47pw18KWpS2XWdUs5LNB22G1gI0QCTGKPtY23K1JNAxBGKRvA5l3CpKF9BPE1ozVfBIyQ1dhShmLSiXDGtbFpNWMgxk6KyHMRpXGBKhdB6EAgWMynFa9xfSeZDIcQaI0gySUo14tTYR01aVMmLZKWZlxz1OHghRmXCOO/p+26Yeqes0aGaCJCMkq8a+FwyOQEiNCHQx87es5jHg0NsTab0dc+Oah4IzpINLMVE1B+iSnacuEF+IuKYTmZg1Pj1+ZwmeJrQkEvm2rVdjS4U4cbBAbPZX2GxvKSdTCkpszab6+uLMjfqfuzu7bG0WMKmbdnY3KRbLnnz5pCjo0NmM02VOLi+z8b6Ot1ywc9+9jO2trZ4/fIVk0lgbTZRM0zxOn0vEVc6Mj2x9JSo55V3E0tB8UjOJhdQ341iaymjaSSaKmESJ3E4VxTgcxVkK8ZQkOE6sTqumEGieolomkpasQJSr+wBBEQBu5QzWcDbuXhVDiRmoCjGmKhAn/7eQMisn7N3ylpQYKEmu1jETLbzNkY9dwVNqfF+MHRNSRkQ6xtTmiYwn2+wtbXF1uYG6/MNNre2aBo1eW3aBkKjx1MavGsYkx7GGmusscYaa6yxxvom688FKIjINvDfAt9H+c//KfAT4H8C3gEeAX+rlHIkemf+O8C/C1wAf7uU8uM/8wWueAaklAb3czCpQtOsIh+l3vyLTRedPW6VzlC3c9UvQUTsBl63Xxv3Pva4oDf4MUZC0AloSpm2DcqYyFkbFWFgITgvK4d5m37WZifVaaRNwtX7IdIYWGIRCmANkQ+BVDKVK6GyjTJM8qHYtHxB22rzXqwpzSlZtKQ3LbnTBhqlVhdjbeCL7XdQNoAPpKi0/Cox8cE8751H5EpaBIVSIi4nistkLyQi4pXl4BJkUc8GX7RBy33RY9dHmiaolAIFP3IuuOwJeDWUzEKgVaO+ojIChzcGhqOZtMReTSirQaRkgaSGeAg04nXbYmb7OJxXo0wRjQfNWUGKIsqYCF7TOkTUIFMQvCgYlPpM22g6RREhmkxFgK7v9bMyECCVbOb+VwxFxRlo5ZUZklVyor4fK6CsXHnNnAd3Upz4YS2o+aEjW1KB2gZkZaSY9GZtNmM6mTKZTJRdk5IRAvSYRUtJuXHjBot+QTNpaScTvvPd71CyroGuWxKCo20C3gW2t7f5wQ9+jbOzt0wmM9bW1phMJrQTlbRomgbgHL0UivMUJ/Ql0RkTpYggKREkGyiWcawYMHoMGFJEVudZueIjoj4E3mtqxVXgrya16GdRl6yudQX3sqaoUAbwTNe4yZVEKHEFQCalFOGmjbKKcrFz0A37JbBiEJGH5JNcCsn8XrDHeeft2MtwXvtqhStqDnmwv8tv/uZvkBJsrG+pPMY3xE5ZSK9fv+To8DUPP7jP5nRfE2pUgDHWWGONNdZYY4011ljfaP15GQq/A/xvpZR/X0RaYA34r4H/s5Ty90Tkt4HfBv4r4G8A79v/vwn8N/bzT63aWABfm0imlJhOpzY1XzX/Tjn7ap7oderrnBq9DYaM5pNApcMb2OC9H4wUdfpvOvBc94UVvT5jrAHwLpBFTdZCcHTLziaqeWABOB/Amozg/NcSKzDfgyoBSDmB0+l2oU41V+aQMUZtCOsEHGUnqNkiSDBGhD5bn1ey+iyI2PS+siwcJauRozIPMINI1b+XXAzfKEMDi7UsYttC0MfZNlyJ5hEh4MCZL4MTncBma/y0yfTkkkkxklImhIZm0tDHTH0XOWV62w+c7ocEBU5iKhRxJBI5JZomkNBUCpXJaBOXU7L3odtNMelrOnelmVQzP3EtfVGGhTaXfvDwwICrVFATzKRRnyEEFsul0t1DQ86ZrjNtvxlBVtYCKGuhWLdcpNDH2pg6RIzanzIxFmPXGLuigHgZ1oU4k7MkTeFwRT+3HPMwWVezzkIqiivFDM40/JILqZjsxnsamdg+OObrm5SUjYnT4n1dr2qSuLnp2NjYRpywWw08jSHk6vsUjxCQ3OClIUomESFmnLT6eEtYKBTwq7jK6sNQS5lKjqaZEKOluRhYqGszUsrq8fV8aUJDsZQXEbFtVhNRwYmxGJwfrjXVb6Uew1JULiReiObFIE69Pyj1TNNS1gfg6znozCg1D+do0zQUkzsJ2PVBGTX6ejX6FTY21uk6fZ99n3nz+oijN8c8f/EVr16+ACI7uxvMr22Tckch4dyKCTPWWGONNdZYY4011ljfRP0rAQUR2QL+DeBvA5RSOqATkb8J/Jv2sP8e+L9QQOFvAv9D0bv23xORbRG5WUr56k9/lUJjU/LqgQCr5j9bo+nM6V2nwkp3987jGjU+TJZ0UFMDKvOhshNqI2Hvi5QzwQwEVV+/OhyTyQTMo8G7gPPZJveO5XKJs7x7ZxIE771KFPo4AAMqnegppdC2LQXoK1CATS9L1HSHoMaFlZpeJSDZYjBLVpq2G5gbOqH2ztObURtSp7AY6GLU7YHR4QYWhVRDy7J6Tp385qwTXG2QihlCAp5VlGUz4XW7Rre+Q+80XSFLGZrqQjHGRxjADmWNaBOsx0MbKDWrVF+Jqs0vKFiRMwpKFAUIKJlQ0zv6aKwTm5SbZ0Ps+2ENVd08NkHOWQ0so5lf+uApORPM8E+9BvR5KaqURf0gEsEH0loixZ7GUhKyfQ4DtV4E543yXmxWnmvja7IVUQ8I9X9YsRFA12RlhohX6YDyGNT/Ig+IQ30GloigUpC6xr017ZV540wqpOtZaEKD4CzpxNF36jGhwJgeXx+8plPY3oWgMaM5ZfrYERo9XxbTOcnABZXP9GTnaETpIjq9z5CU7eEKAxujemBcPTevxrI6MzV1xvjQFBeGyMwQGjNsjaSonxFgAEJlCGEg2dflAcruAe8bBaCKMlUKQsxg+gxlmFQKhRPbF/2IVTKl7BlQ8LGyKkCPZ+M9OWVi3xMaY/DkZEQl4fj4mD/+F59ycnyhMpHkeXt6yeGrI1Lu2dpa5/qN68zn6waiCs5nchlTHsYaa6yxxhprrLHG+mbrz8NQeBd4Bfx3IvJrwO8D/zlw/QpI8By4bn++DXxx5flP7d++BiiIyN8B/g7AwcE1m5LrJO9qA9T3sT5eQYA+IkHwlk7gbcqesiNUKrgY5b9ovGN9PnydSo0xHFLWaau3BskZuyDbtnMpNKHVaWSBJpTBlHElxVAmgbPJ6zA5bcLQPAmrRoMiQ5SlekIUM4lzA8WbAipT10l/6ydIKeSYcLjB6K3S6XNUGn7OSqt2zpNdIfZJEzKw5tPYBs6taNyOqvHXxssZfT0bdVsQcos1tVAk0EzmpJv3OFlekklkDy6tfBsKsISBHZCNMZFiIjaeYqZ6JdUprr4nJ46EGXBeicqk6H7Haj1ZDR0LAxvjqh9HZSoYLcT08/b3lNS3QbtoOtH0gfr5VHAllpqOESneU1JGKKb81+fGbDGiop9F/VVtYMXWUPUHAAbCuuB0nZWV5KEaKOIg2jkxNI5GpamSC0xa4MQbWKP/nKUYg0ClNVlk8OsQ71ii/hUq9XCD5ANRj4OcM9npuaHsGk9f0tcAgGjMgrZt8MfHNJUREwJdVE+DgDFfXCFR7HxVYCXGr5/bUMEEDAA04KFAzNHAIWNt2PlVAapSlAGQ7frRNoHgHLmk4TPgyrVFhmOewaNglL1ezoViDKAaX0ux1FZXI26DyiFsnfjQqBFsSjgDAlNKONAEFwNC1QtilZARY+ZyseDLr57z4stjcm7ou4yThtIXJrMJ1/YOeOede+xsX8NJQJxXWU4aTRnHGmusscYaa6yxxvpm688DKATgN4C/W0r5kYj8DipvGKqUUkTkLzQqK6X8feDvA3zwwcNSJ+dFuwicNZGVNZCNzlwNGr0POPGUYs1PXjXjVyUUsDJZrNsp6PTXiUodSvo67boCBdW4cZBhGPW6aRuwpqs26ikn/BXvh8oyqP4PMUaSJVdUpkXse8RrdN5VGvbQ1Np0V2XlyoYoKZNSVM+Eos1eCAFx4FpH33WUFFXigJr49aThOPgQVE7hGF5Tze1qcyLWsHkGg0FJOJ8o2eOt6d07e8tv/P7vIqWnpQOgL55GNHaxathTSqqjNw15bQRFLfzNU0I16RRn8X5Kx9dYSZVY5KRRhaUkBVoEcooa9Uf9fMtATXcWWamygVXjp7GCagYoaDPbx16lLM7bc8rAlBHUL7MYOKHABQaa6PEqpRBzjVK09IMrTIG6a5WdgDETqlGjd97YExmKNu/YNqu0R8Cek7SZNQlM3Y9coOt6nJcBy6jMk1LPC9A1bAkIbWiV+WEeD9WHRJwekxAakwk4jTTN2hj3scMb2KBsII90sJUXRCISWkKBvIjEDLP1NZa5I0UFL7qu15UmqyZ/YM6YFClnZfWQ84pZkpN5KZj8JgveCZJR35JiCSs5E3sFFchCKRorqgCGAQVAjhE9cRoKTtkY1dehuOFak5Ke50WgFEefImKSD+8cUoSU9T3FlPD65urVRP8rgJQh1SWTcC5AgfnGnFt3buNlRsmBkoXT01P6RWLZLTg6esPTL2Bzu+X6zm0oHmgQ1w7vZ6yxxhprrLHGGmussb6J+vMACk+Bp6WUH9nf/2cUUHhRpQwichN4ab9/Bty98vw79m9/agnyteb26oS//ixGXQ6hscmlxqfVpg4GpjjVU6B6J1xlJ4A2r3LFwPHq73VyWIhZmw/nRKnnstpmzulr4IXGMdYJszVlV/wQasLB4HVg0/EqCYBC30czoKzSDLnyPxalFxX8ENNrFyjOGuZy1T9AWQBFtKH1wZP6rCCINdmxpKGBVXlIGQwK6/Ho+0QXe0ILoM07DkgwWXbsLy/NR0ITJlIEoUdICghJsbhGbVKzHePBCNHAg5IqSOANDFod6wIErzGM2pwnsKjQGKPKTlCqunroKbNBigAmg8HiK1nR6VPujAni6LrOgKCasqHyBGcSBkomZ33/JWeK0eeF6q+pxoxiNHvnbT3lQtMEYk0fqVKGSiMoQBEDELT1zMnYDhSVx0gZgI080Pz1s/dG7y+5qHwlZ1wyLw7duH72XWa5tPfrHE4yjQ9IVH8CxVo0JaUYSIWAT9qYV6lLZQhkS9xIxgRBPFkEFwpkB8lRukzOooBazuq3EQvZ6WcXQmC5XNrxcAYmOAVvih5bKRq/6r3+e9+r3KVkBWS8W8WeineD9GAApLpI8A5MNtK0ntQnlXc4u06YpUHKKsfJIvgQBnlKSgpoUGU8KULOtF5lQCklyKaOQLdTROx87ZCcmTSt+X3odUUQvA/6fj1sb2/ywx9+yOX7Pd1Sk1/OTs95/fyQx198weX5MU+fnbJ3MGPn3n7VuVyRyow11lhjjTXWWGONNdY3U/9KQKGU8lxEvhCR75RSfgL8deCP7f//BPh79vMf2FP+V+A/E5H/ETVjPPmz/RNWjT6sqObFGvjKFgBtPIpRx3PSRANt3lUvXk0FRfLQiAEDs6E6wqfa5Dtnjeyq2RdrErKJpIf9cU6N+Eqdcspqii0rI0l9L8Xc/VevK1eADRub4134E7Rv6+2VFp3roLOYVKHS3J02Tjb1T2biWJUBznkzSqyAizbaMSWcVBmAJWQUKGIdUS5GcRejd3vaiUfISNF0hex0uuudJ0gmF0fMnsY1BNcAGs/Y971tX6oyQI+LrCI7K7tEGQr1+GjyRG0uFazxOFHgxXtPqtN8G8NnMx0UH+yzAyEbcKSmk5pI4MB8BPRTKiy7TnXwxhrw3ivDwWujn6JGcFYfC2UsWMOakh0nCJYicdUHIpdMZ5IdF/zq89fVpkBEWjEVBCE0fgB4vDEeKjzgfKCR6mMwoElUswZNKMnWlFuyAZqcUZkxYiAT5muRS6GI4J1HvNDHaEwEr0YEToxNIvZ3Zb4oy0VsrSsw1OWM74tmOIhAEIrPGoDhHI0LZLFjX1bnZz2fcs6EEAhBTDpyxZPAIjVjv2InOXHmywGN8zgfNBkETTPx3uGksOx7xDsD8dRMMbiAlIJckZk4GIw0nfcgjkSmj70eK1FCAwIxRRzVC8PYD1VWkhOIGql2UdNEqoTF/7/svXuwLdld3/f5rbW69z6Pe859zr1zZzQvCRhJSIJYIEQk2YSnA8EJwjiu4GAcQqXKlYrLGJIqp0gqLip24mBjIC4cyhWXC4fEOGCXwQ5JhAGDMRJGaARoJM1Ic+d5574f55y9u9dav/zx+63eZ0YjJKQkGuH+qTRz5559evfuXt27f9/f95GisZqqSU9qLYQonDy9w4ldk3XE1KHlLKuHL/LIF1zk+Wef5/LlF+h6IdfBI3MLfmTnmmuuueaaa6655prrc1afbsrDfwr8hCc8PAl8Jzar/t9E5D8CngK+zV/7c1hk5Eex2Mjv/FQbl2PgQdd1U5MdY5ymmCFEn1JmN0dMU8MegjUfIWyYDqp1YjJMBolavcGvTq02U73FYkn0bjy6xr3UyugU6SRmzIeYZKDpo9s2TFJhLao1RgZq5FLoUjIfB4+KbI1USySAjRHlxHiolaAbL4ZGBQ+hUmM0U0K1CMSAID7Bbxp9YxJYM2mgSaDroFKdtt0mzsU7fTNErL5v9ldqUZMqhNAhJSIyUCqMWpHUEUske/JD9CQK06C7B4M3/immidLf9z1aClqZmul0TBPfGBJNWtB1iVrUwIeik2Gj9ZubFIWKEOpmLU3O/FU3LBbr6excRShOhR/yejI/bKyCWoufI2N/eBds7AM18AFVUowuxfDYQgw8yHkkxcZgKQRVQjIAoU7MmbbnLuGoirlwmAGjL2ADeYB4zFvDPBRMQiBisZYTMCdQqzM6tJCrTeTNUNN+N9eRQHSQraM2nwlMDiPinh5u9BkjFCO5UFVdpmNsjRgX5t/hwMC6jGgMoJlSFYkdlTBJe6oDTuJMlbZflnRhhoWlVrQGxzCscTdQxEGkYtSCgBm0rldrumVvbKdS0VghRmJKJDHPivVqDRW6rjfTxjyCqgNMgdglQupYDePm3uJgYSkFDQb0xWh+JaWqMQ2CIHUDlDQpjSXCRJdHbQArkQaaGoBBVZRCTJUkSkiKkFguOrZ3e86d2+fatbOc2N9ludWBVGpLzJhNGeea67MrfelVdNyzZpPtIg7r+n/qp7jy5PiGXX+mm+0ef6fNf9bN66ef6eZPLd1Gju2Hf6/Jy7arL9+7aX+Osx+P/1im3fMZwEv3VRonb6655pprrrk+sT4tQEFV3w+89RV+9NWv8FoF/uzvbzcaCNAYBtY8lLEQxRq9GCKq5kEgTrGObp6Yc6VfLieddddF8tom3YpNArNrsZtZYM3qU2eMAr1otHU3InTwIEiY9rJS3NPAGvXGclCnrlfXRpMri8WCIIE8TaBt4qxVXftvoIVNZJM3vpbiICFQ8eY6CNSKSiB0BiQEmLTvBUVc+tG8C3AmRovFDNH8Acbi3hClsOgsfUHFprYSm0miTbQV84xAhKxKCoKQEbHpqEiPaKTrAmNeUcoKCR2l5Emv3wzzWvJD9GYviAE+AY/fi+JgDxb/Nz14GVNCzG2TychSBbXESDsjojY1riMpmSwiwEslLw6iNC17UJNWqCoRsE9voMcw6NTwq7NJTPlg4Ml03t2pX70RVp/4R2kxlT759nVaxg2DpaqinjShCsM4kGKanidV6uSd0GgmSjMpFGK0Y12ryQ+M+VHous6BIqE4M6MipGTMDnFpQ9BCF5MxaWphiIGoGIAQFC3iUaNuoliKgSjRr01nMaivf4s0zahHRvapm+QsogVqpoqnVuRq6ZkOGDWvDRGTUxDsnKQmSQD6FAks7DhUUFGiRLtOolBQumB+GirOcIi4dAm/Jjq0KCkmRG3Ng1Io5JrpuoV5Rqj5hTSDzRDs+slqxyCkDg1ANEPNgCVFGBAoaFZq814F98IA1OQh4LKp3IwaoWRjotj5A63ZJB8hs9hN3Ld7AYIwBjOKRe2zfkJTMtdcc31G1Vrtl6AFYgy5RgbSYO26NCDbSFuTgq2Byvbk4WAxYdqe4baFdgPctP7OzkMxl1im36l+3/5n73kvf/iPvBWJFRWx78HGQrNXHoMfKu0mVLE/RvuTgQca/U/H7iBVec8vvI93/pEvIybcqHmDgxxn2M0111xzzTXX8fp0GQr/35Z1Su5rINM0u9H/1TXMRktuDueulQ4RLXliNVijJxAiMjESjMKcuo4QojMTBibKvCrrcZh2pX1xij9h1FpZD2uidgAWV+hGjRYXWCeZRGMYHDeaG0uZmk3LMsBp1EopMkVOqoMexGCPFqrUombeGKCLkZQCeRio1SjW1uBEe5/RJ67Ni6EaRVyisRhSSghqMZPNFLBuBh54U2qeAGzo9FUpCEUFCoQcyLWgKoxaXL+vSLaGMjgwNObR4xjFGuaUwEEGAA12ggvVdPAi1LFOqRfNrNAE6uYpEHATSgcGYgjmB1EMWMg0JgioBJ/qVD8u9pA3rQ33vKA12ZNRpx0Xa/rz9BpU7bnSpQairmPX5uFgE/RSqwEhzloxw1CTbBiTxNgK4qshxUSgs7XbHmYb4IHQ9QtnvYgzHCqJQPXXJDdnDCqUscVSdhRvSqNEiz6tasdKlC5ExONYqyihVqSKH7NCaA+1nqjRWDTmxfBS5kxjloQglAIpBWc4YNR/CZY6IsGOc5AJqGiP31PMac3EGEhdImFxi7WMlIFJLkOTsoj5SEhUkj/Id103GWiabCiDX3d9ioQUpwjWGE0+kpvZ5DjSpZ4UE+6ogQGBglQlNioJ2HUX7U1LrYxjpnlB1FqN1RQDw5idbWMMqXEo1DoSo11rKSVi6ijFvCDqYOPBIIkoEQ3Z1qQzkqgG+DXfjbnmmuuzK52+ANsEv7rcKTASeP6ZW6wPCgQ4dWabc6e2IMDdw4H1kDm9v00uyo0bdzh/dsfueVVQv4cakUCn73SH6+3+oo1PUKbGvgBRPcFJhDHDP/qZ97J/IiABqgZU4OioMKwGTp/aot1HcQZZQCkCL75wh9s3MxJhb7/nnrM7IMp6VD5+6TpBBQnKfa85RZ8C6wz/8Kd/lW/+5q+gW1RE4/QctPkwc80111xzzfXSenUACo1CWKxBjwIS3JsAGHMm1zJFRILS9Z3roc1fIKVEKZlxzGwttwjRdN7qiRClZJsYBGMAdH0PNAmFAQvhmOdCAwemXfSGI6U0gQYtlSImaz+qez2obgwhY4wE/zy1VkrOhmOkSELIY/bmWRCJkw5bQmAcB0ouxBCJUYgBMzDE5CAt0q+UYpNV2Zg+lmLvFUTMowClW/QE6ag5G/iATAkJ1aMzc61ugmeMjTYyVxU0dMQCvShjqWSpjM3fQgNCdM2/uoSjUqo3kDEBLVLSZzgu6whutBeknccyzU5StAn66NF7Wip5PTp9PPhUabNddW+F4B4UikeLOjulMV1qNZCnHUtFKdk17FOCiLMkqu0HDnSEsPFPkGIsk1wMmZGqqOgkbWnyDUsm6QjSGQPAR1rBPRdM4VCJKZrkwEGq0EVfU+qggkkHUOj7hQElObvnRPPyKJs4w7aGHUBKIZBCIDSWDGaS2NVCJaCSbB1WY8MYyKd0XTx2XoOfN6cCC872qA4WdCYlWa19TeoU5SpOp50meQ7smKwiGOAEUJVcDCBrspHoEhIzRzQZynK5Na0lvIkvx6RNVPU1uWFRiINkiDEEEDsGNZufAUFYxEjshJSE5aKjz9VBNAcWgrMnhAmsaxKevu9QCzQ1OoWIyWhyYL1eIS5H6kKCos66CQyHhcPDIwNLCaTYUaWQkrBY9Cx3+olVRS1AOYYGzjXXXL//aqCyz/ZFUGf+lAK/8f6nec//8VvoEHnx2oqnnl7xt//Wt3D2zBYfeP/H+MAHL/Hd3/W1HB1lfuAv/QN+6K/96YmdNjm+VmcSufKB6iyw9jQjjSvgfAPF7xtKJnD52h3e9xtP8QN/6VsnFkUe4Ed/6NdYdEf8uT//1dN9oAEVqpHHH7/Mz/z0r6NDx+HhwHpc89/95W+jivBTP/UvePLJy6hG/uW//DD//Q9+O1/whef5mq95K9//F/9XvvIrv5jzF3eMsfYKEom55pprrrnmOl6vCkBBEHqnDNvXlvkASJuAOuUcVfoQyLma+7s3n20OoBgoINGofqnrLO5N21d38KZDbAJRiiU4JDNNkxDouo5xHBmGwUCFYPrtqupJDSZDiGLO+7k17R5TmMfRogylPT0w+UMY+JAoefCpdSR2Jneorve37TdteUSDNU/i9P+WGKGYs38I1sQrZvimxZrmmCJUm7rnOrqzvVHjU0oONgRiSJTsAIobEjavCfGJ+ZhHk39UcUPGYNP3AN0xOidSkWJyBHsw8lQG9elyqQ6w2AS71AZG2HRdS4WgdDEZi2QsjDrSdRZFabR7l78AQQNBhRQSNVRWw5qCATljyeaHoR4zGgKabTofPCK0ejJCEiwZwp+bJJiOP2drClNMNP+LiYHSGA3B5DfFH/VSCNQyuq9Co6C6Bl+FEIziH23cPQELxUGdpMnNDjeGkllHSq50XT/FO8ZoTJXg8iD1Br1qsTVfK11v4ATO8tFaSLEz8KUIRJvOS4vtDIHGzo8+nz8GqU2+IW0951yniNPG1ml+A13ozOzSgbmYInkszhqwJn9Ku8BYRHaFittTQpMJtevQwBdvwH3KN+bRGQsgYsyZxk7A13HwiMucM2RlseztPNViUqiqhK6jaz4rVSEFSxPRauaNreFQSJNPR0BSnKJojXXgIoqSjT2S4kbKFWC57FmtD23vayUQEQJ37w585Hc/xpUr11gPts5FhVFHdna3uXjvee5/4F4WZ/bsPhZkShOZa665PptqjES/J/vfXr9yl5/9md/m+77nG9jf6zi4W/i+/+LnuXrtkDqOPPXEyPPPbfMC6fDcAAAgAElEQVTU09c5efIEOe+RR+WJp15EJPDIa88So93YhnXlySdv0PeRhx4+iQAvXjkgxsTlyzfY20lcuHiGJz92lTrCyd2eC/fvUyv8+I/9U/6T7/5qiwQWRSv8n//0Nzm5u+TgsHGp2mfweOwM73vvU3zZl30BX/tVjzIMlb/1P/0q7/+tp7n/Naf5rfc/x1/5y/8eKvDcs+/iR3/0/+a/+W+/hSTCd//HX8eP/dgv8v3/9TeRZSQ6M5Rj8s+55pprrrnmOl6vDkBBmmmiTxpDMB+BWhvbnRCNrm+eAlgTFAxwGEumKvSLhU9J7XdLtQi+EAIxydT8NDlCiJEI08Q1+4RaRFgsFtYcuS+DqjnHt2kpWjcNlGvWN82dNxAVxnE0g76UNp81Jso4eCyiRfmZbCK7iaJugIym38f0+107LkXp+t5i7BA3enTpQFWiyjR5NwZAtsbIqeohCJor1nPrJq6zOfsDIZkvhNE1CzVDiZUaE2VUYsEYDppBCilUVrXa+QOb2IsSOjOhDMm8IdSZD9GbrVIzxUWqlcowDLSoSapF7eViwI01UYo6O6ILycCIWogpMmZrzLUq0gX6roNqRpp4MkPUYGaSPjUvipn8ETw5Q8wnIwqiptXXqs3GwX4m0Rq+wbT3IiapUXW2SAwGbCl0fYeExDiYhrWxS2KIniShEwl2zEbH7zpj0kgUcqmUCozOTvHI0JILwSdTMSUILdZUaekf1BaTakCIVNAQiWKAgEYDpIoasBDpTCbSJt8qxOjK3hgNzKvHGnU3KG1sjAlsGMeXsnxUJkmH4zxMNF1/hBeXjARnP9S62XaLa40xkmIkF2f2pECu2ZkwLr2pSsmeDOEskxgjqUsUKaizDYIzHkQiJWczXHUKwDiuqVqm9YZ6ekUw8Ks6q4LqkaIOLIgnbKTkBpKogzyZFMV9I7qGP0IIrI4yH3viEr/xvg9w986aYRxRKn3sKWKf+Zmnn+dovebh7Udp8EYz65xrrrk+s9p4DjRpnNjDBZDHwjhWtrdN6ri1HXn3H38tv/wvfouHLt7LL/3SCzxzueOLvuAJvuEbv4SqgX/4j9/H73zkMu/5Z8/yU3//u9g7ESkVfuInf5Nnn1rxT372Ej/wV76Cd/7hR/jR//G93LndcfbMXV73wDZbu+d5/wefMrZfKLz7W97C6153gRefW3Hx4kkIDrwG5d/+pi/hN37zMr/4Cx8CDOi3pxv759Ew8mu//jH++v/wJyBUQi/EncidoxU/9b//Ov/ut/whexYROH92j6tXDgnOILtwfp8rl29Ase8ameSPc80111xzzfXK9aoAFEDoF0t0GDzGDm/QLGKtlBGAmDqqNxg1tOl/oI89WmVqcpqxYghhM0EN3iSKgAZvtqpPWvMkT2hO+SEEk0xMefdG/46eHX98IoubqrVt5Gqxlc1/oMkkwNz3RSIp9f7ebvQmgoQ4aSAFMzUMYjkA1vRVIuKRffg0PbgplBIUKhbnV0pBa5n07g1kMRm4gR9DzXQwxTjCxj9CVRmHgRCjEUBV0QSZTFAl2mAEJKJVPHVBDDSo7tOgNkkf80BKERE2XhfiD3BY4xv82I95pO+6ibERXCtv/gaBPJoHQfRYRtOZRjPLxFIYSi5meUA1baqPlkOLWxQ3sHRgQyrT+YrtnFb1RIPK4JN1O+/NJ8NkJSkmiprPgnoqRBSbOydnklCra2JdEqF5StAwnywz6jT9fSFg5n6lFEquVJTU9b4mijXJ7iFRqdTsRpkxENR8BYZx7WkgDgiVQgpCUJPCDLUweHpFHxJkAzuKGEAl1RgNBSGRnK57DHiSjY/CJBHSBnzJBDoYmUARzC+gaiFnjxS1CwJRO78uAZ58GcaSJ5+HBlSYlMNeqFpYjSu75oMgUQgBpBptOGBxmcUZPK2Ce3OIy4t84RM9cYFkjJPox686iyGGYFM6tcjV7OCPvkyKVH09tX2OMU5xogbaBfN0CYkyVA5Xay498yzXb9zmxO4Z7rmwBxibZLmz5Oq1a9y4cY1nnn2BB974RRT31qjMD/lzzfXZV/suMrPEKc1AASmbVwXhHe/8Qv6Xn/hl/sMf/rdYbu3wgcde5N3f+lburkfe/9hT/NFveIi/8D3fyO0bv8IP/+Cv8b3/+dv5kb/xGKkXvvprH+TU6QX//Fcu8c53PULUgXd/8xfx9q+8iAB//i/8X3z9NzzK2VORa9df5Nq1q7z2tRfQ0FFDdWnEJoqZoKhk9wtqcgcru5sHS+8RMU8egSKgzX+nySsc5A0ViJV+O/C1X/8Gfu4f/Sbf9Me+FEnTwfj/42TMNddcc831eVivCkAhhMBya4eKafglmDShuCwgdTIZNqobvTV5QDNBq/54bYaNxSfN6g3yhlpOEFKIFLD3wKITW4MjbBoBESGlzvXVrrsO+pLmu4q5+Eef9BdvdkspE93ZppSusZfN76auAwZEZdJvbgAFofOkhhQTpYyIONXfG6hS67S9GJI1MUUnqreEOBng1eaV4JPWLnVoNXCi6zpjOjgbpDpToqo1q6hYk5ZgIQtrxEMBjMLfpchYIusy0KWOqDC6yWXV5kFt5y+Gjs3zmrEAOlEDJNSacZNvJMah+BQ8UzJm4ijBGQig1YwRVQIS0mRUGfxcKspYTfogwT0LUkSCRW+aJ4alJaS2jrRNyxup3vX+qibfwEwhYxQDUmpr8JuhpTMwiIxjNuBjSmawh8Eq9nAqfq5jZ+fV/B8qqhkFk890iRb/md1/o8lSupQYhzUVm8aP4+AAVtg8+4n6KHzT/GeySTQCaC0QOqT2qI4QM0WhxxInas3UyuQvEt2bxMC0OrGEWnqKgq2Z9vYweXTY/rfry4+pA0TLuHSW0IhWP4cCBDMoTTExDCNg7ByJMslyxIEfi65kAhMsHjT5WmDy96haSV2iNu20iEVaVkuzCCK2Tqa1a3GyZgSrU4SsBLuWarsnuBymMRVELTpSaDKmjUGnJdQYeIo4k6kWdvd2efNb3ky/MGf5frngiSef4ODubdbDilyz3SaOpZfMNddcn1m5ktIr+P3V0xE2SkbAvvZ+6Rd+h69616OkoIQ0EuSIFKBT+ENvup9v+qNfChH+3H/2Vn7wr/8i168f8Z73fJiv//oH+Vfv/TBFAu/6mocJApHM+fMLJFViFb7pGx/isd95gVAPuH4t8G1/8g22P9UFmyrHZBn2/eE21oTJPcHvWFXQcY9aQDsD3aWanKzmXepooL0Et8uhekKPJdTs7iy5fPkWLakSnUkKc80111xzffJ6VQAKEgKx61iGXcacASXXFiUXfPLpkXneULamvtZK3/dTw5Jz3kzDi00WU7QH+Db5tEm0mDM77rgvzQ/BdPGNgdCahBAjxjtnY3gXjbKex8JysWQcBtNzszHba0Zy0c3tqpvrqev3JQabpGLjgzZlEKeTb/YjodImv0CpNpXw5imEiOZC3/fkPDIMa2KL/FObqDeWgrWX5qUQJLJer8zbYdK7J0IAijrYkpx2L1zvlhxu9xRGpAaCJnPW18yYs7EsVFitV8em2Bs/CdSPgWs9U4wIMvlEiEs8UupYD6M9HimT30KQTQxlyZkuNc8BNemLtIl2W10mf4gSzACvmuEd4EaWxlBZLhcWA+nskjYNr84SsQm6TvswujwmdT0pJcYhO3hlEo6ua7GT6qyGaJGGVVlnY5FEb3YDkXEYQUyHb3YGwmq9dpmNr8MpZtIm/zEIbFWqVoJEhnG0hrdN/7USg3iUpp1bBUatzsSoDMMR/WKJDB1nhkN21rcJmJmmtDSHEOyBU11u4hGf46jAaOenZIjmB7CJfxX3mQiTVKg02UKKhGBeDRZ/2daDJyWoyZXGdabkkRL9HAahlmxrIHrShOe2mS+jeXFUrW6SKtN1LCIWITuMEGzddKmzc+mfIQaTIFnwaCDF3oA8tajLqmqP79VC4TQEW2N+TSGB1MWN5MqBzVJGYyG5F4WGioRECImtLdjb22axSNy6fZ0Pffh3OH3mJF3oKFp54fLzDHlFv+gIAiEKWrKDkP9v3IHnmutf35Lpny+7mER4/pnM7duZ/f2OXOGXf/VjfPuf+DJiV6maqHVhvjMVgo6T2ayEChzQd8Lb37bPn/pTX8Kp/QWH6zVXb982v8bavFiMJvfwa0/ztnc8TNTA3/7x3+ajTxzwBV90DjMlEgRLdlEHosOkFmuJEYEnn7zJfffuEUW49PHr/MJ7nuRrv+4RhnVlfbewv7Pk4oXCX/ur/5y3fcUfp0S49PRt7r14iip2J8vrys///L/iL37/t3kmJrN/wlxzzTXXXL9nvSoABYAqgZAs773WSqqVqiO5uN/BxBoIkxwATE6gmxGD66/NcM2mD94A+dC0VtMzG4rvdEbPtUeZmlOtxnmQGKlqWsKmKz9uPgdG167aJBHCOJjpYnRjPhDUIwsbMKKqth8h+PTUmQzN4C24wZxPymMyd/3V0REKUwRkLcawaPRzdePDLiVUC9n12Ij4NFSQkJzSb1N1xOIlo0+hZQJFrIkOAboorHLgysX7uHJ6j4WMxNGZB0GJWgklUCSizp4I0hgleMPn0+lj2nmtRtFX16m3plAaE2FimXipTZotrrNMCQ4SxOUyjrIcez4UdYlFcWRKhSLNtcBkD0dBUC3OADEDSXu7DWMhONPFWskWG+qmWL6fIs6QkUbL94SBNql25o1iNFSQyXCyHScRnZpkkTRJe0tVl+X4si0Wo9km+dmb9db049KZFuHYgCrV5stRyLpmFYVRt0hPfpj9F+7CMFCj+0kUdQBPUKqnYATW62EyCDXGxoaN01hDsGE0TIaODhCJAwkBO9fjOLLou8mXARHGUjxZvZ1M85hosoHkpo+BMMlQALSYkSK+NopHTdqFBhIb8FMp7qdQSrHzC2bG2QVEg/lb1MA4FnAAETeHHHMmRDGvEfdesGs7uLzB9t3YUZ50UZonh5ubAl2K3Hf/RZ55+jLXrt7lY08+wbPPduZPQmXMI/v7uzzwmvtYLDoCJsfZ2MfNNddcn3l5nLB7J6DWPO+f2IJxl+/5nn/MPfcGKsr+6S3OnD0BEgga+Sc/9ySLxYp3f+vbiYs1BLvRRqCPhbNndrhwYZ/v/b5/wLl7liwWmX/nm7+Eh86fI6aRJEoogkblR/7mr7BeL9hZVJ544og//We+GAS6Lvt9BWPaoQQL0CaFEUM67fb243/z13jwgZN81599Oz/8N76Ov/eTv8ov/tJjrA5HFnHJm7/4HbzlzZDLHf7L/+qnCQR+833P8UM/8m2oy7nKWFgdVvZPLGC6/+pGajHXXHPNNddcLys53ox/ruqNb3yD/uRP/l2gxf1Zo2wP95n1eu3T6xZxaE3LOK4dAIAWY2eNAZRqWv0mmzgOAlQ1eUTOozv6W8dmsYWdNyHGhlDXWacYoWxAiura6IJChRRNnoBCdZ8Am0wbbdzME9Wn0jZCz7VQVK35qd70NRaCpyC05r66LCOP2QGV0Zq4qqSQ0FygKjEKRUfGYbCpMUa/LtUYDUECechESROAkPPA0dGRgzPWMMZjxyt1ERHlLoGPP/omLt++xcM3rrI9mmld1UwgEGSLUjO15A0I4O+JCLlkb8LtASXE4JGH4tINOWYOaZPtcRiM8h9N916yyQFSjA6mmOxD3LAKp4KqOIBT1c6zghCIEv3hy89NMU2/SUNsl1tD3Lw4SsmI4saamwl9zoUUNmabGmx7bSJv0YEbiYo2s8RSfeptQFUp1U0IK11qcg1LmVD15BGXO4yDeRH0i94NEe36iDFuEhGcVVD8PHTNMwADY0aKNbQSiSFy2Pdcuv9BHj64wb1P/i6hQJUeoTKMR24iGCaJAMAwDAzrkb7rJ58AdTaLpXjItF9gxy64zKQd42EYiMGMwWotLPqelEyWQRCqBEo2j4XNWyspmSmjikkX7Do3EKJ6VKRWA1RSSB73aRGadcwe6eqGpW7EWIqdSwGiQA4dV9/8ZVy6dZM3P/8UO3kwBoYrMSxpRglJEKl+b7I1OKWIVCWIUn2NLzuTUZSs0z3M2D2Bo8PMk088w8effI7rN24hEuhih4bKzvYW95w/yyOvew1bZ/b43Qdew6nz+zz40Y/w7d/5vXT97md3A55rrn+dy/1tqsc3ioaGd3NwN3PrcAXY9/OJ3QW7Oz0EYTUUrl87ZLEQ9k5uc3D3iJN726BKyXD3cM3u3pKjg4G7t9aEYFKt0+dOoMDB3RU7y57oErVbN1ccHWZn1wknTi3o+sRzl67z03//vXzHn3kXp04vbZBQjQG5Hke2d3pjvwE3bq/Qopw5tYUWuH37iMNhRIGdRc/+3hYAuRRevHZgzzMVzp3ZJcbAzRsH/M9/5z28+1u/kgceOGVMKveVMAbW5+gczTXXXHPN9Tmvt771rbzvfe97xW+CVwVDQYGsZnDXNOyI0ZFDiDZFLBvKdpsGR4melAB955IGtYl9e0hQZZIs5GyReo3CLs2wkWrGiMmUiIrT5iPT5BE25oY0EABwN8INS0JNI02t5GqmeSFE0GrTTIlOp1fPm24TYNPIi3qsYy1tNu4MDfXNm248ps70kJqpudDFSJVqqRQKhIjWSnYzvoqatj1YExvch8IMDiPLfuFTmjiBJu39UNPIF61ULXSHh5w9uMtWLlS15jRIQMLK2SDFgJkWgylmNljUJsIt/iolcZq+gTltCi3YuQkiNi2uZrlozbKDR/4k1Mwy1WUUksyx3yI6HYDybQQx/wyLsCwTk3MYBqOS+3Ym/43mmy3mCRGcNQA4Q0InIKrihAOcmVCLyRdcNqDu7WERhpYT3j7LOG5kOiHYsW4PcFUDeoTJSYSJ+RKOnGpfbYIdpSUWiDM4Np4J6iBDCJGxjpPsIGi0iXm3JN1zL1KLRyamyQxxsVjYMq+VkKKbbdoaXywiiwZs5Jb0YNKBxrKJIZBLNT+JiV1h59UAjeBsBmEsiooa2OLXVc2V2GQXiiWVaLWmvwpS3ZOk1Mn3YCie+uCfWTxWwiQPydazX8sxJjRnuhgmNsGYM0UC2dNCxmEkq8XT1tLOfSFrNblSsuspRCGPmVLsuupTR+PjBIy53I6lMVeCJ8jAer3mxM4JHn7oQc6cOaRWoUs9sYtIEPouMKwLfTZj1ojQhZmGPNdcn3010UOcZEQCqAg7ex07e2nzKmfcKbDsAxcvbtsmVNnf2542lzphf38LRdnd7Tmx04O0pwv7/b0Ty2P9uXLyZMepkz1Md41CpfLA/Wc4vdfzocee4u3veNRIgbEgUUl9j3k/GGB8ct/Me0UNvNg/tcU+S7uvHot47kLg4r0n2ls7e0v53Q88y5lTJ3nNg2eckdm+l5nBhLnmmmuuuT5pvToABW1fsvZtV91UsKpN9fu+I6kyDKNNNAkEz6ZXz6Ufx8HjF4th9ZqtWS+KisUyjnncSAxqYRgGGkVbffspbdIbas2WcmCufJOR3LTPqhPtGlpDatPK5nxvoIbp5Rsbv70e7Os6duYBYUaRTJKGWo+9l9POu66b/AOM0ZFMM+6eEwoUT11QvInM2aQNVSlDJqVE6jvG9ehT5abldI8Jl0a0bTZGgRIsDaBaNKXFYxryIiIELeRaUMSBmzTRvVXNxHBjolnczDIyDCMilb5fULI1smXcMBcCAbQ46OBsjui6+LbPrmaox+jt1SUOzQDPnoeM6h6jkMeRUjaGnMWBHZPTBJOs1OrsAAerMABGq6VQtPhR9aZ4AqeisTpqo/o7aCISaHYcqkoVRaNNx6ZjUyspNPlJ2PhHBNtmjCYXiC5L6OLmQdFn43a8EXvW9MazaHEAKZAkUNVADwO6mixCPL0CZ5lY1KY4PT96ogYokuzdQgw+mW+pEqBunGkeChbFmXOZklDaOYOISASqe2uIb8INyPzeYPIRux/UKgzD6BGRtlZjMtMxM0+1K0tiNKvWopQxo9GAHyQ4YyOa6kndYDIGQlBqNflV1WrXjVpkZbvWzcgVuhiRZA/c5scijHmkSx0pdu6hYKwnnHVUXcYRQrD3i5H1qvDM08/y2499hGGoKAkh0sUFKrAaVsQI5+89w5tPvMUAi2b8+Bndceeaa66pxP1PNv85gQrH/mYCE4CJRdBiGtW3Icdef/yf05ak/e3xnzaWqEkO/Fvfv3Hte/bf/w/eyU/+vZ/l7f/moyblctlda/g339Dh+A5+wmfYqAflJYMDxEwoH//ox/mT3/5VtMhnk6jNd5m55pprrrl+73pVAAqiSqhmpKb+/aXenAYFLDgRwbSE1OqNh2XAD+PAWAuLLtlXbEoEZwEE13UXZy5UN16zBtPlEBLRRlNXZbVa03WWRlBLhWqT5iAbw7lGLcebA63W6FafWlrU4SavPqVkEgSxyUeM0cad1fT9RuNPU7SjNcSbZlR18zSz8Rkwrb+ijKU63Rxw2Uf2abLWymLRU3Mla7ap6ziCNB8FA3DKOGzo/jEee28mMCSI0KfOz5sxE9Sb0FJHcHBGayF2CVzfvgFRTPIgwaI0cx4mE8xa6gTaNNaG+PFCoyUSCBMAZDYB4tPhgAZYjWuTUWApGbhXRWOSNM+BYRypblTZzqkdW2dtRFt3pWQzgqwmH5nOt9qqjMG0tdmbfhHx5lcp7mMADjb57xZVVMvkwWGsBgFRl4w0QEEM9AoymZBCJWeTcdRqDAAJ0dbpcfZErWb06L97POpRtU6xiQ0Usem9TcYacDPJb5wFMq6zMXvUJECKXR/HTRfb+4sIWfNE7W+shmY0atdDmVIOcEBCpcWYmkwpqrNbikWlKjq9Z9eZbGdaWS5PsfQEacQiutSj2dIhDPARv2YrWdvntIlge5BXCkhBYiUmQYfqiRc26YvibBrLuLX7jAMpOY8TsCLB7h20YxwCZb2y41+LAZbR5CR3Dg9YHWTGEWJckodbrPMKCUpM0C1hLIWMUsUScT73grW55vqDUZ+ybX7FF7wSbPAKvyKf6rU+SZj+Hb35VxBlsZ34ju/6Yw72GxiK2neEP4ZsZIaf8A7ye3y2YyhJqHzHd3/N9B3WgA6LVP5k255rrrnmmmuuVwmgAArDihosxrGZ+umoNgnPxafwjqg3j4WqhC7Z5LJkChZ7JBgl2ozQbDIbQ0KD6d6bqV/wabO0SD5w2rbPeVvmPTDUcdKB400ZHsXYmvKuS5DrFD0nrvtXy7FDqxP6W+Qb8rJmm5e8d2v0gGPmf06Z9om7qkkEqlrjF2P0pkwhuB60CjlXT4MwFodqmdIzSinEFIjegB9/OHkJqECYRhxV1Y+ZEENviZqekDHmTC1KSvYg0hrN1syGEFivVmzvLFksFiZFyZWcqwE5tGl4a0wNqCmlWLyfMk1Xjhs3SjTUIzprQTAPDVFr6oz+j3sNWNM5uk9FinZcik/RmykjjQGBMRmMeaJYbGBw5sKxpjxYYzwM62kaFIMZMY55JHq8YkUpFCJxMvUs6zw9cg7jiFaoVYjB1x3qfgtmSDilSvh6s5Wv7hERJrZEW2PmsxBtzWhbw7zkM1RsMmXylELx2NIkAcSAjnHMnsIQ/VrAmRe2j81/o62hxtoxIKa4fGQ5GTAG98sgGMCkgsuZRmcfJDf4dP+TuAE/qljCRTM67Tub6hecOeLsGJFkrAvjBzj7xtNbnKUU0+a8aVAkVsa8No+QyLR2Ywx2/Az1MykNSggdoff9stMIwdg045Bp5mmIELtIUbW1LcK999/PG4/g5tW73L0zcvP6HW4c3URCZLnd0feBC/eep1/2PsgMxr6Yn+/nmuvzvOQT/1MBtXuuBI+RwL/vJRjArseb/c/0RiCT6S7Y85J9gUSM/VBBMmYzGT/D95hrrrnmmusPer0qAAWthdXqFoRAAcZqDWat3tzWYw3QpC9vVGszBqRCrqM1ULWiweMfBZ/CNrS9GTeKUeG9GTOTx3GKCZz2TY1hcJyd0LTuzZm/HBsTipqcor1XSuElU8Sci5v7BVSzpUkUp1tjU8dSje7fEi8a5b3JJmIIIO65YEJ81Ju44HR0mwA7LdwnzjFG2z83cGzsyFIzUiN937Neraz5VCyGsYEU1kNPx6Q1qqptumvyilIKN67f4NKlp3nooYc4c+bcscbRGmRVpesXqBp1vbEEQojQ0gEcTAghIE3G8LLnJmnTmmlNRJIERqf2q4MNzSzwmM2FzWVCQHyCjsdHts3nnL3RNfO+Jnnpuo7sYFZM9vOcR4pWutgZw0DxyNDGLDgOqjhYIbZmq1Q31HLPANpaM2ZGcJPG4wDPBKD4GlafnE/bp8WSqjf8jc1jAIMCXUzG7ojBo0xb/KT4urLjkrrOrpNsx7jk4uvPWCkSwsTEaSyT4I3uxFTI2ePUDDAShChN6mTnDzHgpAaTWJRaScHkHrb2HFhzeYr4Z1XsvKWYXP5USbGjJUOor5OUIqGxh3w7ZijqwJwzo8STWVTMSyOkYJplEWNL+ZprCSZjsajUlgIj+HHQQrcww7VcMwQzFA2IeWCETYSkaKJWEA2shszdgyMOD9dohd2TJ7hw71lOnz3BxdecI/UmOam4cexcc831B6CMidC0ey0FaAPi15cyE6Z7UX0J++EzARdCADUI1gYQL//1Bi7M4OVcc80111yfpF4VgMI4Dlx+4VnX9i+IXU/OFZFk7XEN/vA90KU4NbjVm5HJg8EBCHtINwp59Wn7xs9AJy27+t9ld34HrNuMTrd2mrkZ+G0i+zZu/a3Rj5OpYh5HQtpE6LVt1qa3D77vPh0tzWzSt+nEiol22Cji9jOPxVOdKPANCAFsew5QxNY0+2evNU9xes3gsO+SNcdOowdAmNgATc/ftt9Ai+qATIodnlrZbAs4PFzx0Y8+weOPP87ly5d55zvfxfb2DqrVm2wDHVLaRFTijINmlBhjMmp4KYyjIl2bHhdiEmK042WNXTPdNApISzgIx/4/juP058tamB0AACAASURBVForOWeb5ucysQhq1emciwiS0sRMaHrZlCzJwwAJZRiGqcEP3vwOw2DNa9yYLm4m+OJNcHPONnBhUs02rw11cMbN+457WcQQGEf3B6mV5XI5SUaKryHc+8AMMpUUhRg7UvQ1WssGlJBgEaQxQJaJCWPJJGauWao1w8m9I4z+A0U9gaE0fwgmtsO0KNisZQlmWqhaPVnDr7EGLpSCIKQYEW/Ko0sTjIlix3HyDnCgTxKUPBJDYhETudq2VDaAQZPFRDGmUJkAp0rqe/dvKPSLjlIKa48QTckSLoKaEWvn57aOZvzZh2RsFQdR+j4RkiVYGBBVCSgpBUcb1fcbj261/bny4ot88LEPcv3aAaUkYkiIKCEqxMrh6i7PvTCyc+GUH2MTgc0111yfz/VyULAiYuxHxROhAEj+0mBMx8nltWx+Pr32uETh0ykHLo6BBnLsZ9PkYb7fzDXXXHPN9UnqVQEo2CQ/IQjD0Zq9tKBPvTMWhFwqq2E0mr5PIWNMFh3oWvau66lSKHk0On6pFIUqalT+AHl0TXdI/lzvTAc3nGvshTZVtUg3+8I3unue9POlNAqiR1FKJUr0balPVGUCDNqUXrUaQ0FwXbiZFdZj+vMGVDQ6v8U56jTxbf4C7TXN6K6lR6QumRN+jGY6mBJSeMmUnaqsh8GN55RF303bUgmMHvEoItNnV61TA51LoSKUooRoRpFDXvHRJz5KjJF3vOMdPPnkk3zwg4/xpje9ie3tbUSSGzAaUFI83q+WSt/1SGysC2gSA1WLhlSE2HmT7N4Z4vT64kARvr+ltMQB8WjFMh3DcRxJKU6sinEcJlNBkSZngcPDQwC2trYmtkczvWyNbANdgGndrFZH1FpZLJYsFwuMJmrva59tBKfjx5ggj86+aX4dlSCJkKxJrS3JwmUsxqwJE4OigRql6gQg2TqxCXzJo5shykuYJQ1cGYaRNWuXAplEpJRq4FOM5KoEYCyVMReWi8XEaJiSUlxaU6uvmRgnOUUDOIpWQt3sn0mONoaaOPMnuWlqLrYO1CVFL/G6aM/Lukn/aMkhljAhE6NBXfpSqeTa3NOBEK2hj8bokABJbL11XaBoQMQSIRot2M6HSxxSIJfsx4Lp2o2IxcaqRUbijKcGfIqDJ03VHCQwlEzN2UxgRamMVK30vXC0vsPlF1coA6fO7vOaRx/27RggNRumzTXX53m1LxX832JSBtnQEDguNzCmoE6MQTQcex3OdPj07gsbMmb7Q5N5HkuQmYlQc80111xzfYp6VQAKXb/gnnvu486tW6wPjxhXa3Z2dui3lmQ1X4TQKeOg1IlIYA/yikwP6c1bwDTqNo23JkDRas27mfJVS0fIrj13Wn9r0jbbrxOg0Fza1ZvyjT7cqeb+IGBNfPZmeGNI17Ti0ae7ZkBoSRUokzQjuvxiQ9WPk4Gc1krF3qNVAxhEhL7vzfhRC7UoQSIESxEINga2zy5+fAgkIin29p7DSC3NV2JznFsTGKNFLnZdou86JGf6RUetxgIYhoHbt27z8MMPc+HCBU6cOMFjjz3GjRs36Puew8MV6/Wavu/pUmDRd3acqAyDG2GyAUmqGs2ztIm6P9lUNYO+WuzvNv4FkbHR8MNGKtAab2BiSHRdIufRJtASGcvagKRSKWPmsQ/8NltbW7z+DY9ORpV936HZHP4bi8OPEimZN8EzzzzH888/z2Kx4A2Pvp5Tp04yjpkPfehD3Lx5g62tbWJM7O+f5OGHH5xoptevX6dqpUtLQujY3TnBmEdyHqh1JHWWNhIlTF4IbU1Vb6DNmFGozQNiknpsGnFjM1TK6FRZB8fEYztzcdaBunGpOjjmaRNjNRAn+Pou1SQbNY9Iuz5Qxikd5Ng6sj8A1kijOklOMtX9SJKlI0ggRQNGSimMw2ieKSGQumbuiLFV/H/BP6uZL9r/ksfJimIMiOgO6QGCCgUluu+F+VG0YxXQ6ivOmRzijur2Ge06FcRSVapOMg1U6UJAfe2CAR5FDbRJMfkzv+1XDHD61B6vfe0D3Lp5QOoW1GpsiHU5IvYCFE6d3We57AGdgJK55prrD1IZQ6x5JhxDT/2/X37VN68DednrPt3SY+/VtvVKr3ml955rrrnmmmsuq1cFoADWkG9v75DHwo1b17l19zanz5xm58QOfYyoRvoYGcdKydWp66NRxIGSC1qKsRZyoWC67BAjKk6Zxh7m85DNG01NXx5TMhM8Ng00x/5s71XNYE2O08Lr1MxLsGQHqm4aOGRq7FAlD6ODEXGSUMDm9So2zZVgdHw4Jtfw6L7j1P3jYEKK7j+gasdikkVExKMcJbjJo1pGdZ8iuWRKLkgVQrJjZ74BPlENBthYeGNLhMClAc0vYjPxvntw2+nyI5Z8aNKAo6MVH//4x+n7BQAlD+yf2OH+++9nHAYuX76MiLDc2ka1sru7y97eHuthZDWuiTGyXh1ZwsSiJ4rp0HM2vb0ca5hFIrkUS7vwc9l8LWIwh/7VajUBUaUUur5ntVoRsNM15MzdK1d5tG7WQ87FmRqQixIlTskDIsKNGze5c/s295w9x1OXLvGBD3yQL//yLycE4cqVq6zXAydOnGS1OuLw4A6Hhwd0KXHn8JAnnvgIhwdHVA0IkTe88U3snTjB1atXuXb9RUDpU5oApnvvvZf9/ZMcHh5x9fo1UteTuo6t5RaLuAUIa49ZrSWTUqDWlnzB1NhDA6iCm30JeawGbBkfwhp01/PmsVCCslzGSRIyrgdf14oE82Qo1RhCgkweJeIgUfBkDMEMC4uzGWI0bxCLa23GmOpGmYlcM2OpgBkz4h8jhOjyBTGZQx09NlVZ9AsDn3I2NoMEVJvcCUJIdj2qTqwKap2AyiCbHPbmm5BzJfqaV5eXxCAEzQY2FZM7xSSTOWM7xuYLY7Gq+D1IQuT02T3esv16jlYjy8UWHvpJltF8TFKECN32giC2LykcpznPNddcn9/VruXw0v+cWANy7N/HXnecnfD7LXVJg7TvA92wnj6BvTDXXHPNNddcr1yvCkCh5MJ6dUjsImfuOUXWgVs3b3Dt+jVu37lN3/f0XU/XL2xC26VpIqhqzUYXbTpNo2uHQqnmWWTdjj2Et+YqSPM1CGaWJsIwDiaPwPTepW4a0obS16oT5bB9z7amVMQp6TG5YaM1U9mp8c1nQdUakOxeAqlrXhF10pMjlqQwmeQB4lPJ4xGHMTTH+g3bQt3EsEkgQoiE5PT/WievAWu+MA6lmOFerdX9DUxHz7GP2jwBUG/gvcZxIMaOIIFbt27x+Icf5+q1q1y/fp0nn/g4589fYL1ec+XKFV7/+jewu7PDjWtX+eiHP8L+iRPEGLl+7ToXL14kxchTl57h4OCAt73tbVy9epUPfeTD3Hf/fWitDEcr7r33Anvt967f4OjwiJgsfeD8vRfouo7DgyO6rmOx6Om6jlqLG3DCOGbymAlRNpKSat4aQSwV4+LF+7n8/AuobiQU5vJvcolaBpbbS/I4EkPg8PCAF557nvsu3sfZs2c5c+Ys733v+7h69Srnz58nxsQjj9zPAw88YLKXaA7aqpWDgztsby05e/osVQMf+/glHv/Q43zpv/GlSAwWY5oCoyrPPfccq9WKvb09dnd3uXXrFh/84AdRhFLhzJnTvOENbySlxLVr17l+/RoB2NlesFj03HPuHH2XpvVjkQHBPycEWkpIts9cjOUjKi1500CraU27r0Mufo1sfBzamoxdRx49hlGCXxMWX9qF6GyPSlCLTxzHTCnQB6HvemMDSEKDeKpCwngGzcOkQ4Kt9ZINWLC/NyZPLSbrCTH5s7JOwFgXosuXnAHjz9MhmgdL812BQFVxtbHLINxxPbT3C8mkJdWSXkoBFQMphpwJkkAMBAsSLHqzFkuNiEJaJHZ1SdcYDAqatqbozaLKWiLBwQaTSc185Lnm+ryuVyQWfCrfAnnlP8vLf/Z7l7s2bfCEl7AR7Ibv3LIZVphrrrnmmuuT1qsCUEAr69UBISeUJfsn9xjygJbK1nLJnTu3uXG0JnaR5XJJ1y9Isafvl0hMxjrIBaJHFtZM0QLRGAioTfcFi3HE9eTePxjpTwt9FxnyQNf35p9W2qTSv1xFbNJdxBtznSaYWm1yWkV8khxcj55fogNPDljU4oaAwQwGQwwQA2Usk17bmjNAldR1Jt1o+vWmKRcmfbyEQJTohnQAbgJY6qSjb7T+ltDQhtW5bNgWwaeppRpIAt74BaG52E8GlzGYSV2t1FrY2triwoULnD17lp2dHZ6+9KybKw7cvXt3MnjMeSRXm74icHhwwM72NovlFqdPneapp57mzp0Dbt++w61bt3jggQc4ffYcl597nsuXL7O7s8Ozzz7HwZ0Dzpw5AwJPfuxjXL91k0df/3pu3brNer3moQdfA0G4fesWJQ/E06fRWjk8OGAczUPiaLXiwoXz7GzveCxjJEi0Y6Jm4rhYdJRiGvhxHLh+/Rpdl+y1Lkm5cvVF7rvvPlLqOHPmLGfPnuXmzVucO3duAi5SSiTLNPWJvHLPPefY299judxGMYr/U089C1TO3XOWUydPgFqTOqzXrNdrAMZxRIJw3333sb29w4tXrnLpqY9z6tRJHnzwQdarI25cv04UeOH5Q4IIq8MDXve6103+EoBN5lWhVmN7iLes1eQvDVQrxeNA+zjFpOZx9PUIISVfP8n8ElqCRGEDzCT3hVA3VHWHxVKLSZKCeXbUklFfu7UUl/GYnKV5QaSUICijA25a2nUjfm1GSrYkllqVopngt7xS1BkWo0lDgsWm1pL9mbrdGew6csKRyYjEfn8CF/y6HHPxxBCLjC012/AvGFinIZCzRdgWVUsvMfMMRAJ9ilRt0iR1ZhNsL5eUrJQ8kvroYF6TU8w111yfv9WeLeor/L28wp8/1e/+PtkKx5IlrMLm74DN4GSGE+aaa6655vrk9aoAFFQreT2Am94tt7fY3t7mxcuXOXFil3PnzvDii5c5PLhFHm7SxwVoInVb7O2fod89wbLvQCvj4KFqag1GwczdpAoqZaIbW8qDggSTK2DGeRYbZ9NTrZUqgRhN65/rYI2JT2dtct1ZYzNN8YVRK0HUwQyfNaiZvo1uHCdOA89lpORN0kOYpqrFnfMFidbIR5FNm6NqlH+PmGxGbyEIEsPEXAjSUVz3nfNo8oiuM7d/N5gz4ECmSb1NRAMhJmot+LB2elQRlFIznYMZQQzYiCGwvb3NyZMnOX/+POfOneOJJ54giNLFwMHBXR5//HFvtK9x6uxp+q2Ow7sHPH3pKUII3HP+Xi6/eIUuLUhxQcnK9u42p8+e4sT2NjuPPEQeR1KIHNy+zWq14uK9b2DII6evnOLKtetoFWLqeerxD3PPubNsbS25fu0Ky74jyimkM/kMNVFq5tKTH+PWjWu85S1vMa18NFbI0dERpRa2PN0BmieD0Ped+VXgpnzBY00dKAghsrW1M7FgVqsVTz97iaIjW4sFJ3Z32d/fJ/Ud/XJJdFNMrZWQhH4RjX0D7O5uo1W5e+cOqsojDz/MqVOn2NraInaJ/ZN7xBi498JZ1kc3uXPrCoGLXDh/hlMnTxCAa1evcvXKi9y4fp1hWLFY9EhQVDMiBgi0BA/BPouKNfCokiKE2LMe1wh1+rwSxAEHS3qIqWMcC4GIaw2IKZGlTHKb0Y05+xTMd2HyoFDKuCZ2HV3XQ6kcDSuT2GDGk8Gz0VNvshyTuZikxWQE1uYbPlKnyb4SPBrTrquAkFKH+HWhIZJr3aSLeBSpKkhMjKsViJCS0gWPIC0KuomZlRDMR6GL/jgeKGUkNJhDZfKIwOVRQXw7FTcpFSwXolocaigM48h6NZrMI5rxrNaREPQYVXmuueb6/K3PpmH/bJv942yIT9/Qca655pprrrlavSoABbDYtxBsCjoMa/qUOLG7y+HBXXbvOcsDDzzAC5ef4+6dO4xjpuaROmauHh2xf+oUu/un6FNH7hOljhwerglJ0BpIIbpm2zPopwYoYjaHrrPXav4LJZsDPzbZb/r7issBxMzqGg1+GvMfa+zbl3OLiVQHIiaDQQHVMqU7lNYMqZDz+BIvhmYG1xgEzbRxzCO55mnybW7/dUo4aGkVtRnhBWvGWoSluCQjqe1jyY3ab3YMwWOkggBaaXYQfd/T9wtkvXLDOlBRYuqMJZHa+1uMXi4ZiYHt7S0efvgh9vb2uOf8Wba3En3Xc+PoOl3Xs7uzCwInTuzx4IMPsVgsQIVFt6BLycCWqvSLBTGIJVGI+ntHdna2eeHFK6gquzs7xBi5ceMm6/WCmzdv8sjDD02ShdXRETdv3ZqYFteu3WAYMru7u9NxEJfJNPPDxgrpuo6TJ09O3gotSaKUzHpYISKs1wM5Z7a2tjZJGWOm7zvWw5oXn7jM/fc/wD3n7/EYRDu/t2/d4blnn2Vne5cYhUXfT9fIwcEBi+WS8xcusFgsGHO2yfpiYSyfWlgseoJAlyJ917Poe+7evsOtG9cZ12vuOXeR5F4MiJkQIpgHgJiPgSjkuplQTQalotOwqsl8GogCxkLQamwC1GUDBLQWSx0RkwXkPKK1oGoJHaa6CQ784f4IFuNIkz0oENSAsOLNeUyT74HibB1nC1WUOhaUhUmDksk38pgJydk/2VkRYuc1BY8FrWZZOo6FnKtdC8GAgFoh1zqlfEgXKTlPniWlFEsdwZM1MAAzhOh+EgY6CBaPmkKk5sqdOwc8fekFShaUSNd1Bq5Ek6HUYpPI0w9eIJ2/j+imlrPiYa65Pt/rcwcmtLSZ38svYYYX5pprrrnm+lT1qgEU0IKo0fWH1ZoQAn3XcXBwwK1bdzh9+jSvefB13Lpxk8vPPkdkRKoyrA+5eW1kHFecOn2GPgWGoPSdxc+JKrUWhECp2R7yxejcRTIqkZxtSmq06ELq+snwMHqcZXWtc1U1GUAQpIob2TWdtQ8ePd++udAHieaKj7rzvU2fSynWWKTIODZdtycWxEAtxaURMjEIpsPlb9Z+1po+o3HLlExQ3U9hMo6s9ngQRCgKuZSNJCNagkBLREgxQc1Gda8VWdjkvXjUY2oRl2Ku/zEFTp46yXK5dL8FLK1j0YFA33ecPn2K/f2TxCDEYI1V6jr29vd53Rd+IYvlFiFExmyTcgn2uUOINilP5k9Ra6XUzNHqiGG06MRKpZSR/6e9d421NEvvu37PWut9997nUlVd91tPd3s8Hs8kCooVBaMICyXIMRDFfIiQUQQGLCGkAAFFgjhIRAI+gEAEkCBSFAcHZMVEJgiLuxUi8cnGxCb2OMb2xDPTt6q+VFVXnet+37XWw4fnWe8+PbaFWmR8qqfXv9Xqqn1u79577d3n+T//S4qBIa7Z3z/g0buPuHnrOimOHBxcBRJPnrzP17/xDQ6vHJJz5vT0lLnkpYIxe2Wmqg26sKsKbeGT8zyzWq28dqtVeBr5VLX4xr3y4sULQgh853d+Aag8ePAQAb7y4is8f/6cO3fvorWSS+HF8yO+9rWvISivPnzAZrX258YUDs+ePePatWscHBwYGWQ/1Osft3zw/vvM08S1q1fJ88wwCFGEx48e8fjRIx7cv8/nPvcqm/WKopVxHDk/3y7XLUGIKRA0IFItZFEgJK9DVKVihFVIES3Vz/Iug6CUebECxaCAPVfRqyy1etChqCmEmv1IIIZozQiayfMEBVbj2uopJTCRQYO1bVCZc0a1WCZKiJZh4tkgZc6uuMj+OjZbSsSyzGtVkhNvSlnIOzDCTGMgxQGtwjxl0jQT4kDJlVILq3ENiL9GMxIiwdUQpdgZkGA1k5XKKiazRAQBtSyVJK0mVjk+OuPXf/03efrkBaoDQ1xRpi3DKlnVfFXWeyO/7+CQeVuMUOm/6nd0dHR0dHR0dFwyXg5CQa2z3STMxewGvvHbbDZM08yHT55y7fotrt24w9Ur13nvG9/g6MVHriqYefHRh5S85corrzAEyMkJAYmuHBBEg/+yXxmTV8xVG4ht21ycHKjM2YZLqsm0W0I9LZRQotfX2QCRoikEbIDZDfnzPDMkS6K3r4dcTPJtDQpmYmjRR0ECVarbF2xQjb69DiEsC8mqO+IA8FBIufCQ7jzWNgSb+sH85E4G1Fa3Z1vpkgvFsx4E930DeCBfrUpVJRe/CpewK3jYZOWNN95g/2Cf4laML3/5y0uo4bgaCMHImRSTqyCEFAeGNALiAZWBJMI8TazWIwdl3+v48HWJ/fxr167x1ltv8pVf+WVu3brFo0fvklJEqMQ48ODBA77ylV/io+dP+e4vfIGUzFZwdHTM+bTlu+59F+M4st1uefvddwghMM95eVzNq2/qEhUWQifnzNHRESLCZrNGVRlHs748f/6cO3fucXZ2zvnZGQeHh5RSuH37tkvzlSEN7O3vW1Wkq06ePnnG+x+8x3q95uGDV3nl2jVStAwBEWW7PefFi+dcv/4KaUimEqgVQTk9PeGdt9/h0eNH3Lhxndc/9xrr1coH9sCV/UNW48qG31zcXmPnx8Q6TQnjvn2p/jiapUVcfSOqDEOyFodS4ILSxSNGoFbL1QhCrvYaGpK1RyhQRT3cUqy5wIk81F4vwY6bERAhmDxGxJQvg2Wg5DwzjgMShJyr117auQqxvSbclgAeVGqBnCEaaYm3PMRkmQQhiL/+vL3FpRjznF18FPwOwhLeqMo8Z4YUUIE5G2E5zdYoERByrShKLhUtFnYZghGaolCzokUoWTk/m3j+4oTD/ZtsZzg5Omez2XC4d8jp2SlnZ6ecnszUEhbrVUdHR0dHR0dHR8dl4uUgFMR80G0zTIwg0S0KlhI/zZnnz4+YZuXK/h4PX3uD5x894b133+Hs/BQNlZOTE6Zpy2ZvnzCMUCENiXFcURWmeYYMUgMSow1cdVcpGKJ468MMycP2tBBDNMk6NlArtl2dq5Jn36Srycy1FgrW9GC5BXmRyTdCwOTOkVpNHF3LjFkw5EK6vvm5gwRTWSgW5OZERanZKvhcri1OBOQ5U5fAxEgV8y8sG1jF7RqBueKNEAmwKslaixdENhm6UACJkRwTVpEX0WAS/qaMD1EgJq5ePVysIKrKwZUDz6OAL37xi6zcrhDEUvKneebw8ApvfMd3WDAlZgWRYNkRN2/e4OBgTZTg2Q1lCcC8c+c28/xFPnz6IXyoxACvPrzvQ1vg5s3r3L9/j7fffpNXrr9i2/YYWa1XPPnwQ9566y1u3LjBk6dPmOfZpPExMk+Zk5MTTk5OePHiBTdvXCeG6J58e4y223PgcCF9VqsVDx8+4M033+LK4SF5tjDBO3duE2Pg0aMPyDnz2muvUkvh9PSUk5Mz204fH/HWW2+x3qx4eP8BV69e9ewNtWBPCnmeOT05ZlwN5tGvBagcH5/w7tvv8PzZRzy894CHD+9z5cqhnRGUJIEH9+9TysyHH7zP17/+db5z9QVWm5FS8hLU2UiaEGQhFVAP4USRauRbFTsXIQZy3RJjMkJNI2hdyMFSJlOxuBUnl+wVjaaCECzPADUiLYpt3EUiIQpFdsoFI/eCq5bSQp41G4osFac22BsB4HkiThba2a9m4zHfEzFYjoos9x1QZSozWZM/3wG0WjhlMGLNyEUn24JQsCyEqmbj0NbrHkyRYaRLWN7nYgwIyZUpMyIJ1DIiJETu3L+PzsKbZ2ds9va5d/9V3vz6W2ynI87PZ0pWJAxIfDnevjs6Ojo6Ojo6Oj67eDl+I1WrgMSHtkUvb/FvaFEbPvOWeqrM2zP21hv2r93g4d4hH3zwHk8+fA8tMzpltudPbHBcbdBNRkRZrzZUdbk+5hEXCRDMPy5eI1kphKAED0EMBKhK1kwFD1K0UEeojMOw1OdVz0dogY3Vk+hDgOyKBw07332zLAA+qNogIp7k2MIaSy2WASHqjRR1CZxr1oyWlxDci15924uAum2gFlMhNOJhiMlyHGomYHWK4zBak8G09dA6k3UPq5FhGH2YjL/Fux2j5Ty0D7TrSSmhYuFx9+7dJYlVUtr2X0kxURAePHxIHMynLsEk8RKUg4M99vbGJdAvIFQf0NbrNW+88R28+tpry4bZAjI9uC8Jr732Kq+8coW9g40NwWXm5u2bvP76a7x48ZwYjSC5e/eukz7Cdjrn+PiYoxdHfPU3/h5XDq+wXgeaRGK9XnP79m2vo9wlbN+/f5/j42O+/o2vIxq4e+82N6/fIIiwt7fHz//8z/Phh++zt7fHO++8y9279yil8vjxY77xjbf4whc+T86Zk6NjDg8OgEqI1iwwpMhqNXjuxkwIiWme+fpvfo3333uPz3/+O7l3796imAjeKID/+cH9B2y3W77x5te4/7mHjOvBQhVlJ5y3PIlqQ7ZU26JjxNiYBiOqUGJq9pno1ZCB5AQaVKtVVbVaTs8fTJJAArnmJUSRapmCmhVJ0eoXayV6vsmkmVpnkqQltDRGU9lEoMwzotVfG6ZMSK48cnrCMwuN9JlLcVuPN0uU2YMlLZjVDrJZPmIUwJoshiES5uqWCpZAVHHCJ6bAnGc/+oUQ7fyr2OcFJ+YIrXGiusJDjKwUYRh3xMvz509ZDRsjSc+Oef+D95jzRKGy3t/jyAQhHzt7HR0dHR0dHR0dHZeBl4JQ8OWhBakFRYg2xA6DWQAqjKtErWoZC6WSc2VbKqtxxc27D4jDyAfvPSJqgRrJecvp6THTPFnN3lVBUiIOkUCw1HdVtOTFYmHKA78owerupBgpIGFJwg8eruaJCb6ZtfsRvPpunmdiFFQzMGDjWvucsAzUFr5oSgXcUgDm766iNuiobXDbIN62s83z3UgM84MrpXw8mFFVKSKthmKRqKcYmWcfTEIgJRvEgysyaq0EvMavKvM02fW5HHy5H56on/O8DFAtb6BlDiwDn5jVwX6mX5JiIXQ+hJZalljL6vkOqBKThfCZougQsQAAIABJREFUhSItUvRQbSCM0YPyGh8FbDZr1uuBYUyEIJQ6I1H50pe/yDyZLeP+gwfEFC3ocJ5Zr1d88Ytf4NrVK6xWo5Ml+NCpbnEYSd7+0Eihvb0NX/rSd3N8dAIq7O8fstmsKLVy48Z1vvSl7+bo6AWqyq1bN3n48CEpDaagqcrjx+9xfmb1jndu3+bunTus1ysbSIMwDINdhwde5lx49/FjTo9P2G4njo+OqSWz2ti1ffTRR5yenHN4eJUYImdnE+r+fW3uhmZx8cfMGlLsRZCiq4Rc3WJnys6XKSSsUSFIdNuBnYuaLQtEtakI7LVrA7Cd6diiS2sgDjZYW2uChWxWsa4Ds5m45Ucs2wGt9jqtLeixNTnokm8hEuzxEsi1+Dm2JgeCOuERKUUXi0aluorF806iEIIiAVNVCJSl1cHyP0IEPKy1WRBaO4sCQxqZ55mSZ2Lw1ocQkOCvj3ZO99bcuHmdxx885fH7jxjTyGZvJOeZD589IoaR2/ducHh1n9MhOLnT0dHR0dHR0dHRcbl4KQgFESGFgSyK+rAuvhD2WxCXgKMVCYlSKmenZ8zZhoDV/gH3H77O0w/fYz4/RVSZpy1TOSfMs20nh8S42mNcbYgxkMJACdaqMOdsVY3BiAIbym0jnbNtu/PsH1d1L7rJs4OYqqCqDUsmv4aUom8jzdIQYzI/tdsgYoykYIqH1vYgvuWf5+lCsKKRGja0548NeI1UaI/jN5MMuF9ePQCupfeHEKjFh6NWMelDuaqtjkPzpRMt7M6+MXUZHll86iKRECyMsOEi+dGmn5YFUb1yUBZyxrbjVnlp+Q0iwjAOZiMpxRUg9n1KMUk+nnMgtIlYCDF6m4Pdp1JMIRJjtOclBIawZr226y+1Woq/S+mHYeDw4IDN67twSTsWVpWY82zD6QUyQURYrUdSTGzWG4Sw2F7sjARee+1VhmFcht5Gity7d4/v+75/mFqthrLkmdU4Uts/xaT3t27ddLm8NU+klLh9+w5fO/ka7z56xNGL56zXI9dvXufu3bvEmHj30WN49z2uXL3Gk2fPuHXnLvv7VmcJ2LAbV0YutOwICZ4T4tkImKKmopYtIP4YI1SxqstGqBn5EpyssHaERlzYa1jQXEnRhu7WQFLcxhKDQLAwyBQiqnYGRQWRaucCQYtVnk7bidVm7QqhXfaKKWSsJhVxqwJq+RP+OWDNDopStC4ZKRLsWlWr2aBQtGZyLRbSKor4a9NIhUasib8unXwolgkzpLi8lq3JpnpgYyWEahakIfLaa5/j6HjL8xfHHB4c8vD+XYYx8dGT56CB115/levXr/CeGOnTAlg7Ojo6Ojo6Ojo6LgsvDaEQJBJQ5lxQLTaIuKxfMal+G1JA0eK/VBfLJcjFBqLDazco8wHnp0foyRHTvCWkyNn2jPkkM67O2Kz3GcY1q9WGGBPrcUUaBqZpYppn5nkmhGjp8WI1ivOcbaj27a15tzFVQS0eHodX6Xl6e83LgC9iQ7QNUOIDfXE7Q73wWCjZawtLaQGB9nNbAGMjFZaNaMs6KOVjA1UjAEqtpGge8ByEWliGmxb+aAqNSsl2LZbP4EGSgGi8YKcwFUOdt/b8VFmC8RqJEKNVchbXvDcVCGq2BNFA0WLDnt//EPH77DkKFwZbu3/VCYodkdKqLc0l0lL7g6smdPHhG8FQrMIwmqUixUTOlWEY/Pu56sTvwziOqBY8eIIYA9kJrJjscbyowLAzucsiaE0fXraIBFCK/ezBbCMhBIYhcePGDZfiV+vsdBl/rlbNuN5bc/uO2SxQC3ZUhe/4/Oe5c/ceQxBETZY/rlcA7O3v8eDVV/ngg6ecTRP3HrzKnTu3WK/3kODtJ+LqC2HJBgnu9xdkucZGYim7ATrXulQXJle0GPFjZzDFYckTMILLiALPNCQko8+qqxJElBKMtBCtYEfBWyIiogGLcVRv38AsR0WRaHkj2fNQTOViYY6o/X1IyYMcC7IoaMRbLsz6UBp54aSAqtkcVK3dYYgrtGQjPiQsqgt7fbY8E8smaYkpVi3b8ihY1D9Zs5F1Ac7OT3n27CnjkLh58wZ3bt/h3u2bDKvIvdu3WY1r1puBuDaVjiA7NVVHR0dHR0dHR0fHJeGlIBTMEGx/tL1nxNL+dqnqSQLFQxqFwBCVqhXNE5IitcJcKjEm4nqPgyEhMZFfPGW1GTnY3+P5i+ecnpxxNM2kYcV6dc4wrllvNsRhYL1asVqt2W4nH0Tbz7e6xWY/AJM157yrdGwhi+0ONeLByAnbVldXV4QQ2G4n+/ZBlu33nDMSWPzcTQUQgkmzuUAaNK/4xbrIdlsLfwyejm+bZru2cVyR54n5fEJ9OBepaM1G3KhV/MXYBl7LmNBaKNmk4FngTIRhXFGqUkWo0TMTJDgJZJ9nTRkWLJhSYowDc0yco8y+/VbxNuxmy9CmVBGyS+4tGDIthIUWC8vcef6FEoRSbGgrpaIEhnFAQmUuMxoCkOzztRIlwBh9swySxBsHlDAkUMhZULXK0BCAcaTEQI2BYlcFcbAhV6uZ+7HvZ/OkLBYRjXZWFql9iARJ1JiMzPHHOTMzDOnClt2JkbCPxsgcE5MG5gjp2jWuvXIDKYUU3UISW3hg5Oq4x97te3YfgZSEs2jESogDGmEbErVllngrQQztfuiSadLUM1pto25DdrVAwpqdpEoMgymI5nm28+u5BU1poFXcUuTkQbJBvmoxM5I/ZEHttS5+jhvZU0uhhUYOw8Bc6tIyERSKW4jESaRWmVpVyS1YUq1JIpdiNg8UavGB38nE5kfwrx/D6OSAt6pEa53QbEqYEM3uUUs2y0Wy4FdFKXMmxmSvYa2epRIXYmQ7bXnn3Xd49+0PGDcHnByf8vzZE/b31+ytN2zWGzZ7A4fjTeCmPT5OBnV0dHR0dHR0dHRcFl4KQkGB7Nv7GKyeLRf3aC8p7T5rVpPF12WYCUuLQZmzycPXKxQY12vGeY/TsxP29w+5efMOZ+sTXjw/YrudONnOxOGUMu+x2WwAIaaRIfiW27eZGrDBuUZiSCRvX4jBKuxCDJSCb+NtIG1yZFWzQtTSbAsm3ZfgMnEJ5sZWC9+TxUJgj4MREUqt2dPoA0HEB1Ib8BqhgVrGRPVhx9Pv0FyIQW1r6pWQKrZh1arMcyHPhTgEBrdWtPwEwWTqosKQhRgq5XP3eefmbWINLT6CKgWtGUIL7FsmasTzIswz7k0aNbfdtR8Cry70AQtXI9g/rqdHlrpM+5gP2v5Z9uCF5fpxO0oQ9Vm0+oDZHudGYJjc3bkMRIL73ZviQ1wxUZGFZ3LSwEkvpak6ZPke7dravyLBLTz2uSJxeQFUr1Jcgg2XSyu7wEA1kqio2nPnA7fCkicgbknwh5SKtQcAEKwpQzQT1ENBg3AugYODDfHvvUlgBSETqykpsgc3xhCQKkg1iX6d511VqbSwUQs5La6qkOAEhatF/BWBxoAGUxOIty1AXR4nVSVK8GaPQNHsAZ+Dh7cGF0Y4ibOoccx6Q2lhqUp7BoKoK33sMa21orkpXgKBltcRFoLTrBxGEJgKwn5IHEaiBHse/Pq0ClrUsyns2qs2hUcCJ+pAmYsRMmC5MWU+Z7NZce/eHZ4/O+XDZ8fMWTg9mcjzxJACqzFy5eoe3xV/D/XB58yeEjqh0NHR0dHR0dHRcbl4OQgF9R2hb7RryVaHiMuwfYBq2vZSd5FkJRfUB5sUbGArebbBGlit98il8sEHT7l54wYHB1fZ3zvkxfMXnJ6dUkrh+bOnnB+PxJSIKTKu1kiKpHFl20mx4LhSPOAtepjaha1uiD6EVpPHyzeRIWhl2m6XXIAU7PZqaZRGUMQBqm8/fWgqxYgWkeASfhvwTNTQhlXPR5hnH4orFHGJuQ3eLeRxnmaQgITAXG27XypL/kBt1oVGVHiQXCQwKoSvf410sM8Je2iJUCtFChoqQSpztWaBGCyoT0slhQRiJIvWyjB6WF5pFZB2zTEEpnmy1oA0krNtvfEteIjRNtm1hV/aQJXnTIhedenD9NwqSKlLNoBt16s1V2ASfFxqD/ZY1FoYkocfOjnRggpTc1fUSinKOK7sPmp1D76dyTQMFkopFkzYyIQWVqnVvPlmW6lLa8cuHNFeA82m0rbszTYQUrTzUCz80OwFcSGyWnZEy4cAe6xTSqYUyLOpUpzeqBVWUuDZMXWa0I0SXLpfVAlq5FKzrARc/eJ5GUs7SZMW+PDebDUhKLlYjgdBluyPXApDGPzMBVIQcFImNJItBiQOdhY8Y0PE8kwIdr+yKoGwDNhBIprtsUiDZSRUD/NsCpdGpiS3EX2MbFvIS1MxBPum9rzXCq7OyGpfE4O1fcyT2WeqzsxzoQZ/rEL08EV194xQc7P+KDUIm/WKN15/nWdPTnny7GuEsGK9vsrj54+Zt8ekUDk+Pub2669Ti6AFpmla+LiOjo6Ojo6Ojo6Oy8DLQSig5qMXSy+vTXItNpREH/AUfChl51WP9st983nXUqhZPSAuEojs7x1yhnB6egYK69WKw6vX2D88ZLvd8uzZM6btFvJErZlxPZLGFUPekMY1xAQSLwwiPrAW9S2zXVPVsgxzwSXjbegVArlkG3qqD4bRwiZLKcRkZo/i21OK/SwV8e25fWxZn/rSOsa4SMvdOOD5C7ssBdsS7/QAKq6mwL3+QVC1gbtZOFqQYimmuqiSYc7cf3bOq8dbkhyRFaQUaqiUoKAmW1dVRCE7mbAaVuRpu1yzWT2CXYNXbSq6tCnUXJu2wSTl2rIi4jIg+x1ewiW1VvfMi4dJVidfZNmki1hdYS27gV6C+ELfpeqo5XmIkysxWK5DVc8J8IyHUonDSK2mUiHYAysXtsa7wMoA2hz0LJL5EIJ9/1wW4iy2UMpSFq99u/+7EE4xu4ATN7hKp2U/6KL0sYG7kXM+z1NLIUuBFJEaEIkEYJwmCDOlCJMKlLycH7w1oZTi2R1KGge/vl1AaMsQqKVeOIt2DSF5bWux7IwUI9Fft9IeMJWFAKo1M3srAmKvL5P5ByQ4uRYiifjxQEZ/boc0kFJiO28vPCceFCqmnFkeM//5zdZBs1tUqxUdktgZUSeQ/EzVov4+ICSJXrNqBF6rOq3F3tWs4cSUV1orWoLXZ9p707vvPOLoxTFo4PTkjEEs5DOMK0Rn1us1w2B2ofaYt9dUR0dHR0dHR0dHx2XgpSAUAOYyEWKCKoyr0STgaTBPcs2uXghUrLKuDc2NXMg5L8P7PM8McaRW2wKWWliNG+Zp4vTknPPzLeM4Mowjw2rDw88dcnT0ghcfPWHOypTPyTVzdn7OarXHarNPiANhGIBmsfDh3OXtOXviu/gmUwUoJp1WS/of4riE+KFQZpNrBw3UrMzZhqchtq0qu1Wpb95bTgLs7ncLBazVcgVagr+6kT8Ese2wCLlmhmFg0JF5mii5kGcbpGMjNLTu6vq0MojlKdSkbKoQ5gllMvWGb1y1GDFUtDCMRnKkUmDOxFJMmq62FU8pEUOiiHnai1pFqIgFTsoymNpwljV7JkAm+DDaBlEFKIXYSJBiLQ5alWnaklK0Q64sw7ZSkeIbd2/RqLUwuiUjRcjzTPKshqAZEUgalzrMUiv17AwBkhNaiFhg3zL4e93mfM4wDl436NcRzMZCFaLbQUopRJRIsFyJWheCppQMORMEUhoWAsOemOyKGItwKFoRV3HMuQBlIVZiSKSUmAGqMk1n1FrZDKPVNQaB82wqlhQ/1jCy3W6XOtIQBM3FrRuyBDJSlSElz4koy/0Vse1/FPwxjKSYFtJoR0wISdwakwKaM7nOC9EFkPPshIznl4RElLgjC8LO9rIoG0QWgo3iQaGqTtw4mVeM2Km1UlUsjyEXtBhROY6RUk1tEcXUE7lUC6cUgWhKhL3N2qor1ZRHpRQWLxMW0jhnI0dEhUBgOp948813ePbsI4a0YrN3hb3Vmlu3rnKwv0J14saNQ27duc7ZYEqsecpdodDR0dHR0dHR0XGpeDkIBd80xyCUVrMogXmazGOdVjYc1IIEyFNTAiTPE6i7SjqtDDEybSdfyVqqeowRhtGbFSpn5xMVq/MLMXD95k02mxXHx885On7BNM2IVk5PTpinmc3ePqOuicMIWoiS0BRMftwGGdo2vXnYdSEGxLfGQvCNsasyqOBybW3bztS+vpIkom3rHGUJ6NuFQQ7L4NRC2naDlw3Cw2ADYamFcT1ezLtcQvcEmOf2eLtSQJv9AXsuog3S9lgHoiSKemyEBDQFRAqaFc1q2QsSTE4uLVDTSIhpuzUyRcQyDar/vGqD3zzNrliw6wsWtW+PaTU2J4a45BHYCtsIHVRcJWIbYzCv+nLYfPgW34wvG2sgigUjxgv1n1b0UF0Y4kPqxUYHv05TIuhi44Bim/8hkqINloIFLTYCpVI9+FKXrX7LSpBghApYg8ASpVAt9C/4Y4sP6ur5AkEUcdUMWuzcubImRFCpRmJUJQwBQqJkI+2CBNKQKNoaCXaqiI81Wqhba1zlUdSrMD07ohEE7ayWMqNZiEO4kK2gy3lt6oJm1WihpfYpprAotZJSgBhIMVhtZS2WcVAtb6QRM+37i+xaUJa61WTXsHxeKcQL9w/sbDULhJ1ZC1xUrUQRI+60EvzMgNtEtDpJoFQtSBqXhpHqeSpCZEi7rAbLqBh45eorzNtIqWuuXbvJK1c2HFwd2dsb2GwGVpvIcHWfdxKEFAhxV9Ha0dHR0dHR0dHRcRl4OQgF3W0LxQe7lhcAEa2lpd65bNwS8sGGsNakMAwDOdu2OUWboEKyWroYg2UzREE0LqnvBOX07IxSC5vVhmvXVsS44vnz50zn52gtTOdbyjQzjCMHB1eIe4EwRCREMkqtxlyotvo7oZRMWVogWv6DT3V4ZZ//vQ3ZEqymUoLRDLXUnW4e9YFHl3q65t8Hf/xqtTBGWJQLlrhfLHFeWYZDtbnbA/N8S5+VkBSK+M8ovrW1OkJKoZRs9x2rKQzNllGzycP961rlYwyy/FxVlhyBec6EFBdCI5grwB67qoSUyKXQrOe7jIGw2BdKG0pbMKBCrpVQbcgNnsLfLAXWthHwrDx7Ojxw0CZtXeoF27BbSl7OYliGUojJFDIxhsXK0IZYiz60/7ZhVtxqYJWLlZIzMQ1EEaZpMsl8Gnzrbs9fIHp+htsyFLPNRPsJi9kfKOjSEKJioZiCDZ4ttFBEqEHRqB54qIRq56x4XkCKIzOViNlDggeQNiPHPM9+rSPzXHwxb9WhKSWSV3o24qF9jREGZnkI/lhfDCttxJXi2Rpu5xDPVVBwBZIrMcRqVyGQUiLnFp7pahF/jwhBmEu2oNIguGzAG1cECcmyR0IgxUQMZoXI0s6skyIE8jwRU3BlgV17CImQjIgYV2ZpyDkvmR0iVmlZ5uJ2Dw/U9KyUdUoEiaxXa1555TrPP8q8eL7lxUdPmbeBj46U/f01V68ecP3mNV555YCYLCQ0pG556Ojo6Ojo6OjouFy8HIQC9st59MGibYy12KBds4UUNply8A1nDO3yTWlQcnFywrezUqjFPezYJrnWumyls+n0ERHmXFGXVg/DAVcOE+fplGk+p8wTeZ6Zz845Kcq0ndi7co04rjzfwYZarerXZPLvEK0WTosum0/E/OG5+Ia3YnYAH5aL+hDt1omslZAi2YMA1a+3fb9aqw8vgLTtsTKOoysUzG9u0neWwboFOsYhWSVkVSTstsT2mPkAXNxmQiCo2nAkBW21jT71DxqoNVKcAGgKgOJWDIKgopb5IPY8lmqBefM8E5M9nxJajSSoqNcHepODb/pBfDjfqUEkBCiV7BaAFtIXU7RmkFJM5SJ8jASi2oDqvASKtYjkWtxt0jz8AMFVIp5DoRe2+B48KZ6fgWcX+ANv16cwjmsPhLSfbwGUxVUYnoUhZl0JwUiFECN5mgCvxhTLQ7AtuzIMiZiSye+bvQOQmPz+Vmv2CEKlmGqmQlg25HZtOdvzkXyzP2d7LMcheXPHRYuRBxo6O2O2i53aoJEyzTJRm7pELGuiBYC2Wsfs+QK5zN7o4CGZw7DMzXamraJR3E6QtX2flk0R3SHkIZKNcwpCrroQUe1rJAYqMOfZlUKZKrtMiFrb63YgBphzIQY7MyFGSq6u6tElQ6XWQoimntFS7WNa/Ry1apRKK0M5P5/44IMnPHnyhOPjiTREYEKCtVusVmsePLzLl/b3qQ/Fv89M9zx0dHR0dHR0dHRcJl4KQsFqBCvqm71a8DT3QErDslWPvvEMQ1ryEyRE1utEQMg522ZWhChqYYMCpVpoYUqRPFu4HyLkXHfDD5DbwFQVZGBv7wob3WOezsjTxLTdUmvl7PSEs2ni8No19g4OGYeROZsdIwYouTIk23zWUpZgunnJOxiXwMBaMyGkpVKPWrxmzpsStBAlkLXV8Qm1zqSUlm1/IxSye8NblkTb6quTBepTum1/EzG4V35QUoicn55ZJoVN1aiKEy+ZNI7UXBFJyOzNAeY3IA6RKpWpZEKx/IWi1fIvMPVDCxa0Qdfubc4TMUZiDOTtxK5GUa3twdfiWiqrcUUpmSFGtHgAo1oGgzTrCibnr5oJGpCqFxQeli8gwbbNIQq7ls+27RcC0bItgjCEgTlvPbjPiSplOTOtiaBlYlBt8x92fpIlkBDcxiBCCpFtnkxNotbQUL3CsA3cQxopNaMUKGYD8tO//Mxh5W0Uas0aVq2YPFzQNv2tIaKpBYIoaKEgCxlD9MDLPJu6JBQEddLLLEHFv2c7yy2ToJTCPFtdaLvnO1WFuErGwhyDKmEYyaWYxUJNLaCuGFAt1GqkU9FCCoOrcnYhlimNRiLkSgqBIcVFoZT9ey42i/Z4WJCJVT16m0cjWYxA86BULVa/GYORmzEiMRJThGxqHXfbOOFmKouCtUy0Gkr73sUDTU15Im4riTESseyErJWaTblw9OKYR48fc3K65d79+xwcbjg9eY6kwDwp77/3jPPtI67ev8/xa2fcUpaGio6Ojo6Ojo6Ojo7LwktBKFRVk39H28rmkhnTGomR2YPdINpm2IfmFCLKTk5fwb+++acLQiCmwSX9JqNXNUlyGkaiNzc0P7gNXa6EMC0/WgMpbQgysNnsc74942x7TtXC0fOnlLJlvdljtd4nSLShwVP94xDJxeTeYxoooYCKkwpwMR8geA1gBatJ9JA/0aZCsIq5hjasmdw7L7dBs4qEZUu8bGJdNq/VfN8STLotw0CMA3mafd9pW9laq6XVKzBb8CEu2Y8aIASyVstMECXEwdb4Hg0hakqDFKIPeAUExmRZFnO2sMWYAlEiFN2F/g2jKSdKhSqWLdF87EVdOi/L8wc7pUTCsxOcXKrqU2AQPz8VFVOHmKqkKVdkaTGQKBCCtVDU2Xz3Ahk7j7UN1U0toma/CcGsJcEf8ABUD9tsVaA1WypAnWdEIkUrMXiGBNjA7359pZqCRbwlwrM4VC1LIbhiR6RlUFjIZgjBchW8IaRlAhhJUS1nQkyWX7Qgrg4QMUvIVLMTG8NO+o9lLFTBzkHdWRtMpOC2Hpq1xnCRgKjVKyibmgGo2WwcISULYAyYVUB0+Xo7x5Fpmoy0uZCJkFK6QDgkzxNxy5PiShAjLK1HxpQxO0WBX5eHNqSYmGo2As8bFaqqv98oMRpp03ImIFAVxmFAULbnZ6QUsXIM+5hZZwpRTDGjVQkBkgTyrE6omFVn3Ky4e/c21155g23e8t6jZ7x4ccbZ+Smnp6fUarksJlLqnoeOjo6Ojo6Ojo7Lw0tBKIgIwVsFbALABhYgxOQDg8mGwYc5IITBPctlGdCblF+rV7pN2WTJmpmmTBua0DbW7IL/EFwxEJcNpkh0yXMiU5CUGLCNay4TpydHnBy94PDKNa5eeYVVGtluZ7daiFUNuhQe31jafOjBdChznUlxWDb3S4vDBVvDfGGb2hQIMcry8fY4GnR5rIxsqAwyYByFb9VVd8O4VkqprFZripbl64NEX9y7b9w94bg8Pbhvv9ZKJBDV7itOVJRq5Io1T9RdpkELp5NACMmHtIGKZyC4NN8148SUqOIVoVVNxh9MLVC1eg2kZxVUjETKxdUbdu1Vi2cF2GMcAt5Q0VQKYon9eV7yBloQISERo5BL9p+ppDQQQyDnprwImANgl5swTyahl5Q840GWvIoQol+f0gZSe8ZksU/sEDyDwQbOObfcgUDB7hfFWweybdGj1zSmEJeNfhwCubQBWSAKGjHiCrHmyWwVkRISMUXynP2s2XMo0S07OTP4a7PZGS6Otkt9pdtBWgBiiMkUG9UGe/tkpeRMSEauVTXFQi4T5gaKC2nSXhfaQjMx/upiUGkjP1JKqDeMJA9GlBioKqYGCkb6lGpBi0Z/mUoBr2RUoKiSSyGFlvMQ0EZMFGUuFcEzH/z27TSbyqp5GiQgZKCFdopbdyohDGz2Nqz3Njx5dsbj997j6tU9Pvf6LZ4fbzk+f8pcThhWsN4byIO9Ny4Kk46Ojo6Ojo6Ojo5LwktBKACLr1pLRWKyLa8HCeZqm+1aCsE3+rWArdvFSQEjA1pIHJh0XwW3NsgSZGg/Lthg6ENI0Up1a0T1LbtWV0RUG1uqZJCd7Hs1rpjmiVwrz5895fz0jKuH1xiGzeJjL9nT3pt6wD325stXSp5t0C65mfSRkJjmc/OwzxOr1dr96YFS1FUYypAGG3Jra5OwwQl8sKxNgm2+/1p0aURQ3MdebcgRMUuIzhXxTbaIDU5xGAEb8kqZ/XnxAUwrY0pIxVQEwRoVqgVVoEEo6BKEWKql4asIEmUXzIgNisHDMkWd+AmCGxy8OtKJDa/jrNmeZ7PNWG1h8DqEVm94kaQJIdKqAWNI/hi0IRtUWsOF2vOhBRE1K4STK7j1oRQjT7S0sNCw27oXGyyzTbvWWCEBcXKlqtif1ZshMGsn9B2aAAAXUElEQVSB1tYUsrgwAJimyW0u0QJHfWOOWD5EELGQQs8ayVVJXnGo7bVQjCzI2Qktf+nZFr81S1guhTVGsMtCcDVA+29s7R3BLRE5m0pgSG6zqcvrpLqqot2e1ZtCPAvFLEeVXHKbvT1AdfDnzwMXayGlSFBhnifGIbl1Ke9sP67W0VotqNKvueoFJUIjIqp1rUQswBO3VlX8HHjuQoiWKxI8h8M7PRZyTEIged5EDKaKKlMleJ0qoq4QspDJGO18DLE9VoGrVw95/bWHaE48f3FEzmeghVontudHbPaFVz/3kLv3r/ONMRrpVqVHKHR0dHR0dHR0dFwqXgpCocmGh2FFrZOnl/vAE/BfyE0WH9SH5TlbqBw2ZGXaBl+W79hmwlyqDUiipBjItZA1W20k1bIKpnmxBQgWuBdcZl5qxkIE2wgmlntQ1X6+Dwx5e86xPmO9yYyrDbXaJjF6NoAgzMUCCVs4oYhJ+Am7pbRqYS4TUrCmCAJxGFw44BaNiikhqik3YrQtbqG6yMPqCFubRJQACUoVb27YBUWazUCJtKpEgdKq/zzsTosH2wUb7OKAupVExQMR8faKgg/RkejhdhJsCIzt+REbzpdBvwX4hcR2ngjRlA2WDVA8fV88ZM8G75ILyaUG1qxRSFbrYY+3AFqXx8haHmygn3KheKBkwBojYgqIJstucBJLNVBrYcoTtVbWqxWhWFijuhWh5TSoqCk5quU+6Gzfv1YlhsFIoOgtHqrLdQ3JsxAkkHUywgAPfizt3Eb7WrFWiBgTSSxXpAr2uLrywIgUG67VaYPasjZEGEYLWJynLavViEgy9QMC0Yg7BbPDOKORguVLoCBqqo8UE6VkJCgpBSRZ88cSQOokTIhWQznEsIQqUm3YX9QGfn+Di5RCSERJCykWPSNB/PNqLeQirFYrI+n8Bd/+bBaGRgBYa8mcC0Wzt28khmSEh1WMqFshWpaFKQCqKqW28EuzUkQKpdiZkbAjgoy4c0tQGKwBpRYQs8PEFBF1fYOaOkkkQYA0BO7eukGcI8+PjrhysGE+2xIZuXvrHrduFO4/vMPVK3uMKZLcrtXR0dHR0dHR0dFxmXgpCIUggtRKyRMSbHOZc/YNbvHtpmnCSy3mtU/2S3yINvQMKsxVqTXbkKO2JZdocvWKWu1bHAEfekJkmqoNam2QVkVrRnOlYNvrNoAnUWpVqzz04ZTFe28Kg5OTE87Ot2w2+6RhJA3jko8gwR3cpQ3gHgrpG+ElD6JamF7JhSiReZrIVRnWwVQGnlJ/cYNtjxfgnvoQPBpQq9fp2c9ctsa+QZYYzctvK2pXdGSjZEK066Iu22URIQ2DESjVKiVTTDQvvmp1xbhZGcqFUMBW9bmTp4dl+AzNJrHU/jUZe0CL3f9d1oGRAFE8e0LVzlBMxOA1owgpWoPFknWgivhjNwzD8ripCGm0ykDLjrCKQbvP9hhPkxEztVSCWAjl7lqsnQMR98o3csgIGUvk9+cToWihagvTVKp6BkaFiJpMP1xUbBi51bbvYEP/+ZydSDJyCwWpSvUWCtVquQpitpEQItO0ta18aKoG/abnxMgMAbQUb8qwzb1ZQ3Z5I2WeXU1hrIxqtdeB5x0sVhzs8SiehxIRJNp5SjFSlcWWIhWSRFO0+CDfSCCzUAhoAGZKKZyenhJj9O9z4QXhP1jcfqKeU2IeDyxLoljeSMQDTf1raq1kzai6akJ2qpcQ40I8DsPgah5FIgvBgqo1RQQjMkIQFxPsmihaLaaqhcueHB3x7jvvcPxsy1wKH7x/zovnx4QhmVVLlKdPX7C6dsXsXLVZNDo6Ojo6Ojo6OjouDy8FoSBY+rxUqycsLnIPYltoUwm4D1yibxihUlHNTPOMdQe4SkFs+1dLtdaEGIit8aHMNhAFIwO04rV8AXGPvbh8XNyg3baqNXqIXxxcvdBS3G2QsLC2Qghwvj0hlYmxrlHF5PWCe7htAY6IZwzYsKNVmXKm+lBTciEk28ymsBtkmidd3VbRfr5tZxVRG1RNMm2tEfM8ISXYEORb9VrVbeQuOZ+zDWVeG5m9lcKGomXxT2tqkBCgipEGF2wFIgHxekX7sywDoSXyC6v1ZqmMlCCoBBsy2d1Hq1KMpiBpifmujMg5W0Wn2KZbVD6uunAlRPZAwBjj7ut8098GO0Upmi1XwwmVljfhink/VxYsmZKNcnZu7UmJMTKXbMSRP0ZhMLWC2Xnwpg1FUIKoZS6oSfm1Vmrz4QfMIrFs49WH2uBn060sTiBptajIIMFv80DNIRG0Umsm53nJnUgp2SgadMnUaDaN3fNrd3xJ5fDQQJdtXPDvqxF4EtwepAzDaK/JYCSB5koUU3qMw+BE2Y5kMwIsmgplJ2CxqtTWfqG751bxbb+fqxDjov5Xt1KUuYA3iJjaSd1y4wSXq0CaNSm4msm+p5raws8ualYeVSd1guVhBFckWH6CBXjae4q1vIjYe9Q0Wb1jGqxiNqbIIIHt+Wyve4XTszPefecRzz48Ycqe0CCCBrfSBOHg/TXxYJ/yXY2cCOB2r46Ojo6Ojo6Ojo7LwEtBKNRS2J6fe0+8p/W3jbIEH0YsODCIyX2bFL/5osXXoK0UQlXNLeFyZhtSlOB+fKtwhJj8IfAhTHzIWALfym47bEFvw+JVbwNHTIl5toG1lAwSvRVAyXmy7atvgYNG4pD85xWCpEUVIMjSVJHnvKTj16p+2+xDhA2ZLd3eNtc+HEq7z2UZrtoGOgDb7ZYYk92n4o+pe80lBMqcrf7RswBi83lrIRclzxmRNjS751yVKM1vbwNvq/KLEpEQPNyvycKFnIuFM2IBgi0k8pvT+qsH2Blh4dkEPtj6eOuPR138/iGY1B1YlAYWhlgXMsZuK8QYPNNCyDW7OqBtkqt9H8Gk6Wr5BiUXD3sUb4QISDVZfhpssrXGB7FlOuIkQbTcCImmfDAKxK0k5rGHXaBhU6xcrAcMTv6g1kbQWk0sj6D417bqQms7Uf9HtC7XLQiIZRloNbtDqbvWhJZbgOyyE0wpEVGtzHMlDZEU7WyY7cPPQylY4KYwSqKqkufZv689Z9ZEghMiusvByJaTosHO42q19mG+tbCwXFv0QM9i47WHZaZl6M/VAiqbZQIsVNKqNd1OJK2lA7dKYA0lYoqM4O8lUQRStA/WilQjEuo8EUMin29JQ7JWEK0Iya/ZsklwO4fd5tWbWLUlauGtN25eR8uaD5485/z0lHnOSLIK0dV6JIaRMa05qXau8eeno6Ojo6Ojo6Oj47LwUhAKEgKbzR5VK0OwbWJdgu/8l32xhP9CJaXo2++W/K6e9m+/zMcYqcWHsTYwwI54MO+EbYNVgWp1hG0YrRUtlUpL8Bf/+hbw2K68LgN2bNv1VtUI4GoLJJGn2RUMTla4fzsmszTUXGlBkXPJqA8KVpNnw4nV6yUf1oJbCMQtIjbAVy1GXpTi+XxuH/H7odYYSC0m1a9YBaNUJSRBQyAFqwqsPly3+x4kWuZDxQZNbAgz6bYP7HU35s9zQUNgGGwLu1M8RDRPxCG5ZL8RRmUZ/C8+ZwHfBrMjkMAG4eIe9eV5a1t0EVKKlIL74Juvn8XuYMOY3Q8b0q2SVFGvfxRymQAlhcHJF8+qKMWaBzynQiukIbYfjXhtZy7FrCDZVBSlFoaUiH5/WmiH2QFajaGFkcYYmKb5ghWBC/fRzrGpLzznINmAnc8nwuAqFSctWO5ppWRliMlyHjClSoqDtXFosynIohRppIKKSfubMgDP7ChOzETPPVnqKFsgpL+uUkqmxFAPJEyewIibLHzID2nYWTGc7Grqk+VxKJVaLEQ1pLiEQGoLTsEsG7l60wQVKAxDWgIaQwr2uluIPCMcicJZqbszrbrkNyBKUFPAmE5F7fUfxAMgWRpOLj5H7bmD9r2C23zsBXnl4JDbt+9wdvaE58cTx6dblOJkZuUwrbl16xaHVw45GiOVjITWyNLR0dHR0dHR0dFxOXg5CAUJ7O8dQrS2BQ3C7O0HLYQwTzPb8y1UGGKklF2OQanZB9KWSG/bc8FS1oVgg4kPpk2W3pLq24CBmtTYAtts2CilLo0PMSWX8puqonhIW602qKUYCeI5Ap51YASAGCFSIGu1DAgErUrWmdWwRsLOFiBig5oEsU68YD8Pn4NzzuRcCcGqNtvAmUsmevBdFN9mayFEG3bKPJuFQwuiLpVWIWigUpjzTK7FFA5i6QDzVCwjwRMyRaKrM5QheTuFj6pcyEawnIqdVN1q/2zgm+aZNA7L879ro5Bli9389m2D3Bo+GunQWB3LXOBjQ9s0zW5rYPkezeawy59og556TkdkLrpsppudZL3e+AY/UMgeOmhp/ooPsW6dKGV2n74N96WWXY6En9Vm+8D987v7W1mtVkbY+AAuzWoRduGVTbERgjD71n+XQ2FfN4zJZPl4oOXgKgJYlDpGiLiVxF9jUaJdf7A6TokB1WzXXCZiGNjOM0McXEFU0Gp5EFIVrQHRiFrFByJKKZM3GwRXx3huh2/rUTzfwSs4Y8L1L/78WI6BqUlksV4Mw0gp1Zo2qpFfjUiI0qo3A2Ewu07BWjxmq4chFH/9i5JrJZa4ZGQM40jElEnJg0HNAuJWKYxs0Gohr8EtFLVkYhDm2Z4je28yUmIYBqp6QKP6mbMXDVorJ6cnvPn2O7z77kecT5WDw32G4QppSBwfn3F+fspHT59xcnzEPJ+jTBTd0gmFjo6Ojo6Ojo6Oy8RLQSi4G929y4lKhWDNBrXY1jAXJQ22VBYgSauHVHAJeRAbGhAbrsrcktS9893T9VWVFCIpROZcPMTPP1YUDeYRF4J5vHHlQVFUqm/VI7OHSIKRIlaRV0nBvdcEgiSESPAt7xCTEyY2bEqFGsoS9pjVPOHqAYX4thyBeZ6dvAgLUbHLLfAWBHyLXQskWZLmVdXsFWrqC5FILpnSmgBEbShSq7IUhIjZFWx4Di6vt/sbQqBUI2vaBL6E9ZVdwKRi9oaWgF9cRQIeAFkL4gN4s3C0f1tmwKKucHKilEIthZiSSfh9Q98+3uwPF7f+KaWlWrBeUCvknMnViBjxlobart9rBatJZaC2NgWXrgcWMgtpdgt7DHPOTjI0Kkus8cBDDkppBAHkPBNjWO6zVhZCKsSwI5nKLuCyWR3sfru6peV/+O3Fwz2D7sINtZEJEndhnRJ3w6/bgoaU0BY8KcHIPTF1gop6aGFgHBM6FbRUV5G4vSUEJFprQuCbLBwpWcCmwpQzWsXbOjzcUUztM01bxjEtwZAxBlcNtNdoU93YgB+lfa7dvp22riGw3IpGtrW3nODX157PIQyoVkrOVFf3NFKhWUKClOU8ipr9ob2nNLtUbIGervJBZAkdrf4+EENy1YpCrZydnvL06VOeH51weOU6D169x707t1CUd995zONHj3n67ClHRy88s6IgYu8PHR0dHR0dHR0dHZcF2cmnL/EiRI6AX7vs6+h4KXAT+PCyL6LjpUA/Cx0N/Sx0NPSz0AH9HHTs0M9CR0M/C99avKaqt367D7wkCgV+TVX/wGVfRMflQ0T+r34WOqCfhY4d+lnoaOhnoQP6OejYoZ+FjoZ+Fi4PvXOso6Ojo6Ojo6Ojo6Ojo6PjE6MTCh0dHR0dHR0dHR0dHR0dHZ8YLwuh8Jcu+wI6Xhr0s9DR0M9CR0M/Cx0N/Sx0QD8HHTv0s9DR0M/CJeGlCGXs6Ojo6Ojo6Ojo6Ojo6Oj4dOFlUSh0dHR0dHR0dHR0dHR0dHR8inDphIKI/ICI/JqIfFVE/uxlX0/Htw4i8qqI/C0R+bsi8isi8qf99usi8jMi8hv+31f8dhGR/8zPxi+JyPdc7j3o+PsNEYki8osi8j/4398QkZ/z5/y/EZHRb1/537/qH3/9Mq+74+8vROSaiPyUiPw/IvKrIvIP9feFzyZE5F/3/z98RUT+mois+/vCZwMi8ldE5H0R+cqF2z7x+4CI/LB//m+IyA9fxn3p+P+H3+Es/If+/4hfEpH/TkSuXfjYj/pZ+DUR+aMXbu8zxqcYv905uPCxPyMiKiI3/e/9PeEScamEgohE4D8H/jHgy8A/LSJfvsxr6viWIgN/RlW/DHwv8Kf8+f6zwN9U1S8Af9P/DnYuvuD//ovAX/zdv+SObzH+NPCrF/7+HwB/QVW/E3gG/Ijf/iPAM7/9L/jndXz74D8F/hdV/W7gH8DORH9f+IxBRB4A/yrwB1T19wIR+CH6+8JnBT8O/MA33faJ3gdE5Drw54F/EPiDwJ9vJETHpwo/zm89Cz8D/F5V/X3ArwM/CuC/R/4Q8Hv8a/4LX1b0GePTjx/nt54DRORV4PuBNy/c3N8TLhGXrVD4g8BXVfU3VXUCfhL4wUu+po5vEVT1kar+gv/5CBsaHmDP+V/1T/urwD/pf/5B4L9Sw88C10Tk3u/yZXd8iyAiD4F/AvjL/ncB/jDwU/4p33wW2hn5KeCP+Od3fMohIleB7wN+DEBVJ1X9iP6+8FlFAjYikoA94BH9feEzAVX9P4Cn33TzJ30f+KPAz6jqU1V9hg2hv2Ug6Xi58dudBVX931Q1+19/Fnjof/5B4CdVdauqXwO+is0Xfcb4lON3eE8AI5D/DeBiEGB/T7hEXDah8AB468Lf3/bbOr7N4dLU3w/8HHBHVR/5hx4Dd/zP/Xx8e+M/wf6HUP3vN4CPLvzCcPH5Xs6Cf/y5f37Hpx9vAB8A/6XbX/6yiOzT3xc+c1DVd4D/CNs6PcJe53+b/r7wWcYnfR/o7w+fDfwLwP/sf+5n4TMEEflB4B1V/Tvf9KF+Di4Rl00odHwGISIHwH8L/Guq+uLix9RqR3r1yLc5ROSPAe+r6t++7GvpuHQk4HuAv6iqvx84YSdrBvr7wmcFLkP9QYxkug/s0zdJHY7+PtABICL/Fmah/YnLvpaO312IyB7w54B/+7KvpePjuGxC4R3g1Qt/f+i3dXybQkQGjEz4CVX9G37ze02y7P9932/v5+PbF38I+OMi8nVMhviHMR/9NZc6w8ef7+Us+MevAk9+Ny+441uGt4G3VfXn/O8/hREM/X3hs4d/FPiaqn6gqjPwN7D3iv6+8NnFJ30f6O8P38YQkX8O+GPAn9Rd730/C58dfB4jnP+O//74EPgFEblLPweXissmFH4e+IInOI9YqMpPX/I1dXyL4N7WHwN+VVX/4wsf+mmgpa7+MPDfX7j9n/Xk1u8Fnl+QPnZ8iqGqP6qqD1X1dex1/7+r6p8E/hbwJ/zTvvkstDPyJ/zz+6bq2wCq+hh4S0S+6Df9EeDv0t8XPot4E/heEdnz/1+0s9DfFz67+KTvA/8r8P0i8oorXr7fb+v4lENEfgCzSf5xVT298KGfBn5IrPXlDSyU7/+kzxjfdlDVX1bV26r6uv/++DbwPf57RH9PuESk/+9P+dZBVbOI/MvYExuBv6Kqv3KZ19TxLcUfAv4Z4JdF5P/22/4c8O8Df11EfgT4BvBP+cf+J+AfxwJ2ToF//nf3cjsuAf8m8JMi8u8Bv4gH9fl//2sR+SoW0PNDl3R9Hd8a/CvAT/gvfb+JvdYD/X3hMwVV/TkR+SngFzBJ8y8Cfwn4H+nvC9/2EJG/BvwjwE0ReRtLZv9Evx+o6lMR+XexYRLg31HV3y7UreMlxu9wFn4UWAE/49mrP6uq/5Kq/oqI/HWMfMzAn1LV4t+nzxifYvx250BVf+x3+PT+nnCJkE7md3R0dHR0dHR0dHR0dHR0fFJctuWho6Ojo6Ojo6Ojo6Ojo6PjU4hOKHR0dHR0dHR0dHR0dHR0dHxidEKho6Ojo6Ojo6Ojo6Ojo6PjE6MTCh0dHR0dHR0dHR0dHR0dHZ8YnVDo6Ojo6Ojo6Ojo6Ojo6Oj4xOiEQkdHR0dHR0dHR0dHR0dHxydGJxQ6Ojo6Ojo6Ojo6Ojo6Ojo+MTqh0NHR0dHR0dHR0dHR0dHR8Ynx/wKIAZ6enIbVbwAAAABJRU5ErkJggg=="
+ },
+ "metadata": {
+ "needs_background": "light"
+ }
+ }
+ ],
+ "metadata": {
+ "id": "96hqfaovAGhl",
+ "outputId": "1d5b91b6-8885-4bc2-ca9a-4925d780b4e9",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 498
+ }
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Perform Testing with a Pretrained KIE Model\n",
+ "\n",
+ "We perform testing on the WildReceipt dataset for KIE model by first downloading the .tar file from [Datasets Preparation](https://mmocr.readthedocs.io/en/latest/datasets.html) in MMOCR documentation and then extract the dataset. We have chosen the Visual + Textual moduality test dataset, which we evaluate with Macro F1 metrics."
+ ],
+ "metadata": {
+ "id": "PTWMzvd3E_h8"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "source": [
+ "# Can skip this step if you have downloaded wildreceipt in the last section\n",
+ "# Download the KIE dataset .tar file and extract it to ./data\n",
+ "!mkdir data\n",
+ "!wget https://download.openmmlab.com/mmocr/data/wildreceipt.tar\n",
+ "!tar -xf wildreceipt.tar \n",
+ "!mv wildreceipt ./data"
+ ],
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "--2021-05-17 11:39:10-- https://download.openmmlab.com/mmocr/data/wildreceipt.tar\n",
+ "Resolving download.openmmlab.com (download.openmmlab.com)... 47.75.20.25\n",
+ "Connecting to download.openmmlab.com (download.openmmlab.com)|47.75.20.25|:443... connected.\n",
+ "HTTP request sent, awaiting response... 200 OK\n",
+ "Length: 185323520 (177M) [application/x-tar]\n",
+ "Saving to: ‘wildreceipt.tar.3’\n",
+ "\n",
+ "wildreceipt.tar.3 100%[===================>] 176.74M 17.7MB/s in 10s \n",
+ "\n",
+ "2021-05-17 11:39:21 (17.1 MB/s) - ‘wildreceipt.tar.3’ saved [185323520/185323520]\n",
+ "\n"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "3VEW3PQrFZ0g",
+ "outputId": "885a4d2e-ca78-42ab-f4a2-dddd9a2d8321"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 29,
+ "source": [
+ "# Test the dataset with macro f1 metrics \n",
+ "!python tools/test.py configs/kie/sdmgr/sdmgr_unet16_60e_wildreceipt.py https://download.openmmlab.com/mmocr/kie/sdmgr/sdmgr_unet16_60e_wildreceipt_20210405-16a47642.pth --eval macro_f1"
+ ],
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "Use load_from_http loader\n",
+ "Downloading: \"https://download.openmmlab.com/mmocr/kie/sdmgr/sdmgr_unet16_60e_wildreceipt_20210405-16a47642.pth\" to /root/.cache/torch/hub/checkpoints/sdmgr_unet16_60e_wildreceipt_20210405-16a47642.pth\n",
+ "100% 18.4M/18.4M [00:01<00:00, 10.2MB/s]\n",
+ "[>>] 472/472, 21.1 task/s, elapsed: 22s, ETA: 0s{'macro_f1': 0.87641114}\n"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "p0MHNwybo0iI",
+ "outputId": "2ac962be-9db7-4557-8853-7201c9e0696f"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## Perform Training on a Toy Dataset with MMOCR Recognizer\n",
+ "We now demonstrate how to perform training with an MMOCR recognizer. Since training a full academic dataset is time consuming (usually takes about several hours), we will train on the toy dataset for the SAR text recognition model and visualize the predictions. Text detection and other downstream tasks such as KIE follow similar procedures.\n",
+ "\n",
+ "Training a dataset usually consists of the following steps:\n",
+ "1. Convert the dataset into a format supported by MMOCR (e.g. COCO for text detection). The annotation file can be in either .txt or .lmdb format, depending on the size of the dataset. This step is usually applicable to customized datasets, since the datasets and annotation files we provide are already in supported formats. \n",
+ "2. Modify the config for training. \n",
+ "3. Train the model. \n",
+ "\n",
+ "The toy dataset consisits of ten images as well as annotation files in both txt and lmdb format, which can be found in [ocr_toy_dataset](https://github.com/open-mmlab/mmocr/tree/main/tests/data/toy_dataset). "
+ ],
+ "metadata": {
+ "id": "nYon41X7RTOT"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "### Visualize the Toy Dataset\n",
+ "\n",
+ "We first get a sense of what the toy dataset looks like by visualizing one of the images and labels. "
+ ],
+ "metadata": {
+ "id": "FElJSp1vpEUz"
+ }
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 30,
+ "source": [
+ "import mmcv\n",
+ "import matplotlib.pyplot as plt \n",
+ "\n",
+ "img = mmcv.imread('./tests/data/ocr_toy_dataset/imgs/1036169.jpg')\n",
+ "plt.imshow(mmcv.bgr2rgb(img))\n",
+ "plt.show()"
+ ],
+ "outputs": [
+ {
+ "output_type": "display_data",
+ "data": {
+ "text/plain": [
+ "
"
+ ],
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAQ4AAACBCAYAAAAxIFQcAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjIsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+WH4yJAAAgAElEQVR4nOy9d7glR3Xu/VtV1b3DyWeiNKNRHJQRMoNIApHEBQO2ccAYXwMmCIxJxjZgQGCMAxkDxoh4uSRzjYgiiGSBEEEggVBCQtJoZjQ5nrBjd1Wt+0f1PueMJIIQ8sz9vv0+z8w+u3eH6uquVSu8a5WoKkMMMcQQdwXmUDdgiCGG+H8PQ8ExxBBD3GUMBccQQwxxlzEUHEMMMcRdxlBwDDHEEHcZQ8ExxBBD3GXcI4JDRB4jIjeKyM0i8vJ74hpDDDHEoYP8pnkcImKBnwHnAluBHwJ/oqrX/0YvNMQQQxwy3BMax1nAzaq6UVUL4BPA794D1xliiCEOEe4JwbEGuG3J963VtiGGGOL/I3CH6sIich5wHsDIyMh9TzrppEPVlCGG+P8tNm3axN69e+WuHndPCI5twFFLvq+tth0EVX0v8F6ADRs26BVXXHEPNGWIIYb4RdiwYcOvddw9Yar8EFgvIseKSA48Gfj8PXCdIYYY4hDhN65xqKoXkecDXwEs8EFVve43fZ0hhhji0OEe8XGo6peAL90T5x5iiCEOPYbM0SGGGOIuYyg4hhhiiLuMoeAYYogh7jKGgmOIIYa4yxgKjiGGGOIu45AxR2+P26faye03yuJXYenfWv0tBx2jCydZus/CpoVj0GrbAnfudi3R219laZvk9jtW+y691p00aOkxB11cq//l4Gvp4r4L96pLj7+TZiw28nan1ztp+52dQO78fHeZY7j0FIt3dvvncccNd36GX6sBQ/zGcRgJDq0EQhIAqkuFRxq2Cgv7pHGoaUcElWpI6YK0qA4dDJSY9kOAmD51QdwMTlMdFAenqGDStX0Jvg8uR12+5KDFu1gq4BIG5xLQxUGsqlX7B/sNLq4oBqnu8aBhorFqy+BelwqamIRBVKTXA+sgz9ElQmOhPyWdB10iUmWwz8H9udDN1T6icrsm3zG7Wpa0evCriiKq1fXMgghZIsLTdXXxjg4W1dX9Lengnyv7hrjHcViYKgpEImlAL2oHqEIcCI3qt0qCKEpURQlEAgvlATSCKqpKUK2Gbfo+ED6D60QqwaNL2zLYKwCxakNqS2vjzVz5trfS2bYNQlwYNKnNi/tXTai2K2jVPtXUvsGuRGJqxaKA1JC265Ke0KoviINWL25b2CVAKNFWi6v/7Z3s+u73oPCgSoyp33Sh83Sh/9JXz6B56Rqh6sMl16kEyVI5oUvaWJ1x4bjFNi72pmoA9dV9a7VtcF+68FzTuePC8Wl7SFeJd6JUDfHfjsNCcAhgNYIGDDHNpJVQwFQvUkwTpVRCQaCaly2GdCMDQYJ4NHqsKiaSZlI1SPoJCRajBpvOvDAAVSEgBCyoI1azqwLS69O/+lra73ovl7z676HXQ0IgDYnA4I2WGDEhYmISOBoNYEEENRAloCYJScFg1KAxDSWCINFh1GBkcUCpgEqlLQ00lsE2Hdy3Q7olV/zDa+m841+58nV/z4HNm4CAiEekIBLSviqEGBcGu4gkgSQQ1ZBm/jCQFQSBOBDIQSEoUJJuUCCk5yIoKgGkEswaQEvQiAbSU6ruwwBOFRGtboZKnHiiVuce9P7gtqNWz3JxChji0OCwMVVkwYwYbFDAQ88T9s0w9/3vYkIkGkt+3PGMnHAC1HJwWXoZRZCoxL27OPDdy3BBIBgMgspAGBmKep1lD38o0qyjmUPFVBbEojACKhXfEgHxngOXfpObXvLXTHZ7/NbTnwZOUhuLEin7UPaY+fb3MZ0eUSBOLWP6rLOQeg1yQTEgSUWX4KEIUHRpXXsdYfsO1Aojp59BfuRRUK+hdqCZ6+IsL7ZqZzK7gghGFKOKBuhe9zMmL/supj3Pukc8jMkjVgOKhBL6fYot2+hc/zNcSELCO8f02Q+E8TGMMWBzFoyGGJF+Dy0j5fbb6NxwDdZHvMkZPf008iOXI40R1NrqWQnEkMy50kOrzcx3vo0LJUFy3LrjyE46Eeo1TAaLqoQipUfLEim6zF7+XWyrg8cwefY5mMkpYi0n1YcCkaWm30Jzh/hvxmEjOBRbDeBqeoke+l1u+eTnkK9fQvj8p3CqtFwOp52OPOD+nPI3f41MTCWfAwIhcvW/X0DxvguY7PapRQMSibGkIQ5TKnvGxtnxmldw+jOegWYZZSU0rCahYWM1DxtDRDEakaLHnne+kzWzMxTnPor82KPRPIMYKfcc4CfveieT7VnihZ+hNjdPLzP0V6xk92Mfx9qnP5XRU9YjtgbGIkGRdp+rLng3tZ2bMd/8NiM330JhhP2PeATFOQ/n5Gc/B6nVwBpUKo2jmqUHfohIQHFEwMaI6UdmL/4Ktet/SuvE41j5sHOQRh2igU7kun+/gOyySym+czlNnwRjLzfM/+EfkD/2t1nzqHOhJmAqv0dRsPFLX2b+B1eRX38tfPdSahrpWkft7IcQHvIQTnz2c4mjDjUGA0gZ2Xf1T7j1U59mYs8+ys9cSMMH+sYiJ59CcfZDOeWvX4qdngZXmTkh4vfv5Zp3voOx+RbFRV9gZO9++i5n9+//Hs3HPY61j3kc1DLEKmiZ3hU1yNDJcchw2AiOgdMrSLJOpN1nx8c/RuuNb2J89wHcyATdZdMEEdytm5HrruHGHVs54Q1vxE2vxmTpVtY95jF89xtfIfRKXBEQMWQCuv8AU3v2Mtrvs/H6W0BzRIWcZDQsuOokWeTJfALp9rn1ox8jXnkF3ZE62SPPIVu5CsWCjxQ33oB+8H3Q62Jtg/a6YymMMr11E+aD7+fWSy9l/cc+Rv3YYyFTwv45Nr/5rdQ/9H5qZSudZ9kqakWX4r++jv/h5Ww5cIC1z38BsnwZMnBqHuSDFQSDJaTBEyKzV1/F1o9+hKl6gxPe8x7yU09LfRkiG//tXcjb/5VG5wAsW8Xe8WVYgakd23Af/t/s/to3GP1f/4uJBz0QVJIXZXYGf/GXkM9+Bt+o0zt6HbNqmJzZT/0bX6H7g8u5zTVY87znIiYk5aFfUn7vh9gPfJgyKv01x9Aylmanx9Q119G77qdct2sXp73nPaizGO8pd+/hxhf+JSOXXEKIhuKIo9B1E9T37sV9+kJ2f+sS8naLlX/w+2ijgUhOILmPlwaMhvhvhlY+g0P57773va/GEDXEqKWqhqja+9ktevnKZbp9pKY/XXuU7rrgAxq3bNe4eatufs1rdeP4mF61fEyvffu/aOy0NfqoWniN7XmNM3s17tmpcdcOjTt3abx1s+75qxfojpG6/uTItRpu26naDxpj1BhLjdFrjOn6IXr1vkjbQtRi46268Y/+UDeOjepPH/cYjft3aeyXGoug8cCMXnm/++mm8THdcs5DdOPfvULjlq0aN2/Rm5/yZN00NqpbRkb1W0/6E9XZOdVuV7d+8tP6gxWrdHe9rtefcYbeeN5ztbj6et33yQv11mc+Ta86YrlePT2lM1/4ksZeX9X7qp268E9D1OC9Ru81Fj2N+/fq9vNfpVctX6E3/P7vaziwU2MsNJaltq+/UW967BN0W6Op1515ms5d9DmNO3Zq3LZNd7z+9XrjipW6tTmit77ilRoPHFAteupn9uh1L3uJXrNsSn+09gjd/Y63adx2m8adO3XmU5/Ua04/RXc2GnrL7z1Juzdt1tjvqrbndMvHPqo/XL1cfzI9rZue+RyNt23TuHOf9n90jd7wsIfptmZdbz71ZD1w2WUaez2NrTm96rWv0Z8uX6Zbmg396SMfocVPrtZ421bd8fa3642rV+v2Zl2/d+QKLbfdVj2joGUM6jVo1CHuLu573/uq/hpj9rBwjqY5PkUcjCriPabfYbLfZzarM/2qV7LiT/8YXbkMVkwx8duPpXvyqbiojLTmwBeVhxVivUkYnSROLSNOTyETY5AZ5i78BPOZMP7MpyHjo8RMiJI8roMAY0SJIohxSZf3gWLTLfivfoVOc4SVT38mNEaI1kLp2fi5zzCyfQezzmGf+lSOednLYNUKZMU0R73uH4m/89sUEhjvdaDog++Td1s0Q5+ZFctY9ea3sv7Nb8OsP4HJJzyeo9/yVqaf/3zqoeSGD38Y7XRJ+tDBvaWASHJiSr/HTR/+EK0L3k1flGXPeDpSb6JqoIzMXH01+3/4A+aXr2D1G9/K2DkPh+lpmF7Gquf8Bc0XvZhShB0f+zhxvg3eE/ftY+/HPk6z71n5t69k+Z89A5lahkyOM/HoR7P69W+iOzbB7KWX0Ln+OqT00Omw5UPvZ6zXYvSJv8ua88+H5cth2STZSSew9k2vx9/n3rBlC3u+fDHSLaDwjLbb5IXSvc9ZrH3jG3HrT4BVy1n19D9l4qUvZS7LmCr6SL9AfKg0sIgMfaOHFIeF4KjGfHL8+T7SmuHyl/0NmcLqV72KFU9+MnGkjuYO8oyJU0/lhH9/N53GBHPv/Qid625MXANJdq+KgLFARrljFz97yUtozMwx9pSnsu75L0YaDQRJARuNC159g2A1kaukDDB7gCv/7mVEYO1b3sLU4x6L5g5jApR9elddQzY/z9Sjz2XlE54AzVHIHFrLyNaspPbQB9KeGiGfm6PYsw/tR8rbtiJ4uqesZ+qsDdCsobWMmOfQbLD8AQ/AIHSv+CHabadQbtVPOiBiSBW01Eixczfxy1+h2e6y9k+ewvQDHgTZSBIsCkxNM3PEKjqnn8TUWfdFR+rELHE8pNlk+v73wztDElDJ8UjpqUcIYlj+oAfB6Ahaq0PmoJ6z7H4b6NYcmXhM7EGMECKNMpIHy8Rp98GuWkXMHdEK1BzNE09EjzgCBExMAnv2yivof+SjWErsWb/F6L1Ohlo9cWSaE6z882ew/MV/RV4Evv+yv4N2H1QWWC5DM+XQ4bAQHAkppgEWCk9t3wEkGnRyGkZHGcRdVAScwy5bRuksjZk5TFGkU2giCBkRTAyU+/Zz1ev+ifrFX2WsG7E/u4md//lxdH4O8aG6ZsYgsGsGnvoYoGhz4OIvM3bbDsKZG8hPPwOtN0FcemXLPmOdDjVfoqOjyNg40Uma6cURXY0jf/cPkVPuTbjmanZ+4SJiWbLrumsJxrD8vhuS87PyeAqAy1BrUQ00QpmiIVXXRBlQyZKANSjS77P3C1+Cy6+ktfoIag99CEyME0wVvckcRz7ogdzrtX/Pyf/6DqQ+hopLYU+N6Pwcs1+9GKMlY488B0ZGAIt4gw3KXN0Raga1KfKkChgHtQbZo88lEjnwja+i3kMwuBK6boQiy1FHFW2JKZqU5dQf9UjazTr+6p/Q274VYol0ezStZfre9wZrF4WkMZDnMDqKi5Dt3wtlr4qO2fSeDHHIcPgIDoE40BbEppdDDWIsqmDigCswGGaanKgDngOKxiWxfzwWT31qkna9yezIGOF732H2H87n6re/DXrdKpxnF48fvLW+YNvXL2brP/4TtZ7HPvxRNI4+JmkialAMs9deS/vb3yIaoag3qgApFc1SQB3YUcp8jNGiIC8L7EidIx7/eILJaH3qszDXQoo+1ntsWUK3QLoFThNpLPFLZIFENYAS0dCns2UL2z75aYjC3pNPYdkjHkE0hgHxTA1oI+PoJzye/NjjUeuqCFKEVpst73wH7Q++jyJzrHvSHyETE2i03HTB+8h9YPqJv0e+cgUyuDdjULGQ1Vj1pCejQOczn0X7ntsu/hq6dQf29Hsz+eAHIBIrfo0kY8vmrHz871CMjsFll1FuvpXmCccx8qhHod0+8xd9Hu10kOCRGJCyoHvLTWz/9KcwDEg8A7rcgK02tFcOFQ4bwaED/0bFEIwxvRhavTRpZrZJqJjEvnTBItEkH4UBMUKMibSuJsdNL+PUV5/PiT+6nNHP/idbz34woTGCufTb9DZvqUhmkGZFT6xCGHGuhf/WZYzv2kl28kmsf86zoJmTmE6JBRr37MHu2MGBNes47iUvwVmIJFYkVCR10TTQKqGHs5gVqwjLVlO/bTubXvgCZr75TXT/fnobNzH3tW+w8S9fRMNbiElwDjjjVtO/ASkcX9D+wQ/gxp/RP+Vk7vf2t8FoEyuKlcQwxVRD3lqihWg8QsB0+2z+6Mc58O73EkrIn/4sxs56INEYoER/8mMaPtA47kRsY2zJ8DSVcAdUsSrYMiYe2C0/pbF/KxwxTWPN6iqkXplLGpCoIBlBM2xMP+fLltM74XjaeUa45L/Y8sZ/Ie7bh3S6tK+9ho1/+hSO/NGPcD4Aye8kAiq+os0Pcahw2IRjk6FQMXpEERMX4pCRwWCwlYkvIIJIxQUwlY0ughVTWeuCc5LITeMjTExNsuF97+en552H/8GV7Lr4y6w96cSByyCdD4UiUGzaxP6Pf5yQ11j15D/GTI6DNVVLEmchGEfLOqwxiMsZeGnSCSuKakU/N2IQY8BmrLzf/amdfz67XvFS6l/+Cpu++U2OfPKTaW2+jd53LmNlu02mi5yNAaE7sSUrslrRZ+vFF7Pztf+At7DuRc8nP2JNxWcJoHaBkyViKmFWDX8f8Fu3w8VfZqzbYe7odRz56P+R/DOVplaPnlpRkikQKuexgKosYYgaYsUEBcgUHEKnKECTQzdZjpJ6zIQB9TdNV2qg1mD8EY9g+0UXsXrjRjoXvId98/OYqQn2XfJNVt14E5MhsDd3lf+lYulWjuEhDh0OG42DiuRUTWcEkg9CBsSnmDSR9KIakECQMr1DIQBVvMErEgaqLAwS2qJrQH2ErrWMBk/NFyzkpYhAjGlWbLe5+g2vpx4ia17yEtb+2Z+izpKGSxIOEmHijPsw9siHY/fv5tYPfxgNiVmRDAmfLh0CtRAxFR1dxaDNOhP/45FsOulezC1byaSPdP/3h4jf+w5Zs0F3rEmQJQN94R7iQr6LzraY+8znGdu3jxXnPoKpB94PdXnVRXbBWAPQmCIQxnuMD4S9+/nJK16B//a3aE+Nc/xb3szKhzwE8qx6DkJntIkYYcfHPkp/505AFuj3AuA9Mt8iB/rOgCj9eoOuzSl//GN2XXJpeo5V6CNgkpbWblMrewRriGqJrs6qhzyE49/yZratWYMfm6D9Hx9n7t/eSXbTzygmJ5lpNgnW4o0Bm5L5pDJjh8Lj0OGwEBwLCVLERMASAZslzSMWiaJNhsQ04yU1NSACHiHanBgtlJEdV34P6c9hqsEGlfixAAajdWxwyR2qWmm81SxY9mhd9SPc1dfQO+pomg+4P4w2UFMJNDEEDBghn55AV01SL1roppsRDUhM5DWDgZjR2bSV0T27QQPBLLnOSI1H/Z+PceoV38effz67n/A78LrXsf4H32XFhz7ETJ7TzyxqpXJKDmZrwCv7LvoK+ee+gBtrUn/ABvKVy8ElU02QlCA2SCI1JmkAwdO7+WZueO7zGPv61ynXreGY972PsbMfitbqeEkUdnU5J77pzexu1HFbt0GvV7lbBI/gAQ0lt778r2kUbcy9T4XMcfSznkn71FPI9+3D7j4ApalcEUl4iIdbXvsvLN87g197NLJsZYr8WMv42Wdz3+9fzolXXsmBP3sGu3/niYx+8AOs/MZX6f7eE+lJndp9HgAuOW+HOPQ4LASHIAvmAgi4Gm1XR6Ky/aIv4nfvSY7PAcU4BHZ86lOMdzrM5znRWmzR57bPf5arX/RCdnz6M5gQKu2lusUoUAaavsBonxR+rJKsiFCW7L/iKm5+5atx+w+QP/KRjJ95H6KxyMAMSTHQym4XVHJcMNTLEil61c04VC2qyt5Lvk5x03W0Tl7P6AMfkJx+vS6bv/RVip37kPEm6897Fme9612s/9MnQ73OzV+4iGgMq574RGRiAoxbpFb7gN+9n10XfYFG8Oxbt4a1T3pSyjEZCFMNWNEkONWn9oZI2LmPm1/xavTb36FYtYojX//PjD3ofmjdoZD8FZUJSC3H1xx57GGKLsaXWFVcpXdJhLxX4G3OMc94Jia3SGbpZjVywPZ7UBZI9ECVKi+RvOiCRibPfSRjx69DQoF0O/z0E59IgndyjN/6x9fxgHf+GyvPeTj9To/bvv51ojOc8ezz0Ho9mSlD98Yhx2EhOBIkZW4aC3mdDa96JX1r0W99G3/t9YSd26E9j7Q7xF178Rd9kVqvx8o/eyrN44+Dss/Mdy/jhJtugYu+jL9pI3JgFun0oNVBD8yw7aMfpbjmx8xONumNj1VE85A0nl5B/7LvU7vueupHreH4854FtQamqsWRnH2KpWLPZTn9iRW0syb7vnkp2z91IeWWLdDqIO0ufsutNPduJyMwc+aZjP3WmWCErVdfw7VveAs3Pfd5lLfcTGh3wWSEVovylpvxF19MMMKqc88ljjQXtR0VCCXFTTfS/c5lzC5fzkn/9I8wOo6abKG+h1bFMxZEZlHgd+zmxy94IVNf+waj9TrHvPktTD7gQYgI0mtjel1Mr8CUZVL+G3VmJ8fxErny/Ffit29BOvOYThvZvRe/eTO5V2Ynl1NOLk8Jf5mlv3IVbWO5+YPvZ+5HP0A7baTXw87OUW66hXx+H52RnPbqFdDIIHp+/B//h61vfBM3n/8awt59ybyxBr9vBrbsoNkvaC+fQps11FV0+AGfZYhDhsPEOZpSsGVA4KrXGDnlZMqz7kfz8u+z9Y+fRHjI2Sx73BOI4pj95qWYq66md+Ralj3owdjmKEikeZ8z6Y9/lpEvfJ6bvv41pl/2NzC9HAL4225l7wUX4IzFvuSvOOrPnko0ukCUKnfuYu+b3kDTCOGcc6ivWQNZyo4tJSnIxlRhUutgJOf0v3kRt87sw3/k47T+6m/Yu2Y1a573PKJYdv3LP7Fs/wE645Pc/3VvIDbHEDGsOeNMyrPuR/aB93Hr2Q+n/kdPoXHvM5m7/Nv0vvBpxn2fzmlnYFauqkLREcUlE63sctNLX4wTz9QrX8v4mRvQWg1vDJULcsHqj4AJSnfTZm59+d9y9H99lUbp6T/y8cxv3cT8hbsXdo5GKJo1jnnsY5CRcdyqIzjr3e/htr96CcuvuIKbz3s2k096Emoc3Uu/g37+C9TLHqte+GKm7v9gNDeQRR78r2/mxme1GPvOZWz+86ey4qUvJ2YZ7NjBzNveyvJeCz3rftzrvGej9ZHEHF2+Eh9B/+M/2dwpGHngBmz07L/ws9grr6bMMta9+jXY8SaRUDnEl+YxD3EocJgIDsGYRXNABdzKVRz35jdx7SteSfPy7zHxzUuYv/TbdGxO32bMT09w73/6Z6bPPRd1Fqzj+Cf+ITs7Pbb8/etY1e4w/y9vSGQoVfoW5htN1vz5Mzn2L/4C6g2MWAh9pNfmxve/m/F+n51jo5z57GejeZXNCmSVw1ZNlb2rsSJCjXDEeefx9c9/nqM6HaY3b6TzypfTk4zRIOwcnWT8vPNgbGSQlgXWMNds4BsNJn1B+YkP4//jY+QxUOaOnSet54w3vIGRk06ueCYmqfrtFrs+8Qkmtm4i3OcMxh/0UGhOJA0t9dxBPBIBfGueH736Vay89FtM9Pog0PrMJ5n94udAkwnko8FnNfY0Da1dWzntL14EWc7Y6WfQf+jD2L1jF5NXXc2+H/8Yq4ILkSiOrSefysmPfxw0skTWkoiZGmfyaf+Tq6+5ilWtDvte+RpEPVn01FW4dWKSY57zHGK9CcZgspwTzj2X77zvAjozB5AvfpbeFz9Ns/CMRmFnvU557sMZPet+ULeVWWkqd/lQbBxKiOqhV/k2bNigP7ziCtCqvJxU5GcfCDt30b/mJ2z6+1fRiELbOsZ/+7c54g9+j9qxxyeKsq3yNnyEbof+ps1sef8HKC7/Ptb3ic4QjjuOe73sFWRHrcNMjKKmmsVjQXnz9Vz7J/+T5r4uy85/Jcuf/KTEojSL4V81WpG8Kt9IqspD7LTo7dyObbW55e9eRrZ3L6WxhBNO5F4v/Vvc2rWYyYmkpQBopNyxC929i/3fv4wdH/kwI0WJN47Vf/GXjJ7zMPJ1R6JVbQzRCLFk/5e+yPYXvICxzhzxvOdx7KtflyIhslDsDwaRF0k+Fum22XXhhex+1wWM+JJoBnkeVbRDI2JyCqnRbWac9u/voL7+JMhyKArKPXuJM3PMfesS9nzoA2TB067XWXvecxl/yMOpHbk61cpIdhxoQZido9y1l7h9Nxtf/irqoUs/MzQe/mjWPOWPqR13NNocI0rF1vWe/pZbMQf2sfXCC5n/xn/RjNCxGSe86Y1k91pPvmI5WCWKQXEV8W+YGvubwIYNG7jiiivuck8ePoLjh1ewmNAlC+xHCYAv0ehTmNW4FIlzLoVizUB1dZiYKldp9BBC2n+B9pyl5DVrUTfwGSiUfTa//GX0P/oR/B/+Eaf+8z+ikxOoccm/oVrxIZb2bRXhUAMhoBqJUTFlqmKmJoARxBhELGpz1JhEMFOwXsGHKg8lplCz0QWuB8YRB5pECOjMPja+5pW4j36YnUcfzwO+9k1YtqzilixplWrFF6uYtaGEfkRCFbWyVe9WNFeVynmJSxqLAa1lBOMqtq5ifECCRwfVzoyCc2BqSesyAy56ioqhMRG/AuA9Ke5Fta8Bl+p3eAZFiGKqvRICElL4OEWDbHoG1iA2hXzjoHrYwM0xFBx3G7+u4DhMTBUWeBe6ZAZVImItmBpR6lV5wPSKWhkkZSWmRwp0aCrLZy2SORZ9v4tz8iK/Q6EomLv028SvX4IbnWDV054OI+PpJQc8moQTYFJogFhNdIM6GWoMOtgpS2FLNUpUjxNBq/wZQUGr2prOVHkZiYmZ6G9hoZ0pbFwVVA6RuHsf85+6iOnoOPqFL4LxUdQunXEHwlEwahb8hmozYjNFTKj6J4VrpbIKQypOKBZbhaVVFg5P3ecM6mrpuyRuxkKQu2L6KpaoBmtSukA0ksLDNceARzPoh1QSUbHikzaFgHVEk0M+OCeoVIVbZRCqN4geXMm+asYQhwB3K6oiIptE5BoRuUpErqi2TYvI10Tkpupz6lc61wJHcvCtqm3queoAACAASURBVH0ZF8oNk1649C+ZGclk0MHAYIkPgkRjB1Iolpj4ECzmOfi5A/zoxS+g3L6d4t6nM3HGvdFaqiYmkkK14aCcCF2UGFSnqciiKdNWEZNefCuOOBAMAsS4UGVMKy6KkrSVdKeGEBVVQ1QSh4WIaOR7L38VEoQ9609m6qEPg3ot9c3SiuMLLdSK4h0XKr7rggNk0NkDyZJcqqKaIt2DwU3lDNaQhLKkgbxYiUyISlUvNNG/k+yshKQqSeVIp4zVp1YU/wUiGwCWGKrrs/hJjIPpYDESXt2hDJ7DMLJyyPCbCMc+XFXvo6obqu8vB76hquuBb1TffzkqXbmiMFWvoEWMQSWkmSrGg8ZuqkmRXrY09wmoxUiWnJEyoIBXFzCGKNXcLhFTM0yc/UB+NjXKUee/ArJkToTBC6ueTCJSCRwRxRCqF3dxxh/QT6TaV1gcLclfo5UdUM2aUpVXFosVU0kgg5U8FVVeIG8lAbPmYWczc9rJHPf2f6V+9LEkillilxgGYyhljMaB7W9S+82CjJAqz0QroaQYEUQFWw3kgRBMF48LSyGoCEFMpW1FwKeqapo0DBlk26YLIVWhl0RKr9Lgo2AFjEYMhqgOJQc1yTGuICTzLaUcOBAHOCKWKEnbQ0BNSBrJUNs4ZLhbPg4R2QRsUNW9S7bdCDxMVXeIyBHAN1X1xF90ng0bNugVV/yAg0yLijyhC2q4WTLBDFR/FmcjSbPgwN8+mM8GY2HwZXC7IoqUJf2dO5nZchvLTj0VOzaWiu+mjllypLBQXFAii/WPlpyQwaASltZHWsqrkKXrqtxe317a0AV9PEJQdG6e+W3bmFh/AprlpLyaQXt04bhk5lVCd6BtYVLGMQcZbHdaCGdR29MF4T0Q4QvL1WhkoHek/RdziqpMxCXs3irbWRc9V1WgeIk3a/F5aLVuDEt/kdt1y8I5Bn0wlB53B4fKx6HAVyXFyd6jqu8FVqnqjur3ncCqX+1UcvDfsnTr7cJvA7V6yYyvVMmgC7vIQbsPGitLz+tyamvXsWrtuju0Q+7gfRuMbHPwKy9Lz27ueL3qXgZJZ4u3dyfP6g6bTFJMJieZmJxc2rqDD7rDfVcazu1aLkv2OKiRSy+/9EetRPSSS8hAvVo4kzn4BAudbBbv86BrVRGwg55vdTa5ndC4Eyy+D794vyHuWdxdwXG2qm4TkZXA10TkhqU/qqpWQuUOEJHzgPMA1q1bx89/CeRO/7z97r/KKyS3//YLx+6dnfEXXeWOv8kv/vmX4A4j61c94pe35Zf8sCCc7rQJtz/g5z2IOzvxL+7dX23rUFgcDrhbPg5V3VZ97gY+A5wF7KpMFKrP3T/n2Peq6gZV3bBixYq704whhhjivxm/tuAQkRERGRv8DTwauBb4PPC0arenAZ+7u40cYoghDi/cHVNlFfCZihjlgI+r6sUi8kPgP0XkmcBm4El3v5lDDDHE4YRfW3Co6kbgjDvZvg945N1p1BBDDHF44zBKqx9iiCH+X8FQcAwxxBB3GUPBMcQQQ9xlDAXHEEMMcZdxWGTHqka6RSfV4hhQwhd/ZXGLLKS3DxLbFveqkp/ujBJ50PeKWL1A674dbVlvd/ztmJTpWOUO7C4d0LNhgRm50IRBUtbBzVlKhV+46lImpyylyA/aWSUDVpT4BQZm1c60/8F9dsc+kCVtXnrPg7Yu3XfJL3oQh+v2XPAlX35+AtrB/TLIWOagezn4yKX3MHjGS5/znWHpfBiX0Pt/CXntoHdjcdMd0gOW/qxL7vd2z1HupIkHPZ6Dti4+k6VtWcxQ/MX9utis27d1ybF3SAw0i4mgdxGHRT2O6RWT+uBH35/dO/fQmWvT63axQC2zKBHvA3lWx9kazqXEqH7hKcqAD0oMERWPs+AywagQQyT4iNeAEhBi+t0aajVLrZbRaDSo1WoYNRgsJgrBK2VRUAaPjwGXZeRZjcxlOGMJsSTPLZNTozSbdaII3X5kZrZDq9OnLAPNWo3psQlym2FTBj3iAiZL+R1z8x1anS7tXoGK0mjWcS6theK9JwbF2QznHPNzc7TmW6w+4ggmp6ZAoNNts3//PnzZY3J8lKmxUSYnRgFDp98nxlSGUaOg6gg+EkKgrAoqC5YYLb2ipNvt0+70KIoSVSXPLSOjDdBA8B4NEe89Renph3ReJ5BXtUB8iKgYrHNkeUaWu7TMDREfPMEHjDVkmcW5jCzLkQgalBACMaTERSNKllkUpe9LMAaxjqhVJq5KlRkdMHikWu3PikmpBrHKCRKLdTnGZkQNFL5Dp9+i0y8QYxFrUWMTlT6CVAt4oUok4uqOeqNOZhzWCEXRpd/r4YsSjRFjHIjFh0i312d2voWPgbyRk+UulVKIAV+UOONw1hJVCVWWd5RYvbNp3KWlMwLqFfUCwaR8oGolP40GVQsBVMuqLEHK9IlVflZMD3WhPk2qiSLEaFA1qUKbiRinSCbkeY6zDg3C9Tdtot3t3mU67mGhcSCCdQaX2VTLIgZiDPgyJVRpTAVigi3wPgd1eK8UZaAMkVglVfmo2CjViwTBB0L0RPWIBqJV1AnW5DgbSUvORhzVAkZBiSV4n4r+WjcoV+cxxlKrOYpeIJYFvXZAtIfJa8QAMZbEWKIh4Evo9zqosVgBmwk2T8UDQ4R+0aYsC0IsQcB7IYaUtBXLQAiRYEs05PiiR9Hv0W7NY60hr9UQhCxzCDlExRcFZaeTVmzznhCLtHqkGlBH8KlPve8SY0SjJUZDvwz0+gX9bg/vI8ZYglHKXg/VQAwBYlpVL/pA9D7NWhqJDModCMY6VDOoanOk2j5KjJEYI1YNRnRh7ktvu1ZtiWgcpNsnfSJUyW5J46pqeURJ1UM0IoSUZSsBqmpxuiCAHOoiSA9PoPR9iqJP8AVqBA1C0KS5Gk3ZwSYajBjI0nMoij5qPc4IMRQQS2Lo40uPSCU4fKTX7dHvtik1EG0B1FBjCGWg6PZxYtKCXZIUB+NS/o4vPWUIiJrUhhhS3RWfkhpNrDQPTRqkRoMGQQioVAWVqEpd2VRaMg6SDUWqekrVOsaYVEzaQoghCaDgiS4nJSr+ehrHYSE4rHFMjq9EgsOq40BQuq02ZZFWQ7NW0KhgUvEejSWCxRjFxFR8RsQu5HUpgjFg3aASVVoqIIaAWoOzDucyNArRg2Rp7ZGyLCkLRWxGvdGgMTICkgTR2OgI46NN5g7sp9Oap9ft4b1nZNIhNqdWq+GDUkiJFSiKHqGqkZ5rRmYNxhsCShk8RehjrcVlGZaUcq8hErwSQkwzoqkGg8Lc7Cy+DKxctZrxyUnyrIYvehDS4k+9QhCjaaYWRwg+qdmaqriLSapq1EDpS3wpFEHxIeBjAGPJaznWCN5XwiFGjDicSxU6VCFGj6pS+gJVxeUZiEFsErYxLjV1BGstWZaR5XkqRK2k7c5gxaJRCcGjacH7aoA5JLM469JA9em8GmJV4c1U5YGq8aVV3RQVLIr3JVEDIQa8RmK0CI5AuqdImpFVhYwMIwZnM6yrKppFWViFztoMkxs0QPDpGjEqwQe8H2hMAaNZKpmgDvVK0Y8UoUQE8jwjr2c4l2OMofDttFSpKkYdBIuGEg1lKuCkgmiGaqr8v7BOrlTPFyXEgBjBZQ5E8CHdL5HUVyoYIxhrEWfAKj4GolYauo1Jy70ze+pXwGEhOEQMNddkbCSiHoxY9rOX2fIAGgJSrVUSYxp4BoMxgqvqT4impQiNSVZz0lCSDmfUMKhQhcZUZ9gY8iw9RFOV6DNiqTca1BsWm9WoNZrU6vUF6zPPa6g6jKsjrk+rNYf0S8hrZHWDqQYIqhjVNOsGpYzpu0TQMlBGT7co8L7EmIiKYDKLNRYxFmIklAVEwRnDaL2JU6HT61F0O5T9LhJHqec50Rl8vw8xEkMaiM4YvJbEUC3jIIKx1RCzlugDQVPl1KCK11TnSESqambgo8egVS2UpAEETRqTkOpiFDHgQ1lVXAMrWTJRNGXmGmMXFmMyxiEYQgh478lcllRrTZXSIoGqbBFIqsFiJVU+sVVf5s6CM3gvhJBMC1VPGT0xeHwZMGLJM0OIHh9KfAhVsq7FuBqiHqJPy0IYwarDkuNwWLGYaNO6V8biBm4B45IZlinBC94HNIQ0MBWstWhQtISSCDamQkzG4WPy2RmTUXMjGJdXlfxT/6ZaR0m7kJjWi4kakGgrv4pLNV5MTOUwY3omYlwymYwhSloXR01Mk4MqEgpi8NVaiMksE7HV+xaqfSPGDoob3HUcFoJjkIpdqzcZU8G6DO9LWq05Aqm6VFpF0aTZzSVV08Vkv4Wq7J1UBX9i9PiQ7PM0C4AVC6LpOJeR5xlZJXFDGXDW0WyMUKs3cHmO2LT8EJKKzAQfmW+1EASX5/TLkrLso1ZoBKFeHyXPslRsKAQylxGlUvExlBFiCBRlQdHr4ss+1hoMAbVp5qjVclRL+v30YHPnyGp1xkbq7N23j26vS9nrUPQ72CzZ4JILGgUTBWMNxmTgNWkwMdUZFUnOWmOTjW9smt2TWjZYnBpCjESRpLYbMBIJsaT0AfVp0euBb0BjZf4EkGjJCUl4iGBMVURJqjKjRtHoKfp9isJjGgZrHCEOTMmyqgLmQH1acDs4VF21YLeQ1+u4LKPTi5RB07rAAcqyT7/fJ4RIbnOMM0kgRk/UVLXMSBLsJhqQVKvWYrDicJpqy6aZN2KwOOPQWFalFtOxztXIa4YYKz+RKNZaai6taxu8J8aA5qmOq60J0SaTWp2DPCfYVNsVk6Upz4RUbyVUQiQmDaySvdWa4YKJ1SKgoSRgyWuWLK/jEfqVqS4mPVdjBPGC9jXdPyE965AEsrOKyZIv0Fp75x7cXwGHh+AYqGEi2LzGiLNM9Lt0ey1a8zOU3R79XhcTLVlmsS7ptFGS0AgxFQu2Rshzt2BDp2p2yX8RF2p/Wmq1Go16nTwzqAYKPKIFPgSM7yMuQxUKH5JGEoVep6TXLahlNRDImxbjM3pFgbbbQJYcklr5RkxVYJeI11R0ufQlvujhTKQ+YhkbbYAKMzOzlP0eZnIKa4VazVXmQBuLxZqIME+MLdotj3FdmqMj5LUsCQWt1rXVnBDSgDbGghiCBmJMA9gYg7UWL4EQ04Dr9np0Op00cEmCNLOCs4pz1bPBkdvknA4+qewR0vIRYjAiOBEyI8m8UEvQyhlnIkKBMTDSMIw0G2SuBmJotfp4XyA2qeIh9vC+pIweawy5zcgQgoIvkmO53S0oItSy5IgMEZBUy8PjIfQq30rlN4mA9WnWNckZGUJJWRTg04xrRZIQFovYDGszxArWWWq1Os42MKaasTGpKHQVNTEGbLW8p6KEUOCDp196+t4TglJoD0+RhJMqvlNgSqg7ixWBqmSkkAGGoKkeq0qZtGlVrDU4lxE1UoQusdfHq6Fb+rQou3OIrTRdr2hZJt+araq+acC5HJtnuNzgTFWT99cMjhwegkOUKIEgoCJplp2coIwrUfrs6+zDxz4a0oPKbHK2BUjl71A6faXEoqGBNTnWusrW00qKx/SgnSXPajQbTZyJQImhQwxdVPuVF9+mSIzxleda6AfPfLeg78fI8wZZo4aNjvnZgnanhZiM3NXTsgTWEqoShCFq8txHxZcFoewyNmaYXlZjetkonXbJrl1b6fdzslqdWr1OXs8piw7d/p40IGuGeuMAXucwdo7SzxKZxNiRtN62OiTWiFrHhwLEkWUZpa8crSFWlQHTAFEtKMs5fDFH6M9B6KA+zUzOWozLQZV+P71stWwM5wyZqVF6T1Cf1r8zgskcucuwYtNAz3IIQlEWyVQ0AZGCLFMmJicYHZ2i6MP8XEFbPaH0OE3rsgTfo/TzlLGFOshNlsw4gbLo0+sVtHseHzNKl5O7BlZGMdJM5qx4+r6XZmC1pNKDJHNXFZsJIgVlOUvp5yEWiHokr7Q1qRFiRqcLYmvUag1gNC2/qzY5iUMqSh9CVaGeuBAKNyIEDZRlj16/jRLJnGBNh1DOVpEOpex4rHe4+ijG1Sohl5yuSU6kSCDRE6PBKDRzR5Y5emWHsmgRTVqW3eQpUlg5+lI0sZpMc3JM5lKUzRhMZnFZjczlGJMRSv/zgru/FIeF4FBAquX9rNi0IFMtZ3xilG4nZ27GMz4BzTocsWKU5RN1GvUM44TSKwdmumzf0WLmQGBmtkMZPWoaqLGp5makqrUJSLJLrQgxeKwtGGkG8oYyOlKjOSo0Ryyult67btGn3fbM7lcO7DfMHpin3+vSK+sgWeU8tSnUGdOSCIUviR0FDM7mWGcxVumrJ3OBE09cw7qjxxHbY/u2GVzm6XSSU9P7QLszQ4xtaq7L+GSDtWsnQKaI0iQt8+iwuU3m3HygPS90W300lmTZCAaD9wHUIpXqG2MAItEXdNoz9LsHqGddpsYDYxNjNOqGPLO4zOGcpd/r02r1abWUbqtPr3OA2aJLCIZIsqeNSX4VIxZbRaakstuNcYTYJ4aSPOsyNp5xwvopVq1ex8abdtJuzVMWffq9PtnoCN6X9LrziGsxMV4yvazOqpWjjI/VqOUGX/bodgvmWwVz857WfKAz32Z2f58Y+zTq47i6wdhklmm0BJ8cp1bSoO5150HmGR2NrF5dY3JynNERIc9i8olqRrsV2Le3x8yBPq1WGx9aFEUX60ZQreGjx4eQtJoQktNdS/plJGqJmILRMVi5Omf5yjpTkzUaDYcTS69d0m732b+7w/yByPxsi06nh5UaSMCII0LSOAjJjI6BMkZ8WZBpxLqCsWWBqeU1xqdzxiZq1OpJQy77kXar4MCBPnv3FHRbnl63RV4fwWUWZwXnTPKlwcEl8+4iDgvBAYCFmnN4HymKPpJFak0Yn7T4ssbqVcpRR45y4vrVHLtmmonxJs45uj3Pjh0H+OkNu7jhhr3ceFOf2TlPlB5InRCq+PYCx0Yru72DoUu91md8MrLqiCZrjxpnclnO2ISj0cywuWGu1eLAgRYz+wt2bO/zsxv2sO22NnOz88SYMzoyTZYJ0ZcUpQCOoizotPvU601GR1NI1znBGE89j5x++tGcdu8j2bZ9I3OzM+Q1wWUWaw2F7zA3v51a3mP5dM6ao8c59bRplq1YRWM02dY+Ku2uZ9/eNtu2tdmxrUu36yl9r4rQOEKpGKkWzA4hmXMUFGWbspghxllWLHccc/QYJ6xfxaojJpmYaOBcUv/3759l794WmzbOsOmWObZtnWO+vR+kjrE1xORYm2OMUImNNKPKYCFvko3tu9Rsl4kpy71OWs76449ldmY/G29p0+u18GUkhByNBWU5z1izYO2RNdafOM1JpxzF9FSTesOBqXgTMx327Jhj88b9bLx5jv175mi3e9jMILGGdQ4jDowjBKUs+pXZFvB+FutmWbFyjFNPPYLjjl/FsuVNsixiRCk87Nk1z22b93PDdXvYsrnDfGuedm+OWjZNXpuiDKaiCwwWv0phzm63hTGBsQnLmjU1Tj5lOSedtJKj1k4wNpJjTcbc/jYH9rbYuHEPt9y8jxuvn2f7tj6eEnAYm5Pqsabq9rYqLl3EglCW1MSwYspyzAmjnHjSco49YRlHrZtmdKIJqszPtdi7e45bbt3Hz248wJabu2zbEjBE8jyrImApUjMoMP3r4jARHIpKgXEZaEBcSa83AzrDcSdM87BzVrFsKrB80rByxQiT4zVqWfLU+1KZmBxhxYoVrF/f5d5buvzoqq1cdc1Out0OuR2pQnWQWUtU2Ld/N0ZyjjtmkvXHrWTNulFWrqoxMeWoNSK1BrjMIU4Yn2ywbNk4nXZg3VHKvY47li1bOvzoyk1s2zpL8Mlhat0IUhF9fEyLBxXB0+33yHPFWoc1nsYIZLVAiB127NzK1m1b6XZ7xOjol/NkWcGKFZZjjj6CM888mqPWjLFqVZ3mqCevRYJ6VIUyCNPLmqxYtYzVq3tsuXWeHdv77N07y/+l7k1iLEvTNK3nH850Z7s2u5m5m88eQ0ZkZuRMN5RU3YJGLfWuJVaAkHoDe3rHtrdISEi9QNAbhh0IEIMQUFR2ZlVWVkRkzOEe4ZO5zdOdzvRPLP7rkVU0VFUHKinruFzmfv3K/Nq953zn/7/vfZ/XGYsUgyi5sCFu61zDojzHhxm374zZ3b3J/l6XnRsZq+s5nZ4gy2LxQkhWN3JuLMbcvH2TB49aPvroFR+8f8D5RUNdNgjZQYbYTpSpJMsKtEqiPgGB1ApXGdowZ9yVrK0XdHsB4yacnh1wevoKKVNUEri4PKQ/0Nx/sMmjh0MevTFiaydlvNYhySUqk/HCN5q11YLtjSH7N29w53bJ+voxXz+dcn4xpWokmRyALAhuKfCSgbqZkgTDnXsr3L67y917PW7dHLI67tHvx7t9wGEcDIcF6xsj9nZ3ODqc8cmnz/nooyOcn2FdhlQ9kjzBGA82RnNI4ckzz9Z2jx//5C73H464td9jbVUx6GekiSKRCc2oS729ws2b6zx6Y8Gdu+d89JsTPv30jIvLhkTFCVCQcexrvY89IG3Z2Ei5e2fMu+/s8uZbG4zXFIOhZjTukOYahKdpcta2u2zvr3H/DcPzxzM++fCcZ19NOb+c0JUjsiKPsgETx+nfVgD6O1E4Ah4X2kjHVh5vSpBzsrTm1p0b/Gs/e8Cwa8hUi7ElxnpmlSNYjxKablGw8WjAndvw4IFFKs3J6SWHByXON7E7j8Z5SdsY5r5k2NdsbK7yxptr7N9ZZTiKJ5AXBmNqnBH4FpAJeZLQW9PsbHbwtzNu3awxTUNwDScnLW1bkaadWMiWfRWEwDlLaxrq2iKFJE0D/UFGVmja1vDq4JSDg1OaxuGDwbopvSGsrfb4zjs3+OlPH9HtCqRsaNsJbe2xNsYg6ixjNNQMR5rRqKHoXCKTK67np1RVu8yeKWLuDB5jZ7T2krxouP9gh/feu8ONrR7DvsT5Eutq2jaKw4SWJGnGSkeyfqPH7r5EFTllFbCfvOSkbgi+wYsEQY6UiiTJkFLRGE+QAS0k1je0dkGnN2J1c4DKAtP5NecXZ1xdX5Bnq0gpaMyUtaLHm2/f4Ifv7XL//oii02JDS9m2lAu/TMFTFLrL+mrO7naHrc2Kotun03/Br379lPMLQ6hVbBSiCN7jQ4sLc1Jdc+/hDX70k1vc3CsYDhKccRjjcW7ZwyCQ531G+11u7sLkqkXqwMnpNVeXjqZZkKUFWmu8V0uxoCNJHN2h5423Rvyrv3ef+w/WWBkltPWCumqpSklLTPUrejlrmxvc3Hesb65RdLtczRbMyhnWxtQ7KZev3VmEsOQF3Lk94qc/vcdPfnSfBw83qM2Uuq4xNVHIqAWolLyrGa70uHO7w83dCaPRS4z9lMvpVRzRWo+xDmPMUlz3N7pwBKyvCbbBmIaqmrK6krB/c5t7d4asjQNFEmhrxxdfHPLx50ccH02pF5Zhv+Du7R1++N5brK8PuJHDj360jhCP+PkfvuKjj05wbYpOEmxjCNIwHil2djq88caY+w+HrKwonG+5vGo5u5hzcHjBfNpQ1S1COYoCbu5tcPfuHkUR98d/61+5y2iU8Qd/8AWvDmuUjlsD62KXXQlBwOJdzWzW4Jxkd2/I3s0tev0BjQ2cnzecndU0bYJWhra+YGNtgx/9eI+H98cMB462dVxeLPjy8QsOD09ZzCxCJqxvjbl5e5Xbd7bYWO+R6zj9mU5KXvmK+eQapEfLgrKa07QXrK8L9vbHPHprwP7dIamWXF5N+PyLxxyfXjK5bmgagXGBrd0ht+5ucuvWDcajMW++uUuuCgixwTu5jtGVWkmklFjvET5OgvEBZ+tlo9KxtrHGrdu7IBwvDp8zW0wwzuAWc/Jcsb2V8/Z31vnRD/e4e3eNTg+upzNeHBzz9PkpR6fX1I0jUYqdzXVu7+5w984Oq2s9vvPuFjJtuJgd0X5WcXE2QScZvU4X4xqq+pLxGty5O+LBowH7t3NWhorFrOTLz4/4+utzLs5L6taS5yl37+3z3e++wXglIckc3/neBlV7j/d/fcYXn0+BgkTH7UlrG+pmwcZm4Mc/2+f7793i3r0e/QG0bcvjJ6d89tlLzk9LyoWh11Fs3+jzve/eYW93jZt7fbzfoW4b0vyITz4+Y1Failzince42Nvb3c340Y9u8rf/9gN2d1cAw8vnJzx5csxXX51zOalBB1Y2Unb2Bjy4d5uH9/bZ3euTpjeYzk4wruTgRcN0cokLGqnUt26Mwu9I4YAolyBYvCsJbsHKcJOHd29w84Yg1TOMqTk9X/DhJ6/4w18c8OqgpFo4+j14depIu2u8LeDGduDuXU2abnN6MuerL49xdfQ3tE2DTBxrK2Nu76+yf3PE+kaO0pazsxkvX5Q8eTrlq6+vub4ylOWCQEWvH7g6Axn67O2vsDru8ODRBkJ7Hn/1FVeTEqVi516qZDnCXWbDhprGzpFS0B9ssbO3R5J1mM/nXE08k0mcAGjpSJVjaz3hzUdjdncyYM75ecWTLyf86QfnPHt2ymxukFKzuV0xndcMegU39xTro5xmd8TVRUUzP2F2fYlAInSCFwYbZtzYWePNN0fs3y7oDyQXZzO+fHLEP//VM54+O+N6YqlLQd169u+OeXRpMCbhnTf6bI77dN5WvHzZ5+qsoC1b6tKRZSlJmmLCModWKnxweGewwSG1Yjgcs7q+zsnpK14evmJRl3g8Tb0gSzP2dge88XCV2/tDVlYL5mXNy8MFv/7ghM8/P+Tg1TWLhSORir2diss3A2na4d79NdY3Oty1Q56/6nFxNeXstCY4i9IeY1qsn7G5tcFbb+2wf2vIaCAwbcXhwRXv/8lLPvzNEcenFVUNeaY4OZGk2SqP3hiythHY3U+wdpPT4ylfPW4xboELAudClPZTs77e4wfv7fD2u5usrirmVcXRYcmf/uYlv/7VVxweLzwNAwAAIABJREFUlJQzRzeH2/t9ijSjyBLWV7vcuTWkNTe5njmevrhiXtcI4RAy4AOMNzX3Hg35znfWuf9wlbZpOHh1zYcfvuKDD17xySennJy2BAlrW4p7D4c0i4Rhb8TmZsHefpe33l1hvpgznZ5xfDJHqz6pKn7rf/sWx+9E4ZBSkecFuGop1gqsraXcuNFnNDIEP+XFwSFffHHC48eHXFxakmQF0RUsyhmff3GKc79kcrXL3/vX77G6mhDos7PXYbyqaI2lrkpaY+nkKbf293jwYIfBcEQIirq2HB5N+dP3X/D0acXFpaQuNU2bYF3D+WnJ1dkLzk6n/P7ffYeV0S2ksnQ6ga3tHienhvnM01YGyPDB0bQNhAadtFjboHXO5uYqd/b3ME3Nq4MTZrN62Rys6Xbj3npzfcCgn5BlgnLhefLlEf/r//QFF1eKth0ulZOOp09mmHbG6ihFC8PO5goro5SHD7eYXpUcHBzSGoH1BUEYio7i9r0NHr21xcZmh6qe8OmnX/HHf/SS37x/wclZixAJ3ik8kq+fVFxePkfYjHGvj97r0utr7twZc3m6ydGrIxbTQJHndLoFTRsNe1orjHF426J1IO/kdDpdQHN+PuXp14eUlUPqFOstOknYv73HrVs76ESxWNRcXtR8/fiaX/yfzzi7MNSNxhhJcI751QXX55YiTUmSiv17Q1ZGCW882uX83HPw/Ji2cghpUGnLYCi5f3+L7333Hjc2M5yp+PrJIe//6iUfvn/Ml09qrBO0DZy2jmpxwMXZgn/j79/n935/n34vZXOry/Z2j7X1DscnhsViBkGSacfaesbuzR43druMVzXImsPDE/7oj57z4QfHvDyY0VZdUl2wmM959nTBbz58iZQt3//ubdY3V7lzd40Hr6b86teachFIhMd4T17A3ftjfvCjfW7eyrD+nKfPj/ngT475xc9f8NVXU2ZzDWRUpeH4wFPPJ2CekynFm2+v8uDRmFt3VjCt4tnThiePS7SOWqYQlga/b3H8ThQOISRKZRhbkmhPp5CMVwQrK5q8gGoOB6+uefzVKZdThxBd+r1Ngk+5DhfM5pd88skxvY7j+99fYzQa0h+kbO90uHGrw6ycM5220TeQSXq9Lt3OCnWdcnpimZc1X3+94Mnjaw6PLNYMMEbhrMS6HOsMF2czri4bHr4x4+Ebnl4f8o5kNM7pDxKuryqqJgGRY63D2BYwIFpCMLFnsNJhdXXAl49PePHskPmswS29Gmkq2d5eZW19SJoovLFcXVQ8/eqEjz++ItUrdLprKJnhfM10OueVX/D48yMGXcnaqEtv2GFnN+XFRspwKDi9qGjaOVIGRqMum9tDtraHJGnL8fEFn332gt98cMTJoWdRJqgkRUmFVIqr85KLs5Lx4Ii9nYJ+b5XhaMzubsHF3TEf/uklp8ctSkfRnV+ar4QOBGGp24pOL2F9o8dg1CeEhIuLhpcvr6hKjZQZQnnybsH23k3WN3dI0w6LRcPJUcXLpzOefrWgaUCneexPtZ7LhWU+nbK785KNTc/mjmIwSrm1t8qznYpO54Kmsli3QCc1w5FiZ2fAndubDIeBywvD0y8v+ODXB7x4Zpldg05SnNM0leHgRcPp8SG39nO+++4anTxl0M/Z2Oxx48aIq6sps8kCpRKyTLK5WXBjp8/aRpdOTzGd1ZycnPPxx0959crTVDlaDcl0D28V8/kln39xgkpa9va22dpJWVtT3LzZ4/Z+QbMomU880gdkIti/tco77+6xeSPDmAVPvzrk13/ynMdfzjm/CKR5QpoqjK1pqpbjuSeRFxSpoyga7tztsb7awd/L2Nx8QV5EMZj3FqX03+wVRwBMGygXJb2iZTRUDPoBKSqsDdSNYDoXzBaabm+TnXSMM32Cy+gN1ijLc2aTxyxKy9nZNetrgcFgwHg15db+GqennpfPZygJUgfmswUHB1fUtUJry2Q24/CwpDV90lSiZQelovrROo0z0YDW1A2zacv1dUlWRHVhkgoQjsViwWwmUTqnNdFoF3yUbGtpUdqSphYfak5Pzzk4OGOxMAQEQgW6/ZQbOxuM10ZIBZdXE549O+VqMkMp0LqHVj2StEOic2y7QOK4OKk4OZ7TvgFaC4rcMxwp1jcKrqdzLq9mFJ2CwbBLlgsCNZPpFUfH5xweTbm6grwYo5MUYyzgo3o1cTSt4fJizrNnh9zeF9y712V1XbN9o6DfVySJx3sDOPI8QSoNykfjnCvZGI24dWeblfEqPqQs5oHrSws+R+uEogOdXodub0TRXUOqlMXigpPjisnEkmVJ3IfLOA2TwkdRXvBcXs84u5hgzDpaabIMEhXl23VbQeXoDwzjsabXkyjhCUZTzRTHB4ajA4skYdBPCHRxPkVrqOopdT3n7OSKw4Mzev0Rve6Q1XGfGzdqnj8vubxaIKUgLzLW1nusrfaiR8YaFmXFfGEpS8izMcXmGiJ0wAnyPMEYwby84OS0pW5TpMpANIxGiocPVqnnjsefXyK9oD8UbKx3WV/vUhSwmDccvZpz8LIEMgajDKkLQgClM5q6xZqactbw9VdX3H/Qx7aWoiNJU0tvAL1BYHJV0swdvd7g2yrOfzcKBwi8F9FvoAPjYUq345CiwVpJVUsWVUplCrJiTN4ZU5UJweZonaESQd2c4INlMqspy4J+X7Ay6rO7u8XjLxoIC5JMojRcXEz54kvF06egpKcxLWXtaU0HrRUOBVLEgGnnCMEhlENqcD5gncAFhfeatoWqNEynFbN5Qp43QIJSGuMCxrQMVxUbmx36A4kPNedn5xwdXlI3RImzMOSdjPHaiMGgh1QN00nNixennJ1PsC6yRBAC7z3OO5TSCHIm14brC4trM5RIULKm21UMBwlpGmiqkm63Q7dXkGUa8LStYTZruDivmUyh1+2TZx2kaPG+JoSW4ANCKMq54+T4muvrEYSGXi+wuq5ZW08YjRQ6DQQsSiYoLfDC4akxbsFwdINbt25QdDrMZ4brK8N0CoNeTlEUJEmU6b88OCVNBXmqOT+75osvjzk/r0iSHI/DBYkPrwPIDS6A8xr7WuAlA6mSKATeQd00eNkyWtWM1/r0urFweAPlTHJ9CdOJIsl69NMC41I8GV0Ueu6wvqQqa44Pz9nYyuj31hiPV7ixG+gPTkE0eG/QOmFlpc94PEKphLq2XJzPODudc3npMY2i082RSuMx0WUsE66uPJcTuJ4EpnNPnnvyXHDjRp/DgxnPvgoIr+n3U0aDnF4nQcqauq6ZTCsmUweqS5p0sEv9TNFJkSKhFQneCSZXC+ZTg7MxBDzRgdFIsbaeMJ8b5gtHUWR/wyXngJCSLFF0Cs1woOkVoJXFGE1pAqWRNDZB62h2SmyKEZqgFDLLKfoDkqLFeol1CqUyhoOc7W3FYHiFEEdkaYJOEk7Orri8mlGVFVpJuv0eRbeH0vFNd9YuVwIO72ucmy/9IQn9QUKv30XJnKaumF6zvCAcVd0SREuSRPei92CMYW19xL2H24zXC1pTcnl9zfnljNZKVJIihCXNE/qDLp1+B4RnMnUcvJpydt5QVtGPorUFDD60S5CToq4s5UJQ1wJvJQpItEcnHqWiAUopRZpoovnW4V3AGUm58MznHi0dRS5IZUFA0rQOGSQKTVMbphNPWbY4ZylyS68H6xsZG1sWlSiEioYqZxxeNJi2xLuaQT9ne3sTKSSHh+ecn1dYI5Eyp+j08T5jUVX8Xz9/n1/8wqGkIgRFUwvqKuBCHgu2WCbO2oD3kZmRZ126nQ4QuSvWeKwVWBNoW4dKBFmasrrSod/VCCxNLahKj7MJSirStINKCqRLCWFpq0+6eHlFCILJdcViZsGnDIYpm5uSopMCEWAE0OsN6PcGKKGZzWa8enXKy5eXnJ1avDO0pibRBiEsiY5q08YIJnPP4emCk9MZm1sKrQXdriTPo+dFpwm9XpcklfjQYmxFa0qEAK0EJiQ4D61zEcCUKLROEUmKxSOoovfFxfcuzySra122tvucnk64nnisbfDfUgT2O1M4EMuZdQbDfkKnEAgsxnmqxtB6SVAalEIojdQKJTQqSUhESmoKdBZXA8ZH01eWZwyGgqKTfKMaDUDrwDjPZNYCgdpp+i6h6ETSUtO0OOdQOmDtnEDJ6ppm/3afje2MrJCEoCkXmtMTy9lZTdWE6BFwFqkiicM5j7WwstpnZ3edtBBcT6+5ns6ZLioQHaSMSIAk1XR6OVkWl65lJbm4cEwn0FSSTCU4ozGuxvuGNAuAwhho6kBVRU1CfIsCaRJJUm1jsDYCg36LVpQQXg9+IqODpUXc+yVZS6Z4PN5b2iaSvASQaEGaCnqDhE5P0TSG1kRJtvOe1jW0bY3Wjn4vYzTscjm55vnzYybXFUJkCCLZyzpoKsPl1RxjakCRpgVadSCkeAqCjMVSaU+SCpSGNFesr4/Y3FwhTROaJnA9aZjNDMZFBGGiNb1OznilSydXCBxN46iqlqb1eARSa6ROkUFBiKvEJElIM4lxgfm8pSodgpRuN2G0AmmaEjyYFqyFPOvQKXpIEYv46dmcs7OS6SREz0loIgFONKQaQmgoq4BeOM7P55xdTFhZ7S1/LolKBPY1kyfRIEPUImGjbZ7felFcvHAIIvqxRBBLM18SrykfuSqSgFKe/iBlvNan6FRIUUe3+Le8XH9HCkeAYHChIkkDg2FCtxuXpVULi8ZEYZWEIAVIhUwTEnJ0lkHaYnyByizGuyVSEJRWdDqKPA9o7ZeUrpQs75JmBUGmNE2FJbCoa6yP2oR6sYiwEyxa1/RHngcPV/nJz/bZu12g04ZFLTi/rHjxYsbRUeQzKKUAj3MtIii8i9CblfGA7Z11fHC8OjrhcjKnahxaxYshkRGt1+1Ek1vblixKuJ54FouAMZFB4TwYF0E/SSqBBOcETeOZlw1l1dLvR4Ws1uC8YVFaFmWJad3Suh6JVEKE5VdQMqC0Qyog+OgyTlKkt2SJREpPoiBLEqSMxSnLFUpDNSkxRlJ08qXUfobxNd2uZjBIyVLNyfEZX3z2lOvLmjztEbykXrRU1QJjDMgMnWRIrUlUihAp3km8M0iZILXCtA1aWbod2NpS3Huwwq3bm+S5YDpb8Pz5hMOjKdZ60lRR5AXDfpfRsEtRJAigqmwsBo2ndUusHiqqQEMU4MSFhMa2nqpy1HWkmuVZRq/n0Tr2KZo6YA3oNCHJMiSSppZcnJVcXhoWZeSNCNrlqrUiSyRCOuYLA0pxen7N+WXBHZ+SpAGVBLzwNLHO0xr3DeQo0Rl5VhAEtDbQtBYvHVILhPQ434Jz+KDwGKQKIAyEJjI+hKDbyxitDCi6c5Ru0WkKov5WV+zvRuEI0T/ig0VoSFKB1gIh4hK4tbEgBKKJTCkNJLig4odtI1zGCk+zNAVFRkFAJ4FOF/pDSZFlFN0OWdEnzQqckCRNZH/gA84Zup2E7c0tijxBJ57BwLO6Hrj/sMf9R2OUrjg+PuD5c8OnH19xcjbHRJsu0cnuUdKD96S5otAJK6tD+oMhZ+dHfPnlC87OJlSVJ0laQpAo6VECkiTa3oXU2KCpW7AOkAHjahpTI6QgTTOSJPIcWuOZLxpms4ayNPQ7S7CLD7TWU9eeyaTi/Oyaut5EyZRup8twWDBaSSgKi2krKiEJmUbLQJqDLSMub9BP2dvNWFkpUCqiHEGgtUJKQVmVNDVI1aVpW6bTOVnRMl7tMBpmaOWZXc84PLigWkjSpIe3gqY11KXBOo9KUxKpov5FJvglgUvpCGySQlC3Btu2bKxnvPHGgFs3u6yOu2gtmU4bvng84fnLKdZHe7xpLN56EqVQMjar52XL1bRktmiZlwaZVCSZwLbRXm68o25r5jPDfO6Yzw2tYbnClUgVPw9jo8ZCCEWapqRJgpIJ3mjqStI2sdcil65Z5zymMWiRonQ8X9vWU5Y1Vd1ggyWTgSSVSC1oHdRVy9n5lMXc4VwKBFSi6PU13V6gOq8pK09SJOg0ugt9UDRNQ5Y2DMeSwUiR55Am4JbMXaU0Hon1YKzlz4OY/+rH70ThCBDhrUtEmhThmzc98gmWWDlkdGJqRUDh/GuKlacNgdZ5Whf5DUFExJrW0O1oxmNJnncpugOyootOMoTWmDTDtDW2bcC2jFf6fO9799nY6DHoS7a2MtbXBZ1BiU5LXh0e8vjJK/7ol6d88fmcq2tHkmucA6lEVJDiEAE6HcVoZcDa2iqJLjg/W/DZZ19zcTHHtAG/XJl0M4GW0d4UGQ8KKROCiIzKIBw2NFhXkycFRZGTZQ7vWuom3sHmc0NdWZzTUXVoPKYNtA1MrmpeHV5SLRxSpvR6XcarfTY2coajBRdnE4xpkLJDUihSranqCu8rVlZXePhoi62tLkK0EU8QZFwOC01dVyzmc5J0QNM0zOdz8o5gc2NEv58gMMxnCy4vZuBHFJ0iMlJbj2l95IuKiIckxPfRucgT0YlGSQU+0JRRsbr75jrf/+5Ndnf79HoFxkouLwRffnnN8xczrEvxNjCfVlTzDnhB7PxI6qZlOquYzEomM4cXM7LUQUgQWHwtKauSycSw0neUpcH7eKMSEoKIjWkX9wiIJYQ5SRVKRvCQc7EHA6CUXGIvBV4rEp1E9y4Kb8G0DmsjazQASZIglcQ4uJ4YEuWYXDlMk0IAnSjGaynrG4Kz85qybMhERq4kUqUY31I2JZ2BY3M7Y209p+ioCO9pI37ROhuZpyZQNyYiOb/F8TtROAiSsGQsBh9xZ3EZKbHeYW3ABwUkgHqNTPkG0BrJRjo2GuXyexEvPq0ceZEyGCjyIqfo9kiyIUJlaGtJM0twLcE0KBr2b23xne/cY2MzIc3mjIaWbteRZpqyiu7JLz875ovPrjk4cKByur0M5wOQoKXENIbGtPQHBVvbY4YrQ4JIubioODqc4G2g05FYs+x4KxVBMsEgcSCWzAcblgUzNvp6vS6dboc8l2hlaJoGhMJ5hXM66k5soG0CZWlp6kDTQNtajo/mnJzMuL6qWF2F8bjPO+/uMptLPvpgwtXVgqZt8E6SJppOP7B9s+Dd99b57ve22Nj0OL8ApwFFmuQkaQEsMC5Qtw1VVWHaluFolUdv3KPb1ZwcH3B0eMT0qqLIhwx6eWzI+Qj+lcTpTfCathbfsEK1DgSvWbQLTFOS5y3btwb84Pt7fO/dXVZHOYtpydMXMz766JgnT2bL0XIPQUNbVbRNwJkluDcilTBLopmxgdYYgmgJziCCAxKa2uOtwL9mdxKBv5FEGbd6UkUavli6VyNdPLI5vPP4EFHOzhucaxAikKZxguSMI7iAWPJuXQvOCJyJEOPXLFFnA7NJ4PBgxvOnl6RplzQvePhwn+msoPUvCF/OWNQ1ZSkw0iGkZzB2PHxrhb/9e/s8emuFJJFIkaIkCFFF2BRxRf4advRtjr+0cAgh/jPg7wOnIYS3l4+Ngf8a2AeeAf8whHAlIn/tPwb+TaAE/p0Qwp/+pa9CsLy7SiKGOVZpfFyJ+CXgNq4+BMaxBK8aRFhSq9IofY53hgjXlcsPOU0lnW5slhadLirt4kSC1w7pPAqLDi2d1LGxscba2pjRyMcfQbS0TYNQAetCXO5OSprG44MkzxKUyiBoCBKBwrWW1pQU3QE7exv0egNcK5ldG67OPVIm9LopVWmQwS0bWPGIDbXw56AxoCJWcdAjzzVax5O1sTkupNggsU4uV2DQtJa6sjR1bODVref83PLixRUHL4Z0siHDbp+337pFWyts7XnxbEZVRQCp0o6dnR73Ho54580N9m706XbmGFsSgsR7HVcEOkGqHBdarAVrPUEEhsMu9+7fQoQFX3/9jOOjU6rSkSof+ZxLmrkQ8fsI+ZpHanAR6YW3DlNXlNUEXMnOnRHvvnODt7+zw53bWxhf8+rVlA/eP+DDX7/i/LChnmvyNMH7CPOxLiybiA73mrWpiLoQERktIQRc5DoilYrMWMnyhiQgeISL2mzlI1FLKTByuVIOS2CTCCyxobEnGcA6g3OGVAu0SCOD1pgl4iCOkgPx/bA2NrKxgUxIEuGwbeDgYMqnn5/SGe5w9/46d+71UHqF6ZVB+sDRUcts4UA4uoOEje0u735vh++9d5etNUfbzkmSlBCyaEGQgIhA5Phm/PUpR/9z4D8B/tmfeewfA/9bCOGfCCH+8fLv/yHw94D7y98/Bv7T5de/8Hhtww4uWZKwlwDXb369/iTFN9sW6zw+2HiHJk4EpJBL3L4kLGG8HodQkBaKNM9RSYFDYoPACkWQkZoklhy42XzB48dP6R7VSHVNks7o5J7xWpdev8PWjV1+8MNVhsOSZ0/nPH95zmzakOqMbEn8busot15dH3DvwT55VjC5qri+aKnmgiQLKG2R2Ijok0tcfxyw8DpsKYjIW1VaRrs7gaZaUIboTSjLmqtpQ6enqCoT6eRS4b3AGB95lwGsE0ymno8+PmTYd6z03uT+/XV2tjR8L2XUH3J8WDG5dkBBp5OxupGytgFFp+Lk6JDhyDFagTzP8U4u1bE2XgBC05iAsZ4kk/T6GSsrQ46Ornl5cMJkEpvNTVszmVwtBWJN7MUIGTmjIWbfvA4gauoWaxekSctorHjnnRv85CcPuLW/BlJweHjNx58d8ye/esaXn1/jTEqWdPAuAoXjfcdF0DLLWCYZlvDleHFLLUmiI5HgZXRnhyVrAyLOclm9pdBIoh0iEuOXIj8EloAVS+izjrDQWBgjtFlLhVpGSshlnIMXEGRAyEgj1/r18yTaBzIlkBpeHEz45R8/Z7Q25ub+gCyrubEV+NlPH7C7tcnJSc1sET/33krB+laPtXWJMRVnZ5dM5BWbm+tovRYxBvL1NcYyPuHbHX9p4Qgh/IEQYv//8fA/AH5v+ef/Avg/iIXjHwD/LMQz/5dCiJEQYjuEcPQX/idSoNOMYFOEDEtalwfhYwSCXEJYX//AFoiRH0sCdIS9ihBFQEu+0XJp6vBSIJIUlSSgopei8QFU5C76IBFBUzs4Pl9wNb0kSeZkeU2alfS7kt29dW7tZ2xv3eX2rRXefKPks89e8d//D3/IfL6IoGRdIIQkSSDPYWujz4N7N/G+5fDgiIvLOa0JIB2IgNTRSSuUR4i414+4slg8pAgRQKsc1lcsyhltXdK0JUFGodP1dcmon2KagPMySrmFjtjAEFdrzgbKheDjj64QznBjc5e1dU2W97l9d8Terdu0teP6ukXILv3+Ch5DVV/x5MkHfP74K+7c7vNmf40keGzwLOqaebXAhiibr5sShIuipVGPIu8xnXqePz1nOqlQGlpTMZm9pq97lI5cVNMYpJAomaBlzKgxTYW1DVtbmkdvjvjhz/b4znv7dHLF+dU1n39+wa/++JDffHjO+amh0x2SdToxJiAyKOPNgxhMFM8VidQRTLzkAC8BzxAU8ZwLNjJaQ+SoxhtTu+y/uSVjNCLQffBYb2OwlM8AgZKglzcAKROkjBhG/7pvo9LYpxOBVC+pa1qiE4nUkR/iQkDphLxbcHw6Z16esrdzzb07Nasbnm6nw7vfv8+bbwtmU0PVSpAZeTcnzRNOT4746stfIcMxo/6CNC0YjTYINsO7jODTb66Qb3t82x7H5p8pBsfA5vLPO8DLP/O8g+Vjf2HhECLO1IVUcc9O7KoHIp4uUYpkibQTHvAeEeIKA6L5ybYtwVoyvYT8iLiPswScEDghMAG8jye+D9H6LqRcpmFJ2uBxdWC2FIbFVDKFoOTg8CXPXlzz3ntvcftOj9FIsbeb8eDeCotZw/Wlo65rsjQjTWDYV6yuZIyHBc+fX/Ly5THT6zqeNCohSSQCj5YepWNT1DkXcfrIGFClYwlsGsf1ZMp8bjF1Q9PUIGNKXds4xDITJcYORBHV6yad8zEcEzSTa8tXT0r+5//lc45PK27fXWVvb4PhcECR5/SHBS4kVG3L4dElL54f8MlHzzk+uyQvenz/vVV0KjAhMJlXXE2nlK2laj1NVTEaFmxujVhdX0GpjOtLw4sXcyYTFzNuCDEkhiXGUUUivXEtSiRoldCaGtOUJMoyXpX84Ad7/K3fu8fDt8borObVyZwvPz3h5z9/yscfnTOfB6TOQCa4EOMe4+xHLPmxHi9i30BqhU4k6hsxXEyb80sWaBxPO5QMJIkkzzKyLEEtM2PiCkMRRFxxNa2lbgxNayNNS4QlovG3+gjvA603BNuQpVlc5Wi5LBqS9DVp38cVnHEO42NsRRAJnoT53PLHv3xCVc149OYG9x9tsTou6PW7dEc9uuQYI5ktonny44++5pOPvuDOLcXuT7fpFAOCFyzmNbNpiWnNktL2ekr2L3/8/26OhhCCeM2K+5c4hBD/CPhHAL2VwTJMKPYxrPFYJ0mDREtJngoSLRFymb4RHL/Ni4gwEts2SGfppB2yVCGWoGAXoPGe2lmCMySixQW5hM/GfWyQy95AkOAUrslQKkEbG/fuxuDdlKPTOevre2xtNKysaNbWFHfvDLk4K5leT6nmMfwo1Y7VlZz11YROFphdT3n14pTZtCXPenEqkgtCsEjaKPW2YGqPbfyyYSpIkriUrOpAXVcIDLZ5DWGxoCIrM0k0vV5O0YkEduvAOfXbHkmIzb6qChwdBqrqkOcvp3znnVu88ShwYzswWnF0ujmNbbi+qvjii1c8/uIljx+f0bTwvfdykmyM0DXWl1xNa86vShZloGw883lgPO6xc3OL9Y1VWgMX5w1np57FArI8hii5YJFaLu/aLm4lxRLHFyI/VIiW8arm0Zsr/Pgnd/nJzx6h85Lr6wlfPjnmF7884v33Lzk4KBEhI8k6WC/BeFQqlttPgQ0xTtJ6A1KQZilZrtDJb7eEzjuMW0ZoSOJKUECmFXmWkiQKiNqZ1vhop4/Ba7TGs1hEiLL3Nm41lytk8U1uTEQMONvE8bJ30/PGAAAgAElEQVQSSBVRkkWRkObx5uRcoGwsZeOwAZyMEY9CRODQ51+ccnRyxdHJlMsrwc7OCuubjpWxIE005dxzdHTOV18/5/0/fcaTL6cUeky/d4M0z/FBMCsXXF5c0rZN1OwI+PO5wX/149sWjpPXWxAhxDZwunz8FbD3Z563u3zsXzhCCP8U+KcA6ze3gg8Ggqc1lnnZUteCTq5IlSJPQQdLsDVSdpAarAHnYyiTkopUCTINeRIl11J4fNBYD2VrmJYl3bAgFwWBFu+hbWK9lVIjVQclCpTKUEWxfE8dSTokk6tU5QnWTZlMPVdXC/r9nH5Hsr1dsLHZIXx8zmxuqZuSra2CW7dX2drMSZTh8uKcw8NTmhpWhpv0Bh3SnJhLWk1oG8NiZlnMLE1lkdqgpSFLIvKwaQAsUrBsgMoYGRkgy6AoEsZrXUYrHaCJVCvDN1oCIQPBO3yAuoHLS09jF1xPnvLpp2f0uh16nYysiAiC+bzl8rJmMqlo24qVVY3UPQI53luqxnN23nB6aikrMDbGyYxWRjx69ID19Q1OTq45v6yomwhtFlIRlhERiVIIoSLxSgiKvIM1LWU5J888N3YSfvjeHf7O332HB4/WyDPF0emUzz474p//4XN+8fNLrq8dnpREp3gRwcQCsRSQqUimN4FFaWlNIKDodAoGgw5pIpbUd7nsn8Wgo0RrnHUE30RdjY7aHGta5lXL1eWMxaKhbX08f4xnPm+ZzxucNyjl6eSKLH29XY6JfH7JvQjCRA5rMCiV0BsU9AddlE6oTWA2N8wXNmp3AmitlqoZgbeBRdXy8cfHvHixYNAv6A8S+oMMKTWLmWE2aZhNK07Pp9Fo6XOE6qKShGAks1nF+fk5TdMsV1fqX7ww/4rHty0c/x3wbwP/ZPn1v/0zj/8HQoj/itgUnfyl/Q0gpnI5hAgY45nPaqoqgZEi0YpcOxLlSDAI4SO9yKjlJCPStbWSJDqQZ4FEecBhraKqHE0TMDbgsOjU0OloEq1wLhKrjbE4LzFG4VFIlcZZe3DoNOLkrW0JxlLVMTTatIGiMAwH0b8iZaAxDTZAkhXs7K4wHCYYO+f6+pqrqxmeFYaDEd1ugUoDSia41jKbXzOftywWDU1tyDuGJDF0u6BjPCzW2dgR93F/7ZaTGKUgLzS9gaLoJjHw2ELbxq9SgiR2/hP1uqcCZeVYHM55dTRHBkg0JEnc2jRRhAgChkPoDYsIDBaa1kJZGaYzx2QSt3gBj05gOCq4sbNFmqU8//oVp6eXWOuQMmaV+CUDVAi5zIcl7lpCQCsIiWdzU/P226u89+M9vv+DO6SZYzqd8/jzcz789TGffnzO0XGNUhlaR3AyQeFlAOmXo3pBCJ66tlxdVVS1JJCQZbF4pFnyjeTeL2+44nXco/DgKrQKFIUkSwM2NMxLw+XlhPmixprlqsMuRVxVNL3lmWA8Lhj0E5RyeB/J9YJkqYFZNuhE1Gz0hx2GowE6TWgXgap0NG18XVF16tDSE1IPaTRYXk0qjk8rtII0hTyPPZt64TBtbJO5AP0BJKkmyRKUTmlamE4aLs4rmjqgVZwC/rVNVYQQ/yWxEbomhDgA/iNiwfhvhBD/HvAc+IfLp/+PxFHsE+I49t/9q74QESJSvzWe60nNvMzwSBIFRRbopI48cdgY240UGiU1eL/M3GzItKfI4orDOUM1d1xd1lQlCJmRZZqV1Yy7d9bZWBughGNRLjg6nnJyarm+qmlqMEv1oRAxAFg4j40xF9SNpW4bjJNkwoB26FSQFgKdgtTQH3XY3B6RdhRX00uuphPKuiXNNHnRASnw3qGSDKUzqspxNamZTmI4Upobio5jbSOl11exOWqidkUs0XwQi0aaQ5Y7siKQZQnWCJxNqCpom/CN+THRsDIU9HsJnkBrHWXtl8+DugKdxH1+nFA5tIaVlYztrQ7DfsypqSrPbG5YVIHWLHNRC4fILKOxYjDMmZczPvjoE549P6CqDJ2iR54VaAmYWACFjNMJayyL8opO7tm+IfjRT7b4/b/zFvfvbpDlNWenU548OeMP//en/PrXr7i8FtGcpjOkTBFBEYJA6ygma5saZxu8j9uIk5MpkysLIaPIodcryFMdIx59bFoiQMrlvT0olJT0uoqVlZROTxBkzXyx4OLimsW8Wbpy4yi2rmuapsZ7w2CQcvfONl8/qcizyEpl6epVKvplArEZ2+lqNrfGbGyOSVNB0wYWc4cpQ4yZIODbBp1adBozYRCKqvKoecC7SCtvWk+iNGmWkyhBcB6pLaMVGK7kDFc6yCRQ1obzi4azM09TCdTy5vjXphwNIfxb/x//9Pv/L88NwL//bV6IEgqlcpydM100LCpBICFNoVe09AtPJzdMywXGLVAiQwqDaRuwE5QoyVLo91M63QwpBbNZPPHKGaS6h04Sijywu9fj3u0xiTLMpoFuUeLdgtn1DGe7JEkU/ATvcY0nyBbTLFDBkGhJp5OjEokPDusBqen0OgzHEikD49Uh4601vPIcnZ9QNg3JUu6eFzk+OIIMpEmKaTsgNVVjOTu/YjLVDFYUw5WEm/trbD5xaD2FAM7FnoYSsbeTZ4GNDcHahidNDM61kfcwC5ydWWb/d3tnFqvZlR3kb+99pn++8701u8pj2d122+nudJokKCEEEiE1SHnIE3lAQmKQ4IGHoEgoPIIED0iICESkgBAJBBB5QSIThCbpdrfbbg9l11x169adh3/+z7AHHta51Var2x1bbd9yuEu6qv+e/9Z/1r/POWuvvfZa3xrK7BVF0G5qnnlmmYsXFzERTKYFDzb3eLA+YXDgycvaGEWglDA5oiiwvNjmiSeWmZ+Xrc69/ZytjRGTUSGtIGsUwtycYWU1ptGG/cMx99YfcHDYB5S0K/CSPh4bXQe+RV+lLM3MceF8xosvLfFjX77AZ19cIMsqdncfcO3tQ15/bY+3Xj/k3u0SbRJMonGVll6zdVAyBC8TqJfdOKVhPLJsbkwYDgIqpCRJoNvOWFxI6PXqzM3SY7QsbSqv8c6RJoGFpQbnLs4zt5jhKTnsC8NkMs7BCxs4+IqjoyMOD1tY26Pbjrlwfpm11SNajQPymcXaCVpVaC1tSQmaRsMwt6DFO+k2iRNLVSgO93MGfQFOaQK2zFlZ7rJ6rkVnISJODKNByd5OztbDIePRVCaSYIlijVcGGwKtluHcuYzltS5JM2ZSTNg/nLJ/kDMcACSYKJEG4Z/usnol5KkkJeiUvLAUVYb1Kc3E0WxCp2NpNXMOBzmTWUG37YlMk3LWJ7gD0mREu92mN9+k2W5gXcRo3Gd7a5/RqCCOjrt9aZqNmLleSqxKEm2pisDRYc7923sQWkRGcjtsZamUcEF8NSBJCxYXDSurczSaHus8eTnGhZje3AJnXSCKNGfOnWVhaYnxcJuNrR1cCMwtLJBlPeIslYY7OiLLUrz3tLpzOF/x4OEuF3c0Zy+tsLSyxDPPRrxzbUYSjzBKshilPy5oFWh34clnUi4/lZE1HLN8ymgI+/sF21uOo77EH+JUMTff4Cd+4hW+/OXnaTQVu/tHfO3VN0jMHW6VE9mVCoqqDFgdiOot5dW1Hs9ffYrV5QWKmeL+nSNuXt9nMqzQAaqiIp7XXLq0wLnzLaLYkhfCjXBOkaYp3kOeVxhtZHkGuEro8M0GXLyQ8cUvneWnfuoql5/sksQF21t7vPv2Dl/76jZvvjFld6eqC79KXF7hmUphoZblWFCKOG6SNhKSKKa0JdORY3vDMuwHlEtJjaPT1pw5G3H+ouHBfUdeiLdRWccszzEa2l3P2fNtLj2xwsJii6JU7O1N2Ng4YDopUUHiH8E69raP2N1qY0tPljaZ78HyYptuV9MfFhRlRRKBSTWVle+wvABnzyp6vUCWahQJk6Fi/e6Y7c1ZvXjwVFXg0qVz/OiXn+GJpxdpdw0724dce3uT//V7bzPsTzFKvNzgK6qyosgDZ85mPPXUMmdWF/Bes78/Y319QH8g8ZMolsios/aj2o3HxXDULRox2CpmWCiO+obhOJBFniT1rKzFnJ9kDGcDKrsrHeF9g1QPyZola6tNLlyYp9trgFLM8pLDgwE72/tMZylpoyMl9WWgyGVbs9lyzHdl+3M4NGxvK9K9GdbvYXNPGSxGB7LY0VpyLC83uXQ5YW5e8Hr5xLB/WDKcVJgkYW5egl3La2s0Wl32Dx6ye9gn6IiFpTniZIEk61HaEmU8URLT1Iq1c5fQfkh/VHI0LLA+pttscP58yvNXj3j5lSOuvVewt2+xFWRJoNeDZ56L+cIXz/GZz6zRbgXGowF37024/2DAwZFlNgOvZVvSOU8jS1hcaHDmXIMzF1KCvoC3M2bjdenwNgtUVgLGC0uKy1dSnv1Mj6efXqHXbTEdl9y/PeL29QHTkZPWjBZajZgnr6yxutYkL0f0+yP6/YKyUsRRhgoKX7k64UlTWukP462j12nyI184y5d//CzPv9Ch2fYMBmO2Nnd499o6m1tTShdozUFrXmIvRRlASfKZqXOYgo9wNlCUJd55tIpwhaJ/GNjZHLOxvsfFSxGNRsmzz7foD1cw0R73blmqyhM8aANrZxKee77H1efPsLzSI45jDg4Lth5OWb/bZzK20g4zisF5DndnbD0Ys789YnUxI0sTrlxe4Sf+/DlefW2PO3fH2EIcoSiC7rziMy/1+NzLC6ysGIIvGPYrdh5O2dkoGQ8Cqu5Sb614ZlmmOXemx/lLHdZWI5IoZ+NeymwEoxHy+TqQpNCdg2eebfHyKxe4eGkZSFhfH/PWm5vsbE3rqnGN1lG9s/UpZo6GIIg9rQJlDrOpY/+gYm83J4scC3OB1bUORBIp12pAPtoFp+g0A2tnejz33DkuXVgka2bMZgV7exO2d484HAzxYYlWp0PlK2azwO7OiN2eoXk+YmEuxZgGly50GY8rWp0Je7sDZsaSJYokVsx1DZcu9nj66VXOn0/JmhZcxGSq2N2bsrc/Ii8NzWbG2toKi4tLqChhUlj6oxmYObpzC0SmB1GLiAYeyZbM2j0utJrY2RH55D6jcaAoDY6UZkvz/PNnmJYKr2+Rv35EMYVuGy5fNnzu5UW+8MWneOapFRKluXPnkLfe3uT2nR2mM0fQChNFOGsZDCru3t3k9u0mze4yC8sZn3lhCVsM2N/exlawvw+zXGJmTz3b4kt/bpWXfmSBxdUI7aF/VPLg3oj1u1PyCcRG4V2g1864/MQ5Fhfa9I8O2N4+YDTw2FKTZDHKSb6Gwtdd66VcwBjP0mKLz3/+KV58aZ5We0ZeDJmMxxwdDdjentJsap55LiVohwvS39ZbDZGSLfx6W93ZlN2twL27Y1ylJP9GafKZ58H6Hu++fYc0m2flrOLqC0ukmWY2s5SzQ7Y3HTpAa17zwksr/MzPPsvVzywSJynjUcX+nuXhxpSNBxVlAY20gTYagmM4sGw/nLL5YMLKUofllTaXn1zhr3yli07fJC9usbddUpUwPw+Xnkn4wo+d45WXz7C4kDAZDbl/d8D9O0cc7DmKWUSWJUTGYsuK/b097t+9wxNPZFy61GRhPuLy5ZQXX2pT5g2uX5txtAcYmJ9TXHkm4+UvLPOZz51jcWkRW2ru3R7w9ls7bG1O8U6jVUSkY9D60w0rJgR8CFRe1f1RHf1+YP3BEVGsaXZTkqTFymLM01eg0+oxHlbgJPtuabHNxQtzLMy3UCTsHUy4dn2frZ0ZITRIkw5Zo4txjqAqtndnNNOKbqtHuxkRRxlL8z2uPAG9boeDFekv4pwmMdBtK86eaXD+3DzNRoStKnb2Jty+d8jG9oyDoxn5zDDfhdWlOTrtDrMChmMYTqShcBpnoCKpmVB1zp7XaBORNbsURnE03GJja8Kbb23wTDHPxQtLnDm3wiukuCpw5XyfMo9oZLB6xvD01TnOX1gmihP2D4bcvHvAt9/a4t7GEbPS4TGScOADReG5eXOL+XnoLXi6c8vMdWOuPrvKZPAEly4uMOjHlGVE0JYrz7Z44cV5LlycwxjF+oNdXv/mJuv3x4wHHldqEi3p8wu9JufPnqGRKe5dv8fmw50aLKRwUUATCEphlBR4WFvhvSXLFO2eZmm1S2++hWKCtoY0bbG2sspLL0ZomqSNFkqDRXijPmjQdS0JCmsVRZ7x7lt9djZvU+WWyCSgxWDdv7fPN75h6Mw/QdpuMTefcuWJVX7sS4GluQEHexV54Wi2Yp55bo2rn73I3FJMXiruPxjz6jc3uXN/xDT3KJ0SxRmEgLUBa2F3Z8Zr39wijlK+8KUFOnMxVy63+dEvXKARK/Z3S6wNdHqGMxebfPazq5w910Zj2Nqa8vq37vHuO5vkU4smQoUYSWuq2N2dcOP6Q86d73D2QpuFRc3KUoMXP3uOVtLgyYsV/UNPUI65Vc25SxnPXj3D0vICk6nn/t09br57xIO7E6ZTT5pIky5rpSbqU84cPW6KrNFRiyQ1jGc5N+7uouImc4urdJotkrjN5SdWuXAxxtlAcAJgSQxkqWRNjsaKW3cmvP7tbfYOPVm2TNJYJkk7xNrgQ87W7g42n7HQjWg3F2g3G0RRxtpaj9XVmBASnDf4oNF1QlekcuLIS2JTv+CtGzvcvL3PvY0+g+EM5RRpGlhd6dBtZQz6Q/oDxySPiIjr8nBHUc2gboyMMkIKI8aFlEmRcOP2LsPRAaP+RTqtZRrNDhfONVlbXsP9TIwmk81VNYNoigY2t3Ju3jjim69t89q3tniwXmIrSfpyTmIiReG5cXMH5ycsrTTpzTU4s9pibXWNn/rpecoiIoQ23scESuLGjCgtUFoSuV7/1h3+4A+u83A9J7iIWEdo40lSx/JSl9XlZSrf5/6dBzxc35RS8RCobIXRGqM0SkeP0ukJgSSNSBKN92KwVEggJLQaEVefvcCVC+BDCkFmR6k/kbpoSUQQEpZ3htmkgS9u8K1XN5kMJxikhWdRWjYe9inyIStnY3qL59GmTae9yBe/cJaXX4qlutgrrLNEsQTYQyjZP5zw2utb/O7vv8nGxgyTRMRRmzjK8NbjgyJKHEdDy1f/721c0Fx88mmSZgOlCj734tM898wzWCvBV5METOJoNEuUKhn0DTduHPLVP77D22/u46qUJEsAUzNuJT5R2Zz5+RYLiz2efW6Bs2c7XL36LE9dMdgyw1mDwxFMiY4tSSOiKBNuXn/IH/+fa7zz1g5HB0IyazQyyjJQ5bkstz6iPB6Goy4Y8iDY+VaMLTyDETx4mGOiXdaWmsx123TaTdKsSdpO0Bq8LSlnBTsHY4aDMbs7E967fsD2rqWyDZJGFxW1QTcE0xfAhjaTWeDG7RGz3LG61KLTa9BotUjTlEazKTc5mhActiwYjjyD/oj+YMbOwYyb9w7Y2ZuSlwLecTYnyTy9uQytPYd7AwaHBWVuII4IRFKiraRiU5KOlLSzHOdMBiWzacJ0GNjbOiQfQ1mmnDvfYWWlx8rKEnNLHYyKcM6RF4qj/pT77+3wYP2I967tce3aAbs7lnx6jNs5dtkl/X44tKyvj/mTP1lnPCl46so8T1xaZGVtiU6vQ5Q0CcFgbclhf8LDnSMOD0ZsPRxy9/YIXzVYmJ+j3RQWqVIl7S6srSzTbLTYOdhnb2fAZFTQyCJKE6GCr5EDCvAodZxKH6O1Is81D9bHZA1P8ANUUBiVoXEEG0mODxZlIoLWVMFJaj6AVhitJbYxqxiPLMVMcixCLFuOqTZAyTSvuHFjl6QRGAxWuXixRa/bpdlqkqSZkLVKx6wo6Q9ydrb73F/f5c79AeOZJm3Os5g2iU2HWCUoNCF4aTxlxwQ/YGvX8uo37rN30GNxuUGv16DZ7NCOE7wK+FAxy8c82Bixvzvg3p0Bb72xw61bA4YjaDaFpxuCBy3l8GVZMhwF3nvvCG1usLO9zLPPLbGy2mZ+rkdnrkEUN7A+MJyMOTo64uD+Hg8fHHLjvU1ef+0+O9szrNVEcVJfBycT10etqecxMRwKhdHC41DKYJIYFyzVZMr65pDt7SMuXVji4tmU5eVAr6dodSOiWGhKg2HJxvqMu7e3uHNrh/2DglnRIm3MEXSPoJt44rpaUROnjlkReOe9Pe6vH3Hp4jJnzyqWVxv0uopOGUjSgDFQFp7R2LKzXbL+YMjGplC/+uOCyiniuE2SGVzkSZtSvl+Vlt2tPof7BbZsEpsmaOlEjhe4bgieSClK6xhNCyb9KaMx7O84Boc5G+sPuXXjgOdfOMNnP/skzz3XZPVMkzSW6tfxJHDv/pSvf+0e77y9wZ2bY/aPHOOZZGo6C3FsMMbUFcOesgjs7Vr+6H+vc+2dLV64Os/Lr1zm5R9psLbWIGlUeFdRVBW3bh1w4+Zd7t3eZG93TBbPsTj/BMnKHN4Z+oMDfJiyutbi7PnzGJ0ym3hGgwpXRcz3ukwKYYOUudDIjJft3iiNBVQULP1+4N1rB/QPRzg7INKGNJbGyLbwhCCeio4S0JrSOqwXw6G0klkzRJR5xL3be0xngmvURhEnhjROMKZBYiz37k0ZDDc4OtBMRnOsrCUsLmvaXYU2mqL0jIYVB/tT3r22w3s37nPYz8maZ+nOzRHHbVRI0EGTRCnGRLU3N6bf3+ZoOOGPvnqLu/e7PHf1HOfPL7CwGJE1PGjFNC84OBhy+9Yu16/d581vb7B+p6TIPUa3wDTAGLR2GKexSqPRWOe5dbfPxtaAm7ce8sLd87z04mWuXE5YXM7ImgnWBXZ2Z9y7t88779zkrddvsblRsrdjSZKIKG6iVYT3HqUVBo0PHyOP45MSrZJH/SwrFwgqJcoWsGVK6Vps78aMRxPaGzOSVLYL0YITLHLLsF8yGiim1SI6ViRKEcUtdNyBKK6JYEJfUqYNicG6iEk15faDit2jfeYeTmk2JIFMURGCq0vUNZOpYThW9EctJmVKlEr6jAolWZTRbLaZX1pAxxHTUcFhv6CqpC1BFHeEmBW05GHUMNk0TbEWiiJnMJyyfzCkP6jIZwZbWmyZM53ssvmg4lvf3KLbaws6IEBZVhwe9rl/f4vd3QnDI8+sCJLGoOqlUAiSa+EVikhqdypLNXZYF/DukMNDz/XrIzrdBjqSmEFVBfYPjugfjTA6IcvOkzXmyBrzxCajshYTGdqtHs+9cJWnnr6ADw1ms4goatPtpsTxCl0XKHLPZFRJPYdzx3mdoGFaVDzYHGK/dptWQxNc9SgO4muwhVKy36p1hEcMrSfUXA3xYJSPwBnGo4pms0G726XT7dLqNEmz5HiSRXlLksD+fsQb396jdadPo2lIMo0ySq5FDpOxZzBwzGbzYnzTFK0SVIgkTT2A0jIReRRR0qG7qHHVFFTF/oHnzTcPuX9/QKOpcb4iLyyjSc7h4YS9vSFHB1MGhwpPQpQkKGLB+eUVlSsFmahjYcx4sGVJUZVsPHSMRw/ZWJ+xuLhOoxkRJzHea8bTgv39PkeHffa2C8pC02hkhCAMV4zBGIX3kjEN5iN7HY+H4QgKHSIik0oz36qQYFrUBlJc2WI0njEa5hCmoGZYm2OppAlQiPA+RYUWyswTNyKUDdJBPU5Qpg6m1YlTsmYGHXvKSjMe9jkczNjZn2B0hVKFNMAup5KdqFtgeijdo/ItdGyIogiUwxYDoiRmbj4mbc4xLuBgUNAfOTxNWp0WSsUSvfaglVRHokAFgysrZtMZw8GQ/tGAyTgneC19ZgaWfDpic2NCFG+Ki1/zKqSyUyo0qzIIns4LxyQQMFqqb/Eya4GSfilBgrPTmWdzs2B/b593rh0SR0rg51oLbAeH1hEXL1xgbn6NRqNDkjYFMEQgRBFpq8Xy6gU6vTP0B2MGQ0UULdDpQZouUoZAVXjSrGA2K8jzXAqstK5ZsiXD4YTRaFswTQ4EfxZqSo6ql7FibrxSKGOEcB8DWCFuOUWkE5rNFr3eAq1Oi1a7QbPTJGuJzqFShAq8t4zHI/rDAegKlAMT6noeRQgGQoaJFojTJdI0ARUJ4q/GWyotOEtfQ4eU0SRZB91s421OUYx58OCQra0SpSsmkzH94YTxxDEcFhQzh3eKNMlI0wYQ4R1Y6yjLgqqyRLEhbTSITSTJeCamKAyD4YT+0YSd3YlQ44w8+SEoXBAWiQoOjSGOm7RaLYrCCu2s5pD4IBXE+iPuqMDjYjgAnMbV2HqFxnuLU0o4mFkLqyfYaowiAp+iTIHyDhcUBIPWGcFLKz/vFdYFokSTJAkq0mgl9bT4YzIUeJWAbmBiD1iJwitB2itVYuKeFEGpDEwbTAcdIgENQU2zqlH/PmVnL2eaP+DwoGRvYAkhIY1jCdQFoXYpI9WQeV5ycHDE4cGAve199vcOyWc5ztlH2XwWpJdIcOSlI4RKPIi6Kh2tatqUlhma2igBBP+ogt3XVDGUfxRF9wGKCspS6ju0qinydUl4o5nS6/UwURelG6BTWW4ph04CJm1giVjfPGA4tYyHfbZ3B7jQI04UadaRGqLIkWRtOtYym02Z5rnUqjhodnrksxGz6QBXzQi2hjKhCV7hrMfWSUo6MqRZRmeuS6fXJk6kfWFZWEIFWhmyLKPdbgmmzwgZfjy2BC+BdI3UNjmXUrpKiOZKPBIdCSBb6witGzJpqQbUGErvHN46vBXMYGQk4Ct9SQLEx8S5lCj2xKlDUaCUJ8vadENFFDmMLhjpGVVeEJzHBeHiSkawQJ2IDEYZdFAEG7DBSS8dXYl3pAxBCW+lpiEJ3dzLTo/3hlib+noXBAQSZa2jKhwmEkYq8FHTOB4PwyGzsaotoTwVqo4HaKMwOsKkTSGfk6HxVNZSOitR9aBQxHWjoWPrKg9qZIRtoYJ8nveSMXeMb1M6Jmv0hLSgAkE5Ah6DQwchNikV41WCIwYn9QBS2i8zHTjymWGnytncLhmNPdNSqF0myEWT70nt+Whs6TncP+dHwnEAAAxZSURBVGJzY4f9nUOmkxmhsjUaqh4Vo6WNgaaGwTwqUwGlJWajjo2GjJlGurUR6hJL5SF4Ar4mi1Hj42rmSb2U8UHXBkvSteNEmkVHcSK8CqGDgjIoAyZpkVvP/c0j1jf7TEdj8jzH0SbKYryWlgHa1DQr5cmKlKwopJ9LkHL1Mu8xHjfJpwN8VReCOYWvGyvpssITaLaa9ObnWFxZYGFpnrQhD3wxtdgyoIORa22kgK6sLHlZUZQVLgQ0Ho3HkKBVhlEGtCQL6khoW1GkSKIYrVOCaggPw38HHmUL4YXqY//eSKMs7z3OWhRGrnmakhklCAgFWVBkrUDPKnq9kqPDI4ZHAyajkeASrUfhMTqg4kd0iTrvBQK+Rioe94qN8b6S+1QbICJ46QWjTZDGWE6YqpWrSOIEE0XY3GKtByVcElXvTH0UeSwMBzVXQ5Bt8qAIZAe8teS+rGlYCjDC13RaOqsHYW4EJ7RoYwyNhpFZSitsVUolZRzhSmnnqJUmKOE8ejzUHknlA0FpAgHrHdrL55lIvAwfhFytjRHSdzBSAYnFOU1VeSm5dglpI6pnr4APtu6oJZ5UUVrGwzGT4YzZuMDmjlCGulJUeKtKGVQ4NnKhrp2RZ1v2KLxUviop8vI+PNrmrEdUbkB1vFd/PDshdkVLIZUcEseVoEAbBL0p7SurqsRai60cNvb4Gr1n4gYemExDDVZOUTqRRlDHeD4reRQaaRmhtXiA1A2ZpMNYTJppyrxBVc7IJznTcU5pC/JCaFxJnNHtLrC4uEyz2ZClQ91JzQeF0oZI1/S4ICX0Wkuxmgol0j3T1wZLk5gEozOCkoZccRwRVEVV5NjCYbQlSj0mFh6os7Y2GDIDaOUFtqQkD4dI4SNHQCqtCR7xmyIkz8RjK09kErJGRrcLBkNsEiajMdPpGI0jSSUG5v1xLEhLdznxlWsQtaOqHAHhf2ijMce7kl527ZRRKBzeOcqyRBvBGmhdc1CCwnov6IhPda1KzQEK3teVrwGUkpTmYHFVRTDCciRovJdZxWOkwMk7nAv10yCzjtbyowKYEDDUac7e1tWQ9cf52rupWxEI9MZB0PJxql46BQX1DK/rY4pARALB4Z3FW6lsjLUhMqZmHkhNwzGZq7KW4WjK4eGA/tGI6STHWX/cVo3gvQyH0rVBUPjq2KWQXjNCqRaKmcKj68BvQMA0x1i8oMQHOaZXidWQz8WHR5WRSh9zXo8DyAp8XehXW6rgJN3bK7BBgZGtvaKy0g4gxETGECeynMFK9zeCzMYYUCqqcwdUvcOlIERkscFmGbYqmUQT8CO8nRC8rovCGszPLzI/Py9BUdR3uLLOExDKvVLy/SWxyRBpTRLJeCmV4IJCeUNkpA1B8AZ0IFKGgBZItAs4FErbuiNaHTcK4hVEkbRbMPWOR1TzH50yVK7CWYcPoo9DuClVJS0JlIqIoohG5lFBEZtMEtWUwtmcOFZ4X1FYR/CyRNXBi9dtZOI6bqegdFTfWxqjj0HfMm9oY4QyEmRCCE7jdd2jxojnaStbFwd+ig1HCOCCxXkrNz3yxfF15/S6a7l10ocieFUnAMnspoPC60Bw6lGDZmO0tPPTkhpcFFO5qWo0PD5gdL3DIex4AtQ5B5oojmqXUJiSUmav8a72RrQmMuaRMTE6IorECDkfsL4uHzeAkqh/cBHeO/b3jtjc3OawPyTPZ3KDaPGa1KM4RJDzctx9zTyqAlW1J3HMdwhEwtNEZvgQxDgorwhajE7A1K6phiCGhyDuqlaGoIUvETw4K4VQzWaDLMu+Y4SVkeK/+mYLuu6vEsA76Z6nrSx1QlBoLaS1EAR+ISswXXuO4GxFcFa4IjohylKSqEEz65DP5eTTWZ33EdHtdh4tQ/CgogiFESPlNT5ESFTIPFrqRkZjGq2aASKxL5yv6V+gvPxtCMJ4abU60siqsEL4KgpMFBNHCdpLPoq0sqi5pfUOULCBilDH2xLJaNUxzguXVAL9Gq8Ula2w3mOimN5cg26vzeLSPLPpiMl4xHQ6RmGxoRJPxeVEkSxZtQ7EianzgYxkIh8HxT045R55kVob4jgmMlkdM5SgaAjhEVFeJoxPseFACY3cB4dW5njOw/tQ49ZqS+sR8Gzd3lHV/48gpdte2TroWc+eSktNAZKo44Krg59yWqMMoQ4SBaVkIAk4J9uNcZJQ2YB1EuvQSva+nZPMReflhiAojBYPSaOpkCCmLBMEZSf9Ug3Oa6bTnOFowmw6xVXy4Ais2CHtIahdbmGPKIMExAI1x8JLfc8xsBknszeCyZeZpr60QT2iw6maFxeQbVqCoJ2lf23AK2FnhjouE8cRkTG10ZDZP3gv0fnjS6c1Rh0vlWS5eVw6pWsKsHfS2e4RVDvIdvFxfokwKsRY6zghTVKyNCVPkkc7YUka1bsx1O6UPDzy1VStk3iB1AFjreqOgNoTZPMcvHid3ksejauDx8dd2YKXeIKzkmimTSTXvd7ilpibliVlrYv39TJSaYIy4o3qWDxR7KPlQ8AKShBZLqfNjDhSNJspo1g8k9nMQigI3sszUTPao0j65tZRQHQk/Yt9Ve+S1D8oL+dXul4qRzVMWeBWocYZOu9QHxEbKI/sR62r/SGKUmoEXD9pPb5LloD9k1biu+RUpx8sj5s+8HjrdCmEsPxh//Pj4XHA9RDC509aifeLUuqbpzr9YHncdHrc9IE/mzp99I4sp3Iqp/L/rZwajlM5lVP50PK4GI5/fdIKfA851elPJ4+bTo+bPvBnUKfHIjh6KqdyKp8ueVw8jlM5lVP5FMmJGw6l1F9WSl1XSt1S0vn+pPS4p5R6Syn1hlLqm/WxBaXU7yqlbtb/zn/MOvy6UmpXKfX2+459Tx2UyL+ox+1NpdQrn5A+v6qUeliP0xtKqZ9/33v/sNbnulLqL/2w9anPcUEp9YdKqWtKqXeUUn+vPn4i4/QB+pzYOCmlMqXUq0qpb9c6/eP6+GWl1Nfrc/+WUiqpj6f177fq95/4gScJdTbZSfwABrgNXAES4NvA8yekyz1g6buO/VPgl+vXvwz8k49Zh58EXgHe/kE6II2v/geSa/Ul4OufkD6/CvyD7/G3z9fXLwUu19fVfAw6nQFeqV93gBv1uU9knD5AnxMbp/q7tuvXMfD1+rv/J+AX6+O/Bvyt+vXfBn6tfv2LwG/9oHOctMfxReBWCOFOCKEEfhP4ygnr9H75CvAb9evfAP7qx3myEMIfAYd/Sh2+Avy7IPI1YK7u4/tx6/P95CvAb4YQihDCXaSb3xd/mPrUOm2FEL5Vvx4B7wLnOKFx+gB9vp987ONUf9dx/Wtc/wTgp4Hfro9/9xgdj91vA39BqQ/GGJ+04TgHPHjf7xt88KB/nBKA/6mUek0p9TfrY6vhO71vt4HVE9Dr++lwkmP3d2u3/9fft3z7xPWpXeqXkRn1xMfpu/SBExwnpZRRSr2BNIT/XcSz6YcQ7Pc47yOd6vcHwOIHff5JG47HSX48hPAK8HPA31FK/eT73wzix53oFtTjoAPwr4Angc8BW8A/OwkllFJt4L8Afz+EMHz/eycxTt9DnxMdpxCCCyF8DjiPeDTP/TA//6QNx0Pgwvt+P18f+8QlhPCw/ncX+G/IYO8cu7X1v7snoNr30+FExi6EsFPflB74N3zHzf7E9FFKxchD+h9CCP+1Pnxi4/S99HkcxqnWow/8IfBjyDLtuMzk/ed9pFP9fg84+KDPPWnD8Q3g6TramyCBmd/5pJVQSrWUUp3j18DPAm/XuvxS/We/BPz3T1q3D9Dhd4C/Xu8afAkYvM9V/9jku+IDfw0Zp2N9frGO0F8GngZe/RjOr4B/C7wbQvjn73vrRMbp++lzkuOklFpWSs3VrxvAX0RiL38I/EL9Z989Rsdj9wvAH9Re2/eXH2Y09yNGgH8eiUTfBn7lhHS4gkS6vw28c6wHss77feAm8HvAwsesx39E3NoKWYP+je+nAxI5/5f1uL0FfP4T0uff1+d7s77hzrzv73+l1uc68HMf0xj9OLIMeRN4o/75+ZMapw/Q58TGCXgReL0+99vAP3rfff4qEpD9z0BaH8/q32/V71/5Qec4zRw9lVM5lQ8tJ71UOZVTOZVPoZwajlM5lVP50HJqOE7lVE7lQ8up4TiVUzmVDy2nhuNUTuVUPrScGo5TOZVT+dByajhO5VRO5UPLqeE4lVM5lQ8t/w/98/DYokK+0QAAAABJRU5ErkJggg=="
+ },
+ "metadata": {
+ "needs_background": "light"
+ }
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 146
+ },
+ "id": "k3s27QIGQCnT",
+ "outputId": "c945a860-4358-4939-9ac6-c5d712b2c7d6"
+ }
+ }
+ ]
+}
diff --git a/demo/README.md b/demo/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..321a8dc5c58eaaa5356cc171c75e9feda35e116f
--- /dev/null
+++ b/demo/README.md
@@ -0,0 +1,251 @@
+# Demo
+
+We provide an easy-to-use API for the demo and application purpose in [ocr.py](https://github.com/open-mmlab/mmocr/blob/main/mmocr/utils/ocr.py) script.
+
+The API can be called through command line (CL) or by calling it from another python script.
+
+---
+
+## Example 1: Text Detection
+
+
+
+
+
+
+**Instruction:** Perform detection inference on an image with the TextSnake recognition model, export the result in a json file (default) and save the visualization file.
+
+- CL interface:
+
+```shell
+python mmocr/utils/ocr.py demo/demo_text_det.jpg --output demo/det_out.jpg --det TextSnake --recog None --export demo/
+```
+
+- Python interface:
+
+```python
+from mmocr.utils.ocr import MMOCR
+
+# Load models into memory
+ocr = MMOCR(det='TextSnake', recog=None)
+
+# Inference
+results = ocr.readtext('demo/demo_text_det.jpg', output='demo/det_out.jpg', export='demo/')
+```
+
+## Example 2: Text Recognition
+
+
+
+
+
+
+**Instruction:** Perform batched recognition inference on a folder with hundreds of image with the CRNN_TPS recognition model and save the visualization results in another folder.
+*Batch size is set to 10 to prevent out of memory CUDA runtime errors.*
+
+- CL interface:
+
+```shell
+python mmocr/utils/ocr.py %INPUT_FOLDER_PATH% --det None --recog CRNN_TPS --batch-mode --single-batch-size 10 --output %OUPUT_FOLDER_PATH%
+```
+
+- Python interface:
+
+```python
+from mmocr.utils.ocr import MMOCR
+
+# Load models into memory
+ocr = MMOCR(det=None, recog='CRNN_TPS')
+
+# Inference
+results = ocr.readtext(%INPUT_FOLDER_PATH%, output = %OUTPUT_FOLDER_PATH%, batch_mode=True, single_batch_size = 10)
+```
+
+## Example 3: Text Detection + Recognition
+
+
+
+
+
+
+**Instruction:** Perform ocr (det + recog) inference on the demo/demo_text_det.jpg image with the PANet_IC15 (default) detection model and SAR (default) recognition model, print the result in the terminal and show the visualization.
+
+- CL interface:
+
+```shell
+python mmocr/utils/ocr.py demo/demo_text_ocr.jpg --print-result --imshow
+```
+
+:::{note}
+
+When calling the script from the command line, the script assumes configs are saved in the `configs/` folder. User can customize the directory by specifying the value of `config_dir`.
+
+:::
+
+- Python interface:
+
+```python
+from mmocr.utils.ocr import MMOCR
+
+# Load models into memory
+ocr = MMOCR()
+
+# Inference
+results = ocr.readtext('demo/demo_text_ocr.jpg', print_result=True, imshow=True)
+```
+
+---
+
+## Example 4: Text Detection + Recognition + Key Information Extraction
+
+
+
+
+
+
+**Instruction:** Perform end-to-end ocr (det + recog) inference first with PS_CTW detection model and SAR recognition model, then run KIE inference with SDMGR model on the ocr result and show the visualization.
+
+- CL interface:
+
+```shell
+python mmocr/utils/ocr.py demo/demo_kie.jpeg --det PS_CTW --recog SAR --kie SDMGR --print-result --imshow
+```
+
+:::{note}
+
+Note: When calling the script from the command line, the script assumes configs are saved in the `configs/` folder. User can customize the directory by specifying the value of `config_dir`.
+
+:::
+
+- Python interface:
+
+```python
+from mmocr.utils.ocr import MMOCR
+
+# Load models into memory
+ocr = MMOCR(det='PS_CTW', recog='SAR', kie='SDMGR')
+
+# Inference
+results = ocr.readtext('demo/demo_kie.jpeg', print_result=True, imshow=True)
+```
+
+---
+
+## API Arguments
+
+The API has an extensive list of arguments that you can use. The following tables are for the python interface.
+
+**MMOCR():**
+
+| Arguments | Type | Default | Description |
+| -------------- | --------------------- | ------------- | ----------------------------------------------------------- |
+| `det` | see [models](#models) | PANet_IC15 | Text detection algorithm |
+| `recog` | see [models](#models) | SAR | Text recognition algorithm |
+| `kie` [1] | see [models](#models) | None | Key information extraction algorithm |
+| `config_dir` | str | configs/ | Path to the config directory where all the config files are located |
+| `det_config` | str | None | Path to the custom config file of the selected det model |
+| `det_ckpt` | str | None | Path to the custom checkpoint file of the selected det model |
+| `recog_config` | str | None | Path to the custom config file of the selected recog model |
+| `recog_ckpt` | str | None | Path to the custom checkpoint file of the selected recog model |
+| `kie_config` | str | None | Path to the custom config file of the selected kie model |
+| `kie_ckpt` | str | None | Path to the custom checkpoint file of the selected kie model |
+| `device` | str | None | Device used for inference, accepting all allowed strings by `torch.device`. E.g., 'cuda:0' or 'cpu'. |
+
+[1]: `kie` is only effective when both text detection and recognition models are specified.
+
+:::{note}
+
+User can use default pretrained models by specifying `det` and/or `recog`, which is equivalent to specifying their corresponding `*_config` and `*_ckpt`. However, manually specifying `*_config` and `*_ckpt` will always override values set by `det` and/or `recog`. Similar rules also apply to `kie`, `kie_config` and `kie_ckpt`.
+
+:::
+
+### readtext()
+
+| Arguments | Type | Default | Description |
+| ------------------- | ----------------------- | ------------ | ---------------------------------------------------------------------- |
+| `img` | str/list/tuple/np.array | **required** | img, folder path, np array or list/tuple (with img paths or np arrays) |
+| `output` | str | None | Output result visualization - img path or folder path |
+| `batch_mode` | bool | False | Whether use batch mode for inference [1] |
+| `det_batch_size` | int | 0 | Batch size for text detection (0 for max size) |
+| `recog_batch_size` | int | 0 | Batch size for text recognition (0 for max size) |
+| `single_batch_size` | int | 0 | Batch size for only detection or recognition |
+| `export` | str | None | Folder where the results of each image are exported |
+| `export_format` | str | json | Format of the exported result file(s) |
+| `details` | bool | False | Whether include the text boxes coordinates and confidence values |
+| `imshow` | bool | False | Whether to show the result visualization on screen |
+| `print_result` | bool | False | Whether to show the result for each image |
+| `merge` | bool | False | Whether to merge neighboring boxes [2] |
+| `merge_xdist` | float | 20 | The maximum x-axis distance to merge boxes |
+
+[1]: Make sure that the model is compatible with batch mode.
+
+[2]: Only effective when the script is running in det + recog mode.
+
+All arguments are the same for the cli, all you need to do is add 2 hyphens at the beginning of the argument and replace underscores by hyphens.
+(*Example:* `det_batch_size` becomes `--det-batch-size`)
+
+For bool type arguments, putting the argument in the command stores it as true.
+(*Example:* `python mmocr/utils/ocr.py demo/demo_text_det.jpg --batch_mode --print_result`
+means that `batch_mode` and `print_result` are set to `True`)
+
+---
+
+## Models
+
+**Text detection:**
+
+| Name | Reference | `batch_mode` inference support |
+| ------------- | :------------------------------------------------------------------------------------------------------------------------------------------------------: | :------------------: |
+| DB_r18 | [link](https://mmocr.readthedocs.io/en/latest/textdet_models.html#real-time-scene-text-detection-with-differentiable-binarization) | :x: |
+| DB_r50 | [link](https://mmocr.readthedocs.io/en/latest/textdet_models.html#real-time-scene-text-detection-with-differentiable-binarization) | :x: |
+| DRRG | [link](https://mmocr.readthedocs.io/en/latest/textdet_models.html#drrg) | :x: |
+| FCE_IC15 | [link](https://mmocr.readthedocs.io/en/latest/textdet_models.html#fourier-contour-embedding-for-arbitrary-shaped-text-detection) | :x: |
+| FCE_CTW_DCNv2 | [link](https://mmocr.readthedocs.io/en/latest/textdet_models.html#fourier-contour-embedding-for-arbitrary-shaped-text-detection) | :x: |
+| MaskRCNN_CTW | [link](https://mmocr.readthedocs.io/en/latest/textdet_models.html#mask-r-cnn) | :x: |
+| MaskRCNN_IC15 | [link](https://mmocr.readthedocs.io/en/latest/textdet_models.html#mask-r-cnn) | :x: |
+| MaskRCNN_IC17 | [link](https://mmocr.readthedocs.io/en/latest/textdet_models.html#mask-r-cnn) | :x: |
+| PANet_CTW | [link](https://mmocr.readthedocs.io/en/latest/textdet_models.html#efficient-and-accurate-arbitrary-shaped-text-detection-with-pixel-aggregation-network) | :heavy_check_mark: |
+| PANet_IC15 | [link](https://mmocr.readthedocs.io/en/latest/textdet_models.html#efficient-and-accurate-arbitrary-shaped-text-detection-with-pixel-aggregation-network) | :heavy_check_mark: |
+| PS_CTW | [link](https://mmocr.readthedocs.io/en/latest/textdet_models.html#psenet) | :x: |
+| PS_IC15 | [link](https://mmocr.readthedocs.io/en/latest/textdet_models.html#psenet) | :x: |
+| TextSnake | [link](https://mmocr.readthedocs.io/en/latest/textdet_models.html#textsnake) | :heavy_check_mark: |
+
+**Text recognition:**
+
+| Name | Reference | `batch_mode` inference support |
+| ------------- | :--------------------------------------------------------------------------------------------------------------------------------: | :------------------: |
+| ABINet | [link](https://mmocr.readthedocs.io/en/latest/textrecog_models.html#read-like-humans-autonomous-bidirectional-and-iterative-language-modeling-for-scene-text-recognition) | :heavy_check_mark: |
+| CRNN | [link](https://mmocr.readthedocs.io/en/latest/textrecog_models.html#an-end-to-end-trainable-neural-network-for-image-based-sequence-recognition-and-its-application-to-scene-text-recognition) | :x: |
+| SAR | [link](https://mmocr.readthedocs.io/en/latest/textrecog_models.html#show-attend-and-read-a-simple-and-strong-baseline-for-irregular-text-recognition) | :heavy_check_mark: |
+| SAR_CN * | [link](https://mmocr.readthedocs.io/en/latest/textrecog_models.html#show-attend-and-read-a-simple-and-strong-baseline-for-irregular-text-recognition) | :heavy_check_mark: |
+| NRTR_1/16-1/8 | [link](https://mmocr.readthedocs.io/en/latest/textrecog_models.html#nrtr) | :heavy_check_mark: |
+| NRTR_1/8-1/4 | [link](https://mmocr.readthedocs.io/en/latest/textrecog_models.html#nrtr) | :heavy_check_mark: |
+| RobustScanner | [link](https://mmocr.readthedocs.io/en/latest/textrecog_models.html#robustscanner-dynamically-enhancing-positional-clues-for-robust-text-recognition) | :heavy_check_mark: |
+| SATRN | [link](https://mmocr.readthedocs.io/en/latest/textrecog_models.html#satrn) | :heavy_check_mark: |
+| SATRN_sm | [link](https://mmocr.readthedocs.io/en/latest/textrecog_models.html#satrn) | :heavy_check_mark: |
+| SEG | [link](https://mmocr.readthedocs.io/en/latest/textrecog_models.html#segocr-simple-baseline) | :x: |
+| CRNN_TPS | [link](https://mmocr.readthedocs.io/en/latest/textrecog_models.html#crnn-with-tps-based-stn) | :heavy_check_mark: |
+
+:::{warning}
+
+SAR_CN is the only model that supports Chinese character recognition and it requires
+a Chinese dictionary. Please download the dictionary from [here](https://mmocr.readthedocs.io/en/latest/textrecog_models.html#chinese-dataset) for a successful run.
+
+:::
+
+**Key information extraction:**
+
+| Name | Reference | `batch_mode` support |
+| ------------- | :------------------------------------------------------------------------------------------------------------------------------------------------------: | :------------------: |
+| SDMGR | [link](https://mmocr.readthedocs.io/en/latest/kie_models.html#spatial-dual-modality-graph-reasoning-for-key-information-extraction) | :heavy_check_mark: |
+---
+
+## Additional info
+
+- To perform det + recog inference (end2end ocr), both the `det` and `recog` arguments must be defined.
+- To perform only detection set the `recog` argument to `None`.
+- To perform only recognition set the `det` argument to `None`.
+- `details` argument only works with end2end ocr.
+- `det_batch_size` and `recog_batch_size` arguments define the number of images you want to forward to the model at the same time. For maximum speed, set this to the highest number you can. The max batch size is limited by the model complexity and the GPU VRAM size.
