

Commit
•
74b08a7
1
Parent(s):
3bb0eb9
Upload 9 files
Browse files- README.md +18 -1
- adapter_config.json +21 -0
- adapter_model.bin +3 -0
- all_results.json +7 -0
- finetuning_args.json +13 -0
- train_results.json +7 -0
- trainer_state.json +73 -0
- training_args.bin +3 -0
- training_loss.png +0 -0
README.md
CHANGED
|
@@ -1,3 +1,20 @@
|
|
| 1 |
---
|
| 2 |
-
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
library_name: peft
|
| 3 |
---
|
| 4 |
+
## Training procedure
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
The following `bitsandbytes` quantization config was used during training:
|
| 8 |
+
- load_in_8bit: False
|
| 9 |
+
- load_in_4bit: True
|
| 10 |
+
- llm_int8_threshold: 6.0
|
| 11 |
+
- llm_int8_skip_modules: None
|
| 12 |
+
- llm_int8_enable_fp32_cpu_offload: False
|
| 13 |
+
- llm_int8_has_fp16_weight: False
|
| 14 |
+
- bnb_4bit_quant_type: nf4
|
| 15 |
+
- bnb_4bit_use_double_quant: True
|
| 16 |
+
- bnb_4bit_compute_dtype: float16
|
| 17 |
+
### Framework versions
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
- PEFT 0.5.0.dev0
|
adapter_config.json
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"auto_mapping": null,
|
| 3 |
+
"base_model_name_or_path": "meta-llama/Llama-2-13b-hf",
|
| 4 |
+
"bias": "none",
|
| 5 |
+
"fan_in_fan_out": false,
|
| 6 |
+
"inference_mode": true,
|
| 7 |
+
"init_lora_weights": true,
|
| 8 |
+
"layers_pattern": null,
|
| 9 |
+
"layers_to_transform": null,
|
| 10 |
+
"lora_alpha": 32.0,
|
| 11 |
+
"lora_dropout": 0.1,
|
| 12 |
+
"modules_to_save": null,
|
| 13 |
+
"peft_type": "LORA",
|
| 14 |
+
"r": 8,
|
| 15 |
+
"revision": null,
|
| 16 |
+
"target_modules": [
|
| 17 |
+
"q_proj",
|
| 18 |
+
"v_proj"
|
| 19 |
+
],
|
| 20 |
+
"task_type": "CAUSAL_LM"
|
| 21 |
+
}
|
adapter_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:52b32431c82de7724d85c8f2b834f34e7afef6062f472a4a2c5a0ee138cda5d5
|
| 3 |
+
size 26269517
|
all_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 1.0,
|
| 3 |
+
"train_loss": 1.053490692918951,
|
| 4 |
+
"train_runtime": 628.5043,
|
| 5 |
+
"train_samples_per_second": 2.247,
|
| 6 |
+
"train_steps_per_second": 0.14
|
| 7 |
+
}
|
finetuning_args.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"finetuning_type": "lora",
|
| 3 |
+
"lora_alpha": 32.0,
|
| 4 |
+
"lora_dropout": 0.1,
|
| 5 |
+
"lora_rank": 8,
|
| 6 |
+
"lora_target": [
|
| 7 |
+
"q_proj",
|
| 8 |
+
"v_proj"
|
| 9 |
+
],
|
| 10 |
+
"name_module_trainable": "mlp",
|
| 11 |
+
"num_hidden_layers": 32,
|
| 12 |
+
"num_layer_trainable": 3
|
