Spaces:
Running
on
Zero

Running
on
Zero
init commit
Browse files- .gitattributes +5 -0
- README.md +111 -14
- app.py +243 -0
- assets/BPT.png +0 -0
- assets/teaser.png +3 -0
- config/BPT-open-8k-8-16.yaml +22 -0
- examples/AdventureYouth.glb +3 -0
- examples/Astrologers.glb +3 -0
- examples/Sheep.glb +3 -0
- examples/Spider.glb +3 -0
- main.py +126 -0
- metrics.py +39 -0
- miche/.DS_Store +0 -0
- miche/LICENSE +674 -0
- miche/__init__.py +0 -0
- miche/encode.py +74 -0
- miche/michelangelo/.DS_Store +0 -0
- miche/michelangelo/__init__.py +1 -0
- miche/michelangelo/graphics/__init__.py +1 -0
- miche/michelangelo/graphics/__pycache__/__init__.cpython-38.pyc +0 -0
- miche/michelangelo/graphics/__pycache__/__init__.cpython-39.pyc +0 -0
- miche/michelangelo/graphics/primitives/__init__.py +4 -0
- miche/michelangelo/graphics/primitives/volume.py +21 -0
- miche/michelangelo/models/__init__.py +1 -0
- miche/michelangelo/models/modules/__init__.py +3 -0
- miche/michelangelo/models/modules/checkpoint.py +64 -0
- miche/michelangelo/models/modules/distributions.py +83 -0
- miche/michelangelo/models/modules/embedder.py +213 -0
- miche/michelangelo/models/modules/transformer_blocks.py +286 -0
- miche/michelangelo/models/tsal/__init__.py +1 -0
- miche/michelangelo/models/tsal/asl_pl_module.py +383 -0
- miche/michelangelo/models/tsal/clip_asl_module.py +118 -0
- miche/michelangelo/models/tsal/inference_utils.py +76 -0
- miche/michelangelo/models/tsal/loss.py +130 -0
- miche/michelangelo/models/tsal/sal_perceiver.py +410 -0
- miche/michelangelo/models/tsal/tsal_base.py +125 -0
- miche/michelangelo/utils/__init__.py +3 -0
- miche/michelangelo/utils/misc.py +83 -0
- miche/shapevae-256.yaml +46 -0
- model/.DS_Store +0 -0
- model/__init__.py +0 -0
- model/data_utils.py +194 -0
- model/miche_conditioner.py +86 -0
- model/model.py +379 -0
- model/serializaiton.py +241 -0
- requirements.txt +30 -0
- utils.py +88 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,8 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
assets/teaser.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
examples/AdventureYouth.glb filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
examples/Astrologers.glb filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
examples/Sheep.glb filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
examples/Spider.glb filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,14 +1,111 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
| 14 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Scaling Mesh Generation via Compressive Tokenization
|
| 2 |
+
|
| 3 |
+
### [Project Page](https://whaohan.github.io/bpt) | [Paper](https://arxiv.org/abs/2411.07025) | [Weight](https://huggingface.co/whaohan/bpt/tree/main)
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
## 📑 Open-source Plan
|
| 7 |
+
|
| 8 |
+
- [x] Inference conditioned on point cloud
|
| 9 |
+
- [x] Checkpoints
|
| 10 |
+
- [x] Evaluation metrics
|
| 11 |
+
- [ ] Inference conditioned on images
|
| 12 |
+
- [ ] Training
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
## **Abstract**
|
| 16 |
+
<p align="center">
|
| 17 |
+
<img src="./assets/teaser.png" height=450>
|
| 18 |
+
</p>
|
| 19 |
+
|
| 20 |
+
We propose a compressive yet effective mesh representation, Blocked and Patchified Tokenization (BPT), facilitating the generation of meshes exceeding 8k faces. BPT compresses mesh sequences by employing block-wise indexing and patch aggregation, reducing their length by approximately 75% compared to the original sequences. This compression milestone unlocks the potential to utilize mesh data with significantly more faces, thereby enhancing detail richness and improving generation robustness. Empowered with the BPT, we have built a foundation mesh generative model training on scaled mesh data to support flexible control for point clouds and images. Our model demonstrates the capability to generate meshes with intricate details and accurate topology, achieving SoTA performance on mesh generation and reaching the level for direct product usage.
|
| 21 |
+
|
| 22 |
+
## 🎉 **Blocked and Patchified Tokenization (BPT)**
|
| 23 |
+
|
| 24 |
+
<p align="center">
|
| 25 |
+
<img src="assets/BPT.png" height=300>
|
| 26 |
+
</p>
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
## Get Started
|
| 30 |
+
|
| 31 |
+
#### Begin by cloning the repository:
|
| 32 |
+
|
| 33 |
+
```shell
|
| 34 |
+
git clone https://github.com/whaohan/bpt.git
|
| 35 |
+
cd bpt
|
| 36 |
+
```
|
| 37 |
+
|
| 38 |
+
#### Installation Guide for Linux
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
Install the packages in `requirements.txt`. The code is tested under CUDA version 12.1 and python 3.9.
|
| 42 |
+
|
| 43 |
+
```bash
|
| 44 |
+
conda create -n bpt python=3.9
|
| 45 |
+
conda activate bpt
|
| 46 |
+
pip install torch==2.1.2 torchvision==0.16.2 --index-url https://download.pytorch.org/whl/cu121
|
| 47 |
+
pip install -r requirements.txt
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
#### Download Pretrained Models
|
| 52 |
+
|
| 53 |
+
The models are available at [huggingface](https://huggingface.co/whaohan/bpt/tree/main).
|
| 54 |
+
Currently, we resealse a lite version of model with the point-encoder finetuned from [Michelangelo](https://github.com/NeuralCarver/Michelangelo).
|
| 55 |
+
|
| 56 |
+
To download the model, first install the huggingface-cli. (Detailed instructions are available [here](https://huggingface.co/docs/huggingface_hub/guides/cli).)
|
| 57 |
+
|
| 58 |
+
```shell
|
| 59 |
+
python3 -m pip install "huggingface_hub[cli]"
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
Then download the model using the following commands:
|
| 63 |
+
|
| 64 |
+
```shell
|
| 65 |
+
mkdir weights
|
| 66 |
+
huggingface-cli download whaohan/bpt --local-dir ./weights
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
#### Inference conditioned on point clouds
|
| 70 |
+
For text to 3d generation, we supports bilingual Chinese and English, you can use the following command to inference.
|
| 71 |
+
```python
|
| 72 |
+
python main.py \
|
| 73 |
+
--config 'config/BPT-open-8k-8-16.yaml' \
|
| 74 |
+
--model_path /path/to/model/ckpt \
|
| 75 |
+
--output_path output/ \
|
| 76 |
+
--batch_size 1 \
|
| 77 |
+
--temperature 0.5 \
|
| 78 |
+
--input_type mesh \
|
| 79 |
+
--input_dir /path/to/your/dense/meshes
|
| 80 |
+
```
|
| 81 |
+
It requires ~12GB VRAM to run with fp16 precision. It takes averagely 2mins to generate a single mesh.
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
#### Evaluation
|
| 85 |
+
|
| 86 |
+
```bash
|
| 87 |
+
python metrics.py \
|
| 88 |
+
--input_dir /path/to/dense/meshes \
|
| 89 |
+
--output_dir /path/to/output/meshes
|
| 90 |
+
```
|
| 91 |
+
|
| 92 |
+
### Acknowledgement
|
| 93 |
+
|
| 94 |
+
- [MeshGPT](https://github.com/lucidrains/meshgpt-pytorch)
|
| 95 |
+
- [PivotMesh](https://github.com/whaohan/pivotmesh)
|
| 96 |
+
- [Michelangelo](https://github.com/NeuralCarver/Michelangelo)
|
| 97 |
+
- [MeshAnything](https://github.com/buaacyw/MeshAnythingV2/)
|
| 98 |
+
- [MeshXL](https://github.com/OpenMeshLab/MeshXL/)
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
## Citation
|
| 102 |
+
|
| 103 |
+
If you found this repository helpful, please cite our report:
|
| 104 |
+
```bibtex
|
| 105 |
+
@article{weng2024scaling,
|
| 106 |
+
title={Scaling Mesh Generation via Compressive Tokenization},
|
| 107 |
+
author={Haohan Weng and Zibo Zhao and Biwen Lei and Xianghui Yang and Jian Liu and Zeqiang Lai and Zhuo Chen and Yuhong Liu and Jie Jiang and Chunchao Guo and Tong Zhang and Shenghua Gao and C. L. Philip Chen},
|
| 108 |
+
journal={arXiv preprint arXiv:2411.07025},
|
| 109 |
+
year={2024}
|
| 110 |
+
}
|
| 111 |
+
```
|
app.py
ADDED
|
@@ -0,0 +1,243 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from model.data_utils import to_mesh
|
| 2 |
+
from model.serializaiton import BPT_deserialize
|
| 3 |
+
import spaces
|
| 4 |
+
import os
|
| 5 |
+
import torch
|
| 6 |
+
import trimesh
|
| 7 |
+
from accelerate.utils import set_seed
|
| 8 |
+
import numpy as np
|
| 9 |
+
import gradio as gr
|
| 10 |
+
import time
|
| 11 |
+
import matplotlib.pyplot as plt
|
| 12 |
+
from mpl_toolkits.mplot3d.art3d import Poly3DCollection
|
| 13 |
+
from matplotlib.animation import FuncAnimation
|
| 14 |
+
import yaml
|
| 15 |
+
from huggingface_hub import snapshot_download
|
| 16 |
+
from model.model import MeshTransformer
|
| 17 |
+
from utils import apply_normalize, joint_filter, sample_pc
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
CONFIG_PATH = 'config/BPT-open-8k-8-16.yaml'
|
| 21 |
+
with open(CONFIG_PATH, "r") as f:
|
| 22 |
+
config = yaml.load(f, Loader=yaml.FullLoader)
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def download_models():
|
| 26 |
+
os.makedirs("weights", exist_ok=True)
|
| 27 |
+
try:
|
| 28 |
+
snapshot_download(
|
| 29 |
+
repo_id="whaohan/bpt",
|
| 30 |
+
local_dir="./weights",
|
| 31 |
+
resume_download=True
|
| 32 |
+
)
|
| 33 |
+
print("Successfully downloaded Hunyuan3D-1 model")
|
| 34 |
+
except Exception as e:
|
| 35 |
+
print(f"Error downloading Hunyuan3D-1: {e}")
|
| 36 |
+
|
| 37 |
+
model_path = 'weights/bpt-8-16-500m.pt'
|
| 38 |
+
return model_path
|
| 39 |
+
|
| 40 |
+
MODEL_PATH = download_models()
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
# prepare model with fp16 precision
|
| 44 |
+
model = MeshTransformer(
|
| 45 |
+
dim = config['dim'],
|
| 46 |
+
attn_depth = config['depth'],
|
| 47 |
+
max_seq_len = config['max_seq_len'],
|
| 48 |
+
dropout = config['dropout'],
|
| 49 |
+
mode = config['mode'],
|
| 50 |
+
num_discrete_coors= 2**int(config['quant_bit']),
|
| 51 |
+
block_size = config['block_size'],
|
| 52 |
+
offset_size = config['offset_size'],
|
| 53 |
+
conditioned_on_pc = config['conditioned_on_pc'],
|
| 54 |
+
use_special_block = config['use_special_block'],
|
| 55 |
+
encoder_name = config['encoder_name'],
|
| 56 |
+
encoder_freeze = config['encoder_freeze'],
|
| 57 |
+
)
|
| 58 |
+
model.load(MODEL_PATH)
|
| 59 |
+
model = model.eval()
|
| 60 |
+
model = model.half()
|
| 61 |
+
model = model.cuda()
|
| 62 |
+
device = torch.device('cuda')
|
| 63 |
+
print('Model loaded')
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def create_animation(mesh):
|
| 67 |
+
mesh.vertices = mesh.vertices[:, [2, 0, 1]]
|
| 68 |
+
|
| 69 |
+
bounding_box = mesh.bounds
|
| 70 |
+
center = mesh.centroid
|
| 71 |
+
scale = np.ptp(bounding_box, axis=0).max()
|
| 72 |
+
|
| 73 |
+
fig = plt.figure(figsize=(10, 10))
|
| 74 |
+
|
| 75 |
+
ax = fig.add_subplot(111, projection='3d')
|
| 76 |
+
ax.set_axis_off()
|
| 77 |
+
|
| 78 |
+
# Extract vertices and faces for plotting
|
| 79 |
+
vertices = mesh.vertices
|
| 80 |
+
faces = mesh.faces
|
| 81 |
+
|
| 82 |
+
# Plot faces
|
| 83 |
+
ax.add_collection3d(Poly3DCollection(
|
| 84 |
+
vertices[faces] * 1.4,
|
| 85 |
+
facecolors=[120/255, 154/255, 192/255, 255/255],
|
| 86 |
+
edgecolors='k',
|
| 87 |
+
linewidths=0.5,
|
| 88 |
+
))
|
| 89 |
+
|
| 90 |
+
# Set limits and center the view on the object
|
| 91 |
+
ax.set_xlim(center[0] - scale / 2, center[0] + scale / 2)
|
| 92 |
+
ax.set_ylim(center[1] - scale / 2, center[1] + scale / 2)
|
| 93 |
+
ax.set_zlim(center[2] - scale / 2, center[2] + scale / 2)
|
| 94 |
+
|
| 95 |
+
# Function to update the view angle
|
| 96 |
+
def update_view(num, ax):
|
| 97 |
+
ax.view_init(elev=20, azim=num)
|
| 98 |
+
return ax,
|
| 99 |
+
|
| 100 |
+
# Create the animation
|
| 101 |
+
ani = FuncAnimation(fig, update_view, frames=np.arange(0, 360, 10), interval=100, fargs=(ax,), blit=False)
|
| 102 |
+
|
| 103 |
+
# Save the animation as a GIF
|
| 104 |
+
output_path = f'model_{int(time.time())}.gif'
|
| 105 |
+
ani.save(output_path, writer='pillow', fps=10)
|
| 106 |
+
|
| 107 |
+
# Close the figure
|
| 108 |
+
plt.close(fig)
|
| 109 |
+
|
| 110 |
+
return output_path
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
@spaces.GPU(duration=480)
|
| 114 |
+
def do_inference(input_3d, sample_seed=0, temperature=0.5, top_k_value=50, top_p_value=0.9):
|
| 115 |
+
print('Start Inference')
|
| 116 |
+
set_seed(sample_seed)
|
| 117 |
+
print("Seed value:", sample_seed)
|
| 118 |
+
|
| 119 |
+
mesh = trimesh.load(input_3d, force='mesh')
|
| 120 |
+
mesh = apply_normalize(mesh)
|
| 121 |
+
pc_normal = sample_pc(mesh, pc_num=4096, with_normal=True)
|
| 122 |
+
vertices = mesh.vertices
|
| 123 |
+
|
| 124 |
+
pc_coor = pc_normal[:, :3]
|
| 125 |
+
normals = pc_normal[:, 3:]
|
| 126 |
+
assert (np.linalg.norm(normals, axis=-1) > 0.99).all(), "normals should be unit vectors, something wrong"
|
| 127 |
+
normalized_pc_normal = np.concatenate([pc_coor, normals], axis=-1, dtype=np.float16)
|
| 128 |
+
input = torch.tensor(normalized_pc_normal, dtype=torch.float16, device=device)[None]
|
| 129 |
+
print("Data loaded")
|
| 130 |
+
|
| 131 |
+
with torch.no_grad():
|
| 132 |
+
code = model.generate(
|
| 133 |
+
batch_size = 1,
|
| 134 |
+
temperature = temperature,
|
| 135 |
+
pc = input,
|
| 136 |
+
filter_logits_fn = joint_filter,
|
| 137 |
+
filter_kwargs = dict(k=top_k_value, p=top_p_value),
|
| 138 |
+
return_codes=True,
|
| 139 |
+
)[0]
|
| 140 |
+
|
| 141 |
+
print("Model inference done")
|
| 142 |
+
|
| 143 |
+
# convert to mesh
|
| 144 |
+
code = code[code != model.pad_id].cpu().numpy()
|
| 145 |
+
vertices = BPT_deserialize(
|
| 146 |
+
code,
|
| 147 |
+
block_size = model.block_size,
|
| 148 |
+
offset_size = model.offset_size,
|
| 149 |
+
use_special_block = model.use_special_block,
|
| 150 |
+
)
|
| 151 |
+
faces = torch.arange(1, len(vertices) + 1).view(-1, 3)
|
| 152 |
+
artist_mesh = to_mesh(vertices, faces, transpose=False, post_process=True)
|
| 153 |
+
|
| 154 |
+
# add color for visualization
|
| 155 |
+
num_faces = len(artist_mesh.faces)
|
| 156 |
+
face_color = np.array([120, 154, 192, 255], dtype=np.uint8)
|
| 157 |
+
face_colors = np.tile(face_color, (num_faces, 1))
|
| 158 |
+
artist_mesh.visual.face_colors = face_colors
|
| 159 |
+
|
| 160 |
+
# add time stamp to avoid cache
|
| 161 |
+
save_name = f"output_{int(time.time())}.obj"
|
| 162 |
+
artist_mesh.export(save_name)
|
| 163 |
+
output_render = create_animation(artist_mesh)
|
| 164 |
+
return save_name, output_render
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
_HEADER_ = '''
|
| 168 |
+
<h2><b>Official 🤗 Gradio Demo for Paper</b> <a href='https://github.com/whaohan/bpt' target='_blank'><b>Scaling Mesh Generation with Compressive Tokenization</b></a></h2>
|
| 169 |
+
'''
|
| 170 |
+
|
| 171 |
+
_CITE_ = r"""
|
| 172 |
+
If you found our model is helpful, please help to ⭐ the <a href='https://github.com/whaohan/bpt' target='_blank'>Github Repo</a>. Code: <a href='https://github.com/whaohan/bpt' target='_blank'>GitHub</a>. Arxiv Paper: <a href='https://arxiv.org/abs/2411.07025' target='_blank'>ArXiv</a>.
|
| 173 |
+
|
| 174 |
+
📧 **Contact**
|
| 175 |
+
If you have any questions, feel free to contact <a href='https://whaohan.github.io' target='_blank'>Haohan Weng</a>.
|
| 176 |
+
"""
|
| 177 |
+
|
| 178 |
+
output_model_obj = gr.Model3D(
|
| 179 |
+
label="Generated Mesh (OBJ Format)",
|
| 180 |
+
display_mode="wireframe",
|
| 181 |
+
scale = 2,
|
| 182 |
+
)
|
| 183 |
+
|
| 184 |
+
output_image_render = gr.Image(
|
| 185 |
+
label="Wireframe Render of Generated Mesh",
|
| 186 |
+
scale = 1,
|
| 187 |
+
)
|
| 188 |
+
|
| 189 |
+
with gr.Blocks() as demo:
|
| 190 |
+
gr.Markdown(_HEADER_)
|
| 191 |
+
with gr.Row(variant="panel"):
|
| 192 |
+
with gr.Column(scale=1):
|
| 193 |
+
with gr.Row():
|
| 194 |
+
input_3d = gr.Model3D(
|
| 195 |
+
label="Input Mesh",
|
| 196 |
+
)
|
| 197 |
+
|
| 198 |
+
# with gr.Row():
|
| 199 |
+
# # with gr.Group():
|
| 200 |
+
with gr.Row():
|
| 201 |
+
sample_seed = gr.Number(value=0, label="Seed Value", precision=0)
|
| 202 |
+
temperature = gr.Number(value=0.5, label="Temperature For Sampling", precision=None)
|
| 203 |
+
with gr.Row():
|
| 204 |
+
top_k_value = gr.Number(value=50, label="TopK For Sampling", precision=0)
|
| 205 |
+
top_p_value = gr.Number(value=0.9, label="TopP For Sampling", precision=None)
|
| 206 |
+
|
| 207 |
+
with gr.Row():
|
| 208 |
+
submit = gr.Button("Generate", elem_id="generate", variant="primary")
|
| 209 |
+
|
| 210 |
+
with gr.Row(variant="panel"):
|
| 211 |
+
mesh_examples = gr.Examples(
|
| 212 |
+
examples=[
|
| 213 |
+
os.path.join("examples", img_name) for img_name in sorted(os.listdir("examples"))
|
| 214 |
+
],
|
| 215 |
+
inputs=input_3d,
|
| 216 |
+
outputs=[output_model_obj, output_image_render],
|
| 217 |
+
fn=do_inference,
|
| 218 |
+
cache_examples = False,
|
| 219 |
+
examples_per_page=10
|
| 220 |
+
)
|
| 221 |
+
|
| 222 |
+
with gr.Row():
|
| 223 |
+
gr.Markdown('''Try different <b>Seed Value</b> or <b>Temperature</b> if the result is unsatisfying''')
|
| 224 |
+
|
| 225 |
+
with gr.Column(scale=2):
|
| 226 |
+
with gr.Row(equal_height=True):
|
| 227 |
+
output_model_obj.render()
|
| 228 |
+
output_image_render.render()
|
| 229 |
+
|
| 230 |
+
|
| 231 |
+
gr.Markdown(_CITE_)
|
| 232 |
+
|
| 233 |
+
mv_images = gr.State()
|
| 234 |
+
|
| 235 |
+
submit.click(
|
| 236 |
+
fn=do_inference,
|
| 237 |
+
inputs=[input_3d, sample_seed, temperature, top_k_value, top_p_value],
|
| 238 |
+
outputs = [output_model_obj, output_image_render],
|
| 239 |
+
)
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
demo.launch(share=True)
|
| 243 |
+
|
assets/BPT.png
ADDED
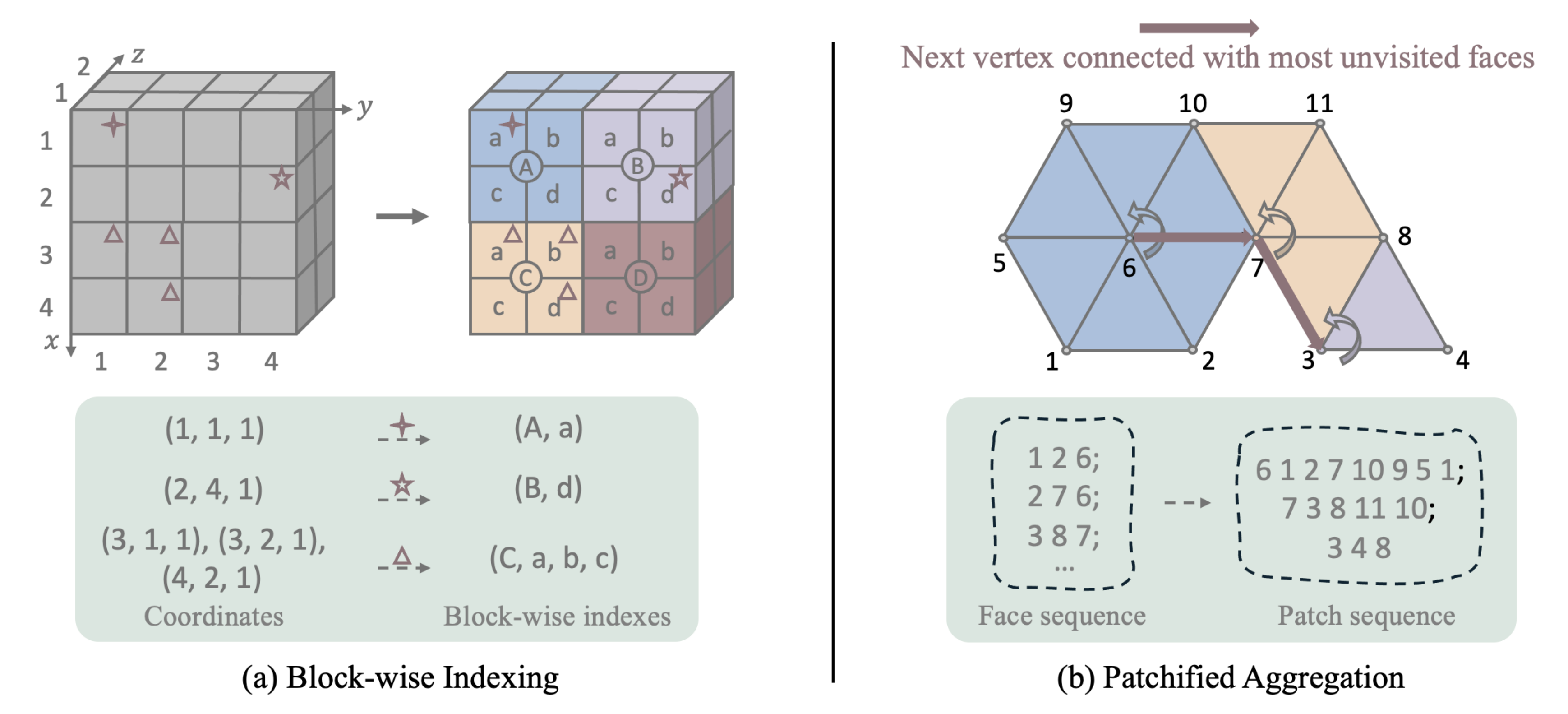
|
assets/teaser.png
ADDED

|
Git LFS Details
|
config/BPT-open-8k-8-16.yaml
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
exp_name: 'BPT-open-8k-8-16'
|
| 2 |
+
logdir: '/path/to/log'
|
| 3 |
+
|
| 4 |
+
# condition
|
| 5 |
+
conditioned_on_pc: True
|
| 6 |
+
encoder_name: miche-256-feature
|
| 7 |
+
encoder_freeze: False
|
| 8 |
+
pc_num: 4096
|
| 9 |
+
|
| 10 |
+
# representation config
|
| 11 |
+
use_special_block: True
|
| 12 |
+
block_compression: True
|
| 13 |
+
block_size: 8
|
| 14 |
+
offset_size: 16
|
| 15 |
+
quant_bit: 7
|
| 16 |
+
|
| 17 |
+
# architecture
|
| 18 |
+
mode: 'vertices'
|
| 19 |
+
dim: 1024
|
| 20 |
+
depth: 24
|
| 21 |
+
dropout: 0.0
|
| 22 |
+
max_seq_len: 10000
|
examples/AdventureYouth.glb
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ec1363c63948a23fe23173ecd0213dbab3e9e2990b9e4ea8edbe134603e6dd72
|
| 3 |
+
size 15541388
|
examples/Astrologers.glb
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0dc3d04b0c72046984d11bd6341460d116e4aeb50928a6f0378ba1b35bc6e16d
|
| 3 |
+
size 13683660
|
examples/Sheep.glb
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:62d36605fca89e316e2a0d8793ecde7a7c46fbdaabc11e80c84b6895586c39fa
|
| 3 |
+
size 15001112
|
examples/Spider.glb
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0cbf4e9ec33dacd139c756431b017f7cb79e77d041a60981aa7767b3c651f6eb
|
| 3 |
+
size 16531988
|
main.py
ADDED
|
@@ -0,0 +1,126 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import yaml
|
| 2 |
+
import torch
|
| 3 |
+
import os
|
| 4 |
+
import argparse
|
| 5 |
+
import trimesh
|
| 6 |
+
import numpy as np
|
| 7 |
+
from model.serializaiton import BPT_deserialize
|
| 8 |
+
from model.model import MeshTransformer
|
| 9 |
+
from utils import joint_filter, Dataset
|
| 10 |
+
from model.data_utils import to_mesh
|
| 11 |
+
|
| 12 |
+
# prepare arguments
|
| 13 |
+
parser = argparse.ArgumentParser()
|
| 14 |
+
parser.add_argument('--config', type=str, default='config/BPT-pc-open-8k-8-16.yaml')
|
| 15 |
+
parser.add_argument('--model_path', type=str)
|
| 16 |
+
parser.add_argument('--input_dir', default=None, type=str)
|
| 17 |
+
parser.add_argument('--input_path', default=None, type=str)
|
| 18 |
+
parser.add_argument('--out_dir', default="output", type=str)
|
| 19 |
+
parser.add_argument('--input_type', choices=['mesh','pc_normal'], default='mesh')
|
| 20 |
+
parser.add_argument('--output_path', type=str, default='output')
|
| 21 |
+
parser.add_argument('--batch_size', type=int, default=1)
|
| 22 |
+
parser.add_argument('--temperature', type=float, default=0.5) # key sampling parameter
|
| 23 |
+
parser.add_argument('--condition', type=str, default='pc')
|
| 24 |
+
args = parser.parse_args()
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
if __name__ == '__main__':
|
| 28 |
+
with open(args.config, "r") as f:
|
| 29 |
+
config = yaml.load(f, Loader=yaml.FullLoader)
|
| 30 |
+
|
| 31 |
+
# prepare model with fp16 precision
|
| 32 |
+
model = MeshTransformer(
|
| 33 |
+
dim = config['dim'],
|
| 34 |
+
attn_depth = config['depth'],
|
| 35 |
+
max_seq_len = config['max_seq_len'],
|
| 36 |
+
dropout = config['dropout'],
|
| 37 |
+
mode = config['mode'],
|
| 38 |
+
num_discrete_coors= 2**int(config['quant_bit']),
|
| 39 |
+
block_size = config['block_size'],
|
| 40 |
+
offset_size = config['offset_size'],
|
| 41 |
+
conditioned_on_pc = config['conditioned_on_pc'],
|
| 42 |
+
use_special_block = config['use_special_block'],
|
| 43 |
+
encoder_name = config['encoder_name'],
|
| 44 |
+
encoder_freeze = config['encoder_freeze'],
|
| 45 |
+
)
|
| 46 |
+
model.load(args.model_path)
|
| 47 |
+
model = model.eval()
|
| 48 |
+
model = model.half()
|
| 49 |
+
model = model.cuda()
|
| 50 |
+
num_params = sum([param.nelement() for param in model.decoder.parameters()])
|
| 51 |
+
print('Number of parameters: %.2f M' % (num_params / 1e6))
|
| 52 |
+
print(f'Block Size: {model.block_size} | Offset Size: {model.offset_size}')
|
| 53 |
+
|
| 54 |
+
# prepare data
|
| 55 |
+
if args.input_dir is not None:
|
| 56 |
+
input_list = sorted(os.listdir(args.input_dir))
|
| 57 |
+
if args.input_type == 'pc_normal':
|
| 58 |
+
# npy file with shape (n, 6):
|
| 59 |
+
# point_cloud (n, 3) + normal (n, 3)
|
| 60 |
+
input_list = [os.path.join(args.input_dir, x) for x in input_list if x.endswith('.npy')]
|
| 61 |
+
else:
|
| 62 |
+
# mesh file (e.g., obj, ply, glb)
|
| 63 |
+
input_list = [os.path.join(args.input_dir, x) for x in input_list]
|
| 64 |
+
dataset = Dataset(args.input_type, input_list)
|
| 65 |
+
|
| 66 |
+
elif args.input_path is not None:
|
| 67 |
+
dataset = Dataset(args.input_type, [args.input_path])
|
| 68 |
+
|
| 69 |
+
else:
|
| 70 |
+
raise ValueError("input_dir or input_path must be provided.")