+
+If you have any suggestions for new features, feel free to open a thread or even PR :)
diff --git a/demo/README_zh-CN.md b/demo/README_zh-CN.md
new file mode 100644
index 0000000000000000000000000000000000000000..a329896e39be0106bd1ea802fa8ad96319501160
--- /dev/null
+++ b/demo/README_zh-CN.md
@@ -0,0 +1,248 @@
+# 演示
+
+MMOCR 为示例和应用,以 [ocr.py](https://github.com/open-mmlab/mmocr/blob/main/mmocr/utils/ocr.py) 脚本形式,提供了方便使用的 API。
+
+该 API 可以通过命令行执行,也可以在 python 脚本内调用。
+
+---
+
+## 案例一:文本检测
+
+
+
+
+**注:** 首先,使用 PS_CTW 检测模型和 SAR 识别模型,进行端到端的 ocr (检测+识别)推理,然后对得到的结果,使用 SDMGR 模型提取关键信息(KIE),并展示可视化结果。
+
+- 命令行执行:
+
+```shell
+python mmocr/utils/ocr.py demo/demo_kie.jpeg --det PS_CTW --recog SAR --kie SDMGR --print-result --imshow
+```
+
+:::{note}
+
+当用户从命令行执行脚本时,默认配置文件都会保存在 `configs/` 目录下。用户可以通过指定 `config_dir` 的值来自定义读取配置文件的文件夹。
+
+:::
+
+- Python 调用:
+
+```python
+from mmocr.utils.ocr import MMOCR
+
+# 导入模型到内存
+ocr = MMOCR(det='PS_CTW', recog='SAR', kie='SDMGR')
+
+# 推理
+results = ocr.readtext('demo/demo_kie.jpeg', print_result=True, imshow=True)
+```
+
+---
+
+## API 参数
+
+该 API 有多个可供使用的参数列表。下表是 python 接口的参数。
+
+**MMOCR():**
+
+| 参数 | 类型 | 默认值 | 描述 |
+| -------------- | --------------------- | ------------- | ----------------------------------------------------------- |
+| `det` | 参考 **模型** 章节 | PANet_IC15 | 文本检测算法 |
+| `recog` | 参考 **模型** 章节 | SAR | 文本识别算法 |
+| `kie` [1] | 参考 **模型** 章节 | None | 关键信息提取算法 |
+| `config_dir` | str | configs/ | 用于存放所有配置文件的文件夹路径 |
+| `det_config` | str | None | 指定检测模型的自定义配置文件路径 |
+| `det_ckpt` | str | None | 指定检测模型的自定义参数文件路径 |
+| `recog_config` | str | None | 指定识别模型的自定义配置文件路径 |
+| `recog_ckpt` | str | None | 指定识别模型的自定义参数文件路径 |
+| `kie_config` | str | None | 指定关键信息提取模型的自定义配置路径 |
+| `kie_ckpt` | str | None | 指定关键信息提取的自定义参数文件路径 |
+| `device` | str | None | 推理时使用的设备标识, 支持 `torch.device` 所包含的所有设备字符. 例如, 'cuda:0' 或 'cpu'. |
+
+[1]: `kie` 当且仅当同时指定了文本检测和识别模型时才有效。
+
+:::{note}
+
+mmocr 为了方便使用提供了预置的模型配置和对应的预训练权重,用户可以通过指定 `det` 和/或 `recog` 值来指定使用,这种方法等同于分别单独指定其对应的 `*_config` 和 `*_ckpt`。需要注意的是,手动指定 `*_config` 和 `*_ckpt` 会覆盖 `det` 和/或 `recog` 指定模型预置的配置和权重值。 同理 `kie`, `kie_config` 和 `kie_ckpt` 的参数设定逻辑相同。
+
+:::
+
+### readtext()
+
+| 参数 | 类型 | 默认值 | 描述 |
+| ------------------- | ----------------------- | ------------ | ---------------------------------------------------------------------- |
+| `img` | str/list/tuple/np.array | **必填** | 图像,文件夹路径,np array 或 list/tuple (包含图片路径或 np arrays) |
+| `output` | str | None | 可视化输出结果 - 图片路径或文件夹路径 |
+| `batch_mode` | bool | False | 是否使用批处理模式推理 [1] |
+| `det_batch_size` | int | 0 | 文本检测的批处理大小(设置为 0 则与待推理图片个数相同) |
+| `recog_batch_size` | int | 0 | 文本识别的批处理大小(设置为 0 则与待推理图片个数相同) |
+| `single_batch_size` | int | 0 | 仅用于检测或识别使用的批处理大小 |
+| `export` | str | None | 存放导出图片结果的文件夹 |
+| `export_format` | str | json | 导出的结果文件格式 |
+| `details` | bool | False | 是否包含文本框的坐标和置信度的值 |
+| `imshow` | bool | False | 是否在屏幕展示可视化结果 |
+| `print_result` | bool | False | 是否展示每个图片的结果 |
+| `merge` | bool | False | 是否对相邻框进行合并 [2] |
+| `merge_xdist` | float | 20 | 合并相邻框的最大x-轴距离 |
+
+[1]: `batch_mode` 需确保模型兼容批处理模式(见下表模型是否支持批处理)。
+
+[2]: `merge` 只有同时运行检测+识别模式,参数才有效。
+
+以上所有参数在命令行同样适用,只需要在参数前简单添加两个连接符,并且将下参数中的下划线替换为连接符即可。
+(*例如:* `det_batch_size` 变成了 `--det-batch-size`)
+
+对于布尔类型参数,添加在命令中默认为true。
+(*例如:* `python mmocr/utils/ocr.py demo/demo_text_det.jpg --batch_mode --print_result` 意为 `batch_mode` 和 `print_result` 的参数值设置为 `True`)
+
+---
+
+## 模型
+
+**文本检测:**
+
+| 名称 | `batch_mode` 推理支持 |
+| ------------- | :------------------: |
+| [DB_r18](https://mmocr.readthedocs.io/en/latest/textdet_models.html#real-time-scene-text-detection-with-differentiable-binarization) | :x: |
+| [DB_r50](https://mmocr.readthedocs.io/en/latest/textdet_models.html#real-time-scene-text-detection-with-differentiable-binarization) | :x: |
+| [DRRG](https://mmocr.readthedocs.io/en/latest/textdet_models.html#drrg) | :x: |
+| [FCE_IC15](https://mmocr.readthedocs.io/en/latest/textdet_models.html#fourier-contour-embedding-for-arbitrary-shaped-text-detection) | :x: |
+| [FCE_CTW_DCNv2](https://mmocr.readthedocs.io/en/latest/textdet_models.html#fourier-contour-embedding-for-arbitrary-shaped-text-detection) | :x: |
+| [MaskRCNN_CTW](https://mmocr.readthedocs.io/en/latest/textdet_models.html#mask-r-cnn) | :x: |
+| [MaskRCNN_IC15](https://mmocr.readthedocs.io/en/latest/textdet_models.html#mask-r-cnn) | :x: |
+| [MaskRCNN_IC17](https://mmocr.readthedocs.io/en/latest/textdet_models.html#mask-r-cnn) | :x: |
+| [PANet_CTW](https://mmocr.readthedocs.io/en/latest/textdet_models.html#efficient-and-accurate-arbitrary-shaped-text-detection-with-pixel-aggregation-network) | :heavy_check_mark: |
+| [PANet_IC15](https://mmocr.readthedocs.io/en/latest/textdet_models.html#efficient-and-accurate-arbitrary-shaped-text-detection-with-pixel-aggregation-network) | :heavy_check_mark: |
+| [PS_CTW](https://mmocr.readthedocs.io/en/latest/textdet_models.html#psenet) | :x: |
+| [PS_IC15](https://mmocr.readthedocs.io/en/latest/textdet_models.html#psenet) | :x: |
+| [TextSnake](https://mmocr.readthedocs.io/en/latest/textdet_models.html#textsnake) | :heavy_check_mark: |
+
+**文本识别:**
+
+| 名称 | `batch_mode` 推理支持 |
+| ------------- |:------------------: |
+| [ABINet](https://mmocr.readthedocs.io/en/latest/textrecog_models.html#read-like-humans-autonomous-bidirectional-and-iterative-language-modeling-for-scene-text-recognition) | :heavy_check_mark: |
+| [CRNN](https://mmocr.readthedocs.io/en/latest/textrecog_models.html#an-end-to-end-trainable-neural-network-for-image-based-sequence-recognition-and-its-application-to-scene-text-recognition) | :x: |
+| [SAR](https://mmocr.readthedocs.io/en/latest/textrecog_models.html#show-attend-and-read-a-simple-and-strong-baseline-for-irregular-text-recognition) | :heavy_check_mark: |
+| [SAR_CN](https://mmocr.readthedocs.io/en/latest/textrecog_models.html#show-attend-and-read-a-simple-and-strong-baseline-for-irregular-text-recognition) | :heavy_check_mark: |
+| [NRTR_1/16-1/8](https://mmocr.readthedocs.io/en/latest/textrecog_models.html#nrtr) | :heavy_check_mark: |
+| [NRTR_1/8-1/4](https://mmocr.readthedocs.io/en/latest/textrecog_models.html#nrtr) | :heavy_check_mark: |
+| [RobustScanner](https://mmocr.readthedocs.io/en/latest/textrecog_models.html#robustscanner-dynamically-enhancing-positional-clues-for-robust-text-recognition) | :heavy_check_mark: |
+| [SATRN](https://mmocr.readthedocs.io/en/latest/textrecog_models.html#satrn) | :heavy_check_mark: |
+| [SATRN_sm](https://mmocr.readthedocs.io/en/latest/textrecog_models.html#satrn) | :heavy_check_mark: |
+| [SEG](https://mmocr.readthedocs.io/en/latest/textrecog_models.html#segocr-simple-baseline) | :x: |
+| [CRNN_TPS](https://mmocr.readthedocs.io/en/latest/textrecog_models.html#crnn-with-tps-based-stn) | :heavy_check_mark: |
+
+:::{note}
+
+SAR_CN 是唯一支持中文字符识别的模型,并且它需要一个中文字典。以便推理能成功运行,请先从 [这里](https://mmocr.readthedocs.io/en/latest/textrecog_models.html#chinese-dataset) 下载辞典。
+
+:::
+
+**关键信息提取:**
+
+| 名称 | `batch_mode` 支持 |
+| ------------- | :------------------: |
+| [SDMGR](https://mmocr.readthedocs.io/en/latest/kie_models.html#spatial-dual-modality-graph-reasoning-for-key-information-extraction) | :heavy_check_mark: |
+---
+
+## 其他需要注意
+
+- 执行检测+识别的推理(端到端 ocr),需要同时定义 `det` 和 `recog` 参数
+- 如果只需要执行检测,则 `recog` 参数设置为 `None`。
+- 如果只需要执行识别,则 `det` 参数设置为 `None`。
+- `details` 参数仅在端到端的 ocr 模型有效。
+- `det_batch_size` 和 `recog_batch_size` 指定了在同时间传递给模型的图片数量。为了提高推理速度,应该尽可能设置你能设置的最大值。最大的批处理值受模型复杂度和 GPU 的显存大小限制。
+
+如果你对新特性有任何建议,请随时开一个 issue,甚至可以提一个 PR:)
diff --git a/demo/demo_densetext_det.jpg b/demo/demo_densetext_det.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..fb70e0cca3b8483b9388a2a2b9432c0a4a849e0b
--- /dev/null
+++ b/demo/demo_densetext_det.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:8756b41a730a1c0563b5b359dfce8394a2e2b640c4ff290135ff543620f27956
+size 633161
diff --git a/demo/demo_kie.jpeg b/demo/demo_kie.jpeg
new file mode 100755
index 0000000000000000000000000000000000000000..51014d8e4c0ddfb24a1c353cb074ddd0118ff86d
Binary files /dev/null and b/demo/demo_kie.jpeg differ
diff --git a/demo/demo_text_det.jpg b/demo/demo_text_det.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..fc517e9705fdd8e60d10c63fa6322b1e96cbf77f
--- /dev/null
+++ b/demo/demo_text_det.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:b3b83c612a0e05196b15ccf503563711267766cc6a47b5622c44e102ac4c6a92
+size 38186
diff --git a/demo/demo_text_ocr.jpg b/demo/demo_text_ocr.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..6eb9de77bf97ed2d31d258b687c877f3c7483005
--- /dev/null
+++ b/demo/demo_text_ocr.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:2f9b4aa42b2dc9687dcc61a188395c0027d2e54dcacf0b059e919a6ff16d05a6
+size 224615
diff --git a/demo/demo_text_recog.jpg b/demo/demo_text_recog.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..859d7d59c3c449dc5b92635aae87bd2e8594bb68
--- /dev/null
+++ b/demo/demo_text_recog.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:46c5cb134a95a4965a5547733340c654f852dab2f19a70574f0405b6b0cc4edd
+size 44539
diff --git a/demo/ner_demo.py b/demo/ner_demo.py
new file mode 100755
index 0000000000000000000000000000000000000000..113d4e31bf0d98a6835e37a01d9f96425ee59440
--- /dev/null
+++ b/demo/ner_demo.py
@@ -0,0 +1,32 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from argparse import ArgumentParser
+
+from mmocr.apis import init_detector
+from mmocr.apis.inference import text_model_inference
+from mmocr.datasets import build_dataset # NOQA
+from mmocr.models import build_detector # NOQA
+
+
+def main():
+ parser = ArgumentParser()
+ parser.add_argument('config', help='Config file.')
+ parser.add_argument('checkpoint', help='Checkpoint file.')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference.')
+ args = parser.parse_args()
+
+ # build the model from a config file and a checkpoint file
+ model = init_detector(args.config, args.checkpoint, device=args.device)
+
+ # test a single text
+ input_sentence = input('Please enter a sentence you want to test: ')
+ result = text_model_inference(model, input_sentence)
+
+ # show the results
+ for pred_entities in result:
+ for entity in pred_entities:
+ print(f'{entity[0]}: {input_sentence[entity[1]:entity[2] + 1]}')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/demo/resources/demo_kie_pred.png b/demo/resources/demo_kie_pred.png
new file mode 100644
index 0000000000000000000000000000000000000000..8c06de774535c4592bca418084375684a6ad615d
--- /dev/null
+++ b/demo/resources/demo_kie_pred.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:e6ee80b7c54bc5321bf563fec0995675e00d1f4b4f243976b15920225baeaae9
+size 648894
diff --git a/demo/resources/demo_ocr_pred.jpg b/demo/resources/demo_ocr_pred.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..96610d6b8f059a27e739cee883278b01392a2d7f
--- /dev/null
+++ b/demo/resources/demo_ocr_pred.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:b8c076ff15635964d31badffcba3fdea34b8872b8d17dd0a3afdf9c66783136d
+size 157397
diff --git a/demo/resources/text_det_pred.jpg b/demo/resources/text_det_pred.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..ee3a3196c70838623bae946253509bae8037e4eb
--- /dev/null
+++ b/demo/resources/text_det_pred.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:222e8cb556c72b1da7fe7cf8161e39699d9b73a5c565a2b60187a608f608279d
+size 63090
diff --git a/demo/resources/text_recog_pred.jpg b/demo/resources/text_recog_pred.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..4658f02995cd4437699a8eac31b3c8105a34caef
--- /dev/null
+++ b/demo/resources/text_recog_pred.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:8ada53a8f221521008898fc7612088b6c56b3ee5f8ccb756fe1e6b64451ec386
+size 16858
diff --git a/demo/webcam_demo.py b/demo/webcam_demo.py
new file mode 100644
index 0000000000000000000000000000000000000000..475c29c208867326ee8c6f0ecc0fbfc74b32d65a
--- /dev/null
+++ b/demo/webcam_demo.py
@@ -0,0 +1,49 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+
+import cv2
+import torch
+
+from mmocr.apis import init_detector, model_inference
+from mmocr.datasets import build_dataset # noqa: F401
+from mmocr.models import build_detector # noqa: F401
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='MMDetection webcam demo.')
+ parser.add_argument('config', help='Test config file path.')
+ parser.add_argument('checkpoint', help='Checkpoint file.')
+ parser.add_argument(
+ '--device', type=str, default='cuda:0', help='CPU/CUDA device option.')
+ parser.add_argument(
+ '--camera-id', type=int, default=0, help='Camera device id.')
+ parser.add_argument(
+ '--score-thr', type=float, default=0.5, help='Bbox score threshold.')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+
+ device = torch.device(args.device)
+
+ model = init_detector(args.config, args.checkpoint, device=device)
+
+ camera = cv2.VideoCapture(args.camera_id)
+
+ print('Press "Esc", "q" or "Q" to exit.')
+ while True:
+ ret_val, img = camera.read()
+ result = model_inference(model, img)
+
+ ch = cv2.waitKey(1)
+ if ch == 27 or ch == ord('q') or ch == ord('Q'):
+ break
+
+ model.show_result(
+ img, result, score_thr=args.score_thr, wait_time=1, show=True)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/docker/Dockerfile b/docker/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..c1e8f601172ec91dccf1e4a88966269a7822d0cd
--- /dev/null
+++ b/docker/Dockerfile
@@ -0,0 +1,24 @@
+ARG PYTORCH="1.6.0"
+ARG CUDA="10.1"
+ARG CUDNN="7"
+
+FROM pytorch/pytorch:${PYTORCH}-cuda${CUDA}-cudnn${CUDNN}-devel
+
+ENV TORCH_CUDA_ARCH_LIST="6.0 6.1 7.0+PTX"
+ENV TORCH_NVCC_FLAGS="-Xfatbin -compress-all"
+ENV CMAKE_PREFIX_PATH="$(dirname $(which conda))/../"
+
+RUN apt-get update && apt-get install -y git ninja-build libglib2.0-0 libsm6 libxrender-dev libxext6 libgl1-mesa-glx \
+ && apt-get clean \
+ && rm -rf /var/lib/apt/lists/*
+
+RUN conda clean --all
+RUN pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.6.0/index.html
+
+RUN pip install mmdet==2.20.0
+
+RUN git clone https://github.com/open-mmlab/mmocr.git /mmocr
+WORKDIR /mmocr
+ENV FORCE_CUDA="1"
+RUN pip install -r requirements.txt
+RUN pip install --no-cache-dir -e .
diff --git a/docs/en/Makefile b/docs/en/Makefile
new file mode 100644
index 0000000000000000000000000000000000000000..d4bb2cbb9eddb1bb1b4f366623044af8e4830919
--- /dev/null
+++ b/docs/en/Makefile
@@ -0,0 +1,20 @@
+# Minimal makefile for Sphinx documentation
+#
+
+# You can set these variables from the command line, and also
+# from the environment for the first two.
+SPHINXOPTS ?=
+SPHINXBUILD ?= sphinx-build
+SOURCEDIR = .
+BUILDDIR = _build
+
+# Put it first so that "make" without argument is like "make help".
+help:
+ @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
+
+.PHONY: help Makefile
+
+# Catch-all target: route all unknown targets to Sphinx using the new
+# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
+%: Makefile
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
diff --git a/docs/en/_static/css/readthedocs.css b/docs/en/_static/css/readthedocs.css
new file mode 100644
index 0000000000000000000000000000000000000000..c4736f9dc728b2b0a49fd8e10d759c5d58e506d1
--- /dev/null
+++ b/docs/en/_static/css/readthedocs.css
@@ -0,0 +1,6 @@
+.header-logo {
+ background-image: url("../images/mmocr.png");
+ background-size: 110px 40px;
+ height: 40px;
+ width: 110px;
+}
diff --git a/docs/en/_static/images/mmocr.png b/docs/en/_static/images/mmocr.png
new file mode 100755
index 0000000000000000000000000000000000000000..725690a463fc9a5ffb8444165349d64f4236eac9
--- /dev/null
+++ b/docs/en/_static/images/mmocr.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:8cf149574b624b759ad134fb7fe90d8448b1e3b57c47ecf4e3a1915f157d8ce1
+size 28627
diff --git a/docs/en/api.rst b/docs/en/api.rst
new file mode 100644
index 0000000000000000000000000000000000000000..63f3ec10f1df6b79b15860eac5dcb5b43f4481db
--- /dev/null
+++ b/docs/en/api.rst
@@ -0,0 +1,180 @@
+mmocr.apis
+-------------
+.. automodule:: mmocr.apis
+ :members:
+
+
+mmocr.core
+-------------
+evaluation
+^^^^^^^^^^
+.. automodule:: mmocr.core.evaluation
+ :members:
+
+
+mmocr.utils
+-------------
+.. automodule:: mmocr.utils
+ :members:
+
+
+mmocr.models
+---------------
+Common Backbones
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.common.backbones
+ :members:
+
+.. automodule:: mmocr.models.common.losses
+ :members:
+
+Text Detection Detectors
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textdet.detectors
+ :members:
+
+Text Detection Heads
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textdet.dense_heads
+ :members:
+
+Text Detection Necks
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textdet.necks
+ :members:
+
+Text Detection Losses
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textdet.losses
+ :members:
+
+Text Detection Postprocessors
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textdet.postprocess
+ :members:
+
+Text Recognition Recognizer
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textrecog.recognizer
+ :members:
+
+Text Recognition Backbones
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textrecog.backbones
+ :members:
+
+Text Recognition Necks
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textrecog.necks
+ :members:
+
+Text Recognition Heads
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textrecog.heads
+ :members:
+
+Text Recognition Preprocessors
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textrecog.preprocessor
+ :members:
+
+Text Recognition Backbones
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textrecog.backbones
+ :members:
+
+Text Recognition Layers
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textrecog.layers
+ :members:
+
+Text Recognition Convertors
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textrecog.convertors
+ :members:
+
+Text Recognition Encoders
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textrecog.encoders
+ :members:
+
+Text Recognition Decoders
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textrecog.decoders
+ :members:
+
+Text Recognition Fusers
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textrecog.fusers
+ :members:
+
+Text Recognition Losses
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textrecog.losses
+ :members:
+
+KIE Extractors
+^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.kie.extractors
+ :members:
+
+KIE Heads
+^^^^^^^^^^^
+.. automodule:: mmocr.models.kie.heads
+ :members:
+
+KIE Losses
+^^^^^^^^^^^
+.. automodule:: mmocr.models.kie.losses
+ :members:
+
+NER Encoders
+^^^^^^^^^^^^
+.. automodule:: mmocr.models.ner.encoders
+ :members:
+
+NER Decoders
+^^^^^^^^^^^^
+.. automodule:: mmocr.models.ner.decoders
+ :members:
+
+NER Losses
+^^^^^^^^^^^
+.. automodule:: mmocr.models.ner.losses
+ :members:
+
+mmocr.datasets
+-----------------
+.. automodule:: mmocr.datasets
+ :members:
+
+datasets
+^^^^^^^^^^^
+.. automodule:: mmocr.datasets.base_dataset
+ :members:
+
+.. automodule:: mmocr.datasets.icdar_dataset
+ :members:
+
+.. automodule:: mmocr.datasets.ocr_dataset
+ :members:
+
+.. automodule:: mmocr.datasets.ocr_seg_dataset
+ :members:
+
+.. automodule:: mmocr.datasets.text_det_dataset
+ :members:
+
+.. automodule:: mmocr.datasets.kie_dataset
+ :members:
+
+
+pipelines
+^^^^^^^^^^^
+.. automodule:: mmocr.datasets.pipelines
+ :members:
+
+utils
+^^^^^^^^^^^
+.. automodule:: mmocr.datasets.utils
+ :members:
diff --git a/docs/en/changelog.md b/docs/en/changelog.md
new file mode 100644
index 0000000000000000000000000000000000000000..4a38ba43ece046fe3f8379a888e8a855347ab599
--- /dev/null
+++ b/docs/en/changelog.md
@@ -0,0 +1,377 @@
+# Changelog
+
+## v0.4.1 (27/01/2022)
+
+### Highlights
+
+1. Visualizing edge weights in OpenSet KIE is now supported! https://github.com/open-mmlab/mmocr/pull/677
+2. Some configurations have been optimized to significantly speed up the training and testing processes! Don't worry - you can still tune these parameters in case these modifications do not work. https://github.com/open-mmlab/mmocr/pull/757
+3. Now you can use CPU to train/debug your model! https://github.com/open-mmlab/mmocr/pull/752
+4. We have fixed a severe bug that causes users unable to call `mmocr.apis.test` with our pre-built wheels. https://github.com/open-mmlab/mmocr/pull/667
+
+### New Features & Enhancements
+
+* Show edge score for openset kie by @cuhk-hbsun in https://github.com/open-mmlab/mmocr/pull/677
+* Download flake8 from github as pre-commit hooks by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/695
+* Deprecate the support for 'python setup.py test' by @Harold-lkk in https://github.com/open-mmlab/mmocr/pull/722
+* Disable multi-processing feature of cv2 to speed up data loading by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/721
+* Extend ctw1500 converter to support text fields by @Harold-lkk in https://github.com/open-mmlab/mmocr/pull/729
+* Extend totaltext converter to support text fields by @Harold-lkk in https://github.com/open-mmlab/mmocr/pull/728
+* Speed up training by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/739
+* Add setup multi-processing both in train and test.py by @Harold-lkk in https://github.com/open-mmlab/mmocr/pull/757
+* Support CPU training/testing by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/752
+* Support specify gpu for testing and training with gpu-id instead of gpu-ids and gpus by @Harold-lkk in https://github.com/open-mmlab/mmocr/pull/756
+* Remove unnecessary custom_import from test.py by @Harold-lkk in https://github.com/open-mmlab/mmocr/pull/758
+
+### Bug Fixes
+
+* Fix satrn onnxruntime test by @AllentDan in https://github.com/open-mmlab/mmocr/pull/679
+* Support both ConcatDataset and UniformConcatDataset by @cuhk-hbsun in https://github.com/open-mmlab/mmocr/pull/675
+* Fix bugs of show_results in single_gpu_test by @cuhk-hbsun in https://github.com/open-mmlab/mmocr/pull/667
+* Fix a bug for sar decoder when bi-rnn is used by @MhLiao in https://github.com/open-mmlab/mmocr/pull/690
+* Fix opencv version to avoid some bugs by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/694
+* Fix py39 ci error by @Harold-lkk in https://github.com/open-mmlab/mmocr/pull/707
+* Update visualize.py by @TommyZihao in https://github.com/open-mmlab/mmocr/pull/715
+* Fix link of config by @cuhk-hbsun in https://github.com/open-mmlab/mmocr/pull/726
+* Use yaml.safe_load instead of load by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/753
+* Add necessary keys to test_pipelines to enable test-time visualization by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/754
+
+### Docs
+
+* Fix recog.md by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/674
+* Add config tutorial by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/683
+* Add MMSelfSup/MMRazor/MMDeploy in readme by @cuhk-hbsun in https://github.com/open-mmlab/mmocr/pull/692
+* Add recog & det model summary by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/693
+* Update docs link by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/710
+* add pull request template.md by @Harold-lkk in https://github.com/open-mmlab/mmocr/pull/711
+* Add website links to readme by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/731
+* update readme according to standard by @Harold-lkk in https://github.com/open-mmlab/mmocr/pull/742
+
+### New Contributors
+
+* @MhLiao made their first contribution in https://github.com/open-mmlab/mmocr/pull/690
+* @TommyZihao made their first contribution in https://github.com/open-mmlab/mmocr/pull/715
+
+**Full Changelog**: https://github.com/open-mmlab/mmocr/compare/v0.4.0...v0.4.1
+
+## v0.4.0 (15/12/2021)
+
+### Highlights
+
+1. We release a new text recognition model - [ABINet](https://arxiv.org/pdf/2103.06495.pdf) (CVPR 2021, Oral). With it dedicated model design and useful data augmentation transforms, ABINet can achieve the best performance on irregular text recognition tasks. [Check it out!](https://mmocr.readthedocs.io/en/latest/textrecog_models.html#read-like-humans-autonomous-bidirectional-and-iterative-language-modeling-for-scene-text-recognition)
+2. We are also working hard to fulfill the requests from our community.
+[OpenSet KIE](https://mmocr.readthedocs.io/en/latest/kie_models.html#wildreceiptopenset) is one of the achievement, which extends the application of SDMGR from text node classification to node-pair relation extraction. We also provide
+a demo script to convert WildReceipt to open set domain, though it cannot
+take the full advantage of OpenSet format. For more information, please read our
+[tutorial](https://mmocr.readthedocs.io/en/latest/tutorials/kie_closeset_openset.html).
+3. APIs of models can be exposed through TorchServe. [Docs](https://mmocr.readthedocs.io/en/latest/model_serving.html)
+
+### Breaking Changes & Migration Guide
+
+#### Postprocessor
+
+Some refactoring processes are still going on. For all text detection models, we unified their `decode` implementations into a new module category, `POSTPROCESSOR`, which is responsible for decoding different raw outputs into boundary instances. In all text detection configs, the `text_repr_type` argument in `bbox_head` is deprecated and will be removed in the future release.
+
+**Migration Guide**: Find a similar line from detection model's config:
+```
+text_repr_type=xxx,
+```
+And replace it with
+```
+postprocessor=dict(type='{MODEL_NAME}Postprocessor', text_repr_type=xxx)),
+```
+Take a snippet of PANet's config as an example. Before the change, its config for `bbox_head` looks like:
+```
+ bbox_head=dict(
+ type='PANHead',
+ text_repr_type='poly',
+ in_channels=[128, 128, 128, 128],
+ out_channels=6,
+ loss=dict(type='PANLoss')),
+```
+Afterwards:
+```
+ bbox_head=dict(
+ type='PANHead',
+ in_channels=[128, 128, 128, 128],
+ out_channels=6,
+ loss=dict(type='PANLoss'),
+ postprocessor=dict(type='PANPostprocessor', text_repr_type='poly')),
+```
+There are other postprocessors and each takes different arguments. Interested users can find their interfaces or implementations in `mmocr/models/textdet/postprocess` or through our [api docs](https://mmocr.readthedocs.io/en/latest/api.html#textdet-postprocess).
+
+#### New Config Structure
+
+We reorganized the `configs/` directory by extracting reusable sections into `configs/_base_`. Now the directory tree of `configs/_base_` is organized as follows:
+
+```
+_base_
+├── det_datasets
+├── det_models
+├── det_pipelines
+├── recog_datasets
+├── recog_models
+├── recog_pipelines
+└── schedules
+```
+
+Most of model configs are making full use of base configs now, which makes the overall structural clearer and facilitates fair
+comparison across models. Despite the seemingly significant hierarchical difference, **these changes would not break the backward compatibility** as the names of model configs remain the same.
+
+### New Features
+* Support openset kie by @cuhk-hbsun in https://github.com/open-mmlab/mmocr/pull/498
+* Add converter for the Open Images v5 text annotations by Krylov et al. by @baudm in https://github.com/open-mmlab/mmocr/pull/497
+* Support Chinese for kie show result by @cuhk-hbsun in https://github.com/open-mmlab/mmocr/pull/464
+* Add TorchServe support for text detection and recognition by @Harold-lkk in https://github.com/open-mmlab/mmocr/pull/522
+* Save filename in text detection test results by @cuhk-hbsun in https://github.com/open-mmlab/mmocr/pull/570
+* Add codespell pre-commit hook and fix typos by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/520
+* Avoid duplicate placeholder docs in CN by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/582
+* Save results to json file for kie. by @cuhk-hbsun in https://github.com/open-mmlab/mmocr/pull/589
+* Add SAR_CN to ocr.py by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/579
+* mim extension for windows by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/641
+* Support muitiple pipelines for different datasets by @cuhk-hbsun in https://github.com/open-mmlab/mmocr/pull/657
+* ABINet Framework by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/651
+
+### Refactoring
+* Refactor textrecog config structure by @cuhk-hbsun in https://github.com/open-mmlab/mmocr/pull/617
+* Refactor text detection config by @cuhk-hbsun in https://github.com/open-mmlab/mmocr/pull/626
+* refactor transformer modules by @cuhk-hbsun in https://github.com/open-mmlab/mmocr/pull/618
+* refactor textdet postprocess by @cuhk-hbsun in https://github.com/open-mmlab/mmocr/pull/640
+
+### Docs
+* C++ example section by @apiaccess21 in https://github.com/open-mmlab/mmocr/pull/593
+* install.md Chinese section by @A465539338 in https://github.com/open-mmlab/mmocr/pull/364
+* Add Chinese Translation of deployment.md. by @fatfishZhao in https://github.com/open-mmlab/mmocr/pull/506
+* Fix a model link and add the metafile for SATRN by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/473
+* Improve docs style by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/474
+* Enhancement & sync Chinese docs by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/492
+* TorchServe docs by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/539
+* Update docs menu by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/564
+* Docs for KIE CloseSet & OpenSet by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/573
+* Fix broken links by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/576
+* Docstring for text recognition models by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/562
+* Add MMFlow & MIM by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/597
+* Add MMFewShot by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/621
+* Update model readme by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/604
+* Add input size check to model_inference by @mpena-vina in https://github.com/open-mmlab/mmocr/pull/633
+* Docstring for textdet models by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/561
+* Add MMHuman3D in readme by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/644
+* Use shared menu from theme instead by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/655
+* Refactor docs structure by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/662
+* Docs fix by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/664
+
+### Enhancements
+* Use bounding box around polygon instead of within polygon by @alexander-soare in https://github.com/open-mmlab/mmocr/pull/469
+* Add CITATION.cff by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/476
+* Add py3.9 CI by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/475
+* update model-index.yml by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/484
+* Use container in CI by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/502
+* CircleCI Setup by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/611
+* Remove unnecessary custom_import from train.py by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/603
+* Change the upper version of mmcv to 1.5.0 by @zhouzaida in https://github.com/open-mmlab/mmocr/pull/628
+* Update CircleCI by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/631
+* Pass custom_hooks to MMCV by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/609
+* Skip CI when some specific files were changed by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/642
+* Add markdown linter in pre-commit hook by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/643
+* Use shape from loaded image by @cuhk-hbsun in https://github.com/open-mmlab/mmocr/pull/652
+* Cancel previous runs that are not completed by @Harold-lkk in https://github.com/open-mmlab/mmocr/pull/666
+
+### Bug Fixes
+* Modify algorithm "sar" weights path in metafile by @ShoupingShan in https://github.com/open-mmlab/mmocr/pull/581
+* Fix Cuda CI by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/472
+* Fix image export in test.py for KIE models by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/486
+* Allow invalid polygons in intersection and union by default by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/471
+* Update checkpoints' links for SATRN by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/518
+* Fix converting to onnx bug because of changing key from img_shape to resize_shape by @Harold-lkk in https://github.com/open-mmlab/mmocr/pull/523
+* Fix PyTorch 1.6 incompatible checkpoints by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/540
+* Fix paper field in metafiles by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/550
+* Unify recognition task names in metafiles by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/548
+* Fix py3.9 CI by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/563
+* Always map location to cpu when loading checkpoint by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/567
+* Fix wrong model builder in recog_test_imgs by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/574
+* Improve dbnet r50 by fixing img std by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/578
+* Fix resource warning: unclosed file by @cuhk-hbsun in https://github.com/open-mmlab/mmocr/pull/577
+* Fix bug that same start_point for different texts in draw_texts_by_pil by @cuhk-hbsun in https://github.com/open-mmlab/mmocr/pull/587
+* Keep original texts for kie by @cuhk-hbsun in https://github.com/open-mmlab/mmocr/pull/588
+* Fix random seed by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/600
+* Fix DBNet_r50 config by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/625
+* Change SBC case to DBC case by @cuhk-hbsun in https://github.com/open-mmlab/mmocr/pull/632
+* Fix kie demo by @innerlee in https://github.com/open-mmlab/mmocr/pull/610
+* fix type check by @cuhk-hbsun in https://github.com/open-mmlab/mmocr/pull/650
+* Remove depreciated image validator in totaltext converter by @gaotongxiao in https://github.com/open-mmlab/mmocr/pull/661
+* Fix change locals() dict by @Fei-Wang in https://github.com/open-mmlab/mmocr/pull/663
+* fix #614: textsnake targets by @HolyCrap96 in https://github.com/open-mmlab/mmocr/pull/660
+
+### New Contributors
+* @alexander-soare made their first contribution in https://github.com/open-mmlab/mmocr/pull/469
+* @A465539338 made their first contribution in https://github.com/open-mmlab/mmocr/pull/364
+* @fatfishZhao made their first contribution in https://github.com/open-mmlab/mmocr/pull/506
+* @baudm made their first contribution in https://github.com/open-mmlab/mmocr/pull/497
+* @ShoupingShan made their first contribution in https://github.com/open-mmlab/mmocr/pull/581
+* @apiaccess21 made their first contribution in https://github.com/open-mmlab/mmocr/pull/593
+* @zhouzaida made their first contribution in https://github.com/open-mmlab/mmocr/pull/628
+* @mpena-vina made their first contribution in https://github.com/open-mmlab/mmocr/pull/633
+* @Fei-Wang made their first contribution in https://github.com/open-mmlab/mmocr/pull/663
+
+**Full Changelog**: https://github.com/open-mmlab/mmocr/compare/v0.3.0...0.4.0
+
+## v0.3.0 (25/8/2021)
+
+### Highlights
+1. We add a new text recognition model -- SATRN! Its pretrained checkpoint achieves the best performance over other provided text recognition models. A lighter version of SATRN is also released which can obtain ~98% of the performance of the original model with only 45 MB in size. ([@2793145003](https://github.com/2793145003)) [#405](https://github.com/open-mmlab/mmocr/pull/405)
+2. Improve the demo script, `ocr.py`, which supports applying end-to-end text detection, text recognition and key information extraction models on images with easy-to-use commands. Users can find its full documentation in the demo section. ([@samayala22](https://github.com/samayala22), [@manjrekarom](https://github.com/manjrekarom)) [#371](https://github.com/open-mmlab/mmocr/pull/371), [#386](https://github.com/open-mmlab/mmocr/pull/386), [#400](https://github.com/open-mmlab/mmocr/pull/400), [#374](https://github.com/open-mmlab/mmocr/pull/374), [#428](https://github.com/open-mmlab/mmocr/pull/428)
+3. Our documentation is reorganized into a clearer structure. More useful contents are on the way! [#409](https://github.com/open-mmlab/mmocr/pull/409), [#454](https://github.com/open-mmlab/mmocr/pull/454)
+4. The requirement of `Polygon3` is removed since this project is no longer maintained or distributed. We unified all its references to equivalent substitutions in `shapely` instead. [#448](https://github.com/open-mmlab/mmocr/pull/448)
+
+### Breaking Changes & Migration Guide
+1. Upgrade version requirement of MMDetection to 2.14.0 to avoid bugs [#382](https://github.com/open-mmlab/mmocr/pull/382)
+2. MMOCR now has its own model and layer registries inherited from MMDetection's or MMCV's counterparts. ([#436](https://github.com/open-mmlab/mmocr/pull/436)) The modified hierarchical structure of the model registries are now organized as follows.
+
+```text
+mmcv.MODELS -> mmdet.BACKBONES -> BACKBONES
+mmcv.MODELS -> mmdet.NECKS -> NECKS
+mmcv.MODELS -> mmdet.ROI_EXTRACTORS -> ROI_EXTRACTORS
+mmcv.MODELS -> mmdet.HEADS -> HEADS
+mmcv.MODELS -> mmdet.LOSSES -> LOSSES
+mmcv.MODELS -> mmdet.DETECTORS -> DETECTORS
+mmcv.ACTIVATION_LAYERS -> ACTIVATION_LAYERS
+mmcv.UPSAMPLE_LAYERS -> UPSAMPLE_LAYERS
+```
+
+To migrate your old implementation to our new backend, you need to change the import path of any registries and their corresponding builder functions (including `build_detectors`) from `mmdet.models.builder` to `mmocr.models.builder`. If you have referred to any model or layer of MMDetection or MMCV in your model config, you need to add `mmdet.` or `mmcv.` prefix to its name to inform the model builder of the right namespace to work on.
+
+Interested users may check out [MMCV's tutorial on Registry](https://mmcv.readthedocs.io/en/latest/understand_mmcv/registry.html) for in-depth explanations on its mechanism.
+
+
+### New Features
+- Automatically replace SyncBN with BN for inference [#420](https://github.com/open-mmlab/mmocr/pull/420), [#453](https://github.com/open-mmlab/mmocr/pull/453)
+- Support batch inference for CRNN and SegOCR [#407](https://github.com/open-mmlab/mmocr/pull/407)
+- Support exporting documentation in pdf or epub format [#406](https://github.com/open-mmlab/mmocr/pull/406)
+- Support `persistent_workers` option in data loader [#459](https://github.com/open-mmlab/mmocr/pull/459)
+
+### Bug Fixes
+- Remove depreciated key in kie_test_imgs.py [#381](https://github.com/open-mmlab/mmocr/pull/381)
+- Fix dimension mismatch in batch testing/inference of DBNet [#383](https://github.com/open-mmlab/mmocr/pull/383)
+- Fix the problem of dice loss which stays at 1 with an empty target given [#408](https://github.com/open-mmlab/mmocr/pull/408)
+- Fix a wrong link in ocr.py ([@naarkhoo](https://github.com/naarkhoo)) [#417](https://github.com/open-mmlab/mmocr/pull/417)
+- Fix undesired assignment to "pretrained" in test.py [#418](https://github.com/open-mmlab/mmocr/pull/418)
+- Fix a problem in polygon generation of DBNet [#421](https://github.com/open-mmlab/mmocr/pull/421), [#443](https://github.com/open-mmlab/mmocr/pull/443)
+- Skip invalid annotations in totaltext_converter [#438](https://github.com/open-mmlab/mmocr/pull/438)
+- Add zero division handler in poly utils, remove Polygon3 [#448](https://github.com/open-mmlab/mmocr/pull/448)
+
+### Improvements
+- Replace lanms-proper with lanms-neo to support installation on Windows (with special thanks to [@gen-ko](https://github.com/gen-ko) who has re-distributed this package!)
+- Support MIM [#394](https://github.com/open-mmlab/mmocr/pull/394)
+- Add tests for PyTorch 1.9 in CI [#401](https://github.com/open-mmlab/mmocr/pull/401)
+- Enables fullscreen layout in readthedocs [#413](https://github.com/open-mmlab/mmocr/pull/413)
+- General documentation enhancement [#395](https://github.com/open-mmlab/mmocr/pull/395)
+- Update version checker [#427](https://github.com/open-mmlab/mmocr/pull/427)
+- Add copyright info [#439](https://github.com/open-mmlab/mmocr/pull/439)
+- Update citation information [#440](https://github.com/open-mmlab/mmocr/pull/440)
+
+### Contributors
+
+We thank [@2793145003](https://github.com/2793145003), [@samayala22](https://github.com/samayala22), [@manjrekarom](https://github.com/manjrekarom), [@naarkhoo](https://github.com/naarkhoo), [@gen-ko](https://github.com/gen-ko), [@duanjiaqi](https://github.com/duanjiaqi), [@gaotongxiao](https://github.com/gaotongxiao), [@cuhk-hbsun](https://github.com/cuhk-hbsun), [@innerlee](https://github.com/innerlee), [@wdsd641417025](https://github.com/wdsd641417025) for their contribution to this release!
+
+## v0.2.1 (20/7/2021)
+
+### Highlights
+1. Upgrade to use MMCV-full **>= 1.3.8** and MMDetection **>= 2.13.0** for latest features
+2. Add ONNX and TensorRT export tool, supporting the deployment of DBNet, PSENet, PANet and CRNN (experimental) [#278](https://github.com/open-mmlab/mmocr/pull/278), [#291](https://github.com/open-mmlab/mmocr/pull/291), [#300](https://github.com/open-mmlab/mmocr/pull/300), [#328](https://github.com/open-mmlab/mmocr/pull/328)
+3. Unified parameter initialization method which uses init_cfg in config files [#365](https://github.com/open-mmlab/mmocr/pull/365)
+
+### New Features
+- Support TextOCR dataset [#293](https://github.com/open-mmlab/mmocr/pull/293)
+- Support Total-Text dataset [#266](https://github.com/open-mmlab/mmocr/pull/266), [#273](https://github.com/open-mmlab/mmocr/pull/273), [#357](https://github.com/open-mmlab/mmocr/pull/357)
+- Support grouping text detection box into lines [#290](https://github.com/open-mmlab/mmocr/pull/290), [#304](https://github.com/open-mmlab/mmocr/pull/304)
+- Add benchmark_processing script that benchmarks data loading process [#261](https://github.com/open-mmlab/mmocr/pull/261)
+- Add SynthText preprocessor for text recognition models [#351](https://github.com/open-mmlab/mmocr/pull/351), [#361](https://github.com/open-mmlab/mmocr/pull/361)
+- Support batch inference during testing [#310](https://github.com/open-mmlab/mmocr/pull/310)
+- Add user-friendly OCR inference script [#366](https://github.com/open-mmlab/mmocr/pull/366)
+
+### Bug Fixes
+
+- Fix improper class ignorance in SDMGR Loss [#221](https://github.com/open-mmlab/mmocr/pull/221)
+- Fix potential numerical zero division error in DRRG [#224](https://github.com/open-mmlab/mmocr/pull/224)
+- Fix installing requirements with pip and mim [#242](https://github.com/open-mmlab/mmocr/pull/242)
+- Fix dynamic input error of DBNet [#269](https://github.com/open-mmlab/mmocr/pull/269)
+- Fix space parsing error in LineStrParser [#285](https://github.com/open-mmlab/mmocr/pull/285)
+- Fix textsnake decode error [#264](https://github.com/open-mmlab/mmocr/pull/264)
+- Correct isort setup [#288](https://github.com/open-mmlab/mmocr/pull/288)
+- Fix a bug in SDMGR config [#316](https://github.com/open-mmlab/mmocr/pull/316)
+- Fix kie_test_img for KIE nonvisual [#319](https://github.com/open-mmlab/mmocr/pull/319)
+- Fix metafiles [#342](https://github.com/open-mmlab/mmocr/pull/342)
+- Fix different device problem in FCENet [#334](https://github.com/open-mmlab/mmocr/pull/334)
+- Ignore improper tailing empty characters in annotation files [#358](https://github.com/open-mmlab/mmocr/pull/358)
+- Docs fixes [#247](https://github.com/open-mmlab/mmocr/pull/247), [#255](https://github.com/open-mmlab/mmocr/pull/255), [#265](https://github.com/open-mmlab/mmocr/pull/265), [#267](https://github.com/open-mmlab/mmocr/pull/267), [#268](https://github.com/open-mmlab/mmocr/pull/268), [#270](https://github.com/open-mmlab/mmocr/pull/270), [#276](https://github.com/open-mmlab/mmocr/pull/276), [#287](https://github.com/open-mmlab/mmocr/pull/287), [#330](https://github.com/open-mmlab/mmocr/pull/330), [#355](https://github.com/open-mmlab/mmocr/pull/355), [#367](https://github.com/open-mmlab/mmocr/pull/367)
+- Fix NRTR config [#356](https://github.com/open-mmlab/mmocr/pull/356), [#370](https://github.com/open-mmlab/mmocr/pull/370)
+
+### Improvements
+- Add backend for resizeocr [#244](https://github.com/open-mmlab/mmocr/pull/244)
+- Skip image processing pipelines in SDMGR novisual [#260](https://github.com/open-mmlab/mmocr/pull/260)
+- Speedup DBNet [#263](https://github.com/open-mmlab/mmocr/pull/263)
+- Update mmcv installation method in workflow [#323](https://github.com/open-mmlab/mmocr/pull/323)
+- Add part of Chinese documentations [#353](https://github.com/open-mmlab/mmocr/pull/353), [#362](https://github.com/open-mmlab/mmocr/pull/362)
+- Add support for ConcatDataset with two workflows [#348](https://github.com/open-mmlab/mmocr/pull/348)
+- Add list_from_file and list_to_file utils [#226](https://github.com/open-mmlab/mmocr/pull/226)
+- Speed up sort_vertex [#239](https://github.com/open-mmlab/mmocr/pull/239)
+- Support distributed evaluation of KIE [#234](https://github.com/open-mmlab/mmocr/pull/234)
+- Add pretrained FCENet on IC15 [#258](https://github.com/open-mmlab/mmocr/pull/258)
+- Support CPU for OCR demo [#227](https://github.com/open-mmlab/mmocr/pull/227)
+- Avoid extra image pre-processing steps [#375](https://github.com/open-mmlab/mmocr/pull/375)
+
+
+## v0.2.0 (18/5/2021)
+
+### Highlights
+
+1. Add the NER approach Bert-softmax (NAACL'2019)
+2. Add the text detection method DRRG (CVPR'2020)
+3. Add the text detection method FCENet (CVPR'2021)
+4. Increase the ease of use via adding text detection and recognition end-to-end demo, and colab online demo.
+5. Simplify the installation.
+
+### New Features
+
+- Add Bert-softmax for Ner task [#148](https://github.com/open-mmlab/mmocr/pull/148)
+- Add DRRG [#189](https://github.com/open-mmlab/mmocr/pull/189)
+- Add FCENet [#133](https://github.com/open-mmlab/mmocr/pull/133)
+- Add end-to-end demo [#105](https://github.com/open-mmlab/mmocr/pull/105)
+- Support batch inference [#86](https://github.com/open-mmlab/mmocr/pull/86) [#87](https://github.com/open-mmlab/mmocr/pull/87) [#178](https://github.com/open-mmlab/mmocr/pull/178)
+- Add TPS preprocessor for text recognition [#117](https://github.com/open-mmlab/mmocr/pull/117) [#135](https://github.com/open-mmlab/mmocr/pull/135)
+- Add demo documentation [#151](https://github.com/open-mmlab/mmocr/pull/151) [#166](https://github.com/open-mmlab/mmocr/pull/166) [#168](https://github.com/open-mmlab/mmocr/pull/168) [#170](https://github.com/open-mmlab/mmocr/pull/170) [#171](https://github.com/open-mmlab/mmocr/pull/171)
+- Add checkpoint for Chinese recognition [#156](https://github.com/open-mmlab/mmocr/pull/156)
+- Add metafile [#175](https://github.com/open-mmlab/mmocr/pull/175) [#176](https://github.com/open-mmlab/mmocr/pull/176) [#177](https://github.com/open-mmlab/mmocr/pull/177) [#182](https://github.com/open-mmlab/mmocr/pull/182) [#183](https://github.com/open-mmlab/mmocr/pull/183)
+- Add support for numpy array inference [#74](https://github.com/open-mmlab/mmocr/pull/74)
+
+### Bug Fixes
+
+- Fix the duplicated point bug due to transform for textsnake [#130](https://github.com/open-mmlab/mmocr/pull/130)
+- Fix CTC loss NaN [#159](https://github.com/open-mmlab/mmocr/pull/159)
+- Fix error raised if result is empty in demo [#144](https://github.com/open-mmlab/mmocr/pull/141)
+- Fix results missing if one image has a large number of boxes [#98](https://github.com/open-mmlab/mmocr/pull/98)
+- Fix package missing in dockerfile [#109](https://github.com/open-mmlab/mmocr/pull/109)
+
+### Improvements
+
+- Simplify installation procedure via removing compiling [#188](https://github.com/open-mmlab/mmocr/pull/188)
+- Speed up panet post processing so that it can detect dense texts [#188](https://github.com/open-mmlab/mmocr/pull/188)
+- Add zh-CN README [#70](https://github.com/open-mmlab/mmocr/pull/70) [#95](https://github.com/open-mmlab/mmocr/pull/95)
+- Support windows [#89](https://github.com/open-mmlab/mmocr/pull/89)
+- Add Colab [#147](https://github.com/open-mmlab/mmocr/pull/147) [#199](https://github.com/open-mmlab/mmocr/pull/199)
+- Add 1-step installation using conda environment [#193](https://github.com/open-mmlab/mmocr/pull/193) [#194](https://github.com/open-mmlab/mmocr/pull/194) [#195](https://github.com/open-mmlab/mmocr/pull/195)
+
+
+## v0.1.0 (7/4/2021)
+
+### Highlights
+
+- MMOCR is released.
+
+### Main Features
+
+- Support text detection, text recognition and the corresponding downstream tasks such as key information extraction.
+- For text detection, support both single-step (`PSENet`, `PANet`, `DBNet`, `TextSnake`) and two-step (`MaskRCNN`) methods.
+- For text recognition, support CTC-loss based method `CRNN`; Encoder-decoder (with attention) based methods `SAR`, `Robustscanner`; Segmentation based method `SegOCR`; Transformer based method `NRTR`.
+- For key information extraction, support GCN based method `SDMG-R`.
+- Provide checkpoints and log files for all of the methods above.
diff --git a/docs/en/code_of_conduct.md b/docs/en/code_of_conduct.md
new file mode 100644
index 0000000000000000000000000000000000000000..efd4305798630a5cd7b17d7cf893b9a811d5501f
--- /dev/null
+++ b/docs/en/code_of_conduct.md
@@ -0,0 +1,76 @@
+# Contributor Covenant Code of Conduct
+
+## Our Pledge
+
+In the interest of fostering an open and welcoming environment, we as
+contributors and maintainers pledge to making participation in our project and
+our community a harassment-free experience for everyone, regardless of age, body
+size, disability, ethnicity, sex characteristics, gender identity and expression,
+level of experience, education, socio-economic status, nationality, personal
+appearance, race, religion, or sexual identity and orientation.
+
+## Our Standards
+
+Examples of behavior that contributes to creating a positive environment
+include:
+
+* Using welcoming and inclusive language
+* Being respectful of differing viewpoints and experiences
+* Gracefully accepting constructive criticism
+* Focusing on what is best for the community
+* Showing empathy towards other community members
+
+Examples of unacceptable behavior by participants include:
+
+* The use of sexualized language or imagery and unwelcome sexual attention or
+ advances
+* Trolling, insulting/derogatory comments, and personal or political attacks
+* Public or private harassment
+* Publishing others' private information, such as a physical or electronic
+ address, without explicit permission
+* Other conduct which could reasonably be considered inappropriate in a
+ professional setting
+
+## Our Responsibilities
+
+Project maintainers are responsible for clarifying the standards of acceptable
+behavior and are expected to take appropriate and fair corrective action in
+response to any instances of unacceptable behavior.
+
+Project maintainers have the right and responsibility to remove, edit, or
+reject comments, commits, code, wiki edits, issues, and other contributions
+that are not aligned to this Code of Conduct, or to ban temporarily or
+permanently any contributor for other behaviors that they deem inappropriate,
+threatening, offensive, or harmful.
+
+## Scope
+
+This Code of Conduct applies both within project spaces and in public spaces
+when an individual is representing the project or its community. Examples of
+representing a project or community include using an official project e-mail
+address, posting via an official social media account, or acting as an appointed
+representative at an online or offline event. Representation of a project may be
+further defined and clarified by project maintainers.
+
+## Enforcement
+
+Instances of abusive, harassing, or otherwise unacceptable behavior may be
+reported by contacting the project team at chenkaidev@gmail.com. All
+complaints will be reviewed and investigated and will result in a response that
+is deemed necessary and appropriate to the circumstances. The project team is
+obligated to maintain confidentiality with regard to the reporter of an incident.
+Further details of specific enforcement policies may be posted separately.
+
+Project maintainers who do not follow or enforce the Code of Conduct in good
+faith may face temporary or permanent repercussions as determined by other
+members of the project's leadership.
+
+## Attribution
+
+This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4,
+available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
+
+[homepage]: https://www.contributor-covenant.org
+
+For answers to common questions about this code of conduct, see
+https://www.contributor-covenant.org/faq
diff --git a/docs/en/conf.py b/docs/en/conf.py
new file mode 100644
index 0000000000000000000000000000000000000000..baad575a4a383db7ba33dd4daac68bc93df45345
--- /dev/null
+++ b/docs/en/conf.py
@@ -0,0 +1,135 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# Configuration file for the Sphinx documentation builder.
+#
+# This file only contains a selection of the most common options. For a full
+# list see the documentation:
+# https://www.sphinx-doc.org/en/master/usage/configuration.html
+
+# -- Path setup --------------------------------------------------------------
+
+# If extensions (or modules to document with autodoc) are in another directory,
+# add these directories to sys.path here. If the directory is relative to the
+# documentation root, use os.path.abspath to make it absolute, like shown here.
+
+import os
+import subprocess
+import sys
+
+import pytorch_sphinx_theme
+
+sys.path.insert(0, os.path.abspath('../../'))
+
+# -- Project information -----------------------------------------------------
+
+project = 'MMOCR'
+copyright = '2020-2030, OpenMMLab'
+author = 'OpenMMLab'
+
+# The full version, including alpha/beta/rc tags
+version_file = '../../mmocr/version.py'
+with open(version_file, 'r') as f:
+ exec(compile(f.read(), version_file, 'exec'))
+__version__ = locals()['__version__']
+release = __version__
+
+# -- General configuration ---------------------------------------------------
+
+# Add any Sphinx extension module names here, as strings. They can be
+# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
+# ones.
+extensions = [
+ 'sphinx.ext.autodoc', 'sphinx.ext.napoleon', 'sphinx.ext.viewcode',
+ 'sphinx_markdown_tables', 'sphinx_copybutton', 'myst_parser'
+]
+
+autodoc_mock_imports = ['mmcv._ext']
+
+# Ignore >>> when copying code
+copybutton_prompt_text = r'>>> |\.\.\. '
+copybutton_prompt_is_regexp = True
+
+# Add any paths that contain templates here, relative to this directory.
+templates_path = ['_templates']
+
+# The suffix(es) of source filenames.
+# You can specify multiple suffix as a list of string:
+#
+source_suffix = {
+ '.rst': 'restructuredtext',
+ '.md': 'markdown',
+}
+
+# The master toctree document.
+master_doc = 'index'
+
+# List of patterns, relative to source directory, that match files and
+# directories to ignore when looking for source files.
+# This pattern also affects html_static_path and html_extra_path.
+exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
+
+# -- Options for HTML output -------------------------------------------------
+
+# The theme to use for HTML and HTML Help pages. See the documentation for
+# a list of builtin themes.
+#
+# html_theme = 'sphinx_rtd_theme'
+html_theme = 'pytorch_sphinx_theme'
+html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]
+html_theme_options = {
+ 'logo_url':
+ 'https://mmocr.readthedocs.io/en/latest/',
+ 'menu': [
+ {
+ 'name':
+ 'Tutorial',
+ 'url':
+ 'https://colab.research.google.com/github/'
+ 'open-mmlab/mmocr/blob/main/demo/MMOCR_Tutorial.ipynb'
+ },
+ {
+ 'name': 'GitHub',
+ 'url': 'https://github.com/open-mmlab/mmocr'
+ },
+ {
+ 'name':
+ 'Upstream',
+ 'children': [
+ {
+ 'name': 'MMCV',
+ 'url': 'https://github.com/open-mmlab/mmcv',
+ 'description': 'Foundational library for computer vision'
+ },
+ {
+ 'name': 'MMDetection',
+ 'url': 'https://github.com/open-mmlab/mmdetection',
+ 'description': 'Object detection toolbox and benchmark'
+ },
+ ]
+ },
+ ],
+ # Specify the language of shared menu
+ 'menu_lang':
+ 'en'
+}
+
+language = 'en'
+
+master_doc = 'index'
+
+# Add any paths that contain custom static files (such as style sheets) here,
+# relative to this directory. They are copied after the builtin static files,
+# so a file named "default.css" will overwrite the builtin "default.css".
+html_static_path = ['_static']
+html_css_files = ['css/readthedocs.css']
+
+# Enable ::: for my_st
+myst_enable_extensions = ['colon_fence']
+
+
+def builder_inited_handler(app):
+ subprocess.run(['./merge_docs.sh'])
+ subprocess.run(['./stats.py'])
+
+
+def setup(app):
+ app.connect('builder-inited', builder_inited_handler)
diff --git a/docs/en/datasets/det.md b/docs/en/datasets/det.md
new file mode 100644
index 0000000000000000000000000000000000000000..93d4fdd3cac1b47b4366b53e36529af46097f504
--- /dev/null
+++ b/docs/en/datasets/det.md
@@ -0,0 +1,214 @@
+
+# Text Detection
+
+## Overview
+
+The structure of the text detection dataset directory is organized as follows.
+
+```text
+├── ctw1500
+│ ├── annotations
+│ ├── imgs
+│ ├── instances_test.json
+│ └── instances_training.json
+├── icdar2015
+│ ├── imgs
+│ ├── instances_test.json
+│ └── instances_training.json
+├── icdar2017
+│ ├── imgs
+│ ├── instances_training.json
+│ └── instances_val.json
+├── synthtext
+│ ├── imgs
+│ └── instances_training.lmdb
+│ ├── data.mdb
+│ └── lock.mdb
+├── textocr
+│ ├── train
+│ ├── instances_training.json
+│ └── instances_val.json
+├── totaltext
+│ ├── imgs
+│ ├── instances_test.json
+│ └── instances_training.json
+├── CurvedSynText150k
+│ ├── syntext_word_eng
+│ ├── emcs_imgs
+│ └── instances_training.json
+|── funsd
+| ├── annotations
+│ ├── imgs
+│ ├── instances_test.json
+│ └── instances_training.json
+```
+
+| Dataset | Images | | Annotation Files | | |
+| :---------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | :------------------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------------------: | :---: |
+| | | training | validation | testing | |
+| CTW1500 | [homepage](https://github.com/Yuliang-Liu/Curve-Text-Detector) | - | - | - |
+| ICDAR2015 | [homepage](https://rrc.cvc.uab.es/?ch=4&com=downloads) | [instances_training.json](https://download.openmmlab.com/mmocr/data/icdar2015/instances_training.json) | - | [instances_test.json](https://download.openmmlab.com/mmocr/data/icdar2015/instances_test.json) |
+| ICDAR2017 | [homepage](https://rrc.cvc.uab.es/?ch=8&com=downloads) | [instances_training.json](https://download.openmmlab.com/mmocr/data/icdar2017/instances_training.json) | [instances_val.json](https://download.openmmlab.com/mmocr/data/icdar2017/instances_val.json) | - | | |
+| Synthtext | [homepage](https://www.robots.ox.ac.uk/~vgg/data/scenetext/) | instances_training.lmdb ([data.mdb](https://download.openmmlab.com/mmocr/data/synthtext/instances_training.lmdb/data.mdb), [lock.mdb](https://download.openmmlab.com/mmocr/data/synthtext/instances_training.lmdb/lock.mdb)) | - | - |
+| TextOCR | [homepage](https://textvqa.org/textocr/dataset) | - | - | - |
+| Totaltext | [homepage](https://github.com/cs-chan/Total-Text-Dataset) | - | - | - |
+| CurvedSynText150k | [homepage](https://github.com/aim-uofa/AdelaiDet/blob/master/datasets/README.md) \| [Part1](https://drive.google.com/file/d/1OSJ-zId2h3t_-I7g_wUkrK-VqQy153Kj/view?usp=sharing) \| [Part2](https://drive.google.com/file/d/1EzkcOlIgEp5wmEubvHb7-J5EImHExYgY/view?usp=sharing) | [instances_training.json](https://download.openmmlab.com/mmocr/data/curvedsyntext/instances_training.json) | - | - |
+| FUNSD | [homepage](https://guillaumejaume.github.io/FUNSD/) | - | - | - |
+
+
+## Important Note
+
+:::{note}
+**For users who want to train models on CTW1500, ICDAR 2015/2017, and Totaltext dataset,** there might be some images containing orientation info in EXIF data. The default OpenCV
+backend used in MMCV would read them and apply the rotation on the images. However, their gold annotations are made on the raw pixels, and such
+inconsistency results in false examples in the training set. Therefore, users should use `dict(type='LoadImageFromFile', color_type='color_ignore_orientation')` in pipelines to change MMCV's default loading behaviour. (see [DBNet's pipeline config](https://github.com/open-mmlab/mmocr/blob/main/configs/_base_/det_pipelines/dbnet_pipeline.py) for example)
+:::
+
+## Preparation Steps
+### ICDAR 2015
+- Step0: Read [Important Note](#important-note)
+- Step1: Download `ch4_training_images.zip`, `ch4_test_images.zip`, `ch4_training_localization_transcription_gt.zip`, `Challenge4_Test_Task1_GT.zip` from [homepage](https://rrc.cvc.uab.es/?ch=4&com=downloads)
+- Step2:
+```bash
+mkdir icdar2015 && cd icdar2015
+mkdir imgs && mkdir annotations
+# For images,
+mv ch4_training_images imgs/training
+mv ch4_test_images imgs/test
+# For annotations,
+mv ch4_training_localization_transcription_gt annotations/training
+mv Challenge4_Test_Task1_GT annotations/test
+```
+- Step3: Download [instances_training.json](https://download.openmmlab.com/mmocr/data/icdar2015/instances_training.json) and [instances_test.json](https://download.openmmlab.com/mmocr/data/icdar2015/instances_test.json) and move them to `icdar2015`
+- Or, generate `instances_training.json` and `instances_test.json` with following command:
+```bash
+python tools/data/textdet/icdar_converter.py /path/to/icdar2015 -o /path/to/icdar2015 -d icdar2015 --split-list training test
+```
+
+### ICDAR 2017
+- Follow similar steps as [ICDAR 2015](#icdar-2015).
+
+### CTW1500
+- Step0: Read [Important Note](#important-note)
+- Step1: Download `train_images.zip`, `test_images.zip`, `train_labels.zip`, `test_labels.zip` from [github](https://github.com/Yuliang-Liu/Curve-Text-Detector)
+```bash
+mkdir ctw1500 && cd ctw1500
+mkdir imgs && mkdir annotations
+
+# For annotations
+cd annotations
+wget -O train_labels.zip https://universityofadelaide.box.com/shared/static/jikuazluzyj4lq6umzei7m2ppmt3afyw.zip
+wget -O test_labels.zip https://cloudstor.aarnet.edu.au/plus/s/uoeFl0pCN9BOCN5/download
+unzip train_labels.zip && mv ctw1500_train_labels training
+unzip test_labels.zip -d test
+cd ..
+# For images
+cd imgs
+wget -O train_images.zip https://universityofadelaide.box.com/shared/static/py5uwlfyyytbb2pxzq9czvu6fuqbjdh8.zip
+wget -O test_images.zip https://universityofadelaide.box.com/shared/static/t4w48ofnqkdw7jyc4t11nsukoeqk9c3d.zip
+unzip train_images.zip && mv train_images training
+unzip test_images.zip && mv test_images test
+```
+- Step2: Generate `instances_training.json` and `instances_test.json` with following command:
+
+```bash
+python tools/data/textdet/ctw1500_converter.py /path/to/ctw1500 -o /path/to/ctw1500 --split-list training test
+```
+
+### SynthText
+
+- Download [data.mdb](https://download.openmmlab.com/mmocr/data/synthtext/instances_training.lmdb/data.mdb) and [lock.mdb](https://download.openmmlab.com/mmocr/data/synthtext/instances_training.lmdb/lock.mdb) to `synthtext/instances_training.lmdb/`.
+
+### TextOCR
+- Step1: Download [train_val_images.zip](https://dl.fbaipublicfiles.com/textvqa/images/train_val_images.zip), [TextOCR_0.1_train.json](https://dl.fbaipublicfiles.com/textvqa/data/textocr/TextOCR_0.1_train.json) and [TextOCR_0.1_val.json](https://dl.fbaipublicfiles.com/textvqa/data/textocr/TextOCR_0.1_val.json) to `textocr/`.
+```bash
+mkdir textocr && cd textocr
+
+# Download TextOCR dataset
+wget https://dl.fbaipublicfiles.com/textvqa/images/train_val_images.zip
+wget https://dl.fbaipublicfiles.com/textvqa/data/textocr/TextOCR_0.1_train.json
+wget https://dl.fbaipublicfiles.com/textvqa/data/textocr/TextOCR_0.1_val.json
+
+# For images
+unzip -q train_val_images.zip
+mv train_images train
+```
+- Step2: Generate `instances_training.json` and `instances_val.json` with the following command:
+```bash
+python tools/data/textdet/textocr_converter.py /path/to/textocr
+```
+### Totaltext
+- Step0: Read [Important Note](#important-note)
+- Step1: Download `totaltext.zip` from [github dataset](https://github.com/cs-chan/Total-Text-Dataset/tree/master/Dataset) and `groundtruth_text.zip` from [github Groundtruth](https://github.com/cs-chan/Total-Text-Dataset/tree/master/Groundtruth/Text) (Our totaltext_converter.py supports groundtruth with both .mat and .txt format).
+```bash
+mkdir totaltext && cd totaltext
+mkdir imgs && mkdir annotations
+
+# For images
+# in ./totaltext
+unzip totaltext.zip
+mv Images/Train imgs/training
+mv Images/Test imgs/test
+
+# For annotations
+unzip groundtruth_text.zip
+cd Groundtruth
+mv Polygon/Train ../annotations/training
+mv Polygon/Test ../annotations/test
+
+```
+- Step2: Generate `instances_training.json` and `instances_test.json` with the following command:
+```bash
+python tools/data/textdet/totaltext_converter.py /path/to/totaltext -o /path/to/totaltext --split-list training test
+```
+
+### CurvedSynText150k
+
+- Step1: Download [syntext1.zip](https://drive.google.com/file/d/1OSJ-zId2h3t_-I7g_wUkrK-VqQy153Kj/view?usp=sharing) and [syntext2.zip](https://drive.google.com/file/d/1EzkcOlIgEp5wmEubvHb7-J5EImHExYgY/view?usp=sharing) to `CurvedSynText150k/`.
+- Step2:
+
+```bash
+unzip -q syntext1.zip
+mv train.json train1.json
+unzip images.zip
+rm images.zip
+
+unzip -q syntext2.zip
+mv train.json train2.json
+unzip images.zip
+rm images.zip
+```
+
+- Step3: Download [instances_training.json](https://download.openmmlab.com/mmocr/data/curvedsyntext/instances_training.json) to `CurvedSynText150k/`
+- Or, generate `instances_training.json` with following command:
+
+```bash
+python tools/data/common/curvedsyntext_converter.py PATH/TO/CurvedSynText150k --nproc 4
+```
+
+### FUNSD
+
+- Step1: Download [dataset.zip](https://guillaumejaume.github.io/FUNSD/dataset.zip) to `funsd/`.
+
+```bash
+mkdir funsd && cd funsd
+
+# Download FUNSD dataset
+wget https://guillaumejaume.github.io/FUNSD/dataset.zip
+unzip -q dataset.zip
+
+# For images
+mv dataset/training_data/images imgs && mv dataset/testing_data/images/* imgs/
+
+# For annotations
+mkdir annotations
+mv dataset/training_data/annotations annotations/training && mv dataset/testing_data/annotations annotations/test
+
+rm dataset.zip && rm -rf dataset
+```
+
+- Step2: Generate `instances_training.json` and `instances_test.json` with following command:
+
+```bash
+python tools/data/textdet/funsd_converter.py PATH/TO/funsd --nproc 4
+```
diff --git a/docs/en/datasets/kie.md b/docs/en/datasets/kie.md
new file mode 100644
index 0000000000000000000000000000000000000000..bd7a83932c597dfd713f71049725f7cf0eaf5954
--- /dev/null
+++ b/docs/en/datasets/kie.md
@@ -0,0 +1,36 @@
+# Key Information Extraction
+
+## Overview
+
+The structure of the key information extraction dataset directory is organized as follows.
+
+```text
+└── wildreceipt
+ ├── class_list.txt
+ ├── dict.txt
+ ├── image_files
+ ├── openset_train.txt
+ ├── openset_test.txt
+ ├── test.txt
+ └── train.txt
+```
+
+## Preparation Steps
+
+### WildReceipt
+
+- Just download and extract [wildreceipt.tar](https://download.openmmlab.com/mmocr/data/wildreceipt.tar).
+
+### WildReceiptOpenset
+
+- Step0: have [WildReceipt](#WildReceipt) prepared.
+- Step1: Convert annotation files to OpenSet format:
+```bash
+# You may find more available arguments by running
+# python tools/data/kie/closeset_to_openset.py -h
+python tools/data/kie/closeset_to_openset.py data/wildreceipt/train.txt data/wildreceipt/openset_train.txt
+python tools/data/kie/closeset_to_openset.py data/wildreceipt/test.txt data/wildreceipt/openset_test.txt
+```
+:::{note}
+You can learn more about the key differences between CloseSet and OpenSet annotations in our [tutorial](../tutorials/kie_closeset_openset.md).
+:::
diff --git a/docs/en/datasets/ner.md b/docs/en/datasets/ner.md
new file mode 100644
index 0000000000000000000000000000000000000000..efda24e8061896f4ba0d1dca06e6157ce5a52fa9
--- /dev/null
+++ b/docs/en/datasets/ner.md
@@ -0,0 +1,22 @@
+# Named Entity Recognition
+
+## Overview
+
+The structure of the named entity recognition dataset directory is organized as follows.
+
+```text
+└── cluener2020
+ ├── cluener_predict.json
+ ├── dev.json
+ ├── README.md
+ ├── test.json
+ ├── train.json
+ └── vocab.txt
+```
+
+## Preparation Steps
+
+### CLUENER2020
+
+- Download and extract [cluener_public.zip](https://storage.googleapis.com/cluebenchmark/tasks/cluener_public.zip) to `cluener2020/`
+- Download [vocab.txt](https://download.openmmlab.com/mmocr/data/cluener_public/vocab.txt) and move `vocab.txt` to `cluener2020/`
diff --git a/docs/en/datasets/recog.md b/docs/en/datasets/recog.md
new file mode 100644
index 0000000000000000000000000000000000000000..47d1e18c76d1c3dcac9a9162cfa3defef67721d7
--- /dev/null
+++ b/docs/en/datasets/recog.md
@@ -0,0 +1,323 @@
+# Text Recognition
+
+## Overview
+
+**The structure of the text recognition dataset directory is organized as follows.**
+
+```text
+├── mixture
+│ ├── coco_text
+│ │ ├── train_label.txt
+│ │ ├── train_words
+│ ├── icdar_2011
+│ │ ├── training_label.txt
+│ │ ├── Challenge1_Training_Task3_Images_GT
+│ ├── icdar_2013
+│ │ ├── train_label.txt
+│ │ ├── test_label_1015.txt
+│ │ ├── test_label_1095.txt
+│ │ ├── Challenge2_Training_Task3_Images_GT
+│ │ ├── Challenge2_Test_Task3_Images
+│ ├── icdar_2015
+│ │ ├── train_label.txt
+│ │ ├── test_label.txt
+│ │ ├── ch4_training_word_images_gt
+│ │ ├── ch4_test_word_images_gt
+│ ├── III5K
+│ │ ├── train_label.txt
+│ │ ├── test_label.txt
+│ │ ├── train
+│ │ ├── test
+│ ├── ct80
+│ │ ├── test_label.txt
+│ │ ├── image
+│ ├── svt
+│ │ ├── test_label.txt
+│ │ ├── image
+│ ├── svtp
+│ │ ├── test_label.txt
+│ │ ├── image
+│ ├── Syn90k
+│ │ ├── shuffle_labels.txt
+│ │ ├── label.txt
+│ │ ├── label.lmdb
+│ │ ├── mnt
+│ ├── SynthText
+│ │ ├── alphanumeric_labels.txt
+│ │ ├── shuffle_labels.txt
+│ │ ├── instances_train.txt
+│ │ ├── label.txt
+│ │ ├── label.lmdb
+│ │ ├── synthtext
+│ ├── SynthAdd
+│ │ ├── label.txt
+│ │ ├── label.lmdb
+│ │ ├── SynthText_Add
+│ ├── TextOCR
+│ │ ├── image
+│ │ ├── train_label.txt
+│ │ ├── val_label.txt
+│ ├── Totaltext
+│ │ ├── imgs
+│ │ ├── annotations
+│ │ ├── train_label.txt
+│ │ ├── test_label.txt
+│ ├── OpenVINO
+│ │ ├── image_1
+│ │ ├── image_2
+│ │ ├── image_5
+│ │ ├── image_f
+│ │ ├── image_val
+│ │ ├── train_1_label.txt
+│ │ ├── train_2_label.txt
+│ │ ├── train_5_label.txt
+│ │ ├── train_f_label.txt
+│ │ ├── val_label.txt
+│ ├── funsd
+│ │ ├── imgs
+│ │ ├── dst_imgs
+│ │ ├── annotations
+│ │ ├── train_label.txt
+│ │ ├── test_label.txt
+```
+
+| Dataset | images | annotation file | annotation file |
+| :-------------------: | :---------------------------------------------------------------------------------------------------: | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | :-----------------------------------------------------------------------------------------------------------------------: |
+| | | training | test |
+| coco_text | [homepage](https://rrc.cvc.uab.es/?ch=5&com=downloads) | [train_label.txt](https://download.openmmlab.com/mmocr/data/mixture/coco_text/train_label.txt) | - | |
+| icdar_2011 | [homepage](http://www.cvc.uab.es/icdar2011competition/?com=downloads) | [train_label.txt](https://download.openmmlab.com/mmocr/data/mixture/icdar_2015/train_label.txt) | - | |
+| icdar_2013 | [homepage](https://rrc.cvc.uab.es/?ch=2&com=downloads) | [train_label.txt](https://download.openmmlab.com/mmocr/data/mixture/icdar_2013/train_label.txt) | [test_label_1015.txt](https://download.openmmlab.com/mmocr/data/mixture/icdar_2013/test_label_1015.txt) | |
+| icdar_2015 | [homepage](https://rrc.cvc.uab.es/?ch=4&com=downloads) | [train_label.txt](https://download.openmmlab.com/mmocr/data/mixture/icdar_2015/train_label.txt) | [test_label.txt](https://download.openmmlab.com/mmocr/data/mixture/icdar_2015/test_label.txt) | |
+| IIIT5K | [homepage](http://cvit.iiit.ac.in/projects/SceneTextUnderstanding/IIIT5K.html) | [train_label.txt](https://download.openmmlab.com/mmocr/data/mixture/IIIT5K/train_label.txt) | [test_label.txt](https://download.openmmlab.com/mmocr/data/mixture/IIIT5K/test_label.txt) | |
+| ct80 | [homepage](http://cs-chan.com/downloads_CUTE80_dataset.html) | - | [test_label.txt](https://download.openmmlab.com/mmocr/data/mixture/ct80/test_label.txt) | |
+| svt | [homepage](http://www.iapr-tc11.org/mediawiki/index.php/The_Street_View_Text_Dataset) | - | [test_label.txt](https://download.openmmlab.com/mmocr/data/mixture/svt/test_label.txt) | |
+| svtp | [unofficial homepage\[1\]](https://github.com/Jyouhou/Case-Sensitive-Scene-Text-Recognition-Datasets) | - | [test_label.txt](https://download.openmmlab.com/mmocr/data/mixture/svtp/test_label.txt) | |
+| MJSynth (Syn90k) | [homepage](https://www.robots.ox.ac.uk/~vgg/data/text/) | [shuffle_labels.txt](https://download.openmmlab.com/mmocr/data/mixture/Syn90k/shuffle_labels.txt) \| [label.txt](https://download.openmmlab.com/mmocr/data/mixture/Syn90k/label.txt) | - | |
+| SynthText (Synth800k) | [homepage](https://www.robots.ox.ac.uk/~vgg/data/scenetext/) | [alphanumeric_labels.txt](https://download.openmmlab.com/mmocr/data/mixture/SynthText/alphanumeric_labels.txt) \|[shuffle_labels.txt](https://download.openmmlab.com/mmocr/data/mixture/SynthText/shuffle_labels.txt) \| [instances_train.txt](https://download.openmmlab.com/mmocr/data/mixture/SynthText/instances_train.txt) \| [label.txt](https://download.openmmlab.com/mmocr/data/mixture/SynthText/label.txt) | - | |
+| SynthAdd | [SynthText_Add.zip](https://pan.baidu.com/s/1uV0LtoNmcxbO-0YA7Ch4dg) (code:627x) | [label.txt](https://download.openmmlab.com/mmocr/data/mixture/SynthAdd/label.txt) | - | |
+| TextOCR | [homepage](https://textvqa.org/textocr/dataset) | - | - | |
+| Totaltext | [homepage](https://github.com/cs-chan/Total-Text-Dataset) | - | - | |
+| OpenVINO | [Open Images](https://github.com/cvdfoundation/open-images-dataset) | [annotations](https://storage.openvinotoolkit.org/repositories/openvino_training_extensions/datasets/open_images_v5_text) | [annotations](https://storage.openvinotoolkit.org/repositories/openvino_training_extensions/datasets/open_images_v5_text) | |
+| FUNSD | [homepage](https://guillaumejaume.github.io/FUNSD/) | - | - | |
+
+
+(*) Since the official homepage is unavailable now, we provide an alternative for quick reference. However, we do not guarantee the correctness of the dataset.
+
+## Preparation Steps
+
+### ICDAR 2013
+- Step1: Download `Challenge2_Test_Task3_Images.zip` and `Challenge2_Training_Task3_Images_GT.zip` from [homepage](https://rrc.cvc.uab.es/?ch=2&com=downloads)
+- Step2: Download [test_label_1015.txt](https://download.openmmlab.com/mmocr/data/mixture/icdar_2013/test_label_1015.txt) and [train_label.txt](https://download.openmmlab.com/mmocr/data/mixture/icdar_2013/train_label.txt)
+
+### ICDAR 2015
+- Step1: Download `ch4_training_word_images_gt.zip` and `ch4_test_word_images_gt.zip` from [homepage](https://rrc.cvc.uab.es/?ch=4&com=downloads)
+- Step2: Download [train_label.txt](https://download.openmmlab.com/mmocr/data/mixture/icdar_2015/train_label.txt) and [test_label.txt](https://download.openmmlab.com/mmocr/data/mixture/icdar_2015/test_label.txt)
+
+### IIIT5K
+ - Step1: Download `IIIT5K-Word_V3.0.tar.gz` from [homepage](http://cvit.iiit.ac.in/projects/SceneTextUnderstanding/IIIT5K.html)
+ - Step2: Download [train_label.txt](https://download.openmmlab.com/mmocr/data/mixture/IIIT5K/train_label.txt) and [test_label.txt](https://download.openmmlab.com/mmocr/data/mixture/IIIT5K/test_label.txt)
+
+### svt
+ - Step1: Download `svt.zip` form [homepage](http://www.iapr-tc11.org/mediawiki/index.php/The_Street_View_Text_Dataset)
+ - Step2: Download [test_label.txt](https://download.openmmlab.com/mmocr/data/mixture/svt/test_label.txt)
+ - Step3:
+ ```bash
+ python tools/data/textrecog/svt_converter.py
+ ```
+
+### ct80
+ - Step1: Download [test_label.txt](https://download.openmmlab.com/mmocr/data/mixture/ct80/test_label.txt)
+
+### svtp
+ - Step1: Download [test_label.txt](https://download.openmmlab.com/mmocr/data/mixture/svtp/test_label.txt)
+
+### coco_text
+ - Step1: Download from [homepage](https://rrc.cvc.uab.es/?ch=5&com=downloads)
+ - Step2: Download [train_label.txt](https://download.openmmlab.com/mmocr/data/mixture/coco_text/train_label.txt)
+
+### MJSynth (Syn90k)
+ - Step1: Download `mjsynth.tar.gz` from [homepage](https://www.robots.ox.ac.uk/~vgg/data/text/)
+ - Step2: Download [label.txt](https://download.openmmlab.com/mmocr/data/mixture/Syn90k/label.txt) (8,919,273 annotations) and [shuffle_labels.txt](https://download.openmmlab.com/mmocr/data/mixture/Syn90k/shuffle_labels.txt) (2,400,000 randomly sampled annotations). **Please make sure you're using the right annotation to train the model by checking its dataset specs in Model Zoo.**
+ - Step3:
+
+ ```bash
+ mkdir Syn90k && cd Syn90k
+
+ mv /path/to/mjsynth.tar.gz .
+
+ tar -xzf mjsynth.tar.gz
+
+ mv /path/to/shuffle_labels.txt .
+ mv /path/to/label.txt .
+
+ # create soft link
+ cd /path/to/mmocr/data/mixture
+
+ ln -s /path/to/Syn90k Syn90k
+ ```
+
+### SynthText (Synth800k)
+- Step1: Download `SynthText.zip` from [homepage](https://www.robots.ox.ac.uk/~vgg/data/scenetext/)
+
+- Step2: According to your actual needs, download the most appropriate one from the following options: [label.txt](https://download.openmmlab.com/mmocr/data/mixture/SynthText/label.txt) (7,266,686 annotations), [shuffle_labels.txt](https://download.openmmlab.com/mmocr/data/mixture/SynthText/shuffle_labels.txt) (2,400,000 randomly sampled annotations), [alphanumeric_labels.txt](https://download.openmmlab.com/mmocr/data/mixture/SynthText/alphanumeric_labels.txt) (7,239,272 annotations with alphanumeric characters only) and [instances_train.txt](https://download.openmmlab.com/mmocr/data/mixture/SynthText/instances_train.txt) (7,266,686 character-level annotations).
+
+:::{warning}
+Please make sure you're using the right annotation to train the model by checking its dataset specs in Model Zoo.
+:::
+
+- Step3:
+
+```bash
+mkdir SynthText && cd SynthText
+mv /path/to/SynthText.zip .
+unzip SynthText.zip
+mv SynthText synthtext
+
+mv /path/to/shuffle_labels.txt .
+mv /path/to/label.txt .
+mv /path/to/alphanumeric_labels.txt .
+mv /path/to/instances_train.txt .
+
+# create soft link
+cd /path/to/mmocr/data/mixture
+ln -s /path/to/SynthText SynthText
+```
+
+- Step4:
+Generate cropped images and labels:
+
+```bash
+cd /path/to/mmocr
+
+python tools/data/textrecog/synthtext_converter.py data/mixture/SynthText/gt.mat data/mixture/SynthText/ data/mixture/SynthText/synthtext/SynthText_patch_horizontal --n_proc 8
+```
+
+### SynthAdd
+- Step1: Download `SynthText_Add.zip` from [SynthAdd](https://pan.baidu.com/s/1uV0LtoNmcxbO-0YA7Ch4dg) (code:627x))
+- Step2: Download [label.txt](https://download.openmmlab.com/mmocr/data/mixture/SynthAdd/label.txt)
+- Step3:
+
+```bash
+mkdir SynthAdd && cd SynthAdd
+
+mv /path/to/SynthText_Add.zip .
+
+unzip SynthText_Add.zip
+
+mv /path/to/label.txt .
+
+# create soft link
+cd /path/to/mmocr/data/mixture
+
+ln -s /path/to/SynthAdd SynthAdd
+```
+:::{tip}
+To convert label file with `txt` format to `lmdb` format,
+```bash
+python tools/data/utils/txt2lmdb.py -i -o
+```
+For example,
+```bash
+python tools/data/utils/txt2lmdb.py -i data/mixture/Syn90k/label.txt -o data/mixture/Syn90k/label.lmdb
+```
+:::
+
+### TextOCR
+ - Step1: Download [train_val_images.zip](https://dl.fbaipublicfiles.com/textvqa/images/train_val_images.zip), [TextOCR_0.1_train.json](https://dl.fbaipublicfiles.com/textvqa/data/textocr/TextOCR_0.1_train.json) and [TextOCR_0.1_val.json](https://dl.fbaipublicfiles.com/textvqa/data/textocr/TextOCR_0.1_val.json) to `textocr/`.
+ ```bash
+ mkdir textocr && cd textocr
+
+ # Download TextOCR dataset
+ wget https://dl.fbaipublicfiles.com/textvqa/images/train_val_images.zip
+ wget https://dl.fbaipublicfiles.com/textvqa/data/textocr/TextOCR_0.1_train.json
+ wget https://dl.fbaipublicfiles.com/textvqa/data/textocr/TextOCR_0.1_val.json
+
+ # For images
+ unzip -q train_val_images.zip
+ mv train_images train
+ ```
+ - Step2: Generate `train_label.txt`, `val_label.txt` and crop images using 4 processes with the following command:
+ ```bash
+ python tools/data/textrecog/textocr_converter.py /path/to/textocr 4
+ ```
+
+### Totaltext
+ - Step1: Download `totaltext.zip` from [github dataset](https://github.com/cs-chan/Total-Text-Dataset/tree/master/Dataset) and `groundtruth_text.zip` from [github Groundtruth](https://github.com/cs-chan/Total-Text-Dataset/tree/master/Groundtruth/Text) (Our totaltext_converter.py supports groundtruth with both .mat and .txt format).
+ ```bash
+ mkdir totaltext && cd totaltext
+ mkdir imgs && mkdir annotations
+
+ # For images
+ # in ./totaltext
+ unzip totaltext.zip
+ mv Images/Train imgs/training
+ mv Images/Test imgs/test
+
+ # For annotations
+ unzip groundtruth_text.zip
+ cd Groundtruth
+ mv Polygon/Train ../annotations/training
+ mv Polygon/Test ../annotations/test
+
+ ```
+ - Step2: Generate cropped images, `train_label.txt` and `test_label.txt` with the following command (the cropped images will be saved to `data/totaltext/dst_imgs/`):
+ ```bash
+ python tools/data/textrecog/totaltext_converter.py /path/to/totaltext -o /path/to/totaltext --split-list training test
+ ```
+
+### OpenVINO
+ - Step0: Install [awscli](https://aws.amazon.com/cli/).
+ - Step1: Download [Open Images](https://github.com/cvdfoundation/open-images-dataset#download-images-with-bounding-boxes-annotations) subsets `train_1`, `train_2`, `train_5`, `train_f`, and `validation` to `openvino/`.
+ ```bash
+ mkdir openvino && cd openvino
+
+ # Download Open Images subsets
+ for s in 1 2 5 f; do
+ aws s3 --no-sign-request cp s3://open-images-dataset/tar/train_${s}.tar.gz .
+ done
+ aws s3 --no-sign-request cp s3://open-images-dataset/tar/validation.tar.gz .
+
+ # Download annotations
+ for s in 1 2 5 f; do
+ wget https://storage.openvinotoolkit.org/repositories/openvino_training_extensions/datasets/open_images_v5_text/text_spotting_openimages_v5_train_${s}.json
+ done
+ wget https://storage.openvinotoolkit.org/repositories/openvino_training_extensions/datasets/open_images_v5_text/text_spotting_openimages_v5_validation.json
+
+ # Extract images
+ mkdir -p openimages_v5/val
+ for s in 1 2 5 f; do
+ tar zxf train_${s}.tar.gz -C openimages_v5
+ done
+ tar zxf validation.tar.gz -C openimages_v5/val
+ ```
+ - Step2: Generate `train_{1,2,5,f}_label.txt`, `val_label.txt` and crop images using 4 processes with the following command:
+ ```bash
+ python tools/data/textrecog/openvino_converter.py /path/to/openvino 4
+ ```
+
+### FUNSD
+
+- Step1: Download [dataset.zip](https://guillaumejaume.github.io/FUNSD/dataset.zip) to `funsd/`.
+
+```bash
+mkdir funsd && cd funsd
+
+# Download FUNSD dataset
+wget https://guillaumejaume.github.io/FUNSD/dataset.zip
+unzip -q dataset.zip
+
+# For images
+mv dataset/training_data/images imgs && mv dataset/testing_data/images/* imgs/
+
+# For annotations
+mkdir annotations
+mv dataset/training_data/annotations annotations/training && mv dataset/testing_data/annotations annotations/test
+
+rm dataset.zip && rm -rf dataset
+```
+
+- Step2: Generate `train_label.txt` and `test_label.txt` and crop images using 4 processes with following command (add `--preserve-vertical` if you wish to preserve the images containing vertical texts):
+
+```bash
+python tools/data/textrecog/funsd_converter.py PATH/TO/funsd --nproc 4
+```
diff --git a/docs/en/deployment.md b/docs/en/deployment.md
new file mode 100644
index 0000000000000000000000000000000000000000..a533fca3e08029a46adae7b1f983a0ce4e3226fa
--- /dev/null
+++ b/docs/en/deployment.md
@@ -0,0 +1,558 @@
+# Deployment
+
+We provide deployment tools under `tools/deployment` directory.
+
+## Convert to ONNX (experimental)
+
+We provide a script to convert the model to [ONNX](https://github.com/onnx/onnx) format. The converted model could be visualized by tools like [Netron](https://github.com/lutzroeder/netron). Besides, we also support comparing the output results between PyTorch and ONNX model.
+
+```bash
+python tools/deployment/pytorch2onnx.py
+ ${MODEL_CONFIG_PATH} \
+ ${MODEL_CKPT_PATH} \
+ ${MODEL_TYPE} \
+ ${IMAGE_PATH} \
+ --output-file ${OUTPUT_FILE} \
+ --device-id ${DEVICE_ID} \
+ --opset-version ${OPSET_VERSION} \
+ --verify \
+ --verbose \
+ --show \
+ --dynamic-export
+```
+
+Description of arguments:
+
+| ARGS | Type | Description |
+| ------------------ | -------------- | -------------------------------------------------------------------------------------------------- |
+| `model_config` | str | The path to a model config file. |
+| `model_ckpt` | str | The path to a model checkpoint file. |
+| `model_type` | 'recog', 'det' | The model type of the config file. |
+| `image_path` | str | The path to input image file. |
+| `--output-file` | str | The path to output ONNX model. Defaults to `tmp.onnx`. |
+| `--device-id` | int | Which GPU to use. Defaults to 0. |
+| `--opset-version` | int | ONNX opset version. Defaults to 11. |
+| `--verify` | bool | Determines whether to verify the correctness of an exported model. Defaults to `False`. |
+| `--verbose` | bool | Determines whether to print the architecture of the exported model. Defaults to `False`. |
+| `--show` | bool | Determines whether to visualize outputs of ONNXRuntime and PyTorch. Defaults to `False`. |
+| `--dynamic-export` | bool | Determines whether to export ONNX model with dynamic input and output shapes. Defaults to `False`. |
+
+:::{note}
+This tool is still experimental. For now, some customized operators are not supported, and we only support a subset of detection and recognition algorithms.
+:::
+
+### List of supported models exportable to ONNX
+
+The table below lists the models that are guaranteed to be exportable to ONNX and runnable in ONNX Runtime.
+
+| Model | Config | Dynamic Shape | Batch Inference | Note |
+| :----: | :----------------------------------------------------------------------------------------------------------------------------------------------: | :-----------: | :-------------: | :------------------------------------: |
+| DBNet | [dbnet_r18_fpnc_1200e_icdar2015.py](https://github.com/open-mmlab/mmocr/blob/main/configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py) | Y | N | |
+| PSENet | [psenet_r50_fpnf_600e_ctw1500.py](https://github.com/open-mmlab/mmocr/blob/main/configs/textdet/psenet/psenet_r50_fpnf_600e_ctw1500.py) | Y | Y | |
+| PSENet | [psenet_r50_fpnf_600e_icdar2015.py](https://github.com/open-mmlab/mmocr/blob/main/configs/textdet/psenet/psenet_r50_fpnf_600e_icdar2015.py) | Y | Y | |
+| PANet | [panet_r18_fpem_ffm_600e_ctw1500.py](https://github.com/open-mmlab/mmocr/blob/main/configs/textdet/panet/panet_r18_fpem_ffm_600e_ctw1500.py) | Y | Y | |
+| PANet | [panet_r18_fpem_ffm_600e_icdar2015.py](https://github.com/open-mmlab/mmocr/blob/main/configs/textdet/panet/panet_r18_fpem_ffm_600e_icdar2015.py) | Y | Y | |
+| CRNN | [crnn_academic_dataset.py](https://github.com/open-mmlab/mmocr/blob/main/configs/textrecog/crnn/crnn_academic_dataset.py) | Y | Y | CRNN only accepts input with height 32 |
+
+:::{note}
+- *All models above are tested with PyTorch==1.8.1 and onnxruntime-gpu == 1.8.1*
+- If you meet any problem with the listed models above, please create an issue and it would be taken care of soon.
+- Because this feature is experimental and may change fast, please always try with the latest `mmcv` and `mmocr`.
+:::
+
+## Convert ONNX to TensorRT (experimental)
+
+We also provide a script to convert [ONNX](https://github.com/onnx/onnx) model to [TensorRT](https://github.com/NVIDIA/TensorRT) format. Besides, we support comparing the output results between ONNX and TensorRT model.
+
+
+```bash
+python tools/deployment/onnx2tensorrt.py
+ ${MODEL_CONFIG_PATH} \
+ ${MODEL_TYPE} \
+ ${IMAGE_PATH} \
+ ${ONNX_FILE} \
+ --trt-file ${OUT_TENSORRT} \
+ --max-shape INT INT INT INT \
+ --min-shape INT INT INT INT \
+ --workspace-size INT \
+ --fp16 \
+ --verify \
+ --show \
+ --verbose
+```
+
+Description of arguments:
+
+| ARGS | Type | Description |
+| ------------------ | -------------- | --------------------------------------------------------------------------------------------------- |
+| `model_config` | str | The path to a model config file. |
+| `model_type` | 'recog', 'det' | The model type of the config file. |
+| `image_path` | str | The path to input image file. |
+| `onnx_file` | str | The path to input ONNX file. |
+| `--trt-file` | str | The path of output TensorRT model. Defaults to `tmp.trt`. |
+| `--max-shape` | int * 4 | Maximum shape of model input. |
+| `--min-shape` | int * 4 | Minimum shape of model input. |
+| `--workspace-size` | int | Max workspace size in GiB. Defaults to 1. |
+| `--fp16` | bool | Determines whether to export TensorRT with fp16 mode. Defaults to `False`. |
+| `--verify` | bool | Determines whether to verify the correctness of an exported model. Defaults to `False`. |
+| `--show` | bool | Determines whether to show the output of ONNX and TensorRT. Defaults to `False`. |
+| `--verbose` | bool | Determines whether to verbose logging messages while creating TensorRT engine. Defaults to `False`. |
+
+:::{note}
+This tool is still experimental. For now, some customized operators are not supported, and we only support a subset of detection and recognition algorithms.
+:::
+
+### List of supported models exportable to TensorRT
+
+The table below lists the models that are guaranteed to be exportable to TensorRT engine and runnable in TensorRT.
+
+| Model | Config | Dynamic Shape | Batch Inference | Note |
+| :----: | :----------------------------------------------------------------------------------------------------------------------------------------------: | :-----------: | :-------------: | :------------------------------------: |
+| DBNet | [dbnet_r18_fpnc_1200e_icdar2015.py](https://github.com/open-mmlab/mmocr/blob/main/configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py) | Y | N | |
+| PSENet | [psenet_r50_fpnf_600e_ctw1500.py](https://github.com/open-mmlab/mmocr/blob/main/configs/textdet/psenet/psenet_r50_fpnf_600e_ctw1500.py) | Y | Y | |
+| PSENet | [psenet_r50_fpnf_600e_icdar2015.py](https://github.com/open-mmlab/mmocr/blob/main/configs/textdet/psenet/psenet_r50_fpnf_600e_icdar2015.py) | Y | Y | |
+| PANet | [panet_r18_fpem_ffm_600e_ctw1500.py](https://github.com/open-mmlab/mmocr/blob/main/configs/textdet/panet/panet_r18_fpem_ffm_600e_ctw1500.py) | Y | Y | |
+| PANet | [panet_r18_fpem_ffm_600e_icdar2015.py](https://github.com/open-mmlab/mmocr/blob/main/configs/textdet/panet/panet_r18_fpem_ffm_600e_icdar2015.py) | Y | Y | |
+| CRNN | [crnn_academic_dataset.py](https://github.com/open-mmlab/mmocr/blob/main/configs/textrecog/crnn/crnn_academic_dataset.py) | Y | Y | CRNN only accepts input with height 32 |
+
+:::{note}
+- *All models above are tested with PyTorch==1.8.1, onnxruntime-gpu==1.8.1 and tensorrt==7.2.1.6*
+- If you meet any problem with the listed models above, please create an issue and it would be taken care of soon.
+- Because this feature is experimental and may change fast, please always try with the latest `mmcv` and `mmocr`.
+:::
+
+
+## Evaluate ONNX and TensorRT Models (experimental)
+
+We provide methods to evaluate TensorRT and ONNX models in `tools/deployment/deploy_test.py`.
+
+### Prerequisite
+To evaluate ONNX and TensorRT models, ONNX, ONNXRuntime and TensorRT should be installed first. Install `mmcv-full` with ONNXRuntime custom ops and TensorRT plugins follow [ONNXRuntime in mmcv](https://mmcv.readthedocs.io/en/latest/onnxruntime_op.html) and [TensorRT plugin in mmcv](https://github.com/open-mmlab/mmcv/blob/master/docs/tensorrt_plugin.md).
+
+### Usage
+
+```bash
+python tools/deploy_test.py \
+ ${CONFIG_FILE} \
+ ${MODEL_PATH} \
+ ${MODEL_TYPE} \
+ ${BACKEND} \
+ --eval ${METRICS} \
+ --device ${DEVICE}
+```
+
+### Description of all arguments
+
+| ARGS | Type | Description |
+| -------------- | ------------------------- | --------------------------------------------------------------------------------------- |
+| `model_config` | str | The path to a model config file. |
+| `model_file` | str | The path to a TensorRT or an ONNX model file. |
+| `model_type` | 'recog', 'det' | Detection or recognition model to deploy. |
+| `backend` | 'TensorRT', 'ONNXRuntime' | The backend for testing. |
+| `--eval` | 'acc', 'hmean-iou' | The evaluation metrics. 'acc' for recognition models, 'hmean-iou' for detection models. |
+| `--device` | str | Device for evaluation. Defaults to `cuda:0`. |
+
+## Results and Models
+
+
+
+
+
+
Model
+
Config
+
Dataset
+
Metric
+
PyTorch
+
ONNX Runtime
+
TensorRT FP32
+
TensorRT FP16
+
+
+
+
+
DBNet
+
dbnet_r18_fpnc_1200e_icdar2015.py
+
icdar2015
+
Recall
+
0.731
+
0.731
+
0.678
+
0.679
+
+
+
Precision
+
0.871
+
0.871
+
0.844
+
0.842
+
+
+
Hmean
+
0.795
+
0.795
+
0.752
+
0.752
+
+
+
DBNet*
+
dbnet_r18_fpnc_1200e_icdar2015.py
+
icdar2015
+
Recall
+
0.720
+
0.720
+
0.720
+
0.718
+
+
+
Precision
+
0.868
+
0.868
+
0.868
+
0.868
+
+
+
Hmean
+
0.787
+
0.787
+
0.787
+
0.786
+
+
+
PSENet
+
psenet_r50_fpnf_600e_icdar2015.py
+
icdar2015
+
Recall
+
0.753
+
0.753
+
0.753
+
0.752
+
+
+
Precision
+
0.867
+
0.867
+
0.867
+
0.867
+
+
+
Hmean
+
0.806
+
0.806
+
0.806
+
0.805
+
+
+
PANet
+
panet_r18_fpem_ffm_600e_icdar2015.py
+
icdar2015
+
Recall
+
0.740
+
0.740
+
0.687
+
N/A
+
+
+
Precision
+
0.860
+
0.860
+
0.815
+
N/A
+
+
+
Hmean
+
0.796
+
0.796
+
0.746
+
N/A
+
+
+
PANet*
+
panet_r18_fpem_ffm_600e_icdar2015.py
+
icdar2015
+
Recall
+
0.736
+
0.736
+
0.736
+
N/A
+
+
+
Precision
+
0.857
+
0.857
+
0.857
+
N/A
+
+
+
Hmean
+
0.792
+
0.792
+
0.792
+
N/A
+
+
+
CRNN
+
crnn_academic_dataset.py
+
IIIT5K
+
Acc
+
0.806
+
0.806
+
0.806
+
0.806
+
+
+
+
+:::{note}
+- TensorRT upsampling operation is a little different from PyTorch. For DBNet and PANet, we suggest replacing upsampling operations with the nearest mode to operations with bilinear mode. [Here](https://github.com/open-mmlab/mmocr/blob/50a25e718a028c8b9d96f497e241767dbe9617d1/mmocr/models/textdet/necks/fpem_ffm.py#L33) for PANet, [here](https://github.com/open-mmlab/mmocr/blob/50a25e718a028c8b9d96f497e241767dbe9617d1/mmocr/models/textdet/necks/fpn_cat.py#L111) and [here](https://github.com/open-mmlab/mmocr/blob/50a25e718a028c8b9d96f497e241767dbe9617d1/mmocr/models/textdet/necks/fpn_cat.py#L121) for DBNet. As is shown in the above table, networks with tag * mean the upsampling mode is changed.
+- Note that changing upsampling mode reduces less performance compared with using the nearest mode. However, the weights of networks are trained through the nearest mode. To pursue the best performance, using bilinear mode for both training and TensorRT deployment is recommended.
+- All ONNX and TensorRT models are evaluated with dynamic shapes on the datasets, and images are preprocessed according to the original config file.
+- This tool is still experimental, and we only support a subset of detection and recognition algorithms for now.
+:::
+
+
+## C++ Inference example with OpenCV
+The example below is tested with Visual Studio 2019 as console application, CPU inference only.
+
+### Prerequisites
+
+1. Project should use OpenCV (tested with version 4.5.4), ONNX Runtime NuGet package (version 1.9.0).
+2. Download *DBNet_r18* detector and *SATRN_small* recognizer models from our [Model Zoo](modelzoo.md), and export them with the following python commands (you may change the paths accordingly):
+
+```bash
+python3.9 ../mmocr/tools/deployment/pytorch2onnx.py --verify --output-file detector.onnx ../mmocr/configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py ./dbnet_r18_fpnc_sbn_1200e_icdar2015_20210329-ba3ab597.pth --dynamic-export det ./sample_big_image_eg_1920x1080.png
+
+python3.9 ../mmocr/tools/deployment/pytorch2onnx.py --opset 14 --verify --output-file recognizer.onnx ../mmocr/configs/textrecog/satrn/satrn_small.py ./satrn_small_20211009-2cf13355.pth recog ./sample_small_image_eg_200x50.png
+```
+
+:::{note}
+- Be aware, while exported `detector.onnx` file is relatively small (about 50 Mb), `recognizer.onnx` is pretty big (more than 600 Mb).
+- *DBNet_r18* can use ONNX opset 11, *SATRN_small* can be exported with opset 14.
+:::
+
+:::{warning}
+Be sure, that verifications of both models are successful - look through the export messages.
+:::
+
+### Example
+Example usage of exported models with C++ is in the code below (don't forget to change paths to \*.onnx files). It's applicable to these two models only, other models have another preprocessing and postprocessing logics.
+
+```C++
+#include
+
+#include
+#include
+#include
+#include
+
+#include
+#pragma comment(lib, "onnxruntime.lib")
+
+// DB_r18
+class Detector {
+public:
+ Detector(const std::string& model_path) {
+ session = Ort::Session{ env, std::wstring(model_path.begin(), model_path.end()).c_str(), Ort::SessionOptions{nullptr} };
+ }
+
+ std::vector inference(const cv::Mat& original, float threshold = 0.3f) {
+
+ cv::Size original_size = original.size();
+
+ const char* input_names[] = { "input" };
+ const char* output_names[] = { "output" };
+
+ std::array input_shape{ 1, 3, height, width };
+
+ cv::Mat image = cv::Mat::zeros(cv::Size(width, height), original.type());
+ cv::resize(original, image, cv::Size(width, height), 0, 0, cv::INTER_AREA);
+
+ image.convertTo(image, CV_32FC3);
+
+ cv::cvtColor(image, image, cv::COLOR_BGR2RGB);
+ image = (image - cv::Scalar(123.675f, 116.28f, 103.53f)) / cv::Scalar(58.395f, 57.12f, 57.375f);
+
+ cv::Mat blob = cv::dnn::blobFromImage(image);
+
+ auto memory_info = Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeDefault);
+ Ort::Value input_tensor = Ort::Value::CreateTensor(memory_info, (float*)blob.data, blob.total(), input_shape.data(), input_shape.size());
+
+ std::vector output_tensor = session.Run(Ort::RunOptions{ nullptr }, input_names, &input_tensor, 1, output_names, 1);
+
+ int sizes[] = { 1, 3, height, width };
+ cv::Mat output(4, sizes, CV_32F, output_tensor.front().GetTensorMutableData());
+
+ std::vector images;
+ cv::dnn::imagesFromBlob(output, images);
+
+ std::vector areas = get_detected(images[0], threshold);
+ std::vector results;
+
+ float x_ratio = original_size.width / (float)width;
+ float y_ratio = original_size.height / (float)height;
+
+ for (int index = 0; index < areas.size(); ++index) {
+ cv::Rect box = areas[index];
+
+ box.x = int(box.x * x_ratio);
+ box.width = int(box.width * x_ratio);
+ box.y = int(box.y * y_ratio);
+ box.height = int(box.height * y_ratio);
+
+ results.push_back(box);
+ }
+
+ return results;
+ }
+
+private:
+ Ort::Env env;
+ Ort::Session session{ nullptr };
+
+ const int width = 1312, height = 736;
+
+ cv::Rect expand_box(const cv::Rect& original, int addition = 5) {
+ cv::Rect box(original);
+ box.x = std::max(0, box.x - addition);
+ box.y = std::max(0, box.y - addition);
+ box.width = (box.x + box.width + addition * 2 > width) ? (width - box.x) : (box.width + addition * 2);
+ box.height = (box.y + box.height + addition * 2) > height ? (height - box.y) : (box.height + addition * 2);
+ return box;
+ }
+
+ std::vector get_detected(const cv::Mat& output, float threshold) {
+ cv::Mat text_mask = cv::Mat::zeros(height, width, CV_32F);
+ std::vector maps;
+ cv::split(output, maps);
+ cv::Mat proba_map = maps[0];
+
+ cv::threshold(proba_map, text_mask, threshold, 1.0f, cv::THRESH_BINARY);
+ cv::multiply(text_mask, 255, text_mask);
+ text_mask.convertTo(text_mask, CV_8U);
+
+ std::vector> contours;
+ cv::findContours(text_mask, contours, cv::RETR_EXTERNAL, cv::CHAIN_APPROX_SIMPLE);
+ std::vector boxes;
+
+ for (int index = 0; index < contours.size(); ++index) {
+ cv::Rect box = expand_box(cv::boundingRect(contours[index]));
+ boxes.push_back(box);
+ }
+
+ return boxes;
+ }
+};
+
+// SATRN_small
+class Recognizer {
+public:
+ Recognizer(const std::string& model_path) {
+ session = Ort::Session{ env, std::wstring(model_path.begin(), model_path.end()).c_str(), Ort::SessionOptions{nullptr} };
+ }
+
+ std::string inference(const cv::Mat& original) {
+ const char* input_names[] = { "input" };
+ const char* output_names[] = { "output" };
+
+ std::array input_shape{ 1, 3, height, width };
+
+ cv::Mat image;
+ cv::resize(original, image, cv::Size(width, height), 0, 0, cv::INTER_AREA);
+ image.convertTo(image, CV_32FC3);
+
+ cv::cvtColor(image, image, cv::COLOR_BGR2RGB);
+ image = (image / 255.0f - cv::Scalar(0.485f, 0.456f, 0.406f)) / cv::Scalar(0.229f, 0.224f, 0.225f);
+
+ cv::Mat blob = cv::dnn::blobFromImage(image);
+
+ auto memory_info = Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeDefault);
+ Ort::Value input_tensor = Ort::Value::CreateTensor(memory_info, (float*)blob.data, blob.total(), input_shape.data(), input_shape.size());
+
+ std::vector output_tensor = session.Run(Ort::RunOptions{ nullptr }, input_names, &input_tensor, 1, output_names, 1);
+
+ int sequence_length = 25;
+ std::string dictionary = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!\"#$%&'()*+,-./:;<=>?@[\\]_`~";
+ int characters = dictionary.length() + 2; // EOS + UNK
+
+ std::vector max_indices;
+ for (int outer = 0; outer < sequence_length; ++outer) {
+ int character_index = -1;
+ float character_value = 0;
+ for (int inner = 0; inner < characters; ++inner) {
+ int counter = outer * characters + inner;
+ float value = output_tensor[0].GetTensorMutableData()[counter];
+ if (value > character_value) {
+ character_value = value;
+ character_index = inner;
+ }
+ }
+ max_indices.push_back(character_index);
+ }
+
+ std::string recognized;
+
+ for (int index = 0; index < max_indices.size(); ++index) {
+ if (max_indices[index] == dictionary.length()) {
+ continue; // unk
+ }
+ if (max_indices[index] == dictionary.length() + 1) {
+ break; // eos
+ }
+ recognized += dictionary[max_indices[index]];
+ }
+
+ return recognized;
+ }
+
+private:
+ Ort::Env env;
+ Ort::Session session{ nullptr };
+
+ const int height = 32;
+ const int width = 100;
+};
+
+int main(int argc, const char* argv[]) {
+ if (argc < 2) {
+ std::cout << "Usage: this_executable.exe c:/path/to/image.png" << std::endl;
+ return 0;
+ }
+
+ std::chrono::steady_clock::time_point begin = std::chrono::steady_clock::now();
+ std::cout << "Loading models..." << std::endl;
+
+ Detector detector("d:/path/to/detector.onnx");
+ Recognizer recognizer("d:/path/to/recognizer.onnx");
+
+ std::chrono::steady_clock::time_point end = std::chrono::steady_clock::now();
+ std::cout << "Loading models done in " << std::chrono::duration_cast(end - begin).count() << " ms" << std::endl;
+
+ cv::Mat image = cv::imread(argv[1], cv::IMREAD_COLOR);
+
+ begin = std::chrono::steady_clock::now();
+ std::vector detections = detector.inference(image);
+ for (int index = 0; index < detections.size(); ++index) {
+ cv::Mat roi = image(detections[index]);
+ std::string text = recognizer.inference(roi);
+ cv::rectangle(image, detections[index], cv::Scalar(255, 255, 255), 2);
+ cv::putText(image, text, cv::Point(detections[index].x, detections[index].y - 10), cv::FONT_HERSHEY_COMPLEX, 0.4, cv::Scalar(255, 255, 255));
+ }
+
+ end = std::chrono::steady_clock::now();
+ std::cout << "Inference time (with drawing): " << std::chrono::duration_cast(end - begin).count() << " ms" << std::endl;
+
+ cv::imshow("Results", image);
+ cv::waitKey(0);
+
+ return 0;
+}
+```
+
+The output should look something like this.
+```
+Loading models...
+Loading models done in 5715 ms
+Inference time (with drawing): 3349 ms
+```
+
+And the sample result should look something like this.
+
diff --git a/docs/en/getting_started.md b/docs/en/getting_started.md
new file mode 100644
index 0000000000000000000000000000000000000000..73b7461cd224495db0731cf40f5cf703aac11b9c
--- /dev/null
+++ b/docs/en/getting_started.md
@@ -0,0 +1,77 @@
+# Getting Started
+
+In this guide we will show you some useful commands and familiarize you with MMOCR. We also provide [a notebook](https://github.com/open-mmlab/mmocr/blob/main/demo/MMOCR_Tutorial.ipynb) that can help you get the most out of MMOCR.
+
+## Installation
+
+Check out our [installation guide](install.md) for full steps.
+
+## Dataset Preparation
+
+MMOCR supports numerous datasets which are classified by the type of their corresponding tasks. You may find their preparation steps in these sections: [Detection Datasets](datasets/det.md), [Recognition Datasets](datasets/recog.md), [KIE Datasets](datasets/kie.md) and [NER Datasets](datasets/ner.md).
+
+## Inference with Pretrained Models
+
+You can perform end-to-end OCR on our demo image with one simple line of command:
+
+```shell
+python mmocr/utils/ocr.py demo/demo_text_ocr.jpg --print-result --imshow
+```
+
+Its detection result will be printed out and a new window will pop up with result visualization. More demo and full instructions can be found in [Demo](demo.md).
+
+## Training
+
+### Training with Toy Dataset
+
+We provide a toy dataset under `tests/data` on which you can get a sense of training before the academic dataset is prepared.
+
+For example, to train a text recognition task with `seg` method and toy dataset,
+```shell
+python tools/train.py configs/textrecog/seg/seg_r31_1by16_fpnocr_toy_dataset.py --work-dir seg
+```
+
+To train a text recognition task with `sar` method and toy dataset,
+```shell
+python tools/train.py configs/textrecog/sar/sar_r31_parallel_decoder_toy_dataset.py --work-dir sar
+```
+
+### Training with Academic Dataset
+
+Once you have prepared required academic dataset following our instruction, the only last thing to check is if the model's config points MMOCR to the correct dataset path. Suppose we want to train DBNet on ICDAR 2015, and part of `configs/_base_/det_datasets/icdar2015.py` looks like the following:
+```python
+dataset_type = 'IcdarDataset'
+data_root = 'data/icdar2015'
+train = dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/instances_training.json',
+ img_prefix=f'{data_root}/imgs',
+ pipeline=None)
+test = dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/instances_test.json',
+ img_prefix=f'{data_root}/imgs',
+ pipeline=None)
+train_list = [train]
+test_list = [test]
+```
+You would need to check if `data/icdar2015` is right. Then you can start training with the command:
+```shell
+python tools/train.py configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py --work-dir dbnet
+```
+
+You can find full training instructions, explanations and useful training configs in [Training](training.md).
+
+## Testing
+
+Suppose now you have finished the training of DBNet and the latest model has been saved in `dbnet/latest.pth`. You can evaluate its performance on the test set using the `hmean-iou` metric with the following command:
+```shell
+python tools/test.py configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py dbnet/latest.pth --eval hmean-iou
+```
+
+Evaluating any pretrained model accessible online is also allowed:
+```shell
+python tools/test.py configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py https://download.openmmlab.com/mmocr/textdet/dbnet/dbnet_r18_fpnc_sbn_1200e_icdar2015_20210329-ba3ab597.pth --eval hmean-iou
+```
+
+More instructions on testing are available in [Testing](testing.md).
diff --git a/docs/en/index.rst b/docs/en/index.rst
new file mode 100644
index 0000000000000000000000000000000000000000..76eb2212b50fc9151dc8530ec5afcf1e12769c07
--- /dev/null
+++ b/docs/en/index.rst
@@ -0,0 +1,68 @@
+Welcome to MMOCR's documentation!
+=======================================
+
+You can switch between English and Chinese in the lower-left corner of the layout.
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Getting Started
+
+ install.md
+ getting_started.md
+ demo.md
+ training.md
+ testing.md
+ deployment.md
+ model_serving.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Tutorials
+
+ tutorials/config.md
+ tutorials/dataset_types.md
+ tutorials/kie_closeset_openset.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Model Zoo
+
+ modelzoo.md
+ model_summary.md
+ textdet_models.md
+ textrecog_models.md
+ kie_models.md
+ ner_models.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Dataset Zoo
+
+ datasets/det.md
+ datasets/recog.md
+ datasets/kie.md
+ datasets/ner.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Miscellaneous
+
+ tools.md
+ changelog.md
+
+.. toctree::
+ :caption: API Reference
+
+ api.rst
+
+.. toctree::
+ :caption: Switch Language
+
+ English
+ 简体中文
+
+Indices and tables
+==================
+
+* :ref:`genindex`
+* :ref:`search`
diff --git a/docs/en/install.md b/docs/en/install.md
new file mode 100644
index 0000000000000000000000000000000000000000..4d2b5d665800325581301c9c87bfbbee143a7aa5
--- /dev/null
+++ b/docs/en/install.md
@@ -0,0 +1,177 @@
+# Installation
+
+## Prerequisites
+
+- Linux | Windows | macOS
+- Python 3.7
+- PyTorch 1.6 or higher
+- torchvision 0.7.0
+- CUDA 10.1
+- NCCL 2
+- GCC 5.4.0 or higher
+- [MMCV](https://mmcv.readthedocs.io/en/latest/#installation)
+- [MMDetection](https://mmdetection.readthedocs.io/en/latest/#installation)
+
+MMOCR has different version requirements on MMCV and MMDetection at each release to guarantee the implementation correctness. Please refer to the table below and ensure the package versions fit the requirement.
+
+| MMOCR | MMCV | MMDetection |
+| ------------ | ---------------------- | ------------------------- |
+| master | 1.3.8 <= mmcv <= 1.5.0 | 2.14.0 <= mmdet <= 3.0.0 |
+| 0.4.0, 0.4.1 | 1.3.8 <= mmcv <= 1.5.0 | 2.14.0 <= mmdet <= 2.20.0 |
+| 0.3.0 | 1.3.8 <= mmcv <= 1.4.0 | 2.14.0 <= mmdet <= 2.20.0 |
+| 0.2.1 | 1.3.8 <= mmcv <= 1.4.0 | 2.13.0 <= mmdet <= 2.20.0 |
+| 0.2.0 | 1.3.4 <= mmcv <= 1.4.0 | 2.11.0 <= mmdet <= 2.13.0 |
+| 0.1.0 | 1.2.6 <= mmcv <= 1.3.4 | 2.9.0 <= mmdet <= 2.11.0 |
+
+We have tested the following versions of OS and software:
+
+- OS: Ubuntu 16.04
+- CUDA: 10.1
+- GCC(G++): 5.4.0
+- MMCV 1.3.8
+- MMDetection 2.14.0
+- PyTorch 1.6.0
+- torchvision 0.7.0
+
+MMOCR depends on PyTorch and mmdetection.
+
+## Step-by-Step Installation Instructions
+
+a. Create a Conda virtual environment and activate it.
+
+```shell
+conda create -n open-mmlab python=3.7 -y
+conda activate open-mmlab
+```
+
+b. Install PyTorch and torchvision following the [official instructions](https://pytorch.org/), e.g.,
+
+```shell
+conda install pytorch==1.6.0 torchvision==0.7.0 cudatoolkit=10.1 -c pytorch
+```
+
+:::{note}
+Make sure that your compilation CUDA version and runtime CUDA version matches.
+You can check the supported CUDA version for precompiled packages on the [PyTorch website](https://pytorch.org/).
+:::
+
+c. Install [mmcv](https://github.com/open-mmlab/mmcv), we recommend you to install the pre-build mmcv as below.
+
+```shell
+pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/{cu_version}/{torch_version}/index.html
+```
+
+Please replace ``{cu_version}`` and ``{torch_version}`` in the url with your desired one. For example, to install the latest ``mmcv-full`` with CUDA 11 and PyTorch 1.7.0, use the following command:
+
+```shell
+pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu110/torch1.7.0/index.html
+```
+
+:::{note}
+mmcv-full is only compiled on PyTorch 1.x.0 because the compatibility usually holds between 1.x.0 and 1.x.1. If your PyTorch version is 1.x.1, you can install mmcv-full compiled with PyTorch 1.x.0 and it usually works well.
+
+```bash
+# We can ignore the micro version of PyTorch
+pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu110/torch1.7/index.html
+```
+
+:::
+:::{note}
+
+If it compiles during installation, then please check that the CUDA version and PyTorch version **exactly** matches the version in the `mmcv-full` installation command.
+
+See official [installation guide](https://github.com/open-mmlab/mmcv#installation) for different versions of MMCV compatible to different PyTorch and CUDA versions.
+:::
+
+:::{warning}
+You need to run `pip uninstall mmcv` first if you have `mmcv` installed. If `mmcv` and `mmcv-full` are both installed, there will be `ModuleNotFoundError`.
+:::
+
+d. Install [mmdet](https://github.com/open-mmlab/mmdetection), we recommend you to install the latest `mmdet` with pip.
+See [here](https://pypi.org/project/mmdet/) for different versions of `mmdet`.
+
+```shell
+pip install mmdet
+```
+
+Optionally you can choose to install `mmdet` following the official [installation guide](https://github.com/open-mmlab/mmdetection/blob/master/docs/get_started.md).
+
+e. Clone the MMOCR repository.
+
+```shell
+git clone https://github.com/open-mmlab/mmocr.git
+cd mmocr
+```
+
+f. Install build requirements and then install MMOCR.
+
+```shell
+pip install -r requirements.txt
+pip install -v -e . # or "python setup.py develop"
+export PYTHONPATH=$(pwd):$PYTHONPATH
+```
+
+## Full Set-up Script
+
+Here is the full script for setting up MMOCR with Conda.
+
+```shell
+conda create -n open-mmlab python=3.7 -y
+conda activate open-mmlab
+
+# install latest pytorch prebuilt with the default prebuilt CUDA version (usually the latest)
+conda install pytorch==1.6.0 torchvision==0.7.0 cudatoolkit=10.1 -c pytorch
+
+# install the latest mmcv-full
+pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.6.0/index.html
+
+# install mmdetection
+pip install mmdet
+
+# install mmocr
+git clone https://github.com/open-mmlab/mmocr.git
+cd mmocr
+
+pip install -r requirements.txt
+pip install -v -e . # or "python setup.py develop"
+export PYTHONPATH=$(pwd):$PYTHONPATH
+```
+
+## Another option: Docker Image
+
+We provide a [Dockerfile](https://github.com/open-mmlab/mmocr/blob/master/docker/Dockerfile) to build an image.
+
+```shell
+# build an image with PyTorch 1.6, CUDA 10.1
+docker build -t mmocr docker/
+```
+
+Run it with
+
+```shell
+docker run --gpus all --shm-size=8g -it -v {DATA_DIR}:/mmocr/data mmocr
+```
+
+## Prepare Datasets
+
+It is recommended to symlink the dataset root to `mmocr/data`. Please refer to [datasets.md](datasets.md) to prepare your datasets.
+If your folder structure is different, you may need to change the corresponding paths in config files.
+
+The `mmocr` folder is organized as follows:
+
+```
+├── configs/
+├── demo/
+├── docker/
+├── docs/
+├── LICENSE
+├── mmocr/
+├── README.md
+├── requirements/
+├── requirements.txt
+├── resources/
+├── setup.cfg
+├── setup.py
+├── tests/
+├── tools/
+```
diff --git a/docs/en/make.bat b/docs/en/make.bat
new file mode 100644
index 0000000000000000000000000000000000000000..8a3a0e25b49a52ade52c4f69ddeb0bc3d12527ff
--- /dev/null
+++ b/docs/en/make.bat
@@ -0,0 +1,36 @@
+@ECHO OFF
+
+pushd %~dp0
+
+REM Command file for Sphinx documentation
+
+if "%SPHINXBUILD%" == "" (
+ set SPHINXBUILD=sphinx-build
+)
+set SOURCEDIR=.
+set BUILDDIR=_build
+
+if "%1" == "" goto help
+
+%SPHINXBUILD% >NUL 2>NUL
+if errorlevel 9009 (
+ echo.
+ echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
+ echo.installed, then set the SPHINXBUILD environment variable to point
+ echo.to the full path of the 'sphinx-build' executable. Alternatively you
+ echo.may add the Sphinx directory to PATH.
+ echo.
+ echo.If you don't have Sphinx installed, grab it from
+ echo.http://sphinx-doc.org/
+ exit /b 1
+)
+
+
+%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+goto end
+
+:help
+%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+
+:end
+popd
diff --git a/docs/en/merge_docs.sh b/docs/en/merge_docs.sh
new file mode 100755
index 0000000000000000000000000000000000000000..34d9b5e6c16aa9cab4a2847664f413385238077f
--- /dev/null
+++ b/docs/en/merge_docs.sh
@@ -0,0 +1,11 @@
+#!/usr/bin/env bash
+
+# gather models
+sed -e '$a\\n' -s ../../configs/kie/*/*.md | sed "s/md###t/html#t/g" | sed "s/#/#&/" | sed '1i\# Key Information Extraction Models' | sed 's/](\/docs\//](/g' | sed 's=](/=](https://github.com/open-mmlab/mmocr/tree/master/=g' >kie_models.md
+sed -e '$a\\n' -s ../../configs/textdet/*/*.md | sed "s/md###t/html#t/g" | sed "s/#/#&/" | sed '1i\# Text Detection Models' | sed 's/](\/docs\//](/g' | sed 's=](/=](https://github.com/open-mmlab/mmocr/tree/master/=g' >textdet_models.md
+sed -e '$a\\n' -s ../../configs/textrecog/*/*.md | sed "s/md###t/html#t/g" | sed "s/#/#&/" | sed '1i\# Text Recognition Models' | sed 's/](\/docs\//](/g' | sed 's=](/=](https://github.com/open-mmlab/mmocr/tree/master/=g' >textrecog_models.md
+sed -e '$a\\n' -s ../../configs/ner/*/*.md | sed "s/md###t/html#t/g" | sed "s/#/#&/" | sed '1i\# Named Entity Recognition Models' | sed 's/](\/docs\//](/g' | sed 's=](/=](https://github.com/open-mmlab/mmocr/tree/master/=g' >ner_models.md
+
+# replace special symbols in demo.md
+cp ../../demo/README.md demo.md
+sed -i 's/:heavy_check_mark:/Yes/g' demo.md && sed -i 's/:x:/No/g' demo.md
diff --git a/docs/en/model_serving.md b/docs/en/model_serving.md
new file mode 100644
index 0000000000000000000000000000000000000000..8b68294285e5b7d68afb529fcf470101f3bc3b7d
--- /dev/null
+++ b/docs/en/model_serving.md
@@ -0,0 +1,180 @@
+# Model Serving
+
+`MMOCR` provides some utilities that facilitate the model serving process.
+Here is a quick walkthrough of necessary steps that let the models to serve through an API.
+
+## Install TorchServe
+
+You can follow the steps on the [official website](https://github.com/pytorch/serve#install-torchserve-and-torch-model-archiver) to install `TorchServe` and
+`torch-model-archiver`.
+
+## Convert model from MMOCR to TorchServe
+
+We provide a handy tool to convert any `.pth` model into `.mar` model
+for TorchServe.
+
+```shell
+python tools/deployment/mmocr2torchserve.py ${CONFIG_FILE} ${CHECKPOINT_FILE} \
+--output-folder ${MODEL_STORE} \
+--model-name ${MODEL_NAME}
+```
+
+:::{note}
+${MODEL_STORE} needs to be an absolute path to a folder.
+:::
+
+For example:
+
+```shell
+python tools/deployment/mmocr2torchserve.py \
+ configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py \
+ checkpoints/dbnet_r18_fpnc_1200e_icdar2015.pth \
+ --output-folder ./checkpoints \
+ --model-name dbnet
+```
+
+## Start Serving
+
+### From your Local Machine
+
+Getting your models prepared, the next step is to start the service with a one-line command:
+
+```bash
+# To load all the models in ./checkpoints
+torchserve --start --model-store ./checkpoints --models all
+# Or, if you only want one model to serve, say dbnet
+torchserve --start --model-store ./checkpoints --models dbnet=dbnet.mar
+```
+
+Then you can access inference, management and metrics services
+through TorchServe's REST API.
+You can find their usages in [TorchServe REST API](https://github.com/pytorch/serve/blob/master/docs/rest_api.md).
+
+| Service | Address |
+| ------------------- | ----------------------- |
+| Inference | `http://127.0.0.1:8080` |
+| Management | `http://127.0.0.1:8081` |
+| Metrics | `http://127.0.0.1:8082` |
+
+:::{note}
+By default, TorchServe binds port number `8080`, `8081` and `8082` to its services.
+You can change such behavior by modifying and saving the contents below to `config.properties`, and running TorchServe with option `--ts-config config.preperties`.
+
+```bash
+inference_address=http://0.0.0.0:8080
+management_address=http://0.0.0.0:8081
+metrics_address=http://0.0.0.0:8082
+number_of_netty_threads=32
+job_queue_size=1000
+model_store=/home/model-server/model-store
+```
+
+:::
+
+
+### From Docker
+
+A better alternative to serve your models is through Docker. We provide a Dockerfile
+that frees you from those tedious and error-prone environmental setup steps.
+
+#### Build `mmocr-serve` Docker image
+
+```shell
+docker build -t mmocr-serve:latest docker/serve/
+```
+
+#### Run `mmocr-serve` with Docker
+
+In order to run Docker in GPU, you need to install [nvidia-docker](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html); or you can omit the `--gpus` argument for a CPU-only session.
+
+The command below will run `mmocr-serve` with a gpu, bind the ports of `8080` (inference),
+`8081` (management) and `8082` (metrics) from container to `127.0.0.1`, and mount
+the checkpoint folder `./checkpoints` from the host machine to `/home/model-server/model-store`
+of the container. For more information, please check the official docs for [running TorchServe with docker](https://github.com/pytorch/serve/blob/master/docker/README.md#running-torchserve-in-a-production-docker-environment).
+
+```shell
+docker run --rm \
+--cpus 8 \
+--gpus device=0 \
+-p8080:8080 -p8081:8081 -p8082:8082 \
+--mount type=bind,source=`realpath ./checkpoints`,target=/home/model-server/model-store \
+mmocr-serve:latest
+```
+
+:::{note}
+`realpath ./checkpoints` points to the absolute path of "./checkpoints", and you can replace it with the absolute path where you store torchserve models.
+:::
+
+Upon running the docker, you can access inference, management and metrics services
+through TorchServe's REST API.
+You can find their usages in [TorchServe REST API](https://github.com/pytorch/serve/blob/master/docs/rest_api.md).
+
+| Service | Address |
+| ------------------- | ----------------------- |
+| Inference | `http://127.0.0.1:8080` |
+| Management | `http://127.0.0.1:8081` |
+| Metrics | `http://127.0.0.1:8082` |
+
+
+
+## 4. Test deployment
+
+Inference API allows user to post an image to a model and returns the prediction result.
+
+```shell
+curl http://127.0.0.1:8080/predictions/${MODEL_NAME} -T demo/demo_text_det.jpg
+```
+
+For example,
+
+```shell
+curl http://127.0.0.1:8080/predictions/dbnet -T demo/demo_text_det.jpg
+```
+
+For detection models, you should obtain a json with an object named `boundary_result`. Each array inside has float numbers representing x, y
+coordinates of boundary vertices in clockwise order, and the last float number as the
+confidence score.
+
+```json
+{
+ "boundary_result": [
+ [
+ 221.18990004062653,
+ 226.875,
+ 221.18990004062653,
+ 212.625,
+ 244.05868631601334,
+ 212.625,
+ 244.05868631601334,
+ 226.875,
+ 0.80883354575186
+ ]
+ ]
+}
+```
+
+For recognition models, the response should look like:
+
+```json
+{
+ "text": "sier",
+ "score": 0.5247521847486496
+}
+```
+
+And you can use `test_torchserve.py` to compare result of TorchServe and PyTorch by visualizing them.
+
+```shell
+python tools/deployment/test_torchserve.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} ${MODEL_NAME}
+[--inference-addr ${INFERENCE_ADDR}] [--device ${DEVICE}]
+```
+
+Example:
+
+```shell
+python tools/deployment/test_torchserve.py \
+ demo/demo_text_det.jpg \
+ configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py \
+ checkpoints/dbnet_r18_fpnc_1200e_icdar2015.pth \
+ dbnet
+```
diff --git a/docs/en/model_summary.md b/docs/en/model_summary.md
new file mode 100644
index 0000000000000000000000000000000000000000..c3771f0869f0880b9928bfea2df4f824d95059d3
--- /dev/null
+++ b/docs/en/model_summary.md
@@ -0,0 +1,178 @@
+# Model Architecture Summary
+
+MMOCR has implemented many models that support various tasks. Depending on the type of tasks, these models have different architectural designs and, therefore, might be a bit confusing for beginners to master. We release a primary design doc to clearly illustrate the basic task-specific architectures and provide quick pointers to docstrings of model components to aid users' understanding.
+
+## Text Detection Models
+
+
+
+
+
+
+The design of text detectors is similar to [SingleStageDetector](https://mmdetection.readthedocs.io/en/latest/api.html#mmdet.models.detectors.SingleStageDetector) in MMDetection. The feature of an image was first extracted by `backbone` (e.g., ResNet), and `neck` further processes raw features into a head-ready format, where the models in MMOCR usually adapt the variants of FPN to extract finer-grained multi-level features. `bbox_head` is the core of text detectors, and its implementation varies in different models.
+
+When training, the output of `bbox_head` is directly fed into the `loss` module, which compares the output with the ground truth and generates a loss dictionary for optimizer's use. When testing, `Postprocessor` converts the outputs from `bbox_head` to bounding boxes, which will be used for evaluation metrics (e.g., hmean-iou) and visualization.
+
+### DBNet
+
+- Backbone: [mmdet.ResNet](https://mmdetection.readthedocs.io/en/latest/api.html#mmdet.models.backbones.ResNet)
+- Neck: [FPNC](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.necks.FPNC)
+- Bbox_head: [DBHead](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.dense_heads.DBHead)
+- Loss: [DBLoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.losses.DBLoss)
+- Postprocessor: [DBPostprocessor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.postprocess.DBPostprocessor)
+
+### DRRG
+
+- Backbone: [mmdet.ResNet](https://mmdetection.readthedocs.io/en/latest/api.html#mmdet.models.backbones.ResNet)
+- Neck: [FPN_UNet](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.necks.FPN_UNet)
+- Bbox_head: [DRRGHead](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.dense_heads.DRRGHead)
+- Loss: [DRRGLoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.losses.DRRGLoss)
+- Postprocessor: [DRRGPostprocessor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.postprocess.DRRGPostprocessor)
+
+### FCENet
+
+- Backbone: [mmdet.ResNet](https://mmdetection.readthedocs.io/en/latest/api.html#mmdet.models.backbones.ResNet)
+- Neck: [mmdet.FPN](https://mmdetection.readthedocs.io/en/latest/api.html#mmdet.models.necks.FPN)
+- Bbox_head: [FCEHead](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.dense_heads.FCEHead)
+- Loss: [FCELoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.losses.FCELoss)
+- Postprocessor: [FCEPostprocessor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.postprocess.FCEPostprocessor)
+
+### Mask R-CNN
+
+We use the same architecture as in MMDetection. See MMDetection's [config documentation](https://mmdetection.readthedocs.io/en/latest/tutorials/config.html#an-example-of-mask-r-cnn) for details.
+
+### PANet
+
+- Backbone: [mmdet.ResNet](https://mmdetection.readthedocs.io/en/latest/api.html#mmdet.models.backbones.ResNet)
+- Neck: [FPEM_FFM](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.necks.FPEM_FFM)
+- Bbox_head: [PANHead](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.dense_heads.PANHead)
+- Loss: [PANLoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.losses.PANLoss)
+- Postprocessor: [PANPostprocessor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.postprocess.PANPostprocessor)
+
+### PSENet
+
+- Backbone: [mmdet.ResNet](https://mmdetection.readthedocs.io/en/latest/api.html#mmdet.models.backbones.ResNet)
+- Neck: [FPNF](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.necks.FPNF)
+- Bbox_head: [PSEHead](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.dense_heads.PSEHead)
+- Loss: [PSELoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.losses.PSELoss)
+- Postprocessor: [PSEPostprocessor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.postprocess.PSEPostprocessor)
+
+### Textsnake
+
+- Backbone: [mmdet.ResNet](https://mmdetection.readthedocs.io/en/latest/api.html#mmdet.models.backbones.ResNet)
+- Neck: [FPN_UNet](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.necks.FPN_UNet)
+- Bbox_head: [TextSnakeHead](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.dense_heads.TextSnakeHead)
+- Loss: [TextSnakeLoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.losses.TextSnakeLoss)
+- Postprocessor: [TextSnakePostprocessor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.postprocess.TextSnakePostprocessor)
+
+## Text Recognition Models
+
+**Most of** the implemented recognizers use the following architecture:
+
+
+
+
+
+
+`preprocessor` refers to any network that processes images before they are fed to `backbone`. `encoder` encodes images features into a hidden vector, which is then transcribed into text tokens by `decoder`.
+
+The architecture diverges at training and test phases. The loss module returns a dictionary during training. In testing, `converter` is invoked to convert raw features into texts, which are wrapped into a dictionary together with confidence scores. Users can access the dictionary with the `text` and `score` keys to query the recognition result.
+
+### ABINet
+
+- Preprocessor: None
+- Backbone: [ResNetABI](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.backbones.ResNetABI)
+- Encoder: [ABIVisionModel](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.encoders.ABIVisionModel)
+- Decoder: [ABIVisionDecoder](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.decoders.ABIVisionDecoder)
+- Fuser: [ABIFuser](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.fusers.ABIFuser)
+- Loss: [ABILoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.losses.ABILoss)
+- Converter: [ABIConvertor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.convertors.ABIConvertor)
+
+:::{note}
+Fuser fuses the feature output from encoder and decoder before generating the final text outputs and computing the loss in full ABINet.
+:::
+
+### CRNN
+
+- Preprocessor: None
+- Backbone: [VeryDeepVgg](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.backbones.VeryDeepVgg)
+- Encoder: None
+- Decoder: [CRNNDecoder](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.decoders.CRNNDecoder)
+- Loss: [CTCLoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.losses.CTCLoss)
+- Converter: [CTCConvertor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.convertors.CTCConvertor)
+
+### CRNN with TPS-based STN
+
+- Preprocessor: [TPSPreprocessor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.preprocessor.TPSPreprocessor)
+- Backbone: [VeryDeepVgg](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.backbones.VeryDeepVgg)
+- Encoder: None
+- Decoder: [CRNNDecoder](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.decoders.CRNNDecoder)
+- Loss: [CTCLoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.losses.CTCLoss)
+- Converter: [CTCConvertor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.convertors.CTCConvertor)
+
+### NRTR
+
+- Preprocessor: None
+- Backbone: [ResNet31OCR](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.backbones.ResNet31OCR)
+- Encoder: [NRTREncoder](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.encoders.NRTREncoder)
+- Decoder: [NRTRDecoder](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.decoders.NRTRDecoder)
+- Loss: [TFLoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.losses.TFLoss)
+- Converter: [AttnConvertor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.convertors.AttnConvertor)
+
+### RobustScanner
+
+- Preprocessor: None
+- Backbone: [ResNet31OCR](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.backbones.ResNet31OCR)
+- Encoder: [ChannelReductionEncoder](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.encoders.ChannelReductionEncoder)
+- Decoder: [ChannelReductionEncoder](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.decoders.RobustScannerDecoder)
+- Loss: [SARLoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.losses.SARLoss)
+- Converter: [AttnConvertor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.convertors.AttnConvertor)
+
+### SAR
+
+- Preprocessor: None
+- Backbone: [ResNet31OCR](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.backbones.ResNet31OCR)
+- Encoder: [SAREncoder](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.encoders.SAREncoder)
+- Decoder: [ParallelSARDecoder](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.decoders.ParallelSARDecoder)
+- Loss: [SARLoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.losses.SARLoss)
+- Converter: [AttnConvertor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.convertors.AttnConvertor)
+
+### SATRN
+
+- Preprocessor: None
+- Backbone: [ShallowCNN](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.backbones.ShallowCNN)
+- Encoder: [SatrnEncoder](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.encoders.SatrnEncoder)
+- Decoder: [NRTRDecoder](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.decoders.NRTRDecoder)
+- Loss: [TFLoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.losses.TFLoss)
+- Converter: [AttnConvertor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.convertors.AttnConvertor)
+
+### SegOCR
+
+- Backbone: [ResNet31OCR](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.backbones.ResNet31OCR)
+- Neck: [FPNOCR](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.necks.FPNOCR)
+- Head: [SegHead](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.heads.SegHead)
+- Loss: [SegLoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.losses.SegLoss)
+- Converter: [SegConvertor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.convertors.SegConvertor)
+
+:::{note}
+SegOCR's architecture is an exception - it is closer to text detection models.
+:::
+
+## Key Information Extraction Models
+
+
+
+
+
+
+The architecture of key information extraction (KIE) models is similar to text detection models, except for the extra feature extractor. As a downstream task of OCR, KIE models are required to run with bounding box annotations indicating the locations of text instances, from which an ROI extractor extracts the cropped features for `bbox_head` to discover relations among them.
+
+The output containing edges and nodes information from `bbox_head` is sufficient for test and inference. Computation of loss also relies on such information.
+
+### SDMGR
+
+- Backbone: [UNet](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.common.backbones.UNet)
+- Neck: None
+- Extractor: [mmdet.SingleRoIExtractor](https://mmdetection.readthedocs.io/en/latest/api.html#mmdet.models.roi_heads.SingleRoIExtractor)
+- Bbox_head: [SDMGRHead](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.kie.heads.SDMGRHead)
+- Loss: [SDMGRLoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.kie.losses.SDMGRLoss)
diff --git a/docs/en/requirements.txt b/docs/en/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..89fbf86c01cb29f10f7e99c910248c4d5229da58
--- /dev/null
+++ b/docs/en/requirements.txt
@@ -0,0 +1,4 @@
+recommonmark
+sphinx
+sphinx_markdown_tables
+sphinx_rtd_theme
diff --git a/docs/en/stats.py b/docs/en/stats.py
new file mode 100755
index 0000000000000000000000000000000000000000..3dee5929448279f503e6f83cf3da10f61fe7c59f
--- /dev/null
+++ b/docs/en/stats.py
@@ -0,0 +1,101 @@
+#!/usr/bin/env python
+# Copyright (c) OpenMMLab. All rights reserved.
+import functools as func
+import glob
+import re
+from os.path import basename, splitext
+
+import numpy as np
+import titlecase
+
+
+def title2anchor(name):
+ return re.sub(r'-+', '-', re.sub(r'[^a-zA-Z0-9]', '-',
+ name.strip().lower())).strip('-')
+
+
+# Count algorithms
+
+files = sorted(glob.glob('*_models.md'))
+
+stats = []
+
+for f in files:
+ with open(f, 'r') as content_file:
+ content = content_file.read()
+
+ # Remove the blackquote notation from the paper link under the title
+ # for better layout in readthedocs
+ expr = r'(^## \s*?.*?\s+?)>\s*?(\[.*?\]\(.*?\))'
+ content = re.sub(expr, r'\1\2', content, flags=re.MULTILINE)
+ with open(f, 'w') as content_file:
+ content_file.write(content)
+
+ # title
+ title = content.split('\n')[0].replace('#', '')
+
+ # count papers
+ exclude_papertype = ['ABSTRACT', 'IMAGE']
+ exclude_expr = ''.join(f'(?!{s})' for s in exclude_papertype)
+ expr = rf''\
+ r'\s*\n.*?\btitle\s*=\s*{(.*?)}'
+ papers = set(
+ (papertype, titlecase.titlecase(paper.lower().strip()))
+ for (papertype, paper) in re.findall(expr, content, re.DOTALL))
+ print(papers)
+ # paper links
+ revcontent = '\n'.join(list(reversed(content.splitlines())))
+ paperlinks = {}
+ for _, p in papers:
+ q = p.replace('\\', '\\\\').replace('?', '\\?')
+ paper_link = title2anchor(
+ re.search(
+ rf'\btitle\s*=\s*{{\s*{q}\s*}}.*?\n## (.*?)\s*[,;]?\s*\n',
+ revcontent, re.DOTALL | re.IGNORECASE).group(1))
+ paperlinks[p] = f'[{p}]({splitext(basename(f))[0]}.html#{paper_link})'
+ paperlist = '\n'.join(
+ sorted(f' - [{t}] {paperlinks[x]}' for t, x in papers))
+ # count configs
+ configs = set(x.lower().strip()
+ for x in re.findall(r'https.*configs/.*\.py', content))
+
+ # count ckpts
+ ckpts = set(x.lower().strip()
+ for x in re.findall(r'https://download.*\.pth', content)
+ if 'mmocr' in x)
+
+ statsmsg = f"""
+## [{title}]({f})
+
+* Number of checkpoints: {len(ckpts)}
+* Number of configs: {len(configs)}
+* Number of papers: {len(papers)}
+{paperlist}
+
+ """
+
+ stats.append((papers, configs, ckpts, statsmsg))
+
+allpapers = func.reduce(lambda a, b: a.union(b), [p for p, _, _, _ in stats])
+allconfigs = func.reduce(lambda a, b: a.union(b), [c for _, c, _, _ in stats])
+allckpts = func.reduce(lambda a, b: a.union(b), [c for _, _, c, _ in stats])
+msglist = '\n'.join(x for _, _, _, x in stats)
+
+papertypes, papercounts = np.unique([t for t, _ in allpapers],
+ return_counts=True)
+countstr = '\n'.join(
+ [f' - {t}: {c}' for t, c in zip(papertypes, papercounts)])
+
+modelzoo = f"""
+# Statistics
+
+* Number of checkpoints: {len(allckpts)}
+* Number of configs: {len(allconfigs)}
+* Number of papers: {len(allpapers)}
+{countstr}
+
+{msglist}
+"""
+
+with open('modelzoo.md', 'w') as f:
+ f.write(modelzoo)
diff --git a/docs/en/testing.md b/docs/en/testing.md
new file mode 100644
index 0000000000000000000000000000000000000000..1c2026fa0d05a818e137af24db4000f73326ac3b
--- /dev/null
+++ b/docs/en/testing.md
@@ -0,0 +1,109 @@
+# Testing
+
+We introduce the way to test pretrained models on datasets here.
+
+## Testing with Single GPU
+
+You can use `tools/test.py` to perform single CPU/GPU inference. For example, to evaluate DBNet on IC15: (You can download pretrained models from [Model Zoo](modelzoo.md)):
+
+```shell
+./tools/dist_test.sh configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py dbnet_r18_fpnc_sbn_1200e_icdar2015_20210329-ba3ab597.pth --eval hmean-iou
+```
+
+And here is the full usage of the script:
+
+```shell
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [ARGS]
+```
+
+:::{note}
+By default, MMOCR prefers GPU(s) to CPU. If you want to test a model on CPU, please empty `CUDA_VISIBLE_DEVICES` or set it to -1 to make GPU(s) invisible to the program. Note that running CPU tests requires **MMCV >= 1.4.4**.
+
+```bash
+CUDA_VISIBLE_DEVICES= python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [ARGS]
+```
+
+:::
+
+
+
+| ARGS | Type | Description |
+| ------------------ | --------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `--out` | str | Output result file in pickle format. |
+| `--fuse-conv-bn` | bool | Path to the custom config of the selected det model. |
+| `--format-only` | bool | Format the output results without performing evaluation. It is useful when you want to format the results to a specific format and submit them to the test server. |
+| `--gpu-id` | int | GPU id to use. Only applicable to non-distributed training. |
+| `--eval` | 'hmean-ic13', 'hmean-iou', 'acc' | The evaluation metrics, which depends on the task. For text detection, the metric should be either 'hmean-ic13' or 'hmean-iou'. For text recognition, the metric should be 'acc'. |
+| `--show` | bool | Whether to show results. |
+| `--show-dir` | str | Directory where the output images will be saved. |
+| `--show-score-thr` | float | Score threshold (default: 0.3). |
+| `--gpu-collect` | bool | Whether to use gpu to collect results. |
+| `--tmpdir` | str | The tmp directory used for collecting results from multiple workers, available when gpu-collect is not specified. |
+| `--cfg-options` | str | Override some settings in the used config, the key-value pair in xxx=yyy format will be merged into the config file. If the value to be overwritten is a list, it should be of the form of either key="[a,b]" or key=a,b. The argument also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]". Note that the quotation marks are necessary and that no white space is allowed. |
+| `--eval-options` | str | Custom options for evaluation, the key-value pair in xxx=yyy format will be kwargs for dataset.evaluate() function. |
+| `--launcher` | 'none', 'pytorch', 'slurm', 'mpi' | Options for job launcher. |
+
+
+## Testing with Multiple GPUs
+
+MMOCR implements **distributed** testing with `MMDistributedDataParallel`.
+
+You can use the following command to test a dataset with multiple GPUs.
+
+```shell
+[PORT={PORT}] ./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [PY_ARGS]
+```
+
+
+| Arguments | Type | Description |
+| --------- | ---- | -------------------------------------------------------------------------------- |
+| `PORT` | int | The master port that will be used by the machine with rank 0. Defaults to 29500. |
+| `PY_ARGS` | str | Arguments to be parsed by `tools/test.py`. |
+
+
+For example,
+
+```shell
+./tools/dist_test.sh configs/example_config.py work_dirs/example_exp/example_model_20200202.pth 1 --eval hmean-iou
+```
+
+## Testing with Slurm
+
+If you run MMOCR on a cluster managed with [Slurm](https://slurm.schedmd.com/), you can use the script `tools/slurm_test.sh`.
+
+
+```shell
+[GPUS=${GPUS}] [GPUS_PER_NODE=${GPUS_PER_NODE}] [SRUN_ARGS=${SRUN_ARGS}] ./tools/slurm_test.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${CHECKPOINT_FILE} [PY_ARGS]
+```
+
+| Arguments | Type | Description |
+| --------------- | ---- | ----------------------------------------------------------------------------------------------------------- |
+| `GPUS` | int | The number of GPUs to be used by this task. Defaults to 8. |
+| `GPUS_PER_NODE` | int | The number of GPUs to be allocated per node. Defaults to 8. |
+| `SRUN_ARGS` | str | Arguments to be parsed by srun. Available options can be found [here](https://slurm.schedmd.com/srun.html). |
+| `PY_ARGS` | str | Arguments to be parsed by `tools/test.py`. |
+
+
+Here is an example of using 8 GPUs to test an example model on the 'dev' partition with job name 'test_job'.
+
+```shell
+GPUS=8 ./tools/slurm_test.sh dev test_job configs/example_config.py work_dirs/example_exp/example_model_20200202.pth --eval hmean-iou
+```
+
+## Batch Testing
+
+By default, MMOCR tests the model image by image. For faster inference, you may change `data.val_dataloader.samples_per_gpu` and `data.test_dataloader.samples_per_gpu` in the config. For example,
+
+```
+data = dict(
+ ...
+ val_dataloader=dict(samples_per_gpu=16),
+ test_dataloader=dict(samples_per_gpu=16),
+ ...
+)
+```
+will test the model with 16 images in a batch.
+
+:::{warning}
+Batch testing may incur performance decrease of the model due to the different behavior of the data preprocessing pipeline.
+:::
diff --git a/docs/en/tools.md b/docs/en/tools.md
new file mode 100644
index 0000000000000000000000000000000000000000..f42cef2471890976807a34101e548734d5439fd3
--- /dev/null
+++ b/docs/en/tools.md
@@ -0,0 +1,32 @@
+# Useful Tools
+
+We provide some useful tools under `mmocr/tools` directory.
+
+## Publish a Model
+
+Before you upload a model to AWS, you may want to
+(1) convert the model weights to CPU tensors, (2) delete the optimizer states and
+(3) compute the hash of the checkpoint file and append the hash id to the filename. These functionalities could be achieved by `tools/publish_model.py`.
+
+```shell
+python tools/publish_model.py ${INPUT_FILENAME} ${OUTPUT_FILENAME}
+```
+
+For example,
+
+```shell
+python tools/publish_model.py work_dirs/psenet/latest.pth psenet_r50_fpnf_sbn_1x_20190801.pth
+```
+
+The final output filename will be `psenet_r50_fpnf_sbn_1x_20190801-{hash id}.pth`.
+
+
+## Convert txt annotation to lmdb format
+Sometimes, loading a large txt annotation file with multiple workers can cause OOM (out of memory) error. You can convert the file into lmdb format using `tools/data/utils/txt2lmdb.py` and use LmdbLoader in your config to avoid this issue.
+```bash
+python tools/data/utils/txt2lmdb.py -i -o
+```
+For example,
+```bash
+python tools/data/utils/txt2lmdb.py -i data/mixture/Syn90k/label.txt -o data/mixture/Syn90k/label.lmdb
+```
diff --git a/docs/en/training.md b/docs/en/training.md
new file mode 100644
index 0000000000000000000000000000000000000000..2ea035d567394f40fd76943d191df9c2e7280993
--- /dev/null
+++ b/docs/en/training.md
@@ -0,0 +1,130 @@
+# Training
+
+## Training on a Single GPU
+
+You can use `tools/train.py` to train a model on a single machine with a CPU and optionally a GPU.
+
+Here is the full usage of the script:
+
+```shell
+python tools/train.py ${CONFIG_FILE} [ARGS]
+```
+
+:::{note}
+By default, MMOCR prefers GPU to CPU. If you want to train a model on CPU, please empty `CUDA_VISIBLE_DEVICES` or set it to -1 to make GPU invisible to the program. Note that CPU training requires **MMCV >= 1.4.4**.
+
+```bash
+CUDA_VISIBLE_DEVICES= python tools/train.py ${CONFIG_FILE} [ARGS]
+```
+
+:::
+
+| ARGS | Type | Description |
+| ----------------- | --------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `--work-dir` | str | The target folder to save logs and checkpoints. Defaults to `./work_dirs`. |
+| `--load-from` | str | Path to the pre-trained model, which will be used to initialize the network parameters. |
+| `--resume-from` | str | Resume training from a previously saved checkpoint, which will inherit the training epoch and optimizer parameters. |
+| `--no-validate` | bool | Disable checkpoint evaluation during training. Defaults to `False`. |
+| `--gpus` | int | **Deprecated, please use --gpu-id.** Numbers of gpus to use. Only applicable to non-distributed training. |
+| `--gpu-ids` | int*N | **Deprecated, please use --gpu-id.** A list of GPU ids to use. Only applicable to non-distributed training. |
+| `--gpu-id` | int | The GPU id to use. Only applicable to non-distributed training. |
+| `--seed` | int | Random seed. |
+| `--diff_seed` | bool | Whether or not set different seeds for different ranks. |
+| `--deterministic` | bool | Whether to set deterministic options for CUDNN backend. |
+| `--cfg-options` | str | Override some settings in the used config, the key-value pair in xxx=yyy format will be merged into the config file. If the value to be overwritten is a list, it should be of the form of either key="[a,b]" or key=a,b. The argument also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]". Note that the quotation marks are necessary and that no white space is allowed. |
+| `--launcher` | 'none', 'pytorch', 'slurm', 'mpi' | Options for job launcher. |
+| `--local_rank` | int | Used for distributed training. |
+| `--mc-config` | str | Memory cache config for image loading speed-up during training. |
+
+## Training on Multiple GPUs
+
+MMOCR implements **distributed** training with `MMDistributedDataParallel`. (Please refer to [datasets.md](datasets.md) to prepare your datasets)
+
+```shell
+[PORT={PORT}] ./tools/dist_train.sh ${CONFIG_FILE} ${WORK_DIR} ${GPU_NUM} [PY_ARGS]
+```
+
+| Arguments | Type | Description |
+| --------- | ---- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
+| `PORT` | int | The master port that will be used by the machine with rank 0. Defaults to 29500. **Note:** If you are launching multiple distrbuted training jobs on a single machine, you need to specify different ports for each job to avoid port conflicts. |
+| `PY_ARGS` | str | Arguments to be parsed by `tools/train.py`. |
+
+## Training on Multiple Machines
+
+MMOCR relies on torch.distributed package for distributed training. Thus, as a basic usage, one can launch distributed training via PyTorch’s [launch utility](https://pytorch.org/docs/stable/distributed.html#launch-utility).
+
+## Training with Slurm
+
+If you run MMOCR on a cluster managed with [Slurm](https://slurm.schedmd.com/), you can use the script `slurm_train.sh`.
+
+```shell
+[GPUS=${GPUS}] [GPUS_PER_NODE=${GPUS_PER_NODE}] [CPUS_PER_TASK=${CPUS_PER_TASK}] [SRUN_ARGS=${SRUN_ARGS}] ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${WORK_DIR} [PY_ARGS]
+```
+
+| Arguments | Type | Description |
+| --------------- | ---- | ----------------------------------------------------------------------------------------------------------- |
+| `GPUS` | int | The number of GPUs to be used by this task. Defaults to 8. |
+| `GPUS_PER_NODE` | int | The number of GPUs to be allocated per node. Defaults to 8. |
+| `CPUS_PER_TASK` | int | The number of CPUs to be allocated per task. Defaults to 5. |
+| `SRUN_ARGS` | str | Arguments to be parsed by srun. Available options can be found [here](https://slurm.schedmd.com/srun.html). |
+| `PY_ARGS` | str | Arguments to be parsed by `tools/train.py`. |
+
+Here is an example of using 8 GPUs to train a text detection model on the dev partition.
+
+```shell
+./tools/slurm_train.sh dev psenet-ic15 configs/textdet/psenet/psenet_r50_fpnf_sbn_1x_icdar2015.py /nfs/xxxx/psenet-ic15
+```
+
+### Running Multiple Training Jobs on a Single Machine
+
+If you are launching multiple training jobs on a single machine with Slurm, you may need to modify the port in configs to avoid communication conflicts.
+
+For example, in `config1.py`,
+
+```python
+dist_params = dict(backend='nccl', port=29500)
+```
+
+In `config2.py`,
+
+```python
+dist_params = dict(backend='nccl', port=29501)
+```
+
+Then you can launch two jobs with `config1.py` ang `config2.py`.
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 GPUS=4 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config1.py ${WORK_DIR}
+CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=4 ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config2.py ${WORK_DIR}
+```
+
+## Commonly Used Training Configs
+
+Here we list some configs that are frequently used during training for quick reference.
+
+```python
+total_epochs = 1200
+data = dict(
+ # Note: User can configure general settings of train, val and test dataloader by specifying them here. However, their values can be overridden in dataloader's config.
+ samples_per_gpu=8, # Batch size per GPU
+ workers_per_gpu=4, # Number of workers to process data for each GPU
+ train_dataloader=dict(samples_per_gpu=10, drop_last=True), # Batch size = 10, workers_per_gpu = 4
+ val_dataloader=dict(samples_per_gpu=6, workers_per_gpu=1), # Batch size = 6, workers_per_gpu = 1
+ test_dataloader=dict(workers_per_gpu=16), # Batch size = 8, workers_per_gpu = 16
+ ...
+)
+# Evaluation
+evaluation = dict(interval=1, by_epoch=True) # Evaluate the model every epoch
+# Saving and Logging
+checkpoint_config = dict(interval=1) # Save a checkpoint every epoch
+log_config = dict(
+ interval=5, # Print out the model's performance every 5 iterations
+ hooks=[
+ dict(type='TextLoggerHook')
+ ])
+# Optimizer
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001) # Supports all optimizers in PyTorch and shares the same parameters
+optimizer_config = dict(grad_clip=None) # Parameters for the optimizer hook. See https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/optimizer.py for implementation details
+# Learning policy
+lr_config = dict(policy='poly', power=0.9, min_lr=1e-7, by_epoch=True)
+```
diff --git a/docs/en/tutorials/config.md b/docs/en/tutorials/config.md
new file mode 100644
index 0000000000000000000000000000000000000000..41098a02280ec07ce2a73602c056d36b03424283
--- /dev/null
+++ b/docs/en/tutorials/config.md
@@ -0,0 +1,354 @@
+# Learn about Configs
+
+We incorporate modular and inheritance design into our config system, which is convenient to conduct various experiments.
+If you wish to inspect the config file, you may run `python tools/misc/print_config.py /PATH/TO/CONFIG` to see the complete config.
+
+## Modify config through script arguments
+
+When submitting jobs using "tools/train.py" or "tools/test.py", you may specify `--cfg-options` to in-place modify the config.
+
+- Update config keys of dict chains.
+
+ The config options can be specified following the order of the dict keys in the original config.
+ For example, `--cfg-options model.backbone.norm_eval=False` changes the all BN modules in model backbones to `train` mode.
+
+- Update keys inside a list of configs.
+
+ Some config dicts are composed as a list in your config. For example, the training pipeline `data.train.pipeline` is normally a list
+ e.g. `[dict(type='LoadImageFromFile'), ...]`. If you want to change `'LoadImageFromFile'` to `'LoadImageFromNdarry'` in the pipeline,
+ you may specify `--cfg-options data.train.pipeline.0.type=LoadImageFromNdarry`.
+
+- Update values of list/tuples.
+
+ If the value to be updated is a list or a tuple. For example, the config file normally sets `workflow=[('train', 1)]`. If you want to
+ change this key, you may specify `--cfg-options workflow="[(train,1),(val,1)]"`. Note that the quotation mark \" is necessary to
+ support list/tuple data types, and that **NO** white space is allowed inside the quotation marks in the specified value.
+
+## Config Name Style
+
+We follow the below style to name full config files (`configs/TASK/*.py`). Contributors are advised to follow the same style.
+
+```
+{model}_[ARCHITECTURE]_[schedule]_{dataset}.py
+```
+
+`{xxx}` is required field and `[yyy]` is optional.
+
+- `{model}`: model type like `dbnet`, `crnn`, etc.
+- `[ARCHITECTURE]`: expands some invoked modules following the order of data flow, and the content depends on the model framework. The following examples show how it is generally expanded.
+ - For text detection tasks, key information tasks, and SegOCR in text recognition task: `{model}_[backbone]_[neck]_[schedule]_{dataset}.py`
+ - For other text recognition tasks, `{model}_[backbone]_[encoder]_[decoder]_[schedule]_{dataset}.py`
+ Note that `backbone`, `neck`, `encoder`, `decoder` are the names of modules, e.g. `r50`, `fpnocr`, etc.
+- `{schedule}`: training schedule. For instance, `1200e` denotes 1200 epochs.
+- `{dataset}`: dataset. It can either be the name of a dataset (`icdar2015`), or a collection of datasets for brevity (e.g. `academic` usually refers to a common practice in academia, which uses MJSynth + SynthText as training set, and IIIT5K, SVT, IC13, IC15, SVTP and CT80 as test set).
+
+Most configs are composed of basic _primitive_ configs in `configs/_base_`, where each _primitive_ config in different subdirectory has a slightly different name style. We present them as follows.
+
+- det_datasets, recog_datasets: `{dataset_name(s)}_[train|test].py`. If [train|test] is not specified, the config should contain both training and test set.
+
+ There are two exceptions: toy_data.py and seg_toy_data.py. In recog_datasets, the first one works for most while the second one contains character level annotations and works for seg baseline only as of Dec 2021.
+- det_models, recog_models: `{model}_[ARCHITECTURE].py`.
+- det_pipelines, recog_pipelines: `{model}_pipeline.py`.
+- schedules: `schedule_{optimizer}_{num_epochs}e.py`.
+
+## Config Structure
+
+For better config reusability, we break many of reusable sections of configs into `configs/_base_`. Now the directory tree of `configs/_base_` is organized as follows:
+
+```
+_base_
+├── det_datasets
+├── det_models
+├── det_pipelines
+├── recog_datasets
+├── recog_models
+├── recog_pipelines
+└── schedules
+```
+
+These _primitive_ configs are categorized by their roles in a complete config. Most of model configs are making full use of _primitive_ configs by including them as parts of `_base_` section. For example, [dbnet_r18_fpnc_1200e_icdar2015.py](https://github.com/open-mmlab/mmocr/blob/5a8859fe6666c096b75fa44db4f6c53d81a2ed62/configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py) takes five _primitive_ configs from `_base_`:
+
+```python
+_base_ = [
+ '../../_base_/runtime_10e.py',
+ '../../_base_/schedules/schedule_sgd_1200e.py',
+ '../../_base_/det_models/dbnet_r18_fpnc.py',
+ '../../_base_/det_datasets/icdar2015.py',
+ '../../_base_/det_pipelines/dbnet_pipeline.py'
+]
+```
+
+From these configs' names we can roughly know this config trains dbnet_r18_fpnc with sgd optimizer in 1200 epochs. It uses the origin dbnet pipeline and icdar2015 as the dataset. We encourage users to follow and take advantage of this convention to organize the config clearly and facilitate fair comparison across different _primitive_ configurations as well as models.
+
+Please refer to [mmcv](https://mmcv.readthedocs.io/en/latest/understand_mmcv/config.html) for detailed documentation.
+
+## Config File Structure
+
+### Model
+
+The parameter `"model"` is a python dictionary in the configuration file, which mainly includes information such as network structure and loss function.
+
+```{note}
+The 'type' in the configuration file is not a constructed parameter, but a class name.
+```
+
+```{note}
+We can also use models from MMDetection by adding `mmdet.` prefix to type name, or from other OpenMMLab projects in a similar way if their backbones are registered in registries.
+```
+
+#### Shared Section
+
+- `type`: Model name.
+
+#### Text Detection / Text Recognition / Key Information Extraction Model
+
+- `backbone`: Backbone configs. [Common Backbones](https://mmocr.readthedocs.io/en/latest/api.html#module-mmocr.models.common.backbones), [TextRecog Backbones](https://mmocr.readthedocs.io/en/latest/api.html#module-mmocr.models.textrecog.backbones)
+- `neck`: Neck network name. [TextDet Necks](https://mmocr.readthedocs.io/en/latest/api.html#module-mmocr.models.textdet.necks), [TextRecog Necks](https://mmocr.readthedocs.io/en/latest/api.html#module-mmocr.models.textrecog.necks).
+- `bbox_head`: Head network name. Applicable to text detection, key information models and *some* text recognition models. [TextDet Heads](https://mmocr.readthedocs.io/en/latest/api.html#module-mmocr.models.textdet.dense_heads), [TextRecog Heads](https://mmocr.readthedocs.io/en/latest/api.html#module-mmocr.models.textrecog.heads), [KIE Heads](https://mmocr.readthedocs.io/en/latest/api.html#module-mmocr.models.kie.heads).
+ - `loss`: Loss function type. [TextDet Losses](https://mmocr.readthedocs.io/en/latest/api.html#module-mmocr.models.textdet.losses), [KIE Losses](https://mmocr.readthedocs.io/en/latest/api.html#module-mmocr.models.kie.losses)
+ - `postprocessor`: (TextDet only) Postprocess type. [TextDet Postprocessors](https://mmocr.readthedocs.io/en/latest/api.html#module-mmocr.models.textdet.postprocess)
+
+#### Text Recognition / Named Entity Extraction Model
+
+- `encoder`: Encoder configs. [TextRecog Encoders](https://mmocr.readthedocs.io/en/latest/api.html#module-mmocr.models.textrecog.encoders)
+- `decoder`: Decoder configs. Applicable to text recognition models. [TextRecog Decoders](https://mmocr.readthedocs.io/en/latest/api.html#module-mmocr.models.textrecog.decoders)
+- `loss`: Loss configs. Applicable to some text recognition models. [TextRecog Losses](https://mmocr.readthedocs.io/en/latest/api.html#module-mmocr.models.textrecog.losses)
+- `label_convertor`: Convert outputs between text, index and tensor. Applicable to text recognition models. [Label Convertors](https://mmocr.readthedocs.io/en/latest/api.html#module-mmocr.models.textrecog.convertors)
+- `max_seq_len`: The maximum sequence length of recognition results. Applicable to text recognition models.
+
+### Data & Pipeline
+
+The parameter `"data"` is a python dictionary in the configuration file, which mainly includes information to construct dataloader:
+
+- `samples_per_gpu` : the BatchSize of each GPU when building the dataloader
+- `workers_per_gpu` : the number of threads per GPU when building dataloader
+- `train | val | test` : config to construct dataset
+ - `type`: Dataset name. Check [dataset types](../dataset_types.md) for supported datasets.
+
+The parameter `evaluation` is also a dictionary, which is the configuration information of `evaluation hook`, mainly including evaluation interval, evaluation index, etc.
+
+```python
+# dataset settings
+dataset_type = 'IcdarDataset' # dataset name,
+data_root = 'data/icdar2015' # dataset root
+img_norm_cfg = dict( # Image normalization config to normalize the input images
+ mean=[123.675, 116.28, 103.53], # Mean values used to pre-training the pre-trained backbone models
+ std=[58.395, 57.12, 57.375], # Standard variance used to pre-training the pre-trained backbone models
+ to_rgb=True) # Whether to invert the color channel, rgb2bgr or bgr2rgb.
+# train data pipeline
+train_pipeline = [ # Training pipeline
+ dict(type='LoadImageFromFile'), # First pipeline to load images from file path
+ dict(
+ type='LoadAnnotations', # Second pipeline to load annotations for current image
+ with_bbox=True, # Whether to use bounding box, True for detection
+ with_mask=True, # Whether to use instance mask, True for instance segmentation
+ poly2mask=False), # Whether to convert the polygon mask to instance mask, set False for acceleration and to save memory
+ dict(
+ type='Resize', # Augmentation pipeline that resize the images and their annotations
+ img_scale=(1333, 800), # The largest scale of image
+ keep_ratio=True
+ ), # whether to keep the ratio between height and width.
+ dict(
+ type='RandomFlip', # Augmentation pipeline that flip the images and their annotations
+ flip_ratio=0.5), # The ratio or probability to flip
+ dict(
+ type='Normalize', # Augmentation pipeline that normalize the input images
+ mean=[123.675, 116.28, 103.53], # These keys are the same of img_norm_cfg since the
+ std=[58.395, 57.12, 57.375], # keys of img_norm_cfg are used here as arguments
+ to_rgb=True),
+ dict(
+ type='Pad', # Padding config
+ size_divisor=32), # The number the padded images should be divisible
+ dict(type='DefaultFormatBundle'), # Default format bundle to gather data in the pipeline
+ dict(
+ type='Collect', # Pipeline that decides which keys in the data should be passed to the detector
+ keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks'])
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'), # First pipeline to load images from file path
+ dict(
+ type='MultiScaleFlipAug', # An encapsulation that encapsulates the testing augmentations
+ img_scale=(1333, 800), # Decides the largest scale for testing, used for the Resize pipeline
+ flip=False, # Whether to flip images during testing
+ transforms=[
+ dict(type='Resize', # Use resize augmentation
+ keep_ratio=True), # Whether to keep the ratio between height and width, the img_scale set here will be suppressed by the img_scale set above.
+ dict(type='RandomFlip'), # Thought RandomFlip is added in pipeline, it is not used because flip=False
+ dict(
+ type='Normalize', # Normalization config, the values are from img_norm_cfg
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ to_rgb=True),
+ dict(
+ type='Pad', # Padding config to pad images divisible by 32.
+ size_divisor=32),
+ dict(
+ type='ImageToTensor', # convert image to tensor
+ keys=['img']),
+ dict(
+ type='Collect', # Collect pipeline that collect necessary keys for testing.
+ keys=['img'])
+ ])
+]
+data = dict(
+ samples_per_gpu=32, # Batch size of a single GPU
+ workers_per_gpu=2, # Worker to pre-fetch data for each single GPU
+ train=dict( # train data config
+ type=dataset_type, # dataset name
+ ann_file=f'{data_root}/instances_training.json', # Path to annotation file
+ img_prefix=f'{data_root}/imgs', # Path to images
+ pipeline=train_pipeline), # train data pipeline
+ test=dict( # test data config
+ type=dataset_type,
+ ann_file=f'{data_root}/instances_test.json', # Path to annotation file
+ img_prefix=f'{data_root}/imgs', # Path to images
+ pipeline=test_pipeline))
+evaluation = dict( # The config to build the evaluation hook, refer to https://github.com/open-mmlab/mmdetection/blob/master/mmdet/core/evaluation/eval_hooks.py#L7 for more details.
+ interval=1, # Evaluation interval
+ metric='hmean-iou') # Metrics used during evaluation
+```
+
+### Training Schedule
+
+Mainly include optimizer settings, `optimizer hook` settings, learning rate schedule and `runner` settings:
+
+- `optimizer`: optimizer setting , support all optimizers in `pytorch`, refer to related [mmcv](https://mmcv.readthedocs.io/en/latest/_modules/mmcv/runner/optimizer/default_constructor.html#DefaultOptimizerConstructor) documentation.
+- `optimizer_config`: `optimizer hook` configuration file, such as setting gradient limit, refer to related [mmcv](https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/optimizer.py#L8) code.
+- `lr_config`: Learning rate scheduler, supports "CosineAnnealing", "Step", "Cyclic", etc. Refer to related [mmcv](https://mmcv.readthedocs.io/en/latest/_modules/mmcv/runner/hooks/lr_updater.html#LrUpdaterHook) documentation for more options.
+- `runner`: For `runner`, please refer to `mmcv` for [`runner`](https://mmcv.readthedocs.io/en/latest/understand_mmcv/runner.html) introduction document.
+
+```python
+# he configuration file used to build the optimizer, support all optimizers in PyTorch.
+optimizer = dict(type='SGD', # Optimizer type
+ lr=0.1, # Learning rate of optimizers, see detail usages of the parameters in the documentation of PyTorch
+ momentum=0.9, # Momentum
+ weight_decay=0.0001) # Weight decay of SGD
+# Config used to build the optimizer hook, refer to https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/optimizer.py#L8 for implementation details.
+optimizer_config = dict(grad_clip=None) # Most of the methods do not use gradient clip
+# Learning rate scheduler config used to register LrUpdater hook
+lr_config = dict(policy='step', # The policy of scheduler, also support CosineAnnealing, Cyclic, etc. Refer to details of supported LrUpdater from https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/lr_updater.py#L9.
+ step=[30, 60, 90]) # Steps to decay the learning rate
+runner = dict(type='EpochBasedRunner', # Type of runner to use (i.e. IterBasedRunner or EpochBasedRunner)
+ max_epochs=100) # Runner that runs the workflow in total max_epochs. For IterBasedRunner use `max_iters`
+```
+
+### Runtime Setting
+
+This part mainly includes saving the checkpoint strategy, log configuration, training parameters, breakpoint weight path, working directory, etc..
+
+```python
+# Config to set the checkpoint hook, Refer to https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/checkpoint.py for implementation.
+checkpoint_config = dict(interval=1) # The save interval is 1
+# config to register logger hook
+log_config = dict(
+ interval=100, # Interval to print the log
+ hooks=[
+ dict(type='TextLoggerHook'), # The Tensorboard logger is also supported
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+dist_params = dict(backend='nccl') # Parameters to setup distributed training, the port can also be set.
+log_level = 'INFO' # The output level of the log.
+resume_from = None # Resume checkpoints from a given path, the training will be resumed from the epoch when the checkpoint's is saved.
+workflow = [('train', 1)] # Workflow for runner. [('train', 1)] means there is only one workflow and the workflow named 'train' is executed once.
+work_dir = 'work_dir' # Directory to save the model checkpoints and logs for the current experiments.
+```
+
+## FAQ
+
+### Ignore some fields in the base configs
+
+Sometimes, you may set `_delete_=True` to ignore some of fields in base configs.
+You may refer to [mmcv](https://mmcv.readthedocs.io/en/latest/understand_mmcv/config.html#inherit-from-base-config-with-ignored-fields) for simple illustration.
+
+### Use intermediate variables in configs
+
+Some intermediate variables are used in the configs files, like `train_pipeline`/`test_pipeline` in datasets.
+It's worth noting that when modifying intermediate variables in the children configs, user need to pass the intermediate variables into corresponding fields again.
+For example, we usually want the data path to be a variable so that we
+
+```python
+dataset_type = 'IcdarDataset'
+data_root = 'data/icdar2015'
+
+train = dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/instances_training.json',
+ img_prefix=f'{data_root}/imgs',
+ pipeline=None)
+
+test = dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/instances_test.json',
+ img_prefix=f'{data_root}/imgs',
+ pipeline=None)
+```
+
+### Use some fields in the base configs
+
+Sometimes, you may refer to some fields in the `_base_` config, so as to avoid duplication of definitions. You can refer to [mmcv](https://mmcv.readthedocs.io/en/latest/understand_mmcv/config.html#reference-variables-from-base) for some more instructions.
+
+This technique has been widely used in MMOCR's configs, where the main configs refer to the dataset and pipeline defined in _base_ configs by:
+
+```python
+train_list = {{_base_.train_list}}
+test_list = {{_base_.test_list}}
+
+train_pipeline = {{_base_.train_pipeline}}
+test_pipeline = {{_base_.test_pipeline}}
+```
+
+Which assumes that its _base_ configs export datasets and pipelines in a way like:
+
+```python
+# base dataset config
+dataset_type = 'IcdarDataset'
+data_root = 'data/icdar2015'
+
+train = dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/instances_training.json',
+ img_prefix=f'{data_root}/imgs',
+ pipeline=None)
+
+test = dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/instances_test.json',
+ img_prefix=f'{data_root}/imgs',
+ pipeline=None)
+
+train_list = [train]
+test_list = [test]
+```
+
+```python
+# base pipeline config
+train_pipeline = dict(...)
+test_pipeline = dict(...)
+```
+
+## Deprecated train_cfg/test_cfg
+
+The `train_cfg` and `test_cfg` are deprecated in config file, please specify them in the model config. The original config structure is as below.
+
+```python
+# deprecated
+model = dict(
+ type=...,
+ ...
+)
+train_cfg=dict(...)
+test_cfg=dict(...)
+```
+
+The migration example is as below.
+
+```python
+# recommended
+model = dict(
+ type=...,
+ ...
+ train_cfg=dict(...),
+ test_cfg=dict(...),
+)
+```
diff --git a/docs/en/tutorials/dataset_types.md b/docs/en/tutorials/dataset_types.md
new file mode 100644
index 0000000000000000000000000000000000000000..290c9d1df3543787d60396e4e7250a9f4ca1872b
--- /dev/null
+++ b/docs/en/tutorials/dataset_types.md
@@ -0,0 +1,180 @@
+# Dataset Types
+
+## General Introduction
+
+To support the tasks of text detection, text recognition and key information extraction, we have designed some new types of dataset which consist of **loader** and **parser** to load and parse different types of annotation files.
+- **loader**: Load the annotation file. There are two types of loader, `HardDiskLoader` and `LmdbLoader`
+ - `HardDiskLoader`: Load `txt` format annotation file from hard disk to memory.
+ - `LmdbLoader`: Load `lmdb` format annotation file with lmdb backend, which is very useful for **extremely large** annotation files to avoid out-of-memory problem when ten or more GPUs are used, since each GPU will start multiple processes to load annotation file to memory.
+- **parser**: Parse the annotation file line-by-line and return with `dict` format. There are two types of parser, `LineStrParser` and `LineJsonParser`.
+ - `LineStrParser`: Parse one line in ann file while treating it as a string and separating it to several parts by a `separator`. It can be used on tasks with simple annotation files such as text recognition where each line of the annotation files contains the `filename` and `label` attribute only.
+ - `LineJsonParser`: Parse one line in ann file while treating it as a json-string and using `json.loads` to convert it to `dict`. It can be used on tasks with complex annotation files such as text detection where each line of the annotation files contains multiple attributes (e.g. `filename`, `height`, `width`, `box`, `segmentation`, `iscrowd`, `category_id`, etc.).
+
+Here we show some examples of using different combination of `loader` and `parser`.
+
+## General Task
+
+### UniformConcatDataset
+
+`UniformConcatDataset` is a dataset wrapper which allows users to apply a universal pipeline on multiple datasets without specifying the pipeline for each of them.
+
+For example, to apply `train_pipeline` on both `train1` and `train2`,
+
+```python
+data = dict(
+ ...
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=[train1, train2],
+ pipeline=train_pipeline))
+```
+
+Also, it support apply different `pipeline` to different `datasets`,
+
+```python
+train_list1 = [train1, train2]
+train_list2 = [train3, train4]
+
+data = dict(
+ ...
+ train=dict(
+ type='UniformConcatDataset',
+ datasets=[train_list1, train_list2],
+ pipeline=[train_pipeline1, train_pipeline2]))
+```
+
+Here, `train_pipeline1` will be applied to `train1` and `train2`, and
+`train_pipeline2` will be applied to `train3` and `train4`.
+
+## Text Detection Task
+
+### TextDetDataset
+
+*Dataset with annotation file in line-json txt format*
+
+```python
+dataset_type = 'TextDetDataset'
+img_prefix = 'tests/data/toy_dataset/imgs'
+test_anno_file = 'tests/data/toy_dataset/instances_test.txt'
+test = dict(
+ type=dataset_type,
+ img_prefix=img_prefix,
+ ann_file=test_anno_file,
+ loader=dict(
+ type='HardDiskLoader',
+ repeat=4,
+ parser=dict(
+ type='LineJsonParser',
+ keys=['file_name', 'height', 'width', 'annotations'])),
+ pipeline=test_pipeline,
+ test_mode=True)
+```
+The results are generated in the same way as the segmentation-based text recognition task above.
+You can check the content of the annotation file in `tests/data/toy_dataset/instances_test.txt`.
+The combination of `HardDiskLoader` and `LineJsonParser` will return a dict for each file by calling `__getitem__`:
+```python
+{"file_name": "test/img_10.jpg", "height": 720, "width": 1280, "annotations": [{"iscrowd": 1, "category_id": 1, "bbox": [260.0, 138.0, 24.0, 20.0], "segmentation": [[261, 138, 284, 140, 279, 158, 260, 158]]}, {"iscrowd": 0, "category_id": 1, "bbox": [288.0, 138.0, 129.0, 23.0], "segmentation": [[288, 138, 417, 140, 416, 161, 290, 157]]}, {"iscrowd": 0, "category_id": 1, "bbox": [743.0, 145.0, 37.0, 18.0], "segmentation": [[743, 145, 779, 146, 780, 163, 746, 163]]}, {"iscrowd": 0, "category_id": 1, "bbox": [783.0, 129.0, 50.0, 26.0], "segmentation": [[783, 129, 831, 132, 833, 155, 785, 153]]}, {"iscrowd": 1, "category_id": 1, "bbox": [831.0, 133.0, 43.0, 23.0], "segmentation": [[831, 133, 870, 135, 874, 156, 835, 155]]}, {"iscrowd": 1, "category_id": 1, "bbox": [159.0, 204.0, 72.0, 15.0], "segmentation": [[159, 205, 230, 204, 231, 218, 159, 219]]}, {"iscrowd": 1, "category_id": 1, "bbox": [785.0, 158.0, 75.0, 21.0], "segmentation": [[785, 158, 856, 158, 860, 178, 787, 179]]}, {"iscrowd": 1, "category_id": 1, "bbox": [1011.0, 157.0, 68.0, 16.0], "segmentation": [[1011, 157, 1079, 160, 1076, 173, 1011, 170]]}]}
+```
+
+
+### IcdarDataset
+
+*Dataset with annotation file in coco-like json format*
+
+For text detection, you can also use an annotation file in a COCO format that is defined in [MMDetection](https://github.com/open-mmlab/mmdetection/blob/master/mmdet/datasets/coco.py):
+```python
+dataset_type = 'IcdarDataset'
+prefix = 'tests/data/toy_dataset/'
+test=dict(
+ type=dataset_type,
+ ann_file=prefix + 'instances_test.json',
+ img_prefix=prefix + 'imgs',
+ pipeline=test_pipeline)
+```
+You can check the content of the annotation file in `tests/data/toy_dataset/instances_test.json`.
+
+:::{note}
+Icdar 2015/2017 and ctw1500 annotations need to be converted into the COCO format following the steps in [datasets.md](datasets.md).
+:::
+
+## Text Recognition Task
+
+### OCRDataset
+
+*Dataset for encoder-decoder based recognizer*
+
+```python
+dataset_type = 'OCRDataset'
+img_prefix = 'tests/data/ocr_toy_dataset/imgs'
+train_anno_file = 'tests/data/ocr_toy_dataset/label.txt'
+train = dict(
+ type=dataset_type,
+ img_prefix=img_prefix,
+ ann_file=train_anno_file,
+ loader=dict(
+ type='HardDiskLoader',
+ repeat=10,
+ parser=dict(
+ type='LineStrParser',
+ keys=['filename', 'text'],
+ keys_idx=[0, 1],
+ separator=' ')),
+ pipeline=train_pipeline,
+ test_mode=False)
+```
+You can check the content of the annotation file in `tests/data/ocr_toy_dataset/label.txt`.
+The combination of `HardDiskLoader` and `LineStrParser` will return a dict for each file by calling `__getitem__`: `{'filename': '1223731.jpg', 'text': 'GRAND'}`.
+
+**Optional Arguments:**
+
+- `repeat`: The number of repeated lines in the annotation files. For example, if there are `10` lines in the annotation file, setting `repeat=10` will generate a corresponding annotation file with size `100`.
+
+If the annotation file is extremely large, you can convert it from txt format to lmdb format with the following command:
+```python
+python tools/data_converter/txt2lmdb.py -i ann_file.txt -o ann_file.lmdb
+```
+
+After that, you can use `LmdbLoader` in dataset like below.
+```python
+img_prefix = 'tests/data/ocr_toy_dataset/imgs'
+train_anno_file = 'tests/data/ocr_toy_dataset/label.lmdb'
+train = dict(
+ type=dataset_type,
+ img_prefix=img_prefix,
+ ann_file=train_anno_file,
+ loader=dict(
+ type='LmdbLoader',
+ repeat=10,
+ parser=dict(
+ type='LineStrParser',
+ keys=['filename', 'text'],
+ keys_idx=[0, 1],
+ separator=' ')),
+ pipeline=train_pipeline,
+ test_mode=False)
+```
+
+### OCRSegDataset
+
+*Dataset for segmentation-based recognizer*
+
+```python
+prefix = 'tests/data/ocr_char_ann_toy_dataset/'
+train = dict(
+ type='OCRSegDataset',
+ img_prefix=prefix + 'imgs',
+ ann_file=prefix + 'instances_train.txt',
+ loader=dict(
+ type='HardDiskLoader',
+ repeat=10,
+ parser=dict(
+ type='LineJsonParser',
+ keys=['file_name', 'annotations', 'text'])),
+ pipeline=train_pipeline,
+ test_mode=True)
+```
+You can check the content of the annotation file in `tests/data/ocr_char_ann_toy_dataset/instances_train.txt`.
+The combination of `HardDiskLoader` and `LineJsonParser` will return a dict for each file by calling `__getitem__` each time:
+```python
+{"file_name": "resort_88_101_1.png", "annotations": [{"char_text": "F", "char_box": [11.0, 0.0, 22.0, 0.0, 12.0, 12.0, 0.0, 12.0]}, {"char_text": "r", "char_box": [23.0, 2.0, 31.0, 1.0, 24.0, 11.0, 16.0, 11.0]}, {"char_text": "o", "char_box": [33.0, 2.0, 43.0, 2.0, 36.0, 12.0, 25.0, 12.0]}, {"char_text": "m", "char_box": [46.0, 2.0, 61.0, 2.0, 53.0, 12.0, 39.0, 12.0]}, {"char_text": ":", "char_box": [61.0, 2.0, 69.0, 2.0, 63.0, 12.0, 55.0, 12.0]}], "text": "From:"}
+```
diff --git a/docs/en/tutorials/kie_closeset_openset.md b/docs/en/tutorials/kie_closeset_openset.md
new file mode 100644
index 0000000000000000000000000000000000000000..5e35ce5aecfe832622fda827e1879826f9e57a56
--- /dev/null
+++ b/docs/en/tutorials/kie_closeset_openset.md
@@ -0,0 +1,74 @@
+# KIE: Difference between CloseSet & OpenSet
+
+Being trained on WildReceipt, SDMG-R, or other KIE models, can identify the types of text boxes on a receipt picture.
+But what SDMG-R can do is far more beyond that. For example, it's able to identify key-value pairs on the picture. To demonstrate such ability and hopefully facilitate future research, we release a demonstrative version of WildReceiptOpenset annotated in OpenSet format, and provide a full training/testing pipeline for KIE models such as SDMG-R.
+Since it might be a *confusing* update, we'll elaborate on the key differences between the OpenSet and CloseSet format, taking WildReceipt as an example.
+
+## CloseSet
+
+WildReceipt ("CloseSet") divides text boxes into 26 categories. There are 12 key-value pairs of fine-grained key information categories, such as (`Prod_item_value`, `Prod_item_key`), (`Prod_price_value`, `Prod_price_key`) and (`Tax_value`, `Tax_key`), plus two more "do not care" categories: `Ignore` and `Others`.
+
+The objective of CloseSet SDMGR is to predict which category fits the text box best, but it will not predict the relations among text boxes. For instance, if there are four text boxes "Hamburger", "Hotdog", "$1" and "$2" on the receipt, the model may assign `Prod_item_value` to the first two boxes and `Prod_price_value` to the last two, but it can't tell if Hamburger sells for $1 or $2. However, this could be achieved in the open-set variant.
+
+
+
+
+
+
+:::{warning}
+
+A `*_key` and `*_value` pair do not necessarily have to both appear on the receipt. For example, we usually won't see `Prod_item_key` appearing on the receipt, while there can be multiple boxes annotated as `Pred_item_value`. In contrast, `Tax_key` and `Tax_value` are likely to appear together since they're usually structured as `Tax`: `11.02` on the receipt.
+
+:::
+
+## OpenSet
+
+In OpenSet, all text boxes, or nodes, have only 4 possible categories: `background`, `key`, `value`, and `others`. The connectivity between nodes are annotated as *edge labels*. If a pair of key-value nodes have the same edge label, they are connected by an valid edge.
+
+Multiple nodes can have the same edge label. However, only key and value nodes will be linked by edges. The nodes of same category will never be connected.
+
+When making OpenSet annotations, each node must have an edge label. It should be an unique one if it falls into non-`key` non-`value` categories.
+
+:::{note}
+You can merge `background` to `others` if telling background apart is not important, and we provide this choice in the conversion script for WildReceipt .
+:::
+
+### Converting WildReceipt from CloseSet to OpenSet
+
+We provide a [conversion script](../datasets/kie.md) that converts WildRecipt-like dataset to OpenSet format. This script links every `key`-`value` pairs following the rules above. Here's an example illustration: (For better understanding, all the node labels are presented as texts)
+
+|box_content | closeset_node_label| closeset_edge_label | openset_node_label | openset_edge_label |
+| :----: | :---: | :----: | :---: | :---: |
+| hello | Ignore | - | Others | 0 |
+| world | Ignore | - | Others | 1 |
+| Actor | Actor_key | - | Key | 2 |
+| Tom | Actor_value | - | Value | 2 |
+| Tony | Actor_value | - | Value | 2 |
+| Tim | Actor_value | - | Value | 2 |
+| something | Ignore | - | Others | 3 |
+| Actress | Actress_key | - | Key | 4 |
+| Lucy | Actress_value | - | Value | 4 |
+| Zora | Actress_value | - | Value | 4 |
+
+:::{warning}
+
+A common request from our community is to extract the relations between food items and food prices. In this case, this conversion script ***is not you need***.
+Wildrecipt doesn't provide necessary information to recover this relation. For instance, there are four text boxes "Hamburger", "Hotdog", "$1" and "$2" on the receipt, and here's how they actually look like before and after the conversion:
+
+|box_content | closeset_node_label| closeset_edge_label | openset_node_label | openset_edge_label |
+| :----: | :---: | :----: | :---: | :---: |
+| Hamburger | Prod_item_value | - | Value | 0 |
+| Hotdog | Prod_item_value | - | Value | 0 |
+| $1 | Prod_price_value | - | Value | 1 |
+| $2 | Prod_price_value | - | Value | 1 |
+
+So there won't be any valid edges connecting them. Nevertheless, OpenSet format is far more general than CloseSet, so this task can be achieved by annotating the data from scratch.
+
+|box_content | openset_node_label | openset_edge_label |
+| :----: | :---: | :---: |
+| Hamburger | Value | 0 |
+| Hotdog | Value | 1 |
+| $1 | Value | 0 |
+| $2 | Value | 1 |
+
+:::
diff --git a/docs/zh_cn/Makefile b/docs/zh_cn/Makefile
new file mode 100644
index 0000000000000000000000000000000000000000..d4bb2cbb9eddb1bb1b4f366623044af8e4830919
--- /dev/null
+++ b/docs/zh_cn/Makefile
@@ -0,0 +1,20 @@
+# Minimal makefile for Sphinx documentation
+#
+
+# You can set these variables from the command line, and also
+# from the environment for the first two.
+SPHINXOPTS ?=
+SPHINXBUILD ?= sphinx-build
+SOURCEDIR = .
+BUILDDIR = _build
+
+# Put it first so that "make" without argument is like "make help".
+help:
+ @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
+
+.PHONY: help Makefile
+
+# Catch-all target: route all unknown targets to Sphinx using the new
+# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
+%: Makefile
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
diff --git a/docs/zh_cn/_static/css/readthedocs.css b/docs/zh_cn/_static/css/readthedocs.css
new file mode 100644
index 0000000000000000000000000000000000000000..c4736f9dc728b2b0a49fd8e10d759c5d58e506d1
--- /dev/null
+++ b/docs/zh_cn/_static/css/readthedocs.css
@@ -0,0 +1,6 @@
+.header-logo {
+ background-image: url("../images/mmocr.png");
+ background-size: 110px 40px;
+ height: 40px;
+ width: 110px;
+}
diff --git a/docs/zh_cn/_static/images/mmocr.png b/docs/zh_cn/_static/images/mmocr.png
new file mode 100755
index 0000000000000000000000000000000000000000..725690a463fc9a5ffb8444165349d64f4236eac9
--- /dev/null
+++ b/docs/zh_cn/_static/images/mmocr.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:8cf149574b624b759ad134fb7fe90d8448b1e3b57c47ecf4e3a1915f157d8ce1
+size 28627
diff --git a/docs/zh_cn/api.rst b/docs/zh_cn/api.rst
new file mode 100644
index 0000000000000000000000000000000000000000..63f3ec10f1df6b79b15860eac5dcb5b43f4481db
--- /dev/null
+++ b/docs/zh_cn/api.rst
@@ -0,0 +1,180 @@
+mmocr.apis
+-------------
+.. automodule:: mmocr.apis
+ :members:
+
+
+mmocr.core
+-------------
+evaluation
+^^^^^^^^^^
+.. automodule:: mmocr.core.evaluation
+ :members:
+
+
+mmocr.utils
+-------------
+.. automodule:: mmocr.utils
+ :members:
+
+
+mmocr.models
+---------------
+Common Backbones
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.common.backbones
+ :members:
+
+.. automodule:: mmocr.models.common.losses
+ :members:
+
+Text Detection Detectors
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textdet.detectors
+ :members:
+
+Text Detection Heads
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textdet.dense_heads
+ :members:
+
+Text Detection Necks
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textdet.necks
+ :members:
+
+Text Detection Losses
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textdet.losses
+ :members:
+
+Text Detection Postprocessors
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textdet.postprocess
+ :members:
+
+Text Recognition Recognizer
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textrecog.recognizer
+ :members:
+
+Text Recognition Backbones
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textrecog.backbones
+ :members:
+
+Text Recognition Necks
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textrecog.necks
+ :members:
+
+Text Recognition Heads
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textrecog.heads
+ :members:
+
+Text Recognition Preprocessors
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textrecog.preprocessor
+ :members:
+
+Text Recognition Backbones
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textrecog.backbones
+ :members:
+
+Text Recognition Layers
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textrecog.layers
+ :members:
+
+Text Recognition Convertors
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textrecog.convertors
+ :members:
+
+Text Recognition Encoders
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textrecog.encoders
+ :members:
+
+Text Recognition Decoders
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textrecog.decoders
+ :members:
+
+Text Recognition Fusers
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textrecog.fusers
+ :members:
+
+Text Recognition Losses
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.textrecog.losses
+ :members:
+
+KIE Extractors
+^^^^^^^^^^^^^^
+.. automodule:: mmocr.models.kie.extractors
+ :members:
+
+KIE Heads
+^^^^^^^^^^^
+.. automodule:: mmocr.models.kie.heads
+ :members:
+
+KIE Losses
+^^^^^^^^^^^
+.. automodule:: mmocr.models.kie.losses
+ :members:
+
+NER Encoders
+^^^^^^^^^^^^
+.. automodule:: mmocr.models.ner.encoders
+ :members:
+
+NER Decoders
+^^^^^^^^^^^^
+.. automodule:: mmocr.models.ner.decoders
+ :members:
+
+NER Losses
+^^^^^^^^^^^
+.. automodule:: mmocr.models.ner.losses
+ :members:
+
+mmocr.datasets
+-----------------
+.. automodule:: mmocr.datasets
+ :members:
+
+datasets
+^^^^^^^^^^^
+.. automodule:: mmocr.datasets.base_dataset
+ :members:
+
+.. automodule:: mmocr.datasets.icdar_dataset
+ :members:
+
+.. automodule:: mmocr.datasets.ocr_dataset
+ :members:
+
+.. automodule:: mmocr.datasets.ocr_seg_dataset
+ :members:
+
+.. automodule:: mmocr.datasets.text_det_dataset
+ :members:
+
+.. automodule:: mmocr.datasets.kie_dataset
+ :members:
+
+
+pipelines
+^^^^^^^^^^^
+.. automodule:: mmocr.datasets.pipelines
+ :members:
+
+utils
+^^^^^^^^^^^
+.. automodule:: mmocr.datasets.utils
+ :members:
diff --git a/docs/zh_cn/conf.py b/docs/zh_cn/conf.py
new file mode 100644
index 0000000000000000000000000000000000000000..5b2e21343250ffbebc4bac476614da28e09d2bdd
--- /dev/null
+++ b/docs/zh_cn/conf.py
@@ -0,0 +1,136 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# Configuration file for the Sphinx documentation builder.
+#
+# This file only contains a selection of the most common options. For a full
+# list see the documentation:
+# https://www.sphinx-doc.org/en/master/usage/configuration.html
+
+# -- Path setup --------------------------------------------------------------
+
+# If extensions (or modules to document with autodoc) are in another directory,
+# add these directories to sys.path here. If the directory is relative to the
+# documentation root, use os.path.abspath to make it absolute, like shown here.
+
+import os
+import subprocess
+import sys
+
+import pytorch_sphinx_theme
+
+sys.path.insert(0, os.path.abspath('../../'))
+
+# -- Project information -----------------------------------------------------
+
+project = 'MMOCR'
+copyright = '2020-2030, OpenMMLab'
+author = 'OpenMMLab'
+
+# The full version, including alpha/beta/rc tags
+version_file = '../../mmocr/version.py'
+with open(version_file, 'r') as f:
+ exec(compile(f.read(), version_file, 'exec'))
+__version__ = locals()['__version__']
+release = __version__
+
+# -- General configuration ---------------------------------------------------
+
+# Add any Sphinx extension module names here, as strings. They can be
+# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
+# ones.
+extensions = [
+ 'sphinx.ext.autodoc', 'sphinx.ext.napoleon', 'sphinx.ext.viewcode',
+ 'sphinx_markdown_tables', 'sphinx_copybutton', 'myst_parser'
+]
+
+autodoc_mock_imports = ['mmcv._ext']
+
+# Ignore >>> when copying code
+copybutton_prompt_text = r'>>> |\.\.\. '
+copybutton_prompt_is_regexp = True
+
+# Add any paths that contain templates here, relative to this directory.
+templates_path = ['_templates']
+
+# The suffix(es) of source filenames.
+# You can specify multiple suffix as a list of string:
+#
+source_suffix = {
+ '.rst': 'restructuredtext',
+ '.md': 'markdown',
+}
+
+# The master toctree document.
+master_doc = 'index'
+
+# List of patterns, relative to source directory, that match files and
+# directories to ignore when looking for source files.
+# This pattern also affects html_static_path and html_extra_path.
+exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
+
+# -- Options for HTML output -------------------------------------------------
+
+# The theme to use for HTML and HTML Help pages. See the documentation for
+# a list of builtin themes.
+#
+# html_theme = 'sphinx_rtd_theme'
+html_theme = 'pytorch_sphinx_theme'
+html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]
+html_theme_options = {
+ 'logo_url':
+ 'https://mmocr.readthedocs.io/zh_CN/latest',
+ 'menu': [
+ {
+ 'name':
+ '教程',
+ 'url':
+ 'https://colab.research.google.com/github/'
+ 'open-mmlab/mmocr/blob/main/demo/MMOCR_Tutorial.ipynb'
+ },
+ {
+ 'name': 'GitHub',
+ 'url': 'https://github.com/open-mmlab/mmocr'
+ },
+ {
+ 'name':
+ '上游库',
+ 'children': [
+ {
+ 'name': 'MMCV',
+ 'url': 'https://github.com/open-mmlab/mmcv',
+ 'description': '基础视觉库'
+ },
+ {
+ 'name': 'MMDetection',
+ 'url': 'https://github.com/open-mmlab/mmdetection',
+ 'description': '目标检测工具箱'
+ },
+ ]
+ },
+ ],
+ # Specify the language of shared menu
+ 'menu_lang':
+ 'cn',
+}
+
+language = 'zh_CN'
+
+master_doc = 'index'
+
+# Add any paths that contain custom static files (such as style sheets) here,
+# relative to this directory. They are copied after the builtin static files,
+# so a file named "default.css" will overwrite the builtin "default.css".
+html_static_path = ['_static']
+html_css_files = ['css/readthedocs.css']
+
+# Enable ::: for my_st
+myst_enable_extensions = ['colon_fence']
+
+
+def builder_inited_handler(app):
+ subprocess.run(['./cp_origin_docs.sh'])
+ subprocess.run(['./merge_docs.sh'])
+ subprocess.run(['./stats.py'])
+
+
+def setup(app):
+ app.connect('builder-inited', builder_inited_handler)
diff --git a/docs/zh_cn/cp_origin_docs.sh b/docs/zh_cn/cp_origin_docs.sh
new file mode 100755
index 0000000000000000000000000000000000000000..1e728323684a0aad1571eb392871d6c5de6644fc
--- /dev/null
+++ b/docs/zh_cn/cp_origin_docs.sh
@@ -0,0 +1,9 @@
+#!/usr/bin/env bash
+
+# Copy *.md files from docs/ if it doesn't have a Chinese translation
+
+for filename in $(find ../en/ -name '*.md' -printf "%P\n");
+do
+ mkdir -p $(dirname $filename)
+ cp -n ../en/$filename ./$filename
+done
diff --git a/docs/zh_cn/datasets/det.md b/docs/zh_cn/datasets/det.md
new file mode 100644
index 0000000000000000000000000000000000000000..4b6490a3992961c08d50dc326ead03411771b633
--- /dev/null
+++ b/docs/zh_cn/datasets/det.md
@@ -0,0 +1,150 @@
+
+# 文字检测
+
+## 概览
+
+文字检测任务的数据集应按如下目录配置:
+
+```text
+├── ctw1500
+│ ├── annotations
+│ ├── imgs
+│ ├── instances_test.json
+│ └── instances_training.json
+├── icdar2015
+│ ├── imgs
+│ ├── instances_test.json
+│ └── instances_training.json
+├── icdar2017
+│ ├── imgs
+│ ├── instances_training.json
+│ └── instances_val.json
+├── synthtext
+│ ├── imgs
+│ └── instances_training.lmdb
+│ ├── data.mdb
+│ └── lock.mdb
+├── textocr
+│ ├── train
+│ ├── instances_training.json
+│ └── instances_val.json
+├── totaltext
+│ ├── imgs
+│ ├── instances_test.json
+│ └── instances_training.json
+```
+
+| 数据集名称 | 数据图片 | | 标注文件 | |
+| :---------: | :----------------------------------------------------------: | :----------------------------------------------------------------------------------------------------: | :-------------------------------------: | :--------------------------------------------------------------------------------------------: |
+| | | 训练集 (training) | 验证集 (validation) | 测试集 (testing) | |
+| CTW1500 | [下载地址](https://github.com/Yuliang-Liu/Curve-Text-Detector) | - | - | - |
+| ICDAR2015 | [下载地址](https://rrc.cvc.uab.es/?ch=4&com=downloads) | [instances_training.json](https://download.openmmlab.com/mmocr/data/icdar2015/instances_training.json) | - | [instances_test.json](https://download.openmmlab.com/mmocr/data/icdar2015/instances_test.json) |
+| ICDAR2017 | [下载地址](https://rrc.cvc.uab.es/?ch=8&com=downloads) | [instances_training.json](https://download.openmmlab.com/mmocr/data/icdar2017/instances_training.json) | [instances_val.json](https://download.openmmlab.com/mmocr/data/icdar2017/instances_val.json) | - | | |
+| Synthtext | [下载地址](https://www.robots.ox.ac.uk/~vgg/data/scenetext/) | instances_training.lmdb ([data.mdb](https://download.openmmlab.com/mmocr/data/synthtext/instances_training.lmdb/data.mdb), [lock.mdb](https://download.openmmlab.com/mmocr/data/synthtext/instances_training.lmdb/lock.mdb)) | - | - |
+| TextOCR | [下载地址](https://textvqa.org/textocr/dataset) | - | - | -
+| Totaltext | [下载地址](https://github.com/cs-chan/Total-Text-Dataset) | - | - | -
+
+## 重要提醒
+
+:::{note}
+**若用户需要在 CTW1500, ICDAR 2015/2017 或 Totaltext 数据集上训练模型**, 请注意这些数据集中有部分图片的 EXIF 信息里保存着方向信息。MMCV 采用的 OpenCV 后端会默认根据方向信息对图片进行旋转;而由于数据集的标注是在原图片上进行的,这种冲突会使得部分训练样本失效。因此,用户应该在配置 pipeline 时使用 `dict(type='LoadImageFromFile', color_type='color_ignore_orientation')` 以避免 MMCV 的这一行为。(配置文件可参考 [DBNet 的 pipeline 配置](https://github.com/open-mmlab/mmocr/blob/main/configs/_base_/det_pipelines/dbnet_pipeline.py))
+:::
+
+
+## 准备步骤
+
+### ICDAR 2015
+- 第一步:从[下载地址](https://rrc.cvc.uab.es/?ch=4&com=downloads)下载 `ch4_training_images.zip`、`ch4_test_images.zip`、`ch4_training_localization_transcription_gt.zip`、`Challenge4_Test_Task1_GT.zip` 四个文件,分别对应训练集数据、测试集数据、训练集标注、测试集标注。
+- 第二步:运行以下命令,移动数据集到对应文件夹
+```bash
+mkdir icdar2015 && cd icdar2015
+mkdir imgs && mkdir annotations
+# 移动数据到目录:
+mv ch4_training_images imgs/training
+mv ch4_test_images imgs/test
+# 移动标注到目录:
+mv ch4_training_localization_transcription_gt annotations/training
+mv Challenge4_Test_Task1_GT annotations/test
+```
+- 第三步:下载 [instances_training.json](https://download.openmmlab.com/mmocr/data/icdar2015/instances_training.json) 和 [instances_test.json](https://download.openmmlab.com/mmocr/data/icdar2015/instances_test.json),并放入 `icdar2015` 文件夹里。或者也可以用以下命令直接生成 `instances_training.json` 和 `instances_test.json`:
+```bash
+python tools/data/textdet/icdar_converter.py /path/to/icdar2015 -o /path/to/icdar2015 -d icdar2015 --split-list training test
+```
+
+### ICDAR 2017
+- 与上述步骤类似。
+
+### CTW1500
+- 第一步:执行以下命令,从 [下载地址](https://github.com/Yuliang-Liu/Curve-Text-Detector) 下载 `train_images.zip`,`test_images.zip`,`train_labels.zip`,`test_labels.zip` 四个文件并配置到对应目录:
+
+```bash
+mkdir ctw1500 && cd ctw1500
+mkdir imgs && mkdir annotations
+
+# 下载并配置标注
+cd annotations
+wget -O train_labels.zip https://universityofadelaide.box.com/shared/static/jikuazluzyj4lq6umzei7m2ppmt3afyw.zip
+wget -O test_labels.zip https://cloudstor.aarnet.edu.au/plus/s/uoeFl0pCN9BOCN5/download
+unzip train_labels.zip && mv ctw1500_train_labels training
+unzip test_labels.zip -d test
+cd ..
+# 下载并配置数据
+cd imgs
+wget -O train_images.zip https://universityofadelaide.box.com/shared/static/py5uwlfyyytbb2pxzq9czvu6fuqbjdh8.zip
+wget -O test_images.zip https://universityofadelaide.box.com/shared/static/t4w48ofnqkdw7jyc4t11nsukoeqk9c3d.zip
+unzip train_images.zip && mv train_images training
+unzip test_images.zip && mv test_images test
+```
+- 第二步:执行以下命令,生成 `instances_training.json` 和 `instances_test.json`。
+
+```bash
+python tools/data/textdet/ctw1500_converter.py /path/to/ctw1500 -o /path/to/ctw1500 --split-list training test
+```
+
+### SynthText
+
+- 下载 [data.mdb](https://download.openmmlab.com/mmocr/data/synthtext/instances_training.lmdb/data.mdb) 和 [lock.mdb](https://download.openmmlab.com/mmocr/data/synthtext/instances_training.lmdb/lock.mdb) 并放置到 `synthtext/instances_training.lmdb/` 中.
+
+### TextOCR
+ - 第一步:下载 [train_val_images.zip](https://dl.fbaipublicfiles.com/textvqa/images/train_val_images.zip),[TextOCR_0.1_train.json](https://dl.fbaipublicfiles.com/textvqa/data/textocr/TextOCR_0.1_train.json) 和 [TextOCR_0.1_val.json](https://dl.fbaipublicfiles.com/textvqa/data/textocr/TextOCR_0.1_val.json) 到 `textocr` 文件夹里。
+ ```bash
+ mkdir textocr && cd textocr
+
+ # 下载 TextOCR 数据集
+ wget https://dl.fbaipublicfiles.com/textvqa/images/train_val_images.zip
+ wget https://dl.fbaipublicfiles.com/textvqa/data/textocr/TextOCR_0.1_train.json
+ wget https://dl.fbaipublicfiles.com/textvqa/data/textocr/TextOCR_0.1_val.json
+
+ # 把图片移到对应目录
+ unzip -q train_val_images.zip
+ mv train_images train
+ ```
+
+ - 第二步:生成 `instances_training.json` 和 `instances_val.json`:
+ ```bash
+ python tools/data/textdet/textocr_converter.py /path/to/textocr
+ ```
+
+### Totaltext
+ - 第一步:从 [github dataset](https://github.com/cs-chan/Total-Text-Dataset/tree/master/Dataset) 下载 `totaltext.zip`,从 [github Groundtruth](https://github.com/cs-chan/Total-Text-Dataset/tree/master/Groundtruth/Text) 下载 `groundtruth_text.zip` 。(建议下载 `.mat` 格式的标注文件,因为我们提供的标注格式转换脚本 `totaltext_converter.py` 仅支持 `.mat` 格式。)
+ ```bash
+ mkdir totaltext && cd totaltext
+ mkdir imgs && mkdir annotations
+
+ # 图像
+ # 在 ./totaltext 中执行
+ unzip totaltext.zip
+ mv Images/Train imgs/training
+ mv Images/Test imgs/test
+
+ # 标注文件
+ unzip groundtruth_text.zip
+ cd Groundtruth
+ mv Polygon/Train ../annotations/training
+ mv Polygon/Test ../annotations/test
+
+ ```
+ - 第二步:用以下命令生成 `instances_training.json` 和 `instances_test.json` :
+ ```bash
+ python tools/data/textdet/totaltext_converter.py /path/to/totaltext -o /path/to/totaltext --split-list training test
+ ```
diff --git a/docs/zh_cn/datasets/kie.md b/docs/zh_cn/datasets/kie.md
new file mode 100644
index 0000000000000000000000000000000000000000..6d189bc7daffde42e6815f8f10725c6065f89240
--- /dev/null
+++ b/docs/zh_cn/datasets/kie.md
@@ -0,0 +1,34 @@
+# 关键信息提取
+
+## 概览
+
+关键信息提取任务的数据集,文件目录应按如下配置:
+
+```text
+└── wildreceipt
+ ├── class_list.txt
+ ├── dict.txt
+ ├── image_files
+ ├── test.txt
+ └── train.txt
+```
+
+## 准备步骤
+
+### WildReceipt
+
+- 下载并解压 [wildreceipt.tar](https://download.openmmlab.com/mmocr/data/wildreceipt.tar)
+
+### WildReceiptOpenset
+
+- 准备好 [WildReceipt](#WildReceipt)。
+- 转换 WildReceipt 成 OpenSet 格式:
+```bash
+# 你可以运行以下命令以获取更多可用参数:
+# python tools/data/kie/closeset_to_openset.py -h
+python tools/data/kie/closeset_to_openset.py data/wildreceipt/train.txt data/wildreceipt/openset_train.txt
+python tools/data/kie/closeset_to_openset.py data/wildreceipt/test.txt data/wildreceipt/openset_test.txt
+```
+:::{note}
+[这篇教程](../tutorials/kie_closeset_openset.md)里讲述了更多 CloseSet 和 OpenSet 数据格式之间的区别。
+:::
diff --git a/docs/zh_cn/datasets/ner.md b/docs/zh_cn/datasets/ner.md
new file mode 100644
index 0000000000000000000000000000000000000000..c68c2ac69ac672c51058112c911c9e0b92f67d6e
--- /dev/null
+++ b/docs/zh_cn/datasets/ner.md
@@ -0,0 +1,24 @@
+# 命名实体识别(专名识别)
+
+## 概览
+
+命名实体识别任务的数据集,文件目录应按如下配置:
+
+```text
+└── cluener2020
+ ├── cluener_predict.json
+ ├── dev.json
+ ├── README.md
+ ├── test.json
+ ├── train.json
+ └── vocab.txt
+
+```
+
+## 准备步骤
+
+### CLUENER2020
+
+- 下载并解压 [cluener_public.zip](https://storage.googleapis.com/cluebenchmark/tasks/cluener_public.zip) 至 `cluener2020/`。
+
+- 下载 [vocab.txt](https://download.openmmlab.com/mmocr/data/cluener_public/vocab.txt) 然后将 `vocab.txt` 移动到 `cluener2020/` 文件夹下
diff --git a/docs/zh_cn/datasets/recog.md b/docs/zh_cn/datasets/recog.md
new file mode 100644
index 0000000000000000000000000000000000000000..091a2bb23d47da502e49670e661ee851748efd2d
--- /dev/null
+++ b/docs/zh_cn/datasets/recog.md
@@ -0,0 +1,283 @@
+# 文字识别
+
+## 概览
+
+**文字识别任务的数据集应按如下目录配置:**
+
+```text
+├── mixture
+│ ├── coco_text
+│ │ ├── train_label.txt
+│ │ ├── train_words
+│ ├── icdar_2011
+│ │ ├── training_label.txt
+│ │ ├── Challenge1_Training_Task3_Images_GT
+│ ├── icdar_2013
+│ │ ├── train_label.txt
+│ │ ├── test_label_1015.txt
+│ │ ├── test_label_1095.txt
+│ │ ├── Challenge2_Training_Task3_Images_GT
+│ │ ├── Challenge2_Test_Task3_Images
+│ ├── icdar_2015
+│ │ ├── train_label.txt
+│ │ ├── test_label.txt
+│ │ ├── ch4_training_word_images_gt
+│ │ ├── ch4_test_word_images_gt
+│ ├── III5K
+│ │ ├── train_label.txt
+│ │ ├── test_label.txt
+│ │ ├── train
+│ │ ├── test
+│ ├── ct80
+│ │ ├── test_label.txt
+│ │ ├── image
+│ ├── svt
+│ │ ├── test_label.txt
+│ │ ├── image
+│ ├── svtp
+│ │ ├── test_label.txt
+│ │ ├── image
+│ ├── Syn90k
+│ │ ├── shuffle_labels.txt
+│ │ ├── label.txt
+│ │ ├── label.lmdb
+│ │ ├── mnt
+│ ├── SynthText
+│ │ ├── alphanumeric_labels.txt
+│ │ ├── shuffle_labels.txt
+│ │ ├── instances_train.txt
+│ │ ├── label.txt
+│ │ ├── label.lmdb
+│ │ ├── synthtext
+│ ├── SynthAdd
+│ │ ├── label.txt
+│ │ ├── label.lmdb
+│ │ ├── SynthText_Add
+│ ├── TextOCR
+│ │ ├── image
+│ │ ├── train_label.txt
+│ │ ├── val_label.txt
+│ ├── Totaltext
+│ │ ├── imgs
+│ │ ├── annotations
+│ │ ├── train_label.txt
+│ │ ├── test_label.txt
+│ ├── OpenVINO
+│ │ ├── image_1
+│ │ ├── image_2
+│ │ ├── image_5
+│ │ ├── image_f
+│ │ ├── image_val
+│ │ ├── train_1_label.txt
+│ │ ├── train_2_label.txt
+│ │ ├── train_5_label.txt
+│ │ ├── train_f_label.txt
+│ │ ├── val_label.txt
+```
+
+| 数据集名称 | 数据图片 | 标注文件 | 标注文件 |
+| :--------: | :-----------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | :-----------------------------------------------------------------------------------------------------: |
+| | | 训练集(training) | 测试集(test) |
+| coco_text | [下载地址](https://rrc.cvc.uab.es/?ch=5&com=downloads) | [train_label.txt](https://download.openmmlab.com/mmocr/data/mixture/coco_text/train_label.txt) | - | |
+| icdar_2011 | [下载地址](http://www.cvc.uab.es/icdar2011competition/?com=downloads) | [train_label.txt](https://download.openmmlab.com/mmocr/data/mixture/icdar_2015/train_label.txt) | - | |
+| icdar_2013 | [下载地址](https://rrc.cvc.uab.es/?ch=2&com=downloads) | [train_label.txt](https://download.openmmlab.com/mmocr/data/mixture/icdar_2013/train_label.txt) | [test_label_1015.txt](https://download.openmmlab.com/mmocr/data/mixture/icdar_2013/test_label_1015.txt) | |
+| icdar_2015 | [下载地址](https://rrc.cvc.uab.es/?ch=4&com=downloads) | [train_label.txt](https://download.openmmlab.com/mmocr/data/mixture/icdar_2015/train_label.txt) | [test_label.txt](https://download.openmmlab.com/mmocr/data/mixture/icdar_2015/test_label.txt) | |
+| IIIT5K | [下载地址](http://cvit.iiit.ac.in/projects/SceneTextUnderstanding/IIIT5K.html) | [train_label.txt](https://download.openmmlab.com/mmocr/data/mixture/IIIT5K/train_label.txt) | [test_label.txt](https://download.openmmlab.com/mmocr/data/mixture/IIIT5K/test_label.txt) | |
+| ct80 | [下载地址](http://cs-chan.com/downloads_CUTE80_dataset.html) | - | [test_label.txt](https://download.openmmlab.com/mmocr/data/mixture/ct80/test_label.txt) | |
+| svt |[下载地址](http://www.iapr-tc11.org/mediawiki/index.php/The_Street_View_Text_Dataset) | - | [test_label.txt](https://download.openmmlab.com/mmocr/data/mixture/svt/test_label.txt) | |
+| svtp | [非官方下载地址*](https://github.com/Jyouhou/Case-Sensitive-Scene-Text-Recognition-Datasets) | - | [test_label.txt](https://download.openmmlab.com/mmocr/data/mixture/svtp/test_label.txt) | |
+| MJSynth (Syn90k) | [下载地址](https://www.robots.ox.ac.uk/~vgg/data/text/) | [shuffle_labels.txt](https://download.openmmlab.com/mmocr/data/mixture/Syn90k/shuffle_labels.txt) \| [label.txt](https://download.openmmlab.com/mmocr/data/mixture/Syn90k/label.txt) | - | |
+| SynthText (Synth800k) | [下载地址](https://www.robots.ox.ac.uk/~vgg/data/scenetext/) |[alphanumeric_labels.txt](https://download.openmmlab.com/mmocr/data/mixture/SynthText/alphanumeric_labels.txt) \| [shuffle_labels.txt](https://download.openmmlab.com/mmocr/data/mixture/SynthText/shuffle_labels.txt) \| [instances_train.txt](https://download.openmmlab.com/mmocr/data/mixture/SynthText/instances_train.txt) \| [label.txt](https://download.openmmlab.com/mmocr/data/mixture/SynthText/label.txt) | - | |
+| SynthAdd | [SynthText_Add.zip](https://pan.baidu.com/s/1uV0LtoNmcxbO-0YA7Ch4dg) (code:627x) | [label.txt](https://download.openmmlab.com/mmocr/data/mixture/SynthAdd/label.txt) | - | |
+| TextOCR | [下载地址](https://textvqa.org/textocr/dataset) | - | - | |
+| Totaltext | [下载地址](https://github.com/cs-chan/Total-Text-Dataset) | - | - | |
+| OpenVINO | [下载地址](https://github.com/cvdfoundation/open-images-dataset) | [下载地址](https://storage.openvinotoolkit.org/repositories/openvino_training_extensions/datasets/open_images_v5_text) |[下载地址](https://storage.openvinotoolkit.org/repositories/openvino_training_extensions/datasets/open_images_v5_text)| |
+
+(*) 注:由于官方的下载地址已经无法访问,我们提供了一个非官方的地址以供参考,但我们无法保证数据的准确性。
+
+## 准备步骤
+
+### ICDAR 2013
+- 第一步:从 [下载地址](https://rrc.cvc.uab.es/?ch=2&com=downloads) 下载 `Challenge2_Test_Task3_Images.zip` 和 `Challenge2_Training_Task3_Images_GT.zip`
+- 第二步:下载 [test_label_1015.txt](https://download.openmmlab.com/mmocr/data/mixture/icdar_2013/test_label_1015.txt) 和 [train_label.txt](https://download.openmmlab.com/mmocr/data/mixture/icdar_2013/train_label.txt)
+
+### ICDAR 2015
+- 第一步:从 [下载地址](https://rrc.cvc.uab.es/?ch=4&com=downloads) 下载 `ch4_training_word_images_gt.zip` 和 `ch4_test_word_images_gt.zip`
+- 第二步:下载 [train_label.txt](https://download.openmmlab.com/mmocr/data/mixture/icdar_2015/train_label.txt) and [test_label.txt](https://download.openmmlab.com/mmocr/data/mixture/icdar_2015/test_label.txt)
+
+### IIIT5K
+- 第一步:从 [下载地址](http://cvit.iiit.ac.in/projects/SceneTextUnderstanding/IIIT5K.html) 下载 `IIIT5K-Word_V3.0.tar.gz`
+- 第二步:下载 [train_label.txt](https://download.openmmlab.com/mmocr/data/mixture/IIIT5K/train_label.txt) 和 [test_label.txt](https://download.openmmlab.com/mmocr/data/mixture/IIIT5K/test_label.txt)
+
+### svt
+- 第一步:从 [下载地址](http://www.iapr-tc11.org/mediawiki/index.php/The_Street_View_Text_Dataset) 下载 `svt.zip`
+- 第二步:下载 [test_label.txt](https://download.openmmlab.com/mmocr/data/mixture/svt/test_label.txt)
+- 第三步:
+```bash
+python tools/data/textrecog/svt_converter.py
+```
+
+### ct80
+- 第一步:下载 [test_label.txt](https://download.openmmlab.com/mmocr/data/mixture/ct80/test_label.txt)
+
+### svtp
+- 第一步:下载 [test_label.txt](https://download.openmmlab.com/mmocr/data/mixture/svtp/test_label.txt)
+
+### coco_text
+ - 第一步:从 [下载地址](https://rrc.cvc.uab.es/?ch=5&com=downloads) 下载文件
+ - 第二步:下载 [train_label.txt](https://download.openmmlab.com/mmocr/data/mixture/coco_text/train_label.txt)
+
+### MJSynth (Syn90k)
+ - 第一步:从 [下载地址](https://www.robots.ox.ac.uk/~vgg/data/text/) 下载 `mjsynth.tar.gz`
+ - 第二步:下载 [shuffle_labels.txt](https://download.openmmlab.com/mmocr/data/mixture/Syn90k/shuffle_labels.txt)
+ - 第三步:
+
+ ```bash
+ mkdir Syn90k && cd Syn90k
+
+ mv /path/to/mjsynth.tar.gz .
+
+ tar -xzf mjsynth.tar.gz
+
+ mv /path/to/shuffle_labels.txt .
+ mv /path/to/label.txt .
+
+ # 创建软链接
+ cd /path/to/mmocr/data/mixture
+
+ ln -s /path/to/Syn90k Syn90k
+ ```
+
+### SynthText (Synth800k)
+ - 第一步:下载 `SynthText.zip`: [下载地址](https://www.robots.ox.ac.uk/~vgg/data/scenetext/)
+
+ - 第二步:请根据你的实际需要,从下列标注中选择最适合的下载:[label.txt](https://download.openmmlab.com/mmocr/data/mixture/SynthText/label.txt) (7,266,686个标注); [shuffle_labels.txt](https://download.openmmlab.com/mmocr/data/mixture/SynthText/shuffle_labels.txt) (2,400,000个随机采样的标注);[alphanumeric_labels.txt](https://download.openmmlab.com/mmocr/data/mixture/SynthText/alphanumeric_labels.txt) (7,239,272个仅包含数字和字母的标注);[instances_train.txt](https://download.openmmlab.com/mmocr/data/mixture/SynthText/instances_train.txt) (7,266,686个字符级别的标注)。
+
+ - 第三步:
+
+ ```bash
+ mkdir SynthText && cd SynthText
+ mv /path/to/SynthText.zip .
+ unzip SynthText.zip
+ mv SynthText synthtext
+
+ mv /path/to/shuffle_labels.txt .
+ mv /path/to/label.txt .
+ mv /path/to/alphanumeric_labels.txt .
+ mv /path/to/instances_train.txt .
+
+ # 创建软链接
+ cd /path/to/mmocr/data/mixture
+ ln -s /path/to/SynthText SynthText
+ ```
+
+ - 第四步:生成裁剪后的图像和标注:
+
+ ```bash
+ cd /path/to/mmocr
+
+ python tools/data/textrecog/synthtext_converter.py data/mixture/SynthText/gt.mat data/mixture/SynthText/ data/mixture/SynthText/synthtext/SynthText_patch_horizontal --n_proc 8
+ ```
+
+### SynthAdd
+ - 第一步:从 [SynthAdd](https://pan.baidu.com/s/1uV0LtoNmcxbO-0YA7Ch4dg) (code:627x) 下载 `SynthText_Add.zip`
+ - 第二步:下载 [label.txt](https://download.openmmlab.com/mmocr/data/mixture/SynthAdd/label.txt)
+ - 第三步:
+
+ ```bash
+ mkdir SynthAdd && cd SynthAdd
+
+ mv /path/to/SynthText_Add.zip .
+
+ unzip SynthText_Add.zip
+
+ mv /path/to/label.txt .
+
+ # 创建软链接
+ cd /path/to/mmocr/data/mixture
+
+ ln -s /path/to/SynthAdd SynthAdd
+ ```
+:::{tip}
+运行以下命令,可以把 `.txt` 格式的标注文件转换成 `.lmdb` 格式:
+```bash
+python tools/data/utils/txt2lmdb.py -i -o
+```
+例如:
+```bash
+python tools/data/utils/txt2lmdb.py -i data/mixture/Syn90k/label.txt -o data/mixture/Syn90k/label.lmdb
+```
+:::
+
+### TextOCR
+ - 第一步:下载 [train_val_images.zip](https://dl.fbaipublicfiles.com/textvqa/images/train_val_images.zip),[TextOCR_0.1_train.json](https://dl.fbaipublicfiles.com/textvqa/data/textocr/TextOCR_0.1_train.json) 和 [TextOCR_0.1_val.json](https://dl.fbaipublicfiles.com/textvqa/data/textocr/TextOCR_0.1_val.json) 到 `textocr/` 目录.
+ ```bash
+ mkdir textocr && cd textocr
+
+ # 下载 TextOCR 数据集
+ wget https://dl.fbaipublicfiles.com/textvqa/images/train_val_images.zip
+ wget https://dl.fbaipublicfiles.com/textvqa/data/textocr/TextOCR_0.1_train.json
+ wget https://dl.fbaipublicfiles.com/textvqa/data/textocr/TextOCR_0.1_val.json
+
+ # 对于数据图像
+ unzip -q train_val_images.zip
+ mv train_images train
+ ```
+ - 第二步:用四个并行进程剪裁图像然后生成 `train_label.txt`,`val_label.txt` ,可以使用以下命令:
+ ```bash
+ python tools/data/textrecog/textocr_converter.py /path/to/textocr 4
+ ```
+
+
+### Totaltext
+ - 第一步:从 [github dataset](https://github.com/cs-chan/Total-Text-Dataset/tree/master/Dataset) 下载 `totaltext.zip`,然后从 [github Groundtruth](https://github.com/cs-chan/Total-Text-Dataset/tree/master/Groundtruth/Text) 下载 `groundtruth_text.zip` (我们建议下载 `.mat` 格式的标注文件,因为我们提供的 `totaltext_converter.py` 标注格式转换工具只支持 `.mat` 文件)
+ ```bash
+ mkdir totaltext && cd totaltext
+ mkdir imgs && mkdir annotations
+
+ # 对于图像数据
+ # 在 ./totaltext 目录下运行
+ unzip totaltext.zip
+ mv Images/Train imgs/training
+ mv Images/Test imgs/test
+
+ # 对于标注文件
+ unzip groundtruth_text.zip
+ cd Groundtruth
+ mv Polygon/Train ../annotations/training
+ mv Polygon/Test ../annotations/test
+ ```
+ - 第二步:用以下命令生成经剪裁后的标注文件 `train_label.txt` 和 `test_label.txt` (剪裁后的图像会被保存在目录 `data/totaltext/dst_imgs/`):
+ ```bash
+ python tools/data/textrecog/totaltext_converter.py /path/to/totaltext -o /path/to/totaltext --split-list training test
+ ```
+
+### OpenVINO
+ - 第零步:安装 [awscli](https://aws.amazon.com/cli/)。
+ - 第一步:下载 [Open Images](https://github.com/cvdfoundation/open-images-dataset#download-images-with-bounding-boxes-annotations) 的子数据集 `train_1`、 `train_2`、 `train_5`、 `train_f` 及 `validation` 至 `openvino/`。
+ ```bash
+ mkdir openvino && cd openvino
+
+ # 下载 Open Images 的子数据集
+ for s in 1 2 5 f; do
+ aws s3 --no-sign-request cp s3://open-images-dataset/tar/train_${s}.tar.gz .
+ done
+ aws s3 --no-sign-request cp s3://open-images-dataset/tar/validation.tar.gz .
+
+ # 下载标注文件
+ for s in 1 2 5 f; do
+ wget https://storage.openvinotoolkit.org/repositories/openvino_training_extensions/datasets/open_images_v5_text/text_spotting_openimages_v5_train_${s}.json
+ done
+ wget https://storage.openvinotoolkit.org/repositories/openvino_training_extensions/datasets/open_images_v5_text/text_spotting_openimages_v5_validation.json
+
+ # 解压数据集
+ mkdir -p openimages_v5/val
+ for s in 1 2 5 f; do
+ tar zxf train_${s}.tar.gz -C openimages_v5
+ done
+ tar zxf validation.tar.gz -C openimages_v5/val
+ ```
+ - 第二步: 运行以下的命令,以用4个进程生成标注 `train_{1,2,5,f}_label.txt` 和 `val_label.txt` 并裁剪原图:
+ ```bash
+ python tools/data/textrecog/openvino_converter.py /path/to/openvino 4
+ ```
diff --git a/docs/zh_cn/deployment.md b/docs/zh_cn/deployment.md
new file mode 100644
index 0000000000000000000000000000000000000000..e4eb3fb6d7f79f03b49ee8fd0188b2e051444461
--- /dev/null
+++ b/docs/zh_cn/deployment.md
@@ -0,0 +1,309 @@
+# 部署
+
+我们在 `tools/deployment` 目录下提供了一些部署工具。
+
+## 转换至 ONNX (试验性的)
+
+我们提供了将模型转换至 [ONNX](https://github.com/onnx/onnx) 格式的脚本。转换后的模型可以使用诸如 [Netron](https://github.com/lutzroeder/netron) 的工具可视化。 此外,我们也支持比较 PyTorch 和 ONNX 模型的输出结果。
+
+```bash
+python tools/deployment/pytorch2onnx.py
+ ${MODEL_CONFIG_PATH} \
+ ${MODEL_CKPT_PATH} \
+ ${MODEL_TYPE} \
+ ${IMAGE_PATH} \
+ --output-file ${OUTPUT_FILE} \
+ --device-id ${DEVICE_ID} \
+ --opset-version ${OPSET_VERSION} \
+ --verify \
+ --verbose \
+ --show \
+ --dynamic-export
+```
+
+参数说明:
+
+| 参数 | 类型 | 描述 |
+| ------------------ | -------------- | ------------------------------------------------------------ |
+| `model_config` | str | 模型配置文件的路径。 |
+| `model_ckpt` | str | 模型权重文件的路径。 |
+| `model_type` | 'recog', 'det' | 配置文件对应的模型类型。 |
+| `image_path` | str | 输入图片的路径。 |
+| `--output-file` | str | 输出的 ONNX 模型路径。 默认为 `tmp.onnx`。 |
+| `--device-id` | int | 使用哪块 GPU。默认为0。 |
+| `--opset-version` | int | ONNX 操作集版本。默认为11。 |
+| `--verify` | bool | 决定是否验证输出模型的正确性。默认为 `False`。 |
+| `--verbose` | bool | 决定是否打印导出模型的结构,默认为 `False`。 |
+| `--show` | bool | 决定是否可视化 ONNXRuntime 和 PyTorch 的输出。默认为 `False`。 |
+| `--dynamic-export` | bool | 决定是否导出有动态输入和输出尺寸的 ONNX 模型。默认为 `False`。 |
+
+:::{note}
+ 这个工具仍然是试验性的。一些定制的操作没有被支持,并且我们目前仅支持一部分的文本检测和文本识别算法。
+:::
+
+### 支持导出到 ONNX 的模型列表
+
+下表列出的模型可以保证导出到 ONNX 并且可以在 ONNX Runtime 下运行。
+
+| 模型 | 配置 | 动态尺寸 | 批推理 | 注 |
+|:------:|:------------------------------------------------------------------------------------------------------------------------------------------------:|:-------------:|:---------------:|:----:|
+| DBNet | [dbnet_r18_fpnc_1200e_icdar2015.py](https://github.com/open-mmlab/mmocr/blob/main/configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py) | Y | N | |
+| PSENet | [psenet_r50_fpnf_600e_ctw1500.py](https://github.com/open-mmlab/mmocr/blob/main/configs/textdet/psenet/psenet_r50_fpnf_600e_ctw1500.py) | Y | Y | |
+| PSENet | [psenet_r50_fpnf_600e_icdar2015.py](https://github.com/open-mmlab/mmocr/blob/main/configs/textdet/psenet/psenet_r50_fpnf_600e_icdar2015.py) | Y | Y | |
+| PANet | [panet_r18_fpem_ffm_600e_ctw1500.py](https://github.com/open-mmlab/mmocr/blob/main/configs/textdet/panet/panet_r18_fpem_ffm_600e_ctw1500.py) | Y | Y | |
+| PANet | [panet_r18_fpem_ffm_600e_icdar2015.py](https://github.com/open-mmlab/mmocr/blob/main/configs/textdet/panet/panet_r18_fpem_ffm_600e_icdar2015.py) | Y | Y | |
+| CRNN | [crnn_academic_dataset.py](https://github.com/open-mmlab/mmocr/blob/main/configs/textrecog/crnn/crnn_academic_dataset.py) | Y | Y | CRNN 仅接受高度为32的输入 |
+
+:::{note}
+- *以上所有模型测试基于 PyTorch==1.8.1,onnxruntime==1.7.0 进行*
+- 如果你在上述模型中遇到问题,请创建一个issue,我们会尽快处理。
+- 因为这个特性是试验性的,可能变动很快,请尽量使用最新版的 `mmcv` 和 `mmocr` 尝试。
+:::
+
+## ONNX 转 TensorRT (试验性的)
+
+我们也提供了从 [ONNX](https://github.com/onnx/onnx) 模型转换至 [TensorRT](https://github.com/NVIDIA/TensorRT) 格式的脚本。另外,我们支持比较 ONNX 和 TensorRT 模型的输出结果。
+
+
+```bash
+python tools/deployment/onnx2tensorrt.py
+ ${MODEL_CONFIG_PATH} \
+ ${MODEL_TYPE} \
+ ${IMAGE_PATH} \
+ ${ONNX_FILE} \
+ --trt-file ${OUT_TENSORRT} \
+ --max-shape INT INT INT INT \
+ --min-shape INT INT INT INT \
+ --workspace-size INT \
+ --fp16 \
+ --verify \
+ --show \
+ --verbose
+```
+
+参数说明:
+
+| 参数 | 类型 | 描述 |
+| ------------------ | -------------- | ------------------------------------------------------------ |
+| `model_config` | str | 模型配置文件的路径。 |
+| `model_type` | 'recog', 'det' | 配置文件对应的模型类型。 |
+| `image_path` | str | 输入图片的路径。 |
+| `onnx_file` | str | 输入的 ONNX 文件路径。 |
+| `--trt-file` | str | 输出的 TensorRT 模型路径。默认为 `tmp.trt`。 |
+| `--max-shape` | int * 4 | 模型输入的最大尺寸。 |
+| `--min-shape` | int * 4 | 模型输入的最小尺寸。 |
+| `--workspace-size` | int | 最大工作空间大小,单位为 GiB。默认为1。 |
+| `--fp16` | bool | 决定是否输出 fp16 模式的 TensorRT 模型。默认为 `False`。 |
+| `--verify` | bool | 决定是否验证输出模型的正确性。默认为 `False`。 |
+| `--show` | bool | 决定是否可视化 ONNX 和 TensorRT 的输出。默认为 `False`。 |
+| `--verbose` | bool | 决定是否在创建 TensorRT 引擎时打印日志信息。默认为 `False`。 |
+
+:::{note}
+ 这个工具仍然是试验性的。一些定制的操作模型没有被支持。我们目前仅支持一部的文本检测和文本识别算法。
+:::
+
+### 支持导出到 TensorRT 的模型列表
+
+下表列出的模型可以保证导出到 TensorRT 引擎并且可以在 TensorRT 下运行。
+
+| 模型 | 配置 | 动态尺寸 | 批推理 | 注 |
+|:------:|:------------------------------------------------------------------------------------------------------------------------------------------------:|:-------------:|:---------------:|:----:|
+| DBNet | [dbnet_r18_fpnc_1200e_icdar2015.py](https://github.com/open-mmlab/mmocr/blob/main/configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py) | Y | N | |
+| PSENet | [psenet_r50_fpnf_600e_ctw1500.py](https://github.com/open-mmlab/mmocr/blob/main/configs/textdet/psenet/psenet_r50_fpnf_600e_ctw1500.py) | Y | Y | |
+| PSENet | [psenet_r50_fpnf_600e_icdar2015.py](https://github.com/open-mmlab/mmocr/blob/main/configs/textdet/psenet/psenet_r50_fpnf_600e_icdar2015.py) | Y | Y | |
+| PANet | [panet_r18_fpem_ffm_600e_ctw1500.py](https://github.com/open-mmlab/mmocr/blob/main/configs/textdet/panet/panet_r18_fpem_ffm_600e_ctw1500.py) | Y | Y | |
+| PANet | [panet_r18_fpem_ffm_600e_icdar2015.py](https://github.com/open-mmlab/mmocr/blob/main/configs/textdet/panet/panet_r18_fpem_ffm_600e_icdar2015.py) | Y | Y | |
+| CRNN | [crnn_academic_dataset.py](https://github.com/open-mmlab/mmocr/blob/main/configs/textrecog/crnn/crnn_academic_dataset.py) | Y | Y | CRNN 仅接受高度为32的输入 |
+
+:::{note}
+- *以上所有模型测试基于 PyTorch==1.8.1,onnxruntime==1.7.0,tensorrt==7.2.1.6 进行*
+- 如果你在上述模型中遇到问题,请创建一个 issue,我们会尽快处理。
+- 因为这个特性是试验性的,可能变动很快,请尽量使用最新版的 `mmcv` 和 `mmocr` 尝试。
+:::
+
+
+## 评估 ONNX 和 TensorRT 模型(试验性的)
+
+我们在 `tools/deployment/deploy_test.py ` 中提供了评估 TensorRT 和 ONNX 模型的方法。
+
+### 前提条件
+在评估 ONNX 和 TensorRT 模型之前,首先需要安装 ONNX,ONNXRuntime 和 TensorRT。根据 [ONNXRuntime in mmcv](https://mmcv.readthedocs.io/en/latest/onnxruntime_op.html) 和 [TensorRT plugin in mmcv](https://github.com/open-mmlab/mmcv/blob/master/docs/tensorrt_plugin.md) 安装 ONNXRuntime 定制操作和 TensorRT 插件。
+
+### 使用
+
+```bash
+python tools/deploy_test.py \
+ ${CONFIG_FILE} \
+ ${MODEL_PATH} \
+ ${MODEL_TYPE} \
+ ${BACKEND} \
+ --eval ${METRICS} \
+ --device ${DEVICE}
+```
+
+### 参数说明
+
+| 参数 | 类型 | 描述 |
+| -------------- | ------------------------- | ------------------------------------------------------ |
+| `model_config` | str | 模型配置文件的路径。 |
+| `model_file` | str | TensorRT 或 ONNX 模型路径。 |
+| `model_type` | 'recog', 'det' | 部署检测还是识别模型。 |
+| `backend` | 'TensorRT', 'ONNXRuntime' | 测试后端。 |
+| `--eval` | 'acc', 'hmean-iou' | 评估指标。“acc”用于识别模型,“hmean-iou”用于检测模型。 |
+| `--device` | str | 评估使用的设备。默认为 `cuda:0`。 |
+
+## 结果和模型
+
+
+
+
+
模型
+
配置
+
数据集
+
指标
+
PyTorch
+
ONNX Runtime
+
TensorRT FP32
+
TensorRT FP16
+
+
+
+
+
DBNet
+
dbnet_r18_fpnc_1200e_icdar2015.py
+
icdar2015
+
Recall
+
0.731
+
0.731
+
0.678
+
0.679
+
+
+
Precision
+
0.871
+
0.871
+
0.844
+
0.842
+
+
+
Hmean
+
0.795
+
0.795
+
0.752
+
0.752
+
+
+
DBNet*
+
dbnet_r18_fpnc_1200e_icdar2015.py
+
icdar2015
+
Recall
+
0.720
+
0.720
+
0.720
+
0.718
+
+
+
Precision
+
0.868
+
0.868
+
0.868
+
0.868
+
+
+
Hmean
+
0.787
+
0.787
+
0.787
+
0.786
+
+
+
PSENet
+
psenet_r50_fpnf_600e_icdar2015.py
+
icdar2015
+
Recall
+
0.753
+
0.753
+
0.753
+
0.752
+
+
+
Precision
+
0.867
+
0.867
+
0.867
+
0.867
+
+
+
Hmean
+
0.806
+
0.806
+
0.806
+
0.805
+
+
+
PANet
+
panet_r18_fpem_ffm_600e_icdar2015.py
+
icdar2015
+
Recall
+
0.740
+
0.740
+
0.687
+
N/A
+
+
+
Precision
+
0.860
+
0.860
+
0.815
+
N/A
+
+
+
Hmean
+
0.796
+
0.796
+
0.746
+
N/A
+
+
+
PANet*
+
panet_r18_fpem_ffm_600e_icdar2015.py
+
icdar2015
+
Recall
+
0.736
+
0.736
+
0.736
+
N/A
+
+
+
Precision
+
0.857
+
0.857
+
0.857
+
N/A
+
+
+
Hmean
+
0.792
+
0.792
+
0.792
+
N/A
+
+
+
CRNN
+
crnn_academic_dataset.py
+
IIIT5K
+
Acc
+
0.806
+
0.806
+
0.806
+
0.806
+
+
+
+
+:::{note}
+- TensorRT 上采样(upsample)操作和 PyTorch 有一点不同。对于 DBNet 和 PANet,我们建议把上采样的最近邻 (nearest) 模式代替成双线性 (bilinear) 模式。 PANet 的替换处在[这里](https://github.com/open-mmlab/mmocr/blob/50a25e718a028c8b9d96f497e241767dbe9617d1/mmocr/models/textdet/necks/fpem_ffm.py#L33) ,DBNet 的替换处在[这里](https://github.com/open-mmlab/mmocr/blob/50a25e718a028c8b9d96f497e241767dbe9617d1/mmocr/models/textdet/necks/fpn_cat.py#L111)和[这里](https://github.com/open-mmlab/mmocr/blob/50a25e718a028c8b9d96f497e241767dbe9617d1/mmocr/models/textdet/necks/fpn_cat.py#L121)。如在上表中显示的,带有标记*的网络的上采样模式均被改变了。
+- 注意到,相比最近邻模式,使用更改后的上采样模式会降低性能。然而,默认网络的权重是通过最近邻模式训练的。为了保持在部署中的最佳性能,建议在训练和 TensorRT 部署中使用双线性模式。
+- 所有 ONNX 和 TensorRT 模型都使用数据集上的动态尺寸进行评估,图像根据原始配置文件进行预处理。
+- 这个工具仍然是试验性的。一些定制的操作模型没有被支持。并且我们目前仅支持一部分的文本检测和文本识别算法。
+:::
diff --git a/docs/zh_cn/getting_started.md b/docs/zh_cn/getting_started.md
new file mode 100644
index 0000000000000000000000000000000000000000..a0419aef35771f913d52df5dd796c469ce438410
--- /dev/null
+++ b/docs/zh_cn/getting_started.md
@@ -0,0 +1,77 @@
+# 开始
+
+在这个指南中,我们将介绍一些常用的命令,来帮助你熟悉 MMOCR。我们同时还提供了[notebook](https://github.com/open-mmlab/mmocr/blob/main/demo/MMOCR_Tutorial.ipynb) 版本的代码,可以让您快速上手 MMOCR。
+
+## 安装
+
+查看[安装指南](install.md),了解完整步骤。
+
+## 数据集准备
+
+MMOCR 支持许多种类数据集,这些数据集根据其相应任务的类型进行分类。可以在以下部分找到它们的准备步骤:[检测数据集](datasets/det.md)、[识别数据集](datasets/recog.md)、[KIE 数据集](datasets/kie.md)和 [NER 数据集](datasets/ner.md)。
+
+## 使用预训练模型进行推理
+
+下面通过一个简单的命令来演示端到端的识别:
+
+```shell
+python mmocr/utils/ocr.py demo/demo_text_ocr.jpg --print-result --imshow
+```
+
+其检测结果将被打印出来,并弹出一个新窗口显示结果。更多示例和完整说明可以在[示例](demo.md)中找到。
+
+## 训练
+
+### 小数据集训练
+
+在`tests/data`目录下提供了一个用于训练演示的小数据集,在准备学术数据集之前,它可以演示一个初步的训练。
+
+例如:用 `seg` 方法和小数据集来训练文本识别任务,
+```shell
+python tools/train.py configs/textrecog/seg/seg_r31_1by16_fpnocr_toy_dataset.py --work-dir seg
+```
+
+用 `sar` 方法和小数据集训练文本识别,
+```shell
+python tools/train.py configs/textrecog/sar/sar_r31_parallel_decoder_toy_dataset.py --work-dir sar
+```
+
+### 使用学术数据集进行训练
+
+按照说明准备好所需的学术数据集后,最后要检查模型的配置是否将 MMOCR 指向正确的数据集路径。假设在 ICDAR2015 数据集上训练 DBNet,部分配置如 `configs/_base_/det_datasets/icdar2015.py` 所示:
+```python
+dataset_type = 'IcdarDataset'
+data_root = 'data/icdar2015'
+train = dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/instances_training.json',
+ img_prefix=f'{data_root}/imgs',
+ pipeline=None)
+test = dict(
+ type=dataset_type,
+ ann_file=f'{data_root}/instances_test.json',
+ img_prefix=f'{data_root}/imgs',
+ pipeline=None)
+train_list = [train]
+test_list = [test]
+```
+这里需要检查数据集路径 `data/icdar2015` 是否正确. 然后可以启动训练命令:
+```shell
+python tools/train.py configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py --work-dir dbnet
+```
+
+想要了解完整的训练参数配置可以查看 [Training](training.md)了解。
+
+## 测试
+
+假设我们完成了 DBNet 模型训练,并将最新的模型保存在 `dbnet/latest.pth`。则可以使用以下命令,及`hmean-iou`指标来评估其在测试集上的性能:
+```shell
+python tools/test.py configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py dbnet/latest.pth --eval hmean-iou
+```
+
+还可以在线评估预训练模型,命令如下:
+```shell
+python tools/test.py configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py https://download.openmmlab.com/mmocr/textdet/dbnet/dbnet_r18_fpnc_sbn_1200e_icdar2015_20210329-ba3ab597.pth --eval hmean-iou
+```
+
+有关测试的更多说明,请参阅 [测试](testing.md).
diff --git a/docs/zh_cn/index.rst b/docs/zh_cn/index.rst
new file mode 100644
index 0000000000000000000000000000000000000000..787cc68b4d9c5a1b4ee81a58447289c2271ae65e
--- /dev/null
+++ b/docs/zh_cn/index.rst
@@ -0,0 +1,68 @@
+欢迎来到 MMOCR 的中文文档!
+=======================================
+
+您可以在页面左下角切换中英文文档。
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 开始
+
+ install.md
+ getting_started.md
+ demo.md
+ training.md
+ testing.md
+ deployment.md
+ model_serving.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 教程
+
+ tutorials/config.md
+ tutorials/dataset_types.md
+ tutorials/kie_closeset_openset.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 模型库
+
+ modelzoo.md
+ model_summary.md
+ textdet_models.md
+ textrecog_models.md
+ kie_models.md
+ ner_models.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 数据集
+
+ datasets/det.md
+ datasets/recog.md
+ datasets/kie.md
+ datasets/ner.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 杂项
+
+ tools.md
+ changelog.md
+
+.. toctree::
+ :caption: API 参考
+
+ api.rst
+
+.. toctree::
+ :caption: 切换语言
+
+ English
+ 简体中文
+
+导引
+==================
+
+* :ref:`genindex`
+* :ref:`search`
diff --git a/docs/zh_cn/install.md b/docs/zh_cn/install.md
new file mode 100644
index 0000000000000000000000000000000000000000..b122e9f9959ee26a370abad682081a385116babf
--- /dev/null
+++ b/docs/zh_cn/install.md
@@ -0,0 +1,176 @@
+# 安装
+
+## 环境依赖
+
+- Linux | Windows | macOS
+- Python 3.7
+- PyTorch 1.6 或更高版本
+- torchvision 0.7.0
+- CUDA 10.1
+- NCCL 2
+- GCC 5.4.0 或更高版本
+- [MMCV](https://mmcv.readthedocs.io/en/latest/#installation)
+- [MMDetection](https://mmdetection.readthedocs.io/en/latest/#installation)
+
+为了确保代码实现的正确性,MMOCR 每个版本都有可能改变对 MMCV 和 MMDetection 版本的依赖。请根据以下表格确保版本之间的相互匹配。
+
+| MMOCR | MMCV | MMDetection |
+| ------------ | ---------------------- | ------------------------- |
+| master | 1.3.8 <= mmcv <= 1.5.0 | 2.14.0 <= mmdet <= 3.0.0 |
+| 0.4.0, 0.4.1 | 1.3.8 <= mmcv <= 1.5.0 | 2.14.0 <= mmdet <= 2.20.0 |
+| 0.3.0 | 1.3.8 <= mmcv <= 1.4.0 | 2.14.0 <= mmdet <= 2.20.0 |
+| 0.2.1 | 1.3.8 <= mmcv <= 1.4.0 | 2.13.0 <= mmdet <= 2.20.0 |
+| 0.2.0 | 1.3.4 <= mmcv <= 1.4.0 | 2.11.0 <= mmdet <= 2.13.0 |
+| 0.1.0 | 1.2.6 <= mmcv <= 1.3.4 | 2.9.0 <= mmdet <= 2.11.0 |
+
+我们已经测试了以下操作系统和软件版本:
+
+- OS: Ubuntu 16.04
+- CUDA: 10.1
+- GCC(G++): 5.4.0
+- MMCV 1.3.8
+- MMDetection 2.14.0
+- PyTorch 1.6.0
+- torchvision 0.7.0
+
+MMOCR 基于 PyTorch 和 MMDetection 项目实现。
+
+## 详细安装步骤
+
+a. 创建一个 Conda 虚拟环境并激活(open-mmlab 为自定义环境名)。
+
+```shell
+conda create -n open-mmlab python=3.7 -y
+conda activate open-mmlab
+```
+
+b. 按照 PyTorch 官网教程安装 PyTorch 和 torchvision ([参见官方链接](https://pytorch.org/)), 例如,
+
+```shell
+conda install pytorch==1.6.0 torchvision==0.7.0 cudatoolkit=10.1 -c pytorch
+```
+
+:::{note}
+请确定 CUDA 编译版本和运行版本一致。你可以在 [PyTorch](https://pytorch.org/) 官网检查预编译 PyTorch 所支持的 CUDA 版本。
+:::
+
+c. 安装 [mmcv](https://github.com/open-mmlab/mmcv),推荐以下方式进行安装。
+
+```shell
+pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/{cu_version}/{torch_version}/index.html
+```
+
+请将上述 url 中 ``{cu_version}`` 和 ``{torch_version}``替换成你环境中对应的 CUDA 版本和 PyTorch 版本。例如,如果想要安装最新版基于 CUDA 11 和 PyTorch 1.7.0 的最新版 `mmcv-full`,请输入以下命令:
+
+```shell
+pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu110/torch1.7.0/index.html
+```
+
+:::{note}
+PyTorch 在 1.x.0 和 1.x.1 之间通常是兼容的,故 mmcv-full 只提供 1.x.0 的编译包。如果你的 PyTorch 版本是 1.x.1,你可以放心地安装在 1.x.0 版本编译的 mmcv-full。
+
+```bash
+# 我们可以忽略 PyTorch 的小版本号
+pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu110/torch1.7/index.html
+```
+
+:::
+
+:::{note}
+如果安装时进行了编译过程,请再次确认安装的 `mmcv-full` 版本与环境中 CUDA 和 PyTorch 的版本匹配。
+
+如有需要,可以在[此处](https://github.com/open-mmlab/mmcv#installation)检查 mmcv 与 CUDA 和 PyTorch 的版本对应关系。
+:::
+
+:::{warning}
+如果你已经安装过 `mmcv`,你需要先运行 `pip uninstall mmcv` 删除 `mmcv`,再安装 `mmcv-full`。 如果环境中同时安装了 `mmcv` 和 `mmcv-full`, 将会出现报错 `ModuleNotFoundError`。
+:::
+
+d. 安装 [mmdet](https://github.com/open-mmlab/mmdetection), 我们推荐使用pip安装最新版 `mmdet`。
+在 [此处](https://pypi.org/project/mmdet/) 可以查看 `mmdet` 版本信息.
