Spaces:
Running

Running
Commit
•
d13100b
1
Parent(s):
5b8cd1f
🎉 init(v0.2):
Browse files- .gitignore +2 -0
- README.md +17 -1
- app.py +64 -0
- assets/example.jpg +0 -0
- requirements.txt +2 -0
- test.py +9 -0
.gitignore
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
flagged
|
| 2 |
+
**/__pycache__/
|
README.md
CHANGED
|
@@ -11,4 +11,20 @@ license: apache-2.0
|
|
| 11 |
short_description: paper title => bib tex
|
| 12 |
---
|
| 13 |
|
| 14 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 11 |
short_description: paper title => bib tex
|
| 12 |
---
|
| 13 |
|
| 14 |
+
# EasyBib
|
| 15 |
+
一个简易的工具,用于将文献标题转化为BibTeX格式。
|
| 16 |
+
|
| 17 |
+

|
| 18 |
+
运行后,会启动一个gradio应用,用户可以输入多个文献标题,每一行是一个标题,输出对应的BibTeX格式,不同论文的BibTex格式中间会空一行。
|
| 19 |
+
|
| 20 |
+
## Changelog
|
| 21 |
+
### v0.2
|
| 22 |
+
* 新增重试机制。SemanticScholar站点限制所有匿名的API请求最多1,000次/秒,所以使用时会出现请求失败的情况,目前用重试机制规避,但时间会加长。
|
| 23 |
+
|
| 24 |
+
### v0.1
|
| 25 |
+
* 支持多行多个论文同时查询
|
| 26 |
+
|
| 27 |
+
## TODO
|
| 28 |
+
- [ ] 支持个人API KEY
|
| 29 |
+
- [ ] 自动改写会议名称,比如'International Conference on Learning Representations' ==> 'ICLR'
|
| 30 |
+
- [ ] 多论文加速
|
app.py
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
# -*- coding: utf-8 -*-
|
| 3 |
+
|
| 4 |
+
import requests
|
| 5 |
+
import gradio as gr
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def get_bibtext_from_title(title, retry_times=100):
|
| 9 |
+
# URL编码查询参数
|
| 10 |
+
encoded_query = requests.utils.quote(title)
|
| 11 |
+
print(f'query: {encoded_query}')
|
| 12 |
+
# 假设API的endpoint为'https://api.example.com/search'
|
| 13 |
+
url = f"https://api.semanticscholar.org/graph/v1/paper/search?query={encoded_query}&offset=0&limit=3&fields=title,citationStyles"
|
| 14 |
+
|
| 15 |
+
for i in range(retry_times):
|
| 16 |
+
# 发送GET请求
|
| 17 |
+
response = requests.get(url)
|
| 18 |
+
|
| 19 |
+
# 检查请求是否成功
|
| 20 |
+
if response.status_code == 200:
|
| 21 |
+
# 如果请求成功,返回JSON格式的数据
|
