

library_name: transformers
license: apache-2.0
language:
- vi
- en
- zh
base_model:
- OpenGVLab/InternViT-300M-448px
- Qwen/Qwen2.5-3B-Instruct
pipeline_tag: visual-question-answering
Vintern-3B-beta 🇻🇳 ❄️ - The LLaVA 🌋 Challenger
What's new in Vintern-3B-beta!
- We successfully reproduced the training process of InternVL from scratch.
- The model is the result of integrating Qwen/Qwen2.5-3B-Instruct and InternViT-300M-448px through an MLP layer.
- Trained with more than 10 Milion Vietnamese QnAs, Descriptions, and 10% English Data from OpenGVLab/InternVL-Chat-V1-2-SFT-Data.
Model Details
| Model Name | Vision Part | Language Part |
|---|---|---|
| Vintern-3B-beta | InternViT-300M-448px | Qwen2.5-3B-Instruct |
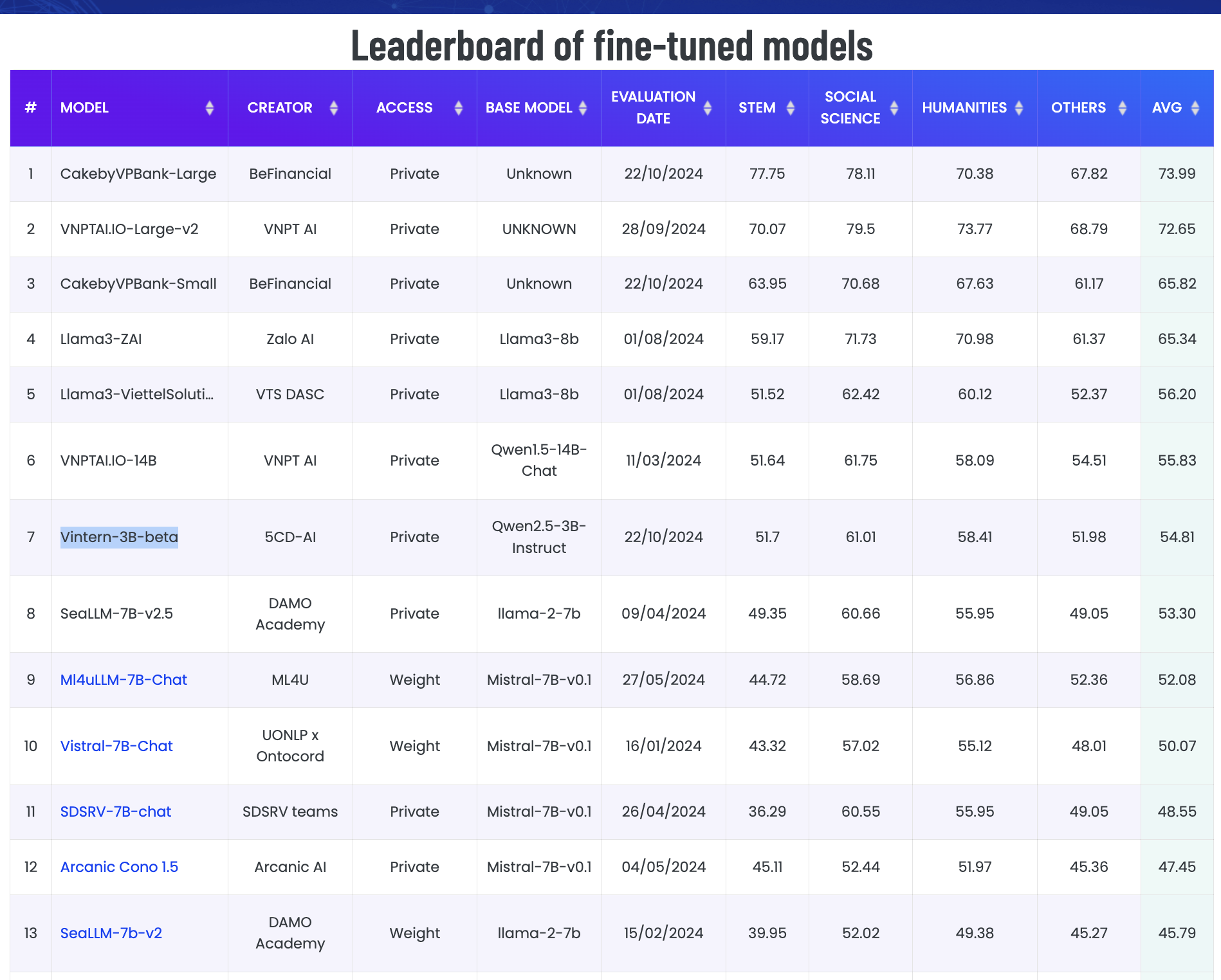
Bytedance/MTVQA Benchmark
We surpassed GPT-4o and are approaching Gemini 1.5 Pro on the MTVQA dataset for Vietnamese. The benchmark result in MTVQA from open_vlm_leaderboard.
| Rank | Method | Param (B) | Language Model | Vision Model | VI |
|---|---|---|---|---|---|
| 1 | Gemini-1.5-Pro | 41.3 | |||
| 2 | Vintern-3B-beta | 3 | Qwen2.5-3B-Instruct | InternViT-300M | 41.289 |
| 3 | GPT-4o (0513, detail-h...) | 39.6 | |||
| 4 | GPT-4o (0806, detail-h...) | 38.9 | |||
| 5 | Gemini-1.5-Flash | 38.9 | |||
| 6 | Qwen-VL-Max-0809 | 72 | Qwen2-72B | ViT-600M | 36.9 |
| 7 | GPT-4o (0513, detail-lo...) | 26.1 | |||
| 8 | Qwen-VL-Plus-0809 | 27.8 | |||
| 9 | GLM-4v-9B | 9 | GLM-4-9B | EVA-02-5B | 26.6 |
| 10 | InternVL2-Llama3-76B | 76 | Llama-3-70B-Instruct | InternViT-6B | 26.7 |
| 11 | Step-1.5V | Step-1.5 | stepencoder | 18.4 | |
| 12 | InternVL2-40B | 40 | Nous-Hermes-2-Yi-34B | InternViT-6B | 21.2 |
| 13 | Pixtral-12B | 13 | Nemo-12B | ViT-400M | 19.7 |
Zalo VMLU Benchmark
The Vintern-3B-beta achieved a score of 54.81 on the Zalo VMLU Benchmark.