+
+```shell
+pip install mmdet
+```
+
+或者,你也可以按照 [安装指南](https://github.com/open-mmlab/mmdetection/blob/master/docs/get_started.md) 中的方法安装 `mmdet`。
+
+e. 克隆 MMOCR 项目到本地.
+
+```shell
+git clone https://github.com/open-mmlab/mmocr.git
+cd mmocr
+```
+
+f. 安装依赖软件环境并安装 MMOCR。
+
+```shell
+pip install -r requirements.txt
+pip install -v -e . # or "python setup.py develop"
+export PYTHONPATH=$(pwd):$PYTHONPATH
+```
+
+## 完整安装命令
+
+以下是 conda 方式安装 mmocr 的完整安装命令。
+
+```shell
+conda create -n open-mmlab python=3.7 -y
+conda activate open-mmlab
+
+# 安装最新的 PyTorch 预编译包
+conda install pytorch==1.6.0 torchvision==0.7.0 cudatoolkit=10.1 -c pytorch
+
+# 安装最新的 mmcv-full
+pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.6.0/index.html
+
+# 安装 mmdet
+pip install mmdet
+
+# 安装 mmocr
+git clone https://github.com/open-mmlab/mmocr.git
+cd mmocr
+
+pip install -r requirements.txt
+pip install -v -e . # 或 "python setup.py develop"
+export PYTHONPATH=$(pwd):$PYTHONPATH
+```
+
+## 可选方式: Docker镜像
+
+我们提供了一个 [Dockerfile](https://github.com/open-mmlab/mmocr/blob/master/docker/Dockerfile) 文件以建立 docker 镜像 。
+
+```shell
+# build an image with PyTorch 1.6, CUDA 10.1
+docker build -t mmocr docker/
+```
+
+使用以下命令运行。
+
+```shell
+docker run --gpus all --shm-size=8g -it -v {实际数据目录}:/mmocr/data mmocr
+```
+
+## 数据集准备
+
+我们推荐建立一个 symlink 路径映射,连接数据集路径到 `mmocr/data`。 详细数据集准备方法请阅读**数据集**章节。
+如果你需要的文件夹路径不同,你可能需要在 configs 文件中修改对应的文件路径信息。
+
+ `mmocr` 文件夹路径结构如下:
+
+```
+├── configs/
+├── demo/
+├── docker/
+├── docs/
+├── LICENSE
+├── mmocr/
+├── README.md
+├── requirements/
+├── requirements.txt
+├── resources/
+├── setup.cfg
+├── setup.py
+├── tests/
+├── tools/
+```
diff --git a/docs/zh_cn/make.bat b/docs/zh_cn/make.bat
new file mode 100644
index 0000000000000000000000000000000000000000..8a3a0e25b49a52ade52c4f69ddeb0bc3d12527ff
--- /dev/null
+++ b/docs/zh_cn/make.bat
@@ -0,0 +1,36 @@
+@ECHO OFF
+
+pushd %~dp0
+
+REM Command file for Sphinx documentation
+
+if "%SPHINXBUILD%" == "" (
+ set SPHINXBUILD=sphinx-build
+)
+set SOURCEDIR=.
+set BUILDDIR=_build
+
+if "%1" == "" goto help
+
+%SPHINXBUILD% >NUL 2>NUL
+if errorlevel 9009 (
+ echo.
+ echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
+ echo.installed, then set the SPHINXBUILD environment variable to point
+ echo.to the full path of the 'sphinx-build' executable. Alternatively you
+ echo.may add the Sphinx directory to PATH.
+ echo.
+ echo.If you don't have Sphinx installed, grab it from
+ echo.http://sphinx-doc.org/
+ exit /b 1
+)
+
+
+%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+goto end
+
+:help
+%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+
+:end
+popd
diff --git a/docs/zh_cn/merge_docs.sh b/docs/zh_cn/merge_docs.sh
new file mode 100755
index 0000000000000000000000000000000000000000..07e8fb79944ac6d63bfc99967cff7253f490c829
--- /dev/null
+++ b/docs/zh_cn/merge_docs.sh
@@ -0,0 +1,11 @@
+#!/usr/bin/env bash
+
+# gather models
+sed -e '$a\\n' -s ../../configs/kie/*/*.md | sed "s/md###t/html#t/g" | sed "s/#/#&/" | sed '1i\# 关键信息提取模型' | sed 's/](\/docs\//](/g' | sed 's=](/=](https://github.com/open-mmlab/mmocr/tree/master/=g' >kie_models.md
+sed -e '$a\\n' -s ../../configs/textdet/*/*.md | sed "s/md###t/html#t/g" | sed "s/#/#&/" | sed '1i\# 文本检测模型' | sed 's/](\/docs\//](/g' | sed 's=](/=](https://github.com/open-mmlab/mmocr/tree/master/=g' >textdet_models.md
+sed -e '$a\\n' -s ../../configs/textrecog/*/*.md | sed "s/md###t/html#t/g" | sed "s/#/#&/" | sed '1i\# 文本识别模型' | sed 's/](\/docs\//](/g' | sed 's=](/=](https://github.com/open-mmlab/mmocr/tree/master/=g' >textrecog_models.md
+sed -e '$a\\n' -s ../../configs/ner/*/*.md | sed "s/md###t/html#t/g" | sed "s/#/#&/" | sed '1i\# 命名实体识别模型' | sed 's/](\/docs\//](/g' | sed 's=](/=](https://github.com/open-mmlab/mmocr/tree/master/=g' >ner_models.md
+
+# replace special symbols in demo.md
+cp ../../demo/README_zh-CN.md demo.md
+sed -i 's/:heavy_check_mark:/Yes/g' demo.md && sed -i 's/:x:/No/g' demo.md
diff --git a/docs/zh_cn/model_serving.md b/docs/zh_cn/model_serving.md
new file mode 100644
index 0000000000000000000000000000000000000000..512b40e4aa1faa7e6573b626a42d0c9c31e8ae7d
--- /dev/null
+++ b/docs/zh_cn/model_serving.md
@@ -0,0 +1,167 @@
+# 服务器部署
+
+`MMOCR` 预先提供了一些脚本来加速模型部署服务流程。下面快速介绍一些在服务器端通过调用 API 来进行模型推理的必要步骤。
+
+## 安装 TorchServe
+
+你可以根据[官网](https://github.com/pytorch/serve#install-torchserve-and-torch-model-archiver)步骤来安装 `TorchServe` 和
+`torch-model-archiver` 两个模块。
+
+## 将 MMOCR 模型转换为 TorchServe 模型格式
+
+我们提供了一个便捷的工具可以将任何以 `.pth` 为后缀的模型转换为以 `.mar` 结尾的模型来满足 TorchServe 使用要求。
+
+```shell
+python tools/deployment/mmocr2torchserve.py ${CONFIG_FILE} ${CHECKPOINT_FILE} \
+--output-folder ${MODEL_STORE} \
+--model-name ${MODEL_NAME}
+```
+
+:::{note}
+${MODEL_STORE} 必须是文件夹的绝对路径。
+:::
+
+例如:
+
+```shell
+python tools/deployment/mmocr2torchserve.py \
+ configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py \
+ checkpoints/dbnet_r18_fpnc_1200e_icdar2015.pth \
+ --output-folder ./checkpoints \
+ --model-name dbnet
+```
+
+## 启动服务
+
+### 本地启动
+
+准备好模型后,使用一行命令即可启动服务:
+
+```bash
+# 加载所有位于 ./checkpoints 中的模型文件
+torchserve --start --model-store ./checkpoints --models all
+# 或者你仅仅使用一个模型服务,比如 dbnet
+torchserve --start --model-store ./checkpoints --models dbnet=dbnet.mar
+```
+
+然后,你可以通过 TorchServe 的 REST API 访问 Inference、 Management、 Metrics 等服务。你可以在[TorchServe REST API](https://github.com/pytorch/serve/blob/master/docs/rest_api.md) 中找到它们的用法。
+
+
+| 服务 | 地址 |
+| ------------------- | ----------------------- |
+| Inference | `http://127.0.0.1:8080` |
+| Management | `http://127.0.0.1:8081` |
+| Metrics | `http://127.0.0.1:8082` |
+
+:::{note}
+TorchServe 默认会将服务绑定到端口 `8080`、 `8081` 、 `8082` 上。你可以通过修改 `config.properties` 来更改端口及存储位置等内容,并通过可选项 `--ts-config config.preperties` 来运行 TorchServe 服务。
+
+```bash
+inference_address=http://0.0.0.0:8080
+management_address=http://0.0.0.0:8081
+metrics_address=http://0.0.0.0:8082
+number_of_netty_threads=32
+job_queue_size=1000
+model_store=/home/model-server/model-store
+```
+
+:::
+
+
+### 通过 Docker 启动
+
+通过 Docker 提供模型服务不失为一种更好的方法。我们提供了一个 Dockerfile,可以让你摆脱那些繁琐且容易出错的环境设置步骤。
+
+#### 构建 `mmocr-serve` Docker 镜像
+
+```shell
+docker build -t mmocr-serve:latest docker/serve/
+```
+
+#### 通过 Docker 运行 `mmocr-serve`
+
+为了在 GPU 环境下运行 Docker, 首先需要安装 [nvidia-docker](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html);或者你也可以只使用 CPU 环境而不必加 `--gpus` 参数。
+
+下面的命令将使用 gpu 运行,将 Inference、 Management、 Metric 的端口分别绑定到8080、8081、8082上,将容器的IP绑定到127.0.0.1上,并将检查点文件夹 `./checkpoints` 从主机挂载到容器的 `/home/model-server/model-store` 文件夹下。更多相关信息,请查看官方文档中 [docker中运行 TorchServe 服务](https://github.com/pytorch/serve/blob/master/docker/README.md#running-torchserve-in-a-production-docker-environment)。
+
+```shell
+docker run --rm \
+--cpus 8 \
+--gpus device=0 \
+-p8080:8080 -p8081:8081 -p8082:8082 \
+--mount type=bind,source=`realpath ./checkpoints`,target=/home/model-server/model-store \
+mmocr-serve:latest
+```
+
+:::{note}
+`realpath ./checkpoints` 指向的是 "./checkpoints" 的绝对路径,你也可以将其替换为你的 torchserve 模型所在的绝对路径。
+:::
+
+运行docker后,你可以通过 TorchServe 的 REST API 访问 Inference、 Management、 Metrics 等服务。具体你可以在[TorchServe REST API](https://github.com/pytorch/serve/blob/master/docs/rest_api.md) 中找到它们的用法。
+
+| 服务 | 地址 |
+| ------------------- | ----------------------- |
+| Inference | http://127.0.0.1:8080 |
+| Management | http://127.0.0.1:8081 |
+| Metrics | http://127.0.0.1:8082 |
+
+
+
+## 4. 测试单张图片推理
+
+推理 API 允许用户上传一张图到模型服务中,并返回相应的预测结果。
+
+```shell
+curl http://127.0.0.1:8080/predictions/${MODEL_NAME} -T demo/demo_text_det.jpg
+```
+
+例如,
+
+```shell
+curl http://127.0.0.1:8080/predictions/dbnet -T demo/demo_text_det.jpg
+```
+
+对于检测模型,你会获取到名为 boundary_result 的 json 对象。内部的每个数组包含以浮点数格式的,按顺时针排序的 x, y 边界顶点坐标。数组的最后一位为置信度分数。
+```json
+{
+ "boundary_result": [
+ [
+ 221.18990004062653,
+ 226.875,
+ 221.18990004062653,
+ 212.625,
+ 244.05868631601334,
+ 212.625,
+ 244.05868631601334,
+ 226.875,
+ 0.80883354575186
+ ]
+ ]
+}
+```
+
+对于识别模型,返回的结果如下:
+
+```json
+{
+ "text": "sier",
+ "score": 0.5247521847486496
+}
+```
+
+同时可以使用 `test_torchserve.py` 来可视化对比 TorchServe 和 PyTorch 结果。
+
+```shell
+python tools/deployment/test_torchserve.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} ${MODEL_NAME}
+[--inference-addr ${INFERENCE_ADDR}] [--device ${DEVICE}]
+```
+
+例如:
+
+```shell
+python tools/deployment/test_torchserve.py \
+ demo/demo_text_det.jpg \
+ configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py \
+ checkpoints/dbnet_r18_fpnc_1200e_icdar2015.pth \
+ dbnet
+```
diff --git a/docs/zh_cn/stats.py b/docs/zh_cn/stats.py
new file mode 100755
index 0000000000000000000000000000000000000000..0d2ece5dd6910446fc896e52027afff78db3e450
--- /dev/null
+++ b/docs/zh_cn/stats.py
@@ -0,0 +1,101 @@
+#!/usr/bin/env python
+# Copyright (c) OpenMMLab. All rights reserved.
+import functools as func
+import glob
+import re
+from os.path import basename, splitext
+
+import numpy as np
+import titlecase
+
+
+def title2anchor(name):
+ return re.sub(r'-+', '-', re.sub(r'[^a-zA-Z0-9]', '-',
+ name.strip().lower())).strip('-')
+
+
+# Count algorithms
+
+files = sorted(glob.glob('*_models.md'))
+
+stats = []
+
+for f in files:
+ with open(f, 'r') as content_file:
+ content = content_file.read()
+
+ # Remove the blackquote notation from the paper link under the title
+ # for better layout in readthedocs
+ expr = r'(^## \s*?.*?\s+?)>\s*?(\[.*?\]\(.*?\))'
+ content = re.sub(expr, r'\1\2', content, flags=re.MULTILINE)
+ with open(f, 'w') as content_file:
+ content_file.write(content)
+
+ # title
+ title = content.split('\n')[0].replace('#', '')
+
+ # count papers
+ exclude_papertype = ['ABSTRACT', 'IMAGE']
+ exclude_expr = ''.join(f'(?!{s})' for s in exclude_papertype)
+ expr = rf''\
+ r'\s*\n.*?\btitle\s*=\s*{(.*?)}'
+ papers = set(
+ (papertype, titlecase.titlecase(paper.lower().strip()))
+ for (papertype, paper) in re.findall(expr, content, re.DOTALL))
+ print(papers)
+ # paper links
+ revcontent = '\n'.join(list(reversed(content.splitlines())))
+ paperlinks = {}
+ for _, p in papers:
+ q = p.replace('\\', '\\\\').replace('?', '\\?')
+ paper_link = title2anchor(
+ re.search(
+ rf'\btitle\s*=\s*{{\s*{q}\s*}}.*?\n## (.*?)\s*[,;]?\s*\n',
+ revcontent, re.DOTALL | re.IGNORECASE).group(1))
+ paperlinks[p] = f'[{p}]({splitext(basename(f))[0]}.html#{paper_link})'
+ paperlist = '\n'.join(
+ sorted(f' - [{t}] {paperlinks[x]}' for t, x in papers))
+ # count configs
+ configs = set(x.lower().strip()
+ for x in re.findall(r'https.*configs/.*\.py', content))
+
+ # count ckpts
+ ckpts = set(x.lower().strip()
+ for x in re.findall(r'https://download.*\.pth', content)
+ if 'mmocr' in x)
+
+ statsmsg = f"""
+## [{title}]({f})
+
+* 模型权重文件数量: {len(ckpts)}
+* 配置文件数量: {len(configs)}
+* 论文数量: {len(papers)}
+{paperlist}
+
+ """
+
+ stats.append((papers, configs, ckpts, statsmsg))
+
+allpapers = func.reduce(lambda a, b: a.union(b), [p for p, _, _, _ in stats])
+allconfigs = func.reduce(lambda a, b: a.union(b), [c for _, c, _, _ in stats])
+allckpts = func.reduce(lambda a, b: a.union(b), [c for _, _, c, _ in stats])
+msglist = '\n'.join(x for _, _, _, x in stats)
+
+papertypes, papercounts = np.unique([t for t, _ in allpapers],
+ return_counts=True)
+countstr = '\n'.join(
+ [f' - {t}: {c}' for t, c in zip(papertypes, papercounts)])
+
+modelzoo = f"""
+# 统计数据
+
+* 模型权重文件数量: {len(allckpts)}
+* 配置文件数量: {len(allconfigs)}
+* 论文数量: {len(allpapers)}
+{countstr}
+
+{msglist}
+"""
+
+with open('modelzoo.md', 'w') as f:
+ f.write(modelzoo)
diff --git a/docs/zh_cn/testing.md b/docs/zh_cn/testing.md
new file mode 100644
index 0000000000000000000000000000000000000000..17b4760ab125fe5d761232cb4384f06b5bac0348
--- /dev/null
+++ b/docs/zh_cn/testing.md
@@ -0,0 +1,108 @@
+# 测试
+
+此文档介绍在数据集上测试预训练模型的方法。
+
+## 使用单 GPU 进行测试
+
+您可以使用 `tools/test.py` 执行单 CPU/GPU 推理。例如,要在 IC15 上评估 DBNet: ( 可以从 [Model Zoo]( ../../README_zh-CN.md#模型库) 下载预训练模型 ):
+
+```shell
+./tools/dist_test.sh configs/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py dbnet_r18_fpnc_sbn_1200e_icdar2015_20210329-ba3ab597.pth --eval hmean-iou
+```
+
+下面是脚本的完整用法:
+
+```shell
+python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [ARGS]
+```
+
+:::{note}
+默认情况下,MMOCR 更偏向于使用 GPU 而非 CPU。如果您想在 CPU 上测试模型,请清空 `CUDA_VISIBLE_DEVICES` 或者将其设置为 -1 以使 GPU(s) 对程序不可见。需要注意的是,运行 CPU 测试需要 **MMCV >= 1.4.4**。
+
+```bash
+CUDA_VISIBLE_DEVICES= python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [ARGS]
+```
+
+:::
+
+
+
+| 参数 | 类型 | 描述 |
+| ------------------ | --------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `--out` | str | 以 pickle 格式输出结果文件。 |
+| `--fuse-conv-bn` | bool | 所选 det 模型的自定义配置的路径。 |
+| `--format-only` | bool | 格式化输出结果文件而不执行评估。 当您想将结果格式化为特定格式并将它们提交到测试服务器时,它很有用。 |
+| `--gpu-id` | int | 要使用的 GPU ID。仅适用于非分布式训练。 |
+| `--eval` | 'hmean-ic13', 'hmean-iou', 'acc' | 不同的任务使用不同的评估指标。对于文本检测任务,指标是 'hmean-ic13' 或者 'hmean-iou'。对于文本识别任务,指标是 'acc'。 |
+| `--show` | bool | 是否显示结果。 |
+| `--show-dir` | str | 将用于保存输出图像的目录。 |
+| `--show-score-thr` | float | 分数阈值 (默认值: 0.3)。 |
+| `--gpu-collect` | bool | 是否使用 gpu 收集结果。 |
+| `--tmpdir` | str | 用于从多个 workers 收集结果的 tmp 目录,在未指定 gpu-collect 时可用。 |
+| `--cfg-options` | str | 覆盖使用的配置中的一些设置,xxx=yyy 格式的键值对将被合并到配置文件中。如果要覆盖的值是一个列表,它应当是 key ="[a,b]" 或者 key=a,b 的形式。该参数还允许嵌套列表/元组值,例如 key="[(a,b),(c,d)]"。请注意,引号是必需的,并且不允许使用空格。 |
+| `--eval-options` | str | 用于评估的自定义选项,xxx=yyy 格式的键值对将是 dataset.evaluate() 函数的 kwargs。 |
+| `--launcher` | 'none', 'pytorch', 'slurm', 'mpi' | 工作启动器的选项。 |
+
+## 使用多 GPU 进行测试
+
+MMOCR 使用 `MMDistributedDataParallel` 实现 **分布式**测试。
+
+您可以使用以下命令测试具有多个 GPU 的数据集。
+
+
+```shell
+[PORT={PORT}] ./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [PY_ARGS]
+```
+
+| 参数 | 类型 | 描述 |
+| --------- | ---- | -------------------------------------------------------------------------------- |
+| `PORT` | int | rank 为 0 的机器将使用的主端口。默认为 29500。 |
+| `PY_ARGS` | str | 由 `tools/test.py` 解析的参数。 |
+
+例如,
+
+```shell
+./tools/dist_test.sh configs/example_config.py work_dirs/example_exp/example_model_20200202.pth 1 --eval hmean-iou
+```
+
+## 使用 Slurm 进行测试
+
+如果您在使用 [Slurm](https://slurm.schedmd.com/) 管理的集群上运行 MMOCR, 则可以使用脚本 `tools/slurm_test.sh`。
+
+```shell
+[GPUS=${GPUS}] [GPUS_PER_NODE=${GPUS_PER_NODE}] [SRUN_ARGS=${SRUN_ARGS}] ./tools/slurm_test.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${CHECKPOINT_FILE} [PY_ARGS]
+```
+
+| 参数 | 类型 | 描述 |
+| --------------- | ---- | ----------------------------------------------------------------------------------------------------------- |
+| `GPUS` | int | 此任务要使用的 GPU 数量。默认为 8。 |
+| `GPUS_PER_NODE` | int | 每个节点要分配的 GPU 数量。默认为 8。 |
+| `SRUN_ARGS` | str | srun 解析的参数。可以在[此处](https://slurm.schedmd.com/srun.html)找到可用选项。|
+| `PY_ARGS` | str | 由 `tools/test.py` 解析的参数。 |
+
+下面是一个在 "dev" 分区上运行任务的示例。该任务名为 "test_job",其调用了 8 个 GPU 对示例模型进行评估 。
+
+```shell
+GPUS=8 ./tools/slurm_test.sh dev test_job configs/example_config.py work_dirs/example_exp/example_model_20200202.pth --eval hmean-iou
+```
+
+## 批量测试
+
+默认情况下,MMOCR 仅对逐张图像进行测试。为了令推理更快,您可以在配置中更改
+`data.val_dataloader.samples_per_gpu` 和 `data.test_dataloader.samples_per_gpu` 字段。
+
+例如,
+```
+data = dict(
+ ...
+ val_dataloader=dict(samples_per_gpu=16),
+ test_dataloader=dict(samples_per_gpu=16),
+ ...
+)
+```
+
+将使用 16 张图像作为一个批大小测试模型。
+
+:::{warning}
+批量测试时数据预处理管道的行为会有所变化,因而可能导致模型的性能下降。
+:::
diff --git a/mmocr/__init__.py b/mmocr/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..011fa8279d545008d83bc681f7cbb0de91daa04f
--- /dev/null
+++ b/mmocr/__init__.py
@@ -0,0 +1,70 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import mmcv
+import mmdet
+from packaging.version import parse
+
+from .version import __version__, short_version
+
+
+def digit_version(version_str: str, length: int = 4):
+ """Convert a version string into a tuple of integers.
+
+ This method is usually used for comparing two versions. For pre-release
+ versions: alpha < beta < rc.
+ Args:
+ version_str (str): The version string.
+ length (int): The maximum number of version levels. Default: 4.
+ Returns:
+ tuple[int]: The version info in digits (integers).
+ """
+ version = parse(version_str)
+ assert version.release, f'failed to parse version {version_str}'
+ release = list(version.release)
+ release = release[:length]
+ if len(release) < length:
+ release = release + [0] * (length - len(release))
+ if version.is_prerelease:
+ mapping = {'a': -3, 'b': -2, 'rc': -1}
+ val = -4
+ # version.pre can be None
+ if version.pre:
+ if version.pre[0] not in mapping:
+ warnings.warn(f'unknown prerelease version {version.pre[0]}, '
+ 'version checking may go wrong')
+ else:
+ val = mapping[version.pre[0]]
+ release.extend([val, version.pre[-1]])
+ else:
+ release.extend([val, 0])
+
+ elif version.is_postrelease:
+ release.extend([1, version.post])
+ else:
+ release.extend([0, 0])
+ return tuple(release)
+
+
+mmcv_minimum_version = '1.3.8'
+mmcv_maximum_version = '1.5.0'
+mmcv_version = digit_version(mmcv.__version__)
+
+assert (mmcv_version >= digit_version(mmcv_minimum_version)
+ and mmcv_version <= digit_version(mmcv_maximum_version)), \
+ f'MMCV {mmcv.__version__} is incompatible with MMOCR {__version__}. ' \
+ f'Please use MMCV >= {mmcv_minimum_version}, ' \
+ f'<= {mmcv_maximum_version} instead.'
+
+mmdet_minimum_version = '2.14.0'
+mmdet_maximum_version = '3.0.0'
+mmdet_version = digit_version(mmdet.__version__)
+
+assert (mmdet_version >= digit_version(mmdet_minimum_version)
+ and mmdet_version <= digit_version(mmdet_maximum_version)), \
+ f'MMDetection {mmdet.__version__} is incompatible ' \
+ f'with MMOCR {__version__}. ' \
+ f'Please use MMDetection >= {mmdet_minimum_version}, ' \
+ f'<= {mmdet_maximum_version} instead.'
+
+__all__ = ['__version__', 'short_version', 'digit_version']
diff --git a/mmocr/apis/__init__.py b/mmocr/apis/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..fae8d52cb7ff94ba457aa54c2fe4bcf029f39763
--- /dev/null
+++ b/mmocr/apis/__init__.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .inference import init_detector, model_inference
+from .test import single_gpu_test
+from .train import init_random_seed, train_detector
+from .utils import (disable_text_recog_aug_test, replace_image_to_tensor,
+ tensor2grayimgs)
+
+__all__ = [
+ 'model_inference', 'train_detector', 'init_detector', 'init_random_seed',
+ 'replace_image_to_tensor', 'disable_text_recog_aug_test',
+ 'single_gpu_test', 'tensor2grayimgs'
+]
diff --git a/mmocr/apis/inference.py b/mmocr/apis/inference.py
new file mode 100644
index 0000000000000000000000000000000000000000..1a8d5eec4bf5f007e8f4f6e563b0feb1281ccbd7
--- /dev/null
+++ b/mmocr/apis/inference.py
@@ -0,0 +1,238 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import mmcv
+import numpy as np
+import torch
+from mmcv.ops import RoIPool
+from mmcv.parallel import collate, scatter
+from mmcv.runner import load_checkpoint
+from mmdet.core import get_classes
+from mmdet.datasets import replace_ImageToTensor
+from mmdet.datasets.pipelines import Compose
+
+from mmocr.models import build_detector
+from mmocr.utils import is_2dlist
+from .utils import disable_text_recog_aug_test
+
+
+def init_detector(config, checkpoint=None, device='cuda:0', cfg_options=None):
+ """Initialize a detector from config file.
+
+ Args:
+ config (str or :obj:`mmcv.Config`): Config file path or the config
+ object.
+ checkpoint (str, optional): Checkpoint path. If left as None, the model
+ will not load any weights.
+ cfg_options (dict): Options to override some settings in the used
+ config.
+
+ Returns:
+ nn.Module: The constructed detector.
+ """
+ if isinstance(config, str):
+ config = mmcv.Config.fromfile(config)
+ elif not isinstance(config, mmcv.Config):
+ raise TypeError('config must be a filename or Config object, '
+ f'but got {type(config)}')
+ if cfg_options is not None:
+ config.merge_from_dict(cfg_options)
+ if config.model.get('pretrained'):
+ config.model.pretrained = None
+ config.model.train_cfg = None
+ model = build_detector(config.model, test_cfg=config.get('test_cfg'))
+ if checkpoint is not None:
+ checkpoint = load_checkpoint(model, checkpoint, map_location='cpu')
+ if 'CLASSES' in checkpoint.get('meta', {}):
+ model.CLASSES = checkpoint['meta']['CLASSES']
+ else:
+ warnings.simplefilter('once')
+ warnings.warn('Class names are not saved in the checkpoint\'s '
+ 'meta data, use COCO classes by default.')
+ model.CLASSES = get_classes('coco')
+ model.cfg = config # save the config in the model for convenience
+ model.to(device)
+ model.eval()
+ return model
+
+
+def model_inference(model,
+ imgs,
+ ann=None,
+ batch_mode=False,
+ return_data=False):
+ """Inference image(s) with the detector.
+
+ Args:
+ model (nn.Module): The loaded detector.
+ imgs (str/ndarray or list[str/ndarray] or tuple[str/ndarray]):
+ Either image files or loaded images.
+ batch_mode (bool): If True, use batch mode for inference.
+ ann (dict): Annotation info for key information extraction.
+ return_data: Return postprocessed data.
+ Returns:
+ result (dict): Predicted results.
+ """
+
+ if isinstance(imgs, (list, tuple)):
+ is_batch = True
+ if len(imgs) == 0:
+ raise Exception('empty imgs provided, please check and try again')
+ if not isinstance(imgs[0], (np.ndarray, str)):
+ raise AssertionError('imgs must be strings or numpy arrays')
+
+ elif isinstance(imgs, (np.ndarray, str)):
+ imgs = [imgs]
+ is_batch = False
+ else:
+ raise AssertionError('imgs must be strings or numpy arrays')
+
+ is_ndarray = isinstance(imgs[0], np.ndarray)
+
+ cfg = model.cfg
+
+ if batch_mode:
+ cfg = disable_text_recog_aug_test(cfg, set_types=['test'])
+
+ device = next(model.parameters()).device # model device
+
+ if cfg.data.test.get('pipeline', None) is None:
+ if is_2dlist(cfg.data.test.datasets):
+ cfg.data.test.pipeline = cfg.data.test.datasets[0][0].pipeline
+ else:
+ cfg.data.test.pipeline = cfg.data.test.datasets[0].pipeline
+ if is_2dlist(cfg.data.test.pipeline):
+ cfg.data.test.pipeline = cfg.data.test.pipeline[0]
+
+ if is_ndarray:
+ cfg = cfg.copy()
+ # set loading pipeline type
+ cfg.data.test.pipeline[0].type = 'LoadImageFromNdarray'
+
+ cfg.data.test.pipeline = replace_ImageToTensor(cfg.data.test.pipeline)
+ test_pipeline = Compose(cfg.data.test.pipeline)
+
+ datas = []
+ for img in imgs:
+ # prepare data
+ if is_ndarray:
+ # directly add img
+ data = dict(
+ img=img,
+ ann_info=ann,
+ img_info=dict(width=img.shape[1], height=img.shape[0]),
+ bbox_fields=[])
+ else:
+ # add information into dict
+ data = dict(
+ img_info=dict(filename=img),
+ img_prefix=None,
+ ann_info=ann,
+ bbox_fields=[])
+ if ann is not None:
+ data.update(dict(**ann))
+
+ # build the data pipeline
+ data = test_pipeline(data)
+ # get tensor from list to stack for batch mode (text detection)
+ if batch_mode:
+ if cfg.data.test.pipeline[1].type == 'MultiScaleFlipAug':
+ for key, value in data.items():
+ data[key] = value[0]
+ datas.append(data)
+
+ if isinstance(datas[0]['img'], list) and len(datas) > 1:
+ raise Exception('aug test does not support '
+ f'inference with batch size '
+ f'{len(datas)}')
+
+ data = collate(datas, samples_per_gpu=len(imgs))
+
+ # process img_metas
+ if isinstance(data['img_metas'], list):
+ data['img_metas'] = [
+ img_metas.data[0] for img_metas in data['img_metas']
+ ]
+ else:
+ data['img_metas'] = data['img_metas'].data
+
+ if isinstance(data['img'], list):
+ data['img'] = [img.data for img in data['img']]
+ if isinstance(data['img'][0], list):
+ data['img'] = [img[0] for img in data['img']]
+ else:
+ data['img'] = data['img'].data
+
+ # for KIE models
+ if ann is not None:
+ data['relations'] = data['relations'].data[0]
+ data['gt_bboxes'] = data['gt_bboxes'].data[0]
+ data['texts'] = data['texts'].data[0]
+ data['img'] = data['img'][0]
+ data['img_metas'] = data['img_metas'][0]
+
+ if next(model.parameters()).is_cuda:
+ # scatter to specified GPU
+ data = scatter(data, [device])[0]
+ else:
+ for m in model.modules():
+ assert not isinstance(
+ m, RoIPool
+ ), 'CPU inference with RoIPool is not supported currently.'
+
+ # forward the model
+ with torch.no_grad():
+ results = model(return_loss=False, rescale=True, **data)
+
+ if not is_batch:
+ if not return_data:
+ return results[0]
+ return results[0], datas[0]
+ else:
+ if not return_data:
+ return results
+ return results, datas
+
+
+def text_model_inference(model, input_sentence):
+ """Inference text(s) with the entity recognizer.
+
+ Args:
+ model (nn.Module): The loaded recognizer.
+ input_sentence (str): A text entered by the user.
+
+ Returns:
+ result (dict): Predicted results.
+ """
+
+ assert isinstance(input_sentence, str)
+
+ cfg = model.cfg
+ if cfg.data.test.get('pipeline', None) is None:
+ if is_2dlist(cfg.data.test.datasets):
+ cfg.data.test.pipeline = cfg.data.test.datasets[0][0].pipeline
+ else:
+ cfg.data.test.pipeline = cfg.data.test.datasets[0].pipeline
+ if is_2dlist(cfg.data.test.pipeline):
+ cfg.data.test.pipeline = cfg.data.test.pipeline[0]
+ test_pipeline = Compose(cfg.data.test.pipeline)
+ data = {'text': input_sentence, 'label': {}}
+
+ # build the data pipeline
+ data = test_pipeline(data)
+ if isinstance(data['img_metas'], dict):
+ img_metas = data['img_metas']
+ else:
+ img_metas = data['img_metas'].data
+
+ assert isinstance(img_metas, dict)
+ img_metas = {
+ 'input_ids': img_metas['input_ids'].unsqueeze(0),
+ 'attention_masks': img_metas['attention_masks'].unsqueeze(0),
+ 'token_type_ids': img_metas['token_type_ids'].unsqueeze(0),
+ 'labels': img_metas['labels'].unsqueeze(0)
+ }
+ # forward the model
+ with torch.no_grad():
+ result = model(None, img_metas, return_loss=False)
+ return result
diff --git a/mmocr/apis/test.py b/mmocr/apis/test.py
new file mode 100644
index 0000000000000000000000000000000000000000..489f6e9225ed05a967476c3a6b148d45ed2d54b4
--- /dev/null
+++ b/mmocr/apis/test.py
@@ -0,0 +1,157 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+
+import mmcv
+import numpy as np
+import torch
+from mmcv.image import tensor2imgs
+from mmcv.parallel import DataContainer
+from mmdet.core import encode_mask_results
+
+from .utils import tensor2grayimgs
+
+
+def retrieve_img_tensor_and_meta(data):
+ """Retrieval img_tensor, img_metas and img_norm_cfg.
+
+ Args:
+ data (dict): One batch data from data_loader.
+
+ Returns:
+ tuple: Returns (img_tensor, img_metas, img_norm_cfg).
+
+ - | img_tensor (Tensor): Input image tensor with shape
+ :math:`(N, C, H, W)`.
+ - | img_metas (list[dict]): The metadata of images.
+ - | img_norm_cfg (dict): Config for image normalization.
+ """
+
+ if isinstance(data['img'], torch.Tensor):
+ # for textrecog with batch_size > 1
+ # and not use 'DefaultFormatBundle' in pipeline
+ img_tensor = data['img']
+ img_metas = data['img_metas'].data[0]
+ elif isinstance(data['img'], list):
+ if isinstance(data['img'][0], torch.Tensor):
+ # for textrecog with aug_test and batch_size = 1
+ img_tensor = data['img'][0]
+ elif isinstance(data['img'][0], DataContainer):
+ # for textdet with 'MultiScaleFlipAug'
+ # and 'DefaultFormatBundle' in pipeline
+ img_tensor = data['img'][0].data[0]
+ img_metas = data['img_metas'][0].data[0]
+ elif isinstance(data['img'], DataContainer):
+ # for textrecog with 'DefaultFormatBundle' in pipeline
+ img_tensor = data['img'].data[0]
+ img_metas = data['img_metas'].data[0]
+
+ must_keys = ['img_norm_cfg', 'ori_filename', 'img_shape', 'ori_shape']
+ for key in must_keys:
+ if key not in img_metas[0]:
+ raise KeyError(
+ f'Please add {key} to the "meta_keys" in the pipeline')
+
+ img_norm_cfg = img_metas[0]['img_norm_cfg']
+ if max(img_norm_cfg['mean']) <= 1:
+ img_norm_cfg['mean'] = [255 * x for x in img_norm_cfg['mean']]
+ img_norm_cfg['std'] = [255 * x for x in img_norm_cfg['std']]
+
+ return img_tensor, img_metas, img_norm_cfg
+
+
+def single_gpu_test(model,
+ data_loader,
+ show=False,
+ out_dir=None,
+ is_kie=False,
+ show_score_thr=0.3):
+ model.eval()
+ results = []
+ dataset = data_loader.dataset
+ prog_bar = mmcv.ProgressBar(len(dataset))
+ for data in data_loader:
+ with torch.no_grad():
+ result = model(return_loss=False, rescale=True, **data)
+
+ batch_size = len(result)
+ if show or out_dir:
+ if is_kie:
+ img_tensor = data['img'].data[0]
+ if img_tensor.shape[0] != 1:
+ raise KeyError('Visualizing KIE outputs in batches is'
+ 'currently not supported.')
+ gt_bboxes = data['gt_bboxes'].data[0]
+ img_metas = data['img_metas'].data[0]
+ must_keys = ['img_norm_cfg', 'ori_filename', 'img_shape']
+ for key in must_keys:
+ if key not in img_metas[0]:
+ raise KeyError(
+ f'Please add {key} to the "meta_keys" in config.')
+ # for no visual model
+ if np.prod(img_tensor.shape) == 0:
+ imgs = []
+ for img_meta in img_metas:
+ try:
+ img = mmcv.imread(img_meta['filename'])
+ except Exception as e:
+ print(f'Load image with error: {e}, '
+ 'use empty image instead.')
+ img = np.ones(
+ img_meta['img_shape'], dtype=np.uint8)
+ imgs.append(img)
+ else:
+ imgs = tensor2imgs(img_tensor,
+ **img_metas[0]['img_norm_cfg'])
+ for i, img in enumerate(imgs):
+ h, w, _ = img_metas[i]['img_shape']
+ img_show = img[:h, :w, :]
+ if out_dir:
+ out_file = osp.join(out_dir,
+ img_metas[i]['ori_filename'])
+ else:
+ out_file = None
+
+ model.module.show_result(
+ img_show,
+ result[i],
+ gt_bboxes[i],
+ show=show,
+ out_file=out_file)
+ else:
+ img_tensor, img_metas, img_norm_cfg = \
+ retrieve_img_tensor_and_meta(data)
+
+ if img_tensor.size(1) == 1:
+ imgs = tensor2grayimgs(img_tensor, **img_norm_cfg)
+ else:
+ imgs = tensor2imgs(img_tensor, **img_norm_cfg)
+ assert len(imgs) == len(img_metas)
+
+ for j, (img, img_meta) in enumerate(zip(imgs, img_metas)):
+ img_shape, ori_shape = img_meta['img_shape'], img_meta[
+ 'ori_shape']
+ img_show = img[:img_shape[0], :img_shape[1]]
+ img_show = mmcv.imresize(img_show,
+ (ori_shape[1], ori_shape[0]))
+
+ if out_dir:
+ out_file = osp.join(out_dir, img_meta['ori_filename'])
+ else:
+ out_file = None
+
+ model.module.show_result(
+ img_show,
+ result[j],
+ show=show,
+ out_file=out_file,
+ score_thr=show_score_thr)
+
+ # encode mask results
+ if isinstance(result[0], tuple):
+ result = [(bbox_results, encode_mask_results(mask_results))
+ for bbox_results, mask_results in result]
+ results.extend(result)
+
+ for _ in range(batch_size):
+ prog_bar.update()
+ return results
diff --git a/mmocr/apis/train.py b/mmocr/apis/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..89ba3be68242f368666a37d31cd47266a6b9623a
--- /dev/null
+++ b/mmocr/apis/train.py
@@ -0,0 +1,185 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import mmcv
+import numpy as np
+import torch
+import torch.distributed as dist
+from mmcv.parallel import MMDataParallel, MMDistributedDataParallel
+from mmcv.runner import (DistSamplerSeedHook, EpochBasedRunner,
+ Fp16OptimizerHook, OptimizerHook, build_optimizer,
+ build_runner, get_dist_info)
+from mmdet.core import DistEvalHook, EvalHook
+from mmdet.datasets import build_dataloader, build_dataset
+
+from mmocr import digit_version
+from mmocr.apis.utils import (disable_text_recog_aug_test,
+ replace_image_to_tensor)
+from mmocr.utils import get_root_logger
+
+
+def train_detector(model,
+ dataset,
+ cfg,
+ distributed=False,
+ validate=False,
+ timestamp=None,
+ meta=None):
+ logger = get_root_logger(cfg.log_level)
+
+ # prepare data loaders
+ dataset = dataset if isinstance(dataset, (list, tuple)) else [dataset]
+ # step 1: give default values and override (if exist) from cfg.data
+ loader_cfg = {
+ **dict(
+ seed=cfg.get('seed'),
+ drop_last=False,
+ dist=distributed,
+ num_gpus=len(cfg.gpu_ids)),
+ **({} if torch.__version__ != 'parrots' else dict(
+ prefetch_num=2,
+ pin_memory=False,
+ )),
+ **dict((k, cfg.data[k]) for k in [
+ 'samples_per_gpu',
+ 'workers_per_gpu',
+ 'shuffle',
+ 'seed',
+ 'drop_last',
+ 'prefetch_num',
+ 'pin_memory',
+ 'persistent_workers',
+ ] if k in cfg.data)
+ }
+
+ # step 2: cfg.data.train_dataloader has highest priority
+ train_loader_cfg = dict(loader_cfg, **cfg.data.get('train_dataloader', {}))
+
+ data_loaders = [build_dataloader(ds, **train_loader_cfg) for ds in dataset]
+
+ # put model on gpus
+ if distributed:
+ find_unused_parameters = cfg.get('find_unused_parameters', False)
+ # Sets the `find_unused_parameters` parameter in
+ # torch.nn.parallel.DistributedDataParallel
+ model = MMDistributedDataParallel(
+ model.cuda(),
+ device_ids=[torch.cuda.current_device()],
+ broadcast_buffers=False,
+ find_unused_parameters=find_unused_parameters)
+ else:
+ if not torch.cuda.is_available():
+ assert digit_version(mmcv.__version__) >= digit_version('1.4.4'), \
+ 'Please use MMCV >= 1.4.4 for CPU training!'
+ model = MMDataParallel(model, device_ids=cfg.gpu_ids)
+
+ # build runner
+ optimizer = build_optimizer(model, cfg.optimizer)
+
+ if 'runner' not in cfg:
+ cfg.runner = {
+ 'type': 'EpochBasedRunner',
+ 'max_epochs': cfg.total_epochs
+ }
+ warnings.warn(
+ 'config is now expected to have a `runner` section, '
+ 'please set `runner` in your config.', UserWarning)
+ else:
+ if 'total_epochs' in cfg:
+ assert cfg.total_epochs == cfg.runner.max_epochs
+
+ runner = build_runner(
+ cfg.runner,
+ default_args=dict(
+ model=model,
+ optimizer=optimizer,
+ work_dir=cfg.work_dir,
+ logger=logger,
+ meta=meta))
+
+ # an ugly workaround to make .log and .log.json filenames the same
+ runner.timestamp = timestamp
+
+ # fp16 setting
+ fp16_cfg = cfg.get('fp16', None)
+ if fp16_cfg is not None:
+ optimizer_config = Fp16OptimizerHook(
+ **cfg.optimizer_config, **fp16_cfg, distributed=distributed)
+ elif distributed and 'type' not in cfg.optimizer_config:
+ optimizer_config = OptimizerHook(**cfg.optimizer_config)
+ else:
+ optimizer_config = cfg.optimizer_config
+
+ # register hooks
+ runner.register_training_hooks(
+ cfg.lr_config,
+ optimizer_config,
+ cfg.checkpoint_config,
+ cfg.log_config,
+ cfg.get('momentum_config', None),
+ custom_hooks_config=cfg.get('custom_hooks', None))
+ if distributed:
+ if isinstance(runner, EpochBasedRunner):
+ runner.register_hook(DistSamplerSeedHook())
+
+ # register eval hooks
+ if validate:
+ val_samples_per_gpu = (cfg.data.get('val_dataloader', {})).get(
+ 'samples_per_gpu', cfg.data.get('samples_per_gpu', 1))
+ if val_samples_per_gpu > 1:
+ # Support batch_size > 1 in test for text recognition
+ # by disable MultiRotateAugOCR since it is useless for most case
+ cfg = disable_text_recog_aug_test(cfg)
+ cfg = replace_image_to_tensor(cfg)
+
+ val_dataset = build_dataset(cfg.data.val, dict(test_mode=True))
+
+ val_loader_cfg = {
+ **loader_cfg,
+ **dict(shuffle=False, drop_last=False),
+ **cfg.data.get('val_dataloader', {}),
+ **dict(samples_per_gpu=val_samples_per_gpu)
+ }
+
+ val_dataloader = build_dataloader(val_dataset, **val_loader_cfg)
+
+ eval_cfg = cfg.get('evaluation', {})
+ eval_cfg['by_epoch'] = cfg.runner['type'] != 'IterBasedRunner'
+ eval_hook = DistEvalHook if distributed else EvalHook
+ runner.register_hook(eval_hook(val_dataloader, **eval_cfg))
+
+ if cfg.resume_from:
+ runner.resume(cfg.resume_from)
+ elif cfg.load_from:
+ runner.load_checkpoint(cfg.load_from)
+ runner.run(data_loaders, cfg.workflow)
+
+
+def init_random_seed(seed=None, device='cuda'):
+ """Initialize random seed. If the seed is None, it will be replaced by a
+ random number, and then broadcasted to all processes.
+
+ Args:
+ seed (int, Optional): The seed.
+ device (str): The device where the seed will be put on.
+
+ Returns:
+ int: Seed to be used.
+ """
+ if seed is not None:
+ return seed
+
+ # Make sure all ranks share the same random seed to prevent
+ # some potential bugs. Please refer to
+ # https://github.com/open-mmlab/mmdetection/issues/6339
+ rank, world_size = get_dist_info()
+ seed = np.random.randint(2**31)
+ if world_size == 1:
+ return seed
+
+ if rank == 0:
+ random_num = torch.tensor(seed, dtype=torch.int32, device=device)
+ else:
+ random_num = torch.tensor(0, dtype=torch.int32, device=device)
+ dist.broadcast(random_num, src=0)
+ return random_num.item()
diff --git a/mmocr/apis/utils.py b/mmocr/apis/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..2f2f68281207b2b53e5a19fc01f5a2a482ccb2c2
--- /dev/null
+++ b/mmocr/apis/utils.py
@@ -0,0 +1,126 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import warnings
+
+import mmcv
+import numpy as np
+import torch
+from mmdet.datasets import replace_ImageToTensor
+
+from mmocr.utils import is_2dlist, is_type_list
+
+
+def update_pipeline(cfg, idx=None):
+ if idx is None:
+ if cfg.pipeline is not None:
+ cfg.pipeline = replace_ImageToTensor(cfg.pipeline)
+ else:
+ cfg.pipeline[idx] = replace_ImageToTensor(cfg.pipeline[idx])
+
+
+def replace_image_to_tensor(cfg, set_types=None):
+ """Replace 'ImageToTensor' to 'DefaultFormatBundle'."""
+ assert set_types is None or isinstance(set_types, list)
+ if set_types is None:
+ set_types = ['val', 'test']
+
+ cfg = copy.deepcopy(cfg)
+ for set_type in set_types:
+ assert set_type in ['val', 'test']
+ uniform_pipeline = cfg.data[set_type].get('pipeline', None)
+ if is_type_list(uniform_pipeline, dict):
+ update_pipeline(cfg.data[set_type])
+ elif is_2dlist(uniform_pipeline):
+ for idx, _ in enumerate(uniform_pipeline):
+ update_pipeline(cfg.data[set_type], idx)
+
+ for dataset in cfg.data[set_type].get('datasets', []):
+ if isinstance(dataset, list):
+ for each_dataset in dataset:
+ update_pipeline(each_dataset)
+ else:
+ update_pipeline(dataset)
+
+ return cfg
+
+
+def update_pipeline_recog(cfg, idx=None):
+ warning_msg = 'Remove "MultiRotateAugOCR" to support batch ' + \
+ 'inference since samples_per_gpu > 1.'
+ if idx is None:
+ if cfg.get('pipeline',
+ None) and cfg.pipeline[1].type == 'MultiRotateAugOCR':
+ warnings.warn(warning_msg)
+ cfg.pipeline = [cfg.pipeline[0], *cfg.pipeline[1].transforms]
+ else:
+ if cfg[idx][1].type == 'MultiRotateAugOCR':
+ warnings.warn(warning_msg)
+ cfg[idx] = [cfg[idx][0], *cfg[idx][1].transforms]
+
+
+def disable_text_recog_aug_test(cfg, set_types=None):
+ """Remove aug_test from test pipeline for text recognition.
+
+ Args:
+ cfg (mmcv.Config): Input config.
+ set_types (list[str]): Type of dataset source. Should be
+ None or sublist of ['test', 'val'].
+ """
+ assert set_types is None or isinstance(set_types, list)
+ if set_types is None:
+ set_types = ['val', 'test']
+
+ cfg = copy.deepcopy(cfg)
+ warnings.simplefilter('once')
+ for set_type in set_types:
+ assert set_type in ['val', 'test']
+ dataset_type = cfg.data[set_type].type
+ if dataset_type not in [
+ 'ConcatDataset', 'UniformConcatDataset', 'OCRDataset',
+ 'OCRSegDataset'
+ ]:
+ continue
+
+ uniform_pipeline = cfg.data[set_type].get('pipeline', None)
+ if is_type_list(uniform_pipeline, dict):
+ update_pipeline_recog(cfg.data[set_type])
+ elif is_2dlist(uniform_pipeline):
+ for idx, _ in enumerate(uniform_pipeline):
+ update_pipeline_recog(cfg.data[set_type].pipeline, idx)
+
+ for dataset in cfg.data[set_type].get('datasets', []):
+ if isinstance(dataset, list):
+ for each_dataset in dataset:
+ update_pipeline_recog(each_dataset)
+ else:
+ update_pipeline_recog(dataset)
+
+ return cfg
+
+
+def tensor2grayimgs(tensor, mean=(127, ), std=(127, ), **kwargs):
+ """Convert tensor to 1-channel gray images.
+
+ Args:
+ tensor (torch.Tensor): Tensor that contains multiple images, shape (
+ N, C, H, W).
+ mean (tuple[float], optional): Mean of images. Defaults to (127).
+ std (tuple[float], optional): Standard deviation of images.
+ Defaults to (127).
+
+ Returns:
+ list[np.ndarray]: A list that contains multiple images.
+ """
+
+ assert torch.is_tensor(tensor) and tensor.ndim == 4
+ assert tensor.size(1) == len(mean) == len(std) == 1
+
+ num_imgs = tensor.size(0)
+ mean = np.array(mean, dtype=np.float32)
+ std = np.array(std, dtype=np.float32)
+ imgs = []
+ for img_id in range(num_imgs):
+ img = tensor[img_id, ...].cpu().numpy().transpose(1, 2, 0)
+ img = mmcv.imdenormalize(img, mean, std, to_bgr=False).astype(np.uint8)
+ imgs.append(np.ascontiguousarray(img))
+ return imgs
diff --git a/mmocr/core/__init__.py b/mmocr/core/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..beae1ba42f375f7c3af16ac3b448160defaac41c
--- /dev/null
+++ b/mmocr/core/__init__.py
@@ -0,0 +1,16 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from . import evaluation
+from .evaluation import * # NOQA
+from .mask import extract_boundary, points2boundary, seg2boundary
+from .visualize import (det_recog_show_result, imshow_edge, imshow_node,
+ imshow_pred_boundary, imshow_text_char_boundary,
+ imshow_text_label, overlay_mask_img, show_feature,
+ show_img_boundary, show_pred_gt)
+
+__all__ = [
+ 'points2boundary', 'seg2boundary', 'extract_boundary', 'overlay_mask_img',
+ 'show_feature', 'show_img_boundary', 'show_pred_gt',
+ 'imshow_pred_boundary', 'imshow_text_char_boundary', 'imshow_text_label',
+ 'imshow_node', 'det_recog_show_result', 'imshow_edge'
+]
+__all__ += evaluation.__all__
diff --git a/mmocr/core/deployment/__init__.py b/mmocr/core/deployment/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1754028f917798f508cd594e17e22c27817c190a
--- /dev/null
+++ b/mmocr/core/deployment/__init__.py
@@ -0,0 +1,8 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .deploy_utils import (ONNXRuntimeDetector, ONNXRuntimeRecognizer,
+ TensorRTDetector, TensorRTRecognizer)
+
+__all__ = [
+ 'ONNXRuntimeRecognizer', 'ONNXRuntimeDetector', 'TensorRTDetector',
+ 'TensorRTRecognizer'
+]
diff --git a/mmocr/core/deployment/deploy_utils.py b/mmocr/core/deployment/deploy_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..9f5b31bb0e0bdbc74b44054bfb12f6aecba2e3ba
--- /dev/null
+++ b/mmocr/core/deployment/deploy_utils.py
@@ -0,0 +1,328 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import warnings
+from typing import Any, Iterable
+
+import numpy as np
+import torch
+from mmdet.models.builder import DETECTORS
+
+from mmocr.models.textdet.detectors.single_stage_text_detector import \
+ SingleStageTextDetector
+from mmocr.models.textdet.detectors.text_detector_mixin import \
+ TextDetectorMixin
+from mmocr.models.textrecog.recognizer.encode_decode_recognizer import \
+ EncodeDecodeRecognizer
+
+
+def inference_with_session(sess, io_binding, input_name, output_names,
+ input_tensor):
+ device_type = input_tensor.device.type
+ device_id = input_tensor.device.index
+ device_id = 0 if device_id is None else device_id
+ io_binding.bind_input(
+ name=input_name,
+ device_type=device_type,
+ device_id=device_id,
+ element_type=np.float32,
+ shape=input_tensor.shape,
+ buffer_ptr=input_tensor.data_ptr())
+ for name in output_names:
+ io_binding.bind_output(name)
+ sess.run_with_iobinding(io_binding)
+ pred = io_binding.copy_outputs_to_cpu()
+ return pred
+
+
+@DETECTORS.register_module()
+class ONNXRuntimeDetector(TextDetectorMixin, SingleStageTextDetector):
+ """The class for evaluating onnx file of detection."""
+
+ def __init__(self,
+ onnx_file: str,
+ cfg: Any,
+ device_id: int,
+ show_score: bool = False):
+ if 'type' in cfg.model:
+ cfg.model.pop('type')
+ SingleStageTextDetector.__init__(self, **(cfg.model))
+ TextDetectorMixin.__init__(self, show_score)
+ import onnxruntime as ort
+
+ # get the custom op path
+ ort_custom_op_path = ''
+ try:
+ from mmcv.ops import get_onnxruntime_op_path
+ ort_custom_op_path = get_onnxruntime_op_path()
+ except (ImportError, ModuleNotFoundError):
+ warnings.warn('If input model has custom op from mmcv, \
+ you may have to build mmcv with ONNXRuntime from source.')
+ session_options = ort.SessionOptions()
+ # register custom op for onnxruntime
+ if osp.exists(ort_custom_op_path):
+ session_options.register_custom_ops_library(ort_custom_op_path)
+ sess = ort.InferenceSession(onnx_file, session_options)
+ providers = ['CPUExecutionProvider']
+ options = [{}]
+ is_cuda_available = ort.get_device() == 'GPU'
+ if is_cuda_available:
+ providers.insert(0, 'CUDAExecutionProvider')
+ options.insert(0, {'device_id': device_id})
+
+ sess.set_providers(providers, options)
+
+ self.sess = sess
+ self.device_id = device_id
+ self.io_binding = sess.io_binding()
+ self.output_names = [_.name for _ in sess.get_outputs()]
+ for name in self.output_names:
+ self.io_binding.bind_output(name)
+ self.cfg = cfg
+
+ def forward_train(self, img, img_metas, **kwargs):
+ raise NotImplementedError('This method is not implemented.')
+
+ def aug_test(self, imgs, img_metas, **kwargs):
+ raise NotImplementedError('This method is not implemented.')
+
+ def extract_feat(self, imgs):
+ raise NotImplementedError('This method is not implemented.')
+
+ def simple_test(self,
+ img: torch.Tensor,
+ img_metas: Iterable,
+ rescale: bool = False):
+ onnx_pred = inference_with_session(self.sess, self.io_binding, 'input',
+ self.output_names, img)
+ onnx_pred = torch.from_numpy(onnx_pred[0])
+ if len(img_metas) > 1:
+ boundaries = [
+ self.bbox_head.get_boundary(*(onnx_pred[i].unsqueeze(0)),
+ [img_metas[i]], rescale)
+ for i in range(len(img_metas))
+ ]
+
+ else:
+ boundaries = [
+ self.bbox_head.get_boundary(*onnx_pred, img_metas, rescale)
+ ]
+
+ return boundaries
+
+
+@DETECTORS.register_module()
+class ONNXRuntimeRecognizer(EncodeDecodeRecognizer):
+ """The class for evaluating onnx file of recognition."""
+
+ def __init__(self,
+ onnx_file: str,
+ cfg: Any,
+ device_id: int,
+ show_score: bool = False):
+ if 'type' in cfg.model:
+ cfg.model.pop('type')
+ EncodeDecodeRecognizer.__init__(self, **(cfg.model))
+ import onnxruntime as ort
+
+ # get the custom op path
+ ort_custom_op_path = ''
+ try:
+ from mmcv.ops import get_onnxruntime_op_path
+ ort_custom_op_path = get_onnxruntime_op_path()
+ except (ImportError, ModuleNotFoundError):
+ warnings.warn('If input model has custom op from mmcv, \
+ you may have to build mmcv with ONNXRuntime from source.')
+ session_options = ort.SessionOptions()
+ # register custom op for onnxruntime
+ if osp.exists(ort_custom_op_path):
+ session_options.register_custom_ops_library(ort_custom_op_path)
+ sess = ort.InferenceSession(onnx_file, session_options)
+ providers = ['CPUExecutionProvider']
+ options = [{}]
+ is_cuda_available = ort.get_device() == 'GPU'
+ if is_cuda_available:
+ providers.insert(0, 'CUDAExecutionProvider')
+ options.insert(0, {'device_id': device_id})
+
+ sess.set_providers(providers, options)
+
+ self.sess = sess
+ self.device_id = device_id
+ self.io_binding = sess.io_binding()
+ self.output_names = [_.name for _ in sess.get_outputs()]
+ for name in self.output_names:
+ self.io_binding.bind_output(name)
+ self.cfg = cfg
+
+ def forward_train(self, img, img_metas, **kwargs):
+ raise NotImplementedError('This method is not implemented.')
+
+ def aug_test(self, imgs, img_metas, **kwargs):
+ if isinstance(imgs, list):
+ for idx, each_img in enumerate(imgs):
+ if each_img.dim() == 3:
+ imgs[idx] = each_img.unsqueeze(0)
+ imgs = imgs[0] # avoid aug_test
+ img_metas = img_metas[0]
+ else:
+ if len(img_metas) == 1 and isinstance(img_metas[0], list):
+ img_metas = img_metas[0]
+ return self.simple_test(imgs, img_metas=img_metas)
+
+ def extract_feat(self, imgs):
+ raise NotImplementedError('This method is not implemented.')
+
+ def simple_test(self,
+ img: torch.Tensor,
+ img_metas: Iterable,
+ rescale: bool = False):
+ """Test function.
+
+ Args:
+ imgs (torch.Tensor): Image input tensor.
+ img_metas (list[dict]): List of image information.
+
+ Returns:
+ list[str]: Text label result of each image.
+ """
+ onnx_pred = inference_with_session(self.sess, self.io_binding, 'input',
+ self.output_names, img)
+ onnx_pred = torch.from_numpy(onnx_pred[0])
+
+ label_indexes, label_scores = self.label_convertor.tensor2idx(
+ onnx_pred, img_metas)
+ label_strings = self.label_convertor.idx2str(label_indexes)
+
+ # flatten batch results
+ results = []
+ for string, score in zip(label_strings, label_scores):
+ results.append(dict(text=string, score=score))
+
+ return results
+
+
+@DETECTORS.register_module()
+class TensorRTDetector(TextDetectorMixin, SingleStageTextDetector):
+ """The class for evaluating TensorRT file of detection."""
+
+ def __init__(self,
+ trt_file: str,
+ cfg: Any,
+ device_id: int,
+ show_score: bool = False):
+ if 'type' in cfg.model:
+ cfg.model.pop('type')
+ SingleStageTextDetector.__init__(self, **(cfg.model))
+ TextDetectorMixin.__init__(self, show_score)
+ from mmcv.tensorrt import TRTWrapper, load_tensorrt_plugin
+ try:
+ load_tensorrt_plugin()
+ except (ImportError, ModuleNotFoundError):
+ warnings.warn('If input model has custom op from mmcv, \
+ you may have to build mmcv with TensorRT from source.')
+ model = TRTWrapper(
+ trt_file, input_names=['input'], output_names=['output'])
+
+ self.model = model
+ self.device_id = device_id
+ self.cfg = cfg
+
+ def forward_train(self, img, img_metas, **kwargs):
+ raise NotImplementedError('This method is not implemented.')
+
+ def aug_test(self, imgs, img_metas, **kwargs):
+ raise NotImplementedError('This method is not implemented.')
+
+ def extract_feat(self, imgs):
+ raise NotImplementedError('This method is not implemented.')
+
+ def simple_test(self,
+ img: torch.Tensor,
+ img_metas: Iterable,
+ rescale: bool = False):
+ with torch.cuda.device(self.device_id), torch.no_grad():
+ trt_pred = self.model({'input': img})['output']
+ if len(img_metas) > 1:
+ boundaries = [
+ self.bbox_head.get_boundary(*(trt_pred[i].unsqueeze(0)),
+ [img_metas[i]], rescale)
+ for i in range(len(img_metas))
+ ]
+
+ else:
+ boundaries = [
+ self.bbox_head.get_boundary(*trt_pred, img_metas, rescale)
+ ]
+
+ return boundaries
+
+
+@DETECTORS.register_module()
+class TensorRTRecognizer(EncodeDecodeRecognizer):
+ """The class for evaluating TensorRT file of recognition."""
+
+ def __init__(self,
+ trt_file: str,
+ cfg: Any,
+ device_id: int,
+ show_score: bool = False):
+ if 'type' in cfg.model:
+ cfg.model.pop('type')
+ EncodeDecodeRecognizer.__init__(self, **(cfg.model))
+ from mmcv.tensorrt import TRTWrapper, load_tensorrt_plugin
+ try:
+ load_tensorrt_plugin()
+ except (ImportError, ModuleNotFoundError):
+ warnings.warn('If input model has custom op from mmcv, \
+ you may have to build mmcv with TensorRT from source.')
+ model = TRTWrapper(
+ trt_file, input_names=['input'], output_names=['output'])
+
+ self.model = model
+ self.device_id = device_id
+ self.cfg = cfg
+
+ def forward_train(self, img, img_metas, **kwargs):
+ raise NotImplementedError('This method is not implemented.')
+
+ def aug_test(self, imgs, img_metas, **kwargs):
+ if isinstance(imgs, list):
+ for idx, each_img in enumerate(imgs):
+ if each_img.dim() == 3:
+ imgs[idx] = each_img.unsqueeze(0)
+ imgs = imgs[0] # avoid aug_test
+ img_metas = img_metas[0]
+ else:
+ if len(img_metas) == 1 and isinstance(img_metas[0], list):
+ img_metas = img_metas[0]
+ return self.simple_test(imgs, img_metas=img_metas)
+
+ def extract_feat(self, imgs):
+ raise NotImplementedError('This method is not implemented.')
+
+ def simple_test(self,
+ img: torch.Tensor,
+ img_metas: Iterable,
+ rescale: bool = False):
+ """Test function.
+
+ Args:
+ imgs (torch.Tensor): Image input tensor.
+ img_metas (list[dict]): List of image information.
+
+ Returns:
+ list[str]: Text label result of each image.
+ """
+ with torch.cuda.device(self.device_id), torch.no_grad():
+ trt_pred = self.model({'input': img})['output']
+
+ label_indexes, label_scores = self.label_convertor.tensor2idx(
+ trt_pred, img_metas)
+ label_strings = self.label_convertor.idx2str(label_indexes)
+
+ # flatten batch results
+ results = []
+ for string, score in zip(label_strings, label_scores):
+ results.append(dict(text=string, score=score))
+
+ return results
diff --git a/mmocr/core/evaluation/__init__.py b/mmocr/core/evaluation/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..ab18b39de4f4183198763f4c571d29a33f8e9b3e
--- /dev/null
+++ b/mmocr/core/evaluation/__init__.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .hmean import eval_hmean
+from .hmean_ic13 import eval_hmean_ic13
+from .hmean_iou import eval_hmean_iou
+from .kie_metric import compute_f1_score
+from .ner_metric import eval_ner_f1
+from .ocr_metric import eval_ocr_metric
+
+__all__ = [
+ 'eval_hmean_ic13', 'eval_hmean_iou', 'eval_ocr_metric', 'eval_hmean',
+ 'compute_f1_score', 'eval_ner_f1'
+]
diff --git a/mmocr/core/evaluation/hmean.py b/mmocr/core/evaluation/hmean.py
new file mode 100644
index 0000000000000000000000000000000000000000..b853b2da01723e82754149f3d47dea47350b0f60
--- /dev/null
+++ b/mmocr/core/evaluation/hmean.py
@@ -0,0 +1,152 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from operator import itemgetter
+
+import mmcv
+from mmcv.utils import print_log
+
+import mmocr.utils as utils
+from mmocr.core.evaluation import hmean_ic13, hmean_iou
+from mmocr.core.evaluation.utils import (filter_2dlist_result,
+ select_top_boundary)
+from mmocr.core.mask import extract_boundary
+
+
+def output_ranklist(img_results, img_infos, out_file):
+ """Output the worst results for debugging.
+
+ Args:
+ img_results (list[dict]): Image result list.
+ img_infos (list[dict]): Image information list.
+ out_file (str): The output file path.
+
+ Returns:
+ sorted_results (list[dict]): Image results sorted by hmean.
+ """
+ assert utils.is_type_list(img_results, dict)
+ assert utils.is_type_list(img_infos, dict)
+ assert isinstance(out_file, str)
+ assert out_file.endswith('json')
+
+ sorted_results = []
+ for idx, result in enumerate(img_results):
+ name = img_infos[idx]['file_name']
+ img_result = result
+ img_result['file_name'] = name
+ sorted_results.append(img_result)
+ sorted_results = sorted(
+ sorted_results, key=itemgetter('hmean'), reverse=False)
+
+ mmcv.dump(sorted_results, file=out_file)
+
+ return sorted_results
+
+
+def get_gt_masks(ann_infos):
+ """Get ground truth masks and ignored masks.
+
+ Args:
+ ann_infos (list[dict]): Each dict contains annotation
+ infos of one image, containing following keys:
+ masks, masks_ignore.
+ Returns:
+ gt_masks (list[list[list[int]]]): Ground truth masks.
+ gt_masks_ignore (list[list[list[int]]]): Ignored masks.
+ """
+ assert utils.is_type_list(ann_infos, dict)
+
+ gt_masks = []
+ gt_masks_ignore = []
+ for ann_info in ann_infos:
+ masks = ann_info['masks']
+ mask_gt = []
+ for mask in masks:
+ assert len(mask[0]) >= 8 and len(mask[0]) % 2 == 0
+ mask_gt.append(mask[0])
+ gt_masks.append(mask_gt)
+
+ masks_ignore = ann_info['masks_ignore']
+ mask_gt_ignore = []
+ for mask_ignore in masks_ignore:
+ assert len(mask_ignore[0]) >= 8 and len(mask_ignore[0]) % 2 == 0
+ mask_gt_ignore.append(mask_ignore[0])
+ gt_masks_ignore.append(mask_gt_ignore)
+
+ return gt_masks, gt_masks_ignore
+
+
+def eval_hmean(results,
+ img_infos,
+ ann_infos,
+ metrics={'hmean-iou'},
+ score_thr=0.3,
+ rank_list=None,
+ logger=None,
+ **kwargs):
+ """Evaluation in hmean metric.
+
+ Args:
+ results (list[dict]): Each dict corresponds to one image,
+ containing the following keys: boundary_result
+ img_infos (list[dict]): Each dict corresponds to one image,
+ containing the following keys: filename, height, width
+ ann_infos (list[dict]): Each dict corresponds to one image,
+ containing the following keys: masks, masks_ignore
+ score_thr (float): Score threshold of prediction map.
+ metrics (set{str}): Hmean metric set, should be one or all of
+ {'hmean-iou', 'hmean-ic13'}
+ Returns:
+ dict[str: float]
+ """
+ assert utils.is_type_list(results, dict)
+ assert utils.is_type_list(img_infos, dict)
+ assert utils.is_type_list(ann_infos, dict)
+ assert len(results) == len(img_infos) == len(ann_infos)
+ assert isinstance(metrics, set)
+
+ gts, gts_ignore = get_gt_masks(ann_infos)
+
+ preds = []
+ pred_scores = []
+ for result in results:
+ _, texts, scores = extract_boundary(result)
+ if len(texts) > 0:
+ assert utils.valid_boundary(texts[0], False)
+ valid_texts, valid_text_scores = filter_2dlist_result(
+ texts, scores, score_thr)
+ preds.append(valid_texts)
+ pred_scores.append(valid_text_scores)
+
+ eval_results = {}
+ for metric in metrics:
+ msg = f'Evaluating {metric}...'
+ if logger is None:
+ msg = '\n' + msg
+ print_log(msg, logger=logger)
+ best_result = dict(hmean=-1)
+ for iter in range(3, 10):
+ thr = iter * 0.1
+ if thr < score_thr:
+ continue
+ top_preds = select_top_boundary(preds, pred_scores, thr)
+ if metric == 'hmean-iou':
+ result, img_result = hmean_iou.eval_hmean_iou(
+ top_preds, gts, gts_ignore)
+ elif metric == 'hmean-ic13':
+ result, img_result = hmean_ic13.eval_hmean_ic13(
+ top_preds, gts, gts_ignore)
+ else:
+ raise NotImplementedError
+ if rank_list is not None:
+ output_ranklist(img_result, img_infos, rank_list)
+
+ print_log(
+ 'thr {0:.2f}, recall: {1[recall]:.3f}, '
+ 'precision: {1[precision]:.3f}, '
+ 'hmean: {1[hmean]:.3f}'.format(thr, result),
+ logger=logger)
+ if result['hmean'] > best_result['hmean']:
+ best_result = result
+ eval_results[metric + ':recall'] = best_result['recall']
+ eval_results[metric + ':precision'] = best_result['precision']
+ eval_results[metric + ':hmean'] = best_result['hmean']
+ return eval_results
diff --git a/mmocr/core/evaluation/hmean_ic13.py b/mmocr/core/evaluation/hmean_ic13.py
new file mode 100644
index 0000000000000000000000000000000000000000..e268a95f87f80b2abc92d18748d395a0c283838e
--- /dev/null
+++ b/mmocr/core/evaluation/hmean_ic13.py
@@ -0,0 +1,217 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+
+import mmocr.utils as utils
+from . import utils as eval_utils
+
+
+def compute_recall_precision(gt_polys, pred_polys):
+ """Compute the recall and the precision matrices between gt and predicted
+ polygons.
+
+ Args:
+ gt_polys (list[Polygon]): List of gt polygons.
+ pred_polys (list[Polygon]): List of predicted polygons.
+
+ Returns:
+ recall (ndarray): Recall matrix of size gt_num x det_num.
+ precision (ndarray): Precision matrix of size gt_num x det_num.
+ """
+ assert isinstance(gt_polys, list)
+ assert isinstance(pred_polys, list)
+
+ gt_num = len(gt_polys)
+ det_num = len(pred_polys)
+ sz = [gt_num, det_num]
+
+ recall = np.zeros(sz)
+ precision = np.zeros(sz)
+ # compute area recall and precision for each (gt, det) pair
+ # in one img
+ for gt_id in range(gt_num):
+ for pred_id in range(det_num):
+ gt = gt_polys[gt_id]
+ det = pred_polys[pred_id]
+
+ inter_area = eval_utils.poly_intersection(det, gt)
+ gt_area = gt.area
+ det_area = det.area
+ if gt_area != 0:
+ recall[gt_id, pred_id] = inter_area / gt_area
+ if det_area != 0:
+ precision[gt_id, pred_id] = inter_area / det_area
+
+ return recall, precision
+
+
+def eval_hmean_ic13(det_boxes,
+ gt_boxes,
+ gt_ignored_boxes,
+ precision_thr=0.4,
+ recall_thr=0.8,
+ center_dist_thr=1.0,
+ one2one_score=1.,
+ one2many_score=0.8,
+ many2one_score=1.):
+ """Evaluate hmean of text detection using the icdar2013 standard.
+
+ Args:
+ det_boxes (list[list[list[float]]]): List of arrays of shape (n, 2k).
+ Each element is the det_boxes for one img. k>=4.
+ gt_boxes (list[list[list[float]]]): List of arrays of shape (m, 2k).
+ Each element is the gt_boxes for one img. k>=4.
+ gt_ignored_boxes (list[list[list[float]]]): List of arrays of
+ (l, 2k). Each element is the ignored gt_boxes for one img. k>=4.
+ precision_thr (float): Precision threshold of the iou of one
+ (gt_box, det_box) pair.
+ recall_thr (float): Recall threshold of the iou of one
+ (gt_box, det_box) pair.
+ center_dist_thr (float): Distance threshold of one (gt_box, det_box)
+ center point pair.
+ one2one_score (float): Reward when one gt matches one det_box.
+ one2many_score (float): Reward when one gt matches many det_boxes.
+ many2one_score (float): Reward when many gts match one det_box.
+
+ Returns:
+ hmean (tuple[dict]): Tuple of dicts which encodes the hmean for
+ the dataset and all images.
+ """
+ assert utils.is_3dlist(det_boxes)
+ assert utils.is_3dlist(gt_boxes)
+ assert utils.is_3dlist(gt_ignored_boxes)
+
+ assert 0 <= precision_thr <= 1
+ assert 0 <= recall_thr <= 1
+ assert center_dist_thr > 0
+ assert 0 <= one2one_score <= 1
+ assert 0 <= one2many_score <= 1
+ assert 0 <= many2one_score <= 1
+
+ img_num = len(det_boxes)
+ assert img_num == len(gt_boxes)
+ assert img_num == len(gt_ignored_boxes)
+
+ dataset_gt_num = 0
+ dataset_pred_num = 0
+ dataset_hit_recall = 0.0
+ dataset_hit_prec = 0.0
+
+ img_results = []
+
+ for i in range(img_num):
+ gt = gt_boxes[i]
+ gt_ignored = gt_ignored_boxes[i]
+ pred = det_boxes[i]
+
+ gt_num = len(gt)
+ ignored_num = len(gt_ignored)
+ pred_num = len(pred)
+
+ accum_recall = 0.
+ accum_precision = 0.
+
+ gt_points = gt + gt_ignored
+ gt_polys = [eval_utils.points2polygon(p) for p in gt_points]
+ gt_ignored_index = [gt_num + i for i in range(len(gt_ignored))]
+ gt_num = len(gt_polys)
+
+ pred_polys, pred_points, pred_ignored_index = eval_utils.ignore_pred(
+ pred, gt_ignored_index, gt_polys, precision_thr)
+
+ if pred_num > 0 and gt_num > 0:
+
+ gt_hit = np.zeros(gt_num, np.int8).tolist()
+ pred_hit = np.zeros(pred_num, np.int8).tolist()
+
+ # compute area recall and precision for each (gt, pred) pair
+ # in one img.
+ recall_mat, precision_mat = compute_recall_precision(
+ gt_polys, pred_polys)
+
+ # match one gt to one pred box.
+ for gt_id in range(gt_num):
+ for pred_id in range(pred_num):
+ if (gt_hit[gt_id] != 0 or pred_hit[pred_id] != 0
+ or gt_id in gt_ignored_index
+ or pred_id in pred_ignored_index):
+ continue
+ match = eval_utils.one2one_match_ic13(
+ gt_id, pred_id, recall_mat, precision_mat, recall_thr,
+ precision_thr)
+
+ if match:
+ gt_point = np.array(gt_points[gt_id])
+ det_point = np.array(pred_points[pred_id])
+
+ norm_dist = eval_utils.box_center_distance(
+ det_point, gt_point)
+ norm_dist /= eval_utils.box_diag(
+ det_point) + eval_utils.box_diag(gt_point)
+ norm_dist *= 2.0
+
+ if norm_dist < center_dist_thr:
+ gt_hit[gt_id] = 1
+ pred_hit[pred_id] = 1
+ accum_recall += one2one_score
+ accum_precision += one2one_score
+
+ # match one gt to many det boxes.
+ for gt_id in range(gt_num):
+ if gt_id in gt_ignored_index:
+ continue
+ match, match_det_set = eval_utils.one2many_match_ic13(
+ gt_id, recall_mat, precision_mat, recall_thr,
+ precision_thr, gt_hit, pred_hit, pred_ignored_index)
+
+ if match:
+ gt_hit[gt_id] = 1
+ accum_recall += one2many_score
+ accum_precision += one2many_score * len(match_det_set)
+ for pred_id in match_det_set:
+ pred_hit[pred_id] = 1
+
+ # match many gt to one det box. One pair of (det,gt) are matched
+ # successfully if their recall, precision, normalized distance
+ # meet some thresholds.
+ for pred_id in range(pred_num):
+ if pred_id in pred_ignored_index:
+ continue
+
+ match, match_gt_set = eval_utils.many2one_match_ic13(
+ pred_id, recall_mat, precision_mat, recall_thr,
+ precision_thr, gt_hit, pred_hit, gt_ignored_index)
+
+ if match:
+ pred_hit[pred_id] = 1
+ accum_recall += many2one_score * len(match_gt_set)
+ accum_precision += many2one_score
+ for gt_id in match_gt_set:
+ gt_hit[gt_id] = 1
+
+ gt_care_number = gt_num - ignored_num
+ pred_care_number = pred_num - len(pred_ignored_index)
+
+ r, p, h = eval_utils.compute_hmean(accum_recall, accum_precision,
+ gt_care_number, pred_care_number)
+
+ img_results.append({'recall': r, 'precision': p, 'hmean': h})
+
+ dataset_gt_num += gt_care_number
+ dataset_pred_num += pred_care_number
+ dataset_hit_recall += accum_recall
+ dataset_hit_prec += accum_precision
+
+ total_r, total_p, total_h = eval_utils.compute_hmean(
+ dataset_hit_recall, dataset_hit_prec, dataset_gt_num, dataset_pred_num)
+
+ dataset_results = {
+ 'num_gts': dataset_gt_num,
+ 'num_dets': dataset_pred_num,
+ 'num_recall': dataset_hit_recall,
+ 'num_precision': dataset_hit_prec,
+ 'recall': total_r,
+ 'precision': total_p,
+ 'hmean': total_h
+ }
+
+ return dataset_results, img_results
diff --git a/mmocr/core/evaluation/hmean_iou.py b/mmocr/core/evaluation/hmean_iou.py
new file mode 100644
index 0000000000000000000000000000000000000000..8b3b07e00150e5f50cf6d174db7f4b0e052cf196
--- /dev/null
+++ b/mmocr/core/evaluation/hmean_iou.py
@@ -0,0 +1,117 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+
+import mmocr.utils as utils
+from . import utils as eval_utils
+
+
+def eval_hmean_iou(pred_boxes,
+ gt_boxes,
+ gt_ignored_boxes,
+ iou_thr=0.5,
+ precision_thr=0.5):
+ """Evaluate hmean of text detection using IOU standard.
+
+ Args:
+ pred_boxes (list[list[list[float]]]): Text boxes for an img list. Each
+ box has 2k (>=8) values.
+ gt_boxes (list[list[list[float]]]): Ground truth text boxes for an img
+ list. Each box has 2k (>=8) values.
+ gt_ignored_boxes (list[list[list[float]]]): Ignored ground truth text
+ boxes for an img list. Each box has 2k (>=8) values.
+ iou_thr (float): Iou threshold when one (gt_box, det_box) pair is
+ matched.
+ precision_thr (float): Precision threshold when one (gt_box, det_box)
+ pair is matched.
+
+ Returns:
+ hmean (tuple[dict]): Tuple of dicts indicates the hmean for the dataset
+ and all images.
+ """
+ assert utils.is_3dlist(pred_boxes)
+ assert utils.is_3dlist(gt_boxes)
+ assert utils.is_3dlist(gt_ignored_boxes)
+ assert 0 <= iou_thr <= 1
+ assert 0 <= precision_thr <= 1
+
+ img_num = len(pred_boxes)
+ assert img_num == len(gt_boxes)
+ assert img_num == len(gt_ignored_boxes)
+
+ dataset_gt_num = 0
+ dataset_pred_num = 0
+ dataset_hit_num = 0
+
+ img_results = []
+
+ for i in range(img_num):
+ gt = gt_boxes[i]
+ gt_ignored = gt_ignored_boxes[i]
+ pred = pred_boxes[i]
+
+ gt_num = len(gt)
+ gt_ignored_num = len(gt_ignored)
+ pred_num = len(pred)
+
+ hit_num = 0
+
+ # get gt polygons.
+ gt_all = gt + gt_ignored
+ gt_polys = [eval_utils.points2polygon(p) for p in gt_all]
+ gt_ignored_index = [gt_num + i for i in range(len(gt_ignored))]
+ gt_num = len(gt_polys)
+ pred_polys, _, pred_ignored_index = eval_utils.ignore_pred(
+ pred, gt_ignored_index, gt_polys, precision_thr)
+
+ # match.
+ if gt_num > 0 and pred_num > 0:
+ sz = [gt_num, pred_num]
+ iou_mat = np.zeros(sz)
+
+ gt_hit = np.zeros(gt_num, np.int8)
+ pred_hit = np.zeros(pred_num, np.int8)
+
+ for gt_id in range(gt_num):
+ for pred_id in range(pred_num):
+ gt_pol = gt_polys[gt_id]
+ det_pol = pred_polys[pred_id]
+
+ iou_mat[gt_id,
+ pred_id] = eval_utils.poly_iou(det_pol, gt_pol)
+
+ for gt_id in range(gt_num):
+ for pred_id in range(pred_num):
+ if (gt_hit[gt_id] != 0 or pred_hit[pred_id] != 0
+ or gt_id in gt_ignored_index
+ or pred_id in pred_ignored_index):
+ continue
+ if iou_mat[gt_id, pred_id] > iou_thr:
+ gt_hit[gt_id] = 1
+ pred_hit[pred_id] = 1
+ hit_num += 1
+
+ gt_care_number = gt_num - gt_ignored_num
+ pred_care_number = pred_num - len(pred_ignored_index)
+
+ r, p, h = eval_utils.compute_hmean(hit_num, hit_num, gt_care_number,
+ pred_care_number)
+
+ img_results.append({'recall': r, 'precision': p, 'hmean': h})
+
+ dataset_hit_num += hit_num
+ dataset_gt_num += gt_care_number
+ dataset_pred_num += pred_care_number
+
+ dataset_r, dataset_p, dataset_h = eval_utils.compute_hmean(
+ dataset_hit_num, dataset_hit_num, dataset_gt_num, dataset_pred_num)
+
+ dataset_results = {
+ 'num_gts': dataset_gt_num,
+ 'num_dets': dataset_pred_num,
+ 'num_match': dataset_hit_num,
+ 'recall': dataset_r,
+ 'precision': dataset_p,
+ 'hmean': dataset_h
+ }
+
+ return dataset_results, img_results
diff --git a/mmocr/core/evaluation/kie_metric.py b/mmocr/core/evaluation/kie_metric.py
new file mode 100644
index 0000000000000000000000000000000000000000..2ba695b5bb778ca792d4aabb7b3f9ed62041e2ee
--- /dev/null
+++ b/mmocr/core/evaluation/kie_metric.py
@@ -0,0 +1,28 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+
+def compute_f1_score(preds, gts, ignores=[]):
+ """Compute the F1-score of prediction.
+
+ Args:
+ preds (Tensor): The predicted probability NxC map
+ with N and C being the sample number and class
+ number respectively.
+ gts (Tensor): The ground truth vector of size N.
+ ignores (list): The index set of classes that are ignored when
+ reporting results.
+ Note: all samples are participated in computing.
+
+ Returns:
+ The numpy list of f1-scores of valid classes.
+ """
+ C = preds.size(1)
+ classes = torch.LongTensor(sorted(set(range(C)) - set(ignores)))
+ hist = torch.bincount(
+ gts * C + preds.argmax(1), minlength=C**2).view(C, C).float()
+ diag = torch.diag(hist)
+ recalls = diag / hist.sum(1).clamp(min=1)
+ precisions = diag / hist.sum(0).clamp(min=1)
+ f1 = 2 * recalls * precisions / (recalls + precisions).clamp(min=1e-8)
+ return f1[classes].cpu().numpy()
diff --git a/mmocr/core/evaluation/ner_metric.py b/mmocr/core/evaluation/ner_metric.py
new file mode 100644
index 0000000000000000000000000000000000000000..52fddfbbe91946c0563ee69d0cc073cf584d1911
--- /dev/null
+++ b/mmocr/core/evaluation/ner_metric.py
@@ -0,0 +1,115 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from collections import Counter
+
+
+def gt_label2entity(gt_infos):
+ """Get all entities from ground truth infos.
+ Args:
+ gt_infos (list[dict]): Ground-truth information contains text and
+ label.
+ Returns:
+ gt_entities (list[list]): Original labeled entities in groundtruth.
+ [[category,start_position,end_position]]
+ """
+ gt_entities = []
+ for gt_info in gt_infos:
+ line_entities = []
+ label = gt_info['label']
+ for key, value in label.items():
+ for _, places in value.items():
+ for place in places:
+ line_entities.append([key, place[0], place[1]])
+ gt_entities.append(line_entities)
+ return gt_entities
+
+
+def _compute_f1(origin, found, right):
+ """Calculate recall, precision, f1-score.
+
+ Args:
+ origin (int): Original entities in groundtruth.
+ found (int): Predicted entities from model.
+ right (int): Predicted entities that
+ can match to the original annotation.
+ Returns:
+ recall (float): Metric of recall.
+ precision (float): Metric of precision.
+ f1 (float): Metric of f1-score.
+ """
+ recall = 0 if origin == 0 else (right / origin)
+ precision = 0 if found == 0 else (right / found)
+ f1 = 0. if recall + precision == 0 else (2 * precision * recall) / (
+ precision + recall)
+ return recall, precision, f1
+
+
+def compute_f1_all(pred_entities, gt_entities):
+ """Calculate precision, recall and F1-score for all categories.
+
+ Args:
+ pred_entities: The predicted entities from model.
+ gt_entities: The entities of ground truth file.
+ Returns:
+ class_info (dict): precision,recall, f1-score in total
+ and each categories.
+ """
+ origins = []
+ founds = []
+ rights = []
+ for i, _ in enumerate(pred_entities):
+ origins.extend(gt_entities[i])
+ founds.extend(pred_entities[i])
+ rights.extend([
+ pre_entity for pre_entity in pred_entities[i]
+ if pre_entity in gt_entities[i]
+ ])
+
+ class_info = {}
+ origin_counter = Counter([x[0] for x in origins])
+ found_counter = Counter([x[0] for x in founds])
+ right_counter = Counter([x[0] for x in rights])
+ for type_, count in origin_counter.items():
+ origin = count
+ found = found_counter.get(type_, 0)
+ right = right_counter.get(type_, 0)
+ recall, precision, f1 = _compute_f1(origin, found, right)
+ class_info[type_] = {
+ 'precision': precision,
+ 'recall': recall,
+ 'f1-score': f1
+ }
+ origin = len(origins)
+ found = len(founds)
+ right = len(rights)
+ recall, precision, f1 = _compute_f1(origin, found, right)
+ class_info['all'] = {
+ 'precision': precision,
+ 'recall': recall,
+ 'f1-score': f1
+ }
+ return class_info
+
+
+def eval_ner_f1(results, gt_infos):
+ """Evaluate for ner task.
+
+ Args:
+ results (list): Predict results of entities.
+ gt_infos (list[dict]): Ground-truth information which contains
+ text and label.
+ Returns:
+ class_info (dict): precision,recall, f1-score of total
+ and each catogory.
+ """
+ assert len(results) == len(gt_infos)
+ gt_entities = gt_label2entity(gt_infos)
+ pred_entities = []
+ for i, gt_info in enumerate(gt_infos):
+ line_entities = []
+ for result in results[i]:
+ line_entities.append(result)
+ pred_entities.append(line_entities)
+ assert len(pred_entities) == len(gt_entities)
+ class_info = compute_f1_all(pred_entities, gt_entities)
+
+ return class_info
diff --git a/mmocr/core/evaluation/ocr_metric.py b/mmocr/core/evaluation/ocr_metric.py
new file mode 100644
index 0000000000000000000000000000000000000000..175bbfb7eb0e46a47191938a92580038dfcf28c0
--- /dev/null
+++ b/mmocr/core/evaluation/ocr_metric.py
@@ -0,0 +1,134 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import re
+from difflib import SequenceMatcher
+
+from rapidfuzz import string_metric
+
+
+def cal_true_positive_char(pred, gt):
+ """Calculate correct character number in prediction.
+
+ Args:
+ pred (str): Prediction text.
+ gt (str): Ground truth text.
+
+ Returns:
+ true_positive_char_num (int): The true positive number.
+ """
+
+ all_opt = SequenceMatcher(None, pred, gt)
+ true_positive_char_num = 0
+ for opt, _, _, s2, e2 in all_opt.get_opcodes():
+ if opt == 'equal':
+ true_positive_char_num += (e2 - s2)
+ else:
+ pass
+ return true_positive_char_num
+
+
+def count_matches(pred_texts, gt_texts):
+ """Count the various match number for metric calculation.
+
+ Args:
+ pred_texts (list[str]): Predicted text string.
+ gt_texts (list[str]): Ground truth text string.
+
+ Returns:
+ match_res: (dict[str: int]): Match number used for
+ metric calculation.
+ """
+ match_res = {
+ 'gt_char_num': 0,
+ 'pred_char_num': 0,
+ 'true_positive_char_num': 0,
+ 'gt_word_num': 0,
+ 'match_word_num': 0,
+ 'match_word_ignore_case': 0,
+ 'match_word_ignore_case_symbol': 0
+ }
+ comp = re.compile('[^A-Z^a-z^0-9^\u4e00-\u9fa5]')
+ norm_ed_sum = 0.0
+ for pred_text, gt_text in zip(pred_texts, gt_texts):
+ if gt_text == pred_text:
+ match_res['match_word_num'] += 1
+ gt_text_lower = gt_text.lower()
+ pred_text_lower = pred_text.lower()
+ if gt_text_lower == pred_text_lower:
+ match_res['match_word_ignore_case'] += 1
+ gt_text_lower_ignore = comp.sub('', gt_text_lower)
+ pred_text_lower_ignore = comp.sub('', pred_text_lower)
+ if gt_text_lower_ignore == pred_text_lower_ignore:
+ match_res['match_word_ignore_case_symbol'] += 1
+ match_res['gt_word_num'] += 1
+
+ # normalized edit distance
+ edit_dist = string_metric.levenshtein(pred_text_lower_ignore,
+ gt_text_lower_ignore)
+ norm_ed = float(edit_dist) / max(1, len(gt_text_lower_ignore),
+ len(pred_text_lower_ignore))
+ norm_ed_sum += norm_ed
+
+ # number to calculate char level recall & precision
+ match_res['gt_char_num'] += len(gt_text_lower_ignore)
+ match_res['pred_char_num'] += len(pred_text_lower_ignore)
+ true_positive_char_num = cal_true_positive_char(
+ pred_text_lower_ignore, gt_text_lower_ignore)
+ match_res['true_positive_char_num'] += true_positive_char_num
+
+ normalized_edit_distance = norm_ed_sum / max(1, len(gt_texts))
+ match_res['ned'] = normalized_edit_distance
+
+ return match_res
+
+
+def eval_ocr_metric(pred_texts, gt_texts):
+ """Evaluate the text recognition performance with metric: word accuracy and
+ 1-N.E.D. See https://rrc.cvc.uab.es/?ch=14&com=tasks for details.
+
+ Args:
+ pred_texts (list[str]): Text strings of prediction.
+ gt_texts (list[str]): Text strings of ground truth.
+
+ Returns:
+ eval_res (dict[str: float]): Metric dict for text recognition, include:
+ - word_acc: Accuracy in word level.
+ - word_acc_ignore_case: Accuracy in word level, ignore letter case.
+ - word_acc_ignore_case_symbol: Accuracy in word level, ignore
+ letter case and symbol. (default metric for
+ academic evaluation)
+ - char_recall: Recall in character level, ignore
+ letter case and symbol.
+ - char_precision: Precision in character level, ignore
+ letter case and symbol.
+ - 1-N.E.D: 1 - normalized_edit_distance.
+ """
+ assert isinstance(pred_texts, list)
+ assert isinstance(gt_texts, list)
+ assert len(pred_texts) == len(gt_texts)
+
+ match_res = count_matches(pred_texts, gt_texts)
+ eps = 1e-8
+ char_recall = 1.0 * match_res['true_positive_char_num'] / (
+ eps + match_res['gt_char_num'])
+ char_precision = 1.0 * match_res['true_positive_char_num'] / (
+ eps + match_res['pred_char_num'])
+ word_acc = 1.0 * match_res['match_word_num'] / (
+ eps + match_res['gt_word_num'])
+ word_acc_ignore_case = 1.0 * match_res['match_word_ignore_case'] / (
+ eps + match_res['gt_word_num'])
+ word_acc_ignore_case_symbol = 1.0 * match_res[
+ 'match_word_ignore_case_symbol'] / (
+ eps + match_res['gt_word_num'])
+
+ eval_res = {}
+ eval_res['word_acc'] = word_acc
+ eval_res['word_acc_ignore_case'] = word_acc_ignore_case
+ eval_res['word_acc_ignore_case_symbol'] = word_acc_ignore_case_symbol
+ eval_res['char_recall'] = char_recall
+ eval_res['char_precision'] = char_precision
+ eval_res['1-N.E.D'] = 1.0 - match_res['ned']
+
+ for key, value in eval_res.items():
+ eval_res[key] = float('{:.4f}'.format(value))
+
+ return eval_res
diff --git a/mmocr/core/evaluation/utils.py b/mmocr/core/evaluation/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..bb02b096f2de12612fe181626ce2aad4eccc6a91
--- /dev/null
+++ b/mmocr/core/evaluation/utils.py
@@ -0,0 +1,547 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+from shapely.geometry import Polygon as plg
+
+import mmocr.utils as utils
+
+
+def ignore_pred(pred_boxes, gt_ignored_index, gt_polys, precision_thr):
+ """Ignore the predicted box if it hits any ignored ground truth.
+
+ Args:
+ pred_boxes (list[ndarray or list]): The predicted boxes of one image.
+ gt_ignored_index (list[int]): The ignored ground truth index list.
+ gt_polys (list[Polygon]): The polygon list of one image.
+ precision_thr (float): The precision threshold.
+
+ Returns:
+ pred_polys (list[Polygon]): The predicted polygon list.
+ pred_points (list[list]): The predicted box list represented
+ by point sequences.
+ pred_ignored_index (list[int]): The ignored text index list.
+ """
+
+ assert isinstance(pred_boxes, list)
+ assert isinstance(gt_ignored_index, list)
+ assert isinstance(gt_polys, list)
+ assert 0 <= precision_thr <= 1
+
+ pred_polys = []
+ pred_points = []
+ pred_ignored_index = []
+
+ gt_ignored_num = len(gt_ignored_index)
+ # get detection polygons
+ for box_id, box in enumerate(pred_boxes):
+ poly = points2polygon(box)
+ pred_polys.append(poly)
+ pred_points.append(box)
+
+ if gt_ignored_num < 1:
+ continue
+
+ # ignore the current detection box
+ # if its overlap with any ignored gt > precision_thr
+ for ignored_box_id in gt_ignored_index:
+ ignored_box = gt_polys[ignored_box_id]
+ inter_area = poly_intersection(poly, ignored_box)
+ area = poly.area
+ precision = 0 if area == 0 else inter_area / area
+ if precision > precision_thr:
+ pred_ignored_index.append(box_id)
+ break
+
+ return pred_polys, pred_points, pred_ignored_index
+
+
+def compute_hmean(accum_hit_recall, accum_hit_prec, gt_num, pred_num):
+ """Compute hmean given hit number, ground truth number and prediction
+ number.
+
+ Args:
+ accum_hit_recall (int|float): Accumulated hits for computing recall.
+ accum_hit_prec (int|float): Accumulated hits for computing precision.
+ gt_num (int): Ground truth number.
+ pred_num (int): Prediction number.
+
+ Returns:
+ recall (float): The recall value.
+ precision (float): The precision value.
+ hmean (float): The hmean value.
+ """
+
+ assert isinstance(accum_hit_recall, (float, int))
+ assert isinstance(accum_hit_prec, (float, int))
+
+ assert isinstance(gt_num, int)
+ assert isinstance(pred_num, int)
+ assert accum_hit_recall >= 0.0
+ assert accum_hit_prec >= 0.0
+ assert gt_num >= 0.0
+ assert pred_num >= 0.0
+
+ if gt_num == 0:
+ recall = 1.0
+ precision = 0.0 if pred_num > 0 else 1.0
+ else:
+ recall = float(accum_hit_recall) / gt_num
+ precision = 0.0 if pred_num == 0 else float(accum_hit_prec) / pred_num
+
+ denom = recall + precision
+
+ hmean = 0.0 if denom == 0 else (2.0 * precision * recall / denom)
+
+ return recall, precision, hmean
+
+
+def box2polygon(box):
+ """Convert box to polygon.
+
+ Args:
+ box (ndarray or list): A ndarray or a list of shape (4)
+ that indicates 2 points.
+
+ Returns:
+ polygon (Polygon): A polygon object.
+ """
+ if isinstance(box, list):
+ box = np.array(box)
+
+ assert isinstance(box, np.ndarray)
+ assert box.size == 4
+ boundary = np.array(
+ [box[0], box[1], box[2], box[1], box[2], box[3], box[0], box[3]])
+
+ point_mat = boundary.reshape([-1, 2])
+ return plg(point_mat)
+
+
+def points2polygon(points):
+ """Convert k points to 1 polygon.
+
+ Args:
+ points (ndarray or list): A ndarray or a list of shape (2k)
+ that indicates k points.
+
+ Returns:
+ polygon (Polygon): A polygon object.
+ """
+ if isinstance(points, list):
+ points = np.array(points)
+
+ assert isinstance(points, np.ndarray)
+ assert (points.size % 2 == 0) and (points.size >= 8)
+
+ point_mat = points.reshape([-1, 2])
+ return plg(point_mat)
+
+
+def poly_make_valid(poly):
+ """Convert a potentially invalid polygon to a valid one by eliminating
+ self-crossing or self-touching parts.
+
+ Args:
+ poly (Polygon): A polygon needed to be converted.
+
+ Returns:
+ A valid polygon.
+ """
+ return poly if poly.is_valid else poly.buffer(0)
+
+
+def poly_intersection(poly_det, poly_gt, invalid_ret=None, return_poly=False):
+ """Calculate the intersection area between two polygon.
+
+ Args:
+ poly_det (Polygon): A polygon predicted by detector.
+ poly_gt (Polygon): A gt polygon.
+ invalid_ret (None|float|int): The return value when the invalid polygon
+ exists. If it is not specified, the function allows the computation
+ to proceed with invalid polygons by cleaning the their
+ self-touching or self-crossing parts.
+ return_poly (bool): Whether to return the polygon of the intersection
+ area.
+
+ Returns:
+ intersection_area (float): The intersection area between two polygons.
+ poly_obj (Polygon, optional): The Polygon object of the intersection
+ area. Set as `None` if the input is invalid.
+ """
+ assert isinstance(poly_det, plg)
+ assert isinstance(poly_gt, plg)
+ assert invalid_ret is None or isinstance(invalid_ret, float) or \
+ isinstance(invalid_ret, int)
+
+ if invalid_ret is None:
+ poly_det = poly_make_valid(poly_det)
+ poly_gt = poly_make_valid(poly_gt)
+
+ poly_obj = None
+ area = invalid_ret
+ if poly_det.is_valid and poly_gt.is_valid:
+ poly_obj = poly_det.intersection(poly_gt)
+ area = poly_obj.area
+ return (area, poly_obj) if return_poly else area
+
+
+def poly_union(poly_det, poly_gt, invalid_ret=None, return_poly=False):
+ """Calculate the union area between two polygon.
+ Args:
+ poly_det (Polygon): A polygon predicted by detector.
+ poly_gt (Polygon): A gt polygon.
+ invalid_ret (None|float|int): The return value when the invalid polygon
+ exists. If it is not specified, the function allows the computation
+ to proceed with invalid polygons by cleaning the their
+ self-touching or self-crossing parts.
+ return_poly (bool): Whether to return the polygon of the intersection
+ area.
+
+ Returns:
+ union_area (float): The union area between two polygons.
+ poly_obj (Polygon|MultiPolygon, optional): The Polygon or MultiPolygon
+ object of the union of the inputs. The type of object depends on
+ whether they intersect or not. Set as `None` if the input is
+ invalid.
+ """
+ assert isinstance(poly_det, plg)
+ assert isinstance(poly_gt, plg)
+ assert invalid_ret is None or isinstance(invalid_ret, float) or \
+ isinstance(invalid_ret, int)
+
+ if invalid_ret is None:
+ poly_det = poly_make_valid(poly_det)
+ poly_gt = poly_make_valid(poly_gt)
+
+ poly_obj = None
+ area = invalid_ret
+ if poly_det.is_valid and poly_gt.is_valid:
+ poly_obj = poly_det.union(poly_gt)
+ area = poly_obj.area
+ return (area, poly_obj) if return_poly else area
+
+
+def boundary_iou(src, target, zero_division=0):
+ """Calculate the IOU between two boundaries.
+
+ Args:
+ src (list): Source boundary.
+ target (list): Target boundary.
+ zero_division (int|float): The return value when invalid
+ boundary exists.
+
+ Returns:
+ iou (float): The iou between two boundaries.
+ """
+ assert utils.valid_boundary(src, False)
+ assert utils.valid_boundary(target, False)
+ src_poly = points2polygon(src)
+ target_poly = points2polygon(target)
+
+ return poly_iou(src_poly, target_poly, zero_division=zero_division)
+
+
+def poly_iou(poly_det, poly_gt, zero_division=0):
+ """Calculate the IOU between two polygons.
+
+ Args:
+ poly_det (Polygon): A polygon predicted by detector.
+ poly_gt (Polygon): A gt polygon.
+ zero_division (int|float): The return value when invalid
+ polygon exists.
+
+ Returns:
+ iou (float): The IOU between two polygons.
+ """
+ assert isinstance(poly_det, plg)
+ assert isinstance(poly_gt, plg)
+ area_inters = poly_intersection(poly_det, poly_gt)
+ area_union = poly_union(poly_det, poly_gt)
+ return area_inters / area_union if area_union != 0 else zero_division
+
+
+def one2one_match_ic13(gt_id, det_id, recall_mat, precision_mat, recall_thr,
+ precision_thr):
+ """One-to-One match gt and det with icdar2013 standards.
+
+ Args:
+ gt_id (int): The ground truth id index.
+ det_id (int): The detection result id index.
+ recall_mat (ndarray): `gt_num x det_num` matrix with element (i,j)
+ being the recall ratio of gt i to det j.
+ precision_mat (ndarray): `gt_num x det_num` matrix with element (i,j)
+ being the precision ratio of gt i to det j.
+ recall_thr (float): The recall threshold.
+ precision_thr (float): The precision threshold.
+ Returns:
+ True|False: Whether the gt and det are matched.
+ """
+ assert isinstance(gt_id, int)
+ assert isinstance(det_id, int)
+ assert isinstance(recall_mat, np.ndarray)
+ assert isinstance(precision_mat, np.ndarray)
+ assert 0 <= recall_thr <= 1
+ assert 0 <= precision_thr <= 1
+
+ cont = 0
+ for i in range(recall_mat.shape[1]):
+ if recall_mat[gt_id,
+ i] > recall_thr and precision_mat[gt_id,
+ i] > precision_thr:
+ cont += 1
+ if cont != 1:
+ return False
+
+ cont = 0
+ for i in range(recall_mat.shape[0]):
+ if recall_mat[i, det_id] > recall_thr and precision_mat[
+ i, det_id] > precision_thr:
+ cont += 1
+ if cont != 1:
+ return False
+
+ if recall_mat[gt_id, det_id] > recall_thr and precision_mat[
+ gt_id, det_id] > precision_thr:
+ return True
+
+ return False
+
+
+def one2many_match_ic13(gt_id, recall_mat, precision_mat, recall_thr,
+ precision_thr, gt_match_flag, det_match_flag,
+ det_ignored_index):
+ """One-to-Many match gt and detections with icdar2013 standards.
+
+ Args:
+ gt_id (int): gt index.
+ recall_mat (ndarray): `gt_num x det_num` matrix with element (i,j)
+ being the recall ratio of gt i to det j.
+ precision_mat (ndarray): `gt_num x det_num` matrix with element (i,j)
+ being the precision ratio of gt i to det j.
+ recall_thr (float): The recall threshold.
+ precision_thr (float): The precision threshold.
+ gt_match_flag (ndarray): An array indicates each gt matched already.
+ det_match_flag (ndarray): An array indicates each box has been
+ matched already or not.
+ det_ignored_index (list): A list indicates each detection box can be
+ ignored or not.
+
+ Returns:
+ tuple (True|False, list): The first indicates the gt is matched or not;
+ the second is the matched detection ids.
+ """
+ assert isinstance(gt_id, int)
+ assert isinstance(recall_mat, np.ndarray)
+ assert isinstance(precision_mat, np.ndarray)
+ assert 0 <= recall_thr <= 1
+ assert 0 <= precision_thr <= 1
+
+ assert isinstance(gt_match_flag, list)
+ assert isinstance(det_match_flag, list)
+ assert isinstance(det_ignored_index, list)
+
+ many_sum = 0.
+ det_ids = []
+ for det_id in range(recall_mat.shape[1]):
+ if gt_match_flag[gt_id] == 0 and det_match_flag[
+ det_id] == 0 and det_id not in det_ignored_index:
+ if precision_mat[gt_id, det_id] >= precision_thr:
+ many_sum += recall_mat[gt_id, det_id]
+ det_ids.append(det_id)
+ if many_sum >= recall_thr:
+ return True, det_ids
+ return False, []
+
+
+def many2one_match_ic13(det_id, recall_mat, precision_mat, recall_thr,
+ precision_thr, gt_match_flag, det_match_flag,
+ gt_ignored_index):
+ """Many-to-One match gt and detections with icdar2013 standards.
+
+ Args:
+ det_id (int): Detection index.
+ recall_mat (ndarray): `gt_num x det_num` matrix with element (i,j)
+ being the recall ratio of gt i to det j.
+ precision_mat (ndarray): `gt_num x det_num` matrix with element (i,j)
+ being the precision ratio of gt i to det j.
+ recall_thr (float): The recall threshold.
+ precision_thr (float): The precision threshold.
+ gt_match_flag (ndarray): An array indicates each gt has been matched
+ already.
+ det_match_flag (ndarray): An array indicates each detection box has
+ been matched already or not.
+ gt_ignored_index (list): A list indicates each gt box can be ignored
+ or not.
+
+ Returns:
+ tuple (True|False, list): The first indicates the detection is matched
+ or not; the second is the matched gt ids.
+ """
+ assert isinstance(det_id, int)
+ assert isinstance(recall_mat, np.ndarray)
+ assert isinstance(precision_mat, np.ndarray)
+ assert 0 <= recall_thr <= 1
+ assert 0 <= precision_thr <= 1
+
+ assert isinstance(gt_match_flag, list)
+ assert isinstance(det_match_flag, list)
+ assert isinstance(gt_ignored_index, list)
+ many_sum = 0.
+ gt_ids = []
+ for gt_id in range(recall_mat.shape[0]):
+ if gt_match_flag[gt_id] == 0 and det_match_flag[
+ det_id] == 0 and gt_id not in gt_ignored_index:
+ if recall_mat[gt_id, det_id] >= recall_thr:
+ many_sum += precision_mat[gt_id, det_id]
+ gt_ids.append(gt_id)
+ if many_sum >= precision_thr:
+ return True, gt_ids
+ return False, []
+
+
+def points_center(points):
+
+ assert isinstance(points, np.ndarray)
+ assert points.size % 2 == 0
+
+ points = points.reshape([-1, 2])
+ return np.mean(points, axis=0)
+
+
+def point_distance(p1, p2):
+ assert isinstance(p1, np.ndarray)
+ assert isinstance(p2, np.ndarray)
+
+ assert p1.size == 2
+ assert p2.size == 2
+
+ dist = np.square(p2 - p1)
+ dist = np.sum(dist)
+ dist = np.sqrt(dist)
+ return dist
+
+
+def box_center_distance(b1, b2):
+ assert isinstance(b1, np.ndarray)
+ assert isinstance(b2, np.ndarray)
+ return point_distance(points_center(b1), points_center(b2))
+
+
+def box_diag(box):
+ assert isinstance(box, np.ndarray)
+ assert box.size == 8
+
+ return point_distance(box[0:2], box[4:6])
+
+
+def filter_2dlist_result(results, scores, score_thr):
+ """Find out detected results whose score > score_thr.
+
+ Args:
+ results (list[list[float]]): The result list.
+ score (list): The score list.
+ score_thr (float): The score threshold.
+ Returns:
+ valid_results (list[list[float]]): The valid results.
+ valid_score (list[float]): The scores which correspond to the valid
+ results.
+ """
+ assert isinstance(results, list)
+ assert len(results) == len(scores)
+ assert isinstance(score_thr, float)
+ assert 0 <= score_thr <= 1
+
+ inds = np.array(scores) > score_thr
+ valid_results = [results[idx] for idx in np.where(inds)[0].tolist()]
+ valid_scores = [scores[idx] for idx in np.where(inds)[0].tolist()]
+ return valid_results, valid_scores
+
+
+def filter_result(results, scores, score_thr):
+ """Find out detected results whose score > score_thr.
+
+ Args:
+ results (ndarray): The results matrix of shape (n, k).
+ score (ndarray): The score vector of shape (n,).
+ score_thr (float): The score threshold.
+ Returns:
+ valid_results (ndarray): The valid results of shape (m,k) with m<=n.
+ valid_score (ndarray): The scores which correspond to the
+ valid results.
+ """
+ assert results.ndim == 2
+ assert scores.shape[0] == results.shape[0]
+ assert isinstance(score_thr, float)
+ assert 0 <= score_thr <= 1
+
+ inds = scores > score_thr
+ valid_results = results[inds, :]
+ valid_scores = scores[inds]
+ return valid_results, valid_scores
+
+
+def select_top_boundary(boundaries_list, scores_list, score_thr):
+ """Select poly boundaries with scores >= score_thr.
+
+ Args:
+ boundaries_list (list[list[list[float]]]): List of boundaries.
+ The 1st, 2nd, and 3rd indices are for image, text and
+ vertice, respectively.
+ scores_list (list(list[float])): List of lists of scores.
+ score_thr (float): The score threshold to filter out bboxes.
+
+ Returns:
+ selected_bboxes (list[list[list[float]]]): List of boundaries.
+ The 1st, 2nd, and 3rd indices are for image, text and vertice,
+ respectively.
+ """
+ assert isinstance(boundaries_list, list)
+ assert isinstance(scores_list, list)
+ assert isinstance(score_thr, float)
+ assert len(boundaries_list) == len(scores_list)
+ assert 0 <= score_thr <= 1
+
+ selected_boundaries = []
+ for boundary, scores in zip(boundaries_list, scores_list):
+ if len(scores) > 0:
+ assert len(scores) == len(boundary)
+ inds = [
+ iter for iter in range(len(scores))
+ if scores[iter] >= score_thr
+ ]
+ selected_boundaries.append([boundary[i] for i in inds])
+ else:
+ selected_boundaries.append(boundary)
+ return selected_boundaries
+
+
+def select_bboxes_via_score(bboxes_list, scores_list, score_thr):
+ """Select bboxes with scores >= score_thr.
+
+ Args:
+ bboxes_list (list[ndarray]): List of bboxes. Each element is ndarray of
+ shape (n,8)
+ scores_list (list(list[float])): List of lists of scores.
+ score_thr (float): The score threshold to filter out bboxes.
+
+ Returns:
+ selected_bboxes (list[ndarray]): List of bboxes. Each element is
+ ndarray of shape (m,8) with m<=n.
+ """
+ assert isinstance(bboxes_list, list)
+ assert isinstance(scores_list, list)
+ assert isinstance(score_thr, float)
+ assert len(bboxes_list) == len(scores_list)
+ assert 0 <= score_thr <= 1
+
+ selected_bboxes = []
+ for bboxes, scores in zip(bboxes_list, scores_list):
+ if len(scores) > 0:
+ assert len(scores) == bboxes.shape[0]
+ inds = [
+ iter for iter in range(len(scores))
+ if scores[iter] >= score_thr
+ ]
+ selected_bboxes.append(bboxes[inds, :])
+ else:
+ selected_bboxes.append(bboxes)
+ return selected_bboxes
diff --git a/mmocr/core/mask.py b/mmocr/core/mask.py
new file mode 100644
index 0000000000000000000000000000000000000000..fd4689b8c1624f071c92012e79f236434768e591
--- /dev/null
+++ b/mmocr/core/mask.py
@@ -0,0 +1,102 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import cv2
+import numpy as np
+
+import mmocr.utils as utils
+
+
+def points2boundary(points, text_repr_type, text_score=None, min_width=-1):
+ """Convert a text mask represented by point coordinates sequence into a
+ text boundary.
+
+ Args:
+ points (ndarray): Mask index of size (n, 2).
+ text_repr_type (str): Text instance encoding type
+ ('quad' for quadrangle or 'poly' for polygon).
+ text_score (float): Text score.
+
+ Returns:
+ boundary (list[float]): The text boundary point coordinates (x, y)
+ list. Return None if no text boundary found.
+ """
+ assert isinstance(points, np.ndarray)
+ assert points.shape[1] == 2
+ assert text_repr_type in ['quad', 'poly']
+ assert text_score is None or 0 <= text_score <= 1
+
+ if text_repr_type == 'quad':
+ rect = cv2.minAreaRect(points)
+ vertices = cv2.boxPoints(rect)
+ boundary = []
+ if min(rect[1]) > min_width:
+ boundary = [p for p in vertices.flatten().tolist()]
+
+ elif text_repr_type == 'poly':
+
+ height = np.max(points[:, 1]) + 10
+ width = np.max(points[:, 0]) + 10
+
+ mask = np.zeros((height, width), np.uint8)
+ mask[points[:, 1], points[:, 0]] = 255
+
+ contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL,
+ cv2.CHAIN_APPROX_SIMPLE)
+ boundary = list(contours[0].flatten().tolist())
+
+ if text_score is not None:
+ boundary = boundary + [text_score]
+ if len(boundary) < 8:
+ return None
+
+ return boundary
+
+
+def seg2boundary(seg, text_repr_type, text_score=None):
+ """Convert a segmentation mask to a text boundary.
+
+ Args:
+ seg (ndarray): The segmentation mask.
+ text_repr_type (str): Text instance encoding type
+ ('quad' for quadrangle or 'poly' for polygon).
+ text_score (float): The text score.
+
+ Returns:
+ boundary (list): The text boundary. Return None if no text found.
+ """
+ assert isinstance(seg, np.ndarray)
+ assert isinstance(text_repr_type, str)
+ assert text_score is None or 0 <= text_score <= 1
+
+ points = np.where(seg)
+ # x, y order
+ points = np.concatenate([points[1], points[0]]).reshape(2, -1).transpose()
+ boundary = None
+ if len(points) != 0:
+ boundary = points2boundary(points, text_repr_type, text_score)
+
+ return boundary
+
+
+def extract_boundary(result):
+ """Extract boundaries and their scores from result.
+
+ Args:
+ result (dict): The detection result with the key 'boundary_result'
+ of one image.
+
+ Returns:
+ boundaries_with_scores (list[list[float]]): The boundary and score
+ list.
+ boundaries (list[list[float]]): The boundary list.
+ scores (list[float]): The boundary score list.
+ """
+ assert isinstance(result, dict)
+ assert 'boundary_result' in result.keys()
+
+ boundaries_with_scores = result['boundary_result']
+ assert utils.is_2dlist(boundaries_with_scores)
+
+ boundaries = [b[:-1] for b in boundaries_with_scores]
+ scores = [b[-1] for b in boundaries_with_scores]
+
+ return (boundaries_with_scores, boundaries, scores)
diff --git a/mmocr/core/visualize.py b/mmocr/core/visualize.py
new file mode 100644
index 0000000000000000000000000000000000000000..35ccdaf523c60f331b5541fd21e460bfb2d59870
--- /dev/null
+++ b/mmocr/core/visualize.py
@@ -0,0 +1,888 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+import os
+import shutil
+import urllib
+import warnings
+
+import cv2
+import mmcv
+import numpy as np
+import torch
+from matplotlib import pyplot as plt
+from PIL import Image, ImageDraw, ImageFont
+
+import mmocr.utils as utils
+
+
+def overlay_mask_img(img, mask):
+ """Draw mask boundaries on image for visualization.
+
+ Args:
+ img (ndarray): The input image.
+ mask (ndarray): The instance mask.
+
+ Returns:
+ img (ndarray): The output image with instance boundaries on it.
+ """
+ assert isinstance(img, np.ndarray)
+ assert isinstance(mask, np.ndarray)
+
+ contours, _ = cv2.findContours(
+ mask.astype(np.uint8), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
+
+ cv2.drawContours(img, contours, -1, (0, 255, 0), 1)
+
+ return img
+
+
+def show_feature(features, names, to_uint8, out_file=None):
+ """Visualize a list of feature maps.
+
+ Args:
+ features (list(ndarray)): The feature map list.
+ names (list(str)): The visualized title list.
+ to_uint8 (list(1|0)): The list indicating whether to convent
+ feature maps to uint8.
+ out_file (str): The output file name. If set to None,
+ the output image will be shown without saving.
+ """
+ assert utils.is_type_list(features, np.ndarray)
+ assert utils.is_type_list(names, str)
+ assert utils.is_type_list(to_uint8, int)
+ assert utils.is_none_or_type(out_file, str)
+ assert utils.equal_len(features, names, to_uint8)
+
+ num = len(features)
+ row = col = math.ceil(math.sqrt(num))
+
+ for i, (f, n) in enumerate(zip(features, names)):
+ plt.subplot(row, col, i + 1)
+ plt.title(n)
+ if to_uint8[i]:
+ f = f.astype(np.uint8)
+ plt.imshow(f)
+ if out_file is None:
+ plt.show()
+ else:
+ plt.savefig(out_file)
+
+
+def show_img_boundary(img, boundary):
+ """Show image and instance boundaires.
+
+ Args:
+ img (ndarray): The input image.
+ boundary (list[float or int]): The input boundary.
+ """
+ assert isinstance(img, np.ndarray)
+ assert utils.is_type_list(boundary, (int, float))
+
+ cv2.polylines(
+ img, [np.array(boundary).astype(np.int32).reshape(-1, 1, 2)],
+ True,
+ color=(0, 255, 0),
+ thickness=1)
+ plt.imshow(img)
+ plt.show()
+
+
+def show_pred_gt(preds,
+ gts,
+ show=False,
+ win_name='',
+ wait_time=0,
+ out_file=None):
+ """Show detection and ground truth for one image.
+
+ Args:
+ preds (list[list[float]]): The detection boundary list.
+ gts (list[list[float]]): The ground truth boundary list.
+ show (bool): Whether to show the image.
+ win_name (str): The window name.
+ wait_time (int): The value of waitKey param.
+ out_file (str): The filename of the output.
+ """
+ assert utils.is_2dlist(preds)
+ assert utils.is_2dlist(gts)
+ assert isinstance(show, bool)
+ assert isinstance(win_name, str)
+ assert isinstance(wait_time, int)
+ assert utils.is_none_or_type(out_file, str)
+
+ p_xy = [p for boundary in preds for p in boundary]
+ gt_xy = [g for gt in gts for g in gt]
+
+ max_xy = np.max(np.array(p_xy + gt_xy).reshape(-1, 2), axis=0)
+
+ width = int(max_xy[0]) + 100
+ height = int(max_xy[1]) + 100
+
+ img = np.ones((height, width, 3), np.int8) * 255
+ pred_color = mmcv.color_val('red')
+ gt_color = mmcv.color_val('blue')
+ thickness = 1
+
+ for boundary in preds:
+ cv2.polylines(
+ img, [np.array(boundary).astype(np.int32).reshape(-1, 1, 2)],
+ True,
+ color=pred_color,
+ thickness=thickness)
+ for gt in gts:
+ cv2.polylines(
+ img, [np.array(gt).astype(np.int32).reshape(-1, 1, 2)],
+ True,
+ color=gt_color,
+ thickness=thickness)
+ if show:
+ mmcv.imshow(img, win_name, wait_time)
+ if out_file is not None:
+ mmcv.imwrite(img, out_file)
+
+ return img
+
+
+def imshow_pred_boundary(img,
+ boundaries_with_scores,
+ labels,
+ score_thr=0,
+ boundary_color='blue',
+ text_color='blue',
+ thickness=1,
+ font_scale=0.5,
+ show=True,
+ win_name='',
+ wait_time=0,
+ out_file=None,
+ show_score=False):
+ """Draw boundaries and class labels (with scores) on an image.
+
+ Args:
+ img (str or ndarray): The image to be displayed.
+ boundaries_with_scores (list[list[float]]): Boundaries with scores.
+ labels (list[int]): Labels of boundaries.
+ score_thr (float): Minimum score of boundaries to be shown.
+ boundary_color (str or tuple or :obj:`Color`): Color of boundaries.
+ text_color (str or tuple or :obj:`Color`): Color of texts.
+ thickness (int): Thickness of lines.
+ font_scale (float): Font scales of texts.
+ show (bool): Whether to show the image.
+ win_name (str): The window name.
+ wait_time (int): Value of waitKey param.
+ out_file (str or None): The filename of the output.
+ show_score (bool): Whether to show text instance score.
+ """
+ assert isinstance(img, (str, np.ndarray))
+ assert utils.is_2dlist(boundaries_with_scores)
+ assert utils.is_type_list(labels, int)
+ assert utils.equal_len(boundaries_with_scores, labels)
+ if len(boundaries_with_scores) == 0:
+ warnings.warn('0 text found in ' + out_file)
+ return None
+
+ utils.valid_boundary(boundaries_with_scores[0])
+ img = mmcv.imread(img)
+
+ scores = np.array([b[-1] for b in boundaries_with_scores])
+ inds = scores > score_thr
+ boundaries = [boundaries_with_scores[i][:-1] for i in np.where(inds)[0]]
+ scores = [scores[i] for i in np.where(inds)[0]]
+ labels = [labels[i] for i in np.where(inds)[0]]
+
+ boundary_color = mmcv.color_val(boundary_color)
+ text_color = mmcv.color_val(text_color)
+ font_scale = 0.5
+
+ for boundary, score in zip(boundaries, scores):
+ boundary_int = np.array(boundary).astype(np.int32)
+
+ cv2.polylines(
+ img, [boundary_int.reshape(-1, 1, 2)],
+ True,
+ color=boundary_color,
+ thickness=thickness)
+
+ if show_score:
+ label_text = f'{score:.02f}'
+ cv2.putText(img, label_text,
+ (boundary_int[0], boundary_int[1] - 2),
+ cv2.FONT_HERSHEY_COMPLEX, font_scale, text_color)
+ if show:
+ mmcv.imshow(img, win_name, wait_time)
+ if out_file is not None:
+ mmcv.imwrite(img, out_file)
+
+ return img
+
+
+def imshow_text_char_boundary(img,
+ text_quads,
+ boundaries,
+ char_quads,
+ chars,
+ show=False,
+ thickness=1,
+ font_scale=0.5,
+ win_name='',
+ wait_time=-1,
+ out_file=None):
+ """Draw text boxes and char boxes on img.
+
+ Args:
+ img (str or ndarray): The img to be displayed.
+ text_quads (list[list[int|float]]): The text boxes.
+ boundaries (list[list[int|float]]): The boundary list.
+ char_quads (list[list[list[int|float]]]): A 2d list of char boxes.
+ char_quads[i] is for the ith text, and char_quads[i][j] is the jth
+ char of the ith text.
+ chars (list[list[char]]). The string for each text box.
+ thickness (int): Thickness of lines.
+ font_scale (float): Font scales of texts.
+ show (bool): Whether to show the image.
+ win_name (str): The window name.
+ wait_time (int): Value of waitKey param.
+ out_file (str or None): The filename of the output.
+ """
+ assert isinstance(img, (np.ndarray, str))
+ assert utils.is_2dlist(text_quads)
+ assert utils.is_2dlist(boundaries)
+ assert utils.is_3dlist(char_quads)
+ assert utils.is_2dlist(chars)
+ assert utils.equal_len(text_quads, char_quads, boundaries)
+
+ img = mmcv.imread(img)
+ char_color = [mmcv.color_val('blue'), mmcv.color_val('green')]
+ text_color = mmcv.color_val('red')
+ text_inx = 0
+ for text_box, boundary, char_box, txt in zip(text_quads, boundaries,
+ char_quads, chars):
+ text_box = np.array(text_box)
+ boundary = np.array(boundary)
+
+ text_box = text_box.reshape(-1, 2).astype(np.int32)
+ cv2.polylines(
+ img, [text_box.reshape(-1, 1, 2)],
+ True,
+ color=text_color,
+ thickness=thickness)
+ if boundary.shape[0] > 0:
+ cv2.polylines(
+ img, [boundary.reshape(-1, 1, 2)],
+ True,
+ color=text_color,
+ thickness=thickness)
+
+ for b in char_box:
+ b = np.array(b)
+ c = char_color[text_inx % 2]
+ b = b.astype(np.int32)
+ cv2.polylines(
+ img, [b.reshape(-1, 1, 2)], True, color=c, thickness=thickness)
+
+ label_text = ''.join(txt)
+ cv2.putText(img, label_text, (text_box[0, 0], text_box[0, 1] - 2),
+ cv2.FONT_HERSHEY_COMPLEX, font_scale, text_color)
+ text_inx = text_inx + 1
+
+ if show:
+ mmcv.imshow(img, win_name, wait_time)
+ if out_file is not None:
+ mmcv.imwrite(img, out_file)
+
+ return img
+
+
+def tile_image(images):
+ """Combined multiple images to one vertically.
+
+ Args:
+ images (list[np.ndarray]): Images to be combined.
+ """
+ assert isinstance(images, list)
+ assert len(images) > 0
+
+ for i, _ in enumerate(images):
+ if len(images[i].shape) == 2:
+ images[i] = cv2.cvtColor(images[i], cv2.COLOR_GRAY2BGR)
+
+ widths = [img.shape[1] for img in images]
+ heights = [img.shape[0] for img in images]
+ h, w = sum(heights), max(widths)
+ vis_img = np.zeros((h, w, 3), dtype=np.uint8)
+
+ offset_y = 0
+ for image in images:
+ img_h, img_w = image.shape[:2]
+ vis_img[offset_y:(offset_y + img_h), 0:img_w, :] = image
+ offset_y += img_h
+
+ return vis_img
+
+
+def imshow_text_label(img,
+ pred_label,
+ gt_label,
+ show=False,
+ win_name='',
+ wait_time=-1,
+ out_file=None):
+ """Draw predicted texts and ground truth texts on images.
+
+ Args:
+ img (str or np.ndarray): Image filename or loaded image.
+ pred_label (str): Predicted texts.
+ gt_label (str): Ground truth texts.
+ show (bool): Whether to show the image.
+ win_name (str): The window name.
+ wait_time (int): Value of waitKey param.
+ out_file (str): The filename of the output.
+ """
+ assert isinstance(img, (np.ndarray, str))
+ assert isinstance(pred_label, str)
+ assert isinstance(gt_label, str)
+ assert isinstance(show, bool)
+ assert isinstance(win_name, str)
+ assert isinstance(wait_time, int)
+
+ img = mmcv.imread(img)
+
+ src_h, src_w = img.shape[:2]
+ resize_height = 64
+ resize_width = int(1.0 * src_w / src_h * resize_height)
+ img = cv2.resize(img, (resize_width, resize_height))
+ h, w = img.shape[:2]
+
+ if is_contain_chinese(pred_label):
+ pred_img = draw_texts_by_pil(img, [pred_label], None)
+ else:
+ pred_img = np.ones((h, w, 3), dtype=np.uint8) * 255
+ cv2.putText(pred_img, pred_label, (5, 40), cv2.FONT_HERSHEY_SIMPLEX,
+ 0.9, (0, 0, 255), 2)
+ images = [pred_img, img]
+
+ if gt_label != '':
+ if is_contain_chinese(gt_label):
+ gt_img = draw_texts_by_pil(img, [gt_label], None)
+ else:
+ gt_img = np.ones((h, w, 3), dtype=np.uint8) * 255
+ cv2.putText(gt_img, gt_label, (5, 40), cv2.FONT_HERSHEY_SIMPLEX,
+ 0.9, (255, 0, 0), 2)
+ images.append(gt_img)
+
+ img = tile_image(images)
+
+ if show:
+ mmcv.imshow(img, win_name, wait_time)
+ if out_file is not None:
+ mmcv.imwrite(img, out_file)
+
+ return img
+
+
+def imshow_node(img,
+ result,
+ boxes,
+ idx_to_cls={},
+ show=False,
+ win_name='',
+ wait_time=-1,
+ out_file=None):
+
+ img = mmcv.imread(img)
+ h, w = img.shape[:2]
+
+ max_value, max_idx = torch.max(result['nodes'].detach().cpu(), -1)
+ node_pred_label = max_idx.numpy().tolist()
+ node_pred_score = max_value.numpy().tolist()
+
+ texts, text_boxes = [], []
+ for i, box in enumerate(boxes):
+ new_box = [[box[0], box[1]], [box[2], box[1]], [box[2], box[3]],
+ [box[0], box[3]]]
+ Pts = np.array([new_box], np.int32)
+ cv2.polylines(
+ img, [Pts.reshape((-1, 1, 2))],
+ True,
+ color=(255, 255, 0),
+ thickness=1)
+ x_min = int(min([point[0] for point in new_box]))
+ y_min = int(min([point[1] for point in new_box]))
+
+ # text
+ pred_label = str(node_pred_label[i])
+ if pred_label in idx_to_cls:
+ pred_label = idx_to_cls[pred_label]
+ pred_score = '{:.2f}'.format(node_pred_score[i])
+ text = pred_label + '(' + pred_score + ')'
+ texts.append(text)
+
+ # text box
+ font_size = int(
+ min(
+ abs(new_box[3][1] - new_box[0][1]),
+ abs(new_box[1][0] - new_box[0][0])))
+ char_num = len(text)
+ text_box = [
+ x_min * 2, y_min, x_min * 2 + font_size * char_num, y_min,
+ x_min * 2 + font_size * char_num, y_min + font_size, x_min * 2,
+ y_min + font_size
+ ]
+ text_boxes.append(text_box)
+
+ pred_img = np.ones((h, w * 2, 3), dtype=np.uint8) * 255
+ pred_img = draw_texts_by_pil(
+ pred_img, texts, text_boxes, draw_box=False, on_ori_img=True)
+
+ vis_img = np.ones((h, w * 3, 3), dtype=np.uint8) * 255
+ vis_img[:, :w] = img
+ vis_img[:, w:] = pred_img
+
+ if show:
+ mmcv.imshow(vis_img, win_name, wait_time)
+ if out_file is not None:
+ mmcv.imwrite(vis_img, out_file)
+
+ return vis_img
+
+
+def gen_color():
+ """Generate BGR color schemes."""
+ color_list = [(101, 67, 254), (154, 157, 252), (173, 205, 249),
+ (123, 151, 138), (187, 200, 178), (148, 137, 69),
+ (169, 200, 200), (155, 175, 131), (154, 194, 182),
+ (178, 190, 137), (140, 211, 222), (83, 156, 222)]
+ return color_list
+
+
+def draw_polygons(img, polys):
+ """Draw polygons on image.
+
+ Args:
+ img (np.ndarray): The original image.
+ polys (list[list[float]]): Detected polygons.
+ Return:
+ out_img (np.ndarray): Visualized image.
+ """
+ dst_img = img.copy()
+ color_list = gen_color()
+ out_img = dst_img
+ for idx, poly in enumerate(polys):
+ poly = np.array(poly).reshape((-1, 1, 2)).astype(np.int32)
+ cv2.drawContours(
+ img,
+ np.array([poly]),
+ -1,
+ color_list[idx % len(color_list)],
+ thickness=cv2.FILLED)
+ out_img = cv2.addWeighted(dst_img, 0.5, img, 0.5, 0)
+ return out_img
+
+
+def get_optimal_font_scale(text, width):
+ """Get optimal font scale for cv2.putText.
+
+ Args:
+ text (str): Text in one box.
+ width (int): The box width.
+ """
+ for scale in reversed(range(0, 60, 1)):
+ textSize = cv2.getTextSize(
+ text,
+ fontFace=cv2.FONT_HERSHEY_SIMPLEX,
+ fontScale=scale / 10,
+ thickness=1)
+ new_width = textSize[0][0]
+ if new_width <= width:
+ return scale / 10
+ return 1
+
+
+def draw_texts(img, texts, boxes=None, draw_box=True, on_ori_img=False):
+ """Draw boxes and texts on empty img.
+
+ Args:
+ img (np.ndarray): The original image.
+ texts (list[str]): Recognized texts.
+ boxes (list[list[float]]): Detected bounding boxes.
+ draw_box (bool): Whether draw box or not. If False, draw text only.
+ on_ori_img (bool): If True, draw box and text on input image,
+ else, on a new empty image.
+ Return:
+ out_img (np.ndarray): Visualized image.
+ """
+ color_list = gen_color()
+ h, w = img.shape[:2]
+ if boxes is None:
+ boxes = [[0, 0, w, 0, w, h, 0, h]]
+ assert len(texts) == len(boxes)
+
+ if on_ori_img:
+ out_img = img
+ else:
+ out_img = np.ones((h, w, 3), dtype=np.uint8) * 255
+ for idx, (box, text) in enumerate(zip(boxes, texts)):
+ if draw_box:
+ new_box = [[x, y] for x, y in zip(box[0::2], box[1::2])]
+ Pts = np.array([new_box], np.int32)
+ cv2.polylines(
+ out_img, [Pts.reshape((-1, 1, 2))],
+ True,
+ color=color_list[idx % len(color_list)],
+ thickness=1)
+ min_x = int(min(box[0::2]))
+ max_y = int(
+ np.mean(np.array(box[1::2])) + 0.2 *
+ (max(box[1::2]) - min(box[1::2])))
+ font_scale = get_optimal_font_scale(
+ text, int(max(box[0::2]) - min(box[0::2])))
+ cv2.putText(out_img, text, (min_x, max_y), cv2.FONT_HERSHEY_SIMPLEX,
+ font_scale, (0, 0, 0), 1)
+
+ return out_img
+
+
+def draw_texts_by_pil(img,
+ texts,
+ boxes=None,
+ draw_box=True,
+ on_ori_img=False,
+ font_size=None,
+ fill_color=None,
+ draw_pos=None,
+ return_text_size=False):
+ """Draw boxes and texts on empty image, especially for Chinese.
+
+ Args:
+ img (np.ndarray): The original image.
+ texts (list[str]): Recognized texts.
+ boxes (list[list[float]]): Detected bounding boxes.
+ draw_box (bool): Whether draw box or not. If False, draw text only.
+ on_ori_img (bool): If True, draw box and text on input image,
+ else on a new empty image.
+ font_size (int, optional): Size to create a font object for a font.
+ fill_color (tuple(int), optional): Fill color for text.
+ draw_pos (list[tuple(int)], optional): Start point to draw each text.
+ return_text_size (bool): If True, return the list of text size.
+
+ Returns:
+ (np.ndarray, list[tuple]) or np.ndarray: Return a tuple
+ ``(out_img, text_sizes)``, where ``out_img`` is the output image
+ with texts drawn on it and ``text_sizes`` are the size of drawing
+ texts. If ``return_text_size`` is False, only the output image will be
+ returned.
+ """
+
+ color_list = gen_color()
+ h, w = img.shape[:2]
+ if boxes is None:
+ boxes = [[0, 0, w, 0, w, h, 0, h]]
+ if draw_pos is None:
+ draw_pos = [None for _ in texts]
+ assert len(boxes) == len(texts) == len(draw_pos)
+
+ if fill_color is None:
+ fill_color = (0, 0, 0)
+
+ if on_ori_img:
+ out_img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
+ else:
+ out_img = Image.new('RGB', (w, h), color=(255, 255, 255))
+ out_draw = ImageDraw.Draw(out_img)
+
+ text_sizes = []
+ for idx, (box, text, ori_point) in enumerate(zip(boxes, texts, draw_pos)):
+ if len(text) == 0:
+ continue
+ min_x, max_x = min(box[0::2]), max(box[0::2])
+ min_y, max_y = min(box[1::2]), max(box[1::2])
+ color = tuple(list(color_list[idx % len(color_list)])[::-1])
+ if draw_box:
+ out_draw.line(box, fill=color, width=1)
+ dirname, _ = os.path.split(os.path.abspath(__file__))
+ font_path = os.path.join(dirname, 'font.TTF')
+ if not os.path.exists(font_path):
+ url = ('https://download.openmmlab.com/mmocr/data/font.TTF')
+ print(f'Downloading {url} ...')
+ local_filename, _ = urllib.request.urlretrieve(url)
+ shutil.move(local_filename, font_path)
+ tmp_font_size = font_size
+ if tmp_font_size is None:
+ box_width = max(max_x - min_x, max_y - min_y)
+ tmp_font_size = int(0.9 * box_width / len(text))
+ fnt = ImageFont.truetype(font_path, tmp_font_size)
+ if ori_point is None:
+ ori_point = (min_x + 1, min_y + 1)
+ out_draw.text(ori_point, text, font=fnt, fill=fill_color)
+ text_sizes.append(fnt.getsize(text))
+
+ del out_draw
+
+ out_img = cv2.cvtColor(np.asarray(out_img), cv2.COLOR_RGB2BGR)
+
+ if return_text_size:
+ return out_img, text_sizes
+
+ return out_img
+
+
+def is_contain_chinese(check_str):
+ """Check whether string contains Chinese or not.
+
+ Args:
+ check_str (str): String to be checked.
+
+ Return True if contains Chinese, else False.
+ """
+ for ch in check_str:
+ if u'\u4e00' <= ch <= u'\u9fff':
+ return True
+ return False
+
+
+def det_recog_show_result(img, end2end_res, out_file=None):
+ """Draw `result`(boxes and texts) on `img`.
+
+ Args:
+ img (str or np.ndarray): The image to be displayed.
+ end2end_res (dict): Text detect and recognize results.
+ out_file (str): Image path where the visualized image should be saved.
+ Return:
+ out_img (np.ndarray): Visualized image.
+ """
+ img = mmcv.imread(img)
+ boxes, texts = [], []
+ for res in end2end_res['result']:
+ boxes.append(res['box'])
+ texts.append(res['text'])
+ box_vis_img = draw_polygons(img, boxes)
+
+ if is_contain_chinese(''.join(texts)):
+ text_vis_img = draw_texts_by_pil(img, texts, boxes)
+ else:
+ text_vis_img = draw_texts(img, texts, boxes)
+
+ h, w = img.shape[:2]
+ out_img = np.ones((h, w * 2, 3), dtype=np.uint8)
+ out_img[:, :w, :] = box_vis_img
+ out_img[:, w:, :] = text_vis_img
+
+ if out_file:
+ mmcv.imwrite(out_img, out_file)
+
+ return out_img
+
+
+def draw_edge_result(img, result, edge_thresh=0.5, keynode_thresh=0.5):
+ """Draw text and their relationship on empty images.
+
+ Args:
+ img (np.ndarray): The original image.
+ result (dict): The result of model forward_test, including:
+ - img_metas (list[dict]): List of meta information dictionary.
+ - nodes (Tensor): Node prediction with size:
+ number_node * node_classes.
+ - edges (Tensor): Edge prediction with size: number_edge * 2.
+ edge_thresh (float): Score threshold for edge classification.
+ keynode_thresh (float): Score threshold for node
+ (``key``) classification.
+
+ Returns:
+ np.ndarray: The image with key, value and relation drawn on it.
+ """
+
+ h, w = img.shape[:2]
+
+ vis_area_width = w // 3 * 2
+ vis_area_height = h
+ dist_key_to_value = vis_area_width // 2
+ dist_pair_to_pair = 30
+
+ bbox_x1 = dist_pair_to_pair
+ bbox_y1 = 0
+
+ new_w = vis_area_width
+ new_h = vis_area_height
+ pred_edge_img = np.ones((new_h, new_w, 3), dtype=np.uint8) * 255
+
+ nodes = result['nodes'].detach().cpu()
+ texts = result['img_metas'][0]['ori_texts']
+ num_nodes = result['nodes'].size(0)
+ edges = result['edges'].detach().cpu()[:, -1].view(num_nodes, num_nodes)
+
+ # (i, j) will be a valid pair
+ # either edge_score(node_i->node_j) > edge_thresh
+ # or edge_score(node_j->node_i) > edge_thresh
+ pairs = (torch.max(edges, edges.T) > edge_thresh).nonzero(as_tuple=True)
+ pairs = (pairs[0].numpy().tolist(), pairs[1].numpy().tolist())
+
+ # 1. "for n1, n2 in zip(*pairs) if n1 < n2":
+ # Only (n1, n2) will be included if n1 < n2 but not (n2, n1), to
+ # avoid duplication.
+ # 2. "(n1, n2) if nodes[n1, 1] > nodes[n1, 2]":
+ # nodes[n1, 1] is the score that this node is predicted as key,
+ # nodes[n1, 2] is the score that this node is predicted as value.
+ # If nodes[n1, 1] > nodes[n1, 2], n1 will be the index of key,
+ # so that n2 will be the index of value.
+ result_pairs = [(n1, n2) if nodes[n1, 1] > nodes[n1, 2] else (n2, n1)
+ for n1, n2 in zip(*pairs) if n1 < n2]
+
+ result_pairs.sort()
+ result_pairs_score = [
+ torch.max(edges[n1, n2], edges[n2, n1]) for n1, n2 in result_pairs
+ ]
+
+ key_current_idx = -1
+ pos_current = (-1, -1)
+ newline_flag = False
+
+ key_font_size = 15
+ value_font_size = 15
+ key_font_color = (0, 0, 0)
+ value_font_color = (0, 0, 255)
+ arrow_color = (0, 0, 255)
+ score_color = (0, 255, 0)
+ for pair, pair_score in zip(result_pairs, result_pairs_score):
+ key_idx = pair[0]
+ if nodes[key_idx, 1] < keynode_thresh:
+ continue
+ if key_idx != key_current_idx:
+ # move y-coords down for a new key
+ bbox_y1 += 10
+ # enlarge blank area to show key-value info
+ if newline_flag:
+ bbox_x1 += vis_area_width
+ tmp_img = np.ones(
+ (new_h, new_w + vis_area_width, 3), dtype=np.uint8) * 255
+ tmp_img[:new_h, :new_w] = pred_edge_img
+ pred_edge_img = tmp_img
+ new_w += vis_area_width
+ newline_flag = False
+ bbox_y1 = 10
+ key_text = texts[key_idx]
+ key_pos = (bbox_x1, bbox_y1)
+ value_idx = pair[1]
+ value_text = texts[value_idx]
+ value_pos = (bbox_x1 + dist_key_to_value, bbox_y1)
+ if key_idx != key_current_idx:
+ # draw text for a new key
+ key_current_idx = key_idx
+ pred_edge_img, text_sizes = draw_texts_by_pil(
+ pred_edge_img, [key_text],
+ draw_box=False,
+ on_ori_img=True,
+ font_size=key_font_size,
+ fill_color=key_font_color,
+ draw_pos=[key_pos],
+ return_text_size=True)
+ pos_right_bottom = (key_pos[0] + text_sizes[0][0],
+ key_pos[1] + text_sizes[0][1])
+ pos_current = (pos_right_bottom[0] + 5, bbox_y1 + 10)
+ pred_edge_img = cv2.arrowedLine(
+ pred_edge_img, (pos_right_bottom[0] + 5, bbox_y1 + 10),
+ (bbox_x1 + dist_key_to_value - 5, bbox_y1 + 10), arrow_color,
+ 1)
+ score_pos_x = int(
+ (pos_right_bottom[0] + bbox_x1 + dist_key_to_value) / 2.)
+ score_pos_y = bbox_y1 + 10 - int(key_font_size * 0.3)
+ else:
+ # draw arrow from key to value
+ if newline_flag:
+ tmp_img = np.ones((new_h + dist_pair_to_pair, new_w, 3),
+ dtype=np.uint8) * 255
+ tmp_img[:new_h, :new_w] = pred_edge_img
+ pred_edge_img = tmp_img
+ new_h += dist_pair_to_pair
+ pred_edge_img = cv2.arrowedLine(pred_edge_img, pos_current,
+ (bbox_x1 + dist_key_to_value - 5,
+ bbox_y1 + 10), arrow_color, 1)
+ score_pos_x = int(
+ (pos_current[0] + bbox_x1 + dist_key_to_value - 5) / 2.)
+ score_pos_y = int((pos_current[1] + bbox_y1 + 10) / 2.)
+ # draw edge score
+ cv2.putText(pred_edge_img, '{:.2f}'.format(pair_score),
+ (score_pos_x, score_pos_y), cv2.FONT_HERSHEY_COMPLEX, 0.4,
+ score_color)
+ # draw text for value
+ pred_edge_img = draw_texts_by_pil(
+ pred_edge_img, [value_text],
+ draw_box=False,
+ on_ori_img=True,
+ font_size=value_font_size,
+ fill_color=value_font_color,
+ draw_pos=[value_pos],
+ return_text_size=False)
+ bbox_y1 += dist_pair_to_pair
+ if bbox_y1 + dist_pair_to_pair >= new_h:
+ newline_flag = True
+
+ return pred_edge_img
+
+
+def imshow_edge(img,
+ result,
+ boxes,
+ show=False,
+ win_name='',
+ wait_time=-1,
+ out_file=None):
+ """Display the prediction results of the nodes and edges of the KIE model.
+
+ Args:
+ img (np.ndarray): The original image.
+ result (dict): The result of model forward_test, including:
+ - img_metas (list[dict]): List of meta information dictionary.
+ - nodes (Tensor): Node prediction with size: \
+ number_node * node_classes.
+ - edges (Tensor): Edge prediction with size: number_edge * 2.
+ boxes (list): The text boxes corresponding to the nodes.
+ show (bool): Whether to show the image. Default: False.
+ win_name (str): The window name. Default: ''
+ wait_time (float): Value of waitKey param. Default: 0.
+ out_file (str or None): The filename to write the image.
+ Default: None.
+
+ Returns:
+ np.ndarray: The image with key, value and relation drawn on it.
+ """
+ img = mmcv.imread(img)
+ h, w = img.shape[:2]
+ color_list = gen_color()
+
+ for i, box in enumerate(boxes):
+ new_box = [[box[0], box[1]], [box[2], box[1]], [box[2], box[3]],
+ [box[0], box[3]]]
+ Pts = np.array([new_box], np.int32)
+ cv2.polylines(
+ img, [Pts.reshape((-1, 1, 2))],
+ True,
+ color=color_list[i % len(color_list)],
+ thickness=1)
+
+ pred_img_h = h
+ pred_img_w = w
+
+ pred_edge_img = draw_edge_result(img, result)
+ pred_img_h = max(pred_img_h, pred_edge_img.shape[0])
+ pred_img_w += pred_edge_img.shape[1]
+
+ vis_img = np.zeros((pred_img_h, pred_img_w, 3), dtype=np.uint8)
+ vis_img[:h, :w] = img
+ vis_img[:, w:] = 255
+
+ height_t, width_t = pred_edge_img.shape[:2]
+ vis_img[:height_t, w:(w + width_t)] = pred_edge_img
+
+ if show:
+ mmcv.imshow(vis_img, win_name, wait_time)
+ if out_file is not None:
+ mmcv.imwrite(vis_img, out_file)
+ res_dic = {
+ 'boxes': boxes,
+ 'nodes': result['nodes'].detach().cpu(),
+ 'edges': result['edges'].detach().cpu(),
+ 'metas': result['img_metas'][0]
+ }
+ mmcv.dump(res_dic, f'{out_file}_res.pkl')
+
+ return vis_img
diff --git a/mmocr/datasets/__init__.py b/mmocr/datasets/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..c16565b1e76b9f9ab92b2da3d057ecf12a0bb593
--- /dev/null
+++ b/mmocr/datasets/__init__.py
@@ -0,0 +1,24 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.datasets.builder import DATASETS, build_dataloader, build_dataset
+
+from . import utils
+from .base_dataset import BaseDataset
+from .icdar_dataset import IcdarDataset
+from .kie_dataset import KIEDataset
+from .ner_dataset import NerDataset
+from .ocr_dataset import OCRDataset
+from .ocr_seg_dataset import OCRSegDataset
+from .openset_kie_dataset import OpensetKIEDataset
+from .pipelines import CustomFormatBundle, DBNetTargets, FCENetTargets
+from .text_det_dataset import TextDetDataset
+from .uniform_concat_dataset import UniformConcatDataset
+from .utils import * # NOQA
+
+__all__ = [
+ 'DATASETS', 'IcdarDataset', 'build_dataloader', 'build_dataset',
+ 'BaseDataset', 'OCRDataset', 'TextDetDataset', 'CustomFormatBundle',
+ 'DBNetTargets', 'OCRSegDataset', 'KIEDataset', 'FCENetTargets',
+ 'NerDataset', 'UniformConcatDataset', 'OpensetKIEDataset'
+]
+
+__all__ += utils.__all__
diff --git a/mmocr/datasets/base_dataset.py b/mmocr/datasets/base_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..5dc54e4673a11ed0255507be3766ee629180e1ed
--- /dev/null
+++ b/mmocr/datasets/base_dataset.py
@@ -0,0 +1,167 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+from mmcv.utils import print_log
+from mmdet.datasets.builder import DATASETS
+from mmdet.datasets.pipelines import Compose
+from torch.utils.data import Dataset
+
+from mmocr.datasets.builder import build_loader
+
+
+@DATASETS.register_module()
+class BaseDataset(Dataset):
+ """Custom dataset for text detection, text recognition, and their
+ downstream tasks.
+
+ 1. The text detection annotation format is as follows:
+ The `annotations` field is optional for testing
+ (this is one line of anno_file, with line-json-str
+ converted to dict for visualizing only).
+
+ {
+ "file_name": "sample.jpg",
+ "height": 1080,
+ "width": 960,
+ "annotations":
+ [
+ {
+ "iscrowd": 0,
+ "category_id": 1,
+ "bbox": [357.0, 667.0, 804.0, 100.0],
+ "segmentation": [[361, 667, 710, 670,
+ 72, 767, 357, 763]]
+ }
+ ]
+ }
+
+ 2. The two text recognition annotation formats are as follows:
+ The `x1,y1,x2,y2,x3,y3,x4,y4` field is used for online crop
+ augmentation during training.
+
+ format1: sample.jpg hello
+ format2: sample.jpg 20 20 100 20 100 40 20 40 hello
+
+ Args:
+ ann_file (str): Annotation file path.
+ pipeline (list[dict]): Processing pipeline.
+ loader (dict): Dictionary to construct loader
+ to load annotation infos.
+ img_prefix (str, optional): Image prefix to generate full
+ image path.
+ test_mode (bool, optional): If set True, try...except will
+ be turned off in __getitem__.
+ """
+
+ def __init__(self,
+ ann_file,
+ loader,
+ pipeline,
+ img_prefix='',
+ test_mode=False):
+ super().__init__()
+ self.test_mode = test_mode
+ self.img_prefix = img_prefix
+ self.ann_file = ann_file
+ # load annotations
+ loader.update(ann_file=ann_file)
+ self.data_infos = build_loader(loader)
+ # processing pipeline
+ self.pipeline = Compose(pipeline)
+ # set group flag and class, no meaning
+ # for text detect and recognize
+ self._set_group_flag()
+ self.CLASSES = 0
+
+ def __len__(self):
+ return len(self.data_infos)
+
+ def _set_group_flag(self):
+ """Set flag."""
+ self.flag = np.zeros(len(self), dtype=np.uint8)
+
+ def pre_pipeline(self, results):
+ """Prepare results dict for pipeline."""
+ results['img_prefix'] = self.img_prefix
+
+ def prepare_train_img(self, index):
+ """Get training data and annotations from pipeline.
+
+ Args:
+ index (int): Index of data.
+
+ Returns:
+ dict: Training data and annotation after pipeline with new keys
+ introduced by pipeline.
+ """
+ img_info = self.data_infos[index]
+ results = dict(img_info=img_info)
+ self.pre_pipeline(results)
+ return self.pipeline(results)
+
+ def prepare_test_img(self, img_info):
+ """Get testing data from pipeline.
+
+ Args:
+ idx (int): Index of data.
+
+ Returns:
+ dict: Testing data after pipeline with new keys introduced by
+ pipeline.
+ """
+ return self.prepare_train_img(img_info)
+
+ def _log_error_index(self, index):
+ """Logging data info of bad index."""
+ try:
+ data_info = self.data_infos[index]
+ img_prefix = self.img_prefix
+ print_log(f'Warning: skip broken file {data_info} '
+ f'with img_prefix {img_prefix}')
+ except Exception as e:
+ print_log(f'load index {index} with error {e}')
+
+ def _get_next_index(self, index):
+ """Get next index from dataset."""
+ self._log_error_index(index)
+ index = (index + 1) % len(self)
+ return index
+
+ def __getitem__(self, index):
+ """Get training/test data from pipeline.
+
+ Args:
+ index (int): Index of data.
+
+ Returns:
+ dict: Training/test data.
+ """
+ if self.test_mode:
+ return self.prepare_test_img(index)
+
+ while True:
+ try:
+ data = self.prepare_train_img(index)
+ if data is None:
+ raise Exception('prepared train data empty')
+ break
+ except Exception as e:
+ print_log(f'prepare index {index} with error {e}')
+ index = self._get_next_index(index)
+ return data
+
+ def format_results(self, results, **kwargs):
+ """Placeholder to format result to dataset-specific output."""
+ pass
+
+ def evaluate(self, results, metric=None, logger=None, **kwargs):
+ """Evaluate the dataset.
+
+ Args:
+ results (list): Testing results of the dataset.
+ metric (str | list[str]): Metrics to be evaluated.
+ logger (logging.Logger | str | None): Logger used for printing
+ related information during evaluation. Default: None.
+ Returns:
+ dict[str: float]
+ """
+ raise NotImplementedError
diff --git a/mmocr/datasets/builder.py b/mmocr/datasets/builder.py
new file mode 100644
index 0000000000000000000000000000000000000000..1e4cc66e11500f135ec4445dce1f8bd2fd96a360
--- /dev/null
+++ b/mmocr/datasets/builder.py
@@ -0,0 +1,15 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.utils import Registry, build_from_cfg
+
+LOADERS = Registry('loader')
+PARSERS = Registry('parser')
+
+
+def build_loader(cfg):
+ """Build anno file loader."""
+ return build_from_cfg(cfg, LOADERS)
+
+
+def build_parser(cfg):
+ """Build anno file parser."""
+ return build_from_cfg(cfg, PARSERS)
diff --git a/mmocr/datasets/icdar_dataset.py b/mmocr/datasets/icdar_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..1340c8b50c29c5649ba6ccede6ebaa19d238af4a
--- /dev/null
+++ b/mmocr/datasets/icdar_dataset.py
@@ -0,0 +1,178 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import mmcv
+import numpy as np
+from mmdet.datasets.api_wrappers import COCO
+from mmdet.datasets.builder import DATASETS
+from mmdet.datasets.coco import CocoDataset
+
+import mmocr.utils as utils
+from mmocr import digit_version
+from mmocr.core.evaluation.hmean import eval_hmean
+
+
+@DATASETS.register_module()
+class IcdarDataset(CocoDataset):
+ """Dataset for text detection while ann_file in coco format.
+
+ Args:
+ ann_file_backend (str): Storage backend for annotation file,
+ should be one in ['disk', 'petrel', 'http']. Default to 'disk'.
+ """
+ CLASSES = ('text')
+
+ def __init__(self,
+ ann_file,
+ pipeline,
+ classes=None,
+ data_root=None,
+ img_prefix='',
+ seg_prefix=None,
+ proposal_file=None,
+ test_mode=False,
+ filter_empty_gt=True,
+ select_first_k=-1,
+ ann_file_backend='disk'):
+ # select first k images for fast debugging.
+ self.select_first_k = select_first_k
+ assert ann_file_backend in ['disk', 'petrel', 'http']
+ self.ann_file_backend = ann_file_backend
+
+ super().__init__(ann_file, pipeline, classes, data_root, img_prefix,
+ seg_prefix, proposal_file, test_mode, filter_empty_gt)
+
+ def load_annotations(self, ann_file):
+ """Load annotation from COCO style annotation file.
+
+ Args:
+ ann_file (str): Path of annotation file.
+
+ Returns:
+ list[dict]: Annotation info from COCO api.
+ """
+ if self.ann_file_backend == 'disk':
+ self.coco = COCO(ann_file)
+ else:
+ mmcv_version = digit_version(mmcv.__version__)
+ if mmcv_version < digit_version('1.3.16'):
+ raise Exception('Please update mmcv to 1.3.16 or higher '
+ 'to enable "get_local_path" of "FileClient".')
+ file_client = mmcv.FileClient(backend=self.ann_file_backend)
+ with file_client.get_local_path(ann_file) as local_path:
+ self.coco = COCO(local_path)
+ self.cat_ids = self.coco.get_cat_ids(cat_names=self.CLASSES)
+ self.cat2label = {cat_id: i for i, cat_id in enumerate(self.cat_ids)}
+ self.img_ids = self.coco.get_img_ids()
+ data_infos = []
+
+ count = 0
+ for i in self.img_ids:
+ info = self.coco.load_imgs([i])[0]
+ info['filename'] = info['file_name']
+ data_infos.append(info)
+ count = count + 1
+ if count > self.select_first_k and self.select_first_k > 0:
+ break
+ return data_infos
+
+ def _parse_ann_info(self, img_info, ann_info):
+ """Parse bbox and mask annotation.
+
+ Args:
+ ann_info (list[dict]): Annotation info of an image.
+
+ Returns:
+ dict: A dict containing the following keys: bboxes, bboxes_ignore,
+ labels, masks, masks_ignore, seg_map. "masks" and
+ "masks_ignore" are represented by polygon boundary
+ point sequences.
+ """
+ gt_bboxes = []
+ gt_labels = []
+ gt_bboxes_ignore = []
+ gt_masks_ignore = []
+ gt_masks_ann = []
+
+ for ann in ann_info:
+ if ann.get('ignore', False):
+ continue
+ x1, y1, w, h = ann['bbox']
+ if ann['area'] <= 0 or w < 1 or h < 1:
+ continue
+ if ann['category_id'] not in self.cat_ids:
+ continue
+ bbox = [x1, y1, x1 + w, y1 + h]
+ if ann.get('iscrowd', False):
+ gt_bboxes_ignore.append(bbox)
+ gt_masks_ignore.append(ann.get(
+ 'segmentation', None)) # to float32 for latter processing
+
+ else:
+ gt_bboxes.append(bbox)
+ gt_labels.append(self.cat2label[ann['category_id']])
+ gt_masks_ann.append(ann.get('segmentation', None))
+ if gt_bboxes:
+ gt_bboxes = np.array(gt_bboxes, dtype=np.float32)
+ gt_labels = np.array(gt_labels, dtype=np.int64)
+ else:
+ gt_bboxes = np.zeros((0, 4), dtype=np.float32)
+ gt_labels = np.array([], dtype=np.int64)
+
+ if gt_bboxes_ignore:
+ gt_bboxes_ignore = np.array(gt_bboxes_ignore, dtype=np.float32)
+ else:
+ gt_bboxes_ignore = np.zeros((0, 4), dtype=np.float32)
+
+ seg_map = img_info['filename'].replace('jpg', 'png')
+
+ ann = dict(
+ bboxes=gt_bboxes,
+ labels=gt_labels,
+ bboxes_ignore=gt_bboxes_ignore,
+ masks_ignore=gt_masks_ignore,
+ masks=gt_masks_ann,
+ seg_map=seg_map)
+
+ return ann
+
+ def evaluate(self,
+ results,
+ metric='hmean-iou',
+ logger=None,
+ score_thr=0.3,
+ rank_list=None,
+ **kwargs):
+ """Evaluate the hmean metric.
+
+ Args:
+ results (list[dict]): Testing results of the dataset.
+ metric (str | list[str]): Metrics to be evaluated.
+ logger (logging.Logger | str | None): Logger used for printing
+ related information during evaluation. Default: None.
+ rank_list (str): json file used to save eval result
+ of each image after ranking.
+ Returns:
+ dict[dict[str: float]]: The evaluation results.
+ """
+ assert utils.is_type_list(results, dict)
+
+ metrics = metric if isinstance(metric, list) else [metric]
+ allowed_metrics = ['hmean-iou', 'hmean-ic13']
+ metrics = set(metrics) & set(allowed_metrics)
+
+ img_infos = []
+ ann_infos = []
+ for i in range(len(self)):
+ img_info = {'filename': self.data_infos[i]['file_name']}
+ img_infos.append(img_info)
+ ann_infos.append(self.get_ann_info(i))
+
+ eval_results = eval_hmean(
+ results,
+ img_infos,
+ ann_infos,
+ metrics=metrics,
+ score_thr=score_thr,
+ logger=logger,
+ rank_list=rank_list)
+
+ return eval_results
diff --git a/mmocr/datasets/kie_dataset.py b/mmocr/datasets/kie_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..bcbf324f56a4a18442a5d1466757e95fc0e56acf
--- /dev/null
+++ b/mmocr/datasets/kie_dataset.py
@@ -0,0 +1,236 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import warnings
+from os import path as osp
+
+import numpy as np
+import torch
+from mmdet.datasets.builder import DATASETS
+
+from mmocr.core import compute_f1_score
+from mmocr.datasets.base_dataset import BaseDataset
+from mmocr.datasets.pipelines import sort_vertex8
+from mmocr.utils import is_type_list, list_from_file
+
+
+@DATASETS.register_module()
+class KIEDataset(BaseDataset):
+ """
+ Args:
+ ann_file (str): Annotation file path.
+ pipeline (list[dict]): Processing pipeline.
+ loader (dict): Dictionary to construct loader
+ to load annotation infos.
+ img_prefix (str, optional): Image prefix to generate full
+ image path.
+ test_mode (bool, optional): If True, try...except will
+ be turned off in __getitem__.
+ dict_file (str): Character dict file path.
+ norm (float): Norm to map value from one range to another.
+ """
+
+ def __init__(self,
+ ann_file=None,
+ loader=None,
+ dict_file=None,
+ img_prefix='',
+ pipeline=None,
+ norm=10.,
+ directed=False,
+ test_mode=True,
+ **kwargs):
+ if ann_file is None and loader is None:
+ warnings.warn(
+ 'KIEDataset is only initialized as a downstream demo task '
+ 'of text detection and recognition '
+ 'without an annotation file.', UserWarning)
+ else:
+ super().__init__(
+ ann_file,
+ loader,
+ pipeline,
+ img_prefix=img_prefix,
+ test_mode=test_mode)
+ assert osp.exists(dict_file)
+
+ self.norm = norm
+ self.directed = directed
+ self.dict = {
+ '': 0,
+ **{
+ line.rstrip('\r\n'): ind
+ for ind, line in enumerate(list_from_file(dict_file), 1)
+ }
+ }
+
+ def pre_pipeline(self, results):
+ results['img_prefix'] = self.img_prefix
+ results['bbox_fields'] = []
+ results['ori_texts'] = results['ann_info']['ori_texts']
+ results['filename'] = osp.join(self.img_prefix,
+ results['img_info']['filename'])
+ results['ori_filename'] = results['img_info']['filename']
+ # a dummy img data
+ results['img'] = np.zeros((0, 0, 0), dtype=np.uint8)
+
+ def _parse_anno_info(self, annotations):
+ """Parse annotations of boxes, texts and labels for one image.
+ Args:
+ annotations (list[dict]): Annotations of one image, where
+ each dict is for one character.
+
+ Returns:
+ dict: A dict containing the following keys:
+
+ - bboxes (np.ndarray): Bbox in one image with shape:
+ box_num * 4. They are sorted clockwise when loading.
+ - relations (np.ndarray): Relations between bbox with shape:
+ box_num * box_num * D.
+ - texts (np.ndarray): Text index with shape:
+ box_num * text_max_len.
+ - labels (np.ndarray): Box Labels with shape:
+ box_num * (box_num + 1).
+ """
+
+ assert is_type_list(annotations, dict)
+ assert len(annotations) > 0, 'Please remove data with empty annotation'
+ assert 'box' in annotations[0]
+ assert 'text' in annotations[0]
+
+ boxes, texts, text_inds, labels, edges = [], [], [], [], []
+ for ann in annotations:
+ box = ann['box']
+ sorted_box = sort_vertex8(box[:8])
+ boxes.append(sorted_box)
+ text = ann['text']
+ texts.append(ann['text'])
+ text_ind = [self.dict[c] for c in text if c in self.dict]
+ text_inds.append(text_ind)
+ labels.append(ann.get('label', 0))
+ edges.append(ann.get('edge', 0))
+
+ ann_infos = dict(
+ boxes=boxes,
+ texts=texts,
+ text_inds=text_inds,
+ edges=edges,
+ labels=labels)
+
+ return self.list_to_numpy(ann_infos)
+
+ def prepare_train_img(self, index):
+ """Get training data and annotations from pipeline.
+
+ Args:
+ index (int): Index of data.
+
+ Returns:
+ dict: Training data and annotation after pipeline with new keys
+ introduced by pipeline.
+ """
+ img_ann_info = self.data_infos[index]
+ img_info = {
+ 'filename': img_ann_info['file_name'],
+ 'height': img_ann_info['height'],
+ 'width': img_ann_info['width']
+ }
+ ann_info = self._parse_anno_info(img_ann_info['annotations'])
+ results = dict(img_info=img_info, ann_info=ann_info)
+
+ self.pre_pipeline(results)
+
+ return self.pipeline(results)
+
+ def evaluate(self,
+ results,
+ metric='macro_f1',
+ metric_options=dict(macro_f1=dict(ignores=[])),
+ **kwargs):
+ # allow some kwargs to pass through
+ assert set(kwargs).issubset(['logger'])
+
+ # Protect ``metric_options`` since it uses mutable value as default
+ metric_options = copy.deepcopy(metric_options)
+
+ metrics = metric if isinstance(metric, list) else [metric]
+ allowed_metrics = ['macro_f1']
+ for m in metrics:
+ if m not in allowed_metrics:
+ raise KeyError(f'metric {m} is not supported')
+
+ return self.compute_macro_f1(results, **metric_options['macro_f1'])
+
+ def compute_macro_f1(self, results, ignores=[]):
+ node_preds = []
+ node_gts = []
+ for idx, result in enumerate(results):
+ node_preds.append(result['nodes'].cpu())
+ box_ann_infos = self.data_infos[idx]['annotations']
+ node_gt = [box_ann_info['label'] for box_ann_info in box_ann_infos]
+ node_gts.append(torch.Tensor(node_gt))
+
+ node_preds = torch.cat(node_preds)
+ node_gts = torch.cat(node_gts).int()
+
+ node_f1s = compute_f1_score(node_preds, node_gts, ignores)
+
+ return {
+ 'macro_f1': node_f1s.mean(),
+ }
+
+ def list_to_numpy(self, ann_infos):
+ """Convert bboxes, relations, texts and labels to ndarray."""
+ boxes, text_inds = ann_infos['boxes'], ann_infos['text_inds']
+ texts = ann_infos['texts']
+ boxes = np.array(boxes, np.int32)
+ relations, bboxes = self.compute_relation(boxes)
+
+ labels = ann_infos.get('labels', None)
+ if labels is not None:
+ labels = np.array(labels, np.int32)
+ edges = ann_infos.get('edges', None)
+ if edges is not None:
+ labels = labels[:, None]
+ edges = np.array(edges)
+ edges = (edges[:, None] == edges[None, :]).astype(np.int32)
+ if self.directed:
+ edges = (edges & labels == 1).astype(np.int32)
+ np.fill_diagonal(edges, -1)
+ labels = np.concatenate([labels, edges], -1)
+ padded_text_inds = self.pad_text_indices(text_inds)
+
+ return dict(
+ bboxes=bboxes,
+ relations=relations,
+ texts=padded_text_inds,
+ ori_texts=texts,
+ labels=labels)
+
+ def pad_text_indices(self, text_inds):
+ """Pad text index to same length."""
+ max_len = max([len(text_ind) for text_ind in text_inds])
+ padded_text_inds = -np.ones((len(text_inds), max_len), np.int32)
+ for idx, text_ind in enumerate(text_inds):
+ padded_text_inds[idx, :len(text_ind)] = np.array(text_ind)
+ return padded_text_inds
+
+ def compute_relation(self, boxes):
+ """Compute relation between every two boxes."""
+ # Get minimal axis-aligned bounding boxes for each of the boxes
+ # yapf: disable
+ bboxes = np.concatenate(
+ [boxes[:, 0::2].min(axis=1, keepdims=True),
+ boxes[:, 1::2].min(axis=1, keepdims=True),
+ boxes[:, 0::2].max(axis=1, keepdims=True),
+ boxes[:, 1::2].max(axis=1, keepdims=True)],
+ axis=1).astype(np.float32)
+ # yapf: enable
+ x1, y1 = bboxes[:, 0:1], bboxes[:, 1:2]
+ x2, y2 = bboxes[:, 2:3], bboxes[:, 3:4]
+ w, h = np.maximum(x2 - x1 + 1, 1), np.maximum(y2 - y1 + 1, 1)
+ dx = (x1.T - x1) / self.norm
+ dy = (y1.T - y1) / self.norm
+ xhh, xwh = h.T / h, w.T / h
+ whs = w / h + np.zeros_like(xhh)
+ relation = np.stack([dx, dy, whs, xhh, xwh], -1).astype(np.float32)
+ return relation, bboxes
diff --git a/mmocr/datasets/ner_dataset.py b/mmocr/datasets/ner_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..923942c343dff8389f4ec20e8f97e7e082a70031
--- /dev/null
+++ b/mmocr/datasets/ner_dataset.py
@@ -0,0 +1,49 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.datasets.builder import DATASETS
+
+from mmocr.core.evaluation.ner_metric import eval_ner_f1
+from mmocr.datasets.base_dataset import BaseDataset
+
+
+@DATASETS.register_module()
+class NerDataset(BaseDataset):
+ """Custom dataset for named entity recognition tasks.
+
+ Args:
+ ann_file (txt): Annotation file path.
+ loader (dict): Dictionary to construct loader
+ to load annotation infos.
+ pipeline (list[dict]): Processing pipeline.
+ test_mode (bool, optional): If True, try...except will
+ be turned off in __getitem__.
+ """
+
+ def prepare_train_img(self, index):
+ """Get training data and annotations after pipeline.
+
+ Args:
+ index (int): Index of data.
+
+ Returns:
+ dict: Training data and annotation after pipeline with new keys \
+ introduced by pipeline.
+ """
+ ann_info = self.data_infos[index]
+
+ return self.pipeline(ann_info)
+
+ def evaluate(self, results, metric=None, logger=None, **kwargs):
+ """Evaluate the dataset.
+
+ Args:
+ results (list): Testing results of the dataset.
+ metric (str | list[str]): Metrics to be evaluated.
+ logger (logging.Logger | str | None): Logger used for printing
+ related information during evaluation. Default: None.
+ Returns:
+ info (dict): A dict containing the following keys:
+ 'acc', 'recall', 'f1-score'.
+ """
+ gt_infos = list(self.data_infos)
+ eval_results = eval_ner_f1(results, gt_infos)
+ return eval_results
diff --git a/mmocr/datasets/ocr_dataset.py b/mmocr/datasets/ocr_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..b24d15d6046d2cdd0c911fe1ecc888933418cd05
--- /dev/null
+++ b/mmocr/datasets/ocr_dataset.py
@@ -0,0 +1,36 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.datasets.builder import DATASETS
+
+from mmocr.core.evaluation.ocr_metric import eval_ocr_metric
+from mmocr.datasets.base_dataset import BaseDataset
+
+
+@DATASETS.register_module()
+class OCRDataset(BaseDataset):
+
+ def pre_pipeline(self, results):
+ results['img_prefix'] = self.img_prefix
+ results['text'] = results['img_info']['text']
+
+ def evaluate(self, results, metric='acc', logger=None, **kwargs):
+ """Evaluate the dataset.
+
+ Args:
+ results (list): Testing results of the dataset.
+ metric (str | list[str]): Metrics to be evaluated.
+ logger (logging.Logger | str | None): Logger used for printing
+ related information during evaluation. Default: None.
+ Returns:
+ dict[str: float]
+ """
+ gt_texts = []
+ pred_texts = []
+ for i in range(len(self)):
+ item_info = self.data_infos[i]
+ text = item_info['text']
+ gt_texts.append(text)
+ pred_texts.append(results[i]['text'])
+
+ eval_results = eval_ocr_metric(pred_texts, gt_texts)
+
+ return eval_results
diff --git a/mmocr/datasets/ocr_seg_dataset.py b/mmocr/datasets/ocr_seg_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..cd4b727d6b28ec9b0b17e3470856608ea7b36e42
--- /dev/null
+++ b/mmocr/datasets/ocr_seg_dataset.py
@@ -0,0 +1,91 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.datasets.builder import DATASETS
+
+import mmocr.utils as utils
+from mmocr.datasets.ocr_dataset import OCRDataset
+
+
+@DATASETS.register_module()
+class OCRSegDataset(OCRDataset):
+
+ def pre_pipeline(self, results):
+ results['img_prefix'] = self.img_prefix
+
+ def _parse_anno_info(self, annotations):
+ """Parse char boxes annotations.
+ Args:
+ annotations (list[dict]): Annotations of one image, where
+ each dict is for one character.
+
+ Returns:
+ dict: A dict containing the following keys:
+
+ - chars (list[str]): List of character strings.
+ - char_rects (list[list[float]]): List of char box, with each
+ in style of rectangle: [x_min, y_min, x_max, y_max].
+ - char_quads (list[list[float]]): List of char box, with each
+ in style of quadrangle: [x1, y1, x2, y2, x3, y3, x4, y4].
+ """
+
+ assert utils.is_type_list(annotations, dict)
+ assert 'char_box' in annotations[0]
+ assert 'char_text' in annotations[0]
+ assert len(annotations[0]['char_box']) in [4, 8]
+
+ chars, char_rects, char_quads = [], [], []
+ for ann in annotations:
+ char_box = ann['char_box']
+ if len(char_box) == 4:
+ char_box_type = ann.get('char_box_type', 'xyxy')
+ if char_box_type == 'xyxy':
+ char_rects.append(char_box)
+ char_quads.append([
+ char_box[0], char_box[1], char_box[2], char_box[1],
+ char_box[2], char_box[3], char_box[0], char_box[3]
+ ])
+ elif char_box_type == 'xywh':
+ x1, y1, w, h = char_box
+ x2 = x1 + w
+ y2 = y1 + h
+ char_rects.append([x1, y1, x2, y2])
+ char_quads.append([x1, y1, x2, y1, x2, y2, x1, y2])
+ else:
+ raise ValueError(f'invalid char_box_type {char_box_type}')
+ elif len(char_box) == 8:
+ x_list, y_list = [], []
+ for i in range(4):
+ x_list.append(char_box[2 * i])
+ y_list.append(char_box[2 * i + 1])
+ x_max, x_min = max(x_list), min(x_list)
+ y_max, y_min = max(y_list), min(y_list)
+ char_rects.append([x_min, y_min, x_max, y_max])
+ char_quads.append(char_box)
+ else:
+ raise Exception(
+ f'invalid num in char box: {len(char_box)} not in (4, 8)')
+ chars.append(ann['char_text'])
+
+ ann = dict(chars=chars, char_rects=char_rects, char_quads=char_quads)
+
+ return ann
+
+ def prepare_train_img(self, index):
+ """Get training data and annotations from pipeline.
+
+ Args:
+ index (int): Index of data.
+
+ Returns:
+ dict: Training data and annotation after pipeline with new keys
+ introduced by pipeline.
+ """
+ img_ann_info = self.data_infos[index]
+ img_info = {
+ 'filename': img_ann_info['file_name'],
+ }
+ ann_info = self._parse_anno_info(img_ann_info['annotations'])
+ results = dict(img_info=img_info, ann_info=ann_info)
+
+ self.pre_pipeline(results)
+
+ return self.pipeline(results)
diff --git a/mmocr/datasets/openset_kie_dataset.py b/mmocr/datasets/openset_kie_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..ef2480c381886fe9413e598467230989e24ad3ff
--- /dev/null
+++ b/mmocr/datasets/openset_kie_dataset.py
@@ -0,0 +1,309 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+import numpy as np
+import torch
+from mmdet.datasets.builder import DATASETS
+
+from mmocr.datasets import KIEDataset
+
+
+@DATASETS.register_module()
+class OpensetKIEDataset(KIEDataset):
+ """Openset KIE classifies the nodes (i.e. text boxes) into bg/key/value
+ categories, and additionally learns key-value relationship among nodes.
+
+ Args:
+ ann_file (str): Annotation file path.
+ loader (dict): Dictionary to construct loader
+ to load annotation infos.
+ dict_file (str): Character dict file path.
+ img_prefix (str, optional): Image prefix to generate full
+ image path.
+ pipeline (list[dict]): Processing pipeline.
+ norm (float): Norm to map value from one range to another.
+ link_type (str): ``one-to-one`` | ``one-to-many`` |
+ ``many-to-one`` | ``many-to-many``. For ``many-to-many``,
+ one key box can have many values and vice versa.
+ edge_thr (float): Score threshold for a valid edge.
+ test_mode (bool, optional): If True, try...except will
+ be turned off in __getitem__.
+ key_node_idx (int): Index of key in node classes.
+ value_node_idx (int): Index of value in node classes.
+ node_classes (int): Number of node classes.
+ """
+
+ def __init__(self,
+ ann_file,
+ loader,
+ dict_file,
+ img_prefix='',
+ pipeline=None,
+ norm=10.,
+ link_type='one-to-one',
+ edge_thr=0.5,
+ test_mode=True,
+ key_node_idx=1,
+ value_node_idx=2,
+ node_classes=4):
+ super().__init__(ann_file, loader, dict_file, img_prefix, pipeline,
+ norm, False, test_mode)
+ assert link_type in [
+ 'one-to-one', 'one-to-many', 'many-to-one', 'many-to-many', 'none'
+ ]
+ self.link_type = link_type
+ self.data_dict = {x['file_name']: x for x in self.data_infos}
+ self.edge_thr = edge_thr
+ self.key_node_idx = key_node_idx
+ self.value_node_idx = value_node_idx
+ self.node_classes = node_classes
+
+ def pre_pipeline(self, results):
+ super().pre_pipeline(results)
+ results['ori_texts'] = results['ann_info']['ori_texts']
+ results['ori_boxes'] = results['ann_info']['ori_boxes']
+
+ def list_to_numpy(self, ann_infos):
+ results = super().list_to_numpy(ann_infos)
+ results.update(dict(ori_texts=ann_infos['texts']))
+ results.update(dict(ori_boxes=ann_infos['boxes']))
+
+ return results
+
+ def evaluate(self,
+ results,
+ metric='openset_f1',
+ metric_options=None,
+ **kwargs):
+ # Protect ``metric_options`` since it uses mutable value as default
+ metric_options = copy.deepcopy(metric_options)
+
+ metrics = metric if isinstance(metric, list) else [metric]
+ allowed_metrics = ['openset_f1']
+ for m in metrics:
+ if m not in allowed_metrics:
+ raise KeyError(f'metric {m} is not supported')
+
+ preds, gts = [], []
+ for result in results:
+ # data for preds
+ pred = self.decode_pred(result)
+ preds.append(pred)
+ # data for gts
+ gt = self.decode_gt(pred['filename'])
+ gts.append(gt)
+
+ return self.compute_openset_f1(preds, gts)
+
+ def _decode_pairs_gt(self, labels, edge_ids):
+ """Find all pairs in gt.
+
+ The first index in the pair (n1, n2) is key.
+ """
+ gt_pairs = []
+ for i, label in enumerate(labels):
+ if label == self.key_node_idx:
+ for j, edge_id in enumerate(edge_ids):
+ if edge_id == edge_ids[i] and labels[
+ j] == self.value_node_idx:
+ gt_pairs.append((i, j))
+
+ return gt_pairs
+
+ @staticmethod
+ def _decode_pairs_pred(nodes,
+ labels,
+ edges,
+ edge_thr=0.5,
+ link_type='one-to-one'):
+ """Find all pairs in prediction.
+
+ The first index in the pair (n1, n2) is more likely to be a key
+ according to prediction in nodes.
+ """
+ edges = torch.max(edges, edges.T)
+ if link_type in ['none', 'many-to-many']:
+ pair_inds = (edges > edge_thr).nonzero(as_tuple=True)
+ pred_pairs = [(n1.item(),
+ n2.item()) if nodes[n1, 1] > nodes[n1, 2] else
+ (n2.item(), n1.item()) for n1, n2 in zip(*pair_inds)
+ if n1 < n2]
+ pred_pairs = [(i, j) for i, j in pred_pairs
+ if labels[i] == 1 and labels[j] == 2]
+ else:
+ links = edges.clone()
+ links[links <= edge_thr] = -1
+ links[labels != 1, :] = -1
+ links[:, labels != 2] = -1
+
+ pred_pairs = []
+ while (links > -1).any():
+ i, j = np.unravel_index(torch.argmax(links), links.shape)
+ pred_pairs.append((i, j))
+ if link_type == 'one-to-one':
+ links[i, :] = -1
+ links[:, j] = -1
+ elif link_type == 'one-to-many':
+ links[:, j] = -1
+ elif link_type == 'many-to-one':
+ links[i, :] = -1
+ else:
+ raise ValueError(f'not supported link type {link_type}')
+
+ pairs_conf = [edges[i, j].item() for i, j in pred_pairs]
+ return pred_pairs, pairs_conf
+
+ def decode_pred(self, result):
+ """Decode prediction.
+
+ Assemble boxes and predicted labels into bboxes, and convert edges into
+ matrix.
+ """
+ filename = result['img_metas'][0]['ori_filename']
+ nodes = result['nodes'].cpu()
+ labels_conf, labels = torch.max(nodes, dim=-1)
+ num_nodes = nodes.size(0)
+ edges = result['edges'][:, -1].view(num_nodes, num_nodes).cpu()
+ annos = self.data_dict[filename]['annotations']
+ boxes = [x['box'] for x in annos]
+ texts = [x['text'] for x in annos]
+ bboxes = torch.Tensor(boxes)[:, [0, 1, 4, 5]]
+ bboxes = torch.cat([bboxes, labels[:, None].float()], -1)
+ pairs, pairs_conf = self._decode_pairs_pred(nodes, labels, edges,
+ self.edge_thr,
+ self.link_type)
+ pred = {
+ 'filename': filename,
+ 'boxes': boxes,
+ 'bboxes': bboxes.tolist(),
+ 'labels': labels.tolist(),
+ 'labels_conf': labels_conf.tolist(),
+ 'texts': texts,
+ 'pairs': pairs,
+ 'pairs_conf': pairs_conf
+ }
+ return pred
+
+ def decode_gt(self, filename):
+ """Decode ground truth.
+
+ Assemble boxes and labels into bboxes.
+ """
+ annos = self.data_dict[filename]['annotations']
+ labels = torch.Tensor([x['label'] for x in annos])
+ texts = [x['text'] for x in annos]
+ edge_ids = [x['edge'] for x in annos]
+ boxes = [x['box'] for x in annos]
+ bboxes = torch.Tensor(boxes)[:, [0, 1, 4, 5]]
+ bboxes = torch.cat([bboxes, labels[:, None].float()], -1)
+ pairs = self._decode_pairs_gt(labels, edge_ids)
+ gt = {
+ 'filename': filename,
+ 'boxes': boxes,
+ 'bboxes': bboxes.tolist(),
+ 'labels': labels.tolist(),
+ 'labels_conf': [1. for _ in labels],
+ 'texts': texts,
+ 'pairs': pairs,
+ 'pairs_conf': [1. for _ in pairs]
+ }
+ return gt
+
+ def compute_openset_f1(self, preds, gts):
+ """Compute openset macro-f1 and micro-f1 score.
+
+ Args:
+ preds: (list[dict]): List of prediction results, including
+ keys: ``filename``, ``pairs``, etc.
+ gts: (list[dict]): List of ground-truth infos, including
+ keys: ``filename``, ``pairs``, etc.
+
+ Returns:
+ dict: Evaluation result with keys: ``node_openset_micro_f1``, \
+ ``node_openset_macro_f1``, ``edge_openset_f1``.
+ """
+
+ total_edge_hit_num, total_edge_gt_num, total_edge_pred_num = 0, 0, 0
+ total_node_hit_num, total_node_gt_num, total_node_pred_num = {}, {}, {}
+ node_inds = list(range(self.node_classes))
+ for node_idx in node_inds:
+ total_node_hit_num[node_idx] = 0
+ total_node_gt_num[node_idx] = 0
+ total_node_pred_num[node_idx] = 0
+
+ img_level_res = {}
+ for pred, gt in zip(preds, gts):
+ filename = pred['filename']
+ img_res = {}
+ # edge metric related
+ pairs_pred = pred['pairs']
+ pairs_gt = gt['pairs']
+ img_res['edge_hit_num'] = 0
+ for pair in pairs_gt:
+ if pair in pairs_pred:
+ img_res['edge_hit_num'] += 1
+ img_res['edge_recall'] = 1.0 * img_res['edge_hit_num'] / max(
+ 1, len(pairs_gt))
+ img_res['edge_precision'] = 1.0 * img_res['edge_hit_num'] / max(
+ 1, len(pairs_pred))
+ img_res['f1'] = 2 * img_res['edge_recall'] * img_res[
+ 'edge_precision'] / max(
+ 1, img_res['edge_recall'] + img_res['edge_precision'])
+ total_edge_hit_num += img_res['edge_hit_num']
+ total_edge_gt_num += len(pairs_gt)
+ total_edge_pred_num += len(pairs_pred)
+
+ # node metric related
+ nodes_pred = pred['labels']
+ nodes_gt = gt['labels']
+ for i, node_gt in enumerate(nodes_gt):
+ node_gt = int(node_gt)
+ total_node_gt_num[node_gt] += 1
+ if nodes_pred[i] == node_gt:
+ total_node_hit_num[node_gt] += 1
+ for node_pred in nodes_pred:
+ total_node_pred_num[node_pred] += 1
+
+ img_level_res[filename] = img_res
+
+ stats = {}
+ # edge f1
+ total_edge_recall = 1.0 * total_edge_hit_num / max(
+ 1, total_edge_gt_num)
+ total_edge_precision = 1.0 * total_edge_hit_num / max(
+ 1, total_edge_pred_num)
+ edge_f1 = 2 * total_edge_recall * total_edge_precision / max(
+ 1, total_edge_recall + total_edge_precision)
+ stats = {'edge_openset_f1': edge_f1}
+
+ # node f1
+ cared_node_hit_num, cared_node_gt_num, cared_node_pred_num = 0, 0, 0
+ node_macro_metric = {}
+ for node_idx in node_inds:
+ if node_idx < 1 or node_idx > 2:
+ continue
+ cared_node_hit_num += total_node_hit_num[node_idx]
+ cared_node_gt_num += total_node_gt_num[node_idx]
+ cared_node_pred_num += total_node_pred_num[node_idx]
+ node_res = {}
+ node_res['recall'] = 1.0 * total_node_hit_num[node_idx] / max(
+ 1, total_node_gt_num[node_idx])
+ node_res['precision'] = 1.0 * total_node_hit_num[node_idx] / max(
+ 1, total_node_pred_num[node_idx])
+ node_res[
+ 'f1'] = 2 * node_res['recall'] * node_res['precision'] / max(
+ 1, node_res['recall'] + node_res['precision'])
+ node_macro_metric[node_idx] = node_res
+
+ node_micro_recall = 1.0 * cared_node_hit_num / max(
+ 1, cared_node_gt_num)
+ node_micro_precision = 1.0 * cared_node_hit_num / max(
+ 1, cared_node_pred_num)
+ node_micro_f1 = 2 * node_micro_recall * node_micro_precision / max(
+ 1, node_micro_recall + node_micro_precision)
+
+ stats['node_openset_micro_f1'] = node_micro_f1
+ stats['node_openset_macro_f1'] = np.mean(
+ [v['f1'] for k, v in node_macro_metric.items()])
+
+ return stats
diff --git a/mmocr/datasets/pipelines/__init__.py b/mmocr/datasets/pipelines/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..2b3876c0a0e910492d2f306e023945a208154a62
--- /dev/null
+++ b/mmocr/datasets/pipelines/__init__.py
@@ -0,0 +1,33 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .box_utils import sort_vertex, sort_vertex8
+from .custom_format_bundle import CustomFormatBundle
+from .dbnet_transforms import EastRandomCrop, ImgAug
+from .kie_transforms import KIEFormatBundle, ResizeNoImg
+from .loading import LoadImageFromNdarray, LoadTextAnnotations
+from .ner_transforms import NerTransform, ToTensorNER
+from .ocr_seg_targets import OCRSegTargets
+from .ocr_transforms import (FancyPCA, NormalizeOCR, OnlineCropOCR,
+ OpencvToPil, PilToOpencv, RandomPaddingOCR,
+ RandomRotateImageBox, ResizeOCR, ToTensorOCR)
+from .test_time_aug import MultiRotateAugOCR
+from .textdet_targets import (DBNetTargets, FCENetTargets, PANetTargets,
+ TextSnakeTargets)
+from .transform_wrappers import OneOfWrapper, RandomWrapper, TorchVisionWrapper
+from .transforms import (ColorJitter, PyramidRescale, RandomCropFlip,
+ RandomCropInstances, RandomCropPolyInstances,
+ RandomRotatePolyInstances, RandomRotateTextDet,
+ RandomScaling, ScaleAspectJitter, SquareResizePad)
+
+__all__ = [
+ 'LoadTextAnnotations', 'NormalizeOCR', 'OnlineCropOCR', 'ResizeOCR',
+ 'ToTensorOCR', 'CustomFormatBundle', 'DBNetTargets', 'PANetTargets',
+ 'ColorJitter', 'RandomCropInstances', 'RandomRotateTextDet',
+ 'ScaleAspectJitter', 'MultiRotateAugOCR', 'OCRSegTargets', 'FancyPCA',
+ 'RandomCropPolyInstances', 'RandomRotatePolyInstances', 'RandomPaddingOCR',
+ 'ImgAug', 'EastRandomCrop', 'RandomRotateImageBox', 'OpencvToPil',
+ 'PilToOpencv', 'KIEFormatBundle', 'SquareResizePad', 'TextSnakeTargets',
+ 'sort_vertex', 'LoadImageFromNdarray', 'sort_vertex8', 'FCENetTargets',
+ 'RandomScaling', 'RandomCropFlip', 'NerTransform', 'ToTensorNER',
+ 'ResizeNoImg', 'PyramidRescale', 'OneOfWrapper', 'RandomWrapper',
+ 'TorchVisionWrapper'
+]
diff --git a/mmocr/datasets/pipelines/box_utils.py b/mmocr/datasets/pipelines/box_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..12447585ee1107e6dd26e0c4909e31a0c490228f
--- /dev/null
+++ b/mmocr/datasets/pipelines/box_utils.py
@@ -0,0 +1,53 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+
+import mmocr.utils as utils
+
+
+def sort_vertex(points_x, points_y):
+ """Sort box vertices in clockwise order from left-top first.
+
+ Args:
+ points_x (list[float]): x of four vertices.
+ points_y (list[float]): y of four vertices.
+ Returns:
+ sorted_points_x (list[float]): x of sorted four vertices.
+ sorted_points_y (list[float]): y of sorted four vertices.
+ """
+ assert utils.is_type_list(points_x, (float, int))
+ assert utils.is_type_list(points_y, (float, int))
+ assert len(points_x) == 4
+ assert len(points_y) == 4
+ vertices = np.stack((points_x, points_y), axis=-1).astype(np.float32)
+ vertices = _sort_vertex(vertices)
+ sorted_points_x = list(vertices[:, 0])
+ sorted_points_y = list(vertices[:, 1])
+ return sorted_points_x, sorted_points_y
+
+
+def _sort_vertex(vertices):
+ assert vertices.ndim == 2
+ assert vertices.shape[-1] == 2
+ N = vertices.shape[0]
+ if N == 0:
+ return vertices
+
+ center = np.mean(vertices, axis=0)
+ directions = vertices - center
+ angles = np.arctan2(directions[:, 1], directions[:, 0])
+ sort_idx = np.argsort(angles)
+ vertices = vertices[sort_idx]
+
+ left_top = np.min(vertices, axis=0)
+ dists = np.linalg.norm(left_top - vertices, axis=-1, ord=2)
+ lefttop_idx = np.argmin(dists)
+ indexes = (np.arange(N, dtype=np.int) + lefttop_idx) % N
+ return vertices[indexes]
+
+
+def sort_vertex8(points):
+ """Sort vertex with 8 points [x1 y1 x2 y2 x3 y3 x4 y4]"""
+ assert len(points) == 8
+ vertices = _sort_vertex(np.array(points, dtype=np.float32).reshape(-1, 2))
+ sorted_box = list(vertices.flatten())
+ return sorted_box
diff --git a/mmocr/datasets/pipelines/crop.py b/mmocr/datasets/pipelines/crop.py
new file mode 100644
index 0000000000000000000000000000000000000000..416339ecded21eb9e96efd1c0a335e928ec8ffd5
--- /dev/null
+++ b/mmocr/datasets/pipelines/crop.py
@@ -0,0 +1,125 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import cv2
+import numpy as np
+from shapely.geometry import LineString, Point
+
+import mmocr.utils as utils
+from .box_utils import sort_vertex
+
+
+def box_jitter(points_x, points_y, jitter_ratio_x=0.5, jitter_ratio_y=0.1):
+ """Jitter on the coordinates of bounding box.
+
+ Args:
+ points_x (list[float | int]): List of y for four vertices.
+ points_y (list[float | int]): List of x for four vertices.
+ jitter_ratio_x (float): Horizontal jitter ratio relative to the height.
+ jitter_ratio_y (float): Vertical jitter ratio relative to the height.
+ """
+ assert len(points_x) == 4
+ assert len(points_y) == 4
+ assert isinstance(jitter_ratio_x, float)
+ assert isinstance(jitter_ratio_y, float)
+ assert 0 <= jitter_ratio_x < 1
+ assert 0 <= jitter_ratio_y < 1
+
+ points = [Point(points_x[i], points_y[i]) for i in range(4)]
+ line_list = [
+ LineString([points[i], points[i + 1 if i < 3 else 0]])
+ for i in range(4)
+ ]
+
+ tmp_h = max(line_list[1].length, line_list[3].length)
+
+ for i in range(4):
+ jitter_pixel_x = (np.random.rand() - 0.5) * 2 * jitter_ratio_x * tmp_h
+ jitter_pixel_y = (np.random.rand() - 0.5) * 2 * jitter_ratio_y * tmp_h
+ points_x[i] += jitter_pixel_x
+ points_y[i] += jitter_pixel_y
+
+
+def warp_img(src_img,
+ box,
+ jitter_flag=False,
+ jitter_ratio_x=0.5,
+ jitter_ratio_y=0.1):
+ """Crop box area from image using opencv warpPerspective w/o box jitter.
+
+ Args:
+ src_img (np.array): Image before cropping.
+ box (list[float | int]): Coordinates of quadrangle.
+ """
+ assert utils.is_type_list(box, (float, int))
+ assert len(box) == 8
+
+ h, w = src_img.shape[:2]
+ points_x = [min(max(x, 0), w) for x in box[0:8:2]]
+ points_y = [min(max(y, 0), h) for y in box[1:9:2]]
+
+ points_x, points_y = sort_vertex(points_x, points_y)
+
+ if jitter_flag:
+ box_jitter(
+ points_x,
+ points_y,
+ jitter_ratio_x=jitter_ratio_x,
+ jitter_ratio_y=jitter_ratio_y)
+
+ points = [Point(points_x[i], points_y[i]) for i in range(4)]
+ edges = [
+ LineString([points[i], points[i + 1 if i < 3 else 0]])
+ for i in range(4)
+ ]
+
+ pts1 = np.float32([[points[i].x, points[i].y] for i in range(4)])
+ box_width = max(edges[0].length, edges[2].length)
+ box_height = max(edges[1].length, edges[3].length)
+
+ pts2 = np.float32([[0, 0], [box_width, 0], [box_width, box_height],
+ [0, box_height]])
+ M = cv2.getPerspectiveTransform(pts1, pts2)
+ dst_img = cv2.warpPerspective(src_img, M,
+ (int(box_width), int(box_height)))
+
+ return dst_img
+
+
+def crop_img(src_img, box, long_edge_pad_ratio=0.4, short_edge_pad_ratio=0.2):
+ """Crop text region with their bounding box.
+
+ Args:
+ src_img (np.array): The original image.
+ box (list[float | int]): Points of quadrangle.
+ long_edge_pad_ratio (float): Box pad ratio for long edge
+ corresponding to font size.
+ short_edge_pad_ratio (float): Box pad ratio for short edge
+ corresponding to font size.
+ """
+ assert utils.is_type_list(box, (float, int))
+ assert len(box) == 8
+ assert 0. <= long_edge_pad_ratio < 1.0
+ assert 0. <= short_edge_pad_ratio < 1.0
+
+ h, w = src_img.shape[:2]
+ points_x = np.clip(np.array(box[0::2]), 0, w)
+ points_y = np.clip(np.array(box[1::2]), 0, h)
+
+ box_width = np.max(points_x) - np.min(points_x)
+ box_height = np.max(points_y) - np.min(points_y)
+ font_size = min(box_height, box_width)
+
+ if box_height < box_width:
+ horizontal_pad = long_edge_pad_ratio * font_size
+ vertical_pad = short_edge_pad_ratio * font_size
+ else:
+ horizontal_pad = short_edge_pad_ratio * font_size
+ vertical_pad = long_edge_pad_ratio * font_size
+
+ left = np.clip(int(np.min(points_x) - horizontal_pad), 0, w)
+ top = np.clip(int(np.min(points_y) - vertical_pad), 0, h)
+ right = np.clip(int(np.max(points_x) + horizontal_pad), 0, w)
+ bottom = np.clip(int(np.max(points_y) + vertical_pad), 0, h)
+
+ dst_img = src_img[top:bottom, left:right]
+
+ return dst_img
diff --git a/mmocr/datasets/pipelines/custom_format_bundle.py b/mmocr/datasets/pipelines/custom_format_bundle.py
new file mode 100644
index 0000000000000000000000000000000000000000..fc63fa8ddfa5389c4b27e3a3cbb1cde1beabcb3b
--- /dev/null
+++ b/mmocr/datasets/pipelines/custom_format_bundle.py
@@ -0,0 +1,66 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+from mmcv.parallel import DataContainer as DC
+from mmdet.datasets.builder import PIPELINES
+from mmdet.datasets.pipelines.formating import DefaultFormatBundle
+
+from mmocr.core.visualize import overlay_mask_img, show_feature
+
+
+@PIPELINES.register_module()
+class CustomFormatBundle(DefaultFormatBundle):
+ """Custom formatting bundle.
+
+ It formats common fields such as 'img' and 'proposals' as done in
+ DefaultFormatBundle, while other fields such as 'gt_kernels' and
+ 'gt_effective_region_mask' will be formatted to DC as follows:
+
+ - gt_kernels: to DataContainer (cpu_only=True)
+ - gt_effective_mask: to DataContainer (cpu_only=True)
+
+ Args:
+ keys (list[str]): Fields to be formatted to DC only.
+ call_super (bool): If True, format common fields
+ by DefaultFormatBundle, else format fields in keys above only.
+ visualize (dict): If flag=True, visualize gt mask for debugging.
+ """
+
+ def __init__(self,
+ keys=[],
+ call_super=True,
+ visualize=dict(flag=False, boundary_key=None)):
+
+ super().__init__()
+ self.visualize = visualize
+ self.keys = keys
+ self.call_super = call_super
+
+ def __call__(self, results):
+
+ if self.visualize['flag']:
+ img = results['img'].astype(np.uint8)
+ boundary_key = self.visualize['boundary_key']
+ if boundary_key is not None:
+ img = overlay_mask_img(img, results[boundary_key].masks[0])
+
+ features = [img]
+ names = ['img']
+ to_uint8 = [1]
+
+ for k in results['mask_fields']:
+ for iter in range(len(results[k].masks)):
+ features.append(results[k].masks[iter])
+ names.append(k + str(iter))
+ to_uint8.append(0)
+ show_feature(features, names, to_uint8)
+
+ if self.call_super:
+ results = super().__call__(results)
+
+ for k in self.keys:
+ results[k] = DC(results[k], cpu_only=True)
+
+ return results
+
+ def __repr__(self):
+ return self.__class__.__name__
diff --git a/mmocr/datasets/pipelines/dbnet_transforms.py b/mmocr/datasets/pipelines/dbnet_transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..8494cdd6b8cc4e5dae3f013d7e1c266e1a428604
--- /dev/null
+++ b/mmocr/datasets/pipelines/dbnet_transforms.py
@@ -0,0 +1,282 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import imgaug
+import imgaug.augmenters as iaa
+import mmcv
+import numpy as np
+from mmdet.core.mask import PolygonMasks
+from mmdet.datasets.builder import PIPELINES
+
+
+class AugmenterBuilder:
+ """Build imgaug object according ImgAug argmentations."""
+
+ def __init__(self):
+ pass
+
+ def build(self, args, root=True):
+ if args is None:
+ return None
+ if isinstance(args, (int, float, str)):
+ return args
+ if isinstance(args, list):
+ if root:
+ sequence = [self.build(value, root=False) for value in args]
+ return iaa.Sequential(sequence)
+ arg_list = [self.to_tuple_if_list(a) for a in args[1:]]
+ return getattr(iaa, args[0])(*arg_list)
+ if isinstance(args, dict):
+ if 'cls' in args:
+ cls = getattr(iaa, args['cls'])
+ return cls(
+ **{
+ k: self.to_tuple_if_list(v)
+ for k, v in args.items() if not k == 'cls'
+ })
+ else:
+ return {
+ key: self.build(value, root=False)
+ for key, value in args.items()
+ }
+ raise RuntimeError('unknown augmenter arg: ' + str(args))
+
+ def to_tuple_if_list(self, obj):
+ if isinstance(obj, list):
+ return tuple(obj)
+ return obj
+
+
+@PIPELINES.register_module()
+class ImgAug:
+ """A wrapper to use imgaug https://github.com/aleju/imgaug.
+
+ Args:
+ args ([list[list|dict]]): The argumentation list. For details, please
+ refer to imgaug document. Take args=[['Fliplr', 0.5],
+ dict(cls='Affine', rotate=[-10, 10]), ['Resize', [0.5, 3.0]]] as an
+ example. The args horizontally flip images with probability 0.5,
+ followed by random rotation with angles in range [-10, 10], and
+ resize with an independent scale in range [0.5, 3.0] for each
+ side of images.
+ """
+
+ def __init__(self, args=None):
+ self.augmenter_args = args
+ self.augmenter = AugmenterBuilder().build(self.augmenter_args)
+
+ def __call__(self, results):
+ # img is bgr
+ image = results['img']
+ aug = None
+ shape = image.shape
+
+ if self.augmenter:
+ aug = self.augmenter.to_deterministic()
+ results['img'] = aug.augment_image(image)
+ results['img_shape'] = results['img'].shape
+ results['flip'] = 'unknown' # it's unknown
+ results['flip_direction'] = 'unknown' # it's unknown
+ target_shape = results['img_shape']
+
+ self.may_augment_annotation(aug, shape, target_shape, results)
+
+ return results
+
+ def may_augment_annotation(self, aug, shape, target_shape, results):
+ if aug is None:
+ return results
+
+ # augment polygon mask
+ for key in results['mask_fields']:
+ masks = self.may_augment_poly(aug, shape, results[key])
+ if len(masks) > 0:
+ results[key] = PolygonMasks(masks, *target_shape[:2])
+
+ # augment bbox
+ for key in results['bbox_fields']:
+ bboxes = self.may_augment_poly(
+ aug, shape, results[key], mask_flag=False)
+ results[key] = np.zeros(0)
+ if len(bboxes) > 0:
+ results[key] = np.stack(bboxes)
+
+ return results
+
+ def may_augment_poly(self, aug, img_shape, polys, mask_flag=True):
+ key_points, poly_point_nums = [], []
+ for poly in polys:
+ if mask_flag:
+ poly = poly[0]
+ poly = poly.reshape(-1, 2)
+ key_points.extend([imgaug.Keypoint(p[0], p[1]) for p in poly])
+ poly_point_nums.append(poly.shape[0])
+ key_points = aug.augment_keypoints(
+ [imgaug.KeypointsOnImage(keypoints=key_points,
+ shape=img_shape)])[0].keypoints
+
+ new_polys = []
+ start_idx = 0
+ for poly_point_num in poly_point_nums:
+ new_poly = []
+ for key_point in key_points[start_idx:(start_idx +
+ poly_point_num)]:
+ new_poly.append([key_point.x, key_point.y])
+ start_idx += poly_point_num
+ new_poly = np.array(new_poly).flatten()
+ new_polys.append([new_poly] if mask_flag else new_poly)
+
+ return new_polys
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ return repr_str
+
+
+@PIPELINES.register_module()
+class EastRandomCrop:
+
+ def __init__(self,
+ target_size=(640, 640),
+ max_tries=10,
+ min_crop_side_ratio=0.1):
+ self.target_size = target_size
+ self.max_tries = max_tries
+ self.min_crop_side_ratio = min_crop_side_ratio
+
+ def __call__(self, results):
+ # sampling crop
+ # crop image, boxes, masks
+ img = results['img']
+ crop_x, crop_y, crop_w, crop_h = self.crop_area(
+ img, results['gt_masks'])
+ scale_w = self.target_size[0] / crop_w
+ scale_h = self.target_size[1] / crop_h
+ scale = min(scale_w, scale_h)
+ h = int(crop_h * scale)
+ w = int(crop_w * scale)
+ padded_img = np.zeros(
+ (self.target_size[1], self.target_size[0], img.shape[2]),
+ img.dtype)
+ padded_img[:h, :w] = mmcv.imresize(
+ img[crop_y:crop_y + crop_h, crop_x:crop_x + crop_w], (w, h))
+
+ # for bboxes
+ for key in results['bbox_fields']:
+ lines = []
+ for box in results[key]:
+ box = box.reshape(2, 2)
+ poly = ((box - (crop_x, crop_y)) * scale)
+ if not self.is_poly_outside_rect(poly, 0, 0, w, h):
+ lines.append(poly.flatten())
+ results[key] = np.array(lines)
+ # for masks
+ for key in results['mask_fields']:
+ polys = []
+ polys_label = []
+ for poly in results[key]:
+ poly = np.array(poly).reshape(-1, 2)
+ poly = ((poly - (crop_x, crop_y)) * scale)
+ if not self.is_poly_outside_rect(poly, 0, 0, w, h):
+ polys.append([poly])
+ polys_label.append(0)
+ results[key] = PolygonMasks(polys, *self.target_size)
+ if key == 'gt_masks':
+ results['gt_labels'] = polys_label
+
+ results['img'] = padded_img
+ results['img_shape'] = padded_img.shape
+
+ return results
+
+ def is_poly_in_rect(self, poly, x, y, w, h):
+ poly = np.array(poly)
+ if poly[:, 0].min() < x or poly[:, 0].max() > x + w:
+ return False
+ if poly[:, 1].min() < y or poly[:, 1].max() > y + h:
+ return False
+ return True
+
+ def is_poly_outside_rect(self, poly, x, y, w, h):
+ poly = np.array(poly).reshape(-1, 2)
+ if poly[:, 0].max() < x or poly[:, 0].min() > x + w:
+ return True
+ if poly[:, 1].max() < y or poly[:, 1].min() > y + h:
+ return True
+ return False
+
+ def split_regions(self, axis):
+ regions = []
+ min_axis = 0
+ for i in range(1, axis.shape[0]):
+ if axis[i] != axis[i - 1] + 1:
+ region = axis[min_axis:i]
+ min_axis = i
+ regions.append(region)
+ return regions
+
+ def random_select(self, axis, max_size):
+ xx = np.random.choice(axis, size=2)
+ xmin = np.min(xx)
+ xmax = np.max(xx)
+ xmin = np.clip(xmin, 0, max_size - 1)
+ xmax = np.clip(xmax, 0, max_size - 1)
+ return xmin, xmax
+
+ def region_wise_random_select(self, regions):
+ selected_index = list(np.random.choice(len(regions), 2))
+ selected_values = []
+ for index in selected_index:
+ axis = regions[index]
+ xx = int(np.random.choice(axis, size=1))
+ selected_values.append(xx)
+ xmin = min(selected_values)
+ xmax = max(selected_values)
+ return xmin, xmax
+
+ def crop_area(self, img, polys):
+ h, w, _ = img.shape
+ h_array = np.zeros(h, dtype=np.int32)
+ w_array = np.zeros(w, dtype=np.int32)
+ for points in polys:
+ points = np.round(
+ points, decimals=0).astype(np.int32).reshape(-1, 2)
+ min_x = np.min(points[:, 0])
+ max_x = np.max(points[:, 0])
+ w_array[min_x:max_x] = 1
+ min_y = np.min(points[:, 1])
+ max_y = np.max(points[:, 1])
+ h_array[min_y:max_y] = 1
+ # ensure the cropped area not across a text
+ h_axis = np.where(h_array == 0)[0]
+ w_axis = np.where(w_array == 0)[0]
+
+ if len(h_axis) == 0 or len(w_axis) == 0:
+ return 0, 0, w, h
+
+ h_regions = self.split_regions(h_axis)
+ w_regions = self.split_regions(w_axis)
+
+ for i in range(self.max_tries):
+ if len(w_regions) > 1:
+ xmin, xmax = self.region_wise_random_select(w_regions)
+ else:
+ xmin, xmax = self.random_select(w_axis, w)
+ if len(h_regions) > 1:
+ ymin, ymax = self.region_wise_random_select(h_regions)
+ else:
+ ymin, ymax = self.random_select(h_axis, h)
+
+ if (xmax - xmin < self.min_crop_side_ratio * w
+ or ymax - ymin < self.min_crop_side_ratio * h):
+ # area too small
+ continue
+ num_poly_in_rect = 0
+ for poly in polys:
+ if not self.is_poly_outside_rect(poly, xmin, ymin, xmax - xmin,
+ ymax - ymin):
+ num_poly_in_rect += 1
+ break
+
+ if num_poly_in_rect > 0:
+ return xmin, ymin, xmax - xmin, ymax - ymin
+
+ return 0, 0, w, h
diff --git a/mmocr/datasets/pipelines/kie_transforms.py b/mmocr/datasets/pipelines/kie_transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..2cdff10c0c424a2198b54ff04a999b90e2cfb3b2
--- /dev/null
+++ b/mmocr/datasets/pipelines/kie_transforms.py
@@ -0,0 +1,90 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+from mmcv import rescale_size
+from mmcv.parallel import DataContainer as DC
+from mmdet.datasets.builder import PIPELINES
+from mmdet.datasets.pipelines.formating import DefaultFormatBundle, to_tensor
+
+
+@PIPELINES.register_module()
+class ResizeNoImg:
+ """Image resizing without img.
+
+ Used for KIE.
+ """
+
+ def __init__(self, img_scale, keep_ratio=True):
+ self.img_scale = img_scale
+ self.keep_ratio = keep_ratio
+
+ def __call__(self, results):
+ w, h = results['img_info']['width'], results['img_info']['height']
+ if self.keep_ratio:
+ (new_w, new_h) = rescale_size((w, h),
+ self.img_scale,
+ return_scale=False)
+ w_scale = new_w / w
+ h_scale = new_h / h
+ else:
+ (new_w, new_h) = self.img_scale
+
+ w_scale = new_w / w
+ h_scale = new_h / h
+ scale_factor = np.array([w_scale, h_scale, w_scale, h_scale],
+ dtype=np.float32)
+ results['img_shape'] = (new_h, new_w, 1)
+ results['scale_factor'] = scale_factor
+ results['keep_ratio'] = True
+
+ return results
+
+
+@PIPELINES.register_module()
+class KIEFormatBundle(DefaultFormatBundle):
+ """Key information extraction formatting bundle.
+
+ Based on the DefaultFormatBundle, itt simplifies the pipeline of formatting
+ common fields, including "img", "proposals", "gt_bboxes", "gt_labels",
+ "gt_masks", "gt_semantic_seg", "relations" and "texts".
+ These fields are formatted as follows.
+
+ - img: (1) transpose, (2) to tensor, (3) to DataContainer (stack=True)
+ - proposals: (1) to tensor, (2) to DataContainer
+ - gt_bboxes: (1) to tensor, (2) to DataContainer
+ - gt_bboxes_ignore: (1) to tensor, (2) to DataContainer
+ - gt_labels: (1) to tensor, (2) to DataContainer
+ - gt_masks: (1) to tensor, (2) to DataContainer (cpu_only=True)
+ - gt_semantic_seg: (1) unsqueeze dim-0 (2) to tensor,
+ (3) to DataContainer (stack=True)
+ - relations: (1) scale, (2) to tensor, (3) to DataContainer
+ - texts: (1) to tensor, (2) to DataContainer
+ """
+
+ def __call__(self, results):
+ """Call function to transform and format common fields in results.
+
+ Args:
+ results (dict): Result dict contains the data to convert.
+
+ Returns:
+ dict: The result dict contains the data that is formatted with
+ default bundle.
+ """
+ super().__call__(results)
+ if 'ann_info' in results:
+ for key in ['relations', 'texts']:
+ value = results['ann_info'][key]
+ if key == 'relations' and 'scale_factor' in results:
+ scale_factor = results['scale_factor']
+ if isinstance(scale_factor, float):
+ sx = sy = scale_factor
+ else:
+ sx, sy = results['scale_factor'][:2]
+ r = sx / sy
+ factor = np.array([sx, sy, r, 1, r]).astype(np.float32)
+ value = value * factor[None, None]
+ results[key] = DC(to_tensor(value))
+ return results
+
+ def __repr__(self):
+ return self.__class__.__name__
diff --git a/mmocr/datasets/pipelines/loading.py b/mmocr/datasets/pipelines/loading.py
new file mode 100644
index 0000000000000000000000000000000000000000..21958c47862cd05da5f5f9bf72393e90bf315f26
--- /dev/null
+++ b/mmocr/datasets/pipelines/loading.py
@@ -0,0 +1,135 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import mmcv
+import numpy as np
+from mmdet.core import BitmapMasks, PolygonMasks
+from mmdet.datasets.builder import PIPELINES
+from mmdet.datasets.pipelines.loading import LoadAnnotations, LoadImageFromFile
+
+
+@PIPELINES.register_module()
+class LoadTextAnnotations(LoadAnnotations):
+ """Load annotations for text detection.
+
+ Args:
+ with_bbox (bool): Whether to parse and load the bbox annotation.
+ Default: True.
+ with_label (bool): Whether to parse and load the label annotation.
+ Default: True.
+ with_mask (bool): Whether to parse and load the mask annotation.
+ Default: False.
+ with_seg (bool): Whether to parse and load the semantic segmentation
+ annotation. Default: False.
+ poly2mask (bool): Whether to convert the instance masks from polygons
+ to bitmaps. Default: True.
+ use_img_shape (bool): Use the shape of loaded image from
+ previous pipeline ``LoadImageFromFile`` to generate mask.
+ """
+
+ def __init__(self,
+ with_bbox=True,
+ with_label=True,
+ with_mask=False,
+ with_seg=False,
+ poly2mask=True,
+ use_img_shape=False):
+ super().__init__(
+ with_bbox=with_bbox,
+ with_label=with_label,
+ with_mask=with_mask,
+ with_seg=with_seg,
+ poly2mask=poly2mask)
+
+ self.use_img_shape = use_img_shape
+
+ def process_polygons(self, polygons):
+ """Convert polygons to list of ndarray and filter invalid polygons.
+
+ Args:
+ polygons (list[list]): Polygons of one instance.
+
+ Returns:
+ list[numpy.ndarray]: Processed polygons.
+ """
+
+ polygons = [np.array(p).astype(np.float32) for p in polygons]
+ valid_polygons = []
+ for polygon in polygons:
+ if len(polygon) % 2 == 0 and len(polygon) >= 6:
+ valid_polygons.append(polygon)
+ return valid_polygons
+
+ def _load_masks(self, results):
+ ann_info = results['ann_info']
+ h, w = results['img_info']['height'], results['img_info']['width']
+ if self.use_img_shape:
+ if results.get('ori_shape', None):
+ h, w = results['ori_shape'][:2]
+ results['img_info']['height'] = h
+ results['img_info']['width'] = w
+ else:
+ warnings.warn('"ori_shape" not in results, use the shape '
+ 'in "img_info" instead.')
+ gt_masks = ann_info['masks']
+ if self.poly2mask:
+ gt_masks = BitmapMasks(
+ [self._poly2mask(mask, h, w) for mask in gt_masks], h, w)
+ else:
+ gt_masks = PolygonMasks(
+ [self.process_polygons(polygons) for polygons in gt_masks], h,
+ w)
+ gt_masks_ignore = ann_info.get('masks_ignore', None)
+ if gt_masks_ignore is not None:
+ if self.poly2mask:
+ gt_masks_ignore = BitmapMasks(
+ [self._poly2mask(mask, h, w) for mask in gt_masks_ignore],
+ h, w)
+ else:
+ gt_masks_ignore = PolygonMasks([
+ self.process_polygons(polygons)
+ for polygons in gt_masks_ignore
+ ], h, w)
+ results['gt_masks_ignore'] = gt_masks_ignore
+ results['mask_fields'].append('gt_masks_ignore')
+
+ results['gt_masks'] = gt_masks
+ results['mask_fields'].append('gt_masks')
+ return results
+
+
+@PIPELINES.register_module()
+class LoadImageFromNdarray(LoadImageFromFile):
+ """Load an image from np.ndarray.
+
+ Similar with :obj:`LoadImageFromFile`, but the image read from
+ ``results['img']``, which is np.ndarray.
+ """
+
+ def __call__(self, results):
+ """Call functions to add image meta information.
+
+ Args:
+ results (dict): Result dict with Webcam read image in
+ ``results['img']``.
+
+ Returns:
+ dict: The dict contains loaded image and meta information.
+ """
+ assert results['img'].dtype == 'uint8'
+
+ img = results['img']
+ if self.color_type == 'grayscale' and img.shape[2] == 3:
+ img = mmcv.bgr2gray(img, keepdim=True)
+ if self.color_type == 'color' and img.shape[2] == 1:
+ img = mmcv.gray2bgr(img)
+ if self.to_float32:
+ img = img.astype(np.float32)
+
+ results['filename'] = None
+ results['ori_filename'] = None
+ results['img'] = img
+ results['img_shape'] = img.shape
+ results['ori_shape'] = img.shape
+ results['img_fields'] = ['img']
+ return results
diff --git a/mmocr/datasets/pipelines/ner_transforms.py b/mmocr/datasets/pipelines/ner_transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..b26fe74b367a94d22a694e3fd1a00e6edea8c179
--- /dev/null
+++ b/mmocr/datasets/pipelines/ner_transforms.py
@@ -0,0 +1,63 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from mmdet.datasets.builder import PIPELINES
+
+from mmocr.models.builder import build_convertor
+
+
+@PIPELINES.register_module()
+class NerTransform:
+ """Convert text to ID and entity in ground truth to label ID. The masks and
+ tokens are generated at the same time. The four parameters will be used as
+ input to the model.
+
+ Args:
+ label_convertor: Convert text to ID and entity
+ in ground truth to label ID.
+ max_len (int): Limited maximum input length.
+ """
+
+ def __init__(self, label_convertor, max_len):
+ self.label_convertor = build_convertor(label_convertor)
+ self.max_len = max_len
+
+ def __call__(self, results):
+ texts = results['text']
+ input_ids = self.label_convertor.convert_text2id(texts)
+ labels = self.label_convertor.convert_entity2label(
+ results['label'], len(texts))
+
+ attention_mask = [0] * self.max_len
+ token_type_ids = [0] * self.max_len
+ # The beginning and end IDs are added to the ID,
+ # so the mask length is increased by 2
+ for i in range(len(texts) + 2):
+ attention_mask[i] = 1
+ results = dict(
+ labels=labels,
+ texts=texts,
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids)
+ return results
+
+
+@PIPELINES.register_module()
+class ToTensorNER:
+ """Convert data with ``list`` type to tensor."""
+
+ def __call__(self, results):
+
+ input_ids = torch.tensor(results['input_ids'])
+ labels = torch.tensor(results['labels'])
+ attention_masks = torch.tensor(results['attention_mask'])
+ token_type_ids = torch.tensor(results['token_type_ids'])
+
+ results = dict(
+ img=[],
+ img_metas=dict(
+ input_ids=input_ids,
+ attention_masks=attention_masks,
+ labels=labels,
+ token_type_ids=token_type_ids))
+ return results
diff --git a/mmocr/datasets/pipelines/ocr_seg_targets.py b/mmocr/datasets/pipelines/ocr_seg_targets.py
new file mode 100644
index 0000000000000000000000000000000000000000..8c9c8aba88aed657b3b408566ab714acca0c266a
--- /dev/null
+++ b/mmocr/datasets/pipelines/ocr_seg_targets.py
@@ -0,0 +1,202 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import cv2
+import numpy as np
+from mmdet.core import BitmapMasks
+from mmdet.datasets.builder import PIPELINES
+
+import mmocr.utils.check_argument as check_argument
+from mmocr.models.builder import build_convertor
+
+
+@PIPELINES.register_module()
+class OCRSegTargets:
+ """Generate gt shrunk kernels for segmentation based OCR framework.
+
+ Args:
+ label_convertor (dict): Dictionary to construct label_convertor
+ to convert char to index.
+ attn_shrink_ratio (float): The area shrunk ratio
+ between attention kernels and gt text masks.
+ seg_shrink_ratio (float): The area shrunk ratio
+ between segmentation kernels and gt text masks.
+ box_type (str): Character box type, should be either
+ 'char_rects' or 'char_quads', with 'char_rects'
+ for rectangle with ``xyxy`` style and 'char_quads'
+ for quadrangle with ``x1y1x2y2x3y3x4y4`` style.
+ """
+
+ def __init__(self,
+ label_convertor=None,
+ attn_shrink_ratio=0.5,
+ seg_shrink_ratio=0.25,
+ box_type='char_rects',
+ pad_val=255):
+
+ assert isinstance(attn_shrink_ratio, float)
+ assert isinstance(seg_shrink_ratio, float)
+ assert 0. < attn_shrink_ratio < 1.0
+ assert 0. < seg_shrink_ratio < 1.0
+ assert label_convertor is not None
+ assert box_type in ('char_rects', 'char_quads')
+
+ self.attn_shrink_ratio = attn_shrink_ratio
+ self.seg_shrink_ratio = seg_shrink_ratio
+ self.label_convertor = build_convertor(label_convertor)
+ self.box_type = box_type
+ self.pad_val = pad_val
+
+ def shrink_char_quad(self, char_quad, shrink_ratio):
+ """Shrink char box in style of quadrangle.
+
+ Args:
+ char_quad (list[float]): Char box with format
+ [x1, y1, x2, y2, x3, y3, x4, y4].
+ shrink_ratio (float): The area shrunk ratio
+ between gt kernels and gt text masks.
+ """
+ points = [[char_quad[0], char_quad[1]], [char_quad[2], char_quad[3]],
+ [char_quad[4], char_quad[5]], [char_quad[6], char_quad[7]]]
+ shrink_points = []
+ for p_idx, point in enumerate(points):
+ p1 = points[(p_idx + 3) % 4]
+ p2 = points[(p_idx + 1) % 4]
+
+ dist1 = self.l2_dist_two_points(p1, point)
+ dist2 = self.l2_dist_two_points(p2, point)
+ min_dist = min(dist1, dist2)
+
+ v1 = [p1[0] - point[0], p1[1] - point[1]]
+ v2 = [p2[0] - point[0], p2[1] - point[1]]
+
+ temp_dist1 = (shrink_ratio * min_dist /
+ dist1) if min_dist != 0 else 0.
+ temp_dist2 = (shrink_ratio * min_dist /
+ dist2) if min_dist != 0 else 0.
+
+ v1 = [temp * temp_dist1 for temp in v1]
+ v2 = [temp * temp_dist2 for temp in v2]
+
+ shrink_point = [
+ round(point[0] + v1[0] + v2[0]),
+ round(point[1] + v1[1] + v2[1])
+ ]
+ shrink_points.append(shrink_point)
+
+ poly = np.array(shrink_points)
+
+ return poly
+
+ def shrink_char_rect(self, char_rect, shrink_ratio):
+ """Shrink char box in style of rectangle.
+
+ Args:
+ char_rect (list[float]): Char box with format
+ [x_min, y_min, x_max, y_max].
+ shrink_ratio (float): The area shrunk ratio
+ between gt kernels and gt text masks.
+ """
+ x_min, y_min, x_max, y_max = char_rect
+ w = x_max - x_min
+ h = y_max - y_min
+ x_min_s = round((x_min + x_max - w * shrink_ratio) / 2)
+ y_min_s = round((y_min + y_max - h * shrink_ratio) / 2)
+ x_max_s = round((x_min + x_max + w * shrink_ratio) / 2)
+ y_max_s = round((y_min + y_max + h * shrink_ratio) / 2)
+ poly = np.array([[x_min_s, y_min_s], [x_max_s, y_min_s],
+ [x_max_s, y_max_s], [x_min_s, y_max_s]])
+
+ return poly
+
+ def generate_kernels(self,
+ resize_shape,
+ pad_shape,
+ char_boxes,
+ char_inds,
+ shrink_ratio=0.5,
+ binary=True):
+ """Generate char instance kernels for one shrink ratio.
+
+ Args:
+ resize_shape (tuple(int, int)): Image size (height, width)
+ after resizing.
+ pad_shape (tuple(int, int)): Image size (height, width)
+ after padding.
+ char_boxes (list[list[float]]): The list of char polygons.
+ char_inds (list[int]): List of char indexes.
+ shrink_ratio (float): The shrink ratio of kernel.
+ binary (bool): If True, return binary ndarray
+ containing 0 & 1 only.
+ Returns:
+ char_kernel (ndarray): The text kernel mask of (height, width).
+ """
+ assert isinstance(resize_shape, tuple)
+ assert isinstance(pad_shape, tuple)
+ assert check_argument.is_2dlist(char_boxes)
+ assert check_argument.is_type_list(char_inds, int)
+ assert isinstance(shrink_ratio, float)
+ assert isinstance(binary, bool)
+
+ char_kernel = np.zeros(pad_shape, dtype=np.int32)
+ char_kernel[:resize_shape[0], resize_shape[1]:] = self.pad_val
+
+ for i, char_box in enumerate(char_boxes):
+ if self.box_type == 'char_rects':
+ poly = self.shrink_char_rect(char_box, shrink_ratio)
+ elif self.box_type == 'char_quads':
+ poly = self.shrink_char_quad(char_box, shrink_ratio)
+
+ fill_value = 1 if binary else char_inds[i]
+ cv2.fillConvexPoly(char_kernel, poly.astype(np.int32),
+ (fill_value))
+
+ return char_kernel
+
+ def l2_dist_two_points(self, p1, p2):
+ return ((p1[0] - p2[0])**2 + (p1[1] - p2[1])**2)**0.5
+
+ def __call__(self, results):
+ img_shape = results['img_shape']
+ resize_shape = results['resize_shape']
+
+ h_scale = 1.0 * resize_shape[0] / img_shape[0]
+ w_scale = 1.0 * resize_shape[1] / img_shape[1]
+
+ char_boxes, char_inds = [], []
+ char_num = len(results['ann_info'][self.box_type])
+ for i in range(char_num):
+ char_box = results['ann_info'][self.box_type][i]
+ num_points = 2 if self.box_type == 'char_rects' else 4
+ for j in range(num_points):
+ char_box[j * 2] = round(char_box[j * 2] * w_scale)
+ char_box[j * 2 + 1] = round(char_box[j * 2 + 1] * h_scale)
+ char_boxes.append(char_box)
+ char = results['ann_info']['chars'][i]
+ char_ind = self.label_convertor.str2idx([char])[0][0]
+ char_inds.append(char_ind)
+
+ resize_shape = tuple(results['resize_shape'][:2])
+ pad_shape = tuple(results['pad_shape'][:2])
+ binary_target = self.generate_kernels(
+ resize_shape,
+ pad_shape,
+ char_boxes,
+ char_inds,
+ shrink_ratio=self.attn_shrink_ratio,
+ binary=True)
+
+ seg_target = self.generate_kernels(
+ resize_shape,
+ pad_shape,
+ char_boxes,
+ char_inds,
+ shrink_ratio=self.seg_shrink_ratio,
+ binary=False)
+
+ mask = np.ones(pad_shape, dtype=np.int32)
+ mask[:resize_shape[0], resize_shape[1]:] = 0
+
+ results['gt_kernels'] = BitmapMasks([binary_target, seg_target, mask],
+ pad_shape[0], pad_shape[1])
+ results['mask_fields'] = ['gt_kernels']
+
+ return results
diff --git a/mmocr/datasets/pipelines/ocr_transforms.py b/mmocr/datasets/pipelines/ocr_transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..9081d4b86a3946b8b792a0e92521b1a8397434d6
--- /dev/null
+++ b/mmocr/datasets/pipelines/ocr_transforms.py
@@ -0,0 +1,454 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import mmcv
+import numpy as np
+import torch
+import torchvision.transforms.functional as TF
+from mmcv.runner.dist_utils import get_dist_info
+from mmdet.datasets.builder import PIPELINES
+from PIL import Image
+from shapely.geometry import Polygon
+from shapely.geometry import box as shapely_box
+
+import mmocr.utils as utils
+from mmocr.datasets.pipelines.crop import warp_img
+
+
+@PIPELINES.register_module()
+class ResizeOCR:
+ """Image resizing and padding for OCR.
+
+ Args:
+ height (int | tuple(int)): Image height after resizing.
+ min_width (none | int | tuple(int)): Image minimum width
+ after resizing.
+ max_width (none | int | tuple(int)): Image maximum width
+ after resizing.
+ keep_aspect_ratio (bool): Keep image aspect ratio if True
+ during resizing, Otherwise resize to the size height *
+ max_width.
+ img_pad_value (int): Scalar to fill padding area.
+ width_downsample_ratio (float): Downsample ratio in horizontal
+ direction from input image to output feature.
+ backend (str | None): The image resize backend type. Options are `cv2`,
+ `pillow`, `None`. If backend is None, the global imread_backend
+ specified by ``mmcv.use_backend()`` will be used. Default: None.
+ """
+
+ def __init__(self,
+ height,
+ min_width=None,
+ max_width=None,
+ keep_aspect_ratio=True,
+ img_pad_value=0,
+ width_downsample_ratio=1.0 / 16,
+ backend=None):
+ assert isinstance(height, (int, tuple))
+ assert utils.is_none_or_type(min_width, (int, tuple))
+ assert utils.is_none_or_type(max_width, (int, tuple))
+ if not keep_aspect_ratio:
+ assert max_width is not None, ('"max_width" must assigned '
+ 'if "keep_aspect_ratio" is False')
+ assert isinstance(img_pad_value, int)
+ if isinstance(height, tuple):
+ assert isinstance(min_width, tuple)
+ assert isinstance(max_width, tuple)
+ assert len(height) == len(min_width) == len(max_width)
+
+ self.height = height
+ self.min_width = min_width
+ self.max_width = max_width
+ self.keep_aspect_ratio = keep_aspect_ratio
+ self.img_pad_value = img_pad_value
+ self.width_downsample_ratio = width_downsample_ratio
+ self.backend = backend
+
+ def __call__(self, results):
+ rank, _ = get_dist_info()
+ if isinstance(self.height, int):
+ dst_height = self.height
+ dst_min_width = self.min_width
+ dst_max_width = self.max_width
+ else:
+ # Multi-scale resize used in distributed training.
+ # Choose one (height, width) pair for one rank id.
+
+ idx = rank % len(self.height)
+ dst_height = self.height[idx]
+ dst_min_width = self.min_width[idx]
+ dst_max_width = self.max_width[idx]
+
+ img_shape = results['img_shape']
+ ori_height, ori_width = img_shape[:2]
+ valid_ratio = 1.0
+ resize_shape = list(img_shape)
+ pad_shape = list(img_shape)
+
+ if self.keep_aspect_ratio:
+ new_width = math.ceil(float(dst_height) / ori_height * ori_width)
+ width_divisor = int(1 / self.width_downsample_ratio)
+ # make sure new_width is an integral multiple of width_divisor.
+ if new_width % width_divisor != 0:
+ new_width = round(new_width / width_divisor) * width_divisor
+ if dst_min_width is not None:
+ new_width = max(dst_min_width, new_width)
+ if dst_max_width is not None:
+ valid_ratio = min(1.0, 1.0 * new_width / dst_max_width)
+ resize_width = min(dst_max_width, new_width)
+ img_resize = mmcv.imresize(
+ results['img'], (resize_width, dst_height),
+ backend=self.backend)
+ resize_shape = img_resize.shape
+ pad_shape = img_resize.shape
+ if new_width < dst_max_width:
+ img_resize = mmcv.impad(
+ img_resize,
+ shape=(dst_height, dst_max_width),
+ pad_val=self.img_pad_value)
+ pad_shape = img_resize.shape
+ else:
+ img_resize = mmcv.imresize(
+ results['img'], (new_width, dst_height),
+ backend=self.backend)
+ resize_shape = img_resize.shape
+ pad_shape = img_resize.shape
+ else:
+ img_resize = mmcv.imresize(
+ results['img'], (dst_max_width, dst_height),
+ backend=self.backend)
+ resize_shape = img_resize.shape
+ pad_shape = img_resize.shape
+
+ results['img'] = img_resize
+ results['img_shape'] = resize_shape
+ results['resize_shape'] = resize_shape
+ results['pad_shape'] = pad_shape
+ results['valid_ratio'] = valid_ratio
+
+ return results
+
+
+@PIPELINES.register_module()
+class ToTensorOCR:
+ """Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor."""
+
+ def __init__(self):
+ pass
+
+ def __call__(self, results):
+ results['img'] = TF.to_tensor(results['img'].copy())
+
+ return results
+
+
+@PIPELINES.register_module()
+class NormalizeOCR:
+ """Normalize a tensor image with mean and standard deviation."""
+
+ def __init__(self, mean, std):
+ self.mean = mean
+ self.std = std
+
+ def __call__(self, results):
+ results['img'] = TF.normalize(results['img'], self.mean, self.std)
+ results['img_norm_cfg'] = dict(mean=self.mean, std=self.std)
+ return results
+
+
+@PIPELINES.register_module()
+class OnlineCropOCR:
+ """Crop text areas from whole image with bounding box jitter. If no bbox is
+ given, return directly.
+
+ Args:
+ box_keys (list[str]): Keys in results which correspond to RoI bbox.
+ jitter_prob (float): The probability of box jitter.
+ max_jitter_ratio_x (float): Maximum horizontal jitter ratio
+ relative to height.
+ max_jitter_ratio_y (float): Maximum vertical jitter ratio
+ relative to height.
+ """
+
+ def __init__(self,
+ box_keys=['x1', 'y1', 'x2', 'y2', 'x3', 'y3', 'x4', 'y4'],
+ jitter_prob=0.5,
+ max_jitter_ratio_x=0.05,
+ max_jitter_ratio_y=0.02):
+ assert utils.is_type_list(box_keys, str)
+ assert 0 <= jitter_prob <= 1
+ assert 0 <= max_jitter_ratio_x <= 1
+ assert 0 <= max_jitter_ratio_y <= 1
+
+ self.box_keys = box_keys
+ self.jitter_prob = jitter_prob
+ self.max_jitter_ratio_x = max_jitter_ratio_x
+ self.max_jitter_ratio_y = max_jitter_ratio_y
+
+ def __call__(self, results):
+
+ if 'img_info' not in results:
+ return results
+
+ crop_flag = True
+ box = []
+ for key in self.box_keys:
+ if key not in results['img_info']:
+ crop_flag = False
+ break
+
+ box.append(float(results['img_info'][key]))
+
+ if not crop_flag:
+ return results
+
+ jitter_flag = np.random.random() > self.jitter_prob
+
+ kwargs = dict(
+ jitter_flag=jitter_flag,
+ jitter_ratio_x=self.max_jitter_ratio_x,
+ jitter_ratio_y=self.max_jitter_ratio_y)
+ crop_img = warp_img(results['img'], box, **kwargs)
+
+ results['img'] = crop_img
+ results['img_shape'] = crop_img.shape
+
+ return results
+
+
+@PIPELINES.register_module()
+class FancyPCA:
+ """Implementation of PCA based image augmentation, proposed in the paper
+ ``Imagenet Classification With Deep Convolutional Neural Networks``.
+
+ It alters the intensities of RGB values along the principal components of
+ ImageNet dataset.
+ """
+
+ def __init__(self, eig_vec=None, eig_val=None):
+ if eig_vec is None:
+ eig_vec = torch.Tensor([
+ [-0.5675, +0.7192, +0.4009],
+ [-0.5808, -0.0045, -0.8140],
+ [-0.5836, -0.6948, +0.4203],
+ ]).t()
+ if eig_val is None:
+ eig_val = torch.Tensor([[0.2175, 0.0188, 0.0045]])
+ self.eig_val = eig_val # 1*3
+ self.eig_vec = eig_vec # 3*3
+
+ def pca(self, tensor):
+ assert tensor.size(0) == 3
+ alpha = torch.normal(mean=torch.zeros_like(self.eig_val)) * 0.1
+ reconst = torch.mm(self.eig_val * alpha, self.eig_vec)
+ tensor = tensor + reconst.view(3, 1, 1)
+
+ return tensor
+
+ def __call__(self, results):
+ img = results['img']
+ tensor = self.pca(img)
+ results['img'] = tensor
+
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ return repr_str
+
+
+@PIPELINES.register_module()
+class RandomPaddingOCR:
+ """Pad the given image on all sides, as well as modify the coordinates of
+ character bounding box in image.
+
+ Args:
+ max_ratio (list[int]): [left, top, right, bottom].
+ box_type (None|str): Character box type. If not none,
+ should be either 'char_rects' or 'char_quads', with
+ 'char_rects' for rectangle with ``xyxy`` style and
+ 'char_quads' for quadrangle with ``x1y1x2y2x3y3x4y4`` style.
+ """
+
+ def __init__(self, max_ratio=None, box_type=None):
+ if max_ratio is None:
+ max_ratio = [0.1, 0.2, 0.1, 0.2]
+ else:
+ assert utils.is_type_list(max_ratio, float)
+ assert len(max_ratio) == 4
+ assert box_type is None or box_type in ('char_rects', 'char_quads')
+
+ self.max_ratio = max_ratio
+ self.box_type = box_type
+
+ def __call__(self, results):
+
+ img_shape = results['img_shape']
+ ori_height, ori_width = img_shape[:2]
+
+ random_padding_left = round(
+ np.random.uniform(0, self.max_ratio[0]) * ori_width)
+ random_padding_top = round(
+ np.random.uniform(0, self.max_ratio[1]) * ori_height)
+ random_padding_right = round(
+ np.random.uniform(0, self.max_ratio[2]) * ori_width)
+ random_padding_bottom = round(
+ np.random.uniform(0, self.max_ratio[3]) * ori_height)
+
+ padding = (random_padding_left, random_padding_top,
+ random_padding_right, random_padding_bottom)
+ img = mmcv.impad(results['img'], padding=padding, padding_mode='edge')
+
+ results['img'] = img
+ results['img_shape'] = img.shape
+
+ if self.box_type is not None:
+ num_points = 2 if self.box_type == 'char_rects' else 4
+ char_num = len(results['ann_info'][self.box_type])
+ for i in range(char_num):
+ for j in range(num_points):
+ results['ann_info'][self.box_type][i][
+ j * 2] += random_padding_left
+ results['ann_info'][self.box_type][i][
+ j * 2 + 1] += random_padding_top
+
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ return repr_str
+
+
+@PIPELINES.register_module()
+class RandomRotateImageBox:
+ """Rotate augmentation for segmentation based text recognition.
+
+ Args:
+ min_angle (int): Minimum rotation angle for image and box.
+ max_angle (int): Maximum rotation angle for image and box.
+ box_type (str): Character box type, should be either
+ 'char_rects' or 'char_quads', with 'char_rects'
+ for rectangle with ``xyxy`` style and 'char_quads'
+ for quadrangle with ``x1y1x2y2x3y3x4y4`` style.
+ """
+
+ def __init__(self, min_angle=-10, max_angle=10, box_type='char_quads'):
+ assert box_type in ('char_rects', 'char_quads')
+
+ self.min_angle = min_angle
+ self.max_angle = max_angle
+ self.box_type = box_type
+
+ def __call__(self, results):
+ in_img = results['img']
+ in_chars = results['ann_info']['chars']
+ in_boxes = results['ann_info'][self.box_type]
+
+ img_width, img_height = in_img.size
+ rotate_center = [img_width / 2., img_height / 2.]
+
+ tan_temp_max_angle = rotate_center[1] / rotate_center[0]
+ temp_max_angle = np.arctan(tan_temp_max_angle) * 180. / np.pi
+
+ random_angle = np.random.uniform(
+ max(self.min_angle, -temp_max_angle),
+ min(self.max_angle, temp_max_angle))
+ random_angle_radian = random_angle * np.pi / 180.
+
+ img_box = shapely_box(0, 0, img_width, img_height)
+
+ out_img = TF.rotate(
+ in_img,
+ random_angle,
+ resample=False,
+ expand=False,
+ center=rotate_center)
+
+ out_boxes, out_chars = self.rotate_bbox(in_boxes, in_chars,
+ random_angle_radian,
+ rotate_center, img_box)
+
+ results['img'] = out_img
+ results['ann_info']['chars'] = out_chars
+ results['ann_info'][self.box_type] = out_boxes
+
+ return results
+
+ @staticmethod
+ def rotate_bbox(boxes, chars, angle, center, img_box):
+ out_boxes = []
+ out_chars = []
+ for idx, bbox in enumerate(boxes):
+ temp_bbox = []
+ for i in range(len(bbox) // 2):
+ point = [bbox[2 * i], bbox[2 * i + 1]]
+ temp_bbox.append(
+ RandomRotateImageBox.rotate_point(point, angle, center))
+ poly_temp_bbox = Polygon(temp_bbox).buffer(0)
+ if poly_temp_bbox.is_valid:
+ if img_box.intersects(poly_temp_bbox) and (
+ not img_box.touches(poly_temp_bbox)):
+ temp_bbox_area = poly_temp_bbox.area
+
+ intersect_area = img_box.intersection(poly_temp_bbox).area
+ intersect_ratio = intersect_area / temp_bbox_area
+
+ if intersect_ratio >= 0.7:
+ out_box = []
+ for p in temp_bbox:
+ out_box.extend(p)
+ out_boxes.append(out_box)
+ out_chars.append(chars[idx])
+
+ return out_boxes, out_chars
+
+ @staticmethod
+ def rotate_point(point, angle, center):
+ cos_theta = math.cos(-angle)
+ sin_theta = math.sin(-angle)
+ c_x = center[0]
+ c_y = center[1]
+ new_x = (point[0] - c_x) * cos_theta - (point[1] -
+ c_y) * sin_theta + c_x
+ new_y = (point[0] - c_x) * sin_theta + (point[1] -
+ c_y) * cos_theta + c_y
+
+ return [new_x, new_y]
+
+
+@PIPELINES.register_module()
+class OpencvToPil:
+ """Convert ``numpy.ndarray`` (bgr) to ``PIL Image`` (rgb)."""
+
+ def __init__(self, **kwargs):
+ pass
+
+ def __call__(self, results):
+ img = results['img'][..., ::-1]
+ img = Image.fromarray(img)
+ results['img'] = img
+
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ return repr_str
+
+
+@PIPELINES.register_module()
+class PilToOpencv:
+ """Convert ``PIL Image`` (rgb) to ``numpy.ndarray`` (bgr)."""
+
+ def __init__(self, **kwargs):
+ pass
+
+ def __call__(self, results):
+ img = np.asarray(results['img'])
+ img = img[..., ::-1]
+ results['img'] = img
+
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ return repr_str
diff --git a/mmocr/datasets/pipelines/test_time_aug.py b/mmocr/datasets/pipelines/test_time_aug.py
new file mode 100644
index 0000000000000000000000000000000000000000..773ea14be823e62f1b7bcd1430a75f0697488832
--- /dev/null
+++ b/mmocr/datasets/pipelines/test_time_aug.py
@@ -0,0 +1,108 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import mmcv
+import numpy as np
+from mmdet.datasets.builder import PIPELINES
+from mmdet.datasets.pipelines.compose import Compose
+
+
+@PIPELINES.register_module()
+class MultiRotateAugOCR:
+ """Test-time augmentation with multiple rotations in the case that
+ img_height > img_width.
+
+ An example configuration is as follows:
+
+ .. code-block::
+
+ rotate_degrees=[0, 90, 270],
+ transforms=[
+ dict(
+ type='ResizeOCR',
+ height=32,
+ min_width=32,
+ max_width=160,
+ keep_aspect_ratio=True),
+ dict(type='ToTensorOCR'),
+ dict(type='NormalizeOCR', **img_norm_cfg),
+ dict(
+ type='Collect',
+ keys=['img'],
+ meta_keys=[
+ 'filename', 'ori_shape', 'img_shape', 'valid_ratio'
+ ]),
+ ]
+
+ After MultiRotateAugOCR with above configuration, the results are wrapped
+ into lists of the same length as follows:
+
+ .. code-block::
+
+ dict(
+ img=[...],
+ img_shape=[...]
+ ...
+ )
+
+ Args:
+ transforms (list[dict]): Transformation applied for each augmentation.
+ rotate_degrees (list[int] | None): Degrees of anti-clockwise rotation.
+ force_rotate (bool): If True, rotate image by 'rotate_degrees'
+ while ignore image aspect ratio.
+ """
+
+ def __init__(self, transforms, rotate_degrees=None, force_rotate=False):
+ self.transforms = Compose(transforms)
+ self.force_rotate = force_rotate
+ if rotate_degrees is not None:
+ self.rotate_degrees = rotate_degrees if isinstance(
+ rotate_degrees, list) else [rotate_degrees]
+ assert mmcv.is_list_of(self.rotate_degrees, int)
+ for degree in self.rotate_degrees:
+ assert 0 <= degree < 360
+ assert degree % 90 == 0
+ if 0 not in self.rotate_degrees:
+ self.rotate_degrees.append(0)
+ else:
+ self.rotate_degrees = [0]
+
+ def __call__(self, results):
+ """Call function to apply test time augment transformation to results.
+
+ Args:
+ results (dict): Result dict contains the data to be transformed.
+
+ Returns:
+ dict[str: list]: The augmented data, where each value is wrapped
+ into a list.