|
| 71 |
+
|
| 72 |
+
dataloader = torch.utils.data.DataLoader(
|
| 73 |
+
dataset,
|
| 74 |
+
batch_size=args.batch_size,
|
| 75 |
+
drop_last = False,
|
| 76 |
+
shuffle = False,
|
| 77 |
+
)
|
| 78 |
+
|
| 79 |
+
os.makedirs(args.output_path, exist_ok=True)
|
| 80 |
+
with torch.no_grad():
|
| 81 |
+
for it, data in enumerate(dataloader):
|
| 82 |
+
if args.condition == 'pc':
|
| 83 |
+
# generate codes with model
|
| 84 |
+
codes = model.generate(
|
| 85 |
+
batch_size = args.batch_size,
|
| 86 |
+
temperature = args.temperature,
|
| 87 |
+
pc = data['pc_normal'].cuda().half(),
|
| 88 |
+
filter_logits_fn = joint_filter,
|
| 89 |
+
filter_kwargs = dict(k=50, p=0.95),
|
| 90 |
+
return_codes=True,
|
| 91 |
+
)
|
| 92 |
+
|
| 93 |
+
coords = []
|
| 94 |
+
try:
|
| 95 |
+
# decoding codes to coordinates
|
| 96 |
+
for i in range(len(codes)):
|
| 97 |
+
code = codes[i]
|
| 98 |
+
code = code[code != model.pad_id].cpu().numpy()
|
| 99 |
+
vertices = BPT_deserialize(
|
| 100 |
+
code,
|
| 101 |
+
block_size = model.block_size,
|
| 102 |
+
offset_size = model.offset_size,
|
| 103 |
+
use_special_block = model.use_special_block,
|
| 104 |
+
)
|
| 105 |
+
coords.append(vertices)
|
| 106 |
+
except:
|
| 107 |
+
coords.append(np.zeros(3, 3))
|
| 108 |
+
|
| 109 |
+
# convert coordinates to mesh
|
| 110 |
+
for i in range(args.batch_size):
|
| 111 |
+
uid = data['uid'][i]
|
| 112 |
+
vertices = coords[i]
|
| 113 |
+
faces = torch.arange(1, len(vertices) + 1).view(-1, 3)
|
| 114 |
+
mesh = to_mesh(vertices, faces, transpose=False, post_process=True)
|
| 115 |
+
num_faces = len(mesh.faces)
|
| 116 |
+
# set the color for mesh
|
| 117 |
+
face_color = np.array([120, 154, 192, 255], dtype=np.uint8)
|
| 118 |
+
face_colors = np.tile(face_color, (num_faces, 1))
|
| 119 |
+
mesh.visual.face_colors = face_colors
|
| 120 |
+
mesh.export(f'{args.output_path}/{uid}_mesh.obj')
|
| 121 |
+
|
| 122 |
+
# save pc
|
| 123 |
+
if args.condition == 'pc':
|
| 124 |
+
pcd = data['pc_normal'][i].cpu().numpy()
|
| 125 |
+
point_cloud = trimesh.points.PointCloud(pcd[..., 0:3])
|
| 126 |
+
point_cloud.export(f'{args.output_path}/{uid}_pc.ply', "ply")
|
metrics.py
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from tqdm import tqdm
|
| 3 |
+
import point_cloud_utils as pcu
|
| 4 |
+
from utils import sample_pc
|
| 5 |
+
import argparse
|
| 6 |
+
|
| 7 |
+
# prepare augments
|
| 8 |
+
parser = argparse.ArgumentParser()
|
| 9 |
+
parser.add_argument('--input_dir', type=str) # directory of dense meshes
|
| 10 |
+
parser.add_argument('--output_dir', type=str) # directory of generated meshes
|
| 11 |
+
args = parser.parse_args()
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def main(sample_dir, ref_dir, pc_num=1024):
|
| 15 |
+
print(sample_dir, ref_dir)
|
| 16 |
+
mesh_list = [name for name in os.listdir(ref_dir) if name.endswith('.obj')]
|
| 17 |
+
|
| 18 |
+
hausdorff_dists, chamfer_dists = [], []
|
| 19 |
+
for mesh_name in tqdm(mesh_list):
|
| 20 |
+
try:
|
| 21 |
+
# sample point cloud from input
|
| 22 |
+
uid = os.path.splitext(mesh_name)[0]
|
| 23 |
+
ref_path = os.path.join(ref_dir, uid + '.obj')
|
| 24 |
+
sample_path = os.path.join(sample_dir, uid + '.obj')
|
| 25 |
+
sample, ref = sample_pc(sample_path, pc_num), sample_pc(ref_path, pc_num)
|
| 26 |
+
|
| 27 |
+
# compute hausdorff and chamfer distance
|
| 28 |
+
hausdorff_dist = pcu.hausdorff_distance(sample, ref)
|
| 29 |
+
chamfer_dist = pcu.chamfer_distance(sample, ref)
|
| 30 |
+
hausdorff_dists.append(hausdorff_dist)
|
| 31 |
+
chamfer_dists.append(chamfer_dist)
|
| 32 |
+
except Exception as e:
|
| 33 |
+
print(e)
|
| 34 |
+
|
| 35 |
+
print('hausdorff distance:', sum(hausdorff_dists) / len(hausdorff_dists))
|
| 36 |
+
print('chamfer distance:', sum(chamfer_dists) / len(chamfer_dists))
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
main(args.input_dir, args.output_dir)
|
miche/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
miche/LICENSE
ADDED
|
@@ -0,0 +1,674 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
GNU GENERAL PUBLIC LICENSE
|
| 2 |
+
Version 3, 29 June 2007
|
| 3 |
+
|
| 4 |
+
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
|
| 5 |
+
Everyone is permitted to copy and distribute verbatim copies
|
| 6 |
+
of this license document, but changing it is not allowed.
|
| 7 |
+
|
| 8 |
+
Preamble
|
| 9 |
+
|
| 10 |
+
The GNU General Public License is a free, copyleft license for
|
| 11 |
+
software and other kinds of works.
|
| 12 |
+
|
| 13 |
+
The licenses for most software and other practical works are designed
|
| 14 |
+
to take away your freedom to share and change the works. By contrast,
|
| 15 |
+
the GNU General Public License is intended to guarantee your freedom to
|
| 16 |
+
share and change all versions of a program--to make sure it remains free
|
| 17 |
+
software for all its users. We, the Free Software Foundation, use the
|
| 18 |
+
GNU General Public License for most of our software; it applies also to
|
| 19 |
+
any other work released this way by its authors. You can apply it to
|
| 20 |
+
your programs, too.
|
| 21 |
+
|
| 22 |
+
When we speak of free software, we are referring to freedom, not
|
| 23 |
+
price. Our General Public Licenses are designed to make sure that you
|
| 24 |
+
have the freedom to distribute copies of free software (and charge for
|
| 25 |
+
them if you wish), that you receive source code or can get it if you
|
| 26 |
+
want it, that you can change the software or use pieces of it in new
|
| 27 |
+
free programs, and that you know you can do these things.
|
| 28 |
+
|
| 29 |
+
To protect your rights, we need to prevent others from denying you
|
| 30 |
+
these rights or asking you to surrender the rights. Therefore, you have
|
| 31 |
+
certain responsibilities if you distribute copies of the software, or if
|
| 32 |
+
you modify it: responsibilities to respect the freedom of others.
|
| 33 |
+
|
| 34 |
+
For example, if you distribute copies of such a program, whether
|
| 35 |
+
gratis or for a fee, you must pass on to the recipients the same
|
| 36 |
+
freedoms that you received. You must make sure that they, too, receive
|
| 37 |
+
or can get the source code. And you must show them these terms so they
|
| 38 |
+
know their rights.
|
| 39 |
+
|
| 40 |
+
Developers that use the GNU GPL protect your rights with two steps:
|
| 41 |
+
(1) assert copyright on the software, and (2) offer you this License
|
| 42 |
+
giving you legal permission to copy, distribute and/or modify it.
|
| 43 |
+
|
| 44 |
+
For the developers' and authors' protection, the GPL clearly explains
|
| 45 |
+
that there is no warranty for this free software. For both users' and
|
| 46 |
+
authors' sake, the GPL requires that modified versions be marked as
|
| 47 |
+
changed, so that their problems will not be attributed erroneously to
|
| 48 |
+
authors of previous versions.
|
| 49 |
+
|
| 50 |
+
Some devices are designed to deny users access to install or run
|
| 51 |
+
modified versions of the software inside them, although the manufacturer
|
| 52 |
+
can do so. This is fundamentally incompatible with the aim of
|
| 53 |
+
protecting users' freedom to change the software. The systematic
|
| 54 |
+
pattern of such abuse occurs in the area of products for individuals to
|
| 55 |
+
use, which is precisely where it is most unacceptable. Therefore, we
|
| 56 |
+
have designed this version of the GPL to prohibit the practice for those
|
| 57 |
+
products. If such problems arise substantially in other domains, we
|
| 58 |
+
stand ready to extend this provision to those domains in future versions
|
| 59 |
+
of the GPL, as needed to protect the freedom of users.
|
| 60 |
+
|
| 61 |
+
Finally, every program is threatened constantly by software patents.
|
| 62 |
+
States should not allow patents to restrict development and use of
|
| 63 |
+
software on general-purpose computers, but in those that do, we wish to
|
| 64 |
+
avoid the special danger that patents applied to a free program could
|
| 65 |
+
make it effectively proprietary. To prevent this, the GPL assures that
|
| 66 |
+
patents cannot be used to render the program non-free.
|
| 67 |
+
|
| 68 |
+
The precise terms and conditions for copying, distribution and
|
| 69 |
+
modification follow.
|
| 70 |
+
|
| 71 |
+
TERMS AND CONDITIONS
|
| 72 |
+
|
| 73 |
+
0. Definitions.
|
| 74 |
+
|
| 75 |
+
"This License" refers to version 3 of the GNU General Public License.
|
| 76 |
+
|
| 77 |
+
"Copyright" also means copyright-like laws that apply to other kinds of
|
| 78 |
+
works, such as semiconductor masks.
|
| 79 |
+
|
| 80 |
+
"The Program" refers to any copyrightable work licensed under this
|
| 81 |
+
License. Each licensee is addressed as "you". "Licensees" and
|
| 82 |
+
"recipients" may be individuals or organizations.
|
| 83 |
+
|
| 84 |
+
To "modify" a work means to copy from or adapt all or part of the work
|
| 85 |
+
in a fashion requiring copyright permission, other than the making of an
|
| 86 |
+
exact copy. The resulting work is called a "modified version" of the
|
| 87 |
+
earlier work or a work "based on" the earlier work.
|
| 88 |
+
|
| 89 |
+
A "covered work" means either the unmodified Program or a work based
|
| 90 |
+
on the Program.
|
| 91 |
+
|
| 92 |
+
To "propagate" a work means to do anything with it that, without
|
| 93 |
+
permission, would make you directly or secondarily liable for
|
| 94 |
+
infringement under applicable copyright law, except executing it on a
|
| 95 |
+
computer or modifying a private copy. Propagation includes copying,
|
| 96 |
+
distribution (with or without modification), making available to the
|
| 97 |
+
public, and in some countries other activities as well.
|
| 98 |
+
|
| 99 |
+
To "convey" a work means any kind of propagation that enables other
|
| 100 |
+
parties to make or receive copies. Mere interaction with a user through
|
| 101 |
+
a computer network, with no transfer of a copy, is not conveying.
|
| 102 |
+
|
| 103 |
+
An interactive user interface displays "Appropriate Legal Notices"
|
| 104 |
+
to the extent that it includes a convenient and prominently visible
|
| 105 |
+
feature that (1) displays an appropriate copyright notice, and (2)
|
| 106 |
+
tells the user that there is no warranty for the work (except to the
|
| 107 |
+
extent that warranties are provided), that licensees may convey the
|
| 108 |
+
work under this License, and how to view a copy of this License. If
|
| 109 |
+
the interface presents a list of user commands or options, such as a
|
| 110 |
+
menu, a prominent item in the list meets this criterion.
|
| 111 |
+
|
| 112 |
+
1. Source Code.
|
| 113 |
+
|
| 114 |
+
The "source code" for a work means the preferred form of the work
|
| 115 |
+
for making modifications to it. "Object code" means any non-source
|
| 116 |
+
form of a work.
|
| 117 |
+
|
| 118 |
+
A "Standard Interface" means an interface that either is an official
|
| 119 |
+
standard defined by a recognized standards body, or, in the case of
|
| 120 |
+
interfaces specified for a particular programming language, one that
|
| 121 |
+
is widely used among developers working in that language.
|
| 122 |
+
|
| 123 |
+
The "System Libraries" of an executable work include anything, other
|
| 124 |
+
than the work as a whole, that (a) is included in the normal form of
|
| 125 |
+
packaging a Major Component, but which is not part of that Major
|
| 126 |
+
Component, and (b) serves only to enable use of the work with that
|
| 127 |
+
Major Component, or to implement a Standard Interface for which an
|
| 128 |
+
implementation is available to the public in source code form. A
|
| 129 |
+
"Major Component", in this context, means a major essential component
|
| 130 |
+
(kernel, window system, and so on) of the specific operating system
|
| 131 |
+
(if any) on which the executable work runs, or a compiler used to
|
| 132 |
+
produce the work, or an object code interpreter used to run it.
|
| 133 |
+
|
| 134 |
+
The "Corresponding Source" for a work in object code form means all
|
| 135 |
+
the source code needed to generate, install, and (for an executable
|
| 136 |
+
work) run the object code and to modify the work, including scripts to
|
| 137 |
+
control those activities. However, it does not include the work's
|
| 138 |
+
System Libraries, or general-purpose tools or generally available free
|
| 139 |
+
programs which are used unmodified in performing those activities but
|
| 140 |
+
which are not part of the work. For example, Corresponding Source
|
| 141 |
+
includes interface definition files associated with source files for
|
| 142 |
+
the work, and the source code for shared libraries and dynamically
|
| 143 |
+
linked subprograms that the work is specifically designed to require,
|
| 144 |
+
such as by intimate data communication or control flow between those
|
| 145 |
+
subprograms and other parts of the work.
|
| 146 |
+
|
| 147 |
+
The Corresponding Source need not include anything that users
|
| 148 |
+
can regenerate automatically from other parts of the Corresponding
|
| 149 |
+
Source.
|
| 150 |
+
|
| 151 |
+
The Corresponding Source for a work in source code form is that
|
| 152 |
+
same work.
|
| 153 |
+
|
| 154 |
+
2. Basic Permissions.
|
| 155 |
+
|
| 156 |
+
All rights granted under this License are granted for the term of
|
| 157 |
+
copyright on the Program, and are irrevocable provided the stated
|
| 158 |
+
conditions are met. This License explicitly affirms your unlimited
|
| 159 |
+
permission to run the unmodified Program. The output from running a
|
| 160 |
+
covered work is covered by this License only if the output, given its
|
| 161 |
+
content, constitutes a covered work. This License acknowledges your
|
| 162 |
+
rights of fair use or other equivalent, as provided by copyright law.
|
| 163 |
+
|
| 164 |
+
You may make, run and propagate covered works that you do not
|
| 165 |
+
convey, without conditions so long as your license otherwise remains
|
| 166 |
+
in force. You may convey covered works to others for the sole purpose
|
| 167 |
+
of having them make modifications exclusively for you, or provide you
|
| 168 |
+
with facilities for running those works, provided that you comply with
|
| 169 |
+
the terms of this License in conveying all material for which you do
|
| 170 |
+
not control copyright. Those thus making or running the covered works
|
| 171 |
+
for you must do so exclusively on your behalf, under your direction
|
| 172 |
+
and control, on terms that prohibit them from making any copies of
|
| 173 |
+
your copyrighted material outside their relationship with you.
|
| 174 |
+
|
| 175 |
+
Conveying under any other circumstances is permitted solely under
|
| 176 |
+
the conditions stated below. Sublicensing is not allowed; section 10
|
| 177 |
+
makes it unnecessary.
|
| 178 |
+
|
| 179 |
+
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
|
| 180 |
+
|
| 181 |
+
No covered work shall be deemed part of an effective technological
|
| 182 |
+
measure under any applicable law fulfilling obligations under article
|
| 183 |
+
11 of the WIPO copyright treaty adopted on 20 December 1996, or
|
| 184 |
+
similar laws prohibiting or restricting circumvention of such
|
| 185 |
+
measures.
|
| 186 |
+
|
| 187 |
+
When you convey a covered work, you waive any legal power to forbid
|
| 188 |
+
circumvention of technological measures to the extent such circumvention
|
| 189 |
+
is effected by exercising rights under this License with respect to
|
| 190 |
+
the covered work, and you disclaim any intention to limit operation or
|
| 191 |
+
modification of the work as a means of enforcing, against the work's
|
| 192 |
+
users, your or third parties' legal rights to forbid circumvention of
|
| 193 |
+
technological measures.
|
| 194 |
+
|
| 195 |
+
4. Conveying Verbatim Copies.
|
| 196 |
+
|
| 197 |
+
You may convey verbatim copies of the Program's source code as you
|
| 198 |
+
receive it, in any medium, provided that you conspicuously and
|
| 199 |
+
appropriately publish on each copy an appropriate copyright notice;
|
| 200 |
+
keep intact all notices stating that this License and any
|
| 201 |
+
non-permissive terms added in accord with section 7 apply to the code;
|
| 202 |
+
keep intact all notices of the absence of any warranty; and give all
|
| 203 |
+
recipients a copy of this License along with the Program.
|
| 204 |
+
|
| 205 |
+
You may charge any price or no price for each copy that you convey,
|
| 206 |
+
and you may offer support or warranty protection for a fee.
|
| 207 |
+
|
| 208 |
+
5. Conveying Modified Source Versions.
|
| 209 |
+
|
| 210 |
+
You may convey a work based on the Program, or the modifications to
|
| 211 |
+
produce it from the Program, in the form of source code under the
|
| 212 |
+
terms of section 4, provided that you also meet all of these conditions:
|
| 213 |
+
|
| 214 |
+
a) The work must carry prominent notices stating that you modified
|
| 215 |
+
it, and giving a relevant date.
|
| 216 |
+
|
| 217 |
+
b) The work must carry prominent notices stating that it is
|
| 218 |
+
released under this License and any conditions added under section
|
| 219 |
+
7. This requirement modifies the requirement in section 4 to
|
| 220 |
+
"keep intact all notices".
|
| 221 |
+
|
| 222 |
+
c) You must license the entire work, as a whole, under this
|
| 223 |
+
License to anyone who comes into possession of a copy. This
|
| 224 |
+
License will therefore apply, along with any applicable section 7
|
| 225 |
+
additional terms, to the whole of the work, and all its parts,
|
| 226 |
+
regardless of how they are packaged. This License gives no
|
| 227 |
+
permission to license the work in any other way, but it does not
|
| 228 |
+
invalidate such permission if you have separately received it.
|
| 229 |
+
|
| 230 |
+
d) If the work has interactive user interfaces, each must display
|
| 231 |
+
Appropriate Legal Notices; however, if the Program has interactive
|
| 232 |
+
interfaces that do not display Appropriate Legal Notices, your
|
| 233 |
+
work need not make them do so.
|
| 234 |
+
|
| 235 |
+
A compilation of a covered work with other separate and independent
|
| 236 |
+
works, which are not by their nature extensions of the covered work,
|
| 237 |
+
and which are not combined with it such as to form a larger program,
|
| 238 |
+
in or on a volume of a storage or distribution medium, is called an
|
| 239 |
+
"aggregate" if the compilation and its resulting copyright are not
|
| 240 |
+
used to limit the access or legal rights of the compilation's users
|
| 241 |
+
beyond what the individual works permit. Inclusion of a covered work
|
| 242 |
+
in an aggregate does not cause this License to apply to the other
|
| 243 |
+
parts of the aggregate.
|
| 244 |
+
|
| 245 |
+
6. Conveying Non-Source Forms.
|
| 246 |
+
|
| 247 |
+
You may convey a covered work in object code form under the terms
|
| 248 |
+
of sections 4 and 5, provided that you also convey the
|
| 249 |
+
machine-readable Corresponding Source under the terms of this License,
|
| 250 |
+
in one of these ways:
|
| 251 |
+
|
| 252 |
+
a) Convey the object code in, or embodied in, a physical product
|
| 253 |
+
(including a physical distribution medium), accompanied by the
|
| 254 |
+
Corresponding Source fixed on a durable physical medium
|
| 255 |
+
customarily used for software interchange.
|
| 256 |
+
|
| 257 |
+
b) Convey the object code in, or embodied in, a physical product
|
| 258 |
+
(including a physical distribution medium), accompanied by a
|
| 259 |
+
written offer, valid for at least three years and valid for as
|
| 260 |
+
long as you offer spare parts or customer support for that product
|
| 261 |
+
model, to give anyone who possesses the object code either (1) a
|
| 262 |
+
copy of the Corresponding Source for all the software in the
|
| 263 |
+
product that is covered by this License, on a durable physical
|
| 264 |
+
medium customarily used for software interchange, for a price no
|
| 265 |
+
more than your reasonable cost of physically performing this
|
| 266 |
+
conveying of source, or (2) access to copy the
|
| 267 |
+
Corresponding Source from a network server at no charge.
|
| 268 |
+
|
| 269 |
+
c) Convey individual copies of the object code with a copy of the
|
| 270 |
+
written offer to provide the Corresponding Source. This
|
| 271 |
+
alternative is allowed only occasionally and noncommercially, and
|
| 272 |
+
only if you received the object code with such an offer, in accord
|
| 273 |
+
with subsection 6b.
|
| 274 |
+
|
| 275 |
+
d) Convey the object code by offering access from a designated
|
| 276 |
+
place (gratis or for a charge), and offer equivalent access to the
|
| 277 |
+
Corresponding Source in the same way through the same place at no
|
| 278 |
+
further charge. You need not require recipients to copy the
|
| 279 |
+
Corresponding Source along with the object code. If the place to
|
| 280 |
+
copy the object code is a network server, the Corresponding Source
|
| 281 |
+
may be on a different server (operated by you or a third party)
|
| 282 |
+
that supports equivalent copying facilities, provided you maintain
|
| 283 |
+
clear directions next to the object code saying where to find the
|
| 284 |
+
Corresponding Source. Regardless of what server hosts the
|
| 285 |
+
Corresponding Source, you remain obligated to ensure that it is
|
| 286 |
+
available for as long as needed to satisfy these requirements.
|
| 287 |
+
|
| 288 |
+
e) Convey the object code using peer-to-peer transmission, provided
|
| 289 |
+
you inform other peers where the object code and Corresponding
|
| 290 |
+
Source of the work are being offered to the general public at no
|
| 291 |
+
charge under subsection 6d.
|
| 292 |
+
|
| 293 |
+
A separable portion of the object code, whose source code is excluded
|
| 294 |
+
from the Corresponding Source as a System Library, need not be
|
| 295 |
+
included in conveying the object code work.
|
| 296 |
+
|
| 297 |
+
A "User Product" is either (1) a "consumer product", which means any
|
| 298 |
+
tangible personal property which is normally used for personal, family,
|
| 299 |
+
or household purposes, or (2) anything designed or sold for incorporation
|
| 300 |
+
into a dwelling. In determining whether a product is a consumer product,
|
| 301 |
+
doubtful cases shall be resolved in favor of coverage. For a particular
|
| 302 |
+
product received by a particular user, "normally used" refers to a
|
| 303 |
+
typical or common use of that class of product, regardless of the status
|
| 304 |
+
of the particular user or of the way in which the particular user
|
| 305 |
+
actually uses, or expects or is expected to use, the product. A product
|
| 306 |
+
is a consumer product regardless of whether the product has substantial
|
| 307 |
+
commercial, industrial or non-consumer uses, unless such uses represent
|
| 308 |
+
the only significant mode of use of the product.
|
| 309 |
+
|
| 310 |
+
"Installation Information" for a User Product means any methods,
|
| 311 |
+
procedures, authorization keys, or other information required to install
|
| 312 |
+
and execute modified versions of a covered work in that User Product from
|
| 313 |
+
a modified version of its Corresponding Source. The information must
|
| 314 |
+
suffice to ensure that the continued functioning of the modified object
|
| 315 |
+
code is in no case prevented or interfered with solely because
|
| 316 |
+
modification has been made.
|
| 317 |
+
|
| 318 |
+
If you convey an object code work under this section in, or with, or
|
| 319 |
+
specifically for use in, a User Product, and the conveying occurs as
|
| 320 |
+
part of a transaction in which the right of possession and use of the
|
| 321 |
+
User Product is transferred to the recipient in perpetuity or for a
|
| 322 |
+
fixed term (regardless of how the transaction is characterized), the
|
| 323 |
+
Corresponding Source conveyed under this section must be accompanied
|
| 324 |
+
by the Installation Information. But this requirement does not apply
|
| 325 |
+
if neither you nor any third party retains the ability to install
|
| 326 |
+
modified object code on the User Product (for example, the work has
|
| 327 |
+
been installed in ROM).
|
| 328 |
+
|
| 329 |
+
The requirement to provide Installation Information does not include a
|
| 330 |
+
requirement to continue to provide support service, warranty, or updates
|
| 331 |
+
for a work that has been modified or installed by the recipient, or for
|
| 332 |
+
the User Product in which it has been modified or installed. Access to a
|
| 333 |
+
network may be denied when the modification itself materially and
|
| 334 |
+
adversely affects the operation of the network or violates the rules and
|
| 335 |
+
protocols for communication across the network.
|
| 336 |
+
|
| 337 |
+
Corresponding Source conveyed, and Installation Information provided,
|
| 338 |
+
in accord with this section must be in a format that is publicly
|
| 339 |
+
documented (and with an implementation available to the public in
|
| 340 |
+
source code form), and must require no special password or key for
|
| 341 |
+
unpacking, reading or copying.
|
| 342 |
+
|
| 343 |
+
7. Additional Terms.
|
| 344 |
+
|
| 345 |
+
"Additional permissions" are terms that supplement the terms of this
|
| 346 |
+
License by making exceptions from one or more of its conditions.
|
| 347 |
+
Additional permissions that are applicable to the entire Program shall
|
| 348 |
+
be treated as though they were included in this License, to the extent
|
| 349 |
+
that they are valid under applicable law. If additional permissions
|
| 350 |
+
apply only to part of the Program, that part may be used separately
|
| 351 |
+
under those permissions, but the entire Program remains governed by
|
| 352 |
+
this License without regard to the additional permissions.
|
| 353 |
+
|
| 354 |
+
When you convey a copy of a covered work, you may at your option
|
| 355 |
+
remove any additional permissions from that copy, or from any part of
|
| 356 |
+
it. (Additional permissions may be written to require their own
|
| 357 |
+
removal in certain cases when you modify the work.) You may place
|
| 358 |
+
additional permissions on material, added by you to a covered work,
|
| 359 |
+
for which you have or can give appropriate copyright permission.
|
| 360 |
+
|
| 361 |
+
Notwithstanding any other provision of this License, for material you
|
| 362 |
+
add to a covered work, you may (if authorized by the copyright holders of
|
| 363 |
+
that material) supplement the terms of this License with terms:
|
| 364 |
+
|
| 365 |
+
a) Disclaiming warranty or limiting liability differently from the
|
| 366 |
+
terms of sections 15 and 16 of this License; or
|
| 367 |
+
|
| 368 |
+
b) Requiring preservation of specified reasonable legal notices or
|
| 369 |
+
author attributions in that material or in the Appropriate Legal
|
| 370 |
+
Notices displayed by works containing it; or
|
| 371 |
+
|
| 372 |
+
c) Prohibiting misrepresentation of the origin of that material, or
|
| 373 |
+
requiring that modified versions of such material be marked in
|
| 374 |
+
reasonable ways as different from the original version; or
|
| 375 |
+
|
| 376 |
+
d) Limiting the use for publicity purposes of names of licensors or
|
| 377 |
+
authors of the material; or
|
| 378 |
+
|
| 379 |
+
e) Declining to grant rights under trademark law for use of some
|
| 380 |
+
trade names, trademarks, or service marks; or
|
| 381 |
+
|
| 382 |
+
f) Requiring indemnification of licensors and authors of that
|
| 383 |
+
material by anyone who conveys the material (or modified versions of
|
| 384 |
+
it) with contractual assumptions of liability to the recipient, for
|
| 385 |
+
any liability that these contractual assumptions directly impose on
|
| 386 |
+
those licensors and authors.
|
| 387 |
+
|
| 388 |
+
All other non-permissive additional terms are considered "further
|
| 389 |
+
restrictions" within the meaning of section 10. If the Program as you
|
| 390 |
+
received it, or any part of it, contains a notice stating that it is
|
| 391 |
+
governed by this License along with a term that is a further
|
| 392 |
+
restriction, you may remove that term. If a license document contains
|
| 393 |
+
a further restriction but permits relicensing or conveying under this
|
| 394 |
+
License, you may add to a covered work material governed by the terms
|
| 395 |
+
of that license document, provided that the further restriction does
|
| 396 |
+
not survive such relicensing or conveying.
