

Commit
•
32d11fc
1
Parent(s):
1207ecb
fix readme
Browse files- .ipynb_checkpoints/README-checkpoint.md +54 -0
- README.md +18 -24
.ipynb_checkpoints/README-checkpoint.md
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
tags:
|
| 4 |
+
- Kandinsky
|
| 5 |
+
- text-image
|
| 6 |
+
- text2image
|
| 7 |
+
- diffusion
|
| 8 |
+
- latent diffusion
|
| 9 |
+
- mCLIP-XLMR
|
| 10 |
+
- mT5
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
# Kandinsky 2.1
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
[Open In Colab](https://colab.research.google.com/drive/1xSbu-b-EwYd6GdaFPRVgvXBX_mciZ41e?usp=sharing)
|
| 17 |
+
|
| 18 |
+
[GitHub repository](https://github.com/ai-forever/Kandinsky-2)
|
| 19 |
+
|
| 20 |
+
[Habr post](https://habr.com/ru/company/sberbank/blog/725282/)
|
| 21 |
+
|
| 22 |
+
[Demo](https://rudalle.ru/)
|
| 23 |
+
|
| 24 |
+
## Architecture
|
| 25 |
+
|
| 26 |
+
Kandinsky 2.1 inherits best practicies from Dall-E 2 and Latent diffucion, while introducing some new ideas.
|
| 27 |
+
|
| 28 |
+
As text and image encoder it uses CLIP model and diffusion image prior (mapping) between latent spaces of CLIP modalities. This approach increases the visual performance of the model and unveils new horizons in blending images and text-guided image manipulation.