+ """
+ img_shape = results['img_shape']
+ ori_height, ori_width = img_shape[:2]
+ if not self.force_rotate and ori_height <= ori_width:
+ rotate_degrees = [0]
+ else:
+ rotate_degrees = self.rotate_degrees
+ aug_data = []
+ for degree in set(rotate_degrees):
+ _results = results.copy()
+ if degree == 0:
+ pass
+ elif degree == 90:
+ _results['img'] = np.rot90(_results['img'], 1)
+ elif degree == 180:
+ _results['img'] = np.rot90(_results['img'], 2)
+ elif degree == 270:
+ _results['img'] = np.rot90(_results['img'], 3)
+ data = self.transforms(_results)
+ aug_data.append(data)
+ # list of dict to dict of list
+ aug_data_dict = {key: [] for key in aug_data[0]}
+ for data in aug_data:
+ for key, val in data.items():
+ aug_data_dict[key].append(val)
+ return aug_data_dict
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(transforms={self.transforms}, '
+ repr_str += f'rotate_degrees={self.rotate_degrees})'
+ return repr_str
diff --git a/mmocr/datasets/pipelines/textdet_targets/__init__.py b/mmocr/datasets/pipelines/textdet_targets/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..2662739aced091200ca4814f76b06da7529702ba
--- /dev/null
+++ b/mmocr/datasets/pipelines/textdet_targets/__init__.py
@@ -0,0 +1,13 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .base_textdet_targets import BaseTextDetTargets
+from .dbnet_targets import DBNetTargets
+from .drrg_targets import DRRGTargets
+from .fcenet_targets import FCENetTargets
+from .panet_targets import PANetTargets
+from .psenet_targets import PSENetTargets
+from .textsnake_targets import TextSnakeTargets
+
+__all__ = [
+ 'BaseTextDetTargets', 'PANetTargets', 'PSENetTargets', 'DBNetTargets',
+ 'FCENetTargets', 'TextSnakeTargets', 'DRRGTargets'
+]
diff --git a/mmocr/datasets/pipelines/textdet_targets/base_textdet_targets.py b/mmocr/datasets/pipelines/textdet_targets/base_textdet_targets.py
new file mode 100644
index 0000000000000000000000000000000000000000..b86d85402a1873a5619a61d62d3b7249a3b12c31
--- /dev/null
+++ b/mmocr/datasets/pipelines/textdet_targets/base_textdet_targets.py
@@ -0,0 +1,168 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import sys
+
+import cv2
+import numpy as np
+import pyclipper
+from mmcv.utils import print_log
+from shapely.geometry import Polygon as plg
+
+import mmocr.utils.check_argument as check_argument
+
+
+class BaseTextDetTargets:
+ """Generate text detector ground truths."""
+
+ def __init__(self):
+ pass
+
+ def point2line(self, xs, ys, point_1, point_2):
+ """Compute the distance from point to a line. This is adapted from
+ https://github.com/MhLiao/DB.
+
+ Args:
+ xs (ndarray): The x coordinates of size hxw.
+ ys (ndarray): The y coordinates of size hxw.
+ point_1 (ndarray): The first point with shape 1x2.
+ point_2 (ndarray): The second point with shape 1x2.
+
+ Returns:
+ result (ndarray): The distance matrix of size hxw.
+ """
+ # suppose a triangle with three edge abc with c=point_1 point_2
+ # a^2
+ a_square = np.square(xs - point_1[0]) + np.square(ys - point_1[1])
+ # b^2
+ b_square = np.square(xs - point_2[0]) + np.square(ys - point_2[1])
+ # c^2
+ c_square = np.square(point_1[0] - point_2[0]) + np.square(point_1[1] -
+ point_2[1])
+ # -cosC=(c^2-a^2-b^2)/2(ab)
+ neg_cos_c = (
+ (c_square - a_square - b_square) /
+ (np.finfo(np.float32).eps + 2 * np.sqrt(a_square * b_square)))
+ # sinC^2=1-cosC^2
+ square_sin = 1 - np.square(neg_cos_c)
+ square_sin = np.nan_to_num(square_sin)
+ # distance=a*b*sinC/c=a*h/c=2*area/c
+ result = np.sqrt(a_square * b_square * square_sin /
+ (np.finfo(np.float32).eps + c_square))
+ # set result to minimum edge if C 0:
+ padded_polygon = np.array(padded_polygon[0])
+ else:
+ print(f'padding {polygon} with {distance} gets {padded_polygon}')
+ padded_polygon = polygon.copy().astype(np.int32)
+
+ x_min = padded_polygon[:, 0].min()
+ x_max = padded_polygon[:, 0].max()
+ y_min = padded_polygon[:, 1].min()
+ y_max = padded_polygon[:, 1].max()
+
+ width = x_max - x_min + 1
+ height = y_max - y_min + 1
+
+ polygon[:, 0] = polygon[:, 0] - x_min
+ polygon[:, 1] = polygon[:, 1] - y_min
+
+ xs = np.broadcast_to(
+ np.linspace(0, width - 1, num=width).reshape(1, width),
+ (height, width))
+ ys = np.broadcast_to(
+ np.linspace(0, height - 1, num=height).reshape(height, 1),
+ (height, width))
+
+ distance_map = np.zeros((polygon.shape[0], height, width),
+ dtype=np.float32)
+ for i in range(polygon.shape[0]):
+ j = (i + 1) % polygon.shape[0]
+ absolute_distance = self.point2line(xs, ys, polygon[i], polygon[j])
+ distance_map[i] = np.clip(absolute_distance / distance, 0, 1)
+ distance_map = distance_map.min(axis=0)
+
+ x_min_valid = min(max(0, x_min), canvas.shape[1] - 1)
+ x_max_valid = min(max(0, x_max), canvas.shape[1] - 1)
+ y_min_valid = min(max(0, y_min), canvas.shape[0] - 1)
+ y_max_valid = min(max(0, y_max), canvas.shape[0] - 1)
+
+ if x_min_valid - x_min >= width or y_min_valid - y_min >= height:
+ return
+
+ cv2.fillPoly(mask, [padded_polygon.astype(np.int32)], 1.0)
+ canvas[y_min_valid:y_max_valid + 1,
+ x_min_valid:x_max_valid + 1] = np.fmax(
+ 1 - distance_map[y_min_valid - y_min:y_max_valid - y_max +
+ height, x_min_valid - x_min:x_max_valid -
+ x_max + width],
+ canvas[y_min_valid:y_max_valid + 1,
+ x_min_valid:x_max_valid + 1])
+
+ def generate_targets(self, results):
+ """Generate the gt targets for DBNet.
+
+ Args:
+ results (dict): The input result dictionary.
+
+ Returns:
+ results (dict): The output result dictionary.
+ """
+ assert isinstance(results, dict)
+
+ if 'bbox_fields' in results:
+ results['bbox_fields'].clear()
+
+ ignore_tags = self.find_invalid(results)
+ results, ignore_tags = self.ignore_texts(results, ignore_tags)
+
+ h, w, _ = results['img_shape']
+ polygons = results['gt_masks'].masks
+
+ # generate gt_shrink_kernel
+ gt_shrink, ignore_tags = self.generate_kernels((h, w),
+ polygons,
+ self.shrink_ratio,
+ ignore_tags=ignore_tags)
+
+ results, ignore_tags = self.ignore_texts(results, ignore_tags)
+ # genenrate gt_shrink_mask
+ polygons_ignore = results['gt_masks_ignore'].masks
+ gt_shrink_mask = self.generate_effective_mask((h, w), polygons_ignore)
+
+ # generate gt_threshold and gt_threshold_mask
+ polygons = results['gt_masks'].masks
+ gt_thr, gt_thr_mask = self.generate_thr_map((h, w), polygons)
+
+ results['mask_fields'].clear() # rm gt_masks encoded by polygons
+ results.pop('gt_labels', None)
+ results.pop('gt_masks', None)
+ results.pop('gt_bboxes', None)
+ results.pop('gt_bboxes_ignore', None)
+
+ mapping = {
+ 'gt_shrink': gt_shrink,
+ 'gt_shrink_mask': gt_shrink_mask,
+ 'gt_thr': gt_thr,
+ 'gt_thr_mask': gt_thr_mask
+ }
+ for key, value in mapping.items():
+ value = value if isinstance(value, list) else [value]
+ results[key] = BitmapMasks(value, h, w)
+ results['mask_fields'].append(key)
+
+ return results
diff --git a/mmocr/datasets/pipelines/textdet_targets/drrg_targets.py b/mmocr/datasets/pipelines/textdet_targets/drrg_targets.py
new file mode 100644
index 0000000000000000000000000000000000000000..fdf3a494535d0820ef8e9c56e76aa2def51a6ea3
--- /dev/null
+++ b/mmocr/datasets/pipelines/textdet_targets/drrg_targets.py
@@ -0,0 +1,534 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import cv2
+import numpy as np
+from lanms import merge_quadrangle_n9 as la_nms
+from mmdet.core import BitmapMasks
+from mmdet.datasets.builder import PIPELINES
+from numpy.linalg import norm
+
+import mmocr.utils.check_argument as check_argument
+from .textsnake_targets import TextSnakeTargets
+
+
+@PIPELINES.register_module()
+class DRRGTargets(TextSnakeTargets):
+ """Generate the ground truth targets of DRRG: Deep Relational Reasoning
+ Graph Network for Arbitrary Shape Text Detection.
+
+ [https://arxiv.org/abs/2003.07493]. This code was partially adapted from
+ https://github.com/GXYM/DRRG licensed under the MIT license.
+
+ Args:
+ orientation_thr (float): The threshold for distinguishing between
+ head edge and tail edge among the horizontal and vertical edges
+ of a quadrangle.
+ resample_step (float): The step size for resampling the text center
+ line.
+ num_min_comps (int): The minimum number of text components, which
+ should be larger than k_hop1 mentioned in paper.
+ num_max_comps (int): The maximum number of text components.
+ min_width (float): The minimum width of text components.
+ max_width (float): The maximum width of text components.
+ center_region_shrink_ratio (float): The shrink ratio of text center
+ regions.
+ comp_shrink_ratio (float): The shrink ratio of text components.
+ comp_w_h_ratio (float): The width to height ratio of text components.
+ min_rand_half_height(float): The minimum half-height of random text
+ components.
+ max_rand_half_height (float): The maximum half-height of random
+ text components.
+ jitter_level (float): The jitter level of text component geometric
+ features.
+ """
+
+ def __init__(self,
+ orientation_thr=2.0,
+ resample_step=8.0,
+ num_min_comps=9,
+ num_max_comps=600,
+ min_width=8.0,
+ max_width=24.0,
+ center_region_shrink_ratio=0.3,
+ comp_shrink_ratio=1.0,
+ comp_w_h_ratio=0.3,
+ text_comp_nms_thr=0.25,
+ min_rand_half_height=8.0,
+ max_rand_half_height=24.0,
+ jitter_level=0.2):
+
+ super().__init__()
+ self.orientation_thr = orientation_thr
+ self.resample_step = resample_step
+ self.num_max_comps = num_max_comps
+ self.num_min_comps = num_min_comps
+ self.min_width = min_width
+ self.max_width = max_width
+ self.center_region_shrink_ratio = center_region_shrink_ratio
+ self.comp_shrink_ratio = comp_shrink_ratio
+ self.comp_w_h_ratio = comp_w_h_ratio
+ self.text_comp_nms_thr = text_comp_nms_thr
+ self.min_rand_half_height = min_rand_half_height
+ self.max_rand_half_height = max_rand_half_height
+ self.jitter_level = jitter_level
+
+ def dist_point2line(self, point, line):
+
+ assert isinstance(line, tuple)
+ point1, point2 = line
+ d = abs(np.cross(point2 - point1, point - point1)) / (
+ norm(point2 - point1) + 1e-8)
+ return d
+
+ def draw_center_region_maps(self, top_line, bot_line, center_line,
+ center_region_mask, top_height_map,
+ bot_height_map, sin_map, cos_map,
+ region_shrink_ratio):
+ """Draw attributes of text components on text center regions.
+
+ Args:
+ top_line (ndarray): The points composing the top side lines of text
+ polygons.
+ bot_line (ndarray): The points composing bottom side lines of text
+ polygons.
+ center_line (ndarray): The points composing the center lines of
+ text instances.
+ center_region_mask (ndarray): The text center region mask.
+ top_height_map (ndarray): The map on which the distance from points
+ to top side lines will be drawn for each pixel in text center
+ regions.
+ bot_height_map (ndarray): The map on which the distance from points
+ to bottom side lines will be drawn for each pixel in text
+ center regions.
+ sin_map (ndarray): The map of vector_sin(top_point - bot_point)
+ that will be drawn on text center regions.
+ cos_map (ndarray): The map of vector_cos(top_point - bot_point)
+ will be drawn on text center regions.
+ region_shrink_ratio (float): The shrink ratio of text center
+ regions.
+ """
+
+ assert top_line.shape == bot_line.shape == center_line.shape
+ assert (center_region_mask.shape == top_height_map.shape ==
+ bot_height_map.shape == sin_map.shape == cos_map.shape)
+ assert isinstance(region_shrink_ratio, float)
+
+ h, w = center_region_mask.shape
+ for i in range(0, len(center_line) - 1):
+
+ top_mid_point = (top_line[i] + top_line[i + 1]) / 2
+ bot_mid_point = (bot_line[i] + bot_line[i + 1]) / 2
+
+ sin_theta = self.vector_sin(top_mid_point - bot_mid_point)
+ cos_theta = self.vector_cos(top_mid_point - bot_mid_point)
+
+ tl = center_line[i] + (top_line[i] -
+ center_line[i]) * region_shrink_ratio
+ tr = center_line[i + 1] + (
+ top_line[i + 1] - center_line[i + 1]) * region_shrink_ratio
+ br = center_line[i + 1] + (
+ bot_line[i + 1] - center_line[i + 1]) * region_shrink_ratio
+ bl = center_line[i] + (bot_line[i] -
+ center_line[i]) * region_shrink_ratio
+ current_center_box = np.vstack([tl, tr, br, bl]).astype(np.int32)
+
+ cv2.fillPoly(center_region_mask, [current_center_box], color=1)
+ cv2.fillPoly(sin_map, [current_center_box], color=sin_theta)
+ cv2.fillPoly(cos_map, [current_center_box], color=cos_theta)
+
+ current_center_box[:, 0] = np.clip(current_center_box[:, 0], 0,
+ w - 1)
+ current_center_box[:, 1] = np.clip(current_center_box[:, 1], 0,
+ h - 1)
+ min_coord = np.min(current_center_box, axis=0).astype(np.int32)
+ max_coord = np.max(current_center_box, axis=0).astype(np.int32)
+ current_center_box = current_center_box - min_coord
+ box_sz = (max_coord - min_coord + 1)
+
+ center_box_mask = np.zeros((box_sz[1], box_sz[0]), dtype=np.uint8)
+ cv2.fillPoly(center_box_mask, [current_center_box], color=1)
+
+ inds = np.argwhere(center_box_mask > 0)
+ inds = inds + (min_coord[1], min_coord[0])
+ inds_xy = np.fliplr(inds)
+ top_height_map[(inds[:, 0], inds[:, 1])] = self.dist_point2line(
+ inds_xy, (top_line[i], top_line[i + 1]))
+ bot_height_map[(inds[:, 0], inds[:, 1])] = self.dist_point2line(
+ inds_xy, (bot_line[i], bot_line[i + 1]))
+
+ def generate_center_mask_attrib_maps(self, img_size, text_polys):
+ """Generate text center region masks and geometric attribute maps.
+
+ Args:
+ img_size (tuple): The image size (height, width).
+ text_polys (list[list[ndarray]]): The list of text polygons.
+
+ Returns:
+ center_lines (list): The list of text center lines.
+ center_region_mask (ndarray): The text center region mask.
+ top_height_map (ndarray): The map on which the distance from points
+ to top side lines will be drawn for each pixel in text center
+ regions.
+ bot_height_map (ndarray): The map on which the distance from points
+ to bottom side lines will be drawn for each pixel in text
+ center regions.
+ sin_map (ndarray): The sin(theta) map where theta is the angle
+ between vector (top point - bottom point) and vector (1, 0).
+ cos_map (ndarray): The cos(theta) map where theta is the angle
+ between vector (top point - bottom point) and vector (1, 0).
+ """
+
+ assert isinstance(img_size, tuple)
+ assert check_argument.is_2dlist(text_polys)
+
+ h, w = img_size
+
+ center_lines = []
+ center_region_mask = np.zeros((h, w), np.uint8)
+ top_height_map = np.zeros((h, w), dtype=np.float32)
+ bot_height_map = np.zeros((h, w), dtype=np.float32)
+ sin_map = np.zeros((h, w), dtype=np.float32)
+ cos_map = np.zeros((h, w), dtype=np.float32)
+
+ for poly in text_polys:
+ assert len(poly) == 1
+ polygon_points = poly[0].reshape(-1, 2)
+ _, _, top_line, bot_line = self.reorder_poly_edge(polygon_points)
+ resampled_top_line, resampled_bot_line = self.resample_sidelines(
+ top_line, bot_line, self.resample_step)
+ resampled_bot_line = resampled_bot_line[::-1]
+ center_line = (resampled_top_line + resampled_bot_line) / 2
+
+ if self.vector_slope(center_line[-1] - center_line[0]) > 2:
+ if (center_line[-1] - center_line[0])[1] < 0:
+ center_line = center_line[::-1]
+ resampled_top_line = resampled_top_line[::-1]
+ resampled_bot_line = resampled_bot_line[::-1]
+ else:
+ if (center_line[-1] - center_line[0])[0] < 0:
+ center_line = center_line[::-1]
+ resampled_top_line = resampled_top_line[::-1]
+ resampled_bot_line = resampled_bot_line[::-1]
+
+ line_head_shrink_len = np.clip(
+ (norm(top_line[0] - bot_line[0]) * self.comp_w_h_ratio),
+ self.min_width, self.max_width) / 2
+ line_tail_shrink_len = np.clip(
+ (norm(top_line[-1] - bot_line[-1]) * self.comp_w_h_ratio),
+ self.min_width, self.max_width) / 2
+ num_head_shrink = int(line_head_shrink_len // self.resample_step)
+ num_tail_shrink = int(line_tail_shrink_len // self.resample_step)
+ if len(center_line) > num_head_shrink + num_tail_shrink + 2:
+ center_line = center_line[num_head_shrink:len(center_line) -
+ num_tail_shrink]
+ resampled_top_line = resampled_top_line[
+ num_head_shrink:len(resampled_top_line) - num_tail_shrink]
+ resampled_bot_line = resampled_bot_line[
+ num_head_shrink:len(resampled_bot_line) - num_tail_shrink]
+ center_lines.append(center_line.astype(np.int32))
+
+ self.draw_center_region_maps(resampled_top_line,
+ resampled_bot_line, center_line,
+ center_region_mask, top_height_map,
+ bot_height_map, sin_map, cos_map,
+ self.center_region_shrink_ratio)
+
+ return (center_lines, center_region_mask, top_height_map,
+ bot_height_map, sin_map, cos_map)
+
+ def generate_rand_comp_attribs(self, num_rand_comps, center_sample_mask):
+ """Generate random text components and their attributes to ensure the
+ the number of text components in an image is larger than k_hop1, which
+ is the number of one hop neighbors in KNN graph.
+
+ Args:
+ num_rand_comps (int): The number of random text components.
+ center_sample_mask (ndarray): The region mask for sampling text
+ component centers .
+
+ Returns:
+ rand_comp_attribs (ndarray): The random text component attributes
+ (x, y, h, w, cos, sin, comp_label=0).
+ """
+
+ assert isinstance(num_rand_comps, int)
+ assert num_rand_comps > 0
+ assert center_sample_mask.ndim == 2
+
+ h, w = center_sample_mask.shape
+
+ max_rand_half_height = self.max_rand_half_height
+ min_rand_half_height = self.min_rand_half_height
+ max_rand_height = max_rand_half_height * 2
+ max_rand_width = np.clip(max_rand_height * self.comp_w_h_ratio,
+ self.min_width, self.max_width)
+ margin = int(
+ np.sqrt((max_rand_height / 2)**2 + (max_rand_width / 2)**2)) + 1
+
+ if 2 * margin + 1 > min(h, w):
+
+ assert min(h, w) > (np.sqrt(2) * (self.min_width + 1))
+ max_rand_half_height = max(min(h, w) / 4, self.min_width / 2 + 1)
+ min_rand_half_height = max(max_rand_half_height / 4,
+ self.min_width / 2)
+
+ max_rand_height = max_rand_half_height * 2
+ max_rand_width = np.clip(max_rand_height * self.comp_w_h_ratio,
+ self.min_width, self.max_width)
+ margin = int(
+ np.sqrt((max_rand_height / 2)**2 +
+ (max_rand_width / 2)**2)) + 1
+
+ inner_center_sample_mask = np.zeros_like(center_sample_mask)
+ inner_center_sample_mask[margin:h - margin, margin:w - margin] = \
+ center_sample_mask[margin:h - margin, margin:w - margin]
+ kernel_size = int(np.clip(max_rand_half_height, 7, 21))
+ inner_center_sample_mask = cv2.erode(
+ inner_center_sample_mask,
+ np.ones((kernel_size, kernel_size), np.uint8))
+
+ center_candidates = np.argwhere(inner_center_sample_mask > 0)
+ num_center_candidates = len(center_candidates)
+ sample_inds = np.random.choice(num_center_candidates, num_rand_comps)
+ rand_centers = center_candidates[sample_inds]
+
+ rand_top_height = np.random.randint(
+ min_rand_half_height,
+ max_rand_half_height,
+ size=(len(rand_centers), 1))
+ rand_bot_height = np.random.randint(
+ min_rand_half_height,
+ max_rand_half_height,
+ size=(len(rand_centers), 1))
+
+ rand_cos = 2 * np.random.random(size=(len(rand_centers), 1)) - 1
+ rand_sin = 2 * np.random.random(size=(len(rand_centers), 1)) - 1
+ scale = np.sqrt(1.0 / (rand_cos**2 + rand_sin**2 + 1e-8))
+ rand_cos = rand_cos * scale
+ rand_sin = rand_sin * scale
+
+ height = (rand_top_height + rand_bot_height)
+ width = np.clip(height * self.comp_w_h_ratio, self.min_width,
+ self.max_width)
+
+ rand_comp_attribs = np.hstack([
+ rand_centers[:, ::-1], height, width, rand_cos, rand_sin,
+ np.zeros_like(rand_sin)
+ ]).astype(np.float32)
+
+ return rand_comp_attribs
+
+ def jitter_comp_attribs(self, comp_attribs, jitter_level):
+ """Jitter text components attributes.
+
+ Args:
+ comp_attribs (ndarray): The text component attributes.
+ jitter_level (float): The jitter level of text components
+ attributes.
+
+ Returns:
+ jittered_comp_attribs (ndarray): The jittered text component
+ attributes (x, y, h, w, cos, sin, comp_label).
+ """
+
+ assert comp_attribs.shape[1] == 7
+ assert comp_attribs.shape[0] > 0
+ assert isinstance(jitter_level, float)
+
+ x = comp_attribs[:, 0].reshape((-1, 1))
+ y = comp_attribs[:, 1].reshape((-1, 1))
+ h = comp_attribs[:, 2].reshape((-1, 1))
+ w = comp_attribs[:, 3].reshape((-1, 1))
+ cos = comp_attribs[:, 4].reshape((-1, 1))
+ sin = comp_attribs[:, 5].reshape((-1, 1))
+ comp_labels = comp_attribs[:, 6].reshape((-1, 1))
+
+ x += (np.random.random(size=(len(comp_attribs), 1)) -
+ 0.5) * (h * np.abs(cos) + w * np.abs(sin)) * jitter_level
+ y += (np.random.random(size=(len(comp_attribs), 1)) -
+ 0.5) * (h * np.abs(sin) + w * np.abs(cos)) * jitter_level
+
+ h += (np.random.random(size=(len(comp_attribs), 1)) -
+ 0.5) * h * jitter_level
+ w += (np.random.random(size=(len(comp_attribs), 1)) -
+ 0.5) * w * jitter_level
+
+ cos += (np.random.random(size=(len(comp_attribs), 1)) -
+ 0.5) * 2 * jitter_level
+ sin += (np.random.random(size=(len(comp_attribs), 1)) -
+ 0.5) * 2 * jitter_level
+
+ scale = np.sqrt(1.0 / (cos**2 + sin**2 + 1e-8))
+ cos = cos * scale
+ sin = sin * scale
+
+ jittered_comp_attribs = np.hstack([x, y, h, w, cos, sin, comp_labels])
+
+ return jittered_comp_attribs
+
+ def generate_comp_attribs(self, center_lines, text_mask,
+ center_region_mask, top_height_map,
+ bot_height_map, sin_map, cos_map):
+ """Generate text component attributes.
+
+ Args:
+ center_lines (list[ndarray]): The list of text center lines .
+ text_mask (ndarray): The text region mask.
+ center_region_mask (ndarray): The text center region mask.
+ top_height_map (ndarray): The map on which the distance from points
+ to top side lines will be drawn for each pixel in text center
+ regions.
+ bot_height_map (ndarray): The map on which the distance from points
+ to bottom side lines will be drawn for each pixel in text
+ center regions.
+ sin_map (ndarray): The sin(theta) map where theta is the angle
+ between vector (top point - bottom point) and vector (1, 0).
+ cos_map (ndarray): The cos(theta) map where theta is the angle
+ between vector (top point - bottom point) and vector (1, 0).
+
+ Returns:
+ pad_comp_attribs (ndarray): The padded text component attributes
+ of a fixed size.
+ """
+
+ assert isinstance(center_lines, list)
+ assert (text_mask.shape == center_region_mask.shape ==
+ top_height_map.shape == bot_height_map.shape == sin_map.shape
+ == cos_map.shape)
+
+ center_lines_mask = np.zeros_like(center_region_mask)
+ cv2.polylines(center_lines_mask, center_lines, 0, 1, 1)
+ center_lines_mask = center_lines_mask * center_region_mask
+ comp_centers = np.argwhere(center_lines_mask > 0)
+
+ y = comp_centers[:, 0]
+ x = comp_centers[:, 1]
+
+ top_height = top_height_map[y, x].reshape(
+ (-1, 1)) * self.comp_shrink_ratio
+ bot_height = bot_height_map[y, x].reshape(
+ (-1, 1)) * self.comp_shrink_ratio
+ sin = sin_map[y, x].reshape((-1, 1))
+ cos = cos_map[y, x].reshape((-1, 1))
+
+ top_mid_points = comp_centers + np.hstack(
+ [top_height * sin, top_height * cos])
+ bot_mid_points = comp_centers - np.hstack(
+ [bot_height * sin, bot_height * cos])
+
+ width = (top_height + bot_height) * self.comp_w_h_ratio
+ width = np.clip(width, self.min_width, self.max_width)
+ r = width / 2
+
+ tl = top_mid_points[:, ::-1] - np.hstack([-r * sin, r * cos])
+ tr = top_mid_points[:, ::-1] + np.hstack([-r * sin, r * cos])
+ br = bot_mid_points[:, ::-1] + np.hstack([-r * sin, r * cos])
+ bl = bot_mid_points[:, ::-1] - np.hstack([-r * sin, r * cos])
+ text_comps = np.hstack([tl, tr, br, bl]).astype(np.float32)
+
+ score = np.ones((text_comps.shape[0], 1), dtype=np.float32)
+ text_comps = np.hstack([text_comps, score])
+ text_comps = la_nms(text_comps, self.text_comp_nms_thr)
+
+ if text_comps.shape[0] >= 1:
+ img_h, img_w = center_region_mask.shape
+ text_comps[:, 0:8:2] = np.clip(text_comps[:, 0:8:2], 0, img_w - 1)
+ text_comps[:, 1:8:2] = np.clip(text_comps[:, 1:8:2], 0, img_h - 1)
+
+ comp_centers = np.mean(
+ text_comps[:, 0:8].reshape((-1, 4, 2)),
+ axis=1).astype(np.int32)
+ x = comp_centers[:, 0]
+ y = comp_centers[:, 1]
+
+ height = (top_height_map[y, x] + bot_height_map[y, x]).reshape(
+ (-1, 1))
+ width = np.clip(height * self.comp_w_h_ratio, self.min_width,
+ self.max_width)
+
+ cos = cos_map[y, x].reshape((-1, 1))
+ sin = sin_map[y, x].reshape((-1, 1))
+
+ _, comp_label_mask = cv2.connectedComponents(
+ center_region_mask, connectivity=8)
+ comp_labels = comp_label_mask[y, x].reshape(
+ (-1, 1)).astype(np.float32)
+
+ x = x.reshape((-1, 1)).astype(np.float32)
+ y = y.reshape((-1, 1)).astype(np.float32)
+ comp_attribs = np.hstack(
+ [x, y, height, width, cos, sin, comp_labels])
+ comp_attribs = self.jitter_comp_attribs(comp_attribs,
+ self.jitter_level)
+
+ if comp_attribs.shape[0] < self.num_min_comps:
+ num_rand_comps = self.num_min_comps - comp_attribs.shape[0]
+ rand_comp_attribs = self.generate_rand_comp_attribs(
+ num_rand_comps, 1 - text_mask)
+ comp_attribs = np.vstack([comp_attribs, rand_comp_attribs])
+ else:
+ comp_attribs = self.generate_rand_comp_attribs(
+ self.num_min_comps, 1 - text_mask)
+
+ num_comps = (
+ np.ones((comp_attribs.shape[0], 1), dtype=np.float32) *
+ comp_attribs.shape[0])
+ comp_attribs = np.hstack([num_comps, comp_attribs])
+
+ if comp_attribs.shape[0] > self.num_max_comps:
+ comp_attribs = comp_attribs[:self.num_max_comps, :]
+ comp_attribs[:, 0] = self.num_max_comps
+
+ pad_comp_attribs = np.zeros(
+ (self.num_max_comps, comp_attribs.shape[1]), dtype=np.float32)
+ pad_comp_attribs[:comp_attribs.shape[0], :] = comp_attribs
+
+ return pad_comp_attribs
+
+ def generate_targets(self, results):
+ """Generate the gt targets for DRRG.
+
+ Args:
+ results (dict): The input result dictionary.
+
+ Returns:
+ results (dict): The output result dictionary.
+ """
+
+ assert isinstance(results, dict)
+
+ polygon_masks = results['gt_masks'].masks
+ polygon_masks_ignore = results['gt_masks_ignore'].masks
+
+ h, w, _ = results['img_shape']
+
+ gt_text_mask = self.generate_text_region_mask((h, w), polygon_masks)
+ gt_mask = self.generate_effective_mask((h, w), polygon_masks_ignore)
+ (center_lines, gt_center_region_mask, gt_top_height_map,
+ gt_bot_height_map, gt_sin_map,
+ gt_cos_map) = self.generate_center_mask_attrib_maps((h, w),
+ polygon_masks)
+
+ gt_comp_attribs = self.generate_comp_attribs(center_lines,
+ gt_text_mask,
+ gt_center_region_mask,
+ gt_top_height_map,
+ gt_bot_height_map,
+ gt_sin_map, gt_cos_map)
+
+ results['mask_fields'].clear() # rm gt_masks encoded by polygons
+ mapping = {
+ 'gt_text_mask': gt_text_mask,
+ 'gt_center_region_mask': gt_center_region_mask,
+ 'gt_mask': gt_mask,
+ 'gt_top_height_map': gt_top_height_map,
+ 'gt_bot_height_map': gt_bot_height_map,
+ 'gt_sin_map': gt_sin_map,
+ 'gt_cos_map': gt_cos_map
+ }
+ for key, value in mapping.items():
+ value = value if isinstance(value, list) else [value]
+ results[key] = BitmapMasks(value, h, w)
+ results['mask_fields'].append(key)
+
+ results['gt_comp_attribs'] = gt_comp_attribs
+ return results
diff --git a/mmocr/datasets/pipelines/textdet_targets/fcenet_targets.py b/mmocr/datasets/pipelines/textdet_targets/fcenet_targets.py
new file mode 100644
index 0000000000000000000000000000000000000000..2d667b580436b3284c7138f1ee98bc3bd9f245f6
--- /dev/null
+++ b/mmocr/datasets/pipelines/textdet_targets/fcenet_targets.py
@@ -0,0 +1,361 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import cv2
+import numpy as np
+from mmdet.datasets.builder import PIPELINES
+from numpy.fft import fft
+from numpy.linalg import norm
+
+import mmocr.utils.check_argument as check_argument
+from .textsnake_targets import TextSnakeTargets
+
+
+@PIPELINES.register_module()
+class FCENetTargets(TextSnakeTargets):
+ """Generate the ground truth targets of FCENet: Fourier Contour Embedding
+ for Arbitrary-Shaped Text Detection.
+
+ [https://arxiv.org/abs/2104.10442]
+
+ Args:
+ fourier_degree (int): The maximum Fourier transform degree k.
+ resample_step (float): The step size for resampling the text center
+ line (TCL). It's better not to exceed half of the minimum width.
+ center_region_shrink_ratio (float): The shrink ratio of text center
+ region.
+ level_size_divisors (tuple(int)): The downsample ratio on each level.
+ level_proportion_range (tuple(tuple(int))): The range of text sizes
+ assigned to each level.
+ """
+
+ def __init__(self,
+ fourier_degree=5,
+ resample_step=4.0,
+ center_region_shrink_ratio=0.3,
+ level_size_divisors=(8, 16, 32),
+ level_proportion_range=((0, 0.4), (0.3, 0.7), (0.6, 1.0))):
+
+ super().__init__()
+ assert isinstance(level_size_divisors, tuple)
+ assert isinstance(level_proportion_range, tuple)
+ assert len(level_size_divisors) == len(level_proportion_range)
+ self.fourier_degree = fourier_degree
+ self.resample_step = resample_step
+ self.center_region_shrink_ratio = center_region_shrink_ratio
+ self.level_size_divisors = level_size_divisors
+ self.level_proportion_range = level_proportion_range
+
+ def generate_center_region_mask(self, img_size, text_polys):
+ """Generate text center region mask.
+
+ Args:
+ img_size (tuple): The image size of (height, width).
+ text_polys (list[list[ndarray]]): The list of text polygons.
+
+ Returns:
+ center_region_mask (ndarray): The text center region mask.
+ """
+
+ assert isinstance(img_size, tuple)
+ assert check_argument.is_2dlist(text_polys)
+
+ h, w = img_size
+
+ center_region_mask = np.zeros((h, w), np.uint8)
+
+ center_region_boxes = []
+ for poly in text_polys:
+ assert len(poly) == 1
+ polygon_points = poly[0].reshape(-1, 2)
+ _, _, top_line, bot_line = self.reorder_poly_edge(polygon_points)
+ resampled_top_line, resampled_bot_line = self.resample_sidelines(
+ top_line, bot_line, self.resample_step)
+ resampled_bot_line = resampled_bot_line[::-1]
+ center_line = (resampled_top_line + resampled_bot_line) / 2
+
+ line_head_shrink_len = norm(resampled_top_line[0] -
+ resampled_bot_line[0]) / 4.0
+ line_tail_shrink_len = norm(resampled_top_line[-1] -
+ resampled_bot_line[-1]) / 4.0
+ head_shrink_num = int(line_head_shrink_len // self.resample_step)
+ tail_shrink_num = int(line_tail_shrink_len // self.resample_step)
+ if len(center_line) > head_shrink_num + tail_shrink_num + 2:
+ center_line = center_line[head_shrink_num:len(center_line) -
+ tail_shrink_num]
+ resampled_top_line = resampled_top_line[
+ head_shrink_num:len(resampled_top_line) - tail_shrink_num]
+ resampled_bot_line = resampled_bot_line[
+ head_shrink_num:len(resampled_bot_line) - tail_shrink_num]
+
+ for i in range(0, len(center_line) - 1):
+ tl = center_line[i] + (resampled_top_line[i] - center_line[i]
+ ) * self.center_region_shrink_ratio
+ tr = center_line[i + 1] + (
+ resampled_top_line[i + 1] -
+ center_line[i + 1]) * self.center_region_shrink_ratio
+ br = center_line[i + 1] + (
+ resampled_bot_line[i + 1] -
+ center_line[i + 1]) * self.center_region_shrink_ratio
+ bl = center_line[i] + (resampled_bot_line[i] - center_line[i]
+ ) * self.center_region_shrink_ratio
+ current_center_box = np.vstack([tl, tr, br,
+ bl]).astype(np.int32)
+ center_region_boxes.append(current_center_box)
+
+ cv2.fillPoly(center_region_mask, center_region_boxes, 1)
+ return center_region_mask
+
+ def resample_polygon(self, polygon, n=400):
+ """Resample one polygon with n points on its boundary.
+
+ Args:
+ polygon (list[float]): The input polygon.
+ n (int): The number of resampled points.
+ Returns:
+ resampled_polygon (list[float]): The resampled polygon.
+ """
+ length = []
+
+ for i in range(len(polygon)):
+ p1 = polygon[i]
+ if i == len(polygon) - 1:
+ p2 = polygon[0]
+ else:
+ p2 = polygon[i + 1]
+ length.append(((p1[0] - p2[0])**2 + (p1[1] - p2[1])**2)**0.5)
+
+ total_length = sum(length)
+ n_on_each_line = (np.array(length) / (total_length + 1e-8)) * n
+ n_on_each_line = n_on_each_line.astype(np.int32)
+ new_polygon = []
+
+ for i in range(len(polygon)):
+ num = n_on_each_line[i]
+ p1 = polygon[i]
+ if i == len(polygon) - 1:
+ p2 = polygon[0]
+ else:
+ p2 = polygon[i + 1]
+
+ if num == 0:
+ continue
+
+ dxdy = (p2 - p1) / num
+ for j in range(num):
+ point = p1 + dxdy * j
+ new_polygon.append(point)
+
+ return np.array(new_polygon)
+
+ def normalize_polygon(self, polygon):
+ """Normalize one polygon so that its start point is at right most.
+
+ Args:
+ polygon (list[float]): The origin polygon.
+ Returns:
+ new_polygon (lost[float]): The polygon with start point at right.
+ """
+ temp_polygon = polygon - polygon.mean(axis=0)
+ x = np.abs(temp_polygon[:, 0])
+ y = temp_polygon[:, 1]
+ index_x = np.argsort(x)
+ index_y = np.argmin(y[index_x[:8]])
+ index = index_x[index_y]
+ new_polygon = np.concatenate([polygon[index:], polygon[:index]])
+ return new_polygon
+
+ def poly2fourier(self, polygon, fourier_degree):
+ """Perform Fourier transformation to generate Fourier coefficients ck
+ from polygon.
+
+ Args:
+ polygon (ndarray): An input polygon.
+ fourier_degree (int): The maximum Fourier degree K.
+ Returns:
+ c (ndarray(complex)): Fourier coefficients.
+ """
+ points = polygon[:, 0] + polygon[:, 1] * 1j
+ c_fft = fft(points) / len(points)
+ c = np.hstack((c_fft[-fourier_degree:], c_fft[:fourier_degree + 1]))
+ return c
+
+ def clockwise(self, c, fourier_degree):
+ """Make sure the polygon reconstructed from Fourier coefficients c in
+ the clockwise direction.
+
+ Args:
+ polygon (list[float]): The origin polygon.
+ Returns:
+ new_polygon (lost[float]): The polygon in clockwise point order.
+ """
+ if np.abs(c[fourier_degree + 1]) > np.abs(c[fourier_degree - 1]):
+ return c
+ elif np.abs(c[fourier_degree + 1]) < np.abs(c[fourier_degree - 1]):
+ return c[::-1]
+ else:
+ if np.abs(c[fourier_degree + 2]) > np.abs(c[fourier_degree - 2]):
+ return c
+ else:
+ return c[::-1]
+
+ def cal_fourier_signature(self, polygon, fourier_degree):
+ """Calculate Fourier signature from input polygon.
+
+ Args:
+ polygon (ndarray): The input polygon.
+ fourier_degree (int): The maximum Fourier degree K.
+ Returns:
+ fourier_signature (ndarray): An array shaped (2k+1, 2) containing
+ real part and image part of 2k+1 Fourier coefficients.
+ """
+ resampled_polygon = self.resample_polygon(polygon)
+ resampled_polygon = self.normalize_polygon(resampled_polygon)
+
+ fourier_coeff = self.poly2fourier(resampled_polygon, fourier_degree)
+ fourier_coeff = self.clockwise(fourier_coeff, fourier_degree)
+
+ real_part = np.real(fourier_coeff).reshape((-1, 1))
+ image_part = np.imag(fourier_coeff).reshape((-1, 1))
+ fourier_signature = np.hstack([real_part, image_part])
+
+ return fourier_signature
+
+ def generate_fourier_maps(self, img_size, text_polys):
+ """Generate Fourier coefficient maps.
+
+ Args:
+ img_size (tuple): The image size of (height, width).
+ text_polys (list[list[ndarray]]): The list of text polygons.
+
+ Returns:
+ fourier_real_map (ndarray): The Fourier coefficient real part maps.
+ fourier_image_map (ndarray): The Fourier coefficient image part
+ maps.
+ """
+
+ assert isinstance(img_size, tuple)
+ assert check_argument.is_2dlist(text_polys)
+
+ h, w = img_size
+ k = self.fourier_degree
+ real_map = np.zeros((k * 2 + 1, h, w), dtype=np.float32)
+ imag_map = np.zeros((k * 2 + 1, h, w), dtype=np.float32)
+
+ for poly in text_polys:
+ assert len(poly) == 1
+ text_instance = [[poly[0][i], poly[0][i + 1]]
+ for i in range(0, len(poly[0]), 2)]
+ mask = np.zeros((h, w), dtype=np.uint8)
+ polygon = np.array(text_instance).reshape((1, -1, 2))
+ cv2.fillPoly(mask, polygon.astype(np.int32), 1)
+ fourier_coeff = self.cal_fourier_signature(polygon[0], k)
+ for i in range(-k, k + 1):
+ if i != 0:
+ real_map[i + k, :, :] = mask * fourier_coeff[i + k, 0] + (
+ 1 - mask) * real_map[i + k, :, :]
+ imag_map[i + k, :, :] = mask * fourier_coeff[i + k, 1] + (
+ 1 - mask) * imag_map[i + k, :, :]
+ else:
+ yx = np.argwhere(mask > 0.5)
+ k_ind = np.ones((len(yx)), dtype=np.int64) * k
+ y, x = yx[:, 0], yx[:, 1]
+ real_map[k_ind, y, x] = fourier_coeff[k, 0] - x
+ imag_map[k_ind, y, x] = fourier_coeff[k, 1] - y
+
+ return real_map, imag_map
+
+ def generate_level_targets(self, img_size, text_polys, ignore_polys):
+ """Generate ground truth target on each level.
+
+ Args:
+ img_size (list[int]): Shape of input image.
+ text_polys (list[list[ndarray]]): A list of ground truth polygons.
+ ignore_polys (list[list[ndarray]]): A list of ignored polygons.
+ Returns:
+ level_maps (list(ndarray)): A list of ground target on each level.
+ """
+ h, w = img_size
+ lv_size_divs = self.level_size_divisors
+ lv_proportion_range = self.level_proportion_range
+ lv_text_polys = [[] for i in range(len(lv_size_divs))]
+ lv_ignore_polys = [[] for i in range(len(lv_size_divs))]
+ level_maps = []
+ for poly in text_polys:
+ assert len(poly) == 1
+ text_instance = [[poly[0][i], poly[0][i + 1]]
+ for i in range(0, len(poly[0]), 2)]
+ polygon = np.array(text_instance, dtype=np.int).reshape((1, -1, 2))
+ _, _, box_w, box_h = cv2.boundingRect(polygon)
+ proportion = max(box_h, box_w) / (h + 1e-8)
+
+ for ind, proportion_range in enumerate(lv_proportion_range):
+ if proportion_range[0] < proportion < proportion_range[1]:
+ lv_text_polys[ind].append([poly[0] / lv_size_divs[ind]])
+
+ for ignore_poly in ignore_polys:
+ assert len(ignore_poly) == 1
+ text_instance = [[ignore_poly[0][i], ignore_poly[0][i + 1]]
+ for i in range(0, len(ignore_poly[0]), 2)]
+ polygon = np.array(text_instance, dtype=np.int).reshape((1, -1, 2))
+ _, _, box_w, box_h = cv2.boundingRect(polygon)
+ proportion = max(box_h, box_w) / (h + 1e-8)
+
+ for ind, proportion_range in enumerate(lv_proportion_range):
+ if proportion_range[0] < proportion < proportion_range[1]:
+ lv_ignore_polys[ind].append(
+ [ignore_poly[0] / lv_size_divs[ind]])
+
+ for ind, size_divisor in enumerate(lv_size_divs):
+ current_level_maps = []
+ level_img_size = (h // size_divisor, w // size_divisor)
+
+ text_region = self.generate_text_region_mask(
+ level_img_size, lv_text_polys[ind])[None]
+ current_level_maps.append(text_region)
+
+ center_region = self.generate_center_region_mask(
+ level_img_size, lv_text_polys[ind])[None]
+ current_level_maps.append(center_region)
+
+ effective_mask = self.generate_effective_mask(
+ level_img_size, lv_ignore_polys[ind])[None]
+ current_level_maps.append(effective_mask)
+
+ fourier_real_map, fourier_image_maps = self.generate_fourier_maps(
+ level_img_size, lv_text_polys[ind])
+ current_level_maps.append(fourier_real_map)
+ current_level_maps.append(fourier_image_maps)
+
+ level_maps.append(np.concatenate(current_level_maps))
+
+ return level_maps
+
+ def generate_targets(self, results):
+ """Generate the ground truth targets for FCENet.
+
+ Args:
+ results (dict): The input result dictionary.
+
+ Returns:
+ results (dict): The output result dictionary.
+ """
+
+ assert isinstance(results, dict)
+
+ polygon_masks = results['gt_masks'].masks
+ polygon_masks_ignore = results['gt_masks_ignore'].masks
+
+ h, w, _ = results['img_shape']
+
+ level_maps = self.generate_level_targets((h, w), polygon_masks,
+ polygon_masks_ignore)
+
+ results['mask_fields'].clear() # rm gt_masks encoded by polygons
+ mapping = {
+ 'p3_maps': level_maps[0],
+ 'p4_maps': level_maps[1],
+ 'p5_maps': level_maps[2]
+ }
+ for key, value in mapping.items():
+ results[key] = value
+
+ return results
diff --git a/mmocr/datasets/pipelines/textdet_targets/panet_targets.py b/mmocr/datasets/pipelines/textdet_targets/panet_targets.py
new file mode 100644
index 0000000000000000000000000000000000000000..92449cdb436e53c7624f4a1975ba33652f25f909
--- /dev/null
+++ b/mmocr/datasets/pipelines/textdet_targets/panet_targets.py
@@ -0,0 +1,65 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.core import BitmapMasks
+from mmdet.datasets.builder import PIPELINES
+
+from . import BaseTextDetTargets
+
+
+@PIPELINES.register_module()
+class PANetTargets(BaseTextDetTargets):
+ """Generate the ground truths for PANet: Efficient and Accurate Arbitrary-
+ Shaped Text Detection with Pixel Aggregation Network.
+
+ [https://arxiv.org/abs/1908.05900]. This code is partially adapted from
+ https://github.com/WenmuZhou/PAN.pytorch.
+
+ Args:
+ shrink_ratio (tuple[float]): The ratios for shrinking text instances.
+ max_shrink (int): The maximum shrink distance.
+ """
+
+ def __init__(self, shrink_ratio=(1.0, 0.5), max_shrink=20):
+ self.shrink_ratio = shrink_ratio
+ self.max_shrink = max_shrink
+
+ def generate_targets(self, results):
+ """Generate the gt targets for PANet.
+
+ Args:
+ results (dict): The input result dictionary.
+
+ Returns:
+ results (dict): The output result dictionary.
+ """
+
+ assert isinstance(results, dict)
+
+ polygon_masks = results['gt_masks'].masks
+ polygon_masks_ignore = results['gt_masks_ignore'].masks
+
+ h, w, _ = results['img_shape']
+ gt_kernels = []
+ for ratio in self.shrink_ratio:
+ mask, _ = self.generate_kernels((h, w),
+ polygon_masks,
+ ratio,
+ max_shrink=self.max_shrink,
+ ignore_tags=None)
+ gt_kernels.append(mask)
+ gt_mask = self.generate_effective_mask((h, w), polygon_masks_ignore)
+
+ results['mask_fields'].clear() # rm gt_masks encoded by polygons
+ if 'bbox_fields' in results:
+ results['bbox_fields'].clear()
+ results.pop('gt_labels', None)
+ results.pop('gt_masks', None)
+ results.pop('gt_bboxes', None)
+ results.pop('gt_bboxes_ignore', None)
+
+ mapping = {'gt_kernels': gt_kernels, 'gt_mask': gt_mask}
+ for key, value in mapping.items():
+ value = value if isinstance(value, list) else [value]
+ results[key] = BitmapMasks(value, h, w)
+ results['mask_fields'].append(key)
+
+ return results
diff --git a/mmocr/datasets/pipelines/textdet_targets/psenet_targets.py b/mmocr/datasets/pipelines/textdet_targets/psenet_targets.py
new file mode 100644
index 0000000000000000000000000000000000000000..0bdc77fa1d22e6f02aced6b94b0e3d0e996f6216
--- /dev/null
+++ b/mmocr/datasets/pipelines/textdet_targets/psenet_targets.py
@@ -0,0 +1,23 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.datasets.builder import PIPELINES
+
+from . import PANetTargets
+
+
+@PIPELINES.register_module()
+class PSENetTargets(PANetTargets):
+ """Generate the ground truth targets of PSENet: Shape robust text detection
+ with progressive scale expansion network.
+
+ [https://arxiv.org/abs/1903.12473]. This code is partially adapted from
+ https://github.com/whai362/PSENet.
+
+ Args:
+ shrink_ratio(tuple(float)): The ratios for shrinking text instances.
+ max_shrink(int): The maximum shrinking distance.
+ """
+
+ def __init__(self,
+ shrink_ratio=(1.0, 0.9, 0.8, 0.7, 0.6, 0.5, 0.4),
+ max_shrink=20):
+ super().__init__(shrink_ratio=shrink_ratio, max_shrink=max_shrink)
diff --git a/mmocr/datasets/pipelines/textdet_targets/textsnake_targets.py b/mmocr/datasets/pipelines/textdet_targets/textsnake_targets.py
new file mode 100644
index 0000000000000000000000000000000000000000..3a8e4d211d4effbe208fdb5e8add748b4e024bd4
--- /dev/null
+++ b/mmocr/datasets/pipelines/textdet_targets/textsnake_targets.py
@@ -0,0 +1,496 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import cv2
+import numpy as np
+from mmdet.core import BitmapMasks
+from mmdet.datasets.builder import PIPELINES
+from numpy.linalg import norm
+
+import mmocr.utils.check_argument as check_argument
+from . import BaseTextDetTargets
+
+
+@PIPELINES.register_module()
+class TextSnakeTargets(BaseTextDetTargets):
+ """Generate the ground truth targets of TextSnake: TextSnake: A Flexible
+ Representation for Detecting Text of Arbitrary Shapes.
+
+ [https://arxiv.org/abs/1807.01544]. This was partially adapted from
+ https://github.com/princewang1994/TextSnake.pytorch.
+
+ Args:
+ orientation_thr (float): The threshold for distinguishing between
+ head edge and tail edge among the horizontal and vertical edges
+ of a quadrangle.
+ """
+
+ def __init__(self,
+ orientation_thr=2.0,
+ resample_step=4.0,
+ center_region_shrink_ratio=0.3):
+
+ super().__init__()
+ self.orientation_thr = orientation_thr
+ self.resample_step = resample_step
+ self.center_region_shrink_ratio = center_region_shrink_ratio
+ self.eps = 1e-8
+
+ def vector_angle(self, vec1, vec2):
+ if vec1.ndim > 1:
+ unit_vec1 = vec1 / (norm(vec1, axis=-1) + self.eps).reshape(
+ (-1, 1))
+ else:
+ unit_vec1 = vec1 / (norm(vec1, axis=-1) + self.eps)
+ if vec2.ndim > 1:
+ unit_vec2 = vec2 / (norm(vec2, axis=-1) + self.eps).reshape(
+ (-1, 1))
+ else:
+ unit_vec2 = vec2 / (norm(vec2, axis=-1) + self.eps)
+ return np.arccos(
+ np.clip(np.sum(unit_vec1 * unit_vec2, axis=-1), -1.0, 1.0))
+
+ def vector_slope(self, vec):
+ assert len(vec) == 2
+ return abs(vec[1] / (vec[0] + self.eps))
+
+ def vector_sin(self, vec):
+ assert len(vec) == 2
+ return vec[1] / (norm(vec) + self.eps)
+
+ def vector_cos(self, vec):
+ assert len(vec) == 2
+ return vec[0] / (norm(vec) + self.eps)
+
+ def find_head_tail(self, points, orientation_thr):
+ """Find the head edge and tail edge of a text polygon.
+
+ Args:
+ points (ndarray): The points composing a text polygon.
+ orientation_thr (float): The threshold for distinguishing between
+ head edge and tail edge among the horizontal and vertical edges
+ of a quadrangle.
+
+ Returns:
+ head_inds (list): The indexes of two points composing head edge.
+ tail_inds (list): The indexes of two points composing tail edge.
+ """
+
+ assert points.ndim == 2
+ assert points.shape[0] >= 4
+ assert points.shape[1] == 2
+ assert isinstance(orientation_thr, float)
+
+ if len(points) > 4:
+ pad_points = np.vstack([points, points[0]])
+ edge_vec = pad_points[1:] - pad_points[:-1]
+
+ theta_sum = []
+ adjacent_vec_theta = []
+ for i, edge_vec1 in enumerate(edge_vec):
+ adjacent_ind = [x % len(edge_vec) for x in [i - 1, i + 1]]
+ adjacent_edge_vec = edge_vec[adjacent_ind]
+ temp_theta_sum = np.sum(
+ self.vector_angle(edge_vec1, adjacent_edge_vec))
+ temp_adjacent_theta = self.vector_angle(
+ adjacent_edge_vec[0], adjacent_edge_vec[1])
+ theta_sum.append(temp_theta_sum)
+ adjacent_vec_theta.append(temp_adjacent_theta)
+ theta_sum_score = np.array(theta_sum) / np.pi
+ adjacent_theta_score = np.array(adjacent_vec_theta) / np.pi
+ poly_center = np.mean(points, axis=0)
+ edge_dist = np.maximum(
+ norm(pad_points[1:] - poly_center, axis=-1),
+ norm(pad_points[:-1] - poly_center, axis=-1))
+ dist_score = edge_dist / (np.max(edge_dist) + self.eps)
+ position_score = np.zeros(len(edge_vec))
+ score = 0.5 * theta_sum_score + 0.15 * adjacent_theta_score
+ score += 0.35 * dist_score
+ if len(points) % 2 == 0:
+ position_score[(len(score) // 2 - 1)] += 1
+ position_score[-1] += 1
+ score += 0.1 * position_score
+ pad_score = np.concatenate([score, score])
+ score_matrix = np.zeros((len(score), len(score) - 3))
+ x = np.arange(len(score) - 3) / float(len(score) - 4)
+ gaussian = 1. / (np.sqrt(2. * np.pi) * 0.5) * np.exp(-np.power(
+ (x - 0.5) / 0.5, 2.) / 2)
+ gaussian = gaussian / np.max(gaussian)
+ for i in range(len(score)):
+ score_matrix[i, :] = score[i] + pad_score[
+ (i + 2):(i + len(score) - 1)] * gaussian * 0.3
+
+ head_start, tail_increment = np.unravel_index(
+ score_matrix.argmax(), score_matrix.shape)
+ tail_start = (head_start + tail_increment + 2) % len(points)
+ head_end = (head_start + 1) % len(points)
+ tail_end = (tail_start + 1) % len(points)
+
+ if head_end > tail_end:
+ head_start, tail_start = tail_start, head_start
+ head_end, tail_end = tail_end, head_end
+ head_inds = [head_start, head_end]
+ tail_inds = [tail_start, tail_end]
+ else:
+ if self.vector_slope(points[1] - points[0]) + self.vector_slope(
+ points[3] - points[2]) < self.vector_slope(
+ points[2] - points[1]) + self.vector_slope(points[0] -
+ points[3]):
+ horizontal_edge_inds = [[0, 1], [2, 3]]
+ vertical_edge_inds = [[3, 0], [1, 2]]
+ else:
+ horizontal_edge_inds = [[3, 0], [1, 2]]
+ vertical_edge_inds = [[0, 1], [2, 3]]
+
+ vertical_len_sum = norm(points[vertical_edge_inds[0][0]] -
+ points[vertical_edge_inds[0][1]]) + norm(
+ points[vertical_edge_inds[1][0]] -
+ points[vertical_edge_inds[1][1]])
+ horizontal_len_sum = norm(
+ points[horizontal_edge_inds[0][0]] -
+ points[horizontal_edge_inds[0][1]]) + norm(
+ points[horizontal_edge_inds[1][0]] -
+ points[horizontal_edge_inds[1][1]])
+
+ if vertical_len_sum > horizontal_len_sum * orientation_thr:
+ head_inds = horizontal_edge_inds[0]
+ tail_inds = horizontal_edge_inds[1]
+ else:
+ head_inds = vertical_edge_inds[0]
+ tail_inds = vertical_edge_inds[1]
+
+ return head_inds, tail_inds
+
+ def reorder_poly_edge(self, points):
+ """Get the respective points composing head edge, tail edge, top
+ sideline and bottom sideline.
+
+ Args:
+ points (ndarray): The points composing a text polygon.
+
+ Returns:
+ head_edge (ndarray): The two points composing the head edge of text
+ polygon.
+ tail_edge (ndarray): The two points composing the tail edge of text
+ polygon.
+ top_sideline (ndarray): The points composing top curved sideline of
+ text polygon.
+ bot_sideline (ndarray): The points composing bottom curved sideline
+ of text polygon.
+ """
+
+ assert points.ndim == 2
+ assert points.shape[0] >= 4
+ assert points.shape[1] == 2
+
+ head_inds, tail_inds = self.find_head_tail(points,
+ self.orientation_thr)
+ head_edge, tail_edge = points[head_inds], points[tail_inds]
+
+ pad_points = np.vstack([points, points])
+ if tail_inds[1] < 1:
+ tail_inds[1] = len(points)
+ sideline1 = pad_points[head_inds[1]:tail_inds[1]]
+ sideline2 = pad_points[tail_inds[1]:(head_inds[1] + len(points))]
+ sideline_mean_shift = np.mean(
+ sideline1, axis=0) - np.mean(
+ sideline2, axis=0)
+
+ if sideline_mean_shift[1] > 0:
+ top_sideline, bot_sideline = sideline2, sideline1
+ else:
+ top_sideline, bot_sideline = sideline1, sideline2
+
+ return head_edge, tail_edge, top_sideline, bot_sideline
+
+ def cal_curve_length(self, line):
+ """Calculate the length of each edge on the discrete curve and the sum.
+
+ Args:
+ line (ndarray): The points composing a discrete curve.
+
+ Returns:
+ tuple: Returns (edges_length, total_length).
+
+ - | edge_length (ndarray): The length of each edge on the
+ discrete curve.
+ - | total_length (float): The total length of the discrete
+ curve.
+ """
+
+ assert line.ndim == 2
+ assert len(line) >= 2
+
+ edges_length = np.sqrt((line[1:, 0] - line[:-1, 0])**2 +
+ (line[1:, 1] - line[:-1, 1])**2)
+ total_length = np.sum(edges_length)
+ return edges_length, total_length
+
+ def resample_line(self, line, n):
+ """Resample n points on a line.
+
+ Args:
+ line (ndarray): The points composing a line.
+ n (int): The resampled points number.
+
+ Returns:
+ resampled_line (ndarray): The points composing the resampled line.
+ """
+
+ assert line.ndim == 2
+ assert line.shape[0] >= 2
+ assert line.shape[1] == 2
+ assert isinstance(n, int)
+ assert n > 2
+
+ edges_length, total_length = self.cal_curve_length(line)
+ t_org = np.insert(np.cumsum(edges_length), 0, 0)
+ unit_t = total_length / (n - 1)
+ t_equidistant = np.arange(1, n - 1, dtype=np.float32) * unit_t
+ edge_ind = 0
+ points = [line[0]]
+ for t in t_equidistant:
+ while edge_ind < len(edges_length) - 1 and t > t_org[edge_ind + 1]:
+ edge_ind += 1
+ t_l, t_r = t_org[edge_ind], t_org[edge_ind + 1]
+ weight = np.array([t_r - t, t - t_l], dtype=np.float32) / (
+ t_r - t_l + self.eps)
+ p_coords = np.dot(weight, line[[edge_ind, edge_ind + 1]])
+ points.append(p_coords)
+ points.append(line[-1])
+ resampled_line = np.vstack(points)
+
+ return resampled_line
+
+ def resample_sidelines(self, sideline1, sideline2, resample_step):
+ """Resample two sidelines to be of the same points number according to
+ step size.
+
+ Args:
+ sideline1 (ndarray): The points composing a sideline of a text
+ polygon.
+ sideline2 (ndarray): The points composing another sideline of a
+ text polygon.
+ resample_step (float): The resampled step size.
+
+ Returns:
+ resampled_line1 (ndarray): The resampled line 1.
+ resampled_line2 (ndarray): The resampled line 2.
+ """
+
+ assert sideline1.ndim == sideline2.ndim == 2
+ assert sideline1.shape[1] == sideline2.shape[1] == 2
+ assert sideline1.shape[0] >= 2
+ assert sideline2.shape[0] >= 2
+ assert isinstance(resample_step, float)
+
+ _, length1 = self.cal_curve_length(sideline1)
+ _, length2 = self.cal_curve_length(sideline2)
+
+ avg_length = (length1 + length2) / 2
+ resample_point_num = max(int(float(avg_length) / resample_step) + 1, 3)
+
+ resampled_line1 = self.resample_line(sideline1, resample_point_num)
+ resampled_line2 = self.resample_line(sideline2, resample_point_num)
+
+ return resampled_line1, resampled_line2
+
+ def draw_center_region_maps(self, top_line, bot_line, center_line,
+ center_region_mask, radius_map, sin_map,
+ cos_map, region_shrink_ratio):
+ """Draw attributes on text center region.
+
+ Args:
+ top_line (ndarray): The points composing top curved sideline of
+ text polygon.
+ bot_line (ndarray): The points composing bottom curved sideline
+ of text polygon.
+ center_line (ndarray): The points composing the center line of text
+ instance.
+ center_region_mask (ndarray): The text center region mask.
+ radius_map (ndarray): The map where the distance from point to
+ sidelines will be drawn on for each pixel in text center
+ region.
+ sin_map (ndarray): The map where vector_sin(theta) will be drawn
+ on text center regions. Theta is the angle between tangent
+ line and vector (1, 0).
+ cos_map (ndarray): The map where vector_cos(theta) will be drawn on
+ text center regions. Theta is the angle between tangent line
+ and vector (1, 0).
+ region_shrink_ratio (float): The shrink ratio of text center.
+ """
+
+ assert top_line.shape == bot_line.shape == center_line.shape
+ assert (center_region_mask.shape == radius_map.shape == sin_map.shape
+ == cos_map.shape)
+ assert isinstance(region_shrink_ratio, float)
+ for i in range(0, len(center_line) - 1):
+
+ top_mid_point = (top_line[i] + top_line[i + 1]) / 2
+ bot_mid_point = (bot_line[i] + bot_line[i + 1]) / 2
+ radius = norm(top_mid_point - bot_mid_point) / 2
+
+ text_direction = center_line[i + 1] - center_line[i]
+ sin_theta = self.vector_sin(text_direction)
+ cos_theta = self.vector_cos(text_direction)
+
+ tl = center_line[i] + (top_line[i] -
+ center_line[i]) * region_shrink_ratio
+ tr = center_line[i + 1] + (
+ top_line[i + 1] - center_line[i + 1]) * region_shrink_ratio
+ br = center_line[i + 1] + (
+ bot_line[i + 1] - center_line[i + 1]) * region_shrink_ratio
+ bl = center_line[i] + (bot_line[i] -
+ center_line[i]) * region_shrink_ratio
+ current_center_box = np.vstack([tl, tr, br, bl]).astype(np.int32)
+
+ cv2.fillPoly(center_region_mask, [current_center_box], color=1)
+ cv2.fillPoly(sin_map, [current_center_box], color=sin_theta)
+ cv2.fillPoly(cos_map, [current_center_box], color=cos_theta)
+ cv2.fillPoly(radius_map, [current_center_box], color=radius)
+
+ def generate_center_mask_attrib_maps(self, img_size, text_polys):
+ """Generate text center region mask and geometric attribute maps.
+
+ Args:
+ img_size (tuple): The image size of (height, width).
+ text_polys (list[list[ndarray]]): The list of text polygons.
+
+ Returns:
+ center_region_mask (ndarray): The text center region mask.
+ radius_map (ndarray): The distance map from each pixel in text
+ center region to top sideline.
+ sin_map (ndarray): The sin(theta) map where theta is the angle
+ between vector (top point - bottom point) and vector (1, 0).
+ cos_map (ndarray): The cos(theta) map where theta is the angle
+ between vector (top point - bottom point) and vector (1, 0).
+ """
+
+ assert isinstance(img_size, tuple)
+ assert check_argument.is_2dlist(text_polys)
+
+ h, w = img_size
+
+ center_region_mask = np.zeros((h, w), np.uint8)
+ radius_map = np.zeros((h, w), dtype=np.float32)
+ sin_map = np.zeros((h, w), dtype=np.float32)
+ cos_map = np.zeros((h, w), dtype=np.float32)
+
+ for poly in text_polys:
+ assert len(poly) == 1
+ text_instance = [[poly[0][i], poly[0][i + 1]]
+ for i in range(0, len(poly[0]), 2)]
+ polygon_points = np.array(text_instance).reshape(-1, 2)
+
+ n = len(polygon_points)
+ keep_inds = []
+ for i in range(n):
+ if norm(polygon_points[i] -
+ polygon_points[(i + 1) % n]) > 1e-5:
+ keep_inds.append(i)
+ polygon_points = polygon_points[keep_inds]
+
+ _, _, top_line, bot_line = self.reorder_poly_edge(polygon_points)
+ resampled_top_line, resampled_bot_line = self.resample_sidelines(
+ top_line, bot_line, self.resample_step)
+ resampled_bot_line = resampled_bot_line[::-1]
+ center_line = (resampled_top_line + resampled_bot_line) / 2
+
+ if self.vector_slope(center_line[-1] - center_line[0]) > 0.9:
+ if (center_line[-1] - center_line[0])[1] < 0:
+ center_line = center_line[::-1]
+ resampled_top_line = resampled_top_line[::-1]
+ resampled_bot_line = resampled_bot_line[::-1]
+ else:
+ if (center_line[-1] - center_line[0])[0] < 0:
+ center_line = center_line[::-1]
+ resampled_top_line = resampled_top_line[::-1]
+ resampled_bot_line = resampled_bot_line[::-1]
+
+ line_head_shrink_len = norm(resampled_top_line[0] -
+ resampled_bot_line[0]) / 4.0
+ line_tail_shrink_len = norm(resampled_top_line[-1] -
+ resampled_bot_line[-1]) / 4.0
+ head_shrink_num = int(line_head_shrink_len // self.resample_step)
+ tail_shrink_num = int(line_tail_shrink_len // self.resample_step)
+
+ if len(center_line) > head_shrink_num + tail_shrink_num + 2:
+ center_line = center_line[head_shrink_num:len(center_line) -
+ tail_shrink_num]
+ resampled_top_line = resampled_top_line[
+ head_shrink_num:len(resampled_top_line) - tail_shrink_num]
+ resampled_bot_line = resampled_bot_line[
+ head_shrink_num:len(resampled_bot_line) - tail_shrink_num]
+
+ self.draw_center_region_maps(resampled_top_line,
+ resampled_bot_line, center_line,
+ center_region_mask, radius_map,
+ sin_map, cos_map,
+ self.center_region_shrink_ratio)
+
+ return center_region_mask, radius_map, sin_map, cos_map
+
+ def generate_text_region_mask(self, img_size, text_polys):
+ """Generate text center region mask and geometry attribute maps.
+
+ Args:
+ img_size (tuple): The image size (height, width).
+ text_polys (list[list[ndarray]]): The list of text polygons.
+
+ Returns:
+ text_region_mask (ndarray): The text region mask.
+ """
+
+ assert isinstance(img_size, tuple)
+ assert check_argument.is_2dlist(text_polys)
+
+ h, w = img_size
+ text_region_mask = np.zeros((h, w), dtype=np.uint8)
+
+ for poly in text_polys:
+ assert len(poly) == 1
+ text_instance = [[poly[0][i], poly[0][i + 1]]
+ for i in range(0, len(poly[0]), 2)]
+ polygon = np.array(
+ text_instance, dtype=np.int32).reshape((1, -1, 2))
+ cv2.fillPoly(text_region_mask, polygon, 1)
+
+ return text_region_mask
+
+ def generate_targets(self, results):
+ """Generate the gt targets for TextSnake.
+
+ Args:
+ results (dict): The input result dictionary.
+
+ Returns:
+ results (dict): The output result dictionary.
+ """
+
+ assert isinstance(results, dict)
+
+ polygon_masks = results['gt_masks'].masks
+ polygon_masks_ignore = results['gt_masks_ignore'].masks
+
+ h, w, _ = results['img_shape']
+
+ gt_text_mask = self.generate_text_region_mask((h, w), polygon_masks)
+ gt_mask = self.generate_effective_mask((h, w), polygon_masks_ignore)
+
+ (gt_center_region_mask, gt_radius_map, gt_sin_map,
+ gt_cos_map) = self.generate_center_mask_attrib_maps((h, w),
+ polygon_masks)
+
+ results['mask_fields'].clear() # rm gt_masks encoded by polygons
+ mapping = {
+ 'gt_text_mask': gt_text_mask,
+ 'gt_center_region_mask': gt_center_region_mask,
+ 'gt_mask': gt_mask,
+ 'gt_radius_map': gt_radius_map,
+ 'gt_sin_map': gt_sin_map,
+ 'gt_cos_map': gt_cos_map
+ }
+ for key, value in mapping.items():
+ value = value if isinstance(value, list) else [value]
+ results[key] = BitmapMasks(value, h, w)
+ results['mask_fields'].append(key)
+
+ return results
diff --git a/mmocr/datasets/pipelines/transform_wrappers.py b/mmocr/datasets/pipelines/transform_wrappers.py
new file mode 100644
index 0000000000000000000000000000000000000000..c85f3d115082fb3c567e19fd173d886881a1e118
--- /dev/null
+++ b/mmocr/datasets/pipelines/transform_wrappers.py
@@ -0,0 +1,128 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import inspect
+import random
+
+import mmcv
+import numpy as np
+import torchvision.transforms as torchvision_transforms
+from mmcv.utils import build_from_cfg
+from mmdet.datasets.builder import PIPELINES
+from mmdet.datasets.pipelines import Compose
+from PIL import Image
+
+
+@PIPELINES.register_module()
+class OneOfWrapper:
+ """Randomly select and apply one of the transforms, each with the equal
+ chance.
+
+ Warning:
+ Different from albumentations, this wrapper only runs the selected
+ transform, but doesn't guarantee the transform can always be applied to
+ the input if the transform comes with a probability to run.
+
+ Args:
+ transforms (list[dict|callable]): Candidate transforms to be applied.
+ """
+
+ def __init__(self, transforms):
+ assert isinstance(transforms, list) or isinstance(transforms, tuple)
+ assert len(transforms) > 0, 'Need at least one transform.'
+ self.transforms = []
+ for t in transforms:
+ if isinstance(t, dict):
+ self.transforms.append(build_from_cfg(t, PIPELINES))
+ elif callable(t):
+ self.transforms.append(t)
+ else:
+ raise TypeError('transform must be callable or a dict')
+
+ def __call__(self, results):
+ return random.choice(self.transforms)(results)
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(transforms={self.transforms})'
+ return repr_str
+
+
+@PIPELINES.register_module()
+class RandomWrapper:
+ """Run a transform or a sequence of transforms with probability p.
+
+ Args:
+ transforms (list[dict|callable]): Transform(s) to be applied.
+ p (int|float): Probability of running transform(s).
+ """
+
+ def __init__(self, transforms, p):
+ assert 0 <= p <= 1
+ self.transforms = Compose(transforms)
+ self.p = p
+
+ def __call__(self, results):
+ return results if np.random.uniform() > self.p else self.transforms(
+ results)
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(transforms={self.transforms}, '
+ repr_str += f'p={self.p})'
+ return repr_str
+
+
+@PIPELINES.register_module()
+class TorchVisionWrapper:
+ """A wrapper of torchvision trasnforms. It applies specific transform to
+ ``img`` and updates ``img_shape`` accordingly.
+
+ Warning:
+ This transform only affects the image but not its associated
+ annotations, such as word bounding boxes and polygon masks. Therefore,
+ it may only be applicable to text recognition tasks.
+
+ Args:
+ op (str): The name of any transform class in
+ :func:`torchvision.transforms`.
+ **kwargs: Arguments that will be passed to initializer of torchvision
+ transform.
+
+ :Required Keys:
+ - | ``img`` (ndarray): The input image.
+
+ :Affected Keys:
+ :Modified:
+ - | ``img`` (ndarray): The modified image.
+ :Added:
+ - | ``img_shape`` (tuple(int)): Size of the modified image.
+ """
+
+ def __init__(self, op, **kwargs):
+ assert type(op) is str
+
+ if mmcv.is_str(op):
+ obj_cls = getattr(torchvision_transforms, op)
+ elif inspect.isclass(op):
+ obj_cls = op
+ else:
+ raise TypeError(
+ f'type must be a str or valid type, but got {type(type)}')
+ self.transform = obj_cls(**kwargs)
+ self.kwargs = kwargs
+
+ def __call__(self, results):
+ assert 'img' in results
+ # BGR -> RGB
+ img = results['img'][..., ::-1]
+ img = Image.fromarray(img)
+ img = self.transform(img)
+ img = np.asarray(img)
+ img = img[..., ::-1]
+ results['img'] = img
+ results['img_shape'] = img.shape
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(transform={self.transform})'
+ return repr_str
diff --git a/mmocr/datasets/pipelines/transforms.py b/mmocr/datasets/pipelines/transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..1ad1d2bc428964785f67c51eab855a6d8270e207
--- /dev/null
+++ b/mmocr/datasets/pipelines/transforms.py
@@ -0,0 +1,1020 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import cv2
+import mmcv
+import numpy as np
+import torchvision.transforms as transforms
+from mmdet.core import BitmapMasks, PolygonMasks
+from mmdet.datasets.builder import PIPELINES
+from mmdet.datasets.pipelines.transforms import Resize
+from PIL import Image
+from shapely.geometry import Polygon as plg
+
+import mmocr.core.evaluation.utils as eval_utils
+from mmocr.utils import check_argument
+
+
+@PIPELINES.register_module()
+class RandomCropInstances:
+ """Randomly crop images and make sure to contain text instances.
+
+ Args:
+ target_size (tuple or int): (height, width)
+ positive_sample_ratio (float): The probability of sampling regions
+ that go through positive regions.
+ """
+
+ def __init__(
+ self,
+ target_size,
+ instance_key,
+ mask_type='inx0', # 'inx0' or 'union_all'
+ positive_sample_ratio=5.0 / 8.0):
+
+ assert mask_type in ['inx0', 'union_all']
+
+ self.mask_type = mask_type
+ self.instance_key = instance_key
+ self.positive_sample_ratio = positive_sample_ratio
+ self.target_size = target_size if (target_size is None or isinstance(
+ target_size, tuple)) else (target_size, target_size)
+
+ def sample_offset(self, img_gt, img_size):
+ h, w = img_size
+ t_h, t_w = self.target_size
+
+ # target size is bigger than origin size
+ t_h = t_h if t_h < h else h
+ t_w = t_w if t_w < w else w
+ if (img_gt is not None
+ and np.random.random_sample() < self.positive_sample_ratio
+ and np.max(img_gt) > 0):
+
+ # make sure to crop the positive region
+
+ # the minimum top left to crop positive region (h,w)
+ tl = np.min(np.where(img_gt > 0), axis=1) - (t_h, t_w)
+ tl[tl < 0] = 0
+ # the maximum top left to crop positive region
+ br = np.max(np.where(img_gt > 0), axis=1) - (t_h, t_w)
+ br[br < 0] = 0
+ # if br is too big so that crop the outside region of img
+ br[0] = min(br[0], h - t_h)
+ br[1] = min(br[1], w - t_w)
+ #
+ h = np.random.randint(tl[0], br[0]) if tl[0] < br[0] else 0
+ w = np.random.randint(tl[1], br[1]) if tl[1] < br[1] else 0
+ else:
+ # make sure not to crop outside of img
+
+ h = np.random.randint(0, h - t_h) if h - t_h > 0 else 0
+ w = np.random.randint(0, w - t_w) if w - t_w > 0 else 0
+
+ return (h, w)
+
+ @staticmethod
+ def crop_img(img, offset, target_size):
+ h, w = img.shape[:2]
+ br = np.min(
+ np.stack((np.array(offset) + np.array(target_size), np.array(
+ (h, w)))),
+ axis=0)
+ return img[offset[0]:br[0], offset[1]:br[1]], np.array(
+ [offset[1], offset[0], br[1], br[0]])
+
+ def crop_bboxes(self, bboxes, canvas_bbox):
+ kept_bboxes = []
+ kept_inx = []
+ canvas_poly = eval_utils.box2polygon(canvas_bbox)
+ tl = canvas_bbox[0:2]
+
+ for idx, bbox in enumerate(bboxes):
+ poly = eval_utils.box2polygon(bbox)
+ area, inters = eval_utils.poly_intersection(
+ poly, canvas_poly, return_poly=True)
+ if area == 0:
+ continue
+ xmin, ymin, xmax, ymax = inters.bounds
+ kept_bboxes += [
+ np.array(
+ [xmin - tl[0], ymin - tl[1], xmax - tl[0], ymax - tl[1]],
+ dtype=np.float32)
+ ]
+ kept_inx += [idx]
+
+ if len(kept_inx) == 0:
+ return np.array([]).astype(np.float32).reshape(0, 4), kept_inx
+
+ return np.stack(kept_bboxes), kept_inx
+
+ @staticmethod
+ def generate_mask(gt_mask, type):
+
+ if type == 'inx0':
+ return gt_mask.masks[0]
+ if type == 'union_all':
+ mask = gt_mask.masks[0].copy()
+ for idx in range(1, len(gt_mask.masks)):
+ mask = np.logical_or(mask, gt_mask.masks[idx])
+ return mask
+
+ raise NotImplementedError
+
+ def __call__(self, results):
+
+ gt_mask = results[self.instance_key]
+ mask = None
+ if len(gt_mask.masks) > 0:
+ mask = self.generate_mask(gt_mask, self.mask_type)
+ results['crop_offset'] = self.sample_offset(mask,
+ results['img'].shape[:2])
+
+ # crop img. bbox = [x1,y1,x2,y2]
+ img, bbox = self.crop_img(results['img'], results['crop_offset'],
+ self.target_size)
+ results['img'] = img
+ img_shape = img.shape
+ results['img_shape'] = img_shape
+
+ # crop masks
+ for key in results.get('mask_fields', []):
+ results[key] = results[key].crop(bbox)
+
+ # for mask rcnn
+ for key in results.get('bbox_fields', []):
+ results[key], kept_inx = self.crop_bboxes(results[key], bbox)
+ if key == 'gt_bboxes':
+ # ignore gt_labels accordingly
+ if 'gt_labels' in results:
+ ori_labels = results['gt_labels']
+ ori_inst_num = len(ori_labels)
+ results['gt_labels'] = [
+ ori_labels[idx] for idx in range(ori_inst_num)
+ if idx in kept_inx
+ ]
+ # ignore g_masks accordingly
+ if 'gt_masks' in results:
+ ori_mask = results['gt_masks'].masks
+ kept_mask = [
+ ori_mask[idx] for idx in range(ori_inst_num)
+ if idx in kept_inx
+ ]
+ target_h, target_w = bbox[3] - bbox[1], bbox[2] - bbox[0]
+ if len(kept_inx) > 0:
+ kept_mask = np.stack(kept_mask)
+ else:
+ kept_mask = np.empty((0, target_h, target_w),
+ dtype=np.float32)
+ results['gt_masks'] = BitmapMasks(kept_mask, target_h,
+ target_w)
+
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ return repr_str
+
+
+@PIPELINES.register_module()
+class RandomRotateTextDet:
+ """Randomly rotate images."""
+
+ def __init__(self, rotate_ratio=1.0, max_angle=10):
+ self.rotate_ratio = rotate_ratio
+ self.max_angle = max_angle
+
+ @staticmethod
+ def sample_angle(max_angle):
+ angle = np.random.random_sample() * 2 * max_angle - max_angle
+ return angle
+
+ @staticmethod
+ def rotate_img(img, angle):
+ h, w = img.shape[:2]
+ rotation_matrix = cv2.getRotationMatrix2D((w / 2, h / 2), angle, 1)
+ img_target = cv2.warpAffine(
+ img, rotation_matrix, (w, h), flags=cv2.INTER_NEAREST)
+ assert img_target.shape == img.shape
+ return img_target
+
+ def __call__(self, results):
+ if np.random.random_sample() < self.rotate_ratio:
+ # rotate imgs
+ results['rotated_angle'] = self.sample_angle(self.max_angle)
+ img = self.rotate_img(results['img'], results['rotated_angle'])
+ results['img'] = img
+ img_shape = img.shape
+ results['img_shape'] = img_shape
+
+ # rotate masks
+ for key in results.get('mask_fields', []):
+ masks = results[key].masks
+ mask_list = []
+ for m in masks:
+ rotated_m = self.rotate_img(m, results['rotated_angle'])
+ mask_list.append(rotated_m)
+ results[key] = BitmapMasks(mask_list, *(img_shape[:2]))
+
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ return repr_str
+
+
+@PIPELINES.register_module()
+class ColorJitter:
+ """An interface for torch color jitter so that it can be invoked in
+ mmdetection pipeline."""
+
+ def __init__(self, **kwargs):
+ self.transform = transforms.ColorJitter(**kwargs)
+
+ def __call__(self, results):
+ # img is bgr
+ img = results['img'][..., ::-1]
+ img = Image.fromarray(img)
+ img = self.transform(img)
+ img = np.asarray(img)
+ img = img[..., ::-1]
+ results['img'] = img
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ return repr_str
+
+
+@PIPELINES.register_module()
+class ScaleAspectJitter(Resize):
+ """Resize image and segmentation mask encoded by coordinates.
+
+ Allowed resize types are `around_min_img_scale`, `long_short_bound`, and
+ `indep_sample_in_range`.
+ """
+
+ def __init__(self,
+ img_scale=None,
+ multiscale_mode='range',
+ ratio_range=None,
+ keep_ratio=False,
+ resize_type='around_min_img_scale',
+ aspect_ratio_range=None,
+ long_size_bound=None,
+ short_size_bound=None,
+ scale_range=None):
+ super().__init__(
+ img_scale=img_scale,
+ multiscale_mode=multiscale_mode,
+ ratio_range=ratio_range,
+ keep_ratio=keep_ratio)
+ assert not keep_ratio
+ assert resize_type in [
+ 'around_min_img_scale', 'long_short_bound', 'indep_sample_in_range'
+ ]
+ self.resize_type = resize_type
+
+ if resize_type == 'indep_sample_in_range':
+ assert ratio_range is None
+ assert aspect_ratio_range is None
+ assert short_size_bound is None
+ assert long_size_bound is None
+ assert scale_range is not None
+ else:
+ assert scale_range is None
+ assert isinstance(ratio_range, tuple)
+ assert isinstance(aspect_ratio_range, tuple)
+ assert check_argument.equal_len(ratio_range, aspect_ratio_range)
+
+ if resize_type in ['long_short_bound']:
+ assert short_size_bound is not None
+ assert long_size_bound is not None
+
+ self.aspect_ratio_range = aspect_ratio_range
+ self.long_size_bound = long_size_bound
+ self.short_size_bound = short_size_bound
+ self.scale_range = scale_range
+
+ @staticmethod
+ def sample_from_range(range):
+ assert len(range) == 2
+ min_value, max_value = min(range), max(range)
+ value = np.random.random_sample() * (max_value - min_value) + min_value
+
+ return value
+
+ def _random_scale(self, results):
+
+ if self.resize_type == 'indep_sample_in_range':
+ w = self.sample_from_range(self.scale_range)
+ h = self.sample_from_range(self.scale_range)
+ results['scale'] = (int(w), int(h)) # (w,h)
+ results['scale_idx'] = None
+ return
+ h, w = results['img'].shape[0:2]
+ if self.resize_type == 'long_short_bound':
+ scale1 = 1
+ if max(h, w) > self.long_size_bound:
+ scale1 = self.long_size_bound / max(h, w)
+ scale2 = self.sample_from_range(self.ratio_range)
+ scale = scale1 * scale2
+ if min(h, w) * scale <= self.short_size_bound:
+ scale = (self.short_size_bound + 10) * 1.0 / min(h, w)
+ elif self.resize_type == 'around_min_img_scale':
+ short_size = min(self.img_scale[0])
+ ratio = self.sample_from_range(self.ratio_range)
+ scale = (ratio * short_size) / min(h, w)
+ else:
+ raise NotImplementedError
+
+ aspect = self.sample_from_range(self.aspect_ratio_range)
+ h_scale = scale * math.sqrt(aspect)
+ w_scale = scale / math.sqrt(aspect)
+ results['scale'] = (int(w * w_scale), int(h * h_scale)) # (w,h)
+ results['scale_idx'] = None
+
+
+@PIPELINES.register_module()
+class AffineJitter:
+ """An interface for torchvision random affine so that it can be invoked in
+ mmdet pipeline."""
+
+ def __init__(self,
+ degrees=4,
+ translate=(0.02, 0.04),
+ scale=(0.9, 1.1),
+ shear=None,
+ resample=False,
+ fillcolor=0):
+ self.transform = transforms.RandomAffine(
+ degrees=degrees,
+ translate=translate,
+ scale=scale,
+ shear=shear,
+ resample=resample,
+ fillcolor=fillcolor)
+
+ def __call__(self, results):
+ # img is bgr
+ img = results['img'][..., ::-1]
+ img = Image.fromarray(img)
+ img = self.transform(img)
+ img = np.asarray(img)
+ img = img[..., ::-1]
+ results['img'] = img
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ return repr_str
+
+
+@PIPELINES.register_module()
+class RandomCropPolyInstances:
+ """Randomly crop images and make sure to contain at least one intact
+ instance."""
+
+ def __init__(self,
+ instance_key='gt_masks',
+ crop_ratio=5.0 / 8.0,
+ min_side_ratio=0.4):
+ super().__init__()
+ self.instance_key = instance_key
+ self.crop_ratio = crop_ratio
+ self.min_side_ratio = min_side_ratio
+
+ def sample_valid_start_end(self, valid_array, min_len, max_start, min_end):
+
+ assert isinstance(min_len, int)
+ assert len(valid_array) > min_len
+
+ start_array = valid_array.copy()
+ max_start = min(len(start_array) - min_len, max_start)
+ start_array[max_start:] = 0
+ start_array[0] = 1
+ diff_array = np.hstack([0, start_array]) - np.hstack([start_array, 0])
+ region_starts = np.where(diff_array < 0)[0]
+ region_ends = np.where(diff_array > 0)[0]
+ region_ind = np.random.randint(0, len(region_starts))
+ start = np.random.randint(region_starts[region_ind],
+ region_ends[region_ind])
+
+ end_array = valid_array.copy()
+ min_end = max(start + min_len, min_end)
+ end_array[:min_end] = 0
+ end_array[-1] = 1
+ diff_array = np.hstack([0, end_array]) - np.hstack([end_array, 0])
+ region_starts = np.where(diff_array < 0)[0]
+ region_ends = np.where(diff_array > 0)[0]
+ region_ind = np.random.randint(0, len(region_starts))
+ end = np.random.randint(region_starts[region_ind],
+ region_ends[region_ind])
+ return start, end
+
+ def sample_crop_box(self, img_size, results):
+ """Generate crop box and make sure not to crop the polygon instances.
+
+ Args:
+ img_size (tuple(int)): The image size (h, w).
+ results (dict): The results dict.
+ """
+
+ assert isinstance(img_size, tuple)
+ h, w = img_size[:2]
+
+ key_masks = results[self.instance_key].masks
+ x_valid_array = np.ones(w, dtype=np.int32)
+ y_valid_array = np.ones(h, dtype=np.int32)
+
+ selected_mask = key_masks[np.random.randint(0, len(key_masks))]
+ selected_mask = selected_mask[0].reshape((-1, 2)).astype(np.int32)
+ max_x_start = max(np.min(selected_mask[:, 0]) - 2, 0)
+ min_x_end = min(np.max(selected_mask[:, 0]) + 3, w - 1)
+ max_y_start = max(np.min(selected_mask[:, 1]) - 2, 0)
+ min_y_end = min(np.max(selected_mask[:, 1]) + 3, h - 1)
+
+ for key in results.get('mask_fields', []):
+ if len(results[key].masks) == 0:
+ continue
+ masks = results[key].masks
+ for mask in masks:
+ assert len(mask) == 1
+ mask = mask[0].reshape((-1, 2)).astype(np.int32)
+ clip_x = np.clip(mask[:, 0], 0, w - 1)
+ clip_y = np.clip(mask[:, 1], 0, h - 1)
+ min_x, max_x = np.min(clip_x), np.max(clip_x)
+ min_y, max_y = np.min(clip_y), np.max(clip_y)
+
+ x_valid_array[min_x - 2:max_x + 3] = 0
+ y_valid_array[min_y - 2:max_y + 3] = 0
+
+ min_w = int(w * self.min_side_ratio)
+ min_h = int(h * self.min_side_ratio)
+
+ x1, x2 = self.sample_valid_start_end(x_valid_array, min_w, max_x_start,
+ min_x_end)
+ y1, y2 = self.sample_valid_start_end(y_valid_array, min_h, max_y_start,
+ min_y_end)
+
+ return np.array([x1, y1, x2, y2])
+
+ def crop_img(self, img, bbox):
+ assert img.ndim == 3
+ h, w, _ = img.shape
+ assert 0 <= bbox[1] < bbox[3] <= h
+ assert 0 <= bbox[0] < bbox[2] <= w
+ return img[bbox[1]:bbox[3], bbox[0]:bbox[2]]
+
+ def __call__(self, results):
+ if len(results[self.instance_key].masks) < 1:
+ return results
+ if np.random.random_sample() < self.crop_ratio:
+ crop_box = self.sample_crop_box(results['img'].shape, results)
+ results['crop_region'] = crop_box
+ img = self.crop_img(results['img'], crop_box)
+ results['img'] = img
+ results['img_shape'] = img.shape
+
+ # crop and filter masks
+ x1, y1, x2, y2 = crop_box
+ w = max(x2 - x1, 1)
+ h = max(y2 - y1, 1)
+ labels = results['gt_labels']
+ valid_labels = []
+ for key in results.get('mask_fields', []):
+ if len(results[key].masks) == 0:
+ continue
+ results[key] = results[key].crop(crop_box)
+ # filter out polygons beyond crop box.
+ masks = results[key].masks
+ valid_masks_list = []
+
+ for ind, mask in enumerate(masks):
+ assert len(mask) == 1
+ polygon = mask[0].reshape((-1, 2))
+ if (polygon[:, 0] >
+ -4).all() and (polygon[:, 0] < w + 4).all() and (
+ polygon[:, 1] > -4).all() and (polygon[:, 1] <
+ h + 4).all():
+ mask[0][::2] = np.clip(mask[0][::2], 0, w)
+ mask[0][1::2] = np.clip(mask[0][1::2], 0, h)
+ if key == self.instance_key:
+ valid_labels.append(labels[ind])
+ valid_masks_list.append(mask)
+
+ results[key] = PolygonMasks(valid_masks_list, h, w)
+ results['gt_labels'] = np.array(valid_labels)
+
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ return repr_str
+
+
+@PIPELINES.register_module()
+class RandomRotatePolyInstances:
+
+ def __init__(self,
+ rotate_ratio=0.5,
+ max_angle=10,
+ pad_with_fixed_color=False,
+ pad_value=(0, 0, 0)):
+ """Randomly rotate images and polygon masks.
+
+ Args:
+ rotate_ratio (float): The ratio of samples to operate rotation.
+ max_angle (int): The maximum rotation angle.
+ pad_with_fixed_color (bool): The flag for whether to pad rotated
+ image with fixed value. If set to False, the rotated image will
+ be padded onto cropped image.
+ pad_value (tuple(int)): The color value for padding rotated image.
+ """
+ self.rotate_ratio = rotate_ratio
+ self.max_angle = max_angle
+ self.pad_with_fixed_color = pad_with_fixed_color
+ self.pad_value = pad_value
+
+ def rotate(self, center, points, theta, center_shift=(0, 0)):
+ # rotate points.
+ (center_x, center_y) = center
+ center_y = -center_y
+ x, y = points[::2], points[1::2]
+ y = -y
+
+ theta = theta / 180 * math.pi
+ cos = math.cos(theta)
+ sin = math.sin(theta)
+
+ x = (x - center_x)
+ y = (y - center_y)
+
+ _x = center_x + x * cos - y * sin + center_shift[0]
+ _y = -(center_y + x * sin + y * cos) + center_shift[1]
+
+ points[::2], points[1::2] = _x, _y
+ return points
+
+ def cal_canvas_size(self, ori_size, degree):
+ assert isinstance(ori_size, tuple)
+ angle = degree * math.pi / 180.0
+ h, w = ori_size[:2]
+
+ cos = math.cos(angle)
+ sin = math.sin(angle)
+ canvas_h = int(w * math.fabs(sin) + h * math.fabs(cos))
+ canvas_w = int(w * math.fabs(cos) + h * math.fabs(sin))
+
+ canvas_size = (canvas_h, canvas_w)
+ return canvas_size
+
+ def sample_angle(self, max_angle):
+ angle = np.random.random_sample() * 2 * max_angle - max_angle
+ return angle
+
+ def rotate_img(self, img, angle, canvas_size):
+ h, w = img.shape[:2]
+ rotation_matrix = cv2.getRotationMatrix2D((w / 2, h / 2), angle, 1)
+ rotation_matrix[0, 2] += int((canvas_size[1] - w) / 2)
+ rotation_matrix[1, 2] += int((canvas_size[0] - h) / 2)
+
+ if self.pad_with_fixed_color:
+ target_img = cv2.warpAffine(
+ img,
+ rotation_matrix, (canvas_size[1], canvas_size[0]),
+ flags=cv2.INTER_NEAREST,
+ borderValue=self.pad_value)
+ else:
+ mask = np.zeros_like(img)
+ (h_ind, w_ind) = (np.random.randint(0, h * 7 // 8),
+ np.random.randint(0, w * 7 // 8))
+ img_cut = img[h_ind:(h_ind + h // 9), w_ind:(w_ind + w // 9)]
+ img_cut = mmcv.imresize(img_cut, (canvas_size[1], canvas_size[0]))
+ mask = cv2.warpAffine(
+ mask,
+ rotation_matrix, (canvas_size[1], canvas_size[0]),
+ borderValue=[1, 1, 1])
+ target_img = cv2.warpAffine(
+ img,
+ rotation_matrix, (canvas_size[1], canvas_size[0]),
+ borderValue=[0, 0, 0])
+ target_img = target_img + img_cut * mask
+
+ return target_img
+
+ def __call__(self, results):
+ if np.random.random_sample() < self.rotate_ratio:
+ img = results['img']
+ h, w = img.shape[:2]
+ angle = self.sample_angle(self.max_angle)
+ canvas_size = self.cal_canvas_size((h, w), angle)
+ center_shift = (int(
+ (canvas_size[1] - w) / 2), int((canvas_size[0] - h) / 2))
+
+ # rotate image
+ results['rotated_poly_angle'] = angle
+ img = self.rotate_img(img, angle, canvas_size)
+ results['img'] = img
+ img_shape = img.shape
+ results['img_shape'] = img_shape
+
+ # rotate polygons
+ for key in results.get('mask_fields', []):
+ if len(results[key].masks) == 0:
+ continue
+ masks = results[key].masks
+ rotated_masks = []
+ for mask in masks:
+ rotated_mask = self.rotate((w / 2, h / 2), mask[0], angle,
+ center_shift)
+ rotated_masks.append([rotated_mask])
+
+ results[key] = PolygonMasks(rotated_masks, *(img_shape[:2]))
+
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ return repr_str
+
+
+@PIPELINES.register_module()
+class SquareResizePad:
+
+ def __init__(self,
+ target_size,
+ pad_ratio=0.6,
+ pad_with_fixed_color=False,
+ pad_value=(0, 0, 0)):
+ """Resize or pad images to be square shape.
+
+ Args:
+ target_size (int): The target size of square shaped image.
+ pad_with_fixed_color (bool): The flag for whether to pad rotated
+ image with fixed value. If set to False, the rescales image will
+ be padded onto cropped image.
+ pad_value (tuple(int)): The color value for padding rotated image.
+ """
+ assert isinstance(target_size, int)
+ assert isinstance(pad_ratio, float)
+ assert isinstance(pad_with_fixed_color, bool)
+ assert isinstance(pad_value, tuple)
+
+ self.target_size = target_size
+ self.pad_ratio = pad_ratio
+ self.pad_with_fixed_color = pad_with_fixed_color
+ self.pad_value = pad_value
+
+ def resize_img(self, img, keep_ratio=True):
+ h, w, _ = img.shape
+ if keep_ratio:
+ t_h = self.target_size if h >= w else int(h * self.target_size / w)
+ t_w = self.target_size if h <= w else int(w * self.target_size / h)
+ else:
+ t_h = t_w = self.target_size
+ img = mmcv.imresize(img, (t_w, t_h))
+ return img, (t_h, t_w)
+
+ def square_pad(self, img):
+ h, w = img.shape[:2]
+ if h == w:
+ return img, (0, 0)
+ pad_size = max(h, w)
+ if self.pad_with_fixed_color:
+ expand_img = np.ones((pad_size, pad_size, 3), dtype=np.uint8)
+ expand_img[:] = self.pad_value
+ else:
+ (h_ind, w_ind) = (np.random.randint(0, h * 7 // 8),
+ np.random.randint(0, w * 7 // 8))
+ img_cut = img[h_ind:(h_ind + h // 9), w_ind:(w_ind + w // 9)]
+ expand_img = mmcv.imresize(img_cut, (pad_size, pad_size))
+ if h > w:
+ y0, x0 = 0, (h - w) // 2
+ else:
+ y0, x0 = (w - h) // 2, 0
+ expand_img[y0:y0 + h, x0:x0 + w] = img
+ offset = (x0, y0)
+
+ return expand_img, offset
+
+ def square_pad_mask(self, points, offset):
+ x0, y0 = offset
+ pad_points = points.copy()
+ pad_points[::2] = pad_points[::2] + x0
+ pad_points[1::2] = pad_points[1::2] + y0
+ return pad_points
+
+ def __call__(self, results):
+ img = results['img']
+
+ if np.random.random_sample() < self.pad_ratio:
+ img, out_size = self.resize_img(img, keep_ratio=True)
+ img, offset = self.square_pad(img)
+ else:
+ img, out_size = self.resize_img(img, keep_ratio=False)
+ offset = (0, 0)
+
+ results['img'] = img
+ results['img_shape'] = img.shape
+
+ for key in results.get('mask_fields', []):
+ if len(results[key].masks) == 0:
+ continue
+ results[key] = results[key].resize(out_size)
+ masks = results[key].masks
+ processed_masks = []
+ for mask in masks:
+ square_pad_mask = self.square_pad_mask(mask[0], offset)
+ processed_masks.append([square_pad_mask])
+
+ results[key] = PolygonMasks(processed_masks, *(img.shape[:2]))
+
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ return repr_str
+
+
+@PIPELINES.register_module()
+class RandomScaling:
+
+ def __init__(self, size=800, scale=(3. / 4, 5. / 2)):
+ """Random scale the image while keeping aspect.
+
+ Args:
+ size (int) : Base size before scaling.
+ scale (tuple(float)) : The range of scaling.
+ """
+ assert isinstance(size, int)
+ assert isinstance(scale, float) or isinstance(scale, tuple)
+ self.size = size
+ self.scale = scale if isinstance(scale, tuple) \
+ else (1 - scale, 1 + scale)
+
+ def __call__(self, results):
+ image = results['img']
+ h, w, _ = results['img_shape']
+
+ aspect_ratio = np.random.uniform(min(self.scale), max(self.scale))
+ scales = self.size * 1.0 / max(h, w) * aspect_ratio
+ scales = np.array([scales, scales])
+ out_size = (int(h * scales[1]), int(w * scales[0]))
+ image = mmcv.imresize(image, out_size[::-1])
+
+ results['img'] = image
+ results['img_shape'] = image.shape
+
+ for key in results.get('mask_fields', []):
+ if len(results[key].masks) == 0:
+ continue
+ results[key] = results[key].resize(out_size)
+
+ return results
+
+
+@PIPELINES.register_module()
+class RandomCropFlip:
+
+ def __init__(self,
+ pad_ratio=0.1,
+ crop_ratio=0.5,
+ iter_num=1,
+ min_area_ratio=0.2):
+ """Random crop and flip a patch of the image.
+
+ Args:
+ crop_ratio (float): The ratio of cropping.
+ iter_num (int): Number of operations.
+ min_area_ratio (float): Minimal area ratio between cropped patch
+ and original image.
+ """
+ assert isinstance(crop_ratio, float)
+ assert isinstance(iter_num, int)
+ assert isinstance(min_area_ratio, float)
+
+ self.pad_ratio = pad_ratio
+ self.epsilon = 1e-2
+ self.crop_ratio = crop_ratio
+ self.iter_num = iter_num
+ self.min_area_ratio = min_area_ratio
+
+ def __call__(self, results):
+ for i in range(self.iter_num):
+ results = self.random_crop_flip(results)
+ return results
+
+ def random_crop_flip(self, results):
+ image = results['img']
+ polygons = results['gt_masks'].masks
+ ignore_polygons = results['gt_masks_ignore'].masks
+ all_polygons = polygons + ignore_polygons
+ if len(polygons) == 0:
+ return results
+
+ if np.random.random() >= self.crop_ratio:
+ return results
+
+ h, w, _ = results['img_shape']
+ area = h * w
+ pad_h = int(h * self.pad_ratio)
+ pad_w = int(w * self.pad_ratio)
+ h_axis, w_axis = self.generate_crop_target(image, all_polygons, pad_h,
+ pad_w)
+ if len(h_axis) == 0 or len(w_axis) == 0:
+ return results
+
+ attempt = 0
+ while attempt < 10:
+ attempt += 1
+ polys_keep = []
+ polys_new = []
+ ign_polys_keep = []
+ ign_polys_new = []
+ xx = np.random.choice(w_axis, size=2)
+ xmin = np.min(xx) - pad_w
+ xmax = np.max(xx) - pad_w
+ xmin = np.clip(xmin, 0, w - 1)
+ xmax = np.clip(xmax, 0, w - 1)
+ yy = np.random.choice(h_axis, size=2)
+ ymin = np.min(yy) - pad_h
+ ymax = np.max(yy) - pad_h
+ ymin = np.clip(ymin, 0, h - 1)
+ ymax = np.clip(ymax, 0, h - 1)
+ if (xmax - xmin) * (ymax - ymin) < area * self.min_area_ratio:
+ # area too small
+ continue
+
+ pts = np.stack([[xmin, xmax, xmax, xmin],
+ [ymin, ymin, ymax, ymax]]).T.astype(np.int32)
+ pp = plg(pts)
+ fail_flag = False
+ for polygon in polygons:
+ ppi = plg(polygon[0].reshape(-1, 2))
+ ppiou = eval_utils.poly_intersection(ppi, pp)
+ if np.abs(ppiou - float(ppi.area)) > self.epsilon and \
+ np.abs(ppiou) > self.epsilon:
+ fail_flag = True
+ break
+ elif np.abs(ppiou - float(ppi.area)) < self.epsilon:
+ polys_new.append(polygon)
+ else:
+ polys_keep.append(polygon)
+
+ for polygon in ignore_polygons:
+ ppi = plg(polygon[0].reshape(-1, 2))
+ ppiou = eval_utils.poly_intersection(ppi, pp)
+ if np.abs(ppiou - float(ppi.area)) > self.epsilon and \
+ np.abs(ppiou) > self.epsilon:
+ fail_flag = True
+ break
+ elif np.abs(ppiou - float(ppi.area)) < self.epsilon:
+ ign_polys_new.append(polygon)
+ else:
+ ign_polys_keep.append(polygon)
+
+ if fail_flag:
+ continue
+ else:
+ break
+
+ cropped = image[ymin:ymax, xmin:xmax, :]
+ select_type = np.random.randint(3)
+ if select_type == 0:
+ img = np.ascontiguousarray(cropped[:, ::-1])
+ elif select_type == 1:
+ img = np.ascontiguousarray(cropped[::-1, :])
+ else:
+ img = np.ascontiguousarray(cropped[::-1, ::-1])
+ image[ymin:ymax, xmin:xmax, :] = img
+ results['img'] = image
+
+ if len(polys_new) + len(ign_polys_new) != 0:
+ height, width, _ = cropped.shape
+ if select_type == 0:
+ for idx, polygon in enumerate(polys_new):
+ poly = polygon[0].reshape(-1, 2)
+ poly[:, 0] = width - poly[:, 0] + 2 * xmin
+ polys_new[idx] = [poly.reshape(-1, )]
+ for idx, polygon in enumerate(ign_polys_new):
+ poly = polygon[0].reshape(-1, 2)
+ poly[:, 0] = width - poly[:, 0] + 2 * xmin
+ ign_polys_new[idx] = [poly.reshape(-1, )]
+ elif select_type == 1:
+ for idx, polygon in enumerate(polys_new):
+ poly = polygon[0].reshape(-1, 2)
+ poly[:, 1] = height - poly[:, 1] + 2 * ymin
+ polys_new[idx] = [poly.reshape(-1, )]
+ for idx, polygon in enumerate(ign_polys_new):
+ poly = polygon[0].reshape(-1, 2)
+ poly[:, 1] = height - poly[:, 1] + 2 * ymin
+ ign_polys_new[idx] = [poly.reshape(-1, )]
+ else:
+ for idx, polygon in enumerate(polys_new):
+ poly = polygon[0].reshape(-1, 2)
+ poly[:, 0] = width - poly[:, 0] + 2 * xmin
+ poly[:, 1] = height - poly[:, 1] + 2 * ymin
+ polys_new[idx] = [poly.reshape(-1, )]
+ for idx, polygon in enumerate(ign_polys_new):
+ poly = polygon[0].reshape(-1, 2)
+ poly[:, 0] = width - poly[:, 0] + 2 * xmin
+ poly[:, 1] = height - poly[:, 1] + 2 * ymin
+ ign_polys_new[idx] = [poly.reshape(-1, )]
+ polygons = polys_keep + polys_new
+ ignore_polygons = ign_polys_keep + ign_polys_new
+ results['gt_masks'] = PolygonMasks(polygons, *(image.shape[:2]))
+ results['gt_masks_ignore'] = PolygonMasks(ignore_polygons,
+ *(image.shape[:2]))
+
+ return results
+
+ def generate_crop_target(self, image, all_polys, pad_h, pad_w):
+ """Generate crop target and make sure not to crop the polygon
+ instances.
+
+ Args:
+ image (ndarray): The image waited to be crop.
+ all_polys (list[list[ndarray]]): All polygons including ground
+ truth polygons and ground truth ignored polygons.
+ pad_h (int): Padding length of height.
+ pad_w (int): Padding length of width.
+ Returns:
+ h_axis (ndarray): Vertical cropping range.
+ w_axis (ndarray): Horizontal cropping range.
+ """
+ h, w, _ = image.shape
+ h_array = np.zeros((h + pad_h * 2), dtype=np.int32)
+ w_array = np.zeros((w + pad_w * 2), dtype=np.int32)
+
+ text_polys = []
+ for polygon in all_polys:
+ rect = cv2.minAreaRect(polygon[0].astype(np.int32).reshape(-1, 2))
+ box = cv2.boxPoints(rect)
+ box = np.int0(box)
+ text_polys.append([box[0], box[1], box[2], box[3]])
+
+ polys = np.array(text_polys, dtype=np.int32)
+ for poly in polys:
+ poly = np.round(poly, decimals=0).astype(np.int32)
+ minx = np.min(poly[:, 0])
+ maxx = np.max(poly[:, 0])
+ w_array[minx + pad_w:maxx + pad_w] = 1
+ miny = np.min(poly[:, 1])
+ maxy = np.max(poly[:, 1])
+ h_array[miny + pad_h:maxy + pad_h] = 1
+
+ h_axis = np.where(h_array == 0)[0]
+ w_axis = np.where(w_array == 0)[0]
+ return h_axis, w_axis
+
+
+@PIPELINES.register_module()
+class PyramidRescale:
+ """Resize the image to the base shape, downsample it with gaussian pyramid,
+ and rescale it back to original size.
+
+ Adapted from https://github.com/FangShancheng/ABINet.
+
+ Args:
+ factor (int): The decay factor from base size, or the number of
+ downsampling operations from the base layer.
+ base_shape (tuple(int)): The shape of the base layer of the pyramid.
+ randomize_factor (bool): If True, the final factor would be a random
+ integer in [0, factor].
+
+ :Required Keys:
+ - | ``img`` (ndarray): The input image.
+
+ :Affected Keys:
+ :Modified:
+ - | ``img`` (ndarray): The modified image.
+ """
+
+ def __init__(self, factor=4, base_shape=(128, 512), randomize_factor=True):
+ assert isinstance(factor, int)
+ assert isinstance(base_shape, list) or isinstance(base_shape, tuple)
+ assert len(base_shape) == 2
+ assert isinstance(randomize_factor, bool)
+ self.factor = factor if not randomize_factor else np.random.randint(
+ 0, factor + 1)
+ self.base_w, self.base_h = base_shape
+
+ def __call__(self, results):
+ assert 'img' in results
+ if self.factor == 0:
+ return results
+ img = results['img']
+ src_h, src_w = img.shape[:2]
+ scale_img = mmcv.imresize(img, (self.base_w, self.base_h))
+ for _ in range(self.factor):
+ scale_img = cv2.pyrDown(scale_img)
+ scale_img = mmcv.imresize(scale_img, (src_w, src_h))
+ results['img'] = scale_img
+ return results
+
+ def __repr__(self):
+ repr_str = self.__class__.__name__
+ repr_str += f'(factor={self.factor}, '
+ repr_str += f'basew={self.basew}, baseh={self.baseh})'
+ return repr_str
diff --git a/mmocr/datasets/text_det_dataset.py b/mmocr/datasets/text_det_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..c150b60d01d4371c45ad9fb9c8713515527b4652
--- /dev/null
+++ b/mmocr/datasets/text_det_dataset.py
@@ -0,0 +1,122 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+from mmdet.datasets.builder import DATASETS
+
+from mmocr.core.evaluation.hmean import eval_hmean
+from mmocr.datasets.base_dataset import BaseDataset
+
+
+@DATASETS.register_module()
+class TextDetDataset(BaseDataset):
+
+ def _parse_anno_info(self, annotations):
+ """Parse bbox and mask annotation.
+ Args:
+ annotations (dict): Annotations of one image.
+
+ Returns:
+ dict: A dict containing the following keys: bboxes, bboxes_ignore,
+ labels, masks, masks_ignore. "masks" and
+ "masks_ignore" are represented by polygon boundary
+ point sequences.
+ """
+ gt_bboxes, gt_bboxes_ignore = [], []
+ gt_masks, gt_masks_ignore = [], []
+ gt_labels = []
+ for ann in annotations:
+ if ann.get('iscrowd', False):
+ gt_bboxes_ignore.append(ann['bbox'])
+ gt_masks_ignore.append(ann.get('segmentation', None))
+ else:
+ gt_bboxes.append(ann['bbox'])
+ gt_labels.append(ann['category_id'])
+ gt_masks.append(ann.get('segmentation', None))
+ if gt_bboxes:
+ gt_bboxes = np.array(gt_bboxes, dtype=np.float32)
+ gt_labels = np.array(gt_labels, dtype=np.int64)
+ else:
+ gt_bboxes = np.zeros((0, 4), dtype=np.float32)
+ gt_labels = np.array([], dtype=np.int64)
+
+ if gt_bboxes_ignore:
+ gt_bboxes_ignore = np.array(gt_bboxes_ignore, dtype=np.float32)
+ else:
+ gt_bboxes_ignore = np.zeros((0, 4), dtype=np.float32)
+
+ ann = dict(
+ bboxes=gt_bboxes,
+ labels=gt_labels,
+ bboxes_ignore=gt_bboxes_ignore,
+ masks_ignore=gt_masks_ignore,
+ masks=gt_masks)
+
+ return ann
+
+ def prepare_train_img(self, index):
+ """Get training data and annotations from pipeline.
+
+ Args:
+ index (int): Index of data.
+
+ Returns:
+ dict: Training data and annotation after pipeline with new keys
+ introduced by pipeline.
+ """
+ img_ann_info = self.data_infos[index]
+ img_info = {
+ 'filename': img_ann_info['file_name'],
+ 'height': img_ann_info['height'],
+ 'width': img_ann_info['width']
+ }
+ ann_info = self._parse_anno_info(img_ann_info['annotations'])
+ results = dict(img_info=img_info, ann_info=ann_info)
+ results['bbox_fields'] = []
+ results['mask_fields'] = []
+ results['seg_fields'] = []
+ self.pre_pipeline(results)
+
+ return self.pipeline(results)
+
+ def evaluate(self,
+ results,
+ metric='hmean-iou',
+ score_thr=0.3,
+ rank_list=None,
+ logger=None,
+ **kwargs):
+ """Evaluate the dataset.
+
+ Args:
+ results (list): Testing results of the dataset.
+ metric (str | list[str]): Metrics to be evaluated.
+ score_thr (float): Score threshold for prediction map.
+ logger (logging.Logger | str | None): Logger used for printing
+ related information during evaluation. Default: None.
+ rank_list (str): json file used to save eval result
+ of each image after ranking.
+ Returns:
+ dict[str: float]
+ """
+ metrics = metric if isinstance(metric, list) else [metric]
+ allowed_metrics = ['hmean-iou', 'hmean-ic13']
+ metrics = set(metrics) & set(allowed_metrics)
+
+ img_infos = []
+ ann_infos = []
+ for i in range(len(self)):
+ img_ann_info = self.data_infos[i]
+ img_info = {'filename': img_ann_info['file_name']}
+ ann_info = self._parse_anno_info(img_ann_info['annotations'])
+ img_infos.append(img_info)
+ ann_infos.append(ann_info)
+
+ eval_results = eval_hmean(
+ results,
+ img_infos,
+ ann_infos,
+ metrics=metrics,
+ score_thr=score_thr,
+ logger=logger,
+ rank_list=rank_list)
+
+ return eval_results
diff --git a/mmocr/datasets/uniform_concat_dataset.py b/mmocr/datasets/uniform_concat_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..286119ba6bcc7cf160f921e16cb62408cfd95657
--- /dev/null
+++ b/mmocr/datasets/uniform_concat_dataset.py
@@ -0,0 +1,67 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+from mmdet.datasets import DATASETS, ConcatDataset, build_dataset
+
+from mmocr.utils import is_2dlist, is_type_list
+
+
+@DATASETS.register_module()
+class UniformConcatDataset(ConcatDataset):
+ """A wrapper of ConcatDataset which support dataset pipeline assignment and
+ replacement.
+
+ Args:
+ datasets (list[dict] | list[list[dict]]): A list of datasets cfgs.
+ separate_eval (bool): Whether to evaluate the results
+ separately if it is used as validation dataset.
+ Defaults to True.
+ pipeline (None | list[dict] | list[list[dict]]): If ``None``,
+ each dataset in datasets use its own pipeline;
+ If ``list[dict]``, it will be assigned to the dataset whose
+ pipeline is None in datasets;
+ If ``list[list[dict]]``, pipeline of dataset which is None
+ in datasets will be replaced by the corresponding pipeline
+ in the list.
+ force_apply (bool): If True, apply pipeline above to each dataset
+ even if it have its own pipeline. Default: False.
+ """
+
+ def __init__(self,
+ datasets,
+ separate_eval=True,
+ pipeline=None,
+ force_apply=False,
+ **kwargs):
+ new_datasets = []
+ if pipeline is not None:
+ assert isinstance(
+ pipeline,
+ list), 'pipeline must be list[dict] or list[list[dict]].'
+ if is_type_list(pipeline, dict):
+ self._apply_pipeline(datasets, pipeline, force_apply)
+ new_datasets = datasets
+ elif is_2dlist(pipeline):
+ assert is_2dlist(datasets)
+ assert len(datasets) == len(pipeline)
+ for sub_datasets, tmp_pipeline in zip(datasets, pipeline):
+ self._apply_pipeline(sub_datasets, tmp_pipeline,
+ force_apply)
+ new_datasets.extend(sub_datasets)
+ else:
+ if is_2dlist(datasets):
+ for sub_datasets in datasets:
+ new_datasets.extend(sub_datasets)
+ else:
+ new_datasets = datasets
+ datasets = [build_dataset(c, kwargs) for c in new_datasets]
+ super().__init__(datasets, separate_eval)
+
+ @staticmethod
+ def _apply_pipeline(datasets, pipeline, force_apply=False):
+ from_cfg = all(isinstance(x, dict) for x in datasets)
+ assert from_cfg, 'datasets should be config dicts'
+ assert all(isinstance(x, dict) for x in pipeline)
+ for dataset in datasets:
+ if dataset['pipeline'] is None or force_apply:
+ dataset['pipeline'] = copy.deepcopy(pipeline)
diff --git a/mmocr/datasets/utils/__init__.py b/mmocr/datasets/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f2fc30a528236846177a621f73a3f10220d679df
--- /dev/null
+++ b/mmocr/datasets/utils/__init__.py
@@ -0,0 +1,8 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .loader import AnnFileLoader, HardDiskLoader, LmdbLoader
+from .parser import LineJsonParser, LineStrParser
+
+__all__ = [
+ 'HardDiskLoader', 'LmdbLoader', 'AnnFileLoader', 'LineStrParser',
+ 'LineJsonParser'
+]
diff --git a/mmocr/datasets/utils/backend.py b/mmocr/datasets/utils/backend.py
new file mode 100644
index 0000000000000000000000000000000000000000..b772c1199fcd47fe9e1bf7e1ac51ad2f3304d392
--- /dev/null
+++ b/mmocr/datasets/utils/backend.py
@@ -0,0 +1,136 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import os.path as osp
+import shutil
+import warnings
+
+import mmcv
+
+from mmocr import digit_version
+from mmocr.utils import list_from_file
+
+
+class LmdbAnnFileBackend:
+ """Lmdb storage backend for annotation file.
+
+ Args:
+ lmdb_path (str): Lmdb file path.
+ """
+
+ def __init__(self, lmdb_path, encoding='utf8'):
+ self.lmdb_path = lmdb_path
+ self.encoding = encoding
+ env = self._get_env()
+ with env.begin(write=False) as txn:
+ self.total_number = int(
+ txn.get('total_number'.encode('utf-8')).decode(self.encoding))
+
+ def __getitem__(self, index):
+ """Retrieve one line from lmdb file by index."""
+ # only attach env to self when __getitem__ is called
+ # because env object cannot be pickle
+ if not hasattr(self, 'env'):
+ self.env = self._get_env()
+
+ with self.env.begin(write=False) as txn:
+ line = txn.get(str(index).encode('utf-8')).decode(self.encoding)
+ return line
+
+ def __len__(self):
+ return self.total_number
+
+ def _get_env(self):
+ try:
+ import lmdb
+ except ImportError:
+ raise ImportError(
+ 'Please install lmdb to enable LmdbAnnFileBackend.')
+ return lmdb.open(
+ self.lmdb_path,
+ max_readers=1,
+ readonly=True,
+ lock=False,
+ readahead=False,
+ meminit=False,
+ )
+
+ def close(self):
+ self.env.close()
+
+
+class HardDiskAnnFileBackend:
+ """Load annotation file with raw hard disks storage backend."""
+
+ def __init__(self, file_format='txt'):
+ assert file_format in ['txt', 'lmdb']
+ self.file_format = file_format
+
+ def __call__(self, ann_file):
+ if self.file_format == 'lmdb':
+ return LmdbAnnFileBackend(ann_file)
+
+ return list_from_file(ann_file)
+
+
+class PetrelAnnFileBackend:
+ """Load annotation file with petrel storage backend."""
+
+ def __init__(self, file_format='txt', save_dir='tmp_dir'):
+ assert file_format in ['txt', 'lmdb']
+ self.file_format = file_format
+ self.save_dir = save_dir
+
+ def __call__(self, ann_file):
+ file_client = mmcv.FileClient(backend='petrel')
+
+ if self.file_format == 'lmdb':
+ mmcv_version = digit_version(mmcv.__version__)
+ if mmcv_version < digit_version('1.3.16'):
+ raise Exception('Please update mmcv to 1.3.16 or higher '
+ 'to enable "get_local_path" of "FileClient".')
+ assert file_client.isdir(ann_file)
+ files = file_client.list_dir_or_file(ann_file)
+
+ ann_file_rel_path = ann_file.split('s3://')[-1]
+ ann_file_dir = osp.dirname(ann_file_rel_path)
+ ann_file_name = osp.basename(ann_file_rel_path)
+ local_dir = osp.join(self.save_dir, ann_file_dir, ann_file_name)
+ if osp.exists(local_dir):
+ warnings.warn(
+ f'local_ann_file: {local_dir} is already existed and '
+ 'will be used. If it is not the correct ann_file '
+ 'corresponding to {ann_file}, please remove it or '
+ 'change "save_dir" first then try again.')
+ else:
+ os.makedirs(local_dir, exist_ok=True)
+ print(f'Fetching {ann_file} to {local_dir}...')
+ for each_file in files:
+ tmp_file_path = file_client.join_path(ann_file, each_file)
+ with file_client.get_local_path(
+ tmp_file_path) as local_path:
+ shutil.copy(local_path, osp.join(local_dir, each_file))
+
+ return LmdbAnnFileBackend(local_dir)
+
+ lines = str(file_client.get(ann_file), encoding='utf-8').split('\n')
+
+ return [x for x in lines if x.strip() != '']
+
+
+class HTTPAnnFileBackend:
+ """Load annotation file with http storage backend."""
+
+ def __init__(self, file_format='txt'):
+ assert file_format in ['txt', 'lmdb']
+ self.file_format = file_format
+
+ def __call__(self, ann_file):
+ file_client = mmcv.FileClient(backend='http')
+
+ if self.file_format == 'lmdb':
+ raise NotImplementedError(
+ 'Loading lmdb file on http is not supported yet.')
+
+ lines = str(file_client.get(ann_file), encoding='utf-8').split('\n')
+
+ return [x for x in lines if x.strip() != '']
diff --git a/mmocr/datasets/utils/loader.py b/mmocr/datasets/utils/loader.py
new file mode 100644
index 0000000000000000000000000000000000000000..969049f1cb67da04122be1ec7195d38b1fbecd13
--- /dev/null
+++ b/mmocr/datasets/utils/loader.py
@@ -0,0 +1,108 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+from mmocr.datasets.builder import LOADERS, build_parser
+from .backend import (HardDiskAnnFileBackend, HTTPAnnFileBackend,
+ PetrelAnnFileBackend)
+
+
+@LOADERS.register_module()
+class AnnFileLoader:
+ """Annotation file loader to load annotations from ann_file, and parse raw
+ annotation to dict format with certain parser.
+
+ Args:
+ ann_file (str): Annotation file path.
+ parser (dict): Dictionary to construct parser
+ to parse original annotation infos.
+ repeat (int|float): Repeated times of dataset.
+ file_storage_backend (str): The storage backend type for annotation
+ file. Options are "disk", "http" and "petrel". Default: "disk".
+ file_format (str): The format of annotation file. Options are
+ "txt" and "lmdb". Default: "txt".
+ """
+
+ _backends = {
+ 'disk': HardDiskAnnFileBackend,
+ 'petrel': PetrelAnnFileBackend,
+ 'http': HTTPAnnFileBackend
+ }
+
+ def __init__(self,
+ ann_file,
+ parser,
+ repeat=1,
+ file_storage_backend='disk',
+ file_format='txt',
+ **kwargs):
+ assert isinstance(ann_file, str)
+ assert isinstance(repeat, (int, float))
+ assert isinstance(parser, dict)
+ assert repeat > 0
+ assert file_storage_backend in ['disk', 'http', 'petrel']
+ assert file_format in ['txt', 'lmdb']
+
+ self.parser = build_parser(parser)
+ self.repeat = repeat
+ self.ann_file_backend = self._backends[file_storage_backend](
+ file_format, **kwargs)
+ self.ori_data_infos = self._load(ann_file)
+
+ def __len__(self):
+ return int(len(self.ori_data_infos) * self.repeat)
+
+ def _load(self, ann_file):
+ """Load annotation file."""
+
+ return self.ann_file_backend(ann_file)
+
+ def __getitem__(self, index):
+ """Retrieve anno info of one instance with dict format."""
+ return self.parser.get_item(self.ori_data_infos, index)
+
+ def __iter__(self):
+ self._n = 0
+ return self
+
+ def __next__(self):
+ if self._n < len(self):
+ data = self[self._n]
+ self._n += 1
+ return data
+ raise StopIteration
+
+ def close(self):
+ """For ann_file with lmdb format only."""
+ self.ori_data_infos.close()
+
+
+@LOADERS.register_module()
+class HardDiskLoader(AnnFileLoader):
+ """Load txt format annotation file from hard disks."""
+
+ def __init__(self, ann_file, parser, repeat=1):
+ warnings.warn(
+ 'HardDiskLoader is deprecated, please use '
+ 'AnnFileLoader instead.', UserWarning)
+ super().__init__(
+ ann_file,
+ parser,
+ repeat,
+ file_storage_backend='disk',
+ file_format='txt')
+
+
+@LOADERS.register_module()
+class LmdbLoader(AnnFileLoader):
+ """Load lmdb format annotation file from hard disks."""
+
+ def __init__(self, ann_file, parser, repeat=1):
+ warnings.warn(
+ 'LmdbLoader is deprecated, please use '
+ 'AnnFileLoader instead.', UserWarning)
+ super().__init__(
+ ann_file,
+ parser,
+ repeat,
+ file_storage_backend='disk',
+ file_format='lmdb')
diff --git a/mmocr/datasets/utils/parser.py b/mmocr/datasets/utils/parser.py
new file mode 100644
index 0000000000000000000000000000000000000000..498c6609b67c02747a13ae375ed808e7a049d441
--- /dev/null
+++ b/mmocr/datasets/utils/parser.py
@@ -0,0 +1,72 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+
+from mmocr.datasets.builder import PARSERS
+from mmocr.utils import StringStrip
+
+
+@PARSERS.register_module()
+class LineStrParser:
+ """Parse string of one line in annotation file to dict format.
+
+ Args:
+ keys (list[str]): Keys in result dict.
+ keys_idx (list[int]): Value index in sub-string list
+ for each key above.
+ separator (str): Separator to separate string to list of sub-string.
+ """
+
+ def __init__(self,
+ keys=['filename', 'text'],
+ keys_idx=[0, 1],
+ separator=' ',
+ **kwargs):
+ assert isinstance(keys, list)
+ assert isinstance(keys_idx, list)
+ assert isinstance(separator, str)
+ assert len(keys) > 0
+ assert len(keys) == len(keys_idx)
+ self.keys = keys
+ self.keys_idx = keys_idx
+ self.separator = separator
+ self.strip_cls = StringStrip(**kwargs)
+
+ def get_item(self, data_ret, index):
+ map_index = index % len(data_ret)
+ line_str = data_ret[map_index]
+ line_str = self.strip_cls(line_str)
+ line_str = line_str.split(self.separator)
+ if len(line_str) <= max(self.keys_idx):
+ raise Exception(
+ f'key index: {max(self.keys_idx)} out of range: {line_str}')
+
+ line_info = {}
+ for i, key in enumerate(self.keys):
+ line_info[key] = line_str[self.keys_idx[i]]
+ return line_info
+
+
+@PARSERS.register_module()
+class LineJsonParser:
+ """Parse json-string of one line in annotation file to dict format.
+
+ Args:
+ keys (list[str]): Keys in both json-string and result dict.
+ """
+
+ def __init__(self, keys=[]):
+ assert isinstance(keys, list)
+ assert len(keys) > 0
+ self.keys = keys
+
+ def get_item(self, data_ret, index):
+ map_index = index % len(data_ret)
+ json_str = data_ret[map_index]
+ line_json_obj = json.loads(json_str)
+ line_info = {}
+ for key in self.keys:
+ if key not in line_json_obj:
+ raise Exception(f'key {key} not in line json {line_json_obj}')
+ line_info[key] = line_json_obj[key]
+
+ return line_info
diff --git a/mmocr/models/__init__.py b/mmocr/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e0c7bb8903fb1c163d5708b0df87907b8e7291bc
--- /dev/null
+++ b/mmocr/models/__init__.py
@@ -0,0 +1,19 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from . import common, kie, textdet, textrecog
+from .builder import (BACKBONES, CONVERTORS, DECODERS, DETECTORS, ENCODERS,
+ HEADS, LOSSES, NECKS, PREPROCESSOR, build_backbone,
+ build_convertor, build_decoder, build_detector,
+ build_encoder, build_loss, build_preprocessor)
+from .common import * # NOQA
+from .kie import * # NOQA
+from .ner import * # NOQA
+from .textdet import * # NOQA
+from .textrecog import * # NOQA
+
+__all__ = [
+ 'BACKBONES', 'DETECTORS', 'HEADS', 'LOSSES', 'NECKS', 'build_backbone',
+ 'build_detector', 'build_loss', 'CONVERTORS', 'ENCODERS', 'DECODERS',
+ 'PREPROCESSOR', 'build_convertor', 'build_encoder', 'build_decoder',
+ 'build_preprocessor'
+]
+__all__ += common.__all__ + kie.__all__ + textdet.__all__ + textrecog.__all__
diff --git a/mmocr/models/builder.py b/mmocr/models/builder.py
new file mode 100644
index 0000000000000000000000000000000000000000..9305b7bdbebce063e66f046f05784a6623a49fba
--- /dev/null
+++ b/mmocr/models/builder.py
@@ -0,0 +1,152 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import torch.nn as nn
+from mmcv.cnn import ACTIVATION_LAYERS as MMCV_ACTIVATION_LAYERS
+from mmcv.cnn import UPSAMPLE_LAYERS as MMCV_UPSAMPLE_LAYERS
+from mmcv.utils import Registry, build_from_cfg
+from mmdet.models.builder import BACKBONES as MMDET_BACKBONES
+
+CONVERTORS = Registry('convertor')
+ENCODERS = Registry('encoder')
+DECODERS = Registry('decoder')
+PREPROCESSOR = Registry('preprocessor')
+POSTPROCESSOR = Registry('postprocessor')
+
+UPSAMPLE_LAYERS = Registry('upsample layer', parent=MMCV_UPSAMPLE_LAYERS)
+BACKBONES = Registry('models', parent=MMDET_BACKBONES)
+LOSSES = BACKBONES
+DETECTORS = BACKBONES
+ROI_EXTRACTORS = BACKBONES
+HEADS = BACKBONES
+NECKS = BACKBONES
+FUSERS = BACKBONES
+RECOGNIZERS = BACKBONES
+
+ACTIVATION_LAYERS = Registry('activation layer', parent=MMCV_ACTIVATION_LAYERS)
+
+
+def build_recognizer(cfg, train_cfg=None, test_cfg=None):
+ """Build recognizer."""
+ return build_from_cfg(cfg, RECOGNIZERS,
+ dict(train_cfg=train_cfg, test_cfg=test_cfg))
+
+
+def build_convertor(cfg):
+ """Build label convertor for scene text recognizer."""
+ return build_from_cfg(cfg, CONVERTORS)
+
+
+def build_encoder(cfg):
+ """Build encoder for scene text recognizer."""
+ return build_from_cfg(cfg, ENCODERS)
+
+
+def build_decoder(cfg):
+ """Build decoder for scene text recognizer."""
+ return build_from_cfg(cfg, DECODERS)
+
+
+def build_preprocessor(cfg):
+ """Build preprocessor for scene text recognizer."""
+ return build_from_cfg(cfg, PREPROCESSOR)
+
+
+def build_postprocessor(cfg):
+ """Build postprocessor for scene text detector."""
+ return build_from_cfg(cfg, POSTPROCESSOR)
+
+
+def build_roi_extractor(cfg):
+ """Build roi extractor."""
+ return ROI_EXTRACTORS.build(cfg)
+
+
+def build_loss(cfg):
+ """Build loss."""
+ return LOSSES.build(cfg)
+
+
+def build_backbone(cfg):
+ """Build backbone."""
+ return BACKBONES.build(cfg)
+
+
+def build_head(cfg):
+ """Build head."""
+ return HEADS.build(cfg)
+
+
+def build_neck(cfg):
+ """Build neck."""
+ return NECKS.build(cfg)
+
+
+def build_fuser(cfg):
+ """Build fuser."""
+ return FUSERS.build(cfg)
+
+
+def build_upsample_layer(cfg, *args, **kwargs):
+ """Build upsample layer.
+
+ Args:
+ cfg (dict): The upsample layer config, which should contain:
+
+ - type (str): Layer type.
+ - scale_factor (int): Upsample ratio, which is not applicable to
+ deconv.
+ - layer args: Args needed to instantiate a upsample layer.
+ args (argument list): Arguments passed to the ``__init__``
+ method of the corresponding conv layer.
+ kwargs (keyword arguments): Keyword arguments passed to the
+ ``__init__`` method of the corresponding conv layer.
+
+ Returns:
+ nn.Module: Created upsample layer.
+ """
+ if not isinstance(cfg, dict):
+ raise TypeError(f'cfg must be a dict, but got {type(cfg)}')
+ if 'type' not in cfg:
+ raise KeyError(
+ f'the cfg dict must contain the key "type", but got {cfg}')
+ cfg_ = cfg.copy()
+
+ layer_type = cfg_.pop('type')
+ if layer_type not in UPSAMPLE_LAYERS:
+ raise KeyError(f'Unrecognized upsample type {layer_type}')
+ else:
+ upsample = UPSAMPLE_LAYERS.get(layer_type)
+
+ if upsample is nn.Upsample:
+ cfg_['mode'] = layer_type
+ layer = upsample(*args, **kwargs, **cfg_)
+ return layer
+
+
+def build_activation_layer(cfg):
+ """Build activation layer.
+
+ Args:
+ cfg (dict): The activation layer config, which should contain:
+ - type (str): Layer type.
+ - layer args: Args needed to instantiate an activation layer.
+
+ Returns:
+ nn.Module: Created activation layer.
+ """
+ return build_from_cfg(cfg, ACTIVATION_LAYERS)
+
+
+def build_detector(cfg, train_cfg=None, test_cfg=None):
+ """Build detector."""
+ if train_cfg is not None or test_cfg is not None:
+ warnings.warn(
+ 'train_cfg and test_cfg is deprecated, '
+ 'please specify them in model', UserWarning)
+ assert cfg.get('train_cfg') is None or train_cfg is None, \
+ 'train_cfg specified in both outer field and model field '
+ assert cfg.get('test_cfg') is None or test_cfg is None, \
+ 'test_cfg specified in both outer field and model field '
+ return DETECTORS.build(
+ cfg, default_args=dict(train_cfg=train_cfg, test_cfg=test_cfg))
diff --git a/mmocr/models/common/__init__.py b/mmocr/models/common/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..94464711b51aaed6bb644bb94d8782573a3c211b
--- /dev/null
+++ b/mmocr/models/common/__init__.py
@@ -0,0 +1,8 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from . import backbones, layers, losses, modules
+from .backbones import * # NOQA
+from .layers import * # NOQA
+from .losses import * # NOQA
+from .modules import * # NOQA
+
+__all__ = backbones.__all__ + losses.__all__ + layers.__all__ + modules.__all__
diff --git a/mmocr/models/common/backbones/__init__.py b/mmocr/models/common/backbones/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..3c384ba3010dd3fc81b562f7101c63ecaef1e0a6
--- /dev/null
+++ b/mmocr/models/common/backbones/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .unet import UNet
+
+__all__ = ['UNet']
diff --git a/mmocr/models/common/backbones/unet.py b/mmocr/models/common/backbones/unet.py
new file mode 100644
index 0000000000000000000000000000000000000000..a69e9f724d17de9ae888ed9654304e17d45ba87a
--- /dev/null
+++ b/mmocr/models/common/backbones/unet.py
@@ -0,0 +1,516 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.utils.checkpoint as cp
+from mmcv.cnn import ConvModule, build_norm_layer
+from mmcv.runner import BaseModule
+from mmcv.utils.parrots_wrapper import _BatchNorm
+
+from mmocr.models.builder import (BACKBONES, UPSAMPLE_LAYERS,
+ build_activation_layer, build_upsample_layer)
+
+
+class UpConvBlock(nn.Module):
+ """Upsample convolution block in decoder for UNet.
+
+ This upsample convolution block consists of one upsample module
+ followed by one convolution block. The upsample module expands the
+ high-level low-resolution feature map and the convolution block fuses
+ the upsampled high-level low-resolution feature map and the low-level
+ high-resolution feature map from encoder.
+
+ Args:
+ conv_block (nn.Sequential): Sequential of convolutional layers.
+ in_channels (int): Number of input channels of the high-level
+ skip_channels (int): Number of input channels of the low-level
+ high-resolution feature map from encoder.
+ out_channels (int): Number of output channels.
+ num_convs (int): Number of convolutional layers in the conv_block.
+ Default: 2.
+ stride (int): Stride of convolutional layer in conv_block. Default: 1.
+ dilation (int): Dilation rate of convolutional layer in conv_block.
+ Default: 1.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ conv_cfg (dict | None): Config dict for convolution layer.
+ Default: None.
+ norm_cfg (dict | None): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict | None): Config dict for activation layer in ConvModule.
+ Default: dict(type='ReLU').
+ upsample_cfg (dict): The upsample config of the upsample module in
+ decoder. Default: dict(type='InterpConv'). If the size of
+ high-level feature map is the same as that of skip feature map
+ (low-level feature map from encoder), it does not need upsample the
+ high-level feature map and the upsample_cfg is None.
+ dcn (bool): Use deformable convolution in convolutional layer or not.
+ Default: None.
+ plugins (dict): plugins for convolutional layers. Default: None.
+ """
+
+ def __init__(self,
+ conv_block,
+ in_channels,
+ skip_channels,
+ out_channels,
+ num_convs=2,
+ stride=1,
+ dilation=1,
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ upsample_cfg=dict(type='InterpConv'),
+ dcn=None,
+ plugins=None):
+ super().__init__()
+ assert dcn is None, 'Not implemented yet.'
+ assert plugins is None, 'Not implemented yet.'
+
+ self.conv_block = conv_block(
+ in_channels=2 * skip_channels,
+ out_channels=out_channels,
+ num_convs=num_convs,
+ stride=stride,
+ dilation=dilation,
+ with_cp=with_cp,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ dcn=None,
+ plugins=None)
+ if upsample_cfg is not None:
+ self.upsample = build_upsample_layer(
+ cfg=upsample_cfg,
+ in_channels=in_channels,
+ out_channels=skip_channels,
+ with_cp=with_cp,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ else:
+ self.upsample = ConvModule(
+ in_channels,
+ skip_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+
+ def forward(self, skip, x):
+ """Forward function."""
+
+ x = self.upsample(x)
+ out = torch.cat([skip, x], dim=1)
+ out = self.conv_block(out)
+
+ return out
+
+
+class BasicConvBlock(nn.Module):
+ """Basic convolutional block for UNet.
+
+ This module consists of several plain convolutional layers.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ num_convs (int): Number of convolutional layers. Default: 2.
+ stride (int): Whether use stride convolution to downsample
+ the input feature map. If stride=2, it only uses stride convolution
+ in the first convolutional layer to downsample the input feature
+ map. Options are 1 or 2. Default: 1.
+ dilation (int): Whether use dilated convolution to expand the
+ receptive field. Set dilation rate of each convolutional layer and
+ the dilation rate of the first convolutional layer is always 1.
+ Default: 1.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ conv_cfg (dict | None): Config dict for convolution layer.
+ Default: None.
+ norm_cfg (dict | None): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict | None): Config dict for activation layer in ConvModule.
+ Default: dict(type='ReLU').
+ dcn (bool): Use deformable convolution in convolutional layer or not.
+ Default: None.
+ plugins (dict): plugins for convolutional layers. Default: None.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ num_convs=2,
+ stride=1,
+ dilation=1,
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ dcn=None,
+ plugins=None):
+ super().__init__()
+ assert dcn is None, 'Not implemented yet.'
+ assert plugins is None, 'Not implemented yet.'
+
+ self.with_cp = with_cp
+ convs = []
+ for i in range(num_convs):
+ convs.append(
+ ConvModule(
+ in_channels=in_channels if i == 0 else out_channels,
+ out_channels=out_channels,
+ kernel_size=3,
+ stride=stride if i == 0 else 1,
+ dilation=1 if i == 0 else dilation,
+ padding=1 if i == 0 else dilation,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg))
+
+ self.convs = nn.Sequential(*convs)
+
+ def forward(self, x):
+ """Forward function."""
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(self.convs, x)
+ else:
+ out = self.convs(x)
+ return out
+
+
+@UPSAMPLE_LAYERS.register_module()
+class DeconvModule(nn.Module):
+ """Deconvolution upsample module in decoder for UNet (2X upsample).
+
+ This module uses deconvolution to upsample feature map in the decoder
+ of UNet.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ norm_cfg (dict | None): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict | None): Config dict for activation layer in ConvModule.
+ Default: dict(type='ReLU').
+ kernel_size (int): Kernel size of the convolutional layer. Default: 4.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ with_cp=False,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ *,
+ kernel_size=4,
+ scale_factor=2):
+ super().__init__()
+
+ assert (
+ kernel_size - scale_factor >= 0
+ and (kernel_size - scale_factor) % 2 == 0), (
+ f'kernel_size should be greater than or equal to scale_factor '
+ f'and (kernel_size - scale_factor) should be even numbers, '
+ f'while the kernel size is {kernel_size} and scale_factor is '
+ f'{scale_factor}.')
+
+ stride = scale_factor
+ padding = (kernel_size - scale_factor) // 2
+ self.with_cp = with_cp
+ deconv = nn.ConvTranspose2d(
+ in_channels,
+ out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding)
+
+ _, norm = build_norm_layer(norm_cfg, out_channels)
+ activate = build_activation_layer(act_cfg)
+ self.deconv_upsamping = nn.Sequential(deconv, norm, activate)
+
+ def forward(self, x):
+ """Forward function."""
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(self.deconv_upsamping, x)
+ else:
+ out = self.deconv_upsamping(x)
+ return out
+
+
+@UPSAMPLE_LAYERS.register_module()
+class InterpConv(nn.Module):
+ """Interpolation upsample module in decoder for UNet.
+
+ This module uses interpolation to upsample feature map in the decoder
+ of UNet. It consists of one interpolation upsample layer and one
+ convolutional layer. It can be one interpolation upsample layer followed
+ by one convolutional layer (conv_first=False) or one convolutional layer
+ followed by one interpolation upsample layer (conv_first=True).
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ norm_cfg (dict | None): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict | None): Config dict for activation layer in ConvModule.
+ Default: dict(type='ReLU').
+ conv_cfg (dict | None): Config dict for convolution layer.
+ Default: None.
+ conv_first (bool): Whether convolutional layer or interpolation
+ upsample layer first. Default: False. It means interpolation
+ upsample layer followed by one convolutional layer.
+ kernel_size (int): Kernel size of the convolutional layer. Default: 1.
+ stride (int): Stride of the convolutional layer. Default: 1.
+ padding (int): Padding of the convolutional layer. Default: 1.
+ upsample_cfg (dict): Interpolation config of the upsample layer.
+ Default: dict(
+ scale_factor=2, mode='bilinear', align_corners=False).
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ with_cp=False,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ *,
+ conv_cfg=None,
+ conv_first=False,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ upsample_cfg=dict(
+ scale_factor=2, mode='bilinear', align_corners=False)):
+ super().__init__()
+
+ self.with_cp = with_cp
+ conv = ConvModule(
+ in_channels,
+ out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg)
+ upsample = nn.Upsample(**upsample_cfg)
+ if conv_first:
+ self.interp_upsample = nn.Sequential(conv, upsample)
+ else:
+ self.interp_upsample = nn.Sequential(upsample, conv)
+
+ def forward(self, x):
+ """Forward function."""
+
+ if self.with_cp and x.requires_grad:
+ out = cp.checkpoint(self.interp_upsample, x)
+ else:
+ out = self.interp_upsample(x)
+ return out
+
+
+@BACKBONES.register_module()
+class UNet(BaseModule):
+ """UNet backbone.
+ U-Net: Convolutional Networks for Biomedical Image Segmentation.
+ https://arxiv.org/pdf/1505.04597.pdf
+
+ Args:
+ in_channels (int): Number of input image channels. Default" 3.
+ base_channels (int): Number of base channels of each stage.
+ The output channels of the first stage. Default: 64.
+ num_stages (int): Number of stages in encoder, normally 5. Default: 5.
+ strides (Sequence[int 1 | 2]): Strides of each stage in encoder.
+ len(strides) is equal to num_stages. Normally the stride of the
+ first stage in encoder is 1. If strides[i]=2, it uses stride
+ convolution to downsample in the correspondence encoder stage.
+ Default: (1, 1, 1, 1, 1).
+ enc_num_convs (Sequence[int]): Number of convolutional layers in the
+ convolution block of the correspondence encoder stage.
+ Default: (2, 2, 2, 2, 2).
+ dec_num_convs (Sequence[int]): Number of convolutional layers in the
+ convolution block of the correspondence decoder stage.
+ Default: (2, 2, 2, 2).
+ downsamples (Sequence[int]): Whether use MaxPool to downsample the
+ feature map after the first stage of encoder
+ (stages: [1, num_stages)). If the correspondence encoder stage use
+ stride convolution (strides[i]=2), it will never use MaxPool to
+ downsample, even downsamples[i-1]=True.
+ Default: (True, True, True, True).
+ enc_dilations (Sequence[int]): Dilation rate of each stage in encoder.
+ Default: (1, 1, 1, 1, 1).
+ dec_dilations (Sequence[int]): Dilation rate of each stage in decoder.
+ Default: (1, 1, 1, 1).
+ with_cp (bool): Use checkpoint or not. Using checkpoint will save some
+ memory while slowing down the training speed. Default: False.
+ conv_cfg (dict | None): Config dict for convolution layer.
+ Default: None.
+ norm_cfg (dict | None): Config dict for normalization layer.
+ Default: dict(type='BN').
+ act_cfg (dict | None): Config dict for activation layer in ConvModule.
+ Default: dict(type='ReLU').
+ upsample_cfg (dict): The upsample config of the upsample module in
+ decoder. Default: dict(type='InterpConv').
+ norm_eval (bool): Whether to set norm layers to eval mode, namely,
+ freeze running stats (mean and var). Note: Effect on Batch Norm
+ and its variants only. Default: False.
+ dcn (bool): Use deformable convolution in convolutional layer or not.
+ Default: None.
+ plugins (dict): plugins for convolutional layers. Default: None.
+
+ Notice:
+ The input image size should be divisible by the whole downsample rate
+ of the encoder. More detail of the whole downsample rate can be found
+ in UNet._check_input_divisible.
+
+ """
+
+ def __init__(self,
+ in_channels=3,
+ base_channels=64,
+ num_stages=5,
+ strides=(1, 1, 1, 1, 1),
+ enc_num_convs=(2, 2, 2, 2, 2),
+ dec_num_convs=(2, 2, 2, 2),
+ downsamples=(True, True, True, True),
+ enc_dilations=(1, 1, 1, 1, 1),
+ dec_dilations=(1, 1, 1, 1),
+ with_cp=False,
+ conv_cfg=None,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'),
+ upsample_cfg=dict(type='InterpConv'),
+ norm_eval=False,
+ dcn=None,
+ plugins=None,
+ init_cfg=[
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(
+ type='Constant',
+ layer=['_BatchNorm', 'GroupNorm'],
+ val=1)
+ ]):
+ super().__init__(init_cfg=init_cfg)
+ assert dcn is None, 'Not implemented yet.'
+ assert plugins is None, 'Not implemented yet.'
+ assert len(strides) == num_stages, (
+ 'The length of strides should be equal to num_stages, '
+ f'while the strides is {strides}, the length of '
+ f'strides is {len(strides)}, and the num_stages is '
+ f'{num_stages}.')
+ assert len(enc_num_convs) == num_stages, (
+ 'The length of enc_num_convs should be equal to num_stages, '
+ f'while the enc_num_convs is {enc_num_convs}, the length of '
+ f'enc_num_convs is {len(enc_num_convs)}, and the num_stages is '
+ f'{num_stages}.')
+ assert len(dec_num_convs) == (num_stages - 1), (
+ 'The length of dec_num_convs should be equal to (num_stages-1), '
+ f'while the dec_num_convs is {dec_num_convs}, the length of '
+ f'dec_num_convs is {len(dec_num_convs)}, and the num_stages is '
+ f'{num_stages}.')
+ assert len(downsamples) == (num_stages - 1), (
+ 'The length of downsamples should be equal to (num_stages-1), '
+ f'while the downsamples is {downsamples}, the length of '
+ f'downsamples is {len(downsamples)}, and the num_stages is '
+ f'{num_stages}.')
+ assert len(enc_dilations) == num_stages, (
+ 'The length of enc_dilations should be equal to num_stages, '
+ f'while the enc_dilations is {enc_dilations}, the length of '
+ f'enc_dilations is {len(enc_dilations)}, and the num_stages is '
+ f'{num_stages}.')
+ assert len(dec_dilations) == (num_stages - 1), (
+ 'The length of dec_dilations should be equal to (num_stages-1), '
+ f'while the dec_dilations is {dec_dilations}, the length of '
+ f'dec_dilations is {len(dec_dilations)}, and the num_stages is '
+ f'{num_stages}.')
+ self.num_stages = num_stages
+ self.strides = strides
+ self.downsamples = downsamples
+ self.norm_eval = norm_eval
+ self.base_channels = base_channels
+
+ self.encoder = nn.ModuleList()
+ self.decoder = nn.ModuleList()
+
+ for i in range(num_stages):
+ enc_conv_block = []
+ if i != 0:
+ if strides[i] == 1 and downsamples[i - 1]:
+ enc_conv_block.append(nn.MaxPool2d(kernel_size=2))
+ upsample = (strides[i] != 1 or downsamples[i - 1])
+ self.decoder.append(
+ UpConvBlock(
+ conv_block=BasicConvBlock,
+ in_channels=base_channels * 2**i,
+ skip_channels=base_channels * 2**(i - 1),
+ out_channels=base_channels * 2**(i - 1),
+ num_convs=dec_num_convs[i - 1],
+ stride=1,
+ dilation=dec_dilations[i - 1],
+ with_cp=with_cp,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ upsample_cfg=upsample_cfg if upsample else None,
+ dcn=None,
+ plugins=None))
+
+ enc_conv_block.append(
+ BasicConvBlock(
+ in_channels=in_channels,
+ out_channels=base_channels * 2**i,
+ num_convs=enc_num_convs[i],
+ stride=strides[i],
+ dilation=enc_dilations[i],
+ with_cp=with_cp,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ dcn=None,
+ plugins=None))
+ self.encoder.append((nn.Sequential(*enc_conv_block)))
+ in_channels = base_channels * 2**i
+
+ def forward(self, x):
+ self._check_input_divisible(x)
+ enc_outs = []
+ for enc in self.encoder:
+ x = enc(x)
+ enc_outs.append(x)
+ dec_outs = [x]
+ for i in reversed(range(len(self.decoder))):
+ x = self.decoder[i](enc_outs[i], x)
+ dec_outs.append(x)
+
+ return dec_outs
+
+ def train(self, mode=True):
+ """Convert the model into training mode while keep normalization layer
+ freezed."""
+ super().train(mode)
+ if mode and self.norm_eval:
+ for m in self.modules():
+ # trick: eval have effect on BatchNorm only
+ if isinstance(m, _BatchNorm):
+ m.eval()
+
+ def _check_input_divisible(self, x):
+ h, w = x.shape[-2:]
+ whole_downsample_rate = 1
+ for i in range(1, self.num_stages):
+ if self.strides[i] == 2 or self.downsamples[i - 1]:
+ whole_downsample_rate *= 2
+ assert (
+ h % whole_downsample_rate == 0 and w % whole_downsample_rate == 0
+ ), (f'The input image size {(h, w)} should be divisible by the whole '
+ f'downsample rate {whole_downsample_rate}, when num_stages is '
+ f'{self.num_stages}, strides is {self.strides}, and downsamples '
+ f'is {self.downsamples}.')
diff --git a/mmocr/models/common/detectors/__init__.py b/mmocr/models/common/detectors/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..609824a1b0e67b0110b5b101151243bcd0e338ec
--- /dev/null
+++ b/mmocr/models/common/detectors/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .single_stage import SingleStageDetector
+
+__all__ = ['SingleStageDetector']
diff --git a/mmocr/models/common/detectors/single_stage.py b/mmocr/models/common/detectors/single_stage.py
new file mode 100644
index 0000000000000000000000000000000000000000..d3a8aebb4ecb0369e07ff5adf02805732dcd7b18
--- /dev/null
+++ b/mmocr/models/common/detectors/single_stage.py
@@ -0,0 +1,39 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+from mmdet.models.detectors import \
+ SingleStageDetector as MMDET_SingleStageDetector
+
+from mmocr.models.builder import (DETECTORS, build_backbone, build_head,
+ build_neck)
+
+
+@DETECTORS.register_module()
+class SingleStageDetector(MMDET_SingleStageDetector):
+ """Base class for single-stage detectors.
+
+ Single-stage detectors directly and densely predict bounding boxes on the
+ output features of the backbone+neck.
+ """
+
+ def __init__(self,
+ backbone,
+ neck=None,
+ bbox_head=None,
+ train_cfg=None,
+ test_cfg=None,
+ pretrained=None,
+ init_cfg=None):
+ super(MMDET_SingleStageDetector, self).__init__(init_cfg=init_cfg)
+ if pretrained:
+ warnings.warn('DeprecationWarning: pretrained is deprecated, '
+ 'please use "init_cfg" instead')
+ backbone.pretrained = pretrained
+ self.backbone = build_backbone(backbone)
+ if neck is not None:
+ self.neck = build_neck(neck)
+ bbox_head.update(train_cfg=train_cfg)
+ bbox_head.update(test_cfg=test_cfg)
+ self.bbox_head = build_head(bbox_head)
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
diff --git a/mmocr/models/common/layers/__init__.py b/mmocr/models/common/layers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1d1a921fdc8b57e2de15cedd6a214df77d9bdb42
--- /dev/null
+++ b/mmocr/models/common/layers/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .transformer_layers import TFDecoderLayer, TFEncoderLayer
+
+__all__ = ['TFEncoderLayer', 'TFDecoderLayer']
diff --git a/mmocr/models/common/layers/transformer_layers.py b/mmocr/models/common/layers/transformer_layers.py
new file mode 100644
index 0000000000000000000000000000000000000000..a491ac670774edc3a59eb472824923558c77eb96
--- /dev/null
+++ b/mmocr/models/common/layers/transformer_layers.py
@@ -0,0 +1,167 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+from mmcv.runner import BaseModule
+
+from mmocr.models.common.modules import (MultiHeadAttention,
+ PositionwiseFeedForward)
+
+
+class TFEncoderLayer(BaseModule):
+ """Transformer Encoder Layer.
+
+ Args:
+ d_model (int): The number of expected features
+ in the decoder inputs (default=512).
+ d_inner (int): The dimension of the feedforward
+ network model (default=256).
+ n_head (int): The number of heads in the
+ multiheadattention models (default=8).
+ d_k (int): Total number of features in key.
+ d_v (int): Total number of features in value.
+ dropout (float): Dropout layer on attn_output_weights.
+ qkv_bias (bool): Add bias in projection layer. Default: False.
+ act_cfg (dict): Activation cfg for feedforward module.
+ operation_order (tuple[str]): The execution order of operation
+ in transformer. Such as ('self_attn', 'norm', 'ffn', 'norm')
+ or ('norm', 'self_attn', 'norm', 'ffn').
+ Default:None.
+ """
+
+ def __init__(self,
+ d_model=512,
+ d_inner=256,
+ n_head=8,
+ d_k=64,
+ d_v=64,
+ dropout=0.1,
+ qkv_bias=False,
+ act_cfg=dict(type='mmcv.GELU'),
+ operation_order=None):
+ super().__init__()
+ self.attn = MultiHeadAttention(
+ n_head, d_model, d_k, d_v, qkv_bias=qkv_bias, dropout=dropout)
+ self.norm1 = nn.LayerNorm(d_model)
+ self.mlp = PositionwiseFeedForward(
+ d_model, d_inner, dropout=dropout, act_cfg=act_cfg)
+ self.norm2 = nn.LayerNorm(d_model)
+
+ self.operation_order = operation_order
+ if self.operation_order is None:
+ self.operation_order = ('norm', 'self_attn', 'norm', 'ffn')
+
+ assert self.operation_order in [('norm', 'self_attn', 'norm', 'ffn'),
+ ('self_attn', 'norm', 'ffn', 'norm')]
+
+ def forward(self, x, mask=None):
+ if self.operation_order == ('self_attn', 'norm', 'ffn', 'norm'):
+ residual = x
+ x = residual + self.attn(x, x, x, mask)
+ x = self.norm1(x)
+
+ residual = x
+ x = residual + self.mlp(x)
+ x = self.norm2(x)
+ elif self.operation_order == ('norm', 'self_attn', 'norm', 'ffn'):
+ residual = x
+ x = self.norm1(x)
+ x = residual + self.attn(x, x, x, mask)
+
+ residual = x
+ x = self.norm2(x)
+ x = residual + self.mlp(x)
+
+ return x
+
+
+class TFDecoderLayer(nn.Module):
+ """Transformer Decoder Layer.
+
+ Args:
+ d_model (int): The number of expected features
+ in the decoder inputs (default=512).
+ d_inner (int): The dimension of the feedforward
+ network model (default=256).
+ n_head (int): The number of heads in the
+ multiheadattention models (default=8).
+ d_k (int): Total number of features in key.
+ d_v (int): Total number of features in value.
+ dropout (float): Dropout layer on attn_output_weights.
+ qkv_bias (bool): Add bias in projection layer. Default: False.
+ act_cfg (dict): Activation cfg for feedforward module.
+ operation_order (tuple[str]): The execution order of operation
+ in transformer. Such as ('self_attn', 'norm', 'enc_dec_attn',
+ 'norm', 'ffn', 'norm') or ('norm', 'self_attn', 'norm',
+ 'enc_dec_attn', 'norm', 'ffn').
+ Default:None.
+ """
+
+ def __init__(self,
+ d_model=512,
+ d_inner=256,
+ n_head=8,
+ d_k=64,
+ d_v=64,
+ dropout=0.1,
+ qkv_bias=False,
+ act_cfg=dict(type='mmcv.GELU'),
+ operation_order=None):
+ super().__init__()
+
+ self.norm1 = nn.LayerNorm(d_model)
+ self.norm2 = nn.LayerNorm(d_model)
+ self.norm3 = nn.LayerNorm(d_model)
+
+ self.self_attn = MultiHeadAttention(
+ n_head, d_model, d_k, d_v, dropout=dropout, qkv_bias=qkv_bias)
+
+ self.enc_attn = MultiHeadAttention(
+ n_head, d_model, d_k, d_v, dropout=dropout, qkv_bias=qkv_bias)
+
+ self.mlp = PositionwiseFeedForward(
+ d_model, d_inner, dropout=dropout, act_cfg=act_cfg)
+
+ self.operation_order = operation_order
+ if self.operation_order is None:
+ self.operation_order = ('norm', 'self_attn', 'norm',
+ 'enc_dec_attn', 'norm', 'ffn')
+ assert self.operation_order in [
+ ('norm', 'self_attn', 'norm', 'enc_dec_attn', 'norm', 'ffn'),
+ ('self_attn', 'norm', 'enc_dec_attn', 'norm', 'ffn', 'norm')
+ ]
+
+ def forward(self,
+ dec_input,
+ enc_output,
+ self_attn_mask=None,
+ dec_enc_attn_mask=None):
+ if self.operation_order == ('self_attn', 'norm', 'enc_dec_attn',
+ 'norm', 'ffn', 'norm'):
+ dec_attn_out = self.self_attn(dec_input, dec_input, dec_input,
+ self_attn_mask)
+ dec_attn_out += dec_input
+ dec_attn_out = self.norm1(dec_attn_out)
+
+ enc_dec_attn_out = self.enc_attn(dec_attn_out, enc_output,
+ enc_output, dec_enc_attn_mask)
+ enc_dec_attn_out += dec_attn_out
+ enc_dec_attn_out = self.norm2(enc_dec_attn_out)
+
+ mlp_out = self.mlp(enc_dec_attn_out)
+ mlp_out += enc_dec_attn_out
+ mlp_out = self.norm3(mlp_out)
+ elif self.operation_order == ('norm', 'self_attn', 'norm',
+ 'enc_dec_attn', 'norm', 'ffn'):
+ dec_input_norm = self.norm1(dec_input)
+ dec_attn_out = self.self_attn(dec_input_norm, dec_input_norm,
+ dec_input_norm, self_attn_mask)
+ dec_attn_out += dec_input
+
+ enc_dec_attn_in = self.norm2(dec_attn_out)
+ enc_dec_attn_out = self.enc_attn(enc_dec_attn_in, enc_output,
+ enc_output, dec_enc_attn_mask)
+ enc_dec_attn_out += dec_attn_out
+
+ mlp_out = self.mlp(self.norm3(enc_dec_attn_out))
+ mlp_out += enc_dec_attn_out
+
+ return mlp_out
diff --git a/mmocr/models/common/losses/__init__.py b/mmocr/models/common/losses/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..67151b69efe038431fc1b9f9094dc7d972fda42b
--- /dev/null
+++ b/mmocr/models/common/losses/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .dice_loss import DiceLoss
+from .focal_loss import FocalLoss
+
+__all__ = ['DiceLoss', 'FocalLoss']
diff --git a/mmocr/models/common/losses/dice_loss.py b/mmocr/models/common/losses/dice_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..0777200b967377edec5f141d43805714b96b5ea8
--- /dev/null
+++ b/mmocr/models/common/losses/dice_loss.py
@@ -0,0 +1,31 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+
+from mmocr.models.builder import LOSSES
+
+
+@LOSSES.register_module()
+class DiceLoss(nn.Module):
+
+ def __init__(self, eps=1e-6):
+ super().__init__()
+ assert isinstance(eps, float)
+ self.eps = eps
+
+ def forward(self, pred, target, mask=None):
+
+ pred = pred.contiguous().view(pred.size()[0], -1)
+ target = target.contiguous().view(target.size()[0], -1)
+
+ if mask is not None:
+ mask = mask.contiguous().view(mask.size()[0], -1)
+ pred = pred * mask
+ target = target * mask
+
+ a = torch.sum(pred * target)
+ b = torch.sum(pred)
+ c = torch.sum(target)
+ d = (2 * a) / (b + c + self.eps)
+
+ return 1 - d
diff --git a/mmocr/models/common/losses/focal_loss.py b/mmocr/models/common/losses/focal_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..1a42ab013e278832fe6c8eed20f4a4c879f4d8cf
--- /dev/null
+++ b/mmocr/models/common/losses/focal_loss.py
@@ -0,0 +1,31 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+class FocalLoss(nn.Module):
+ """Multi-class Focal loss implementation.
+
+ Args:
+ gamma (float): The larger the gamma, the smaller
+ the loss weight of easier samples.
+ weight (float): A manual rescaling weight given to each
+ class.
+ ignore_index (int): Specifies a target value that is ignored
+ and does not contribute to the input gradient.
+ """
+
+ def __init__(self, gamma=2, weight=None, ignore_index=-100):
+ super().__init__()
+ self.gamma = gamma
+ self.weight = weight
+ self.ignore_index = ignore_index
+
+ def forward(self, input, target):
+ logit = F.log_softmax(input, dim=1)
+ pt = torch.exp(logit)
+ logit = (1 - pt)**self.gamma * logit
+ loss = F.nll_loss(
+ logit, target, self.weight, ignore_index=self.ignore_index)
+ return loss
diff --git a/mmocr/models/common/modules/__init__.py b/mmocr/models/common/modules/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..30960fd5dd45f069c4ae2f6c74ec66d5eecb13b8
--- /dev/null
+++ b/mmocr/models/common/modules/__init__.py
@@ -0,0 +1,9 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .transformer_module import (MultiHeadAttention, PositionalEncoding,
+ PositionwiseFeedForward,
+ ScaledDotProductAttention)
+
+__all__ = [
+ 'ScaledDotProductAttention', 'MultiHeadAttention',
+ 'PositionwiseFeedForward', 'PositionalEncoding'
+]
diff --git a/mmocr/models/common/modules/transformer_module.py b/mmocr/models/common/modules/transformer_module.py
new file mode 100644
index 0000000000000000000000000000000000000000..d67095289b8a9af8a78b2f51c8b9b855d02d2b35
--- /dev/null
+++ b/mmocr/models/common/modules/transformer_module.py
@@ -0,0 +1,164 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from mmocr.models.builder import build_activation_layer
+
+
+class ScaledDotProductAttention(nn.Module):
+ """Scaled Dot-Product Attention Module. This code is adopted from
+ https://github.com/jadore801120/attention-is-all-you-need-pytorch.
+
+ Args:
+ temperature (float): The scale factor for softmax input.
+ attn_dropout (float): Dropout layer on attn_output_weights.
+ """
+
+ def __init__(self, temperature, attn_dropout=0.1):
+ super().__init__()
+ self.temperature = temperature
+ self.dropout = nn.Dropout(attn_dropout)
+
+ def forward(self, q, k, v, mask=None):
+
+ attn = torch.matmul(q / self.temperature, k.transpose(2, 3))
+
+ if mask is not None:
+ attn = attn.masked_fill(mask == 0, float('-inf'))
+
+ attn = self.dropout(F.softmax(attn, dim=-1))
+ output = torch.matmul(attn, v)
+
+ return output, attn
+
+
+class MultiHeadAttention(nn.Module):
+ """Multi-Head Attention module.
+
+ Args:
+ n_head (int): The number of heads in the
+ multiheadattention models (default=8).
+ d_model (int): The number of expected features
+ in the decoder inputs (default=512).
+ d_k (int): Total number of features in key.
+ d_v (int): Total number of features in value.
+ dropout (float): Dropout layer on attn_output_weights.
+ qkv_bias (bool): Add bias in projection layer. Default: False.
+ """
+
+ def __init__(self,
+ n_head=8,
+ d_model=512,
+ d_k=64,
+ d_v=64,
+ dropout=0.1,
+ qkv_bias=False):
+ super().__init__()
+ self.n_head = n_head
+ self.d_k = d_k
+ self.d_v = d_v
+
+ self.dim_k = n_head * d_k
+ self.dim_v = n_head * d_v
+
+ self.linear_q = nn.Linear(self.dim_k, self.dim_k, bias=qkv_bias)
+ self.linear_k = nn.Linear(self.dim_k, self.dim_k, bias=qkv_bias)
+ self.linear_v = nn.Linear(self.dim_v, self.dim_v, bias=qkv_bias)
+
+ self.attention = ScaledDotProductAttention(d_k**0.5, dropout)
+
+ self.fc = nn.Linear(self.dim_v, d_model, bias=qkv_bias)
+ self.proj_drop = nn.Dropout(dropout)
+
+ def forward(self, q, k, v, mask=None):
+ batch_size, len_q, _ = q.size()
+ _, len_k, _ = k.size()
+
+ q = self.linear_q(q).view(batch_size, len_q, self.n_head, self.d_k)
+ k = self.linear_k(k).view(batch_size, len_k, self.n_head, self.d_k)
+ v = self.linear_v(v).view(batch_size, len_k, self.n_head, self.d_v)
+
+ q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)
+
+ if mask is not None:
+ if mask.dim() == 3:
+ mask = mask.unsqueeze(1)
+ elif mask.dim() == 2:
+ mask = mask.unsqueeze(1).unsqueeze(1)
+
+ attn_out, _ = self.attention(q, k, v, mask=mask)
+
+ attn_out = attn_out.transpose(1, 2).contiguous().view(
+ batch_size, len_q, self.dim_v)
+
+ attn_out = self.fc(attn_out)
+ attn_out = self.proj_drop(attn_out)
+
+ return attn_out
+
+
+class PositionwiseFeedForward(nn.Module):
+ """Two-layer feed-forward module.
+
+ Args:
+ d_in (int): The dimension of the input for feedforward
+ network model.
+ d_hid (int): The dimension of the feedforward
+ network model.
+ dropout (float): Dropout layer on feedforward output.
+ act_cfg (dict): Activation cfg for feedforward module.
+ """
+
+ def __init__(self, d_in, d_hid, dropout=0.1, act_cfg=dict(type='Relu')):
+ super().__init__()
+ self.w_1 = nn.Linear(d_in, d_hid)
+ self.w_2 = nn.Linear(d_hid, d_in)
+ self.act = build_activation_layer(act_cfg)
+ self.dropout = nn.Dropout(dropout)
+
+ def forward(self, x):
+ x = self.w_1(x)
+ x = self.act(x)
+ x = self.w_2(x)
+ x = self.dropout(x)
+
+ return x
+
+
+class PositionalEncoding(nn.Module):
+ """Fixed positional encoding with sine and cosine functions."""
+
+ def __init__(self, d_hid=512, n_position=200, dropout=0):
+ super().__init__()
+ self.dropout = nn.Dropout(p=dropout)
+
+ # Not a parameter
+ # Position table of shape (1, n_position, d_hid)
+ self.register_buffer(
+ 'position_table',
+ self._get_sinusoid_encoding_table(n_position, d_hid))
+
+ def _get_sinusoid_encoding_table(self, n_position, d_hid):
+ """Sinusoid position encoding table."""
+ denominator = torch.Tensor([
+ 1.0 / np.power(10000, 2 * (hid_j // 2) / d_hid)
+ for hid_j in range(d_hid)
+ ])
+ denominator = denominator.view(1, -1)
+ pos_tensor = torch.arange(n_position).unsqueeze(-1).float()
+ sinusoid_table = pos_tensor * denominator
+ sinusoid_table[:, 0::2] = torch.sin(sinusoid_table[:, 0::2])
+ sinusoid_table[:, 1::2] = torch.cos(sinusoid_table[:, 1::2])
+
+ return sinusoid_table.unsqueeze(0)
+
+ def forward(self, x):
+ """
+ Args:
+ x (Tensor): Tensor of shape (batch_size, pos_len, d_hid, ...)
+ """
+ self.device = x.device
+ x = x + self.position_table[:, :x.size(1)].clone().detach()
+ return self.dropout(x)
diff --git a/mmocr/models/kie/__init__.py b/mmocr/models/kie/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..b8e8c2c09fc2bbbce20f77fc372984319ee1d546
--- /dev/null
+++ b/mmocr/models/kie/__init__.py
@@ -0,0 +1,7 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from . import extractors, heads, losses
+from .extractors import * # NOQA
+from .heads import * # NOQA
+from .losses import * # NOQA
+
+__all__ = extractors.__all__ + heads.__all__ + losses.__all__
diff --git a/mmocr/models/kie/extractors/__init__.py b/mmocr/models/kie/extractors/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..914d0f6903cefec1236107346e59901ac9d64fd4
--- /dev/null
+++ b/mmocr/models/kie/extractors/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .sdmgr import SDMGR
+
+__all__ = ['SDMGR']
diff --git a/mmocr/models/kie/extractors/sdmgr.py b/mmocr/models/kie/extractors/sdmgr.py
new file mode 100644
index 0000000000000000000000000000000000000000..9fa08cccc9a4ae893cad2dd8d4e3408ecc1d2b29
--- /dev/null
+++ b/mmocr/models/kie/extractors/sdmgr.py
@@ -0,0 +1,166 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import mmcv
+from mmdet.core import bbox2roi
+from torch import nn
+from torch.nn import functional as F
+
+from mmocr.core import imshow_edge, imshow_node
+from mmocr.models.builder import DETECTORS, build_roi_extractor
+from mmocr.models.common.detectors import SingleStageDetector
+from mmocr.utils import list_from_file
+
+
+@DETECTORS.register_module()
+class SDMGR(SingleStageDetector):
+ """The implementation of the paper: Spatial Dual-Modality Graph Reasoning
+ for Key Information Extraction. https://arxiv.org/abs/2103.14470.
+
+ Args:
+ visual_modality (bool): Whether use the visual modality.
+ class_list (None | str): Mapping file of class index to
+ class name. If None, class index will be shown in
+ `show_results`, else class name.
+ """
+
+ def __init__(self,
+ backbone,
+ neck=None,
+ bbox_head=None,
+ extractor=dict(
+ type='mmdet.SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=7),
+ featmap_strides=[1]),
+ visual_modality=False,
+ train_cfg=None,
+ test_cfg=None,
+ class_list=None,
+ init_cfg=None,
+ openset=False):
+ super().__init__(
+ backbone, neck, bbox_head, train_cfg, test_cfg, init_cfg=init_cfg)
+ self.visual_modality = visual_modality
+ if visual_modality:
+ self.extractor = build_roi_extractor({
+ **extractor, 'out_channels':
+ self.backbone.base_channels
+ })
+ self.maxpool = nn.MaxPool2d(extractor['roi_layer']['output_size'])
+ else:
+ self.extractor = None
+ self.class_list = class_list
+ self.openset = openset
+
+ def forward_train(self, img, img_metas, relations, texts, gt_bboxes,
+ gt_labels):
+ """
+ Args:
+ img (tensor): Input images of shape (N, C, H, W).
+ Typically these should be mean centered and std scaled.
+ img_metas (list[dict]): A list of image info dict where each dict
+ contains: 'img_shape', 'scale_factor', 'flip', and may also
+ contain 'filename', 'ori_shape', 'pad_shape', and
+ 'img_norm_cfg'. For details of the values of these keys,
+ please see :class:`mmdet.datasets.pipelines.Collect`.
+ relations (list[tensor]): Relations between bboxes.
+ texts (list[tensor]): Texts in bboxes.
+ gt_bboxes (list[tensor]): Each item is the truth boxes for each
+ image in [tl_x, tl_y, br_x, br_y] format.
+ gt_labels (list[tensor]): Class indices corresponding to each box.
+
+ Returns:
+ dict[str, tensor]: A dictionary of loss components.
+ """
+ x = self.extract_feat(img, gt_bboxes)
+ node_preds, edge_preds = self.bbox_head.forward(relations, texts, x)
+ return self.bbox_head.loss(node_preds, edge_preds, gt_labels)
+
+ def forward_test(self,
+ img,
+ img_metas,
+ relations,
+ texts,
+ gt_bboxes,
+ rescale=False):
+ x = self.extract_feat(img, gt_bboxes)
+ node_preds, edge_preds = self.bbox_head.forward(relations, texts, x)
+ return [
+ dict(
+ img_metas=img_metas,
+ nodes=F.softmax(node_preds, -1),
+ edges=F.softmax(edge_preds, -1))
+ ]
+
+ def extract_feat(self, img, gt_bboxes):
+ if self.visual_modality:
+ x = super().extract_feat(img)[-1]
+ feats = self.maxpool(self.extractor([x], bbox2roi(gt_bboxes)))
+ return feats.view(feats.size(0), -1)
+ return None
+
+ def show_result(self,
+ img,
+ result,
+ boxes,
+ win_name='',
+ show=False,
+ wait_time=0,
+ out_file=None,
+ **kwargs):
+ """Draw `result` on `img`.
+
+ Args:
+ img (str or tensor): The image to be displayed.
+ result (dict): The results to draw on `img`.
+ boxes (list): Bbox of img.
+ win_name (str): The window name.
+ wait_time (int): Value of waitKey param.
+ Default: 0.
+ show (bool): Whether to show the image.
+ Default: False.
+ out_file (str or None): The output filename.
+ Default: None.
+
+ Returns:
+ img (tensor): Only if not `show` or `out_file`.
+ """
+ img = mmcv.imread(img)
+ img = img.copy()
+
+ idx_to_cls = {}
+ if self.class_list is not None:
+ for line in list_from_file(self.class_list):
+ class_idx, class_label = line.strip().split()
+ idx_to_cls[class_idx] = class_label
+
+ # if out_file specified, do not show image in window
+ if out_file is not None:
+ show = False
+
+ if self.openset:
+ img = imshow_edge(
+ img,
+ result,
+ boxes,
+ show=show,
+ win_name=win_name,
+ wait_time=wait_time,
+ out_file=out_file)
+ else:
+ img = imshow_node(
+ img,
+ result,
+ boxes,
+ idx_to_cls=idx_to_cls,
+ show=show,
+ win_name=win_name,
+ wait_time=wait_time,
+ out_file=out_file)
+
+ if not (show or out_file):
+ warnings.warn('show==False and out_file is not specified, only '
+ 'result image will be returned')
+ return img
+
+ return img
diff --git a/mmocr/models/kie/heads/__init__.py b/mmocr/models/kie/heads/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c08ed6ffa4f8b177c56a947da9b49980ab0a2c2
--- /dev/null
+++ b/mmocr/models/kie/heads/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .sdmgr_head import SDMGRHead
+
+__all__ = ['SDMGRHead']
diff --git a/mmocr/models/kie/heads/sdmgr_head.py b/mmocr/models/kie/heads/sdmgr_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..8fb9078c8f37a0a2235efa08bd43d0b42f5bf90c
--- /dev/null
+++ b/mmocr/models/kie/heads/sdmgr_head.py
@@ -0,0 +1,196 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from mmcv.runner import BaseModule
+from torch import nn
+from torch.nn import functional as F
+
+from mmocr.models.builder import HEADS, build_loss
+
+
+@HEADS.register_module()
+class SDMGRHead(BaseModule):
+
+ def __init__(self,
+ num_chars=92,
+ visual_dim=64,
+ fusion_dim=1024,
+ node_input=32,
+ node_embed=256,
+ edge_input=5,
+ edge_embed=256,
+ num_gnn=2,
+ num_classes=26,
+ loss=dict(type='SDMGRLoss'),
+ bidirectional=False,
+ train_cfg=None,
+ test_cfg=None,
+ init_cfg=dict(
+ type='Normal',
+ override=dict(name='edge_embed'),
+ mean=0,
+ std=0.01)):
+ super().__init__(init_cfg=init_cfg)
+
+ self.fusion = Block([visual_dim, node_embed], node_embed, fusion_dim)
+ self.node_embed = nn.Embedding(num_chars, node_input, 0)
+ hidden = node_embed // 2 if bidirectional else node_embed
+ self.rnn = nn.LSTM(
+ input_size=node_input,
+ hidden_size=hidden,
+ num_layers=1,
+ batch_first=True,
+ bidirectional=bidirectional)
+ self.edge_embed = nn.Linear(edge_input, edge_embed)
+ self.gnn_layers = nn.ModuleList(
+ [GNNLayer(node_embed, edge_embed) for _ in range(num_gnn)])
+ self.node_cls = nn.Linear(node_embed, num_classes)
+ self.edge_cls = nn.Linear(edge_embed, 2)
+ self.loss = build_loss(loss)
+
+ def forward(self, relations, texts, x=None):
+ node_nums, char_nums = [], []
+ for text in texts:
+ node_nums.append(text.size(0))
+ char_nums.append((text > 0).sum(-1))
+
+ max_num = max([char_num.max() for char_num in char_nums])
+ all_nodes = torch.cat([
+ torch.cat(
+ [text,
+ text.new_zeros(text.size(0), max_num - text.size(1))], -1)
+ for text in texts
+ ])
+ embed_nodes = self.node_embed(all_nodes.clamp(min=0).long())
+ rnn_nodes, _ = self.rnn(embed_nodes)
+
+ nodes = rnn_nodes.new_zeros(*rnn_nodes.shape[::2])
+ all_nums = torch.cat(char_nums)
+ valid = all_nums > 0
+ nodes[valid] = rnn_nodes[valid].gather(
+ 1, (all_nums[valid] - 1).unsqueeze(-1).unsqueeze(-1).expand(
+ -1, -1, rnn_nodes.size(-1))).squeeze(1)
+
+ if x is not None:
+ nodes = self.fusion([x, nodes])
+
+ all_edges = torch.cat(
+ [rel.view(-1, rel.size(-1)) for rel in relations])
+ embed_edges = self.edge_embed(all_edges.float())
+ embed_edges = F.normalize(embed_edges)
+
+ for gnn_layer in self.gnn_layers:
+ nodes, cat_nodes = gnn_layer(nodes, embed_edges, node_nums)
+
+ node_cls, edge_cls = self.node_cls(nodes), self.edge_cls(cat_nodes)
+ return node_cls, edge_cls
+
+
+class GNNLayer(nn.Module):
+
+ def __init__(self, node_dim=256, edge_dim=256):
+ super().__init__()
+ self.in_fc = nn.Linear(node_dim * 2 + edge_dim, node_dim)
+ self.coef_fc = nn.Linear(node_dim, 1)
+ self.out_fc = nn.Linear(node_dim, node_dim)
+ self.relu = nn.ReLU()
+
+ def forward(self, nodes, edges, nums):
+ start, cat_nodes = 0, []
+ for num in nums:
+ sample_nodes = nodes[start:start + num]
+ cat_nodes.append(
+ torch.cat([
+ sample_nodes.unsqueeze(1).expand(-1, num, -1),
+ sample_nodes.unsqueeze(0).expand(num, -1, -1)
+ ], -1).view(num**2, -1))
+ start += num
+ cat_nodes = torch.cat([torch.cat(cat_nodes), edges], -1)
+ cat_nodes = self.relu(self.in_fc(cat_nodes))
+ coefs = self.coef_fc(cat_nodes)
+
+ start, residuals = 0, []
+ for num in nums:
+ residual = F.softmax(
+ -torch.eye(num).to(coefs.device).unsqueeze(-1) * 1e9 +
+ coefs[start:start + num**2].view(num, num, -1), 1)
+ residuals.append(
+ (residual *
+ cat_nodes[start:start + num**2].view(num, num, -1)).sum(1))
+ start += num**2
+
+ nodes += self.relu(self.out_fc(torch.cat(residuals)))
+ return nodes, cat_nodes
+
+
+class Block(nn.Module):
+
+ def __init__(self,
+ input_dims,
+ output_dim,
+ mm_dim=1600,
+ chunks=20,
+ rank=15,
+ shared=False,
+ dropout_input=0.,
+ dropout_pre_lin=0.,
+ dropout_output=0.,
+ pos_norm='before_cat'):
+ super().__init__()
+ self.rank = rank
+ self.dropout_input = dropout_input
+ self.dropout_pre_lin = dropout_pre_lin
+ self.dropout_output = dropout_output
+ assert (pos_norm in ['before_cat', 'after_cat'])
+ self.pos_norm = pos_norm
+ # Modules
+ self.linear0 = nn.Linear(input_dims[0], mm_dim)
+ self.linear1 = (
+ self.linear0 if shared else nn.Linear(input_dims[1], mm_dim))
+ self.merge_linears0 = nn.ModuleList()
+ self.merge_linears1 = nn.ModuleList()
+ self.chunks = self.chunk_sizes(mm_dim, chunks)
+ for size in self.chunks:
+ ml0 = nn.Linear(size, size * rank)
+ self.merge_linears0.append(ml0)
+ ml1 = ml0 if shared else nn.Linear(size, size * rank)
+ self.merge_linears1.append(ml1)
+ self.linear_out = nn.Linear(mm_dim, output_dim)
+
+ def forward(self, x):
+ x0 = self.linear0(x[0])
+ x1 = self.linear1(x[1])
+ bs = x1.size(0)
+ if self.dropout_input > 0:
+ x0 = F.dropout(x0, p=self.dropout_input, training=self.training)
+ x1 = F.dropout(x1, p=self.dropout_input, training=self.training)
+ x0_chunks = torch.split(x0, self.chunks, -1)
+ x1_chunks = torch.split(x1, self.chunks, -1)
+ zs = []
+ for x0_c, x1_c, m0, m1 in zip(x0_chunks, x1_chunks,
+ self.merge_linears0,
+ self.merge_linears1):
+ m = m0(x0_c) * m1(x1_c) # bs x split_size*rank
+ m = m.view(bs, self.rank, -1)
+ z = torch.sum(m, 1)
+ if self.pos_norm == 'before_cat':
+ z = torch.sqrt(F.relu(z)) - torch.sqrt(F.relu(-z))
+ z = F.normalize(z)
+ zs.append(z)
+ z = torch.cat(zs, 1)
+ if self.pos_norm == 'after_cat':
+ z = torch.sqrt(F.relu(z)) - torch.sqrt(F.relu(-z))
+ z = F.normalize(z)
+
+ if self.dropout_pre_lin > 0:
+ z = F.dropout(z, p=self.dropout_pre_lin, training=self.training)
+ z = self.linear_out(z)
+ if self.dropout_output > 0:
+ z = F.dropout(z, p=self.dropout_output, training=self.training)
+ return z
+
+ @staticmethod
+ def chunk_sizes(dim, chunks):
+ split_size = (dim + chunks - 1) // chunks
+ sizes_list = [split_size] * chunks
+ sizes_list[-1] = sizes_list[-1] - (sum(sizes_list) - dim)
+ return sizes_list
diff --git a/mmocr/models/kie/losses/__init__.py b/mmocr/models/kie/losses/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..4a72f8cac52cc3b0a98f20c570e7c23f9710fd2c
--- /dev/null
+++ b/mmocr/models/kie/losses/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .sdmgr_loss import SDMGRLoss
+
+__all__ = ['SDMGRLoss']
diff --git a/mmocr/models/kie/losses/sdmgr_loss.py b/mmocr/models/kie/losses/sdmgr_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..dba2d12d1ba9534ff014e38f408e3efaeb281bf0
--- /dev/null
+++ b/mmocr/models/kie/losses/sdmgr_loss.py
@@ -0,0 +1,41 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+from mmdet.models.losses import accuracy
+from torch import nn
+
+from mmocr.models.builder import LOSSES
+
+
+@LOSSES.register_module()
+class SDMGRLoss(nn.Module):
+ """The implementation the loss of key information extraction proposed in
+ the paper: Spatial Dual-Modality Graph Reasoning for Key Information
+ Extraction.
+
+ https://arxiv.org/abs/2103.14470.
+ """
+
+ def __init__(self, node_weight=1.0, edge_weight=1.0, ignore=-100):
+ super().__init__()
+ self.loss_node = nn.CrossEntropyLoss(ignore_index=ignore)
+ self.loss_edge = nn.CrossEntropyLoss(ignore_index=-1)
+ self.node_weight = node_weight
+ self.edge_weight = edge_weight
+ self.ignore = ignore
+
+ def forward(self, node_preds, edge_preds, gts):
+ node_gts, edge_gts = [], []
+ for gt in gts:
+ node_gts.append(gt[:, 0])
+ edge_gts.append(gt[:, 1:].contiguous().view(-1))
+ node_gts = torch.cat(node_gts).long()
+ edge_gts = torch.cat(edge_gts).long()
+
+ node_valids = torch.nonzero(
+ node_gts != self.ignore, as_tuple=False).view(-1)
+ edge_valids = torch.nonzero(edge_gts != -1, as_tuple=False).view(-1)
+ return dict(
+ loss_node=self.node_weight * self.loss_node(node_preds, node_gts),
+ loss_edge=self.edge_weight * self.loss_edge(edge_preds, edge_gts),
+ acc_node=accuracy(node_preds[node_valids], node_gts[node_valids]),
+ acc_edge=accuracy(edge_preds[edge_valids], edge_gts[edge_valids]))
diff --git a/mmocr/models/ner/__init__.py b/mmocr/models/ner/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..2d9866e755153cedb20aed79c43aa72a4860933e
--- /dev/null
+++ b/mmocr/models/ner/__init__.py
@@ -0,0 +1,11 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from . import classifiers, convertors, decoders, encoders, losses
+from .classifiers import * # NOQA
+from .convertors import * # NOQA
+from .decoders import * # NOQA
+from .encoders import * # NOQA
+from .losses import * # NOQA
+
+__all__ = (
+ classifiers.__all__ + convertors.__all__ + decoders.__all__ +
+ encoders.__all__ + losses.__all__)
diff --git a/mmocr/models/ner/classifiers/__init__.py b/mmocr/models/ner/classifiers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..638918743c6d64e18514c0a0905ee7ec98abf570
--- /dev/null
+++ b/mmocr/models/ner/classifiers/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .ner_classifier import NerClassifier
+
+__all__ = ['NerClassifier']
diff --git a/mmocr/models/ner/classifiers/ner_classifier.py b/mmocr/models/ner/classifiers/ner_classifier.py
new file mode 100644
index 0000000000000000000000000000000000000000..7fefef607e4d8f1ae7f9394adaba3caf58bea77d
--- /dev/null
+++ b/mmocr/models/ner/classifiers/ner_classifier.py
@@ -0,0 +1,52 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.models.builder import (DETECTORS, build_convertor, build_decoder,
+ build_encoder, build_loss)
+from mmocr.models.textrecog.recognizer.base import BaseRecognizer
+
+
+@DETECTORS.register_module()
+class NerClassifier(BaseRecognizer):
+ """Base class for NER classifier."""
+
+ def __init__(self,
+ encoder,
+ decoder,
+ loss,
+ label_convertor,
+ train_cfg=None,
+ test_cfg=None,
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ self.label_convertor = build_convertor(label_convertor)
+
+ self.encoder = build_encoder(encoder)
+
+ decoder.update(num_labels=self.label_convertor.num_labels)
+ self.decoder = build_decoder(decoder)
+
+ loss.update(num_labels=self.label_convertor.num_labels)
+ self.loss = build_loss(loss)
+
+ def extract_feat(self, imgs):
+ """Extract features from images."""
+ raise NotImplementedError(
+ 'Extract feature module is not implemented yet.')
+
+ def forward_train(self, imgs, img_metas, **kwargs):
+ encode_out = self.encoder(img_metas)
+ logits, _ = self.decoder(encode_out)
+ loss = self.loss(logits, img_metas)
+ return loss
+
+ def forward_test(self, imgs, img_metas, **kwargs):
+ encode_out = self.encoder(img_metas)
+ _, preds = self.decoder(encode_out)
+ pred_entities = self.label_convertor.convert_pred2entities(
+ preds, img_metas['attention_masks'])
+ return pred_entities
+
+ def aug_test(self, imgs, img_metas, **kwargs):
+ raise NotImplementedError('Augmentation test is not implemented yet.')
+
+ def simple_test(self, img, img_metas, **kwargs):
+ raise NotImplementedError('Simple test is not implemented yet.')
diff --git a/mmocr/models/ner/convertors/__init__.py b/mmocr/models/ner/convertors/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..4d4e15c3dbd6086e63e0d38f477b8feb4a27333a
--- /dev/null
+++ b/mmocr/models/ner/convertors/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .ner_convertor import NerConvertor
+
+__all__ = ['NerConvertor']
diff --git a/mmocr/models/ner/convertors/ner_convertor.py b/mmocr/models/ner/convertors/ner_convertor.py
new file mode 100644
index 0000000000000000000000000000000000000000..ca7288bc2b889bb906b65a82ff6c3f0f13edc194
--- /dev/null
+++ b/mmocr/models/ner/convertors/ner_convertor.py
@@ -0,0 +1,173 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+
+from mmocr.models.builder import CONVERTORS
+from mmocr.utils import list_from_file
+
+
+@CONVERTORS.register_module()
+class NerConvertor:
+ """Convert between text, index and tensor for NER pipeline.
+
+ Args:
+ annotation_type (str): BIO((B-begin, I-inside, O-outside)),
+ BIOES(B-begin, I-inside, O-outside, E-end, S-single)
+ vocab_file (str): File to convert words to ids.
+ categories (list[str]): All entity categories supported by the model.
+ max_len (int): The maximum length of the input text.
+ unknown_id (int): For words that do not appear in vocab.txt.
+ start_id (int): Each input is prefixed with an input ID.
+ end_id (int): Each output is prefixed with an output ID.
+ """
+
+ def __init__(self,
+ annotation_type='bio',
+ vocab_file=None,
+ categories=None,
+ max_len=None,
+ unknown_id=100,
+ start_id=101,
+ end_id=102):
+ self.annotation_type = annotation_type
+ self.categories = categories
+ self.word2ids = {}
+ self.max_len = max_len
+ self.unknown_id = unknown_id
+ self.start_id = start_id
+ self.end_id = end_id
+ assert self.max_len > 2
+ assert self.annotation_type in ['bio', 'bioes']
+
+ vocabs = list_from_file(vocab_file)
+ self.vocab_size = len(vocabs)
+ for idx, vocab in enumerate(vocabs):
+ self.word2ids.update({vocab: idx})
+
+ if self.annotation_type == 'bio':
+ self.label2id_dict, self.id2label, self.ignore_id = \
+ self._generate_labelid_dict()
+ elif self.annotation_type == 'bioes':
+ raise NotImplementedError('Bioes format is not supported yet!')
+
+ assert self.ignore_id is not None
+ assert self.id2label is not None
+ self.num_labels = len(self.id2label)
+
+ def _generate_labelid_dict(self):
+ """Generate a dictionary that maps input to ID and ID to output."""
+ num_classes = len(self.categories)
+ label2id_dict = {}
+ ignore_id = 2 * num_classes + 1
+ id2label_dict = {
+ 0: 'X',
+ ignore_id: 'O',
+ 2 * num_classes + 2: '[START]',
+ 2 * num_classes + 3: '[END]'
+ }
+
+ for index, category in enumerate(self.categories):
+ start_label = index + 1
+ end_label = index + 1 + num_classes
+ label2id_dict.update({category: [start_label, end_label]})
+ id2label_dict.update({start_label: 'B-' + category})
+ id2label_dict.update({end_label: 'I-' + category})
+
+ return label2id_dict, id2label_dict, ignore_id
+
+ def convert_text2id(self, text):
+ """Convert characters to ids.
+
+ If the input is uppercase,
+ convert to lowercase first.
+ Args:
+ text (list[char]): Annotations of one paragraph.
+ Returns:
+ input_ids (list): Corresponding IDs after conversion.
+ """
+ ids = []
+ for word in text.lower():
+ if word in self.word2ids:
+ ids.append(self.word2ids[word])
+ else:
+ ids.append(self.unknown_id)
+ # Text that exceeds the maximum length is truncated.
+ valid_len = min(len(text), self.max_len)
+ input_ids = [0] * self.max_len
+ input_ids[0] = self.start_id
+ for i in range(1, valid_len + 1):
+ input_ids[i] = ids[i - 1]
+ input_ids[i + 1] = self.end_id
+
+ return input_ids
+
+ def convert_entity2label(self, label, text_len):
+ """Convert labeled entities to ids.
+
+ Args:
+ label (dict): Labels of entities.
+ text_len (int): The length of input text.
+ Returns:
+ labels (list): Label ids of an input text.
+ """
+ labels = [0] * self.max_len
+ for j in range(min(text_len + 2, self.max_len)):
+ labels[j] = self.ignore_id
+ categories = label
+ for key in categories:
+ for text in categories[key]:
+ for place in categories[key][text]:
+ # Remove the label position beyond the maximum length.
+ if place[0] + 1 < len(labels):
+ labels[place[0] + 1] = self.label2id_dict[key][0]
+ for i in range(place[0] + 1, place[1] + 1):
+ if i + 1 < len(labels):
+ labels[i + 1] = self.label2id_dict[key][1]
+ return labels
+
+ def convert_pred2entities(self, preds, masks):
+ """Gets entities from preds.
+
+ Args:
+ preds (list): Sequence of preds.
+ masks (tensor): The valid part is 1 and the invalid part is 0.
+ Returns:
+ pred_entities (list): List of [[[entity_type,
+ entity_start, entity_end]]].
+ """
+
+ masks = masks.detach().cpu().numpy()
+ pred_entities = []
+ assert isinstance(preds, list)
+ for index, pred in enumerate(preds):
+ entities = []
+ entity = [-1, -1, -1]
+ results = (masks[index][1:] * np.array(pred[1:])).tolist()
+ for index, tag in enumerate(results):
+ if not isinstance(tag, str):
+ tag = self.id2label[tag]
+ if self.annotation_type == 'bio':
+ if tag.startswith('B-'):
+ if entity[2] != -1 and entity[1] < entity[2]:
+ entities.append(entity)
+ entity = [-1, -1, -1]
+ entity[1] = index
+ entity[0] = tag.split('-')[1]
+ entity[2] = index
+ if index == len(results) - 1 and entity[1] < entity[2]:
+ entities.append(entity)
+ elif tag.startswith('I-') and entity[1] != -1:
+ _type = tag.split('-')[1]
+ if _type == entity[0]:
+ entity[2] = index
+
+ if index == len(results) - 1 and entity[1] < entity[2]:
+ entities.append(entity)
+ else:
+ if entity[2] != -1 and entity[1] < entity[2]:
+ entities.append(entity)
+ entity = [-1, -1, -1]
+ else:
+ raise NotImplementedError(
+ 'The data format is not supported yet!')
+ pred_entities.append(entities)
+ return pred_entities
diff --git a/mmocr/models/ner/decoders/__init__.py b/mmocr/models/ner/decoders/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..737e98fa91ef98fb26d489f63f60335dba77ff38
--- /dev/null
+++ b/mmocr/models/ner/decoders/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .fc_decoder import FCDecoder
+
+__all__ = ['FCDecoder']
diff --git a/mmocr/models/ner/decoders/fc_decoder.py b/mmocr/models/ner/decoders/fc_decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..b88302f1d56f09cf6086b19f1a0b578debc84d2e
--- /dev/null
+++ b/mmocr/models/ner/decoders/fc_decoder.py
@@ -0,0 +1,41 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.runner import BaseModule
+
+from mmocr.models.builder import DECODERS
+
+
+@DECODERS.register_module()
+class FCDecoder(BaseModule):
+ """FC Decoder class for Ner.
+
+ Args:
+ num_labels (int): Number of categories mapped by entity label.
+ hidden_dropout_prob (float): The dropout probability of hidden layer.
+ hidden_size (int): Hidden layer output layer channels.
+ """
+
+ def __init__(self,
+ num_labels=None,
+ hidden_dropout_prob=0.1,
+ hidden_size=768,
+ init_cfg=[
+ dict(type='Xavier', layer='Conv2d'),
+ dict(type='Uniform', layer='BatchNorm2d')
+ ]):
+ super().__init__(init_cfg=init_cfg)
+ self.num_labels = num_labels
+
+ self.dropout = nn.Dropout(hidden_dropout_prob)
+ self.classifier = nn.Linear(hidden_size, self.num_labels)
+
+ def forward(self, outputs):
+ sequence_output = outputs[0]
+ sequence_output = self.dropout(sequence_output)
+ logits = self.classifier(sequence_output)
+ softmax = F.softmax(logits, dim=2)
+ preds = softmax.detach().cpu().numpy()
+ preds = np.argmax(preds, axis=2).tolist()
+ return logits, preds
diff --git a/mmocr/models/ner/encoders/__init__.py b/mmocr/models/ner/encoders/__init__.py
new file mode 100755
index 0000000000000000000000000000000000000000..4d7629bde82f0d3d60ffe87fc75b35f3924e07a3
--- /dev/null
+++ b/mmocr/models/ner/encoders/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .bert_encoder import BertEncoder
+
+__all__ = ['BertEncoder']
diff --git a/mmocr/models/ner/encoders/bert_encoder.py b/mmocr/models/ner/encoders/bert_encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..24c60aae24511c36da648eac6344a1db6f9783cf
--- /dev/null
+++ b/mmocr/models/ner/encoders/bert_encoder.py
@@ -0,0 +1,76 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.runner import BaseModule
+
+from mmocr.models.builder import ENCODERS
+from mmocr.models.ner.utils.bert import BertModel
+
+
+@ENCODERS.register_module()
+class BertEncoder(BaseModule):
+ """Bert encoder
+ Args:
+ num_hidden_layers (int): The number of hidden layers.
+ initializer_range (float):
+ vocab_size (int): Number of words supported.
+ hidden_size (int): Hidden size.
+ max_position_embeddings (int): Max positions embedding size.
+ type_vocab_size (int): The size of type_vocab.
+ layer_norm_eps (float): Epsilon of layer norm.
+ hidden_dropout_prob (float): The dropout probability of hidden layer.
+ output_attentions (bool): Whether use the attentions in output.
+ output_hidden_states (bool): Whether use the hidden_states in output.
+ num_attention_heads (int): The number of attention heads.
+ attention_probs_dropout_prob (float): The dropout probability
+ of attention.
+ intermediate_size (int): The size of intermediate layer.
+ hidden_act_cfg (dict): Hidden layer activation.
+ """
+
+ def __init__(self,
+ num_hidden_layers=12,
+ initializer_range=0.02,
+ vocab_size=21128,
+ hidden_size=768,
+ max_position_embeddings=128,
+ type_vocab_size=2,
+ layer_norm_eps=1e-12,
+ hidden_dropout_prob=0.1,
+ output_attentions=False,
+ output_hidden_states=False,
+ num_attention_heads=12,
+ attention_probs_dropout_prob=0.1,
+ intermediate_size=3072,
+ hidden_act_cfg=dict(type='GeluNew'),
+ init_cfg=[
+ dict(type='Xavier', layer='Conv2d'),
+ dict(type='Uniform', layer='BatchNorm2d')
+ ]):
+ super().__init__(init_cfg=init_cfg)
+ self.bert = BertModel(
+ num_hidden_layers=num_hidden_layers,
+ initializer_range=initializer_range,
+ vocab_size=vocab_size,
+ hidden_size=hidden_size,
+ max_position_embeddings=max_position_embeddings,
+ type_vocab_size=type_vocab_size,
+ layer_norm_eps=layer_norm_eps,
+ hidden_dropout_prob=hidden_dropout_prob,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ num_attention_heads=num_attention_heads,
+ attention_probs_dropout_prob=attention_probs_dropout_prob,
+ intermediate_size=intermediate_size,
+ hidden_act_cfg=hidden_act_cfg)
+
+ def forward(self, results):
+
+ device = next(self.bert.parameters()).device
+ input_ids = results['input_ids'].to(device)
+ attention_masks = results['attention_masks'].to(device)
+ token_type_ids = results['token_type_ids'].to(device)
+
+ outputs = self.bert(
+ input_ids=input_ids,
+ attention_masks=attention_masks,
+ token_type_ids=token_type_ids)
+ return outputs
diff --git a/mmocr/models/ner/losses/__init__.py b/mmocr/models/ner/losses/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..44cb725b24ae1a225b76cecc38fbaba12baad13a
--- /dev/null
+++ b/mmocr/models/ner/losses/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .masked_cross_entropy_loss import MaskedCrossEntropyLoss
+from .masked_focal_loss import MaskedFocalLoss
+
+__all__ = ['MaskedCrossEntropyLoss', 'MaskedFocalLoss']
diff --git a/mmocr/models/ner/losses/masked_cross_entropy_loss.py b/mmocr/models/ner/losses/masked_cross_entropy_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..034fb29590b9e8d420a2b0537a38c4e92b3d4acd
--- /dev/null
+++ b/mmocr/models/ner/losses/masked_cross_entropy_loss.py
@@ -0,0 +1,56 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from torch import nn
+from torch.nn import CrossEntropyLoss
+
+from mmocr.models.builder import LOSSES
+
+
+@LOSSES.register_module()
+class MaskedCrossEntropyLoss(nn.Module):
+ """The implementation of masked cross entropy loss.
+
+ The mask has 1 for real tokens and 0 for padding tokens,
+ which only keep active parts of the cross entropy loss.
+ Args:
+ num_labels (int): Number of classes in labels.
+ ignore_index (int): Specifies a target value that is ignored
+ and does not contribute to the input gradient.
+ """
+
+ def __init__(self, num_labels=None, ignore_index=0):
+ super().__init__()
+ self.num_labels = num_labels
+ self.criterion = CrossEntropyLoss(ignore_index=ignore_index)
+
+ def forward(self, logits, img_metas):
+ '''Loss forword.
+ Args:
+ logits: Model output with shape [N, C].
+ img_metas (dict): A dict containing the following keys:
+ - img (list]): This parameter is reserved.
+ - labels (list[int]): The labels for each word
+ of the sequence.
+ - texts (list): The words of the sequence.
+ - input_ids (list): The ids for each word of
+ the sequence.
+ - attention_mask (list): The mask for each word
+ of the sequence. The mask has 1 for real tokens
+ and 0 for padding tokens. Only real tokens are
+ attended to.
+ - token_type_ids (list): The tokens for each word
+ of the sequence.
+ '''
+
+ labels = img_metas['labels']
+ attention_masks = img_metas['attention_masks']
+
+ # Only keep active parts of the loss
+ if attention_masks is not None:
+ active_loss = attention_masks.view(-1) == 1
+ active_logits = logits.view(-1, self.num_labels)[active_loss]
+ active_labels = labels.view(-1)[active_loss]
+ loss = self.criterion(active_logits, active_labels)
+ else:
+ loss = self.criterion(
+ logits.view(-1, self.num_labels), labels.view(-1))
+ return {'loss_cls': loss}
diff --git a/mmocr/models/ner/losses/masked_focal_loss.py b/mmocr/models/ner/losses/masked_focal_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..065dc781db3d8af4ba9fd78c4cf27cca95f799eb
--- /dev/null
+++ b/mmocr/models/ner/losses/masked_focal_loss.py
@@ -0,0 +1,56 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from torch import nn
+
+from mmocr.models.builder import LOSSES
+from mmocr.models.common.losses.focal_loss import FocalLoss
+
+
+@LOSSES.register_module()
+class MaskedFocalLoss(nn.Module):
+ """The implementation of masked focal loss.
+
+ The mask has 1 for real tokens and 0 for padding tokens,
+ which only keep active parts of the focal loss
+ Args:
+ num_labels (int): Number of classes in labels.
+ ignore_index (int): Specifies a target value that is ignored
+ and does not contribute to the input gradient.
+ """
+
+ def __init__(self, num_labels=None, ignore_index=0):
+ super().__init__()
+ self.num_labels = num_labels
+ self.criterion = FocalLoss(ignore_index=ignore_index)
+
+ def forward(self, logits, img_metas):
+ '''Loss forword.
+ Args:
+ logits: Model output with shape [N, C].
+ img_metas (dict): A dict containing the following keys:
+ - img (list]): This parameter is reserved.
+ - labels (list[int]): The labels for each word
+ of the sequence.
+ - texts (list): The words of the sequence.
+ - input_ids (list): The ids for each word of
+ the sequence.
+ - attention_mask (list): The mask for each word
+ of the sequence. The mask has 1 for real tokens
+ and 0 for padding tokens. Only real tokens are
+ attended to.
+ - token_type_ids (list): The tokens for each word
+ of the sequence.
+ '''
+
+ labels = img_metas['labels']
+ attention_masks = img_metas['attention_masks']
+
+ # Only keep active parts of the loss
+ if attention_masks is not None:
+ active_loss = attention_masks.view(-1) == 1
+ active_logits = logits.view(-1, self.num_labels)[active_loss]
+ active_labels = labels.view(-1)[active_loss]
+ loss = self.criterion(active_logits, active_labels)
+ else:
+ loss = self.criterion(
+ logits.view(-1, self.num_labels), labels.view(-1))
+ return {'loss_cls': loss}
diff --git a/mmocr/models/ner/utils/__init__.py b/mmocr/models/ner/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..076239cd389027258c1b755405c816e40cccae1c
--- /dev/null
+++ b/mmocr/models/ner/utils/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .activations import GeluNew
+from .bert import BertModel
+
+__all__ = ['BertModel', 'GeluNew']
diff --git a/mmocr/models/ner/utils/activations.py b/mmocr/models/ner/utils/activations.py
new file mode 100644
index 0000000000000000000000000000000000000000..eb3cd55a7176cd1893a3f8328b3ba6d8a5068bf0
--- /dev/null
+++ b/mmocr/models/ner/utils/activations.py
@@ -0,0 +1,32 @@
+# ------------------------------------------------------------------------------
+# Adapted from https://github.com/lonePatient/BERT-NER-Pytorch
+# Original licence: Copyright (c) 2020 Weitang Liu, under the MIT License.
+# ------------------------------------------------------------------------------
+
+import math
+
+import torch
+import torch.nn as nn
+
+from mmocr.models.builder import ACTIVATION_LAYERS
+
+
+@ACTIVATION_LAYERS.register_module()
+class GeluNew(nn.Module):
+ """Implementation of the gelu activation function currently in Google Bert
+ repo (identical to OpenAI GPT).
+
+ Also see https://arxiv.org/abs/1606.08415
+ """
+
+ def forward(self, x):
+ """Forward function.
+
+ Args:
+ x (torch.Tensor): The input tensor.
+
+ Returns:
+ torch.Tensor: Activated tensor.
+ """
+ return 0.5 * x * (1 + torch.tanh(
+ math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
diff --git a/mmocr/models/ner/utils/bert.py b/mmocr/models/ner/utils/bert.py
new file mode 100644
index 0000000000000000000000000000000000000000..1e40c9e9fb595e6ad38b0a100e02f4c16721b1e4
--- /dev/null
+++ b/mmocr/models/ner/utils/bert.py
@@ -0,0 +1,485 @@
+# ------------------------------------------------------------------------------
+# Adapted from https://github.com/lonePatient/BERT-NER-Pytorch
+# Original licence: Copyright (c) 2020 Weitang Liu, under the MIT License.
+# ------------------------------------------------------------------------------
+
+import math
+
+import torch
+import torch.nn as nn
+
+from mmocr.models.builder import build_activation_layer
+
+
+class BertModel(nn.Module):
+ """Implement Bert model for named entity recognition task.
+
+ The code is adapted from https://github.com/lonePatient/BERT-NER-Pytorch
+ Args:
+ num_hidden_layers (int): The number of hidden layers.
+ initializer_range (float):
+ vocab_size (int): Number of words supported.
+ hidden_size (int): Hidden size.
+ max_position_embeddings (int): Max positionsembedding size.
+ type_vocab_size (int): The size of type_vocab.
+ layer_norm_eps (float): eps.
+ hidden_dropout_prob (float): The dropout probability of hidden layer.
+ output_attentions (bool): Whether use the attentions in output
+ output_hidden_states (bool): Whether use the hidden_states in output.
+ num_attention_heads (int): The number of attention heads.
+ attention_probs_dropout_prob (float): The dropout probability
+ for the attention probabilities normalized from
+ the attention scores.
+ intermediate_size (int): The size of intermediate layer.
+ hidden_act_cfg (str): hidden layer activation
+ """
+
+ def __init__(self,
+ num_hidden_layers=12,
+ initializer_range=0.02,
+ vocab_size=21128,
+ hidden_size=768,
+ max_position_embeddings=128,
+ type_vocab_size=2,
+ layer_norm_eps=1e-12,
+ hidden_dropout_prob=0.1,
+ output_attentions=False,
+ output_hidden_states=False,
+ num_attention_heads=12,
+ attention_probs_dropout_prob=0.1,
+ intermediate_size=3072,
+ hidden_act_cfg=dict(type='GeluNew')):
+ super().__init__()
+ self.embeddings = BertEmbeddings(
+ vocab_size=vocab_size,
+ hidden_size=hidden_size,
+ max_position_embeddings=max_position_embeddings,
+ type_vocab_size=type_vocab_size,
+ layer_norm_eps=layer_norm_eps,
+ hidden_dropout_prob=hidden_dropout_prob)
+ self.encoder = BertEncoder(
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ num_hidden_layers=num_hidden_layers,
+ hidden_size=hidden_size,
+ num_attention_heads=num_attention_heads,
+ attention_probs_dropout_prob=attention_probs_dropout_prob,
+ layer_norm_eps=layer_norm_eps,
+ hidden_dropout_prob=hidden_dropout_prob,
+ intermediate_size=intermediate_size,
+ hidden_act_cfg=hidden_act_cfg)
+ self.pooler = BertPooler(hidden_size=hidden_size)
+ self.num_hidden_layers = num_hidden_layers
+ self.initializer_range = initializer_range
+ self.init_weights()
+
+ def _resize_token_embeddings(self, new_num_tokens):
+ old_embeddings = self.embeddings.word_embeddings
+ new_embeddings = self._get_resized_embeddings(old_embeddings,
+ new_num_tokens)
+ self.embeddings.word_embeddings = new_embeddings
+ return self.embeddings.word_embeddings
+
+ def forward(self,
+ input_ids,
+ attention_masks=None,
+ token_type_ids=None,
+ position_ids=None,
+ head_mask=None):
+ if attention_masks is None:
+ attention_masks = torch.ones_like(input_ids)
+ if token_type_ids is None:
+ token_type_ids = torch.zeros_like(input_ids)
+ attention_masks = attention_masks[:, None, None]
+ attention_masks = attention_masks.to(
+ dtype=next(self.parameters()).dtype)
+ attention_masks = (1.0 - attention_masks) * -10000.0
+ if head_mask is not None:
+ if head_mask.dim() == 1:
+ head_mask = head_mask[None, None, :, None, None]
+ elif head_mask.dim() == 2:
+ head_mask = head_mask[None, :, None, None]
+ head_mask = head_mask.to(dtype=next(self.parameters()).dtype)
+ else:
+ head_mask = [None] * self.num_hidden_layers
+
+ embedding_output = self.embeddings(
+ input_ids,
+ position_ids=position_ids,
+ token_type_ids=token_type_ids)
+ sequence_output, *encoder_outputs = self.encoder(
+ embedding_output, attention_masks, head_mask=head_mask)
+ # sequence_output = encoder_outputs[0]
+ pooled_output = self.pooler(sequence_output)
+
+ # add hidden_states and attentions if they are here
+ # sequence_output, pooled_output, (hidden_states), (attentions)
+ outputs = (
+ sequence_output,
+ pooled_output,
+ ) + tuple(encoder_outputs)
+ return outputs
+
+ def _init_weights(self, module):
+ """Initialize the weights."""
+ if isinstance(module, (nn.Linear, nn.Embedding)):
+ # Slightly different from the TF version which
+ # uses truncated_normal for initialization
+ # cf https://github.com/pytorch/pytorch/pull/5617
+ module.weight.data.normal_(mean=0.0, std=self.initializer_range)
+ elif isinstance(module, torch.nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+ if isinstance(module, nn.Linear) and module.bias is not None:
+ module.bias.data.zero_()
+
+ def init_weights(self):
+ """Initialize and prunes weights if needed."""
+ # Initialize weights
+ self.apply(self._init_weights)
+
+
+class BertEmbeddings(nn.Module):
+ """Construct the embeddings from word, position and token_type embeddings.
+
+ The code is adapted from https://github.com/lonePatient/BERT-NER-Pytorch.
+ Args:
+ vocab_size (int): Number of words supported.
+ hidden_size (int): Hidden size.
+ max_position_embeddings (int): Max positions embedding size.
+ type_vocab_size (int): The size of type_vocab.
+ layer_norm_eps (float): eps.
+ hidden_dropout_prob (float): The dropout probability of hidden layer.
+ """
+
+ def __init__(self,
+ vocab_size=21128,
+ hidden_size=768,
+ max_position_embeddings=128,
+ type_vocab_size=2,
+ layer_norm_eps=1e-12,
+ hidden_dropout_prob=0.1):
+ super().__init__()
+
+ self.word_embeddings = nn.Embedding(
+ vocab_size, hidden_size, padding_idx=0)
+ self.position_embeddings = nn.Embedding(max_position_embeddings,
+ hidden_size)
+ self.token_type_embeddings = nn.Embedding(type_vocab_size, hidden_size)
+
+ # self.LayerNorm is not snake-cased to stick with
+ # TensorFlow model variable name and be able to load
+ # any TensorFlow checkpoint file
+ self.LayerNorm = torch.nn.LayerNorm(hidden_size, eps=layer_norm_eps)
+ self.dropout = nn.Dropout(hidden_dropout_prob)
+
+ def forward(self, input_ids, token_type_ids=None, position_ids=None):
+ seq_length = input_ids.size(1)
+ if position_ids is None:
+ position_ids = torch.arange(
+ seq_length, dtype=torch.long, device=input_ids.device)
+ position_ids = position_ids.unsqueeze(0).expand_as(input_ids)
+ if token_type_ids is None:
+ token_type_ids = torch.zeros_like(input_ids)
+
+ words_emb = self.word_embeddings(input_ids)
+ position_emb = self.position_embeddings(position_ids)
+ token_type_emb = self.token_type_embeddings(token_type_ids)
+ embeddings = words_emb + position_emb + token_type_emb
+ embeddings = self.LayerNorm(embeddings)
+ embeddings = self.dropout(embeddings)
+ return embeddings
+
+
+class BertEncoder(nn.Module):
+ """The code is adapted from https://github.com/lonePatient/BERT-NER-
+ Pytorch."""
+
+ def __init__(self,
+ output_attentions=False,
+ output_hidden_states=False,
+ num_hidden_layers=12,
+ hidden_size=768,
+ num_attention_heads=12,
+ attention_probs_dropout_prob=0.1,
+ layer_norm_eps=1e-12,
+ hidden_dropout_prob=0.1,
+ intermediate_size=3072,
+ hidden_act_cfg=dict(type='GeluNew')):
+ super().__init__()
+ self.output_attentions = output_attentions
+ self.output_hidden_states = output_hidden_states
+ self.layer = nn.ModuleList([
+ BertLayer(
+ hidden_size=hidden_size,
+ num_attention_heads=num_attention_heads,
+ output_attentions=output_attentions,
+ attention_probs_dropout_prob=attention_probs_dropout_prob,
+ layer_norm_eps=layer_norm_eps,
+ hidden_dropout_prob=hidden_dropout_prob,
+ intermediate_size=intermediate_size,
+ hidden_act_cfg=hidden_act_cfg)
+ for _ in range(num_hidden_layers)
+ ])
+
+ def forward(self, hidden_states, attention_mask=None, head_mask=None):
+ all_hidden_states = ()
+ all_attentions = ()
+ for i, layer_module in enumerate(self.layer):
+ if self.output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states, )
+
+ layer_outputs = layer_module(hidden_states, attention_mask,
+ head_mask[i])
+ hidden_states = layer_outputs[0]
+
+ if self.output_attentions:
+ all_attentions = all_attentions + (layer_outputs[1], )
+
+ # Add last layer
+ if self.output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states, )
+
+ outputs = (hidden_states, )
+ if self.output_hidden_states:
+ outputs = outputs + (all_hidden_states, )
+ if self.output_attentions:
+ outputs = outputs + (all_attentions, )
+ # last-layer hidden state, (all hidden states), (all attentions)
+ return outputs
+
+
+class BertPooler(nn.Module):
+
+ def __init__(self, hidden_size=768):
+ super().__init__()
+ self.dense = nn.Linear(hidden_size, hidden_size)
+ self.activation = nn.Tanh()
+
+ def forward(self, hidden_states):
+ # We "pool" the model by simply taking the hidden state corresponding
+ # to the first token.
+ first_token_tensor = hidden_states[:, 0]
+ pooled_output = self.dense(first_token_tensor)
+ pooled_output = self.activation(pooled_output)
+ return pooled_output
+
+
+class BertLayer(nn.Module):
+ """Bert layer.
+
+ The code is adapted from https://github.com/lonePatient/BERT-NER-Pytorch.
+ """
+
+ def __init__(self,
+ hidden_size=768,
+ num_attention_heads=12,
+ output_attentions=False,
+ attention_probs_dropout_prob=0.1,
+ layer_norm_eps=1e-12,
+ hidden_dropout_prob=0.1,
+ intermediate_size=3072,
+ hidden_act_cfg=dict(type='GeluNew')):
+ super().__init__()
+ self.attention = BertAttention(
+ hidden_size=hidden_size,
+ num_attention_heads=num_attention_heads,
+ output_attentions=output_attentions,
+ attention_probs_dropout_prob=attention_probs_dropout_prob,
+ layer_norm_eps=layer_norm_eps,
+ hidden_dropout_prob=hidden_dropout_prob)
+ self.intermediate = BertIntermediate(
+ hidden_size=hidden_size,
+ intermediate_size=intermediate_size,
+ hidden_act_cfg=hidden_act_cfg)
+ self.output = BertOutput(
+ intermediate_size=intermediate_size,
+ hidden_size=hidden_size,
+ layer_norm_eps=layer_norm_eps,
+ hidden_dropout_prob=hidden_dropout_prob)
+
+ def forward(self, hidden_states, attention_mask=None, head_mask=None):
+ attention_outputs = self.attention(hidden_states, attention_mask,
+ head_mask)
+ attention_output = attention_outputs[0]
+ intermediate_output = self.intermediate(attention_output)
+ layer_output = self.output(intermediate_output, attention_output)
+ outputs = (layer_output, ) + attention_outputs[
+ 1:] # add attentions if we output them
+ return outputs
+
+
+class BertSelfAttention(nn.Module):
+ """Bert self attention module.
+
+ The code is adapted from https://github.com/lonePatient/BERT-NER-Pytorch.
+ """
+
+ def __init__(self,
+ hidden_size=768,
+ num_attention_heads=12,
+ output_attentions=False,
+ attention_probs_dropout_prob=0.1):
+ super().__init__()
+ if hidden_size % num_attention_heads != 0:
+ raise ValueError('The hidden size (%d) is not a multiple of'
+ 'the number of attention heads (%d)' %
+ (hidden_size, num_attention_heads))
+ self.output_attentions = output_attentions
+
+ self.num_attention_heads = num_attention_heads
+ self.att_head_size = int(hidden_size / num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.att_head_size
+
+ self.query = nn.Linear(hidden_size, self.all_head_size)
+ self.key = nn.Linear(hidden_size, self.all_head_size)
+ self.value = nn.Linear(hidden_size, self.all_head_size)
+
+ self.dropout = nn.Dropout(attention_probs_dropout_prob)
+
+ def transpose_for_scores(self, x):
+ new_x_shape = x.size()[:-1] + (self.num_attention_heads,
+ self.att_head_size)
+ x = x.view(*new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ def forward(self, hidden_states, attention_mask=None, head_mask=None):
+ mixed_query_layer = self.query(hidden_states)
+ mixed_key_layer = self.key(hidden_states)
+ mixed_value_layer = self.value(hidden_states)
+
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+ key_layer = self.transpose_for_scores(mixed_key_layer)
+ value_layer = self.transpose_for_scores(mixed_value_layer)
+
+ # Take the dot product between "query" and
+ # "key" to get the raw attention scores.
+ attention_scores = torch.matmul(query_layer,
+ key_layer.transpose(-1, -2))
+ attention_scores = attention_scores / math.sqrt(self.att_head_size)
+ if attention_mask is not None:
+ # Apply the attention mask is precomputed for
+ # all layers in BertModel forward() function.
+ attention_scores = attention_scores + attention_mask
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.Softmax(dim=-1)(attention_scores)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.dropout(attention_probs)
+
+ # Mask heads if we want to.
+ if head_mask is not None:
+ attention_probs = attention_probs * head_mask
+
+ context_layer = torch.matmul(attention_probs, value_layer)
+
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (
+ self.all_head_size, )
+ context_layer = context_layer.view(*new_context_layer_shape)
+
+ outputs = (context_layer,
+ attention_probs) if self.output_attentions else (
+ context_layer, )
+ return outputs
+
+
+class BertSelfOutput(nn.Module):
+ """Bert self output.
+
+ The code is adapted from https://github.com/lonePatient/BERT-NER-Pytorch.
+ """
+
+ def __init__(self,
+ hidden_size=768,
+ layer_norm_eps=1e-12,
+ hidden_dropout_prob=0.1):
+ super().__init__()
+ self.dense = nn.Linear(hidden_size, hidden_size)
+ self.LayerNorm = torch.nn.LayerNorm(hidden_size, eps=layer_norm_eps)
+ self.dropout = nn.Dropout(hidden_dropout_prob)
+
+ def forward(self, hidden_states, input_tensor):
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states + input_tensor)
+ return hidden_states
+
+
+class BertAttention(nn.Module):
+ """Bert Attention module implementation.
+
+ The code is adapted from https://github.com/lonePatient/BERT-NER-Pytorch.
+ """
+
+ def __init__(self,
+ hidden_size=768,
+ num_attention_heads=12,
+ output_attentions=False,
+ attention_probs_dropout_prob=0.1,
+ layer_norm_eps=1e-12,
+ hidden_dropout_prob=0.1):
+ super().__init__()
+ self.self = BertSelfAttention(
+ hidden_size=hidden_size,
+ num_attention_heads=num_attention_heads,
+ output_attentions=output_attentions,
+ attention_probs_dropout_prob=attention_probs_dropout_prob)
+ self.output = BertSelfOutput(
+ hidden_size=hidden_size,
+ layer_norm_eps=layer_norm_eps,
+ hidden_dropout_prob=hidden_dropout_prob)
+
+ def forward(self, input_tensor, attention_mask=None, head_mask=None):
+ self_outputs = self.self(input_tensor, attention_mask, head_mask)
+ attention_output = self.output(self_outputs[0], input_tensor)
+ outputs = (attention_output,
+ ) + self_outputs[1:] # add attentions if we output them
+ return outputs
+
+
+class BertIntermediate(nn.Module):
+ """Bert BertIntermediate module implementation.
+
+ The code is adapted from https://github.com/lonePatient/BERT-NER-Pytorch.
+ """
+
+ def __init__(self,
+ hidden_size=768,
+ intermediate_size=3072,
+ hidden_act_cfg=dict(type='GeluNew')):
+ super().__init__()
+
+ self.dense = nn.Linear(hidden_size, intermediate_size)
+ self.intermediate_act_fn = build_activation_layer(hidden_act_cfg)
+
+ def forward(self, hidden_states):
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.intermediate_act_fn(hidden_states)
+ return hidden_states
+
+
+class BertOutput(nn.Module):
+ """Bert output module.
+
+ The code is adapted from https://github.com/lonePatient/BERT-NER-Pytorch.
+ """
+
+ def __init__(self,
+ intermediate_size=3072,
+ hidden_size=768,
+ layer_norm_eps=1e-12,
+ hidden_dropout_prob=0.1):
+
+ super().__init__()
+ self.dense = nn.Linear(intermediate_size, hidden_size)
+ self.LayerNorm = torch.nn.LayerNorm(hidden_size, eps=layer_norm_eps)
+ self.dropout = nn.Dropout(hidden_dropout_prob)
+
+ def forward(self, hidden_states, input_tensor):
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states + input_tensor)
+ return hidden_states
diff --git a/mmocr/models/textdet/__init__.py b/mmocr/models/textdet/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..027e812f790d9572ec5d83b78ee9ce33a5ed415a
--- /dev/null
+++ b/mmocr/models/textdet/__init__.py
@@ -0,0 +1,11 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from . import dense_heads, detectors, losses, necks, postprocess
+from .dense_heads import * # NOQA
+from .detectors import * # NOQA
+from .losses import * # NOQA
+from .necks import * # NOQA
+from .postprocess import * # NOQA
+
+__all__ = (
+ dense_heads.__all__ + detectors.__all__ + losses.__all__ + necks.__all__ +
+ postprocess.__all__)
diff --git a/mmocr/models/textdet/dense_heads/__init__.py b/mmocr/models/textdet/dense_heads/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..3c2eaa7fe29143fce8cbef8d770a1afe6f9c3c24
--- /dev/null
+++ b/mmocr/models/textdet/dense_heads/__init__.py
@@ -0,0 +1,13 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .db_head import DBHead
+from .drrg_head import DRRGHead
+from .fce_head import FCEHead
+from .head_mixin import HeadMixin
+from .pan_head import PANHead
+from .pse_head import PSEHead
+from .textsnake_head import TextSnakeHead
+
+__all__ = [
+ 'PSEHead', 'PANHead', 'DBHead', 'FCEHead', 'TextSnakeHead', 'DRRGHead',
+ 'HeadMixin'
+]
diff --git a/mmocr/models/textdet/dense_heads/db_head.py b/mmocr/models/textdet/dense_heads/db_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..b843c29fd2ae25591abec40e5c89275ca984194b
--- /dev/null
+++ b/mmocr/models/textdet/dense_heads/db_head.py
@@ -0,0 +1,95 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import torch
+import torch.nn as nn
+from mmcv.runner import BaseModule, Sequential
+
+from mmocr.models.builder import HEADS
+from .head_mixin import HeadMixin
+
+
+@HEADS.register_module()
+class DBHead(HeadMixin, BaseModule):
+ """The class for DBNet head.
+
+ This was partially adapted from https://github.com/MhLiao/DB
+
+ Args:
+ in_channels (int): The number of input channels of the db head.
+ with_bias (bool): Whether add bias in Conv2d layer.
+ downsample_ratio (float): The downsample ratio of ground truths.
+ loss (dict): Config of loss for dbnet.
+ postprocessor (dict): Config of postprocessor for dbnet.
+ """
+
+ def __init__(
+ self,
+ in_channels,
+ with_bias=False,
+ downsample_ratio=1.0,
+ loss=dict(type='DBLoss'),
+ postprocessor=dict(type='DBPostprocessor', text_repr_type='quad'),
+ init_cfg=[
+ dict(type='Kaiming', layer='Conv'),
+ dict(type='Constant', layer='BatchNorm', val=1., bias=1e-4)
+ ],
+ train_cfg=None,
+ test_cfg=None,
+ **kwargs):
+ old_keys = ['text_repr_type', 'decoding_type']
+ for key in old_keys:
+ if kwargs.get(key, None):
+ postprocessor[key] = kwargs.get(key)
+ warnings.warn(
+ f'{key} is deprecated, please specify '
+ 'it in postprocessor config dict. See '
+ 'https://github.com/open-mmlab/mmocr/pull/640'
+ ' for details.', UserWarning)
+ BaseModule.__init__(self, init_cfg=init_cfg)
+ HeadMixin.__init__(self, loss, postprocessor)
+
+ assert isinstance(in_channels, int)
+
+ self.in_channels = in_channels
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+ self.downsample_ratio = downsample_ratio
+
+ self.binarize = Sequential(
+ nn.Conv2d(
+ in_channels, in_channels // 4, 3, bias=with_bias, padding=1),
+ nn.BatchNorm2d(in_channels // 4), nn.ReLU(inplace=True),
+ nn.ConvTranspose2d(in_channels // 4, in_channels // 4, 2, 2),
+ nn.BatchNorm2d(in_channels // 4), nn.ReLU(inplace=True),
+ nn.ConvTranspose2d(in_channels // 4, 1, 2, 2), nn.Sigmoid())
+
+ self.threshold = self._init_thr(in_channels)
+
+ def diff_binarize(self, prob_map, thr_map, k):
+ return torch.reciprocal(1.0 + torch.exp(-k * (prob_map - thr_map)))
+
+ def forward(self, inputs):
+ """
+ Args:
+ inputs (Tensor): Shape (batch_size, hidden_size, h, w).
+
+ Returns:
+ Tensor: A tensor of the same shape as input.
+ """
+ prob_map = self.binarize(inputs)
+ thr_map = self.threshold(inputs)
+ binary_map = self.diff_binarize(prob_map, thr_map, k=50)
+ outputs = torch.cat((prob_map, thr_map, binary_map), dim=1)
+ return outputs
+
+ def _init_thr(self, inner_channels, bias=False):
+ in_channels = inner_channels
+ seq = Sequential(
+ nn.Conv2d(
+ in_channels, inner_channels // 4, 3, padding=1, bias=bias),
+ nn.BatchNorm2d(inner_channels // 4), nn.ReLU(inplace=True),
+ nn.ConvTranspose2d(inner_channels // 4, inner_channels // 4, 2, 2),
+ nn.BatchNorm2d(inner_channels // 4), nn.ReLU(inplace=True),
+ nn.ConvTranspose2d(inner_channels // 4, 1, 2, 2), nn.Sigmoid())
+ return seq
diff --git a/mmocr/models/textdet/dense_heads/drrg_head.py b/mmocr/models/textdet/dense_heads/drrg_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..e3135ee0e79b3f347a5785580b1a0e3e5aa8843f
--- /dev/null
+++ b/mmocr/models/textdet/dense_heads/drrg_head.py
@@ -0,0 +1,257 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.runner import BaseModule
+
+from mmocr.models.builder import HEADS, build_loss
+from mmocr.models.textdet.modules import GCN, LocalGraphs, ProposalLocalGraphs
+from mmocr.utils import check_argument
+from .head_mixin import HeadMixin
+
+
+@HEADS.register_module()
+class DRRGHead(HeadMixin, BaseModule):
+ """The class for DRRG head: `Deep Relational Reasoning Graph Network for
+ Arbitrary Shape Text Detection `_.
+
+ Args:
+ k_at_hops (tuple(int)): The number of i-hop neighbors, i = 1, 2.
+ num_adjacent_linkages (int): The number of linkages when constructing
+ adjacent matrix.
+ node_geo_feat_len (int): The length of embedded geometric feature
+ vector of a component.
+ pooling_scale (float): The spatial scale of rotated RoI-Align.
+ pooling_output_size (tuple(int)): The output size of RRoI-Aligning.
+ nms_thr (float): The locality-aware NMS threshold of text components.
+ min_width (float): The minimum width of text components.
+ max_width (float): The maximum width of text components.
+ comp_shrink_ratio (float): The shrink ratio of text components.
+ comp_ratio (float): The reciprocal of aspect ratio of text components.
+ comp_score_thr (float): The score threshold of text components.
+ text_region_thr (float): The threshold for text region probability map.
+ center_region_thr (float): The threshold for text center region
+ probability map.
+ center_region_area_thr (int): The threshold for filtering small-sized
+ text center region.
+ local_graph_thr (float): The threshold to filter identical local
+ graphs.
+ loss (dict): The config of loss that DRRGHead uses..
+ postprocessor (dict): Config of postprocessor for Drrg.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self,
+ in_channels,
+ k_at_hops=(8, 4),
+ num_adjacent_linkages=3,
+ node_geo_feat_len=120,
+ pooling_scale=1.0,
+ pooling_output_size=(4, 3),
+ nms_thr=0.3,
+ min_width=8.0,
+ max_width=24.0,
+ comp_shrink_ratio=1.03,
+ comp_ratio=0.4,
+ comp_score_thr=0.3,
+ text_region_thr=0.2,
+ center_region_thr=0.2,
+ center_region_area_thr=50,
+ local_graph_thr=0.7,
+ loss=dict(type='DRRGLoss'),
+ postprocessor=dict(type='DRRGPostprocessor', link_thr=0.85),
+ train_cfg=None,
+ test_cfg=None,
+ init_cfg=dict(
+ type='Normal',
+ override=dict(name='out_conv'),
+ mean=0,
+ std=0.01),
+ **kwargs):
+ old_keys = ['text_repr_type', 'decoding_type', 'link_thr']
+ for key in old_keys:
+ if kwargs.get(key, None):
+ postprocessor[key] = kwargs.get(key)
+ warnings.warn(
+ f'{key} is deprecated, please specify '
+ 'it in postprocessor config dict. See '
+ 'https://github.com/open-mmlab/mmocr/pull/640'
+ ' for details.', UserWarning)
+ BaseModule.__init__(self, init_cfg=init_cfg)
+ HeadMixin.__init__(self, loss, postprocessor)
+
+ assert isinstance(in_channels, int)
+ assert isinstance(k_at_hops, tuple)
+ assert isinstance(num_adjacent_linkages, int)
+ assert isinstance(node_geo_feat_len, int)
+ assert isinstance(pooling_scale, float)
+ assert isinstance(pooling_output_size, tuple)
+ assert isinstance(comp_shrink_ratio, float)
+ assert isinstance(nms_thr, float)
+ assert isinstance(min_width, float)
+ assert isinstance(max_width, float)
+ assert isinstance(comp_ratio, float)
+ assert isinstance(comp_score_thr, float)
+ assert isinstance(text_region_thr, float)
+ assert isinstance(center_region_thr, float)
+ assert isinstance(center_region_area_thr, int)
+ assert isinstance(local_graph_thr, float)
+
+ self.in_channels = in_channels
+ self.out_channels = 6
+ self.downsample_ratio = 1.0
+ self.k_at_hops = k_at_hops
+ self.num_adjacent_linkages = num_adjacent_linkages
+ self.node_geo_feat_len = node_geo_feat_len
+ self.pooling_scale = pooling_scale
+ self.pooling_output_size = pooling_output_size
+ self.comp_shrink_ratio = comp_shrink_ratio
+ self.nms_thr = nms_thr
+ self.min_width = min_width
+ self.max_width = max_width
+ self.comp_ratio = comp_ratio
+ self.comp_score_thr = comp_score_thr
+ self.text_region_thr = text_region_thr
+ self.center_region_thr = center_region_thr
+ self.center_region_area_thr = center_region_area_thr
+ self.local_graph_thr = local_graph_thr
+ self.loss_module = build_loss(loss)
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+
+ self.out_conv = nn.Conv2d(
+ in_channels=self.in_channels,
+ out_channels=self.out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0)
+
+ self.graph_train = LocalGraphs(self.k_at_hops,
+ self.num_adjacent_linkages,
+ self.node_geo_feat_len,
+ self.pooling_scale,
+ self.pooling_output_size,
+ self.local_graph_thr)
+
+ self.graph_test = ProposalLocalGraphs(
+ self.k_at_hops, self.num_adjacent_linkages, self.node_geo_feat_len,
+ self.pooling_scale, self.pooling_output_size, self.nms_thr,
+ self.min_width, self.max_width, self.comp_shrink_ratio,
+ self.comp_ratio, self.comp_score_thr, self.text_region_thr,
+ self.center_region_thr, self.center_region_area_thr)
+
+ pool_w, pool_h = self.pooling_output_size
+ node_feat_len = (pool_w * pool_h) * (
+ self.in_channels + self.out_channels) + self.node_geo_feat_len
+ self.gcn = GCN(node_feat_len)
+
+ def forward(self, inputs, gt_comp_attribs):
+ """
+ Args:
+ inputs (Tensor): Shape of :math:`(N, C, H, W)`.
+ gt_comp_attribs (list[ndarray]): The padded text component
+ attributes. Shape: (num_component, 8).
+
+ Returns:
+ tuple: Returns (pred_maps, (gcn_pred, gt_labels)).
+
+ - | pred_maps (Tensor): Prediction map with shape
+ :math:`(N, C_{out}, H, W)`.
+ - | gcn_pred (Tensor): Prediction from GCN module, with
+ shape :math:`(N, 2)`.
+ - | gt_labels (Tensor): Ground-truth label with shape
+ :math:`(N, 8)`.
+ """
+ pred_maps = self.out_conv(inputs)
+ feat_maps = torch.cat([inputs, pred_maps], dim=1)
+ node_feats, adjacent_matrices, knn_inds, gt_labels = self.graph_train(
+ feat_maps, np.stack(gt_comp_attribs))
+
+ gcn_pred = self.gcn(node_feats, adjacent_matrices, knn_inds)
+
+ return pred_maps, (gcn_pred, gt_labels)
+
+ def single_test(self, feat_maps):
+ r"""
+ Args:
+ feat_maps (Tensor): Shape of :math:`(N, C, H, W)`.
+
+ Returns:
+ tuple: Returns (edge, score, text_comps).
+
+ - | edge (ndarray): The edge array of shape :math:`(N, 2)`
+ where each row is a pair of text component indices
+ that makes up an edge in graph.
+ - | score (ndarray): The score array of shape :math:`(N,)`,
+ corresponding to the edge above.
+ - | text_comps (ndarray): The text components of shape
+ :math:`(N, 9)` where each row corresponds to one box and
+ its score: (x1, y1, x2, y2, x3, y3, x4, y4, score).
+ """
+ pred_maps = self.out_conv(feat_maps)
+ feat_maps = torch.cat([feat_maps, pred_maps], dim=1)
+
+ none_flag, graph_data = self.graph_test(pred_maps, feat_maps)
+
+ (local_graphs_node_feat, adjacent_matrices, pivots_knn_inds,
+ pivot_local_graphs, text_comps) = graph_data
+
+ if none_flag:
+ return None, None, None
+
+ gcn_pred = self.gcn(local_graphs_node_feat, adjacent_matrices,
+ pivots_knn_inds)
+ pred_labels = F.softmax(gcn_pred, dim=1)
+
+ edges = []
+ scores = []
+ pivot_local_graphs = pivot_local_graphs.long().squeeze().cpu().numpy()
+
+ for pivot_ind, pivot_local_graph in enumerate(pivot_local_graphs):
+ pivot = pivot_local_graph[0]
+ for k_ind, neighbor_ind in enumerate(pivots_knn_inds[pivot_ind]):
+ neighbor = pivot_local_graph[neighbor_ind.item()]
+ edges.append([pivot, neighbor])
+ scores.append(
+ pred_labels[pivot_ind * pivots_knn_inds.shape[1] + k_ind,
+ 1].item())
+
+ edges = np.asarray(edges)
+ scores = np.asarray(scores)
+
+ return edges, scores, text_comps
+
+ def get_boundary(self, edges, scores, text_comps, img_metas, rescale):
+ """Compute text boundaries via post processing.
+
+ Args:
+ edges (ndarray): The edge array of shape N * 2, each row is a pair
+ of text component indices that makes up an edge in graph.
+ scores (ndarray): The edge score array.
+ text_comps (ndarray): The text components.
+ img_metas (list[dict]): The image meta infos.
+ rescale (bool): Rescale boundaries to the original image
+ resolution.
+
+ Returns:
+ dict: The result dict containing key `boundary_result`.
+ """
+
+ assert check_argument.is_type_list(img_metas, dict)
+ assert isinstance(rescale, bool)
+
+ boundaries = []
+ if edges is not None:
+ boundaries = self.postprocessor(edges, scores, text_comps)
+
+ if rescale:
+ boundaries = self.resize_boundary(
+ boundaries,
+ 1.0 / self.downsample_ratio / img_metas[0]['scale_factor'])
+
+ results = dict(boundary_result=boundaries)
+
+ return results
diff --git a/mmocr/models/textdet/dense_heads/fce_head.py b/mmocr/models/textdet/dense_heads/fce_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..07855578107ef0538403a6abea7cc5f53fed1c50
--- /dev/null
+++ b/mmocr/models/textdet/dense_heads/fce_head.py
@@ -0,0 +1,149 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import torch.nn as nn
+from mmcv.runner import BaseModule
+from mmdet.core import multi_apply
+
+from mmocr.models.builder import HEADS
+from ..postprocess.utils import poly_nms
+from .head_mixin import HeadMixin
+
+
+@HEADS.register_module()
+class FCEHead(HeadMixin, BaseModule):
+ """The class for implementing FCENet head.
+
+ FCENet(CVPR2021): `Fourier Contour Embedding for Arbitrary-shaped Text
+ Detection `_
+
+ Args:
+ in_channels (int): The number of input channels.
+ scales (list[int]) : The scale of each layer.
+ fourier_degree (int) : The maximum Fourier transform degree k.
+ nms_thr (float) : The threshold of nms.
+ loss (dict): Config of loss for FCENet.
+ postprocessor (dict): Config of postprocessor for FCENet.
+ """
+
+ def __init__(self,
+ in_channels,
+ scales,
+ fourier_degree=5,
+ nms_thr=0.1,
+ loss=dict(type='FCELoss', num_sample=50),
+ postprocessor=dict(
+ type='FCEPostprocessor',
+ text_repr_type='poly',
+ num_reconstr_points=50,
+ alpha=1.0,
+ beta=2.0,
+ score_thr=0.3),
+ train_cfg=None,
+ test_cfg=None,
+ init_cfg=dict(
+ type='Normal',
+ mean=0,
+ std=0.01,
+ override=[
+ dict(name='out_conv_cls'),
+ dict(name='out_conv_reg')
+ ]),
+ **kwargs):
+ old_keys = [
+ 'text_repr_type', 'decoding_type', 'num_reconstr_points', 'alpha',
+ 'beta', 'score_thr'
+ ]
+ for key in old_keys:
+ if kwargs.get(key, None):
+ postprocessor[key] = kwargs.get(key)
+ warnings.warn(
+ f'{key} is deprecated, please specify '
+ 'it in postprocessor config dict. See '
+ 'https://github.com/open-mmlab/mmocr/pull/640'
+ ' for details.', UserWarning)
+ if kwargs.get('num_sample', None):
+ loss['num_sample'] = kwargs.get('num_sample')
+ warnings.warn(
+ 'num_sample is deprecated, please specify '
+ 'it in loss config dict. See '
+ 'https://github.com/open-mmlab/mmocr/pull/640'
+ ' for details.', UserWarning)
+ BaseModule.__init__(self, init_cfg=init_cfg)
+ loss['fourier_degree'] = fourier_degree
+ postprocessor['fourier_degree'] = fourier_degree
+ postprocessor['nms_thr'] = nms_thr
+ HeadMixin.__init__(self, loss, postprocessor)
+
+ assert isinstance(in_channels, int)
+
+ self.downsample_ratio = 1.0
+ self.in_channels = in_channels
+ self.scales = scales
+ self.fourier_degree = fourier_degree
+
+ self.nms_thr = nms_thr
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+ self.out_channels_cls = 4
+ self.out_channels_reg = (2 * self.fourier_degree + 1) * 2
+
+ self.out_conv_cls = nn.Conv2d(
+ self.in_channels,
+ self.out_channels_cls,
+ kernel_size=3,
+ stride=1,
+ padding=1)
+ self.out_conv_reg = nn.Conv2d(
+ self.in_channels,
+ self.out_channels_reg,
+ kernel_size=3,
+ stride=1,
+ padding=1)
+
+ def forward(self, feats):
+ """
+ Args:
+ feats (list[Tensor]): Each tensor has the shape of :math:`(N, C_i,
+ H_i, W_i)`.
+
+ Returns:
+ list[[Tensor, Tensor]]: Each pair of tensors corresponds to the
+ classification result and regression result computed from the input
+ tensor with the same index. They have the shapes of :math:`(N,
+ C_{cls,i}, H_i, W_i)` and :math:`(N, C_{out,i}, H_i, W_i)`.
+ """
+ cls_res, reg_res = multi_apply(self.forward_single, feats)
+ level_num = len(cls_res)
+ preds = [[cls_res[i], reg_res[i]] for i in range(level_num)]
+ return preds
+
+ def forward_single(self, x):
+ cls_predict = self.out_conv_cls(x)
+ reg_predict = self.out_conv_reg(x)
+ return cls_predict, reg_predict
+
+ def get_boundary(self, score_maps, img_metas, rescale):
+ assert len(score_maps) == len(self.scales)
+
+ boundaries = []
+ for idx, score_map in enumerate(score_maps):
+ scale = self.scales[idx]
+ boundaries = boundaries + self._get_boundary_single(
+ score_map, scale)
+
+ # nms
+ boundaries = poly_nms(boundaries, self.nms_thr)
+
+ if rescale:
+ boundaries = self.resize_boundary(
+ boundaries, 1.0 / img_metas[0]['scale_factor'])
+
+ results = dict(boundary_result=boundaries)
+ return results
+
+ def _get_boundary_single(self, score_map, scale):
+ assert len(score_map) == 2
+ assert score_map[1].shape[1] == 4 * self.fourier_degree + 2
+
+ return self.postprocessor(score_map, scale)
diff --git a/mmocr/models/textdet/dense_heads/head_mixin.py b/mmocr/models/textdet/dense_heads/head_mixin.py
new file mode 100644
index 0000000000000000000000000000000000000000..c232e3bea95c2ee5e40b64c65162dfca4884e2d2
--- /dev/null
+++ b/mmocr/models/textdet/dense_heads/head_mixin.py
@@ -0,0 +1,91 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+
+from mmocr.models.builder import HEADS, build_loss, build_postprocessor
+from mmocr.utils import check_argument
+
+
+@HEADS.register_module()
+class HeadMixin:
+ """Base head class for text detection, including loss calcalation and
+ postprocess.
+
+ Args:
+ loss (dict): Config to build loss.
+ postprocessor (dict): Config to build postprocessor.
+ """
+
+ def __init__(self, loss, postprocessor):
+ assert isinstance(loss, dict)
+ assert isinstance(postprocessor, dict)
+
+ self.loss_module = build_loss(loss)
+ self.postprocessor = build_postprocessor(postprocessor)
+
+ def resize_boundary(self, boundaries, scale_factor):
+ """Rescale boundaries via scale_factor.
+
+ Args:
+ boundaries (list[list[float]]): The boundary list. Each boundary
+ has :math:`2k+1` elements with :math:`k>=4`.
+ scale_factor (ndarray): The scale factor of size :math:`(4,)`.
+
+ Returns:
+ list[list[float]]: The scaled boundaries.
+ """
+ assert check_argument.is_2dlist(boundaries)
+ assert isinstance(scale_factor, np.ndarray)
+ assert scale_factor.shape[0] == 4
+
+ for b in boundaries:
+ sz = len(b)
+ check_argument.valid_boundary(b, True)
+ b[:sz -
+ 1] = (np.array(b[:sz - 1]) *
+ (np.tile(scale_factor[:2], int(
+ (sz - 1) / 2)).reshape(1, sz - 1))).flatten().tolist()
+ return boundaries
+
+ def get_boundary(self, score_maps, img_metas, rescale):
+ """Compute text boundaries via post processing.
+
+ Args:
+ score_maps (Tensor): The text score map.
+ img_metas (dict): The image meta info.
+ rescale (bool): Rescale boundaries to the original image resolution
+ if true, and keep the score_maps resolution if false.
+
+ Returns:
+ dict: A dict where boundary results are stored in
+ ``boundary_result``.
+ """
+
+ assert check_argument.is_type_list(img_metas, dict)
+ assert isinstance(rescale, bool)
+
+ score_maps = score_maps.squeeze()
+ boundaries = self.postprocessor(score_maps)
+
+ if rescale:
+ boundaries = self.resize_boundary(
+ boundaries,
+ 1.0 / self.downsample_ratio / img_metas[0]['scale_factor'])
+
+ results = dict(
+ boundary_result=boundaries, filename=img_metas[0]['filename'])
+
+ return results
+
+ def loss(self, pred_maps, **kwargs):
+ """Compute the loss for scene text detection.
+
+ Args:
+ pred_maps (Tensor): The input score maps of shape
+ :math:`(NxCxHxW)`.
+
+ Returns:
+ dict: The dict for losses.
+ """
+ losses = self.loss_module(pred_maps, self.downsample_ratio, **kwargs)
+
+ return losses
diff --git a/mmocr/models/textdet/dense_heads/pan_head.py b/mmocr/models/textdet/dense_heads/pan_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..cd696aa368e46b91fb28fa3e2e5d5026ca123f97
--- /dev/null
+++ b/mmocr/models/textdet/dense_heads/pan_head.py
@@ -0,0 +1,90 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import numpy as np
+import torch
+import torch.nn as nn
+from mmcv.runner import BaseModule
+
+from mmocr.models.builder import HEADS
+from mmocr.utils import check_argument
+from .head_mixin import HeadMixin
+
+
+@HEADS.register_module()
+class PANHead(HeadMixin, BaseModule):
+ """The class for PANet head.