|
| 397 |
+
|
| 398 |
+
If you add terms to a covered work in accord with this section, you
|
| 399 |
+
must place, in the relevant source files, a statement of the
|
| 400 |
+
additional terms that apply to those files, or a notice indicating
|
| 401 |
+
where to find the applicable terms.
|
| 402 |
+
|
| 403 |
+
Additional terms, permissive or non-permissive, may be stated in the
|
| 404 |
+
form of a separately written license, or stated as exceptions;
|
| 405 |
+
the above requirements apply either way.
|
| 406 |
+
|
| 407 |
+
8. Termination.
|
| 408 |
+
|
| 409 |
+
You may not propagate or modify a covered work except as expressly
|
| 410 |
+
provided under this License. Any attempt otherwise to propagate or
|
| 411 |
+
modify it is void, and will automatically terminate your rights under
|
| 412 |
+
this License (including any patent licenses granted under the third
|
| 413 |
+
paragraph of section 11).
|
| 414 |
+
|
| 415 |
+
However, if you cease all violation of this License, then your
|
| 416 |
+
license from a particular copyright holder is reinstated (a)
|
| 417 |
+
provisionally, unless and until the copyright holder explicitly and
|
| 418 |
+
finally terminates your license, and (b) permanently, if the copyright
|
| 419 |
+
holder fails to notify you of the violation by some reasonable means
|
| 420 |
+
prior to 60 days after the cessation.
|
| 421 |
+
|
| 422 |
+
Moreover, your license from a particular copyright holder is
|
| 423 |
+
reinstated permanently if the copyright holder notifies you of the
|
| 424 |
+
violation by some reasonable means, this is the first time you have
|
| 425 |
+
received notice of violation of this License (for any work) from that
|
| 426 |
+
copyright holder, and you cure the violation prior to 30 days after
|
| 427 |
+
your receipt of the notice.
|
| 428 |
+
|
| 429 |
+
Termination of your rights under this section does not terminate the
|
| 430 |
+
licenses of parties who have received copies or rights from you under
|
| 431 |
+
this License. If your rights have been terminated and not permanently
|
| 432 |
+
reinstated, you do not qualify to receive new licenses for the same
|
| 433 |
+
material under section 10.
|
| 434 |
+
|
| 435 |
+
9. Acceptance Not Required for Having Copies.
|
| 436 |
+
|
| 437 |
+
You are not required to accept this License in order to receive or
|
| 438 |
+
run a copy of the Program. Ancillary propagation of a covered work
|
| 439 |
+
occurring solely as a consequence of using peer-to-peer transmission
|
| 440 |
+
to receive a copy likewise does not require acceptance. However,
|
| 441 |
+
nothing other than this License grants you permission to propagate or
|
| 442 |
+
modify any covered work. These actions infringe copyright if you do
|
| 443 |
+
not accept this License. Therefore, by modifying or propagating a
|
| 444 |
+
covered work, you indicate your acceptance of this License to do so.
|
| 445 |
+
|
| 446 |
+
10. Automatic Licensing of Downstream Recipients.
|
| 447 |
+
|
| 448 |
+
Each time you convey a covered work, the recipient automatically
|
| 449 |
+
receives a license from the original licensors, to run, modify and
|
| 450 |
+
propagate that work, subject to this License. You are not responsible
|
| 451 |
+
for enforcing compliance by third parties with this License.
|
| 452 |
+
|
| 453 |
+
An "entity transaction" is a transaction transferring control of an
|
| 454 |
+
organization, or substantially all assets of one, or subdividing an
|
| 455 |
+
organization, or merging organizations. If propagation of a covered
|
| 456 |
+
work results from an entity transaction, each party to that
|
| 457 |
+
transaction who receives a copy of the work also receives whatever
|
| 458 |
+
licenses to the work the party's predecessor in interest had or could
|
| 459 |
+
give under the previous paragraph, plus a right to possession of the
|
| 460 |
+
Corresponding Source of the work from the predecessor in interest, if
|
| 461 |
+
the predecessor has it or can get it with reasonable efforts.
|
| 462 |
+
|
| 463 |
+
You may not impose any further restrictions on the exercise of the
|
| 464 |
+
rights granted or affirmed under this License. For example, you may
|
| 465 |
+
not impose a license fee, royalty, or other charge for exercise of
|
| 466 |
+
rights granted under this License, and you may not initiate litigation
|
| 467 |
+
(including a cross-claim or counterclaim in a lawsuit) alleging that
|
| 468 |
+
any patent claim is infringed by making, using, selling, offering for
|
| 469 |
+
sale, or importing the Program or any portion of it.
|
| 470 |
+
|
| 471 |
+
11. Patents.
|
| 472 |
+
|
| 473 |
+
A "contributor" is a copyright holder who authorizes use under this
|
| 474 |
+
License of the Program or a work on which the Program is based. The
|
| 475 |
+
work thus licensed is called the contributor's "contributor version".
|
| 476 |
+
|
| 477 |
+
A contributor's "essential patent claims" are all patent claims
|
| 478 |
+
owned or controlled by the contributor, whether already acquired or
|
| 479 |
+
hereafter acquired, that would be infringed by some manner, permitted
|
| 480 |
+
by this License, of making, using, or selling its contributor version,
|
| 481 |
+
but do not include claims that would be infringed only as a
|
| 482 |
+
consequence of further modification of the contributor version. For
|
| 483 |
+
purposes of this definition, "control" includes the right to grant
|
| 484 |
+
patent sublicenses in a manner consistent with the requirements of
|
| 485 |
+
this License.
|
| 486 |
+
|
| 487 |
+
Each contributor grants you a non-exclusive, worldwide, royalty-free
|
| 488 |
+
patent license under the contributor's essential patent claims, to
|
| 489 |
+
make, use, sell, offer for sale, import and otherwise run, modify and
|
| 490 |
+
propagate the contents of its contributor version.
|
| 491 |
+
|
| 492 |
+
In the following three paragraphs, a "patent license" is any express
|
| 493 |
+
agreement or commitment, however denominated, not to enforce a patent
|
| 494 |
+
(such as an express permission to practice a patent or covenant not to
|
| 495 |
+
sue for patent infringement). To "grant" such a patent license to a
|
| 496 |
+
party means to make such an agreement or commitment not to enforce a
|
| 497 |
+
patent against the party.
|
| 498 |
+
|
| 499 |
+
If you convey a covered work, knowingly relying on a patent license,
|
| 500 |
+
and the Corresponding Source of the work is not available for anyone
|
| 501 |
+
to copy, free of charge and under the terms of this License, through a
|
| 502 |
+
publicly available network server or other readily accessible means,
|
| 503 |
+
then you must either (1) cause the Corresponding Source to be so
|
| 504 |
+
available, or (2) arrange to deprive yourself of the benefit of the
|
| 505 |
+
patent license for this particular work, or (3) arrange, in a manner
|
| 506 |
+
consistent with the requirements of this License, to extend the patent
|
| 507 |
+
license to downstream recipients. "Knowingly relying" means you have
|
| 508 |
+
actual knowledge that, but for the patent license, your conveying the
|
| 509 |
+
covered work in a country, or your recipient's use of the covered work
|
| 510 |
+
in a country, would infringe one or more identifiable patents in that
|
| 511 |
+
country that you have reason to believe are valid.
|
| 512 |
+
|
| 513 |
+
If, pursuant to or in connection with a single transaction or
|
| 514 |
+
arrangement, you convey, or propagate by procuring conveyance of, a
|
| 515 |
+
covered work, and grant a patent license to some of the parties
|
| 516 |
+
receiving the covered work authorizing them to use, propagate, modify
|
| 517 |
+
or convey a specific copy of the covered work, then the patent license
|
| 518 |
+
you grant is automatically extended to all recipients of the covered
|
| 519 |
+
work and works based on it.
|
| 520 |
+
|
| 521 |
+
A patent license is "discriminatory" if it does not include within
|
| 522 |
+
the scope of its coverage, prohibits the exercise of, or is
|
| 523 |
+
conditioned on the non-exercise of one or more of the rights that are
|
| 524 |
+
specifically granted under this License. You may not convey a covered
|
| 525 |
+
work if you are a party to an arrangement with a third party that is
|
| 526 |
+
in the business of distributing software, under which you make payment
|
| 527 |
+
to the third party based on the extent of your activity of conveying
|
| 528 |
+
the work, and under which the third party grants, to any of the
|
| 529 |
+
parties who would receive the covered work from you, a discriminatory
|
| 530 |
+
patent license (a) in connection with copies of the covered work
|
| 531 |
+
conveyed by you (or copies made from those copies), or (b) primarily
|
| 532 |
+
for and in connection with specific products or compilations that
|
| 533 |
+
contain the covered work, unless you entered into that arrangement,
|
| 534 |
+
or that patent license was granted, prior to 28 March 2007.
|
| 535 |
+
|
| 536 |
+
Nothing in this License shall be construed as excluding or limiting
|
| 537 |
+
any implied license or other defenses to infringement that may
|
| 538 |
+
otherwise be available to you under applicable patent law.
|
| 539 |
+
|
| 540 |
+
12. No Surrender of Others' Freedom.
|
| 541 |
+
|
| 542 |
+
If conditions are imposed on you (whether by court order, agreement or
|
| 543 |
+
otherwise) that contradict the conditions of this License, they do not
|
| 544 |
+
excuse you from the conditions of this License. If you cannot convey a
|
| 545 |
+
covered work so as to satisfy simultaneously your obligations under this
|
| 546 |
+
License and any other pertinent obligations, then as a consequence you may
|
| 547 |
+
not convey it at all. For example, if you agree to terms that obligate you
|
| 548 |
+
to collect a royalty for further conveying from those to whom you convey
|
| 549 |
+
the Program, the only way you could satisfy both those terms and this
|
| 550 |
+
License would be to refrain entirely from conveying the Program.
|
| 551 |
+
|
| 552 |
+
13. Use with the GNU Affero General Public License.
|
| 553 |
+
|
| 554 |
+
Notwithstanding any other provision of this License, you have
|
| 555 |
+
permission to link or combine any covered work with a work licensed
|
| 556 |
+
under version 3 of the GNU Affero General Public License into a single
|
| 557 |
+
combined work, and to convey the resulting work. The terms of this
|
| 558 |
+
License will continue to apply to the part which is the covered work,
|
| 559 |
+
but the special requirements of the GNU Affero General Public License,
|
| 560 |
+
section 13, concerning interaction through a network will apply to the
|
| 561 |
+
combination as such.
|
| 562 |
+
|
| 563 |
+
14. Revised Versions of this License.
|
| 564 |
+
|
| 565 |
+
The Free Software Foundation may publish revised and/or new versions of
|
| 566 |
+
the GNU General Public License from time to time. Such new versions will
|
| 567 |
+
be similar in spirit to the present version, but may differ in detail to
|
| 568 |
+
address new problems or concerns.
|
| 569 |
+
|
| 570 |
+
Each version is given a distinguishing version number. If the
|
| 571 |
+
Program specifies that a certain numbered version of the GNU General
|
| 572 |
+
Public License "or any later version" applies to it, you have the
|
| 573 |
+
option of following the terms and conditions either of that numbered
|
| 574 |
+
version or of any later version published by the Free Software
|
| 575 |
+
Foundation. If the Program does not specify a version number of the
|
| 576 |
+
GNU General Public License, you may choose any version ever published
|
| 577 |
+
by the Free Software Foundation.
|
| 578 |
+
|
| 579 |
+
If the Program specifies that a proxy can decide which future
|
| 580 |
+
versions of the GNU General Public License can be used, that proxy's
|
| 581 |
+
public statement of acceptance of a version permanently authorizes you
|
| 582 |
+
to choose that version for the Program.
|
| 583 |
+
|
| 584 |
+
Later license versions may give you additional or different
|
| 585 |
+
permissions. However, no additional obligations are imposed on any
|
| 586 |
+
author or copyright holder as a result of your choosing to follow a
|
| 587 |
+
later version.
|
| 588 |
+
|
| 589 |
+
15. Disclaimer of Warranty.
|
| 590 |
+
|
| 591 |
+
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
|
| 592 |
+
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
|
| 593 |
+
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
|
| 594 |
+
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
|
| 595 |
+
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
| 596 |
+
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
|
| 597 |
+
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
|
| 598 |
+
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
|
| 599 |
+
|
| 600 |
+
16. Limitation of Liability.
|
| 601 |
+
|
| 602 |
+
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
|
| 603 |
+
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
|
| 604 |
+
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
|
| 605 |
+
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
|
| 606 |
+
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
|
| 607 |
+
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
|
| 608 |
+
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
|
| 609 |
+
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
|
| 610 |
+
SUCH DAMAGES.
|
| 611 |
+
|
| 612 |
+
17. Interpretation of Sections 15 and 16.
|
| 613 |
+
|
| 614 |
+
If the disclaimer of warranty and limitation of liability provided
|
| 615 |
+
above cannot be given local legal effect according to their terms,
|
| 616 |
+
reviewing courts shall apply local law that most closely approximates
|
| 617 |
+
an absolute waiver of all civil liability in connection with the
|
| 618 |
+
Program, unless a warranty or assumption of liability accompanies a
|
| 619 |
+
copy of the Program in return for a fee.
|
| 620 |
+
|
| 621 |
+
END OF TERMS AND CONDITIONS
|
| 622 |
+
|
| 623 |
+
How to Apply These Terms to Your New Programs
|
| 624 |
+
|
| 625 |
+
If you develop a new program, and you want it to be of the greatest
|
| 626 |
+
possible use to the public, the best way to achieve this is to make it
|
| 627 |
+
free software which everyone can redistribute and change under these terms.
|
| 628 |
+
|
| 629 |
+
To do so, attach the following notices to the program. It is safest
|
| 630 |
+
to attach them to the start of each source file to most effectively
|
| 631 |
+
state the exclusion of warranty; and each file should have at least
|
| 632 |
+
the "copyright" line and a pointer to where the full notice is found.
|
| 633 |
+
|
| 634 |
+
<one line to give the program's name and a brief idea of what it does.>
|
| 635 |
+
Copyright (C) <year> <name of author>
|
| 636 |
+
|
| 637 |
+
This program is free software: you can redistribute it and/or modify
|
| 638 |
+
it under the terms of the GNU General Public License as published by
|
| 639 |
+
the Free Software Foundation, either version 3 of the License, or
|
| 640 |
+
(at your option) any later version.
|
| 641 |
+
|
| 642 |
+
This program is distributed in the hope that it will be useful,
|
| 643 |
+
but WITHOUT ANY WARRANTY; without even the implied warranty of
|
| 644 |
+
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
| 645 |
+
GNU General Public License for more details.
|
| 646 |
+
|
| 647 |
+
You should have received a copy of the GNU General Public License
|
| 648 |
+
along with this program. If not, see <https://www.gnu.org/licenses/>.
|
| 649 |
+
|
| 650 |
+
Also add information on how to contact you by electronic and paper mail.
|
| 651 |
+
|
| 652 |
+
If the program does terminal interaction, make it output a short
|
| 653 |
+
notice like this when it starts in an interactive mode:
|
| 654 |
+
|
| 655 |
+
<program> Copyright (C) <year> <name of author>
|
| 656 |
+
This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
|
| 657 |
+
This is free software, and you are welcome to redistribute it
|
| 658 |
+
under certain conditions; type `show c' for details.
|
| 659 |
+
|
| 660 |
+
The hypothetical commands `show w' and `show c' should show the appropriate
|
| 661 |
+
parts of the General Public License. Of course, your program's commands
|
| 662 |
+
might be different; for a GUI interface, you would use an "about box".
|
| 663 |
+
|
| 664 |
+
You should also get your employer (if you work as a programmer) or school,
|
| 665 |
+
if any, to sign a "copyright disclaimer" for the program, if necessary.
|
| 666 |
+
For more information on this, and how to apply and follow the GNU GPL, see
|
| 667 |
+
<https://www.gnu.org/licenses/>.
|
| 668 |
+
|
| 669 |
+
The GNU General Public License does not permit incorporating your program
|
| 670 |
+
into proprietary programs. If your program is a subroutine library, you
|
| 671 |
+
may consider it more useful to permit linking proprietary applications with
|
| 672 |
+
the library. If this is what you want to do, use the GNU Lesser General
|
| 673 |
+
Public License instead of this License. But first, please read
|
| 674 |
+
<https://www.gnu.org/licenses/why-not-lgpl.html>.
|
miche/__init__.py
ADDED
|
File without changes
|
miche/encode.py
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
import argparse
|
| 3 |
+
from omegaconf import OmegaConf
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
from .michelangelo.utils.misc import instantiate_from_config
|
| 7 |
+
|
| 8 |
+
def load_surface(fp):
|
| 9 |
+
|
| 10 |
+
with np.load(fp) as input_pc:
|
| 11 |
+
surface = input_pc['points']
|
| 12 |
+
normal = input_pc['normals']
|
| 13 |
+
|
| 14 |
+
rng = np.random.default_rng()
|
| 15 |
+
ind = rng.choice(surface.shape[0], 4096, replace=False)
|
| 16 |
+
surface = torch.FloatTensor(surface[ind])
|
| 17 |
+
normal = torch.FloatTensor(normal[ind])
|
| 18 |
+
|
| 19 |
+
surface = torch.cat([surface, normal], dim=-1).unsqueeze(0).cuda()
|
| 20 |
+
|
| 21 |
+
return surface
|
| 22 |
+
|
| 23 |
+
def reconstruction(args, model, bounds=(-1.25, -1.25, -1.25, 1.25, 1.25, 1.25), octree_depth=7, num_chunks=10000):
|
| 24 |
+
|
| 25 |
+
surface = load_surface(args.pointcloud_path)
|
| 26 |
+
# old_surface = surface.clone()
|
| 27 |
+
|
| 28 |
+
# surface[0,:,0]*=-1
|
| 29 |
+
# surface[0,:,1]*=-1
|
| 30 |
+
surface[0,:,2]*=-1
|
| 31 |
+
|
| 32 |
+
# encoding
|
| 33 |
+
shape_embed, shape_latents = model.model.encode_shape_embed(surface, return_latents=True)
|
| 34 |
+
shape_zq, posterior = model.model.shape_model.encode_kl_embed(shape_latents)
|
| 35 |
+
|
| 36 |
+
# decoding
|
| 37 |
+
latents = model.model.shape_model.decode(shape_zq)
|
| 38 |
+
# geometric_func = partial(model.model.shape_model.query_geometry, latents=latents)
|
| 39 |
+
|
| 40 |
+
return 0
|
| 41 |
+
|
| 42 |
+
def load_model(ckpt_path="miche/shapevae-256.ckpt", config_path="miche/shapevae-256.yaml"):
|
| 43 |
+
model_config = OmegaConf.load(config_path)
|
| 44 |
+
# print(model_config)
|
| 45 |
+
if hasattr(model_config, "model"):
|
| 46 |
+
model_config = model_config.model
|
| 47 |
+
|
| 48 |
+
model = instantiate_from_config(model_config, ckpt_path=ckpt_path)
|
| 49 |
+
model = model.eval()
|
| 50 |
+
|
| 51 |
+
return model
|
| 52 |
+
if __name__ == "__main__":
|
| 53 |
+
'''
|
| 54 |
+
1. Reconstruct point cloud
|
| 55 |
+
2. Image-conditioned generation
|
| 56 |
+
3. Text-conditioned generation
|
| 57 |
+
'''
|
| 58 |
+
parser = argparse.ArgumentParser()
|
| 59 |
+
parser.add_argument("--config_path", type=str, required=True)
|
| 60 |
+
parser.add_argument("--ckpt_path", type=str, required=True)
|
| 61 |
+
parser.add_argument("--pointcloud_path", type=str, default='./example_data/surface.npz',
|
| 62 |
+
help='Path to the input point cloud')
|
| 63 |
+
parser.add_argument("--image_path", type=str, help='Path to the input image')
|
| 64 |
+
parser.add_argument("--text", type=str,
|
| 65 |
+
help='Input text within a format: A 3D model of motorcar; Porsche 911.')
|
| 66 |
+
parser.add_argument("--output_dir", type=str, default='./output')
|
| 67 |
+
parser.add_argument("-s", "--seed", type=int, default=0)
|
| 68 |
+
args = parser.parse_args()
|
| 69 |
+
|
| 70 |
+
print(f'-----------------------------------------------------------------------------')
|
| 71 |
+
print(f'>>> Output directory: {args.output_dir}')
|
| 72 |
+
print(f'-----------------------------------------------------------------------------')
|
| 73 |
+
|
| 74 |
+
reconstruction(args, load_model(args))
|
miche/michelangelo/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
miche/michelangelo/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
miche/michelangelo/graphics/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
miche/michelangelo/graphics/__pycache__/__init__.cpython-38.pyc
ADDED
|
Binary file (180 Bytes). View file
|
|
|
miche/michelangelo/graphics/__pycache__/__init__.cpython-39.pyc
ADDED
|
Binary file (180 Bytes). View file
|
|
|
miche/michelangelo/graphics/primitives/__init__.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
from .volume import generate_dense_grid_points
|
| 4 |
+
|
miche/michelangelo/graphics/primitives/volume.py
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
|
| 5 |
+
# produce dense points
|
| 6 |
+
def generate_dense_grid_points(bbox_min: np.ndarray,
|
| 7 |
+
bbox_max: np.ndarray,
|
| 8 |
+
octree_depth: int,
|
| 9 |
+
indexing: str = "ij"):
|
| 10 |
+
length = bbox_max - bbox_min
|
| 11 |
+
num_cells = np.exp2(octree_depth)
|
| 12 |
+
x = np.linspace(bbox_min[0], bbox_max[0], int(num_cells) + 1, dtype=np.float32)
|
| 13 |
+
y = np.linspace(bbox_min[1], bbox_max[1], int(num_cells) + 1, dtype=np.float32)
|
| 14 |
+
z = np.linspace(bbox_min[2], bbox_max[2], int(num_cells) + 1, dtype=np.float32)
|
| 15 |
+
[xs, ys, zs] = np.meshgrid(x, y, z, indexing=indexing)
|
| 16 |
+
xyz = np.stack((xs, ys, zs), axis=-1)
|
| 17 |
+
xyz = xyz.reshape(-1, 3)
|
| 18 |
+
grid_size = [int(num_cells) + 1, int(num_cells) + 1, int(num_cells) + 1]
|
| 19 |
+
|
| 20 |
+
return xyz, grid_size, length
|
| 21 |
+
|
miche/michelangelo/models/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
miche/michelangelo/models/modules/__init__.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
from .checkpoint import checkpoint
|
miche/michelangelo/models/modules/checkpoint.py
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from typing import Callable, Iterable, Sequence, Union
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def checkpoint(
|
| 8 |
+
func: Callable[..., Union[torch.Tensor, Sequence[torch.Tensor]]],
|
| 9 |
+
inputs: Sequence[torch.Tensor],
|
| 10 |
+
params: Iterable[torch.Tensor],
|
| 11 |
+
flag: bool,
|
| 12 |
+
use_deepspeed: bool = False
|
| 13 |
+
):
|
| 14 |
+
# Evaluate a function without caching intermediate activations, allowing for
|
| 15 |
+
# reduced memory at the expense of extra compute in the backward pass.
|
| 16 |
+
# :param func: the function to evaluate.
|
| 17 |
+
# :param inputs: the argument sequence to pass to `func`.
|
| 18 |
+
# :param params: a sequence of parameters `func` depends on but does not
|
| 19 |
+
# explicitly take as arguments.
|
| 20 |
+
# :param flag: if False, disable gradient checkpointing.
|
| 21 |
+
# :param use_deepspeed: if True, use deepspeed
|
| 22 |
+
if flag:
|
| 23 |
+
if use_deepspeed:
|
| 24 |
+
import deepspeed
|
| 25 |
+
return deepspeed.checkpointing.checkpoint(func, *inputs)
|
| 26 |
+
|
| 27 |
+
args = tuple(inputs) + tuple(params)
|
| 28 |
+
return CheckpointFunction.apply(func, len(inputs), *args)
|
| 29 |
+
else:
|
| 30 |
+
return func(*inputs)
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
class CheckpointFunction(torch.autograd.Function):
|
| 34 |
+
@staticmethod
|
| 35 |
+
@torch.cuda.amp.custom_fwd
|
| 36 |
+
def forward(ctx, run_function, length, *args):
|
| 37 |
+
ctx.run_function = run_function
|
| 38 |
+
ctx.input_tensors = list(args[:length])
|
| 39 |
+
ctx.input_params = list(args[length:])
|
| 40 |
+
|
| 41 |
+
with torch.no_grad():
|
| 42 |
+
output_tensors = ctx.run_function(*ctx.input_tensors)
|
| 43 |
+
return output_tensors
|
| 44 |
+
|
| 45 |
+
@staticmethod
|
| 46 |
+
@torch.cuda.amp.custom_bwd
|
| 47 |
+
def backward(ctx, *output_grads):
|
| 48 |
+
ctx.input_tensors = [x.detach().requires_grad_(True) for x in ctx.input_tensors]
|
| 49 |
+
with torch.enable_grad():
|
| 50 |
+
# Fixes a bug where the first op in run_function modifies the
|
| 51 |
+
# Tensor storage in place, which is not allowed for detach()'d
|
| 52 |
+
# Tensors.
|
| 53 |
+
shallow_copies = [x.view_as(x) for x in ctx.input_tensors]
|
| 54 |
+
output_tensors = ctx.run_function(*shallow_copies)
|
| 55 |
+
input_grads = torch.autograd.grad(
|
| 56 |
+
output_tensors,
|
| 57 |
+
ctx.input_tensors + ctx.input_params,
|
| 58 |
+
output_grads,
|
| 59 |
+
allow_unused=True,
|
| 60 |
+
)
|
| 61 |
+
del ctx.input_tensors
|
| 62 |
+
del ctx.input_params
|
| 63 |
+
del output_tensors
|
| 64 |
+
return (None, None) + input_grads
|
miche/michelangelo/models/modules/distributions.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import numpy as np
|
| 5 |
+
from typing import Union, List
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class DiagonalGaussianDistribution(object):
|
| 9 |
+
# Gaussian distribution
|
| 10 |
+
def __init__(self, parameters: Union[torch.Tensor, List[torch.Tensor]], deterministic=False, feat_dim=1):
|
| 11 |
+
self.feat_dim = feat_dim
|
| 12 |
+
self.parameters = parameters
|
| 13 |
+
|
| 14 |
+
if isinstance(parameters, list):
|
| 15 |
+
self.mean = parameters[0]
|
| 16 |
+
self.logvar = parameters[1]
|
| 17 |
+
else:
|
| 18 |
+
self.mean, self.logvar = torch.chunk(parameters, 2, dim=feat_dim)
|
| 19 |
+
|
| 20 |
+
self.logvar = torch.clamp(self.logvar, -30.0, 20.0)
|
| 21 |
+
self.deterministic = deterministic
|
| 22 |
+
self.std = torch.exp(0.5 * self.logvar)
|
| 23 |
+
self.var = torch.exp(self.logvar)
|
| 24 |
+
if self.deterministic:
|
| 25 |
+
self.var = self.std = torch.zeros_like(self.mean)
|
| 26 |
+
|
| 27 |
+
# sample from the guassian distribution
|
| 28 |
+
def sample(self):
|
| 29 |
+
x = self.mean + self.std * torch.randn_like(self.mean)
|
| 30 |
+
return x
|
| 31 |
+
|
| 32 |
+
def kl(self, other=None, dims=(1, 2, 3)):
|
| 33 |
+
if self.deterministic:
|
| 34 |
+
return torch.Tensor([0.])
|
| 35 |
+
else:
|
| 36 |
+
if other is None:
|
| 37 |
+
return 0.5 * torch.mean(torch.pow(self.mean, 2)
|
| 38 |
+
+ self.var - 1.0 - self.logvar,
|
| 39 |
+
dim=dims)
|
| 40 |
+
else:
|
| 41 |
+
return 0.5 * torch.mean(
|
| 42 |
+
torch.pow(self.mean - other.mean, 2) / other.var
|
| 43 |
+
+ self.var / other.var - 1.0 - self.logvar + other.logvar,
|
| 44 |
+
dim=dims)
|
| 45 |
+
|
| 46 |
+
def nll(self, sample, dims=(1, 2, 3)):
|
| 47 |
+
if self.deterministic:
|
| 48 |
+
return torch.Tensor([0.])
|
| 49 |
+
logtwopi = np.log(2.0 * np.pi)
|
| 50 |
+
return 0.5 * torch.sum(
|
| 51 |
+
logtwopi + self.logvar + torch.pow(sample - self.mean, 2) / self.var,
|
| 52 |
+
dim=dims)
|
| 53 |
+
|
| 54 |
+
def mode(self):
|
| 55 |
+
return self.mean
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def normal_kl(mean1, logvar1, mean2, logvar2):
|
| 59 |
+
# Compute the KL divergence between two gaussians.
|
| 60 |
+
# Shapes are automatically broadcasted, so batches can be compared to
|
| 61 |
+
# scalars, among other use cases.
|
| 62 |
+
|
| 63 |
+
tensor = None
|
| 64 |
+
for obj in (mean1, logvar1, mean2, logvar2):
|
| 65 |
+
if isinstance(obj, torch.Tensor):
|
| 66 |
+
tensor = obj
|
| 67 |
+
break
|
| 68 |
+
assert tensor is not None, "at least one argument must be a Tensor"
|
| 69 |
+
|
| 70 |
+
# Force variances to be Tensors. Broadcasting helps convert scalars to
|
| 71 |
+
# Tensors, but it does not work for torch.exp().
|
| 72 |
+
logvar1, logvar2 = [
|
| 73 |
+
x if isinstance(x, torch.Tensor) else torch.tensor(x).to(tensor)
|
| 74 |
+
for x in (logvar1, logvar2)
|
| 75 |
+
]
|
| 76 |
+
|
| 77 |
+
return 0.5 * (
|
| 78 |
+
-1.0
|
| 79 |
+
+ logvar2
|
| 80 |
+
- logvar1
|
| 81 |
+
+ torch.exp(logvar1 - logvar2)
|
| 82 |
+
+ ((mean1 - mean2) ** 2) * torch.exp(-logvar2)
|
| 83 |
+
)
|
miche/michelangelo/models/modules/embedder.py
ADDED
|
@@ -0,0 +1,213 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
import math
|
| 7 |
+
|
| 8 |
+
VALID_EMBED_TYPES = ["identity", "fourier", "hashgrid", "sphere_harmonic", "triplane_fourier"]
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class FourierEmbedder(nn.Module):
|
| 12 |
+
"""The sin/cosine positional embedding. Given an input tensor `x` of shape [n_batch, ..., c_dim], it converts
|
| 13 |
+
each feature dimension of `x[..., i]` into:
|
| 14 |
+
[
|
| 15 |
+
sin(x[..., i]),
|
| 16 |
+
sin(f_1*x[..., i]),
|
| 17 |
+
sin(f_2*x[..., i]),
|
| 18 |
+
...
