---
license: mit
language:
- en
- ru
library_name: transformers
---
---
# IsaNLP RST Parser v3
This repository hosts several versions of the IsaNLP RST Parser. For more details, visit the [GitHub repository](https://github.com/tchewik/isanlp_rst).
## Performance
The following table summarizes the end-to-end performance metrics of different model versions across various corpora:
### Corpora
- **English:** GUM9.1, RST-DT
- **Russian:** RRT2.1, RRGGUM-9.1
| Tag | Language | Train Data | Test Data | Seg | S | N | R | Full |
|--------------|------------|-------------|-------------|------|------|------|------|-------|
| `gumrrg` | En, Ru | GUM, RRG | GUM | 95.5 | 67.4 | 56.2 | 49.6 | 48.7 |
| | | | RRG | 97.0 | 67.1 | 54.6 | 46.5 | 45.4 |
| `rstdt` | En | RST-DT | RST-DT | 97.8 | 75.6 | 65.0 | 55.6 | 53.9 |
| `rstreebank` | Ru | RRT | RRT | 92.1 | 66.2 | 53.1 | 46.1 | 46.2 |
## Usage
To use the IsaNLP RST Parser with Hugging Face, follow these steps:
1. **Install the necessary Python package:**
You will need the `isanlp` library, which is available via pip:
```bash
pip install isanlp
```
2. **Example code for parsing RST:**
The following Python code demonstrates how to run a specific version of the parser using the Hugging Face model:
```python
from isanlp.processor_rst3 import ProcessorRST3
# Define the version of the model you want to use
version = 'gumrrg' # from {'gumrrg', 'rstdt', 'rstreebank'}
# Initialize the parser with the desired version
parser = ProcessorRST3(hf_model_name='tchewik/isanlp_rst_v3', hf_model_version=version, cuda_device=0)
# Example text for parsing
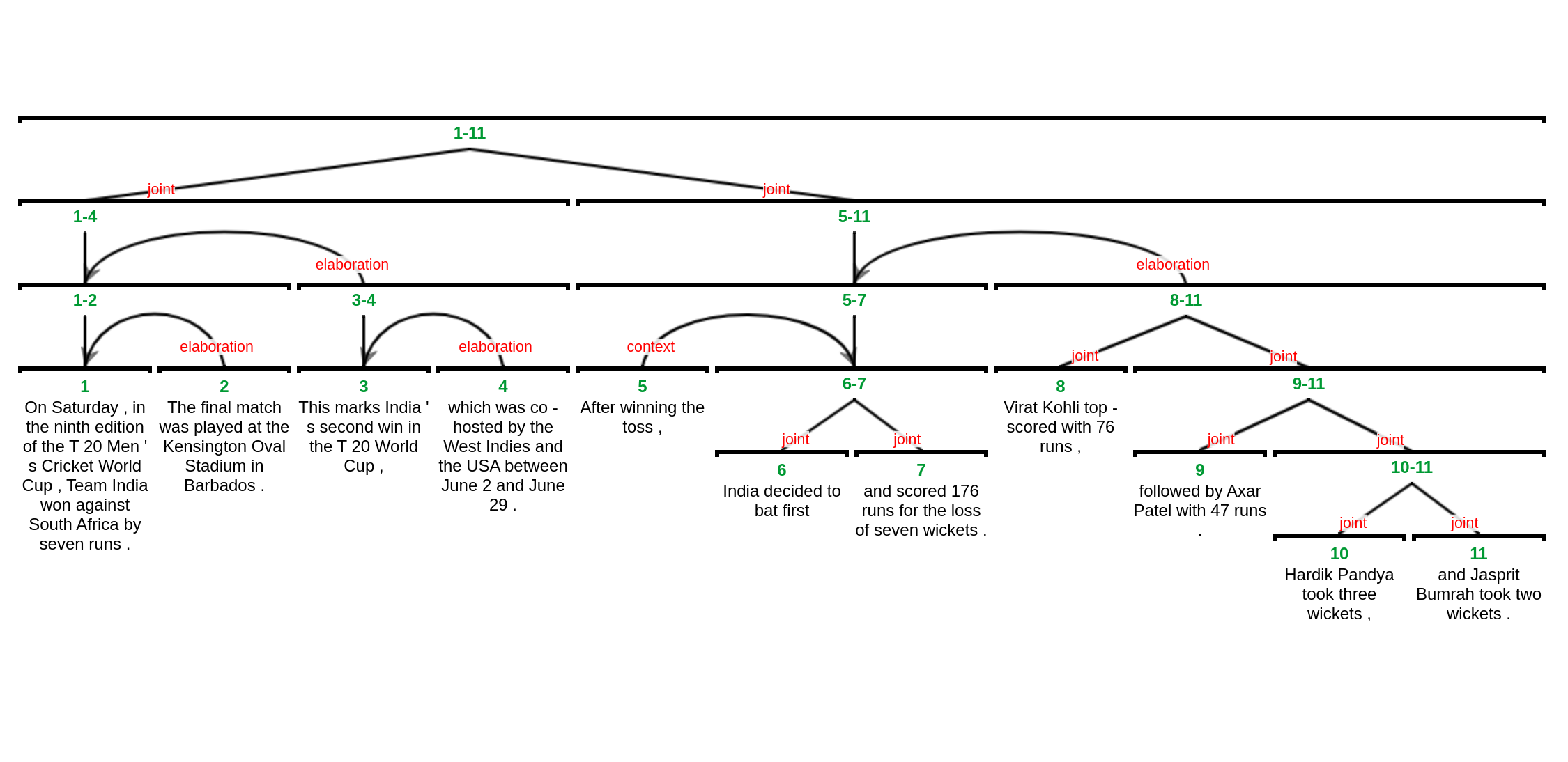
text = """
On Saturday, in the ninth edition of the T20 Men's Cricket World Cup, Team India won against South Africa by seven runs.
The final match was played at the Kensington Oval Stadium in Barbados. This marks India's second win in the T20 World Cup,
which was co-hosted by the West Indies and the USA between June 2 and June 29.