+
+ Args:
+ in_channels (list[int]): A list of 4 numbers of input channels.
+ out_channels (int): Number of output channels.
+ downsample_ratio (float): Downsample ratio.
+ loss (dict): Configuration dictionary for loss type. Supported loss
+ types are "PANLoss" and "PSELoss".
+ postprocessor (dict): Config of postprocessor for PANet.
+ train_cfg, test_cfg (dict): Depreciated.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ downsample_ratio=0.25,
+ loss=dict(type='PANLoss'),
+ postprocessor=dict(
+ type='PANPostprocessor', text_repr_type='poly'),
+ train_cfg=None,
+ test_cfg=None,
+ init_cfg=dict(
+ type='Normal',
+ mean=0,
+ std=0.01,
+ override=dict(name='out_conv')),
+ **kwargs):
+ old_keys = ['text_repr_type', 'decoding_type']
+ for key in old_keys:
+ if kwargs.get(key, None):
+ postprocessor[key] = kwargs.get(key)
+ warnings.warn(
+ f'{key} is deprecated, please specify '
+ 'it in postprocessor config dict. See '
+ 'https://github.com/open-mmlab/mmocr/pull/640'
+ ' for details.', UserWarning)
+
+ BaseModule.__init__(self, init_cfg=init_cfg)
+ HeadMixin.__init__(self, loss, postprocessor)
+
+ assert check_argument.is_type_list(in_channels, int)
+ assert isinstance(out_channels, int)
+
+ assert 0 <= downsample_ratio <= 1
+
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.downsample_ratio = downsample_ratio
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+
+ self.out_conv = nn.Conv2d(
+ in_channels=np.sum(np.array(in_channels)),
+ out_channels=out_channels,
+ kernel_size=1)
+
+ def forward(self, inputs):
+ r"""
+ Args:
+ inputs (list[Tensor] | Tensor): Each tensor has the shape of
+ :math:`(N, C_i, W, H)`, where :math:`\sum_iC_i=C_{in}` and
+ :math:`C_{in}` is ``input_channels``.
+
+ Returns:
+ Tensor: A tensor of shape :math:`(N, C_{out}, W, H)` where
+ :math:`C_{out}` is ``output_channels``.
+ """
+ if isinstance(inputs, tuple):
+ outputs = torch.cat(inputs, dim=1)
+ else:
+ outputs = inputs
+ outputs = self.out_conv(outputs)
+
+ return outputs
diff --git a/mmocr/models/textdet/dense_heads/pse_head.py b/mmocr/models/textdet/dense_heads/pse_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..4952e0a1900af437f6eca6ee7e81c34f160abfed
--- /dev/null
+++ b/mmocr/models/textdet/dense_heads/pse_head.py
@@ -0,0 +1,42 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.models.builder import HEADS
+from . import PANHead
+
+
+@HEADS.register_module()
+class PSEHead(PANHead):
+ """The class for PSENet head.
+
+ Args:
+ in_channels (list[int]): A list of 4 numbers of input channels.
+ out_channels (int): Number of output channels.
+ downsample_ratio (float): Downsample ratio.
+ loss (dict): Configuration dictionary for loss type. Supported loss
+ types are "PANLoss" and "PSELoss".
+ postprocessor (dict): Config of postprocessor for PSENet.
+ train_cfg, test_cfg (dict): Depreciated.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ downsample_ratio=0.25,
+ loss=dict(type='PSELoss'),
+ postprocessor=dict(
+ type='PSEPostprocessor', text_repr_type='poly'),
+ train_cfg=None,
+ test_cfg=None,
+ init_cfg=None,
+ **kwargs):
+
+ super().__init__(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ downsample_ratio=downsample_ratio,
+ loss=loss,
+ postprocessor=postprocessor,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ init_cfg=init_cfg,
+ **kwargs)
diff --git a/mmocr/models/textdet/dense_heads/textsnake_head.py b/mmocr/models/textdet/dense_heads/textsnake_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..777bd703840869b25e8c8c4d71779402e005e8ad
--- /dev/null
+++ b/mmocr/models/textdet/dense_heads/textsnake_head.py
@@ -0,0 +1,81 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import torch.nn as nn
+from mmcv.runner import BaseModule
+
+from mmocr.models.builder import HEADS
+from .head_mixin import HeadMixin
+
+
+@HEADS.register_module()
+class TextSnakeHead(HeadMixin, BaseModule):
+ """The class for TextSnake head: TextSnake: A Flexible Representation for
+ Detecting Text of Arbitrary Shapes.
+
+ TextSnake: `A Flexible Representation for Detecting Text of Arbitrary
+ Shapes `_.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ downsample_ratio (float): Downsample ratio.
+ loss (dict): Configuration dictionary for loss type.
+ postprocessor (dict): Config of postprocessor for TextSnake.
+ train_cfg, test_cfg: Depreciated.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels=5,
+ downsample_ratio=1.0,
+ loss=dict(type='TextSnakeLoss'),
+ postprocessor=dict(
+ type='TextSnakePostprocessor', text_repr_type='poly'),
+ train_cfg=None,
+ test_cfg=None,
+ init_cfg=dict(
+ type='Normal',
+ override=dict(name='out_conv'),
+ mean=0,
+ std=0.01),
+ **kwargs):
+ old_keys = ['text_repr_type', 'decoding_type']
+ for key in old_keys:
+ if kwargs.get(key, None):
+ postprocessor[key] = kwargs.get(key)
+ warnings.warn(
+ f'{key} is deprecated, please specify '
+ 'it in postprocessor config dict. See '
+ 'https://github.com/open-mmlab/mmocr/pull/640 '
+ 'for details.', UserWarning)
+ BaseModule.__init__(self, init_cfg=init_cfg)
+ HeadMixin.__init__(self, loss, postprocessor)
+
+ assert isinstance(in_channels, int)
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.downsample_ratio = downsample_ratio
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+
+ self.out_conv = nn.Conv2d(
+ in_channels=self.in_channels,
+ out_channels=self.out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0)
+
+ def forward(self, inputs):
+ """
+ Args:
+ inputs (Tensor): Shape :math:`(N, C_{in}, H, W)`, where
+ :math:`C_{in}` is ``in_channels``. :math:`H` and :math:`W`
+ should be the same as the input of backbone.
+
+ Returns:
+ Tensor: A tensor of shape :math:`(N, 5, H, W)`.
+ """
+ outputs = self.out_conv(inputs)
+ return outputs
diff --git a/mmocr/models/textdet/detectors/__init__.py b/mmocr/models/textdet/detectors/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..290beee915cf7065559ac3cfde016ad7127bed85
--- /dev/null
+++ b/mmocr/models/textdet/detectors/__init__.py
@@ -0,0 +1,15 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .dbnet import DBNet
+from .drrg import DRRG
+from .fcenet import FCENet
+from .ocr_mask_rcnn import OCRMaskRCNN
+from .panet import PANet
+from .psenet import PSENet
+from .single_stage_text_detector import SingleStageTextDetector
+from .text_detector_mixin import TextDetectorMixin
+from .textsnake import TextSnake
+
+__all__ = [
+ 'TextDetectorMixin', 'SingleStageTextDetector', 'OCRMaskRCNN', 'DBNet',
+ 'PANet', 'PSENet', 'TextSnake', 'FCENet', 'DRRG'
+]
diff --git a/mmocr/models/textdet/detectors/dbnet.py b/mmocr/models/textdet/detectors/dbnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..643e321399967705a20e16068fb0e08b2d20987e
--- /dev/null
+++ b/mmocr/models/textdet/detectors/dbnet.py
@@ -0,0 +1,27 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.models.builder import DETECTORS
+from .single_stage_text_detector import SingleStageTextDetector
+from .text_detector_mixin import TextDetectorMixin
+
+
+@DETECTORS.register_module()
+class DBNet(TextDetectorMixin, SingleStageTextDetector):
+ """The class for implementing DBNet text detector: Real-time Scene Text
+ Detection with Differentiable Binarization.
+
+ [https://arxiv.org/abs/1911.08947].
+ """
+
+ def __init__(self,
+ backbone,
+ neck,
+ bbox_head,
+ train_cfg=None,
+ test_cfg=None,
+ pretrained=None,
+ show_score=False,
+ init_cfg=None):
+ SingleStageTextDetector.__init__(self, backbone, neck, bbox_head,
+ train_cfg, test_cfg, pretrained,
+ init_cfg)
+ TextDetectorMixin.__init__(self, show_score)
diff --git a/mmocr/models/textdet/detectors/drrg.py b/mmocr/models/textdet/detectors/drrg.py
new file mode 100644
index 0000000000000000000000000000000000000000..a5bbc2b8b89ae462139c0c5fc1c9d86d55fdb50a
--- /dev/null
+++ b/mmocr/models/textdet/detectors/drrg.py
@@ -0,0 +1,54 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.models.builder import DETECTORS
+from .single_stage_text_detector import SingleStageTextDetector
+from .text_detector_mixin import TextDetectorMixin
+
+
+@DETECTORS.register_module()
+class DRRG(TextDetectorMixin, SingleStageTextDetector):
+ """The class for implementing DRRG text detector. Deep Relational Reasoning
+ Graph Network for Arbitrary Shape Text Detection.
+
+ [https://arxiv.org/abs/2003.07493]
+ """
+
+ def __init__(self,
+ backbone,
+ neck,
+ bbox_head,
+ train_cfg=None,
+ test_cfg=None,
+ pretrained=None,
+ show_score=False,
+ init_cfg=None):
+ SingleStageTextDetector.__init__(self, backbone, neck, bbox_head,
+ train_cfg, test_cfg, pretrained,
+ init_cfg)
+ TextDetectorMixin.__init__(self, show_score)
+
+ def forward_train(self, img, img_metas, **kwargs):
+ """
+ Args:
+ img (Tensor): Input images of shape (N, C, H, W).
+ Typically these should be mean centered and std scaled.
+ img_metas (list[dict]): A List of image info dict where each dict
+ has: 'img_shape', 'scale_factor', 'flip', and may also contain
+ 'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
+ For details of the values of these keys see
+ :class:`mmdet.datasets.pipelines.Collect`.
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ x = self.extract_feat(img)
+ gt_comp_attribs = kwargs.pop('gt_comp_attribs')
+ preds = self.bbox_head(x, gt_comp_attribs)
+ losses = self.bbox_head.loss(preds, **kwargs)
+ return losses
+
+ def simple_test(self, img, img_metas, rescale=False):
+
+ x = self.extract_feat(img)
+ outs = self.bbox_head.single_test(x)
+ boundaries = self.bbox_head.get_boundary(*outs, img_metas, rescale)
+
+ return [boundaries]
diff --git a/mmocr/models/textdet/detectors/fcenet.py b/mmocr/models/textdet/detectors/fcenet.py
new file mode 100644
index 0000000000000000000000000000000000000000..da9bcb7cf3b2cc210e097945f359dc4952592d81
--- /dev/null
+++ b/mmocr/models/textdet/detectors/fcenet.py
@@ -0,0 +1,35 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.models.builder import DETECTORS
+from .single_stage_text_detector import SingleStageTextDetector
+from .text_detector_mixin import TextDetectorMixin
+
+
+@DETECTORS.register_module()
+class FCENet(TextDetectorMixin, SingleStageTextDetector):
+ """The class for implementing FCENet text detector
+ FCENet(CVPR2021): Fourier Contour Embedding for Arbitrary-shaped Text
+ Detection
+
+ [https://arxiv.org/abs/2104.10442]
+ """
+
+ def __init__(self,
+ backbone,
+ neck,
+ bbox_head,
+ train_cfg=None,
+ test_cfg=None,
+ pretrained=None,
+ show_score=False,
+ init_cfg=None):
+ SingleStageTextDetector.__init__(self, backbone, neck, bbox_head,
+ train_cfg, test_cfg, pretrained,
+ init_cfg)
+ TextDetectorMixin.__init__(self, show_score)
+
+ def simple_test(self, img, img_metas, rescale=False):
+ x = self.extract_feat(img)
+ outs = self.bbox_head(x)
+ boundaries = self.bbox_head.get_boundary(outs, img_metas, rescale)
+
+ return [boundaries]
diff --git a/mmocr/models/textdet/detectors/ocr_mask_rcnn.py b/mmocr/models/textdet/detectors/ocr_mask_rcnn.py
new file mode 100644
index 0000000000000000000000000000000000000000..3cfbff57856fed3066df9548e80d20bc8f4d467e
--- /dev/null
+++ b/mmocr/models/textdet/detectors/ocr_mask_rcnn.py
@@ -0,0 +1,69 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.models.detectors import MaskRCNN
+
+from mmocr.core import seg2boundary
+from mmocr.models.builder import DETECTORS
+from .text_detector_mixin import TextDetectorMixin
+
+
+@DETECTORS.register_module()
+class OCRMaskRCNN(TextDetectorMixin, MaskRCNN):
+ """Mask RCNN tailored for OCR."""
+
+ def __init__(self,
+ backbone,
+ rpn_head,
+ roi_head,
+ train_cfg,
+ test_cfg,
+ neck=None,
+ pretrained=None,
+ text_repr_type='quad',
+ show_score=False,
+ init_cfg=None):
+ TextDetectorMixin.__init__(self, show_score)
+ MaskRCNN.__init__(
+ self,
+ backbone=backbone,
+ neck=neck,
+ rpn_head=rpn_head,
+ roi_head=roi_head,
+ train_cfg=train_cfg,
+ test_cfg=test_cfg,
+ pretrained=pretrained,
+ init_cfg=init_cfg)
+ assert text_repr_type in ['quad', 'poly']
+ self.text_repr_type = text_repr_type
+
+ def get_boundary(self, results):
+ """Convert segmentation into text boundaries.
+
+ Args:
+ results (tuple): The result tuple. The first element is
+ segmentation while the second is its scores.
+ Returns:
+ dict: A result dict containing 'boundary_result'.
+ """
+
+ assert isinstance(results, tuple)
+
+ instance_num = len(results[1][0])
+ boundaries = []
+ for i in range(instance_num):
+ seg = results[1][0][i]
+ score = results[0][0][i][-1]
+ boundary = seg2boundary(seg, self.text_repr_type, score)
+ if boundary is not None:
+ boundaries.append(boundary)
+
+ results = dict(boundary_result=boundaries)
+ return results
+
+ def simple_test(self, img, img_metas, proposals=None, rescale=False):
+
+ results = super().simple_test(img, img_metas, proposals, rescale)
+
+ boundaries = self.get_boundary(results[0])
+ boundaries = boundaries if isinstance(boundaries,
+ list) else [boundaries]
+ return boundaries
diff --git a/mmocr/models/textdet/detectors/panet.py b/mmocr/models/textdet/detectors/panet.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c95251380ebe1455de4d8fef2d0104160458643
--- /dev/null
+++ b/mmocr/models/textdet/detectors/panet.py
@@ -0,0 +1,27 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.models.builder import DETECTORS
+from .single_stage_text_detector import SingleStageTextDetector
+from .text_detector_mixin import TextDetectorMixin
+
+
+@DETECTORS.register_module()
+class PANet(TextDetectorMixin, SingleStageTextDetector):
+ """The class for implementing PANet text detector:
+
+ Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel
+ Aggregation Network [https://arxiv.org/abs/1908.05900].
+ """
+
+ def __init__(self,
+ backbone,
+ neck,
+ bbox_head,
+ train_cfg=None,
+ test_cfg=None,
+ pretrained=None,
+ show_score=False,
+ init_cfg=None):
+ SingleStageTextDetector.__init__(self, backbone, neck, bbox_head,
+ train_cfg, test_cfg, pretrained,
+ init_cfg)
+ TextDetectorMixin.__init__(self, show_score)
diff --git a/mmocr/models/textdet/detectors/psenet.py b/mmocr/models/textdet/detectors/psenet.py
new file mode 100644
index 0000000000000000000000000000000000000000..58dabccbb3d9e6c887e187ad653e28865ef96c7b
--- /dev/null
+++ b/mmocr/models/textdet/detectors/psenet.py
@@ -0,0 +1,27 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.models.builder import DETECTORS
+from .single_stage_text_detector import SingleStageTextDetector
+from .text_detector_mixin import TextDetectorMixin
+
+
+@DETECTORS.register_module()
+class PSENet(TextDetectorMixin, SingleStageTextDetector):
+ """The class for implementing PSENet text detector: Shape Robust Text
+ Detection with Progressive Scale Expansion Network.
+
+ [https://arxiv.org/abs/1806.02559].
+ """
+
+ def __init__(self,
+ backbone,
+ neck,
+ bbox_head,
+ train_cfg=None,
+ test_cfg=None,
+ pretrained=None,
+ show_score=False,
+ init_cfg=None):
+ SingleStageTextDetector.__init__(self, backbone, neck, bbox_head,
+ train_cfg, test_cfg, pretrained,
+ init_cfg)
+ TextDetectorMixin.__init__(self, show_score)
diff --git a/mmocr/models/textdet/detectors/single_stage_text_detector.py b/mmocr/models/textdet/detectors/single_stage_text_detector.py
new file mode 100644
index 0000000000000000000000000000000000000000..d6d27ba24c8840d6f87fd13fa343a0feddfd02e7
--- /dev/null
+++ b/mmocr/models/textdet/detectors/single_stage_text_detector.py
@@ -0,0 +1,61 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmocr.models.builder import DETECTORS
+from mmocr.models.common.detectors import SingleStageDetector
+
+
+@DETECTORS.register_module()
+class SingleStageTextDetector(SingleStageDetector):
+ """The class for implementing single stage text detector."""
+
+ def __init__(self,
+ backbone,
+ neck,
+ bbox_head,
+ train_cfg=None,
+ test_cfg=None,
+ pretrained=None,
+ init_cfg=None):
+ SingleStageDetector.__init__(self, backbone, neck, bbox_head,
+ train_cfg, test_cfg, pretrained, init_cfg)
+
+ def forward_train(self, img, img_metas, **kwargs):
+ """
+ Args:
+ img (Tensor): Input images of shape (N, C, H, W).
+ Typically these should be mean centered and std scaled.
+ img_metas (list[dict]): A list of image info dict where each dict
+ has: 'img_shape', 'scale_factor', 'flip', and may also contain
+ 'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
+ For details on the values of these keys, see
+ :class:`mmdet.datasets.pipelines.Collect`.
+ Returns:
+ dict[str, Tensor]: A dictionary of loss components.
+ """
+ x = self.extract_feat(img)
+ preds = self.bbox_head(x)
+ losses = self.bbox_head.loss(preds, **kwargs)
+ return losses
+
+ def simple_test(self, img, img_metas, rescale=False):
+ x = self.extract_feat(img)
+ outs = self.bbox_head(x)
+
+ # early return to avoid post processing
+ if torch.onnx.is_in_onnx_export():
+ return outs
+
+ if len(img_metas) > 1:
+ boundaries = [
+ self.bbox_head.get_boundary(*(outs[i].unsqueeze(0)),
+ [img_metas[i]], rescale)
+ for i in range(len(img_metas))
+ ]
+
+ else:
+ boundaries = [
+ self.bbox_head.get_boundary(*outs, img_metas, rescale)
+ ]
+
+ return boundaries
diff --git a/mmocr/models/textdet/detectors/text_detector_mixin.py b/mmocr/models/textdet/detectors/text_detector_mixin.py
new file mode 100644
index 0000000000000000000000000000000000000000..e779b26685a1822f08b1ac1468ea4cf32e47f2ee
--- /dev/null
+++ b/mmocr/models/textdet/detectors/text_detector_mixin.py
@@ -0,0 +1,81 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import mmcv
+
+from mmocr.core import imshow_pred_boundary
+
+
+class TextDetectorMixin:
+ """Base class for text detector, only to show results.
+
+ Args:
+ show_score (bool): Whether to show text instance score.
+ """
+
+ def __init__(self, show_score):
+ self.show_score = show_score
+
+ def show_result(self,
+ img,
+ result,
+ score_thr=0.5,
+ bbox_color='green',
+ text_color='green',
+ thickness=1,
+ font_scale=0.5,
+ win_name='',
+ show=False,
+ wait_time=0,
+ out_file=None):
+ """Draw `result` over `img`.
+
+ Args:
+ img (str or Tensor): The image to be displayed.
+ result (dict): The results to draw over `img`.
+ score_thr (float, optional): Minimum score of bboxes to be shown.
+ Default: 0.3.
+ bbox_color (str or tuple or :obj:`Color`): Color of bbox lines.
+ text_color (str or tuple or :obj:`Color`): Color of texts.
+ thickness (int): Thickness of lines.
+ font_scale (float): Font scales of texts.
+ win_name (str): The window name.
+ wait_time (int): Value of waitKey param.
+ Default: 0.
+ show (bool): Whether to show the image.
+ Default: False.
+ out_file (str or None): The filename to write the image.
+ Default: None.imshow_pred_boundary`
+ """
+ img = mmcv.imread(img)
+ img = img.copy()
+ boundaries = None
+ labels = None
+ if 'boundary_result' in result.keys():
+ boundaries = result['boundary_result']
+ labels = [0] * len(boundaries)
+
+ # if out_file specified, do not show image in window
+ if out_file is not None:
+ show = False
+ # draw bounding boxes
+ if boundaries is not None:
+ imshow_pred_boundary(
+ img,
+ boundaries,
+ labels,
+ score_thr=score_thr,
+ boundary_color=bbox_color,
+ text_color=text_color,
+ thickness=thickness,
+ font_scale=font_scale,
+ win_name=win_name,
+ show=show,
+ wait_time=wait_time,
+ out_file=out_file,
+ show_score=self.show_score)
+
+ if not (show or out_file):
+ warnings.warn('show==False and out_file is not specified, '
+ 'result image will be returned')
+ return img
diff --git a/mmocr/models/textdet/detectors/textsnake.py b/mmocr/models/textdet/detectors/textsnake.py
new file mode 100644
index 0000000000000000000000000000000000000000..1b9bc3e28be5f3b4aeb53af16083f291568f5143
--- /dev/null
+++ b/mmocr/models/textdet/detectors/textsnake.py
@@ -0,0 +1,27 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.models.builder import DETECTORS
+from .single_stage_text_detector import SingleStageTextDetector
+from .text_detector_mixin import TextDetectorMixin
+
+
+@DETECTORS.register_module()
+class TextSnake(TextDetectorMixin, SingleStageTextDetector):
+ """The class for implementing TextSnake text detector: TextSnake: A
+ Flexible Representation for Detecting Text of Arbitrary Shapes.
+
+ [https://arxiv.org/abs/1807.01544]
+ """
+
+ def __init__(self,
+ backbone,
+ neck,
+ bbox_head,
+ train_cfg=None,
+ test_cfg=None,
+ pretrained=None,
+ show_score=False,
+ init_cfg=None):
+ SingleStageTextDetector.__init__(self, backbone, neck, bbox_head,
+ train_cfg, test_cfg, pretrained,
+ init_cfg)
+ TextDetectorMixin.__init__(self, show_score)
diff --git a/mmocr/models/textdet/losses/__init__.py b/mmocr/models/textdet/losses/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..a4f247b6e9da94192505faf104cacbc4d00ac384
--- /dev/null
+++ b/mmocr/models/textdet/losses/__init__.py
@@ -0,0 +1,11 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .db_loss import DBLoss
+from .drrg_loss import DRRGLoss
+from .fce_loss import FCELoss
+from .pan_loss import PANLoss
+from .pse_loss import PSELoss
+from .textsnake_loss import TextSnakeLoss
+
+__all__ = [
+ 'PANLoss', 'PSELoss', 'DBLoss', 'TextSnakeLoss', 'FCELoss', 'DRRGLoss'
+]
diff --git a/mmocr/models/textdet/losses/db_loss.py b/mmocr/models/textdet/losses/db_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..20ca2259826680d0b41390ecb66bb42c1e43390f
--- /dev/null
+++ b/mmocr/models/textdet/losses/db_loss.py
@@ -0,0 +1,165 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+from mmocr.models.builder import LOSSES
+from mmocr.models.common.losses.dice_loss import DiceLoss
+
+
+@LOSSES.register_module()
+class DBLoss(nn.Module):
+ """The class for implementing DBNet loss.
+
+ This is partially adapted from https://github.com/MhLiao/DB.
+
+ Args:
+ alpha (float): The binary loss coef.
+ beta (float): The threshold loss coef.
+ reduction (str): The way to reduce the loss.
+ negative_ratio (float): The ratio of positives to negatives.
+ eps (float): Epsilon in the threshold loss function.
+ bbce_loss (bool): Whether to use balanced bce for probability loss.
+ If False, dice loss will be used instead.
+ """
+
+ def __init__(self,
+ alpha=1,
+ beta=1,
+ reduction='mean',
+ negative_ratio=3.0,
+ eps=1e-6,
+ bbce_loss=False):
+ super().__init__()
+ assert reduction in ['mean',
+ 'sum'], " reduction must in ['mean','sum']"
+ self.alpha = alpha
+ self.beta = beta
+ self.reduction = reduction
+ self.negative_ratio = negative_ratio
+ self.eps = eps
+ self.bbce_loss = bbce_loss
+ self.dice_loss = DiceLoss(eps=eps)
+
+ def bitmasks2tensor(self, bitmasks, target_sz):
+ """Convert Bitmasks to tensor.
+
+ Args:
+ bitmasks (list[BitmapMasks]): The BitmapMasks list. Each item is
+ for one img.
+ target_sz (tuple(int, int)): The target tensor of size
+ :math:`(H, W)`.
+
+ Returns:
+ list[Tensor]: The list of kernel tensors. Each element stands for
+ one kernel level.
+ """
+ assert isinstance(bitmasks, list)
+ assert isinstance(target_sz, tuple)
+
+ batch_size = len(bitmasks)
+ num_levels = len(bitmasks[0])
+
+ result_tensors = []
+
+ for level_inx in range(num_levels):
+ kernel = []
+ for batch_inx in range(batch_size):
+ mask = torch.from_numpy(bitmasks[batch_inx].masks[level_inx])
+ mask_sz = mask.shape
+ pad = [
+ 0, target_sz[1] - mask_sz[1], 0, target_sz[0] - mask_sz[0]
+ ]
+ mask = F.pad(mask, pad, mode='constant', value=0)
+ kernel.append(mask)
+ kernel = torch.stack(kernel)
+ result_tensors.append(kernel)
+
+ return result_tensors
+
+ def balance_bce_loss(self, pred, gt, mask):
+
+ positive = (gt * mask)
+ negative = ((1 - gt) * mask)
+ positive_count = int(positive.float().sum())
+ negative_count = min(
+ int(negative.float().sum()),
+ int(positive_count * self.negative_ratio))
+
+ assert gt.max() <= 1 and gt.min() >= 0
+ assert pred.max() <= 1 and pred.min() >= 0
+ loss = F.binary_cross_entropy(pred, gt, reduction='none')
+ positive_loss = loss * positive.float()
+ negative_loss = loss * negative.float()
+
+ negative_loss, _ = torch.topk(negative_loss.view(-1), negative_count)
+
+ balance_loss = (positive_loss.sum() + negative_loss.sum()) / (
+ positive_count + negative_count + self.eps)
+
+ return balance_loss
+
+ def l1_thr_loss(self, pred, gt, mask):
+ thr_loss = torch.abs((pred - gt) * mask).sum() / (
+ mask.sum() + self.eps)
+ return thr_loss
+
+ def forward(self, preds, downsample_ratio, gt_shrink, gt_shrink_mask,
+ gt_thr, gt_thr_mask):
+ """Compute DBNet loss.
+
+ Args:
+ preds (Tensor): The output tensor with size :math:`(N, 3, H, W)`.
+ downsample_ratio (float): The downsample ratio for the
+ ground truths.
+ gt_shrink (list[BitmapMasks]): The mask list with each element
+ being the shrunk text mask for one img.
+ gt_shrink_mask (list[BitmapMasks]): The effective mask list with
+ each element being the shrunk effective mask for one img.
+ gt_thr (list[BitmapMasks]): The mask list with each element
+ being the threshold text mask for one img.
+ gt_thr_mask (list[BitmapMasks]): The effective mask list with
+ each element being the threshold effective mask for one img.
+
+ Returns:
+ dict: The dict for dbnet losses with "loss_prob", "loss_db" and
+ "loss_thresh".
+ """
+ assert isinstance(downsample_ratio, float)
+
+ assert isinstance(gt_shrink, list)
+ assert isinstance(gt_shrink_mask, list)
+ assert isinstance(gt_thr, list)
+ assert isinstance(gt_thr_mask, list)
+
+ pred_prob = preds[:, 0, :, :]
+ pred_thr = preds[:, 1, :, :]
+ pred_db = preds[:, 2, :, :]
+ feature_sz = preds.size()
+
+ keys = ['gt_shrink', 'gt_shrink_mask', 'gt_thr', 'gt_thr_mask']
+ gt = {}
+ for k in keys:
+ gt[k] = eval(k)
+ gt[k] = [item.rescale(downsample_ratio) for item in gt[k]]
+ gt[k] = self.bitmasks2tensor(gt[k], feature_sz[2:])
+ gt[k] = [item.to(preds.device) for item in gt[k]]
+ gt['gt_shrink'][0] = (gt['gt_shrink'][0] > 0).float()
+ if self.bbce_loss:
+ loss_prob = self.balance_bce_loss(pred_prob, gt['gt_shrink'][0],
+ gt['gt_shrink_mask'][0])
+ else:
+ loss_prob = self.dice_loss(pred_prob, gt['gt_shrink'][0],
+ gt['gt_shrink_mask'][0])
+
+ loss_db = self.dice_loss(pred_db, gt['gt_shrink'][0],
+ gt['gt_shrink_mask'][0])
+ loss_thr = self.l1_thr_loss(pred_thr, gt['gt_thr'][0],
+ gt['gt_thr_mask'][0])
+
+ results = dict(
+ loss_prob=self.alpha * loss_prob,
+ loss_db=loss_db,
+ loss_thr=self.beta * loss_thr)
+
+ return results
diff --git a/mmocr/models/textdet/losses/drrg_loss.py b/mmocr/models/textdet/losses/drrg_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..a59868d942baaba7586554e90414d19e6de9ec29
--- /dev/null
+++ b/mmocr/models/textdet/losses/drrg_loss.py
@@ -0,0 +1,253 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn.functional as F
+from mmdet.core import BitmapMasks
+from torch import nn
+
+from mmocr.models.builder import LOSSES
+from mmocr.utils import check_argument
+
+
+@LOSSES.register_module()
+class DRRGLoss(nn.Module):
+ """The class for implementing DRRG loss. This is partially adapted from
+ https://github.com/GXYM/DRRG licensed under the MIT license.
+
+ DRRG: `Deep Relational Reasoning Graph Network for Arbitrary Shape Text
+ Detection `_.
+
+ Args:
+ ohem_ratio (float): The negative/positive ratio in ohem.
+ """
+
+ def __init__(self, ohem_ratio=3.0):
+ super().__init__()
+ self.ohem_ratio = ohem_ratio
+
+ def balance_bce_loss(self, pred, gt, mask):
+ """Balanced Binary-CrossEntropy Loss.
+
+ Args:
+ pred (Tensor): Shape of :math:`(1, H, W)`.
+ gt (Tensor): Shape of :math:`(1, H, W)`.
+ mask (Tensor): Shape of :math:`(1, H, W)`.
+
+ Returns:
+ Tensor: Balanced bce loss.
+ """
+ assert pred.shape == gt.shape == mask.shape
+ assert torch.all(pred >= 0) and torch.all(pred <= 1)
+ assert torch.all(gt >= 0) and torch.all(gt <= 1)
+ positive = gt * mask
+ negative = (1 - gt) * mask
+ positive_count = int(positive.float().sum())
+ gt = gt.float()
+ if positive_count > 0:
+ loss = F.binary_cross_entropy(pred, gt, reduction='none')
+ positive_loss = torch.sum(loss * positive.float())
+ negative_loss = loss * negative.float()
+ negative_count = min(
+ int(negative.float().sum()),
+ int(positive_count * self.ohem_ratio))
+ else:
+ positive_loss = torch.tensor(0.0, device=pred.device)
+ loss = F.binary_cross_entropy(pred, gt, reduction='none')
+ negative_loss = loss * negative.float()
+ negative_count = 100
+ negative_loss, _ = torch.topk(negative_loss.view(-1), negative_count)
+
+ balance_loss = (positive_loss + torch.sum(negative_loss)) / (
+ float(positive_count + negative_count) + 1e-5)
+
+ return balance_loss
+
+ def gcn_loss(self, gcn_data):
+ """CrossEntropy Loss from gcn module.
+
+ Args:
+ gcn_data (tuple(Tensor, Tensor)): The first is the
+ prediction with shape :math:`(N, 2)` and the
+ second is the gt label with shape :math:`(m, n)`
+ where :math:`m * n = N`.
+
+ Returns:
+ Tensor: CrossEntropy loss.
+ """
+ gcn_pred, gt_labels = gcn_data
+ gt_labels = gt_labels.view(-1).to(gcn_pred.device)
+ loss = F.cross_entropy(gcn_pred, gt_labels)
+
+ return loss
+
+ def bitmasks2tensor(self, bitmasks, target_sz):
+ """Convert Bitmasks to tensor.
+
+ Args:
+ bitmasks (list[BitmapMasks]): The BitmapMasks list. Each item is
+ for one img.
+ target_sz (tuple(int, int)): The target tensor of size
+ :math:`(H, W)`.
+
+ Returns:
+ list[Tensor]: The list of kernel tensors. Each element stands for
+ one kernel level.
+ """
+ assert check_argument.is_type_list(bitmasks, BitmapMasks)
+ assert isinstance(target_sz, tuple)
+
+ batch_size = len(bitmasks)
+ num_masks = len(bitmasks[0])
+
+ results = []
+
+ for level_inx in range(num_masks):
+ kernel = []
+ for batch_inx in range(batch_size):
+ mask = torch.from_numpy(bitmasks[batch_inx].masks[level_inx])
+ # hxw
+ mask_sz = mask.shape
+ # left, right, top, bottom
+ pad = [
+ 0, target_sz[1] - mask_sz[1], 0, target_sz[0] - mask_sz[0]
+ ]
+ mask = F.pad(mask, pad, mode='constant', value=0)
+ kernel.append(mask)
+ kernel = torch.stack(kernel)
+ results.append(kernel)
+
+ return results
+
+ def forward(self, preds, downsample_ratio, gt_text_mask,
+ gt_center_region_mask, gt_mask, gt_top_height_map,
+ gt_bot_height_map, gt_sin_map, gt_cos_map):
+ """Compute Drrg loss.
+
+ Args:
+ preds (tuple(Tensor)): The first is the prediction map
+ with shape :math:`(N, C_{out}, H, W)`.
+ The second is prediction from GCN module, with
+ shape :math:`(N, 2)`.
+ The third is ground-truth label with shape :math:`(N, 8)`.
+ downsample_ratio (float): The downsample ratio.
+ gt_text_mask (list[BitmapMasks]): Text mask.
+ gt_center_region_mask (list[BitmapMasks]): Center region mask.
+ gt_mask (list[BitmapMasks]): Effective mask.
+ gt_top_height_map (list[BitmapMasks]): Top height map.
+ gt_bot_height_map (list[BitmapMasks]): Bottom height map.
+ gt_sin_map (list[BitmapMasks]): Sinusoid map.
+ gt_cos_map (list[BitmapMasks]): Cosine map.
+
+ Returns:
+ dict: A loss dict with ``loss_text``, ``loss_center``,
+ ``loss_height``, ``loss_sin``, ``loss_cos``, and ``loss_gcn``.
+ """
+ assert isinstance(preds, tuple)
+ assert isinstance(downsample_ratio, float)
+ assert check_argument.is_type_list(gt_text_mask, BitmapMasks)
+ assert check_argument.is_type_list(gt_center_region_mask, BitmapMasks)
+ assert check_argument.is_type_list(gt_mask, BitmapMasks)
+ assert check_argument.is_type_list(gt_top_height_map, BitmapMasks)
+ assert check_argument.is_type_list(gt_bot_height_map, BitmapMasks)
+ assert check_argument.is_type_list(gt_sin_map, BitmapMasks)
+ assert check_argument.is_type_list(gt_cos_map, BitmapMasks)
+
+ pred_maps, gcn_data = preds
+ pred_text_region = pred_maps[:, 0, :, :]
+ pred_center_region = pred_maps[:, 1, :, :]
+ pred_sin_map = pred_maps[:, 2, :, :]
+ pred_cos_map = pred_maps[:, 3, :, :]
+ pred_top_height_map = pred_maps[:, 4, :, :]
+ pred_bot_height_map = pred_maps[:, 5, :, :]
+ feature_sz = pred_maps.size()
+ device = pred_maps.device
+
+ # bitmask 2 tensor
+ mapping = {
+ 'gt_text_mask': gt_text_mask,
+ 'gt_center_region_mask': gt_center_region_mask,
+ 'gt_mask': gt_mask,
+ 'gt_top_height_map': gt_top_height_map,
+ 'gt_bot_height_map': gt_bot_height_map,
+ 'gt_sin_map': gt_sin_map,
+ 'gt_cos_map': gt_cos_map
+ }
+ gt = {}
+ for key, value in mapping.items():
+ gt[key] = value
+ if abs(downsample_ratio - 1.0) < 1e-2:
+ gt[key] = self.bitmasks2tensor(gt[key], feature_sz[2:])
+ else:
+ gt[key] = [item.rescale(downsample_ratio) for item in gt[key]]
+ gt[key] = self.bitmasks2tensor(gt[key], feature_sz[2:])
+ if key in ['gt_top_height_map', 'gt_bot_height_map']:
+ gt[key] = [item * downsample_ratio for item in gt[key]]
+ gt[key] = [item.to(device) for item in gt[key]]
+
+ scale = torch.sqrt(1.0 / (pred_sin_map**2 + pred_cos_map**2 + 1e-8))
+ pred_sin_map = pred_sin_map * scale
+ pred_cos_map = pred_cos_map * scale
+
+ loss_text = self.balance_bce_loss(
+ torch.sigmoid(pred_text_region), gt['gt_text_mask'][0],
+ gt['gt_mask'][0])
+
+ text_mask = (gt['gt_text_mask'][0] * gt['gt_mask'][0]).float()
+ negative_text_mask = ((1 - gt['gt_text_mask'][0]) *
+ gt['gt_mask'][0]).float()
+ loss_center_map = F.binary_cross_entropy(
+ torch.sigmoid(pred_center_region),
+ gt['gt_center_region_mask'][0].float(),
+ reduction='none')
+ if int(text_mask.sum()) > 0:
+ loss_center_positive = torch.sum(
+ loss_center_map * text_mask) / torch.sum(text_mask)
+ else:
+ loss_center_positive = torch.tensor(0.0, device=device)
+ loss_center_negative = torch.sum(
+ loss_center_map *
+ negative_text_mask) / torch.sum(negative_text_mask)
+ loss_center = loss_center_positive + 0.5 * loss_center_negative
+
+ center_mask = (gt['gt_center_region_mask'][0] *
+ gt['gt_mask'][0]).float()
+ if int(center_mask.sum()) > 0:
+ map_sz = pred_top_height_map.size()
+ ones = torch.ones(map_sz, dtype=torch.float, device=device)
+ loss_top = F.smooth_l1_loss(
+ pred_top_height_map / (gt['gt_top_height_map'][0] + 1e-2),
+ ones,
+ reduction='none')
+ loss_bot = F.smooth_l1_loss(
+ pred_bot_height_map / (gt['gt_bot_height_map'][0] + 1e-2),
+ ones,
+ reduction='none')
+ gt_height = (
+ gt['gt_top_height_map'][0] + gt['gt_bot_height_map'][0])
+ loss_height = torch.sum(
+ (torch.log(gt_height + 1) *
+ (loss_top + loss_bot)) * center_mask) / torch.sum(center_mask)
+
+ loss_sin = torch.sum(
+ F.smooth_l1_loss(
+ pred_sin_map, gt['gt_sin_map'][0], reduction='none') *
+ center_mask) / torch.sum(center_mask)
+ loss_cos = torch.sum(
+ F.smooth_l1_loss(
+ pred_cos_map, gt['gt_cos_map'][0], reduction='none') *
+ center_mask) / torch.sum(center_mask)
+ else:
+ loss_height = torch.tensor(0.0, device=device)
+ loss_sin = torch.tensor(0.0, device=device)
+ loss_cos = torch.tensor(0.0, device=device)
+
+ loss_gcn = self.gcn_loss(gcn_data)
+
+ results = dict(
+ loss_text=loss_text,
+ loss_center=loss_center,
+ loss_height=loss_height,
+ loss_sin=loss_sin,
+ loss_cos=loss_cos,
+ loss_gcn=loss_gcn)
+
+ return results
diff --git a/mmocr/models/textdet/losses/fce_loss.py b/mmocr/models/textdet/losses/fce_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..e956f10ed4be9afc3bd5803073b8bba0c723a714
--- /dev/null
+++ b/mmocr/models/textdet/losses/fce_loss.py
@@ -0,0 +1,207 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import torch
+import torch.nn.functional as F
+from mmdet.core import multi_apply
+from torch import nn
+
+from mmocr.models.builder import LOSSES
+
+
+@LOSSES.register_module()
+class FCELoss(nn.Module):
+ """The class for implementing FCENet loss.
+
+ FCENet(CVPR2021): `Fourier Contour Embedding for Arbitrary-shaped Text
+ Detection `_
+
+ Args:
+ fourier_degree (int) : The maximum Fourier transform degree k.
+ num_sample (int) : The sampling points number of regression
+ loss. If it is too small, fcenet tends to be overfitting.
+ ohem_ratio (float): the negative/positive ratio in OHEM.
+ """
+
+ def __init__(self, fourier_degree, num_sample, ohem_ratio=3.):
+ super().__init__()
+ self.fourier_degree = fourier_degree
+ self.num_sample = num_sample
+ self.ohem_ratio = ohem_ratio
+
+ def forward(self, preds, _, p3_maps, p4_maps, p5_maps):
+ """Compute FCENet loss.
+
+ Args:
+ preds (list[list[Tensor]]): The outer list indicates images
+ in a batch, and the inner list indicates the classification
+ prediction map (with shape :math:`(N, C, H, W)`) and
+ regression map (with shape :math:`(N, C, H, W)`).
+ p3_maps (list[ndarray]): List of leval 3 ground truth target map
+ with shape :math:`(C, H, W)`.
+ p4_maps (list[ndarray]): List of leval 4 ground truth target map
+ with shape :math:`(C, H, W)`.
+ p5_maps (list[ndarray]): List of leval 5 ground truth target map
+ with shape :math:`(C, H, W)`.
+
+ Returns:
+ dict: A loss dict with ``loss_text``, ``loss_center``,
+ ``loss_reg_x`` and ``loss_reg_y``.
+ """
+ assert isinstance(preds, list)
+ assert p3_maps[0].shape[0] == 4 * self.fourier_degree + 5,\
+ 'fourier degree not equal in FCEhead and FCEtarget'
+
+ device = preds[0][0].device
+ # to tensor
+ gts = [p3_maps, p4_maps, p5_maps]
+ for idx, maps in enumerate(gts):
+ gts[idx] = torch.from_numpy(np.stack(maps)).float().to(device)
+
+ losses = multi_apply(self.forward_single, preds, gts)
+
+ loss_tr = torch.tensor(0., device=device).float()
+ loss_tcl = torch.tensor(0., device=device).float()
+ loss_reg_x = torch.tensor(0., device=device).float()
+ loss_reg_y = torch.tensor(0., device=device).float()
+
+ for idx, loss in enumerate(losses):
+ if idx == 0:
+ loss_tr += sum(loss)
+ elif idx == 1:
+ loss_tcl += sum(loss)
+ elif idx == 2:
+ loss_reg_x += sum(loss)
+ else:
+ loss_reg_y += sum(loss)
+
+ results = dict(
+ loss_text=loss_tr,
+ loss_center=loss_tcl,
+ loss_reg_x=loss_reg_x,
+ loss_reg_y=loss_reg_y,
+ )
+
+ return results
+
+ def forward_single(self, pred, gt):
+ cls_pred = pred[0].permute(0, 2, 3, 1).contiguous()
+ reg_pred = pred[1].permute(0, 2, 3, 1).contiguous()
+ gt = gt.permute(0, 2, 3, 1).contiguous()
+
+ k = 2 * self.fourier_degree + 1
+ tr_pred = cls_pred[:, :, :, :2].view(-1, 2)
+ tcl_pred = cls_pred[:, :, :, 2:].view(-1, 2)
+ x_pred = reg_pred[:, :, :, 0:k].view(-1, k)
+ y_pred = reg_pred[:, :, :, k:2 * k].view(-1, k)
+
+ tr_mask = gt[:, :, :, :1].view(-1)
+ tcl_mask = gt[:, :, :, 1:2].view(-1)
+ train_mask = gt[:, :, :, 2:3].view(-1)
+ x_map = gt[:, :, :, 3:3 + k].view(-1, k)
+ y_map = gt[:, :, :, 3 + k:].view(-1, k)
+
+ tr_train_mask = train_mask * tr_mask
+ device = x_map.device
+ # tr loss
+ loss_tr = self.ohem(tr_pred, tr_mask.long(), train_mask.long())
+
+ # tcl loss
+ loss_tcl = torch.tensor(0.).float().to(device)
+ tr_neg_mask = 1 - tr_train_mask
+ if tr_train_mask.sum().item() > 0:
+ loss_tcl_pos = F.cross_entropy(
+ tcl_pred[tr_train_mask.bool()],
+ tcl_mask[tr_train_mask.bool()].long())
+ loss_tcl_neg = F.cross_entropy(tcl_pred[tr_neg_mask.bool()],
+ tcl_mask[tr_neg_mask.bool()].long())
+ loss_tcl = loss_tcl_pos + 0.5 * loss_tcl_neg
+
+ # regression loss
+ loss_reg_x = torch.tensor(0.).float().to(device)
+ loss_reg_y = torch.tensor(0.).float().to(device)
+ if tr_train_mask.sum().item() > 0:
+ weight = (tr_mask[tr_train_mask.bool()].float() +
+ tcl_mask[tr_train_mask.bool()].float()) / 2
+ weight = weight.contiguous().view(-1, 1)
+
+ ft_x, ft_y = self.fourier2poly(x_map, y_map)
+ ft_x_pre, ft_y_pre = self.fourier2poly(x_pred, y_pred)
+
+ loss_reg_x = torch.mean(weight * F.smooth_l1_loss(
+ ft_x_pre[tr_train_mask.bool()],
+ ft_x[tr_train_mask.bool()],
+ reduction='none'))
+ loss_reg_y = torch.mean(weight * F.smooth_l1_loss(
+ ft_y_pre[tr_train_mask.bool()],
+ ft_y[tr_train_mask.bool()],
+ reduction='none'))
+
+ return loss_tr, loss_tcl, loss_reg_x, loss_reg_y
+
+ def ohem(self, predict, target, train_mask):
+ device = train_mask.device
+ pos = (target * train_mask).bool()
+ neg = ((1 - target) * train_mask).bool()
+
+ n_pos = pos.float().sum()
+
+ if n_pos.item() > 0:
+ loss_pos = F.cross_entropy(
+ predict[pos], target[pos], reduction='sum')
+ loss_neg = F.cross_entropy(
+ predict[neg], target[neg], reduction='none')
+ n_neg = min(
+ int(neg.float().sum().item()),
+ int(self.ohem_ratio * n_pos.float()))
+ else:
+ loss_pos = torch.tensor(0.).to(device)
+ loss_neg = F.cross_entropy(
+ predict[neg], target[neg], reduction='none')
+ n_neg = 100
+ if len(loss_neg) > n_neg:
+ loss_neg, _ = torch.topk(loss_neg, n_neg)
+
+ return (loss_pos + loss_neg.sum()) / (n_pos + n_neg).float()
+
+ def fourier2poly(self, real_maps, imag_maps):
+ """Transform Fourier coefficient maps to polygon maps.
+
+ Args:
+ real_maps (tensor): A map composed of the real parts of the
+ Fourier coefficients, whose shape is (-1, 2k+1)
+ imag_maps (tensor):A map composed of the imag parts of the
+ Fourier coefficients, whose shape is (-1, 2k+1)
+
+ Returns
+ x_maps (tensor): A map composed of the x value of the polygon
+ represented by n sample points (xn, yn), whose shape is (-1, n)
+ y_maps (tensor): A map composed of the y value of the polygon
+ represented by n sample points (xn, yn), whose shape is (-1, n)
+ """
+
+ device = real_maps.device
+
+ k_vect = torch.arange(
+ -self.fourier_degree,
+ self.fourier_degree + 1,
+ dtype=torch.float,
+ device=device).view(-1, 1)
+ i_vect = torch.arange(
+ 0, self.num_sample, dtype=torch.float, device=device).view(1, -1)
+
+ transform_matrix = 2 * np.pi / self.num_sample * torch.mm(
+ k_vect, i_vect)
+
+ x1 = torch.einsum('ak, kn-> an', real_maps,
+ torch.cos(transform_matrix))
+ x2 = torch.einsum('ak, kn-> an', imag_maps,
+ torch.sin(transform_matrix))
+ y1 = torch.einsum('ak, kn-> an', real_maps,
+ torch.sin(transform_matrix))
+ y2 = torch.einsum('ak, kn-> an', imag_maps,
+ torch.cos(transform_matrix))
+
+ x_maps = x1 - x2
+ y_maps = y1 + y2
+
+ return x_maps, y_maps
diff --git a/mmocr/models/textdet/losses/pan_loss.py b/mmocr/models/textdet/losses/pan_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..04f691eb2b458edf9a950052834618840cb02871
--- /dev/null
+++ b/mmocr/models/textdet/losses/pan_loss.py
@@ -0,0 +1,333 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import itertools
+import warnings
+
+import numpy as np
+import torch
+import torch.nn.functional as F
+from mmdet.core import BitmapMasks
+from torch import nn
+
+from mmocr.models.builder import LOSSES
+from mmocr.utils import check_argument
+
+
+@LOSSES.register_module()
+class PANLoss(nn.Module):
+ """The class for implementing PANet loss. This was partially adapted from
+ https://github.com/WenmuZhou/PAN.pytorch.
+
+ PANet: `Efficient and Accurate Arbitrary-
+ Shaped Text Detection with Pixel Aggregation Network
+ `_.
+
+ Args:
+ alpha (float): The kernel loss coef.
+ beta (float): The aggregation and discriminative loss coef.
+ delta_aggregation (float): The constant for aggregation loss.
+ delta_discrimination (float): The constant for discriminative loss.
+ ohem_ratio (float): The negative/positive ratio in ohem.
+ reduction (str): The way to reduce the loss.
+ speedup_bbox_thr (int): Speed up if speedup_bbox_thr > 0
+ and < bbox num.
+ """
+
+ def __init__(self,
+ alpha=0.5,
+ beta=0.25,
+ delta_aggregation=0.5,
+ delta_discrimination=3,
+ ohem_ratio=3,
+ reduction='mean',
+ speedup_bbox_thr=-1):
+ super().__init__()
+ assert reduction in ['mean', 'sum'], "reduction must in ['mean','sum']"
+ self.alpha = alpha
+ self.beta = beta
+ self.delta_aggregation = delta_aggregation
+ self.delta_discrimination = delta_discrimination
+ self.ohem_ratio = ohem_ratio
+ self.reduction = reduction
+ self.speedup_bbox_thr = speedup_bbox_thr
+
+ def bitmasks2tensor(self, bitmasks, target_sz):
+ """Convert Bitmasks to tensor.
+
+ Args:
+ bitmasks (list[BitmapMasks]): The BitmapMasks list. Each item is
+ for one img.
+ target_sz (tuple(int, int)): The target tensor of size
+ :math:`(H, W)`.
+
+ Returns:
+ list[Tensor]: The list of kernel tensors. Each element stands for
+ one kernel level.
+ """
+ assert check_argument.is_type_list(bitmasks, BitmapMasks)
+ assert isinstance(target_sz, tuple)
+
+ batch_size = len(bitmasks)
+ num_masks = len(bitmasks[0])
+
+ results = []
+
+ for level_inx in range(num_masks):
+ kernel = []
+ for batch_inx in range(batch_size):
+ mask = torch.from_numpy(bitmasks[batch_inx].masks[level_inx])
+ # hxw
+ mask_sz = mask.shape
+ # left, right, top, bottom
+ pad = [
+ 0, target_sz[1] - mask_sz[1], 0, target_sz[0] - mask_sz[0]
+ ]
+ mask = F.pad(mask, pad, mode='constant', value=0)
+ kernel.append(mask)
+ kernel = torch.stack(kernel)
+ results.append(kernel)
+
+ return results
+
+ def forward(self, preds, downsample_ratio, gt_kernels, gt_mask):
+ """Compute PANet loss.
+
+ Args:
+ preds (Tensor): The output tensor of size :math:`(N, 6, H, W)`.
+ downsample_ratio (float): The downsample ratio between preds
+ and the input img.
+ gt_kernels (list[BitmapMasks]): The kernel list with each element
+ being the text kernel mask for one img.
+ gt_mask (list[BitmapMasks]): The effective mask list
+ with each element being the effective mask for one img.
+
+ Returns:
+ dict: A loss dict with ``loss_text``, ``loss_kernel``,
+ ``loss_aggregation`` and ``loss_discrimination``.
+ """
+
+ assert check_argument.is_type_list(gt_kernels, BitmapMasks)
+ assert check_argument.is_type_list(gt_mask, BitmapMasks)
+ assert isinstance(downsample_ratio, float)
+
+ pred_texts = preds[:, 0, :, :]
+ pred_kernels = preds[:, 1, :, :]
+ inst_embed = preds[:, 2:, :, :]
+ feature_sz = preds.size()
+
+ mapping = {'gt_kernels': gt_kernels, 'gt_mask': gt_mask}
+ gt = {}
+ for key, value in mapping.items():
+ gt[key] = value
+ gt[key] = [item.rescale(downsample_ratio) for item in gt[key]]
+ gt[key] = self.bitmasks2tensor(gt[key], feature_sz[2:])
+ gt[key] = [item.to(preds.device) for item in gt[key]]
+ loss_aggrs, loss_discrs = self.aggregation_discrimination_loss(
+ gt['gt_kernels'][0], gt['gt_kernels'][1], inst_embed)
+ # compute text loss
+ sampled_mask = self.ohem_batch(pred_texts.detach(),
+ gt['gt_kernels'][0], gt['gt_mask'][0])
+ loss_texts = self.dice_loss_with_logits(pred_texts,
+ gt['gt_kernels'][0],
+ sampled_mask)
+
+ # compute kernel loss
+
+ sampled_masks_kernel = (gt['gt_kernels'][0] > 0.5).float() * (
+ gt['gt_mask'][0].float())
+ loss_kernels = self.dice_loss_with_logits(pred_kernels,
+ gt['gt_kernels'][1],
+ sampled_masks_kernel)
+ losses = [loss_texts, loss_kernels, loss_aggrs, loss_discrs]
+ if self.reduction == 'mean':
+ losses = [item.mean() for item in losses]
+ elif self.reduction == 'sum':
+ losses = [item.sum() for item in losses]
+ else:
+ raise NotImplementedError
+
+ coefs = [1, self.alpha, self.beta, self.beta]
+ losses = [item * scale for item, scale in zip(losses, coefs)]
+
+ results = dict()
+ results.update(
+ loss_text=losses[0],
+ loss_kernel=losses[1],
+ loss_aggregation=losses[2],
+ loss_discrimination=losses[3])
+ return results
+
+ def aggregation_discrimination_loss(self, gt_texts, gt_kernels,
+ inst_embeds):
+ """Compute the aggregation and discrimnative losses.
+
+ Args:
+ gt_texts (Tensor): The ground truth text mask of size
+ :math:`(N, 1, H, W)`.
+ gt_kernels (Tensor): The ground truth text kernel mask of
+ size :math:`(N, 1, H, W)`.
+ inst_embeds(Tensor): The text instance embedding tensor
+ of size :math:`(N, 1, H, W)`.
+
+ Returns:
+ (Tensor, Tensor): A tuple of aggregation loss and discriminative
+ loss before reduction.
+ """
+
+ batch_size = gt_texts.size()[0]
+ gt_texts = gt_texts.contiguous().reshape(batch_size, -1)
+ gt_kernels = gt_kernels.contiguous().reshape(batch_size, -1)
+
+ assert inst_embeds.shape[1] == 4
+ inst_embeds = inst_embeds.contiguous().reshape(batch_size, 4, -1)
+
+ loss_aggrs = []
+ loss_discrs = []
+
+ for text, kernel, embed in zip(gt_texts, gt_kernels, inst_embeds):
+
+ # for each image
+ text_num = int(text.max().item())
+ loss_aggr_img = []
+ kernel_avgs = []
+ select_num = self.speedup_bbox_thr
+ if 0 < select_num < text_num:
+ inds = np.random.choice(
+ text_num, select_num, replace=False) + 1
+ else:
+ inds = range(1, text_num + 1)
+
+ for i in inds:
+ # for each text instance
+ kernel_i = (kernel == i) # 0.2ms
+ if kernel_i.sum() == 0 or (text == i).sum() == 0: # 0.2ms
+ continue
+
+ # compute G_Ki in Eq (2)
+ avg = embed[:, kernel_i].mean(1) # 0.5ms
+ kernel_avgs.append(avg)
+
+ embed_i = embed[:, text == i] # 0.6ms
+ # ||F(p) - G(K_i)|| - delta_aggregation, shape: nums
+ distance = (embed_i - avg.reshape(4, 1)).norm( # 0.5ms
+ 2, dim=0) - self.delta_aggregation
+ # compute D(p,K_i) in Eq (2)
+ hinge = torch.max(
+ distance,
+ torch.tensor(0, device=distance.device,
+ dtype=torch.float)).pow(2)
+
+ aggr = torch.log(hinge + 1).mean()
+ loss_aggr_img.append(aggr)
+
+ num_inst = len(loss_aggr_img)
+ if num_inst > 0:
+ loss_aggr_img = torch.stack(loss_aggr_img).mean()
+ else:
+ loss_aggr_img = torch.tensor(
+ 0, device=gt_texts.device, dtype=torch.float)
+ loss_aggrs.append(loss_aggr_img)
+
+ loss_discr_img = 0
+ for avg_i, avg_j in itertools.combinations(kernel_avgs, 2):
+ # delta_discrimination - ||G(K_i) - G(K_j)||
+ distance_ij = self.delta_discrimination - (avg_i -
+ avg_j).norm(2)
+ # D(K_i,K_j)
+ D_ij = torch.max(
+ distance_ij,
+ torch.tensor(
+ 0, device=distance_ij.device,
+ dtype=torch.float)).pow(2)
+ loss_discr_img += torch.log(D_ij + 1)
+
+ if num_inst > 1:
+ loss_discr_img /= (num_inst * (num_inst - 1))
+ else:
+ loss_discr_img = torch.tensor(
+ 0, device=gt_texts.device, dtype=torch.float)
+ if num_inst == 0:
+ warnings.warn('num of instance is 0')
+ loss_discrs.append(loss_discr_img)
+ return torch.stack(loss_aggrs), torch.stack(loss_discrs)
+
+ def dice_loss_with_logits(self, pred, target, mask):
+
+ smooth = 0.001
+
+ pred = torch.sigmoid(pred)
+ target[target <= 0.5] = 0
+ target[target > 0.5] = 1
+ pred = pred.contiguous().view(pred.size()[0], -1)
+ target = target.contiguous().view(target.size()[0], -1)
+ mask = mask.contiguous().view(mask.size()[0], -1)
+
+ pred = pred * mask
+ target = target * mask
+
+ a = torch.sum(pred * target, 1) + smooth
+ b = torch.sum(pred * pred, 1) + smooth
+ c = torch.sum(target * target, 1) + smooth
+ d = (2 * a) / (b + c)
+ return 1 - d
+
+ def ohem_img(self, text_score, gt_text, gt_mask):
+ """Sample the top-k maximal negative samples and all positive samples.
+
+ Args:
+ text_score (Tensor): The text score of size :math:`(H, W)`.
+ gt_text (Tensor): The ground truth text mask of size
+ :math:`(H, W)`.
+ gt_mask (Tensor): The effective region mask of size :math:`(H, W)`.
+
+ Returns:
+ Tensor: The sampled pixel mask of size :math:`(H, W)`.
+ """
+ assert isinstance(text_score, torch.Tensor)
+ assert isinstance(gt_text, torch.Tensor)
+ assert isinstance(gt_mask, torch.Tensor)
+ assert len(text_score.shape) == 2
+ assert text_score.shape == gt_text.shape
+ assert gt_text.shape == gt_mask.shape
+
+ pos_num = (int)(torch.sum(gt_text > 0.5).item()) - (int)(
+ torch.sum((gt_text > 0.5) * (gt_mask <= 0.5)).item())
+ neg_num = (int)(torch.sum(gt_text <= 0.5).item())
+ neg_num = (int)(min(pos_num * self.ohem_ratio, neg_num))
+
+ if pos_num == 0 or neg_num == 0:
+ warnings.warn('pos_num = 0 or neg_num = 0')
+ return gt_mask.bool()
+
+ neg_score = text_score[gt_text <= 0.5]
+ neg_score_sorted, _ = torch.sort(neg_score, descending=True)
+ threshold = neg_score_sorted[neg_num - 1]
+ sampled_mask = (((text_score >= threshold) + (gt_text > 0.5)) > 0) * (
+ gt_mask > 0.5)
+ return sampled_mask
+
+ def ohem_batch(self, text_scores, gt_texts, gt_mask):
+ """OHEM sampling for a batch of imgs.
+
+ Args:
+ text_scores (Tensor): The text scores of size :math:`(H, W)`.
+ gt_texts (Tensor): The gt text masks of size :math:`(H, W)`.
+ gt_mask (Tensor): The gt effective mask of size :math:`(H, W)`.
+
+ Returns:
+ Tensor: The sampled mask of size :math:`(H, W)`.
+ """
+ assert isinstance(text_scores, torch.Tensor)
+ assert isinstance(gt_texts, torch.Tensor)
+ assert isinstance(gt_mask, torch.Tensor)
+ assert len(text_scores.shape) == 3
+ assert text_scores.shape == gt_texts.shape
+ assert gt_texts.shape == gt_mask.shape
+
+ sampled_masks = []
+ for i in range(text_scores.shape[0]):
+ sampled_masks.append(
+ self.ohem_img(text_scores[i], gt_texts[i], gt_mask[i]))
+
+ sampled_masks = torch.stack(sampled_masks)
+
+ return sampled_masks
diff --git a/mmocr/models/textdet/losses/pse_loss.py b/mmocr/models/textdet/losses/pse_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..8ab1c0e130691dac34cb10cf2c2d50731a6544d2
--- /dev/null
+++ b/mmocr/models/textdet/losses/pse_loss.py
@@ -0,0 +1,106 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmdet.core import BitmapMasks
+
+from mmocr.models.builder import LOSSES
+from mmocr.utils import check_argument
+from . import PANLoss
+
+
+@LOSSES.register_module()
+class PSELoss(PANLoss):
+ r"""The class for implementing PSENet loss. This is partially adapted from
+ https://github.com/whai362/PSENet.
+
+ PSENet: `Shape Robust Text Detection with
+ Progressive Scale Expansion Network `_.
+
+ Args:
+ alpha (float): Text loss coefficient, and :math:`1-\alpha` is the
+ kernel loss coefficient.
+ ohem_ratio (float): The negative/positive ratio in ohem.
+ reduction (str): The way to reduce the loss. Available options are
+ "mean" and "sum".
+ """
+
+ def __init__(self,
+ alpha=0.7,
+ ohem_ratio=3,
+ reduction='mean',
+ kernel_sample_type='adaptive'):
+ super().__init__()
+ assert reduction in ['mean', 'sum'
+ ], "reduction must be either of ['mean','sum']"
+ self.alpha = alpha
+ self.ohem_ratio = ohem_ratio
+ self.reduction = reduction
+ self.kernel_sample_type = kernel_sample_type
+
+ def forward(self, score_maps, downsample_ratio, gt_kernels, gt_mask):
+ """Compute PSENet loss.
+
+ Args:
+ score_maps (tensor): The output tensor with size of Nx6xHxW.
+ downsample_ratio (float): The downsample ratio between score_maps
+ and the input img.
+ gt_kernels (list[BitmapMasks]): The kernel list with each element
+ being the text kernel mask for one img.
+ gt_mask (list[BitmapMasks]): The effective mask list
+ with each element being the effective mask for one img.
+
+ Returns:
+ dict: A loss dict with ``loss_text`` and ``loss_kernel``.
+ """
+
+ assert check_argument.is_type_list(gt_kernels, BitmapMasks)
+ assert check_argument.is_type_list(gt_mask, BitmapMasks)
+ assert isinstance(downsample_ratio, float)
+ losses = []
+
+ pred_texts = score_maps[:, 0, :, :]
+ pred_kernels = score_maps[:, 1:, :, :]
+ feature_sz = score_maps.size()
+
+ gt_kernels = [item.rescale(downsample_ratio) for item in gt_kernels]
+ gt_kernels = self.bitmasks2tensor(gt_kernels, feature_sz[2:])
+ gt_kernels = [item.to(score_maps.device) for item in gt_kernels]
+
+ gt_mask = [item.rescale(downsample_ratio) for item in gt_mask]
+ gt_mask = self.bitmasks2tensor(gt_mask, feature_sz[2:])
+ gt_mask = [item.to(score_maps.device) for item in gt_mask]
+
+ # compute text loss
+ sampled_masks_text = self.ohem_batch(pred_texts.detach(),
+ gt_kernels[0], gt_mask[0])
+ loss_texts = self.dice_loss_with_logits(pred_texts, gt_kernels[0],
+ sampled_masks_text)
+ losses.append(self.alpha * loss_texts)
+
+ # compute kernel loss
+ if self.kernel_sample_type == 'hard':
+ sampled_masks_kernel = (gt_kernels[0] > 0.5).float() * (
+ gt_mask[0].float())
+ elif self.kernel_sample_type == 'adaptive':
+ sampled_masks_kernel = (pred_texts > 0).float() * (
+ gt_mask[0].float())
+ else:
+ raise NotImplementedError
+
+ num_kernel = pred_kernels.shape[1]
+ assert num_kernel == len(gt_kernels) - 1
+ loss_list = []
+ for idx in range(num_kernel):
+ loss_kernels = self.dice_loss_with_logits(
+ pred_kernels[:, idx, :, :], gt_kernels[1 + idx],
+ sampled_masks_kernel)
+ loss_list.append(loss_kernels)
+
+ losses.append((1 - self.alpha) * sum(loss_list) / len(loss_list))
+
+ if self.reduction == 'mean':
+ losses = [item.mean() for item in losses]
+ elif self.reduction == 'sum':
+ losses = [item.sum() for item in losses]
+ else:
+ raise NotImplementedError
+ results = dict(loss_text=losses[0], loss_kernel=losses[1])
+ return results
diff --git a/mmocr/models/textdet/losses/textsnake_loss.py b/mmocr/models/textdet/losses/textsnake_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..d36abb561c3fb4ce9e802a7d66535bd1d7b9956c
--- /dev/null
+++ b/mmocr/models/textdet/losses/textsnake_loss.py
@@ -0,0 +1,200 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn.functional as F
+from mmdet.core import BitmapMasks
+from torch import nn
+
+from mmocr.models.builder import LOSSES
+from mmocr.utils import check_argument
+
+
+@LOSSES.register_module()
+class TextSnakeLoss(nn.Module):
+ """The class for implementing TextSnake loss. This is partially adapted
+ from https://github.com/princewang1994/TextSnake.pytorch.
+
+ TextSnake: `A Flexible Representation for Detecting Text of Arbitrary
+ Shapes `_.
+
+ Args:
+ ohem_ratio (float): The negative/positive ratio in ohem.
+ """
+
+ def __init__(self, ohem_ratio=3.0):
+ super().__init__()
+ self.ohem_ratio = ohem_ratio
+
+ def balanced_bce_loss(self, pred, gt, mask):
+
+ assert pred.shape == gt.shape == mask.shape
+ positive = gt * mask
+ negative = (1 - gt) * mask
+ positive_count = int(positive.float().sum())
+ gt = gt.float()
+ if positive_count > 0:
+ loss = F.binary_cross_entropy(pred, gt, reduction='none')
+ positive_loss = torch.sum(loss * positive.float())
+ negative_loss = loss * negative.float()
+ negative_count = min(
+ int(negative.float().sum()),
+ int(positive_count * self.ohem_ratio))
+ else:
+ positive_loss = torch.tensor(0.0, device=pred.device)
+ loss = F.binary_cross_entropy(pred, gt, reduction='none')
+ negative_loss = loss * negative.float()
+ negative_count = 100
+ negative_loss, _ = torch.topk(negative_loss.view(-1), negative_count)
+
+ balance_loss = (positive_loss + torch.sum(negative_loss)) / (
+ float(positive_count + negative_count) + 1e-5)
+
+ return balance_loss
+
+ def bitmasks2tensor(self, bitmasks, target_sz):
+ """Convert Bitmasks to tensor.
+
+ Args:
+ bitmasks (list[BitmapMasks]): The BitmapMasks list. Each item is
+ for one img.
+ target_sz (tuple(int, int)): The target tensor of size
+ :math:`(H, W)`.
+
+ Returns:
+ list[Tensor]: The list of kernel tensors. Each element stands for
+ one kernel level.
+ """
+ assert check_argument.is_type_list(bitmasks, BitmapMasks)
+ assert isinstance(target_sz, tuple)
+
+ batch_size = len(bitmasks)
+ num_masks = len(bitmasks[0])
+
+ results = []
+
+ for level_inx in range(num_masks):
+ kernel = []
+ for batch_inx in range(batch_size):
+ mask = torch.from_numpy(bitmasks[batch_inx].masks[level_inx])
+ # hxw
+ mask_sz = mask.shape
+ # left, right, top, bottom
+ pad = [
+ 0, target_sz[1] - mask_sz[1], 0, target_sz[0] - mask_sz[0]
+ ]
+ mask = F.pad(mask, pad, mode='constant', value=0)
+ kernel.append(mask)
+ kernel = torch.stack(kernel)
+ results.append(kernel)
+
+ return results
+
+ def forward(self, pred_maps, downsample_ratio, gt_text_mask,
+ gt_center_region_mask, gt_mask, gt_radius_map, gt_sin_map,
+ gt_cos_map):
+ """
+ Args:
+ pred_maps (Tensor): The prediction map of shape
+ :math:`(N, 5, H, W)`, where each dimension is the map of
+ "text_region", "center_region", "sin_map", "cos_map", and
+ "radius_map" respectively.
+ downsample_ratio (float): Downsample ratio.
+ gt_text_mask (list[BitmapMasks]): Gold text masks.
+ gt_center_region_mask (list[BitmapMasks]): Gold center region
+ masks.
+ gt_mask (list[BitmapMasks]): Gold general masks.
+ gt_radius_map (list[BitmapMasks]): Gold radius maps.
+ gt_sin_map (list[BitmapMasks]): Gold sin maps.
+ gt_cos_map (list[BitmapMasks]): Gold cos maps.
+
+ Returns:
+ dict: A loss dict with ``loss_text``, ``loss_center``,
+ ``loss_radius``, ``loss_sin`` and ``loss_cos``.
+ """
+
+ assert isinstance(downsample_ratio, float)
+ assert check_argument.is_type_list(gt_text_mask, BitmapMasks)
+ assert check_argument.is_type_list(gt_center_region_mask, BitmapMasks)
+ assert check_argument.is_type_list(gt_mask, BitmapMasks)
+ assert check_argument.is_type_list(gt_radius_map, BitmapMasks)
+ assert check_argument.is_type_list(gt_sin_map, BitmapMasks)
+ assert check_argument.is_type_list(gt_cos_map, BitmapMasks)
+
+ pred_text_region = pred_maps[:, 0, :, :]
+ pred_center_region = pred_maps[:, 1, :, :]
+ pred_sin_map = pred_maps[:, 2, :, :]
+ pred_cos_map = pred_maps[:, 3, :, :]
+ pred_radius_map = pred_maps[:, 4, :, :]
+ feature_sz = pred_maps.size()
+ device = pred_maps.device
+
+ # bitmask 2 tensor
+ mapping = {
+ 'gt_text_mask': gt_text_mask,
+ 'gt_center_region_mask': gt_center_region_mask,
+ 'gt_mask': gt_mask,
+ 'gt_radius_map': gt_radius_map,
+ 'gt_sin_map': gt_sin_map,
+ 'gt_cos_map': gt_cos_map
+ }
+ gt = {}
+ for key, value in mapping.items():
+ gt[key] = value
+ if abs(downsample_ratio - 1.0) < 1e-2:
+ gt[key] = self.bitmasks2tensor(gt[key], feature_sz[2:])
+ else:
+ gt[key] = [item.rescale(downsample_ratio) for item in gt[key]]
+ gt[key] = self.bitmasks2tensor(gt[key], feature_sz[2:])
+ if key == 'gt_radius_map':
+ gt[key] = [item * downsample_ratio for item in gt[key]]
+ gt[key] = [item.to(device) for item in gt[key]]
+
+ scale = torch.sqrt(1.0 / (pred_sin_map**2 + pred_cos_map**2 + 1e-8))
+ pred_sin_map = pred_sin_map * scale
+ pred_cos_map = pred_cos_map * scale
+
+ loss_text = self.balanced_bce_loss(
+ torch.sigmoid(pred_text_region), gt['gt_text_mask'][0],
+ gt['gt_mask'][0])
+
+ text_mask = (gt['gt_text_mask'][0] * gt['gt_mask'][0]).float()
+ loss_center_map = F.binary_cross_entropy(
+ torch.sigmoid(pred_center_region),
+ gt['gt_center_region_mask'][0].float(),
+ reduction='none')
+ if int(text_mask.sum()) > 0:
+ loss_center = torch.sum(
+ loss_center_map * text_mask) / torch.sum(text_mask)
+ else:
+ loss_center = torch.tensor(0.0, device=device)
+
+ center_mask = (gt['gt_center_region_mask'][0] *
+ gt['gt_mask'][0]).float()
+ if int(center_mask.sum()) > 0:
+ map_sz = pred_radius_map.size()
+ ones = torch.ones(map_sz, dtype=torch.float, device=device)
+ loss_radius = torch.sum(
+ F.smooth_l1_loss(
+ pred_radius_map / (gt['gt_radius_map'][0] + 1e-2),
+ ones,
+ reduction='none') * center_mask) / torch.sum(center_mask)
+ loss_sin = torch.sum(
+ F.smooth_l1_loss(
+ pred_sin_map, gt['gt_sin_map'][0], reduction='none') *
+ center_mask) / torch.sum(center_mask)
+ loss_cos = torch.sum(
+ F.smooth_l1_loss(
+ pred_cos_map, gt['gt_cos_map'][0], reduction='none') *
+ center_mask) / torch.sum(center_mask)
+ else:
+ loss_radius = torch.tensor(0.0, device=device)
+ loss_sin = torch.tensor(0.0, device=device)
+ loss_cos = torch.tensor(0.0, device=device)
+
+ results = dict(
+ loss_text=loss_text,
+ loss_center=loss_center,
+ loss_radius=loss_radius,
+ loss_sin=loss_sin,
+ loss_cos=loss_cos)
+
+ return results
diff --git a/mmocr/models/textdet/modules/__init__.py b/mmocr/models/textdet/modules/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1a863d0f67b65ad86f46948392979f5ef7d29949
--- /dev/null
+++ b/mmocr/models/textdet/modules/__init__.py
@@ -0,0 +1,6 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .gcn import GCN
+from .local_graph import LocalGraphs
+from .proposal_local_graph import ProposalLocalGraphs
+
+__all__ = ['LocalGraphs', 'ProposalLocalGraphs', 'GCN']
diff --git a/mmocr/models/textdet/modules/gcn.py b/mmocr/models/textdet/modules/gcn.py
new file mode 100644
index 0000000000000000000000000000000000000000..092d646350b1577e7c535d0f846ff666384ec3a4
--- /dev/null
+++ b/mmocr/models/textdet/modules/gcn.py
@@ -0,0 +1,76 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch.nn import init
+
+
+class MeanAggregator(nn.Module):
+
+ def forward(self, features, A):
+ x = torch.bmm(A, features)
+ return x
+
+
+class GraphConv(nn.Module):
+
+ def __init__(self, in_dim, out_dim):
+ super().__init__()
+ self.in_dim = in_dim
+ self.out_dim = out_dim
+ self.weight = nn.Parameter(torch.FloatTensor(in_dim * 2, out_dim))
+ self.bias = nn.Parameter(torch.FloatTensor(out_dim))
+ init.xavier_uniform_(self.weight)
+ init.constant_(self.bias, 0)
+ self.aggregator = MeanAggregator()
+
+ def forward(self, features, A):
+ b, n, d = features.shape
+ assert d == self.in_dim
+ agg_feats = self.aggregator(features, A)
+ cat_feats = torch.cat([features, agg_feats], dim=2)
+ out = torch.einsum('bnd,df->bnf', cat_feats, self.weight)
+ out = F.relu(out + self.bias)
+ return out
+
+
+class GCN(nn.Module):
+ """Graph convolutional network for clustering. This was from repo
+ https://github.com/Zhongdao/gcn_clustering licensed under the MIT license.
+
+ Args:
+ feat_len(int): The input node feature length.
+ """
+
+ def __init__(self, feat_len):
+ super(GCN, self).__init__()
+ self.bn0 = nn.BatchNorm1d(feat_len, affine=False).float()
+ self.conv1 = GraphConv(feat_len, 512)
+ self.conv2 = GraphConv(512, 256)
+ self.conv3 = GraphConv(256, 128)
+ self.conv4 = GraphConv(128, 64)
+ self.classifier = nn.Sequential(
+ nn.Linear(64, 32), nn.PReLU(32), nn.Linear(32, 2))
+
+ def forward(self, x, A, knn_inds):
+
+ num_local_graphs, num_max_nodes, feat_len = x.shape
+
+ x = x.view(-1, feat_len)
+ x = self.bn0(x)
+ x = x.view(num_local_graphs, num_max_nodes, feat_len)
+
+ x = self.conv1(x, A)
+ x = self.conv2(x, A)
+ x = self.conv3(x, A)
+ x = self.conv4(x, A)
+ k = knn_inds.size(-1)
+ mid_feat_len = x.size(-1)
+ edge_feat = torch.zeros((num_local_graphs, k, mid_feat_len),
+ device=x.device)
+ for graph_ind in range(num_local_graphs):
+ edge_feat[graph_ind, :, :] = x[graph_ind, knn_inds[graph_ind]]
+ edge_feat = edge_feat.view(-1, mid_feat_len)
+ pred = self.classifier(edge_feat)
+
+ return pred
diff --git a/mmocr/models/textdet/modules/local_graph.py b/mmocr/models/textdet/modules/local_graph.py
new file mode 100644
index 0000000000000000000000000000000000000000..861582030313ae4f393e070c3eab5e496ecdd78a
--- /dev/null
+++ b/mmocr/models/textdet/modules/local_graph.py
@@ -0,0 +1,297 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import torch
+from mmcv.ops import RoIAlignRotated
+
+from .utils import (euclidean_distance_matrix, feature_embedding,
+ normalize_adjacent_matrix)
+
+
+class LocalGraphs:
+ """Generate local graphs for GCN to classify the neighbors of a pivot for
+ DRRG: Deep Relational Reasoning Graph Network for Arbitrary Shape Text
+ Detection.
+
+ [https://arxiv.org/abs/2003.07493]. This code was partially adapted from
+ https://github.com/GXYM/DRRG licensed under the MIT license.
+
+ Args:
+ k_at_hops (tuple(int)): The number of i-hop neighbors, i = 1, 2.
+ num_adjacent_linkages (int): The number of linkages when constructing
+ adjacent matrix.
+ node_geo_feat_len (int): The length of embedded geometric feature
+ vector of a text component.
+ pooling_scale (float): The spatial scale of rotated RoI-Align.
+ pooling_output_size (tuple(int)): The output size of rotated RoI-Align.
+ local_graph_thr(float): The threshold for filtering out identical local
+ graphs.
+ """
+
+ def __init__(self, k_at_hops, num_adjacent_linkages, node_geo_feat_len,
+ pooling_scale, pooling_output_size, local_graph_thr):
+
+ assert len(k_at_hops) == 2
+ assert all(isinstance(n, int) for n in k_at_hops)
+ assert isinstance(num_adjacent_linkages, int)
+ assert isinstance(node_geo_feat_len, int)
+ assert isinstance(pooling_scale, float)
+ assert all(isinstance(n, int) for n in pooling_output_size)
+ assert isinstance(local_graph_thr, float)
+
+ self.k_at_hops = k_at_hops
+ self.num_adjacent_linkages = num_adjacent_linkages
+ self.node_geo_feat_dim = node_geo_feat_len
+ self.pooling = RoIAlignRotated(pooling_output_size, pooling_scale)
+ self.local_graph_thr = local_graph_thr
+
+ def generate_local_graphs(self, sorted_dist_inds, gt_comp_labels):
+ """Generate local graphs for GCN to predict which instance a text
+ component belongs to.
+
+ Args:
+ sorted_dist_inds (ndarray): The complete graph node indices, which
+ is sorted according to the Euclidean distance.
+ gt_comp_labels(ndarray): The ground truth labels define the
+ instance to which the text components (nodes in graphs) belong.
+
+ Returns:
+ pivot_local_graphs(list[list[int]]): The list of local graph
+ neighbor indices of pivots.
+ pivot_knns(list[list[int]]): The list of k-nearest neighbor indices
+ of pivots.
+ """
+
+ assert sorted_dist_inds.ndim == 2
+ assert (sorted_dist_inds.shape[0] == sorted_dist_inds.shape[1] ==
+ gt_comp_labels.shape[0])
+
+ knn_graph = sorted_dist_inds[:, 1:self.k_at_hops[0] + 1]
+ pivot_local_graphs = []
+ pivot_knns = []
+ for pivot_ind, knn in enumerate(knn_graph):
+
+ local_graph_neighbors = set(knn)
+
+ for neighbor_ind in knn:
+ local_graph_neighbors.update(
+ set(sorted_dist_inds[neighbor_ind,
+ 1:self.k_at_hops[1] + 1]))
+
+ local_graph_neighbors.discard(pivot_ind)
+ pivot_local_graph = list(local_graph_neighbors)
+ pivot_local_graph.insert(0, pivot_ind)
+ pivot_knn = [pivot_ind] + list(knn)
+
+ if pivot_ind < 1:
+ pivot_local_graphs.append(pivot_local_graph)
+ pivot_knns.append(pivot_knn)
+ else:
+ add_flag = True
+ for graph_ind, added_knn in enumerate(pivot_knns):
+ added_pivot_ind = added_knn[0]
+ added_local_graph = pivot_local_graphs[graph_ind]
+
+ union = len(
+ set(pivot_local_graph[1:]).union(
+ set(added_local_graph[1:])))
+ intersect = len(
+ set(pivot_local_graph[1:]).intersection(
+ set(added_local_graph[1:])))
+ local_graph_iou = intersect / (union + 1e-8)
+
+ if (local_graph_iou > self.local_graph_thr
+ and pivot_ind in added_knn
+ and gt_comp_labels[added_pivot_ind]
+ == gt_comp_labels[pivot_ind]
+ and gt_comp_labels[pivot_ind] != 0):
+ add_flag = False
+ break
+ if add_flag:
+ pivot_local_graphs.append(pivot_local_graph)
+ pivot_knns.append(pivot_knn)
+
+ return pivot_local_graphs, pivot_knns
+
+ def generate_gcn_input(self, node_feat_batch, node_label_batch,
+ local_graph_batch, knn_batch,
+ sorted_dist_ind_batch):
+ """Generate graph convolution network input data.
+
+ Args:
+ node_feat_batch (List[Tensor]): The batched graph node features.
+ node_label_batch (List[ndarray]): The batched text component
+ labels.
+ local_graph_batch (List[List[list[int]]]): The local graph node
+ indices of image batch.
+ knn_batch (List[List[list[int]]]): The knn graph node indices of
+ image batch.
+ sorted_dist_ind_batch (list[ndarray]): The node indices sorted
+ according to the Euclidean distance.
+
+ Returns:
+ local_graphs_node_feat (Tensor): The node features of graph.
+ adjacent_matrices (Tensor): The adjacent matrices of local graphs.
+ pivots_knn_inds (Tensor): The k-nearest neighbor indices in
+ local graph.
+ gt_linkage (Tensor): The surpervision signal of GCN for linkage
+ prediction.
+ """
+ assert isinstance(node_feat_batch, list)
+ assert isinstance(node_label_batch, list)
+ assert isinstance(local_graph_batch, list)
+ assert isinstance(knn_batch, list)
+ assert isinstance(sorted_dist_ind_batch, list)
+
+ num_max_nodes = max([
+ len(pivot_local_graph) for pivot_local_graphs in local_graph_batch
+ for pivot_local_graph in pivot_local_graphs
+ ])
+
+ local_graphs_node_feat = []
+ adjacent_matrices = []
+ pivots_knn_inds = []
+ pivots_gt_linkage = []
+
+ for batch_ind, sorted_dist_inds in enumerate(sorted_dist_ind_batch):
+ node_feats = node_feat_batch[batch_ind]
+ pivot_local_graphs = local_graph_batch[batch_ind]
+ pivot_knns = knn_batch[batch_ind]
+ node_labels = node_label_batch[batch_ind]
+ device = node_feats.device
+
+ for graph_ind, pivot_knn in enumerate(pivot_knns):
+ pivot_local_graph = pivot_local_graphs[graph_ind]
+ num_nodes = len(pivot_local_graph)
+ pivot_ind = pivot_local_graph[0]
+ node2ind_map = {j: i for i, j in enumerate(pivot_local_graph)}
+
+ knn_inds = torch.tensor(
+ [node2ind_map[i] for i in pivot_knn[1:]])
+ pivot_feats = node_feats[pivot_ind]
+ normalized_feats = node_feats[pivot_local_graph] - pivot_feats
+
+ adjacent_matrix = np.zeros((num_nodes, num_nodes),
+ dtype=np.float32)
+ for node in pivot_local_graph:
+ neighbors = sorted_dist_inds[node,
+ 1:self.num_adjacent_linkages +
+ 1]
+ for neighbor in neighbors:
+ if neighbor in pivot_local_graph:
+
+ adjacent_matrix[node2ind_map[node],
+ node2ind_map[neighbor]] = 1
+ adjacent_matrix[node2ind_map[neighbor],
+ node2ind_map[node]] = 1
+
+ adjacent_matrix = normalize_adjacent_matrix(adjacent_matrix)
+ pad_adjacent_matrix = torch.zeros(
+ (num_max_nodes, num_max_nodes),
+ dtype=torch.float,
+ device=device)
+ pad_adjacent_matrix[:num_nodes, :num_nodes] = torch.from_numpy(
+ adjacent_matrix)
+
+ pad_normalized_feats = torch.cat([
+ normalized_feats,
+ torch.zeros(
+ (num_max_nodes - num_nodes, normalized_feats.shape[1]),
+ dtype=torch.float,
+ device=device)
+ ],
+ dim=0)
+
+ local_graph_labels = node_labels[pivot_local_graph]
+ knn_labels = local_graph_labels[knn_inds]
+ link_labels = ((node_labels[pivot_ind] == knn_labels) &
+ (node_labels[pivot_ind] > 0)).astype(np.int64)
+ link_labels = torch.from_numpy(link_labels)
+
+ local_graphs_node_feat.append(pad_normalized_feats)
+ adjacent_matrices.append(pad_adjacent_matrix)
+ pivots_knn_inds.append(knn_inds)
+ pivots_gt_linkage.append(link_labels)
+
+ local_graphs_node_feat = torch.stack(local_graphs_node_feat, 0)
+ adjacent_matrices = torch.stack(adjacent_matrices, 0)
+ pivots_knn_inds = torch.stack(pivots_knn_inds, 0)
+ pivots_gt_linkage = torch.stack(pivots_gt_linkage, 0)
+
+ return (local_graphs_node_feat, adjacent_matrices, pivots_knn_inds,
+ pivots_gt_linkage)
+
+ def __call__(self, feat_maps, comp_attribs):
+ """Generate local graphs as GCN input.
+
+ Args:
+ feat_maps (Tensor): The feature maps to extract the content
+ features of text components.
+ comp_attribs (ndarray): The text component attributes.
+
+ Returns:
+ local_graphs_node_feat (Tensor): The node features of graph.
+ adjacent_matrices (Tensor): The adjacent matrices of local graphs.
+ pivots_knn_inds (Tensor): The k-nearest neighbor indices in local
+ graph.
+ gt_linkage (Tensor): The surpervision signal of GCN for linkage
+ prediction.
+ """
+
+ assert isinstance(feat_maps, torch.Tensor)
+ assert comp_attribs.ndim == 3
+ assert comp_attribs.shape[2] == 8
+
+ sorted_dist_inds_batch = []
+ local_graph_batch = []
+ knn_batch = []
+ node_feat_batch = []
+ node_label_batch = []
+ device = feat_maps.device
+
+ for batch_ind in range(comp_attribs.shape[0]):
+ num_comps = int(comp_attribs[batch_ind, 0, 0])
+ comp_geo_attribs = comp_attribs[batch_ind, :num_comps, 1:7]
+ node_labels = comp_attribs[batch_ind, :num_comps,
+ 7].astype(np.int32)
+
+ comp_centers = comp_geo_attribs[:, 0:2]
+ distance_matrix = euclidean_distance_matrix(
+ comp_centers, comp_centers)
+
+ batch_id = np.zeros(
+ (comp_geo_attribs.shape[0], 1), dtype=np.float32) * batch_ind
+ comp_geo_attribs[:, -2] = np.clip(comp_geo_attribs[:, -2], -1, 1)
+ angle = np.arccos(comp_geo_attribs[:, -2]) * np.sign(
+ comp_geo_attribs[:, -1])
+ angle = angle.reshape((-1, 1))
+ rotated_rois = np.hstack(
+ [batch_id, comp_geo_attribs[:, :-2], angle])
+ rois = torch.from_numpy(rotated_rois).to(device)
+ content_feats = self.pooling(feat_maps[batch_ind].unsqueeze(0),
+ rois)
+
+ content_feats = content_feats.view(content_feats.shape[0],
+ -1).to(feat_maps.device)
+ geo_feats = feature_embedding(comp_geo_attribs,
+ self.node_geo_feat_dim)
+ geo_feats = torch.from_numpy(geo_feats).to(device)
+ node_feats = torch.cat([content_feats, geo_feats], dim=-1)
+
+ sorted_dist_inds = np.argsort(distance_matrix, axis=1)
+ pivot_local_graphs, pivot_knns = self.generate_local_graphs(
+ sorted_dist_inds, node_labels)
+
+ node_feat_batch.append(node_feats)
+ node_label_batch.append(node_labels)
+ local_graph_batch.append(pivot_local_graphs)
+ knn_batch.append(pivot_knns)
+ sorted_dist_inds_batch.append(sorted_dist_inds)
+
+ (node_feats, adjacent_matrices, knn_inds, gt_linkage) = \
+ self.generate_gcn_input(node_feat_batch,
+ node_label_batch,
+ local_graph_batch,
+ knn_batch,
+ sorted_dist_inds_batch)
+
+ return node_feats, adjacent_matrices, knn_inds, gt_linkage
diff --git a/mmocr/models/textdet/modules/proposal_local_graph.py b/mmocr/models/textdet/modules/proposal_local_graph.py
new file mode 100644
index 0000000000000000000000000000000000000000..ce6c7f80a86e5ed0dce82ff176343ae75aabace6
--- /dev/null
+++ b/mmocr/models/textdet/modules/proposal_local_graph.py
@@ -0,0 +1,414 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import cv2
+import numpy as np
+import torch
+from lanms import merge_quadrangle_n9 as la_nms
+from mmcv.ops import RoIAlignRotated
+
+from mmocr.models.textdet.postprocess.utils import fill_hole
+from .utils import (euclidean_distance_matrix, feature_embedding,
+ normalize_adjacent_matrix)
+
+
+class ProposalLocalGraphs:
+ """Propose text components and generate local graphs for GCN to classify
+ the k-nearest neighbors of a pivot in DRRG: Deep Relational Reasoning Graph
+ Network for Arbitrary Shape Text Detection.
+
+ [https://arxiv.org/abs/2003.07493]. This code was partially adapted from
+ https://github.com/GXYM/DRRG licensed under the MIT license.
+
+ Args:
+ k_at_hops (tuple(int)): The number of i-hop neighbors, i = 1, 2.
+ num_adjacent_linkages (int): The number of linkages when constructing
+ adjacent matrix.
+ node_geo_feat_len (int): The length of embedded geometric feature
+ vector of a text component.
+ pooling_scale (float): The spatial scale of rotated RoI-Align.
+ pooling_output_size (tuple(int)): The output size of rotated RoI-Align.
+ nms_thr (float): The locality-aware NMS threshold for text components.
+ min_width (float): The minimum width of text components.
+ max_width (float): The maximum width of text components.
+ comp_shrink_ratio (float): The shrink ratio of text components.
+ comp_w_h_ratio (float): The width to height ratio of text components.
+ comp_score_thr (float): The score threshold of text component.
+ text_region_thr (float): The threshold for text region probability map.
+ center_region_thr (float): The threshold for text center region
+ probability map.
+ center_region_area_thr (int): The threshold for filtering small-sized
+ text center region.
+ """
+
+ def __init__(self, k_at_hops, num_adjacent_linkages, node_geo_feat_len,
+ pooling_scale, pooling_output_size, nms_thr, min_width,
+ max_width, comp_shrink_ratio, comp_w_h_ratio, comp_score_thr,
+ text_region_thr, center_region_thr, center_region_area_thr):
+
+ assert len(k_at_hops) == 2
+ assert isinstance(k_at_hops, tuple)
+ assert isinstance(num_adjacent_linkages, int)
+ assert isinstance(node_geo_feat_len, int)
+ assert isinstance(pooling_scale, float)
+ assert isinstance(pooling_output_size, tuple)
+ assert isinstance(nms_thr, float)
+ assert isinstance(min_width, float)
+ assert isinstance(max_width, float)
+ assert isinstance(comp_shrink_ratio, float)
+ assert isinstance(comp_w_h_ratio, float)
+ assert isinstance(comp_score_thr, float)
+ assert isinstance(text_region_thr, float)
+ assert isinstance(center_region_thr, float)
+ assert isinstance(center_region_area_thr, int)
+
+ self.k_at_hops = k_at_hops
+ self.active_connection = num_adjacent_linkages
+ self.local_graph_depth = len(self.k_at_hops)
+ self.node_geo_feat_dim = node_geo_feat_len
+ self.pooling = RoIAlignRotated(pooling_output_size, pooling_scale)
+ self.nms_thr = nms_thr
+ self.min_width = min_width
+ self.max_width = max_width
+ self.comp_shrink_ratio = comp_shrink_ratio
+ self.comp_w_h_ratio = comp_w_h_ratio
+ self.comp_score_thr = comp_score_thr
+ self.text_region_thr = text_region_thr
+ self.center_region_thr = center_region_thr
+ self.center_region_area_thr = center_region_area_thr
+
+ def propose_comps(self, score_map, top_height_map, bot_height_map, sin_map,
+ cos_map, comp_score_thr, min_width, max_width,
+ comp_shrink_ratio, comp_w_h_ratio):
+ """Propose text components.
+
+ Args:
+ score_map (ndarray): The score map for NMS.
+ top_height_map (ndarray): The predicted text height map from each
+ pixel in text center region to top sideline.
+ bot_height_map (ndarray): The predicted text height map from each
+ pixel in text center region to bottom sideline.
+ sin_map (ndarray): The predicted sin(theta) map.
+ cos_map (ndarray): The predicted cos(theta) map.
+ comp_score_thr (float): The score threshold of text component.
+ min_width (float): The minimum width of text components.
+ max_width (float): The maximum width of text components.
+ comp_shrink_ratio (float): The shrink ratio of text components.
+ comp_w_h_ratio (float): The width to height ratio of text
+ components.
+
+ Returns:
+ text_comps (ndarray): The text components.
+ """
+
+ comp_centers = np.argwhere(score_map > comp_score_thr)
+ comp_centers = comp_centers[np.argsort(comp_centers[:, 0])]
+ y = comp_centers[:, 0]
+ x = comp_centers[:, 1]
+
+ top_height = top_height_map[y, x].reshape((-1, 1)) * comp_shrink_ratio
+ bot_height = bot_height_map[y, x].reshape((-1, 1)) * comp_shrink_ratio
+ sin = sin_map[y, x].reshape((-1, 1))
+ cos = cos_map[y, x].reshape((-1, 1))
+
+ top_mid_pts = comp_centers + np.hstack(
+ [top_height * sin, top_height * cos])
+ bot_mid_pts = comp_centers - np.hstack(
+ [bot_height * sin, bot_height * cos])
+
+ width = (top_height + bot_height) * comp_w_h_ratio
+ width = np.clip(width, min_width, max_width)
+ r = width / 2
+
+ tl = top_mid_pts[:, ::-1] - np.hstack([-r * sin, r * cos])
+ tr = top_mid_pts[:, ::-1] + np.hstack([-r * sin, r * cos])
+ br = bot_mid_pts[:, ::-1] + np.hstack([-r * sin, r * cos])
+ bl = bot_mid_pts[:, ::-1] - np.hstack([-r * sin, r * cos])
+ text_comps = np.hstack([tl, tr, br, bl]).astype(np.float32)
+
+ score = score_map[y, x].reshape((-1, 1))
+ text_comps = np.hstack([text_comps, score])
+
+ return text_comps
+
+ def propose_comps_and_attribs(self, text_region_map, center_region_map,
+ top_height_map, bot_height_map, sin_map,
+ cos_map):
+ """Generate text components and attributes.
+
+ Args:
+ text_region_map (ndarray): The predicted text region probability
+ map.
+ center_region_map (ndarray): The predicted text center region
+ probability map.
+ top_height_map (ndarray): The predicted text height map from each
+ pixel in text center region to top sideline.
+ bot_height_map (ndarray): The predicted text height map from each
+ pixel in text center region to bottom sideline.
+ sin_map (ndarray): The predicted sin(theta) map.
+ cos_map (ndarray): The predicted cos(theta) map.
+
+ Returns:
+ comp_attribs (ndarray): The text component attributes.
+ text_comps (ndarray): The text components.
+ """
+
+ assert (text_region_map.shape == center_region_map.shape ==
+ top_height_map.shape == bot_height_map.shape == sin_map.shape
+ == cos_map.shape)
+ text_mask = text_region_map > self.text_region_thr
+ center_region_mask = (center_region_map >
+ self.center_region_thr) * text_mask
+
+ scale = np.sqrt(1.0 / (sin_map**2 + cos_map**2 + 1e-8))
+ sin_map, cos_map = sin_map * scale, cos_map * scale
+
+ center_region_mask = fill_hole(center_region_mask)
+ center_region_contours, _ = cv2.findContours(
+ center_region_mask.astype(np.uint8), cv2.RETR_TREE,
+ cv2.CHAIN_APPROX_SIMPLE)
+
+ mask_sz = center_region_map.shape
+ comp_list = []
+ for contour in center_region_contours:
+ current_center_mask = np.zeros(mask_sz)
+ cv2.drawContours(current_center_mask, [contour], -1, 1, -1)
+ if current_center_mask.sum() <= self.center_region_area_thr:
+ continue
+ score_map = text_region_map * current_center_mask
+
+ text_comps = self.propose_comps(score_map, top_height_map,
+ bot_height_map, sin_map, cos_map,
+ self.comp_score_thr,
+ self.min_width, self.max_width,
+ self.comp_shrink_ratio,
+ self.comp_w_h_ratio)
+
+ text_comps = la_nms(text_comps, self.nms_thr)
+ text_comp_mask = np.zeros(mask_sz)
+ text_comp_boxes = text_comps[:, :8].reshape(
+ (-1, 4, 2)).astype(np.int32)
+
+ cv2.drawContours(text_comp_mask, text_comp_boxes, -1, 1, -1)
+ if (text_comp_mask * text_mask).sum() < text_comp_mask.sum() * 0.5:
+ continue
+ if text_comps.shape[-1] > 0:
+ comp_list.append(text_comps)
+
+ if len(comp_list) <= 0:
+ return None, None
+
+ text_comps = np.vstack(comp_list)
+ text_comp_boxes = text_comps[:, :8].reshape((-1, 4, 2))
+ centers = np.mean(text_comp_boxes, axis=1).astype(np.int32)
+ x = centers[:, 0]
+ y = centers[:, 1]
+
+ scores = []
+ for text_comp_box in text_comp_boxes:
+ text_comp_box[:, 0] = np.clip(text_comp_box[:, 0], 0,
+ mask_sz[1] - 1)
+ text_comp_box[:, 1] = np.clip(text_comp_box[:, 1], 0,
+ mask_sz[0] - 1)
+ min_coord = np.min(text_comp_box, axis=0).astype(np.int32)
+ max_coord = np.max(text_comp_box, axis=0).astype(np.int32)
+ text_comp_box = text_comp_box - min_coord
+ box_sz = (max_coord - min_coord + 1)
+ temp_comp_mask = np.zeros((box_sz[1], box_sz[0]), dtype=np.uint8)
+ cv2.fillPoly(temp_comp_mask, [text_comp_box.astype(np.int32)], 1)
+ temp_region_patch = text_region_map[min_coord[1]:(max_coord[1] +
+ 1),
+ min_coord[0]:(max_coord[0] +
+ 1)]
+ score = cv2.mean(temp_region_patch, temp_comp_mask)[0]
+ scores.append(score)
+ scores = np.array(scores).reshape((-1, 1))
+ text_comps = np.hstack([text_comps[:, :-1], scores])
+
+ h = top_height_map[y, x].reshape(
+ (-1, 1)) + bot_height_map[y, x].reshape((-1, 1))
+ w = np.clip(h * self.comp_w_h_ratio, self.min_width, self.max_width)
+ sin = sin_map[y, x].reshape((-1, 1))
+ cos = cos_map[y, x].reshape((-1, 1))
+
+ x = x.reshape((-1, 1))
+ y = y.reshape((-1, 1))
+ comp_attribs = np.hstack([x, y, h, w, cos, sin])
+
+ return comp_attribs, text_comps
+
+ def generate_local_graphs(self, sorted_dist_inds, node_feats):
+ """Generate local graphs and graph convolution network input data.
+
+ Args:
+ sorted_dist_inds (ndarray): The node indices sorted according to
+ the Euclidean distance.
+ node_feats (tensor): The features of nodes in graph.
+
+ Returns:
+ local_graphs_node_feats (tensor): The features of nodes in local
+ graphs.
+ adjacent_matrices (tensor): The adjacent matrices.
+ pivots_knn_inds (tensor): The k-nearest neighbor indices in
+ local graphs.
+ pivots_local_graphs (tensor): The indices of nodes in local
+ graphs.
+ """
+
+ assert sorted_dist_inds.ndim == 2
+ assert (sorted_dist_inds.shape[0] == sorted_dist_inds.shape[1] ==
+ node_feats.shape[0])
+
+ knn_graph = sorted_dist_inds[:, 1:self.k_at_hops[0] + 1]
+ pivot_local_graphs = []
+ pivot_knns = []
+ device = node_feats.device
+
+ for pivot_ind, knn in enumerate(knn_graph):
+
+ local_graph_neighbors = set(knn)
+
+ for neighbor_ind in knn:
+ local_graph_neighbors.update(
+ set(sorted_dist_inds[neighbor_ind,
+ 1:self.k_at_hops[1] + 1]))
+
+ local_graph_neighbors.discard(pivot_ind)
+ pivot_local_graph = list(local_graph_neighbors)
+ pivot_local_graph.insert(0, pivot_ind)
+ pivot_knn = [pivot_ind] + list(knn)
+
+ pivot_local_graphs.append(pivot_local_graph)
+ pivot_knns.append(pivot_knn)
+
+ num_max_nodes = max([
+ len(pivot_local_graph) for pivot_local_graph in pivot_local_graphs
+ ])
+
+ local_graphs_node_feat = []
+ adjacent_matrices = []
+ pivots_knn_inds = []
+ pivots_local_graphs = []
+
+ for graph_ind, pivot_knn in enumerate(pivot_knns):
+ pivot_local_graph = pivot_local_graphs[graph_ind]
+ num_nodes = len(pivot_local_graph)
+ pivot_ind = pivot_local_graph[0]
+ node2ind_map = {j: i for i, j in enumerate(pivot_local_graph)}
+
+ knn_inds = torch.tensor([node2ind_map[i]
+ for i in pivot_knn[1:]]).long().to(device)
+ pivot_feats = node_feats[pivot_ind]
+ normalized_feats = node_feats[pivot_local_graph] - pivot_feats
+
+ adjacent_matrix = np.zeros((num_nodes, num_nodes))
+ for node in pivot_local_graph:
+ neighbors = sorted_dist_inds[node,
+ 1:self.active_connection + 1]
+ for neighbor in neighbors:
+ if neighbor in pivot_local_graph:
+ adjacent_matrix[node2ind_map[node],
+ node2ind_map[neighbor]] = 1
+ adjacent_matrix[node2ind_map[neighbor],
+ node2ind_map[node]] = 1
+
+ adjacent_matrix = normalize_adjacent_matrix(adjacent_matrix)
+ pad_adjacent_matrix = torch.zeros((num_max_nodes, num_max_nodes),
+ dtype=torch.float,
+ device=device)
+ pad_adjacent_matrix[:num_nodes, :num_nodes] = torch.from_numpy(
+ adjacent_matrix)
+
+ pad_normalized_feats = torch.cat([
+ normalized_feats,
+ torch.zeros(
+ (num_max_nodes - num_nodes, normalized_feats.shape[1]),
+ dtype=torch.float,
+ device=device)
+ ],
+ dim=0)
+
+ local_graph_nodes = torch.tensor(pivot_local_graph)
+ local_graph_nodes = torch.cat([
+ local_graph_nodes,
+ torch.zeros(num_max_nodes - num_nodes, dtype=torch.long)
+ ],
+ dim=-1)
+
+ local_graphs_node_feat.append(pad_normalized_feats)
+ adjacent_matrices.append(pad_adjacent_matrix)
+ pivots_knn_inds.append(knn_inds)
+ pivots_local_graphs.append(local_graph_nodes)
+
+ local_graphs_node_feat = torch.stack(local_graphs_node_feat, 0)
+ adjacent_matrices = torch.stack(adjacent_matrices, 0)
+ pivots_knn_inds = torch.stack(pivots_knn_inds, 0)
+ pivots_local_graphs = torch.stack(pivots_local_graphs, 0)
+
+ return (local_graphs_node_feat, adjacent_matrices, pivots_knn_inds,
+ pivots_local_graphs)
+
+ def __call__(self, preds, feat_maps):
+ """Generate local graphs and graph convolutional network input data.
+
+ Args:
+ preds (tensor): The predicted maps.
+ feat_maps (tensor): The feature maps to extract content feature of
+ text components.
+
+ Returns:
+ none_flag (bool): The flag showing whether the number of proposed
+ text components is 0.
+ local_graphs_node_feats (tensor): The features of nodes in local
+ graphs.
+ adjacent_matrices (tensor): The adjacent matrices.
+ pivots_knn_inds (tensor): The k-nearest neighbor indices in
+ local graphs.
+ pivots_local_graphs (tensor): The indices of nodes in local
+ graphs.
+ text_comps (ndarray): The predicted text components.
+ """
+
+ if preds.ndim == 4:
+ assert preds.shape[0] == 1
+ preds = torch.squeeze(preds)
+ pred_text_region = torch.sigmoid(preds[0]).data.cpu().numpy()
+ pred_center_region = torch.sigmoid(preds[1]).data.cpu().numpy()
+ pred_sin_map = preds[2].data.cpu().numpy()
+ pred_cos_map = preds[3].data.cpu().numpy()
+ pred_top_height_map = preds[4].data.cpu().numpy()
+ pred_bot_height_map = preds[5].data.cpu().numpy()
+ device = preds.device
+
+ comp_attribs, text_comps = self.propose_comps_and_attribs(
+ pred_text_region, pred_center_region, pred_top_height_map,
+ pred_bot_height_map, pred_sin_map, pred_cos_map)
+
+ if comp_attribs is None or len(comp_attribs) < 2:
+ none_flag = True
+ return none_flag, (0, 0, 0, 0, 0)
+
+ comp_centers = comp_attribs[:, 0:2]
+ distance_matrix = euclidean_distance_matrix(comp_centers, comp_centers)
+
+ geo_feats = feature_embedding(comp_attribs, self.node_geo_feat_dim)
+ geo_feats = torch.from_numpy(geo_feats).to(preds.device)
+
+ batch_id = np.zeros((comp_attribs.shape[0], 1), dtype=np.float32)
+ comp_attribs = comp_attribs.astype(np.float32)
+ angle = np.arccos(comp_attribs[:, -2]) * np.sign(comp_attribs[:, -1])
+ angle = angle.reshape((-1, 1))
+ rotated_rois = np.hstack([batch_id, comp_attribs[:, :-2], angle])
+ rois = torch.from_numpy(rotated_rois).to(device)
+
+ content_feats = self.pooling(feat_maps, rois)
+ content_feats = content_feats.view(content_feats.shape[0],
+ -1).to(device)
+ node_feats = torch.cat([content_feats, geo_feats], dim=-1)
+
+ sorted_dist_inds = np.argsort(distance_matrix, axis=1)
+ (local_graphs_node_feat, adjacent_matrices, pivots_knn_inds,
+ pivots_local_graphs) = self.generate_local_graphs(
+ sorted_dist_inds, node_feats)
+
+ none_flag = False
+ return none_flag, (local_graphs_node_feat, adjacent_matrices,
+ pivots_knn_inds, pivots_local_graphs, text_comps)
diff --git a/mmocr/models/textdet/modules/utils.py b/mmocr/models/textdet/modules/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..48e2eff1bf5ef9a8ea74fc1fa9349058e352a62a
--- /dev/null
+++ b/mmocr/models/textdet/modules/utils.py
@@ -0,0 +1,107 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+
+
+def normalize_adjacent_matrix(A):
+ """Normalize adjacent matrix for GCN. This code was partially adapted from
+ https://github.com/GXYM/DRRG licensed under the MIT license.
+
+ Args:
+ A (ndarray): The adjacent matrix.
+
+ returns:
+ G (ndarray): The normalized adjacent matrix.
+ """
+ assert A.ndim == 2
+ assert A.shape[0] == A.shape[1]
+
+ A = A + np.eye(A.shape[0])
+ d = np.sum(A, axis=0)
+ d = np.clip(d, 0, None)
+ d_inv = np.power(d, -0.5).flatten()
+ d_inv[np.isinf(d_inv)] = 0.0
+ d_inv = np.diag(d_inv)
+ G = A.dot(d_inv).transpose().dot(d_inv)
+ return G
+
+
+def euclidean_distance_matrix(A, B):
+ """Calculate the Euclidean distance matrix.
+
+ Args:
+ A (ndarray): The point sequence.
+ B (ndarray): The point sequence with the same dimensions as A.
+
+ returns:
+ D (ndarray): The Euclidean distance matrix.
+ """
+ assert A.ndim == 2
+ assert B.ndim == 2
+ assert A.shape[1] == B.shape[1]
+
+ m = A.shape[0]
+ n = B.shape[0]
+
+ A_dots = (A * A).sum(axis=1).reshape((m, 1)) * np.ones(shape=(1, n))
+ B_dots = (B * B).sum(axis=1) * np.ones(shape=(m, 1))
+ D_squared = A_dots + B_dots - 2 * A.dot(B.T)
+
+ zero_mask = np.less(D_squared, 0.0)
+ D_squared[zero_mask] = 0.0
+ D = np.sqrt(D_squared)
+ return D
+
+
+def feature_embedding(input_feats, out_feat_len):
+ """Embed features. This code was partially adapted from
+ https://github.com/GXYM/DRRG licensed under the MIT license.
+
+ Args:
+ input_feats (ndarray): The input features of shape (N, d), where N is
+ the number of nodes in graph, d is the input feature vector length.
+ out_feat_len (int): The length of output feature vector.
+
+ Returns:
+ embedded_feats (ndarray): The embedded features.
+ """
+ assert input_feats.ndim == 2
+ assert isinstance(out_feat_len, int)
+ assert out_feat_len >= input_feats.shape[1]
+
+ num_nodes = input_feats.shape[0]
+ feat_dim = input_feats.shape[1]
+ feat_repeat_times = out_feat_len // feat_dim
+ residue_dim = out_feat_len % feat_dim
+
+ if residue_dim > 0:
+ embed_wave = np.array([
+ np.power(1000, 2.0 * (j // 2) / feat_repeat_times + 1)
+ for j in range(feat_repeat_times + 1)
+ ]).reshape((feat_repeat_times + 1, 1, 1))
+ repeat_feats = np.repeat(
+ np.expand_dims(input_feats, axis=0), feat_repeat_times, axis=0)
+ residue_feats = np.hstack([
+ input_feats[:, 0:residue_dim],
+ np.zeros((num_nodes, feat_dim - residue_dim))
+ ])
+ residue_feats = np.expand_dims(residue_feats, axis=0)
+ repeat_feats = np.concatenate([repeat_feats, residue_feats], axis=0)
+ embedded_feats = repeat_feats / embed_wave
+ embedded_feats[:, 0::2] = np.sin(embedded_feats[:, 0::2])
+ embedded_feats[:, 1::2] = np.cos(embedded_feats[:, 1::2])
+ embedded_feats = np.transpose(embedded_feats, (1, 0, 2)).reshape(
+ (num_nodes, -1))[:, 0:out_feat_len]
+ else:
+ embed_wave = np.array([
+ np.power(1000, 2.0 * (j // 2) / feat_repeat_times)
+ for j in range(feat_repeat_times)
+ ]).reshape((feat_repeat_times, 1, 1))
+ repeat_feats = np.repeat(
+ np.expand_dims(input_feats, axis=0), feat_repeat_times, axis=0)
+ embedded_feats = repeat_feats / embed_wave
+ embedded_feats[:, 0::2] = np.sin(embedded_feats[:, 0::2])
+ embedded_feats[:, 1::2] = np.cos(embedded_feats[:, 1::2])
+ embedded_feats = np.transpose(embedded_feats, (1, 0, 2)).reshape(
+ (num_nodes, -1)).astype(np.float32)
+
+ return embedded_feats
diff --git a/mmocr/models/textdet/necks/__init__.py b/mmocr/models/textdet/necks/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..0b21bf192b93f8a09278989837f8b9b762052f7e
--- /dev/null
+++ b/mmocr/models/textdet/necks/__init__.py
@@ -0,0 +1,7 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .fpem_ffm import FPEM_FFM
+from .fpn_cat import FPNC
+from .fpn_unet import FPN_UNet
+from .fpnf import FPNF
+
+__all__ = ['FPEM_FFM', 'FPNF', 'FPNC', 'FPN_UNet']
diff --git a/mmocr/models/textdet/necks/fpem_ffm.py b/mmocr/models/textdet/necks/fpem_ffm.py
new file mode 100644
index 0000000000000000000000000000000000000000..e27d3f650ca36b22e13d2b55f5fbdb4be4c687b9
--- /dev/null
+++ b/mmocr/models/textdet/necks/fpem_ffm.py
@@ -0,0 +1,173 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn.functional as F
+from mmcv.runner import BaseModule, ModuleList
+from torch import nn
+
+from mmocr.models.builder import NECKS
+
+
+class FPEM(BaseModule):
+ """FPN-like feature fusion module in PANet.
+
+ Args:
+ in_channels (int): Number of input channels.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self, in_channels=128, init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ self.up_add1 = SeparableConv2d(in_channels, in_channels, 1)
+ self.up_add2 = SeparableConv2d(in_channels, in_channels, 1)
+ self.up_add3 = SeparableConv2d(in_channels, in_channels, 1)
+ self.down_add1 = SeparableConv2d(in_channels, in_channels, 2)
+ self.down_add2 = SeparableConv2d(in_channels, in_channels, 2)
+ self.down_add3 = SeparableConv2d(in_channels, in_channels, 2)
+
+ def forward(self, c2, c3, c4, c5):
+ """
+ Args:
+ c2, c3, c4, c5 (Tensor): Each has the shape of
+ :math:`(N, C_i, H_i, W_i)`.
+
+ Returns:
+ list[Tensor]: A list of 4 tensors of the same shape as input.
+ """
+ # upsample
+ c4 = self.up_add1(self._upsample_add(c5, c4)) # c4 shape
+ c3 = self.up_add2(self._upsample_add(c4, c3))
+ c2 = self.up_add3(self._upsample_add(c3, c2))
+
+ # downsample
+ c3 = self.down_add1(self._upsample_add(c3, c2))
+ c4 = self.down_add2(self._upsample_add(c4, c3))
+ c5 = self.down_add3(self._upsample_add(c5, c4)) # c4 / 2
+ return c2, c3, c4, c5
+
+ def _upsample_add(self, x, y):
+ return F.interpolate(x, size=y.size()[2:]) + y
+
+
+class SeparableConv2d(BaseModule):
+
+ def __init__(self, in_channels, out_channels, stride=1, init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+
+ self.depthwise_conv = nn.Conv2d(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ kernel_size=3,
+ padding=1,
+ stride=stride,
+ groups=in_channels)
+ self.pointwise_conv = nn.Conv2d(
+ in_channels=in_channels, out_channels=out_channels, kernel_size=1)
+ self.bn = nn.BatchNorm2d(out_channels)
+ self.relu = nn.ReLU()
+
+ def forward(self, x):
+ x = self.depthwise_conv(x)
+ x = self.pointwise_conv(x)
+ x = self.bn(x)
+ x = self.relu(x)
+ return x
+
+
+@NECKS.register_module()
+class FPEM_FFM(BaseModule):
+ """This code is from https://github.com/WenmuZhou/PAN.pytorch.
+
+ Args:
+ in_channels (list[int]): A list of 4 numbers of input channels.
+ conv_out (int): Number of output channels.
+ fpem_repeat (int): Number of FPEM layers before FFM operations.
+ align_corners (bool): The interpolation behaviour in FFM operation,
+ used in :func:`torch.nn.functional.interpolate`.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self,
+ in_channels,
+ conv_out=128,
+ fpem_repeat=2,
+ align_corners=False,
+ init_cfg=dict(
+ type='Xavier', layer='Conv2d', distribution='uniform')):
+ super().__init__(init_cfg=init_cfg)
+ # reduce layers
+ self.reduce_conv_c2 = nn.Sequential(
+ nn.Conv2d(
+ in_channels=in_channels[0],
+ out_channels=conv_out,
+ kernel_size=1), nn.BatchNorm2d(conv_out), nn.ReLU())
+ self.reduce_conv_c3 = nn.Sequential(
+ nn.Conv2d(
+ in_channels=in_channels[1],
+ out_channels=conv_out,
+ kernel_size=1), nn.BatchNorm2d(conv_out), nn.ReLU())
+ self.reduce_conv_c4 = nn.Sequential(
+ nn.Conv2d(
+ in_channels=in_channels[2],
+ out_channels=conv_out,
+ kernel_size=1), nn.BatchNorm2d(conv_out), nn.ReLU())
+ self.reduce_conv_c5 = nn.Sequential(
+ nn.Conv2d(
+ in_channels=in_channels[3],
+ out_channels=conv_out,
+ kernel_size=1), nn.BatchNorm2d(conv_out), nn.ReLU())
+ self.align_corners = align_corners
+ self.fpems = ModuleList()
+ for _ in range(fpem_repeat):
+ self.fpems.append(FPEM(conv_out))
+
+ def forward(self, x):
+ """
+ Args:
+ x (list[Tensor]): A list of four tensors of shape
+ :math:`(N, C_i, H_i, W_i)`, representing C2, C3, C4, C5
+ features respectively. :math:`C_i` should matches the number in
+ ``in_channels``.
+
+ Returns:
+ list[Tensor]: Four tensors of shape
+ :math:`(N, C_{out}, H_0, W_0)` where :math:`C_{out}` is
+ ``conv_out``.
+ """
+ c2, c3, c4, c5 = x
+ # reduce channel
+ c2 = self.reduce_conv_c2(c2)
+ c3 = self.reduce_conv_c3(c3)
+ c4 = self.reduce_conv_c4(c4)
+ c5 = self.reduce_conv_c5(c5)
+
+ # FPEM
+ for i, fpem in enumerate(self.fpems):
+ c2, c3, c4, c5 = fpem(c2, c3, c4, c5)
+ if i == 0:
+ c2_ffm = c2
+ c3_ffm = c3
+ c4_ffm = c4
+ c5_ffm = c5
+ else:
+ c2_ffm += c2
+ c3_ffm += c3
+ c4_ffm += c4
+ c5_ffm += c5
+
+ # FFM
+ c5 = F.interpolate(
+ c5_ffm,
+ c2_ffm.size()[-2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ c4 = F.interpolate(
+ c4_ffm,
+ c2_ffm.size()[-2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ c3 = F.interpolate(
+ c3_ffm,
+ c2_ffm.size()[-2:],
+ mode='bilinear',
+ align_corners=self.align_corners)
+ outs = [c2_ffm, c3, c4, c5]
+ return tuple(outs)
diff --git a/mmocr/models/textdet/necks/fpn_cat.py b/mmocr/models/textdet/necks/fpn_cat.py
new file mode 100644
index 0000000000000000000000000000000000000000..90d9d222d3775bfe82feddf72d60b4d3bd634043
--- /dev/null
+++ b/mmocr/models/textdet/necks/fpn_cat.py
@@ -0,0 +1,143 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmcv.runner import BaseModule, ModuleList, auto_fp16
+
+from mmocr.models.builder import NECKS
+
+
+@NECKS.register_module()
+class FPNC(BaseModule):
+ """FPN-like fusion module in Real-time Scene Text Detection with
+ Differentiable Binarization.
+
+ This was partially adapted from https://github.com/MhLiao/DB and
+ https://github.com/WenmuZhou/DBNet.pytorch.
+
+ Args:
+ in_channels (list[int]): A list of numbers of input channels.
+ lateral_channels (int): Number of channels for lateral layers.
+ out_channels (int): Number of output channels.
+ bias_on_lateral (bool): Whether to use bias on lateral convolutional
+ layers.
+ bn_re_on_lateral (bool): Whether to use BatchNorm and ReLU
+ on lateral convolutional layers.
+ bias_on_smooth (bool): Whether to use bias on smoothing layer.
+ bn_re_on_smooth (bool): Whether to use BatchNorm and ReLU on smoothing
+ layer.
+ conv_after_concat (bool): Whether to add a convolution layer after
+ the concatenation of predictions.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self,
+ in_channels,
+ lateral_channels=256,
+ out_channels=64,
+ bias_on_lateral=False,
+ bn_re_on_lateral=False,
+ bias_on_smooth=False,
+ bn_re_on_smooth=False,
+ conv_after_concat=False,
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ assert isinstance(in_channels, list)
+ self.in_channels = in_channels
+ self.lateral_channels = lateral_channels
+ self.out_channels = out_channels
+ self.num_ins = len(in_channels)
+ self.bn_re_on_lateral = bn_re_on_lateral
+ self.bn_re_on_smooth = bn_re_on_smooth
+ self.conv_after_concat = conv_after_concat
+ self.lateral_convs = ModuleList()
+ self.smooth_convs = ModuleList()
+ self.num_outs = self.num_ins
+
+ for i in range(self.num_ins):
+ norm_cfg = None
+ act_cfg = None
+ if self.bn_re_on_lateral:
+ norm_cfg = dict(type='BN')
+ act_cfg = dict(type='ReLU')
+ l_conv = ConvModule(
+ in_channels[i],
+ lateral_channels,
+ 1,
+ bias=bias_on_lateral,
+ conv_cfg=None,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ inplace=False)
+ norm_cfg = None
+ act_cfg = None
+ if self.bn_re_on_smooth:
+ norm_cfg = dict(type='BN')
+ act_cfg = dict(type='ReLU')
+
+ smooth_conv = ConvModule(
+ lateral_channels,
+ out_channels,
+ 3,
+ bias=bias_on_smooth,
+ padding=1,
+ conv_cfg=None,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ inplace=False)
+
+ self.lateral_convs.append(l_conv)
+ self.smooth_convs.append(smooth_conv)
+ if self.conv_after_concat:
+ norm_cfg = dict(type='BN')
+ act_cfg = dict(type='ReLU')
+ self.out_conv = ConvModule(
+ out_channels * self.num_outs,
+ out_channels * self.num_outs,
+ 3,
+ padding=1,
+ conv_cfg=None,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ inplace=False)
+
+ @auto_fp16()
+ def forward(self, inputs):
+ """
+ Args:
+ inputs (list[Tensor]): Each tensor has the shape of
+ :math:`(N, C_i, H_i, W_i)`. It usually expects 4 tensors
+ (C2-C5 features) from ResNet.
+
+ Returns:
+ Tensor: A tensor of shape :math:`(N, C_{out}, H_0, W_0)` where
+ :math:`C_{out}` is ``out_channels``.
+ """
+ assert len(inputs) == len(self.in_channels)
+ # build laterals
+ laterals = [
+ lateral_conv(inputs[i])
+ for i, lateral_conv in enumerate(self.lateral_convs)
+ ]
+ used_backbone_levels = len(laterals)
+ # build top-down path
+ for i in range(used_backbone_levels - 1, 0, -1):
+ prev_shape = laterals[i - 1].shape[2:]
+ laterals[i - 1] += F.interpolate(
+ laterals[i], size=prev_shape, mode='nearest')
+ # build outputs
+ # part 1: from original levels
+ outs = [
+ self.smooth_convs[i](laterals[i])
+ for i in range(used_backbone_levels)
+ ]
+
+ for i, out in enumerate(outs):
+ outs[i] = F.interpolate(
+ outs[i], size=outs[0].shape[2:], mode='nearest')
+ out = torch.cat(outs, dim=1)
+
+ if self.conv_after_concat:
+ out = self.out_conv(out)
+
+ return out
diff --git a/mmocr/models/textdet/necks/fpn_unet.py b/mmocr/models/textdet/necks/fpn_unet.py
new file mode 100644
index 0000000000000000000000000000000000000000..c5c4860408513f299dc48dc137ae03e6c4190744
--- /dev/null
+++ b/mmocr/models/textdet/necks/fpn_unet.py
@@ -0,0 +1,107 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn.functional as F
+from mmcv.runner import BaseModule
+from torch import nn
+
+from mmocr.models.builder import NECKS
+
+
+class UpBlock(BaseModule):
+ """Upsample block for DRRG and TextSnake."""
+
+ def __init__(self, in_channels, out_channels, init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+
+ assert isinstance(in_channels, int)
+ assert isinstance(out_channels, int)
+
+ self.conv1x1 = nn.Conv2d(
+ in_channels, in_channels, kernel_size=1, stride=1, padding=0)
+ self.conv3x3 = nn.Conv2d(
+ in_channels, out_channels, kernel_size=3, stride=1, padding=1)
+ self.deconv = nn.ConvTranspose2d(
+ out_channels, out_channels, kernel_size=4, stride=2, padding=1)
+
+ def forward(self, x):
+ x = F.relu(self.conv1x1(x))
+ x = F.relu(self.conv3x3(x))
+ x = self.deconv(x)
+ return x
+
+
+@NECKS.register_module()
+class FPN_UNet(BaseModule):
+ """The class for implementing DRRG and TextSnake U-Net-like FPN.
+
+ DRRG: `Deep Relational Reasoning Graph Network for Arbitrary Shape
+ Text Detection `_.
+
+ TextSnake: `A Flexible Representation for Detecting Text of Arbitrary
+ Shapes `_.
+
+ Args:
+ in_channels (list[int]): Number of input channels at each scale. The
+ length of the list should be 4.
+ out_channels (int): The number of output channels.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ init_cfg=dict(
+ type='Xavier',
+ layer=['Conv2d', 'ConvTranspose2d'],
+ distribution='uniform')):
+ super().__init__(init_cfg=init_cfg)
+
+ assert len(in_channels) == 4
+ assert isinstance(out_channels, int)
+
+ blocks_out_channels = [out_channels] + [
+ min(out_channels * 2**i, 256) for i in range(4)
+ ]
+ blocks_in_channels = [blocks_out_channels[1]] + [
+ in_channels[i] + blocks_out_channels[i + 2] for i in range(3)
+ ] + [in_channels[3]]
+
+ self.up4 = nn.ConvTranspose2d(
+ blocks_in_channels[4],
+ blocks_out_channels[4],
+ kernel_size=4,
+ stride=2,
+ padding=1)
+ self.up_block3 = UpBlock(blocks_in_channels[3], blocks_out_channels[3])
+ self.up_block2 = UpBlock(blocks_in_channels[2], blocks_out_channels[2])
+ self.up_block1 = UpBlock(blocks_in_channels[1], blocks_out_channels[1])
+ self.up_block0 = UpBlock(blocks_in_channels[0], blocks_out_channels[0])
+
+ def forward(self, x):
+ """
+ Args:
+ x (list[Tensor] | tuple[Tensor]): A list of four tensors of shape
+ :math:`(N, C_i, H_i, W_i)`, representing C2, C3, C4, C5
+ features respectively. :math:`C_i` should matches the number in
+ ``in_channels``.
+
+ Returns:
+ Tensor: Shape :math:`(N, C, H, W)` where :math:`H=4H_0` and
+ :math:`W=4W_0`.
+ """
+ c2, c3, c4, c5 = x
+
+ x = F.relu(self.up4(c5))
+
+ x = torch.cat([x, c4], dim=1)
+ x = F.relu(self.up_block3(x))
+
+ x = torch.cat([x, c3], dim=1)
+ x = F.relu(self.up_block2(x))
+
+ x = torch.cat([x, c2], dim=1)
+ x = F.relu(self.up_block1(x))
+
+ x = self.up_block0(x)
+ # the output should be of the same height and width as backbone input
+ return x
diff --git a/mmocr/models/textdet/necks/fpnf.py b/mmocr/models/textdet/necks/fpnf.py
new file mode 100644
index 0000000000000000000000000000000000000000..f63eba55c375ed5bfa851a5c789eb7d90162e51f
--- /dev/null
+++ b/mmocr/models/textdet/necks/fpnf.py
@@ -0,0 +1,128 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmcv.runner import BaseModule, ModuleList, auto_fp16
+
+from mmocr.models.builder import NECKS
+
+
+@NECKS.register_module()
+class FPNF(BaseModule):
+ """FPN-like fusion module in Shape Robust Text Detection with Progressive
+ Scale Expansion Network.
+
+ Args:
+ in_channels (list[int]): A list of number of input channels.
+ out_channels (int): The number of output channels.
+ fusion_type (str): Type of the final feature fusion layer. Available
+ options are "concat" and "add".
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self,
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ fusion_type='concat',
+ init_cfg=dict(
+ type='Xavier', layer='Conv2d', distribution='uniform')):
+ super().__init__(init_cfg=init_cfg)
+ conv_cfg = None
+ norm_cfg = dict(type='BN')
+ act_cfg = dict(type='ReLU')
+
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+
+ self.lateral_convs = ModuleList()
+ self.fpn_convs = ModuleList()
+ self.backbone_end_level = len(in_channels)
+ for i in range(self.backbone_end_level):
+ l_conv = ConvModule(
+ in_channels[i],
+ out_channels,
+ 1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ inplace=False)
+ self.lateral_convs.append(l_conv)
+
+ if i < self.backbone_end_level - 1:
+ fpn_conv = ConvModule(
+ out_channels,
+ out_channels,
+ 3,
+ padding=1,
+ conv_cfg=conv_cfg,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ inplace=False)
+ self.fpn_convs.append(fpn_conv)
+
+ self.fusion_type = fusion_type
+
+ if self.fusion_type == 'concat':
+ feature_channels = 1024
+ elif self.fusion_type == 'add':
+ feature_channels = 256
+ else:
+ raise NotImplementedError
+
+ self.output_convs = ConvModule(
+ feature_channels,
+ out_channels,
+ 3,
+ padding=1,
+ conv_cfg=None,
+ norm_cfg=norm_cfg,
+ act_cfg=act_cfg,
+ inplace=False)
+
+ @auto_fp16()
+ def forward(self, inputs):
+ """
+ Args:
+ inputs (list[Tensor]): Each tensor has the shape of
+ :math:`(N, C_i, H_i, W_i)`. It usually expects 4 tensors
+ (C2-C5 features) from ResNet.
+
+ Returns:
+ Tensor: A tensor of shape :math:`(N, C_{out}, H_0, W_0)` where
+ :math:`C_{out}` is ``out_channels``.
+ """
+ assert len(inputs) == len(self.in_channels)
+
+ # build laterals
+ laterals = [
+ lateral_conv(inputs[i])
+ for i, lateral_conv in enumerate(self.lateral_convs)
+ ]
+
+ # build top-down path
+ used_backbone_levels = len(laterals)
+ for i in range(used_backbone_levels - 1, 0, -1):
+ # step 1: upsample to level i-1 size and add level i-1
+ prev_shape = laterals[i - 1].shape[2:]
+ laterals[i - 1] += F.interpolate(
+ laterals[i], size=prev_shape, mode='nearest')
+ # step 2: smooth level i-1
+ laterals[i - 1] = self.fpn_convs[i - 1](laterals[i - 1])
+
+ # upsample and cont
+ bottom_shape = laterals[0].shape[2:]
+ for i in range(1, used_backbone_levels):
+ laterals[i] = F.interpolate(
+ laterals[i], size=bottom_shape, mode='nearest')
+
+ if self.fusion_type == 'concat':
+ out = torch.cat(laterals, 1)
+ elif self.fusion_type == 'add':
+ out = laterals[0]
+ for i in range(1, used_backbone_levels):
+ out += laterals[i]
+ else:
+ raise NotImplementedError
+ out = self.output_convs(out)
+
+ return out
diff --git a/mmocr/models/textdet/postprocess/__init__.py b/mmocr/models/textdet/postprocess/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..2011897710fddf2e02c544f895ec149ab37571bc
--- /dev/null
+++ b/mmocr/models/textdet/postprocess/__init__.py
@@ -0,0 +1,14 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .base_postprocessor import BasePostprocessor
+from .db_postprocessor import DBPostprocessor
+from .drrg_postprocessor import DRRGPostprocessor
+from .fce_postprocessor import FCEPostprocessor
+from .pan_postprocessor import PANPostprocessor
+from .pse_postprocessor import PSEPostprocessor
+from .textsnake_postprocessor import TextSnakePostprocessor
+
+__all__ = [
+ 'BasePostprocessor', 'PSEPostprocessor', 'PANPostprocessor',
+ 'DBPostprocessor', 'DRRGPostprocessor', 'FCEPostprocessor',
+ 'TextSnakePostprocessor'
+]
diff --git a/mmocr/models/textdet/postprocess/base_postprocessor.py b/mmocr/models/textdet/postprocess/base_postprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..734f87b6d1783fbe7cb8f12a74a6d12d734a30ad
--- /dev/null
+++ b/mmocr/models/textdet/postprocess/base_postprocessor.py
@@ -0,0 +1,15 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+
+class BasePostprocessor:
+
+ def __init__(self, text_repr_type='poly'):
+ assert text_repr_type in ['poly', 'quad'
+ ], f'Invalid text repr type {text_repr_type}'
+
+ self.text_repr_type = text_repr_type
+
+ def is_valid_instance(self, area, confidence, area_thresh,
+ confidence_thresh):
+
+ return bool(area >= area_thresh and confidence > confidence_thresh)
diff --git a/mmocr/models/textdet/postprocess/db_postprocessor.py b/mmocr/models/textdet/postprocess/db_postprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..d9dbbeb2da684fa4c7597615e07e4b5395772e1b
--- /dev/null
+++ b/mmocr/models/textdet/postprocess/db_postprocessor.py
@@ -0,0 +1,91 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import cv2
+import numpy as np
+
+from mmocr.core import points2boundary
+from mmocr.models.builder import POSTPROCESSOR
+from .base_postprocessor import BasePostprocessor
+from .utils import box_score_fast, unclip
+
+
+@POSTPROCESSOR.register_module()
+class DBPostprocessor(BasePostprocessor):
+ """Decoding predictions of DbNet to instances. This is partially adapted
+ from https://github.com/MhLiao/DB.
+
+ Args:
+ text_repr_type (str): The boundary encoding type 'poly' or 'quad'.
+ mask_thr (float): The mask threshold value for binarization.
+ min_text_score (float): The threshold value for converting binary map
+ to shrink text regions.
+ min_text_width (int): The minimum width of boundary polygon/box
+ predicted.
+ unclip_ratio (float): The unclip ratio for text regions dilation.
+ max_candidates (int): The maximum candidate number.
+ """
+
+ def __init__(self,
+ text_repr_type='poly',
+ mask_thr=0.3,
+ min_text_score=0.3,
+ min_text_width=5,
+ unclip_ratio=1.5,
+ max_candidates=3000,
+ **kwargs):
+ super().__init__(text_repr_type)
+ self.mask_thr = mask_thr
+ self.min_text_score = min_text_score
+ self.min_text_width = min_text_width
+ self.unclip_ratio = unclip_ratio
+ self.max_candidates = max_candidates
+
+ def __call__(self, preds):
+ """
+ Args:
+ preds (Tensor): Prediction map with shape :math:`(C, H, W)`.
+
+ Returns:
+ list[list[float]]: The predicted text boundaries.
+ """
+ assert preds.dim() == 3
+
+ prob_map = preds[0, :, :]
+ text_mask = prob_map > self.mask_thr
+
+ score_map = prob_map.data.cpu().numpy().astype(np.float32)
+ text_mask = text_mask.data.cpu().numpy().astype(np.uint8) # to numpy
+
+ contours, _ = cv2.findContours((text_mask * 255).astype(np.uint8),
+ cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
+
+ boundaries = []
+ for i, poly in enumerate(contours):
+ if i > self.max_candidates:
+ break
+ epsilon = 0.01 * cv2.arcLength(poly, True)
+ approx = cv2.approxPolyDP(poly, epsilon, True)
+ points = approx.reshape((-1, 2))
+ if points.shape[0] < 4:
+ continue
+ score = box_score_fast(score_map, points)
+ if score < self.min_text_score:
+ continue
+ poly = unclip(points, unclip_ratio=self.unclip_ratio)
+ if len(poly) == 0 or isinstance(poly[0], list):
+ continue
+ poly = poly.reshape(-1, 2)
+
+ if self.text_repr_type == 'quad':
+ poly = points2boundary(poly, self.text_repr_type, score,
+ self.min_text_width)
+ elif self.text_repr_type == 'poly':
+ poly = poly.flatten().tolist()
+ if score is not None:
+ poly = poly + [score]
+ if len(poly) < 8:
+ poly = None
+
+ if poly is not None:
+ boundaries.append(poly)
+
+ return boundaries
diff --git a/mmocr/models/textdet/postprocess/drrg_postprocessor.py b/mmocr/models/textdet/postprocess/drrg_postprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..ebfb17b9c646720f21fba6bbd1d3b01848b452ba
--- /dev/null
+++ b/mmocr/models/textdet/postprocess/drrg_postprocessor.py
@@ -0,0 +1,41 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.models.builder import POSTPROCESSOR
+from .base_postprocessor import BasePostprocessor
+from .utils import (clusters2labels, comps2boundaries, connected_components,
+ graph_propagation, remove_single)
+
+
+@POSTPROCESSOR.register_module()
+class DRRGPostprocessor(BasePostprocessor):
+ """Merge text components and construct boundaries of text instances.
+
+ Args:
+ link_thr (float): The edge score threshold.
+ """
+
+ def __init__(self, link_thr, **kwargs):
+ assert isinstance(link_thr, float)
+ self.link_thr = link_thr
+
+ def __call__(self, edges, scores, text_comps):
+ """
+ Args:
+ edges (ndarray): The edge array of shape N * 2, each row is a node
+ index pair that makes up an edge in graph.
+ scores (ndarray): The edge score array of shape (N,).
+ text_comps (ndarray): The text components.
+
+ Returns:
+ List[list[float]]: The predicted boundaries of text instances.
+ """
+ assert len(edges) == len(scores)
+ assert text_comps.ndim == 2
+ assert text_comps.shape[1] == 9
+
+ vertices, score_dict = graph_propagation(edges, scores, text_comps)
+ clusters = connected_components(vertices, score_dict, self.link_thr)
+ pred_labels = clusters2labels(clusters, text_comps.shape[0])
+ text_comps, pred_labels = remove_single(text_comps, pred_labels)
+ boundaries = comps2boundaries(text_comps, pred_labels)
+
+ return boundaries
diff --git a/mmocr/models/textdet/postprocess/fce_postprocessor.py b/mmocr/models/textdet/postprocess/fce_postprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..226e3bd749531a19ba1c95aed9ad0f275d6a8990
--- /dev/null
+++ b/mmocr/models/textdet/postprocess/fce_postprocessor.py
@@ -0,0 +1,110 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import cv2
+import numpy as np
+
+from mmocr.models.builder import POSTPROCESSOR
+from .base_postprocessor import BasePostprocessor
+from .utils import fill_hole, fourier2poly, poly_nms
+
+
+@POSTPROCESSOR.register_module()
+class FCEPostprocessor(BasePostprocessor):
+ """Decoding predictions of FCENet to instances.
+
+ Args:
+ fourier_degree (int): The maximum Fourier transform degree k.
+ num_reconstr_points (int): The points number of the polygon
+ reconstructed from predicted Fourier coefficients.
+ text_repr_type (str): Boundary encoding type 'poly' or 'quad'.
+ scale (int): The down-sample scale of the prediction.
+ alpha (float): The parameter to calculate final scores. Score_{final}
+ = (Score_{text region} ^ alpha)
+ * (Score_{text center region}^ beta)
+ beta (float): The parameter to calculate final score.
+ score_thr (float): The threshold used to filter out the final
+ candidates.
+ nms_thr (float): The threshold of nms.
+ """
+
+ def __init__(self,
+ fourier_degree,
+ num_reconstr_points,
+ text_repr_type='poly',
+ alpha=1.0,
+ beta=2.0,
+ score_thr=0.3,
+ nms_thr=0.1,
+ **kwargs):
+ super().__init__(text_repr_type)
+ self.fourier_degree = fourier_degree
+ self.num_reconstr_points = num_reconstr_points
+ self.alpha = alpha
+ self.beta = beta
+ self.score_thr = score_thr
+ self.nms_thr = nms_thr
+
+ def __call__(self, preds, scale):
+ """
+ Args:
+ preds (list[Tensor]): Classification prediction and regression
+ prediction.
+ scale (float): Scale of current layer.
+
+ Returns:
+ list[list[float]]: The instance boundary and confidence.
+ """
+ assert isinstance(preds, list)
+ assert len(preds) == 2
+
+ cls_pred = preds[0][0]
+ tr_pred = cls_pred[0:2].softmax(dim=0).data.cpu().numpy()
+ tcl_pred = cls_pred[2:].softmax(dim=0).data.cpu().numpy()
+
+ reg_pred = preds[1][0].permute(1, 2, 0).data.cpu().numpy()
+ x_pred = reg_pred[:, :, :2 * self.fourier_degree + 1]
+ y_pred = reg_pred[:, :, 2 * self.fourier_degree + 1:]
+
+ score_pred = (tr_pred[1]**self.alpha) * (tcl_pred[1]**self.beta)
+ tr_pred_mask = (score_pred) > self.score_thr
+ tr_mask = fill_hole(tr_pred_mask)
+
+ tr_contours, _ = cv2.findContours(
+ tr_mask.astype(np.uint8), cv2.RETR_TREE,
+ cv2.CHAIN_APPROX_SIMPLE) # opencv4
+
+ mask = np.zeros_like(tr_mask)
+ boundaries = []
+ for cont in tr_contours:
+ deal_map = mask.copy().astype(np.int8)
+ cv2.drawContours(deal_map, [cont], -1, 1, -1)
+
+ score_map = score_pred * deal_map
+ score_mask = score_map > 0
+ xy_text = np.argwhere(score_mask)
+ dxy = xy_text[:, 1] + xy_text[:, 0] * 1j
+
+ x, y = x_pred[score_mask], y_pred[score_mask]
+ c = x + y * 1j
+ c[:, self.fourier_degree] = c[:, self.fourier_degree] + dxy
+ c *= scale
+
+ polygons = fourier2poly(c, self.num_reconstr_points)
+ score = score_map[score_mask].reshape(-1, 1)
+ polygons = poly_nms(
+ np.hstack((polygons, score)).tolist(), self.nms_thr)
+
+ boundaries = boundaries + polygons
+
+ boundaries = poly_nms(boundaries, self.nms_thr)
+
+ if self.text_repr_type == 'quad':
+ new_boundaries = []
+ for boundary in boundaries:
+ poly = np.array(boundary[:-1]).reshape(-1,
+ 2).astype(np.float32)
+ score = boundary[-1]
+ points = cv2.boxPoints(cv2.minAreaRect(poly))
+ points = np.int0(points)
+ new_boundaries.append(points.reshape(-1).tolist() + [score])
+
+ return boundaries
diff --git a/mmocr/models/textdet/postprocess/pan_postprocessor.py b/mmocr/models/textdet/postprocess/pan_postprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..11271418a9e370700618126e05fcc2f22db08641
--- /dev/null
+++ b/mmocr/models/textdet/postprocess/pan_postprocessor.py
@@ -0,0 +1,85 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import cv2
+import numpy as np
+import torch
+from mmcv.ops import pixel_group
+
+from mmocr.core import points2boundary
+from mmocr.models.builder import POSTPROCESSOR
+from .base_postprocessor import BasePostprocessor
+
+
+@POSTPROCESSOR.register_module()
+class PANPostprocessor(BasePostprocessor):
+ """Convert scores to quadrangles via post processing in PANet. This is
+ partially adapted from https://github.com/WenmuZhou/PAN.pytorch.
+
+ Args:
+ text_repr_type (str): The boundary encoding type 'poly' or 'quad'.
+ min_text_confidence (float): The minimal text confidence.
+ min_kernel_confidence (float): The minimal kernel confidence.
+ min_text_avg_confidence (float): The minimal text average confidence.
+ min_text_area (int): The minimal text instance region area.
+ """
+
+ def __init__(self,
+ text_repr_type='poly',
+ min_text_confidence=0.5,
+ min_kernel_confidence=0.5,
+ min_text_avg_confidence=0.85,
+ min_text_area=16,
+ **kwargs):
+ super().__init__(text_repr_type)
+
+ self.min_text_confidence = min_text_confidence
+ self.min_kernel_confidence = min_kernel_confidence
+ self.min_text_avg_confidence = min_text_avg_confidence
+ self.min_text_area = min_text_area
+
+ def __call__(self, preds):
+ """
+ Args:
+ preds (Tensor): Prediction map with shape :math:`(C, H, W)`.
+
+ Returns:
+ list[list[float]]: The instance boundary and its confidence.
+ """
+ assert preds.dim() == 3
+
+ preds[:2, :, :] = torch.sigmoid(preds[:2, :, :])
+ preds = preds.detach().cpu().numpy()
+
+ text_score = preds[0].astype(np.float32)
+ text = preds[0] > self.min_text_confidence
+ kernel = (preds[1] > self.min_kernel_confidence) * text
+ embeddings = preds[2:].transpose((1, 2, 0)) # (h, w, 4)
+
+ region_num, labels = cv2.connectedComponents(
+ kernel.astype(np.uint8), connectivity=4)
+ contours, _ = cv2.findContours((kernel * 255).astype(np.uint8),
+ cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE)
+ kernel_contours = np.zeros(text.shape, dtype='uint8')
+ cv2.drawContours(kernel_contours, contours, -1, 255)
+ text_points = pixel_group(text_score, text, embeddings, labels,
+ kernel_contours, region_num,
+ self.min_text_avg_confidence)
+
+ boundaries = []
+ for text_point in text_points:
+ text_confidence = text_point[0]
+ text_point = text_point[2:]
+ text_point = np.array(text_point, dtype=int).reshape(-1, 2)
+ area = text_point.shape[0]
+
+ if not self.is_valid_instance(area, text_confidence,
+ self.min_text_area,
+ self.min_text_avg_confidence):
+ continue
+
+ vertices_confidence = points2boundary(text_point,
+ self.text_repr_type,
+ text_confidence)
+ if vertices_confidence is not None:
+ boundaries.append(vertices_confidence)
+
+ return boundaries
diff --git a/mmocr/models/textdet/postprocess/pse_postprocessor.py b/mmocr/models/textdet/postprocess/pse_postprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..4cf536611c9c289cf0a6a5b53a470c6346137063
--- /dev/null
+++ b/mmocr/models/textdet/postprocess/pse_postprocessor.py
@@ -0,0 +1,88 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+import cv2
+import numpy as np
+import torch
+from mmcv.ops import contour_expand
+
+from mmocr.core import points2boundary
+from mmocr.models.builder import POSTPROCESSOR
+from .base_postprocessor import BasePostprocessor
+
+
+@POSTPROCESSOR.register_module()
+class PSEPostprocessor(BasePostprocessor):
+ """Decoding predictions of PSENet to instances. This is partially adapted
+ from https://github.com/whai362/PSENet.
+
+ Args:
+ text_repr_type (str): The boundary encoding type 'poly' or 'quad'.
+ min_kernel_confidence (float): The minimal kernel confidence.
+ min_text_avg_confidence (float): The minimal text average confidence.
+ min_kernel_area (int): The minimal text kernel area.
+ min_text_area (int): The minimal text instance region area.
+ """
+
+ def __init__(self,
+ text_repr_type='poly',
+ min_kernel_confidence=0.5,
+ min_text_avg_confidence=0.85,
+ min_kernel_area=0,
+ min_text_area=16,
+ **kwargs):
+ super().__init__(text_repr_type)
+
+ assert 0 <= min_kernel_confidence <= 1
+ assert 0 <= min_text_avg_confidence <= 1
+ assert isinstance(min_kernel_area, int)
+ assert isinstance(min_text_area, int)
+
+ self.min_kernel_confidence = min_kernel_confidence
+ self.min_text_avg_confidence = min_text_avg_confidence
+ self.min_kernel_area = min_kernel_area
+ self.min_text_area = min_text_area
+
+ def __call__(self, preds):
+ """
+ Args:
+ preds (Tensor): Prediction map with shape :math:`(C, H, W)`.
+
+ Returns:
+ list[list[float]]: The instance boundary and its confidence.
+ """
+ assert preds.dim() == 3
+
+ preds = torch.sigmoid(preds) # text confidence
+
+ score = preds[0, :, :]
+ masks = preds > self.min_kernel_confidence
+ text_mask = masks[0, :, :]
+ kernel_masks = masks[0:, :, :] * text_mask
+
+ score = score.data.cpu().numpy().astype(np.float32)
+
+ kernel_masks = kernel_masks.data.cpu().numpy().astype(np.uint8)
+
+ region_num, labels = cv2.connectedComponents(
+ kernel_masks[-1], connectivity=4)
+
+ labels = contour_expand(kernel_masks, labels, self.min_kernel_area,
+ region_num)
+ labels = np.array(labels)
+ label_num = np.max(labels)
+ boundaries = []
+ for i in range(1, label_num + 1):
+ points = np.array(np.where(labels == i)).transpose((1, 0))[:, ::-1]
+ area = points.shape[0]
+ score_instance = np.mean(score[labels == i])
+ if not self.is_valid_instance(area, score_instance,
+ self.min_text_area,
+ self.min_text_avg_confidence):
+ continue
+
+ vertices_confidence = points2boundary(points, self.text_repr_type,
+ score_instance)
+ if vertices_confidence is not None:
+ boundaries.append(vertices_confidence)
+
+ return boundaries
diff --git a/mmocr/models/textdet/postprocess/textsnake_postprocessor.py b/mmocr/models/textdet/postprocess/textsnake_postprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..3e37154c7d267db146a07fc03496c616d12d6f71
--- /dev/null
+++ b/mmocr/models/textdet/postprocess/textsnake_postprocessor.py
@@ -0,0 +1,115 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+import cv2
+import numpy as np
+import torch
+from skimage.morphology import skeletonize
+
+from mmocr.models.builder import POSTPROCESSOR
+from .base_postprocessor import BasePostprocessor
+from .utils import centralize, fill_hole, merge_disks
+
+
+@POSTPROCESSOR.register_module()
+class TextSnakePostprocessor(BasePostprocessor):
+ """Decoding predictions of TextSnake to instances. This was partially
+ adapted from https://github.com/princewang1994/TextSnake.pytorch.
+
+ Args:
+ text_repr_type (str): The boundary encoding type 'poly' or 'quad'.
+ min_text_region_confidence (float): The confidence threshold of text
+ region in TextSnake.
+ min_center_region_confidence (float): The confidence threshold of text
+ center region in TextSnake.
+ min_center_area (int): The minimal text center region area.
+ disk_overlap_thr (float): The radius overlap threshold for merging
+ disks.
+ radius_shrink_ratio (float): The shrink ratio of ordered disks radii.
+ """
+
+ def __init__(self,
+ text_repr_type='poly',
+ min_text_region_confidence=0.6,
+ min_center_region_confidence=0.2,
+ min_center_area=30,
+ disk_overlap_thr=0.03,
+ radius_shrink_ratio=1.03,
+ **kwargs):
+ super().__init__(text_repr_type)
+ assert text_repr_type == 'poly'
+ self.min_text_region_confidence = min_text_region_confidence
+ self.min_center_region_confidence = min_center_region_confidence
+ self.min_center_area = min_center_area
+ self.disk_overlap_thr = disk_overlap_thr
+ self.radius_shrink_ratio = radius_shrink_ratio
+
+ def __call__(self, preds):
+ """
+ Args:
+ preds (Tensor): Prediction map with shape :math:`(C, H, W)`.
+
+ Returns:
+ list[list[float]]: The instance boundary and its confidence.
+ """
+ assert preds.dim() == 3
+
+ preds[:2, :, :] = torch.sigmoid(preds[:2, :, :])
+ preds = preds.detach().cpu().numpy()
+
+ pred_text_score = preds[0]
+ pred_text_mask = pred_text_score > self.min_text_region_confidence
+ pred_center_score = preds[1] * pred_text_score
+ pred_center_mask = \
+ pred_center_score > self.min_center_region_confidence
+ pred_sin = preds[2]
+ pred_cos = preds[3]
+ pred_radius = preds[4]
+ mask_sz = pred_text_mask.shape
+
+ scale = np.sqrt(1.0 / (pred_sin**2 + pred_cos**2 + 1e-8))
+ pred_sin = pred_sin * scale
+ pred_cos = pred_cos * scale
+
+ pred_center_mask = fill_hole(pred_center_mask).astype(np.uint8)
+ center_contours, _ = cv2.findContours(pred_center_mask, cv2.RETR_TREE,
+ cv2.CHAIN_APPROX_SIMPLE)
+
+ boundaries = []
+ for contour in center_contours:
+ if cv2.contourArea(contour) < self.min_center_area:
+ continue
+ instance_center_mask = np.zeros(mask_sz, dtype=np.uint8)
+ cv2.drawContours(instance_center_mask, [contour], -1, 1, -1)
+ skeleton = skeletonize(instance_center_mask)
+ skeleton_yx = np.argwhere(skeleton > 0)
+ y, x = skeleton_yx[:, 0], skeleton_yx[:, 1]
+ cos = pred_cos[y, x].reshape((-1, 1))
+ sin = pred_sin[y, x].reshape((-1, 1))
+ radius = pred_radius[y, x].reshape((-1, 1))
+
+ center_line_yx = centralize(skeleton_yx, cos, -sin, radius,
+ instance_center_mask)
+ y, x = center_line_yx[:, 0], center_line_yx[:, 1]
+ radius = (pred_radius[y, x] * self.radius_shrink_ratio).reshape(
+ (-1, 1))
+ score = pred_center_score[y, x].reshape((-1, 1))
+ instance_disks = np.hstack(
+ [np.fliplr(center_line_yx), radius, score])
+ instance_disks = merge_disks(instance_disks, self.disk_overlap_thr)
+
+ instance_mask = np.zeros(mask_sz, dtype=np.uint8)
+ for x, y, radius, score in instance_disks:
+ if radius > 1:
+ cv2.circle(instance_mask, (int(x), int(y)), int(radius), 1,
+ -1)
+ contours, _ = cv2.findContours(instance_mask, cv2.RETR_TREE,
+ cv2.CHAIN_APPROX_SIMPLE)
+
+ score = np.sum(instance_mask * pred_text_score) / (
+ np.sum(instance_mask) + 1e-8)
+ if (len(contours) > 0 and cv2.contourArea(contours[0]) > 0
+ and contours[0].size > 8):
+ boundary = contours[0].flatten().tolist()
+ boundaries.append(boundary + [score])
+
+ return boundaries
diff --git a/mmocr/models/textdet/postprocess/utils.py b/mmocr/models/textdet/postprocess/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..faae589577ceae6e874714595a1a425043ebe9fc
--- /dev/null
+++ b/mmocr/models/textdet/postprocess/utils.py
@@ -0,0 +1,482 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import functools
+import operator
+
+import cv2
+import numpy as np
+import pyclipper
+from numpy.fft import ifft
+from numpy.linalg import norm
+from shapely.geometry import Polygon
+
+from mmocr.core.evaluation.utils import boundary_iou
+
+
+def filter_instance(area, confidence, min_area, min_confidence):
+ return bool(area < min_area or confidence < min_confidence)
+
+
+def box_score_fast(bitmap, _box):
+ h, w = bitmap.shape[:2]
+ box = _box.copy()
+ xmin = np.clip(np.floor(box[:, 0].min()).astype(np.int32), 0, w - 1)
+ xmax = np.clip(np.ceil(box[:, 0].max()).astype(np.int32), 0, w - 1)
+ ymin = np.clip(np.floor(box[:, 1].min()).astype(np.int32), 0, h - 1)
+ ymax = np.clip(np.ceil(box[:, 1].max()).astype(np.int32), 0, h - 1)
+
+ mask = np.zeros((ymax - ymin + 1, xmax - xmin + 1), dtype=np.uint8)
+ box[:, 0] = box[:, 0] - xmin
+ box[:, 1] = box[:, 1] - ymin
+ cv2.fillPoly(mask, box.reshape(1, -1, 2).astype(np.int32), 1)
+ return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0]
+
+
+def unclip(box, unclip_ratio=1.5):
+ poly = Polygon(box)
+ distance = poly.area * unclip_ratio / poly.length
+ offset = pyclipper.PyclipperOffset()
+ offset.AddPath(box, pyclipper.JT_ROUND, pyclipper.ET_CLOSEDPOLYGON)
+ expanded = np.array(offset.Execute(distance))
+ return expanded
+
+
+def fill_hole(input_mask):
+ h, w = input_mask.shape
+ canvas = np.zeros((h + 2, w + 2), np.uint8)
+ canvas[1:h + 1, 1:w + 1] = input_mask.copy()
+
+ mask = np.zeros((h + 4, w + 4), np.uint8)
+
+ cv2.floodFill(canvas, mask, (0, 0), 1)
+ canvas = canvas[1:h + 1, 1:w + 1].astype(np.bool)
+
+ return ~canvas | input_mask
+
+
+def centralize(points_yx,
+ normal_sin,
+ normal_cos,
+ radius,
+ contour_mask,
+ step_ratio=0.03):
+
+ h, w = contour_mask.shape
+ top_yx = bot_yx = points_yx
+ step_flags = np.ones((len(points_yx), 1), dtype=np.bool)
+ step = step_ratio * radius * np.hstack([normal_sin, normal_cos])
+ while np.any(step_flags):
+ next_yx = np.array(top_yx + step, dtype=np.int32)
+ next_y, next_x = next_yx[:, 0], next_yx[:, 1]
+ step_flags = (next_y >= 0) & (next_y < h) & (next_x > 0) & (
+ next_x < w) & contour_mask[np.clip(next_y, 0, h - 1),
+ np.clip(next_x, 0, w - 1)]
+ top_yx = top_yx + step_flags.reshape((-1, 1)) * step
+ step_flags = np.ones((len(points_yx), 1), dtype=np.bool)
+ while np.any(step_flags):
+ next_yx = np.array(bot_yx - step, dtype=np.int32)
+ next_y, next_x = next_yx[:, 0], next_yx[:, 1]
+ step_flags = (next_y >= 0) & (next_y < h) & (next_x > 0) & (
+ next_x < w) & contour_mask[np.clip(next_y, 0, h - 1),
+ np.clip(next_x, 0, w - 1)]
+ bot_yx = bot_yx - step_flags.reshape((-1, 1)) * step
+ centers = np.array((top_yx + bot_yx) * 0.5, dtype=np.int32)
+ return centers
+
+
+def merge_disks(disks, disk_overlap_thr):
+ xy = disks[:, 0:2]
+ radius = disks[:, 2]
+ scores = disks[:, 3]
+ order = scores.argsort()[::-1]
+
+ merged_disks = []
+ while order.size > 0:
+ if order.size == 1:
+ merged_disks.append(disks[order])
+ break
+ i = order[0]
+ d = norm(xy[i] - xy[order[1:]], axis=1)
+ ri = radius[i]
+ r = radius[order[1:]]
+ d_thr = (ri + r) * disk_overlap_thr
+
+ merge_inds = np.where(d <= d_thr)[0] + 1
+ if merge_inds.size > 0:
+ merge_order = np.hstack([i, order[merge_inds]])
+ merged_disks.append(np.mean(disks[merge_order], axis=0))
+ else:
+ merged_disks.append(disks[i])
+
+ inds = np.where(d > d_thr)[0] + 1
+ order = order[inds]
+ merged_disks = np.vstack(merged_disks)
+
+ return merged_disks
+
+
+def poly_nms(polygons, threshold):
+ assert isinstance(polygons, list)
+
+ polygons = np.array(sorted(polygons, key=lambda x: x[-1]))
+
+ keep_poly = []
+ index = [i for i in range(polygons.shape[0])]
+
+ while len(index) > 0:
+ keep_poly.append(polygons[index[-1]].tolist())
+ A = polygons[index[-1]][:-1]
+ index = np.delete(index, -1)
+
+ iou_list = np.zeros((len(index), ))
+ for i in range(len(index)):
+ B = polygons[index[i]][:-1]
+
+ iou_list[i] = boundary_iou(A, B, 1)
+ remove_index = np.where(iou_list > threshold)
+ index = np.delete(index, remove_index)
+
+ return keep_poly
+
+
+def fourier2poly(fourier_coeff, num_reconstr_points=50):
+ """ Inverse Fourier transform
+ Args:
+ fourier_coeff (ndarray): Fourier coefficients shaped (n, 2k+1),
+ with n and k being candidates number and Fourier degree
+ respectively.
+ num_reconstr_points (int): Number of reconstructed polygon points.
+ Returns:
+ Polygons (ndarray): The reconstructed polygons shaped (n, n')
+ """
+
+ a = np.zeros((len(fourier_coeff), num_reconstr_points), dtype='complex')
+ k = (len(fourier_coeff[0]) - 1) // 2
+
+ a[:, 0:k + 1] = fourier_coeff[:, k:]
+ a[:, -k:] = fourier_coeff[:, :k]
+
+ poly_complex = ifft(a) * num_reconstr_points
+ polygon = np.zeros((len(fourier_coeff), num_reconstr_points, 2))
+ polygon[:, :, 0] = poly_complex.real
+ polygon[:, :, 1] = poly_complex.imag
+ return polygon.astype('int32').reshape((len(fourier_coeff), -1))
+
+
+class Node:
+
+ def __init__(self, ind):
+ self.__ind = ind
+ self.__links = set()
+
+ @property
+ def ind(self):
+ return self.__ind
+
+ @property
+ def links(self):
+ return set(self.__links)
+
+ def add_link(self, link_node):
+ self.__links.add(link_node)
+ link_node.__links.add(self)
+
+
+def graph_propagation(edges, scores, text_comps, edge_len_thr=50.):
+ """Propagate edge score information and construct graph. This code was
+ partially adapted from https://github.com/GXYM/DRRG licensed under the MIT
+ license.
+
+ Args:
+ edges (ndarray): The edge array of shape N * 2, each row is a node
+ index pair that makes up an edge in graph.
+ scores (ndarray): The edge score array.
+ text_comps (ndarray): The text components.
+ edge_len_thr (float): The edge length threshold.
+
+ Returns:
+ vertices (list[Node]): The Nodes in graph.
+ score_dict (dict): The edge score dict.
+ """
+ assert edges.ndim == 2
+ assert edges.shape[1] == 2
+ assert edges.shape[0] == scores.shape[0]
+ assert text_comps.ndim == 2
+ assert isinstance(edge_len_thr, float)
+
+ edges = np.sort(edges, axis=1)
+ score_dict = {}
+ for i, edge in enumerate(edges):
+ if text_comps is not None:
+ box1 = text_comps[edge[0], :8].reshape(4, 2)
+ box2 = text_comps[edge[1], :8].reshape(4, 2)
+ center1 = np.mean(box1, axis=0)
+ center2 = np.mean(box2, axis=0)
+ distance = norm(center1 - center2)
+ if distance > edge_len_thr:
+ scores[i] = 0
+ if (edge[0], edge[1]) in score_dict:
+ score_dict[edge[0], edge[1]] = 0.5 * (
+ score_dict[edge[0], edge[1]] + scores[i])
+ else:
+ score_dict[edge[0], edge[1]] = scores[i]
+
+ nodes = np.sort(np.unique(edges.flatten()))
+ mapping = -1 * np.ones((np.max(nodes) + 1), dtype=np.int)
+ mapping[nodes] = np.arange(nodes.shape[0])
+ order_inds = mapping[edges]
+ vertices = [Node(node) for node in nodes]
+ for ind in order_inds:
+ vertices[ind[0]].add_link(vertices[ind[1]])
+
+ return vertices, score_dict
+
+
+def connected_components(nodes, score_dict, link_thr):
+ """Conventional connected components searching. This code was partially
+ adapted from https://github.com/GXYM/DRRG licensed under the MIT license.
+
+ Args:
+ nodes (list[Node]): The list of Node objects.
+ score_dict (dict): The edge score dict.
+ link_thr (float): The link threshold.
+
+ Returns:
+ clusters (List[list[Node]]): The clustered Node objects.
+ """
+ assert isinstance(nodes, list)
+ assert all([isinstance(node, Node) for node in nodes])
+ assert isinstance(score_dict, dict)
+ assert isinstance(link_thr, float)
+
+ clusters = []
+ nodes = set(nodes)
+ while nodes:
+ node = nodes.pop()
+ cluster = {node}
+ node_queue = [node]
+ while node_queue:
+ node = node_queue.pop(0)
+ neighbors = set([
+ neighbor for neighbor in node.links if
+ score_dict[tuple(sorted([node.ind, neighbor.ind]))] >= link_thr
+ ])
+ neighbors.difference_update(cluster)
+ nodes.difference_update(neighbors)
+ cluster.update(neighbors)
+ node_queue.extend(neighbors)
+ clusters.append(list(cluster))
+ return clusters
+
+
+def clusters2labels(clusters, num_nodes):
+ """Convert clusters of Node to text component labels. This code was
+ partially adapted from https://github.com/GXYM/DRRG licensed under the MIT
+ license.
+
+ Args:
+ clusters (List[list[Node]]): The clusters of Node objects.
+ num_nodes (int): The total node number of graphs in an image.
+
+ Returns:
+ node_labels (ndarray): The node label array.
+ """
+ assert isinstance(clusters, list)
+ assert all([isinstance(cluster, list) for cluster in clusters])
+ assert all(
+ [isinstance(node, Node) for cluster in clusters for node in cluster])
+ assert isinstance(num_nodes, int)
+
+ node_labels = np.zeros(num_nodes)
+ for cluster_ind, cluster in enumerate(clusters):
+ for node in cluster:
+ node_labels[node.ind] = cluster_ind
+ return node_labels
+
+
+def remove_single(text_comps, comp_pred_labels):
+ """Remove isolated text components. This code was partially adapted from
+ https://github.com/GXYM/DRRG licensed under the MIT license.
+
+ Args:
+ text_comps (ndarray): The text components.
+ comp_pred_labels (ndarray): The clustering labels of text components.
+
+ Returns:
+ filtered_text_comps (ndarray): The text components with isolated ones
+ removed.
+ comp_pred_labels (ndarray): The clustering labels with labels of
+ isolated text components removed.
+ """
+ assert text_comps.ndim == 2
+ assert text_comps.shape[0] == comp_pred_labels.shape[0]
+
+ single_flags = np.zeros_like(comp_pred_labels)
+ pred_labels = np.unique(comp_pred_labels)
+ for label in pred_labels:
+ current_label_flag = (comp_pred_labels == label)
+ if np.sum(current_label_flag) == 1:
+ single_flags[np.where(current_label_flag)[0][0]] = 1
+ keep_ind = [i for i in range(len(comp_pred_labels)) if not single_flags[i]]
+ filtered_text_comps = text_comps[keep_ind, :]
+ filtered_labels = comp_pred_labels[keep_ind]
+
+ return filtered_text_comps, filtered_labels
+
+
+def norm2(point1, point2):
+ return ((point1[0] - point2[0])**2 + (point1[1] - point2[1])**2)**0.5
+
+
+def min_connect_path(points):
+ """Find the shortest path to traverse all points. This code was partially
+ adapted from https://github.com/GXYM/DRRG licensed under the MIT license.
+
+ Args:
+ points(List[list[int]]): The point sequence [[x0, y0], [x1, y1], ...].
+
+ Returns:
+ shortest_path(List[list[int]]): The shortest index path.
+ """
+ assert isinstance(points, list)
+ assert all([isinstance(point, list) for point in points])
+ assert all([isinstance(coord, int) for point in points for coord in point])
+
+ points_queue = points.copy()
+ shortest_path = []
+ current_edge = [[], []]
+
+ edge_dict0 = {}
+ edge_dict1 = {}
+ current_edge[0] = points_queue[0]
+ current_edge[1] = points_queue[0]
+ points_queue.remove(points_queue[0])
+ while points_queue:
+ for point in points_queue:
+ length0 = norm2(point, current_edge[0])
+ edge_dict0[length0] = [point, current_edge[0]]
+ length1 = norm2(current_edge[1], point)
+ edge_dict1[length1] = [current_edge[1], point]
+ key0 = min(edge_dict0.keys())
+ key1 = min(edge_dict1.keys())
+
+ if key0 <= key1:
+ start = edge_dict0[key0][0]
+ end = edge_dict0[key0][1]
+ shortest_path.insert(0, [points.index(start), points.index(end)])
+ points_queue.remove(start)
+ current_edge[0] = start
+ else:
+ start = edge_dict1[key1][0]
+ end = edge_dict1[key1][1]
+ shortest_path.append([points.index(start), points.index(end)])
+ points_queue.remove(end)
+ current_edge[1] = end
+
+ edge_dict0 = {}
+ edge_dict1 = {}
+
+ shortest_path = functools.reduce(operator.concat, shortest_path)
+ shortest_path = sorted(set(shortest_path), key=shortest_path.index)
+
+ return shortest_path
+
+
+def in_contour(cont, point):
+ x, y = point
+ is_inner = cv2.pointPolygonTest(cont, (int(x), int(y)), False) > 0.5
+ return is_inner
+
+
+def fix_corner(top_line, bot_line, start_box, end_box):
+ """Add corner points to predicted side lines. This code was partially
+ adapted from https://github.com/GXYM/DRRG licensed under the MIT license.
+
+ Args:
+ top_line (List[list[int]]): The predicted top sidelines of text
+ instance.
+ bot_line (List[list[int]]): The predicted bottom sidelines of text
+ instance.
+ start_box (ndarray): The first text component box.
+ end_box (ndarray): The last text component box.
+
+ Returns:
+ top_line (List[list[int]]): The top sidelines with corner point added.
+ bot_line (List[list[int]]): The bottom sidelines with corner point
+ added.
+ """
+ assert isinstance(top_line, list)
+ assert all(isinstance(point, list) for point in top_line)
+ assert isinstance(bot_line, list)
+ assert all(isinstance(point, list) for point in bot_line)
+ assert start_box.shape == end_box.shape == (4, 2)
+
+ contour = np.array(top_line + bot_line[::-1])
+ start_left_mid = (start_box[0] + start_box[3]) / 2
+ start_right_mid = (start_box[1] + start_box[2]) / 2
+ end_left_mid = (end_box[0] + end_box[3]) / 2
+ end_right_mid = (end_box[1] + end_box[2]) / 2
+ if not in_contour(contour, start_left_mid):
+ top_line.insert(0, start_box[0].tolist())
+ bot_line.insert(0, start_box[3].tolist())
+ elif not in_contour(contour, start_right_mid):
+ top_line.insert(0, start_box[1].tolist())
+ bot_line.insert(0, start_box[2].tolist())
+ if not in_contour(contour, end_left_mid):
+ top_line.append(end_box[0].tolist())
+ bot_line.append(end_box[3].tolist())
+ elif not in_contour(contour, end_right_mid):
+ top_line.append(end_box[1].tolist())
+ bot_line.append(end_box[2].tolist())
+ return top_line, bot_line
+
+
+def comps2boundaries(text_comps, comp_pred_labels):
+ """Construct text instance boundaries from clustered text components. This
+ code was partially adapted from https://github.com/GXYM/DRRG licensed under
+ the MIT license.
+
+ Args:
+ text_comps (ndarray): The text components.
+ comp_pred_labels (ndarray): The clustering labels of text components.
+
+ Returns:
+ boundaries (List[list[float]]): The predicted boundaries of text
+ instances.
+ """
+ assert text_comps.ndim == 2
+ assert len(text_comps) == len(comp_pred_labels)
+ boundaries = []
+ if len(text_comps) < 1:
+ return boundaries
+ for cluster_ind in range(0, int(np.max(comp_pred_labels)) + 1):
+ cluster_comp_inds = np.where(comp_pred_labels == cluster_ind)
+ text_comp_boxes = text_comps[cluster_comp_inds, :8].reshape(
+ (-1, 4, 2)).astype(np.int32)
+ score = np.mean(text_comps[cluster_comp_inds, -1])
+
+ if text_comp_boxes.shape[0] < 1:
+ continue
+
+ elif text_comp_boxes.shape[0] > 1:
+ centers = np.mean(
+ text_comp_boxes, axis=1).astype(np.int32).tolist()
+ shortest_path = min_connect_path(centers)
+ text_comp_boxes = text_comp_boxes[shortest_path]
+ top_line = np.mean(
+ text_comp_boxes[:, 0:2, :], axis=1).astype(np.int32).tolist()
+ bot_line = np.mean(
+ text_comp_boxes[:, 2:4, :], axis=1).astype(np.int32).tolist()
+ top_line, bot_line = fix_corner(top_line, bot_line,
+ text_comp_boxes[0],
+ text_comp_boxes[-1])
+ boundary_points = top_line + bot_line[::-1]
+
+ else:
+ top_line = text_comp_boxes[0, 0:2, :].astype(np.int32).tolist()
+ bot_line = text_comp_boxes[0, 2:4:-1, :].astype(np.int32).tolist()
+ boundary_points = top_line + bot_line
+
+ boundary = [p for coord in boundary_points for p in coord] + [score]
+ boundaries.append(boundary)
+
+ return boundaries
diff --git a/mmocr/models/textrecog/__init__.py b/mmocr/models/textrecog/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..9a813067469597a3fe5f8ab926ce1309def41733
--- /dev/null
+++ b/mmocr/models/textrecog/__init__.py
@@ -0,0 +1,20 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from . import (backbones, convertors, decoders, encoders, fusers, heads,
+ losses, necks, plugins, preprocessor, recognizer)
+from .backbones import * # NOQA
+from .convertors import * # NOQA
+from .decoders import * # NOQA
+from .encoders import * # NOQA
+from .fusers import * # NOQA
+from .heads import * # NOQA
+from .losses import * # NOQA
+from .necks import * # NOQA
+from .plugins import * # NOQA
+from .preprocessor import * # NOQA
+from .recognizer import * # NOQA
+
+__all__ = (
+ backbones.__all__ + convertors.__all__ + decoders.__all__ +
+ encoders.__all__ + heads.__all__ + losses.__all__ + necks.__all__ +
+ preprocessor.__all__ + recognizer.__all__ + fusers.__all__ +
+ plugins.__all__)
diff --git a/mmocr/models/textrecog/backbones/__init__.py b/mmocr/models/textrecog/backbones/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e9b68c389b0c84bd66a29ece09c1bac9de68db3e
--- /dev/null
+++ b/mmocr/models/textrecog/backbones/__init__.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .nrtr_modality_transformer import NRTRModalityTransform
+from .resnet import ResNet
+from .resnet31_ocr import ResNet31OCR
+from .resnet_abi import ResNetABI
+from .shallow_cnn import ShallowCNN
+from .very_deep_vgg import VeryDeepVgg
+
+__all__ = [
+ 'ResNet31OCR', 'VeryDeepVgg', 'NRTRModalityTransform', 'ShallowCNN',
+ 'ResNetABI', 'ResNet'
+]
diff --git a/mmocr/models/textrecog/backbones/nrtr_modality_transformer.py b/mmocr/models/textrecog/backbones/nrtr_modality_transformer.py
new file mode 100644
index 0000000000000000000000000000000000000000..a514ffdf30108175dbc25bb0fcf7e11caef01c75
--- /dev/null
+++ b/mmocr/models/textrecog/backbones/nrtr_modality_transformer.py
@@ -0,0 +1,56 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+from mmcv.runner import BaseModule
+
+from mmocr.models.builder import BACKBONES
+
+
+@BACKBONES.register_module()
+class NRTRModalityTransform(BaseModule):
+
+ def __init__(self,
+ input_channels=3,
+ init_cfg=[
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(type='Uniform', layer='BatchNorm2d')
+ ]):
+ super().__init__(init_cfg=init_cfg)
+
+ self.conv_1 = nn.Conv2d(
+ in_channels=input_channels,
+ out_channels=32,
+ kernel_size=3,
+ stride=2,
+ padding=1)
+ self.relu_1 = nn.ReLU(True)
+ self.bn_1 = nn.BatchNorm2d(32)
+
+ self.conv_2 = nn.Conv2d(
+ in_channels=32,
+ out_channels=64,
+ kernel_size=3,
+ stride=2,
+ padding=1)
+ self.relu_2 = nn.ReLU(True)
+ self.bn_2 = nn.BatchNorm2d(64)
+
+ self.linear = nn.Linear(512, 512)
+
+ def forward(self, x):
+ x = self.conv_1(x)
+ x = self.relu_1(x)
+ x = self.bn_1(x)
+
+ x = self.conv_2(x)
+ x = self.relu_2(x)
+ x = self.bn_2(x)
+
+ n, c, h, w = x.size()
+
+ x = x.permute(0, 3, 2, 1).contiguous().view(n, w, h * c)
+
+ x = self.linear(x)
+
+ x = x.permute(0, 2, 1).contiguous().view(n, -1, 1, w)
+
+ return x
diff --git a/mmocr/models/textrecog/backbones/resnet.py b/mmocr/models/textrecog/backbones/resnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..ed0627c5b156d0140557f5b6a21c202111b3a420
--- /dev/null
+++ b/mmocr/models/textrecog/backbones/resnet.py
@@ -0,0 +1,232 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.cnn import ConvModule, build_plugin_layer
+from mmcv.runner import BaseModule, Sequential
+
+import mmocr.utils as utils
+from mmocr.models.builder import BACKBONES
+from mmocr.models.textrecog.layers import BasicBlock
+
+
+@BACKBONES.register_module()
+class ResNet(BaseModule):
+ """
+ Args:
+ in_channels (int): Number of channels of input image tensor.
+ stem_channels (list[int]): List of channels in each stem layer. E.g.,
+ [64, 128] stands for 64 and 128 channels in the first and second
+ stem layers.
+ block_cfgs (dict): Configs of block
+ arch_layers (list[int]): List of Block number for each stage.
+ arch_channels (list[int]): List of channels for each stage.
+ strides (Sequence[int] | Sequence[tuple]): Strides of the first block
+ of each stage.
+ out_indices (None | Sequence[int]): Indices of output stages. If not
+ specified, only the last stage will be returned.
+ stage_plugins (dict): Configs of stage plugins
+ init_cfg (dict or list[dict], optional): Initialization config dict.
+ """
+
+ def __init__(self,
+ in_channels,
+ stem_channels,
+ block_cfgs,
+ arch_layers,
+ arch_channels,
+ strides,
+ out_indices=None,
+ plugins=None,
+ init_cfg=[
+ dict(type='Xavier', layer='Conv2d'),
+ dict(type='Constant', val=1, layer='BatchNorm2d'),
+ ]):
+ super().__init__(init_cfg=init_cfg)
+ assert isinstance(in_channels, int)
+ assert isinstance(stem_channels, int) or utils.is_type_list(
+ stem_channels, int)
+ assert utils.is_type_list(arch_layers, int)
+ assert utils.is_type_list(arch_channels, int)
+ assert utils.is_type_list(strides, tuple) or utils.is_type_list(
+ strides, int)
+ assert len(arch_layers) == len(arch_channels) == len(strides)
+ assert out_indices is None or isinstance(out_indices, (list, tuple))
+
+ self.out_indices = out_indices
+ self._make_stem_layer(in_channels, stem_channels)
+ self.num_stages = len(arch_layers)
+ self.use_plugins = False
+ self.arch_channels = arch_channels
+ self.res_layers = []
+ if plugins is not None:
+ self.plugin_ahead_names = []
+ self.plugin_after_names = []
+ self.use_plugins = True
+ for i, num_blocks in enumerate(arch_layers):
+ stride = strides[i]
+ channel = arch_channels[i]
+
+ if self.use_plugins:
+ self._make_stage_plugins(plugins, stage_idx=i)
+
+ res_layer = self._make_layer(
+ block_cfgs=block_cfgs,
+ inplanes=self.inplanes,
+ planes=channel,
+ blocks=num_blocks,
+ stride=stride,
+ )
+ self.inplanes = channel
+ layer_name = f'layer{i + 1}'
+ self.add_module(layer_name, res_layer)
+ self.res_layers.append(layer_name)
+
+ def _make_layer(self, block_cfgs, inplanes, planes, blocks, stride):
+ layers = []
+ downsample = None
+ block_cfgs_ = block_cfgs.copy()
+ if isinstance(stride, int):
+ stride = (stride, stride)
+
+ if stride[0] != 1 or stride[1] != 1 or inplanes != planes:
+ downsample = ConvModule(
+ inplanes,
+ planes,
+ 1,
+ stride,
+ norm_cfg=dict(type='BN'),
+ act_cfg=None)
+
+ if block_cfgs_['type'] == 'BasicBlock':
+ block = BasicBlock
+ block_cfgs_.pop('type')
+ else:
+ raise ValueError('{} not implement yet'.format(block['type']))
+
+ layers.append(
+ block(
+ inplanes,
+ planes,
+ stride=stride,
+ downsample=downsample,
+ **block_cfgs_))
+ inplanes = planes
+ for _ in range(1, blocks):
+ layers.append(block(inplanes, planes, **block_cfgs_))
+
+ return Sequential(*layers)
+
+ def _make_stem_layer(self, in_channels, stem_channels):
+ if isinstance(stem_channels, int):
+ stem_channels = [stem_channels]
+ stem_layers = []
+ for _, channels in enumerate(stem_channels):
+ stem_layer = ConvModule(
+ in_channels,
+ channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'))
+ in_channels = channels
+ stem_layers.append(stem_layer)
+ self.stem_layers = Sequential(*stem_layers)
+ self.inplanes = stem_channels[-1]
+
+ def _make_stage_plugins(self, plugins, stage_idx):
+ """Make plugins for ResNet ``stage_idx`` th stage.
+
+ Currently we support inserting ``nn.Maxpooling``,
+ ``mmcv.cnn.Convmodule``into the backbone. Originally designed
+ for ResNet31-like architectures.
+
+ Examples:
+ >>> plugins=[
+ ... dict(cfg=dict(type="Maxpooling", arg=(2,2)),
+ ... stages=(True, True, False, False),
+ ... position='before_stage'),
+ ... dict(cfg=dict(type="Maxpooling", arg=(2,1)),
+ ... stages=(False, False, True, Flase),
+ ... position='before_stage'),
+ ... dict(cfg=dict(
+ ... type='ConvModule',
+ ... kernel_size=3,
+ ... stride=1,
+ ... padding=1,
+ ... norm_cfg=dict(type='BN'),
+ ... act_cfg=dict(type='ReLU')),
+ ... stages=(True, True, True, True),
+ ... position='after_stage')]
+
+ Suppose ``stage_idx=1``, the structure of stage would be:
+
+ .. code-block:: none
+
+ Maxpooling -> A set of Basicblocks -> ConvModule
+
+ Args:
+ plugins (list[dict]): List of plugins cfg to build.
+ stage_idx (int): Index of stage to build
+
+ Returns:
+ list[dict]: Plugins for current stage
+ """
+ in_channels = self.arch_channels[stage_idx]
+ self.plugin_ahead_names.append([])
+ self.plugin_after_names.append([])
+ for plugin in plugins:
+ plugin = plugin.copy()
+ stages = plugin.pop('stages', None)
+ position = plugin.pop('position', None)
+ assert stages is None or len(stages) == self.num_stages
+ if stages[stage_idx]:
+ if position == 'before_stage':
+ name, layer = build_plugin_layer(
+ plugin['cfg'],
+ f'_before_stage_{stage_idx+1}',
+ in_channels=in_channels,
+ out_channels=in_channels)
+ self.plugin_ahead_names[stage_idx].append(name)
+ self.add_module(name, layer)
+ elif position == 'after_stage':
+ name, layer = build_plugin_layer(
+ plugin['cfg'],
+ f'_after_stage_{stage_idx+1}',
+ in_channels=in_channels,
+ out_channels=in_channels)
+ self.plugin_after_names[stage_idx].append(name)
+ self.add_module(name, layer)
+ else:
+ raise ValueError('uncorrect plugin position')
+
+ def forward_plugin(self, x, plugin_name):
+ out = x
+ for name in plugin_name:
+ out = getattr(self, name)(x)
+ return out
+
+ def forward(self, x):
+ """
+ Args: x (Tensor): Image tensor of shape :math:`(N, 3, H, W)`.
+
+ Returns:
+ Tensor or list[Tensor]: Feature tensor. It can be a list of
+ feature outputs at specific layers if ``out_indices`` is specified.
+ """
+ x = self.stem_layers(x)
+
+ outs = []
+ for i, layer_name in enumerate(self.res_layers):
+ res_layer = getattr(self, layer_name)
+ if not self.use_plugins:
+ x = res_layer(x)
+ if self.out_indices and i in self.out_indices:
+ outs.append(x)
+ else:
+ x = self.forward_plugin(x, self.plugin_ahead_names[i])
+ x = res_layer(x)
+ x = self.forward_plugin(x, self.plugin_after_names[i])
+ if self.out_indices and i in self.out_indices:
+ outs.append(x)
+
+ return tuple(outs) if self.out_indices else x
diff --git a/mmocr/models/textrecog/backbones/resnet31_ocr.py b/mmocr/models/textrecog/backbones/resnet31_ocr.py
new file mode 100644
index 0000000000000000000000000000000000000000..bf83546f667c2efed4c223b0c96d3dc5ed4faff6
--- /dev/null
+++ b/mmocr/models/textrecog/backbones/resnet31_ocr.py
@@ -0,0 +1,145 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+from mmcv.runner import BaseModule, Sequential
+
+import mmocr.utils as utils
+from mmocr.models.builder import BACKBONES
+from mmocr.models.textrecog.layers import BasicBlock
+
+
+@BACKBONES.register_module()
+class ResNet31OCR(BaseModule):
+ """Implement ResNet backbone for text recognition, modified from
+ `ResNet `_
+ Args:
+ base_channels (int): Number of channels of input image tensor.
+ layers (list[int]): List of BasicBlock number for each stage.
+ channels (list[int]): List of out_channels of Conv2d layer.
+ out_indices (None | Sequence[int]): Indices of output stages.
+ stage4_pool_cfg (dict): Dictionary to construct and configure
+ pooling layer in stage 4.
+ last_stage_pool (bool): If True, add `MaxPool2d` layer to last stage.
+ """
+
+ def __init__(self,
+ base_channels=3,
+ layers=[1, 2, 5, 3],
+ channels=[64, 128, 256, 256, 512, 512, 512],
+ out_indices=None,
+ stage4_pool_cfg=dict(kernel_size=(2, 1), stride=(2, 1)),
+ last_stage_pool=False,
+ init_cfg=[
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(type='Uniform', layer='BatchNorm2d')
+ ]):
+ super().__init__(init_cfg=init_cfg)
+ assert isinstance(base_channels, int)
+ assert utils.is_type_list(layers, int)
+ assert utils.is_type_list(channels, int)
+ assert out_indices is None or isinstance(out_indices, (list, tuple))
+ assert isinstance(last_stage_pool, bool)
+
+ self.out_indices = out_indices
+ self.last_stage_pool = last_stage_pool
+
+ # conv 1 (Conv, Conv)
+ self.conv1_1 = nn.Conv2d(
+ base_channels, channels[0], kernel_size=3, stride=1, padding=1)
+ self.bn1_1 = nn.BatchNorm2d(channels[0])
+ self.relu1_1 = nn.ReLU(inplace=True)
+
+ self.conv1_2 = nn.Conv2d(
+ channels[0], channels[1], kernel_size=3, stride=1, padding=1)
+ self.bn1_2 = nn.BatchNorm2d(channels[1])
+ self.relu1_2 = nn.ReLU(inplace=True)
+
+ # conv 2 (Max-pooling, Residual block, Conv)
+ self.pool2 = nn.MaxPool2d(
+ kernel_size=2, stride=2, padding=0, ceil_mode=True)
+ self.block2 = self._make_layer(channels[1], channels[2], layers[0])
+ self.conv2 = nn.Conv2d(
+ channels[2], channels[2], kernel_size=3, stride=1, padding=1)
+ self.bn2 = nn.BatchNorm2d(channels[2])
+ self.relu2 = nn.ReLU(inplace=True)
+
+ # conv 3 (Max-pooling, Residual block, Conv)
+ self.pool3 = nn.MaxPool2d(
+ kernel_size=2, stride=2, padding=0, ceil_mode=True)
+ self.block3 = self._make_layer(channels[2], channels[3], layers[1])
+ self.conv3 = nn.Conv2d(
+ channels[3], channels[3], kernel_size=3, stride=1, padding=1)
+ self.bn3 = nn.BatchNorm2d(channels[3])
+ self.relu3 = nn.ReLU(inplace=True)
+
+ # conv 4 (Max-pooling, Residual block, Conv)
+ self.pool4 = nn.MaxPool2d(padding=0, ceil_mode=True, **stage4_pool_cfg)
+ self.block4 = self._make_layer(channels[3], channels[4], layers[2])
+ self.conv4 = nn.Conv2d(
+ channels[4], channels[4], kernel_size=3, stride=1, padding=1)
+ self.bn4 = nn.BatchNorm2d(channels[4])
+ self.relu4 = nn.ReLU(inplace=True)
+
+ # conv 5 ((Max-pooling), Residual block, Conv)
+ self.pool5 = None
+ if self.last_stage_pool:
+ self.pool5 = nn.MaxPool2d(
+ kernel_size=2, stride=2, padding=0, ceil_mode=True) # 1/16
+ self.block5 = self._make_layer(channels[4], channels[5], layers[3])
+ self.conv5 = nn.Conv2d(
+ channels[5], channels[5], kernel_size=3, stride=1, padding=1)
+ self.bn5 = nn.BatchNorm2d(channels[5])
+ self.relu5 = nn.ReLU(inplace=True)
+
+ def _make_layer(self, input_channels, output_channels, blocks):
+ layers = []
+ for _ in range(blocks):
+ downsample = None
+ if input_channels != output_channels:
+ downsample = Sequential(
+ nn.Conv2d(
+ input_channels,
+ output_channels,
+ kernel_size=1,
+ stride=1,
+ bias=False),
+ nn.BatchNorm2d(output_channels),
+ )
+ layers.append(
+ BasicBlock(
+ input_channels, output_channels, downsample=downsample))
+ input_channels = output_channels
+
+ return Sequential(*layers)
+
+ def forward(self, x):
+
+ x = self.conv1_1(x)
+ x = self.bn1_1(x)
+ x = self.relu1_1(x)
+
+ x = self.conv1_2(x)
+ x = self.bn1_2(x)
+ x = self.relu1_2(x)
+
+ outs = []
+ for i in range(4):
+ layer_index = i + 2
+ pool_layer = getattr(self, f'pool{layer_index}')
+ block_layer = getattr(self, f'block{layer_index}')
+ conv_layer = getattr(self, f'conv{layer_index}')
+ bn_layer = getattr(self, f'bn{layer_index}')
+ relu_layer = getattr(self, f'relu{layer_index}')
+
+ if pool_layer is not None:
+ x = pool_layer(x)
+ x = block_layer(x)
+ x = conv_layer(x)
+ x = bn_layer(x)
+ x = relu_layer(x)
+
+ outs.append(x)
+
+ if self.out_indices is not None:
+ return tuple([outs[i] for i in self.out_indices])
+
+ return x
diff --git a/mmocr/models/textrecog/backbones/resnet_abi.py b/mmocr/models/textrecog/backbones/resnet_abi.py
new file mode 100644
index 0000000000000000000000000000000000000000..026a786fdfc9ae715be21ddafa29388595f53ba0
--- /dev/null
+++ b/mmocr/models/textrecog/backbones/resnet_abi.py
@@ -0,0 +1,121 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+from mmcv.runner import BaseModule, Sequential
+
+import mmocr.utils as utils
+from mmocr.models.builder import BACKBONES
+from mmocr.models.textrecog.layers import BasicBlock
+
+
+@BACKBONES.register_module()
+class ResNetABI(BaseModule):
+ """Implement ResNet backbone for text recognition, modified from `ResNet.
+
+ `_ and
+ ``_
+
+ Args:
+ in_channels (int): Number of channels of input image tensor.
+ stem_channels (int): Number of stem channels.
+ base_channels (int): Number of base channels.
+ arch_settings (list[int]): List of BasicBlock number for each stage.
+ strides (Sequence[int]): Strides of the first block of each stage.
+ out_indices (None | Sequence[int]): Indices of output stages. If not
+ specified, only the last stage will be returned.
+ last_stage_pool (bool): If True, add `MaxPool2d` layer to last stage.
+ """
+
+ def __init__(self,
+ in_channels=3,
+ stem_channels=32,
+ base_channels=32,
+ arch_settings=[3, 4, 6, 6, 3],
+ strides=[2, 1, 2, 1, 1],
+ out_indices=None,
+ last_stage_pool=False,
+ init_cfg=[
+ dict(type='Xavier', layer='Conv2d'),
+ dict(type='Constant', val=1, layer='BatchNorm2d')
+ ]):
+ super().__init__(init_cfg=init_cfg)
+ assert isinstance(in_channels, int)
+ assert isinstance(stem_channels, int)
+ assert utils.is_type_list(arch_settings, int)
+ assert utils.is_type_list(strides, int)
+ assert len(arch_settings) == len(strides)
+ assert out_indices is None or isinstance(out_indices, (list, tuple))
+ assert isinstance(last_stage_pool, bool)
+
+ self.out_indices = out_indices
+ self.last_stage_pool = last_stage_pool
+ self.block = BasicBlock
+ self.inplanes = stem_channels
+
+ self._make_stem_layer(in_channels, stem_channels)
+
+ self.res_layers = []
+ planes = base_channels
+ for i, num_blocks in enumerate(arch_settings):
+ stride = strides[i]
+ res_layer = self._make_layer(
+ block=self.block,
+ inplanes=self.inplanes,
+ planes=planes,
+ blocks=num_blocks,
+ stride=stride)
+ self.inplanes = planes * self.block.expansion
+ planes *= 2
+ layer_name = f'layer{i + 1}'
+ self.add_module(layer_name, res_layer)
+ self.res_layers.append(layer_name)
+
+ def _make_layer(self, block, inplanes, planes, blocks, stride=1):
+ layers = []
+ downsample = None
+ if stride != 1 or inplanes != planes:
+ downsample = nn.Sequential(
+ nn.Conv2d(inplanes, planes, 1, stride, bias=False),
+ nn.BatchNorm2d(planes),
+ )
+ layers.append(
+ block(
+ inplanes,
+ planes,
+ use_conv1x1=True,
+ stride=stride,
+ downsample=downsample))
+ inplanes = planes
+ for _ in range(1, blocks):
+ layers.append(block(inplanes, planes, use_conv1x1=True))
+
+ return Sequential(*layers)
+
+ def _make_stem_layer(self, in_channels, stem_channels):
+ self.conv1 = nn.Conv2d(
+ in_channels, stem_channels, kernel_size=3, stride=1, padding=1)
+ self.bn1 = nn.BatchNorm2d(stem_channels)
+ self.relu1 = nn.ReLU(inplace=True)
+
+ def forward(self, x):
+ """
+ Args:
+ x (Tensor): Image tensor of shape :math:`(N, 3, H, W)`.
+
+ Returns:
+ Tensor or list[Tensor]: Feature tensor. Its shape depends on
+ ResNetABI's config. It can be a list of feature outputs at specific
+ layers if ``out_indices`` is specified.
+ """
+
+ x = self.conv1(x)
+ x = self.bn1(x)
+ x = self.relu1(x)
+
+ outs = []
+ for i, layer_name in enumerate(self.res_layers):
+ res_layer = getattr(self, layer_name)
+ x = res_layer(x)
+ if self.out_indices and i in self.out_indices:
+ outs.append(x)
+
+ return tuple(outs) if self.out_indices else x
diff --git a/mmocr/models/textrecog/backbones/shallow_cnn.py b/mmocr/models/textrecog/backbones/shallow_cnn.py
new file mode 100644
index 0000000000000000000000000000000000000000..f2cd89a6bde472fa83cee6b0876d4a89eaf79958
--- /dev/null
+++ b/mmocr/models/textrecog/backbones/shallow_cnn.py
@@ -0,0 +1,69 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmcv.runner import BaseModule
+
+from mmocr.models.builder import BACKBONES
+
+
+@BACKBONES.register_module()
+class ShallowCNN(BaseModule):
+ """Implement Shallow CNN block for SATRN.
+
+ SATRN: `On Recognizing Texts of Arbitrary Shapes with 2D Self-Attention
+ `_.
+
+ Args:
+ base_channels (int): Number of channels of input image tensor
+ :math:`D_i`.
+ hidden_dim (int): Size of hidden layers of the model :math:`D_m`.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self,
+ input_channels=1,
+ hidden_dim=512,
+ init_cfg=[
+ dict(type='Kaiming', layer='Conv2d'),
+ dict(type='Uniform', layer='BatchNorm2d')
+ ]):
+ super().__init__(init_cfg=init_cfg)
+ assert isinstance(input_channels, int)
+ assert isinstance(hidden_dim, int)
+
+ self.conv1 = ConvModule(
+ input_channels,
+ hidden_dim // 2,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'))
+ self.conv2 = ConvModule(
+ hidden_dim // 2,
+ hidden_dim,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'))
+ self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
+
+ def forward(self, x):
+ """
+ Args:
+ x (Tensor): Input image feature :math:`(N, D_i, H, W)`.
+
+ Returns:
+ Tensor: A tensor of shape :math:`(N, D_m, H/4, W/4)`.
+ """
+
+ x = self.conv1(x)
+ x = self.pool(x)
+
+ x = self.conv2(x)
+ x = self.pool(x)
+
+ return x
diff --git a/mmocr/models/textrecog/backbones/very_deep_vgg.py b/mmocr/models/textrecog/backbones/very_deep_vgg.py
new file mode 100644
index 0000000000000000000000000000000000000000..2831f2b3169e088d3d5d5d65f74550bc7e60bd05
--- /dev/null
+++ b/mmocr/models/textrecog/backbones/very_deep_vgg.py
@@ -0,0 +1,79 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+from mmcv.runner import BaseModule, Sequential
+
+from mmocr.models.builder import BACKBONES
+
+
+@BACKBONES.register_module()
+class VeryDeepVgg(BaseModule):
+ """Implement VGG-VeryDeep backbone for text recognition, modified from
+ `VGG-VeryDeep `_
+
+ Args:
+ leaky_relu (bool): Use leakyRelu or not.
+ input_channels (int): Number of channels of input image tensor.
+ """
+
+ def __init__(self,
+ leaky_relu=True,
+ input_channels=3,
+ init_cfg=[
+ dict(type='Xavier', layer='Conv2d'),
+ dict(type='Uniform', layer='BatchNorm2d')
+ ]):
+ super().__init__(init_cfg=init_cfg)
+
+ ks = [3, 3, 3, 3, 3, 3, 2]
+ ps = [1, 1, 1, 1, 1, 1, 0]
+ ss = [1, 1, 1, 1, 1, 1, 1]
+ nm = [64, 128, 256, 256, 512, 512, 512]
+
+ self.channels = nm
+
+ # cnn = nn.Sequential()
+ cnn = Sequential()
+
+ def conv_relu(i, batch_normalization=False):
+ n_in = input_channels if i == 0 else nm[i - 1]
+ n_out = nm[i]
+ cnn.add_module('conv{0}'.format(i),
+ nn.Conv2d(n_in, n_out, ks[i], ss[i], ps[i]))
+ if batch_normalization:
+ cnn.add_module('batchnorm{0}'.format(i), nn.BatchNorm2d(n_out))
+ if leaky_relu:
+ cnn.add_module('relu{0}'.format(i),
+ nn.LeakyReLU(0.2, inplace=True))
+ else:
+ cnn.add_module('relu{0}'.format(i), nn.ReLU(True))
+
+ conv_relu(0)
+ cnn.add_module('pooling{0}'.format(0), nn.MaxPool2d(2, 2)) # 64x16x64
+ conv_relu(1)
+ cnn.add_module('pooling{0}'.format(1), nn.MaxPool2d(2, 2)) # 128x8x32
+ conv_relu(2, True)
+ conv_relu(3)
+ cnn.add_module('pooling{0}'.format(2),
+ nn.MaxPool2d((2, 2), (2, 1), (0, 1))) # 256x4x16
+ conv_relu(4, True)
+ conv_relu(5)
+ cnn.add_module('pooling{0}'.format(3),
+ nn.MaxPool2d((2, 2), (2, 1), (0, 1))) # 512x2x16
+ conv_relu(6, True) # 512x1x16
+
+ self.cnn = cnn
+
+ def out_channels(self):
+ return self.channels[-1]
+
+ def forward(self, x):
+ """
+ Args:
+ x (Tensor): Images of shape :math:`(N, C, H, W)`.
+
+ Returns:
+ Tensor: The feature Tensor of shape :math:`(N, 512, H/32, (W/4+1)`.
+ """
+ output = self.cnn(x)
+
+ return output
diff --git a/mmocr/models/textrecog/convertors/__init__.py b/mmocr/models/textrecog/convertors/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..c624837390d77906830743c9b968ccdce2f8538e
--- /dev/null
+++ b/mmocr/models/textrecog/convertors/__init__.py
@@ -0,0 +1,11 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .abi import ABIConvertor
+from .attn import AttnConvertor
+from .base import BaseConvertor
+from .ctc import CTCConvertor
+from .seg import SegConvertor
+
+__all__ = [
+ 'BaseConvertor', 'CTCConvertor', 'AttnConvertor', 'SegConvertor',
+ 'ABIConvertor'
+]
diff --git a/mmocr/models/textrecog/convertors/abi.py b/mmocr/models/textrecog/convertors/abi.py
new file mode 100644
index 0000000000000000000000000000000000000000..e924399231a3c19a73882161d2a84d9af03f7a26
--- /dev/null
+++ b/mmocr/models/textrecog/convertors/abi.py
@@ -0,0 +1,68 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+import mmocr.utils as utils
+from mmocr.models.builder import CONVERTORS
+from .attn import AttnConvertor
+
+
+@CONVERTORS.register_module()
+class ABIConvertor(AttnConvertor):
+ """Convert between text, index and tensor for encoder-decoder based
+ pipeline. Modified from AttnConvertor to get closer to ABINet's original
+ implementation.
+
+ Args:
+ dict_type (str): Type of dict, should be one of {'DICT36', 'DICT90'}.
+ dict_file (None|str): Character dict file path. If not none,
+ higher priority than dict_type.
+ dict_list (None|list[str]): Character list. If not none, higher
+ priority than dict_type, but lower than dict_file.
+ with_unknown (bool): If True, add `UKN` token to class.
+ max_seq_len (int): Maximum sequence length of label.
+ lower (bool): If True, convert original string to lower case.
+ start_end_same (bool): Whether use the same index for
+ start and end token or not. Default: True.
+ """
+
+ def str2tensor(self, strings):
+ """
+ Convert text-string into tensor. Different from
+ :obj:`mmocr.models.textrecog.convertors.AttnConvertor`, the targets
+ field returns target index no longer than max_seq_len (EOS token
+ included).
+
+ Args:
+ strings (list[str]): For instance, ['hello', 'world']
+
+ Returns:
+ dict: A dict with two tensors.
+
+ - | targets (list[Tensor]): [torch.Tensor([1,2,3,3,4,8]),
+ torch.Tensor([5,4,6,3,7,8])]
+ - | padded_targets (Tensor): Tensor of shape
+ (bsz * max_seq_len)).
+ """
+ assert utils.is_type_list(strings, str)
+
+ tensors, padded_targets = [], []
+ indexes = self.str2idx(strings)
+ for index in indexes:
+ tensor = torch.LongTensor(index[:self.max_seq_len - 1] +
+ [self.end_idx])
+ tensors.append(tensor)
+ # target tensor for loss
+ src_target = torch.LongTensor(tensor.size(0) + 1).fill_(0)
+ src_target[0] = self.start_idx
+ src_target[1:] = tensor
+ padded_target = (torch.ones(self.max_seq_len) *
+ self.padding_idx).long()
+ char_num = src_target.size(0)
+ if char_num > self.max_seq_len:
+ padded_target = src_target[:self.max_seq_len]
+ else:
+ padded_target[:char_num] = src_target
+ padded_targets.append(padded_target)
+ padded_targets = torch.stack(padded_targets, 0).long()
+
+ return {'targets': tensors, 'padded_targets': padded_targets}
diff --git a/mmocr/models/textrecog/convertors/attn.py b/mmocr/models/textrecog/convertors/attn.py
new file mode 100644
index 0000000000000000000000000000000000000000..e90f841e43f820bb6d455c74a6dc0eeeea7a1218
--- /dev/null
+++ b/mmocr/models/textrecog/convertors/attn.py
@@ -0,0 +1,141 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+import mmocr.utils as utils
+from mmocr.models.builder import CONVERTORS
+from .base import BaseConvertor
+
+
+@CONVERTORS.register_module()
+class AttnConvertor(BaseConvertor):
+ """Convert between text, index and tensor for encoder-decoder based
+ pipeline.
+
+ Args:
+ dict_type (str): Type of dict, should be one of {'DICT36', 'DICT90'}.
+ dict_file (None|str): Character dict file path. If not none,
+ higher priority than dict_type.
+ dict_list (None|list[str]): Character list. If not none, higher
+ priority than dict_type, but lower than dict_file.
+ with_unknown (bool): If True, add `UKN` token to class.
+ max_seq_len (int): Maximum sequence length of label.
+ lower (bool): If True, convert original string to lower case.
+ start_end_same (bool): Whether use the same index for
+ start and end token or not. Default: True.
+ """
+
+ def __init__(self,
+ dict_type='DICT90',
+ dict_file=None,
+ dict_list=None,
+ with_unknown=True,
+ max_seq_len=40,
+ lower=False,
+ start_end_same=True,
+ **kwargs):
+ super().__init__(dict_type, dict_file, dict_list)
+ assert isinstance(with_unknown, bool)
+ assert isinstance(max_seq_len, int)
+ assert isinstance(lower, bool)
+
+ self.with_unknown = with_unknown
+ self.max_seq_len = max_seq_len
+ self.lower = lower
+ self.start_end_same = start_end_same
+
+ self.update_dict()
+
+ def update_dict(self):
+ start_end_token = ''
+ unknown_token = ''
+ padding_token = ''
+
+ # unknown
+ self.unknown_idx = None
+ if self.with_unknown:
+ self.idx2char.append(unknown_token)
+ self.unknown_idx = len(self.idx2char) - 1
+
+ # BOS/EOS
+ self.idx2char.append(start_end_token)
+ self.start_idx = len(self.idx2char) - 1
+ if not self.start_end_same:
+ self.idx2char.append(start_end_token)
+ self.end_idx = len(self.idx2char) - 1
+
+ # padding
+ self.idx2char.append(padding_token)
+ self.padding_idx = len(self.idx2char) - 1
+
+ # update char2idx
+ self.char2idx = {}
+ for idx, char in enumerate(self.idx2char):
+ self.char2idx[char] = idx
+
+ def str2tensor(self, strings):
+ """
+ Convert text-string into tensor.
+ Args:
+ strings (list[str]): ['hello', 'world']
+ Returns:
+ dict (str: Tensor | list[tensor]):
+ tensors (list[Tensor]): [torch.Tensor([1,2,3,3,4]),
+ torch.Tensor([5,4,6,3,7])]
+ padded_targets (Tensor(bsz * max_seq_len))
+ """
+ assert utils.is_type_list(strings, str)
+
+ tensors, padded_targets = [], []
+ indexes = self.str2idx(strings)
+ for index in indexes:
+ tensor = torch.LongTensor(index)
+ tensors.append(tensor)
+ # target tensor for loss
+ src_target = torch.LongTensor(tensor.size(0) + 2).fill_(0)
+ src_target[-1] = self.end_idx
+ src_target[0] = self.start_idx
+ src_target[1:-1] = tensor
+ padded_target = (torch.ones(self.max_seq_len) *
+ self.padding_idx).long()
+ char_num = src_target.size(0)
+ if char_num > self.max_seq_len:
+ padded_target = src_target[:self.max_seq_len]
+ else:
+ padded_target[:char_num] = src_target
+ padded_targets.append(padded_target)
+ padded_targets = torch.stack(padded_targets, 0).long()
+
+ return {'targets': tensors, 'padded_targets': padded_targets}
+
+ def tensor2idx(self, outputs, img_metas=None):
+ """
+ Convert output tensor to text-index
+ Args:
+ outputs (tensor): model outputs with size: N * T * C
+ img_metas (list[dict]): Each dict contains one image info.
+ Returns:
+ indexes (list[list[int]]): [[1,2,3,3,4], [5,4,6,3,7]]
+ scores (list[list[float]]): [[0.9,0.8,0.95,0.97,0.94],
+ [0.9,0.9,0.98,0.97,0.96]]
+ """
+ batch_size = outputs.size(0)
+ ignore_indexes = [self.padding_idx]
+ indexes, scores = [], []
+ for idx in range(batch_size):
+ seq = outputs[idx, :, :]
+ max_value, max_idx = torch.max(seq, -1)
+ str_index, str_score = [], []
+ output_index = max_idx.cpu().detach().numpy().tolist()
+ output_score = max_value.cpu().detach().numpy().tolist()
+ for char_index, char_score in zip(output_index, output_score):
+ if char_index in ignore_indexes:
+ continue
+ if char_index == self.end_idx:
+ break
+ str_index.append(char_index)
+ str_score.append(char_score)
+
+ indexes.append(str_index)
+ scores.append(str_score)
+
+ return indexes, scores
diff --git a/mmocr/models/textrecog/convertors/base.py b/mmocr/models/textrecog/convertors/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..976299d9947dd1b3d32af37fd0ce03040b15c419
--- /dev/null
+++ b/mmocr/models/textrecog/convertors/base.py
@@ -0,0 +1,116 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.models.builder import CONVERTORS
+from mmocr.utils import list_from_file
+
+
+@CONVERTORS.register_module()
+class BaseConvertor:
+ """Convert between text, index and tensor for text recognize pipeline.
+
+ Args:
+ dict_type (str): Type of dict, should be either 'DICT36' or 'DICT90'.
+ dict_file (None|str): Character dict file path. If not none,
+ the dict_file is of higher priority than dict_type.
+ dict_list (None|list[str]): Character list. If not none, the list
+ is of higher priority than dict_type, but lower than dict_file.
+ """
+ start_idx = end_idx = padding_idx = 0
+ unknown_idx = None
+ lower = False
+
+ DICT36 = tuple('0123456789abcdefghijklmnopqrstuvwxyz')
+ DICT90 = tuple('0123456789abcdefghijklmnopqrstuvwxyz'
+ 'ABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&\'()'
+ '*+,-./:;<=>?@[\\]_`~')
+
+ def __init__(self, dict_type='DICT90', dict_file=None, dict_list=None):
+ assert dict_type in ('DICT36', 'DICT90')
+ assert dict_file is None or isinstance(dict_file, str)
+ assert dict_list is None or isinstance(dict_list, list)
+ self.idx2char = []
+ if dict_file is not None:
+ for line in list_from_file(dict_file):
+ line = line.strip()
+ if line != '':
+ self.idx2char.append(line)
+ elif dict_list is not None:
+ self.idx2char = dict_list
+ else:
+ if dict_type == 'DICT36':
+ self.idx2char = list(self.DICT36)
+ else:
+ self.idx2char = list(self.DICT90)
+
+ self.char2idx = {}
+ for idx, char in enumerate(self.idx2char):
+ self.char2idx[char] = idx
+
+ def num_classes(self):
+ """Number of output classes."""
+ return len(self.idx2char)
+
+ def str2idx(self, strings):
+ """Convert strings to indexes.
+
+ Args:
+ strings (list[str]): ['hello', 'world'].
+ Returns:
+ indexes (list[list[int]]): [[1,2,3,3,4], [5,4,6,3,7]].
+ """
+ assert isinstance(strings, list)
+
+ indexes = []
+ for string in strings:
+ if self.lower:
+ string = string.lower()
+ index = []
+ for char in string:
+ char_idx = self.char2idx.get(char, self.unknown_idx)
+ if char_idx is None:
+ raise Exception(f'Chararcter: {char} not in dict,'
+ f' please check gt_label and use'
+ f' custom dict file,'
+ f' or set "with_unknown=True"')
+ index.append(char_idx)
+ indexes.append(index)
+
+ return indexes
+
+ def str2tensor(self, strings):
+ """Convert text-string to input tensor.
+
+ Args:
+ strings (list[str]): ['hello', 'world'].
+ Returns:
+ tensors (list[torch.Tensor]): [torch.Tensor([1,2,3,3,4]),
+ torch.Tensor([5,4,6,3,7])].
+ """
+ raise NotImplementedError
+
+ def idx2str(self, indexes):
+ """Convert indexes to text strings.
+
+ Args:
+ indexes (list[list[int]]): [[1,2,3,3,4], [5,4,6,3,7]].
+ Returns:
+ strings (list[str]): ['hello', 'world'].
+ """
+ assert isinstance(indexes, list)
+
+ strings = []
+ for index in indexes:
+ string = [self.idx2char[i] for i in index]
+ strings.append(''.join(string))
+
+ return strings
+
+ def tensor2idx(self, output):
+ """Convert model output tensor to character indexes and scores.
+ Args:
+ output (tensor): The model outputs with size: N * T * C
+ Returns:
+ indexes (list[list[int]]): [[1,2,3,3,4], [5,4,6,3,7]].
+ scores (list[list[float]]): [[0.9,0.8,0.95,0.97,0.94],
+ [0.9,0.9,0.98,0.97,0.96]].
+ """
+ raise NotImplementedError
diff --git a/mmocr/models/textrecog/convertors/ctc.py b/mmocr/models/textrecog/convertors/ctc.py
new file mode 100644
index 0000000000000000000000000000000000000000..ec4d037d8ff842db34d1e0103dbfe2f1b4965c8f
--- /dev/null
+++ b/mmocr/models/textrecog/convertors/ctc.py
@@ -0,0 +1,145 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import torch
+import torch.nn.functional as F
+
+import mmocr.utils as utils
+from mmocr.models.builder import CONVERTORS
+from .base import BaseConvertor
+
+
+@CONVERTORS.register_module()
+class CTCConvertor(BaseConvertor):
+ """Convert between text, index and tensor for CTC loss-based pipeline.
+
+ Args:
+ dict_type (str): Type of dict, should be either 'DICT36' or 'DICT90'.
+ dict_file (None|str): Character dict file path. If not none, the file
+ is of higher priority than dict_type.
+ dict_list (None|list[str]): Character list. If not none, the list
+ is of higher priority than dict_type, but lower than dict_file.
+ with_unknown (bool): If True, add `UKN` token to class.
+ lower (bool): If True, convert original string to lower case.
+ """
+
+ def __init__(self,
+ dict_type='DICT90',
+ dict_file=None,
+ dict_list=None,
+ with_unknown=True,
+ lower=False,
+ **kwargs):
+ super().__init__(dict_type, dict_file, dict_list)
+ assert isinstance(with_unknown, bool)
+ assert isinstance(lower, bool)
+
+ self.with_unknown = with_unknown
+ self.lower = lower
+ self.update_dict()
+
+ def update_dict(self):
+ # CTC-blank
+ blank_token = ''
+ self.blank_idx = 0
+ self.idx2char.insert(0, blank_token)
+
+ # unknown
+ self.unknown_idx = None
+ if self.with_unknown:
+ self.idx2char.append('')
+ self.unknown_idx = len(self.idx2char) - 1
+
+ # update char2idx
+ self.char2idx = {}
+ for idx, char in enumerate(self.idx2char):
+ self.char2idx[char] = idx
+
+ def str2tensor(self, strings):
+ """Convert text-string to ctc-loss input tensor.
+
+ Args:
+ strings (list[str]): ['hello', 'world'].
+ Returns:
+ dict (str: tensor | list[tensor]):
+ tensors (list[tensor]): [torch.Tensor([1,2,3,3,4]),
+ torch.Tensor([5,4,6,3,7])].
+ flatten_targets (tensor): torch.Tensor([1,2,3,3,4,5,4,6,3,7]).
+ target_lengths (tensor): torch.IntTensot([5,5]).
+ """
+ assert utils.is_type_list(strings, str)
+
+ tensors = []
+ indexes = self.str2idx(strings)
+ for index in indexes:
+ tensor = torch.IntTensor(index)
+ tensors.append(tensor)
+ target_lengths = torch.IntTensor([len(t) for t in tensors])
+ flatten_target = torch.cat(tensors)
+
+ return {
+ 'targets': tensors,
+ 'flatten_targets': flatten_target,
+ 'target_lengths': target_lengths
+ }
+
+ def tensor2idx(self, output, img_metas, topk=1, return_topk=False):
+ """Convert model output tensor to index-list.
+ Args:
+ output (tensor): The model outputs with size: N * T * C.
+ img_metas (list[dict]): Each dict contains one image info.
+ topk (int): The highest k classes to be returned.
+ return_topk (bool): Whether to return topk or just top1.
+ Returns:
+ indexes (list[list[int]]): [[1,2,3,3,4], [5,4,6,3,7]].
+ scores (list[list[float]]): [[0.9,0.8,0.95,0.97,0.94],
+ [0.9,0.9,0.98,0.97,0.96]]
+ (
+ indexes_topk (list[list[list[int]->len=topk]]):
+ scores_topk (list[list[list[float]->len=topk]])
+ ).
+ """
+ assert utils.is_type_list(img_metas, dict)
+ assert len(img_metas) == output.size(0)
+ assert isinstance(topk, int)
+ assert topk >= 1
+
+ valid_ratios = [
+ img_meta.get('valid_ratio', 1.0) for img_meta in img_metas
+ ]
+
+ batch_size = output.size(0)
+ output = F.softmax(output, dim=2)
+ output = output.cpu().detach()
+ batch_topk_value, batch_topk_idx = output.topk(topk, dim=2)
+ batch_max_idx = batch_topk_idx[:, :, 0]
+ scores_topk, indexes_topk = [], []
+ scores, indexes = [], []
+ feat_len = output.size(1)
+ for b in range(batch_size):
+ valid_ratio = valid_ratios[b]
+ decode_len = min(feat_len, math.ceil(feat_len * valid_ratio))
+ pred = batch_max_idx[b, :]
+ select_idx = []
+ prev_idx = self.blank_idx
+ for t in range(decode_len):
+ tmp_value = pred[t].item()
+ if tmp_value not in (prev_idx, self.blank_idx):
+ select_idx.append(t)
+ prev_idx = tmp_value
+ select_idx = torch.LongTensor(select_idx)
+ topk_value = torch.index_select(batch_topk_value[b, :, :], 0,
+ select_idx) # valid_seqlen * topk
+ topk_idx = torch.index_select(batch_topk_idx[b, :, :], 0,
+ select_idx)
+ topk_idx_list, topk_value_list = topk_idx.numpy().tolist(
+ ), topk_value.numpy().tolist()
+ indexes_topk.append(topk_idx_list)
+ scores_topk.append(topk_value_list)
+ indexes.append([x[0] for x in topk_idx_list])
+ scores.append([x[0] for x in topk_value_list])
+
+ if return_topk:
+ return indexes_topk, scores_topk
+
+ return indexes, scores
diff --git a/mmocr/models/textrecog/convertors/seg.py b/mmocr/models/textrecog/convertors/seg.py
new file mode 100644
index 0000000000000000000000000000000000000000..5bc115d1cff641348e0488853f0448517d703c00
--- /dev/null
+++ b/mmocr/models/textrecog/convertors/seg.py
@@ -0,0 +1,127 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import cv2
+import numpy as np
+import torch
+
+import mmocr.utils as utils
+from mmocr.models.builder import CONVERTORS
+from .base import BaseConvertor
+
+
+@CONVERTORS.register_module()
+class SegConvertor(BaseConvertor):
+ """Convert between text, index and tensor for segmentation based pipeline.
+
+ Args:
+ dict_type (str): Type of dict, should be either 'DICT36' or 'DICT90'.
+ dict_file (None|str): Character dict file path. If not none, the
+ file is of higher priority than dict_type.
+ dict_list (None|list[str]): Character list. If not none, the list
+ is of higher priority than dict_type, but lower than dict_file.
+ with_unknown (bool): If True, add `UKN` token to class.
+ lower (bool): If True, convert original string to lower case.
+ """
+
+ def __init__(self,
+ dict_type='DICT36',
+ dict_file=None,
+ dict_list=None,
+ with_unknown=True,
+ lower=False,
+ **kwargs):
+ super().__init__(dict_type, dict_file, dict_list)
+ assert isinstance(with_unknown, bool)
+ assert isinstance(lower, bool)
+
+ self.with_unknown = with_unknown
+ self.lower = lower
+ self.update_dict()
+
+ def update_dict(self):
+ # background
+ self.idx2char.insert(0, '')
+
+ # unknown
+ self.unknown_idx = None
+ if self.with_unknown:
+ self.idx2char.append('')
+ self.unknown_idx = len(self.idx2char) - 1
+
+ # update char2idx
+ self.char2idx = {}
+ for idx, char in enumerate(self.idx2char):
+ self.char2idx[char] = idx
+
+ def tensor2str(self, output, img_metas=None):
+ """Convert model output tensor to string labels.
+ Args:
+ output (tensor): Model outputs with size: N * C * H * W
+ img_metas (list[dict]): Each dict contains one image info.
+ Returns:
+ texts (list[str]): Decoded text labels.
+ scores (list[list[float]]): Decoded chars scores.
+ """
+ assert utils.is_type_list(img_metas, dict)
+ assert len(img_metas) == output.size(0)
+
+ texts, scores = [], []
+ for b in range(output.size(0)):
+ seg_pred = output[b].detach()
+ valid_width = int(
+ output.size(-1) * img_metas[b]['valid_ratio'] + 1)
+ seg_res = torch.argmax(
+ seg_pred[:, :, :valid_width],
+ dim=0).cpu().numpy().astype(np.int32)
+
+ seg_thr = np.where(seg_res == 0, 0, 255).astype(np.uint8)
+ _, labels, stats, centroids = cv2.connectedComponentsWithStats(
+ seg_thr)
+
+ component_num = stats.shape[0]
+
+ all_res = []
+ for i in range(component_num):
+ temp_loc = (labels == i)
+ temp_value = seg_res[temp_loc]
+ temp_center = centroids[i]
+
+ temp_max_num = 0
+ temp_max_cls = -1
+ temp_total_num = 0
+ for c in range(len(self.idx2char)):
+ c_num = np.sum(temp_value == c)
+ temp_total_num += c_num
+ if c_num > temp_max_num:
+ temp_max_num = c_num
+ temp_max_cls = c
+
+ if temp_max_cls == 0:
+ continue
+ temp_max_score = 1.0 * temp_max_num / temp_total_num
+ all_res.append(
+ [temp_max_cls, temp_center, temp_max_num, temp_max_score])
+
+ all_res = sorted(all_res, key=lambda s: s[1][0])
+ chars, char_scores = [], []
+ for res in all_res:
+ temp_area = res[2]
+ if temp_area < 20:
+ continue
+ temp_char_index = res[0]
+ if temp_char_index >= len(self.idx2char):
+ temp_char = ''
+ elif temp_char_index <= 0:
+ temp_char = ''
+ elif temp_char_index == self.unknown_idx:
+ temp_char = ''
+ else:
+ temp_char = self.idx2char[temp_char_index]
+ chars.append(temp_char)
+ char_scores.append(res[3])
+
+ text = ''.join(chars)
+
+ texts.append(text)
+ scores.append(char_scores)
+
+ return texts, scores
diff --git a/mmocr/models/textrecog/decoders/__init__.py b/mmocr/models/textrecog/decoders/__init__.py
new file mode 100755
index 0000000000000000000000000000000000000000..ae91b8bb8571736d74a63a820257dc42700a725f
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/__init__.py
@@ -0,0 +1,18 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .abinet_language_decoder import ABILanguageDecoder
+from .abinet_vision_decoder import ABIVisionDecoder
+from .base_decoder import BaseDecoder
+from .crnn_decoder import CRNNDecoder
+from .nrtr_decoder import NRTRDecoder
+from .position_attention_decoder import PositionAttentionDecoder
+from .robust_scanner_decoder import RobustScannerDecoder
+from .sar_decoder import ParallelSARDecoder, SequentialSARDecoder
+from .sar_decoder_with_bs import ParallelSARDecoderWithBS
+from .sequence_attention_decoder import SequenceAttentionDecoder
+
+__all__ = [
+ 'CRNNDecoder', 'ParallelSARDecoder', 'SequentialSARDecoder',
+ 'ParallelSARDecoderWithBS', 'NRTRDecoder', 'BaseDecoder',
+ 'SequenceAttentionDecoder', 'PositionAttentionDecoder',
+ 'RobustScannerDecoder', 'ABILanguageDecoder', 'ABIVisionDecoder'
+]
diff --git a/mmocr/models/textrecog/decoders/abinet_language_decoder.py b/mmocr/models/textrecog/decoders/abinet_language_decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..4c4ce96eb3d69a76a14e530537e090204d15c92a
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/abinet_language_decoder.py
@@ -0,0 +1,181 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+import torch
+import torch.nn as nn
+from mmcv.cnn.bricks.transformer import BaseTransformerLayer
+from mmcv.runner import ModuleList
+
+from mmocr.models.builder import DECODERS
+from mmocr.models.common.modules import PositionalEncoding
+from .base_decoder import BaseDecoder
+
+
+@DECODERS.register_module()
+class ABILanguageDecoder(BaseDecoder):
+ r"""Transformer-based language model responsible for spell correction.
+ Implementation of language model of \
+ `ABINet `_.
+
+ Args:
+ d_model (int): Hidden size of input.
+ n_head (int): Number of multi-attention heads.
+ d_inner (int): Hidden size of feedforward network model.
+ n_layers (int): The number of similar decoding layers.
+ max_seq_len (int): Maximum text sequence length :math:`T`.
+ dropout (float): Dropout rate.
+ detach_tokens (bool): Whether to block the gradient flow at input
+ tokens.
+ num_chars (int): Number of text characters :math:`C`.
+ use_self_attn (bool): If True, use self attention in decoder layers,
+ otherwise cross attention will be used.
+ pad_idx (bool): The index of the token indicating the end of output,
+ which is used to compute the length of output. It is usually the
+ index of `` or `` token.
+ init_cfg (dict): Specifies the initialization method for model layers.
+ """
+
+ def __init__(self,
+ d_model=512,
+ n_head=8,
+ d_inner=2048,
+ n_layers=4,
+ max_seq_len=40,
+ dropout=0.1,
+ detach_tokens=True,
+ num_chars=90,
+ use_self_attn=False,
+ pad_idx=0,
+ init_cfg=None,
+ **kwargs):
+ super().__init__(init_cfg=init_cfg)
+ self.detach_tokens = detach_tokens
+
+ self.d_model = d_model
+ self.max_seq_len = max_seq_len
+
+ self.proj = nn.Linear(num_chars, d_model, False)
+ self.token_encoder = PositionalEncoding(
+ d_model, n_position=self.max_seq_len, dropout=0.1)
+ self.pos_encoder = PositionalEncoding(
+ d_model, n_position=self.max_seq_len)
+ self.pad_idx = pad_idx
+
+ if use_self_attn:
+ operation_order = ('self_attn', 'norm', 'cross_attn', 'norm',
+ 'ffn', 'norm')
+ else:
+ operation_order = ('cross_attn', 'norm', 'ffn', 'norm')
+
+ decoder_layer = BaseTransformerLayer(
+ operation_order=operation_order,
+ attn_cfgs=dict(
+ type='MultiheadAttention',
+ embed_dims=d_model,
+ num_heads=n_head,
+ attn_drop=dropout,
+ dropout_layer=dict(type='Dropout', drop_prob=dropout),
+ ),
+ ffn_cfgs=dict(
+ type='FFN',
+ embed_dims=d_model,
+ feedforward_channels=d_inner,
+ ffn_drop=dropout,
+ ),
+ norm_cfg=dict(type='LN'),
+ )
+ self.decoder_layers = ModuleList(
+ [copy.deepcopy(decoder_layer) for _ in range(n_layers)])
+
+ self.cls = nn.Linear(d_model, num_chars)
+
+ def forward_train(self, feat, logits, targets_dict, img_metas):
+ """
+ Args:
+ logits (Tensor): Raw language logitis. Shape (N, T, C).
+
+ Returns:
+ A dict with keys ``feature`` and ``logits``.
+ feature (Tensor): Shape (N, T, E). Raw textual features for vision
+ language aligner.
+ logits (Tensor): Shape (N, T, C). The raw logits for characters
+ after spell correction.
+ """
+ lengths = self._get_length(logits)
+ lengths.clamp_(2, self.max_seq_len)
+ tokens = torch.softmax(logits, dim=-1)
+ if self.detach_tokens:
+ tokens = tokens.detach()
+ embed = self.proj(tokens) # (N, T, E)
+ embed = self.token_encoder(embed) # (N, T, E)
+ padding_mask = self._get_padding_mask(lengths, self.max_seq_len)
+
+ zeros = embed.new_zeros(*embed.shape)
+ query = self.pos_encoder(zeros)
+ query = query.permute(1, 0, 2) # (T, N, E)
+ embed = embed.permute(1, 0, 2)
+ location_mask = self._get_location_mask(self.max_seq_len,
+ tokens.device)
+ output = query
+ for m in self.decoder_layers:
+ output = m(
+ query=output,
+ key=embed,
+ value=embed,
+ attn_masks=location_mask,
+ key_padding_mask=padding_mask)
+ output = output.permute(1, 0, 2) # (N, T, E)
+
+ logits = self.cls(output) # (N, T, C)
+ return {'feature': output, 'logits': logits}
+
+ def forward_test(self, feat, out_enc, img_metas):
+ return self.forward_train(feat, out_enc, None, img_metas)
+
+ def _get_length(self, logit, dim=-1):
+ """Greedy decoder to obtain length from logit.
+
+ Returns the first location of padding index or the length of the entire
+ tensor otherwise.
+ """
+ # out as a boolean vector indicating the existence of end token(s)
+ out = (logit.argmax(dim=-1) == self.pad_idx)
+ abn = out.any(dim)
+ # Get the first index of end token
+ out = ((out.cumsum(dim) == 1) & out).max(dim)[1]
+ out = out + 1
+ out = torch.where(abn, out, out.new_tensor(logit.shape[1]))
+ return out
+
+ @staticmethod
+ def _get_location_mask(seq_len, device=None):
+ """Generate location masks given input sequence length.
+
+ Args:
+ seq_len (int): The length of input sequence to transformer.
+ device (torch.device or str, optional): The device on which the
+ masks will be placed.
+
+ Returns:
+ Tensor: A mask tensor of shape (seq_len, seq_len) with -infs on
+ diagonal and zeros elsewhere.
+ """
+ mask = torch.eye(seq_len, device=device)
+ mask = mask.float().masked_fill(mask == 1, float('-inf'))
+ return mask
+
+ @staticmethod
+ def _get_padding_mask(length, max_length):
+ """Generate padding masks.
+
+ Args:
+ length (Tensor): Shape :math:`(N,)`.
+ max_length (int): The maximum sequence length :math:`T`.
+
+ Returns:
+ Tensor: A bool tensor of shape :math:`(N, T)` with Trues on
+ elements located over the length, or Falses elsewhere.
+ """
+ length = length.unsqueeze(-1)
+ grid = torch.arange(0, max_length, device=length.device).unsqueeze(0)
+ return grid >= length
diff --git a/mmocr/models/textrecog/decoders/abinet_vision_decoder.py b/mmocr/models/textrecog/decoders/abinet_vision_decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..7c565bd92789b59bd3718ca5b0c2605de92e8129
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/abinet_vision_decoder.py
@@ -0,0 +1,167 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+
+from mmocr.models.builder import DECODERS
+from mmocr.models.common.modules import PositionalEncoding
+from .base_decoder import BaseDecoder
+
+
+@DECODERS.register_module()
+class ABIVisionDecoder(BaseDecoder):
+ """Converts visual features into text characters.
+
+ Implementation of VisionEncoder in
+ `ABINet `_.
+
+ Args:
+ in_channels (int): Number of channels :math:`E` of input vector.
+ num_channels (int): Number of channels of hidden vectors in mini U-Net.
+ h (int): Height :math:`H` of input image features.
+ w (int): Width :math:`W` of input image features.
+
+ in_channels (int): Number of channels of input image features.
+ num_channels (int): Number of channels of hidden vectors in mini U-Net.
+ attn_height (int): Height :math:`H` of input image features.
+ attn_width (int): Width :math:`W` of input image features.
+ attn_mode (str): Upsampling mode for :obj:`torch.nn.Upsample` in mini
+ U-Net.
+ max_seq_len (int): Maximum text sequence length :math:`T`.
+ num_chars (int): Number of text characters :math:`C`.
+ init_cfg (dict): Specifies the initialization method for model layers.
+ """
+
+ def __init__(self,
+ in_channels=512,
+ num_channels=64,
+ attn_height=8,
+ attn_width=32,
+ attn_mode='nearest',
+ max_seq_len=40,
+ num_chars=90,
+ init_cfg=dict(type='Xavier', layer='Conv2d'),
+ **kwargs):
+ super().__init__(init_cfg=init_cfg)
+
+ self.max_seq_len = max_seq_len
+
+ # For mini-Unet
+ self.k_encoder = nn.Sequential(
+ self._encoder_layer(in_channels, num_channels, stride=(1, 2)),
+ self._encoder_layer(num_channels, num_channels, stride=(2, 2)),
+ self._encoder_layer(num_channels, num_channels, stride=(2, 2)),
+ self._encoder_layer(num_channels, num_channels, stride=(2, 2)))
+
+ self.k_decoder = nn.Sequential(
+ self._decoder_layer(
+ num_channels, num_channels, scale_factor=2, mode=attn_mode),
+ self._decoder_layer(
+ num_channels, num_channels, scale_factor=2, mode=attn_mode),
+ self._decoder_layer(
+ num_channels, num_channels, scale_factor=2, mode=attn_mode),
+ self._decoder_layer(
+ num_channels,
+ in_channels,
+ size=(attn_height, attn_width),
+ mode=attn_mode))
+
+ self.pos_encoder = PositionalEncoding(in_channels, max_seq_len)
+ self.project = nn.Linear(in_channels, in_channels)
+ self.cls = nn.Linear(in_channels, num_chars)
+
+ def forward_train(self,
+ feat,
+ out_enc=None,
+ targets_dict=None,
+ img_metas=None):
+ """
+ Args:
+ feat (Tensor): Image features of shape (N, E, H, W).
+
+ Returns:
+ dict: A dict with keys ``feature``, ``logits`` and ``attn_scores``.
+
+ - | feature (Tensor): Shape (N, T, E). Raw visual features for
+ language decoder.
+ - | logits (Tensor): Shape (N, T, C). The raw logits for
+ characters.
+ - | attn_scores (Tensor): Shape (N, T, H, W). Intermediate result
+ for vision-language aligner.
+ """
+ # Position Attention
+ N, E, H, W = feat.size()
+ k, v = feat, feat # (N, E, H, W)
+
+ # Apply mini U-Net on k
+ features = []
+ for i in range(len(self.k_encoder)):
+ k = self.k_encoder[i](k)
+ features.append(k)
+ for i in range(len(self.k_decoder) - 1):
+ k = self.k_decoder[i](k)
+ k = k + features[len(self.k_decoder) - 2 - i]
+ k = self.k_decoder[-1](k)
+
+ # q = positional encoding
+ zeros = feat.new_zeros((N, self.max_seq_len, E)) # (N, T, E)
+ q = self.pos_encoder(zeros) # (N, T, E)
+ q = self.project(q) # (N, T, E)
+
+ # Attention encoding
+ attn_scores = torch.bmm(q, k.flatten(2, 3)) # (N, T, (H*W))
+ attn_scores = attn_scores / (E**0.5)
+ attn_scores = torch.softmax(attn_scores, dim=-1)
+ v = v.permute(0, 2, 3, 1).view(N, -1, E) # (N, (H*W), E)
+ attn_vecs = torch.bmm(attn_scores, v) # (N, T, E)
+
+ logits = self.cls(attn_vecs)
+ result = {
+ 'feature': attn_vecs,
+ 'logits': logits,
+ 'attn_scores': attn_scores.view(N, -1, H, W)
+ }
+ return result
+
+ def forward_test(self, feat, out_enc=None, img_metas=None):
+ return self.forward_train(feat, out_enc=out_enc, img_metas=img_metas)
+
+ def _encoder_layer(self,
+ in_channels,
+ out_channels,
+ kernel_size=3,
+ stride=2,
+ padding=1):
+ return ConvModule(
+ in_channels,
+ out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'))
+
+ def _decoder_layer(self,
+ in_channels,
+ out_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ mode='nearest',
+ scale_factor=None,
+ size=None):
+ align_corners = None if mode == 'nearest' else True
+ return nn.Sequential(
+ nn.Upsample(
+ size=size,
+ scale_factor=scale_factor,
+ mode=mode,
+ align_corners=align_corners),
+ ConvModule(
+ in_channels,
+ out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU')))
diff --git a/mmocr/models/textrecog/decoders/base_decoder.py b/mmocr/models/textrecog/decoders/base_decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..09e2db88fde3c6ca02f20f3bb57ee0da0f8b1ce7
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/base_decoder.py
@@ -0,0 +1,30 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.runner import BaseModule
+
+from mmocr.models.builder import DECODERS
+
+
+@DECODERS.register_module()
+class BaseDecoder(BaseModule):
+ """Base decoder class for text recognition."""
+
+ def __init__(self, init_cfg=None, **kwargs):
+ super().__init__(init_cfg=init_cfg)
+
+ def forward_train(self, feat, out_enc, targets_dict, img_metas):
+ raise NotImplementedError
+
+ def forward_test(self, feat, out_enc, img_metas):
+ raise NotImplementedError
+
+ def forward(self,
+ feat,
+ out_enc,
+ targets_dict=None,
+ img_metas=None,
+ train_mode=True):
+ self.train_mode = train_mode
+ if train_mode:
+ return self.forward_train(feat, out_enc, targets_dict, img_metas)
+
+ return self.forward_test(feat, out_enc, img_metas)
diff --git a/mmocr/models/textrecog/decoders/crnn_decoder.py b/mmocr/models/textrecog/decoders/crnn_decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..9f40f4e2b9bbf776138678149a6229928f32d8f8
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/crnn_decoder.py
@@ -0,0 +1,70 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+from mmcv.runner import Sequential
+
+from mmocr.models.builder import DECODERS
+from mmocr.models.textrecog.layers import BidirectionalLSTM
+from .base_decoder import BaseDecoder
+
+
+@DECODERS.register_module()
+class CRNNDecoder(BaseDecoder):
+ """Decoder for CRNN.
+
+ Args:
+ in_channels (int): Number of input channels.
+ num_classes (int): Number of output classes.
+ rnn_flag (bool): Use RNN or CNN as the decoder.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self,
+ in_channels=None,
+ num_classes=None,
+ rnn_flag=False,
+ init_cfg=dict(type='Xavier', layer='Conv2d'),
+ **kwargs):
+ super().__init__(init_cfg=init_cfg)
+ self.num_classes = num_classes
+ self.rnn_flag = rnn_flag
+
+ if rnn_flag:
+ self.decoder = Sequential(
+ BidirectionalLSTM(in_channels, 256, 256),
+ BidirectionalLSTM(256, 256, num_classes))
+ else:
+ self.decoder = nn.Conv2d(
+ in_channels, num_classes, kernel_size=1, stride=1)
+
+ def forward_train(self, feat, out_enc, targets_dict, img_metas):
+ """
+ Args:
+ feat (Tensor): A Tensor of shape :math:`(N, H, 1, W)`.
+
+ Returns:
+ Tensor: The raw logit tensor. Shape :math:`(N, W, C)` where
+ :math:`C` is ``num_classes``.
+ """
+ assert feat.size(2) == 1, 'feature height must be 1'
+ if self.rnn_flag:
+ x = feat.squeeze(2) # [N, C, W]
+ x = x.permute(2, 0, 1) # [W, N, C]
+ x = self.decoder(x) # [W, N, C]
+ outputs = x.permute(1, 0, 2).contiguous()
+ else:
+ x = self.decoder(feat)
+ x = x.permute(0, 3, 1, 2).contiguous()
+ n, w, c, h = x.size()
+ outputs = x.view(n, w, c * h)
+ return outputs
+
+ def forward_test(self, feat, out_enc, img_metas):
+ """
+ Args:
+ feat (Tensor): A Tensor of shape :math:`(N, H, 1, W)`.
+
+ Returns:
+ Tensor: The raw logit tensor. Shape :math:`(N, W, C)` where
+ :math:`C` is ``num_classes``.
+ """
+ return self.forward_train(feat, out_enc, None, img_metas)
diff --git a/mmocr/models/textrecog/decoders/nrtr_decoder.py b/mmocr/models/textrecog/decoders/nrtr_decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..c21c0248484bd9e58ed7bfabc90c7917aae61cc1
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/nrtr_decoder.py
@@ -0,0 +1,177 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.runner import ModuleList
+
+from mmocr.models.builder import DECODERS
+from mmocr.models.common import PositionalEncoding, TFDecoderLayer
+from .base_decoder import BaseDecoder
+
+
+@DECODERS.register_module()
+class NRTRDecoder(BaseDecoder):
+ """Transformer Decoder block with self attention mechanism.
+
+ Args:
+ n_layers (int): Number of attention layers.
+ d_embedding (int): Language embedding dimension.
+ n_head (int): Number of parallel attention heads.
+ d_k (int): Dimension of the key vector.
+ d_v (int): Dimension of the value vector.
+ d_model (int): Dimension :math:`D_m` of the input from previous model.
+ d_inner (int): Hidden dimension of feedforward layers.
+ n_position (int): Length of the positional encoding vector. Must be
+ greater than ``max_seq_len``.
+ dropout (float): Dropout rate.
+ num_classes (int): Number of output classes :math:`C`.
+ max_seq_len (int): Maximum output sequence length :math:`T`.
+ start_idx (int): The index of ``.
+ padding_idx (int): The index of ``.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+
+ Warning:
+ This decoder will not predict the final class which is assumed to be
+ ``. Therefore, its output size is always :math:`C - 1`. ``
+ is also ignored by loss as specified in
+ :obj:`mmocr.models.textrecog.recognizer.EncodeDecodeRecognizer`.
+ """
+
+ def __init__(self,
+ n_layers=6,
+ d_embedding=512,
+ n_head=8,
+ d_k=64,
+ d_v=64,
+ d_model=512,
+ d_inner=256,
+ n_position=200,
+ dropout=0.1,
+ num_classes=93,
+ max_seq_len=40,
+ start_idx=1,
+ padding_idx=92,
+ init_cfg=None,
+ **kwargs):
+ super().__init__(init_cfg=init_cfg)
+
+ self.padding_idx = padding_idx
+ self.start_idx = start_idx
+ self.max_seq_len = max_seq_len
+
+ self.trg_word_emb = nn.Embedding(
+ num_classes, d_embedding, padding_idx=padding_idx)
+
+ self.position_enc = PositionalEncoding(
+ d_embedding, n_position=n_position)
+ self.dropout = nn.Dropout(p=dropout)
+
+ self.layer_stack = ModuleList([
+ TFDecoderLayer(
+ d_model, d_inner, n_head, d_k, d_v, dropout=dropout, **kwargs)
+ for _ in range(n_layers)
+ ])
+ self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
+
+ pred_num_class = num_classes - 1 # ignore padding_idx
+ self.classifier = nn.Linear(d_model, pred_num_class)
+
+ @staticmethod
+ def get_pad_mask(seq, pad_idx):
+
+ return (seq != pad_idx).unsqueeze(-2)
+
+ @staticmethod
+ def get_subsequent_mask(seq):
+ """For masking out the subsequent info."""
+ len_s = seq.size(1)
+ subsequent_mask = 1 - torch.triu(
+ torch.ones((len_s, len_s), device=seq.device), diagonal=1)
+ subsequent_mask = subsequent_mask.unsqueeze(0).bool()
+
+ return subsequent_mask
+
+ def _attention(self, trg_seq, src, src_mask=None):
+ trg_embedding = self.trg_word_emb(trg_seq)
+ trg_pos_encoded = self.position_enc(trg_embedding)
+ tgt = self.dropout(trg_pos_encoded)
+
+ trg_mask = self.get_pad_mask(
+ trg_seq,
+ pad_idx=self.padding_idx) & self.get_subsequent_mask(trg_seq)
+ output = tgt
+ for dec_layer in self.layer_stack:
+ output = dec_layer(
+ output,
+ src,
+ self_attn_mask=trg_mask,
+ dec_enc_attn_mask=src_mask)
+ output = self.layer_norm(output)
+
+ return output
+
+ def _get_mask(self, logit, img_metas):
+ valid_ratios = None
+ if img_metas is not None:
+ valid_ratios = [
+ img_meta.get('valid_ratio', 1.0) for img_meta in img_metas
+ ]
+ N, T, _ = logit.size()
+ mask = None
+ if valid_ratios is not None:
+ mask = logit.new_zeros((N, T))
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_width = min(T, math.ceil(T * valid_ratio))
+ mask[i, :valid_width] = 1
+
+ return mask
+
+ def forward_train(self, feat, out_enc, targets_dict, img_metas):
+ r"""
+ Args:
+ feat (None): Unused.
+ out_enc (Tensor): Encoder output of shape :math:`(N, T, D_m)`
+ where :math:`D_m` is ``d_model``.
+ targets_dict (dict): A dict with the key ``padded_targets``, a
+ tensor of shape :math:`(N, T)`. Each element is the index of a
+ character.
+ img_metas (dict): A dict that contains meta information of input
+ images. Preferably with the key ``valid_ratio``.
+
+ Returns:
+ Tensor: The raw logit tensor. Shape :math:`(N, T, C)`.
+ """
+ src_mask = self._get_mask(out_enc, img_metas)
+ targets = targets_dict['padded_targets'].to(out_enc.device)
+ attn_output = self._attention(targets, out_enc, src_mask=src_mask)
+ outputs = self.classifier(attn_output)
+
+ return outputs
+
+ def forward_test(self, feat, out_enc, img_metas):
+ src_mask = self._get_mask(out_enc, img_metas)
+ N = out_enc.size(0)
+ init_target_seq = torch.full((N, self.max_seq_len + 1),
+ self.padding_idx,
+ device=out_enc.device,
+ dtype=torch.long)
+ # bsz * seq_len
+ init_target_seq[:, 0] = self.start_idx
+
+ outputs = []
+ for step in range(0, self.max_seq_len):
+ decoder_output = self._attention(
+ init_target_seq, out_enc, src_mask=src_mask)
+ # bsz * seq_len * C
+ step_result = F.softmax(
+ self.classifier(decoder_output[:, step, :]), dim=-1)
+ # bsz * num_classes
+ outputs.append(step_result)
+ _, step_max_index = torch.max(step_result, dim=-1)
+ init_target_seq[:, step + 1] = step_max_index
+
+ outputs = torch.stack(outputs, dim=1)
+
+ return outputs
diff --git a/mmocr/models/textrecog/decoders/position_attention_decoder.py b/mmocr/models/textrecog/decoders/position_attention_decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..37ab7389b09d4afb2ba84ad728a925ca9aee20ea
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/position_attention_decoder.py
@@ -0,0 +1,194 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import torch
+import torch.nn as nn
+
+from mmocr.models.builder import DECODERS
+from mmocr.models.textrecog.layers import (DotProductAttentionLayer,
+ PositionAwareLayer)
+from .base_decoder import BaseDecoder
+
+
+@DECODERS.register_module()
+class PositionAttentionDecoder(BaseDecoder):
+ """Position attention decoder for RobustScanner.
+
+ RobustScanner: `RobustScanner: Dynamically Enhancing Positional Clues for
+ Robust Text Recognition `_
+
+ Args:
+ num_classes (int): Number of output classes :math:`C`.
+ rnn_layers (int): Number of RNN layers.
+ dim_input (int): Dimension :math:`D_i` of input vector ``feat``.
+ dim_model (int): Dimension :math:`D_m` of the model. Should also be the
+ same as encoder output vector ``out_enc``.
+ max_seq_len (int): Maximum output sequence length :math:`T`.
+ mask (bool): Whether to mask input features according to
+ ``img_meta['valid_ratio']``.
+ return_feature (bool): Return feature or logits as the result.
+ encode_value (bool): Whether to use the output of encoder ``out_enc``
+ as `value` of attention layer. If False, the original feature
+ ``feat`` will be used.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+
+ Warning:
+ This decoder will not predict the final class which is assumed to be
+ ``. Therefore, its output size is always :math:`C - 1`. ``
+ is also ignored by loss as specified in
+ :obj:`mmocr.models.textrecog.recognizer.EncodeDecodeRecognizer`.