|
| 19 |
+
sin(f_N * x[..., i]),
|
| 20 |
+
cos(x[..., i]),
|
| 21 |
+
cos(f_1*x[..., i]),
|
| 22 |
+
cos(f_2*x[..., i]),
|
| 23 |
+
...
|
| 24 |
+
cos(f_N * x[..., i]),
|
| 25 |
+
x[..., i] # only present if include_input is True.
|
| 26 |
+
], here f_i is the frequency.
|
| 27 |
+
|
| 28 |
+
Denote the space is [0 / num_freqs, 1 / num_freqs, 2 / num_freqs, 3 / num_freqs, ..., (num_freqs - 1) / num_freqs].
|
| 29 |
+
If logspace is True, then the frequency f_i is [2^(0 / num_freqs), ..., 2^(i / num_freqs), ...];
|
| 30 |
+
Otherwise, the frequencies are linearly spaced between [1.0, 2^(num_freqs - 1)].
|
| 31 |
+
|
| 32 |
+
Args:
|
| 33 |
+
num_freqs (int): the number of frequencies, default is 6;
|
| 34 |
+
logspace (bool): If logspace is True, then the frequency f_i is [..., 2^(i / num_freqs), ...],
|
| 35 |
+
otherwise, the frequencies are linearly spaced between [1.0, 2^(num_freqs - 1)];
|
| 36 |
+
input_dim (int): the input dimension, default is 3;
|
| 37 |
+
include_input (bool): include the input tensor or not, default is True.
|
| 38 |
+
|
| 39 |
+
Attributes:
|
| 40 |
+
frequencies (torch.Tensor): If logspace is True, then the frequency f_i is [..., 2^(i / num_freqs), ...],
|
| 41 |
+
otherwise, the frequencies are linearly spaced between [1.0, 2^(num_freqs - 1);
|
| 42 |
+
|
| 43 |
+
out_dim (int): the embedding size, if include_input is True, it is input_dim * (num_freqs * 2 + 1),
|
| 44 |
+
otherwise, it is input_dim * num_freqs * 2.
|
| 45 |
+
|
| 46 |
+
"""
|
| 47 |
+
|
| 48 |
+
def __init__(self,
|
| 49 |
+
num_freqs: int = 6,
|
| 50 |
+
logspace: bool = True,
|
| 51 |
+
input_dim: int = 3,
|
| 52 |
+
include_input: bool = True,
|
| 53 |
+
include_pi: bool = True) -> None:
|
| 54 |
+
|
| 55 |
+
"""The initialization"""
|
| 56 |
+
|
| 57 |
+
super().__init__()
|
| 58 |
+
|
| 59 |
+
if logspace:
|
| 60 |
+
frequencies = 2.0 ** torch.arange(
|
| 61 |
+
num_freqs,
|
| 62 |
+
dtype=torch.float32
|
| 63 |
+
)
|
| 64 |
+
else:
|
| 65 |
+
frequencies = torch.linspace(
|
| 66 |
+
1.0,
|
| 67 |
+
2.0 ** (num_freqs - 1),
|
| 68 |
+
num_freqs,
|
| 69 |
+
dtype=torch.float32
|
| 70 |
+
)
|
| 71 |
+
|
| 72 |
+
if include_pi:
|
| 73 |
+
frequencies *= torch.pi
|
| 74 |
+
|
| 75 |
+
self.register_buffer("frequencies", frequencies, persistent=False)
|
| 76 |
+
self.include_input = include_input
|
| 77 |
+
self.num_freqs = num_freqs
|
| 78 |
+
|
| 79 |
+
self.out_dim = self.get_dims(input_dim)
|
| 80 |
+
|
| 81 |
+
def get_dims(self, input_dim):
|
| 82 |
+
temp = 1 if self.include_input or self.num_freqs == 0 else 0
|
| 83 |
+
out_dim = input_dim * (self.num_freqs * 2 + temp)
|
| 84 |
+
|
| 85 |
+
return out_dim
|
| 86 |
+
|
| 87 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 88 |
+
""" Forward process.
|
| 89 |
+
|
| 90 |
+
Args:
|
| 91 |
+
x: tensor of shape [..., dim]
|
| 92 |
+
|
| 93 |
+
Returns:
|
| 94 |
+
embedding: an embedding of `x` of shape [..., dim * (num_freqs * 2 + temp)]
|
| 95 |
+
where temp is 1 if include_input is True and 0 otherwise.
|
| 96 |
+
"""
|
| 97 |
+
|
| 98 |
+
if self.num_freqs > 0:
|
| 99 |
+
embed = (x[..., None].contiguous() * self.frequencies).view(*x.shape[:-1], -1)
|
| 100 |
+
if self.include_input:
|
| 101 |
+
return torch.cat((x, embed.sin(), embed.cos()), dim=-1)
|
| 102 |
+
else:
|
| 103 |
+
return torch.cat((embed.sin(), embed.cos()), dim=-1)
|
| 104 |
+
else:
|
| 105 |
+
return x
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
class LearnedFourierEmbedder(nn.Module):
|
| 109 |
+
""" following @crowsonkb "s lead with learned sinusoidal pos emb """
|
| 110 |
+
""" https://github.com/crowsonkb/v-diffusion-jax/blob/master/diffusion/models/danbooru_128.py#L8 """
|
| 111 |
+
|
| 112 |
+
def __init__(self, in_channels, dim):
|
| 113 |
+
super().__init__()
|
| 114 |
+
assert (dim % 2) == 0
|
| 115 |
+
half_dim = dim // 2
|
| 116 |
+
per_channel_dim = half_dim // in_channels
|
| 117 |
+
self.weights = nn.Parameter(torch.randn(per_channel_dim))
|
| 118 |
+
|
| 119 |
+
def forward(self, x):
|
| 120 |
+
"""
|
| 121 |
+
|
| 122 |
+
Args:
|
| 123 |
+
x (torch.FloatTensor): [..., c]
|
| 124 |
+
|
| 125 |
+
Returns:
|
| 126 |
+
x (torch.FloatTensor): [..., d]
|
| 127 |
+
"""
|
| 128 |
+
|
| 129 |
+
# [b, t, c, 1] * [1, d] = [b, t, c, d] -> [b, t, c * d]
|
| 130 |
+
freqs = (x[..., None] * self.weights[None] * 2 * np.pi).view(*x.shape[:-1], -1)
|
| 131 |
+
fouriered = torch.cat((x, freqs.sin(), freqs.cos()), dim=-1)
|
| 132 |
+
return fouriered
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
class TriplaneLearnedFourierEmbedder(nn.Module):
|
| 136 |
+
def __init__(self, in_channels, dim):
|
| 137 |
+
super().__init__()
|
| 138 |
+
|
| 139 |
+
self.yz_plane_embedder = LearnedFourierEmbedder(in_channels, dim)
|
| 140 |
+
self.xz_plane_embedder = LearnedFourierEmbedder(in_channels, dim)
|
| 141 |
+
self.xy_plane_embedder = LearnedFourierEmbedder(in_channels, dim)
|
| 142 |
+
|
| 143 |
+
self.out_dim = in_channels + dim
|
| 144 |
+
|
| 145 |
+
def forward(self, x):
|
| 146 |
+
|
| 147 |
+
yz_embed = self.yz_plane_embedder(x)
|
| 148 |
+
xz_embed = self.xz_plane_embedder(x)
|
| 149 |
+
xy_embed = self.xy_plane_embedder(x)
|
| 150 |
+
|
| 151 |
+
embed = yz_embed + xz_embed + xy_embed
|
| 152 |
+
|
| 153 |
+
return embed
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
def sequential_pos_embed(num_len, embed_dim):
|
| 157 |
+
assert embed_dim % 2 == 0
|
| 158 |
+
|
| 159 |
+
pos = torch.arange(num_len, dtype=torch.float32)
|
| 160 |
+
omega = torch.arange(embed_dim // 2, dtype=torch.float32)
|
| 161 |
+
omega /= embed_dim / 2.
|
| 162 |
+
omega = 1. / 10000 ** omega # (D/2,)
|
| 163 |
+
|
| 164 |
+
pos = pos.reshape(-1) # (M,)
|
| 165 |
+
out = torch.einsum("m,d->md", pos, omega) # (M, D/2), outer product
|
| 166 |
+
|
| 167 |
+
emb_sin = torch.sin(out) # (M, D/2)
|
| 168 |
+
emb_cos = torch.cos(out) # (M, D/2)
|
| 169 |
+
|
| 170 |
+
embeddings = torch.cat([emb_sin, emb_cos], dim=1) # (M, D)
|
| 171 |
+
|
| 172 |
+
return embeddings
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
def timestep_embedding(timesteps, dim, max_period=10000):
|
| 176 |
+
"""
|
| 177 |
+
Create sinusoidal timestep embeddings.
|
| 178 |
+
:param timesteps: a 1-D Tensor of N indices, one per batch element.
|
| 179 |
+
These may be fractional.
|
| 180 |
+
:param dim: the dimension of the output.
|
| 181 |
+
:param max_period: controls the minimum frequency of the embeddings.
|
| 182 |
+
:return: an [N x dim] Tensor of positional embeddings.
|
| 183 |
+
"""
|
| 184 |
+
half = dim // 2
|
| 185 |
+
freqs = torch.exp(
|
| 186 |
+
-math.log(max_period) * torch.arange(start=0, end=half, dtype=torch.float32) / half
|
| 187 |
+
).to(device=timesteps.device)
|
| 188 |
+
args = timesteps[:, None].to(timesteps.dtype) * freqs[None]
|
| 189 |
+
embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)
|
| 190 |
+
if dim % 2:
|
| 191 |
+
embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1)
|
| 192 |
+
return embedding
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
def get_embedder(embed_type="fourier", num_freqs=-1, input_dim=3, degree=4,
|
| 196 |
+
num_levels=16, level_dim=2, per_level_scale=2, base_resolution=16,
|
| 197 |
+
log2_hashmap_size=19, desired_resolution=None):
|
| 198 |
+
if embed_type == "identity" or (embed_type == "fourier" and num_freqs == -1):
|
| 199 |
+
return nn.Identity(), input_dim
|
| 200 |
+
|
| 201 |
+
elif embed_type == "fourier":
|
| 202 |
+
embedder_obj = FourierEmbedder(num_freqs=num_freqs, input_dim=input_dim,
|
| 203 |
+
logspace=True, include_input=True)
|
| 204 |
+
return embedder_obj, embedder_obj.out_dim
|
| 205 |
+
|
| 206 |
+
elif embed_type == "hashgrid":
|
| 207 |
+
raise NotImplementedError
|
| 208 |
+
|
| 209 |
+
elif embed_type == "sphere_harmonic":
|
| 210 |
+
raise NotImplementedError
|
| 211 |
+
|
| 212 |
+
else:
|
| 213 |
+
raise ValueError(f"{embed_type} is not valid. Currently only supprts {VALID_EMBED_TYPES}")
|
miche/michelangelo/models/modules/transformer_blocks.py
ADDED
|
@@ -0,0 +1,286 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
import math
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
from typing import Optional
|
| 8 |
+
|
| 9 |
+
from miche.michelangelo.models.modules.checkpoint import checkpoint
|
| 10 |
+
|
| 11 |
+
# Initialize linear layers with normal distribution weights and zero biases
|
| 12 |
+
def init_linear(l, stddev):
|
| 13 |
+
nn.init.normal_(l.weight, std=stddev)
|
| 14 |
+
if l.bias is not None:
|
| 15 |
+
nn.init.constant_(l.bias, 0.0)
|
| 16 |
+
|
| 17 |
+
# Multihead attention module
|
| 18 |
+
class MultiheadAttention(nn.Module):
|
| 19 |
+
def __init__(
|
| 20 |
+
self,
|
| 21 |
+
*,
|
| 22 |
+
device: torch.device,
|
| 23 |
+
dtype: torch.dtype,
|
| 24 |
+
n_ctx: int, # Context size
|
| 25 |
+
width: int, # Width of the input tensor
|
| 26 |
+
heads: int, # Number of attention heads
|
| 27 |
+
init_scale: float, # Initialization scale for weights
|
| 28 |
+
qkv_bias: bool, # Whether to use bias in QKV layers
|
| 29 |
+
flash: bool = False # Whether to use flash attention
|
| 30 |
+
):
|
| 31 |
+
super().__init__()
|
| 32 |
+
self.n_ctx = n_ctx
|
| 33 |
+
self.width = width
|
| 34 |
+
self.heads = heads
|
| 35 |
+
self.c_qkv = nn.Linear(width, width * 3, bias=qkv_bias, device=device, dtype=dtype)
|
| 36 |
+
self.c_proj = nn.Linear(width, width, device=device, dtype=dtype)
|
| 37 |
+
self.attention = QKVMultiheadAttention(device=device, dtype=dtype, heads=heads, n_ctx=n_ctx, flash=flash)
|
| 38 |
+
init_linear(self.c_qkv, init_scale)
|
| 39 |
+
init_linear(self.c_proj, init_scale)
|
| 40 |
+
|
| 41 |
+
def forward(self, x):
|
| 42 |
+
x = self.c_qkv(x)
|
| 43 |
+
x = checkpoint(self.attention, (x,), (), True)
|
| 44 |
+
x = self.c_proj(x)
|
| 45 |
+
return x
|
| 46 |
+
|
| 47 |
+
# QKV multihead attention module
|
| 48 |
+
class QKVMultiheadAttention(nn.Module):
|
| 49 |
+
def __init__(self, *, device: torch.device, dtype: torch.dtype, heads: int, n_ctx: int, flash: bool = False):
|
| 50 |
+
super().__init__()
|
| 51 |
+
self.device = device
|
| 52 |
+
self.dtype = dtype
|
| 53 |
+
self.heads = heads
|
| 54 |
+
self.n_ctx = n_ctx
|
| 55 |
+
self.flash = flash
|
| 56 |
+
|
| 57 |
+
def forward(self, qkv):
|
| 58 |
+
bs, n_ctx, width = qkv.shape
|
| 59 |
+
attn_ch = width // self.heads // 3
|
| 60 |
+
scale = 1 / math.sqrt(math.sqrt(attn_ch))
|
| 61 |
+
qkv = qkv.view(bs, n_ctx, self.heads, -1)
|
| 62 |
+
q, k, v = torch.split(qkv, attn_ch, dim=-1)
|
| 63 |
+
|
| 64 |
+
if self.flash:
|
| 65 |
+
out = F.scaled_dot_product_attention(q, k, v)
|
| 66 |
+
else:
|
| 67 |
+
weight = torch.einsum(
|
| 68 |
+
"bthc,bshc->bhts", q * scale, k * scale
|
| 69 |
+
) # More stable with f16 than dividing afterwards
|
| 70 |
+
wdtype = weight.dtype
|
| 71 |
+
weight = torch.softmax(weight.float(), dim=-1).type(wdtype)
|
| 72 |
+
out = torch.einsum("bhts,bshc->bthc", weight, v).reshape(bs, n_ctx, -1)
|
| 73 |
+
|
| 74 |
+
return out
|
| 75 |
+
|
| 76 |
+
# Residual attention block module
|
| 77 |
+
class ResidualAttentionBlock(nn.Module):
|
| 78 |
+
def __init__(
|
| 79 |
+
self,
|
| 80 |
+
*,
|
| 81 |
+
device: torch.device,
|
| 82 |
+
dtype: torch.dtype,
|
| 83 |
+
use_checkpoint: bool = False,
|
| 84 |
+
n_ctx: int, # Context size
|
| 85 |
+
width: int, # Width of the input tensor
|
| 86 |
+
heads: int, # Number of attention heads
|
| 87 |
+
init_scale: float, # Initialization scale for weights
|
| 88 |
+
qkv_bias: bool, # Whether to use bias in QKV layers
|
| 89 |
+
flash: bool = False # Whether to use flash attention
|
| 90 |
+
):
|
| 91 |
+
super().__init__()
|
| 92 |
+
|
| 93 |
+
self.use_checkpoint = use_checkpoint
|
| 94 |
+
|
| 95 |
+
self.attn = MultiheadAttention(
|
| 96 |
+
device=device,
|
| 97 |
+
dtype=dtype,
|
| 98 |
+
n_ctx=n_ctx,
|
| 99 |
+
width=width,
|
| 100 |
+
heads=heads,
|
| 101 |
+
init_scale=init_scale,
|
| 102 |
+
qkv_bias=qkv_bias,
|
| 103 |
+
flash=flash
|
| 104 |
+
)
|
| 105 |
+
self.ln_1 = nn.LayerNorm(width, device=device, dtype=dtype)
|
| 106 |
+
self.mlp = MLP(device=device, dtype=dtype, width=width, init_scale=init_scale)
|
| 107 |
+
self.ln_2 = nn.LayerNorm(width, device=device, dtype=dtype)
|
| 108 |
+
|
| 109 |
+
def _forward(self, x: torch.Tensor):
|
| 110 |
+
x = x + self.attn(self.ln_1(x))
|
| 111 |
+
x = x + self.mlp(self.ln_2(x))
|
| 112 |
+
return x
|
| 113 |
+
|
| 114 |
+
def forward(self, x: torch.Tensor):
|
| 115 |
+
return checkpoint(self._forward, (x,), self.parameters(), self.use_checkpoint)
|
| 116 |
+
|
| 117 |
+
# Multihead cross attention module
|
| 118 |
+
class MultiheadCrossAttention(nn.Module):
|
| 119 |
+
def __init__(
|
| 120 |
+
self,
|
| 121 |
+
*,
|
| 122 |
+
device: torch.device,
|
| 123 |
+
dtype: torch.dtype,
|
| 124 |
+
n_data: Optional[int] = None,
|
| 125 |
+
data_width: Optional[int] = None,
|
| 126 |
+
width: int, # Width of the input tensor
|
| 127 |
+
heads: int, # Number of attention heads
|
| 128 |
+
init_scale: float, # Initialization scale for weights
|
| 129 |
+
qkv_bias: bool, # Whether to use bias in QKV layers
|
| 130 |
+
flash: bool = False # Whether to use flash attention
|
| 131 |
+
):
|
| 132 |
+
super().__init__()
|
| 133 |
+
self.n_data = n_data
|
| 134 |
+
self.width = width
|
| 135 |
+
self.heads = heads
|
| 136 |
+
self.data_width = width if data_width is None else data_width
|
| 137 |
+
self.c_q = nn.Linear(width, width, bias=qkv_bias, device=device, dtype=dtype)
|
| 138 |
+
self.c_kv = nn.Linear(self.data_width, width * 2, bias=qkv_bias, device=device, dtype=dtype)
|
| 139 |
+
self.c_proj = nn.Linear(width, width, device=device, dtype=dtype)
|
| 140 |
+
self.attention = QKVMultiheadCrossAttention(
|
| 141 |
+
device=device, dtype=dtype, heads=heads, n_data=n_data, flash=flash
|
| 142 |
+
)
|
| 143 |
+
init_linear(self.c_q, init_scale)
|
| 144 |
+
init_linear(self.c_kv, init_scale)
|
| 145 |
+
init_linear(self.c_proj, init_scale)
|
| 146 |
+
|
| 147 |
+
def forward(self, x, data):
|
| 148 |
+
x = self.c_q(x)
|
| 149 |
+
data = self.c_kv(data)
|
| 150 |
+
x = checkpoint(self.attention, (x, data), (), True)
|
| 151 |
+
x = self.c_proj(x)
|
| 152 |
+
return x
|
| 153 |
+
|
| 154 |
+
# QKV multihead cross attention module
|
| 155 |
+
class QKVMultiheadCrossAttention(nn.Module):
|
| 156 |
+
def __init__(self, *, device: torch.device, dtype: torch.dtype, heads: int,
|
| 157 |
+
flash: bool = False, n_data: Optional[int] = None):
|
| 158 |
+
|
| 159 |
+
super().__init__()
|
| 160 |
+
self.device = device
|
| 161 |
+
self.dtype = dtype
|
| 162 |
+
self.heads = heads
|
| 163 |
+
self.n_data = n_data
|
| 164 |
+
self.flash = flash
|
| 165 |
+
|
| 166 |
+
def forward(self, q, kv):
|
| 167 |
+
_, n_ctx, _ = q.shape
|
| 168 |
+
bs, n_data, width = kv.shape
|
| 169 |
+
attn_ch = width // self.heads // 2
|
| 170 |
+
scale = 1 / math.sqrt(math.sqrt(attn_ch))
|
| 171 |
+
q = q.view(bs, n_ctx, self.heads, -1)
|
| 172 |
+
kv = kv.view(bs, n_data, self.heads, -1)
|
| 173 |
+
k, v = torch.split(kv, attn_ch, dim=-1)
|
| 174 |
+
|
| 175 |
+
if self.flash:
|
| 176 |
+
out = F.scaled_dot_product_attention(q, k, v)
|
| 177 |
+
else:
|
| 178 |
+
weight = torch.einsum(
|
| 179 |
+
"bthc,bshc->bhts", q * scale, k * scale
|
| 180 |
+
) # More stable with f16 than dividing afterwards
|
| 181 |
+
wdtype = weight.dtype
|
| 182 |
+
weight = torch.softmax(weight.float(), dim=-1).type(wdtype)
|
| 183 |
+
out = torch.einsum("bhts,bshc->bthc", weight, v).reshape(bs, n_ctx, -1)
|
| 184 |
+
|
| 185 |
+
return out
|
| 186 |
+
|
| 187 |
+
# Residual cross attention block module
|
| 188 |
+
class ResidualCrossAttentionBlock(nn.Module):
|
| 189 |
+
def __init__(
|
| 190 |
+
self,
|
| 191 |
+
*,
|
| 192 |
+
device: Optional[torch.device],
|
| 193 |
+
dtype: Optional[torch.dtype],
|
| 194 |
+
n_data: Optional[int] = None,
|
| 195 |
+
data_width: Optional[int] = None,
|
| 196 |
+
width: int, # Width of the input tensor
|
| 197 |
+
heads: int, # Number of attention heads
|
| 198 |
+
init_scale: float, # Initialization scale for weights
|
| 199 |
+
qkv_bias: bool, # Whether to use bias in QKV layers
|
| 200 |
+
flash: bool = False # Whether to use flash attention
|
| 201 |
+
):
|
| 202 |
+
super().__init__()
|
| 203 |
+
|
| 204 |
+
if data_width is None:
|
| 205 |
+
data_width = width
|
| 206 |
+
|
| 207 |
+
self.attn = MultiheadCrossAttention(
|
| 208 |
+
device=device,
|
| 209 |
+
dtype=dtype,
|
| 210 |
+
n_data=n_data,
|
| 211 |
+
width=width,
|
| 212 |
+
heads=heads,
|
| 213 |
+
data_width=data_width,
|
| 214 |
+
init_scale=init_scale,
|
| 215 |
+
qkv_bias=qkv_bias,
|
| 216 |
+
flash=flash,
|
| 217 |
+
)
|
| 218 |
+
self.ln_1 = nn.LayerNorm(width, device=device, dtype=dtype)
|
| 219 |
+
self.ln_2 = nn.LayerNorm(data_width, device=device, dtype=dtype)
|
| 220 |
+
self.mlp = MLP(device=device, dtype=dtype, width=width, init_scale=init_scale)
|
| 221 |
+
self.ln_3 = nn.LayerNorm(width, device=device, dtype=dtype)
|
| 222 |
+
|
| 223 |
+
def forward(self, x: torch.Tensor, data: torch.Tensor):
|
| 224 |
+
x = x + self.attn(self.ln_1(x), self.ln_2(data))
|
| 225 |
+
x = x + self.mlp(self.ln_3(x))
|
| 226 |
+
return x
|
| 227 |
+
|
| 228 |
+
# MLP Module
|
| 229 |
+
class MLP(nn.Module):
|
| 230 |
+
def __init__(self, *,
|
| 231 |
+
device: Optional[torch.device],
|
| 232 |
+
dtype: Optional[torch.dtype],
|
| 233 |
+
width: int,
|
| 234 |
+
init_scale: float):
|
| 235 |
+
super().__init__()
|
| 236 |
+
self.width = width
|
| 237 |
+
self.c_fc = nn.Linear(width, width * 4, device=device, dtype=dtype)
|
| 238 |
+
self.c_proj = nn.Linear(width * 4, width, device=device, dtype=dtype)
|
| 239 |
+
self.gelu = nn.GELU()
|
| 240 |
+
init_linear(self.c_fc, init_scale)
|
| 241 |
+
init_linear(self.c_proj, init_scale)
|
| 242 |
+
|
| 243 |
+
def forward(self, x):
|
| 244 |
+
return self.c_proj(self.gelu(self.c_fc(x)))
|
| 245 |
+
|
| 246 |
+
# Transformer Module
|
| 247 |
+
class Transformer(nn.Module):
|
| 248 |
+
def __init__(
|
| 249 |
+
self,
|
| 250 |
+
*,
|
| 251 |
+
device: Optional[torch.device],
|
| 252 |
+
dtype: Optional[torch.dtype],
|
| 253 |
+
layers: int,
|
| 254 |
+
use_checkpoint: bool = False,
|
| 255 |
+
n_ctx: int, # Context size
|
| 256 |
+
width: int, # Width of the input tensor
|
| 257 |
+
heads: int, # Number of attention heads
|
| 258 |
+
init_scale: float, # Initialization scale for weights
|
| 259 |
+
qkv_bias: bool, # Whether to use bias in QKV layers
|
| 260 |
+
flash: bool = False # Whether to use flash attention
|
| 261 |
+
):
|
| 262 |
+
super().__init__()
|
| 263 |
+
self.n_ctx = n_ctx
|
| 264 |
+
self.width = width
|
| 265 |
+
self.layers = layers
|
| 266 |
+
self.resblocks = nn.ModuleList(
|
| 267 |
+
[
|
| 268 |
+
ResidualAttentionBlock(
|
| 269 |
+
device=device,
|
| 270 |
+
dtype=dtype,
|
| 271 |
+
n_ctx=n_ctx,
|
| 272 |
+
width=width,
|
| 273 |
+
heads=heads,
|
| 274 |
+
init_scale=init_scale,
|
| 275 |
+
qkv_bias=qkv_bias,
|
| 276 |
+
flash=flash,
|
| 277 |
+
use_checkpoint=use_checkpoint
|
| 278 |
+
)
|
| 279 |
+
for _ in range(layers)
|
| 280 |
+
]
|
| 281 |
+
)
|
| 282 |
+
|
| 283 |
+
def forward(self, x: torch.Tensor):
|
| 284 |
+
for block in self.resblocks:
|
| 285 |
+
x = block(x)
|
| 286 |
+
return x
|
miche/michelangelo/models/tsal/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
miche/michelangelo/models/tsal/asl_pl_module.py
ADDED
|
@@ -0,0 +1,383 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
from typing import List, Tuple, Dict, Optional
|
| 4 |
+
from omegaconf import DictConfig
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
import torch.nn.functional as F
|
| 8 |
+
from torch import nn
|
| 9 |
+
from torch.optim import lr_scheduler
|
| 10 |
+
from typing import Union
|
| 11 |
+
from functools import partial
|
| 12 |
+
|
| 13 |
+
from miche.michelangelo.utils import instantiate_from_config
|
| 14 |
+
|
| 15 |
+
from .tsal_base import (
|
| 16 |
+
AlignedShapeAsLatentModule,
|
| 17 |
+
ShapeAsLatentModule,
|
| 18 |
+
Latent2MeshOutput,
|
| 19 |
+
AlignedMeshOutput
|
| 20 |
+
)
|
| 21 |
+
from miche.michelangelo.models.tsal.inference_utils import extract_geometry
|
| 22 |
+
import trimesh
|
| 23 |
+
|
| 24 |
+
class AlignedShapeAsLatentPLModule(nn.Module):
|
| 25 |
+
def __init__(self, *,
|
| 26 |
+
shape_module_cfg,
|
| 27 |
+
aligned_module_cfg,
|
| 28 |
+
loss_cfg,
|
| 29 |
+
optimizer_cfg: Optional[DictConfig] = None,
|
| 30 |
+
ckpt_path: Optional[str] = None,
|
| 31 |
+
ignore_keys: Union[Tuple[str], List[str]] = ()):
|
| 32 |
+
|
| 33 |
+
super().__init__()
|
| 34 |
+
|
| 35 |
+
shape_model: ShapeAsLatentModule = instantiate_from_config(
|
| 36 |
+
shape_module_cfg, device=None, dtype=None
|
| 37 |
+
)
|
| 38 |
+
self.model: AlignedShapeAsLatentModule = instantiate_from_config(
|
| 39 |
+
aligned_module_cfg, shape_model=shape_model
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
self.loss = instantiate_from_config(loss_cfg)
|
| 43 |
+
|
| 44 |
+
self.optimizer_cfg = optimizer_cfg
|
| 45 |
+
|
| 46 |
+
if ckpt_path is not None:
|
| 47 |
+
self.init_from_ckpt(ckpt_path, ignore_keys=ignore_keys)
|
| 48 |
+
|
| 49 |
+
def set_shape_model_only(self):
|
| 50 |
+
self.model.set_shape_model_only()
|
| 51 |
+
|
| 52 |
+
@property
|
| 53 |
+
def latent_shape(self):
|
| 54 |
+
return self.model.shape_model.latent_shape
|
| 55 |
+
|
| 56 |
+
@property
|
| 57 |
+
def zero_rank(self):
|
| 58 |
+
if self._trainer:
|
| 59 |
+
zero_rank = self.trainer.local_rank == 0
|
| 60 |
+
else:
|
| 61 |
+
zero_rank = True
|
| 62 |
+
|
| 63 |
+
return zero_rank
|
| 64 |
+
|
| 65 |
+
def init_from_ckpt(self, path, ignore_keys=()):
|
| 66 |
+
state_dict = torch.load(path, map_location="cpu")["state_dict"]
|
| 67 |
+
|
| 68 |
+
keys = list(state_dict.keys())
|
| 69 |
+
for k in keys:
|
| 70 |
+
for ik in ignore_keys:
|
| 71 |
+
if k.startswith(ik):
|
| 72 |
+
print("Deleting key {} from state_dict.".format(k))
|
| 73 |
+
del state_dict[k]
|
| 74 |
+
|
| 75 |
+
missing, unexpected = self.load_state_dict(state_dict, strict=False)
|
| 76 |
+
print(f"Restored from {path} with {len(missing)} missing and {len(unexpected)} unexpected keys")
|
| 77 |
+
if len(missing) > 0:
|
| 78 |
+
print(f"Missing Keys: {missing}")
|
| 79 |
+
print(f"Unexpected Keys: {unexpected}")
|
| 80 |
+
|
| 81 |
+
def configure_optimizers(self) -> Tuple[List, List]:
|
| 82 |
+
lr = self.learning_rate
|
| 83 |
+
|
| 84 |
+
trainable_parameters = list(self.model.parameters())
|
| 85 |
+
|
| 86 |
+
if self.optimizer_cfg is None:
|
| 87 |
+
optimizers = [torch.optim.AdamW(trainable_parameters, lr=lr, betas=(0.9, 0.99), weight_decay=1e-3)]
|
| 88 |
+
schedulers = []
|
| 89 |
+
else:
|
| 90 |
+
optimizer = instantiate_from_config(self.optimizer_cfg.optimizer, params=trainable_parameters)
|
| 91 |
+
scheduler_func = instantiate_from_config(
|
| 92 |
+
self.optimizer_cfg.scheduler,
|
| 93 |
+
max_decay_steps=self.trainer.max_steps,
|
| 94 |
+
lr_max=lr
|
| 95 |
+
)
|
| 96 |
+
scheduler = {
|
| 97 |
+
"scheduler": lr_scheduler.LambdaLR(optimizer, lr_lambda=scheduler_func.schedule),
|
| 98 |
+
"interval": "step",
|
| 99 |
+
"frequency": 1
|
| 100 |
+
}
|
| 101 |
+
optimizers = [optimizer]
|
| 102 |
+
schedulers = [scheduler]
|
| 103 |
+
|
| 104 |
+
return optimizers, schedulers
|
| 105 |
+
|
| 106 |
+
def forward(self,
|
| 107 |
+
surface: torch.FloatTensor,
|
| 108 |
+
image: torch.FloatTensor,
|
| 109 |
+
text: torch.FloatTensor,
|
| 110 |
+
volume_queries: torch.FloatTensor):
|
| 111 |
+
# Args:
|
| 112 |
+
# surface (torch.FloatTensor):
|
| 113 |
+
# image (torch.FloatTensor):
|
| 114 |
+
# text (torch.FloatTensor):
|
| 115 |
+
# volume_queries (torch.FloatTensor):
|
| 116 |
+
#
|
| 117 |
+
# Returns:
|
| 118 |
+
|
| 119 |
+
embed_outputs, shape_z = self.model(surface, image, text)
|
| 120 |
+
|
| 121 |
+
shape_zq, posterior = self.model.shape_model.encode_kl_embed(shape_z)
|
| 122 |
+
latents = self.model.shape_model.decode(shape_zq)
|
| 123 |
+
logits = self.model.shape_model.query_geometry(volume_queries, latents)
|
| 124 |
+
|
| 125 |
+
return embed_outputs, logits, posterior
|
| 126 |
+
|
| 127 |
+
def encode(self, surface: torch.FloatTensor, sample_posterior=True):
|
| 128 |
+
|
| 129 |
+
pc = surface[..., 0:3]
|
| 130 |
+
feats = surface[..., 3:6]
|
| 131 |
+
|
| 132 |
+
shape_embed, shape_zq, posterior = self.model.shape_model.encode(
|
| 133 |
+
pc=pc, feats=feats, sample_posterior=sample_posterior
|
| 134 |
+
)
|
| 135 |
+
|
| 136 |
+
return shape_zq
|
| 137 |
+
|
| 138 |
+
def encode_latents(self, surface: torch.FloatTensor):
|
| 139 |
+
|
| 140 |
+
pc = surface[..., 0:3]
|
| 141 |
+
feats = surface[..., 3:6]
|
| 142 |
+
|
| 143 |
+
shape_embed, shape_latents = self.model.shape_model.encode_latents(
|
| 144 |
+
pc=pc, feats=feats
|
| 145 |
+
)
|
| 146 |
+
shape_embed = shape_embed.unsqueeze(1)
|
| 147 |
+
assert shape_embed.shape[1] == 1 and shape_latents.shape[1] == 256
|
| 148 |
+
cat_latents = torch.cat([shape_embed, shape_latents], dim=1)
|
| 149 |
+
|
| 150 |
+
return cat_latents
|
| 151 |
+
|
| 152 |
+
def recon(self, surface):
|
| 153 |
+
cat_latents = self.encode_latents(surface)
|
| 154 |
+
shape_latents = cat_latents[:, 1:]
|
| 155 |
+
shape_zq, posterior = self.model.shape_model.encode_kl_embed(shape_latents)
|
| 156 |
+
|
| 157 |
+
# decoding
|
| 158 |
+
latents = self.model.shape_model.decode(shape_zq)
|
| 159 |
+
geometric_func = partial(self.model.shape_model.query_geometry, latents=latents)
|
| 160 |
+
|
| 161 |
+
# reconstruction
|
| 162 |
+
mesh_v_f, has_surface = extract_geometry(
|
| 163 |
+
geometric_func=geometric_func,
|
| 164 |
+
device=surface.device,
|
| 165 |
+
batch_size=surface.shape[0],
|
| 166 |
+
bounds=(-1.25, -1.25, -1.25, 1.25, 1.25, 1.25),
|
| 167 |
+
octree_depth=7,
|
| 168 |
+
num_chunks=10000,
|
| 169 |
+
)
|
| 170 |
+
recon_mesh = trimesh.Trimesh(mesh_v_f[0][0], mesh_v_f[0][1])
|
| 171 |
+
|
| 172 |
+
return recon_mesh
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
def to_shape_latents(self, latents):
|
| 176 |
+
|
| 177 |
+
shape_zq, posterior = self.model.shape_model.encode_kl_embed(latents, sample_posterior = False)
|
| 178 |
+
return self.model.shape_model.decode(shape_zq)
|
| 179 |
+
|
| 180 |
+
def decode(self,
|
| 181 |
+
z_q,
|
| 182 |
+
bounds: Union[Tuple[float], List[float], float] = 1.1,
|
| 183 |
+
octree_depth: int = 7,
|
| 184 |
+
num_chunks: int = 10000) -> List[Latent2MeshOutput]:
|
| 185 |
+
|
| 186 |
+
latents = self.model.shape_model.decode(z_q) # latents: [bs, num_latents, dim]
|
| 187 |
+
outputs = self.latent2mesh(latents, bounds=bounds, octree_depth=octree_depth, num_chunks=num_chunks)
|
| 188 |
+
|
| 189 |
+
return outputs
|
| 190 |
+
|
| 191 |
+
def training_step(self, batch: Dict[str, torch.FloatTensor],
|
| 192 |
+
batch_idx: int, optimizer_idx: int = 0) -> torch.FloatTensor:
|
| 193 |
+
#Args:
|
| 194 |
+
# batch (dict): the batch sample, and it contains:
|
| 195 |
+
# - surface (torch.FloatTensor): [bs, n_surface, (3 + input_dim)]
|
| 196 |
+
# - image (torch.FloatTensor): [bs, 3, 224, 224]
|
| 197 |
+
# - text (torch.FloatTensor): [bs, num_templates, 77]
|
| 198 |
+
# - geo_points (torch.FloatTensor): [bs, n_pts, (3 + 1)]
|
| 199 |
+
#
|
| 200 |
+
# batch_idx (int):
|
| 201 |
+
#
|
| 202 |
+
# optimizer_idx (int):
|
| 203 |
+
#
|
| 204 |
+
# Returns:
|
| 205 |
+
# loss (torch.FloatTensor):
|
| 206 |
+
|
| 207 |
+
surface = batch["surface"]
|
| 208 |
+
image = batch["image"]
|
| 209 |
+
text = batch["text"]
|
| 210 |
+
|
| 211 |
+
volume_queries = batch["geo_points"][..., 0:3]
|
| 212 |
+
shape_labels = batch["geo_points"][..., -1]
|
| 213 |
+
|
| 214 |
+
embed_outputs, shape_logits, posteriors = self(surface, image, text, volume_queries)
|
| 215 |
+
|
| 216 |
+
aeloss, log_dict_ae = self.loss(
|
| 217 |
+
**embed_outputs,
|
| 218 |
+
posteriors=posteriors,
|
| 219 |
+
shape_logits=shape_logits,
|
| 220 |
+
shape_labels=shape_labels,
|
| 221 |
+
split="train"
|
| 222 |
+
)
|
| 223 |
+
|
| 224 |
+
self.log_dict(log_dict_ae, prog_bar=True, logger=True, batch_size=shape_logits.shape[0],
|
| 225 |
+
sync_dist=False, rank_zero_only=True)
|
| 226 |
+
|
| 227 |
+
return aeloss
|
| 228 |
+
|
| 229 |
+
def validation_step(self, batch: Dict[str, torch.FloatTensor], batch_idx: int) -> torch.FloatTensor:
|
| 230 |
+
|
| 231 |
+
surface = batch["surface"]
|
| 232 |
+
image = batch["image"]
|
| 233 |
+
text = batch["text"]
|
| 234 |
+
|
| 235 |
+
volume_queries = batch["geo_points"][..., 0:3]
|
| 236 |
+
shape_labels = batch["geo_points"][..., -1]
|
| 237 |
+
|
| 238 |
+
embed_outputs, shape_logits, posteriors = self(surface, image, text, volume_queries)
|
| 239 |
+
|
| 240 |
+
aeloss, log_dict_ae = self.loss(
|
| 241 |
+
**embed_outputs,
|
| 242 |
+
posteriors=posteriors,
|
| 243 |
+
shape_logits=shape_logits,
|
| 244 |
+
shape_labels=shape_labels,
|
| 245 |
+
split="val"
|
| 246 |
+
)
|
| 247 |
+
self.log_dict(log_dict_ae, prog_bar=True, logger=True, batch_size=shape_logits.shape[0],
|
| 248 |
+
sync_dist=False, rank_zero_only=True)
|
| 249 |
+
|
| 250 |
+
return aeloss
|
| 251 |
+
|
| 252 |
+
def visual_alignment(self,
|
| 253 |
+
surface: torch.FloatTensor,
|
| 254 |
+
image: torch.FloatTensor,
|
| 255 |
+
text: torch.FloatTensor,
|
| 256 |
+
description: Optional[List[str]] = None,
|
| 257 |
+
bounds: Union[Tuple[float], List[float]] = (-1.25, -1.25, -1.25, 1.25, 1.25, 1.25),
|
| 258 |
+
octree_depth: int = 7,
|
| 259 |
+
num_chunks: int = 10000) -> List[AlignedMeshOutput]:
|
| 260 |
+
|
| 261 |
+
"""
|
| 262 |
+
|
| 263 |
+
Args:
|
| 264 |
+
surface:
|
| 265 |
+
image:
|
| 266 |
+
text:
|
| 267 |
+
description:
|
| 268 |
+
bounds:
|
| 269 |
+
octree_depth:
|
| 270 |
+
num_chunks:
|
| 271 |
+
|
| 272 |
+
Returns:
|
| 273 |
+
mesh_outputs (List[AlignedMeshOutput]): the mesh outputs list.
|
| 274 |
+
|
| 275 |
+
"""
|
| 276 |
+
|
| 277 |
+
outputs = []
|
| 278 |
+
|
| 279 |
+
device = surface.device
|
| 280 |
+
bs = surface.shape[0]
|
| 281 |
+
|
| 282 |
+
embed_outputs, shape_z = self.model(surface, image, text)
|
| 283 |
+
|
| 284 |
+
# calculate the similarity
|
| 285 |
+
image_embed = embed_outputs["image_embed"]
|
| 286 |
+
text_embed = embed_outputs["text_embed"]
|
| 287 |
+
shape_embed = embed_outputs["shape_embed"]
|
| 288 |
+
|
| 289 |
+
# normalized features
|
| 290 |
+
shape_embed = F.normalize(shape_embed, dim=-1, p=2)
|
| 291 |
+
text_embed = F.normalize(text_embed, dim=-1, p=2)
|
| 292 |
+
image_embed = F.normalize(image_embed, dim=-1, p=2)
|
| 293 |
+
|
| 294 |
+
# B x B
|
| 295 |
+
shape_text_similarity = (100.0 * shape_embed @ text_embed.T).softmax(dim=-1)
|
| 296 |
+
|
| 297 |
+
# B x B
|
| 298 |
+
shape_image_similarity = (100.0 * shape_embed @ image_embed.T).softmax(dim=-1)
|
| 299 |
+
|
| 300 |
+
# shape reconstruction
|
| 301 |
+
shape_zq, posterior = self.model.shape_model.encode_kl_embed(shape_z)
|
| 302 |
+
latents = self.model.shape_model.decode(shape_zq)
|
| 303 |
+
geometric_func = partial(self.model.shape_model.query_geometry, latents=latents)
|
| 304 |
+
|
| 305 |
+
# 2. decode geometry
|
| 306 |
+
mesh_v_f, has_surface = extract_geometry(
|
| 307 |
+
geometric_func=geometric_func,
|
| 308 |
+
device=device,
|
| 309 |
+
batch_size=bs,
|
| 310 |
+
bounds=bounds,
|
| 311 |
+
octree_depth=octree_depth,
|
| 312 |
+
num_chunks=num_chunks,
|
| 313 |
+
disable=not self.zero_rank
|
| 314 |
+
)
|
| 315 |
+
|
| 316 |
+
# 3. decode texture
|
| 317 |
+
for i, ((mesh_v, mesh_f), is_surface) in enumerate(zip(mesh_v_f, has_surface)):
|
| 318 |
+
if not is_surface:
|
| 319 |
+
outputs.append(None)
|
| 320 |
+
continue
|
| 321 |
+
|
| 322 |
+
out = AlignedMeshOutput()
|
| 323 |
+
out.mesh_v = mesh_v
|
| 324 |
+
out.mesh_f = mesh_f
|
| 325 |
+
out.surface = surface[i].cpu().numpy()
|
| 326 |
+
out.image = image[i].cpu().numpy()
|
| 327 |
+
if description is not None:
|
| 328 |
+
out.text = description[i]
|
| 329 |
+
out.shape_text_similarity = shape_text_similarity[i, i]
|
| 330 |
+
out.shape_image_similarity = shape_image_similarity[i, i]
|
| 331 |
+
|
| 332 |
+
outputs.append(out)
|
| 333 |
+
|
| 334 |
+
return outputs
|
| 335 |
+
|
| 336 |
+
def latent2mesh(self,
|
| 337 |
+
latents: torch.FloatTensor,
|
| 338 |
+
bounds: Union[Tuple[float], List[float], float] = 1.1,
|
| 339 |
+
octree_depth: int = 7,
|
| 340 |
+
num_chunks: int = 10000) -> List[Latent2MeshOutput]:
|
| 341 |
+
|
| 342 |
+
"""
|
| 343 |
+
|
| 344 |
+
Args:
|
| 345 |
+
latents: [bs, num_latents, dim]
|
| 346 |
+
bounds:
|
| 347 |
+
octree_depth:
|
| 348 |
+
num_chunks:
|
| 349 |
+
|
| 350 |
+
Returns:
|
| 351 |
+
mesh_outputs (List[MeshOutput]): the mesh outputs list.
|
| 352 |
+
|
| 353 |
+
"""
|
| 354 |
+
|
| 355 |
+
outputs = []
|
| 356 |
+
|
| 357 |
+
geometric_func = partial(self.model.shape_model.query_geometry, latents=latents)
|
| 358 |
+
|
| 359 |
+
# 2. decode geometry
|
| 360 |
+
device = latents.device
|
| 361 |
+
mesh_v_f, has_surface = extract_geometry(
|
| 362 |
+
geometric_func=geometric_func,
|
| 363 |
+
device=device,
|
| 364 |
+
batch_size=len(latents),
|
| 365 |
+
bounds=bounds,
|
| 366 |
+
octree_depth=octree_depth,
|
| 367 |
+
num_chunks=num_chunks,
|
| 368 |
+
disable=not self.zero_rank
|
| 369 |
+
)
|
| 370 |
+
|
| 371 |
+
# 3. decode texture
|
| 372 |
+
for i, ((mesh_v, mesh_f), is_surface) in enumerate(zip(mesh_v_f, has_surface)):
|
| 373 |
+
if not is_surface:
|
| 374 |
+
outputs.append(None)
|
| 375 |
+
continue
|
| 376 |
+
|
| 377 |
+
out = Latent2MeshOutput()
|
| 378 |
+
out.mesh_v = mesh_v
|
| 379 |
+
out.mesh_f = mesh_f
|
| 380 |
+
|
| 381 |
+
outputs.append(out)
|
| 382 |
+
|
| 383 |
+
return outputs
|
miche/michelangelo/models/tsal/clip_asl_module.py
ADDED
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from torch import nn
|
| 5 |
+
from einops import rearrange
|
| 6 |
+
from transformers import CLIPModel
|
| 7 |
+
|
| 8 |
+
from miche.michelangelo.models.tsal.tsal_base import AlignedShapeAsLatentModule
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class CLIPAlignedShapeAsLatentModule(AlignedShapeAsLatentModule):
|
| 12 |
+
|
| 13 |
+
def __init__(self, *,
|
| 14 |
+
shape_model,
|
| 15 |
+
clip_model_version: str = "openai/clip-vit-large-patch14"):
|
| 16 |
+
|
| 17 |
+
super().__init__()
|
| 18 |
+
|
| 19 |
+
# self.clip_model: CLIPModel = CLIPModel.from_pretrained(clip_model_version)
|
| 20 |
+
# for params in self.clip_model.parameters():
|
| 21 |
+
# params.requires_grad = False
|
| 22 |
+
self.clip_model = None
|
| 23 |
+
self.shape_model = shape_model
|
| 24 |
+
self.shape_projection = nn.Parameter(torch.empty(self.shape_model.width, self.shape_model.width))
|
| 25 |
+
# nn.init.normal_(self.shape_projection, std=self.shape_model.width ** -0.5)
|
| 26 |
+
|
| 27 |
+
def set_shape_model_only(self):
|
| 28 |
+
self.clip_model = None
|
| 29 |
+
|
| 30 |
+
def encode_shape_embed(self, surface, return_latents: bool = False):
|
| 31 |
+
"""
|
| 32 |
+
|
| 33 |
+
Args:
|
| 34 |
+
surface (torch.FloatTensor): [bs, n, 3 + c]
|
| 35 |
+
return_latents (bool):
|
| 36 |
+
|
| 37 |
+
Returns:
|
| 38 |
+
x (torch.FloatTensor): [bs, projection_dim]
|
| 39 |
+
shape_latents (torch.FloatTensor): [bs, m, d]
|
| 40 |
+
"""
|
| 41 |
+
|
| 42 |
+
pc = surface[..., 0:3]
|
| 43 |
+
feats = surface[..., 3:]
|
| 44 |
+
|
| 45 |
+
shape_embed, shape_latents = self.shape_model.encode_latents(pc, feats)
|
| 46 |
+
x = shape_embed @ self.shape_projection
|
| 47 |
+
|
| 48 |
+
if return_latents:
|
| 49 |
+
return x, shape_latents
|
| 50 |
+
else:
|
| 51 |
+
return x
|
| 52 |
+
|
| 53 |
+
def encode_image_embed(self, image):
|
| 54 |
+
"""
|
| 55 |
+
|
| 56 |
+
Args:
|
| 57 |
+
image (torch.FloatTensor): [bs, 3, h, w]
|
| 58 |
+
|
| 59 |
+
Returns:
|
| 60 |
+
x (torch.FloatTensor): [bs, projection_dim]
|
| 61 |
+
"""
|
| 62 |
+
|
| 63 |
+
x = self.clip_model.get_image_features(image)
|
| 64 |
+
|
| 65 |
+
return x
|
| 66 |
+
|
| 67 |
+
def encode_text_embed(self, text):
|
| 68 |
+
x = self.clip_model.get_text_features(text)
|
| 69 |
+
return x
|
| 70 |
+
|
| 71 |
+
def forward(self, surface, image, text):
|
| 72 |
+
"""
|
| 73 |
+
|
| 74 |
+
Args:
|
| 75 |
+
surface (torch.FloatTensor):
|
| 76 |
+
image (torch.FloatTensor): [bs, 3, 224, 224]
|
| 77 |
+
text (torch.LongTensor): [bs, num_templates, 77]
|
| 78 |
+
|
| 79 |
+
Returns:
|
| 80 |
+
embed_outputs (dict): the embedding outputs, and it contains:
|
| 81 |
+
- image_embed (torch.FloatTensor):
|
| 82 |
+
- text_embed (torch.FloatTensor):
|
| 83 |
+
- shape_embed (torch.FloatTensor):
|
| 84 |
+
- logit_scale (float):
|
| 85 |
+
"""
|
| 86 |
+
|
| 87 |
+
# # text embedding
|
| 88 |
+
# text_embed_all = []
|
| 89 |
+
# for i in range(text.shape[0]):
|
| 90 |
+
# text_for_one_sample = text[i]
|
| 91 |
+
# text_embed = self.encode_text_embed(text_for_one_sample)
|
| 92 |
+
# text_embed = text_embed / text_embed.norm(dim=-1, keepdim=True)
|
| 93 |
+
# text_embed = text_embed.mean(dim=0)
|
| 94 |
+
# text_embed = text_embed / text_embed.norm(dim=-1, keepdim=True)
|
| 95 |
+
# text_embed_all.append(text_embed)
|
| 96 |
+
# text_embed_all = torch.stack(text_embed_all)
|
| 97 |
+
|
| 98 |
+
b = text.shape[0]
|
| 99 |
+
text_tokens = rearrange(text, "b t l -> (b t) l")
|
| 100 |
+
text_embed = self.encode_text_embed(text_tokens)
|
| 101 |
+
text_embed = rearrange(text_embed, "(b t) d -> b t d", b=b)
|
| 102 |
+
text_embed = text_embed.mean(dim=1)
|
| 103 |
+
text_embed = text_embed / text_embed.norm(dim=-1, keepdim=True)
|
| 104 |
+
|
| 105 |
+
# image embedding
|
| 106 |
+
image_embed = self.encode_image_embed(image)
|
| 107 |
+
|
| 108 |
+
# shape embedding
|
| 109 |
+
shape_embed, shape_latents = self.encode_shape_embed(surface, return_latents=True)
|
| 110 |
+
|
| 111 |
+
embed_outputs = {
|
| 112 |
+
"image_embed": image_embed,
|
| 113 |
+
"text_embed": text_embed,
|
| 114 |
+
"shape_embed": shape_embed,
|
| 115 |
+
# "logit_scale": self.clip_model.logit_scale.exp()
|
| 116 |
+
}
|
| 117 |
+
|
| 118 |
+
return embed_outputs, shape_latents
|
miche/michelangelo/models/tsal/inference_utils.py
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from tqdm import tqdm
|
| 5 |
+
from einops import repeat
|
| 6 |
+
import numpy as np
|
| 7 |
+
from typing import Callable, Tuple, List, Union, Optional
|
| 8 |
+
from skimage import measure
|
| 9 |
+
|
| 10 |
+
from miche.michelangelo.graphics.primitives import generate_dense_grid_points
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
@torch.no_grad()
|
| 14 |
+
def extract_geometry(geometric_func: Callable,
|
| 15 |
+
device: torch.device,
|
| 16 |
+
batch_size: int = 1,
|
| 17 |
+
bounds: Union[Tuple[float], List[float], float] = (-1.25, -1.25, -1.25, 1.25, 1.25, 1.25),
|
| 18 |
+
octree_depth: int = 7,
|
| 19 |
+
num_chunks: int = 10000,
|
| 20 |
+
disable: bool = True):
|
| 21 |
+
|
| 22 |
+
# Args:
|
| 23 |
+
# geometric_func:
|
| 24 |
+
# device:
|
| 25 |
+
# bounds:
|
| 26 |
+
# octree_depth:
|
| 27 |
+
# batch_size:
|
| 28 |
+
# num_chunks:
|
| 29 |
+
# disable:
|
| 30 |
+
# Returns:
|
| 31 |
+
|
| 32 |
+
if isinstance(bounds, float):
|
| 33 |
+
bounds = [-bounds, -bounds, -bounds, bounds, bounds, bounds]
|
| 34 |
+
|
| 35 |
+
bbox_min = np.array(bounds[0:3])
|
| 36 |
+
bbox_max = np.array(bounds[3:6])
|
| 37 |
+
bbox_size = bbox_max - bbox_min
|
| 38 |
+
|
| 39 |
+
xyz_samples, grid_size, length = generate_dense_grid_points(
|
| 40 |
+
bbox_min=bbox_min,
|
| 41 |
+
bbox_max=bbox_max,
|
| 42 |
+
octree_depth=octree_depth,
|
| 43 |
+
indexing="ij"
|
| 44 |
+
)
|
| 45 |
+
xyz_samples = torch.FloatTensor(xyz_samples)
|
| 46 |
+
|
| 47 |
+
batch_logits = []
|
| 48 |
+
for start in tqdm(range(0, xyz_samples.shape[0], num_chunks),
|
| 49 |
+
desc="Implicit Function:", disable=disable, leave=False):
|
| 50 |
+
queries = xyz_samples[start: start + num_chunks, :].to(device)
|
| 51 |
+
batch_queries = repeat(queries, "p c -> b p c", b=batch_size)
|
| 52 |
+
|
| 53 |
+
logits = geometric_func(batch_queries)
|
| 54 |
+
batch_logits.append(logits.cpu())
|
| 55 |
+
|
| 56 |
+
grid_logits = torch.cat(batch_logits, dim=1).view((batch_size, grid_size[0], grid_size[1], grid_size[2])).numpy()
|
| 57 |
+
|
| 58 |
+
mesh_v_f = []
|
| 59 |
+
has_surface = np.zeros((batch_size,), dtype=np.bool_)
|
| 60 |
+
for i in range(batch_size):
|
| 61 |
+
try:
|
| 62 |
+
vertices, faces, normals, _ = measure.marching_cubes(grid_logits[i], 0, method="lewiner")
|
| 63 |
+
vertices = vertices / grid_size * bbox_size + bbox_min
|
| 64 |
+
# vertices[:, [0, 1]] = vertices[:, [1, 0]]
|
| 65 |
+
mesh_v_f.append((vertices.astype(np.float32), np.ascontiguousarray(faces)))
|
| 66 |
+
has_surface[i] = True
|
| 67 |
+
|
| 68 |
+
except ValueError:
|
| 69 |
+
mesh_v_f.append((None, None))
|
| 70 |
+
has_surface[i] = False
|
| 71 |
+
|
| 72 |
+
except RuntimeError:
|
| 73 |
+
mesh_v_f.append((None, None))
|
| 74 |
+
has_surface[i] = False
|
| 75 |
+
|
| 76 |
+
return mesh_v_f, has_surface
|
miche/michelangelo/models/tsal/loss.py
ADDED
|
@@ -0,0 +1,130 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
|
| 6 |
+
from typing import Optional
|
| 7 |
+
|
| 8 |
+
from miche.michelangelo.models.modules.distributions import DiagonalGaussianDistribution
|
| 9 |
+
from miche.michelangelo.utils import misc
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class ContrastKLNearFar(nn.Module):
|
| 13 |
+
def __init__(self,
|
| 14 |
+
contrast_weight: float = 1.0,
|
| 15 |
+
near_weight: float = 0.1,
|
| 16 |
+
kl_weight: float = 1.0,
|
| 17 |
+
num_near_samples: Optional[int] = None):
|
| 18 |
+
|
| 19 |
+
super().__init__()
|
| 20 |
+
|
| 21 |
+
self.labels = None
|
| 22 |
+
self.last_local_batch_size = None
|
| 23 |
+
|
| 24 |
+
self.contrast_weight = contrast_weight
|
| 25 |
+
self.near_weight = near_weight
|
| 26 |
+
self.kl_weight = kl_weight
|
| 27 |
+
self.num_near_samples = num_near_samples
|
| 28 |
+
self.geo_criterion = nn.BCEWithLogitsLoss()
|
| 29 |
+
|
| 30 |
+
def forward(self,
|
| 31 |
+
shape_embed: torch.FloatTensor,
|
| 32 |
+
text_embed: torch.FloatTensor,
|
| 33 |
+
image_embed: torch.FloatTensor,
|
| 34 |
+
logit_scale: torch.FloatTensor,
|
| 35 |
+
posteriors: Optional[DiagonalGaussianDistribution],
|
| 36 |
+
shape_logits: torch.FloatTensor,
|
| 37 |
+
shape_labels: torch.FloatTensor,
|
| 38 |
+
split: Optional[str] = "train", **kwargs):
|
| 39 |
+
|
| 40 |
+
# shape_embed: torch.FloatTensor
|
| 41 |
+
# text_embed: torch.FloatTensor
|
| 42 |
+
# image_embed: torch.FloatTensor
|
| 43 |
+
# logit_scale: torch.FloatTensor
|
| 44 |
+
# posteriors: Optional[DiagonalGaussianDistribution]
|
| 45 |
+
# shape_logits: torch.FloatTensor
|
| 46 |
+
# shape_labels: torch.FloatTensor
|
| 47 |
+
|
| 48 |
+
local_batch_size = shape_embed.size(0)
|
| 49 |
+
|
| 50 |
+
if local_batch_size != self.last_local_batch_size:
|
| 51 |
+
self.labels = local_batch_size * misc.get_rank() + torch.arange(
|
| 52 |
+
local_batch_size, device=shape_embed.device
|
| 53 |
+
).long()
|
| 54 |
+
self.last_local_batch_size = local_batch_size
|
| 55 |
+
|
| 56 |
+
# normalized features
|
| 57 |
+
shape_embed = F.normalize(shape_embed, dim=-1, p=2)
|
| 58 |
+
text_embed = F.normalize(text_embed, dim=-1, p=2)
|
| 59 |
+
image_embed = F.normalize(image_embed, dim=-1, p=2)
|
| 60 |
+
|
| 61 |
+
# gather features from all GPUs
|
| 62 |
+
shape_embed_all, text_embed_all, image_embed_all = misc.all_gather_batch(
|
| 63 |
+
[shape_embed, text_embed, image_embed]
|
| 64 |
+
)
|
| 65 |
+
|
| 66 |
+
# cosine similarity as logits
|
| 67 |
+
logits_per_shape_text = logit_scale * shape_embed @ text_embed_all.t()
|
| 68 |
+
logits_per_text_shape = logit_scale * text_embed @ shape_embed_all.t()
|
| 69 |
+
logits_per_shape_image = logit_scale * shape_embed @ image_embed_all.t()
|
| 70 |
+
logits_per_image_shape = logit_scale * image_embed @ shape_embed_all.t()
|
| 71 |
+
contrast_loss = (F.cross_entropy(logits_per_shape_text, self.labels) +
|
| 72 |
+
F.cross_entropy(logits_per_text_shape, self.labels)) / 2 + \
|
| 73 |
+
(F.cross_entropy(logits_per_shape_image, self.labels) +
|
| 74 |
+
F.cross_entropy(logits_per_image_shape, self.labels)) / 2
|
| 75 |
+
|
| 76 |
+
# shape reconstruction
|
| 77 |
+
if self.num_near_samples is None:
|
| 78 |
+
num_vol = shape_logits.shape[1] // 2
|
| 79 |
+
else:
|
| 80 |
+
num_vol = shape_logits.shape[1] - self.num_near_samples
|
| 81 |
+
|
| 82 |
+
vol_logits = shape_logits[:, 0:num_vol]
|
| 83 |
+
vol_labels = shape_labels[:, 0:num_vol]
|
| 84 |
+
|
| 85 |
+
near_logits = shape_logits[:, num_vol:]
|
| 86 |
+
near_labels = shape_labels[:, num_vol:]
|
| 87 |
+
|
| 88 |
+
# occupancy loss
|
| 89 |
+