After winning the toss, India decided to bat first and scored 176 runs for the loss of seven wickets.
Virat Kohli top-scored with 76 runs, followed by Axar Patel with 47 runs. Hardik Pandya took three wickets,
and Jasprit Bumrah took two wickets.
"""
# Parse the text to obtain the RST tree
res = parser(text) # res['rst'] contains the binary discourse tree
# Display the structure of the RST tree
vars(res['rst'])
```
3. **Understanding the Output:**
```python
{
'id': 7,
'left': ,
'right': ,
'relation': 'elaboration',
'nuclearity': 'NS',
'start': 0,
'end': 336,
'text': "On Saturday, ... took two wickets .",
}
```
- **id**: A unique identifier for the discourse unit.
- **left** and **right**: The left and right children of the current discourse unit.
- **relation**: The rhetorical relation between the two sub-units. In this example, the relation is "elaboration," indicating that one part provides additional detail about the other.
- **nuclearity**: Indicates the nuclearity of the relation. "NS" means that the left unit is the nucleus (N) and the right unit is the satellite (S).
- **start** and **end**: The character offsets in the text for this discourse unit.
- **text**: The text span corresponding to this discourse unit.
4. **(Optional) Save the result in RS3 format:**
If you wish to save the resulting RST tree in the *.rs3 file, you can easily do so using the following command:
```python
# Export the RST tree to an RS3 file
res['rst'][0].to_rs3('filename.rs3')
```
The `filename.rs3` can then be opened in RSTTool or rstWeb for visualization or editing:
 ## Citation
If you use the IsaNLP RST Parser in your research, please cite our work as follows:
- **For versions `gumrrg`, `rstdt`, and `rstreebank`:** `TBA`
## Citation
If you use the IsaNLP RST Parser in your research, please cite our work as follows:
- **For versions `gumrrg`, `rstdt`, and `rstreebank`:** `TBA`