+ """
+
+ def __init__(self,
+ num_classes=None,
+ rnn_layers=2,
+ dim_input=512,
+ dim_model=128,
+ max_seq_len=40,
+ mask=True,
+ return_feature=False,
+ encode_value=False,
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+
+ self.num_classes = num_classes
+ self.dim_input = dim_input
+ self.dim_model = dim_model
+ self.max_seq_len = max_seq_len
+ self.return_feature = return_feature
+ self.encode_value = encode_value
+ self.mask = mask
+
+ self.embedding = nn.Embedding(self.max_seq_len + 1, self.dim_model)
+
+ self.position_aware_module = PositionAwareLayer(
+ self.dim_model, rnn_layers)
+
+ self.attention_layer = DotProductAttentionLayer()
+
+ self.prediction = None
+ if not self.return_feature:
+ pred_num_classes = num_classes - 1
+ self.prediction = nn.Linear(
+ dim_model if encode_value else dim_input, pred_num_classes)
+
+ def _get_position_index(self, length, batch_size, device=None):
+ position_index = torch.arange(0, length, device=device)
+ position_index = position_index.repeat([batch_size, 1])
+ position_index = position_index.long()
+ return position_index
+
+ def forward_train(self, feat, out_enc, targets_dict, img_metas):
+ """
+ Args:
+ feat (Tensor): Tensor of shape :math:`(N, D_i, H, W)`.
+ out_enc (Tensor): Encoder output of shape
+ :math:`(N, D_m, H, W)`.
+ targets_dict (dict): A dict with the key ``padded_targets``, a
+ tensor of shape :math:`(N, T)`. Each element is the index of a
+ character.
+ img_metas (dict): A dict that contains meta information of input
+ images. Preferably with the key ``valid_ratio``.
+
+ Returns:
+ Tensor: A raw logit tensor of shape :math:`(N, T, C-1)` if
+ ``return_feature=False``. Otherwise it will be the hidden feature
+ before the prediction projection layer, whose shape is
+ :math:`(N, T, D_m)`.
+ """
+ valid_ratios = [
+ img_meta.get('valid_ratio', 1.0) for img_meta in img_metas
+ ] if self.mask else None
+
+ targets = targets_dict['padded_targets'].to(feat.device)
+
+ #
+ n, c_enc, h, w = out_enc.size()
+ assert c_enc == self.dim_model
+ _, c_feat, _, _ = feat.size()
+ assert c_feat == self.dim_input
+ _, len_q = targets.size()
+ assert len_q <= self.max_seq_len
+
+ position_index = self._get_position_index(len_q, n, feat.device)
+
+ position_out_enc = self.position_aware_module(out_enc)
+
+ query = self.embedding(position_index)
+ query = query.permute(0, 2, 1).contiguous()
+ key = position_out_enc.view(n, c_enc, h * w)
+ if self.encode_value:
+ value = out_enc.view(n, c_enc, h * w)
+ else:
+ value = feat.view(n, c_feat, h * w)
+
+ mask = None
+ if valid_ratios is not None:
+ mask = query.new_zeros((n, h, w))
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_width = min(w, math.ceil(w * valid_ratio))
+ mask[i, :, valid_width:] = 1
+ mask = mask.bool()
+ mask = mask.view(n, h * w)
+
+ attn_out = self.attention_layer(query, key, value, mask)
+ attn_out = attn_out.permute(0, 2, 1).contiguous() # [n, len_q, dim_v]
+
+ if self.return_feature:
+ return attn_out
+
+ return self.prediction(attn_out)
+
+ def forward_test(self, feat, out_enc, img_metas):
+ """
+ Args:
+ feat (Tensor): Tensor of shape :math:`(N, D_i, H, W)`.
+ out_enc (Tensor): Encoder output of shape
+ :math:`(N, D_m, H, W)`.
+ img_metas (dict): A dict that contains meta information of input
+ images. Preferably with the key ``valid_ratio``.
+
+ Returns:
+ Tensor: A raw logit tensor of shape :math:`(N, T, C-1)` if
+ ``return_feature=False``. Otherwise it would be the hidden feature
+ before the prediction projection layer, whose shape is
+ :math:`(N, T, D_m)`.
+ """
+ valid_ratios = [
+ img_meta.get('valid_ratio', 1.0) for img_meta in img_metas
+ ] if self.mask else None
+
+ seq_len = self.max_seq_len
+ n, c_enc, h, w = out_enc.size()
+ assert c_enc == self.dim_model
+ _, c_feat, _, _ = feat.size()
+ assert c_feat == self.dim_input
+
+ position_index = self._get_position_index(seq_len, n, feat.device)
+
+ position_out_enc = self.position_aware_module(out_enc)
+
+ query = self.embedding(position_index)
+ query = query.permute(0, 2, 1).contiguous()
+ key = position_out_enc.view(n, c_enc, h * w)
+ if self.encode_value:
+ value = out_enc.view(n, c_enc, h * w)
+ else:
+ value = feat.view(n, c_feat, h * w)
+
+ mask = None
+ if valid_ratios is not None:
+ mask = query.new_zeros((n, h, w))
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_width = min(w, math.ceil(w * valid_ratio))
+ mask[i, :, valid_width:] = 1
+ mask = mask.bool()
+ mask = mask.view(n, h * w)
+
+ attn_out = self.attention_layer(query, key, value, mask)
+ attn_out = attn_out.permute(0, 2, 1).contiguous()
+
+ if self.return_feature:
+ return attn_out
+
+ return self.prediction(attn_out)
diff --git a/mmocr/models/textrecog/decoders/robust_scanner_decoder.py b/mmocr/models/textrecog/decoders/robust_scanner_decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..0e2bbd475d6a81faca1514b765bdf7d869da46ec
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/robust_scanner_decoder.py
@@ -0,0 +1,160 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from mmocr.models.builder import DECODERS, build_decoder
+from mmocr.models.textrecog.layers import RobustScannerFusionLayer
+from .base_decoder import BaseDecoder
+
+
+@DECODERS.register_module()
+class RobustScannerDecoder(BaseDecoder):
+ """Decoder for RobustScanner.
+
+ RobustScanner: `RobustScanner: Dynamically Enhancing Positional Clues for
+ Robust Text Recognition `_
+
+ Args:
+ num_classes (int): Number of output classes :math:`C`.
+ dim_input (int): Dimension :math:`D_i` of input vector ``feat``.
+ dim_model (int): Dimension :math:`D_m` of the model. Should also be the
+ same as encoder output vector ``out_enc``.
+ max_seq_len (int): Maximum output sequence length :math:`T`.
+ start_idx (int): The index of ``.
+ mask (bool): Whether to mask input features according to
+ ``img_meta['valid_ratio']``.
+ padding_idx (int): The index of ``.
+ encode_value (bool): Whether to use the output of encoder ``out_enc``
+ as `value` of attention layer. If False, the original feature
+ ``feat`` will be used.
+ hybrid_decoder (dict): Configuration dict for hybrid decoder.
+ position_decoder (dict): Configuration dict for position decoder.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+
+ Warning:
+ This decoder will not predict the final class which is assumed to be
+ ``. Therefore, its output size is always :math:`C - 1`. ``
+ is also ignored by loss as specified in
+ :obj:`mmocr.models.textrecog.recognizer.EncodeDecodeRecognizer`.
+ """
+
+ def __init__(self,
+ num_classes=None,
+ dim_input=512,
+ dim_model=128,
+ max_seq_len=40,
+ start_idx=0,
+ mask=True,
+ padding_idx=None,
+ encode_value=False,
+ hybrid_decoder=None,
+ position_decoder=None,
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ self.num_classes = num_classes
+ self.dim_input = dim_input
+ self.dim_model = dim_model
+ self.max_seq_len = max_seq_len
+ self.encode_value = encode_value
+ self.start_idx = start_idx
+ self.padding_idx = padding_idx
+ self.mask = mask
+
+ # init hybrid decoder
+ hybrid_decoder.update(num_classes=self.num_classes)
+ hybrid_decoder.update(dim_input=self.dim_input)
+ hybrid_decoder.update(dim_model=self.dim_model)
+ hybrid_decoder.update(start_idx=self.start_idx)
+ hybrid_decoder.update(padding_idx=self.padding_idx)
+ hybrid_decoder.update(max_seq_len=self.max_seq_len)
+ hybrid_decoder.update(mask=self.mask)
+ hybrid_decoder.update(encode_value=self.encode_value)
+ hybrid_decoder.update(return_feature=True)
+
+ self.hybrid_decoder = build_decoder(hybrid_decoder)
+
+ # init position decoder
+ position_decoder.update(num_classes=self.num_classes)
+ position_decoder.update(dim_input=self.dim_input)
+ position_decoder.update(dim_model=self.dim_model)
+ position_decoder.update(max_seq_len=self.max_seq_len)
+ position_decoder.update(mask=self.mask)
+ position_decoder.update(encode_value=self.encode_value)
+ position_decoder.update(return_feature=True)
+
+ self.position_decoder = build_decoder(position_decoder)
+
+ self.fusion_module = RobustScannerFusionLayer(
+ self.dim_model if encode_value else dim_input)
+
+ pred_num_classes = num_classes - 1
+ self.prediction = nn.Linear(dim_model if encode_value else dim_input,
+ pred_num_classes)
+
+ def forward_train(self, feat, out_enc, targets_dict, img_metas):
+ """
+ Args:
+ feat (Tensor): Tensor of shape :math:`(N, D_i, H, W)`.
+ out_enc (Tensor): Encoder output of shape
+ :math:`(N, D_m, H, W)`.
+ targets_dict (dict): A dict with the key ``padded_targets``, a
+ tensor of shape :math:`(N, T)`. Each element is the index of a
+ character.
+ img_metas (dict): A dict that contains meta information of input
+ images. Preferably with the key ``valid_ratio``.
+
+ Returns:
+ Tensor: A raw logit tensor of shape :math:`(N, T, C-1)`.
+ """
+ hybrid_glimpse = self.hybrid_decoder.forward_train(
+ feat, out_enc, targets_dict, img_metas)
+ position_glimpse = self.position_decoder.forward_train(
+ feat, out_enc, targets_dict, img_metas)
+
+ fusion_out = self.fusion_module(hybrid_glimpse, position_glimpse)
+
+ out = self.prediction(fusion_out)
+
+ return out
+
+ def forward_test(self, feat, out_enc, img_metas):
+ """
+ Args:
+ feat (Tensor): Tensor of shape :math:`(N, D_i, H, W)`.
+ out_enc (Tensor): Encoder output of shape
+ :math:`(N, D_m, H, W)`.
+ img_metas (dict): A dict that contains meta information of input
+ images. Preferably with the key ``valid_ratio``.
+
+ Returns:
+ Tensor: The output logit sequence tensor of shape
+ :math:`(N, T, C-1)`.
+ """
+ seq_len = self.max_seq_len
+ batch_size = feat.size(0)
+
+ decode_sequence = (feat.new_ones(
+ (batch_size, seq_len)) * self.start_idx).long()
+
+ position_glimpse = self.position_decoder.forward_test(
+ feat, out_enc, img_metas)
+
+ outputs = []
+ for i in range(seq_len):
+ hybrid_glimpse_step = self.hybrid_decoder.forward_test_step(
+ feat, out_enc, decode_sequence, i, img_metas)
+
+ fusion_out = self.fusion_module(hybrid_glimpse_step,
+ position_glimpse[:, i, :])
+
+ char_out = self.prediction(fusion_out)
+ char_out = F.softmax(char_out, -1)
+ outputs.append(char_out)
+ _, max_idx = torch.max(char_out, dim=1, keepdim=False)
+ if i < seq_len - 1:
+ decode_sequence[:, i + 1] = max_idx
+
+ outputs = torch.stack(outputs, 1)
+
+ return outputs
diff --git a/mmocr/models/textrecog/decoders/sar_decoder.py b/mmocr/models/textrecog/decoders/sar_decoder.py
new file mode 100755
index 0000000000000000000000000000000000000000..ee79e8c05f7246d3fe2172493ea883ceb9848f0f
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/sar_decoder.py
@@ -0,0 +1,478 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+import mmocr.utils as utils
+from mmocr.models.builder import DECODERS
+from .base_decoder import BaseDecoder
+
+
+@DECODERS.register_module()
+class ParallelSARDecoder(BaseDecoder):
+ """Implementation Parallel Decoder module in `SAR.
+
+ `_.
+
+ Args:
+ num_classes (int): Output class number :math:`C`.
+ channels (list[int]): Network layer channels.
+ enc_bi_rnn (bool): If True, use bidirectional RNN in encoder.
+ dec_bi_rnn (bool): If True, use bidirectional RNN in decoder.
+ dec_do_rnn (float): Dropout of RNN layer in decoder.
+ dec_gru (bool): If True, use GRU, else LSTM in decoder.
+ d_model (int): Dim of channels from backbone :math:`D_i`.
+ d_enc (int): Dim of encoder RNN layer :math:`D_m`.
+ d_k (int): Dim of channels of attention module.
+ pred_dropout (float): Dropout probability of prediction layer.
+ max_seq_len (int): Maximum sequence length for decoding.
+ mask (bool): If True, mask padding in feature map.
+ start_idx (int): Index of start token.
+ padding_idx (int): Index of padding token.
+ pred_concat (bool): If True, concat glimpse feature from
+ attention with holistic feature and hidden state.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+
+ Warning:
+ This decoder will not predict the final class which is assumed to be
+ ``. Therefore, its output size is always :math:`C - 1`. ``
+ is also ignored by loss as specified in
+ :obj:`mmocr.models.textrecog.recognizer.EncodeDecodeRecognizer`.
+ """
+
+ def __init__(self,
+ num_classes=37,
+ enc_bi_rnn=False,
+ dec_bi_rnn=False,
+ dec_do_rnn=0.0,
+ dec_gru=False,
+ d_model=512,
+ d_enc=512,
+ d_k=64,
+ pred_dropout=0.0,
+ max_seq_len=40,
+ mask=True,
+ start_idx=0,
+ padding_idx=92,
+ pred_concat=False,
+ init_cfg=None,
+ **kwargs):
+ super().__init__(init_cfg=init_cfg)
+
+ self.num_classes = num_classes
+ self.enc_bi_rnn = enc_bi_rnn
+ self.d_k = d_k
+ self.start_idx = start_idx
+ self.max_seq_len = max_seq_len
+ self.mask = mask
+ self.pred_concat = pred_concat
+
+ encoder_rnn_out_size = d_enc * (int(enc_bi_rnn) + 1)
+ decoder_rnn_out_size = encoder_rnn_out_size * (int(dec_bi_rnn) + 1)
+ # 2D attention layer
+ self.conv1x1_1 = nn.Linear(decoder_rnn_out_size, d_k)
+ self.conv3x3_1 = nn.Conv2d(
+ d_model, d_k, kernel_size=3, stride=1, padding=1)
+ self.conv1x1_2 = nn.Linear(d_k, 1)
+
+ # Decoder RNN layer
+ kwargs = dict(
+ input_size=encoder_rnn_out_size,
+ hidden_size=encoder_rnn_out_size,
+ num_layers=2,
+ batch_first=True,
+ dropout=dec_do_rnn,
+ bidirectional=dec_bi_rnn)
+ if dec_gru:
+ self.rnn_decoder = nn.GRU(**kwargs)
+ else:
+ self.rnn_decoder = nn.LSTM(**kwargs)
+
+ # Decoder input embedding
+ self.embedding = nn.Embedding(
+ self.num_classes, encoder_rnn_out_size, padding_idx=padding_idx)
+
+ # Prediction layer
+ self.pred_dropout = nn.Dropout(pred_dropout)
+ pred_num_classes = num_classes - 1 # ignore padding_idx in prediction
+ if pred_concat:
+ fc_in_channel = decoder_rnn_out_size + d_model + \
+ encoder_rnn_out_size
+ else:
+ fc_in_channel = d_model
+ self.prediction = nn.Linear(fc_in_channel, pred_num_classes)
+
+ def _2d_attention(self,
+ decoder_input,
+ feat,
+ holistic_feat,
+ valid_ratios=None):
+ y = self.rnn_decoder(decoder_input)[0]
+ # y: bsz * (seq_len + 1) * hidden_size
+
+ attn_query = self.conv1x1_1(y) # bsz * (seq_len + 1) * attn_size
+ bsz, seq_len, attn_size = attn_query.size()
+ attn_query = attn_query.view(bsz, seq_len, attn_size, 1, 1)
+
+ attn_key = self.conv3x3_1(feat)
+ # bsz * attn_size * h * w
+ attn_key = attn_key.unsqueeze(1)
+ # bsz * 1 * attn_size * h * w
+
+ attn_weight = torch.tanh(torch.add(attn_key, attn_query, alpha=1))
+ # bsz * (seq_len + 1) * attn_size * h * w
+ attn_weight = attn_weight.permute(0, 1, 3, 4, 2).contiguous()
+ # bsz * (seq_len + 1) * h * w * attn_size
+ attn_weight = self.conv1x1_2(attn_weight)
+ # bsz * (seq_len + 1) * h * w * 1
+ bsz, T, h, w, c = attn_weight.size()
+ assert c == 1
+
+ if valid_ratios is not None:
+ # cal mask of attention weight
+ attn_mask = torch.zeros_like(attn_weight)
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_width = min(w, math.ceil(w * valid_ratio))
+ attn_mask[i, :, :, valid_width:, :] = 1
+ attn_weight = attn_weight.masked_fill(attn_mask.bool(),
+ float('-inf'))
+
+ attn_weight = attn_weight.view(bsz, T, -1)
+ attn_weight = F.softmax(attn_weight, dim=-1)
+ attn_weight = attn_weight.view(bsz, T, h, w,
+ c).permute(0, 1, 4, 2, 3).contiguous()
+
+ attn_feat = torch.sum(
+ torch.mul(feat.unsqueeze(1), attn_weight), (3, 4), keepdim=False)
+ # bsz * (seq_len + 1) * C
+
+ # linear transformation
+ if self.pred_concat:
+ hf_c = holistic_feat.size(-1)
+ holistic_feat = holistic_feat.expand(bsz, seq_len, hf_c)
+ y = self.prediction(torch.cat((y, attn_feat, holistic_feat), 2))
+ else:
+ y = self.prediction(attn_feat)
+ # bsz * (seq_len + 1) * num_classes
+ if self.train_mode:
+ y = self.pred_dropout(y)
+
+ return y
+
+ def forward_train(self, feat, out_enc, targets_dict, img_metas):
+ """
+ Args:
+ feat (Tensor): Tensor of shape :math:`(N, D_i, H, W)`.
+ out_enc (Tensor): Encoder output of shape
+ :math:`(N, D_m, H, W)`.
+ targets_dict (dict): A dict with the key ``padded_targets``, a
+ tensor of shape :math:`(N, T)`. Each element is the index of a
+ character.
+ img_metas (dict): A dict that contains meta information of input
+ images. Preferably with the key ``valid_ratio``.
+
+ Returns:
+ Tensor: A raw logit tensor of shape :math:`(N, T, C-1)`.
+ """
+ if img_metas is not None:
+ assert utils.is_type_list(img_metas, dict)
+ assert len(img_metas) == feat.size(0)
+
+ valid_ratios = None
+ if img_metas is not None:
+ valid_ratios = [
+ img_meta.get('valid_ratio', 1.0) for img_meta in img_metas
+ ] if self.mask else None
+
+ targets = targets_dict['padded_targets'].to(feat.device)
+ tgt_embedding = self.embedding(targets)
+ # bsz * seq_len * emb_dim
+ out_enc = out_enc.unsqueeze(1)
+ # bsz * 1 * emb_dim
+ in_dec = torch.cat((out_enc, tgt_embedding), dim=1)
+ # bsz * (seq_len + 1) * C
+ out_dec = self._2d_attention(
+ in_dec, feat, out_enc, valid_ratios=valid_ratios)
+ # bsz * (seq_len + 1) * num_classes
+
+ return out_dec[:, 1:, :] # bsz * seq_len * num_classes
+
+ def forward_test(self, feat, out_enc, img_metas):
+ """
+ Args:
+ feat (Tensor): Tensor of shape :math:`(N, D_i, H, W)`.
+ out_enc (Tensor): Encoder output of shape
+ :math:`(N, D_m, H, W)`.
+ img_metas (dict): A dict that contains meta information of input
+ images. Preferably with the key ``valid_ratio``.
+
+ Returns:
+ Tensor: A raw logit tensor of shape :math:`(N, T, C-1)`.
+ """
+ if img_metas is not None:
+ assert utils.is_type_list(img_metas, dict)
+ assert len(img_metas) == feat.size(0)
+
+ valid_ratios = None
+ if img_metas is not None:
+ valid_ratios = [
+ img_meta.get('valid_ratio', 1.0) for img_meta in img_metas
+ ] if self.mask else None
+
+ seq_len = self.max_seq_len
+
+ bsz = feat.size(0)
+ start_token = torch.full((bsz, ),
+ self.start_idx,
+ device=feat.device,
+ dtype=torch.long)
+ # bsz
+ start_token = self.embedding(start_token)
+ # bsz * emb_dim
+ start_token = start_token.unsqueeze(1).expand(-1, seq_len, -1)
+ # bsz * seq_len * emb_dim
+ out_enc = out_enc.unsqueeze(1)
+ # bsz * 1 * emb_dim
+ decoder_input = torch.cat((out_enc, start_token), dim=1)
+ # bsz * (seq_len + 1) * emb_dim
+
+ outputs = []
+ for i in range(1, seq_len + 1):
+ decoder_output = self._2d_attention(
+ decoder_input, feat, out_enc, valid_ratios=valid_ratios)
+ char_output = decoder_output[:, i, :] # bsz * num_classes
+ char_output = F.softmax(char_output, -1)
+ outputs.append(char_output)
+ _, max_idx = torch.max(char_output, dim=1, keepdim=False)
+ char_embedding = self.embedding(max_idx) # bsz * emb_dim
+ if i < seq_len:
+ decoder_input[:, i + 1, :] = char_embedding
+
+ outputs = torch.stack(outputs, 1) # bsz * seq_len * num_classes
+
+ return outputs
+
+
+@DECODERS.register_module()
+class SequentialSARDecoder(BaseDecoder):
+ """Implementation Sequential Decoder module in `SAR.
+
+ `_.
+
+ Args:
+ num_classes (int): Output class number :math:`C`.
+ enc_bi_rnn (bool): If True, use bidirectional RNN in encoder.
+ dec_bi_rnn (bool): If True, use bidirectional RNN in decoder.
+ dec_do_rnn (float): Dropout of RNN layer in decoder.
+ dec_gru (bool): If True, use GRU, else LSTM in decoder.
+ d_k (int): Dim of conv layers in attention module.
+ d_model (int): Dim of channels from backbone :math:`D_i`.
+ d_enc (int): Dim of encoder RNN layer :math:`D_m`.
+ pred_dropout (float): Dropout probability of prediction layer.
+ max_seq_len (int): Maximum sequence length during decoding.
+ mask (bool): If True, mask padding in feature map.
+ start_idx (int): Index of start token.
+ padding_idx (int): Index of padding token.
+ pred_concat (bool): If True, concat glimpse feature from
+ attention with holistic feature and hidden state.
+ """
+
+ def __init__(self,
+ num_classes=37,
+ enc_bi_rnn=False,
+ dec_bi_rnn=False,
+ dec_gru=False,
+ d_k=64,
+ d_model=512,
+ d_enc=512,
+ pred_dropout=0.0,
+ mask=True,
+ max_seq_len=40,
+ start_idx=0,
+ padding_idx=92,
+ pred_concat=False,
+ init_cfg=None,
+ **kwargs):
+ super().__init__(init_cfg=init_cfg)
+
+ self.num_classes = num_classes
+ self.enc_bi_rnn = enc_bi_rnn
+ self.d_k = d_k
+ self.start_idx = start_idx
+ self.dec_gru = dec_gru
+ self.max_seq_len = max_seq_len
+ self.mask = mask
+ self.pred_concat = pred_concat
+
+ encoder_rnn_out_size = d_enc * (int(enc_bi_rnn) + 1)
+ decoder_rnn_out_size = encoder_rnn_out_size * (int(dec_bi_rnn) + 1)
+ # 2D attention layer
+ self.conv1x1_1 = nn.Conv2d(
+ decoder_rnn_out_size, d_k, kernel_size=1, stride=1)
+ self.conv3x3_1 = nn.Conv2d(
+ d_model, d_k, kernel_size=3, stride=1, padding=1)
+ self.conv1x1_2 = nn.Conv2d(d_k, 1, kernel_size=1, stride=1)
+
+ # Decoder rnn layer
+ if dec_gru:
+ self.rnn_decoder_layer1 = nn.GRUCell(encoder_rnn_out_size,
+ encoder_rnn_out_size)
+ self.rnn_decoder_layer2 = nn.GRUCell(encoder_rnn_out_size,
+ encoder_rnn_out_size)
+ else:
+ self.rnn_decoder_layer1 = nn.LSTMCell(encoder_rnn_out_size,
+ encoder_rnn_out_size)
+ self.rnn_decoder_layer2 = nn.LSTMCell(encoder_rnn_out_size,
+ encoder_rnn_out_size)
+
+ # Decoder input embedding
+ self.embedding = nn.Embedding(
+ self.num_classes, encoder_rnn_out_size, padding_idx=padding_idx)
+
+ # Prediction layer
+ self.pred_dropout = nn.Dropout(pred_dropout)
+ pred_num_class = num_classes - 1 # ignore padding index
+ if pred_concat:
+ fc_in_channel = decoder_rnn_out_size + d_model + d_enc
+ else:
+ fc_in_channel = d_model
+ self.prediction = nn.Linear(fc_in_channel, pred_num_class)
+
+ def _2d_attention(self,
+ y_prev,
+ feat,
+ holistic_feat,
+ hx1,
+ cx1,
+ hx2,
+ cx2,
+ valid_ratios=None):
+ _, _, h_feat, w_feat = feat.size()
+ if self.dec_gru:
+ hx1 = cx1 = self.rnn_decoder_layer1(y_prev, hx1)
+ hx2 = cx2 = self.rnn_decoder_layer2(hx1, hx2)
+ else:
+ hx1, cx1 = self.rnn_decoder_layer1(y_prev, (hx1, cx1))
+ hx2, cx2 = self.rnn_decoder_layer2(hx1, (hx2, cx2))
+
+ tile_hx2 = hx2.view(hx2.size(0), hx2.size(1), 1, 1)
+ attn_query = self.conv1x1_1(tile_hx2) # bsz * attn_size * 1 * 1
+ attn_query = attn_query.expand(-1, -1, h_feat, w_feat)
+ attn_key = self.conv3x3_1(feat)
+ attn_weight = torch.tanh(torch.add(attn_key, attn_query, alpha=1))
+ attn_weight = self.conv1x1_2(attn_weight)
+ bsz, c, h, w = attn_weight.size()
+ assert c == 1
+
+ if valid_ratios is not None:
+ # cal mask of attention weight
+ attn_mask = torch.zeros_like(attn_weight)
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_width = min(w, math.ceil(w * valid_ratio))
+ attn_mask[i, :, :, valid_width:] = 1
+ attn_weight = attn_weight.masked_fill(attn_mask.bool(),
+ float('-inf'))
+
+ attn_weight = F.softmax(attn_weight.view(bsz, -1), dim=-1)
+ attn_weight = attn_weight.view(bsz, c, h, w)
+
+ attn_feat = torch.sum(
+ torch.mul(feat, attn_weight), (2, 3), keepdim=False) # n * c
+
+ # linear transformation
+ if self.pred_concat:
+ y = self.prediction(torch.cat((hx2, attn_feat, holistic_feat), 1))
+ else:
+ y = self.prediction(attn_feat)
+
+ return y, hx1, hx1, hx2, hx2
+
+ def forward_train(self, feat, out_enc, targets_dict, img_metas=None):
+ """
+ Args:
+ feat (Tensor): Tensor of shape :math:`(N, D_i, H, W)`.
+ out_enc (Tensor): Encoder output of shape
+ :math:`(N, D_m, H, W)`.
+ targets_dict (dict): A dict with the key ``padded_targets``, a
+ tensor of shape :math:`(N, T)`. Each element is the index of a
+ character.
+ img_metas (dict): A dict that contains meta information of input
+ images. Preferably with the key ``valid_ratio``.
+
+ Returns:
+ Tensor: A raw logit tensor of shape :math:`(N, T, C-1)`.
+ """
+ if img_metas is not None:
+ assert utils.is_type_list(img_metas, dict)
+ assert len(img_metas) == feat.size(0)
+
+ valid_ratios = None
+ if img_metas is not None:
+ valid_ratios = [
+ img_meta.get('valid_ratio', 1.0) for img_meta in img_metas
+ ] if self.mask else None
+
+ if self.train_mode:
+ targets = targets_dict['padded_targets'].to(feat.device)
+ tgt_embedding = self.embedding(targets)
+
+ outputs = []
+ start_token = torch.full((feat.size(0), ),
+ self.start_idx,
+ device=feat.device,
+ dtype=torch.long)
+ start_token = self.embedding(start_token)
+ for i in range(-1, self.max_seq_len):
+ if i == -1:
+ if self.dec_gru:
+ hx1 = cx1 = self.rnn_decoder_layer1(out_enc)
+ hx2 = cx2 = self.rnn_decoder_layer2(hx1)
+ else:
+ hx1, cx1 = self.rnn_decoder_layer1(out_enc)
+ hx2, cx2 = self.rnn_decoder_layer2(hx1)
+ if not self.train_mode:
+ y_prev = start_token
+ else:
+ if self.train_mode:
+ y_prev = tgt_embedding[:, i, :]
+ y, hx1, cx1, hx2, cx2 = self._2d_attention(
+ y_prev,
+ feat,
+ out_enc,
+ hx1,
+ cx1,
+ hx2,
+ cx2,
+ valid_ratios=valid_ratios)
+ if self.train_mode:
+ y = self.pred_dropout(y)
+ else:
+ y = F.softmax(y, -1)
+ _, max_idx = torch.max(y, dim=1, keepdim=False)
+ char_embedding = self.embedding(max_idx)
+ y_prev = char_embedding
+ outputs.append(y)
+
+ outputs = torch.stack(outputs, 1)
+
+ return outputs
+
+ def forward_test(self, feat, out_enc, img_metas):
+ """
+ Args:
+ feat (Tensor): Tensor of shape :math:`(N, D_i, H, W)`.
+ out_enc (Tensor): Encoder output of shape
+ :math:`(N, D_m, H, W)`.
+ img_metas (dict): A dict that contains meta information of input
+ images. Preferably with the key ``valid_ratio``.
+
+ Returns:
+ Tensor: A raw logit tensor of shape :math:`(N, T, C-1)`.
+ """
+ if img_metas is not None:
+ assert utils.is_type_list(img_metas, dict)
+ assert len(img_metas) == feat.size(0)
+
+ return self.forward_train(feat, out_enc, None, img_metas)
diff --git a/mmocr/models/textrecog/decoders/sar_decoder_with_bs.py b/mmocr/models/textrecog/decoders/sar_decoder_with_bs.py
new file mode 100755
index 0000000000000000000000000000000000000000..d00e385df3099a1585e95065fe709d4b32bccf84
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/sar_decoder_with_bs.py
@@ -0,0 +1,162 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from queue import PriorityQueue
+
+import torch
+import torch.nn.functional as F
+
+import mmocr.utils as utils
+from mmocr.models.builder import DECODERS
+from . import ParallelSARDecoder
+
+
+class DecodeNode:
+ """Node class to save decoded char indices and scores.
+
+ Args:
+ indexes (list[int]): Char indices that decoded yes.
+ scores (list[float]): Char scores that decoded yes.
+ """
+
+ def __init__(self, indexes=[1], scores=[0.9]):
+ assert utils.is_type_list(indexes, int)
+ assert utils.is_type_list(scores, float)
+ assert utils.equal_len(indexes, scores)
+
+ self.indexes = indexes
+ self.scores = scores
+
+ def eval(self):
+ """Calculate accumulated score."""
+ accu_score = sum(self.scores)
+ return accu_score
+
+
+@DECODERS.register_module()
+class ParallelSARDecoderWithBS(ParallelSARDecoder):
+ """Parallel Decoder module with beam-search in SAR.
+
+ Args:
+ beam_width (int): Width for beam search.
+ """
+
+ def __init__(self,
+ beam_width=5,
+ num_classes=37,
+ enc_bi_rnn=False,
+ dec_bi_rnn=False,
+ dec_do_rnn=0,
+ dec_gru=False,
+ d_model=512,
+ d_enc=512,
+ d_k=64,
+ pred_dropout=0.0,
+ max_seq_len=40,
+ mask=True,
+ start_idx=0,
+ padding_idx=0,
+ pred_concat=False,
+ init_cfg=None,
+ **kwargs):
+ super().__init__(
+ num_classes,
+ enc_bi_rnn,
+ dec_bi_rnn,
+ dec_do_rnn,
+ dec_gru,
+ d_model,
+ d_enc,
+ d_k,
+ pred_dropout,
+ max_seq_len,
+ mask,
+ start_idx,
+ padding_idx,
+ pred_concat,
+ init_cfg=init_cfg)
+ assert isinstance(beam_width, int)
+ assert beam_width > 0
+
+ self.beam_width = beam_width
+
+ def forward_test(self, feat, out_enc, img_metas):
+ assert utils.is_type_list(img_metas, dict)
+ assert len(img_metas) == feat.size(0)
+
+ valid_ratios = [
+ img_meta.get('valid_ratio', 1.0) for img_meta in img_metas
+ ] if self.mask else None
+
+ seq_len = self.max_seq_len
+ bsz = feat.size(0)
+ assert bsz == 1, 'batch size must be 1 for beam search.'
+
+ start_token = torch.full((bsz, ),
+ self.start_idx,
+ device=feat.device,
+ dtype=torch.long)
+ # bsz
+ start_token = self.embedding(start_token)
+ # bsz * emb_dim
+ start_token = start_token.unsqueeze(1).expand(-1, seq_len, -1)
+ # bsz * seq_len * emb_dim
+ out_enc = out_enc.unsqueeze(1)
+ # bsz * 1 * emb_dim
+ decoder_input = torch.cat((out_enc, start_token), dim=1)
+ # bsz * (seq_len + 1) * emb_dim
+
+ # Initialize beam-search queue
+ q = PriorityQueue()
+ init_node = DecodeNode([self.start_idx], [0.0])
+ q.put((-init_node.eval(), init_node))
+
+ for i in range(1, seq_len + 1):
+ next_nodes = []
+ beam_width = self.beam_width if i > 1 else 1
+ for _ in range(beam_width):
+ _, node = q.get()
+
+ input_seq = torch.clone(decoder_input) # bsz * T * emb_dim
+ # fill previous input tokens (step 1...i) in input_seq
+ for t, index in enumerate(node.indexes):
+ input_token = torch.full((bsz, ),
+ index,
+ device=input_seq.device,
+ dtype=torch.long)
+ input_token = self.embedding(input_token) # bsz * emb_dim
+ input_seq[:, t + 1, :] = input_token
+
+ output_seq = self._2d_attention(
+ input_seq, feat, out_enc, valid_ratios=valid_ratios)
+
+ output_char = output_seq[:, i, :] # bsz * num_classes
+ output_char = F.softmax(output_char, -1)
+ topk_value, topk_idx = output_char.topk(self.beam_width, dim=1)
+ topk_value, topk_idx = topk_value.squeeze(0), topk_idx.squeeze(
+ 0)
+
+ for k in range(self.beam_width):
+ kth_score = topk_value[k].item()
+ kth_idx = topk_idx[k].item()
+ next_node = DecodeNode(node.indexes + [kth_idx],
+ node.scores + [kth_score])
+ delta = k * 1e-6
+ next_nodes.append(
+ (-node.eval() - kth_score - delta, next_node))
+ # Use minus since priority queue sort
+ # with ascending order
+
+ while not q.empty():
+ q.get()
+
+ # Put all candidates to queue
+ for next_node in next_nodes:
+ q.put(next_node)
+
+ best_node = q.get()
+ num_classes = self.num_classes - 1 # ignore padding index
+ outputs = torch.zeros(bsz, seq_len, num_classes)
+ for i in range(seq_len):
+ idx = best_node[1].indexes[i + 1]
+ outputs[0, i, idx] = best_node[1].scores[i + 1]
+
+ return outputs
diff --git a/mmocr/models/textrecog/decoders/sequence_attention_decoder.py b/mmocr/models/textrecog/decoders/sequence_attention_decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..a6a10f720b3eda702d9e9eea719f8de1b05a8ee9
--- /dev/null
+++ b/mmocr/models/textrecog/decoders/sequence_attention_decoder.py
@@ -0,0 +1,237 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from mmocr.models.builder import DECODERS
+from mmocr.models.textrecog.layers import DotProductAttentionLayer
+from .base_decoder import BaseDecoder
+
+
+@DECODERS.register_module()
+class SequenceAttentionDecoder(BaseDecoder):
+ """Sequence attention decoder for RobustScanner.
+
+ RobustScanner: `RobustScanner: Dynamically Enhancing Positional Clues for
+ Robust Text Recognition `_
+
+ Args:
+ num_classes (int): Number of output classes :math:`C`.
+ rnn_layers (int): Number of RNN layers.
+ dim_input (int): Dimension :math:`D_i` of input vector ``feat``.
+ dim_model (int): Dimension :math:`D_m` of the model. Should also be the
+ same as encoder output vector ``out_enc``.
+ max_seq_len (int): Maximum output sequence length :math:`T`.
+ start_idx (int): The index of ``.
+ mask (bool): Whether to mask input features according to
+ ``img_meta['valid_ratio']``.
+ padding_idx (int): The index of ``.
+ dropout (float): Dropout rate.
+ return_feature (bool): Return feature or logits as the result.
+ encode_value (bool): Whether to use the output of encoder ``out_enc``
+ as `value` of attention layer. If False, the original feature
+ ``feat`` will be used.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+
+ Warning:
+ This decoder will not predict the final class which is assumed to be
+ ``. Therefore, its output size is always :math:`C - 1`. ``
+ is also ignored by loss as specified in
+ :obj:`mmocr.models.textrecog.recognizer.EncodeDecodeRecognizer`.
+ """
+
+ def __init__(self,
+ num_classes=None,
+ rnn_layers=2,
+ dim_input=512,
+ dim_model=128,
+ max_seq_len=40,
+ start_idx=0,
+ mask=True,
+ padding_idx=None,
+ dropout=0,
+ return_feature=False,
+ encode_value=False,
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+
+ self.num_classes = num_classes
+ self.dim_input = dim_input
+ self.dim_model = dim_model
+ self.return_feature = return_feature
+ self.encode_value = encode_value
+ self.max_seq_len = max_seq_len
+ self.start_idx = start_idx
+ self.mask = mask
+
+ self.embedding = nn.Embedding(
+ self.num_classes, self.dim_model, padding_idx=padding_idx)
+
+ self.sequence_layer = nn.LSTM(
+ input_size=dim_model,
+ hidden_size=dim_model,
+ num_layers=rnn_layers,
+ batch_first=True,
+ dropout=dropout)
+
+ self.attention_layer = DotProductAttentionLayer()
+
+ self.prediction = None
+ if not self.return_feature:
+ pred_num_classes = num_classes - 1
+ self.prediction = nn.Linear(
+ dim_model if encode_value else dim_input, pred_num_classes)
+
+ def forward_train(self, feat, out_enc, targets_dict, img_metas):
+ """
+ Args:
+ feat (Tensor): Tensor of shape :math:`(N, D_i, H, W)`.
+ out_enc (Tensor): Encoder output of shape
+ :math:`(N, D_m, H, W)`.
+ targets_dict (dict): A dict with the key ``padded_targets``, a
+ tensor of shape :math:`(N, T)`. Each element is the index of a
+ character.
+ img_metas (dict): A dict that contains meta information of input
+ images. Preferably with the key ``valid_ratio``.
+
+ Returns:
+ Tensor: A raw logit tensor of shape :math:`(N, T, C-1)` if
+ ``return_feature=False``. Otherwise it would be the hidden feature
+ before the prediction projection layer, whose shape is
+ :math:`(N, T, D_m)`.
+ """
+ valid_ratios = [
+ img_meta.get('valid_ratio', 1.0) for img_meta in img_metas
+ ] if self.mask else None
+
+ targets = targets_dict['padded_targets'].to(feat.device)
+ tgt_embedding = self.embedding(targets)
+
+ n, c_enc, h, w = out_enc.size()
+ assert c_enc == self.dim_model
+ _, c_feat, _, _ = feat.size()
+ assert c_feat == self.dim_input
+ _, len_q, c_q = tgt_embedding.size()
+ assert c_q == self.dim_model
+ assert len_q <= self.max_seq_len
+
+ query, _ = self.sequence_layer(tgt_embedding)
+ query = query.permute(0, 2, 1).contiguous()
+ key = out_enc.view(n, c_enc, h * w)
+ if self.encode_value:
+ value = key
+ else:
+ value = feat.view(n, c_feat, h * w)
+
+ mask = None
+ if valid_ratios is not None:
+ mask = query.new_zeros((n, h, w))
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_width = min(w, math.ceil(w * valid_ratio))
+ mask[i, :, valid_width:] = 1
+ mask = mask.bool()
+ mask = mask.view(n, h * w)
+
+ attn_out = self.attention_layer(query, key, value, mask)
+ attn_out = attn_out.permute(0, 2, 1).contiguous()
+
+ if self.return_feature:
+ return attn_out
+
+ out = self.prediction(attn_out)
+
+ return out
+
+ def forward_test(self, feat, out_enc, img_metas):
+ """
+ Args:
+ feat (Tensor): Tensor of shape :math:`(N, D_i, H, W)`.
+ out_enc (Tensor): Encoder output of shape
+ :math:`(N, D_m, H, W)`.
+ img_metas (dict): A dict that contains meta information of input
+ images. Preferably with the key ``valid_ratio``.
+
+ Returns:
+ Tensor: The output logit sequence tensor of shape
+ :math:`(N, T, C-1)`.
+ """
+ seq_len = self.max_seq_len
+ batch_size = feat.size(0)
+
+ decode_sequence = (feat.new_ones(
+ (batch_size, seq_len)) * self.start_idx).long()
+
+ outputs = []
+ for i in range(seq_len):
+ step_out = self.forward_test_step(feat, out_enc, decode_sequence,
+ i, img_metas)
+ outputs.append(step_out)
+ _, max_idx = torch.max(step_out, dim=1, keepdim=False)
+ if i < seq_len - 1:
+ decode_sequence[:, i + 1] = max_idx
+
+ outputs = torch.stack(outputs, 1)
+
+ return outputs
+
+ def forward_test_step(self, feat, out_enc, decode_sequence, current_step,
+ img_metas):
+ """
+ Args:
+ feat (Tensor): Tensor of shape :math:`(N, D_i, H, W)`.
+ out_enc (Tensor): Encoder output of shape
+ :math:`(N, D_m, H, W)`.
+ decode_sequence (Tensor): Shape :math:`(N, T)`. The tensor that
+ stores history decoding result.
+ current_step (int): Current decoding step.
+ img_metas (dict): A dict that contains meta information of input
+ images. Preferably with the key ``valid_ratio``.
+
+ Returns:
+ Tensor: Shape :math:`(N, C-1)`. The logit tensor of predicted
+ tokens at current time step.
+ """
+ valid_ratios = [
+ img_meta.get('valid_ratio', 1.0) for img_meta in img_metas
+ ] if self.mask else None
+
+ embed = self.embedding(decode_sequence)
+
+ n, c_enc, h, w = out_enc.size()
+ assert c_enc == self.dim_model
+ _, c_feat, _, _ = feat.size()
+ assert c_feat == self.dim_input
+ _, _, c_q = embed.size()
+ assert c_q == self.dim_model
+
+ query, _ = self.sequence_layer(embed)
+ query = query.permute(0, 2, 1).contiguous()
+ key = out_enc.view(n, c_enc, h * w)
+ if self.encode_value:
+ value = key
+ else:
+ value = feat.view(n, c_feat, h * w)
+
+ mask = None
+ if valid_ratios is not None:
+ mask = query.new_zeros((n, h, w))
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_width = min(w, math.ceil(w * valid_ratio))
+ mask[i, :, valid_width:] = 1
+ mask = mask.bool()
+ mask = mask.view(n, h * w)
+
+ # [n, c, l]
+ attn_out = self.attention_layer(query, key, value, mask)
+
+ out = attn_out[:, :, current_step]
+
+ if self.return_feature:
+ return out
+
+ out = self.prediction(out)
+ out = F.softmax(out, dim=-1)
+
+ return out
diff --git a/mmocr/models/textrecog/encoders/__init__.py b/mmocr/models/textrecog/encoders/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..12abd08c8ff7d79b702b4bef0b9135853d5e6628
--- /dev/null
+++ b/mmocr/models/textrecog/encoders/__init__.py
@@ -0,0 +1,13 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .abinet_vision_model import ABIVisionModel
+from .base_encoder import BaseEncoder
+from .channel_reduction_encoder import ChannelReductionEncoder
+from .nrtr_encoder import NRTREncoder
+from .sar_encoder import SAREncoder
+from .satrn_encoder import SatrnEncoder
+from .transformer import TransformerEncoder
+
+__all__ = [
+ 'SAREncoder', 'NRTREncoder', 'BaseEncoder', 'ChannelReductionEncoder',
+ 'SatrnEncoder', 'TransformerEncoder', 'ABIVisionModel'
+]
diff --git a/mmocr/models/textrecog/encoders/abinet_vision_model.py b/mmocr/models/textrecog/encoders/abinet_vision_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..5c19c8ef160cbed697fa81fe018a4109032c50a0
--- /dev/null
+++ b/mmocr/models/textrecog/encoders/abinet_vision_model.py
@@ -0,0 +1,45 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.models.builder import ENCODERS, build_decoder, build_encoder
+from .base_encoder import BaseEncoder
+
+
+@ENCODERS.register_module()
+class ABIVisionModel(BaseEncoder):
+ """A wrapper of visual feature encoder and language token decoder that
+ converts visual features into text tokens.
+
+ Implementation of VisionEncoder in
+ `ABINet `_.
+
+ Args:
+ encoder (dict): Config for image feature encoder.
+ decoder (dict): Config for language token decoder.
+ init_cfg (dict): Specifies the initialization method for model layers.
+ """
+
+ def __init__(self,
+ encoder=dict(type='TransformerEncoder'),
+ decoder=dict(type='ABIVisionDecoder'),
+ init_cfg=dict(type='Xavier', layer='Conv2d'),
+ **kwargs):
+ super().__init__(init_cfg=init_cfg)
+ self.encoder = build_encoder(encoder)
+ self.decoder = build_decoder(decoder)
+
+ def forward(self, feat, img_metas=None):
+ """
+ Args:
+ feat (Tensor): Images of shape (N, E, H, W).
+
+ Returns:
+ dict: A dict with keys ``feature``, ``logits`` and ``attn_scores``.
+
+ - | feature (Tensor): Shape (N, T, E). Raw visual features for
+ language decoder.
+ - | logits (Tensor): Shape (N, T, C). The raw logits for
+ characters. C is the number of characters.
+ - | attn_scores (Tensor): Shape (N, T, H, W). Intermediate result
+ for vision-language aligner.
+ """
+ feat = self.encoder(feat)
+ return self.decoder(feat=feat, out_enc=None)
diff --git a/mmocr/models/textrecog/encoders/base_encoder.py b/mmocr/models/textrecog/encoders/base_encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..726c78a8c938e8feb6423f91ace4ebf319f167c7
--- /dev/null
+++ b/mmocr/models/textrecog/encoders/base_encoder.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.runner import BaseModule
+
+from mmocr.models.builder import ENCODERS
+
+
+@ENCODERS.register_module()
+class BaseEncoder(BaseModule):
+ """Base Encoder class for text recognition."""
+
+ def forward(self, feat, **kwargs):
+ return feat
diff --git a/mmocr/models/textrecog/encoders/channel_reduction_encoder.py b/mmocr/models/textrecog/encoders/channel_reduction_encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..0e957f858b95b373c281ecf71e0a8ecd2d6d8688
--- /dev/null
+++ b/mmocr/models/textrecog/encoders/channel_reduction_encoder.py
@@ -0,0 +1,37 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+
+from mmocr.models.builder import ENCODERS
+from .base_encoder import BaseEncoder
+
+
+@ENCODERS.register_module()
+class ChannelReductionEncoder(BaseEncoder):
+ """Change the channel number with a one by one convoluational layer.
+
+ Args:
+ in_channels (int): Number of input channels.
+ out_channels (int): Number of output channels.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ init_cfg=dict(type='Xavier', layer='Conv2d')):
+ super().__init__(init_cfg=init_cfg)
+
+ self.layer = nn.Conv2d(
+ in_channels, out_channels, kernel_size=1, stride=1, padding=0)
+
+ def forward(self, feat, img_metas=None):
+ """
+ Args:
+ feat (Tensor): Image features with the shape of
+ :math:`(N, C_{in}, H, W)`.
+ img_metas (None): Unused.
+
+ Returns:
+ Tensor: A tensor of shape :math:`(N, C_{out}, H, W)`.
+ """
+ return self.layer(feat)
diff --git a/mmocr/models/textrecog/encoders/nrtr_encoder.py b/mmocr/models/textrecog/encoders/nrtr_encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..72b229f04adaa5805bcd6b288a3cd6b090824ce4
--- /dev/null
+++ b/mmocr/models/textrecog/encoders/nrtr_encoder.py
@@ -0,0 +1,87 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import torch.nn as nn
+from mmcv.runner import ModuleList
+
+from mmocr.models.builder import ENCODERS
+from mmocr.models.common import TFEncoderLayer
+from .base_encoder import BaseEncoder
+
+
+@ENCODERS.register_module()
+class NRTREncoder(BaseEncoder):
+ """Transformer Encoder block with self attention mechanism.
+
+ Args:
+ n_layers (int): The number of sub-encoder-layers
+ in the encoder (default=6).
+ n_head (int): The number of heads in the
+ multiheadattention models (default=8).
+ d_k (int): Total number of features in key.
+ d_v (int): Total number of features in value.
+ d_model (int): The number of expected features
+ in the decoder inputs (default=512).
+ d_inner (int): The dimension of the feedforward
+ network model (default=256).
+ dropout (float): Dropout layer on attn_output_weights.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self,
+ n_layers=6,
+ n_head=8,
+ d_k=64,
+ d_v=64,
+ d_model=512,
+ d_inner=256,
+ dropout=0.1,
+ init_cfg=None,
+ **kwargs):
+ super().__init__(init_cfg=init_cfg)
+ self.d_model = d_model
+ self.layer_stack = ModuleList([
+ TFEncoderLayer(
+ d_model, d_inner, n_head, d_k, d_v, dropout=dropout, **kwargs)
+ for _ in range(n_layers)
+ ])
+ self.layer_norm = nn.LayerNorm(d_model)
+
+ def _get_mask(self, logit, img_metas):
+ valid_ratios = None
+ if img_metas is not None:
+ valid_ratios = [
+ img_meta.get('valid_ratio', 1.0) for img_meta in img_metas
+ ]
+ N, T, _ = logit.size()
+ mask = None
+ if valid_ratios is not None:
+ mask = logit.new_zeros((N, T))
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_width = min(T, math.ceil(T * valid_ratio))
+ mask[i, :valid_width] = 1
+
+ return mask
+
+ def forward(self, feat, img_metas=None):
+ r"""
+ Args:
+ feat (Tensor): Backbone output of shape :math:`(N, C, H, W)`.
+ img_metas (dict): A dict that contains meta information of input
+ images. Preferably with the key ``valid_ratio``.
+
+ Returns:
+ Tensor: The encoder output tensor. Shape :math:`(N, T, C)`.
+ """
+ n, c, h, w = feat.size()
+
+ feat = feat.view(n, c, h * w).permute(0, 2, 1).contiguous()
+
+ mask = self._get_mask(feat, img_metas)
+
+ output = feat
+ for enc_layer in self.layer_stack:
+ output = enc_layer(output, mask)
+ output = self.layer_norm(output)
+
+ return output
diff --git a/mmocr/models/textrecog/encoders/sar_encoder.py b/mmocr/models/textrecog/encoders/sar_encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..d2f0a8e13267a2418101429731a559afb265e753
--- /dev/null
+++ b/mmocr/models/textrecog/encoders/sar_encoder.py
@@ -0,0 +1,111 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+import mmocr.utils as utils
+from mmocr.models.builder import ENCODERS
+from .base_encoder import BaseEncoder
+
+
+@ENCODERS.register_module()
+class SAREncoder(BaseEncoder):
+ """Implementation of encoder module in `SAR.
+
+ `_.
+
+ Args:
+ enc_bi_rnn (bool): If True, use bidirectional RNN in encoder.
+ enc_do_rnn (float): Dropout probability of RNN layer in encoder.
+ enc_gru (bool): If True, use GRU, else LSTM in encoder.
+ d_model (int): Dim :math:`D_i` of channels from backbone.
+ d_enc (int): Dim :math:`D_m` of encoder RNN layer.
+ mask (bool): If True, mask padding in RNN sequence.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self,
+ enc_bi_rnn=False,
+ enc_do_rnn=0.0,
+ enc_gru=False,
+ d_model=512,
+ d_enc=512,
+ mask=True,
+ init_cfg=[
+ dict(type='Xavier', layer='Conv2d'),
+ dict(type='Uniform', layer='BatchNorm2d')
+ ],
+ **kwargs):
+ super().__init__(init_cfg=init_cfg)
+ assert isinstance(enc_bi_rnn, bool)
+ assert isinstance(enc_do_rnn, (int, float))
+ assert 0 <= enc_do_rnn < 1.0
+ assert isinstance(enc_gru, bool)
+ assert isinstance(d_model, int)
+ assert isinstance(d_enc, int)
+ assert isinstance(mask, bool)
+
+ self.enc_bi_rnn = enc_bi_rnn
+ self.enc_do_rnn = enc_do_rnn
+ self.mask = mask
+
+ # LSTM Encoder
+ kwargs = dict(
+ input_size=d_model,
+ hidden_size=d_enc,
+ num_layers=2,
+ batch_first=True,
+ dropout=enc_do_rnn,
+ bidirectional=enc_bi_rnn)
+ if enc_gru:
+ self.rnn_encoder = nn.GRU(**kwargs)
+ else:
+ self.rnn_encoder = nn.LSTM(**kwargs)
+
+ # global feature transformation
+ encoder_rnn_out_size = d_enc * (int(enc_bi_rnn) + 1)
+ self.linear = nn.Linear(encoder_rnn_out_size, encoder_rnn_out_size)
+
+ def forward(self, feat, img_metas=None):
+ """
+ Args:
+ feat (Tensor): Tensor of shape :math:`(N, D_i, H, W)`.
+ img_metas (dict): A dict that contains meta information of input
+ images. Preferably with the key ``valid_ratio``.
+
+ Returns:
+ Tensor: A tensor of shape :math:`(N, D_m)`.
+ """
+ if img_metas is not None:
+ assert utils.is_type_list(img_metas, dict)
+ assert len(img_metas) == feat.size(0)
+
+ valid_ratios = None
+ if img_metas is not None:
+ valid_ratios = [
+ img_meta.get('valid_ratio', 1.0) for img_meta in img_metas
+ ] if self.mask else None
+
+ h_feat = feat.size(2)
+ feat_v = F.max_pool2d(
+ feat, kernel_size=(h_feat, 1), stride=1, padding=0)
+ feat_v = feat_v.squeeze(2) # bsz * C * W
+ feat_v = feat_v.permute(0, 2, 1).contiguous() # bsz * W * C
+
+ holistic_feat = self.rnn_encoder(feat_v)[0] # bsz * T * C
+
+ if valid_ratios is not None:
+ valid_hf = []
+ T = holistic_feat.size(1)
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_step = min(T, math.ceil(T * valid_ratio)) - 1
+ valid_hf.append(holistic_feat[i, valid_step, :])
+ valid_hf = torch.stack(valid_hf, dim=0)
+ else:
+ valid_hf = holistic_feat[:, -1, :] # bsz * C
+
+ holistic_feat = self.linear(valid_hf) # bsz * C
+
+ return holistic_feat
diff --git a/mmocr/models/textrecog/encoders/satrn_encoder.py b/mmocr/models/textrecog/encoders/satrn_encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..00af0826c2786080a2fcb616f699ede6d787e9ac
--- /dev/null
+++ b/mmocr/models/textrecog/encoders/satrn_encoder.py
@@ -0,0 +1,86 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import torch.nn as nn
+from mmcv.runner import ModuleList
+
+from mmocr.models.builder import ENCODERS
+from mmocr.models.textrecog.layers import (Adaptive2DPositionalEncoding,
+ SatrnEncoderLayer)
+from .base_encoder import BaseEncoder
+
+
+@ENCODERS.register_module()
+class SatrnEncoder(BaseEncoder):
+ """Implement encoder for SATRN, see `SATRN.
+
+ `_.
+
+ Args:
+ n_layers (int): Number of attention layers.
+ n_head (int): Number of parallel attention heads.
+ d_k (int): Dimension of the key vector.
+ d_v (int): Dimension of the value vector.
+ d_model (int): Dimension :math:`D_m` of the input from previous model.
+ n_position (int): Length of the positional encoding vector. Must be
+ greater than ``max_seq_len``.
+ d_inner (int): Hidden dimension of feedforward layers.
+ dropout (float): Dropout rate.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self,
+ n_layers=12,
+ n_head=8,
+ d_k=64,
+ d_v=64,
+ d_model=512,
+ n_position=100,
+ d_inner=256,
+ dropout=0.1,
+ init_cfg=None,
+ **kwargs):
+ super().__init__(init_cfg=init_cfg)
+ self.d_model = d_model
+ self.position_enc = Adaptive2DPositionalEncoding(
+ d_hid=d_model,
+ n_height=n_position,
+ n_width=n_position,
+ dropout=dropout)
+ self.layer_stack = ModuleList([
+ SatrnEncoderLayer(
+ d_model, d_inner, n_head, d_k, d_v, dropout=dropout)
+ for _ in range(n_layers)
+ ])
+ self.layer_norm = nn.LayerNorm(d_model)
+
+ def forward(self, feat, img_metas=None):
+ """
+ Args:
+ feat (Tensor): Feature tensor of shape :math:`(N, D_m, H, W)`.
+ img_metas (dict): A dict that contains meta information of input
+ images. Preferably with the key ``valid_ratio``.
+
+ Returns:
+ Tensor: A tensor of shape :math:`(N, T, D_m)`.
+ """
+ valid_ratios = [1.0 for _ in range(feat.size(0))]
+ if img_metas is not None:
+ valid_ratios = [
+ img_meta.get('valid_ratio', 1.0) for img_meta in img_metas
+ ]
+ feat += self.position_enc(feat)
+ n, c, h, w = feat.size()
+ mask = feat.new_zeros((n, h, w))
+ for i, valid_ratio in enumerate(valid_ratios):
+ valid_width = min(w, math.ceil(w * valid_ratio))
+ mask[i, :, :valid_width] = 1
+ mask = mask.view(n, h * w)
+ feat = feat.view(n, c, h * w)
+
+ output = feat.permute(0, 2, 1).contiguous()
+ for enc_layer in self.layer_stack:
+ output = enc_layer(output, h, w, mask)
+ output = self.layer_norm(output)
+
+ return output
diff --git a/mmocr/models/textrecog/encoders/transformer.py b/mmocr/models/textrecog/encoders/transformer.py
new file mode 100644
index 0000000000000000000000000000000000000000..887b4ef8d781c1b25cac9784ed6c9755eab29fc8
--- /dev/null
+++ b/mmocr/models/textrecog/encoders/transformer.py
@@ -0,0 +1,74 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+from mmcv.cnn.bricks.transformer import BaseTransformerLayer
+from mmcv.runner import BaseModule, ModuleList
+
+from mmocr.models.builder import ENCODERS
+from mmocr.models.common.modules import PositionalEncoding
+
+
+@ENCODERS.register_module()
+class TransformerEncoder(BaseModule):
+ """Implement transformer encoder for text recognition, modified from
+ ``.
+
+ Args:
+ n_layers (int): Number of attention layers.
+ n_head (int): Number of parallel attention heads.
+ d_model (int): Dimension :math:`D_m` of the input from previous model.
+ d_inner (int): Hidden dimension of feedforward layers.
+ dropout (float): Dropout rate.
+ max_len (int): Maximum output sequence length :math:`T`.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self,
+ n_layers=2,
+ n_head=8,
+ d_model=512,
+ d_inner=2048,
+ dropout=0.1,
+ max_len=8 * 32,
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+
+ assert d_model % n_head == 0, 'd_model must be divisible by n_head'
+
+ self.pos_encoder = PositionalEncoding(d_model, n_position=max_len)
+ encoder_layer = BaseTransformerLayer(
+ operation_order=('self_attn', 'norm', 'ffn', 'norm'),
+ attn_cfgs=dict(
+ type='MultiheadAttention',
+ embed_dims=d_model,
+ num_heads=n_head,
+ attn_drop=dropout,
+ dropout_layer=dict(type='Dropout', drop_prob=dropout),
+ ),
+ ffn_cfgs=dict(
+ type='FFN',
+ embed_dims=d_model,
+ feedforward_channels=d_inner,
+ ffn_drop=dropout,
+ ),
+ norm_cfg=dict(type='LN'),
+ )
+ self.transformer = ModuleList(
+ [copy.deepcopy(encoder_layer) for _ in range(n_layers)])
+
+ def forward(self, feature):
+ """
+ Args:
+ feature (Tensor): Feature tensor of shape :math:`(N, D_m, H, W)`.
+
+ Returns:
+ Tensor: Features of shape :math:`(N, D_m, H, W)`.
+ """
+ n, c, h, w = feature.shape
+ feature = feature.view(n, c, -1).transpose(1, 2) # (n, h*w, c)
+ feature = self.pos_encoder(feature) # (n, h*w, c)
+ feature = feature.transpose(0, 1) # (h*w, n, c)
+ for m in self.transformer:
+ feature = m(feature)
+ feature = feature.permute(1, 2, 0).view(n, c, h, w)
+ return feature
diff --git a/mmocr/models/textrecog/fusers/__init__.py b/mmocr/models/textrecog/fusers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..96b5516e52cede2a00d174469ad94179b37e0662
--- /dev/null
+++ b/mmocr/models/textrecog/fusers/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .abi_fuser import ABIFuser
+
+__all__ = ['ABIFuser']
diff --git a/mmocr/models/textrecog/fusers/abi_fuser.py b/mmocr/models/textrecog/fusers/abi_fuser.py
new file mode 100644
index 0000000000000000000000000000000000000000..310cf6f0421ea3575f1935489440f1b37964a194
--- /dev/null
+++ b/mmocr/models/textrecog/fusers/abi_fuser.py
@@ -0,0 +1,51 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.runner import BaseModule
+
+from mmocr.models.builder import FUSERS
+
+
+@FUSERS.register_module()
+class ABIFuser(BaseModule):
+ """Mix and align visual feature and linguistic feature Implementation of
+ language model of `ABINet `_.
+
+ Args:
+ d_model (int): Hidden size of input.
+ max_seq_len (int): Maximum text sequence length :math:`T`.
+ num_chars (int): Number of text characters :math:`C`.
+ init_cfg (dict): Specifies the initialization method for model layers.
+ """
+
+ def __init__(self,
+ d_model=512,
+ max_seq_len=40,
+ num_chars=90,
+ init_cfg=None,
+ **kwargs):
+ super().__init__(init_cfg=init_cfg)
+
+ self.max_seq_len = max_seq_len + 1 # additional stop token
+ self.w_att = nn.Linear(2 * d_model, d_model)
+ self.cls = nn.Linear(d_model, num_chars)
+
+ def forward(self, l_feature, v_feature):
+ """
+ Args:
+ l_feature: (N, T, E) where T is length, N is batch size and
+ d is dim of model.
+ v_feature: (N, T, E) shape the same as l_feature.
+
+ Returns:
+ A dict with key ``logits``
+ The logits of shape (N, T, C) where N is batch size, T is length
+ and C is the number of characters.
+ """
+ f = torch.cat((l_feature, v_feature), dim=2)
+ f_att = torch.sigmoid(self.w_att(f))
+ output = f_att * v_feature + (1 - f_att) * l_feature
+
+ logits = self.cls(output) # (N, T, C)
+
+ return {'logits': logits}
diff --git a/mmocr/models/textrecog/heads/__init__.py b/mmocr/models/textrecog/heads/__init__.py
new file mode 100755
index 0000000000000000000000000000000000000000..03e276068e3c3c2b0f5e1ea61bef86afd45e8263
--- /dev/null
+++ b/mmocr/models/textrecog/heads/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .seg_head import SegHead
+
+__all__ = ['SegHead']
diff --git a/mmocr/models/textrecog/heads/seg_head.py b/mmocr/models/textrecog/heads/seg_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..e8686db8e1294607d8eb8709928dfd4b958b9609
--- /dev/null
+++ b/mmocr/models/textrecog/heads/seg_head.py
@@ -0,0 +1,64 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmcv.runner import BaseModule
+from torch import nn
+
+from mmocr.models.builder import HEADS
+
+
+@HEADS.register_module()
+class SegHead(BaseModule):
+ """Head for segmentation based text recognition.
+
+ Args:
+ in_channels (int): Number of input channels :math:`C`.
+ num_classes (int): Number of output classes :math:`C_{out}`.
+ upsample_param (dict | None): Config dict for interpolation layer.
+ Default: ``dict(scale_factor=1.0, mode='nearest')``
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self,
+ in_channels=128,
+ num_classes=37,
+ upsample_param=None,
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ assert isinstance(num_classes, int)
+ assert num_classes > 0
+ assert upsample_param is None or isinstance(upsample_param, dict)
+
+ self.upsample_param = upsample_param
+
+ self.seg_conv = ConvModule(
+ in_channels,
+ in_channels,
+ 3,
+ stride=1,
+ padding=1,
+ norm_cfg=dict(type='BN'))
+
+ # prediction
+ self.pred_conv = nn.Conv2d(
+ in_channels, num_classes, kernel_size=1, stride=1, padding=0)
+
+ def forward(self, out_neck):
+ """
+ Args:
+ out_neck (list[Tensor]): A list of tensor of shape
+ :math:`(N, C_i, H_i, W_i)`. The network only uses the last one
+ (``out_neck[-1]``).
+
+ Returns:
+ Tensor: A tensor of shape :math:`(N, C_{out}, kH, kW)` where
+ :math:`k` is determined by ``upsample_param``.
+ """
+
+ seg_map = self.seg_conv(out_neck[-1])
+ seg_map = self.pred_conv(seg_map)
+
+ if self.upsample_param is not None:
+ seg_map = F.interpolate(seg_map, **self.upsample_param)
+
+ return seg_map
diff --git a/mmocr/models/textrecog/layers/__init__.py b/mmocr/models/textrecog/layers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..c92fef5409c2906645aab25296e390e82a78c02c
--- /dev/null
+++ b/mmocr/models/textrecog/layers/__init__.py
@@ -0,0 +1,13 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .conv_layer import BasicBlock, Bottleneck
+from .dot_product_attention_layer import DotProductAttentionLayer
+from .lstm_layer import BidirectionalLSTM
+from .position_aware_layer import PositionAwareLayer
+from .robust_scanner_fusion_layer import RobustScannerFusionLayer
+from .satrn_layers import Adaptive2DPositionalEncoding, SatrnEncoderLayer
+
+__all__ = [
+ 'BidirectionalLSTM', 'Adaptive2DPositionalEncoding', 'BasicBlock',
+ 'Bottleneck', 'RobustScannerFusionLayer', 'DotProductAttentionLayer',
+ 'PositionAwareLayer', 'SatrnEncoderLayer'
+]
diff --git a/mmocr/models/textrecog/layers/conv_layer.py b/mmocr/models/textrecog/layers/conv_layer.py
new file mode 100644
index 0000000000000000000000000000000000000000..d3d812767637c91dfd7f38601b9e005afacfcbc6
--- /dev/null
+++ b/mmocr/models/textrecog/layers/conv_layer.py
@@ -0,0 +1,182 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+from mmcv.cnn import build_plugin_layer
+
+
+def conv3x3(in_planes, out_planes, stride=1):
+ """3x3 convolution with padding."""
+ return nn.Conv2d(
+ in_planes,
+ out_planes,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ bias=False)
+
+
+def conv1x1(in_planes, out_planes):
+ """1x1 convolution with padding."""
+ return nn.Conv2d(
+ in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False)
+
+
+class BasicBlock(nn.Module):
+
+ expansion = 1
+
+ def __init__(self,
+ inplanes,
+ planes,
+ stride=1,
+ downsample=None,
+ use_conv1x1=False,
+ plugins=None):
+ super(BasicBlock, self).__init__()
+
+ if use_conv1x1:
+ self.conv1 = conv1x1(inplanes, planes)
+ self.conv2 = conv3x3(planes, planes * self.expansion, stride)
+ else:
+ self.conv1 = conv3x3(inplanes, planes, stride)
+ self.conv2 = conv3x3(planes, planes * self.expansion)
+
+ self.with_plugins = False
+ if plugins:
+ if isinstance(plugins, dict):
+ plugins = [plugins]
+ self.with_plugins = True
+ # collect plugins for conv1/conv2/
+ self.before_conv1_plugin = [
+ plugin['cfg'] for plugin in plugins
+ if plugin['position'] == 'before_conv1'
+ ]
+ self.after_conv1_plugin = [
+ plugin['cfg'] for plugin in plugins
+ if plugin['position'] == 'after_conv1'
+ ]
+ self.after_conv2_plugin = [
+ plugin['cfg'] for plugin in plugins
+ if plugin['position'] == 'after_conv2'
+ ]
+ self.after_shortcut_plugin = [
+ plugin['cfg'] for plugin in plugins
+ if plugin['position'] == 'after_shortcut'
+ ]
+
+ self.planes = planes
+ self.bn1 = nn.BatchNorm2d(planes)
+ self.relu = nn.ReLU(inplace=True)
+ self.bn2 = nn.BatchNorm2d(planes * self.expansion)
+ self.downsample = downsample
+ self.stride = stride
+
+ if self.with_plugins:
+ self.before_conv1_plugin_names = self.make_block_plugins(
+ inplanes, self.before_conv1_plugin)
+ self.after_conv1_plugin_names = self.make_block_plugins(
+ planes, self.after_conv1_plugin)
+ self.after_conv2_plugin_names = self.make_block_plugins(
+ planes, self.after_conv2_plugin)
+ self.after_shortcut_plugin_names = self.make_block_plugins(
+ planes, self.after_shortcut_plugin)
+
+ def make_block_plugins(self, in_channels, plugins):
+ """make plugins for block.
+
+ Args:
+ in_channels (int): Input channels of plugin.
+ plugins (list[dict]): List of plugins cfg to build.
+
+ Returns:
+ list[str]: List of the names of plugin.
+ """
+ assert isinstance(plugins, list)
+ plugin_names = []
+ for plugin in plugins:
+ plugin = plugin.copy()
+ name, layer = build_plugin_layer(
+ plugin,
+ in_channels=in_channels,
+ out_channels=in_channels,
+ postfix=plugin.pop('postfix', ''))
+ assert not hasattr(self, name), f'duplicate plugin {name}'
+ self.add_module(name, layer)
+ plugin_names.append(name)
+ return plugin_names
+
+ def forward_plugin(self, x, plugin_names):
+ out = x
+ for name in plugin_names:
+ out = getattr(self, name)(x)
+ return out
+
+ def forward(self, x):
+ if self.with_plugins:
+ x = self.forward_plugin(x, self.before_conv1_plugin_names)
+ residual = x
+
+ out = self.conv1(x)
+ out = self.bn1(out)
+ out = self.relu(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv1_plugin_names)
+
+ out = self.conv2(out)
+ out = self.bn2(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_conv2_plugin_names)
+
+ if self.downsample is not None:
+ residual = self.downsample(x)
+
+ out += residual
+ out = self.relu(out)
+
+ if self.with_plugins:
+ out = self.forward_plugin(out, self.after_shortcut_plugin_names)
+
+ return out
+
+
+class Bottleneck(nn.Module):
+ expansion = 4
+
+ def __init__(self, inplanes, planes, stride=1, downsample=False):
+ super().__init__()
+ self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
+ self.bn1 = nn.BatchNorm2d(planes)
+ self.conv2 = nn.Conv2d(planes, planes, 3, stride, 1, bias=False)
+ self.bn2 = nn.BatchNorm2d(planes)
+ self.conv3 = nn.Conv2d(
+ planes, planes * self.expansion, kernel_size=1, bias=False)
+ self.bn3 = nn.BatchNorm2d(planes * self.expansion)
+ self.relu = nn.ReLU(inplace=True)
+ if downsample:
+ self.downsample = nn.Sequential(
+ nn.Conv2d(
+ inplanes, planes * self.expansion, 1, stride, bias=False),
+ nn.BatchNorm2d(planes * self.expansion),
+ )
+ else:
+ self.downsample = nn.Sequential()
+
+ def forward(self, x):
+ residual = self.downsample(x)
+
+ out = self.conv1(x)
+ out = self.bn1(out)
+ out = self.relu(out)
+
+ out = self.conv2(out)
+ out = self.bn2(out)
+ out = self.relu(out)
+
+ out = self.conv3(out)
+ out = self.bn3(out)
+
+ out += residual
+ out = self.relu(out)
+
+ return out
diff --git a/mmocr/models/textrecog/layers/dot_product_attention_layer.py b/mmocr/models/textrecog/layers/dot_product_attention_layer.py
new file mode 100644
index 0000000000000000000000000000000000000000..6d9cdb6528d90d9ec6e0bf0ac2a2343bd7227cc2
--- /dev/null
+++ b/mmocr/models/textrecog/layers/dot_product_attention_layer.py
@@ -0,0 +1,28 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+class DotProductAttentionLayer(nn.Module):
+
+ def __init__(self, dim_model=None):
+ super().__init__()
+
+ self.scale = dim_model**-0.5 if dim_model is not None else 1.
+
+ def forward(self, query, key, value, mask=None):
+ n, seq_len = mask.size()
+ logits = torch.matmul(query.permute(0, 2, 1), key) * self.scale
+
+ if mask is not None:
+ mask = mask.view(n, 1, seq_len)
+ logits = logits.masked_fill(mask, float('-inf'))
+
+ weights = F.softmax(logits, dim=2)
+
+ glimpse = torch.matmul(weights, value.transpose(1, 2))
+
+ glimpse = glimpse.permute(0, 2, 1).contiguous()
+
+ return glimpse
diff --git a/mmocr/models/textrecog/layers/lstm_layer.py b/mmocr/models/textrecog/layers/lstm_layer.py
new file mode 100644
index 0000000000000000000000000000000000000000..16d3c1a4e5285c238176d2e0be76463657f282e5
--- /dev/null
+++ b/mmocr/models/textrecog/layers/lstm_layer.py
@@ -0,0 +1,21 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+
+
+class BidirectionalLSTM(nn.Module):
+
+ def __init__(self, nIn, nHidden, nOut):
+ super().__init__()
+
+ self.rnn = nn.LSTM(nIn, nHidden, bidirectional=True)
+ self.embedding = nn.Linear(nHidden * 2, nOut)
+
+ def forward(self, input):
+ recurrent, _ = self.rnn(input)
+ T, b, h = recurrent.size()
+ t_rec = recurrent.view(T * b, h)
+
+ output = self.embedding(t_rec) # [T * b, nOut]
+ output = output.view(T, b, -1)
+
+ return output
diff --git a/mmocr/models/textrecog/layers/position_aware_layer.py b/mmocr/models/textrecog/layers/position_aware_layer.py
new file mode 100644
index 0000000000000000000000000000000000000000..2c994e372782aa882e9c3a32cec4e9bf733008ae
--- /dev/null
+++ b/mmocr/models/textrecog/layers/position_aware_layer.py
@@ -0,0 +1,36 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+
+
+class PositionAwareLayer(nn.Module):
+
+ def __init__(self, dim_model, rnn_layers=2):
+ super().__init__()
+
+ self.dim_model = dim_model
+
+ self.rnn = nn.LSTM(
+ input_size=dim_model,
+ hidden_size=dim_model,
+ num_layers=rnn_layers,
+ batch_first=True)
+
+ self.mixer = nn.Sequential(
+ nn.Conv2d(
+ dim_model, dim_model, kernel_size=3, stride=1, padding=1),
+ nn.ReLU(True),
+ nn.Conv2d(
+ dim_model, dim_model, kernel_size=3, stride=1, padding=1))
+
+ def forward(self, img_feature):
+ n, c, h, w = img_feature.size()
+
+ rnn_input = img_feature.permute(0, 2, 3, 1).contiguous()
+ rnn_input = rnn_input.view(n * h, w, c)
+ rnn_output, _ = self.rnn(rnn_input)
+ rnn_output = rnn_output.view(n, h, w, c)
+ rnn_output = rnn_output.permute(0, 3, 1, 2).contiguous()
+
+ out = self.mixer(rnn_output)
+
+ return out
diff --git a/mmocr/models/textrecog/layers/robust_scanner_fusion_layer.py b/mmocr/models/textrecog/layers/robust_scanner_fusion_layer.py
new file mode 100644
index 0000000000000000000000000000000000000000..af2568743874d4c6b9a8e804485a0665f6d29c2d
--- /dev/null
+++ b/mmocr/models/textrecog/layers/robust_scanner_fusion_layer.py
@@ -0,0 +1,24 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+from mmcv.runner import BaseModule
+
+
+class RobustScannerFusionLayer(BaseModule):
+
+ def __init__(self, dim_model, dim=-1, init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+
+ self.dim_model = dim_model
+ self.dim = dim
+
+ self.linear_layer = nn.Linear(dim_model * 2, dim_model * 2)
+ self.glu_layer = nn.GLU(dim=dim)
+
+ def forward(self, x0, x1):
+ assert x0.size() == x1.size()
+ fusion_input = torch.cat([x0, x1], self.dim)
+ output = self.linear_layer(fusion_input)
+ output = self.glu_layer(output)
+
+ return output
diff --git a/mmocr/models/textrecog/layers/satrn_layers.py b/mmocr/models/textrecog/layers/satrn_layers.py
new file mode 100644
index 0000000000000000000000000000000000000000..d75b6dac3354ba7fb2e07c34c383ed0c14e8ea88
--- /dev/null
+++ b/mmocr/models/textrecog/layers/satrn_layers.py
@@ -0,0 +1,167 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import torch
+import torch.nn as nn
+from mmcv.cnn import ConvModule
+from mmcv.runner import BaseModule
+
+from mmocr.models.common import MultiHeadAttention
+
+
+class SatrnEncoderLayer(BaseModule):
+ """"""
+
+ def __init__(self,
+ d_model=512,
+ d_inner=512,
+ n_head=8,
+ d_k=64,
+ d_v=64,
+ dropout=0.1,
+ qkv_bias=False,
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ self.norm1 = nn.LayerNorm(d_model)
+ self.attn = MultiHeadAttention(
+ n_head, d_model, d_k, d_v, qkv_bias=qkv_bias, dropout=dropout)
+ self.norm2 = nn.LayerNorm(d_model)
+ self.feed_forward = LocalityAwareFeedforward(
+ d_model, d_inner, dropout=dropout)
+
+ def forward(self, x, h, w, mask=None):
+ n, hw, c = x.size()
+ residual = x
+ x = self.norm1(x)
+ x = residual + self.attn(x, x, x, mask)
+ residual = x
+ x = self.norm2(x)
+ x = x.transpose(1, 2).contiguous().view(n, c, h, w)
+ x = self.feed_forward(x)
+ x = x.view(n, c, hw).transpose(1, 2)
+ x = residual + x
+ return x
+
+
+class LocalityAwareFeedforward(BaseModule):
+ """Locality-aware feedforward layer in SATRN, see `SATRN.
+
+ `_
+ """
+
+ def __init__(self,
+ d_in,
+ d_hid,
+ dropout=0.1,
+ init_cfg=[
+ dict(type='Xavier', layer='Conv2d'),
+ dict(type='Constant', layer='BatchNorm2d', val=1, bias=0)
+ ]):
+ super().__init__(init_cfg=init_cfg)
+ self.conv1 = ConvModule(
+ d_in,
+ d_hid,
+ kernel_size=1,
+ padding=0,
+ bias=False,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'))
+
+ self.depthwise_conv = ConvModule(
+ d_hid,
+ d_hid,
+ kernel_size=3,
+ padding=1,
+ bias=False,
+ groups=d_hid,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'))
+
+ self.conv2 = ConvModule(
+ d_hid,
+ d_in,
+ kernel_size=1,
+ padding=0,
+ bias=False,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU'))
+
+ def forward(self, x):
+ x = self.conv1(x)
+ x = self.depthwise_conv(x)
+ x = self.conv2(x)
+
+ return x
+
+
+class Adaptive2DPositionalEncoding(BaseModule):
+ """Implement Adaptive 2D positional encoder for SATRN, see
+ `SATRN `_
+ Modified from https://github.com/Media-Smart/vedastr
+ Licensed under the Apache License, Version 2.0 (the "License");
+ Args:
+ d_hid (int): Dimensions of hidden layer.
+ n_height (int): Max height of the 2D feature output.
+ n_width (int): Max width of the 2D feature output.
+ dropout (int): Size of hidden layers of the model.
+ """
+
+ def __init__(self,
+ d_hid=512,
+ n_height=100,
+ n_width=100,
+ dropout=0.1,
+ init_cfg=[dict(type='Xavier', layer='Conv2d')]):
+ super().__init__(init_cfg=init_cfg)
+
+ h_position_encoder = self._get_sinusoid_encoding_table(n_height, d_hid)
+ h_position_encoder = h_position_encoder.transpose(0, 1)
+ h_position_encoder = h_position_encoder.view(1, d_hid, n_height, 1)
+
+ w_position_encoder = self._get_sinusoid_encoding_table(n_width, d_hid)
+ w_position_encoder = w_position_encoder.transpose(0, 1)
+ w_position_encoder = w_position_encoder.view(1, d_hid, 1, n_width)
+
+ self.register_buffer('h_position_encoder', h_position_encoder)
+ self.register_buffer('w_position_encoder', w_position_encoder)
+
+ self.h_scale = self.scale_factor_generate(d_hid)
+ self.w_scale = self.scale_factor_generate(d_hid)
+ self.pool = nn.AdaptiveAvgPool2d(1)
+ self.dropout = nn.Dropout(p=dropout)
+
+ def _get_sinusoid_encoding_table(self, n_position, d_hid):
+ """Sinusoid position encoding table."""
+ denominator = torch.Tensor([
+ 1.0 / np.power(10000, 2 * (hid_j // 2) / d_hid)
+ for hid_j in range(d_hid)
+ ])
+ denominator = denominator.view(1, -1)
+ pos_tensor = torch.arange(n_position).unsqueeze(-1).float()
+ sinusoid_table = pos_tensor * denominator
+ sinusoid_table[:, 0::2] = torch.sin(sinusoid_table[:, 0::2])
+ sinusoid_table[:, 1::2] = torch.cos(sinusoid_table[:, 1::2])
+
+ return sinusoid_table
+
+ def scale_factor_generate(self, d_hid):
+ scale_factor = nn.Sequential(
+ nn.Conv2d(d_hid, d_hid, kernel_size=1), nn.ReLU(inplace=True),
+ nn.Conv2d(d_hid, d_hid, kernel_size=1), nn.Sigmoid())
+
+ return scale_factor
+
+ def forward(self, x):
+ b, c, h, w = x.size()
+
+ avg_pool = self.pool(x)
+
+ h_pos_encoding = \
+ self.h_scale(avg_pool) * self.h_position_encoder[:, :, :h, :]
+ w_pos_encoding = \
+ self.w_scale(avg_pool) * self.w_position_encoder[:, :, :, :w]
+
+ out = x + h_pos_encoding + w_pos_encoding
+
+ out = self.dropout(out)
+
+ return out
diff --git a/mmocr/models/textrecog/losses/__init__.py b/mmocr/models/textrecog/losses/__init__.py
new file mode 100755
index 0000000000000000000000000000000000000000..afab422263462b1f1d3311f0b6632df2d172a6ea
--- /dev/null
+++ b/mmocr/models/textrecog/losses/__init__.py
@@ -0,0 +1,7 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .ce_loss import CELoss, SARLoss, TFLoss
+from .ctc_loss import CTCLoss
+from .mix_loss import ABILoss
+from .seg_loss import SegLoss
+
+__all__ = ['CELoss', 'SARLoss', 'CTCLoss', 'TFLoss', 'SegLoss', 'ABILoss']
diff --git a/mmocr/models/textrecog/losses/ce_loss.py b/mmocr/models/textrecog/losses/ce_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..e718a8ca3061e256fdcf797598f68201dadc2316
--- /dev/null
+++ b/mmocr/models/textrecog/losses/ce_loss.py
@@ -0,0 +1,133 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+
+from mmocr.models.builder import LOSSES
+
+
+@LOSSES.register_module()
+class CELoss(nn.Module):
+ """Implementation of loss module for encoder-decoder based text recognition
+ method with CrossEntropy loss.
+
+ Args:
+ ignore_index (int): Specifies a target value that is
+ ignored and does not contribute to the input gradient.
+ reduction (str): Specifies the reduction to apply to the output,
+ should be one of the following: ('none', 'mean', 'sum').
+ ignore_first_char (bool): Whether to ignore the first token in target (
+ usually the start token). If ``True``, the last token of the output
+ sequence will also be removed to be aligned with the target length.
+ """
+
+ def __init__(self,
+ ignore_index=-1,
+ reduction='none',
+ ignore_first_char=False):
+ super().__init__()
+ assert isinstance(ignore_index, int)
+ assert isinstance(reduction, str)
+ assert reduction in ['none', 'mean', 'sum']
+ assert isinstance(ignore_first_char, bool)
+
+ self.loss_ce = nn.CrossEntropyLoss(
+ ignore_index=ignore_index, reduction=reduction)
+ self.ignore_first_char = ignore_first_char
+
+ def format(self, outputs, targets_dict):
+ targets = targets_dict['padded_targets']
+ if self.ignore_first_char:
+ targets = targets[:, 1:].contiguous()
+ outputs = outputs[:, :-1, :]
+
+ outputs = outputs.permute(0, 2, 1).contiguous()
+
+ return outputs, targets
+
+ def forward(self, outputs, targets_dict, img_metas=None):
+ """
+ Args:
+ outputs (Tensor): A raw logit tensor of shape :math:`(N, T, C)`.
+ targets_dict (dict): A dict with a key ``padded_targets``, which is
+ a tensor of shape :math:`(N, T)`. Each element is the index of
+ a character.
+ img_metas (None): Unused.
+
+ Returns:
+ dict: A loss dict with the key ``loss_ce``.
+ """
+ outputs, targets = self.format(outputs, targets_dict)
+
+ loss_ce = self.loss_ce(outputs, targets.to(outputs.device))
+ losses = dict(loss_ce=loss_ce)
+
+ return losses
+
+
+@LOSSES.register_module()
+class SARLoss(CELoss):
+ """Implementation of loss module in `SAR.
+
+ `_.
+
+ Args:
+ ignore_index (int): Specifies a target value that is
+ ignored and does not contribute to the input gradient.
+ reduction (str): Specifies the reduction to apply to the output,
+ should be one of the following: ("none", "mean", "sum").
+
+ Warning:
+ SARLoss assumes that the first input token is always ``.
+ """
+
+ def __init__(self, ignore_index=0, reduction='mean', **kwargs):
+ super().__init__(ignore_index, reduction)
+
+ def format(self, outputs, targets_dict):
+ targets = targets_dict['padded_targets']
+ # targets[0, :], [start_idx, idx1, idx2, ..., end_idx, pad_idx...]
+ # outputs[0, :, 0], [idx1, idx2, ..., end_idx, ...]
+
+ # ignore first index of target in loss calculation
+ targets = targets[:, 1:].contiguous()
+ # ignore last index of outputs to be in same seq_len with targets
+ outputs = outputs[:, :-1, :].permute(0, 2, 1).contiguous()
+
+ return outputs, targets
+
+
+@LOSSES.register_module()
+class TFLoss(CELoss):
+ """Implementation of loss module for transformer.
+
+ Args:
+ ignore_index (int, optional): The character index to be ignored in
+ loss computation.
+ reduction (str): Type of reduction to apply to the output,
+ should be one of the following: ("none", "mean", "sum").
+ flatten (bool): Whether to flatten the vectors for loss computation.
+
+ Warning:
+ TFLoss assumes that the first input token is always ``.
+ """
+
+ def __init__(self,
+ ignore_index=-1,
+ reduction='none',
+ flatten=True,
+ **kwargs):
+ super().__init__(ignore_index, reduction)
+ assert isinstance(flatten, bool)
+
+ self.flatten = flatten
+
+ def format(self, outputs, targets_dict):
+ outputs = outputs[:, :-1, :].contiguous()
+ targets = targets_dict['padded_targets']
+ targets = targets[:, 1:].contiguous()
+ if self.flatten:
+ outputs = outputs.view(-1, outputs.size(-1))
+ targets = targets.view(-1)
+ else:
+ outputs = outputs.permute(0, 2, 1).contiguous()
+
+ return outputs, targets
diff --git a/mmocr/models/textrecog/losses/ctc_loss.py b/mmocr/models/textrecog/losses/ctc_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..24c6390b8f82a6c65ad243f52974dc8aedc576a7
--- /dev/null
+++ b/mmocr/models/textrecog/losses/ctc_loss.py
@@ -0,0 +1,103 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import torch
+import torch.nn as nn
+
+from mmocr.models.builder import LOSSES
+
+
+@LOSSES.register_module()
+class CTCLoss(nn.Module):
+ """Implementation of loss module for CTC-loss based text recognition.
+
+ Args:
+ flatten (bool): If True, use flattened targets, else padded targets.
+ blank (int): Blank label. Default 0.
+ reduction (str): Specifies the reduction to apply to the output,
+ should be one of the following: ('none', 'mean', 'sum').
+ zero_infinity (bool): Whether to zero infinite losses and
+ the associated gradients. Default: False.
+ Infinite losses mainly occur when the inputs
+ are too short to be aligned to the targets.
+ """
+
+ def __init__(self,
+ flatten=True,
+ blank=0,
+ reduction='mean',
+ zero_infinity=False,
+ **kwargs):
+ super().__init__()
+ assert isinstance(flatten, bool)
+ assert isinstance(blank, int)
+ assert isinstance(reduction, str)
+ assert isinstance(zero_infinity, bool)
+
+ self.flatten = flatten
+ self.blank = blank
+ self.ctc_loss = nn.CTCLoss(
+ blank=blank, reduction=reduction, zero_infinity=zero_infinity)
+
+ def forward(self, outputs, targets_dict, img_metas=None):
+ """
+ Args:
+ outputs (Tensor): A raw logit tensor of shape :math:`(N, T, C)`.
+ targets_dict (dict): A dict with 3 keys ``target_lengths``,
+ ``flatten_targets`` and ``targets``.
+
+ - | ``target_lengths`` (Tensor): A tensor of shape :math:`(N)`.
+ Each item is the length of a word.
+
+ - | ``flatten_targets`` (Tensor): Used if ``self.flatten=True``
+ (default). A tensor of shape
+ (sum(targets_dict['target_lengths'])). Each item is the
+ index of a character.
+
+ - | ``targets`` (Tensor): Used if ``self.flatten=False``. A
+ tensor of :math:`(N, T)`. Empty slots are padded with
+ ``self.blank``.
+
+ img_metas (dict): A dict that contains meta information of input
+ images. Preferably with the key ``valid_ratio``.
+
+ Returns:
+ dict: The loss dict with key ``loss_ctc``.
+ """
+ valid_ratios = None
+ if img_metas is not None:
+ valid_ratios = [
+ img_meta.get('valid_ratio', 1.0) for img_meta in img_metas
+ ]
+
+ outputs = torch.log_softmax(outputs, dim=2)
+ bsz, seq_len = outputs.size(0), outputs.size(1)
+ outputs_for_loss = outputs.permute(1, 0, 2).contiguous() # T * N * C
+
+ if self.flatten:
+ targets = targets_dict['flatten_targets']
+ else:
+ targets = torch.full(
+ size=(bsz, seq_len), fill_value=self.blank, dtype=torch.long)
+ for idx, tensor in enumerate(targets_dict['targets']):
+ valid_len = min(tensor.size(0), seq_len)
+ targets[idx, :valid_len] = tensor[:valid_len]
+
+ target_lengths = targets_dict['target_lengths']
+ target_lengths = torch.clamp(target_lengths, min=1, max=seq_len).long()
+
+ input_lengths = torch.full(
+ size=(bsz, ), fill_value=seq_len, dtype=torch.long)
+ if not self.flatten and valid_ratios is not None:
+ input_lengths = [
+ math.ceil(valid_ratio * seq_len)
+ for valid_ratio in valid_ratios
+ ]
+ input_lengths = torch.Tensor(input_lengths).long()
+
+ loss_ctc = self.ctc_loss(outputs_for_loss, targets, input_lengths,
+ target_lengths)
+
+ losses = dict(loss_ctc=loss_ctc)
+
+ return losses
diff --git a/mmocr/models/textrecog/losses/mix_loss.py b/mmocr/models/textrecog/losses/mix_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..e7f05f45eca7d2c8f8e8d76f35f3824b907553b3
--- /dev/null
+++ b/mmocr/models/textrecog/losses/mix_loss.py
@@ -0,0 +1,109 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from mmocr.models.builder import LOSSES
+
+
+@LOSSES.register_module()
+class ABILoss(nn.Module):
+ """Implementation of ABINet multiloss that allows mixing different types of
+ losses with weights.
+
+ Args:
+ enc_weight (float): The weight of encoder loss. Defaults to 1.0.
+ dec_weight (float): The weight of decoder loss. Defaults to 1.0.
+ fusion_weight (float): The weight of fuser (aligner) loss.
+ Defaults to 1.0.
+ num_classes (int): Number of unique output language tokens.
+
+ Returns:
+ A dictionary whose key/value pairs are the losses of three modules.
+ """
+
+ def __init__(self,
+ enc_weight=1.0,
+ dec_weight=1.0,
+ fusion_weight=1.0,
+ num_classes=37,
+ **kwargs):
+ assert isinstance(enc_weight, float) or isinstance(enc_weight, int)
+ assert isinstance(dec_weight, float) or isinstance(dec_weight, int)
+ assert isinstance(fusion_weight, float) or \
+ isinstance(fusion_weight, int)
+ super().__init__()
+ self.enc_weight = enc_weight
+ self.dec_weight = dec_weight
+ self.fusion_weight = fusion_weight
+ self.num_classes = num_classes
+
+ def _flatten(self, logits, target_lens):
+ flatten_logits = torch.cat(
+ [s[:target_lens[i]] for i, s in enumerate((logits))])
+ return flatten_logits
+
+ def _ce_loss(self, logits, targets):
+ targets_one_hot = F.one_hot(targets, self.num_classes)
+ log_prob = F.log_softmax(logits, dim=-1)
+ loss = -(targets_one_hot.to(log_prob.device) * log_prob).sum(dim=-1)
+ return loss.mean()
+
+ def _loss_over_iters(self, outputs, targets):
+ """
+ Args:
+ outputs (list[Tensor]): Each tensor has shape (N, T, C) where N is
+ the batch size, T is the sequence length and C is the number of
+ classes.
+ targets_dicts (dict): The dictionary with at least `padded_targets`
+ defined.
+ """
+ iter_num = len(outputs)
+ dec_outputs = torch.cat(outputs, dim=0)
+ flatten_targets_iternum = targets.repeat(iter_num)
+ return self._ce_loss(dec_outputs, flatten_targets_iternum)
+
+ def forward(self, outputs, targets_dict, img_metas=None):
+ """
+ Args:
+ outputs (dict): The output dictionary with at least one of
+ ``out_enc``, ``out_dec`` and ``out_fusers`` specified.
+ targets_dict (dict): The target dictionary containing the key
+ ``padded_targets``, which represents target sequences in
+ shape (batch_size, sequence_length).
+
+ Returns:
+ A loss dictionary with ``loss_visual``, ``loss_lang`` and
+ ``loss_fusion``. Each should either be the loss tensor or ``0`` if
+ the output of its corresponding module is not given.
+ """
+ assert 'out_enc' in outputs or \
+ 'out_dec' in outputs or 'out_fusers' in outputs
+ losses = {}
+
+ target_lens = [len(t) for t in targets_dict['targets']]
+ flatten_targets = torch.cat([t for t in targets_dict['targets']])
+
+ if outputs.get('out_enc', None):
+ enc_input = self._flatten(outputs['out_enc']['logits'],
+ target_lens)
+ enc_loss = self._ce_loss(enc_input,
+ flatten_targets) * self.enc_weight
+ losses['loss_visual'] = enc_loss
+ if outputs.get('out_decs', None):
+ dec_logits = [
+ self._flatten(o['logits'], target_lens)
+ for o in outputs['out_decs']
+ ]
+ dec_loss = self._loss_over_iters(dec_logits,
+ flatten_targets) * self.dec_weight
+ losses['loss_lang'] = dec_loss
+ if outputs.get('out_fusers', None):
+ fusion_logits = [
+ self._flatten(o['logits'], target_lens)
+ for o in outputs['out_fusers']
+ ]
+ fusion_loss = self._loss_over_iters(
+ fusion_logits, flatten_targets) * self.fusion_weight
+ losses['loss_fusion'] = fusion_loss
+ return losses
diff --git a/mmocr/models/textrecog/losses/seg_loss.py b/mmocr/models/textrecog/losses/seg_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..5adc2873ff10813e03308cf823b36667d5704275
--- /dev/null
+++ b/mmocr/models/textrecog/losses/seg_loss.py
@@ -0,0 +1,80 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from mmocr.models.builder import LOSSES
+
+
+@LOSSES.register_module()
+class SegLoss(nn.Module):
+ """Implementation of loss module for segmentation based text recognition
+ method.
+
+ Args:
+ seg_downsample_ratio (float): Downsample ratio of
+ segmentation map.
+ seg_with_loss_weight (bool): If True, set weight for
+ segmentation loss.
+ ignore_index (int): Specifies a target value that is ignored
+ and does not contribute to the input gradient.
+ """
+
+ def __init__(self,
+ seg_downsample_ratio=0.5,
+ seg_with_loss_weight=True,
+ ignore_index=255,
+ **kwargs):
+ super().__init__()
+
+ assert isinstance(seg_downsample_ratio, (int, float))
+ assert 0 < seg_downsample_ratio <= 1
+ assert isinstance(ignore_index, int)
+
+ self.seg_downsample_ratio = seg_downsample_ratio
+ self.seg_with_loss_weight = seg_with_loss_weight
+ self.ignore_index = ignore_index
+
+ def seg_loss(self, out_head, gt_kernels):
+ seg_map = out_head # bsz * num_classes * H/2 * W/2
+ seg_target = [
+ item[1].rescale(self.seg_downsample_ratio).to_tensor(
+ torch.long, seg_map.device) for item in gt_kernels
+ ]
+ seg_target = torch.stack(seg_target).squeeze(1)
+
+ loss_weight = None
+ if self.seg_with_loss_weight:
+ N = torch.sum(seg_target != self.ignore_index)
+ N_neg = torch.sum(seg_target == 0)
+ weight_val = 1.0 * N_neg / (N - N_neg)
+ loss_weight = torch.ones(seg_map.size(1), device=seg_map.device)
+ loss_weight[1:] = weight_val
+
+ loss_seg = F.cross_entropy(
+ seg_map,
+ seg_target,
+ weight=loss_weight,
+ ignore_index=self.ignore_index)
+
+ return loss_seg
+
+ def forward(self, out_neck, out_head, gt_kernels):
+ """
+ Args:
+ out_neck (None): Unused.
+ out_head (Tensor): The output from head whose shape
+ is :math:`(N, C, H, W)`.
+ gt_kernels (BitmapMasks): The ground truth masks.
+
+ Returns:
+ dict: A loss dictionary with the key ``loss_seg``.
+ """
+
+ losses = {}
+
+ loss_seg = self.seg_loss(out_head, gt_kernels)
+
+ losses['loss_seg'] = loss_seg
+
+ return losses
diff --git a/mmocr/models/textrecog/necks/__init__.py b/mmocr/models/textrecog/necks/__init__.py
new file mode 100755
index 0000000000000000000000000000000000000000..81a5714481121cf1dd0c8fef480d1785f381f1f1
--- /dev/null
+++ b/mmocr/models/textrecog/necks/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .fpn_ocr import FPNOCR
+
+__all__ = ['FPNOCR']
diff --git a/mmocr/models/textrecog/necks/fpn_ocr.py b/mmocr/models/textrecog/necks/fpn_ocr.py
new file mode 100644
index 0000000000000000000000000000000000000000..e1a6aae14c690d2d1f2c40b2c632a58419ad855b
--- /dev/null
+++ b/mmocr/models/textrecog/necks/fpn_ocr.py
@@ -0,0 +1,87 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn.functional as F
+from mmcv.cnn import ConvModule
+from mmcv.runner import BaseModule, ModuleList
+
+from mmocr.models.builder import NECKS
+
+
+@NECKS.register_module()
+class FPNOCR(BaseModule):
+ """FPN-like Network for segmentation based text recognition.
+
+ Args:
+ in_channels (list[int]): Number of input channels :math:`C_i` for each
+ scale.
+ out_channels (int): Number of output channels :math:`C_{out}` for each
+ scale.
+ last_stage_only (bool): If True, output last stage only.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ last_stage_only=True,
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.num_ins = len(in_channels)
+
+ self.last_stage_only = last_stage_only
+
+ self.lateral_convs = ModuleList()
+ self.smooth_convs_1x1 = ModuleList()
+ self.smooth_convs_3x3 = ModuleList()
+
+ for i in range(self.num_ins):
+ l_conv = ConvModule(
+ in_channels[i], out_channels, 1, norm_cfg=dict(type='BN'))
+ self.lateral_convs.append(l_conv)
+
+ for i in range(self.num_ins - 1):
+ s_conv_1x1 = ConvModule(
+ out_channels * 2, out_channels, 1, norm_cfg=dict(type='BN'))
+ s_conv_3x3 = ConvModule(
+ out_channels,
+ out_channels,
+ 3,
+ padding=1,
+ norm_cfg=dict(type='BN'))
+ self.smooth_convs_1x1.append(s_conv_1x1)
+ self.smooth_convs_3x3.append(s_conv_3x3)
+
+ def _upsample_x2(self, x):
+ return F.interpolate(x, scale_factor=2, mode='bilinear')
+
+ def forward(self, inputs):
+ """
+ Args:
+ inputs (list[Tensor]): A list of n tensors. Each tensor has the
+ shape of :math:`(N, C_i, H_i, W_i)`. It usually expects 4
+ tensors (C2-C5 features) from ResNet.
+
+ Returns:
+ tuple(Tensor): A tuple of n-1 tensors. Each has the of shape
+ :math:`(N, C_{out}, H_{n-2-i}, W_{n-2-i})`. If
+ ``last_stage_only=True`` (default), the size of the
+ tuple is 1 and only the last element will be returned.
+ """
+ lateral_features = [
+ l_conv(inputs[i]) for i, l_conv in enumerate(self.lateral_convs)
+ ]
+
+ outs = []
+ for i in range(len(self.smooth_convs_3x3), 0, -1): # 3, 2, 1
+ last_out = lateral_features[-1] if len(outs) == 0 else outs[-1]
+ upsample = self._upsample_x2(last_out)
+ upsample_cat = torch.cat((upsample, lateral_features[i - 1]),
+ dim=1)
+ smooth_1x1 = self.smooth_convs_1x1[i - 1](upsample_cat)
+ smooth_3x3 = self.smooth_convs_3x3[i - 1](smooth_1x1)
+ outs.append(smooth_3x3)
+
+ return tuple(outs[-1:]) if self.last_stage_only else tuple(outs)
diff --git a/mmocr/models/textrecog/plugins/__init__.py b/mmocr/models/textrecog/plugins/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f65819c828d81eb5a650d8cb12f33d8583e087ae
--- /dev/null
+++ b/mmocr/models/textrecog/plugins/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .common import Maxpool2d
+
+__all__ = ['Maxpool2d']
diff --git a/mmocr/models/textrecog/plugins/common.py b/mmocr/models/textrecog/plugins/common.py
new file mode 100644
index 0000000000000000000000000000000000000000..a12b9e144aaa0d2e58728f835b4b17714ff2a00d
--- /dev/null
+++ b/mmocr/models/textrecog/plugins/common.py
@@ -0,0 +1,28 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch.nn as nn
+from mmcv.cnn import PLUGIN_LAYERS
+
+
+@PLUGIN_LAYERS.register_module()
+class Maxpool2d(nn.Module):
+ """A wrapper around nn.Maxpool2d().
+
+ Args:
+ kernel_size (int or tuple(int)): Kernel size for max pooling layer
+ stride (int or tuple(int)): Stride for max pooling layer
+ padding (int or tuple(int)): Padding for pooling layer
+ """
+
+ def __init__(self, kernel_size, stride, padding=0, **kwargs):
+ super(Maxpool2d, self).__init__()
+ self.model = nn.MaxPool2d(kernel_size, stride, padding)
+
+ def forward(self, x):
+ """
+ Args:
+ x (Tensor): Input feature map
+
+ Returns:
+ Tensor: The tensor after Maxpooling layer.
+ """
+ return self.model(x)
diff --git a/mmocr/models/textrecog/preprocessor/__init__.py b/mmocr/models/textrecog/preprocessor/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..57ea828a3c923b9031daf1f0c5205629a1786de2
--- /dev/null
+++ b/mmocr/models/textrecog/preprocessor/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .base_preprocessor import BasePreprocessor
+from .tps_preprocessor import TPSPreprocessor
+
+__all__ = ['BasePreprocessor', 'TPSPreprocessor']
diff --git a/mmocr/models/textrecog/preprocessor/base_preprocessor.py b/mmocr/models/textrecog/preprocessor/base_preprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..ddd4a8f78c8d39de6bf6741735b8916a1dbcb21c
--- /dev/null
+++ b/mmocr/models/textrecog/preprocessor/base_preprocessor.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.runner import BaseModule
+
+from mmocr.models.builder import PREPROCESSOR
+
+
+@PREPROCESSOR.register_module()
+class BasePreprocessor(BaseModule):
+ """Base Preprocessor class for text recognition."""
+
+ def forward(self, x, **kwargs):
+ return x
diff --git a/mmocr/models/textrecog/preprocessor/tps_preprocessor.py b/mmocr/models/textrecog/preprocessor/tps_preprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..44c332dbe051d731fbcb7c0b324fe49e53c67c52
--- /dev/null
+++ b/mmocr/models/textrecog/preprocessor/tps_preprocessor.py
@@ -0,0 +1,275 @@
+# Modified from https://github.com/clovaai/deep-text-recognition-benchmark
+#
+# Licensed under the Apache License, Version 2.0 (the "License");s
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from mmocr.models.builder import PREPROCESSOR
+from .base_preprocessor import BasePreprocessor
+
+
+@PREPROCESSOR.register_module()
+class TPSPreprocessor(BasePreprocessor):
+ """Rectification Network of RARE, namely TPS based STN in
+ https://arxiv.org/pdf/1603.03915.pdf.
+
+ Args:
+ num_fiducial (int): Number of fiducial points of TPS-STN.
+ img_size (tuple(int, int)): Size :math:`(H, W)` of the input image.
+ rectified_img_size (tuple(int, int)): Size :math:`(H_r, W_r)` of
+ the rectified image.
+ num_img_channel (int): Number of channels of the input image.
+ init_cfg (dict or list[dict], optional): Initialization configs.
+ """
+
+ def __init__(self,
+ num_fiducial=20,
+ img_size=(32, 100),
+ rectified_img_size=(32, 100),
+ num_img_channel=1,
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ assert isinstance(num_fiducial, int)
+ assert num_fiducial > 0
+ assert isinstance(img_size, tuple)
+ assert isinstance(rectified_img_size, tuple)
+ assert isinstance(num_img_channel, int)
+
+ self.num_fiducial = num_fiducial
+ self.img_size = img_size
+ self.rectified_img_size = rectified_img_size
+ self.num_img_channel = num_img_channel
+ self.LocalizationNetwork = LocalizationNetwork(self.num_fiducial,
+ self.num_img_channel)
+ self.GridGenerator = GridGenerator(self.num_fiducial,
+ self.rectified_img_size)
+
+ def forward(self, batch_img):
+ """
+ Args:
+ batch_img (Tensor): Images to be rectified with size
+ :math:`(N, C, H, W)`.
+
+ Returns:
+ Tensor: Rectified image with size :math:`(N, C, H_r, W_r)`.
+ """
+ batch_C_prime = self.LocalizationNetwork(
+ batch_img) # batch_size x K x 2
+ build_P_prime = self.GridGenerator.build_P_prime(
+ batch_C_prime, batch_img.device
+ ) # batch_size x n (= rectified_img_width x rectified_img_height) x 2
+ build_P_prime_reshape = build_P_prime.reshape([
+ build_P_prime.size(0), self.rectified_img_size[0],
+ self.rectified_img_size[1], 2
+ ])
+
+ batch_rectified_img = F.grid_sample(
+ batch_img,
+ build_P_prime_reshape,
+ padding_mode='border',
+ align_corners=True)
+
+ return batch_rectified_img
+
+
+class LocalizationNetwork(nn.Module):
+ """Localization Network of RARE, which predicts C' (K x 2) from input
+ (img_width x img_height)
+
+ Args:
+ num_fiducial (int): Number of fiducial points of TPS-STN.
+ num_img_channel (int): Number of channels of the input image.
+ """
+
+ def __init__(self, num_fiducial, num_img_channel):
+ super().__init__()
+ self.num_fiducial = num_fiducial
+ self.num_img_channel = num_img_channel
+ self.conv = nn.Sequential(
+ nn.Conv2d(
+ in_channels=self.num_img_channel,
+ out_channels=64,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False),
+ nn.BatchNorm2d(64),
+ nn.ReLU(True),
+ nn.MaxPool2d(2, 2), # batch_size x 64 x img_height/2 x img_width/2
+ nn.Conv2d(64, 128, 3, 1, 1, bias=False),
+ nn.BatchNorm2d(128),
+ nn.ReLU(True),
+ nn.MaxPool2d(2, 2), # batch_size x 128 x img_h/4 x img_w/4
+ nn.Conv2d(128, 256, 3, 1, 1, bias=False),
+ nn.BatchNorm2d(256),
+ nn.ReLU(True),
+ nn.MaxPool2d(2, 2), # batch_size x 256 x img_h/8 x img_w/8
+ nn.Conv2d(256, 512, 3, 1, 1, bias=False),
+ nn.BatchNorm2d(512),
+ nn.ReLU(True),
+ nn.AdaptiveAvgPool2d(1) # batch_size x 512
+ )
+
+ self.localization_fc1 = nn.Sequential(
+ nn.Linear(512, 256), nn.ReLU(True))
+ self.localization_fc2 = nn.Linear(256, self.num_fiducial * 2)
+
+ # Init fc2 in LocalizationNetwork
+ self.localization_fc2.weight.data.fill_(0)
+ ctrl_pts_x = np.linspace(-1.0, 1.0, int(num_fiducial / 2))
+ ctrl_pts_y_top = np.linspace(0.0, -1.0, num=int(num_fiducial / 2))
+ ctrl_pts_y_bottom = np.linspace(1.0, 0.0, num=int(num_fiducial / 2))
+ ctrl_pts_top = np.stack([ctrl_pts_x, ctrl_pts_y_top], axis=1)
+ ctrl_pts_bottom = np.stack([ctrl_pts_x, ctrl_pts_y_bottom], axis=1)
+ initial_bias = np.concatenate([ctrl_pts_top, ctrl_pts_bottom], axis=0)
+ self.localization_fc2.bias.data = torch.from_numpy(
+ initial_bias).float().view(-1)
+
+ def forward(self, batch_img):
+ """
+ Args:
+ batch_img (Tensor): Batch input image of shape
+ :math:`(N, C, H, W)`.
+
+ Returns:
+ Tensor: Predicted coordinates of fiducial points for input batch.
+ The shape is :math:`(N, F, 2)` where :math:`F` is ``num_fiducial``.
+ """
+ batch_size = batch_img.size(0)
+ features = self.conv(batch_img).view(batch_size, -1)
+ batch_C_prime = self.localization_fc2(
+ self.localization_fc1(features)).view(batch_size,
+ self.num_fiducial, 2)
+ return batch_C_prime
+
+
+class GridGenerator(nn.Module):
+ """Grid Generator of RARE, which produces P_prime by multiplying T with P.
+
+ Args:
+ num_fiducial (int): Number of fiducial points of TPS-STN.
+ rectified_img_size (tuple(int, int)):
+ Size :math:`(H_r, W_r)` of the rectified image.
+ """
+
+ def __init__(self, num_fiducial, rectified_img_size):
+ """Generate P_hat and inv_delta_C for later."""
+ super().__init__()
+ self.eps = 1e-6
+ self.rectified_img_height = rectified_img_size[0]
+ self.rectified_img_width = rectified_img_size[1]
+ self.num_fiducial = num_fiducial
+ self.C = self._build_C(self.num_fiducial) # num_fiducial x 2
+ self.P = self._build_P(self.rectified_img_width,
+ self.rectified_img_height)
+ # for multi-gpu, you need register buffer
+ self.register_buffer(
+ 'inv_delta_C',
+ torch.tensor(self._build_inv_delta_C(
+ self.num_fiducial,
+ self.C)).float()) # num_fiducial+3 x num_fiducial+3
+ self.register_buffer('P_hat',
+ torch.tensor(
+ self._build_P_hat(
+ self.num_fiducial, self.C,
+ self.P)).float()) # n x num_fiducial+3
+ # for fine-tuning with different image width,
+ # you may use below instead of self.register_buffer
+ # self.inv_delta_C = torch.tensor(
+ # self._build_inv_delta_C(
+ # self.num_fiducial,
+ # self.C)).float().cuda() # num_fiducial+3 x num_fiducial+3
+ # self.P_hat = torch.tensor(
+ # self._build_P_hat(self.num_fiducial, self.C,
+ # self.P)).float().cuda() # n x num_fiducial+3
+
+ def _build_C(self, num_fiducial):
+ """Return coordinates of fiducial points in rectified_img; C."""
+ ctrl_pts_x = np.linspace(-1.0, 1.0, int(num_fiducial / 2))
+ ctrl_pts_y_top = -1 * np.ones(int(num_fiducial / 2))
+ ctrl_pts_y_bottom = np.ones(int(num_fiducial / 2))
+ ctrl_pts_top = np.stack([ctrl_pts_x, ctrl_pts_y_top], axis=1)
+ ctrl_pts_bottom = np.stack([ctrl_pts_x, ctrl_pts_y_bottom], axis=1)
+ C = np.concatenate([ctrl_pts_top, ctrl_pts_bottom], axis=0)
+ return C # num_fiducial x 2
+
+ def _build_inv_delta_C(self, num_fiducial, C):
+ """Return inv_delta_C which is needed to calculate T."""
+ hat_C = np.zeros((num_fiducial, num_fiducial), dtype=float)
+ for i in range(0, num_fiducial):
+ for j in range(i, num_fiducial):
+ r = np.linalg.norm(C[i] - C[j])
+ hat_C[i, j] = r
+ hat_C[j, i] = r
+ np.fill_diagonal(hat_C, 1)
+ hat_C = (hat_C**2) * np.log(hat_C)
+ # print(C.shape, hat_C.shape)
+ delta_C = np.concatenate( # num_fiducial+3 x num_fiducial+3
+ [
+ np.concatenate([np.ones((num_fiducial, 1)), C, hat_C],
+ axis=1), # num_fiducial x num_fiducial+3
+ np.concatenate([np.zeros(
+ (2, 3)), np.transpose(C)], axis=1), # 2 x num_fiducial+3
+ np.concatenate([np.zeros(
+ (1, 3)), np.ones((1, num_fiducial))],
+ axis=1) # 1 x num_fiducial+3
+ ],
+ axis=0)
+ inv_delta_C = np.linalg.inv(delta_C)
+ return inv_delta_C # num_fiducial+3 x num_fiducial+3
+
+ def _build_P(self, rectified_img_width, rectified_img_height):
+ rectified_img_grid_x = (
+ np.arange(-rectified_img_width, rectified_img_width, 2) +
+ 1.0) / rectified_img_width # self.rectified_img_width
+ rectified_img_grid_y = (
+ np.arange(-rectified_img_height, rectified_img_height, 2) +
+ 1.0) / rectified_img_height # self.rectified_img_height
+ P = np.stack( # self.rectified_img_w x self.rectified_img_h x 2
+ np.meshgrid(rectified_img_grid_x, rectified_img_grid_y),
+ axis=2)
+ return P.reshape([
+ -1, 2
+ ]) # n (= self.rectified_img_width x self.rectified_img_height) x 2
+
+ def _build_P_hat(self, num_fiducial, C, P):
+ n = P.shape[
+ 0] # n (= self.rectified_img_width x self.rectified_img_height)
+ P_tile = np.tile(np.expand_dims(P, axis=1),
+ (1, num_fiducial,
+ 1)) # n x 2 -> n x 1 x 2 -> n x num_fiducial x 2
+ C_tile = np.expand_dims(C, axis=0) # 1 x num_fiducial x 2
+ P_diff = P_tile - C_tile # n x num_fiducial x 2
+ rbf_norm = np.linalg.norm(
+ P_diff, ord=2, axis=2, keepdims=False) # n x num_fiducial
+ rbf = np.multiply(np.square(rbf_norm),
+ np.log(rbf_norm + self.eps)) # n x num_fiducial
+ P_hat = np.concatenate([np.ones((n, 1)), P, rbf], axis=1)
+ return P_hat # n x num_fiducial+3
+
+ def build_P_prime(self, batch_C_prime, device='cuda'):
+ """Generate Grid from batch_C_prime [batch_size x num_fiducial x 2]"""
+ batch_size = batch_C_prime.size(0)
+ batch_inv_delta_C = self.inv_delta_C.repeat(batch_size, 1, 1)
+ batch_P_hat = self.P_hat.repeat(batch_size, 1, 1)
+ batch_C_prime_with_zeros = torch.cat(
+ (batch_C_prime, torch.zeros(batch_size, 3, 2).float().to(device)),
+ dim=1) # batch_size x num_fiducial+3 x 2
+ batch_T = torch.bmm(
+ batch_inv_delta_C,
+ batch_C_prime_with_zeros) # batch_size x num_fiducial+3 x 2
+ batch_P_prime = torch.bmm(batch_P_hat, batch_T) # batch_size x n x 2
+ return batch_P_prime # batch_size x n x 2
diff --git a/mmocr/models/textrecog/recognizer/__init__.py b/mmocr/models/textrecog/recognizer/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e26a92e624e3b07a3903e7ff197fd84623e93529
--- /dev/null
+++ b/mmocr/models/textrecog/recognizer/__init__.py
@@ -0,0 +1,15 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .abinet import ABINet
+from .base import BaseRecognizer
+from .crnn import CRNNNet
+from .encode_decode_recognizer import EncodeDecodeRecognizer
+from .nrtr import NRTR
+from .robust_scanner import RobustScanner
+from .sar import SARNet
+from .satrn import SATRN
+from .seg_recognizer import SegRecognizer
+
+__all__ = [
+ 'BaseRecognizer', 'EncodeDecodeRecognizer', 'CRNNNet', 'SARNet', 'NRTR',
+ 'SegRecognizer', 'RobustScanner', 'SATRN', 'ABINet'
+]
diff --git a/mmocr/models/textrecog/recognizer/abinet.py b/mmocr/models/textrecog/recognizer/abinet.py
new file mode 100644
index 0000000000000000000000000000000000000000..43cd9d8c3d7df5d51d2b4585063fa3d95c2280f6
--- /dev/null
+++ b/mmocr/models/textrecog/recognizer/abinet.py
@@ -0,0 +1,192 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import torch
+
+from mmocr.models.builder import (RECOGNIZERS, build_backbone, build_convertor,
+ build_decoder, build_encoder, build_fuser,
+ build_loss, build_preprocessor)
+from .encode_decode_recognizer import EncodeDecodeRecognizer
+
+
+@RECOGNIZERS.register_module()
+class ABINet(EncodeDecodeRecognizer):
+ """Implementation of `Read Like Humans: Autonomous, Bidirectional and
+ Iterative LanguageModeling for Scene Text Recognition.
+
+ `_
+ """
+
+ def __init__(self,
+ preprocessor=None,
+ backbone=None,
+ encoder=None,
+ decoder=None,
+ iter_size=1,
+ fuser=None,
+ loss=None,
+ label_convertor=None,
+ train_cfg=None,
+ test_cfg=None,
+ max_seq_len=40,
+ pretrained=None,
+ init_cfg=None):
+ super(EncodeDecodeRecognizer, self).__init__(init_cfg=init_cfg)
+
+ # Label convertor (str2tensor, tensor2str)
+ assert label_convertor is not None
+ label_convertor.update(max_seq_len=max_seq_len)
+ self.label_convertor = build_convertor(label_convertor)
+
+ # Preprocessor module, e.g., TPS
+ self.preprocessor = None
+ if preprocessor is not None:
+ self.preprocessor = build_preprocessor(preprocessor)
+
+ # Backbone
+ assert backbone is not None
+ self.backbone = build_backbone(backbone)
+
+ # Encoder module
+ self.encoder = None
+ if encoder is not None:
+ self.encoder = build_encoder(encoder)
+
+ # Decoder module
+ self.decoder = None
+ if decoder is not None:
+ decoder.update(num_classes=self.label_convertor.num_classes())
+ decoder.update(start_idx=self.label_convertor.start_idx)
+ decoder.update(padding_idx=self.label_convertor.padding_idx)
+ decoder.update(max_seq_len=max_seq_len)
+ self.decoder = build_decoder(decoder)
+
+ # Loss
+ assert loss is not None
+ self.loss = build_loss(loss)
+
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+ self.max_seq_len = max_seq_len
+
+ if pretrained is not None:
+ warnings.warn('DeprecationWarning: pretrained is a deprecated \
+ key, please consider using init_cfg')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+
+ self.iter_size = iter_size
+
+ self.fuser = None
+ if fuser is not None:
+ self.fuser = build_fuser(fuser)
+
+ def forward_train(self, img, img_metas):
+ """
+ Args:
+ img (tensor): Input images of shape (N, C, H, W).
+ Typically these should be mean centered and std scaled.
+ img_metas (list[dict]): A list of image info dict where each dict
+ contains: 'img_shape', 'filename', and may also contain
+ 'ori_shape', and 'img_norm_cfg'.
+ For details on the values of these keys see
+ :class:`mmdet.datasets.pipelines.Collect`.
+
+ Returns:
+ dict[str, tensor]: A dictionary of loss components.
+ """
+ for img_meta in img_metas:
+ valid_ratio = 1.0 * img_meta['resize_shape'][1] / img.size(-1)
+ img_meta['valid_ratio'] = valid_ratio
+
+ feat = self.extract_feat(img)
+
+ gt_labels = [img_meta['text'] for img_meta in img_metas]
+
+ targets_dict = self.label_convertor.str2tensor(gt_labels)
+
+ text_logits = None
+ out_enc = None
+ if self.encoder is not None:
+ out_enc = self.encoder(feat)
+ text_logits = out_enc['logits']
+
+ out_decs = []
+ out_fusers = []
+ for _ in range(self.iter_size):
+ if self.decoder is not None:
+ out_dec = self.decoder(
+ feat,
+ text_logits,
+ targets_dict,
+ img_metas,
+ train_mode=True)
+ out_decs.append(out_dec)
+
+ if self.fuser is not None:
+ out_fuser = self.fuser(out_enc['feature'], out_dec['feature'])
+ text_logits = out_fuser['logits']
+ out_fusers.append(out_fuser)
+
+ outputs = dict(
+ out_enc=out_enc, out_decs=out_decs, out_fusers=out_fusers)
+
+ losses = self.loss(outputs, targets_dict, img_metas)
+
+ return losses
+
+ def simple_test(self, img, img_metas, **kwargs):
+ """Test function with test time augmentation.
+
+ Args:
+ imgs (torch.Tensor): Image input tensor.
+ img_metas (list[dict]): List of image information.
+
+ Returns:
+ list[str]: Text label result of each image.
+ """
+ for img_meta in img_metas:
+ valid_ratio = 1.0 * img_meta['resize_shape'][1] / img.size(-1)
+ img_meta['valid_ratio'] = valid_ratio
+
+ feat = self.extract_feat(img)
+
+ text_logits = None
+ out_enc = None
+ if self.encoder is not None:
+ out_enc = self.encoder(feat)
+ text_logits = out_enc['logits']
+
+ out_decs = []
+ out_fusers = []
+ for _ in range(self.iter_size):
+ if self.decoder is not None:
+ out_dec = self.decoder(
+ feat, text_logits, img_metas=img_metas, train_mode=False)
+ out_decs.append(out_dec)
+
+ if self.fuser is not None:
+ out_fuser = self.fuser(out_enc['feature'], out_dec['feature'])
+ text_logits = out_fuser['logits']
+ out_fusers.append(out_fuser)
+
+ if len(out_fusers) > 0:
+ ret = out_fusers[-1]
+ elif len(out_decs) > 0:
+ ret = out_decs[-1]
+ else:
+ ret = out_enc
+
+ # early return to avoid post processing
+ if torch.onnx.is_in_onnx_export():
+ return ret['logits']
+
+ label_indexes, label_scores = self.label_convertor.tensor2idx(
+ ret['logits'], img_metas)
+ label_strings = self.label_convertor.idx2str(label_indexes)
+
+ # flatten batch results
+ results = []
+ for string, score in zip(label_strings, label_scores):
+ results.append(dict(text=string, score=score))
+
+ return results
diff --git a/mmocr/models/textrecog/recognizer/base.py b/mmocr/models/textrecog/recognizer/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..4c22fa9072104ba3cfe8fe83135e305ccea2edd1
--- /dev/null
+++ b/mmocr/models/textrecog/recognizer/base.py
@@ -0,0 +1,232 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from abc import ABCMeta, abstractmethod
+from collections import OrderedDict
+
+import mmcv
+import torch
+import torch.distributed as dist
+from mmcv.runner import BaseModule, auto_fp16
+
+from mmocr.core import imshow_text_label
+
+
+class BaseRecognizer(BaseModule, metaclass=ABCMeta):
+ """Base class for text recognition."""
+
+ def __init__(self, init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+ self.fp16_enabled = False
+
+ @abstractmethod
+ def extract_feat(self, imgs):
+ """Extract features from images."""
+ pass
+
+ @abstractmethod
+ def forward_train(self, imgs, img_metas, **kwargs):
+ """
+ Args:
+ img (tensor): tensors with shape (N, C, H, W).
+ Typically should be mean centered and std scaled.
+ img_metas (list[dict]): List of image info dict where each dict
+ has: 'img_shape', 'scale_factor', 'flip', and may also contain
+ 'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
+ For details of the values of these keys, see
+ :class:`mmdet.datasets.pipelines.Collect`.
+ kwargs (keyword arguments): Specific to concrete implementation.
+ """
+ pass
+
+ @abstractmethod
+ def simple_test(self, img, img_metas, **kwargs):
+ pass
+
+ @abstractmethod
+ def aug_test(self, imgs, img_metas, **kwargs):
+ """Test function with test time augmentation.
+
+ Args:
+ imgs (list[tensor]): Tensor should have shape NxCxHxW,
+ which contains all images in the batch.
+ img_metas (list[list[dict]]): The metadata of images.
+ """
+ pass
+
+ def forward_test(self, imgs, img_metas, **kwargs):
+ """
+ Args:
+ imgs (tensor | list[tensor]): Tensor should have shape NxCxHxW,
+ which contains all images in the batch.
+ img_metas (list[dict] | list[list[dict]]):
+ The outer list indicates images in a batch.
+ """
+ if isinstance(imgs, list):
+ assert len(imgs) > 0
+ assert imgs[0].size(0) == 1, ('aug test does not support '
+ f'inference with batch size '
+ f'{imgs[0].size(0)}')
+ assert len(imgs) == len(img_metas)
+ return self.aug_test(imgs, img_metas, **kwargs)
+
+ return self.simple_test(imgs, img_metas, **kwargs)
+
+ @auto_fp16(apply_to=('img', ))
+ def forward(self, img, img_metas, return_loss=True, **kwargs):
+ """Calls either :func:`forward_train` or :func:`forward_test` depending
+ on whether ``return_loss`` is ``True``.
+
+ Note that img and img_meta are single-nested (i.e. tensor and
+ list[dict]).
+ """
+
+ if return_loss:
+ return self.forward_train(img, img_metas, **kwargs)
+
+ if isinstance(img, list):
+ for idx, each_img in enumerate(img):
+ if each_img.dim() == 3:
+ img[idx] = each_img.unsqueeze(0)
+ else:
+ if len(img_metas) == 1 and isinstance(img_metas[0], list):
+ img_metas = img_metas[0]
+
+ return self.forward_test(img, img_metas, **kwargs)
+
+ def _parse_losses(self, losses):
+ """Parse the raw outputs (losses) of the network.
+
+ Args:
+ losses (dict): Raw outputs of the network, which usually contain
+ losses and other necessary information.
+
+ Returns:
+ tuple[tensor, dict]: (loss, log_vars), loss is the loss tensor
+ which may be a weighted sum of all losses, log_vars contains
+ all the variables to be sent to the logger.
+ """
+ log_vars = OrderedDict()
+ for loss_name, loss_value in losses.items():
+ if isinstance(loss_value, torch.Tensor):
+ log_vars[loss_name] = loss_value.mean()
+ elif isinstance(loss_value, list):
+ log_vars[loss_name] = sum(_loss.mean() for _loss in loss_value)
+ else:
+ raise TypeError(
+ f'{loss_name} is not a tensor or list of tensors')
+
+ loss = sum(_value for _key, _value in log_vars.items()
+ if 'loss' in _key)
+
+ log_vars['loss'] = loss
+ for loss_name, loss_value in log_vars.items():
+ # reduce loss when distributed training
+ if dist.is_available() and dist.is_initialized():
+ loss_value = loss_value.data.clone()
+ dist.all_reduce(loss_value.div_(dist.get_world_size()))
+ log_vars[loss_name] = loss_value.item()
+
+ return loss, log_vars
+
+ def train_step(self, data, optimizer):
+ """The iteration step during training.
+
+ This method defines an iteration step during training, except for the
+ back propagation and optimizer update, which are done by an optimizer
+ hook. Note that in some complicated cases or models (e.g. GAN),
+ the whole process (including the back propagation and optimizer update)
+ is also defined by this method.
+
+ Args:
+ data (dict): The outputs of dataloader.
+ optimizer (:obj:`torch.optim.Optimizer` | dict): The optimizer of
+ runner is passed to ``train_step()``. This argument is unused
+ and reserved.
+
+ Returns:
+ dict: It should contain at least 3 keys: ``loss``, ``log_vars``,
+ ``num_samples``.
+
+ - ``loss`` is a tensor for back propagation, which is a
+ weighted sum of multiple losses.
+ - ``log_vars`` contains all the variables to be sent to the
+ logger.
+ - ``num_samples`` indicates the batch size used for
+ averaging the logs (Note: for the
+ DDP model, num_samples refers to the batch size for each GPU).
+ """
+ losses = self(**data)
+ loss, log_vars = self._parse_losses(losses)
+
+ outputs = dict(
+ loss=loss, log_vars=log_vars, num_samples=len(data['img_metas']))
+
+ return outputs
+
+ def val_step(self, data, optimizer):
+ """The iteration step during validation.
+
+ This method shares the same signature as :func:`train_step`, but is
+ used during val epochs. Note that the evaluation after training epochs
+ is not implemented by this method, but by an evaluation hook.
+ """
+ losses = self(**data)
+ loss, log_vars = self._parse_losses(losses)
+
+ outputs = dict(
+ loss=loss, log_vars=log_vars, num_samples=len(data['img_metas']))
+
+ return outputs
+
+ def show_result(self,
+ img,
+ result,
+ gt_label='',
+ win_name='',
+ show=False,
+ wait_time=0,
+ out_file=None,
+ **kwargs):
+ """Draw `result` on `img`.
+
+ Args:
+ img (str or tensor): The image to be displayed.
+ result (dict): The results to draw on `img`.
+ gt_label (str): Ground truth label of img.
+ win_name (str): The window name.
+ wait_time (int): Value of waitKey param.
+ Default: 0.
+ show (bool): Whether to show the image.
+ Default: False.
+ out_file (str or None): The output filename.
+ Default: None.
+
+ Returns:
+ img (tensor): Only if not `show` or `out_file`.
+ """
+ img = mmcv.imread(img)
+ img = img.copy()
+ pred_label = None
+ if 'text' in result.keys():
+ pred_label = result['text']
+
+ # if out_file specified, do not show image in window
+ if out_file is not None:
+ show = False
+ # draw text label
+ if pred_label is not None:
+ img = imshow_text_label(
+ img,
+ pred_label,
+ gt_label,
+ show=show,
+ win_name=win_name,
+ wait_time=wait_time,
+ out_file=out_file)
+
+ if not (show or out_file):
+ warnings.warn('show==False and out_file is not specified, only '
+ 'result image will be returned')
+ return img
+
+ return img
diff --git a/mmocr/models/textrecog/recognizer/crnn.py b/mmocr/models/textrecog/recognizer/crnn.py
new file mode 100644
index 0000000000000000000000000000000000000000..d4ab90b9704c64a9733a176e80c0984bb00838bd
--- /dev/null
+++ b/mmocr/models/textrecog/recognizer/crnn.py
@@ -0,0 +1,8 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.models.builder import RECOGNIZERS
+from .encode_decode_recognizer import EncodeDecodeRecognizer
+
+
+@RECOGNIZERS.register_module()
+class CRNNNet(EncodeDecodeRecognizer):
+ """CTC-loss based recognizer."""
diff --git a/mmocr/models/textrecog/recognizer/encode_decode_recognizer.py b/mmocr/models/textrecog/recognizer/encode_decode_recognizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..f219a857349515905d4bea54f1f4f189e719edff
--- /dev/null
+++ b/mmocr/models/textrecog/recognizer/encode_decode_recognizer.py
@@ -0,0 +1,183 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+import torch
+
+from mmocr.models.builder import (RECOGNIZERS, build_backbone, build_convertor,
+ build_decoder, build_encoder, build_loss,
+ build_preprocessor)
+from .base import BaseRecognizer
+
+
+@RECOGNIZERS.register_module()
+class EncodeDecodeRecognizer(BaseRecognizer):
+ """Base class for encode-decode recognizer."""
+
+ def __init__(self,
+ preprocessor=None,
+ backbone=None,
+ encoder=None,
+ decoder=None,
+ loss=None,
+ label_convertor=None,
+ train_cfg=None,
+ test_cfg=None,
+ max_seq_len=40,
+ pretrained=None,
+ init_cfg=None):
+
+ super().__init__(init_cfg=init_cfg)
+
+ # Label convertor (str2tensor, tensor2str)
+ assert label_convertor is not None
+ label_convertor.update(max_seq_len=max_seq_len)
+ self.label_convertor = build_convertor(label_convertor)
+
+ # Preprocessor module, e.g., TPS
+ self.preprocessor = None
+ if preprocessor is not None:
+ self.preprocessor = build_preprocessor(preprocessor)
+
+ # Backbone
+ assert backbone is not None
+ self.backbone = build_backbone(backbone)
+
+ # Encoder module
+ self.encoder = None
+ if encoder is not None:
+ self.encoder = build_encoder(encoder)
+
+ # Decoder module
+ assert decoder is not None
+ decoder.update(num_classes=self.label_convertor.num_classes())
+ decoder.update(start_idx=self.label_convertor.start_idx)
+ decoder.update(padding_idx=self.label_convertor.padding_idx)
+ decoder.update(max_seq_len=max_seq_len)
+ self.decoder = build_decoder(decoder)
+
+ # Loss
+ assert loss is not None
+ loss.update(ignore_index=self.label_convertor.padding_idx)
+ self.loss = build_loss(loss)
+
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+ self.max_seq_len = max_seq_len
+
+ if pretrained is not None:
+ warnings.warn('DeprecationWarning: pretrained is a deprecated \
+ key, please consider using init_cfg')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+
+ def extract_feat(self, img):
+ """Directly extract features from the backbone."""
+ if self.preprocessor is not None:
+ img = self.preprocessor(img)
+
+ x = self.backbone(img)
+
+ return x
+
+ def forward_train(self, img, img_metas):
+ """
+ Args:
+ img (tensor): Input images of shape (N, C, H, W).
+ Typically these should be mean centered and std scaled.
+ img_metas (list[dict]): A list of image info dict where each dict
+ contains: 'img_shape', 'filename', and may also contain
+ 'ori_shape', and 'img_norm_cfg'.
+ For details on the values of these keys see
+ :class:`mmdet.datasets.pipelines.Collect`.
+
+ Returns:
+ dict[str, tensor]: A dictionary of loss components.
+ """
+ for img_meta in img_metas:
+ valid_ratio = 1.0 * img_meta['resize_shape'][1] / img.size(-1)
+ img_meta['valid_ratio'] = valid_ratio
+
+ feat = self.extract_feat(img)
+
+ gt_labels = [img_meta['text'] for img_meta in img_metas]
+
+ targets_dict = self.label_convertor.str2tensor(gt_labels)
+
+ out_enc = None
+ if self.encoder is not None:
+ out_enc = self.encoder(feat, img_metas)
+
+ out_dec = self.decoder(
+ feat, out_enc, targets_dict, img_metas, train_mode=True)
+
+ loss_inputs = (
+ out_dec,
+ targets_dict,
+ img_metas,
+ )
+ losses = self.loss(*loss_inputs)
+
+ return losses
+
+ def simple_test(self, img, img_metas, **kwargs):
+ """Test function with test time augmentation.
+
+ Args:
+ imgs (torch.Tensor): Image input tensor.
+ img_metas (list[dict]): List of image information.
+
+ Returns:
+ list[str]: Text label result of each image.
+ """
+ for img_meta in img_metas:
+ valid_ratio = 1.0 * img_meta['resize_shape'][1] / img.size(-1)
+ img_meta['valid_ratio'] = valid_ratio
+
+ feat = self.extract_feat(img)
+
+ out_enc = None
+ if self.encoder is not None:
+ out_enc = self.encoder(feat, img_metas)
+
+ out_dec = self.decoder(
+ feat, out_enc, None, img_metas, train_mode=False)
+
+ # early return to avoid post processing
+ if torch.onnx.is_in_onnx_export():
+ return out_dec
+
+ label_indexes, label_scores = self.label_convertor.tensor2idx(
+ out_dec, img_metas)
+ label_strings = self.label_convertor.idx2str(label_indexes)
+
+ # flatten batch results
+ results = []
+ for string, score in zip(label_strings, label_scores):
+ results.append(dict(text=string, score=score))
+
+ return results
+
+ def merge_aug_results(self, aug_results):
+ out_text, out_score = '', -1
+ for result in aug_results:
+ text = result[0]['text']
+ score = sum(result[0]['score']) / max(1, len(text))
+ if score > out_score:
+ out_text = text
+ out_score = score
+ out_results = [dict(text=out_text, score=out_score)]
+ return out_results
+
+ def aug_test(self, imgs, img_metas, **kwargs):
+ """Test function as well as time augmentation.
+
+ Args:
+ imgs (list[tensor]): Tensor should have shape NxCxHxW,
+ which contains all images in the batch.
+ img_metas (list[list[dict]]): The metadata of images.
+ """
+ aug_results = []
+ for img, img_meta in zip(imgs, img_metas):
+ result = self.simple_test(img, img_meta, **kwargs)
+ aug_results.append(result)
+
+ return self.merge_aug_results(aug_results)
diff --git a/mmocr/models/textrecog/recognizer/nrtr.py b/mmocr/models/textrecog/recognizer/nrtr.py
new file mode 100644
index 0000000000000000000000000000000000000000..36096bedc6f65d250a9af41b4970e5ccaea51301
--- /dev/null
+++ b/mmocr/models/textrecog/recognizer/nrtr.py
@@ -0,0 +1,8 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.models.builder import RECOGNIZERS
+from .encode_decode_recognizer import EncodeDecodeRecognizer
+
+
+@RECOGNIZERS.register_module()
+class NRTR(EncodeDecodeRecognizer):
+ """Implementation of `NRTR `_"""
diff --git a/mmocr/models/textrecog/recognizer/robust_scanner.py b/mmocr/models/textrecog/recognizer/robust_scanner.py
new file mode 100644
index 0000000000000000000000000000000000000000..666be91e6308c51b46cd6de1aa6af42509f3fbc6
--- /dev/null
+++ b/mmocr/models/textrecog/recognizer/robust_scanner.py
@@ -0,0 +1,11 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.models.builder import RECOGNIZERS
+from .encode_decode_recognizer import EncodeDecodeRecognizer
+
+
+@RECOGNIZERS.register_module()
+class RobustScanner(EncodeDecodeRecognizer):
+ """Implementation of `RobustScanner.
+
+
+ """
diff --git a/mmocr/models/textrecog/recognizer/sar.py b/mmocr/models/textrecog/recognizer/sar.py
new file mode 100644
index 0000000000000000000000000000000000000000..3f84cd00112a03aabf151d86396620eb4ca52e99
--- /dev/null
+++ b/mmocr/models/textrecog/recognizer/sar.py
@@ -0,0 +1,8 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.models.builder import RECOGNIZERS
+from .encode_decode_recognizer import EncodeDecodeRecognizer
+
+
+@RECOGNIZERS.register_module()
+class SARNet(EncodeDecodeRecognizer):
+ """Implementation of `SAR `_"""
diff --git a/mmocr/models/textrecog/recognizer/satrn.py b/mmocr/models/textrecog/recognizer/satrn.py
new file mode 100644
index 0000000000000000000000000000000000000000..c2d3121ba64e80d03b897603634dde8bee55bb04
--- /dev/null
+++ b/mmocr/models/textrecog/recognizer/satrn.py
@@ -0,0 +1,8 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr.models.builder import RECOGNIZERS
+from .encode_decode_recognizer import EncodeDecodeRecognizer
+
+
+@RECOGNIZERS.register_module()
+class SATRN(EncodeDecodeRecognizer):
+ """Implementation of `SATRN `_"""
diff --git a/mmocr/models/textrecog/recognizer/seg_recognizer.py b/mmocr/models/textrecog/recognizer/seg_recognizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..1746dbf98d38c47e077adfe52a7ed44a9b813f46
--- /dev/null
+++ b/mmocr/models/textrecog/recognizer/seg_recognizer.py
@@ -0,0 +1,150 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+
+from mmocr.models.builder import (RECOGNIZERS, build_backbone, build_convertor,
+ build_head, build_loss, build_neck,
+ build_preprocessor)
+from .base import BaseRecognizer
+
+
+@RECOGNIZERS.register_module()
+class SegRecognizer(BaseRecognizer):
+ """Base class for segmentation based recognizer."""
+
+ def __init__(self,
+ preprocessor=None,
+ backbone=None,
+ neck=None,
+ head=None,
+ loss=None,
+ label_convertor=None,
+ train_cfg=None,
+ test_cfg=None,
+ pretrained=None,
+ init_cfg=None):
+ super().__init__(init_cfg=init_cfg)
+
+ # Label_convertor
+ assert label_convertor is not None
+ self.label_convertor = build_convertor(label_convertor)
+
+ # Preprocessor module, e.g., TPS
+ self.preprocessor = None
+ if preprocessor is not None:
+ self.preprocessor = build_preprocessor(preprocessor)
+
+ # Backbone
+ assert backbone is not None
+ self.backbone = build_backbone(backbone)
+
+ # Neck
+ assert neck is not None
+ self.neck = build_neck(neck)
+
+ # Head
+ assert head is not None
+ head.update(num_classes=self.label_convertor.num_classes())
+ self.head = build_head(head)
+
+ # Loss
+ assert loss is not None
+ self.loss = build_loss(loss)
+
+ self.train_cfg = train_cfg
+ self.test_cfg = test_cfg
+ if pretrained is not None:
+ warnings.warn('DeprecationWarning: pretrained is a deprecated \
+ key, please consider using init_cfg')
+ self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
+
+ def extract_feat(self, img):
+ """Directly extract features from the backbone."""
+ if self.preprocessor is not None:
+ img = self.preprocessor(img)
+
+ x = self.backbone(img)
+
+ return x
+
+ def forward_train(self, img, img_metas, gt_kernels=None):
+ """
+ Args:
+ img (tensor): Input images of shape (N, C, H, W).
+ Typically these should be mean centered and std scaled.
+ img_metas (list[dict]): A list of image info dict where each dict
+ contains: 'img_shape', 'filename', and may also contain
+ 'ori_shape', and 'img_norm_cfg'.
+ For details on the values of these keys see
+ :class:`mmdet.datasets.pipelines.Collect`.
+
+ Returns:
+ dict[str, tensor]: A dictionary of loss components.
+ """
+
+ feats = self.extract_feat(img)
+
+ out_neck = self.neck(feats)
+
+ out_head = self.head(out_neck)
+
+ loss_inputs = (out_neck, out_head, gt_kernels)
+
+ losses = self.loss(*loss_inputs)
+
+ return losses
+
+ def simple_test(self, img, img_metas, **kwargs):
+ """Test function without test time augmentation.
+
+ Args:
+ imgs (torch.Tensor): Image input tensor.
+ img_metas (list[dict]): List of image information.
+
+ Returns:
+ list[str]: Text label result of each image.
+ """
+
+ feat = self.extract_feat(img)
+
+ out_neck = self.neck(feat)
+
+ out_head = self.head(out_neck)
+
+ for img_meta in img_metas:
+ valid_ratio = 1.0 * img_meta['resize_shape'][1] / img.size(-1)
+ img_meta['valid_ratio'] = valid_ratio
+
+ texts, scores = self.label_convertor.tensor2str(out_head, img_metas)
+
+ # flatten batch results
+ results = []
+ for text, score in zip(texts, scores):
+ results.append(dict(text=text, score=score))
+
+ return results
+
+ def merge_aug_results(self, aug_results):
+ out_text, out_score = '', -1
+ for result in aug_results:
+ text = result[0]['text']
+ score = sum(result[0]['score']) / max(1, len(text))
+ if score > out_score:
+ out_text = text
+ out_score = score
+ out_results = [dict(text=out_text, score=out_score)]
+ return out_results
+
+ def aug_test(self, imgs, img_metas, **kwargs):
+ """Test function with test time augmentation.
+
+ Args:
+ imgs (list[tensor]): Tensor should have shape NxCxHxW,
+ which contains all images in the batch.
+ img_metas (list[list[dict]]): The metadata of images.
+ """
+ aug_results = []
+ for img, img_meta in zip(imgs, img_metas):
+ result = self.simple_test(img, img_meta, **kwargs)
+ aug_results.append(result)
+
+ return self.merge_aug_results(aug_results)
diff --git a/mmocr/utils/__init__.py b/mmocr/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1ecb97fe5fe693dff1c259b1bc847a408932128a
--- /dev/null
+++ b/mmocr/utils/__init__.py
@@ -0,0 +1,26 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.utils import Registry, build_from_cfg
+
+from .box_util import (bezier_to_polygon, is_on_same_line, sort_points,
+ stitch_boxes_into_lines)
+from .check_argument import (equal_len, is_2dlist, is_3dlist, is_none_or_type,
+ is_type_list, valid_boundary)
+from .collect_env import collect_env
+from .data_convert_util import convert_annotations
+from .fileio import list_from_file, list_to_file
+from .img_util import drop_orientation, is_not_png
+from .lmdb_util import lmdb_converter
+from .logger import get_root_logger
+from .model import revert_sync_batchnorm
+from .setup_env import setup_multi_processes
+from .string_util import StringStrip
+
+__all__ = [
+ 'Registry', 'build_from_cfg', 'get_root_logger', 'collect_env',
+ 'is_3dlist', 'is_type_list', 'is_none_or_type', 'equal_len', 'is_2dlist',
+ 'valid_boundary', 'lmdb_converter', 'drop_orientation',
+ 'convert_annotations', 'is_not_png', 'list_to_file', 'list_from_file',
+ 'is_on_same_line', 'stitch_boxes_into_lines', 'StringStrip',
+ 'revert_sync_batchnorm', 'bezier_to_polygon', 'sort_points',
+ 'setup_multi_processes'
+]
diff --git a/mmocr/utils/box_util.py b/mmocr/utils/box_util.py
new file mode 100644
index 0000000000000000000000000000000000000000..de7be7aa645c042eede51a96f123b6775f58e4f5
--- /dev/null
+++ b/mmocr/utils/box_util.py
@@ -0,0 +1,199 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import functools
+
+import numpy as np
+
+from mmocr.utils.check_argument import is_2dlist, is_type_list
+
+
+def is_on_same_line(box_a, box_b, min_y_overlap_ratio=0.8):
+ """Check if two boxes are on the same line by their y-axis coordinates.
+
+ Two boxes are on the same line if they overlap vertically, and the length
+ of the overlapping line segment is greater than min_y_overlap_ratio * the
+ height of either of the boxes.
+
+ Args:
+ box_a (list), box_b (list): Two bounding boxes to be checked
+ min_y_overlap_ratio (float): The minimum vertical overlapping ratio
+ allowed for boxes in the same line
+
+ Returns:
+ The bool flag indicating if they are on the same line
+ """
+ a_y_min = np.min(box_a[1::2])
+ b_y_min = np.min(box_b[1::2])
+ a_y_max = np.max(box_a[1::2])
+ b_y_max = np.max(box_b[1::2])
+
+ # Make sure that box a is always the box above another
+ if a_y_min > b_y_min:
+ a_y_min, b_y_min = b_y_min, a_y_min
+ a_y_max, b_y_max = b_y_max, a_y_max
+
+ if b_y_min <= a_y_max:
+ if min_y_overlap_ratio is not None:
+ sorted_y = sorted([b_y_min, b_y_max, a_y_max])
+ overlap = sorted_y[1] - sorted_y[0]
+ min_a_overlap = (a_y_max - a_y_min) * min_y_overlap_ratio
+ min_b_overlap = (b_y_max - b_y_min) * min_y_overlap_ratio
+ return overlap >= min_a_overlap or \
+ overlap >= min_b_overlap
+ else:
+ return True
+ return False
+
+
+def stitch_boxes_into_lines(boxes, max_x_dist=10, min_y_overlap_ratio=0.8):
+ """Stitch fragmented boxes of words into lines.
+
+ Note: part of its logic is inspired by @Johndirr
+ (https://github.com/faustomorales/keras-ocr/issues/22)
+
+ Args:
+ boxes (list): List of ocr results to be stitched
+ max_x_dist (int): The maximum horizontal distance between the closest
+ edges of neighboring boxes in the same line
+ min_y_overlap_ratio (float): The minimum vertical overlapping ratio
+ allowed for any pairs of neighboring boxes in the same line
+
+ Returns:
+ merged_boxes(list[dict]): List of merged boxes and texts
+ """
+
+ if len(boxes) <= 1:
+ return boxes
+
+ merged_boxes = []
+
+ # sort groups based on the x_min coordinate of boxes
+ x_sorted_boxes = sorted(boxes, key=lambda x: np.min(x['box'][::2]))
+ # store indexes of boxes which are already parts of other lines
+ skip_idxs = set()
+
+ i = 0
+ # locate lines of boxes starting from the leftmost one
+ for i in range(len(x_sorted_boxes)):
+ if i in skip_idxs:
+ continue
+ # the rightmost box in the current line
+ rightmost_box_idx = i
+ line = [rightmost_box_idx]
+ for j in range(i + 1, len(x_sorted_boxes)):
+ if j in skip_idxs:
+ continue
+ if is_on_same_line(x_sorted_boxes[rightmost_box_idx]['box'],
+ x_sorted_boxes[j]['box'], min_y_overlap_ratio):
+ line.append(j)
+ skip_idxs.add(j)
+ rightmost_box_idx = j
+
+ # split line into lines if the distance between two neighboring
+ # sub-lines' is greater than max_x_dist
+ lines = []
+ line_idx = 0
+ lines.append([line[0]])
+ for k in range(1, len(line)):
+ curr_box = x_sorted_boxes[line[k]]
+ prev_box = x_sorted_boxes[line[k - 1]]
+ dist = np.min(curr_box['box'][::2]) - np.max(prev_box['box'][::2])
+ if dist > max_x_dist:
+ line_idx += 1
+ lines.append([])
+ lines[line_idx].append(line[k])
+
+ # Get merged boxes
+ for box_group in lines:
+ merged_box = {}
+ merged_box['text'] = ' '.join(
+ [x_sorted_boxes[idx]['text'] for idx in box_group])
+ x_min, y_min = float('inf'), float('inf')
+ x_max, y_max = float('-inf'), float('-inf')
+ for idx in box_group:
+ x_max = max(np.max(x_sorted_boxes[idx]['box'][::2]), x_max)
+ x_min = min(np.min(x_sorted_boxes[idx]['box'][::2]), x_min)
+ y_max = max(np.max(x_sorted_boxes[idx]['box'][1::2]), y_max)
+ y_min = min(np.min(x_sorted_boxes[idx]['box'][1::2]), y_min)
+ merged_box['box'] = [
+ x_min, y_min, x_max, y_min, x_max, y_max, x_min, y_max
+ ]
+ merged_boxes.append(merged_box)
+
+ return merged_boxes
+
+
+def bezier_to_polygon(bezier_points, num_sample=20):
+ """Sample points from the boundary of a polygon enclosed by two Bezier
+ curves, which are controlled by ``bezier_points``.
+
+ Args:
+ bezier_points (ndarray): A :math:`(2, 4, 2)` array of 8 Bezeir points
+ or its equalivance. The first 4 points control the curve at one
+ side and the last four control the other side.
+ num_sample (int): The number of sample points at each Bezeir curve.
+
+ Returns:
+ list[ndarray]: A list of 2*num_sample points representing the polygon
+ extracted from Bezier curves.
+
+ Warning:
+ The points are not guaranteed to be ordered. Please use
+ :func:`mmocr.utils.sort_points` to sort points if necessary.
+ """
+ assert num_sample > 0
+
+ bezier_points = np.asarray(bezier_points)
+ assert np.prod(
+ bezier_points.shape) == 16, 'Need 8 Bezier control points to continue!'
+
+ bezier = bezier_points.reshape(2, 4, 2).transpose(0, 2, 1).reshape(4, 4)
+ u = np.linspace(0, 1, num_sample)
+
+ points = np.outer((1 - u) ** 3, bezier[:, 0]) \
+ + np.outer(3 * u * ((1 - u) ** 2), bezier[:, 1]) \
+ + np.outer(3 * (u ** 2) * (1 - u), bezier[:, 2]) \
+ + np.outer(u ** 3, bezier[:, 3])
+
+ # Convert points to polygon
+ points = np.concatenate((points[:, :2], points[:, 2:]), axis=0)
+ return points.tolist()
+
+
+def sort_points(points):
+ """Sort arbitory points in clockwise order. Reference:
+ https://stackoverflow.com/a/6989383.
+
+ Args:
+ points (list[ndarray] or ndarray or list[list]): A list of unsorted
+ boundary points.
+
+ Returns:
+ list[ndarray]: A list of points sorted in clockwise order.
+ """
+
+ assert is_type_list(points, np.ndarray) or isinstance(points, np.ndarray) \
+ or is_2dlist(points)
+
+ points = np.array(points)
+ center = np.mean(points, axis=0)
+
+ def cmp(a, b):
+ oa = a - center
+ ob = b - center
+
+ # Some corner cases
+ if oa[0] >= 0 and ob[0] < 0:
+ return 1
+ if oa[0] < 0 and ob[0] >= 0:
+ return -1
+
+ prod = np.cross(oa, ob)
+ if prod > 0:
+ return 1
+ if prod < 0:
+ return -1
+
+ # a, b are on the same line from the center
+ return 1 if (oa**2).sum() < (ob**2).sum() else -1
+
+ return sorted(points, key=functools.cmp_to_key(cmp))
diff --git a/mmocr/utils/check_argument.py b/mmocr/utils/check_argument.py
new file mode 100644
index 0000000000000000000000000000000000000000..34cbe8dc2658d725c328eb5cd98652633a22aa24
--- /dev/null
+++ b/mmocr/utils/check_argument.py
@@ -0,0 +1,72 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+
+def is_3dlist(x):
+ """check x is 3d-list([[[1], []]]) or 2d empty list([[], []]) or 1d empty
+ list([]).
+
+ Notice:
+ The reason that it contains 1d or 2d empty list is because
+ some arguments from gt annotation file or model prediction
+ may be empty, but usually, it should be 3d-list.
+ """
+ if not isinstance(x, list):
+ return False
+ if len(x) == 0:
+ return True
+ for sub_x in x:
+ if not is_2dlist(sub_x):
+ return False
+
+ return True
+
+
+def is_2dlist(x):
+ """check x is 2d-list([[1], []]) or 1d empty list([]).
+
+ Notice:
+ The reason that it contains 1d empty list is because
+ some arguments from gt annotation file or model prediction
+ may be empty, but usually, it should be 2d-list.
+ """
+ if not isinstance(x, list):
+ return False
+ if len(x) == 0:
+ return True
+
+ return all(isinstance(item, list) for item in x)
+
+
+def is_type_list(x, type):
+
+ if not isinstance(x, list):
+ return False
+
+ return all(isinstance(item, type) for item in x)
+
+
+def is_none_or_type(x, type):
+
+ return isinstance(x, type) or x is None
+
+
+def equal_len(*argv):
+ assert len(argv) > 0
+
+ num_arg = len(argv[0])
+ for arg in argv:
+ if len(arg) != num_arg:
+ return False
+ return True
+
+
+def valid_boundary(x, with_score=True):
+ num = len(x)
+ if num < 8:
+ return False
+ if num % 2 == 0 and (not with_score):
+ return True
+ if num % 2 == 1 and with_score:
+ return True
+
+ return False
diff --git a/mmocr/utils/collect_env.py b/mmocr/utils/collect_env.py
new file mode 100644
index 0000000000000000000000000000000000000000..a8cb3c40c17edcaea8c7a5a7842e56dca2039ffc
--- /dev/null
+++ b/mmocr/utils/collect_env.py
@@ -0,0 +1,17 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmcv.utils import collect_env as collect_base_env
+from mmcv.utils import get_git_hash
+
+import mmocr
+
+
+def collect_env():
+ """Collect the information of the running environments."""
+ env_info = collect_base_env()
+ env_info['MMOCR'] = mmocr.__version__ + '+' + get_git_hash()[:7]
+ return env_info
+
+
+if __name__ == '__main__':
+ for name, val in collect_env().items():
+ print(f'{name}: {val}')
diff --git a/mmocr/utils/data_convert_util.py b/mmocr/utils/data_convert_util.py
new file mode 100644
index 0000000000000000000000000000000000000000..77580fc766f1f079f00b805e3a9deceef4623432
--- /dev/null
+++ b/mmocr/utils/data_convert_util.py
@@ -0,0 +1,42 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import mmcv
+
+
+def convert_annotations(image_infos, out_json_name):
+ """Convert the annotation into coco style.
+
+ Args:
+ image_infos(list): The list of image information dicts
+ out_json_name(str): The output json filename
+
+ Returns:
+ out_json(dict): The coco style dict
+ """
+ assert isinstance(image_infos, list)
+ assert isinstance(out_json_name, str)
+ assert out_json_name
+
+ out_json = dict()
+ img_id = 0
+ ann_id = 0
+ out_json['images'] = []
+ out_json['categories'] = []
+ out_json['annotations'] = []
+ for image_info in image_infos:
+ image_info['id'] = img_id
+ anno_infos = image_info.pop('anno_info')
+ out_json['images'].append(image_info)
+ for anno_info in anno_infos:
+ anno_info['image_id'] = img_id
+ anno_info['id'] = ann_id
+ out_json['annotations'].append(anno_info)
+ ann_id += 1
+ img_id += 1
+ cat = dict(id=1, name='text')
+ out_json['categories'].append(cat)
+
+ if len(out_json['annotations']) == 0:
+ out_json.pop('annotations')
+ mmcv.dump(out_json, out_json_name)
+
+ return out_json
diff --git a/mmocr/utils/fileio.py b/mmocr/utils/fileio.py
new file mode 100644
index 0000000000000000000000000000000000000000..2e455daf46261f89a02d56a04f1bc867058ffb1a
--- /dev/null
+++ b/mmocr/utils/fileio.py
@@ -0,0 +1,38 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+
+import mmcv
+
+
+def list_to_file(filename, lines):
+ """Write a list of strings to a text file.
+
+ Args:
+ filename (str): The output filename. It will be created/overwritten.
+ lines (list(str)): Data to be written.
+ """
+ mmcv.mkdir_or_exist(os.path.dirname(filename))
+ with open(filename, 'w', encoding='utf-8') as fw:
+ for line in lines:
+ fw.write(f'{line}\n')
+
+
+def list_from_file(filename, encoding='utf-8'):
+ """Load a text file and parse the content as a list of strings. The
+ trailing "\\r" and "\\n" of each line will be removed.
+
+ Note:
+ This will be replaced by mmcv's version after it supports encoding.
+
+ Args:
+ filename (str): Filename.
+ encoding (str): Encoding used to open the file. Default utf-8.
+
+ Returns:
+ list[str]: A list of strings.
+ """
+ item_list = []
+ with open(filename, 'r', encoding=encoding) as f:
+ for line in f:
+ item_list.append(line.rstrip('\n\r'))
+ return item_list
diff --git a/mmocr/utils/img_util.py b/mmocr/utils/img_util.py
new file mode 100644
index 0000000000000000000000000000000000000000..0804cfa006cca84a583a791116459e109de407a4
--- /dev/null
+++ b/mmocr/utils/img_util.py
@@ -0,0 +1,52 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+
+import mmcv
+
+
+def drop_orientation(img_file):
+ """Check if the image has orientation information. If yes, ignore it by
+ converting the image format to png, and return new filename, otherwise
+ return the original filename.
+
+ Args:
+ img_file(str): The image path
+
+ Returns:
+ The converted image filename with proper postfix
+ """
+ assert isinstance(img_file, str)
+ assert img_file
+
+ # read imgs with ignoring orientations
+ img = mmcv.imread(img_file, 'unchanged')
+ # read imgs with orientations as dataloader does when training and testing
+ img_color = mmcv.imread(img_file, 'color')
+ # make sure imgs have no orientation info, or annotation gt is wrong.
+ if img.shape[:2] == img_color.shape[:2]:
+ return img_file
+
+ target_file = os.path.splitext(img_file)[0] + '.png'
+ # read img with ignoring orientation information
+ img = mmcv.imread(img_file, 'unchanged')
+ mmcv.imwrite(img, target_file)
+ os.remove(img_file)
+ print(f'{img_file} has orientation info. Ignore it by converting to png')
+ return target_file
+
+
+def is_not_png(img_file):
+ """Check img_file is not png image.
+
+ Args:
+ img_file(str): The input image file name
+
+ Returns:
+ The bool flag indicating whether it is not png
+ """
+ assert isinstance(img_file, str)
+ assert img_file
+
+ suffix = os.path.splitext(img_file)[1]
+
+ return suffix not in ['.PNG', '.png']
diff --git a/mmocr/utils/lmdb_util.py b/mmocr/utils/lmdb_util.py
new file mode 100644
index 0000000000000000000000000000000000000000..ea890ff687d4760296b56c4b46b649a2969908c3
--- /dev/null
+++ b/mmocr/utils/lmdb_util.py
@@ -0,0 +1,52 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import shutil
+import sys
+import time
+from pathlib import Path
+
+import lmdb
+
+from mmocr.utils import list_from_file
+
+
+def lmdb_converter(img_list_file,
+ output,
+ batch_size=1000,
+ coding='utf-8',
+ lmdb_map_size=109951162776):
+ # read img_list_file
+ lines = list_from_file(img_list_file)
+
+ # create lmdb database
+ if Path(output).is_dir():
+ while True:
+ print('%s already exist, delete or not? [Y/n]' % output)
+ Yn = input().strip()
+ if Yn in ['Y', 'y']:
+ shutil.rmtree(output)
+ break
+ if Yn in ['N', 'n']:
+ return
+ print('create database %s' % output)
+ Path(output).mkdir(parents=True, exist_ok=False)
+ env = lmdb.open(output, map_size=lmdb_map_size)
+
+ # build lmdb
+ beg_time = time.strftime('%H:%M:%S')
+ for beg_index in range(0, len(lines), batch_size):
+ end_index = min(beg_index + batch_size, len(lines))
+ sys.stdout.write('\r[%s-%s], processing [%d-%d] / %d' %
+ (beg_time, time.strftime('%H:%M:%S'), beg_index,
+ end_index, len(lines)))
+ sys.stdout.flush()
+ batch = [(str(index).encode(coding), lines[index].encode(coding))
+ for index in range(beg_index, end_index)]
+ with env.begin(write=True) as txn:
+ cursor = txn.cursor()
+ cursor.putmulti(batch, dupdata=False, overwrite=True)
+ sys.stdout.write('\n')
+ with env.begin(write=True) as txn:
+ key = 'total_number'.encode(coding)
+ value = str(len(lines)).encode(coding)
+ txn.put(key, value)
+ print('done', flush=True)
diff --git a/mmocr/utils/logger.py b/mmocr/utils/logger.py
new file mode 100644
index 0000000000000000000000000000000000000000..294837fa6aec1e1896de8c8accf470f366f81296
--- /dev/null
+++ b/mmocr/utils/logger.py
@@ -0,0 +1,25 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import logging
+
+from mmcv.utils import get_logger
+
+
+def get_root_logger(log_file=None, log_level=logging.INFO):
+ """Use `get_logger` method in mmcv to get the root logger.
+
+ The logger will be initialized if it has not been initialized. By default a
+ StreamHandler will be added. If `log_file` is specified, a FileHandler will
+ also be added. The name of the root logger is the top-level package name,
+ e.g., "mmpose".
+
+ Args:
+ log_file (str | None): The log filename. If specified, a FileHandler
+ will be added to the root logger.
+ log_level (int): The root logger level. Note that only the process of
+ rank 0 is affected, while other processes will set the level to
+ "Error" and be silent most of the time.
+
+ Returns:
+ logging.Logger: The root logger.
+ """
+ return get_logger(__name__.split('.')[0], log_file, log_level)
diff --git a/mmocr/utils/model.py b/mmocr/utils/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..4a126006b69c70d7780a310de46c0c2e0a0495ba
--- /dev/null
+++ b/mmocr/utils/model.py
@@ -0,0 +1,51 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+
+class _BatchNormXd(torch.nn.modules.batchnorm._BatchNorm):
+ """A general BatchNorm layer without input dimension check.
+
+ Reproduced from @kapily's work:
+ (https://github.com/pytorch/pytorch/issues/41081#issuecomment-783961547)
+ The only difference between BatchNorm1d, BatchNorm2d, BatchNorm3d, etc
+ is `_check_input_dim` that is designed for tensor sanity checks.
+ The check has been bypassed in this class for the convenience of converting
+ SyncBatchNorm.
+ """
+
+ def _check_input_dim(self, input):
+ return
+
+
+def revert_sync_batchnorm(module):
+ """Helper function to convert all `SyncBatchNorm` layers in the model to
+ `BatchNormXd` layers.
+
+ Adapted from @kapily's work:
+ (https://github.com/pytorch/pytorch/issues/41081#issuecomment-783961547)
+
+ Args:
+ module (nn.Module): The module containing `SyncBatchNorm` layers.
+
+ Returns:
+ module_output: The converted module with `BatchNormXd` layers.
+ """
+ module_output = module
+ if isinstance(module, torch.nn.modules.batchnorm.SyncBatchNorm):
+ module_output = _BatchNormXd(module.num_features, module.eps,
+ module.momentum, module.affine,
+ module.track_running_stats)
+ if module.affine:
+ with torch.no_grad():
+ module_output.weight = module.weight
+ module_output.bias = module.bias
+ module_output.running_mean = module.running_mean
+ module_output.running_var = module.running_var
+ module_output.num_batches_tracked = module.num_batches_tracked
+ module_output.training = module.training
+ if hasattr(module, 'qconfig'):
+ module_output.qconfig = module.qconfig
+ for name, child in module.named_children():
+ module_output.add_module(name, revert_sync_batchnorm(child))
+ del module
+ return module_output
diff --git a/mmocr/utils/ocr.py b/mmocr/utils/ocr.py
new file mode 100755
index 0000000000000000000000000000000000000000..d99dbe69a2589b258aeda0da338be7e966d72d0d
--- /dev/null
+++ b/mmocr/utils/ocr.py
@@ -0,0 +1,720 @@
+#!/usr/bin/env python
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import os
+import warnings
+from argparse import ArgumentParser, Namespace
+from pathlib import Path
+
+import mmcv
+import numpy as np
+import torch
+from mmcv.image.misc import tensor2imgs
+from mmcv.runner import load_checkpoint
+from mmcv.utils.config import Config
+
+from mmocr.apis import init_detector
+from mmocr.apis.inference import model_inference
+from mmocr.core.visualize import det_recog_show_result
+from mmocr.datasets.kie_dataset import KIEDataset
+from mmocr.datasets.pipelines.crop import crop_img
+from mmocr.models import build_detector
+from mmocr.utils.box_util import stitch_boxes_into_lines
+from mmocr.utils.fileio import list_from_file
+from mmocr.utils.model import revert_sync_batchnorm
+
+
+# Parse CLI arguments
+def parse_args():
+ parser = ArgumentParser()
+ parser.add_argument(
+ 'img', type=str, help='Input image file or folder path.')
+ parser.add_argument(
+ '--output',
+ type=str,
+ default='',
+ help='Output file/folder name for visualization')
+ parser.add_argument(
+ '--det',
+ type=str,
+ default='PANet_IC15',
+ help='Pretrained text detection algorithm')
+ parser.add_argument(
+ '--det-config',
+ type=str,
+ default='',
+ help='Path to the custom config file of the selected det model. It '
+ 'overrides the settings in det')
+ parser.add_argument(
+ '--det-ckpt',
+ type=str,
+ default='',
+ help='Path to the custom checkpoint file of the selected det model. '
+ 'It overrides the settings in det')
+ parser.add_argument(
+ '--recog',
+ type=str,
+ default='SEG',
+ help='Pretrained text recognition algorithm')
+ parser.add_argument(
+ '--recog-config',
+ type=str,
+ default='',
+ help='Path to the custom config file of the selected recog model. It'
+ 'overrides the settings in recog')
+ parser.add_argument(
+ '--recog-ckpt',
+ type=str,
+ default='',
+ help='Path to the custom checkpoint file of the selected recog model. '
+ 'It overrides the settings in recog')
+ parser.add_argument(
+ '--kie',
+ type=str,
+ default='',
+ help='Pretrained key information extraction algorithm')
+ parser.add_argument(
+ '--kie-config',
+ type=str,
+ default='',
+ help='Path to the custom config file of the selected kie model. It'
+ 'overrides the settings in kie')
+ parser.add_argument(
+ '--kie-ckpt',
+ type=str,
+ default='',
+ help='Path to the custom checkpoint file of the selected kie model. '
+ 'It overrides the settings in kie')
+ parser.add_argument(
+ '--config-dir',
+ type=str,
+ default=os.path.join(str(Path.cwd()), 'configs/'),
+ help='Path to the config directory where all the config files '
+ 'are located. Defaults to "configs/"')
+ parser.add_argument(
+ '--batch-mode',
+ action='store_true',
+ help='Whether use batch mode for inference')
+ parser.add_argument(
+ '--recog-batch-size',
+ type=int,
+ default=0,
+ help='Batch size for text recognition')
+ parser.add_argument(
+ '--det-batch-size',
+ type=int,
+ default=0,
+ help='Batch size for text detection')
+ parser.add_argument(
+ '--single-batch-size',
+ type=int,
+ default=0,
+ help='Batch size for separate det/recog inference')
+ parser.add_argument(
+ '--device', default=None, help='Device used for inference.')
+ parser.add_argument(
+ '--export',
+ type=str,
+ default='',
+ help='Folder where the results of each image are exported')
+ parser.add_argument(
+ '--export-format',
+ type=str,
+ default='json',
+ help='Format of the exported result file(s)')
+ parser.add_argument(
+ '--details',
+ action='store_true',
+ help='Whether include the text boxes coordinates and confidence values'
+ )
+ parser.add_argument(
+ '--imshow',
+ action='store_true',
+ help='Whether show image with OpenCV.')
+ parser.add_argument(
+ '--print-result',
+ action='store_true',
+ help='Prints the recognised text')
+ parser.add_argument(
+ '--merge', action='store_true', help='Merge neighboring boxes')
+ parser.add_argument(
+ '--merge-xdist',
+ type=float,
+ default=20,
+ help='The maximum x-axis distance to merge boxes')
+ args = parser.parse_args()
+ if args.det == 'None':
+ args.det = None
+ if args.recog == 'None':
+ args.recog = None
+ # Warnings
+ if args.merge and not (args.det and args.recog):
+ warnings.warn(
+ 'Box merging will not work if the script is not'
+ ' running in detection + recognition mode.', UserWarning)
+ if not os.path.samefile(args.config_dir, os.path.join(str(
+ Path.cwd()))) and (args.det_config != ''
+ or args.recog_config != ''):
+ warnings.warn(
+ 'config_dir will be overridden by det-config or recog-config.',
+ UserWarning)
+ return args
+
+
+class MMOCR:
+
+ def __init__(self,
+ det='PANet_IC15',
+ det_config='',
+ det_ckpt='',
+ recog='SEG',
+ recog_config='',
+ recog_ckpt='',
+ kie='',
+ kie_config='',
+ kie_ckpt='',
+ config_dir=os.path.join(str(Path.cwd()), 'configs/'),
+ device=None,
+ **kwargs):
+
+ textdet_models = {
+ 'DB_r18': {
+ 'config':
+ 'dbnet/dbnet_r18_fpnc_1200e_icdar2015.py',
+ 'ckpt':
+ 'dbnet/'
+ 'dbnet_r18_fpnc_sbn_1200e_icdar2015_20210329-ba3ab597.pth'
+ },
+ 'DB_r50': {
+ 'config':
+ 'dbnet/dbnet_r50dcnv2_fpnc_1200e_icdar2015.py',
+ 'ckpt':
+ 'dbnet/'
+ 'dbnet_r50dcnv2_fpnc_sbn_1200e_icdar2015_20211025-9fe3b590.pth'
+ },
+ 'DRRG': {
+ 'config':
+ 'drrg/drrg_r50_fpn_unet_1200e_ctw1500.py',
+ 'ckpt':
+ 'drrg/drrg_r50_fpn_unet_1200e_ctw1500_20211022-fb30b001.pth'
+ },
+ 'FCE_IC15': {
+ 'config':
+ 'fcenet/fcenet_r50_fpn_1500e_icdar2015.py',
+ 'ckpt':
+ 'fcenet/fcenet_r50_fpn_1500e_icdar2015_20211022-daefb6ed.pth'
+ },
+ 'FCE_CTW_DCNv2': {
+ 'config':
+ 'fcenet/fcenet_r50dcnv2_fpn_1500e_ctw1500.py',
+ 'ckpt':
+ 'fcenet/' +
+ 'fcenet_r50dcnv2_fpn_1500e_ctw1500_20211022-e326d7ec.pth'
+ },
+ 'MaskRCNN_CTW': {
+ 'config':
+ 'maskrcnn/mask_rcnn_r50_fpn_160e_ctw1500.py',
+ 'ckpt':
+ 'maskrcnn/'
+ 'mask_rcnn_r50_fpn_160e_ctw1500_20210219-96497a76.pth'
+ },
+ 'MaskRCNN_IC15': {
+ 'config':
+ 'maskrcnn/mask_rcnn_r50_fpn_160e_icdar2015.py',
+ 'ckpt':
+ 'maskrcnn/'
+ 'mask_rcnn_r50_fpn_160e_icdar2015_20210219-8eb340a3.pth'
+ },
+ 'MaskRCNN_IC17': {
+ 'config':
+ 'maskrcnn/mask_rcnn_r50_fpn_160e_icdar2017.py',
+ 'ckpt':
+ 'maskrcnn/'
+ 'mask_rcnn_r50_fpn_160e_icdar2017_20210218-c6ec3ebb.pth'
+ },
+ 'PANet_CTW': {
+ 'config':
+ 'panet/panet_r18_fpem_ffm_600e_ctw1500.py',
+ 'ckpt':
+ 'panet/'
+ 'panet_r18_fpem_ffm_sbn_600e_ctw1500_20210219-3b3a9aa3.pth'
+ },
+ 'PANet_IC15': {
+ 'config':
+ 'panet/panet_r18_fpem_ffm_600e_icdar2015.py',
+ 'ckpt':
+ 'panet/'
+ 'panet_r18_fpem_ffm_sbn_600e_icdar2015_20210219-42dbe46a.pth'
+ },
+ 'PS_CTW': {
+ 'config': 'psenet/psenet_r50_fpnf_600e_ctw1500.py',
+ 'ckpt':
+ 'psenet/psenet_r50_fpnf_600e_ctw1500_20210401-216fed50.pth'
+ },
+ 'PS_IC15': {
+ 'config':
+ 'psenet/psenet_r50_fpnf_600e_icdar2015.py',
+ 'ckpt':
+ 'psenet/psenet_r50_fpnf_600e_icdar2015_pretrain-eefd8fe6.pth'
+ },
+ 'TextSnake': {
+ 'config':
+ 'textsnake/textsnake_r50_fpn_unet_1200e_ctw1500.py',
+ 'ckpt':
+ 'textsnake/textsnake_r50_fpn_unet_1200e_ctw1500-27f65b64.pth'
+ }
+ }
+
+ textrecog_models = {
+ 'CRNN': {
+ 'config': 'crnn/crnn_academic_dataset.py',
+ 'ckpt': 'crnn/crnn_academic-a723a1c5.pth'
+ },
+ 'SAR': {
+ 'config': 'sar/sar_r31_parallel_decoder_academic.py',
+ 'ckpt': 'sar/sar_r31_parallel_decoder_academic-dba3a4a3.pth'
+ },
+ 'SAR_CN': {
+ 'config':
+ 'sar/sar_r31_parallel_decoder_chinese.py',
+ 'ckpt':
+ 'sar/sar_r31_parallel_decoder_chineseocr_20210507-b4be8214.pth'
+ },
+ 'NRTR_1/16-1/8': {
+ 'config': 'nrtr/nrtr_r31_1by16_1by8_academic.py',
+ 'ckpt':
+ 'nrtr/nrtr_r31_1by16_1by8_academic_20211124-f60cebf4.pth'
+ },
+ 'NRTR_1/8-1/4': {
+ 'config': 'nrtr/nrtr_r31_1by8_1by4_academic.py',
+ 'ckpt':
+ 'nrtr/nrtr_r31_1by8_1by4_academic_20211123-e1fdb322.pth'
+ },
+ 'RobustScanner': {
+ 'config': 'robust_scanner/robustscanner_r31_academic.py',
+ 'ckpt': 'robustscanner/robustscanner_r31_academic-5f05874f.pth'
+ },
+ 'SATRN': {
+ 'config': 'satrn/satrn_academic.py',
+ 'ckpt': 'satrn/satrn_academic_20211009-cb8b1580.pth'
+ },
+ 'SATRN_sm': {
+ 'config': 'satrn/satrn_small.py',
+ 'ckpt': 'satrn/satrn_small_20211009-2cf13355.pth'
+ },
+ 'ABINet': {
+ 'config': 'abinet/abinet_academic.py',
+ 'ckpt': 'abinet/abinet_academic-f718abf6.pth'
+ },
+ 'SEG': {
+ 'config': 'seg/seg_r31_1by16_fpnocr_academic.py',
+ 'ckpt': 'seg/seg_r31_1by16_fpnocr_academic-72235b11.pth'
+ },
+ 'CRNN_TPS': {
+ 'config': 'tps/crnn_tps_academic_dataset.py',
+ 'ckpt': 'tps/crnn_tps_academic_dataset_20210510-d221a905.pth'
+ }
+ }
+
+ kie_models = {
+ 'SDMGR': {
+ 'config': 'sdmgr/sdmgr_unet16_60e_wildreceipt.py',
+ 'ckpt':
+ 'sdmgr/sdmgr_unet16_60e_wildreceipt_20210520-7489e6de.pth'
+ }
+ }
+
+ self.td = det
+ self.tr = recog
+ self.kie = kie
+ self.device = device
+ if self.device is None:
+ self.device = torch.device(
+ 'cuda' if torch.cuda.is_available() else 'cpu')
+
+ # Check if the det/recog model choice is valid
+ if self.td and self.td not in textdet_models:
+ raise ValueError(self.td,
+ 'is not a supported text detection algorthm')
+ elif self.tr and self.tr not in textrecog_models:
+ raise ValueError(self.tr,
+ 'is not a supported text recognition algorithm')
+ elif self.kie:
+ if self.kie not in kie_models:
+ raise ValueError(
+ self.kie, 'is not a supported key information extraction'
+ ' algorithm')
+ elif not (self.td and self.tr):
+ raise NotImplementedError(
+ self.kie, 'has to run together'
+ ' with text detection and recognition algorithms.')
+
+ self.detect_model = None
+ if self.td:
+ # Build detection model
+ if not det_config:
+ det_config = os.path.join(config_dir, 'textdet/',
+ textdet_models[self.td]['config'])
+ if not det_ckpt:
+ det_ckpt = 'https://download.openmmlab.com/mmocr/textdet/' + \
+ textdet_models[self.td]['ckpt']
+
+ self.detect_model = init_detector(
+ det_config, det_ckpt, device=self.device)
+ self.detect_model = revert_sync_batchnorm(self.detect_model)
+
+ self.recog_model = None
+ if self.tr:
+ # Build recognition model
+ if not recog_config:
+ recog_config = os.path.join(
+ config_dir, 'textrecog/',
+ textrecog_models[self.tr]['config'])
+ if not recog_ckpt:
+ recog_ckpt = 'https://download.openmmlab.com/mmocr/' + \
+ 'textrecog/' + textrecog_models[self.tr]['ckpt']
+
+ self.recog_model = init_detector(
+ recog_config, recog_ckpt, device=self.device)
+ self.recog_model = revert_sync_batchnorm(self.recog_model)
+
+ self.kie_model = None
+ if self.kie:
+ # Build key information extraction model
+ if not kie_config:
+ kie_config = os.path.join(config_dir, 'kie/',
+ kie_models[self.kie]['config'])
+ if not kie_ckpt:
+ kie_ckpt = 'https://download.openmmlab.com/mmocr/' + \
+ 'kie/' + kie_models[self.kie]['ckpt']
+
+ kie_cfg = Config.fromfile(kie_config)
+ self.kie_model = build_detector(
+ kie_cfg.model, test_cfg=kie_cfg.get('test_cfg'))
+ self.kie_model = revert_sync_batchnorm(self.kie_model)
+ self.kie_model.cfg = kie_cfg
+ load_checkpoint(self.kie_model, kie_ckpt, map_location=self.device)
+
+ # Attribute check
+ for model in list(filter(None, [self.recog_model, self.detect_model])):
+ if hasattr(model, 'module'):
+ model = model.module
+
+ def readtext(self,
+ img,
+ output=None,
+ details=False,
+ export=None,
+ export_format='json',
+ batch_mode=False,
+ recog_batch_size=0,
+ det_batch_size=0,
+ single_batch_size=0,
+ imshow=False,
+ print_result=False,
+ merge=False,
+ merge_xdist=20,
+ **kwargs):
+ args = locals().copy()
+ [args.pop(x, None) for x in ['kwargs', 'self']]
+ args = Namespace(**args)
+
+ # Input and output arguments processing
+ self._args_processing(args)
+ self.args = args
+
+ pp_result = None
+
+ # Send args and models to the MMOCR model inference API
+ # and call post-processing functions for the output
+ if self.detect_model and self.recog_model:
+ det_recog_result = self.det_recog_kie_inference(
+ self.detect_model, self.recog_model, kie_model=self.kie_model)
+ pp_result = self.det_recog_pp(det_recog_result)
+ else:
+ for model in list(
+ filter(None, [self.recog_model, self.detect_model])):
+ result = self.single_inference(model, args.arrays,
+ args.batch_mode,
+ args.single_batch_size)
+ pp_result = self.single_pp(result, model)
+
+ return pp_result
+
+ # Post processing function for end2end ocr
+ def det_recog_pp(self, result):
+ final_results = []
+ args = self.args
+ for arr, output, export, det_recog_result in zip(
+ args.arrays, args.output, args.export, result):
+ if output or args.imshow:
+ if self.kie_model:
+ res_img = det_recog_show_result(arr, det_recog_result)
+ else:
+ res_img = det_recog_show_result(
+ arr, det_recog_result, out_file=output)
+ if args.imshow and not self.kie_model:
+ mmcv.imshow(res_img, 'inference results')
+ if not args.details:
+ simple_res = {}
+ simple_res['filename'] = det_recog_result['filename']
+ simple_res['text'] = [
+ x['text'] for x in det_recog_result['result']
+ ]
+ final_result = simple_res
+ else:
+ final_result = det_recog_result
+ if export:
+ mmcv.dump(final_result, export, indent=4)
+ if args.print_result:
+ print(final_result, end='\n\n')
+ final_results.append(final_result)
+ return final_results
+
+ # Post processing function for separate det/recog inference
+ def single_pp(self, result, model):
+ for arr, output, export, res in zip(self.args.arrays, self.args.output,
+ self.args.export, result):
+ if export:
+ mmcv.dump(res, export, indent=4)
+ if output or self.args.imshow:
+ res_img = model.show_result(arr, res, out_file=output)
+ if self.args.imshow:
+ mmcv.imshow(res_img, 'inference results')
+ if self.args.print_result:
+ print(res, end='\n\n')
+ return result
+
+ def generate_kie_labels(self, result, boxes, class_list):
+ idx_to_cls = {}
+ if class_list is not None:
+ for line in list_from_file(class_list):
+ class_idx, class_label = line.strip().split()
+ idx_to_cls[class_idx] = class_label
+
+ max_value, max_idx = torch.max(result['nodes'].detach().cpu(), -1)
+ node_pred_label = max_idx.numpy().tolist()
+ node_pred_score = max_value.numpy().tolist()
+ labels = []
+ for i in range(len(boxes)):
+ pred_label = str(node_pred_label[i])
+ if pred_label in idx_to_cls:
+ pred_label = idx_to_cls[pred_label]
+ pred_score = node_pred_score[i]
+ labels.append((pred_label, pred_score))
+ return labels
+
+ def visualize_kie_output(self,
+ model,
+ data,
+ result,
+ out_file=None,
+ show=False):
+ """Visualizes KIE output."""
+ img_tensor = data['img'].data
+ img_meta = data['img_metas'].data
+ gt_bboxes = data['gt_bboxes'].data.numpy().tolist()
+ if img_tensor.dtype == torch.uint8:
+ # The img tensor is the raw input not being normalized
+ # (For SDMGR non-visual)
+ img = img_tensor.cpu().numpy().transpose(1, 2, 0)
+ else:
+ img = tensor2imgs(
+ img_tensor.unsqueeze(0), **img_meta.get('img_norm_cfg', {}))[0]
+ h, w, _ = img_meta.get('img_shape', img.shape)
+ img_show = img[:h, :w, :]
+ model.show_result(
+ img_show, result, gt_bboxes, show=show, out_file=out_file)
+
+ # End2end ocr inference pipeline
+ def det_recog_kie_inference(self, det_model, recog_model, kie_model=None):
+ end2end_res = []
+ # Find bounding boxes in the images (text detection)
+ det_result = self.single_inference(det_model, self.args.arrays,
+ self.args.batch_mode,
+ self.args.det_batch_size)
+ bboxes_list = [res['boundary_result'] for res in det_result]
+
+ if kie_model:
+ kie_dataset = KIEDataset(
+ dict_file=kie_model.cfg.data.test.dict_file)
+
+ # For each bounding box, the image is cropped and
+ # sent to the recognition model either one by one
+ # or all together depending on the batch_mode
+ for filename, arr, bboxes, out_file in zip(self.args.filenames,
+ self.args.arrays,
+ bboxes_list,
+ self.args.output):
+ img_e2e_res = {}
+ img_e2e_res['filename'] = filename
+ img_e2e_res['result'] = []
+ box_imgs = []
+ for bbox in bboxes:
+ box_res = {}
+ box_res['box'] = [round(x) for x in bbox[:-1]]
+ box_res['box_score'] = float(bbox[-1])
+ box = bbox[:8]
+ if len(bbox) > 9:
+ min_x = min(bbox[0:-1:2])
+ min_y = min(bbox[1:-1:2])
+ max_x = max(bbox[0:-1:2])
+ max_y = max(bbox[1:-1:2])
+ box = [
+ min_x, min_y, max_x, min_y, max_x, max_y, min_x, max_y
+ ]
+ box_img = crop_img(arr, box)
+ if self.args.batch_mode:
+ box_imgs.append(box_img)
+ else:
+ recog_result = model_inference(recog_model, box_img)
+ text = recog_result['text']
+ text_score = recog_result['score']
+ if isinstance(text_score, list):
+ text_score = sum(text_score) / max(1, len(text))
+ box_res['text'] = text
+ box_res['text_score'] = text_score
+ img_e2e_res['result'].append(box_res)
+
+ if self.args.batch_mode:
+ recog_results = self.single_inference(
+ recog_model, box_imgs, True, self.args.recog_batch_size)
+ for i, recog_result in enumerate(recog_results):
+ text = recog_result['text']
+ text_score = recog_result['score']
+ if isinstance(text_score, (list, tuple)):
+ text_score = sum(text_score) / max(1, len(text))
+ img_e2e_res['result'][i]['text'] = text
+ img_e2e_res['result'][i]['text_score'] = text_score
+
+ if self.args.merge:
+ img_e2e_res['result'] = stitch_boxes_into_lines(
+ img_e2e_res['result'], self.args.merge_xdist, 0.5)
+
+ if kie_model:
+ annotations = copy.deepcopy(img_e2e_res['result'])
+ # Customized for kie_dataset, which
+ # assumes that boxes are represented by only 4 points
+ for i, ann in enumerate(annotations):
+ min_x = min(ann['box'][::2])
+ min_y = min(ann['box'][1::2])
+ max_x = max(ann['box'][::2])
+ max_y = max(ann['box'][1::2])
+ annotations[i]['box'] = [
+ min_x, min_y, max_x, min_y, max_x, max_y, min_x, max_y
+ ]
+ ann_info = kie_dataset._parse_anno_info(annotations)
+ ann_info['ori_bboxes'] = ann_info.get('ori_bboxes',
+ ann_info['bboxes'])
+ ann_info['gt_bboxes'] = ann_info.get('gt_bboxes',
+ ann_info['bboxes'])
+ kie_result, data = model_inference(
+ kie_model,
+ arr,
+ ann=ann_info,
+ return_data=True,
+ batch_mode=self.args.batch_mode)
+ # visualize KIE results
+ self.visualize_kie_output(
+ kie_model,
+ data,
+ kie_result,
+ out_file=out_file,
+ show=self.args.imshow)
+ gt_bboxes = data['gt_bboxes'].data.numpy().tolist()
+ labels = self.generate_kie_labels(kie_result, gt_bboxes,
+ kie_model.class_list)
+ for i in range(len(gt_bboxes)):
+ img_e2e_res['result'][i]['label'] = labels[i][0]
+ img_e2e_res['result'][i]['label_score'] = labels[i][1]
+
+ end2end_res.append(img_e2e_res)
+ return end2end_res
+
+ # Separate det/recog inference pipeline
+ def single_inference(self, model, arrays, batch_mode, batch_size=0):
+ result = []
+ if batch_mode:
+ if batch_size == 0:
+ result = model_inference(model, arrays, batch_mode=True)
+ else:
+ n = batch_size
+ arr_chunks = [
+ arrays[i:i + n] for i in range(0, len(arrays), n)
+ ]
+ for chunk in arr_chunks:
+ result.extend(
+ model_inference(model, chunk, batch_mode=True))
+ else:
+ for arr in arrays:
+ result.append(model_inference(model, arr, batch_mode=False))
+ return result
+
+ # Arguments pre-processing function
+ def _args_processing(self, args):
+ # Check if the input is a list/tuple that
+ # contains only np arrays or strings
+ if isinstance(args.img, (list, tuple)):
+ img_list = args.img
+ if not all([isinstance(x, (np.ndarray, str)) for x in args.img]):
+ raise AssertionError('Images must be strings or numpy arrays')
+
+ # Create a list of the images
+ if isinstance(args.img, str):
+ img_path = Path(args.img)
+ if img_path.is_dir():
+ img_list = [str(x) for x in img_path.glob('*')]
+ else:
+ img_list = [str(img_path)]
+ elif isinstance(args.img, np.ndarray):
+ img_list = [args.img]
+
+ # Read all image(s) in advance to reduce wasted time
+ # re-reading the images for visualization output
+ args.arrays = [mmcv.imread(x) for x in img_list]
+
+ # Create a list of filenames (used for output images and result files)
+ if isinstance(img_list[0], str):
+ args.filenames = [str(Path(x).stem) for x in img_list]
+ else:
+ args.filenames = [str(x) for x in range(len(img_list))]
+
+ # If given an output argument, create a list of output image filenames
+ num_res = len(img_list)
+ if args.output:
+ output_path = Path(args.output)
+ if output_path.is_dir():
+ args.output = [
+ str(output_path / f'out_{x}.png') for x in args.filenames
+ ]
+ else:
+ args.output = [str(args.output)]
+ if args.batch_mode:
+ raise AssertionError('Output of multiple images inference'
+ ' must be a directory')
+ else:
+ args.output = [None] * num_res
+
+ # If given an export argument, create a list of
+ # result filenames for each image
+ if args.export:
+ export_path = Path(args.export)
+ args.export = [
+ str(export_path / f'out_{x}.{args.export_format}')
+ for x in args.filenames
+ ]
+ else:
+ args.export = [None] * num_res
+
+ return args
+
+
+# Create an inference pipeline with parsed arguments
+def main():
+ args = parse_args()
+ ocr = MMOCR(**vars(args))
+ ocr.readtext(**vars(args))
+
+
+if __name__ == '__main__':
+ main()
diff --git a/mmocr/utils/setup_env.py b/mmocr/utils/setup_env.py
new file mode 100644
index 0000000000000000000000000000000000000000..21def2f0809153a5f755af2431f7e702db625e5c
--- /dev/null
+++ b/mmocr/utils/setup_env.py
@@ -0,0 +1,47 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import platform
+import warnings
+
+import cv2
+import torch.multiprocessing as mp
+
+
+def setup_multi_processes(cfg):
+ """Setup multi-processing environment variables."""
+ # set multi-process start method as `fork` to speed up the training
+ if platform.system() != 'Windows':
+ mp_start_method = cfg.get('mp_start_method', 'fork')
+ current_method = mp.get_start_method(allow_none=True)
+ if current_method is not None and current_method != mp_start_method:
+ warnings.warn(
+ f'Multi-processing start method `{mp_start_method}` is '
+ f'different from the previous setting `{current_method}`.'
+ f'It will be force set to `{mp_start_method}`. You can change '
+ f'this behavior by changing `mp_start_method` in your config.')
+ mp.set_start_method(mp_start_method, force=True)
+
+ # disable opencv multithreading to avoid system being overloaded
+ opencv_num_threads = cfg.get('opencv_num_threads', 0)
+ cv2.setNumThreads(opencv_num_threads)
+
+ # setup OMP threads
+ # This code is referred from https://github.com/pytorch/pytorch/blob/master/torch/distributed/run.py # noqa
+ if 'OMP_NUM_THREADS' not in os.environ and cfg.data.workers_per_gpu > 1:
+ omp_num_threads = 1
+ warnings.warn(
+ f'Setting OMP_NUM_THREADS environment variable for each process '
+ f'to be {omp_num_threads} in default, to avoid your system being '
+ f'overloaded, please further tune the variable for optimal '
+ f'performance in your application as needed.')
+ os.environ['OMP_NUM_THREADS'] = str(omp_num_threads)
+
+ # setup MKL threads
+ if 'MKL_NUM_THREADS' not in os.environ and cfg.data.workers_per_gpu > 1:
+ mkl_num_threads = 1
+ warnings.warn(
+ f'Setting MKL_NUM_THREADS environment variable for each process '
+ f'to be {mkl_num_threads} in default, to avoid your system being '
+ f'overloaded, please further tune the variable for optimal '
+ f'performance in your application as needed.')
+ os.environ['MKL_NUM_THREADS'] = str(mkl_num_threads)
diff --git a/mmocr/utils/string_util.py b/mmocr/utils/string_util.py
new file mode 100644
index 0000000000000000000000000000000000000000..5a8946ee6969074ebad50747758ec919d611e933
--- /dev/null
+++ b/mmocr/utils/string_util.py
@@ -0,0 +1,36 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+class StringStrip:
+ """Removing the leading and/or the trailing characters based on the string
+ argument passed.
+
+ Args:
+ strip (bool): Whether remove characters from both left and right of
+ the string. Default: True.
+ strip_pos (str): Which position for removing, can be one of
+ ('both', 'left', 'right'), Default: 'both'.
+ strip_str (str|None): A string specifying the set of characters
+ to be removed from the left and right part of the string.
+ If None, all leading and trailing whitespaces
+ are removed from the string. Default: None.
+ """
+
+ def __init__(self, strip=True, strip_pos='both', strip_str=None):
+ assert isinstance(strip, bool)
+ assert strip_pos in ('both', 'left', 'right')
+ assert strip_str is None or isinstance(strip_str, str)
+
+ self.strip = strip
+ self.strip_pos = strip_pos
+ self.strip_str = strip_str
+
+ def __call__(self, in_str):
+
+ if not self.strip:
+ return in_str
+
+ if self.strip_pos == 'left':
+ return in_str.lstrip(self.strip_str)
+ elif self.strip_pos == 'right':
+ return in_str.rstrip(self.strip_str)
+ else:
+ return in_str.strip(self.strip_str)
diff --git a/mmocr/version.py b/mmocr/version.py
new file mode 100644
index 0000000000000000000000000000000000000000..6697c2f4d34b42fb7af44990757f6cca7f75abe0
--- /dev/null
+++ b/mmocr/version.py
@@ -0,0 +1,4 @@
+# Copyright (c) Open-MMLab. All rights reserved.
+
+__version__ = '0.4.1'
+short_version = __version__
diff --git a/model-index.yml b/model-index.yml
new file mode 100644
index 0000000000000000000000000000000000000000..099f7d55a642c089eff47e7d31e63f12310ca153
--- /dev/null
+++ b/model-index.yml
@@ -0,0 +1,17 @@
+Import:
+ - configs/textdet/dbnet/metafile.yml
+ - configs/textdet/maskrcnn/metafile.yml
+ - configs/textdet/drrg/metafile.yml
+ - configs/textdet/fcenet/metafile.yml
+ - configs/textdet/panet/metafile.yml
+ - configs/textdet/psenet/metafile.yml
+ - configs/textdet/textsnake/metafile.yml
+ - configs/textrecog/abinet/metafile.yml
+ - configs/textrecog/crnn/metafile.yml
+ - configs/textrecog/nrtr/metafile.yml
+ - configs/textrecog/robust_scanner/metafile.yml
+ - configs/textrecog/sar/metafile.yml
+ - configs/textrecog/seg/metafile.yml
+ - configs/textrecog/tps/metafile.yml
+ - configs/textrecog/satrn/metafile.yml
+ - configs/kie/sdmgr/metafile.yml
diff --git a/requirements.txt b/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..6981bd723391a980c0f22baeab39d0adbcb68679
--- /dev/null
+++ b/requirements.txt
@@ -0,0 +1,4 @@
+-r requirements/build.txt
+-r requirements/optional.txt
+-r requirements/runtime.txt
+-r requirements/tests.txt
diff --git a/requirements/build.txt b/requirements/build.txt
new file mode 100644
index 0000000000000000000000000000000000000000..e06b090722e0079badeb07d094d39571754995e4
--- /dev/null
+++ b/requirements/build.txt
@@ -0,0 +1,4 @@
+# These must be installed before building mmocr
+numpy
+pyclipper
+torch>=1.1
diff --git a/requirements/docs.txt b/requirements/docs.txt
new file mode 100644
index 0000000000000000000000000000000000000000..8e98c16fc722dc4bc962215685f897d08813d905
--- /dev/null
+++ b/requirements/docs.txt
@@ -0,0 +1,6 @@
+docutils==0.16.0
+myst-parser
+-e git+https://github.com/open-mmlab/pytorch_sphinx_theme.git#egg=pytorch_sphinx_theme
+sphinx==4.0.2
+sphinx_copybutton
+sphinx_markdown_tables
diff --git a/requirements/mminstall.txt b/requirements/mminstall.txt
new file mode 100644
index 0000000000000000000000000000000000000000..6d52842eff771251e90173850bec131b4c5609a9
--- /dev/null
+++ b/requirements/mminstall.txt
@@ -0,0 +1,2 @@
+mmcv-full>=1.3.4
+mmdet>=2.11.0
diff --git a/requirements/optional.txt b/requirements/optional.txt
new file mode 100644
index 0000000000000000000000000000000000000000..0bfcc417845aa4f847e1087a7ca1ce5545a3ff01
--- /dev/null
+++ b/requirements/optional.txt
@@ -0,0 +1 @@
+albumentations>=1.1.0
diff --git a/requirements/readthedocs.txt b/requirements/readthedocs.txt
new file mode 100644
index 0000000000000000000000000000000000000000..de89d2ecdee32870911c4d6ae1e786a59a2bef59
--- /dev/null
+++ b/requirements/readthedocs.txt
@@ -0,0 +1,16 @@
+imgaug
+kwarray
+lanms-neo==1.0.2
+lmdb
+matplotlib
+mmcv
+mmdet
+pyclipper
+rapidfuzz
+regex
+scikit-image
+scipy
+shapely
+titlecase
+torch
+torchvision
diff --git a/requirements/runtime.txt b/requirements/runtime.txt
new file mode 100644
index 0000000000000000000000000000000000000000..20b978e2df2aa386a090e85d234a045a714b55f6
--- /dev/null
+++ b/requirements/runtime.txt
@@ -0,0 +1,13 @@
+imgaug
+lanms-neo==1.0.2
+lmdb
+matplotlib
+numba>=0.45.1
+numpy
+opencv-python-headless<=4.5.4.60
+pyclipper
+pycocotools<=2.0.2
+rapidfuzz
+scikit-image
+six
+terminaltables
diff --git a/requirements/tests.txt b/requirements/tests.txt
new file mode 100644
index 0000000000000000000000000000000000000000..c3e76b7311cb9e9640ebfa6da3f1a2be75ee3b03
--- /dev/null
+++ b/requirements/tests.txt
@@ -0,0 +1,12 @@
+asynctest
+codecov
+flake8
+isort
+# Note: used for kwarray.group_items, this may be ported to mmcv in the future.
+kwarray
+pytest
+pytest-cov
+pytest-runner
+ubelt
+xdoctest >= 0.10.0
+yapf
diff --git a/resources/illustration.jpg b/resources/illustration.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..55d1c93019b42eae936351e2267c617a0cf69d34
--- /dev/null
+++ b/resources/illustration.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:5bb02a664a6ab4ffe30c5dec81b6dc7de459e04c2d352b9626b29037e1f67f91
+size 211547
diff --git a/resources/kie.jpg b/resources/kie.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..eb10cefe6c4ba6f23a787bdca4cbad38e78405f7
--- /dev/null
+++ b/resources/kie.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:eed7d13feb6964478112a65312ceb61463746e8f3aeb1eff33a6159a194f370e
+size 14624
diff --git a/resources/mmocr-logo.png b/resources/mmocr-logo.png
new file mode 100644
index 0000000000000000000000000000000000000000..2041fe0fb936f42904c4e84244777caae544378f
--- /dev/null
+++ b/resources/mmocr-logo.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:66af8191b73f39c37747cfd219e20efb2ee28795bf52480bff31fd835f9edac2
+size 191915
diff --git a/resources/qq_group_qrcode.jpg b/resources/qq_group_qrcode.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..cfd399858cac8bd164cf172140a76d8c8a7b8bf2
--- /dev/null
+++ b/resources/qq_group_qrcode.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:7afbe414bbdfb299d0efec06baf4f21d9121897f338f8d6684592e215e9e7317
+size 204806
diff --git a/resources/textdet.jpg b/resources/textdet.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..dbdee910c6ccc05f146f0da01ff6f86c4c7813de
--- /dev/null
+++ b/resources/textdet.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:78bbb4a9fa47df826e466317583377ece166a13ca6af53e7cc53aab02d2f8d45
+size 13721
diff --git a/resources/textrecog.jpg b/resources/textrecog.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..080a4996f419ff57a53b9ee2f9397b763016f7e6
--- /dev/null
+++ b/resources/textrecog.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:a7df6c5377adc5f7a22574fc8b1127d04522419ee232a35e7b6c656d01b0a731
+size 14377
diff --git a/resources/zhihu_qrcode.jpg b/resources/zhihu_qrcode.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..f791e858c942e8d4da3098e8d18a687b7eca6f73
--- /dev/null
+++ b/resources/zhihu_qrcode.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:171db0200db2735325ab96a5aa6955343852c12af90dc79c9ae36f73694611c7
+size 397245
diff --git a/setup.cfg b/setup.cfg
new file mode 100644
index 0000000000000000000000000000000000000000..01acd45ee32f29f410755a9dcd96f895e5b9d0a2
--- /dev/null
+++ b/setup.cfg
@@ -0,0 +1,30 @@
+[bdist_wheel]
+universal=1
+
+[aliases]
+test=pytest
+
+[tool:pytest]
+norecursedirs=tests/integration/*
+addopts=tests
+
+[yapf]
+based_on_style = pep8
+blank_line_before_nested_class_or_def = true
+split_before_expression_after_opening_paren = true
+split_penalty_import_names=0
+SPLIT_PENALTY_AFTER_OPENING_BRACKET=800
+
+[isort]
+line_length = 79
+multi_line_output = 0
+extra_standard_library = setuptools
+known_first_party = mmocr
+known_third_party = PIL,cv2,imgaug,lanms,lmdb,matplotlib,mmcv,mmdet,numpy,packaging,pyclipper,pytest,pytorch_sphinx_theme,rapidfuzz,requests,scipy,shapely,skimage,titlecase,torch,torchvision,ts,yaml
+no_lines_before = STDLIB,LOCALFOLDER
+default_section = THIRDPARTY
+
+[style]
+BASED_ON_STYLE = pep8
+BLANK_LINE_BEFORE_NESTED_CLASS_OR_DEF = true
+SPLIT_BEFORE_EXPRESSION_AFTER_OPENING_PAREN = true
diff --git a/setup.py b/setup.py
new file mode 100644
index 0000000000000000000000000000000000000000..09a88c3e176e606c05a7ca6f869a7f35163b1f06
--- /dev/null
+++ b/setup.py
@@ -0,0 +1,201 @@
+import os
+import os.path as osp
+import shutil
+import sys
+import warnings
+from setuptools import find_packages, setup
+
+
+def readme():
+ with open('README.md', encoding='utf-8') as f:
+ content = f.read()
+ return content
+
+
+version_file = 'mmocr/version.py'
+is_windows = sys.platform == 'win32'
+
+
+def add_mim_extention():
+ """Add extra files that are required to support MIM into the package.
+
+ These files will be added by creating a symlink to the originals if the
+ package is installed in `editable` mode (e.g. pip install -e .), or by
+ copying from the originals otherwise.
+ """
+
+ # parse installment mode
+ if 'develop' in sys.argv:
+ # installed by `pip install -e .`
+ mode = 'symlink'
+ elif 'sdist' in sys.argv or 'bdist_wheel' in sys.argv:
+ # installed by `pip install .`
+ # or create source distribution by `python setup.py sdist`
+ mode = 'copy'
+ else:
+ return
+
+ filenames = ['tools', 'configs', 'model-index.yml']
+ repo_path = osp.dirname(__file__)
+ mim_path = osp.join(repo_path, 'mmocr', '.mim')
+ os.makedirs(mim_path, exist_ok=True)
+
+ for filename in filenames:
+ if osp.exists(filename):
+ src_path = osp.join(repo_path, filename)
+ tar_path = osp.join(mim_path, filename)
+
+ if osp.isfile(tar_path) or osp.islink(tar_path):
+ os.remove(tar_path)
+ elif osp.isdir(tar_path):
+ shutil.rmtree(tar_path)
+
+ if mode == 'symlink':
+ src_relpath = osp.relpath(src_path, osp.dirname(tar_path))
+ try:
+ os.symlink(src_relpath, tar_path)
+ except OSError:
+ # Creating a symbolic link on windows may raise an
+ # `OSError: [WinError 1314]` due to privilege. If
+ # the error happens, the src file will be copied
+ mode = 'copy'
+ warnings.warn(
+ f'Failed to create a symbolic link for {src_relpath}, '
+ f'and it will be copied to {tar_path}')
+ else:
+ continue
+
+ if mode == 'copy':
+ if osp.isfile(src_path):
+ shutil.copyfile(src_path, tar_path)
+ elif osp.isdir(src_path):
+ shutil.copytree(src_path, tar_path)
+ else:
+ warnings.warn(f'Cannot copy file {src_path}.')
+ else:
+ raise ValueError(f'Invalid mode {mode}')
+
+
+def get_version():
+ with open(version_file, 'r') as f:
+ exec(compile(f.read(), version_file, 'exec'))
+ import sys
+
+ # return short version for sdist
+ if 'sdist' in sys.argv or 'bdist_wheel' in sys.argv:
+ return locals()['short_version']
+ else:
+ return locals()['__version__']
+
+
+def parse_requirements(fname='requirements.txt', with_version=True):
+ """Parse the package dependencies listed in a requirements file but strip
+ specific version information.
+
+ Args:
+ fname (str): Path to requirements file.
+ with_version (bool, default=False): If True, include version specs.
+ Returns:
+ info (list[str]): List of requirements items.
+ CommandLine:
+ python -c "import setup; print(setup.parse_requirements())"
+ """
+ import re
+ import sys
+ from os.path import exists
+ require_fpath = fname
+
+ def parse_line(line):
+ """Parse information from a line in a requirements text file."""
+ if line.startswith('-r '):
+ # Allow specifying requirements in other files
+ target = line.split(' ')[1]
+ for info in parse_require_file(target):
+ yield info
+ else:
+ info = {'line': line}
+ if line.startswith('-e '):
+ info['package'] = line.split('#egg=')[1]
+ else:
+ # Remove versioning from the package
+ pat = '(' + '|'.join(['>=', '==', '>']) + ')'
+ parts = re.split(pat, line, maxsplit=1)
+ parts = [p.strip() for p in parts]
+
+ info['package'] = parts[0]
+ if len(parts) > 1:
+ op, rest = parts[1:]
+ if ';' in rest:
+ # Handle platform specific dependencies
+ # http://setuptools.readthedocs.io/en/latest/setuptools.html#declaring-platform-specific-dependencies
+ version, platform_deps = map(str.strip,
+ rest.split(';'))
+ info['platform_deps'] = platform_deps
+ else:
+ version = rest # NOQA
+ info['version'] = (op, version)
+ yield info
+
+ def parse_require_file(fpath):
+ with open(fpath, 'r') as f:
+ for line in f.readlines():
+ line = line.strip()
+ if line and not line.startswith('#'):
+ for info in parse_line(line):
+ yield info
+
+ def gen_packages_items():
+ if exists(require_fpath):
+ for info in parse_require_file(require_fpath):
+ parts = [info['package']]
+ if with_version and 'version' in info:
+ parts.extend(info['version'])
+ if not sys.version.startswith('3.4'):
+ # apparently package_deps are broken in 3.4
+ platform_deps = info.get('platform_deps')
+ if platform_deps is not None:
+ parts.append(';' + platform_deps)
+ item = ''.join(parts)
+ yield item
+
+ packages = list(gen_packages_items())
+ return packages
+
+
+if __name__ == '__main__':
+ add_mim_extention()
+ library_dirs = [
+ lp for lp in os.environ.get('LD_LIBRARY_PATH', '').split(':')
+ if len(lp) > 1
+ ]
+ setup(
+ name='mmocr',
+ version=get_version(),
+ description='OpenMMLab Text Detection, OCR, and NLP Toolbox',
+ long_description=readme(),
+ long_description_content_type='text/markdown',
+ maintainer='MMOCR Authors',
+ maintainer_email='openmmlab@gmail.com',
+ keywords='Text Detection, OCR, KIE, NLP',
+ packages=find_packages(exclude=('configs', 'tools', 'demo')),
+ include_package_data=True,
+ url='https://github.com/open-mmlab/mmocr',
+ classifiers=[
+ 'Development Status :: 4 - Beta',
+ 'License :: OSI Approved :: Apache Software License',
+ 'Operating System :: OS Independent',
+ 'Programming Language :: Python :: 3',
+ 'Programming Language :: Python :: 3.6',
+ 'Programming Language :: Python :: 3.7',
+ 'Programming Language :: Python :: 3.8',
+ 'Programming Language :: Python :: 3.9',
+ ],
+ license='Apache License 2.0',
+ install_requires=parse_requirements('requirements/runtime.txt'),
+ extras_require={
+ 'all': parse_requirements('requirements.txt'),
+ 'tests': parse_requirements('requirements/tests.txt'),
+ 'build': parse_requirements('requirements/build.txt'),
+ 'optional': parse_requirements('requirements/optional.txt'),
+ },
+ zip_safe=False)
diff --git a/tests/data/kie_toy_dataset/class_list.txt b/tests/data/kie_toy_dataset/class_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..0c4f0adb64c50800b03a805e897ab9a4e1b24ec4
--- /dev/null
+++ b/tests/data/kie_toy_dataset/class_list.txt
@@ -0,0 +1,26 @@
+0 Ignore
+1 Store_name_value
+2 Store_name_key
+3 Store_addr_value
+4 Store_addr_key
+5 Tel_value
+6 Tel_key
+7 Date_value
+8 Date_key
+9 Time_value
+10 Time_key
+11 Prod_item_value
+12 Prod_item_key
+13 Prod_quantity_value
+14 Prod_quantity_key
+15 Prod_price_value
+16 Prod_price_key
+17 Subtotal_value
+18 Subtotal_key
+19 Tax_value
+20 Tax_key
+21 Tips_value
+22 Tips_key
+23 Total_value
+24 Total_key
+25 Others
\ No newline at end of file
diff --git a/tests/data/kie_toy_dataset/dict.txt b/tests/data/kie_toy_dataset/dict.txt
new file mode 100644
index 0000000000000000000000000000000000000000..b68274119a13962dc989c7330edd371d5c43ced4
--- /dev/null
+++ b/tests/data/kie_toy_dataset/dict.txt
@@ -0,0 +1,91 @@
+/
+\
+.
+$
+£
+€
+¥
+:
+-
+,
+*
+#
+(
+)
+%
+@
+!
+'
+&
+=
+>
++
+"
+×
+?
+<
+[
+]
+_
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+a
+b
+c
+d
+e
+f
+g
+h
+i
+j
+k
+l
+m
+n
+o
+p
+q
+r
+s
+t
+u
+v
+w
+x
+y
+z
+A
+B
+C
+D
+E
+F
+G
+H
+I
+J
+K
+L
+M
+N
+O
+P
+Q
+R
+S
+T
+U
+V
+W
+X
+Y
+Z
\ No newline at end of file
diff --git a/tests/data/ocr_char_ann_toy_dataset/imgs/resort_88_101_1.png b/tests/data/ocr_char_ann_toy_dataset/imgs/resort_88_101_1.png
new file mode 100644
index 0000000000000000000000000000000000000000..96a2f8aa7d98d2948929f9c53c62fa4b6e0a24e2
--- /dev/null
+++ b/tests/data/ocr_char_ann_toy_dataset/imgs/resort_88_101_1.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:dca084fbeb8af364fa93d6e0a2bcb75ebc545d8f4d589e0ac0f49da8eee2786d
+size 1766
diff --git a/tests/data/ocr_char_ann_toy_dataset/imgs/resort_95_53_6.png b/tests/data/ocr_char_ann_toy_dataset/imgs/resort_95_53_6.png
new file mode 100644
index 0000000000000000000000000000000000000000..6af46762517e6e935fbcee35a85b1ff93e298f96
--- /dev/null
+++ b/tests/data/ocr_char_ann_toy_dataset/imgs/resort_95_53_6.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:0e5d983402b5f06e37bdfc3d0cba170f12043a3c29baef8bafd3d2110ed79fdb
+size 1595
diff --git a/tests/data/ocr_char_ann_toy_dataset/imgs/richard+feynman_101_8_6.png b/tests/data/ocr_char_ann_toy_dataset/imgs/richard+feynman_101_8_6.png
new file mode 100644
index 0000000000000000000000000000000000000000..a6ae74596622fb2403ebc40112f5ad940736b867
--- /dev/null
+++ b/tests/data/ocr_char_ann_toy_dataset/imgs/richard+feynman_101_8_6.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:1dc993615b81a32e5f8c985f5cd8af965da4b5e0e5646ae0ff1b6c21216c59fe
+size 2408
diff --git a/tests/data/ocr_char_ann_toy_dataset/imgs/richard+feynman_104_58_9.png b/tests/data/ocr_char_ann_toy_dataset/imgs/richard+feynman_104_58_9.png
new file mode 100644
index 0000000000000000000000000000000000000000..ad267a96185853ecdc1af7ce2c2a4fcf6d21d5a3
--- /dev/null
+++ b/tests/data/ocr_char_ann_toy_dataset/imgs/richard+feynman_104_58_9.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:4ee6fc6537df59ce5fd0f4a78960edb753ff056856bc5f4a92c4e4d5858e55a8
+size 7675
diff --git a/tests/data/ocr_char_ann_toy_dataset/imgs/richard+feynman_110_1_6.png b/tests/data/ocr_char_ann_toy_dataset/imgs/richard+feynman_110_1_6.png
new file mode 100644
index 0000000000000000000000000000000000000000..c43096327708a89181fd342a1313bcfbb7321a2c
--- /dev/null
+++ b/tests/data/ocr_char_ann_toy_dataset/imgs/richard+feynman_110_1_6.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:40cd4fc678629efaa0fb866904892c38e7cb8fe31e9079d7fdccc843c4f5613e
+size 5105
diff --git a/tests/data/ocr_char_ann_toy_dataset/imgs/richard+feynman_12_61_4.png b/tests/data/ocr_char_ann_toy_dataset/imgs/richard+feynman_12_61_4.png
new file mode 100644
index 0000000000000000000000000000000000000000..dedf9999de4a6500abced1b1a28e82b5ea323952
--- /dev/null
+++ b/tests/data/ocr_char_ann_toy_dataset/imgs/richard+feynman_12_61_4.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:9f303830f077c78c1c9b1e88d3620b7590a71106860d079e59775c293fa1b5d8
+size 9040
diff --git a/tests/data/ocr_char_ann_toy_dataset/imgs/richard+feynman_130_74_1.png b/tests/data/ocr_char_ann_toy_dataset/imgs/richard+feynman_130_74_1.png
new file mode 100644
index 0000000000000000000000000000000000000000..3ca05db4c0b10491d055aecaa551506821f44bed
--- /dev/null
+++ b/tests/data/ocr_char_ann_toy_dataset/imgs/richard+feynman_130_74_1.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:068b0c3c83ad06e4a4eaa9b53f8350f1717f29eeabaf018762a1d7decc74ec3e
+size 7362
diff --git a/tests/data/ocr_char_ann_toy_dataset/imgs/richard+feynman_134_30_15.png b/tests/data/ocr_char_ann_toy_dataset/imgs/richard+feynman_134_30_15.png
new file mode 100644
index 0000000000000000000000000000000000000000..68e44facf8ff9c52ba446d9a9af6ebb69d10715c
--- /dev/null
+++ b/tests/data/ocr_char_ann_toy_dataset/imgs/richard+feynman_134_30_15.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:07fa1a0ca22857f3f4e6fa8a69435eb186bdaf0bc9ac460c551e76eb71de7f58
+size 6461
diff --git a/tests/data/ocr_char_ann_toy_dataset/imgs/richard+feynman_15_43_4.png b/tests/data/ocr_char_ann_toy_dataset/imgs/richard+feynman_15_43_4.png
new file mode 100644
index 0000000000000000000000000000000000000000..2b7b73ce890eb1b987752d773f618984ea765d12
--- /dev/null
+++ b/tests/data/ocr_char_ann_toy_dataset/imgs/richard+feynman_15_43_4.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:d3f2cab8aa33ca99973d07e9a9d5150e1d2d288d0e358a1b21c7a5ffcbc1d71f
+size 1828
diff --git a/tests/data/ocr_char_ann_toy_dataset/imgs/richard+feynman_18_18_5.png b/tests/data/ocr_char_ann_toy_dataset/imgs/richard+feynman_18_18_5.png
new file mode 100644
index 0000000000000000000000000000000000000000..00fefca3840857111023e78d921be5271aac908b
--- /dev/null
+++ b/tests/data/ocr_char_ann_toy_dataset/imgs/richard+feynman_18_18_5.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:955a0ff01b52a1cf578a6e46bc124b32350a2bd24d00a833dbaa2fe29d1bf1a7
+size 9033
diff --git a/tests/data/ocr_char_ann_toy_dataset/instances_test.txt b/tests/data/ocr_char_ann_toy_dataset/instances_test.txt
new file mode 100644
index 0000000000000000000000000000000000000000..59b63e0681a8bcb3382950b6ba93249536715635
--- /dev/null
+++ b/tests/data/ocr_char_ann_toy_dataset/instances_test.txt
@@ -0,0 +1,10 @@
+resort_88_101_1.png From:
+resort_95_53_6.png out
+richard+feynman_101_8_6.png the
+richard+feynman_104_58_9.png fast
+richard+feynman_110_1_6.png many
+richard+feynman_12_61_4.png the
+richard+feynman_130_74_1.png the
+richard+feynman_134_30_15.png how
+richard+feynman_15_43_4.png the
+richard+feynman_18_18_5.png Lines:
diff --git a/tests/data/ocr_char_ann_toy_dataset/instances_train.txt b/tests/data/ocr_char_ann_toy_dataset/instances_train.txt
new file mode 100644
index 0000000000000000000000000000000000000000..c3c0fb3628e16805e3f25c2fa1744f57c0045afe
--- /dev/null
+++ b/tests/data/ocr_char_ann_toy_dataset/instances_train.txt
@@ -0,0 +1,10 @@
+{"file_name": "resort_88_101_1.png", "annotations": [{"char_text": "F", "char_box": [11.0, 0.0, 22.0, 0.0, 12.0, 12.0, 0.0, 12.0]}, {"char_text": "r", "char_box": [23.0, 2.0, 31.0, 1.0, 24.0, 11.0, 16.0, 11.0]}, {"char_text": "o", "char_box": [33.0, 2.0, 43.0, 2.0, 36.0, 12.0, 25.0, 12.0]}, {"char_text": "m", "char_box": [46.0, 2.0, 61.0, 2.0, 53.0, 12.0, 39.0, 12.0]}, {"char_text": ":", "char_box": [61.0, 2.0, 69.0, 2.0, 63.0, 12.0, 55.0, 12.0]}], "text": "From:"}
+{"file_name": "resort_95_53_6.png", "annotations": [{"char_text": "o", "char_box": [0.0, 5.0, 7.0, 5.0, 9.0, 15.0, 2.0, 15.0]}, {"char_text": "u", "char_box": [7.0, 4.0, 14.0, 4.0, 18.0, 18.0, 11.0, 18.0]}, {"char_text": "t", "char_box": [13.0, 1.0, 19.0, 2.0, 24.0, 18.0, 17.0, 18.0]}], "text": "out"}
+{"file_name": "richard+feynman_101_8_6.png", "annotations": [{"char_text": "t", "char_box": [5.0, 3.0, 13.0, 6.0, 10.0, 21.0, 1.0, 18.0]}, {"char_text": "h", "char_box": [14.0, 3.0, 27.0, 8.0, 22.0, 25.0, 10.0, 21.0]}, {"char_text": "e", "char_box": [25.0, 14.0, 35.0, 17.0, 32.0, 29.0, 22.0, 25.0]}], "text": "the"}
+{"file_name": "richard+feynman_104_58_9.png", "annotations": [{"char_text": "f", "char_box": [22.0, 19.0, 30.0, 15.0, 20.0, 51.0, 12.0, 54.0]}, {"char_text": "a", "char_box": [27.0, 27.0, 37.0, 21.0, 31.0, 46.0, 21.0, 50.0]}, {"char_text": "s", "char_box": [37.0, 22.0, 47.0, 16.0, 40.0, 41.0, 30.0, 46.0]}, {"char_text": "t", "char_box": [50.0, 5.0, 58.0, 0.0, 47.0, 38.0, 40.0, 41.0]}], "text": "fast"}
+{"file_name": "richard+feynman_110_1_6.png", "annotations": [{"char_text": "m", "char_box": [6.0, 33.0, 21.0, 23.0, 19.0, 31.0, 4.0, 41.0]}, {"char_text": "a", "char_box": [21.0, 22.0, 33.0, 15.0, 31.0, 24.0, 19.0, 31.0]}, {"char_text": "n", "char_box": [32.0, 16.0, 45.0, 8.0, 43.0, 17.0, 30.0, 25.0]}, {"char_text": "y", "char_box": [45.0, 8.0, 57.0, 0.0, 55.0, 11.0, 43.0, 19.0]}], "text": "many"}
+{"file_name": "richard+feynman_12_61_4.png", "annotations": [{"char_text": "t", "char_box": [5.0, 0.0, 35.0, 6.0, 35.0, 34.0, 4.0, 28.0]}, {"char_text": "h", "char_box": [33.0, 6.0, 71.0, 13.0, 70.0, 40.0, 32.0, 33.0]}, {"char_text": "e", "char_box": [71.0, 13.0, 98.0, 18.0, 98.0, 45.0, 70.0, 40.0]}], "text": "the"}
+{"file_name": "richard+feynman_130_74_1.png", "annotations": [{"char_text": "t", "char_box": [4.0, 12.0, 27.0, 10.0, 26.0, 47.0, 4.0, 49.0]}, {"char_text": "h", "char_box": [30.0, 3.0, 48.0, 2.0, 48.0, 45.0, 29.0, 47.0]}, {"char_text": "e", "char_box": [50.0, 17.0, 68.0, 15.0, 68.0, 44.0, 50.0, 46.0]}], "text": "the"}
+{"file_name": "richard+feynman_134_30_15.png", "annotations": [{"char_text": "h", "char_box": [5.0, 1.0, 24.0, 7.0, 23.0, 23.0, 4.0, 17.0]}, {"char_text": "o", "char_box": [25.0, 12.0, 42.0, 18.0, 41.0, 29.0, 24.0, 24.0]}, {"char_text": "w", "char_box": [40.0, 18.0, 69.0, 26.0, 67.0, 37.0, 39.0, 28.0]}], "text": "how"}
+{"file_name": "richard+feynman_15_43_4.png", "annotations": [{"char_text": "t", "char_box": [4.0, 8.0, 12.0, 5.0, 12.0, 19.0, 4.0, 22.0]}, {"char_text": "h", "char_box": [13.0, 5.0, 21.0, 2.0, 21.0, 16.0, 13.0, 19.0]}, {"char_text": "e", "char_box": [21.0, 2.0, 28.0, 0.0, 28.0, 14.0, 21.0, 16.0]}], "text": "the"}
+{"file_name": "richard+feynman_18_18_5.png", "annotations": [{"char_text": "L", "char_box": [13.0, 14.0, 32.0, 12.0, 23.0, 36.0, 3.0, 38.0]}, {"char_text": "i", "char_box": [35.0, 7.0, 46.0, 6.0, 37.0, 31.0, 26.0, 32.0]}, {"char_text": "n", "char_box": [47.0, 9.0, 66.0, 8.0, 60.0, 27.0, 41.0, 29.0]}, {"char_text": "e", "char_box": [67.0, 9.0, 85.0, 8.0, 80.0, 27.0, 61.0, 28.0]}, {"char_text": "s", "char_box": [88.0, 7.0, 106.0, 6.0, 101.0, 27.0, 82.0, 28.0]}, {"char_text": ":", "char_box": [106.0, 8.0, 118.0, 7.0, 113.0, 29.0, 101.0, 29.0]}], "text": "Lines:"}
diff --git a/tests/data/ocr_toy_dataset/imgs/1036169.jpg b/tests/data/ocr_toy_dataset/imgs/1036169.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..062e96d6bc2b61b25e86664438b3a2a35e7902f2
--- /dev/null
+++ b/tests/data/ocr_toy_dataset/imgs/1036169.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:ade08779be5e20eebb237a726aaa1ad1a5fbbef9fc1beac90f24ae6d6797acd6
+size 4216
diff --git a/tests/data/ocr_toy_dataset/imgs/1058891.jpg b/tests/data/ocr_toy_dataset/imgs/1058891.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..7b2637f923358ee037008fd5325add95fe8cdd72
--- /dev/null
+++ b/tests/data/ocr_toy_dataset/imgs/1058891.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:fc4ccd98497959f2dcb1b99e95321bc47dfed4c08e9e796127e3cb0908d019ba
+size 4734
diff --git a/tests/data/ocr_toy_dataset/imgs/1058892.jpg b/tests/data/ocr_toy_dataset/imgs/1058892.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..8ce19e06fcd5fdfc397ced8ba3ac5e0e71020cf7
--- /dev/null
+++ b/tests/data/ocr_toy_dataset/imgs/1058892.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:5892a78288111d6af02641436f8af63127ed1b387ab1904a36c18d6f69112d2f
+size 2685
diff --git a/tests/data/ocr_toy_dataset/imgs/1190237.jpg b/tests/data/ocr_toy_dataset/imgs/1190237.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..4f81e6aee22438b4401689564be8dfdf65a9b5cb
--- /dev/null
+++ b/tests/data/ocr_toy_dataset/imgs/1190237.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:8c75b8fd38c9a8d103959a393d80b3e4fb805bf91ae8e69057f8715d0cad031c
+size 1280
diff --git a/tests/data/ocr_toy_dataset/imgs/1210236.jpg b/tests/data/ocr_toy_dataset/imgs/1210236.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..fef16f7392028ebddb202fec0cb7ec920a4216fa
--- /dev/null
+++ b/tests/data/ocr_toy_dataset/imgs/1210236.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:67c09758e6bfa535bd178d80891895569a19b9d00707bc8f74472f3468f312da
+size 1665
diff --git a/tests/data/ocr_toy_dataset/imgs/1223729.jpg b/tests/data/ocr_toy_dataset/imgs/1223729.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..98e7e73f909698cb023489840abbe0fcf73c9a39
--- /dev/null
+++ b/tests/data/ocr_toy_dataset/imgs/1223729.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:c51d7967656a9196e5cfa6051e79240aeb2621de229f64e3bae5d0008e2a19d3
+size 1817
diff --git a/tests/data/ocr_toy_dataset/imgs/1223731.jpg b/tests/data/ocr_toy_dataset/imgs/1223731.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..d4e1f574d3c75104dbdd99d25002f9971af76565
--- /dev/null
+++ b/tests/data/ocr_toy_dataset/imgs/1223731.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:8e208ad4ca548db6048c965b4ab9ed472ee465de78c94d340d96614b5ba5d096
+size 2075
diff --git a/tests/data/ocr_toy_dataset/imgs/1223732.jpg b/tests/data/ocr_toy_dataset/imgs/1223732.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..520d1b7bc46f8eead458ff0c0bad0aeefe362ba2
--- /dev/null
+++ b/tests/data/ocr_toy_dataset/imgs/1223732.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:12e4713338b19c85c4e5d48b5a0a903a1c51d3da07b9642916e59da2796b610e
+size 1392
diff --git a/tests/data/ocr_toy_dataset/imgs/1223733.jpg b/tests/data/ocr_toy_dataset/imgs/1223733.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..988f979a7cc5d93d6ec4b105ad947d19e7abe87a
--- /dev/null
+++ b/tests/data/ocr_toy_dataset/imgs/1223733.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:bd6f21b96c801b39102422fe009b0c2d7978325d41c4177bc76e7182545059b9
+size 1284
diff --git a/tests/data/ocr_toy_dataset/imgs/1240078.jpg b/tests/data/ocr_toy_dataset/imgs/1240078.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..5f4777b67ed0be130303d909286aa458816980e4
--- /dev/null
+++ b/tests/data/ocr_toy_dataset/imgs/1240078.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:babef34b3b527861b570fc138fe2782e4081b837f8ce5836482df86aa25e4755
+size 1235
diff --git a/tests/data/ocr_toy_dataset/label.lmdb/data.mdb b/tests/data/ocr_toy_dataset/label.lmdb/data.mdb
new file mode 100644
index 0000000000000000000000000000000000000000..5876a2581a5c1972c04fef9a4dee4cf55f995510
Binary files /dev/null and b/tests/data/ocr_toy_dataset/label.lmdb/data.mdb differ
diff --git a/tests/data/ocr_toy_dataset/label.lmdb/lock.mdb b/tests/data/ocr_toy_dataset/label.lmdb/lock.mdb
new file mode 100644
index 0000000000000000000000000000000000000000..2ad277ed77ec6f846fefbaf7ca3f0744a96fb1c3
Binary files /dev/null and b/tests/data/ocr_toy_dataset/label.lmdb/lock.mdb differ
diff --git a/tests/data/ocr_toy_dataset/label.txt b/tests/data/ocr_toy_dataset/label.txt
new file mode 100644
index 0000000000000000000000000000000000000000..4b20ed5a69575ebee55a81b0c72bda477bab6865
--- /dev/null
+++ b/tests/data/ocr_toy_dataset/label.txt
@@ -0,0 +1,10 @@
+1223731.jpg GRAND
+1223733.jpg HOTEL
+1223732.jpg HOTEL
+1223729.jpg PACIFIC
+1036169.jpg 03/09/2009
+1190237.jpg ANING
+1058891.jpg Virgin
+1058892.jpg america
+1240078.jpg ATTACK
+1210236.jpg DAVIDSON
diff --git a/tests/data/test_img1.jpg b/tests/data/test_img1.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..c77ebb691ead27f098681b18a1039d0564ad2281
--- /dev/null
+++ b/tests/data/test_img1.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:2c5ba373f1dfc627f12466e9df09f7699839295a1ae2960fde18be6a74bf6deb
+size 604609
diff --git a/tests/data/test_img1.png b/tests/data/test_img1.png
new file mode 100644
index 0000000000000000000000000000000000000000..94c44ee73654d375e145878114f3bf42c7792666
--- /dev/null
+++ b/tests/data/test_img1.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:12a30e1465980a8e8edee324d19690b12aaca390fab4af508a2b00e643650e9c
+size 2637748
diff --git a/tests/data/test_img2.jpg b/tests/data/test_img2.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..78a398a44c673ad21442616d1e5ada2128e33b47
--- /dev/null
+++ b/tests/data/test_img2.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:1d3e29c37dc5bad06058c7e87f541995181b789496f8bb21952977fc03efac86
+size 1047772
diff --git a/tests/data/toy_dataset/annotations/test/gt_img_1.txt b/tests/data/toy_dataset/annotations/test/gt_img_1.txt
new file mode 100644
index 0000000000000000000000000000000000000000..1b22ebbd2e1affab6e7244341c7cb1c7c1670465
--- /dev/null
+++ b/tests/data/toy_dataset/annotations/test/gt_img_1.txt
@@ -0,0 +1,7 @@
+377,117,463,117,465,130,378,130,Genaxis Theatre
+493,115,519,115,519,131,493,131,[06]
+374,155,409,155,409,170,374,170,###
+492,151,551,151,551,170,492,170,62-03
+376,198,422,198,422,212,376,212,Carpark
+494,190,539,189,539,205,494,206,###
+374,1,494,0,492,85,372,86,###
diff --git a/tests/data/toy_dataset/annotations/test/gt_img_10.txt b/tests/data/toy_dataset/annotations/test/gt_img_10.txt
new file mode 100644
index 0000000000000000000000000000000000000000..01334be187dc67d809e30b119387178d416722f2
--- /dev/null
+++ b/tests/data/toy_dataset/annotations/test/gt_img_10.txt
@@ -0,0 +1,8 @@
+261,138,284,140,279,158,260,158,###
+288,138,417,140,416,161,290,157,HarbourFront
+743,145,779,146,780,163,746,163,CC22
+783,129,831,132,833,155,785,153,bua
+831,133,870,135,874,156,835,155,###
+159,205,230,204,231,218,159,219,###
+785,158,856,158,860,178,787,179,###
+1011,157,1079,160,1076,173,1011,170,###
diff --git a/tests/data/toy_dataset/annotations/test/gt_img_2.txt b/tests/data/toy_dataset/annotations/test/gt_img_2.txt
new file mode 100644
index 0000000000000000000000000000000000000000..19b427c262b896b8603c79cd48202a41635b4bd8
--- /dev/null
+++ b/tests/data/toy_dataset/annotations/test/gt_img_2.txt
@@ -0,0 +1,2 @@
+602,173,635,175,634,197,602,196,EXIT
+734,310,792,320,792,364,738,361,I2R
diff --git a/tests/data/toy_dataset/annotations/test/gt_img_3.txt b/tests/data/toy_dataset/annotations/test/gt_img_3.txt
new file mode 100644
index 0000000000000000000000000000000000000000..484f6c576a7891ef590b14bf663831f1efcd1b24
--- /dev/null
+++ b/tests/data/toy_dataset/annotations/test/gt_img_3.txt
@@ -0,0 +1,13 @@
+58,80,191,71,194,114,61,123,fusionopolis
+147,21,176,21,176,36,147,36,###
+328,75,391,81,387,112,326,113,###
+401,76,448,84,445,108,402,111,###
+780,7,1015,6,1016,37,788,42,###
+221,72,311,80,312,117,222,118,fusionopolis
+113,19,144,19,144,33,113,33,###
+257,28,308,28,308,57,257,57,###
+140,120,196,115,195,129,141,133,###
+86,176,110,177,112,189,89,196,###
+101,193,129,185,132,198,103,204,###
+223,175,244,150,294,183,235,197,###
+140,239,174,232,176,247,142,256,###
diff --git a/tests/data/toy_dataset/annotations/test/gt_img_4.txt b/tests/data/toy_dataset/annotations/test/gt_img_4.txt
new file mode 100644
index 0000000000000000000000000000000000000000..8b40444af787c74e2a843e86eb267ef7b734e4d9
--- /dev/null
+++ b/tests/data/toy_dataset/annotations/test/gt_img_4.txt
@@ -0,0 +1,3 @@
+692,268,710,268,710,293,692,293,###
+663,224,733,230,737,246,661,242,###
+668,242,737,244,734,260,670,256,###
diff --git a/tests/data/toy_dataset/annotations/test/gt_img_5.txt b/tests/data/toy_dataset/annotations/test/gt_img_5.txt
new file mode 100644
index 0000000000000000000000000000000000000000..815420f9b1a1cd2e0cda83db0322a2a7ba906c24
--- /dev/null
+++ b/tests/data/toy_dataset/annotations/test/gt_img_5.txt
@@ -0,0 +1,2 @@
+408,409,437,436,434,461,405,433,###
+437,434,443,440,441,467,435,462,###
diff --git a/tests/data/toy_dataset/annotations/test/gt_img_6.txt b/tests/data/toy_dataset/annotations/test/gt_img_6.txt
new file mode 100644
index 0000000000000000000000000000000000000000..0d483f22c7494dc3b98c6ac9fd8bbb16f1c53667
--- /dev/null
+++ b/tests/data/toy_dataset/annotations/test/gt_img_6.txt
@@ -0,0 +1,20 @@
+875,92,910,92,910,112,875,112,###
+748,95,787,95,787,109,748,109,###
+106,395,150,394,153,425,106,424,###
+165,393,213,396,210,421,165,421,###
+706,52,747,49,746,62,705,64,###
+111,459,206,461,207,482,113,480,Reserve
+831,9,894,9,894,22,831,22,###
+641,456,693,454,693,467,641,469,CAUTION
+839,32,891,32,891,47,839,47,###
+788,46,831,46,831,59,788,59,###
+830,95,872,95,872,106,830,106,###
+921,92,952,92,952,111,921,111,###
+968,40,1013,40,1013,53,968,53,###
+1002,89,1031,89,1031,100,1002,100,###
+1043,38,1098,38,1098,52,1043,52,###
+1069,85,1138,85,1138,99,1069,99,###
+1128,36,1178,36,1178,52,1128,52,###
+1168,84,1200,84,1200,97,1168,97,###
+1223,27,1259,27,1255,49,1219,49,###
+1264,28,1279,28,1279,46,1264,46,###
diff --git a/tests/data/toy_dataset/annotations/test/gt_img_7.txt b/tests/data/toy_dataset/annotations/test/gt_img_7.txt
new file mode 100644
index 0000000000000000000000000000000000000000..58171fc44b868bb8d3257c89f51b1594f6765b09
--- /dev/null
+++ b/tests/data/toy_dataset/annotations/test/gt_img_7.txt
@@ -0,0 +1,15 @@
+346,133,400,130,401,148,345,153,###
+301,127,349,123,351,154,303,158,###
+869,67,920,61,923,85,872,91,citi
+886,144,934,141,932,157,884,160,smrt
+634,106,812,86,816,104,634,121,###
+418,117,469,112,471,143,420,148,###
+634,124,781,107,783,123,635,135,###
+634,138,844,117,843,141,636,155,###
+468,124,518,117,525,138,468,143,###
+301,181,532,162,530,182,301,201,###
+296,157,396,147,400,165,300,174,###
+420,151,526,136,527,154,421,163,###
+617,251,657,250,656,282,616,285,###
+695,246,738,243,738,276,698,278,###
+739,241,760,241,763,260,742,262,###
diff --git a/tests/data/toy_dataset/annotations/test/gt_img_8.txt b/tests/data/toy_dataset/annotations/test/gt_img_8.txt
new file mode 100644
index 0000000000000000000000000000000000000000..65a32e41acdcff02a468a4b683f9641d73fbf8dd
--- /dev/null
+++ b/tests/data/toy_dataset/annotations/test/gt_img_8.txt
@@ -0,0 +1,8 @@
+568,347,623,350,617,380,568,375,WHY
+626,347,673,345,668,382,625,380,PAY
+675,351,725,350,726,381,678,379,FOR
+598,381,728,385,724,420,598,413,NOTHING?