vol_bce = self.geo_criterion(vol_logits.float(), vol_labels.float())
|
| 90 |
+
near_bce = self.geo_criterion(near_logits.float(), near_labels.float())
|
| 91 |
+
|
| 92 |
+
if posteriors is None:
|
| 93 |
+
kl_loss = torch.tensor(0.0, dtype=vol_logits.dtype, device=vol_logits.device)
|
| 94 |
+
else:
|
| 95 |
+
kl_loss = posteriors.kl(dims=(1, 2))
|
| 96 |
+
kl_loss = torch.mean(kl_loss)
|
| 97 |
+
|
| 98 |
+
loss = vol_bce + near_bce * self.near_weight + kl_loss * self.kl_weight + contrast_loss * self.contrast_weight
|
| 99 |
+
|
| 100 |
+
# compute accuracy
|
| 101 |
+
with torch.no_grad():
|
| 102 |
+
pred = torch.argmax(logits_per_shape_text, dim=-1)
|
| 103 |
+
correct = pred.eq(self.labels).sum()
|
| 104 |
+
shape_text_acc = 100 * correct / local_batch_size
|
| 105 |
+
|
| 106 |
+
pred = torch.argmax(logits_per_shape_image, dim=-1)
|
| 107 |
+
correct = pred.eq(self.labels).sum()
|
| 108 |
+
shape_image_acc = 100 * correct / local_batch_size
|
| 109 |
+
|
| 110 |
+
preds = shape_logits >= 0
|
| 111 |
+
accuracy = (preds == shape_labels).float()
|
| 112 |
+
accuracy = accuracy.mean()
|
| 113 |
+
|
| 114 |
+
log = {
|
| 115 |
+
"{}/contrast".format(split): contrast_loss.clone().detach(),
|
| 116 |
+
"{}/near".format(split): near_bce.detach(),
|
| 117 |
+
"{}/far".format(split): vol_bce.detach(),
|
| 118 |
+
"{}/kl".format(split): kl_loss.detach(),
|
| 119 |
+
"{}/shape_text_acc".format(split): shape_text_acc,
|
| 120 |
+
"{}/shape_image_acc".format(split): shape_image_acc,
|
| 121 |
+
"{}/total_loss".format(split): loss.clone().detach(),
|
| 122 |
+
"{}/accuracy".format(split): accuracy,
|
| 123 |
+
}
|
| 124 |
+
|
| 125 |
+
if posteriors is not None:
|
| 126 |
+
log[f"{split}/mean"] = posteriors.mean.mean().detach()
|
| 127 |
+
log[f"{split}/std_mean"] = posteriors.std.mean().detach()
|
| 128 |
+
log[f"{split}/std_max"] = posteriors.std.max().detach()
|
| 129 |
+
|
| 130 |
+
return loss, log
|
miche/michelangelo/models/tsal/sal_perceiver.py
ADDED
|
@@ -0,0 +1,410 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
from typing import Optional
|
| 6 |
+
from einops import repeat
|
| 7 |
+
import math
|
| 8 |
+
|
| 9 |
+
from miche.michelangelo.models.modules import checkpoint
|
| 10 |
+
from miche.michelangelo.models.modules.embedder import FourierEmbedder
|
| 11 |
+
from miche.michelangelo.models.modules.distributions import DiagonalGaussianDistribution
|
| 12 |
+
from miche.michelangelo.models.modules.transformer_blocks import (
|
| 13 |
+
ResidualCrossAttentionBlock,
|
| 14 |
+
Transformer
|
| 15 |
+
)
|
| 16 |
+
|
| 17 |
+
from .tsal_base import ShapeAsLatentModule
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class CrossAttentionEncoder(nn.Module):
|
| 21 |
+
|
| 22 |
+
def __init__(self, *,
|
| 23 |
+
device: Optional[torch.device],
|
| 24 |
+
dtype: Optional[torch.dtype],
|
| 25 |
+
num_latents: int,
|
| 26 |
+
fourier_embedder: FourierEmbedder,
|
| 27 |
+
point_feats: int,
|
| 28 |
+
width: int,
|
| 29 |
+
heads: int,
|
| 30 |
+
layers: int,
|
| 31 |
+
init_scale: float = 0.25,
|
| 32 |
+
qkv_bias: bool = True,
|
| 33 |
+
flash: bool = False,
|
| 34 |
+
use_ln_post: bool = False,
|
| 35 |
+
use_checkpoint: bool = False):
|
| 36 |
+
|
| 37 |
+
super().__init__()
|
| 38 |
+
|
| 39 |
+
self.use_checkpoint = use_checkpoint
|
| 40 |
+
self.num_latents = num_latents
|
| 41 |
+
|
| 42 |
+
self.query = nn.Parameter(torch.randn((num_latents, width), device=device, dtype=dtype) * 0.02)
|
| 43 |
+
|
| 44 |
+
self.fourier_embedder = fourier_embedder
|
| 45 |
+
self.input_proj = nn.Linear(self.fourier_embedder.out_dim + point_feats, width, device=device, dtype=dtype)
|
| 46 |
+
self.cross_attn = ResidualCrossAttentionBlock(
|
| 47 |
+
device=device,
|
| 48 |
+
dtype=dtype,
|
| 49 |
+
width=width,
|
| 50 |
+
heads=heads,
|
| 51 |
+
init_scale=init_scale,
|
| 52 |
+
qkv_bias=qkv_bias,
|
| 53 |
+
flash=flash,
|
| 54 |
+
)
|
| 55 |
+
|
| 56 |
+
self.self_attn = Transformer(
|
| 57 |
+
device=device,
|
| 58 |
+
dtype=dtype,
|
| 59 |
+
n_ctx=num_latents,
|
| 60 |
+
width=width,
|
| 61 |
+
layers=layers,
|
| 62 |
+
heads=heads,
|
| 63 |
+
init_scale=init_scale,
|
| 64 |
+
qkv_bias=qkv_bias,
|
| 65 |
+
flash=flash,
|
| 66 |
+
use_checkpoint=False
|
| 67 |
+
)
|
| 68 |
+
|
| 69 |
+
if use_ln_post:
|
| 70 |
+
self.ln_post = nn.LayerNorm(width, dtype=dtype, device=device)
|
| 71 |
+
else:
|
| 72 |
+
self.ln_post = None
|
| 73 |
+
|
| 74 |
+
def _forward(self, pc, feats):
|
| 75 |
+
|
| 76 |
+
# Args:
|
| 77 |
+
# pc (torch.FloatTensor): [B, N, 3]
|
| 78 |
+
# feats (torch.FloatTensor or None): [B, N, C]
|
| 79 |
+
|
| 80 |
+
bs = pc.shape[0]
|
| 81 |
+
|
| 82 |
+
data = self.fourier_embedder(pc)
|
| 83 |
+
if feats is not None:
|
| 84 |
+
data = torch.cat([data, feats], dim=-1)
|
| 85 |
+
data = self.input_proj(data)
|
| 86 |
+
|
| 87 |
+
query = repeat(self.query, "m c -> b m c", b=bs)
|
| 88 |
+
latents = self.cross_attn(query, data)
|
| 89 |
+
latents = self.self_attn(latents)
|
| 90 |
+
|
| 91 |
+
if self.ln_post is not None:
|
| 92 |
+
latents = self.ln_post(latents)
|
| 93 |
+
|
| 94 |
+
return latents, pc
|
| 95 |
+
|
| 96 |
+
def forward(self, pc: torch.FloatTensor, feats: Optional[torch.FloatTensor] = None):
|
| 97 |
+
|
| 98 |
+
# Args:
|
| 99 |
+
# pc (torch.FloatTensor): [B, N, 3]
|
| 100 |
+
# feats (torch.FloatTensor or None): [B, N, C]
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
return checkpoint(self._forward, (pc, feats), self.parameters(), self.use_checkpoint)
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
class CrossAttentionDecoder(nn.Module):
|
| 107 |
+
|
| 108 |
+
def __init__(self, *,
|
| 109 |
+
device: Optional[torch.device],
|
| 110 |
+
dtype: Optional[torch.dtype],
|
| 111 |
+
num_latents: int,
|
| 112 |
+
out_channels: int,
|
| 113 |
+
fourier_embedder: FourierEmbedder,
|
| 114 |
+
width: int,
|
| 115 |
+
heads: int,
|
| 116 |
+
init_scale: float = 0.25,
|
| 117 |
+
qkv_bias: bool = True,
|
| 118 |
+
flash: bool = False,
|
| 119 |
+
use_checkpoint: bool = False):
|
| 120 |
+
|
| 121 |
+
super().__init__()
|
| 122 |
+
|
| 123 |
+
self.use_checkpoint = use_checkpoint
|
| 124 |
+
self.fourier_embedder = fourier_embedder
|
| 125 |
+
|
| 126 |
+
self.query_proj = nn.Linear(self.fourier_embedder.out_dim, width, device=device, dtype=dtype)
|
| 127 |
+
|
| 128 |
+
self.cross_attn_decoder = ResidualCrossAttentionBlock(
|
| 129 |
+
device=device,
|
| 130 |
+
dtype=dtype,
|
| 131 |
+
n_data=num_latents,
|
| 132 |
+
width=width,
|
| 133 |
+
heads=heads,
|
| 134 |
+
init_scale=init_scale,
|
| 135 |
+
qkv_bias=qkv_bias,
|
| 136 |
+
flash=flash
|
| 137 |
+
)
|
| 138 |
+
|
| 139 |
+
self.ln_post = nn.LayerNorm(width, device=device, dtype=dtype)
|
| 140 |
+
self.output_proj = nn.Linear(width, out_channels, device=device, dtype=dtype)
|
| 141 |
+
|
| 142 |
+
def _forward(self, queries: torch.FloatTensor, latents: torch.FloatTensor):
|
| 143 |
+
queries = self.query_proj(self.fourier_embedder(queries))
|
| 144 |
+
x = self.cross_attn_decoder(queries, latents)
|
| 145 |
+
x = self.ln_post(x)
|
| 146 |
+
x = self.output_proj(x)
|
| 147 |
+
return x
|
| 148 |
+
|
| 149 |
+
def forward(self, queries: torch.FloatTensor, latents: torch.FloatTensor):
|
| 150 |
+
return checkpoint(self._forward, (queries, latents), self.parameters(), self.use_checkpoint)
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
class ShapeAsLatentPerceiver(ShapeAsLatentModule):
|
| 154 |
+
def __init__(self, *,
|
| 155 |
+
device: Optional[torch.device],
|
| 156 |
+
dtype: Optional[torch.dtype],
|
| 157 |
+
num_latents: int,
|
| 158 |
+
point_feats: int = 0,
|
| 159 |
+
embed_dim: int = 0,
|
| 160 |
+
num_freqs: int = 8,
|
| 161 |
+
include_pi: bool = True,
|
| 162 |
+
width: int,
|
| 163 |
+
heads: int,
|
| 164 |
+
num_encoder_layers: int,
|
| 165 |
+
num_decoder_layers: int,
|
| 166 |
+
init_scale: float = 0.25,
|
| 167 |
+
qkv_bias: bool = True,
|
| 168 |
+
flash: bool = False,
|
| 169 |
+
use_ln_post: bool = False,
|
| 170 |
+
use_checkpoint: bool = False):
|
| 171 |
+
|
| 172 |
+
super().__init__()
|
| 173 |
+
|
| 174 |
+
self.use_checkpoint = use_checkpoint
|
| 175 |
+
|
| 176 |
+
self.num_latents = num_latents
|
| 177 |
+
self.fourier_embedder = FourierEmbedder(num_freqs=num_freqs, include_pi=include_pi)
|
| 178 |
+
|
| 179 |
+
init_scale = init_scale * math.sqrt(1.0 / width)
|
| 180 |
+
self.encoder = CrossAttentionEncoder(
|
| 181 |
+
device=device,
|
| 182 |
+
dtype=dtype,
|
| 183 |
+
fourier_embedder=self.fourier_embedder,
|
| 184 |
+
num_latents=num_latents,
|
| 185 |
+
point_feats=point_feats,
|
| 186 |
+
width=width,
|
| 187 |
+
heads=heads,
|
| 188 |
+
layers=num_encoder_layers,
|
| 189 |
+
init_scale=init_scale,
|
| 190 |
+
qkv_bias=qkv_bias,
|
| 191 |
+
flash=flash,
|
| 192 |
+
use_ln_post=use_ln_post,
|
| 193 |
+
use_checkpoint=use_checkpoint
|
| 194 |
+
)
|
| 195 |
+
|
| 196 |
+
self.embed_dim = embed_dim
|
| 197 |
+
if embed_dim > 0:
|
| 198 |
+
# VAE embed
|
| 199 |
+
self.pre_kl = nn.Linear(width, embed_dim * 2, device=device, dtype=dtype)
|
| 200 |
+
self.post_kl = nn.Linear(embed_dim, width, device=device, dtype=dtype)
|
| 201 |
+
self.latent_shape = (num_latents, embed_dim)
|
| 202 |
+
else:
|
| 203 |
+
self.latent_shape = (num_latents, width)
|
| 204 |
+
|
| 205 |
+
self.transformer = Transformer(
|
| 206 |
+
device=device,
|
| 207 |
+
dtype=dtype,
|
| 208 |
+
n_ctx=num_latents,
|
| 209 |
+
width=width,
|
| 210 |
+
layers=num_decoder_layers,
|
| 211 |
+
heads=heads,
|
| 212 |
+
init_scale=init_scale,
|
| 213 |
+
qkv_bias=qkv_bias,
|
| 214 |
+
flash=flash,
|
| 215 |
+
use_checkpoint=use_checkpoint
|
| 216 |
+
)
|
| 217 |
+
|
| 218 |
+
# geometry decoder
|
| 219 |
+
self.geo_decoder = CrossAttentionDecoder(
|
| 220 |
+
device=device,
|
| 221 |
+
dtype=dtype,
|
| 222 |
+
fourier_embedder=self.fourier_embedder,
|
| 223 |
+
out_channels=1,
|
| 224 |
+
num_latents=num_latents,
|
| 225 |
+
width=width,
|
| 226 |
+
heads=heads,
|
| 227 |
+
init_scale=init_scale,
|
| 228 |
+
qkv_bias=qkv_bias,
|
| 229 |
+
flash=flash,
|
| 230 |
+
use_checkpoint=use_checkpoint
|
| 231 |
+
)
|
| 232 |
+
|
| 233 |
+
def encode(self,
|
| 234 |
+
pc: torch.FloatTensor,
|
| 235 |
+
feats: Optional[torch.FloatTensor] = None,
|
| 236 |
+
sample_posterior: bool = True):
|
| 237 |
+
|
| 238 |
+
|
| 239 |
+
# Args:
|
| 240 |
+
# pc (torch.FloatTensor): [B, N, 3]
|
| 241 |
+
# feats (torch.FloatTensor or None): [B, N, C]
|
| 242 |
+
# sample_posterior (bool):
|
| 243 |
+
|
| 244 |
+
# Returns:
|
| 245 |
+
# latents (torch.FloatTensor)
|
| 246 |
+
# center_pos (torch.FloatTensor or None):
|
| 247 |
+
# posterior (DiagonalGaussianDistribution or None):
|
| 248 |
+
|
| 249 |
+
|
| 250 |
+
latents, center_pos = self.encoder(pc, feats)
|
| 251 |
+
|
| 252 |
+
posterior = None
|
| 253 |
+
if self.embed_dim > 0:
|
| 254 |
+
moments = self.pre_kl(latents)
|
| 255 |
+
posterior = DiagonalGaussianDistribution(moments, feat_dim=-1)
|
| 256 |
+
|
| 257 |
+
if sample_posterior:
|
| 258 |
+
latents = posterior.sample()
|
| 259 |
+
else:
|
| 260 |
+
latents = posterior.mode()
|
| 261 |
+
|
| 262 |
+
return latents, center_pos, posterior
|
| 263 |
+
|
| 264 |
+
def decode(self, latents: torch.FloatTensor):
|
| 265 |
+
latents = self.post_kl(latents)
|
| 266 |
+
return self.transformer(latents)
|
| 267 |
+
|
| 268 |
+
def query_geometry(self, queries: torch.FloatTensor, latents: torch.FloatTensor):
|
| 269 |
+
logits = self.geo_decoder(queries, latents).squeeze(-1)
|
| 270 |
+
return logits
|
| 271 |
+
|
| 272 |
+
def forward(self,
|
| 273 |
+
pc: torch.FloatTensor,
|
| 274 |
+
feats: torch.FloatTensor,
|
| 275 |
+
volume_queries: torch.FloatTensor,
|
| 276 |
+
sample_posterior: bool = True):
|
| 277 |
+
|
| 278 |
+
# Args:
|
| 279 |
+
# pc (torch.FloatTensor): [B, N, 3]
|
| 280 |
+
# feats (torch.FloatTensor or None): [B, N, C]
|
| 281 |
+
# volume_queries (torch.FloatTensor): [B, P, 3]
|
| 282 |
+
# sample_posterior (bool):
|
| 283 |
+
|
| 284 |
+
# Returns:
|
| 285 |
+
# logits (torch.FloatTensor): [B, P]
|
| 286 |
+
# center_pos (torch.FloatTensor): [B, M, 3]
|
| 287 |
+
# posterior (DiagonalGaussianDistribution or None).
|
| 288 |
+
|
| 289 |
+
|
| 290 |
+
|
| 291 |
+
latents, center_pos, posterior = self.encode(pc, feats, sample_posterior=sample_posterior)
|
| 292 |
+
|
| 293 |
+
latents = self.decode(latents)
|
| 294 |
+
logits = self.query_geometry(volume_queries, latents)
|
| 295 |
+
|
| 296 |
+
return logits, center_pos, posterior
|
| 297 |
+
|
| 298 |
+
|
| 299 |
+
class AlignedShapeLatentPerceiver(ShapeAsLatentPerceiver):
|
| 300 |
+
|
| 301 |
+
def __init__(self, *,
|
| 302 |
+
device: Optional[torch.device],
|
| 303 |
+
dtype: Optional[torch.dtype],
|
| 304 |
+
num_latents: int,
|
| 305 |
+
point_feats: int = 0,
|
| 306 |
+
embed_dim: int = 0,
|
| 307 |
+
num_freqs: int = 8,
|
| 308 |
+
include_pi: bool = True,
|
| 309 |
+
width: int,
|
| 310 |
+
heads: int,
|
| 311 |
+
num_encoder_layers: int,
|
| 312 |
+
num_decoder_layers: int,
|
| 313 |
+
init_scale: float = 0.25,
|
| 314 |
+
qkv_bias: bool = True,
|
| 315 |
+
flash: bool = False,
|
| 316 |
+
use_ln_post: bool = False,
|
| 317 |
+
use_checkpoint: bool = False):
|
| 318 |
+
|
| 319 |
+
super().__init__(
|
| 320 |
+
device=device,
|
| 321 |
+
dtype=dtype,
|
| 322 |
+
num_latents=1 + num_latents,
|
| 323 |
+
point_feats=point_feats,
|
| 324 |
+
embed_dim=embed_dim,
|
| 325 |
+
num_freqs=num_freqs,
|
| 326 |
+
include_pi=include_pi,
|
| 327 |
+
width=width,
|
| 328 |
+
heads=heads,
|
| 329 |
+
num_encoder_layers=num_encoder_layers,
|
| 330 |
+
num_decoder_layers=num_decoder_layers,
|
| 331 |
+
init_scale=init_scale,
|
| 332 |
+
qkv_bias=qkv_bias,
|
| 333 |
+
flash=flash,
|
| 334 |
+
use_ln_post=use_ln_post,
|
| 335 |
+
use_checkpoint=use_checkpoint
|
| 336 |
+
)
|
| 337 |
+
|
| 338 |
+
self.width = width
|
| 339 |
+
|
| 340 |
+
def encode(self,
|
| 341 |
+
pc: torch.FloatTensor,
|
| 342 |
+
feats: Optional[torch.FloatTensor] = None,
|
| 343 |
+
sample_posterior: bool = True):
|
| 344 |
+
|
| 345 |
+
# Args:
|
| 346 |
+
# pc (torch.FloatTensor): [B, N, 3]
|
| 347 |
+
# feats (torch.FloatTensor or None): [B, N, c]
|
| 348 |
+
# sample_posterior (bool):
|
| 349 |
+
|
| 350 |
+
# Returns:
|
| 351 |
+
# shape_embed (torch.FloatTensor)
|
| 352 |
+
# kl_embed (torch.FloatTensor):
|
| 353 |
+
# posterior (DiagonalGaussianDistribution or None):
|
| 354 |
+
|
| 355 |
+
|
| 356 |
+
shape_embed, latents = self.encode_latents(pc, feats)
|
| 357 |
+
kl_embed, posterior = self.encode_kl_embed(latents, sample_posterior)
|
| 358 |
+
|
| 359 |
+
return shape_embed, kl_embed, posterior
|
| 360 |
+
|
| 361 |
+
def encode_latents(self,
|
| 362 |
+
pc: torch.FloatTensor,
|
| 363 |
+
feats: Optional[torch.FloatTensor] = None):
|
| 364 |
+
|
| 365 |
+
x, _ = self.encoder(pc, feats)
|
| 366 |
+
|
| 367 |
+
shape_embed = x[:, 0]
|
| 368 |
+
latents = x[:, 1:]
|
| 369 |
+
|
| 370 |
+
return shape_embed, latents
|
| 371 |
+
|
| 372 |
+
def encode_kl_embed(self, latents: torch.FloatTensor, sample_posterior: bool = True):
|
| 373 |
+
posterior = None
|
| 374 |
+
if self.embed_dim > 0:
|
| 375 |
+
moments = self.pre_kl(latents)
|
| 376 |
+
posterior = DiagonalGaussianDistribution(moments, feat_dim=-1)
|
| 377 |
+
|
| 378 |
+
if sample_posterior:
|
| 379 |
+
kl_embed = posterior.sample()
|
| 380 |
+
else:
|
| 381 |
+
kl_embed = posterior.mode()
|
| 382 |
+
else:
|
| 383 |
+
kl_embed = latents
|
| 384 |
+
|
| 385 |
+
return kl_embed, posterior
|
| 386 |
+
|
| 387 |
+
def forward(self,
|
| 388 |
+
pc: torch.FloatTensor,
|
| 389 |
+
feats: torch.FloatTensor,
|
| 390 |
+
volume_queries: torch.FloatTensor,
|
| 391 |
+
sample_posterior: bool = True):
|
| 392 |
+
|
| 393 |
+
# Args:
|
| 394 |
+
# pc (torch.FloatTensor): [B, N, 3]
|
| 395 |
+
# feats (torch.FloatTensor or None): [B, N, C]
|
| 396 |
+
# volume_queries (torch.FloatTensor): [B, P, 3]
|
| 397 |
+
# sample_posterior (bool):
|
| 398 |
+
|
| 399 |
+
# Returns:
|
| 400 |
+
# shape_embed (torch.FloatTensor): [B, projection_dim]
|
| 401 |
+
# logits (torch.FloatTensor): [B, M]
|
| 402 |
+
# posterior (DiagonalGaussianDistribution or None).
|
| 403 |
+
|
| 404 |
+
|
| 405 |
+
shape_embed, kl_embed, posterior = self.encode(pc, feats, sample_posterior=sample_posterior)
|
| 406 |
+
|
| 407 |
+
latents = self.decode(kl_embed)
|
| 408 |
+
logits = self.query_geometry(volume_queries, latents)
|
| 409 |
+
|
| 410 |
+
return shape_embed, logits, posterior
|
miche/michelangelo/models/tsal/tsal_base.py
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
from typing import Tuple, List, Optional
|
| 5 |
+
|
| 6 |
+
# Base class for output of Point to Mesh transformation
|
| 7 |
+
class Point2MeshOutput(object):
|
| 8 |
+
def __init__(self):
|
| 9 |
+
self.mesh_v = None # Vertices of the mesh
|
| 10 |
+
self.mesh_f = None # Faces of the mesh
|
| 11 |
+
self.center = None # Center of the mesh
|
| 12 |
+
self.pc = None # Point cloud data
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
# Base class for output of Latent to Mesh transformation
|
| 16 |
+
class Latent2MeshOutput(object):
|
| 17 |
+
def __init__(self):
|
| 18 |
+
self.mesh_v = None # Vertices of the mesh
|
| 19 |
+
self.mesh_f = None # Faces of the mesh
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
# Base class for output of Aligned Mesh transformation
|
| 23 |
+
class AlignedMeshOutput(object):
|
| 24 |
+
def __init__(self):
|
| 25 |
+
self.mesh_v = None # Vertices of the mesh
|
| 26 |
+
self.mesh_f = None # Faces of the mesh
|
| 27 |
+
self.surface = None # Surface data
|
| 28 |
+
self.image = None # Aligned image data
|
| 29 |
+
self.text: Optional[str] = None # Aligned text data
|
| 30 |
+
self.shape_text_similarity: Optional[float] = None # Similarity between shape and text
|
| 31 |
+
self.shape_image_similarity: Optional[float] = None # Similarity between shape and image
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
# Base class for Shape as Latent with Point to Mesh transformation module
|
| 35 |
+
class ShapeAsLatentPLModule(nn.Module):
|
| 36 |
+
latent_shape: Tuple[int] # Shape of the latent space
|
| 37 |
+
|
| 38 |
+
def encode(self, surface, *args, **kwargs):
|
| 39 |
+
raise NotImplementedError
|
| 40 |
+
|
| 41 |
+
def decode(self, z_q, *args, **kwargs):
|
| 42 |
+
raise NotImplementedError
|
| 43 |
+
|
| 44 |
+
def latent2mesh(self, latents, *args, **kwargs) -> List[Latent2MeshOutput]:
|
| 45 |
+
raise NotImplementedError
|
| 46 |
+
|
| 47 |
+
def point2mesh(self, *args, **kwargs) -> List[Point2MeshOutput]:
|
| 48 |
+
raise NotImplementedError
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
# Base class for Shape as Latent module
|
| 52 |
+
class ShapeAsLatentModule(nn.Module):
|
| 53 |
+
latent_shape: Tuple[int, int] # Shape of the latent space
|
| 54 |
+
|
| 55 |
+
def __init__(self, *args, **kwargs):
|
| 56 |
+
super().__init__()
|
| 57 |
+
|
| 58 |
+
def encode(self, *args, **kwargs):
|
| 59 |
+
raise NotImplementedError
|
| 60 |
+
|
| 61 |
+
def decode(self, *args, **kwargs):
|
| 62 |
+
raise NotImplementedError
|
| 63 |
+
|
| 64 |
+
def query_geometry(self, *args, **kwargs):
|
| 65 |
+
raise NotImplementedError
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
# Base class for Aligned Shape as Latent with Point to Mesh transformation module
|
| 69 |
+
class AlignedShapeAsLatentPLModule(nn.Module):
|
| 70 |
+
latent_shape: Tuple[int] # Shape of the latent space
|
| 71 |
+
|
| 72 |
+
def set_shape_model_only(self):
|
| 73 |
+
raise NotImplementedError
|
| 74 |
+
|
| 75 |
+
def encode(self, surface, *args, **kwargs):
|
| 76 |
+
raise NotImplementedError
|
| 77 |
+
|
| 78 |
+
def decode(self, z_q, *args, **kwargs):
|
| 79 |
+
raise NotImplementedError
|
| 80 |
+
|
| 81 |
+
def latent2mesh(self, latents, *args, **kwargs) -> List[Latent2MeshOutput]:
|
| 82 |
+
raise NotImplementedError
|
| 83 |
+
|
| 84 |
+
def point2mesh(self, *args, **kwargs) -> List[Point2MeshOutput]:
|
| 85 |
+
raise NotImplementedError
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
# Base class for Aligned Shape as Latent module
|
| 89 |
+
class AlignedShapeAsLatentModule(nn.Module):
|
| 90 |
+
shape_model: ShapeAsLatentModule # Shape model module
|
| 91 |
+
latent_shape: Tuple[int, int] # Shape of the latent space
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def __init__(self, *args, **kwargs):
|
| 95 |
+
super().__init__()
|
| 96 |
+
|
| 97 |
+
def set_shape_model_only(self):
|
| 98 |
+
raise NotImplementedError
|
| 99 |
+
|
| 100 |
+
def encode_image_embed(self, *args, **kwargs):
|
| 101 |
+
raise NotImplementedError
|
| 102 |
+
|
| 103 |
+
def encode_text_embed(self, *args, **kwargs):
|
| 104 |
+
raise NotImplementedError
|
| 105 |
+
|
| 106 |
+
def encode_shape_embed(self, *args, **kwargs):
|
| 107 |
+
raise NotImplementedError
|
| 108 |
+
|
| 109 |
+
# Base class for Textured Shape as Latent module
|
| 110 |
+
class TexturedShapeAsLatentModule(nn.Module):
|
| 111 |
+
|
| 112 |
+
def __init__(self, *args, **kwargs):
|
| 113 |
+
super().__init__()
|
| 114 |
+
|
| 115 |
+
def encode(self, *args, **kwargs):
|
| 116 |
+
raise NotImplementedError
|
| 117 |
+
|
| 118 |
+
def decode(self, *args, **kwargs):
|
| 119 |
+
raise NotImplementedError
|
| 120 |
+
|
| 121 |
+
def query_geometry(self, *args, **kwargs):
|
| 122 |
+
raise NotImplementedError
|
| 123 |
+
|
| 124 |
+
def query_color(self, *args, **kwargs):
|
| 125 |
+
raise NotImplementedError
|
miche/michelangelo/utils/__init__.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
from .misc import instantiate_from_config
|
miche/michelangelo/utils/misc.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
import importlib
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
import torch.distributed as dist
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def get_obj_from_str(string, reload=False):
|
| 11 |
+
module, cls = string.rsplit(".", 1)
|
| 12 |
+
if reload:
|
| 13 |
+
module_imp = importlib.import_module(module)
|
| 14 |
+
importlib.reload(module_imp)
|
| 15 |
+
return getattr(importlib.import_module(module, package=None), cls)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def get_obj_from_config(config):
|
| 19 |
+
if "target" not in config:
|
| 20 |
+
raise KeyError("Expected key `target` to instantiate.")