generation_config = dict(max_new_tokens= 64, do_sample=False, num_beams = 1, repetition_penalty=1.5)
question = "Bạn là trợ lý AI giải trắc nghiệm rất chính xác. Bạn biết chắc chắn đáp án đúng nhất. Chỉ đưa ra chữ cái đứng trước câu trả lời đúng của câu hỏi trắc nghiệm sau: Các cơ quan nào sau đây là cơ quan tư pháp? Lựa Chọn:\nA. Viện kiểm sát nhân dân\nB. Tòa án nhân dân\nC. Chính phủ\nD. Cả A và B\nCâu trả lời đúng nhất là:"
model.chat(tokenizer, None, question, generation_config)
OpenCompass Benchmark
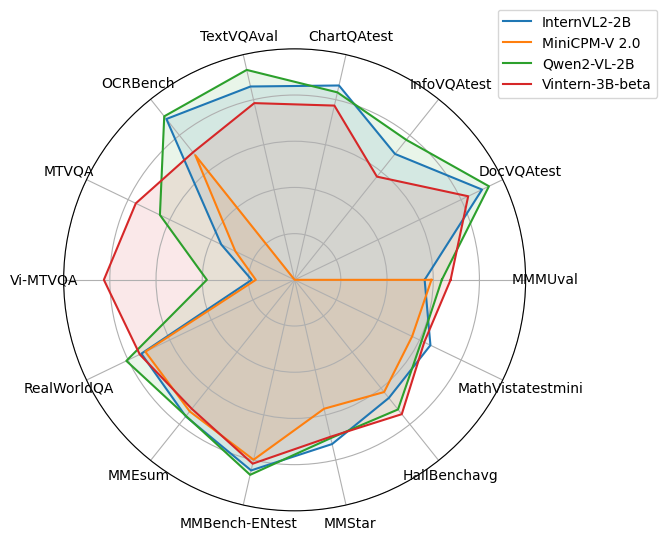
We are creating a pull request for the OpenCompass team to test once more and make the metrics public on the open_vlm_leaderboard.
The current results are at a quite good level, and we are expanding the training set in English and other languages to approach models within a comparable parameter range.
"The table is referenced from the repo Qwen/Qwen2-VL-2B-Instruct."
| Benchmark | InternVL2-2B | MiniCPM-V 2.0 | Qwen2-VL-2B | Vintern-3B-beta |
|---|---|---|---|---|
| MMMUval | 36.3 | 38.2 | 41.1 | 43.55 |
| DocVQAtest | 86.9 | - | 90.1 | 80.47 |
| InfoVQAtest | 58.9 | - | 65.5 | 48.28 |
| ChartQAtest | 76.2 | - | 73.5 | 68.32 |
| TextVQAval | 73.4 | - | 79.7 | 67.09 |
| OCRBench | 781 | 605 | 794 | 619 |
| MTVQA | 10.9 | 8.8 | 20.0 | 23.58 |
| Vi-MTVQA | 9.3 | 8.4 | - | 41.29 |
| RealWorldQA | 57.3 | 55.8 | 62.9 | 57.9 |
| MMEsum | 1876.8 | 1808.6 | 1872.0 | 1772.9 |
| MMBench-ENtest | 73.2 | 69.1 | 74.9 | 70.62 |
| MMStar | 49.8 | 39.1 | 48.0 | 47.6 |
| HallBenchavg | 38.0 | 36.1 | 41.7 | 43.22 |
| MathVistatestmini | 46.0 | 39.8 | 43.0 | 43.9 |
Examples

User: <image>
Liệt kê toàn bộ bài thơ có trong ảnh.
Assistant: Đi khắp thế gian không ai tốt bằng mẹ Gánh nặng cuộc đời không ai khổ bằng cha
Quickstart
Here provides a code snippet to show you how to load the tokenizer and model and how to generate contents. To run inference using the model, follow the steps outlined in our Colab inference notebook
import numpy as np
import torch
import torchvision.transforms as T
# from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
model = AutoModel.from_pretrained(
"5CD-AI/Vintern-3B-beta",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True,
).eval().cuda()
tokenizer = AutoTokenizer.from_pretrained("5CD-AI/Vintern-3B-beta", trust_remote_code=True, use_fast=False)
test_image = 'test-image.jpg'
pixel_values = load_image(test_image, max_num=6).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens= 512, do_sample=False, num_beams = 3, repetition_penalty=3.5)
question = '<image>\nMô tả hình ảnh một cách chi tiết.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
#question = "Câu hỏi khác ......"
#response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
#print(f'User: {question}\nAssistant: {response}')
Citation
@misc{doan2024vintern1befficientmultimodallarge,
title={Vintern-1B: An Efficient Multimodal Large Language Model for Vietnamese},
author={Khang T. Doan and Bao G. Huynh and Dung T. Hoang and Thuc D. Pham and Nhat H. Pham and Quan T. M. Nguyen and Bang Q. Vo and Suong N. Hoang},
year={2024},
eprint={2408.12480},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2408.12480},
}