+762,351,845,357,845,380,760,377,###
+562,588,613,588,611,632,564,633,###
+615,593,730,603,727,646,614,634,###
+560,634,730,650,730,691,556,678,###
diff --git a/tests/data/toy_dataset/annotations/test/gt_img_9.txt b/tests/data/toy_dataset/annotations/test/gt_img_9.txt
new file mode 100644
index 0000000000000000000000000000000000000000..f59d7d9059d2b50677ca81b6ddc3646382b00c9e
--- /dev/null
+++ b/tests/data/toy_dataset/annotations/test/gt_img_9.txt
@@ -0,0 +1,4 @@
+344,206,384,207,381,228,342,227,EXIT
+47,183,94,183,83,212,42,206,###
+913,515,1068,526,1081,595,921,578,STAGE
+240,291,273,291,273,298,240,297,###
diff --git a/tests/data/toy_dataset/img_list.txt b/tests/data/toy_dataset/img_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..206384cfac518fa861fba3152ea41c08fafa17c5
--- /dev/null
+++ b/tests/data/toy_dataset/img_list.txt
@@ -0,0 +1,10 @@
+img_10.jpg
+img_1.jpg
+img_2.jpg
+img_3.jpg
+img_4.jpg
+img_5.jpg
+img_6.jpg
+img_7.jpg
+img_8.jpg
+img_9.jpg
diff --git a/tests/data/toy_dataset/imgs/test/img_1.jpg b/tests/data/toy_dataset/imgs/test/img_1.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..6da1bc1cbe9048dcdd9be0a86af2c383db1dbaa3
--- /dev/null
+++ b/tests/data/toy_dataset/imgs/test/img_1.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:7ebd8740f9f0057c5fe274e84c0089a2b8e8434320c3a41fc561daa70cf0142f
+size 46361
diff --git a/tests/data/toy_dataset/imgs/test/img_10.jpg b/tests/data/toy_dataset/imgs/test/img_10.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..e429f2f2e4b01a17f2a3aa0f1e2f8b14d66ef23c
--- /dev/null
+++ b/tests/data/toy_dataset/imgs/test/img_10.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:8dd3bad7cd819955e315d58f5123ea97cd74fc0ea5ae8578df799f8225f99c8f
+size 84988
diff --git a/tests/data/toy_dataset/imgs/test/img_2.jpg b/tests/data/toy_dataset/imgs/test/img_2.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..4672e0241dae1708b0ae020803d856ee2ce889e4
--- /dev/null
+++ b/tests/data/toy_dataset/imgs/test/img_2.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:1a09c72186e6d56d404f384e469cf81d2cbe5ec4453a909aaac5aaa34103235b
+size 50669
diff --git a/tests/data/toy_dataset/imgs/test/img_3.jpg b/tests/data/toy_dataset/imgs/test/img_3.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..2807a5f659bffd5fb958ec2706ab11ee432833c0
--- /dev/null
+++ b/tests/data/toy_dataset/imgs/test/img_3.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:a2e99b7042a848e6ef74279636d736345c8e79b6b5aa74e451d5e3768a3fb06d
+size 74669
diff --git a/tests/data/toy_dataset/imgs/test/img_4.jpg b/tests/data/toy_dataset/imgs/test/img_4.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..be39894402a8f70ac22783b5f3570a9b855779e0
--- /dev/null
+++ b/tests/data/toy_dataset/imgs/test/img_4.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:2d12f916d672f8dfe01a69ac0c77a5b2c27715ba3a523691429b8c115f38170a
+size 79599
diff --git a/tests/data/toy_dataset/imgs/test/img_5.jpg b/tests/data/toy_dataset/imgs/test/img_5.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..510df1b5c22b7d7aa2e2d2bf1005fcb7de654c2d
--- /dev/null
+++ b/tests/data/toy_dataset/imgs/test/img_5.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:8de8b165ac0f782126719429b8626e7bf1b124405d063892646eb0cab9d23dab
+size 127104
diff --git a/tests/data/toy_dataset/imgs/test/img_6.jpg b/tests/data/toy_dataset/imgs/test/img_6.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..aa392568307637c8e98fea5f6e12db6be0cda58e
--- /dev/null
+++ b/tests/data/toy_dataset/imgs/test/img_6.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:bde72eca4678085102d9ceb835d2b6992b7df403ed706bf17e67b12dea3f4d40
+size 78275
diff --git a/tests/data/toy_dataset/imgs/test/img_7.jpg b/tests/data/toy_dataset/imgs/test/img_7.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..2f50298e82a67d94f9ae2b25eb731dfc4153d926
--- /dev/null
+++ b/tests/data/toy_dataset/imgs/test/img_7.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:be5aa25fa2ccf280d2dd7a40776b031cb6ef01395cc0bcd9e3e799069b96f426
+size 95042
diff --git a/tests/data/toy_dataset/imgs/test/img_8.jpg b/tests/data/toy_dataset/imgs/test/img_8.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..394c099f37db754c526d1d8cb83db8d817e6df1e
--- /dev/null
+++ b/tests/data/toy_dataset/imgs/test/img_8.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:a0245b2ffda7511ebf9f4db09f3e699f4dd7557d55f36b8159e109c52852e308
+size 100922
diff --git a/tests/data/toy_dataset/imgs/test/img_9.jpg b/tests/data/toy_dataset/imgs/test/img_9.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..c9e682102ba885bff9363dc3e4ab7887383f1856
--- /dev/null
+++ b/tests/data/toy_dataset/imgs/test/img_9.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:62a819051b21818f276fbf07e0f7de0c711817cc4f878f73675c56e898cd75c6
+size 91319
diff --git a/tests/data/toy_dataset/instances_test.json b/tests/data/toy_dataset/instances_test.json
new file mode 100644
index 0000000000000000000000000000000000000000..1dd51cc89909d207e87f664c02cff853f9162b28
--- /dev/null
+++ b/tests/data/toy_dataset/instances_test.json
@@ -0,0 +1 @@
+{"images": [{"file_name": "test/img_10.jpg", "height": 720, "width": 1280, "segm_file": "test/gt_img_10.txt", "id": 0}, {"file_name": "test/img_2.jpg", "height": 720, "width": 1280, "segm_file": "test/gt_img_2.txt", "id": 1}, {"file_name": "test/img_6.jpg", "height": 720, "width": 1280, "segm_file": "test/gt_img_6.txt", "id": 2}, {"file_name": "test/img_3.jpg", "height": 720, "width": 1280, "segm_file": "test/gt_img_3.txt", "id": 3}, {"file_name": "test/img_9.jpg", "height": 720, "width": 1280, "segm_file": "test/gt_img_9.txt", "id": 4}, {"file_name": "test/img_8.jpg", "height": 720, "width": 1280, "segm_file": "test/gt_img_8.txt", "id": 5}, {"file_name": "test/img_1.jpg", "height": 720, "width": 1280, "segm_file": "test/gt_img_1.txt", "id": 6}, {"file_name": "test/img_5.jpg", "height": 720, "width": 1280, "segm_file": "test/gt_img_5.txt", "id": 7}, {"file_name": "test/img_7.jpg", "height": 720, "width": 1280, "segm_file": "test/gt_img_7.txt", "id": 8}, {"file_name": "test/img_4.jpg", "height": 720, "width": 1280, "segm_file": "test/gt_img_4.txt", "id": 9}], "categories": [{"id": 1, "name": "text"}], "annotations": [{"iscrowd": 1, "category_id": 1, "bbox": [260.0, 138.0, 24.0, 20.0], "area": 402.0, "segmentation": [[261, 138, 284, 140, 279, 158, 260, 158]], "image_id": 0, "id": 0}, {"iscrowd": 0, "category_id": 1, "bbox": [288.0, 138.0, 129.0, 23.0], "area": 2548.5, "segmentation": [[288, 138, 417, 140, 416, 161, 290, 157]], "image_id": 0, "id": 1}, {"iscrowd": 0, "category_id": 1, "bbox": [743.0, 145.0, 37.0, 18.0], "area": 611.5, "segmentation": [[743, 145, 779, 146, 780, 163, 746, 163]], "image_id": 0, "id": 2}, {"iscrowd": 0, "category_id": 1, "bbox": [783.0, 129.0, 50.0, 26.0], "area": 1123.0, "segmentation": [[783, 129, 831, 132, 833, 155, 785, 153]], "image_id": 0, "id": 3}, {"iscrowd": 1, "category_id": 1, "bbox": [831.0, 133.0, 43.0, 23.0], "area": 832.5, "segmentation": [[831, 133, 870, 135, 874, 156, 835, 155]], "image_id": 0, "id": 4}, {"iscrowd": 1, "category_id": 1, "bbox": [159.0, 204.0, 72.0, 15.0], "area": 1001.5, "segmentation": [[159, 205, 230, 204, 231, 218, 159, 219]], "image_id": 0, "id": 5}, {"iscrowd": 1, "category_id": 1, "bbox": [785.0, 158.0, 75.0, 21.0], "area": 1477.5, "segmentation": [[785, 158, 856, 158, 860, 178, 787, 179]], "image_id": 0, "id": 6}, {"iscrowd": 1, "category_id": 1, "bbox": [1011.0, 157.0, 68.0, 16.0], "area": 869.0, "segmentation": [[1011, 157, 1079, 160, 1076, 173, 1011, 170]], "image_id": 0, "id": 7}, {"iscrowd": 0, "category_id": 1, "bbox": [602.0, 173.0, 33.0, 24.0], "area": 732.0, "segmentation": [[602, 173, 635, 175, 634, 197, 602, 196]], "image_id": 1, "id": 8}, {"iscrowd": 0, "category_id": 1, "bbox": [734.0, 310.0, 58.0, 54.0], "area": 2647.0, "segmentation": [[734, 310, 792, 320, 792, 364, 738, 361]], "image_id": 1, "id": 9}, {"iscrowd": 1, "category_id": 1, "bbox": [875.0, 92.0, 35.0, 20.0], "area": 700.0, "segmentation": [[875, 92, 910, 92, 910, 112, 875, 112]], "image_id": 2, "id": 10}, {"iscrowd": 1, "category_id": 1, "bbox": [748.0, 95.0, 39.0, 14.0], "area": 546.0, "segmentation": [[748, 95, 787, 95, 787, 109, 748, 109]], "image_id": 2, "id": 11}, {"iscrowd": 1, "category_id": 1, "bbox": [106.0, 394.0, 47.0, 31.0], "area": 1365.0, "segmentation": [[106, 395, 150, 394, 153, 425, 106, 424]], "image_id": 2, "id": 12}, {"iscrowd": 1, "category_id": 1, "bbox": [165.0, 393.0, 48.0, 28.0], "area": 1234.5, "segmentation": [[165, 393, 213, 396, 210, 421, 165, 421]], "image_id": 2, "id": 13}, {"iscrowd": 1, "category_id": 1, "bbox": [705.0, 49.0, 42.0, 15.0], "area": 510.0, "segmentation": [[706, 52, 747, 49, 746, 62, 705, 64]], "image_id": 2, "id": 14}, {"iscrowd": 0, "category_id": 1, "bbox": [111.0, 459.0, 96.0, 23.0], "area": 1981.5, "segmentation": [[111, 459, 206, 461, 207, 482, 113, 480]], "image_id": 2, "id": 15}, {"iscrowd": 1, "category_id": 1, "bbox": [831.0, 9.0, 63.0, 13.0], "area": 819.0, "segmentation": [[831, 9, 894, 9, 894, 22, 831, 22]], "image_id": 2, "id": 16}, {"iscrowd": 0, "category_id": 1, "bbox": [641.0, 454.0, 52.0, 15.0], "area": 676.0, "segmentation": [[641, 456, 693, 454, 693, 467, 641, 469]], "image_id": 2, "id": 17}, {"iscrowd": 1, "category_id": 1, "bbox": [839.0, 32.0, 52.0, 15.0], "area": 780.0, "segmentation": [[839, 32, 891, 32, 891, 47, 839, 47]], "image_id": 2, "id": 18}, {"iscrowd": 1, "category_id": 1, "bbox": [788.0, 46.0, 43.0, 13.0], "area": 559.0, "segmentation": [[788, 46, 831, 46, 831, 59, 788, 59]], "image_id": 2, "id": 19}, {"iscrowd": 1, "category_id": 1, "bbox": [830.0, 95.0, 42.0, 11.0], "area": 462.0, "segmentation": [[830, 95, 872, 95, 872, 106, 830, 106]], "image_id": 2, "id": 20}, {"iscrowd": 1, "category_id": 1, "bbox": [921.0, 92.0, 31.0, 19.0], "area": 589.0, "segmentation": [[921, 92, 952, 92, 952, 111, 921, 111]], "image_id": 2, "id": 21}, {"iscrowd": 1, "category_id": 1, "bbox": [968.0, 40.0, 45.0, 13.0], "area": 585.0, "segmentation": [[968, 40, 1013, 40, 1013, 53, 968, 53]], "image_id": 2, "id": 22}, {"iscrowd": 1, "category_id": 1, "bbox": [1002.0, 89.0, 29.0, 11.0], "area": 319.0, "segmentation": [[1002, 89, 1031, 89, 1031, 100, 1002, 100]], "image_id": 2, "id": 23}, {"iscrowd": 1, "category_id": 1, "bbox": [1043.0, 38.0, 55.0, 14.0], "area": 770.0, "segmentation": [[1043, 38, 1098, 38, 1098, 52, 1043, 52]], "image_id": 2, "id": 24}, {"iscrowd": 1, "category_id": 1, "bbox": [1069.0, 85.0, 69.0, 14.0], "area": 966.0, "segmentation": [[1069, 85, 1138, 85, 1138, 99, 1069, 99]], "image_id": 2, "id": 25}, {"iscrowd": 1, "category_id": 1, "bbox": [1128.0, 36.0, 50.0, 16.0], "area": 800.0, "segmentation": [[1128, 36, 1178, 36, 1178, 52, 1128, 52]], "image_id": 2, "id": 26}, {"iscrowd": 1, "category_id": 1, "bbox": [1168.0, 84.0, 32.0, 13.0], "area": 416.0, "segmentation": [[1168, 84, 1200, 84, 1200, 97, 1168, 97]], "image_id": 2, "id": 27}, {"iscrowd": 1, "category_id": 1, "bbox": [1219.0, 27.0, 40.0, 22.0], "area": 792.0, "segmentation": [[1223, 27, 1259, 27, 1255, 49, 1219, 49]], "image_id": 2, "id": 28}, {"iscrowd": 1, "category_id": 1, "bbox": [1264.0, 28.0, 15.0, 18.0], "area": 270.0, "segmentation": [[1264, 28, 1279, 28, 1279, 46, 1264, 46]], "image_id": 2, "id": 29}, {"iscrowd": 0, "category_id": 1, "bbox": [58.0, 71.0, 136.0, 52.0], "area": 5746.0, "segmentation": [[58, 80, 191, 71, 194, 114, 61, 123]], "image_id": 3, "id": 30}, {"iscrowd": 1, "category_id": 1, "bbox": [147.0, 21.0, 29.0, 15.0], "area": 435.0, "segmentation": [[147, 21, 176, 21, 176, 36, 147, 36]], "image_id": 3, "id": 31}, {"iscrowd": 1, "category_id": 1, "bbox": [326.0, 75.0, 65.0, 38.0], "area": 2146.5, "segmentation": [[328, 75, 391, 81, 387, 112, 326, 113]], "image_id": 3, "id": 32}, {"iscrowd": 1, "category_id": 1, "bbox": [401.0, 76.0, 47.0, 35.0], "area": 1330.0, "segmentation": [[401, 76, 448, 84, 445, 108, 402, 111]], "image_id": 3, "id": 33}, {"iscrowd": 1, "category_id": 1, "bbox": [780.0, 6.0, 236.0, 36.0], "area": 7653.0, "segmentation": [[780, 7, 1015, 6, 1016, 37, 788, 42]], "image_id": 3, "id": 34}, {"iscrowd": 0, "category_id": 1, "bbox": [221.0, 72.0, 91.0, 46.0], "area": 3731.5, "segmentation": [[221, 72, 311, 80, 312, 117, 222, 118]], "image_id": 3, "id": 35}, {"iscrowd": 1, "category_id": 1, "bbox": [113.0, 19.0, 31.0, 14.0], "area": 434.0, "segmentation": [[113, 19, 144, 19, 144, 33, 113, 33]], "image_id": 3, "id": 36}, {"iscrowd": 1, "category_id": 1, "bbox": [257.0, 28.0, 51.0, 29.0], "area": 1479.0, "segmentation": [[257, 28, 308, 28, 308, 57, 257, 57]], "image_id": 3, "id": 37}, {"iscrowd": 1, "category_id": 1, "bbox": [140.0, 115.0, 56.0, 18.0], "area": 742.5, "segmentation": [[140, 120, 196, 115, 195, 129, 141, 133]], "image_id": 3, "id": 38}, {"iscrowd": 1, "category_id": 1, "bbox": [86.0, 176.0, 26.0, 20.0], "area": 383.5, "segmentation": [[86, 176, 110, 177, 112, 189, 89, 196]], "image_id": 3, "id": 39}, {"iscrowd": 1, "category_id": 1, "bbox": [101.0, 185.0, 31.0, 19.0], "area": 359.5, "segmentation": [[101, 193, 129, 185, 132, 198, 103, 204]], "image_id": 3, "id": 40}, {"iscrowd": 1, "category_id": 1, "bbox": [223.0, 150.0, 71.0, 47.0], "area": 1704.5, "segmentation": [[223, 175, 244, 150, 294, 183, 235, 197]], "image_id": 3, "id": 41}, {"iscrowd": 1, "category_id": 1, "bbox": [140.0, 232.0, 36.0, 24.0], "area": 560.0, "segmentation": [[140, 239, 174, 232, 176, 247, 142, 256]], "image_id": 3, "id": 42}, {"iscrowd": 0, "category_id": 1, "bbox": [342.0, 206.0, 42.0, 22.0], "area": 832.0, "segmentation": [[344, 206, 384, 207, 381, 228, 342, 227]], "image_id": 4, "id": 43}, {"iscrowd": 1, "category_id": 1, "bbox": [42.0, 183.0, 52.0, 29.0], "area": 1168.0, "segmentation": [[47, 183, 94, 183, 83, 212, 42, 206]], "image_id": 4, "id": 44}, {"iscrowd": 0, "category_id": 1, "bbox": [913.0, 515.0, 168.0, 80.0], "area": 10248.0, "segmentation": [[913, 515, 1068, 526, 1081, 595, 921, 578]], "image_id": 4, "id": 45}, {"iscrowd": 1, "category_id": 1, "bbox": [240.0, 291.0, 33.0, 7.0], "area": 214.5, "segmentation": [[240, 291, 273, 291, 273, 298, 240, 297]], "image_id": 4, "id": 46}, {"iscrowd": 0, "category_id": 1, "bbox": [568.0, 347.0, 55.0, 33.0], "area": 1520.0, "segmentation": [[568, 347, 623, 350, 617, 380, 568, 375]], "image_id": 5, "id": 47}, {"iscrowd": 0, "category_id": 1, "bbox": [625.0, 345.0, 48.0, 37.0], "area": 1575.0, "segmentation": [[626, 347, 673, 345, 668, 382, 625, 380]], "image_id": 5, "id": 48}, {"iscrowd": 0, "category_id": 1, "bbox": [675.0, 350.0, 51.0, 31.0], "area": 1444.5, "segmentation": [[675, 351, 725, 350, 726, 381, 678, 379]], "image_id": 5, "id": 49}, {"iscrowd": 0, "category_id": 1, "bbox": [598.0, 381.0, 130.0, 39.0], "area": 4299.0, "segmentation": [[598, 381, 728, 385, 724, 420, 598, 413]], "image_id": 5, "id": 50}, {"iscrowd": 1, "category_id": 1, "bbox": [760.0, 351.0, 85.0, 29.0], "area": 2062.5, "segmentation": [[762, 351, 845, 357, 845, 380, 760, 377]], "image_id": 5, "id": 51}, {"iscrowd": 1, "category_id": 1, "bbox": [562.0, 588.0, 51.0, 45.0], "area": 2180.5, "segmentation": [[562, 588, 613, 588, 611, 632, 564, 633]], "image_id": 5, "id": 52}, {"iscrowd": 1, "category_id": 1, "bbox": [614.0, 593.0, 116.0, 53.0], "area": 4810.0, "segmentation": [[615, 593, 730, 603, 727, 646, 614, 634]], "image_id": 5, "id": 53}, {"iscrowd": 1, "category_id": 1, "bbox": [556.0, 634.0, 174.0, 57.0], "area": 7339.0, "segmentation": [[560, 634, 730, 650, 730, 691, 556, 678]], "image_id": 5, "id": 54}, {"iscrowd": 0, "category_id": 1, "bbox": [377.0, 117.0, 88.0, 13.0], "area": 1124.5, "segmentation": [[377, 117, 463, 117, 465, 130, 378, 130]], "image_id": 6, "id": 55}, {"iscrowd": 0, "category_id": 1, "bbox": [493.0, 115.0, 26.0, 16.0], "area": 416.0, "segmentation": [[493, 115, 519, 115, 519, 131, 493, 131]], "image_id": 6, "id": 56}, {"iscrowd": 1, "category_id": 1, "bbox": [374.0, 155.0, 35.0, 15.0], "area": 525.0, "segmentation": [[374, 155, 409, 155, 409, 170, 374, 170]], "image_id": 6, "id": 57}, {"iscrowd": 0, "category_id": 1, "bbox": [492.0, 151.0, 59.0, 19.0], "area": 1121.0, "segmentation": [[492, 151, 551, 151, 551, 170, 492, 170]], "image_id": 6, "id": 58}, {"iscrowd": 0, "category_id": 1, "bbox": [376.0, 198.0, 46.0, 14.0], "area": 644.0, "segmentation": [[376, 198, 422, 198, 422, 212, 376, 212]], "image_id": 6, "id": 59}, {"iscrowd": 1, "category_id": 1, "bbox": [494.0, 189.0, 45.0, 17.0], "area": 720.0, "segmentation": [[494, 190, 539, 189, 539, 205, 494, 206]], "image_id": 6, "id": 60}, {"iscrowd": 1, "category_id": 1, "bbox": [372.0, 0.0, 122.0, 86.0], "area": 10198.0, "segmentation": [[374, 1, 494, 0, 492, 85, 372, 86]], "image_id": 6, "id": 61}, {"iscrowd": 1, "category_id": 1, "bbox": [405.0, 409.0, 32.0, 52.0], "area": 793.0, "segmentation": [[408, 409, 437, 436, 434, 461, 405, 433]], "image_id": 7, "id": 62}, {"iscrowd": 1, "category_id": 1, "bbox": [435.0, 434.0, 8.0, 33.0], "area": 176.0, "segmentation": [[437, 434, 443, 440, 441, 467, 435, 462]], "image_id": 7, "id": 63}, {"iscrowd": 1, "category_id": 1, "bbox": [345.0, 130.0, 56.0, 23.0], "area": 1045.0, "segmentation": [[346, 133, 400, 130, 401, 148, 345, 153]], "image_id": 8, "id": 64}, {"iscrowd": 1, "category_id": 1, "bbox": [301.0, 123.0, 50.0, 35.0], "area": 1496.0, "segmentation": [[301, 127, 349, 123, 351, 154, 303, 158]], "image_id": 8, "id": 65}, {"iscrowd": 0, "category_id": 1, "bbox": [869.0, 61.0, 54.0, 30.0], "area": 1242.0, "segmentation": [[869, 67, 920, 61, 923, 85, 872, 91]], "image_id": 8, "id": 66}, {"iscrowd": 0, "category_id": 1, "bbox": [884.0, 141.0, 50.0, 19.0], "area": 762.0, "segmentation": [[886, 144, 934, 141, 932, 157, 884, 160]], "image_id": 8, "id": 67}, {"iscrowd": 1, "category_id": 1, "bbox": [634.0, 86.0, 182.0, 35.0], "area": 3007.0, "segmentation": [[634, 106, 812, 86, 816, 104, 634, 121]], "image_id": 8, "id": 68}, {"iscrowd": 1, "category_id": 1, "bbox": [418.0, 112.0, 53.0, 36.0], "area": 1591.0, "segmentation": [[418, 117, 469, 112, 471, 143, 420, 148]], "image_id": 8, "id": 69}, {"iscrowd": 1, "category_id": 1, "bbox": [634.0, 107.0, 149.0, 28.0], "area": 2013.0, "segmentation": [[634, 124, 781, 107, 783, 123, 635, 135]], "image_id": 8, "id": 70}, {"iscrowd": 1, "category_id": 1, "bbox": [634.0, 117.0, 210.0, 38.0], "area": 4283.0, "segmentation": [[634, 138, 844, 117, 843, 141, 636, 155]], "image_id": 8, "id": 71}, {"iscrowd": 1, "category_id": 1, "bbox": [468.0, 117.0, 57.0, 26.0], "area": 1091.0, "segmentation": [[468, 124, 518, 117, 525, 138, 468, 143]], "image_id": 8, "id": 72}, {"iscrowd": 1, "category_id": 1, "bbox": [301.0, 162.0, 231.0, 39.0], "area": 4581.0, "segmentation": [[301, 181, 532, 162, 530, 182, 301, 201]], "image_id": 8, "id": 73}, {"iscrowd": 1, "category_id": 1, "bbox": [296.0, 147.0, 104.0, 27.0], "area": 1788.0, "segmentation": [[296, 157, 396, 147, 400, 165, 300, 174]], "image_id": 8, "id": 74}, {"iscrowd": 1, "category_id": 1, "bbox": [420.0, 136.0, 107.0, 27.0], "area": 1602.0, "segmentation": [[420, 151, 526, 136, 527, 154, 421, 163]], "image_id": 8, "id": 75}, {"iscrowd": 1, "category_id": 1, "bbox": [616.0, 250.0, 41.0, 35.0], "area": 1318.0, "segmentation": [[617, 251, 657, 250, 656, 282, 616, 285]], "image_id": 8, "id": 76}, {"iscrowd": 1, "category_id": 1, "bbox": [695.0, 243.0, 43.0, 35.0], "area": 1352.5, "segmentation": [[695, 246, 738, 243, 738, 276, 698, 278]], "image_id": 8, "id": 77}, {"iscrowd": 1, "category_id": 1, "bbox": [739.0, 241.0, 24.0, 21.0], "area": 423.0, "segmentation": [[739, 241, 760, 241, 763, 260, 742, 262]], "image_id": 8, "id": 78}, {"iscrowd": 1, "category_id": 1, "bbox": [692.0, 268.0, 18.0, 25.0], "area": 450.0, "segmentation": [[692, 268, 710, 268, 710, 293, 692, 293]], "image_id": 9, "id": 79}, {"iscrowd": 1, "category_id": 1, "bbox": [661.0, 224.0, 76.0, 22.0], "area": 1236.0, "segmentation": [[663, 224, 733, 230, 737, 246, 661, 242]], "image_id": 9, "id": 80}, {"iscrowd": 1, "category_id": 1, "bbox": [668.0, 242.0, 69.0, 18.0], "area": 999.0, "segmentation": [[668, 242, 737, 244, 734, 260, 670, 256]], "image_id": 9, "id": 81}]}
diff --git a/tests/data/toy_dataset/instances_test.txt b/tests/data/toy_dataset/instances_test.txt
new file mode 100644
index 0000000000000000000000000000000000000000..af3e8e65424cf42e5802209dc37e8d650a6b8226
--- /dev/null
+++ b/tests/data/toy_dataset/instances_test.txt
@@ -0,0 +1,10 @@
+{"file_name": "test/img_10.jpg", "height": 720, "width": 1280, "annotations": [{"iscrowd": 1, "category_id": 1, "bbox": [260.0, 138.0, 24.0, 20.0], "segmentation": [[261, 138, 284, 140, 279, 158, 260, 158]]}, {"iscrowd": 0, "category_id": 1, "bbox": [288.0, 138.0, 129.0, 23.0], "segmentation": [[288, 138, 417, 140, 416, 161, 290, 157]]}, {"iscrowd": 0, "category_id": 1, "bbox": [743.0, 145.0, 37.0, 18.0], "segmentation": [[743, 145, 779, 146, 780, 163, 746, 163]]}, {"iscrowd": 0, "category_id": 1, "bbox": [783.0, 129.0, 50.0, 26.0], "segmentation": [[783, 129, 831, 132, 833, 155, 785, 153]]}, {"iscrowd": 1, "category_id": 1, "bbox": [831.0, 133.0, 43.0, 23.0], "segmentation": [[831, 133, 870, 135, 874, 156, 835, 155]]}, {"iscrowd": 1, "category_id": 1, "bbox": [159.0, 204.0, 72.0, 15.0], "segmentation": [[159, 205, 230, 204, 231, 218, 159, 219]]}, {"iscrowd": 1, "category_id": 1, "bbox": [785.0, 158.0, 75.0, 21.0], "segmentation": [[785, 158, 856, 158, 860, 178, 787, 179]]}, {"iscrowd": 1, "category_id": 1, "bbox": [1011.0, 157.0, 68.0, 16.0], "segmentation": [[1011, 157, 1079, 160, 1076, 173, 1011, 170]]}]}
+{"file_name": "test/img_2.jpg", "height": 720, "width": 1280, "annotations": [{"iscrowd": 0, "category_id": 1, "bbox": [602.0, 173.0, 33.0, 24.0], "segmentation": [[602, 173, 635, 175, 634, 197, 602, 196]]}, {"iscrowd": 0, "category_id": 1, "bbox": [734.0, 310.0, 58.0, 54.0], "segmentation": [[734, 310, 792, 320, 792, 364, 738, 361]]}]}
+{"file_name": "test/img_6.jpg", "height": 720, "width": 1280, "annotations": [{"iscrowd": 1, "category_id": 1, "bbox": [875.0, 92.0, 35.0, 20.0], "segmentation": [[875, 92, 910, 92, 910, 112, 875, 112]]}, {"iscrowd": 1, "category_id": 1, "bbox": [748.0, 95.0, 39.0, 14.0], "segmentation": [[748, 95, 787, 95, 787, 109, 748, 109]]}, {"iscrowd": 1, "category_id": 1, "bbox": [106.0, 394.0, 47.0, 31.0], "segmentation": [[106, 395, 150, 394, 153, 425, 106, 424]]}, {"iscrowd": 1, "category_id": 1, "bbox": [165.0, 393.0, 48.0, 28.0], "segmentation": [[165, 393, 213, 396, 210, 421, 165, 421]]}, {"iscrowd": 1, "category_id": 1, "bbox": [705.0, 49.0, 42.0, 15.0], "segmentation": [[706, 52, 747, 49, 746, 62, 705, 64]]}, {"iscrowd": 0, "category_id": 1, "bbox": [111.0, 459.0, 96.0, 23.0], "segmentation": [[111, 459, 206, 461, 207, 482, 113, 480]]}, {"iscrowd": 1, "category_id": 1, "bbox": [831.0, 9.0, 63.0, 13.0], "segmentation": [[831, 9, 894, 9, 894, 22, 831, 22]]}, {"iscrowd": 0, "category_id": 1, "bbox": [641.0, 454.0, 52.0, 15.0], "segmentation": [[641, 456, 693, 454, 693, 467, 641, 469]]}, {"iscrowd": 1, "category_id": 1, "bbox": [839.0, 32.0, 52.0, 15.0], "segmentation": [[839, 32, 891, 32, 891, 47, 839, 47]]}, {"iscrowd": 1, "category_id": 1, "bbox": [788.0, 46.0, 43.0, 13.0], "segmentation": [[788, 46, 831, 46, 831, 59, 788, 59]]}, {"iscrowd": 1, "category_id": 1, "bbox": [830.0, 95.0, 42.0, 11.0], "segmentation": [[830, 95, 872, 95, 872, 106, 830, 106]]}, {"iscrowd": 1, "category_id": 1, "bbox": [921.0, 92.0, 31.0, 19.0], "segmentation": [[921, 92, 952, 92, 952, 111, 921, 111]]}, {"iscrowd": 1, "category_id": 1, "bbox": [968.0, 40.0, 45.0, 13.0], "segmentation": [[968, 40, 1013, 40, 1013, 53, 968, 53]]}, {"iscrowd": 1, "category_id": 1, "bbox": [1002.0, 89.0, 29.0, 11.0], "segmentation": [[1002, 89, 1031, 89, 1031, 100, 1002, 100]]}, {"iscrowd": 1, "category_id": 1, "bbox": [1043.0, 38.0, 55.0, 14.0], "segmentation": [[1043, 38, 1098, 38, 1098, 52, 1043, 52]]}, {"iscrowd": 1, "category_id": 1, "bbox": [1069.0, 85.0, 69.0, 14.0], "segmentation": [[1069, 85, 1138, 85, 1138, 99, 1069, 99]]}, {"iscrowd": 1, "category_id": 1, "bbox": [1128.0, 36.0, 50.0, 16.0], "segmentation": [[1128, 36, 1178, 36, 1178, 52, 1128, 52]]}, {"iscrowd": 1, "category_id": 1, "bbox": [1168.0, 84.0, 32.0, 13.0], "segmentation": [[1168, 84, 1200, 84, 1200, 97, 1168, 97]]}, {"iscrowd": 1, "category_id": 1, "bbox": [1219.0, 27.0, 40.0, 22.0], "segmentation": [[1223, 27, 1259, 27, 1255, 49, 1219, 49]]}, {"iscrowd": 1, "category_id": 1, "bbox": [1264.0, 28.0, 15.0, 18.0], "segmentation": [[1264, 28, 1279, 28, 1279, 46, 1264, 46]]}]}
+{"file_name": "test/img_3.jpg", "height": 720, "width": 1280, "annotations": [{"iscrowd": 0, "category_id": 1, "bbox": [58.0, 71.0, 136.0, 52.0], "segmentation": [[58, 80, 191, 71, 194, 114, 61, 123]]}, {"iscrowd": 1, "category_id": 1, "bbox": [147.0, 21.0, 29.0, 15.0], "segmentation": [[147, 21, 176, 21, 176, 36, 147, 36]]}, {"iscrowd": 1, "category_id": 1, "bbox": [326.0, 75.0, 65.0, 38.0], "segmentation": [[328, 75, 391, 81, 387, 112, 326, 113]]}, {"iscrowd": 1, "category_id": 1, "bbox": [401.0, 76.0, 47.0, 35.0], "segmentation": [[401, 76, 448, 84, 445, 108, 402, 111]]}, {"iscrowd": 1, "category_id": 1, "bbox": [780.0, 6.0, 236.0, 36.0], "segmentation": [[780, 7, 1015, 6, 1016, 37, 788, 42]]}, {"iscrowd": 0, "category_id": 1, "bbox": [221.0, 72.0, 91.0, 46.0], "segmentation": [[221, 72, 311, 80, 312, 117, 222, 118]]}, {"iscrowd": 1, "category_id": 1, "bbox": [113.0, 19.0, 31.0, 14.0], "segmentation": [[113, 19, 144, 19, 144, 33, 113, 33]]}, {"iscrowd": 1, "category_id": 1, "bbox": [257.0, 28.0, 51.0, 29.0], "segmentation": [[257, 28, 308, 28, 308, 57, 257, 57]]}, {"iscrowd": 1, "category_id": 1, "bbox": [140.0, 115.0, 56.0, 18.0], "segmentation": [[140, 120, 196, 115, 195, 129, 141, 133]]}, {"iscrowd": 1, "category_id": 1, "bbox": [86.0, 176.0, 26.0, 20.0], "segmentation": [[86, 176, 110, 177, 112, 189, 89, 196]]}, {"iscrowd": 1, "category_id": 1, "bbox": [101.0, 185.0, 31.0, 19.0], "segmentation": [[101, 193, 129, 185, 132, 198, 103, 204]]}, {"iscrowd": 1, "category_id": 1, "bbox": [223.0, 150.0, 71.0, 47.0], "segmentation": [[223, 175, 244, 150, 294, 183, 235, 197]]}, {"iscrowd": 1, "category_id": 1, "bbox": [140.0, 232.0, 36.0, 24.0], "segmentation": [[140, 239, 174, 232, 176, 247, 142, 256]]}]}
+{"file_name": "test/img_9.jpg", "height": 720, "width": 1280, "annotations": [{"iscrowd": 0, "category_id": 1, "bbox": [342.0, 206.0, 42.0, 22.0], "segmentation": [[344, 206, 384, 207, 381, 228, 342, 227]]}, {"iscrowd": 1, "category_id": 1, "bbox": [42.0, 183.0, 52.0, 29.0], "segmentation": [[47, 183, 94, 183, 83, 212, 42, 206]]}, {"iscrowd": 0, "category_id": 1, "bbox": [913.0, 515.0, 168.0, 80.0], "segmentation": [[913, 515, 1068, 526, 1081, 595, 921, 578]]}, {"iscrowd": 1, "category_id": 1, "bbox": [240.0, 291.0, 33.0, 7.0], "segmentation": [[240, 291, 273, 291, 273, 298, 240, 297]]}]}
+{"file_name": "test/img_8.jpg", "height": 720, "width": 1280, "annotations": [{"iscrowd": 0, "category_id": 1, "bbox": [568.0, 347.0, 55.0, 33.0], "segmentation": [[568, 347, 623, 350, 617, 380, 568, 375]]}, {"iscrowd": 0, "category_id": 1, "bbox": [625.0, 345.0, 48.0, 37.0], "segmentation": [[626, 347, 673, 345, 668, 382, 625, 380]]}, {"iscrowd": 0, "category_id": 1, "bbox": [675.0, 350.0, 51.0, 31.0], "segmentation": [[675, 351, 725, 350, 726, 381, 678, 379]]}, {"iscrowd": 0, "category_id": 1, "bbox": [598.0, 381.0, 130.0, 39.0], "segmentation": [[598, 381, 728, 385, 724, 420, 598, 413]]}, {"iscrowd": 1, "category_id": 1, "bbox": [760.0, 351.0, 85.0, 29.0], "segmentation": [[762, 351, 845, 357, 845, 380, 760, 377]]}, {"iscrowd": 1, "category_id": 1, "bbox": [562.0, 588.0, 51.0, 45.0], "segmentation": [[562, 588, 613, 588, 611, 632, 564, 633]]}, {"iscrowd": 1, "category_id": 1, "bbox": [614.0, 593.0, 116.0, 53.0], "segmentation": [[615, 593, 730, 603, 727, 646, 614, 634]]}, {"iscrowd": 1, "category_id": 1, "bbox": [556.0, 634.0, 174.0, 57.0], "segmentation": [[560, 634, 730, 650, 730, 691, 556, 678]]}]}
+{"file_name": "test/img_1.jpg", "height": 720, "width": 1280, "annotations": [{"iscrowd": 0, "category_id": 1, "bbox": [377.0, 117.0, 88.0, 13.0], "segmentation": [[377, 117, 463, 117, 465, 130, 378, 130]]}, {"iscrowd": 0, "category_id": 1, "bbox": [493.0, 115.0, 26.0, 16.0], "segmentation": [[493, 115, 519, 115, 519, 131, 493, 131]]}, {"iscrowd": 1, "category_id": 1, "bbox": [374.0, 155.0, 35.0, 15.0], "segmentation": [[374, 155, 409, 155, 409, 170, 374, 170]]}, {"iscrowd": 0, "category_id": 1, "bbox": [492.0, 151.0, 59.0, 19.0], "segmentation": [[492, 151, 551, 151, 551, 170, 492, 170]]}, {"iscrowd": 0, "category_id": 1, "bbox": [376.0, 198.0, 46.0, 14.0], "segmentation": [[376, 198, 422, 198, 422, 212, 376, 212]]}, {"iscrowd": 1, "category_id": 1, "bbox": [494.0, 189.0, 45.0, 17.0], "segmentation": [[494, 190, 539, 189, 539, 205, 494, 206]]}, {"iscrowd": 1, "category_id": 1, "bbox": [372.0, 0.0, 122.0, 86.0], "segmentation": [[374, 1, 494, 0, 492, 85, 372, 86]]}]}
+{"file_name": "test/img_5.jpg", "height": 720, "width": 1280, "annotations": [{"iscrowd": 1, "category_id": 1, "bbox": [405.0, 409.0, 32.0, 52.0], "segmentation": [[408, 409, 437, 436, 434, 461, 405, 433]]}, {"iscrowd": 1, "category_id": 1, "bbox": [435.0, 434.0, 8.0, 33.0], "segmentation": [[437, 434, 443, 440, 441, 467, 435, 462]]}]}
+{"file_name": "test/img_7.jpg", "height": 720, "width": 1280, "annotations": [{"iscrowd": 1, "category_id": 1, "bbox": [345.0, 130.0, 56.0, 23.0], "segmentation": [[346, 133, 400, 130, 401, 148, 345, 153]]}, {"iscrowd": 1, "category_id": 1, "bbox": [301.0, 123.0, 50.0, 35.0], "segmentation": [[301, 127, 349, 123, 351, 154, 303, 158]]}, {"iscrowd": 0, "category_id": 1, "bbox": [869.0, 61.0, 54.0, 30.0], "segmentation": [[869, 67, 920, 61, 923, 85, 872, 91]]}, {"iscrowd": 0, "category_id": 1, "bbox": [884.0, 141.0, 50.0, 19.0], "segmentation": [[886, 144, 934, 141, 932, 157, 884, 160]]}, {"iscrowd": 1, "category_id": 1, "bbox": [634.0, 86.0, 182.0, 35.0], "segmentation": [[634, 106, 812, 86, 816, 104, 634, 121]]}, {"iscrowd": 1, "category_id": 1, "bbox": [418.0, 112.0, 53.0, 36.0], "segmentation": [[418, 117, 469, 112, 471, 143, 420, 148]]}, {"iscrowd": 1, "category_id": 1, "bbox": [634.0, 107.0, 149.0, 28.0], "segmentation": [[634, 124, 781, 107, 783, 123, 635, 135]]}, {"iscrowd": 1, "category_id": 1, "bbox": [634.0, 117.0, 210.0, 38.0], "segmentation": [[634, 138, 844, 117, 843, 141, 636, 155]]}, {"iscrowd": 1, "category_id": 1, "bbox": [468.0, 117.0, 57.0, 26.0], "segmentation": [[468, 124, 518, 117, 525, 138, 468, 143]]}, {"iscrowd": 1, "category_id": 1, "bbox": [301.0, 162.0, 231.0, 39.0], "segmentation": [[301, 181, 532, 162, 530, 182, 301, 201]]}, {"iscrowd": 1, "category_id": 1, "bbox": [296.0, 147.0, 104.0, 27.0], "segmentation": [[296, 157, 396, 147, 400, 165, 300, 174]]}, {"iscrowd": 1, "category_id": 1, "bbox": [420.0, 136.0, 107.0, 27.0], "segmentation": [[420, 151, 526, 136, 527, 154, 421, 163]]}, {"iscrowd": 1, "category_id": 1, "bbox": [616.0, 250.0, 41.0, 35.0], "segmentation": [[617, 251, 657, 250, 656, 282, 616, 285]]}, {"iscrowd": 1, "category_id": 1, "bbox": [695.0, 243.0, 43.0, 35.0], "segmentation": [[695, 246, 738, 243, 738, 276, 698, 278]]}, {"iscrowd": 1, "category_id": 1, "bbox": [739.0, 241.0, 24.0, 21.0], "segmentation": [[739, 241, 760, 241, 763, 260, 742, 262]]}]}
+{"file_name": "test/img_4.jpg", "height": 720, "width": 1280, "annotations": [{"iscrowd": 1, "category_id": 1, "bbox": [692.0, 268.0, 18.0, 25.0], "segmentation": [[692, 268, 710, 268, 710, 293, 692, 293]]}, {"iscrowd": 1, "category_id": 1, "bbox": [661.0, 224.0, 76.0, 22.0], "segmentation": [[663, 224, 733, 230, 737, 246, 661, 242]]}, {"iscrowd": 1, "category_id": 1, "bbox": [668.0, 242.0, 69.0, 18.0], "segmentation": [[668, 242, 737, 244, 734, 260, 670, 256]]}]}
diff --git a/tests/test_apis/test_image_misc.py b/tests/test_apis/test_image_misc.py
new file mode 100644
index 0000000000000000000000000000000000000000..1e047523d68f42df274045e0d12e923cd8092fb2
--- /dev/null
+++ b/tests/test_apis/test_image_misc.py
@@ -0,0 +1,42 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import pytest
+import torch
+from numpy.testing import assert_array_equal
+
+from mmocr.apis.utils import tensor2grayimgs
+
+
+@pytest.mark.skipif(not torch.cuda.is_available(), reason='requires cuda')
+def test_tensor2grayimgs():
+
+ # test tensor obj
+ with pytest.raises(AssertionError):
+ tensor = np.random.rand(2, 3, 3)
+ tensor2grayimgs(tensor)
+
+ # test tensor ndim
+ with pytest.raises(AssertionError):
+ tensor = torch.randn(2, 3, 3)
+ tensor2grayimgs(tensor)
+
+ # test tensor dim-1
+ with pytest.raises(AssertionError):
+ tensor = torch.randn(2, 3, 5, 5)
+ tensor2grayimgs(tensor)
+
+ # test mean length
+ with pytest.raises(AssertionError):
+ tensor = torch.randn(2, 1, 5, 5)
+ tensor2grayimgs(tensor, mean=(1, 1, 1))
+
+ # test std length
+ with pytest.raises(AssertionError):
+ tensor = torch.randn(2, 1, 5, 5)
+ tensor2grayimgs(tensor, std=(1, 1, 1))
+
+ tensor = torch.randn(2, 1, 5, 5)
+ gts = [t.squeeze(0).cpu().numpy().astype(np.uint8) for t in tensor]
+ outputs = tensor2grayimgs(tensor, mean=(0, ), std=(1, ))
+ for gt, output in zip(gts, outputs):
+ assert_array_equal(gt, output)
diff --git a/tests/test_apis/test_model_inference.py b/tests/test_apis/test_model_inference.py
new file mode 100644
index 0000000000000000000000000000000000000000..9c09fa80b84b258e40e678bc19cffdc8d86ab0ff
--- /dev/null
+++ b/tests/test_apis/test_model_inference.py
@@ -0,0 +1,127 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import platform
+
+import pytest
+from mmcv.image import imread
+
+from mmocr.apis.inference import init_detector, model_inference
+from mmocr.datasets import build_dataset # noqa: F401
+from mmocr.models import build_detector # noqa: F401
+from mmocr.utils import revert_sync_batchnorm
+
+
+def build_model(config_file):
+ device = 'cpu'
+ model = init_detector(config_file, checkpoint=None, device=device)
+ model = revert_sync_batchnorm(model)
+
+ return model
+
+
+@pytest.mark.skipif(
+ platform.system() == 'Windows',
+ reason='Win container on Github Action does not have enough RAM to run')
+@pytest.mark.parametrize('cfg_file', [
+ '../configs/textrecog/sar/sar_r31_parallel_decoder_academic.py',
+ '../configs/textrecog/abinet/abinet_academic.py',
+ '../configs/textrecog/crnn/crnn_academic_dataset.py',
+ '../configs/textrecog/seg/seg_r31_1by16_fpnocr_academic.py',
+ '../configs/textdet/psenet/psenet_r50_fpnf_600e_icdar2017.py'
+])
+def test_model_inference(cfg_file):
+ tmp_dir = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))
+ config_file = os.path.join(tmp_dir, cfg_file)
+ model = build_model(config_file)
+ with pytest.raises(AssertionError):
+ model_inference(model, 1)
+
+ sample_img_path = os.path.join(tmp_dir, '../demo/demo_text_det.jpg')
+ model_inference(model, sample_img_path)
+
+ # numpy inference
+ img = imread(sample_img_path)
+
+ model_inference(model, img)
+
+
+@pytest.mark.skipif(
+ platform.system() == 'Windows',
+ reason='Win container on Github Action does not have enough RAM to run')
+@pytest.mark.parametrize(
+ 'cfg_file',
+ ['../configs/textdet/psenet/psenet_r50_fpnf_600e_icdar2017.py'])
+def test_model_batch_inference_det(cfg_file):
+ tmp_dir = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))
+ config_file = os.path.join(tmp_dir, cfg_file)
+ model = build_model(config_file)
+
+ sample_img_path = os.path.join(tmp_dir, '../demo/demo_text_det.jpg')
+ results = model_inference(model, [sample_img_path], batch_mode=True)
+
+ assert len(results) == 1
+
+ # numpy inference
+ img = imread(sample_img_path)
+ results = model_inference(model, [img], batch_mode=True)
+
+ assert len(results) == 1
+
+
+@pytest.mark.parametrize('cfg_file', [
+ '../configs/textrecog/sar/sar_r31_parallel_decoder_academic.py',
+])
+def test_model_batch_inference_raises_exception_error_aug_test_recog(cfg_file):
+ tmp_dir = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))
+ config_file = os.path.join(tmp_dir, cfg_file)
+ model = build_model(config_file)
+
+ with pytest.raises(
+ Exception,
+ match='aug test does not support inference with batch size'):
+ sample_img_path = os.path.join(tmp_dir, '../demo/demo_text_det.jpg')
+ model_inference(model, [sample_img_path, sample_img_path])
+
+ with pytest.raises(
+ Exception,
+ match='aug test does not support inference with batch size'):
+ img = imread(sample_img_path)
+ model_inference(model, [img, img])
+
+
+@pytest.mark.parametrize('cfg_file', [
+ '../configs/textrecog/sar/sar_r31_parallel_decoder_academic.py',
+])
+def test_model_batch_inference_recog(cfg_file):
+ tmp_dir = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))
+ config_file = os.path.join(tmp_dir, cfg_file)
+ model = build_model(config_file)
+
+ sample_img_path = os.path.join(tmp_dir, '../demo/demo_text_recog.jpg')
+ results = model_inference(
+ model, [sample_img_path, sample_img_path], batch_mode=True)
+
+ assert len(results) == 2
+
+ # numpy inference
+ img = imread(sample_img_path)
+ results = model_inference(model, [img, img], batch_mode=True)
+
+ assert len(results) == 2
+
+
+@pytest.mark.parametrize(
+ 'cfg_file',
+ ['../configs/textdet/psenet/psenet_r50_fpnf_600e_icdar2017.py'])
+def test_model_batch_inference_empty_detection(cfg_file):
+ tmp_dir = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))
+ config_file = os.path.join(tmp_dir, cfg_file)
+ model = build_model(config_file)
+
+ empty_detection = []
+
+ with pytest.raises(
+ Exception,
+ match='empty imgs provided, please check and try again'):
+
+ model_inference(model, empty_detection, batch_mode=True)
diff --git a/tests/test_apis/test_single_gpu_test.py b/tests/test_apis/test_single_gpu_test.py
new file mode 100644
index 0000000000000000000000000000000000000000..64fd99fe92187aedd9ab2a2dc574e693f504191b
--- /dev/null
+++ b/tests/test_apis/test_single_gpu_test.py
@@ -0,0 +1,205 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import json
+import os
+import os.path as osp
+import tempfile
+
+import mmcv
+import numpy as np
+import pytest
+import torch
+from mmcv import Config
+from mmcv.parallel import MMDataParallel
+
+from mmocr.apis.test import single_gpu_test
+from mmocr.datasets import build_dataloader, build_dataset
+from mmocr.models import build_detector
+from mmocr.utils import check_argument, list_to_file, revert_sync_batchnorm
+
+
+def build_model(cfg):
+ model = build_detector(cfg.model, test_cfg=cfg.get('test_cfg'))
+ model = revert_sync_batchnorm(model)
+ model = MMDataParallel(model)
+
+ return model
+
+
+def generate_sample_dataloader(cfg, curr_dir, img_prefix='', ann_file=''):
+ must_keys = ['img_norm_cfg', 'ori_filename', 'img_shape', 'ori_shape']
+ test_pipeline = cfg.data.test.pipeline
+ for key in must_keys:
+ if test_pipeline[1].type == 'MultiRotateAugOCR':
+ collect_pipeline = test_pipeline[1]['transforms'][-1]
+ else:
+ collect_pipeline = test_pipeline[-1]
+ if 'meta_keys' not in collect_pipeline:
+ continue
+ collect_pipeline['meta_keys'].append(key)
+
+ img_prefix = osp.join(curr_dir, img_prefix)
+ ann_file = osp.join(curr_dir, ann_file)
+ test = copy.deepcopy(cfg.data.test.datasets[0])
+ test.img_prefix = img_prefix
+ test.ann_file = ann_file
+ cfg.data.workers_per_gpu = 0
+ cfg.data.test.datasets = [test]
+ dataset = build_dataset(cfg.data.test)
+
+ loader_cfg = {
+ **dict((k, cfg.data[k]) for k in [
+ 'workers_per_gpu', 'samples_per_gpu'
+ ] if k in cfg.data)
+ }
+ test_loader_cfg = {
+ **loader_cfg,
+ **dict(shuffle=False, drop_last=False),
+ **cfg.data.get('test_dataloader', {})
+ }
+
+ data_loader = build_dataloader(dataset, **test_loader_cfg)
+
+ return data_loader
+
+
+@pytest.mark.skipif(not torch.cuda.is_available(), reason='requires cuda')
+@pytest.mark.parametrize('cfg_file', [
+ '../configs/textrecog/sar/sar_r31_parallel_decoder_academic.py',
+ '../configs/textrecog/crnn/crnn_academic_dataset.py',
+ '../configs/textrecog/seg/seg_r31_1by16_fpnocr_academic.py'
+])
+def test_single_gpu_test_recog(cfg_file):
+ curr_dir = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))
+ config_file = os.path.join(curr_dir, cfg_file)
+ cfg = Config.fromfile(config_file)
+
+ model = build_model(cfg)
+ img_prefix = 'data/ocr_toy_dataset/imgs'
+ ann_file = 'data/ocr_toy_dataset/label.txt'
+ data_loader = generate_sample_dataloader(cfg, curr_dir, img_prefix,
+ ann_file)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ out_dir = osp.join(tmpdirname, 'tmp')
+ results = single_gpu_test(model, data_loader, out_dir=out_dir)
+ assert check_argument.is_type_list(results, dict)
+
+
+@pytest.mark.skipif(not torch.cuda.is_available(), reason='requires cuda')
+@pytest.mark.parametrize(
+ 'cfg_file',
+ ['../configs/textdet/psenet/psenet_r50_fpnf_600e_icdar2017.py'])
+def test_single_gpu_test_det(cfg_file):
+ curr_dir = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))
+ config_file = os.path.join(curr_dir, cfg_file)
+ cfg = Config.fromfile(config_file)
+
+ model = build_model(cfg)
+ img_prefix = 'data/toy_dataset/imgs'
+ ann_file = 'data/toy_dataset/instances_test.json'
+ data_loader = generate_sample_dataloader(cfg, curr_dir, img_prefix,
+ ann_file)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ out_dir = osp.join(tmpdirname, 'tmp')
+ results = single_gpu_test(model, data_loader, out_dir=out_dir)
+ assert check_argument.is_type_list(results, dict)
+
+
+def gene_sdmgr_model_dataloader(cfg, dirname, curr_dir, empty_img=False):
+ json_obj = {
+ 'file_name':
+ '1.jpg',
+ 'height':
+ 348,
+ 'width':
+ 348,
+ 'annotations': [{
+ 'box': [114.0, 19.0, 230.0, 19.0, 230.0, 1.0, 114.0, 1.0],
+ 'text':
+ 'CHOEUN',
+ 'label':
+ 1
+ }]
+ }
+ ann_file = osp.join(dirname, 'test.txt')
+ list_to_file(ann_file, [json.dumps(json_obj, ensure_ascii=False)])
+
+ if not empty_img:
+ img = np.ones((348, 348, 3), dtype=np.uint8)
+ img_file = osp.join(dirname, '1.jpg')
+ mmcv.imwrite(img, img_file)
+
+ test = copy.deepcopy(cfg.data.test)
+ test.ann_file = ann_file
+ test.img_prefix = dirname
+ test.dict_file = osp.join(curr_dir, 'data/kie_toy_dataset/dict.txt')
+ cfg.data.workers_per_gpu = 1
+ cfg.data.test = test
+ cfg.model.class_list = osp.join(curr_dir,
+ 'data/kie_toy_dataset/class_list.txt')
+
+ dataset = build_dataset(cfg.data.test)
+
+ loader_cfg = {
+ **dict((k, cfg.data[k]) for k in [
+ 'workers_per_gpu', 'samples_per_gpu'
+ ] if k in cfg.data)
+ }
+ test_loader_cfg = {
+ **loader_cfg,
+ **dict(shuffle=False, drop_last=False),
+ **cfg.data.get('test_dataloader', {})
+ }
+
+ data_loader = build_dataloader(dataset, **test_loader_cfg)
+ model = build_model(cfg)
+
+ return model, data_loader
+
+
+@pytest.mark.skipif(not torch.cuda.is_available(), reason='requires cuda')
+@pytest.mark.parametrize(
+ 'cfg_file', ['../configs/kie/sdmgr/sdmgr_unet16_60e_wildreceipt.py'])
+def test_single_gpu_test_kie(cfg_file):
+ curr_dir = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))
+ config_file = os.path.join(curr_dir, cfg_file)
+ cfg = Config.fromfile(config_file)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ out_dir = osp.join(tmpdirname, 'tmp')
+ model, data_loader = gene_sdmgr_model_dataloader(
+ cfg, out_dir, curr_dir)
+ results = single_gpu_test(
+ model, data_loader, out_dir=out_dir, is_kie=True)
+ assert check_argument.is_type_list(results, dict)
+
+
+@pytest.mark.skipif(not torch.cuda.is_available(), reason='requires cuda')
+@pytest.mark.parametrize(
+ 'cfg_file', ['../configs/kie/sdmgr/sdmgr_novisual_60e_wildreceipt.py'])
+def test_single_gpu_test_kie_novisual(cfg_file):
+ curr_dir = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))
+ config_file = os.path.join(curr_dir, cfg_file)
+ cfg = Config.fromfile(config_file)
+ meta_keys = list(cfg.data.test.pipeline[-1]['meta_keys'])
+ must_keys = ['img_norm_cfg', 'ori_filename', 'img_shape']
+ for key in must_keys:
+ meta_keys.append(key)
+
+ cfg.data.test.pipeline[-1]['meta_keys'] = tuple(meta_keys)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ out_dir = osp.join(tmpdirname, 'tmp')
+ model, data_loader = gene_sdmgr_model_dataloader(
+ cfg, out_dir, curr_dir, empty_img=True)
+ results = single_gpu_test(
+ model, data_loader, out_dir=out_dir, is_kie=True)
+ assert check_argument.is_type_list(results, dict)
+
+ model, data_loader = gene_sdmgr_model_dataloader(
+ cfg, out_dir, curr_dir)
+ results = single_gpu_test(
+ model, data_loader, out_dir=out_dir, is_kie=True)
+ assert check_argument.is_type_list(results, dict)
diff --git a/tests/test_apis/test_utils.py b/tests/test_apis/test_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..9d015512e272cd6696c95bbde14c6a52de567163
--- /dev/null
+++ b/tests/test_apis/test_utils.py
@@ -0,0 +1,107 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import os
+
+import pytest
+from mmcv import Config
+
+from mmocr.apis.utils import (disable_text_recog_aug_test,
+ replace_image_to_tensor)
+
+
+@pytest.mark.parametrize('cfg_file', [
+ '../configs/textrecog/sar/sar_r31_parallel_decoder_academic.py',
+])
+def test_disable_text_recog_aug_test(cfg_file):
+ tmp_dir = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))
+ config_file = os.path.join(tmp_dir, cfg_file)
+
+ cfg = Config.fromfile(config_file)
+ test = cfg.data.test.datasets[0]
+
+ # cfg.data.test.type is 'OCRDataset'
+ cfg1 = copy.deepcopy(cfg)
+ test1 = copy.deepcopy(test)
+ test1.pipeline = cfg1.data.test.pipeline
+ cfg1.data.test = test1
+ cfg1 = disable_text_recog_aug_test(cfg1, set_types=['test'])
+ assert cfg1.data.test.pipeline[1].type != 'MultiRotateAugOCR'
+
+ # cfg.data.test.type is 'UniformConcatDataset'
+ # and cfg.data.test.pipeline is list[dict]
+ cfg2 = copy.deepcopy(cfg)
+ test2 = copy.deepcopy(test)
+ test2.pipeline = cfg2.data.test.pipeline
+ cfg2.data.test.datasets = [test2]
+ cfg2 = disable_text_recog_aug_test(cfg2, set_types=['test'])
+ assert cfg2.data.test.pipeline[1].type != 'MultiRotateAugOCR'
+ assert cfg2.data.test.datasets[0].pipeline[1].type != 'MultiRotateAugOCR'
+
+ # cfg.data.test.type is 'ConcatDataset'
+ cfg3 = copy.deepcopy(cfg)
+ test3 = copy.deepcopy(test)
+ test3.pipeline = cfg3.data.test.pipeline
+ cfg3.data.test = Config(dict(type='ConcatDataset', datasets=[test3]))
+ cfg3 = disable_text_recog_aug_test(cfg3, set_types=['test'])
+ assert cfg3.data.test.datasets[0].pipeline[1].type != 'MultiRotateAugOCR'
+
+ # cfg.data.test.type is 'UniformConcatDataset'
+ # and cfg.data.test.pipeline is list[list[dict]]
+ cfg4 = copy.deepcopy(cfg)
+ test4 = copy.deepcopy(test)
+ test4.pipeline = cfg4.data.test.pipeline
+ cfg4.data.test.datasets = [[test4], [test]]
+ cfg4.data.test.pipeline = [
+ cfg4.data.test.pipeline, cfg4.data.test.pipeline
+ ]
+ cfg4 = disable_text_recog_aug_test(cfg4, set_types=['test'])
+ assert cfg4.data.test.datasets[0][0].pipeline[1].type != \
+ 'MultiRotateAugOCR'
+
+ # cfg.data.test.type is 'UniformConcatDataset'
+ # and cfg.data.test.pipeline is None
+ cfg5 = copy.deepcopy(cfg)
+ test5 = copy.deepcopy(test)
+ test5.pipeline = copy.deepcopy(cfg5.data.test.pipeline)
+ cfg5.data.test.datasets = [test5]
+ cfg5.data.test.pipeline = None
+ cfg5 = disable_text_recog_aug_test(cfg5, set_types=['test'])
+ assert cfg5.data.test.datasets[0].pipeline[1].type != 'MultiRotateAugOCR'
+
+
+@pytest.mark.parametrize('cfg_file', [
+ '../configs/textdet/psenet/psenet_r50_fpnf_600e_ctw1500.py',
+])
+def test_replace_image_to_tensor(cfg_file):
+ tmp_dir = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))
+ config_file = os.path.join(tmp_dir, cfg_file)
+
+ cfg = Config.fromfile(config_file)
+ test = cfg.data.test.datasets[0]
+
+ # cfg.data.test.pipeline is list[dict]
+ # and cfg.data.test.datasets is list[dict]
+ cfg1 = copy.deepcopy(cfg)
+ test1 = copy.deepcopy(test)
+ test1.pipeline = copy.deepcopy(cfg.data.test.pipeline)
+ cfg1.data.test.datasets = [test1]
+ cfg1 = replace_image_to_tensor(cfg1, set_types=['test'])
+ assert cfg1.data.test.pipeline[1]['transforms'][3][
+ 'type'] == 'DefaultFormatBundle'
+ assert cfg1.data.test.datasets[0].pipeline[1]['transforms'][3][
+ 'type'] == 'DefaultFormatBundle'
+
+ # cfg.data.test.pipeline is list[list[dict]]
+ # and cfg.data.test.datasets is list[list[dict]]
+ cfg2 = copy.deepcopy(cfg)
+ test2 = copy.deepcopy(test)
+ test2.pipeline = copy.deepcopy(cfg.data.test.pipeline)
+ cfg2.data.test.datasets = [[test2], [test2]]
+ cfg2.data.test.pipeline = [
+ cfg2.data.test.pipeline, cfg2.data.test.pipeline
+ ]
+ cfg2 = replace_image_to_tensor(cfg2, set_types=['test'])
+ assert cfg2.data.test.pipeline[0][1]['transforms'][3][
+ 'type'] == 'DefaultFormatBundle'
+ assert cfg2.data.test.datasets[0][0].pipeline[1]['transforms'][3][
+ 'type'] == 'DefaultFormatBundle'
diff --git a/tests/test_core/test_deploy_utils.py b/tests/test_core/test_deploy_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..10541ca8f77edc86f5be6848f82579a04e454343
--- /dev/null
+++ b/tests/test_core/test_deploy_utils.py
@@ -0,0 +1,225 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import tempfile
+from functools import partial
+
+import mmcv
+import numpy as np
+import pytest
+import torch
+from packaging import version
+
+from mmocr.core.deployment import (ONNXRuntimeDetector, ONNXRuntimeRecognizer,
+ TensorRTDetector, TensorRTRecognizer)
+from mmocr.models import build_detector
+
+
+@pytest.mark.skipif(torch.__version__ == 'parrots', reason='skip parrots.')
+@pytest.mark.skipif(
+ version.parse(torch.__version__) < version.parse('1.4.0'),
+ reason='skip if torch=1.3.x')
+@pytest.mark.skipif(
+ not torch.cuda.is_available(), reason='skip if on cpu device')
+def test_detector_wrapper():
+ try:
+ import onnxruntime as ort # noqa: F401
+ import tensorrt as trt
+ from mmcv.tensorrt import onnx2trt, save_trt_engine
+ except ImportError:
+ pytest.skip('ONNXRuntime or TensorRT is not available.')
+
+ cfg = dict(
+ model=dict(
+ type='DBNet',
+ backbone=dict(
+ type='ResNet',
+ depth=18,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=-1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ init_cfg=dict(
+ type='Pretrained', checkpoint='torchvision://resnet18'),
+ norm_eval=False,
+ style='caffe'),
+ neck=dict(
+ type='FPNC',
+ in_channels=[64, 128, 256, 512],
+ lateral_channels=256),
+ bbox_head=dict(
+ type='DBHead',
+ text_repr_type='quad',
+ in_channels=256,
+ loss=dict(type='DBLoss', alpha=5.0, beta=10.0,
+ bbce_loss=True)),
+ train_cfg=None,
+ test_cfg=None))
+
+ cfg = mmcv.Config(cfg)
+
+ pytorch_model = build_detector(cfg.model, None, None)
+
+ # prepare data
+ inputs = torch.rand(1, 3, 224, 224)
+ img_metas = [{
+ 'img_shape': [1, 3, 224, 224],
+ 'ori_shape': [1, 3, 224, 224],
+ 'pad_shape': [1, 3, 224, 224],
+ 'filename': None,
+ 'scale_factor': np.array([1, 1, 1, 1])
+ }]
+
+ pytorch_model.forward = pytorch_model.forward_dummy
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ onnx_path = f'{tmpdirname}/tmp.onnx'
+ with torch.no_grad():
+ torch.onnx.export(
+ pytorch_model,
+ inputs,
+ onnx_path,
+ input_names=['input'],
+ output_names=['output'],
+ export_params=True,
+ keep_initializers_as_inputs=False,
+ verbose=False,
+ opset_version=11)
+
+ # TensorRT part
+ def get_GiB(x: int):
+ """return x GiB."""
+ return x * (1 << 30)
+
+ trt_path = onnx_path.replace('.onnx', '.trt')
+ min_shape = [1, 3, 224, 224]
+ max_shape = [1, 3, 224, 224]
+ # create trt engine and wrapper
+ opt_shape_dict = {'input': [min_shape, min_shape, max_shape]}
+ max_workspace_size = get_GiB(1)
+ trt_engine = onnx2trt(
+ onnx_path,
+ opt_shape_dict,
+ log_level=trt.Logger.ERROR,
+ fp16_mode=False,
+ max_workspace_size=max_workspace_size)
+ save_trt_engine(trt_engine, trt_path)
+ print(f'Successfully created TensorRT engine: {trt_path}')
+
+ wrap_onnx = ONNXRuntimeDetector(onnx_path, cfg, 0)
+ wrap_trt = TensorRTDetector(trt_path, cfg, 0)
+
+ assert isinstance(wrap_onnx, ONNXRuntimeDetector)
+ assert isinstance(wrap_trt, TensorRTDetector)
+
+ with torch.no_grad():
+ onnx_outputs = wrap_onnx.simple_test(inputs, img_metas, rescale=False)
+ trt_outputs = wrap_onnx.simple_test(inputs, img_metas, rescale=False)
+
+ assert isinstance(onnx_outputs[0], dict)
+ assert isinstance(trt_outputs[0], dict)
+ assert 'boundary_result' in onnx_outputs[0]
+ assert 'boundary_result' in trt_outputs[0]
+
+
+@pytest.mark.skipif(torch.__version__ == 'parrots', reason='skip parrots.')
+@pytest.mark.skipif(
+ version.parse(torch.__version__) < version.parse('1.4.0'),
+ reason='skip if torch=1.3.x')
+@pytest.mark.skipif(
+ not torch.cuda.is_available(), reason='skip if on cpu device')
+def test_recognizer_wrapper():
+ try:
+ import onnxruntime as ort # noqa: F401
+ import tensorrt as trt
+ from mmcv.tensorrt import onnx2trt, save_trt_engine
+ except ImportError:
+ pytest.skip('ONNXRuntime or TensorRT is not available.')
+
+ cfg = dict(
+ label_convertor=dict(
+ type='CTCConvertor',
+ dict_type='DICT36',
+ with_unknown=False,
+ lower=True),
+ model=dict(
+ type='CRNNNet',
+ preprocessor=None,
+ backbone=dict(
+ type='VeryDeepVgg', leaky_relu=False, input_channels=1),
+ encoder=None,
+ decoder=dict(type='CRNNDecoder', in_channels=512, rnn_flag=True),
+ loss=dict(type='CTCLoss'),
+ label_convertor=dict(
+ type='CTCConvertor',
+ dict_type='DICT36',
+ with_unknown=False,
+ lower=True),
+ pretrained=None),
+ train_cfg=None,
+ test_cfg=None)
+
+ cfg = mmcv.Config(cfg)
+
+ pytorch_model = build_detector(cfg.model, None, None)
+
+ # prepare data
+ inputs = torch.rand(1, 1, 32, 32)
+ img_metas = [{
+ 'img_shape': [1, 1, 32, 32],
+ 'ori_shape': [1, 1, 32, 32],
+ 'pad_shape': [1, 1, 32, 32],
+ 'filename': None,
+ 'scale_factor': np.array([1, 1, 1, 1])
+ }]
+
+ pytorch_model.forward = partial(
+ pytorch_model.forward,
+ img_metas=img_metas,
+ return_loss=False,
+ rescale=True)
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ onnx_path = f'{tmpdirname}/tmp.onnx'
+ with torch.no_grad():
+ torch.onnx.export(
+ pytorch_model,
+ inputs,
+ onnx_path,
+ input_names=['input'],
+ output_names=['output'],
+ export_params=True,
+ keep_initializers_as_inputs=False,
+ verbose=False,
+ opset_version=11)
+
+ # TensorRT part
+ def get_GiB(x: int):
+ """return x GiB."""
+ return x * (1 << 30)
+
+ trt_path = onnx_path.replace('.onnx', '.trt')
+ min_shape = [1, 1, 32, 32]
+ max_shape = [1, 1, 32, 32]
+ # create trt engine and wrapper
+ opt_shape_dict = {'input': [min_shape, min_shape, max_shape]}
+ max_workspace_size = get_GiB(1)
+ trt_engine = onnx2trt(
+ onnx_path,
+ opt_shape_dict,
+ log_level=trt.Logger.ERROR,
+ fp16_mode=False,
+ max_workspace_size=max_workspace_size)
+ save_trt_engine(trt_engine, trt_path)
+ print(f'Successfully created TensorRT engine: {trt_path}')
+
+ wrap_onnx = ONNXRuntimeRecognizer(onnx_path, cfg, 0)
+ wrap_trt = TensorRTRecognizer(trt_path, cfg, 0)
+
+ assert isinstance(wrap_onnx, ONNXRuntimeRecognizer)
+ assert isinstance(wrap_trt, TensorRTRecognizer)
+
+ with torch.no_grad():
+ onnx_outputs = wrap_onnx.simple_test(inputs, img_metas, rescale=False)
+ trt_outputs = wrap_onnx.simple_test(inputs, img_metas, rescale=False)
+
+ assert isinstance(onnx_outputs[0], dict)
+ assert isinstance(trt_outputs[0], dict)
+ assert 'text' in onnx_outputs[0]
+ assert 'text' in trt_outputs[0]
diff --git a/tests/test_core/test_end2end_vis.py b/tests/test_core/test_end2end_vis.py
new file mode 100644
index 0000000000000000000000000000000000000000..2e7a6812e564e80fa03b2a86a11184654ab66c38
--- /dev/null
+++ b/tests/test_core/test_end2end_vis.py
@@ -0,0 +1,25 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+
+from mmocr.core import det_recog_show_result
+
+
+def test_det_recog_show_result():
+ img = np.ones((100, 100, 3), dtype=np.uint8) * 255
+ det_recog_res = {
+ 'result': [{
+ 'box': [51, 88, 51, 62, 85, 62, 85, 88],
+ 'box_score': 0.9417,
+ 'text': 'hell',
+ 'text_score': 0.8834
+ }]
+ }
+
+ vis_img = det_recog_show_result(img, det_recog_res)
+
+ assert vis_img.shape[0] == 100
+ assert vis_img.shape[1] == 200
+ assert vis_img.shape[2] == 3
+
+ det_recog_res['result'][0]['text'] = '中文'
+ det_recog_show_result(img, det_recog_res)
diff --git a/tests/test_dataset/test_base_dataset.py b/tests/test_dataset/test_base_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..b11aea00738a2e9861dd8646c3c1694d7c19c663
--- /dev/null
+++ b/tests/test_dataset/test_base_dataset.py
@@ -0,0 +1,75 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import tempfile
+
+import numpy as np
+import pytest
+
+from mmocr.datasets.base_dataset import BaseDataset
+
+
+def _create_dummy_ann_file(ann_file):
+ ann_info1 = 'sample1.jpg hello'
+ ann_info2 = 'sample2.jpg world'
+
+ with open(ann_file, 'w') as fw:
+ for ann_info in [ann_info1, ann_info2]:
+ fw.write(ann_info + '\n')
+
+
+def _create_dummy_loader():
+ loader = dict(
+ type='HardDiskLoader',
+ repeat=1,
+ parser=dict(type='LineStrParser', keys=['file_name', 'text']))
+ return loader
+
+
+def test_custom_dataset():
+ tmp_dir = tempfile.TemporaryDirectory()
+ # create dummy data
+ ann_file = osp.join(tmp_dir.name, 'fake_data.txt')
+ _create_dummy_ann_file(ann_file)
+ loader = _create_dummy_loader()
+
+ for mode in [True, False]:
+ dataset = BaseDataset(ann_file, loader, pipeline=[], test_mode=mode)
+
+ # test len
+ assert len(dataset) == len(dataset.data_infos)
+
+ # test set group flag
+ assert np.allclose(dataset.flag, [0, 0])
+
+ # test prepare_train_img
+ expect_results = {
+ 'img_info': {
+ 'file_name': 'sample1.jpg',
+ 'text': 'hello'
+ },
+ 'img_prefix': ''
+ }
+ assert dataset.prepare_train_img(0) == expect_results
+
+ # test prepare_test_img
+ assert dataset.prepare_test_img(0) == expect_results
+
+ # test __getitem__
+ assert dataset[0] == expect_results
+
+ # test get_next_index
+ assert dataset._get_next_index(0) == 1
+
+ # test format_resuls
+ expect_results_copy = {
+ key: value
+ for key, value in expect_results.items()
+ }
+ dataset.format_results(expect_results)
+ assert expect_results_copy == expect_results
+
+ # test evaluate
+ with pytest.raises(NotImplementedError):
+ dataset.evaluate(expect_results)
+
+ tmp_dir.cleanup()
diff --git a/tests/test_dataset/test_crop.py b/tests/test_dataset/test_crop.py
new file mode 100644
index 0000000000000000000000000000000000000000..f180619847deca1f789a8fe040d44829786d466b
--- /dev/null
+++ b/tests/test_dataset/test_crop.py
@@ -0,0 +1,105 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from itertools import chain, permutations
+
+import numpy as np
+import pytest
+
+from mmocr.datasets.pipelines.box_utils import sort_vertex, sort_vertex8
+from mmocr.datasets.pipelines.crop import box_jitter, crop_img, warp_img
+
+
+def test_order_vertex():
+ dummy_points_x = [20, 20, 120, 120]
+ dummy_points_y = [20, 40, 40, 20]
+
+ expect_points_x = [20, 120, 120, 20]
+ expect_points_y = [20, 20, 40, 40]
+
+ with pytest.raises(AssertionError):
+ sort_vertex([], dummy_points_y)
+ with pytest.raises(AssertionError):
+ sort_vertex(dummy_points_x, [])
+
+ for perm in set(permutations([0, 1, 2, 3])):
+ points_x = [dummy_points_x[i] for i in perm]
+ points_y = [dummy_points_y[i] for i in perm]
+ ordered_points_x, ordered_points_y = sort_vertex(points_x, points_y)
+
+ assert np.allclose(ordered_points_x, expect_points_x)
+ assert np.allclose(ordered_points_y, expect_points_y)
+
+
+def test_sort_vertex8():
+ dummy_points_x = [21, 21, 122, 122]
+ dummy_points_y = [21, 39, 39, 21]
+
+ expect_points = [21, 21, 122, 21, 122, 39, 21, 39]
+
+ for perm in set(permutations([0, 1, 2, 3])):
+ points_x = [dummy_points_x[i] for i in perm]
+ points_y = [dummy_points_y[i] for i in perm]
+ points = list(chain.from_iterable(zip(points_x, points_y)))
+ ordered_points = sort_vertex8(points)
+
+ assert np.allclose(ordered_points, expect_points)
+
+
+def test_box_jitter():
+ dummy_points_x = [20, 120, 120, 20]
+ dummy_points_y = [20, 20, 40, 40]
+
+ kwargs = dict(jitter_ratio_x=0.0, jitter_ratio_y=0.0)
+
+ with pytest.raises(AssertionError):
+ box_jitter([], dummy_points_y)
+ with pytest.raises(AssertionError):
+ box_jitter(dummy_points_x, [])
+ with pytest.raises(AssertionError):
+ box_jitter(dummy_points_x, dummy_points_y, jitter_ratio_x=1.)
+ with pytest.raises(AssertionError):
+ box_jitter(dummy_points_x, dummy_points_y, jitter_ratio_y=1.)
+
+ box_jitter(dummy_points_x, dummy_points_y, **kwargs)
+
+ assert np.allclose(dummy_points_x, [20, 120, 120, 20])
+ assert np.allclose(dummy_points_y, [20, 20, 40, 40])
+
+
+def test_opencv_crop():
+ dummy_img = np.ones((600, 600, 3), dtype=np.uint8)
+ dummy_box = [20, 20, 120, 20, 120, 40, 20, 40]
+
+ cropped_img = warp_img(dummy_img, dummy_box)
+
+ with pytest.raises(AssertionError):
+ warp_img(dummy_img, [])
+ with pytest.raises(AssertionError):
+ warp_img(dummy_img, [20, 40, 40, 20])
+
+ assert math.isclose(cropped_img.shape[0], 20)
+ assert math.isclose(cropped_img.shape[1], 100)
+
+
+def test_min_rect_crop():
+ dummy_img = np.ones((600, 600, 3), dtype=np.uint8)
+ dummy_box = [20, 20, 120, 20, 120, 40, 20, 40]
+
+ cropped_img = crop_img(
+ dummy_img,
+ dummy_box,
+ 0.,
+ 0.,
+ )
+
+ with pytest.raises(AssertionError):
+ crop_img(dummy_img, [])
+ with pytest.raises(AssertionError):
+ crop_img(dummy_img, [20, 40, 40, 20])
+ with pytest.raises(AssertionError):
+ crop_img(dummy_img, dummy_box, 4, 0.2)
+ with pytest.raises(AssertionError):
+ crop_img(dummy_img, dummy_box, 0.4, 1.2)
+
+ assert math.isclose(cropped_img.shape[0], 20)
+ assert math.isclose(cropped_img.shape[1], 100)
diff --git a/tests/test_dataset/test_dbnet_transforms.py b/tests/test_dataset/test_dbnet_transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..71c1e1c9c25c7c48b6332e4a6ecdadc6ea82b9eb
--- /dev/null
+++ b/tests/test_dataset/test_dbnet_transforms.py
@@ -0,0 +1,36 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+
+import mmocr.datasets.pipelines.dbnet_transforms as transforms
+
+
+def test_imgaug():
+ args = [['Fliplr', 0.5],
+ dict(cls='Affine', rotate=[-10, 10]), ['Resize', [0.5, 3.0]]]
+ imgaug = transforms.ImgAug(args)
+ img = np.random.rand(3, 100, 200)
+ poly = np.array([[[0, 0, 50, 0, 50, 50, 0, 50]],
+ [[20, 20, 50, 20, 50, 50, 20, 50]]])
+ box = np.array([[0, 0, 50, 50], [20, 20, 50, 50]])
+ results = dict(img=img, masks=poly, bboxes=box)
+ results['mask_fields'] = ['masks']
+ results['bbox_fields'] = ['bboxes']
+ results = imgaug(results)
+ assert np.allclose(results['bboxes'][0],
+ results['masks'].masks[0][0][[0, 1, 4, 5]])
+ assert np.allclose(results['bboxes'][1],
+ results['masks'].masks[1][0][[0, 1, 4, 5]])
+
+
+def test_eastrandomcrop():
+ crop = transforms.EastRandomCrop(target_size=(60, 60), max_tries=100)
+ img = np.random.rand(3, 100, 200)
+ poly = np.array([[[0, 0, 50, 0, 50, 50, 0, 50]],
+ [[20, 20, 50, 20, 50, 50, 20, 50]]])
+ box = np.array([[0, 0, 50, 50], [20, 20, 50, 50]])
+ results = dict(img=img, gt_masks=poly, bboxes=box)
+ results['mask_fields'] = ['gt_masks']
+ results['bbox_fields'] = ['bboxes']
+ results = crop(results)
+ assert np.allclose(results['bboxes'][0],
+ results['gt_masks'].masks[0][0][[0, 2]].flatten())
diff --git a/tests/test_dataset/test_detect_dataset.py b/tests/test_dataset/test_detect_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..b2015ba30494a599d3ed811d700eeef4d8ea5bc3
--- /dev/null
+++ b/tests/test_dataset/test_detect_dataset.py
@@ -0,0 +1,84 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+import os.path as osp
+import tempfile
+
+import numpy as np
+
+from mmocr.datasets.text_det_dataset import TextDetDataset
+
+
+def _create_dummy_ann_file(ann_file):
+ ann_info1 = {
+ 'file_name':
+ 'sample1.jpg',
+ 'height':
+ 640,
+ 'width':
+ 640,
+ 'annotations': [{
+ 'iscrowd': 0,
+ 'category_id': 1,
+ 'bbox': [50, 70, 80, 100],
+ 'segmentation': [[50, 70, 80, 70, 80, 100, 50, 100]]
+ }, {
+ 'iscrowd':
+ 1,
+ 'category_id':
+ 1,
+ 'bbox': [120, 140, 200, 200],
+ 'segmentation': [[120, 140, 200, 140, 200, 200, 120, 200]]
+ }]
+ }
+
+ with open(ann_file, 'w') as fw:
+ fw.write(json.dumps(ann_info1) + '\n')
+
+
+def _create_dummy_loader():
+ loader = dict(
+ type='HardDiskLoader',
+ repeat=1,
+ parser=dict(
+ type='LineJsonParser',
+ keys=['file_name', 'height', 'width', 'annotations']))
+ return loader
+
+
+def test_detect_dataset():
+ tmp_dir = tempfile.TemporaryDirectory()
+ # create dummy data
+ ann_file = osp.join(tmp_dir.name, 'fake_data.txt')
+ _create_dummy_ann_file(ann_file)
+
+ # test initialization
+ loader = _create_dummy_loader()
+ dataset = TextDetDataset(ann_file, loader, pipeline=[])
+
+ # test _parse_ann_info
+ img_ann_info = dataset.data_infos[0]
+ ann = dataset._parse_anno_info(img_ann_info['annotations'])
+ print(ann['bboxes'])
+ assert np.allclose(ann['bboxes'], [[50., 70., 80., 100.]])
+ assert np.allclose(ann['labels'], [1])
+ assert np.allclose(ann['bboxes_ignore'], [[120, 140, 200, 200]])
+ assert np.allclose(ann['masks'], [[[50, 70, 80, 70, 80, 100, 50, 100]]])
+ assert np.allclose(ann['masks_ignore'],
+ [[[120, 140, 200, 140, 200, 200, 120, 200]]])
+
+ tmp_dir.cleanup()
+
+ # test prepare_train_img
+ pipeline_results = dataset.prepare_train_img(0)
+ assert np.allclose(pipeline_results['bbox_fields'], [])
+ assert np.allclose(pipeline_results['mask_fields'], [])
+ assert np.allclose(pipeline_results['seg_fields'], [])
+ expect_img_info = {'filename': 'sample1.jpg', 'height': 640, 'width': 640}
+ assert pipeline_results['img_info'] == expect_img_info
+
+ # test evluation
+ metrics = 'hmean-iou'
+ results = [{'boundary_result': [[50, 70, 80, 70, 80, 100, 50, 100, 1]]}]
+ eval_res = dataset.evaluate(results, metrics)
+
+ assert eval_res['hmean-iou:hmean'] == 1
diff --git a/tests/test_dataset/test_icdar_dataset.py b/tests/test_dataset/test_icdar_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..26a3307fdb1e4fc917ecce1bbbec50631ca04136
--- /dev/null
+++ b/tests/test_dataset/test_icdar_dataset.py
@@ -0,0 +1,156 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import tempfile
+
+import mmcv
+import numpy as np
+
+from mmocr.datasets.icdar_dataset import IcdarDataset
+
+
+def _create_dummy_icdar_json(json_name):
+ image_1 = {
+ 'id': 0,
+ 'width': 640,
+ 'height': 640,
+ 'file_name': 'fake_name.jpg',
+ }
+ image_2 = {
+ 'id': 1,
+ 'width': 640,
+ 'height': 640,
+ 'file_name': 'fake_name1.jpg',
+ }
+
+ annotation_1 = {
+ 'id': 1,
+ 'image_id': 0,
+ 'category_id': 0,
+ 'area': 400,
+ 'bbox': [50, 60, 20, 20],
+ 'iscrowd': 0,
+ 'segmentation': [[50, 60, 70, 60, 70, 80, 50, 80]]
+ }
+
+ annotation_2 = {
+ 'id': 2,
+ 'image_id': 0,
+ 'category_id': 0,
+ 'area': 900,
+ 'bbox': [100, 120, 30, 30],
+ 'iscrowd': 0,
+ 'segmentation': [[100, 120, 130, 120, 120, 150, 100, 150]]
+ }
+
+ annotation_3 = {
+ 'id': 3,
+ 'image_id': 0,
+ 'category_id': 0,
+ 'area': 1600,
+ 'bbox': [150, 160, 40, 40],
+ 'iscrowd': 1,
+ 'segmentation': [[150, 160, 190, 160, 190, 200, 150, 200]]
+ }
+
+ annotation_4 = {
+ 'id': 4,
+ 'image_id': 0,
+ 'category_id': 0,
+ 'area': 10000,
+ 'bbox': [250, 260, 100, 100],
+ 'iscrowd': 1,
+ 'segmentation': [[250, 260, 350, 260, 350, 360, 250, 360]]
+ }
+ annotation_5 = {
+ 'id': 5,
+ 'image_id': 1,
+ 'category_id': 0,
+ 'area': 10000,
+ 'bbox': [250, 260, 100, 100],
+ 'iscrowd': 1,
+ 'segmentation': [[250, 260, 350, 260, 350, 360, 250, 360]]
+ }
+
+ categories = [{
+ 'id': 0,
+ 'name': 'text',
+ 'supercategory': 'text',
+ }]
+
+ fake_json = {
+ 'images': [image_1, image_2],
+ 'annotations':
+ [annotation_1, annotation_2, annotation_3, annotation_4, annotation_5],
+ 'categories':
+ categories
+ }
+
+ mmcv.dump(fake_json, json_name)
+
+
+def test_icdar_dataset():
+ tmp_dir = tempfile.TemporaryDirectory()
+ # create dummy data
+ fake_json_file = osp.join(tmp_dir.name, 'fake_data.json')
+ _create_dummy_icdar_json(fake_json_file)
+
+ # test initialization
+ dataset = IcdarDataset(ann_file=fake_json_file, pipeline=[])
+ assert dataset.CLASSES == ('text')
+ assert dataset.img_ids == [0, 1]
+ assert dataset.select_first_k == -1
+
+ # test _parse_ann_info
+ ann = dataset.get_ann_info(0)
+ assert np.allclose(ann['bboxes'],
+ [[50., 60., 70., 80.], [100., 120., 130., 150.]])
+ assert np.allclose(ann['labels'], [0, 0])
+ assert np.allclose(ann['bboxes_ignore'],
+ [[150., 160., 190., 200.], [250., 260., 350., 360.]])
+ assert np.allclose(ann['masks'],
+ [[[50, 60, 70, 60, 70, 80, 50, 80]],
+ [[100, 120, 130, 120, 120, 150, 100, 150]]])
+ assert np.allclose(ann['masks_ignore'],
+ [[[150, 160, 190, 160, 190, 200, 150, 200]],
+ [[250, 260, 350, 260, 350, 360, 250, 360]]])
+ assert dataset.cat_ids == [0]
+
+ tmp_dir.cleanup()
+
+ # test rank output
+ # result = [[]]
+ # out_file = tempfile.NamedTemporaryFile().name
+
+ # with pytest.raises(AssertionError):
+ # dataset.output_ranklist(result, out_file)
+
+ # result = [{'hmean': 1}, {'hmean': 0.5}]
+
+ # output = dataset.output_ranklist(result, out_file)
+
+ # assert output[0]['hmean'] == 0.5
+
+ # test get_gt_mask
+ # output = dataset.get_gt_mask()
+ # assert np.allclose(output[0][0],
+ # [[50, 60, 70, 60, 70, 80, 50, 80],
+ # [100, 120, 130, 120, 120, 150, 100, 150]])
+ # assert output[0][1] == []
+ # assert np.allclose(output[1][0],
+ # [[150, 160, 190, 160, 190, 200, 150, 200],
+ # [250, 260, 350, 260, 350, 360, 250, 360]])
+ # assert np.allclose(output[1][1],
+ # [[250, 260, 350, 260, 350, 360, 250, 360]])
+
+ # test evluation
+ metrics = ['hmean-iou', 'hmean-ic13']
+ results = [{
+ 'boundary_result': [[50, 60, 70, 60, 70, 80, 50, 80, 1],
+ [100, 120, 130, 120, 120, 150, 100, 150, 1]]
+ }, {
+ 'boundary_result': []
+ }]
+ output = dataset.evaluate(results, metrics)
+
+ assert output['hmean-iou:hmean'] == 1
+ assert output['hmean-ic13:hmean'] == 1
diff --git a/tests/test_dataset/test_kie_dataset.py b/tests/test_dataset/test_kie_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..2291f355d8aa070e0d699c575704775d6cc1f75e
--- /dev/null
+++ b/tests/test_dataset/test_kie_dataset.py
@@ -0,0 +1,128 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+import math
+import os.path as osp
+import tempfile
+
+import pytest
+import torch
+
+from mmocr.datasets.kie_dataset import KIEDataset
+
+
+def _create_dummy_ann_file(ann_file):
+ ann_info1 = {
+ 'file_name':
+ 'sample1.png',
+ 'height':
+ 200,
+ 'width':
+ 200,
+ 'annotations': [{
+ 'text': 'store',
+ 'box': [11.0, 0.0, 22.0, 0.0, 12.0, 12.0, 0.0, 12.0],
+ 'label': 1
+ }, {
+ 'text': 'address',
+ 'box': [23.0, 2.0, 31.0, 1.0, 24.0, 11.0, 16.0, 11.0],
+ 'label': 1
+ }, {
+ 'text': 'price',
+ 'box': [33.0, 2.0, 43.0, 2.0, 36.0, 12.0, 25.0, 12.0],
+ 'label': 1
+ }, {
+ 'text': '1.0',
+ 'box': [46.0, 2.0, 61.0, 2.0, 53.0, 12.0, 39.0, 12.0],
+ 'label': 1
+ }, {
+ 'text': 'google',
+ 'box': [61.0, 2.0, 69.0, 2.0, 63.0, 12.0, 55.0, 12.0],
+ 'label': 1
+ }]
+ }
+ with open(ann_file, 'w') as fw:
+ for ann_info in [ann_info1]:
+ fw.write(json.dumps(ann_info) + '\n')
+
+ return ann_info1
+
+
+def _create_dummy_dict_file(dict_file):
+ dict_str = '0123'
+ with open(dict_file, 'w') as fw:
+ for char in list(dict_str):
+ fw.write(char + '\n')
+
+ return dict_str
+
+
+def _create_dummy_loader():
+ loader = dict(
+ type='HardDiskLoader',
+ repeat=1,
+ parser=dict(
+ type='LineJsonParser',
+ keys=['file_name', 'height', 'width', 'annotations']))
+ return loader
+
+
+def test_kie_dataset():
+ tmp_dir = tempfile.TemporaryDirectory()
+ # create dummy data
+ ann_file = osp.join(tmp_dir.name, 'fake_data.txt')
+ ann_info1 = _create_dummy_ann_file(ann_file)
+
+ dict_file = osp.join(tmp_dir.name, 'fake_dict.txt')
+ _create_dummy_dict_file(dict_file)
+
+ # test initialization
+ loader = _create_dummy_loader()
+ dataset = KIEDataset(ann_file, loader, dict_file, pipeline=[])
+
+ tmp_dir.cleanup()
+
+ dataset.prepare_train_img(0)
+
+ # test pre_pipeline
+ img_ann_info = dataset.data_infos[0]
+ img_info = {
+ 'filename': img_ann_info['file_name'],
+ 'height': img_ann_info['height'],
+ 'width': img_ann_info['width']
+ }
+ ann_info = dataset._parse_anno_info(img_ann_info['annotations'])
+ results = dict(img_info=img_info, ann_info=ann_info)
+ dataset.pre_pipeline(results)
+ assert results['img_prefix'] == dataset.img_prefix
+
+ # test _parse_anno_info
+ annos = ann_info1['annotations']
+ with pytest.raises(AssertionError):
+ dataset._parse_anno_info(annos[0])
+ tmp_annos = [{
+ 'text': 'store',
+ 'box': [11.0, 0.0, 22.0, 0.0, 12.0, 12.0, 0.0, 12.0]
+ }]
+ dataset._parse_anno_info(tmp_annos)
+ tmp_annos = [{'text': 'store'}]
+ with pytest.raises(AssertionError):
+ dataset._parse_anno_info(tmp_annos)
+
+ return_anno = dataset._parse_anno_info(annos)
+ assert 'bboxes' in return_anno
+ assert 'relations' in return_anno
+ assert 'texts' in return_anno
+ assert 'labels' in return_anno
+
+ # test evaluation
+ result = {}
+ result['nodes'] = torch.full((5, 5), 1, dtype=torch.float)
+ result['nodes'][:, 1] = 100.
+ print('hello', result['nodes'].size())
+ results = [result for _ in range(5)]
+
+ eval_res = dataset.evaluate(results)
+ assert math.isclose(eval_res['macro_f1'], 0.2, abs_tol=1e-4)
+
+
+test_kie_dataset()
diff --git a/tests/test_dataset/test_loader.py b/tests/test_dataset/test_loader.py
new file mode 100644
index 0000000000000000000000000000000000000000..41a4bb374c29dbb1425b48e50ecacde5ac95659e
--- /dev/null
+++ b/tests/test_dataset/test_loader.py
@@ -0,0 +1,88 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+import os.path as osp
+import tempfile
+
+import pytest
+
+from mmocr.datasets.utils.backend import (HardDiskAnnFileBackend,
+ HTTPAnnFileBackend,
+ PetrelAnnFileBackend)
+from mmocr.datasets.utils.loader import (AnnFileLoader, HardDiskLoader,
+ LmdbLoader)
+from mmocr.utils import lmdb_converter
+
+
+def _create_dummy_line_str_file(ann_file):
+ ann_info1 = 'sample1.jpg hello'
+ ann_info2 = 'sample2.jpg world'
+
+ with open(ann_file, 'w') as fw:
+ for ann_info in [ann_info1, ann_info2]:
+ fw.write(ann_info + '\n')
+
+
+def _create_dummy_line_json_file(ann_file):
+ ann_info1 = {'filename': 'sample1.jpg', 'text': 'hello'}
+ ann_info2 = {'filename': 'sample2.jpg', 'text': 'world'}
+
+ with open(ann_file, 'w') as fw:
+ for ann_info in [ann_info1, ann_info2]:
+ fw.write(json.dumps(ann_info) + '\n')
+
+
+def test_loader():
+ tmp_dir = tempfile.TemporaryDirectory()
+ # create dummy data
+ ann_file = osp.join(tmp_dir.name, 'fake_data.txt')
+ _create_dummy_line_str_file(ann_file)
+
+ parser = dict(
+ type='LineStrParser',
+ keys=['filename', 'text'],
+ keys_idx=[0, 1],
+ separator=' ')
+
+ with pytest.raises(AssertionError):
+ AnnFileLoader(ann_file, parser, repeat=0)
+ with pytest.raises(AssertionError):
+ AnnFileLoader(ann_file, [], repeat=1)
+
+ # test text loader and line str parser
+ text_loader = HardDiskLoader(ann_file, parser, repeat=1)
+ assert len(text_loader) == 2
+ assert text_loader.ori_data_infos[0] == 'sample1.jpg hello'
+ assert text_loader[0] == {'filename': 'sample1.jpg', 'text': 'hello'}
+
+ # test text loader and linedict parser
+ _create_dummy_line_json_file(ann_file)
+ json_parser = dict(type='LineJsonParser', keys=['filename', 'text'])
+ text_loader = HardDiskLoader(ann_file, json_parser, repeat=1)
+ assert text_loader[0] == {'filename': 'sample1.jpg', 'text': 'hello'}
+
+ # test text loader and linedict parser
+ _create_dummy_line_json_file(ann_file)
+ json_parser = dict(type='LineJsonParser', keys=['filename', 'text'])
+ text_loader = HardDiskLoader(ann_file, json_parser, repeat=1)
+ it = iter(text_loader)
+ with pytest.raises(StopIteration):
+ for _ in range(len(text_loader) + 1):
+ next(it)
+
+ # test lmdb loader and line str parser
+ _create_dummy_line_str_file(ann_file)
+ lmdb_file = osp.join(tmp_dir.name, 'fake_data.lmdb')
+ lmdb_converter(ann_file, lmdb_file, lmdb_map_size=102400)
+
+ lmdb_loader = LmdbLoader(lmdb_file, parser, repeat=1)
+ assert lmdb_loader[0] == {'filename': 'sample1.jpg', 'text': 'hello'}
+ lmdb_loader.close()
+
+ with pytest.raises(AssertionError):
+ HardDiskAnnFileBackend(file_format='json')
+ with pytest.raises(AssertionError):
+ PetrelAnnFileBackend(file_format='json')
+ with pytest.raises(AssertionError):
+ HTTPAnnFileBackend(file_format='json')
+
+ tmp_dir.cleanup()
diff --git a/tests/test_dataset/test_loading.py b/tests/test_dataset/test_loading.py
new file mode 100644
index 0000000000000000000000000000000000000000..112bbb558c49f6bfa0c74554d411966de3526e7c
--- /dev/null
+++ b/tests/test_dataset/test_loading.py
@@ -0,0 +1,86 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+import numpy as np
+
+from mmocr.datasets.pipelines import LoadImageFromNdarray, LoadTextAnnotations
+
+
+def _create_dummy_ann():
+ results = {}
+ results['img_info'] = {}
+ results['img_info']['height'] = 1000
+ results['img_info']['width'] = 1000
+ results['ann_info'] = {}
+ results['ann_info']['masks'] = []
+ results['mask_fields'] = []
+ results['ann_info']['masks_ignore'] = [
+ [[499, 94, 531, 94, 531, 124, 499, 124]],
+ [[3, 156, 81, 155, 78, 181, 0, 182]],
+ [[11, 223, 59, 221, 59, 234, 11, 236]],
+ [[500, 156, 551, 156, 550, 165, 499, 165]]
+ ]
+
+ return results
+
+
+def test_loadtextannotation():
+
+ results = _create_dummy_ann()
+ with_bbox = True
+ with_label = True
+ with_mask = True
+ with_seg = False
+ poly2mask = False
+
+ # If no 'ori_shape' in result but use_img_shape=True,
+ # result['img_info']['height'] and result['img_info']['width']
+ # will be used to generate mask.
+ loader = LoadTextAnnotations(
+ with_bbox,
+ with_label,
+ with_mask,
+ with_seg,
+ poly2mask,
+ use_img_shape=True)
+ tmp_results = copy.deepcopy(results)
+ output = loader._load_masks(tmp_results)
+ assert len(output['gt_masks_ignore']) == 4
+ assert np.allclose(output['gt_masks_ignore'].masks[0],
+ [[499, 94, 531, 94, 531, 124, 499, 124]])
+ assert output['gt_masks_ignore'].height == results['img_info']['height']
+
+ # If 'ori_shape' in result and use_img_shape=True,
+ # result['ori_shape'] will be used to generate mask.
+ loader = LoadTextAnnotations(
+ with_bbox,
+ with_label,
+ with_mask,
+ with_seg,
+ poly2mask=True,
+ use_img_shape=True)
+ tmp_results = copy.deepcopy(results)
+ tmp_results['ori_shape'] = (640, 640, 3)
+ output = loader._load_masks(tmp_results)
+ assert output['img_info']['height'] == 640
+ assert output['gt_masks_ignore'].height == 640
+
+
+def test_load_img_from_numpy():
+ result = {'img': np.ones((32, 100, 3), dtype=np.uint8)}
+
+ load = LoadImageFromNdarray(color_type='color')
+ output = load(result)
+
+ assert output['img'].shape[2] == 3
+ assert len(output['img'].shape) == 3
+
+ result = {'img': np.ones((32, 100, 1), dtype=np.uint8)}
+ load = LoadImageFromNdarray(color_type='color')
+ output = load(result)
+ assert output['img'].shape[2] == 3
+
+ result = {'img': np.ones((32, 100, 3), dtype=np.uint8)}
+ load = LoadImageFromNdarray(color_type='grayscale', to_float32=True)
+ output = load(result)
+ assert output['img'].shape[2] == 1
diff --git a/tests/test_dataset/test_ner_dataset.py b/tests/test_dataset/test_ner_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..145b731cdc89bba2e3a6d78c4f4beb259f7f29ba
--- /dev/null
+++ b/tests/test_dataset/test_ner_dataset.py
@@ -0,0 +1,114 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+import os.path as osp
+import tempfile
+
+import torch
+
+from mmocr.datasets.ner_dataset import NerDataset
+from mmocr.models.ner.convertors.ner_convertor import NerConvertor
+from mmocr.utils import list_to_file
+
+
+def _create_dummy_ann_file(ann_file):
+ data = {
+ 'text': '彭小军认为,国内银行现在走的是台湾的发卡模式',
+ 'label': {
+ 'address': {
+ '台湾': [[15, 16]]
+ },
+ 'name': {
+ '彭小军': [[0, 2]]
+ }
+ }
+ }
+
+ list_to_file(ann_file, [json.dumps(data, ensure_ascii=False)])
+
+
+def _create_dummy_vocab_file(vocab_file):
+ for char in list(map(chr, range(ord('a'), ord('z') + 1))):
+ list_to_file(vocab_file, [json.dumps(char + '\n', ensure_ascii=False)])
+
+
+def _create_dummy_loader():
+ loader = dict(
+ type='HardDiskLoader',
+ repeat=1,
+ parser=dict(type='LineJsonParser', keys=['text', 'label']))
+ return loader
+
+
+def test_ner_dataset():
+ # test initialization
+ loader = _create_dummy_loader()
+ categories = [
+ 'address', 'book', 'company', 'game', 'government', 'movie', 'name',
+ 'organization', 'position', 'scene'
+ ]
+
+ # create dummy data
+ tmp_dir = tempfile.TemporaryDirectory()
+ ann_file = osp.join(tmp_dir.name, 'fake_data.txt')
+ vocab_file = osp.join(tmp_dir.name, 'fake_vocab.txt')
+ _create_dummy_ann_file(ann_file)
+ _create_dummy_vocab_file(vocab_file)
+
+ max_len = 128
+ ner_convertor = dict(
+ type='NerConvertor',
+ annotation_type='bio',
+ vocab_file=vocab_file,
+ categories=categories,
+ max_len=max_len)
+
+ test_pipeline = [
+ dict(
+ type='NerTransform',
+ label_convertor=ner_convertor,
+ max_len=max_len),
+ dict(type='ToTensorNER')
+ ]
+ dataset = NerDataset(ann_file, loader, pipeline=test_pipeline)
+
+ # test pre_pipeline
+ img_info = dataset.data_infos[0]
+ results = dict(img_info=img_info)
+ dataset.pre_pipeline(results)
+
+ # test prepare_train_img
+ dataset.prepare_train_img(0)
+
+ # test evaluation
+ result = [[['address', 15, 16], ['name', 0, 2]]]
+
+ dataset.evaluate(result)
+
+ # test pred convert2entity function
+ pred = [
+ 21, 7, 17, 17, 21, 21, 21, 21, 21, 21, 13, 21, 21, 21, 21, 21, 1, 11,
+ 21, 21, 7, 17, 17, 21, 21, 21, 21, 21, 21, 13, 21, 21, 21, 21, 21, 1,
+ 11, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21,
+ 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21,
+ 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21,
+ 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21,
+ 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21,
+ 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 1, 21, 21, 21, 21, 21,
+ 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 1, 21, 21, 21, 21,
+ 21, 21
+ ]
+ preds = [pred[:128]]
+ mask = [0] * 128
+ for i in range(10):
+ mask[i] = 1
+ assert len(preds[0]) == len(mask)
+ masks = torch.tensor([mask])
+ convertor = NerConvertor(
+ annotation_type='bio',
+ vocab_file=vocab_file,
+ categories=categories,
+ max_len=128)
+ all_entities = convertor.convert_pred2entities(preds=preds, masks=masks)
+ assert len(all_entities[0][0]) == 3
+
+ tmp_dir.cleanup()
diff --git a/tests/test_dataset/test_ocr_dataset.py b/tests/test_dataset/test_ocr_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..5d8d5dd3df2db32fe94c1c81b36c7a435d77c7ee
--- /dev/null
+++ b/tests/test_dataset/test_ocr_dataset.py
@@ -0,0 +1,52 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+import os.path as osp
+import tempfile
+
+from mmocr.datasets.ocr_dataset import OCRDataset
+
+
+def _create_dummy_ann_file(ann_file):
+ ann_info1 = 'sample1.jpg hello'
+ ann_info2 = 'sample2.jpg world'
+
+ with open(ann_file, 'w') as fw:
+ for ann_info in [ann_info1, ann_info2]:
+ fw.write(ann_info + '\n')
+
+
+def _create_dummy_loader():
+ loader = dict(
+ type='HardDiskLoader',
+ repeat=1,
+ parser=dict(type='LineStrParser', keys=['file_name', 'text']))
+ return loader
+
+
+def test_detect_dataset():
+ tmp_dir = tempfile.TemporaryDirectory()
+ # create dummy data
+ ann_file = osp.join(tmp_dir.name, 'fake_data.txt')
+ _create_dummy_ann_file(ann_file)
+
+ # test initialization
+ loader = _create_dummy_loader()
+ dataset = OCRDataset(ann_file, loader, pipeline=[])
+
+ tmp_dir.cleanup()
+
+ # test pre_pipeline
+ img_info = dataset.data_infos[0]
+ results = dict(img_info=img_info)
+ dataset.pre_pipeline(results)
+ assert results['img_prefix'] == dataset.img_prefix
+ assert results['text'] == img_info['text']
+
+ # test evluation
+ metric = 'acc'
+ results = [{'text': 'hello'}, {'text': 'worl'}]
+ eval_res = dataset.evaluate(results, metric)
+
+ assert math.isclose(eval_res['word_acc'], 0.5, abs_tol=1e-4)
+ assert math.isclose(eval_res['char_precision'], 1.0, abs_tol=1e-4)
+ assert math.isclose(eval_res['char_recall'], 0.9, abs_tol=1e-4)
diff --git a/tests/test_dataset/test_ocr_seg_dataset.py b/tests/test_dataset/test_ocr_seg_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..f7678123ea5340826c6562c5fba3502068a8ddd4
--- /dev/null
+++ b/tests/test_dataset/test_ocr_seg_dataset.py
@@ -0,0 +1,128 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+import math
+import os.path as osp
+import tempfile
+
+import pytest
+
+from mmocr.datasets.ocr_seg_dataset import OCRSegDataset
+
+
+def _create_dummy_ann_file(ann_file):
+ ann_info1 = {
+ 'file_name':
+ 'sample1.png',
+ 'annotations': [{
+ 'char_text':
+ 'F',
+ 'char_box': [11.0, 0.0, 22.0, 0.0, 12.0, 12.0, 0.0, 12.0]
+ }, {
+ 'char_text':
+ 'r',
+ 'char_box': [23.0, 2.0, 31.0, 1.0, 24.0, 11.0, 16.0, 11.0]
+ }, {
+ 'char_text':
+ 'o',
+ 'char_box': [33.0, 2.0, 43.0, 2.0, 36.0, 12.0, 25.0, 12.0]
+ }, {
+ 'char_text':
+ 'm',
+ 'char_box': [46.0, 2.0, 61.0, 2.0, 53.0, 12.0, 39.0, 12.0]
+ }, {
+ 'char_text':
+ ':',
+ 'char_box': [61.0, 2.0, 69.0, 2.0, 63.0, 12.0, 55.0, 12.0]
+ }],
+ 'text':
+ 'From:'
+ }
+ ann_info2 = {
+ 'file_name':
+ 'sample2.png',
+ 'annotations': [{
+ 'char_text': 'o',
+ 'char_box': [0.0, 5.0, 7.0, 5.0, 9.0, 15.0, 2.0, 15.0]
+ }, {
+ 'char_text':
+ 'u',
+ 'char_box': [7.0, 4.0, 14.0, 4.0, 18.0, 18.0, 11.0, 18.0]
+ }, {
+ 'char_text':
+ 't',
+ 'char_box': [13.0, 1.0, 19.0, 2.0, 24.0, 18.0, 17.0, 18.0]
+ }],
+ 'text':
+ 'out'
+ }
+
+ with open(ann_file, 'w') as fw:
+ for ann_info in [ann_info1, ann_info2]:
+ fw.write(json.dumps(ann_info) + '\n')
+
+ return ann_info1, ann_info2
+
+
+def _create_dummy_loader():
+ loader = dict(
+ type='HardDiskLoader',
+ repeat=1,
+ parser=dict(
+ type='LineJsonParser', keys=['file_name', 'text', 'annotations']))
+ return loader
+
+
+def test_ocr_seg_dataset():
+ tmp_dir = tempfile.TemporaryDirectory()
+ # create dummy data
+ ann_file = osp.join(tmp_dir.name, 'fake_data.txt')
+ ann_info1, ann_info2 = _create_dummy_ann_file(ann_file)
+
+ # test initialization
+ loader = _create_dummy_loader()
+ dataset = OCRSegDataset(ann_file, loader, pipeline=[])
+
+ tmp_dir.cleanup()
+
+ # test pre_pipeline
+ img_info = dataset.data_infos[0]
+ results = dict(img_info=img_info)
+ dataset.pre_pipeline(results)
+ assert results['img_prefix'] == dataset.img_prefix
+
+ # test _parse_anno_info
+ annos = ann_info1['annotations']
+ with pytest.raises(AssertionError):
+ dataset._parse_anno_info(annos[0])
+ annos2 = ann_info2['annotations']
+ with pytest.raises(AssertionError):
+ dataset._parse_anno_info([{'char_text': 'i'}])
+ with pytest.raises(AssertionError):
+ dataset._parse_anno_info([{'char_box': [1, 2, 3, 4, 5, 6, 7, 8]}])
+ annos2[0]['char_box'] = [1, 2, 3]
+ with pytest.raises(AssertionError):
+ dataset._parse_anno_info(annos2)
+
+ return_anno = dataset._parse_anno_info(annos)
+ assert return_anno['chars'] == ['F', 'r', 'o', 'm', ':']
+ assert len(return_anno['char_rects']) == 5
+
+ # test prepare_train_img
+ expect_results = {
+ 'img_info': {
+ 'filename': 'sample1.png'
+ },
+ 'img_prefix': '',
+ 'ann_info': return_anno
+ }
+ data = dataset.prepare_train_img(0)
+ assert data == expect_results
+
+ # test evluation
+ metric = 'acc'
+ results = [{'text': 'From:'}, {'text': 'ou'}]
+ eval_res = dataset.evaluate(results, metric)
+
+ assert math.isclose(eval_res['word_acc'], 0.5, abs_tol=1e-4)
+ assert math.isclose(eval_res['char_precision'], 1.0, abs_tol=1e-4)
+ assert math.isclose(eval_res['char_recall'], 0.857, abs_tol=1e-4)
diff --git a/tests/test_dataset/test_ocr_seg_target.py b/tests/test_dataset/test_ocr_seg_target.py
new file mode 100644
index 0000000000000000000000000000000000000000..54f78bf053733f23beb1aac51fcc283d6c05bc45
--- /dev/null
+++ b/tests/test_dataset/test_ocr_seg_target.py
@@ -0,0 +1,94 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import tempfile
+
+import numpy as np
+import pytest
+
+from mmocr.datasets.pipelines.ocr_seg_targets import OCRSegTargets
+
+
+def _create_dummy_dict_file(dict_file):
+ chars = list('0123456789')
+ with open(dict_file, 'w') as fw:
+ for char in chars:
+ fw.write(char + '\n')
+
+
+def test_ocr_segm_targets():
+ tmp_dir = tempfile.TemporaryDirectory()
+ # create dummy dict file
+ dict_file = osp.join(tmp_dir.name, 'fake_chars.txt')
+ _create_dummy_dict_file(dict_file)
+ # dummy label convertor
+ label_convertor = dict(
+ type='SegConvertor',
+ dict_file=dict_file,
+ with_unknown=True,
+ lower=True)
+ # test init
+ with pytest.raises(AssertionError):
+ OCRSegTargets(None, 0.5, 0.5)
+ with pytest.raises(AssertionError):
+ OCRSegTargets(label_convertor, '1by2', 0.5)
+ with pytest.raises(AssertionError):
+ OCRSegTargets(label_convertor, 0.5, 2)
+
+ ocr_seg_tgt = OCRSegTargets(label_convertor, 0.5, 0.5)
+ # test generate kernels
+ img_size = (8, 8)
+ pad_size = (8, 10)
+ char_boxes = [[2, 2, 6, 6]]
+ char_idxs = [2]
+
+ with pytest.raises(AssertionError):
+ ocr_seg_tgt.generate_kernels(8, pad_size, char_boxes, char_idxs, 0.5,
+ True)
+ with pytest.raises(AssertionError):
+ ocr_seg_tgt.generate_kernels(img_size, pad_size, [2, 2, 6, 6],
+ char_idxs, 0.5, True)
+ with pytest.raises(AssertionError):
+ ocr_seg_tgt.generate_kernels(img_size, pad_size, char_boxes, 2, 0.5,
+ True)
+
+ attn_tgt = ocr_seg_tgt.generate_kernels(
+ img_size, pad_size, char_boxes, char_idxs, 0.5, binary=True)
+ expect_attn_tgt = [[0, 0, 0, 0, 0, 0, 0, 0, 255, 255],
+ [0, 0, 0, 0, 0, 0, 0, 0, 255, 255],
+ [0, 0, 0, 0, 0, 0, 0, 0, 255, 255],
+ [0, 0, 0, 1, 1, 1, 0, 0, 255, 255],
+ [0, 0, 0, 1, 1, 1, 0, 0, 255, 255],
+ [0, 0, 0, 1, 1, 1, 0, 0, 255, 255],
+ [0, 0, 0, 0, 0, 0, 0, 0, 255, 255],
+ [0, 0, 0, 0, 0, 0, 0, 0, 255, 255]]
+ assert np.allclose(attn_tgt, np.array(expect_attn_tgt, dtype=np.int32))
+
+ segm_tgt = ocr_seg_tgt.generate_kernels(
+ img_size, pad_size, char_boxes, char_idxs, 0.5, binary=False)
+ expect_segm_tgt = [[0, 0, 0, 0, 0, 0, 0, 0, 255, 255],
+ [0, 0, 0, 0, 0, 0, 0, 0, 255, 255],
+ [0, 0, 0, 0, 0, 0, 0, 0, 255, 255],
+ [0, 0, 0, 2, 2, 2, 0, 0, 255, 255],
+ [0, 0, 0, 2, 2, 2, 0, 0, 255, 255],
+ [0, 0, 0, 2, 2, 2, 0, 0, 255, 255],
+ [0, 0, 0, 0, 0, 0, 0, 0, 255, 255],
+ [0, 0, 0, 0, 0, 0, 0, 0, 255, 255]]
+ assert np.allclose(segm_tgt, np.array(expect_segm_tgt, dtype=np.int32))
+
+ # test __call__
+ results = {}
+ results['img_shape'] = (4, 4, 3)
+ results['resize_shape'] = (8, 8, 3)
+ results['pad_shape'] = (8, 10)
+ results['ann_info'] = {}
+ results['ann_info']['char_rects'] = [[1, 1, 3, 3]]
+ results['ann_info']['chars'] = ['1']
+
+ results = ocr_seg_tgt(results)
+ assert results['mask_fields'] == ['gt_kernels']
+ assert np.allclose(results['gt_kernels'].masks[0],
+ np.array(expect_attn_tgt, dtype=np.int32))
+ assert np.allclose(results['gt_kernels'].masks[1],
+ np.array(expect_segm_tgt, dtype=np.int32))
+
+ tmp_dir.cleanup()
diff --git a/tests/test_dataset/test_ocr_transforms.py b/tests/test_dataset/test_ocr_transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..612cea1275edfffa743ce5ffc14fa767689ccac4
--- /dev/null
+++ b/tests/test_dataset/test_ocr_transforms.py
@@ -0,0 +1,141 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+import unittest.mock as mock
+
+import numpy as np
+import torch
+import torchvision.transforms.functional as TF
+from PIL import Image
+
+import mmocr.datasets.pipelines.ocr_transforms as transforms
+
+
+def test_resize_ocr():
+ input_img = np.ones((64, 256, 3), dtype=np.uint8)
+
+ rci = transforms.ResizeOCR(
+ 32, min_width=32, max_width=160, keep_aspect_ratio=True)
+ results = {'img_shape': input_img.shape, 'img': input_img}
+
+ # test call
+ results = rci(results)
+ assert np.allclose([32, 160, 3], results['pad_shape'])
+ assert np.allclose([32, 160, 3], results['img'].shape)
+ assert 'valid_ratio' in results
+ assert math.isclose(results['valid_ratio'], 0.8)
+ assert math.isclose(np.sum(results['img'][:, 129:, :]), 0)
+
+ rci = transforms.ResizeOCR(
+ 32, min_width=32, max_width=160, keep_aspect_ratio=False)
+ results = {'img_shape': input_img.shape, 'img': input_img}
+ results = rci(results)
+ assert math.isclose(results['valid_ratio'], 1)
+
+
+def test_to_tensor():
+ input_img = np.ones((64, 256, 3), dtype=np.uint8)
+
+ expect_output = TF.to_tensor(input_img)
+ rci = transforms.ToTensorOCR()
+
+ results = {'img': input_img}
+ results = rci(results)
+
+ assert np.allclose(results['img'].numpy(), expect_output.numpy())
+
+
+def test_normalize():
+ inputs = torch.zeros(3, 10, 10)
+
+ expect_output = torch.ones_like(inputs) * (-1)
+ rci = transforms.NormalizeOCR(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
+
+ results = {'img': inputs}
+ results = rci(results)
+
+ assert np.allclose(results['img'].numpy(), expect_output.numpy())
+
+
+@mock.patch('%s.transforms.np.random.random' % __name__)
+def test_online_crop(mock_random):
+ kwargs = dict(
+ box_keys=['x1', 'y1', 'x2', 'y2', 'x3', 'y3', 'x4', 'y4'],
+ jitter_prob=0.5,
+ max_jitter_ratio_x=0.05,
+ max_jitter_ratio_y=0.02)
+
+ mock_random.side_effect = [0.1, 1, 1, 1]
+
+ src_img = np.ones((100, 100, 3), dtype=np.uint8)
+ results = {
+ 'img': src_img,
+ 'img_info': {
+ 'x1': '20',
+ 'y1': '20',
+ 'x2': '40',
+ 'y2': '20',
+ 'x3': '40',
+ 'y3': '40',
+ 'x4': '20',
+ 'y4': '40'
+ }
+ }
+
+ rci = transforms.OnlineCropOCR(**kwargs)
+
+ results = rci(results)
+
+ assert np.allclose(results['img_shape'], [20, 20, 3])
+
+ # test not crop
+ mock_random.side_effect = [0.1, 1, 1, 1]
+ results['img_info'] = {}
+ results['img'] = src_img
+
+ results = rci(results)
+ assert np.allclose(results['img'].shape, [100, 100, 3])
+
+
+def test_fancy_pca():
+ input_tensor = torch.rand(3, 32, 100)
+
+ rci = transforms.FancyPCA()
+
+ results = {'img': input_tensor}
+ results = rci(results)
+
+ assert results['img'].shape == torch.Size([3, 32, 100])
+
+
+@mock.patch('%s.transforms.np.random.uniform' % __name__)
+def test_random_padding(mock_random):
+ kwargs = dict(max_ratio=[0.0, 0.0, 0.0, 0.0], box_type=None)
+
+ mock_random.side_effect = [1, 1, 1, 1]
+
+ src_img = np.ones((32, 100, 3), dtype=np.uint8)
+ results = {'img': src_img, 'img_shape': (32, 100, 3)}
+
+ rci = transforms.RandomPaddingOCR(**kwargs)
+
+ results = rci(results)
+ print(results['img'].shape)
+ assert np.allclose(results['img_shape'], [96, 300, 3])
+
+
+def test_opencv2pil():
+ src_img = np.ones((32, 100, 3), dtype=np.uint8)
+ results = {'img': src_img}
+ rci = transforms.OpencvToPil()
+
+ results = rci(results)
+ assert np.allclose(results['img'].size, (100, 32))
+
+
+def test_pil2opencv():
+ src_img = Image.new('RGB', (100, 32), color=(255, 255, 255))
+ results = {'img': src_img}
+ rci = transforms.PilToOpencv()
+
+ results = rci(results)
+ assert np.allclose(results['img'].shape, (32, 100, 3))
diff --git a/tests/test_dataset/test_openset_kie_dataset.py b/tests/test_dataset/test_openset_kie_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..e726bcbbe878cd059dacd082997413e110a4575b
--- /dev/null
+++ b/tests/test_dataset/test_openset_kie_dataset.py
@@ -0,0 +1,98 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+import math
+import os.path as osp
+import tempfile
+
+import torch
+
+from mmocr.datasets.openset_kie_dataset import OpensetKIEDataset
+from mmocr.utils import list_to_file
+
+
+def _create_dummy_ann_file(ann_file):
+ ann_info1 = {
+ 'file_name':
+ '1.png',
+ 'height':
+ 200,
+ 'width':
+ 200,
+ 'annotations': [{
+ 'text': 'store',
+ 'box': [11.0, 0.0, 22.0, 0.0, 12.0, 12.0, 0.0, 12.0],
+ 'label': 1,
+ 'edge': 1
+ }, {
+ 'text': 'MyFamily',
+ 'box': [23.0, 2.0, 31.0, 1.0, 24.0, 11.0, 16.0, 11.0],
+ 'label': 2,
+ 'edge': 1
+ }]
+ }
+ list_to_file(ann_file, [json.dumps(ann_info1)])
+
+ return ann_info1
+
+
+def _create_dummy_dict_file(dict_file):
+ dict_str = '0123'
+ list_to_file(dict_file, list(dict_str))
+
+
+def _create_dummy_loader():
+ loader = dict(
+ type='HardDiskLoader',
+ repeat=1,
+ parser=dict(
+ type='LineJsonParser',
+ keys=['file_name', 'height', 'width', 'annotations']))
+ return loader
+
+
+def test_openset_kie_dataset():
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ # create dummy data
+ ann_file = osp.join(tmp_dir_name, 'fake_data.txt')
+ ann_info1 = _create_dummy_ann_file(ann_file)
+
+ dict_file = osp.join(tmp_dir_name, 'fake_dict.txt')
+ _create_dummy_dict_file(dict_file)
+
+ # test initialization
+ loader = _create_dummy_loader()
+ dataset = OpensetKIEDataset(ann_file, loader, dict_file, pipeline=[])
+
+ dataset.prepare_train_img(0)
+
+ # test pre_pipeline
+ img_ann_info = dataset.data_infos[0]
+ img_info = {
+ 'filename': img_ann_info['file_name'],
+ 'height': img_ann_info['height'],
+ 'width': img_ann_info['width']
+ }
+ ann_info = dataset._parse_anno_info(img_ann_info['annotations'])
+ results = dict(img_info=img_info, ann_info=ann_info)
+ dataset.pre_pipeline(results)
+ assert results['img_prefix'] == dataset.img_prefix
+ assert 'ori_texts' in results
+
+ # test evaluation
+ result = {
+ 'img_metas': [{
+ 'filename': ann_info1['file_name'],
+ 'ori_filename': ann_info1['file_name'],
+ 'ori_texts': [],
+ 'ori_boxes': []
+ }]
+ }
+ for anno in ann_info1['annotations']:
+ result['img_metas'][0]['ori_texts'].append(anno['text'])
+ result['img_metas'][0]['ori_boxes'].append(anno['box'])
+ result['nodes'] = torch.tensor([[0.01, 0.8, 0.01, 0.18],
+ [0.01, 0.01, 0.9, 0.08]])
+ result['edges'] = torch.Tensor([[0.01, 0.99] for _ in range(4)])
+
+ eval_res = dataset.evaluate([result])
+ assert math.isclose(eval_res['edge_openset_f1'], 1.0, abs_tol=1e-4)
diff --git a/tests/test_dataset/test_parser.py b/tests/test_dataset/test_parser.py
new file mode 100644
index 0000000000000000000000000000000000000000..e20f3fbe662e1ff36e870a7ff254636834398781
--- /dev/null
+++ b/tests/test_dataset/test_parser.py
@@ -0,0 +1,64 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+
+import pytest
+
+from mmocr.datasets.utils.parser import LineJsonParser, LineStrParser
+
+
+def test_line_str_parser():
+ data_ret = ['sample1.jpg hello\n', 'sample2.jpg world']
+ keys = ['filename', 'text']
+ keys_idx = [0, 1]
+ separator = ' '
+
+ # test init
+ with pytest.raises(AssertionError):
+ parser = LineStrParser('filename', keys_idx, separator)
+ with pytest.raises(AssertionError):
+ parser = LineStrParser(keys, keys_idx, [' '])
+ with pytest.raises(AssertionError):
+ parser = LineStrParser(keys, [0], separator)
+
+ # test get_item
+ parser = LineStrParser(keys, keys_idx, separator)
+ assert parser.get_item(data_ret, 0) == {
+ 'filename': 'sample1.jpg',
+ 'text': 'hello'
+ }
+
+ with pytest.raises(Exception):
+ parser = LineStrParser(['filename', 'text', 'ignore'], [0, 1, 2],
+ separator)
+ parser.get_item(data_ret, 0)
+
+
+def test_line_dict_parser():
+ data_ret = [
+ json.dumps({
+ 'filename': 'sample1.jpg',
+ 'text': 'hello'
+ }),
+ json.dumps({
+ 'filename': 'sample2.jpg',
+ 'text': 'world'
+ })
+ ]
+ keys = ['filename', 'text']
+
+ # test init
+ with pytest.raises(AssertionError):
+ parser = LineJsonParser('filename')
+ with pytest.raises(AssertionError):
+ parser = LineJsonParser([])
+
+ # test get_item
+ parser = LineJsonParser(keys)
+ assert parser.get_item(data_ret, 0) == {
+ 'filename': 'sample1.jpg',
+ 'text': 'hello'
+ }
+
+ with pytest.raises(Exception):
+ parser = LineJsonParser(['img_name', 'text'])
+ parser.get_item(data_ret, 0)
diff --git a/tests/test_dataset/test_test_time_aug.py b/tests/test_dataset/test_test_time_aug.py
new file mode 100644
index 0000000000000000000000000000000000000000..5d68ac42ee3f5fd17fc05cef3632173b9396681c
--- /dev/null
+++ b/tests/test_dataset/test_test_time_aug.py
@@ -0,0 +1,34 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import pytest
+
+from mmocr.datasets.pipelines.test_time_aug import MultiRotateAugOCR
+
+
+def test_resize_ocr():
+ input_img1 = np.ones((64, 256, 3), dtype=np.uint8)
+ input_img2 = np.ones((64, 32, 3), dtype=np.uint8)
+
+ rci = MultiRotateAugOCR(transforms=[], rotate_degrees=[0, 90, 270])
+
+ # test invalid arguments
+ with pytest.raises(AssertionError):
+ MultiRotateAugOCR(transforms=[], rotate_degrees=[45])
+ with pytest.raises(AssertionError):
+ MultiRotateAugOCR(transforms=[], rotate_degrees=[20.5])
+
+ # test call with input_img1
+ results = {'img_shape': input_img1.shape, 'img': input_img1}
+ results = rci(results)
+ assert np.allclose([64, 256, 3], results['img_shape'])
+ assert len(results['img']) == 1
+ assert len(results['img_shape']) == 1
+ assert np.allclose([64, 256, 3], results['img_shape'][0])
+
+ # test call with input_img2
+ results = {'img_shape': input_img2.shape, 'img': input_img2}
+ results = rci(results)
+ assert np.allclose([64, 32, 3], results['img_shape'])
+ assert len(results['img']) == 3
+ assert len(results['img_shape']) == 3
+ assert np.allclose([64, 32, 3], results['img_shape'][0])
diff --git a/tests/test_dataset/test_textdet_targets.py b/tests/test_dataset/test_textdet_targets.py
new file mode 100644
index 0000000000000000000000000000000000000000..2008c5c6faaa0efc05325c9e48ba821859a43f47
--- /dev/null
+++ b/tests/test_dataset/test_textdet_targets.py
@@ -0,0 +1,367 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from unittest import mock
+
+import numpy as np
+from mmdet.core import PolygonMasks
+
+import mmocr.datasets.pipelines.custom_format_bundle as cf_bundle
+import mmocr.datasets.pipelines.textdet_targets as textdet_targets
+
+
+@mock.patch('%s.cf_bundle.show_feature' % __name__)
+def test_gen_pannet_targets(mock_show_feature):
+
+ target_generator = textdet_targets.PANetTargets()
+ assert target_generator.max_shrink == 20
+
+ # test generate_kernels
+ img_size = (3, 10)
+ text_polys = [[np.array([0, 0, 1, 0, 1, 1, 0, 1])],
+ [np.array([2, 0, 3, 0, 3, 1, 2, 1])]]
+ shrink_ratio = 1.0
+ kernel = np.array([[1, 1, 2, 2, 0, 0, 0, 0, 0, 0],
+ [1, 1, 2, 2, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
+ output, _ = target_generator.generate_kernels(img_size, text_polys,
+ shrink_ratio)
+ print(output)
+ assert np.allclose(output, kernel)
+
+ # test generate_effective_mask
+ polys_ignore = text_polys
+ output = target_generator.generate_effective_mask((3, 10), polys_ignore)
+ target = np.array([[0, 0, 0, 0, 1, 1, 1, 1, 1, 1],
+ [0, 0, 0, 0, 1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])
+
+ assert np.allclose(output, target)
+
+ # test generate_targets
+ results = {}
+ results['img'] = np.zeros((3, 10, 3), np.uint8)
+ results['gt_masks'] = PolygonMasks(text_polys, 3, 10)
+ results['gt_masks_ignore'] = PolygonMasks([], 3, 10)
+ results['img_shape'] = (3, 10, 3)
+ results['mask_fields'] = []
+ output = target_generator(results)
+ assert len(output['gt_kernels']) == 2
+ assert len(output['gt_mask']) == 1
+
+ bundle = cf_bundle.CustomFormatBundle(
+ keys=['gt_kernels', 'gt_mask'],
+ visualize=dict(flag=True, boundary_key='gt_kernels'))
+ bundle(output)
+ assert 'gt_kernels' in output.keys()
+ assert 'gt_mask' in output.keys()
+ mock_show_feature.assert_called_once()
+
+
+def test_gen_psenet_targets():
+ target_generator = textdet_targets.PSENetTargets()
+ assert target_generator.max_shrink == 20
+ assert target_generator.shrink_ratio == (1.0, 0.9, 0.8, 0.7, 0.6, 0.5, 0.4)
+
+
+# Test DBNetTargets
+
+
+def test_dbnet_targets_find_invalid():
+ target_generator = textdet_targets.DBNetTargets()
+ assert target_generator.shrink_ratio == 0.4
+ assert target_generator.thr_min == 0.3
+ assert target_generator.thr_max == 0.7
+
+ results = {}
+ text_polys = [[np.array([0, 0, 10, 0, 10, 10, 0, 10])],
+ [np.array([20, 0, 30, 0, 30, 10, 20, 10])]]
+ results['gt_masks'] = PolygonMasks(text_polys, 40, 40)
+
+ ignore_tags = target_generator.find_invalid(results)
+ assert np.allclose(ignore_tags, [False, False])
+
+
+def test_dbnet_targets():
+ target_generator = textdet_targets.DBNetTargets()
+ assert target_generator.shrink_ratio == 0.4
+ assert target_generator.thr_min == 0.3
+ assert target_generator.thr_max == 0.7
+
+
+def test_dbnet_ignore_texts():
+ target_generator = textdet_targets.DBNetTargets()
+ ignore_tags = [True, False]
+ results = {}
+ text_polys = [[np.array([0, 0, 10, 0, 10, 10, 0, 10])],
+ [np.array([20, 0, 30, 0, 30, 10, 20, 10])]]
+ text_polys_ignore = [[np.array([0, 0, 15, 0, 15, 10, 0, 10])]]
+
+ results['gt_masks_ignore'] = PolygonMasks(text_polys_ignore, 40, 40)
+ results['gt_masks'] = PolygonMasks(text_polys, 40, 40)
+ results['gt_bboxes'] = np.array([[0, 0, 10, 10], [20, 0, 30, 10]])
+ results['gt_labels'] = np.array([0, 1])
+
+ target_generator.ignore_texts(results, ignore_tags)
+
+ assert np.allclose(results['gt_labels'], np.array([1]))
+ assert len(results['gt_masks_ignore'].masks) == 2
+ assert np.allclose(results['gt_masks_ignore'].masks[1][0],
+ text_polys[0][0])
+ assert len(results['gt_masks'].masks) == 1
+
+
+def test_dbnet_generate_thr_map():
+ target_generator = textdet_targets.DBNetTargets()
+ text_polys = [[np.array([0, 0, 10, 0, 10, 10, 0, 10])],
+ [np.array([20, 0, 30, 0, 30, 10, 20, 10])]]
+ thr_map, thr_mask = target_generator.generate_thr_map((40, 40), text_polys)
+ assert np.all((thr_map >= 0.29) * (thr_map <= 0.71))
+
+
+def test_dbnet_draw_border_map():
+ target_generator = textdet_targets.DBNetTargets()
+ poly = np.array([[20, 21], [-14, 20], [-11, 30], [-22, 26]])
+ img_size = (40, 40)
+ thr_map = np.zeros(img_size, dtype=np.float32)
+ thr_mask = np.zeros(img_size, dtype=np.uint8)
+
+ target_generator.draw_border_map(poly, thr_map, thr_mask)
+
+
+def test_dbnet_generate_targets():
+ target_generator = textdet_targets.DBNetTargets()
+ text_polys = [[np.array([0, 0, 10, 0, 10, 10, 0, 10])],
+ [np.array([20, 0, 30, 0, 30, 10, 20, 10])]]
+ text_polys_ignore = [[np.array([0, 0, 15, 0, 15, 10, 0, 10])]]
+
+ results = {}
+ results['mask_fields'] = []
+ results['img_shape'] = (40, 40, 3)
+ results['gt_masks_ignore'] = PolygonMasks(text_polys_ignore, 40, 40)
+ results['gt_masks'] = PolygonMasks(text_polys, 40, 40)
+ results['gt_bboxes'] = np.array([[0, 0, 10, 10], [20, 0, 30, 10]])
+ results['gt_labels'] = np.array([0, 1])
+
+ target_generator.generate_targets(results)
+ assert 'gt_shrink' in results['mask_fields']
+ assert 'gt_shrink_mask' in results['mask_fields']
+ assert 'gt_thr' in results['mask_fields']
+ assert 'gt_thr_mask' in results['mask_fields']
+
+
+@mock.patch('%s.cf_bundle.show_feature' % __name__)
+def test_gen_textsnake_targets(mock_show_feature):
+
+ target_generator = textdet_targets.TextSnakeTargets()
+ assert np.allclose(target_generator.orientation_thr, 2.0)
+ assert np.allclose(target_generator.resample_step, 4.0)
+ assert np.allclose(target_generator.center_region_shrink_ratio, 0.3)
+
+ # test vector_angle
+ vec1 = np.array([[-1, 0], [0, 1]])
+ vec2 = np.array([[1, 0], [0, 1]])
+ angles = target_generator.vector_angle(vec1, vec2)
+ assert np.allclose(angles, np.array([np.pi, 0]), atol=1e-3)
+
+ # test find_head_tail for quadrangle
+ polygon = np.array([[1.0, 1.0], [5.0, 1.0], [5.0, 3.0], [1.0, 3.0]])
+ head_inds, tail_inds = target_generator.find_head_tail(polygon, 2.0)
+ assert np.allclose(head_inds, [3, 0])
+ assert np.allclose(tail_inds, [1, 2])
+ polygon = np.array([[1.0, 1.0], [1.0, 3.0], [5.0, 3.0], [5.0, 1.0]])
+ head_inds, tail_inds = target_generator.find_head_tail(polygon, 2.0)
+ assert np.allclose(head_inds, [0, 1])
+ assert np.allclose(tail_inds, [2, 3])
+
+ # test find_head_tail for polygon
+ polygon = np.array([[0., 10.], [3., 3.], [10., 0.], [17., 3.], [20., 10.],
+ [15., 10.], [13.5, 6.5], [10., 5.], [6.5, 6.5],
+ [5., 10.]])
+ head_inds, tail_inds = target_generator.find_head_tail(polygon, 2.0)
+ assert np.allclose(head_inds, [9, 0])
+ assert np.allclose(tail_inds, [4, 5])
+
+ # test resample_line
+ line = np.array([[0, 0], [0, 1], [0, 3], [0, 4], [0, 7], [0, 8]])
+ resampled_line = target_generator.resample_line(line, 3)
+ assert len(resampled_line) == 3
+ assert np.allclose(resampled_line, np.array([[0, 0], [0, 4], [0, 8]]))
+ line = np.array([[0, 0], [0, 0]])
+ resampled_line = target_generator.resample_line(line, 4)
+ assert len(resampled_line) == 4
+ assert np.allclose(resampled_line,
+ np.array([[0, 0], [0, 0], [0, 0], [0, 0]]))
+
+ # test generate_text_region_mask
+ img_size = (3, 10)
+ text_polys = [[np.array([0, 0, 1, 0, 1, 1, 0, 1])],
+ [np.array([2, 0, 3, 0, 3, 1, 2, 1])]]
+ output = target_generator.generate_text_region_mask(img_size, text_polys)
+ target = np.array([[1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
+ [1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
+ assert np.allclose(output, target)
+
+ # test generate_center_region_mask
+ target_generator.center_region_shrink_ratio = 1.0
+ (center_region_mask, radius_map, sin_map,
+ cos_map) = target_generator.generate_center_mask_attrib_maps(
+ img_size, text_polys)
+ target = np.array([[1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
+ [1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
+ assert np.allclose(center_region_mask, target)
+ assert np.allclose(sin_map, np.zeros(img_size))
+ assert np.allclose(cos_map, target)
+
+ # test generate_effective_mask
+ polys_ignore = text_polys
+ output = target_generator.generate_effective_mask(img_size, polys_ignore)
+ target = np.array([[0, 0, 0, 0, 1, 1, 1, 1, 1, 1],
+ [0, 0, 0, 0, 1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])
+ assert np.allclose(output, target)
+
+ # test generate_targets
+ results = {}
+ results['img'] = np.zeros((3, 10, 3), np.uint8)
+ results['gt_masks'] = PolygonMasks(text_polys, 3, 10)
+ results['gt_masks_ignore'] = PolygonMasks([], 3, 10)
+ results['img_shape'] = (3, 10, 3)
+ results['mask_fields'] = []
+ output = target_generator(results)
+ assert len(output['gt_text_mask']) == 1
+ assert len(output['gt_center_region_mask']) == 1
+ assert len(output['gt_mask']) == 1
+ assert len(output['gt_radius_map']) == 1
+ assert len(output['gt_sin_map']) == 1
+ assert len(output['gt_cos_map']) == 1
+
+ bundle = cf_bundle.CustomFormatBundle(
+ keys=[
+ 'gt_text_mask', 'gt_center_region_mask', 'gt_mask',
+ 'gt_radius_map', 'gt_sin_map', 'gt_cos_map'
+ ],
+ visualize=dict(flag=True, boundary_key='gt_text_mask'))
+ bundle(output)
+ assert 'gt_text_mask' in output.keys()
+ assert 'gt_center_region_mask' in output.keys()
+ assert 'gt_mask' in output.keys()
+ assert 'gt_radius_map' in output.keys()
+ assert 'gt_sin_map' in output.keys()
+ assert 'gt_cos_map' in output.keys()
+ mock_show_feature.assert_called_once()
+
+
+def test_fcenet_generate_targets():
+ fourier_degree = 5
+ target_generator = textdet_targets.FCENetTargets(
+ fourier_degree=fourier_degree)
+
+ h, w, c = (64, 64, 3)
+ text_polys = [[np.array([0, 0, 10, 0, 10, 10, 0, 10])],
+ [np.array([20, 0, 30, 0, 30, 10, 20, 10])]]
+ text_polys_ignore = [[np.array([0, 0, 15, 0, 15, 10, 0, 10])]]
+
+ results = {}
+ results['mask_fields'] = []
+ results['img_shape'] = (h, w, c)
+ results['gt_masks_ignore'] = PolygonMasks(text_polys_ignore, h, w)
+ results['gt_masks'] = PolygonMasks(text_polys, h, w)
+ results['gt_bboxes'] = np.array([[0, 0, 10, 10], [20, 0, 30, 10]])
+ results['gt_labels'] = np.array([0, 1])
+
+ target_generator.generate_targets(results)
+ assert 'p3_maps' in results.keys()
+ assert 'p4_maps' in results.keys()
+ assert 'p5_maps' in results.keys()
+
+
+def test_gen_drrg_targets():
+ target_generator = textdet_targets.DRRGTargets()
+ assert np.allclose(target_generator.orientation_thr, 2.0)
+ assert np.allclose(target_generator.resample_step, 8.0)
+ assert target_generator.num_min_comps == 9
+ assert target_generator.num_max_comps == 600
+ assert np.allclose(target_generator.min_width, 8.0)
+ assert np.allclose(target_generator.max_width, 24.0)
+ assert np.allclose(target_generator.center_region_shrink_ratio, 0.3)
+ assert np.allclose(target_generator.comp_shrink_ratio, 1.0)
+ assert np.allclose(target_generator.comp_w_h_ratio, 0.3)
+ assert np.allclose(target_generator.text_comp_nms_thr, 0.25)
+ assert np.allclose(target_generator.min_rand_half_height, 8.0)
+ assert np.allclose(target_generator.max_rand_half_height, 24.0)
+ assert np.allclose(target_generator.jitter_level, 0.2)
+
+ # test generate_targets
+ target_generator = textdet_targets.DRRGTargets(
+ min_width=2.,
+ max_width=4.,
+ min_rand_half_height=3.,
+ max_rand_half_height=5.)
+
+ results = {}
+ results['img'] = np.zeros((64, 64, 3), np.uint8)
+ text_polys = [[np.array([4, 2, 30, 2, 30, 10, 4, 10])],
+ [np.array([36, 12, 8, 12, 8, 22, 36, 22])],
+ [np.array([48, 20, 52, 20, 52, 50, 48, 50])],
+ [np.array([44, 50, 38, 50, 38, 20, 44, 20])]]
+ results['gt_masks'] = PolygonMasks(text_polys, 20, 30)
+ results['gt_masks_ignore'] = PolygonMasks([], 64, 64)
+ results['img_shape'] = (64, 64, 3)
+ results['mask_fields'] = []
+ output = target_generator(results)
+ assert len(output['gt_text_mask']) == 1
+ assert len(output['gt_center_region_mask']) == 1
+ assert len(output['gt_mask']) == 1
+ assert len(output['gt_top_height_map']) == 1
+ assert len(output['gt_bot_height_map']) == 1
+ assert len(output['gt_sin_map']) == 1
+ assert len(output['gt_cos_map']) == 1
+ assert output['gt_comp_attribs'].shape[-1] == 8
+
+ # test generate_targets with the number of proposed text components exceeds
+ # num_max_comps
+ target_generator = textdet_targets.DRRGTargets(
+ min_width=2.,
+ max_width=4.,
+ min_rand_half_height=3.,
+ max_rand_half_height=5.,
+ num_max_comps=6)
+ output = target_generator(results)
+ assert output['gt_comp_attribs'].ndim == 2
+ assert output['gt_comp_attribs'].shape[0] == 6
+
+ # test generate_targets with blank polygon masks
+ target_generator = textdet_targets.DRRGTargets(
+ min_width=2.,
+ max_width=4.,
+ min_rand_half_height=3.,
+ max_rand_half_height=5.)
+ results = {}
+ results['img'] = np.zeros((20, 30, 3), np.uint8)
+ results['gt_masks'] = PolygonMasks([], 20, 30)
+ results['gt_masks_ignore'] = PolygonMasks([], 20, 30)
+ results['img_shape'] = (20, 30, 3)
+ results['mask_fields'] = []
+ output = target_generator(results)
+ assert output['gt_comp_attribs'][0, 0] > 8
+
+ # test generate_targets with one proposed text component
+ text_polys = [[np.array([13, 6, 17, 6, 17, 14, 13, 14])]]
+ target_generator = textdet_targets.DRRGTargets(
+ min_width=4.,
+ max_width=8.,
+ min_rand_half_height=3.,
+ max_rand_half_height=5.)
+ results['gt_masks'] = PolygonMasks(text_polys, 20, 30)
+ output = target_generator(results)
+ assert output['gt_comp_attribs'][0, 0] > 8
+
+ # test generate_targets with shrunk margin in generate_rand_comp_attribs
+ target_generator = textdet_targets.DRRGTargets(
+ min_width=2.,
+ max_width=30.,
+ min_rand_half_height=3.,
+ max_rand_half_height=30.)
+ output = target_generator(results)
+ assert output['gt_comp_attribs'][0, 0] > 8
diff --git a/tests/test_dataset/test_transform_wrappers.py b/tests/test_dataset/test_transform_wrappers.py
new file mode 100644
index 0000000000000000000000000000000000000000..4639ed3a86184e9a793fb4be39b5e07e7dea1df2
--- /dev/null
+++ b/tests/test_dataset/test_transform_wrappers.py
@@ -0,0 +1,66 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import unittest.mock as mock
+
+import numpy as np
+import pytest
+
+from mmocr.datasets.pipelines import (OneOfWrapper, RandomWrapper,
+ TorchVisionWrapper)
+from mmocr.datasets.pipelines.transforms import ColorJitter
+
+
+def test_torchvision_wrapper():
+ x = {'img': np.ones((128, 100, 3), dtype=np.uint8)}
+ # object not found error
+ with pytest.raises(Exception):
+ TorchVisionWrapper(op='NonExist')
+ with pytest.raises(TypeError):
+ TorchVisionWrapper()
+ f = TorchVisionWrapper('Grayscale')
+ with pytest.raises(AssertionError):
+ f({})
+ results = f(x)
+ assert results['img'].shape == (128, 100)
+ assert results['img_shape'] == (128, 100)
+
+
+@mock.patch('random.choice')
+def test_oneof(rand_choice):
+ color_jitter = dict(type='TorchVisionWrapper', op='ColorJitter')
+ gray_scale = dict(type='TorchVisionWrapper', op='Grayscale')
+ x = {'img': np.random.randint(0, 256, size=(128, 100, 3), dtype=np.uint8)}
+ f = OneOfWrapper([color_jitter, gray_scale])
+ # Use color_jitter at the first call
+ rand_choice.side_effect = lambda x: x[0]
+ results = f(x)
+ assert results['img'].shape == (128, 100, 3)
+ # Use gray_scale at the second call
+ rand_choice.side_effect = lambda x: x[1]
+ results = f(x)
+ assert results['img'].shape == (128, 100)
+
+ # Passing object
+ f = OneOfWrapper([ColorJitter(), gray_scale])
+ # Use color_jitter at the first call
+ results = f(x)
+ assert results['img'].shape == (128, 100)
+
+ # Test invalid inputs
+ with pytest.raises(AssertionError):
+ f = OneOfWrapper(None)
+ with pytest.raises(AssertionError):
+ f = OneOfWrapper([])
+ with pytest.raises(AssertionError):
+ f = OneOfWrapper({})
+
+
+@mock.patch('numpy.random.uniform')
+def test_runwithprob(np_random_uniform):
+ np_random_uniform.side_effect = [0.1, 0.9]
+ f = RandomWrapper([dict(type='TorchVisionWrapper', op='Grayscale')], 0.5)
+ img = np.random.randint(0, 256, size=(128, 100, 3), dtype=np.uint8)
+ results = f({'img': copy.deepcopy(img)})
+ assert results['img'].shape == (128, 100)
+ results = f({'img': copy.deepcopy(img)})
+ assert results['img'].shape == (128, 100, 3)
diff --git a/tests/test_dataset/test_transforms.py b/tests/test_dataset/test_transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..fc51f3d7b20c7a50bc747a40336b3cf4bf6454ed
--- /dev/null
+++ b/tests/test_dataset/test_transforms.py
@@ -0,0 +1,373 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import unittest.mock as mock
+
+import numpy as np
+import pytest
+import torchvision.transforms as TF
+from mmdet.core import BitmapMasks, PolygonMasks
+from PIL import Image
+
+import mmocr.datasets.pipelines.transforms as transforms
+
+
+@mock.patch('%s.transforms.np.random.random_sample' % __name__)
+@mock.patch('%s.transforms.np.random.randint' % __name__)
+def test_random_crop_instances(mock_randint, mock_sample):
+
+ img_gt = np.array([[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 1, 1, 1],
+ [0, 0, 1, 1, 1], [0, 0, 1, 1, 1]])
+ # test target is bigger than img size in sample_offset
+ mock_sample.side_effect = [1]
+ rci = transforms.RandomCropInstances(6, instance_key='gt_kernels')
+ (i, j) = rci.sample_offset(img_gt, (5, 5))
+ assert i == 0
+ assert j == 0
+
+ # test the second branch in sample_offset
+
+ rci = transforms.RandomCropInstances(3, instance_key='gt_kernels')
+ mock_sample.side_effect = [1]
+ mock_randint.side_effect = [1, 2]
+ (i, j) = rci.sample_offset(img_gt, (5, 5))
+ assert i == 1
+ assert j == 2
+
+ mock_sample.side_effect = [1]
+ mock_randint.side_effect = [1, 2]
+ rci = transforms.RandomCropInstances(5, instance_key='gt_kernels')
+ (i, j) = rci.sample_offset(img_gt, (5, 5))
+ assert i == 0
+ assert j == 0
+
+ # test the first bracnh is sample_offset
+
+ rci = transforms.RandomCropInstances(3, instance_key='gt_kernels')
+ mock_sample.side_effect = [0.1]
+ mock_randint.side_effect = [1, 1]
+ (i, j) = rci.sample_offset(img_gt, (5, 5))
+ assert i == 1
+ assert j == 1
+
+ # test crop_img(img, offset, target_size)
+
+ img = img_gt
+ offset = [0, 0]
+ target = [6, 6]
+ crop = rci.crop_img(img, offset, target)
+ assert np.allclose(img, crop[0])
+ assert np.allclose(crop[1], [0, 0, 5, 5])
+
+ target = [3, 2]
+ crop = rci.crop_img(img, offset, target)
+ assert np.allclose(np.array([[0, 0], [0, 0], [0, 0]]), crop[0])
+ assert np.allclose(crop[1], [0, 0, 2, 3])
+
+ # test crop_bboxes
+ canvas_box = np.array([2, 3, 5, 5])
+ bboxes = np.array([[2, 3, 4, 4], [0, 0, 1, 1], [1, 2, 4, 4],
+ [0, 0, 10, 10]])
+ kept_bboxes, kept_idx = rci.crop_bboxes(bboxes, canvas_box)
+ assert np.allclose(kept_bboxes,
+ np.array([[0, 0, 2, 1], [0, 0, 2, 1], [0, 0, 3, 2]]))
+ assert kept_idx == [0, 2, 3]
+
+ bboxes = np.array([[10, 10, 11, 11], [0, 0, 1, 1]])
+ kept_bboxes, kept_idx = rci.crop_bboxes(bboxes, canvas_box)
+ assert kept_bboxes.size == 0
+ assert kept_bboxes.shape == (0, 4)
+ assert len(kept_idx) == 0
+
+ # test __call__
+ rci = transforms.RandomCropInstances(3, instance_key='gt_kernels')
+ results = {}
+ gt_kernels = [img_gt, img_gt.copy()]
+ results['gt_kernels'] = BitmapMasks(gt_kernels, 5, 5)
+ results['img'] = img_gt.copy()
+ results['mask_fields'] = ['gt_kernels']
+ mock_sample.side_effect = [0.1]
+ mock_randint.side_effect = [1, 1]
+ output = rci(results)
+ target = np.array([[0, 0, 0], [0, 1, 1], [0, 1, 1]])
+ assert output['img_shape'] == (3, 3)
+
+ assert np.allclose(output['img'], target)
+
+ assert np.allclose(output['gt_kernels'].masks[0], target)
+ assert np.allclose(output['gt_kernels'].masks[1], target)
+
+
+@mock.patch('%s.transforms.np.random.random_sample' % __name__)
+def test_scale_aspect_jitter(mock_random):
+ img_scale = [(3000, 1000)] # unused
+ ratio_range = (0.5, 1.5)
+ aspect_ratio_range = (1, 1)
+ multiscale_mode = 'value'
+ long_size_bound = 2000
+ short_size_bound = 640
+ resize_type = 'long_short_bound'
+ keep_ratio = False
+ jitter = transforms.ScaleAspectJitter(
+ img_scale=img_scale,
+ ratio_range=ratio_range,
+ aspect_ratio_range=aspect_ratio_range,
+ multiscale_mode=multiscale_mode,
+ long_size_bound=long_size_bound,
+ short_size_bound=short_size_bound,
+ resize_type=resize_type,
+ keep_ratio=keep_ratio)
+ mock_random.side_effect = [0.5]
+
+ # test sample_from_range
+
+ result = jitter.sample_from_range([100, 200])
+ assert result == 150
+
+ # test _random_scale
+ results = {}
+ results['img'] = np.zeros((4000, 1000))
+ mock_random.side_effect = [0.5, 1]
+ jitter._random_scale(results)
+ # scale1 0.5, scale2=1 scale =0.5 650/1000, w, h
+ # print(results['scale'])
+ assert results['scale'] == (650, 2600)
+
+
+@mock.patch('%s.transforms.np.random.random_sample' % __name__)
+def test_random_rotate(mock_random):
+
+ mock_random.side_effect = [0.5, 0]
+ results = {}
+ img = np.random.rand(5, 5)
+ results['img'] = img.copy()
+ results['mask_fields'] = ['masks']
+ gt_kernels = [results['img'].copy()]
+ results['masks'] = BitmapMasks(gt_kernels, 5, 5)
+
+ rotater = transforms.RandomRotateTextDet()
+
+ results = rotater(results)
+ assert np.allclose(results['img'], img)
+ assert np.allclose(results['masks'].masks, img)
+
+
+def test_color_jitter():
+ img = np.ones((64, 256, 3), dtype=np.uint8)
+ results = {'img': img}
+
+ pt_official_color_jitter = TF.ColorJitter()
+ output1 = pt_official_color_jitter(img)
+
+ color_jitter = transforms.ColorJitter()
+ output2 = color_jitter(results)
+
+ assert np.allclose(output1, output2['img'])
+
+
+def test_affine_jitter():
+ img = np.ones((64, 256, 3), dtype=np.uint8)
+ results = {'img': img}
+
+ pt_official_affine_jitter = TF.RandomAffine(degrees=0)
+ output1 = pt_official_affine_jitter(Image.fromarray(img))
+
+ affine_jitter = transforms.AffineJitter(
+ degrees=0,
+ translate=None,
+ scale=None,
+ shear=None,
+ resample=False,
+ fillcolor=0)
+ output2 = affine_jitter(results)
+
+ assert np.allclose(np.array(output1), output2['img'])
+
+
+def test_random_scale():
+ h, w, c = 100, 100, 3
+ img = np.ones((h, w, c), dtype=np.uint8)
+ results = {'img': img, 'img_shape': (h, w, c)}
+
+ polygon = np.array([0., 0., 0., 10., 10., 10., 10., 0.])
+
+ results['gt_masks'] = PolygonMasks([[polygon]], *(img.shape[:2]))
+ results['mask_fields'] = ['gt_masks']
+
+ size = 100
+ scale = (2., 2.)
+ random_scaler = transforms.RandomScaling(size=size, scale=scale)
+
+ results = random_scaler(results)
+
+ out_img = results['img']
+ out_poly = results['gt_masks'].masks[0][0]
+ gt_poly = polygon * 2
+
+ assert np.allclose(out_img.shape, (2 * h, 2 * w, c))
+ assert np.allclose(out_poly, gt_poly)
+
+
+@mock.patch('%s.transforms.np.random.randint' % __name__)
+def test_random_crop_flip(mock_randint):
+ img = np.ones((10, 10, 3), dtype=np.uint8)
+ img[0, 0, :] = 0
+ results = {'img': img, 'img_shape': img.shape}
+
+ polygon = np.array([0., 0., 0., 10., 10., 10., 10., 0.])
+
+ results['gt_masks'] = PolygonMasks([[polygon]], *(img.shape[:2]))
+ results['gt_masks_ignore'] = PolygonMasks([], *(img.shape[:2]))
+ results['mask_fields'] = ['gt_masks', 'gt_masks_ignore']
+
+ crop_ratio = 1.1
+ iter_num = 3
+ random_crop_fliper = transforms.RandomCropFlip(
+ crop_ratio=crop_ratio, iter_num=iter_num)
+
+ # test crop_target
+ pad_ratio = 0.1
+ h, w = img.shape[:2]
+ pad_h = int(h * pad_ratio)
+ pad_w = int(w * pad_ratio)
+ all_polys = results['gt_masks'].masks
+ h_axis, w_axis = random_crop_fliper.generate_crop_target(
+ img, all_polys, pad_h, pad_w)
+
+ assert np.allclose(h_axis, (0, 11))
+ assert np.allclose(w_axis, (0, 11))
+
+ # test __call__
+ polygon = np.array([1., 1., 1., 9., 9., 9., 9., 1.])
+ results['gt_masks'] = PolygonMasks([[polygon]], *(img.shape[:2]))
+ results['gt_masks_ignore'] = PolygonMasks([[polygon]], *(img.shape[:2]))
+
+ mock_randint.side_effect = [0, 1, 2]
+ results = random_crop_fliper(results)
+
+ out_img = results['img']
+ out_poly = results['gt_masks'].masks[0][0]
+ gt_img = img
+ gt_poly = polygon
+
+ assert np.allclose(out_img, gt_img)
+ assert np.allclose(out_poly, gt_poly)
+
+
+@mock.patch('%s.transforms.np.random.random_sample' % __name__)
+@mock.patch('%s.transforms.np.random.randint' % __name__)
+def test_random_crop_poly_instances(mock_randint, mock_sample):
+ results = {}
+ img = np.zeros((30, 30, 3))
+ poly_masks = PolygonMasks([[
+ np.array([5., 5., 25., 5., 25., 10., 5., 10.])
+ ], [np.array([5., 20., 25., 20., 25., 25., 5., 25.])]], 30, 30)
+ results['img'] = img
+ results['gt_masks'] = poly_masks
+ results['gt_masks_ignore'] = PolygonMasks([], 30, 30)
+ results['mask_fields'] = ['gt_masks', 'gt_masks_ignore']
+ results['gt_labels'] = [1, 1]
+ rcpi = transforms.RandomCropPolyInstances(
+ instance_key='gt_masks', crop_ratio=1.0, min_side_ratio=0.3)
+
+ # test sample_crop_box(img_size, results)
+ mock_randint.side_effect = [0, 0, 0, 0, 30, 0, 0, 0, 15]
+ crop_box = rcpi.sample_crop_box((30, 30), results)
+ assert np.allclose(np.array(crop_box), np.array([0, 0, 30, 15]))
+
+ # test __call__
+ mock_randint.side_effect = [0, 0, 0, 0, 30, 0, 15, 0, 30]
+ mock_sample.side_effect = [0.1]
+ output = rcpi(results)
+ target = np.array([5., 5., 25., 5., 25., 10., 5., 10.])
+ assert len(output['gt_masks']) == 1
+ assert len(output['gt_masks_ignore']) == 0
+ assert np.allclose(output['gt_masks'].masks[0][0], target)
+ assert output['img'].shape == (15, 30, 3)
+
+ # test __call__ with blank instace_key masks
+ mock_randint.side_effect = [0, 0, 0, 0, 30, 0, 15, 0, 30]
+ mock_sample.side_effect = [0.1]
+ rcpi = transforms.RandomCropPolyInstances(
+ instance_key='gt_masks_ignore', crop_ratio=1.0, min_side_ratio=0.3)
+ results['img'] = img
+ results['gt_masks'] = poly_masks
+ output = rcpi(results)
+ assert len(output['gt_masks']) == 2
+ assert np.allclose(output['gt_masks'].masks[0][0], poly_masks.masks[0][0])
+ assert np.allclose(output['gt_masks'].masks[1][0], poly_masks.masks[1][0])
+ assert output['img'].shape == (30, 30, 3)
+
+
+@mock.patch('%s.transforms.np.random.random_sample' % __name__)
+def test_random_rotate_poly_instances(mock_sample):
+ results = {}
+ img = np.zeros((30, 30, 3))
+ poly_masks = PolygonMasks(
+ [[np.array([10., 10., 20., 10., 20., 20., 10., 20.])]], 30, 30)
+ results['img'] = img
+ results['gt_masks'] = poly_masks
+ results['mask_fields'] = ['gt_masks']
+ rrpi = transforms.RandomRotatePolyInstances(rotate_ratio=1.0, max_angle=90)
+
+ mock_sample.side_effect = [0., 1.]
+ output = rrpi(results)
+ assert np.allclose(output['gt_masks'].masks[0][0],
+ np.array([10., 20., 10., 10., 20., 10., 20., 20.]))
+ assert output['img'].shape == (30, 30, 3)
+
+
+@mock.patch('%s.transforms.np.random.random_sample' % __name__)
+def test_square_resize_pad(mock_sample):
+ results = {}
+ img = np.zeros((15, 30, 3))
+ polygon = np.array([10., 5., 20., 5., 20., 10., 10., 10.])
+ poly_masks = PolygonMasks([[polygon]], 15, 30)
+ results['img'] = img
+ results['gt_masks'] = poly_masks
+ results['mask_fields'] = ['gt_masks']
+ srp = transforms.SquareResizePad(target_size=40, pad_ratio=0.5)
+
+ # test resize with padding
+ mock_sample.side_effect = [0.]
+ output = srp(results)
+ target = 4. / 3 * polygon
+ target[1::2] += 10.
+ assert np.allclose(output['gt_masks'].masks[0][0], target)
+ assert output['img'].shape == (40, 40, 3)
+
+ # test resize to square without padding
+ results['img'] = img
+ results['gt_masks'] = poly_masks
+ mock_sample.side_effect = [1.]
+ output = srp(results)
+ target = polygon.copy()
+ target[::2] *= 4. / 3
+ target[1::2] *= 8. / 3
+ assert np.allclose(output['gt_masks'].masks[0][0], target)
+ assert output['img'].shape == (40, 40, 3)
+
+
+def test_pyramid_rescale():
+ img = np.random.randint(0, 256, size=(128, 100, 3), dtype=np.uint8)
+ x = {'img': copy.deepcopy(img)}
+ f = transforms.PyramidRescale()
+ results = f(x)
+ assert results['img'].shape == (128, 100, 3)
+
+ # Test invalid inputs
+ with pytest.raises(AssertionError):
+ transforms.PyramidRescale(base_shape=(128))
+ with pytest.raises(AssertionError):
+ transforms.PyramidRescale(base_shape=128)
+ with pytest.raises(AssertionError):
+ transforms.PyramidRescale(factor=[])
+ with pytest.raises(AssertionError):
+ transforms.PyramidRescale(randomize_factor=[])
+ with pytest.raises(AssertionError):
+ f({})
+
+ # Test factor = 0
+ f_derandomized = transforms.PyramidRescale(
+ factor=0, randomize_factor=False)
+ results = f_derandomized({'img': copy.deepcopy(img)})
+ assert np.all(results['img'] == img)
diff --git a/tests/test_dataset/test_uniform_concat_dataset.py b/tests/test_dataset/test_uniform_concat_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..0b0acb34f11d5fad76be0a6fdf88b2f4def22097
--- /dev/null
+++ b/tests/test_dataset/test_uniform_concat_dataset.py
@@ -0,0 +1,60 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+
+from mmocr.datasets import UniformConcatDataset
+from mmocr.utils import list_from_file
+
+
+def test_dataset_warpper():
+ pipeline1 = [dict(type='LoadImageFromFile')]
+ pipeline2 = [dict(type='LoadImageFromFile'), dict(type='ColorJitter')]
+
+ img_prefix = 'tests/data/ocr_toy_dataset/imgs'
+ ann_file = 'tests/data/ocr_toy_dataset/label.txt'
+ train1 = dict(
+ type='OCRDataset',
+ img_prefix=img_prefix,
+ ann_file=ann_file,
+ loader=dict(
+ type='HardDiskLoader',
+ repeat=1,
+ parser=dict(
+ type='LineStrParser',
+ keys=['filename', 'text'],
+ keys_idx=[0, 1],
+ separator=' ')),
+ pipeline=None,
+ test_mode=False)
+
+ train2 = {key: value for key, value in train1.items()}
+ train2['pipeline'] = pipeline2
+
+ # pipeline is 1d list
+ copy_train1 = copy.deepcopy(train1)
+ copy_train2 = copy.deepcopy(train2)
+ tmp_dataset = UniformConcatDataset(
+ datasets=[copy_train1, copy_train2],
+ pipeline=pipeline1,
+ force_apply=True)
+
+ assert len(tmp_dataset) == 2 * len(list_from_file(ann_file))
+ assert len(tmp_dataset.datasets[0].pipeline.transforms) == len(
+ tmp_dataset.datasets[1].pipeline.transforms)
+
+ # pipeline is None
+ copy_train2 = copy.deepcopy(train2)
+ tmp_dataset = UniformConcatDataset(datasets=[copy_train2], pipeline=None)
+ assert len(tmp_dataset.datasets[0].pipeline.transforms) == len(pipeline2)
+
+ copy_train2 = copy.deepcopy(train2)
+ tmp_dataset = UniformConcatDataset(
+ datasets=[[copy_train2], [copy_train2]], pipeline=None)
+ assert len(tmp_dataset.datasets[0].pipeline.transforms) == len(pipeline2)
+
+ # pipeline is 2d list
+ copy_train1 = copy.deepcopy(train1)
+ copy_train2 = copy.deepcopy(train2)
+ tmp_dataset = UniformConcatDataset(
+ datasets=[[copy_train1], [copy_train2]],
+ pipeline=[pipeline1, pipeline2])
+ assert len(tmp_dataset.datasets[0].pipeline.transforms) == len(pipeline1)
diff --git a/tests/test_metrics/test_eval_utils.py b/tests/test_metrics/test_eval_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..a4f7778475041982aedc7f12b0c0eaa4509484ef
--- /dev/null
+++ b/tests/test_metrics/test_eval_utils.py
@@ -0,0 +1,462 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""Tests the utils of evaluation."""
+import numpy as np
+import pytest
+from shapely.geometry import MultiPolygon, Polygon
+
+import mmocr.core.evaluation.utils as utils
+
+
+def test_ignore_pred():
+
+ # test invalid arguments
+ box = [0, 0, 1, 0, 1, 1, 0, 1]
+ det_boxes = [box]
+ gt_dont_care_index = [0]
+ gt_polys = [utils.points2polygon(box)]
+ precision_thr = 0.5
+
+ with pytest.raises(AssertionError):
+ det_boxes_tmp = 1
+ utils.ignore_pred(det_boxes_tmp, gt_dont_care_index, gt_polys,
+ precision_thr)
+ with pytest.raises(AssertionError):
+ gt_dont_care_index_tmp = 1
+ utils.ignore_pred(det_boxes, gt_dont_care_index_tmp, gt_polys,
+ precision_thr)
+ with pytest.raises(AssertionError):
+ gt_polys_tmp = 1
+ utils.ignore_pred(det_boxes, gt_dont_care_index, gt_polys_tmp,
+ precision_thr)
+ with pytest.raises(AssertionError):
+ precision_thr_tmp = 1.1
+ utils.ignore_pred(det_boxes, gt_dont_care_index, gt_polys,
+ precision_thr_tmp)
+
+ # test ignored cases
+ result = utils.ignore_pred(det_boxes, gt_dont_care_index, gt_polys,
+ precision_thr)
+ assert result[2] == [0]
+ # test unignored cases
+ gt_dont_care_index_tmp = []
+ result = utils.ignore_pred(det_boxes, gt_dont_care_index_tmp, gt_polys,
+ precision_thr)
+ assert result[2] == []
+
+ det_boxes_tmp = [[10, 10, 15, 10, 15, 15, 10, 15]]
+ result = utils.ignore_pred(det_boxes_tmp, gt_dont_care_index, gt_polys,
+ precision_thr)
+ assert result[2] == []
+
+
+def test_compute_hmean():
+
+ # test invalid arguments
+ with pytest.raises(AssertionError):
+ utils.compute_hmean(0, 0, 0.0, 0)
+ with pytest.raises(AssertionError):
+ utils.compute_hmean(0, 0, 0, 0.0)
+ with pytest.raises(AssertionError):
+ utils.compute_hmean([1], 0, 0, 0)
+ with pytest.raises(AssertionError):
+ utils.compute_hmean(0, [1], 0, 0)
+
+ _, _, hmean = utils.compute_hmean(2, 2, 2, 2)
+ assert hmean == 1
+
+ _, _, hmean = utils.compute_hmean(0, 0, 2, 2)
+ assert hmean == 0
+
+
+def test_points2polygon():
+
+ # test unsupported type
+ with pytest.raises(AssertionError):
+ points = 2
+ utils.points2polygon(points)
+
+ # test unsupported size
+ with pytest.raises(AssertionError):
+ points = [1, 2, 3, 4, 5, 6, 7]
+ utils.points2polygon(points)
+ with pytest.raises(AssertionError):
+ points = [1, 2, 3, 4, 5, 6]
+ utils.points2polygon(points)
+
+ # test np.array
+ points = np.array([1, 2, 3, 4, 5, 6, 7, 8])
+ poly = utils.points2polygon(points)
+ i = 0
+ for coord in poly.exterior.coords[:-1]:
+ assert coord[0] == points[i]
+ assert coord[1] == points[i + 1]
+ i += 2
+
+ points = [1, 2, 3, 4, 5, 6, 7, 8]
+ poly = utils.points2polygon(points)
+ i = 0
+ for coord in poly.exterior.coords[:-1]:
+ assert coord[0] == points[i]
+ assert coord[1] == points[i + 1]
+ i += 2
+
+
+def test_poly_intersection():
+
+ # test unsupported type
+ with pytest.raises(AssertionError):
+ utils.poly_intersection(0, 1)
+
+ # test non-overlapping polygons
+
+ points = [0, 0, 0, 1, 1, 1, 1, 0]
+ points1 = [10, 20, 30, 40, 50, 60, 70, 80]
+ points2 = [0, 0, 0, 0, 0, 0, 0, 0] # Invalid polygon
+ points3 = [0, 0, 0, 1, 1, 0, 1, 1] # Self-intersected polygon
+ points4 = [0.5, 0, 1.5, 0, 1.5, 1, 0.5, 1]
+ poly = utils.points2polygon(points)
+ poly1 = utils.points2polygon(points1)
+ poly2 = utils.points2polygon(points2)
+ poly3 = utils.points2polygon(points3)
+ poly4 = utils.points2polygon(points4)
+
+ area_inters = utils.poly_intersection(poly, poly1)
+
+ assert area_inters == 0
+
+ # test overlapping polygons
+ area_inters = utils.poly_intersection(poly, poly)
+ assert area_inters == 1
+ area_inters = utils.poly_intersection(poly, poly4)
+ assert area_inters == 0.5
+
+ # test invalid polygons
+ assert utils.poly_intersection(poly2, poly2) == 0
+ assert utils.poly_intersection(poly3, poly3, invalid_ret=1) == 1
+ # The return value depends on the implementation of the package
+ assert utils.poly_intersection(poly3, poly3, invalid_ret=None) == 0.25
+
+ # test poly return
+ _, poly = utils.poly_intersection(poly, poly4, return_poly=True)
+ assert isinstance(poly, Polygon)
+ _, poly = utils.poly_intersection(
+ poly3, poly3, invalid_ret=None, return_poly=True)
+ assert isinstance(poly, Polygon)
+ _, poly = utils.poly_intersection(
+ poly2, poly3, invalid_ret=1, return_poly=True)
+ assert poly is None
+
+
+def test_poly_union():
+
+ # test unsupported type
+ with pytest.raises(AssertionError):
+ utils.poly_union(0, 1)
+
+ # test non-overlapping polygons
+
+ points = [0, 0, 0, 1, 1, 1, 1, 0]
+ points1 = [2, 2, 2, 3, 3, 3, 3, 2]
+ points2 = [0, 0, 0, 0, 0, 0, 0, 0] # Invalid polygon
+ points3 = [0, 0, 0, 1, 1, 0, 1, 1] # Self-intersected polygon
+ points4 = [0.5, 0.5, 1, 0, 1, 1, 0.5, 0.5]
+ poly = utils.points2polygon(points)
+ poly1 = utils.points2polygon(points1)
+ poly2 = utils.points2polygon(points2)
+ poly3 = utils.points2polygon(points3)
+ poly4 = utils.points2polygon(points4)
+
+ assert utils.poly_union(poly, poly1) == 2
+
+ # test overlapping polygons
+ assert utils.poly_union(poly, poly) == 1
+
+ # test invalid polygons
+ assert utils.poly_union(poly2, poly2) == 0
+ assert utils.poly_union(poly3, poly3, invalid_ret=1) == 1
+
+ # The return value depends on the implementation of the package
+ assert utils.poly_union(poly3, poly3, invalid_ret=None) == 0.25
+ assert utils.poly_union(poly2, poly3) == 0.25
+ assert utils.poly_union(poly3, poly4) == 0.5
+
+ # test poly return
+ _, poly = utils.poly_union(poly, poly1, return_poly=True)
+ assert isinstance(poly, MultiPolygon)
+ _, poly = utils.poly_union(poly3, poly3, return_poly=True)
+ assert isinstance(poly, Polygon)
+ _, poly = utils.poly_union(poly2, poly3, invalid_ret=0, return_poly=True)
+ assert poly is None
+
+
+def test_poly_iou():
+
+ # test unsupported type
+ with pytest.raises(AssertionError):
+ utils.poly_iou([1], [2])
+
+ points = [0, 0, 0, 1, 1, 1, 1, 0]
+ points1 = [10, 20, 30, 40, 50, 60, 70, 80]
+ points2 = [0, 0, 0, 0, 0, 0, 0, 0] # Invalid polygon
+ points3 = [0, 0, 0, 1, 1, 0, 1, 1] # Self-intersected polygon
+
+ poly = utils.points2polygon(points)
+ poly1 = utils.points2polygon(points1)
+ poly2 = utils.points2polygon(points2)
+ poly3 = utils.points2polygon(points3)
+
+ assert utils.poly_iou(poly, poly1) == 0
+
+ # test overlapping polygons
+ assert utils.poly_iou(poly, poly) == 1
+
+ # test invalid polygons
+ assert utils.poly_iou(poly2, poly2) == 0
+ assert utils.poly_iou(poly3, poly3, zero_division=1) == 1
+ assert utils.poly_iou(poly2, poly3) == 0
+
+
+def test_boundary_iou():
+ points = [0, 0, 0, 1, 1, 1, 1, 0]
+ points1 = [10, 20, 30, 40, 50, 60, 70, 80]
+ points2 = [0, 0, 0, 0, 0, 0, 0, 0] # Invalid polygon
+ points3 = [0, 0, 0, 1, 1, 0, 1, 1] # Self-intersected polygon
+
+ assert utils.boundary_iou(points, points1) == 0
+
+ # test overlapping boundaries
+ assert utils.boundary_iou(points, points) == 1
+
+ # test invalid boundaries
+ assert utils.boundary_iou(points2, points2) == 0
+ assert utils.boundary_iou(points3, points3, zero_division=1) == 1
+ assert utils.boundary_iou(points2, points3) == 0
+
+
+def test_points_center():
+
+ # test unsupported type
+ with pytest.raises(AssertionError):
+ utils.points_center([1])
+ with pytest.raises(AssertionError):
+ points = np.array([1, 2, 3])
+ utils.points_center(points)
+
+ points = np.array([1, 2, 3, 4])
+ assert np.array_equal(utils.points_center(points), np.array([2, 3]))
+
+
+def test_point_distance():
+ # test unsupported type
+ with pytest.raises(AssertionError):
+ utils.point_distance([1, 2], [1, 2])
+
+ with pytest.raises(AssertionError):
+ p = np.array([1, 2, 3])
+ utils.point_distance(p, p)
+
+ p = np.array([1, 2])
+ assert utils.point_distance(p, p) == 0
+
+ p1 = np.array([2, 2])
+ assert utils.point_distance(p, p1) == 1
+
+
+def test_box_center_distance():
+ p1 = np.array([1, 1, 3, 3])
+ p2 = np.array([2, 2, 4, 2])
+
+ assert utils.box_center_distance(p1, p2) == 1
+
+
+def test_box_diag():
+ # test unsupported type
+ with pytest.raises(AssertionError):
+ utils.box_diag([1, 2])
+ with pytest.raises(AssertionError):
+ utils.box_diag(np.array([1, 2, 3, 4]))
+
+ box = np.array([0, 0, 1, 1, 0, 10, -10, 0])
+
+ assert utils.box_diag(box) == 10
+
+
+def test_one2one_match_ic13():
+ gt_id = 0
+ det_id = 0
+ recall_mat = np.array([[1, 0], [0, 0]])
+ precision_mat = np.array([[1, 0], [0, 0]])
+ recall_thr = 0.5
+ precision_thr = 0.5
+ # test invalid arguments.
+ with pytest.raises(AssertionError):
+ utils.one2one_match_ic13(0.0, det_id, recall_mat, precision_mat,
+ recall_thr, precision_thr)
+ with pytest.raises(AssertionError):
+ utils.one2one_match_ic13(gt_id, 0.0, recall_mat, precision_mat,
+ recall_thr, precision_thr)
+ with pytest.raises(AssertionError):
+ utils.one2one_match_ic13(gt_id, det_id, [0, 0], precision_mat,
+ recall_thr, precision_thr)
+ with pytest.raises(AssertionError):
+ utils.one2one_match_ic13(gt_id, det_id, recall_mat, [0, 0], recall_thr,
+ precision_thr)
+ with pytest.raises(AssertionError):
+ utils.one2one_match_ic13(gt_id, det_id, recall_mat, precision_mat, 1.1,
+ precision_thr)
+ with pytest.raises(AssertionError):
+ utils.one2one_match_ic13(gt_id, det_id, recall_mat, precision_mat,
+ recall_thr, 1.1)
+
+ assert utils.one2one_match_ic13(gt_id, det_id, recall_mat, precision_mat,
+ recall_thr, precision_thr)
+ recall_mat = np.array([[1, 0], [0.6, 0]])
+ precision_mat = np.array([[1, 0], [0.6, 0]])
+ assert not utils.one2one_match_ic13(
+ gt_id, det_id, recall_mat, precision_mat, recall_thr, precision_thr)
+ recall_mat = np.array([[1, 0.6], [0, 0]])
+ precision_mat = np.array([[1, 0.6], [0, 0]])
+ assert not utils.one2one_match_ic13(
+ gt_id, det_id, recall_mat, precision_mat, recall_thr, precision_thr)
+
+
+def test_one2many_match_ic13():
+ gt_id = 0
+ recall_mat = np.array([[1, 0], [0, 0]])
+ precision_mat = np.array([[1, 0], [0, 0]])
+ recall_thr = 0.5
+ precision_thr = 0.5
+ gt_match_flag = [0, 0]
+ det_match_flag = [0, 0]
+ det_dont_care_index = []
+ # test invalid arguments.
+ with pytest.raises(AssertionError):
+ gt_id_tmp = 0.0
+ utils.one2many_match_ic13(gt_id_tmp, recall_mat, precision_mat,
+ recall_thr, precision_thr, gt_match_flag,
+ det_match_flag, det_dont_care_index)
+ with pytest.raises(AssertionError):
+ recall_mat_tmp = [1, 0]
+ utils.one2many_match_ic13(gt_id, recall_mat_tmp, precision_mat,
+ recall_thr, precision_thr, gt_match_flag,
+ det_match_flag, det_dont_care_index)
+ with pytest.raises(AssertionError):
+ precision_mat_tmp = [1, 0]
+ utils.one2many_match_ic13(gt_id, recall_mat, precision_mat_tmp,
+ recall_thr, precision_thr, gt_match_flag,
+ det_match_flag, det_dont_care_index)
+ with pytest.raises(AssertionError):
+
+ utils.one2many_match_ic13(gt_id, recall_mat, precision_mat, 1.1,
+ precision_thr, gt_match_flag, det_match_flag,
+ det_dont_care_index)
+ with pytest.raises(AssertionError):
+
+ utils.one2many_match_ic13(gt_id, recall_mat, precision_mat, recall_thr,
+ 1.1, gt_match_flag, det_match_flag,
+ det_dont_care_index)
+ with pytest.raises(AssertionError):
+ gt_match_flag_tmp = np.array([0, 1])
+ utils.one2many_match_ic13(gt_id, recall_mat, precision_mat, recall_thr,
+ precision_thr, gt_match_flag_tmp,
+ det_match_flag, det_dont_care_index)
+ with pytest.raises(AssertionError):
+ det_match_flag_tmp = np.array([0, 1])
+ utils.one2many_match_ic13(gt_id, recall_mat, precision_mat, recall_thr,
+ precision_thr, gt_match_flag,
+ det_match_flag_tmp, det_dont_care_index)
+ with pytest.raises(AssertionError):
+ det_dont_care_index_tmp = np.array([0, 1])
+ utils.one2many_match_ic13(gt_id, recall_mat, precision_mat, recall_thr,
+ precision_thr, gt_match_flag, det_match_flag,
+ det_dont_care_index_tmp)
+
+ # test matched case
+
+ result = utils.one2many_match_ic13(gt_id, recall_mat, precision_mat,
+ recall_thr, precision_thr,
+ gt_match_flag, det_match_flag,
+ det_dont_care_index)
+ assert result[0]
+ assert result[1] == [0]
+
+ # test unmatched case
+ gt_match_flag_tmp = [1, 0]
+ result = utils.one2many_match_ic13(gt_id, recall_mat, precision_mat,
+ recall_thr, precision_thr,
+ gt_match_flag_tmp, det_match_flag,
+ det_dont_care_index)
+ assert not result[0]
+ assert result[1] == []
+
+
+def test_many2one_match_ic13():
+ det_id = 0
+ recall_mat = np.array([[1, 0], [0, 0]])
+ precision_mat = np.array([[1, 0], [0, 0]])
+ recall_thr = 0.5
+ precision_thr = 0.5
+ gt_match_flag = [0, 0]
+ det_match_flag = [0, 0]
+ gt_dont_care_index = []
+ # test invalid arguments.
+ with pytest.raises(AssertionError):
+ det_id_tmp = 1.0
+ utils.many2one_match_ic13(det_id_tmp, recall_mat, precision_mat,
+ recall_thr, precision_thr, gt_match_flag,
+ det_match_flag, gt_dont_care_index)
+ with pytest.raises(AssertionError):
+ recall_mat_tmp = [[1, 0], [0, 0]]
+ utils.many2one_match_ic13(det_id, recall_mat_tmp, precision_mat,
+ recall_thr, precision_thr, gt_match_flag,
+ det_match_flag, gt_dont_care_index)
+ with pytest.raises(AssertionError):
+ precision_mat_tmp = [[1, 0], [0, 0]]
+ utils.many2one_match_ic13(det_id, recall_mat, precision_mat_tmp,
+ recall_thr, precision_thr, gt_match_flag,
+ det_match_flag, gt_dont_care_index)
+ with pytest.raises(AssertionError):
+ recall_thr_tmp = 1.1
+ utils.many2one_match_ic13(det_id, recall_mat, precision_mat,
+ recall_thr_tmp, precision_thr, gt_match_flag,
+ det_match_flag, gt_dont_care_index)
+ with pytest.raises(AssertionError):
+ precision_thr_tmp = 1.1
+ utils.many2one_match_ic13(det_id, recall_mat, precision_mat,
+ recall_thr, precision_thr_tmp, gt_match_flag,
+ det_match_flag, gt_dont_care_index)
+ with pytest.raises(AssertionError):
+ gt_match_flag_tmp = np.array([0, 1])
+ utils.many2one_match_ic13(det_id, recall_mat, precision_mat,
+ recall_thr, precision_thr, gt_match_flag_tmp,
+ det_match_flag, gt_dont_care_index)
+ with pytest.raises(AssertionError):
+ det_match_flag_tmp = np.array([0, 1])
+ utils.many2one_match_ic13(det_id, recall_mat, precision_mat,
+ recall_thr, precision_thr, gt_match_flag,
+ det_match_flag_tmp, gt_dont_care_index)
+ with pytest.raises(AssertionError):
+ gt_dont_care_index_tmp = np.array([0, 1])
+ utils.many2one_match_ic13(det_id, recall_mat, precision_mat,
+ recall_thr, precision_thr, gt_match_flag,
+ det_match_flag, gt_dont_care_index_tmp)
+
+ # test matched cases
+
+ result = utils.many2one_match_ic13(det_id, recall_mat, precision_mat,
+ recall_thr, precision_thr,
+ gt_match_flag, det_match_flag,
+ gt_dont_care_index)
+ assert result[0]
+ assert result[1] == [0]
+
+ # test unmatched cases
+
+ gt_dont_care_index = [0]
+
+ result = utils.many2one_match_ic13(det_id, recall_mat, precision_mat,
+ recall_thr, precision_thr,
+ gt_match_flag, det_match_flag,
+ gt_dont_care_index)
+ assert not result[0]
+ assert result[1] == []
diff --git a/tests/test_metrics/test_hmean_detect.py b/tests/test_metrics/test_hmean_detect.py
new file mode 100644
index 0000000000000000000000000000000000000000..18bcda1e985c37ce507582355dd5f592d2a31ee8
--- /dev/null
+++ b/tests/test_metrics/test_hmean_detect.py
@@ -0,0 +1,72 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import tempfile
+
+import numpy as np
+import pytest
+
+from mmocr.core.evaluation.hmean import (eval_hmean, get_gt_masks,
+ output_ranklist)
+
+
+def _create_dummy_ann_infos():
+ ann_infos = {
+ 'bboxes': np.array([[50., 70., 80., 100.]], dtype=np.float32),
+ 'labels': np.array([1], dtype=np.int64),
+ 'bboxes_ignore': np.array([[120, 140, 200, 200]], dtype=np.float32),
+ 'masks': [[[50, 70, 80, 70, 80, 100, 50, 100]]],
+ 'masks_ignore': [[[120, 140, 200, 140, 200, 200, 120, 200]]]
+ }
+ return [ann_infos]
+
+
+def test_output_ranklist():
+ result = [{'hmean': 1}, {'hmean': 0.5}]
+ file_name = tempfile.NamedTemporaryFile().name
+ img_infos = [{'file_name': 'sample1.jpg'}, {'file_name': 'sample2.jpg'}]
+
+ json_file = file_name + '.json'
+ with pytest.raises(AssertionError):
+ output_ranklist([[]], img_infos, json_file)
+ with pytest.raises(AssertionError):
+ output_ranklist(result, [[]], json_file)
+ with pytest.raises(AssertionError):
+ output_ranklist(result, img_infos, file_name)
+
+ sorted_outputs = output_ranklist(result, img_infos, json_file)
+
+ assert sorted_outputs[0]['hmean'] == 0.5
+
+
+def test_get_gt_mask():
+ ann_infos = _create_dummy_ann_infos()
+ gt_masks, gt_masks_ignore = get_gt_masks(ann_infos)
+
+ assert np.allclose(gt_masks[0], [[50, 70, 80, 70, 80, 100, 50, 100]])
+ assert np.allclose(gt_masks_ignore[0],
+ [[120, 140, 200, 140, 200, 200, 120, 200]])
+
+
+def test_eval_hmean():
+ metrics = set(['hmean-iou', 'hmean-ic13'])
+ results = [{
+ 'boundary_result': [[50, 70, 80, 70, 80, 100, 50, 100, 1],
+ [120, 140, 200, 140, 200, 200, 120, 200, 1]]
+ }]
+
+ img_infos = [{'file_name': 'sample1.jpg'}]
+ ann_infos = _create_dummy_ann_infos()
+
+ # test invalid arguments
+ with pytest.raises(AssertionError):
+ eval_hmean(results, [[]], ann_infos, metrics=metrics)
+ with pytest.raises(AssertionError):
+ eval_hmean(results, img_infos, [[]], metrics=metrics)
+ with pytest.raises(AssertionError):
+ eval_hmean([[]], img_infos, ann_infos, metrics=metrics)
+ with pytest.raises(AssertionError):
+ eval_hmean(results, img_infos, ann_infos, metrics='hmean-iou')
+
+ eval_results = eval_hmean(results, img_infos, ann_infos, metrics=metrics)
+
+ assert eval_results['hmean-iou:hmean'] == 1
+ assert eval_results['hmean-ic13:hmean'] == 1
diff --git a/tests/test_metrics/test_hmean_ic13.py b/tests/test_metrics/test_hmean_ic13.py
new file mode 100644
index 0000000000000000000000000000000000000000..ac02b38e67c1b0f28f96a93eececdb8225f2e802
--- /dev/null
+++ b/tests/test_metrics/test_hmean_ic13.py
@@ -0,0 +1,117 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""Test hmean_ic13."""
+import math
+
+import pytest
+
+import mmocr.core.evaluation.hmean_ic13 as hmean_ic13
+import mmocr.core.evaluation.utils as utils
+
+
+def test_compute_recall_precision():
+
+ gt_polys = []
+ det_polys = []
+
+ # test invalid arguments.
+ with pytest.raises(AssertionError):
+ hmean_ic13.compute_recall_precision(1, 1)
+
+ box1 = [0, 0, 1, 0, 1, 1, 0, 1]
+
+ box2 = [0, 0, 10, 0, 10, 1, 0, 1]
+
+ gt_polys = [utils.points2polygon(box1)]
+ det_polys = [utils.points2polygon(box2)]
+ recall, precision = hmean_ic13.compute_recall_precision(
+ gt_polys, det_polys)
+ assert recall == 1
+ assert precision == 0.1
+
+
+def test_eval_hmean_ic13():
+ det_boxes = []
+ gt_boxes = []
+ gt_ignored_boxes = []
+ precision_thr = 0.4
+ recall_thr = 0.8
+ center_dist_thr = 1.0
+ one2one_score = 1.
+ one2many_score = 0.8
+ many2one_score = 1
+ # test invalid arguments.
+
+ with pytest.raises(AssertionError):
+ hmean_ic13.eval_hmean_ic13([1], gt_boxes, gt_ignored_boxes,
+ precision_thr, recall_thr, center_dist_thr,
+ one2one_score, one2many_score,
+ many2one_score)
+
+ with pytest.raises(AssertionError):
+ hmean_ic13.eval_hmean_ic13(det_boxes, 1, gt_ignored_boxes,
+ precision_thr, recall_thr, center_dist_thr,
+ one2one_score, one2many_score,
+ many2one_score)
+ with pytest.raises(AssertionError):
+ hmean_ic13.eval_hmean_ic13(det_boxes, gt_boxes, 1, precision_thr,
+ recall_thr, center_dist_thr, one2one_score,
+ one2many_score, many2one_score)
+ with pytest.raises(AssertionError):
+ hmean_ic13.eval_hmean_ic13(det_boxes, gt_boxes, gt_ignored_boxes, 1.1,
+ recall_thr, center_dist_thr, one2one_score,
+ one2many_score, many2one_score)
+ with pytest.raises(AssertionError):
+ hmean_ic13.eval_hmean_ic13(det_boxes, gt_boxes, gt_ignored_boxes,
+ precision_thr, 1.1, center_dist_thr,
+ one2one_score, one2many_score,
+ many2one_score)
+ with pytest.raises(AssertionError):
+ hmean_ic13.eval_hmean_ic13(det_boxes, gt_boxes, gt_ignored_boxes,
+ precision_thr, recall_thr, -1,
+ one2one_score, one2many_score,
+ many2one_score)
+ with pytest.raises(AssertionError):
+ hmean_ic13.eval_hmean_ic13(det_boxes, gt_boxes, gt_ignored_boxes,
+ precision_thr, recall_thr, center_dist_thr,
+ -1, one2many_score, many2one_score)
+ with pytest.raises(AssertionError):
+ hmean_ic13.eval_hmean_ic13(det_boxes, gt_boxes, gt_ignored_boxes,
+ precision_thr, recall_thr, center_dist_thr,
+ one2one_score, -1, many2one_score)
+ with pytest.raises(AssertionError):
+ hmean_ic13.eval_hmean_ic13(det_boxes, gt_boxes, gt_ignored_boxes,
+ precision_thr, recall_thr, center_dist_thr,
+ one2one_score, one2many_score, -1)
+
+ # test one2one match
+ det_boxes = [[[0, 0, 1, 0, 1, 1, 0, 1], [10, 0, 11, 0, 11, 1, 10, 1]]]
+ gt_boxes = [[[0, 0, 1, 0, 1, 1, 0, 1]]]
+ gt_ignored_boxes = [[]]
+ dataset_result, img_result = hmean_ic13.eval_hmean_ic13(
+ det_boxes, gt_boxes, gt_ignored_boxes, precision_thr, recall_thr,
+ center_dist_thr, one2one_score, one2many_score, many2one_score)
+ assert img_result[0]['recall'] == 1
+ assert img_result[0]['precision'] == 0.5
+ assert math.isclose(img_result[0]['hmean'], 2 * (0.5) / 1.5)
+
+ # test one2many match
+ gt_boxes = [[[0, 0, 2, 0, 2, 1, 0, 1]]]
+ det_boxes = [[[0, 0, 1, 0, 1, 1, 0, 1], [1, 0, 2, 0, 2, 1, 1, 1]]]
+ dataset_result, img_result = hmean_ic13.eval_hmean_ic13(
+ det_boxes, gt_boxes, gt_ignored_boxes, precision_thr, recall_thr,
+ center_dist_thr, one2one_score, one2many_score, many2one_score)
+ assert img_result[0]['recall'] == 0.8
+ assert img_result[0]['precision'] == 1.6 / 2
+ assert math.isclose(img_result[0]['hmean'], 2 * (0.64) / 1.6)
+
+ # test many2one match
+ precision_thr = 0.6
+ recall_thr = 0.8
+ det_boxes = [[[0, 0, 2, 0, 2, 1, 0, 1]]]
+ gt_boxes = [[[0, 0, 1, 0, 1, 1, 0, 1], [1, 0, 2, 0, 2, 1, 1, 1]]]
+ dataset_result, img_result = hmean_ic13.eval_hmean_ic13(
+ det_boxes, gt_boxes, gt_ignored_boxes, precision_thr, recall_thr,
+ center_dist_thr, one2one_score, one2many_score, many2one_score)
+ assert img_result[0]['recall'] == 1
+ assert img_result[0]['precision'] == 1
+ assert math.isclose(img_result[0]['hmean'], 1)
diff --git a/tests/test_metrics/test_hmean_iou.py b/tests/test_metrics/test_hmean_iou.py
new file mode 100644
index 0000000000000000000000000000000000000000..6aa5eaa9a7406f4bf1087a445c088cae983ea606
--- /dev/null
+++ b/tests/test_metrics/test_hmean_iou.py
@@ -0,0 +1,41 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""Test hmean_iou."""
+import pytest
+
+import mmocr.core.evaluation.hmean_iou as hmean_iou
+
+
+def test_eval_hmean_iou():
+
+ pred_boxes = []
+ gt_boxes = []
+ gt_ignored_boxes = []
+ iou_thr = 0.5
+ precision_thr = 0.5
+
+ # test invalid arguments.
+
+ with pytest.raises(AssertionError):
+ hmean_iou.eval_hmean_iou([1], gt_boxes, gt_ignored_boxes, iou_thr,
+ precision_thr)
+ with pytest.raises(AssertionError):
+ hmean_iou.eval_hmean_iou(pred_boxes, [1], gt_ignored_boxes, iou_thr,
+ precision_thr)
+ with pytest.raises(AssertionError):
+ hmean_iou.eval_hmean_iou(pred_boxes, gt_boxes, [1], iou_thr,
+ precision_thr)
+ with pytest.raises(AssertionError):
+ hmean_iou.eval_hmean_iou(pred_boxes, gt_boxes, gt_ignored_boxes, 1.1,
+ precision_thr)
+ with pytest.raises(AssertionError):
+ hmean_iou.eval_hmean_iou(pred_boxes, gt_boxes, gt_ignored_boxes,
+ iou_thr, 1.1)
+
+ pred_boxes = [[[0, 0, 1, 0, 1, 1, 0, 1], [2, 0, 3, 0, 3, 1, 2, 1]]]
+ gt_boxes = [[[0, 0, 1, 0, 1, 1, 0, 1], [2, 0, 3, 0, 3, 1, 2, 1]]]
+ gt_ignored_boxes = [[]]
+ results = hmean_iou.eval_hmean_iou(pred_boxes, gt_boxes, gt_ignored_boxes,
+ iou_thr, precision_thr)
+ assert results[1][0]['recall'] == 1
+ assert results[1][0]['precision'] == 1
+ assert results[1][0]['hmean'] == 1
diff --git a/tests/test_models/test_detector.py b/tests/test_models/test_detector.py
new file mode 100644
index 0000000000000000000000000000000000000000..474cd8af100c1c53aea5c1a0ff8bb57389d4961e
--- /dev/null
+++ b/tests/test_models/test_detector.py
@@ -0,0 +1,517 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""pytest tests/test_detector.py."""
+import copy
+import tempfile
+from functools import partial
+from os.path import dirname, exists, join
+
+import numpy as np
+import pytest
+import torch
+
+from mmocr.utils import revert_sync_batchnorm
+
+
+def _demo_mm_inputs(num_kernels=0, input_shape=(1, 3, 300, 300),
+ num_items=None, num_classes=1): # yapf: disable
+ """Create a superset of inputs needed to run test or train batches.
+
+ Args:
+ input_shape (tuple): Input batch dimensions.
+
+ num_items (None | list[int]): Specifies the number of boxes
+ for each batch item.
+
+ num_classes (int): Number of distinct labels a box might have.
+ """
+ from mmdet.core import BitmapMasks
+
+ (N, C, H, W) = input_shape
+
+ rng = np.random.RandomState(0)
+
+ imgs = rng.rand(*input_shape)
+
+ img_metas = [{
+ 'img_shape': (H, W, C),
+ 'ori_shape': (H, W, C),
+ 'pad_shape': (H, W, C),
+ 'filename': '.png',
+ 'scale_factor': np.array([1, 1, 1, 1]),
+ 'flip': False,
+ } for _ in range(N)]
+
+ gt_bboxes = []
+ gt_labels = []
+ gt_masks = []
+ gt_kernels = []
+ gt_effective_mask = []
+
+ for batch_idx in range(N):
+ if num_items is None:
+ num_boxes = rng.randint(1, 10)
+ else:
+ num_boxes = num_items[batch_idx]
+
+ cx, cy, bw, bh = rng.rand(num_boxes, 4).T
+
+ tl_x = ((cx * W) - (W * bw / 2)).clip(0, W)
+ tl_y = ((cy * H) - (H * bh / 2)).clip(0, H)
+ br_x = ((cx * W) + (W * bw / 2)).clip(0, W)
+ br_y = ((cy * H) + (H * bh / 2)).clip(0, H)
+
+ boxes = np.vstack([tl_x, tl_y, br_x, br_y]).T
+ class_idxs = [0] * num_boxes
+
+ gt_bboxes.append(torch.FloatTensor(boxes))
+ gt_labels.append(torch.LongTensor(class_idxs))
+ kernels = []
+ for kernel_inx in range(num_kernels):
+ kernel = np.random.rand(H, W)
+ kernels.append(kernel)
+ gt_kernels.append(BitmapMasks(kernels, H, W))
+ gt_effective_mask.append(BitmapMasks([np.ones((H, W))], H, W))
+
+ mask = np.random.randint(0, 2, (len(boxes), H, W), dtype=np.uint8)
+ gt_masks.append(BitmapMasks(mask, H, W))
+
+ mm_inputs = {
+ 'imgs': torch.FloatTensor(imgs).requires_grad_(True),
+ 'img_metas': img_metas,
+ 'gt_bboxes': gt_bboxes,
+ 'gt_labels': gt_labels,
+ 'gt_bboxes_ignore': None,
+ 'gt_masks': gt_masks,
+ 'gt_kernels': gt_kernels,
+ 'gt_mask': gt_effective_mask,
+ 'gt_thr_mask': gt_effective_mask,
+ 'gt_text_mask': gt_effective_mask,
+ 'gt_center_region_mask': gt_effective_mask,
+ 'gt_radius_map': gt_kernels,
+ 'gt_sin_map': gt_kernels,
+ 'gt_cos_map': gt_kernels,
+ }
+ return mm_inputs
+
+
+def _get_config_directory():
+ """Find the predefined detector config directory."""
+ try:
+ # Assume we are running in the source mmocr repo
+ repo_dpath = dirname(dirname(dirname(__file__)))
+ except NameError:
+ # For IPython development when this __file__ is not defined
+ import mmocr
+ repo_dpath = dirname(dirname(mmocr.__file__))
+ config_dpath = join(repo_dpath, 'configs')
+ if not exists(config_dpath):
+ raise Exception('Cannot find config path')
+ return config_dpath
+
+
+def _get_config_module(fname):
+ """Load a configuration as a python module."""
+ from mmcv import Config
+ config_dpath = _get_config_directory()
+ config_fpath = join(config_dpath, fname)
+ config_mod = Config.fromfile(config_fpath)
+ return config_mod
+
+
+def _get_detector_cfg(fname):
+ """Grab configs necessary to create a detector.
+
+ These are deep copied to allow for safe modification of parameters without
+ influencing other tests.
+ """
+ config = _get_config_module(fname)
+ model = copy.deepcopy(config.model)
+ return model
+
+
+@pytest.mark.parametrize('cfg_file', [
+ 'textdet/maskrcnn/mask_rcnn_r50_fpn_160e_ctw1500.py',
+ 'textdet/maskrcnn/mask_rcnn_r50_fpn_160e_icdar2015.py',
+ 'textdet/maskrcnn/mask_rcnn_r50_fpn_160e_icdar2017.py'
+])
+def test_ocr_mask_rcnn(cfg_file):
+ model = _get_detector_cfg(cfg_file)
+ model['pretrained'] = None
+
+ from mmocr.models import build_detector
+ detector = build_detector(model)
+
+ input_shape = (1, 3, 224, 224)
+ mm_inputs = _demo_mm_inputs(0, input_shape)
+
+ imgs = mm_inputs.pop('imgs')
+ img_metas = mm_inputs.pop('img_metas')
+ gt_labels = mm_inputs.pop('gt_labels')
+ gt_masks = mm_inputs.pop('gt_masks')
+
+ # Test forward train
+ gt_bboxes = mm_inputs['gt_bboxes']
+ losses = detector.forward(
+ imgs,
+ img_metas,
+ gt_bboxes=gt_bboxes,
+ gt_labels=gt_labels,
+ gt_masks=gt_masks)
+ assert isinstance(losses, dict)
+
+ # Test forward test
+ with torch.no_grad():
+ img_list = [g[None, :] for g in imgs]
+ batch_results = []
+ for one_img, one_meta in zip(img_list, img_metas):
+ result = detector.forward([one_img], [[one_meta]],
+ return_loss=False)
+ batch_results.append(result)
+
+ # Test show_result
+
+ results = {'boundary_result': [[0, 0, 1, 0, 1, 1, 0, 1, 0.9]]}
+ img = np.random.rand(5, 5)
+ detector.show_result(img, results)
+
+
+@pytest.mark.parametrize('cfg_file', [
+ 'textdet/panet/panet_r18_fpem_ffm_600e_ctw1500.py',
+ 'textdet/panet/panet_r18_fpem_ffm_600e_icdar2015.py',
+ 'textdet/panet/panet_r50_fpem_ffm_600e_icdar2017.py'
+])
+def test_panet(cfg_file):
+ model = _get_detector_cfg(cfg_file)
+ model['pretrained'] = None
+
+ from mmocr.models import build_detector
+ detector = build_detector(model)
+ detector = revert_sync_batchnorm(detector)
+
+ input_shape = (1, 3, 224, 224)
+ num_kernels = 2
+ mm_inputs = _demo_mm_inputs(num_kernels, input_shape)
+
+ imgs = mm_inputs.pop('imgs')
+ img_metas = mm_inputs.pop('img_metas')
+ gt_kernels = mm_inputs.pop('gt_kernels')
+ gt_mask = mm_inputs.pop('gt_mask')
+
+ # Test forward train
+ losses = detector.forward(
+ imgs, img_metas, gt_kernels=gt_kernels, gt_mask=gt_mask)
+ assert isinstance(losses, dict)
+
+ # Test forward test
+ with torch.no_grad():
+ img_list = [g[None, :] for g in imgs]
+ batch_results = []
+ for one_img, one_meta in zip(img_list, img_metas):
+ result = detector.forward([one_img], [[one_meta]],
+ return_loss=False)
+ batch_results.append(result)
+
+ # Test onnx export
+ detector.forward = partial(
+ detector.simple_test, img_metas=img_metas, rescale=True)
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ onnx_path = f'{tmpdirname}/tmp.onnx'
+ torch.onnx.export(
+ detector, (img_list[0], ),
+ onnx_path,
+ input_names=['input'],
+ output_names=['output'],
+ export_params=True,
+ keep_initializers_as_inputs=False)
+
+ # Test show result
+ results = {'boundary_result': [[0, 0, 1, 0, 1, 1, 0, 1, 0.9]]}
+ img = np.random.rand(5, 5)
+ detector.show_result(img, results)
+
+
+@pytest.mark.parametrize('cfg_file', [
+ 'textdet/psenet/psenet_r50_fpnf_600e_icdar2015.py',
+ 'textdet/psenet/psenet_r50_fpnf_600e_icdar2017.py',
+ 'textdet/psenet/psenet_r50_fpnf_600e_ctw1500.py'
+])
+def test_psenet(cfg_file):
+ model = _get_detector_cfg(cfg_file)
+ model['pretrained'] = None
+
+ from mmocr.models import build_detector
+ detector = build_detector(model)
+ detector = revert_sync_batchnorm(detector)
+
+ input_shape = (1, 3, 224, 224)
+ num_kernels = 7
+ mm_inputs = _demo_mm_inputs(num_kernels, input_shape)
+
+ imgs = mm_inputs.pop('imgs')
+ img_metas = mm_inputs.pop('img_metas')
+ gt_kernels = mm_inputs.pop('gt_kernels')
+ gt_mask = mm_inputs.pop('gt_mask')
+
+ # Test forward train
+ losses = detector.forward(
+ imgs, img_metas, gt_kernels=gt_kernels, gt_mask=gt_mask)
+ assert isinstance(losses, dict)
+
+ # Test forward test
+ with torch.no_grad():
+ img_list = [g[None, :] for g in imgs]
+ batch_results = []
+ for one_img, one_meta in zip(img_list, img_metas):
+ result = detector.forward([one_img], [[one_meta]],
+ return_loss=False)
+ batch_results.append(result)
+
+ # Test show result
+ results = {'boundary_result': [[0, 0, 1, 0, 1, 1, 0, 1, 0.9]]}
+ img = np.random.rand(5, 5)
+ detector.show_result(img, results)
+
+
+@pytest.mark.skipif(not torch.cuda.is_available(), reason='requires cuda')
+@pytest.mark.parametrize('cfg_file', [
+ 'textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py',
+ 'textdet/dbnet/dbnet_r50dcnv2_fpnc_1200e_icdar2015.py'
+])
+def test_dbnet(cfg_file):
+ model = _get_detector_cfg(cfg_file)
+ model['pretrained'] = None
+
+ from mmocr.models import build_detector
+ detector = build_detector(model)
+ detector = revert_sync_batchnorm(detector)
+ detector = detector.cuda()
+ input_shape = (1, 3, 224, 224)
+ num_kernels = 7
+ mm_inputs = _demo_mm_inputs(num_kernels, input_shape)
+
+ imgs = mm_inputs.pop('imgs')
+ imgs = imgs.cuda()
+ img_metas = mm_inputs.pop('img_metas')
+ gt_shrink = mm_inputs.pop('gt_kernels')
+ gt_shrink_mask = mm_inputs.pop('gt_mask')
+ gt_thr = mm_inputs.pop('gt_masks')
+ gt_thr_mask = mm_inputs.pop('gt_thr_mask')
+
+ # Test forward train
+ losses = detector.forward(
+ imgs,
+ img_metas,
+ gt_shrink=gt_shrink,
+ gt_shrink_mask=gt_shrink_mask,
+ gt_thr=gt_thr,
+ gt_thr_mask=gt_thr_mask)
+ assert isinstance(losses, dict)
+
+ # Test forward test
+ with torch.no_grad():
+ img_list = [g[None, :] for g in imgs]
+ batch_results = []
+ for one_img, one_meta in zip(img_list, img_metas):
+ result = detector.forward([one_img], [[one_meta]],
+ return_loss=False)
+ batch_results.append(result)
+
+ # Test show result
+ results = {'boundary_result': [[0, 0, 1, 0, 1, 1, 0, 1, 0.9]]}
+ img = np.random.rand(5, 5)
+ detector.show_result(img, results)
+
+
+@pytest.mark.parametrize(
+ 'cfg_file',
+ ['textdet/textsnake/'
+ 'textsnake_r50_fpn_unet_1200e_ctw1500.py'])
+def test_textsnake(cfg_file):
+ model = _get_detector_cfg(cfg_file)
+ model['pretrained'] = None
+
+ from mmocr.models import build_detector
+ detector = build_detector(model)
+ detector = revert_sync_batchnorm(detector)
+ input_shape = (1, 3, 224, 224)
+ num_kernels = 1
+ mm_inputs = _demo_mm_inputs(num_kernels, input_shape)
+
+ imgs = mm_inputs.pop('imgs')
+ img_metas = mm_inputs.pop('img_metas')
+ gt_text_mask = mm_inputs.pop('gt_text_mask')
+ gt_center_region_mask = mm_inputs.pop('gt_center_region_mask')
+ gt_mask = mm_inputs.pop('gt_mask')
+ gt_radius_map = mm_inputs.pop('gt_radius_map')
+ gt_sin_map = mm_inputs.pop('gt_sin_map')
+ gt_cos_map = mm_inputs.pop('gt_cos_map')
+
+ # Test forward train
+ losses = detector.forward(
+ imgs,
+ img_metas,
+ gt_text_mask=gt_text_mask,
+ gt_center_region_mask=gt_center_region_mask,
+ gt_mask=gt_mask,
+ gt_radius_map=gt_radius_map,
+ gt_sin_map=gt_sin_map,
+ gt_cos_map=gt_cos_map)
+ assert isinstance(losses, dict)
+
+ # Test forward test get_boundary
+ maps = torch.zeros((1, 5, 224, 224), dtype=torch.float)
+ maps[:, 0:2, :, :] = -10.
+ maps[:, 0, 60:100, 12:212] = 10.
+ maps[:, 1, 70:90, 22:202] = 10.
+ maps[:, 2, 70:90, 22:202] = 0.
+ maps[:, 3, 70:90, 22:202] = 1.
+ maps[:, 4, 70:90, 22:202] = 10.
+
+ one_meta = img_metas[0]
+ result = detector.bbox_head.get_boundary(maps, [one_meta], False)
+ assert 'boundary_result' in result
+ assert 'filename' in result
+
+ # Test show result
+ results = {'boundary_result': [[0, 0, 1, 0, 1, 1, 0, 1, 0.9]]}
+ img = np.random.rand(5, 5)
+ detector.show_result(img, results)
+
+
+@pytest.mark.skipif(not torch.cuda.is_available(), reason='requires cuda')
+@pytest.mark.parametrize('cfg_file', [
+ 'textdet/fcenet/fcenet_r50dcnv2_fpn_1500e_ctw1500.py',
+ 'textdet/fcenet/fcenet_r50_fpn_1500e_icdar2015.py'
+])
+def test_fcenet(cfg_file):
+ model = _get_detector_cfg(cfg_file)
+ model['pretrained'] = None
+
+ from mmocr.models import build_detector
+ detector = build_detector(model)
+ detector = revert_sync_batchnorm(detector)
+ detector = detector.cuda()
+
+ fourier_degree = 5
+ input_shape = (1, 3, 256, 256)
+ (n, c, h, w) = input_shape
+
+ imgs = torch.randn(n, c, h, w).float().cuda()
+ img_metas = [{
+ 'img_shape': (h, w, c),
+ 'ori_shape': (h, w, c),
+ 'pad_shape': (h, w, c),
+ 'filename': '.png',
+ 'scale_factor': np.array([1, 1, 1, 1]),
+ 'flip': False,
+ } for _ in range(n)]
+
+ p3_maps = []
+ p4_maps = []
+ p5_maps = []
+ for _ in range(n):
+ p3_maps.append(
+ np.random.random((5 + 4 * fourier_degree, h // 8, w // 8)))
+ p4_maps.append(
+ np.random.random((5 + 4 * fourier_degree, h // 16, w // 16)))
+ p5_maps.append(
+ np.random.random((5 + 4 * fourier_degree, h // 32, w // 32)))
+
+ # Test forward train
+ losses = detector.forward(
+ imgs, img_metas, p3_maps=p3_maps, p4_maps=p4_maps, p5_maps=p5_maps)
+ assert isinstance(losses, dict)
+
+ # Test forward test
+ with torch.no_grad():
+ img_list = [g[None, :] for g in imgs]
+ batch_results = []
+ for one_img, one_meta in zip(img_list, img_metas):
+ result = detector.forward([one_img], [[one_meta]],
+ return_loss=False)
+ batch_results.append(result)
+
+ # Test show result
+ results = {'boundary_result': [[0, 0, 1, 0, 1, 1, 0, 1, 0.9]]}
+ img = np.random.rand(5, 5)
+ detector.show_result(img, results)
+
+
+@pytest.mark.parametrize(
+ 'cfg_file', ['textdet/drrg/'
+ 'drrg_r50_fpn_unet_1200e_ctw1500.py'])
+def test_drrg(cfg_file):
+ model = _get_detector_cfg(cfg_file)
+ model['pretrained'] = None
+
+ from mmocr.models import build_detector
+ detector = build_detector(model)
+ detector = revert_sync_batchnorm(detector)
+
+ input_shape = (1, 3, 224, 224)
+ num_kernels = 1
+ mm_inputs = _demo_mm_inputs(num_kernels, input_shape)
+
+ imgs = mm_inputs.pop('imgs')
+ img_metas = mm_inputs.pop('img_metas')
+ gt_text_mask = mm_inputs.pop('gt_text_mask')
+ gt_center_region_mask = mm_inputs.pop('gt_center_region_mask')
+ gt_mask = mm_inputs.pop('gt_mask')
+ gt_top_height_map = mm_inputs.pop('gt_radius_map')
+ gt_bot_height_map = gt_top_height_map.copy()
+ gt_sin_map = mm_inputs.pop('gt_sin_map')
+ gt_cos_map = mm_inputs.pop('gt_cos_map')
+ num_rois = 32
+ x = np.random.randint(4, 224, (num_rois, 1))
+ y = np.random.randint(4, 224, (num_rois, 1))
+ h = 4 * np.ones((num_rois, 1))
+ w = 4 * np.ones((num_rois, 1))
+ angle = (np.random.random_sample((num_rois, 1)) * 2 - 1) * np.pi / 2
+ cos, sin = np.cos(angle), np.sin(angle)
+ comp_labels = np.random.randint(1, 3, (num_rois, 1))
+ num_rois = num_rois * np.ones((num_rois, 1))
+ comp_attribs = np.hstack([num_rois, x, y, h, w, cos, sin, comp_labels])
+ gt_comp_attribs = np.expand_dims(comp_attribs.astype(np.float32), axis=0)
+
+ # Test forward train
+ losses = detector.forward(
+ imgs,
+ img_metas,
+ gt_text_mask=gt_text_mask,
+ gt_center_region_mask=gt_center_region_mask,
+ gt_mask=gt_mask,
+ gt_top_height_map=gt_top_height_map,
+ gt_bot_height_map=gt_bot_height_map,
+ gt_sin_map=gt_sin_map,
+ gt_cos_map=gt_cos_map,
+ gt_comp_attribs=gt_comp_attribs)
+ assert isinstance(losses, dict)
+
+ # Test forward test
+ model['bbox_head']['in_channels'] = 6
+ model['bbox_head']['text_region_thr'] = 0.8
+ model['bbox_head']['center_region_thr'] = 0.8
+ detector = build_detector(model)
+ maps = torch.zeros((1, 6, 224, 224), dtype=torch.float)
+ maps[:, 0:2, :, :] = -10.
+ maps[:, 0, 60:100, 50:170] = 10.
+ maps[:, 1, 75:85, 60:160] = 10.
+ maps[:, 2, 75:85, 60:160] = 0.
+ maps[:, 3, 75:85, 60:160] = 1.
+ maps[:, 4, 75:85, 60:160] = 10.
+ maps[:, 5, 75:85, 60:160] = 10.
+
+ with torch.no_grad():
+ full_pass_weight = torch.zeros((6, 6, 1, 1))
+ for i in range(6):
+ full_pass_weight[i, i, 0, 0] = 1
+ detector.bbox_head.out_conv.weight.data = full_pass_weight
+ detector.bbox_head.out_conv.bias.data.fill_(0.)
+ outs = detector.bbox_head.single_test(maps)
+ boundaries = detector.bbox_head.get_boundary(*outs, img_metas, True)
+ assert len(boundaries) == 1
+
+ # Test show result
+ results = {'boundary_result': [[0, 0, 1, 0, 1, 1, 0, 1, 0.9]]}
+ img = np.random.rand(5, 5)
+ detector.show_result(img, results)
diff --git a/tests/test_models/test_kie_config.py b/tests/test_models/test_kie_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..b2b1f351537a47bc8f89f1fc5684a76e311a6cfa
--- /dev/null
+++ b/tests/test_models/test_kie_config.py
@@ -0,0 +1,131 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from os.path import dirname, exists, join
+
+import numpy as np
+import pytest
+import torch
+
+
+def _demo_mm_inputs(num_kernels=0, input_shape=(1, 3, 300, 300),
+ num_items=None): # yapf: disable
+ """Create a superset of inputs needed to run test or train batches.
+
+ Args:
+ input_shape (tuple): Input batch dimensions.
+
+ num_items (None | list[int]): Specifies the number of boxes
+ for each batch item.
+ """
+
+ (N, C, H, W) = input_shape
+ rng = np.random.RandomState(0)
+ imgs = rng.rand(*input_shape)
+
+ img_metas = [{
+ 'img_shape': (H, W, C),
+ 'ori_shape': (H, W, C),
+ 'pad_shape': (H, W, C),
+ 'filename': '.png',
+ } for _ in range(N)]
+ relations = [torch.randn(10, 10, 5) for _ in range(N)]
+ texts = [torch.ones(10, 16) for _ in range(N)]
+ gt_bboxes = [torch.Tensor([[2, 2, 4, 4]]).expand(10, 4) for _ in range(N)]
+ gt_labels = [torch.ones(10, 11).long() for _ in range(N)]
+
+ mm_inputs = {
+ 'imgs': torch.FloatTensor(imgs).requires_grad_(True),
+ 'img_metas': img_metas,
+ 'relations': relations,
+ 'texts': texts,
+ 'gt_bboxes': gt_bboxes,
+ 'gt_labels': gt_labels
+ }
+ return mm_inputs
+
+
+def _get_config_directory():
+ """Find the predefined detector config directory."""
+ try:
+ # Assume we are running in the source mmocr repo
+ repo_dpath = dirname(dirname(dirname(__file__)))
+ except NameError:
+ # For IPython development when this __file__ is not defined
+ import mmocr
+ repo_dpath = dirname(dirname(mmocr.__file__))
+ config_dpath = join(repo_dpath, 'configs')
+ if not exists(config_dpath):
+ raise Exception('Cannot find config path')
+ return config_dpath
+
+
+def _get_config_module(fname):
+ """Load a configuration as a python module."""
+ from mmcv import Config
+ config_dpath = _get_config_directory()
+ config_fpath = join(config_dpath, fname)
+ config_mod = Config.fromfile(config_fpath)
+ return config_mod
+
+
+def _get_detector_cfg(fname):
+ """Grab configs necessary to create a detector.
+
+ These are deep copied to allow for safe modification of parameters without
+ influencing other tests.
+ """
+ config = _get_config_module(fname)
+ config.model.class_list = None
+ model = copy.deepcopy(config.model)
+ return model
+
+
+@pytest.mark.parametrize('cfg_file', [
+ 'kie/sdmgr/sdmgr_novisual_60e_wildreceipt.py',
+ 'kie/sdmgr/sdmgr_unet16_60e_wildreceipt.py'
+])
+def test_sdmgr_pipeline(cfg_file):
+ model = _get_detector_cfg(cfg_file)
+
+ from mmocr.models import build_detector
+ detector = build_detector(model)
+
+ input_shape = (1, 3, 128, 128)
+
+ mm_inputs = _demo_mm_inputs(0, input_shape)
+
+ imgs = mm_inputs.pop('imgs')
+ img_metas = mm_inputs.pop('img_metas')
+ relations = mm_inputs.pop('relations')
+ texts = mm_inputs.pop('texts')
+ gt_bboxes = mm_inputs.pop('gt_bboxes')
+ gt_labels = mm_inputs.pop('gt_labels')
+
+ # Test forward train
+ losses = detector.forward(
+ imgs,
+ img_metas,
+ relations=relations,
+ texts=texts,
+ gt_bboxes=gt_bboxes,
+ gt_labels=gt_labels)
+ assert isinstance(losses, dict)
+
+ # Test forward test
+ with torch.no_grad():
+ batch_results = []
+ for idx in range(len(img_metas)):
+ result = detector.forward(
+ imgs[idx:idx + 1],
+ None,
+ return_loss=False,
+ relations=[relations[idx]],
+ texts=[texts[idx]],
+ gt_bboxes=[gt_bboxes[idx]])
+ batch_results.append(result)
+
+ # Test show_result
+ results = {'nodes': torch.randn(1, 3)}
+ boxes = [[1, 1, 2, 1, 2, 2, 1, 2]]
+ img = np.random.rand(5, 5, 3)
+ detector.show_result(img, results, boxes)
diff --git a/tests/test_models/test_label_convertor/test_attn_label_convertor.py b/tests/test_models/test_label_convertor/test_attn_label_convertor.py
new file mode 100644
index 0000000000000000000000000000000000000000..62c53466a4c2a6c54a12d940df4a0afcd5b01a92
--- /dev/null
+++ b/tests/test_models/test_label_convertor/test_attn_label_convertor.py
@@ -0,0 +1,105 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import tempfile
+
+import numpy as np
+import pytest
+import torch
+
+from mmocr.models.textrecog.convertors import ABIConvertor, AttnConvertor
+
+
+def _create_dummy_dict_file(dict_file):
+ characters = list('helowrd')
+ with open(dict_file, 'w') as fw:
+ for char in characters:
+ fw.write(char + '\n')
+
+
+def test_attn_label_convertor():
+ tmp_dir = tempfile.TemporaryDirectory()
+ # create dummy data
+ dict_file = osp.join(tmp_dir.name, 'fake_dict.txt')
+ _create_dummy_dict_file(dict_file)
+
+ # test invalid arguments
+ with pytest.raises(AssertionError):
+ AttnConvertor(5)
+ with pytest.raises(AssertionError):
+ AttnConvertor('DICT90', dict_file, '1')
+ with pytest.raises(AssertionError):
+ AttnConvertor('DICT90', dict_file, True, '1')
+
+ label_convertor = AttnConvertor(dict_file=dict_file, max_seq_len=10)
+ # test init and parse_dict
+ assert label_convertor.num_classes() == 10
+ assert len(label_convertor.idx2char) == 10
+ assert label_convertor.idx2char[0] == 'h'
+ assert label_convertor.idx2char[1] == 'e'
+ assert label_convertor.idx2char[-3] == ''
+ assert label_convertor.char2idx['h'] == 0
+ assert label_convertor.unknown_idx == 7
+
+ # test encode str to tensor
+ strings = ['hell']
+ targets_dict = label_convertor.str2tensor(strings)
+ assert torch.allclose(targets_dict['targets'][0],
+ torch.LongTensor([0, 1, 2, 2]))
+ assert torch.allclose(targets_dict['padded_targets'][0],
+ torch.LongTensor([8, 0, 1, 2, 2, 8, 9, 9, 9, 9]))
+
+ # test decode output to index
+ dummy_output = torch.Tensor([[[100, 2, 3, 4, 5, 6, 7, 8, 9],
+ [1, 100, 3, 4, 5, 6, 7, 8, 9],
+ [1, 2, 100, 4, 5, 6, 7, 8, 9],
+ [1, 2, 100, 4, 5, 6, 7, 8, 9],
+ [1, 2, 3, 4, 5, 6, 7, 8, 100],
+ [1, 2, 3, 4, 5, 6, 7, 100, 9],
+ [1, 2, 3, 4, 5, 6, 7, 100, 9],
+ [1, 2, 3, 4, 5, 6, 7, 100, 9],
+ [1, 2, 3, 4, 5, 6, 7, 100, 9],
+ [1, 2, 3, 4, 5, 6, 7, 100, 9]]])
+ indexes, scores = label_convertor.tensor2idx(dummy_output)
+ assert np.allclose(indexes, [[0, 1, 2, 2]])
+
+ # test encode_str_label_to_index
+ with pytest.raises(AssertionError):
+ label_convertor.str2idx('hell')
+ tmp_indexes = label_convertor.str2idx(strings)
+ assert np.allclose(tmp_indexes, [[0, 1, 2, 2]])
+
+ # test decode_index to str_label
+ input_indexes = [[0, 1, 2, 2]]
+ with pytest.raises(AssertionError):
+ label_convertor.idx2str('hell')
+ output_strings = label_convertor.idx2str(input_indexes)
+ assert output_strings[0] == 'hell'
+
+ tmp_dir.cleanup()
+
+
+def test_abi_label_convertor():
+ tmp_dir = tempfile.TemporaryDirectory()
+ # create dummy data
+ dict_file = osp.join(tmp_dir.name, 'fake_dict.txt')
+ _create_dummy_dict_file(dict_file)
+
+ label_convertor = ABIConvertor(dict_file=dict_file, max_seq_len=10)
+
+ label_convertor.end_idx
+ # test encode str to tensor
+ strings = ['hell']
+ targets_dict = label_convertor.str2tensor(strings)
+ assert torch.allclose(targets_dict['targets'][0],
+ torch.LongTensor([0, 1, 2, 2, 8]))
+ assert torch.allclose(targets_dict['padded_targets'][0],
+ torch.LongTensor([8, 0, 1, 2, 2, 8, 9, 9, 9, 9]))
+
+ strings = ['hellhellhell']
+ targets_dict = label_convertor.str2tensor(strings)
+ assert torch.allclose(targets_dict['targets'][0],
+ torch.LongTensor([0, 1, 2, 2, 0, 1, 2, 2, 0, 8]))
+ assert torch.allclose(targets_dict['padded_targets'][0],
+ torch.LongTensor([8, 0, 1, 2, 2, 0, 1, 2, 2, 0]))
+
+ tmp_dir.cleanup()
diff --git a/tests/test_models/test_label_convertor/test_ctc_label_convertor.py b/tests/test_models/test_label_convertor/test_ctc_label_convertor.py
new file mode 100644
index 0000000000000000000000000000000000000000..df677e688f92f992587a0a7bb3a7ac53482c0f4f
--- /dev/null
+++ b/tests/test_models/test_label_convertor/test_ctc_label_convertor.py
@@ -0,0 +1,80 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import tempfile
+
+import numpy as np
+import pytest
+import torch
+
+from mmocr.models.textrecog.convertors import BaseConvertor, CTCConvertor
+
+
+def _create_dummy_dict_file(dict_file):
+ chars = list('helowrd')
+ with open(dict_file, 'w') as fw:
+ for char in chars:
+ fw.write(char + '\n')
+
+
+def test_ctc_label_convertor():
+ tmp_dir = tempfile.TemporaryDirectory()
+ # create dummy data
+ dict_file = osp.join(tmp_dir.name, 'fake_chars.txt')
+ _create_dummy_dict_file(dict_file)
+
+ # test invalid arguments
+ with pytest.raises(AssertionError):
+ CTCConvertor(5)
+
+ label_convertor = CTCConvertor(dict_file=dict_file, with_unknown=False)
+ # test init and parse_chars
+ assert label_convertor.num_classes() == 8
+ assert len(label_convertor.idx2char) == 8
+ assert label_convertor.idx2char[0] == ''
+ assert label_convertor.char2idx['h'] == 1
+ assert label_convertor.unknown_idx is None
+
+ # test encode str to tensor
+ strings = ['hell']
+ expect_tensor = torch.IntTensor([1, 2, 3, 3])
+ targets_dict = label_convertor.str2tensor(strings)
+ assert torch.allclose(targets_dict['targets'][0], expect_tensor)
+ assert torch.allclose(targets_dict['flatten_targets'], expect_tensor)
+ assert torch.allclose(targets_dict['target_lengths'], torch.IntTensor([4]))
+
+ # test decode output to index
+ dummy_output = torch.Tensor([[[1, 100, 3, 4, 5, 6, 7, 8],
+ [100, 2, 3, 4, 5, 6, 7, 8],
+ [1, 2, 100, 4, 5, 6, 7, 8],
+ [1, 2, 100, 4, 5, 6, 7, 8],
+ [100, 2, 3, 4, 5, 6, 7, 8],
+ [1, 2, 3, 100, 5, 6, 7, 8],
+ [100, 2, 3, 4, 5, 6, 7, 8],
+ [1, 2, 3, 100, 5, 6, 7, 8]]])
+ indexes, scores = label_convertor.tensor2idx(
+ dummy_output, img_metas=[{
+ 'valid_ratio': 1.0
+ }])
+ assert np.allclose(indexes, [[1, 2, 3, 3]])
+
+ # test encode_str_label_to_index
+ with pytest.raises(AssertionError):
+ label_convertor.str2idx('hell')
+ tmp_indexes = label_convertor.str2idx(strings)
+ assert np.allclose(tmp_indexes, [[1, 2, 3, 3]])
+
+ # test deocde_index_to_str_label
+ input_indexes = [[1, 2, 3, 3]]
+ with pytest.raises(AssertionError):
+ label_convertor.idx2str('hell')
+ output_strings = label_convertor.idx2str(input_indexes)
+ assert output_strings[0] == 'hell'
+
+ tmp_dir.cleanup()
+
+
+def test_base_label_convertor():
+ with pytest.raises(NotImplementedError):
+ label_convertor = BaseConvertor()
+ label_convertor.str2tensor(None)
+ label_convertor.tensor2idx(None)
diff --git a/tests/test_models/test_loss.py b/tests/test_models/test_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..edef12020ffe84ab941d0f06f145387daab98874
--- /dev/null
+++ b/tests/test_models/test_loss.py
@@ -0,0 +1,159 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import torch
+from mmdet.core import BitmapMasks
+
+import mmocr.models.textdet.losses as losses
+
+
+def test_panloss():
+ panloss = losses.PANLoss()
+
+ # test bitmasks2tensor
+ mask = [[1, 0, 1], [1, 1, 1], [0, 0, 1]]
+ target = [[1, 0, 1, 0, 0], [1, 1, 1, 0, 0], [0, 0, 1, 0, 0],
+ [0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]]
+ masks = [np.array(mask)]
+ bitmasks = BitmapMasks(masks, 3, 3)
+ target_sz = (6, 5)
+ results = panloss.bitmasks2tensor([bitmasks], target_sz)
+ assert len(results) == 1
+ assert torch.sum(torch.abs(results[0].float() -
+ torch.Tensor(target))).item() == 0
+
+
+def test_textsnakeloss():
+ textsnakeloss = losses.TextSnakeLoss()
+
+ # test balanced_bce_loss
+ pred = torch.tensor([[0, 1, 0], [1, 1, 1], [0, 1, 0]], dtype=torch.float)
+ target = torch.tensor([[0, 1, 0], [1, 0, 1], [0, 1, 0]], dtype=torch.long)
+ mask = torch.tensor([[0, 1, 0], [1, 0, 1], [0, 1, 0]], dtype=torch.long)
+ bce_loss = textsnakeloss.balanced_bce_loss(pred, target, mask).item()
+
+ assert np.allclose(bce_loss, 0)
+
+
+def test_fcenetloss():
+ k = 5
+ fcenetloss = losses.FCELoss(fourier_degree=k, num_sample=10)
+
+ input_shape = (1, 3, 64, 64)
+ (n, c, h, w) = input_shape
+
+ # test ohem
+ pred = torch.ones((200, 2), dtype=torch.float)
+ target = torch.ones(200, dtype=torch.long)
+ target[20:] = 0
+ mask = torch.ones(200, dtype=torch.long)
+
+ ohem_loss1 = fcenetloss.ohem(pred, target, mask)
+ ohem_loss2 = fcenetloss.ohem(pred, target, 1 - mask)
+ assert isinstance(ohem_loss1, torch.Tensor)
+ assert isinstance(ohem_loss2, torch.Tensor)
+
+ # test forward
+ preds = []
+ for i in range(n):
+ scale = 8 * 2**i
+ pred = []
+ pred.append(torch.rand(n, 4, h // scale, w // scale))
+ pred.append(torch.rand(n, 4 * k + 2, h // scale, w // scale))
+ preds.append(pred)
+
+ p3_maps = []
+ p4_maps = []
+ p5_maps = []
+ for _ in range(n):
+ p3_maps.append(np.random.random((5 + 4 * k, h // 8, w // 8)))
+ p4_maps.append(np.random.random((5 + 4 * k, h // 16, w // 16)))
+ p5_maps.append(np.random.random((5 + 4 * k, h // 32, w // 32)))
+
+ loss = fcenetloss(preds, 0, p3_maps, p4_maps, p5_maps)
+ assert isinstance(loss, dict)
+
+
+def test_drrgloss():
+ drrgloss = losses.DRRGLoss()
+ assert np.allclose(drrgloss.ohem_ratio, 3.0)
+
+ # test balance_bce_loss
+ pred = torch.tensor([[0, 1, 0], [1, 1, 1], [0, 1, 0]], dtype=torch.float)
+ target = torch.tensor([[0, 1, 0], [1, 0, 1], [0, 1, 0]], dtype=torch.long)
+ mask = torch.tensor([[0, 1, 0], [1, 0, 1], [0, 1, 0]], dtype=torch.long)
+ bce_loss = drrgloss.balance_bce_loss(pred, target, mask).item()
+ assert np.allclose(bce_loss, 0)
+
+ # test balance_bce_loss with positive_count equal to zero
+ pred = torch.ones((16, 16), dtype=torch.float)
+ target = torch.ones((16, 16), dtype=torch.long)
+ mask = torch.zeros((16, 16), dtype=torch.long)
+ bce_loss = drrgloss.balance_bce_loss(pred, target, mask).item()
+ assert np.allclose(bce_loss, 0)
+
+ # test gcn_loss
+ gcn_preds = torch.tensor([[0., 1.], [1., 0.]])
+ labels = torch.tensor([1, 0], dtype=torch.long)
+ gcn_loss = drrgloss.gcn_loss((gcn_preds, labels))
+ assert gcn_loss.item()
+
+ # test bitmasks2tensor
+ mask = [[1, 0, 1], [1, 1, 1], [0, 0, 1]]
+ target = [[1, 0, 1, 0, 0], [1, 1, 1, 0, 0], [0, 0, 1, 0, 0],
+ [0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]]
+ masks = [np.array(mask)]
+ bitmasks = BitmapMasks(masks, 3, 3)
+ target_sz = (6, 5)
+ results = drrgloss.bitmasks2tensor([bitmasks], target_sz)
+ assert len(results) == 1
+ assert torch.sum(torch.abs(results[0].float() -
+ torch.Tensor(target))).item() == 0
+
+ # test forward
+ target_maps = [BitmapMasks([np.random.randn(20, 20)], 20, 20)]
+ target_masks = [BitmapMasks([np.ones((20, 20))], 20, 20)]
+ gt_masks = [BitmapMasks([np.ones((20, 20))], 20, 20)]
+ preds = (torch.randn((1, 6, 20, 20)), (gcn_preds, labels))
+ loss_dict = drrgloss(preds, 1., target_masks, target_masks, gt_masks,
+ target_maps, target_maps, target_maps, target_maps)
+
+ assert isinstance(loss_dict, dict)
+ assert 'loss_text' in loss_dict.keys()
+ assert 'loss_center' in loss_dict.keys()
+ assert 'loss_height' in loss_dict.keys()
+ assert 'loss_sin' in loss_dict.keys()
+ assert 'loss_cos' in loss_dict.keys()
+ assert 'loss_gcn' in loss_dict.keys()
+
+ # test forward with downsample_ratio less than 1.
+ target_maps = [BitmapMasks([np.random.randn(40, 40)], 40, 40)]
+ target_masks = [BitmapMasks([np.ones((40, 40))], 40, 40)]
+ gt_masks = [BitmapMasks([np.ones((40, 40))], 40, 40)]
+ preds = (torch.randn((1, 6, 20, 20)), (gcn_preds, labels))
+ loss_dict = drrgloss(preds, 0.5, target_masks, target_masks, gt_masks,
+ target_maps, target_maps, target_maps, target_maps)
+
+ assert isinstance(loss_dict, dict)
+
+ # test forward with blank gt_mask.
+ target_maps = [BitmapMasks([np.random.randn(20, 20)], 20, 20)]
+ target_masks = [BitmapMasks([np.ones((20, 20))], 20, 20)]
+ gt_masks = [BitmapMasks([np.zeros((20, 20))], 20, 20)]
+ preds = (torch.randn((1, 6, 20, 20)), (gcn_preds, labels))
+ loss_dict = drrgloss(preds, 1., target_masks, target_masks, gt_masks,
+ target_maps, target_maps, target_maps, target_maps)
+
+ assert isinstance(loss_dict, dict)
+
+
+def test_dice_loss():
+ pred = torch.Tensor([[[-1000, -1000, -1000], [-1000, -1000, -1000],
+ [-1000, -1000, -1000]]])
+ target = torch.Tensor([[[0, 0, 0], [0, 0, 0], [0, 0, 0]]])
+ mask = torch.Tensor([[[1, 1, 1], [1, 1, 1], [1, 1, 1]]])
+
+ pan_loss = losses.PANLoss()
+
+ dice_loss = pan_loss.dice_loss_with_logits(pred, target, mask)
+
+ assert np.allclose(dice_loss.item(), 0)
diff --git a/tests/test_models/test_modules.py b/tests/test_models/test_modules.py
new file mode 100644
index 0000000000000000000000000000000000000000..9e19ea3b2b7b9f9f1429a0ebcc8705b699dbbceb
--- /dev/null
+++ b/tests/test_models/test_modules.py
@@ -0,0 +1,133 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import torch
+
+from mmocr.models.textdet.modules import GCN, LocalGraphs, ProposalLocalGraphs
+from mmocr.models.textdet.modules.utils import (feature_embedding,
+ normalize_adjacent_matrix)
+
+
+def test_local_graph_forward_train():
+ geo_feat_len = 24
+ pooling_h, pooling_w = pooling_out_size = (2, 2)
+ num_rois = 32
+
+ local_graph_generator = LocalGraphs((4, 4), 3, geo_feat_len, 1.0,
+ pooling_out_size, 0.5)
+
+ feature_maps = torch.randn((2, 3, 128, 128), dtype=torch.float)
+ x = np.random.randint(4, 124, (num_rois, 1))
+ y = np.random.randint(4, 124, (num_rois, 1))
+ h = 4 * np.ones((num_rois, 1))
+ w = 4 * np.ones((num_rois, 1))
+ angle = (np.random.random_sample((num_rois, 1)) * 2 - 1) * np.pi / 2
+ cos, sin = np.cos(angle), np.sin(angle)
+ comp_labels = np.random.randint(1, 3, (num_rois, 1))
+ num_rois = num_rois * np.ones((num_rois, 1))
+ comp_attribs = np.hstack([num_rois, x, y, h, w, cos, sin, comp_labels])
+ comp_attribs = comp_attribs.astype(np.float32)
+ comp_attribs_ = comp_attribs.copy()
+ comp_attribs = np.stack([comp_attribs, comp_attribs_])
+
+ (node_feats, adjacent_matrix, knn_inds,
+ linkage_labels) = local_graph_generator(feature_maps, comp_attribs)
+ feat_len = geo_feat_len + feature_maps.size()[1] * pooling_h * pooling_w
+
+ assert node_feats.dim() == adjacent_matrix.dim() == 3
+ assert node_feats.size()[-1] == feat_len
+ assert knn_inds.size()[-1] == 4
+ assert linkage_labels.size()[-1] == 4
+ assert (node_feats.size()[0] == adjacent_matrix.size()[0] ==
+ knn_inds.size()[0] == linkage_labels.size()[0])
+ assert (node_feats.size()[1] == adjacent_matrix.size()[1] ==
+ adjacent_matrix.size()[2])
+
+
+def test_local_graph_forward_test():
+ geo_feat_len = 24
+ pooling_h, pooling_w = pooling_out_size = (2, 2)
+
+ local_graph_generator = ProposalLocalGraphs(
+ (4, 4), 2, geo_feat_len, 1., pooling_out_size, 0.1, 3., 6., 1., 0.5,
+ 0.3, 0.5, 0.5, 2)
+
+ maps = torch.zeros((1, 6, 224, 224), dtype=torch.float)
+ maps[:, 0:2, :, :] = -10.
+ maps[:, 0, 60:100, 50:170] = 10.
+ maps[:, 1, 75:85, 60:160] = 10.
+ maps[:, 2, 75:85, 60:160] = 0.
+ maps[:, 3, 75:85, 60:160] = 1.
+ maps[:, 4, 75:85, 60:160] = 10.
+ maps[:, 5, 75:85, 60:160] = 10.
+ feature_maps = torch.randn((2, 6, 224, 224), dtype=torch.float)
+ feat_len = geo_feat_len + feature_maps.size()[1] * pooling_h * pooling_w
+
+ none_flag, graph_data = local_graph_generator(maps, feature_maps)
+ (node_feats, adjacent_matrices, knn_inds, local_graphs,
+ text_comps) = graph_data
+
+ assert none_flag is False
+ assert text_comps.ndim == 2
+ assert text_comps.shape[0] > 0
+ assert text_comps.shape[1] == 9
+ assert (node_feats.size()[0] == adjacent_matrices.size()[0] ==
+ knn_inds.size()[0] == local_graphs.size()[0] ==
+ text_comps.shape[0])
+ assert (node_feats.size()[1] == adjacent_matrices.size()[1] ==
+ adjacent_matrices.size()[2] == local_graphs.size()[1])
+ assert node_feats.size()[-1] == feat_len
+
+ # test proposal local graphs with area of center region less than threshold
+ maps[:, 1, 75:85, 60:160] = -10.
+ maps[:, 1, 80, 80] = 10.
+ none_flag, _ = local_graph_generator(maps, feature_maps)
+ assert none_flag
+
+ # test proposal local graphs with one text component
+ local_graph_generator = ProposalLocalGraphs(
+ (4, 4), 2, geo_feat_len, 1., pooling_out_size, 0.1, 8., 20., 1., 0.5,
+ 0.3, 0.5, 0.5, 2)
+ maps[:, 1, 78:82, 78:82] = 10.
+ none_flag, _ = local_graph_generator(maps, feature_maps)
+ assert none_flag
+
+ # test proposal local graphs with text components out of text region
+ maps[:, 0, 60:100, 50:170] = -10.
+ maps[:, 0, 78:82, 78:82] = 10.
+ none_flag, _ = local_graph_generator(maps, feature_maps)
+ assert none_flag
+
+
+def test_gcn():
+ num_local_graphs = 32
+ num_max_graph_nodes = 16
+ input_feat_len = 512
+ k = 8
+ gcn = GCN(input_feat_len)
+ node_feat = torch.randn(
+ (num_local_graphs, num_max_graph_nodes, input_feat_len))
+ adjacent_matrix = torch.rand(
+ (num_local_graphs, num_max_graph_nodes, num_max_graph_nodes))
+ knn_inds = torch.randint(1, num_max_graph_nodes, (num_local_graphs, k))
+ output = gcn(node_feat, adjacent_matrix, knn_inds)
+ assert output.size() == (num_local_graphs * k, 2)
+
+
+def test_normalize_adjacent_matrix():
+ adjacent_matrix = np.random.randint(0, 2, (16, 16))
+ normalized_matrix = normalize_adjacent_matrix(adjacent_matrix)
+ assert normalized_matrix.shape == adjacent_matrix.shape
+
+
+def test_feature_embedding():
+ out_feat_len = 48
+
+ # test without residue dimensions
+ feats = np.random.randn(10, 8)
+ embed_feats = feature_embedding(feats, out_feat_len)
+ assert embed_feats.shape == (10, out_feat_len)
+
+ # test with residue dimensions
+ feats = np.random.randn(10, 9)
+ embed_feats = feature_embedding(feats, out_feat_len)
+ assert embed_feats.shape == (10, out_feat_len)
diff --git a/tests/test_models/test_ner_model.py b/tests/test_models/test_ner_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..1fa68c9f69ddf5ccb660d3616fe93d9c08e39253
--- /dev/null
+++ b/tests/test_models/test_ner_model.py
@@ -0,0 +1,78 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import os.path as osp
+import tempfile
+
+import pytest
+import torch
+
+from mmocr.models import build_detector
+
+
+def _create_dummy_vocab_file(vocab_file):
+ with open(vocab_file, 'w') as fw:
+ for char in list(map(chr, range(ord('a'), ord('z') + 1))):
+ fw.write(char + '\n')
+
+
+def _get_config_module(fname):
+ """Load a configuration as a python module."""
+ from mmcv import Config
+ config_mod = Config.fromfile(fname)
+ return config_mod
+
+
+def _get_detector_cfg(fname):
+ """Grab configs necessary to create a detector.
+
+ These are deep copied to allow for safe modification of parameters without
+ influencing other tests.
+ """
+ config = _get_config_module(fname)
+ model = copy.deepcopy(config.model)
+ return model
+
+
+@pytest.mark.parametrize(
+ 'cfg_file', ['configs/ner/bert_softmax/bert_softmax_cluener_18e.py'])
+def test_bert_softmax(cfg_file):
+ # prepare data
+ texts = ['中'] * 47
+ img = [31] * 47
+ labels = [31] * 128
+ input_ids = [0] * 128
+ attention_mask = [0] * 128
+ token_type_ids = [0] * 128
+ img_metas = {
+ 'texts': texts,
+ 'labels': torch.tensor(labels).unsqueeze(0),
+ 'img': img,
+ 'input_ids': torch.tensor(input_ids).unsqueeze(0),
+ 'attention_masks': torch.tensor(attention_mask).unsqueeze(0),
+ 'token_type_ids': torch.tensor(token_type_ids).unsqueeze(0)
+ }
+
+ # create dummy data
+ tmp_dir = tempfile.TemporaryDirectory()
+ vocab_file = osp.join(tmp_dir.name, 'fake_vocab.txt')
+ _create_dummy_vocab_file(vocab_file)
+
+ model = _get_detector_cfg(cfg_file)
+ model['label_convertor']['vocab_file'] = vocab_file
+
+ detector = build_detector(model)
+ losses = detector.forward(img, img_metas)
+ assert isinstance(losses, dict)
+
+ model['loss']['type'] = 'MaskedFocalLoss'
+ detector = build_detector(model)
+ losses = detector.forward(img, img_metas)
+ assert isinstance(losses, dict)
+
+ tmp_dir.cleanup()
+
+ # Test forward test
+ with torch.no_grad():
+ batch_results = []
+ result = detector.forward(None, img_metas, return_loss=False)
+ batch_results.append(result)
diff --git a/tests/test_models/test_ocr_backbone.py b/tests/test_models/test_ocr_backbone.py
new file mode 100644
index 0000000000000000000000000000000000000000..7fc3a2b9b92ffacfd4626f62150915b04c3b3020
--- /dev/null
+++ b/tests/test_models/test_ocr_backbone.py
@@ -0,0 +1,125 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmocr.models.textrecog.backbones import (ResNet, ResNet31OCR, ResNetABI,
+ ShallowCNN, VeryDeepVgg)
+
+
+def test_resnet31_ocr_backbone():
+ """Test resnet backbone."""
+ with pytest.raises(AssertionError):
+ ResNet31OCR(2.5)
+
+ with pytest.raises(AssertionError):
+ ResNet31OCR(3, layers=5)
+
+ with pytest.raises(AssertionError):
+ ResNet31OCR(3, channels=5)
+
+ # Test ResNet18 forward
+ model = ResNet31OCR()
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 32, 160)
+ feat = model(imgs)
+ assert feat.shape == torch.Size([1, 512, 4, 40])
+
+
+def test_vgg_deep_vgg_ocr_backbone():
+
+ model = VeryDeepVgg()
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 3, 32, 160)
+ feats = model(imgs)
+ assert feats.shape == torch.Size([1, 512, 1, 41])
+
+
+def test_shallow_cnn_ocr_backbone():
+
+ model = ShallowCNN()
+ model.init_weights()
+ model.train()
+
+ imgs = torch.randn(1, 1, 32, 100)
+ feat = model(imgs)
+ assert feat.shape == torch.Size([1, 512, 8, 25])
+
+
+def test_resnet_abi():
+ """Test resnet backbone."""
+ with pytest.raises(AssertionError):
+ ResNetABI(2.5)
+
+ with pytest.raises(AssertionError):
+ ResNetABI(3, arch_settings=5)
+
+ with pytest.raises(AssertionError):
+ ResNetABI(3, stem_channels=None)
+
+ with pytest.raises(AssertionError):
+ ResNetABI(arch_settings=[3, 4, 6, 6], strides=[1, 2, 1, 2, 1])
+
+ # Test forwarding
+ model = ResNetABI()
+ model.train()
+
+ imgs = torch.randn(1, 3, 32, 160)
+ feat = model(imgs)
+ assert feat.shape == torch.Size([1, 512, 8, 40])
+
+
+def test_resnet():
+ """Test all ResNet backbones."""