|
| 29 |
+
|
| 30 |
+
For diffusion mapping of latent spaces we use transformer with num_layers=20, num_heads=32 and hidden_size=2048.
|
| 31 |
+
|
| 32 |
+
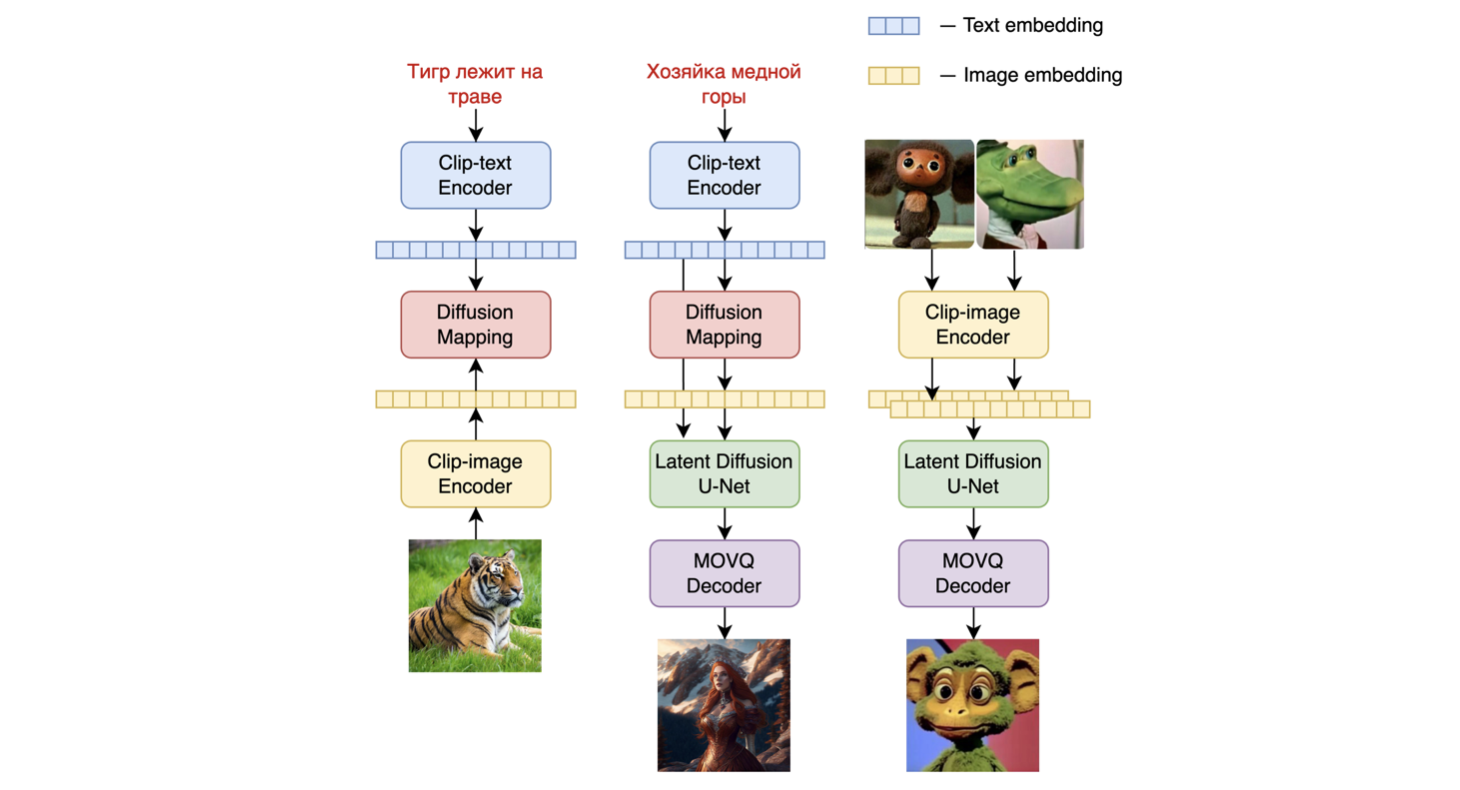
|
| 33 |
+
|
| 34 |
+
Other architecture parts:
|
| 35 |
+
|
| 36 |
+
+ Text encoder (XLM-Roberta-Large-Vit-L-14) - 560M
|
| 37 |
+
+ Diffusion Image Prior — 1B
|
| 38 |
+
+ CLIP image encoder (ViT-L/14) - 427M
|
| 39 |
+
+ Latent Diffusion U-Net - 1.22B
|
| 40 |
+
+ MoVQ encoder/decoder - 67M
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+

|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
# Authors
|
| 47 |
+
|
| 48 |
+
+ Arseniy Shakhmatov: [Github](https://github.com/cene555), [Blog](https://t.me/gradientdip)
|
| 49 |
+
+ Anton Razzhigaev: [Github](https://github.com/razzant), [Blog](https://t.me/abstractDL)
|
| 50 |
+
+ Aleksandr Nikolich: [Github](https://github.com/AlexWortega), [Blog](https://t.me/lovedeathtransformers)
|
| 51 |
+
+ Vladimir Arkhipkin: [Github](https://github.com/oriBetelgeuse)
|
| 52 |
+
+ Igor Pavlov: [Github](https://github.com/boomb0om)
|
| 53 |
+
+ Andrey Kuznetsov: [Github](https://github.com/kuznetsoffandrey)
|
| 54 |
+
+ Denis Dimitrov: [Github](https://github.com/denndimitrov)
|
README.md
CHANGED
|
@@ -10,41 +10,38 @@ tags:
|
|
| 10 |
- mT5
|
| 11 |
---
|
| 12 |
|
| 13 |
-
# Kandinsky 2.
|
| 14 |
|
| 15 |
|
| 16 |
-
|
| 17 |
|
| 18 |
-
[
|
| 19 |
|
| 20 |
-
[
|
| 21 |
-
|
| 22 |
-
[Habr post](https://habr.com/ru/company/sberbank/blog/701162/)
|
| 23 |
|
| 24 |
[Demo](https://rudalle.ru/)
|
| 25 |
|
| 26 |
-
|
|
|
|
|
|
|
| 27 |
|
| 28 |
-
|
| 29 |
|
| 30 |
-
|
| 31 |
-
* mCLIP-XLMR (560M parameters)
|
| 32 |
-
* mT5-encoder-small (146M parameters)
|
| 33 |
|
|
|
|
| 34 |
|
| 35 |
-
|
| 36 |
|
| 37 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 38 |
|
| 39 |
-
# How to use
|
| 40 |
|
| 41 |
-
|
| 42 |
-
pip install "git+https://github.com/ai-forever/Kandinsky-2.0.git"
|
| 43 |
|
| 44 |
-
from kandinsky2 import get_kandinsky2
|
| 45 |
-
model = get_kandinsky2('cuda', task_type='text2img')
|
| 46 |
-
images = model.generate_text2img('кошка в космосе', batch_size=4, h=512, w=512, num_steps=75, denoised_type='dynamic_threshold', dynamic_threshold_v=99.5, sampler='ddim_sampler', ddim_eta=0.01, guidance_scale=10)
|
| 47 |
-
```
|
| 48 |
|
| 49 |
# Authors
|
| 50 |
|
|
@@ -54,7 +51,4 @@ images = model.generate_text2img('кошка в космосе', batch_size=4, h
|
|
| 54 |
+ Vladimir Arkhipkin: [Github](https://github.com/oriBetelgeuse)
|
| 55 |
+ Igor Pavlov: [Github](https://github.com/boomb0om)
|
| 56 |
+ Andrey Kuznetsov: [Github](https://github.com/kuznetsoffandrey)
|
| 57 |
-
+ Denis Dimitrov: [Github](https://github.com/denndimitrov)
|
| 58 |
-
|
| 59 |
-
|
| 60 |
-
|
|
|
|
| 10 |
- mT5
|
| 11 |
---
|
| 12 |
|
| 13 |
+
# Kandinsky 2.1
|
| 14 |
|
| 15 |
|
| 16 |
+
[Open In Colab](https://colab.research.google.com/drive/1xSbu-b-EwYd6GdaFPRVgvXBX_mciZ41e?usp=sharing)
|
| 17 |
|
| 18 |
+
[GitHub repository](https://github.com/ai-forever/Kandinsky-2)
|
| 19 |
|
| 20 |
+
[Habr post](https://habr.com/ru/company/sberbank/blog/725282/)
|
|
|
|
|
|
|
| 21 |
|
| 22 |
[Demo](https://rudalle.ru/)
|
| 23 |
|
| 24 |
+
## Architecture
|
| 25 |
+
|
| 26 |
+
Kandinsky 2.1 inherits best practicies from Dall-E 2 and Latent diffucion, while introducing some new ideas.
|
| 27 |
|
| 28 |
+
As text and image encoder it uses CLIP model and diffusion image prior (mapping) between latent spaces of CLIP modalities. This approach increases the visual performance of the model and unveils new horizons in blending images and text-guided image manipulation.
|
| 29 |
|
| 30 |
+
For diffusion mapping of latent spaces we use transformer with num_layers=20, num_heads=32 and hidden_size=2048.
|
|
|
|
|
|
|
| 31 |
|
| 32 |
+

|
| 33 |
|
| 34 |
+
Other architecture parts:
|
| 35 |
|
| 36 |
+
+ Text encoder (XLM-Roberta-Large-Vit-L-14) - 560M
|
| 37 |
+
+ Diffusion Image Prior — 1B
|
| 38 |
+
+ CLIP image encoder (ViT-L/14) - 427M
|
| 39 |
+
+ Latent Diffusion U-Net - 1.22B
|
| 40 |
+
+ MoVQ encoder/decoder - 67M
|
| 41 |
|
|
|
|
| 42 |
|
| 43 |
+

|
|
|
|
| 44 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 45 |
|
| 46 |
# Authors
|
| 47 |
|
|
|
|
| 51 |
+ Vladimir Arkhipkin: [Github](https://github.com/oriBetelgeuse)
|
| 52 |
+ Igor Pavlov: [Github](https://github.com/boomb0om)
|
| 53 |
+ Andrey Kuznetsov: [Github](https://github.com/kuznetsoffandrey)
|
| 54 |
+
+ Denis Dimitrov: [Github](https://github.com/denndimitrov)
|
|
|
|
|
|
|
|
|