# Model Architecture Summary
MMOCR has implemented many models that support various tasks. Depending on the type of tasks, these models have different architectural designs and, therefore, might be a bit confusing for beginners to master. We release a primary design doc to clearly illustrate the basic task-specific architectures and provide quick pointers to docstrings of model components to aid users' understanding.
## Text Detection Models
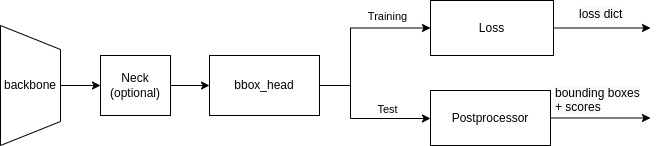
The design of text detectors is similar to [SingleStageDetector](https://mmdetection.readthedocs.io/en/latest/api.html#mmdet.models.detectors.SingleStageDetector) in MMDetection. The feature of an image was first extracted by `backbone` (e.g., ResNet), and `neck` further processes raw features into a head-ready format, where the models in MMOCR usually adapt the variants of FPN to extract finer-grained multi-level features. `bbox_head` is the core of text detectors, and its implementation varies in different models.
When training, the output of `bbox_head` is directly fed into the `loss` module, which compares the output with the ground truth and generates a loss dictionary for optimizer's use. When testing, `Postprocessor` converts the outputs from `bbox_head` to bounding boxes, which will be used for evaluation metrics (e.g., hmean-iou) and visualization.
### DBNet
- Backbone: [mmdet.ResNet](https://mmdetection.readthedocs.io/en/latest/api.html#mmdet.models.backbones.ResNet)
- Neck: [FPNC](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.necks.FPNC)
- Bbox_head: [DBHead](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.dense_heads.DBHead)
- Loss: [DBLoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.losses.DBLoss)
- Postprocessor: [DBPostprocessor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.postprocess.DBPostprocessor)
### DRRG
- Backbone: [mmdet.ResNet](https://mmdetection.readthedocs.io/en/latest/api.html#mmdet.models.backbones.ResNet)
- Neck: [FPN_UNet](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.necks.FPN_UNet)
- Bbox_head: [DRRGHead](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.dense_heads.DRRGHead)
- Loss: [DRRGLoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.losses.DRRGLoss)
- Postprocessor: [DRRGPostprocessor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.postprocess.DRRGPostprocessor)
### FCENet
- Backbone: [mmdet.ResNet](https://mmdetection.readthedocs.io/en/latest/api.html#mmdet.models.backbones.ResNet)
- Neck: [mmdet.FPN](https://mmdetection.readthedocs.io/en/latest/api.html#mmdet.models.necks.FPN)
- Bbox_head: [FCEHead](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.dense_heads.FCEHead)
- Loss: [FCELoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.losses.FCELoss)
- Postprocessor: [FCEPostprocessor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.postprocess.FCEPostprocessor)
### Mask R-CNN
We use the same architecture as in MMDetection. See MMDetection's [config documentation](https://mmdetection.readthedocs.io/en/latest/tutorials/config.html#an-example-of-mask-r-cnn) for details.
### PANet
- Backbone: [mmdet.ResNet](https://mmdetection.readthedocs.io/en/latest/api.html#mmdet.models.backbones.ResNet)
- Neck: [FPEM_FFM](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.necks.FPEM_FFM)
- Bbox_head: [PANHead](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.dense_heads.PANHead)
- Loss: [PANLoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.losses.PANLoss)
- Postprocessor: [PANPostprocessor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.postprocess.PANPostprocessor)
### PSENet
- Backbone: [mmdet.ResNet](https://mmdetection.readthedocs.io/en/latest/api.html#mmdet.models.backbones.ResNet)
- Neck: [FPNF](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.necks.FPNF)
- Bbox_head: [PSEHead](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.dense_heads.PSEHead)
- Loss: [PSELoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.losses.PSELoss)
- Postprocessor: [PSEPostprocessor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.postprocess.PSEPostprocessor)
### Textsnake
- Backbone: [mmdet.ResNet](https://mmdetection.readthedocs.io/en/latest/api.html#mmdet.models.backbones.ResNet)
- Neck: [FPN_UNet](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.necks.FPN_UNet)
- Bbox_head: [TextSnakeHead](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.dense_heads.TextSnakeHead)
- Loss: [TextSnakeLoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.losses.TextSnakeLoss)
- Postprocessor: [TextSnakePostprocessor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textdet.postprocess.TextSnakePostprocessor)
## Text Recognition Models
**Most of** the implemented recognizers use the following architecture:
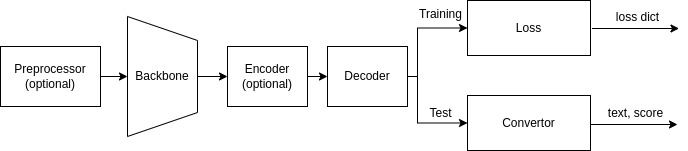
`preprocessor` refers to any network that processes images before they are fed to `backbone`. `encoder` encodes images features into a hidden vector, which is then transcribed into text tokens by `decoder`.