+
+ resnet45_aster = ResNet(
+ in_channels=3,
+ stem_channels=[64, 128],
+ block_cfgs=dict(type='BasicBlock', use_conv1x1='True'),
+ arch_layers=[3, 4, 6, 6, 3],
+ arch_channels=[32, 64, 128, 256, 512],
+ strides=[(2, 2), (2, 2), (2, 1), (2, 1), (2, 1)])
+
+ resnet45_abi = ResNet(
+ in_channels=3,
+ stem_channels=32,
+ block_cfgs=dict(type='BasicBlock', use_conv1x1='True'),
+ arch_layers=[3, 4, 6, 6, 3],
+ arch_channels=[32, 64, 128, 256, 512],
+ strides=[2, 1, 2, 1, 1])
+
+ resnet_31 = ResNet(
+ in_channels=3,
+ stem_channels=[64, 128],
+ block_cfgs=dict(type='BasicBlock'),
+ arch_layers=[1, 2, 5, 3],
+ arch_channels=[256, 256, 512, 512],
+ strides=[1, 1, 1, 1],
+ plugins=[
+ dict(
+ cfg=dict(type='Maxpool2d', kernel_size=2, stride=(2, 2)),
+ stages=(True, True, False, False),
+ position='before_stage'),
+ dict(
+ cfg=dict(type='Maxpool2d', kernel_size=(2, 1), stride=(2, 1)),
+ stages=(False, False, True, False),
+ position='before_stage'),
+ dict(
+ cfg=dict(
+ type='ConvModule',
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='ReLU')),
+ stages=(True, True, True, True),
+ position='after_stage')
+ ])
+ img = torch.rand(1, 3, 32, 100)
+
+ assert resnet45_aster(img).shape == torch.Size([1, 512, 1, 25])
+ assert resnet45_abi(img).shape == torch.Size([1, 512, 8, 25])
+ assert resnet_31(img).shape == torch.Size([1, 512, 4, 25])
diff --git a/tests/test_models/test_ocr_decoder.py b/tests/test_models/test_ocr_decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..c8aad4b96d1e3c8750e03310d682230379979105
--- /dev/null
+++ b/tests/test_models/test_ocr_decoder.py
@@ -0,0 +1,134 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+
+import pytest
+import torch
+
+from mmocr.models.textrecog.decoders import (ABILanguageDecoder,
+ ABIVisionDecoder, BaseDecoder,
+ NRTRDecoder, ParallelSARDecoder,
+ ParallelSARDecoderWithBS,
+ SequentialSARDecoder)
+from mmocr.models.textrecog.decoders.sar_decoder_with_bs import DecodeNode
+
+
+def _create_dummy_input():
+ feat = torch.rand(1, 512, 4, 40)
+ out_enc = torch.rand(1, 512)
+ tgt_dict = {'padded_targets': torch.LongTensor([[1, 1, 1, 1, 36]])}
+ img_metas = [{'valid_ratio': 1.0}]
+
+ return feat, out_enc, tgt_dict, img_metas
+
+
+def test_base_decoder():
+ decoder = BaseDecoder()
+ with pytest.raises(NotImplementedError):
+ decoder.forward_train(None, None, None, None)
+ with pytest.raises(NotImplementedError):
+ decoder.forward_test(None, None, None)
+
+
+def test_parallel_sar_decoder():
+ # test parallel sar decoder
+ decoder = ParallelSARDecoder(num_classes=37, padding_idx=36, max_seq_len=5)
+ decoder.init_weights()
+ decoder.train()
+
+ feat, out_enc, tgt_dict, img_metas = _create_dummy_input()
+ with pytest.raises(AssertionError):
+ decoder(feat, out_enc, tgt_dict, [], True)
+ with pytest.raises(AssertionError):
+ decoder(feat, out_enc, tgt_dict, img_metas * 2, True)
+
+ out_train = decoder(feat, out_enc, tgt_dict, img_metas, True)
+ assert out_train.shape == torch.Size([1, 5, 36])
+
+ out_test = decoder(feat, out_enc, tgt_dict, img_metas, False)
+ assert out_test.shape == torch.Size([1, 5, 36])
+
+
+def test_sequential_sar_decoder():
+ # test parallel sar decoder
+ decoder = SequentialSARDecoder(
+ num_classes=37, padding_idx=36, max_seq_len=5)
+ decoder.init_weights()
+ decoder.train()
+
+ feat, out_enc, tgt_dict, img_metas = _create_dummy_input()
+ with pytest.raises(AssertionError):
+ decoder(feat, out_enc, tgt_dict, [])
+ with pytest.raises(AssertionError):
+ decoder(feat, out_enc, tgt_dict, img_metas * 2)
+
+ out_train = decoder(feat, out_enc, tgt_dict, img_metas, True)
+ assert out_train.shape == torch.Size([1, 5, 36])
+
+ out_test = decoder(feat, out_enc, tgt_dict, img_metas, False)
+ assert out_test.shape == torch.Size([1, 5, 36])
+
+
+def test_parallel_sar_decoder_with_beam_search():
+ with pytest.raises(AssertionError):
+ ParallelSARDecoderWithBS(beam_width='beam')
+ with pytest.raises(AssertionError):
+ ParallelSARDecoderWithBS(beam_width=0)
+
+ feat, out_enc, tgt_dict, img_metas = _create_dummy_input()
+ decoder = ParallelSARDecoderWithBS(
+ beam_width=1, num_classes=37, padding_idx=36, max_seq_len=5)
+ decoder.init_weights()
+ decoder.train()
+ with pytest.raises(AssertionError):
+ decoder(feat, out_enc, tgt_dict, [])
+ with pytest.raises(AssertionError):
+ decoder(feat, out_enc, tgt_dict, img_metas * 2)
+
+ out_test = decoder(feat, out_enc, tgt_dict, img_metas, train_mode=False)
+ assert out_test.shape == torch.Size([1, 5, 36])
+
+ # test decodenode
+ with pytest.raises(AssertionError):
+ DecodeNode(1, 1)
+ with pytest.raises(AssertionError):
+ DecodeNode([1, 2], ['4', '3'])
+ with pytest.raises(AssertionError):
+ DecodeNode([1, 2], [0.5])
+ decode_node = DecodeNode([1, 2], [0.7, 0.8])
+ assert math.isclose(decode_node.eval(), 1.5)
+
+
+def test_transformer_decoder():
+ decoder = NRTRDecoder(num_classes=37, padding_idx=36, max_seq_len=5)
+ decoder.init_weights()
+ decoder.train()
+
+ out_enc = torch.rand(1, 25, 512)
+ tgt_dict = {'padded_targets': torch.LongTensor([[1, 1, 1, 1, 36]])}
+ img_metas = [{'valid_ratio': 1.0}]
+ tgt_dict['padded_targets'] = tgt_dict['padded_targets']
+
+ out_train = decoder(None, out_enc, tgt_dict, img_metas, True)
+ assert out_train.shape == torch.Size([1, 5, 36])
+
+ out_test = decoder(None, out_enc, tgt_dict, img_metas, False)
+ assert out_test.shape == torch.Size([1, 5, 36])
+
+
+def test_abi_language_decoder():
+ decoder = ABILanguageDecoder(max_seq_len=25)
+ logits = torch.randn(2, 25, 90)
+ result = decoder(
+ feat=None, out_enc=logits, targets_dict=None, img_metas=None)
+ assert result['feature'].shape == torch.Size([2, 25, 512])
+ assert result['logits'].shape == torch.Size([2, 25, 90])
+
+
+def test_abi_vision_decoder():
+ model = ABIVisionDecoder(
+ in_channels=128, num_channels=16, max_seq_len=10, use_result=None)
+ x = torch.randn(2, 128, 8, 32)
+ result = model(x, None)
+ assert result['feature'].shape == torch.Size([2, 10, 128])
+ assert result['logits'].shape == torch.Size([2, 10, 90])
+ assert result['attn_scores'].shape == torch.Size([2, 10, 8, 32])
diff --git a/tests/test_models/test_ocr_encoder.py b/tests/test_models/test_ocr_encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..2b0aef7045db5f12fe0cd4fbe691baa0458b89ce
--- /dev/null
+++ b/tests/test_models/test_ocr_encoder.py
@@ -0,0 +1,81 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmocr.models.textrecog.encoders import (ABIVisionModel, BaseEncoder,
+ NRTREncoder, SAREncoder,
+ SatrnEncoder, TransformerEncoder)
+
+
+def test_sar_encoder():
+ with pytest.raises(AssertionError):
+ SAREncoder(enc_bi_rnn='bi')
+ with pytest.raises(AssertionError):
+ SAREncoder(enc_do_rnn=2)
+ with pytest.raises(AssertionError):
+ SAREncoder(enc_gru='gru')
+ with pytest.raises(AssertionError):
+ SAREncoder(d_model=512.5)
+ with pytest.raises(AssertionError):
+ SAREncoder(d_enc=200.5)
+ with pytest.raises(AssertionError):
+ SAREncoder(mask='mask')
+
+ encoder = SAREncoder()
+ encoder.init_weights()
+ encoder.train()
+
+ feat = torch.randn(1, 512, 4, 40)
+ img_metas = [{'valid_ratio': 1.0}]
+ with pytest.raises(AssertionError):
+ encoder(feat, img_metas * 2)
+ out_enc = encoder(feat, img_metas)
+
+ assert out_enc.shape == torch.Size([1, 512])
+
+
+def test_nrtr_encoder():
+ tf_encoder = NRTREncoder()
+ tf_encoder.init_weights()
+ tf_encoder.train()
+
+ feat = torch.randn(1, 512, 1, 25)
+ out_enc = tf_encoder(feat)
+ print('hello', out_enc.size())
+ assert out_enc.shape == torch.Size([1, 25, 512])
+
+
+def test_satrn_encoder():
+ satrn_encoder = SatrnEncoder()
+ satrn_encoder.init_weights()
+ satrn_encoder.train()
+
+ feat = torch.randn(1, 512, 8, 25)
+ out_enc = satrn_encoder(feat)
+ assert out_enc.shape == torch.Size([1, 200, 512])
+
+
+def test_base_encoder():
+ encoder = BaseEncoder()
+ encoder.init_weights()
+ encoder.train()
+
+ feat = torch.randn(1, 256, 4, 40)
+ out_enc = encoder(feat)
+ assert out_enc.shape == torch.Size([1, 256, 4, 40])
+
+
+def test_transformer_encoder():
+ model = TransformerEncoder()
+ x = torch.randn(10, 512, 8, 32)
+ assert model(x).shape == torch.Size([10, 512, 8, 32])
+
+
+def test_abi_vision_model():
+ model = ABIVisionModel(
+ decoder=dict(type='ABIVisionDecoder', max_seq_len=10, use_result=None))
+ x = torch.randn(1, 512, 8, 32)
+ result = model(x)
+ assert result['feature'].shape == torch.Size([1, 10, 512])
+ assert result['logits'].shape == torch.Size([1, 10, 90])
+ assert result['attn_scores'].shape == torch.Size([1, 10, 8, 32])
diff --git a/tests/test_models/test_ocr_fuser.py b/tests/test_models/test_ocr_fuser.py
new file mode 100644
index 0000000000000000000000000000000000000000..8eaab7775416b0a4072d414c8656fa05868054b3
--- /dev/null
+++ b/tests/test_models/test_ocr_fuser.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmocr.models.textrecog.fusers import ABIFuser
+
+
+def test_base_alignment():
+ model = ABIFuser(d_model=512, num_chars=90, max_seq_len=40)
+ l_feat = torch.randn(1, 40, 512)
+ v_feat = torch.randn(1, 40, 512)
+ result = model(l_feat, v_feat)
+ assert result['logits'].shape == torch.Size([1, 40, 90])
diff --git a/tests/test_models/test_ocr_head.py b/tests/test_models/test_ocr_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..761bd1294d39bdaae9f4b4c79018278b6397df38
--- /dev/null
+++ b/tests/test_models/test_ocr_head.py
@@ -0,0 +1,17 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmocr.models.textrecog import SegHead
+
+
+def test_seg_head():
+ with pytest.raises(AssertionError):
+ SegHead(num_classes='100')
+ with pytest.raises(AssertionError):
+ SegHead(num_classes=-1)
+
+ seg_head = SegHead(num_classes=37)
+ out_neck = (torch.rand(1, 128, 32, 32), )
+ out_head = seg_head(out_neck)
+ assert out_head.shape == torch.Size([1, 37, 32, 32])
diff --git a/tests/test_models/test_ocr_layer.py b/tests/test_models/test_ocr_layer.py
new file mode 100644
index 0000000000000000000000000000000000000000..e4b4a39bad17db3c25e2dbfff10c6d00a2a6be6d
--- /dev/null
+++ b/tests/test_models/test_ocr_layer.py
@@ -0,0 +1,63 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmocr.models.common import (PositionalEncoding, TFDecoderLayer,
+ TFEncoderLayer)
+from mmocr.models.textrecog.layers import BasicBlock, Bottleneck
+from mmocr.models.textrecog.layers.conv_layer import conv3x3
+
+
+def test_conv_layer():
+ conv3by3 = conv3x3(3, 6)
+ assert conv3by3.in_channels == 3
+ assert conv3by3.out_channels == 6
+ assert conv3by3.kernel_size == (3, 3)
+
+ x = torch.rand(1, 64, 224, 224)
+ # test basic block
+ basic_block = BasicBlock(64, 64)
+ assert basic_block.expansion == 1
+
+ out = basic_block(x)
+
+ assert out.shape == torch.Size([1, 64, 224, 224])
+
+ # test bottle neck
+ bottle_neck = Bottleneck(64, 64, downsample=True)
+ assert bottle_neck.expansion == 4
+
+ out = bottle_neck(x)
+
+ assert out.shape == torch.Size([1, 256, 224, 224])
+
+
+def test_transformer_layer():
+ # test decoder_layer
+ decoder_layer = TFDecoderLayer()
+ in_dec = torch.rand(1, 30, 512)
+ out_enc = torch.rand(1, 128, 512)
+ out_dec = decoder_layer(in_dec, out_enc)
+ assert out_dec.shape == torch.Size([1, 30, 512])
+
+ decoder_layer = TFDecoderLayer(
+ operation_order=('self_attn', 'norm', 'enc_dec_attn', 'norm', 'ffn',
+ 'norm'))
+ out_dec = decoder_layer(in_dec, out_enc)
+ assert out_dec.shape == torch.Size([1, 30, 512])
+
+ # test positional_encoding
+ pos_encoder = PositionalEncoding()
+ x = torch.rand(1, 30, 512)
+ out = pos_encoder(x)
+ assert out.size() == x.size()
+
+ # test encoder_layer
+ encoder_layer = TFEncoderLayer()
+ in_enc = torch.rand(1, 20, 512)
+ out_enc = encoder_layer(in_enc)
+ assert out_dec.shape == torch.Size([1, 30, 512])
+
+ encoder_layer = TFEncoderLayer(
+ operation_order=('self_attn', 'norm', 'ffn', 'norm'))
+ out_enc = encoder_layer(in_enc)
+ assert out_dec.shape == torch.Size([1, 30, 512])
diff --git a/tests/test_models/test_ocr_loss.py b/tests/test_models/test_ocr_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..c88dd3239e5ff8bf06b6552a566ac9c296c322c1
--- /dev/null
+++ b/tests/test_models/test_ocr_loss.py
@@ -0,0 +1,133 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmocr.models.common.losses import DiceLoss
+from mmocr.models.textrecog.losses import (ABILoss, CELoss, CTCLoss, SARLoss,
+ TFLoss)
+
+
+def test_ctc_loss():
+ with pytest.raises(AssertionError):
+ CTCLoss(flatten='flatten')
+ with pytest.raises(AssertionError):
+ CTCLoss(blank=None)
+ with pytest.raises(AssertionError):
+ CTCLoss(reduction=1)
+ with pytest.raises(AssertionError):
+ CTCLoss(zero_infinity='zero')
+ # test CTCLoss
+ ctc_loss = CTCLoss()
+ outputs = torch.zeros(2, 40, 37)
+ targets_dict = {
+ 'flatten_targets': torch.IntTensor([1, 2, 3, 4, 5]),
+ 'target_lengths': torch.LongTensor([2, 3])
+ }
+
+ losses = ctc_loss(outputs, targets_dict)
+ assert isinstance(losses, dict)
+ assert 'loss_ctc' in losses
+ assert torch.allclose(losses['loss_ctc'],
+ torch.tensor(losses['loss_ctc'].item()).float())
+
+
+def test_ce_loss():
+ with pytest.raises(AssertionError):
+ CELoss(ignore_index='ignore')
+ with pytest.raises(AssertionError):
+ CELoss(reduction=1)
+ with pytest.raises(AssertionError):
+ CELoss(reduction='avg')
+
+ ce_loss = CELoss(ignore_index=0)
+ outputs = torch.rand(1, 10, 37)
+ targets_dict = {
+ 'padded_targets': torch.LongTensor([[1, 2, 3, 4, 0, 0, 0, 0, 0, 0]])
+ }
+ losses = ce_loss(outputs, targets_dict)
+ assert isinstance(losses, dict)
+ assert 'loss_ce' in losses
+ assert losses['loss_ce'].size(1) == 10
+
+ ce_loss = CELoss(ignore_first_char=True)
+ outputs = torch.rand(1, 10, 37)
+ targets_dict = {
+ 'padded_targets': torch.LongTensor([[1, 2, 3, 4, 0, 0, 0, 0, 0, 0]])
+ }
+ new_output, new_target = ce_loss.format(outputs, targets_dict)
+ assert new_output.shape == torch.Size([1, 37, 9])
+ assert new_target.shape == torch.Size([1, 9])
+
+
+def test_sar_loss():
+ outputs = torch.rand(1, 10, 37)
+ targets_dict = {
+ 'padded_targets': torch.LongTensor([[1, 2, 3, 4, 0, 0, 0, 0, 0, 0]])
+ }
+ sar_loss = SARLoss()
+ new_output, new_target = sar_loss.format(outputs, targets_dict)
+ assert new_output.shape == torch.Size([1, 37, 9])
+ assert new_target.shape == torch.Size([1, 9])
+
+
+def test_tf_loss():
+ with pytest.raises(AssertionError):
+ TFLoss(flatten=1.0)
+
+ outputs = torch.rand(1, 10, 37)
+ targets_dict = {
+ 'padded_targets': torch.LongTensor([[1, 2, 3, 4, 0, 0, 0, 0, 0, 0]])
+ }
+ tf_loss = TFLoss(flatten=False)
+ new_output, new_target = tf_loss.format(outputs, targets_dict)
+ assert new_output.shape == torch.Size([1, 37, 9])
+ assert new_target.shape == torch.Size([1, 9])
+
+
+def test_dice_loss():
+ with pytest.raises(AssertionError):
+ DiceLoss(eps='1')
+
+ dice_loss = DiceLoss()
+ pred = torch.rand(1, 1, 32, 32)
+ gt = torch.rand(1, 1, 32, 32)
+
+ loss = dice_loss(pred, gt, None)
+ assert isinstance(loss, torch.Tensor)
+
+ mask = torch.rand(1, 1, 1, 1)
+ loss = dice_loss(pred, gt, mask)
+ assert isinstance(loss, torch.Tensor)
+
+
+def test_abi_loss():
+ loss = ABILoss(num_classes=90)
+ outputs = dict(
+ out_enc=dict(logits=torch.randn(2, 10, 90)),
+ out_decs=[
+ dict(logits=torch.randn(2, 10, 90)),
+ dict(logits=torch.randn(2, 10, 90))
+ ],
+ out_fusers=[
+ dict(logits=torch.randn(2, 10, 90)),
+ dict(logits=torch.randn(2, 10, 90))
+ ])
+ targets_dict = {
+ 'padded_targets': torch.LongTensor([[1, 2, 3, 4, 0, 0, 0, 0, 0, 0]]),
+ 'targets':
+ [torch.LongTensor([1, 2, 3, 4]),
+ torch.LongTensor([1, 2, 3])]
+ }
+ result = loss(outputs, targets_dict)
+ assert isinstance(result, dict)
+ assert isinstance(result['loss_visual'], torch.Tensor)
+ assert isinstance(result['loss_lang'], torch.Tensor)
+ assert isinstance(result['loss_fusion'], torch.Tensor)
+
+ outputs.pop('out_enc')
+ loss(outputs, targets_dict)
+ outputs.pop('out_decs')
+ loss(outputs, targets_dict)
+ outputs.pop('out_fusers')
+ with pytest.raises(AssertionError):
+ loss(outputs, targets_dict)
diff --git a/tests/test_models/test_ocr_neck.py b/tests/test_models/test_ocr_neck.py
new file mode 100644
index 0000000000000000000000000000000000000000..3454eab362c56209553d8c1e4796a157b382a34b
--- /dev/null
+++ b/tests/test_models/test_ocr_neck.py
@@ -0,0 +1,18 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+
+from mmocr.models.textrecog.necks import FPNOCR
+
+
+def test_fpn_ocr():
+ in_s1 = torch.rand(1, 128, 32, 256)
+ in_s2 = torch.rand(1, 256, 16, 128)
+ in_s3 = torch.rand(1, 512, 8, 64)
+ in_s4 = torch.rand(1, 512, 4, 32)
+
+ fpn_ocr = FPNOCR(in_channels=[128, 256, 512, 512], out_channels=256)
+ fpn_ocr.init_weights()
+ fpn_ocr.train()
+
+ out_neck = fpn_ocr((in_s1, in_s2, in_s3, in_s4))
+ assert out_neck[0].shape == torch.Size([1, 256, 32, 256])
diff --git a/tests/test_models/test_ocr_preprocessor.py b/tests/test_models/test_ocr_preprocessor.py
new file mode 100644
index 0000000000000000000000000000000000000000..2a694e339138932842e5986738f6f34b0a93edcd
--- /dev/null
+++ b/tests/test_models/test_ocr_preprocessor.py
@@ -0,0 +1,39 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmocr.models.textrecog.preprocessor import (BasePreprocessor,
+ TPSPreprocessor)
+
+
+def test_tps_preprocessor():
+ with pytest.raises(AssertionError):
+ TPSPreprocessor(num_fiducial=-1)
+ with pytest.raises(AssertionError):
+ TPSPreprocessor(img_size=32)
+ with pytest.raises(AssertionError):
+ TPSPreprocessor(rectified_img_size=100)
+ with pytest.raises(AssertionError):
+ TPSPreprocessor(num_img_channel='bgr')
+
+ tps_preprocessor = TPSPreprocessor(
+ num_fiducial=20,
+ img_size=(32, 100),
+ rectified_img_size=(32, 100),
+ num_img_channel=1)
+ tps_preprocessor.init_weights()
+ tps_preprocessor.train()
+
+ batch_img = torch.randn(1, 1, 32, 100)
+ processed = tps_preprocessor(batch_img)
+ assert processed.shape == torch.Size([1, 1, 32, 100])
+
+
+def test_base_preprocessor():
+ preprocessor = BasePreprocessor()
+ preprocessor.init_weights()
+ preprocessor.train()
+
+ batch_img = torch.randn(1, 1, 32, 100)
+ processed = preprocessor(batch_img)
+ assert processed.shape == torch.Size([1, 1, 32, 100])
diff --git a/tests/test_models/test_panhead.py b/tests/test_models/test_panhead.py
new file mode 100644
index 0000000000000000000000000000000000000000..52635500ac717b5dc1cba3820538bee985bcbab0
--- /dev/null
+++ b/tests/test_models/test_panhead.py
@@ -0,0 +1,35 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import pytest
+
+import mmocr.models.textdet.dense_heads.pan_head as pan_head
+
+
+def test_panhead():
+ in_channels = [128]
+ out_channels = 128
+ text_repr_type = 'poly' # 'poly' or 'quad'
+ downsample_ratio = 0.25
+ loss = dict(type='PANLoss')
+
+ # test invalid arguments
+ with pytest.raises(AssertionError):
+ panheader = pan_head.PANHead(128, out_channels, downsample_ratio, loss)
+ with pytest.raises(AssertionError):
+ panheader = pan_head.PANHead(in_channels, [out_channels],
+ downsample_ratio, loss)
+ with pytest.raises(AssertionError):
+ panheader = pan_head.PANHead(in_channels, out_channels, text_repr_type,
+ 1.1, loss)
+
+ panheader = pan_head.PANHead(in_channels, out_channels, downsample_ratio,
+ loss)
+
+ # test resize_boundary
+ boundaries = [[0, 0, 0, 1, 1, 1, 0, 1, 0.9],
+ [0, 0, 0, 0.1, 0.1, 0.1, 0, 0.1, 0.9]]
+ target_boundary = [[0, 0, 0, 0.5, 1, 0.5, 0, 0.5, 0.9],
+ [0, 0, 0, 0.05, 0.1, 0.05, 0, 0.05, 0.9]]
+ scale_factor = np.array([1, 0.5, 1, 0.5])
+ resized_boundary = panheader.resize_boundary(boundaries, scale_factor)
+ assert np.allclose(resized_boundary, target_boundary)
diff --git a/tests/test_models/test_recog_config.py b/tests/test_models/test_recog_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..5084f4adf47026798ac3d0160b6bc730a3aee9a5
--- /dev/null
+++ b/tests/test_models/test_recog_config.py
@@ -0,0 +1,157 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from os.path import dirname, exists, join
+
+import numpy as np
+import pytest
+import torch
+
+
+def _demo_mm_inputs(num_kernels=0, input_shape=(1, 3, 300, 300),
+ num_items=None): # yapf: disable
+ """Create a superset of inputs needed to run test or train batches.
+
+ Args:
+ input_shape (tuple): Input batch dimensions.
+
+ num_items (None | list[int]): Specifies the number of boxes
+ for each batch item.
+ """
+
+ (N, C, H, W) = input_shape
+
+ rng = np.random.RandomState(0)
+
+ imgs = rng.rand(*input_shape)
+
+ img_metas = [{
+ 'img_shape': (H, W, C),
+ 'ori_shape': (H, W, C),
+ 'resize_shape': (H, W, C),
+ 'filename': '.png',
+ 'text': 'hello',
+ 'valid_ratio': 1.0,
+ } for _ in range(N)]
+
+ mm_inputs = {
+ 'imgs': torch.FloatTensor(imgs).requires_grad_(True),
+ 'img_metas': img_metas
+ }
+ return mm_inputs
+
+
+def _demo_gt_kernel_inputs(num_kernels=3, input_shape=(1, 3, 300, 300),
+ num_items=None): # yapf: disable
+ """Create a superset of inputs needed to run test or train batches.
+
+ Args:
+ input_shape (tuple): Input batch dimensions.
+
+ num_items (None | list[int]): Specifies the number of boxes
+ for each batch item.
+ """
+ from mmdet.core import BitmapMasks
+
+ (N, C, H, W) = input_shape
+ gt_kernels = []
+
+ for batch_idx in range(N):
+ kernels = []
+ for kernel_inx in range(num_kernels):
+ kernel = np.random.rand(H, W)
+ kernels.append(kernel)
+ gt_kernels.append(BitmapMasks(kernels, H, W))
+
+ return gt_kernels
+
+
+def _get_config_directory():
+ """Find the predefined detector config directory."""
+ try:
+ # Assume we are running in the source mmocr repo
+ repo_dpath = dirname(dirname(dirname(__file__)))
+ except NameError:
+ # For IPython development when this __file__ is not defined
+ import mmocr
+ repo_dpath = dirname(dirname(mmocr.__file__))
+ config_dpath = join(repo_dpath, 'configs')
+ if not exists(config_dpath):
+ raise Exception('Cannot find config path')
+ return config_dpath
+
+
+def _get_config_module(fname):
+ """Load a configuration as a python module."""
+ from mmcv import Config
+ config_dpath = _get_config_directory()
+ config_fpath = join(config_dpath, fname)
+ config_mod = Config.fromfile(config_fpath)
+ return config_mod
+
+
+def _get_detector_cfg(fname):
+ """Grab configs necessary to create a detector.
+
+ These are deep copied to allow for safe modification of parameters without
+ influencing other tests.
+ """
+ config = _get_config_module(fname)
+ model = copy.deepcopy(config.model)
+ return model
+
+
+@pytest.mark.parametrize('cfg_file', [
+ 'textrecog/sar/sar_r31_parallel_decoder_academic.py',
+ 'textrecog/sar/sar_r31_parallel_decoder_toy_dataset.py',
+ 'textrecog/sar/sar_r31_sequential_decoder_academic.py',
+ 'textrecog/crnn/crnn_toy_dataset.py',
+ 'textrecog/crnn/crnn_academic_dataset.py',
+ 'textrecog/nrtr/nrtr_r31_1by16_1by8_academic.py',
+ 'textrecog/nrtr/nrtr_modality_transform_academic.py',
+ 'textrecog/nrtr/nrtr_modality_transform_toy_dataset.py',
+ 'textrecog/nrtr/nrtr_r31_1by8_1by4_academic.py',
+ 'textrecog/robust_scanner/robustscanner_r31_academic.py',
+ 'textrecog/seg/seg_r31_1by16_fpnocr_academic.py',
+ 'textrecog/seg/seg_r31_1by16_fpnocr_toy_dataset.py',
+ 'textrecog/satrn/satrn_academic.py', 'textrecog/satrn/satrn_small.py',
+ 'textrecog/tps/crnn_tps_academic_dataset.py'
+])
+def test_recognizer_pipeline(cfg_file):
+ model = _get_detector_cfg(cfg_file)
+ model['pretrained'] = None
+
+ from mmocr.models import build_detector
+ detector = build_detector(model)
+
+ input_shape = (1, 3, 32, 160)
+ if 'crnn' in cfg_file:
+ input_shape = (1, 1, 32, 160)
+ mm_inputs = _demo_mm_inputs(0, input_shape)
+ gt_kernels = None
+ if 'seg' in cfg_file:
+ gt_kernels = _demo_gt_kernel_inputs(3, input_shape)
+
+ imgs = mm_inputs.pop('imgs')
+ img_metas = mm_inputs.pop('img_metas')
+
+ # Test forward train
+ if 'seg' in cfg_file:
+ losses = detector.forward(imgs, img_metas, gt_kernels=gt_kernels)
+ else:
+ losses = detector.forward(imgs, img_metas)
+ assert isinstance(losses, dict)
+
+ # Test forward test
+ with torch.no_grad():
+ img_list = [g[None, :] for g in imgs]
+ batch_results = []
+ for one_img, one_meta in zip(img_list, img_metas):
+ result = detector.forward([one_img], [[one_meta]],
+ return_loss=False)
+ batch_results.append(result)
+
+ # Test show_result
+
+ results = {'text': 'hello', 'score': 1.0}
+ img = np.random.rand(5, 5, 3)
+ detector.show_result(img, results)
diff --git a/tests/test_models/test_recognizer.py b/tests/test_models/test_recognizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..3813e7361adea2ba45f4edfa02ca59d53bb9847d
--- /dev/null
+++ b/tests/test_models/test_recognizer.py
@@ -0,0 +1,192 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import tempfile
+from functools import partial
+
+import numpy as np
+import pytest
+import torch
+from mmdet.core import BitmapMasks
+
+from mmocr.models.textrecog.recognizer import (EncodeDecodeRecognizer,
+ SegRecognizer)
+
+
+def _create_dummy_dict_file(dict_file):
+ chars = list('helowrd')
+ with open(dict_file, 'w') as fw:
+ for char in chars:
+ fw.write(char + '\n')
+
+
+def test_base_recognizer():
+ tmp_dir = tempfile.TemporaryDirectory()
+ # create dummy data
+ dict_file = osp.join(tmp_dir.name, 'fake_chars.txt')
+ _create_dummy_dict_file(dict_file)
+
+ label_convertor = dict(
+ type='CTCConvertor', dict_file=dict_file, with_unknown=False)
+
+ preprocessor = None
+ backbone = dict(type='VeryDeepVgg', leaky_relu=False)
+ encoder = None
+ decoder = dict(type='CRNNDecoder', in_channels=512, rnn_flag=True)
+ loss = dict(type='CTCLoss')
+
+ with pytest.raises(AssertionError):
+ EncodeDecodeRecognizer(backbone=None)
+ with pytest.raises(AssertionError):
+ EncodeDecodeRecognizer(decoder=None)
+ with pytest.raises(AssertionError):
+ EncodeDecodeRecognizer(loss=None)
+ with pytest.raises(AssertionError):
+ EncodeDecodeRecognizer(label_convertor=None)
+
+ recognizer = EncodeDecodeRecognizer(
+ preprocessor=preprocessor,
+ backbone=backbone,
+ encoder=encoder,
+ decoder=decoder,
+ loss=loss,
+ label_convertor=label_convertor)
+
+ recognizer.init_weights()
+ recognizer.train()
+
+ imgs = torch.rand(1, 3, 32, 160)
+
+ # test extract feat
+ feat = recognizer.extract_feat(imgs)
+ assert feat.shape == torch.Size([1, 512, 1, 41])
+
+ # test forward train
+ img_metas = [{
+ 'text': 'hello',
+ 'resize_shape': (32, 120, 3),
+ 'valid_ratio': 1.0
+ }]
+ losses = recognizer.forward_train(imgs, img_metas)
+ assert isinstance(losses, dict)
+ assert 'loss_ctc' in losses
+
+ # test simple test
+ results = recognizer.simple_test(imgs, img_metas)
+ assert isinstance(results, list)
+ assert isinstance(results[0], dict)
+ assert 'text' in results[0]
+ assert 'score' in results[0]
+
+ # test onnx export
+ recognizer.forward = partial(
+ recognizer.simple_test,
+ img_metas=img_metas,
+ return_loss=False,
+ rescale=True)
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ onnx_path = f'{tmpdirname}/tmp.onnx'
+ torch.onnx.export(
+ recognizer, (imgs, ),
+ onnx_path,
+ input_names=['input'],
+ output_names=['output'],
+ export_params=True,
+ keep_initializers_as_inputs=False)
+
+ # test aug_test
+ aug_results = recognizer.aug_test([imgs, imgs], [img_metas, img_metas])
+ assert isinstance(aug_results, list)
+ assert isinstance(aug_results[0], dict)
+ assert 'text' in aug_results[0]
+ assert 'score' in aug_results[0]
+
+ tmp_dir.cleanup()
+
+
+def test_seg_recognizer():
+ tmp_dir = tempfile.TemporaryDirectory()
+ # create dummy data
+ dict_file = osp.join(tmp_dir.name, 'fake_chars.txt')
+ _create_dummy_dict_file(dict_file)
+
+ label_convertor = dict(
+ type='SegConvertor', dict_file=dict_file, with_unknown=False)
+
+ preprocessor = None
+ backbone = dict(
+ type='ResNet31OCR',
+ layers=[1, 2, 5, 3],
+ channels=[32, 64, 128, 256, 512, 512],
+ out_indices=[0, 1, 2, 3],
+ stage4_pool_cfg=dict(kernel_size=2, stride=2),
+ last_stage_pool=True)
+ neck = dict(
+ type='FPNOCR', in_channels=[128, 256, 512, 512], out_channels=256)
+ head = dict(
+ type='SegHead',
+ in_channels=256,
+ upsample_param=dict(scale_factor=2.0, mode='nearest'))
+ loss = dict(type='SegLoss', seg_downsample_ratio=1.0)
+
+ with pytest.raises(AssertionError):
+ SegRecognizer(backbone=None)
+ with pytest.raises(AssertionError):
+ SegRecognizer(neck=None)
+ with pytest.raises(AssertionError):
+ SegRecognizer(head=None)
+ with pytest.raises(AssertionError):
+ SegRecognizer(loss=None)
+ with pytest.raises(AssertionError):
+ SegRecognizer(label_convertor=None)
+
+ recognizer = SegRecognizer(
+ preprocessor=preprocessor,
+ backbone=backbone,
+ neck=neck,
+ head=head,
+ loss=loss,
+ label_convertor=label_convertor)
+
+ recognizer.init_weights()
+ recognizer.train()
+
+ imgs = torch.rand(1, 3, 64, 256)
+
+ # test extract feat
+ feats = recognizer.extract_feat(imgs)
+ assert len(feats) == 4
+
+ assert feats[0].shape == torch.Size([1, 128, 32, 128])
+ assert feats[1].shape == torch.Size([1, 256, 16, 64])
+ assert feats[2].shape == torch.Size([1, 512, 8, 32])
+ assert feats[3].shape == torch.Size([1, 512, 4, 16])
+
+ attn_tgt = np.zeros((64, 256), dtype=np.float32)
+ segm_tgt = np.zeros((64, 256), dtype=np.float32)
+ mask = np.zeros((64, 256), dtype=np.float32)
+ gt_kernels = BitmapMasks([attn_tgt, segm_tgt, mask], 64, 256)
+
+ # test forward train
+ img_metas = [{
+ 'text': 'hello',
+ 'resize_shape': (64, 256, 3),
+ 'valid_ratio': 1.0
+ }]
+ losses = recognizer.forward_train(imgs, img_metas, gt_kernels=[gt_kernels])
+ assert isinstance(losses, dict)
+
+ # test simple test
+ results = recognizer.simple_test(imgs, img_metas)
+ assert isinstance(results, list)
+ assert isinstance(results[0], dict)
+ assert 'text' in results[0]
+ assert 'score' in results[0]
+
+ # test aug_test
+ aug_results = recognizer.aug_test([imgs, imgs], [img_metas, img_metas])
+ assert isinstance(aug_results, list)
+ assert isinstance(aug_results[0], dict)
+ assert 'text' in aug_results[0]
+ assert 'score' in aug_results[0]
+
+ tmp_dir.cleanup()
diff --git a/tests/test_models/test_targets.py b/tests/test_models/test_targets.py
new file mode 100644
index 0000000000000000000000000000000000000000..6030a2563f5b4638b7efd0a595daa5a6edbd0889
--- /dev/null
+++ b/tests/test_models/test_targets.py
@@ -0,0 +1,33 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+
+from mmocr.datasets.pipelines.textdet_targets.dbnet_targets import DBNetTargets
+
+
+def test_invalid_polys():
+
+ dbtarget = DBNetTargets()
+
+ poly = np.array([[256.1229216, 347.17471155], [257.63126133, 347.0069367],
+ [257.70317729, 347.65337423],
+ [256.19488113, 347.82114909]])
+
+ assert dbtarget.invalid_polygon(poly)
+
+ poly = np.array([[570.34735492,
+ 335.00214526], [570.99778839, 335.00327318],
+ [569.69077318, 338.47009908],
+ [569.04038393, 338.46894904]])
+ assert dbtarget.invalid_polygon(poly)
+
+ poly = np.array([[481.18343777,
+ 305.03190065], [479.88478587, 305.10684512],
+ [479.90976971, 305.53968843], [480.99197962,
+ 305.4772347]])
+ assert dbtarget.invalid_polygon(poly)
+
+ poly = np.array([[0, 0], [2, 0], [2, 2], [0, 2]])
+ assert dbtarget.invalid_polygon(poly)
+
+ poly = np.array([[0, 0], [10, 0], [10, 10], [0, 10]])
+ assert not dbtarget.invalid_polygon(poly)
diff --git a/tests/test_models/test_textdet_head.py b/tests/test_models/test_textdet_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..6723f5e5002c25f697e5e26cf7f5fbfba2a3a6d9
--- /dev/null
+++ b/tests/test_models/test_textdet_head.py
@@ -0,0 +1,82 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import torch
+
+from mmocr.models.textdet.dense_heads import DRRGHead
+
+
+def test_drrg_head():
+ in_channels = 10
+ drrg_head = DRRGHead(in_channels)
+ assert drrg_head.in_channels == in_channels
+ assert drrg_head.k_at_hops == (8, 4)
+ assert drrg_head.num_adjacent_linkages == 3
+ assert drrg_head.node_geo_feat_len == 120
+ assert np.allclose(drrg_head.pooling_scale, 1.0)
+ assert drrg_head.pooling_output_size == (4, 3)
+ assert np.allclose(drrg_head.nms_thr, 0.3)
+ assert np.allclose(drrg_head.min_width, 8.0)
+ assert np.allclose(drrg_head.max_width, 24.0)
+ assert np.allclose(drrg_head.comp_shrink_ratio, 1.03)
+ assert np.allclose(drrg_head.comp_ratio, 0.4)
+ assert np.allclose(drrg_head.comp_score_thr, 0.3)
+ assert np.allclose(drrg_head.text_region_thr, 0.2)
+ assert np.allclose(drrg_head.center_region_thr, 0.2)
+ assert drrg_head.center_region_area_thr == 50
+ assert np.allclose(drrg_head.local_graph_thr, 0.7)
+
+ # test forward train
+ num_rois = 16
+ feature_maps = torch.randn((2, 10, 128, 128), dtype=torch.float)
+ x = np.random.randint(4, 124, (num_rois, 1))
+ y = np.random.randint(4, 124, (num_rois, 1))
+ h = 4 * np.ones((num_rois, 1))
+ w = 4 * np.ones((num_rois, 1))
+ angle = (np.random.random_sample((num_rois, 1)) * 2 - 1) * np.pi / 2
+ cos, sin = np.cos(angle), np.sin(angle)
+ comp_labels = np.random.randint(1, 3, (num_rois, 1))
+ num_rois = num_rois * np.ones((num_rois, 1))
+ comp_attribs = np.hstack([num_rois, x, y, h, w, cos, sin, comp_labels])
+ comp_attribs = comp_attribs.astype(np.float32)
+ comp_attribs_ = comp_attribs.copy()
+ comp_attribs = np.stack([comp_attribs, comp_attribs_])
+ pred_maps, gcn_data = drrg_head(feature_maps, comp_attribs)
+ pred_labels, gt_labels = gcn_data
+ assert pred_maps.size() == (2, 6, 128, 128)
+ assert pred_labels.ndim == gt_labels.ndim == 2
+ assert gt_labels.size()[0] * gt_labels.size()[1] == pred_labels.size()[0]
+ assert pred_labels.size()[1] == 2
+
+ # test forward test
+ with torch.no_grad():
+ feat_maps = torch.zeros((1, 10, 128, 128))
+ drrg_head.out_conv.bias.data.fill_(-10)
+ preds = drrg_head.single_test(feat_maps)
+ assert all([pred is None for pred in preds])
+
+ # test get_boundary
+ edges = np.stack([np.arange(0, 10), np.arange(1, 11)]).transpose()
+ edges = np.vstack([edges, np.array([1, 0])])
+ scores = np.ones(11, dtype=np.float32) * 0.9
+ x1 = np.arange(2, 22, 2)
+ x2 = x1 + 2
+ y1 = np.ones(10) * 2
+ y2 = y1 + 2
+ comp_scores = np.ones(10, dtype=np.float32) * 0.9
+ text_comps = np.stack([x1, y1, x2, y1, x2, y2, x1, y2,
+ comp_scores]).transpose()
+ outlier = np.array([50, 50, 52, 50, 52, 52, 50, 52, 0.9])
+ text_comps = np.vstack([text_comps, outlier])
+
+ (C, H, W) = (10, 128, 128)
+ img_metas = [{
+ 'img_shape': (H, W, C),
+ 'ori_shape': (H, W, C),
+ 'pad_shape': (H, W, C),
+ 'filename': '.png',
+ 'scale_factor': np.array([1, 1, 1, 1]),
+ 'flip': False,
+ }]
+ results = drrg_head.get_boundary(
+ edges, scores, text_comps, img_metas, rescale=True)
+ assert 'boundary_result' in results.keys()
diff --git a/tests/test_models/test_textdet_neck.py b/tests/test_models/test_textdet_neck.py
new file mode 100644
index 0000000000000000000000000000000000000000..7bee9d7e932e77762769497030c565ca8d59e515
--- /dev/null
+++ b/tests/test_models/test_textdet_neck.py
@@ -0,0 +1,51 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+
+from mmocr.models.textdet.necks import FPNC, FPN_UNet
+
+
+def test_fpnc():
+
+ in_channels = [64, 128, 256, 512]
+ size = [112, 56, 28, 14]
+ for flag in [False, True]:
+ fpnc = FPNC(
+ in_channels=in_channels,
+ bias_on_lateral=flag,
+ bn_re_on_lateral=flag,
+ bias_on_smooth=flag,
+ bn_re_on_smooth=flag,
+ conv_after_concat=flag)
+ fpnc.init_weights()
+ inputs = []
+ for i in range(4):
+ inputs.append(torch.rand(1, in_channels[i], size[i], size[i]))
+ outputs = fpnc.forward(inputs)
+ assert list(outputs.size()) == [1, 256, 112, 112]
+
+
+def test_fpn_unet_neck():
+ s = 64
+ feat_sizes = [s // 2**i for i in range(4)] # [64, 32, 16, 8]
+ in_channels = [8, 16, 32, 64]
+ out_channels = 4
+
+ # len(in_channcels) is not equal to 4
+ with pytest.raises(AssertionError):
+ FPN_UNet(in_channels + [128], out_channels)
+
+ # `out_channels` is not int type
+ with pytest.raises(AssertionError):
+ FPN_UNet(in_channels, [2, 4])
+
+ feats = [
+ torch.rand(1, in_channels[i], feat_sizes[i], feat_sizes[i])
+ for i in range(len(in_channels))
+ ]
+
+ fpn_unet_neck = FPN_UNet(in_channels, out_channels)
+ fpn_unet_neck.init_weights()
+
+ out_neck = fpn_unet_neck(feats)
+ assert out_neck.shape == torch.Size([1, out_channels, s * 4, s * 4])
diff --git a/tests/test_tools/test_data_converter.py b/tests/test_tools/test_data_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..76ff0047fcaedb3940e1ae487ff6c653f9989f06
--- /dev/null
+++ b/tests/test_tools/test_data_converter.py
@@ -0,0 +1,19 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""Test orientation check and ignore method."""
+
+import shutil
+import tempfile
+
+from mmocr.utils import drop_orientation
+
+
+def test_drop_orientation():
+ img_file = 'tests/data/test_img2.jpg'
+ output_file = drop_orientation(img_file)
+ assert output_file is img_file
+
+ img_file = 'tests/data/test_img1.jpg'
+ tmp_dir = tempfile.TemporaryDirectory()
+ dst_file = shutil.copy(img_file, tmp_dir.name)
+ output_file = drop_orientation(dst_file)
+ assert output_file[-3:] == 'png'
diff --git a/tests/test_utils/test_box.py b/tests/test_utils/test_box.py
new file mode 100644
index 0000000000000000000000000000000000000000..9af23cc51a04b48ee04658be2afffa03e4dc1532
--- /dev/null
+++ b/tests/test_utils/test_box.py
@@ -0,0 +1,128 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import pytest
+
+from mmocr.utils import (bezier_to_polygon, is_on_same_line, sort_points,
+ stitch_boxes_into_lines)
+
+
+def test_box_on_line():
+ # regular boxes
+ box1 = [0, 0, 1, 0, 1, 1, 0, 1]
+ box2 = [2, 0.5, 3, 0.5, 3, 1.5, 2, 1.5]
+ box3 = [4, 0.8, 5, 0.8, 5, 1.8, 4, 1.8]
+ assert is_on_same_line(box1, box2, 0.5)
+ assert not is_on_same_line(box1, box3, 0.5)
+
+ # irregular box4
+ box4 = [0, 0, 1, 1, 1, 2, 0, 1]
+ box5 = [2, 1.5, 3, 1.5, 3, 2.5, 2, 2.5]
+ box6 = [2, 1.6, 3, 1.6, 3, 2.6, 2, 2.6]
+ assert is_on_same_line(box4, box5, 0.5)
+ assert not is_on_same_line(box4, box6, 0.5)
+
+
+def test_stitch_boxes_into_lines():
+ boxes = [ # regular boxes
+ [0, 0, 1, 0, 1, 1, 0, 1],
+ [2, 0.5, 3, 0.5, 3, 1.5, 2, 1.5],
+ [3, 1.2, 4, 1.2, 4, 2.2, 3, 2.2],
+ [5, 0.5, 6, 0.5, 6, 1.5, 5, 1.5],
+ # irregular box
+ [6, 1.5, 7, 1.25, 7, 1.75, 6, 1.75]
+ ]
+ raw_input = [{'box': boxes[i], 'text': str(i)} for i in range(len(boxes))]
+ result = stitch_boxes_into_lines(raw_input, 1, 0.5)
+ # Final lines: [0, 1], [2], [3, 4]
+ # box 0, 1, 3, 4 are on the same line but box 3 is 2 pixels away from box 1
+ # box 3 and 4 are on the same line since the length of overlapping part >=
+ # 0.5 * the y-axis length of box 5
+ expected_result = [{
+ 'box': [0, 0, 3, 0, 3, 1.5, 0, 1.5],
+ 'text': '0 1'
+ }, {
+ 'box': [3, 1.2, 4, 1.2, 4, 2.2, 3, 2.2],
+ 'text': '2'
+ }, {
+ 'box': [5, 0.5, 7, 0.5, 7, 1.75, 5, 1.75],
+ 'text': '3 4'
+ }]
+ result.sort(key=lambda x: x['box'][0])
+ expected_result.sort(key=lambda x: x['box'][0])
+ assert result == expected_result
+
+
+def test_bezier_to_polygon():
+ bezier_points = [
+ 37.0, 249.0, 72.5, 229.55, 95.34, 220.65, 134.0, 216.0, 132.0, 233.0,
+ 82.11, 240.2, 72.46, 247.16, 38.0, 263.0
+ ]
+ pts = bezier_to_polygon(bezier_points)
+ target = np.array([[37.0, 249.0], [42.50420761043885, 246.01570199737577],
+ [47.82291296107305, 243.2012392477038],
+ [52.98102930456334, 240.5511007435486],
+ [58.00346989357049, 238.05977547747486],
+ [62.91514798075522, 235.721752442047],
+ [67.74097681877824, 233.53152062982943],
+ [72.50586966030032, 231.48356903338674],
+ [77.23473975798221, 229.57238664528356],
+ [81.95250036448464, 227.79246245808432],
+ [86.68406473246829, 226.13828546435346],
+ [91.45434611459396, 224.60434465665548],
+ [96.28825776352238, 223.18512902755504],
+ [101.21071293191426, 221.87512756961655],
+ [106.24662487243039, 220.6688292754046],
+ [111.42090683773145, 219.5607231374836],
+ [116.75847208047819, 218.5452981484181],
+ [122.28423385333137, 217.6170433007727],
+ [128.02310540895172, 216.77044758711182],
+ [134.0, 216.0], [132.0, 233.0],
+ [124.4475521213005, 234.13617728531858],
+ [117.50700976818779, 235.2763434903047],
+ [111.12146960198277, 236.42847645429362],
+ [105.2340282840064, 237.6005540166205],
+ [99.78778247557953, 238.80055401662054],
+ [94.72582883802303, 240.0364542936288],
+ [89.99126403265781, 241.31623268698053],
+ [85.52718472080478, 242.64786703601104],
+ [81.27668756378483, 244.03933518005545],
+ [77.1828692229188, 245.49861495844874],
+ [73.18882635952762, 247.0336842105263],
+ [69.23765563493221, 248.65252077562326],
+ [65.27245371045342, 250.3631024930748],
+ [61.23631724741216, 252.17340720221605],
+ [57.07234290712931, 254.09141274238226],
+ [52.723627350925796, 256.12509695290856],
+ [48.13326724012247, 258.2824376731302],
+ [43.24435923604024, 260.5714127423822], [38.0, 263.0]])
+ assert np.allclose(pts, target)
+
+ bezier_points = [0, 0, 0, 1, 0, 2, 0, 3, 1, 0, 1, 1, 1, 2, 1, 3]
+ pts = bezier_to_polygon(bezier_points, num_sample=3)
+ target = np.array([[0, 0], [0, 1.5], [0, 3], [1, 0], [1, 1.5], [1, 3]])
+ assert np.allclose(pts, target)
+
+ with pytest.raises(AssertionError):
+ bezier_to_polygon(bezier_points, num_sample=-1)
+
+ bezier_points = [0, 1]
+ with pytest.raises(AssertionError):
+ bezier_to_polygon(bezier_points)
+
+
+def test_sort_points():
+ points = np.array([[1, 1], [0, 0], [1, -1], [2, -2], [0, 2], [1, 1],
+ [0, 1], [-1, 1], [-1, -1]])
+ target = np.array([[-1, -1], [0, 0], [-1, 1], [0, 1], [0, 2], [1, 1],
+ [1, 1], [2, -2], [1, -1]])
+ assert np.allclose(target, sort_points(points))
+
+ points = np.array([[1, 1], [1, -1], [-1, 1], [-1, -1]])
+ target = np.array([[-1, -1], [-1, 1], [1, 1], [1, -1]])
+ assert np.allclose(target, sort_points(points))
+
+ points = [[1, 1], [1, -1], [-1, 1], [-1, -1]]
+ assert np.allclose(target, sort_points(points))
+
+ with pytest.raises(AssertionError):
+ sort_points([1, 2])
diff --git a/tests/test_utils/test_check_argument.py b/tests/test_utils/test_check_argument.py
new file mode 100644
index 0000000000000000000000000000000000000000..bd639e37744bad06aa8677e84fb6ef44b961029c
--- /dev/null
+++ b/tests/test_utils/test_check_argument.py
@@ -0,0 +1,48 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+
+import mmocr.utils as utils
+
+
+def test_is_3dlist():
+
+ assert utils.is_3dlist([])
+ assert utils.is_3dlist([[]])
+ assert utils.is_3dlist([[[]]])
+ assert utils.is_3dlist([[[1]]])
+ assert not utils.is_3dlist([[1, 2]])
+ assert not utils.is_3dlist([[np.array([1, 2])]])
+
+
+def test_is_2dlist():
+
+ assert utils.is_2dlist([])
+ assert utils.is_2dlist([[]])
+ assert utils.is_2dlist([[1]])
+
+
+def test_is_type_list():
+ assert utils.is_type_list([], int)
+ assert utils.is_type_list([], float)
+ assert utils.is_type_list([np.array([])], np.ndarray)
+ assert utils.is_type_list([1], int)
+ assert utils.is_type_list(['str'], str)
+
+
+def test_is_none_or_type():
+
+ assert utils.is_none_or_type(None, int)
+ assert utils.is_none_or_type(1.0, float)
+ assert utils.is_none_or_type(np.ndarray([]), np.ndarray)
+ assert utils.is_none_or_type(1, int)
+ assert utils.is_none_or_type('str', str)
+
+
+def test_valid_boundary():
+
+ x = [0, 0, 1, 0, 1, 1, 0, 1]
+ assert not utils.valid_boundary(x, True)
+ assert not utils.valid_boundary([0])
+ assert utils.valid_boundary(x, False)
+ x = [0, 0, 1, 0, 1, 1, 0, 1, 1]
+ assert utils.valid_boundary(x, True)
diff --git a/tests/test_utils/test_mask/test_mask_utils.py b/tests/test_utils/test_mask/test_mask_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..12319bbbc734e9e74555ad48f0122dcf0b041372
--- /dev/null
+++ b/tests/test_utils/test_mask/test_mask_utils.py
@@ -0,0 +1,198 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""Test text mask_utils."""
+import tempfile
+from unittest import mock
+
+import numpy as np
+import pytest
+
+import mmocr.core.evaluation.utils as eval_utils
+import mmocr.core.mask as mask_utils
+import mmocr.core.visualize as visualize_utils
+
+
+def test_points2boundary():
+
+ points = np.array([[1, 2]])
+ text_repr_type = 'quad'
+ text_score = None
+
+ # test invalid arguments
+ with pytest.raises(AssertionError):
+ mask_utils.points2boundary([], text_repr_type, text_score)
+
+ with pytest.raises(AssertionError):
+ mask_utils.points2boundary(points, '', text_score)
+ with pytest.raises(AssertionError):
+ mask_utils.points2boundary(points, '', 1.1)
+
+ # test quad
+ points = np.array([[0, 0], [1, 0], [2, 0], [0, 1], [1, 1], [2, 1], [0, 2],
+ [1, 2], [2, 2]])
+ text_repr_type = 'quad'
+ text_score = None
+
+ result = mask_utils.points2boundary(points, text_repr_type, text_score)
+ pred_poly = eval_utils.points2polygon(result)
+ target_poly = eval_utils.points2polygon([2, 2, 0, 2, 0, 0, 2, 0])
+ assert eval_utils.poly_iou(pred_poly, target_poly) == 1
+
+ # test poly
+ text_repr_type = 'poly'
+ result = mask_utils.points2boundary(points, text_repr_type, text_score)
+ pred_poly = eval_utils.points2polygon(result)
+ target_poly = eval_utils.points2polygon([0, 0, 0, 2, 2, 2, 2, 0])
+ assert eval_utils.poly_iou(pred_poly, target_poly) == 1
+
+
+def test_seg2boundary():
+
+ seg = np.array([[]])
+ text_repr_type = 'quad'
+ text_score = None
+ # test invalid arguments
+ with pytest.raises(AssertionError):
+ mask_utils.seg2boundary([[]], text_repr_type, text_score)
+ with pytest.raises(AssertionError):
+ mask_utils.seg2boundary(seg, 1, text_score)
+ with pytest.raises(AssertionError):
+ mask_utils.seg2boundary(seg, text_repr_type, 1.1)
+
+ seg = np.array([[1, 1, 1], [1, 1, 1], [1, 1, 1]])
+ result = mask_utils.seg2boundary(seg, text_repr_type, text_score)
+ pred_poly = eval_utils.points2polygon(result)
+ target_poly = eval_utils.points2polygon([2, 2, 0, 2, 0, 0, 2, 0])
+ assert eval_utils.poly_iou(pred_poly, target_poly) == 1
+
+
+@mock.patch('%s.visualize_utils.plt' % __name__)
+def test_show_feature(mock_plt):
+
+ features = [np.random.rand(10, 10)]
+ names = ['test']
+ to_uint8 = [0]
+ out_file = None
+
+ # test invalid arguments
+ with pytest.raises(AssertionError):
+ visualize_utils.show_feature([], names, to_uint8, out_file)
+ with pytest.raises(AssertionError):
+ visualize_utils.show_feature(features, [1], to_uint8, out_file)
+ with pytest.raises(AssertionError):
+ visualize_utils.show_feature(features, names, ['a'], out_file)
+ with pytest.raises(AssertionError):
+ visualize_utils.show_feature(features, names, to_uint8, 1)
+ with pytest.raises(AssertionError):
+ visualize_utils.show_feature(features, names, to_uint8, [0, 1])
+
+ visualize_utils.show_feature(features, names, to_uint8)
+
+ # test showing img
+ mock_plt.title.assert_called_once_with('test')
+ mock_plt.show.assert_called_once()
+
+ # test saving fig
+ out_file = tempfile.NamedTemporaryFile().name
+ visualize_utils.show_feature(features, names, to_uint8, out_file)
+ mock_plt.savefig.assert_called_once()
+
+
+@mock.patch('%s.visualize_utils.plt' % __name__)
+def test_show_img_boundary(mock_plt):
+ img = np.random.rand(10, 10)
+ boundary = [0, 0, 1, 0, 1, 1, 0, 1]
+ # test invalid arguments
+ with pytest.raises(AssertionError):
+ visualize_utils.show_img_boundary([], boundary)
+ with pytest.raises(AssertionError):
+ visualize_utils.show_img_boundary(img, np.array([]))
+
+ # test showing img
+
+ visualize_utils.show_img_boundary(img, boundary)
+ mock_plt.imshow.assert_called_once()
+ mock_plt.show.assert_called_once()
+
+
+@mock.patch('%s.visualize_utils.mmcv' % __name__)
+def test_show_pred_gt(mock_mmcv):
+ preds = [[0, 0, 1, 0, 1, 1, 0, 1]]
+ gts = [[0, 0, 1, 0, 1, 1, 0, 1]]
+ show = True
+ win_name = 'test'
+ wait_time = 0
+ out_file = tempfile.NamedTemporaryFile().name
+
+ with pytest.raises(AssertionError):
+ visualize_utils.show_pred_gt(np.array([]), gts)
+ with pytest.raises(AssertionError):
+ visualize_utils.show_pred_gt(preds, np.array([]))
+
+ # test showing img
+
+ visualize_utils.show_pred_gt(preds, gts, show, win_name, wait_time,
+ out_file)
+ mock_mmcv.imshow.assert_called_once()
+ mock_mmcv.imwrite.assert_called_once()
+
+
+@mock.patch('%s.visualize_utils.mmcv.imshow' % __name__)
+@mock.patch('%s.visualize_utils.mmcv.imwrite' % __name__)
+def test_imshow_pred_boundary(mock_imshow, mock_imwrite):
+ img = './tests/data/test_img1.jpg'
+ boundaries_with_scores = [[0, 0, 1, 0, 1, 1, 0, 1, 1]]
+ labels = [1]
+ file = tempfile.NamedTemporaryFile().name
+ visualize_utils.imshow_pred_boundary(
+ img, boundaries_with_scores, labels, show=True, out_file=file)
+ mock_imwrite.assert_called_once()
+ mock_imshow.assert_called_once()
+
+
+@mock.patch('%s.visualize_utils.mmcv.imshow' % __name__)
+@mock.patch('%s.visualize_utils.mmcv.imwrite' % __name__)
+def test_imshow_text_char_boundary(mock_imshow, mock_imwrite):
+
+ img = './tests/data/test_img1.jpg'
+ text_quads = [[0, 0, 1, 0, 1, 1, 0, 1]]
+ boundaries = [[0, 0, 1, 0, 1, 1, 0, 1]]
+ char_quads = [[[0, 0, 1, 0, 1, 1, 0, 1], [0, 0, 1, 0, 1, 1, 0, 1]]]
+ chars = [['a', 'b']]
+ show = True,
+ out_file = tempfile.NamedTemporaryFile().name
+ visualize_utils.imshow_text_char_boundary(
+ img,
+ text_quads,
+ boundaries,
+ char_quads,
+ chars,
+ show=show,
+ out_file=out_file)
+ mock_imwrite.assert_called_once()
+ mock_imshow.assert_called_once()
+
+
+@mock.patch('%s.visualize_utils.cv2.drawContours' % __name__)
+def test_overlay_mask_img(mock_drawContours):
+
+ img = np.random.rand(10, 10)
+ mask = np.zeros((10, 10))
+ visualize_utils.overlay_mask_img(img, mask)
+ mock_drawContours.assert_called_once()
+
+
+def test_extract_boundary():
+ result = {}
+
+ # test invalid arguments
+ with pytest.raises(AssertionError):
+ mask_utils.extract_boundary(result)
+
+ result = {'boundary_result': [0, 1]}
+ with pytest.raises(AssertionError):
+ mask_utils.extract_boundary(result)
+
+ result = {'boundary_result': [[0, 0, 1, 0, 1, 1, 0, 1, 1]]}
+
+ output = mask_utils.extract_boundary(result)
+ assert output[2] == [1]
diff --git a/tests/test_utils/test_model.py b/tests/test_utils/test_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..d86d821aa07e30338e268797b14f4a7ee85d4123
--- /dev/null
+++ b/tests/test_utils/test_model.py
@@ -0,0 +1,22 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+import torch
+from mmcv.cnn.bricks import ConvModule
+
+from mmocr.utils import revert_sync_batchnorm
+
+
+def test_revert_sync_batchnorm():
+ conv_syncbn = ConvModule(3, 8, 2, norm_cfg=dict(type='SyncBN')).to('cpu')
+ conv_syncbn.train()
+ x = torch.randn(1, 3, 10, 10)
+ # Will raise an ValueError saying SyncBN does not run on CPU
+ with pytest.raises(ValueError):
+ y = conv_syncbn(x)
+ conv_bn = revert_sync_batchnorm(conv_syncbn)
+ y = conv_bn(x)
+ assert y.shape == (1, 8, 9, 9)
+ assert conv_bn.training == conv_syncbn.training
+ conv_syncbn.eval()
+ conv_bn = revert_sync_batchnorm(conv_syncbn)
+ assert conv_bn.training == conv_syncbn.training
diff --git a/tests/test_utils/test_ocr.py b/tests/test_utils/test_ocr.py
new file mode 100644
index 0000000000000000000000000000000000000000..c2332abe150bc56821c181022c465dc7cfbc5f14
--- /dev/null
+++ b/tests/test_utils/test_ocr.py
@@ -0,0 +1,371 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import io
+import json
+import os
+import platform
+import random
+import sys
+import tempfile
+from pathlib import Path
+from unittest import mock
+
+import mmcv
+import numpy as np
+import pytest
+import torch
+
+from mmocr.apis import init_detector
+from mmocr.datasets.kie_dataset import KIEDataset
+from mmocr.utils.ocr import MMOCR
+
+
+def test_ocr_init_errors():
+ # Test assertions
+ with pytest.raises(ValueError):
+ _ = MMOCR(det='test')
+ with pytest.raises(ValueError):
+ _ = MMOCR(recog='test')
+ with pytest.raises(ValueError):
+ _ = MMOCR(kie='test')
+ with pytest.raises(NotImplementedError):
+ _ = MMOCR(det=None, recog=None, kie='SDMGR')
+ with pytest.raises(NotImplementedError):
+ _ = MMOCR(det='DB_r18', recog=None, kie='SDMGR')
+
+
+cfg_default_prefix = os.path.join(str(Path.cwd()), 'configs/')
+
+
+@pytest.mark.parametrize(
+ 'det, recog, kie, config_dir, gt_cfg, gt_ckpt',
+ [('DB_r18', None, '', '',
+ cfg_default_prefix + 'textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py',
+ 'https://download.openmmlab.com/mmocr/textdet/'
+ 'dbnet/dbnet_r18_fpnc_sbn_1200e_icdar2015_20210329-ba3ab597.pth'),
+ (None, 'CRNN', '', '',
+ cfg_default_prefix + 'textrecog/crnn/crnn_academic_dataset.py',
+ 'https://download.openmmlab.com/mmocr/textrecog/'
+ 'crnn/crnn_academic-a723a1c5.pth'),
+ ('DB_r18', 'CRNN', 'SDMGR', '', [
+ cfg_default_prefix +
+ 'textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py',
+ cfg_default_prefix + 'textrecog/crnn/crnn_academic_dataset.py',
+ cfg_default_prefix + 'kie/sdmgr/sdmgr_unet16_60e_wildreceipt.py'
+ ], [
+ 'https://download.openmmlab.com/mmocr/textdet/'
+ 'dbnet/dbnet_r18_fpnc_sbn_1200e_icdar2015_20210329-ba3ab597.pth',
+ 'https://download.openmmlab.com/mmocr/textrecog/'
+ 'crnn/crnn_academic-a723a1c5.pth',
+ 'https://download.openmmlab.com/mmocr/kie/'
+ 'sdmgr/sdmgr_unet16_60e_wildreceipt_20210520-7489e6de.pth'
+ ]),
+ ('DB_r18', 'CRNN', 'SDMGR', 'test/', [
+ 'test/textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py',
+ 'test/textrecog/crnn/crnn_academic_dataset.py',
+ 'test/kie/sdmgr/sdmgr_unet16_60e_wildreceipt.py'
+ ], [
+ 'https://download.openmmlab.com/mmocr/textdet/'
+ 'dbnet/dbnet_r18_fpnc_sbn_1200e_icdar2015_20210329-ba3ab597.pth',
+ 'https://download.openmmlab.com/mmocr/textrecog/'
+ 'crnn/crnn_academic-a723a1c5.pth',
+ 'https://download.openmmlab.com/mmocr/kie/'
+ 'sdmgr/sdmgr_unet16_60e_wildreceipt_20210520-7489e6de.pth'
+ ])],
+)
+@mock.patch('mmocr.utils.ocr.init_detector')
+@mock.patch('mmocr.utils.ocr.build_detector')
+@mock.patch('mmocr.utils.ocr.Config.fromfile')
+@mock.patch('mmocr.utils.ocr.load_checkpoint')
+def test_ocr_init(mock_loading, mock_config, mock_build_detector,
+ mock_init_detector, det, recog, kie, config_dir, gt_cfg,
+ gt_ckpt):
+
+ def loadcheckpoint_assert(*args, **kwargs):
+ assert args[1] == gt_ckpt[-1]
+ assert kwargs['map_location'] == torch.device(
+ 'cuda' if torch.cuda.is_available() else 'cpu')
+
+ mock_loading.side_effect = loadcheckpoint_assert
+ with mock.patch('mmocr.utils.ocr.revert_sync_batchnorm'):
+ if kie == '':
+ if config_dir == '':
+ _ = MMOCR(det=det, recog=recog)
+ else:
+ _ = MMOCR(det=det, recog=recog, config_dir=config_dir)
+ else:
+ if config_dir == '':
+ _ = MMOCR(det=det, recog=recog, kie=kie)
+ else:
+ _ = MMOCR(det=det, recog=recog, kie=kie, config_dir=config_dir)
+ if isinstance(gt_cfg, str):
+ gt_cfg = [gt_cfg]
+ if isinstance(gt_ckpt, str):
+ gt_ckpt = [gt_ckpt]
+
+ i_range = range(len(gt_cfg))
+ if kie:
+ i_range = i_range[:-1]
+ mock_config.assert_called_with(gt_cfg[-1])
+ mock_build_detector.assert_called_once()
+ mock_loading.assert_called_once()
+ device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
+ calls = [
+ mock.call(gt_cfg[i], gt_ckpt[i], device=device) for i in i_range
+ ]
+ mock_init_detector.assert_has_calls(calls)
+
+
+@pytest.mark.parametrize(
+ 'det, det_config, det_ckpt, recog, recog_config, recog_ckpt,'
+ 'kie, kie_config, kie_ckpt, config_dir, gt_cfg, gt_ckpt',
+ [('DB_r18', 'test.py', '', 'CRNN', 'test.py', '', 'SDMGR', 'test.py', '',
+ 'configs/', ['test.py', 'test.py', 'test.py'], [
+ 'https://download.openmmlab.com/mmocr/textdet/'
+ 'dbnet/dbnet_r18_fpnc_sbn_1200e_icdar2015_20210329-ba3ab597.pth',
+ 'https://download.openmmlab.com/mmocr/textrecog/'
+ 'crnn/crnn_academic-a723a1c5.pth',
+ 'https://download.openmmlab.com/mmocr/kie/'
+ 'sdmgr/sdmgr_unet16_60e_wildreceipt_20210520-7489e6de.pth'
+ ]),
+ ('DB_r18', '', 'test.ckpt', 'CRNN', '', 'test.ckpt', 'SDMGR', '',
+ 'test.ckpt', '', [
+ 'textdet/dbnet/dbnet_r18_fpnc_1200e_icdar2015.py',
+ 'textrecog/crnn/crnn_academic_dataset.py',
+ 'kie/sdmgr/sdmgr_unet16_60e_wildreceipt.py'
+ ], ['test.ckpt', 'test.ckpt', 'test.ckpt']),
+ ('DB_r18', 'test.py', 'test.ckpt', 'CRNN', 'test.py', 'test.ckpt',
+ 'SDMGR', 'test.py', 'test.ckpt', '', ['test.py', 'test.py', 'test.py'],
+ ['test.ckpt', 'test.ckpt', 'test.ckpt'])])
+@mock.patch('mmocr.utils.ocr.init_detector')
+@mock.patch('mmocr.utils.ocr.build_detector')
+@mock.patch('mmocr.utils.ocr.Config.fromfile')
+@mock.patch('mmocr.utils.ocr.load_checkpoint')
+def test_ocr_init_customize_config(mock_loading, mock_config,
+ mock_build_detector, mock_init_detector,
+ det, det_config, det_ckpt, recog,
+ recog_config, recog_ckpt, kie, kie_config,
+ kie_ckpt, config_dir, gt_cfg, gt_ckpt):
+
+ def loadcheckpoint_assert(*args, **kwargs):
+ assert args[1] == gt_ckpt[-1]
+
+ mock_loading.side_effect = loadcheckpoint_assert
+ with mock.patch('mmocr.utils.ocr.revert_sync_batchnorm'):
+ _ = MMOCR(
+ det=det,
+ det_config=det_config,
+ det_ckpt=det_ckpt,
+ recog=recog,
+ recog_config=recog_config,
+ recog_ckpt=recog_ckpt,
+ kie=kie,
+ kie_config=kie_config,
+ kie_ckpt=kie_ckpt,
+ config_dir=config_dir)
+
+ i_range = range(len(gt_cfg))
+ if kie:
+ i_range = i_range[:-1]
+ mock_config.assert_called_with(gt_cfg[-1])
+ mock_build_detector.assert_called_once()
+ mock_loading.assert_called_once()
+ device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
+ calls = [
+ mock.call(gt_cfg[i], gt_ckpt[i], device=device) for i in i_range
+ ]
+ mock_init_detector.assert_has_calls(calls)
+
+
+@mock.patch('mmocr.utils.ocr.init_detector')
+@mock.patch('mmocr.utils.ocr.build_detector')
+@mock.patch('mmocr.utils.ocr.Config.fromfile')
+@mock.patch('mmocr.utils.ocr.load_checkpoint')
+@mock.patch('mmocr.utils.ocr.model_inference')
+def test_single_inference(mock_model_inference, mock_loading, mock_config,
+ mock_build_detector, mock_init_detector):
+
+ def dummy_inference(model, arr, batch_mode):
+ return arr
+
+ mock_model_inference.side_effect = dummy_inference
+ mmocr = MMOCR()
+
+ data = list(range(20))
+ model = 'dummy'
+ res = mmocr.single_inference(model, data, batch_mode=False)
+ assert (data == res)
+ mock_model_inference.reset_mock()
+
+ res = mmocr.single_inference(model, data, batch_mode=True)
+ assert (data == res)
+ mock_model_inference.assert_called_once()
+ mock_model_inference.reset_mock()
+
+ res = mmocr.single_inference(model, data, batch_mode=True, batch_size=100)
+ assert (data == res)
+ mock_model_inference.assert_called_once()
+ mock_model_inference.reset_mock()
+
+ res = mmocr.single_inference(model, data, batch_mode=True, batch_size=3)
+ assert (data == res)
+
+
+@mock.patch('mmocr.utils.ocr.init_detector')
+@mock.patch('mmocr.utils.ocr.load_checkpoint')
+def MMOCR_testobj(mock_loading, mock_init_detector, **kwargs):
+ # returns an MMOCR object bypassing the
+ # checkpoint initialization step
+ def init_detector_skip_ckpt(config, ckpt, device):
+ return init_detector(config, device=device)
+
+ def modify_kie_class(model, ckpt, map_location):
+ model.class_list = 'tests/data/kie_toy_dataset/class_list.txt'
+
+ mock_init_detector.side_effect = init_detector_skip_ckpt
+ mock_loading.side_effect = modify_kie_class
+ kwargs['det'] = kwargs.get('det', 'DB_r18')
+ kwargs['recog'] = kwargs.get('recog', 'CRNN')
+ kwargs['kie'] = kwargs.get('kie', 'SDMGR')
+ device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
+ return MMOCR(**kwargs, device=device)
+
+
+@pytest.mark.skipif(
+ platform.system() == 'Windows',
+ reason='Win container on Github Action does not have enough RAM to run')
+@mock.patch('mmocr.utils.ocr.KIEDataset')
+def test_readtext(mock_kiedataset):
+ # Fixing the weights of models to prevent them from
+ # generating invalid results and triggering other assertion errors
+ torch.manual_seed(4)
+ random.seed(4)
+ mmocr = MMOCR_testobj()
+ mmocr_det = MMOCR_testobj(kie='', recog='')
+ mmocr_recog = MMOCR_testobj(kie='', det='', recog='CRNN_TPS')
+ mmocr_det_recog = MMOCR_testobj(kie='')
+
+ def readtext(imgs, ocr_obj=mmocr, **kwargs):
+ # filename can be different depends on how
+ # the the image was loaded
+ e2e_res = ocr_obj.readtext(imgs, **kwargs)
+ for res in e2e_res:
+ res.pop('filename')
+ return e2e_res
+
+ def kiedataset_with_test_dict(**kwargs):
+ kwargs['dict_file'] = 'tests/data/kie_toy_dataset/dict.txt'
+ return KIEDataset(**kwargs)
+
+ mock_kiedataset.side_effect = kiedataset_with_test_dict
+
+ # Single image
+ toy_dir = 'tests/data/toy_dataset/imgs/test/'
+ toy_img1_path = toy_dir + 'img_1.jpg'
+ str_e2e_res = readtext(toy_img1_path)
+ toy_img1 = mmcv.imread(toy_img1_path)
+ np_e2e_res = readtext(toy_img1)
+ assert str_e2e_res == np_e2e_res
+
+ # Multiple images
+ toy_img2_path = toy_dir + 'img_2.jpg'
+ toy_img2 = mmcv.imread(toy_img2_path)
+ toy_imgs = [toy_img1, toy_img2]
+ toy_img_paths = [toy_img1_path, toy_img2_path]
+ np_e2e_results = readtext(toy_imgs)
+ str_e2e_results = readtext(toy_img_paths)
+ str_tuple_e2e_results = readtext(tuple(toy_img_paths))
+ assert np_e2e_results == str_e2e_results
+ assert str_e2e_results == str_tuple_e2e_results
+
+ # Batch mode test
+ toy_imgs.append(toy_dir + 'img_3.jpg')
+ e2e_res = readtext(toy_imgs)
+ full_batch_e2e_res = readtext(toy_imgs, batch_mode=True)
+ assert full_batch_e2e_res == e2e_res
+ batch_e2e_res = readtext(
+ toy_imgs, batch_mode=True, recog_batch_size=2, det_batch_size=2)
+ assert batch_e2e_res == full_batch_e2e_res
+
+ # Batch mode test with DBNet only
+ full_batch_det_res = mmocr_det.readtext(toy_imgs, batch_mode=True)
+ det_res = mmocr_det.readtext(toy_imgs)
+ batch_det_res = mmocr_det.readtext(
+ toy_imgs, batch_mode=True, single_batch_size=2)
+ assert len(full_batch_det_res) == len(det_res)
+ assert len(batch_det_res) == len(det_res)
+ assert all([
+ np.allclose(full_batch_det_res[i]['boundary_result'],
+ det_res[i]['boundary_result'])
+ for i in range(len(full_batch_det_res))
+ ])
+ assert all([
+ np.allclose(batch_det_res[i]['boundary_result'],
+ det_res[i]['boundary_result'])
+ for i in range(len(batch_det_res))
+ ])
+
+ # Batch mode test with CRNN_TPS only (CRNN doesn't support batch inference)
+ full_batch_recog_res = mmocr_recog.readtext(toy_imgs, batch_mode=True)
+ recog_res = mmocr_recog.readtext(toy_imgs)
+ batch_recog_res = mmocr_recog.readtext(
+ toy_imgs, batch_mode=True, single_batch_size=2)
+ full_batch_recog_res.sort(key=lambda x: x['text'])
+ batch_recog_res.sort(key=lambda x: x['text'])
+ recog_res.sort(key=lambda x: x['text'])
+ assert np.all([
+ np.allclose(full_batch_recog_res[i]['score'], recog_res[i]['score'])
+ for i in range(len(full_batch_recog_res))
+ ])
+ assert np.all([
+ np.allclose(batch_recog_res[i]['score'], recog_res[i]['score'])
+ for i in range(len(full_batch_recog_res))
+ ])
+
+ # Test export
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ mmocr.readtext(toy_imgs, export=tmpdirname)
+ assert len(os.listdir(tmpdirname)) == len(toy_imgs)
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ mmocr_det.readtext(toy_imgs, export=tmpdirname)
+ assert len(os.listdir(tmpdirname)) == len(toy_imgs)
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ mmocr_recog.readtext(toy_imgs, export=tmpdirname)
+ assert len(os.listdir(tmpdirname)) == len(toy_imgs)
+
+ # Test output
+ # Single image
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ tmp_output = os.path.join(tmpdirname, '1.jpg')
+ mmocr.readtext(toy_imgs[0], output=tmp_output)
+ assert os.path.exists(tmp_output)
+ # Multiple images
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ mmocr.readtext(toy_imgs, output=tmpdirname)
+ assert len(os.listdir(tmpdirname)) == len(toy_imgs)
+
+ # Test imshow
+ with mock.patch('mmocr.utils.ocr.mmcv.imshow') as mock_imshow:
+ mmocr.readtext(toy_img1_path, imshow=True)
+ mock_imshow.assert_called_once()
+ mock_imshow.reset_mock()
+ mmocr.readtext(toy_imgs, imshow=True)
+ assert mock_imshow.call_count == len(toy_imgs)
+
+ # Test print_result
+ with io.StringIO() as capturedOutput:
+ sys.stdout = capturedOutput
+ res = mmocr.readtext(toy_imgs, print_result=True)
+ assert json.loads('[%s]' % capturedOutput.getvalue().strip().replace(
+ '\n\n', ',').replace("'", '"')) == res
+ sys.stdout = sys.__stdout__
+ with io.StringIO() as capturedOutput:
+ sys.stdout = capturedOutput
+ res = mmocr.readtext(toy_imgs, details=True, print_result=True)
+ assert json.loads('[%s]' % capturedOutput.getvalue().strip().replace(
+ '\n\n', ',').replace("'", '"')) == res
+ sys.stdout = sys.__stdout__
+
+ # Test merge
+ with mock.patch('mmocr.utils.ocr.stitch_boxes_into_lines') as mock_merge:
+ mmocr_det_recog.readtext(toy_imgs, merge=True)
+ assert mock_merge.call_count == len(toy_imgs)
diff --git a/tests/test_utils/test_setup_env.py b/tests/test_utils/test_setup_env.py
new file mode 100644
index 0000000000000000000000000000000000000000..b65b9647ca2f2777a147efd4445a648a73f040d0
--- /dev/null
+++ b/tests/test_utils/test_setup_env.py
@@ -0,0 +1,68 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import multiprocessing as mp
+import os
+import platform
+
+import cv2
+from mmcv import Config
+
+from mmocr.utils import setup_multi_processes
+
+
+def test_setup_multi_processes():
+ # temp save system setting
+ sys_start_mehod = mp.get_start_method(allow_none=True)
+ sys_cv_threads = cv2.getNumThreads()
+ # pop and temp save system env vars
+ sys_omp_threads = os.environ.pop('OMP_NUM_THREADS', default=None)
+ sys_mkl_threads = os.environ.pop('MKL_NUM_THREADS', default=None)
+
+ # test config without setting env
+ config = dict(data=dict(workers_per_gpu=2))
+ cfg = Config(config)
+ setup_multi_processes(cfg)
+ assert os.getenv('OMP_NUM_THREADS') == '1'
+ assert os.getenv('MKL_NUM_THREADS') == '1'
+ # when set to 0, the num threads will be 1
+ assert cv2.getNumThreads() == 1
+ if platform.system() != 'Windows':
+ assert mp.get_start_method() == 'fork'
+
+ # test num workers <= 1
+ os.environ.pop('OMP_NUM_THREADS')
+ os.environ.pop('MKL_NUM_THREADS')
+ config = dict(data=dict(workers_per_gpu=0))
+ cfg = Config(config)
+ setup_multi_processes(cfg)
+ assert 'OMP_NUM_THREADS' not in os.environ
+ assert 'MKL_NUM_THREADS' not in os.environ
+
+ # test manually set env var
+ os.environ['OMP_NUM_THREADS'] = '4'
+ config = dict(data=dict(workers_per_gpu=2))
+ cfg = Config(config)
+ setup_multi_processes(cfg)
+ assert os.getenv('OMP_NUM_THREADS') == '4'
+
+ # test manually set opencv threads and mp start method
+ config = dict(
+ data=dict(workers_per_gpu=2),
+ opencv_num_threads=4,
+ mp_start_method='spawn')
+ cfg = Config(config)
+ setup_multi_processes(cfg)
+ assert cv2.getNumThreads() == 4
+ assert mp.get_start_method() == 'spawn'
+
+ # revert setting to avoid affecting other programs
+ if sys_start_mehod:
+ mp.set_start_method(sys_start_mehod, force=True)
+ cv2.setNumThreads(sys_cv_threads)
+ if sys_omp_threads:
+ os.environ['OMP_NUM_THREADS'] = sys_omp_threads
+ else:
+ os.environ.pop('OMP_NUM_THREADS')
+ if sys_mkl_threads:
+ os.environ['MKL_NUM_THREADS'] = sys_mkl_threads
+ else:
+ os.environ.pop('MKL_NUM_THREADS')
diff --git a/tests/test_utils/test_string_util.py b/tests/test_utils/test_string_util.py
new file mode 100644
index 0000000000000000000000000000000000000000..c0eb467892c1a7c2dc4d64db1a4e12bfb67b7cda
--- /dev/null
+++ b/tests/test_utils/test_string_util.py
@@ -0,0 +1,35 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import pytest
+
+from mmocr.utils import StringStrip
+
+
+def test_string_strip():
+ strip_list = [True, False]
+ strip_pos_list = ['both', 'left', 'right']
+ strip_str_list = [None, ' ']
+
+ in_str_list = [
+ ' hello ', 'hello ', ' hello', ' hello', 'hello ', 'hello ', 'hello',
+ 'hello', 'hello', 'hello', 'hello', 'hello'
+ ]
+ out_str_list = [
+ 'hello', 'hello', 'hello', 'hello', 'hello', 'hello', 'hello', 'hello',
+ 'hello', 'hello', 'hello', 'hello'
+ ]
+
+ for idx1, strip in enumerate(strip_list):
+ for idx2, strip_pos in enumerate(strip_pos_list):
+ for idx3, strip_str in enumerate(strip_str_list):
+ tmp_args = dict(
+ strip=strip, strip_pos=strip_pos, strip_str=strip_str)
+ strip_class = StringStrip(**tmp_args)
+ i = idx1 * len(strip_pos_list) * len(
+ strip_str_list) + idx2 * len(strip_str_list) + idx3
+
+ assert strip_class(in_str_list[i]) == out_str_list[i]
+
+ with pytest.raises(AssertionError):
+ StringStrip(strip='strip')
+ StringStrip(strip_pos='head')
+ StringStrip(strip_str=['\n', '\t'])
diff --git a/tests/test_utils/test_text/test_text_utils.py b/tests/test_utils/test_text/test_text_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..aa3b2d240e94e7278e04dd76b1f02ef490317350
--- /dev/null
+++ b/tests/test_utils/test_text/test_text_utils.py
@@ -0,0 +1,67 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""Test text label visualize."""
+import os.path as osp
+import random
+import tempfile
+from unittest import mock
+
+import numpy as np
+import pytest
+
+import mmocr.core.visualize as visualize_utils
+
+
+def test_tile_image():
+ dummp_imgs, heights, widths = [], [], []
+ for _ in range(3):
+ h = random.randint(100, 300)
+ w = random.randint(100, 300)
+ heights.append(h)
+ widths.append(w)
+ # dummy_img = Image.new('RGB', (w, h), Image.ANTIALIAS)
+ dummy_img = np.ones((h, w, 3), dtype=np.uint8)
+ dummp_imgs.append(dummy_img)
+ joint_img = visualize_utils.tile_image(dummp_imgs)
+ assert joint_img.shape[0] == sum(heights)
+ assert joint_img.shape[1] == max(widths)
+
+ # test invalid arguments
+ with pytest.raises(AssertionError):
+ visualize_utils.tile_image(dummp_imgs[0])
+ with pytest.raises(AssertionError):
+ visualize_utils.tile_image([])
+
+
+@mock.patch('%s.visualize_utils.mmcv.imread' % __name__)
+@mock.patch('%s.visualize_utils.mmcv.imshow' % __name__)
+@mock.patch('%s.visualize_utils.mmcv.imwrite' % __name__)
+def test_show_text_label(mock_imwrite, mock_imshow, mock_imread):
+ img = np.ones((32, 160), dtype=np.uint8)
+ pred_label = 'hello'
+ gt_label = 'world'
+
+ tmp_dir = tempfile.TemporaryDirectory()
+ out_file = osp.join(tmp_dir.name, 'tmp.jpg')
+
+ # test invalid arguments
+ with pytest.raises(AssertionError):
+ visualize_utils.imshow_text_label(5, pred_label, gt_label)
+ with pytest.raises(AssertionError):
+ visualize_utils.imshow_text_label(img, pred_label, 4)
+ with pytest.raises(AssertionError):
+ visualize_utils.imshow_text_label(img, 3, gt_label)
+ with pytest.raises(AssertionError):
+ visualize_utils.imshow_text_label(
+ img, pred_label, gt_label, show=True, wait_time=0.1)
+
+ mock_imread.side_effect = [img, img]
+ visualize_utils.imshow_text_label(
+ img, pred_label, gt_label, out_file=out_file)
+ visualize_utils.imshow_text_label(
+ img, '中文', '中文', out_file=None, show=True)
+
+ # test showing img
+ mock_imshow.assert_called_once()
+ mock_imwrite.assert_called_once()
+
+ tmp_dir.cleanup()
diff --git a/tests/test_utils/test_textio.py b/tests/test_utils/test_textio.py
new file mode 100644
index 0000000000000000000000000000000000000000..88d6f19beb54cf635171eac4a3a018e953aca470
--- /dev/null
+++ b/tests/test_utils/test_textio.py
@@ -0,0 +1,104 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+import tempfile
+
+from mmocr.utils import list_from_file, list_to_file
+
+lists = [
+ [],
+ [' '],
+ ['\t'],
+ ['a'],
+ [1],
+ [1.],
+ ['a', 'b'],
+ ['a', 1, 1.],
+ [1, 1., 'a'],
+ ['啊', '啊啊'],
+ ['選択', 'noël', 'Информацией', 'ÄÆä'],
+]
+
+dicts = [
+ [{
+ 'text': []
+ }],
+ [{
+ 'text': [' ']
+ }],
+ [{
+ 'text': ['\t']
+ }],
+ [{
+ 'text': ['a']
+ }],
+ [{
+ 'text': [1]
+ }],
+ [{
+ 'text': [1.]
+ }],
+ [{
+ 'text': ['a', 'b']
+ }],
+ [{
+ 'text': ['a', 1, 1.]
+ }],
+ [{
+ 'text': [1, 1., 'a']
+ }],
+ [{
+ 'text': ['啊', '啊啊']
+ }],
+ [{
+ 'text': ['選択', 'noël', 'Информацией', 'ÄÆä']
+ }],
+]
+
+
+def test_list_to_file():
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ # test txt
+ for i, lines in enumerate(lists):
+ filename = f'{tmpdirname}/{i}.txt'
+ list_to_file(filename, lines)
+ lines2 = [
+ line.rstrip('\r\n')
+ for line in open(filename, 'r', encoding='utf-8').readlines()
+ ]
+ lines = list(map(str, lines))
+ assert len(lines) == len(lines2)
+ assert all(line1 == line2 for line1, line2 in zip(lines, lines2))
+ # test jsonl
+ for i, lines in enumerate(dicts):
+ filename = f'{tmpdirname}/{i}.jsonl'
+ list_to_file(filename, [json.dumps(line) for line in lines])
+ lines2 = [
+ json.loads(line.rstrip('\r\n'))['text']
+ for line in open(filename, 'r', encoding='utf-8').readlines()
+ ][0]
+
+ lines = list(lines[0]['text'])
+ assert len(lines) == len(lines2)
+ assert all(line1 == line2 for line1, line2 in zip(lines, lines2))
+
+
+def test_list_from_file():
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ # test txt file
+ for i, lines in enumerate(lists):
+ filename = f'{tmpdirname}/{i}.txt'
+ with open(filename, 'w', encoding='utf-8') as f:
+ f.writelines(f'{line}\n' for line in lines)
+ lines2 = list_from_file(filename, encoding='utf-8')
+ lines = list(map(str, lines))
+ assert len(lines) == len(lines2)
+ assert all(line1 == line2 for line1, line2 in zip(lines, lines2))
+ # test jsonl file
+ for i, lines in enumerate(dicts):
+ filename = f'{tmpdirname}/{i}.jsonl'
+ with open(filename, 'w', encoding='utf-8') as f:
+ f.writelines(f'{line}\n' for line in lines)
+ lines2 = list_from_file(filename, encoding='utf-8')
+ lines = list(map(str, lines))
+ assert len(lines) == len(lines2)
+ assert all(line1 == line2 for line1, line2 in zip(lines, lines2))
diff --git a/tests/test_utils/test_version_utils.py b/tests/test_utils/test_version_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..ad43344d8ed390f6619752e9fc14ba131bb04c16
--- /dev/null
+++ b/tests/test_utils/test_version_utils.py
@@ -0,0 +1,21 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmocr import digit_version
+
+
+def test_digit_version():
+ assert digit_version('0.2.16') == (0, 2, 16, 0, 0, 0)
+ assert digit_version('1.2.3') == (1, 2, 3, 0, 0, 0)
+ assert digit_version('1.2.3rc0') == (1, 2, 3, 0, -1, 0)
+ assert digit_version('1.2.3rc1') == (1, 2, 3, 0, -1, 1)
+ assert digit_version('1.0rc0') == (1, 0, 0, 0, -1, 0)
+ assert digit_version('1.0') == digit_version('1.0.0')
+ assert digit_version('1.5.0+cuda90_cudnn7.6.3_lms') == digit_version('1.5')
+ assert digit_version('1.0.0dev') < digit_version('1.0.0a')
+ assert digit_version('1.0.0a') < digit_version('1.0.0a1')
+ assert digit_version('1.0.0a') < digit_version('1.0.0b')
+ assert digit_version('1.0.0b') < digit_version('1.0.0rc')
+ assert digit_version('1.0.0rc1') < digit_version('1.0.0')
+ assert digit_version('1.0.0') < digit_version('1.0.0post')
+ assert digit_version('1.0.0post') < digit_version('1.0.0post1')
+ assert digit_version('v1') == (1, 0, 0, 0, 0, 0)
+ assert digit_version('v1.1.5') == (1, 1, 5, 0, 0, 0)
diff --git a/tests/test_utils/test_wrapper.py b/tests/test_utils/test_wrapper.py
new file mode 100644
index 0000000000000000000000000000000000000000..cb8668f8cb857cb9c1920cd341d3664db73173b7
--- /dev/null
+++ b/tests/test_utils/test_wrapper.py
@@ -0,0 +1,112 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import numpy as np
+import pytest
+import torch
+
+from mmocr.models.textdet.postprocess import (DBPostprocessor,
+ FCEPostprocessor,
+ TextSnakePostprocessor)
+from mmocr.models.textdet.postprocess.utils import comps2boundaries, poly_nms
+
+
+def test_db_boxes_from_bitmaps():
+ """Test the boxes_from_bitmaps function in db_decoder."""
+ pred = np.array([[[0.8, 0.8, 0.8, 0.8, 0], [0.8, 0.8, 0.8, 0.8, 0],
+ [0.8, 0.8, 0.8, 0.8, 0], [0.8, 0.8, 0.8, 0.8, 0],
+ [0.8, 0.8, 0.8, 0.8, 0]]])
+ preds = torch.FloatTensor(pred).requires_grad_(True)
+ db_decode = DBPostprocessor(text_repr_type='quad', min_text_width=0)
+ boxes = db_decode(preds)
+ assert len(boxes) == 1
+
+
+def test_fcenet_decode():
+
+ k = 1
+ preds = []
+ preds.append(torch.ones(1, 4, 10, 10))
+ preds.append(torch.ones(1, 4 * k + 2, 10, 10))
+ fcenet_decode = FCEPostprocessor(
+ fourier_degree=k, num_reconstr_points=50, nms_thr=0.01)
+ boundaries = fcenet_decode(preds=preds, scale=1)
+
+ assert isinstance(boundaries, list)
+
+
+def test_poly_nms():
+ threshold = 0
+ polygons = []
+ polygons.append([10, 10, 10, 30, 30, 30, 30, 10, 0.95])
+ polygons.append([15, 15, 15, 25, 25, 25, 25, 15, 0.9])
+ polygons.append([40, 40, 40, 50, 50, 50, 50, 40, 0.85])
+ polygons.append([5, 5, 5, 15, 15, 15, 15, 5, 0.7])
+
+ keep_poly = poly_nms(polygons, threshold)
+ assert isinstance(keep_poly, list)
+
+
+def test_comps2boundaries():
+
+ # test comps2boundaries
+ x1 = np.arange(2, 18, 2)
+ x2 = x1 + 2
+ y1 = np.ones(8) * 2
+ y2 = y1 + 2
+ comp_scores = np.ones(8, dtype=np.float32) * 0.9
+ text_comps = np.stack([x1, y1, x2, y1, x2, y2, x1, y2,
+ comp_scores]).transpose()
+ comp_labels = np.array([1, 1, 1, 1, 1, 3, 5, 5])
+ shuffle = [3, 2, 5, 7, 6, 0, 4, 1]
+ boundaries = comps2boundaries(text_comps[shuffle], comp_labels[shuffle])
+ assert len(boundaries) == 3
+
+ # test comps2boundaries with blank inputs
+ boundaries = comps2boundaries(text_comps[[]], comp_labels[[]])
+ assert len(boundaries) == 0
+
+
+def test_textsnake_decode():
+
+ maps = torch.zeros((1, 6, 224, 224), dtype=torch.float)
+ maps[:, 0:2, :, :] = -10.
+ maps[:, 0, 60:100, 50:170] = 10.
+ maps[:, 1, 75:85, 60:160] = 10.
+ maps[:, 2, 75:85, 60:160] = 0.
+ maps[:, 3, 75:85, 60:160] = 1.
+ maps[:, 4, 75:85, 60:160] = 10.
+ # test decoding with text center region of small area
+ maps[:, 0:2, 150:152, 5:7] = 10.
+ textsnake_decode = TextSnakePostprocessor()
+ results = textsnake_decode(torch.squeeze(maps))
+ assert len(results) == 1
+
+ # test decoding with small radius
+ maps.fill_(0.)
+ maps[:, 0:2, :, :] = -10.
+ maps[:, 0, 120:140, 20:40] = 10.
+ maps[:, 1, 120:140, 20:40] = 10.
+ maps[:, 2, 120:140, 20:40] = 0.
+ maps[:, 3, 120:140, 20:40] = 1.
+ maps[:, 4, 120:140, 20:40] = 0.5
+
+ results = textsnake_decode(torch.squeeze(maps))
+ assert len(results) == 0
+
+
+def test_db_decode():
+ pred = torch.zeros((1, 8, 8))
+ pred[0, 2:7, 2:7] = 0.8
+ expect_result_quad = [[
+ 1.0, 8.0, 1.0, 1.0, 8.0, 1.0, 8.0, 8.0, 0.800000011920929
+ ]]
+ expect_result_poly = [[
+ 8, 2, 8, 6, 6, 8, 2, 8, 1, 6, 1, 2, 2, 1, 6, 1, 0.800000011920929
+ ]]
+ with pytest.raises(AssertionError):
+ DBPostprocessor(text_repr_type='dummpy')
+ db_decode = DBPostprocessor(text_repr_type='quad', min_text_width=1)
+ result_quad = db_decode(preds=pred)
+ db_decode = DBPostprocessor(text_repr_type='poly', min_text_width=1)
+ result_poly = db_decode(preds=pred)
+ assert result_quad == expect_result_quad
+ assert result_poly == expect_result_poly
diff --git a/tools/benchmark_processing.py b/tools/benchmark_processing.py
new file mode 100755
index 0000000000000000000000000000000000000000..13b215ef640ef43a09df579b68642db1fb97c633
--- /dev/null
+++ b/tools/benchmark_processing.py
@@ -0,0 +1,60 @@
+#!/usr/bin/env python
+# Copyright (c) OpenMMLab. All rights reserved.
+"""This file is for benchmark data loading process. It can also be used to
+refresh the memcached cache. The command line to run this file is:
+
+$ python -m cProfile -o program.prof tools/analysis/benchmark_processing.py
+configs/task/method/[config filename]
+
+Note: When debugging, the `workers_per_gpu` in the config should be set to 0
+during benchmark.
+
+It use cProfile to record cpu running time and output to program.prof
+To visualize cProfile output program.prof, use Snakeviz and run:
+$ snakeviz program.prof
+"""
+import argparse
+
+import mmcv
+from mmcv import Config
+from mmdet.datasets import build_dataloader
+
+from mmocr.datasets import build_dataset
+
+assert build_dataset is not None
+
+
+def main():
+ parser = argparse.ArgumentParser(description='Benchmark data loading')
+ parser.add_argument('config', help='Train config file path.')
+ args = parser.parse_args()
+ cfg = Config.fromfile(args.config)
+
+ dataset = build_dataset(cfg.data.train)
+
+ # prepare data loaders
+ if 'imgs_per_gpu' in cfg.data:
+ cfg.data.samples_per_gpu = cfg.data.imgs_per_gpu
+
+ data_loader = build_dataloader(
+ dataset,
+ cfg.data.samples_per_gpu,
+ cfg.data.workers_per_gpu,
+ 1,
+ dist=False,
+ seed=None)
+
+ # Start progress bar after first 5 batches
+ prog_bar = mmcv.ProgressBar(
+ len(dataset) - 5 * cfg.data.samples_per_gpu, start=False)
+ for i, data in enumerate(data_loader):
+ if i == 5:
+ prog_bar.start()
+ for _ in range(len(data['img'])):
+ if i < 5:
+ continue
+ prog_bar.update()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/data/common/curvedsyntext_converter.py b/tools/data/common/curvedsyntext_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..ddffd50e2af44e464d21260fbc2dbe58f70da2cf
--- /dev/null
+++ b/tools/data/common/curvedsyntext_converter.py
@@ -0,0 +1,129 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+from functools import partial
+
+import mmcv
+import numpy as np
+
+from mmocr.utils import bezier_to_polygon, sort_points
+
+# The default dictionary used by CurvedSynthText
+dict95 = [
+ ' ', '!', '"', '#', '$', '%', '&', '\'', '(', ')', '*', '+', ',', '-', '.',
+ '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', ';', '<', '=',
+ '>', '?', '@', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L',
+ 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '[',
+ '\\', ']', '^', '_', '`', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j',
+ 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y',
+ 'z', '{', '|', '}', '~'
+]
+UNK = len(dict95)
+EOS = UNK + 1
+
+
+def digit2text(rec):
+ res = []
+ for d in rec:
+ assert d <= EOS
+ if d == EOS:
+ break
+ if d == UNK:
+ print('Warning: Has a UNK character')
+ res.append('口') # Or any special character not in the target dict
+ res.append(dict95[d])
+ return ''.join(res)
+
+
+def modify_annotation(ann, num_sample, start_img_id=0, start_ann_id=0):
+ ann['text'] = digit2text(ann.pop('rec'))
+ # Get hide egmentation points
+ polygon_pts = bezier_to_polygon(ann['bezier_pts'], num_sample=num_sample)
+ ann['segmentation'] = np.asarray(sort_points(polygon_pts)).reshape(
+ 1, -1).tolist()
+ ann['image_id'] += start_img_id
+ ann['id'] += start_ann_id
+ return ann
+
+
+def modify_image_info(image_info, path_prefix, start_img_id=0):
+ image_info['file_name'] = osp.join(path_prefix, image_info['file_name'])
+ image_info['id'] += start_img_id
+ return image_info
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert CurvedSynText150k to COCO format')
+ parser.add_argument('root_path', help='CurvedSynText150k root path')
+ parser.add_argument('-o', '--out-dir', help='Output path')
+ parser.add_argument(
+ '-n',
+ '--num-sample',
+ type=int,
+ default=4,
+ help='Number of sample points at each Bezier curve.')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of processes')
+ args = parser.parse_args()
+ return args
+
+
+def convert_annotations(data,
+ path_prefix,
+ num_sample,
+ nproc,
+ start_img_id=0,
+ start_ann_id=0):
+ modify_image_info_with_params = partial(
+ modify_image_info, path_prefix=path_prefix, start_img_id=start_img_id)
+ modify_annotation_with_params = partial(
+ modify_annotation,
+ num_sample=num_sample,
+ start_img_id=start_img_id,
+ start_ann_id=start_ann_id)
+ if nproc > 1:
+ data['annotations'] = mmcv.track_parallel_progress(
+ modify_annotation_with_params, data['annotations'], nproc=nproc)
+ data['images'] = mmcv.track_parallel_progress(
+ modify_image_info_with_params, data['images'], nproc=nproc)
+ else:
+ data['annotations'] = mmcv.track_progress(
+ modify_annotation_with_params, data['annotations'])
+ data['images'] = mmcv.track_progress(
+ modify_image_info_with_params,
+ data['images'],
+ )
+ data['categories'] = [{'id': 1, 'name': 'text'}]
+ return data
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ out_dir = args.out_dir if args.out_dir else root_path
+ mmcv.mkdir_or_exist(out_dir)
+
+ anns = mmcv.load(osp.join(root_path, 'train1.json'))
+ data1 = convert_annotations(anns, 'syntext_word_eng', args.num_sample,
+ args.nproc)
+
+ # Get the maximum image id from data1
+ start_img_id = max(data1['images'], key=lambda x: x['id'])['id'] + 1
+ start_ann_id = max(data1['annotations'], key=lambda x: x['id'])['id'] + 1
+ anns = mmcv.load(osp.join(root_path, 'train2.json'))
+ data2 = convert_annotations(
+ anns,
+ 'emcs_imgs',
+ args.num_sample,
+ args.nproc,
+ start_img_id=start_img_id,
+ start_ann_id=start_ann_id)
+
+ data1['images'] += data2['images']
+ data1['annotations'] += data2['annotations']
+ mmcv.dump(data1, osp.join(out_dir, 'instances_training.json'))
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/data/kie/closeset_to_openset.py b/tools/data/kie/closeset_to_openset.py
new file mode 100644
index 0000000000000000000000000000000000000000..4c2480bfa7a20c4141a282cd5a3e2e31012eb84c
--- /dev/null
+++ b/tools/data/kie/closeset_to_openset.py
@@ -0,0 +1,122 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import json
+from functools import partial
+
+import mmcv
+
+from mmocr.utils import list_from_file, list_to_file
+
+
+def convert(closeset_line, merge_bg_others=False, ignore_idx=0, others_idx=25):
+ """Convert line-json str of closeset to line-json str of openset. Note that
+ this function is designed for closeset-wildreceipt to openset-wildreceipt.
+ It may not be suitable to your own dataset.
+
+ Args:
+ closeset_line (str): The string to be deserialized to
+ the closeset dictionary object.
+ merge_bg_others (bool): If True, give the same label to "background"
+ class and "others" class.
+ ignore_idx (int): Index for ``ignore`` class.
+ others_idx (int): Index for ``others`` class.
+ """
+ # Two labels at the same index of the following two lists
+ # make up a key-value pair. For example, in wildreceipt,
+ # closeset_key_inds[0] maps to "Store_name_key"
+ # and closeset_value_inds[0] maps to "Store_addr_value".
+ closeset_key_inds = list(range(2, others_idx, 2))
+ closeset_value_inds = list(range(1, others_idx, 2))
+
+ openset_node_label_mapping = {'bg': 0, 'key': 1, 'value': 2, 'others': 3}
+ if merge_bg_others:
+ openset_node_label_mapping['others'] = openset_node_label_mapping['bg']
+
+ closeset_obj = json.loads(closeset_line)
+ openset_obj = {
+ 'file_name': closeset_obj['file_name'],
+ 'height': closeset_obj['height'],
+ 'width': closeset_obj['width'],
+ 'annotations': []
+ }
+
+ edge_idx = 1
+ label_to_edge = {}
+ for anno in closeset_obj['annotations']:
+ label = anno['label']
+ if label == ignore_idx:
+ anno['label'] = openset_node_label_mapping['bg']
+ anno['edge'] = edge_idx
+ edge_idx += 1
+ elif label == others_idx:
+ anno['label'] = openset_node_label_mapping['others']
+ anno['edge'] = edge_idx
+ edge_idx += 1
+ else:
+ edge = label_to_edge.get(label, None)
+ if edge is not None:
+ anno['edge'] = edge
+ if label in closeset_key_inds:
+ anno['label'] = openset_node_label_mapping['key']
+ elif label in closeset_value_inds:
+ anno['label'] = openset_node_label_mapping['value']
+ else:
+ tmp_key = 'key'
+ if label in closeset_key_inds:
+ label_with_same_edge = closeset_value_inds[
+ closeset_key_inds.index(label)]
+ elif label in closeset_value_inds:
+ label_with_same_edge = closeset_key_inds[
+ closeset_value_inds.index(label)]
+ tmp_key = 'value'
+ edge_counterpart = label_to_edge.get(label_with_same_edge,
+ None)
+ if edge_counterpart is not None:
+ anno['edge'] = edge_counterpart
+ else:
+ anno['edge'] = edge_idx
+ edge_idx += 1
+ anno['label'] = openset_node_label_mapping[tmp_key]
+ label_to_edge[label] = anno['edge']
+
+ openset_obj['annotations'] = closeset_obj['annotations']
+
+ return json.dumps(openset_obj, ensure_ascii=False)
+
+
+def process(closeset_file, openset_file, merge_bg_others=False, n_proc=10):
+ closeset_lines = list_from_file(closeset_file)
+
+ convert_func = partial(convert, merge_bg_others=merge_bg_others)
+
+ openset_lines = mmcv.track_parallel_progress(
+ convert_func, closeset_lines, nproc=n_proc)
+
+ list_to_file(openset_file, openset_lines)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('in_file', help='Annotation file for closeset.')
+ parser.add_argument('out_file', help='Annotation file for openset.')
+ parser.add_argument(
+ '--merge',
+ action='store_true',
+ help='Merge two classes: "background" and "others" in closeset '
+ 'to one class in openset.')
+ parser.add_argument(
+ '--n_proc', type=int, default=10, help='Number of process.')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+
+ process(args.in_file, args.out_file, args.merge, args.n_proc)
+
+ print('finish')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/data/textdet/coco_to_line_dict.py b/tools/data/textdet/coco_to_line_dict.py
new file mode 100644
index 0000000000000000000000000000000000000000..b8d0583ea7090b27efb0beda1ce60f827c6d90ac
--- /dev/null
+++ b/tools/data/textdet/coco_to_line_dict.py
@@ -0,0 +1,67 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import json
+
+import mmcv
+
+from mmocr.utils import list_to_file
+
+
+def parse_coco_json(in_path):
+ json_obj = mmcv.load(in_path)
+ image_infos = json_obj['images']
+ annotations = json_obj['annotations']
+ imgid2imgname = {}
+ img_ids = []
+ for image_info in image_infos:
+ imgid2imgname[image_info['id']] = image_info
+ img_ids.append(image_info['id'])
+ imgid2anno = {}
+ for img_id in img_ids:
+ imgid2anno[img_id] = []
+ for anno in annotations:
+ img_id = anno['image_id']
+ new_anno = {}
+ new_anno['iscrowd'] = anno['iscrowd']
+ new_anno['category_id'] = anno['category_id']
+ new_anno['bbox'] = anno['bbox']
+ new_anno['segmentation'] = anno['segmentation']
+ if img_id in imgid2anno.keys():
+ imgid2anno[img_id].append(new_anno)
+
+ return imgid2imgname, imgid2anno
+
+
+def gen_line_dict_file(out_path, imgid2imgname, imgid2anno):
+ lines = []
+ for key, value in imgid2imgname.items():
+ if key in imgid2anno:
+ anno = imgid2anno[key]
+ line_dict = {}
+ line_dict['file_name'] = value['file_name']
+ line_dict['height'] = value['height']
+ line_dict['width'] = value['width']
+ line_dict['annotations'] = anno
+ lines.append(json.dumps(line_dict))
+ list_to_file(out_path, lines)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--in-path', help='input json path with coco format')
+ parser.add_argument(
+ '--out-path', help='output txt path with line-json format')
+
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ imgid2imgname, imgid2anno = parse_coco_json(args.in_path)
+ gen_line_dict_file(args.out_path, imgid2imgname, imgid2anno)
+ print('finish')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/data/textdet/ctw1500_converter.py b/tools/data/textdet/ctw1500_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..40dfbc1db6ee04d8599d25cd01a43ee07361def6
--- /dev/null
+++ b/tools/data/textdet/ctw1500_converter.py
@@ -0,0 +1,231 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import glob
+import os.path as osp
+import xml.etree.ElementTree as ET
+from functools import partial
+
+import mmcv
+import numpy as np
+from shapely.geometry import Polygon
+
+from mmocr.utils import convert_annotations, list_from_file
+
+
+def collect_files(img_dir, gt_dir, split):
+ """Collect all images and their corresponding groundtruth files.
+
+ Args:
+ img_dir(str): The image directory
+ gt_dir(str): The groundtruth directory
+ split(str): The split of dataset. Namely: training or test
+
+ Returns:
+ files(list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+
+ # note that we handle png and jpg only. Pls convert others such as gif to
+ # jpg or png offline
+ suffixes = ['.png', '.PNG', '.jpg', '.JPG', '.jpeg', '.JPEG']
+
+ imgs_list = []
+ for suffix in suffixes:
+ imgs_list.extend(glob.glob(osp.join(img_dir, '*' + suffix)))
+
+ files = []
+ if split == 'training':
+ for img_file in imgs_list:
+ gt_file = gt_dir + '/' + osp.splitext(
+ osp.basename(img_file))[0] + '.xml'
+ files.append((img_file, gt_file))
+ assert len(files), f'No images found in {img_dir}'
+ print(f'Loaded {len(files)} images from {img_dir}')
+ elif split == 'test':
+ for img_file in imgs_list:
+ gt_file = gt_dir + '/000' + osp.splitext(
+ osp.basename(img_file))[0] + '.txt'
+ files.append((img_file, gt_file))
+ assert len(files), f'No images found in {img_dir}'
+ print(f'Loaded {len(files)} images from {img_dir}')
+
+ return files
+
+
+def collect_annotations(files, split, nproc=1):
+ """Collect the annotation information.
+
+ Args:
+ files(list): The list of tuples (image_file, groundtruth_file)
+ split(str): The split of dataset. Namely: training or test
+ nproc(int): The number of process to collect annotations
+
+ Returns:
+ images(list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(split, str)
+ assert isinstance(nproc, int)
+
+ load_img_info_with_split = partial(load_img_info, split=split)
+ if nproc > 1:
+ images = mmcv.track_parallel_progress(
+ load_img_info_with_split, files, nproc=nproc)
+ else:
+ images = mmcv.track_progress(load_img_info_with_split, files)
+
+ return images
+
+
+def load_txt_info(gt_file, img_info):
+ anno_info = []
+ for line in list_from_file(gt_file):
+ # each line has one ploygen (n vetices), and one text.
+ # e.g., 695,885,866,888,867,1146,696,1143,####Latin 9
+ line = line.strip()
+ strs = line.split(',')
+ category_id = 1
+ assert strs[28][0] == '#'
+ xy = [int(x) for x in strs[0:28]]
+ assert len(xy) == 28
+ coordinates = np.array(xy).reshape(-1, 2)
+ polygon = Polygon(coordinates)
+ iscrowd = 0
+ area = polygon.area
+ # convert to COCO style XYWH format
+ min_x, min_y, max_x, max_y = polygon.bounds
+ bbox = [min_x, min_y, max_x - min_x, max_y - min_y]
+ text = strs[28][4:]
+
+ anno = dict(
+ iscrowd=iscrowd,
+ category_id=category_id,
+ bbox=bbox,
+ area=area,
+ text=text,
+ segmentation=[xy])
+ anno_info.append(anno)
+ img_info.update(anno_info=anno_info)
+ return img_info
+
+
+def load_xml_info(gt_file, img_info):
+
+ obj = ET.parse(gt_file)
+ anno_info = []
+ for image in obj.getroot(): # image
+ for box in image: # image
+ h = box.attrib['height']
+ w = box.attrib['width']
+ x = box.attrib['left']
+ y = box.attrib['top']
+ text = box[0].text
+ segs = box[1].text
+ pts = segs.strip().split(',')
+ pts = [int(x) for x in pts]
+ assert len(pts) == 28
+ # pts = []
+ # for iter in range(2,len(box)):
+ # pts.extend([int(box[iter].attrib['x']),
+ # int(box[iter].attrib['y'])])
+ iscrowd = 0
+ category_id = 1
+ bbox = [int(x), int(y), int(w), int(h)]
+
+ coordinates = np.array(pts).reshape(-1, 2)
+ polygon = Polygon(coordinates)
+ area = polygon.area
+ anno = dict(
+ iscrowd=iscrowd,
+ category_id=category_id,
+ bbox=bbox,
+ area=area,
+ text=text,
+ segmentation=[pts])
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def load_img_info(files, split):
+ """Load the information of one image.
+
+ Args:
+ files(tuple): The tuple of (img_file, groundtruth_file)
+ split(str): The split of dataset: training or test
+
+ Returns:
+ img_info(dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+ assert isinstance(split, str)
+
+ img_file, gt_file = files
+ # read imgs with ignoring orientations
+ img = mmcv.imread(img_file, 'unchanged')
+
+ split_name = osp.basename(osp.dirname(img_file))
+ img_info = dict(
+ # remove img_prefix for filename
+ file_name=osp.join(split_name, osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ # anno_info=anno_info,
+ segm_file=osp.join(split_name, osp.basename(gt_file)))
+
+ if split == 'training':
+ img_info = load_xml_info(gt_file, img_info)
+ elif split == 'test':
+ img_info = load_txt_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert ctw1500 annotations to COCO format')
+ parser.add_argument('root_path', help='ctw1500 root path')
+ parser.add_argument('-o', '--out-dir', help='output path')
+ parser.add_argument(
+ '--split-list',
+ nargs='+',
+ help='a list of splits. e.g., "--split-list training test"')
+
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ out_dir = args.out_dir if args.out_dir else root_path
+ mmcv.mkdir_or_exist(out_dir)
+
+ img_dir = osp.join(root_path, 'imgs')
+ gt_dir = osp.join(root_path, 'annotations')
+
+ set_name = {}
+ for split in args.split_list:
+ set_name.update({split: 'instances_' + split + '.json'})
+ assert osp.exists(osp.join(img_dir, split))
+
+ for split, json_name in set_name.items():
+ print(f'Converting {split} into {json_name}')
+ with mmcv.Timer(print_tmpl='It takes {}s to convert icdar annotation'):
+ files = collect_files(
+ osp.join(img_dir, split), osp.join(gt_dir, split), split)
+ image_infos = collect_annotations(files, split, nproc=args.nproc)
+ convert_annotations(image_infos, osp.join(out_dir, json_name))
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/data/textdet/funsd_converter.py b/tools/data/textdet/funsd_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..6e3cf5dc8b4daa9da9a215803d45671fe9d8a017
--- /dev/null
+++ b/tools/data/textdet/funsd_converter.py
@@ -0,0 +1,157 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import math
+import os
+import os.path as osp
+
+import mmcv
+
+from mmocr.utils import convert_annotations
+
+
+def collect_files(img_dir, gt_dir):
+ """Collect all images and their corresponding groundtruth files.
+
+ Args:
+ img_dir (str): The image directory
+ gt_dir (str): The groundtruth directory
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+
+ ann_list, imgs_list = [], []
+ for gt_file in os.listdir(gt_dir):
+ ann_list.append(osp.join(gt_dir, gt_file))
+ imgs_list.append(osp.join(img_dir, gt_file.replace('.json', '.png')))
+
+ files = list(zip(sorted(imgs_list), sorted(ann_list)))
+ assert len(files), f'No images found in {img_dir}'
+ print(f'Loaded {len(files)} images from {img_dir}')
+
+ return files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmcv.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmcv.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ assert osp.basename(gt_file).split('.')[0] == osp.basename(img_file).split(
+ '.')[0]
+ # read imgs while ignoring orientations
+ img = mmcv.imread(img_file, 'unchanged')
+
+ img_info = dict(
+ file_name=osp.join(osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.join(osp.basename(gt_file)))
+
+ if osp.splitext(gt_file)[1] == '.json':
+ img_info = load_json_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_json_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ Args:
+ gt_file (str): The path to ground-truth
+ img_info (dict): The dict of the img and annotation information
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ annotation = mmcv.load(gt_file)
+ anno_info = []
+ for form in annotation['form']:
+ for ann in form['words']:
+
+ iscrowd = 1 if len(ann['text']) == 0 else 0
+
+ x1, y1, x2, y2 = ann['box']
+ x = max(0, min(math.floor(x1), math.floor(x2)))
+ y = max(0, min(math.floor(y1), math.floor(y2)))
+ w, h = math.ceil(abs(x2 - x1)), math.ceil(abs(y2 - y1))
+ bbox = [x, y, w, h]
+ segmentation = [x, y, x + w, y, x + w, y + h, x, y + h]
+
+ anno = dict(
+ iscrowd=iscrowd,
+ category_id=1,
+ bbox=bbox,
+ area=w * h,
+ segmentation=[segmentation])
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and test set of FUNSD ')
+ parser.add_argument('root_path', help='Root dir path of FUNSD')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+
+ for split in ['training', 'test']:
+ print(f'Processing {split} set...')
+ with mmcv.Timer(print_tmpl='It takes {}s to convert FUNSD annotation'):
+ files = collect_files(
+ osp.join(root_path, 'imgs'),
+ osp.join(root_path, 'annotations', split))
+ image_infos = collect_annotations(files, nproc=args.nproc)
+ convert_annotations(
+ image_infos, osp.join(root_path,
+ 'instances_' + split + '.json'))
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/data/textdet/icdar_converter.py b/tools/data/textdet/icdar_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..e478f8c62d9aeb81f71f4c595a62309cc9ef5ae5
--- /dev/null
+++ b/tools/data/textdet/icdar_converter.py
@@ -0,0 +1,183 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import glob
+import os.path as osp
+from functools import partial
+
+import mmcv
+import numpy as np
+from shapely.geometry import Polygon
+
+from mmocr.utils import convert_annotations, list_from_file
+
+
+def collect_files(img_dir, gt_dir):
+ """Collect all images and their corresponding groundtruth files.
+
+ Args:
+ img_dir(str): The image directory
+ gt_dir(str): The groundtruth directory
+
+ Returns:
+ files(list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+
+ # note that we handle png and jpg only. Pls convert others such as gif to
+ # jpg or png offline
+ suffixes = ['.png', '.PNG', '.jpg', '.JPG', '.jpeg', '.JPEG']
+ imgs_list = []
+ for suffix in suffixes:
+ imgs_list.extend(glob.glob(osp.join(img_dir, '*' + suffix)))
+
+ files = []
+ for img_file in imgs_list:
+ gt_file = gt_dir + '/gt_' + osp.splitext(
+ osp.basename(img_file))[0] + '.txt'
+ files.append((img_file, gt_file))
+ assert len(files), f'No images found in {img_dir}'
+ print(f'Loaded {len(files)} images from {img_dir}')
+
+ return files
+
+
+def collect_annotations(files, dataset, nproc=1):
+ """Collect the annotation information.
+
+ Args:
+ files(list): The list of tuples (image_file, groundtruth_file)
+ dataset(str): The dataset name, icdar2015 or icdar2017
+ nproc(int): The number of process to collect annotations
+
+ Returns:
+ images(list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(dataset, str)
+ assert dataset
+ assert isinstance(nproc, int)
+
+ load_img_info_with_dataset = partial(load_img_info, dataset=dataset)
+ if nproc > 1:
+ images = mmcv.track_parallel_progress(
+ load_img_info_with_dataset, files, nproc=nproc)
+ else:
+ images = mmcv.track_progress(load_img_info_with_dataset, files)
+
+ return images
+
+
+def load_img_info(files, dataset):
+ """Load the information of one image.
+
+ Args:
+ files(tuple): The tuple of (img_file, groundtruth_file)
+ dataset(str): Dataset name, icdar2015 or icdar2017
+
+ Returns:
+ img_info(dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+ assert isinstance(dataset, str)
+ assert dataset
+
+ img_file, gt_file = files
+ # read imgs with ignoring orientations
+ img = mmcv.imread(img_file, 'unchanged')
+
+ if dataset == 'icdar2017':
+ gt_list = list_from_file(gt_file)
+ elif dataset == 'icdar2015':
+ gt_list = list_from_file(gt_file, encoding='utf-8-sig')
+ else:
+ raise NotImplementedError(f'Not support {dataset}')
+
+ anno_info = []
+ for line in gt_list:
+ # each line has one ploygen (4 vetices), and others.
+ # e.g., 695,885,866,888,867,1146,696,1143,Latin,9
+ line = line.strip()
+ strs = line.split(',')
+ category_id = 1
+ xy = [int(x) for x in strs[0:8]]
+ coordinates = np.array(xy).reshape(-1, 2)
+ polygon = Polygon(coordinates)
+ iscrowd = 0
+ # set iscrowd to 1 to ignore 1.
+ if (dataset == 'icdar2015'
+ and strs[8] == '###') or (dataset == 'icdar2017'
+ and strs[9] == '###'):
+ iscrowd = 1
+ print('ignore text')
+
+ area = polygon.area
+ # convert to COCO style XYWH format
+ min_x, min_y, max_x, max_y = polygon.bounds
+ bbox = [min_x, min_y, max_x - min_x, max_y - min_y]
+
+ anno = dict(
+ iscrowd=iscrowd,
+ category_id=category_id,
+ bbox=bbox,
+ area=area,
+ segmentation=[xy])
+ anno_info.append(anno)
+ split_name = osp.basename(osp.dirname(img_file))
+ img_info = dict(
+ # remove img_prefix for filename
+ file_name=osp.join(split_name, osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ anno_info=anno_info,
+ segm_file=osp.join(split_name, osp.basename(gt_file)))
+ return img_info
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert Icdar2015 or Icdar2017 annotations to COCO format'
+ )
+ parser.add_argument('icdar_path', help='icdar root path')
+ parser.add_argument('-o', '--out-dir', help='output path')
+ parser.add_argument(
+ '-d', '--dataset', required=True, help='icdar2017 or icdar2015')
+ parser.add_argument(
+ '--split-list',
+ nargs='+',
+ help='a list of splits. e.g., "--split-list training test"')
+
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ icdar_path = args.icdar_path
+ out_dir = args.out_dir if args.out_dir else icdar_path
+ mmcv.mkdir_or_exist(out_dir)
+
+ img_dir = osp.join(icdar_path, 'imgs')
+ gt_dir = osp.join(icdar_path, 'annotations')
+
+ set_name = {}
+ for split in args.split_list:
+ set_name.update({split: 'instances_' + split + '.json'})
+ assert osp.exists(osp.join(img_dir, split))
+
+ for split, json_name in set_name.items():
+ print(f'Converting {split} into {json_name}')
+ with mmcv.Timer(print_tmpl='It takes {}s to convert icdar annotation'):
+ files = collect_files(
+ osp.join(img_dir, split), osp.join(gt_dir, split))
+ image_infos = collect_annotations(
+ files, args.dataset, nproc=args.nproc)
+ convert_annotations(image_infos, osp.join(out_dir, json_name))
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/data/textdet/synthtext_converter.py b/tools/data/textdet/synthtext_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..9c7964023037401ea8f2ba51b7e415462498d0d7
--- /dev/null
+++ b/tools/data/textdet/synthtext_converter.py
@@ -0,0 +1,179 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import json
+import os.path as osp
+import time
+
+import lmdb
+import mmcv
+import numpy as np
+from scipy.io import loadmat
+from shapely.geometry import Polygon
+
+from mmocr.utils import check_argument
+
+
+def trace_boundary(char_boxes):
+ """Trace the boundary point of text.
+
+ Args:
+ char_boxes (list[ndarray]): The char boxes for one text. Each element
+ is 4x2 ndarray.
+
+ Returns:
+ boundary (ndarray): The boundary point sets with size nx2.
+ """
+ assert check_argument.is_type_list(char_boxes, np.ndarray)
+
+ # from top left to to right
+ p_top = [box[0:2] for box in char_boxes]
+ # from bottom right to bottom left
+ p_bottom = [
+ char_boxes[idx][[2, 3], :]
+ for idx in range(len(char_boxes) - 1, -1, -1)
+ ]
+
+ p = p_top + p_bottom
+
+ boundary = np.concatenate(p).astype(int)
+
+ return boundary
+
+
+def match_bbox_char_str(bboxes, char_bboxes, strs):
+ """match the bboxes, char bboxes, and strs.
+
+ Args:
+ bboxes (ndarray): The text boxes of size (2, 4, num_box).
+ char_bboxes (ndarray): The char boxes of size (2, 4, num_char_box).
+ strs (ndarray): The string of size (num_strs,)
+ """
+ assert isinstance(bboxes, np.ndarray)
+ assert isinstance(char_bboxes, np.ndarray)
+ assert isinstance(strs, np.ndarray)
+ bboxes = bboxes.astype(np.int32)
+ char_bboxes = char_bboxes.astype(np.int32)
+
+ if len(char_bboxes.shape) == 2:
+ char_bboxes = np.expand_dims(char_bboxes, axis=2)
+ char_bboxes = np.transpose(char_bboxes, (2, 1, 0))
+ if len(bboxes.shape) == 2:
+ bboxes = np.expand_dims(bboxes, axis=2)
+ bboxes = np.transpose(bboxes, (2, 1, 0))
+ chars = ''.join(strs).replace('\n', '').replace(' ', '')
+ num_boxes = bboxes.shape[0]
+
+ poly_list = [Polygon(bboxes[iter]) for iter in range(num_boxes)]
+ poly_box_list = [bboxes[iter] for iter in range(num_boxes)]
+
+ poly_char_list = [[] for iter in range(num_boxes)]
+ poly_char_idx_list = [[] for iter in range(num_boxes)]
+ poly_charbox_list = [[] for iter in range(num_boxes)]
+
+ words = []
+ for s in strs:
+ words += s.split()
+ words_len = [len(w) for w in words]
+ words_end_inx = np.cumsum(words_len)
+ start_inx = 0
+ for word_inx, end_inx in enumerate(words_end_inx):
+ for char_inx in range(start_inx, end_inx):
+ poly_char_idx_list[word_inx].append(char_inx)
+ poly_char_list[word_inx].append(chars[char_inx])
+ poly_charbox_list[word_inx].append(char_bboxes[char_inx])
+ start_inx = end_inx
+
+ for box_inx in range(num_boxes):
+ assert len(poly_charbox_list[box_inx]) > 0
+
+ poly_boundary_list = []
+ for item in poly_charbox_list:
+ boundary = np.ndarray((0, 2))
+ if len(item) > 0:
+ boundary = trace_boundary(item)
+ poly_boundary_list.append(boundary)
+
+ return (poly_list, poly_box_list, poly_boundary_list, poly_charbox_list,
+ poly_char_idx_list, poly_char_list)
+
+
+def convert_annotations(root_path, gt_name, lmdb_name):
+ """Convert the annotation into lmdb dataset.
+
+ Args:
+ root_path (str): The root path of dataset.
+ gt_name (str): The ground truth filename.
+ lmdb_name (str): The output lmdb filename.
+ """
+ assert isinstance(root_path, str)
+ assert isinstance(gt_name, str)
+ assert isinstance(lmdb_name, str)
+ start_time = time.time()
+ gt = loadmat(gt_name)
+ img_num = len(gt['imnames'][0])
+ env = lmdb.open(lmdb_name, map_size=int(1e9 * 40))
+ with env.begin(write=True) as txn:
+ for img_id in range(img_num):
+ if img_id % 1000 == 0 and img_id > 0:
+ total_time_sec = time.time() - start_time
+ avg_time_sec = total_time_sec / img_id
+ eta_mins = (avg_time_sec * (img_num - img_id)) / 60
+ print(f'\ncurrent_img/total_imgs {img_id}/{img_num} | '
+ f'eta: {eta_mins:.3f} mins')
+ # for each img
+ img_file = osp.join(root_path, 'imgs', gt['imnames'][0][img_id][0])
+ img = mmcv.imread(img_file, 'unchanged')
+ height, width = img.shape[0:2]
+ img_json = {}
+ img_json['file_name'] = gt['imnames'][0][img_id][0]
+ img_json['height'] = height
+ img_json['width'] = width
+ img_json['annotations'] = []
+ wordBB = gt['wordBB'][0][img_id]
+ charBB = gt['charBB'][0][img_id]
+ txt = gt['txt'][0][img_id]
+ poly_list, _, poly_boundary_list, _, _, _ = match_bbox_char_str(
+ wordBB, charBB, txt)
+ for poly_inx in range(len(poly_list)):
+
+ polygon = poly_list[poly_inx]
+ min_x, min_y, max_x, max_y = polygon.bounds
+ bbox = [min_x, min_y, max_x - min_x, max_y - min_y]
+ anno_info = dict()
+ anno_info['iscrowd'] = 0
+ anno_info['category_id'] = 1
+ anno_info['bbox'] = bbox
+ anno_info['segmentation'] = [
+ poly_boundary_list[poly_inx].flatten().tolist()
+ ]
+
+ img_json['annotations'].append(anno_info)
+ string = json.dumps(img_json)
+ txn.put(str(img_id).encode('utf8'), string.encode('utf8'))
+ key = 'total_number'.encode('utf8')
+ value = str(img_num).encode('utf8')
+ txn.put(key, value)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert synthtext to lmdb dataset')
+ parser.add_argument('synthtext_path', help='synthetic root path')
+ parser.add_argument('-o', '--out-dir', help='output path')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ synthtext_path = args.synthtext_path
+ out_dir = args.out_dir if args.out_dir else synthtext_path
+ mmcv.mkdir_or_exist(out_dir)
+
+ gt_name = osp.join(synthtext_path, 'gt.mat')
+ lmdb_name = 'synthtext.lmdb'
+ convert_annotations(synthtext_path, gt_name, osp.join(out_dir, lmdb_name))
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/data/textdet/textocr_converter.py b/tools/data/textdet/textocr_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..50b6a62add453a9c6e850aa555d661041a0587fb
--- /dev/null
+++ b/tools/data/textdet/textocr_converter.py
@@ -0,0 +1,75 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import math
+import os.path as osp
+
+import mmcv
+
+from mmocr.utils import convert_annotations
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and validation set of TextOCR ')
+ parser.add_argument('root_path', help='Root dir path of TextOCR')
+ args = parser.parse_args()
+ return args
+
+
+def collect_textocr_info(root_path, annotation_filename, print_every=1000):
+
+ annotation_path = osp.join(root_path, annotation_filename)
+ if not osp.exists(annotation_path):
+ raise Exception(
+ f'{annotation_path} not exists, please check and try again.')
+
+ annotation = mmcv.load(annotation_path)
+
+ # img_idx = img_start_idx
+ img_infos = []
+ for i, img_info in enumerate(annotation['imgs'].values()):
+ if i > 0 and i % print_every == 0:
+ print(f'{i}/{len(annotation["imgs"].values())}')
+
+ img_info['segm_file'] = annotation_path
+ ann_ids = annotation['imgToAnns'][img_info['id']]
+ anno_info = []
+ for ann_id in ann_ids:
+ ann = annotation['anns'][ann_id]
+
+ # Ignore illegible or non-English words
+ text_label = ann['utf8_string']
+ iscrowd = 1 if text_label == '.' else 0
+
+ x, y, w, h = ann['bbox']
+ x, y = max(0, math.floor(x)), max(0, math.floor(y))
+ w, h = math.ceil(w), math.ceil(h)
+ bbox = [x, y, w, h]
+ segmentation = [max(0, int(x)) for x in ann['points']]
+ anno = dict(
+ iscrowd=iscrowd,
+ category_id=1,
+ bbox=bbox,
+ area=ann['area'],
+ segmentation=[segmentation])
+ anno_info.append(anno)
+ img_info.update(anno_info=anno_info)
+ img_infos.append(img_info)
+ return img_infos
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ print('Processing training set...')
+ training_infos = collect_textocr_info(root_path, 'TextOCR_0.1_train.json')
+ convert_annotations(training_infos,
+ osp.join(root_path, 'instances_training.json'))
+ print('Processing validation set...')
+ val_infos = collect_textocr_info(root_path, 'TextOCR_0.1_val.json')
+ convert_annotations(val_infos, osp.join(root_path, 'instances_val.json'))
+ print('Finish')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/data/textdet/totaltext_converter.py b/tools/data/textdet/totaltext_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..abe4739c71bfddef5354db0882382b807f144ec0
--- /dev/null
+++ b/tools/data/textdet/totaltext_converter.py
@@ -0,0 +1,407 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import glob
+import os
+import os.path as osp
+import re
+
+import cv2
+import mmcv
+import numpy as np
+import scipy.io as scio
+import yaml
+from shapely.geometry import Polygon
+
+from mmocr.utils import convert_annotations
+
+
+def collect_files(img_dir, gt_dir, split):
+ """Collect all images and their corresponding groundtruth files.
+
+ Args:
+ img_dir(str): The image directory
+ gt_dir(str): The groundtruth directory
+ split(str): The split of dataset. Namely: training or test
+ Returns:
+ files(list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+
+ # note that we handle png and jpg only. Pls convert others such as gif to
+ # jpg or png offline
+ suffixes = ['.png', '.PNG', '.jpg', '.JPG', '.jpeg', '.JPEG']
+ # suffixes = ['.png']
+
+ imgs_list = []
+ for suffix in suffixes:
+ imgs_list.extend(glob.glob(osp.join(img_dir, '*' + suffix)))
+
+ imgs_list = sorted(imgs_list)
+ ann_list = sorted(
+ [osp.join(gt_dir, gt_file) for gt_file in os.listdir(gt_dir)])
+
+ files = list(zip(imgs_list, ann_list))
+ assert len(files), f'No images found in {img_dir}'
+ print(f'Loaded {len(files)} images from {img_dir}')
+
+ return files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+
+ Args:
+ files(list): The list of tuples (image_file, groundtruth_file)
+ nproc(int): The number of process to collect annotations
+ Returns:
+ images(list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmcv.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmcv.track_progress(load_img_info, files)
+
+ return images
+
+
+def get_contours_mat(gt_path):
+ """Get the contours and words for each ground_truth mat file.
+
+ Args:
+ gt_path(str): The relative path of the ground_truth mat file
+ Returns:
+ contours(list[lists]): A list of lists of contours
+ for the text instances
+ words(list[list]): A list of lists of words (string)
+ for the text instances
+ """
+ assert isinstance(gt_path, str)
+
+ contours = []
+ words = []
+ data = scio.loadmat(gt_path)
+ # 'gt' for the latest version; 'polygt' for the legacy version
+ data_polygt = data.get('polygt', data['gt'])
+
+ for i, lines in enumerate(data_polygt):
+ X = np.array(lines[1])
+ Y = np.array(lines[3])
+
+ point_num = len(X[0])
+ word = lines[4]
+ if len(word) == 0:
+ word = '???'
+ else:
+ word = word[0]
+
+ if word == '#':
+ word = '###'
+ continue
+
+ words.append(word)
+
+ arr = np.concatenate([X, Y]).T
+ contour = []
+ for i in range(point_num):
+ contour.append(arr[i][0])
+ contour.append(arr[i][1])
+ contours.append(np.asarray(contour))
+
+ return contours, words
+
+
+def load_mat_info(img_info, gt_file):
+ """Load the information of one ground truth in .mat format.
+
+ Args:
+ img_info(dict): The dict of only the image information
+ gt_file(str): The relative path of the ground_truth mat
+ file for one image
+ Returns:
+ img_info(dict): The dict of the img and annotation information
+ """
+ assert isinstance(img_info, dict)
+ assert isinstance(gt_file, str)
+
+ contours, texts = get_contours_mat(gt_file)
+ anno_info = []
+ for contour, text in zip(contours, texts):
+ if contour.shape[0] == 2:
+ continue
+ category_id = 1
+ coordinates = np.array(contour).reshape(-1, 2)
+ polygon = Polygon(coordinates)
+ iscrowd = 0
+
+ area = polygon.area
+ # convert to COCO style XYWH format
+ min_x, min_y, max_x, max_y = polygon.bounds
+ bbox = [min_x, min_y, max_x - min_x, max_y - min_y]
+
+ anno = dict(
+ iscrowd=iscrowd,
+ category_id=category_id,
+ bbox=bbox,
+ area=area,
+ text=text,
+ segmentation=[contour])
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def process_line(line, contours, words):
+ """Get the contours and words by processing each line in the gt file.
+
+ Args:
+ line(str): The line in gt file containing annotation info
+ contours(list[lists]): A list of lists of contours
+ for the text instances
+ words(list[list]): A list of lists of words (string)
+ for the text instances
+ Returns:
+ contours(list[lists]): A list of lists of contours
+ for the text instances
+ words(list[list]): A list of lists of words (string)
+ for the text instances
+ """
+
+ line = '{' + line.replace('[[', '[').replace(']]', ']') + '}'
+ ann_dict = re.sub('([0-9]) +([0-9])', r'\1,\2', line)
+ ann_dict = re.sub('([0-9]) +([ 0-9])', r'\1,\2', ann_dict)
+ ann_dict = re.sub('([0-9]) -([0-9])', r'\1,-\2', ann_dict)
+ ann_dict = ann_dict.replace("[u',']", "[u'#']")
+ ann_dict = yaml.safe_load(ann_dict)
+
+ X = np.array([ann_dict['x']])
+ Y = np.array([ann_dict['y']])
+
+ if len(ann_dict['transcriptions']) == 0:
+ word = '???'
+ else:
+ word = ann_dict['transcriptions'][0]
+ if len(ann_dict['transcriptions']) > 1:
+ for ann_word in ann_dict['transcriptions'][1:]:
+ word += ',' + ann_word
+ word = str(eval(word))
+ words.append(word)
+
+ point_num = len(X[0])
+
+ arr = np.concatenate([X, Y]).T
+ contour = []
+ for i in range(point_num):
+ contour.append(arr[i][0])
+ contour.append(arr[i][1])
+ contours.append(np.asarray(contour))
+
+ return contours, words
+
+
+def get_contours_txt(gt_path):
+ """Get the contours and words for each ground_truth txt file.
+
+ Args:
+ gt_path(str): The relative path of the ground_truth mat file
+ Returns:
+ contours(list[lists]): A list of lists of contours
+ for the text instances
+ words(list[list]): A list of lists of words (string)
+ for the text instances
+ """
+ assert isinstance(gt_path, str)
+
+ contours = []
+ words = []
+
+ with open(gt_path, 'r') as f:
+ tmp_line = ''
+ for idx, line in enumerate(f):
+ line = line.strip()
+ if idx == 0:
+ tmp_line = line
+ continue
+ if not line.startswith('x:'):
+ tmp_line += ' ' + line
+ continue
+ else:
+ complete_line = tmp_line
+ tmp_line = line
+ contours, words = process_line(complete_line, contours, words)
+
+ if tmp_line != '':
+ contours, words = process_line(tmp_line, contours, words)
+
+ words = ['###' if word == '#' else word for word in words]
+
+ return contours, words
+
+
+def load_txt_info(gt_file, img_info):
+ """Load the information of one ground truth in .txt format.
+
+ Args:
+ img_info(dict): The dict of only the image information
+ gt_file(str): The relative path of the ground_truth mat
+ file for one image
+ Returns:
+ img_info(dict): The dict of the img and annotation information
+ """
+
+ contours, texts = get_contours_txt(gt_file)
+ anno_info = []
+ for contour, text in zip(contours, texts):
+ if contour.shape[0] == 2:
+ continue
+ category_id = 1
+ coordinates = np.array(contour).reshape(-1, 2)
+ polygon = Polygon(coordinates)
+ iscrowd = 0
+
+ area = polygon.area
+ # convert to COCO style XYWH format
+ min_x, min_y, max_x, max_y = polygon.bounds
+ bbox = [min_x, min_y, max_x - min_x, max_y - min_y]
+
+ anno = dict(
+ iscrowd=iscrowd,
+ category_id=category_id,
+ bbox=bbox,
+ area=area,
+ text=text,
+ segmentation=[contour])
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def load_png_info(gt_file, img_info):
+ """Load the information of one ground truth in .png format.
+
+ Args:
+ gt_file(str): The relative path of the ground_truth file for one image
+ img_info(dict): The dict of only the image information
+ Returns:
+ img_info(dict): The dict of the img and annotation information
+ """
+ assert isinstance(gt_file, str)
+ assert isinstance(img_info, dict)
+ gt_img = cv2.imread(gt_file, 0)
+ contours, _ = cv2.findContours(gt_img, cv2.RETR_EXTERNAL,
+ cv2.CHAIN_APPROX_SIMPLE)
+
+ anno_info = []
+ for contour in contours:
+ if contour.shape[0] == 2:
+ continue
+ category_id = 1
+ xy = np.array(contour).flatten().tolist()
+
+ coordinates = np.array(contour).reshape(-1, 2)
+ polygon = Polygon(coordinates)
+ iscrowd = 0
+
+ area = polygon.area
+ # convert to COCO style XYWH format
+ min_x, min_y, max_x, max_y = polygon.bounds
+ bbox = [min_x, min_y, max_x - min_x, max_y - min_y]
+
+ anno = dict(
+ iscrowd=iscrowd,
+ category_id=category_id,
+ bbox=bbox,
+ area=area,
+ segmentation=[xy])
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def load_img_info(files):
+ """Load the information of one image.
+
+ Args:
+ files(tuple): The tuple of (img_file, groundtruth_file)
+ Returns:
+ img_info(dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ # read imgs with ignoring orientations
+ img = mmcv.imread(img_file, 'unchanged')
+
+ split_name = osp.basename(osp.dirname(img_file))
+ img_info = dict(
+ # remove img_prefix for filename
+ file_name=osp.join(split_name, osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ # anno_info=anno_info,
+ segm_file=osp.join(split_name, osp.basename(gt_file)))
+
+ if osp.splitext(gt_file)[1] == '.mat':
+ img_info = load_mat_info(img_info, gt_file)
+ elif osp.splitext(gt_file)[1] == '.txt':
+ img_info = load_txt_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert totaltext annotations to COCO format')
+ parser.add_argument('root_path', help='totaltext root path')
+ parser.add_argument('-o', '--out-dir', help='output path')
+ parser.add_argument(
+ '--split-list',
+ nargs='+',
+ help='a list of splits. e.g., "--split_list training test"')
+
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ out_dir = args.out_dir if args.out_dir else root_path
+ mmcv.mkdir_or_exist(out_dir)
+
+ img_dir = osp.join(root_path, 'imgs')
+ gt_dir = osp.join(root_path, 'annotations')
+
+ set_name = {}
+ for split in args.split_list:
+ set_name.update({split: 'instances_' + split + '.json'})
+ assert osp.exists(osp.join(img_dir, split))
+
+ for split, json_name in set_name.items():
+ print(f'Converting {split} into {json_name}')
+ with mmcv.Timer(
+ print_tmpl='It takes {}s to convert totaltext annotation'):
+ files = collect_files(
+ osp.join(img_dir, split), osp.join(gt_dir, split), split)
+ image_infos = collect_annotations(files, nproc=args.nproc)
+ convert_annotations(image_infos, osp.join(out_dir, json_name))
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/data/textrecog/funsd_converter.py b/tools/data/textrecog/funsd_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..da9c9e5084786efc885bb2bc500187053977d386
--- /dev/null
+++ b/tools/data/textrecog/funsd_converter.py
@@ -0,0 +1,223 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import json
+import math
+import os
+import os.path as osp
+
+import mmcv
+
+from mmocr.datasets.pipelines.crop import crop_img
+from mmocr.utils.fileio import list_to_file
+
+
+def collect_files(img_dir, gt_dir):
+ """Collect all images and their corresponding groundtruth files.
+
+ Args:
+ img_dir (str): The image directory
+ gt_dir (str): The groundtruth directory
+
+ Returns:
+ files (list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+
+ ann_list, imgs_list = [], []
+ for gt_file in os.listdir(gt_dir):
+ ann_list.append(osp.join(gt_dir, gt_file))
+ imgs_list.append(osp.join(img_dir, gt_file.replace('.json', '.png')))
+
+ files = list(zip(sorted(imgs_list), sorted(ann_list)))
+ assert len(files), f'No images found in {img_dir}'
+ print(f'Loaded {len(files)} images from {img_dir}')
+
+ return files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+
+ Args:
+ files (list): The list of tuples (image_file, groundtruth_file)
+ nproc (int): The number of process to collect annotations
+
+ Returns:
+ images (list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmcv.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmcv.track_progress(load_img_info, files)
+
+ return images
+
+
+def load_img_info(files):
+ """Load the information of one image.
+
+ Args:
+ files (tuple): The tuple of (img_file, groundtruth_file)
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ assert osp.basename(gt_file).split('.')[0] == osp.basename(img_file).split(
+ '.')[0]
+ # read imgs while ignoring orientations
+ img = mmcv.imread(img_file, 'unchanged')
+
+ img_info = dict(
+ file_name=osp.join(osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ segm_file=osp.join(osp.basename(gt_file)))
+
+ if osp.splitext(gt_file)[1] == '.json':
+ img_info = load_json_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def load_json_info(gt_file, img_info):
+ """Collect the annotation information.
+
+ Args:
+ gt_file (str): The path to ground-truth
+ img_info (dict): The dict of the img and annotation information
+
+ Returns:
+ img_info (dict): The dict of the img and annotation information
+ """
+
+ annotation = mmcv.load(gt_file)
+ anno_info = []
+ for form in annotation['form']:
+ for ann in form['words']:
+
+ # Ignore illegible samples
+ if len(ann['text']) == 0:
+ continue
+
+ x1, y1, x2, y2 = ann['box']
+ x = max(0, min(math.floor(x1), math.floor(x2)))
+ y = max(0, min(math.floor(y1), math.floor(y2)))
+ w, h = math.ceil(abs(x2 - x1)), math.ceil(abs(y2 - y1))
+ bbox = [x, y, x + w, y, x + w, y + h, x, y + h]
+ word = ann['text']
+
+ anno = dict(bbox=bbox, word=word)
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+
+ return img_info
+
+
+def generate_ann(root_path, split, image_infos, preserve_vertical, format):
+ """Generate cropped annotations and label txt file.
+
+ Args:
+ root_path (str): The root path of the dataset
+ split (str): The split of dataset. Namely: training or test
+ image_infos (list[dict]): A list of dicts of the img and
+ annotation information
+ preserve_vertical (bool): Whether to preserve vertical texts
+ format (str): Using jsonl(dict) or str to format annotations
+ """
+
+ dst_image_root = osp.join(root_path, 'dst_imgs', split)
+ if split == 'training':
+ dst_label_file = osp.join(root_path, 'train_label.txt')
+ elif split == 'test':
+ dst_label_file = osp.join(root_path, 'test_label.txt')
+ os.makedirs(dst_image_root, exist_ok=True)
+
+ lines = []
+ for image_info in image_infos:
+ index = 1
+ src_img_path = osp.join(root_path, 'imgs', image_info['file_name'])
+ image = mmcv.imread(src_img_path)
+ src_img_root = image_info['file_name'].split('.')[0]
+
+ for anno in image_info['anno_info']:
+ word = anno['word']
+ dst_img = crop_img(image, anno['bbox'])
+ h, w, _ = dst_img.shape
+
+ # Skip invalid annotations
+ if min(dst_img.shape) == 0:
+ continue
+ # Skip vertical texts
+ if not preserve_vertical and h / w > 2:
+ continue
+
+ dst_img_name = f'{src_img_root}_{index}.png'
+ index += 1
+ dst_img_path = osp.join(dst_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+ if format == 'txt':
+ lines.append(f'{osp.basename(dst_image_root)}/{dst_img_name} '
+ f'{word}')
+ elif format == 'jsonl':
+ lines.append(
+ json.dumps({
+ 'filename':
+ f'{osp.basename(dst_image_root)}/{dst_img_name}',
+ 'text': word
+ }),
+ ensure_ascii=False)
+ else:
+ raise NotImplementedError
+
+ list_to_file(dst_label_file, lines)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and test set of FUNSD ')
+ parser.add_argument('root_path', help='Root dir path of FUNSD')
+ parser.add_argument(
+ '--preserve_vertical',
+ help='Preserve samples containing vertical texts',
+ action='store_true')
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='Number of processes')
+ parser.add_argument(
+ '--format',
+ default='jsonl',
+ help='Use jsonl or string to format annotations',
+ choices=['jsonl', 'txt'])
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+
+ for split in ['training', 'test']:
+ print(f'Processing {split} set...')
+ with mmcv.Timer(print_tmpl='It takes {}s to convert FUNSD annotation'):
+ files = collect_files(
+ osp.join(root_path, 'imgs'),
+ osp.join(root_path, 'annotations', split))
+ image_infos = collect_annotations(files, nproc=args.nproc)
+ generate_ann(root_path, split, image_infos, args.preserve_vertical,
+ args.format)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/data/textrecog/openvino_converter.py b/tools/data/textrecog/openvino_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..6c00d8024ae1b9eda0054fb0ca9f8f431b69da0d
--- /dev/null
+++ b/tools/data/textrecog/openvino_converter.py
@@ -0,0 +1,116 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+import os
+import os.path as osp
+from argparse import ArgumentParser
+from functools import partial
+
+import mmcv
+from PIL import Image
+
+from mmocr.utils.fileio import list_to_file
+
+
+def parse_args():
+ parser = ArgumentParser(description='Generate training and validation set '
+ 'of OpenVINO annotations for Open '
+ 'Images by cropping box image.')
+ parser.add_argument(
+ 'root_path', help='Root dir containing images and annotations')
+ parser.add_argument(
+ 'n_proc', default=1, type=int, help='Number of processes to run')
+ args = parser.parse_args()
+ return args
+
+
+def process_img(args, src_image_root, dst_image_root):
+ # Dirty hack for multi-processing
+ img_idx, img_info, anns = args
+ src_img = Image.open(osp.join(src_image_root, img_info['file_name']))
+ labels = []
+ for ann_idx, ann in enumerate(anns):
+ attrs = ann['attributes']
+ text_label = attrs['transcription']
+
+ # Ignore illegible or non-English words
+ if not attrs['legible'] or attrs['language'] != 'english':
+ continue
+
+ x, y, w, h = ann['bbox']
+ x, y = max(0, math.floor(x)), max(0, math.floor(y))
+ w, h = math.ceil(w), math.ceil(h)
+ dst_img = src_img.crop((x, y, x + w, y + h))
+ dst_img_name = f'img_{img_idx}_{ann_idx}.jpg'
+ dst_img_path = osp.join(dst_image_root, dst_img_name)
+ # Preserve JPEG quality
+ dst_img.save(dst_img_path, qtables=src_img.quantization)
+ labels.append(f'{osp.basename(dst_image_root)}/{dst_img_name}'
+ f' {text_label}')
+ src_img.close()
+ return labels
+
+
+def convert_openimages(root_path,
+ dst_image_path,
+ dst_label_filename,
+ annotation_filename,
+ img_start_idx=0,
+ nproc=1):
+ annotation_path = osp.join(root_path, annotation_filename)
+ if not osp.exists(annotation_path):
+ raise Exception(
+ f'{annotation_path} not exists, please check and try again.')
+ src_image_root = root_path
+
+ # outputs
+ dst_label_file = osp.join(root_path, dst_label_filename)
+ dst_image_root = osp.join(root_path, dst_image_path)
+ os.makedirs(dst_image_root, exist_ok=True)
+
+ annotation = mmcv.load(annotation_path)
+
+ process_img_with_path = partial(
+ process_img,
+ src_image_root=src_image_root,
+ dst_image_root=dst_image_root)
+ tasks = []
+ anns = {}
+ for ann in annotation['annotations']:
+ anns.setdefault(ann['image_id'], []).append(ann)
+ for img_idx, img_info in enumerate(annotation['images']):
+ tasks.append((img_idx + img_start_idx, img_info, anns[img_info['id']]))
+ labels_list = mmcv.track_parallel_progress(
+ process_img_with_path, tasks, keep_order=True, nproc=nproc)
+ final_labels = []
+ for label_list in labels_list:
+ final_labels += label_list
+ list_to_file(dst_label_file, final_labels)
+ return len(annotation['images'])
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ print('Processing training set...')
+ num_train_imgs = 0
+ for s in '125f':
+ num_train_imgs = convert_openimages(
+ root_path=root_path,
+ dst_image_path=f'image_{s}',
+ dst_label_filename=f'train_{s}_label.txt',
+ annotation_filename=f'text_spotting_openimages_v5_train_{s}.json',
+ img_start_idx=num_train_imgs,
+ nproc=args.n_proc)
+ print('Processing validation set...')
+ convert_openimages(
+ root_path=root_path,
+ dst_image_path='image_val',
+ dst_label_filename='val_label.txt',
+ annotation_filename='text_spotting_openimages_v5_validation.json',
+ img_start_idx=num_train_imgs,
+ nproc=args.n_proc)
+ print('Finish')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/data/textrecog/seg_synthtext_converter.py b/tools/data/textrecog/seg_synthtext_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..2d3e192810e6fd5cbb85a3dec1cf5f4f9febf83e
--- /dev/null
+++ b/tools/data/textrecog/seg_synthtext_converter.py
@@ -0,0 +1,89 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import json
+import os.path as osp
+
+import cv2
+
+from mmocr.utils import list_from_file, list_to_file
+
+
+def parse_old_label(data_root, in_path, img_size=False):
+ imgid2imgname = {}
+ imgid2anno = {}
+ idx = 0
+ for line in list_from_file(in_path):
+ line = line.strip().split()
+ img_full_path = osp.join(data_root, line[0])
+ if not osp.exists(img_full_path):
+ continue
+ ann_file = osp.join(data_root, line[1])
+ if not osp.exists(ann_file):
+ continue
+
+ img_info = {}
+ img_info['file_name'] = line[0]
+ if img_size:
+ img = cv2.imread(img_full_path)
+ h, w = img.shape[:2]
+ img_info['height'] = h
+ img_info['width'] = w
+ imgid2imgname[idx] = img_info
+
+ imgid2anno[idx] = []
+ char_annos = []
+ for t, ann_line in enumerate(list_from_file(ann_file)):
+ ann_line = ann_line.strip()
+ if t == 0:
+ img_info['text'] = ann_line
+ else:
+ char_box = [float(x) for x in ann_line.split()]
+ char_text = img_info['text'][t - 1]
+ char_ann = dict(char_box=char_box, char_text=char_text)
+ char_annos.append(char_ann)
+ imgid2anno[idx] = char_annos
+ idx += 1
+
+ return imgid2imgname, imgid2anno
+
+
+def gen_line_dict_file(out_path, imgid2imgname, imgid2anno, img_size=False):
+ lines = []
+ for key, value in imgid2imgname.items():
+ if key in imgid2anno:
+ anno = imgid2anno[key]
+ line_dict = {}
+ line_dict['file_name'] = value['file_name']
+ line_dict['text'] = value['text']
+ if img_size:
+ line_dict['height'] = value['height']
+ line_dict['width'] = value['width']
+ line_dict['annotations'] = anno
+ lines.append(json.dumps(line_dict))
+ list_to_file(out_path, lines)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ '--data-root', help='data root for both image file and anno file')
+ parser.add_argument(
+ '--in-path',
+ help='mapping file of image_name and ann_file,'
+ ' "image_name ann_file" in each line')
+ parser.add_argument(
+ '--out-path', help='output txt path with line-json format')
+
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ imgid2imgname, imgid2anno = parse_old_label(args.data_root, args.in_path)
+ gen_line_dict_file(args.out_path, imgid2imgname, imgid2anno)
+ print('finish')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/data/textrecog/svt_converter.py b/tools/data/textrecog/svt_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..0ecb3e73ea1fbdffda423957243b878188d782c6
--- /dev/null
+++ b/tools/data/textrecog/svt_converter.py
@@ -0,0 +1,83 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+import xml.etree.ElementTree as ET
+
+import cv2
+
+from mmocr.utils.fileio import list_to_file
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate testset of svt by cropping box image.')
+ parser.add_argument(
+ 'root_path',
+ help='Root dir path of svt, where test.xml in,'
+ 'for example, "data/mixture/svt/svt1/"')
+ parser.add_argument(
+ '--resize',
+ action='store_true',
+ help='Whether resize cropped image to certain size.')
+ parser.add_argument('--height', default=32, help='Resize height.')
+ parser.add_argument('--width', default=100, help='Resize width.')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+
+ # inputs
+ src_label_file = osp.join(root_path, 'test.xml')
+ if not osp.exists(src_label_file):
+ raise Exception(
+ f'{src_label_file} not exists, please check and try again.')
+ src_image_root = root_path
+
+ # outputs
+ dst_label_file = osp.join(root_path, 'test_label.txt')
+ dst_image_root = osp.join(root_path, 'image')
+ os.makedirs(dst_image_root, exist_ok=True)
+
+ tree = ET.parse(src_label_file)
+ root = tree.getroot()
+
+ index = 1
+ lines = []
+ total_img_num = len(root)
+ i = 1
+ for image_node in root.findall('image'):
+ image_name = image_node.find('imageName').text
+ print(f'[{i}/{total_img_num}] Process image: {image_name}')
+ i += 1
+ lexicon = image_node.find('lex').text.lower()
+ lexicon_list = lexicon.split(',')
+ lex_size = len(lexicon_list)
+ src_img = cv2.imread(osp.join(src_image_root, image_name))
+ for rectangle in image_node.find('taggedRectangles'):
+ x = int(rectangle.get('x'))
+ y = int(rectangle.get('y'))
+ w = int(rectangle.get('width'))
+ h = int(rectangle.get('height'))
+ rb, re = max(0, y), max(0, y + h)
+ cb, ce = max(0, x), max(0, x + w)
+ dst_img = src_img[rb:re, cb:ce]
+ text_label = rectangle.find('tag').text.lower()
+ if args.resize:
+ dst_img = cv2.resize(dst_img, (args.width, args.height))
+ dst_img_name = f'img_{index:04}' + '.jpg'
+ index += 1
+ dst_img_path = osp.join(dst_image_root, dst_img_name)
+ cv2.imwrite(dst_img_path, dst_img)
+ lines.append(f'{osp.basename(dst_image_root)}/{dst_img_name} '
+ f'{text_label} {lex_size} {lexicon}')
+ list_to_file(dst_label_file, lines)
+ print(f'Finish to generate svt testset, '
+ f'with label file {dst_label_file}')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/data/textrecog/synthtext_converter.py b/tools/data/textrecog/synthtext_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..aa004926adff04b7a37d51c2a4830ff958732886
--- /dev/null
+++ b/tools/data/textrecog/synthtext_converter.py
@@ -0,0 +1,144 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+from functools import partial
+
+import mmcv
+import numpy as np
+from scipy.io import loadmat
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Crop images in Synthtext-style dataset in '
+ 'prepration for MMOCR\'s use')
+ parser.add_argument(
+ 'anno_path', help='Path to gold annotation data (gt.mat)')
+ parser.add_argument('img_path', help='Path to images')
+ parser.add_argument('out_dir', help='Path of output images and labels')
+ parser.add_argument(
+ '--n_proc',
+ default=1,
+ type=int,
+ help='Number of processes to run with')
+ args = parser.parse_args()
+ return args
+
+
+def load_gt_datum(datum):
+ img_path, txt, wordBB, charBB = datum
+ words = []
+ word_bboxes = []
+ char_bboxes = []
+
+ # when there's only one word in txt
+ # scipy will load it as a string
+ if type(txt) is str:
+ words = txt.split()
+ else:
+ for line in txt:
+ words += line.split()
+
+ # From (2, 4, num_boxes) to (num_boxes, 4, 2)
+ if len(wordBB.shape) == 2:
+ wordBB = wordBB[:, :, np.newaxis]
+ cur_wordBB = wordBB.transpose(2, 1, 0)
+ for box in cur_wordBB:
+ word_bboxes.append(
+ [max(round(coord), 0) for pt in box for coord in pt])
+
+ # Validate word bboxes.
+ if len(words) != len(word_bboxes):
+ return
+
+ # From (2, 4, num_boxes) to (num_boxes, 4, 2)
+ cur_charBB = charBB.transpose(2, 1, 0)
+ for box in cur_charBB:
+ char_bboxes.append(
+ [max(round(coord), 0) for pt in box for coord in pt])
+
+ char_bbox_idx = 0
+ char_bbox_grps = []
+
+ for word in words:
+ temp_bbox = char_bboxes[char_bbox_idx:char_bbox_idx + len(word)]
+ char_bbox_idx += len(word)
+ char_bbox_grps.append(temp_bbox)
+
+ # Validate char bboxes.
+ # If the length of the last char bbox is correct, then
+ # all the previous bboxes are also valid
+ if len(char_bbox_grps[len(words) - 1]) != len(words[-1]):
+ return
+
+ return img_path, words, word_bboxes, char_bbox_grps
+
+
+def load_gt_data(filename, n_proc):
+ mat_data = loadmat(filename, simplify_cells=True)
+ imnames = mat_data['imnames']
+ txt = mat_data['txt']
+ wordBB = mat_data['wordBB']
+ charBB = mat_data['charBB']
+ return mmcv.track_parallel_progress(
+ load_gt_datum, list(zip(imnames, txt, wordBB, charBB)), nproc=n_proc)
+
+
+def process(data, img_path_prefix, out_dir):
+ if data is None:
+ return
+ # Dirty hack for multi-processing
+ img_path, words, word_bboxes, char_bbox_grps = data
+ img_dir, img_name = os.path.split(img_path)
+ img_name = os.path.splitext(img_name)[0]
+ input_img = mmcv.imread(os.path.join(img_path_prefix, img_path))
+
+ output_sub_dir = os.path.join(out_dir, img_dir)
+ if not os.path.exists(output_sub_dir):
+ try:
+ os.makedirs(output_sub_dir)
+ except FileExistsError:
+ pass # occurs when multi-proessing
+
+ for i, word in enumerate(words):
+ output_image_patch_name = f'{img_name}_{i}.png'
+ output_label_name = f'{img_name}_{i}.txt'
+ output_image_patch_path = os.path.join(output_sub_dir,
+ output_image_patch_name)
+ output_label_path = os.path.join(output_sub_dir, output_label_name)
+ if os.path.exists(output_image_patch_path) and os.path.exists(
+ output_label_path):
+ continue
+
+ word_bbox = word_bboxes[i]
+ min_x, max_x = int(min(word_bbox[::2])), int(max(word_bbox[::2]))
+ min_y, max_y = int(min(word_bbox[1::2])), int(max(word_bbox[1::2]))
+ cropped_img = input_img[min_y:max_y, min_x:max_x]
+ if cropped_img.shape[0] <= 0 or cropped_img.shape[1] <= 0:
+ continue
+
+ char_bbox_grp = np.array(char_bbox_grps[i])
+ char_bbox_grp[:, ::2] -= min_x
+ char_bbox_grp[:, 1::2] -= min_y
+
+ mmcv.imwrite(cropped_img, output_image_patch_path)
+ with open(output_label_path, 'w') as output_label_file:
+ output_label_file.write(word + '\n')
+ for cbox in char_bbox_grp:
+ output_label_file.write('%d %d %d %d %d %d %d %d\n' %
+ tuple(cbox.tolist()))
+
+
+def main():
+ args = parse_args()
+ print('Loading annoataion data...')
+ data = load_gt_data(args.anno_path, args.n_proc)
+ process_with_outdir = partial(
+ process, img_path_prefix=args.img_path, out_dir=args.out_dir)
+ print('Creating cropped images and gold labels...')
+ mmcv.track_parallel_progress(process_with_outdir, data, nproc=args.n_proc)
+ print('Done')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/data/textrecog/textocr_converter.py b/tools/data/textrecog/textocr_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..2c16178861dcd4c84b1ce0215276d1138c57cf15
--- /dev/null
+++ b/tools/data/textrecog/textocr_converter.py
@@ -0,0 +1,108 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import math
+import os
+import os.path as osp
+from functools import partial
+
+import mmcv
+
+from mmocr.utils.fileio import list_to_file
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Generate training and validation set of TextOCR '
+ 'by cropping box image.')
+ parser.add_argument('root_path', help='Root dir path of TextOCR')
+ parser.add_argument(
+ 'n_proc', default=1, type=int, help='Number of processes to run')
+ args = parser.parse_args()
+ return args
+
+
+def process_img(args, src_image_root, dst_image_root):
+ # Dirty hack for multi-processing
+ img_idx, img_info, anns = args
+ src_img = mmcv.imread(osp.join(src_image_root, img_info['file_name']))
+ labels = []
+ for ann_idx, ann in enumerate(anns):
+ text_label = ann['utf8_string']
+
+ # Ignore illegible or non-English words
+ if text_label == '.':
+ continue
+
+ x, y, w, h = ann['bbox']
+ x, y = max(0, math.floor(x)), max(0, math.floor(y))
+ w, h = math.ceil(w), math.ceil(h)
+ dst_img = src_img[y:y + h, x:x + w]
+ dst_img_name = f'img_{img_idx}_{ann_idx}.jpg'
+ dst_img_path = osp.join(dst_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+ labels.append(f'{osp.basename(dst_image_root)}/{dst_img_name}'
+ f' {text_label}')
+ return labels
+
+
+def convert_textocr(root_path,
+ dst_image_path,
+ dst_label_filename,
+ annotation_filename,
+ img_start_idx=0,
+ nproc=1):
+
+ annotation_path = osp.join(root_path, annotation_filename)
+ if not osp.exists(annotation_path):
+ raise Exception(
+ f'{annotation_path} not exists, please check and try again.')
+ src_image_root = root_path
+
+ # outputs
+ dst_label_file = osp.join(root_path, dst_label_filename)
+ dst_image_root = osp.join(root_path, dst_image_path)
+ os.makedirs(dst_image_root, exist_ok=True)
+
+ annotation = mmcv.load(annotation_path)
+
+ process_img_with_path = partial(
+ process_img,
+ src_image_root=src_image_root,
+ dst_image_root=dst_image_root)
+ tasks = []
+ for img_idx, img_info in enumerate(annotation['imgs'].values()):
+ ann_ids = annotation['imgToAnns'][img_info['id']]
+ anns = [annotation['anns'][ann_id] for ann_id in ann_ids]
+ tasks.append((img_idx + img_start_idx, img_info, anns))
+ labels_list = mmcv.track_parallel_progress(
+ process_img_with_path, tasks, keep_order=True, nproc=nproc)
+ final_labels = []
+ for label_list in labels_list:
+ final_labels += label_list
+ list_to_file(dst_label_file, final_labels)
+ return len(annotation['imgs'])
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ print('Processing training set...')
+ num_train_imgs = convert_textocr(
+ root_path=root_path,
+ dst_image_path='image',
+ dst_label_filename='train_label.txt',
+ annotation_filename='TextOCR_0.1_train.json',
+ nproc=args.n_proc)
+ print('Processing validation set...')
+ convert_textocr(
+ root_path=root_path,
+ dst_image_path='image',
+ dst_label_filename='val_label.txt',
+ annotation_filename='TextOCR_0.1_val.json',
+ img_start_idx=num_train_imgs,
+ nproc=args.n_proc)
+ print('Finish')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/data/textrecog/totaltext_converter.py b/tools/data/textrecog/totaltext_converter.py
new file mode 100644
index 0000000000000000000000000000000000000000..38b5b9f4fc4f2b99c83f493dadd17d6ae7e3e01a
--- /dev/null
+++ b/tools/data/textrecog/totaltext_converter.py
@@ -0,0 +1,386 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import glob
+import os
+import os.path as osp
+import re
+
+import mmcv
+import numpy as np
+import scipy.io as scio
+import yaml
+from shapely.geometry import Polygon
+
+from mmocr.datasets.pipelines.crop import crop_img
+from mmocr.utils.fileio import list_to_file
+
+
+def collect_files(img_dir, gt_dir, split):
+ """Collect all images and their corresponding groundtruth files.
+
+ Args:
+ img_dir(str): The image directory
+ gt_dir(str): The groundtruth directory
+ split(str): The split of dataset. Namely: training or test
+ Returns:
+ files(list): The list of tuples (img_file, groundtruth_file)
+ """
+ assert isinstance(img_dir, str)
+ assert img_dir
+ assert isinstance(gt_dir, str)
+ assert gt_dir
+
+ # note that we handle png and jpg only. Pls convert others such as gif to
+ # jpg or png offline
+ suffixes = ['.png', '.PNG', '.jpg', '.JPG', '.jpeg', '.JPEG']
+ # suffixes = ['.png']
+
+ imgs_list = []
+ for suffix in suffixes:
+ imgs_list.extend(glob.glob(osp.join(img_dir, '*' + suffix)))
+
+ imgs_list = sorted(imgs_list)
+ ann_list = sorted(
+ [osp.join(gt_dir, gt_file) for gt_file in os.listdir(gt_dir)])
+
+ files = [(img_file, gt_file)
+ for (img_file, gt_file) in zip(imgs_list, ann_list)]
+ assert len(files), f'No images found in {img_dir}'
+ print(f'Loaded {len(files)} images from {img_dir}')
+
+ return files
+
+
+def collect_annotations(files, nproc=1):
+ """Collect the annotation information.
+
+ Args:
+ files(list): The list of tuples (image_file, groundtruth_file)
+ nproc(int): The number of process to collect annotations
+ Returns:
+ images(list): The list of image information dicts
+ """
+ assert isinstance(files, list)
+ assert isinstance(nproc, int)
+
+ if nproc > 1:
+ images = mmcv.track_parallel_progress(
+ load_img_info, files, nproc=nproc)
+ else:
+ images = mmcv.track_progress(load_img_info, files)
+
+ return images
+
+
+def get_contours_mat(gt_path):
+ """Get the contours and words for each ground_truth mat file.
+
+ Args:
+ gt_path(str): The relative path of the ground_truth mat file
+ Returns:
+ contours(list[lists]): A list of lists of contours
+ for the text instances
+ words(list[list]): A list of lists of words (string)
+ for the text instances
+ """
+ assert isinstance(gt_path, str)
+
+ contours = []
+ words = []
+ data = scio.loadmat(gt_path)
+ data_polygt = data['polygt']
+
+ for i, lines in enumerate(data_polygt):
+ X = np.array(lines[1])
+ Y = np.array(lines[3])
+
+ point_num = len(X[0])
+ word = lines[4]
+ if len(word) == 0:
+ word = '???'
+ else:
+ word = word[0]
+
+ if word == '#':
+ word = '###'
+ continue
+
+ words.append(word)
+
+ arr = np.concatenate([X, Y]).T
+ contour = []
+ for i in range(point_num):
+ contour.append(arr[i][0])
+ contour.append(arr[i][1])
+ contours.append(np.asarray(contour))
+
+ return contours, words
+
+
+def load_mat_info(img_info, gt_file):
+ """Load the information of one ground truth in .mat format.
+
+ Args:
+ img_info(dict): The dict of only the image information
+ gt_file(str): The relative path of the ground_truth mat
+ file for one image
+ Returns:
+ img_info(dict): The dict of the img and annotation information
+ """
+ assert isinstance(img_info, dict)
+ assert isinstance(gt_file, str)
+
+ contours, words = get_contours_mat(gt_file)
+ anno_info = []
+ for contour, word in zip(contours, words):
+ if contour.shape[0] == 2:
+ continue
+ coordinates = np.array(contour).reshape(-1, 2)
+ polygon = Polygon(coordinates)
+
+ # convert to COCO style XYWH format
+ min_x, min_y, max_x, max_y = polygon.bounds
+ bbox = [min_x, min_y, max_x, min_y, max_x, max_y, min_x, max_y]
+ anno = dict(word=word, bbox=bbox)
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+ return img_info
+
+
+def process_line(line, contours, words):
+ """Get the contours and words by processing each line in the gt file.
+
+ Args:
+ line(str): The line in gt file containing annotation info
+ contours(list[lists]): A list of lists of contours
+ for the text instances
+ words(list[list]): A list of lists of words (string)
+ for the text instances
+ Returns:
+ contours(list[lists]): A list of lists of contours
+ for the text instances
+ words(list[list]): A list of lists of words (string)
+ for the text instances
+ """
+
+ line = '{' + line.replace('[[', '[').replace(']]', ']') + '}'
+ ann_dict = re.sub('([0-9]) +([0-9])', r'\1,\2', line)
+ ann_dict = re.sub('([0-9]) +([ 0-9])', r'\1,\2', ann_dict)
+ ann_dict = re.sub('([0-9]) -([0-9])', r'\1,-\2', ann_dict)
+ ann_dict = ann_dict.replace("[u',']", "[u'#']")
+ ann_dict = yaml.safe_load(ann_dict)
+
+ X = np.array([ann_dict['x']])
+ Y = np.array([ann_dict['y']])
+
+ if len(ann_dict['transcriptions']) == 0:
+ word = '???'
+ else:
+ word = ann_dict['transcriptions'][0]
+ if len(ann_dict['transcriptions']) > 1:
+ for ann_word in ann_dict['transcriptions'][1:]:
+ word += ',' + ann_word
+ word = str(eval(word))
+ words.append(word)
+
+ point_num = len(X[0])
+
+ arr = np.concatenate([X, Y]).T
+ contour = []
+ for i in range(point_num):
+ contour.append(arr[i][0])
+ contour.append(arr[i][1])
+ contours.append(np.asarray(contour))
+
+ return contours, words
+
+
+def get_contours_txt(gt_path):
+ """Get the contours and words for each ground_truth txt file.
+
+ Args:
+ gt_path(str): The relative path of the ground_truth mat file
+ Returns:
+ contours(list[lists]): A list of lists of contours
+ for the text instances
+ words(list[list]): A list of lists of words (string)
+ for the text instances
+ """
+ assert isinstance(gt_path, str)
+
+ contours = []
+ words = []
+
+ with open(gt_path, 'r') as f:
+ tmp_line = ''
+ for idx, line in enumerate(f):
+ line = line.strip()
+ if idx == 0:
+ tmp_line = line
+ continue
+ if not line.startswith('x:'):
+ tmp_line += ' ' + line
+ continue
+ else:
+ complete_line = tmp_line
+ tmp_line = line
+ contours, words = process_line(complete_line, contours, words)
+
+ if tmp_line != '':
+ contours, words = process_line(tmp_line, contours, words)
+
+ for word in words:
+
+ if word == '#':
+ word = '###'
+ continue
+
+ return contours, words
+
+
+def load_txt_info(gt_file, img_info):
+ """Load the information of one ground truth in .txt format.
+
+ Args:
+ img_info(dict): The dict of only the image information
+ gt_file(str): The relative path of the ground_truth mat
+ file for one image
+ Returns:
+ img_info(dict): The dict of the img and annotation information
+ """
+
+ contours, words = get_contours_txt(gt_file)
+ anno_info = []
+ for contour, word in zip(contours, words):
+ if contour.shape[0] == 2:
+ continue
+ coordinates = np.array(contour).reshape(-1, 2)
+ polygon = Polygon(coordinates)
+
+ # convert to COCO style XYWH format
+ min_x, min_y, max_x, max_y = polygon.bounds
+ bbox = [min_x, min_y, max_x, min_y, max_x, max_y, min_x, max_y]
+ anno = dict(word=word, bbox=bbox)
+ anno_info.append(anno)
+
+ img_info.update(anno_info=anno_info)
+ return img_info
+
+
+def generate_ann(root_path, split, image_infos):
+ """Generate cropped annotations and label txt file.
+
+ Args:
+ root_path(str): The relative path of the totaltext file
+ split(str): The split of dataset. Namely: training or test
+ image_infos(list[dict]): A list of dicts of the img and
+ annotation information
+ """
+
+ dst_image_root = osp.join(root_path, 'dst_imgs', split)
+ if split == 'training':
+ dst_label_file = osp.join(root_path, 'train_label.txt')
+ elif split == 'test':
+ dst_label_file = osp.join(root_path, 'test_label.txt')
+ os.makedirs(dst_image_root, exist_ok=True)
+
+ lines = []
+ for image_info in image_infos:
+ index = 1
+ src_img_path = osp.join(root_path, 'imgs', image_info['file_name'])
+ image = mmcv.imread(src_img_path)
+ src_img_root = osp.splitext(image_info['file_name'])[0].split('/')[1]
+
+ for anno in image_info['anno_info']:
+ word = anno['word']
+ dst_img = crop_img(image, anno['bbox'])
+
+ # Skip invalid annotations
+ if min(dst_img.shape) == 0:
+ continue
+
+ dst_img_name = f'{src_img_root}_{index}.png'
+ index += 1
+ dst_img_path = osp.join(dst_image_root, dst_img_name)
+ mmcv.imwrite(dst_img, dst_img_path)
+ lines.append(f'{osp.basename(dst_image_root)}/{dst_img_name} '
+ f'{word}')
+ list_to_file(dst_label_file, lines)
+
+
+def load_img_info(files):
+ """Load the information of one image.
+
+ Args:
+ files(tuple): The tuple of (img_file, groundtruth_file)
+ Returns:
+ img_info(dict): The dict of the img and annotation information
+ """
+ assert isinstance(files, tuple)
+
+ img_file, gt_file = files
+ # read imgs with ignoring orientations
+ img = mmcv.imread(img_file, 'unchanged')
+
+ split_name = osp.basename(osp.dirname(img_file))
+ img_info = dict(
+ # remove img_prefix for filename
+ file_name=osp.join(split_name, osp.basename(img_file)),
+ height=img.shape[0],
+ width=img.shape[1],
+ # anno_info=anno_info,
+ segm_file=osp.join(split_name, osp.basename(gt_file)))
+
+ if osp.splitext(gt_file)[1] == '.mat':
+ img_info = load_mat_info(img_info, gt_file)
+ elif osp.splitext(gt_file)[1] == '.txt':
+ img_info = load_txt_info(gt_file, img_info)
+ else:
+ raise NotImplementedError
+
+ return img_info
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert totaltext annotations to COCO format')
+ parser.add_argument('root_path', help='totaltext root path')
+ parser.add_argument('-o', '--out-dir', help='output path')
+ parser.add_argument(
+ '--split-list',
+ nargs='+',
+ help='a list of splits. e.g., "--split_list training test"')
+
+ parser.add_argument(
+ '--nproc', default=1, type=int, help='number of process')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ root_path = args.root_path
+ out_dir = args.out_dir if args.out_dir else root_path
+ mmcv.mkdir_or_exist(out_dir)
+
+ img_dir = osp.join(root_path, 'imgs')
+ gt_dir = osp.join(root_path, 'annotations')
+
+ set_name = {}
+ for split in args.split_list:
+ set_name.update({split: 'instances_' + split + '.json'})
+ assert osp.exists(osp.join(img_dir, split))
+
+ for split, json_name in set_name.items():
+ print(f'Converting {split} into {json_name}')
+ with mmcv.Timer(
+ print_tmpl='It takes {}s to convert totaltext annotation'):
+ files = collect_files(
+ osp.join(img_dir, split), osp.join(gt_dir, split), split)
+ image_infos = collect_annotations(files, nproc=args.nproc)
+ generate_ann(root_path, split, image_infos)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/data/utils/txt2lmdb.py b/tools/data/utils/txt2lmdb.py
new file mode 100644
index 0000000000000000000000000000000000000000..7fd561fae1f1c7a33a7cef10b1e0b370b48c0fe2
--- /dev/null
+++ b/tools/data/utils/txt2lmdb.py
@@ -0,0 +1,40 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+
+from mmocr.utils import lmdb_converter
+
+
+def main():
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ '--imglist', '-i', required=True, help='input imglist path')
+ parser.add_argument(
+ '--output', '-o', required=True, help='output lmdb path')
+ parser.add_argument(
+ '--batch_size',
+ '-b',
+ type=int,
+ default=10000,
+ help='processing batch size, default 10000')
+ parser.add_argument(
+ '--coding',
+ '-c',
+ default='utf8',
+ help='bytes coding scheme, default utf8')
+ parser.add_argument(
+ '--lmdb_map_size',
+ '-l',
+ default='109951162776',
+ help='maximum size database may grow to , default 109951162776 bytes')
+ opt = parser.parse_args()
+
+ lmdb_converter(
+ opt.imglist,
+ opt.output,
+ batch_size=opt.batch_size,
+ coding=opt.coding,
+ lmdb_map_size=opt.lmdb_map_size)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/deployment/deploy_test.py b/tools/deployment/deploy_test.py
new file mode 100644
index 0000000000000000000000000000000000000000..11e0fa2d6a4a08ea4adafc83d654c64fc5a5a355
--- /dev/null
+++ b/tools/deployment/deploy_test.py
@@ -0,0 +1,109 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import warnings
+
+from mmcv import Config
+from mmcv.parallel import MMDataParallel
+from mmcv.runner import get_dist_info
+from mmdet.apis import single_gpu_test
+
+from mmocr.apis.inference import disable_text_recog_aug_test
+from mmocr.core.deployment import (ONNXRuntimeDetector, ONNXRuntimeRecognizer,
+ TensorRTDetector, TensorRTRecognizer)
+from mmocr.datasets import build_dataloader, build_dataset
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='MMOCR test (and eval) a onnx or tensorrt model.')
+ parser.add_argument('model_config', type=str, help='Config file.')
+ parser.add_argument(
+ 'model_file', type=str, help='Input file name for evaluation.')
+ parser.add_argument(
+ 'model_type',
+ type=str,
+ help='Detection or recognition model to deploy.',
+ choices=['recog', 'det'])
+ parser.add_argument(
+ 'backend',
+ type=str,
+ help='Which backend to test, TensorRT or ONNXRuntime.',
+ choices=['TensorRT', 'ONNXRuntime'])
+ parser.add_argument(
+ '--eval',
+ type=str,
+ nargs='+',
+ help='The evaluation metrics, which depends on the dataset, e.g.,'
+ '"bbox", "seg", "proposal" for COCO, and "mAP", "recall" for'
+ 'PASCAL VOC.')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference.')
+
+ args = parser.parse_args()
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ # Following strings of text style are from colorama package
+ bright_style, reset_style = '\x1b[1m', '\x1b[0m'
+ red_text, blue_text = '\x1b[31m', '\x1b[34m'
+ white_background = '\x1b[107m'
+
+ msg = white_background + bright_style + red_text
+ msg += 'DeprecationWarning: This tool will be deprecated in future. '
+ msg += blue_text + 'Welcome to use the unified model deployment toolbox '
+ msg += 'MMDeploy: https://github.com/open-mmlab/mmdeploy'
+ msg += reset_style
+ warnings.warn(msg)
+
+ if args.device == 'cpu':
+ args.device = None
+
+ cfg = Config.fromfile(args.model_config)
+
+ # build the model
+ if args.model_type == 'det':
+ if args.backend == 'TensorRT':
+ model = TensorRTDetector(args.model_file, cfg, 0)
+ else:
+ model = ONNXRuntimeDetector(args.model_file, cfg, 0)
+ else:
+ if args.backend == 'TensorRT':
+ model = TensorRTRecognizer(args.model_file, cfg, 0)
+ else:
+ model = ONNXRuntimeRecognizer(args.model_file, cfg, 0)
+
+ # build the dataloader
+ samples_per_gpu = 1
+ cfg = disable_text_recog_aug_test(cfg)
+ dataset = build_dataset(cfg.data.test)
+ data_loader = build_dataloader(
+ dataset,
+ samples_per_gpu=samples_per_gpu,
+ workers_per_gpu=cfg.data.workers_per_gpu,
+ dist=False,
+ shuffle=False)
+
+ model = MMDataParallel(model, device_ids=[0])
+ outputs = single_gpu_test(model, data_loader)
+
+ rank, _ = get_dist_info()
+ if rank == 0:
+ kwargs = {}
+ if args.eval:
+ eval_kwargs = cfg.get('evaluation', {}).copy()
+ # hard-code way to remove EvalHook args
+ for key in [
+ 'interval', 'tmpdir', 'start', 'gpu_collect', 'save_best',
+ 'rule'
+ ]:
+ eval_kwargs.pop(key, None)
+ eval_kwargs.update(dict(metric=args.eval, **kwargs))
+ print(dataset.evaluate(outputs, **eval_kwargs))
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/deployment/mmocr2torchserve.py b/tools/deployment/mmocr2torchserve.py
new file mode 100644
index 0000000000000000000000000000000000000000..9f9e2f470f2dbc476f1c6bce114723ed5b612715
--- /dev/null
+++ b/tools/deployment/mmocr2torchserve.py
@@ -0,0 +1,110 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from argparse import ArgumentParser, Namespace
+from pathlib import Path
+from tempfile import TemporaryDirectory
+
+import mmcv
+
+try:
+ from model_archiver.model_packaging import package_model
+ from model_archiver.model_packaging_utils import ModelExportUtils
+except ImportError:
+ package_model = None
+
+
+def mmocr2torchserve(
+ config_file: str,
+ checkpoint_file: str,
+ output_folder: str,
+ model_name: str,
+ model_version: str = '1.0',
+ force: bool = False,
+):
+ """Converts MMOCR model (config + checkpoint) to TorchServe `.mar`.
+
+ Args:
+ config_file:
+ In MMOCR config format.
+ The contents vary for each task repository.
+ checkpoint_file:
+ In MMOCR checkpoint format.
+ The contents vary for each task repository.
+ output_folder:
+ Folder where `{model_name}.mar` will be created.
+ The file created will be in TorchServe archive format.
+ model_name:
+ If not None, used for naming the `{model_name}.mar` file
+ that will be created under `output_folder`.
+ If None, `{Path(checkpoint_file).stem}` will be used.
+ model_version:
+ Model's version.
+ force:
+ If True, if there is an existing `{model_name}.mar`
+ file under `output_folder` it will be overwritten.
+ """
+ mmcv.mkdir_or_exist(output_folder)
+
+ config = mmcv.Config.fromfile(config_file)
+
+ with TemporaryDirectory() as tmpdir:
+ config.dump(f'{tmpdir}/config.py')
+
+ args = Namespace(
+ **{
+ 'model_file': f'{tmpdir}/config.py',
+ 'serialized_file': checkpoint_file,
+ 'handler': f'{Path(__file__).parent}/mmocr_handler.py',
+ 'model_name': model_name or Path(checkpoint_file).stem,
+ 'version': model_version,
+ 'export_path': output_folder,
+ 'force': force,
+ 'requirements_file': None,
+ 'extra_files': None,
+ 'runtime': 'python',
+ 'archive_format': 'default'
+ })
+ manifest = ModelExportUtils.generate_manifest_json(args)
+ package_model(args, manifest)
+
+
+def parse_args():
+ parser = ArgumentParser(
+ description='Convert MMOCR models to TorchServe `.mar` format.')
+ parser.add_argument('config', type=str, help='config file path')
+ parser.add_argument('checkpoint', type=str, help='checkpoint file path')
+ parser.add_argument(
+ '--output-folder',
+ type=str,
+ required=True,
+ help='Folder where `{model_name}.mar` will be created.')
+ parser.add_argument(
+ '--model-name',
+ type=str,
+ default=None,
+ help='If not None, used for naming the `{model_name}.mar`'
+ 'file that will be created under `output_folder`.'
+ 'If None, `{Path(checkpoint_file).stem}` will be used.')
+ parser.add_argument(
+ '--model-version',
+ type=str,
+ default='1.0',
+ help='Number used for versioning.')
+ parser.add_argument(
+ '-f',
+ '--force',
+ action='store_true',
+ help='overwrite the existing `{model_name}.mar`')
+ args = parser.parse_args()
+
+ return args
+
+
+if __name__ == '__main__':
+ args = parse_args()
+
+ if package_model is None:
+ raise ImportError('`torch-model-archiver` is required.'
+ 'Try: pip install torch-model-archiver')
+
+ mmocr2torchserve(args.config, args.checkpoint, args.output_folder,
+ args.model_name, args.model_version, args.force)
diff --git a/tools/deployment/mmocr_handler.py b/tools/deployment/mmocr_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..a667f039ee2512c703a94612665baa4be1189997
--- /dev/null
+++ b/tools/deployment/mmocr_handler.py
@@ -0,0 +1,51 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import base64
+import os
+
+import mmcv
+import torch
+from ts.torch_handler.base_handler import BaseHandler
+
+from mmocr.apis import init_detector, model_inference
+from mmocr.datasets.pipelines import * # NOQA
+
+
+class MMOCRHandler(BaseHandler):
+ threshold = 0.5
+
+ def initialize(self, context):
+ properties = context.system_properties
+ self.map_location = 'cuda' if torch.cuda.is_available() else 'cpu'
+ self.device = torch.device(self.map_location + ':' +
+ str(properties.get('gpu_id')) if torch.cuda.
+ is_available() else self.map_location)
+ self.manifest = context.manifest
+
+ model_dir = properties.get('model_dir')
+ serialized_file = self.manifest['model']['serializedFile']
+ checkpoint = os.path.join(model_dir, serialized_file)
+ self.config_file = os.path.join(model_dir, 'config.py')
+
+ self.model = init_detector(self.config_file, checkpoint, self.device)
+ self.initialized = True
+
+ def preprocess(self, data):
+ images = []
+
+ for row in data:
+ image = row.get('data') or row.get('body')
+ if isinstance(image, str):
+ image = base64.b64decode(image)
+ image = mmcv.imfrombytes(image)
+ images.append(image)
+
+ return images
+
+ def inference(self, data, *args, **kwargs):
+
+ results = model_inference(self.model, data)
+ return results
+
+ def postprocess(self, data):
+ # Format output following the example OCRHandler format
+ return data
diff --git a/tools/deployment/onnx2tensorrt.py b/tools/deployment/onnx2tensorrt.py
new file mode 100644
index 0000000000000000000000000000000000000000..6decbcd0e7d0b7f440ffafa51414c9fc7b006650
--- /dev/null
+++ b/tools/deployment/onnx2tensorrt.py
@@ -0,0 +1,294 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+import warnings
+from typing import Iterable
+
+import cv2
+import mmcv
+import numpy as np
+import torch
+from mmcv.parallel import collate
+from mmcv.tensorrt import is_tensorrt_plugin_loaded, onnx2trt, save_trt_engine
+from mmdet.datasets import replace_ImageToTensor
+from mmdet.datasets.pipelines import Compose
+
+from mmocr.core.deployment import (ONNXRuntimeDetector, ONNXRuntimeRecognizer,
+ TensorRTDetector, TensorRTRecognizer)
+from mmocr.datasets.pipelines.crop import crop_img # noqa: F401
+from mmocr.utils import is_2dlist
+
+
+def get_GiB(x: int):
+ """return x GiB."""
+ return x * (1 << 30)
+
+
+def _prepare_input_img(imgs, test_pipeline: Iterable[dict]):
+ """Inference image(s) with the detector.
+
+ Args:
+ imgs (str/ndarray or list[str/ndarray] or tuple[str/ndarray]):
+ Either image files or loaded images.
+ test_pipeline (Iterable[dict]): Test pipline of configuration.
+ Returns:
+ result (dict): Predicted results.
+ """
+ if isinstance(imgs, (list, tuple)):
+ if not isinstance(imgs[0], (np.ndarray, str)):
+ raise AssertionError('imgs must be strings or numpy arrays')
+
+ elif isinstance(imgs, (np.ndarray, str)):
+ imgs = [imgs]
+ else:
+ raise AssertionError('imgs must be strings or numpy arrays')
+
+ test_pipeline = replace_ImageToTensor(test_pipeline)
+ test_pipeline = Compose(test_pipeline)
+
+ data = []
+ for img in imgs:
+ # prepare data
+ # add information into dict
+ datum = dict(img_info=dict(filename=img), img_prefix=None)
+
+ # build the data pipeline
+ datum = test_pipeline(datum)
+ # get tensor from list to stack for batch mode (text detection)
+ data.append(datum)
+
+ if isinstance(data[0]['img'], list) and len(data) > 1:
+ raise Exception('aug test does not support '
+ f'inference with batch size '
+ f'{len(data)}')
+
+ data = collate(data, samples_per_gpu=len(imgs))
+
+ # process img_metas
+ if isinstance(data['img_metas'], list):
+ data['img_metas'] = [
+ img_metas.data[0] for img_metas in data['img_metas']
+ ]
+ else:
+ data['img_metas'] = data['img_metas'].data
+
+ if isinstance(data['img'], list):
+ data['img'] = [img.data for img in data['img']]
+ if isinstance(data['img'][0], list):
+ data['img'] = [img[0] for img in data['img']]
+ else:
+ data['img'] = data['img'].data
+ return data
+
+
+def onnx2tensorrt(onnx_file: str,
+ model_type: str,
+ trt_file: str,
+ config: dict,
+ input_config: dict,
+ fp16: bool = False,
+ verify: bool = False,
+ show: bool = False,
+ workspace_size: int = 1,
+ verbose: bool = False):
+ import tensorrt as trt
+ min_shape = input_config['min_shape']
+ max_shape = input_config['max_shape']
+ # create trt engine and wrapper
+ opt_shape_dict = {'input': [min_shape, min_shape, max_shape]}
+ max_workspace_size = get_GiB(workspace_size)
+ trt_engine = onnx2trt(
+ onnx_file,
+ opt_shape_dict,
+ log_level=trt.Logger.VERBOSE if verbose else trt.Logger.ERROR,
+ fp16_mode=fp16,
+ max_workspace_size=max_workspace_size)
+ save_dir, _ = osp.split(trt_file)
+ if save_dir:
+ os.makedirs(save_dir, exist_ok=True)
+ save_trt_engine(trt_engine, trt_file)
+ print(f'Successfully created TensorRT engine: {trt_file}')
+
+ if verify:
+ mm_inputs = _prepare_input_img(input_config['input_path'],
+ config.data.test.pipeline)
+
+ imgs = mm_inputs.pop('img')
+ img_metas = mm_inputs.pop('img_metas')
+
+ if isinstance(imgs, list):
+ imgs = imgs[0]
+
+ img_list = [img[None, :] for img in imgs]
+
+ # Get results from ONNXRuntime
+ if model_type == 'det':
+ onnx_model = ONNXRuntimeDetector(onnx_file, config, 0)
+ else:
+ onnx_model = ONNXRuntimeRecognizer(onnx_file, config, 0)
+ onnx_out = onnx_model.simple_test(
+ img_list[0], img_metas[0], rescale=True)
+
+ # Get results from TensorRT
+ if model_type == 'det':
+ trt_model = TensorRTDetector(trt_file, config, 0)
+ else:
+ trt_model = TensorRTRecognizer(trt_file, config, 0)
+ img_list[0] = img_list[0].to(torch.device('cuda:0'))
+ trt_out = trt_model.simple_test(
+ img_list[0], img_metas[0], rescale=True)
+
+ # compare results
+ same_diff = 'same'
+ if model_type == 'recog':
+ for onnx_result, trt_result in zip(onnx_out, trt_out):
+ if onnx_result['text'] != trt_result['text'] or \
+ not np.allclose(
+ np.array(onnx_result['score']),
+ np.array(trt_result['score']),
+ rtol=1e-4,
+ atol=1e-4):
+ same_diff = 'different'
+ break
+ else:
+ for onnx_result, trt_result in zip(onnx_out[0]['boundary_result'],
+ trt_out[0]['boundary_result']):
+ if not np.allclose(
+ np.array(onnx_result),
+ np.array(trt_result),
+ rtol=1e-4,
+ atol=1e-4):
+ same_diff = 'different'
+ break
+ print('The outputs are {} between TensorRT and ONNX'.format(same_diff))
+
+ if show:
+ onnx_img = onnx_model.show_result(
+ input_config['input_path'],
+ onnx_out[0],
+ out_file='onnx.jpg',
+ show=False)
+ trt_img = trt_model.show_result(
+ input_config['input_path'],
+ trt_out[0],
+ out_file='tensorrt.jpg',
+ show=False)
+ if onnx_img is None:
+ onnx_img = cv2.imread(input_config['input_path'])
+ if trt_img is None:
+ trt_img = cv2.imread(input_config['input_path'])
+
+ cv2.imshow('TensorRT', trt_img)
+ cv2.imshow('ONNXRuntime', onnx_img)
+ cv2.waitKey()
+ return
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Convert MMOCR models from ONNX to TensorRT')
+ parser.add_argument('model_config', help='Config file of the model')
+ parser.add_argument(
+ 'model_type',
+ type=str,
+ help='Detection or recognition model to deploy.',
+ choices=['recog', 'det'])
+ parser.add_argument('image_path', type=str, help='Image for test')
+ parser.add_argument('onnx_file', help='Path to the input ONNX model')
+ parser.add_argument(
+ '--trt-file',
+ type=str,
+ help='Path to the output TensorRT engine',
+ default='tmp.trt')
+ parser.add_argument(
+ '--max-shape',
+ type=int,
+ nargs=4,
+ default=[1, 3, 400, 600],
+ help='Maximum shape of model input.')
+ parser.add_argument(
+ '--min-shape',
+ type=int,
+ nargs=4,
+ default=[1, 3, 400, 600],
+ help='Minimum shape of model input.')
+ parser.add_argument(
+ '--workspace-size',
+ type=int,
+ default=1,
+ help='Max workspace size in GiB.')
+ parser.add_argument('--fp16', action='store_true', help='Enable fp16 mode')
+ parser.add_argument(
+ '--verify',
+ action='store_true',
+ help='Whether Verify the outputs of ONNXRuntime and TensorRT.',
+ default=True)
+ parser.add_argument(
+ '--show',
+ action='store_true',
+ help='Whether visiualize outputs of ONNXRuntime and TensorRT.',
+ default=True)
+ parser.add_argument(
+ '--verbose',
+ action='store_true',
+ help='Whether to verbose logging messages while creating \
+ TensorRT engine.')
+ args = parser.parse_args()
+ return args
+
+
+if __name__ == '__main__':
+
+ assert is_tensorrt_plugin_loaded(), 'TensorRT plugin should be compiled.'
+ args = parse_args()
+
+ # Following strings of text style are from colorama package
+ bright_style, reset_style = '\x1b[1m', '\x1b[0m'
+ red_text, blue_text = '\x1b[31m', '\x1b[34m'
+ white_background = '\x1b[107m'
+
+ msg = white_background + bright_style + red_text
+ msg += 'DeprecationWarning: This tool will be deprecated in future. '
+ msg += blue_text + 'Welcome to use the unified model deployment toolbox '
+ msg += 'MMDeploy: https://github.com/open-mmlab/mmdeploy'
+ msg += reset_style
+ warnings.warn(msg)
+
+ # check arguments
+ assert osp.exists(args.model_config), 'Config {} not found.'.format(
+ args.model_config)
+ assert osp.exists(args.onnx_file), \
+ 'ONNX model {} not found.'.format(args.onnx_file)
+ assert args.workspace_size >= 0, 'Workspace size less than 0.'
+ for max_value, min_value in zip(args.max_shape, args.min_shape):
+ assert max_value >= min_value, \
+ 'max_shape should be larger than min shape'
+
+ input_config = {
+ 'min_shape': args.min_shape,
+ 'max_shape': args.max_shape,
+ 'input_path': args.image_path
+ }
+
+ cfg = mmcv.Config.fromfile(args.model_config)
+ if cfg.data.test.get('pipeline', None) is None:
+ if is_2dlist(cfg.data.test.datasets):
+ cfg.data.test.pipeline = \
+ cfg.data.test.datasets[0][0].pipeline
+ else:
+ cfg.data.test.pipeline = \
+ cfg.data.test['datasets'][0].pipeline
+ if is_2dlist(cfg.data.test.pipeline):
+ cfg.data.test.pipeline = cfg.data.test.pipeline[0]
+ onnx2tensorrt(
+ args.onnx_file,
+ args.model_type,
+ args.trt_file,
+ cfg,
+ input_config,
+ fp16=args.fp16,
+ verify=args.verify,
+ show=args.show,
+ workspace_size=args.workspace_size,
+ verbose=args.verbose)
diff --git a/tools/deployment/pytorch2onnx.py b/tools/deployment/pytorch2onnx.py
new file mode 100644
index 0000000000000000000000000000000000000000..fce63e907226728fb1f5db231742ede394835ca8
--- /dev/null
+++ b/tools/deployment/pytorch2onnx.py
@@ -0,0 +1,368 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import warnings
+from argparse import ArgumentParser
+from functools import partial
+
+import cv2
+import numpy as np
+import torch
+from mmcv.onnx import register_extra_symbolics
+from mmcv.parallel import collate
+from mmdet.datasets import replace_ImageToTensor
+from mmdet.datasets.pipelines import Compose
+from torch import nn
+
+from mmocr.apis import init_detector
+from mmocr.core.deployment import ONNXRuntimeDetector, ONNXRuntimeRecognizer
+from mmocr.datasets.pipelines.crop import crop_img # noqa: F401
+from mmocr.utils import is_2dlist
+
+
+def _convert_batchnorm(module):
+ module_output = module
+ if isinstance(module, torch.nn.SyncBatchNorm):
+ module_output = torch.nn.BatchNorm2d(module.num_features, module.eps,
+ module.momentum, module.affine,
+ module.track_running_stats)
+ if module.affine:
+ module_output.weight.data = module.weight.data.clone().detach()
+ module_output.bias.data = module.bias.data.clone().detach()
+ # keep requires_grad unchanged
+ module_output.weight.requires_grad = module.weight.requires_grad
+ module_output.bias.requires_grad = module.bias.requires_grad
+ module_output.running_mean = module.running_mean
+ module_output.running_var = module.running_var
+ module_output.num_batches_tracked = module.num_batches_tracked
+ for name, child in module.named_children():
+ module_output.add_module(name, _convert_batchnorm(child))
+ del module
+ return module_output
+
+
+def _prepare_data(cfg, imgs):
+ """Inference image(s) with the detector.
+
+ Args:
+ model (nn.Module): The loaded detector.
+ imgs (str/ndarray or list[str/ndarray] or tuple[str/ndarray]):
+ Either image files or loaded images.
+ Returns:
+ result (dict): Predicted results.
+ """
+ if isinstance(imgs, (list, tuple)):
+ if not isinstance(imgs[0], (np.ndarray, str)):
+ raise AssertionError('imgs must be strings or numpy arrays')
+
+ elif isinstance(imgs, (np.ndarray, str)):
+ imgs = [imgs]
+ else:
+ raise AssertionError('imgs must be strings or numpy arrays')
+
+ is_ndarray = isinstance(imgs[0], np.ndarray)
+
+ if is_ndarray:
+ cfg = cfg.copy()
+ # set loading pipeline type
+ cfg.data.test.pipeline[0].type = 'LoadImageFromNdarray'
+
+ cfg.data.test.pipeline = replace_ImageToTensor(cfg.data.test.pipeline)
+ test_pipeline = Compose(cfg.data.test.pipeline)
+
+ data = []
+ for img in imgs:
+ # prepare data
+ if is_ndarray:
+ # directly add img
+ datum = dict(img=img)
+ else:
+ # add information into dict
+ datum = dict(img_info=dict(filename=img), img_prefix=None)
+
+ # build the data pipeline
+ datum = test_pipeline(datum)
+ # get tensor from list to stack for batch mode (text detection)
+ data.append(datum)
+
+ if isinstance(data[0]['img'], list) and len(data) > 1:
+ raise Exception('aug test does not support '
+ f'inference with batch size '
+ f'{len(data)}')
+
+ data = collate(data, samples_per_gpu=len(imgs))
+
+ # process img_metas
+ if isinstance(data['img_metas'], list):
+ data['img_metas'] = [
+ img_metas.data[0] for img_metas in data['img_metas']
+ ]
+ else:
+ data['img_metas'] = data['img_metas'].data
+
+ if isinstance(data['img'], list):
+ data['img'] = [img.data for img in data['img']]
+ if isinstance(data['img'][0], list):
+ data['img'] = [img[0] for img in data['img']]
+ else:
+ data['img'] = data['img'].data
+ return data
+
+
+def pytorch2onnx(model: nn.Module,
+ model_type: str,
+ img_path: str,
+ verbose: bool = False,
+ show: bool = False,
+ opset_version: int = 11,
+ output_file: str = 'tmp.onnx',
+ verify: bool = False,
+ dynamic_export: bool = False,
+ device_id: int = 0):
+ """Export PyTorch model to ONNX model and verify the outputs are same
+ between PyTorch and ONNX.
+
+ Args:
+ model (nn.Module): PyTorch model we want to export.
+ model_type (str): Model type, detection or recognition model.
+ img_path (str): We need to use this input to execute the model.
+ opset_version (int): The onnx op version. Default: 11.
+ verbose (bool): Whether print the computation graph. Default: False.
+ show (bool): Whether visialize final results. Default: False.
+ output_file (string): The path to where we store the output ONNX model.
+ Default: `tmp.onnx`.
+ verify (bool): Whether compare the outputs between PyTorch and ONNX.
+ Default: False.
+ dynamic_export (bool): Whether apply dynamic export.
+ Default: False.
+ device_id (id): Device id to place model and data.
+ Default: 0
+ """
+ device = torch.device(type='cuda', index=device_id)
+ model.to(device).eval()
+ _convert_batchnorm(model)
+
+ # prepare inputs
+ mm_inputs = _prepare_data(cfg=model.cfg, imgs=img_path)
+ imgs = mm_inputs.pop('img')
+ img_metas = mm_inputs.pop('img_metas')
+
+ if isinstance(imgs, list):
+ imgs = imgs[0]
+
+ img_list = [img[None, :].to(device) for img in imgs]
+
+ origin_forward = model.forward
+ if (model_type == 'det'):
+ model.forward = partial(
+ model.simple_test, img_metas=img_metas, rescale=True)
+ else:
+ model.forward = partial(
+ model.forward,
+ img_metas=img_metas,
+ return_loss=False,
+ rescale=True)
+
+ # pytorch has some bug in pytorch1.3, we have to fix it
+ # by replacing these existing op
+ register_extra_symbolics(opset_version)
+ dynamic_axes = None
+ if dynamic_export and model_type == 'det':
+ dynamic_axes = {
+ 'input': {
+ 0: 'batch',
+ 2: 'height',
+ 3: 'width'
+ },
+ 'output': {
+ 0: 'batch',
+ 2: 'height',
+ 3: 'width'
+ }
+ }
+ elif dynamic_export and model_type == 'recog':
+ dynamic_axes = {
+ 'input': {
+ 0: 'batch',
+ 3: 'width'
+ },
+ 'output': {
+ 0: 'batch',
+ 1: 'seq_len',
+ 2: 'num_classes'
+ }
+ }
+ with torch.no_grad():
+ torch.onnx.export(
+ model, (img_list[0], ),
+ output_file,
+ input_names=['input'],
+ output_names=['output'],
+ export_params=True,
+ keep_initializers_as_inputs=False,
+ verbose=verbose,
+ opset_version=opset_version,
+ dynamic_axes=dynamic_axes)
+ print(f'Successfully exported ONNX model: {output_file}')
+ if verify:
+ # check by onnx
+ import onnx
+ onnx_model = onnx.load(output_file)
+ onnx.checker.check_model(onnx_model)
+
+ scale_factor = (0.5, 0.5) if model_type == 'det' else (1, 0.5)
+ if dynamic_export:
+ # scale image for dynamic shape test
+ img_list = [
+ nn.functional.interpolate(_, scale_factor=scale_factor)
+ for _ in img_list
+ ]
+ if model_type == 'det':
+ img_metas[0][0][
+ 'scale_factor'] = img_metas[0][0]['scale_factor'] * (
+ scale_factor * 2)
+
+ # check the numerical value
+ # get pytorch output
+ with torch.no_grad():
+ model.forward = origin_forward
+ pytorch_out = model.simple_test(
+ img_list[0], img_metas[0], rescale=True)
+
+ # get onnx output
+ if model_type == 'det':
+ onnx_model = ONNXRuntimeDetector(output_file, model.cfg, device_id)
+ else:
+ onnx_model = ONNXRuntimeRecognizer(output_file, model.cfg,
+ device_id)
+ onnx_out = onnx_model.simple_test(
+ img_list[0], img_metas[0], rescale=True)
+
+ # compare results
+ same_diff = 'same'
+ if model_type == 'recog':
+ for onnx_result, pytorch_result in zip(onnx_out, pytorch_out):
+ if onnx_result['text'] != pytorch_result[
+ 'text'] or not np.allclose(
+ np.array(onnx_result['score']),
+ np.array(pytorch_result['score']),
+ rtol=1e-4,
+ atol=1e-4):
+ same_diff = 'different'
+ break
+ else:
+ for onnx_result, pytorch_result in zip(
+ onnx_out[0]['boundary_result'],
+ pytorch_out[0]['boundary_result']):
+ if not np.allclose(
+ np.array(onnx_result),
+ np.array(pytorch_result),
+ rtol=1e-4,
+ atol=1e-4):
+ same_diff = 'different'
+ break
+ print('The outputs are {} between PyTorch and ONNX'.format(same_diff))
+
+ if show:
+ onnx_img = onnx_model.show_result(
+ img_path, onnx_out[0], out_file='onnx.jpg', show=False)
+ pytorch_img = model.show_result(
+ img_path, pytorch_out[0], out_file='pytorch.jpg', show=False)
+ if onnx_img is None:
+ onnx_img = cv2.imread(img_path)
+ if pytorch_img is None:
+ pytorch_img = cv2.imread(img_path)
+
+ cv2.imshow('PyTorch', pytorch_img)
+ cv2.imshow('ONNXRuntime', onnx_img)
+ cv2.waitKey()
+ return
+
+
+def main():
+ parser = ArgumentParser(
+ description='Convert MMOCR models from pytorch to ONNX')
+ parser.add_argument('model_config', type=str, help='Config file.')
+ parser.add_argument(
+ 'model_ckpt', type=str, help='Checkpint file (local or url).')
+ parser.add_argument(
+ 'model_type',
+ type=str,
+ help='Detection or recognition model to deploy.',
+ choices=['recog', 'det'])
+ parser.add_argument('image_path', type=str, help='Input Image file.')
+ parser.add_argument(
+ '--output-file',
+ type=str,
+ help='Output file name of the onnx model.',
+ default='tmp.onnx')
+ parser.add_argument(
+ '--device-id', default=0, help='Device used for inference.')
+ parser.add_argument(
+ '--opset-version',
+ type=int,
+ help='ONNX opset version, default to 11.',
+ default=11)
+ parser.add_argument(
+ '--verify',
+ action='store_true',
+ help='Whether verify the outputs of onnx and pytorch are same.',
+ default=False)
+ parser.add_argument(
+ '--verbose',
+ action='store_true',
+ help='Whether print the computation graph.',
+ default=False)
+ parser.add_argument(
+ '--show',
+ action='store_true',
+ help='Whether visualize final output.',
+ default=False)
+ parser.add_argument(
+ '--dynamic-export',
+ action='store_true',
+ help='Whether dynamically export onnx model.',
+ default=False)
+ args = parser.parse_args()
+
+ # Following strings of text style are from colorama package
+ bright_style, reset_style = '\x1b[1m', '\x1b[0m'
+ red_text, blue_text = '\x1b[31m', '\x1b[34m'
+ white_background = '\x1b[107m'
+
+ msg = white_background + bright_style + red_text
+ msg += 'DeprecationWarning: This tool will be deprecated in future. '
+ msg += blue_text + 'Welcome to use the unified model deployment toolbox '
+ msg += 'MMDeploy: https://github.com/open-mmlab/mmdeploy'
+ msg += reset_style
+ warnings.warn(msg)
+
+ device = torch.device(type='cuda', index=args.device_id)
+
+ # build model
+ model = init_detector(args.model_config, args.model_ckpt, device=device)
+ if hasattr(model, 'module'):
+ model = model.module
+ if model.cfg.data.test.get('pipeline', None) is None:
+ if is_2dlist(model.cfg.data.test.datasets):
+ model.cfg.data.test.pipeline = \
+ model.cfg.data.test.datasets[0][0].pipeline
+ else:
+ model.cfg.data.test.pipeline = \
+ model.cfg.data.test['datasets'][0].pipeline
+ if is_2dlist(model.cfg.data.test.pipeline):
+ model.cfg.data.test.pipeline = model.cfg.data.test.pipeline[0]
+
+ pytorch2onnx(
+ model,
+ model_type=args.model_type,
+ output_file=args.output_file,
+ img_path=args.image_path,
+ opset_version=args.opset_version,
+ verify=args.verify,
+ verbose=args.verbose,
+ show=args.show,
+ device_id=args.device_id,
+ dynamic_export=args.dynamic_export)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/deployment/test_torchserve.py b/tools/deployment/test_torchserve.py
new file mode 100644
index 0000000000000000000000000000000000000000..2ffde9557dd44b044090ac610169e7c952eb931d
--- /dev/null
+++ b/tools/deployment/test_torchserve.py
@@ -0,0 +1,63 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from argparse import ArgumentParser
+
+import numpy as np
+import requests
+
+from mmocr.apis import init_detector, model_inference
+
+
+def parse_args():
+ parser = ArgumentParser()
+ parser.add_argument('img', help='Image file')
+ parser.add_argument('config', help='Config file')
+ parser.add_argument('checkpoint', help='Checkpoint file')
+ parser.add_argument('model_name', help='The model name in the server')
+ parser.add_argument(
+ '--inference-addr',
+ default='127.0.0.1:8080',
+ help='Address and port of the inference server')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference')
+ parser.add_argument(
+ '--score-thr', type=float, default=0.5, help='bbox score threshold')
+ args = parser.parse_args()
+ return args
+
+
+def main(args):
+ # build the model from a config file and a checkpoint file
+ model = init_detector(args.config, args.checkpoint, device=args.device)
+ # test a single image
+ model_results = model_inference(model, args.img)
+ model.show_result(
+ args.img,
+ model_results,
+ win_name='model_results',
+ show=True,
+ score_thr=args.score_thr)
+ url = 'http://' + args.inference_addr + '/predictions/' + args.model_name
+ with open(args.img, 'rb') as image:
+ response = requests.post(url, image)
+ serve_results = response.json()
+ model.show_result(
+ args.img,
+ serve_results,
+ show=True,
+ win_name='serve_results',
+ score_thr=args.score_thr)
+ assert serve_results.keys() == model_results.keys()
+ for key in serve_results.keys():
+ for model_result, serve_result in zip(model_results[key],
+ serve_results[key]):
+ if isinstance(model_result[0], (int, float)):
+ assert np.allclose(model_result, serve_result)
+ elif isinstance(model_result[0], str):
+ assert model_result == serve_result
+ else:
+ raise TypeError
+
+
+if __name__ == '__main__':
+ args = parse_args()
+ main(args)
diff --git a/tools/det_test_imgs.py b/tools/det_test_imgs.py
new file mode 100755
index 0000000000000000000000000000000000000000..75ddf298fe139e9adb097c729a915e8813eaf08e
--- /dev/null
+++ b/tools/det_test_imgs.py
@@ -0,0 +1,111 @@
+#!/usr/bin/env python
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from argparse import ArgumentParser
+
+import mmcv
+from mmcv.utils import ProgressBar
+
+from mmocr.apis import init_detector, model_inference
+from mmocr.models import build_detector # noqa: F401
+from mmocr.utils import list_from_file, list_to_file
+
+
+def gen_target_path(target_root_path, src_name, suffix):
+ """Gen target file path.
+
+ Args:
+ target_root_path (str): The target root path.
+ src_name (str): The source file name.
+ suffix (str): The suffix of target file.
+ """
+ assert isinstance(target_root_path, str)
+ assert isinstance(src_name, str)
+ assert isinstance(suffix, str)
+
+ file_name = osp.split(src_name)[-1]
+ name = osp.splitext(file_name)[0]
+ return osp.join(target_root_path, name + suffix)
+
+
+def save_results(result, out_dir, img_name, score_thr=0.3):
+ """Save result of detected bounding boxes (quadrangle or polygon) to txt
+ file.
+
+ Args:
+ result (dict): Text Detection result for one image.
+ img_name (str): Image file name.
+ out_dir (str): Dir of txt files to save detected results.
+ score_thr (float, optional): Score threshold to filter bboxes.
+ """
+ assert 'boundary_result' in result
+ assert score_thr > 0 and score_thr < 1
+
+ txt_file = gen_target_path(out_dir, img_name, '.txt')
+ valid_boundary_res = [
+ res for res in result['boundary_result'] if res[-1] > score_thr
+ ]
+ lines = [
+ ','.join([str(round(x)) for x in row]) for row in valid_boundary_res
+ ]
+ list_to_file(txt_file, lines)
+
+
+def main():
+ parser = ArgumentParser()
+ parser.add_argument('img_root', type=str, help='Image root path')
+ parser.add_argument('img_list', type=str, help='Image path list file')
+ parser.add_argument('config', type=str, help='Config file')
+ parser.add_argument('checkpoint', type=str, help='Checkpoint file')
+ parser.add_argument(
+ '--score-thr', type=float, default=0.5, help='Bbox score threshold')
+ parser.add_argument(
+ '--out-dir',
+ type=str,
+ default='./results',
+ help='Dir to save '
+ 'visualize images '
+ 'and bbox')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference.')
+ args = parser.parse_args()
+
+ assert 0 < args.score_thr < 1
+
+ # build the model from a config file and a checkpoint file
+ model = init_detector(args.config, args.checkpoint, device=args.device)
+ if hasattr(model, 'module'):
+ model = model.module
+
+ # Start Inference
+ out_vis_dir = osp.join(args.out_dir, 'out_vis_dir')
+ mmcv.mkdir_or_exist(out_vis_dir)
+ out_txt_dir = osp.join(args.out_dir, 'out_txt_dir')
+ mmcv.mkdir_or_exist(out_txt_dir)
+
+ lines = list_from_file(args.img_list)
+ progressbar = ProgressBar(task_num=len(lines))
+ for line in lines:
+ progressbar.update()
+ img_path = osp.join(args.img_root, line.strip())
+ if not osp.exists(img_path):
+ raise FileNotFoundError(img_path)
+ # Test a single image
+ result = model_inference(model, img_path)
+ img_name = osp.basename(img_path)
+ # save result
+ save_results(result, out_txt_dir, img_name, score_thr=args.score_thr)
+ # show result
+ out_file = osp.join(out_vis_dir, img_name)
+ kwargs_dict = {
+ 'score_thr': args.score_thr,
+ 'show': False,
+ 'out_file': out_file
+ }
+ model.show_result(img_path, result, **kwargs_dict)
+
+ print(f'\nInference done, and results saved in {args.out_dir}\n')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dist_test.sh b/tools/dist_test.sh
new file mode 100755
index 0000000000000000000000000000000000000000..6e305059205947224bd85b538c365a98a46cfec4
--- /dev/null
+++ b/tools/dist_test.sh
@@ -0,0 +1,16 @@
+#!/usr/bin/env bash
+
+if [ $# -lt 3 ]
+then
+ echo "Usage: bash $0 CONFIG CHECKPOINT GPUS"
+ exit
+fi
+
+CONFIG=$1
+CHECKPOINT=$2
+GPUS=$3
+PORT=${PORT:-29500}
+
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
+python -m torch.distributed.launch --nproc_per_node=$GPUS --master_port=$PORT \
+ $(dirname "$0")/test.py $CONFIG $CHECKPOINT --launcher pytorch ${@:4}
diff --git a/tools/dist_train.sh b/tools/dist_train.sh
new file mode 100755
index 0000000000000000000000000000000000000000..ee3a8efec67eeed4a987aa22805c1d69c4b008fa
--- /dev/null
+++ b/tools/dist_train.sh
@@ -0,0 +1,22 @@
+#!/usr/bin/env bash
+
+if [ $# -lt 3 ]
+then
+ echo "Usage: bash $0 CONFIG WORK_DIR GPUS"
+ exit
+fi
+
+CONFIG=$1
+WORK_DIR=$2
+GPUS=$3
+
+PORT=${PORT:-29500}
+
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
+
+if [ ${GPUS} == 1 ]; then
+ python $(dirname "$0")/train.py $CONFIG --work-dir=${WORK_DIR} ${@:4}
+else
+ python -m torch.distributed.launch --nproc_per_node=$GPUS --master_port=$PORT \
+ $(dirname "$0")/train.py $CONFIG --work-dir=${WORK_DIR} --launcher pytorch ${@:4}
+fi
diff --git a/tools/kie_test_imgs.py b/tools/kie_test_imgs.py
new file mode 100755
index 0000000000000000000000000000000000000000..caabc5d52a964a09cc411306f1a9df9faa4bbd73
--- /dev/null
+++ b/tools/kie_test_imgs.py
@@ -0,0 +1,161 @@
+#!/usr/bin/env python
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import ast
+import os
+import os.path as osp
+
+import mmcv
+import numpy as np
+import torch
+from mmcv import Config
+from mmcv.image import tensor2imgs
+from mmcv.parallel import MMDataParallel
+from mmcv.runner import load_checkpoint
+
+from mmocr.datasets import build_dataloader, build_dataset
+from mmocr.models import build_detector
+
+
+def save_results(model, img_meta, gt_bboxes, result, out_dir):
+ assert 'filename' in img_meta, ('Please add "filename" '
+ 'to "meta_keys" in config.')
+ assert 'ori_texts' in img_meta, ('Please add "ori_texts" '
+ 'to "meta_keys" in config.')
+
+ out_json_file = osp.join(out_dir,
+ osp.basename(img_meta['filename']) + '.json')
+
+ idx_to_cls = {}
+ if model.module.class_list is not None:
+ for line in mmcv.list_from_file(model.module.class_list):
+ class_idx, class_label = line.strip().split()
+ idx_to_cls[int(class_idx)] = class_label
+
+ json_result = [{
+ 'text':
+ text,
+ 'box':
+ box,
+ 'pred':
+ idx_to_cls.get(
+ pred.argmax(-1).cpu().item(),
+ pred.argmax(-1).cpu().item()),
+ 'conf':
+ pred.max(-1)[0].cpu().item()
+ } for text, box, pred in zip(img_meta['ori_texts'], gt_bboxes,
+ result['nodes'])]
+
+ mmcv.dump(json_result, out_json_file)
+
+
+def test(model, data_loader, show=False, out_dir=None):
+ model.eval()
+ results = []
+ dataset = data_loader.dataset
+ prog_bar = mmcv.ProgressBar(len(dataset))
+ for i, data in enumerate(data_loader):
+ with torch.no_grad():
+ result = model(return_loss=False, rescale=True, **data)
+
+ batch_size = len(result)
+ if show or out_dir:
+ img_tensor = data['img'].data[0]
+ img_metas = data['img_metas'].data[0]
+ if np.prod(img_tensor.shape) == 0:
+ imgs = [mmcv.imread(m['filename']) for m in img_metas]
+ else:
+ imgs = tensor2imgs(img_tensor, **img_metas[0]['img_norm_cfg'])
+ assert len(imgs) == len(img_metas)
+ gt_bboxes = [data['gt_bboxes'].data[0][0].numpy().tolist()]
+
+ for i, (img, img_meta) in enumerate(zip(imgs, img_metas)):
+ if 'img_shape' in img_meta:
+ h, w, _ = img_meta['img_shape']
+ img_show = img[:h, :w, :]
+ else:
+ img_show = img
+
+ if out_dir:
+ out_file = osp.join(out_dir,
+ osp.basename(img_meta['filename']))
+ else:
+ out_file = None
+
+ model.module.show_result(
+ img_show,
+ result[i],
+ gt_bboxes[i],
+ show=show,
+ out_file=out_file)
+
+ if out_dir:
+ save_results(model, img_meta, gt_bboxes[i], result[i],
+ out_dir)
+
+ for _ in range(batch_size):
+ prog_bar.update()
+ return results
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='MMOCR visualize for kie model.')
+ parser.add_argument('config', help='Test config file path.')
+ parser.add_argument('checkpoint', help='Checkpoint file.')
+ parser.add_argument('--show', action='store_true', help='Show results.')
+ parser.add_argument(
+ '--out-dir',
+ help='Directory where the output images and results will be saved.')
+ parser.add_argument('--local_rank', type=int, default=0)
+ parser.add_argument(
+ '--device',
+ help='Use int or int list for gpu. Default is cpu',
+ default=None)
+ args = parser.parse_args()
+ if 'LOCAL_RANK' not in os.environ:
+ os.environ['LOCAL_RANK'] = str(args.local_rank)
+
+ return args
+
+
+def main():
+ args = parse_args()
+ assert args.show or args.out_dir, ('Please specify at least one '
+ 'operation (show the results / save )'
+ 'the results with the argument '
+ '"--show" or "--out-dir".')
+ device = args.device
+ if device is not None:
+ device = ast.literal_eval(f'[{device}]')
+ cfg = Config.fromfile(args.config)
+ # import modules from string list.
+ if cfg.get('custom_imports', None):
+ from mmcv.utils import import_modules_from_strings
+ import_modules_from_strings(**cfg['custom_imports'])
+ # set cudnn_benchmark
+ if cfg.get('cudnn_benchmark', False):
+ torch.backends.cudnn.benchmark = True
+
+ distributed = False
+
+ # build the dataloader
+ dataset = build_dataset(cfg.data.test)
+ data_loader = build_dataloader(
+ dataset,
+ samples_per_gpu=1,
+ workers_per_gpu=cfg.data.workers_per_gpu,
+ dist=distributed,
+ shuffle=False)
+
+ # build the model and load checkpoint
+ cfg.model.train_cfg = None
+ model = build_detector(cfg.model, test_cfg=cfg.get('test_cfg'))
+ load_checkpoint(model, args.checkpoint, map_location='cpu')
+
+ model = MMDataParallel(model, device_ids=device)
+ test(model, data_loader, args.show, args.out_dir)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/misc/print_config.py b/tools/misc/print_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..e44cda06234cffb7dcf709c76bbf5d5abeb4faf8
--- /dev/null
+++ b/tools/misc/print_config.py
@@ -0,0 +1,55 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import warnings
+
+from mmcv import Config, DictAction
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Print the whole config')
+ parser.add_argument('config', help='config file path')
+ parser.add_argument(
+ '--options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file (deprecate), '
+ 'change to --cfg-options instead.')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ args = parser.parse_args()
+
+ if args.options and args.cfg_options:
+ raise ValueError(
+ '--options and --cfg-options cannot be both '
+ 'specified, --options is deprecated in favor of --cfg-options')
+ if args.options:
+ warnings.warn('--options is deprecated in favor of --cfg-options')
+ args.cfg_options = args.options
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ cfg = Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+ # import modules from string list.
+ if cfg.get('custom_imports', None):
+ from mmcv.utils import import_modules_from_strings
+ import_modules_from_strings(**cfg['custom_imports'])
+ print(f'Config:\n{cfg.pretty_text}')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/publish_model.py b/tools/publish_model.py
new file mode 100755
index 0000000000000000000000000000000000000000..73b8a8cb1256bcec269cbd1b88943472f9b0ad54
--- /dev/null
+++ b/tools/publish_model.py
@@ -0,0 +1,39 @@
+#!/usr/bin/env python
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import subprocess
+
+import torch
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='Process a checkpoint to be published')
+ parser.add_argument('in_file', help='input checkpoint filename')
+ parser.add_argument('out_file', help='output checkpoint filename')
+ args = parser.parse_args()
+ return args
+
+
+def process_checkpoint(in_file, out_file):
+ checkpoint = torch.load(in_file, map_location='cpu')
+ # remove optimizer for smaller file size
+ if 'optimizer' in checkpoint:
+ del checkpoint['optimizer']
+ # if it is necessary to remove some sensitive data in checkpoint['meta'],
+ # add the code here.
+ if 'meta' in checkpoint:
+ checkpoint['meta'] = {'CLASSES': 0}
+ torch.save(checkpoint, out_file, _use_new_zipfile_serialization=False)
+ sha = subprocess.check_output(['sha256sum', out_file]).decode()
+ final_file = out_file.rstrip('.pth') + '-{}.pth'.format(sha[:8])
+ subprocess.Popen(['mv', out_file, final_file])
+
+
+def main():
+ args = parse_args()
+ process_checkpoint(args.in_file, args.out_file)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/recog_test_imgs.py b/tools/recog_test_imgs.py
new file mode 100755
index 0000000000000000000000000000000000000000..6b6da088153690a76cc732cab0c7c0ab8d133bfd
--- /dev/null
+++ b/tools/recog_test_imgs.py
@@ -0,0 +1,125 @@
+#!/usr/bin/env python
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import shutil
+import time
+from argparse import ArgumentParser
+from itertools import compress
+
+import mmcv
+from mmcv.utils import ProgressBar
+
+from mmocr.apis import init_detector, model_inference
+from mmocr.core.evaluation.ocr_metric import eval_ocr_metric
+from mmocr.datasets import build_dataset # noqa: F401
+from mmocr.models import build_detector # noqa: F401
+from mmocr.utils import get_root_logger, list_from_file, list_to_file
+
+
+def save_results(img_paths, pred_labels, gt_labels, res_dir):
+ """Save predicted results to txt file.
+
+ Args:
+ img_paths (list[str])
+ pred_labels (list[str])
+ gt_labels (list[str])
+ res_dir (str)
+ """
+ assert len(img_paths) == len(pred_labels) == len(gt_labels)
+ corrects = [pred == gt for pred, gt in zip(pred_labels, gt_labels)]
+ wrongs = [not c for c in corrects]
+ lines = [
+ f'{img} {pred} {gt}'
+ for img, pred, gt in zip(img_paths, pred_labels, gt_labels)
+ ]
+ list_to_file(osp.join(res_dir, 'results.txt'), lines)
+ list_to_file(osp.join(res_dir, 'correct.txt'), compress(lines, corrects))
+ list_to_file(osp.join(res_dir, 'wrong.txt'), compress(lines, wrongs))
+
+
+def main():
+ parser = ArgumentParser()
+ parser.add_argument('img_root_path', type=str, help='Image root path')
+ parser.add_argument('img_list', type=str, help='Image path list file')
+ parser.add_argument('config', type=str, help='Config file')
+ parser.add_argument('checkpoint', type=str, help='Checkpoint file')
+ parser.add_argument(
+ '--out_dir', type=str, default='./results', help='Dir to save results')
+ parser.add_argument(
+ '--show', action='store_true', help='show image or save')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference.')
+ args = parser.parse_args()
+
+ # init the logger before other steps
+ timestamp = time.strftime('%Y%m%d_%H%M%S', time.localtime())
+ log_file = osp.join(args.out_dir, f'{timestamp}.log')
+ logger = get_root_logger(log_file=log_file, log_level='INFO')
+
+ # build the model from a config file and a checkpoint file
+ model = init_detector(args.config, args.checkpoint, device=args.device)
+ if hasattr(model, 'module'):
+ model = model.module
+
+ # Start Inference
+ out_vis_dir = osp.join(args.out_dir, 'out_vis_dir')
+ mmcv.mkdir_or_exist(out_vis_dir)
+ correct_vis_dir = osp.join(args.out_dir, 'correct')
+ mmcv.mkdir_or_exist(correct_vis_dir)
+ wrong_vis_dir = osp.join(args.out_dir, 'wrong')
+ mmcv.mkdir_or_exist(wrong_vis_dir)
+ img_paths, pred_labels, gt_labels = [], [], []
+
+ lines = list_from_file(args.img_list)
+ progressbar = ProgressBar(task_num=len(lines))
+ num_gt_label = 0
+ for line in lines:
+ progressbar.update()
+ item_list = line.strip().split()
+ img_file = item_list[0]
+ gt_label = ''
+ if len(item_list) >= 2:
+ gt_label = item_list[1]
+ num_gt_label += 1
+ img_path = osp.join(args.img_root_path, img_file)
+ if not osp.exists(img_path):
+ raise FileNotFoundError(img_path)
+ # Test a single image
+ result = model_inference(model, img_path)
+ pred_label = result['text']
+
+ out_img_name = '_'.join(img_file.split('/'))
+ out_file = osp.join(out_vis_dir, out_img_name)
+ kwargs_dict = {
+ 'gt_label': gt_label,
+ 'show': args.show,
+ 'out_file': '' if args.show else out_file
+ }
+ model.show_result(img_path, result, **kwargs_dict)
+ if gt_label != '':
+ if gt_label == pred_label:
+ dst_file = osp.join(correct_vis_dir, out_img_name)
+ else:
+ dst_file = osp.join(wrong_vis_dir, out_img_name)
+ shutil.copy(out_file, dst_file)
+ img_paths.append(img_path)
+ gt_labels.append(gt_label)
+ pred_labels.append(pred_label)
+
+ # Save results
+ save_results(img_paths, pred_labels, gt_labels, args.out_dir)
+
+ if num_gt_label == len(pred_labels):
+ # eval
+ eval_results = eval_ocr_metric(pred_labels, gt_labels)
+ logger.info('\n' + '-' * 100)
+ info = ('eval on testset with img_root_path '
+ f'{args.img_root_path} and img_list {args.img_list}\n')
+ logger.info(info)
+ logger.info(eval_results)
+
+ print(f'\nInference done, and results saved in {args.out_dir}\n')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/slurm_test.sh b/tools/slurm_test.sh
new file mode 100755
index 0000000000000000000000000000000000000000..865f45599ad883d216f0df0248a3815700615c17
--- /dev/null
+++ b/tools/slurm_test.sh
@@ -0,0 +1,22 @@
+#!/usr/bin/env bash
+
+set -x
+export PYTHONPATH=`pwd`:$PYTHONPATH
+
+PARTITION=$1
+JOB_NAME=$2
+CONFIG=$3
+CHECKPOINT=$4
+GPUS=${GPUS:-8}
+GPUS_PER_NODE=${GPUS_PER_NODE:-8}
+PY_ARGS=${@:5}
+SRUN_ARGS=${SRUN_ARGS:-""}
+
+srun -p ${PARTITION} \
+ --job-name=${JOB_NAME} \
+ --gres=gpu:${GPUS_PER_NODE} \
+ --ntasks=${GPUS} \
+ --ntasks-per-node=${GPUS_PER_NODE} \
+ --kill-on-bad-exit=1 \
+ ${SRUN_ARGS} \
+ python -u tools/test.py ${CONFIG} ${CHECKPOINT} --launcher="slurm" ${PY_ARGS}
diff --git a/tools/slurm_train.sh b/tools/slurm_train.sh
new file mode 100755
index 0000000000000000000000000000000000000000..452b09454a08ac522a9df2304c3039487ea517bd
--- /dev/null
+++ b/tools/slurm_train.sh
@@ -0,0 +1,25 @@
+#!/usr/bin/env bash
+export MASTER_PORT=$((12000 + $RANDOM % 20000))
+
+set -x
+
+PARTITION=$1
+JOB_NAME=$2
+CONFIG=$3
+WORK_DIR=$4
+GPUS=${GPUS:-8}
+GPUS_PER_NODE=${GPUS_PER_NODE:-8}
+CPUS_PER_TASK=${CPUS_PER_TASK:-5}
+PY_ARGS=${@:5}
+SRUN_ARGS=${SRUN_ARGS:-""}
+
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
+srun -p ${PARTITION} \
+ --job-name=${JOB_NAME} \
+ --gres=gpu:${GPUS_PER_NODE} \
+ --ntasks=${GPUS} \
+ --ntasks-per-node=${GPUS_PER_NODE} \
+ --cpus-per-task=${CPUS_PER_TASK} \
+ --kill-on-bad-exit=1 \
+ ${SRUN_ARGS} \
+ python -u tools/train.py ${CONFIG} --work-dir=${WORK_DIR} --launcher="slurm" ${PY_ARGS}
diff --git a/tools/test.py b/tools/test.py
new file mode 100755
index 0000000000000000000000000000000000000000..d7f50120163c197a5f9d6a0e1e1ab5fc1cb791b3
--- /dev/null
+++ b/tools/test.py
@@ -0,0 +1,235 @@
+#!/usr/bin/env python
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import warnings
+
+import mmcv
+import torch
+from mmcv import Config, DictAction
+from mmcv.cnn import fuse_conv_bn
+from mmcv.parallel import MMDataParallel, MMDistributedDataParallel
+from mmcv.runner import (get_dist_info, init_dist, load_checkpoint,
+ wrap_fp16_model)
+from mmdet.apis import multi_gpu_test
+
+from mmocr.apis.test import single_gpu_test
+from mmocr.apis.utils import (disable_text_recog_aug_test,
+ replace_image_to_tensor)
+from mmocr.datasets import build_dataloader, build_dataset
+from mmocr.models import build_detector
+from mmocr.utils import revert_sync_batchnorm, setup_multi_processes
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='MMOCR test (and eval) a model.')
+ parser.add_argument('config', help='Test config file path.')
+ parser.add_argument('checkpoint', help='Checkpoint file.')
+ parser.add_argument('--out', help='Output result file in pickle format.')
+ parser.add_argument(
+ '--fuse-conv-bn',
+ action='store_true',
+ help='Whether to fuse conv and bn, this will slightly increase'
+ 'the inference speed.')
+ parser.add_argument(
+ '--gpu-id',
+ type=int,
+ default=0,
+ help='id of gpu to use '
+ '(only applicable to non-distributed testing)')
+ parser.add_argument(
+ '--format-only',
+ action='store_true',
+ help='Format the output results without performing evaluation. It is'
+ 'useful when you want to format the results to a specific format and '
+ 'submit them to the test server.')
+ parser.add_argument(
+ '--eval',
+ type=str,
+ nargs='+',
+ help='The evaluation metrics, which depends on the dataset, e.g.,'
+ '"bbox", "seg", "proposal" for COCO, and "mAP", "recall" for'
+ 'PASCAL VOC.')
+ parser.add_argument('--show', action='store_true', help='Show results.')
+ parser.add_argument(
+ '--show-dir', help='Directory where the output images will be saved.')
+ parser.add_argument(
+ '--show-score-thr',
+ type=float,
+ default=0.3,
+ help='Score threshold (default: 0.3).')
+ parser.add_argument(
+ '--gpu-collect',
+ action='store_true',
+ help='Whether to use gpu to collect results.')
+ parser.add_argument(
+ '--tmpdir',
+ help='The tmp directory used for collecting results from multiple '
+ 'workers, available when gpu-collect is not specified.')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='Override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into the config file. If the value '
+ 'to be overwritten is a list, it should be of the form of either '
+ 'key="[a,b]" or key=a,b. The argument also allows nested list/tuple '
+ 'values, e.g. key="[(a,b),(c,d)]". Note that the quotation marks '
+ 'are necessary and that no white space is allowed.')
+ parser.add_argument(
+ '--options',
+ nargs='+',
+ action=DictAction,
+ help='Custom options for evaluation, the key-value pair in xxx=yyy '
+ 'format will be kwargs for dataset.evaluate() function (deprecate), '
+ 'change to --eval-options instead.')
+ parser.add_argument(
+ '--eval-options',
+ nargs='+',
+ action=DictAction,
+ help='Custom options for evaluation, the key-value pair in xxx=yyy '
+ 'format will be kwargs for dataset.evaluate() function.')
+ parser.add_argument(
+ '--launcher',
+ choices=['none', 'pytorch', 'slurm', 'mpi'],
+ default='none',
+ help='Options for job launcher.')
+ parser.add_argument('--local_rank', type=int, default=0)
+ args = parser.parse_args()
+ if 'LOCAL_RANK' not in os.environ:
+ os.environ['LOCAL_RANK'] = str(args.local_rank)
+
+ if args.options and args.eval_options:
+ raise ValueError(
+ '--options and --eval-options cannot be both '
+ 'specified, --options is deprecated in favor of --eval-options.')
+ if args.options:
+ warnings.warn('--options is deprecated in favor of --eval-options.')
+ args.eval_options = args.options
+ return args
+
+
+def main():
+ args = parse_args()
+
+ assert (
+ args.out or args.eval or args.format_only or args.show
+ or args.show_dir), (
+ 'Please specify at least one operation (save/eval/format/show the '
+ 'results / save the results) with the argument "--out", "--eval"'
+ ', "--format-only", "--show" or "--show-dir".')
+
+ if args.eval and args.format_only:
+ raise ValueError('--eval and --format_only cannot be both specified.')
+
+ if args.out is not None and not args.out.endswith(('.pkl', '.pickle')):
+ raise ValueError('The output file must be a pkl file.')
+
+ cfg = Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+ setup_multi_processes(cfg)
+
+ # set cudnn_benchmark
+ if cfg.get('cudnn_benchmark', False):
+ torch.backends.cudnn.benchmark = True
+ if cfg.model.get('pretrained'):
+ cfg.model.pretrained = None
+ if cfg.model.get('neck'):
+ if isinstance(cfg.model.neck, list):
+ for neck_cfg in cfg.model.neck:
+ if neck_cfg.get('rfp_backbone'):
+ if neck_cfg.rfp_backbone.get('pretrained'):
+ neck_cfg.rfp_backbone.pretrained = None
+ elif cfg.model.neck.get('rfp_backbone'):
+ if cfg.model.neck.rfp_backbone.get('pretrained'):
+ cfg.model.neck.rfp_backbone.pretrained = None
+
+ # in case the test dataset is concatenated
+ samples_per_gpu = (cfg.data.get('test_dataloader', {})).get(
+ 'samples_per_gpu', cfg.data.get('samples_per_gpu', 1))
+ if samples_per_gpu > 1:
+ cfg = disable_text_recog_aug_test(cfg)
+ cfg = replace_image_to_tensor(cfg)
+
+ # init distributed env first, since logger depends on the dist info.
+ if args.launcher == 'none':
+ cfg.gpu_ids = [args.gpu_id]
+ distributed = False
+ else:
+ distributed = True
+ init_dist(args.launcher, **cfg.dist_params)
+
+ # build the dataloader
+ dataset = build_dataset(cfg.data.test, dict(test_mode=True))
+ # step 1: give default values and override (if exist) from cfg.data
+ loader_cfg = {
+ **dict(seed=cfg.get('seed'), drop_last=False, dist=distributed),
+ **({} if torch.__version__ != 'parrots' else dict(
+ prefetch_num=2,
+ pin_memory=False,
+ )),
+ **dict((k, cfg.data[k]) for k in [
+ 'workers_per_gpu',
+ 'seed',
+ 'prefetch_num',
+ 'pin_memory',
+ 'persistent_workers',
+ ] if k in cfg.data)
+ }
+ test_loader_cfg = {
+ **loader_cfg,
+ **dict(shuffle=False, drop_last=False),
+ **cfg.data.get('test_dataloader', {}),
+ **dict(samples_per_gpu=samples_per_gpu)
+ }
+
+ data_loader = build_dataloader(dataset, **test_loader_cfg)
+
+ # build the model and load checkpoint
+ cfg.model.train_cfg = None
+ model = build_detector(cfg.model, test_cfg=cfg.get('test_cfg'))
+ model = revert_sync_batchnorm(model)
+ fp16_cfg = cfg.get('fp16', None)
+ if fp16_cfg is not None:
+ wrap_fp16_model(model)
+ load_checkpoint(model, args.checkpoint, map_location='cpu')
+ if args.fuse_conv_bn:
+ model = fuse_conv_bn(model)
+
+ if not distributed:
+ model = MMDataParallel(model, device_ids=cfg.gpu_ids)
+ is_kie = cfg.model.type in ['SDMGR']
+ outputs = single_gpu_test(model, data_loader, args.show, args.show_dir,
+ is_kie, args.show_score_thr)
+ else:
+ model = MMDistributedDataParallel(
+ model.cuda(),
+ device_ids=[torch.cuda.current_device()],
+ broadcast_buffers=False)
+ outputs = multi_gpu_test(model, data_loader, args.tmpdir,
+ args.gpu_collect)
+
+ rank, _ = get_dist_info()
+ if rank == 0:
+ if args.out:
+ print(f'\nwriting results to {args.out}')
+ mmcv.dump(outputs, args.out)
+ kwargs = {} if args.eval_options is None else args.eval_options
+ if args.format_only:
+ dataset.format_results(outputs, **kwargs)
+ if args.eval:
+ eval_kwargs = cfg.get('evaluation', {}).copy()
+ # hard-code way to remove EvalHook args
+ for key in [
+ 'interval', 'tmpdir', 'start', 'gpu_collect', 'save_best',
+ 'rule'
+ ]:
+ eval_kwargs.pop(key, None)
+ eval_kwargs.update(dict(metric=args.eval, **kwargs))
+ print(dataset.evaluate(outputs, **eval_kwargs))
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/train.py b/tools/train.py
new file mode 100755
index 0000000000000000000000000000000000000000..7def527fafc02bf5b400e1ea6ac57fb7a9d82936
--- /dev/null
+++ b/tools/train.py
@@ -0,0 +1,230 @@
+#!/usr/bin/env python
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import copy
+import os
+import os.path as osp
+import time
+import warnings
+
+import mmcv
+import torch
+import torch.distributed as dist
+from mmcv import Config, DictAction
+from mmcv.runner import get_dist_info, init_dist, set_random_seed
+from mmcv.utils import get_git_hash
+
+from mmocr import __version__
+from mmocr.apis import init_random_seed, train_detector
+from mmocr.datasets import build_dataset
+from mmocr.models import build_detector
+from mmocr.utils import (collect_env, get_root_logger, is_2dlist,
+ setup_multi_processes)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Train a detector.')
+ parser.add_argument('config', help='Train config file path.')
+ parser.add_argument('--work-dir', help='The dir to save logs and models.')
+ parser.add_argument(
+ '--load-from', help='The checkpoint file to load from.')
+ parser.add_argument(
+ '--resume-from', help='The checkpoint file to resume from.')
+ parser.add_argument(
+ '--no-validate',
+ action='store_true',
+ help='Whether not to evaluate the checkpoint during training.')
+ group_gpus = parser.add_mutually_exclusive_group()
+ group_gpus.add_argument(
+ '--gpus',
+ type=int,
+ help='(Deprecated, please use --gpu-id) number of gpus to use '
+ '(only applicable to non-distributed training).')
+ group_gpus.add_argument(
+ '--gpu-ids',
+ type=int,
+ nargs='+',
+ help='(Deprecated, please use --gpu-id) ids of gpus to use '
+ '(only applicable to non-distributed training)')
+ group_gpus.add_argument(
+ '--gpu-id',
+ type=int,
+ default=0,
+ help='id of gpu to use '
+ '(only applicable to non-distributed training)')
+ parser.add_argument('--seed', type=int, default=None, help='Random seed.')
+ parser.add_argument(
+ '--diff_seed',
+ action='store_true',
+ help='Whether or not set different seeds for different ranks')
+ parser.add_argument(
+ '--deterministic',
+ action='store_true',
+ help='Whether to set deterministic options for CUDNN backend.')
+ parser.add_argument(
+ '--options',
+ nargs='+',
+ action=DictAction,
+ help='Override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file (deprecate), '
+ 'change to --cfg-options instead.')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='Override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be of the form of either '
+ 'key="[a,b]" or key=a,b .The argument also allows nested list/tuple '
+ 'values, e.g. key="[(a,b),(c,d)]". Note that the quotation marks '
+ 'are necessary and that no white space is allowed.')
+ parser.add_argument(
+ '--launcher',
+ choices=['none', 'pytorch', 'slurm', 'mpi'],
+ default='none',
+ help='Options for job launcher.')
+ parser.add_argument('--local_rank', type=int, default=0)
+
+ args = parser.parse_args()
+ if 'LOCAL_RANK' not in os.environ:
+ os.environ['LOCAL_RANK'] = str(args.local_rank)
+
+ if args.options and args.cfg_options:
+ raise ValueError(
+ '--options and --cfg-options cannot be both '
+ 'specified, --options is deprecated in favor of --cfg-options')
+ if args.options:
+ warnings.warn('--options is deprecated in favor of --cfg-options')
+ args.cfg_options = args.options
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ cfg = Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ setup_multi_processes(cfg)
+
+ # set cudnn_benchmark
+ if cfg.get('cudnn_benchmark', False):
+ torch.backends.cudnn.benchmark = True
+
+ # work_dir is determined in this priority: CLI > segment in file > filename
+ if args.work_dir is not None:
+ # update configs according to CLI args if args.work_dir is not None
+ cfg.work_dir = args.work_dir
+ elif cfg.get('work_dir', None) is None:
+ # use config filename as default work_dir if cfg.work_dir is None
+ cfg.work_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+ if args.load_from is not None:
+ cfg.load_from = args.load_from
+ if args.resume_from is not None:
+ cfg.resume_from = args.resume_from
+ if args.gpus is not None:
+ cfg.gpu_ids = range(1)
+ warnings.warn('`--gpus` is deprecated because we only support '
+ 'single GPU mode in non-distributed training. '
+ 'Use `gpus=1` now.')
+ if args.gpu_ids is not None:
+ cfg.gpu_ids = args.gpu_ids[0:1]
+ warnings.warn('`--gpu-ids` is deprecated, please use `--gpu-id`. '
+ 'Because we only support single GPU mode in '
+ 'non-distributed training. Use the first GPU '
+ 'in `gpu_ids` now.')
+ if args.gpus is None and args.gpu_ids is None:
+ cfg.gpu_ids = [args.gpu_id]
+
+ # init distributed env first, since logger depends on the dist info.
+ if args.launcher == 'none':
+ distributed = False
+ else:
+ distributed = True
+ init_dist(args.launcher, **cfg.dist_params)
+ # re-set gpu_ids with distributed training mode
+ _, world_size = get_dist_info()
+ cfg.gpu_ids = range(world_size)
+
+ # create work_dir
+ mmcv.mkdir_or_exist(osp.abspath(cfg.work_dir))
+ # dump config
+ cfg.dump(osp.join(cfg.work_dir, osp.basename(args.config)))
+ # init the logger before other steps
+ timestamp = time.strftime('%Y%m%d_%H%M%S', time.localtime())
+ log_file = osp.join(cfg.work_dir, f'{timestamp}.log')
+ logger = get_root_logger(log_file=log_file, log_level=cfg.log_level)
+
+ # init the meta dict to record some important information such as
+ # environment info and seed, which will be logged
+ meta = dict()
+ # log env info
+ env_info_dict = collect_env()
+ env_info = '\n'.join([(f'{k}: {v}') for k, v in env_info_dict.items()])
+ dash_line = '-' * 60 + '\n'
+ logger.info('Environment info:\n' + dash_line + env_info + '\n' +
+ dash_line)
+ meta['env_info'] = env_info
+ meta['config'] = cfg.pretty_text
+ # log some basic info
+ logger.info(f'Distributed training: {distributed}')
+ logger.info(f'Config:\n{cfg.pretty_text}')
+
+ # set random seeds
+ seed = init_random_seed(args.seed)
+ seed = seed + dist.get_rank() if args.diff_seed else seed
+ logger.info(f'Set random seed to {seed}, '
+ f'deterministic: {args.deterministic}')
+ set_random_seed(seed, deterministic=args.deterministic)
+ cfg.seed = seed
+ meta['seed'] = seed
+ meta['exp_name'] = osp.basename(args.config)
+
+ model = build_detector(
+ cfg.model,
+ train_cfg=cfg.get('train_cfg'),
+ test_cfg=cfg.get('test_cfg'))
+ model.init_weights()
+
+ datasets = [build_dataset(cfg.data.train)]
+ if len(cfg.workflow) == 2:
+ val_dataset = copy.deepcopy(cfg.data.val)
+ if cfg.data.train.get('pipeline', None) is None:
+ if is_2dlist(cfg.data.train.datasets):
+ train_pipeline = cfg.data.train.datasets[0][0].pipeline
+ else:
+ train_pipeline = cfg.data.train.datasets[0].pipeline
+ elif is_2dlist(cfg.data.train.pipeline):
+ train_pipeline = cfg.data.train.pipeline[0]
+ else:
+ train_pipeline = cfg.data.train.pipeline
+
+ if val_dataset['type'] in ['ConcatDataset', 'UniformConcatDataset']:
+ for dataset in val_dataset['datasets']:
+ dataset.pipeline = train_pipeline
+ else:
+ val_dataset.pipeline = train_pipeline
+ datasets.append(build_dataset(val_dataset))
+ if cfg.checkpoint_config is not None:
+ # save mmdet version, config file content and class names in
+ # checkpoints as meta data
+ cfg.checkpoint_config.meta = dict(
+ mmocr_version=__version__ + get_git_hash()[:7],
+ CLASSES=datasets[0].CLASSES)
+ # add an attribute for visualization convenience
+ model.CLASSES = datasets[0].CLASSES
+ train_detector(
+ model,
+ datasets,
+ cfg,
+ distributed=distributed,
+ validate=(not args.no_validate),
+ timestamp=timestamp,
+ meta=meta)
+
+
+if __name__ == '__main__':
+ main()
 +
+
 +
+ +
+ +
+ +
+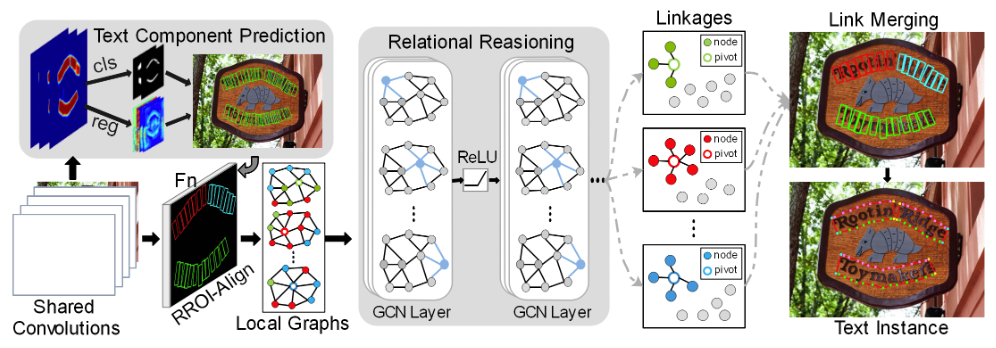 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+