| 13 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 1.0,
|
| 3 |
+
"train_loss": 1.053490692918951,
|
| 4 |
+
"train_runtime": 628.5043,
|
| 5 |
+
"train_samples_per_second": 2.247,
|
| 6 |
+
"train_steps_per_second": 0.14
|
| 7 |
+
}
|
trainer_state.json
ADDED
|
@@ -0,0 +1,73 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
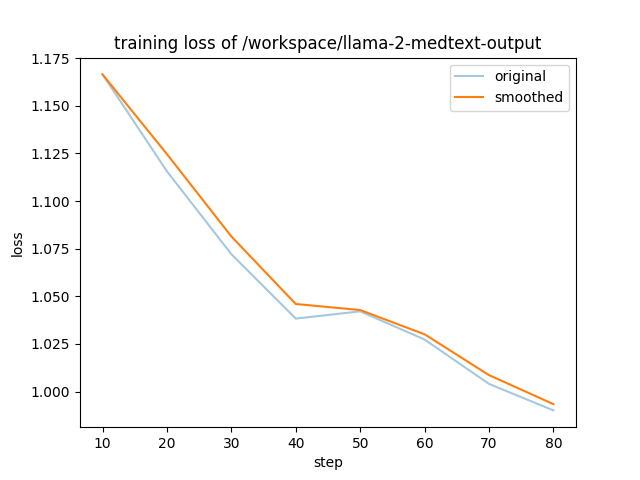
| 1 |
+
{
|
| 2 |
+
"best_metric": null,
|
| 3 |
+
"best_model_checkpoint": null,
|
| 4 |
+
"epoch": 0.9971671388101983,
|
| 5 |
+
"global_step": 88,
|
| 6 |
+
"is_hyper_param_search": false,
|
| 7 |
+
"is_local_process_zero": true,
|
| 8 |
+
"is_world_process_zero": true,
|
| 9 |
+
"log_history": [
|
| 10 |
+
{
|
| 11 |
+
"epoch": 0.11,
|
| 12 |
+
"learning_rate": 1.936949724999762e-05,
|
| 13 |
+
"loss": 1.1665,
|
| 14 |
+
"step": 10
|
| 15 |
+
},
|
| 16 |
+
{
|
| 17 |
+
"epoch": 0.23,
|
| 18 |
+
"learning_rate": 1.7557495743542586e-05,
|
| 19 |
+
"loss": 1.1156,
|
| 20 |
+
"step": 20
|
| 21 |
+
},
|
| 22 |
+
{
|
| 23 |
+
"epoch": 0.34,
|
| 24 |
+
"learning_rate": 1.479248986720057e-05,
|
| 25 |
+
"loss": 1.0721,
|
| 26 |
+
"step": 30
|
| 27 |
+
},
|
| 28 |
+
{
|
| 29 |
+
"epoch": 0.45,
|
| 30 |
+
"learning_rate": 1.1423148382732854e-05,
|
| 31 |
+
"loss": 1.0383,
|
| 32 |
+
"step": 40
|
| 33 |
+
},
|
| 34 |
+
{
|
| 35 |
+
"epoch": 0.57,
|
| 36 |
+
"learning_rate": 7.874347104470234e-06,
|
| 37 |
+
"loss": 1.0421,
|
| 38 |
+
"step": 50
|
| 39 |
+
},
|
| 40 |
+
{
|
| 41 |
+
"epoch": 0.68,
|
| 42 |
+
"learning_rate": 4.593591825444028e-06,
|
| 43 |
+
"loss": 1.0273,
|
| 44 |
+
"step": 60
|
| 45 |
+
},
|
| 46 |
+
{
|
| 47 |
+
"epoch": 0.79,
|
| 48 |
+
"learning_rate": 1.994587590756397e-06,
|
| 49 |
+
"loss": 1.004,
|
| 50 |
+
"step": 70
|
| 51 |
+
},
|
| 52 |
+
{
|
| 53 |
+
"epoch": 0.91,
|
| 54 |
+
"learning_rate": 4.0507026385502747e-07,
|
| 55 |
+
"loss": 0.9901,
|
| 56 |
+
"step": 80
|
| 57 |
+
},
|
| 58 |
+
{
|
| 59 |
+
"epoch": 1.0,
|
| 60 |
+
"step": 88,
|
| 61 |
+
"total_flos": 1.29608516683776e+16,
|
| 62 |
+
"train_loss": 1.053490692918951,
|
| 63 |
+
"train_runtime": 628.5043,
|
| 64 |
+
"train_samples_per_second": 2.247,
|
| 65 |
+
"train_steps_per_second": 0.14
|
| 66 |
+
}
|
| 67 |
+
],
|
| 68 |
+
"max_steps": 88,
|
| 69 |
+
"num_train_epochs": 1,
|
| 70 |
+
"total_flos": 1.29608516683776e+16,
|
| 71 |
+
"trial_name": null,
|
| 72 |
+
"trial_params": null
|
| 73 |
+
}
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:92bf9afb6506438b2c6093e5a34af126ee23b5a5f9fe5f21573589cf045d9e50
|
| 3 |
+
size 3368
|
training_loss.png
ADDED
|