The architecture diverges at training and test phases. The loss module returns a dictionary during training. In testing, `converter` is invoked to convert raw features into texts, which are wrapped into a dictionary together with confidence scores. Users can access the dictionary with the `text` and `score` keys to query the recognition result.
### ABINet
- Preprocessor: None
- Backbone: [ResNetABI](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.backbones.ResNetABI)
- Encoder: [ABIVisionModel](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.encoders.ABIVisionModel)
- Decoder: [ABIVisionDecoder](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.decoders.ABIVisionDecoder)
- Fuser: [ABIFuser](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.fusers.ABIFuser)
- Loss: [ABILoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.losses.ABILoss)
- Converter: [ABIConvertor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.convertors.ABIConvertor)
:::{note}
Fuser fuses the feature output from encoder and decoder before generating the final text outputs and computing the loss in full ABINet.
:::
### CRNN
- Preprocessor: None
- Backbone: [VeryDeepVgg](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.backbones.VeryDeepVgg)
- Encoder: None
- Decoder: [CRNNDecoder](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.decoders.CRNNDecoder)
- Loss: [CTCLoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.losses.CTCLoss)
- Converter: [CTCConvertor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.convertors.CTCConvertor)
### CRNN with TPS-based STN
- Preprocessor: [TPSPreprocessor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.preprocessor.TPSPreprocessor)
- Backbone: [VeryDeepVgg](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.backbones.VeryDeepVgg)
- Encoder: None
- Decoder: [CRNNDecoder](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.decoders.CRNNDecoder)
- Loss: [CTCLoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.losses.CTCLoss)
- Converter: [CTCConvertor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.convertors.CTCConvertor)
### NRTR
- Preprocessor: None
- Backbone: [ResNet31OCR](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.backbones.ResNet31OCR)
- Encoder: [NRTREncoder](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.encoders.NRTREncoder)
- Decoder: [NRTRDecoder](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.decoders.NRTRDecoder)
- Loss: [TFLoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.losses.TFLoss)
- Converter: [AttnConvertor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.convertors.AttnConvertor)
### RobustScanner
- Preprocessor: None
- Backbone: [ResNet31OCR](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.backbones.ResNet31OCR)
- Encoder: [ChannelReductionEncoder](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.encoders.ChannelReductionEncoder)
- Decoder: [ChannelReductionEncoder](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.decoders.RobustScannerDecoder)
- Loss: [SARLoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.losses.SARLoss)
- Converter: [AttnConvertor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.convertors.AttnConvertor)
### SAR
- Preprocessor: None
- Backbone: [ResNet31OCR](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.backbones.ResNet31OCR)
- Encoder: [SAREncoder](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.encoders.SAREncoder)
- Decoder: [ParallelSARDecoder](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.decoders.ParallelSARDecoder)
- Loss: [SARLoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.losses.SARLoss)
- Converter: [AttnConvertor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.convertors.AttnConvertor)
### SATRN
- Preprocessor: None
- Backbone: [ShallowCNN](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.backbones.ShallowCNN)
- Encoder: [SatrnEncoder](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.encoders.SatrnEncoder)
- Decoder: [NRTRDecoder](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.decoders.NRTRDecoder)
- Loss: [TFLoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.losses.TFLoss)
- Converter: [AttnConvertor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.convertors.AttnConvertor)
### SegOCR
- Backbone: [ResNet31OCR](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.backbones.ResNet31OCR)
- Neck: [FPNOCR](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.necks.FPNOCR)
- Head: [SegHead](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.heads.SegHead)
- Loss: [SegLoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.losses.SegLoss)
- Converter: [SegConvertor](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.textrecog.convertors.SegConvertor)
:::{note}
SegOCR's architecture is an exception - it is closer to text detection models.
:::
## Key Information Extraction Models
The architecture of key information extraction (KIE) models is similar to text detection models, except for the extra feature extractor. As a downstream task of OCR, KIE models are required to run with bounding box annotations indicating the locations of text instances, from which an ROI extractor extracts the cropped features for `bbox_head` to discover relations among them.
The output containing edges and nodes information from `bbox_head` is sufficient for test and inference. Computation of loss also relies on such information.
### SDMGR
- Backbone: [UNet](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.common.backbones.UNet)
- Neck: None
- Extractor: [mmdet.SingleRoIExtractor](https://mmdetection.readthedocs.io/en/latest/api.html#mmdet.models.roi_heads.SingleRoIExtractor)
- Bbox_head: [SDMGRHead](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.kie.heads.SDMGRHead)
- Loss: [SDMGRLoss](https://mmocr.readthedocs.io/en/latest/api.html#mmocr.models.kie.losses.SDMGRLoss)