| 22 |
+
try:
|
| 23 |
+
data = response.json()['data']
|
| 24 |
+
bibtex = data[0]['citationStyles']['bibtex']
|
| 25 |
+
return bibtex
|
| 26 |
+
except:
|
| 27 |
+
msg = f"Failed to parse response: {response.json()}"
|
| 28 |
+
return msg
|
| 29 |
+
elif response.status_code == 429:
|
| 30 |
+
print(f'retry {i} times')
|
| 31 |
+
continue
|
| 32 |
+
else:
|
| 33 |
+
# 如果请求失败,打印错误信息
|
| 34 |
+
msg = "Failed to retrieve data: {response.json()}"
|
| 35 |
+
return msg
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def process_text(input_text):
|
| 39 |
+
titles = input_text.split('\n')
|
| 40 |
+
# 在这个例子中,我们仅仅将输入的文本原样返回。
|
| 41 |
+
# 你可以在这个函数中加入任何你想要的文本处理逻辑。
|
| 42 |
+
output = []
|
| 43 |
+
for title in titles:
|
| 44 |
+
if not title:
|
| 45 |
+
continue
|
| 46 |
+
bibtex = get_bibtext_from_title(title)
|
| 47 |
+
print(bibtex)
|
| 48 |
+
if bibtex is not None:
|
| 49 |
+
output.append(bibtex)
|
| 50 |
+
else:
|
| 51 |
+
output.append("Failed to process: " + title + '\n')
|
| 52 |
+
return '\n'.join(output)
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
# 创建Gradio界面
|
| 56 |
+
iface = gr.Interface(
|
| 57 |
+
fn=process_text, # 要调用的处理函数
|
| 58 |
+
inputs=gr.Textbox(lines=10, placeholder="请在此输入论文标题..."), # 输入组件:文本框,设置多行输入
|
| 59 |
+
outputs=gr.Textbox(lines=20, placeholder="输出BibTex信息将会在此显示..."), # 输出组件:文本框,设置多行输出
|
| 60 |
+
)
|
| 61 |
+
|
| 62 |
+
if __name__ == "__main__":
|
| 63 |
+
# 启动界面
|
| 64 |
+
iface.launch()
|
assets/example.jpg
ADDED
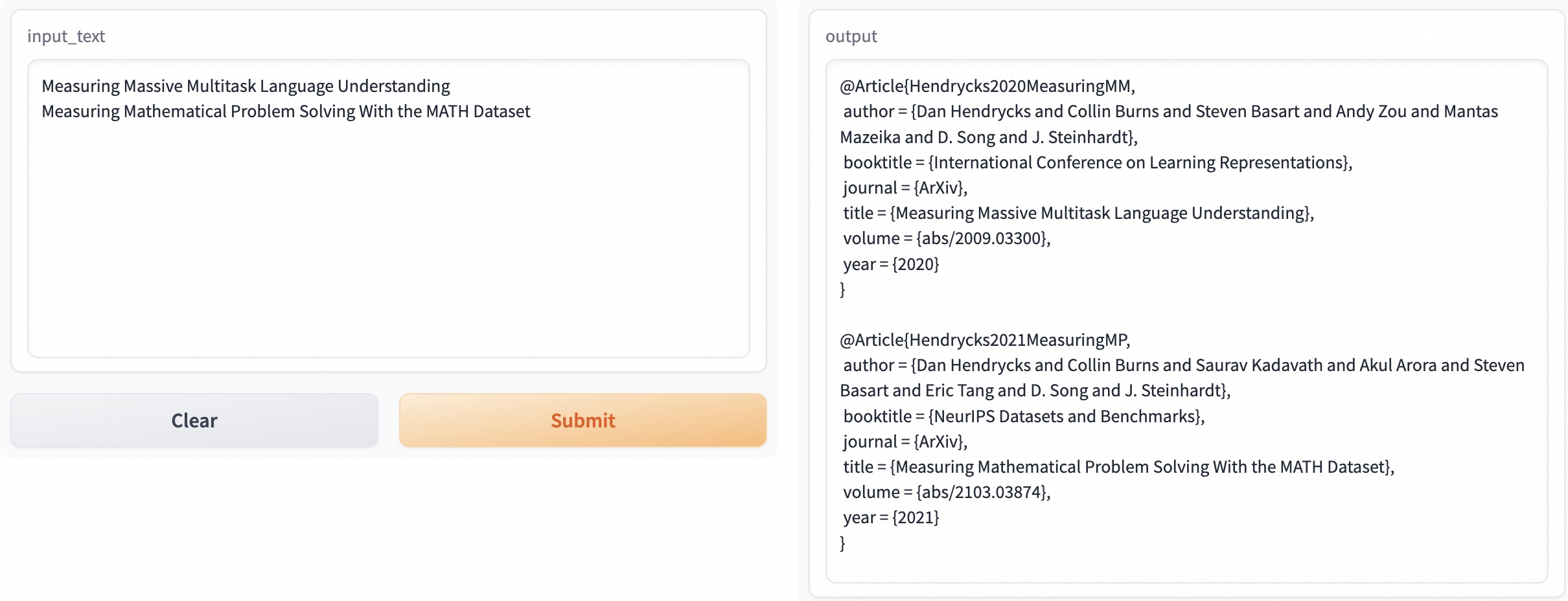
|
requirements.txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
gradio
|
| 2 |
+
requests
|
test.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
#!/usr/bin/env python3
|
| 3 |
+
# -*- coding: utf-8 -*-
|
| 4 |
+
|
| 5 |
+
from app import process_text
|
| 6 |
+
|
| 7 |
+
if __name__ == "__main__":
|
| 8 |
+
output = process_text("Language Models are Few-Shot Learners")
|
| 9 |
+
print(output)
|