|
| 21 |
+
|
| 22 |
+
return get_obj_from_str(config["target"])
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def instantiate_from_config(config, **kwargs):
|
| 26 |
+
if "target" not in config:
|
| 27 |
+
raise KeyError("Expected key `target` to instantiate.")
|
| 28 |
+
|
| 29 |
+
cls = get_obj_from_str(config["target"])
|
| 30 |
+
|
| 31 |
+
params = config.get("params", dict())
|
| 32 |
+
# params.update(kwargs)
|
| 33 |
+
# instance = cls(**params)
|
| 34 |
+
kwargs.update(params)
|
| 35 |
+
instance = cls(**kwargs)
|
| 36 |
+
|
| 37 |
+
return instance
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def is_dist_avail_and_initialized():
|
| 41 |
+
if not dist.is_available():
|
| 42 |
+
return False
|
| 43 |
+
if not dist.is_initialized():
|
| 44 |
+
return False
|
| 45 |
+
return True
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def get_rank():
|
| 49 |
+
if not is_dist_avail_and_initialized():
|
| 50 |
+
return 0
|
| 51 |
+
return dist.get_rank()
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def get_world_size():
|
| 55 |
+
if not is_dist_avail_and_initialized():
|
| 56 |
+
return 1
|
| 57 |
+
return dist.get_world_size()
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def all_gather_batch(tensors):
|
| 61 |
+
"""
|
| 62 |
+
Performs all_gather operation on the provided tensors.
|
| 63 |
+
"""
|
| 64 |
+
# Queue the gathered tensors
|
| 65 |
+
world_size = get_world_size()
|
| 66 |
+
# There is no need for reduction in the single-proc case
|
| 67 |
+
if world_size == 1:
|
| 68 |
+
return tensors
|
| 69 |
+
tensor_list = []
|
| 70 |
+
output_tensor = []
|
| 71 |
+
for tensor in tensors:
|
| 72 |
+
tensor_all = [torch.ones_like(tensor) for _ in range(world_size)]
|
| 73 |
+
dist.all_gather(
|
| 74 |
+
tensor_all,
|
| 75 |
+
tensor,
|
| 76 |
+
async_op=False # performance opt
|
| 77 |
+
)
|
| 78 |
+
|
| 79 |
+
tensor_list.append(tensor_all)
|
| 80 |
+
|
| 81 |
+
for tensor_all in tensor_list:
|
| 82 |
+
output_tensor.append(torch.cat(tensor_all, dim=0))
|
| 83 |
+
return output_tensor
|
miche/shapevae-256.yaml
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
target: miche.michelangelo.models.tsal.asl_pl_module.AlignedShapeAsLatentPLModule
|
| 3 |
+
params:
|
| 4 |
+
shape_module_cfg:
|
| 5 |
+
target: miche.michelangelo.models.tsal.sal_perceiver.AlignedShapeLatentPerceiver
|
| 6 |
+
params:
|
| 7 |
+
num_latents: 256
|
| 8 |
+
embed_dim: 64
|
| 9 |
+
point_feats: 3 # normal
|
| 10 |
+
num_freqs: 8
|
| 11 |
+
include_pi: false
|
| 12 |
+
heads: 12
|
| 13 |
+
width: 768
|
| 14 |
+
num_encoder_layers: 8
|
| 15 |
+
num_decoder_layers: 16
|
| 16 |
+
use_ln_post: true
|
| 17 |
+
init_scale: 0.25
|
| 18 |
+
qkv_bias: false
|
| 19 |
+
use_checkpoint: true
|
| 20 |
+
aligned_module_cfg:
|
| 21 |
+
target: miche.michelangelo.models.tsal.clip_asl_module.CLIPAlignedShapeAsLatentModule
|
| 22 |
+
params:
|
| 23 |
+
clip_model_version: "./checkpoints/clip/clip-vit-large-patch14"
|
| 24 |
+
|
| 25 |
+
loss_cfg:
|
| 26 |
+
target: miche.michelangelo.models.tsal.loss.ContrastKLNearFar
|
| 27 |
+
params:
|
| 28 |
+
contrast_weight: 0.1
|
| 29 |
+
near_weight: 0.1
|
| 30 |
+
kl_weight: 0.001
|
| 31 |
+
|
| 32 |
+
optimizer_cfg:
|
| 33 |
+
optimizer:
|
| 34 |
+
target: torch.optim.AdamW
|
| 35 |
+
params:
|
| 36 |
+
betas: [0.9, 0.99]
|
| 37 |
+
eps: 1.e-6
|
| 38 |
+
weight_decay: 1.e-2
|
| 39 |
+
|
| 40 |
+
scheduler:
|
| 41 |
+
target: miche.michelangelo.utils.trainings.lr_scheduler.LambdaWarmUpCosineFactorScheduler
|
| 42 |
+
params:
|
| 43 |
+
warm_up_steps: 5000
|
| 44 |
+
f_start: 1.e-6
|
| 45 |
+
f_min: 1.e-3
|
| 46 |
+
f_max: 1.0
|
model/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
model/__init__.py
ADDED
|
File without changes
|
model/data_utils.py
ADDED
|
@@ -0,0 +1,194 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Mesh data utilities."""
|
| 2 |
+
import random
|
| 3 |
+
import networkx as nx
|
| 4 |
+
import numpy as np
|
| 5 |
+
# import pyrr
|
| 6 |
+
from six.moves import range
|
| 7 |
+
import trimesh
|
| 8 |
+
from scipy.spatial.transform import Rotation
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def to_mesh(vertices, faces, transpose=True, post_process=False):
|
| 12 |
+
if transpose:
|
| 13 |
+
vertices = vertices[:, [1, 2, 0]]
|
| 14 |
+
|
| 15 |
+
if faces.min() == 1:
|
| 16 |
+
faces = (np.array(faces) - 1).tolist()
|
| 17 |
+
mesh = trimesh.Trimesh(vertices=vertices, faces=faces, process=False)
|
| 18 |
+
|
| 19 |
+
if post_process:
|
| 20 |
+
mesh.merge_vertices()
|
| 21 |
+
mesh.update_faces(mesh.unique_faces())
|
| 22 |
+
mesh.fix_normals()
|
| 23 |
+
return mesh
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def center_vertices(vertices):
|
| 27 |
+
"""Translate the vertices so that bounding box is centered at zero."""
|
| 28 |
+
vert_min = vertices.min(axis=0)
|
| 29 |
+
vert_max = vertices.max(axis=0)
|
| 30 |
+
vert_center = 0.5 * (vert_min + vert_max)
|
| 31 |
+
# vert_center = np.mean(vertices, axis=0)
|
| 32 |
+
return vertices - vert_center
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def face_to_cycles(face):
|
| 36 |
+
"""Find cycles in face."""
|
| 37 |
+
g = nx.Graph()
|
| 38 |
+
for v in range(len(face) - 1):
|
| 39 |
+
g.add_edge(face[v], face[v + 1])
|
| 40 |
+
g.add_edge(face[-1], face[0])
|
| 41 |
+
return list(nx.cycle_basis(g))
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def block_index(vertex, block_size=32):
|
| 45 |
+
return (vertex[2] // block_size, vertex[1] // block_size, vertex[0] // block_size)
|
| 46 |
+
|
| 47 |
+
def block_id(block_index, num_blocks=4):
|
| 48 |
+
return block_index[0] * num_blocks**2 + block_index[1] * num_blocks + block_index[2]
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def normalize_vertices_scale(vertices, scale=0.95):
|
| 52 |
+
"""Scale the vertices so that the long axis of the bounding box is one."""
|
| 53 |
+
vert_min = vertices.min(axis=0)
|
| 54 |
+
vert_max = vertices.max(axis=0)
|
| 55 |
+
extents = (vert_max - vert_min).max()
|
| 56 |
+
return 2.0 * scale * vertices / (extents + 1e-6)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
def quantize_process_mesh(vertices, faces, quantization_bits=8, block_first_order=True, block_size=32, num_blocks=4):
|
| 60 |
+
"""Quantize vertices, remove resulting duplicates and reindex faces."""
|
| 61 |
+
vertices = discretize(vertices, num_discrete=2**quantization_bits)
|
| 62 |
+
vertices, inv = np.unique(vertices, axis=0, return_inverse=True)
|
| 63 |
+
|
| 64 |
+
if block_first_order:
|
| 65 |
+
block_indices = np.array([block_index(v, block_size) for v in vertices])
|
| 66 |
+
block_ids = np.array([block_id(b, num_blocks) for b in block_indices])
|
| 67 |
+
sort_inds = np.lexsort((vertices[:, 0], vertices[:, 1], vertices[:, 2], block_ids))
|
| 68 |
+
else:
|
| 69 |
+
# Sort vertices by z then y then x.
|
| 70 |
+
sort_inds = np.lexsort(vertices.T)
|
| 71 |
+
|
| 72 |
+
vertices = vertices[sort_inds]
|
| 73 |
+
faces = [np.argsort(sort_inds)[inv[f]] for f in faces]
|
| 74 |
+
|
| 75 |
+
sub_faces = []
|
| 76 |
+
for f in faces:
|
| 77 |
+
cliques = face_to_cycles(f)
|
| 78 |
+
for c in cliques:
|
| 79 |
+
c_length = len(c)
|
| 80 |
+
if c_length > 2:
|
| 81 |
+
d = np.argmin(f)
|
| 82 |
+
sub_faces.append([f[(d + i) % c_length] for i in range(c_length)])
|
| 83 |
+
|
| 84 |
+
faces = sub_faces
|
| 85 |
+
|
| 86 |
+
# Sort faces by lowest vertex indices. If two faces have the same lowest
|
| 87 |
+
# index then sort by next lowest and so on.
|
| 88 |
+
faces.sort(key=lambda f: tuple(sorted(f)))
|
| 89 |
+
num_verts = vertices.shape[0]
|
| 90 |
+
vert_connected = np.equal(
|
| 91 |
+
np.arange(num_verts)[:, None], np.hstack(faces)[None]
|
| 92 |
+
).any(axis=-1)
|
| 93 |
+
vertices = vertices[vert_connected]
|
| 94 |
+
|
| 95 |
+
# Re-index faces to re-ordered vertices.
|
| 96 |
+
vert_indices = np.arange(num_verts) - np.cumsum(1 - vert_connected.astype("int"))
|
| 97 |
+
faces = [vert_indices[f].tolist() for f in faces]
|
| 98 |
+
|
| 99 |
+
return vertices, faces
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def process_mesh(vertices, faces, quantization_bits=8, augment=True, augment_dict=None):
|
| 103 |
+
"""Process mesh vertices and faces."""
|
| 104 |
+
|
| 105 |
+
# Transpose so that z-axis is vertical.
|
| 106 |
+
vertices = vertices[:, [2, 0, 1]]
|
| 107 |
+
|
| 108 |
+
# Translate the vertices so that bounding box is centered at zero.
|
| 109 |
+
vertices = center_vertices(vertices)
|
| 110 |
+
|
| 111 |
+
if augment:
|
| 112 |
+
vertices = augment_mesh(vertices, **augment_dict)
|
| 113 |
+
|
| 114 |
+
# Scale the vertices so that the long diagonal of the bounding box is equal
|
| 115 |
+
# to one.
|
| 116 |
+
vertices = normalize_vertices_scale(vertices)
|
| 117 |
+
|
| 118 |
+
# Quantize and sort vertices, remove resulting duplicates, sort and reindex
|
| 119 |
+
# faces.
|
| 120 |
+
vertices, faces = quantize_process_mesh(
|
| 121 |
+
vertices, faces, quantization_bits=quantization_bits
|
| 122 |
+
)
|
| 123 |
+
vertices = undiscretize(vertices, num_discrete=2**quantization_bits)
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
# Discard degenerate meshes without faces.
|
| 127 |
+
return {
|
| 128 |
+
"vertices": vertices,
|
| 129 |
+
"faces": faces,
|
| 130 |
+
}
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
def load_process_mesh(mesh_obj_path, quantization_bits=8, augment=False, augment_dict=None):
|
| 134 |
+
"""Load obj file and process."""
|
| 135 |
+
# Load mesh
|
| 136 |
+
mesh = trimesh.load(mesh_obj_path, force='mesh', process=False)
|
| 137 |
+
return process_mesh(mesh.vertices, mesh.faces, quantization_bits, augment=augment, augment_dict=augment_dict)
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
def augment_mesh(vertices, scale_min=0.95, scale_max=1.05, rotation=0., jitter_strength=0.):
|
| 141 |
+
'''scale vertices by a factor in [0.75, 1.25]'''
|
| 142 |
+
|
| 143 |
+
# vertices [nv, 3]
|
| 144 |
+
for i in range(3):
|
| 145 |
+
# Generate a random scale factor
|
| 146 |
+
scale = random.uniform(scale_min, scale_max)
|
| 147 |
+
|
| 148 |
+
# independently applied scaling across each axis of vertices
|
| 149 |
+
vertices[:, i] *= scale
|
| 150 |
+
|
| 151 |
+
if rotation != 0.:
|
| 152 |
+
axis = [random.uniform(-1, 1), random.uniform(-1, 1), random.uniform(-1, 1)]
|
| 153 |
+
radian = np.pi / 180 * rotation
|
| 154 |
+
rotation = Rotation.from_rotvec(radian * np.array(axis))
|
| 155 |
+
vertices =rotation.apply(vertices)
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
if jitter_strength != 0.:
|
| 159 |
+
jitter_amount = np.random.uniform(-jitter_strength, jitter_strength)
|
| 160 |
+
vertices += jitter_amount
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
return vertices
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
def discretize(
|
| 167 |
+
t,
|
| 168 |
+
continuous_range = (-1, 1),
|
| 169 |
+
num_discrete: int = 128
|
| 170 |
+
):
|
| 171 |
+
lo, hi = continuous_range
|
| 172 |
+
assert hi > lo
|
| 173 |
+
|
| 174 |
+
t = (t - lo) / (hi - lo)
|
| 175 |
+
t *= num_discrete
|
| 176 |
+
t -= 0.5
|
| 177 |
+
|
| 178 |
+
return t.round().astype(np.int32).clip(min = 0, max = num_discrete - 1)
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
def undiscretize(
|
| 182 |
+
t,
|
| 183 |
+
continuous_range = (-1, 1),
|
| 184 |
+
num_discrete: int = 128
|
| 185 |
+
):
|
| 186 |
+
lo, hi = continuous_range
|
| 187 |
+
assert hi > lo
|
| 188 |
+
|
| 189 |
+
t = t.astype(np.float32)
|
| 190 |
+
|
| 191 |
+
t += 0.5
|
| 192 |
+
t /= num_discrete
|
| 193 |
+
return t * (hi - lo) + lo
|
| 194 |
+
|
model/miche_conditioner.py
ADDED
|
@@ -0,0 +1,86 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch import nn
|
| 3 |
+
from beartype import beartype
|
| 4 |
+
from miche.encode import load_model
|
| 5 |
+
|
| 6 |
+
# helper functions
|
| 7 |
+
|
| 8 |
+
def exists(val):
|
| 9 |
+
return val is not None
|
| 10 |
+
|
| 11 |
+
def default(*values):
|
| 12 |
+
for value in values:
|
| 13 |
+
if exists(value):
|
| 14 |
+
return value
|
| 15 |
+
return None
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
# point-cloud encoder from Michelangelo
|
| 19 |
+
@beartype
|
| 20 |
+
class PointConditioner(torch.nn.Module):
|
| 21 |
+
def __init__(
|
| 22 |
+
self,
|
| 23 |
+
*,
|
| 24 |
+
dim_latent = None,
|
| 25 |
+
model_name = 'miche-256-feature',
|
| 26 |
+
cond_dim = 768,
|
| 27 |
+
freeze = True,
|
| 28 |
+
):
|
| 29 |
+
super().__init__()
|
| 30 |
+
|
| 31 |
+
# open-source version of miche
|
| 32 |
+
if model_name == 'miche-256-feature':
|
| 33 |
+
ckpt_path = None
|
| 34 |
+
config_path = 'miche/shapevae-256.yaml'
|
| 35 |
+
|
| 36 |
+
self.feature_dim = 1024 # embedding dimension
|
| 37 |
+
self.cond_length = 257 # length of embedding
|
| 38 |
+
self.point_encoder = load_model(ckpt_path=ckpt_path, config_path=config_path)
|
| 39 |
+
|
| 40 |
+
# additional layers to connect miche and GPT
|
| 41 |
+
self.cond_head_proj = nn.Linear(cond_dim, self.feature_dim)
|
| 42 |
+
self.cond_proj = nn.Linear(cond_dim, self.feature_dim)
|
| 43 |
+
|
| 44 |
+
else:
|
| 45 |
+
raise NotImplementedError
|
| 46 |
+
|
| 47 |
+
# whether to finetuen point-cloud encoder
|
| 48 |
+
if freeze:
|
| 49 |
+
for parameter in self.point_encoder.parameters():
|
| 50 |
+
parameter.requires_grad = False
|
| 51 |
+
|
| 52 |
+
self.freeze = freeze
|
| 53 |
+
self.model_name = model_name
|
| 54 |
+
self.dim_latent = default(dim_latent, self.feature_dim)
|
| 55 |
+
|
| 56 |
+
self.register_buffer('_device_param', torch.tensor(0.), persistent = False)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
@property
|
| 60 |
+
def device(self):
|
| 61 |
+
return next(self.buffers()).device
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def embed_pc(self, pc_normal):
|
| 65 |
+
# encode point cloud to embeddings
|
| 66 |
+
if self.model_name == 'miche-256-feature':
|
| 67 |
+
point_feature = self.point_encoder.encode_latents(pc_normal)
|
| 68 |
+
pc_embed_head = self.cond_head_proj(point_feature[:, 0:1])
|
| 69 |
+
pc_embed = self.cond_proj(point_feature[:, 1:])
|
| 70 |
+
pc_embed = torch.cat([pc_embed_head, pc_embed], dim=1)
|
| 71 |
+
|
| 72 |
+
return pc_embed
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def forward(
|
| 76 |
+
self,
|
| 77 |
+
pc = None,
|
| 78 |
+
pc_embeds = None,
|
| 79 |
+
):
|
| 80 |
+
if pc_embeds is None:
|
| 81 |
+
pc_embeds = self.embed_pc(pc.to(next(self.buffers()).dtype))
|
| 82 |
+
|
| 83 |
+
assert not torch.any(torch.isnan(pc_embeds)), 'NAN values in pc embedings'
|
| 84 |
+
|
| 85 |
+
return pc_embeds
|
| 86 |
+
|
model/model.py
ADDED
|
@@ -0,0 +1,379 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch import nn, Tensor
|
| 3 |
+
from torch.nn import Module
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
from einops import rearrange, repeat, pack
|
| 6 |
+
from pytorch_custom_utils import save_load
|
| 7 |
+
from beartype import beartype
|
| 8 |
+
from beartype.typing import Union, Tuple, Callable, Optional, Any
|
| 9 |
+
from einops import rearrange, repeat, pack
|
| 10 |
+
from x_transformers import Decoder
|
| 11 |
+
from x_transformers.x_transformers import LayerIntermediates
|
| 12 |
+
from x_transformers.autoregressive_wrapper import (
|
| 13 |
+
eval_decorator,
|
| 14 |
+
top_k,
|
| 15 |
+
)
|
| 16 |
+
from .miche_conditioner import PointConditioner
|
| 17 |
+
from functools import partial
|
| 18 |
+
from tqdm import tqdm
|
| 19 |
+
from .data_utils import discretize
|
| 20 |
+
|
| 21 |
+
# helper functions
|
| 22 |
+
|
| 23 |
+
def exists(v):
|
| 24 |
+
return v is not None
|
| 25 |
+
|
| 26 |
+
def default(v, d):
|
| 27 |
+
return v if exists(v) else d
|
| 28 |
+
|
| 29 |
+
def first(it):
|
| 30 |
+
return it[0]
|
| 31 |
+
|
| 32 |
+
def divisible_by(num, den):
|
| 33 |
+
return (num % den) == 0
|
| 34 |
+
|
| 35 |
+
def pad_at_dim(t, padding, dim = -1, value = 0):
|
| 36 |
+
ndim = t.ndim
|
| 37 |
+
right_dims = (ndim - dim - 1) if dim >= 0 else (-dim - 1)
|
| 38 |
+
zeros = (0, 0) * right_dims
|
| 39 |
+
return F.pad(t, (*zeros, *padding), value = value)
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
# main class of auto-regressive Transformer
|
| 43 |
+
@save_load()
|
| 44 |
+
class MeshTransformer(Module):
|
| 45 |
+
@beartype
|
| 46 |
+
def __init__(
|
| 47 |
+
self,
|
| 48 |
+
*,
|
| 49 |
+
dim: Union[int, Tuple[int, int]] = 512, # hidden size of Transformer
|
| 50 |
+
max_seq_len = 9600, # max sequence length
|
| 51 |
+
flash_attn = True, # wether to use flash attention
|
| 52 |
+
attn_depth = 12, # number of layers
|
| 53 |
+
attn_dim_head = 64, # dim for each head
|
| 54 |
+
attn_heads = 16, # number of heads
|
| 55 |
+
attn_kwargs: dict = dict(
|
| 56 |
+
ff_glu = True,
|
| 57 |
+
num_mem_kv = 4,
|
| 58 |
+
attn_qk_norm = True,
|
| 59 |
+
),
|
| 60 |
+
dropout = 0.,
|
| 61 |
+
pad_id = -1,
|
| 62 |
+
coor_continuous_range = (-1., 1.),
|
| 63 |
+
num_discrete_coors = 128,
|
| 64 |
+
block_size = 8,
|
| 65 |
+
offset_size = 16,
|
| 66 |
+
mode = 'vertices',
|
| 67 |
+
special_token = -2,
|
| 68 |
+
use_special_block = False,
|
| 69 |
+
conditioned_on_pc = False,
|
| 70 |
+
encoder_name = 'miche-256-feature',
|
| 71 |
+
encoder_freeze = True,
|
| 72 |
+
):
|
| 73 |
+
super().__init__()
|
| 74 |
+
|
| 75 |
+
if use_special_block:
|
| 76 |
+
# block_ids, offset_ids, special_block_ids
|
| 77 |
+
vocab_size = block_size**3 + offset_size**3 + block_size**3
|
| 78 |
+
self.sp_block_embed = nn.Parameter(torch.randn(1, dim))
|
| 79 |
+
else:
|
| 80 |
+
# block_ids, offset_ids, special_token
|
| 81 |
+
vocab_size = block_size**3 + offset_size**3 + 1
|
| 82 |
+
self.special_token = special_token
|
| 83 |
+
self.special_token_cb = block_size**3 + offset_size**3
|
| 84 |
+
|
| 85 |
+
self.use_special_block = use_special_block
|
| 86 |
+
|
| 87 |
+
self.sos_token = nn.Parameter(torch.randn(dim))
|
| 88 |
+
self.eos_token_id = vocab_size
|
| 89 |
+
self.mode = mode
|
| 90 |
+
self.token_embed = nn.Embedding(vocab_size + 1, dim)
|
| 91 |
+
self.num_discrete_coors = num_discrete_coors
|
| 92 |
+
self.coor_continuous_range = coor_continuous_range
|
| 93 |
+
self.block_size = block_size
|
| 94 |
+
self.offset_size = offset_size
|
| 95 |
+
self.abs_pos_emb = nn.Embedding(max_seq_len, dim)
|
| 96 |
+
self.max_seq_len = max_seq_len
|
| 97 |
+
self.conditioner = None
|
| 98 |
+
self.conditioned_on_pc = conditioned_on_pc
|
| 99 |
+
cross_attn_dim_context = None
|
| 100 |
+
|
| 101 |
+
self.block_embed = nn.Parameter(torch.randn(1, dim))
|
| 102 |
+
self.offset_embed = nn.Parameter(torch.randn(1, dim))
|
| 103 |
+
|
| 104 |
+
assert self.block_size * self.offset_size == self.num_discrete_coors
|
| 105 |
+
|
| 106 |
+
# load point_cloud encoder
|
| 107 |
+
if conditioned_on_pc:
|
| 108 |
+
print(f'Point cloud encoder: {encoder_name} | freeze: {encoder_freeze}')
|
| 109 |
+
self.conditioner = PointConditioner(model_name=encoder_name, freeze=encoder_freeze)
|
| 110 |
+
cross_attn_dim_context = self.conditioner.dim_latent
|
| 111 |
+
else:
|
| 112 |
+
raise NotImplementedError
|
| 113 |
+
|
| 114 |
+
# main autoregressive attention network
|
| 115 |
+
self.decoder = Decoder(
|
| 116 |
+
dim = dim,
|
| 117 |
+
depth = attn_depth,
|
| 118 |
+
dim_head = attn_dim_head,
|
| 119 |
+
heads = attn_heads,
|
| 120 |
+
attn_flash = flash_attn,
|
| 121 |
+
attn_dropout = dropout,
|
| 122 |
+
ff_dropout = dropout,
|
| 123 |
+
cross_attend = conditioned_on_pc,
|
| 124 |
+
cross_attn_dim_context = cross_attn_dim_context,
|
| 125 |
+
cross_attn_num_mem_kv = 4, # needed for preventing nan when dropping out text condition
|
| 126 |
+
**attn_kwargs
|
| 127 |
+
)
|
| 128 |
+
|
| 129 |
+
self.to_logits = nn.Linear(dim, vocab_size + 1)
|
| 130 |
+
self.pad_id = pad_id
|
| 131 |
+
self.discretize_face_coords = partial(
|
| 132 |
+
discretize,
|
| 133 |
+
num_discrete = num_discrete_coors,
|
| 134 |
+
continuous_range = coor_continuous_range
|
| 135 |
+
)
|
| 136 |
+
|
| 137 |
+
@property
|
| 138 |
+
def device(self):
|
| 139 |
+
return next(self.parameters()).device
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
@eval_decorator
|
| 143 |
+
@torch.no_grad()
|
| 144 |
+
@beartype
|
| 145 |
+
def generate(
|
| 146 |
+
self,
|
| 147 |
+
prompt: Optional[Tensor] = None,
|
| 148 |
+
pc: Optional[Tensor] = None,
|
| 149 |
+
cond_embeds: Optional[Tensor] = None,
|
| 150 |
+
batch_size: Optional[int] = None,
|
| 151 |
+
filter_logits_fn: Callable = top_k,
|
| 152 |
+
filter_kwargs: dict = dict(),
|
| 153 |
+
temperature = 1.,
|
| 154 |
+
return_codes = False,
|
| 155 |
+
cache_kv = True,
|
| 156 |
+
max_seq_len = None,
|
| 157 |
+
face_coords_to_file: Optional[Callable[[Tensor], Any]] = None,
|
| 158 |
+
tqdm_position = 0,
|
| 159 |
+
):
|
| 160 |
+
max_seq_len = default(max_seq_len, self.max_seq_len)
|
| 161 |
+
|
| 162 |
+
if exists(prompt):
|
| 163 |
+
assert not exists(batch_size)
|
| 164 |
+
|
| 165 |
+
prompt = rearrange(prompt, 'b ... -> b (...)')
|
| 166 |
+
assert prompt.shape[-1] <= self.max_seq_len
|
| 167 |
+
|
| 168 |
+
batch_size = prompt.shape[0]
|
| 169 |
+
|
| 170 |
+
# encode point cloud
|
| 171 |
+
if cond_embeds is None:
|
| 172 |
+
if self.conditioned_on_pc:
|
| 173 |
+
cond_embeds = self.conditioner(pc = pc)
|
| 174 |
+
|
| 175 |
+
batch_size = default(batch_size, 1)
|
| 176 |
+
|
| 177 |
+
codes = default(prompt, torch.empty((batch_size, 0), dtype = torch.long, device = self.device))
|
| 178 |
+
|
| 179 |
+
curr_length = codes.shape[-1]
|
| 180 |
+
|
| 181 |
+
cache = None
|
| 182 |
+
|
| 183 |
+
# predict tokens auto-regressively
|
| 184 |
+
for i in tqdm(range(curr_length, max_seq_len), position=tqdm_position,
|
| 185 |
+
desc=f'Process: {tqdm_position}', dynamic_ncols=True, leave=False):
|
| 186 |
+
|
| 187 |
+
output = self.forward_on_codes(
|
| 188 |
+
codes,
|
| 189 |
+
return_loss = False,
|
| 190 |
+
return_cache = cache_kv,
|
| 191 |
+
append_eos = False,
|
| 192 |
+
cond_embeds = cond_embeds,
|
| 193 |
+
cache = cache
|
| 194 |
+
)
|
| 195 |
+
|
| 196 |
+
if cache_kv:
|
| 197 |
+
logits, cache = output
|
| 198 |
+
|
| 199 |
+
else:
|
| 200 |
+
logits = output
|
| 201 |
+
|
| 202 |
+
# sample code from logits
|
| 203 |
+
logits = logits[:, -1]
|
| 204 |
+
filtered_logits = filter_logits_fn(logits, **filter_kwargs)
|
| 205 |
+
probs = F.softmax(filtered_logits / temperature, dim = -1)
|
| 206 |
+
sample = torch.multinomial(probs, 1)
|
| 207 |
+
codes, _ = pack([codes, sample], 'b *')
|
| 208 |
+
|
| 209 |
+
# check for all rows to have [eos] to terminate
|
| 210 |
+
|
| 211 |
+
is_eos_codes = (codes == self.eos_token_id)
|
| 212 |
+
|
| 213 |
+
if is_eos_codes.any(dim = -1).all():
|
| 214 |
+
break
|
| 215 |
+
|
| 216 |
+
# mask out to padding anything after the first eos
|
| 217 |
+
|
| 218 |
+
mask = is_eos_codes.float().cumsum(dim = -1) >= 1
|
| 219 |
+
codes = codes.masked_fill(mask, self.pad_id)
|
| 220 |
+
|
| 221 |
+
# early return of raw residual quantizer codes
|
| 222 |
+
|
| 223 |
+
if return_codes:
|
| 224 |
+
# codes = rearrange(codes, 'b (n q) -> b n q', q = 2)
|
| 225 |
+
if not self.use_special_block:
|
| 226 |
+
codes[codes == self.special_token_cb] = self.special_token
|
| 227 |
+
return codes
|
| 228 |
+
|
| 229 |
+
face_coords, face_mask = self.decode_codes(codes)
|
| 230 |
+
|
| 231 |
+
if not exists(face_coords_to_file):
|
| 232 |
+
return face_coords, face_mask
|
| 233 |
+
|
| 234 |
+
files = [face_coords_to_file(coords[mask]) for coords, mask in zip(face_coords, face_mask)]
|
| 235 |
+
return files
|
| 236 |
+
|
| 237 |
+
|
| 238 |
+
def forward(
|
| 239 |
+
self,
|
| 240 |
+
*,
|
| 241 |
+
codes: Optional[Tensor] = None,
|
| 242 |
+
cache: Optional[LayerIntermediates] = None,
|
| 243 |
+
**kwargs
|
| 244 |
+
):
|
| 245 |
+
# convert special tokens
|
| 246 |
+
if not self.use_special_block:
|
| 247 |
+
codes[codes == self.special_token] = self.special_token_cb
|
| 248 |
+
|
| 249 |
+
return self.forward_on_codes(codes, cache = cache, **kwargs)
|
| 250 |
+
|
| 251 |
+
|
| 252 |
+
def forward_on_codes(
|
| 253 |
+
self,
|
| 254 |
+
codes = None,
|
| 255 |
+
return_loss = True,
|
| 256 |
+
return_cache = False,
|
| 257 |
+
append_eos = True,
|
| 258 |
+
cache = None,
|
| 259 |
+
pc = None,
|
| 260 |
+
cond_embeds = None,
|
| 261 |
+
):
|
| 262 |
+
# handle conditions
|
| 263 |
+
|
| 264 |
+
attn_context_kwargs = dict()
|
| 265 |
+
|
| 266 |
+
if self.conditioned_on_pc:
|
| 267 |
+
assert exists(pc) ^ exists(cond_embeds), 'point cloud should be given'
|
| 268 |
+
|
| 269 |
+
# preprocess faces and vertices
|
| 270 |
+
if not exists(cond_embeds):
|
| 271 |
+
cond_embeds = self.conditioner(
|
| 272 |
+
pc = pc,
|
| 273 |
+
pc_embeds = cond_embeds,
|
| 274 |
+
)
|
| 275 |
+
|
| 276 |
+
attn_context_kwargs = dict(
|
| 277 |
+
context = cond_embeds,
|
| 278 |
+
context_mask = None,
|
| 279 |
+
)
|
| 280 |
+
|
| 281 |
+
# take care of codes that may be flattened
|
| 282 |
+
|
| 283 |
+
if codes.ndim > 2:
|
| 284 |
+
codes = rearrange(codes, 'b ... -> b (...)')
|
| 285 |
+
|
| 286 |
+
# prepare mask for position embedding of block and offset tokens
|
| 287 |
+
block_mask = (0 <= codes) & (codes < self.block_size**3)
|
| 288 |
+
offset_mask = (self.block_size**3 <= codes) & (codes < self.block_size**3 + self.offset_size**3)
|
| 289 |
+
if self.use_special_block:
|
| 290 |
+
sp_block_mask = (
|
| 291 |
+
self.block_size**3 + self.offset_size**3 <= codes
|
| 292 |
+
) & (
|
| 293 |
+
codes < self.block_size**3 + self.offset_size**3 + self.block_size**3
|
| 294 |
+
)
|
| 295 |
+
|
| 296 |
+
|
| 297 |
+
# get some variable
|
| 298 |
+
|
| 299 |
+
batch, seq_len, device = *codes.shape, codes.device
|
| 300 |
+
|
| 301 |
+
assert seq_len <= self.max_seq_len, \
|
| 302 |
+
f'received codes of length {seq_len} but needs to be less than {self.max_seq_len}'
|
| 303 |
+
|
| 304 |
+
# auto append eos token
|
| 305 |
+
|
| 306 |
+
if append_eos:
|
| 307 |
+
assert exists(codes)
|
| 308 |
+
|
| 309 |
+
code_lens = ((codes == self.pad_id).cumsum(dim = -1) == 0).sum(dim = -1)
|
| 310 |
+
|
| 311 |
+
codes = F.pad(codes, (0, 1), value = 0) # value=-1
|
| 312 |
+
|
| 313 |
+
batch_arange = torch.arange(batch, device = device)
|
| 314 |
+
|
| 315 |
+
batch_arange = rearrange(batch_arange, '... -> ... 1')
|
| 316 |
+
code_lens = rearrange(code_lens, '... -> ... 1')
|
| 317 |
+
|
| 318 |
+
codes[batch_arange, code_lens] = self.eos_token_id
|
| 319 |
+
|
| 320 |
+
|
| 321 |
+
# if returning loss, save the labels for cross entropy
|
| 322 |
+
|
| 323 |
+
if return_loss:
|
| 324 |
+
assert seq_len > 0
|
| 325 |
+
codes, labels = codes[:, :-1], codes
|
| 326 |
+
|
| 327 |
+
# token embed
|
| 328 |
+
|
| 329 |
+
codes = codes.masked_fill(codes == self.pad_id, 0)
|
| 330 |
+
codes = self.token_embed(codes)
|
| 331 |
+
|
| 332 |
+
# codebook embed + absolute positions
|
| 333 |
+
|
| 334 |
+
seq_arange = torch.arange(codes.shape[-2], device = device)
|
| 335 |
+
codes = codes + self.abs_pos_emb(seq_arange)
|
| 336 |
+
|
| 337 |
+
# add positional embedding for block and offset token
|
| 338 |
+
block_embed = repeat(self.block_embed, '1 d -> b n d', n = seq_len, b = batch)
|
| 339 |
+
offset_embed = repeat(self.offset_embed, '1 d -> b n d', n = seq_len, b = batch)
|
| 340 |
+
codes[block_mask] += block_embed[block_mask]
|
| 341 |
+
codes[offset_mask] += offset_embed[offset_mask]
|
| 342 |
+
|
| 343 |
+
if self.use_special_block:
|
| 344 |
+
sp_block_embed = repeat(self.sp_block_embed, '1 d -> b n d', n = seq_len, b = batch)
|
| 345 |
+
codes[sp_block_mask] += sp_block_embed[sp_block_mask]
|
| 346 |
+
|
| 347 |
+
# auto prepend sos token
|
| 348 |
+
|
| 349 |
+
sos = repeat(self.sos_token, 'd -> b d', b = batch)
|
| 350 |
+
codes, _ = pack([sos, codes], 'b * d')
|
| 351 |
+
|
| 352 |
+
# attention
|
| 353 |
+
|
| 354 |
+
attended, intermediates_with_cache = self.decoder(
|
| 355 |
+
codes,
|
| 356 |
+
cache = cache,
|
| 357 |
+
return_hiddens = True,
|
| 358 |
+
**attn_context_kwargs
|
| 359 |
+
)
|
| 360 |
+
|
| 361 |
+
# logits
|
| 362 |
+
|
| 363 |
+
logits = self.to_logits(attended)
|
| 364 |
+
|
| 365 |
+
if not return_loss:
|
| 366 |
+
if not return_cache:
|
| 367 |
+
return logits
|
| 368 |
+
|
| 369 |
+
return logits, intermediates_with_cache
|
| 370 |
+
|
| 371 |
+
# loss
|
| 372 |
+
|
| 373 |
+
ce_loss = F.cross_entropy(
|
| 374 |
+
rearrange(logits, 'b n c -> b c n'),
|
| 375 |
+
labels,
|
| 376 |
+
ignore_index = self.pad_id
|
| 377 |
+
)
|
| 378 |
+
|
| 379 |
+
return ce_loss
|
model/serializaiton.py
ADDED
|
@@ -0,0 +1,241 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import trimesh
|
| 2 |
+
import numpy as np
|
| 3 |
+
from .data_utils import discretize, undiscretize
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def patchified_mesh(mesh: trimesh.Trimesh, special_token = -2, fix_orient=True):
|
| 7 |
+
sequence = []
|
| 8 |
+
unvisited = np.full(len(mesh.faces), True)
|
| 9 |
+
degrees = mesh.vertex_degree.copy()
|
| 10 |
+
|
| 11 |
+
# with fix_orient=True, the normal would be correct.
|
| 12 |
+
# but this may increase the difficulty for learning.
|
| 13 |
+
if fix_orient:
|
| 14 |
+
face_orient = {}
|
| 15 |
+
for ind, face in enumerate(mesh.faces):
|
| 16 |
+
v0, v1, v2 = face[0], face[1], face[2]
|
| 17 |
+
face_orient['{}-{}-{}'.format(v0, v1, v2)] = True
|
| 18 |
+
face_orient['{}-{}-{}'.format(v1, v2, v0)] = True
|
| 19 |
+
face_orient['{}-{}-{}'.format(v2, v0, v1)] = True
|
| 20 |
+
face_orient['{}-{}-{}'.format(v2, v1, v0)] = False
|
| 21 |
+
face_orient['{}-{}-{}'.format(v1, v0, v2)] = False
|
| 22 |
+
face_orient['{}-{}-{}'.format(v0, v2, v1)] = False
|
| 23 |
+
|
| 24 |
+
while sum(unvisited):
|
| 25 |
+
unvisited_faces = mesh.faces[unvisited]
|
| 26 |
+
|
| 27 |
+
# select the patch center
|
| 28 |
+
cur_face = unvisited_faces[0]
|
| 29 |
+
max_deg_vertex_id = np.argmax(degrees[cur_face])
|
| 30 |
+
max_deg_vertex = cur_face[max_deg_vertex_id]
|
| 31 |
+
|
| 32 |
+
# find all connected faces
|
| 33 |
+
selected_faces = []
|
| 34 |
+
for face_idx in mesh.vertex_faces[max_deg_vertex]:
|
| 35 |
+
if face_idx != -1 and unvisited[face_idx]:
|
| 36 |
+
face = mesh.faces[face_idx]
|
| 37 |
+
u, v = sorted([vertex for vertex in face if vertex != max_deg_vertex])
|
| 38 |
+
selected_faces.append([u, v, face_idx])
|
| 39 |
+
|
| 40 |
+
face_patch = set()
|
| 41 |
+
selected_faces = sorted(selected_faces)
|
| 42 |
+
|
| 43 |
+
# select the start vertex, select it if it only appears once (the start or end),
|
| 44 |
+
# else select the lowest index
|
| 45 |
+
cnt = {}
|
| 46 |
+
for u, v, _ in selected_faces:
|
| 47 |
+
cnt[u] = cnt.get(u, 0) + 1
|
| 48 |
+
cnt[v] = cnt.get(v, 0) + 1
|
| 49 |
+
starts = []
|
| 50 |
+
for vertex, num in cnt.items():
|
| 51 |
+
if num == 1:
|
| 52 |
+
starts.append(vertex)
|
| 53 |
+
start_idx = min(starts) if len(starts) else selected_faces[0][0]
|
| 54 |
+
|
| 55 |
+
res = [start_idx]
|
| 56 |
+
while len(res) <= len(selected_faces):
|
| 57 |
+
vertex = res[-1]
|
| 58 |
+
for u_i, v_i, face_idx_i in selected_faces:
|
| 59 |
+
if face_idx_i not in face_patch and vertex in (u_i, v_i):
|
| 60 |
+
u_i, v_i = (u_i, v_i) if vertex == u_i else (v_i, u_i)
|
| 61 |
+
res.append(v_i)
|
| 62 |
+
face_patch.add(face_idx_i)
|
| 63 |
+
break
|
| 64 |
+
|
| 65 |
+
if res[-1] == vertex:
|
| 66 |
+
break
|
| 67 |
+
|
| 68 |
+
if fix_orient and len(res) >= 2 and not face_orient['{}-{}-{}'.format(max_deg_vertex, res[0], res[1])]:
|
| 69 |
+
res = res[::-1]
|
| 70 |
+
|
| 71 |
+
# reduce the degree of related vertices and mark the visited faces
|
| 72 |
+
degrees[max_deg_vertex] = len(selected_faces) - len(res) + 1
|
| 73 |
+
for pos_idx, vertex in enumerate(res):
|
| 74 |
+
if pos_idx in [0, len(res) - 1]:
|
| 75 |
+
degrees[vertex] -= 1
|
| 76 |
+
else:
|
| 77 |
+
degrees[vertex] -= 2
|
| 78 |
+
for face_idx in face_patch:
|
| 79 |
+
unvisited[face_idx] = False
|
| 80 |
+
sequence.extend(
|
| 81 |
+
[mesh.vertices[max_deg_vertex]] +
|
| 82 |
+
[mesh.vertices[vertex_idx] for vertex_idx in res] +
|
| 83 |
+
[[special_token] * 3]
|
| 84 |
+
)
|
| 85 |
+
|
| 86 |
+
assert sum(degrees) == 0, 'All degrees should be zero'
|
| 87 |
+
|
| 88 |
+
return np.array(sequence)
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
def get_block_representation(
|
| 93 |
+
sequence,
|
| 94 |
+
block_size=8,
|
| 95 |
+
offset_size=16,
|
| 96 |
+
block_compressed=True,
|
| 97 |
+
special_token=-2,
|
| 98 |
+
use_special_block=True
|
| 99 |
+
):
|
| 100 |
+
'''
|
| 101 |
+
convert coordinates from Cartesian system to block indexes.
|
| 102 |
+
'''
|
| 103 |
+
special_block_base = block_size**3 + offset_size**3
|
| 104 |
+
# prepare coordinates
|
| 105 |
+
sp_mask = sequence != special_token
|
| 106 |
+
sp_mask = np.all(sp_mask, axis=1)
|
| 107 |
+
coords = sequence[sp_mask].reshape(-1, 3)
|
| 108 |
+
coords = discretize(coords)
|
| 109 |
+
|
| 110 |
+
# convert [x, y, z] to [block_id, offset_id]
|
| 111 |
+
block_id = coords // offset_size
|
| 112 |
+
block_id = block_id[:, 0] * block_size**2 + block_id[:, 1] * block_size + block_id[:, 2]
|
| 113 |
+
offset_id = coords % offset_size
|
| 114 |
+
offset_id = offset_id[:, 0] * offset_size**2 + offset_id[:, 1] * offset_size + offset_id[:, 2]
|
| 115 |
+
offset_id += block_size**3
|
| 116 |
+
block_coords = np.concatenate([block_id[..., None], offset_id[..., None]], axis=-1).astype(np.int64)
|
| 117 |
+
sequence[:, :2][sp_mask] = block_coords
|
| 118 |
+
sequence = sequence[:, :2]
|
| 119 |
+
|
| 120 |
+
# convert to codes
|
| 121 |
+
codes = []
|
| 122 |
+
cur_block_id = sequence[0, 0]
|
| 123 |
+
codes.append(cur_block_id)
|
| 124 |
+
for i in range(len(sequence)):
|
| 125 |
+
if sequence[i, 0] == special_token:
|
| 126 |
+
if not use_special_block:
|
| 127 |
+
codes.append(special_token)
|
| 128 |
+
cur_block_id = special_token
|
| 129 |
+
|
| 130 |
+
elif sequence[i, 0] == cur_block_id:
|
| 131 |
+
if block_compressed:
|
| 132 |
+
codes.append(sequence[i, 1])
|
| 133 |
+
else:
|
| 134 |
+
codes.extend([sequence[i, 0], sequence[i, 1]])
|
| 135 |
+
|
| 136 |
+
else:
|
| 137 |
+
if use_special_block and cur_block_id == special_token:
|
| 138 |
+
block_id = sequence[i, 0] + special_block_base
|
| 139 |
+
else:
|
| 140 |
+
block_id = sequence[i, 0]
|
| 141 |
+
codes.extend([block_id, sequence[i, 1]])
|
| 142 |
+
cur_block_id = block_id
|
| 143 |
+
|
| 144 |
+
codes = np.array(codes).astype(np.int64)
|
| 145 |
+
sequence = codes
|
| 146 |
+
|
| 147 |
+
return sequence.flatten()
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
def BPT_serialize(mesh: trimesh.Trimesh):
|
| 151 |
+
# serialize mesh with BPT
|
| 152 |
+
|
| 153 |
+
# 1. patchify faces into patches
|
| 154 |
+
sequence = patchified_mesh(mesh, special_token=-2)
|
| 155 |
+
|
| 156 |
+
# 2. convert coordinates to block-wise indexes
|
| 157 |
+
codes = get_block_representation(
|
| 158 |
+
sequence, block_size=8, offset_size=16,
|
| 159 |
+
block_compressed=True, special_token=-2, use_special_block=True
|
| 160 |
+
)
|
| 161 |
+
return codes
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
def decode_block(sequence, compressed=True, block_size=8, offset_size=16):
|
| 165 |
+
|
| 166 |
+
# decode from compressed representation
|
| 167 |
+
if compressed:
|
| 168 |
+
res = []
|
| 169 |
+
res_block = 0
|
| 170 |
+
for token_id in range(len(sequence)):
|
| 171 |
+
if block_size**3 + offset_size**3 > sequence[token_id] >= block_size**3:
|
| 172 |
+
res.append([res_block, sequence[token_id]])
|
| 173 |
+
elif block_size**3 > sequence[token_id] >= 0:
|
| 174 |
+
res_block = sequence[token_id]
|
| 175 |
+
else:
|
| 176 |
+
print('[Warning] too large offset idx!', token_id, sequence[token_id])
|
| 177 |
+
sequence = np.array(res)
|
| 178 |
+
|
| 179 |
+
block_id, offset_id = np.array_split(sequence, 2, axis=-1)
|
| 180 |
+
|
| 181 |
+
# from hash representation to xyz
|
| 182 |
+
coords = []
|
| 183 |
+
offset_id -= block_size**3
|
| 184 |
+
for i in [2, 1, 0]:
|
| 185 |
+
axis = (block_id // block_size**i) * offset_size + (offset_id // offset_size**i)
|
| 186 |
+
block_id %= block_size**i
|
| 187 |
+
offset_id %= offset_size**i
|
| 188 |
+
coords.append(axis)
|
| 189 |
+
|
| 190 |
+
coords = np.concatenate(coords, axis=-1) # (nf 3)
|
| 191 |
+
|
| 192 |
+
# back to continuous space
|
| 193 |
+
coords = undiscretize(coords)
|
| 194 |
+
|
| 195 |
+
return coords
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
def BPT_deserialize(sequence, block_size=8, offset_size=16, compressed=True, special_token=-2, use_special_block=True):
|
| 199 |
+
# decode codes back to coordinates
|
| 200 |
+
|
| 201 |
+
special_block_base = block_size**3 + offset_size**3
|
| 202 |
+
start_idx = 0
|
| 203 |
+
vertices = []
|
| 204 |
+
for i in range(len(sequence)):
|
| 205 |
+
sub_seq = []
|
| 206 |
+
if not use_special_block and (sequence[i] == special_token or i == len(sequence) - 1):
|
| 207 |
+
sub_seq = sequence[start_idx:i]
|
| 208 |
+
sub_seq = decode_block(sub_seq, compressed=compressed, block_size=block_size, offset_size=offset_size)
|
| 209 |
+
start_idx = i + 1
|
| 210 |
+
|
| 211 |
+
elif use_special_block and \
|
| 212 |
+
(special_block_base <= sequence[i] < special_block_base + block_size**3 or i == len(sequence)-1):
|
| 213 |
+
if i != 0:
|
| 214 |
+
sub_seq = sequence[start_idx:i] if i != len(sequence) - 1 else sequence[start_idx: i+1]
|
| 215 |
+
if special_block_base <= sub_seq[0] < special_block_base + block_size**3:
|
| 216 |
+
sub_seq[0] -= special_block_base
|
| 217 |
+
sub_seq = decode_block(sub_seq, compressed=compressed, block_size=block_size, offset_size=offset_size)
|
| 218 |
+
start_idx = i
|
| 219 |
+
|
| 220 |
+
if len(sub_seq):
|
| 221 |
+
center, sub_seq = sub_seq[0], sub_seq[1:]
|
| 222 |
+
for j in range(len(sub_seq) - 1):
|
| 223 |
+
vertices.extend([center.reshape(1, 3), sub_seq[j].reshape(1, 3), sub_seq[j+1].reshape(1, 3)])
|
| 224 |
+
|
| 225 |
+
# (nf, 3)
|
| 226 |
+
return np.concatenate(vertices, axis=0)
|
| 227 |
+
|
| 228 |
+
|
| 229 |
+
if __name__ == '__main__':
|
| 230 |
+
# a simple demo for serialize and deserialize mesh with bpt
|
| 231 |
+
from data_utils import load_process_mesh, to_mesh
|
| 232 |
+
import torch
|
| 233 |
+
mesh = load_process_mesh('/path/to/your/mesh', quantization_bits=7)
|
| 234 |
+
mesh['faces'] = np.array(mesh['faces'])
|
| 235 |
+
mesh = to_mesh(mesh['vertices'], mesh['faces'], transpose=True)
|
| 236 |
+
mesh.export('gt.obj')
|
| 237 |
+
codes = BPT_serialize(mesh)
|
| 238 |
+
coordinates = BPT_deserialize(codes)
|
| 239 |
+
faces = torch.arange(1, len(coordinates) + 1).view(-1, 3)
|
| 240 |
+
mesh = to_mesh(coordinates, faces, transpose=False, post_process=False)
|
| 241 |
+
mesh.export('reconstructed.obj')
|
requirements.txt
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
meshgpt_pytorch==0.6.7
|
| 2 |
+
pytorch-custom-utils==0.0.21
|
| 3 |
+
accelerate>=0.25.0
|
| 4 |
+
beartype
|
| 5 |
+
classifier-free-guidance-pytorch==0.5.1
|
| 6 |
+
einops>=0.7.0
|
| 7 |
+
ema-pytorch
|
| 8 |
+
pytorch-warmup
|
| 9 |
+
torch_geometric
|
| 10 |
+
torchtyping
|
| 11 |
+
vector-quantize-pytorch==1.12.8
|
| 12 |
+
x-transformers==1.26.6
|
| 13 |
+
tqdm
|
| 14 |
+
matplotlib
|
| 15 |
+
wandb
|
| 16 |
+
pyrr
|
| 17 |
+
trimesh
|
| 18 |
+
opencv-python
|
| 19 |
+
pyrender
|
| 20 |
+
open3d-python
|
| 21 |
+
easydict
|
| 22 |
+
chardet
|
| 23 |
+
deepspeed
|
| 24 |
+
omegaconf
|
| 25 |
+
scikit-image
|
| 26 |
+
setuptools
|
| 27 |
+
pytorch_lightning
|
| 28 |
+
mesh2sdf
|
| 29 |
+
numpy==1.26.4
|
| 30 |
+
point-cloud-utils
|
utils.py
ADDED
|
@@ -0,0 +1,88 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import trimesh
|
| 2 |
+
import numpy as np
|
| 3 |
+
from x_transformers.autoregressive_wrapper import top_p, top_k
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class Dataset:
|
| 7 |
+
'''
|
| 8 |
+
A toy dataset for inference
|
| 9 |
+
'''
|
| 10 |
+
def __init__(self, input_type, input_list):
|
| 11 |
+
super().__init__()
|
| 12 |
+
self.data = []
|
| 13 |
+
if input_type == 'pc_normal':
|
| 14 |
+
for input_path in input_list:
|
| 15 |
+
# load npy
|
| 16 |
+
cur_data = np.load(input_path)
|
| 17 |
+
# sample 4096
|
| 18 |
+
assert cur_data.shape[0] >= 4096, "input pc_normal should have at least 4096 points"
|
| 19 |
+
idx = np.random.choice(cur_data.shape[0], 4096, replace=False)
|
| 20 |
+
cur_data = cur_data[idx]
|
| 21 |
+
self.data.append({'pc_normal': cur_data, 'uid': input_path.split('/')[-1].split('.')[0]})
|
| 22 |
+
|
| 23 |
+
elif input_type == 'mesh':
|
| 24 |
+
mesh_list, pc_list = [], []
|
| 25 |
+
for input_path in input_list:
|
| 26 |
+
# sample point cloud and normal from mesh
|
| 27 |
+
cur_data = trimesh.load(input_path, force='mesh')
|
| 28 |
+
cur_data = apply_normalize(cur_data)
|
| 29 |
+
mesh_list.append(cur_data)
|
| 30 |
+
pc_list.append(sample_pc(cur_data, pc_num=4096, with_normal=True))
|
| 31 |
+
|
| 32 |
+
for input_path, cur_data in zip(input_list, pc_list):
|
| 33 |
+
self.data.append({'pc_normal': cur_data, 'uid': input_path.split('/')[-1].split('.')[0]})
|
| 34 |
+
|
| 35 |
+
print(f"dataset total data samples: {len(self.data)}")
|
| 36 |
+
|
| 37 |
+
def __len__(self):
|
| 38 |
+
return len(self.data)
|
| 39 |
+
|
| 40 |
+
def __getitem__(self, idx):
|
| 41 |
+
data_dict = {}
|
| 42 |
+
data_dict['pc_normal'] = self.data[idx]['pc_normal']
|
| 43 |
+
data_dict['uid'] = self.data[idx]['uid']
|
| 44 |
+
|
| 45 |
+
return data_dict
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def joint_filter(logits, k = 50, p=0.95):
|
| 49 |
+
logits = top_k(logits, k = k)
|
| 50 |
+
logits = top_p(logits, thres = p)
|
| 51 |
+
return logits
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def apply_normalize(mesh):
|
| 55 |
+
'''
|
| 56 |
+
normalize mesh to [-1, 1]
|
| 57 |
+
'''
|
| 58 |
+
bbox = mesh.bounds
|
| 59 |
+
center = (bbox[1] + bbox[0]) / 2
|
| 60 |
+
scale = (bbox[1] - bbox[0]).max()
|
| 61 |
+
|
| 62 |
+
mesh.apply_translation(-center)
|
| 63 |
+
mesh.apply_scale(1 / scale * 2 * 0.95)
|
| 64 |
+
|
| 65 |
+
return mesh
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def sample_pc(mesh_path, pc_num, with_normal=False):
|
| 70 |
+
|
| 71 |
+
mesh = trimesh.load(mesh_path, force='mesh', process=False)
|
| 72 |
+
mesh = apply_normalize(mesh)
|
| 73 |
+
|
| 74 |
+
if not with_normal:
|
| 75 |
+
points, _ = mesh.sample(pc_num, return_index=True)
|
| 76 |
+
return points
|
| 77 |
+
|
| 78 |
+
points, face_idx = mesh.sample(50000, return_index=True)
|
| 79 |
+
normals = mesh.face_normals[face_idx]
|
| 80 |
+
pc_normal = np.concatenate([points, normals], axis=-1, dtype=np.float16)
|
| 81 |
+
|
| 82 |
+
# random sample point cloud
|
| 83 |
+
ind = np.random.choice(pc_normal.shape[0], pc_num, replace=False)
|
| 84 |
+
pc_normal = pc_normal[ind]
|
| 85 |
+
|
| 86 |
+
return pc_normal
|
| 87 |
+
|
| 88 |
+
|